Embed Size (px)
Citation preview

Psychological Review1982, VoT 89, No. 5, 573-594
Copyright 1982 by the American Psychological Association, Inc.0033-295X/82/8905-0573$00.75
An Activation-Verification Model for Letter and WordRecognition: The Word-Superiority Effect
Kenneth R. Paap, Sandra L. Newsome, James E. McDonald, andRoger W. SchvaneveldtNew Mexico State University
An activation-verification model for letter and word recognition yielded predic-tions of two-alternative forced-choice performance for 864 individual stimuli thatwere either words, orthographically regular nonwords, or orthographically irreg-ular nonwords. The encoding algorithm (programmed in APL) uses empiricallydetermined confusion matrices to activate units in both an alphabetum and alexicon. In general, predicted performance is enhanced when decisions are basedon lexical information, because activity in the lexicon tends to constrain theidentity of test letters more than the activity in the alphabetum. Thus, the modelpredicts large advantages of words over irregular nonwords, and smaller advan-tages of words over regular nonwords. The predicted differences are close to thoseobtained in a number of experiments and clearly demonstrate that the effects ofmanipulating lexicality and orthography can be predicted on the basis of lexicalconstraint alone. Furthermore, within each class (word, regular nonword, irreg-ular nonword) there are significant correlations between the simulated and ob-tained performance on individual items. Our activation-verification model iscontrasted with McClelland and Rumelhart's (1981) interactive activation model.
The goal of the activation-verificationmodel is to account for the effects of priorand concurrent context on word and letterrecognition in a variety of experimental par-adigms (McDonald, 1980; Paap & Newsome,Note 1, Note 2; Paap, Newsome, & Mc-Donald, Note 3; Schvaneveldt & McDonald,Note 4). An interactive activation model, in-spired by the same set of sweeping goals, hasrecently been described by McClelland and
Portions of this research were presented at the meet-ings of the Psychonomic Society, St. Louis, November1980; the Southwestern Psychological Association,Houston, April 1981; and the Psychonomic Society,Philadelphia, November 1981. The project was partiallysupported by Milligram Award 1 -2-02190 from the Artsand Sciences Research Center at New Mexico StateUniversity. We would like to thank Ron Noel, Jerry SueThompson, and Wayne Whitemore for their contribu-tions to various stages of this research. Also, we appre-ciate the thoughtful reviews of a first draft of this paperprovided by Jay McClelland, Dom Massaro, and GarvinChastain.
Sandra Newsome is now at Rensselaer PolytechnicInstitute in Troy, New York. James McDonald is nowat IBM in Boulder, Colorado.
Requests for reprints should be sent to Kerineth R.Paap, Department of Psychology, Box 3452, New Mex-ico State University, Las Cruces, New Mexico, 88003.
Rumelhart (1981). Although the modelscomplement one another nicely with regardto some aspects, we will contrast the two ap-proaches in our final discussion and highlightthe very important differences between them.
The verification model was originally de-veloped to account for reaction time datafrom lexical-decision and naming tasks(Becker, 1976, 1980; Becker &Killion, 1977;McDonald, 1980; Schvaneveldt, & Mc-Donald, 1981; Schvaneveldt, Meyer, &Becker, 1976; Becker, Schvaneveldt, &Gomez, Note 5). Although the various dis-cussions of the verification model differabout certain details, there has been generalagreement about the basic structure of themodel. The basic operations involved inword and letter recognition are encoding,verification, and decision. We refer to themodel described in the present paper as theactivation-verification model to emphasizethe extensive treatment given to encodingprocesses that are based on activation of let-ter and word detectors. The activation pro-cess shares many features with the logogenmodel proposed by Morton (1969). In theactivation-verification model, we have at-tempted to formalize earlier verbal state-
573

574 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
ments about the verification model. As wewill show, this formalization permits a quan-titative evaluation of aspects of the modelwith data from the word-superiority para-digm.
The activation-verification model consistsof encoding, verification, and decision op-erations. Encoding is used to describe theearly operations that lead to the unconsciousactivation of learned units in memory. In thecase of words, the most highly activated lex-ical entries are referred to as the set of can-didate words.
Verification follows encoding and usuallyleads to the conscious recognition of a singlelexical entry from the set of candidates. Ver-ification should be viewed as an independent,top-down analysis of the stimulus that isguided by a stored representation of a word.Verification determines whether a refinedperceptual representation of the stimulusword is sufficiently similar to a particularword, supported by the evidence of an earlier,less refined analysis of the stimulus. This gen-eral definition of verification is sufficient forthe current tests of the activation-verifica-tion model, but more specific assumptionshave been suggested (e.g., Becker, 1980;McDonald, 1980; Schvaneveldt & Mc-Donald, 1981) and could be the focus of fu-ture work. For example, verification has beendescribed as a comparison between a pro-totypical representation of a candidate wordand a holistic representation of the test stim-ulus. However, within the framework of ourmodel, we could just as easily suggest thatverification involves a comparison betweenthe letter information available in an acti-vated word unit and the updated activity ofthe letter units in the alphabetum.
The verification process has been instan-tiated in a computer simulation that mimicsthe real-time processing involved in verifi-cation (McDonald, 1980). The simulatedverification process is a serial-comparisonoperation on the set of candidate words gen-erated during encoding. Thus, verificationresults in a match or mismatch. If the degreeof fit between the visual evidence and thecandidate word exceeds a decision criterion,then the word is consciously recognized. Ifthe match does not exceed the criterion, thenthe candidate is rejected and the next can-
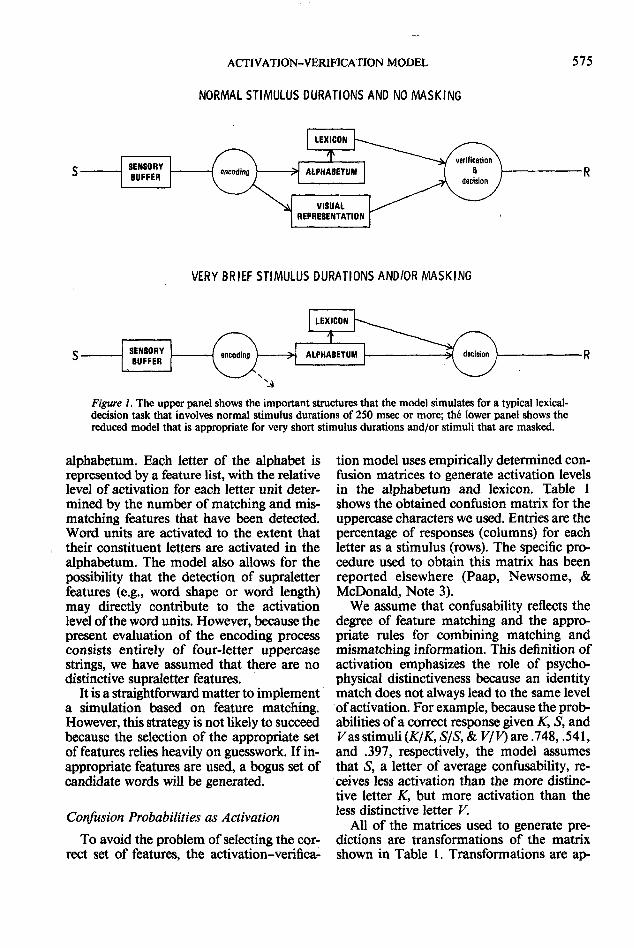
didate is verified. Semantic context affects thedefinition of the candidate set, whereas wordfrequency affects the order of verification forwords in the candidate set. Those words inthe candidate set that are related to the con-text will be verified before those that are not.If the verification process finds no matchamong the set of related words, it proceedsto check the remaining candidates in a de-creasing order of word frequency. These pro-visions produce semantic-priming and word-frequency effects in a simulated lexical-de-cision task. The upper panel of Figure 1depicts the important structures and pro-cesses that are simulated for a typical lexical-decision task that involves normal stimulusdurations of 250 msec or more.
The factors affecting the speed and accu-racy ofperformance in a particular paradigmdepend on whether decisions are based pri-marily on information from encoding orfrom verification. Because verification relieson a comparison that involves continuingperceptual analysis of the stimulus, the po-tential contribution of verification should beseverely attenuated whenever a backwardmask overwrites or erases the sensory buffer.Thus, paradigms that present masked letterstrings offer a potential showcase for the pre-dictive power of our simulated encoding pro-cess. The bottom panel of Figure 1 shows thereduced model that is appropriate for veryshort stimulus durations or stimuli that aremasked.
Of primary importance is the model's abil-ity to explain why letters embedded in wordsare recognized more accurately than lettersembedded in nonwords. The current versionof the model predicts not only this word-su-periority effect (WSE) as a general phenom-enon but also the relative performance forany given letter string. The predictions arederived from the following descriptions ofthe encoding process and the decision rule.
Encoding
Feature Matching
Like many others, we view encoding as aprocess that involves matching features tovarious types of units. The model assumestwo types of units: whole words stored in alexicon and individual letters stored in an
ACTIVATION-VERIFICATION MODEL
NORMAL STIMULUS DURATIONS AND NO MASKING
575
VERY BRIEF STIMULUS DURATIONS AND/OR MASKING
Figure 1. The upper panel shows the important structures that the model simulates for a typical lexical-decision task that involves normal stimulus durations of 250 msec or more; the lower panel shows thereduced model that is appropriate for very short stimulus durations and/or stimuli that are masked.
alphabetum. Each letter of the alphabet isrepresented by a feature list, with the relativelevel of activation for each letter unit deter-mined by the number of matching and mis-matching features that have been detected.Word units are activated to the extent thattheir constituent letters are activated in thealphabetum. The model also allows for thepossibility that the detection of supraletterfeatures (e.g., word shape or word length)may directly contribute to the activationlevel of the word units. However, because thepresent evaluation of the encoding processconsists entirely of four-letter uppercasestrings, we have assumed that there are nodistinctive supraletter features.
It is a straightforward matter to implementa simulation based on feature matching.However, this strategy is not likely to succeedbecause the selection of the appropriate setof features relies heavily on guesswork. If in-appropriate features are used, a bogus set ofcandidate words will be generated.
Confusion Probabilities as Activation
To avoid the problem of selecting the cor-rect set of features, the activation-verifica-
tion model uses empirically determined con-fusion matrices to generate activation levelsin the alphabetum and lexicon. Table 1shows the obtained confusion matrix for theuppercase characters we used. Entries are thepercentage of responses (columns) for eachletter as a stimulus (rows). The specific pro-cedure used to obtain this matrix has beenreported elsewhere (Paap, Newsome, &McDonald, Note 3).
We assume that confusability reflects thedegree of feature matching and the appro-priate rules for combining matching andmismatching information. This definition ofactivation emphasizes the role of psycho-physical distinctiveness because an identitymatch does not always lead to the same levelof activation. For example, because the prob-abilities of a correct response given K, S, andFas stimuli (K/K, S/S, & VIV) are .748, .541,and .397, respectively, the model assumesthat S, a letter of average confusability, re-ceives less activation than the more distinc-tive letter K, but more activation than theless distinctive letter V.
All of the matrices used to generate pre-dictions are transformations of the matrixshown in Table 1. Transformations are ap-
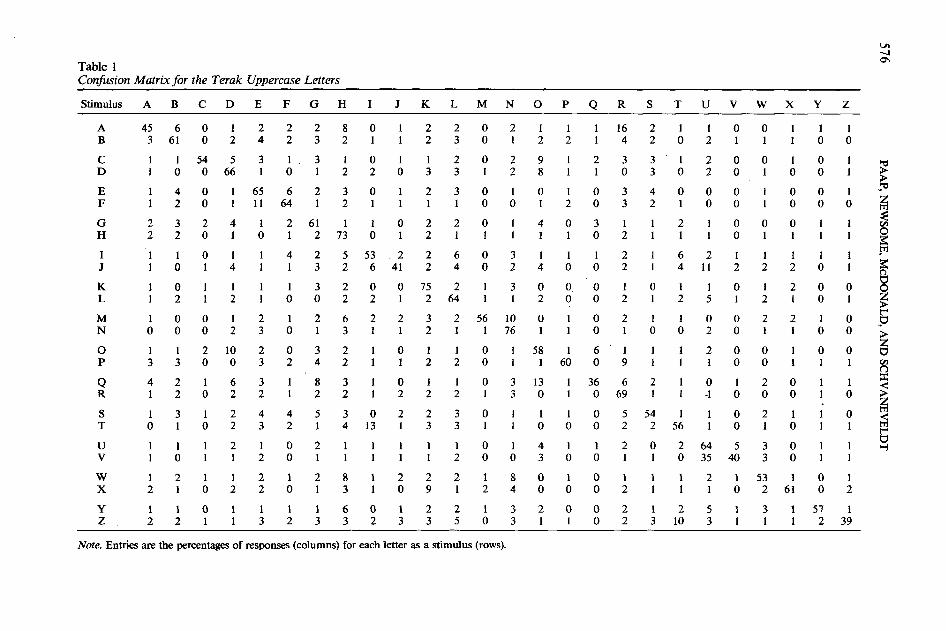
Table 1Confusion Matrix for the Terak Uppercase Letters
ON
Stimulus
AB
CD
EF
GH
IJ
KL
MN
0P
QR
ST
UV
wX
YZ
A
453
11
11
22
11
11
10
13
41
10
11
12
12
B
661
10
42
32
10
02
00
13
22
31
10
21
12
C
00
540
00
20
01
11
00
20
10
10
1110
01
D
12
566
11
41
14
12
12
100
62
22
21
12
11
E
24
31
6511
10
11
11
23
23
32
43
12
22
13
F
22
10
664
21
41
10
10
02
11
42
00
10
12
G
23
31
21
612
23
30
21
34
82
51
21
21
13
H
82
12
32
173
52
22
63
22
32
34
11
83
63
I
01
02
01
10
536
02
21
11
11
013
11
11
02
J
11
10
11
01
. 241
01
21
01
02
21
11
20
13
K
22
13
21
22
22
752
32
12
12
23
11
29
23
L
23
23
31
21
64
264
21
12
12
33
12
21
25
M
00
01
00
01
00
11
561
00
01
01
00
12
10
N
21
22
10
11
32
31
1076
11
33
11
10
84
33
O
12
98
01
41
14
02
01
581
130
10
43
00
21
P
12
11
12
01
10
00
111
60
11
10
10
10
01
Q
1121
00
30
10
00
00
60
360
00
10
00
00
R
164
30
33
12
22
12
21
19
669
52
21
12
22
S
22
33
42
11
11
01
10
11
21
542
01
11
13
T
10
10
0121
64
12
10
11
11
156
20
11
210
U
12
22
00
11
211
15
02
21
04
11
6435
21
53
V
01
00
00
00
12
01
00
00
10
00
540
10
11
W
0101110112
12
21
00
20
21
33
532
31
X
11
10
00
01
12
21
21
11
00
10
00
161
11
Y
10
00
00
11
10
00
10
01
00
572
Z
10
1110
11110100
01
10
011112
139
>
Z>
S
08i-m
§̂e5>§o<
<wrD
Note. Entries are the percentages of responses (columns) for each letter as a stimulus (rows).

ACTIVATION-VERIFICATION MODEL 577
plied to model any variable that is assumedto affect stimulus quality. For example, if theonset asynchrony between stimulus and maskis greater than the 17 msec used to generatethe percentages shown in Table 1, then thevalues on the main diagonal (for correct re-sponses) should be increased, whereas the off-diagonal values (for incorrect responses) aredecreased. The particular adjustment usedincreases each correct response percentage bya percentage of the distance to the ceiling anddecreases each incorrect response percentageby a percentage of the distance to the floor.The increments and decrements are such thatthe rows always sum to 100%. The procedureis reversed when stimulus quality is degradedrather than enhanced.
Another effect that the model can captureby appropriate transformations of the basicmatrix is loss of acuity for letters at greaterdistances from the average fixation point. Allof the predictions reported later access sep-arate matrices for each of the four spatial
positions. The extent to which separate ma-trices improve the model's predictions de-pends on whether correlations between ob-tained and predicted data are based on allstimulus items or only those that test thesame target position. To demonstrate this wederived a single matrix in which each cellentry was the mean of the four confusionprobabilities found in the separate matrices.When the single matrix is used, correlationsbetween predicted and obtained perfor-mance are significantly higher for the subsetsof stimuli that all share the same target po-sition than across the entire set of stimuli.When separate confusion matrices are used,the correlation for the entire set of stimulirises to about the same level as the separatecorrelations on each position.
As an example of how the encoding pro-cess uses the confusion matrices, consider thepresentation of the input string PORE. As in-dicated in Figure 2, position-specific units inthe alphabetum are assumed to be activated
"PORE"SENSORY
BUFFER
f( MCI
^
J
~Ndinn 1oing l —
r^\
VISUALREPRESENTATION
X
LEXICON(GEOMETRIC MEANS)
PORE .533PORK . 276GORE . 275
BORE . 254
LORE . 245
POKE . 242}\\ m
ALPHABETUMENTRIES AND CONFUSION PROBABILITIES
Pos. 1 Pos. 2 Pos. 3 Pos. 4P .54 0 .66 R .58 E .39R .09 D .08 N .03 F .07B .04 a .04 H .03 s .05A .03 G .03 B .03 B .05B .03 . K .03 L .04H .02 , E .02 R .04L .02 . e .02 H .04
o .03K .03
Figure 2. Encoding the word PORE. (Activation strengths for letter units in the alphabetum are determinedby letter-confusion probabilities. Activation strengths for word units in the lexicon are determined bytaking the geometric mean of the corresponding letter-confusion probabilities.)

578 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
in direct proportion to their confusability. Inthe first position the input letter P activatesthe corresponding P unit the most (.538), theR unit more than any other remaining unit(.091), and several other units (G, A, B, H,and L) to lesser extents. Patterns of activationare established in a similar manner for theother three spatial positions.
Activity in the alphabetum continuouslyfeeds into the lexicon. The encoding algo-rithm estimates the activation strength foreach word in the lexicon by taking the geo-metric mean of the activity levels associatedwith the constituent letters. One consequenceof using the geometric mean is that one veryinactive letter unit (close to zero) may pre-vent activation of a potential word unit thatis receiving high levels of activation fromthree other letter units. This may mirror psy-chological reality because otherwise identicalversions of the model yield poorer fits to theobtained data if the geometric mean is re-placed by the arithmetic mean or the squareroot of the sum of squares (the vector dis-tance between another word and the inputword in a space generated from the letter-confusion probabilities).
The Word-Unit Criterion
The decision system does not monitor allof the activity in the lexicon. The model as-sumes that the activity in a word unit can beaccessed by the decision system only if thelevel of activation exceeds a preset criterion.The predictions reported in this paper are allbased on a word-unit criterion of .24. Withthis criterion word stimuli generate an av-erage of about 3.4 words in the candidate setcompared to about 2.1 words for stimuli thatare orthographically regular pseudowords. Ifthe word-unit criterion is raised, fewer wordswill be accessible to the decision system. Inour final discussion we will suggest that a highcriterion may offer an alternative explana-tion for the pseudoword-expectancy effectreported by Carr, Davidson, and Hawkins(1978).
For the example illustrated in Figure 2, sixword units exceed the criterion for the inputword PORE: PORE (.533), PORK (.276), GORE(.275), BORE (.254), LORE (.245), and POKE(.242). Nonwords can also activate the lexi-con through the same mechanism. For ex-
ample, when the pseudoword DORE is inputto the simulation, three word units exceeda geometric mean of .240: DONE (.268), LORE(.265), and SORE (.261). Nonwords withlower levels of orthographic structure tendto produce less lexical activity. For example,when EPRO (an anagram of PORE) is pre-sented to the encoding algorithm, no wordunits exceed the .240 criterion.
Decision
Decision Criterion
If the task requires detection or recogni-tion of a letter from the stimulus, the decisionprocess is assumed to have access to the rel-ative activation levels of all units in the al-phabetum and those units in the lexicon thatexceed the word-unit criterion. It is furtherassumed that when total lexical activity ex-ceeds some preset criterion, the decision willbe based on lexical rather than alphabeticevidence. This decision criterion is differentfrom the individual word-unit criterion, andthe distinction should be kept clearly inmind. Exceeding a word-unit criterion makesthat particular lexical entry accessible to thedecision system. Exceeding the decision cri-terion leads to a decision based on lexicalactivity rather than alphabetic activity.
It is advantageous to base a decision onlexical evidence when there is some minimalamount of activation, because many wordscan be completely specified on the basis offewer features than would be necessary tospecify their constituent letters when pre-sented in isolation. Accordingly, lexical can-didates will tend toward greater veracity thanalphabetic candidates whenever decisions aremade on the basis of partial information.
The specific decision rules used to predictperformance in a two-alternative, forced-choice letter-recognition task are as follows:For any stimulus, the predicted proportioncorrect (PPC) depends on contributions fromboth the lexicon and alphabetum. More spe-cifically, PPC is the weighted sum of theprobability of a correct response based onlexical evidence and the probability of a cor-rect response based on alphabetic evidence:
PPC = P(L) X P(C/L)
+ P(A) X P(C/A), (1)

ACTIVATION-VERIFICATION MODEL 579
where P(L) is the probability of a lexicallybased decision, P(C/L) is the conditionalprobability of a correct response given thata decision is based on the lexicon, P(A) is theprobability of an alphabetically based deci-sion, and P(C/A) is the conditional proba-bility of a correct response based on alpha-betic information. Because the decision foreach trial is made on the basis of either lexicalor alphabetic information, P(A) is equal to1 - P(L).
Correct Responses From the Lexicon
The probability of a correct response givena decision based in the lexicon is
P(C/L) = 1.0 X (Swc/Sw) + .5
X (Swn/Sw) + 0 X (SWj/Sw), (2)
where Swc is the activation strength of wordunits that support the target letter, Swn is theactivation strength of word units that supportneither the correct nor the incorrect alter-native, Sw; is the activation strength of wordunits that support the incorrect alternative,and Sw is the total lexical activity.
The general expression for P(C/L) shownin Equation 2 was selected for reasons ofparsimony and programming efficiency. Theequation can be viewed as the application ofa simple high-threshold model (Luce, 1963)to each lexical entry. When a word unit ex-ceeds the criterion, the decision system will(a) select the correct alternative with a prob-ability of 1.0 whenever the letter in the crit-ical position supports the correct alternative,(b) select the correct alternative with a prob-ability of 0.0 whenever the letter in the crit-ical position supports the incorrect alterna-tive, and (c) guess whenever the critical lettersupports neither alternative. The only addi-tional assumption required is that the deci-sion system combine the probabilities fromeach lexical entry by simply weighting themin proportion to their activation strengths.For the following examples, words had toexceed a criterion of .24 in order to be con-sidered by the decision system.
If the decision for any single trial is basedon lexical activity, our underlying processmodel assumes that something like Equation2 does apply. That is, we have adopted theworking hypothesis that decisions based on
unverified lexical evidence involve a weightedstrength of the word units supporting eachof the two-choice alternatives. Alternatively,P(C/L) could be viewed as the probability ofcertain word units being the most highly ac-tivated units on individual trials. We note asan aside that our general approach has beento find a set of simple algorithms (with plau-sible psychological underpinnings) that do agood job of predicting performance. An al-ternative approach is to begin with very spe-cific ideas about the underlying psychologicalprocesses and then derive algorithms to suitthese particular assumptions. We have shiedaway from this latter strategy in the beliefthat both the tests and selection of particularpsychological explanations would be easieronce we had developed a formal model thatpredicts performance in several paradigmswith a fair amount of success.
The factors that determine the probabilityof a correct response from the lexicon canbe easily understood by examining specificexamples. If the stimulus word PORE is pre-sented (see Figure 2) and the third positionis probed with the alternatives R and K, wehave
P(C/L) = 1 X (1.583/1.825) + .5
X (0/1.825)4-0 = .867. (3)
This relatively high probability of a correctresponse is reasonable because five of thehighly activated words (BORE, PORK, GORE,LORE, PORE) support the correct alternative,whereas only POKE supports the incorrectalternative. In general, P(C/L) will be .70 orgreater for words; but exceptions do occur.For example, when the word GONE is pre-sented to the simulation, the following words,with their activation strengths in parentheses,exceed the cutoff: DONE (.281), GONE (.549),TONE (.243), BONE (.278), CONE (.256), andLONE (.251). If the first position is probedwith the alternatives G and B, we have
P(C/L) = 1 X (.549/1.858) + .5
X (1.031/1.858)+ 0 = .57 (4)
Lower values of P(C/L) tend to occur whenthere is a highly activated word that supportsthe incorrect alternative and/or when thereare several highly activated words that sup-port neither alternative.

580 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
Correct Responses From the Alphabetum
The probability of a correct response givena decision based on the alphabetum is
P(C/A)= 1.0X(ac/Sa) + .5
X (San/Sa) + 0 X ta/Sa), (5)
where «c is the activation strength of the letterunit corresponding to the correct alternative,San is the activation strength of the letterunits that are neither the correct nor the in-correct alternative, and Sa is the total al-phabetic activity. The only difference be-tween the decision rule for the alphabetumand that for the lexicon is that alphabeticactivity is not filtered by a criterion.
Assuming that the third position is probedwith the alternatives R and K, the P(C/A) forthe stimulus word PORE is
P(C/A) = 1 X (.585/1.000) + .5
X(.390/1.000) + 0 = .780. (6)
This value would, of course, be the same forthe pseudoword DORE, the anagram EPRO,or any other stimulus that contains R in thethird position.
Probability of a Decision Based on theLexicon
For any given trial, it is assumed that adecision will be made on the basis of lexicalinformation if total lexical activity exceedsthe decision criterion. Given noise intro-duced by variations in the subject's fixationor attention, and within the visual processingsystem itself, it is reasonable to assume thata specific stimulus will exceed or fall shortof the decision criterion on a probabilistic,rather than an all-or-none, basis. Accord-ingly, the mathematical instantiation of ourverbal model estimates, for each stimulus,the probability that its lexical activity willexceed the decision criterion. This probabil-ity will, of course, depend on both the av-erage amount of lexical activity produced bythe stimulus in question and the currentvalue of the decision criterion.
The first step in estimating P(L) normal-izes the total lexical activity produced byeach individual stimulus to that stimulus thatproduced the greatest amount of lexical ac-
tivity. Of the 288 words that have been usedas input to the encoding algorithm, the wordSEAR has produced the greatest number ofwords above criterion (9) and the greatestamount of total lexical activity (2.779). Thus,normalization involves dividing the total lex-ical activity for a given stimulus by 2.779.
Normalization is simply a convenience toensure that the amount of lexical activitygenerated by each stimulus will fall in therange of 0 to 1 and, consequently, that P(L)will also be bounded by 0 and 1. Because thistransformation simply involves dividing bya constant, we are not altering the relativelexical strengths that were initially obtainedby summing the geometric means of allwords above the word-unit criterion. In anyevent, we certainly do not mean to infer thatsubjects must somehow know in advance thegreatest amount of lexical activity that theywill experience during the course of the ex-periment. Rather, we simply assume that to-tal lexical activity is one important deter-miner of P(L).
The contribution of the decision rule toP(L) is reflected by a second step that raiseseach of the normalized activation levels bya constant power between 0 and 1. Thisyields the estimated P(L) for each stimulus.Stringent decision criteria can be modeled byusing high exponents (near 1). This proce-dure generates a wide range of P(L) acrossitems, and a decrease in the average P(L).Lax decision criteria can be modeled by usinglow exponents (near 0). A very lax criterioncompresses the range toward the upperboundary and thus causes the mean P(L) toapproach 1. Consequently, when a very laxcriterion is used, P(L) tends to be quite highfor any level of lexical activity. Using an ex-ponential transformation is a convenient wayto operationalize decision rules as diverse as"use lexical evidence whenever it is avail-able" (exponents near 0) to "use lexical ev-idence only for those stimuli that producesubstantial amounts of lexical activity" (ex-ponents near 1). All of the predictions dis-cussed later are based on a constant value(.5) for this parameter.
Because P(L) is derived from total lexicalactivity, it will generally be the case that stim-uli like PORE that excite six word units abovethreshold will have higher probabilities than

ACTIVATION-VERIFICATION MODEL 581
stimuli like RAMP which produce only onesuprathreshold word unit. In summary, theprobability that a decision will be based onlexical evidence is estimated for each stim-ulus using the following equation:
P(L) = (7)
where W{ is the total lexical activity for stim-ulus i, Wmax is the total lexical activity for thestimulus producing the greatest activity, andthe exponent n is a parameter that reflectsthe stringency of the criterion. P(L) for thestimulus PORE would be
P(L) = (1.825/2.779)-5 = .810. (8)
When the exponent « is set to .5, f\L) forword stimuli will range from about .4 to 1.0,with a mean of about .6.
Finally, it is assumed that when total lex-ical activity is less than the criterion, the de-cision will, by default, be based on alphabeticinformation. Accordingly, the probability ofan alphabetic decision, P(A\ is
P(A)=l- P(L). (9)
Predicted Probability Correct
Table 2 uses Equation 1 to show the der-ivation of the overall probability of a correctresponse for two sets of stimuli. Each set con-sists of a word, a pseudoword that sharesthree letters in common with the word, andan anagram of the word. The first set was
chosen because it produces predictions thatare similar to most sets of words and non-words and illustrates why the model will yielddifferent mean PPCs for words, pseudo-words, and anagrams. The second set is ab-normal and illustrates some principles thataccount for variations within stimulus classes.
As exemplified by PORE, the probabilityof a correct response based on lexical evi-dence is usually greater than that based onalphabetic evidence. The overall proportioncorrect falls somewhere between the lexicaland alphabetic probabilities and will ap-proach the lexical value as P(L), the prob-ability of a lexical decision, increases. In gen-eral, words should provide better contextthan nonwords to the extent that (a) P(C/L) > P(C/A) and (b) P(L) is high. Becausethese conditions are met for the stimulusPORE, the model predicts a 4.2% advantageover the pseudoword DORE and a 6.6% ad-vantage over the anagram EPRO.
The model predicts that some words shouldactually produce word-inferiority effects. Thiscan only occur, as in the example LEAF, whenlexical evidence is poorer than alphabeticevidence. Because the probability of a lexicaldecision is estimated from total lexical activ-ity, regardless of the veridicality of that in-formation, the model predicts that LEAF willbe judged on the basis of the inferior lexicalevidence about two thirds of the time. Thisleads to a predicted 8.4% disadvantage rela-tive to the pseudoword BEAF and a 6.1% dis-advantage relative to the anagram ELAF.
Table 2Simulation of Word, Pseudoword, and Anagram Differences for Two Examples
Simulated values
Class Stimulus Alternatives WSE SPC = P(L) X P(C/L) + P(A) X P(C/A)
TypicalWordPseudowordAnagram
AtypicalWordPseudowordAnagram
POREDOREEPRO
LEAFBEAFELAF
R, KR, KR,K
F.PF, PF, P
+.042+.066
-.084-.061
.852
.810
.786
.621
.705
.682
= .810= .535= .000
= .591= .428= .000
X .867X.831X .000
X.677X .736X.OOO
+ .190+ .465+ 1.000
+ .323+ .572+ 1.000
X.786X.786X .786
X .682X .682X .682
Note. WSE = word-superiority effect; SPC is the simulated proportion correct; P(C/L) is the probability of a correctresponse from the lexicon; P(C/A) is the probability of a correct response from the alphabetum; and P(L) is theprobability of basing a decision on lexical information.

582 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
Test and Evaluation of the Model
The model can be tested at two levels.First, by averaging across stimuli in the sameclass, the model can be used to predict themagnitude of the WSE for words over pseu-dowords or words over anagrams. Second,the model should be able to predict item vari-ation within a stimulus class.
Four experiments provide the basis for thefollowing tests (Paap & Newsome, Note 1,Note 2; Paap, Newsome, McDonald, &Schvaneveldt, Note 6). All experiments usedthe two-alternative, forced-choice letter-rec-ognition task. Each experiment comparedperformance on a set of 288 four-letter wordsto a set of 288 nonwords. The nonwords usedin two of the experiments were orthograph-ically regular pseudowords. In the remainingtwo experiments, the nonwords were formedby selecting that anagram for each word stim-ulus that minimized the amount of ortho-graphic structure. The two alternatives se-lected for each stimulus both formed wordsfor word stimuli and nonwords for the non-word stimuli.
Word and Pseudoword Advantages
Our first approach to evaluating the modelwas to use the algorithm described in the in-troduction to predict the proportion correctfor each of the 288 words, pseudowords, andanagrams. The mean output of the model forwords, pseudowords, and anagrams is shownin Table 3. The simulation predicts a 2.8%advantage for words (.841) over pseudowords(.813), and an 8.6% advantage for words overanagrams (.755). These differences compare
favorably to the obtained WSEs of 2.6% and8.8%, respectively.
Across all 288 words, the number of lexicalentries exceeding the cutoff ranged from 1to 9, with a mean of 3.4. These word unitsconstrain the identity of the critical lettermore effectively than it is constrained by theactivity within the alphabetum. Thus, theword advantages predicted by the modeloccur because lexical information is used63% of the time and the mean probability ofa correct response from the lexicon (.897) isgreater than that based on the alpha-betum (.758).
The major reason why the model yieldslower proportions correct for nonwords thanwords is not the quality of the available lex-ical evidence, but rather its frequent absence.That is, the probability of a correct responsebased on lexical evidence for the 253 pseu-dowords that produce at least one wordabove threshold is nearly identical (about.90) to that for the 288 words. Similarly, P(C/L) for the 44 anagrams that produce, at leastone word above the cutoff is .94. Thus, thequantity and not the quality of lexical infor-mation is the basis for the WSE. Orthograph-ically regular pseudowords excite the lexiconalmost as much as words (2.1 vs. 3.4 entries)and lead to small word advantages, whereasorthographically irregular anagrams generatemuch less lexical activity (.2 vs. 3.4 entries)and show much larger word advantages.
Item-Specific Effects
The model's ability to predict performanceon specific stimuli is limited by the sensitivityand reliability of the data. Our previous workprovides two sets of word data and one set
Table 3Simulated Values for Words. Pseudowords, and Anagrams
Lexical class
WordsPseudowordsAnagrams
PPC
.841
.813
.755
P(C/L)
.897
.791
.144
Simulated values
P(C/A)
.758
.758
.758
P(L)
.634
.415
.073
NW
3.42.1.2
Note. PPC is the predicted proportion correct; P(C/L) is the probability of a correct response from the lexicon;P(C/A) is the probability of a correct response from the alphabetum; P(L) is the probability of basing a decisionon lexical information; and NW is the number of words that exceeded the criterion.

ACTIVATION-VERIFICATION MODEL 583
for each of the two types of nonwords. Eachof the 288 items in a set was presented to 24different subjects. This means that the ob-tained proportions correct for individualitems vary in steps of .04. Given these lim-itations, a correlation of data against dataprovides an index of the maximum amountof variation that could be accounted for bythe model. The correlation between the twosets of word data was .56. A similar deter-mination of the reliability of the pseudowordand anagram data yielded correlations of .48and .39, respectively. However, because only24 subjects saw each nonword stimulus, theselower correlations are due, in part, to the factthat each half consisted of only 12 observa-tions compared with the 24 available in theword analysis.
Table 4 shows the correlations between thevarious sets of obtained data and the valuesgenerated by the model. Because each cor-relation is based on a large number (288) ofpairs, significant values of r need only exceed.12. For all three stimulus classes, there aresignificant correlations between the obtaineddata and (a) the predicted proportion correct,(b) the probability of a correct response fromthe lexicon, and (c) the probability of a cor-rect response from the alphabetum. The cor-relations are quite high considering the lim-itations discussed above. For example, thecorrelation between the first set of word dataand the predicted proportion correct is .30compared to .56 for data against data. Takingthe ratio of the squared values of these cor-relations (.09 and .31, respectively) leads tothe conclusion that the model can accountfor 29% of the consistent item variation (both
correlations are based on 24 observations perdata point, and no correction for n is needed).
As a final check on the model's ability topredict variation within words, the 288 wordswere partitioned into thirds on the basis oftheir predicted performance, and mean ob-tained performance was computed for eachgroup. Obtained proportion correct for theupper third was .85 compared to .82, and.78 for the middle and bottom thirds.
The source of the model's success in pre-dicting interitem variation is difficult to trace.Because decisions about word stimuli aremade on the basis of lexical evidence moreoften than on alphabetic evidence, P(L) =.63, it is clear that both the lexicon and al-phabetum contribute substantially to theoverall PPC, and accordingly, both branchesmust enjoy some predictive power in orderto avoid diluting the overall correlation be-tween obtained and predicted correct. Fur-thermore, it should be noted that the corre-lation between P(C/L) and the obtained datais quite sensitive to the word-unit criterion(because this affects the average number ofcandidate words). This is consistent with theview that the predictive power of the lexicalbranch primarily depends on getting the cor-rect set of candidate words and is not a simpletransformation of alphabetic activity.
The item-specific predictions are far fromexact, but they are quite encouraging becauseour lexicon contains only the 1,600 four-let-ter words listed in the Kucera and Francis(1967) norms. Because P(C/L) for any itemis determined by the activation strengths ofvisually similar words in the lexicon, sub-stantial variation for a particular item can be
Table 4Correlations Between Obtained Proportion Correct and Simulated Values
Stimulustype
WordsSetlSet 2
AnagramsPseudowords
PPC
+.30+.26+.37+.35
P(C/L)
+.28+.23+.21+.17
Simulated values
P(C/A)
+.29+.27+.34+.38
P(L)
-.05+.01+.17+.15
NW
-.05.00
+.14+.16
Note. PPC is the predicted proportion correct; P(C/L) is the probability of a correct response from the lexicon;P(C/A) is the probability of a correct response from the alphabetum; P(L) is the probability of basing a decisionon lexical information; and NW is the number of words that exceeded the criterion.

584 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
introduced if just one highly similar word iseither added of deleted from the lexicon.
Lexical Constraint
The test words consisted of the 288 wordsused by Johnston (1978) in his influential testof sophisticated-guessing theory. Half of thewords were defined by Johnston as high-con-straint words, and the other half as low-con-straint words. Johnston assumed that lexicalknowledge will constrain the identity of thecritical letter in inverse proportion to thenumber of different letters that will formwords given the remaining context. For ex-ample, the context _ATE supplies much lessconstraint than the context _RIP because 10letters form words in the former context, butonly three in the latter. Johnston rejected thehypothesis that lexical constraint contributesto the WSE because performance on thehigh-constraint words (.77) was slightly lowerthan performance on the low-constraintwords (.80).
Our model shows that when the same par-tial information, in the form of letter-con-fusion probabilities, is provided to both thealphabetum and lexicon, lexical activity cansupport the critical letter more often thandoes the alphabetic activity. This differencebetween P(C/L) and P(C/A) provides an in-dex of the potential amount of lexical benefitfor any word. We view this measure of lexicalbenefit as an alternative definition for theglobal concept of lexical constraint. Thus,Johnston's (1978) conclusion that lexicalconstraint does not contribute to the WSEmay have been premature and the productof a less appropriate definition of lexical con-straint. Concerns that we have raised previ-ously (Paap & Newsome, 1980a) can now beextended in the context of our model and thealternative definition for lexical constraint.
Johnston (1978) obtained both free-recalland forced-choice responses. First, considerthose trials on which the three context letterswere correctly reported. The conditionalprobabilities of a correct critical-letter reportgiven a correct report of all three context let-ters were .90 and .86 for high- and low-con-straint pairs, respectively. This is extremelyhigh performance for free recall, and any sig-nificant differences due to lexical constraint
may be obscured by a ceiling effect. More-over, if one assumes that the same stimulipresented to the same subjects under thesame conditions would yield performancedistributions with some variability, then itwould seem quite reasonable to characterizethese trials as samples that have been drawnfrom the upper end of the distribution andthat reflect trials on which the level of visualinformation was unusually high.
When stimulus information is high, theeffects of lexical constraint may be low. Ourmodel makes exactly this prediction. If stim-ulus quality is enhanced by transforming thecorrect responses in the confusion matricesupward, and the incorrect responses down-ward, the difference between the lexical andalphabetic branches disappear. For example,if stimulus quality is raised to the extent thatthe probability of a correct response basedon the alphabetum is increased from .758 to.889, the advantage of lexical over alphabeticevidence decreases from 13.9% to -.5%.
When stimulus information is low (whenonly a few features are detected in each letterlocation), lexical knowledge should be morebeneficial. However, when the subject hasonly partial information about each letter,Johnston's (1978) procedure for computinglexical constraint (based on complete knowl-edge of the three context letters and no in-formation about the target) may no longercorrelate with the lexical constraint providedby a partial set of features at each letter lo-cation. Our analysis completely supports thishypothesis: Johnston's high-constraint wordsyield a PPC of .830 compared to .852 for thelow-constraint set. Furthermore, the averagenumber of word units exceeding criterion isexactly the same (3.4) for both sets of words.It is clear that there is absolutely no relationbetween the number of letters that will forma word in the critical position of a test word(Johnston's definition of lexical constraint)and the number of words that are visuallysimilar to that word (the candidate words inthe activation-verification model).
In contrast, when lexical constraint is de-fined as the amount of lexical benefit, theeffects of lexical constraint are apparent inthe data. For each of the 288 stimuli of eachtype, we subtracted P(C/A) from P(C/L) andthen partitioned the stimuli into thirds on

ACTIVATION-VERIFICATION MODEL 585
the basis of these differences. For both setsof word data and the pseudoword data, ob-tained performance on the most highly con-strained third is about 5% greater than thaton the bottom third. There were no differ-ences for the anagrams, but this is to be ex-pected because our anagrams rarely activatethe lexicon. Although the effect of lexicalconstraint (denned as lexical benefit) is small,it appears in all three data sets where it waspredicted to occur. Furthermore, this mea-sure provides a pure index of the predictivepower of the lexical branch of our model.This is true because the psychophysical dis-tinctiveness of the target letter is removed bysubtracting P(C/A). Differences in lexicalconstraint are due only to the mixture of can-didate words that support the correct, incor-rect, or neither alternative.
Another way of appreciating the role oflexical constraint in our data is to comparethe high-constraint (top third) and low-con-straint (bottom third) words to the high- andlow-constraint anagrams. The magnitude ofthe WSE is about 10% for the high-constraintset compared to only 5% for the low-con-straint set. One might speculate that a com-parable effect of lexical constraint could befound in Johnston's (1978) data if they wereanalyzed on the basis of our new measure oflexical constraint.
Orthography
Massaro and his associates (Massaro, 1973,1979; Massaro, Taylor, Venezky, Jastrzemb-ski, & Lucas, 1980; Massaro, Venezky, &Taylor, 1979), have convincingly advocateda model in which letter recognition is guidedby inferences drawn from knowledge of or-thographic structure. Our model has no pro-vision for the dynamic use of orthographicrules, nor does it assume a syllabary of com-monly occurring letter clusters that could beactivated by, or in parallel with, the alpha-betum. Although it is clear that the modeldoes not need any orthographic mechanismin order to predict the advantage of the reg-ular pseudowords over the irregular ana-grams, the present experiments offer a largeset of stimuli and data to assess the possiblecontribution of orthography within the word,pseudoword, and anagram classes.
In accordance with the procedure advo-cated by Massaro, the sum of the logarithmsof the bigram frequencies (SLBF) wascomputed for each stimulus. The correla-tions between SLBF and the two sets of worddata were . 11 and .04. Apparently, there isno relation between this measure of ortho-graphic structure and performance on indi-vidual items. This is also true for the correla-tion between SLBF and the pseudoword data(r = .09). In contrast, the correlation betweenSLBF and the anagram data is much higher(r = .30). This pattern of correlation is similarto a previous analysis of orthographic struc-ture (Paap & Newsome, 1980b) and furthersupports our conclusion that orthographicstructure will predict performance only whenvery low levels are compared to somewhathigher levels of structure.
Although current data do not permit oneto rule out the use of orthographic rules inletter and word recognition, our model showsthat both the lexical (advantage of words overwell-formed pseudowords) and orthographic(advantage of pseudowords over irregularstrings) component of the WSE can be pre-dicted on the basis of lexical constraint alone.Furthermore, lexical access may also accountfor the apparent effect of orthography on an-agram performance. In the activation-veri-fication model, the contribution of lexicalactivity is determined by the probability ofa decision based on the lexicon, P(L), andthe probability of a correct response basedon lexical activity, P(C/L). The correlationbetween orthography (SLBF) for each ana-gram and its corresponding P(L) is .49. Fur-thermore, the correlation between SLBF andP(C/L) is also .49. In terms of our model,there is no direct effect of orthographic struc-ture on letter recognition. Rather, it is simplythe case that extremely irregular letter stringsrarely excite the lexicon and, therefore, can-not benefit from lexical access. On the otherhand, less irregular anagrams will occasion-ally activate a word unit, and that unit islikely to support the correct alternative.
Recently, Massaro (Note 7) conductedsimulations of his fuzzy logical model thatare similar to the activation-verificationmodel in that top-down evidence (e.g., logbigram frequencies) is combined with an in-dex of visual evidence based on letter-con-

586 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
fusion probabilities. For six-letter anagramsvisual evidence alone is a poor predictor; thecorrelation between predicted and observedresults for 160 anagrams is only .08. Addingthe log-bigram frequency component to themodel raises the correlation to .59. Orthog-raphy does seem to have a considerable im-pact and suggests the possibility that percep-tion of longer strings may-be influenced byorthographic regularity to a much greaterextent than is perception of shorter strings.On the other hand, it is entirely possible thatthe activation-verification model may alsobe able to account for the orthographic ef-fects in Massaro's six-letter anagrams on thebasis of lexical access and without recourseto any orthographic mechanism.
The outcome of Massaro's simulation forthe 40 six-letter words is less informative.The correlation between obtained data andthat predicted from the visual componentalone was .48 compared to only .43 for themodel that combines both the visual andorthographic components. This suggests thatthe impact of orthography on the perceptionof six-letter words may be quite weak, but itmay be important to note that performancelevels were not at all comparable for thewords (90% correct) and anagrams (75% cor-rect).
Comparisons of the Interactive Activationand Activation-Verification Models
McClelland and Rumelhart (1981; Ru-melhart & McClelland, 1982) have proposedan interactive activation model that extendsto the same wide scope of letter and wordrecognition paradigms that have been the tar-get of our activation-verification model.Both models share many basic assumptions:(a) that stimulus input activates spatiallyspecific letter units, (b) that activated letterunits modulate the activity of word units,and (c) that letter and word recognition arefrequently affected by important top-downprocesses. These generally stated assump-tions permit both models to predict and ex-plain the effects of lexicality, orthography,word frequency, and priming. However, thespecific operations used to instantiate thesegeneral assumptions in McClelland and Ru-melhart's computer simulation and in our
computational algorithms offer a large num-ber of provocative differences with respect tothe specific mechanisms responsible for thevarious contextual phenomena. Further-more, the two models are not always equallyadept in accounting for the various contexteffects.
The Word and Pseudoword Advantage
The WSE is often characterized as con-sisting of two effects. The lexical effect refersto the benefits that accrue from accessing thelexicon and is estimated from the obtainedadvantage of words over well-formed pseu-dowords. The orthographic effect refers to thebenefits derived from the reader's knowledgeof orthographic redundancy and can be es-timated from the obtained advantage ofpseudowords over irregular nonwords. Boththe activation-verification and interactiveactivation models assume that lexical acti-vation accounts for both lexical and ortho-graphic effects.
In the interactive activation model, lexicalaccess facilitates letter recognition throughexcitatory feedback from activated wordunits to their constitutent letter units. Wordstimuli are very likely to activate word unitsthat reinforce the letters presented, therebyincreasing the perceptibility of the letters. Incontrast, irregular nonwords will rarely ac-tivate a word unit, and accordingly, the per-sistence of activity in the correct letters unitswill not be extended by feedback. Becausepseudowords share many letters in commonwith words, they too activate word units thatproduce excitatory feedback and strengthenthe letter units that give rise to them.
Given the detailed encoding assumptionsof the interactive activation model and theparticular set of parameter values needed topredict the basic pseudoword advantage,McClelland and Rumelhart conclude thatthe amount of feedback, and hence theamount of facilitation, depends primarily onthe activation of word units that share threeletters with the stimulus. They call the set ofwords that share three letters with the stim-ulus its neighborhood. The amount of facil-itation for any particular target letter will beprimarly determined by the number of wordunits in the neighborhood that support the

ACTIVATION-VERIFICATION MODEL 587
target ("friends") and the number that sup-port some other letter ("enemies").
This generalization provides a good basisfor comparing the two models, because theamount of facilitation produced by lexicalaccess in our model will be primarily deter-mined by the number of friends and enemiesin the candidate set generated by our encod-ing algorithm. The set of words in the neigh-borhood of a particular stimulus is likely tobe quite different from the set of candidatewords. One major reason for this (as pointedout earlier in the discussion of the geometricmean as a measure of word-unit activation)is that word units that share three letters withthe stimulus will fail to exceed the word-unitcriterion if the mismatching letter is not veryconfusable with the letter actually presented.For example, for the input string SINK withS as the test letter, our encoding algorithmgenerates only three friends (SING, SINE, andSINK) and four enemies (LINK, WINK, FINK,and RINK). In addition to all of these words,the neighborhood includes five new friends(SICK, SANK, SINS, SILK, and SUNK) and twonew enemies (PINK and MINK). Thus, theratio of friends to enemies is 3:4 for ourmodel compared to 8:6 for their model.
Using the candidate set generated by ourmodel and the neighborhood denned by asearch of our lexicon (the 1,600 four-letterwords in the Kucera and Francis, 1967,norms), we computed the proportion offriends for each stimulus according to eachof the two models. In order to compare thepredictive power of the two models, we thencorrelated the proportion of friends againstthe two sets of word data, the anagram data,and the pseudoword data. For all four casesthe proportion of friends in the candidate setyielded higher correlations than the propor-tion of friends in the neighborhood. The av-erage correlation for our model was .24 com-pared to .14 for the interactive activationmodel. In summary, our model seems tohave a slight edge in its ability to account forconsistent interitem variation that accruesfrom lexical access.
We were also curious as to the implicationsthat McClelland and Rumelhart's encodingassumptions would have for the average per-formance on our words, pseudowords, andanagrams. To this end the alphabetic branch
of our model was modified so that (a) theactivity of each word was boosted by .07 foreach matching letter and reduced by .04 foreach mismatching letter and (b) the word-unit criterion would be exceeded by all thoselexical entries that shared at least three lettersin common with the stimulus. The first mod-ification is based on the values of letter-to-word excitation and inhibition used byMcClelland and Rumelhart and amounts toassigning a strength of .28 to the word unitcorresponding to a word stimulus, and astrength of. 17 to all the word units that sharethree letters with a stimulus. The probabilityof a decision based on the lexicon, P(L), andthe probability of a correct response basedon lexical access, P(C/L), were then com-puted as usual.
The decision rule was also the same, butdeserves a brief comment. To extend Mc-Clelland and Rumelhart's analysis of theneighborhood to predictions of proportioncorrect in a two-alternative forced-choicetask, it is necessary to separate nonalignedneighbors from true enemies. That is, wordunits in the neighborhood that support theincorrect alternative (true enemies) will havea much more disruptive effect on perfor-mance than words that support neither al-ternative (nonaligned neighbors). This isessentially what is done in Equation 2 for ourmodel when we assume that friends contrib-ute to a correct response with a probabilityof 1, nonaligned neighbors with a probabilityof .5, and true enemies with a probabilityofO.
When a neighborhood based on the char-acteristics of the interactive activation modelis substituted for the candidate set generatedby our encoding algorithm, and all other op-erations are identical, the average predictedperformance is .80 for words, .84 for pseu-dowords, and .74 for anagrams. This will notdo at all, because the advantage of words overanagrams is too small and, more impor-tantly, words are predicted to be inferior topseudowords! McClelland and Rumelharthave already discussed why pseudowordstend to have a high proportion of friends. Weadd to their analysis a similar account of whywords tends to have a lower proportion offriends.
Experimenters select stimulus words in

588 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
pairs that differ by only a single letter. Thisensures that the two alternatives in the targetlocation will both form words in the remain-ing context. For example, two of Johnston's(1978) high-constraint words were SINK andWINK, with the first position being probedwith the alternatives S and W. One conse-quence of this is that every word stimuluswill have at least one friend (itself) and onetrue enemy (its mate). Experimenters createpseudowords by substituting one of the con-text letters from the original word pair. Forexample, we created the pseudowords SONKand WONK by replacing the Is from SINK andWINK with Os. The consequence of this isthat every pseudoword has at least one friend(SINK for SONK and WINK for WONK) but nobuilt-in enemy (WONK is not an enemy ofSONK because it is not a word). This system-atic bias introduced in the selection of thematerials results in the words' neighborhoodaveraging only 70% friends compared to 79%for the pseudowords. Thus, models baseddirectly on the composition of the neighbor-hood will predict an advantage of pseudo-words over words.
In fairness to the interactive activationmodel, it should be clearly pointed out thatwhen its encoding assumptions are placed inthe context of its own complete model, ratherthan our complete model, the simulationshows the correct ordering for the words,pseudowords, and single letters used byMcClelland and Johnston (1977). We sus-pect that their full simulation would also pro-duce the correct ordering of our words, pseu-dowords, and anagrams. The reason for thisis that the complete interactive activationmodel assumes large (parameter value = .21)amounts of inhibition between competingword units. Thus, when a word is presented,the initial strength of the corresponding wordunit (about .28) will quickly dominate theinitial activity (about .17) of any potentialenemy. Thus, the effects of lexical access forword stimuli are almost entirely determinedby feedback from the corresponding wordunit and no others. This is an interesting con-trast between the two models. We assumethat both the word advantage and the pseu-doword advantage are mediated by decisionsbased on the activity of a small set of can-didate words. McClelland and Rumelhart
assume that the word advantage is mediatedby feedback from a single word unit (the lex-ical entry corresponding to the word pre-sented) but that the pseudoword advantageis mediated by feedback from large neigh-borhoods.
This inherent difference between wordsand pseudowords in the interactive activa-tion model produces some undesirable fall-out. Specifically, if high levels of interwordinhibition permit the stimulus word to dom-inate any potential competition, then thestimulus-driven differences between variouswords will be eliminated. In short, high levelsof interword inhibition mean that the func-tional amount of activation produced by thepresentation of all words will be about thesame. Thus, the significant correlations be-tween obtained performance and that pre-dicted from our model would stand unchal-lenged by the interactive activation model.It is true that the interactive activation modeldoes predict some variation between wordsthat is not stimulus driven, namely, that theresting levels of word units increase withword frequency, but we will show in a sub-sequent section that this assumption is nota good one.
Throughout the preceding section we havecompared the predictive power of our model'scandidate sets to that of McClelland andRumelhart's neighborhood. Our encodingalgorithm, which is highly sensitive to visual-confusability effects, seems to enjoy a con-sistent advantage in the tests we have con-ducted. However, this should not be viewedas a permanent disadvantage for the inter-active activation model because the neigh-borhoods we tested conform to those ob-tained when their parameter, p, for visual-feature extraction is set to 1.0. If a valuelower than 1.0 is used, their model will gen-erate neighborhoods sensitive to visual con-fusability in a way similar to that of our can-didate words. However, one of the difficultiesin using the interactive activation model asa heuristic device is its inherent complexity.Accordingly, it is difficult to anticipate theresults of simulations that have not been con-ducted. It should not be presumed in advancethat the interactive activation model wouldaccurately predict the relative differences be-tween words, pseudowords, and anagrams

ACTIVATION-VERIFICATION MODEL 589
when only partial information is gained fromeach letter location. Furthermore, when thecontribution of visual confusability is intro-duced through the partial sampling of sub-jectively denned features it is not as likely tobe as predictive as when confusability isbased on an empirically derived confusionmatrix.
The Pseudoword Expectancy Effect
One potential problem for any model thateschews any direct contribution of ortho-graphic knowledge is that the pseudowordadvantage seems to be more susceptible toexpectancy effects than the word advantage.Carr, Davidson, and Hawkins (1978) haveshown that if subjects do not expect to seeany pseudowords, then performance on anunexpected pseudoword will be no betterthan that obtained with irregular nonwords.In contrast, they showed that the advantageof words over irregular nonwords was thesame regardless of whether the subject ex-pected all words or all nonwords.
McClelland and Rumelhart can accountfor this pattern of expectancy effects by as-suming that subjects have strategic controlover the degree of inhibition between thealphabetum and lexicon. They assume thatif subjects expect only words or only irregularnonwords, they will adopt a large value ofletter-to-word inhibition. More specifically,the inhibition parameter in their simulationis set so that the excitation produced by threematching letters will be precisely counteredby the inhibition from the remaining mis-match. Accordingly, the only word unit thatwill produce appreciable feedback to the let-ter units is the word presented. This meansthat the word advantage will be about thesame as always but that the pseudoword ad-vantage will be eliminated.
Our activation-verification model can alsopredict the pseudoword expectancy results byassuming that subjects have control over oneparameter, namely, the word-unit criterion.All of the predictions reported earlier useda word-unit criterion of .24. The averagenumbers of candidate words produced by thethree classes of stimuli were 3.4 for words,2.1 for pseudowords, and .2 for anagrams.By adopting this fairly lax criterion, the sub-
ject can take advantage of beneficial lexicalevidence for both words and, more impor-tantly, pseudowords. However, because theword unit corresponding to a word stimuluswould exceed a much stiffer criterion, sub-jects have no motivation to maintain a lowcriterion and, therefore, to consider largersets of word units unless they expect to seesome pseudowords.
The expectancy effect was modeled byraising the word-unit criterion from .24 to.29. This resulted in a reduction of the num-ber of candidate words to 1.4 for word stim-uli, .40 for pseudowords, and .04 for ana-grams. The effect of this on the predictedproportion correct is negligible for words(.841 versus .856) and anagrams (.755 versus.747) but results in a sizable decrease in pseu-doword performance (.813 to .760). In sum-mary, raising the word-unit criterion can re-sult in the elimination of the pseudowordadvantage while having very little effect onthe word advantage. Although a higher cri-terion does lead to an increase in P(C/L) forword stimuli, this tends to be countered bya decrease in the total amount of lexical ac-tivity and, hence, a decrease in P(L).
Both models can predict the pseudowordexpectancy effect reported by Carr et al.(1978). Although introspection is at best aweak test of two opposing theories, we yieldto the temptation to point out that it seemsto us more natural that a subject-controlledstrategy might involve the adjustment of acriterion for considering lexical evidencerather than the adjustment of the amount ofinhibition between letter and word detectors.
Word-Frequency Effects for MaskedStimuli
Under normal conditions of stimulus pre-sentation, familiar words can be processedmore effectively than less familiar ones. Forexample, high-frequency words are consis-tently classified faster than low-frequencywords in lexical-decision tasks (Landauer &Freedman, 1968; Rubenstein, Garfield, &Millikan, 1970; Scarborough, Cortese, &Scarborough., 1977). Our complete modelcaptures this familiarity effect by assumingthat the order of verification is determined,in part, by word frequency. However, it was

590 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
assumed that the brief stimulus durationsused in the present experiments, togetherwith the masking fields, would prevent ver-ification from taking place.
Two studies have systematically manipu-lated word frequency under conditions ofbackward masking. In his first experimentManelis (1977) selected 32-word sets fromthe Kucera and Francis (1967) norms withhigh (94-895), medium (23-74), and low (2-10) frequency counts. Although proportionof correct recognitions increased with fre-quency from .775 to .794 to .800, the differ-ences were not significant. In the second ex-periment pairs of high- and low-frequencywords shared the same critical letter and asmany context letters as possible. Again, therewere no differences between common (.762)and rare (.757) words. In a set of three ex-periments described by Paap and Newsome(1980b), 80 words were selected from theThorndike-Lorge (1944) count so that therewere equal numbers of words with frequen-cies of 1, 2, 5, 14, and 23 per million. Wordsin the five frequency classes were matchedin terms of the identity and position of thetarget letter. The proportions of correct re-sponses, in increasing order of frequency,were .67, .62, .65, .66, and .65.
The results described above support ourassumption that verification does not occurwhen stimulus words are followed by a mask.We have also tested for word-frequency ef-fects in the data we obtained with Johnston's(1978) words. The Kucera and Francis fre-quency counts were determined for each ofthe 288 words and correlated against bothsets of word data. These correlations areshown in parentheses in Table 5. There areno significant correlations between word fre-quency and proportion correct, and in fact,the trend is toward poorer performance withhigher word frequency. However, when a log-arithmic transformation is applied to the fre-quency counts, positive correlations appearin each of the data sets.
Because many of Johnston's (1978) wordsare quite uncommon and may not be enteredin the subjective lexicon of our typical sub-ject, it is possible that this small word-fre-quency effect reflects nothing more than theprobability of the word appearing in the lex-icon. This interpretation was investigated bysequentially removing the words with the
lowest frequency from the original set of 288words. As shown in Table 5, the correlationbetween the logarithm of word frequencyand performance systematically decreases asrare words are removed from the sample.When only words with frequencies greaterthan three are considered, there is no effectof relative frequency.
In order to further support our claim thatmany of Johnston's (1978) words are unfa-miliar to our population of undergraduatesubjects, we had 147 students classify eachof the words as either (a) a word that I knowthe meaning of, (b) a word that I don't knowthe meaning of, or (c) a nonword. Thirteenwords were classified as nonwords by a ma-jority of the subjects (LAVE, TING, BOON,CRAG, WHET, JILL, BOLL, WILE, HONE, HEWN,FIFE, BANS, VATS). Furthermore, for manywords the responses were distributed quiteevenly across the three categories (e.g., FIFE,BANS, VATS, TEEM, HEMP, PENT, WANE,NAVE, SLAT). When we removed the 35words that are most often classified as non-words (and the meaning of which is knownby only a minority of the subjects), there wereno significant correlations between the datafor the individual words and the logarithmof their frequency. This purging of our lex-icon also led to a slight improvement in thecorrelation between predicted and obtainedperformance for the 288 words, r = .32.
These tests lead us to conclude that mask-ing almost always prevents verification andthat there is no need to build word-frequencyeffects into our encoding algorithm. In orderto make sure that word frequency could notenhance the ability of our encoding algo-rithm to predict variation between words, wetried several different ways of having the log-arithm of word frequency modulate the ac-tivity of the word units. Our basic strategy,like that of McClelland and Rumelhart, wasto decrease the stimulus-driven activity ofword units in inverse relation to their fre-quency. Because the correlation between ourobtained word data and log word frequencywas .16, we searched for a frequency effectthat would produce a comparable correlationbetween our predicted data and log word fre-quency. The desired impact of word fre-quency was achieved when the amount ofstimulus-driven activity was reduced by about5% for each half-log unit drop in word fre-

ACTIVATION-VERIFICATION MODEL 591
quency. This means that the most commonwords in our lexicon would receive no re-duction in activity, and those with a fre-quency of only one would be reducedby 40%.
Because the word-frequency effect leads toan overall reduction in lexical activity, it wasnecessary to lower the word-unit criterionsubstantially (,14) in order to maintain can-didate sets of about 3.3 words. Under theseconditions the predicted performance for allwords was exactly the same (PPC = .84) asthat predicted from the original model thathas no provision for word-frequency effects.The question of interest can now be an-swered: Does word frequency enhance themodel's ability to account for variation be-tween words? No, the correlations betweenpredicted data and two sets of obtained datashow that introducing word-frequency effectsproduces no change for one data set and adecline of .06 for the other.
In summary, we can find no evidence inour data or elsewhere that two-alternativeforced-choice performance on masked worddisplays shows a word-frequency effect. Thisis consistent with the activation-verificationmodel, because we assume that word fre-quency does not affect activation of the wordunits, but will affect the order of verificationwhen the stimulus-presentation conditionspermit verification to occur. The magnitudeof the word-frequency effects generated bythe interactive activation model is not known.Although their model specifically assumesthat the resting activity of word units is de-termined by familiarity, other factors, suchas the decision rules adopted for the forced-
choice task, may severely attenuate the initialfrequency differences between word unitsand, thereby, permit the prediction of noword-frequency effect. A fair conclusion withrespect to word frequency is that the acti-vation-verification model can correctly pre-dict the magnitude of familiarity effects inboth tachistoscopic and reaction time studiesand that the interactive activation modelmay be able to do so.
Reaction Time Studies
As we mentioned in the introduction, theconcepts embodied in our activation-verifi-cation model were originally developed inthe context of reaction time studies using lex-ical-decision and naming tasks. With thishistory it is to be expected that the modelcan handle a variety of reaction time data.There are too many findings to cover in detailhere, but it may be useful to review some ofthis earlier work to provide some idea aboutthe performance of the model. Because theinteractive activation model has not beenspecifically applied to lexical-decision data,we cannot draw specific comparisons. How-ever, the interactive activation model hasbeen used to explain the effects of semanticcontext and word frequency in other reactiontime tasks (e.g., naming tasks), and we willcomment on the applicability of analogousexplanations of findings from the lexical-de-cision task.
The interactive activation model and ouractivation-verification model differ aboutthe nature of effects of prior semantic contextand word frequency when stimuli are pre-
Table 5Correlations Between Obtained Proportion Correct and Log Word Frequency
Data set
Word frequencies included
All All> 1 All>2 All> 3
Word set12
Number of words/•=.05
.16 (-.04)
.14 (-.09)
288.12
.14 (-.06)
.11 (-.11)
249.13
.09 (+.04)
.07 (+.01)
228.13
.04 (-.08)
.04 (-.14)
220.13
Note. Correlations between proportion correct and the absolute word-frequency counts are shown in parentheses."All > 1" means all stimulus words with a frequency greater than 1.

592 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
sented for normal durations and withoutmasking. In the interactive activation model,these two factors both have the effect of in-creasing activation levels in relevant wordunits. The base activation level of the wordunits increases as a function of word fre-quency. Also, word units that are related tothe context have increased activity levels rel-ative to word units for unrelated words. Per-haps word units that are inconsistent withthe context would have depressed activitylevels as well.
In contrast, our activation-verificationmodel places the effects of word frequencysubsequent to the activation of word units.Word frequency determines the order inwhich lexical units are verified in the verifi-cation process. The activation-verificationmodel also assumes that context increases theactivity level of lexical units that are relatedto the context, but this activity increase maybe high enough to cause the word units toexceed the criterion for inclusion in the can-didate set. The verification process is thenresponsible for the analysis of stimulus in-formation. Thus, verification can prevent apremature response. There appears to be nocomparable mechanism in the interactiveactivation model.
In lexical-decision tasks, there is evidencethat context and frequency have differenteffects on the time required to classify a letterstring as a word. Becker and Killion (1977)found that context interacts with the qualityof the visual stimulus whereas frequency andvisual quality show additive effects. Thesefindings imply that frequency and contextexert their influence on performance in dif-ferent ways, contrary to expectations, derivedfrom the interactive, activation model.McDonald (1980) developed a computersimulation of the verification model (whichwas the precursor to our activation-verifi-cation model). McDonald's simulation pro-duced both the additivity of frequency andvisual quality and the interaction of contextand visual quality. Further, as we discussedearlier, there are apparently no word-fre-quency effects in the word-superiority para-digm. This result follows naturally from ourmodel because frequency does not affect theactivation process, which is the basis of thedecision in the word-superiority paradigm.
The activation-verification model is alsoconsistent with findings on effects of contexton the classification of nonwords in the lex-ical-decision task. Several models (includingthe interactive activation model) handle con-text effects by inducing a bias in favor of re-lated words. This approach leads to the ex-pectation that nonwords that are very similarto particular words should be erroneouslyclassified as words more often in a relatedcontext than in an unrelated context. Forexample, the nonword NERSE should be mis-classified more often following a word relatedto NURSE (e.g., DOCTOR) than following anunrelated word (e.g., LAMP). In contrast, ourmodel assumes that lexical decisions aremade on the basis of verification rather thanactivation and that the quality of the verifi-cation process is not affected by context.Context affects the availability of lexical unitsfor verification, but not the quality of theverification process itself. Thus, contextshould have no effect on the liklihood of clas-sifying a nonword as a word.
The evidence on the classification of non-words supports the predictions of the acti-vation-verification model. Schvaneveldt andMcDonald (1981) found no effect of contexton classifying nonwords when stimuli re-mained available until the response occurred.Context did facilitate response time to wordsin their experiments. Other studies have pro-duced similar results (Antos, 1979; Lapinski,1979; McDonald, 1977, 1980; Lapinski &Tweedy, Note 8). O'Connor and Forster(1981) concluded that a bias explanation wasruled out by their findings even though oneof their experiments showed bias effects. Inthat experiment, however, error rates wereover 35% on the critical items, which is un-usually high. In the context of the activation-verification model, such error rates suggestthat subjects are responding without verifi-cation on a substantial proportion of thetrials. If verification is optional, speed-ac-curacy trade-offs may be partly due to theprobability of verification in a particular task.Schvaneveldt and McDonald (1981) alsoshowed bias effects of context with a briefstimulus display followed by a masking stim-ulus. As we argued earlier, we assume that'these stimulus conditions prevent verifica-tion.

ACTIVATION-VERIFICATION MODEL 593
Overall, the activation-verification modelappears to handle a considerable amount ofdata from reaction time experiments (seeBecker, 1980, and McDonald, 1980, for fur-ther examples). We believe that one impor-tant characteristic of the model lies in theindependent top-down analysis of the stim-ulus (verification) that is sensitive to devia-tions from the stored representation of aword. These deviations might be further di-vided into permissible (identity preserving)and illegal (identity transforming) distortionsof the stored representation. Verification,then, amounts to determining whether thestimulus impinging on the senses could bereasonably interpreted as a particular wordafter context or the senses had suggested thatthe stimulus might be that word.
We have presented our solution to whatwe perceive as an important theoretical prob-lem in pattern-recognition theory in generaland word recognition in particular. Thatproblem is to specify the nature and inter-action of bottom-up and top-down infor-mation-processng activities in recognition.There seems to be wide acceptance of thenecessity for both of these types of processes.There is less agreement about just what theyare and how they interact. Our solution tothis theoretical problem provides a top-downprocess that involves comparing stimulus in-formation to prototypes stored in memory.As such, the top-down process may enhanceperception of discrepancies rather than in-duce a perceptual or decision bias in favorof expected stimuli. We believe that the ev-idence supports our view, but we are eagerto pursue the matter further with additionalresearch. We hope that our theoretical anal-ysis and the contrasts of two theoretical ap-proaches will help to focus further experi-mentation.
Reference Notes1. Paap, K. R., & Newsome, S. L. The role of word-
shape and lexical constraint in the word superiorityeffect. In C. Cofer (Chair), Some new perspectives onword recognition. Symposium presented at the meet-ing of the Southwestern Psychological Association,Houston, April 1981.
2. Paap, K. R., & Newsome, S. L. Lexical constraint:Redefined and resurrected. Paper presented at themeeting of the Psychonomic Society, Philadelphia,November 1981.
3. Paap, K. R., Newsome, S. L., & McDonald, J. E.Further tests of the contribution of perceptual confu-sions to the WSE. Paper presented at the meeting ofthe Psychonomic Society, St. Louis, November 1980.
4. Schvaneveldt, R. S., & McDonald, J. E. The verifi-cation model of word recognition. In C. Cofer(Chair), Some new perspectives on word recognition.Symposium presented at the meeting of the South-western Psychological Association, Houston, April1981.
5. Becker, C. A., Schvaneveldt, R. W., & Gomez, L.Semantic, graphemic, and phonetic factors in wordrecognition. Paper presented at the meeting of thePsychonomic Society, St. Louis, November 1973.
6. Paap, K. R., Newsome, S. L., McDonald, J. E., &Schvaneveldt, R. W. The activation verification model:The effects of cuing, masking, and visual angle.Manuscript in preparation, 1982.
7. Massaro, D. W. Simulating letter and word recog-nition: A fuzzy logical model of integrating visual in-formation and orthographic structure in reading. Pa-per presented at the European Conference on Artif-ical Intelligence, Orsay, France, July 1982.
8. Lapinsky, R. H., & Tweedy, J. R. Associate-like non-words in a lexical-decision task: Paradoxical seman-tic context effects. Paper presented at the Mathemat-ical Psychology meetings, New York University, Au-gust 1976.
ReferencesAntos, S. J. Processing facilitation in a lexical decision
task. Journal of Experimental Psychology: HumanPerception and Performance, 1979, 5, 527-545.
Becker, C. A. Allocation of attention during visual wordrecognition. Journal of Experimental Psychology:Human Perception and Performance, 1976, 2, 556-566.
Becker, C. A. Semantic context effects in visual wordrecognition: An analysis of semantic strategies. Mem-ory and Cognition, 1980, 8, 493-512.
Becker, C. A., & Killion, T. H. Interaction of visual andcognitive effects in word recognition. Journal of Ex-perimental Psychology: Human Perception and Per-formance, 1977, 3, 389-401.
Carr, T. H., Davidson, B. J., & Hawkins, H. L. Percep-tual flexibility in word recognition. Strategies affectorthographic computation but not lexical access.Journal of Experimental Psychology: Human Percep-tion and Performance, 1978, 4, 674-690.
Johnston, J. C. A test of the sophisticated guessing theoryof word perception. Cognitive Psychology, 1978, 10,123-153.
Kucera, H., & Francis, W. N. Computational analysisof present-day American English. Providence, R.I.:Brown University Press, 1967.
Landauer, T., & Freedman, J. Information retrievalfrom long-term memory: Category size and recogni-tion time. Journal of Verbal Learning and VerbalBehavior, 1968, 7, 291-295.
Lapinsky, R. H. Sensitivity and bias in the lexical de-cision task. Unpublished doctoral dissertation, StateUniversity of New York at Stony Brook, 1979.
Luce, R. D. A threshold theory for simple detection ex-periments. Psychological Review, 1963, 70, 61-79.

594 PAAP, NEWSOME, MCDONALD, AND SCHVANEVELDT
Manelis, J. Frequency and meaningfulness in tachisto-scopic word perception. American Journal of Psy-chology, 1977, 99, 269-280.
Massaro, D. W. Perception of letters, words, and non-words. Journal of Experimental Psychology, 1973,100, 349-353.
Massaro, D. W. Letter information and orthographiccontext in word perception. Journal of ExperimentalPsychology,: Human Perception and Performance,1979, 5, 595-609.
Massaro, D. W., Venezky, R. L., & Taylor, G. A. Or-thographic regularity, positional frequency, and visualprocessing of letter strings. Journal of ExperimentalPsychology: General, 1979, 108, 107-124.
Massaro, D. W., Taylor, G. A., Venezky, R. L., Jas-trzembski, J. E., & Lucas, P. A. Letter and word per-ception: Orthographic structure and visual processingin reading. Amsterdam: North Holland, 1980.
McClelland, J. L., & Johnston, J. C. The role of familiarunits in perception of words and nonwords. Percep-tion & Psychophysics, 1977, 22, 249-261.
McClelland, J. L., & Rumelhart, D. E. An interactiveactivation model of context effects in letter percep-tion: Part 1. An account of basic findings. Psycholog-ical Review, 1981, 88, 375-407.
McDonald, J. E. Strategy in a lexical decision task.Unpublished master's thesis, New Mexico State Uni-versity, 1977.
McDonald, J. E. An information processing analysis ofword recognition. Unpublished doctoral dissertation,New Mexico State University, 1980.
Morton, J. Interaction of information in word recog-nition. Psychological Review, 1969, 76, 165-178.
O'Connor, R. E., & Forster, K. I. Criterion bias andsearch sequence bias in word recognition. Memory& Cognition, 1981, 9, 78-92.
Paap, K. R., & Newsome, S. L. Do small visual anglesproduce a word superiority effect or differential lateralmasking? Memory & Cognition, 1980, 8, 1-14. (a)
Paap, K. R., & Newsome, S. L. A perceptual-confusionaccount of the WSE in the target search paradigm.Perception & Psychophysics, 1980, 27, 444-456. (b)
Rubenstein, H., Garfield, L., & Millikan, J. Homo-graphic entries in the internal lexicon. Journal of Ver-bal Learning and Verbal Behavior, 1970, 9, 487-494.
Rumelhart, D. E., & McClelland, J. L. An interactiveactivation model of context effects in letter percep-tion: Part 2. The contextual enhancement effect andsome tests and extensions of the model. PsychologicalReview, 1982, 89, 60-94.
Scarborough, D. L., Cortese, C., & Scarborough, H. S.Frequency and repetition effects in lexical memory.Journal of Experimental Psychology: Human Percep-tion and Performance, 1977, 3, 1-17.
Schvaneveldt, R. W., & McDonald, J. E. Semantic con-text and the encoding of words: Evidence for twomodes of stimulus analysis. Journal of ExperimentalPsychology: Human Perception and Performance,1981, 7, 673-687.
Schvaneveldt, R. W., Meyer, D. E., & Becker, C. A.Lexical ambiguity, semantic context, and visual wordrecognition. Journal of Experimental Psychology:Human Perception and Performance, 1976, 2, 243-256.
Thorndike, E. L., <Sf Lorge, I. The teacher's word bookof 30,000 words. New York: Teacher's College Press,1944.
Received October 21, 1981Revision received January 28, 1982





























