Embed Size (px)
Citation preview

An HPspmd Programming Model
Bryan Carpenter
NPAC at Syracuse UniversitySyracuse, NY [email protected]

Goals of this lecture Motivate a parallel programming
model that combines data parallel features from HPF with an explicitly SPMD programming style.
Review in detail a specific HPspmd language called HPJava.

Contents of Lecture Introduction.
HPspmd language extensions. Integration of high-level libraries.
HPJava. Processes and distributed arrays. Mapping arrays. Array sections. Rules and definitions A distributed array communication library

HPF status Standard is more than 6 years old. Many companies involved in the HPF
forum no longer in business; many of those remaining abandoned their HPF projects.
Problems: Language too complex—robust compilers very
difficult to implement. Perception that language inflexible—limited
demand from application developers. Most parallel applications still developed
in direct SPMD style, using MPI, etc.

High-level SPMD libraries While the HPF language hit problems,
various data-parallel SPMD libraries have been deployed: ScaLAPACK PetSc Kelp Global Array Toolkit PARTI/CHAOS Adlib
Higher-level libraries support programming with distributed arrays in essentially MPI-like environment.

Idea of HPspmd Library approach to distributed arrays
clearly works, but lacks uniformity and elegance of data-parallel languages. No unifying framework.
Can we take a minimal subset of the ideas from HPF—unified syntax for distributed arrays—to make the library-based SPMD approach more attractive?

Features of HPspmd Adopts ideas, run-time technologies and
some compilation techniques from HPF. Abandon:
single, logical, global thread of control, compiler-determined placement of computations, compiler-generated, automatic insertion of
communications. Left with:
explicitly MIMD (SPMD) programming model, syntax for representing distributed arrays, syntax for expressing placement of computation.

Benefits Translators are much easier to implement
than HPF compilers. No compiler magic needed.
Attractive framework for library development, avoiding inconsistent parametrizations of distributed array arguments.
Better prospects for handling irregular problems—easier to fall back on specialized libraries as required.
Ultimate fall-back: can directly call MPI functions from within an HPspmd program.

Language extensions HPspmd languages extended from standard
base languages (Fortran, C++, Java, . . .). A program (fragment) that doesn’t use the
extensions should be executed exactly as a SPMD program—in independent processes with their own threads of control.
Distributed array types added. Strictly separate from sequential arrays of base
language—no attempt to conceal the distinction. Distributed control constructs added.
Most important is a distributed, data-parallel loop.

An HPspmd programProcs p = new Procs2(P, P);on(p) { Range x = new ExtBlockRange(N, p.dim(0), 1); Range y = new ExtBlockRange(N, p.dim(1), 1);
float [[,]] u = new float [[x, y]]; . . . some code to initialize ‘u’
for (int iter = 0; iter < NITER; iter++) { Adlib.writeHalo(u);
overall (i = x for 1 : N-2) overall (j = y for 1 + (i` + iter) % 2 : N-2 : 2) u[i, j] = 0.25 * (u[i-1, j] + u[i+1, j] + u[i, j-1] + u[i,
j+1]); }}
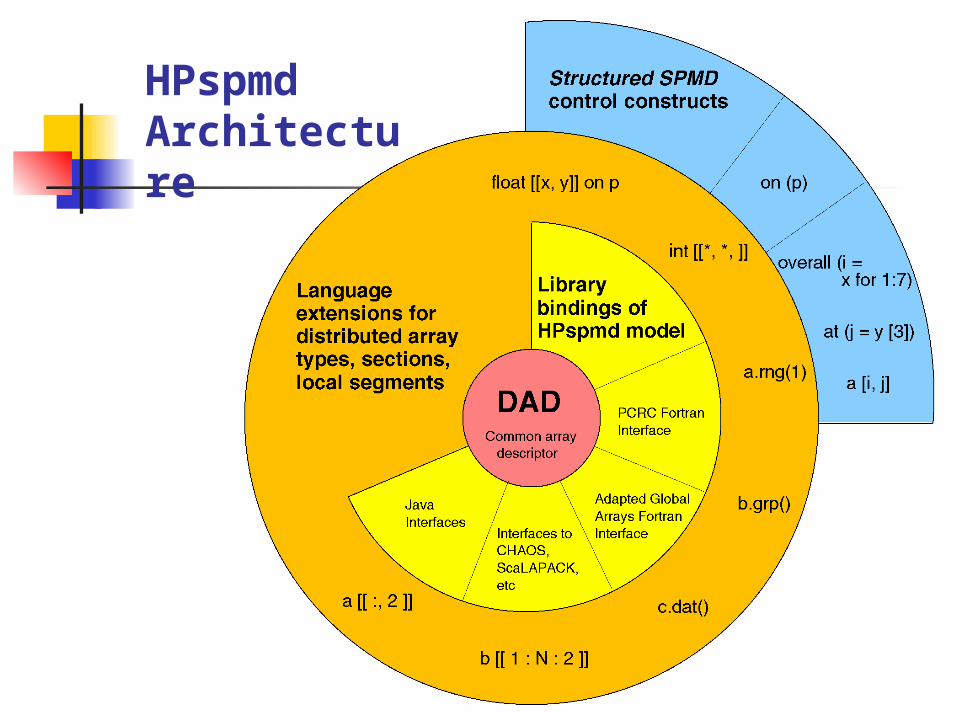
HPspmd Architecture

HPJava Language for parallel programming. Extends Java with syntax for manipulating
distributed arrays. Implements the HPspmd model—
independent processes executing same program, sharing elements of distributed arrays.
Processes operate directly on locally owned elements. Explicit communication needed in program to permit access to elements owned by other processes.

Processes and Process Grids HPJava program started concurrently in
some set of processes. Processes named through grid objects:
Procs p = new Procs2(2, 3); Assumes program currently executing
on 6 or more processes. Restrict execution to processes within
grid by on construct: on(p) { . . . }

Basic use of grids
HPJava program:
Procs p = new Procs2(2, 3);on(p) { Dimension d = p.dim(0), e =
p.dim(1);
System.out.prinln(“My coordinates are(“
+ d.crd() + “, “ + e.crd() + “)”);}
Sample output:
My coordinates are (0, 2)
My coordinates are (1, 2)
My coordinates are (0, 0)
My coordinates are (1, 0)
My coordinates are (1, 1)
My coordinates are (0, 1)

Distributed Arrays in HPJava
Many differences between distributed arrays and ordinary arrays of Java. New kind of container class with special syntax.
Type signatures, constructors use double brackets to emphasize distinction: Procs2 p = new Procs2(2, 3); on(p) { Range x = new BlockRange(N, p.dim(0)); Range y = new BlockRange(N, p.dim(1));
float [[,]] a = new float [[x, y]]; . . . }

2-dimensional array distributed over p

Parallel programming Matrix addition:
Procs2 p = new Procs2(2, 3);on(p) { Range x = new BlockRange(N, p.dim(0)); Range y = new BlockRange(N, p.dim(1));
float [[,]] a = new float [[x, y]], b = new float [[x, y]], c = new float [[x, y]]; . . . initialize values in ‘a’, ‘b’
overall (i = x for :) overall (j = y for :) c[i, j] = a[i, j] + b[i, j]; }

The overall construct Second special control construct (after on)—a
distributed parallel loop. General form parametrized by index triplet:
overall (i = x for l : u : s) { . . . }
l = lower bound, u = upper bound, s = step. All indices must be within range x.
Special forms:
overall (i = x for l : u) { . . . }
stride defaults to 1, and:
overall (i = x for :) { . . . }
lower bound = 0, upper bound = x.size() - 1.

A parallel stencil update program float [[,]] u = new float [[x, y]]; . . . initialize values in ‘u’
float [[,]] n = new float [[x, y]], s = new float [[x, y]],
e = new float [[x, y]], w = new float [[x, y]]; Adlib.shift(n, u, 1, 0); Adlib.shift(s, u, -1, 0); Adlib.shift(e, u, 1, 1); Adlib.shift(w, u, -1, 1);
overall (i = x for 1 : N - 2) overall (j = y for 1 : N - 2) u[i, j] = 0.25 * (n[i, j] + s[i, j] + e[i, j] + w[i, j]);

Shift communication As, advertised, communication goes
through library call. Use a binding of the Adlib function, shift:
void shift(float [[,]] dst, float [[,]] src, int amount, int dimension);
Destination and source arrays must be identically aligned.
Implements “edge-off” shift. Overloaded to apply to different array
ranks, types.

About overall loop indexes Why does language demand use of shift?
Could we just write:
overall (i = x for 1 : N - 2) overall (j = y for 1 : N - 2) u[i, j] = 0.25 * (u[i-1, j] + u[i+1, j] + u[i, j-1] + u[i, j+1]);
? Generally, no. Symbols i, j are not integer
loop indexes. They are distributed indexes.
Value of a distributed index is a location—an abstract element of a distributed range.
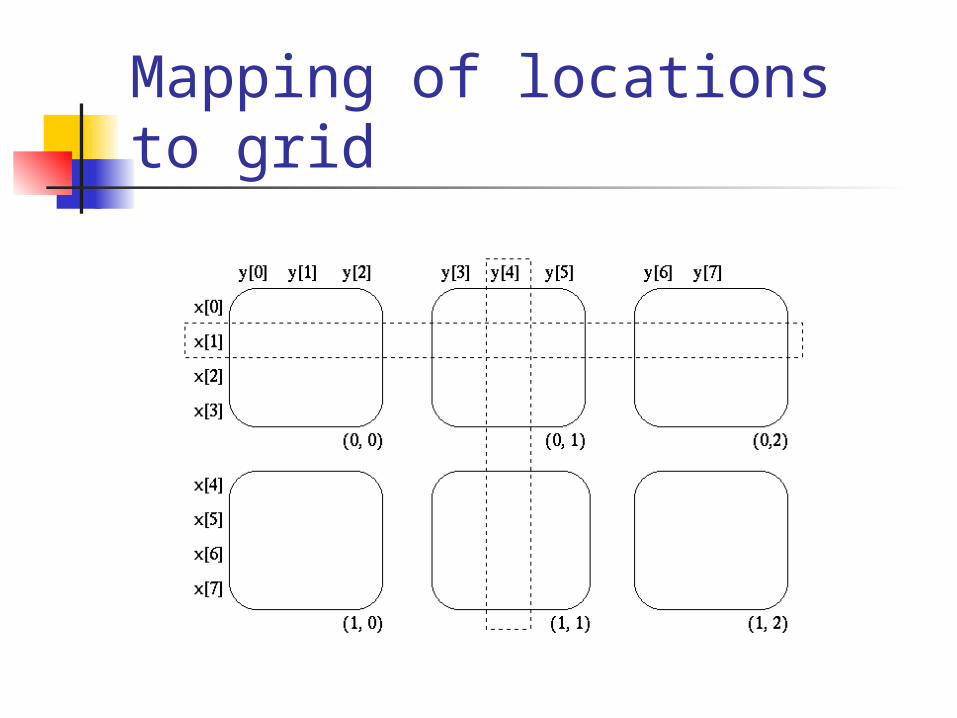
Mapping of locations to grid

Distributed indexes Can only be declared in header of overall
construct (or at construct—see next slide). No other location-valued variables (no Java
type associated with a location). In general a subscript used in a distributed
array element reference must be a distributed index, whose value is a location in the associated range of the array.
Dramatically limits patterns of subscripting.

The at construct If a is a distributed array, generally cannot write:
a [1, 4] = 73 ;
to assign element. 1, 4 not distributed indexes. If x and y are the ranges of a, can write:
at (i = x [1]) at (j = y [4]) a [i, j] = 73 ;
at is the final special control construct of HPJava. Similar to on—restricts execution of body to processes holding specified location.

Relationship between overall and at If s>0, the construct:
overall (i = x for l : u : s) {. . .}
is equivalent to
for (int n = l; n <= u; n += s) at (i = x [n]) {. . .}
If s<0, it is equivalent to
for (int n = l; n >= u; n += s) at (i = x [n]) {. . .}

Global index expression Inside the body of the construct:
at (i = x [n]) { . . . }
the expression i` stands for the integer value, n.
Most useful in overall. According to the equivalence in the previous slide, i` is then the global index value.

A Complete exampleProcs2 p = new Procs2(P, P);on(p) { Range x = new BlockRange(N, p.dim(0)); Range y = new BlockRange(N, p.dim(1));
float [[,]] u = new float [[x, y]], r = new float [[x, y]]; . . . Initialize ‘u’, ‘r’
float [[,]] n = new float [[x, y]], s = new float [[x, y]], e = new float [[x, y]], w = new float [[x, y]];
. . . Main loop
Adlib.printArray(u);}

Initialize ‘u’, ‘r’
overall (i = x for :) overall (j = y for :) if (i` == 0 || i` == N - 1 || j` == 0 || j` == N - 1) { u[i, j] = (float) (i` * i` - j` * j`); r[i, j] = 0.0; } else u[i, j] = 0.0;

Main loopdo { Adlib.shift(n, u, 1, 0); Adlib.shift(s, u, -1, 0); Adlib.shift(e, u, 1, 1); Adlib.shift(w, u, -1, 1);
overall (i = x for 1 : N - 2) overall (j = y for 1 : N - 2) { float newU = 0.25 * (n[i, j] + s[i, j] + e[i, j] + w[i, j]);
r[i, j] = Math.abs(newU – u[i, j]); u[i, j] = newU; }
} while(Adlib.maxval(r) > EPS);

Load balancing—Mandelbrot set example Set of complex numbers, c, such that the
limit of the iteration: z = c 1 2 z = c + (z ) i+1 i
has absolute value less than 2: 2 |z | < 4
Numerical computation of set: points outside the set are eliminated quickly; points inside or close to the set are computed for many iterations.

Mandelbrot set computation
Procs2 p = new Procs2(2, 3);on(p) { Range x = new BlockRange(N, p.dim(0)); Range y = new BlockRange(N, p.dim(1));
boolean [[,]] set = new boolean [[x, y]];
overall (i = x for :) overall (j = y for :) { float cr = (4.0 * i` - 2 * N) / N; float ci = (4.0 * j` - 2 * N) / N;
. . . Inner loop }
Adlib.printArray(set);}

Inner loopset[i, j] = false;int k = 0;while(zr * zr + zi * zi < 4.0) { if (k++ == CUTOFF) { set[i, j] = true; break; }
// z = c + z * z
float newr = cr + zr * zr – zi * zi; float newi = ci + 2 * zr * zi;
zr = newr; zi = newi;}

Changing mapping of problem Block distribution leads to poor
load-balancing. To go over to cyclic decomposition,
just change Range x = new BlockRange(N, p.dim(0)); Range y = new BlockRange(N, p.dim(1));
to Range x = new CyclicRange(N, p.dim(0)); Range y = new CyclicRange(N, p.dim(1));
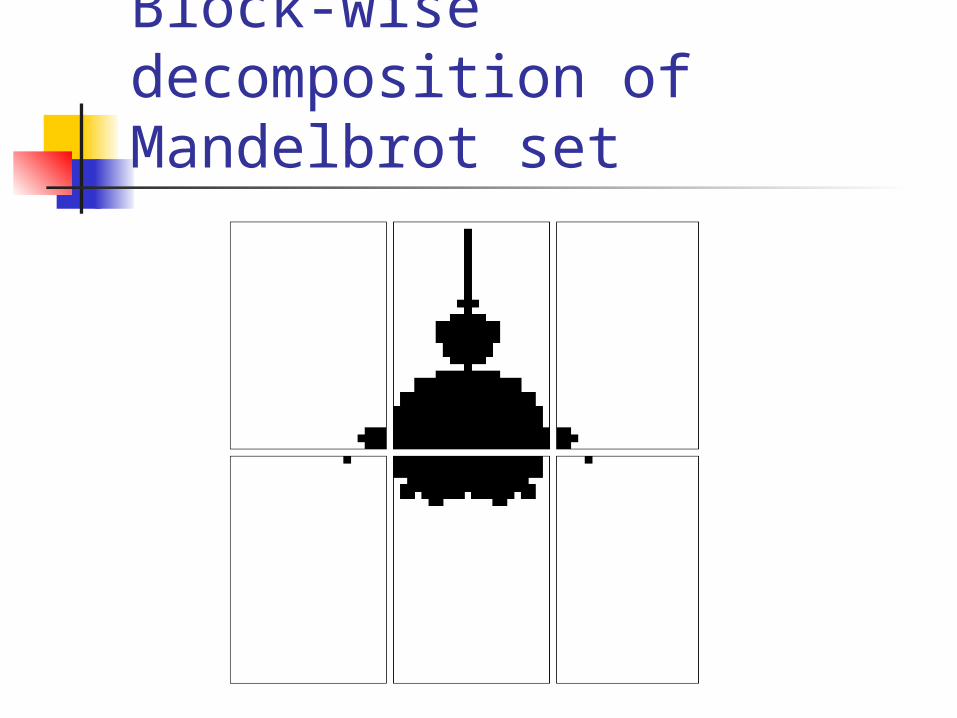
Block-wise decomposition of Mandelbrot set
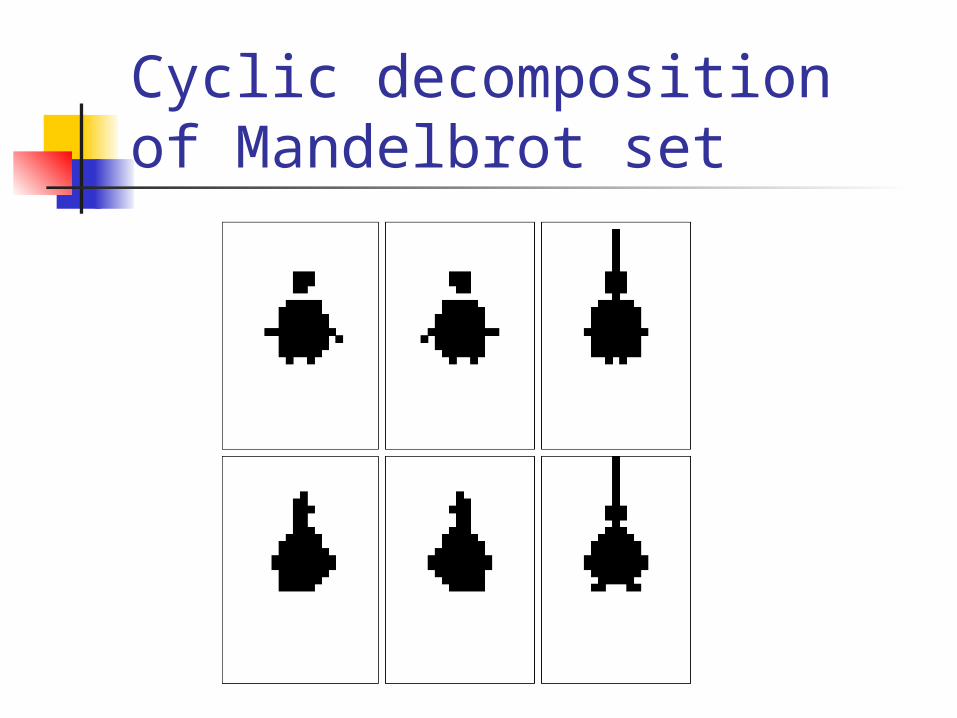
Cyclic decomposition of Mandelbrot set

Using ghost regions As discussed in previous lecture, ghost
regions are extremely useful in parallel stencil updates.
Usually in HPJava, distributed array subscripts must be distributed indexes. Special syntax extension for subscripting arrays with ghost regions:
shifted indexes allowed.

Shifted indexes If i is a distributed index, then:
i ± expression
is a shifted index. Here expression is an integer, usually a small constant.
Assuming array a has suitable ghost regions, can write, say: overall (i = x for 1 : N-2) overall (j = y for 1 : N-2) a[i, j] = 0.25 * (a[i-1, j] + a[i+1, j] + a[i, j-1] + a[i, j+1]);

Creating arrays with ghost regions. No special syntax, but new range
classes. ExtBlockRange is a range class alignment-equivalent to BlockRange, but with ghost extensions.
Size of extensions specified in constructor of range object.

Filling ghost regions Ghost regions not magic. They
must be explicitly filled with values from (usually) neighboring processes.
Adlib has a collective communication operation, writeHalo, that does this.

Laplace equation using ghost regions
Procs2 p = new Procs2(P, P);on(p) { Range x = new ExtBlockRange(N, p.dim(0), 1, 1); Range y = new ExtBlockRange(N, p.dim(1), 1, 1);
float [[,]] a = new float [[x, y]];
… Set boundary values of ‘a’
… Main loop}

Main loop
float [[,]] b = new float [[x, y]], r = new float [[x, y]];do { Adlib.writeHalo(a);
overall (i = x for 1 : N-2) overall (j = y for 1 : N-2) { b[i, j] = 0.25 * (a[i-1, j] + a[i+1, j] + a[i, j-1] + a[i,
j+1]);
r[i, j] = Math.abs(b[i, j] - a[i, j]); }
HPspmd.copy(a, b);
} while(Adlib.maxval(r) > EPS);

Red-black version
float [[,]] r = new float [[x, y]];HPspmd.init(r, 0.0);
int iter = 0;do { Adlib.writeHalo(a);
overall (i = x for 1 : N-2) overall (j = y for 1 + (i` + iter) % 2 : N-2 : 2) {
float newA = 0.25 * (a[i-1, j] + a[i+1, j] + a[i, j-1] + a[i, j+1]);
r[i, j] = Math.abs(newA - a[i, j]);
a[i, j] = newA; }
iter++;} while(Adlib.maxval(r) > EPS);

Conway’s Life using ghost regions
int mode [] = {Adlib.CYCL, Adlib.CYCL};
Procs2 p = new Procs2(P, P);
on(p) { Range x = new ExtBlockRange(N, p.dim(0), 1, 1); Range y = new ExtBlockRange(N, p.dim(1), 1, 1);
int [[,]] state = new int [[x, y]];
… Define initial state of Life board, ‘state’.
… Main loop}

Main loopint [[,]] sums = new int [[x, y]];for (int iter = 0; iter < NITER; iter++) { Adlib.writeHalo(state, mode);
overall (i = x for :) overall (j = y for :) sums[i, j] = state[i-1, j-1] + state[i-1, j] + state[i-1, j+1]
+ state[i, j-1] + state[i, j+1] + state[i+1, j-1] + state[i+1, j] + state[i+1, j+1]; overall (i = x for :) overall (j = y for :) switch (sums [i, j]) { case 2: break; case 3: state[i, j] = 1; break; default: state[i, j] = 0; break; }}

Collapsed Distributions CollapsedRange subclass of Range
stands for range that is not distributed.
In: Range x = CollapsedRange(N); Range y = BlockRange(M, p.dim(0)); float [[,]] a = new float [[x, y]];
first dimension of a is collapsed.

Sequential array dimensions
Subscripts in first dimension of array declared above must still be distributed indexes, although effectively a sequential array w.r.t. that dimension.
Very convenient to use integer subscripts in sequential dimensions.
Introduce “subtypes” of distributed arrays with sequential dimensions. Example becomes:
Range y = BlockRange(M, p.dim(0)); float [[*,]] a = new float [[N, y]];

Syntax for sequential dimensions Asterisk, *, appears in slot of type
signature for sequential dimension. Integer expression (rather than
range) appears in constructor slot. If x is a range, the expression new int [[10, x]]
has type int [[*,]]. Can use integer expressions for
subscripts in element references!

Replicated distributions Collapsed distributions mean array rank
can be larger than process grid rank. Also allowed for array rank to be smaller
than grid rank: Procs2 p = new Procs2(P, P);
on(p) { Range x = new BlockRange(N, p.dim(0)); float [[]] b = new float [[x]]; }
Array b is replicated over p.dim(1).

Aside: replicated variables versus replicated values The HPJava language does not enforce that
all copies of replicated variables hold the same value at corresponding points of program execution.
However, a common programming practice is to maintain same values in all copies (most of the time)—“canonical style”.
Adlib communication library, for example, typically broadcasts results to replicated destination arrays.

Matrix multiplication example
float [[,]] c = new float [[x, y]];float [[,*]] a = new float [[x, N]];float [[*,]] b = new float [[N, y]];
… Initialize ‘a’, ‘b’
overall (i = x for :) overall (j = y for :) { c [i, j] = 0.0; for(int k = 0; k < N; k++) c[i, j] += a[i, k] * b[k, j]; }

Remarks on matrix example
Assumes a very specific set of alignment relations between a, b and c: First dimension of a aligned with first
dimension of c; second dimension collapsed; whole array replicated over process dimension associated with second dimension of c.
A general matrix multiplication procedure may accept any distributions for arguments, then remap them to the required relation.

General matrix multiplication
void matmul(float [[,]] c, float [[,]] a, float [[,]] b) { Group p = c.grp(); Range x = c.rng(0), y = c.rng(1);
int n = a.rng(1).size();
float [[,*]] t1 = new float [[x, n]] on p; Adlib.remap(t1, a);
float [[*,]] t2 = new float [[n, y]] on p; Adlib.remap(t2, b);
on(p) … overall nest, c = t1 * t2. As previous
example.}

Distribution group of arrays matmul procedure illustrates general form
of distributed array constructor, with on clause.
In general this specifies the distribution group of the array.
Distribution group defaults to the active process group—in all previous examples this was set by an enclosing on construct.
(Must call remap outside on(p){} here, because b, c may have elements outside group p.)

Array sections HPJava has a way of representing
regular sub-arrays, similar to Fortran 90.
Syntax similar to element references, but: uses double brackets, and freer rules about subscripts.
In particular, subscripts can be triplets.

A two-dimensional FFT 2d FFT can be implemented simply by
applying 1d FFT in parallel to all rows, then in parallel to all columns.
Pseudocode assumes existence of fictitious complex primitive type. For real code, split complex arrays into two float arrays—real and imaginary parts.
(Java Grande Numerics WG drafted proposals for adding complex to Java.)

2d FFT (pseudocode)void fft1d(complex [[*]] u) {… Sequential
FFT…}
complex [[,*]] a = new complex [[x, N]];complex [[*,]] b = new complex [[N, x]];
… Initial values in ‘a’
overall (i = x for :) fft1d(a [[i, :]]);
Adlib.remap(b, a);
overall(i = x for :) fft1d(b [[:, i]]);
… Result in ‘b’

Aside: an array section expression is not a variable...
An array element reference is a variable: a[i, j] = 23.0;
An array section expression is not a variable: a[[:, 1]] = b; // Semantic error!
Assuming b is a one-dimensional array, may copy elements by: HPspmd.copy(a[[:, 1]], b);
Usual rule for object-valued expressions.

Cholesky decomposition example Similar to LU decomposition of
earlier lecture, but applies to symmetric matrix.
Choose to distribute by columns, instead of 2d decomposition.
k-th column is broadcast by passing sections to remap.

Cholesky decomposition code
float [[*,]] a = new float [[N, x]];… Some code to initialize ‘a’
float [[*]] col = new float [[N]]; // Collapsed, replicated
for (int k = 0; k < N-1; k++) { … Normalize k-th column of ‘a’
Adlib.remap(col [[k+1 : N-1]], a [[k+1 : N-1, k]]);
overall (j = x for k+1 : N-1) for (int i = j`; i < N; i++) a[i, j] -= col[i] * col[j`];}… Normalize element a[N-1, N-1]

Column normalization details
. . . // Normalize k-th column of ‘a’: at (j = x[k]) { float diag = Math.sqrt(a [k, j]); a[k, j] = diag; for (int i = k+1; i < N; i++) a[i, j] /= diag; }. . .// Normalize element a[N-1, N-1]:at (j = x[N-1]) a[N-1, j] = Math.sqrt(a[N-1, j]);

Aside: correct use of subscripts In the assignment:
a[i, j] -= col[i] * col[j`];
may not write col[j]. j is a location in the range x. The
array col has a different, collapsed range.
This is not a “type” error, but it would be trapped as a runtime exception. Like ordinary array-bound checking.

Subranges Dimension of an array section
produced by a triplet subscript is generally a subrange of the range of the parent.
Syntax for direct creation of subrange objects: Range u = x [0 : N/2 - 1]; Range v = y [0 : N-1 : 2];

Restricted groups Discussed in the context of distributed
array descriptors in an earlier lecture. In HPJava a natural characterization of
a restricted group is as a subgroup to which a particular location is mapped.
Syntax for direct creation of a restricted group: p / x [1] p / x [1] / y [4]

Rules of HPJava Various rules are imposed to
ensure that all accesses to array elements really are local.
These are automatically enforced by compiler or run-time checks.
First formally define active process group.

The active process group Executing the construct:
on(p) {. . .}
changes the APG to p in its body.
If current APG is p, executing the constructs: at (i = x[n]) {. . .}
or: overall (i = x for l : u : s) {. . .}
changes the APG to p/ i in the body.

Rules for distributed control constructs
The construct: on(p) {. . .}
can only appear if p is contained in the current APG.
The constructs: at (i = x[n]) {. . .}
or: overall (i = x for l : u : s) {. . .}
can only appear if x is distributed over a dimension of the APG.

Rules for distributed array constructors The expression
new T [[e , . . ., e , . . .]] on p 0 r
can only appear if p is contained in the APG.
All e’s that are non-collapsed range objects are distributed over distinct dimensions of p.
If “on p” is omitted, the distribution group defaults to the APG.

Rules for element reference subscripts If a is a distributed array, in
a[e , . . ., e , . . .] 0 r
an e can be an integer expression only if the dimension has the sequential attribute. Otherwise it must be a distributed index whose value is a location in the relevant array range.

General rule for element access If a is a distributed array and the location-
valued subscripts in the element reference: a[e , . . ., e , . . .] 0 r
are i, j, …, the home group of the element is: p / i / j / . . .
An element may only be accessed when the active process group is contained in the home group of the element.





























