Embed Size (px)
Citation preview

Amazon RedshiftHandbuch „Erste Schritte“API-Version 2012-12-01

Amazon Redshift Handbuch „Erste Schritte“
Amazon Redshift: Handbuch „Erste Schritte“Copyright © 2018 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any mannerthat is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks notowned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored byAmazon.

Amazon Redshift Handbuch „Erste Schritte“
Table of ContentsErste Schritte ..................................................................................................................................... 1
Schritt 1: Einrichten der Voraussetzungen ...................................................................................... 2Anmelden bei AWS ............................................................................................................. 2Installieren von SQL-Client-Treibern und -Tools ....................................................................... 2Festlegen von Firewall-Regeln .............................................................................................. 3
Schritt 2: Erstellen einer IAM-Rolle ................................................................................................ 3Erstellen einer IAM-Rolle für Amazon Redshift ...................................................................... 3
Schritt 3: Starten eines Clusters ................................................................................................... 4Starten eines Amazon Redshift-Clusters ................................................................................. 4
Schritt 4: Autorisieren des Zugriffs auf den Cluster ......................................................................... 10Konfigurieren der VPC-Sicherheitsgruppe (EC2-VPC-Plattform) ................................................ 11Konfigurieren der Amazon Redshift-Sicherheitsgruppen .......................................................... 12
Schritt 5: Verbinden mit dem Cluster ........................................................................................... 13Abrufen der Verbindungszeichenfolge .................................................................................. 13Herstellen einer Verbindung zwischen SQL Workbench/J und Cluster ........................................ 14
Schritt 6: Laden von Beispieldaten .............................................................................................. 16Schritt 7: Suchen von zusätzlichen Ressourcen und Zurücksetzen der Umgebung ............................... 20
Wie geht es weiter? .......................................................................................................... 21Dokumentverlauf ............................................................................................................................... 25
API-Version 2012-12-01iii

Amazon Redshift Handbuch „Erste Schritte“
Erste Schritte mit Amazon RedshiftWillkommen beim Erste Schritte mit Amazon Redshift-Handbuch. Amazon Redshift ist ein vollständigverwalteter Data-Warehouse-Service in Petabytegröße in der Cloud. Ein Amazon Redshift-Data-Warehouse ist eine Sammlung von Datenverarbeitungsressourcen, den so genannten Knoten, die zuGruppen, den so genannten Clustern, zusammengefasst werden. In jedem Cluster wird ein AmazonRedshift-Modul ausgeführt, und er enthält mindestens eine Datenbank.
Wenn Sie Amazon Redshift zum ersten Mal verwenden, empfehlen wir, die folgenden Abschnitte zu lesen:
• Amazon Redshift Management Overview – dieses Thema vermittelt eine Übersicht über AmazonRedshift.
• Service Highlights and Pricing – auf dieser Produktdetailseite finden Sie das Wert-Angebot, die Service-Merkmale und die Preise von Amazon Redshift.
• Erste Schritte mit Amazon Redshift (das vorliegende Handbuch) – dieses Handbuch enthält ein Tutorial,das Ihnen zeigt, wie Sie Amazon Redshift für die Erstellung eines Beispiel-Clusters und für die Arbeit mitBeispieldaten verwenden können.
Wenn Sie eine Lösung für einen Machbarkeitsnachweis mit Amazon Redshift erstellen, sollten Sie denArtikel Building a Proof of Concept for Amazon Redshift lesen.
Mit dem Tutorial in diesem Handbuch werden Sie durch den Prozess der Erstellung eines AmazonRedshift-Beispiel-Clusters geführt. Anhand dieses Beispiel-Clusters können Sie den Amazon Redshift-Service auswerten. Im Einzelnen führen Sie in diesem Tutorial die folgenden Schritte durch:
• Schritt 1: Einrichten der Voraussetzungen (p. 2)• Schritt 2: Erstellen einer IAM-Rolle (p. 3)• Schritt 3: Starten eines Amazon Redshift-Beispiel-Clusters (p. 4)• Schritt 4: Autorisieren des Zugriffs auf den Cluster (p. 10)• Schritt 5: Verbinden mit dem Beispiel-Cluster (p. 13)• Schritt 6: Laden von Beispieldaten aus Amazon S3 (p. 16)• Schritt 7: Suchen von zusätzlichen Ressourcen und Zurücksetzen der Umgebung (p. 20)
Nach Abschluss dieses Tutorials finden Sie weitere Informationen über Amazon Redshift sowie dienächsten Schritte unter Wie geht es weiter? (p. 21)
Important
Der erstellte Beispiel-Cluster wird in einer Live-Umgebung ausgeführt. Der bedarfsabhängige Preisfür die Verwendung des in diesem Tutorial konzipierten Beispiel-Clusters liegt bei 0,25 USD proStunde. Er gilt so lange, bis Sie den Cluster löschen. Weitere Informationen zu Preisen finden Siein der Amazon Redshift-Preisliste. Bei weiteren Fragen oder Problemen können Sie sich an dasAmazon Redshift-Team wenden, indem Sie einen Beitrag im Diskussionsforum veröffentlichen.
In diesem Tutorial wird nur oberflächlich auf die Optionen eingegangen; es ist daher nicht fürProduktionsumgebungen geeignet. Wenn Sie das Tutorial abgeschlossen haben, finden Sie im AbschnittWeitere Ressourcen (p. 21) detaillierte Informationen für die Planung, Bereitstellung und Instandhaltungvon Clustern sowie für die Datenverarbeitung im Data Warehouse.
API-Version 2012-12-011

Amazon Redshift Handbuch „Erste Schritte“Schritt 1: Einrichten der Voraussetzungen
Schritt 1: Einrichten der VoraussetzungenVergewissern Sie sich vor der Einrichtung eines Amazon Redshift-Clusters, dass die im folgendenAbschnitt genannten Voraussetzungen erfüllt sind:
• Anmelden bei AWS (p. 2)• Installieren von SQL-Client-Treibern und -Tools (p. 2)• Festlegen von Firewall-Regeln (p. 3)
Anmelden bei AWSWenn Sie noch kein AWS-Konto haben, müssen Sie eines eröffnen. Wenn Sie bereits ein Konto besitzen,können Sie diesen Schritt überspringen und Ihr vorhandenes Konto verwenden.
1. Rufen Sie https://aws.amazon.com/ auf und wählen Sie Create an AWS Account aus.
Note
Diese Option wird möglicherweise nicht im Browser angezeigt, wenn Sie sich zuvor bei derAWS Management Console angemeldet haben. Klicken Sie in diesem Fall auf Sign in to adifferent account und danach auf Create a new AWS account.
2. Folgen Sie den Onlineanweisungen.
Der Anmeldeprozess beinhaltet auch einen Telefonanruf und die Eingabe einer PIN über dieTelefontastatur.
Installieren von SQL-Client-Treibern und -ToolsSie können die meisten SQL-Client-Tools mit JDBC- oder ODBC-Treibern für Amazon Redshiftverwenden, um eine Verbindung mit einem Amazon Redshift-Cluster herzustellen. In diesem Tutorialzeigen wir Ihnen, wie Sie die Verbindung mithilfe von SQL Workbench/J herstellen, einem kostenlosenplattformübergreifenden SQL-Abfrage-Tool, das nicht von einem bestimmten DBMS abhängig ist. Wenn Siedieses Tutorial mit SQL Workbench/J abschließen möchten, führen Sie die nachfolgenden Schritte für dieEinrichtung des JDBC-Treibers für Amazon Redshift und von SQL Workbench/J aus. Eine ausführlichereAnleitung für die Installation von SQL Workbench/J finden Sie im Amazon Redshift Cluster ManagementGuide unter Setting Up the SQL Workbench/J Client. Wenn Sie als Client-Computer eine Instanz vonAmazon EC2 verwenden, müssen Sie SQL Workbench/J und die erforderlichen Treiber in der Instanzinstallieren.
Note
Alle Tools von Drittanbietern, die Sie im Cluster verwenden möchten, müssen Sie selberinstallieren; im Serviceumfang von Amazon Redshift sind keine Tools oder Bibliotheken vonDrittanbietern enthalten.
Installieren von SQL Workbench/J auf dem Client-Computer1. Lesen Sie die Softwarelizenz zu SQL Workbench/J.2. Laden Sie sich auf der SQL Workbench/J-Website das entsprechende Paket für Ihr Betriebssystem
herunter.3. Rufen Sie die Seite Installing and starting SQL Workbench/J auf und installieren Sie SQL Workbench/
J.
API-Version 2012-12-012

Amazon Redshift Handbuch „Erste Schritte“Festlegen von Firewall-Regeln
Important
Beachten Sie die JRE-Versionsvorgabe für SQL Workbench/J und vergewissern Sie sich,dass Sie die richtige Version verwenden; andernfalls kann die Client-Anwendung nichtausgeführt werden.
4. Rufen Sie die Seite Configure a JDBC Connection auf und laden Sie einen JDBC-Treiber für AmazonRedshift herunter, damit SQL Workbench/J eine Verbindung zum Cluster herstellen kann.
Weitere Informationen über die Verwendung der JDBC- oder ODBC-Treiber für Amazon Redshift finden Sieunter Configuring Connections in Amazon Redshift.
Festlegen von Firewall-RegelnIm Rahmen dieses Tutorials geben Sie einen Port für den Start des Amazon Redshift-Clusters an. DesWeiteren erstellen Sie eine Zugangsregel für eingehenden Datenverkehr in einer Sicherheitsgruppe, dieden Zugriff auf den Cluster über den Port regelt.
Wenn vor dem Client-Computer eine Firewall geschaltet ist, müssen Sie wissen, welcher Port offen ist,sodass Sie von einem SQL-Client-Tool eine Verbindung zum Cluster herstellen und Abfragen ausführenkönnen. Sollten Sie das nicht wissen, bitten Sie jemanden, der sich mit den Firewall-Regeln in IhremNetzwerk auskennt, einen offenen Port in der Firewall zu ermitteln. Standardmäßig verwendet AmazonRedshift Port 5439. Eine Verbindung ist aber nur möglich, wenn dieser Port in der Firewall auch geöffnetist. Die Portnummer für den Amazon Redshift-Cluster kann nach der Erstellung nicht mehr geändertwerden; vergewissern Sie sich daher, dass Sie während des Cluster-Startvorgangs einen offenen Portangeben, der in Ihrer Umgebung auch funktioniert.
Schritt 2: Erstellen einer IAM-RolleFür jede Operation, die einen Datenzugriff in einer anderen AWS-Ressource erfordert, z. B. die Ausführungdes COPY-Befehls zum Laden von Daten aus Amazon S3, benötigt der Cluster eine Berechtigung,um in Ihrem Namen auf die Ressource und die darin befindlichen Daten zugreifen zu können. SolcheBerechtigungen können Sie mithilfe von AWS Identity and Access Management bereitstellen – entwederüber eine IAM-Rolle, die Sie an den Cluster anfügen, oder indem Sie einem IAM-Benutzer, der dieerforderlichen Berechtigungen hat, den AWS-Zugriffsschlüssel bereitstellen.
Für den bestmöglichen Schutz ihrer vertraulichen Daten und die sichere Speicherung derAnmeldeinformationen für den Zugriff auf AWS empfehlen wir, eine IAM-Rolle zu erstellen und diese anden Cluster anzufügen. Weitere Informationen über die Gewährung von Zugriffsberechtigungen finden Sieunter Permissions to Access Other AWS Resources.
In diesem Schritt erstellen Sie eine neue IAM-Rolle, über die Amazon Redshift Daten aus Amazon S3-Buckets laden kann. Der nächste Schritt besteht darin, die Rolle an den Cluster anzufügen.
Erstellen einer IAM-Rolle für Amazon Redshift1. Melden Sie sich bei der AWS Management Console an und öffnen Sie die IAM-Konsole unter https://
console.aws.amazon.com/iam/.2. Wählen Sie im linken Navigationsbereich Roles aus.3. Wählen Sie Create role aus4. Klicken Sie in der Gruppe AWS Service auf Redshift.5. Klicken Sie unter Select your use case auf Redshift - Customizable und dann auf Next: Permissions.
API-Version 2012-12-013

Amazon Redshift Handbuch „Erste Schritte“Schritt 3: Starten eines Clusters
6. Wählen Sie auf der Seite Attach permissions policies die Richtlinie AmazonS3ReadOnlyAccess ausund klicken Sie dann auf Next: Review.
7. Geben Sie unter Role name einen Namen für die Rolle ein. Geben Sie in diesem TutorialmyRedshiftRole ein.
8. Prüfen Sie die Rolleninformationen und klicken Sie dann auf Create Role.9. Wählen Sie den Rollennamen der Rolle aus, die Sie gerade erstellt haben.10. Kopieren Sie den Rollen-ARN (Role ARN) in die Zwischenablage. Hierbei handelt es sich um den
Amazon-Ressourcennamen (ARN) für die soeben erstellte Rolle. Sie verwenden diesen Wert,wenn Sie den COPY-Befehl nutzen, um Daten in Schritt 6: Laden von Beispieldaten aus AmazonS3 (p. 16) zu laden.
Nachdem Sie die neue Rolle erstellt haben, fügen Sie diese im nächsten Schritt Ihrem Cluster an. Siekönnen die Rolle beim Starten eines neuen Clusters oder einem vorhandenen Cluster hinzufügen. Dernächste Schritt besteht darin, die Rolle einem neuen Cluster anzufügen.
Schritt 3: Starten eines Amazon Redshift-Beispiel-Clusters
Da nun alle Voraussetzungen erfüllt sind, können Sie den Amazon Redshift-Cluster starten.
Important
Der Cluster, den Sie gleich starten werden, wird live sein. Er wird nicht in einer Sandboxausgeführt. Es werden so lange die standardmäßigen Amazon Redshift-Nutzungsgebühren fürden Cluster anfallen, bis Sie ihn löschen. Wenn Sie das vorliegende Tutorial in einer Sitzungdurchlaufen und den Cluster nach Abschluss löschen, werden die Gesamtkosten minimal sein.
Starten eines Amazon Redshift-Clusters1. Melden Sie sich in der AWS Management Console an und öffnen Sie die Amazon Redshift-Konsole
unter https://console.aws.amazon.com/redshift/.
Important
Wenn Sie die IAM-Benutzeranmeldeinformationen verwenden, vergewissern Sie sich, dassder Benutzer über die erforderlichen Berechtigungen für die Cluster-Operationen verfügt.Weitere Informationen finden Sie im Amazon Redshift Cluster Management Guide unterControlling Access to IAM Users.
2. Wählen Sie im Hauptmenü die Region aus, in der Sie den Cluster erstellen möchten. Wählen Sie indiesem Tutorial USA West (Oregon) aus.
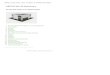
3. Wählen Sie im Amazon Redshift-Dashboard die Option Launch Cluster aus.
Das Amazon Redshift-Dashboard sollte wie folgt aussehen:
API-Version 2012-12-014
Amazon Redshift Handbuch „Erste Schritte“Starten eines Amazon Redshift-Clusters
4. Geben Sie auf der Seite "Cluster Details" folgende Werte ein und klicken Sie auf Continue:
• Cluster Identifier: Geben Sie examplecluster ein.• Database Name: Lassen Sie dieses Feld leer. Amazon Redshift erstellt eine Standarddatenbank mit
dem Namen dev.• Database Port: Geben Sie die Portnummer ein, über die die Datenbank Verbindungen annimmt. Die
Portnummer haben Sie bereits in den erforderlichen Schritten dieses Tutorials festgelegt. Sie könnendie Portnummer nach dem Starten des Clusters nicht mehr ändern. Vergewissern Sie sich daher,dass Sie Ihre Firewall einen offenen Port aufweist, über den Sie eine Verbindung zwischen SQL-Client-Tools und Datenbank im Cluster herstellen können.
• Master User Name: Geben Sie masteruser ein. Mit diesem Benutzernamen und diesem Passwortstellen Sie eine Verbindung zur Datenbank her, nachdem der Cluster verfügbar ist.
• Master User Password und Confirm Password: Geben Sie ein Passwort für dasMasterbenutzerkonto ein.
API-Version 2012-12-015

Amazon Redshift Handbuch „Erste Schritte“Starten eines Amazon Redshift-Clusters
5. Wählen Sie auf der Seite "Node Configuration" folgende Werte aus und klicken Sie auf Continue:
• Node Type: dc2.large• Cluster Type: Single Node
API-Version 2012-12-016

Amazon Redshift Handbuch „Erste Schritte“Starten eines Amazon Redshift-Clusters
6. Auf der Seite "Additional Configuration" sehen Sie je nach AWS-Konto, das den vom Clusterverwendeten Plattformtyp bestimmt, unterschiedliche Optionen. Dieses Tutorial soll möglichst einfachsein. Daher müssen Sie nicht unbedingt den Unterschied zwischen den Plattformen EC2-Classicund EC2-VPC kennen. Wenn Sie nach dem Tutorial mehr erfahren möchten, sehen Sie sich denAmazon Redshift Cluster Management Guide an, den Sie anhand der Informationen unter WeitereRessourcen (p. 21) finden.
EC2-VPC
Wenn Sie in der ausgewählten Region eine Standard-VPC haben, verwenden Sie zum Starten desClusters die EC2-VPC-Plattform. Ihr Bildschirm sollte wie folgt aussehen:
API-Version 2012-12-017

Amazon Redshift Handbuch „Erste Schritte“Starten eines Amazon Redshift-Clusters
Verwenden Sie die folgenden Werte, wenn Sie Ihren Cluster in der EC2-VPC-Plattform starten:
• Cluster Parameter Group: Wählen Sie die Standardparametergruppe aus.• Encrypt Database: None.• Choose a VPC: Default VPC (vpc-xxxxxxxx)• Cluster Subnet Group: default• Publicly Accessible: Yes• Choose a Public IP Address: No• Enhanced VPC Routing: No• Availability Zone: No Preference• VPC Security Groups: default (sg-xxxxxxxx)• Create CloudWatch Alarm: No• Maintenance Track (Wartungsspur): Current (Aktuelle)
EC2-Classic
Wenn Sie keine VPC haben, verwenden Sie zum Starten des Clusters die EC2-Classic-Plattform. IhrBildschirm sollte wie folgt aussehen:
API-Version 2012-12-018

Amazon Redshift Handbuch „Erste Schritte“Starten eines Amazon Redshift-Clusters
Verwenden Sie die folgenden Werte, wenn Sie Ihren Cluster in der EC2-Classic-Plattform starten:
• Cluster Parameter Group: Wählen Sie die Standardparametergruppe aus.• Encrypt Database: None.• Choose a VPC: Not in VPC• Availability Zone: No Preference• Cluster Security Groups: default• Create CloudWatch Alarm: No• Maintenance Track (Wartungsspur): Current (Aktuelle)
7. Verknüpfen Sie eine IAM-Rolle mit dem Cluster.
Wählen Sie unter AvailableRoles die Option myRedshiftRole und anschließend Continue aus.
8. Überprüfen Sie auf der Seite "Review" die ausgewählten Optionen und klicken Sie anschließend aufLaunch Cluster.
Ihr Bildschirm sollte wie folgt aussehen:
API-Version 2012-12-019

Amazon Redshift Handbuch „Erste Schritte“Schritt 4: Autorisieren des Zugriffs auf den Cluster
9. Es wird eine Bestätigungsseite angezeigt und der Cluster wird in ein paar Minuten fertig gestellt sein.Klicken Sie auf Close, um zur Liste der Cluster zurückzukehren.
10. Wählen Sie auf der Seite "Cluster" den soeben gestarteten Cluster aus und sehen Sie sich dieInformationen unter Cluster Status an. Vergewissern Sie sich, dass unter Cluster Status der Wertavailable und unter Database Health der Wert healthy angezeigt wird, bevor Sie später in diesemTutorial versuchen, eine Verbindung zur Datenbank herzustellen.
Schritt 4: Autorisieren des Zugriffs auf den ClusterIm vorherigen Schritt haben Sie den Amazon Redshift-Cluster gestartet. Vor der Herstellung einerVerbindung mit dem Cluster müssen Sie zunächst eine Sicherheitsgruppe konfigurieren, um den Zugriff zuautorisieren:
API-Version 2012-12-0110

Amazon Redshift Handbuch „Erste Schritte“Konfigurieren der VPC-
Sicherheitsgruppe (EC2-VPC-Plattform)
• Wenn Sie Ihren Cluster in der EC2-VPC-Plattform gestartet haben, führen Sie die Schritte unterKonfigurieren der VPC-Sicherheitsgruppe (EC2-VPC-Plattform) (p. 11) aus.
• Wenn Sie Ihren Cluster in der EC2-Classic-Plattform gestartet haben, führen Sie die Schritte unterKonfigurieren der Amazon Redshift-Sicherheitsgruppen (p. 12) aus.
Note
Sie müssen nur einen der beiden Sicherheitsgruppentypen konfigurieren. Führen Sie dieentsprechenden Schritte für die Plattform aus, in der Sie den Cluster gestartet haben.
Konfigurieren der VPC-Sicherheitsgruppe (EC2-VPC-Plattform)1. Wählen Sie im Navigationsbereich der Amazon Redshift-Konsole die Option Clusters aus.2. Öffnen Sie den Cluster examplecluster und wechseln Sie gegebenenfalls zur Registerkarte
Configuration.3. Wählen Sie unter Cluster Properties als VPC Security Groups Ihre Sicherheitsgruppe aus.
4. Wenn Ihre Sicherheitsgruppe in der Amazon EC2-Konsole geöffnet wird, wählen Sie die RegisterkarteInbound aus.
5. Wählen Sie Edit, geben Sie folgende Informationen ein und klicken Sie auf Save:
• Type: Custom TCP Rule.• Protocol: TCP.• Port Range: Geben Sie die Portnummer ein, die Sie beim Starten des Clusters verwendet haben.
Der Standardport für Amazon Redshift lautet 5439; Ihr Port kann jedoch davon abweichen.• Source: Wählen Sie Custom IP aus und geben Sie 0.0.0.0/0 ein.
Important
Die Eingabe von 0.0.0.0/0 wird nur zu Demonstrationszwecken empfohlen, weil diese IP-Adresse den Zugriff von beliebigen Computern über das Internet zulässt. In einer realenUmgebung würden Sie stattdessen basierend auf Ihren Netzwerkeinstellungen Regeln füreingehenden Datenverkehr erstellen.
API-Version 2012-12-0111

Amazon Redshift Handbuch „Erste Schritte“Konfigurieren der Amazon Redshift-Sicherheitsgruppen
Konfigurieren der Amazon Redshift-Sicherheitsgruppen1. Wählen Sie im Navigationsbereich der Amazon Redshift-Konsole die Option Clusters aus.2. Öffnen Sie den Cluster examplecluster und wechseln Sie gegebenenfalls zur Registerkarte
Configuration.3. Wählen Sie unter Cluster Properties für Cluster Security Groups die Option default aus, um die
Standardsicherheitsgruppe zu öffnen.
4. Wählen Sie die auf der Registerkarte Security Groups in der Cluster-Sicherheitsgruppe die Gruppeaus, deren Regeln Sie verwalten möchten.
5. Wählen Sie auf der Registerkarte Security Group Connections die Option Add Connection Type aus.
6. Wählen Sie im Feld Connection Type den Eintrag CIDR/IP aus.
Geben Sie unter CIDR/IP to Authorize die Adresse 0.0.0.0/0 ein und klicken Sie auf Authorize.
Important
Die Eingabe von 0.0.0.0/0 wird nur zu Demonstrationszwecken empfohlen, weil diese IP-Adresse den Zugriff von beliebigen Computern über das Internet zulässt. In einer realenUmgebung würden Sie stattdessen basierend auf Ihren Netzwerkeinstellungen Regeln füreingehenden Datenverkehr erstellen.
API-Version 2012-12-0112

Amazon Redshift Handbuch „Erste Schritte“Schritt 5: Verbinden mit dem Cluster
Schritt 5: Verbinden mit dem Beispiel-ClusterSie stellen nun mit einem SQL-Client-Tool eine Verbindung zum Cluster her und führen eine einfacheAbfrage zum Testen der Verbindung aus. Hierfür können Sie die meisten mit PostgreSQL kompatiblenSQL-Client-Tools verwenden. In diesem Tutorial verwenden Sie den SQL Workbench/J-Client, den Siebereits im Abschnitt "Voraussetzungen" installiert haben. Führen Sie die folgenden Schritte aus, um diesenAbschnitt abzuschließen:
• Abrufen der Verbindungszeichenfolge (p. 13)• Herstellen einer Verbindung zwischen SQL Workbench/J und Cluster (p. 14)
Nach Abschluss dieses Schritts können Sie wahlweise Beispieldaten aus Amazon S3 laden (Schritt 6:Laden von Beispieldaten aus Amazon S3 (p. 16)) oder weitere Informationen über Amazon Redshifterhalten und Ihre Umgebung zurücksetzen (Wie geht es weiter? (p. 21)).
Abrufen der Verbindungszeichenfolge1. Wählen Sie im Navigationsbereich der Amazon Redshift-Konsole die Option Clusters aus.2. Öffnen Sie den Cluster examplecluster und wechseln Sie gegebenenfalls zur Registerkarte
Configuration.3. Kopieren Sie auf der Registerkarte Configuration unter Cluster Database Properties den JDBC-URL
des Clusters.
Note
Der Endpunkt des Clusters ist erst verfügbar, wenn der Cluster erstellt wurde und verfügbarist.
API-Version 2012-12-0113

Amazon Redshift Handbuch „Erste Schritte“Herstellen einer Verbindung zwischen
SQL Workbench/J und Cluster
Herstellen einer Verbindung zwischen SQLWorkbench/J und ClusterDieser Schritt setzt voraus, dass Sie SQL Workbench/J in Schritt 1: Einrichten derVoraussetzungen (p. 2) installiert haben.
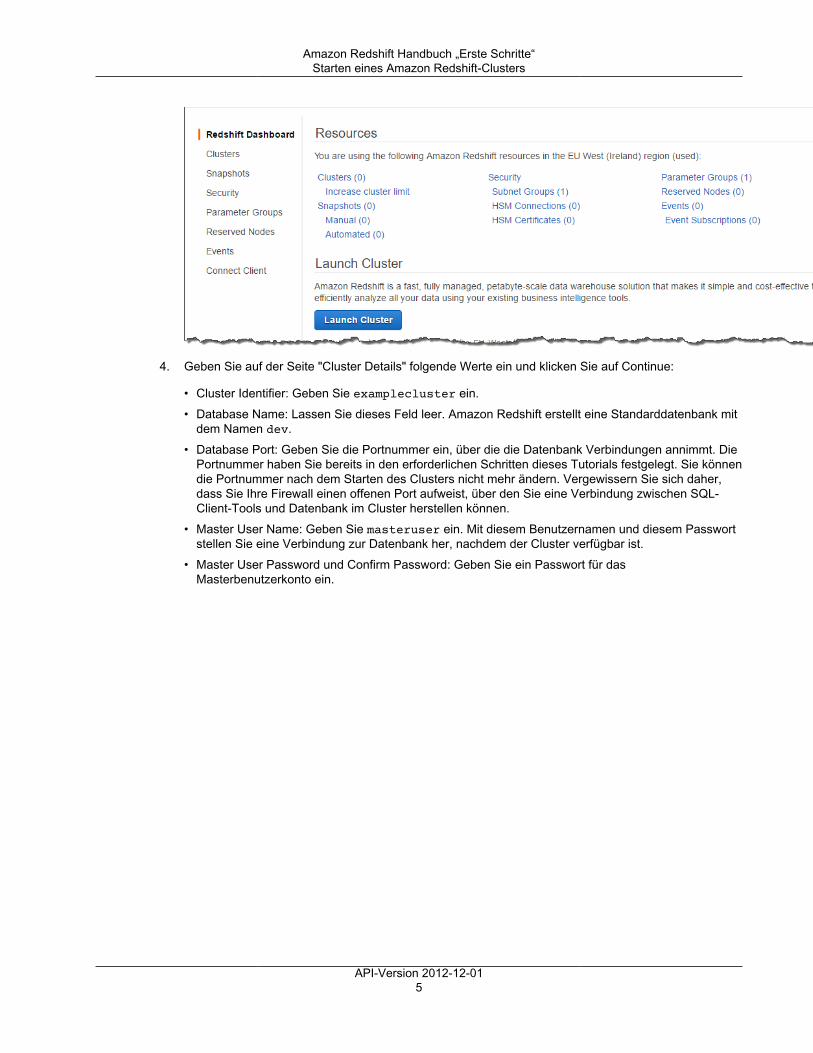
1. Öffnen Sie SQL Workbench/J.2. Wählen Sie File und anschließend Connect window aus.3. Wählen Sie Create a new connection profile.4. Geben Sie im Feld New profile einen Namen für das Profil ein.5. Wählen Sie Manage Drivers aus. Das Dialogfeld Manage Drivers wird geöffnet.6. Klicken Sie auf Create a new entry. Geben Sie im Feld Name den Namen des Treibers ein.
Klicken Sie auf das Ordnersymbol neben dem Feld Library, navigieren Sie zum Speicherort desTreibers, wählen Sie ihn aus und klicken Sie auf Open.
API-Version 2012-12-0114
Amazon Redshift Handbuch „Erste Schritte“Herstellen einer Verbindung zwischen
SQL Workbench/J und Cluster
Wenn das Dialogfeld Please select one driver angezeigt wird, wählen Sie entwedercom.amazon.redshift.jdbc4.Driver oder com.amazon.redshift.jdbc41.Driver aus und klicken Sieanschließend auf OK. Das Feld Classname wird von SQL Workbench/J automatisch ausgefüllt. LassenSie das Feld Sample URL leer und klicken Sie auf OK.
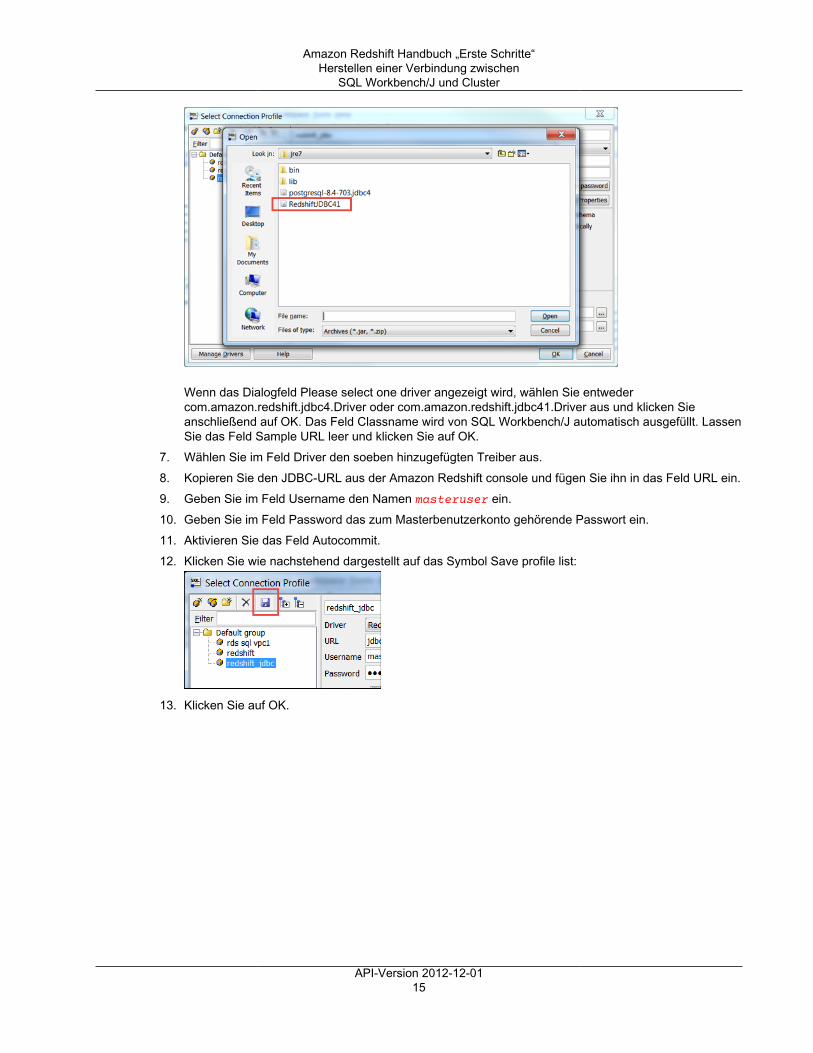
7. Wählen Sie im Feld Driver den soeben hinzugefügten Treiber aus.8. Kopieren Sie den JDBC-URL aus der Amazon Redshift console und fügen Sie ihn in das Feld URL ein.9. Geben Sie im Feld Username den Namen masteruser ein.10. Geben Sie im Feld Password das zum Masterbenutzerkonto gehörende Passwort ein.11. Aktivieren Sie das Feld Autocommit.12. Klicken Sie wie nachstehend dargestellt auf das Symbol Save profile list:
13. Klicken Sie auf OK.
API-Version 2012-12-0115

Amazon Redshift Handbuch „Erste Schritte“Schritt 6: Laden von Beispieldaten
Schritt 6: Laden von Beispieldaten aus Amazon S3Sie haben bereits eine Datenbank mit dem Namen dev erstellt und die Verbindung aufgebaut. Nun werdenSie Tabellen in der Datenbank anlegen, Daten hochladen und testweise eine Abfrage durchführen. DieBeispieldaten werden der Einfachheit halber in einem Amazon S3-Bucket bereitgestellt.
Note
Vergewissern Sie sich, bevor Sie fortfahren, dass der SQL Workbench/J-Client mit dem Clusterverbunden ist.
Nach Abschluss dieses Schritts finden Sie weitere Informationen über Amazon Redshift sowie über dasZurücksetzen Ihrer Umgebung unter Wie geht es weiter? (p. 21).
1. Erstellen Sie Tabellen.
Kopieren Sie die folgenden Anweisungen und führen Sie aus, um Tabellen in der dev-Datenbank zuerstellen. Weitere Informationen über die Syntax finden Sie im Amazon Redshift Database DeveloperGuide unter CREATE TABLE.
create table users( userid integer not null distkey sortkey, username char(8), firstname varchar(30), lastname varchar(30), city varchar(30), state char(2), email varchar(100), phone char(14), likesports boolean, liketheatre boolean, likeconcerts boolean, likejazz boolean, likeclassical boolean, likeopera boolean, likerock boolean, likevegas boolean, likebroadway boolean, likemusicals boolean);
API-Version 2012-12-0116

Amazon Redshift Handbuch „Erste Schritte“Schritt 6: Laden von Beispieldaten
create table venue( venueid smallint not null distkey sortkey, venuename varchar(100), venuecity varchar(30), venuestate char(2), venueseats integer);
create table category( catid smallint not null distkey sortkey, catgroup varchar(10), catname varchar(10), catdesc varchar(50));
create table date( dateid smallint not null distkey sortkey, caldate date not null, day character(3) not null, week smallint not null, month character(5) not null, qtr character(5) not null, year smallint not null, holiday boolean default('N'));
create table event( eventid integer not null distkey, venueid smallint not null, catid smallint not null, dateid smallint not null sortkey, eventname varchar(200), starttime timestamp);
create table listing( listid integer not null distkey, sellerid integer not null, eventid integer not null, dateid smallint not null sortkey, numtickets smallint not null, priceperticket decimal(8,2), totalprice decimal(8,2), listtime timestamp);
create table sales( salesid integer not null, listid integer not null distkey, sellerid integer not null, buyerid integer not null, eventid integer not null, dateid smallint not null sortkey, qtysold smallint not null, pricepaid decimal(8,2), commission decimal(8,2), saletime timestamp);
2. Laden Sie mit dem COPY-Befehl Beispieldaten aus Amazon S3.
Note
Es wird empfohlen, zum Laden von großen Datenmengen aus Amazon S3 oder DynamoDBin Amazon Redshift den COPY-Befehl zu verwenden. Weitere Informationen über die Syntaxdes COPY-Befehls finden Sie im Amazon Redshift Database Developer Guide unter COPY.
Die Beispieldaten für dieses Tutorial werden in einem Amazon S3-Bucket bereitgestellt, der AmazonRedshift gehört. Gemäß den für den Bucket konfigurierten Berechtigungen haben alle authentifiziertenAWS-Benutzer Lesezugriff für die Dateien mit den Beispieldaten.
API-Version 2012-12-0117

Amazon Redshift Handbuch „Erste Schritte“Schritt 6: Laden von Beispieldaten
Stellen Sie zum Laden der Beispieldaten und für den Zugriff auf Amazon S3 die Authentifizierung fürden Cluster bereit. Sowohl die rollen- als auch die schlüsselbasierte Authentifizierung sind zulässig.Es wird empfohlen, die rollenbasierte Authentifizierung zu verwenden. Weitere Informationen überdie beiden Authentifizierungsarten finden Sie im Amazon Redshift Database Developer Guide unterCREDENTIALS.
In diesem Schritt referenzieren Sie zur Bereitstellung der Authentifizierung die soeben erstellte und anden Cluster angefügte IAM-Rolle.
Note
Wenn Sie keine ausreichende Berechtigung für den Zugriff auf Amazon S3 haben,erhalten Sie bei Ausführung des COPY-Befehls die folgende Fehlermeldung:S3ServiceException: Access Denied.
Die COPY-Befehle enthalten einen Platzhalter für den Rollen-ARN IAM; siehe hierzu folgendesBeispiel.
copy users from 's3://awssampledbuswest2/tickit/allusers_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' region 'us-west-2';
Ersetzen Sie für die Zugriffsautorisierung mittels IAM-Rolle in der ParameterzeichenfolgeCREDENTIALS den Platzhalter <iam-role-arn> durch den Rollen-ARN für die in Schritt 2: Erstelleneiner IAM-Rolle (p. 3) erstellte IAM-Rolle.
Der COPY-Befehl sollte dann wie folgt aussehen.
copy users from 's3://awssampledbuswest2/tickit/allusers_pipe.txt' credentials 'aws_iam_role=arn:aws:iam::123456789012:role/myRedshiftRole' delimiter '|' region 'us-west-2';
Ersetzen Sie zum Laden der Beispieldaten den Teil <iam-role-arn> der folgenden COPY-Befehledurch Ihren Rollen-ARN. Führen Sie die Befehle anschließend im SQL-Client-Tool aus.
copy users from 's3://awssampledbuswest2/tickit/allusers_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' region 'us-west-2';
copy venue from 's3://awssampledbuswest2/tickit/venue_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' region 'us-west-2';
copy category from 's3://awssampledbuswest2/tickit/category_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' region 'us-west-2';
copy date from 's3://awssampledbuswest2/tickit/date2008_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' region 'us-west-2';
copy event from 's3://awssampledbuswest2/tickit/allevents_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' timeformat 'YYYY-MM-DD HH:MI:SS' region 'us-west-2';
copy listing from 's3://awssampledbuswest2/tickit/listings_pipe.txt' credentials 'aws_iam_role=<iam-role-arn>' delimiter '|' region 'us-west-2';
API-Version 2012-12-0118

Amazon Redshift Handbuch „Erste Schritte“Schritt 6: Laden von Beispieldaten
copy sales from 's3://awssampledbuswest2/tickit/sales_tab.txt'credentials 'aws_iam_role=<iam-role-arn>'delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS' region 'us-west-2';
3. Führen Sie nun einige Beispielabfragen aus. Weitere Informationen finden Sie im Amazon Redshift-Entwicklerhandbuch unter SELECT.
-- Get definition for the sales table.SELECT * FROM pg_table_def WHERE tablename = 'sales';
-- Find total sales on a given calendar date.SELECT sum(qtysold) FROM sales, date WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
-- Find top 10 buyers by quantity.SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, usersWHERE Q.buyerid = useridORDER BY Q.total_quantity desc;
-- Find events in the 99.9 percentile in terms of all time gross sales.SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1ORDER BY total_price desc;
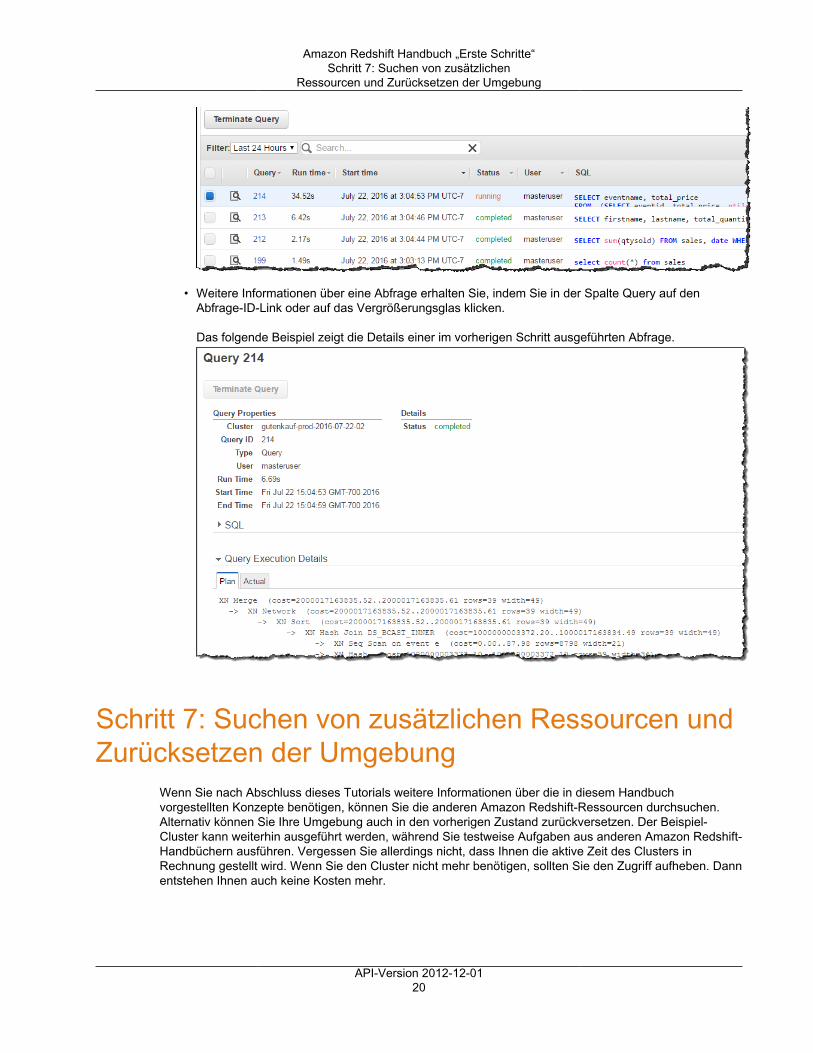
4. Wenn Sie möchten, können Sie die ausgeführten Abfragen in der Amazon Redshift-Konsoleüberprüfen. Die Registerkarte Queries enthält eine Liste der im angegebenen Zeitraum ausgeführtenAbfragen. Standardmäßig werden in der Konsole die Abfragen der letzten 24 Stunden einschließlichder gerade laufenden Abfragen aufgeführt.
• Melden Sie sich in der AWS Management Console an und öffnen Sie die Amazon Redshift-Konsoleunter https://console.aws.amazon.com/redshift/.
• Wählen Sie in der Cluster-Liste im rechten Teilfenster den Eintrag examplecluster aus.• Wählen Sie die Registerkarte Queries aus.
In der Konsole wird, wie im nachfolgenden Beispiel dargestellt, eine Liste der ausgeführten Abfragenangezeigt.
API-Version 2012-12-0119
Amazon Redshift Handbuch „Erste Schritte“Schritt 7: Suchen von zusätzlichen
Ressourcen und Zurücksetzen der Umgebung
• Weitere Informationen über eine Abfrage erhalten Sie, indem Sie in der Spalte Query auf denAbfrage-ID-Link oder auf das Vergrößerungsglas klicken.
Das folgende Beispiel zeigt die Details einer im vorherigen Schritt ausgeführten Abfrage.
Schritt 7: Suchen von zusätzlichen Ressourcen undZurücksetzen der Umgebung
Wenn Sie nach Abschluss dieses Tutorials weitere Informationen über die in diesem Handbuchvorgestellten Konzepte benötigen, können Sie die anderen Amazon Redshift-Ressourcen durchsuchen.Alternativ können Sie Ihre Umgebung auch in den vorherigen Zustand zurückversetzen. Der Beispiel-Cluster kann weiterhin ausgeführt werden, während Sie testweise Aufgaben aus anderen Amazon Redshift-Handbüchern ausführen. Vergessen Sie allerdings nicht, dass Ihnen die aktive Zeit des Clusters inRechnung gestellt wird. Wenn Sie den Cluster nicht mehr benötigen, sollten Sie den Zugriff aufheben. Dannentstehen Ihnen auch keine Kosten mehr.
API-Version 2012-12-0120

Amazon Redshift Handbuch „Erste Schritte“Wie geht es weiter?
Wie geht es weiter?Weitere RessourcenWenn Sie sich eingehender mit den in diesem Handbuch vorgestellten Konzepten befassen möchten,empfehlen wir Ihnen die folgenden Ressourcen:
• Amazon Redshift Management Overview: Dieses Thema vermittelt eine Übersicht über Amazon Redshift.• Amazon Redshift Cluster Management Guide: Dieses auf dem Erste Schritte mit Amazon Redshift
aufbauende Handbuch informiert detailliert über die Konzepte und Aufgaben für die Erstellung,Verwaltung und Überwachung von Clustern.
• Amazon Redshift Database Developer Guide: Dieses auf dem Erste Schritte mit Amazon Redshiftaufbauende Handbuch richtet sich an Datenbankentwickler und vermittelt fundierte Kenntnisse in denGebieten Entwurf, Entwicklung, Abfrage und Verwaltung von Datenbanken in einem Data Warehouse.
Zurücksetzen der UmgebungNach Abschluss dieses Tutorials sollten Sie Ihre Umgebung in den vorherigen Zustand zurückversetzen.Gehen Sie dabei folgendermaßen vor:
• Heben Sie den zuvor autorisierten Zugriff auf den Port and die CIDR/IP-Adresse auf:
Wenn Sie Ihren Cluster in der EC2-VPC-Plattform gestartet haben, führen Sie die Schritte unterAufheben des Zugriffs der VPC-Sicherheitsgruppe (p. 21) aus.
Wenn Sie Ihren Cluster in der EC2-Classic-Plattform gestartet haben, führen Sie die Schritte unterAufheben des Zugriffs der Cluster-Sicherheitsgruppe (p. 22) aus.
• Löschen Sie den Beispiel-Cluster. Es werden so lange die standardmäßigen Amazon Redshift-Nutzungsgebühren für den Cluster anfallen, bis Sie ihn löschen. Führen Sie die Schritte unter Löschendes Beispiel-Clusters (p. 23) aus.
Aufheben des Zugriffs der VPC-Sicherheitsgruppe
1. Wählen Sie im Navigationsbereich der Amazon Redshift-Konsole die Option Clusters aus.2. Öffnen Sie den Cluster examplecluster und wechseln Sie gegebenenfalls zur Registerkarte
Configuration.3. Wählen Sie unter Cluster Properties die VPC-Sicherheitsgruppe aus.
4. Rufen Sie bei ausgewählter Standardsicherheitsgruppe die Registerkarte Inbound auf und klicken Sieauf Edit.
API-Version 2012-12-0121

Amazon Redshift Handbuch „Erste Schritte“Wie geht es weiter?
5. Löschen Sie die benutzerdefinierte Zugangsregel für TCP/IP-Datenverkehr, die Sie für den Port unddie CIDR/IP-Adresse 0.0.0.0/0 erstellt haben. Behalten Sie andere Regeln wie die Regel All traffic bei;diese wurde standardmäßig für die Sicherheitsgruppe erstellt. Wählen Sie Save aus.
Aufheben des Zugriffs der Cluster-Sicherheitsgruppe
1. Wählen Sie im Navigationsbereich der Amazon Redshift-Konsole die Option Clusters aus.2. Öffnen Sie den Cluster "examplecluster" und wechseln Sie gegebenenfalls zur Registerkarte
Configuration.3. Wählen Sie unter Cluster Properties für Cluster Security Groups die Option default aus, um die
Standardsicherheitsgruppe zu öffnen.
4. Wählen Sie die auf der Registerkarte Security Groups in der Cluster-Sicherheitsgruppe die Cluster-Standardsicherheitsgruppe aus.
5. Wählen Sie auf der Registerkarte Security Group Connections die benutzerdefinierte CIDR/IP-Zugangsregel aus, die Sie für die CIDR/IP-Adresse 0.0.0.0/0 erstellt haben, und klicken Sieanschließend auf Revoke.
API-Version 2012-12-0122

Amazon Redshift Handbuch „Erste Schritte“Wie geht es weiter?
Löschen des Beispiel-Clusters
1. Wählen Sie im Navigationsbereich der Amazon Redshift-Konsole die Option Clusters aus.2. Öffnen Sie den Cluster "examplecluster" und wechseln Sie gegebenenfalls zur Registerkarte
Configuration.3. Klicken Sie im Menü Cluster auf Delete.
4. Wählen Sie im Fenster Delete Cluster unter Create snapshot die Option No aus und klicken Sieanschließend auf Delete.
5. Im Fenster mit den Cluster-Details sehen Sie dann unter Cluster Status, dass der Cluster geradegelöscht wird.
API-Version 2012-12-0123

Amazon Redshift Handbuch „Erste Schritte“Wie geht es weiter?
API-Version 2012-12-0124

Amazon Redshift Handbuch „Erste Schritte“
DokumentverlaufIn der folgenden Tabelle werden wichtige Änderungen seit der letzten Veröffentlichung des Handbuchs"Erste Schritte" für Amazon Redshift beschrieben.
Letzte Aktualisierung der Dokumentation: 28. Juli 2015
Änderung Beschreibung Veröffentlichungsdatum
Neue Funktion Das Handbuch enthält nun Informationen zum Starten vonClustern über das Amazon Redshift-Dashboard.
28. Juli 2015
Neue Funktion Das Handbuch enthält nun Informationen zur Verwendungvon neuen Knotentypnamen.
9. Juni 2015
Aktualisierung derDokumentation
Die Dokumentation enthält aktualisierte Screenshots undVerfahren zur Konfiguration der VPC-Sicherheitsgruppen.
30. April 2015
Aktualisierung derDokumentation
Die Dokumentation enthält aktualisierte Screenshotsund beschreibt, wie sich die aktuelle Konsole und dieScreenshots aufeinander abstimmen lassen.
12. November 2014
Aktualisierung derDokumentation
Zur besseren Auffindbarkeit wurden die Informationenzum Laden von Daten von Amazon S3 in einen separatenAbschnitt verschoben und der Abschnitt mit den nächstenSchritten wurde in den letzten Schritt integriert.
13. Mai 2014
Aktualisierung derDokumentation
Die Willkommensseite wurde entfernt; ihr Inhalt befindetsich nun auf der Hauptseite der Seite "Erste Schritte".
14. März 2014
Aktualisierung derDokumentation
Bei dieser Dokumentation handelt es sich um eine neueVersion des Handbuchs "Erste Schritte" für AmazonRedshift mit Informationen zu Kundenfeedback undService-Updates.
14. März 2014
Neues Handbuch Dies ist die erste Version des Handbuchs "Erste Schritte"für Amazon Redshift.
14. Februar 2013
API-Version 2012-12-0125