Embed Size (px)
Citation preview

1
and the Big Data Landscape
Chen LiInformation Systems Group
CS DepartmentUC Irvine
#AsterixDB 2
Big Data / Web WarehousingSo what went on – and why? What’s going
on right now?
What’s going on…?

3
Notes:• Storage manager
per node• Upper layers
orchestrate them• One way in/out:
via the SQL door
Big Data in the Database World• Enterprises needed to store and query historical
business data (data warehouses)– 1980’s: Parallel database systems based on “shared-
nothing” architectures (Gamma/GRACE, Teradata)– 2000’s: Netezza, Aster Data, DATAllegro, Greenplum,
Vertica, ParAccel (“Big $”acquisitions!)• OLTP is another category (a source of Big Data)
– 1980’s: Tandem’s NonStop SQL system

4
Big Data in the Systems World• Late 1990’s brought a need to index and query the
rapidly exploding content of the Web– DB technology tried but failed (e.g., Inktomi)– Google, Yahoo! et al needed to do something
• Google responded by laying a new foundation– Google File System (GFS)
• OS-level byte stream files spanning 1000’s of machines• Three-way replication for fault-tolerance (availability)
– MapReduce (MR) programming model• User functions: Map and Reduce (and optionally Combine)• “Parallel programming for dummies” – MR runtime does the
heavy lifting via partitioned parallelism
5
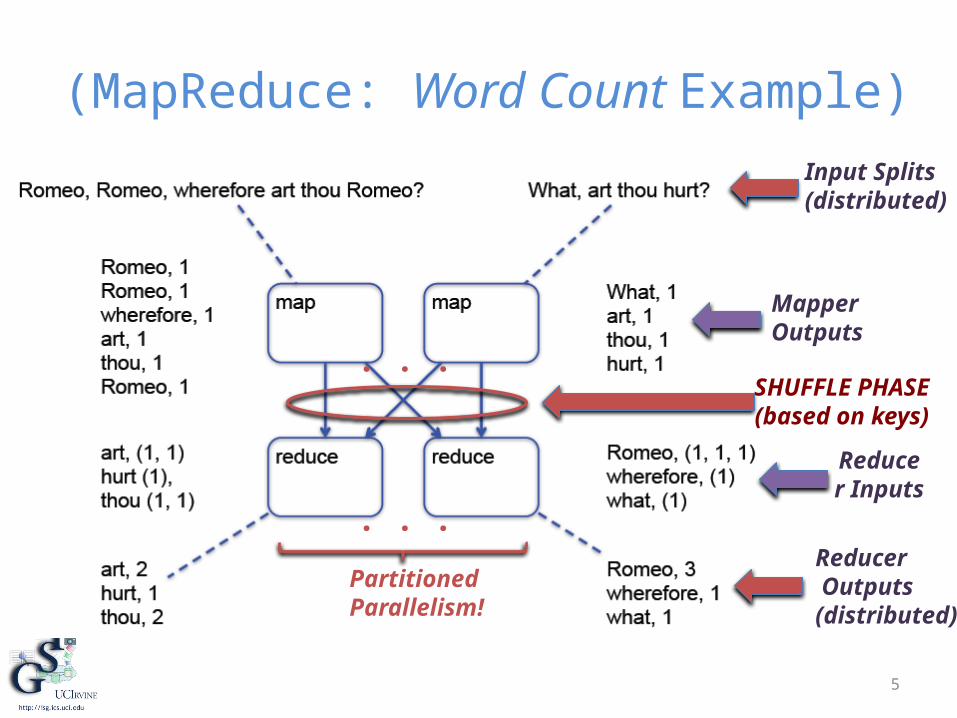
Input Splits (distributed)
MapperOutputs
Reducer Inputs
Reducer Outputs (distributed)
SHUFFLE PHASE(based on keys)
(MapReduce: Word Count Example)
PartitionedParallelism!
. . .
. . .

6
Soon a Star Was Born…• Yahoo!, Facebook, and friends read the papers
– HDFS and Hadoop MapReduce now in wide use for indexing, clickstream analysis, log analysis, …
• Higher-level languages subsequently developed – Pig (Yahoo!), Hive (Facebook), Jaql (IBM)
• Key-value (“NoSQL”) stores are another category– Used to power scalable social sites, online games, …– BigTableHBase, DynamoCassandra, MongoDB, …
Notes:•Giant byte sequence files
at the bottom•Map, sort, shuffle, reduce
layer in middle•Possible storage layer in
middle as well•Now at the top: HLL’s
(Huh…?)

7
Apache Pig (PigLatin)
• Scripting language inspired by the relational algebra– Compiles down to a series of Hadoop MR jobs– Relational operators include LOAD, FOREACH, FILTER,
GROUP, COGROUP, JOIN, ORDER BY, LIMIT, ...

8
Apache Hive (HiveQL)
• Query language inspired by an old favorite: SQL– Compiles down to a series of Hadoop MR jobs– Supports various HDFS file formats (text, columnar, ...)– Numerous contenders appearing that take a non-MR-
based runtime approach (duh!) – these include Impala, Stinger, Spark SQL, ...
Other Up-and-Coming Platforms (I)
9
Distributedmemory
Input
query 1
query 2
query 3
. . .
one-time processing
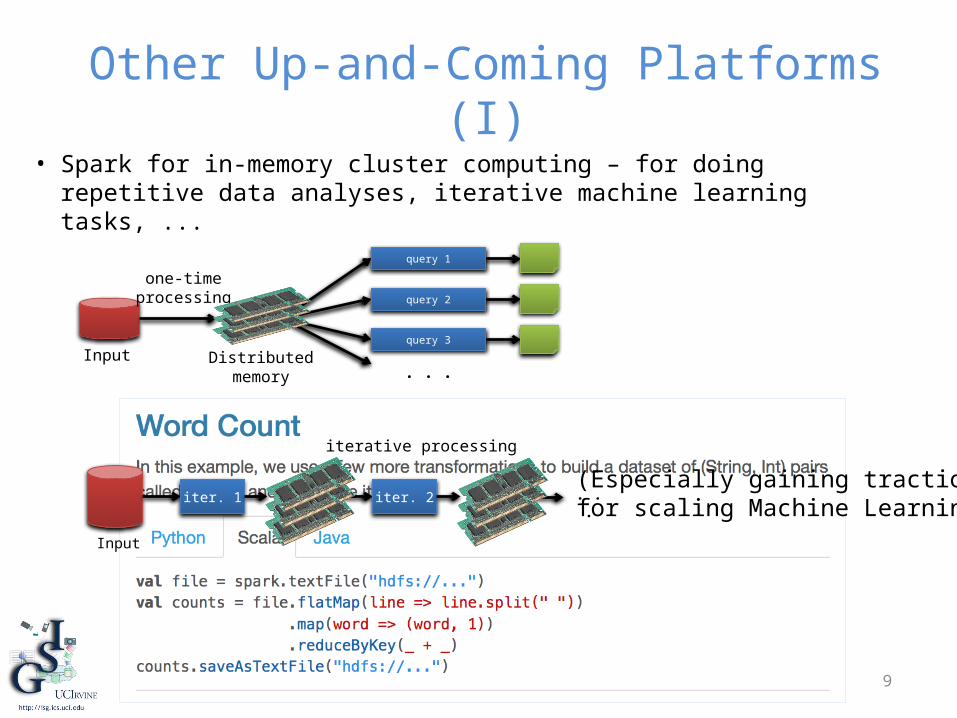
• Spark for in-memory cluster computing – for doing repetitive data analyses, iterative machine learning tasks, ...
iter. 1 iter. 2 . . .
Input
iterative processing
(Especially gaining tractionfor scaling Machine Learning)
10
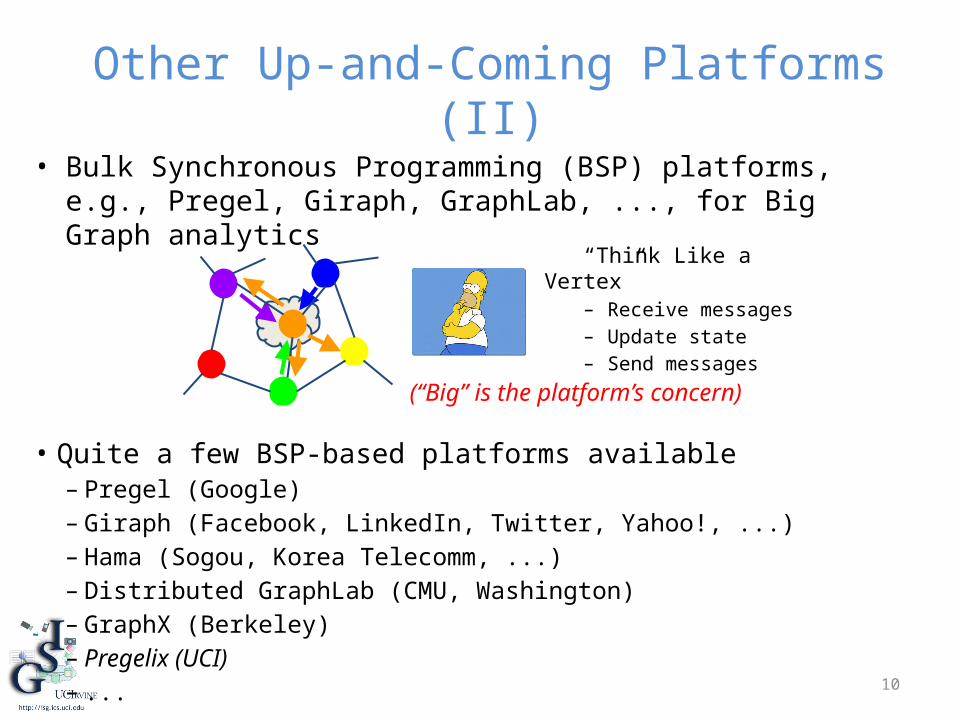
Other Up-and-Coming Platforms (II)• Bulk Synchronous Programming (BSP) platforms, e.g., Pregel,
Giraph, GraphLab, ..., for Big Graph analytics
(“Big” is the platform’s concern)
“Think Like a Vertex”– Receive messages– Update state– Send messages
• Quite a few BSP-based platforms available– Pregel (Google)– Giraph (Facebook, LinkedIn, Twitter, Yahoo!, ...)– Hama (Sogou, Korea Telecomm, ...)– Distributed GraphLab (CMU, Washington)– GraphX (Berkeley)– Pregelix (UCI)– ...
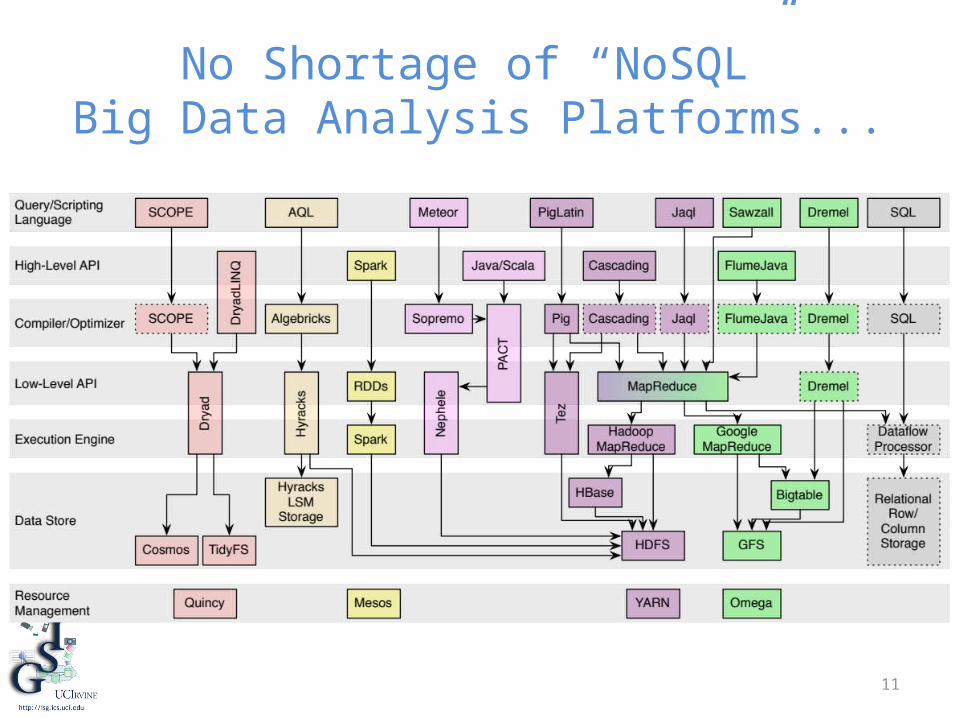
11
No Shortage of “NoSQL”Big Data Analysis Platforms...

12
(Pig)
Also: Today’s Big Data Tangle

13
AsterixDB: “One Size Fits a Bunch”Semistructured
Data Management
ParallelDatabase Systems
World ofHadoop & Friends
BDMS Desiderata:• Flexible data model• Efficient runtime• Full query capability• Cost proportional to
task at hand (!)• Designed for
continuous data ingestion
• Support today’s “Big Data data types”
• • •

14
create dataverse TinySocial;use dataverse TinySocial;
create type MugshotUserType as { id: int32, alias: string, name: string, user-since: datetime, address: { street: string, city: string, state: string, zip: string, country: string }, friend-ids: {{ int32 }}, employment: [EmploymentType]}
ASTERIX Data Model (ADM)
create dataset MugshotUsers(MugshotUserType) primary key id;
Highlights include:• JSON++ based data model• Rich type support (spatial, temporal, …)• Records, lists, bags• Open vs. closed types
create type EmploymentType as open { organization-name: string, start-date: date, end-date: date?}

15
create dataverse TinySocial;use dataverse TinySocial;
create type MugshotUserType as { id: int32, alias: string, name: string, user-since: datetime, address: { street: string, city: string, state: string, zip: string, country: string }, friend-ids: {{ int32 }}, employment: [EmploymentType]}
create dataverse TinySocial;use dataverse TinySocial;
create type MugshotUserType as { id: int32}
ASTERIX Data Model (ADM)
create dataset MugshotUsers(MugshotUserType) primary key id;
Highlights include:• JSON++ based data model• Rich type support (spatial, temporal, …)• Records, lists, bags• Open vs. closed types
create type EmploymentType as open { organization-name: string, start-date: date, end-date: date?}

16
create dataverse TinySocial;use dataverse TinySocial;
create type MugshotUserType as { id: int32, alias: string, name: string, user-since: datetime, address: { street: string, city: string, state: string, zip: string, country: string }, friend-ids: {{ int32 }}, employment: [EmploymentType]}
create dataverse TinySocial;use dataverse TinySocial;
create type MugshotUserType as { id: int32}
create type MugshotMessageType as closed { message-id: int32, author-id: int32, timestamp: datetime, in-response-to: int32?, sender-location: point?, tags: {{ string }}, message: string}
ASTERIX Data Model (ADM)
create dataset MugshotUsers(MugshotUserType) primary key id;create dataset MugshotMessages(MugshotMessageType) primary key message-id;
Highlights include:• JSON++ based data model• Rich type support (spatial, temporal, …)• Records, lists, bags• Open vs. closed types
create type EmploymentType as open { organization-name: string, start-date: date, end-date: date?}

17
{ "id":1, "alias":"Margarita", "name":"MargaritaStoddard", "address”:{ "street":"234 Thomas Ave", "city":"San Hugo", "zip":"98765", "state":"CA", "country":"USA" } "user-since":datetime("2012-08-20T10:10:00"), "friend-ids":{{ 2, 3, 6, 10 }}, "employment":[{ "organization-name":"Codetechno”, "start-date":date("2006-08-06") }] }
{ "id":2, "alias":"Isbel", "name":"IsbelDull", "address":{ "street":"345 James Ave", "city":"San Hugo", "zip":"98765”, "state":"CA", "country":"USA" }, "user-since":datetime("2011-01-22T10:10:00"), "friend-ids":{{ 1, 4 }}, "employment":[{ "organization-name":"Hexviafind”, "start-date":date("2010-04-27") }] }
{ "id":3, "alias":"Emory", "name":"EmoryUnk", "address":{ "street":"456 Jose Ave", "city":"San Hugo", "zip":"98765", "state":"CA", "country":"USA" }, "user-since”: datetime("2012-07-10T10:10:00"), "friend-ids":{{ 1, 5, 8, 9 }}, "employment”:[{ "organization-name":"geomedia”, "start-date":date("2010-06-17"), "end-date":date("2010-01-26") }] }...
Ex: MugshotUsers Data

18
create index msUserSinceIdx on MugshotUsers(user-since);create index msTimestampIdx on MugshotMessages(timestamp);create index msAuthorIdx on MugshotMessages(author-id) type btree;create index msSenderLocIndex on MugshotMessages(sender-location) type rtree;create index msMessageIdx on MugshotMessages(message) type keyword;
create type AccessLogType as closed { ip: string, time: string, user: string, verb: string, path: string, stat: int32, size: int32 };create external dataset AccessLog(AccessLogType) using localfs (("path"="{hostname}://{path}"), ("format"="delimited-text"), ("delimiter"="|"));
create feed socket_feed using socket_adaptor (("sockets"="{address}:{port}"), ("addressType"="IP"), ("type-name"="MugshotMessageType"), ("format"="adm"));connect feed socket_feed to dataset MugshotMessages;
Other DDL Features
External data highlights:• Common HDFS file
formats + indexing• Feed adaptors for
sources like Twitter

19
• Ex: List the user name and messages sent by those users who joined the Mugshot social network in a certain time window:
from $user in dataset MugshotUserswhere $user.user-since >= datetime('2010-07-22T00:00:00') and $user.user-since <= datetime('2012-07-29T23:59:59')select { "uname" : $user.name, "messages" : from $message in dataset MugshotMessages where $message.author-id = $user.id select $message.message};
19
ASTERIX Query Language (AQL)

20
AQL (cont.)
• Ex: Identify active users and group/count them by country:
with $end := current-datetime( )with $start := $end - duration("P30D")from $user in dataset MugshotUserswhere some $logrecord in dataset AccessLog satisfies $user.alias = $logrecord.user and datetime($logrecord.time) >= $start and datetime($logrecord.time) <= $endgroup by $country := $user.address.country with $userselect { "country" : $country, "active users" : count($user)}
AQL highlights:• Lots of other features (see website!)• Spatial predicates and aggregation• Set-similarity (fuzzy) matching• And plans for more…

21
Fuzzy Queries in AQL
• Ex: Find Tweets with similar content:
for $tweet1 in dataset('TweetMessages')for $tweet2 in dataset('TweetMessages')where $tweet1.tweetid != $tweet2.tweetid and $tweet1.message-text ~= $tweet2.message-textreturn { "tweet1-text": $tweet1.message-text, "tweet2-text": $tweet2.message-text}
• Or: Find Tweets about similar topics:
for $tweet1 in dataset('TweetMessages')for $tweet2 in dataset('TweetMessages')where $tweet1.tweetid != $tweet2.tweetid and $tweet1.referred-topics ~= $tweet2.referred-topicsreturn { "tweet1-text": $tweet1.message-text, "tweet2-text": $tweet2.message-text}

22
Updates (and Transactions)
• Key-value store-like transaction semantics
• Insert/delete ops with indexing
• Concurrency control (locking)
• Crash recovery• Backup/restore
• Ex: Add a new user to Mugshot.com:
insert into dataset MugshotUsers( { "id":11, "alias":"John", "name":"JohnDoe", "address":{ "street":"789 Jane St", "city":"San Harry", "zip":"98767", "state":"CA", "country":"USA" }, "user-since":datetime("2010-08-15T08:10:00"), "friend-ids":{ { 5, 9, 11 } }, "employment":[{ "organization-name":"Kongreen", "start-date":date("20012-06-05") }] } );
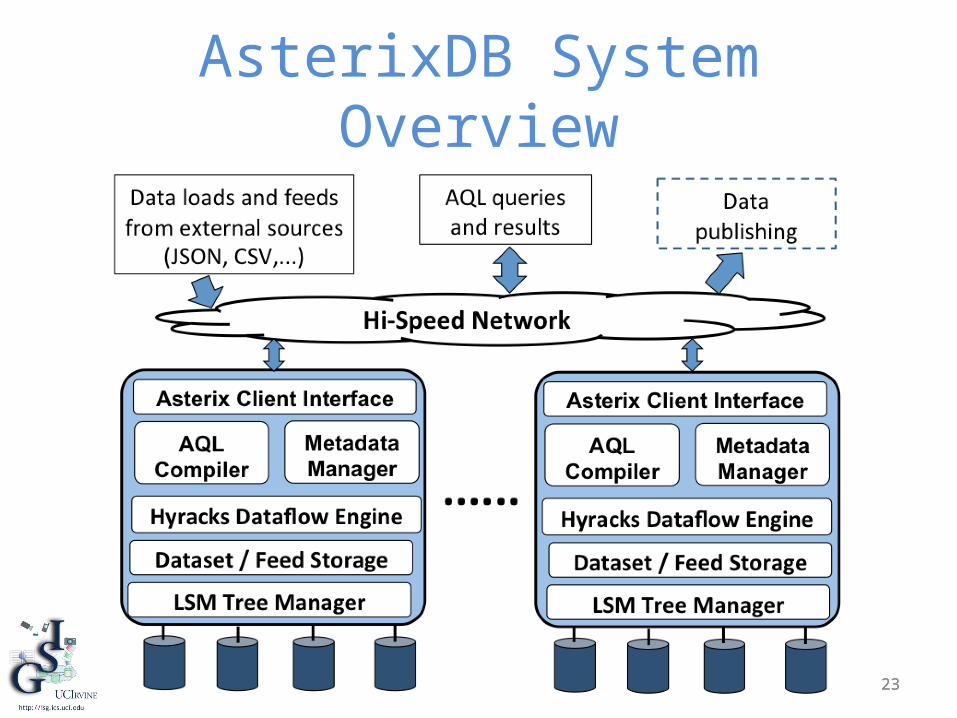
23
AsterixDB System Overview
23
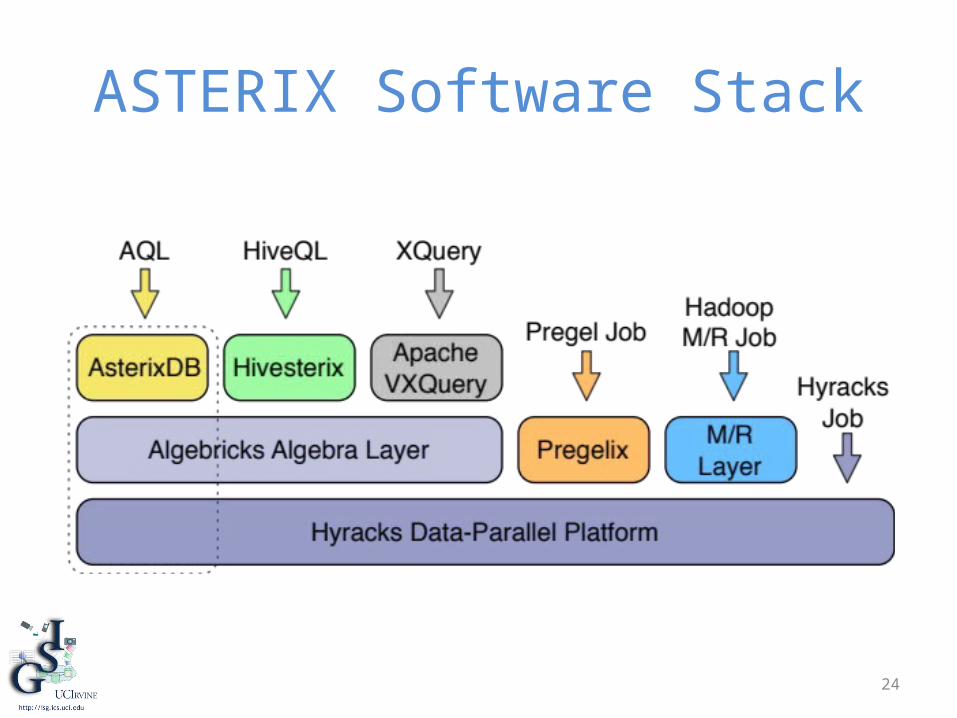
24
ASTERIX Software Stack
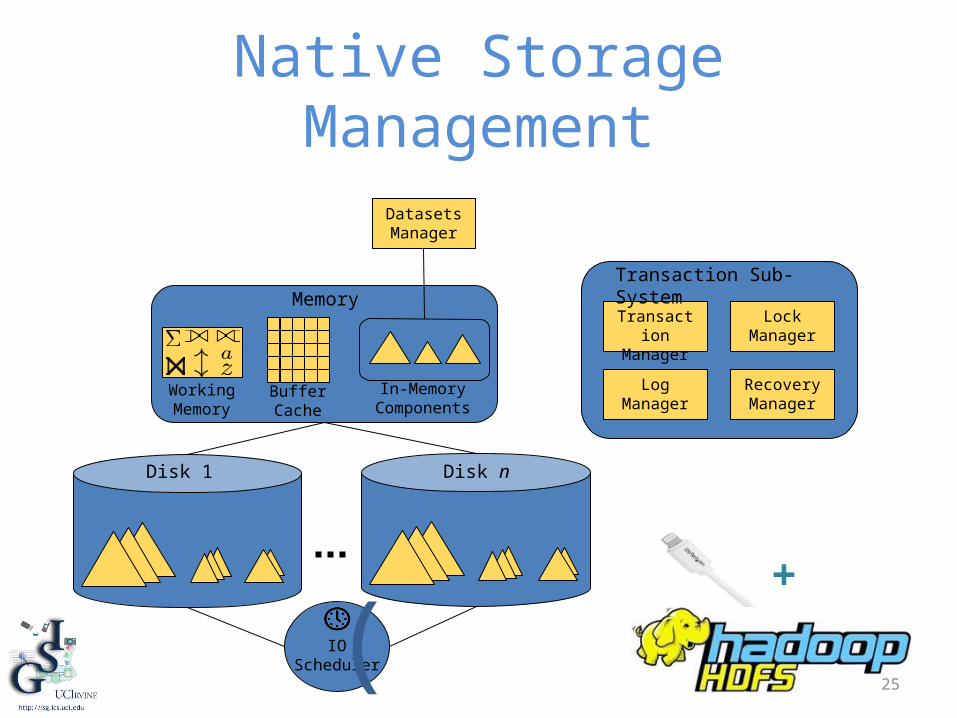
25
Native Storage Management
Transaction Manager
Transaction Sub-System
Recovery Manager
Lock Manager
Log Manager
IOScheduler
Disk 1 Disk n
Memory
Buffer Cache
In-Memory Components
Working Memory
DatasetsManager
( )+
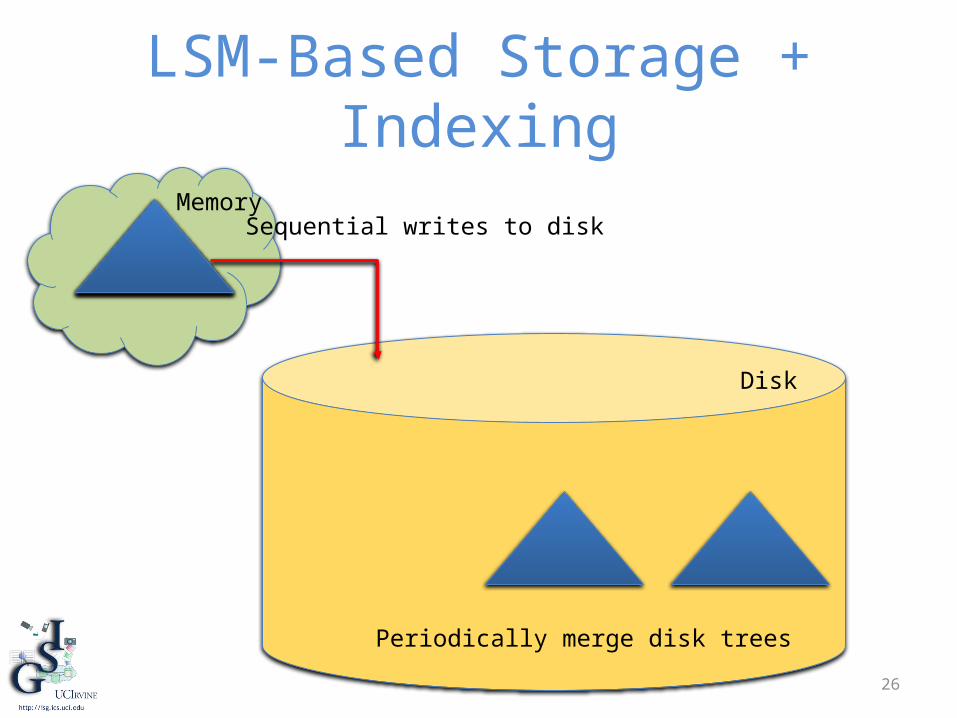
26
LSM-Based Storage + Indexing
Memory
Disk
Sequential writes to disk
Periodically merge disk trees
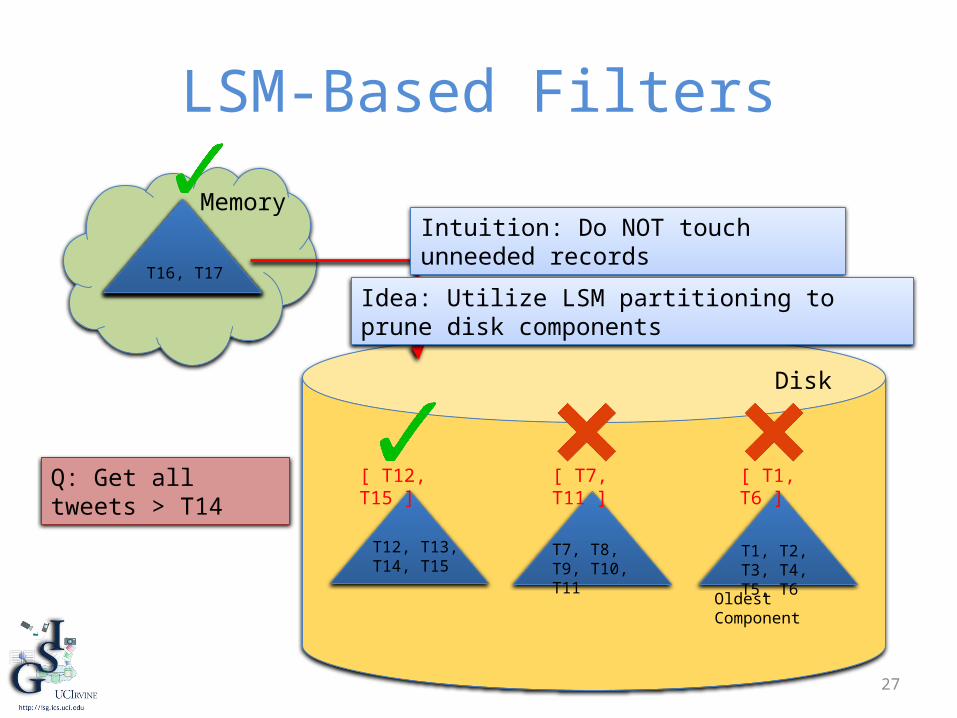
27
LSM-Based Filters
Memory
Disk
T1, T2, T3, T4, T5, T6
T7, T8, T9, T10, T11
T12, T13, T14, T15
T16, T17
Oldest Component
[ T12, T15 ] [ T7, T11 ] [ T1, T6 ]
Intuition: Do NOT touch unneeded records
Idea: Utilize LSM partitioning to prune disk components
Q: Get all tweets > T14

28
• Recent/projected use case areas include– Behavioral science (at UCI)– Social data analytics– Cell phone event analytics– Education (MOOC analytics)– Power usage monitoring– Public health (joint effort with UCLA)– Cluster management log analytics
Some Example Use Cases

29
Behavioral Science (HCI)
• First study to use logging and biosensors to measure stress and ICT use of college students in their real world environment (Gloria Mark, UCI Informatics)– Focus: Multitasking and stress among “Millennials”
• Multiple data channels– Computer logging– Heart rate monitors– Daily surveys– General survey– Exit interview
Learnings for AsterixDB:•Nature of their analyses•Extended binning support•Data format(s) in and out•Bugs and pain points
#AsterixDB 30
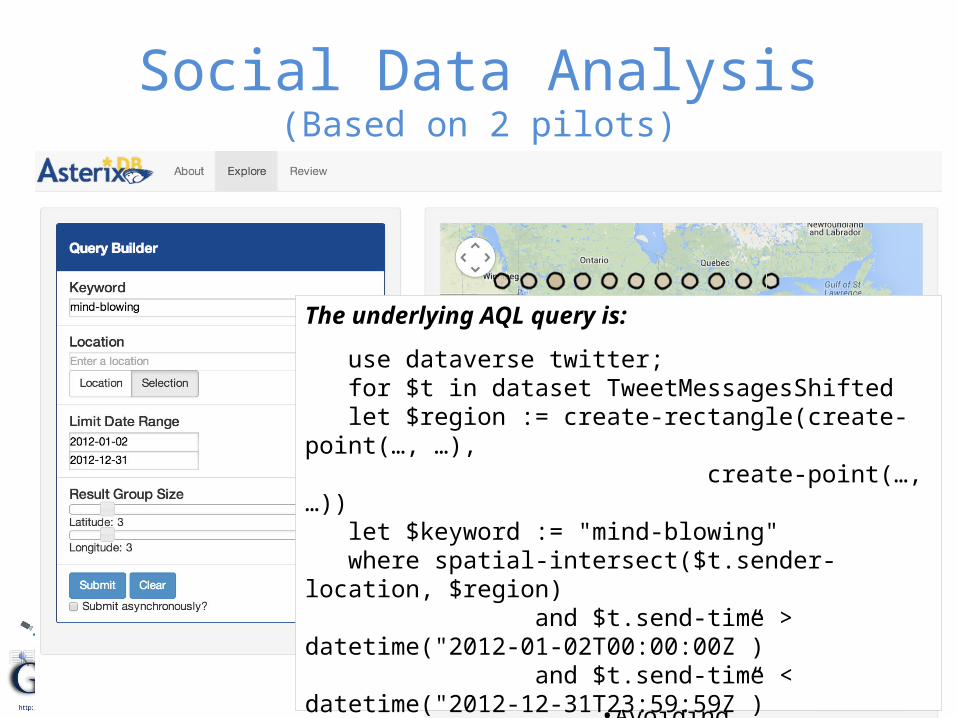
Social Data Analysis(Based on 2 pilots)
Learnings for AsterixDB:•Nature of their analyses•Real vs. synthetic data•Parallelism (grouping)•Avoiding materialization•Bugs and pain points
The underlying AQL query is:
use dataverse twitter; for $t in dataset TweetMessagesShifted let $region := create-rectangle(create-point(…, …), create-point(…, …)) let $keyword := "mind-blowing" where spatial-intersect($t.sender-location, $region) and $t.send-time > datetime("2012-01-02T00:00:00Z”) and $t.send-time < datetime("2012-12-31T23:59:59Z”) and contains($t.message-text, $keyword) group by $c := spatial-cell($t.sender-location, create-point(…), 3.0, 3.0) with $t return { "cell” : $c, "count”: count($t) }

Current Status
• 4 year initial NSF project (250+ KLOC @ UCI/UCR)• AsterixDB BDMS is here! (Shared on June 6th, 2013)
– Semistructured “NoSQL” style data model– Declarative (parallel) queries, inserts, deletes, …– LSM-based storage/indexes (primary & secondary)– Internal and external datasets both supported– Rich set of data types (including text, time, location)– Fuzzy and spatial query processing– NoSQL-like transactions (for inserts/deletes)– Data feeds and external indexes in next release
• Performance competitive (at least!) with a popular parallel RDBMS, MongoDB, and Hive (see papers)
• Now in Apache incubation mode! 31

32
For More Info
AsterixDB project page: http://asterixdb.ics.uci.edu
Open source code base:• ASTERIX: http://code.google.com/p/asterixdb/• Hyracks: http://code.google.com/p/hyracks• (Pregelix: http://hyracks.org/projects/pregelix/)





























