Embed Size (px)
Citation preview


An Economy of LogicA scalable Discrete Fourier Transform Algorithm
for the
Field Programmable Gate Array
Gordon Eric Inggs
INGGOR001
13th October 2009

Contents
1 Introduction 1
1.1 Introduction of Project . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Problem Statement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Context . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.1 Digital Signal Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3.2 Reconfigurable Computing . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.4 Project Requirements . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4.1 Validity . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4.2 Parallelism . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4.3 Error Stability . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5 Project Specification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5.1 Constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5.2 Project Goals . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.6 The Rest of the Report . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2 Literature Review 6
2.1 The DFT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.1 Mathematical Description and Analysis . . . . . . . . . . . . . . . . . . . . 6
2.1.2 Application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 The FFT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Multidimensional Index Map:Cooley-Tukey Radix-2 Algorithm . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Single Dimensional Index:Winograd DFT Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3 Scalable Fourier Transforms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.1 Case Study 1 - FFTW . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.2 Case Study 2 - SPIRAL . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.4 Fourier Transform implementations onFPGAs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
i

3 Design and Implementation 15
3.1 Proposed Solution -Hybrid FFT-DFT Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Design Considerations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.2 Proposed Solution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1.3 Justification of Selected Solution . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Algorithm Description . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.2 Cooley-Tukey Style Divide and Conquer . . . . . . . . . . . . . . . . . . . . 21
3.2.3 Direct Discrete Fourier Transformation Calculation . . . . . . . . . . . . . . 21
3.2.4 Decoding the Resulting Decimation . . . . . . . . . . . . . . . . . . . . . . 23
3.2.5 Controlling the Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 Development Process . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.1 Sequential Prototyping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.2 Parallel Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4 Experimentation 28
4.1 Overview of Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1.1 Validity of Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.1.2 Parallelism Assessment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.1.3 Stability of Accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2.1 Validity of Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4.2.2 Parallelism of Algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2.3 Accuracy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5 Conclusion 36
5.1 Evaluation of Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.2 Specification Fulfilment . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3.1 Lessons learnt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3.2 Further Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Bibliography 39
ii

List of Figures
2.1 1Hz Sine Wave being sampled at 20Hz[22] . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Magnitude of the DFT of 1Hz Sine wave, rotated so that the centre of the spectrumis in the middle[22] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Radix-2 Butterfly[8] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.4 Overview of 8 point Radix-2 Decimation in Frequency Cooley-Tukey FFT[8] . . . . 11
3.1 Overview of Hybrid FFT-DFT Algorithm . . . . . . . . . . . . . . . . . . . . . . . 16
3.2 Operations Overview of Hybrid DFT-FFT Algorithm, for 8 sample points, using aDFT of width 4 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 Use Case Diagrams for Hybrid Algorithm . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Data-path of Hybrid Algorithm, with a DFT of size N4 , i.e. 3 stages of Divide and
Conquer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.5 Class Diagram of Hybrid Algorithm Processing Blocks . . . . . . . . . . . . . . . . 20
3.6 Activity Diagram of generic Hybrid Algorithm Signal Processing Block . . . . . . . 20
3.7 Activity Diagram of Divide and Conquer Block . . . . . . . . . . . . . . . . . . . . 21
3.8 Activity Diagram of Mux Block . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.9 Activity Diagram of DFT Block . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.10 Activity Diagram of Unscrambler Block . . . . . . . . . . . . . . . . . . . . . . . . 23
3.11 Reordering of data during 8 point FFT[2] . . . . . . . . . . . . . . . . . . . . . . . 24
3.12 Overview of 16 point FFT[8] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.13 Depiction of Control Relationship between two signal processing blocks . . . . . . 27
4.1 Signals used to assess the validity of the Hybrid FFT-DFT Algorithm . . . . . . . 29
4.2 Examples of Early Stem Plot Results obtained . . . . . . . . . . . . . . . . . . . . 31
4.3 Example of Final Stem Plot Results - the Scipy FFT is overlaid over the Algorithm’splot . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.4 Results of 1024 Sample runtime Experiments . . . . . . . . . . . . . . . . . . . . . 33
4.5 Results of 128 Sample runtime Experiment . . . . . . . . . . . . . . . . . . . . . . 33
4.6 Results of 1024 Sample Mean Square Error Calculations . . . . . . . . . . . . . . . 34
4.7 Results of 128 Sample Mean Square Error Calculations . . . . . . . . . . . . . . . . 35
1 Transformed Sine Wave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
2 Transformed Square Wave . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
iii

3 Transformed Plots from Sequential Algorithm . . . . . . . . . . . . . . . . . . . . . 46
4 Transformed Plots from Parallel Algorithm . . . . . . . . . . . . . . . . . . . . . . 47
5 Transformed Plots from Sequential Algorithm . . . . . . . . . . . . . . . . . . . . . 48
6 Transformed Plots from Parallel Algorithm . . . . . . . . . . . . . . . . . . . . . . 49
iv

Acknowledgements
Google Scholar, the academic version of the popular Internet search engine, has the phrase ‘standon the shoulder of giants’ predominately displayed on its home page. I believe this to be botha tribute and a challenge. A tribute to those that have understood so much, and shared thatunderstanding, and it is a challenge to see further. While this metaphor wonderfully encapsulatesthe inductive nature of Science, I believe it also speaks volumes about the relationships betweenanyone undertaking such work, and those that support them.
I would like to recognise the following ‘giants’ in my own life:
• My teachers and lecturers - Right from Miss William’s Sub A class at Simon’s Town HighSchool, to boarding school at SACS, to the University of Cape Town. My two greatest teach-ers have however been my parents, Mike and Trish, with special mention of my grandmother,Joan. I’ve learnt everything I know from you.
• Those that have in particular have been of assistance during this project - Dr Paichard, mysupervisor, Simon Winberg, Andrew van der Byl, Andrew Woods and Dr Alan Langman.The advice I’ve received from them has been invaluable. My uncle, Graham Inggs was alsoof great help, providing access and software support for the Chemical Engineering ChimeraComputing Cluster.
• Another uncle, Bernard Napier, lent his professional touch to the front cover, and for this Iam extremely thankful.
• My friends and colleagues in the Electrical Engineering 2009 class, particularly those in theElectrical and Computer Engineering stream. One couldn’t ask for better companions.
• My fellow volunteers in SHAWCO - child by child, we’re winning guys. To the communityparticipants who have put up with my teaching over the years, I hope you’ve learnt as muchfrom me as I have from you.
• And those that remain, because they don’t fit the categories well, or because I fill all thesame categories as them! John, Wade, Simon, Bontle and Pia.
• And of course, the rest of my family, for their love and support.
• Daena, my Love.
v

Plagiarism Declaration
I, Gordon Inggs, hereby declare that the report which follows is the result of my own efforts.
I have not knowingly committed intellectual dishonesty of any kind, and I have made every effortto ensure that I am not guilty of such. Where the ideas and work of others have been used orreferred to, it has been properly referenced using the IEEE numbered referencing system.
G.E. Inggs
13 October 2009
vi

Chapter 1
Introduction
1.1 Introduction of Project
Economics is the study of scarce resources in an environment of limitless need. Field ProgrammableGate Arrays, often envisaged as a sea of uncommitted logic, offer a limitless set of possibilities.At first, this almost seems to contradict the laws of the before mentioned social science, howeverthe realisation soon comes that it is a large number of possible configurations that exist, and notinfinite resources. However there is opportunity in this flexibility, allowing for the possibility ofsolving old problems in new ways. Fourier Analysis is a good hunting ground for development inthis regard, as it is a problem domain which lends itself to many different forms of computationand has seen many breakthroughs as a result of this.
The project which has been undertaken has been centered around the thesis that a scalable algo-rithm for performing the Discrete Fourier Transform (DFT) operation on the Field ProgrammableGate Array (FPGA) exists, and can be implemented. Scalability here initially means that algo-rithm is flexible with regards to the size of the data set being processed at any given time. Howeverthis definition soon evovles into a more holistic meaning of the word, and the algorithm becomesscalable both with regards to the need of the user and the platform under consideration. Thisreport details the systematic approach which was taken to analyse the problem, and the processof designing this algorithm, and beginnings of implementing a proposed solution to this problem.
This Introduction Chapter will present the problem under consideration in full, and analyse itin terms of the current technological context and the underlying needs. Initially the problemidentified will be stated as if by an end user, providing the initial insight as to why a scalablealgorithm for performing a Fourier Transform on the FPGA platform is required. Then two topicswhich are most relevant to the context of the project are presented: The current state of digitalsignal processing and the emergence of reconfigurable computing as a serious computational tool.Both topics will highlight the current intersection between these fields, which is very firmly wherethis project lies. In light of the full problem statement and the context of the project, a set ofthe objectives will be derived. Then a formal specification will be laid out, identifying the keyconstraints and performance targets for this particular project. Finally the chapter will concludeby describing the rest of the report, and the further progression of this design process.
1.2 Problem Statement
FPGAs are quickly emerging as a platform of choice for digital signal processing[23, 24, 29].
That being said, not a lot of work has been performed in providing scalable tools for common DSPtasks[31, 16]. If one desires to perform a Fourier Transform on a FPGA platform for a particular
1

frequency resolution1, a hand coded FPGA core is required to be sourced or programmed. Giventhe highly structured and simplistic nature of this algorithm, this state of affairs is somewhatbizarre. Furthermore the low level nature of Hardware Descriptor Languages is typically notthe environment which most users want to work in. This suggests that there is a particularneed for a high-level programming solution which is able to assist automatically in the creationof hardware descriptor language signal processing implementations, especially for performing theFourier Transform.
The task is to prove that a algorithm exists which provides a hardware solution to a standardDSP task, the Discrete Fourier Transform, in a manner which would be suitable for general FPGAdeployment. Essentially the user should be able to describe the Fourier Transform which needs tobe performed in terms of input dataset length, and this algorithm would provide the structure forcomputing that transform.
1.3 Context
This section provides background to the problem stated above, by considering the status quo in dig-ital signal processing and reconfigurable computing, and highlighting that the latter is increasinglybecoming a popular platform for implementing the former[23].
The macro-context of DSP is that it is one of the most rich examples of applied computing,concerning itself with the study of methods for processing analogue signals in a discrete manner.The field has applications in remote sensing, statistical analysis, telecommunications to name but afew. FPGA computing is one of the technologies at the forefront of the parallel revolution currentlyoccurring in modern computing[5]. Thus the context of this project is an investigation of a commonelement of a highly relevant field of applications utilising a promising technology.
1.3.1 Digital Signal Processing
Digital Signal Processing is a subset of signal processing. It is mainly concerned with operationsbeing performed upon discrete data which has resulted from a sampling performed upon analoguesignals. This is contrasted against analogue signal processing, which performs operations upon theunderlying analogue signal. The advantages leveraged by digital signal processing is the greaterflexibility and interoperability of digital data[3, 30].
Since the 1980s, specialised digital signal processors and application specific integrated circuits(ASICs) have been used to perform signal processing operations. These use varying degrees ofhardware optimisations of specific signal processing tasks. While these DSP chips and circuitsare popular and in wide use, they are inflexible and notoriously difficult to interface into systems.Increasingly interest is turning to FPGAs, which offer the same benefits of the optimised DSPchips, in terms of providing highly task specific hardware, while also allowing a large degree offlexibility [23, 24, 31, 29].
1.3.2 Reconfigurable Computing
Reconfigurable Computing is an approach to computing which utilises a system which has a degreeof reconfigurable with respect to its hardware. Fundamentally it tries to bring the flexibility ofgeneral purpose processors and the performance of dedicated hardware closer together. Reconfig-urable Computing as a field of research has been attracting a large degree of interest in the last twodecades, as the availability of reconfigurable platforms and programming tools (i.e. FPGAs) havebecome more affordable and accessible. Initially reconfigurable devices were used as ”glue-logic”,providing customisable interfaces between different hardware. But a decrease in cost, as well as
1This is intimately related to the input dataset length of the DFT, see the Section 2.1 for further details
2

improved clock speeds in the last 10 years has allowed these devices to be used as serious computingplatforms[18, 23, 16].
The explosion of availability of FPGAs has allowed for reconfigurable computing to become in-creasingly mainstream. The lower clock speeds, higher relative cost and longer development timeof reconfigurable systems compared to conventional processors are viewed as major constraints onthis new computing paradigm. However the dramatic increase in performance due to the inher-ent parallelism seen in most tasks, as well as the portability of these solutions continues to driveinterest up and costs down.
1.4 Project Requirements
‘Don’t talk to me about progress. Progress just means bad things happening faster.’ -Terry Pratchett[25]
While the problem statement encapsulates the aims of the project, it does not provide sufficientdetail to evaluate any proposed solution. This section analysis the underlying needs as derivedfrom the problem statement above, and hence provides a natural framework for evaluating thesuccess of the proposed algorithm.
As will be proved later, the bandwidth resolution of a Fourier Transform is proportional to therate at which the signal is sampled, and inversely proportional to the size of the transform dataset.Thus it is generally required that the transform input dataset be as large as is possible so as tominimise the size of the resolution of each sample. The real requirement for this project in thisregard is that the solution proposed is able to scale up or down according to the input data setsize required. This requirement is that which the solution should be formulated around. However,the following other performance factors should be considered.
The performance required by the solution is informed by the need for the DFT operation to beperformed within a certain degree of accuracy, and to be highly scalable in terms of its data setsize and use of available resources. This naturally conditions the success of the algorithm on itsvalidity, degree of parallelism and error stability.
1.4.1 Validity
First and Foremost, the proposed algorithm needs to perform the Discrete Fourier Transformcorrectly. This is defined as receiving time domain input data, and producing frequency domainoutput data in the correct order, at the right bandwidth resolution.
The validity of the algorithm can be evaluated by comparing it to other, established DiscreteFourier Transform implementations, and by ensuring that the theoretical underpinnings of theproposed algorithm are sound.
1.4.2 Parallelism
Parallelism is a further requirement, as it pertains to the efficient use of FPGA resources.
A key measure of the the degree of parallelism is the latency with which it performs the discretetransform. This is a measure of how long the system takes to compute the DFT for a given set ofdata. As a general rule, the lower the latency the better, especially in time-critical applications.For real world applications, latency must be measured in “wall time” and so includes any constraintssuch as data transfer and bottlenecks incurred as part of the solution.
The latency performance should be assessed in two ways:
3

1. A parallel version of the algorithm implemented should out perform a sequential version ofthe same algorithm, while performing the exact same transform, within the constraints ofthe overhead in implementing parallelism on the test platform.
2. The algorithm must compare favourably to other FPGA implementations of DFTs, but notnecessarily out perform these other implementations, as some performance cost is expectedfor the algorithm’s generality. By keeping the latency reasonable, the generated DFT willmake the algorithm worthy of consideration with respect to other FFT implementations.
1.4.3 Error Stability
An implicit performance requirement is the accuracy of the DFT computations being performed.Typically FPGA computations offer fixed precision accuracy, with single and double floating pointprecision only available through complex structures being overlaid on the existing architecture. Theimplementation of the DFT on the FPGA proposed with this project needs to assessed comparedto other popular implementations, which have accepted errors in computations.
Deriving a fixed target is difficult due to the fact that DFTs are used for a wide variety of tasks,all of which require varying degrees of accuracy. As such, a level of accuracy that is relativelycomparable to accepted implementations of other FFTs on the FPGA would be acceptable.
1.5 Project Specification
The project specification outlines the exact constraints and project goals succinctly. The successof the project will be assessed according the fulfillment of these goals, while remaining within theconstraints described.
1.5.1 Constraints
The project must:
• not have an error outside of acceptable limits, i.e. competing DFT implementations
• be scalable within a reasonable range of input data set sizes and hardware configurations
• make significant progress in a short period of time.
1.5.2 Project Goals
The proposed solution must:
• be able to scale with regards to any DFT input length as specified by the user
• utilise the resources of the FPGA platform as economically as possible
• have FPGA resource usage that is linearly related to the size of the transform that is beingimplemented
4

1.6 The Rest of the Report
This Chapter has introduced the problem under consideration - the design and implementation ofa scalable Algorithm for computing the Discrete Fourier Transform for the Field ProgrammableGate Array. This was done by considering the problem statement, and the context within whichthe project lies.
Chapter 2, the Literature Review will discuss the underlying theory that is necessary for formulatingan approach for implementing a scalable Discrete Fourier Transform on the FPGA. This comprises afull discussion of the Discrete Fourier Transform and Fast Fourier Transform theory. By describingboth in abstract mathematics, a far clearer idea of the potential mathematical tools available fora scalable DFT implementation is obtained. It will then describe the current state of the art withregards to scalable DFTs as well as implementing DFTs on FPGAs, as described by the availableliterature. This will provide a set of practical considerations which will complement the theorydeveloped.
Chapter 3, the Implementation chapter details the design and creation of a scalable DFT algo-rithm for the FPGA. This was approached by considering the design choices presented in theliterature review. Based upon the evaluation of the implementation options available, a hybridFFT-DFT method was selected. The System Description subsection expands on the hybrid FFT-DFT algorithm further, fully describing the solution’s structure and functionality as modeled asa system. Finally the development process utilised will be discussed, with special mention of therapid prototyping approach adopted.
Chapter 4, the Experimentation section describes and gives the results of the evaluations performedon the proposed hybrid FFT-DFT algorithm, aimed at assessing its validity, parallelism and accu-racy. These evaluations were performed using a variety of simulations and models as opposed tothe complex and time-consuming, low-level FPGA approach.
In Chapter 5, the discussion of the thesis is brought to a conclusion. The results of experimentsperformed will be discussed, evaluating the performance of the proposed Hybrid DFT-FFT Algo-rithm as tested in the previous chapter. This discussion will naturally lead into a formal evaluationof the fulfillment of the original specification. And finally, several remarks will be made, reflectingon lessons learnt and suggesting future avenues of development.
5

Chapter 2
Literature Review
‘“Oh, history,” said Lord Selachii. “That’s all in the past!” ’ - Terry Pratchett[25]
This chapter will discuss and evaluate the relevant theoretical and technical background knowledgewhich informs the problem, and hence any proposed solution. This chapter has been broken downinto the Discrete Fourier Transform (DFT), the mathematical operation that lies at the heart ofmuch of signal processing and this problem; the Fast Fourier Transform (FFT) algorithms, whichare the proposed methods for optimising the DFT on various computing platforms. Then two casestudies of state of the art scalable Fourier transform applications are considered - FFTW and Spiral.As part of the final section, an assessment of the many current FPGA FFT implementations willbe performed, identifying what should be the key considerations when designing a scalable FourierTransform for a FPGA platform. By considering the mathematical theory reviewed, the scalabletransformation implementations and the practical FPGA-based FFT implementations, the Litera-ture Review provides all of the information necessary to approach the design and implementationof a scalable Fourier Transform algorithm for the FPGA computing platform.
2.1 The DFT
2.1.1 Mathematical Description and Analysis
This subsection describes how the discrete frequency domain representation of a signal is generatedfrom a discrete time domain of that signal via Discrete Fourier Transform, along with relevantcomments with regards to the computation of that transformation.
Let x[n] be a digital signal, sampled at a rate of fs Hz. Thus there are N samples with a time periodT between each sample. For now it is assumed that there are no frequency components higherthan fs
2 (This is effected in reality by applying a windowing function to the sampled data[30]).
According to Fourier Series Analysis[30], if T0 is the fundamental period and hence ω0 = 2πT0
is thefundamental radial frequency, then the coefficients of a Fourier series expansion of a signal x(t) aregiven by:
ck =1T0
�
T0
x(t)e−jkω0tdt k�Z
For a discrete time signal of a finite length, x[n], then T0 = NT and that one, finite period isconsidered so dt = T and t = nT , and so:
ck =1N
N−1�
n=0
x(n)e−j 2πknN k�Z
6

Figure 2.1: 1Hz Sine Wave being sampled at 20Hz[22]
In order to obtain the DFT coefficients, X(k), the Fourier Series Coefficients as described aboveare multiplied by a factor of N:
X(k) = Nck =N−1�
n=0
x[n]e−j 2πknN k�Z
These discrete coefficients are described in terms of k, which can be related to frequency (i.e. Hz)by fk = fs
N k k�Z. Hence, in order to achieve a better frequency resolution, a larger number ofsamples is required[30].
Furthermore, given e−j(2π) = 1, thus e−j( 2π(kn+N)N ) = e−j(2π)e−j( 2πkn
N ) = e−j( 2πknN ). Thus the am-
plitude spectrum is periodic, and can be conveniently expressed in full by considering the rangek = 0, 1, 2, . . . , N − 1.
Additionally, the e−j 2πknN factors is often expressed as Wnk
N , commonly called a “twiddle factor”[30]. A fact useful for computation is:
WN = e−j 2π
N = cos(2π
N)− jsin(
2π
N)
This gives a constant value for WN for a given value of N. Thus each twiddle factor is the result ofcomputing that constant raised to the power of the product of kn, which itself remains constantfor a given transform input size.
If this equation is analysed using big O notation, it is clear that there are O(n2) operations required- n multiplications and a sum of n terms.
2.1.2 Application
The Discrete Fourier Transform has many applications, one of the most popular being powerspectrum analysis[30].
7

Figure 2.2: Magnitude of the DFT of 1Hz Sine wave, rotated so that the centre of the spectrum isin the middle[22]
Power Spectrum analysis is primarily concerned with analysing the frequencies which containthe power of the signal. This is achieved by calculating the amplitude spectrum from the DFTrepresentation of the signal, as is represented below:
X(k) =N−1�
n=0
x(n)e−j 2πknN k = 0, 1, 2, . . . , N − 1
Ak =1N
�(Real(X(k)))2 + (Imag(X(k))2 k = 0, 1, 2, . . . , N − 1
If Akis considered a voltage value, then the Power spectrum may be calculated trivially:
Pk = (Ak)2 k = 0, 1, 2, . . . , N − 1
The power spectrum is useful in many fields, especially telecommunications, where the electro-magnetic spectrum is considered a national resource by most countries. By regulating the levelof transmitted power at specific frequencies, frequency bands may be designated for a particulartype of use. For example, mobile telephone operators apply for the use of a certain part of theelectromagnetic spectrum in a certain geographic locality. This allows them to provide a mobiletelephone service in that area, to the benefit of the economy and the convenience of the generalpublic. Another example is the limitation on transmission power at the 2.4GHz ISM band, whichallows for multiple, uncoordinated wireless computer networking devices to operate in relativeproximity.
It is not an exaggeration to state that the current digital wireless revolution would not be pos-sible if this mathematical tool for analysing and regulating the spectrum did not exist. Becausethere is such a broad spectrum, with so many different uses for that spectrum, all using differingbandwidths. To effectively monitor and analyse that spectrum, varying sizes of DFTs would berequired with as minimum fuss as possible. Furthermore, as the power requirements for FPGAscome down, embedded system engineers are increasingly looking to these devices to replace digi-tal signal processors, and even general processing units in mobile devices. Thus this applicationillustrates the need for a scalable DFT implementation for FPGAs.
8

From this application, the key performance parameters identified for this particular DFT imple-mentation: Bandwidth resolution, accuracy and latency are all marked as being key performancefactors for DFT implementations generally. This suggests that in addition to comparing the DFTsolutions generated to commonplace hand-optimised techniques, the performance of the proposedDFT solution takes on practical meaning.
2.2 The FFT
The Fast Fourier Transform is the name given to any algorithm which computes the DFT moreefficiently than the explicit definition, typically by reducing the number of computations requiredto obtain the discrete frequency domain representation of a digital signal. Broadly these algorithmscan be divided into those which use a multidimensional index map in order to effect this speedup,and those that do not[23, 14, 9]. Below two of the most prominent of each variety are presented.
2.2.1 Multidimensional Index Map:
Cooley-Tukey Radix-2 Algorithm
This FFT is widely attributed to Cooley-Tukey, but was in fact a special case of a solution foundby Gauss for solving trigonometric series [27, 23, 14, 12]. Contrary to popular belief, this algorithmis not in fact limited to power of 2 data series, and can in fact be applied to any data set, providedthat there are relatively low prime factors of the length N[23, 27, 12]. The method describedbelow is radix-2 decimation-in-frequency[30, 12], which allows for data to be input temporally insequence, but will required a reordering after the DFT operation.
The DFT formulation is:
X(k) =N−1�
n=0
x(n)W knN k = 0, 1, 2, . . . , N − 1
By rewriting the formulation in two parts, Utilising that WN2
N = e−j2π N
2N = −1 , and if k = 2m or
k = 2m + 1:
X(2m) =
N2 −1�
n=0
(x(n) + x(n +N
2))W 2mn
N m = 0, 1, 2, . . . ,N
2− 1
X(2m + 1) =
N2 −1�
n=0
(x(n)− x(n +N
2))Wn
NW2mnN m = 0, 1, 2, . . . ,
N
2− 1
Utilising that W 2N = e
−j 2πN2 = WN
2, the expressions above can be formulated as odd and even
components:
X(2m) =
N2 −1�
n=0
a(n)WmnN2
m = 0, 1, 2, . . . ,N
2− 1
X(2m + 1) =
N2 −1�
n=0
b(n)WnNW
mnN2
m = 0, 1, 2, . . . ,N
2− 1
9

Figure 2.3: Radix-2 Butterfly[8]
where a(n) and b(n) may be expressed by
a(n) = x(n) + x(n +N
2) n = 0, 1, 2, . . . ,
N
2− 1
b(n) = x(n)− x(n +N
2) n = 0, 1, 2, . . . ,
N
2− 1
As can be seen from the original formulation, a N point DFT requires N2 complex multiplications.By re-expressing the transform as two N
2 point DFTs, the number of complex multiplications isreduced by just under half. By recursively applying the technique, N
2 2 point DFTs may be used tocalculate the N point DFT, requiring only N
2 log2 N complex multiplications, at the cost of morecomplex additions, an arithmetically simpler task.
A key tool in restructuring the DFT operation is the “butterfly” [32, 31] or Divide and Conqueroperation, as pictured in figure 2.3 for the case of an input sample of 21. The butterfly operationis when two signal samples are combined, the upper output being the addition, while the loweris the subtraction of the lower from the upper. This restructuring is used in the Cooley-Tukeymethod, as its restructuring is an inherent multiplication by a trivial Twiddle Factor (i.e. onewhich evaluates to ±1) for the lower factor. Although the output contains as many samples as theinput, each output value is now complete, in that each contains both input values.
1In cases of higher numbers of input values, the number of samples is divided into an upper and lower region,and then combined
10

Figure 2.4: Overview of 8 point Radix-2 Decimation in Frequency Cooley-Tukey FFT[8]
The diagram above presents a signal flow graph for an 8 point DFT performed using the Cooley-Tukey Radix-2 algorithm. The input data set is initially divided into those with even and oddnumbered indices, with the odd numbered indices multiplied by the factor Wn
N . The process isrepeated twice, until 2 point DFTs are being performed, with the two input points being made upof the summation of several points from the original DFT.
2.2.2 Single Dimensional Index:
Winograd DFT Algorithm
What is popularly called Winograd’s DFT Algorithm uses a combination of Radar’s Algorithm totranslate the required DFT into a cyclic convolution operation, and then applies Winograd’s shortconvolution algorithm in order to solve for the discrete Fourier coefficients[23].
Radar’s Algorithm transforms the DFT formulation from:
X(k) =N−1�
n=0
x(n)W knN k = 0, 1, 2, . . . , N − 1
Utilising the fact that N is prime, g is given as a generator for the values of k and n:
n = gnmod N
k = gkmod N
Thus the DFT formulation is changed to:
X(gkmod N)−X(0) =
N−2�
n=0
x(gnmod N)W g(n+k)Mod N
N k = 0, 1, 2, . . . , N − 2
11

This formulation may then changed into a cyclic convolution, which may be computed usingWinograd’s Short Convolution Algorithm[10]:
X(gkmod N)−X(0) = [x(g0
mod N), x(g1mod N), . . . , x(gN−2
mod N)]
⊗[WN ,WgN , . . . ,W
g(N−2)Mod NN ]
This algorithm is recognised for requiring the lowest number of complex multiplications of anyFourier Transform algorithms, however it comes at the cost of requiring the DFT length N to beprime, or be re-expressed so that it might be several prime DFTs. Its also incurs more complexadditions.[23, 28, 9].
2.3 Scalable Fourier Transforms
This section investigates two popular scalable Fourier Transform implementations which have seenwidespread success, and as such have approaches which should be considered when implementing ascalable Fourier Transform for FPGAs. The first case study under consideration is the very widelyknown Fastest Fourier Transform in the West (FFTW) Intelligent Library which is meant to behardware independent. The second considered is the Spiral Project, which aims to develop a toolfor automatically generating code optimised for performance digital signal processing. Both im-plementations are good examples of software “tuners”, aiding and supplanting the role of compilersin parallel computing[5].
2.3.1 Case Study 1 - FFTW
The Fastest Fourier Transform in the West (FFTW) is one of the most widely accepted and usedfree software libraries for computing the Fourier Transform on a digital computer. It is notedfor being extremely competitive to other, often commercial Fourier Transform implementations.The library itself is written in C, limiting it to architectures which support the programminglanguage2. The library avoids the trade-off between optimisation and flexibility by introducing adegree of intelligence as to the method the library uses to compute the DFT[15, 21]. The overallstructure of the library is described below.
The user specifies the “problem” to the library. This problem provides the library with the shapeof the input data, in terms of dimensionality, complexity and memory structure. The library inturn yields a “plan” for solving the specified “problem”. This “plan” is an executable which acceptsinput data as specified by the “problem” and returns the desired transform. The intelligent aspectof the library is provided by a “planner” module in the library, which assemblies all of the possible“plans” which could solve the specified “problem”, and performs runtime tests on the hardware inorder to select the best performing “plan” for the user’s purposes[15].
As described in the mathematical section above, the Discrete Fourier Transform problem is onewhich lends itself to being broken down into further sub-problems3. The FFTW library exploitsthis fact, and incurs a large one-time cost in order to find the optimal method for transforming aparticular dataset. This is done by analysing the full set of possible methods for solving all of thepossible sub-problems[15].
FFTW has made a significant contribution to the field of scalable Fourier Transforms, however itsusefulness when considering FPGA implementations is limited for two reasons:
1. The library is implemented in C. While there is a lot of interest in C-to-HDL converters,there is no definitive solution for implementing C code in hardware.
2. The time taken to implement many “plans” for performance testing on a particular hardwarewould be unacceptably high, due to the long time to perform place-and-routes on FPGAs.
2Although almost all conventional computing platforms support the language3Indeed this is the very fact that the Cooley-Tukey Fast Fourier Transform exploits
12

2.3.2 Case Study 2 - SPIRAL
SPIRAL is another project which aims to auto-generate code tuned to a specific hardware. Theproblem domain it considers is linear signal processing. The project was started based on therealisation that optimisation of modern computers is a lot more complex than simply reducing op-erations, as well as that compilers by their very nature often can not generate machine optimisedcode[26]. The founders of the project cite the fact that there is a lack of reliable optimisation strate-gies for modern, complex digital systems, and that the many of the most powerful optimisationsare not accessible from a high-level description of a routine[26].
SPIRAL approaches the problem of automatically generating platform-optimised code by exploit-ing the mathematical structure of signal processing algorithms. Similar to the FFTW approach,the code generates a variety of alternative solutions to a particular problem, and evaluates theperformance of those approaches in order to select the most optimal approach[26]. However, it isdifferent from FFTW, in that it utilises search and machine learning techniques while evaluatingthe potential solutions, keeping the number of solutions directly tested as low as possible[26]. Thisavoids the large ”one-time” cost identified by the FFTW project, which would often be unaccept-ably high for reconfigurable hardware platforms.
In order to allow as much flexibility as possible, SPIRAL requires the user to specify the desiredtransform using a “Signal Processing Language” (SPL), which makes use of a “tensor-product”description of the problem[26, 15]. While potentially allowing the project to stay relevant forlonger, this approach does limit the acceptability of the work, as the SPL description of theproblem might be unduly mathematically intensive for most end users. The project does howeverachieve good results, suggesting that optimal machine-generated code can be created.
2.4 Fourier Transform implementations onFPGAs
There is a wide amount of interest in implementing Fourier Transforms on FPGAs. Most ofthe literature is however concerned with the practical implementation and optimisation of thetransform on the FPGA platform. Many of these implementations are limited to a particular size ofDFT, aiming to maximise accuracy and transform bandwidth resolution, while minimising latencyand resource. Although in order to maximise performance, efficient use of resources is required,often these implementations become too specialised, exploiting the resource configuration of aparticular FPGA to maximise the performance of implementation[16, 31]. If one is consideringsolely considering how to achieve the best possible FFT for a particular FPGA the findings ofthese papers are suitable. If one is considering how to generally implement FFTs across FPGAplatforms, this approach is not optimal. However, valuable lessons can be learnt on implementingFourier Transforms on FPGAs from this literature.
The section below details a number of such “lessons learnt” from FPGA FFT implementations:
• High Latency Performance for a radix-4 Cooley-Tukey style FFT on a FPGA is achievable,with a 1024 point DFTs being computed in 10.1 uS[32]. This is comparable to currentDSPs[29]. Key considerations in optimising latency are memory mapping, twiddle factorgeneration and overflow control.
• It is possible to implement a variety of FFT algorithms including the radix-2, radix-4, split-radix and Fast Hartley transform on the FPGA in a standardised manner[32, 31]. Further-more it is possible to achieve this using a higher level language, such as Handel-C[32, 31]. Theradix-4 algorithm yields the best latency, while the radix-2 algorithm uses the least amountof system logic, while the Fast Hartley transform uses the least memory[31].
• Implementing Floating Point numbers is quite a challenge on FPGAs, greatly increasing thehardware complexity[17]. It is thus advisable to rather decide upon an acceptable tolerance
13

of fixed point accuracy, which is highly application specific. The data width used impactsupon performance, affecting both the amount of logic and memory used on the FPGA[17, 7].
• Perhaps paradoxically a fully parallel transform structure requires more memory and latencythan a pipe-lined architecture - this is primarily due to the time taken to fill the inputbuffer[16, 19]. A fully-parallel FFT structure is also inherently more inflexible, due to therequirements of the sub-DFTs for all of the data to be present. A potential trade off is toutilise multiple serial pipe-lined FFTs[19, 16].
• Complex Multiplication are the most intensive operation being performed during the FFT -utilising hardware multipliers can often speed this operation up[21]. Complex multiplicationcan be simplified from (a + bj)(c + dj) = a.c − b.d + (a.d + b.c)j to (a + bj)(c + dj) =[a(c + d)− (a + b)d] + [a(c + d) + (a− b)c]j, reducing the number of multiplications requiredby one, because of the common first term in both computations[7, 21].
14

Chapter 3
Design and Implementation
This chapter details the design and implementation of a scalable DFT algorithm for the FPGAplatform. First, the design considerations resulting from the literature review will be discussed asthey pertain to the implementation of a scalable DFT, in general as well as with regards to partic-ular implementation on a FPGA. Resulting from this discussion, the hybrid FFT-DFT algorithmicmodel will be presented, with a justification for the design choices made. The System Descriptionsubsection then expands on the hybrid FFT-DFT algorithm further, providing a detailed descrip-tion of the structure of the algorithm and its components. The final subsection discusses thedevelopment process utilised, including the rapid prototyping of the proposed algorithm utilisingthe Python programming language, to create first a sequential and then parallel model for thealgorithm for testing.
3.1 Proposed Solution -Hybrid FFT-DFT Algorithm
From the final two sections of the Literature Review, several design choices became apparent inimplementing a scalable DFT algorithm on the FPGA. Those choices identified are presentedbelow, along with pertinent information to making those choices. The solution selected, a hybridFFT-DFT is then presented, along with a justification for that solution.
3.1.1 Design Considerations
FPGAs are inherently parallel platforms, allowing for the complete spectrum of parallelism. How-ever the limitation of resources available have to be considered in any design. Any design whichhopes to maximise the use of the FPGA must take full advantage of these resources.
Multiplications are the key operation in Signal Processing, and this is especially true for DiscreteFourier Transforms[24, 21]. This is an unfortunate fact because multiplications, complex multi-plications in particular, are computationally expensive on FPGAs, requiring a large number oflogic gates, and are hence fairly slow. As a result of this, manufacturers are starting to put anincreasing number of hardware multipliers on FPGA platforms[29, 13]. These hardware multipliersare dedicated units within the FPGA which can perform only the multiplication operation, butcan do so at a significantly reduced speed then one implemented in general logic. As a result ofthis, any implementation of the DFT which was to maximise the use of the hardware multipliers,would be more efficient in terms of logic used, as well as latency.
The generation of the Twiddle factors used in the computation are another key consideration,as in theory, all the values used could be precomputed, providing a saving in latency during the
15

execution of the DFT1 and reducing the complexity of the DFT design. That being said, if memoryis in fact in short supply, then a twiddle factor generation unit may be used to reduce the overheadof memory required[17, 32, 31, 21]. Another consideration is that there are certain trivial twiddlefactors (WN
N or WN2
N ) which evaluate to ±1. This fact is already exploited by the Cooley-Tukeymethods, but can be exploited further.
Floating point numbers provide a high degree of flexibility and accuracy, but are complex andexpensive to implement on the FPGA. Fixed point numbers are further attractive as the FPGAplatform does not require numbers to have standard bit lengths, and as such the required degreeof accuracy may be implemented [17].
Finally the trade off between parallisation and pipe-lining is possibly the key design choice whichmust be made when implementing the DFT on the FPGA[16, 31, 19]. Parallisation provides thefaster computation, by performing as much of the DFT as possible at once. In particular the DFTconsists of a large number of multiplications (a task suited to parallelism) with a large numberof additions (a task which can be suited to parallisation, depending on the number of terms),which suggests that the parallisation of the algorithm would result in a net speed up. However,the parallisation of practical datasets (1024 samples or more) would incur an unacceptably highnumber of logic gates (especially given the relatively small number of hardware multipliers). Thussome degree of pipe-lining is necessary, to allow for the reuse of hardware. Pipe-lining is notwithout its cost, and as such requires more memory between the different stages. Furthermoreboth parallisation and pipe-lining provide increasingly complex control considerations.
3.1.2 Proposed Solution
Figure 3.1: Overview of Hybrid FFT-DFT Algorithm
In light of the above considerations, a hybrid FFT-DFT approach was chosen. It uses the Cooley-Tukey Radix-2 decimation in frequency method to break down the input data set to a sufficientsize so that the DFT can be performed directly, according to the limitations of the FPGA,. Theprinciple limitation considered in computing the DFT directly is the number of hardware multipliersavailable on the FPGA, and so the algorithm scales according to this fact. T. For example, if agiven FPGA, such as the Xilinx Virtex 5 VLX50T has 48 hardware multipliers[13], the algorithmwould implement a DFT of length 16 samples2, and employ as many Cooley-Tukey Divide andConquer stages as necessary to compute the required transform. So, given a input sample set ofsize 128 samples, 3 stages would be necessary to break the input dataset down to subsets of size16. The additional multiplications required in the Divide and Conquer stages would be performedby multipliers constructed from FPGA logic.
It should be noted however, that if an FPGA had only two hardware multipliers, than this algorithmsimply becomes the Cooley-Tukey Algorithm Radix-2 Algorithm.
This approach inherently lends itself to pipe-lining, because as the input data set is broken down,differing numbers of operations have to be performed on the different subsets, depending that
1This is assuming a memory look-up is faster than the exponential calculation required, which it often is2As noted earlier, three normal multiplications are required for every complex one
16

Figure 3.2: Operations Overview of Hybrid DFT-FFT Algorithm, for 8 sample points, using aDFT of width 4
subsets location. This allows for a constant resuse of hardware, in particular the part of thesystem which performs the DFT operation. It thus maximises the use of the FPGA hardwaremultipliers.
The twiddle factors for the algorithm are all precomputed in this algorithm, and hard-coded intothe FPGA, as all remain constant within the algorithm. Significant memory usage would occur inthe DFT unit, which would require the number of twiddle factors to be the square of the numberof length of the DFT being performed. Fixed point numbers would be used, of a sufficient widthto provide accuracy competitive with other implementations.
3.1.3 Justification of Selected Solution
The Cooley-Tukey FFT algorithm exploits the cyclic nature of the Fourier Transform, in par-ticular that of the Twiddle Factors, to avoid complex multiplications3. However it increases thesequentially of the algorithm with each divide and conquer stage performed4[12]. By computingthe DFT as directly as possible, the hybrid algorithm performs the overall operation as efficientlyand simply parallel as possible for any sized data set[4]. The algorithm finds the balance betweenpipe-lining and parallelism by structuring itself around the bottleneck in the system, multiplicationand hardware multiplier units. It is for this reason that Twiddle factors are precomputed - so asto not repeat multiplications.
An additional consideration is that by fragmenting the multiplications, the FFT Algorithm greatlycomplicates the control path of the system, considering that the multiplications need to be done byindependent hardware multipliers to avoid unacceptable latency. The Hybrid DFT-FFT Algorithmpresented avoids this complication by concentrating all of the hardware multiplications in the
3It is analogous to a large factorisation in this sense4The subtraction stage must occur before the multiplication stage, which holds everything up in the lower branch
of the butterfly
17

DFT operation, and allowing for other multiplication operations to be performed using multipliersconstructed from logic.
Using fixed point of numbers of a sufficient width, sufficient accuracy is obtained, and as such it isnot necessary for complex floating point arithmetic to be introduced.
Most importantly however, is that this algorithm scales economically according to the input datasetspecified - the resource usage should be directly proportional to the size of the datasets beinghandled.
3.2 Algorithm Description
The subsections below describe in detail the algorithm proposed above for implementing a scalableDFT on the FPGA. As the algorithm was developed specifically with the FPGA platform in mind,with a view to practical implementation, it lends itself to being modeled as a digital system. Thusit is natural to utilise flow charts and the Unified Modeling Language (UML) to describe it. Firstan overview of the components of the algorithm are presented, with the similarities between thedifferent elements identified using a common parent component. Then each subsystem or block isdescribed, using the UML Activity diagram for that subsection as well as a colloquial description.The description ends off on a note about the control flow of the system, introducing the simpleself-clocking mechanism used by the system.
3.2.1 Overview
As mentioned in the introduction to this section, the hybrid DFT-FFT algorithm may be function-ally described as a system. This is illustrated in figure 3.3, which defines the inputs and outputsto the “system” using the UML Use Case diagram. However, it should be noted that the systemdescribed is not limited to a particular sized dataset or hardware configuration. And the structureof the system changes based upon the DFT bandwidth resolution specified, and the number ofhardware multiplier resources available5.
Figure 3.3: Use Case Diagrams for Hybrid Algorithm
It is assumed that the input time data is transferred into the system, and transferred out en-masse.This isn’t necessarily true, depending on whether a serial or parallel bus is used, but as far as thealgorithmic structure is concerned, this detail is irrelevant.
Once the data enters the system, it has a series of operations performed upon it. These operationsare separated into discrete signal processing blocks according to the data sets upon which theywork, and the particular operation performed by that block. Figure 3.4 illustrates this, using a flow
5This is why the algorithm is described as scalable
18

chart to track the data-flow through a particular configuration of the hybrid algorithm. As can beseen in the figure, the Cooley-Tukey style divide and conquer operations are performed until theinput dataset has been broken up into sufficiently small subsets so that the DFT of that datasetmay by computed directly. Once all of the DFT values have been computed for a given dataset,an unscrambling operation must be performed to reorder the dataset, so as to compensate for thedecimation in frequency introduced by this algorithm. This unscrambling operation is contingentupon the number of divide and conquer stages which preceded the DFT. Once the dataset hasbeen unscrambled, it is ready to be output as the correctly computed DFT.
Figure 3.4: Data-path of Hybrid Algorithm, with a DFT of size N4 , i.e. 3 stages of Divide and
Conquer
Despite the different signal processing blocks performing different operations upon a given dataset,there is similarity in all of their structure. This is well represented by the inheritance relationshipfound in software classes in Object Orientated Programming, and as such, the different signalprocessing blocks have been represented using a class diagram in figure 3.5. The common elementspresent in all classes are in the base Signal Processing Block class, with all of the processing blocksinheriting from this class. This base class has an input and output dataset, which self-evidentlyrepresents the data flow in and out of the processing block6. An enable flag is needed to providecontrol over the processing block, allowing for it to be turned on and off. The trigger flag representthe need for a method by which to signal to the block that a new dataset is ready to be processed,although the process operation and signalling mechanisms will be discussed later. Finally the doneflag is needed by the signal processing block to indicate that it has finished processing the latestdataset.
Each processing stage of the algorithm adds its own attributes to this base class:
• The Divide and Conquer Block would need to produce two data output sets, as that is thepurpose of the block. As such an additional completion signaling flag would be needed.Furthermore twiddle factors would be needed for the multiplication which is performed onthe lower branch of the butterfly operation. In the FPGA, these multiplications would beperformed using multipliers built up out of logic - due to the structure of the algorithm, theextra time taken by these multiplications can be adsorbed. This is illustrated in Figure 3.2.
• The Mux block differs from all of the other processing blocks in that it accepts an array ofinput datasets and trigger flags. The purpose of this block is to feed data into the DFTblock, and so must account for all of the smaller datasets and flags produced by the divideand conquer operations. Additionally, an index variable is needed to keep track of whichinput dataset and flag is currently being operated upon.
6Note that the size of neither the input or output dataset is specified for any block
19

• The DFT block would also require twiddle factors, although a much greater set - N2, if N isthe number of samples in the DFT. However, there is a degree of symmetry in the TwiddleFactor matrix which may be exploited.
• The Unscrambler block also requires an index variable, so that it can unscramble the dec-imation on the complete transformed data set. The exact unscrambling operation will bedescribed below.
Figure 3.5: Class Diagram of Hybrid Algorithm Processing Blocks
The final aspect of the algorithm which needs to be described is the operations performed by eachsub-element. In order to do this, the UML Activity Diagram is used. In figure 3.6 the activitydiagram for the generic signal processing block is given as the starting point for the discussion ofthe operation of each part of the algorithm. Upon activation, each subsystem would check thatthe enable flag has been set. From this check, each system proceeds to an idle state where uponit continuously checks if the trigger flag has been set. Upon activation via the trigger flag, thealgorithmic step performs its operation and enters a complete state. Only when the done flag,which was set high as a result of the processing operation, does this subsystem leave the completestate and enter the idle state once again, provided the enable flag is still set.
Figure 3.6: Activity Diagram of generic Hybrid Algorithm Signal Processing Block
20

3.2.2 Cooley-Tukey Style Divide and Conquer
The Cooley-Tukey Divide and Conquer operation, or butterfly is needed to break the input datasetdown in such a way that the DFT may be computed directly upon those smaller subset. EachDivide and Conquer stage breaks the input dataset into two equal parts. The number of stagesrequired by the algorithm is dependent upon the size of the DFT being performed, which is itselfcontingent on the number of hardware multipliers available.
Figure 3.7: Activity Diagram of Divide and Conquer Block
The systematised formulation of the operation modifies the base signal processing blocks processby forking after the block has been triggered. One sub-process performs the addition required forthe upper branch of the butterfly, outputs the data on the correct dataset, and sets the requiredflag high. The other sub-process performs the lower half of the butterfly, i.e. it subtracts the lowerpart of the dataset from the upper, and then multiplies by the first N
2 twiddle factors. Note thattwo done flags are necessary, one for each output dataset, and that both are required to be set lowbefore the block will be either power down, or re-enter the idle state.
3.2.3 Direct Discrete Fourier Transformation Calculation
Two sub-processes are required to compute the DFT in the algorithm. The first is the Mux unit,which is required to select the subdataset-set produced by all of the Divide and Conquer stages,as well as the DFT subroutine itself. Both are described below, again using the UML activitydiagram.
21

Figure 3.8: Activity Diagram of Mux Block
The Mux operation is fairly straight forward, selecting the correct output dataset from the finalstage of the Divide and Conquer Blocks and outputting it to the DFT module. However, thisunit inherently controls the flow of data, by cycling through the datasets sequentially. This isrepresented by the index flag incrementing during the complete state. This does not hamper theperformance of the algorithm, because of the restructuring process of the Divide and Conqueroperations, which take longer for the later datasets7. Figure 3.2 illustrates this sequential aspectof the algorithm. As well as cycling through the input datasets, the Mux block also cycles throughthe input trigger flags, thus only copying a dataset across when it is available.
Figure 3.9: Activity Diagram of DFT Block
Once the correct dataset has been presented to the DFT block, it gets triggered, and computesthe DFT of the input dataset. This is computed using the original formulation of the DFT,X(k) =
�Nn=0 x[n]W kn
N , with all of the values of the input dataset being multiplied by the cor-rect twiddle factors in parallel (using hardware multipliers), and then summed to calculate one
7i.e. Those datasets which form part of the lower part of the Divide and Conquer Operation, hence requiring themultiplication by twiddle factors
22

frequency output. The twiddle factors for the hybrid algorithm would be precomputed and storedin the DFT block as a 2 dimensional array, with k being represented by the rows and n by thecolumns. The algorithm is thus required to run as many times as the length of the DFT beingcomputed directly. The output will also be decimated in frequency, meaning that the frequencyvalues will not be output in ascending frequency order. This is due to the Divide and ConquerOperations, which while exploiting the inherent periodicity of the twiddle factors, result in valuesgetting shuffled at each stage of the Divide and Conquer Operations. This decimation is undone,using the unscrambling operation below.
3.2.4 Decoding the Resulting Decimation
The Unscrambling part of the hybrid algorithm plays two roles:
1. Collect together all of the processed subsets of data from the DFT
2. Once of the input values have been processed, to reorder all of the output values, so that theoutput from the algorithm as a whole is in ascending frequency order
Figure 3.10: Activity Diagram of Unscrambler Block
The first role is relatively simple - the block collects the various outputs from the DFT and storesthem all in a large internal array, using an index to keep track of the current location in the array.However once the index has researched the size of the output dataset, i.e. the size of the transformbeing performed by the whole algorithm, the subroutine reorders the data into sequential frequencyorder. The exact reordering is based upon the number of stages of Divide and Conquer that areperformed.
As can be seen in figure 3.11, the reordering which occurs at each divide and conquer stage issimple - the top and bottom values are retained, but all other values in the Divide and Conquerinterweave into two sets of alternating values. For the first stage this is clearly always odd andeven. In the example given in figure 3.11, x[1] shifts to the position x[4] was in, as it is the firstalternate value after the midpoint of the operation. However, the complications ensue when thereare multiple stages of decimation, and the swapped indices become difficult to predict, due to themultiple shifts which have occurred, as illustrated by Figure 3.12. For the FFT algorithm, due tothe final DFT being of size 2, the output index becomes the bit-reversal of its correct index[8, 23].
23

Figure 3.11: Reordering of data during 8 point FFT[2]
The hybrid algorithm approaches the unscrambling operation by reversing the decimation stage,by stage. This is done by first taking back the first and last values which are already in the correctposition, and then iterating over the remaining values in the two divide and conquer outputs andplacing them back in the original order of the input dataset. This process is repeated for eachstage of divide and conquer that occurred in the initial algorithm. The pseudo-code in Algorithm3.1 presents an overview of this algorithm which reverses the decimation.
This wouldn’t be implemented on the FPGA, rather it would instead be precalculated like thetwiddle factors, and the correct value remapping would be hard coded into the Unscrambler module,greatly reducing the amount of time required to perform the operation.
3.2.5 Controlling the Pipeline
Finally, this short section will describe how the control path of the Hybrid Algorithm works.
As mentioned before, all of the signal processing blocks have one or more trigger and done flags,which are used to regulate the flow of data through the system. Each block activates upon thetrigger flag going high, and when complete sets the done flag high. The block then waits until thedone flag is set low by the next block to ensure that the next block has read the output data, beforechecking if its own trigger flag has gone high. When the block is finished using the input data,it sets the trigger flag low to signal to the preceding block that more data may be written to theinput dataset. This self-clocking mechanism is robust, and simple, however it also allows for pipe-lining by allowing the elements of the algorithm to communicate between each other indicatingavailability, and so avoiding one stage holding up the entire pipeline.
Certain blocks, the Divide and Conquer and Mux Blocks, do not have only one input or outputdataset and flags, but the principle remains the same: perform action upon trigger signal, signalnext block upon completion and wait for confirmation before checking for the next trigger.
24

Algorithm 3.1 Overview of Unscrambling algorithm for reversing the frequency decimation
N = ( s i z e o f output datase t )input_dataset = [ c o l l e c t e d data from DFT ope ra t i on s ]number_DFTs = (number o f DFT ope ra t i on s performed i . e . data subse t s ] )d f t_s i z e = ( s i z e o f DFT performed )number_stages = (number o f s t ag e s in o v e r a l l a lgor i thm )
for ( k=0,k<number_stages , k++)temp_array = array (0 , l ength=N) #crea t i n g b lank array f o r data
to be copied in t o
for ( i =0, i<number_DFTs/2 , i++) #loop f o r r e v e r s i n g a s t a g e o fdecimation
s t a r t = i ∗ d f t_s i z e ∗2f i n i s h = i ∗ d f t_s i z e ∗2 + df t_s i z e ∗2−1
temp_array [ s t a r t ] = input_dataset [ s t a r t ] #Copying datafrom input da t a s e t i n t o temporary array
temp_array [ f i n i s h ] = output_datset [ f i n i s h ]
upper_set = s t a r t + 1 #Se t t i n g up i nd i c e s f o r i t e r a t i n gover the two su b s e t s w i th in the input da t a s e t
lower_set = s t a r t + d f t_s i z e
index_t = s t a r t+1 #Se t t i n g up index f o r temporary array
for ( j =0, j<dft_s ize −1, j++) #loop f o r r e v e r s i n g thedecimation wi th in two su b s e t s
temp_array [ index_t ] = input_dataset [ lower_set ]temp_array [ index_t+1] = input_dataset [ upper_set
]
index_t += 2 #I t e r a t i n g the array i nd i c e slower_set++upper_set++
input_dataset = temp_array #copying over input da t a s e t wi thnewly undecimated data
d f t_s i z e = d f t_s i z e ∗2 #For the next s tage , the DFT w i l l betw ice the s i z e
number_DFTs = number_DFTs/2 #For the next s tage , the number o fDFTs w i l l be h a l f
25

Figure 3.12: Overview of 16 point FFT[8]
3.3 Development Process
The strategy undertaken to further refine and implement the algorithm was a pragmatic one,informed by two facts: limited time was available for development, and FPGAs are a notoriouslydifficult platform to develop on8. There have been several different approaches suggested to counteract this, including using a higher level language such as C, which can be compiled directly to VHDLwith varying degrees of success[32, 29]. Given that the focus of this project was on the creationof a truly scalable algorithm and not the implementation of a limited FFT on a FPGA9, it wasdecided to work in a high level language, Python, which would support algorithmic developmentbest, and then at a later point convert the solution into one which may be implemented in VHDL.As an in-between step, multithreaded programming without shared memory protection was usedto simulate the algorithm in a “parallel” environment.
3.3.1 Sequential Prototyping
The first implementation of the algorithm written in Python was simply to prove that the algorithmcould compute the Discrete Fourier Transform correctly. As Python is natively a single-threadedlanguage[6], this prototype is completely sequential. As a result, none of the considerations aroundflow control had to be considered as of yet. This prototype hence only deals with the data pathof the algorithm, as depicted in figure 3.4. Furthermore it was not necessary for the system to bepartitioned into independent units, because of the lack of need for minute control10. Python alsohandles complex numbers, not necessitating special arithmetic or structures to cater for them. Assuch the prototype script provides a good reference as a working model of the algorithm in theideal, completely linear world.
8VHDL is frequently compared to assembly in this regard9As has been done ad nauseum, see Literature Review
10The control is implicit in the ordering of the instructions
26

Figure 3.13: Depiction of Control Relationship between two signal processing blocks
The source code for the Sequential Python Prototype may be found in Appendix A, and in theCD supplied with this report.
3.3.2 Parallel Model
The next significant step in prototyping the algorithm, and hence preparing for implementationon the FPGA, was to introduce parallelism into the system. This model had to consider all of thecontrol challenges associated with a system implemented in physical logic. Furthermore this modelalso handles complex numbers as if there was only support for standard arithmetic, in order totruly approximate the complexity of a system implemented on the FPGA.
This was also done in Python, using the multiprocessing library[1] recently introduced, whichallows for “true” multithreading in the language. Each signal processing element, as identified inthe above system description was implemented in a separate Operating System process, allowingall to operate concurrently[1]11. Unprotected, shared memory structures were used to simulatedata-flow conditions on an FPGA, relying on control being implemented along with the algorithm.
Certain facets of the FPGA could not be implemented so easily in software - this is largely the“hard-coded” elements which don’t really have an analogy in software. As such, the twiddle factormultiplications and the unscrambling operation were unable to function as closely to the FPGAimplementation as the other elements of the system, however their overall behaviour was similarenough not to bring the model into disrepute.
The source code for the Parallel Model may be found in the CD supplied with this report.
11Of course limited by the number of CPUs available on the test system. However more on this later
27

Chapter 4
Experimentation
‘A person ignorant of the possibility of failure can be a halfbrick in the path of thebicycle of history’ - Terry Pratchett[25]
This Chapter presents the experimentation process undertaken to assess the overall correctness ofthe hybrid FFT-DFT algorithm and the prototypes described in the previous chapter. It will beginwith a description of the three experiments undertaken to evaluate different aspects of the proposedalgorithm: the validity of the algorithm, an assessment of the “parallelism” of the algorithm and theaccuracy performance of the implementation. Finally the results of the experiments are presentedin a variety of formats. From this chapter a clear idea of what experiments were performed,
4.1 Overview of Experiments
This section presents the three experiments performed upon the algorithm prototypes developed inthe previous chapter. The purpose of these experiments is to assess the suitability of the algorithmfor FPGA implementation by considering three factors:
1. How valid is the Algorithm? In other words, how correct is it?
2. Is the Hybrid Algorithm an algorithm suited to parallelism? Is its performance related tothe degree of parallelism introduced?
3. What is the accuracy performance of the algorithm? How stable is that accuracy?
Each subsection expands upon these three factors, as well as presenting the methodology in as-sessing these performance criteria
Input sample sizes of 128 and 1024 were used throughout all of the experiments. This is becauseboth represent significantly sized transforms, while being an order of magnitude different in size.Furthermore, order of 2 numbers are easier to with using the Divide and Conquer stages. TheChimera cluster of supercomputers was used for all experiments, operated by the Chemical En-gineering Department of the University of Cape Town. All experiments were run on 2.2 GHz,quad-core AMD Opteron CPUs, which provides a reasonable approximate of a parallel environ-ment.
4.1.1 Validity of Algorithm
The first experiment was meant to test how valid the proposed algorithm is, asking if the proposedsolution actually calculated the Discrete Fourier Transform. From the Literature Review andImplementation Chapters, it is clear that the Algorithm is theoretically sound, however empiricallytesting is needed to verify this theory.
28

(a) Sinusoidal Signal
(b) Square Wave Signal
(c) Gaussian Noise
Figure 4.1: Signals used to assess the validity of the Hybrid FFT-DFT Algorithm
29

This was assessed by generating three common, yet very different signals: a sinusoid, a squarewave and random Gaussian Noise, and performing the transform operation upon them. This wasdone using the sequential and parallel implementations of the algorithm, as well the SciPy’s FFTalgorithm, which is a standard implementation of the Cooley-Tukey FFT Algorithm[22].
The Performance of the sequential version of the algorithm demonstrates how well the algorithmperforms, while the performance of the parallel version indicates how sound the implemented FPGAsystem would function.
The primary means of assessment was an “eye-ball” test, comparing overlaid plots of the threealgorithms, as well as considering the calculated mean square error using a reasonable sized DFT.However as the accuracy is assessed more carefully in another experiment, it was used here as averification of the other results
4.1.2 Parallelism Assessment
How suitable the algorithm is for parallelism, and hence implementation on a FPGA, was assessedby measuring the run times of the sequential prototype and parallel model on a multiple processorcomputer. This was done for the two input sample sizes of 128 and 1024, along with varying powersof 2 sized DFTs. Each experimental trial was performed 10 times, and the result averaged to givethe values found in Appendix B.
By evaluating the run time performances of the sequential and parallel models of the algorithm,the parallel suitability of the algorithm may be assessed, particularly with regards to how thealgorithm scales up to larger datasets, and larger sized DFTs. To demonstrate that the algorithmscales efficiently, the parallel implementation should perform comparatively similarly, across thevarious data set sizes.
4.1.3 Stability of Accuracy
The Stability of the accuracy of the Algorithm was assessed by averaging the mean square differencebetween the Sequential and Parallel versions of the algorithm, and the Scipy FFT for differing sizesof the DFT for the 1024 and 128 sample sets.
How stable the accuracy of the algorithm is, directly impacts upon the effectiveness of its scalability.The yardstick being used in this case is the Scipy FFT library, which uses double precision valuesto computer the DFT[22], and so should be at least 10−15 more accurate than the implementedsolutions, which use single precision floating point numbers.
4.2 Results
The results for the experiments described above are given below. In all cases some sort of graphicalmethod is used to display the results, as well as a summary of the data values gathered.
All of the full experimental results may be found in Appendix B.
4.2.1 Validity of Algorithm
Figure 4.2 illustrates some of the early stem plot results obtained, while developing the algorithm.
30

Figure 4.2: Examples of Early Stem Plot Results obtained
Figure 4.3 illustrates a set of the stem plots obtained from the final Hybrid Algorithm, as describedin the previous chapter. Table 4.1 provides a few mean square error values obtained from the finalalgorithm implemented.
31

Figure 4.3: Example of Final Stem Plot Results - the Scipy FFT is overlaid over the Algorithm’splot
DFT Size Sequential MSE Parallel MSE128 2.86884316922e-15 3.88256893274e-141024 1.22998958917e-15 1.1256895347e-13
Table 4.1: Mean Square Error Performance of Algorithm using a DFT of size 16
4.2.2 Parallelism of Algorithm
Figures 4.4 and 4.5 present logarithmic graphs for the run times of the parallel and sequentialversions of the algorithm against the sizes of the DFTs used. The Red line is the parallel code,while the blue is the sequential.
32

Figure 4.4: Results of 1024 Sample runtime Experiments
Figure 4.5: Results of 128 Sample runtime Experiment
Tables 4.3 and 4.4 present a summary of the results which produced these graphs.
33

DFT Size Sequential runtime Parallel runtime2 0.154483795166 18.327700853332 0.173330068588 23.2153348923128 0.658499002457 97.8129720688512 4.07981801033 11.2651050091
Table 4.2: Table of Summary Results from Parallelism Experiment, for a dataset of 1024 values
DFT Size Sequential runtime Parallel runtime2 0.015429019928 19.21709203728 0.0101201534271 8.6558439731632 0.0248908996582 0.4742469787664 0.194833040237 0.290598869324
Table 4.3: Table of Summary Results from Parallelism Experiment, for a dataset of 128 values
4.2.3 Accuracy
Figures 4.6 and 4.7 present the means square error performance for 128 and 1024 sample signals,for varying sizes of DFT. Again, the blue represents the sequential prototype, while the red, theparallel model.
Figure 4.6: Results of 1024 Sample Mean Square Error Calculations
34

Figure 4.7: Results of 128 Sample Mean Square Error Calculations
Tables 4.4 and 4.5 present a summary of the data results obtained from the accuracy experimentsperformed.
DFT Size Sequential runtime Parallel runtime2 7.58483384218e-17 1.54842229671e-1232 2.04290948371e-15 8.2562224767e-14128 4.039144248e-14 1.93141040839e-13512 3.47564459487e-12 1.30382407539e-13
Table 4.4: Table of Summary Results from MSE Experiment, for a dataset of 1024 values
DFT Size Sequential runtime Parallel runtime2 1.99850436809e-16 1.36886619219e-138 1.01106434771e-15 4.5017653968e-1432 6.75950893187e-15 5.08427732608e-1464 6.27950651062e-14 4.0605608495e-14
Table 4.5: Table of Summary Results from MSE Experiment, for a dataset of 128 values
35

Chapter 5
Conclusion
This chapter concludes this report on designing a scalable DFT algorithm for the FPGA platform.First the results of the experiments conducted will be discussed, deriving conclusions with regardsto the performance of the hybrid FFT-DFT algorithm. Then the outcomes from the experimenta-tion will be tested against the original goals and constraints, evaluating the overall success of theproject. Finally some concluding remarks will be made, particularly relating to the lessons whichhave been learnt during this project, both with regards to implementing scalable DFTs and doingso for the FPGA platform. Finally that work which still needs to be done in order to realise thefull potential of the work begun with this project will presented.
5.1 Evaluation of Results
This penultimate section discusses the results of the experiments performed on the Hybrid DFT-FFT algorithm, as described in the previous chapter.
The first set of experiments performed, in order to test the validity of the algorithm overwhelmingfind that the algorithm does compute the Discrete Fourier Transform on three sufficiently differentwaveforms, and can be accepted as a method for computing the Discrete Fourier Transform. Themean square errors calculated confirm this result, all being fairly close to the expected 10−15 degreeof accuracy, as identified in the previous chapter. During the development process, as illustrated inthe results, this experiment proved a useful too in developing the algorithm. Issues with how thedivide and conquer and unscrambling operations were discovered and solved using the “eye-ball”test.
The second set of results indicate that the performance of the parallel and sequentially model ofthe algorithms converge, as the size of the direct DFT used in the algorithm is increased. It isexpected that the sequential algorithm would slow down as the DFT size is increased - the numberof multiplications required is being increased exponentially. As the size of the DFT is increased,the parallel algorithm starts to become more efficient, and starts performing comparatively to thesequential algorithm, because more of the algorithm is being performed in parallel.
From a DFT size of 2 to 512, for the 1024 sample input data set, the sequential algorithm sees a×26.41 nett slow down, while the parallel algorithm sees a ×1.6 nett speed up. As an even moredramatic speed up is seen for the smaller data set, this suggests that the parallel algorithm makesefficient use of larger DFT sizes, and given the overhead in parallising the algorithm, is probablyseeing a speed up compared to the sequential algorithm.
The timing results for the parallel algorithm are erratic, which is due to the method by whichmultiprocessing is implemented in Python, which is still very new[6, 1]. Furthermore the limitednumber of CPUs used does hinder the simulation of a truly parallel environment.
The final set of results show that the error for the parallel implementation, while the sequentialimplementation becomes unstable as the DFT used grows too large. This is to be expected, as
36

rounding errors are able to accumulate in a single thread of execution, while expect separate andisolated in the many threads of the parallel execution. This furthermore demonstrates that theparallel implementation of this algorithm can computer the DFT with an acceptable degree oferror.
5.2 Specification Fulfilment
The Fundamental Specification was that an algorithm for computing the Discrete Fourier Trans-form Algorithm which can be scaled to the user’s requirement was created. This need was fulfilled.The Algorithm described in the previous chapters is adaptable to any size of input dataset, andcomputes that transform within acceptable accuracy. This Algorithm is suitable for the FPGAplatform, as a working, analogously parallel model has been created of it.
Furthermore, the implicit need for this algorithm to be efficient on the FPGA platform, showsstrong signs of being fulfilled, as the proposed algorithm becomes more efficient when more parallelresources are made available to it. The resources required by this algorithm is directly related tothe size of the datasets concerned, also satisfying that aspect of scalability.
The Algorithm was developed as fully as possible in the short space available, by designing forthe FPGA platform, as opposed to on it. This was a deliberate design trade-off, considering thatmany FPGA FFT implementations exist, while the set of scalable FFT for FPGAs algorithms isrelatively small.
Overall this project fulfilled the design specification identified as best as possible, while remainingwithin constraints.
5.3 Concluding Remarks
‘Woolly Thinking. Which is like Fuzzy Logic, only less so.’ - Terry Pratchett[25]
This final section describes the experience gained from this project, while also identifying the pathfuture work based upon this project should take.
5.3.1 Lessons learnt
1. Much can be learned about the nature of a project by truly grappling with what is generallyaccepted as the best solution to that problem, as FFTs are for DFTs. Simply using thatsolution doesn’t necessarily lend that insight.
2. This project attempted to use a flexible platform to provide a flexible solution as per theuser’s requirement. However, there are always constraints, such as hardware multipliers,which have to be considered to obtain the best result.
3. Any decent solution to a problem needs to be equally grounded in theory and empiricalexperimentation.
5.3.2 Further Work
‘The thing about stories is that you have to pick the ones that last.’ - Terry Pratchett[25]
A more reliable parallel model should be developed, in a programming language with more matureparallel support, such as C. From this model, the performance of the algorithm may be better anal-ysed, completely verifying the underlying assertion that the Algorithm reduces the sequentionalityof the FFT algorithm by introducing a direct DFT computation.
37

Then a prototype of the algorithm, for a fixed size input sample, with a fixed number of multipliersshould be implemented on the FPGA, in order to gauge how effective the algorithm is on itsintended platform. From this prototype, a clear idea of the performance and efficiency of thisalgorithm against other FPGA FFT implementations can be developed.
Finally a software tool for generating hardware code as specified by this algorithm, according tothe user’s data set size needs and the resources available on the target FPGA should be created,to truly automate the process of creating a scalable Discrete Fourier Transform Algorithm for theFPGA.
38

Bibliography
[1] October 2009. URL http://docs.python.org/library/multiprocessing.html.
[2] URL http://www.cmlab.csie.ntu.edu.tw/cml/dsp/training/coding/transform/fft.html.
[3] John R. Buck Alan V. Oppenheim, Ronald W. Schafer. Discrete-time signal processing. Pren-tice Hall, 2 edition, 1999.
[4] Gene M. Amdahl. Validity of the single processor approach to achieving large scalecomputing capabilities. In AFIPS ’67 (Spring): Proceedings of the April 18-20, 1967,spring joint computer conference, pages 483–485, New York, NY, USA, 1967. ACM. doi:10.1145/1465482.1465560. URL http://dx.doi.org/10.1145/1465482.1465560.
[5] Krste Asanovic, Ras Bodik, Bryan Christopher Catanzaro, Joseph James Gebis,Parry Husbands, Kurt Keutzer, David A. Patterson, William Lester Plishker, JohnShalf, Samuel Webb Williams, and Katherine A. Yelick. The landscape of par-allel computing research: A view from berkeley. Technical Report UCB/EECS-2006-183, EECS Department, University of California, Berkeley, 2006. URLhttp://www.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-183.html.
[6] David Beazley. Inside the python gil. Presentation, June 2009.
[7] Yingning Peng Bin Zhou and David Hwang. Pipeline fft architectures optimized for fpgas.International Journal of Reconfigurable Computing, 2009(219140):9, 2009.
[8] C Burrus. The cooley-tukey fast fourier transform algorithm, September 2009. URLhttp://cnx.org/content/m16334/1.13/.
[9] C. Burrus. The prime factor and winograd fourier transform algorithms, September 2009.URL http://cnx.org/content/m16335/1.9/.
[10] I. Selesnicl C. Burrus. Winograd’s short dft algorithms, September 2009. URLhttp://cnx.org/content/m16333/1.13/.
[11] Chu Chad, Zhang Qin, Xie Yingke, and Han Chengde. Design of a high performance fft pro-cessor based on fpga. In Design Automation Conference, 2005. Proceedings of the ASP-DAC2005. Asia and South Pacific, volume 2, pages 920–923 Vol. 2, Jan. 2005. doi: 10.1109/ASP-DAC.2005.1466489.
[12] James W. Cooley and John W. Tukey. An algorithm for the machine calculation of complexfourier series. Mathematics of Computation, 19(90):297–301, 1965. ISSN 00255718. URLhttp://www.jstor.org/stable/2003354.
[13] Xilinx Corporation. Virtex-5 family overview. Datasheet, February 2009.
[14] P. Duhamel and M. Vetterli. Fast fourier transforms: a tutorial review and a state of the art.Signal Process., 19(4):259–299, 1990. ISSN 0165-1684. doi: http://dx.doi.org/10.1016/0165-1684(90)90158-U.
39

[15] Matteo Frigo and Steven G. Johnson. The design and implementation of FFTW3. Proceedingsof the IEEE, 93(2):216–231, 2005. Special issue on “Program Generation, Optimization, andPlatform Adaptation”.
[16] M.E. Grandmaison, J. Belzile, C. Thibeault, and F. Gagnon. Reconfigurable and efficientfft/ifft architecture. In Electrical and Computer Engineering, 2004. Canadian Conference on,volume 2, pages 1115–1118 Vol.2, May 2004.
[17] Grant Hampson. Implementation of a single fft processor, July 2002. URLhttp://esl.eng.ohio-state.edu/ rstheory/iip/fftimplem.pdf.
[18] R. Hartenstein. A decade of reconfigurable computing: a visionary retrospective. In DATE’01: Proceedings of the conference on Design, automation and test in Europe, pages 642–649,Piscataway, NJ, USA, 2001. IEEE Press. ISBN 0-7695-0993-2.
[19] Preston A. Jackson, Cy P. Chan, Jonathan E. Scalera, Charles M. Rader, and M. Michael Vai.A systolic fft architecture for real time fpga systems,” high performance embedded computingconference (hpec04. In In High Performance Embedded Computing Conference (HPEC04,2004.
[20] Douglas Jones. Decimation-in-frequency (dif) radix-2 fft, September 2006. URLhttp://cnx.org/content/m12018/1.6/.
[21] Douglas Jones. Efficient fft algorithm and programming tricks, February 2007. URLhttp://cnx.org/content/m12021/1.6/.
[22] Eric Jones, Travis Oliphant, Pearu Peterson, et al. SciPy: Open source scientific tools forPython, 2001–. URL http://www.scipy.org/.
[23] Uwe Meyer-Baese. Digital signal processing with field programmable gate arrays, volume 3,Illustrated. Springer, 2007.
[24] Russell J. Petersen and Brad L. Hutchings. An assessment of the suitability of fpga-basedsystems for use in digital signal processing. In in Digital Signal Processing. In 5th InternationalWorkshop on Field-Programmable Logic and Applications, pages 293–302, 1995.
[25] Terry Pratchet. The Wit and Wisdom of Discworld. Corgi, corgi edition, 2008.
[26] Markus Püschel, José M. F. Moura, Jeremy Johnson, David Padua, Manuela Veloso,Bryan Singer, Jianxin Xiong, Franz Franchetti, Aca Gacic, Yevgen Voronenko, Kang Chen,Robert W. Johnson, and Nicholas Rizzolo. SPIRAL: Code generation for DSP transforms.Proceedings of the IEEE, special issue on “Program Generation, Optimization, and Adapta-tion”, 93(2):232– 275, 2005.
[27] Daniel N. Rockmore. The fft: An algorithm the whole family can use. Com-puting in Science and Engineering, 2(1):60–64, 2000. ISSN 1521-9615. doi:http://doi.ieeecomputersociety.org/10.1109/5992.814659.
[28] Ivan W. Selesnick and C. Sidney Burrus. Extending winograd’s small convolution algorithmto longer lengths. In Proc. IEEE Intl. Symposium on Circuits and Systems, pages 449–452,1994.
[29] Andrew Crosland Sheac Yee Lim. Implementing fft in an fpga co-processor. DSP ApplicationsUsing FPGAs 1, Altera Corporation, 101 Innovation Drive, San Jose, CA 95134, May 2005.
[30] Li Tan. Digital Signal Processing: Fundamentals and Applications. Elsevier, San Diego, CA,2008.
[31] I.S. Uzun and A.A.A. Bouridane. Fpga implementations of fast fourier transforms forreal-time signal and image processing. In Field-Programmable Technology (FPT), 2003.Proceedings. 2003 IEEE International Conference on, pages 102–109, Dec. 2003. doi:10.1109/FPT.2003.1275737.
40

[32] I.S. Uzun, A. Amira, A. AhmedSaid, and F. Bensaali. Towards a general framework foran fpga-based fft coprocessor. In Signal Processing and Its Applications, 2003. Proceed-ings. Seventh International Symposium on, volume 1, pages 617–620 vol.1, July 2003. doi:10.1109/ISSPA.2003.1224779.
[33] S. Winograd. On computing the discrete fourier transform. Mathematics of Computation, 32(141):175–199, 1978.
41

Appendix A - Sequential PrototypeScript
#Gordon Inggs#INGGOR001#September 2009#sequen t ia l_pro to type . py − Sequen t i a l Prototype Sc r i p t f o r Sca l a b l e DFT Algorithm
for FPGA#This Sc r i p t demonstrates the hybr id DFT−FFT algor i thm proposed fo r the FPGAimport s c ipyimport matp lo t l i b . pyplot as p l timport numpyimport randomimport timeimport sys
def tw idd l e_fac to r s (N, stage_length ) :"""Function� f o r �Computing�Twiddle� Factors �need�during �Divide �and�Conquer�
Operat ions .�������� Parameters� are �N�−� l ength � o f � input �data� s e t � f o r �Divide �and�Conquer , �and� the
� l ength � o f � that � pa r t i c u l a r � s tage """
segments = 2∗numpy . p i /NWn = numpy . cos ( segments )−1.0 j ∗numpy . s i n ( segments ) #Computing Constant va lue
f o r Wt f = [ ]s tage = numpy . l og (N/ stage_length ) /numpy . l og (2 ) #Ca lcu l a t ing which s tage o f
the d i v i d e and conquer opera t ion t h i s i s
for i in range ( stage_length ) : #For the l eng t h o f the stage , each tw idd l ef a c t o r i s c a l c u l a t e d
t f . append (pow(Wn, i ∗pow(2 , stage −1) ) )
return t f #l i s t o f tw i dd l e f a c t o r s i s re turned
def DFT( data ) :"""Function� f o r �Computing� the �DFT, � given �a� datase t �data"""segments = 2∗numpy . p i / l en ( data ) #Ca lcu l a t ing Twiddle Factors f o r DFTWn = numpy . cos ( segments )−1.0 j ∗numpy . s i n ( segments )t f = [ ]
for i in range ( l en ( data ) ) : t f . append (pow(Wn, i ) )
d f t = [ ]for w in t f :
temp = 0n = 0
for d in data :temp += d∗pow(w, n)n += 1d f t . append ( temp)
return d f t
42

#Star t o f Sc r i p ti f ( l en ( sys . argv )<3) : print "Usage� o f � sequent ia l_prototype . py : \ nsequent ia l_prototype
. py� [ s i z e � o f � input �data ] � [ s i z e � o f �DFT] "
else :#Source Datas i g n a l =[ ]number_samps = sys . argv [ 1 ] #Length o f sample be ing operated on i s g iven in
command l i n e
s i gna l_ f r eq = 1 #Creating a s inuso idsamp_freq = 20for i in range (number_samps ) : s i g n a l . append ( s c ipy . s i n (2∗ s c ipy . p i ∗ s i gna l_ f r eq
/samp_freq∗ i ) ) #generate a s inuso id at s i gna l_freq , sampled atsamp_freq
#Hybrid FFT−DFT Algorithmnum_multi = sys . argv [ 2 ] #DFT s i z e g iven by second command l i n e argumentnum_stages = in t (numpy . c e i l (numpy . l og (number_samps/num_multi ) /numpy . l og (2 ) )
)+1 #Ca lcu l a t ing number o f s t a g e s requ i r ed
s tar t_t = time . time ( ) #s t a r t o f t iming opera t ion
#Divide and Conquer Operationsubarrays = [ s i g n a l ] #Sta r t i n g out with the complete s i g n a lfor i in range (1 , num_stages ) : #Loop fo r each s tage
stage_length = number_samps/(pow(2 , i ) ) #Ca lcu l a t ing the l eng t h o fthe subarrays at t h i s l en g t h
temp = [ ]for subset in subarrays : #Breakdown of each subarray in to two
f u r t h e r subarraysupper = numpy . array ( subset [ : s tage_length ] ) #s p l i t t i n g
subarray in to upper and lower par t s o f b u t t e r f l ylower = numpy . array ( subset [ stage_length : ] )
temp . append ( l i s t ( upper+lower ) )#upper branch o f b u t t e r f l y i ssummation
temp . append ( l i s t ( ( upper−lower ) ∗ tw idd l e_fac to r s (number_samps, stage_length ) ) ) #Lower par t o f the b u t t e r f l y i smu l t i p l i e d by tw i dd l e f a c t o r
subarrays = temp #the subarrays r ep l a ce the l a r g e r the su b s e t s
temp = subarrayssubarrays = [ ]
#DFT Operationfor t in temp : subarrays . append (DFT( t ) ) #Ca lcu l a t ing the DFTs of the
subarrays
#Recombining a l l o f the Datay = [ ]
for s in subarrays : y . extend ( s )#recombining a l l o f the subarrays
#Unscrambling the da ta s e tN_D = number_samps/num_multi #Number o f DFTs performed fo r a p a r t i c u l a r
s tage , s t a r t i n g with the f i n a l s t ageD_S = num_multi #The s i z e o f a DFT performed fo r a p a r t i c u l a r s tage
for k in range ( num_stages−1) : #For each s tage o f decimationtemp = [ 0 . 0 ] ∗ l en (y ) #Creating temp l i s t f o r p l a c ing the unscrambled
data in to
for i in range (N_D/2) : #I t e r a t i n g over the data in t h i s s t age o fdecimation
s t a r t = i ∗D_S∗2 #s t a r t and f i n i s h va lue s are not rearranged, and so are copied s t r a i g h t across
43

f i n i s h = i ∗D_S∗2 + D_S∗2−1temp [ s t a r t ] = y [ s t a r t ]temp [ f i n i s h ] = y [ f i n i s h ]
upper = s t a r t+1 #s t a r t i n g po in t f o r the upper and lowerbranches o f the rearrangement opera t ion are c a l c u l a t e d
lower = s t a r t+D_Sindex = s t a r t+1
for j in range (D_S−1) : #I t e r a t i n g over the remaining datain t h i s s t age o f decimation , and as s i gn ing va lue s tothe co r r ec t par t o f the da ta s e t
temp [ index ] = y [ lower ] #lower va lue s are f i r s t ,then the upper va lue
temp [ index +1] = y [ upper ]
index += 2 #ind i c e s are i t e r a t e dlower += 1upper += 1
y = temp #copy the unscrambled data to the output array
D_S = D_S∗2 #Increase the s i z e o f the "DFT" fo r the next s t age o fdecimation r e v e r s a l
N_D = N_D/2 #Half the number o f DFTs performed
f i n i s h_t = time . time ( ) #End of t iming opera t ionprint "Run�Time : �%f " % ( f in i sh_t−s tar t_t )
yy = l i s t ( s c ipy . f f t ( s i g n a l ) ) #Using numpy FFT package to prov ide re f e r enceprint "Mean�Square�Error : �%f " % ( abs (numpy . mean(numpy . array ( yy )−numpy . array
(y ) ) ) ) #Ca lcu l a t ing the mean square error , a measure o f accuracy
44

Appendix B - Full ExperimentalResults
Validity Experiments
1024 Sample Set
Figure 1: Transformed Sine Wave
45

Figure 2: Transformed Square Wave
(a) Transformed Gaussian Noise
Figure 3: Transformed Plots from Sequential Algorithm
46

(a) Transformed Sine Wave
(b) Transformed Square Wave
(c) Transformed Gaussian Noise
Figure 4: Transformed Plots from Parallel Algorithm
128 Sample Set
47

(a) Transformed Sine Wave
(b) Transformed Square Wave
(c) Transformed Gaussian Noise
Figure 5: Transformed Plots from Sequential Algorithm
48

(a) Transformed Sine Wave
(b) Transformed Square Wave
(c) Transformed Gaussian Noise
Figure 6: Transformed Plots from Parallel Algorithm
49

Parallelism Experiments
1024 Sample Set
DFT Size Sequential runtime Parallel runtime2 0.154483795166 18.32770085334 0.110455989838 3.494137048728 0.0956490039825 44.884290933616 0.112020015717 20.421461105332 0.173330068588 23.215334892364 0.29200720787 145.698745966128 0.658499002457 97.8129720688256 1.39305019379 93.4463920593512 4.07981801033 11.26510500911024 11.8366789818 15.3264350891
128 Sample Set
DFT Size Sequential runtime Parallel runtime2 0.015429019928 19.21709203724 0.0111548900604 18.09624409688 0.0101201534271 8.6558439731616 0.0134229660034 0.52330803871232 0.0248908996582 0.4742469787664 0.0638270378113 0.598129034042128 0.194833040237 0.290598869324
Accuracy Experiments
1024 Sample Set
DFT Size Sequential MSE Parallel MSE2 7.58483384218e-17 1.54842229671e-124 3.40415561247e-17 1.15514448449e-128 3.15767435345e-16 8.35221882313e-1416 1.22998958917e-15 1.1256895347e-1332 2.04290948371e-15 8.2562224767e-1464 2.18324747921e-14 1.05836948528e-13128 4.039144248e-14 1.93141040839e-13256 3.9829074919e-14 1.57161550525e-13512 3.47564459487e-12 1.30382407539e-131024 0.00166583910258 2.98226906991e-14
128 Sample Set
50

DFT Size Sequential runtime Parallel runtime2 1.99850436809e-16 1.36886619219e-134 2.48436020924e-16 1.10128260227e-138 1.01106434771e-15 4.5017653968e-1416 2.86884316922e-15 3.88256893274e-1432 6.75950893187e-15 5.08427732608e-1464 6.27950651062e-14 4.0605608495e-14128 0.0423199161563 2.80187023011e-14
51




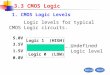























![Course admin stuff - Circuits and Systemscas.ee.ic.ac.uk/people/dt10/teaching/2014/hpce/hpce-lec1...Expectations for coursework • Coursework is not lab [1] –You have to manage](https://img.pdfslide.us/doc/110x75/5e27e89ddc200450f918867e/course-admin-stuff-circuits-and-expectations-for-coursework-a-coursework.jpg)