Embed Size (px)
Citation preview

Image and Vision Computing 31 (2013) 748–755
Contents lists available at ScienceDirect
Image and Vision Computing
j ourna l homepage: www.e lsev ie r .com/ locate / imav is
An efficient approach for scene categorization based on discriminativecodebook learning in bag-of-words framework☆
Zhen Li ⁎, Kim-Hui YapSchool of Electrical and Electronic Engineering, Nanyang Technological University, Singapore
☆ This paper has been recommended for acceptance by⁎ Corresponding author. Tel.: +65 91819691.
E-mail addresses: [email protected] (Z. Li), EKHYap
0262-8856/$ – see front matter © 2013 Elsevier B.V. All rihttp://dx.doi.org/10.1016/j.imavis.2013.07.001
a b s t r a c t
a r t i c l e i n f oArticle history:Received 16 May 2011Received in revised form 8 February 2013Accepted 18 July 2013
Keywords:Scene categorizationCodebook learningBag-of-words
This paper proposes an efficient technique for learning a discriminative codebook for scene categorization. Astate-of-the-art approach for scene categorization is the Bag-of-Words (BoW) framework, where codebookgeneration plays an important role in determining the performance of the system. Traditionally, the codebookgeneration methods adopted in the BoW techniques are designed to minimize the quantization error, ratherthan optimize the classification accuracy. In view of this, this paper tries to address the issue by careful designof the codewords such that the resulting image histograms for each category will retain strong discriminatingpower, while the online categorization of the testing image is as efficient as in the baseline BoW. The codewordsare refined iteratively to improve their discriminative power offline. The proposed method is validated on UIUCScene-15 dataset and NTU Scene-25 dataset and it is shown to outperform other state-of-the-art codebookgeneration methods in scene categorization.
© 2013 Elsevier B.V. All rights reserved.
1. Introduction
Scene categorization is an important problem in pattern recognitionand computer vision. It has many applications such as keyword sugges-tion (offering some semantic labels that are associated with the imagecontent), retrieval (filtering images in Internet based on the keywords),and browsing (grouping of images based on keywords instead of featureclustering of content). In recent years, many automatic techniques forassigning semantic labels to images have been designed to improve theperformance of these applications. Early work on scene categorizationused low-level global features extracted from the whole image. Howev-er, these representations lacked local information and were only used toclassify images into a small number of categories such as indoor/outdoorandman-made/natural.More recent approaches exploit local statistics inimages. These representations oftenmodel scenes as a collection of localdescriptors using interest point detectors, dense sampling patches, orsegmentation. For example, bag-of-words models for image categoriza-tion Csurka et al. [1], Sivic and Zisserman [2], and Zhang et al. [3] usethe following steps: (i) quantizing high-dimensional descriptors oflocal image patches into discrete codewords, (ii) forming BoW histo-grams based on the codeword distribution, and (iii) training classifiersbased on these histograms. The BoW framework is widely used inmultimedia categorizations due to its effectiveness and high efficiency.
Clustering methods are often used to train codebooks, and amongstthese, K-means is a popularmethod used for codebook learning in scene
Bastian Leibe.
@ntu.edu.sg (K.-H. Yap).
ghts reserved.
categorization. In the conventional K-mean clustering, the objective inthe codebook design is to minimize the expected distortion that issuitable for compressing high-dimensional data. However, the code-book designed in this manner does not ensure that the codewords areeffective for categorization. In order to train more effective classifiersusing the histograms obtained from the codebook, the codewordsshould be designed to be discriminative amongst different categories.
There are several existing supervised learning approaches for code-book generation. Kohonen [4] proposed Learning Vector Quantizationfor supervised quantizer design using Voronoi partitions based onself-organizing maps. A semantic vocabulary is presented by Vogeland Schiele [5]. The authors construct a vocabulary by labeling imagepatches with a semantic label, e.g. sky, water or vegetation. Jurie andTriggs [6] combined on-line clustering andmean-shift algorithm to gen-erate the codebook for image classification. Zhang et al. [7] proposed acodebook generation method called Codebook + which minimizesthe ratio of within-class variation to the between-class variation.
Winn et al. [8] proposed that each visual word is described by a mix-ture of Gaussians in feature space, and the compact and light-weight vo-cabulary is constructed by greedily merging an initially large vocabulary.Specifically, by assuming a Gaussian distribution of image histograms,the probability that a histogram belongs to a certain object class can beestimated. Then the goal of the learning algorithm is to find themappingϕ between histograms which maximizes the conditional probability ofthe ground truth labels based on the training data. The mapping ϕgiven by the algorithm is actually defined by the merging operations ofvisual words in the original vocabulary. By observing the conditionalprobability of the ground truth labels with every possible grouping ofcluster bins, the optimal mapping is chosen, producing a better discrim-ination of the vocabulary.

749Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
Perronnin [9] proposed that an image can be characterized by a setof histograms for each class, where each histogram describes whetherthe image content is best modeled by the universal vocabulary or thecorresponding class vocabulary. Gaussian Mixture Models (GMMs) areconstructed from the data samples. Then the universal vocabulary istrained using maximum likelihood estimation (MLE) and the classvocabularies are adapted based on the universal vocabulary using themaximum a posteriori (MAP) criterion. When applying the MAPadaption, relevance factors for Gaussian weight, mean and varianceparameters are added to the standard expectation maximizationprocedure. The relevance factors are enforced to be equal and thendetermined by experiments to maximize the classification accuracy.
All the abovementioned schemes can be regarded as clustering imagepatch descriptors according to some certain objective functions. In thesemethods, the codebook is trained to be discriminative, however, the den-sities of the descriptors over the codewords are estimated by a histogramwhich is essentially a nearest-neighbor quantization. Recently, Jan C. vanGemert et al. [10] presented a codebook generationmethod based on thetheory of kernel density estimation. Three criteria are used: kernel code-book, codeword plausibility, and codeword uncertainty. In their scheme,‘codeword uncertainty’ (UNC) based on kernel density estimation showsconsistently superior performance over the histogram-basedmethods inBoW. However, with UNC, the codewords are not trained to be discrimi-native and the generation of image histogramswill involve typically hun-dreds of thousands of computations of Gaussian function. So thecomputationally efficient methods need to be investigated.
In this paper,wewill present a newefficientmethod for iteratively re-fining the discriminative codewords based on the theory of kernel densi-ty estimation. The proposed iterative clusteringmethodwill be validatedto be competitive to state-of-the-art algorithms. In addition, the proposedmethod imposes no extra computational cost of online feature extractionwhen compared to the baseline BoW. Themain contribution of this paperis to develop a newmethod for codebook generation in scene categoriza-tion that determines the discriminative power of a codeword based onkernel density estimation without increasing the computation of onlinecategorization of testing images. The codewords are tuned iterativelyaccording to the soft relevance of image patch descriptors of different cat-egories. Experimental results demonstrate its superiority in classificationaccuracy and efficiency when compared to the histogram-based methodand the codeword uncertainty.
The rest of this paper is organized as follows. Section 2 outlines theoverview of our proposed method. Section 3 illustrates the proposed
Fig. 1. Framework of the proposed discrim
codebook generation method together with the associated iterativeoptimization algorithm. Section 4 validates our method of generatingeffective codewords for bag-of-words image categorization with com-parison to other state-of-the-art work. Finally, Section 5 concludes thepaper.
2. Overview of the proposed scheme
The main idea of our paper is to find discriminative codewords, thatis, to find codewords that are representative for a specific category andyet sufficiently discriminative from other categories. In order to achievethis goal, first we estimate the density distribution of image patch de-scriptors using the theory of kernel density estimation (KDE) insteadof the conventional BoW histogram. Using these density distributions,we can evaluate the discriminative power of each codeword accordingto its kernel densities over all categories. Then by calculating the soft rel-evance factors of all training image patch descriptors, codewords can beiteratively adjusted by weighted kernel K-means to enhance their dis-criminative powers.
The flow chart of the proposed scheme is illustrated in Fig. 1, wherethe Voronoi boundaries are shown amongst different clusters in the left,and the corresponding normalized histograms are shown in the right.Based on the codewords directly generated by clustering SIFT descrip-tors without the proposed iterative scheme, histograms of imagesfrom different categories may be similar and difficult to differentiate,as shown in the top right of the diagram in Fig. 1. After improving thediscriminative powers of codewords with the proposed scheme, thefinal refined histograms are easier to differentiate, as in the bottomleft of the diagram in Fig. 1. This will enhance training of the classifiersbased on the refined histograms.
3. The proposed codebook generation method
After clustering the SIFT descriptors of training image patches, weobtain the codewords which are the cluster centers. For each codeword cin the codebookCB, traditional codebookmodel estimates the distributionof codewords in an image by a histogram as follows:
H cð Þ ¼ 1N
XNi¼1
I c ¼ argminw
D w; við Þð Þ� �
w∈CB; ð1Þ
inative codebook generation method.
750 Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
where N is the number of patches in an image, vi is the descriptor of animage patch, D(⋅,⋅) is the Euclidean distance, and I(⋅) is the identityfunction.
A robust alternative to histograms for estimating a probabilitydensity function is kernel density estimation (KDE) by Scott [11].KDE uses a kernel function to smooth the local neighborhood ofdata samples. KDE is advantageous over histograms. First, it canmodel feature distributions for a broad and diverse set of scenesdue to its nonparametric property. Second, in contrast to the hard-assignment estimator using histograms, it is relatively insensitiveto small descriptor variations due to its smoothing parameter. Ahigh-dimensional estimator with kernel K and bandwidth parame-ter B is given by
f cð Þ ¼ 1N
XNi¼1
KB vi‐cð Þ: ð2Þ
In this paper we use the SIFT descriptor that draws on the Euclideandistance as its distance function. Since the Euclidean distance that we
−4 −3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
4
5
−4 −3 −2 −1 0 1 2 3 4 5−3
−2
−1
0
1
2
3
4
5
(a)
(c)
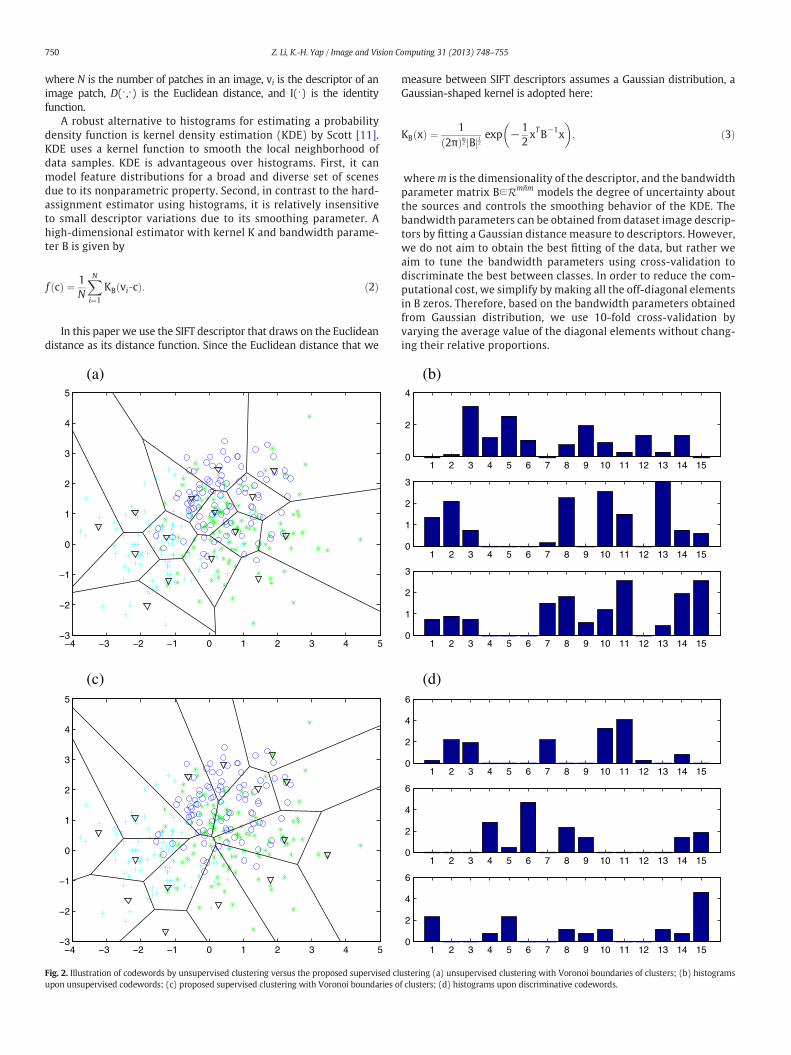
Fig. 2. Illustration of codewords by unsupervised clustering versus the proposed supervised clupon unsupervised codewords; (c) proposed supervised clustering with Voronoi boundaries o
measure between SIFT descriptors assumes a Gaussian distribution, aGaussian-shaped kernel is adopted here:
KB xð Þ ¼ 12πð Þm
2 Bj j12 exp −12xTB−1x
� �; ð3Þ
wherem is the dimensionality of the descriptor, and the bandwidthparameter matrix B∈Rmñm models the degree of uncertainty aboutthe sources and controls the smoothing behavior of the KDE. Thebandwidth parameters can be obtained from dataset image descrip-tors by fitting a Gaussian distance measure to descriptors. However,we do not aim to obtain the best fitting of the data, but rather weaim to tune the bandwidth parameters using cross-validation todiscriminate the best between classes. In order to reduce the com-putational cost, we simplify by making all the off-diagonal elementsin B zeros. Therefore, based on the bandwidth parameters obtainedfrom Gaussian distribution, we use 10-fold cross-validation byvarying the average value of the diagonal elements without chang-ing their relative proportions.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
2
4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
1
2
3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
1
2
3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
2
4
6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
2
4
6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
2
4
6
(b)
(d)
ustering (a) unsupervised clustering with Voronoi boundaries of clusters; (b) histogramsf clusters; (d) histograms upon discriminative codewords.

751Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
After KDE, the density of each training image patch descriptor overeach codeword is available. By observing these densities, the weightassociated with each codeword can be evaluated. First we sum up allthe kernel densities of the descriptors that belong to each category jover a codeword c, and normalize it:
F j cð Þ ¼
Xvi∈C j
KB vi−cð ÞXw∈CB
Xvi∈C j
KB vi−wð Þ; ð4Þ
where Cj is the j-th category, vi is the descriptor of a patch in an imagethat belongs to the j-th category. All the kernel density summationsfor the codeword c can form a vector F(c) = [F1(c), F2(c), …, FM(c)],where M is the number of categories.
Then we observe F(c) and evaluate the discriminative power ofeach codeword. Intuitively, if a codeword has a high kernel densitysummation over one category and relatively low kernel density sum-mations over the other categories, then this codeword is representa-tive for this category. If a codeword has relatively uniform kerneldensity summations over all categories, then this codeword willhave little discriminative power. Based on this observation, we canevaluate the discriminative power of a codeword as the sparsity ofF(c) as follow:
p cð Þ ¼ log 2− μ2
μ2 þ σ2
!= log2; ð5Þ
where μ and σ are the mean value and standard deviation of F(c) re-spectively, and p(c) is the discriminative weight for the codeword c.If the vector F(c) has uniform elements, then σ = 0, so p(c) = 0. Onthe other hand, if F(c) has few high values and many small values, μwill be small and σwill be large, so p(c) tends to be 1. The calculation ofthe discriminative power of codewords utilizes the class label informa-tion, and therefore the proposed clustering method is supervised.
The codeword with high discriminative power tends to be close tothe descriptors in a target category and far away from descriptors inother categories in the feature space. It is expected that the descriptorhistogram over the codewords will be easily classified when all thecodewords have high discriminative power. As such we need a cluster-ingmethod to iteratively adjust the codewords to make themmore dis-criminative amongst different categories.
Fig. 2 illustrates the codewords by the conventional unsupervisedclustering versus the proposed supervised weighted clustering algo-rithm. In Fig. 2, the small dots represent image patch descriptors, de-scriptors from different categories are distinguished by differentcolors, and the red triangle marks indicate the codewords found byclustering of image descriptors. By the conventional unsupervisedclustering in which the class label information is not considered,the codewords tend to locate in the center of all descriptors asshown in Fig. 2(a). We can notice that the generated codewordsfocus on representing the overall distribution, rather than the dis-criminative information of respective classes. The resulting histo-grams by unsupervised learning are not so discriminative as shownin Fig. 2(b). By utilizing the class label information, we can evaluate thediscriminative power of the codewords by (5), and iteratively adjustthe codewords so that each codeword represents the descriptors froma target category as shown in Fig. 2(c). Therefore it is expected that theresulted histograms of image patch descriptors from different categoriesare more discriminative than those by the unsupervised clustering, asshown in Fig. 2(d).
As for the clustering method, by using the conventional K-meanclustering, the image patch descriptors are represented in the originalfeature space, and descriptors from different categories are hard to beseparated linearly. Hence the discriminative power of the codewordswill not be high where the descriptors from different categories
overlap. In view of this, we adopt kernel k-means which uses a kernelfunction to map descriptors to a higher-dimensional feature spacefor better descriptor separation. Therefore we can expect that thecodewordswill be adjusted to bemore discriminative amongst descrip-tors from different categories. In addition, image patch descriptors arenot of the same importance in generating discriminative codewords,therefore it is natural to use weighted kernel k-means. In order toapply weighted kernel k-means in this work, the bandwidth parametercan be estimated from cross-validation, and the soft relevance factor ofeach training image patch is also required to indicate how representa-tive it is for the category that it belongs to. We can calculate the softrelevance factor of the j-th descriptor as follows:
s v j
� �¼XMi¼1
p cið ÞKB v j−ci� �
; ð6Þ
where M is the size of the codebook, ci is the i-th codeword fori = 1, 2, ⋯, M, vj is the j-th descriptor amongst all image patches andp(ci) is the discriminative weight of the i-th codeword. When the softrelevance factor of a descriptor is high, it is discriminative and represen-tative for its corresponding category and thus suitable to generate thecodeword.
Then the objective function for weighted kernel k-means can beexpressed as:
O ¼XMi¼1
Xvk∈Ei
s vkð Þ ϕ vkð Þ−cik k; ð7Þ
where ϕ(vk) is the mapped version of vk in the high-dimensionalspace, Gaussian kernel is used, the i-th cluster is denoted by Ei,and the best representative for cluster Ei is codeword ci calculatedas follow:
ci ¼
Xv j∈Ei
s v j
� �ϕ v j
� �Xv j∈Ei
s v j
� � : ð8Þ
Using this weighted version of the cluster center, the descriptorswith high soft relevance factors that are discriminative and representa-tive for their corresponding categories will contribute more to thecodeword generation. For calculating 7, the term ‖φ(vk) − ci‖2 can beexpanded as
φ vkð Þ−cik k2 ¼ φ vkð ÞTφ vkð Þ−2Xv j∈Ei
s v j
� �ϕ vkð ÞTϕ v j
� �X
v j∈Eis v j
� �
þ2X
v j ;vk∈Ei
s vkð Þs v j
� �ϕ vkð ÞTϕ v j
� �X
v j∈Eis v j
� �� �2
: ð9Þ
Using the kernel matrix K, the above may be rewritten as:
φ vkð Þ−cik k2 ¼ Kkk−
2Xv j∈Ei
s v j
� �Kkj
Xv j∈Ei
s v j
� � þ2X
v j ;vk∈Ei
s vkð Þs v j
� �Kkj
Xv j∈Ei
s v j
� �� �2 : ð10Þ
So the objective function can be easily obtained by the kernel matrixand the soft relevance factors of training image patch descriptors. Aftereach iteration of weighted kernel k-means, the original codewords areupdated, and the weights for the updated codewords are computed inthe same way as computing the weights of the original codewords.

752 Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
Also the weights for each descriptor are updated. This iterative proce-dure terminates when the updated codewords converge, and finallywe obtain the histograms that have better discriminative power. Thedeveloped weighted K-means algorithm to generate discriminativecodewords is summarized in Algorithm 1.
Compared to the UNC in Jan C. van Gemert et al. [10] which focuseson soft assignment in histogram calculation based on conventional K-means clustering, the proposed weighted clustering method focuseson generating discriminative codewords by incorporating the classlabels of descriptors. Although the offline training of the discriminativecodebook requires more computation, once it is trained, we can use theSIFT descriptor histogram based on the trained codebook as the imagehistogram for online categorization. This ensures that the online catego-rization of a testing image is computationally efficient. In contrast, withUNC, the online generation of an image histogram is based on post-processing of the codebook in BoW, and typically involves hundreds ofthousands of computations of Gaussian function.
Algorithm 1. Weighted Kernel K-means Clustering
Input: a set of N SIFT descriptors V = {v1, ⋯,vN};Output: The codebook CBwith M discriminative codewords.
1) Initialize a codebook by using the standard k-means clusteringwith-out soft relevance factors;
2) Apply the modified weighted K-means by incorporating the soft rel-evance of SIFT descriptors as the weighting factor:
• Assign each SIFT descriptor to its nearest visual word, obtainingsamples Ei that are closest to each codeword ci, i = 1, ⋯, M;
• Compute the discriminative power of current codewords by (4)and (5), utilizing the class label information;
• Compute the soft relevance factors of each SIFT descriptor by (6);
Fig. 3. Sample images from th
• Update the codeword ci, i = 1, ⋯, M using the sample weightsby (8);
• The weighted cost function is calculated by (7) and (10);• Repeat theweighted clustering procedure until there is no decreaseof theweighted cost function or the number ofmaximum iterationsis reached.
4. Experimental Evaluations
4.1. Datasets
This section presents experimental evaluations on two datasets:UIUC Scene-15 dataset [12] and NTU Scene-25 dataset. The Scene-15dataset is commonly used by many other works as the benchmark forcomparison. It consists of 4485 images taken from 15 different scenecategories and is quite challenging— for example, it is difficult to distin-guish indoor categories such as bedroom and living room. The sampleimages of the UIUC Scene-15 dataset are shown in Fig. 3.
In order to further validate the effectiveness of the proposed meth-od, we have created a natural scene image database consisting of 3916images in 25 categories of common activities/scenes/landmarks whichcover the campus in Nanyang Technological University (NTU). Sampleimages of the NTU Scene-25 dataset are shown in Fig. 4.
4.2. Parameter setting
For training and testing set partition, we randomly select 100images per category as a training set and the remaining images asthe testing set for UIUC Scene-15 dataset, and also randomly select30 images per category as a testing set and the remaining imagesas the training set for NTU Scene-25 dataset. To obtain reliable
e UIUC Scene-15 dataset.
Fig. 4. Sample images from the NTU Scene-25 dataset.
753Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
results, we repeat the experiments 10 times. We select 10 randomsubsets from the data to create 10 pairs of training and testingdata. For each of these pairs we create a codeword vocabulary onthe training set. For classification, we use an SVM with a histogram in-tersection kernel. We use 10-fold cross-validation on the training setto tune the bandwidth parameter of the codebook kernel to achievethe maximum classification accuracy. This bandwidth is also usedlater for weighted kernel k-means. The classification rate we report isthe average of the per-category recognition rates which are also aver-aged over the 10 randomly partitioned testing sets. For image featureswe follow Lazebnik et al. [13], and use a SIFT descriptor sampled on aregular grid. We compute all SIFT descriptors on overlapping 16 × 16pixel patches, computed over a dense grid sampled in space of 8 pixels.To create a bag-of-words representation, we first form a codebook byrunning k-means on 15,000 patches randomly sampled from each
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.865
66
67
68
69
70
71
72
73
74
75
average diagonal value of bandwidth B
valid
atio
n ac
cura
cy
(a)
Fig. 5.Validation accuracy versus different parameters (a) average diagonal value of bandwidthScene-25 dataset.
class in the training set, so there are in total 225,000 and 375,000patch descriptors for clustering for UIUC Scene-15 dataset and NTUScene-25 dataset, respectively.
To determine the diagonal value of the bandwidth matrix B in (3),we use 10-fold cross validation on a subset of training dataset as the val-idation set. With a codebook size of 400, the classification rates withvarious diagonal values of the bandwidth matrix are shown inFig. 5(a). We can notice that when the bandwidth value is about 0.28,the classification rate reaches its peak. So we set 0.28 as the optimalvalue for the average diagonal value of B. In order to validate the gener-alization of the proposed algorithm, we use this value for both UIUCScene-15 dataset and NTU Scene-25 dataset. With the optimal band-width matrix confirmed, we report the classification rate in terms ofthe number of iterations of the proposed iterative clustering methodin Fig. 5(b). We can notice that, when the number of iterations is
0 2 4 6 8 1070
70.5
71
71.5
72
72.5
73
73.5
74
iterations
valid
atio
n ac
cura
cy
(b)
matrix on UIUC Scene-15 dataset (b) number of iterations of the proposedmethod onNTU
0 100 200 300 400 500 600 700 80050
55
60
65
70
75
80
number of clusters
clas
sific
atio
n ac
cura
cy
BoW baselineGemert’s methodProposed method with 3 iterationsPerronnin’s methodWinn’s methodProposed method with 5 iterations
Fig. 6. Performance comparison on UIUC Scene-15 dataset.
Table 1Comparison of time (minutes) for offline clustering of image patch descriptors.
BoW baseline Gemert's Winn's Perronnin's Proposed
UIUC 45 45 70 67 90NTU 75 75 120 110 150
754 Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
more than 5, the improvement of the classification rate is not obvious.Therefore we use 5 iterations as the tradeoff between the classificationrate and the offline computational cost for both datasets.
4.3. Performance evaluation
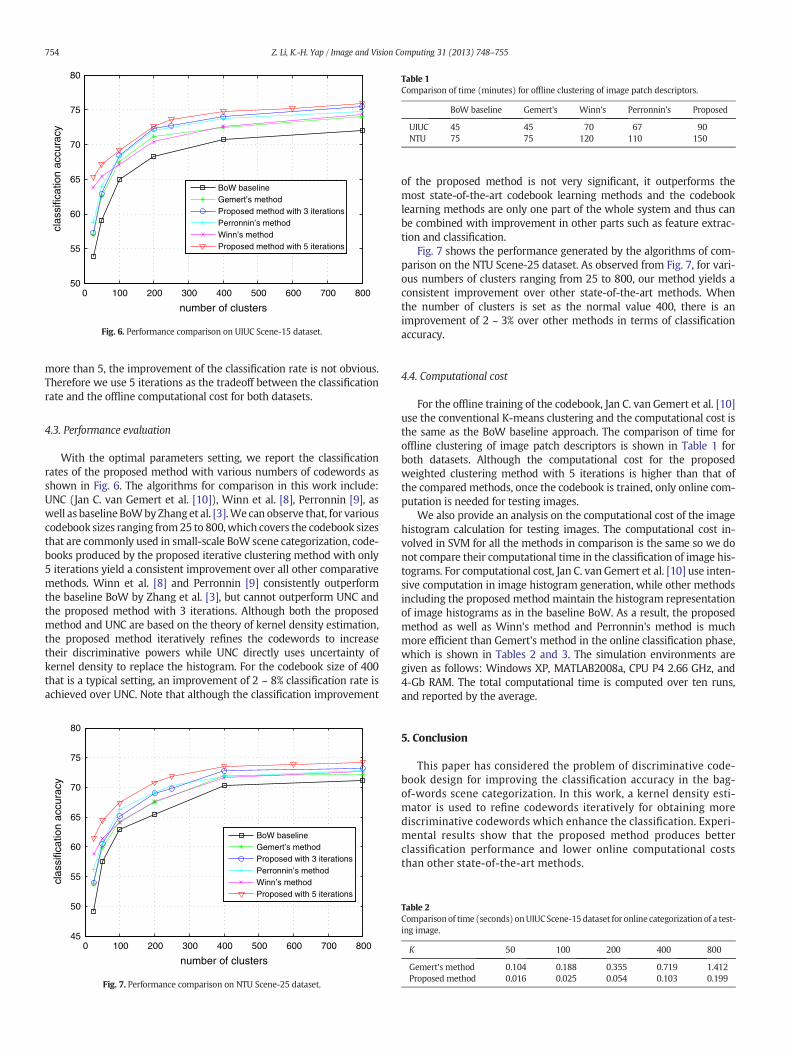
With the optimal parameters setting, we report the classificationrates of the proposed method with various numbers of codewords asshown in Fig. 6. The algorithms for comparison in this work include:UNC (Jan C. van Gemert et al. [10]), Winn et al. [8], Perronnin [9], aswell as baselineBoWbyZhang et al. [3].We can observe that, for variouscodebook sizes ranging from25 to 800,which covers the codebook sizesthat are commonly used in small-scale BoW scene categorization, code-books produced by the proposed iterative clustering method with only5 iterations yield a consistent improvement over all other comparativemethods. Winn et al. [8] and Perronnin [9] consistently outperformthe baseline BoW by Zhang et al. [3], but cannot outperform UNC andthe proposed method with 3 iterations. Although both the proposedmethod and UNC are based on the theory of kernel density estimation,the proposed method iteratively refines the codewords to increasetheir discriminative powers while UNC directly uses uncertainty ofkernel density to replace the histogram. For the codebook size of 400that is a typical setting, an improvement of 2 ~ 8% classification rate isachieved over UNC. Note that although the classification improvement
0 100 200 300 400 500 600 700 80045
50
55
60
65
70
75
80
number of clusters
clas
sific
atio
n ac
cura
cy
BoW baselineGemert’s methodProposed with 3 iterationsPerronnin’s methodWinn’s methodProposed with 5 iterations
Fig. 7. Performance comparison on NTU Scene-25 dataset.
of the proposed method is not very significant, it outperforms themost state-of-the-art codebook learning methods and the codebooklearning methods are only one part of the whole system and thus canbe combined with improvement in other parts such as feature extrac-tion and classification.
Fig. 7 shows the performance generated by the algorithms of com-parison on the NTU Scene-25 dataset. As observed from Fig. 7, for vari-ous numbers of clusters ranging from 25 to 800, our method yields aconsistent improvement over other state-of-the-art methods. Whenthe number of clusters is set as the normal value 400, there is animprovement of 2 ~ 3% over other methods in terms of classificationaccuracy.
4.4. Computational cost
For the offline training of the codebook, Jan C. van Gemert et al. [10]use the conventional K-means clustering and the computational cost isthe same as the BoW baseline approach. The comparison of time foroffline clustering of image patch descriptors is shown in Table 1 forboth datasets. Although the computational cost for the proposedweighted clustering method with 5 iterations is higher than that ofthe compared methods, once the codebook is trained, only online com-putation is needed for testing images.
We also provide an analysis on the computational cost of the imagehistogram calculation for testing images. The computational cost in-volved in SVM for all the methods in comparison is the same so we donot compare their computational time in the classification of image his-tograms. For computational cost, Jan C. van Gemert et al. [10] use inten-sive computation in image histogram generation, while other methodsincluding the proposed method maintain the histogram representationof image histograms as in the baseline BoW. As a result, the proposedmethod as well as Winn's method and Perronnin's method is muchmore efficient than Gemert's method in the online classification phase,which is shown in Tables 2 and 3. The simulation environments aregiven as follows: Windows XP, MATLAB2008a, CPU P4 2.66 GHz, and4-Gb RAM. The total computational time is computed over ten runs,and reported by the average.
5. Conclusion
This paper has considered the problem of discriminative code-book design for improving the classification accuracy in the bag-of-words scene categorization. In this work, a kernel density esti-mator is used to refine codewords iteratively for obtaining morediscriminative codewords which enhance the classification. Experi-mental results show that the proposed method produces betterclassification performance and lower online computational coststhan other state-of-the-art methods.
Table 2Comparison of time (seconds) onUIUCScene-15 dataset for online categorization of a test-ing image.
K 50 100 200 400 800
Gemert's method 0.104 0.188 0.355 0.719 1.412Proposed method 0.016 0.025 0.054 0.103 0.199
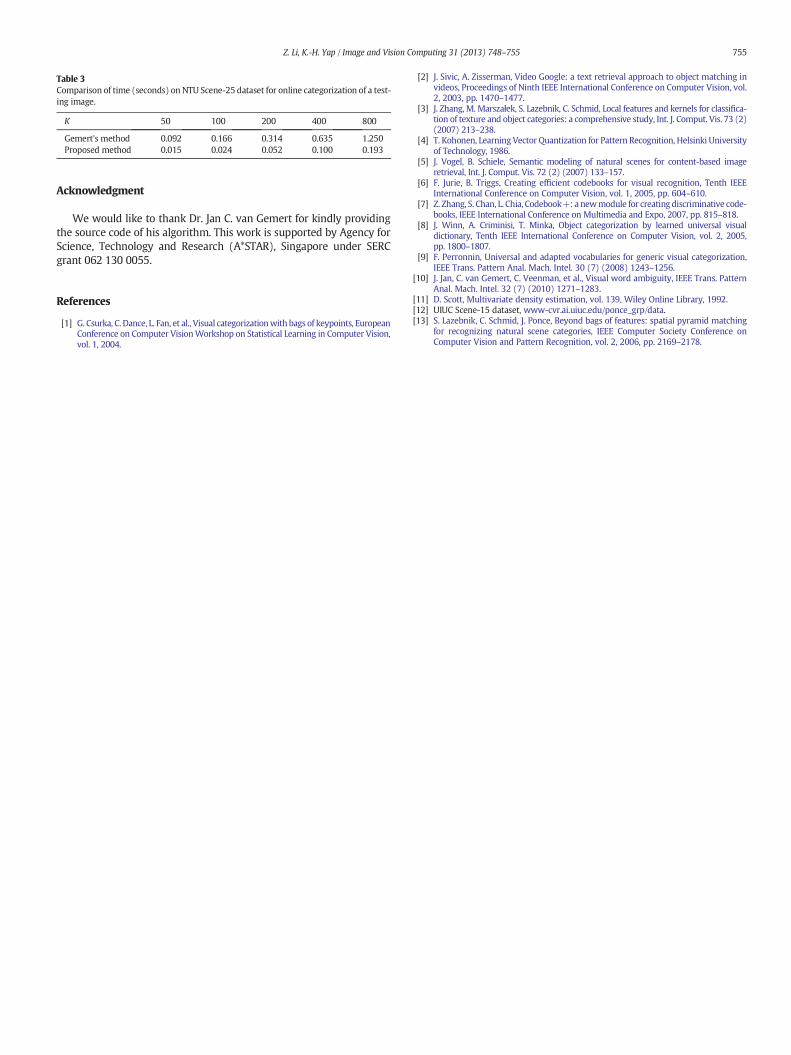
Table 3Comparison of time (seconds) on NTU Scene-25 dataset for online categorization of a test-ing image.
K 50 100 200 400 800
Gemert's method 0.092 0.166 0.314 0.635 1.250Proposed method 0.015 0.024 0.052 0.100 0.193
755Z. Li, K.-H. Yap / Image and Vision Computing 31 (2013) 748–755
Acknowledgment
We would like to thank Dr. Jan C. van Gemert for kindly providingthe source code of his algorithm. This work is supported by Agency forScience, Technology and Research (A*STAR), Singapore under SERCgrant 062 130 0055.
References
[1] G. Csurka, C. Dance, L. Fan, et al., Visual categorizationwith bags of keypoints, EuropeanConference on Computer VisionWorkshop on Statistical Learning in Computer Vision,vol. 1, 2004.
[2] J. Sivic, A. Zisserman, Video Google: a text retrieval approach to object matching invideos, Proceedings of Ninth IEEE International Conference on Computer Vision, vol.2, 2003, pp. 1470–1477.
[3] J. Zhang, M. Marszałek, S. Lazebnik, C. Schmid, Local features and kernels for classifica-tion of texture and object categories: a comprehensive study, Int. J. Comput. Vis. 73 (2)(2007) 213–238.
[4] T. Kohonen, Learning Vector Quantization for Pattern Recognition, Helsinki Universityof Technology, 1986.
[5] J. Vogel, B. Schiele, Semantic modeling of natural scenes for content-based imageretrieval, Int. J. Comput. Vis. 72 (2) (2007) 133–157.
[6] F. Jurie, B. Triggs, Creating efficient codebooks for visual recognition, Tenth IEEEInternational Conference on Computer Vision, vol. 1, 2005, pp. 604–610.
[7] Z. Zhang, S. Chan, L. Chia, Codebook+: a newmodule for creating discriminative code-books, IEEE International Conference on Multimedia and Expo, 2007, pp. 815–818.
[8] J. Winn, A. Criminisi, T. Minka, Object categorization by learned universal visualdictionary, Tenth IEEE International Conference on Computer Vision, vol. 2, 2005,pp. 1800–1807.
[9] F. Perronnin, Universal and adapted vocabularies for generic visual categorization,IEEE Trans. Pattern Anal. Mach. Intel. 30 (7) (2008) 1243–1256.
[10] J. Jan, C. van Gemert, C. Veenman, et al., Visual word ambiguity, IEEE Trans. PatternAnal. Mach. Intel. 32 (7) (2010) 1271–1283.
[11] D. Scott, Multivariate density estimation, vol. 139, Wiley Online Library, 1992.[12] UIUC Scene-15 dataset, www-cvr.ai.uiuc.edu/ponce_grp/data.[13] S. Lazebnik, C. Schmid, J. Ponce, Beyond bags of features: spatial pyramid matching
for recognizing natural scene categories, IEEE Computer Society Conference onComputer Vision and Pattern Recognition, vol. 2, 2006, pp. 2169–2178.





























