Embed Size (px)
Citation preview

ANL 2014 - Chicago
Elastic and Efficient Execution of Data-Intensive Applications on Hybrid Cloud
Tekin Bicer
Computer Science and Engineering
Ohio State University

ANL 2014 - Chicago
Introduction
• Scientific simulations and instruments– X-ray Photon Correlation Spectroscopy
• CCD Detector: 120MB/s now; 44GB/s by 2015
– Global Cloud Resolving Model• 1PB for 4km grid-cell
• Performed on local clusters– Not sufficient
• Problems– Data Analysis, Storage, I/O performance
• Cloud Technologies– Elasticity– Pay-as-you-go Model
2

ANL 2014 - Chicago
Hybrid Cloud Motivation
• Cloud technologies– Typically associated with
computational resources• Massive data generation
– Exhaust local storage• Hybrid Cloud
– Local Resources: Base– Cloud Resources: Additional
• Cloud– Compute and storage
resources
3
Local Resources

ANL 2014 - Chicago
Cloud Storage
Usage of Hybrid Cloud
4
Local Storage
Data Source
Local Nodes
Cloud Compute Nodes

ANL 2014 - Chicago
Challenges
• Data-Intensive Processing– Transparent Data Access and
Analysis
– Programmability of Large-Scale Applications
• Meeting User Constraints– Enabling Cloud Bursting
• Minimizing Storage and I/O Cost– Domain Specific Compression– In-Situ and In-Transit Data
Analysis
5
MATE-HC: Map-reduce with AlternaTE APIover Hybrid Cloud
Dynamic Resource Allocation Framework
for Hybrid Cloud
Compression Methodology and
System for Large-Scale App.

ANL 2014 - Chicago
Programmability of Large-Scale Applications on Hybrid Cloud
• Geographically distributed resources• Ease of programmability
– Reduction-based programming structures• MATE-HC
– A middleware for transparent data access and processing
– Selective job assignment– Multi-threaded data retrieval
6

ANL 2014 - Chicago
Middleware for Hybrid Cloud
...
...Data
Slaves
MasterLocal Cluster
LocalReduction
Job Assignment
...
...Data
Slaves
Master
Cloud Environment
Job Assignment
LocalReduction
Index
7
Remote DataAnalysis
Job Assignment
Job Assignment
GlobalReduction
GlobalReduction

ANL 2014 - Chicago
MATE vs. Map-Reduce Processing Structure
8
• Reduction Object represents the intermediate state of the execution
• Reduce func. is commutative and associative• Sorting, grouping.. overheads are eliminated with red. func/obj.

ANL 2014 - Chicago
Simple Example
3 5 8 4 1 3 5 2 6 7 9 4 2 4 8
9
Our large Dataset
Our Compute NodesRobj[1]= Robj[1]= Robj[1]=
Local Reduction (+) Local Reduction(+)Local Reduction(+)
8 15 1421 23 27
Result= 71 Global Reduction(+)

ANL 2014 - Chicago
Experiments
• 2 geographically distributed clusters– Cloud: EC2 instances running on Virginia
– 22 nodes x 8 cores– Local: Campus cluster (Columbus, OH)
– 150 nodes x 8 cores
• 3 applications with 120GB of data– KMeans: k=1000; KNN: k=1000; – PageRank: 50x10 links w/ 9.2x10 edges
• Goals:
– Evaluating the system overhead with different job distributions– Evaluating the scalability of the system
10
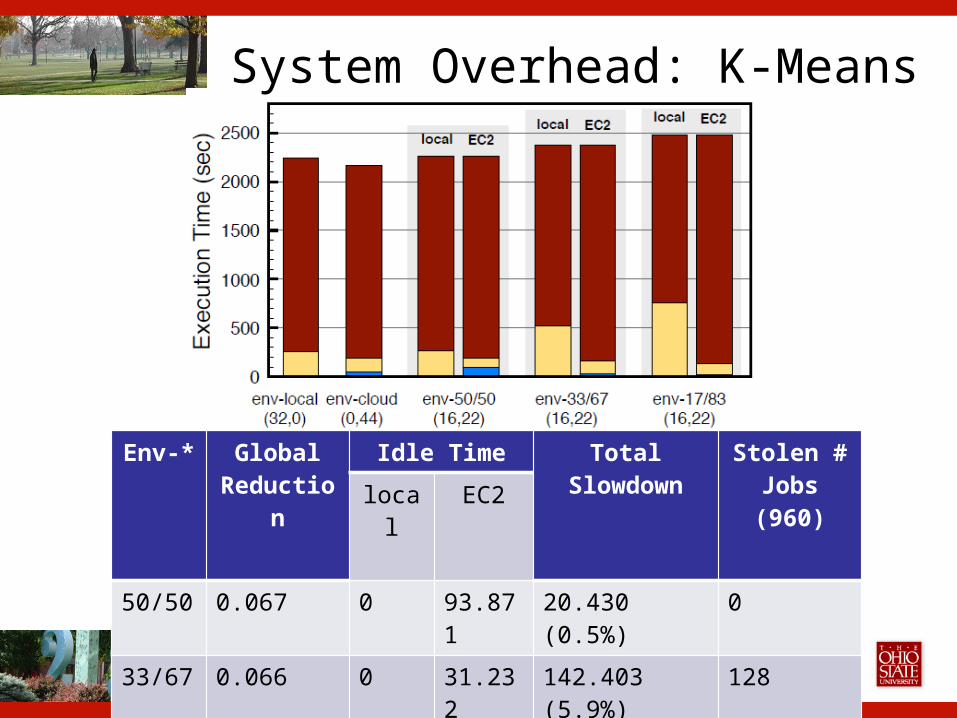
ANL 2014 - Chicago
System Overhead: K-Means
11
Env-* Global Reduction
Idle Time Total Slowdown
Stolen # Jobs (960)local EC2
50/50 0.067 0 93.871 20.430 (0.5%) 0
33/67 0.066 0 31.232 142.403 (5.9%) 128
17/83 0.066 0 25.101 243.31 (10.4%) 240

ANL 2014 - Chicago
Scalability: K-Means
12

ANL 2014 - Chicago
Summary
• MATE-HC is a data-intensive middleware developed for Hybrid Cloud
• Our results show that – Low inter-cluster comm. overhead– Job distribution is important– Overall slowdown is modest – Proposed system is scalable
13

ANL 2014 - Chicago
Outline
• Data-Intensive Processing– Programmability of Large-Scale
Applications– Transparent Data Access and
Analysis
• Meeting User Constraints– Enabling Cloud Bursting
• Minimizing Storage and I/O Cost– Domain Specific Compression– In-Situ and In-Transit Data
Analysis
14
MATE-HC: Map-reduce with AlternaTE APIover Hybrid Cloud
Dynamic Resource Allocation Framework
for Cloud Bursting
Compression Methodology and
System for Large-Scale App.

ANL 2014 - Chicago
Dynamic Resource Allocation for Cloud Bursting
• Performance of cloud resources and workload vary– Problems:
• Extended execution times• Unable to meet user constraints
– Cloud resources can dynamically scale• Cloud Bursting
– In-house resources: Base workload– Cloud resources: Adopt performance requirements
• Dynamic Resource Allocation Framework– A model for capturing “Time” and “Cost” constraints
with cloud bursting
15

ANL 2014 - Chicago
System Components
• Local cluster and Cloud • MATE-HC processing structure• Pull-based job distribution• Head Node
– Coarse grained job assignment– Consideration of locality
• Master node– Fine grained job assignment
• Job Stealing– Remote data processing
16

ANL 2014 - Chicago
Resource Allocation FrameworkEstimate required time for local cluster processing
Estimate required time for cloud cluster processing
All variables can be profiled during execution, except estimated # stolen jobs
Estimate remaining # jobs after local jobs are consumed
Ratio of local computational throughput in system
17
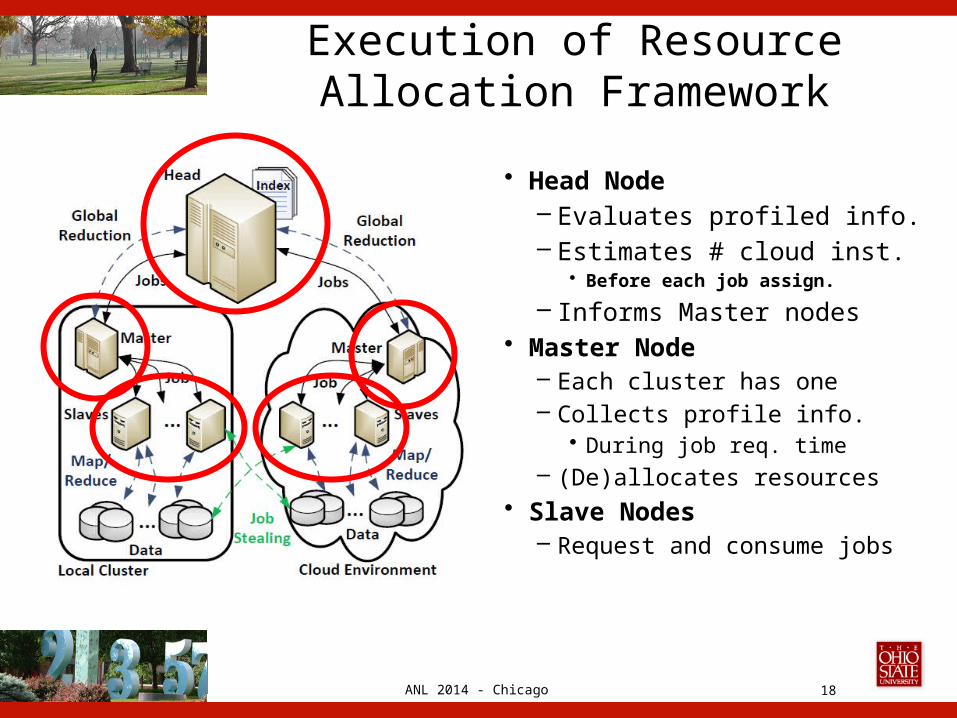
ANL 2014 - Chicago
Execution of Resource Allocation Framework
• Head Node– Evaluates profiled info.– Estimates # cloud inst.
• Before each job assign.
– Informs Master nodes• Master Node
– Each cluster has one– Collects profile info.
• During job req. time– (De)allocates resources
• Slave Nodes– Request and consume jobs
18

ANL 2014 - Chicago
Experimental Setup
• Two Applications– KMeans (520GB): Local=104GB; Cloud=416GB– PageRank (520GB): Local=104GB; Cloud=416GB
• Local cluster: Max. 16 nodes x 8 cores = 128 cores
• Cloud resources: Max. 16 nodes x 8 cores = 128 cores
• Evaluation of model– Local nodes are dropped during execution– Observed how system is adopted
19

ANL 2014 - Chicago
KMeans – Time Constraint
# Local Inst.: 16 (fixed)# Cloud Inst.: Max 16 (Varies)Local: 104GB, Cloud:416GB
• System is not able to meet the time constraint because max. # of cloud instances is reached• All other configurations meet the time constraint with <1.5% error rate
20

ANL 2014 - Chicago
KMeans – Cloud Bursting
• 4 local nodes are dropped …• After 25% and 50% of time constraints are elapsed, error rate <1.9%• After 75% of time constraint is elapsed, error rate <3.6%
• Reason of higher error rate: Shorter time to profile new environment
# Local Inst.: 16 (fixed)# Cloud Inst.: Max 16 (Varies)Local: 104GB, Cloud:416GB
21

ANL 2014 - Chicago
Summary
• MATE-HC: MapReduce type of processing– Federated resources
• Developed a resource allocation model– Based on feedback mechanism– Time and cost constraints
• Two data-intensive applications (KMeans, PR)– Error rate for time < 3.6%– Error rate for cost < 1.2%
22

ANL 2014 - Chicago
Outline
• Data-Intensive Processing– Programmability of Large-Scale
Applications– Transparent Data Access and
Analysis
• Meeting User Constraints– Enabling Cloud Bursting
• Minimizing Storage and I/O Cost– Domain Specific Compression– In-Situ and In-Transit Data
Analysis
23
MATE-HC: Map-reduce with AlternaTE API
over HC
Dynamic Resource Allocation Framework
for Cloud Bursting
Compression Methodology and
System for Large-Scale App.

ANL 2014 - Chicago
Data Management using Compression
• Generic compression algorithms– Good for low entropy sequence of bytes– Scientific dataset are hard to compress
• Floating point numbers: Exponent and mantissa• Mantissa can be highly entropic
• Using compression is challenging– Suitable compression algorithms– Utilization of available resources– Integration of compression algorithms
24

ANL 2014 - Chicago
Compression Methodology• Common properties of scientific datasets
– Multidimensional arrays– Consist of floating point numbers– Relationship between neighboring values
• Domain specific solutions can help• Approach:
– Prediction-based differential compression• Predict the values of neighboring cells• Store the difference
25

ANL 2014 - Chicago
Example: GCRM Temperature Variable Compression
• E.g.: Temperature record• The values of neighboring cells
are highly related• X’ table (after prediction):
• X’’ compressed values– 5bits for prediction +
difference• Lossless and lossy comp.• Fast and good compression
ratios
26

ANL 2014 - Chicago
Compression Framework
• Improve end-to-end application performance• Minimize the application I/O time
– Pipelining I/O and (de)compression operations• Hide computational overhead
– Overlapping application computation with compression framework
• Easy implementation of compression algorithms• Easy integration with applications
– Similar API to POSIX I/O
27

ANL 2014 - Chicago
A Compression Framework for Data Intensive Applications
Chunk Resource Allocation (CRA) Layer• Initialization of the system• Generate chunk requests, enqueue processing • Converting original offset and data size requests to
compressed
28
Parallel Compression Engine (PCE)• Applies encode(), decode() functions to chunks• Manages in-memory cache with informed prefetching• Creates I/O requests
Parallel I/O Layer (PIOL)• Creates parallel chunk requests to storage medium• Each chunk request is handled by a group of threads• Provides abstraction for different data transfer
protocols
28

ANL 2014 - Chicago
Integration with a Data-Intensive Computing System
• Remote data processing– Sensitive to I/O bandwidth
• Processes data in…– local cluster– cloud– or both (Hybrid Cloud)
29

ANL 2014 - Chicago
Experimental Setup
• Two datasets:– GCRM: 375GB (L:270 + R:105)– NPB: 237GB (L:166 + R:71)
• 16x8 cores (Intel Xeon 2.53GHz)• Storage of datasets
– Lustre FS (14 storage nodes)– Amazon S3 (Northern Virginia)
• Compression algorithms– CC, FPC, LZO, bzip, gzip, lzma
• Applications: AT, MMAT, KMeans
30

ANL 2014 - Chicago
Performance of MMAT
31
Local Remote Hybrid0
200
400
600
800
1000
1200
1400
1600
1800OriginalLZOCC
Exec
ution
Tim
e (s
ecs)
Original CC Original CCLocal Remote
0
200
400
600
800
1000 ReadDecomp.Reduction
Exe
cuti
on
Tim
e (s
ec)
Speedups
Local Remote Hybrid
CC 1.63 1.90 1.85
LZO 1.04 1.24 1.14
Compression Ratios
CC 51.68% (186GB)
LZO 20.40% (299GB)
Breakdown of Performance• Overhead (Local): 15.41%• Read Speedup: 1.96
I/O Throughput (128np)
GB/sec Orig. CC
Local 1.62 3.21
Remote 0.1 0.19

ANL 2014 - Chicago
Lossy Compression (MMAT)
32
Local Remote Hybrid0
100
200
300
400
500
600
700
800
900
1000CCLossy 2eLossy 4e
Exec
ution
Tim
e (s
ec)
Speedups
Local Remote Hybrid
2e vs CC 1.07 1.18 1.09
4e vs CC 1.13 1.43 1.18
4e vs orig. 1.76 2.41 2.18
Compression Ratios
Lossless 51.68%
2e 56.88% (162GB)
4e 62.93% (139GB)
Lossy• #e: # dropped bits• Error bound: 5x(1/10^5)

ANL 2014 - Chicago
Summary• Management and analysis of scientific datasets are
challenging– Generic compression algorithms are inefficient for
scientific datasets• Proposed a compression framework and methodology
– Domain specific compression algorithms are fast and space efficient• 51.68% compression ratio• 53.27% improvement in exec. time
– Easy plug-and-play of compression– Integration of the proposed framework and methodology
with a data analysis middleware
33
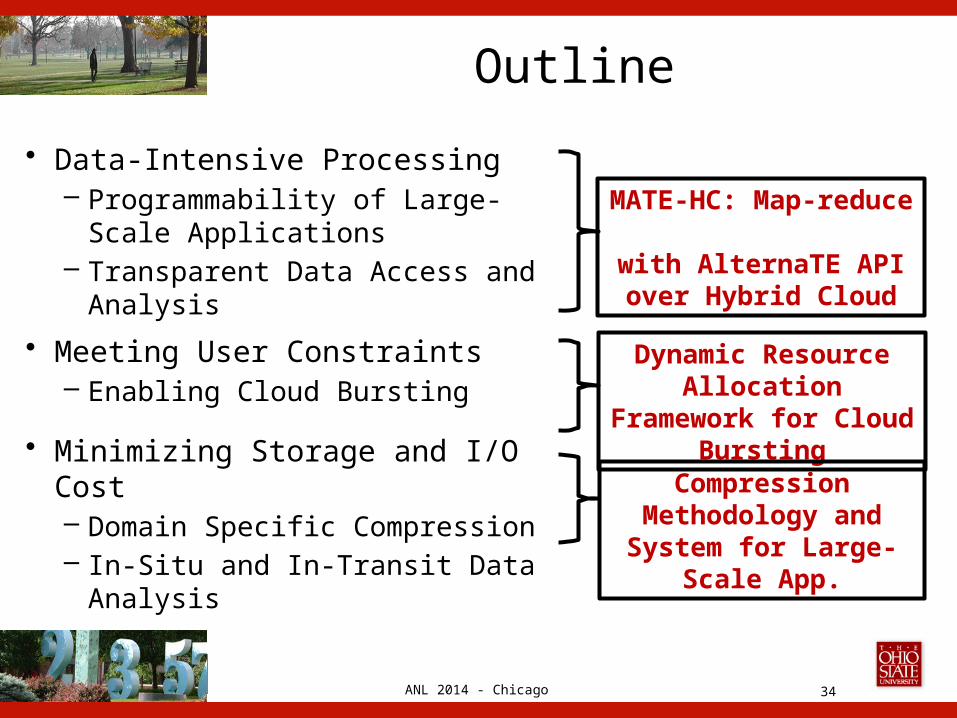
ANL 2014 - Chicago
Outline
• Data-Intensive Processing– Programmability of Large-Scale
Applications– Transparent Data Access and
Analysis
• Meeting User Constraints– Enabling Cloud Bursting
• Minimizing Storage and I/O Cost– Domain Specific Compression– In-Situ and In-Transit Data
Analysis
34
MATE-HC: Map-reduce with AlternaTE APIover Hybrid Cloud
Dynamic Resource Allocation Framework
for Cloud Bursting
Compression Methodology and
System for Large-Scale App.

ANL 2014 - Chicago
In-Situ and In-Transit Analysis
• Compression can ease data management– But may not always be sufficient
• In-situ data analysis– Co-locate data source and analysis code– Data analysis during data generation
• In-transit data analysis– Remote resources are utilized– Forward generated data to “staging nodes”
35

ANL 2014 - Chicago
In-Situ and In-Transit Data Analysis
• Significant reduction in generated dataset size– Noise elimination, data filtering, stream mining…– Timely insights
• Parallel data analysis– MATE-Stream
• Dynamic resource allocation and load balancing– Hybrid data analysis– Both in-situ and in-transit
36

ANL 2014 - Chicago
Robj[...]
Robj[...]
Robj[...]
Robj[...]
LR
LR
LR
LR
Parallel In-Situ Data Analysis
37
DataSource
Disp LRobj[...]
Local Combination• Intermediate results• Timely insights• Continuous global red.
Local Reduction• Filtering, stream mining• Data reduction• Continuous local red.
Data Generation• Scientific instruments,
simulations, etc.• (Un)bounded data

ANL 2014 - Chicago
Robj[...]
Robj[...]
Robj[...]
Robj[...]
LR
LR
LR
LR
Robj[...]
Robj[...]
Robj[...]
Robj[...]
LR
LR
LR
LR
Elastic In-Situ Data Analysis
38
DataSource
Disp
LRobj[...]
Insufficient resource utilization• Dynamically extend resources• New local reduction proc.

ANL 2014 - Chicago
Robj[...]
Robj[...]
Robj[...]
Robj[...]
LR
LR
LR
LR
Robj[...]
Robj[...]
Robj[...]
Robj[...]
LR
LR
LR
LR
Elastic In-Situ and In-Transit Data Analysis
39
DataSource
Disp LRobj[...]
Disp LRobj[...]
GRobj[...]
Staging node is set• Forward dataReduction process:1. Local comb.2. Global comb.
N0
N1

ANL 2014 - Chicago
Future Directions
• Scientific applications are difficult to modify– Integration with existing data sources– GridFTP, (P)NetCDF and HDF5 etc.
• Data transfer is expensive (especially for in-transit)– Utilization of advanced network technologies– Software-Defined Networking (SDN)
• Long running nature of large-scale app.– Failures are inevitable– Exploit features of processing structure
40

ANL 2014 - Chicago
Conclusions
• Data-intensive applications and instruments can easily exhaust local resources
• Hybrid cloud can provide additional resources • Challenges: Transparent data access and processing; meeting user
constraints; minimizing I/O and storage cost• MATE-HC: Transparent and efficient data processing on Hybrid
Cloud• Developed a “dynamic resource allocation framework” and
integrated with MATE-HC– Time and cost sensitive data processing
• Proposed a “compression methodology and a system” to minimize storage cost and I/O bottleneck
• Design of “in-situ and in-transit data analysis” (on going work)
41

ANL 2014 - Chicago 42
Thanks for your attention!

ANL 2014 - Chicago
MATE-EC2 Design
• Data organization– Three levels: Buckets, Chunks and Units– Metadata information
• Chunk Retrieval– Threaded Data Retrieval– Selective Job Assignment
• Load Balancing and handling heterogeneity– Pooling mechanism
43

ANL 2014 - Chicago
MATE-EC2 vs. EMR
44
• KMeans• Speedups
• vs. combine3.54 – 4.58
• PageRank• Speedups
• vs. combine4.08 – 7.54

ANL 2014 - Chicago
Different Chunk Sizes
• KMeans• 1 retrieval threads• Performance
increase– 128KB vs. >8M– 2.07 to 2.49
45

ANL 2014 - Chicago
K-Means (Data Retrieval)
• Fig 1: 16 Retrieval Threads– 8M vs. others speedup: 1.13-1.30
• Fig. 2: 128M Chunk Size– 1 Thread vs. others speedup: 1.37-1.90
46
Fig. 1 Fig. 2
• Dataset: 8.2GB
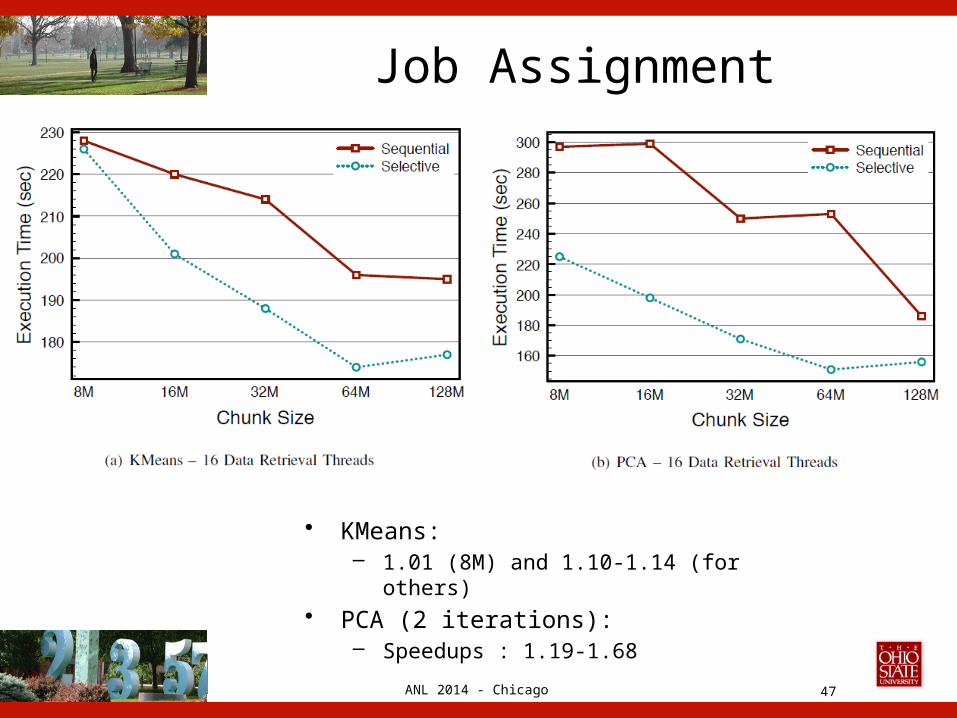
ANL 2014 - Chicago
Job Assignment
47
• KMeans: – 1.01 (8M) and 1.10-1.14 (for others)
• PCA (2 iterations):– Speedups : 1.19-1.68

ANL 2014 - Chicago
Heterogeneous Conf.
48
Overheads– KMeans: 1%– PCA: 1.1%, 7.4%, 11.7%

ANL 2014 - Chicago
Kmeans – Cost Constraint
• System meets the cost constraints with <1.1% error rate• Maximum # cloud instances is allocated error rate is again <1.1%
• System tries to minimize the execution time with provided cost constraint
49

ANL 2014 - Chicago
Prefetching and In-Memory Cache
• Overlapping application layer computation with I/O
• Reusability of already accessed data is small
• Prefetching and caching the prospective chunks– Default is LRU– User can analyze history and
provide prospective chunk list
• Cache uses row-based locking scheme for efficient consecutive chunk requests
50
Informed Prefetching
prefetch(…)

ANL 2014 - Chicago 51
Local Remote Hybrid0
100
200
300
400
500
600
700
800
900
1000FPC2P – 4IO4P – 8IO
Exec
ution
Tim
e (s
ec)
Local Remote Hybrid0
200
400
600
800
1000
1200OriginalFPC
Exec
ution
Tim
e (s
ec)
Performance of KMeans
Speedups
Local Remote Hybrid
FPC 0.75 1.30 1.12
Speedups w/ multithreading
Local Remote Hybrid
2P - 4IO 1.25 1.17 1.19
4P - 8IO 1.37 1.16 1.21
4P – 8IO vs Orig.
1.03 1.51 1.36
• NPB dataset• Comp ratio: 24.01% (180GB)• More computation
– More opportunity to fetch and decompression





























