Embed Size (px)
Citation preview

Amazon RedshiftGuide de la gestion du clusterVersion de l'API 2012-12-01

Amazon Redshift Guide de la gestion du cluster
Amazon Redshift: Guide de la gestion du clusterCopyright © 2018 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any mannerthat is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks notowned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored byAmazon.

Amazon Redshift Guide de la gestion du cluster
Table of ContentsQu'est-ce qu'Amazon Redshift ? ........................................................................................................... 1
Utilisez-vous Amazon Redshift pour la première fois ? ...................................................................... 1Présentation de la gestion Amazon Redshift ................................................................................... 1
Gestion du cluster .............................................................................................................. 2Accès et sécurité des clusters .............................................................................................. 2Supervision des clusters ...................................................................................................... 3Bases de données .............................................................................................................. 4
Clusters ............................................................................................................................................. 5Présentation ............................................................................................................................... 5Clusters et nœuds ...................................................................................................................... 5
Migration de nœuds de type DC1 vers des nœuds de type DC2 ................................................ 6Détails de type de nœud ..................................................................................................... 7Détermination du nombre de nœuds ..................................................................................... 8
Redimensionnement d'un cluster ................................................................................................... 9Plateformes prises en charge pour lancer votre cluster ................................................................... 10
Plateforme EC2-Classic ..................................................................................................... 11Plateforme EC2-VPC ......................................................................................................... 11Choisir une plateforme ....................................................................................................... 11
Considérations sur les régions et les zones de disponibilité ............................................................. 12Fenêtres de maintenance ........................................................................................................... 12Alarme d'espace disque par défaut .............................................................................................. 13Renommer les clusters .............................................................................................................. 13Arrêt et suppression de clusters .................................................................................................. 14Statut du cluster ....................................................................................................................... 15Gestion des clusters à l'aide de la console ................................................................................... 16
Création d'un cluster ......................................................................................................... 17Modification d'un cluster ..................................................................................................... 24Suppression d'un cluster .................................................................................................... 26Redémarrage d'un cluster .................................................................................................. 28Redimensionnement d'un cluster ......................................................................................... 29Obtention d'informations sur la configuration du cluster ........................................................... 30Obtention d'une vue d'ensemble de l'état du cluster ............................................................... 31Prise d'un instantané d'un cluster ........................................................................................ 31Modification de l'alarme par défaut de l'espace disque ............................................................ 33Utilisation des données de performance du cluster ................................................................. 34
Gestion des clusters à l'aide du kit AWS SDK pour Java ................................................................ 34Gérer les clusters à l'aide de l'interface de ligne de commande Amazon Redshift et de l'API .................. 36Gestion des clusters dans un Amazon Virtual Private Cloud (VPC) ................................................... 36
Présentation ..................................................................................................................... 36Création d'un cluster dans un VPC ...................................................................................... 38Gestion des groupes de sécurité VPC pour un Cluster ........................................................... 39Groupes de sous-réseaux du cluster .................................................................................... 40
Sélection du suivi de maintenance des clusters ............................................................................. 46Définition du suivi de maintenance pour un cluster avec la console ........................................... 47Définition du suivi de maintenance pour un cluster avec l'AWS CLI ........................................... 48
Gestion des versions de cluster .................................................................................................. 48Historique des versions de cluster ............................................................................................... 50
Version 1.0.3324 ............................................................................................................... 50Version 1.0.3025 ............................................................................................................... 51Versions 1.0.2762, 1.0.2819, 10.2842 .................................................................................. 51Versions 1.0.2524, 1.0.2557, 1.02610, 1.0.2679, 1.02719 ........................................................ 52Version 1.0.2294, 1.0.2369 ................................................................................................. 53Version 1.0.2058 ............................................................................................................... 53Version 1.0.2044 ............................................................................................................... 54
Version de l'API 2012-12-01iii

Amazon Redshift Guide de la gestion du cluster
Versions 1.0.1792, 1.0.1793, 1.0.1808, 1.0.1865 .................................................................... 54Versions 1.0.1691 et 1.0.1703 ............................................................................................. 55Version 1.0.1636 ............................................................................................................... 56
Routage VPC amélioré ...................................................................................................................... 57Utilisation des points de terminaison d'un VPC .............................................................................. 58Activation du routage VPC amélioré ............................................................................................ 58
Groupes de paramètres ..................................................................................................................... 61Présentation ............................................................................................................................. 61A propos des groupes de paramètres .......................................................................................... 61Valeurs des paramètres par défaut .............................................................................................. 62Configuration des valeurs des paramètres à l'aide de l'AWS CLI ...................................................... 63Configuration de la gestion de la charge de travail ......................................................................... 64
Propriétés WLM dynamiques et statiques ............................................................................. 64Propriétés du paramètre wlm_json_configuration .................................................................... 65Configuration du paramètre wlm_json_configuration à l'aide de l'AWS CLI ................................. 67
Gestion des groupes de paramètres à l'aide de la console .............................................................. 73Création d'un groupe de paramètres .................................................................................... 74Modification d'un groupe de paramètres ............................................................................... 74Création ou modification d'une règle de surveillance de requête à l'aide de la console .................. 77Suppression d'un groupe de paramètres .............................................................................. 80Association d'un groupe de paramètres à un cluster ............................................................... 81
Gestion des groupes de paramètres à l'aide du kit AWS SDK pour Java ............................................ 81Gestion des groupes de paramètres à l'aide de l'interface de ligne de commande Amazon Redshift etde l'API ................................................................................................................................... 84
Instantanés ...................................................................................................................................... 86Présentation ............................................................................................................................. 86
Instantanés automatiques ................................................................................................... 86Instantanés manuels ......................................................................................................... 87Exclusion des tables des instantanés ................................................................................... 87Copie d'instantanés sur une autre région .............................................................................. 87Restauration d'un cluster à partir d'un instantané ................................................................... 88Restauration d'une table à partir d'un instantané .................................................................... 88Partage d'un instantané ..................................................................................................... 91
Gestion d'instantanés à l'aide de la console .................................................................................. 93Création d'un instantané manuel ......................................................................................... 93Suppression d'un instantané manuel .................................................................................... 94Copie d'un instantané automatique ...................................................................................... 95Restauration d'un cluster à partir d'un instantané ................................................................... 96Partage d'un instantané de cluster ....................................................................................... 98Configuration d'une copie d'instantané entre régions pour un cluster non chiffré .......................... 99Configurer une copie d'instantané entre régions pour un cluster chiffré par AWS KMS ................ 100Modification de la période de conservation pour la copie d'instantanés entre régions .................. 100Désactivation de la copie d'instantanés entre régions ............................................................ 101
Gestion des instantanés à l'aide du kit AWS SDK pour Java .......................................................... 101Gestion des instantanés à l'aide de l'interface de ligne de commande et de l'API Amazon Redshift ........ 103
Chiffrement de la base de données ................................................................................................... 105Chiffrement de base de données pour Amazon Redshift à l'aide d'AWS KMS .................................... 105
Copie d'instantanés chiffrés par AWS KMS dans une autre région .......................................... 106Chiffrement pour Amazon Redshift à l'aide de modules de sécurité matérielle ................................... 107
Configuration d'une connexion approuvée entre Amazon Redshift et un HSM ............................ 108A propos de la rotation des clés de chiffrement dans Amazon Redshift ............................................ 108Migration vers un cluster chiffré ................................................................................................. 109Configuration du chiffrement de base de données à l'aide de la console .......................................... 111
Configuration de Amazon Redshift pour utiliser un module de sécurité matérielle avec AmazonRedshift console ............................................................................................................. 111Rotation des clés de chiffrement avec Amazon Redshift console ............................................. 116
Configuration du chiffrement de la base de données à l'aide de l'API et l'AWS CLI Amazon Redshift ...... 117
Version de l'API 2012-12-01iv

Amazon Redshift Guide de la gestion du cluster
Configuration de Amazon Redshift pour utiliser les clés de chiffrement AWS KMS à l'aide de l'APIet l'AWS CLI Amazon Redshift .......................................................................................... 117Configuration de Amazon Redshift pour utiliser HSM à l'aide de l'API et de l'AWS CLI AmazonRedshift ......................................................................................................................... 118Rotation des clés de chiffrement à l'aide de l'API et de l'AWS CLI Amazon Redshift ................... 118
Achat de nœuds réservés ................................................................................................................ 119Présentation ........................................................................................................................... 119
A propos des offres de nœuds réservés ............................................................................. 119Comparaison de prix entre les offres de nœuds réservés ...................................................... 120Fonctionnement des nœuds réservés ................................................................................. 121Nœuds réservés et facturation consolidée ........................................................................... 121Exemples de nœuds réservés ........................................................................................... 121
Achat d'une offre de nœuds réservés avec la console .................................................................. 123Mettre à niveau un nœud réservé ...................................................................................... 124
Achat d'une offre de nœuds réservés à l'aide de Java .................................................................. 127Achat d'une offre de nœud réservé à l'aide de l'AWS CLI et de l'API Amazon Redshift ........................ 129
Sécurité ......................................................................................................................................... 131Authentification et contrôle d'accès ............................................................................................ 131
Authentification ............................................................................................................... 132Contrôle d'accès ............................................................................................................. 133Présentation de la gestion de l'accès ................................................................................. 133Utilisation des stratégies basées sur une identité (stratégies IAM) ........................................... 138Référence des autorisations d'API Amazon Redshift ............................................................. 146Utilisation des rôles liés à un service ................................................................................. 146
Groupes de sécurité ................................................................................................................ 148Présentation ................................................................................................................... 149Gestion des groupes de sécurité du cluster à l'aide de la console ........................................... 149Gestion des groupes de sécurité du cluster à l'aide du kit AWS SDK pour Java ......................... 158Gérer les groupes de sécurité de cluster à l'aide de l'interface de ligne de commande et de l'APIAmazon Redshift ............................................................................................................. 161
Utilisation de l'authentification IAM pour générer des informations d'identification de l'utilisateur de base dedonnées ......................................................................................................................................... 162
Présentation ........................................................................................................................... 162Création d'informations d'identification temporaires de l'utilisateur IAM ............................................. 163
Créer un rôle IAM pour un accès IAM avec authentification unique (SSO) ................................ 164Configurer des assertions SAML pour votre IdP ................................................................... 164Créer un rôle ou un utilisateur IAM avec des autorisations d'appeler GetClusterCredentials .......... 165Créer un utilisateur de base de données et des groupes de bases de données .......................... 167Configurer une connexion JDBC ou ODBC pour utiliser des informations d'identification IAM ........ 168
Options visant à fournir des informations d'identification IAM .......................................................... 174Options JDBC et ODBC visant à fournir des informations d'identification IAM ............................ 175Utilisation d'un plug-in de fournisseur d'informations d'identification ......................................... 175Utilisation d'un profil de configuration ................................................................................. 177
Options JDBC et ODBC pour la création d'informations d'identification de l'utilisateur de base dedonnées ................................................................................................................................. 178Génération des informations d'identification de base de données IAM à l'aide de l'interface de ligne decommande ou de l'API Amazon Redshift .................................................................................... 179
Autorisation de Amazon Redshift à accéder aux services AWS .............................................................. 181Création d'un rôle IAM pour autoriser votre cluster Amazon Redshift à accéder aux services AWS ........ 181Restriction de l'accès aux rôles IAM ........................................................................................... 182Restriction d'un rôle IAM à une région AWS ................................................................................ 183Création de chaînes de rôles IAM ............................................................................................. 184Rubriques connexes ................................................................................................................ 186Autorisation d'opérations COPY, UNLOAD et CREATE EXTERNAL SCHEMA à l'aide de rôles IAM ...... 186
Association des rôles IAM aux clusters ............................................................................... 186Accès aux clusters et aux bases de données Amazon Redshift .............................................................. 191
Utilisation des interfaces de gestion Amazon Redshift ................................................................... 191
Version de l'API 2012-12-01v

Amazon Redshift Guide de la gestion du cluster
Utilisation du kit AWS SDK pour Java ................................................................................ 192Signature d'une requête HTTP .......................................................................................... 194Configuration de l'interface de ligne de commande Amazon Redshift ....................................... 197
Connexion à un cluster ............................................................................................................ 201Configuration de connexions dans Amazon Redshift ............................................................. 201Configurer une connexion JDBC ........................................................................................ 203Configurer la connexion ODBC ......................................................................................... 219Configurer les options de sécurité des connexions ............................................................... 238Connexion aux clusters à partir des outils client et du code .................................................... 244Résolution des problèmes de connexion dans Amazon Redshift ............................................. 253
Surveillance des performances de cluster ........................................................................................... 259Présentation ........................................................................................................................... 259Données de performance ......................................................................................................... 260
Métriques Amazon Redshift .............................................................................................. 260Données de performance de chargement/requête Amazon Redshift ........................................ 264
Utilisation des données de performance ..................................................................................... 265Affichage des données de performances de cluster .............................................................. 266Affichage des données de performance des requêtes ........................................................... 268Affichage des métriques du cluster pendant les opérations de chargement ............................... 277Analyse des performances de la charge de travail ................................................................ 279Création d'une alarme ...................................................................................................... 282Utilisation des métriques de performance dans la console Amazon CloudWatch ........................ 284
Événements ................................................................................................................................... 286Présentation ........................................................................................................................... 286Affichage des événements à l'aide de la console ......................................................................... 286
Filtrage des événements .................................................................................................. 287Affichage d'événements à l'aide du kit AWS SDK pour Java .......................................................... 287Afficher les événements à l'aide de l'API et de l'interface de ligne de commande Amazon Redshift ........ 289Notifications d'événements ........................................................................................................ 289
Présentation ................................................................................................................... 289Catégories d'événements et messages d'événements Amazon Redshift ................................... 291Gestion des notifications d'événement à l'aide de la console Amazon Redshift .......................... 298Gestion des notifications d'événement à l'aide de l'interface de ligne de commande et de l'APIAmazon Redshift ............................................................................................................. 303
Journalisation des audits de base de données ..................................................................................... 305Présentation ........................................................................................................................... 305Journaux Amazon Redshift ....................................................................................................... 305
Journal de connexion ....................................................................................................... 306Journal utilisateur ............................................................................................................ 306Journal d'activité utilisateur ............................................................................................... 307
Activation de la journalisation .................................................................................................... 308Gestion des fichiers journaux .................................................................................................... 308
Autorisations de compartiment pour la journalisation d'audit Amazon Redshift ........................... 308Structure du compartiment pour la journalisation d'audit Amazon Redshift ................................ 310
Résolution des problèmes de journalisation d'audit Amazon Redshift ............................................... 311Journalisation des appels d'API Amazon Redshift avec AWS CloudTrail ........................................... 311
Informations Amazon Redshift dans CloudTrail .................................................................... 312Présentation des entrées des fichiers journaux Amazon Redshift ............................................ 312
ID de compte Amazon Redshift dans les journaux AWS CloudTrail ................................................. 314Configuration d'audit à l'aide de la console .................................................................................. 316
Activation de la journalisation d'audit grâce à la console ........................................................ 316Modification du compartiment pour la journalisation d'audit .................................................... 318Désactivation de la journalisation d'audit grâce à la console ................................................... 318
Configuration de la journalisation à l'aide de l'interface de ligne de commande et de l'API AmazonRedshift ................................................................................................................................. 318
Redimensionnement des clusters ...................................................................................................... 320Présentation ........................................................................................................................... 320
Version de l'API 2012-12-01vi

Amazon Redshift Guide de la gestion du cluster
Présentation de l'opération de redimensionnement ....................................................................... 320Présentation des opérations d'instantané, de restauration et de redimensionnement ........................... 321Didacticiel : Utilisation de l'opération Resize pour redimensionner un cluster ..................................... 322
Prérequis ....................................................................................................................... 323Étape 1 : Redimensionner le cluster ................................................................................... 323Étape 2 : Supprimer l'exemple de cluster ............................................................................ 324
Didacticiel : Utilisation des opérations d'instantané, de restauration et de redimensionnement pourredimensionner un cluster ........................................................................................................ 324
Prérequis ....................................................................................................................... 325Étape 1 : Prendre un instantané ........................................................................................ 325Étape 2 : Restaurer l'instantané sur le cluster cible ............................................................... 326Étape 3 : Vérifier les données dans le cluster cible ............................................................... 327Étape 4 : Redimensionner le cluster cible ............................................................................ 328Étape 5 : Copier les données post-instantané du cluster source vers le cluster cible ................... 329Étape 6 : Renommer les clusters source et cible .................................................................. 330Étape 7 : Supprimer le cluster source ................................................................................. 331Étape 8 : Nettoyer votre environnement .............................................................................. 332
Restrictions .................................................................................................................................... 333Quotas et limites ..................................................................................................................... 333Contraintes d'affectation de noms .............................................................................................. 334
Ajout de balises .............................................................................................................................. 336Présentation du balisage .......................................................................................................... 336
Balisage des exigences .................................................................................................... 337Gestion des balises des ressources à l'aide de la console ............................................................. 337
Comment ouvrir la fenêtre de gestion des balises ................................................................ 338Comment gérer les balises dans la console Amazon Redshift ................................................ 339
Gestion des balises à l'aide de l'API Amazon Redshift .................................................................. 339Historique du document ................................................................................................................... 341
Version de l'API 2012-12-01vii

Amazon Redshift Guide de la gestion du clusterUtilisez-vous Amazon Redshift pour la première fois ?
Qu'est-ce qu'Amazon Redshift ?Bienvenue dans le manuel Amazon Redshift Cluster Management Guide. Amazon Redshift est un serviced'entreposage de données dans le cloud entièrement géré et d'une capacité de plusieurs Po. Vous pouvezcommencer par quelques centaines de gigaoctets, puis passer à un pétaoctet ou plus. Cela vous permetd'utiliser vos données et d'acquérir de nouvelles connaissances pour votre entreprise et vos clients.
La première étape pour créer un entrepôt de données consiste à lancer un ensemble de nœuds, appelécluster Amazon Redshift. Une fois que avez mis en service votre cluster, vous pouvez télécharger votreensemble de données, puis exécuter les requêtes d'analyse de données. Quelle que soit la taille del'ensemble de données, Amazon Redshift offre des performances de requêtes rapides grâce aux outilsSQL et aux applications d'aide à la décision que vous utilisez déjà.
Utilisez-vous Amazon Redshift pour la premièrefois ?
Si vous utilisez Amazon Redshift pour la première fois, nous vous recommandons de commencer par lireles sections suivantes :
• Présentation de la gestion Amazon Redshift (p. 1) – fournit une vue d'ensemble de Amazon Redshift.• Description des tarifs et services – fournit la proposition de valeur Amazon Redshift, les points forts du
service et la tarification.• Amazon Redshift Mise en route – explique le processus de création d'un cluster, de création de tables de
base de données, de chargement des données et de test des requêtes.• Amazon Redshift Cluster Management Guide (ce guide) – explique comment créer et gérer les clusters
Amazon Redshift.• Amazon Redshift Database Developer Guide – si vous êtes un développeur de base de données, ce
guide explique comment concevoir, développer, interroger et gérer les bases de données qui constituentvotre entrepôt de données.
Il existe plusieurs façons de gérer les clusters. Si vous préférez une façon plus interactive de gérer lesclusters, vous pouvez utiliser la console Amazon Redshift console ou l'interface de ligne de commandeAWS Command Line Interface (AWS CLI). Si vous êtes un développeur d'applications, vous pouvez utiliserl'API Query Amazon Redshift ou les bibliothèques du Kit de développement (SDK) AWS pour gérer lesclusters par programmation. Si vous utilisez l'API Query Amazon Redshift, vous devez vous authentifierchaque demande HTTP ou HTTPS de l'API en vous y connectant. Pour plus d'informations sur la signaturedes demandes, consultez Signature d'une requête HTTP (p. 194).
Pour plus d'informations sur l'interface de ligne de commande, les API et les kits de développement logicielSDK, consultez les liens suivants :
• AWS CLI Command Reference• Amazon Redshift API Reference• Références SDK dans Outils Amazon Web Services.
Présentation de la gestion Amazon RedshiftLe service Amazon Redshift gère toutes les tâches de configuration, d'exploitation et de mise à l'échelled'un entrepôt de données. Ces tâches incluent la capacité de mise en service, de surveillance et de
Version de l'API 2012-12-011
Amazon Redshift Guide de la gestion du clusterGestion du cluster
sauvegarde du cluster, ainsi que l'application de correctifs et de mises à niveau au moteur AmazonRedshift.
Gestion du clusterUn cluster Amazon Redshift cluster est un ensemble de nœuds qui se compose d'un nœud principal et d'unou de plusieurs nœuds de calcul. Le type et le nombre de nœuds de calcul dont vous avez besoin dépendde la taille de vos données, du nombre de requêtes que vous exécutez et des performances d'exécutiondes requêtes dont vous avez besoin.
Création et gestion de clustersEn fonction de vos besoins en entrepôt de données, vous pouvez commencer par un petit cluster à unseul nœud et facile à agrandir en un cluster plus grand et à plusieurs nœuds, au fur et à mesure que vosbesoins évoluent. Vous pouvez ajouter des nœuds de calcul au cluster ou en supprimer sans interrompre leservice. Pour plus d'informations, consultez Clusters Amazon Redshift (p. 5).
Réservation de nœuds de calculSi vous souhaitez que votre cluster s'exécute pendant un an ou plus, vous pouvez économiser de l'argenten réservant des nœuds de calcul pour une période d'un an ou de trois ans. La réservation de nœudsde calcul offre des économies importantes par rapport aux taux horaires que vous payez lorsque vousmettez en service des nœuds de calcul à la demande. Pour plus d'informations, consultez Achat de nœudsréservés Amazon Redshift (p. 119).
Création d'instantanés de clusterLes instantanés sont des sauvegardes du cluster à un instant donné. Il existe deux types d'instantanés :automatiques et manuels. Amazon Redshift stocke ces instantanés en interne dans Amazon SimpleStorage Service (Amazon S3) à l'aide d'une connexion chiffrée SSL (Secure Sockets Layer). Si vous devezrestaurer à partir d'un instantané, Amazon Redshift crée un nouveau cluster et importe les données à partirde l'instantané que vous spécifiez. Pour plus d'informations sur les instantanés, consultez InstantanésAmazon Redshift (p. 86).
Accès et sécurité des clustersIl existe plusieurs fonctions liées à l'accès au cluster et à la sécurité dans Amazon Redshift. Cesfonctionnalités vous permettent de contrôler l'accès à votre cluster, de définir des règles de connectivité etde chiffrer les données et les connexions. Ces fonctions viennent en complément des fonctionnalités liéesà l'accès aux bases de données et à leur sécurité dans Amazon Redshift. Pour plus d'informations sur lasécurité des base de données, consultez Gestion de la sécurité des bases de données dans le manuelAmazon Redshift Database Developer Guide.
Comptes AWS et informations d'identification IAMPar défaut, un cluster Amazon Redshift est uniquement accessible par le compte AWS qui crée le cluster.Le cluster est verrouillé afin que personne d'autre n'y ait accès. Au sein de votre compte AWS, vousutilisez le service AWS Identity and Access Management (IAM) pour créer des comptes d'utilisateur etgérer leurs autorisations pour contrôler les opérations de cluster. Pour plus d'informations, consultezSécurité (p. 131).
Groupes de sécuritéPar défaut, un cluster que vous créez est fermé pour tout le monde. Les informations d'identification IAMcontrôlent uniquement l'accès aux ressources liées à l'API Amazon Redshift : Amazon Redshift console,
Version de l'API 2012-12-012

Amazon Redshift Guide de la gestion du clusterSupervision des clusters
l'interface de ligne de commande (CLI), l'API et le kit SDK. Pour autoriser l'accès au cluster à partir d'outilsclients SQL via ODBC ou JDBC, vous utilisez des groupes de sécurité :
• Si vous utilisez la plateforme EC2-Classic pour votre cluster Amazon Redshift, vous devez utiliser lesgroupes de sécurité Amazon Redshift.
• Si vous utilisez la plateforme EC2-VPC pour votre cluster Amazon Redshift, vous devez utiliser lesgroupes de sécurité VPC.
Dans les deux cas, vous ajoutez des règles au groupe de sécurité pour accorder l'accès entrant expliciteà une plage d'adresses CIDR/IP spécifique ou à un groupe de sécurité Amazon Elastic Compute Cloud(Amazon EC2) si votre client SQL s'exécute sur une instance Amazon EC2. Pour plus d'informations,consultez Groupes de sécurité du cluster Amazon Redshift (p. 148).
Outre les règles de l'accès entrant, vous créez des utilisateurs de base de données pour fournir lesinformations d'identification afin de s'authentifier auprès de la base de données au sein du cluster lui-même. Pour plus d'informations, consultez Bases de données (p. 4) dans cette rubrique.
ChiffrementLorsque vous mettez en service le cluster, vous pouvez choisir, le cas échéant, de chiffrer le cluster pourplus de sécurité. Lorsque vous activez le chiffrement, Amazon Redshift stocke toutes les données destables créées par l'utilisateur en un format chiffré. Vous pouvez utiliser AWS Key Management Service(AWS KMS) pour gérer vos clés de chiffrement Amazon Redshift.
Le chiffrement est une propriété immuable du cluster. Le seul moyen de passer d'un cluster chiffré àun cluster non chiffré consiste à décharger les données et à les recharger dans un nouveau cluster. Lechiffrement s'applique au cluster et à toutes les sauvegardes. Lors de la restauration d'un cluster à partird'un instantané chiffré, le nouveau cluster est également chiffré.
Pour plus d'informations sur le chiffrement, les clés et les modules de sécurité matérielle, consultezChiffrement de base de données Amazon Redshift (p. 105).
Connexions SSLVous pouvez utiliser le chiffrement SSL (Secure Sockets Layer) pour chiffrer la connexion entre votreclient SQL et votre cluster. Pour plus d'informations, consultez Configurer les options de sécurité desconnexions (p. 238).
Supervision des clustersIl existe plusieurs fonctions liées à la supervision dans Amazon Redshift. Vous pouvez utiliser lajournalisation des audits de base de données pour générer les journaux d'activité, configurer lesabonnements aux événements et aux notifications afin de suivre les informations dignes d'intérêt, etutiliser les métriques de Amazon Redshift et Amazon CloudWatch afin d'en savoir plus sur l'état et lesperformances de vos clusters et bases de données.
Journalisation des audits de base de donnéesVous pouvez utiliser la journalisation des audits de base de données pour suivre les informations surles tentatives d'authentification, les connexions, les déconnexions, les modifications apportées auxdéfinitions des utilisateurs de la base de données et les requêtes s'exécutant dans la base de données.Ces informations sont utiles pour la sécurité et le dépannage de Amazon Redshift. Les journaux sontstockés dans des compartiments Amazon S3. Pour plus d'informations, consultez Journalisation des auditsde base de données (p. 305).
Version de l'API 2012-12-013

Amazon Redshift Guide de la gestion du clusterBases de données
Événements et notificationsAmazon Redshift suit les événements et conserve les informations à leur sujet dans votre compte AWSpendant plusieurs semaines. Pour chaque événement, Amazon Redshift prend en charge les informationstelles que la date à laquelle l'événement s'est produit, une description, la source de l'événement (uncluster, un groupe de paramètres ou un instantané, par exemple) et l'ID source. Vous pouvez créer desabonnements aux notifications d'événements Amazon Redshift qui spécifient un ensemble de filtresd'événement. Quand se produit un événement qui correspond aux critères de filtre, Amazon Redshift utiliseAmazon Simple Notification Service pour vous informer activement que l'événement a eu lieu. Pour plusd'informations sur les événements et les notifications, consultez Événements Amazon Redshift (p. 286).
PerformancesAmazon Redshift fournit les métriques de performance et les données de telle sorte que vous puissiezsuivre l'état et les performances de vos clusters et bases de données. Amazon Redshift utilise lesmétriques Amazon CloudWatch pour surveiller les aspects physiques du cluster, telles que l'utilisationde l'UC, la latence et le débit. Amazon Redshift fournit également les données de performances derequêtes et de charges pour vous aider à surveiller l'activité de base de données de votre cluster. Pourplus d'informations sur les métriques de performance et leur supervision, consultez Surveillance desperformances de cluster Amazon Redshift (p. 259).
Bases de donnéesAmazon Redshift crée une base de données lorsque vous mettez en service un cluster. Il s'agit de labase de données que vous utilisez pour charger les données et exécuter des requêtes sur vos données.Vous pouvez créer des bases de données supplémentaires en fonction des besoins en exécutant unecommande SQL. Pour plus d'informations sur la création d'autres bases de données, consultez Étape 1 :Créer une base de données dans le manuel Amazon Redshift Database Developer Guide.
Lorsque vous mettez en service un cluster, vous spécifiez un utilisateur principal qui a accès à toutesles bases de données créées au sein du cluster. Cet utilisateur principal est un super-utilisateur, qui estle seul utilisateur ayant accès initialement à la base de données, même si cet utilisateur peut créer desutilisateurs et des super-utilisateurs supplémentaires. Pour plus d'informations, consultez Super-utilisateurset utilisateurs dans le manuel Amazon Redshift Database Developer Guide.
Amazon Redshift utilise les groupes de paramètres pour définir le comportement de toutes les bases dedonnées d'un cluster, comme le style de présentation des dates et la précision en virgule flottante. Si vousne spécifiez pas un groupe de paramètres lorsque vous mettez en service votre cluster, Amazon Redshiftassocie un groupe de paramètres par défaut au cluster. Pour plus d'informations, consultez Groupes deparamètres Amazon Redshift (p. 61).
Pour plus d'informations sur les bases de données dans Amazon Redshift, consultez Amazon RedshiftDatabase Developer Guide.
Version de l'API 2012-12-014

Amazon Redshift Guide de la gestion du clusterPrésentation
Clusters Amazon RedshiftPrésentation
Un entrepôt de données Amazon Redshift est un ensemble de ressources informatiques appelées nœuds,qui sont organisées en un groupe appelé cluster. Chaque cluster exécute un moteur Amazon Redshift etcontient une ou plusieurs bases de données.
Note
A ce jour, le moteur Amazon Redshift version 1.0 est disponible. Cependant, au fur et à mesurele moteur est mis à jour, vous pouvez avoir le choix entre plusieurs versions de moteur AmazonRedshift.
Vous pouvez déterminer les versions du moteur Amazon Redshift et de la base de données de votrecluster dans le champ Version du cluster de la console. Les deux premières sections du numérocorrespondent à la version du cluster et la dernière section est le numéro de révision spécifique de la basede données du cluster. Dans l'exemple suivant, la version du cluster est 1.0 et le numéro de révision de labase de données est 884.
Note
Bien que la console affiche ces informations dans un même champ, il s'agit de deux paramètresdans l'API Amazon Redshift : ClusterVersion et ClusterRevisionNumber. Pour plusd'informations, consultez Cluster dans le manuel Amazon Redshift API Reference.
Amazon Redshift propose un paramètre Autoriser la mise à niveau de la version, pour spécifierautomatiquement si le moteur Amazon Redshift de votre cluster doit être automatiquement mis à jourlorsqu'une nouvelle version du moteur devient disponible. Ce paramètre n'affecte pas les mises à niveau dela version de base de données, qui sont appliquées pendant la fenêtre de maintenance que vous spécifiezpour votre cluster. Les mises à niveau du moteur Amazon Redshift sont des mises à niveau de versionmajeure et les mises à niveau de base de données Amazon Redshift sont des mises à niveau de versionmineure. Vous pouvez désactiver les mises à niveau de version automatique pour les versions majeuresuniquement. Pour plus d'informations sur les fenêtres de maintenance des mises à niveau de versionmineure consultez Fenêtres de maintenance (p. 12).
Clusters et des nœuds dans Amazon RedshiftUn cluster Amazon Redshift se compose de nœuds. Chaque cluster possède un nœud principal et unou plusieurs nœuds de calcul. Le nœud principal reçoit les requêtes d'applications clientes, analyse les
Version de l'API 2012-12-015

Amazon Redshift Guide de la gestion du clusterMigration de nœuds de type DC1
vers des nœuds de type DC2
requêtes et développe les plans d'exécution de requête. Le nœud principal coordonne ensuite l'exécutionparallèle de ces plans avec les nœuds de calcul et regroupe les résultats intermédiaires de ces nœuds.Enfin, il renvoie ensuite les résultats aux applications clientes.
Les nœuds de calcul exécutent les plans d'exécution de requête et communiquent les données entre euxafin de traiter ces requêtes. Les résultats intermédiaires sont renvoyés au nœud « leader » afin d'êtrecompilés, puis transmis aux applications clientes. Pour plus d'informations sur les nœuds principaux etles nœuds de calcul, consultez Architecture système de l'entrepôt de données dans le manuel AmazonRedshift Database Developer Guide.
Lorsque vous lancez un cluster, vous spécifiez notamment l'option correspondant au type de nœud. Letype de nœud détermine l'UC, la mémoire vive, la capacité de stockage et le type de disque de stockage dechaque nœud. Les nœuds de type dense storage (DS, stockage dense) sont optimisés pour le stockage.Les nœuds de type dense compute (DC, calcul dense) sont optimisés pour le calcul.
Les types de nœud DS2 sont optimisés pour les charges de travail de données volumineuses et l'utilisationdu stockage HDD.
Les nœuds DC1 et DC2 sont optimisés pour des charges de travail gourmandes en performances. Dansla mesure où ils utilisent le stockage SSD, les types de nœuds DC1 et DC2 fournissent des entrées/sortiesbien plus rapides que les types de nœud DS, mais ils offrent moins d'espace de stockage.
Les clusters utilisant les types de nœuds DC2 sont lancés dans un cloud privé virtuel (Virtual PrivateCloud, VPC). Vous ne pouvez pas lancer de clusters DC2 en mode EC2 Classic. Pour plus d'informations,consultez Création d'un cluster dans un VPC (p. 38).
Le type de nœud que vous choisissez dépend fortement de trois éléments :
• La quantité de données que vous importez dans Amazon Redshift• La complexité des requêtes et des opérations que vous exécutez dans la base de données• Les besoins des systèmes en aval qui reposent sur les résultats de ces requêtes et opérations
Les types de nœuds sont disponibles en différentes tailles. Les nœuds DS2 sont disponibles dans lestailles xlarge and 8xlarge. Les nœuds DC2 sont disponibles dans les tailles large and 8xlarge. La taille denœud et le nombre de nœuds de déterminent le stockage total d'un cluster.
Certains types de nœud autorisent un nœud (type à nœud unique) ou deux ou plusieurs nœuds (typeà plusieurs nœuds). Le minimum pour les clusters 8xlarge est de deux nœuds. Sur un cluster à un seulnœud, le nœud est partagé pour les fonctionnalités « principal » et « calcul ». Sur un cluster à plusieursnœuds, le nœud principal est distinct des nœuds de calcul.
Amazon Redshift applique des quotas aux ressources pour chaque compte AWS dans chaque région.Un quota limite le nombre de ressources que votre compte peut créer pour un type de ressource donnée,comme les nœuds ou les instantanés, au sein d'une région. Pour plus d'informations sur les quotas pardéfaut qui s'appliquent aux ressources Amazon Redshift, consultez Limites Amazon Redshift dans lemanuel Référence générale d'Amazon Web Services. Pour demander une augmentation, envoyez unformulaire d'augmentation de limite Amazon Redshift.
Le coût de votre cluster dépend de la région, du type de nœud, du nombre de nœuds et du fait que lesnœuds sont réservés ou pas à l'avance. Pour plus d'informations sur le coût des nœuds, consultez la pageTarification Amazon Redshift.
Migration de nœuds de type DC1 vers des nœuds detype DC2Pour bénéficier d'améliorations de performances, vous pouvez migrer votre cluster DC1 vers des nœuds detype DC2 plus récents.
Version de l'API 2012-12-016

Amazon Redshift Guide de la gestion du clusterDétails de type de nœud
Les clusters utilisant les types de nœuds DC2 doivent être lancés dans un cloud privé virtuel, ou VirtualPrivate Cloud (EC2-VPC). Si votre cluster ne se trouve pas dans un VPC (EC2-CLASSIC), commencez parcréer un instantané de votre cluster, puis choisissez l'une des options suivantes :
• Pour un cluster dc1.large, procédez à une restauration directe d'un cluster dc2.large dans un VPC.• Pour un cluster dc1.8xlarge dans EC2-CLASSIC, procédez d'abord à la restauration d'un cluster
dc1.8xlarge dans un VPC, puis redimensionnez votre cluster dc1.8xlarge en cluster dc2.8xlarge. Vous nepouvez pas procéder directement à une restauration en cluster dc2.8xl car le type de nœud dc2.8xlargene dispose pas du même nombre de sections que le type de nœud dc1.8xlarge.
Si votre cluster se trouve dans un VPC, choisissez l'une des options suivantes :
• Pour un cluster dc1.large, procédez à une restauration directe d'un cluster dc2.large dans un VPC.• Pour un cluster dc1.8xlarge, redimensionnez votre cluster dc1.8xl en cluster dc2.8xlarge. Vous ne
pouvez pas procéder directement à une restauration en cluster dc2.8xlarge car le type de nœuddc2.8xlarge ne dispose pas du même nombre de sections que le type de nœud dc1.8xlarge.
Pour plus d'informations, consultez Instantanés Amazon Redshift (p. 86) et Redimensionnement desclusters (p. 320).
Détails de type de nœudLes tableaux suivants résument les spécifications de nœud de chaque type de nœud et taille. Dans lesdeux tableaux suivants, ces titres ont la signification suivante :
• vCPU correspond au nombre de processeurs virtuels de chaque nœud.• ECU correspond au nombre d'unités de calcul Amazon EC2 de chaque nœud.• RAM correspond à la quantité de mémoire en gibioctets (Gio) de chaque nœud.• Slices per Node correspond au nombre de tranches dans lequel un nœud de calcul est partitionné.• Storage correspond à la capacité et au type de stockage de chaque nœud.• Node Range correspond aux nombres minimal et maximal de nœuds qu'Amazon Redshift prend en
charge pour le type de nœud et la taille.
Note
Vous pouvez vous retrouver limité à moins de nœuds en fonction du quota appliqué à votrecompte AWS dans la région sélectionnée, comme indiqué précédemment.
• Total Capacity correspond à la capacité de stockage total pour le cluster si vous déployez le nombremaximal de nœuds spécifié dans la plage de nœuds.
Important
Les types de nœuds DS1 sont obsolètes. Les nouveaux types de nœuds DS2 fournissent desperformances supérieures à celles des nœuds DS1 sans frais supplémentaires. Si vous avezacheté des nœuds réservés DS1, contactez [email protected] pour obtenir de l'aide lorsde la transition vers les types de nœuds DS2.
Types de nœud de stockage dense
Node Size vCPU ECU RAM(Gio)
Slices PerNode
Storage PerNode
Node Range TotalCapacity
ds2.xlarge 4 13 31 2 2 To HDD 1–32 64 To
Version de l'API 2012-12-017
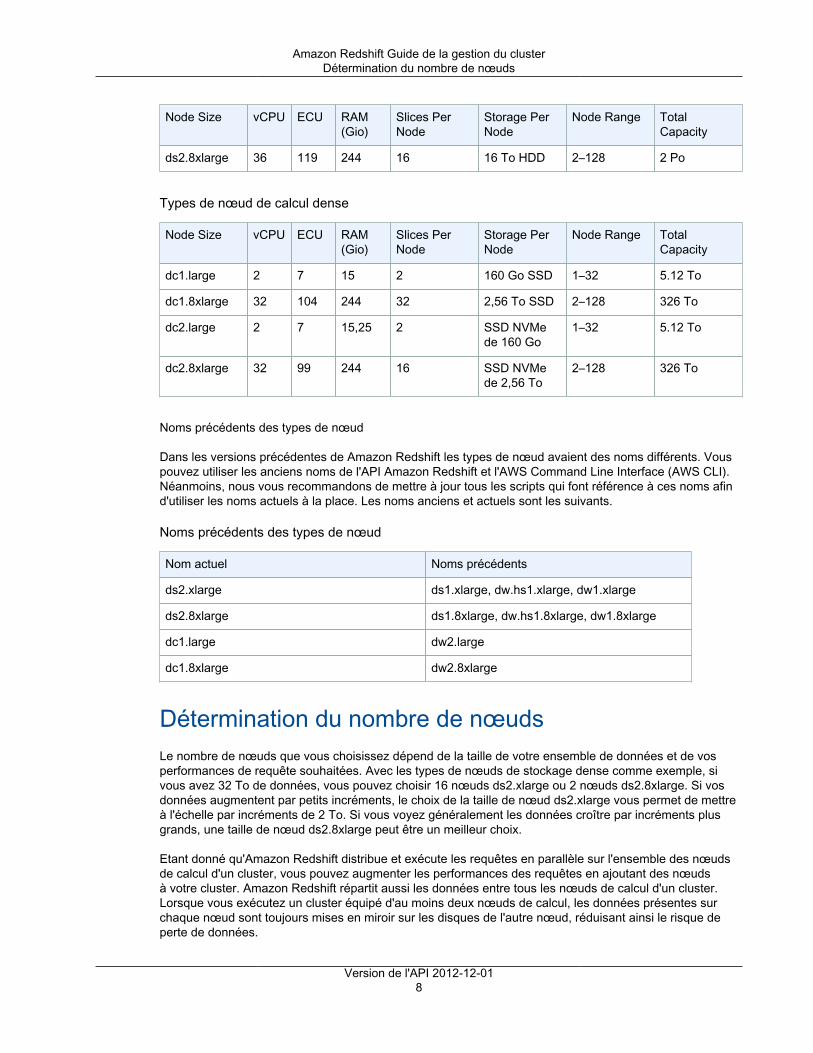
Amazon Redshift Guide de la gestion du clusterDétermination du nombre de nœuds
Node Size vCPU ECU RAM(Gio)
Slices PerNode
Storage PerNode
Node Range TotalCapacity
ds2.8xlarge 36 119 244 16 16 To HDD 2–128 2 Po
Types de nœud de calcul dense
Node Size vCPU ECU RAM(Gio)
Slices PerNode
Storage PerNode
Node Range TotalCapacity
dc1.large 2 7 15 2 160 Go SSD 1–32 5.12 To
dc1.8xlarge 32 104 244 32 2,56 To SSD 2–128 326 To
dc2.large 2 7 15,25 2 SSD NVMede 160 Go
1–32 5.12 To
dc2.8xlarge 32 99 244 16 SSD NVMede 2,56 To
2–128 326 To
Noms précédents des types de nœud
Dans les versions précédentes de Amazon Redshift les types de nœud avaient des noms différents. Vouspouvez utiliser les anciens noms de l'API Amazon Redshift et l'AWS Command Line Interface (AWS CLI).Néanmoins, nous vous recommandons de mettre à jour tous les scripts qui font référence à ces noms afind'utiliser les noms actuels à la place. Les noms anciens et actuels sont les suivants.
Noms précédents des types de nœud
Nom actuel Noms précédents
ds2.xlarge ds1.xlarge, dw.hs1.xlarge, dw1.xlarge
ds2.8xlarge ds1.8xlarge, dw.hs1.8xlarge, dw1.8xlarge
dc1.large dw2.large
dc1.8xlarge dw2.8xlarge
Détermination du nombre de nœudsLe nombre de nœuds que vous choisissez dépend de la taille de votre ensemble de données et de vosperformances de requête souhaitées. Avec les types de nœuds de stockage dense comme exemple, sivous avez 32 To de données, vous pouvez choisir 16 nœuds ds2.xlarge ou 2 nœuds ds2.8xlarge. Si vosdonnées augmentent par petits incréments, le choix de la taille de nœud ds2.xlarge vous permet de mettreà l'échelle par incréments de 2 To. Si vous voyez généralement les données croître par incréments plusgrands, une taille de nœud ds2.8xlarge peut être un meilleur choix.
Etant donné qu'Amazon Redshift distribue et exécute les requêtes en parallèle sur l'ensemble des nœudsde calcul d'un cluster, vous pouvez augmenter les performances des requêtes en ajoutant des nœudsà votre cluster. Amazon Redshift répartit aussi les données entre tous les nœuds de calcul d'un cluster.Lorsque vous exécutez un cluster équipé d'au moins deux nœuds de calcul, les données présentes surchaque nœud sont toujours mises en miroir sur les disques de l'autre nœud, réduisant ainsi le risque deperte de données.
Version de l'API 2012-12-018

Amazon Redshift Guide de la gestion du clusterRedimensionnement d'un cluster
Quel que soit votre choix, vous pouvez surveiller les performances des requêtes dans Amazon Redshiftconsole et avec les métriques Amazon CloudWatch. Vous pouvez également ajouter ou supprimer desnœuds en fonction des besoins afin de parvenir à l'équilibre qui vous convient le mieux entre stockageet performances. Lorsque vous demandez un nœud supplémentaire, Amazon Redshift prend en chargetous les détails du déploiement, de l'équilibrage de charge et de la maintenance des données. Pour plusd'informations sur les performances des clusters, consultez Surveillance des performances de clusterAmazon Redshift (p. 259).
Si vous prévoyez que votre cluster s'exécute en continu pendant une période prolongée (un an ou plus,par exemple), vous pouvez payer nettement moins en réservant les nœuds de calcul pour une période d'unan ou de trois ans. Pour réserver les nœuds de calcul, vous achetez ce qu'on appelle les offres de nœudsréservés. Vous acheter une offre pour chaque nœud de calcul que vous souhaitez réserver. Lorsque vousréservez un nœud de calcul, vous payez des frais fixes initiaux, puis des frais horaires récurrents, quevotre cluster soit en cours d'exécution ou non. Les frais horaires, cependant, sont nettement inférieurs àceux d'une utilisation à la demande. Pour plus d'informations, consultez Achat de nœuds réservés AmazonRedshift (p. 119).
Redimensionnement d'un clusterSi vos besoins en stockage et en performances évoluent après que vous avez initialement provisionnévotre cluster, vous pouvez redimensionner celui-ci. Vous pouvez agrandir ou diminuer le cluster en ajoutantou en supprimant des nœuds. En outre, vous pouvez agrandir ou diminuer le cluster en spécifiant un typede nœud différent.
Par exemple, vous pouvez ajouter d'autres nœuds, modifier les types de nœud, modifier un cluster à nœudunique en un cluster à plusieurs nœuds, ou modifier un cluster à plusieurs nœuds en un cluster à nœudunique. Cependant, vous devez vous assurer que le cluster qui en résulte est suffisamment grand pourcontenir les données dont vous disposez actuellement ou bien le redimensionnement échoue. Lorsquevous utilisez l'API, vous devez spécifier le type de nœud, la taille du nœud et le nombre de nœuds, mêmesi vous ne modifiez que l'un des deux.
La section suivante décrit le processus de redimensionnement :
1. Lorsque vous lancez le processus de redimensionnement, Amazon Redshift envoie une notificationd'événement qui reconnaît la demande de redimensionnement et commence à mettre en service lenouveau cluster (cible).
2. Lorsque le nouveau cluster (cible) est mis en service, Amazon Redshift envoie une notificationd'événement indiquant que le redimensionnement a commencé, puis redémarre votre cluster (source)existant en mode lecture seule. Le redémarrage met fin à toutes les connexions existantes du cluster.Toutes les transactions non validées (y compris COPY) sont annulées. Lorsque le cluster est en modelecture seule, vous pouvez exécuter des requêtes en lecture, mais pas des requêtes en écriture.
3. Amazon Redshift commence à copier les données depuis le cluster source vers le cluster cible.4. Lorsque le processus de redimensionnement est presque terminé, Amazon Redshift met à jour le point
de terminaison du cluster cible et toutes les connexions sont mises hors service.5. Une fois le redimensionnement terminé, Amazon Redshift envoie une notification d'événement pour
indiquer la fin du redimensionnement. Vous pouvez vous connecter au cluster cible et reprendrel'exécution des requêtes en lecture et en écriture.
Lorsque vous redimensionnez votre cluster, il demeure en mode lecture seule jusqu'à ce que leredimensionnement soit terminé. Vous pouvez afficher la progression du redimensionner sous l'ongletÉtat d'Amazon Redshift console. Le temps nécessaire au redimensionnement d'un cluster dépend de laquantité de données de chaque nœud. Généralement, le processus de redimensionner varie de quelquesheures à une journée, même si les clusters avec de plus grandes quantités de données peuvent prendre
Version de l'API 2012-12-019
Amazon Redshift Guide de la gestion du clusterPlateformes prises en charge pour lancer votre cluster
encore plus de temps. La raison en est que les données sont copiées en parallèle depuis chaque nœuddu cluster source vers les nœuds du cluster cible. Pour plus d'informations sur le redimensionnementdes clusters, consultez Didacticiel : Redimensionnement des clusters dans Amazon Redshift (p. 320) etRedimensionnement d'un cluster (p. 29).
Amazon Redshift ne trie pas les tables pendant une opération de redimensionnement. Lorsque vousredimensionnez un cluster, Amazon Redshift répartit les tables de base de données sur les nouveauxnœuds de calcul en fonction de leurs styles de distribution et exécute une opération ANALYZE pour mettreà jour les statistiques. Comme les lignes marquées en vue de leur suppression ne sont pas transférées,vous ne devez exécuter une opération VACUUM que si vos tables doivent être triées à nouveau. Pour plusd'informations, consultez Exécution de l'opération VACUUM sur les tables dans le manuel Amazon RedshiftDatabase Developer Guide.
Si votre cluster est public et se trouve dans un VPC, il conserve la même adresse IP Elastic pour le nœudprincipal après redimensionnement. Si votre cluster est privé et se trouve dans un VPC, il conserve lamême adresse IP privée pour le nœud principal après redimensionnement. Si votre cluster n'est pas dansun VPC, une nouvelle adresse IP publique est attribuée au nœud principal dans le cadre de l'opération deredimensionnement.
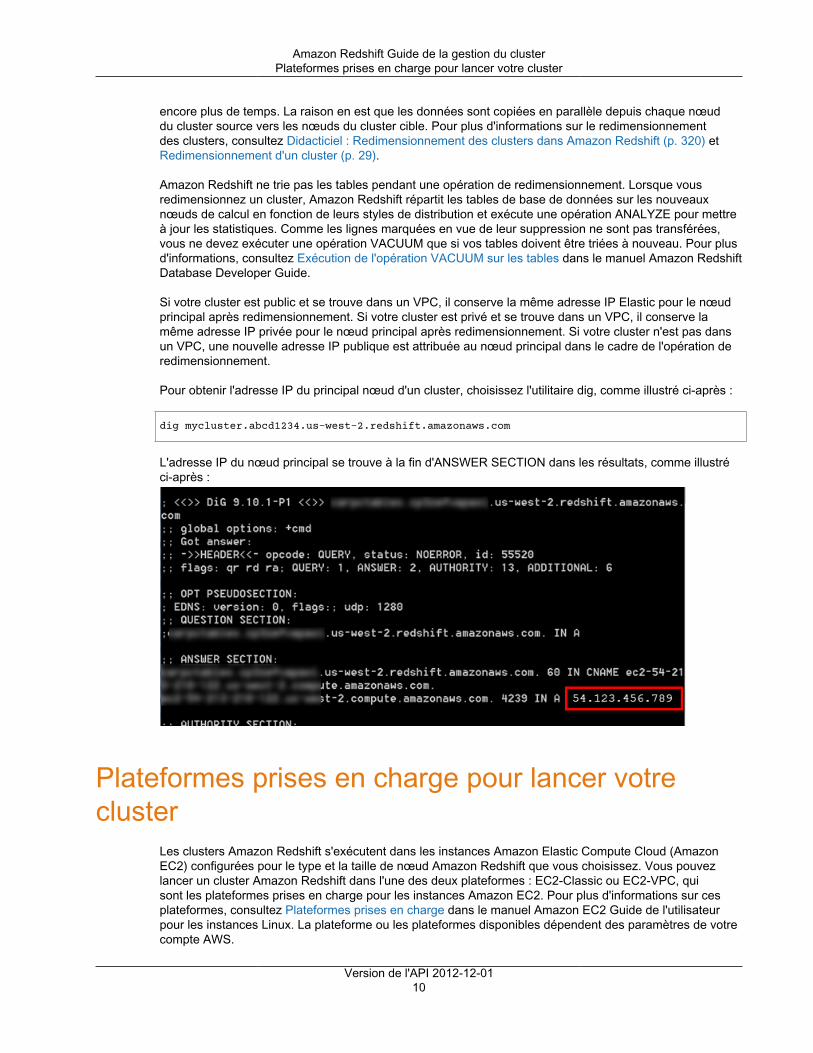
Pour obtenir l'adresse IP du principal nœud d'un cluster, choisissez l'utilitaire dig, comme illustré ci-après :
dig mycluster.abcd1234.us-west-2.redshift.amazonaws.com
L'adresse IP du nœud principal se trouve à la fin d'ANSWER SECTION dans les résultats, comme illustréci-après :
Plateformes prises en charge pour lancer votrecluster
Les clusters Amazon Redshift s'exécutent dans les instances Amazon Elastic Compute Cloud (AmazonEC2) configurées pour le type et la taille de nœud Amazon Redshift que vous choisissez. Vous pouvezlancer un cluster Amazon Redshift dans l'une des deux plateformes : EC2-Classic ou EC2-VPC, quisont les plateformes prises en charge pour les instances Amazon EC2. Pour plus d'informations sur cesplateformes, consultez Plateformes prises en charge dans le manuel Amazon EC2 Guide de l'utilisateurpour les instances Linux. La plateforme ou les plateformes disponibles dépendent des paramètres de votrecompte AWS.
Version de l'API 2012-12-0110

Amazon Redshift Guide de la gestion du clusterPlateforme EC2-Classic
Note
Afin d'éviter les problèmes de connexion entre les outils clients SQL et la base de donnéesAmazon Redshift, nous vous conseillons d'opter pour l'une des deux approches suivantes.Vous pouvez configurer une règle de trafic entrant qui permet aux hôtes de négocier la tailledes paquets. Vous pouvez aussi désactiver les trames jumbo TCP/IP en définissant l'unité detransmission maximale (MTU) sur 1 500 sur l'interface réseau (carte réseau) de vos instancesAmazon EC2. Pour plus d'informations sur ces approches, consultez Des requêtes semblent sebloquer et parfois échouent à atteindre le cluster (p. 257).
Plateforme EC2-ClassicDans la plateforme EC2-Classic, votre cluster s'exécute dans un seul réseau plat que vous partagez avecd'autres clients AWS. Si vous provisionnez votre cluster dans la plateforme EC2-Classic, vous contrôlezl'accès à votre cluster en associant un ou plusieurs groupes de sécurité de cluster Amazon Redshift aucluster. Pour plus d'informations, consultez Groupes de sécurité du cluster Amazon Redshift (p. 148).
Plateforme EC2-VPCDans la plateforme EC2-VPC, votre cluster s'exécute dans un Virtual Private Cloud (VPC) qui estlogiquement isolé de votre compte AWS. Si vous mettez en service votre cluster dans la plateforme EC2-VPC, vous contrôlez l'accès à votre cluster en associant un ou plusieurs groupes de sécurité VPC aucluster. Pour plus d'informations, consultez Groupes de sécurité de votre VPC dans le manuel AmazonVPC Guide de l'utilisateur.
Pour créer un cluster dans un VPC, vous devez d'abord créer un groupe de sous-réseaux de clusterAmazon Redshift en fournissant les informations de sous-réseau de votre VPC, puis en fournissant legroupe de sous-réseaux lors du lancement du cluster. Pour plus d'informations, consultez Groupes desous-réseaux de cluster Amazon Redshift (p. 40).
Pour plus d'informations sur Amazon Virtual Private Cloud (Amazon VPC), consultez la page de détails duproduit Amazon VPC.
Choisir une plateformeVotre compte AWS est capable de lancer les instances sur les deux plateformes, ou seulement sur EC2-VPC, région par région. Pour déterminer la plateforme que votre compte prend en charge, puis lancer uncluster, procédez comme suit :
1. Décidez de la région AWS dans laquelle vous souhaitez déployer un cluster. Pour obtenir la listedes régions AWS dans lesquelles Amazon Redshift est disponible, consultez Régions et points determinaison dans le manuel Référence générale d'Amazon Web Services.
2. Découvrez les plateformes Amazon EC2 que votre compte prend en charge dans la région AWS choisie.Vous pouvez trouver ces informations dans la console Amazon EC2. Pour obtenir les instructions pas àpas, consultez Plateformes prises en charge dans le manuel Amazon EC2 Guide de l'utilisateur pour lesinstances Linux.
3. Si votre compte prend en charge les deux plateformes, choisissez celle sur laquelle vous souhaitezdéployer votre cluster Amazon Redshift. Si votre compte ne prend en charge qu'EC2-VPC, vous devezdéployer votre cluster dans VPC.
4. Déployez votre cluster Amazon Redshift. Vous pouvez déployer un cluster en utilisant AmazonRedshift console ou par programmation à l'aide de l'API Amazon Redshift, de l'interface de ligne decommande ou des bibliothèques SDK. Pour plus d'informations sur ces options et sur les liens vers ladocumentation associée, consultez Qu'est-ce qu'Amazon Redshift ? (p. 1).
Version de l'API 2012-12-0111

Amazon Redshift Guide de la gestion du clusterConsidérations sur les régions et les zones de disponibilité
Considérations sur les régions et les zones dedisponibilité
Amazon Redshift est disponible dans plusieurs régions AWS. Par défaut, Amazon Redshift alloue votrecluster dans une zone de disponibilité sélectionnée de façon aléatoire au sein de la région AWS que voussélectionnez. Tous les nœuds de cluster sont provisionnés dans la même zone de disponibilité.
Vous pouvez demander le cas échéant une zone de disponibilité spécifique si Amazon Redshift estdisponible dans cette zone. Par exemple, si vous avez déjà une instance Amazon EC2 en coursd'exécution dans une zone de disponibilité, vous pouvez créer votre cluster Amazon Redshift dans lamême zone de disponibilité pour réduire la latence. D'un autre côté, vous pouvez choisir une autre zone dedisponibilité pour une plus grande disponibilité. Amazon Redshift peut ne pas être disponibles dans toutesles zones de disponibilité d'une région.
Pour obtenir la liste des régions AWS prises en charge où vous pouvez provisionner un cluster AmazonRedshift, consultez Régions et points de terminaison dans le manuel Référence générale d'Amazon WebServices.
Fenêtres de maintenanceAmazon Redshift effectue régulièrement une maintenance pour appliquer les mises à niveau à votrecluster. Au cours de ces mises à jour, votre cluster Amazon Redshift cluster n'est pas disponible pour lesopérations normales.
Amazon Redshift attribue une fenêtre de maintenance aléatoire de 30 minutes sur une période de 8 heurespar région, un jour au hasard de la semaine (du lundi au dimanche inclus). La liste suivante répertorie lespériodes de chaque région au sein desquelles les fenêtres de maintenance par défaut sont attribuées :
• Région USA Est (Virginie du Nord) : 03:00–11:00 UTC• Région USA Est (Ohio) : 03:00–11:00 UTC• Région USA Ouest (Californie du Nord) : 06:00–14:00 UTC• Région USA Ouest (Oregon) : 06:00–14:00 UTC• Région fCanada (Centre) : 03:00–11:00 UTC• Région Asie-Pacifique (Mumbai) : 16:30–00:30 UTC• Région Asie-Pacifique (Séoul) : 13:00–21:00 UTC• Région Asie-Pacifique (Singapour) : 14:00–22:00 UTC• Région Asie-Pacifique (Sydney) : 12:00–20:00 UTC• Région Asie-Pacifique (Tokyo) : 13:00–21:00 UTC• Région UE (Francfort) : 06:00–14:00 UTC• Région Chine (Pékin) : 13:00–21:00 UTC• Région UE (Irlande) : 22:00–06:00 UTC• Région UE (Londres) : 22:00–06:00 UTC• Région Amérique du Sud (São Paulo) : 19:00–03:00 UTC
Si un événement de maintenance est planifié pour une semaine donnée, il démarre pendant la fenêtrede maintenance de 30 minutes attribuée. Pendant qu'Amazon Redshift effectue la maintenance, il met finà toutes les requêtes ou autres opérations en cours. La plus grande partie de la maintenance s'effectuependant la fenêtre de maintenance de 30 minutes, mais certaines tâches de maintenance peuventcontinuer à s'exécuter après la fermeture de la fenêtre. S'il n'y a aucune tâche de maintenance à effectuer
Version de l'API 2012-12-0112

Amazon Redshift Guide de la gestion du clusterAlarme d'espace disque par défaut
pendant la fenêtre de maintenance planifiée, votre cluster continue à fonctionner normalement jusqu'à laprochaine fenêtre de maintenance.
Vous pouvez changer la fenêtre de maintenance planifiée en modifiant le cluster par programmation ouavec Amazon Redshift console. La fenêtre doit être comprise entre 30 minutes et 24 heures. Pour plusd'informations, consultez Gestion des clusters à l'aide de la console (p. 16).
Alarme d'espace disque par défautLorsque vous créez un cluster Amazon Redshift, vous pouvez configurer le cas échéant une alarmeAmazon CloudWatch pour surveiller le pourcentage moyen d'espace disque utilisé sur tous les nœuds devotre cluster. Nous nous référons à cette alarme comme alarme d'espace disque par défaut.
Le but d'une alarme d'espace disque par défaut consiste à vous aider à surveiller la capacité de stockagede votre cluster. Vous pouvez configurer cette alarme selon les besoins de votre entrepôt de données.Par exemple, vous pouvez utiliser l'avertissement comme indicateur vous signalant que vous devezredimensionner le cluster. Vous pouvez redimensionner votre cluster soit en un type de nœud différent, soitpour ajouter des nœuds, ou encore pour acheter des nœuds réservés en vue d'une expansion future.
L'alarme d'espace disque par défaut se déclenche lorsque l'utilisation du disque atteint ou dépasseun pourcentage spécifié un certain nombre de fois et sur une durée spécifiée. Par défaut, l'alarme sedéclenche lorsque le pourcentage que vous spécifiez est atteint, puis demeure à cette valeur ou à unevaleur supérieure pendant cinq minutes ou plus. Vous pouvez modifier les valeurs par défaut après quevous avez lancé le cluster.
Lorsque l'alarme CloudWatch se déclenche, Amazon Simple Notification Service (Amazon SNS) envoieune notification aux destinataires spécifiés pour les avertir que le seuil de pourcentage est atteint. AmazonSNS utilise une rubrique pour spécifier les destinataires et le message transmis dans une notification. Vouspouvez utiliser une rubrique Amazon SNS existante ; sinon, une rubrique est créée selon les paramètresque vous spécifiez lors du lancement du cluster. Vous pouvez modifier la rubrique de cette alarme aprèsavoir lancé le cluster. Pour plus d'informations sur la création de rubriques Amazon SNS, consultez Mise enroute avec Amazon Simple Notification Service .
Une fois que vous avez lancé le cluster, vous pouvez afficher et modifier l'alarme à partir de la fenêtre Étatdu cluster sous Alarmes CloudWatch. Le nom est percentage-disk-space-used-default-<chaîne>. Vouspouvez ouvrir l'alarme pour afficher la rubrique Amazon SNS à laquelle elle est associée et modifier lesparamètres de l'alarme. Si vous n'avez pas sélectionné une rubrique Amazon SNS existante à utiliser,celle créée pour vous est appelée < nom_cluster>-default-alarms (<destinataire>) ; par exemple,examplecluster-default-alarms ([email protected]).
Pour plus d'informations sur la configuration et la modification de l'alarme d'espace disque pardéfaut, consultez Création d'un cluster (p. 17) et Modification de l'alarme par défaut de l'espacedisque (p. 33).
Note
Si vous supprimez votre cluster, l'alarme associée au cluster n'est pas supprimée, mais elle ne sedéclenchera pas. Vous pouvez supprimer l'alarme à partir de la console CloudWatch si vous n'enavez plus besoin.
Renommer les clustersVous pouvez renommer un cluster si vous souhaitez que le cluster utilise un autre nom. Comme le point determinaison de votre cluster inclut le nom du cluster (également appelé identificateur de cluster), le pointde terminaison va changer pour utiliser le nouveau nom. Par exemple, si vous avez un cluster nommé
Version de l'API 2012-12-0113

Amazon Redshift Guide de la gestion du clusterArrêt et suppression de clusters
examplecluster et que vous le renommez newcluster, le point de terminaison va changer pour utiliserl'identificateur newcluster. Toutes les applications qui se connectent au cluster doivent être mises à jouravec le nouveau point de terminaison.
Vous pouvez renommer un cluster si vous voulez modifier le cluster auquel se connectent vos applicationssans devoir changer le point de terminaison de ces applications. Dans ce cas, vous devez d'abordrenommer le cluster d'origine, puis modifier le deuxième cluster pour réutiliser le nom du cluster d'origineavant de le renommer. Cela est nécessaire, car l'identifiant de cluster doit être unique au sein de votrecompte et de la région (le cluster d'origine et le second cluster ne peuvent pas avoir le même nom).Vous pouvez agir ainsi si vous restaurez un cluster à partir d'un instantané et ne voulez pas modifier lespropriétés de connexion d'applications dépendantes.
Note
Si vous supprimez le cluster d'origine, vous êtes responsable de la suppression des instantanésde cluster indésirables.
Lorsque vous renommez un cluster, l'état du cluster devient renaming jusqu'à la fin du processus.L'ancien nom DNS qui a été utilisé par le cluster est immédiatement supprimé, même s'il peut demeurermis en cache pendant quelques minutes. Le nouveau nom DNS du cluster renommé devient effectif aubout de 10 minutes environ. Le cluster renommé n'est pas disponible jusqu'à ce que le nouveau nom nedevienne effectif. Le cluster est redémarré et toutes les connexions existantes au cluster sont supprimées.Une fois l'opération terminée, le point de terminaison est modifié pour utiliser le nouveau nom. Pour cetteraison, vous devez arrêter l'exécution des requêtes avant de démarrer la définition du nouveau nom et laredémarrer une fois le nouveau nom créé.
Les instantanés de cluster sont conservés, et tous les instantanés associés à un cluster demeurentassociés à ce cluster après qu'il a été renommé. Par exemple, supposons que vous disposiez d'un clusterqui sert votre base de données de production et que le cluster ait plusieurs instantanés. Si vous renommezle cluster, puis le remplacez dans l'environnement de production par un instantané, le cluster que vousavez renommé continue de conserver les instantanés existants qui lui sont associés.
Les alarmes Amazon CloudWatch et les notifications d'événement Amazon Simple Notification Service(Amazon SNS) sont associées au nom du cluster. Si vous renommez le cluster, vous devez mettre à jources informations en conséquence. Vous pouvez mettre à jour les alarmes CloudWatch dans la consoleCloudWatch, et vous pouvez mettre à jour les notifications d'événement Amazon SNS dans la consoleAmazon Redshift, dans le volet Événements. Les données de charge et de requête du cluster continuentd'afficher les données antérieures et postérieures à l'attribution du nouveau nom. Cependant, les donnéesde performance sont réinitialisées une fois le processus d'attribution de nouveau nom terminé.
Pour plus d'informations, consultez Modification d'un cluster (p. 24).
Arrêt et suppression de clustersVous pouvez arrêter votre cluster si vous voulez qu'il cesse de s'exécuter et d'entraîner des frais. Lorsquevous l'arrêtez, vous pouvez, le cas échéant, créer un instantané final. Si vous créez un instantané final,Amazon Redshift crée un instantané manuel de votre cluster avant de l'arrêter. Vous pouvez par la suiterestaurer l'instantané si vous souhaitez reprendre l'exécution du cluster et l'interrogation des données.
Si vous n'avez plus besoin du cluster et de ses données, vous pouvez l'arrêter sans créer un instantanéfinal. Dans ce cas, le cluster et les données sont supprimés définitivement. Pour plus d'informations surl'arrêt et la suppression des clusters, consultez Suppression d'un cluster (p. 26).
Que vous arrêtiez ou pas votre cluster avec un instantané manuel final, tous les instantanés automatiquesassociés au cluster sont supprimés une fois que le cluster est arrêté. Les instantanés manuels associés aucluster sont conservés. Les instantanés manuels qui sont conservés, y compris l'instantané final facultatif,sont facturés au prix de stockage Amazon Simple Storage Service si vous n'avez pas d'autres clusters en
Version de l'API 2012-12-0114
Amazon Redshift Guide de la gestion du clusterStatut du cluster
cours d'exécution lorsque vous arrêtez le cluster ou si vous dépasserez le stockage gratuit disponible quiest fourni à vos clusters Amazon Redshift en cours d'exécution. Pour plus d'informations sur les frais destockage des instantanés, consultez Tarification Amazon Redshift.
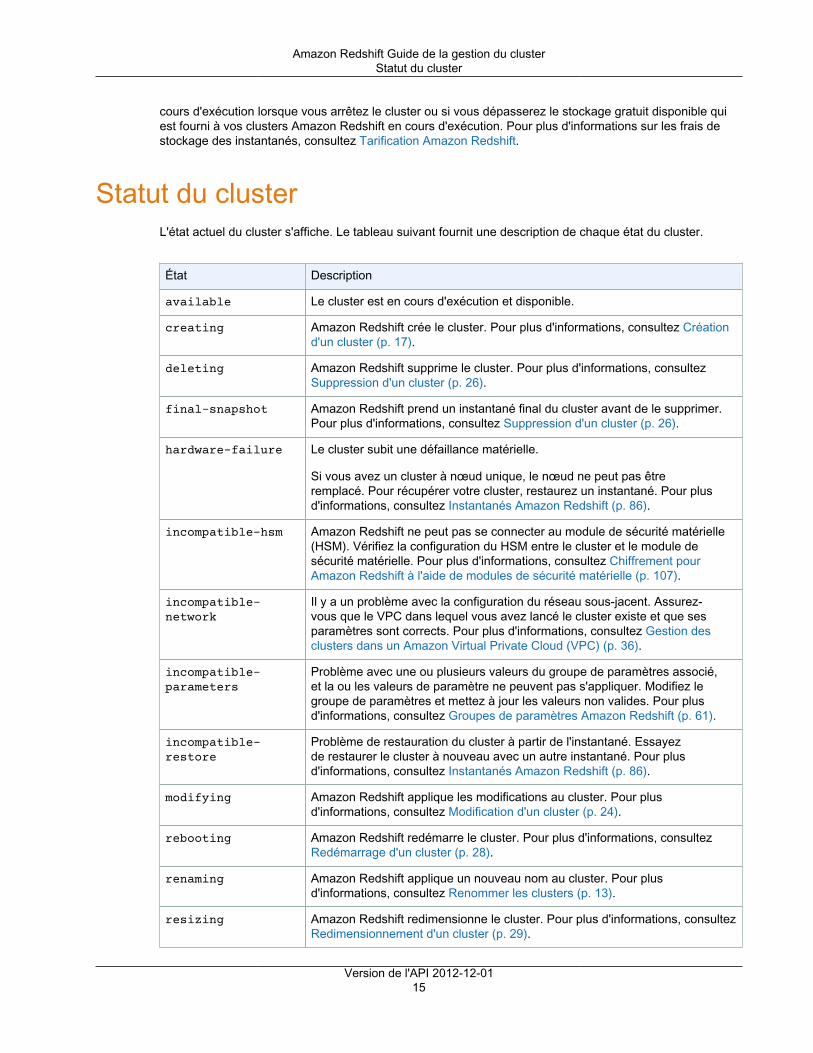
Statut du clusterL'état actuel du cluster s'affiche. Le tableau suivant fournit une description de chaque état du cluster.
État Description
available Le cluster est en cours d'exécution et disponible.
creating Amazon Redshift crée le cluster. Pour plus d'informations, consultez Créationd'un cluster (p. 17).
deleting Amazon Redshift supprime le cluster. Pour plus d'informations, consultezSuppression d'un cluster (p. 26).
final-snapshot Amazon Redshift prend un instantané final du cluster avant de le supprimer.Pour plus d'informations, consultez Suppression d'un cluster (p. 26).
hardware-failure Le cluster subit une défaillance matérielle.
Si vous avez un cluster à nœud unique, le nœud ne peut pas êtreremplacé. Pour récupérer votre cluster, restaurez un instantané. Pour plusd'informations, consultez Instantanés Amazon Redshift (p. 86).
incompatible-hsm Amazon Redshift ne peut pas se connecter au module de sécurité matérielle(HSM). Vérifiez la configuration du HSM entre le cluster et le module desécurité matérielle. Pour plus d'informations, consultez Chiffrement pourAmazon Redshift à l'aide de modules de sécurité matérielle (p. 107).
incompatible-network
Il y a un problème avec la configuration du réseau sous-jacent. Assurez-vous que le VPC dans lequel vous avez lancé le cluster existe et que sesparamètres sont corrects. Pour plus d'informations, consultez Gestion desclusters dans un Amazon Virtual Private Cloud (VPC) (p. 36).
incompatible-parameters
Problème avec une ou plusieurs valeurs du groupe de paramètres associé,et la ou les valeurs de paramètre ne peuvent pas s'appliquer. Modifiez legroupe de paramètres et mettez à jour les valeurs non valides. Pour plusd'informations, consultez Groupes de paramètres Amazon Redshift (p. 61).
incompatible-restore
Problème de restauration du cluster à partir de l'instantané. Essayezde restaurer le cluster à nouveau avec un autre instantané. Pour plusd'informations, consultez Instantanés Amazon Redshift (p. 86).
modifying Amazon Redshift applique les modifications au cluster. Pour plusd'informations, consultez Modification d'un cluster (p. 24).
rebooting Amazon Redshift redémarre le cluster. Pour plus d'informations, consultezRedémarrage d'un cluster (p. 28).
renaming Amazon Redshift applique un nouveau nom au cluster. Pour plusd'informations, consultez Renommer les clusters (p. 13).
resizing Amazon Redshift redimensionne le cluster. Pour plus d'informations, consultezRedimensionnement d'un cluster (p. 29).
Version de l'API 2012-12-0115

Amazon Redshift Guide de la gestion du clusterGestion des clusters à l'aide de la console
État Description
rotating-keys Amazon Redshift effectue une rotation des clés de chiffrement pour le cluster.Pour plus d'informations, consultez A propos de la rotation des clés dechiffrement dans Amazon Redshift (p. 108).
storage-full Le cluster a atteint sa capacité de stockage. Redimensionnez le clusterpour ajouter des nœuds ou choisir une autre taille de nœud. Pour plusd'informations, consultez Redimensionnement d'un cluster (p. 29).
updating-hsm Amazon Redshift met à jour la configuration HSM. .
Gestion des clusters à l'aide de la consolePour créer, modifier, redimensionner, supprimer, redémarrer et sauvegarder les clusters, vous pouvezutiliser la section Clusters d'Amazon Redshift console.
Lorsque vous n'avez pas de clusters dans une région et que vous accédez à la page Clusters, vous voyezune option pour lancer un cluster. Dans la capture d'écran suivante, la région est Région USA Est (Virginiedu N.) et il n'y a aucun cluster pour ce compte.
Lorsque vous avez au moins un cluster dans la région que vous avez sélectionnée, la section Clustersaffiche un sous-ensemble d'informations sur tous les clusters du compte de cette région. Dans la captured'écran suivante, il y a un cluster créé pour ce compte dans la région sélectionnée.
Vous pouvez développer le cluster pour afficher plus d'informations sur le cluster, telles que les détails dupoint de terminaison, les propriétés du cluster et de la base de données, les balises, et ainsi de suite. Dansla capture d'écran suivante, examplecluster est développé pour afficher un résumé des informations sur lecluster.
Version de l'API 2012-12-0116
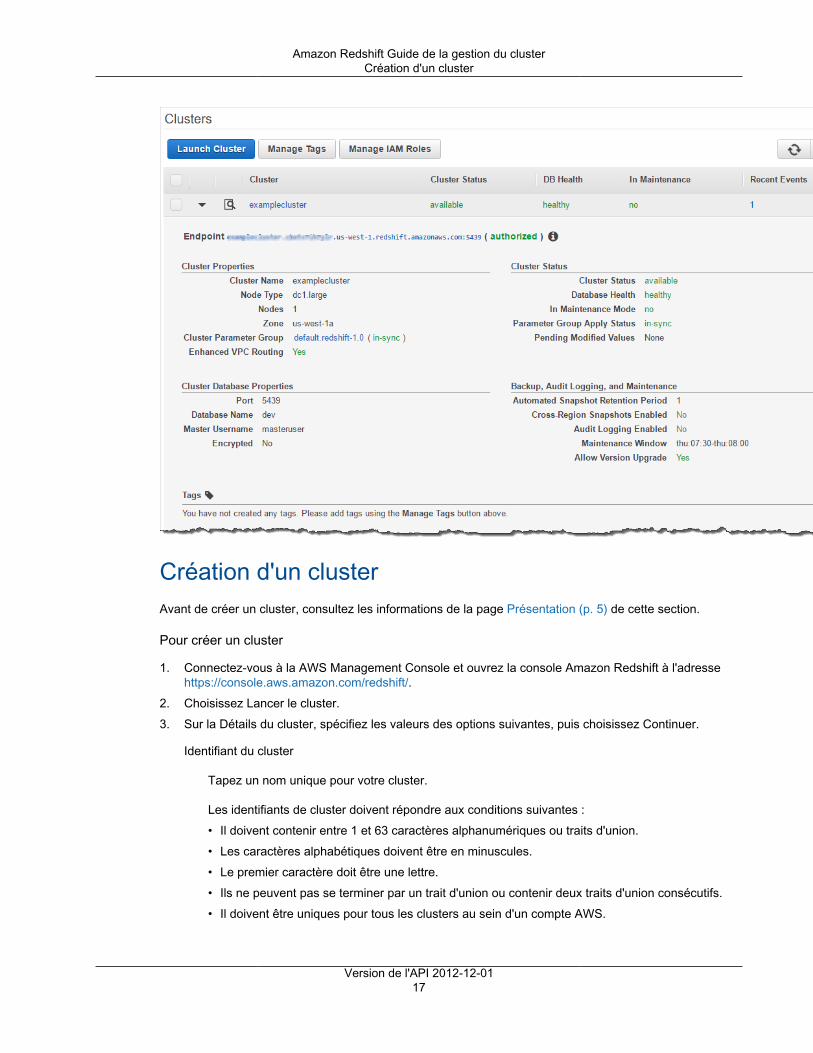
Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
Création d'un clusterAvant de créer un cluster, consultez les informations de la page Présentation (p. 5) de cette section.
Pour créer un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Choisissez Lancer le cluster.3. Sur la Détails du cluster, spécifiez les valeurs des options suivantes, puis choisissez Continuer.
Identifiant du cluster
Tapez un nom unique pour votre cluster.
Les identifiants de cluster doivent répondre aux conditions suivantes :• Il doivent contenir entre 1 et 63 caractères alphanumériques ou traits d'union.• Les caractères alphabétiques doivent être en minuscules.• Le premier caractère doit être une lettre.• Ils ne peuvent pas se terminer par un trait d'union ou contenir deux traits d'union consécutifs.• Il doivent être uniques pour tous les clusters au sein d'un compte AWS.
Version de l'API 2012-12-0117

Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
Database Name
Tapez un nom si vous souhaitez créer une base de données avec un nom personnalisé (parexemple, mydb). Ce champ est facultatif. Une base de données par défaut nommée dev est crééepour le cluster que vous ayez spécifié un nom de base de données personnalisé ou pas.
Les noms de base de données doivent répondre aux conditions suivantes :• Ils doivent contenir entre 1 et 64 caractères alphanumériques.• Ils doivent contenir uniquement des lettres minuscules.• Un nom de base de données ne peut pas être un mot réservé. Pour plus d'informations,
accédez à Mots réservés dans le manuel Amazon Redshift Database Developer Guide.Database Port
Tapez un numéro de port via lequel vous vous connectez à partir des applications clientes àla base de données. Le numéro de port doit être inclus dans la chaîne de connexion lors del'ouverture des connexions ODBC ou JDBC aux bases de données du cluster.
Le numéro de port doit répondre aux conditions suivantes :• Il doit contenir uniquement des caractères numériques.• Il doit s'inscrire dans la plage de 1150 à 65535. La valeur par défaut du port est 5439.• Il doit spécifier un port ouvert qui accepte les connexions entrantes, si vous êtes derrière un
pare-feu.Master User Name
Tapez un nom de compte pour l'utilisateur principal de la base de données.
Les noms utilisateur principal doivent répondre aux conditions suivantes :• Ils doivent contenir entre 1 et 128 caractères alphanumériques.• Le premier caractère doit être une lettre.• Un nom utilisateur principal ne peut pas être un mot réservé. Pour plus d'informations, accédez
à Mots réservés dans le manuel Amazon Redshift Database Developer Guide.Master User Password et Confirm Password
Tapez un mot de passe pour le compte utilisateur principal, puis saisissez-le à nouveau pour leconfirmer.
Le mot de passe doit répondre aux conditions suivantes :• Sa longueur doit être comprise entre 8 et 64 caractères.• Il doit contenir au moins une lettre en majuscule.• Il doit contenir au moins une lettre en minuscule.• Il doit contenir au moins un chiffre.• Il peut s'agir de n'importe quel caractère ASCII imprimable (code ASCII 33 à 126), à l'exception
del'apostrophe, des guillemets doubles, de \, /, @, ou de l'espace.
Dans la capture d'écran suivante, examplecluster est l'identifiant du cluster, aucun nom de basede données personnalisé n'est spécifié, 5439 est le port et masteruser désigne le nom d'utilisateurprincipal.
Version de l'API 2012-12-0118
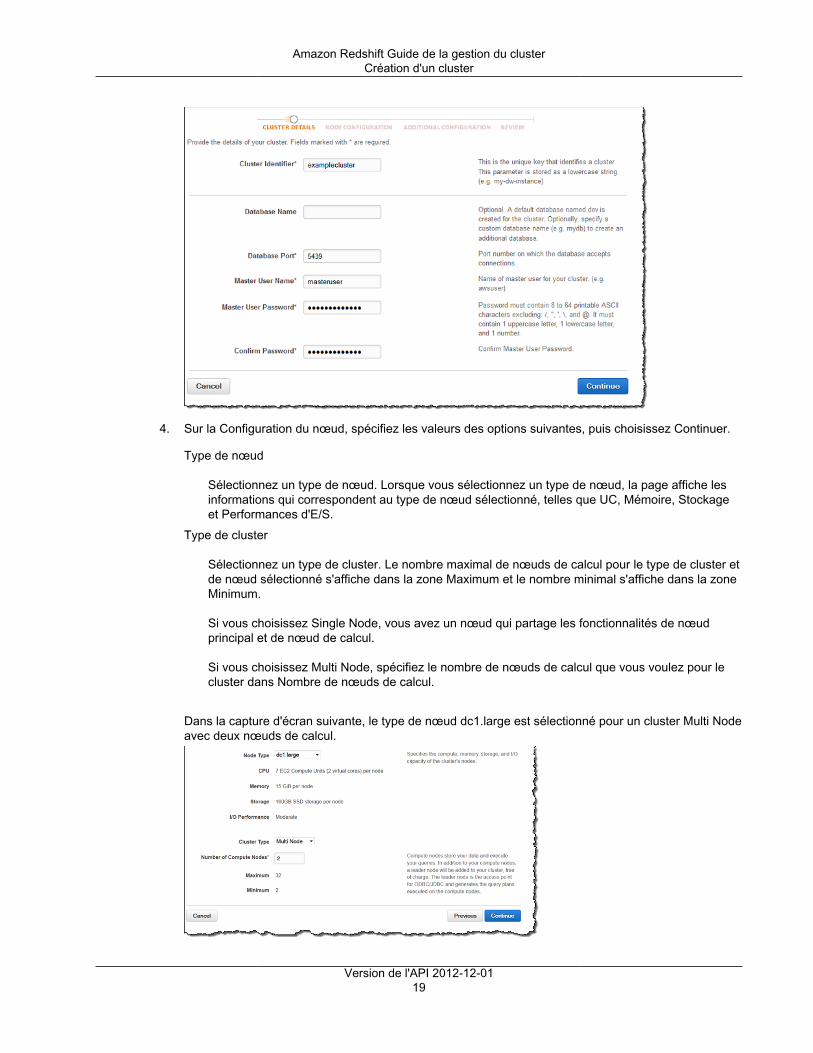
Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
4. Sur la Configuration du nœud, spécifiez les valeurs des options suivantes, puis choisissez Continuer.
Type de nœud
Sélectionnez un type de nœud. Lorsque vous sélectionnez un type de nœud, la page affiche lesinformations qui correspondent au type de nœud sélectionné, telles que UC, Mémoire, Stockageet Performances d'E/S.
Type de cluster
Sélectionnez un type de cluster. Le nombre maximal de nœuds de calcul pour le type de cluster etde nœud sélectionné s'affiche dans la zone Maximum et le nombre minimal s'affiche dans la zoneMinimum.
Si vous choisissez Single Node, vous avez un nœud qui partage les fonctionnalités de nœudprincipal et de nœud de calcul.
Si vous choisissez Multi Node, spécifiez le nombre de nœuds de calcul que vous voulez pour lecluster dans Nombre de nœuds de calcul.
Dans la capture d'écran suivante, le type de nœud dc1.large est sélectionné pour un cluster Multi Nodeavec deux nœuds de calcul.
Version de l'API 2012-12-0119

Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
5. Sur la Configuration supplémentaire, spécifiez les valeurs des options suivantes, puis choisissezContinuer.
a. Pour Fournissez les détails de configuration supplémentaires facultatifs ci-dessous, configurez lesoptions suivantes :
Groupe de paramètres du cluster
Sélectionnez un groupe de paramètres de cluster à associer au cluster. Si vous n'ensélectionnez pas un, le cluster utilise le groupe de paramètres par défaut.
Chiffrer la base de données
Choisissez si vous voulez chiffrer toutes les données au sein du cluster et ses instantanés. Sivous laissez le paramètre par défaut, Aucun, le chiffrement n'est pas activé. Si vous souhaitezactiver le chiffrement, sélectionnez si vous voulez utiliser AWS Key Management Service(AWS KMS) ou un module de sécurité matérielle (HSM), puis configurez les paramètresassociés. Pour plus d'informations sur le chiffrement dans Amazon Redshift, consultezChiffrement de base de données Amazon Redshift (p. 105).• KMS
Choisissez KMS si vous voulez activer le chiffrement et utilisez AWS KMS pour gérer votreclé de chiffrement. Dans Clé principale, choisissez (par défaut) aws/redshift pour utiliserune clé par défaut client ou choisissez une autre clé de votre compte AWS.
Note
Si vous souhaitez utiliser une clé d'un autre compte AWS, choisissez Entrez unARN de clé dans Clé principale. Puis, entrez l'ARN de la clé à utiliser. Vous devezavoir l'autorisation d'utiliser la clé. Pour plus d'informations sur l'accès aux clésdans AWS KMS accédez à Contrôle de l'accès à vos clés dans le manuel AWSKey Management Service Developer Guide.
Pour plus d'informations sur l'utilisation des clés de chiffrement AWS KMS dans AmazonRedshift, consultez Chiffrement de base de données pour Amazon Redshift à l'aide d'AWSKMS (p. 105).
• HSM
Choisissez HSM si vous voulez activer le chiffrement et utiliser un module de sécuritématérielle (HSM) pour gérer votre clé de chiffrement.
Si vous choisissez HSM, sélectionnez les valeurs de Connexion HSM et Certificat declient HSM. Ces valeurs sont requises pour Amazon Redshift et le module HSM de façonà former une connexion approuvée au travers de laquelle la clé de cluster peut êtretransmise. La connexion et le certificat de client HSM doivent être configurés dans AmazonRedshift avant que vous ne lanciez un cluster. Pour plus d'informations sur la configurationdes connexions et des certificats de clients HSM, consultez Chiffrement pour AmazonRedshift à l'aide de modules de sécurité matérielle (p. 107).
b. Pour Configurez les options de mise en réseau, vous choisissez de lancer votre cluster dansun Virtual Private Cloud (VPC) ou à l'extérieur d'un VPC. L'option que vous choisissez affecteles autres options disponibles dans cette section. Amazon Redshift utilise les plateformes EC2-Classic et EC2-VPC pour lancer les clusters. Votre compte AWS détermine les plateformesauxquelles votre cluster peut accéder. Pour plus d'informations, consultez Plateformes prises encharge dans le manuel Amazon EC2 Guide de l'utilisateur pour les instances Linux.
Choisir un VPC
Pour lancer votre cluster dans un Virtual Private Cloud (VPC), sélectionnez le VPC que vousvoulez utiliser. Vous devez avoir au moins un groupe de sous-réseaux Amazon RedshiftVersion de l'API 2012-12-01
20

Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
configuré pour pouvoir utiliser les VPC. Pour plus d'informations, consultez Groupes de sous-réseaux de cluster Amazon Redshift (p. 40).
Pour lancer votre cluster à l'extérieur d'un VPC, choisissez Pas dans le VPC. Cette optionest disponible uniquement pour les comptes AWS qui prennent en charge la plateforme EC2-Classic. Sinon, vous devez lancer votre cluster dans un VPC.
Groupe de sous-réseaux du cluster
Sélectionnez le groupe de sous-réseaux Amazon Redshift dans lequel vous lancez le cluster.
Note
Cette option est disponible uniquement pour les clusters d'un VPC.Publicly Accessible
Choisissez Oui pour activer les connexions au cluster en dehors du VPC dans lequel vouslancez le cluster. Choisissez Non si vous voulez limiter les connexions au cluster depuisl'intérieur du VPC uniquement.
Note
Cette option est disponible uniquement pour les clusters d'un VPC.Choisir une adresse IP publique
Si vous définissez Accessible publiquement sur Oui, choisissez Non ici pour qu'AmazonRedshift fournisse une adresse IP Elastic (EIP) pour le cluster, ou choisissez Yes si voussouhaitez utiliser une adresse IP Elastic que vous avez créée et gérée. Si Amazon Redshiftdoit créer l'EIP, l'action est gérée par Amazon Redshift.
Note
Cette option est disponible uniquement pour les clusters d'un VPC où Accessiblepubliquement a la valeur Oui.
Version de l'API 2012-12-0121

Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
Adresses IP Elastic
Sélectionnez l'adresse IP Elastic que vous souhaitez utiliser pour vous connecter au clusterdepuis l'extérieur du VPC.
Note
Cette option est disponible uniquement pour les clusters d'un VPC où Accessiblepubliquement et Choisir une adresse IP publique ont la valeur Oui.
Zone de disponibilité
Choisissez Aucune préférence pour qu'Amazon Redshift sélectionne la zone de disponibilitédans laquelle le cluster sera créé. Sinon, sélectionnez une zone de disponibilité spécifique.
Routage VPC amélioré
Choisissez Yes pour activer le routage de VPC amélioré. Le routage de VPC amélioré peutnécessiter une configuration supplémentaire. Pour de plus amples informations, veuillezconsulter Routage VPC amélioré Amazon Redshift (p. 57)
c. Pour Le cas échéant, associer votre cluster à un ou plusieurs groupes de sécurité, spécifiez lesvaleurs des options suivantes :
Groupes de sécurité du cluster
Sélectionnez un ou plusieurs groupes de sécurité Amazon Redshift pour le cluster. Pardéfaut, le groupe de sécurité sélectionné est le groupe de sécurité par défaut. Pour plusd'informations sur les groupes de sécurité de cluster, consultez Groupes de sécurité ducluster Amazon Redshift (p. 148).
Note
Cette option est uniquement disponible si vous lancez votre cluster dans laplateforme EC2-Classic.
Groupes de sécurité VPC
Sélectionnez un ou plusieurs groupes de sécurité VPC pour le cluster. Par défaut, le groupede sécurité sélectionné est le groupe de sécurité VPC par défaut. Pour plus d'informations surles groupes de sécurité VPC, consultez Groupes de sécurité pour votre VPC dans le manuelAmazon VPC Guide de l'utilisateur.
Note
Cette option est uniquement disponible si vous lancez votre cluster dans laplateforme EC2-VPC.
d. Pour Vous pouvez aussi créer une alarme de base pour ce cluster, configurez les optionssuivantes et choisissez Continuer :
Version de l'API 2012-12-0122

Amazon Redshift Guide de la gestion du clusterCréation d'un cluster
Créer une alarme CloudWatch
Choisissez Oui si vous souhaitez créer une alarme qui surveille l'utilisation du disque de votrecluster, puis spécifiez les valeurs des options correspondantes. Choisissez Non si vous nevoulez pas créer d'alarme.
Seuil d'utilisation du disque
Sélectionnez un pourcentage d'utilisation moyenne du disque qui a été atteint ou dépassé, etauquel l'alarme doit être déclenché.
Utiliser la rubrique existante
Choisissez Non si vous voulez créer une rubrique Amazon Simple Notification Service(Amazon SNS) pour cette alarme. Dans la zone Rubrique, modifiez le nom par défaut, sinécessaire. Pour Destinataires, saisissez les adresses e-mail de tous les destinataires quidoivent recevoir la notification lorsque l'alarme est déclenchée.
Choisissez Oui si vous voulez sélectionner une rubrique Amazon SNS existante pour cettealarme, puis, dans la liste Rubrique, sélectionnez la rubrique que vous voulez utiliser.
e. Pour Optionally, select your maintenance track for this cluster (Vous pouvez égalementsélectionner votre suivi de maintenance pour ce cluster), choisissez Current (Actuel) ou Trailing(Précédent).
Si vous choisissez Current (Actuel), votre cluster est mis à jour en fonction de la dernière versionapprouvée durant votre créneau de maintenance. Si vous choisissez Trailing (Précédent), votrecluster est mis à jour en fonction de la version approuvée précédemment.
6. Sur la page Révision, passez en revue les détails du cluster. Si tout est satisfaisant, choisissezLancer le cluster pour démarrer le processus de création. Sinon, choisissez Retour pour effectuer lesmodifications nécessaires, puis choisissez Continuer pour revenir à la page Révision.
Note
Certaines propriétés du cluster, telles que les valeurs Port de la base de données et MasterUser Name, ne peuvent pas être modifiées ultérieurement. Si vous avez besoin de lesmodifier, choisissez Retour pour les changer maintenant.
La capture d'écran suivante présente un résumé des différentes options sélectionnées pendant leprocessus de lancement du cluster.
Version de l'API 2012-12-0123
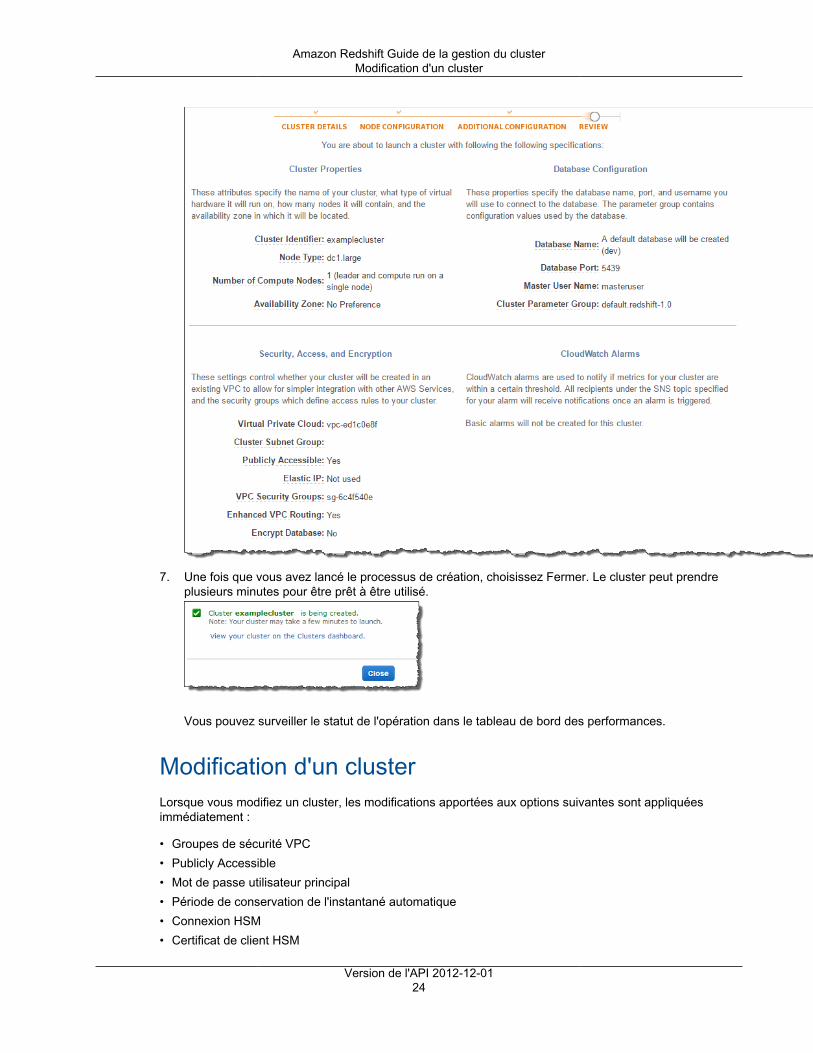
Amazon Redshift Guide de la gestion du clusterModification d'un cluster
7. Une fois que vous avez lancé le processus de création, choisissez Fermer. Le cluster peut prendreplusieurs minutes pour être prêt à être utilisé.
Vous pouvez surveiller le statut de l'opération dans le tableau de bord des performances.
Modification d'un clusterLorsque vous modifiez un cluster, les modifications apportées aux options suivantes sont appliquéesimmédiatement :
• Groupes de sécurité VPC• Publicly Accessible• Mot de passe utilisateur principal• Période de conservation de l'instantané automatique• Connexion HSM• Certificat de client HSM
Version de l'API 2012-12-0124
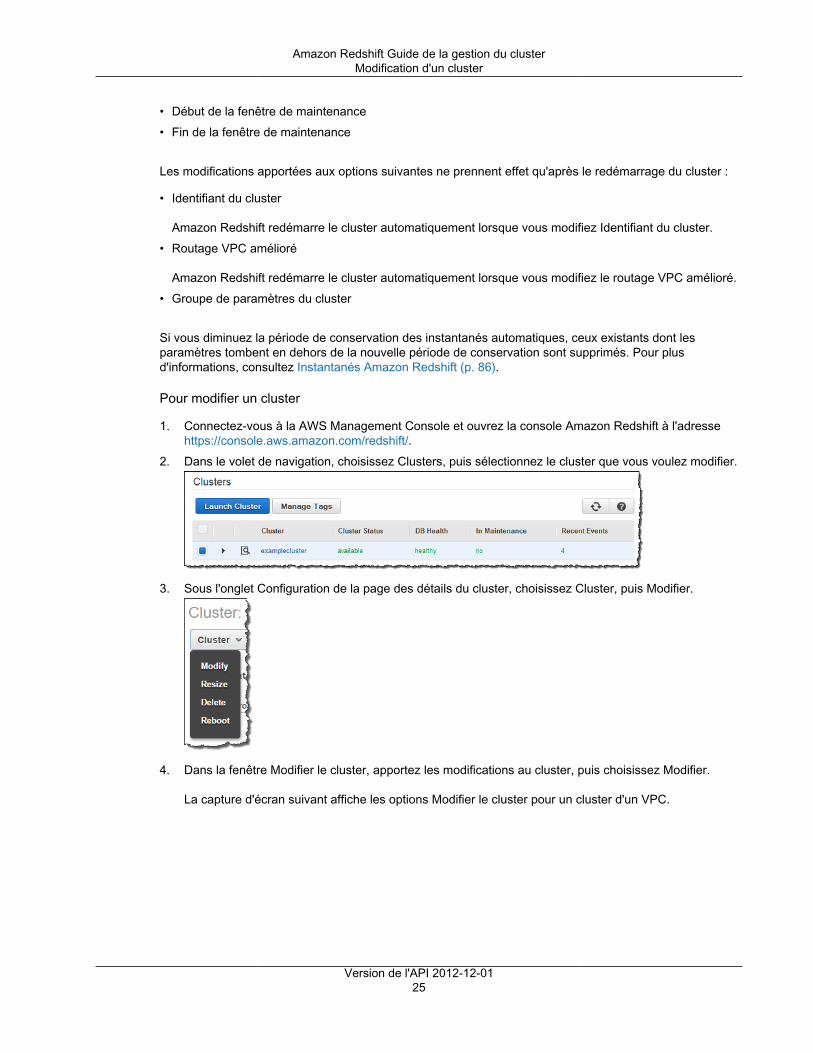
Amazon Redshift Guide de la gestion du clusterModification d'un cluster
• Début de la fenêtre de maintenance• Fin de la fenêtre de maintenance
Les modifications apportées aux options suivantes ne prennent effet qu'après le redémarrage du cluster :
• Identifiant du cluster
Amazon Redshift redémarre le cluster automatiquement lorsque vous modifiez Identifiant du cluster.• Routage VPC amélioré
Amazon Redshift redémarre le cluster automatiquement lorsque vous modifiez le routage VPC amélioré.• Groupe de paramètres du cluster
Si vous diminuez la période de conservation des instantanés automatiques, ceux existants dont lesparamètres tombent en dehors de la nouvelle période de conservation sont supprimés. Pour plusd'informations, consultez Instantanés Amazon Redshift (p. 86).
Pour modifier un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters, puis sélectionnez le cluster que vous voulez modifier.
3. Sous l'onglet Configuration de la page des détails du cluster, choisissez Cluster, puis Modifier.
4. Dans la fenêtre Modifier le cluster, apportez les modifications au cluster, puis choisissez Modifier.
La capture d'écran suivant affiche les options Modifier le cluster pour un cluster d'un VPC.
Version de l'API 2012-12-0125
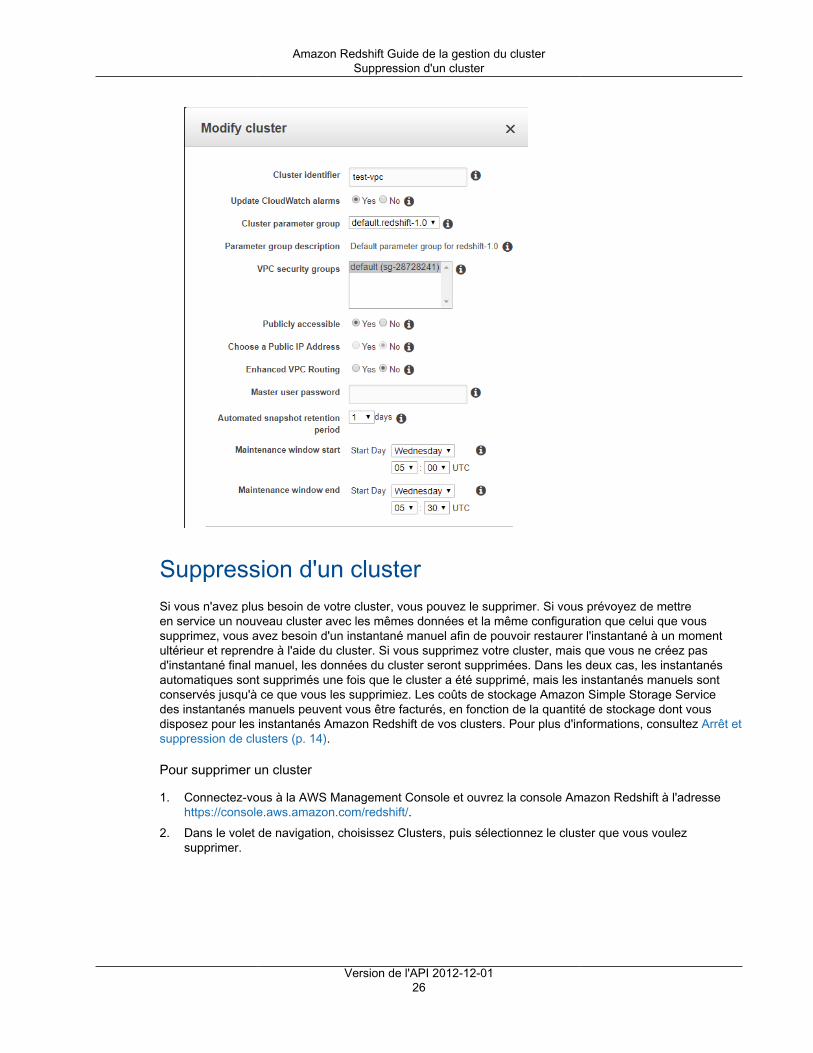
Amazon Redshift Guide de la gestion du clusterSuppression d'un cluster
Suppression d'un clusterSi vous n'avez plus besoin de votre cluster, vous pouvez le supprimer. Si vous prévoyez de mettreen service un nouveau cluster avec les mêmes données et la même configuration que celui que voussupprimez, vous avez besoin d'un instantané manuel afin de pouvoir restaurer l'instantané à un momentultérieur et reprendre à l'aide du cluster. Si vous supprimez votre cluster, mais que vous ne créez pasd'instantané final manuel, les données du cluster seront supprimées. Dans les deux cas, les instantanésautomatiques sont supprimés une fois que le cluster a été supprimé, mais les instantanés manuels sontconservés jusqu'à ce que vous les supprimiez. Les coûts de stockage Amazon Simple Storage Servicedes instantanés manuels peuvent vous être facturés, en fonction de la quantité de stockage dont vousdisposez pour les instantanés Amazon Redshift de vos clusters. Pour plus d'informations, consultez Arrêt etsuppression de clusters (p. 14).
Pour supprimer un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters, puis sélectionnez le cluster que vous voulezsupprimer.
Version de l'API 2012-12-0126
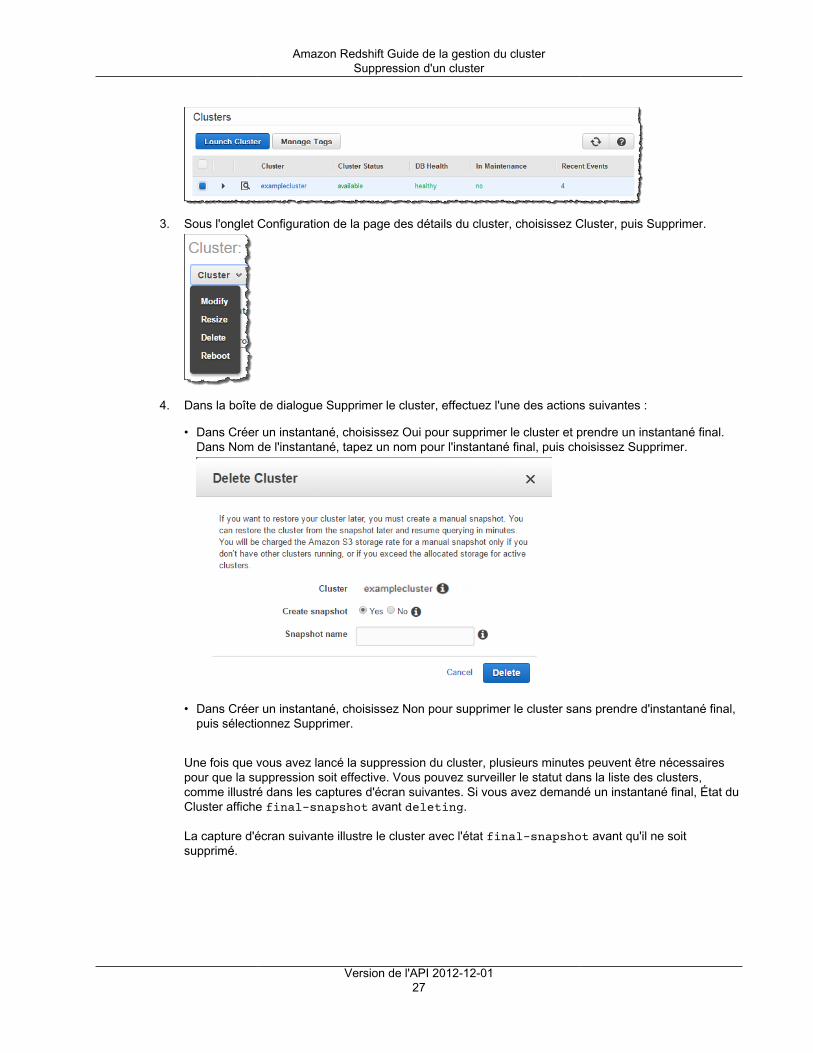
Amazon Redshift Guide de la gestion du clusterSuppression d'un cluster
3. Sous l'onglet Configuration de la page des détails du cluster, choisissez Cluster, puis Supprimer.
4. Dans la boîte de dialogue Supprimer le cluster, effectuez l'une des actions suivantes :
• Dans Créer un instantané, choisissez Oui pour supprimer le cluster et prendre un instantané final.Dans Nom de l'instantané, tapez un nom pour l'instantané final, puis choisissez Supprimer.
• Dans Créer un instantané, choisissez Non pour supprimer le cluster sans prendre d'instantané final,puis sélectionnez Supprimer.
Une fois que vous avez lancé la suppression du cluster, plusieurs minutes peuvent être nécessairespour que la suppression soit effective. Vous pouvez surveiller le statut dans la liste des clusters,comme illustré dans les captures d'écran suivantes. Si vous avez demandé un instantané final, État duCluster affiche final-snapshot avant deleting.
La capture d'écran suivante illustre le cluster avec l'état final-snapshot avant qu'il ne soitsupprimé.
Version de l'API 2012-12-0127
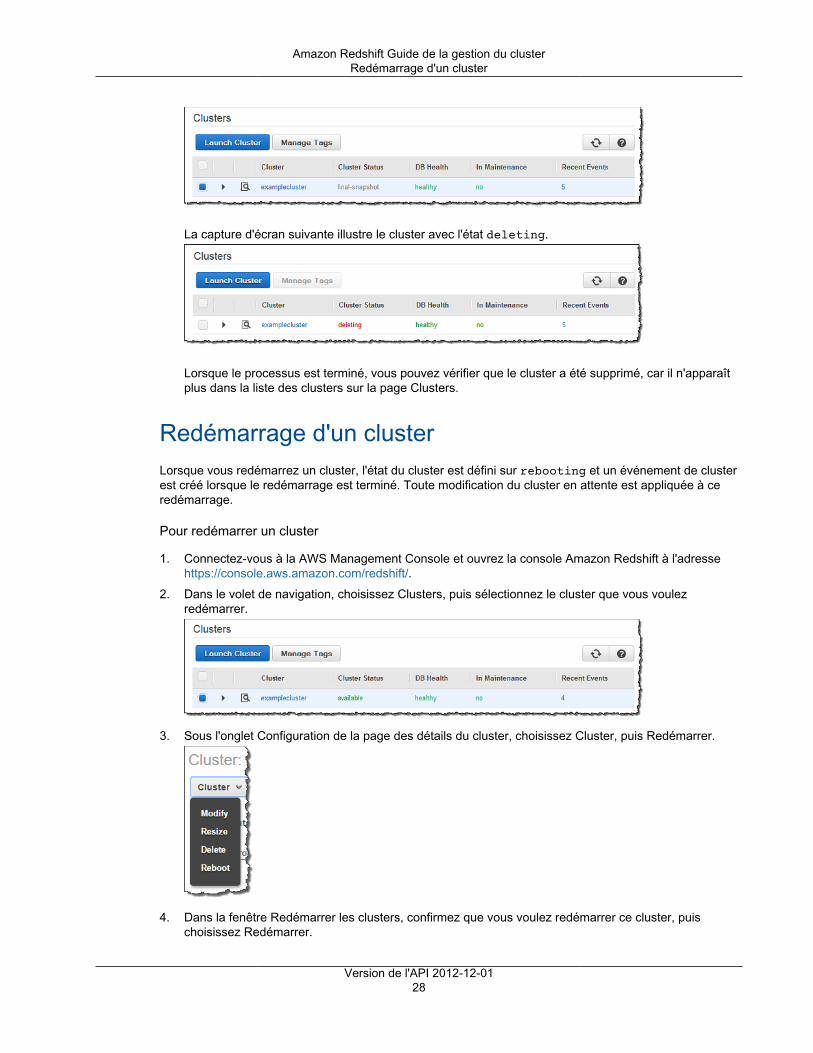
Amazon Redshift Guide de la gestion du clusterRedémarrage d'un cluster
La capture d'écran suivante illustre le cluster avec l'état deleting.
Lorsque le processus est terminé, vous pouvez vérifier que le cluster a été supprimé, car il n'apparaîtplus dans la liste des clusters sur la page Clusters.
Redémarrage d'un clusterLorsque vous redémarrez un cluster, l'état du cluster est défini sur rebooting et un événement de clusterest créé lorsque le redémarrage est terminé. Toute modification du cluster en attente est appliquée à ceredémarrage.
Pour redémarrer un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters, puis sélectionnez le cluster que vous voulezredémarrer.
3. Sous l'onglet Configuration de la page des détails du cluster, choisissez Cluster, puis Redémarrer.
4. Dans la fenêtre Redémarrer les clusters, confirmez que vous voulez redémarrer ce cluster, puischoisissez Redémarrer.
Version de l'API 2012-12-0128
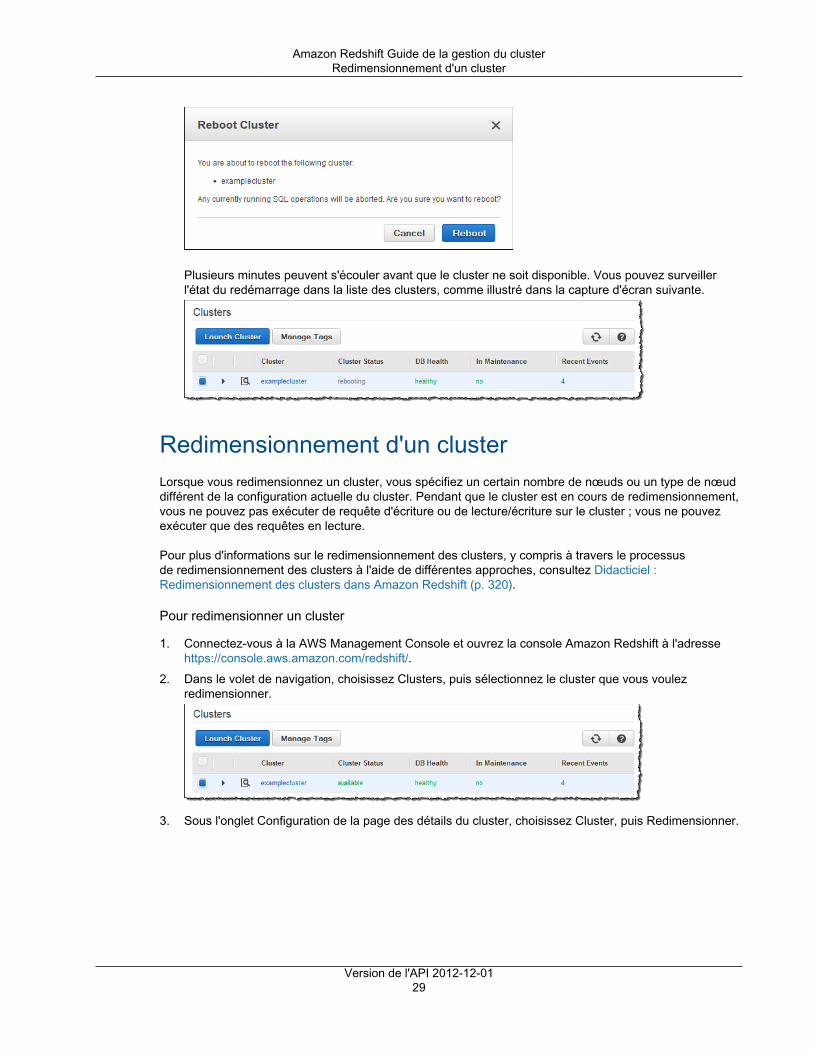
Amazon Redshift Guide de la gestion du clusterRedimensionnement d'un cluster
Plusieurs minutes peuvent s'écouler avant que le cluster ne soit disponible. Vous pouvez surveillerl'état du redémarrage dans la liste des clusters, comme illustré dans la capture d'écran suivante.
Redimensionnement d'un clusterLorsque vous redimensionnez un cluster, vous spécifiez un certain nombre de nœuds ou un type de nœuddifférent de la configuration actuelle du cluster. Pendant que le cluster est en cours de redimensionnement,vous ne pouvez pas exécuter de requête d'écriture ou de lecture/écriture sur le cluster ; vous ne pouvezexécuter que des requêtes en lecture.
Pour plus d'informations sur le redimensionnement des clusters, y compris à travers le processusde redimensionnement des clusters à l'aide de différentes approches, consultez Didacticiel :Redimensionnement des clusters dans Amazon Redshift (p. 320).
Pour redimensionner un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters, puis sélectionnez le cluster que vous voulezredimensionner.
3. Sous l'onglet Configuration de la page des détails du cluster, choisissez Cluster, puis Redimensionner.
Version de l'API 2012-12-0129

Amazon Redshift Guide de la gestion du clusterObtention d'informations sur la configuration du cluster
4. Dans la fenêtre Redimensionner les clusters, configurez les paramètres de redimensionnement ycompris Type de nœud, Type de cluster et Nombre de nœuds, puis choisissez Redimensionner.
Vous pouvez surveiller l'avancement du redimensionnement sous l'onglet État.
Obtention d'informations sur la configuration du clusterPour obtenir les détails de configuration du cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, sélectionnez Clusters, puis choisissez le cluster pour lequel voussouhaitez afficher les informations de configuration.
Version de l'API 2012-12-0130
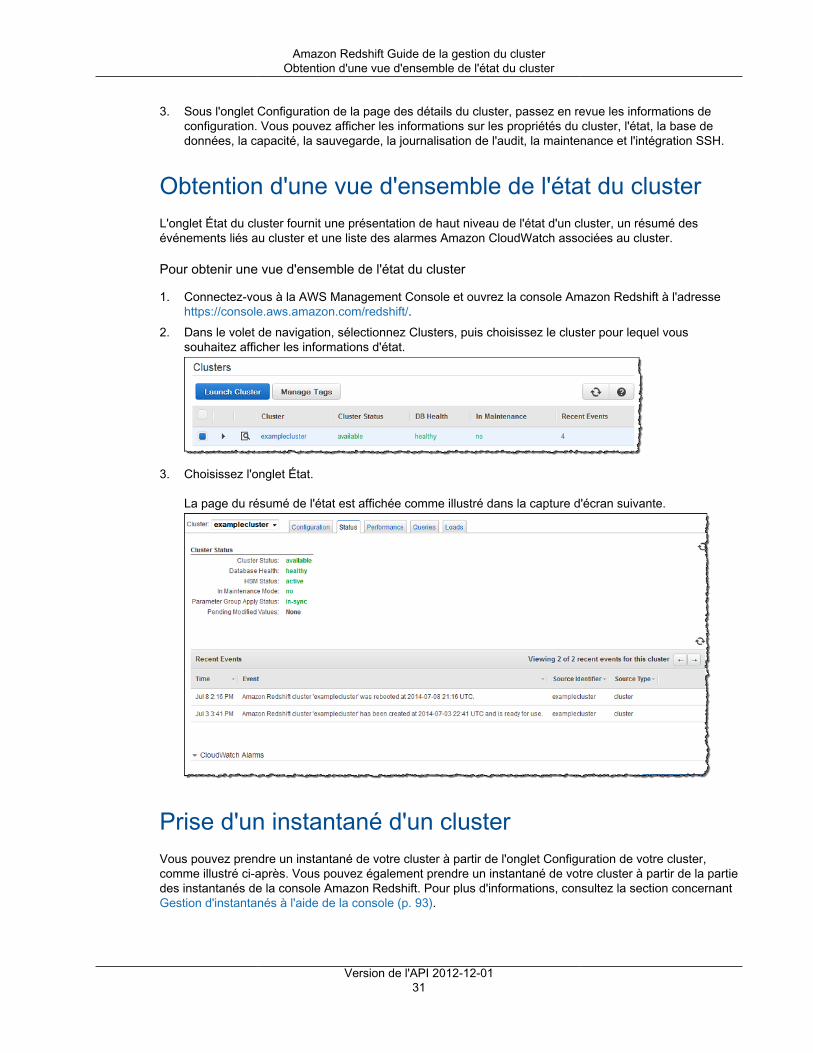
Amazon Redshift Guide de la gestion du clusterObtention d'une vue d'ensemble de l'état du cluster
3. Sous l'onglet Configuration de la page des détails du cluster, passez en revue les informations deconfiguration. Vous pouvez afficher les informations sur les propriétés du cluster, l'état, la base dedonnées, la capacité, la sauvegarde, la journalisation de l'audit, la maintenance et l'intégration SSH.
Obtention d'une vue d'ensemble de l'état du clusterL'onglet État du cluster fournit une présentation de haut niveau de l'état d'un cluster, un résumé desévénements liés au cluster et une liste des alarmes Amazon CloudWatch associées au cluster.
Pour obtenir une vue d'ensemble de l'état du cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, sélectionnez Clusters, puis choisissez le cluster pour lequel voussouhaitez afficher les informations d'état.
3. Choisissez l'onglet État.
La page du résumé de l'état est affichée comme illustré dans la capture d'écran suivante.
Prise d'un instantané d'un clusterVous pouvez prendre un instantané de votre cluster à partir de l'onglet Configuration de votre cluster,comme illustré ci-après. Vous pouvez également prendre un instantané de votre cluster à partir de la partiedes instantanés de la console Amazon Redshift. Pour plus d'informations, consultez la section concernantGestion d'instantanés à l'aide de la console (p. 93).
Version de l'API 2012-12-0131
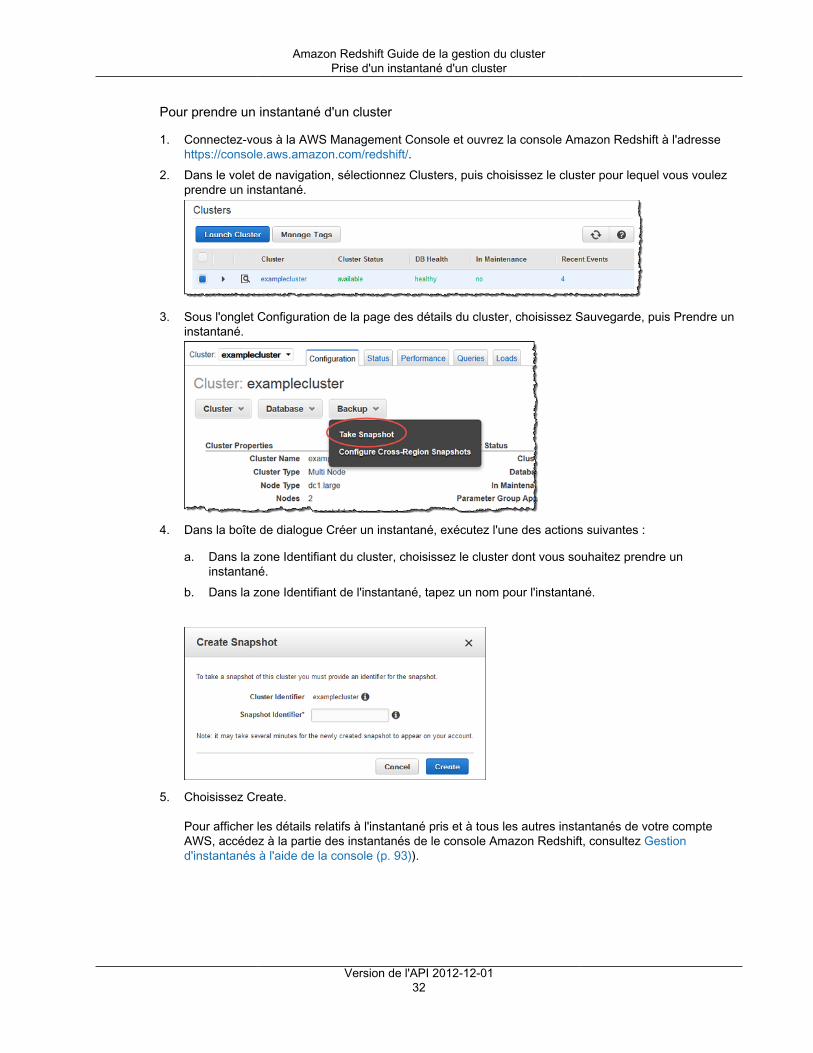
Amazon Redshift Guide de la gestion du clusterPrise d'un instantané d'un cluster
Pour prendre un instantané d'un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, sélectionnez Clusters, puis choisissez le cluster pour lequel vous voulezprendre un instantané.
3. Sous l'onglet Configuration de la page des détails du cluster, choisissez Sauvegarde, puis Prendre uninstantané.
4. Dans la boîte de dialogue Créer un instantané, exécutez l'une des actions suivantes :
a. Dans la zone Identifiant du cluster, choisissez le cluster dont vous souhaitez prendre uninstantané.
b. Dans la zone Identifiant de l'instantané, tapez un nom pour l'instantané.
5. Choisissez Create.
Pour afficher les détails relatifs à l'instantané pris et à tous les autres instantanés de votre compteAWS, accédez à la partie des instantanés de le console Amazon Redshift, consultez Gestiond'instantanés à l'aide de la console (p. 93)).
Version de l'API 2012-12-0132
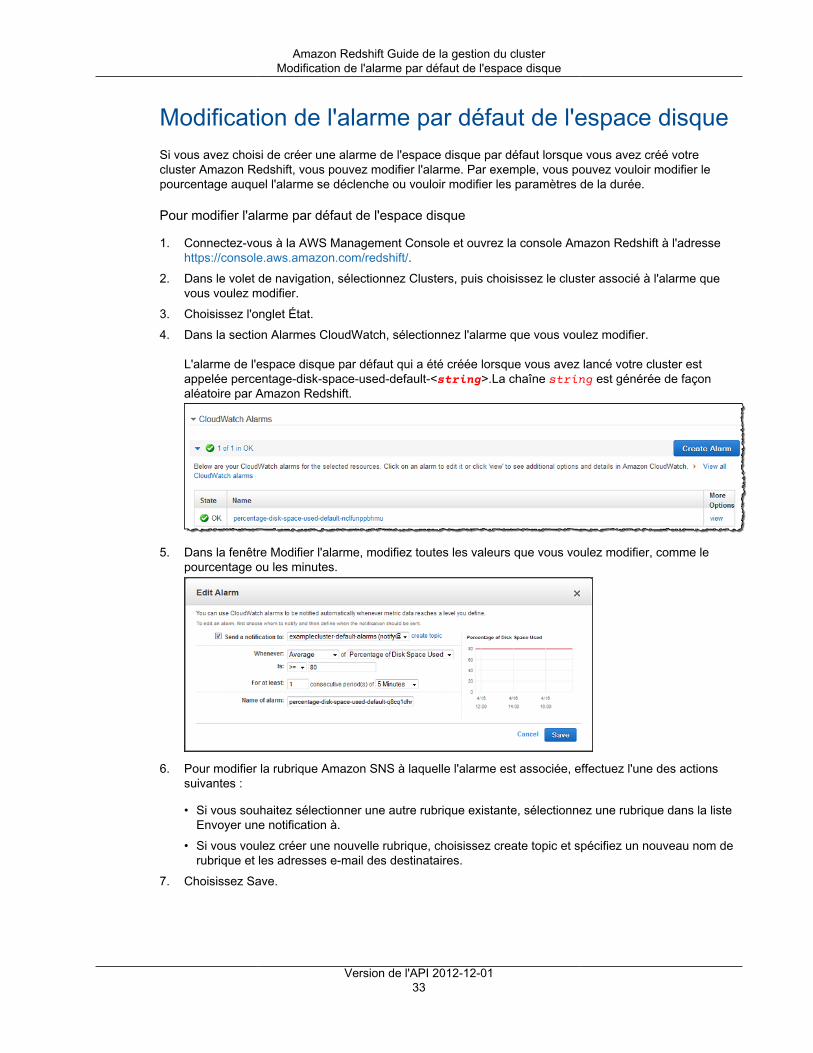
Amazon Redshift Guide de la gestion du clusterModification de l'alarme par défaut de l'espace disque
Modification de l'alarme par défaut de l'espace disqueSi vous avez choisi de créer une alarme de l'espace disque par défaut lorsque vous avez créé votrecluster Amazon Redshift, vous pouvez modifier l'alarme. Par exemple, vous pouvez vouloir modifier lepourcentage auquel l'alarme se déclenche ou vouloir modifier les paramètres de la durée.
Pour modifier l'alarme par défaut de l'espace disque
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, sélectionnez Clusters, puis choisissez le cluster associé à l'alarme quevous voulez modifier.
3. Choisissez l'onglet État.4. Dans la section Alarmes CloudWatch, sélectionnez l'alarme que vous voulez modifier.
L'alarme de l'espace disque par défaut qui a été créée lorsque vous avez lancé votre cluster estappelée percentage-disk-space-used-default-<string>.La chaîne string est générée de façonaléatoire par Amazon Redshift.
5. Dans la fenêtre Modifier l'alarme, modifiez toutes les valeurs que vous voulez modifier, comme lepourcentage ou les minutes.
6. Pour modifier la rubrique Amazon SNS à laquelle l'alarme est associée, effectuez l'une des actionssuivantes :
• Si vous souhaitez sélectionner une autre rubrique existante, sélectionnez une rubrique dans la listeEnvoyer une notification à.
• Si vous voulez créer une nouvelle rubrique, choisissez create topic et spécifiez un nouveau nom derubrique et les adresses e-mail des destinataires.
7. Choisissez Save.
Version de l'API 2012-12-0133

Amazon Redshift Guide de la gestion du clusterUtilisation des données de performance du cluster
Utilisation des données de performance du clusterVous pouvez utiliser les données de performance du cluster à l'aide des onglets Performance, Requêteset Charges. Pour plus d'informations sur l'utilisation des performances du cluster, consultez Utilisation desdonnées de performance dans la console Amazon Redshift (p. 265).
Gestion des clusters à l'aide du kit AWS SDK pourJava
L'exemple de code Java suivant montre les opérations courantes de gestion de cluster, parmi lesquelles :
• Création d'un cluster.• Affichage des métadonnées d'un cluster.• Modification des options de configuration.
Une fois que vous lancez la demande pour que le cluster soit créé, vous devez attendre que le clustersoit dans l'état available avant de pouvoir le modifier. Cet exemple utilise une boucle pour vérifierpériodiquement l'état du cluster à l'aide de la méthode describeClusters. Lorsque le cluster estdisponible, la fenêtre de maintenance préférée du cluster est modifiée.
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193). Vous devez mettre à jour le code et spécifier unidentificateur de cluster.
Example
import java.io.IOException;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;import com.amazonaws.services.redshift.model.*;
public class CreateAndModifyCluster {
public static AmazonRedshiftClient client; public static String clusterIdentifier = "***provide a cluster identifier***"; public static long sleepTime = 20; public static void main(String[] args) throws IOException {
AWSCredentials credentials = new PropertiesCredentials( CreateAndModifyCluster.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { createCluster(); waitForClusterReady(); describeClusters(); modifyCluster(); describeClusters(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage()); } }
Version de l'API 2012-12-0134

Amazon Redshift Guide de la gestion du clusterGestion des clusters à l'aide du kit AWS SDK pour Java
private static void createCluster() { CreateClusterRequest request = new CreateClusterRequest() .withClusterIdentifier(clusterIdentifier) .withMasterUsername("masteruser") .withMasterUserPassword("12345678Aa") .withNodeType("ds1.xlarge") .withNumberOfNodes(2); Cluster createResponse = client.createCluster(request); System.out.println("Created cluster " + createResponse.getClusterIdentifier()); } private static void describeClusters() { DescribeClustersRequest request = new DescribeClustersRequest() .withClusterIdentifier(clusterIdentifier); DescribeClustersResult result = client.describeClusters(request); printResult(result); }
private static void modifyCluster() { ModifyClusterRequest request = new ModifyClusterRequest() .withClusterIdentifier(clusterIdentifier) .withPreferredMaintenanceWindow("wed:07:30-wed:08:00"); client.modifyCluster(request); System.out.println("Modified cluster " + clusterIdentifier); } private static void printResult(DescribeClustersResult result) { if (result == null) { System.out.println("Describe clusters result is null."); return; }
System.out.println("Cluster property:"); System.out.format("Preferred Maintenance Window: %s\n", result.getClusters().get(0).getPreferredMaintenanceWindow()); } private static void waitForClusterReady() throws InterruptedException { Boolean clusterReady = false; System.out.println("Wating for cluster to become available."); while (!clusterReady) { DescribeClustersResult result = client.describeClusters(new DescribeClustersRequest() .withClusterIdentifier(clusterIdentifier)); String status = (result.getClusters()).get(0).getClusterStatus(); if (status.equalsIgnoreCase("available")) { clusterReady = true; } else { System.out.print("."); Thread.sleep(sleepTime*1000); } } }}
Version de l'API 2012-12-0135

Amazon Redshift Guide de la gestion du clusterGérer les clusters à l'aide de l'interface de ligne
de commande Amazon Redshift et de l'API
Gérer les clusters à l'aide de l'interface de ligne decommande Amazon Redshift et de l'API
Vous pouvez utiliser les opérations d'interface de ligne de commande Amazon Redshift suivantes pourgérer les clusters.
• create-cluster• delete-cluster• describe-clusters• describe-cluster-versions• describe-orderable-cluster-options• modify-cluster• reboot-cluster
Vous pouvez utiliser les opérations d'API Amazon Redshift suivantes pour gérer les clusters.
• CreateCluster• DeleteCluster• DescribeClusters• DescribeClusterVersions• DescribeOrderableClusterOptions• ModifyCluster• RebootCluster
Gestion des clusters dans un Amazon VirtualPrivate Cloud (VPC)
Rubriques• Présentation (p. 36)• Création d'un cluster dans un VPC (p. 38)• Gestion des groupes de sécurité VPC pour un Cluster (p. 39)• Groupes de sous-réseaux de cluster Amazon Redshift (p. 40)
PrésentationAmazon Redshift prend en charge les plateformes EC2-VPC et EC2-Classic pour lancer un cluster. Pourplus d'informations, consultez Plateformes prises en charge pour lancer votre cluster (p. 10).
Note
Amazon Redshift prend en charge le lancement des clusters dans des VPC de location dédiée.Pour plus d'informations, consultez Instances dédiées dans le manuel Amazon VPC Guide del'utilisateur.
Lors de la mise en service d'un cluster dans un VPC, vous devez effectuer les opérations suivantes :
• Fournissez des informations de VPC.
Version de l'API 2012-12-0136

Amazon Redshift Guide de la gestion du clusterPrésentation
Lorsque vous demandez à Amazon Redshift de créer un cluster dans votre VPC, vous devez fournir vosinformations de VPC, telles que l'ID de VPC, ainsi qu'une liste de sous-réseaux de votre VPC en créantd'abord un groupe de sous-réseaux de cluster. Lorsque vous lancez un cluster vous fournissez le groupede sous-réseaux du cluster afin que Amazon Redshift puisse mettre en service votre cluster dans l'undes sous-réseaux du VPC. Pour plus d'informations sur la création de groupes de sous-réseaux dansAmazon Redshift, consultez Groupes de sous-réseaux de cluster Amazon Redshift (p. 40). Pour plusd'informations sur la configuration d'un VPC, consultez Mise en route sur Amazon VPC dans le manuelAmazon VPC Guide de mise en route.
• Le cas échéant, configurez les options accessibles au public.
Si vous configurez votre cluster pour être accessible au public, vous pouvez sélectionner le cas échéantune adresse IP Elastic (EIP) à utiliser pour l'adresse IP externe. Une EIP est une adresse IP statiqueassociée à votre compte AWS. Vous pouvez utiliser une EIP pour vous connecter à votre cluster depuisl'extérieur du VPC. Une EIP vous permet de modifier votre configuration sous-jacente sans affecterl'adresse IP que les clients utilisent pour se connecter à votre cluster. Cette approche peut être utile pourdes situations telles que la récupération après une défaillance.
Si vous souhaitez utiliser une EIP associée à votre propre compte AWS, vous devez la créer dansAmazon EC2 avant de lancer votre cluster Amazon Redshift. Sinon, elle ne sera pas disponible pendantle processus de lancement. Vous pouvez également faire configurer à Amazon Redshift une EIP àutiliser pour le VPC, mais l'EIP affectée sera gérée par le service Amazon Redshift et ne sera pasassociée à votre compte AWS. Pour plus d'informations, accédez à Adresses IP Elastic (EIP) dans lemanuel Amazon EC2 Guide de l'utilisateur pour les instances Linux.
Si vous disposez d'un cluster accessible publiquement dans un VPC, et que vous voulez vous connecterà celui-ci à l'aide de l'adresse IP privée depuis le VPC, vous devez définir les paramètres du VPCsuivants sur true :• DNS resolution
• DNS hostnames
Si vous disposez d'un cluster accessible publiquement dans un VPC, mais que vous ne définissez pasces paramètres sur true dans le VPC, les connexions effectuées depuis le VPC se résolvent dans l'EIPdu cluster au lieu de l'adresse IP privée. Nous vous recommandons de définir ces paramètres sur trueet d'utiliser l'adresse IP privée pour un cluster accessible publiquement lors de la connexion depuis leVPC. Pour plus d'informations, consultez Utilisation de DNS avec votre VPC dans le guide Amazon VPCGuide de l'utilisateur.
Note
Si vous disposez d'un cluster accessible publiquement existant dans un VPC, les connexionsdepuis le VPC continueront d'utiliser l'EIP pour se connecter au cluster même avec cesparamètres définis tant que vous n'aurez pas redimensionné le cluster. Les nouveaux clusterssuivront le nouveau comportement consistant à utiliser l'adresse IP privée lors de la connexionau cluster accessible publiquement depuis le même VPC.
En outre, notez que l'EIP est une adresse IP externe permettant d'accéder au cluster en dehors d'unVPC, mais elle ne se rapporte pas aux adresses IP publiques privées et aux adresses IP privées denœud de cluster qui s'affichent dans la Amazon Redshift console sous Paramètres d'intégration SSH.Les adresses IP de nœud de cluster publiques et privées nœud s'affichent, que le cluster soit accessibleou non. Elles sont utilisées dans certains cas pour configurer les règles de trafic entrant sur l'hôte distantlors du chargement de données depuis une instance Amazon EC2 ou un autre hôte distant à l'aide d'uneconnexion Secure Shell (SSH). Pour plus d'informations, consultez Étape 1 : Récupérer la clé publiquede cluster et les adresses IP de nœud de cluster dans le manuel Amazon Redshift Database DeveloperGuide.
L'option permettant d'associer un cluster à une EIP est disponible uniquement lorsque vous créez lecluster ou que vous restaurez le cluster à partir d'un instantané. Vous ne pouvez pas attacher d'EIP
Version de l'API 2012-12-0137

Amazon Redshift Guide de la gestion du clusterCréation d'un cluster dans un VPC
une fois le cluster créé ou restauré. Si vous souhaitez associer le cluster à une EIP ou modifier une EIPassociée au cluster, vous devez restaurer celui-ci à partir d'un instantané et spécifier l'EIP à ce moment-là.
• Associer un groupe de sécurité VPC.
Ensuite, vous accordez l'accès entrant à l'aide d'un groupe de sécurité VPC. Ce groupe de sécuritéVPC doit autoriser l'accès via le port de la base de données au cluster afin que vous puissiez vousconnecter à l'aide d'outils clients SQL. Vous pouvez le configurer à l'avance ou y ajouter des règlesaprès avoir lancé le cluster. Pour plus d'informations, accédez à Sécurité au sein de votre VPC dansle manuel Amazon VPC Guide de l'utilisateur. Vous ne pouvez pas utiliser les groupes de sécurité ducluster Amazon Redshift pour accorder l'accès entrant au cluster.
Pour plus d'informations sur l'utilisation de clusters dans le VPC, consultez Création d'un cluster dans unVPC (p. 38).
Restauration d'un instantané d'un cluster dans le VPC
Un instantané d'un cluster dans le VPC peut être restauré uniquement dans un VPC, pas en dehors duVPC. Vous pouvez le restaurer dans le même VPC ou dans un autre VPC de votre compte. Pour plusd'informations sur les instantanés, consultez Instantanés Amazon Redshift (p. 86).
Création d'un cluster dans un VPCVoici les grandes étapes que vous devez suivre pour déployer un cluster dans votre VPC.
Pour créer un cluster dans un VPC
1. Configurez un VPC.
Vous pouvez créer votre cluster dans le VPC par défaut pour votre compte, si votre compte en aun, ou dans un VPC que vous avez créé. Pour plus d'informations, consultez Plateformes prises encharge pour lancer votre cluster (p. 10). Pour créer un VPC, suivez les étapes 2 et 3 du Guide dedémarrage Amazon Virtual Private Cloud. Prenez note de l'identificateur de VPC, du sous-réseau etde la zone de disponibilité du sous-réseau. Vous aurez besoin de ces informations au moment dulancement de votre cluster.
Note
Vous devez disposer d'au moins un sous-réseau défini dans votre VPC afin de l'ajouter augroupe de sous-réseaux du cluster à la prochaine étape. Si vous utilisez l'assistant VPC, unsous-réseau pour votre VPC est créé automatiquement pour vous. Pour plus d'informationssur l'ajout d'un sous-réseau à votre VPC, consultez Ajout d'un sous-réseau à votre VPC.
2. Créez un groupe de sous-réseaux du cluster Amazon Redshift qui spécifie lequel des sous-réseaux duVPC peut être utilisé par le cluster Amazon Redshift.
Vous pouvez créer le groupe de sous-réseaux du cluster à l'aide de la console Amazon Redshift oupar programmation. Pour plus d'informations, consultez Groupes de sous-réseaux de cluster AmazonRedshift (p. 40).
3. Autorisez l'accès aux connexions entrantes dans un groupe de sécurité VPC que vous allez associerau cluster.
Pour activer un client en dehors du VPC (sur le réseau Internet public) afin de vous connecter aucluster, vous devez associer le cluster à un groupe de sécurité VPC qui accorde l'accès entrant auport que vous avez utilisé au lancement du cluster. Pour obtenir des exemples de règles de groupesde sécurité, accédez à Règles des groupes de sécurité dans le manuel Amazon VPC Guide del'utilisateur.
4. Lancez un cluster dans votre VPC.
Version de l'API 2012-12-0138

Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécurité VPC pour un Cluster
Vous pouvez utiliser la procédure décrite dans la mise en route pour lancer le cluster dans votreVPC. Pour plus d'informations, consultez Étape 2 : Lancer un cluster. A mesure que vous avancezdans l'assistant, dans la section Configure Network Options sur la page CONFIGURATIONSUPPLEMENTAIRE, spécifiez les informations suivantes :
• Choisir un VPC Sélectionnez le VPC dans la liste déroulante.• Groupe de sous-réseau du cluster Sélectionnez le groupe de sous-réseaux du cluster créé à
l'étape 2.• Dans Accessible publiquement Sélectionnez Oui si vous voulez que le cluster dispose d'une adresse
IP publique accessible depuis l'Internet public, sélectionnez Non si vous souhaitez que le clusterdispose d'une adresse IP privée uniquement accessible depuis le VPC. Si votre compte AWS vouspermet de créer des clusters EC2-Classic, la valeur par défaut est Non, dans le cas contraire, lavaleur par défaut est Oui.
• Choisir une adresse IP publique Sélectionnez Oui si vous voulez sélectionner une adresse IP Elastic(EIP) que vous avez déjà configurée. Dans le cas contraire, sélectionnez Non pour que AmazonRedshift crée une EIP pour votre instance.
• Dans Adresses IP élastiques Sélectionnez une EIP à utiliser pour vous connecter au cluster depuisl'extérieur du VPC.
• Zone de disponibilité Sélectionnez Aucune préférence afin que Amazon Redshift sélectionnez lazone de disponibilité dans laquelle le cluster sera créé. Sinon, sélectionnez une zone de disponibilitéspécifique.
• Sélectionnez le groupe de sécurité VPC qui autorise des appareils approuvés à accéder au cluster.
Voici un exemple de capture d'écran de la section Configure Networking Options de la pageCONFIGURATION SUPPLEMENTAIRE.
Vous êtes à présent prêt à utiliser le cluster. Vous pouvez suivre les étapes de mise en route pour tester lecluster, par exemple en chargeant des exemples de données et en essayant d'exécuter des exemples derequêtes.
Gestion des groupes de sécurité VPC pour un ClusterLorsque vous mettez en service un cluster Amazon Redshift, il est verrouillé par défaut afin que personnen'y ait accès. Pour autoriser d'autres utilisateurs à accéder à un cluster Amazon Redshift, associez lecluster à un groupe de sécurité. Si vous vous trouvez sur la plateforme EC2-VPC, vous pouvez utiliserun groupe de sécurité Amazon VPC existant ou en définir un nouveau et l'associer ensuite à un clustercomme décrit ci-après. Si vous vous trouvez sur la plateforme EC2-Classic, définissez un groupe desécurité du cluster et associez-le à un cluster. Pour plus d'informations sur l'utilisation des groupes desécurité de cluster sur la plateforme EC2-Classic, consultez Groupes de sécurité du cluster AmazonRedshift (p. 148).
Version de l'API 2012-12-0139

Amazon Redshift Guide de la gestion du clusterGroupes de sous-réseaux du cluster
Un groupe de sécurité VPC se compose d'un ensemble de règles qui contrôlent l'accès à une instance duVPC, tel que votre cluster. Des règles individuelles définissent l'accès en fonction de plages d'adresses IPou sur d'autres groupes de sécurité VPC. Lorsque vous associez un groupe de sécurité VPC à un cluster,les règles définies dans le groupe de sécurité VPC contrôlent l'accès au cluster.
Chaque cluster que vous mettez en service sur la plateforme EC2-VPC est associé à un ou plusieursgroupes de sécurité Amazon VPC. Amazon VPC fournit un groupe de sécurité VPC appelé default, quiest créé automatiquement lorsque vous créez un VPC. Chaque cluster que vous lancez dans le VPC estautomatiquement associé au groupe de sécurité VPC par défaut si vous ne spécifiez pas un autre groupede sécurité VPC lors de la création du cluster. Vous pouvez associer un groupe de sécurité VPC à uncluster lorsque vous créez le cluster ou vous pouvez associer un groupe de sécurité VPC ultérieurementen modifiant le cluster. Pour plus d'informations sur l'association d'un groupe de sécurité VPC à un cluster,consultez Pour créer un cluster (p. 17) et Pour modifier un cluster (p. 25).
Le tableau ci-après décrit les règles par défaut pour le groupe de sécurité VPC par défaut.
Vous pouvez modifier les règles du groupe de sécurité VPC par défaut en fonction des besoins de votrecluster Amazon Redshift.
Si le groupe de sécurité VPC par défaut vous suffit, vous n'avez pas besoin d'en créer un autre.Cependant, vous pouvez éventuellement créer des groupes de sécurité VPC supplémentaires pour mieuxgérer l'accès entrant à votre cluster. Par exemple, supposons que vous exécutiez un service sur un clusterAmazon Redshift et que vous ayez plusieurs niveaux de service distincts à fournir à vos clients. Si vousne voulez pas fournir le même accès à tous les niveaux de service, vous pouvez créer des groupes desécurité VPC distincts, un par niveau de service. Vous pouvez ensuite associer ces groupes de sécuritéVPC à votre cluster.
Gardez à l'esprit que bien que vous puissiez créer jusqu'à 100 groupes de sécurité VPC pour un VPC, etque vous puissiez associer un groupe de sécurité VPC à de nombreux clusters, vous ne pouvez associerque 5 groupes de sécurité VPC au maximum à un cluster donné.
Amazon Redshift applique immédiatement les modifications à un groupe de sécurité VPC. Donc, si vousavez associé le groupe de sécurité VPC à un cluster, les règles d'accès au cluster entrant dans le groupede sécurité VPC mis à jour s'appliquent immédiatement.
Vous pouvez créer et modifier des groupes de sécurité VPC dans la console https://console.aws.amazon.com/vpc/. Vous pouvez également gérer des groupes de sécurité VPC parprogrammation à l'aide de l'AWS CLI, la ligne de commande AWS EC2 et les outils AWS pour WindowsPowerShell. Pour plus d'informations sur l'utilisation des groupes de sécurité VPC, consultez Groupes desécurité pour votre VPC dans le manuel Amazon VPC Guide de l'utilisateur.
Groupes de sous-réseaux de cluster Amazon RedshiftPrésentationVous créez un groupe de sous-réseaux de cluster si vous mettez en service votre cluster dans votre VirtualPrivate Cloud (VPC). Pour plus d'informations sur le VPC, consultez la page des détails du produit AmazonVirtual Private Cloud (Amazon VPC).
Votre VPC peut disposer d'un ou de plusieurs sous-réseaux, sous-ensemble d'adresses IP au sein devotre VPC, qui vous permettent de regrouper vos ressources en fonction de vos besoins en sécurité et en
Version de l'API 2012-12-0140
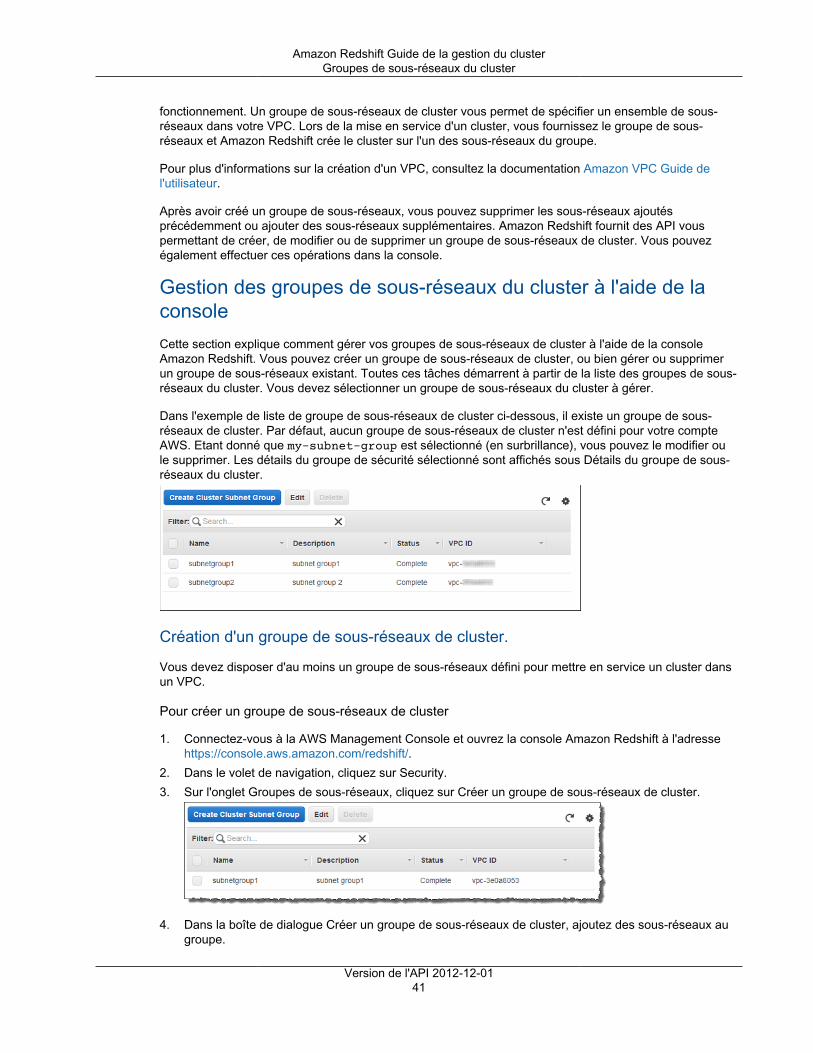
Amazon Redshift Guide de la gestion du clusterGroupes de sous-réseaux du cluster
fonctionnement. Un groupe de sous-réseaux de cluster vous permet de spécifier un ensemble de sous-réseaux dans votre VPC. Lors de la mise en service d'un cluster, vous fournissez le groupe de sous-réseaux et Amazon Redshift crée le cluster sur l'un des sous-réseaux du groupe.
Pour plus d'informations sur la création d'un VPC, consultez la documentation Amazon VPC Guide del'utilisateur.
Après avoir créé un groupe de sous-réseaux, vous pouvez supprimer les sous-réseaux ajoutésprécédemment ou ajouter des sous-réseaux supplémentaires. Amazon Redshift fournit des API vouspermettant de créer, de modifier ou de supprimer un groupe de sous-réseaux de cluster. Vous pouvezégalement effectuer ces opérations dans la console.
Gestion des groupes de sous-réseaux du cluster à l'aide de laconsoleCette section explique comment gérer vos groupes de sous-réseaux de cluster à l'aide de la consoleAmazon Redshift. Vous pouvez créer un groupe de sous-réseaux de cluster, ou bien gérer ou supprimerun groupe de sous-réseaux existant. Toutes ces tâches démarrent à partir de la liste des groupes de sous-réseaux du cluster. Vous devez sélectionner un groupe de sous-réseaux du cluster à gérer.
Dans l'exemple de liste de groupe de sous-réseaux de cluster ci-dessous, il existe un groupe de sous-réseaux de cluster. Par défaut, aucun groupe de sous-réseaux de cluster n'est défini pour votre compteAWS. Etant donné que my-subnet-group est sélectionné (en surbrillance), vous pouvez le modifier oule supprimer. Les détails du groupe de sécurité sélectionné sont affichés sous Détails du groupe de sous-réseaux du cluster.
Création d'un groupe de sous-réseaux de cluster.
Vous devez disposer d'au moins un groupe de sous-réseaux défini pour mettre en service un cluster dansun VPC.
Pour créer un groupe de sous-réseaux de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sous-réseaux, cliquez sur Créer un groupe de sous-réseaux de cluster.
4. Dans la boîte de dialogue Créer un groupe de sous-réseaux de cluster, ajoutez des sous-réseaux augroupe.
Version de l'API 2012-12-0141
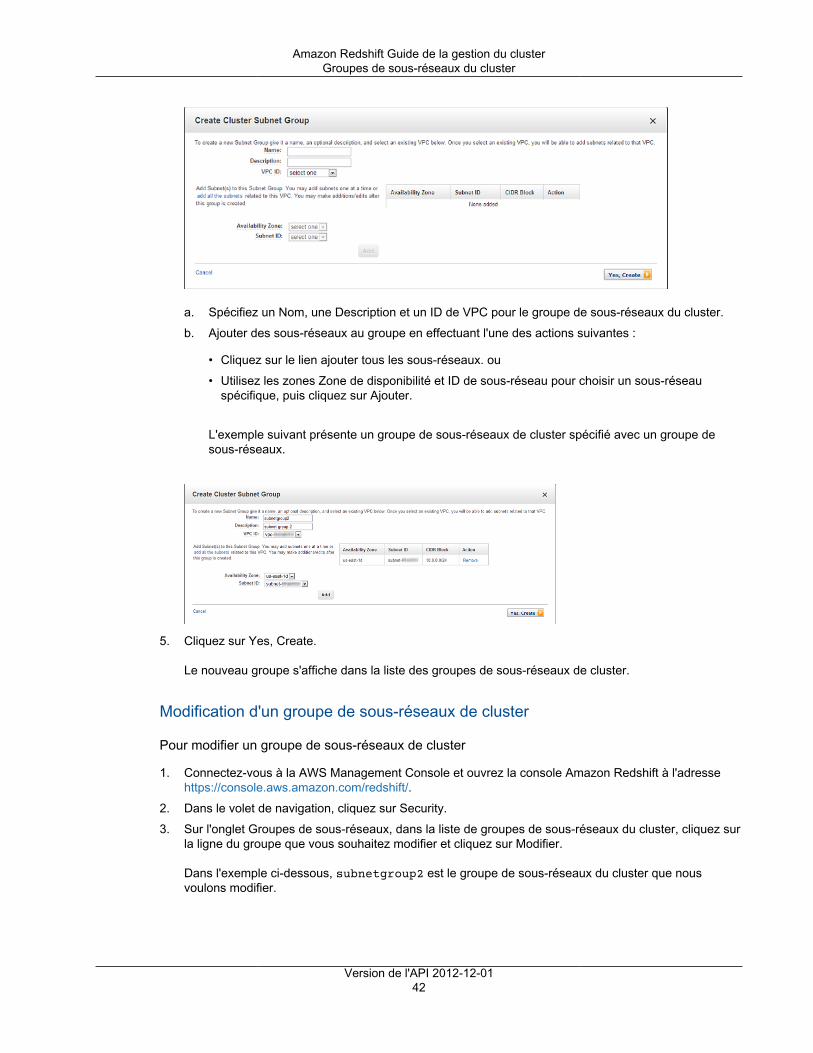
Amazon Redshift Guide de la gestion du clusterGroupes de sous-réseaux du cluster
a. Spécifiez un Nom, une Description et un ID de VPC pour le groupe de sous-réseaux du cluster.b. Ajouter des sous-réseaux au groupe en effectuant l'une des actions suivantes :
• Cliquez sur le lien ajouter tous les sous-réseaux. ou• Utilisez les zones Zone de disponibilité et ID de sous-réseau pour choisir un sous-réseau
spécifique, puis cliquez sur Ajouter.
L'exemple suivant présente un groupe de sous-réseaux de cluster spécifié avec un groupe desous-réseaux.
5. Cliquez sur Yes, Create.
Le nouveau groupe s'affiche dans la liste des groupes de sous-réseaux de cluster.
Modification d'un groupe de sous-réseaux de cluster
Pour modifier un groupe de sous-réseaux de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sous-réseaux, dans la liste de groupes de sous-réseaux du cluster, cliquez sur
la ligne du groupe que vous souhaitez modifier et cliquez sur Modifier.
Dans l'exemple ci-dessous, subnetgroup2 est le groupe de sous-réseaux du cluster que nousvoulons modifier.
Version de l'API 2012-12-0142
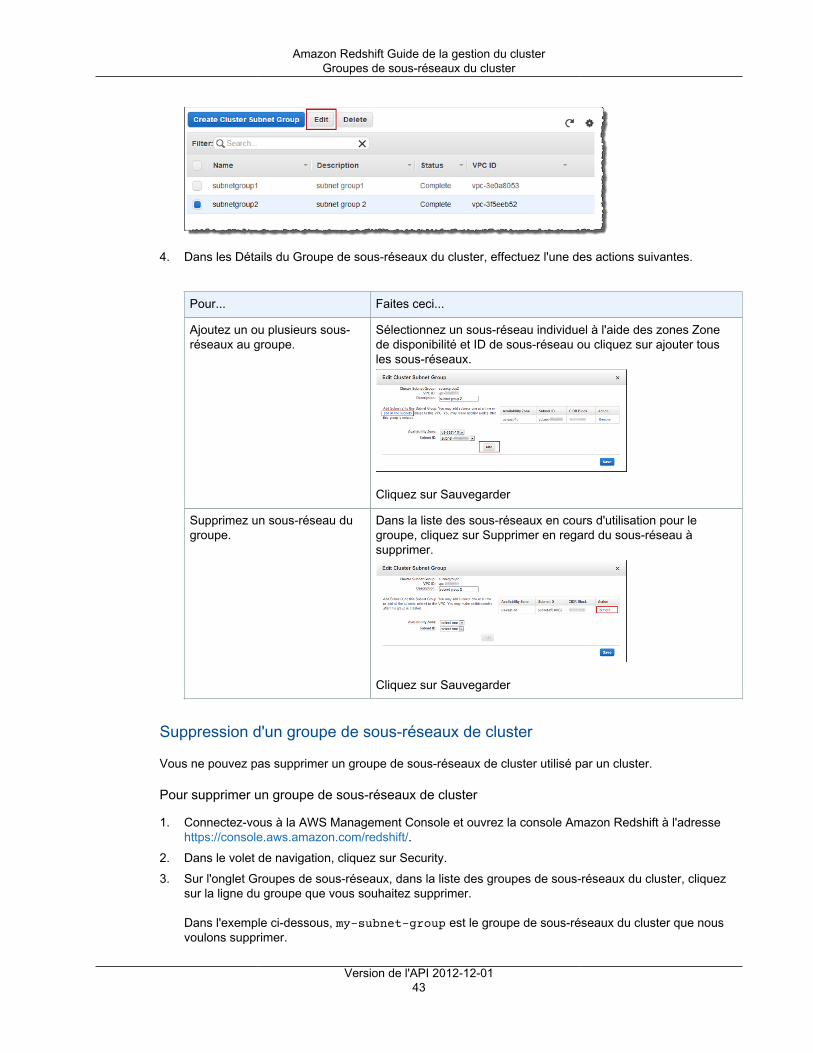
Amazon Redshift Guide de la gestion du clusterGroupes de sous-réseaux du cluster
4. Dans les Détails du Groupe de sous-réseaux du cluster, effectuez l'une des actions suivantes.
Pour... Faites ceci...
Ajoutez un ou plusieurs sous-réseaux au groupe.
Sélectionnez un sous-réseau individuel à l'aide des zones Zonede disponibilité et ID de sous-réseau ou cliquez sur ajouter tousles sous-réseaux.
Cliquez sur Sauvegarder
Supprimez un sous-réseau dugroupe.
Dans la liste des sous-réseaux en cours d'utilisation pour legroupe, cliquez sur Supprimer en regard du sous-réseau àsupprimer.
Cliquez sur Sauvegarder
Suppression d'un groupe de sous-réseaux de cluster
Vous ne pouvez pas supprimer un groupe de sous-réseaux de cluster utilisé par un cluster.
Pour supprimer un groupe de sous-réseaux de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sous-réseaux, dans la liste des groupes de sous-réseaux du cluster, cliquez
sur la ligne du groupe que vous souhaitez supprimer.
Dans l'exemple ci-dessous, my-subnet-group est le groupe de sous-réseaux du cluster que nousvoulons supprimer.
Version de l'API 2012-12-0143
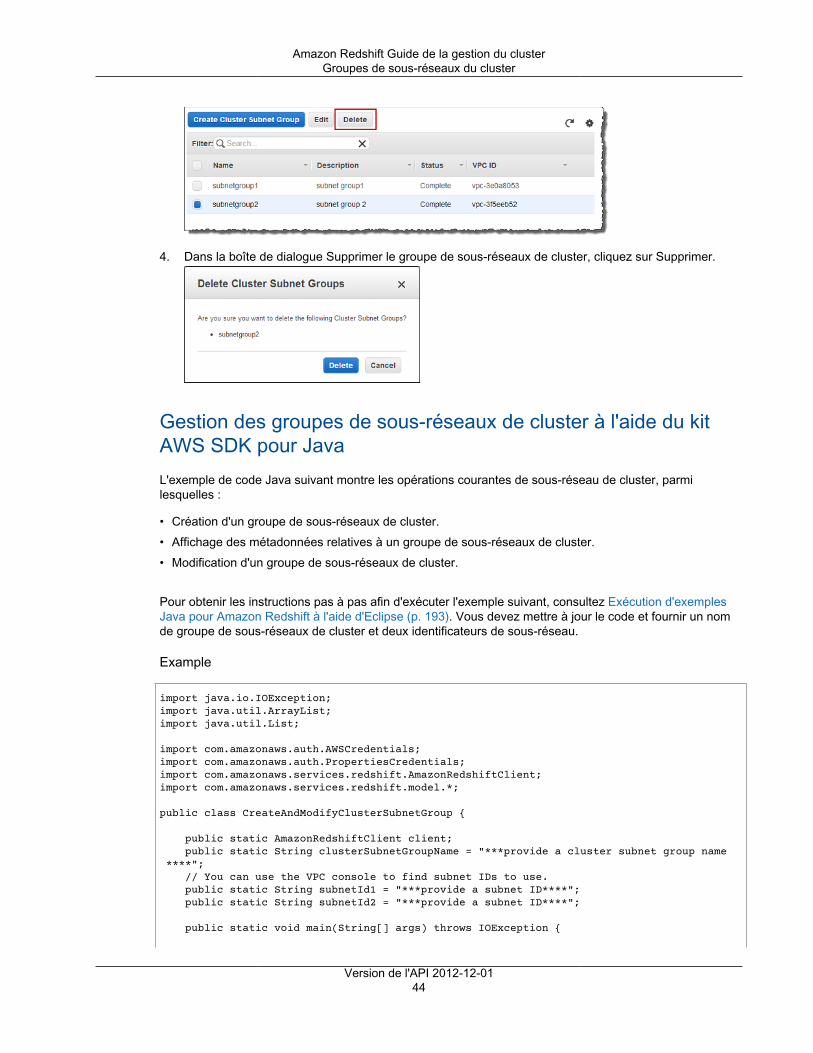
Amazon Redshift Guide de la gestion du clusterGroupes de sous-réseaux du cluster
4. Dans la boîte de dialogue Supprimer le groupe de sous-réseaux de cluster, cliquez sur Supprimer.
Gestion des groupes de sous-réseaux de cluster à l'aide du kitAWS SDK pour JavaL'exemple de code Java suivant montre les opérations courantes de sous-réseau de cluster, parmilesquelles :
• Création d'un groupe de sous-réseaux de cluster.• Affichage des métadonnées relatives à un groupe de sous-réseaux de cluster.• Modification d'un groupe de sous-réseaux de cluster.
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193). Vous devez mettre à jour le code et fournir un nomde groupe de sous-réseaux de cluster et deux identificateurs de sous-réseau.
Example
import java.io.IOException;import java.util.ArrayList;import java.util.List;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;import com.amazonaws.services.redshift.model.*;
public class CreateAndModifyClusterSubnetGroup {
public static AmazonRedshiftClient client; public static String clusterSubnetGroupName = "***provide a cluster subnet group name ****"; // You can use the VPC console to find subnet IDs to use. public static String subnetId1 = "***provide a subnet ID****"; public static String subnetId2 = "***provide a subnet ID****"; public static void main(String[] args) throws IOException {
Version de l'API 2012-12-0144

Amazon Redshift Guide de la gestion du clusterGroupes de sous-réseaux du cluster
AWSCredentials credentials = new PropertiesCredentials( CreateAndModifyClusterSubnetGroup.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { createClusterSubnetGroup(); describeClusterSubnetGroups(); modifyClusterSubnetGroup(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage()); } }
private static void createClusterSubnetGroup() { CreateClusterSubnetGroupRequest request = new CreateClusterSubnetGroupRequest() .withClusterSubnetGroupName(clusterSubnetGroupName) .withDescription("my cluster subnet group") .withSubnetIds(subnetId1); client.createClusterSubnetGroup(request); System.out.println("Created cluster subnet group: " + clusterSubnetGroupName); } private static void modifyClusterSubnetGroup() { // Get existing subnet list. DescribeClusterSubnetGroupsRequest request1 = new DescribeClusterSubnetGroupsRequest() .withClusterSubnetGroupName(clusterSubnetGroupName); DescribeClusterSubnetGroupsResult result1 = client.describeClusterSubnetGroups(request1); List<String> subnetNames = new ArrayList<String>(); // We can work with just the first group returned since we requested info about one group. for (Subnet subnet : result1.getClusterSubnetGroups().get(0).getSubnets()) { subnetNames.add(subnet.getSubnetIdentifier()); } // Add to existing subnet list. subnetNames.add(subnetId2);
ModifyClusterSubnetGroupRequest request = new ModifyClusterSubnetGroupRequest() .withClusterSubnetGroupName(clusterSubnetGroupName) .withSubnetIds(subnetNames); ClusterSubnetGroup result2 = client.modifyClusterSubnetGroup(request); System.out.println("\nSubnet group modified."); printResultSubnetGroup(result2); }
private static void describeClusterSubnetGroups() { DescribeClusterSubnetGroupsRequest request = new DescribeClusterSubnetGroupsRequest() .withClusterSubnetGroupName(clusterSubnetGroupName); DescribeClusterSubnetGroupsResult result = client.describeClusterSubnetGroups(request); printResultSubnetGroups(result); }
private static void printResultSubnetGroups(DescribeClusterSubnetGroupsResult result) { if (result == null) { System.out.println("\nDescribe cluster subnet groups result is null."); return; }
Version de l'API 2012-12-0145

Amazon Redshift Guide de la gestion du clusterSélection du suivi de maintenance des clusters
for (ClusterSubnetGroup group : result.getClusterSubnetGroups()) { printResultSubnetGroup(group); } } private static void printResultSubnetGroup(ClusterSubnetGroup group) { System.out.format("Name: %s, Description: %s\n", group.getClusterSubnetGroupName(), group.getDescription()); for (Subnet subnet : group.getSubnets()) { System.out.format(" Subnet: %s, %s, %s\n", subnet.getSubnetIdentifier(), subnet.getSubnetAvailabilityZone().getName(), subnet.getSubnetStatus()); } }}
Gérer les groupes de sous-réseaux de cluster à l'aide del'interface de ligne de commande et de l'API Amazon RedshiftVous pouvez utiliser les opérations de la ligne de commande Amazon Redshift suivantes pour gérer lesgroupes de sous-réseaux du cluster.
• create-cluster-subnet-group• delete-cluster-subnet-group• describe-cluster-subnet-groups• modify-cluster-subnet-group
Vous pouvez utiliser les API Amazon Redshift suivantes pour gérer les groupes de sous-réseaux ducluster.
• CreateClusterSubnetGroup• DeleteClusterSubnetGroup• DescribeClusterSubnetGroups• ModifyClusterSubnetGroup
Sélection du suivi de maintenance des clustersLorsqu'une nouvelle version d'Amazon Redshift devient disponible, votre cluster est mis à jour pendantson créneau de maintenance. Vous pouvez contrôler si votre cluster est mis à jour avec la dernière versionapprouvée ou la précédente.
Pour cela, vous devez définir la valeur de suivi de maintenance pour le cluster. Les deux valeurs possiblessont les suivantes :
• Current (Actuelle) – Le cluster est mis à jour avec la toute dernière version approuvée d'AmazonRedshift.
• Trailing (Précédente) – Le cluster est mis à jour avec la version approuvée d'Amazon Redshift avant latoute dernière.
Par exemple, si votre cluster exécute la version 1.0.2762 et que vous définissez la valeur de suivi demaintenance sur Current (Actuelle), votre cluster est mis à jour avec la version 1.0.3072 (la version
Version de l'API 2012-12-0146

Amazon Redshift Guide de la gestion du clusterDéfinition du suivi de maintenance
pour un cluster avec la console
approuvée suivante) au cours du prochain créneau de maintenance. Si la valeur du suivi de maintenancede votre cluster est définie sur Trailing (Précédente), votre cluster sera mis à jour uniquement une fois qu'ily aura une version postérieure à 1.0.3072.
Changement de suivi de maintenance
Le changement de suivi pour un cluster est généralement une décision unique et vous devez faire preuvede prudence lorsque vous procédez à cette modification. Si vous passez du suivi de maintenance Trailing(Précédente) à Current (Actuelle), nous appliquerons le suivi Current (Actuelle) pour le cluster lors duprochain créneau de maintenance. Toutefois, si vous faites passer le suivi de maintenance du clusterde Current (Actuelle) à Trailing (Précédente), nous ne pourrons pas mettre en place le suivi Trailing(Précédente) tant que la version Trailing (Précédente) n'aura pas rattrapé la version de cluster qui était lasienne lorsque vous avez effectué la modification.
Utilisation des suivis de maintenance et des opérations de restauration ou de redimensionnement
Lorsque vous prenez un instantané, celui-ci hérite du paramètre de suivi de maintenance du cluster. Avecle temps, il est possible que l'instantané ait un suivi de maintenance différent de celui du cluster ayant servide source pour l'instantané. Par exemple, supposons que vous preniez un instantané d'un cluster mis àjour avec la version actuelle et que vous changiez le cluster source afin qu'il soit mis à jour avec la versionprécédente. Dans ce cas, l'instantané et le cluster source ont des suivis de maintenance différents. Lorsquevous restaurerez à partir de l'instantané sur un nouveau cluster, ce dernier aura un suivi de maintenancehérité du cluster source. Vous pourrez modifier le suivi de maintenance après avoir terminé l'opération derestauration.
Redimensionnement d'un cluster (p. 9) n'a aucun impact sur le suivi de maintenance du cluster.
Définition du suivi de maintenance pour un clusteravec la consoleVous pouvez définir le suivi de maintenance pour un cluster avec la console.
Pour définir un suivi de maintenance pour un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Choisissez le cluster à modifier.3. Choisissez Advanced Settings (Paramètres avancés).4. Choisissez Current (Actuelle) ou Trailing (Précédente).5. Sélectionnez Modify.
Version de l'API 2012-12-0147
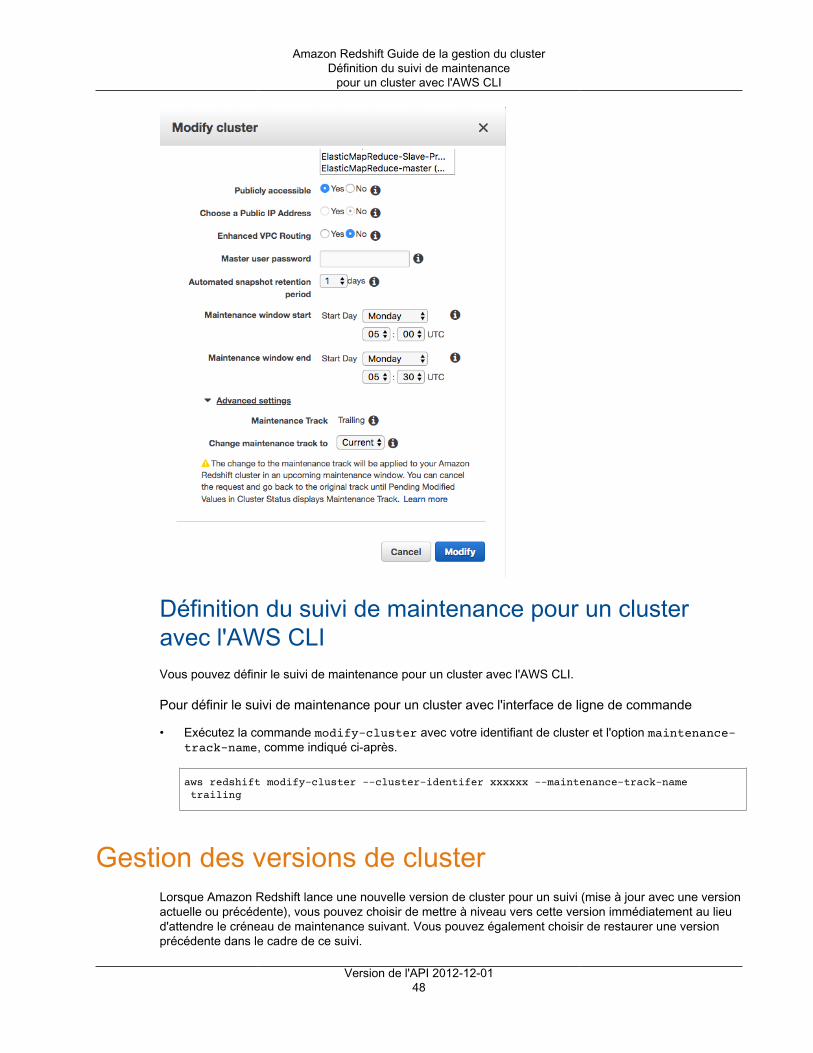
Amazon Redshift Guide de la gestion du clusterDéfinition du suivi de maintenance
pour un cluster avec l'AWS CLI
Définition du suivi de maintenance pour un clusteravec l'AWS CLIVous pouvez définir le suivi de maintenance pour un cluster avec l'AWS CLI.
Pour définir le suivi de maintenance pour un cluster avec l'interface de ligne de commande
• Exécutez la commande modify-cluster avec votre identifiant de cluster et l'option maintenance-track-name, comme indiqué ci-après.
aws redshift modify-cluster --cluster-identifer xxxxxx --maintenance-track-name trailing
Gestion des versions de clusterLorsque Amazon Redshift lance une nouvelle version de cluster pour un suivi (mise à jour avec une versionactuelle ou précédente), vous pouvez choisir de mettre à niveau vers cette version immédiatement au lieud'attendre le créneau de maintenance suivant. Vous pouvez également choisir de restaurer une versionprécédente dans le cadre de ce suivi.
Version de l'API 2012-12-0148
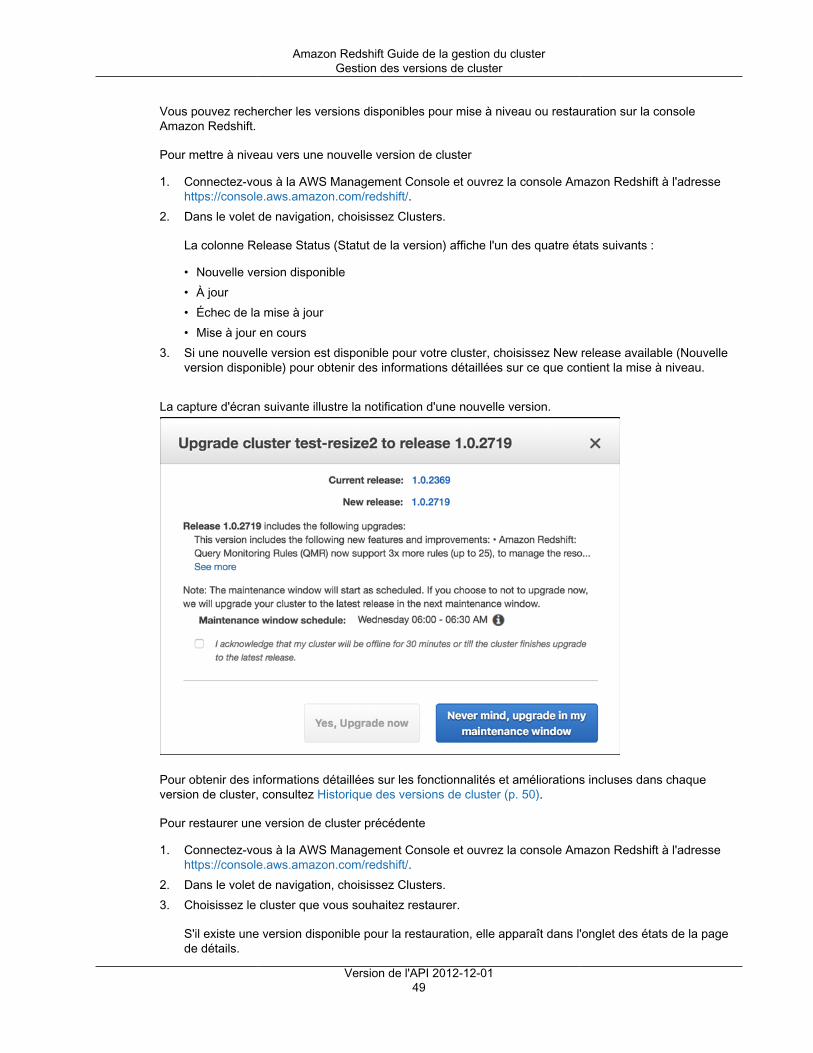
Amazon Redshift Guide de la gestion du clusterGestion des versions de cluster
Vous pouvez rechercher les versions disponibles pour mise à niveau ou restauration sur la consoleAmazon Redshift.
Pour mettre à niveau vers une nouvelle version de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.
La colonne Release Status (Statut de la version) affiche l'un des quatre états suivants :
• Nouvelle version disponible• À jour• Échec de la mise à jour• Mise à jour en cours
3. Si une nouvelle version est disponible pour votre cluster, choisissez New release available (Nouvelleversion disponible) pour obtenir des informations détaillées sur ce que contient la mise à niveau.
La capture d'écran suivante illustre la notification d'une nouvelle version.
Pour obtenir des informations détaillées sur les fonctionnalités et améliorations incluses dans chaqueversion de cluster, consultez Historique des versions de cluster (p. 50).
Pour restaurer une version de cluster précédente
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Choisissez le cluster que vous souhaitez restaurer.
S'il existe une version disponible pour la restauration, elle apparaît dans l'onglet des états de la pagede détails.
Version de l'API 2012-12-0149
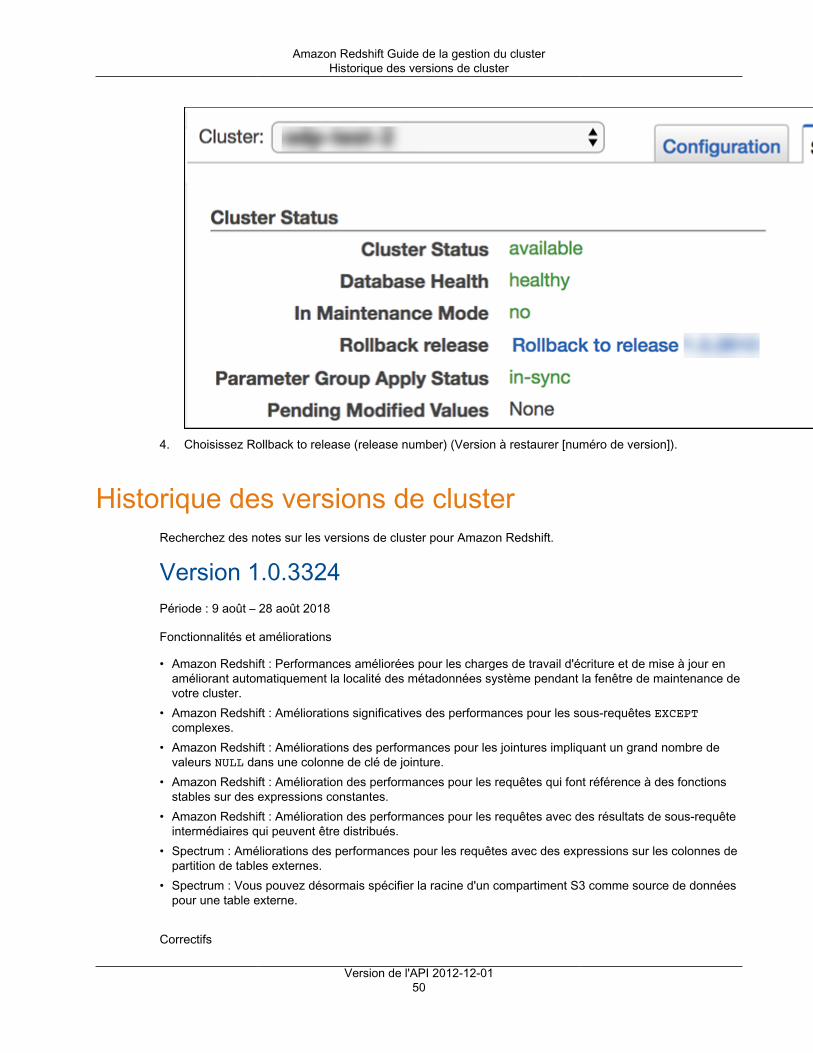
Amazon Redshift Guide de la gestion du clusterHistorique des versions de cluster
4. Choisissez Rollback to release (release number) (Version à restaurer [numéro de version]).
Historique des versions de clusterRecherchez des notes sur les versions de cluster pour Amazon Redshift.
Version 1.0.3324Période : 9 août – 28 août 2018
Fonctionnalités et améliorations
• Amazon Redshift : Performances améliorées pour les charges de travail d'écriture et de mise à jour enaméliorant automatiquement la localité des métadonnées système pendant la fenêtre de maintenance devotre cluster.
• Amazon Redshift : Améliorations significatives des performances pour les sous-requêtes EXCEPTcomplexes.
• Amazon Redshift : Améliorations des performances pour les jointures impliquant un grand nombre devaleurs NULL dans une colonne de clé de jointure.
• Amazon Redshift : Amélioration des performances pour les requêtes qui font référence à des fonctionsstables sur des expressions constantes.
• Amazon Redshift : Amélioration des performances pour les requêtes avec des résultats de sous-requêteintermédiaires qui peuvent être distribués.
• Spectrum : Améliorations des performances pour les requêtes avec des expressions sur les colonnes departition de tables externes.
• Spectrum : Vous pouvez désormais spécifier la racine d'un compartiment S3 comme source de donnéespour une table externe.
Correctifs
Version de l'API 2012-12-0150
Amazon Redshift Guide de la gestion du clusterVersion 1.0.3025
• Résolution d'une erreur d'autorisation lorsque la définition d'une vue standard fait référence à une vue àliaison tardive.
• Résolution d'une erreur de variable non trouvée dans des listes de cibles de sous-plan qui affectaitcertaines requêtes.
Version 1.0.3025Période : 19 juillet – 8 août 2018
Fonctionnalités et améliorations
• Amazon Redshift : les requêtes peuvent désormais faire référence à un alias de colonne avec la mêmerequête juste après sa déclaration, ce qui améliore la lisibilité des requêtes SQL complexes.
• Amazon Redshift : les nœuds réservés DC1 peuvent désormais être migrés gratuitement vers DC2 sansaucune modification de la durée.
• Amazon Redshift : une nouvelle métrique Amazon CloudWatch suit le nombre actuel de requêtes enattente par file d'attente de gestion de la charge de travail (WLM).
• Amazon Redshift : améliorations importantes des performances pour les insertions d'une seule lignedans une table.
• Amazon Redshift : améliorations importantes des performances pour les requêtes intervenant sur lescolonnes CHAR et VARCHAR.
• Amazon Redshift : amélioration des performances pour les jointures de hachage ayant des dimensionsde filtrage dans les jointures internes ou les jointures externes droites.
• Amazon Redshift : amélioration des performances pour les requêtes qui font référence à des fonctionsstables avec des expressions constantes.
• Redshift Spectrum : extension de la vue du catalogue SVV_COLUMNS pour fournir des informations surles colonnes des vues à liaison tardive.
Correctifs
• Gestion de la mémoire améliorée pour les extractions préalables pour les analyses ou les agrégations detables volumineuses.
• Comportement amélioré pour les requêtes longues sur les tables externes Redshift Spectrum avec ungrand nombre de petits fichiers.
Versions 1.0.2762, 1.0.2819, 10.2842Période : 27 juin 2018 – 18 juillet 2018
Fonctionnalités et améliorations
• Amazon Redshift : traitement amélioré des requêtes de lecture courtes, qui réduit les conflits et améliorel'utilisation du système.
• Amazon Redshift : amélioration sensible de la fonctionnalité de redimensionnement des clustersRedshift, vous permettant ainsi de créer des tables temporaires au cours de l'opération deredimensionnement.
• Amazon Redshift : nouvelles améliorations du cache de code compilé afin d'augmenter les performancesglobales des requêtes en réduisant le nombre de segments à recompiler.
• Amazon Redshift : améliorations des performances de l'opération COPY lors de l'ingestion de données àpartir des formats de fichier Parquet et ORC.
Version de l'API 2012-12-0151

Amazon Redshift Guide de la gestion du clusterVersions 1.0.2524, 1.0.2557, 1.02610, 1.0.2679, 1.02719
• Redshift Spectrum : vous pouvez désormais interroger les colonnes externes pendant l'opération deredimensionnement.
• Redshift Spectrum : améliorations des performances pour les requêtes Redshift Spectrum avecagrégations sur les colonnes de partition.
Correctifs
• Résolution d'un problème lors de la réaffectation d'une requête provenant d'une courte file d'attente derequête à une file d'attente d'utilisateur.
• Résolution d'un problème lié au transfert des prédicats lors de la réécriture d'une requête.• Résolution d'un problème lié à la fonction DATE_TRUNC dans les fuseaux horaires DST.• Résolution d'un problème qui se produit lorsque la fonction LOWER est évaluée sur des séquences de
caractères multioctets spécifiques.• Résolution d'un problème de dérivation de type de données dans une instruction CREATE TABLE AS
(CTAS).• Amélioration des messages d'erreur générés lorsque le nombre de tables externes dépasse le nombre
total maximal de colonnes de table Redshift.
Versions 1.0.2524, 1.0.2557, 1.02610, 1.0.2679,1.02719Période : 7 juin 2018 – 5 juillet 2018
Fonctionnalités et améliorations
• Amazon Redshift : Les règles de surveillance de requête (QMR) prennent désormais en charge troisfois plus de règles (jusqu'à 25). Vous pouvez utiliser les règles de surveillance de requête pour gérerl'allocation des ressources de votre cluster Amazon Redshift en fonction des limites d'exécution desrequêtes pour les files d'attente WLM, et effectuer automatiquement une action lorsqu'une requêtedépasse ces limites.
• Amazon Redshift : une nouvelle métrique Amazon CloudWatch, QueryRuntimeBreakdown, estdésormais disponible. Vous pouvez utiliser cette métrique pour obtenir des détails sur les différentesétapes d'exécution des requêtes. Pour plus d'informations, consultez Données de performance AmazonRedshift (p. 260).
• Redshift Spectrum : vous pouvez désormais renommer les colonnes externes.• Redshift Spectrum : vous pouvez désormais spécifier le type de compression des tables externes.• Amazon Redshift : amélioration des performances des jointures par hachage lorsque les requêtes
impliquent des jointures de grande taille. Certaines requêtes complexes sont désormais exécutées troisfois plus vite.
• Amazon Redshift : améliorations sensibles de la commande VACUUM DELETE afin qu'elle libère del'espace disque supplémentaire et soit plus performante.
• Amazon Redshift : la matérialisation tardive prend désormais en charge les opérations DELETE etUPDATE et améliore ainsi les performances de requête.
• Amazon Redshift : amélioration des performances des opérations de redimensionnement des clusters.• Redshift Spectrum : prise en charge d'un nombre accru d'opérations d'ajout et de suppression sur une
même table Redshift Spectrum externe.• Redshift Spectrum : efficacité accrue du filtrage des prédicats lors de l'utilisation de la fonctionDATE_TRUNC pour les colonnes d'horodatage.
Correctifs
Version de l'API 2012-12-0152

Amazon Redshift Guide de la gestion du clusterVersion 1.0.2294, 1.0.2369
• Résolution d'un problème lié aux requêtes basées sur certaines vues contenant des constantes.• Résolution d'un problème lors de l'accès à certaines vues à liaison tardive lorsqu'un schéma a été
renommé.• Résolution d'un problème lié à un type de jointure non pris en charge.• Résolution d'un problème lors du saut de requête dans la gestion de la charge de travail Amazon
Redshift.• Résolution d'un problème lors de la compilation de certaines requêtes de très grande taille.• Résolution d'un problème de traitement des espaces dans la chaîne de format de la fonction TO_DATE.• Résolution d'un problème lors de l'annulation de certaines requêtes.• Résolution d'un problème lors de la jointure sur une colonne de partition de type CHAR ou DECIMAL.
Version 1.0.2294, 1.0.2369Période : 17 mai 2018 – 14 juin 2018
Fonctionnalités et améliorations
• Amazon Redshift : la commande COPY accepte désormais le chargement de données dans AmazonRedshift aux formats en colonnes Parquet et ORC.
• Amazon Redshift : l'accélération des requêtes courtes détermine désormais automatiquement etdynamiquement la durée d'exécution maximale des requêtes courtes en fonction de votre charge detravail afin d'améliorer encore les performances de requête.
• Redshift Spectrum : ALTER TABLE ADD/DROP COLUMN pour les tables externes est désormais pris encharge en utilisant les appels JDBC standard.
• Redshift Spectrum : Amazon Redshift peut désormais envoyer la fonction de chaîne LENGTH() àSpectrum et améliorer ainsi les performances.
• Amazon Redshift : améliorations sensibles de l'efficacité du cache de code compilé afin d'augmenter lesperformances globales des requêtes en réduisant le nombre de segments à recompiler.
• Amazon Redshift : amélioration des performances de certaines requêtes UNION ALL.• Amazon Redshift : amélioration des performances de la couche de communication lors de la gestion des
paquets réseau envoyés dans le désordre.
Correctifs
• Résolution d'un problème lors de la génération de valeurs NULL pour certaines requêtes.
Version 1.0.2058Période : 19 avril 2018 – 8 mai 2018
Fonctionnalités et améliorations
• Surveillance des améliorations des fonctionnalités et des performances – les métriques AmazonCloudWatch pour Amazon Redshift fournissent des informations détaillées sur l'état et les performancesde votre cluster. Vous pouvez désormais utiliser avec Amazon Redshift les métriques Débit de requête etLatence de requête qui ont été ajoutées.
• Les performances de la console concernant les détails d'exécution du plan de requête ont étésensiblement améliorées – Pour plus d'informations, consultez Données de performance AmazonRedshift (p. 260).
• Amazon Redshift : amélioration des performances pour les requêtes d'agrégation.
Version de l'API 2012-12-0153

Amazon Redshift Guide de la gestion du clusterVersion 1.0.2044
• Amazon Redshift : ajout de la prise en charge de la fermeture des connexions client si keepalive n'a pasété reconnu.
• Redshift Spectrum : prise en charge d'un nombre accru d'opérations d'ajout et de suppression sur unemême table Redshift Spectrum externe.
• Redshift Spectrum : efficacité accrue du filtrage des prédicats lors de l'utilisation de la fonctionDATE_TRUNC pour les colonnes d'horodatage.
Correctifs
• Résolution d'un problème au cours de l'optimisation de certaines requêtes complexes ayant une clauseEXISTS.
• Résolution d'une erreur d'autorisation lorsque certaines vues à liaison tardive sont imbriquées dans desvues standard.
• Résolution d'un problème lors de la création de certaines vues à liaison tardive qui spécifient WITH NOSCHEMA BINDING lorsque la définition de vue sous-jacente a une clause WITH.
• Résolution d'un problème qui se produit lors de la dérivation des types de données des colonnes decertaines instructions CREATE TABLE AS SELECT impliquant des requêtes UNION ALL.
• Résolution d'un problème Redshift Spectrum lié à DROP TABLE IF EXISTS lorsque la table estinexistante.
Version 1.0.2044Période couverte : 16 mars 2018 – 18 avril 2018
Fonctionnalités et améliorations
• Nombre de tables que vous pouvez créer porté à 20 000 pour les types de clusters de type8xlarge – vous disposez désormais d'une granularité et d'un contrôle supérieurs pour les données avecdeux fois plus de tables.
• Nouveaux modèles de recherche pour REGEXP_INSTR et REGEXP_SUBSTR – vous pouvez désormaisrechercher une occurrence spécifique d'un modèle d'expression régulière et spécifier la sensibilité à lacasse.
• Amazon Redshift : les performances des fonctions de fenêtre ont été sensiblement améliorées pour lesclusters de type 8xlarge.
• Amazon Redshift : amélioration des performances des opérations de redimensionnement.• Redshift Spectrum : désormais disponible dans les régions Asie-Pacifique (Mumbai) et Amérique du Sud
(São Paulo).• Redshift Spectrum : prise en charge d'ALTER TABLE ADD/DROP COLUMN pour les tables externes.• Redshift Spectrum : nouvelle colonne ajoutée à stl_s3query, svl_s3query etsvl_s3query_summary contenant les formats de fichiers des tables externes.
Correctifs
• Résolution d'un problème lors de l'annulation de requêtes.• Résolution d'un problème lors de la suppression des tables temporaires.• Résolution d'un problème lors de la modification d'une table.
Versions 1.0.1792, 1.0.1793, 1.0.1808, 1.0.1865Période couverte : 22 février 2018 – 15 mars 2018
Version de l'API 2012-12-0154

Amazon Redshift Guide de la gestion du clusterVersions 1.0.1691 et 1.0.1703
Fonctionnalités et améliorations
• Amazon Redshift : ajout de la planification de l'heure de début afin d'améliorer le temps de réponse desrequêtes complexes décomposées en plusieurs sous-requêtes.
• Redshift Spectrum Vous pouvez désormais traiter les formats de fichiers JSON et ION scalaires pour lestables externes dans Amazon S3.
• Amazon Redshift : accélération des requêtes courtes : meilleure précision du classificateur ML pour lesrequêtes très sélectives.
• Amazon Redshift : amélioration de la durée d'exécution de la jointure par hachage.• Amazon Redshift : amélioration de la durée d'exécution des opérations vacuum delete sur les tables
DISTALL.• Redshift Spectrum : amélioration de la durée d'exécution des requêtes des tables externes composées
de plusieurs petits fichiers.• Redshift Spectrum : amélioration des performances d'interrogation de svv_external_tables etsvv_external_columns.
Correctifs
• Amélioration du traitement des prédicats booléens pendant les réécritures des requêtes.• Résolution d'un problème lié aux états incohérents des tables temporaires.• Correction d'une condition de concurrence entre les instructions drop et select.• Amélioration de la résilience pendant l'annulation de certaines requêtes avec des instructions préparées.• Amélioration de la résilience de certaines réécritures de requêtes.
Versions 1.0.1691 et 1.0.1703Période : 1 février 2018 – 23 février 2018
Fonctionnalités et améliorations
• Amazon Redshift : amélioration de la prise en charge des expressions régulières. REGEXP_INSTR() etREGEXP_SUBSTR() peuvent désormais émettre un appel msearch pour une occurrence spécifique d'unmodèle d'expression régulière et spécifier la sensibilité à la casse lors de la mise en correspondance d'unmodèle.
• Amazon Redshift : amélioration de la mise en cache des résultats pour prendre en charge les requêtesde curseur et les instructions préparées.
• Amazon Redshift : amélioration de l'accélération des requêtes courtes pour traiter une rafale de requêtescourtes.
• Amazon Redshift : ajout de la prise en charge de la création de chaînes de rôles IAM qui couvrent lescomptes.
• Redshift Spectrum : transmission à Spectrum des fonctions F_TIMESTAMP_PL_INTERVAL etT_CoalesceExpr, ainsi que des fonctions relatives à DATE.
Correctifs
• Corrections du calcul des délais d'expiration des très petits fichiers sur S3.• PSQL-c a été modifié afin de respecter le comportement de validation automatique pour TRUNCATE• Correction d'une erreur d'échec de compilation de requête.• Ajout de la prise en charge des noms de colonne en trois parties dans les vues à liaison tardive.• Correction des requêtes à prédicats booléens dans les expressions complexes.
Version de l'API 2012-12-0155

Amazon Redshift Guide de la gestion du clusterVersion 1.0.1636
• Redshift Spectrum : augmentation du parallélisme en réduisant les tailles de division.
Version 1.0.1636Période : 11 janvier 2018 – 25 janvier 2018
Fonctionnalités et améliorations
• Amazon Redshift : accélération des requêtes courtes élastiques, qui améliore la réactivité du systèmepour une rafale de requêtes courtes dans une charge de travail.
• Amazon Redshift : activation de la mise en cache des résultats pour les requêtes de lecture dans un blocde transaction.
• Redshift Spectrum : ajout de la prise en charge des colonnes DATE dans les fichiers Parquet et pourl'exécution de la commande CREATE EXTERNAL TABLE avec les colonnes DATE.
• Redshift Spectrum : ajout de la prise en charge de IF NOT EXISTS avec la commande ADDPARTITION.
• Amazon Redshift : certaines requêtes courtes sur les tables avec les attributs DISTSTYLE de KET ouALL s'exécutent désormais trois fois plus vite.
Correctifs
•• Correction d'une erreur d'assertion intermittente pendant le traitement de la requête. Le message
d'assertion se présente sous la forme p - id=380 not in rowsets list• Correction d'une fuite de mémoire lors du traitement des exceptions de certaines requêtes.• Les résultats incohérents entre CTAS et INSERT ont été résolus.
Version de l'API 2012-12-0156

Amazon Redshift Guide de la gestion du cluster
Routage VPC amélioré AmazonRedshift
Lorsque vous utilisez le routage VPC amélioré Amazon Redshift, Amazon Redshift force l'ensemble dutrafic COPY et UNLOAD entre votre cluster et vos référentiels de données via votre Amazon VPC. Vouspouvez maintenant utiliser les fonctionnalités VPC standard, telles que les groupes de sécurité VPC, leslistes de contrôle d'accès (ACL) réseau, les points de terminaison d'un VPC, les stratégies de point determinaison d'un VPC, les passerelles Internet et les serveurs de système de noms de domaine (DNS) pourgérer de près le flux de données entre votre cluster Amazon Redshift et d'autres ressources. Lorsque vousutilisez le routage VPC amélioré pour acheminer le trafic via votre VPC, vous pouvez également utiliser lesjournaux de flux VPC pour surveiller le trafic COPY et UNLOAD.
Si le routage VPC amélioré n'est pas activé, Amazon Redshift achemine le trafic via Internet, y compris letrafic vers d'autres services au sein du réseau AWS.
Important
Comme le routage VPC amélioré affecte la façon dont Amazon Redshift accède à d'autresressources, les commandes COPY et UNLOAD peuvent échouer, sauf si vous configurez votreVPC correctement. Vous devez créer spécifiquement un chemin d'accès réseau entre le VPC devotre cluster et vos ressources de données, comme décrit ci-après.
Lorsque vous exécutez une commande COPY ou UNLOAD sur un cluster dont le routage VPC amélioréest activé, votre VPC achemine le trafic à la ressource spécifiée à l'aide du chemin d'accès disponible leplus strict, ou le plus spécifique.
Par exemple, vous pouvez configurer les chemins suivants dans votre VPC :
• Points de terminaison d'un VPC – Pour le trafic vers un compartiment Amazon S3 dans la mêmerégion que celle de votre cluster, vous pouvez créer un point de terminaison d'un VPC pour diriger letrafic directement dans le compartiment. Lorsque vous utilisez des points de terminaison d'un VPC,vous pouvez lier une stratégie de point de terminaison pour gérer l'accès à Amazon S3. Pour plusd'informations sur l'utilisation des points de terminaison avec Amazon Redshift, consultez Utilisation despoints de terminaison d'un VPC (p. 58).
• Passerelle NAT – Pour vous connecter à un compartiment Amazon S3 dans une autre région ou à unautre service au sein du réseau AWS, ou pour accéder à une instance de l'hôte en dehors du réseauAWS, vous pouvez configurer une passerelle de traduction d'adresses réseau (NAT).
• Passerelle Internet – Pour vous connecter aux services AWS en dehors de votre VPC, vous pouvez lierune passerelle Internet à votre sous-réseau VPC. Pour utiliser une passerelle Internet, le cluster doitavoir une adresse IP publique afin que d'autres services puissent communiquer avec lui.
Pour plus d'informations, consultez Points de terminaison d'un VPC dans le Amazon VPC Guide del'utilisateur.
L'utilisation du routage VPC amélioré n'implique aucun coût supplémentaire. Des coûts supplémentaires detransfert de données seront peut-être appliqués pour certaines opérations, telles les opérations UNLOADvers Amazon S3 dans une autre région ou COPY depuis Amazon EMR ou SSH avec des adresses IPpubliques. Pour plus d'informations sur la tarification, consultez Tarification Amazon EC2.
Rubriques• Utilisation des points de terminaison d'un VPC (p. 58)• Activation du routage VPC amélioré (p. 58)
Version de l'API 2012-12-0157

Amazon Redshift Guide de la gestion du clusterUtilisation des points de terminaison d'un VPC
Utilisation des points de terminaison d'un VPCVous pouvez utiliser un point de terminaison d'un VPC pour créer une connexion gérée entre votrecluster Amazon Redshift dans un VPC et dans Amazon Simple Storage Service (Amazon S3). Lorsquevous procédez ainsi, le trafic COPY et UNLOAD entre votre cluster et vos données sur Amazon S3reste dans votre Amazon VPC. Vous pouvez lier une stratégie de point de terminaison à votre point determinaison pour gérer de plus près l'accès à vos données. Par exemple, vous pouvez ajouter une stratégieà votre point de terminaison d'un VPC qui autorise le déchargement des données uniquement vers uncompartiment Amazon S3 spécifique de votre compte.
Important
Actuellement, Amazon Redshift prend en charge les points de terminaison d'un VPC uniquementpour la connexion à Amazon S3. Si Amazon VPC ajoute la prise en charge des autres servicesAWS pour utiliser les points de terminaison d'un VPC, Amazon Redshift prend égalementen charge ces connexions de points de terminaison d'un VPC. Pour que vous puissiez vousconnecter à un compartiment Amazon S3 à l'aide du point de terminaison d'un VPC, le clusterAmazon Redshift et le compartiment Amazon S3 auquel il se connecte doivent être dans la mêmerégion.
Pour utiliser les points de terminaison d'un VPC, créez un point de terminaison d'un VPC pour le VPC danslequel votre cluster se trouve, puis activez le routage VPC amélioré pour votre cluster. Vous pouvez activerle routage VPC amélioré lorsque vous créez votre cluster dans un VPC, ou vous pouvez modifier un clusterdans un VPC pour utiliser le routage VPC amélioré.
Un point de terminaison d'un VPC utilise des tables de routage pour contrôler l'acheminement du traficentre un cluster dans le VPC et dans Amazon S3. Tous les clusters des sous-réseaux associés aux tablesde routage spécifiées utilisent automatiquement ce point de terminaison pour accéder au service.
Votre VPC utilise le chemin le plus spécifique ou le plus restrictif, qui correspond au trafic de votre clusterpour déterminer comment acheminer le trafic. Par exemple, si vous disposez d'un chemin dans votretable de routage pour tout le trafic Internet (0.0.0.0/0) qui pointe vers une passerelle Internet et un pointde terminaison d'Amazon S3, le chemin du point de terminaison est prioritaire pour tout le trafic destiné àAmazon S3, car la plage d'adresses IP pour le service Amazon S3 est plus spécifique que 0.0.0.0/0. Danscet exemple, tout le reste du trafic Internet est acheminé vers votre passerelle Internet, y compris le traficdestiné aux compartiments Amazon S3 dans d'autres régions.
Pour plus d'informations sur la création de points de terminaison, consultez Points de terminaison d'un VPCdans le Amazon VPC Guide de l'utilisateur.
Vous utilisez les stratégies de point de terminaison pour contrôler l'accès depuis votre cluster auxcompartiments Amazon S3 qui contiennent vos fichiers de données. Par défaut, l'assistant Créer un pointde terminaison lie une stratégie de point de terminaison qui ne limite pas davantage l'accès d'un utilisateurou d'un service au sein du VPC. Pour un contrôle plus spécifique, vous pouvez éventuellement lier unestratégie de point de terminaison personnalisé. Pour plus d'informations, consultez Utilisation des stratégiesde point de terminaison.
Il n'y a pas de frais supplémentaires pour l'utilisation de points de terminaison. Des frais standardss'appliquent pour le transfert de données et l'utilisation de ressources. Pour plus d'informations sur latarification, consultez Tarification Amazon EC2.
Activation du routage VPC amélioréVous pouvez activer le routage VPC amélioré lorsque vous créez un cluster ou vous pouvez modifier uncluster existant pour activer le routage VPC amélioré.
Version de l'API 2012-12-0158

Amazon Redshift Guide de la gestion du clusterActivation du routage VPC amélioré
Pour utiliser le routage VPC amélioré, votre cluster doit répondre aux exigences et aux contraintessuivantes :
• Votre cluster doit se trouver dans un VPC.
Si vous liez un point de terminaison d'un VPC Amazon S3, votre cluster utilise le point de terminaisond'un VPC uniquement pour accéder aux compartiments Amazon S3 dans la même région. Pouraccéder aux compartiments dans une autre région (sans utiliser le point de terminaison d'un VPC) oupour accéder aux autres services AWS, rendez votre cluster accessible publiquement ou utilisez unepasserelle de traduction d'adresses réseau (NAT). Pour plus d'informations, consultez Création d'uncluster dans un VPC (p. 38).
• Vous devez activer la résolution DNS (Domain Name Service) dans votre VPC ou, si vous utilisez votrepropre serveur DNS, vous devez vous assurer que les demandes DNS à Amazon S3 sont résoluescorrectement en adresses IP gérées par AWS. Pour plus d'informations, consultez Utilisation de DNSavec votre VPC.
• Les noms d'hôte DNS doivent être activés dans votre VPC. Les noms d'hôte DNS sont activés pardéfaut.
• Vos stratégies de point de terminaison d'un VPC doivent autoriser l'accès aux compartiments Amazon S3utilisés avec les appels COPY, UNLOAD ou CREATE LIBRARY dans Amazon Redshift, y comprisl'accès à tous les fichiers manifeste impliqués. Pour la commande COPY depuis des hôtes distants,vos stratégies de point de terminaison doivent autoriser l'accès à chaque ordinateur hôte. Pour plusd'informations, consultez Autorisations IAM pour les commandes COPY, UNLOAD et CREATE LIBRARYdans le Amazon Redshift Database Developer Guide.
Pour créer un cluster dont le routage VPC amélioré est activé à l'aide d'AWS Management Console,choisissez oui pour l'option Routage VPC amélioré dans la section Configurez les options de mise enréseau de l'Assistant de lancement du cluster, comme illustré ci-après. Pour plus d'informations, consultezCréation d'un cluster (p. 17).
Pour modifier un cluster en vue d'activer le routage VPC amélioré à l'aide de la console, choisissezle cluster, puis choisissez Modifier le cluster et choisissez oui pour l'option Activation du routage VPCamélioré option dans la boîte de dialogue Modifier le cluster. Pour plus d'informations, consultezModification d'un cluster (p. 24).
Note
Lorsque vous modifiez un cluster afin d'activer le routage VPC amélioré, le cluster redémarreautomatiquement pour appliquer la modification.
Version de l'API 2012-12-0159
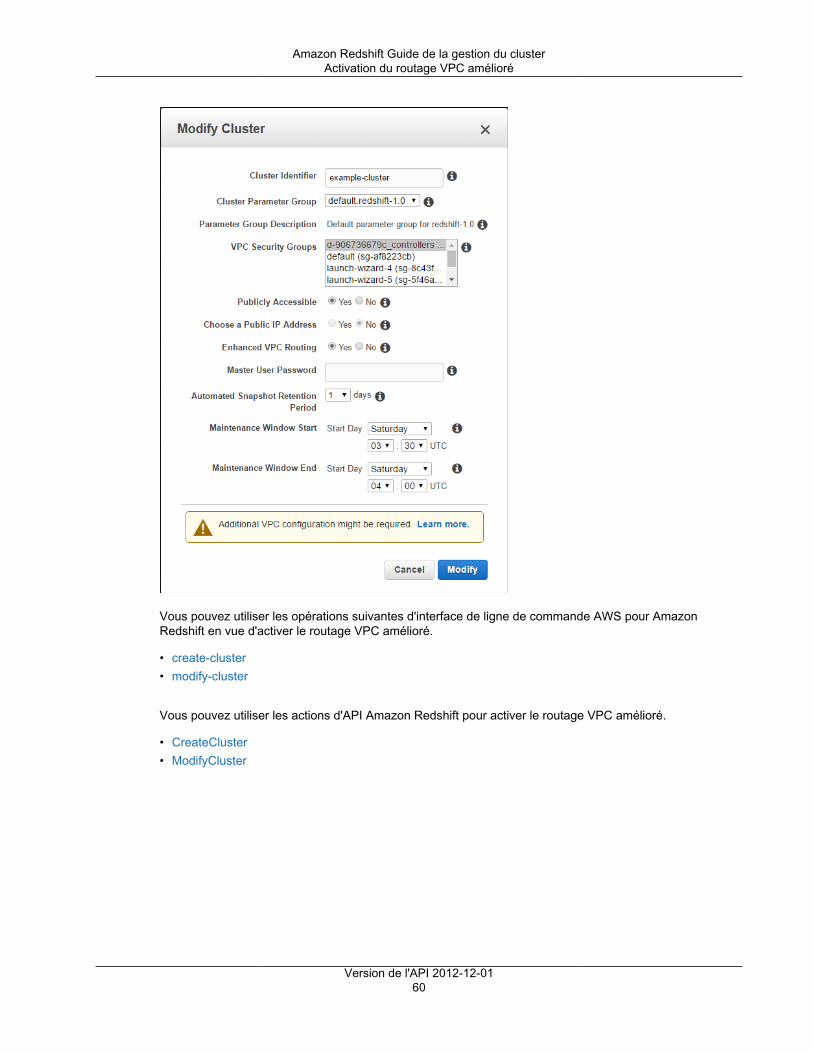
Amazon Redshift Guide de la gestion du clusterActivation du routage VPC amélioré
Vous pouvez utiliser les opérations suivantes d'interface de ligne de commande AWS pour AmazonRedshift en vue d'activer le routage VPC amélioré.
• create-cluster• modify-cluster
Vous pouvez utiliser les actions d'API Amazon Redshift pour activer le routage VPC amélioré.
• CreateCluster• ModifyCluster
Version de l'API 2012-12-0160

Amazon Redshift Guide de la gestion du clusterPrésentation
Groupes de paramètres AmazonRedshiftPrésentation
Dans Amazon Redshift vous associez un groupe de paramètres avec chaque cluster que vous créez. Legroupe de paramètres est un groupe de paramètres qui s'appliquent à toutes les bases de données quevous créez dans le cluster. Ces paramètres configurent les paramètres de base de données tels que ledélai de requête et le style de date.
A propos des groupes de paramètresChaque groupe de paramètres possède plusieurs paramètres pour configurer les paramètres de la basede données. La liste des paramètres disponibles dépend de la famille de groupe de paramètres auquelce dernier appartient. La famille de groupe de paramètres est la version du moteur Amazon Redshift àlaquelle les paramètres du groupe de paramètres s'appliquent. Le format du nom de famille de groupe deparamètres est redshift-version où version désigne la version de moteur. Par exemple, la versionactuelle du moteur est redshift-1.0.
Amazon Redshift fournit un groupe de paramètres par défaut pour chaque famille de groupe deparamètres. Le groupe de paramètres par défaut a des valeurs prédéfinies pour chacun de sesparamètres, et ne peut pas être modifié. Le format du nom du groupe de paramètres par défaut estdefault.parameter_group_family, où parameter_group_family est la version du moteurauquel appartient le groupe de paramètres. Par exemple, le groupe de paramètres par défaut de la versionredshift-1.0 se nomme default.redshift-1.0.
Note
Pour l'instant, redshift-1.0 est la seule version du moteur Amazon Redshift. Par conséquent,default.redshift-1.0 est le seul groupe de paramètres par défaut.
Si vous souhaitez utiliser d'autres valeurs de paramètres que le groupe de paramètres par défaut, vousdevez créer un groupe de paramètres personnalisés, puis lui associer votre cluster. A l'origine, les valeursdes paramètres d'un groupe de paramètres personnalisés sont les mêmes que celles du groupe deparamètres par défaut. La source initiale de tous les paramètres est engine-default, car les valeurssont prédéfinies par Amazon Redshift. Une fois que vous avez modifié une valeur de paramètre, la sourcese change en user pour indiquer que la valeur a été modifiée par rapport à sa valeur par défaut.
Note
La Amazon Redshift console n'affiche pas la source de chaque paramètre. Vous devez utiliserl'API Amazon Redshift, l'AWS CLI ou l'un des kits SDK AWS pour afficher la source.
Pour les groupes de paramètres que vous créez, vous pouvez modifier une valeur de paramètre à toutmoment, ou vous pouvez réinitialiser toutes les valeurs des paramètres à leurs valeurs par défaut. Vouspouvez aussi associer un autre groupe de paramètres à un cluster. Si vous modifiez les valeurs desparamètres d'un groupe de paramètres qui est déjà associé à un cluster ou que vous associez un autregroupe de paramètres au cluster, vous devrez peut-être redémarrer le cluster pour que les valeurs desparamètres mis à jour prennent effet. Si le cluster échoue et est redémarré par Amazon Redshift, vos
Version de l'API 2012-12-0161
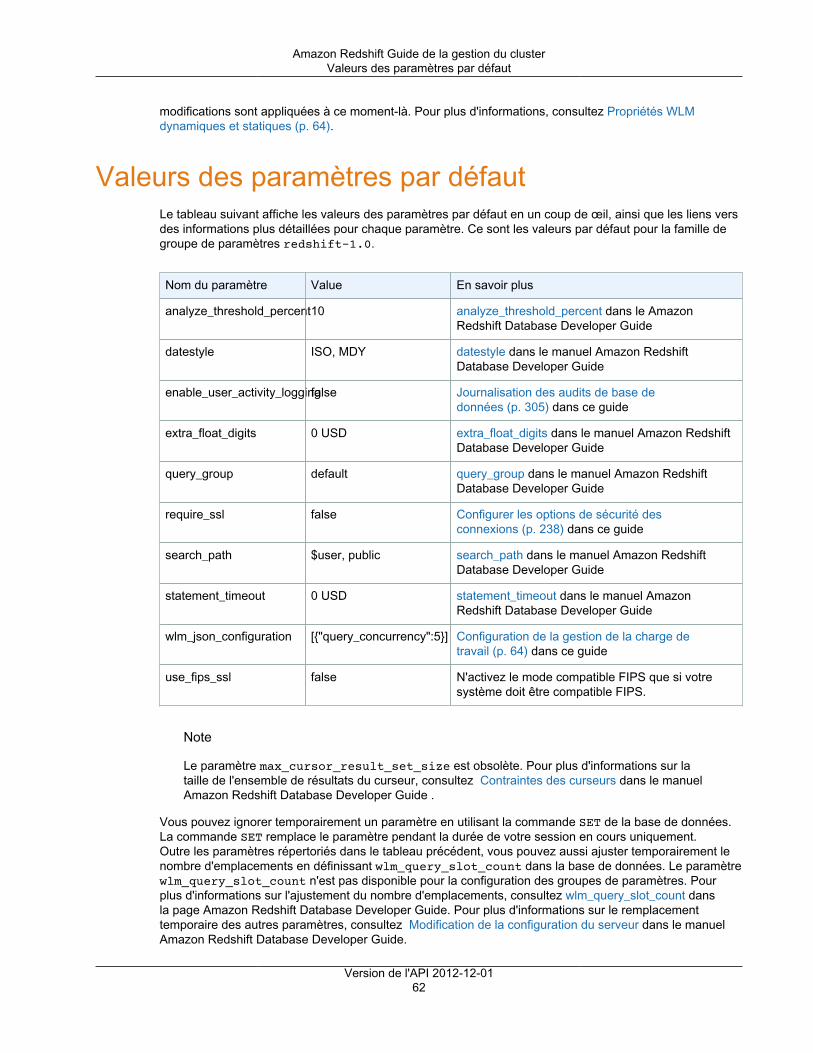
Amazon Redshift Guide de la gestion du clusterValeurs des paramètres par défaut
modifications sont appliquées à ce moment-là. Pour plus d'informations, consultez Propriétés WLMdynamiques et statiques (p. 64).
Valeurs des paramètres par défautLe tableau suivant affiche les valeurs des paramètres par défaut en un coup de œil, ainsi que les liens versdes informations plus détaillées pour chaque paramètre. Ce sont les valeurs par défaut pour la famille degroupe de paramètres redshift-1.0.
Nom du paramètre Value En savoir plus
analyze_threshold_percent10 analyze_threshold_percent dans le AmazonRedshift Database Developer Guide
datestyle ISO, MDY datestyle dans le manuel Amazon RedshiftDatabase Developer Guide
enable_user_activity_loggingfalse Journalisation des audits de base dedonnées (p. 305) dans ce guide
extra_float_digits 0 USD extra_float_digits dans le manuel Amazon RedshiftDatabase Developer Guide
query_group default query_group dans le manuel Amazon RedshiftDatabase Developer Guide
require_ssl false Configurer les options de sécurité desconnexions (p. 238) dans ce guide
search_path $user, public search_path dans le manuel Amazon RedshiftDatabase Developer Guide
statement_timeout 0 USD statement_timeout dans le manuel AmazonRedshift Database Developer Guide
wlm_json_configuration [{"query_concurrency":5}] Configuration de la gestion de la charge detravail (p. 64) dans ce guide
use_fips_ssl false N'activez le mode compatible FIPS que si votresystème doit être compatible FIPS.
Note
Le paramètre max_cursor_result_set_size est obsolète. Pour plus d'informations sur lataille de l'ensemble de résultats du curseur, consultez Contraintes des curseurs dans le manuelAmazon Redshift Database Developer Guide .
Vous pouvez ignorer temporairement un paramètre en utilisant la commande SET de la base de données.La commande SET remplace le paramètre pendant la durée de votre session en cours uniquement.Outre les paramètres répertoriés dans le tableau précédent, vous pouvez aussi ajuster temporairement lenombre d'emplacements en définissant wlm_query_slot_count dans la base de données. Le paramètrewlm_query_slot_count n'est pas disponible pour la configuration des groupes de paramètres. Pourplus d'informations sur l'ajustement du nombre d'emplacements, consultez wlm_query_slot_count dansla page Amazon Redshift Database Developer Guide. Pour plus d'informations sur le remplacementtemporaire des autres paramètres, consultez Modification de la configuration du serveur dans le manuelAmazon Redshift Database Developer Guide.
Version de l'API 2012-12-0162

Amazon Redshift Guide de la gestion du clusterConfiguration des valeurs des
paramètres à l'aide de l'AWS CLI
Configuration des valeurs des paramètres à l'aidede l'AWS CLI
Pour configurer les paramètres Amazon Redshift à l'aide de l'AWS CLI, vous utilisez la commandemodify-cluster-parameter-group pour un groupe de paramètres spécifiques. Vous spécifiez legroupe de paramètres à modifier dans parameter-group-name. Vous utilisez le paramètre parameters(pour la commande modify-cluster-parameter-group afin de spécifier les paires nom/valeur dechaque paramètre que vous voulez modifier dans le groupe de paramètres.
Note
Il existe des considérations particulières lors de la configuration du paramètrewlm_json_configuration à l'aide de l'AWS CLI. Les exemples de cette section s'appliquent àtous les paramètres, à l'exception de wlm_json_configuration. Pour plus d'informations sur laconfiguration de wlm_json_configuration à l'aide de l'AWS CLI. , consultez Configuration dela gestion de la charge de travail (p. 64).
Une fois que vous avez modifié les valeurs des paramètres, vous devez redémarrer les clustersqui sont associées au groupe de paramètres modifié. L'état du cluster affiche applying pourParameterApplyStatus, tandis que les valeurs sont appliquées, puis pending-reboot une fois queles valeurs ont été appliquées. Après le redémarrage, les bases de données de votre cluster commencentà utiliser les nouvelles valeurs des paramètres. Pour plus d'informations sur le redémarrage des clusters,consultez Redémarrage d'un cluster (p. 28).
Note
Le paramètre wlm_json_configuration contient certaines propriétés qui sont dynamiqueset qui ne nécessitent pas de redémarrer les clusters associés pour que les modifications soientappliquées. Pour plus d'informations sur les propriétés dynamiques et statiques, consultezPropriétés WLM dynamiques et statiques (p. 64).
Syntaxe
La syntaxe suivante montre comment utiliser la commande modify-cluster-parameter-group pourconfigurer un paramètre. Vous spécifiez parameter_group_name et vous remplacez parameter_nameet parameter_value par un véritable paramètre à modifier et une valeur pour ce paramètre. Si vousvoulez modifier plusieurs paramètres en même temps, séparez chaque ensemble de paramètre et devaleur du suivant avec un espace.
aws redshift modify-cluster-parameter-group --parameter-group-name parameter_group_name --parameters ParameterName=parameter_name,ParameterValue=parameter_value
exemple
L'exemple suivant montre comment configurer les paramètres statement_timeout etenable_user_activity_logging pour le groupe de paramètres myclusterparametergroup.
Note
Pour des raisons de lisibilité, l'exemple s'affiche sur plusieurs lignes, mais dans l'AWS CLI réelle, ilne s'agit que d'une seule ligne.
aws redshift modify-cluster-parameter-group --parameter-group-name myclusterparametergroup --parameters ParameterName=statement_timeout,ParameterValue=20000 ParameterName=enable_user_activity_logging,ParameterValue=true
Version de l'API 2012-12-0163

Amazon Redshift Guide de la gestion du clusterConfiguration de la gestion de la charge de travail
Configuration de la gestion de la charge de travailDans Amazon Redshift vous utilisez la gestion de la charge de travail (WLM) pour définir le nombre defiles d'attente de requêtes qui sont disponibles, ainsi que le nombre de requêtes acheminées vers ces filesd'attente en vue de leur traitement. WLM fait partie de la configuration du groupe de paramètres. Un clusterutilise la configuration WLM spécifiée dans son groupe de paramètres associé.
Lorsque vous créez un groupe de paramètres, la configuration WLM par défaut contient une seule filed'attente qui peut exécuter jusqu'à cinq requêtes simultanément. Vous pouvez ajouter d'autres filesd'attente et configurer les propriétés WLM de chacune d'elles si vous souhaitez plus de contrôle sur letraitement des requêtes. Chaque file d'attente que vous ajoutez possède la même configuration WLM pardéfaut jusqu'à ce que vous configuriez ses propriétés.
Lorsque vous ajoutez des files d'attente supplémentaires, la dernière file d'attente de la configuration estla file d'attente par défaut. A moins qu'une requête ne soit acheminée vers une autre file d'attente selonles critères de la configuration WLM, elle est traitée par la file d'attente par défaut. Vous ne pouvez passpécifier de groupes d'utilisateurs ou de groupes de requêtes pour la file d'attente par défaut.
Comme pour d'autres paramètres, vous ne pouvez pas modifier la configuration WLM du groupe deparamètres par défaut. Les clusters associés au groupe de paramètres par défaut utilisent toujours laconfiguration WLM par défaut. Si vous voulez modifier la configuration WLM, vous devez créer un groupede paramètres, puis l'associer à ce groupe de paramètres avec les clusters nécessitant votre configurationWLM personnalisée.
Propriétés WLM dynamiques et statiquesLes propriétés de la configuration WLM sont dynamiques ou statiques. Les propriétés dynamiquespeuvent être appliquées à la base de données sans redémarrage du cluster, mais les propriétés statiquesnécessitent un redémarrage du cluster pour que les modifications prennent effet. Cependant, si vousmodifiez les propriétés dynamiques et statiques en même temps, vous devez redémarrer le cluster pourque toutes les modifications prennent effet, que les propriétés soient statiques ou dynamiques. Pendantl'application des propriétés dynamiques, votre cluster aura le statut modifying.
Les propriétés WLM suivantes sont statiques :
• Groupes d'utilisateurs• Caractère générique de groupe d'utilisateurs• Groupes de requêtes• Caractère générique de groupe de requêtes
L'ajout, la suppression ou la réorganisation des files d'attente est une modification statique et nécessite unredémarrage du cluster pour prendre effet.
Les propriétés WLM suivantes sont dynamiques :
• Activer l'accélération des requêtes courtes• Durée d'exécution maximale pour les requêtes courtes• Simultanéité• Pourcentage de mémoire à utiliser• Expiration
Si la valeur du délai d'attente est modifiée, la nouvelle valeur est appliquée à toute requête dont l'exécutiondémarre une fois que la valeur a été modifiée. Si la concurrence ou le pourcentage de mémoire à utiliser
Version de l'API 2012-12-0164

Amazon Redshift Guide de la gestion du clusterPropriétés du paramètre wlm_json_configuration
sont modifiées, Amazon Redshift passe à la nouvelle configuration dynamiquement, de telle sorte queles requêtes en cours d'exécution ne sont pas affectées par le changement. Pour plus d'informations,consultez Allocation de mémoire dynamique WLM.
Propriétés du paramètre wlm_json_configurationVous pouvez configurer WLM en utilisant la Amazon Redshift console, l'AWS CLI, l'API Amazon Redshiftou l'un des kits SDK AWS. La configuration WLM utilise plusieurs propriétés pour définir un comportementde file d'attente, telles que l'allocation mémoire entre les files d'attente, le nombre de requêtes pouvants'exécuter simultanément dans une file d'attente, et ainsi de suite. La liste suivante décrit les propriétésWLM que vous pouvez configurer pour chaque file d'attente.
Note
Les propriétés suivantes sont accompagnées de leurs noms Amazon Redshift console, avec lesnoms de propriété JSON correspondants dans les descriptions.
Activer l'accélération des requêtes courtes
L'accélération des requêtes courtes (SQA) établit la priorité des requêtes de courte duréesélectionnées sur les requêtes de longue durée. La SQA exécute des requêtes de courte durée dansun espace dédié, afin que les requêtes SQA ne soient pas forcées d'attendre dans des files d'attentederrière les requêtes de longue durée. Avec la SQA, les requêtes de courte durée commencent às'exécuter plus rapidement et les utilisateurs obtiennent les résultats plus rapidement. Lorsque vousactivez la SQA, vous pouvez également spécifier le délai d'exécution maximal des requêtes courtes.Pour activer la SQA, spécifiez true. La valeur par défaut est false.
Propriété JSON : short_query_queueDurée d'exécution maximale pour les requêtes courtes
Lorsque vous activez SQA, vous pouvez également spécifier la valeur 0 pour permettre à WLM dedéfinir le délai d'exécution maximal des requêtes courtes. Vous pouvez aussi spécifier une valeurcomprise entre 1 et 20 secondes, en millisecondes. La valeur par défaut est 0.
Propriété JSON : max_execution_timeSimultanéité
Nombre de requêtes qui peuvent s'exécuter simultanément dans une file d'attente. Quand une filed'attente atteint le niveau de concurrence, les requêtes suivantes attendent dans la file d'attentejusqu'à ce que les ressources soient disponibles pour les traiter. La plage est comprise entre 1 et 50.
Propriété JSON : query_concurrencyGroupes d'utilisateurs
Liste séparée par des virgules de noms de groupes d'utilisateurs. Lorsque les membres du grouped'utilisateurs exécutent les requêtes de la base de données, leurs requêtes sont acheminées vers lafile d'attente associée à leur groupe d'utilisateurs.
Propriété JSON : user_groupCaractère générique du groupe d'utilisateurs
Une valeur booléenne qui indique s'il convient d'activer les caractères génériques pour les groupesd'utilisateurs. Si la valeur est 0, les caractères génériques sont désactivés ; si la valeur est 1, lescaractères génériques sont activés. Lorsque les caractères génériques sont activés, vous pouvezutiliser « * » ou « ? » pour spécifier plusieurs groupes d'utilisateurs lors de l'exécution des requêtes.
Propriété JSON : user_group_wild_card
Version de l'API 2012-12-0165

Amazon Redshift Guide de la gestion du clusterPropriétés du paramètre wlm_json_configuration
Groupes de requêtes
Liste séparée par des virgules de groupes de requêtes. Lorsque les membres du groupe de requêtesexécutent les requêtes de la base de données, leurs requêtes sont acheminées vers la file d'attenteassociée à leur groupe d'utilisateurs.
Propriété JSON : query_groupCaractère générique de groupe de requêtes
Valeur booléenne qui indique s'il convient d'activer les caractères génériques pour les groupesde requêtes. Si la valeur est 0, les caractères génériques sont désactivés ; si la valeur est 1, lescaractères génériques sont activés. Lorsque les caractères génériques sont activés, vous pouvezutiliser « * » ou « ? » pour spécifier plusieurs groupes de requêtes lors de l'exécution des requêtes.
Propriété JSON : query_group_wild_cardDélai (ms)
Durée maximale, en millisecondes, pendant laquelle les requêtes peuvent s'exécuter avant d'êtreannulées. Si une requête en lecture seule, telle qu'une instruction SELECT, est annulée en raisond'un délai WLM, WLM tente d'acheminer la requête vers la file d'attente correspondante suivanteen fonction des règles d'affectation de file d'attente de WLM. Si la requête ne correspond pas à uneautre définition de file d'attente, la requête est annulée ; elle n'est pas affectée à la file d'attente pardéfaut. Pour plus d'informations, consultez Saut de file d'attente des requêtes WLM. Le délai WLMne s'applique pas à une requête qui a atteint l'état returning. Pour afficher l'état d'une requête,consultez la table système STV_WLM_QUERY_STATE.
Propriété JSON : max_execution_timeMémoire (%)
Pourcentage de mémoire à allouer à la file d'attente. Si vous spécifiez un pourcentage de mémoirepour une file d'attente au moins, vous devez indiquer un pourcentage pour toutes les autres filesd'attente afin d'atteindre un total de 100 %. Si votre allocation mémoire est inférieure à 100 % surtoutes les files d'attente, la mémoire non allouée est gérée par le service et peut être temporairementattribuée à une file d'attente qui demande de la mémoire supplémentaire pour le traitement.
Propriété JSON : memory_percent_to_useRègles de surveillance de requête
Vous pouvez utiliser les règles de surveillance de requête WLM afin de surveiller en permanence vosfiles d'attente WLM en fonction de critères ou de prédicats que vous spécifiez. Par exemple, vouspouvez surveiller les requêtes qui tendent à consommer des ressources système excessives, puisinitier une action donnée lorsqu'une requête dépasse les limites de performance que vous indiquez.
Note
Si vous créez des règles par programmation, il est recommandé d'utiliser la console afin degénérer les données JSON à inclure dans la définition du groupe de paramètres.
Vous associez une règle de surveillance de requête à une file d'attente de requêtes spécifique. Vouspouvez disposer de jusqu'à huit règles par file d'attente et la limite totale pour toutes les files d'attenteest de huit règles.
Propriété JSON : rules
Propriétés de hiérarchie JSON
rules rule_name
Version de l'API 2012-12-0166

Amazon Redshift Guide de la gestion du clusterConfiguration du paramètre
wlm_json_configuration à l'aide de l'AWS CLI
predicate metric_name operator value action
Pour chaque règle, vous spécifiez les propriétés suivantes :• rule_name – Les noms de règles doivent être uniques au sein de la configuration WLM. Les noms
de règles peut comporter jusqu'à 32 caractères alphanumériques ou traits de soulignement et nedoivent pas contenir d'espaces ni de guillemets. Vous pouvez disposer de jusqu'à huit règles par filed'attente et la limite totale pour toutes les files d'attente est de huit règles.• predicate – Chaque règle peut comporter jusqu'à trois prédicats. Pour chaque prédicats, vous
spécifiez les propriétés suivantes.• metric_name – Pour obtenir une liste des métriques, consultez Métriques de surveillance de
requête dans le Amazon Redshift Database Developer Guide.• operator – Les opérations sont =, < et >.• value – La valeur de seuil pour la métrique spécifiée déclenchant une action.
• action – Chaque règle est associée à une action. Les actions valides sont :• log
• hop
• abort
L'exemple suivant présente le fichier JSON pour une règle de surveillance de requête WLM nomméerule_1, avec deux prédicats et l'action hop.
"rules": [ { "rule_name": "rule_1", "predicate": [ { "metric_name": "query_cpu_time", "operator": ">", "value": 100000 }, { "metric_name": "query_blocks_read", "operator": ">", "value": 1000 } ], "action": "hop" } ]
Pour plus d'informations sur chacune de ces propriétés et les stratégies de configuration des files d'attentede requête, consultez Définition des files d'attente de requête et Implémentation de la gestion de la chargede travail dans le manuel Amazon Redshift Database Developer Guide.
Configuration du paramètre wlm_json_configuration àl'aide de l'AWS CLIPour configurer WLM, vous modifiez le paramètre wlm_json_configuration. La valeur est au formatJSON (JavaScript Objet Notation). Si vous configurez WLM en utilisant l'AWS CLI, Amazon Redshift, l'APIou l'un des kits SDK AWS, utilisez le reste de cette section pour apprendre à construire la structure JSONdu paramètre wlm_json_configuration.
Version de l'API 2012-12-0167

Amazon Redshift Guide de la gestion du clusterConfiguration du paramètre
wlm_json_configuration à l'aide de l'AWS CLI
Note
Si vous configurez WLM en utilisant Amazon Redshift console vous n'avez pas besoin decomprendre le format JSON, car la console offre un moyen simple d'ajouter des files d'attente etde configurer leurs propriétés. Pour plus d'informations sur la configuration de WLM à l'aide de laAmazon Redshift console, consultez Modification d'un groupe de paramètres (p. 74).
exemple
L'exemple suivant est la configuration WLM par défaut, qui définit une file d'attente avec un niveau deconcurrence égal à cinq.
{ "query_concurrency":5}
Syntaxe
La configuration WLM par défaut est très simple, avec une seule file d'attente et une seule propriété.Vous pouvez ajouter plus de files d'attente et configurer plusieurs propriétés pour chaque file d'attente dela structure JSON. La syntaxe suivante représente la structure JSON que vous utilisez pour configurerplusieurs files d'attente avec plusieurs propriétés :
[ { "ParameterName":"wlm_json_configuration", "ParameterValue": "[ { "q1_first_property_name":"q1_first_property_value", "q1_second_property_name":"q1_second_property_value", ... }, { "q2_first_property_name":"q2_first_property_value", "q2_second_property_name":"q2_second_property_value", ... } ...
]" }]
Dans l'exemple précédent, les propriétés représentatives qui commencent par q1 sont les objets d'untableau de la première file d'attente. Chacun de ces objets est une paire nom-valeur ; name et valuedéfinissent ensemble les propriétés WLM de la première file d'attente. Les propriétés représentatives quicommencent par q2 sont les objets d'un tableau de la deuxième file d'attente. Si vous avez besoin de plusde files d'attente, vous ajoutez un autre tableau pour chaque file d'attente supplémentaire et définissez lespropriétés de chaque objet.
Lorsque vous modifiez la configuration WLM, vous devez y inclure la totalité de la structure de vosfiles d'attente, même si vous ne voulez modifier qu'une seule propriété au sein d'une file d'attente. Laraison en est que toute la structure JSON est passée sous forme de chaîne comme valeur du paramètrewlm_json_configuration.
Mise en forme de la commande de l'AWS CLILe paramètre wlm_json_configuration nécessite un format spécifique lorsque vous utilisez l'AWSCLI. Le format que vous utilisez dépend du système d'exploitation de votre client. Comme les systèmesd'exploitation ont différentes façons de joindre la structure JSON, elle est transmise correctement à partir
Version de l'API 2012-12-0168

Amazon Redshift Guide de la gestion du clusterConfiguration du paramètre
wlm_json_configuration à l'aide de l'AWS CLI
de la ligne de commande. Pour plus d'informations sur la façon de construire la commande appropriéedans les systèmes d'exploitation Linux, Mac OS X et Windows, consultez les sections suivantes. Pour plusd'informations sur les différentes insertions des structures de données JSON dans l'AWS CLI en général,consultez Insertion des chaînes entre guillemets dans le manuel AWS Command Line Interface Guide del'utilisateur.
Exemples
L'exemple de commande suivant configure WLM pour un groupe de paramètres appelé example-parameter-group. La configuration permet l'accélération des requêtes courtes avec une duréed'exécution maximale pour les requêtes courtes définie sur 0, ce qui demande à WLM de définir lavaleur dynamiquement. Le paramètre ApplyType a la valeur dynamic. Cette valeur signifie que toutemodification apportée aux propriétés dynamiques du paramètre est appliquée immédiatement, à moins qued'autres modifications statiques n'aient été apportées à la configuration. La configuration définit trois filesd'attente avec les éléments suivants :
• La première file d'attente permet aux utilisateurs de spécifier report comme étiquette (tel qu'indiquédans la propriété query_groups) dans leurs requêtes pour aider à acheminer les requêtes vers cettefile d'attente. Comme les recherches par caractères génériques sont activées pour l'étiquette report,l'étiquette n'a pas besoin d'être exacte pour que les requêtes soient acheminées vers la file d'attente. Parexemple, reports et reporting correspondent également à ce groupe de requêtes. La file d'attentese voit allouer 25 % de la mémoire totale sur toutes les files d'attente et peut exécuter jusqu'à quatrerequêtes en même temps. Les requêtes sont limitées à une durée maximale de 20 000 millisecondes(ms).
• La deuxième file d'attente permet aux utilisateurs qui sont membres des groupes admin ou dba dela base de données d'avoir leurs requêtes acheminées vers la file d'attente en vue de leur traitement.Comme les recherches par caractères génériques sont désactivées pour les groupes d'utilisateurs,les utilisateurs doivent correspondre exactement aux groupes de la base de données pour que leursrequêtes soient acheminées vers la file d'attente. La file d'attente se voit allouer 40 % de la mémoiretotale sur toutes les files d'attente et peut exécuter jusqu'à cinq requêtes en même temps.
• La dernière file d'attente de la configuration est la file d'attente par défaut. Cette file d'attente se voitallouer 35 % de la mémoire totale sur toutes les files d'attente et peut traiter jusqu'à cinq requêtes à lafois.
Note
L'exemple est affiché sur plusieurs lignes à des fins de démonstration. Les commandes réelles necomportent pas de sauts de ligne.
aws redshift modify-cluster-parameter-group --parameter-group-name example-parameter-group --parameters'[ { "ParameterName":"wlm_json_configuration", "ParameterValue":"[ { "query_group":["report"], "query_group_wild_card":1, "query_concurrency":4, "max_execution_time":20000, "memory_percent_to_use":25 }, { "user_group":["admin","dba"], "user_group_wild_card":0, "query_concurrency":5, "memory_percent_to_use":40 },
Version de l'API 2012-12-0169

Amazon Redshift Guide de la gestion du clusterConfiguration du paramètre
wlm_json_configuration à l'aide de l'AWS CLI
{ "query_concurrency":5, "memory_percent_to_use":35 }, { "short_query_queue": true, "max_execution_time": 0 } ]", "ApplyType":"dynamic" }]'
Voici un exemple de configuration de règle de surveillance de requête WLM. L'exemple crée un groupe deparamètres nommé example-monitoring-rules. La configuration définit les mêmes trois files d'attenteque dans l'exemple précédent et ajoute les règles suivantes :
• La première file d'attente définit une règle nommée rule_1. La règle a deux prédicats :query_cpu_time > 10000000 et query_blocks_read > 1000. L'action de la règle est log.
• La deuxième file d'attente définit une règle nommée rule_2. La règle a deux prédicats :query_execution_time > 600000000 et scan_row_count > 1000000000. L'action de la règleest hop.
• La dernière file d'attente de la configuration est la file d'attente par défaut.
Note
L'exemple est affiché sur plusieurs lignes à des fins de démonstration. Les commandes réelles necomportent pas de sauts de ligne.
aws redshift modify-cluster-parameter-group --parameter-group-name example-monitoring-rules --parameters'[ { "ParameterName":"wlm_json_configuration", "ParameterValue":"[ { "query_group":["report"], "query_group_wild_card":1, "query_concurrency":4, "max_execution_time":20000, "memory_percent_to_use":25, "rules": [{"rule_name": "rule_1", "predicate": [ {"metric_name": "query_cpu_time", "operator": ">", "value": 1000000}, {"metric_name": "query_blocks_read", "operator": ">", "value": 1000}], "action": "log"}] }, { "user_group":["admin","dba"], "user_group_wild_card":0, "query_concurrency":5, "memory_percent_to_use":40, "rules": [{"rule_name": "rule_2", "predicate": [ {"metric_name": "query_execution_time", "operator": ">",
Version de l'API 2012-12-0170

Amazon Redshift Guide de la gestion du clusterConfiguration du paramètre
wlm_json_configuration à l'aide de l'AWS CLI
"value": 600000000}, {"metric_name": "scan_row_count", "operator": ">", "value": 1000000000}], "action": "hop"}]
}, { "query_concurrency":5, "memory_percent_to_use":35 }, { "short_query_queue": true, "max_execution_time": 5000 } ]", "ApplyType":"dynamic" }]'
Règles de la configuration WLM à l'aide de l'AWS CLI sur les systèmesd'exploitation Linux et Mac OS X
• Toute la structure JSON doit être placée entre guillemets simples (') et entre crochets ([ ]).• Tous les noms de paramètre et valeurs de paramètre doivent se trouver entre guillemets doubles (").• Au sein de la valeur ParameterValue, vous devez placer toute la structure imbriquée entre guillemets
doubles (") et entre crochets ([ ]).• Au sein de la structure imbriquée, chacune des propriétés et des valeurs de chaque file d'attente doivent
être placées entre accolades ({}).• Au sein de la structure imbriquée, vous devez utiliser le caractère d'échappement barre oblique inverse
(\) avant chaque guillemet double (").• Pour les paires nom-valeur, un signe deux-points (:) sépare chaque propriété de sa valeur.• Chaque paire nom-valeur est séparée d'une autre paire par une virgule (,).• Plusieurs files d'attente sont séparées par une virgule (,) entre la fin d'accolade d'une file d'attente (}) et
le début d'accolade de la file d'attente suivante ({).
exemple
L'exemple suivant montre comment configurer les files d'attente décrites dans cette section en utilisantl'AWS CLI sur les systèmes d'exploitation Linux et Mac OS X.
Note
Cet exemple doit être envoyé sur une seule ligne dans l'AWS CLI.
aws redshift modify-cluster-parameter-group --parameter-group-name example-parameter-group --parameters '[{"ParameterName":"wlm_json_configuration","ParameterValue":\"[{\"query_group\":[\"reports\"],\"query_group_wild_card\":0,\"query_concurrency\":4,\"max_execution_time\":20000,\"memory_percent_to_use\":25},{\"user_group\":[\"admin\",\"dba\"],\"user_group_wild_card\":1,\"query_concurrency\":5,\"memory_percent_to_use\":40},{\"query_concurrency\":5,\"memory_percent_to_use\":35},{\"short_query_queue\": true, \"max_execution_time\": 5000 }]\",\"ApplyType\":\"dynamic\"}]'
Règles de la configuration WLM à l'aide de l'AWS CLI de Windows PowerShell surles systèmes d'exploitation Microsoft Windows
• Toute la structure JSON doit être placée entre guillemets simples (') et entre crochets ([ ]).
Version de l'API 2012-12-0171

Amazon Redshift Guide de la gestion du clusterConfiguration du paramètre
wlm_json_configuration à l'aide de l'AWS CLI
• Tous les noms de paramètre et valeurs de paramètre doivent se trouver entre guillemets doubles (").• Au sein de la valeur ParameterValue, vous devez placer toute la structure imbriquée entre guillemets
doubles (") et entre crochets ([ ]).• Au sein de la structure imbriquée, chacune des propriétés et des valeurs de chaque file d'attente doivent
être placées entre accolades ({}).• Au sein de la structure imbriquée, vous devez utiliser le caractère d'échappement de barre oblique
inverse (\) avant chaque guillemet double (") et son caractère d'échappement de barre oblique inverse (\).Cette exigence signifie que vous utiliserez trois barres obliques et un guillemet double pour vous assurerque les propriétés sont correctement transmises (\\\:).
• Pour les paires nom-valeur, un signe deux-points (:) sépare chaque propriété de sa valeur.• Chaque paire nom-valeur est séparée d'une autre paire par une virgule (,).• Plusieurs files d'attente sont séparées par une virgule (,) entre la fin d'accolade d'une file d'attente (}) et
le début d'accolade de la file d'attente suivante ({).
exemple
L'exemple suivant montre comment configurer les files d'attente décrites dans cette section à l'aide del'AWS CLI de Windows PowerShell sur les systèmes d'exploitation Windows.
Note
Cet exemple doit être envoyé sur une seule ligne dans l'AWS CLI.
aws redshift modify-cluster-parameter-group --parameter-group-name example-parameter-group --parameters '[{\"ParameterName\":\"wlm_json_configuration\",\"ParameterValue\":\"[{\\\"query_group\\\":[\\\"reports\\\"],\\\"query_group_wild_card\\\":0,\\\"query_concurrency\\\":4,\\\"max_execution_time\\\":20000,\\\"memory_percent_to_use\\\":25},{\\\"user_group\\\":[\\\"admin\\\",\\\"dba\\\"],\\\"user_group_wild_card\\\":1,\\\"query_concurrency\\\":5,\\\"memory_percent_to_use\\\":40},{\\\"query_concurrency\\\":5,\\\"memory_percent_to_use\\\":35},{ \\\"short_query_queue\\\": true, \\\"max_execution_time\\\": 5000 }]\",\"ApplyType\":\"dynamic\"}]'
Règles de la configuration WLM à l'aide de l'invite de commande sur les systèmesd'exploitation Windows
• Toute la structure JSON doit être placée entre guillemets doubles (") et entre crochets ([ ]).• Tous les noms de paramètre et valeurs de paramètre doivent se trouver entre guillemets doubles (").• Au sein de la valeur ParameterValue, vous devez placer toute la structure imbriquée entre guillemets
doubles (") et entre crochets ([ ]).• Au sein de la structure imbriquée, chacune des propriétés et des valeurs de chaque file d'attente doivent
être placées entre accolades ({}).• Au sein de la structure imbriquée, vous devez utiliser le caractère d'échappement de barre oblique
inverse (\) avant chaque guillemet double (") et son caractère d'échappement de barre oblique inverse (\).Cette exigence signifie que vous utiliserez trois barres obliques et un guillemet double pour vous assurerque les propriétés sont correctement transmises (\\\:).
• Pour les paires nom-valeur, un signe deux-points (:) sépare chaque propriété de sa valeur.• Chaque paire nom-valeur est séparée d'une autre paire par une virgule (,).• Plusieurs files d'attente sont séparées par une virgule (,) entre la fin d'accolade d'une file d'attente (}) et
le début d'accolade de la file d'attente suivante ({).
exemple
L'exemple suivant montre comment configurer les files d'attente décrites dans cette section en utilisantl'AWS CLI dans l'invite de commande sur les systèmes d'exploitation Windows.
Version de l'API 2012-12-0172
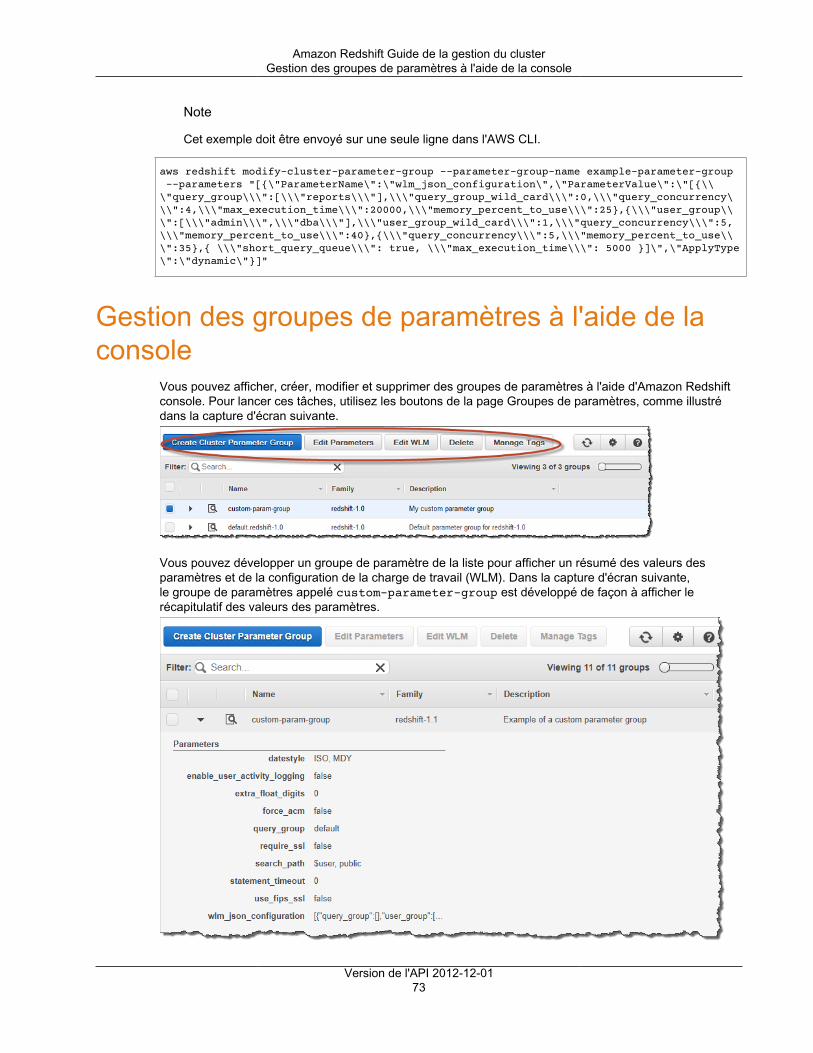
Amazon Redshift Guide de la gestion du clusterGestion des groupes de paramètres à l'aide de la console
Note
Cet exemple doit être envoyé sur une seule ligne dans l'AWS CLI.
aws redshift modify-cluster-parameter-group --parameter-group-name example-parameter-group --parameters "[{\"ParameterName\":\"wlm_json_configuration\",\"ParameterValue\":\"[{\\\"query_group\\\":[\\\"reports\\\"],\\\"query_group_wild_card\\\":0,\\\"query_concurrency\\\":4,\\\"max_execution_time\\\":20000,\\\"memory_percent_to_use\\\":25},{\\\"user_group\\\":[\\\"admin\\\",\\\"dba\\\"],\\\"user_group_wild_card\\\":1,\\\"query_concurrency\\\":5,\\\"memory_percent_to_use\\\":40},{\\\"query_concurrency\\\":5,\\\"memory_percent_to_use\\\":35},{ \\\"short_query_queue\\\": true, \\\"max_execution_time\\\": 5000 }]\",\"ApplyType\":\"dynamic\"}]"
Gestion des groupes de paramètres à l'aide de laconsole
Vous pouvez afficher, créer, modifier et supprimer des groupes de paramètres à l'aide d'Amazon Redshiftconsole. Pour lancer ces tâches, utilisez les boutons de la page Groupes de paramètres, comme illustrédans la capture d'écran suivante.
Vous pouvez développer un groupe de paramètre de la liste pour afficher un résumé des valeurs desparamètres et de la configuration de la charge de travail (WLM). Dans la capture d'écran suivante,le groupe de paramètres appelé custom-parameter-group est développé de façon à afficher lerécapitulatif des valeurs des paramètres.
Version de l'API 2012-12-0173
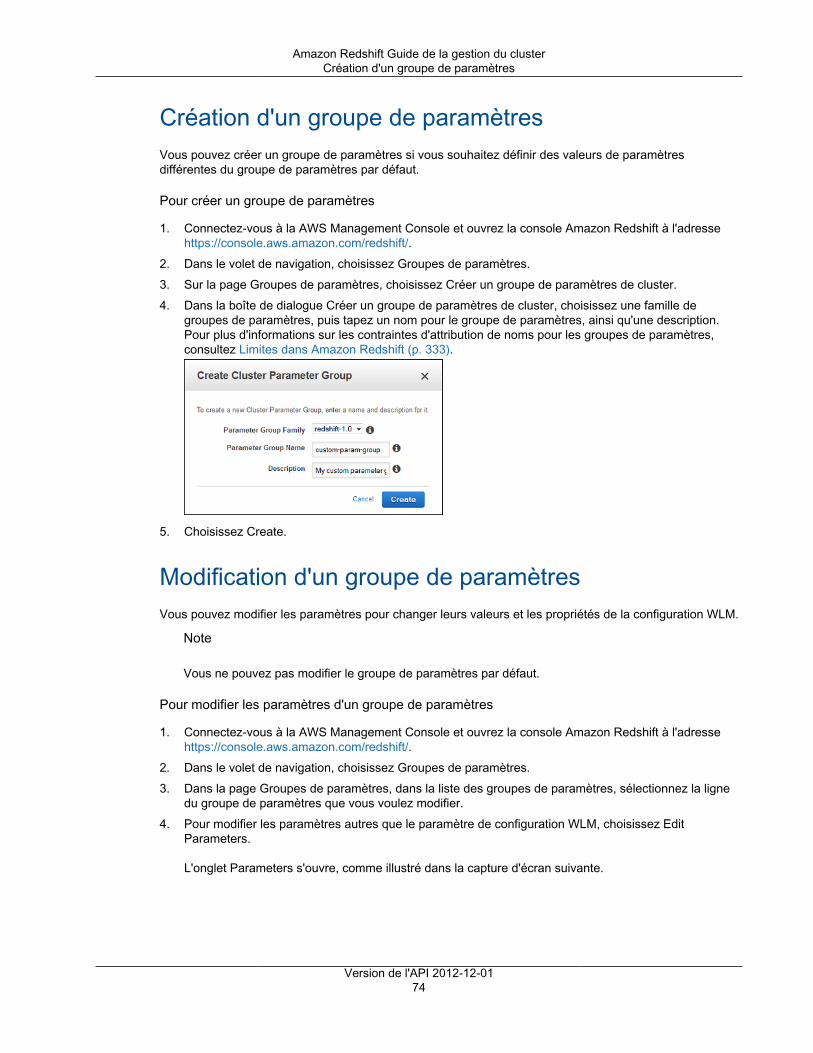
Amazon Redshift Guide de la gestion du clusterCréation d'un groupe de paramètres
Création d'un groupe de paramètresVous pouvez créer un groupe de paramètres si vous souhaitez définir des valeurs de paramètresdifférentes du groupe de paramètres par défaut.
Pour créer un groupe de paramètres
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Groupes de paramètres.3. Sur la page Groupes de paramètres, choisissez Créer un groupe de paramètres de cluster.4. Dans la boîte de dialogue Créer un groupe de paramètres de cluster, choisissez une famille de
groupes de paramètres, puis tapez un nom pour le groupe de paramètres, ainsi qu'une description.Pour plus d'informations sur les contraintes d'attribution de noms pour les groupes de paramètres,consultez Limites dans Amazon Redshift (p. 333).
5. Choisissez Create.
Modification d'un groupe de paramètresVous pouvez modifier les paramètres pour changer leurs valeurs et les propriétés de la configuration WLM.
Note
Vous ne pouvez pas modifier le groupe de paramètres par défaut.
Pour modifier les paramètres d'un groupe de paramètres
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Groupes de paramètres.3. Dans la page Groupes de paramètres, dans la liste des groupes de paramètres, sélectionnez la ligne
du groupe de paramètres que vous voulez modifier.4. Pour modifier les paramètres autres que le paramètre de configuration WLM, choisissez Edit
Parameters.
L'onglet Parameters s'ouvre, comme illustré dans la capture d'écran suivante.
Version de l'API 2012-12-0174
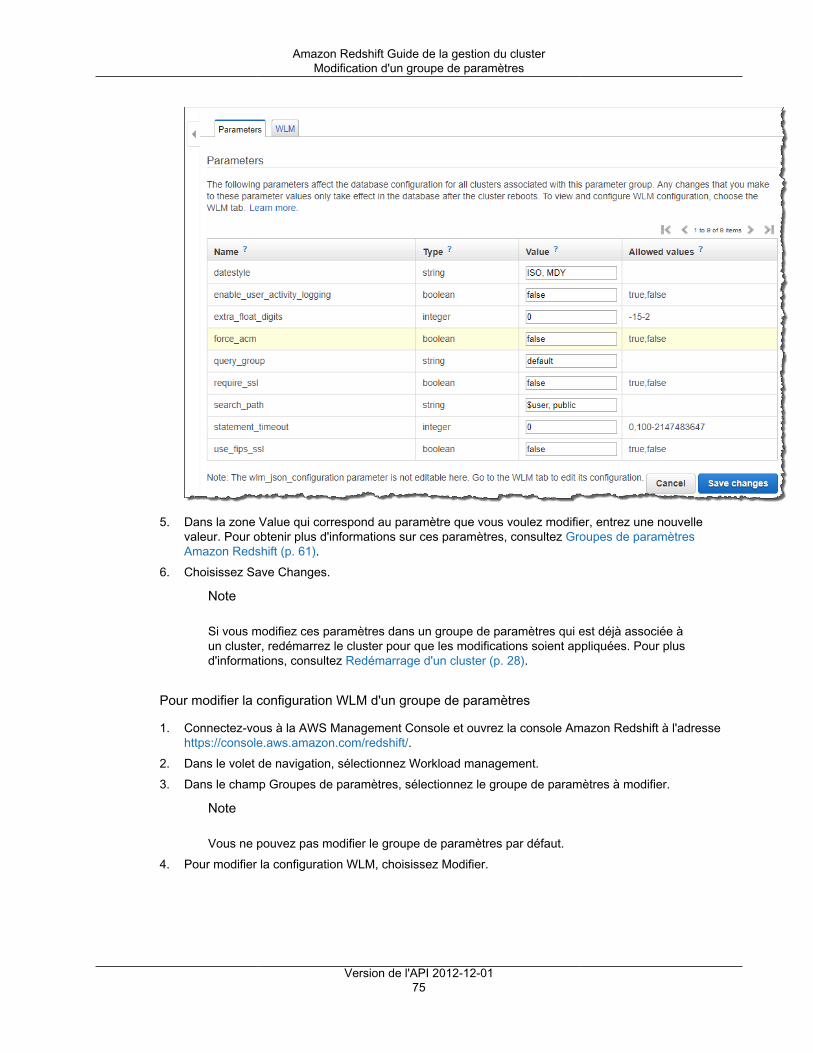
Amazon Redshift Guide de la gestion du clusterModification d'un groupe de paramètres
5. Dans la zone Value qui correspond au paramètre que vous voulez modifier, entrez une nouvellevaleur. Pour obtenir plus d'informations sur ces paramètres, consultez Groupes de paramètresAmazon Redshift (p. 61).
6. Choisissez Save Changes.
Note
Si vous modifiez ces paramètres dans un groupe de paramètres qui est déjà associée àun cluster, redémarrez le cluster pour que les modifications soient appliquées. Pour plusd'informations, consultez Redémarrage d'un cluster (p. 28).
Pour modifier la configuration WLM d'un groupe de paramètres
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, sélectionnez Workload management.3. Dans le champ Groupes de paramètres, sélectionnez le groupe de paramètres à modifier.
Note
Vous ne pouvez pas modifier le groupe de paramètres par défaut.4. Pour modifier la configuration WLM, choisissez Modifier.
Version de l'API 2012-12-0175
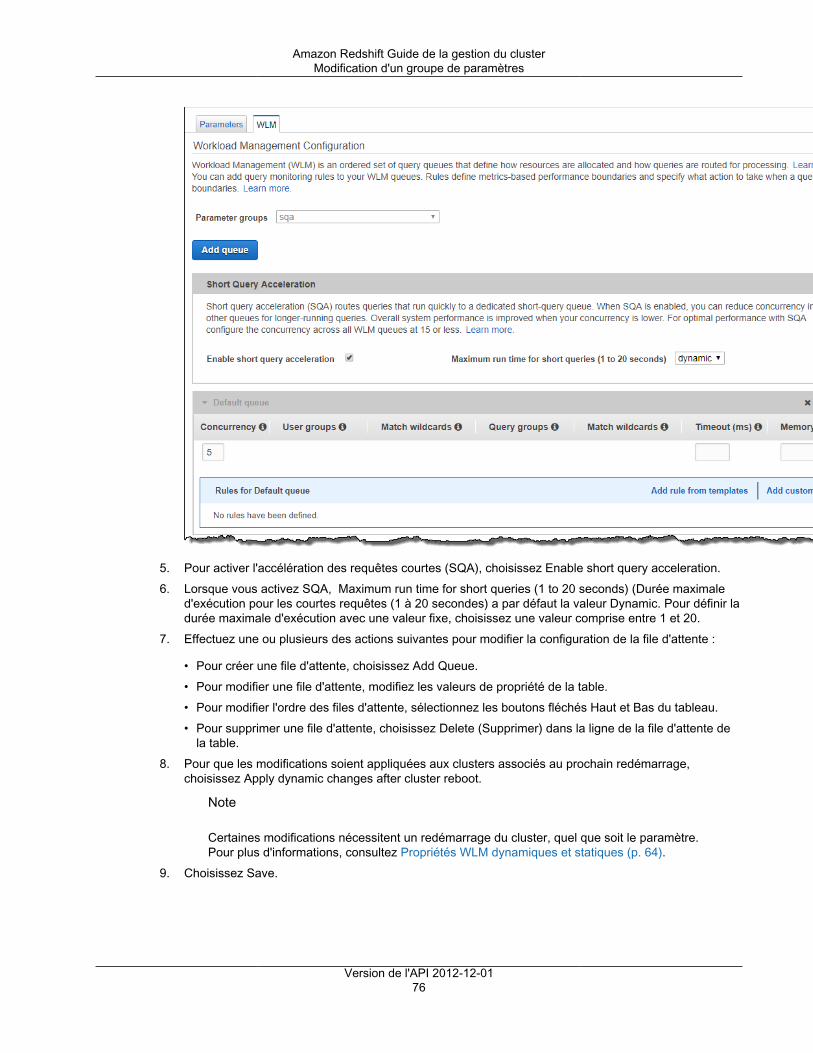
Amazon Redshift Guide de la gestion du clusterModification d'un groupe de paramètres
5. Pour activer l'accélération des requêtes courtes (SQA), choisissez Enable short query acceleration.6. Lorsque vous activez SQA, Maximum run time for short queries (1 to 20 seconds) (Durée maximale
d'exécution pour les courtes requêtes (1 à 20 secondes) a par défaut la valeur Dynamic. Pour définir ladurée maximale d'exécution avec une valeur fixe, choisissez une valeur comprise entre 1 et 20.
7. Effectuez une ou plusieurs des actions suivantes pour modifier la configuration de la file d'attente :
• Pour créer une file d'attente, choisissez Add Queue.• Pour modifier une file d'attente, modifiez les valeurs de propriété de la table.• Pour modifier l'ordre des files d'attente, sélectionnez les boutons fléchés Haut et Bas du tableau.• Pour supprimer une file d'attente, choisissez Delete (Supprimer) dans la ligne de la file d'attente de
la table.8. Pour que les modifications soient appliquées aux clusters associés au prochain redémarrage,
choisissez Apply dynamic changes after cluster reboot.
Note
Certaines modifications nécessitent un redémarrage du cluster, quel que soit le paramètre.Pour plus d'informations, consultez Propriétés WLM dynamiques et statiques (p. 64).
9. Choisissez Save.
Version de l'API 2012-12-0176
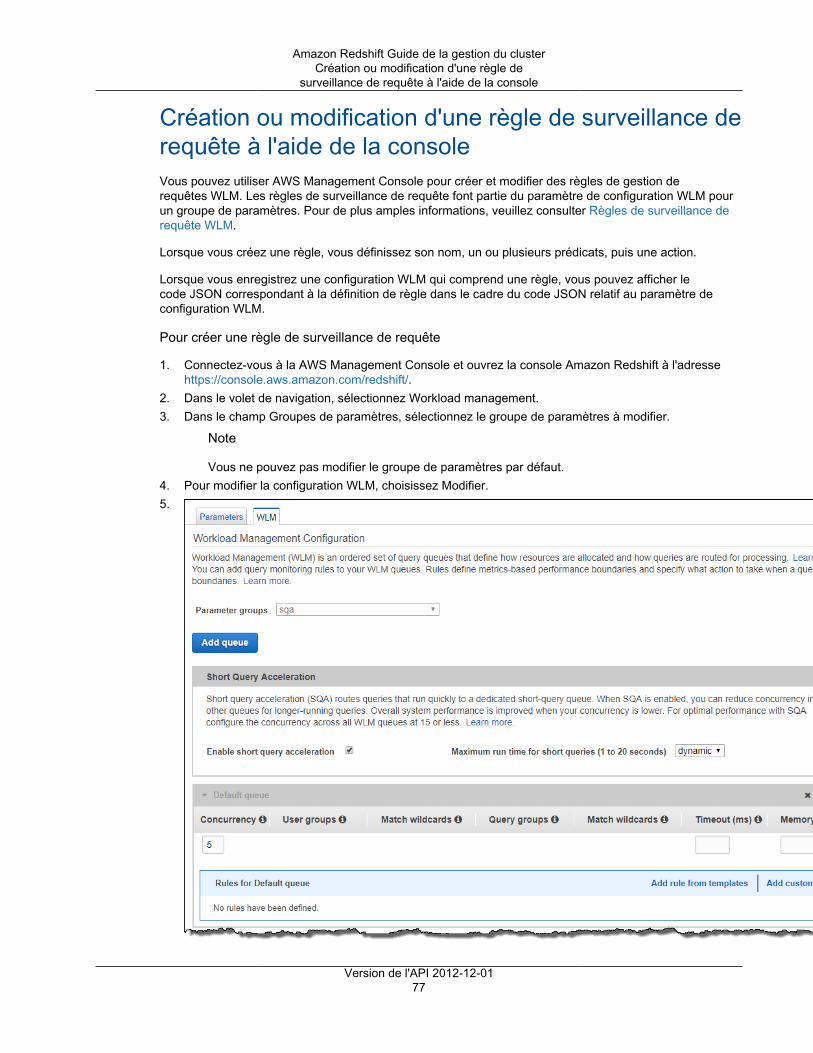
Amazon Redshift Guide de la gestion du clusterCréation ou modification d'une règle de
surveillance de requête à l'aide de la console
Création ou modification d'une règle de surveillance derequête à l'aide de la consoleVous pouvez utiliser AWS Management Console pour créer et modifier des règles de gestion derequêtes WLM. Les règles de surveillance de requête font partie du paramètre de configuration WLM pourun groupe de paramètres. Pour de plus amples informations, veuillez consulter Règles de surveillance derequête WLM.
Lorsque vous créez une règle, vous définissez son nom, un ou plusieurs prédicats, puis une action.
Lorsque vous enregistrez une configuration WLM qui comprend une règle, vous pouvez afficher lecode JSON correspondant à la définition de règle dans le cadre du code JSON relatif au paramètre deconfiguration WLM.
Pour créer une règle de surveillance de requête
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, sélectionnez Workload management.3. Dans le champ Groupes de paramètres, sélectionnez le groupe de paramètres à modifier.
Note
Vous ne pouvez pas modifier le groupe de paramètres par défaut.4. Pour modifier la configuration WLM, choisissez Modifier.5.
Version de l'API 2012-12-0177
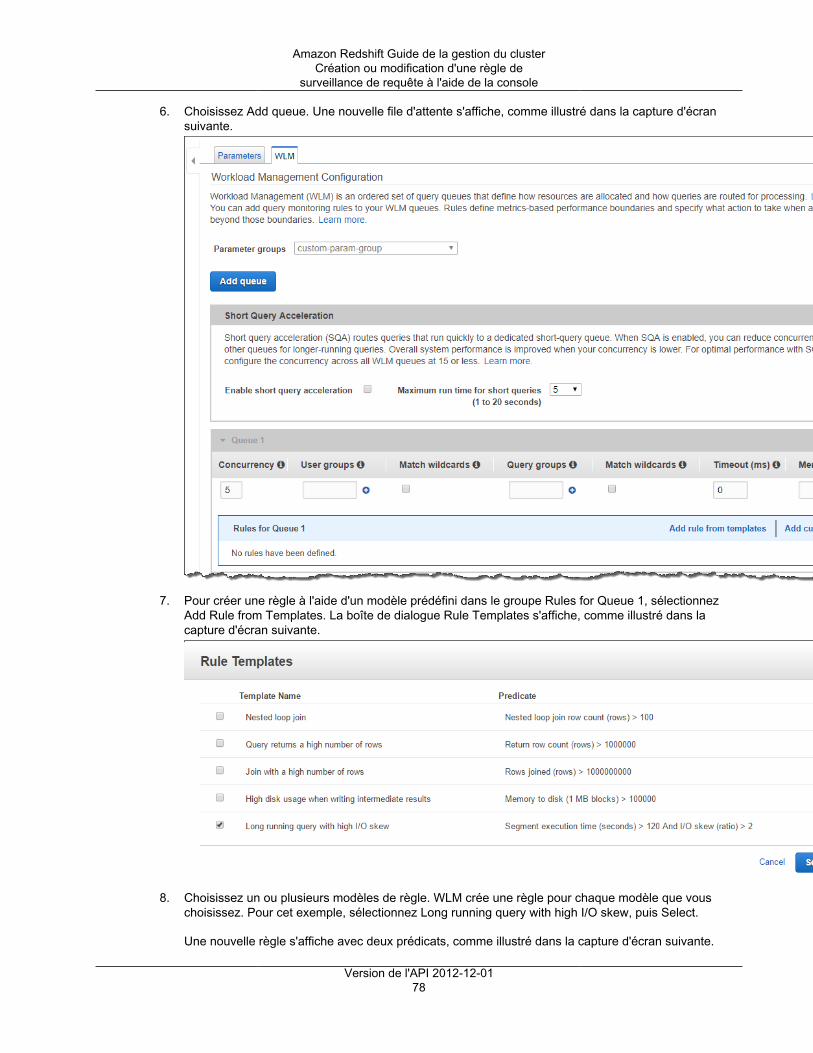
Amazon Redshift Guide de la gestion du clusterCréation ou modification d'une règle de
surveillance de requête à l'aide de la console
6. Choisissez Add queue. Une nouvelle file d'attente s'affiche, comme illustré dans la capture d'écransuivante.
7. Pour créer une règle à l'aide d'un modèle prédéfini dans le groupe Rules for Queue 1, sélectionnezAdd Rule from Templates. La boîte de dialogue Rule Templates s'affiche, comme illustré dans lacapture d'écran suivante.
8. Choisissez un ou plusieurs modèles de règle. WLM crée une règle pour chaque modèle que vouschoisissez. Pour cet exemple, sélectionnez Long running query with high I/O skew, puis Select.
Une nouvelle règle s'affiche avec deux prédicats, comme illustré dans la capture d'écran suivante.
Version de l'API 2012-12-0178
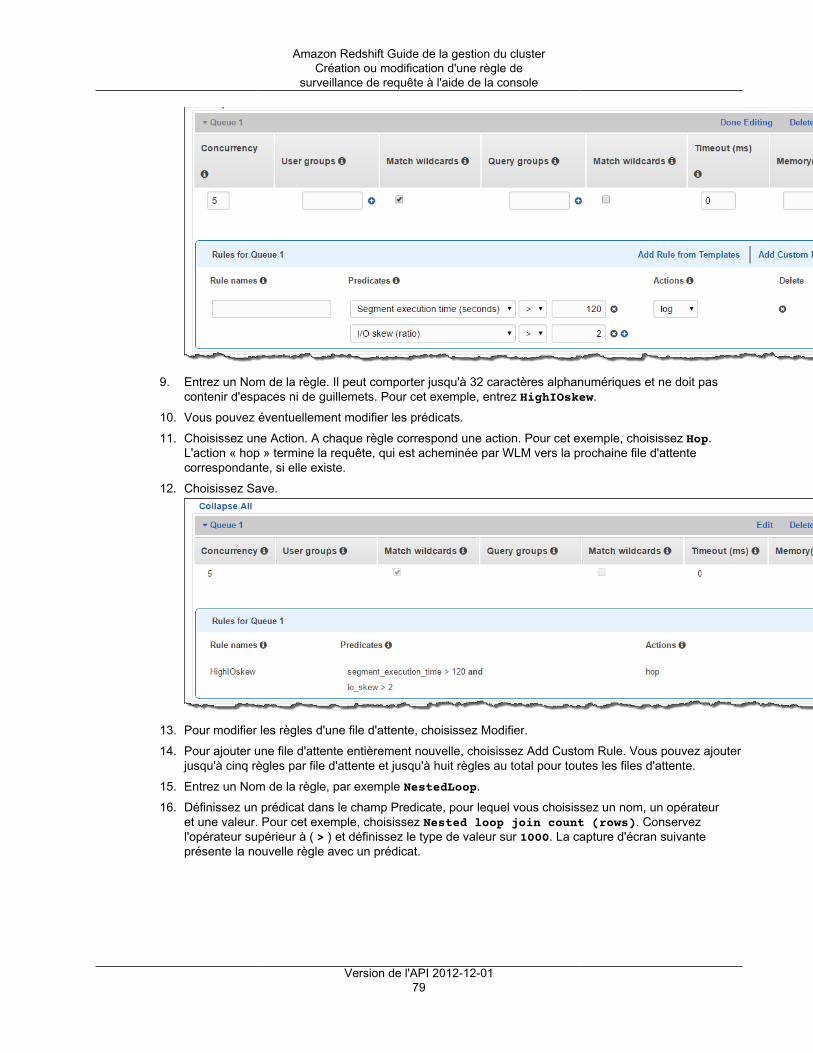
Amazon Redshift Guide de la gestion du clusterCréation ou modification d'une règle de
surveillance de requête à l'aide de la console
9. Entrez un Nom de la règle. Il peut comporter jusqu'à 32 caractères alphanumériques et ne doit pascontenir d'espaces ni de guillemets. Pour cet exemple, entrez HighIOskew.
10. Vous pouvez éventuellement modifier les prédicats.11. Choisissez une Action. A chaque règle correspond une action. Pour cet exemple, choisissez Hop.
L'action « hop » termine la requête, qui est acheminée par WLM vers la prochaine file d'attentecorrespondante, si elle existe.
12. Choisissez Save.
13. Pour modifier les règles d'une file d'attente, choisissez Modifier.14. Pour ajouter une file d'attente entièrement nouvelle, choisissez Add Custom Rule. Vous pouvez ajouter
jusqu'à cinq règles par file d'attente et jusqu'à huit règles au total pour toutes les files d'attente.15. Entrez un Nom de la règle, par exemple NestedLoop.16. Définissez un prédicat dans le champ Predicate, pour lequel vous choisissez un nom, un opérateur
et une valeur. Pour cet exemple, choisissez Nested loop join count (rows). Conservezl'opérateur supérieur à ( > ) et définissez le type de valeur sur 1000. La capture d'écran suivanteprésente la nouvelle règle avec un prédicat.
Version de l'API 2012-12-0179
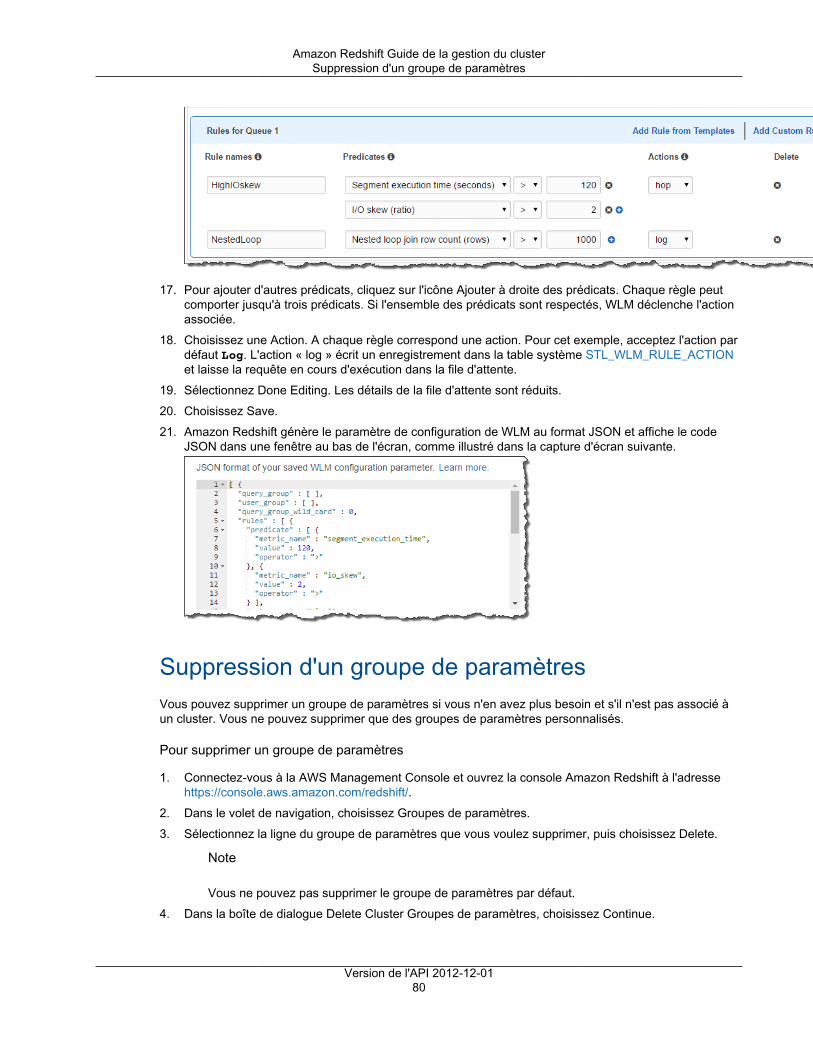
Amazon Redshift Guide de la gestion du clusterSuppression d'un groupe de paramètres
17. Pour ajouter d'autres prédicats, cliquez sur l'icône Ajouter à droite des prédicats. Chaque règle peutcomporter jusqu'à trois prédicats. Si l'ensemble des prédicats sont respectés, WLM déclenche l'actionassociée.
18. Choisissez une Action. A chaque règle correspond une action. Pour cet exemple, acceptez l'action pardéfaut Log. L'action « log » écrit un enregistrement dans la table système STL_WLM_RULE_ACTIONet laisse la requête en cours d'exécution dans la file d'attente.
19. Sélectionnez Done Editing. Les détails de la file d'attente sont réduits.20. Choisissez Save.21. Amazon Redshift génère le paramètre de configuration de WLM au format JSON et affiche le code
JSON dans une fenêtre au bas de l'écran, comme illustré dans la capture d'écran suivante.
Suppression d'un groupe de paramètresVous pouvez supprimer un groupe de paramètres si vous n'en avez plus besoin et s'il n'est pas associé àun cluster. Vous ne pouvez supprimer que des groupes de paramètres personnalisés.
Pour supprimer un groupe de paramètres
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Groupes de paramètres.3. Sélectionnez la ligne du groupe de paramètres que vous voulez supprimer, puis choisissez Delete.
Note
Vous ne pouvez pas supprimer le groupe de paramètres par défaut.4. Dans la boîte de dialogue Delete Cluster Groupes de paramètres, choisissez Continue.
Version de l'API 2012-12-0180
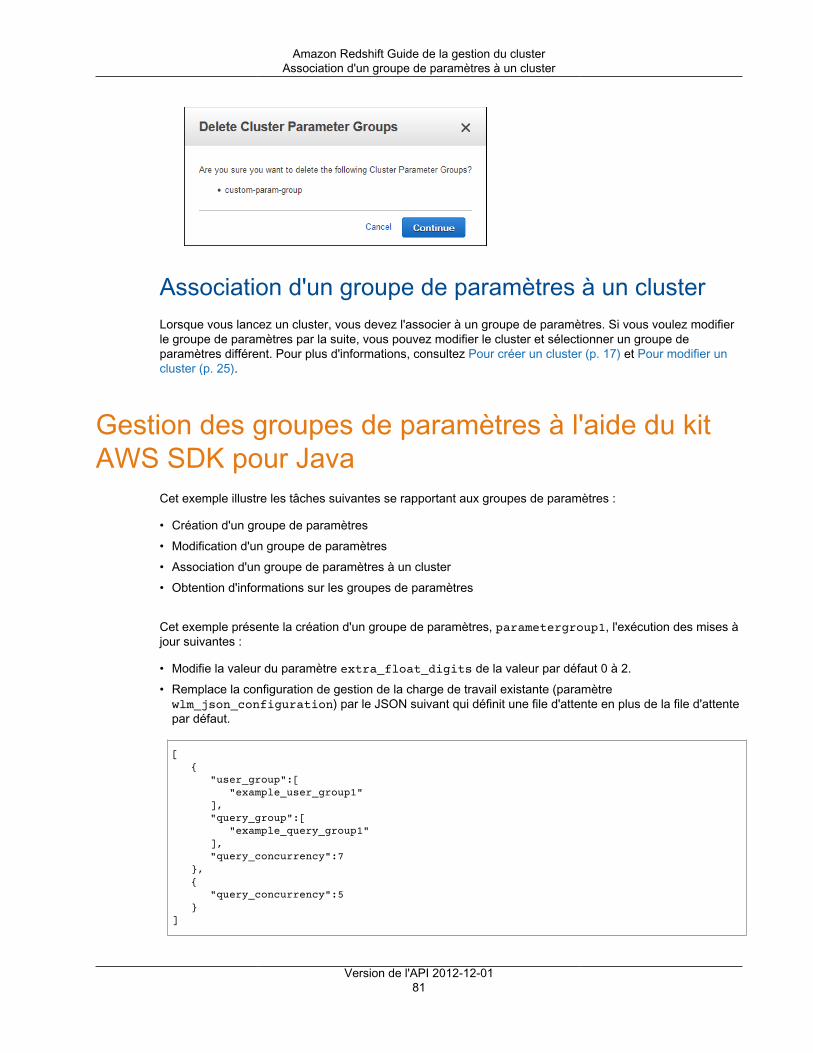
Amazon Redshift Guide de la gestion du clusterAssociation d'un groupe de paramètres à un cluster
Association d'un groupe de paramètres à un clusterLorsque vous lancez un cluster, vous devez l'associer à un groupe de paramètres. Si vous voulez modifierle groupe de paramètres par la suite, vous pouvez modifier le cluster et sélectionner un groupe deparamètres différent. Pour plus d'informations, consultez Pour créer un cluster (p. 17) et Pour modifier uncluster (p. 25).
Gestion des groupes de paramètres à l'aide du kitAWS SDK pour Java
Cet exemple illustre les tâches suivantes se rapportant aux groupes de paramètres :
• Création d'un groupe de paramètres• Modification d'un groupe de paramètres• Association d'un groupe de paramètres à un cluster• Obtention d'informations sur les groupes de paramètres
Cet exemple présente la création d'un groupe de paramètres, parametergroup1, l'exécution des mises àjour suivantes :
• Modifie la valeur du paramètre extra_float_digits de la valeur par défaut 0 à 2.• Remplace la configuration de gestion de la charge de travail existante (paramètrewlm_json_configuration) par le JSON suivant qui définit une file d'attente en plus de la file d'attentepar défaut.
[ { "user_group":[ "example_user_group1" ], "query_group":[ "example_query_group1" ], "query_concurrency":7 }, { "query_concurrency":5 }]
Version de l'API 2012-12-0181

Amazon Redshift Guide de la gestion du clusterGestion des groupes de paramètresà l'aide du kit AWS SDK pour Java
Le JSON précédent est un tableau de deux objets, un pour chaque file d'attente. Le premier objet définitune file d'attente avec le groupe d'utilisateurs et le groupe de requêtes spécifiques. Il définit également leniveau de simultanéité sur 7.
{ "user_group":[ "example_user_group1" ], "query_group":[ "example_query_group1" ], "query_concurrency":7}
Du fait que cet exemple remplace la configuration WLM, cette configuration JSON définit également la filed'attente par défaut sans groupe d'utilisateurs ou groupe de requêtes spécifique. Il définit la simultanéité surla valeur par défaut, 5.
{ "query_concurrency":5}
Pour plus d'informations sur la configuration de la gestion de la charge de travail (WML), accédez à Miseen œuvre de la gestion de la charge de travail.
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193). Vous devez mettre à jour le code et fournir unidentificateur de cluster.
Example
import java.io.IOException;import java.util.ArrayList;import java.util.List;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;import com.amazonaws.services.redshift.model.*;
public class CreateAndModifyClusterParameterGroup {
public static AmazonRedshiftClient client; public static String clusterParameterGroupName = "parametergroup1"; public static String clusterIdentifier = "***provide cluster identifier***"; public static String parameterGroupFamily = "redshift-1.0"; public static void main(String[] args) throws IOException { AWSCredentials credentials = new PropertiesCredentials( CreateAndModifyClusterParameterGroup.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { createClusterParameterGroup(); modifyClusterParameterGroup(); associateParameterGroupWithCluster(); describeClusterParameterGroups(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage());
Version de l'API 2012-12-0182

Amazon Redshift Guide de la gestion du clusterGestion des groupes de paramètresà l'aide du kit AWS SDK pour Java
} }
private static void createClusterParameterGroup() { CreateClusterParameterGroupRequest request = new CreateClusterParameterGroupRequest() .withDescription("my cluster parameter group") .withParameterGroupName(clusterParameterGroupName) .withParameterGroupFamily(parameterGroupFamily); client.createClusterParameterGroup(request); System.out.println("Created cluster parameter group."); } private static void describeClusterParameterGroups() { DescribeClusterParameterGroupsResult result = client.describeClusterParameterGroups(); printResultClusterParameterGroups(result); }
private static void modifyClusterParameterGroup() { List<Parameter> parameters = new ArrayList<Parameter>(); parameters.add(new Parameter() .withParameterName("extra_float_digits") .withParameterValue("2")); // Replace WLM configuration. The new configuration defines a queue (in addition to the default). parameters.add(new Parameter() .withParameterName("wlm_json_configuration") .withParameterValue("[{\"user_group\":[\"example_user_group1\"],\"query_group\":[\"example_query_group1\"],\"query_concurrency\":7},{\"query_concurrency\":5}]")); ModifyClusterParameterGroupRequest request = new ModifyClusterParameterGroupRequest() .withParameterGroupName(clusterParameterGroupName) .withParameters(parameters); client.modifyClusterParameterGroup(request); }
private static void associateParameterGroupWithCluster() {
ModifyClusterRequest request = new ModifyClusterRequest() .withClusterIdentifier(clusterIdentifier) .withClusterParameterGroupName(clusterParameterGroupName); Cluster result = client.modifyCluster(request); System.out.format("Parameter Group %s is used for Cluster %s\n", clusterParameterGroupName, result.getClusterParameterGroups().get(0).getParameterGroupName()); } private static void printResultClusterParameterGroups(DescribeClusterParameterGroupsResult result) { if (result == null) { System.out.println("\nDescribe cluster parameter groups result is null."); return; }
System.out.println("\nPrinting parameter group results:\n"); for (ClusterParameterGroup group : result.getParameterGroups()) { System.out.format("\nDescription: %s\n", group.getDescription()); System.out.format("Group Family Name: %s\n", group.getParameterGroupFamily()); System.out.format("Group Name: %s\n", group.getParameterGroupName());
Version de l'API 2012-12-0183

Amazon Redshift Guide de la gestion du clusterGestion des groupes de paramètres à l'aide de l'interface
de ligne de commande Amazon Redshift et de l'API
describeClusterParameters(group.getParameterGroupName()); } } private static void describeClusterParameters(String parameterGroupName) { DescribeClusterParametersRequest request = new DescribeClusterParametersRequest() .withParameterGroupName(parameterGroupName); DescribeClusterParametersResult result = client.describeClusterParameters(request); printResultClusterParameters(result, parameterGroupName); }
private static void printResultClusterParameters(DescribeClusterParametersResult result, String parameterGroupName) { if (result == null) { System.out.println("\nCluster parameters is null."); return; }
System.out.format("\nPrinting cluster parameters for \"%s\"\n", parameterGroupName); for (Parameter parameter : result.getParameters()) { System.out.println(" Name: " + parameter.getParameterName() + ", Value: " + parameter.getParameterValue()); System.out.println(" DataType: " + parameter.getDataType() + ", MinEngineVersion: " + parameter.getMinimumEngineVersion()); System.out.println(" AllowedValues: " + parameter.getAllowedValues() + ", Source: " + parameter.getSource()); System.out.println(" IsModifiable: " + parameter.getIsModifiable() + ", Description: " + parameter.getDescription()); } }}
Gestion des groupes de paramètres à l'aide del'interface de ligne de commande Amazon Redshiftet de l'API
Vous pouvez utiliser les opérations d'interface de ligne de commande Amazon Redshift suivantes pourgérer les groupes de paramètres.
• create-cluster-parameter-group• delete-cluster-parameter-group• describe-cluster-parameters• describe-cluster-parameter-groups• describe-default-cluster-parameters• modify-cluster-parameter-group• reset-cluster-parameter-group
Vous pouvez utiliser les API Amazon Redshift suivantes pour gérer les groupes de paramètres.
• CreateClusterParameterGroup
Version de l'API 2012-12-0184

Amazon Redshift Guide de la gestion du clusterGestion des groupes de paramètres à l'aide de l'interface
de ligne de commande Amazon Redshift et de l'API
• DeleteClusterParameterGroup• DescribeClusterParameters• DescribeClusterParameterGroups• DescribeDefaultClusterParameters• ModifyClusterParameterGroup• ResetClusterParameterGroup
Version de l'API 2012-12-0185

Amazon Redshift Guide de la gestion du clusterPrésentation
Instantanés Amazon RedshiftRubriques
• Présentation (p. 86)• Gestion d'instantanés à l'aide de la console (p. 93)• Gestion des instantanés à l'aide du kit AWS SDK pour Java (p. 101)• Gestion des instantanés à l'aide de l'interface de ligne de commande et de l'API Amazon
Redshift (p. 103)
PrésentationLes instantanés sont des sauvegardes du cluster à un instant donné. Il existe deux types d'instantanés :automatiques et manuels. Amazon Redshift stocke ces instantanés en interne dans Amazon S3 à l'aided'une connexion chiffrée SSL (Secure Sockets Layer). Si vous devez restaurer à partir d'un instantané,Amazon Redshift crée un nouveau cluster et importe les données à partir de l'instantané que vousspécifiez.
Lorsque vous restaurez à partir d'un instantané, Amazon Redshift crée un nouveau cluster et le renddisponible avant que toutes les données ne soient chargées ; en conséquence, vous pouvez commencerà interroger le nouveau cluster immédiatement. Le cluster diffuse les données à la demande à partir del'instantané en réponse aux requêtes actives, puis charge le reste des données à l'arrière-plan.
Régulièrement, Amazon Redshift prend des instantanés incrémentaux qui effectuent le suivi desmodifications du cluster depuis l'instantané précédent. Amazon Redshift conserve toutes les donnéesrequises pour restaurer un cluster à partir d'un instantané.
Vous pouvez contrôler la progression des instantanés en affichant les détails de l'instantané dans AWSManagement Console. ou en appelant describe-cluster-snapshots dans l'interface de ligne de commandeou l'action d'API DescribeClusterSnapshots. Pour un instantané en cours, sont affichées les informationstelles que la taille de l'instantané incrémentiel, la vitesse de transfert, le temps passé et la durée restanteestimée.
Amazon Redshift fournit un stockage gratuit pour les instantanés égal à la capacité de stockage de votrecluster jusqu'à ce que vous le supprimiez. Une fois que vous atteignez la limite de stockage gratuit desinstantanés, tout stockage supplémentaire vous est facturé au prix normal. Pour cette raison, vous devezévaluer le nombre de jours pendant lesquels vous devez garder les instantanés automatiques et configurerleur période de conservation en conséquence, ainsi que supprimer les instantanés manuels dont vousn'avez plus besoin. Pour les informations de tarification, consultez la page Amazon Redshift détaillée duproduit.
Instantanés automatiquesLorsque les instantanés automatiques sont activés pour un cluster, Amazon Redshift prend régulièrementdes instantanés de ce cluster, généralement toutes les huit heures ou tous les 5 Go par nœud demodifications de données, selon la première de ces deux éventualités. Les instantanés automatiques sontactivés par défaut lorsque vous créez un cluster. Ces instantanés sont supprimés à la fin d'une période deconservation. La période de conservation par défaut est d'un jour, mais vous pouvez la modifier à l'aide dela console Amazon Redshift ou par programmation en utilisant l'API Amazon Redshift.
Pour désactiver les instantanés automatiques, définissez la période de conservation sur zéro. Si vousdésactivez les instantanés automatiques, Amazon Redshift cesse de prendre des instantanés et supprimeles instantanés automatiques existants pour le cluster.
Version de l'API 2012-12-0186

Amazon Redshift Guide de la gestion du clusterInstantanés manuels
Seul Amazon Redshift peut supprimer un instantané automatique ; vous ne pouvez pas les supprimermanuellement. Amazon Redshift supprime les instantanés automatiques à la fin de la période deconservation d'un instantané, lorsque vous désactivez les instantanés automatiques ou que voussupprimez le cluster. Amazon Redshift conserve l'instantané automatique le plus récent jusqu'à ce quevous désactiviez les instantanés automatiques ou que vous supprimiez le cluster.
Si vous souhaitez conserver un instantané automatique pendant une période plus longue, vous pouvezen créer une copie en tant qu'instantané manuel. L'instantané automatique est conservé jusqu'à la fin dela période de conservation, mais l'instantané manuel correspondant est conservé jusqu'à ce que vous lesupprimiez manuellement.
Instantanés manuelsIndépendamment de savoir si vous activez ou pas les instantanés automatiques, vous pouvez prendreun instantané manuel chaque fois que vous le souhaitez. Amazon Redshift ne supprime jamaisautomatiquement un instantané manuel. Les instantanés manuels sont conservés même après lasuppression de votre cluster.
Comme les instantanés manuels entraînent des frais de stockage, il est important que vous les supprimiezmanuellement si vous n'en avez plus besoin. Si vous supprimez un manuel instantané, vous ne pouvez pasredémarrer de nouvelles opérations qui font référence à cet instantané. Cependant, si une opération derestauration est en cours, elle s'exécute intégralement.
Amazon Redshift dispose d'un quota qui limite le nombre total d'instantanés manuels que vous pouvezcréer ; ce quota est par compte AWS par région. Le quota par défaut est répertorié dans Limites de serviceAWS.
Exclusion des tables des instantanésPar défaut, toutes les tables permanentes définies par l'utilisateur sont incluses dans les instantanés. Siune table, par exemple une table intermédiaire, n'a pas besoin d'être sauvegardée, vous pouvez réduireconsidérablement le temps nécessaire à la création d'instantanés et à la restauration à partir d'instantanés.Vous réduisez également l'espace de stockage sur Amazon S3 à l'aide d'une table sans sauvegarde. Pourcréer une table sans sauvegarde, incluez le paramètre BACKUP NO lorsque vous créez la table. Pourplus d'informations, consultez CREATE TABLE et CREATE TABLE AS dans le manuel Amazon RedshiftDatabase Developer Guide.
Copie d'instantanés sur une autre régionVous pouvez configurer Amazon Redshift pour qu'il copie automatiquement les instantanés (automatiquesou manuels) d'un cluster sur une autre région. Quand un instantané est créé dans la région principale ducluster, il est copié dans une région secondaire ; ces deux régions sont appelées respectivement régionsource et région de destination. En stockant une copie de vos instantanés dans une autre région, vousavez la possibilité de restaurer votre cluster à partir des données récentes si quoi que ce soit affecte larégion principale. Vous pouvez configurer votre cluster pour ne copier les instantanés que sur une seulerégion de destination à la fois. Pour obtenir la liste des régions Amazon Redshift, consultez Régions etpoints de terminaison du manuel Référence générale d'Amazon Web Services.
Lorsque vous activez Amazon Redshift pour qu'il copie automatiquement les instantanés sur une autrerégion, vous spécifiez la région de destination où vous voulez que les instantanés soient copiés. Dansle cas d'instantanés automatiques, vous pouvez également spécifier la période de conservation pendantlaquelle ils doivent être conservés dans la région de destination. Une fois qu'un instantané automatiquea été copié dans la région de destination et qu'il a atteint la durée de conservation définie, il est suppriméde la région de destination, ce qui maintient votre utilisation de l'instantané à un niveau bas. Vous pouvezmodifier cette période de conservation si vous avez besoin de conserver les instantanés automatiquespendant une durée plus courte ou plus longue dans la région de destination.
Version de l'API 2012-12-0187
Amazon Redshift Guide de la gestion du clusterRestauration d'un cluster à partir d'un instantané
La période de conservation que vous avez définie pour les instantanés automatiques copiés sur la régionde destination est distincte de celle des instantanés automatiques de la région source. La période deconservation par défaut pour les instantanés copiés est de 7 jours. Cette période de sept jours s'appliqueuniquement aux instantanés automatiques. Les instantanés manuels ne sont pas concernés par la périodede conservation que ce soit dans les régions source ou les régions de destination ; ils y restent jusqu'à ceque vous les supprimiez manuellement.
Vous pouvez désactiver la copie d'instantané automatique d'un cluster à tout moment. Lorsque vousdésactivez cette fonctionnalité, les instantanés ne sont plus copiés de la région source vers la région dedestination. Les instantanés automatiques copiés sur la région de destination sont supprimés dès qu'ilsatteignent la limite de leur période de conservation, sauf si vous en créez des copies d'instantané manuel.Ces instantanés manuels, et les instantanés manuels qui ont été copiés à partir de la région de destination,sont conservés dans la région de destination jusqu'à ce que vous les supprimiez manuellement.
Si vous voulez modifier la région de destination sur laquelle vous copiez les instantanés, vous devezd'abord désactiver la fonctionnalité de copie automatique, puis la réactiver en spécifiant la nouvelle régionde destination.
La copie d'instantanés entre les régions entraîne des frais de transfert de données. Une fois qu'uninstantané est copié dans la région de destination, il devient actif et disponible à des fins de restauration.
Si vous voulez copier les instantanés de clusters chiffrés AWS KMS sur une autre région, vous devez créerune autorisation pour qu'Amazon Redshift utilise une clé principale de client (CMK) AWS KMS dans larégion de destination. Ensuite, vous devez sélectionner cette autorisation lorsque vous activez la copied'instantanés de la région source. Pour plus d'informations sur la configuration des autorisations de copied'instantané, consultez Copie d'instantanés chiffrés par AWS KMS dans une autre région (p. 106).
Restauration d'un cluster à partir d'un instantanéUn instantané contient les données des bases de données qui s'exécutent sur votre cluster, ainsi que desinformations sur votre cluster, y compris le nombre de nœuds, le type de nœud et le nom de l'utilisateurprincipal. Si vous devez restaurer votre cluster à partir d'un instantané, Amazon Redshift utilise lesinformations de cluster pour créer un cluster, puis restaure toutes les bases de données à partir desdonnées de l'instantané. Le nouveau cluster qu'Amazon Redshift crée à partir de l'instantané aura la mêmeconfiguration, y compris le nombre et le type de nœuds, que le cluster original à partir duquel l'instantanéa été pris. Le cluster est restauré dans la même région et la même zone de disponibilité, sauf si vousspécifiez une autre zone de disponibilité dans votre demande.
Vous pouvez surveiller la progression d'une restauration en appelant l'action d'API DescribeClusters ouen affichant les détails du cluster dans AWS Management Console. Pour une restauration en cours, sontaffichées les informations telles que la taille des données de l'instantané, la vitesse de transfert, le tempspassé et la durée restante estimée. Pour une description de ces métriques, consultez RestoreStatus.
Vous ne pouvez pas utiliser un instantané pour rétablir un cluster actif à un état antérieur.
Note
Lorsque vous restaurez un instantané sur un nouveau cluster, les groupe de sécurité et groupe deparamètres par défaut sont utilisés, sauf si vous spécifiez des valeurs différentes.
Restauration d'une table à partir d'un instantanéVous pouvez restaurer une table à partir d'un instantané au lieu de restaurer l'intégralité du cluster. Lorsquevous restaurez une seule table à partir d'un instantané, vous spécifiez l'instantané source, la base dedonnées, le schéma et le nom de la table, ainsi que le cluster cible, le schéma et un nouveau nom de tablepour la table restaurée.
Version de l'API 2012-12-0188

Amazon Redshift Guide de la gestion du clusterRestauration d'une table à partir d'un instantané
Le nouveau nom de table ne peut pas être le nom d'une table existante. Pour remplacer une table existantepar une table restaurée à partir d'un instantané, renommez ou supprimez la table existante avant derestaurer la table à partir de l'instantané.
La table cible est créée à l'aide des définitions de colonne de la table source, des attributs de table et desattributs de colonne à l'exception des clés étrangères. Pour éviter les conflits liés aux dépendances, la tablecible n'hérite pas les clés étrangères de la table source. Toutes les dépendances, telles que les vues ou lesautorisations accordées sur la table source, ne sont pas appliquées à la table cible.
Si le propriétaire de la table source existe, l'utilisateur est le propriétaire de la table restaurée, à conditionque l'utilisateur dispose des autorisations suffisantes pour devenir le propriétaire d'une relation du schémaet de la base de données spécifiés. Sinon, la table restaurée appartient à l'utilisateur principal qui a étécréé lorsque le cluster a été lancé.
La table restaurée retourne à l'état où elle était au moment de la sauvegarde. Cela inclut les règles devisibilité des transactions, définies par l'adhésion de Redshift au principe d'isolement sérialisable, quisignifie que les données sont immédiatement visibles des transactions en cours démarrées après lasauvegarde.
La restauration d'une table à partir d'un instantané présente les limitations suivantes :
• Vous ne pouvez restaurer une table que sur le cluster actif en cours d'exécution, et à partir d'uninstantané de ce cluster.
• Vous ne pouvez restaurer qu'une seule table à la fois.• Vous ne pouvez pas restaurer une table à partir d'un instantané de cluster pris avant un
redimensionnement.
Pour restaurer une table à partir d'un instantané à l'aide de la console Amazon Redshift
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Choisissez Clusters.3. Choisissez l'onglet Restauration de table.
4. Choisissez Restaurer une table.5. Dans le voletRestauration de table, sélectionnez une plage de dates contenant l'instantané de cluster à
partir duquel vous souhaitez effectuer la restauration. Par exemple, vous pouvez sélectionner Last 1Week pour les instantanés de cluster pris la semaine précédente.
6. Ajoutez les informations suivantes :
• A partir de l'instantané – l'identifiant de l'instantané de cluster qui contient la table à partir de laquelleeffectuer la restauration.
• Table source à partir de laquelle la restauration est effectuée• Base de données – le nom de la base de données de l'instantané de cluster qui contient la table à
partir de laquelle effectuer la restauration.
Version de l'API 2012-12-0189
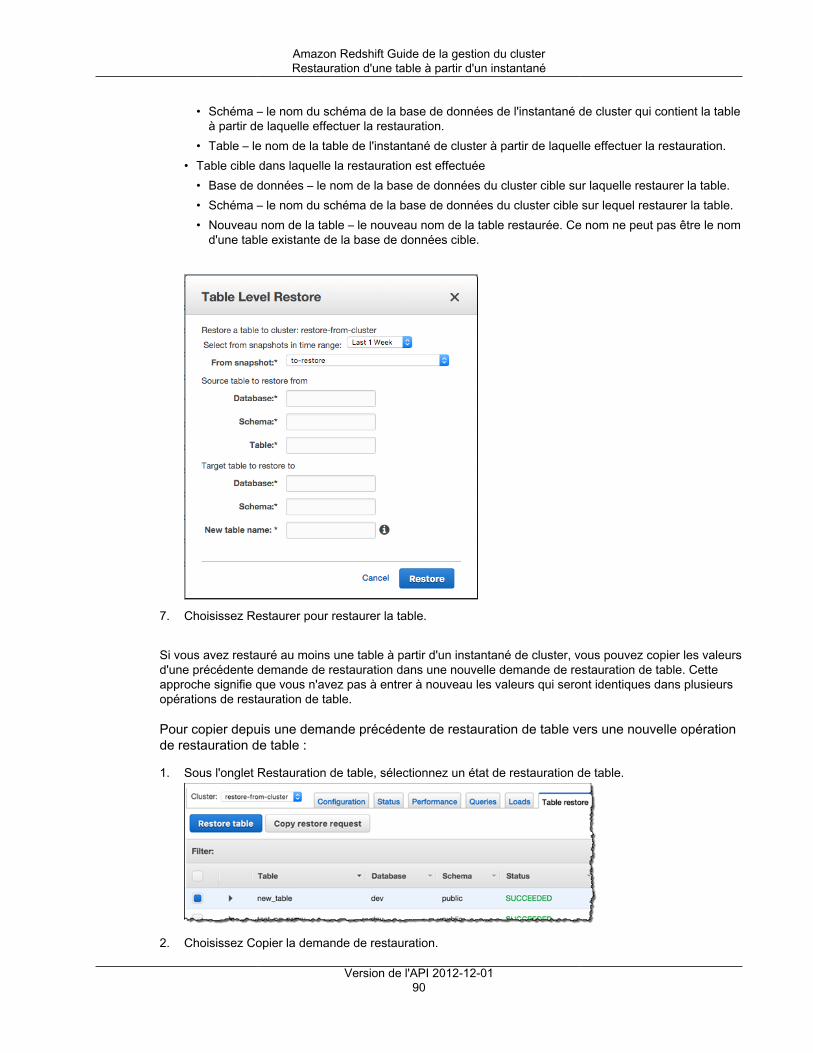
Amazon Redshift Guide de la gestion du clusterRestauration d'une table à partir d'un instantané
• Schéma – le nom du schéma de la base de données de l'instantané de cluster qui contient la tableà partir de laquelle effectuer la restauration.
• Table – le nom de la table de l'instantané de cluster à partir de laquelle effectuer la restauration.• Table cible dans laquelle la restauration est effectuée
• Base de données – le nom de la base de données du cluster cible sur laquelle restaurer la table.• Schéma – le nom du schéma de la base de données du cluster cible sur lequel restaurer la table.• Nouveau nom de la table – le nouveau nom de la table restaurée. Ce nom ne peut pas être le nom
d'une table existante de la base de données cible.
7. Choisissez Restaurer pour restaurer la table.
Si vous avez restauré au moins une table à partir d'un instantané de cluster, vous pouvez copier les valeursd'une précédente demande de restauration dans une nouvelle demande de restauration de table. Cetteapproche signifie que vous n'avez pas à entrer à nouveau les valeurs qui seront identiques dans plusieursopérations de restauration de table.
Pour copier depuis une demande précédente de restauration de table vers une nouvelle opérationde restauration de table :
1. Sous l'onglet Restauration de table, sélectionnez un état de restauration de table.
2. Choisissez Copier la demande de restauration.
Version de l'API 2012-12-0190

Amazon Redshift Guide de la gestion du clusterPartage d'un instantané
Example Exemple : restauration d'une table à partir d'un instantané à l'aide de l'interface de lignede commande AWS
L'exemple suivant utilise la commande restore-table-from-cluster-snapshot de l'interfacede ligne de commande AWS pour restaurer la table my-source-table à partir du schéma sample-database de my-snapshot-id. L'exemple restaure l'instantané sur le cluster mycluster-exampleavec le nouveau nom de table my-new-table.
aws redshift restore-table-from-cluster-snapshot --cluster-identifier mycluster-example --new-table-name my-new-table --snapshot-identifier my-snapshot-id --source-database-name sample-database --source-table-name my-source-table
Partage d'un instantanéVous pouvez partager un instantané manuel avec d'autres comptes clients AWS en autorisant l'accèsà l'instantané. Vous pouvez autoriser jusqu'à 20 comptes pour chaque instantané et 100 comptes pourchaque clé AWS Key Management Service (AWS KMS). Autrement dit, si vous avez 10 instantanés chiffrésavec une seule clé KMS, vous pouvez autoriser 10 comptes AWS pour restaurer chaque instantané,ou autres combinaisons qui s'ajoutent jusqu'à 100 comptes, sans dépasser 20 comptes pour chaqueinstantané. Une personne connectée comme utilisateur dans l'un des comptes autorisés peut alors décrirel'instantané ou le restaurer pour créer un nouveau cluster Amazon Redshift sous son compte. Par exemple,si vous utilisez des comptes AWS distincts pour la production et les tests, un utilisateur peut se connecter àl'aide du compte production et partager un instantané avec les utilisateurs du compte tests. Une personneconnectée comme utilisateur d'un compte tests peut alors restaurer l'instantané pour créer un nouveaucluster, détenu par le compte tests, à des fins de tests ou de diagnostic.
Un instantané manuel est détenu en permanence par le compte client AWS sous lequel il a été créé.Seuls les utilisateurs du compte détenteurs de l'instantané peuvent autoriser d'autres comptes àaccéder à l'instantané ou à révoquer les autorisations. Les utilisateurs des comptes autorisés peuventuniquement décrire ou restaurer un instantané qu'ils ont partagé ; ils ne peuvent pas copier ou supprimerdes instantanés qu'ils ont partagés. Une autorisation reste en vigueur jusqu'à ce que le propriétaire del'instantané la révoque. Si une autorisation est révoquée, l'utilisateur précédemment autorisé perd lavisibilité de l'instantané et ne peut pas lancer de nouvelles actions faisant référence à l'instantané. Si lecompte est en train de restaurer l'instantané lorsque l'accès est révoqué, la restauration s'exécute jusqu'àla fin. Vous ne pouvez pas supprimer un instantané pendant qu'il a des autorisations actives ; vous devezd'abord révoquer toutes les autorisations.
Les comptes clients AWS sont toujours autorisés à accéder aux instantanés détenus par le compte. Lestentatives d'autorisation ou de révocation de l'accès au compte propriétaire entraînent une erreur. Vous nepouvez pas restaurer ou décrire un instantané détenu par un compte client AWS inactif.
Une fois que vous avez autorisé l'accès à un compte client AWS, aucun utilisateur IAM de ce compte nepeut effectuer d'actions sur l'instantané, à moins de disposer des stratégies IAM qui l'y autorisent.
• Les utilisateurs IAM du compte propriétaire de l'instantané ne peuvent autoriser et révoquer l'accès à uninstantané que s'ils ont une stratégie IAM qui leur permet d'exécuter ces actions avec une spécificationde ressource incluant l'instantané. Par exemple, la stratégie suivante permet à un utilisateur d'uncompte AWS 012345678912 d'autoriser les autres comptes à accéder à un instantané nommé my-snapshot20130829 :
{ "Version": "2012-10-17", "Statement":[
Version de l'API 2012-12-0191

Amazon Redshift Guide de la gestion du clusterPartage d'un instantané
{ "Effect":"Allow", "Action":[ "redshift:AuthorizeSnapshotAccess", "redshift:RevokeSnapshotAccess" ], "Resource":[ "arn:aws:redshift:us-east-1:012345678912:snapshot:*/my-snapshot20130829" ] } ]}
• Les utilisateurs IAM d'un compte AWS avec lequel un instantané a été partagé ne peuvent pas exécuterd'actions sur cet instantané, à moins d'avoir les stratégies IAM autorisant ces actions :• Pour afficher ou décrire un instantané, ils doivent avoir une stratégie IAM autorisant l'actionDescribeClusterSnapshots. Le code suivant en présente un exemple :
{ "Version": "2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "redshift:DescribeClusterSnapshots" ], "Resource":[ "*" ] } ]}
• Pour restaurer un instantané, les utilisateurs doivent avoir une stratégie IAM permettant l'actionRestoreFromClusterSnapshot et ayant un élément de ressource qui couvre à la fois le clusterqu'ils créent et l'instantané. Par exemple, si un utilisateur du compte 012345678912 a partagél'instantané my-snapshot20130829 avec le compte 219876543210, pour pouvoir créer un clusteren restaurant l'instantané, un utilisateur du compte 219876543210 doit avoir une stratégie telle que lasuivante :
{ "Version": "2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "redshift:RestoreFromClusterSnapshot" ], "Resource":[ "arn:aws:redshift:us-east-1:012345678912:snapshot:*/my-snapshot20130829", "arn:aws:redshift:us-east-1:219876543210:cluster:from-another-account" ] } ]}
• Une fois que l'accès à un instantané a été annulé à partir d'un compte AWS, aucun utilisateur de cecompte ne peut accéder à l'instantané, même s'il possède les stratégies IAM qui autorisent des actionssur la ressource d'instantané précédemment partagée.
Version de l'API 2012-12-0192

Amazon Redshift Guide de la gestion du clusterGestion d'instantanés à l'aide de la console
Gestion d'instantanés à l'aide de la consoleAmazon Redshift effectue régulièrement des instantanés incrémentiels automatiques de vos données etles enregistre dans Amazon S3. De plus, vous pouvez effectuer des instantanés manuels de vos donnéesquand vous le souhaitez. Cette section explique comment gérer vos instantanés dans la console AmazonRedshift. Pour plus d'informations sur les instantanés, consultez Instantanés Amazon Redshift (p. 86).
Toutes les tâches d'instantanés dans la console Amazon Redshift démarrent à partir de la liste desinstantanés. Vous pouvez filtrer la liste en fonction du type d'instantané, de la plage de temps et du clusterassocié à l'instantané. Lorsque vous sélectionnez un instantané existant, les détails de celui-ci sontaffichés en ligne dans la liste, comme illustré dans l'exemple suivant. Selon le type d'instantané que vouschoisissez, vous disposerez de différentes options pour utiliser l'instantané.
Création d'un instantané manuelVous pouvez créer un instantané manuel d'un cluster dans la liste des instantanés comme suit. Sinon,vous pouvez effectuer un instantané d'un cluster dans le volet de configuration du cluster. Pour plusd'informations, consultez Prise d'un instantané d'un cluster (p. 31).
Pour créer un snapshot manuel
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Instantanés.3. Cliquez sur Créer un instantané.
4. Dans la boîte de dialogue Créer un instantané, exécutez l'une des actions suivantes :
a. Dans la zone Identifiant du cluster, cliquez sur le cluster dont vous souhaitez prendre uninstantané.
b. Dans la zone Identifiant de l'instantané, tapez un nom pour l'instantané.
Version de l'API 2012-12-0193

Amazon Redshift Guide de la gestion du clusterSuppression d'un instantané manuel
5. Cliquez sur Create.
L'instantané peut prendre du temps. Le nouvel instantané s'affiche dans la liste des instantanés avecson statut actuel. L'exemple suivant indique que examplecluster-manual-02-13-13 est en coursde création.
Suppression d'un instantané manuelPour supprimer un instantané manuel
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Instantanés.3. Si vous avez besoin de filtrer la liste afin de trouver l'instantané que vous souhaitez supprimer,
exécutez l'une des opérations suivantes :
• Dans la zone Plage de temps, cliquez sur une plage de temps qui permettra d'affiner votrerecherche en conséquence.
• Dans la zone Type, cliquez sur manuel.• Dans la zone Cluster, cliquez sur le cluster dont vous souhaitez supprimer l'instantané.
4. Dans la liste des instantanés, cliquez sur la ligne qui contient l'instantané que vous souhaitezsupprimer.
5. Cliquez sur Supprimer l'instantané manuel.
Version de l'API 2012-12-0194
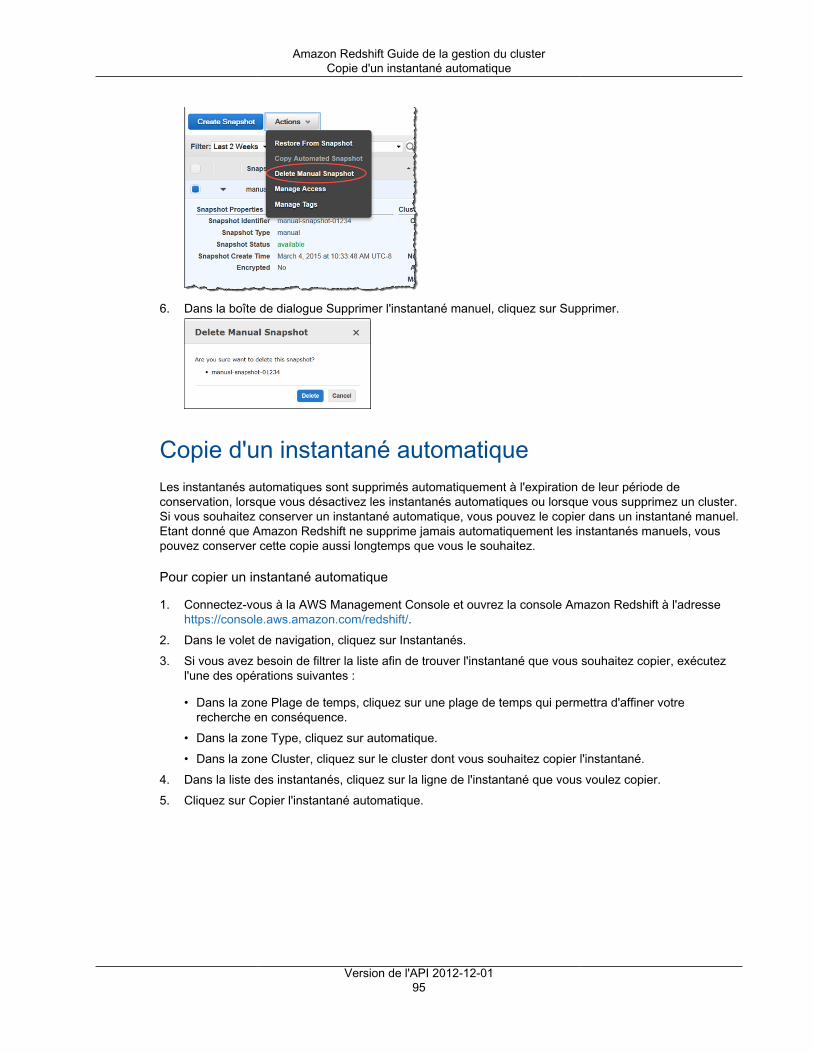
Amazon Redshift Guide de la gestion du clusterCopie d'un instantané automatique
6. Dans la boîte de dialogue Supprimer l'instantané manuel, cliquez sur Supprimer.
Copie d'un instantané automatiqueLes instantanés automatiques sont supprimés automatiquement à l'expiration de leur période deconservation, lorsque vous désactivez les instantanés automatiques ou lorsque vous supprimez un cluster.Si vous souhaitez conserver un instantané automatique, vous pouvez le copier dans un instantané manuel.Etant donné que Amazon Redshift ne supprime jamais automatiquement les instantanés manuels, vouspouvez conserver cette copie aussi longtemps que vous le souhaitez.
Pour copier un instantané automatique
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Instantanés.3. Si vous avez besoin de filtrer la liste afin de trouver l'instantané que vous souhaitez copier, exécutez
l'une des opérations suivantes :
• Dans la zone Plage de temps, cliquez sur une plage de temps qui permettra d'affiner votrerecherche en conséquence.
• Dans la zone Type, cliquez sur automatique.• Dans la zone Cluster, cliquez sur le cluster dont vous souhaitez copier l'instantané.
4. Dans la liste des instantanés, cliquez sur la ligne de l'instantané que vous voulez copier.5. Cliquez sur Copier l'instantané automatique.
Version de l'API 2012-12-0195
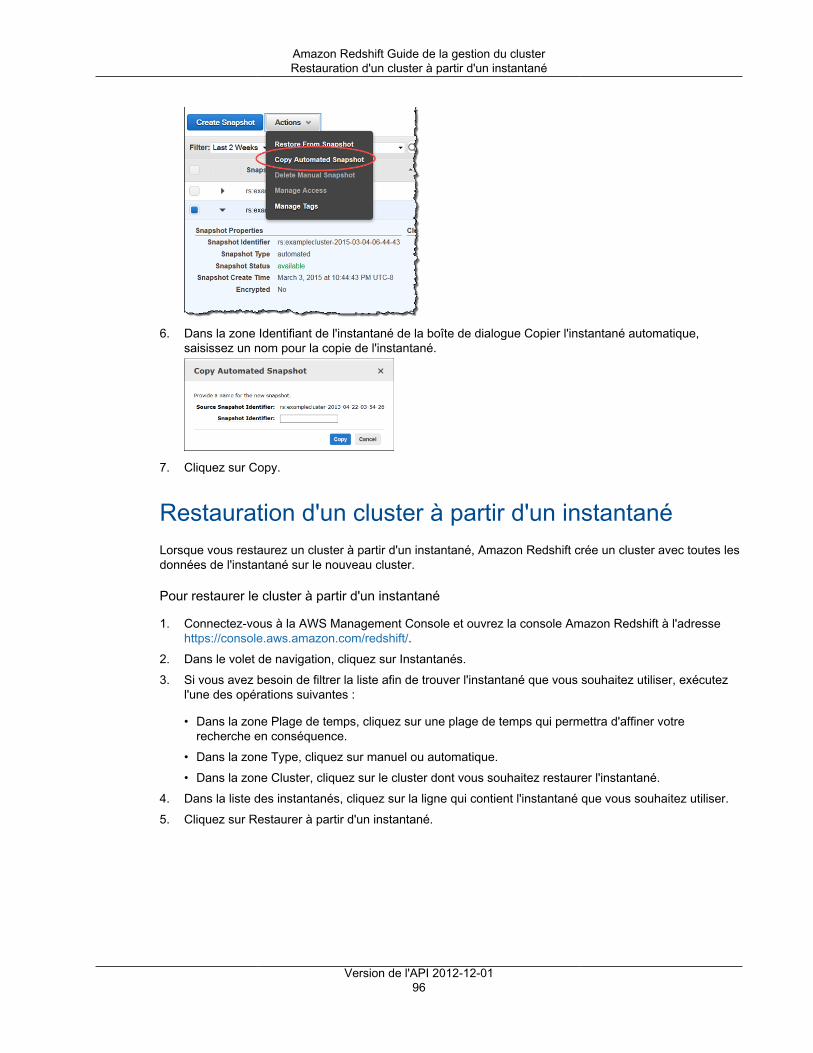
Amazon Redshift Guide de la gestion du clusterRestauration d'un cluster à partir d'un instantané
6. Dans la zone Identifiant de l'instantané de la boîte de dialogue Copier l'instantané automatique,saisissez un nom pour la copie de l'instantané.
7. Cliquez sur Copy.
Restauration d'un cluster à partir d'un instantanéLorsque vous restaurez un cluster à partir d'un instantané, Amazon Redshift crée un cluster avec toutes lesdonnées de l'instantané sur le nouveau cluster.
Pour restaurer le cluster à partir d'un instantané
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Instantanés.3. Si vous avez besoin de filtrer la liste afin de trouver l'instantané que vous souhaitez utiliser, exécutez
l'une des opérations suivantes :
• Dans la zone Plage de temps, cliquez sur une plage de temps qui permettra d'affiner votrerecherche en conséquence.
• Dans la zone Type, cliquez sur manuel ou automatique.• Dans la zone Cluster, cliquez sur le cluster dont vous souhaitez restaurer l'instantané.
4. Dans la liste des instantanés, cliquez sur la ligne qui contient l'instantané que vous souhaitez utiliser.5. Cliquez sur Restaurer à partir d'un instantané.
Version de l'API 2012-12-0196

Amazon Redshift Guide de la gestion du clusterRestauration d'un cluster à partir d'un instantané
6. Dans la boîte de dialogue Restaurer le cluster à partir d'un instantané, procédez comme suit :
a. Dans la zone Identifiant du cluster, entrez un identifiant de cluster pour le cluster restauré.
Les identifiants de cluster doivent répondre aux conditions suivantes :
• Il doivent contenir entre 1 et 255 caractères alphanumériques ou traits d'union.• Les caractères alphabétiques doivent être en minuscules.• Le premier caractère doit être une lettre.• Ils ne peuvent pas se terminer par un trait d'union ou contenir deux traits d'union consécutifs.• Il doivent être uniques pour tous les clusters au sein d'un compte AWS.
b. Dans la zone Port, acceptez le port de l'instantané ou modifiez la valeur le cas échéant.c. Sélectionnez Autoriser la mise à niveau de la version le cas échéant.d. Dans Groupe de sous-réseaux du cluster, sélectionnez le groupe de sous-réseaux dans lequel
vous souhaitez restaurer le cluster.
Cette option s'affiche uniquement si vous restaurez le cluster sur la plateforme EC2-VPC.e. Dans Accessible publiquement, sélectionnez Oui si vous voulez que le cluster ait une adresse
IP publique accessible via une connexion publique à Internet, puis sélectionnez Non si voussouhaitez que le cluster ait une adresse IP privée uniquement accessible depuis le VPC. Si votrecompte AWS vous permet de créer des clusters EC2-Classic, la valeur par défaut est Non. Sinon,la valeur par défaut est Yes.
Cette option s'affiche uniquement si vous restaurez le cluster sur la plateforme EC2-VPC.f. Dans Choisir une adresse IP publique, sélectionnez Oui si vous voulez sélectionner une adresse
IP Elastic (EIP) que vous avez déjà configurée. Dans le cas contraire, sélectionnez Non pour queAmazon Redshift crée une EIP pour votre instance.
Cette option s'affiche uniquement si vous restaurez le cluster sur la plateforme EC2-VPC.g. Dans Adresses IP élastiques, sélectionnez une EIP à utiliser pour vous connecter au cluster
depuis l'extérieur du VPC.
Cette option s'affiche uniquement si vous restaurez le cluster sur la plateforme EC2-VPC et quevous sélectionnez Oui dans Choisir une adresse IP publique.
h. Dans la zone Zone de disponibilité, acceptez la zone de disponibilité de l'instantané ou modifiez lavaleur le cas échéant.
i. Dans Groupe de paramètres du cluster, sélectionnez un groupe de paramètres à associer aucluster.
j. Dans Groupes de sécurité du cluster ou Groupes de sécurité VPC, sélectionnez un groupe desécurité à associer au cluster. Les types de groupes de sécurité qui s'affichent ici varient selonque vous restaurez le cluster sur la plateforme EC2-Classic ou EC2-VPC.
Version de l'API 2012-12-0197
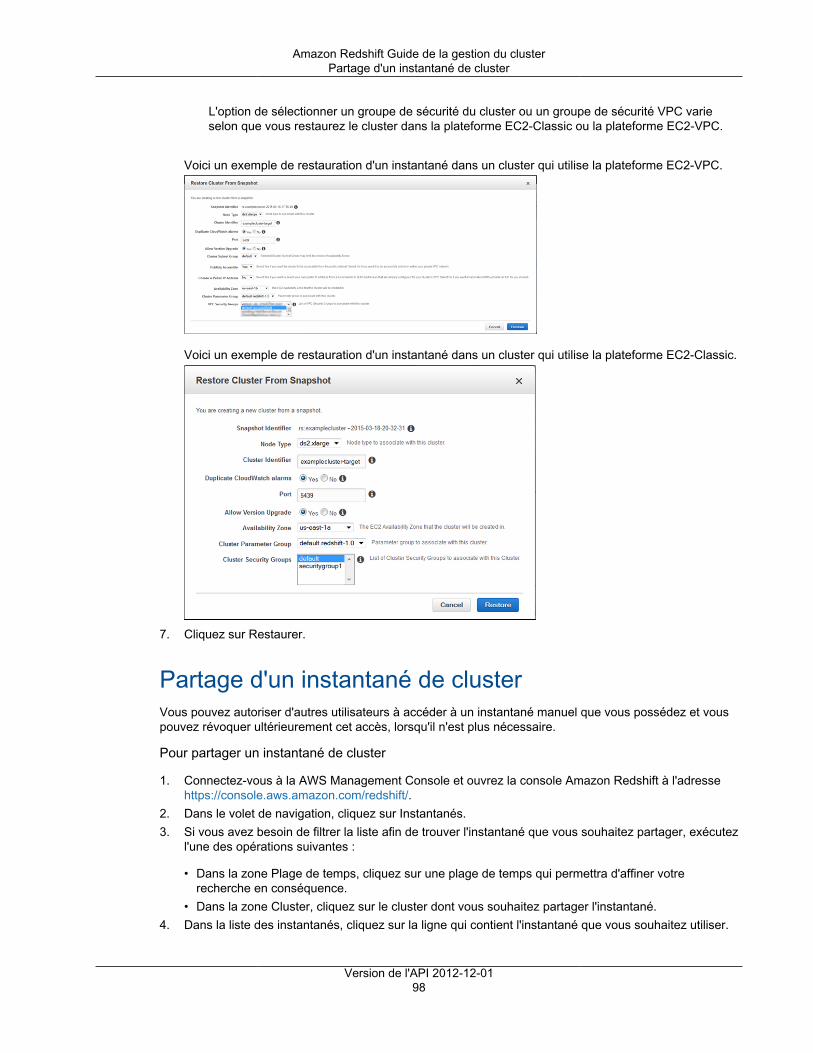
Amazon Redshift Guide de la gestion du clusterPartage d'un instantané de cluster
L'option de sélectionner un groupe de sécurité du cluster ou un groupe de sécurité VPC varieselon que vous restaurez le cluster dans la plateforme EC2-Classic ou la plateforme EC2-VPC.
Voici un exemple de restauration d'un instantané dans un cluster qui utilise la plateforme EC2-VPC.
Voici un exemple de restauration d'un instantané dans un cluster qui utilise la plateforme EC2-Classic.
7. Cliquez sur Restaurer.
Partage d'un instantané de clusterVous pouvez autoriser d'autres utilisateurs à accéder à un instantané manuel que vous possédez et vouspouvez révoquer ultérieurement cet accès, lorsqu'il n'est plus nécessaire.
Pour partager un instantané de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Instantanés.3. Si vous avez besoin de filtrer la liste afin de trouver l'instantané que vous souhaitez partager, exécutez
l'une des opérations suivantes :
• Dans la zone Plage de temps, cliquez sur une plage de temps qui permettra d'affiner votrerecherche en conséquence.
• Dans la zone Cluster, cliquez sur le cluster dont vous souhaitez partager l'instantané.4. Dans la liste des instantanés, cliquez sur la ligne qui contient l'instantané que vous souhaitez utiliser.
Version de l'API 2012-12-0198

Amazon Redshift Guide de la gestion du clusterConfiguration d'une copie d'instantané
entre régions pour un cluster non chiffré
5. Cliquez sur Gérer l'accès.6. Dans la boîte de dialogue Gérer l'accès aux instantanés, vous pouvez autoriser un utilisateur à
accéder à l'instantané ou révoquer l'accès autorisé précédemment.
• Pour autoriser un utilisateur à accéder à l'instantané, saisissez l'ID de compte AWS à 12 chiffres decet utilisateur dans la zone (sans les tirets), puis cliquez sur Ajouter un compte.
• Pour révoquer l'autorisation d'un utilisateur, cliquez sur le symbole X situé à côté de l'ID de compteAWS de l'utilisateur.
7. Cliquez sur Enregistrer pour enregistrer vos modifications ou Annuler pour restaurer les modifications.
Configuration d'une copie d'instantané entre régionspour un cluster non chiffréVous pouvez configurer Amazon Redshift pour copier les instantanés entre un cluster et une autre région.Pour configurer la copie d'instantané entre régions, vous devez activer cette fonction de copie pour chaquecluster, et configurer à quel emplacement copier les instantanés et combien de temps conserver lesinstantanés automatiques copiés dans la région de destination. Lorsque la copie entre régions est activéepour un cluster, tous les nouveaux instantanés automatiques ou manuels sont copiés dans la régionspécifiée. Les noms d'instantané copiés sont préfixés par copy:.
Pour configurer une copie d'instantané entre régions pour un cluster non chiffré
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Clusters.3. Cliquez sur Sauvegarde, puis sur Configurer les instantanés entre régions.4. Dans la boîte de dialogue Configurer les instantanés entre régions, pour Copier les instantanés,
cliquez sur Oui.5. Dans Région de destination, cliquez sur la région dans laquelle vous souhaitez copier les instantanés.6. Dans Période de conservation (jours), choisissez le nombre de jours pendant lesquels vous souhaitez
que les instantanés automatiques soient conserver dans la région de destination avant qu'ils soientsupprimés.
7. Cliquez sur Sauvegarder
Version de l'API 2012-12-0199

Amazon Redshift Guide de la gestion du clusterConfigurer une copie d'instantané entre
régions pour un cluster chiffré par AWS KMS
Configurer une copie d'instantané entre régions pourun cluster chiffré par AWS KMSLorsque vous lancez un cluster Amazon Redshift, vous pouvez choisir de le chiffrer avec une clé principalede l'AWS Key Management Service (AWS KMS). Les clés AWS KMS sont propres à une région. Si voussouhaitez activer la copie d'instantané entre régions pour un cluster chiffré par AWS KMS, vous devezconfigurer une Autorisation de copie d'instantanés pour une clé principale dans la région de destinationafin que Amazon Redshift peuvent effectuer des opérations de chiffrement dans la région de destination.La procédure suivante décrit le processus d'activation de la copie d'instantanés entre régions pour uncluster chiffré par AWS KMS. Pour plus d'informations sur le chiffrement dans Amazon Redshift et lesautorisations de copie d'instantanés, consultez Copie d'instantanés chiffrés par AWS KMS dans une autrerégion (p. 106).
Pour configurer une copie d'instantané entre régions pour un cluster chiffré par AWS KMS
1. Ouvrez la console Amazon Redshift à l'adresse https://console.aws.amazon.com/redshift/.2. Dans le volet de navigation, cliquez sur Clusters.3. Dans la liste de clusters, choisissez un nom de cluster pour ouvrir la vue Configuration pour le cluster.4. Cliquez sur Sauvegarde, puis sur Configurer les instantanés entre régions.5. Dans la boîte de dialogue Configurer les instantanés entre régions, pour Copier les instantanés,
cliquez sur Oui.6. Dans Région de destination, cliquez sur la région dans laquelle vous souhaitez copier les instantanés.7. Dans Période de conservation (jours), choisissez le nombre de jours pendant lesquels vous souhaitez
que les instantanés automatiques soient conserver dans la région de destination avant qu'ils soientsupprimés.
8. Pour Autorisation de copie d'instantanés existante, effectuez l'une des opérations suivantes :
a. Choisissez Non pour créer une nouvelle autorisation de copie d'instantanés. Pour Clé KMS,choisissez la clé AWS KMS pour laquelle créer l'autorisation, puis tapez un nom dans Nom del'autorisation de copie d'instantanés.
b. Choisissez Oui pour choisir une autorisation de copie d'instantanés existante dans la région dedestination. Puis choisissez une autorisation dans Autorisation de copie d'instantanés.
9. Cliquez sur Sauvegarder
Modification de la période de conservation pour lacopie d'instantanés entre régionsAprès avoir configuré une copie d'instantanés entre régions, vous pouvez modifier les paramètres. Vouspouvez facilement modifier la période de conservation en sélectionnant un nouveau nombre de jours et enenregistrant les modifications.
Warning
Vous ne pouvez pas modifier la région de destination une fois que la copie d'instantanés entrerégions est configurée. Si vous voulez copier les instantanés dans une autre région, vous devezd'abord désactiver la copie d'instantanés entre régions, puis la réactiver avec une nouvellerégion de destination et une nouvelle période de conservation. Etant donné que les instantanésautomatiques copiés sont supprimés une fois que vous désactivez la copie d'instantanés entrerégions, vous devez déterminer si vous souhaitez en conserver certains et les copier dans lesinstantanés manuels avant la désactivation de la copie d'instantanés entre régions.
Version de l'API 2012-12-01100

Amazon Redshift Guide de la gestion du clusterDésactivation de la copie d'instantanés entre régions
Pour modifier la période de conservation des instantanés copiés vers un cluster de destination
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Clusters.3. Cliquez sur Sauvegarde, puis sur Configurer les instantanés entre régions.4. Dans la zone Période de conservation, sélectionnez le nouveau nombre de jours pendant lesquels
vous voulez que les instantanés automatiques soient conservés dans la région de destination.
Si vous sélectionnez un nombre inférieur de jours de conservation des instantanés dans la régionde destination, tous les instantanés automatisés qui ont été effectués avant la nouvelle période deconservation seront supprimés. Si vous sélectionnez un nombre supérieur de jours de conservationdes instantanés dans la région de destination, la période de conservation des instantanés automatisésexistants sera étendue de la différence entre l'ancienne valeur et la nouvelle valeur.
5. Cliquez sur Save Configuration.
Désactivation de la copie d'instantanés entre régionsVous pouvez désactiver la copie d'instantanés entre régions pour un cluster lorsque vous ne souhaitez plusque Amazon Redshift copie les instantanés dans une région de destination.
Pour désactiver la copie d'instantanés entre régions pour un cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Clusters.3. Cliquez sur Sauvegarde, puis sur Configurer les instantanés entre régions pour ouvrir la boîte de
dialogue Configurer les instantanés entre régions.4. Dans la zone Enable Cross Region Snapshots , cliquez sur Non.5. Cliquez sur Save Configuration.
Gestion des instantanés à l'aide du kit AWS SDKpour Java
L'exemple suivant illustre ces opérations courantes impliquant un instantané :
• Création de l'instantané de cluster manuel d'un cluster.• Affichage des informations sur tous les instantanés d'un cluster.• Suppression des instantanés manuels d'un cluster.
Dans cet exemple, un instantané du cluster est démarré. Lorsque l'instantané est créé avec succès,tous les instantanés manuels du cluster qui ont été créées avant le nouvel instantané sont supprimés.Lorsque la création de l'instantané manuel est initiée, l'instantané n'est pas disponible immédiatement. Parconséquent, cet exemple utilise une boucle pour interroger le statut de l'instantané en appelant la méthodedescribeClusterSnapshot. Il faut généralement quelques instants avant qu'un instantané ne deviennedisponible après le début. Pour plus d'informations sur les instantanés, consultez Instantanés AmazonRedshift (p. 86).
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193). Vous devez mettre à jour le code et fournir unidentificateur de cluster.
Version de l'API 2012-12-01101

Amazon Redshift Guide de la gestion du clusterGestion des instantanés à l'aide du kit AWS SDK pour Java
Example
import java.io.IOException;import java.text.SimpleDateFormat;import java.util.Date;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;import com.amazonaws.services.redshift.model.CreateClusterSnapshotRequest;import com.amazonaws.services.redshift.model.DeleteClusterSnapshotRequest;import com.amazonaws.services.redshift.model.DescribeClusterSnapshotsRequest;import com.amazonaws.services.redshift.model.DescribeClusterSnapshotsResult;import com.amazonaws.services.redshift.model.Snapshot;
public class CreateAndDescribeSnapshot {
public static AmazonRedshiftClient client; public static String clusterIdentifier = "***provide cluster identifier***"; public static long sleepTime = 10; public static void main(String[] args) throws IOException { AWSCredentials credentials = new PropertiesCredentials( CreateAndDescribeSnapshot.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { // Unique snapshot identifier String snapshotId = "my-snapshot-" + (new SimpleDateFormat("yyyy-MM-dd-HH-mm-ss")).format(new Date());
Date createDate = createManualSnapshot(snapshotId); waitForSnapshotAvailable(snapshotId); describeSnapshots(); deleteManualSnapshotsBefore(createDate); describeSnapshots(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage()); } }
private static Date createManualSnapshot(String snapshotId) { CreateClusterSnapshotRequest request = new CreateClusterSnapshotRequest() .withClusterIdentifier(clusterIdentifier) .withSnapshotIdentifier(snapshotId); Snapshot snapshot = client.createClusterSnapshot(request); System.out.format("Created cluster snapshot: %s\n", snapshotId); return snapshot.getSnapshotCreateTime(); } private static void describeSnapshots() {
DescribeClusterSnapshotsRequest request = new DescribeClusterSnapshotsRequest() .withClusterIdentifier(clusterIdentifier); DescribeClusterSnapshotsResult result = client.describeClusterSnapshots(request); printResultSnapshots(result); }
private static void deleteManualSnapshotsBefore(Date creationDate) {
Version de l'API 2012-12-01102

Amazon Redshift Guide de la gestion du clusterGestion des instantanés à l'aide de l'interface deligne de commande et de l'API Amazon Redshift
DescribeClusterSnapshotsRequest request = new DescribeClusterSnapshotsRequest() .withEndTime(creationDate) .withClusterIdentifier(clusterIdentifier) .withSnapshotType("manual"); DescribeClusterSnapshotsResult result = client.describeClusterSnapshots(request); for (Snapshot s : result.getSnapshots()) { DeleteClusterSnapshotRequest deleteRequest = new DeleteClusterSnapshotRequest() .withSnapshotIdentifier(s.getSnapshotIdentifier()); Snapshot deleteResult = client.deleteClusterSnapshot(deleteRequest); System.out.format("Deleted snapshot %s\n", deleteResult.getSnapshotIdentifier()); } } private static void printResultSnapshots(DescribeClusterSnapshotsResult result) { System.out.println("\nSnapshot listing:"); for (Snapshot snapshot : result.getSnapshots()) { System.out.format("Identifier: %s\n", snapshot.getSnapshotIdentifier()); System.out.format("Snapshot type: %s\n", snapshot.getSnapshotType()); System.out.format("Snapshot create time: %s\n", snapshot.getSnapshotCreateTime()); System.out.format("Snapshot status: %s\n\n", snapshot.getStatus()); } } private static Boolean waitForSnapshotAvailable(String snapshotId) throws InterruptedException { Boolean snapshotAvailable = false; System.out.println("Wating for snapshot to become available."); while (!snapshotAvailable) { DescribeClusterSnapshotsResult result = client.describeClusterSnapshots(new DescribeClusterSnapshotsRequest() .withSnapshotIdentifier(snapshotId)); String status = (result.getSnapshots()).get(0).getStatus(); if (status.equalsIgnoreCase("available")) { snapshotAvailable = true; } else { System.out.print("."); Thread.sleep(sleepTime*1000); } } return snapshotAvailable; }
}
Gestion des instantanés à l'aide de l'interface deligne de commande et de l'API Amazon Redshift
Vous pouvez utiliser les opérations d'interface de ligne de commande Amazon Redshift suivantes pourgérer les instantanés.
• authorize-snapshot-access• copy-cluster-snapshot• create-cluster-snapshot
Version de l'API 2012-12-01103
Amazon Redshift Guide de la gestion du clusterGestion des instantanés à l'aide de l'interface deligne de commande et de l'API Amazon Redshift
• delete-cluster-snapshot• describe-cluster-snapshots• disable-snapshot-copy• enable-snapshot-copy• modify-snapshot-copy-retention-period• restore-from-cluster-snapshot• revoke-snapshot-access
Vous pouvez utiliser les actions d'API Amazon Redshift suivantes pour gérer les instantanés.
• AuthorizeSnapshotAccess• CopyClusterSnapshot• CreateClusterSnapshot• DeleteClusterSnapshot• DescribeClusterSnapshots• DisableSnapshotCopy• EnableSnapshotCopy• ModifySnapshotCopyRetentionPeriod• RestoreFromClusterSnapshot• RevokeSnapshotAccess
Pour plus d'informations sur les instantanés Amazon Redshift, consultez Instantanés AmazonRedshift (p. 86).
Version de l'API 2012-12-01104

Amazon Redshift Guide de la gestion du clusterChiffrement de base de données pourAmazon Redshift à l'aide d'AWS KMS
Chiffrement de base de donnéesAmazon Redshift
Dans Amazon Redshift, vous pouvez activer le chiffrement de base de données pour vos clusters afind'améliorer la protection des données inactives. Lorsque vous activez le chiffrement pour un cluster, lesblocs de données et les métadonnées système sont chiffrés pour le cluster et ses instantanés.
Le chiffrement est un paramètre facultatif et immuable d'un cluster. Si vous souhaitez utiliser le chiffrement,vous pouvez l'activer lors de la procédure de lancement du cluster. Pour passer d'un cluster non chiffré àun cluster chiffré ou l'inverse, vous devez décharger vos données du cluster existant et les recharger dansun nouveau cluster avec le paramètre de chiffrement choisi. Pour plus d'informations, consultez Migrationd'un cluster non chiffré ver un cluster chiffré (p. 109)
Bien que le chiffrement soit un paramètre facultatif dans Amazon Redshift, nous vous recommandons del'activer pour les clusters qui contiennent des données sensibles. En outre, vous pouvez être contraintd'utiliser le chiffrement en fonction des directives ou règlements régissant vos données. Par exemple, lanorme PCI DSS (Payment Card Industry Data Security Standard), les lois américaines Sarbanes-Oxley(SOX) et HIPAA (Health Insurance Portability et Accountability Act) et d'autres règlements similairesfournissent des directives permettant de gérer des types de données spécifiques.
Amazon Redshift utilise une hiérarchie de clés de chiffrement pour chiffrer la base de données. Vouspouvez utiliser AWS Key Management Service (AWS KMS) ou un module de sécurité matérielle (HSM)pour gérer les clés de chiffrement de niveau supérieur dans cette hiérarchie. Le processus de chiffrementde Amazon Redshift diffère en fonction de la façon dont vous gérez les clés.
En outre, Amazon Redshift s'intègre automatiquement à AWS KMS mais pas avec un HSM. Lorsque vousutilisez un HSM, vous devez utiliser des certificats client et de serveur pour configurer une connexionapprouvée entre Amazon Redshift et votre HSM.
Chiffrement de base de données pour AmazonRedshift à l'aide d'AWS KMS
Lorsque vous choisissez AWS KMS pour la gestion des clés avec Amazon Redshift, il existe une hiérarchiede quatre niveaux des clés de chiffrement. Ces clés, par ordre hiérarchique, sont la clé principale, uneclé de chiffrement du cluster (CEK), une clé de chiffrement de base de données (DEK) et les clés dechiffrement de données.
Lorsque vous lancez votre cluster, Amazon Redshift renvoie une liste des clés principales du client (CMK)que votre compte AWS a créé ou est autorisé à utiliser dans AWS KMS. Vous sélectionnez une clé CMKen guise de clé principale dans la hiérarchie de chiffrement.
Par défaut, Amazon Redshift sélectionne votre clé par défaut en tant que clé principale. Votre clé pardéfaut est une clé gérée par AWS qui est créée pour votre compte AWS à utiliser dans Amazon Redshift.AWS KMS crée cette clé la première fois que vous lancez un cluster chiffré dans une région et que voussélectionnez la clé par défaut.
Si vous ne voulez pas utiliser la clé par défaut, vous devez disposer (ou créer) d'une clé CMK géréepar le client séparément dans AWS KMS, avant de lancer votre cluster dans Amazon Redshift. Les clésCMK gérées par le client vous donnent davantage de flexibilité, en vous permettant notamment de créer,d'effectuer la rotation, de désactiver et de définir le contrôle d'accès, ainsi que de contrôler les clés dechiffrement utilisées pour protéger vos données. Pour en savoir plus sur la création de clés CMK, consultezCréation de clés dans le manuel AWS Key Management Service Developer Guide.
Version de l'API 2012-12-01105

Amazon Redshift Guide de la gestion du clusterCopie d'instantanés chiffrés par
AWS KMS dans une autre région
Si vous souhaitez utiliser une clé AWS KMS d'un autre compte AWS, vous devez avoir la permissiond'utiliser la clé et spécifier son ARN dans Amazon Redshift. Pour plus d'informations sur l'accès aux clésdans AWS KMS accédez à Contrôle de l'accès à vos clés dans le manuel AWS Key Management ServiceDeveloper Guide.
Une fois que vous choisissez une clé principale, Amazon Redshift demande à AWS KMS de générer uneclé de données et de la chiffrer à l'aide de la clé principale sélectionnée. Cette clé de données est utiliséecomme clé CEK dans Amazon Redshift. AWS KMS exporte la clé CEK chiffrée vers Amazon Redshift, oùelle est stockée en interne sur un disque sur un réseau distinct du cluster avec l'affectation de la clé CMKet le contexte de chiffrement de la clé CEK. Seule la clé CEK chiffrée est exportée vers Amazon Redshift,la clé CMK reste dans AWS KMS. Amazon Redshift transmet également au cluster la clé CEK chiffrée viaun canal sécurisé et la charge dans la mémoire. Puis, Amazon Redshift appelle AWS KMS pour déchiffrerla clé CEK et charge la clé CEK déchiffrée dans la mémoire. Pour plus d'informations sur les affectations,le contexte de chiffrement et autres concepts liés à AWS KMS, accédez à Concepts dans le manuel AWSKey Management Service Developer Guide.
Ensuite, Amazon Redshift génère une clé de manière aléatoire à utiliser en tant que clé DEK et la chargeen mémoire dans le cluster. La clé CEK déchiffrée est utilisée pour chiffrer la clé DEK, qui est ensuitetransmise via un canal sécurisé depuis le cluster pour être stockée en interne par Amazon Redshift surle disque dans un autre réseau que celui du cluster. A l'instar de la clé CEK, les versions chiffrées etdéchiffrées de la clé DEK sont chargées en mémoire dans le cluster. La version déchiffrée de la clé DEKest ensuite utilisée pour chiffrer les clés de chiffrement individuelles qui sont générées de façon aléatoirepour chaque bloc de données de la base de données.
Lorsque le cluster redémarre, Amazon Redshift commence par les versions stockées en interne et chiffréesdes clés CEK et DEK, les recharge dans la mémoire, puis appelle AWS KMS pour déchiffrer la clé CEKavec la clé CMK à nouveau afin qu'elle puisse être chargée en mémoire. La clé CEK déchiffrée est ensuiteutilisée pour déchiffrer la clé DEK à nouveau, et la clé DEK déchiffré est chargée dans la mémoire etutilisée pour chiffrer et déchiffrer les clés de bloc de données en fonction des besoins.
Pour plus d'informations sur la création de clusters Amazon Redshift chiffrés avec clés AWS KMS,consultez Création d'un cluster (p. 17) et Gérer les clusters à l'aide de l'interface de ligne de commandeAmazon Redshift et de l'API (p. 36).
Copie d'instantanés chiffrés par AWS KMS dans uneautre régionLes clés AWS KMS sont propres à une région. Si vous activez la copie des instantanés Amazon Redshiftdans une autre région et que le cluster source et ses instantanés sont chiffrés à l'aide d'une clé principaledans AWS KMS, vous devez configurer une autorisation pour Amazon Redshift afin d'utiliser une cléprincipale dans la région de destination. Cette autorisation permet à Amazon Redshift de chiffrer lesinstantanés dans la région de destination. Pour plus d'informations sur la copie d'instantanés entre régions,consultez Copie d'instantanés sur une autre région (p. 87).
Note
Si vous activez la copie d'instantanés à partir d'un cluster chiffré et que vous utilisez AWS KMSpour votre clé principale, vous ne pouvez pas renommer votre cluster, car le nom du clusters'inscrit dans le contexte de chiffrement. Si vous devez renommer votre cluster, vous pouvezdésactiver la copie des instantanés de la région source, renommer le cluster et puis configurer etactiver à nouveau la copie des instantanés.
Le processus permettant de configurer l'autorisation de copier des instantanés est le suivant.
1. Dans la région de destination, créez une autorisation de copie d'instantanés en procédant comme suit :• Si vous ne possédez pas encore de clé AWS KMS à utiliser, créez-en une. Pour en savoir plus sur
la création de clés AWS KMS, consultez Création de clés dans le manuel AWS Key ManagementService Developer Guide.
Version de l'API 2012-12-01106

Amazon Redshift Guide de la gestion du clusterChiffrement pour Amazon Redshift à
l'aide de modules de sécurité matérielle
• Spécifiez un nom pour l'autorisation de copie d'instantanés. Ce nom doit être unique dans cette régionpour votre compte AWS.
• Spécifiez l'ID de clé AWS KMS pour laquelle vous créez l'autorisation. Si vous ne spécifiez pas d'ID declé, l'autorisation s'applique à votre clé par défaut.
2. Dans la région source, activez la copie des instantanés et précisez le nom de l'autorisation de copied'instantanés que vous avez créée dans la région de destination.
Ce processus préalable n'est nécessaire que si vous activez la copie des instantanés à l'aide de l'AWSCLI, l'API Amazon Redshift ou des kits SDK. Si vous utilisez la console, Amazon Redshift fournit le flux detravail approprié pour configurer l'autorisation lorsque vous activez la copie d'instantanés entre régions.Pour plus d'informations sur la configuration de copie d'instantanés entre régions pour les clusters chiffréspar AWS KMS à l'aide de la console, consultez Configurer une copie d'instantané entre régions pour uncluster chiffré par AWS KMS (p. 100).
Avant que l'instantané soit copié dans la région de destination, Amazon Redshift le déchiffre à l'aide de laclé principale dans la région source et le chiffre à nouveau temporairement à l'aide d'une clé RSA généréede façon aléatoire que Amazon Redshift gère en interne. Amazon Redshift copie ensuite l'instantané via uncanal sécurisé vers la région de destination, déchiffre l'instantané à l'aide de la clé RSA gérée en interne etpuis re-chiffre l'instantané à l'aide de la clé principale dans la région de destination.
Pour plus d'informations sur la configuration de l'autorisation de copie d'instantanés pour les clusterschiffrés par AWS KMS, consultez Configuration de Amazon Redshift pour utiliser les clés de chiffrementAWS KMS à l'aide de l'API et l'AWS CLI Amazon Redshift (p. 117).
Chiffrement pour Amazon Redshift à l'aide demodules de sécurité matérielle
Si vous n'utilisez pas AWS KMS pour la gestion des clés, vous pouvez utiliser un module de sécuritématérielle (HSM) pour la gestion des clés avec Amazon Redshift.
Important
Le chiffrement HSM n'est pas pris en charge pour les types de nœuds DC2.
Les HSM sont des dispositifs qui permettent de contrôler directement la génération et la gestion des clés.Ils fournissent une plus grande sécurité en séparant la gestion des clés des couches d'applications et debase de données. Amazon Redshift prend en charge AWS CloudHSM Classic pour la gestion des clés. Leprocessus de chiffrement est différent lorsque vous utilisez HSM pour gérer vos clés de chiffrement au lieude AWS KMS.
Important
Amazon Redshift prend uniquement en charge AWS CloudHSM Classic. Nous ne prenons pas encharge le service AWS CloudHSM plus récent. AWS CloudHSM Classic n'est pas disponible danstoutes les régions. Pour plus d'informations sur les régions disponibles, consultez le tableau desrégions.
Lorsque vous configurez votre cluster pour utiliser un HSM, Amazon Redshift envoie une demande auHSM pour générer et stocker une clé à utiliser comme clé CEK. Toutefois, contrairement à AWS KMS leHSM n'exporte pas la clé CEK vers Amazon Redshift. Au lieu de cela, Amazon Redshift génère de manièrealéatoire la clé DEK dans le cluster et la transmet au HSM pour qu'elle soit chiffrée par la clé CEK. Le HSMrenvoie la clé DEK chiffrée à Amazon Redshift où elle est encore chiffré à l'aide d'une clé principale internegénérée de manière aléatoire et stockée en interne sur un disque sur un autre réseau que celui du cluster.Amazon Redshift charge également la version déchiffrée de la clé DEK en mémoire dans le cluster afin quecelle-ci puisse être utilisée pour chiffrer et déchiffrer les clés individuelles pour les blocs de données.
Version de l'API 2012-12-01107

Amazon Redshift Guide de la gestion du clusterConfiguration d'une connexion approuvée
entre Amazon Redshift et un HSM
Si le cluster est redémarré, Amazon Redshift déchiffre la clé DEK doublement chiffré, stockée en interneà l'aide de la clé principale interne pour renvoyer la clé DEK stockée en interne à l'état de chiffrementCEK. La clé DEK chiffrée par la clé CEK est ensuite transmise au HSM pour être déchiffrée et transmiseà Amazon Redshift où elle peut être chargée en mémoire à nouveau pour être utilisée avec des blocs dedonnées individuels.
Configuration d'une connexion approuvée entreAmazon Redshift et un HSMLorsque vous optez pour utiliser un HSM pour la gestion de votre clé de cluster, vous devez configurerun lien réseau de confiance entre Amazon Redshift et votre HSM. Cela nécessite une configurationde certificats de client et de serveur. La connexion approuvée est utilisée pour transmettre les clés dechiffrement entre le HSM et Amazon Redshift pendant les opérations de chiffrement et de déchiffrement.
Amazon Redshift crée un certificat de client public à partir d'une paire de clés privée et publique généréede façon aléatoire. Celles-ci sont chiffrées et stockées en interne. Vous téléchargez et enregistrez lecertificat de client public dans votre HSM et l'affectez à la partition HSM applicable.
Vous fournissez à Amazon Redshift l'adresse IP HSM, le nom de la partition HSM, le mot de passe departition HSM et un certificat de serveur HSM public, qui est chiffré à l'aide d'une clé principale interne.Amazon Redshift termine le processus de configuration et vérifie qu'il peut se connecter au HSM. S'il nepeut pas, le cluster est passé à l'État INCOMPATIBLE_HSM et le cluster n'est pas créé. Dans ce cas, vousdevez supprimer le cluster incomplet, puis réessayer.
Important
Lorsque vous modifiez votre cluster afin d'utiliser une autre partition HSM, Amazon Redshiftvérifie qu'il peut se connecter à la nouvelle partition, mais il ne vérifie pas s'il existe une clé dechiffrement valide. Avant d'utiliser la nouvelle partition, vous devez répliquer vos clés sur lanouvelle partition. Si le cluster est redémarré et que Amazon Redshift ne peut pas trouver de clévalide, le redémarrage échoue. Pour plus d'informations, consultez Réplication de clés entre HSM.
Pour plus d'informations sur la configuration de Amazon Redshift pour utiliser un HSM, consultezConfiguration de Amazon Redshift pour utiliser un module de sécurité matérielle avec Amazon Redshiftconsole (p. 111) et Configuration de Amazon Redshift pour utiliser HSM à l'aide de l'API et de l'AWS CLIAmazon Redshift (p. 118).
Après la configuration initiale, si Amazon Redshift échoue pour vous connecter au HSM, un événementest consigné. Pour plus d'informations sur ces événements, consultez Notifications d'événements AmazonRedshift.
A propos de la rotation des clés de chiffrement dansAmazon Redshift
Dans Amazon Redshift vous pouvez effectuer une rotation des clés de chiffrement pour les clusterschiffrés. Lorsque vous démarrez le processus de rotation des clés, Amazon Redshift effectue une rotationde la clé CEK pour le cluster spécifié et pour les instantanés automatiques ou manuels du cluster. AmazonRedshift effectue également une rotation de la clé DEK pour le cluster spécifié, mais ne peut pas effectuerune rotation de la clé DEK pour les instantanés pendant qu'ils sont stockés en interne dans Amazon SimpleStorage Service (Amazon S3) et chiffrés à l'aide de la clé DEK existante.
Alors que la rotation est en cours, le cluster est placé dans un état ROTATING_KEYS jusqu'à la fin, aumoment le cluster retourne à l'état AVAILABLE. Amazon Redshift gère le déchiffrement et le chiffrementpendant le processus de rotation des clés.
Version de l'API 2012-12-01108

Amazon Redshift Guide de la gestion du clusterMigration vers un cluster chiffré
Note
Vous ne pouvez pas effectuer une rotation des clés pour des instantanés sans cluster source.Avant de supprimer un cluster, demandez-vous si ses instantanés reposent sur la rotation desclés.
Etant donné que le cluster est temporairement indisponible pendant le processus de rotation des clés,vous devez effectuer la rotation des clés uniquement dès que les données le nécessitent ou lorsquevous pensez que les clés ont été volées. La bonne pratique consiste à examiner le type de données quevous stockez et à prévoir à quelle fréquence effectuer la rotation des clés de chiffrement des données.La fréquence à laquelle effectuer la rotation des clés varie en fonction de vos stratégies d'entrepriseconcernant la sécurité des données et des normes du secteur relatives aux données sensibles et à laconformité réglementaire. Assurez-vous que votre plan tient compte des besoins en matière de sécuritéautant que des considérations concernant la disponibilité de votre cluster.
Pour plus d'informations sur la rotation des clés, consultez Rotation des clés de chiffrement avec AmazonRedshift console (p. 116) et Rotation des clés de chiffrement à l'aide de l'API et de l'AWS CLI AmazonRedshift (p. 118).
Migration d'un cluster non chiffré ver un clusterchiffré
Vous activez le chiffrement lorsque vous lancez le cluster. Si vous souhaitez passer d'un cluster non chiffréà un cluster chiffré, vous devez d'abord décharger vos données du cluster source existant. Vous devezensuite les recharger dans un nouveau cluster cible avec le paramètre de chiffrement choisi. Pour plusd'informations sur le lancement d'un cluster chiffré, consultez Chiffrement de base de données AmazonRedshift (p. 105). Jusqu'à la dernière étape du processus de migration, votre cluster source restedisponible pour les requêtes en lecture seule. La dernière étape consiste à renommer les clusters sourceet cible afin de permuter les points de terminaison de manière à ce que la totalité du trafic soit redirigéevers le nouveau cluster cible. Le cluster cible est indisponible tant que vous ne l'avez pas redémarré aprèsl'avoir renommé. Suspendez tous les chargements de données et autres opérations en écriture sur lecluster source pendant le transfert des données.
Pour préparer la migration
1. Identifiez tous les systèmes dépendants qui interagissent avec Amazon Redshift, tels que les outilsd'aide à la décision (BI) et les systèmes d'extraction, de transformation et de chargement (ETL).
2. Identifiez les requêtes de validation permettant de tester la migration.
Par exemple, vous pouvez utiliser la requête suivante pour trouver le nombre de tables définies parl'utilisateur.
select count(*)from pg_table_defwhere schemaname != 'pg_catalog';
La requête suivante renvoie la liste de toutes les tables définies par l'utilisateur et le nombre de lignesde chacune d'entre elles.
select "table", tbl_rowsfrom svv_table_info;
3. Choisissez le moment opportun pour réaliser la migration. Pour savoir quand l'utilisation du clusterest à son plus bas, surveillez les mesures relatives au cluster, notamment l'utilisation de la CPU et
Version de l'API 2012-12-01109

Amazon Redshift Guide de la gestion du clusterMigration vers un cluster chiffré
le nombre de connexions à la base de données. Pour plus d'informations, consultez Affichage desdonnées de performances de cluster (p. 266).
4. Ignorez les tables inutilisées.
Pour obtenir la liste des tables et la fréquence d'interrogation de chacune, exécutez la requêtesuivante.
select database,schema,table_id,"table",round(size::float/(1024*1024)::float,2) as size,sortkey1,nvl(s.num_qs,0) num_qsfrom svv_table_info tleft join (select tbl,perm_table_name,count(distinct query) num_qsfrom stl_scan swhere s.userid > 1and s.perm_table_name not in ('internal worktable','s3')group by tbl,perm_table_name) s on s.tbl = t.table_idwhere t."schema" not in ('pg_internal');
5. Lancez un nouveau cluster chiffré.
Indiquez le même numéro de port pour le cluster cible que celui qu'utilisait le cluster source. Pourplus d'informations sur le lancement d'un cluster chiffré, consultez Chiffrement de base de donnéesAmazon Redshift (p. 105).
6. Configurez les processus de déchargement et chargement des données.
Vous pouvez faire appel à l'utilitaire de déchargement/copie Amazon Redshift pour vous aider àeffectuer la migration des données entre les deux clusters. L'utilitaire exporte les données depuis lecluster source vers un emplacement sur Amazon S3. Les données sont chiffrées avec AWS KMS.L'utilitaire importe ensuite automatiquement les données sur le cluster cible. Une fois la migrationterminée, vous pouvez éventuellement nettoyer Amazon S3 avec l'utilitaire.
7. Effectuez un test afin de vérifier que le processus fonctionne et d'estimer la durée pendant laquelle lesopérations en écriture doivent être suspendues.
Lors des opérations de déchargement et chargement des données, vous devez préserver lacohérence des données en suspendant tous les chargements habituels et autres opérations enécriture. Utilisez l'une de vos plus grandes tables pour exécuter le test de déchargement/chargementet estimer les délais requis.
8. Créez des objets de base de données, tels que des schémas, vues ou tables. Pour générer lesinstructions de langage de définition de données (Data Definition Language, DDL) requises, vouspouvez vous aider des scripts sous AdminViews dans le référentiel GitHub AWS.
Pour migrer votre cluster :
1. Arrêtez tous les processus ETL sur le cluster source.
Pour vérifier qu'il n'y a aucune opération d'écriture en cours, utilisez la console de gestion AmazonRedshift afin de surveiller les IOPS d'écriture. Pour plus d'informations, consultez Affichage desdonnées de performances de cluster (p. 266).
2. Exécutez les requêtes de validation que vous avez identifiées précédemment afin de collecter desinformations sur le cluster source chiffré avant de procéder à la migration.
Version de l'API 2012-12-01110

Amazon Redshift Guide de la gestion du clusterConfiguration du chiffrement de base
de données à l'aide de la console
3. (Facultatif) Créez une file d'attente de gestion de la charge de travail (WLM) pour exploiter lemaximum de ressources disponibles à la fois dans le cluster source et le cible. Par exemple, créezune file d'attente nommée data_migrate et configurez-la avec 95 % de mémoire et un niveau desimultanéité de 4. Pour plus d'informations, consultez Acheminement des requêtes vers les filesd'attente en fonction des groupes d'utilisateurs et des groupes de requêtes dans le Amazon RedshiftDatabase Developer Guide.
4. Avec la file data_migrate, exécutez l'utilitaire de déchargement/copie (UnloadCopyUtility).
Surveillez la progression des opérations UNLOAD et COPY à l'aide de la console Amazon Redshift.5. Exécutez à nouveau les requêtes de validation et vérifiez que leurs résultats correspondent à ceux du
cluster source.6. Renommez vos clusters source et cible pour permuter les points de terminaison. Pour plus
d'informations, consultez Étape 6 : Renommer les clusters source et cible (p. 330). Pour éviter uneinterruption de l'activité, effectuez cette opération en dehors des heures de travail,
7. Vérifiez que vous pouvez vous connecter au cluster cible à partir de tous vos clients SQL, notammentvia les outils ETL et de génération de rapports.
8. Fermez le cluster source non chiffré.
Configuration du chiffrement de base de données àl'aide de la console
Vous pouvez utiliser Amazon Redshift console pour configurer Amazon Redshift afin d'utiliser un modèlede sécurité matérielle (HSM) et pour appliquer une rotation aux clés de chiffrement. Pour obtenir desinformations sur la création de clusters à l'aide des clés de chiffrement AWS KMS, consultez Création d'uncluster (p. 17) et Gérer les clusters à l'aide de l'interface de ligne de commande Amazon Redshift et del'API (p. 36).
Configuration de Amazon Redshift pour utiliser unmodule de sécurité matérielle avec Amazon RedshiftconsoleVous pouvez utiliser les procédures suivantes pour spécifier une connexion HSM et les informations deconfiguration de Amazon Redshift avec Amazon Redshift console.
Pour créer une connexion HSM
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de gauche, cliquez sur Security, puis sur l'onglet HSM Connections.3. Cliquez sur Create HSM Connection.
4. Sur la page Create HSM Connection, tapez les informations suivantes :
Version de l'API 2012-12-01111
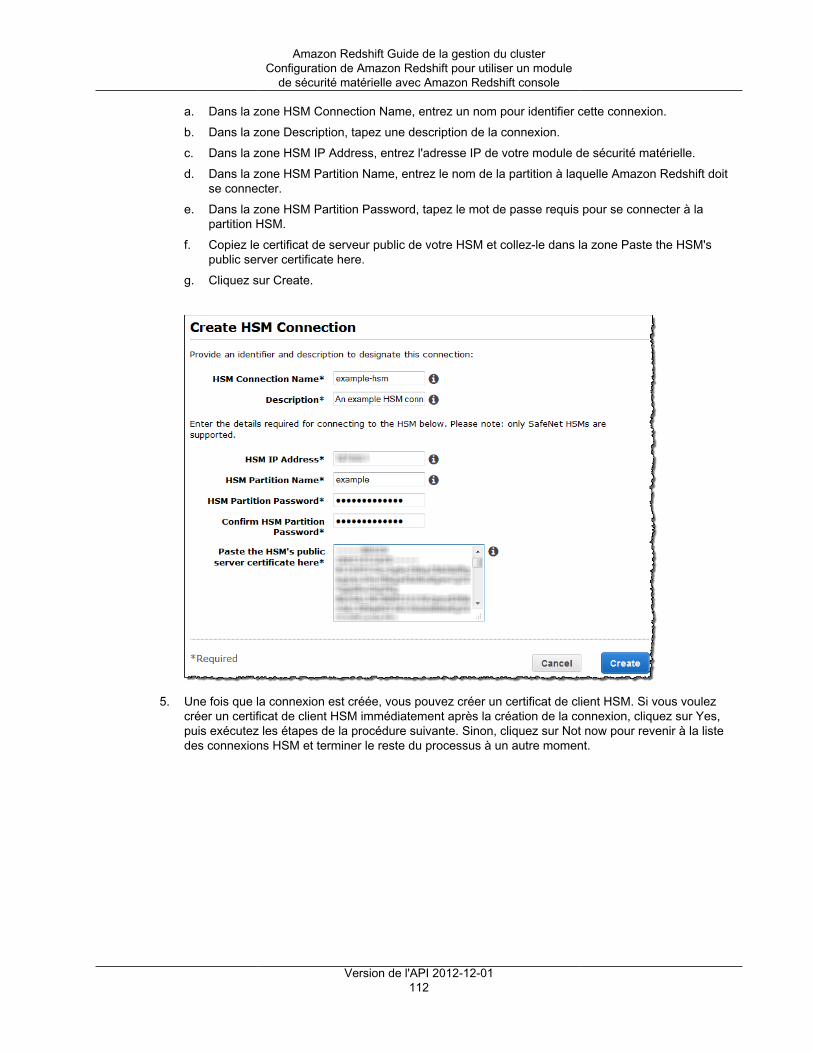
Amazon Redshift Guide de la gestion du clusterConfiguration de Amazon Redshift pour utiliser un module
de sécurité matérielle avec Amazon Redshift console
a. Dans la zone HSM Connection Name, entrez un nom pour identifier cette connexion.b. Dans la zone Description, tapez une description de la connexion.c. Dans la zone HSM IP Address, entrez l'adresse IP de votre module de sécurité matérielle.d. Dans la zone HSM Partition Name, entrez le nom de la partition à laquelle Amazon Redshift doit
se connecter.e. Dans la zone HSM Partition Password, tapez le mot de passe requis pour se connecter à la
partition HSM.f. Copiez le certificat de serveur public de votre HSM et collez-le dans la zone Paste the HSM's
public server certificate here.g. Cliquez sur Create.
5. Une fois que la connexion est créée, vous pouvez créer un certificat de client HSM. Si vous voulezcréer un certificat de client HSM immédiatement après la création de la connexion, cliquez sur Yes,puis exécutez les étapes de la procédure suivante. Sinon, cliquez sur Not now pour revenir à la listedes connexions HSM et terminer le reste du processus à un autre moment.
Version de l'API 2012-12-01112
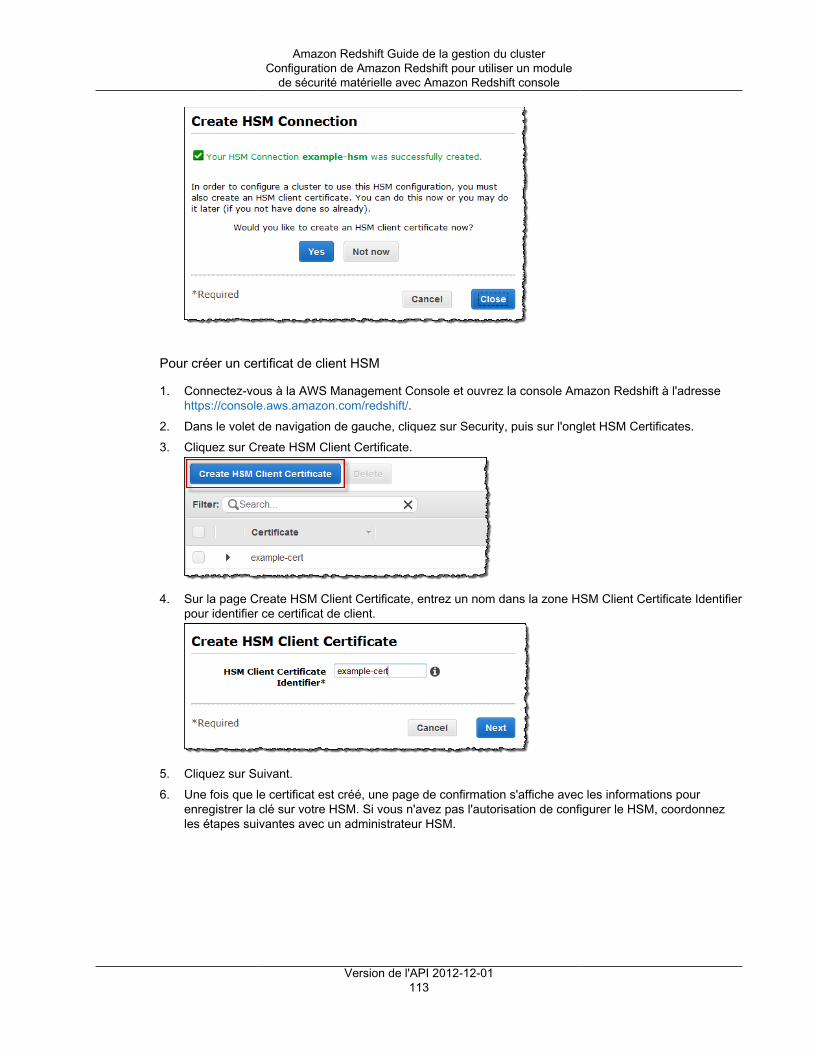
Amazon Redshift Guide de la gestion du clusterConfiguration de Amazon Redshift pour utiliser un module
de sécurité matérielle avec Amazon Redshift console
Pour créer un certificat de client HSM
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de gauche, cliquez sur Security, puis sur l'onglet HSM Certificates.3. Cliquez sur Create HSM Client Certificate.
4. Sur la page Create HSM Client Certificate, entrez un nom dans la zone HSM Client Certificate Identifierpour identifier ce certificat de client.
5. Cliquez sur Suivant.6. Une fois que le certificat est créé, une page de confirmation s'affiche avec les informations pour
enregistrer la clé sur votre HSM. Si vous n'avez pas l'autorisation de configurer le HSM, coordonnezles étapes suivantes avec un administrateur HSM.
Version de l'API 2012-12-01113

Amazon Redshift Guide de la gestion du clusterConfiguration de Amazon Redshift pour utiliser un module
de sécurité matérielle avec Amazon Redshift console
a. Sur votre ordinateur, ouvrez un nouveau fichier texte.b. Dans Amazon Redshift console; sur la page de confirmation Create HSM Client Certificate, copiez
la clé publique.c. Collez la clé publique dans le fichier ouvert et enregistrez celui-ci sous le nom de fichier affiché
à l'étape 1 à partir de la page de confirmation. Assurez-vous que vous enregistrez le fichier avecl'extension .pem : par exemple, 123456789mykey.pem.
d. Téléchargez le fichier .pem sur votre HSM.e. Sur le module de sécurité matérielle, ouvrez une fenêtre d'invite de commande et exécutez
les commandes répertoriées à l'étape 4 sur la page de confirmation pour enregistrer la clé.La commande utilise le format suivant, avec les valeurs ClientName, KeyFilename etPartitionName que vous devez remplacer par vos propres valeurs :
client register -client ClientName -hostname KeyFilename
client assignPartition -client ClientName -partition PartitionName
Exemples :
client register -client MyClient -hostname 123456789mykey
client assignPartition -client MyClient -partition MyPartition
f. Une fois que vous avez enregistré la clé sur le HSM, cliquez sur Next.7. Une fois que le certificat de client HSM est créé et enregistré, cliquez sur l'un des boutons suivants :
Version de l'API 2012-12-01114
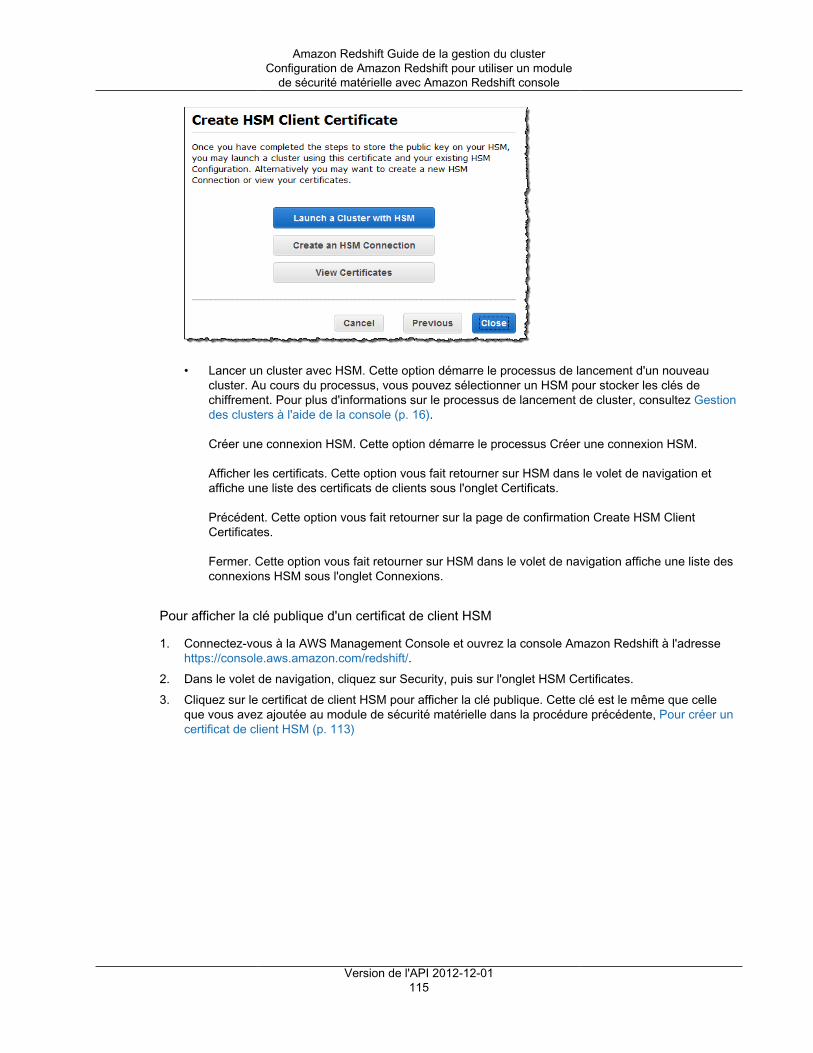
Amazon Redshift Guide de la gestion du clusterConfiguration de Amazon Redshift pour utiliser un module
de sécurité matérielle avec Amazon Redshift console
• Lancer un cluster avec HSM. Cette option démarre le processus de lancement d'un nouveaucluster. Au cours du processus, vous pouvez sélectionner un HSM pour stocker les clés dechiffrement. Pour plus d'informations sur le processus de lancement de cluster, consultez Gestiondes clusters à l'aide de la console (p. 16).
Créer une connexion HSM. Cette option démarre le processus Créer une connexion HSM.
Afficher les certificats. Cette option vous fait retourner sur HSM dans le volet de navigation etaffiche une liste des certificats de clients sous l'onglet Certificats.
Précédent. Cette option vous fait retourner sur la page de confirmation Create HSM ClientCertificates.
Fermer. Cette option vous fait retourner sur HSM dans le volet de navigation affiche une liste desconnexions HSM sous l'onglet Connexions.
Pour afficher la clé publique d'un certificat de client HSM
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security, puis sur l'onglet HSM Certificates.3. Cliquez sur le certificat de client HSM pour afficher la clé publique. Cette clé est le même que celle
que vous avez ajoutée au module de sécurité matérielle dans la procédure précédente, Pour créer uncertificat de client HSM (p. 113)
Version de l'API 2012-12-01115
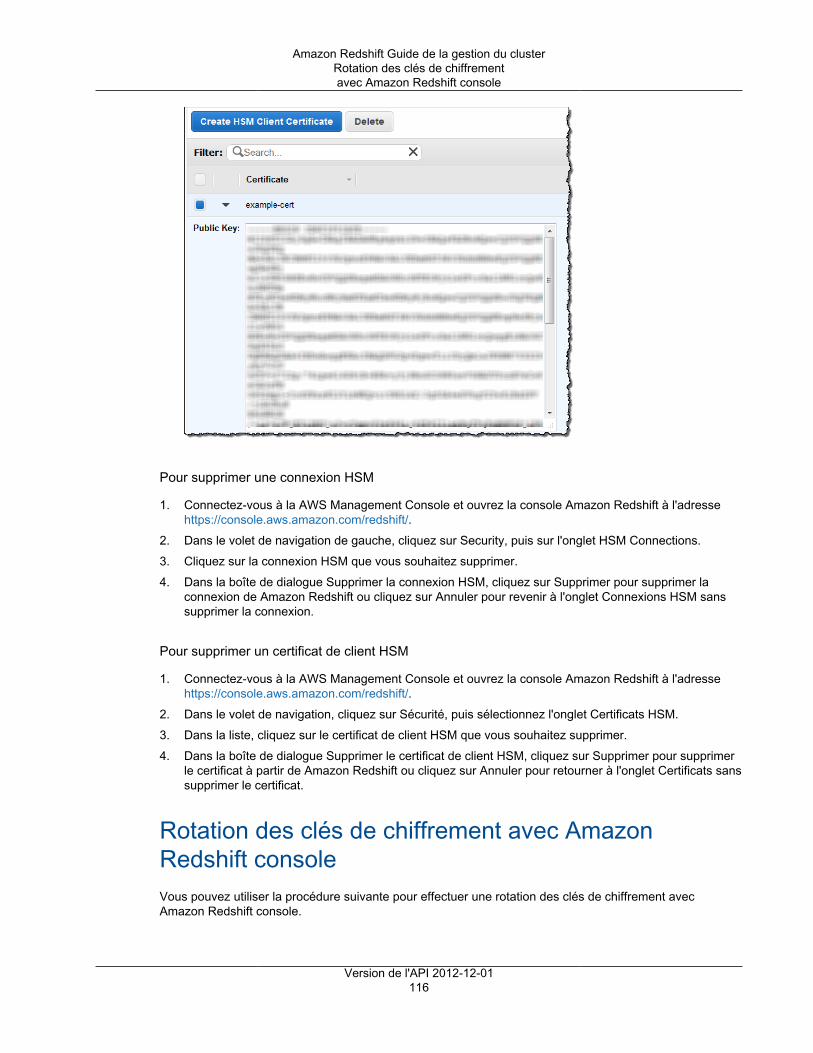
Amazon Redshift Guide de la gestion du clusterRotation des clés de chiffrementavec Amazon Redshift console
Pour supprimer une connexion HSM
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de gauche, cliquez sur Security, puis sur l'onglet HSM Connections.3. Cliquez sur la connexion HSM que vous souhaitez supprimer.4. Dans la boîte de dialogue Supprimer la connexion HSM, cliquez sur Supprimer pour supprimer la
connexion de Amazon Redshift ou cliquez sur Annuler pour revenir à l'onglet Connexions HSM sanssupprimer la connexion.
Pour supprimer un certificat de client HSM
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Sécurité, puis sélectionnez l'onglet Certificats HSM.3. Dans la liste, cliquez sur le certificat de client HSM que vous souhaitez supprimer.4. Dans la boîte de dialogue Supprimer le certificat de client HSM, cliquez sur Supprimer pour supprimer
le certificat à partir de Amazon Redshift ou cliquez sur Annuler pour retourner à l'onglet Certificats sanssupprimer le certificat.
Rotation des clés de chiffrement avec AmazonRedshift consoleVous pouvez utiliser la procédure suivante pour effectuer une rotation des clés de chiffrement avecAmazon Redshift console.
Version de l'API 2012-12-01116

Amazon Redshift Guide de la gestion du clusterConfiguration du chiffrement de la base de données
à l'aide de l'API et l'AWS CLI Amazon Redshift
Pour effectuer la rotation d'une clé de chiffrement
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Clusters.3. Dans la liste, cliquez sur le cluster pour lequel vous souhaitez effectuer une rotation des clés.4. Cliquez sur Base de données, puis cliquez sur Effectuer une rotation des clés de chiffrement.5. Cliquez sur Yes, Rotate Keys si vous souhaitez effectuer une rotation des clés ou sur Cancel dans le
cas contraire.
Note
Votre cluster sera temporairement indisponible jusqu'à ce que le processus de rotation desclés soit terminé.
Configuration du chiffrement de la base de donnéesà l'aide de l'API et l'AWS CLI Amazon Redshift
Utilisez l'API et l'AWS Command Line Interface (AWS CLI) Amazon Redshift pour configurer les optionsde clés de chiffrement pour les bases de données Amazon Redshift. Pour plus d'informations sur lechiffrement de la base de données, consultez Chiffrement de base de données Amazon Redshift (p. 105).
Configuration de Amazon Redshift pour utiliser les clésde chiffrement AWS KMS à l'aide de l'API et l'AWS CLIAmazon RedshiftVous pouvez utiliser les actions d'API Amazon Redshift suivantes pour configurer Amazon Redshift afinqu'il utilise des clés de chiffrement AWS KMS.
• CreateCluster• CreateSnapshotCopyGrant• DescribeSnapshotCopyGrants• DeleteSnapshotCopyGrant• DisableSnapshotCopy• EnableSnapshotCopy
Vous pouvez utiliser les opérations de l'interface de ligne de commande Amazon Redshift suivantes pourconfigurer Amazon Redshift afin qu'il utilise des clés de chiffrement AWS KMS.
• create-cluster• create-snapshot-copy-grant• describe-snapshot-copy-grants• delete-snapshot-copy-grant• disable-snapshot-copy• enable-snapshot-copy
Version de l'API 2012-12-01117

Amazon Redshift Guide de la gestion du clusterConfiguration de Amazon Redshift pour utiliser HSM
à l'aide de l'API et de l'AWS CLI Amazon Redshift
Configuration de Amazon Redshift pour utiliser HSM àl'aide de l'API et de l'AWS CLI Amazon RedshiftVous pouvez utiliser des actions d'API Amazon Redshift suivantes pour gérer les modules de sécuritématérielle.
• CreateHsmClientCertificate• CreateHsmConfiguration• DeleteHsmClientCertificate• DeleteHsmConfiguration• DescribeHsmClientCertificates• DescribeHsmConfigurations
Vous pouvez utiliser les opérations de l'AWS CLI suivantes pour gérer les modules de sécurité matérielle.
• create-hsm-client-certificate• create-hsm-configuration• delete-hsm-client-certificate• delete-hsm-configuration• describe-hsm-client-certificates• describe-hsm-configurations
Rotation des clés de chiffrement à l'aide de l'API et del'AWS CLI Amazon RedshiftVous pouvez utiliser les actions d'API Amazon Redshift suivantes pour effectuer une rotation des clés dechiffrement.
• RotateEncryptionKey
Vous pouvez utiliser les opérations de l'AWS CLI suivantes pour effectuer une rotation des clés dechiffrement.
• rotate-encryption-key
Version de l'API 2012-12-01118

Amazon Redshift Guide de la gestion du clusterPrésentation
Achat de nœuds réservés AmazonRedshiftPrésentation
Dans AWS, les frais que vous payez pour l'utilisation de Amazon Redshift reposent sur les nœuds decalcul. Chaque nœud de calcul est facturé à un taux horaire. Le taux horaire varie en fonction de critèrestels que la région, le type de nœud et si le nœud reçoit une tarification de nœud à la demande ou unetarification de nœud réservé.
La tarification de nœud à la demande est l'option la plus onéreuse, mais la plus souple de AmazonRedshift. Avec les tarifs à la demande, vous ne payez que les nœuds de calcul que vous avez dans uncluster en cours d'exécution. Si vous arrêtez ou supprimez un cluster, vous n'êtes plus facturé pour lesnœuds de calcul qui étaient dans ce cluster. Vous êtes facturé uniquement pour les nœuds de calcul quevous utilisez, et pas plus. Le taux horaire qui vous est facturé pour chaque nœud de calcul varie en fonctionde facteurs tels que la région et le type de nœud.
La tarification de nœud réservé est moins onéreuse que la tarification à la demande, car les nœuds decalcul sont facturés à des tarifs horaires réduits. Cependant, pour recevoir ces tarifs réduits, vous devezacheter des offres de nœuds réservés. Lorsque vous achetez une offre, vous faites une réservation. Laréservation définit un tarif réduit pour chaque nœud que vous réservez pour la durée de la réservation. Letarif réduit d'une offre varie en fonction de critères tels que la région, le type de nœud, la durée et l'optionde paiement.
Cette rubrique explique ce que sont les offres de nœuds réservés et comment vous pouvez les acheterafin de réduire le coût d'exécution de vos clusters Amazon Redshift. Cette rubrique présente les tarifs entermes généraux tels que les tarifs à la demande ou les tarifs réduits afin que vous puissiez comprendre lesconcepts de tarification et la façon dont la tarification affecte la facturation. Pour plus d'informations sur lestarifs spécifiques, consultez Tarification Amazon Redshift.
A propos des offres de nœuds réservésSi vous prévoyez que votre cluster Amazon Redshift s'exécute en continu pendant une période prolongée,envisagez d'acquérir des offres de nœuds réservés. Ces offres fournissent des économies importantes surla tarification à la demande, mais nécessitent que vous réserviez des nœuds de calcul et que vous vousengagiez à payer ces nœuds pendant une durée d'un an ou de trois ans.
Les nœuds réservés sont un concept de facturation strictement utilisé pour déterminer à quel taux lesnœuds vous sont facturés. La réservation d'un nœud ne crée pas de fait de nœuds pour vous. Vous êtesfacturé pour les nœuds réservés quelle que soit l'utilisation, ce qui signifie que vous devez payer chaquenœud que vous réservez pour la durée de la réservation, que vous ayez ou pas des nœuds dans un clusteren cours d'exécution auquel le tarif réduit s'applique.
Dans la phase d'évaluation de votre projet ou lorsque vous développez une preuve de concept, latarification à la demande vous donne la possibilité de payer à la demande, de payer seulement pour ceque vous utilisez et de cesser de payer à tout moment en arrêtant ou en supprimant des clusters. Une foisque vous avez établi les besoins de votre environnement de production et commencé la phase de mise enœuvre, vous devez envisager de réserver des nœuds de calcul en achetant une ou plusieurs offres.
Une offre peut s'appliquer à un ou plusieurs nœuds de calcul. Vous spécifiez le nombre de nœuds decalcul à réserver lorsque vous achetez l'offre. Vous pouvez choisir d'acheter une offre pour plusieurs
Version de l'API 2012-12-01119
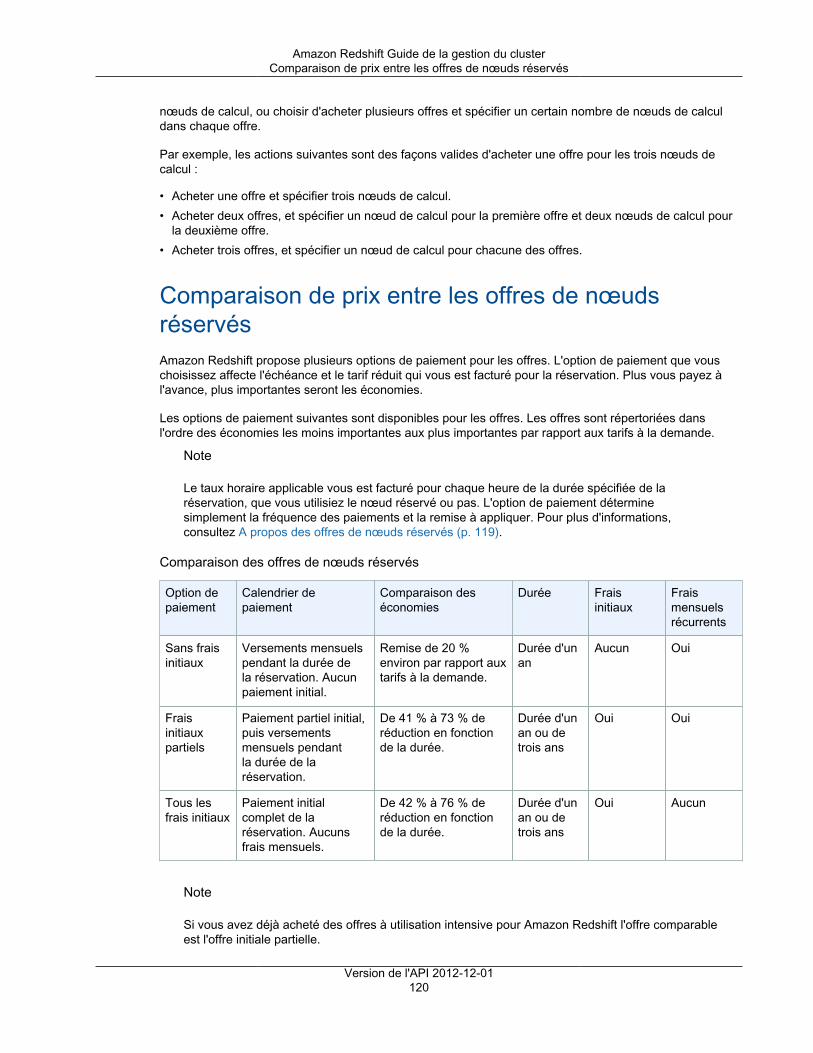
Amazon Redshift Guide de la gestion du clusterComparaison de prix entre les offres de nœuds réservés
nœuds de calcul, ou choisir d'acheter plusieurs offres et spécifier un certain nombre de nœuds de calculdans chaque offre.
Par exemple, les actions suivantes sont des façons valides d'acheter une offre pour les trois nœuds decalcul :
• Acheter une offre et spécifier trois nœuds de calcul.• Acheter deux offres, et spécifier un nœud de calcul pour la première offre et deux nœuds de calcul pour
la deuxième offre.• Acheter trois offres, et spécifier un nœud de calcul pour chacune des offres.
Comparaison de prix entre les offres de nœudsréservésAmazon Redshift propose plusieurs options de paiement pour les offres. L'option de paiement que vouschoisissez affecte l'échéance et le tarif réduit qui vous est facturé pour la réservation. Plus vous payez àl'avance, plus importantes seront les économies.
Les options de paiement suivantes sont disponibles pour les offres. Les offres sont répertoriées dansl'ordre des économies les moins importantes aux plus importantes par rapport aux tarifs à la demande.
Note
Le taux horaire applicable vous est facturé pour chaque heure de la durée spécifiée de laréservation, que vous utilisiez le nœud réservé ou pas. L'option de paiement déterminesimplement la fréquence des paiements et la remise à appliquer. Pour plus d'informations,consultez A propos des offres de nœuds réservés (p. 119).
Comparaison des offres de nœuds réservés
Option depaiement
Calendrier depaiement
Comparaison deséconomies
Durée Fraisinitiaux
Fraismensuelsrécurrents
Sans fraisinitiaux
Versements mensuelspendant la durée dela réservation. Aucunpaiement initial.
Remise de 20 %environ par rapport auxtarifs à la demande.
Durée d'unan
Aucun Oui
Fraisinitiauxpartiels
Paiement partiel initial,puis versementsmensuels pendantla durée de laréservation.
De 41 % à 73 % deréduction en fonctionde la durée.
Durée d'unan ou detrois ans
Oui Oui
Tous lesfrais initiaux
Paiement initialcomplet de laréservation. Aucunsfrais mensuels.
De 42 % à 76 % deréduction en fonctionde la durée.
Durée d'unan ou detrois ans
Oui Aucun
Note
Si vous avez déjà acheté des offres à utilisation intensive pour Amazon Redshift l'offre comparableest l'offre initiale partielle.
Version de l'API 2012-12-01120

Amazon Redshift Guide de la gestion du clusterFonctionnement des nœuds réservés
Fonctionnement des nœuds réservésAvec les offres de nœuds réservés, vous payez selon les conditions de paiement, comme décrit dans lasection précédente. Vous payez de cette façon que vous ayez déjà un cluster en cours d'exécution ou quevous lanciez un cluster après avoir effectué une réservation.
Lorsque vous achetez une offre, votre réservation a le statut en attente de paiement jusqu'à ce que laréservation soit traitée. Si le traitement de la réservation échoue, le statut affiché est échec du paiementet vous pouvez réessayer le processus. Une fois que votre réservation a été traitée avec succès, sonstatut devient active. Le tarif réduit applicable de votre réservation n'est pas appliqué à votre facture tantque le statut n'est pas active. Après expiration de la durée de la réservation, le statut devient retires maisvous pouvez continuer à accéder aux informations sur la réservation à des fins d'historique. Quand uneréservation a le statut retired, vos clusters continuent à s'exécuter, mais vous pouvez être facturé au tarif àla demande, sauf si vous avez une autre réservation qui applique une tarification réduite aux nœuds.
Les nœuds réservés sont spécifiques à la région dans laquelle vous achetez l'offre. Si vous achetezune offre à l'aide de la console Amazon Redshift, sélectionnez la région AWS dans laquelle voussouhaitez acheter une offre, puis complétez le processus de réservation. Si vous achetez une offre parprogrammation, la région est déterminée par le point de terminaison Amazon Redshift auquel vous vousconnectez. Pour plus d'informations sur les régions Amazon Redshift, consultez Régions et points determinaison dans le manuel Référence générale d'Amazon Web Services.
Pour garantir que le tarif réduit est appliqué à tous les nœuds lorsque vous lancez un cluster, assurez-vous que la région, le type de nœud et le nombre de nœuds que vous sélectionnez correspondent à uneou plusieurs réservations actives. Sinon, vous serez facturé au tarif à la demande pour les nœuds qui necorrespondent pas à une réservation active.
Dans un cluster en cours d'exécution, si vous dépassez le nombre de nœuds que vous avez réservés,vous commencez à accumuler les frais pour ces nœuds supplémentaires au tarif à la demande. Cetteaccumulation signifie qu'il est possible que différents tarifs vous soient facturés pour les nœuds du mêmecluster selon le nombre de nœuds que vous avez réservés. Vous pouvez acheter une autre offre afin decouvrir ces nœuds supplémentaires, et le tarif réduit est alors appliqué à ces nœuds pour le reste de ladurée une fois que la réservation a pour statut active.
Si vous redimensionnez votre cluster en un type de nœud différent et que vous n'avez pas réservé denœuds de ce type, vous serez facturé au tarif à la demande. Vous pouvez acheter une autre offre avecle nouveau type de nœud si vous souhaitez obtenir des tarifs réduits pour votre cluster redimensionné.Cependant, vous continuez à payer pour la réservation d'origine jusqu'à ce que l'expiration de sa durée. Sivous avez besoin de modifier vos réservations avant leur expiration, créez une demande de support à l'aidede la console AWS.
Nœuds réservés et facturation consolidéeLes avantages de tarification des nœuds réservés sont partagés lorsque le compte d'achat fait partie d'unensemble de comptes facturés réunis sous un même compte payeur de facturation consolidée. Le coûthoraire pour tous les sous-comptes est regroupé dans le compte payeur tous les mois. Cette fonctionnalitéest généralement utile pour les sociétés disposant de plusieurs équipes ou groupes fonctionnels. Ensuite,la logique standard des nœuds réservés est appliquée pour calculer le montant de la facture. Pour plusd'informations, consultez Facturation consolidée dans le manuel AWS Billing and Cost Management Guidede l'utilisateur.
Exemples de nœuds réservésLes scénarios de cette section montrent comment les nœuds accumulent les frais en fonction des tarifs à lademande et des tarifs réduits en utilisant les informations de réservation suivantes :
• Région : USA Ouest (Oregon)
Version de l'API 2012-12-01121

Amazon Redshift Guide de la gestion du clusterExemples de nœuds réservés
• Type de nœud : ds1.xlarge• Option de paiement : aucun paiement initial• Durée : une année• Nombre de nœuds réservés : 16
Exemple 1Vous avez un cluster ds1.xlarge dans la région USA Ouest (Oregon) avec 20 nœuds.
Dans ce scénario, 16 des nœuds reçoivent le tarif réduit de la réservation, mais les 4 autres nœuds ducluster sont facturés au tarif à la demande.
Exemple 2Vous avez un cluster ds1.xlarge dans la région USA Ouest (Oregon) avec 12 nœuds.
Dans ce scénario, les 12 nœuds du cluster bénéficient du tarif réduit de la réservation. Cependant, vouspayez aussi les nœuds réservés restants de la réservation même si vous n'avez pas actuellement uncluster en cours d'exécution auquel ils s'appliquent.
Exemple 3Vous avez un cluster ds1.xlarge dans la région USA Ouest (Oregon) avec 12 nœuds. Vous exécutezle cluster pendant plusieurs mois avec cette configuration, puis avez besoin d'ajouter des nœuds aucluster. Vous redimensionnez le cluster, en choisissant le même type de nœud et en spécifiant un total de16 nœuds.
Dans ce scénario, vous êtes facturé au tarif réduit de 16 nœuds. Vos coûts demeurent les mêmes pendantla durée totale de l'année, car le nombre de nœuds que vous avez dans le cluster est égal au nombre denœuds que vous avez réservés.
Exemple 4Vous avez un cluster ds1.xlarge dans la région USA Ouest (Oregon) avec 16 nœuds. Vous exécutezle cluster pendant plusieurs mois avec cette configuration, puis avez besoin d'ajouter des nœuds. Vousredimensionnez le cluster, en choisissant le même type de nœud et en spécifiant un total de 20 nœuds.
Dans ce scénario, vous êtes facturé au tarif réduit pour tous les nœuds antérieurs au redimensionnement.Après le redimensionnement, vous êtes facturé au tarif réduit pour 16 des nœuds pendant le reste del'année et vous êtes facturé au tarif à la demande pour les 4 nœuds supplémentaires que vous avezajoutés au cluster.
Exemple 5Vous avez deux clusters ds1.xlarge dans la région USA Ouest (Oregon). L'un des clusters a 6 nœuds etl'autre 10 nœuds.
Dans ce scénario, vous êtes facturé au tarif réduit pour tous les nœuds, car le nombre total de nœuds desdeux clusters est égal au nombre de nœuds que vous avez réservés.
Exemple 6Vous avez deux clusters ds1.xlarge dans la région USA Ouest (Oregon). L'un des clusters a 4 nœuds etl'autre 6 nœuds.
Version de l'API 2012-12-01122
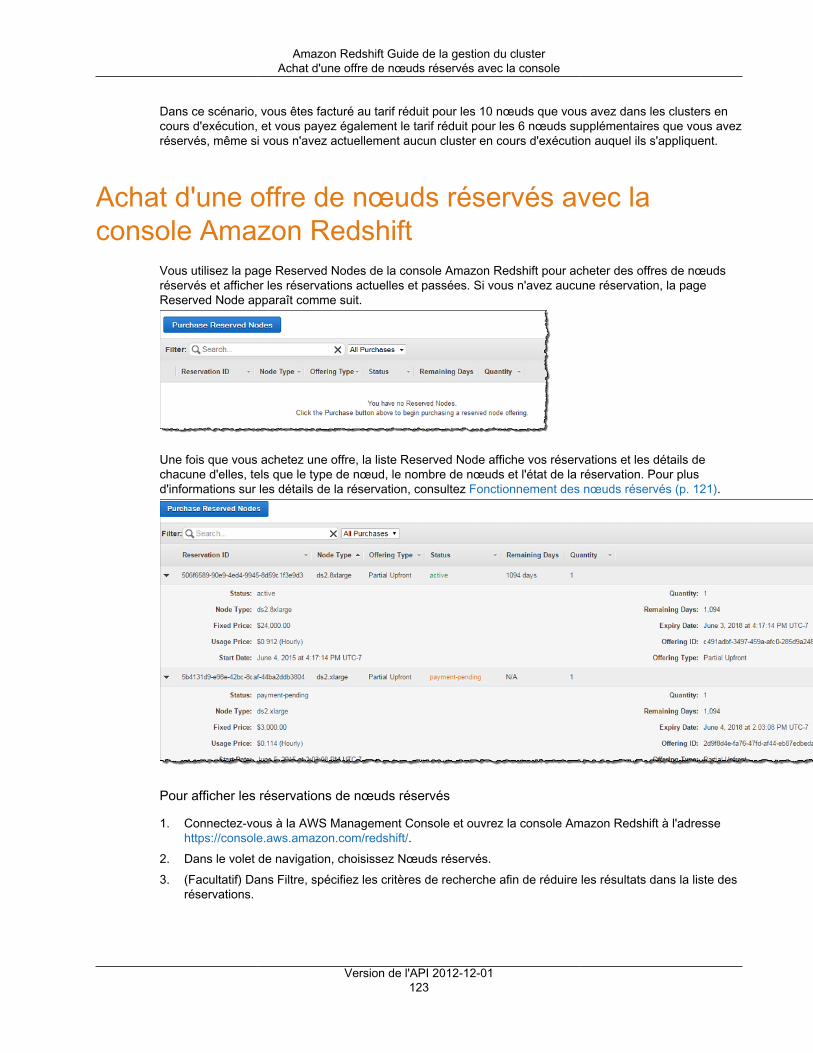
Amazon Redshift Guide de la gestion du clusterAchat d'une offre de nœuds réservés avec la console
Dans ce scénario, vous êtes facturé au tarif réduit pour les 10 nœuds que vous avez dans les clusters encours d'exécution, et vous payez également le tarif réduit pour les 6 nœuds supplémentaires que vous avezréservés, même si vous n'avez actuellement aucun cluster en cours d'exécution auquel ils s'appliquent.
Achat d'une offre de nœuds réservés avec laconsole Amazon Redshift
Vous utilisez la page Reserved Nodes de la console Amazon Redshift pour acheter des offres de nœudsréservés et afficher les réservations actuelles et passées. Si vous n'avez aucune réservation, la pageReserved Node apparaît comme suit.
Une fois que vous achetez une offre, la liste Reserved Node affiche vos réservations et les détails dechacune d'elles, tels que le type de nœud, le nombre de nœuds et l'état de la réservation. Pour plusd'informations sur les détails de la réservation, consultez Fonctionnement des nœuds réservés (p. 121).
Pour afficher les réservations de nœuds réservés
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Nœuds réservés.3. (Facultatif) Dans Filtre, spécifiez les critères de recherche afin de réduire les résultats dans la liste des
réservations.
Version de l'API 2012-12-01123

Amazon Redshift Guide de la gestion du clusterMettre à niveau un nœud réservé
Pour acheter une offre de nœud réservés
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Nœuds réservés.3. Choisissez Acheter des nœuds réservés.4. Dans l'Assistant Acheter des nœuds réservés, sélectionnez Type de nœud, Durée et Type d'offre.
5. Pour Nombre de nœuds, tapez le nombre de nœuds à réserver.6. Choisissez Continue.7. Passez en revue les détails de l'offre, puis choisissez Acheter.
8. Sur la page Nœuds réservés, la réservation s'affiche dans la liste des réservations avec l'état payment-pending.
Mettre à niveau un nœud réservé de DC1 à DC2Vous pouvez mettre à niveau vos nœuds réservés DC1 vers les nœuds DC2 pour le reste de votre contratactuel gratuitement. DC2 est conçu pour les charges de travail d'entrepôt de données exigeantes quinécessitent une faible latence et un débit élevé.
Version de l'API 2012-12-01124
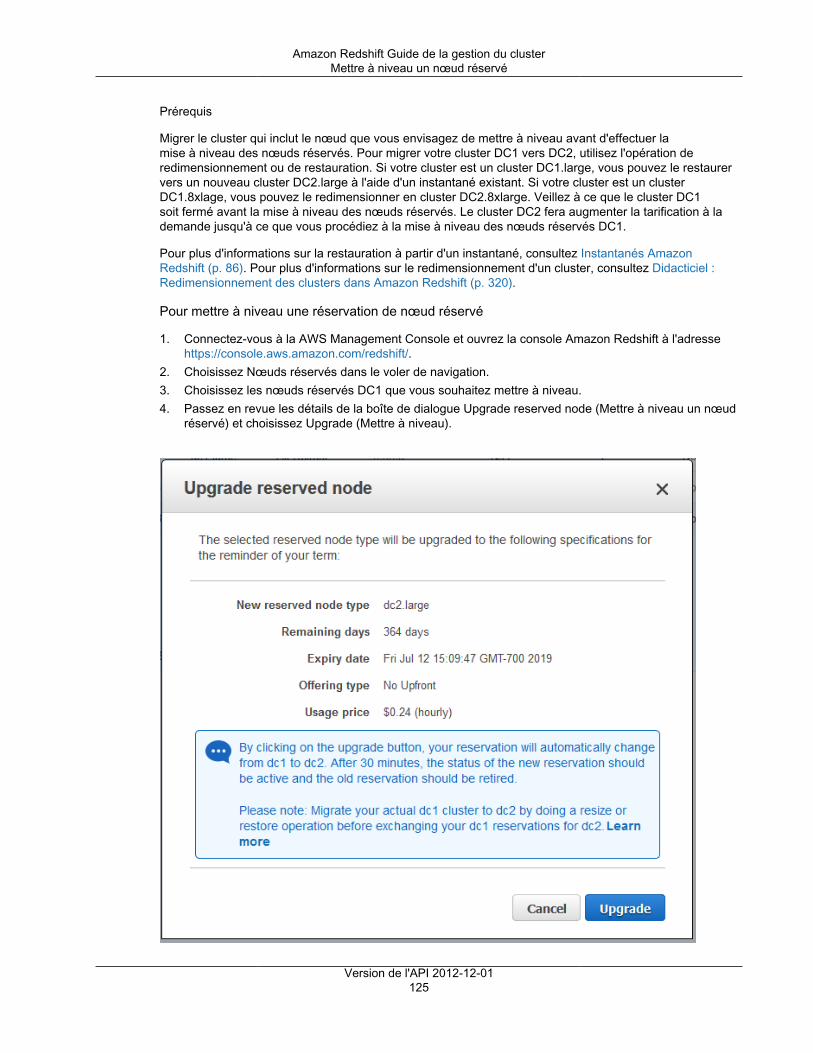
Amazon Redshift Guide de la gestion du clusterMettre à niveau un nœud réservé
Prérequis
Migrer le cluster qui inclut le nœud que vous envisagez de mettre à niveau avant d'effectuer lamise à niveau des nœuds réservés. Pour migrer votre cluster DC1 vers DC2, utilisez l'opération deredimensionnement ou de restauration. Si votre cluster est un cluster DC1.large, vous pouvez le restaurervers un nouveau cluster DC2.large à l'aide d'un instantané existant. Si votre cluster est un clusterDC1.8xlage, vous pouvez le redimensionner en cluster DC2.8xlarge. Veillez à ce que le cluster DC1soit fermé avant la mise à niveau des nœuds réservés. Le cluster DC2 fera augmenter la tarification à lademande jusqu'à ce que vous procédiez à la mise à niveau des nœuds réservés DC1.
Pour plus d'informations sur la restauration à partir d'un instantané, consultez Instantanés AmazonRedshift (p. 86). Pour plus d'informations sur le redimensionnement d'un cluster, consultez Didacticiel :Redimensionnement des clusters dans Amazon Redshift (p. 320).
Pour mettre à niveau une réservation de nœud réservé
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Choisissez Nœuds réservés dans le voler de navigation.3. Choisissez les nœuds réservés DC1 que vous souhaitez mettre à niveau.4. Passez en revue les détails de la boîte de dialogue Upgrade reserved node (Mettre à niveau un nœud
réservé) et choisissez Upgrade (Mettre à niveau).
Version de l'API 2012-12-01125

Amazon Redshift Guide de la gestion du clusterMettre à niveau un nœud réservé
Pour mettre à niveau une réservation de nœud réservé avec l'interface de ligne de commandeAmazon
1. Procurez-vous la liste des ReservedNodeOfferingID pour les offres qui conviennent à vos besoins entermes de type de règlement, de délai et de frais. L'exemple suivant illustre cette étape :
aws redshift get-reserved-node-exchange-offerings --reserved-node-id xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx{ "ReservedNodeOfferings": [ { "Duration": 31536000, "ReservedNodeOfferingId": "yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy", "UsagePrice": 0.0, "NodeType": "dc2.large", "RecurringCharges": [ { "RecurringChargeFrequency": "Hourly", "RecurringChargeAmount": 0.2 } ], "CurrencyCode": "USD", "OfferingType": "No Upfront", "ReservedNodeOfferingType": "Regular", "FixedPrice": 0.0 } ]}
2. Appelez accept-reserved-node-exchange et fournissez l'ID du nœud réservé DC1 que vousvoulez échanger, ainsi que le ReservedNodeOfferingID que vous avez obtenu à l'étape précédente.
L'exemple suivant illustre cette étape :
aws redshift accept-reserved-node-exchange --reserved-node-id xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --target-reserved-node-offering-id yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyyy{ "ExchangedReservedNode": { "UsagePrice": 0.0, "OfferingType": "No Upfront", "State": "exchanging", "FixedPrice": 0.0, "CurrencyCode": "USD", "ReservedNodeId": "zzzzzzzz-zzzz-zzzz-zzzz-zzzzzzzzzzzz", "NodeType": "dc2.large", "NodeCount": 1, "RecurringCharges": [ { "RecurringChargeFrequency": "Hourly", "RecurringChargeAmount": 0.2 } ], "ReservedNodeOfferingType": "Regular", "StartTime": "2018-06-27T18:02:58Z", "ReservedNodeOfferingId": "yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyyy", "Duration": 31536000 }}
Version de l'API 2012-12-01126

Amazon Redshift Guide de la gestion du clusterAchat d'une offre de nœuds réservés à l'aide de Java
Vous pouvez vérifier que l'échange est terminé en appelant describe-reserved-nodes et en vérifiant lavaleur de Node type.
Achat d'une offre de nœuds réservés à l'aide du kitAWS SDK pour Java
L'exemple suivant montre comment utiliser le kit AWS SDK pour Java pour effectuer les opérationssuivantes :
• Afficher les nœuds réservés existants.• Rechercher une nouvelle offre de nœuds réservés en fonction des critères de nœud spécifiés.• Acheter un nœud réservé.
D'abord, cet exemple sélectionne toutes les offres de nœuds réservés qui correspondent à un type denœud spécifié et à une valeur de prix fixée. Ensuite, l'exemple parcourt chaque offre trouvée et vouspermet de l'acheter.
Important
Si vous exécutez cet exemple et acceptez l'offre d'achat d'une offre de nœuds réservés, l'offrevous sera facturée.
Pour obtenir les instructions pas à pas de l'exécution de l'exemple, consultez Exécution d'exemples Javapour Amazon Redshift à l'aide d'Eclipse (p. 193). Pour obtenir des informations sur un type de nœud etun prix autres que ceux mentionnés, mettez à jour le code et fournissez le type de nœud et le prix.
Example
import java.io.DataInput;import java.io.DataInputStream;import java.io.IOException;import java.util.ArrayList;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;import com.amazonaws.services.redshift.model.DescribeReservedNodeOfferingsRequest;import com.amazonaws.services.redshift.model.DescribeReservedNodeOfferingsResult;import com.amazonaws.services.redshift.model.DescribeReservedNodesResult;import com.amazonaws.services.redshift.model.PurchaseReservedNodeOfferingRequest;import com.amazonaws.services.redshift.model.ReservedNode;import com.amazonaws.services.redshift.model.ReservedNodeAlreadyExistsException;import com.amazonaws.services.redshift.model.ReservedNodeOffering;import com.amazonaws.services.redshift.model.ReservedNodeOfferingNotFoundException;import com.amazonaws.services.redshift.model.ReservedNodeQuotaExceededException;
public class ListAndPurchaseReservedNodeOffering {
public static AmazonRedshiftClient client; public static String nodeTypeToPurchase = "ds1.xlarge"; public static Double fixedPriceLimit = 10000.00; public static ArrayList<ReservedNodeOffering> matchingNodes = new ArrayList<ReservedNodeOffering>(); public static void main(String[] args) throws IOException {
Version de l'API 2012-12-01127

Amazon Redshift Guide de la gestion du clusterAchat d'une offre de nœuds réservés à l'aide de Java
AWSCredentials credentials = new PropertiesCredentials( ListAndPurchaseReservedNodeOffering.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { listReservedNodes(); findReservedNodeOffer(); purchaseReservedNodeOffer(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage()); } }
private static void listReservedNodes() { DescribeReservedNodesResult result = client.describeReservedNodes(); System.out.println("Listing nodes already purchased."); for (ReservedNode node : result.getReservedNodes()) { printReservedNodeDetails(node); } }
private static void findReservedNodeOffer() { DescribeReservedNodeOfferingsRequest request = new DescribeReservedNodeOfferingsRequest(); DescribeReservedNodeOfferingsResult result = client.describeReservedNodeOfferings(request); Integer count = 0; System.out.println("\nFinding nodes to purchase."); for (ReservedNodeOffering offering : result.getReservedNodeOfferings()) { if (offering.getNodeType().equals(nodeTypeToPurchase)){ if (offering.getFixedPrice() < fixedPriceLimit) { matchingNodes.add(offering); printOfferingDetails(offering); count +=1; } } } if (count == 0) { System.out.println("\nNo reserved node offering matches found."); } else { System.out.println("\nFound " + count + " matches."); } }
private static void purchaseReservedNodeOffer() throws IOException { if (matchingNodes.size() == 0) { return; } else { System.out.println("\nPurchasing nodes.");
for (ReservedNodeOffering offering : matchingNodes) { printOfferingDetails(offering); System.out.println("WARNING: purchasing this offering will incur costs."); System.out.println("Purchase this offering [Y or N]?"); DataInput in = new DataInputStream(System.in); String purchaseOpt = in.readLine(); if (purchaseOpt.equalsIgnoreCase("y")){ try {
Version de l'API 2012-12-01128

Amazon Redshift Guide de la gestion du clusterAchat d'une offre de nœud réservé à l'aidede l'AWS CLI et de l'API Amazon Redshift
PurchaseReservedNodeOfferingRequest request = new PurchaseReservedNodeOfferingRequest() .withReservedNodeOfferingId(offering.getReservedNodeOfferingId()); ReservedNode reservedNode = client.purchaseReservedNodeOffering(request); printReservedNodeDetails(reservedNode); } catch (ReservedNodeAlreadyExistsException ex1){ } catch (ReservedNodeOfferingNotFoundException ex2){ } catch (ReservedNodeQuotaExceededException ex3){ } catch (Exception ex4){ } } } System.out.println("Finished.");
} } private static void printOfferingDetails( ReservedNodeOffering offering) { System.out.println("\nOffering Match:"); System.out.format("Id: %s\n", offering.getReservedNodeOfferingId()); System.out.format("Node Type: %s\n", offering.getNodeType()); System.out.format("Fixed Price: %s\n", offering.getFixedPrice()); System.out.format("Offering Type: %s\n", offering.getOfferingType()); System.out.format("Duration: %s\n", offering.getDuration()); } private static void printReservedNodeDetails(ReservedNode node) { System.out.println("\nPurchased Node Details:"); System.out.format("Id: %s\n", node.getReservedNodeOfferingId()); System.out.format("State: %s\n", node.getState()); System.out.format("Node Type: %s\n", node.getNodeType()); System.out.format("Start Time: %s\n", node.getStartTime()); System.out.format("Fixed Price: %s\n", node.getFixedPrice()); System.out.format("Offering Type: %s\n", node.getOfferingType()); System.out.format("Duration: %s\n", node.getDuration()); }}
Achat d'une offre de nœud réservé à l'aide del'AWS CLI et de l'API Amazon Redshift
Vous pouvez utiliser les opérations de l'AWS CLI pour acheter des offres de nœuds réservés.
• purchase-reserved-node-offering• describe-reserved-node-offerings• describe-orderable-cluster-options
Vous pouvez utiliser les API Amazon Redshift suivantes pour acheter des offres de nœud réservés.
• PurchaseReservedNodeOffering• DescribeReservedNodeOfferings
Version de l'API 2012-12-01129

Amazon Redshift Guide de la gestion du clusterAchat d'une offre de nœud réservé à l'aidede l'AWS CLI et de l'API Amazon Redshift
• DescribeOrderableClusterOptions
Version de l'API 2012-12-01130

Amazon Redshift Guide de la gestion du clusterAuthentification et contrôle d'accès
SécuritéL'accès aux ressources Amazon Redshift est contrôlé à quatre niveaux :
• Gestion de cluster : la possibilité de créer, configurer et supprimer des clusters est contrôlée par lesautorisations accordées à l'utilisateur ou au compte associé à vos informations d'identification de sécuritéAWS. Les utilisateurs AWS ayant les autorisations appropriées peuvent utiliser l'AWS ManagementConsole, l'AWS Command Line Interface (CLI) ou l'API (Application Programming Interface) AmazonRedshift pour gérer leurs clusters. Cet accès est géré à l'aide de stratégies IAM. Pour plus d'informations,consultez Authentification et contrôle d'accès pour Amazon Redshift (p. 131).
• Connectivité du cluster : les groupes de sécurité Amazon Redshift spécifient les instances AWS quisont autorisées à se connecter à un cluster Amazon Redshift au format CIDR (Classless Inter-DomainRouting). Pour plus d'informations sur la création de groupes de sécurité Amazon Redshift, Amazon EC2et Amazon VPC et leur association à des clusters, consultez la section Groupes de sécurité du clusterAmazon Redshift (p. 148).
• Accès à la base de données : la possibilité d'accéder aux objets de base de données, tels que les tableset les vues, est contrôlée par les comptes d'utilisateur dans la base de données Amazon Redshift.Les utilisateurs peuvent uniquement accéder aux ressources de la base de données auxquelles leurscomptes d'utilisateur ont l'autorisation d'accéder. Vous créez ces comptes d'utilisateur Amazon Redshiftet gérez les autorisations à l'aide des instructions SQL CREATE USER, CREATE GROUP, GRANT etREVOKE. Pour plus d'informations, accédez à Gestion de la sécurité de la base de données.
• Informations d'identification temporaires de base de données et authentification unique : en plus de créeret de gérer les utilisateurs de base de données à l'aide des commandes SQL, telles que CREATE USERet ALTER USER, vous pouvez configurer votre client SQL avec des pilotes JDBC ou ODBC AmazonRedshift personnalisés qui gèrent la création d'utilisateurs de base de données et de mots de passetemporaires dans le cadre du processus de connexion à une base de données.
Les pilotes authentifient les utilisateurs de base de données sur la base de l'authentification d'AWSIdentity and Access Management (IAM). Si vous gérez déjà des identités utilisateur en dehors d'AWS,vous pouvez utiliser un fournisseur d'identité (IdP) conforme SAML 2.0 pour gérer l'accès aux ressourcesAmazon Redshift. A l'aide d'un rôle IAM, vous pouvez configurer votre IdP et AWS de manière àpermettre à vos utilisateurs fédérés de générer des informations d'identification temporaires de base dedonnées et de se connecter aux bases de données Amazon Redshift. Pour plus d'informations, consultezUtilisation de l'authentification IAM pour générer des informations d'identification de l'utilisateur de basede données (p. 162).
Authentification et contrôle d'accès pour AmazonRedshift
L'accès à Amazon Redshift requiert des informations d'identification qu'AWS peut utiliser pour authentifiervos demandes. Ces informations d'identification doivent disposer d'autorisations pour accéder auxressources AWS, telles qu'un cluster Amazon Redshift. Les sections suivantes fournissent des détails surla façon dont vous pouvez utiliser AWS Identity and Access Management (IAM) et Amazon Redshift pourcontribuer à sécuriser vos ressources en contrôlant qui peut y accéder :
• Authentification (p. 132)• Contrôle d'accès (p. 133)
Version de l'API 2012-12-01131

Amazon Redshift Guide de la gestion du clusterAuthentification
AuthentificationVous pouvez utiliser les types d'identité suivants pour accéder à AWS :
• Utilisateur racine d'un compte AWS – Lorsque vous créez un compte AWS, vous commencez avecune seule identité de connexion disposant d'un accès complet à tous les services et ressources AWSdu compte. Cette identité est appelée utilisateur racine du compte AWS et elle est accessible aprèsconnexion à l'aide de l'adresse e-mail et du mot de passe utilisés pour la création du compte. Il estvivement recommandé de ne pas utiliser l'utilisateur racine pour vos tâches quotidiennes, y comprispour les tâches administratives. Au lieu de cela, respectez la bonne pratique qui consiste à avoir recoursà l'utilisateur racine uniquement pour créer le premier utilisateur IAM. Ensuite, mettez en sécurité lesinformations d'identification utilisateur racine et utilisez-les pour effectuer uniquement certaines tâches degestion des comptes et des services.
• Utilisateur IAM – Un utilisateur IAM est une identité au sein de votre compte AWS qui disposed'autorisations personnalisées spécifiques (par exemple, des autorisations pour créer a cluster dansAmazon Redshift). Vous pouvez utiliser un nom d'utilisateur et un mot de passe IAM pour vous connecteraux pages Web AWS sécurisées telles que AWS Management Console, les forums de discussion AWSet le AWS Support Center.
En plus de générer un nom utilisateur et un mot de passe, vous pouvez générer des clés d'accèspour chaque utilisateur. Vous pouvez utiliser ces clés lorsque vous accédez aux services AWS parprogrammation, soit par le biais d'un kit SDK soit à l'aide d'AWS Command Line Interface (CLI). Lesoutils de l'interface de ligne de commande et les kits SDK utilisent les clés d'accès pour signer de façoncryptographique votre demande. Si vous n'utilisez pas les outils AWS, vous devez signer la demandevous-même. Amazon Redshift supports prend en charge Signature Version 4, un protocole permettantl'authentification des demandes d'API entrantes. Pour plus d'informations sur l'authentification desdemandes, consultez la rubrique Processus de signature Signature Version 4 dans la documentationAWS General Reference.
• Rôle IAM – Un rôle IAM est une identité IAM que vous pouvez créer dans votre compte et qui dispose
d'autorisations spécifiques. Le concept ressemble à celui d'utilisateur IAM, mais le rôle IAM n'est pasassocié à une personne en particulier. Un rôle IAM vous permet d'obtenir des clés d'accès temporairesqui peuvent être utilisées pour accéder aux ressources et services AWS. Les rôles IAM avec desinformations d'identification temporaires sont utiles dans les cas suivants :
• Accès d'utilisateurs fédérés – Au lieu de créer un utilisateur IAM, vous pouvez utiliser des identités
d'utilisateur existantes d'AWS Directory Service, l'annuaire utilisateurs de votre entreprise, ou d'unfournisseur d'identité web. Ces derniers sont appelés utilisateurs fédérés. AWS attribue un rôle à unutilisateur fédéré lorsque l'accès est demandé via un fournisseur d'identité. Pour plus d'informationssur les utilisateurs fédérés, consultez Utilisateurs fédérés et rôles dans le manuel IAM Guide del'utilisateur.
• Accès d'un service AWS – Vous pouvez utiliser un rôle IAM de votre compte pour autoriser un autre
service AWS à accéder aux ressources de votre compte. Par exemple, vous pouvez créer un rôle quipermet à Amazon Redshift d'accéder à un compartiment Amazon S3 en votre nom, puis de charger lesdonnées stockées dans le compartiment dans un cluster Amazon Redshift. Pour plus d'informations,consultez la rubrique Création d'un rôle pour déléguer des autorisations à un service AWS dans le IAMGuide de l'utilisateur.
Version de l'API 2012-12-01132

Amazon Redshift Guide de la gestion du clusterContrôle d'accès
• Applications qui s'exécutent sur Amazon EC2 – Vous pouvez utiliser un rôle IAM pour gérer desinformations d'identification temporaires pour les applications qui s'exécutent sur une instance EC2et effectuent des demandes d'API AWS. Cette solution est préférable au stockage des clés d'accèsau sein de l'instance EC2. Pour attribuer un rôle AWS à une instance EC2 et le rendre disponible àtoutes les applications associées, vous pouvez créer un profil d'instance attaché à l'instance. Un profild'instance contient le rôle et permet aux programmes qui s'exécutent sur l'instance EC2 d'obtenir desinformations d'identification temporaires. Pour plus d'informations, consultez Utilisation d'un rôle IAMpour accorder des autorisations à des applications s'exécutant sur des instances Amazon EC2 dans leIAM Guide de l'utilisateur.
Contrôle d'accèsVous pouvez avoir des informations d'identification valides pour authentifier vos demandes, mais à moinsd'avoir les autorisations requises, vous ne pouvez pas créer de ressources Amazon Redshift ni accéderà de telles ressources. Par exemple, vous devez avoir des autorisations pour créer un cluster AmazonRedshift, créer un snapshot DB, ajouter un abonnement aux événements, etc.
Les sections suivantes décrivent comment gérer les autorisations pour Amazon Redshift. Nous vousrecommandons de commencer par lire la présentation.
• Présentation de la gestion des autorisations d'accès à vos ressources Amazon Redshift (p. 133)• Utilisation des stratégies basées sur l'identité (stratégies IAM) pour Amazon Redshift (p. 138)
Présentation de la gestion des autorisations d'accès àvos ressources Amazon RedshiftChaque ressource AWS appartient à un compte AWS et les autorisations permettant de créer desressources et d'y accéder sont régies par les stratégies d'autorisation. Un administrateur de compte peutattacher des stratégies d'autorisation aux identités IAM (c'est-à-dire aux utilisateurs, groupes et rôles),et certains services (tels que AWS Lambda) prennent également en charge l'attachement de stratégiesd'autorisation aux ressources.
Note
Un administrateur de compte (ou utilisateur administrateur) est un utilisateur doté des privilègesd'administrateur. Pour plus d'informations, consultez Bonnes pratiques IAM dans le manuel IAMGuide de l'utilisateur.
Lorsque vous accordez des autorisations, vous décidez qui doit les obtenir, à quelles ressources cesautorisations s'appliquent et les actions spécifiques que vous souhaitez autoriser sur ces ressources.
Ressources et opérations Amazon RedshiftDans Amazon Redshift, la principale ressource est un cluster. Amazon Redshift prend en charge d'autresressources qui peuvent être utilisées avec la ressource principale, telles que les instantanés, les groupesde paramètres et les abonnements aux événements. Celles-ci sont appelées sous-ressources.
Ces ressources et sous-ressources ont des noms ARN (Amazon Resource Name) uniques associés,comme cela est illustré dans le tableau suivant.
Type de ressource Format ARN
Cluster arn:aws:redshift:region:account-id:cluster:cluster-name
Version de l'API 2012-12-01133
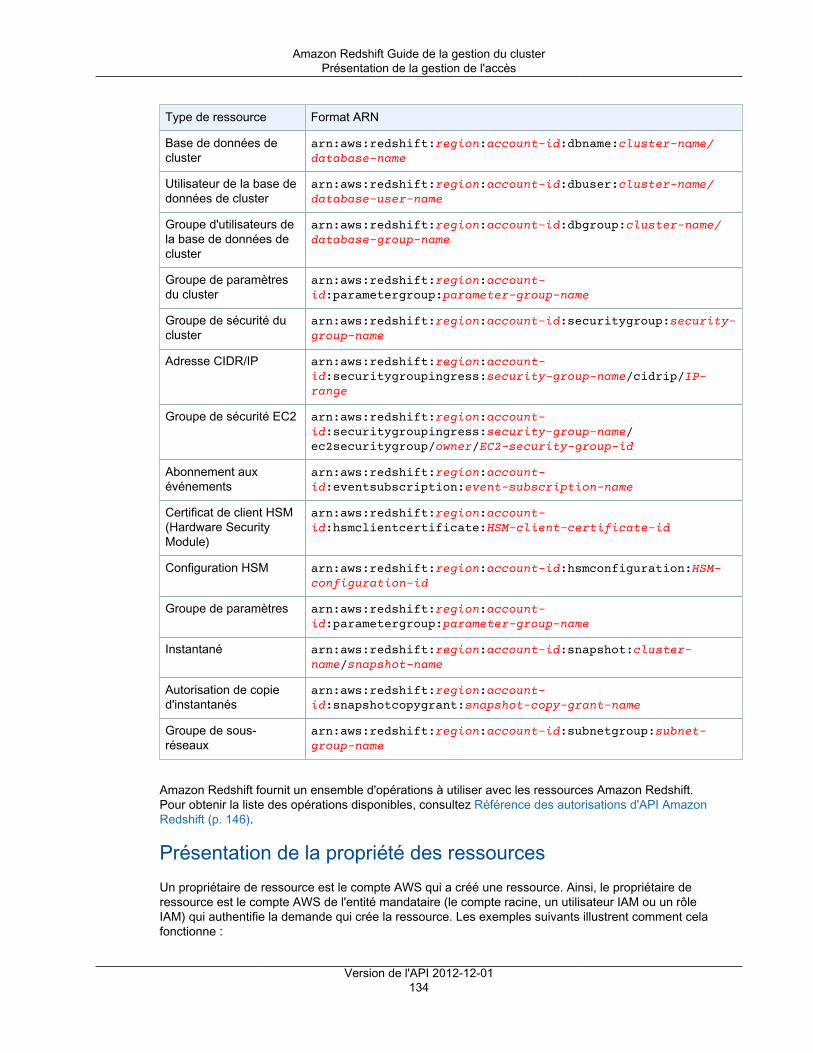
Amazon Redshift Guide de la gestion du clusterPrésentation de la gestion de l'accès
Type de ressource Format ARN
Base de données decluster
arn:aws:redshift:region:account-id:dbname:cluster-name/database-name
Utilisateur de la base dedonnées de cluster
arn:aws:redshift:region:account-id:dbuser:cluster-name/database-user-name
Groupe d'utilisateurs dela base de données decluster
arn:aws:redshift:region:account-id:dbgroup:cluster-name/database-group-name
Groupe de paramètresdu cluster
arn:aws:redshift:region:account-id:parametergroup:parameter-group-name
Groupe de sécurité ducluster
arn:aws:redshift:region:account-id:securitygroup:security-group-name
Adresse CIDR/IP arn:aws:redshift:region:account-id:securitygroupingress:security-group-name/cidrip/IP-range
Groupe de sécurité EC2 arn:aws:redshift:region:account-id:securitygroupingress:security-group-name/ec2securitygroup/owner/EC2-security-group-id
Abonnement auxévénements
arn:aws:redshift:region:account-id:eventsubscription:event-subscription-name
Certificat de client HSM(Hardware SecurityModule)
arn:aws:redshift:region:account-id:hsmclientcertificate:HSM-client-certificate-id
Configuration HSM arn:aws:redshift:region:account-id:hsmconfiguration:HSM-configuration-id
Groupe de paramètres arn:aws:redshift:region:account-id:parametergroup:parameter-group-name
Instantané arn:aws:redshift:region:account-id:snapshot:cluster-name/snapshot-name
Autorisation de copied'instantanés
arn:aws:redshift:region:account-id:snapshotcopygrant:snapshot-copy-grant-name
Groupe de sous-réseaux
arn:aws:redshift:region:account-id:subnetgroup:subnet-group-name
Amazon Redshift fournit un ensemble d'opérations à utiliser avec les ressources Amazon Redshift.Pour obtenir la liste des opérations disponibles, consultez Référence des autorisations d'API AmazonRedshift (p. 146).
Présentation de la propriété des ressourcesUn propriétaire de ressource est le compte AWS qui a créé une ressource. Ainsi, le propriétaire deressource est le compte AWS de l'entité mandataire (le compte racine, un utilisateur IAM ou un rôleIAM) qui authentifie la demande qui crée la ressource. Les exemples suivants illustrent comment celafonctionne :
Version de l'API 2012-12-01134

Amazon Redshift Guide de la gestion du clusterPrésentation de la gestion de l'accès
• Si vous utilisez les informations d'identification de compte racine de votre compte AWS pour créer uncluster DB, votre compte AWS est le propriétaire de la ressource Amazon Redshift.
• Si vous créez un utilisateur IAM dans votre compte AWS et que vous autorisez cet utilisateur à créer desressources Amazon Redshift, l'utilisateur peut créer des ressources Amazon Redshift. Toutefois, votrecompte AWS, auquel l'utilisateur appartient, détient les ressources Amazon Redshift.
• Si vous créez un rôle IAM dans votre compte AWS doté d'autorisations lui permettant de créer desressources Amazon Redshift, quiconque peut assumer le rôle peut créer des ressources AmazonRedshift. Votre compte AWS, auquel le rôle appartient, détient les ressources Amazon Redshift.
Gestion de l'accès aux ressourcesUne stratégie d'autorisation décrit qui a accès à quoi. La section suivante explique les options disponiblespour créer des stratégies d'autorisation.
Note
Cette section décrit l'utilisation d'IAM dans le contexte de Amazon Redshift. Elle ne fournit pasd'informations détaillées sur le service IAM. Pour accéder à la documentation complète d'IAM,consultez Qu'est-ce qu'IAM ? du manuel IAM Guide de l'utilisateur. Pour plus d'informations sur lasyntaxe des stratégies IAM et des descriptions, consultez Présentation des stratégies IAM AWSdans le manuel IAM Guide de l'utilisateur.
Les stratégies attachées à une identité IAM sont appelées stratégies basées sur une entité (stratégies IAM)et les stratégies attachées à une ressource sont appelées stratégies basées sur une ressource. AmazonRedshift prend en charge uniquement les stratégies basées sur une identité (stratégies IAM).
Stratégies basées sur une identité (stratégies IAM)
Vous pouvez attacher des stratégies à des identités IAM. Par exemple, vous pouvez effectuer lesopérations suivantes :
• Attacher une stratégie d'autorisation à un utilisateur ou à un groupe dans votre compte : unadministrateur de compte peut utiliser une stratégie d'autorisation associée à un utilisateur donné pourautoriser celui-ci à créer une ressource Amazon Redshift, telle qu'un cluster.
• Attacher une stratégie d'autorisation à un rôle (accorder des autorisations entre comptes) – Vous pouvezattacher une stratégie d'autorisation basée sur une identité à un rôle IAM pour accorder des autorisationsentre comptes. Par exemple, l'administrateur dans le Compte A peut créer un rôle pour accorder desautorisations entre comptes à un autre compte AWS (par exemple, le Compte B) ou à un service AWScomme suit :1. L'administrateur du Compte A crée un rôle IAM et attache une stratégie d'autorisation à ce rôle qui
accorde des autorisations sur les ressources dans le Compte A.2. L'administrateur du Compte A attache une stratégie d'approbation au rôle identifiant le Compte B
comme mandataire pouvant assumer ce rôle.3. L'administrateur du Compte B peut alors déléguer des autorisations pour assumer le rôle à tous
les utilisateurs figurant dans le Compte B. Cela autorise les utilisateurs du Compte B à créer desressources ou à y accéder dans le Compte A. Le mandataire dans la stratégie d'approbation peutégalement être un mandataire de service AWS si vous souhaitez accorder à un service AWS desautorisations pour assumer ce rôle.
Pour plus d'informations sur l'utilisation d'IAM pour déléguer des autorisations, consultez Gestion d'accèsdans le manuel IAM Guide de l'utilisateur.
Voici un exemple de stratégie vous permettant de créer, supprimer, modifier et redémarrer les clustersAmazon Redshift de votre compte AWS.
Version de l'API 2012-12-01135

Amazon Redshift Guide de la gestion du clusterPrésentation de la gestion de l'accès
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowManageClusters", "Effect":"Allow", "Action": [ "redshift:CreateCluster", "redshift:DeleteCluster", "redshift:ModifyCluster", "redshift:RebootCluster" ], "Resource":"*" } ]}
Pour plus d'informations sur l'utilisation des stratégies basées sur une identité avec Amazon Redshift,consultez Utilisation des stratégies basées sur l'identité (stratégies IAM) pour Amazon Redshift (p. 138).Pour plus d'informations sur les utilisateurs, les groupes, les rôles et les autorisations, consultez Identités(utilisateurs, groupes et rôles) dans le manuel IAM Guide de l'utilisateur.
Stratégies basées sur une ressource
D'autres services, tels que Amazon S3, prennent également en charge les stratégies d'autorisation baséessur une ressource. Par exemple, vous pouvez attacher une stratégie à un compartiment S3 pour gérer lesautorisations d'accès à ce compartiment. Amazon Redshift ne prend pas en charge les stratégies baséessur une ressource.
Spécification des éléments d'une stratégie : actions, effets,ressources et mandatairesPour chaque ressource Amazon Redshift (consultez Ressources et opérations AmazonRedshift (p. 133)), le service définit un ensemble d'opérations d'API (consultez Actions). Pour accorderdes autorisations pour ces opérations d'API, Amazon Redshift définit un ensemble d'actions que vouspouvez spécifier dans une stratégie. Notez que l'exécution d'une opération d'API peut exiger desautorisations pour plusieurs actions.
Voici les éléments de base d'une stratégie :
• Ressource – Dans une stratégie, vous utilisez un Amazon Resource Name (ARN) pour identifier laressource à laquelle la stratégie s'applique. Pour plus d'informations, consultez Ressources et opérationsAmazon Redshift (p. 133).
• Action – Vous utilisez des mots clés d'action pour identifier les opérations de ressource que vous voulezaccorder ou refuser. Par exemple, l'autorisation redshift:DescribeClusters permet à l'utilisateurd'effectuer l'opération DescribeClusters de Amazon Redshift.
• Effet – Vous spécifiez l'effet produit lorsque l'utilisateur demande l'action spécifique, qui peut être unaccord ou un refus. Si vous n'accordez pas explicitement l'accès pour (autoriser) une ressource, l'accèsest implicitement refusé. Vous pouvez aussi explicitement refuser l'accès à une ressource, ce que vouspouvez faire afin de vous assurer qu'un utilisateur n'y a pas accès, même si une stratégie différenteaccorde l'accès.
• Mandataire – Dans les stratégies basées sur une identité (stratégies IAM), l'utilisateur auquel la stratégieest attachée est le mandataire implicite. Pour les stratégies basées sur une ressource, vous spécifiezl'utilisateur, le compte, le service ou une autre entité qui doit recevoir les autorisations (s'appliqueuniquement aux stratégies basées sur une ressource). Amazon Redshift ne prend pas en charge lesstratégies basées sur une ressource.
Version de l'API 2012-12-01136

Amazon Redshift Guide de la gestion du clusterPrésentation de la gestion de l'accès
Pour plus d'informations sur la syntaxe des stratégies IAM et obtenir des descriptions, consultezPrésentation des stratégies IAM AWS dans le manuel IAM Guide de l'utilisateur.
Pour visualiser un tableau répertoriant toutes les actions d'API de Amazon Redshift et les ressourcesqu'elles appliquent, consultez Référence des autorisations d'API Amazon Redshift (p. 146).
Spécification des conditions dans une stratégieLorsque vous accordez des autorisations, vous pouvez utiliser le langage d'access policy pour spécifier lesconditions définissant quand une stratégie doit prendre effet. Par exemple, il est possible d'appliquer unestratégie après seulement une date spécifique. Pour plus d'informations sur la spécification de conditionsdans un langage d'access policy, consultez la section Éléments de stratégie JSON IAM : Condition dans leIAM Guide de l'utilisateur.
Pour identifier les conditions dans lesquelles une stratégie d'autorisations s'applique, incluez un élémentCondition à votre stratégie d'autorisations IAM. Par exemple, vous pouvez créer une stratégie quiautorise un utilisateur à créer un cluster à l'aide de l'action redshift:CreateCluster et vous pouvezajouter un élément Condition pour limiter cet utilisateur à la création du cluster dans une régionspécifique uniquement. Pour plus d'informations, consultez Utilisation de conditions de stratégie IAMpour un contrôle d'accès précis (p. 137). Pour obtenir une liste affichant toutes les valeurs des clés decondition, ainsi que les actions et ressources Amazon Redshift auxquelles elles s'appliquent, consultezRéférence des autorisations d'API Amazon Redshift (p. 146).
Utilisation de conditions de stratégie IAM pour un contrôle d'accès précis
Dans Amazon Redshift, vous pouvez utiliser deux clés de condition pour limiter l'accès aux ressourcesbasées sur les balises de ces ressources. Vous trouverez ci-dessous des clés de condition AmazonRedshift courantes.
Clé de condition Description
redshift:RequestTag Nécessite que les utilisateurs incluent une clé de balise (nom) et unevaleur chaque fois qu'ils créent une ressource. La clé de conditionredshift:RequestTag s'applique uniquement aux actions d'API AmazonRedshift qui créent une ressource.
redshift:ResourceTagLimite l'accès utilisateur aux ressources basées sur des clés et des valeurs debalise spécifiques.
Pour plus d'informations sur les balises, consultez Présentation du balisage (p. 336).
Pour obtenir une liste des actions d'API qui prennent en charge les clés de conditionredshift:RequestTag et redshift:ResourceTag, consultez Référence des autorisations d'APIAmazon Redshift (p. 146).
Les clés de condition suivantes peuvent être utilisées avec l'action Amazon Redshift GetClusterCredentials.
Clé de condition Description
redshift:DurationSecondsLimite le nombre de secondes qui peut être spécifié pour la durée.
redshift:DbName Limite les noms de base de données qui peuvent être spécifiés.
redshift:DbUser Limite les noms d'utilisateur de base de données qui peuvent être spécifiés.
Version de l'API 2012-12-01137

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
Exemple 1 : Restriction de l'accès à l'aide de la clé de condition redshift:ResourceTag
Vous pouvez utiliser la stratégie IAM suivante pour autoriser un utilisateur à modifier un cluster AmazonRedshift uniquement pour un compte AWS spécifique dans la région us-west-2 ayant une balisenommée environment avec test comme valeur de balise.
{ "Version": "2012-10-17", "Statement": { "Sid":"AllowModifyTestCluster", "Effect": "Allow", "Action": "redshift:ModifyCluster", "Resource": "arn:aws:redshift:us-west-2:123456789012:cluster:*" "Condition":{"StringEquals":{"redshift:ResourceTag/environment":"test"} }}
Exemple 2 : Restriction de l'accès à l'aide de la clé de condition redshift:RequestTag
Vous pouvez utiliser la stratégie IAM suivante pour permettre à un utilisateur de créer un cluster AmazonRedshift uniquement si la commande permettant de créer le cluster inclut une balise nommée usage etune valeur de balise production.
{ "Version": "2012-10-17", "Statement": { "Sid":"AllowCreateProductionCluster", "Effect": "Allow", "Action": "redshift:CreateCluster", "Resource": "*" "Condition":{"StringEquals":{"redshift:RequestTag/usage":"production"} }}
Utilisation des stratégies basées sur l'identité(stratégies IAM) pour Amazon RedshiftCette rubrique fournit des exemples de stratégies basées sur une identité dans lesquelles un administrateurde compte peut attacher des stratégies d'autorisation aux identités IAM (c'est-à-dire aux utilisateurs,groupes et rôles).
Important
Nous vous recommandons tout d'abord d'examiner les rubriques de présentation qui détaillent lesconcepts de base et les options disponibles pour gérer l'accès à vos ressources Amazon Redshift.Pour plus d'informations, consultez Présentation de la gestion des autorisations d'accès à vosressources Amazon Redshift (p. 133).
Les sections de cette rubrique couvrent les sujets suivants :
Rubriques• Autorisations requises pour utiliser la console Amazon Redshift (p. 139)• Stratégies de ressources pour GetClusterCredentials (p. 140)• Stratégies gérées AWS (prédéfinies) pour Amazon Redshift (p. 140)• Exemples de stratégies gérées par le client (p. 141)• Exemple de stratégie d'utilisation de GetClusterCredentials (p. 145)
Version de l'API 2012-12-01138

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
Un exemple de stratégie d'autorisation est exposé ci-dessous. La stratégie permet à un utilisateur de créer,supprimer, modifier et redémarrer tous les clusters, puis refuse l'autorisation de supprimer ou de modifierles clusters si l'identifiant du cluster commence par production.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowClusterManagement", "Action": [ "redshift:CreateCluster", "redshift:DeleteCluster", "redshift:ModifyCluster", "redshift:RebootCluster" ], "Resource": [ "*" ], "Effect": "Allow" }, { "Sid":"DenyDeleteModifyProtected", "Action": [ "redshift:DeleteCluster", "redshift:ModifyCluster" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:cluster:production*" ], "Effect": "Deny" } ]}
La stratégie possède deux énoncés:
• Le premier énoncé accorde des autorisations à un utilisateur pour créer, supprimer, modifier etredémarrer des clusters. L'énoncé spécifie un caractère générique (*) en tant que valeur Resource afinque la stratégie s'applique à toutes les ressources Amazon Redshift appartenant au compte AWS racine.
• Le second énoncé refuse l'autorisation de supprimer ou de modifier un cluster. L'énoncé spécifie uncluster Amazon Resource Name (ARN) pour la valeur Resource qui inclut un caractère générique (*).En conséquence, cet énoncé s'applique à tous les clusters Amazon Redshift appartenant au compteAWS racine où l'identifiant du cluster commence par production.
Autorisations requises pour utiliser la console Amazon RedshiftPour qu'un utilisateur puisse utiliser la console Amazon Redshift, il doit disposer d'un ensemble minimald'autorisations lui permettant de décrire les ressources Amazon Redshift de son compte AWS et d'autresinformations associées, dont les informations de réseau et de sécurité Amazon EC2.
Si vous créez une stratégie IAM plus restrictive que les autorisations minimales requises, la console nefonctionnera pas comme prévu pour les utilisateurs dotés de cette stratégie IAM. Pour garantir que cesutilisateurs pourront continuer à utiliser la console Amazon Redshift, attachez également la stratégiegérée AmazonRedshiftReadOnlyAccess à l'utilisateur, comme décrit dans Stratégies gérées AWS(prédéfinies) pour Amazon Redshift (p. 140).
Vous n'avez pas besoin d'accorder les autorisations minimales de console aux utilisateurs qui effectuentdes appels uniquement à l'AWS CLI ou l'API Amazon Redshift.
Version de l'API 2012-12-01139

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
Stratégies de ressources pour GetClusterCredentialsPour vous connecter à une base de données de cluster à l'aide d'une connexion JDBC ou ODBCavec des informations d'identification de base de données IAM, ou pour appeler par programmationl'action GetClusterCredentials, vous devez disposer, au minimum, de l'autorisation d'appeler l'actionredshift:GetClusterCredentials avec accès à une ressource dbuser.
Si vous utilisez une connexion JDBC ou ODBC, au lieu de server et de port, vous pouvezspécifier cluster_id et region, mais pour ce faire, votre stratégie doit autoriser l'actionredshift:DescribeClusters avec accès à la ressource cluster.
Si vous appelez l'action GetClusterCredentials avec les paramètres facultatifs Autocreate, DbGroupset DbName, vous devrez aussi autoriser les actions et permettre d'accéder aux ressources répertoriéesdans le tableau suivant :
ParamètreGetClusterCredentials
Action Ressource
Autocreate redshift:CreateClusterUserdbuser
DbGroups redshift:JoinGroupdbgroup
DbName NA dbname
Pour plus d'informations sur les ressources, consultez Ressources et opérations AmazonRedshift (p. 133).
Vous pouvez aussi inclure les conditions suivantes dans votre stratégie :
• redshift:DurationSeconds• redshift:DbName• redshift:DbUser
Pour plus d'informations sur les conditions, consultez Spécification des conditions dans unestratégie (p. 137)
Stratégies gérées AWS (prédéfinies) pour Amazon RedshiftAWS est approprié pour de nombreux cas d'utilisation courants et fournit des stratégies IAM autonomes quisont créées et administrées par AWS. Les stratégies gérées octroient les autorisations requises dans lescas d'utilisation courants et vous évitent d'avoir à réfléchir aux autorisations qui sont requises. Pour plusd'informations, consultez Stratégies gérées par AWS dans le manuel IAM Guide de l'utilisateur.
Les stratégies gérées par AWS, répertoriées ci-dessous, que vous pouvez attacher aux utilisateurs dansvotre compte, sont spécifiques à Amazon Redshift :
• AmazonRedshiftReadOnlyAccess : accorde un accès en lecture seule à toutes les ressources AmazonRedshift pour le compte AWS.
• AmazonRedshiftFullAccess : accorde l'accès total à toutes les ressources Amazon Redshift pour lecompte AWS.
Vous pouvez également créer vos propres stratégies IAM personnalisées afin d'accorder des autorisationspour les actions et les ressources de l'API Amazon Redshift. Vous pouvez attacher ces stratégiespersonnalisées aux utilisateurs ou groupes IAM qui nécessitent ces autorisations.
Version de l'API 2012-12-01140

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
Exemples de stratégies gérées par le clientDans cette section, vous trouverez des exemples de stratégies utilisateur qui accordent des autorisationspour diverses actions Amazon Redshift. Ces stratégies fonctionnent lorsque vous utilisez les API AmazonRedshift, les kits SDK AWS ou l'interface de ligne de commande AWS.
Note
Tous les exemples utilisent la région USA Ouest (Oregon) (us-west-2) et contiennent des ID decompte fictifs.
Exemple 1 : Autoriser l'accès total à l'utilisateur à toutes les actions et ressourcesAmazon Redshift
La stratégie suivante autorise l'accès à toutes les actions Amazon Redshift sur toutes les ressources.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowRedshift", "Action": [ "redshift:*" ], "Effect": "Allow", "Resource": "*" } ]}
La valeur redshift:* dans l'élément Action indique toutes les actions dans Amazon Redshift.
Exemple 2 : Refuser l'accès utilisateur à un ensemble d'actions Amazon Redshift
Par défaut, toutes les autorisations sont refusées. Cependant, vous devrez parfois refuser explicitementl'accès à une action ou à un ensemble d'actions spécifique. La stratégie suivante autorise l'accès à toutesles actions Amazon Redshift et refuse explicitement l'accès à toutes les actions Amazon Redshift dont lenom commence par Delete. Cette stratégie s'applique à toutes les ressources Amazon Redshift dans us-west-2.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowUSWest2Region", "Action": [ "redshift:*" ], "Effect": "Allow", "Resource": "arn:aws:redshift:us-west-2:*" }, { "Sid":"DenyDeleteUSWest2Region", "Action": [ "redshift:Delete*" ], "Effect": "Deny", "Resource": "arn:aws:redshift:us-west-2:*" } ]
Version de l'API 2012-12-01141

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
}
Exemple 3 : Autoriser un utilisateur à gérer les clustersLa stratégie suivante permet à un utilisateur de créer, supprimer, modifier et redémarrer tous les clusters,puis refuse l'autorisation de supprimer les clusters si le nom du cluster commence par protected.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowClusterManagement", "Action": [ "redshift:CreateCluster", "redshift:DeleteCluster", "redshift:ModifyCluster", "redshift:RebootCluster" ], "Resource": [ "*" ], "Effect": "Allow" }, { "Sid":"DenyDeleteProtected", "Action": [ "redshift:DeleteCluster" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:cluster:protected*" ], "Effect": "Deny" } ]}
Exemple 4 : Autoriser un utilisateur à accorder et à révoquer l'accès auxinstantanésLa stratégie suivante autorise un utilisateur, par exemple l'utilisateur A, à effectuer les opérationssuivantes :
• Autoriser l'accès à n'importe quel instantané créé à partir d'un cluster nommé shared.• Annuler l'accès aux instantanés pour tous les instantanés créés à partir du cluster shared dont le nom
d'instantané commence par revokable.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowSharedSnapshots", "Action": [ "redshift:AuthorizeSnapshotAccess" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:shared/*" ], "Effect": "Allow" }, {
Version de l'API 2012-12-01142

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
"Sid":"AllowRevokableSnapshot", "Action": [ "redshift:RevokeSnapshotAccess" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:snapshot:*/revokable*" ], "Effect": "Allow" } ]}
Si l'utilisateur A a autorisé l'utilisateur B à accéder à un instantané, l'utilisateur B doit disposer d'unestratégie telle que les suivantes pour autoriser l'utilisateur B à restaurer un cluster à partir de l'instantané.La stratégie suivante permet à l'utilisateur B de décrire et de restaurer à partir d'un instantané et de créerdes clusters. Le nom de ces clusters doit commencer par from-other-account.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowDescribeSnapshots", "Action": [ "redshift:DescribeClusterSnapshots" ], "Resource": [ "*" ], "Effect": "Allow" }, { "Sid":"AllowUserRestoreFromSnapshot", "Action": [ "redshift:RestoreFromClusterSnapshot" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:snapshot:*/*", "arn:aws:redshift:us-west-2:444455556666:cluster:from-other-account*" ], "Effect": "Allow" } ]}
Exemple 5 : Permettre à un utilisateur de copier un instantané du cluster et derestaurer un cluster à partir d'un instantanéLa stratégie suivante permet à un utilisateur de copier n'importe quel instantané créé à partir ducluster nommé big-cluster-1 et de restaurer n'importe quel instantané dont le nom commence parsnapshot-for-restore.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowCopyClusterSnapshot", "Action": [ "redshift:CopyClusterSnapshot" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:snapshot:big-cluster-1/*" ],
Version de l'API 2012-12-01143

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
"Effect": "Allow" }, { "Sid":"AllowRestoreFromClusterSnapshot", "Action": [ "redshift:RestoreFromClusterSnapshot" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:snapshot:*/snapshot-for-restore*", "arn:aws:redshift:us-west-2:123456789012:cluster:*" ], "Effect": "Allow" } ]}
Exemple 6 : Autoriser un accès utilisateur à Amazon Redshift et aux actions etressources communes pour les services AWS associés
L'exemple de stratégie suivant autorise l'accès à toutes les actions et ressources pour Amazon Redshift,Amazon Simple Notification Service (Amazon SNS) et Amazon CloudWatch, et permet des actions définiessur toutes leurs ressources Amazon EC2 du compte.
Note
Les autorisations au niveau des ressources ne sont pas prises en charge pour les actions AmazonEC2 spécifiées dans cet exemple de stratégie.
{ "Version": "2012-10-17", "Statement": [ { "Sid":"AllowRedshift", "Effect": "Allow", "Action": [ "redshift:*" ], "Resource": [ "*" ] }, { "Sid":"AllowSNS", "Effect": "Allow", "Action": [ "sns:*" ], "Resource": [ "*" ] }, { "Sid":"AllowCloudWatch", "Effect": "Allow", "Action": [ "cloudwatch:*" ], "Resource": [ "*" ] }, { "Sid":"AllowEC2Actions",
Version de l'API 2012-12-01144

Amazon Redshift Guide de la gestion du clusterUtilisation des stratégies baséessur une identité (stratégies IAM)
"Effect": "Allow", "Action": [ "ec2:AllocateAddress", "ec2:AssociateAddress", "ec2:AttachNetworkInterface", "ec2:DescribeAccountAttributes", "ec2:DescribeAddresses", "ec2:DescribeAvailabilityZones", "ec2:DescribeInternetGateways", "ec2:DescribeSecurityGroups", "ec2:DescribeSubnets", "ec2:DescribeVpcs" ], "Resource": [ "*" ] } ]}
Exemple de stratégie d'utilisation de GetClusterCredentialsLa stratégie suivante utilise ces exemples de valeurs de paramètre :
• Région: us-west-2• Compte AWS: 123456789012• Nom du cluster: examplecluster
La stratégie suivante active les actions GetCredentials, CreateCluserUser et JoinGroup actions.La stratégie utilise des clés de condition pour autoriser les actions GetClusterCredentials etCreateClusterUser seulement quand l'ID utilisateur AWS correspond à "AIDIODR4TAW7CSEXAMPLE:${redshift:DbUser}@yourdomain.com". L'accès IAM est demandé pour la base de données"testdb" uniquement. La stratégie autorise également les utilisateurs à rejoindre un groupe nommé"common_group".
{"Version": "2012-10-17", "Statement": [ { "Sid": "GetClusterCredsStatement", "Effect": "Allow", "Action": [ "redshift:GetClusterCredentials" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:dbuser:examplecluster/${redshift:DbUser}", "arn:aws:redshift:us-west-2:123456789012:dbname:examplecluster/testdb", "arn:aws:redshift:us-west-2:123456789012:dbgroup:examplecluster/common_group" ], "Condition": { "StringEquals": { "aws:userid":"AIDIODR4TAW7CSEXAMPLE:${redshift:DbUser}@yourdomain.com" } } }, { "Sid": "CreateClusterUserStatement", "Effect": "Allow", "Action": [ "redshift:CreateClusterUser" ],
Version de l'API 2012-12-01145

Amazon Redshift Guide de la gestion du clusterRéférence des autorisations d'API Amazon Redshift
"Resource": [ "arn:aws:redshift:us-west-2:123456789012:dbuser:examplecluster/${redshift:DbUser}" ], "Condition": { "StringEquals": { "aws:userid":"AIDIODR4TAW7CSEXAMPLE:${redshift:DbUser}@yourdomain.com" } } }, { "Sid": "RedshiftJoinGroupStatement", "Effect": "Allow", "Action": [ "redshift:JoinGroup" ], "Resource": [ "arn:aws:redshift:us-west-2:123456789012:dbgroup:examplecluster/common_group" ] } ]} }}
Référence des autorisations d'API Amazon RedshiftLorsque vous configurez des stratégies d'autorisation d'écriture et de Contrôle d'accès (p. 133) quevous pouvez attacher à une entité IAM (stratégies basées sur une identité), vous pouvez utiliser le tableauci-dessous comme référence. Cette la liste inclut chaque opération d'API Amazon Redshift, les actionscorrespondantes pour lesquelles vous pouvez accorder des autorisations, la ressource AWS pour laquellevous pouvez accorder les autorisations, et les clés des condition que vous pouvez inclure pour un contrôled'accès précis (pour plus d'informations sur les conditions, consultez Utilisation de conditions de stratégieIAM pour un contrôle d'accès précis (p. 137)). Vous spécifiez les actions dans le champ Action de lastratégie, la valeur de ressource dans le champ Resource de la stratégie, et les conditions dans le champCondition de la stratégie.
Note
Pour spécifier une action, utilisez le préfixe redshift: suivi du nom de l'opération d'API (parexemple, redshift:CreateCluster).
Redshift prend également en charge les actions suivantes qui ne sont pas basées sur l'API AmazonRedshift :
• L'action redshift:ViewQueriesInConsole contrôle si un utilisateur peut voir les requêtes dans laAmazon Redshift console dans l'onglet Queries de la section Cluster.
• L'action redshift:CancelQuerySession contrôle si un utilisateur peut terminer l'exécution desrequêtes et des charges de la section Cluster dans la Amazon Redshift console.
Utilisation des rôles liés à un service pour AmazonRedshiftAmazon Redshift utilise les rôles liés à un service AWS Identity and Access Management (IAM). Un rôle liéà un service est un type unique de rôle IAM lié directement à Amazon Redshift. Les rôles liés à un servicesont prédéfinis par Amazon Redshift et incluent toutes les autorisations que le service requiert pour appelerles services AWS au nom de votre Amazon Redshift cluster.
Version de l'API 2012-12-01146

Amazon Redshift Guide de la gestion du clusterUtilisation des rôles liés à un service
Un rôle lié à un service simplifie la configuration d'Amazon Redshift, car vous n'avez pas besoin d'ajoutermanuellement les autorisations requises. Le rôle est lié au cas d'utilisation d'Amazon Redshift et possèdedes autorisations prédéfinies. Seul Amazon Redshift peut endosser le rôle et seul le rôle lié au servicepeut utiliser la stratégie d'autorisations prédéfinie. Amazon Redshift crée un rôle lié au service dans votrecompte la première fois que vous créez un cluster. Vous pouvez supprimer le rôle lié à un service aprèsque vous avez supprimé tous les clusters Amazon Redshift de votre compte. Vos ressources AmazonRedshift sont ainsi protégées, car vous ne pouvez pas involontairement supprimer les autorisationsnécessaires pour y accéder.
Pour plus d'informations sur les autres services qui prennent en charge les rôles liés à un service,consultez Services AWS qui fonctionnent avec IAM et recherchez les services qui comportent Oui dans lacolonne Rôle lié à un service. Choisissez un Oui ayant un lien permettant de consulter la documentation durôle lié à un service, pour ce service.
Autorisations des rôles liés à un service pour Amazon RedshiftAmazon Redshift utilise le rôle lié à un service intitulé AWSServiceRoleForRedshift – Allows AmazonRedshift to call AWS services on your behalf.
Le rôle lié à un service AWSServiceRoleForRedshift n'approuve que redshift.amazonaws.com pourendosser le rôle.
La stratégie des autorisations d'un rôle lié à un service AWSServiceRoleForRedshift permet à AmazonRedshift de compléter les actions suivantes sur toutes les ressources associées :
• ec2:DescribeVpcs
• ec2:DescribeSubnets
• ec2:DescribeNetworkInterfaces
• ec2:DescribeAddress
• ec2:AssociateAddress
• ec2:DisassociateAddress
• ec2:CreateNetworkInterface
• ec2:DeleteNetworkInterface
• ec2:ModifyNetworkInterfaceAttribute
Pour permettre à une entité IAM de créer des rôles liés à un service AWSServiceRoleForRedshift
Ajoutez la déclaration de stratégie suivante aux autorisations de cette entité IAM :
{ "Effect": "Allow", "Action": [ "iam:CreateServiceLinkedRole" ], "Resource": "arn:aws:iam::<AWS-account-ID>:role/aws-service-role/redshift.amazonaws.com/AWSServiceRoleForRedshift", "Condition": {"StringLike": {"iam:AWSServiceName": "redshift.amazonaws.com"}}}
Pour permettre à une entité IAM de supprimer des rôles liés à un service AWSServiceRoleForRedshift
Ajoutez la déclaration de stratégie suivante aux autorisations de cette entité IAM :
{ "Effect": "Allow", "Action": [
Version de l'API 2012-12-01147

Amazon Redshift Guide de la gestion du clusterGroupes de sécurité
"iam:DeleteServiceLinkedRole", "iam:GetServiceLinkedRoleDeletionStatus" ], "Resource": "arn:aws:iam::<AWS-account-ID>:role/aws-service-role/redshift.amazonaws.com/AWSServiceRoleForRedshift", "Condition": {"StringLike": {"iam:AWSServiceName": "redshift.amazonaws.com"}}}
Sinon, vous pouvez utiliser une stratégie gérée AWS pour fournir un accès complet à Amazon Redshift.
Création d'un rôle lié à un service pour Amazon RedshiftVous n'avez pas besoin de créer manuellement un rôle lié à un service AWSServiceRoleForRedshift.Amazon Redshift crée automatiquement le rôle lié au service. Si le rôle lié à un serviceAWSServiceRoleForRedshift a été supprimé de votre compte, Amazon Redshift crée le rôle lorsque vouslancez un nouveau cluster Amazon Redshift.
Important
Si vous utilisiez le service Amazon Redshift avant September 18, 2017, quand les rôlesliés à un service ont commencé à être pris en charge, Amazon Redshift a créé le rôleAWSServiceRoleForRedshift dans votre compte. Pour en savoir plus, consultez Un nouveau rôleest apparu dans mon compte IAM.
Modification d'un rôle lié à un service pour Amazon RedshiftAmazon Redshift ne vous permet pas de modifier le rôle lié à un service AWSServiceRoleForRedshift.Une fois que vous avez créé un rôle lié à un service, vous ne pouvez pas changer le nom du rôle, carplusieurs entités peuvent faire référence au rôle. Cependant, vous pouvez modifier la description du rôle àl'aide de la console IAM, de l'interface de ligne de commande AWS (AWS CLI) ou de l'API IAM. Pour plusd'informations, consultez Modification d'un rôle dans le IAM Guide de l'utilisateur.
Suppression d'un rôle lié à un service pour Amazon RedshiftSi vous n'avez plus besoin d'utiliser une fonction ou un service qui nécessite un rôle lié à un service, nousvous recommandons de supprimer ce rôle. De cette façon, vous n'avez aucune entité inutilisée qui n'estpas surveillée ou géré activement.
Avant de pouvoir supprimer un rôle lié à un service pour un compte, vous devez arrêter et supprimer tousles clusters du compte. Pour plus d'informations, consultez Arrêt et suppression de clusters (p. 14).
Vous pouvez utiliser la console IAM;, l'interface de ligne de commande AWS; ou l'API IAM pour supprimerun rôle lié à un service. Pour plus d'informations, consultez Création d'un rôle pour un service AWS dans leIAM Guide de l'utilisateur.
Groupes de sécurité du cluster Amazon RedshiftLorsque vous mettez en service un cluster Amazon Redshift, il est verrouillé par défaut afin que personnen'y ait accès. Pour autoriser d'autres utilisateurs à accéder à un cluster Amazon Redshift, associez lecluster à un groupe de sécurité. Si vous êtes sur la plateforme EC2-Classic, définissez un groupe desécurité du cluster que vous associez à un cluster comme décrit ci-après. Si vous êtes sur la plateformeEC2-VPC, vous pouvez utiliser un groupe de sécurité Amazon VPC existant ou en définir un nouveau etl'associer ensuite à un cluster. Pour plus d'informations sur la gestion d'un cluster sur la plateforme EC2-VPC, consultez la section Gestion des clusters dans un Amazon Virtual Private Cloud (VPC) (p. 36).
Rubriques• Présentation (p. 149)
Version de l'API 2012-12-01148

Amazon Redshift Guide de la gestion du clusterPrésentation
• Gestion des groupes de sécurité du cluster à l'aide de la console (p. 149)• Gestion des groupes de sécurité du cluster à l'aide du kit AWS SDK pour Java (p. 158)• Gérer les groupes de sécurité de cluster à l'aide de l'interface de ligne de commande et de l'API
Amazon Redshift (p. 161)
PrésentationUn groupe de sécurité du cluster se compose d'un ensemble de règles qui contrôlent l'accès à votrecluster. Des règles individuelles identifient soit une plage d'adresses IP, soit un groupe de sécurité AmazonEC2 qui est autorisé à accéder à votre cluster. Lorsque vous associez un groupe de sécurité du cluster àun cluster, les règles définies dans le groupe de sécurité du cluster contrôlent l'accès au cluster.
Vous pouvez créer des groupes de sécurité de cluster indépendants de la mise en service d'un cluster.Vous pouvez associer un groupe de sécurité du cluster avec un cluster Amazon Redshift au moment oùvous mettez en service le cluster ou plus tard. En outre, vous pouvez associer un groupe de sécurité ducluster à plusieurs clusters.
Amazon Redshift fournit un groupe de sécurité du cluster appelé par défaut qui est créé automatiquementlorsque vous lancez votre premier cluster. A l'origine, ce groupe de sécurité du cluster est vide. Vouspouvez ajouter des règles d'accès entrant au groupe de sécurité du cluster par défaut, puis l'associer àvotre cluster Amazon Redshift.
Si le groupe de sécurité du cluster par défaut est suffisant pour vous, vous n'avez pas besoin de créer levôtre. Cependant, vous pouvez créer vos propres groupes de sécurité du cluster pour mieux gérer l'accèsentrant à votre cluster. Par exemple, supposons que vous exécutiez un service sur un cluster AmazonRedshift et que vous ayez quelques entreprises comme clients. Si vous ne voulez pas fournir le mêmeaccès à tous vos clients, vous pouvez créer des groupes de sécurité du cluster distincts, un par société.Vous pouvez ajouter des règles à chaque groupe de sécurité du cluster pour identifier les groupes desécurité Amazon EC2 et les plages d'adresses IP spécifiques à une société. Vous pouvez ensuite associertous ces groupes de sécurité du cluster à votre cluster.
Vous pouvez associer un groupe de sécurité du cluster à plusieurs clusters, et vous pouvez associerplusieurs groupes de sécurité de cluster à un cluster, conformément aux limites du service AWS. Pour plusd'informations, consultez Limites Amazon Redshift.
Vous pouvez gérer les groupes de sécurité de cluster à l'aide de la console Amazon Redshift et vouspouvez gérer les groupes de sécurité de cluster par programmation en utilisant l'API Amazon Redshift oules kits SDK AWS.
Amazon Redshift applique les modifications immédiatement à un groupe de sécurité du cluster. Donc, sivous avez associé le groupe de sécurité du cluster à un cluster, les règles d'accès au cluster entrant dansle groupe de sécurité du cluster mis à jour s'appliquent immédiatement.
Gestion des groupes de sécurité du cluster à l'aide dela consoleVous pouvez créer, modifier et supprimer des groupes de sécurité du cluster à l'aide de la console AmazonRedshift. Vous pouvez également gérer le groupe de sécurité du cluster par défaut dans la consoleAmazon Redshift. Toutes les tâches démarrent à partir de la liste des groupes de sécurité du cluster. Vousdevez sélectionner un groupe de sécurité du cluster à gérer.
L'exemple de liste de groupes de sécurité du cluster ci-dessous comporte deux groupes de sécurité ducluster, le groupe de sécurité du cluster default et un groupe de sécurité du cluster personnalisé appelésecuritygroup1. Du fait que securitygroup1 est sélectionné (en surbrillance), vous pouvez lesupprimer ou gérer des balises pour lui, ainsi qu'afficher les règles et les balises associées à celui-ci.
Version de l'API 2012-12-01149
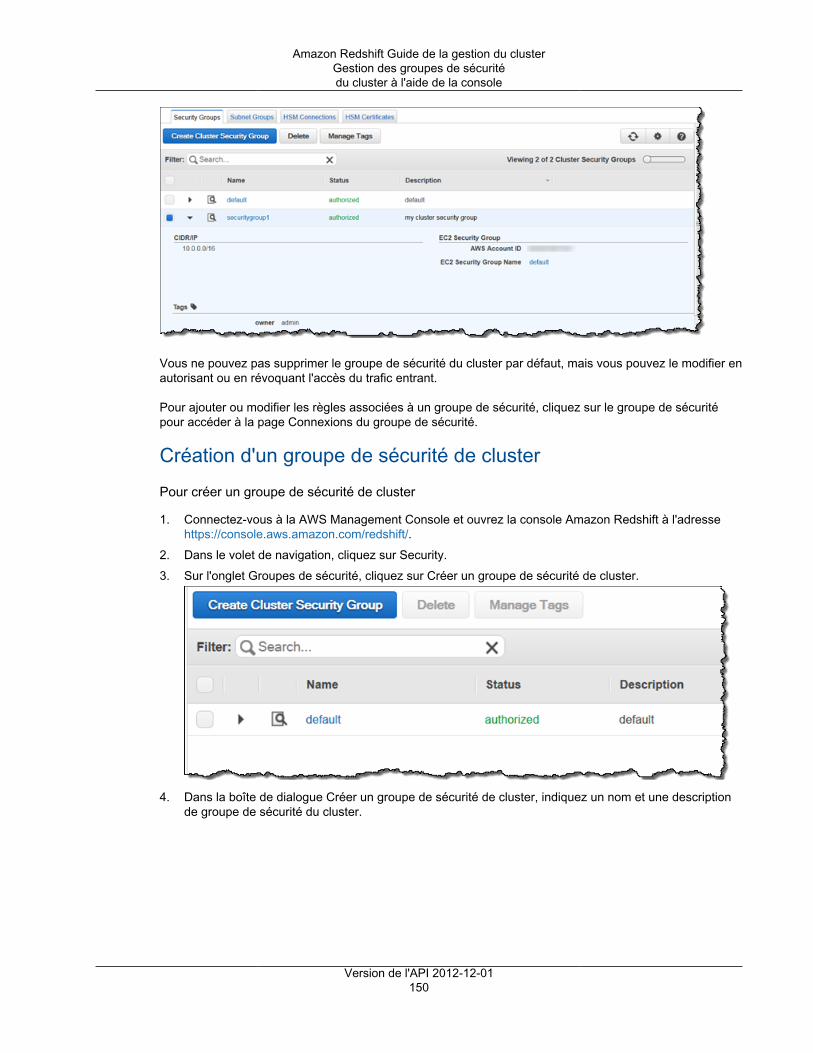
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
Vous ne pouvez pas supprimer le groupe de sécurité du cluster par défaut, mais vous pouvez le modifier enautorisant ou en révoquant l'accès du trafic entrant.
Pour ajouter ou modifier les règles associées à un groupe de sécurité, cliquez sur le groupe de sécuritépour accéder à la page Connexions du groupe de sécurité.
Création d'un groupe de sécurité de clusterPour créer un groupe de sécurité de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sécurité, cliquez sur Créer un groupe de sécurité de cluster.
4. Dans la boîte de dialogue Créer un groupe de sécurité de cluster, indiquez un nom et une descriptionde groupe de sécurité du cluster.
Version de l'API 2012-12-01150
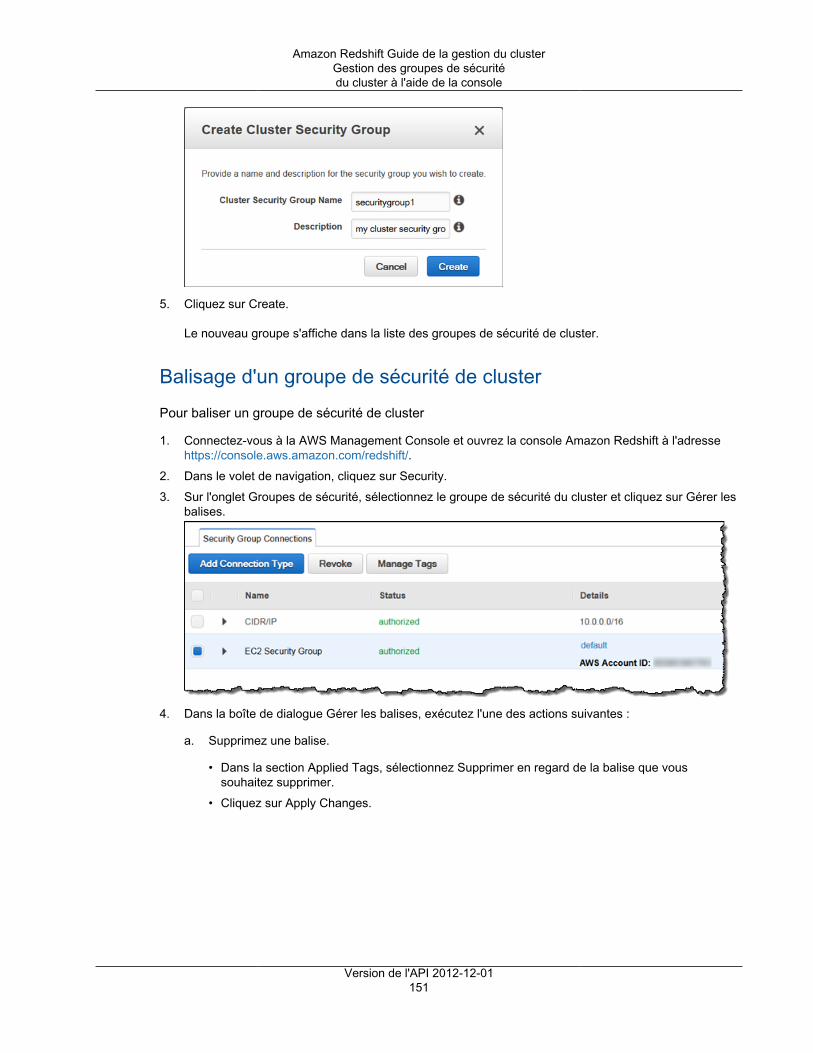
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
5. Cliquez sur Create.
Le nouveau groupe s'affiche dans la liste des groupes de sécurité de cluster.
Balisage d'un groupe de sécurité de clusterPour baliser un groupe de sécurité de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sécurité, sélectionnez le groupe de sécurité du cluster et cliquez sur Gérer les
balises.
4. Dans la boîte de dialogue Gérer les balises, exécutez l'une des actions suivantes :
a. Supprimez une balise.
• Dans la section Applied Tags, sélectionnez Supprimer en regard de la balise que voussouhaitez supprimer.
• Cliquez sur Apply Changes.
Version de l'API 2012-12-01151
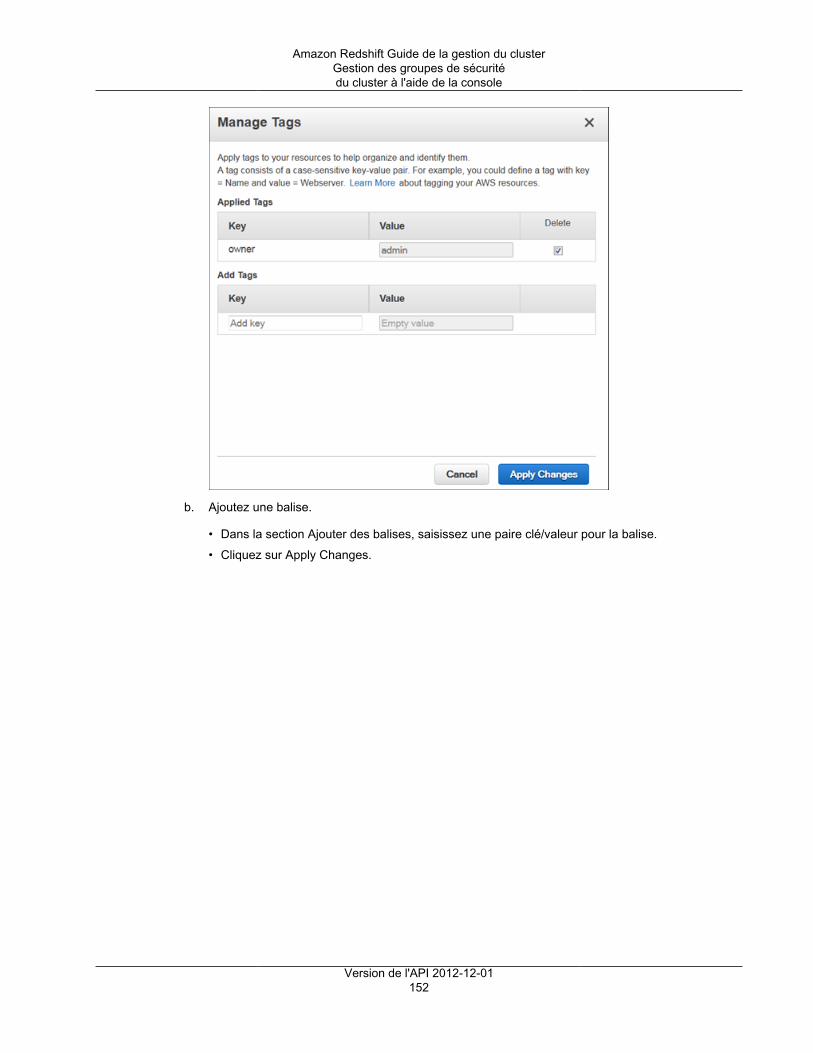
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
b. Ajoutez une balise.
• Dans la section Ajouter des balises, saisissez une paire clé/valeur pour la balise.• Cliquez sur Apply Changes.
Version de l'API 2012-12-01152
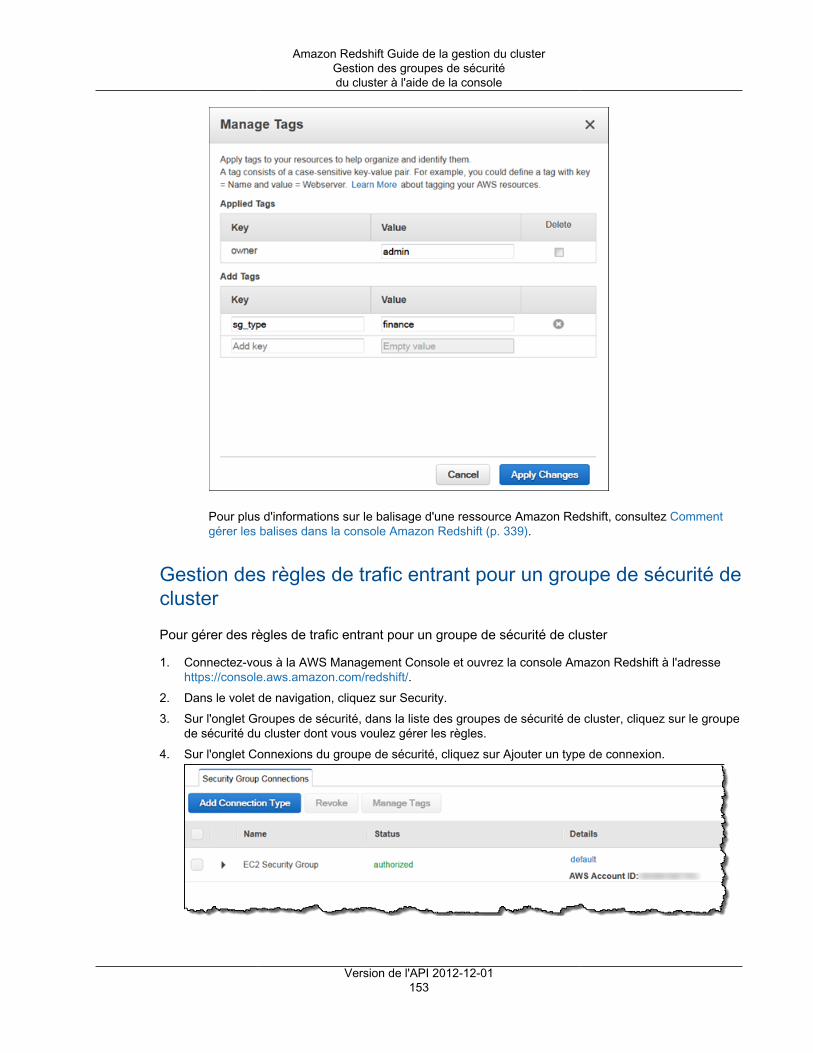
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
Pour plus d'informations sur le balisage d'une ressource Amazon Redshift, consultez Commentgérer les balises dans la console Amazon Redshift (p. 339).
Gestion des règles de trafic entrant pour un groupe de sécurité declusterPour gérer des règles de trafic entrant pour un groupe de sécurité de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sécurité, dans la liste des groupes de sécurité de cluster, cliquez sur le groupe
de sécurité du cluster dont vous voulez gérer les règles.4. Sur l'onglet Connexions du groupe de sécurité, cliquez sur Ajouter un type de connexion.
Version de l'API 2012-12-01153
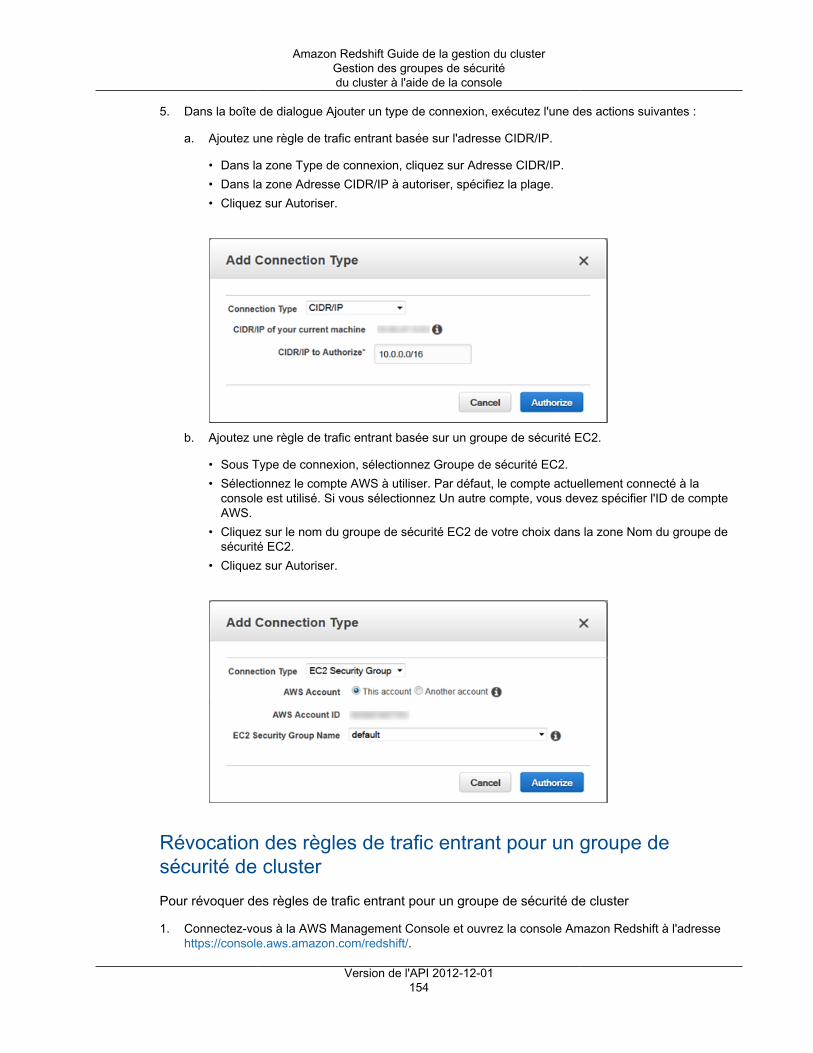
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
5. Dans la boîte de dialogue Ajouter un type de connexion, exécutez l'une des actions suivantes :
a. Ajoutez une règle de trafic entrant basée sur l'adresse CIDR/IP.
• Dans la zone Type de connexion, cliquez sur Adresse CIDR/IP.• Dans la zone Adresse CIDR/IP à autoriser, spécifiez la plage.• Cliquez sur Autoriser.
b. Ajoutez une règle de trafic entrant basée sur un groupe de sécurité EC2.
• Sous Type de connexion, sélectionnez Groupe de sécurité EC2.• Sélectionnez le compte AWS à utiliser. Par défaut, le compte actuellement connecté à la
console est utilisé. Si vous sélectionnez Un autre compte, vous devez spécifier l'ID de compteAWS.
• Cliquez sur le nom du groupe de sécurité EC2 de votre choix dans la zone Nom du groupe desécurité EC2.
• Cliquez sur Autoriser.
Révocation des règles de trafic entrant pour un groupe desécurité de clusterPour révoquer des règles de trafic entrant pour un groupe de sécurité de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
Version de l'API 2012-12-01154
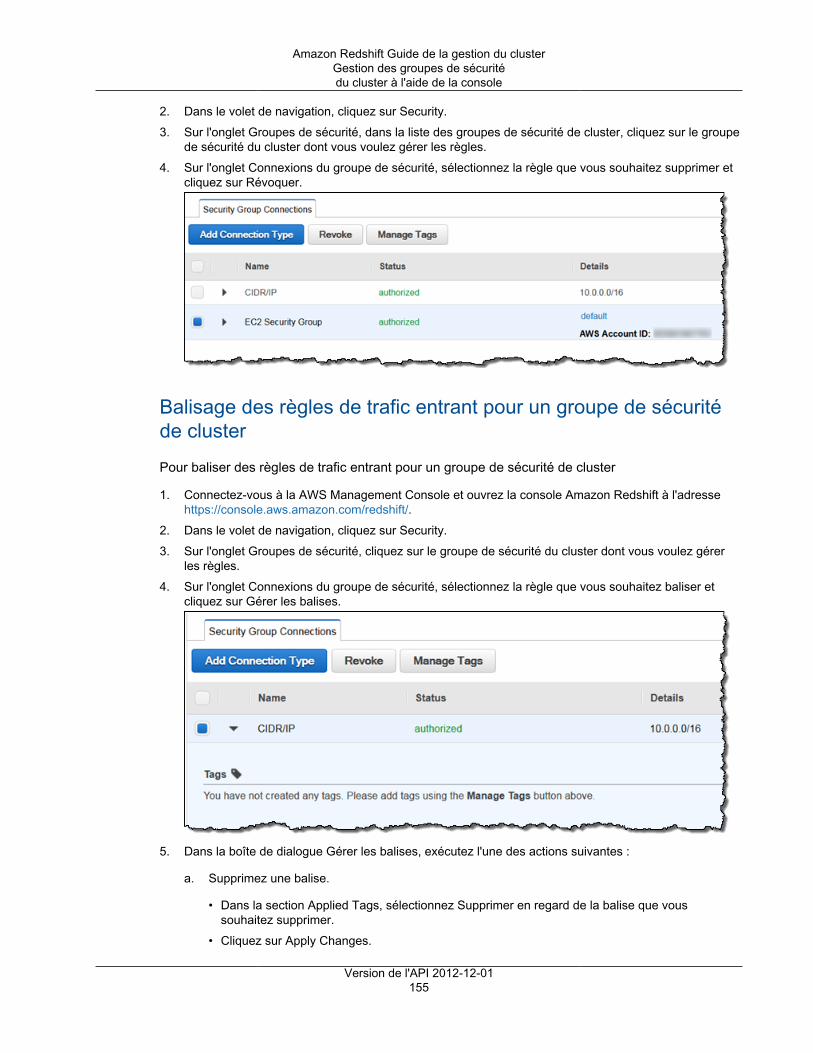
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sécurité, dans la liste des groupes de sécurité de cluster, cliquez sur le groupe
de sécurité du cluster dont vous voulez gérer les règles.4. Sur l'onglet Connexions du groupe de sécurité, sélectionnez la règle que vous souhaitez supprimer et
cliquez sur Révoquer.
Balisage des règles de trafic entrant pour un groupe de sécuritéde clusterPour baliser des règles de trafic entrant pour un groupe de sécurité de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sécurité, cliquez sur le groupe de sécurité du cluster dont vous voulez gérer
les règles.4. Sur l'onglet Connexions du groupe de sécurité, sélectionnez la règle que vous souhaitez baliser et
cliquez sur Gérer les balises.
5. Dans la boîte de dialogue Gérer les balises, exécutez l'une des actions suivantes :
a. Supprimez une balise.
• Dans la section Applied Tags, sélectionnez Supprimer en regard de la balise que voussouhaitez supprimer.
• Cliquez sur Apply Changes.
Version de l'API 2012-12-01155
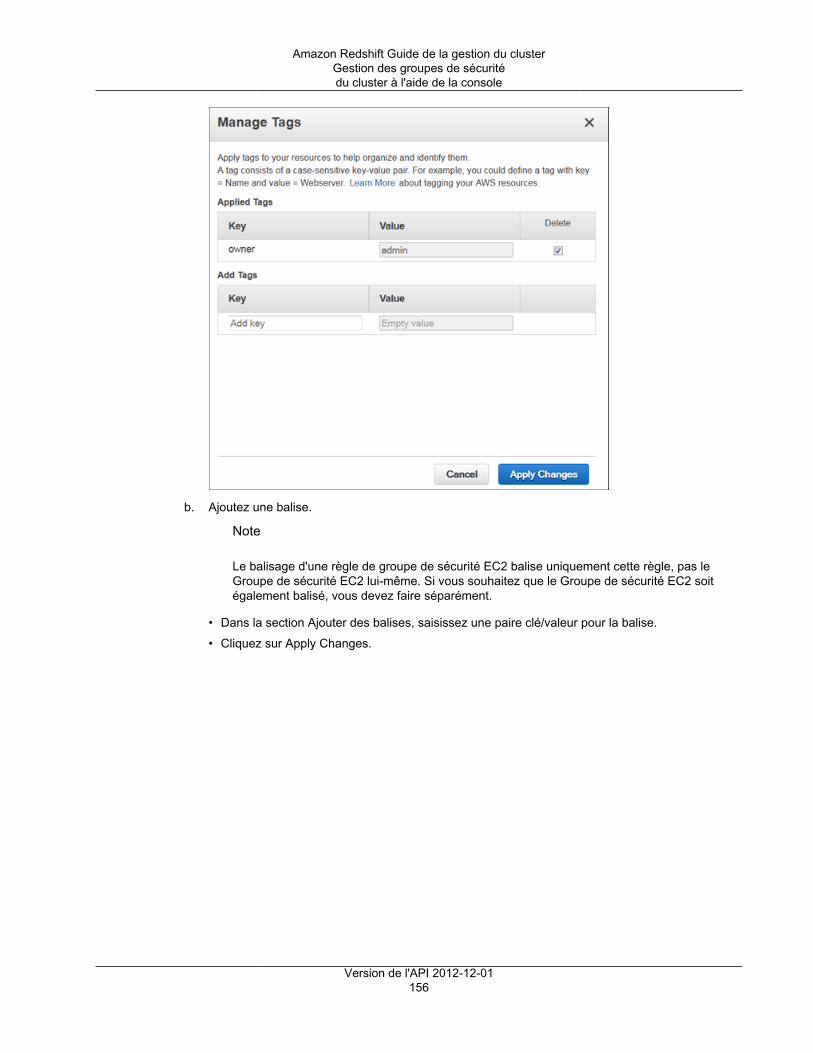
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
b. Ajoutez une balise.
Note
Le balisage d'une règle de groupe de sécurité EC2 balise uniquement cette règle, pas leGroupe de sécurité EC2 lui-même. Si vous souhaitez que le Groupe de sécurité EC2 soitégalement balisé, vous devez faire séparément.
• Dans la section Ajouter des balises, saisissez une paire clé/valeur pour la balise.• Cliquez sur Apply Changes.
Version de l'API 2012-12-01156
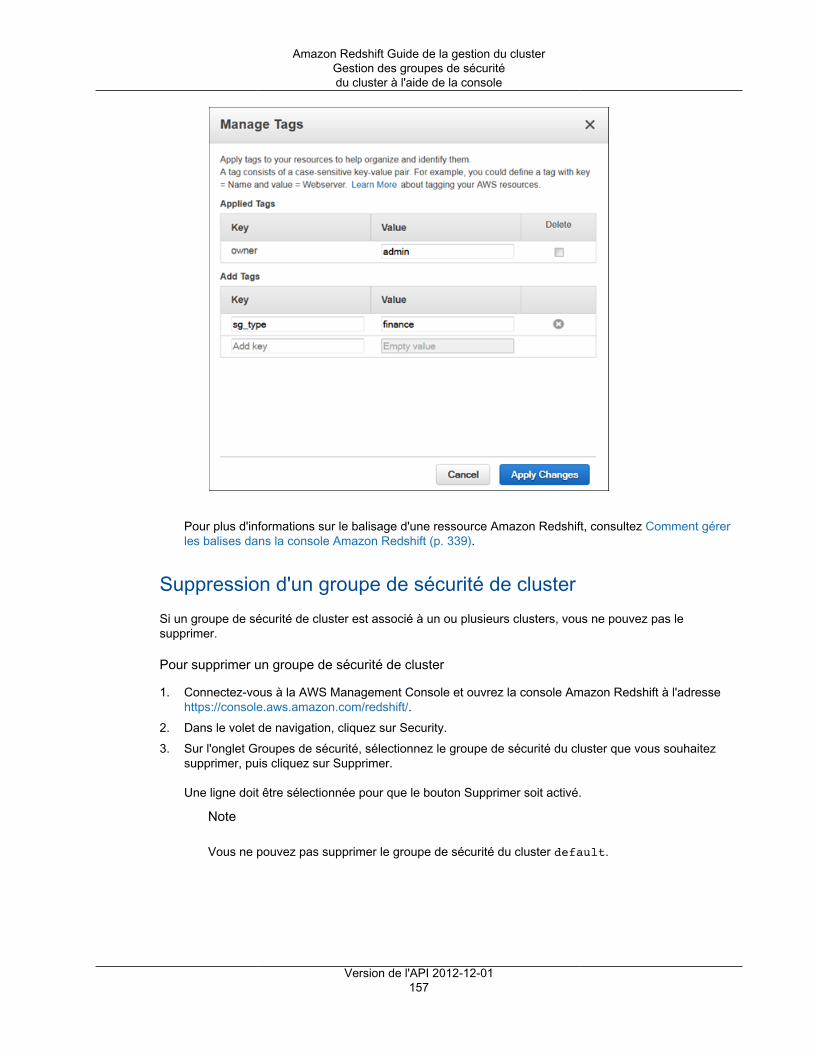
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécuritédu cluster à l'aide de la console
Pour plus d'informations sur le balisage d'une ressource Amazon Redshift, consultez Comment gérerles balises dans la console Amazon Redshift (p. 339).
Suppression d'un groupe de sécurité de clusterSi un groupe de sécurité de cluster est associé à un ou plusieurs clusters, vous ne pouvez pas lesupprimer.
Pour supprimer un groupe de sécurité de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Security.3. Sur l'onglet Groupes de sécurité, sélectionnez le groupe de sécurité du cluster que vous souhaitez
supprimer, puis cliquez sur Supprimer.
Une ligne doit être sélectionnée pour que le bouton Supprimer soit activé.
Note
Vous ne pouvez pas supprimer le groupe de sécurité du cluster default.
Version de l'API 2012-12-01157
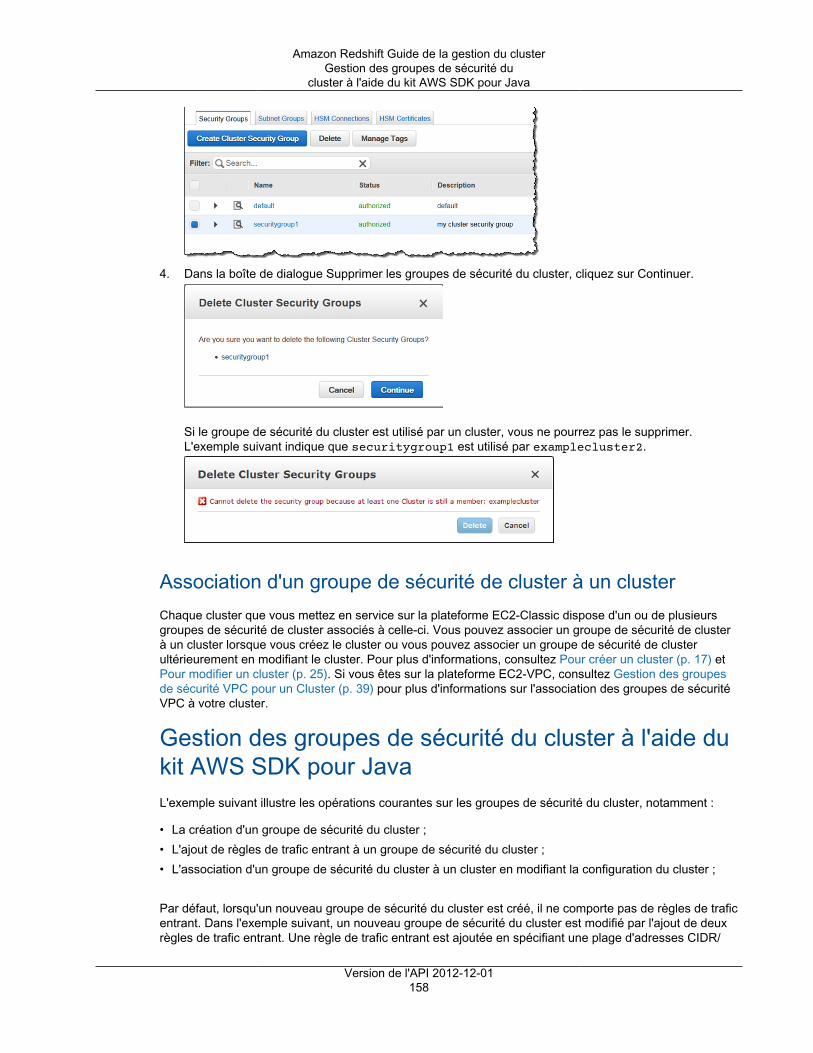
Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécurité du
cluster à l'aide du kit AWS SDK pour Java
4. Dans la boîte de dialogue Supprimer les groupes de sécurité du cluster, cliquez sur Continuer.
Si le groupe de sécurité du cluster est utilisé par un cluster, vous ne pourrez pas le supprimer.L'exemple suivant indique que securitygroup1 est utilisé par examplecluster2.
Association d'un groupe de sécurité de cluster à un clusterChaque cluster que vous mettez en service sur la plateforme EC2-Classic dispose d'un ou de plusieursgroupes de sécurité de cluster associés à celle-ci. Vous pouvez associer un groupe de sécurité de clusterà un cluster lorsque vous créez le cluster ou vous pouvez associer un groupe de sécurité de clusterultérieurement en modifiant le cluster. Pour plus d'informations, consultez Pour créer un cluster (p. 17) etPour modifier un cluster (p. 25). Si vous êtes sur la plateforme EC2-VPC, consultez Gestion des groupesde sécurité VPC pour un Cluster (p. 39) pour plus d'informations sur l'association des groupes de sécuritéVPC à votre cluster.
Gestion des groupes de sécurité du cluster à l'aide dukit AWS SDK pour JavaL'exemple suivant illustre les opérations courantes sur les groupes de sécurité du cluster, notamment :
• La création d'un groupe de sécurité du cluster ;• L'ajout de règles de trafic entrant à un groupe de sécurité du cluster ;• L'association d'un groupe de sécurité du cluster à un cluster en modifiant la configuration du cluster ;
Par défaut, lorsqu'un nouveau groupe de sécurité du cluster est créé, il ne comporte pas de règles de traficentrant. Dans l'exemple suivant, un nouveau groupe de sécurité du cluster est modifié par l'ajout de deuxrègles de trafic entrant. Une règle de trafic entrant est ajoutée en spécifiant une plage d'adresses CIDR/
Version de l'API 2012-12-01158

Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécurité du
cluster à l'aide du kit AWS SDK pour Java
IP ; l'autre est ajoutée en spécifiant une combinaison d'ID de propriétaire et de groupe de sécurité AmazonEC2.
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193). Vous devez mettre à jour le code et fournir unidentifiant de cluster et un numéro de compte AWS.
Example
import java.io.IOException;import java.util.ArrayList;import java.util.List;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;import com.amazonaws.services.redshift.model.*;
public class CreateAndModifyClusterSecurityGroup {
public static AmazonRedshiftClient client; public static String clusterSecurityGroupName = "securitygroup1"; public static String clusterIdentifier = "***provide cluster identifier***"; public static String ownerID = "***provide account id****"; public static void main(String[] args) throws IOException { AWSCredentials credentials = new PropertiesCredentials( CreateAndModifyClusterSecurityGroup.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { createClusterSecurityGroup(); describeClusterSecurityGroups(); addIngressRules(); associateSecurityGroupWithCluster(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage()); } }
private static void createClusterSecurityGroup() { CreateClusterSecurityGroupRequest request = new CreateClusterSecurityGroupRequest() .withDescription("my cluster security group") .withClusterSecurityGroupName(clusterSecurityGroupName); client.createClusterSecurityGroup(request); System.out.format("Created cluster security group: '%s'\n", clusterSecurityGroupName); } private static void addIngressRules() {
AuthorizeClusterSecurityGroupIngressRequest request = new AuthorizeClusterSecurityGroupIngressRequest() .withClusterSecurityGroupName(clusterSecurityGroupName) .withCIDRIP("192.168.40.5/32"); ClusterSecurityGroup result = client.authorizeClusterSecurityGroupIngress(request); request = new AuthorizeClusterSecurityGroupIngressRequest() .withClusterSecurityGroupName(clusterSecurityGroupName)
Version de l'API 2012-12-01159

Amazon Redshift Guide de la gestion du clusterGestion des groupes de sécurité du
cluster à l'aide du kit AWS SDK pour Java
.withEC2SecurityGroupName("default") .withEC2SecurityGroupOwnerId(ownerID); result = client.authorizeClusterSecurityGroupIngress(request); System.out.format("\nAdded ingress rules to security group '%s'\n", clusterSecurityGroupName); printResultSecurityGroup(result); } private static void associateSecurityGroupWithCluster() {
// Get existing security groups used by the cluster. DescribeClustersRequest request = new DescribeClustersRequest() .withClusterIdentifier(clusterIdentifier); DescribeClustersResult result = client.describeClusters(request); List<ClusterSecurityGroupMembership> membershipList = result.getClusters().get(0).getClusterSecurityGroups();
List<String> secGroupNames = new ArrayList<String>(); for (ClusterSecurityGroupMembership mem : membershipList) { secGroupNames.add(mem.getClusterSecurityGroupName()); } // Add new security group to the list. secGroupNames.add(clusterSecurityGroupName); // Apply the change to the cluster. ModifyClusterRequest request2 = new ModifyClusterRequest() .withClusterIdentifier(clusterIdentifier) .withClusterSecurityGroups(secGroupNames); Cluster result2 = client.modifyCluster(request2); System.out.format("\nAssociated security group '%s' to cluster '%s'.", clusterSecurityGroupName, clusterIdentifier); }
private static void describeClusterSecurityGroups() { DescribeClusterSecurityGroupsRequest request = new DescribeClusterSecurityGroupsRequest(); DescribeClusterSecurityGroupsResult result = client.describeClusterSecurityGroups(request); printResultSecurityGroups(result.getClusterSecurityGroups()); }
private static void printResultSecurityGroups(List<ClusterSecurityGroup> groups) { if (groups == null) { System.out.println("\nDescribe cluster security groups result is null."); return; }
System.out.println("\nPrinting security group results:"); for (ClusterSecurityGroup group : groups) { printResultSecurityGroup(group); } } private static void printResultSecurityGroup(ClusterSecurityGroup group) { System.out.format("\nName: '%s', Description: '%s'\n", group.getClusterSecurityGroupName(), group.getDescription()); for (EC2SecurityGroup g : group.getEC2SecurityGroups()) { System.out.format("EC2group: '%s', '%s', '%s'\n", g.getEC2SecurityGroupName(), g.getEC2SecurityGroupOwnerId(), g.getStatus()); } for (IPRange range : group.getIPRanges()) {
Version de l'API 2012-12-01160
Amazon Redshift Guide de la gestion du clusterGérer les groupes de sécurité de
cluster à l'aide de l'interface de ligne decommande et de l'API Amazon Redshift
System.out.format("IPRanges: '%s', '%s'\n", range.getCIDRIP(), range.getStatus());
} }}
Gérer les groupes de sécurité de cluster à l'aide del'interface de ligne de commande et de l'API AmazonRedshiftVous pouvez utiliser les opérations de la ligne de commande Amazon Redshift suivantes pour gérer lesgroupes de sécurité de cluster.
• authorize-cluster-security-group-ingress• create-cluster-security-group• delete-cluster-security-group• describe-cluster-security-groups• revoke-cluster-security-group-ingress
Vous pouvez utiliser les API Amazon Redshift suivantes pour gérer les groupes de sécurité du cluster.
• AuthorizeClusterSecurityGroupIngress• CreateClusterSecurityGroup• DeleteClusterSecurityGroup• DescribeClusterSecurityGroups• RevokeClusterSecurityGroupIngress
Version de l'API 2012-12-01161

Amazon Redshift Guide de la gestion du clusterPrésentation
Utilisation de l'authentification IAMpour générer des informationsd'identification de l'utilisateur de basede données
Afin de mieux gérer l'accès à votre base de données Amazon Redshift accordé à vos utilisateurs, vouspouvez générer des informations d'identification temporaires de base de données en fonction desautorisations accordées via une stratégie d'autorisations AWS Identity and Access Management (IAM).
Généralement, les utilisateurs de base de données Amazon Redshift se connectent à la base de donnéesen fournissant un nom d'utilisateur de base de données et un mot de passe. Au lieu de gérer des nomsd'utilisateur et mots de passe dans votre base de données Amazon Redshift, vous pouvez configurer votresystème de manière à permettre aux utilisateurs de créer des informations d'identification utilisateur et dese connecter aux bases de données en fonction de leurs informations d'identification IAM. Vous pouvezaussi configurer votre système pour permettre aux utilisateurs de se connecter à l'aide de l'authentificationunique (SSO) fédérée via un fournisseur d'identité conforme SAML 2.0.
Rubriques• Présentation (p. 162)• Création d'informations d'identification temporaires de l'utilisateur IAM (p. 163)• Options visant à fournir des informations d'identification IAM (p. 174)• Options JDBC et ODBC pour la création d'informations d'identification de l'utilisateur de base de
données (p. 178)• Génération des informations d'identification de base de données IAM à l'aide de l'interface de ligne de
commande ou de l'API Amazon Redshift (p. 179)
PrésentationAmazon Redshift fournit l'action d'API GetClusterCredentials pour générer des informations d'identificationtemporaires de l'utilisateur de base de données. Vous pouvez configurer votre client SQL avec des pilotesJDBC ou ODBC Amazon Redshift qui gèrent le processus d'appel de l'action GetClusterCredentials.Pour ce faire, ils récupèrent les informations d'identification de l'utilisateur de base de données et ilsétablissent une connexion entre votre client SQL et votre base de données Amazon Redshift. Vouspouvez également utiliser votre application de base de données pour appeler par programmation l'actionGetClusterCredentials, récupérer les informations d'identification de l'utilisateur de base de données etvous connecter à la base de données.
Si vous gérez déjà des identités utilisateur en dehors d'AWS, vous pouvez utiliser un fournisseur d'identité(IdP) conforme SAML 2.0 pour gérer l'accès aux ressources Amazon Redshift. Vous pouvez configurervotre IdP de manière à permettre à vos utilisateurs fédérés d'accéder à un rôle IAM. Avec ce rôle IAM, vouspouvez générer des informations d'identification temporaires de base de données et vous connecter auxbases de données Amazon Redshift.
Version de l'API 2012-12-01162

Amazon Redshift Guide de la gestion du clusterCréation d'informations d'identification
temporaires de l'utilisateur IAM
Votre client SQL doit disposer des autorisations requises pour appeler l'action GetClusterCredentials envotre nom. Vous gérez ces autorisations en créant un rôle IAM et en attachant une stratégie d'autorisationsIAM qui accorde ou restreint l'accès à l'action GetClusterCredentials et aux actions associées.
La stratégie accorde ou restreint également l'accès à des ressources spécifiques, telles que des clustersAmazon Redshift, des bases de données, des noms d'utilisateur de base de données et des noms degroupes d'utilisateurs.
Note
Nous vous recommandons d'utiliser les pilotes JDBC ou ODBC Amazon Redshift pour gérer leprocessus d'appel de l'action GetClusterCredentials et de connexion à la base de données. Pourplus de simplicité, nous supposons que vous utilisez un client SQL avec les pilotes JDBC ouODBC dans cette rubrique. Pour obtenir des détails et des exemples spécifiques d'utilisation del'action GetClusterCredentials ou de l'action d'interface de ligne de commande en parallèle get-cluster-credentials, consultez GetClusterCredentials et get-cluster-credentials.
Création d'informations d'identification temporairesde l'utilisateur IAM
Dans cette section, vous trouverez les étapes de configuration de votre système pour générer desinformations temporaires d'identification de l'utilisateur de base de données basées sur IAM et vousconnecter à votre base de données à l'aide de ces nouvelles informations d'identification.
Au niveau général, le processus se déroule comme suit :
1. Etape 1 : Créer un rôle IAM pour un accès IAM avec authentification unique (SSO) (p. 164)
(Facultatif) Vous pouvez authentifier des utilisateurs pour l'accès à une base de données AmazonRedshift en intégrant l'authentification IAM et un fournisseur d'identité (IdP) tiers, tel que PingFederate,Okta ou ADFS.
2. Etape 2 : Configurer des assertions SAML pour votre IdP (p. 164)
(Facultatif) Pour utiliser l'authentification IAM à l'aide d'un IdP, vous devez définir une règlede demande dans votre application d'IdP qui mappe des utilisateurs ou des groupes de votreorganisation au rôle IAM. Vous pouvez aussi inclure des éléments d'attribut pour définir les paramètresGetClusterCredentials.
3. Etape 3 : Créer un rôle ou un utilisateur IAM avec des autorisations d'appelerGetClusterCredentials (p. 165)
Votre application client SQL a le rôle IAM lorsqu'elle appelle l'action GetClusterCredentials. Si vous avezcréé un rôle IAM pour l'accès au fournisseur d'identité, vous pouvez ajouter l'autorisation nécessaire à cerôle.
4. Etape 4 : Créer un utilisateur de base de données et des groupes de bases de données (p. 167)
(Facultatif) Par défaut, GetClusterCredentials renvoie les informations d'identification pour les utilisateursexistants. Vous pouvez choisir d'utiliser GetClusterCredentials pour créer un utilisateur si le nomd'utilisateur n'existe pas. Vous pouvez également choisir de spécifier les groupes d'utilisateurs que lesutilisateurs rejoignent lors de la connexion. Par défaut, les utilisateurs de base de données rejoignent legroupe PUBLIC.
5. Etape 5 : Configurer une connexion JDBC ou ODBC pour utiliser des informations d'identificationIAM (p. 168)
Afin de vous connecter à votre base de données Amazon Redshift, vous configurez votre client SQLpour utiliser un pilote JDBC ou ODBC Amazon Redshift.
Version de l'API 2012-12-01163

Amazon Redshift Guide de la gestion du clusterCréer un rôle IAM pour un accès IAMavec authentification unique (SSO)
Etape 1 : Créer un rôle IAM pour un accès IAM avecauthentification unique (SSO)Si vous n'utilisez pas de fournisseur d'identité pour l'accès avec authentification unique, vous pouvezignorer cette étape.
Si vous gérez déjà les identités utilisateur en dehors d'AWS, vous pouvez authentifier des utilisateurspour l'accès à une base de données Amazon Redshift en intégrant l'authentification IAM et un fournisseurd'identité (IdP) SAML-2.0 tiers, tel qu'ADFS, PingFederate ou Okta.
Pour plus d'informations, consultez Fournisseurs d'identité et fédération dans le Guide de l'utilisateur AWSIAM.
Pour pouvoir utiliser l'authentification d'IdP Amazon Redshift, vous devez créer un fournisseur d'identitéSAML AWS. Vous créez un fournisseur d'identité dans la console IAM pour informer AWS de l'IdP et saconfiguration. Cette opération établit une relation de confiance entre votre compte AWS et l'IdP. Pour lesétapes de création d'un rôle, consultez Création d'un rôle pour la fédération SAML 2.0 (console).
Etape 2 : Configurer des assertions SAML pour votreIdPUne fois que vous avez créé le rôle IAM, vous devez définir une règle de demande dans votreapplication d'IdP qui mappe des utilisateurs ou des groupes de votre organisation au rôle IAM. Pour plusd'informations, consultez Configuration des assertions SAML pour la réponse d'authentification.
Si vous choisissez d'utiliser les paramètres facultatifs GetClusterCredentials DbUser, AutoCreate etDbGroups, vous pouvez définir les valeurs pour les paramètres avec votre connexion JDBC ou ODBC.Vous aussi la possibilité de définir ces valeurs en ajoutant des éléments d'attribut SAML à votre IdP. Pourplus d'informations sur les paramètres DbUser, AutoCreate et DbGroups, consultez Etape 5 : Configurerune connexion JDBC ou ODBC pour utiliser des informations d'identification IAM (p. 168).
Note
Si vous utilisez la variable de stratégie IAM ${redshift:DbUser}, comme décrit dansStratégies de ressources pour GetClusterCredentials (p. 140), la valeur pour DbUser estremplacée par la valeur récupérée par le contexte de demande de l'opération d'API. Les pilotesAmazon Redshift utilisent la valeur de la variable DbUser fournie par l'URL de connexion, au lieude la valeur fournie par l'attribut SAML.Pour sécuriser cette configuration, nous vous recommandons d'utiliser une condition dans unestratégie IAM pour valider la valeur DbUser avec le RoleSessionName. Vous pouvez trouverdes exemples montrant comment définir une condition dans une stratégie IAM dans Exemple destratégie d'utilisation de GetClusterCredentials (p. 145).
Afin de configurer votre IdP pour définir les paramètres DbUser, AutoCreate et DbGroups, incluez leséléments de l'attribut suivant :
• Un élément de l'attribut avec l'attribut Name défini sur "https://redshift.amazon.com/SAML/Attributes/DbUser"
Définissez AttributeValue sur le nom d'un utilisateur qui se connectera à la base de données AmazonRedshift.
La valeur de l'élément AttributeValue doit être en minuscules, commencer par une lettre, contenirseulement des caractères alphanumériques, des traits de soulignement ('_'), des signes plus ('+'), despoints ('.'), des arobases ('@') ou des tirets ('-') et comporter moins de 128 caractères. Généralement,le nom d'utilisateur et un ID utilisateur (par exemple, bobsmith) ou une adresse e-mail (par exemple
Version de l'API 2012-12-01164

Amazon Redshift Guide de la gestion du clusterCréer un rôle ou un utilisateur IAM avec des
autorisations d'appeler GetClusterCredentials
[email protected]). La valeur ne peut pas contenir d'espace (par exemple, un nom completd'utilisateur comme Bob Smith).
<Attribute Name="https://redshift.amazon.com/SAML/Attributes/DbUser"> <AttributeValue>user-name</AttributeValue></Attribute>
• Un élément de l'attribut avec l'attribut Name défini sur "https://redshift.amazon.com/SAML/Attributes/AutoCreate"
Définissez l'élément AttributeValue sur true pour créer un utilisateur de base de données s'il n'en existepas. Définissez AttributeValue sur false pour spécifier que l'utilisateur de base de données doit existerdans la base de données Amazon Redshift.
<Attribute Name="https://redshift.amazon.com/SAML/Attributes/AutoCreate"> <AttributeValue>true</AttributeValue></Attribute>
• Un élément de l'attribut avec l'attribut Name défini sur "https://redshift.amazon.com/SAML/Attributes/DbGroups"
Cet élément contient un ou plusieurs éléments AttributeValue. Définissez chaque élément AttributeValuesur un nom de groupe de bases de données que DbUser rejoint pendant la durée de la session lorsqu'ilse connecte à la base de données Amazon Redshift.
<Attribute Name="https://redshift.amazon.com/SAML/Attributes/DbGroups"> <AttributeValue>group1</AttributeValue> <AttributeValue>group2</AttributeValue> <AttributeValue>group3</AttributeValue></Attribute>
Etape 3 : Créer un rôle ou un utilisateur IAM avec desautorisations d'appeler GetClusterCredentialsVotre client SQL doit disposer de l'autorisation requise pour appeler l'action GetClusterCredentials en votrenom. Pour fournir cette autorisation, vous créez un utilisateur ou un rôle IAM et vous attachez une stratégiequi accorde les autorisations nécessaires.
Pour créer un rôle IAM avec des autorisations d'appeler GetClusterCredentials
1. A l'aide du service IAM, créez un utilisateur ou un rôle IAM. Vous pouvez aussi utiliser un utilisateurou un rôle existant. Par exemple, si vous avez créé un rôle IAM pour l'accès au fournisseur d'identité,vous pouvez attacher les stratégies IAM nécessaires à ce rôle.
2. Attachez une stratégie d'autorisation avec l'autorisation d'appeler l'actionredshift:GetClusterCredentials. En fonction des paramètres facultatifs que vous spécifiez,vous pouvez aussi autoriser ou restreindre des actions et des ressources supplémentaires dans votrestratégie :
• Pour autoriser votre client SQL à récupérer l'ID de cluster, la région et le port, incluez l'autorisationd'appeler l'action redshift:DescribeClusters avec la ressource de cluster Redshift.
• Si vous utilisez l'option AutoCreate, incluez l'autorisation d'appelerredshift:CreateClusterUser avec la ressource dbuser. L'Amazon Resource Name (ARN)suivant spécifie dbuser Amazon Redshift. Remplacez région, id-compte et nom-clusterpar les valeurs de votre région, compte et cluster, respectivement. Pour nom-base de donnée,spécifiez le nom d'utilisateur qui sera utilisé pour la connexion à la base de données de cluster.
Version de l'API 2012-12-01165

Amazon Redshift Guide de la gestion du clusterCréer un rôle ou un utilisateur IAM avec des
autorisations d'appeler GetClusterCredentials
arn:aws:redshift:region:account-id:dbuser:cluster-name/dbuser-name
• Vous pouvez aussi ajouter un ARN qui spécifie la ressource dbname Amazon Redshift au formatsuivant. Remplacez région, id-compte et nom-cluster par les valeurs de votre région, compteet cluster, respectivement. Pour nom-base de donnée, spécifiez le nom d'une base de données àlaquelle l'utilisateur se connectera.
arn:aws:redshift:region:account-id:dbname:cluster-name/database-name
• Si vous utilisez l'option DbGroups, incluez l'autorisation d'appeler l'action redshift:JoinGroupavec la ressource dbgroup Amazon Redshift au format suivant. Remplacez région, id-compteet nom-cluster par les valeurs de votre région, compte et cluster, respectivement. Pour nom-groupe de bases de données, spécifiez le nom d'un groupe d'utilisateurs que l'utilisateur rejointlors de la connexion.
arn:aws:redshift:region:account-id:dbgroup:cluster-name/dbgroup-name
Pour plus d'informations et d'exemples, consultez Stratégies de ressources pourGetClusterCredentials (p. 140).
L'exemple suivant illustre une stratégie qui autorise le rôle IAM à appeler l'actionGetClusterCredentials. Spécifier la ressource dbuser Amazon Redshift accorde l'accès au rôle aunom de l'utilisateur de la base de données temp_creds_user sur le cluster nommé examplecluster.
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": "arn:aws:redshift:us-west-2:123456789012:dbuser:examplecluster/temp_creds_user" }}
Vous pouvez utiliser un caractère générique (*) pour remplacer tout ou partie du nom de cluster, dunom d'utilisateur et des noms de groupes de bases de données. L'exemple suivant autorise tout nomd'utilisateur commençant par temp_ avec tout cluster dans le compte spécifié.
Important
L'instruction de l'exemple suivant spécifie un caractère générique (*) comme valeur pour laressource de telle sorte que la stratégie autorise n'importe quelle ressource commençant parles caractères spécifiés. L'utilisation d'un caractère générique dans les stratégies IAM peut êtreexcessivement permissive. En tant que bonne pratique, il est recommandé d'utiliser la stratégie laplus restrictive acceptable pour votre application métier.
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "redshift:GetClusterCredentials", "Resource": "arn:aws:redshift:us-west-2:123456789012:dbuser:*/temp_*" }}
Version de l'API 2012-12-01166

Amazon Redshift Guide de la gestion du clusterCréer un utilisateur de base de données
et des groupes de bases de données
L'exemple suivant montre une stratégie qui autorise le rôle IAM à appeler l'actionGetClusterCredentials avec l'option de créer automatiquement un nouvel utilisateur et de spécifierles groupes que l'utilisateur rejoint lors de la connexion. La clause "Resource": "*" accorde au rôlel'accès à n'importe quelle ressource, y compris les clusters, utilisateurs de base de données ou groupesd'utilisateurs.
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": [ "redshift:GetClusterCredentials", "redshift:CreateClusterUser", "redshift:JoinGroup" ], "Resource": "*" }}
Pour plus d'informations, consultez Syntaxe de l'ARN Amazon Redshift.
Etape 4 : Créer un utilisateur de base de données etdes groupes de bases de donnéesVous pouvez aussi créer un utilisateur de base de données que vous utilisez pour vous connecter à labase de données de cluster. Si vous créez des informations d'identification utilisateur temporaires pourun utilisateur existant, vous pouvez désactiver le mot de passe de l'utilisateur pour forcer ce dernierà se connecter à l'aide du mot de passe temporaire. Vous pouvez aussi utiliser l'option AutocreateGetClusterCredentials pour créer automatiquement un utilisateur de base de données.
Vous pouvez créer les groupes d'utilisateurs de bases de données avec les autorisations que voussouhaitez que l'utilisateur de base de données IAM rejoigne lors de la connexion. Lorsque vous appelezl'action GetClusterCredentials, vous pouvez spécifier une liste de noms de groupes d'utilisateurs que lenouvel utilisateur rejoint lors de la connexion. Ces appartenances à des groupes sont valides uniquementpour les sessions créées avec les informations d'identification générées à l'aide de la demande donnée.
Pour créer un utilisateur de base de données et des groupes de bases de données
1. Connectez-vous à votre base de données Amazon Redshift et créez un utilisateur de base de donnéesen utilisant CREATE USER ou modifiez un utilisateur existant en utilisant ALTER USER.
2. Vous pouvez aussi spécifier l'option PASSWORD DISABLE pour empêcher l'utilisateur d'utiliser unmot de passe. Lorsque le mot de passe d'un utilisateur est désactivé, l'utilisateur peut se connecteruniquement à l'aide d'informations d'identification temporaires d'utilisateur IAM. Si le mot de passen'est pas désactivé, l'utilisateur peut se connecter avec le mot de passe ou à l'aide d'informationsd'identification temporaires d'utilisateur IAM. Vous ne pouvez pas désactiver le mot de passe d'unsuper-utilisateur.
L'exemple suivant crée un utilisateur dont le mot de passe est désactivé.
create user temp_creds_user password disable;
L'exemple suivant désactive le mot de passe pour un utilisateur existant.
alter user temp_creds_user password disable;
3. Créez des groupes d'utilisateurs de bases de données à l'aide de CREATE GROUP.4. Utilisez la commande GRANT pour définir les privilèges d'accès pour les groupes.
Version de l'API 2012-12-01167

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC ou ODBC pour
utiliser des informations d'identification IAM
Etape 5 : Configurer une connexion JDBC ou ODBCpour utiliser des informations d'identification IAMVous pouvez configurer votre client SQL avec un pilote JDBC ou ODBC Amazon Redshift qui gère leprocessus de création des informations d'identification de l'utilisateur de base de données et de connexionde votre client SQL à votre base de données Amazon Redshift.
Pour configurer une connexion JDBC pour utiliser des informations d'identification IAM
1. Téléchargez le pilote JDBC Amazon Redshift le plus récent à partir de la page Configurer uneconnexion JDBC (p. 203).
Important
La version du pilote JDBC Amazon Redshift doit être 1.2.7.1003 ou une version ultérieure.2. Créez une URL JDBC avec les options d'informations d'identification IAM dans un des formats
suivants. Pour utiliser l'authentification IAM, ajoutez iam: à l'URL JDBC Amazon Redshift aprèsjdbc:redshift:, comme indiqué dans l'exemple suivant.
jdbc:redshift:iam://
Remplacez nom-cluster, région et nom_base_de_données par les valeurs de votre nom decluster, région et nom de base de données. Le pilote JDBC utilise les informations de votre compteIAM et le nom du cluster pour récupérer l'ID de cluster, la région et le numéro de port. Pour ce faire,votre utilisateur ou rôle IAM doit avoir l'autorisation d'appeler l'action redshift:DescribeClusters avec lecluster spécifié.
jdbc:redshift:iam://cluster-name:region/dbname
Si votre utilisateur ou rôle IAM n'a pas l'autorisation d'appeler l'actionredshift:DescribeClusters, incluez l'ID de cluster, la région et le port, comme indiqué dansl'exemple suivant. Le numéro de port est facultatif. La valeur par défaut du port est 5439.
jdbc:redshift:iam://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev
3. Ajoutez des options JDBC pour fournir des informations d'identification IAM. Vous utilisez différentescombinaisons d'options JDBC pour fournir des informations d'identification IAM. Pour plusd'informations, consultez Options JDBC et ODBC pour la création d'informations d'identification del'utilisateur de base de données (p. 178).
L'URL suivante spécifie AccessKeyID et SecretAccessKey pour un utilisateur IAM.
jdbc:redshift:iam://examplecluster:us-west-2/dev?AccessKeyID=AKIAIOSFODNN7EXAMPLE&SecretAccessKey=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
L'exemple suivant spécifie un profil nommé qui contient les informations d'identification IAM.
jdbc:redshift:iam://examplecluster:us-west-2/dev?Profile=user2
4. Ajoutez les options JDBC que le pilote JDBC utilise pour appeler l'action d'API GetClusterCredentials.N'incluez pas ces options si vous appelez l'action d'API GetClusterCredentials par programmation.Pour en savoir plus, consultez Configurer une connexion JDBC ou ODBC pour utiliser des informationsd'identification IAM (p. 168).
Version de l'API 2012-12-01168

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC ou ODBC pour
utiliser des informations d'identification IAM
L'exemple suivant inclut les options GetClusterCredentials JDBC.
jdbc:redshift:iam://examplecluster:us-west-2/dev?Profile=user2&DbUser=newuser&AutoCreate=true&DbGroups=group1,group2
Pour configurer une connexion ODBC pour utiliser des informations d'identification IAM
Dans cette rubrique, vous trouverez des étapes concernant uniquement la configuration de l'authentificationIAM. Pour connaître les étapes permettant d'utiliser l'authentification standard, avec un nom d'utilisateur debase de données et un mot de passe, consultez Configurer la connexion ODBC (p. 219).
1. 1. Installez et configurez le pilote OBDC Amazon Redshift le plus récent pour votre systèmed'exploitation. Pour plus d'informations, consultez Configurer la connexion ODBC (p. 219).
Important
La version du pilote ODBC Amazon Redshift doit être 1.3.6.1000 ou une version ultérieure.2. Suivez les étapes pour votre système d'exploitation afin de configurer les paramètres de connexion.
Pour plus d'informations, consultez l'une des rubriques suivantes :
• Installer et configurer le pilote ODBC Amazon Redshift sur les systèmes d'exploitation MicrosoftWindows (p. 221)
• Configurer le pilote ODBC sur les systèmes d'exploitation Linux et Mac OS X (p. 227)3. Sur les systèmes d'exploitation Microsoft Windows, accédez à la fenêtre Amazon Redshift ODBC
Driver DSN Setup.
1. Sous Connection Settings, saisissez les informations suivantes :
• Nom de la source de données• Server (facultatif)• Port (facultatif)• Base de données
Si votre utilisateur ou rôle IAM a l'autorisation d'appeler l'action redshift:DescribeClusters,seuls Data Source Name et Database sont requis. Amazon Redshift utilise ClusterId et Regionpour obtenir le serveur et le port en appelant l'action DescribeCluster.
Si votre utilisateur ou rôle IAM n'a pas l'autorisation d'appeler l'actionredshift:DescribeClusters, spécifiez Server et Port. La valeur par défaut du port est 5439.
2. Sous Authentication, effectuez un choix dans Auth Type.
Pour chaque type d'authentification, des champs spécifiques s'affichent, comme illustré ci-dessous.
Version de l'API 2012-12-01169
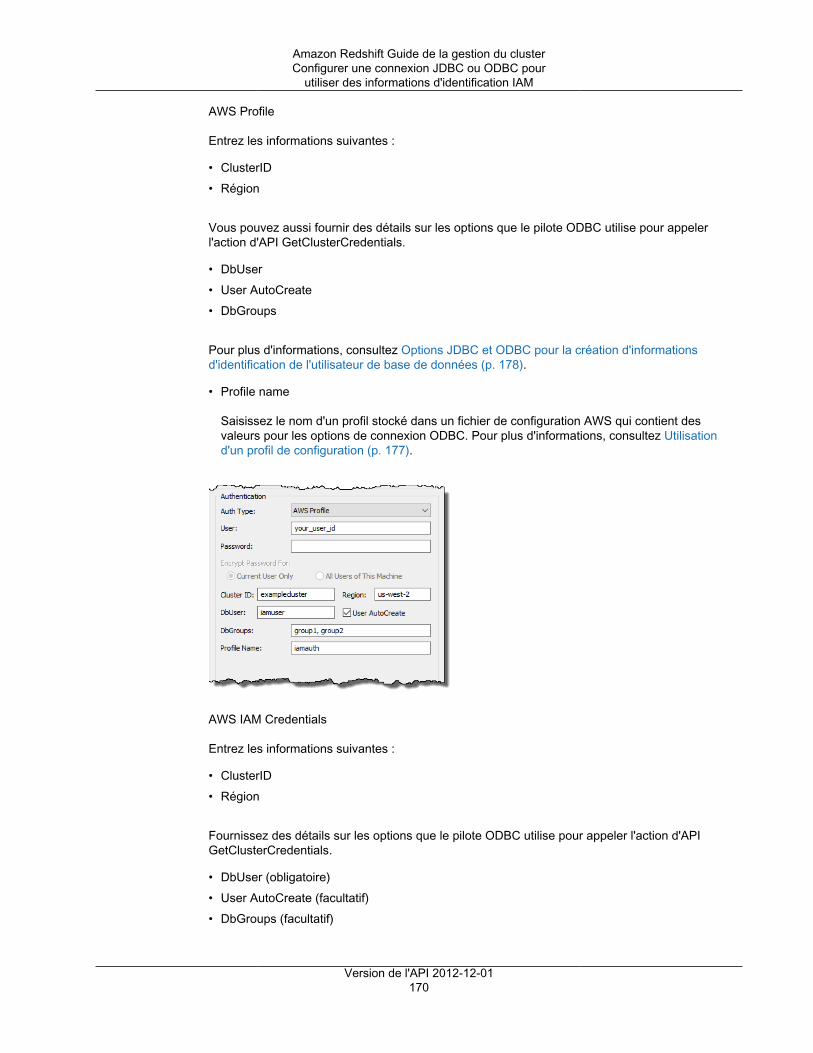
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC ou ODBC pour
utiliser des informations d'identification IAM
AWS Profile
Entrez les informations suivantes :
• ClusterID• Région
Vous pouvez aussi fournir des détails sur les options que le pilote ODBC utilise pour appelerl'action d'API GetClusterCredentials.
• DbUser• User AutoCreate• DbGroups
Pour plus d'informations, consultez Options JDBC et ODBC pour la création d'informationsd'identification de l'utilisateur de base de données (p. 178).
• Profile name
Saisissez le nom d'un profil stocké dans un fichier de configuration AWS qui contient desvaleurs pour les options de connexion ODBC. Pour plus d'informations, consultez Utilisationd'un profil de configuration (p. 177).
AWS IAM Credentials
Entrez les informations suivantes :
• ClusterID• Région
Fournissez des détails sur les options que le pilote ODBC utilise pour appeler l'action d'APIGetClusterCredentials.
• DbUser (obligatoire)• User AutoCreate (facultatif)• DbGroups (facultatif)
Version de l'API 2012-12-01170
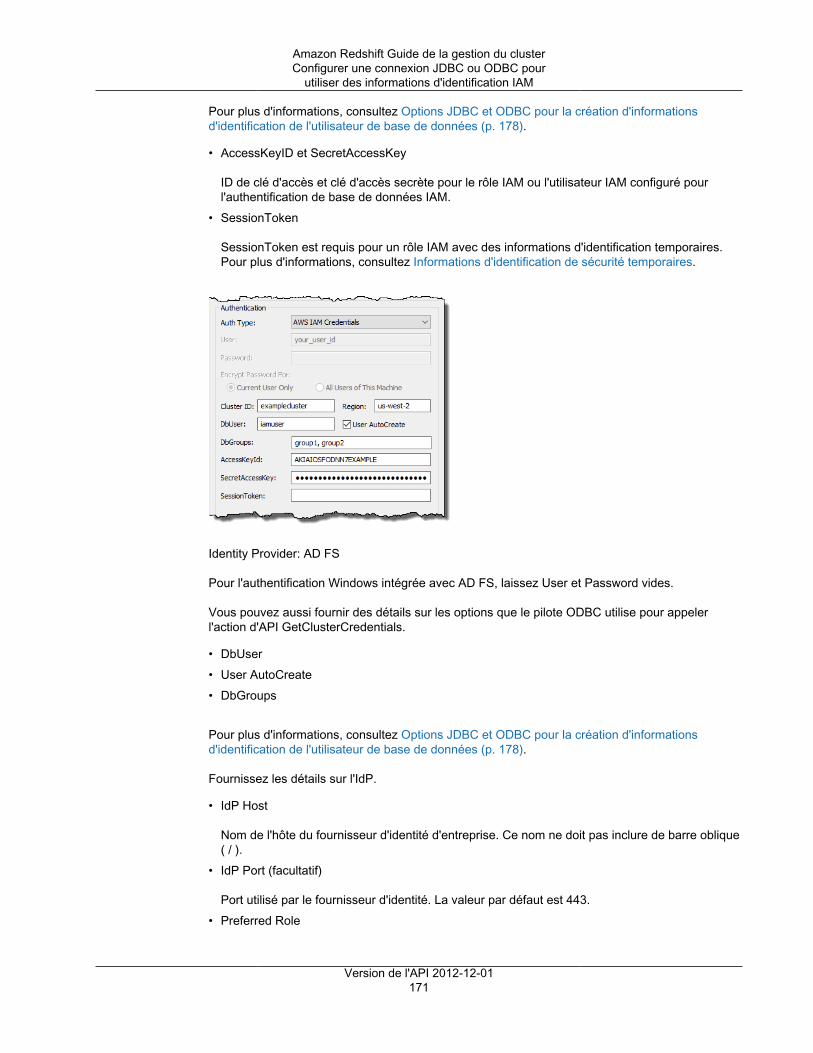
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC ou ODBC pour
utiliser des informations d'identification IAM
Pour plus d'informations, consultez Options JDBC et ODBC pour la création d'informationsd'identification de l'utilisateur de base de données (p. 178).
• AccessKeyID et SecretAccessKey
ID de clé d'accès et clé d'accès secrète pour le rôle IAM ou l'utilisateur IAM configuré pourl'authentification de base de données IAM.
• SessionToken
SessionToken est requis pour un rôle IAM avec des informations d'identification temporaires.Pour plus d'informations, consultez Informations d'identification de sécurité temporaires.
Identity Provider: AD FS
Pour l'authentification Windows intégrée avec AD FS, laissez User et Password vides.
Vous pouvez aussi fournir des détails sur les options que le pilote ODBC utilise pour appelerl'action d'API GetClusterCredentials.
• DbUser• User AutoCreate• DbGroups
Pour plus d'informations, consultez Options JDBC et ODBC pour la création d'informationsd'identification de l'utilisateur de base de données (p. 178).
Fournissez les détails sur l'IdP.
• IdP Host
Nom de l'hôte du fournisseur d'identité d'entreprise. Ce nom ne doit pas inclure de barre oblique( / ).
• IdP Port (facultatif)
Port utilisé par le fournisseur d'identité. La valeur par défaut est 443.• Preferred Role
Version de l'API 2012-12-01171
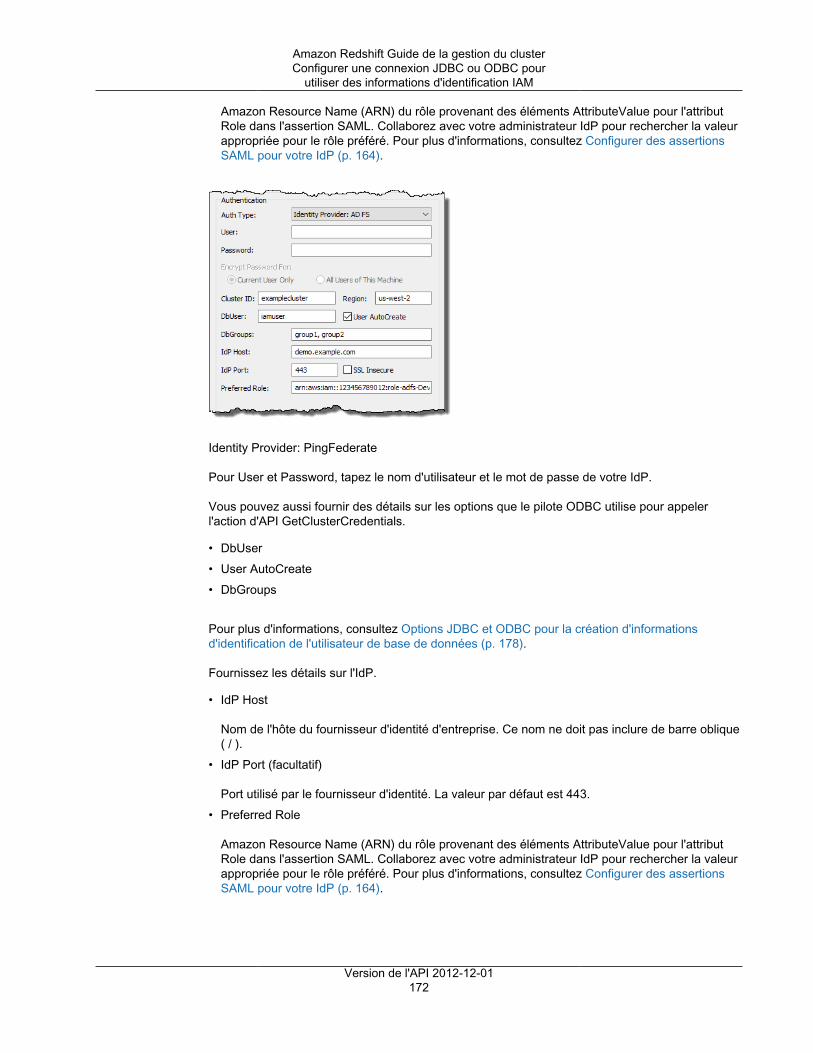
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC ou ODBC pour
utiliser des informations d'identification IAM
Amazon Resource Name (ARN) du rôle provenant des éléments AttributeValue pour l'attributRole dans l'assertion SAML. Collaborez avec votre administrateur IdP pour rechercher la valeurappropriée pour le rôle préféré. Pour plus d'informations, consultez Configurer des assertionsSAML pour votre IdP (p. 164).
Identity Provider: PingFederate
Pour User et Password, tapez le nom d'utilisateur et le mot de passe de votre IdP.
Vous pouvez aussi fournir des détails sur les options que le pilote ODBC utilise pour appelerl'action d'API GetClusterCredentials.
• DbUser• User AutoCreate• DbGroups
Pour plus d'informations, consultez Options JDBC et ODBC pour la création d'informationsd'identification de l'utilisateur de base de données (p. 178).
Fournissez les détails sur l'IdP.
• IdP Host
Nom de l'hôte du fournisseur d'identité d'entreprise. Ce nom ne doit pas inclure de barre oblique( / ).
• IdP Port (facultatif)
Port utilisé par le fournisseur d'identité. La valeur par défaut est 443.• Preferred Role
Amazon Resource Name (ARN) du rôle provenant des éléments AttributeValue pour l'attributRole dans l'assertion SAML. Collaborez avec votre administrateur IdP pour rechercher la valeurappropriée pour le rôle préféré. Pour plus d'informations, consultez Configurer des assertionsSAML pour votre IdP (p. 164).
Version de l'API 2012-12-01172
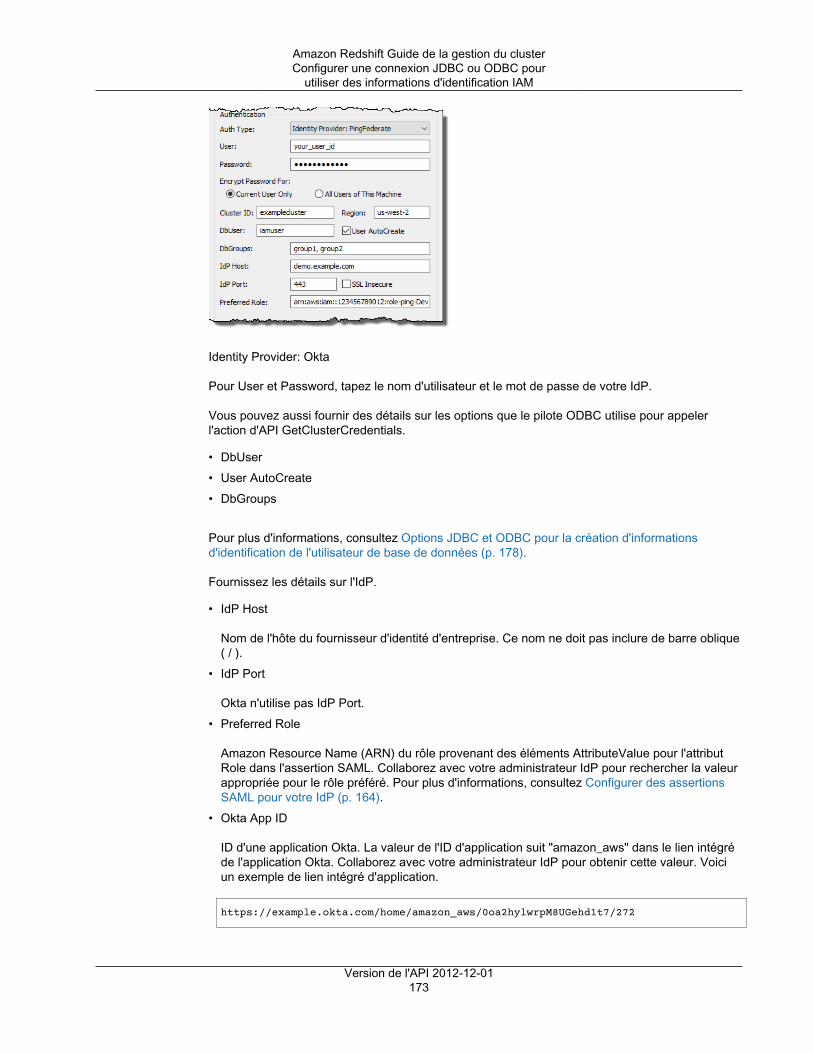
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC ou ODBC pour
utiliser des informations d'identification IAM
Identity Provider: Okta
Pour User et Password, tapez le nom d'utilisateur et le mot de passe de votre IdP.
Vous pouvez aussi fournir des détails sur les options que le pilote ODBC utilise pour appelerl'action d'API GetClusterCredentials.
• DbUser• User AutoCreate• DbGroups
Pour plus d'informations, consultez Options JDBC et ODBC pour la création d'informationsd'identification de l'utilisateur de base de données (p. 178).
Fournissez les détails sur l'IdP.
• IdP Host
Nom de l'hôte du fournisseur d'identité d'entreprise. Ce nom ne doit pas inclure de barre oblique( / ).
• IdP Port
Okta n'utilise pas IdP Port.• Preferred Role
Amazon Resource Name (ARN) du rôle provenant des éléments AttributeValue pour l'attributRole dans l'assertion SAML. Collaborez avec votre administrateur IdP pour rechercher la valeurappropriée pour le rôle préféré. Pour plus d'informations, consultez Configurer des assertionsSAML pour votre IdP (p. 164).
• Okta App ID
ID d'une application Okta. La valeur de l'ID d'application suit "amazon_aws" dans le lien intégréde l'application Okta. Collaborez avec votre administrateur IdP pour obtenir cette valeur. Voiciun exemple de lien intégré d'application.
https://example.okta.com/home/amazon_aws/0oa2hylwrpM8UGehd1t7/272
Version de l'API 2012-12-01173
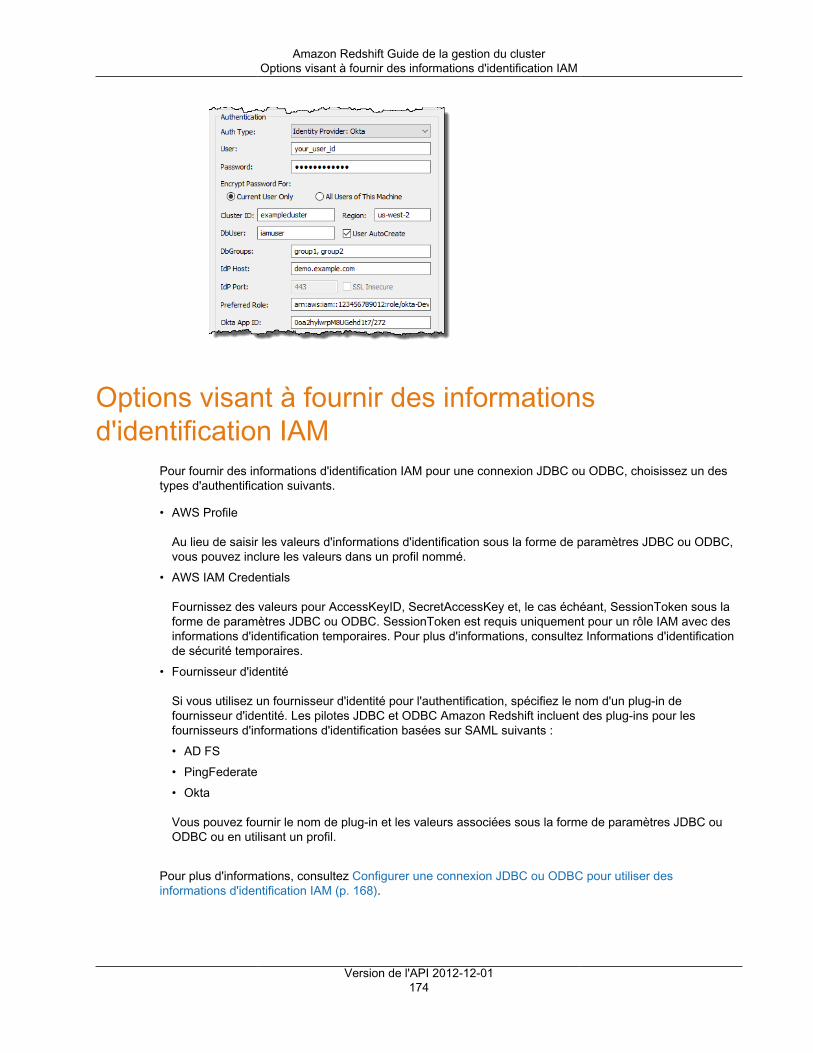
Amazon Redshift Guide de la gestion du clusterOptions visant à fournir des informations d'identification IAM
Options visant à fournir des informationsd'identification IAM
Pour fournir des informations d'identification IAM pour une connexion JDBC ou ODBC, choisissez un destypes d'authentification suivants.
• AWS Profile
Au lieu de saisir les valeurs d'informations d'identification sous la forme de paramètres JDBC ou ODBC,vous pouvez inclure les valeurs dans un profil nommé.
• AWS IAM Credentials
Fournissez des valeurs pour AccessKeyID, SecretAccessKey et, le cas échéant, SessionToken sous laforme de paramètres JDBC ou ODBC. SessionToken est requis uniquement pour un rôle IAM avec desinformations d'identification temporaires. Pour plus d'informations, consultez Informations d'identificationde sécurité temporaires.
• Fournisseur d'identité
Si vous utilisez un fournisseur d'identité pour l'authentification, spécifiez le nom d'un plug-in defournisseur d'identité. Les pilotes JDBC et ODBC Amazon Redshift incluent des plug-ins pour lesfournisseurs d'informations d'identification basées sur SAML suivants :• AD FS• PingFederate• Okta
Vous pouvez fournir le nom de plug-in et les valeurs associées sous la forme de paramètres JDBC ouODBC ou en utilisant un profil.
Pour plus d'informations, consultez Configurer une connexion JDBC ou ODBC pour utiliser desinformations d'identification IAM (p. 168).
Version de l'API 2012-12-01174

Amazon Redshift Guide de la gestion du clusterOptions JDBC et ODBC visant à fournir
des informations d'identification IAM
Options JDBC et ODBC visant à fournir desinformations d'identification IAMLe tableau suivant répertorie les Options JDBC et ODBC visant à fournir des informations d'identificationIAM.
Option Description
Iam A utiliser uniquement dans une chaîne de connexion ODBC. Définissez sur 1 pour utiliserl'authentification IAM.
AccessKeyID
SecretAccessKey
SessionToken
ID de clé d'accès et clé d'accès secrète pour le rôle IAM ou l'utilisateur IAM configuré pourl'authentification de base de données IAM. SessionToken est requis uniquement pour unrôle IAM avec des informations d'identification temporaires. SessionToken n'est pas utilisépour un utilisateur IAM. Pour plus d'informations, consultez Informations d'identification desécurité temporaires.
Plugin_Name Nom de classe complet qui implémente un fournisseur d'informations d'identification.Le pilote JDBC Amazon Redshift inclut des plug-ins de fournisseurs d'informationsd'identification basées sur SAML. Si plugin_name est fourni, d'autres paramètres associéssont disponibles. Pour plus d'informations, consultez Utilisation d'un plug-in de fournisseurd'informations d'identification (p. 175).
Profil Nom d'un profil stocké dans un fichier d'informations d'identification AWS ou dans unfichier de configuration qui contient des valeurs pour les options de connexion JDBC. Pourplus d'informations, consultez Utilisation d'un profil de configuration (p. 177).
Utilisation d'un plug-in de fournisseur d'informationsd'identificationLes plug-ins de fournisseur d'informations d'identification suivants sont inclus avec le pilote JDBC AmazonRedshift.
• Active directory federation service (AD FS)• Ping Federate (Ping)
Le test ping est pris en charge uniquement avec l'adaptateur d'IdP PingFederate prédéterminé faisantappel à l'authentification par formulaire.
• Okta
Okta est pris en charge uniquement pour l'application par défaut de console AWS fournie par Okta.
Pour utiliser un plug-in de fournisseur d'informations d'identification basées sur SAML, spécifiez les optionssuivantes à l'aide des options JBDC ou ODBC ou dans un profil nommé :
Option Description
plugin_name Pour JDBC, nom de classe qui implémente un fournisseur d'informations d'identification.Spécifiez l'un des éléments suivants :
• Pour ADFS
Version de l'API 2012-12-01175
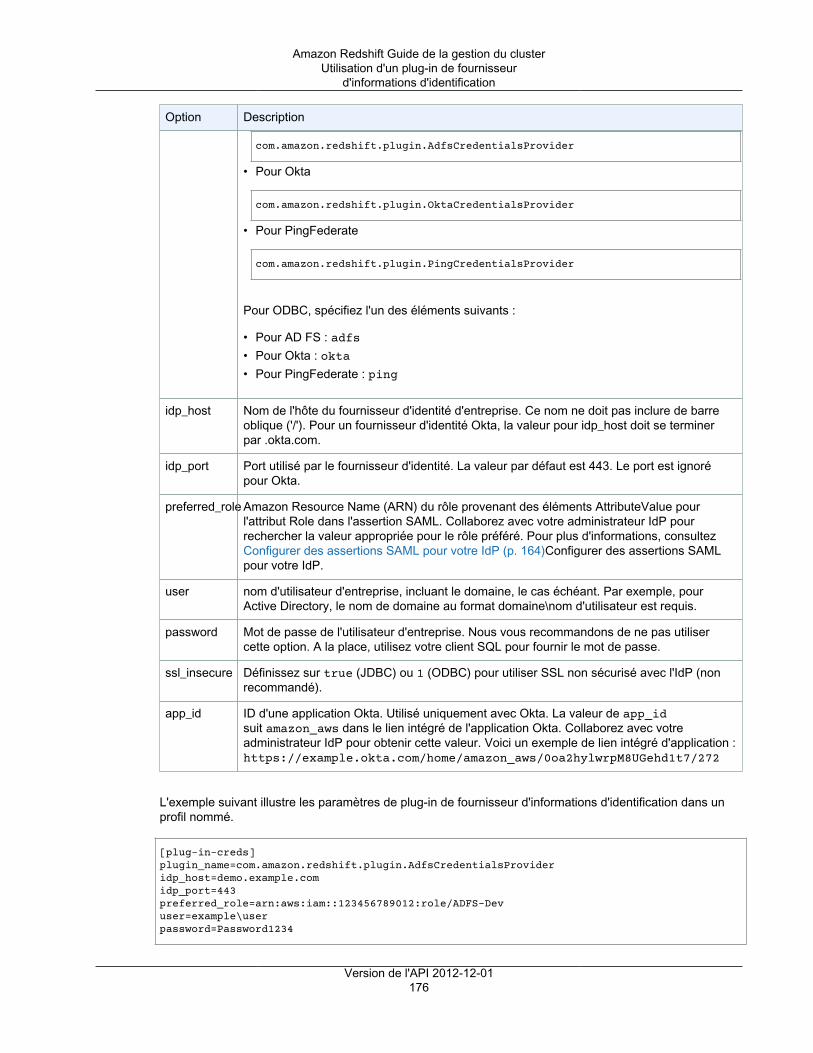
Amazon Redshift Guide de la gestion du clusterUtilisation d'un plug-in de fournisseur
d'informations d'identification
Option Description
com.amazon.redshift.plugin.AdfsCredentialsProvider
• Pour Okta
com.amazon.redshift.plugin.OktaCredentialsProvider
• Pour PingFederate
com.amazon.redshift.plugin.PingCredentialsProvider
Pour ODBC, spécifiez l'un des éléments suivants :
• Pour AD FS : adfs• Pour Okta : okta• Pour PingFederate : ping
idp_host Nom de l'hôte du fournisseur d'identité d'entreprise. Ce nom ne doit pas inclure de barreoblique ('/'). Pour un fournisseur d'identité Okta, la valeur pour idp_host doit se terminerpar .okta.com.
idp_port Port utilisé par le fournisseur d'identité. La valeur par défaut est 443. Le port est ignorépour Okta.
preferred_role Amazon Resource Name (ARN) du rôle provenant des éléments AttributeValue pourl'attribut Role dans l'assertion SAML. Collaborez avec votre administrateur IdP pourrechercher la valeur appropriée pour le rôle préféré. Pour plus d'informations, consultezConfigurer des assertions SAML pour votre IdP (p. 164)Configurer des assertions SAMLpour votre IdP.
user nom d'utilisateur d'entreprise, incluant le domaine, le cas échéant. Par exemple, pourActive Directory, le nom de domaine au format domaine\nom d'utilisateur est requis.
password Mot de passe de l'utilisateur d'entreprise. Nous vous recommandons de ne pas utilisercette option. A la place, utilisez votre client SQL pour fournir le mot de passe.
ssl_insecure Définissez sur true (JDBC) ou 1 (ODBC) pour utiliser SSL non sécurisé avec l'IdP (nonrecommandé).
app_id ID d'une application Okta. Utilisé uniquement avec Okta. La valeur de app_idsuit amazon_aws dans le lien intégré de l'application Okta. Collaborez avec votreadministrateur IdP pour obtenir cette valeur. Voici un exemple de lien intégré d'application :https://example.okta.com/home/amazon_aws/0oa2hylwrpM8UGehd1t7/272
L'exemple suivant illustre les paramètres de plug-in de fournisseur d'informations d'identification dans unprofil nommé.
[plug-in-creds]plugin_name=com.amazon.redshift.plugin.AdfsCredentialsProvideridp_host=demo.example.comidp_port=443 preferred_role=arn:aws:iam::123456789012:role/ADFS-Devuser=example\userpassword=Password1234
Version de l'API 2012-12-01176

Amazon Redshift Guide de la gestion du clusterUtilisation d'un profil de configuration
Utilisation d'un profil de configurationVous pouvez fournir les options d'informations d'identification IAM et les options GetClusterCredentials entant que paramètres dans des profils nommés dans votre fichier de configuration AWS. Fournissez le nomde profil en utilisant l'option Profile JDBC.
La configuration est stockée dans un fichier nommé config dans un dossier nommé .aws dans votrerépertoire de base. L'emplacement du répertoire de base varie, mais il peut être référencé à l'aide devariables d'environnement %UserProfile% sous Windows et de $HOME ou ~ (tilde) sur les systèmesUNIX.
Lorsque vous utilisez le pilote JDBC Amazon Redshift ou le pilote ODBC avec un plug-in de fournisseurd'informations d'identification basées sur SAML fourni, les paramètres suivants sont pris en charge. Siplugin_name n'est pas utilisé, les options de la liste sont ignorées.
• plugin_name• idp_host• idp_port• preferred_role• user• password• ssl_insecure• app_id (pour Okta uniquement)
L'exemple suivant illustre un fichier de configuration avec trois profils. L'exemple plug-in-creds inclutles options facultatives DbUser, AutoCreate et DbGroups.
[default]aws_access_key_id=AKIAIOSFODNN7EXAMPLEaws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
[user2]aws_access_key_id=AKIAI44QH8DHBEXAMPLEaws_secret_access_key=je7MtGbClwBF/2Zp9Utk/h3yCo8nvbEXAMPLEKEYsession_token=AQoDYXdzEPT//////////wEXAMPLEtc764bNrC9SAPBSM22wDOk4x4HIZ8j4FZTwdQWLWsKWHGBuFqwAeMicRXmxfpSPfIeoIYRqTflfKD8YUuwthAx7mSEI/qkPpKPi/kMcGdQrmGdeehM4IC1NtBmUpp2wUE8phUZampKsburEDy0KPkyQDYwT7WZ0wq5VSXDvp75YU9HFvlRd8Tx6q6fE8YQcHNVXAkiY9q6d+xo0rKwT38xVqr7ZD0u0iPPkUL64lIZbqBAz+scqKmlzm8FDrypNC9Yjc8fPOLn9FX9KSYvKTr4rvx3iSIlTJabIQwj2ICCR/oLxBA==
[plug-in-creds]plugin_name=com.amazon.redshift.plugin.AdfsCredentialsProvideridp_host=demo.example.comidp_port=443preferred_role=arn:aws:iam::1234567:role/ADFS-Devuser=example\userpassword=Password1234
Pour utiliser les informations d'identification pour l'exemple user2, spécifiez Profile=user2 dansl'URL JDBC. Pour utiliser les informations d'identification pour l'exemple plug-in creds, spécifiezProfile=plug-in-creds dans l'URL JDBC.
Pour plus d'informations, consultez Profils nommés dans le document AWS Command Line Interface Guidede l'utilisateur.
Version de l'API 2012-12-01177

Amazon Redshift Guide de la gestion du clusterOptions JDBC et ODBC pour la création d'informations
d'identification de l'utilisateur de base de données
Options JDBC et ODBC pour la créationd'informations d'identification de l'utilisateur de basede données
Pour utiliser le pilote JDBC ou ODBC Amazon Redshift pour créer des informations d'identification del'utilisateur de base de données, fournissez le nom de l'utilisateur de la base de données en tant qu'optionJDBC ou ODBC. Vous pouvez aussi faire en sorte que le pilote crée un nouvel utilisateur de base dedonnées s'il n'en existe pas, et vous pouvez spécifier une liste de groupes d'utilisateurs de bases dedonnées que l'utilisateur rejoint lors de la connexion.
Si vous utilisez un fournisseur d'identité (IdP), collaborez avec votre administrateur IdP pour déterminer lesvaleurs correctes pour ces options. Votre administrateur IdP peut aussi configurer votre IdP pour fournirces options, auquel cas il n'est pas nécessaire que vous les fournissiez en tant qu'options JDBC ou ODBC.Pour plus d'informations, consultez Configurer des assertions SAML pour votre IdP (p. 164).
Note
Si vous utilisez la variable de stratégie IAM ${redshift:DbUser}, comme décrit dansStratégies de ressources pour GetClusterCredentials (p. 140), la valeur pour DbUser estremplacée par la valeur récupérée par le contexte de demande de l'opération d'API. Les pilotesAmazon Redshift utilisent la valeur de la variable DbUser fournie par l'URL de connexion, au lieude la valeur fournie par l'attribut SAML.Pour sécuriser cette configuration, nous vous recommandons d'utiliser une condition dans unestratégie IAM pour valider la valeur DbUser avec le RoleSessionName. Vous pouvez trouverdes exemples montrant comment définir une condition dans une stratégie IAM dans Exemple destratégie d'utilisation de GetClusterCredentials (p. 145).
Le tableau suivant répertorie les options à utiliser la création d'informations d'identification de l'utilisateur debase de données.
Option Description
DbUser Nom d'un utilisateur de la base de données. Si un utilisateur nommé DbUser existe dansla base de données, les informations d'identification utilisateur temporaires ont les mêmesautorisations que l'utilisateur existant. Si DbUser n'existe pas dans la base de donnéeset qu'AutoCreate a la valeur true, un nouvel utilisateur nommé DbUser est créé. Vouspouvez aussi désactiver le mot de passe d'un utilisateur existant. Pour plus d'informations,consultez ALTER_USER
AutoCreate Spécifiez true pour créer un utilisateur de la base de données avec le nom spécifié pourDbUser s'il n'en existe pas. La valeur par défaut est false.
DbGroups Liste séparée par des virgules des noms d'un ou plusieurs groupes de bases de donnéesexistants que l'utilisateur de la base de données rejoint pour la session en cours. Pardéfaut, le nouvel utilisateur est ajouté uniquement à PUBLIC.
Version de l'API 2012-12-01178

Amazon Redshift Guide de la gestion du clusterGénération des informations d'identification debase de données IAM à l'aide de l'interface de
ligne de commande ou de l'API Amazon Redshift
Génération des informations d'identification de basede données IAM à l'aide de l'interface de ligne decommande ou de l'API Amazon Redshift
Pour générer par programmation des informations d'identification temporaires de l'utilisateur de basede données, Amazon Redshift fournit la commande get-cluster-credentials pour l'interface de ligne decommande AWS (AWS CLI) et l'action d'API GetClusterCredentials. Vous pouvez aussi configurer votreclient SQL avec des pilotes JDBC ou ODBC Amazon Redshift qui gèrent le processus d'appel de l'actionGetClusterCredentials, de récupération des informations d'identification de l'utilisateur de base de donnéeset de connexion de votre client SQL à votre base de données Amazon Redshift. Pour plus d'informations,consultez Options JDBC et ODBC pour la création d'informations d'identification de l'utilisateur de base dedonnées (p. 178).
Note
Nous recommandons d'utiliser les pilotes JDBC ou ODBC Amazon Redshift pour générer desinformations d'identification de l'utilisateur de base de données.
Dans cette section, vous trouverez des étapes concernant l'appel par programmation de l'actionGetClusterCredentials ou de la commande or get-cluster-credentials, la récupération des informationsd'identification de l'utilisateur de base de données et la connexion à la base de données.
Pour générer et utiliser des informations d'identification temporaires de base de données
1. Créez ou modifiez un utilisateur ou un rôle IAM avec les autorisations requises. Pour plusd'informations sur les autorisations IAM, consultez Créer un rôle ou un utilisateur IAM avec desautorisations d'appeler GetClusterCredentials (p. 165).
2. En tant qu'utilisateur ou rôle IAM que vous avez autorisé à l'étape précédente, exécutez lacommande de l'interface de ligne de commande get-cluster-credentials ou appelez l'action d'APIGetClusterCredentials et fournissez les valeurs suivantes :
• Identifiant du cluster – nom du cluster qui contient la base de données.• Nom d'utilisateur de la base de données – nom d'un utilisateur de base de données existant ou
nouveau.• Si l'utilisateur n'existe pas dans la base de données et qu'AutoCreate a la valeur true, un nouvel
utilisateur est créé avec PASSWORD désactivé.• Si l'utilisateur n'existe pas, et qu'AutoCreate est défini sur false, la demande échoue.• Pour cet exemple, le nom de l'utilisateur de la base de données est temp_creds_user.
• Autocreate – (facultatif) créez un utilisateur si le nom de l'utilisateur de la base de données n'existepas.
• Nom de base de données – (facultatif) nom de la base de données à laquelle l'utilisateur est autoriséà se connecter. Si aucun nom de base de données n'est spécifié, l'utilisateur peut se connecter àn'importe quelle base de données de cluster.
• Groupes de bases de données – (facultatif) liste des groupes d'utilisateurs de bases de donnéesexistants. Lorsque la connexion réussit, l'utilisateur de base de données est ajouté aux groupesd'utilisateurs spécifiés. Si aucun groupe n'est spécifié, l'utilisateur dispose seulement desautorisations PUBLIC. Ces noms de groupes d'utilisateurs doivent correspondre aux ARN deressources dbgroup spécifiés dans la stratégie IAM attachée à l'utilisateur ou au rôle IAM.
• Durée d'expiration – (facultatif) durée, en secondes, après laquelle les informations d'identificationtemporaires expirent. Vous pouvez spécifier une valeur comprise entre 900 secondes (15 minutes)et 3 600 secondes (60 minutes). Le durée par défaut est 900 secondes.
3. Amazon Redshift vérifie que l'utilisateur IAM dispose de l'autorisation pour appeler l'opérationGetClusterCredentials avec les ressources spécifiées.
Version de l'API 2012-12-01179

Amazon Redshift Guide de la gestion du clusterGénération des informations d'identification debase de données IAM à l'aide de l'interface de
ligne de commande ou de l'API Amazon Redshift4. Amazon Redshift renvoie un mot de passe temporaire et le nom de l'utilisateur de la base de données.
L'exemple suivant utilise l'interface de ligne de commande Amazon Redshift pour générer desinformations d'identification temporaires de base de données pour un utilisateur existant nommétemp_creds_user.
aws redshift get-cluster-credentials --cluster-identifier examplecluster --db-user temp_creds_user --db-name exampledb --duration-seconds 3600
Le résultat est le suivant.
{ "DbUser": "IAM:temp_creds_user", "Expiration": "2016-12-08T21:12:53Z", "DbPassword": "EXAMPLEjArE3hcnQj8zt4XQj9Xtma8oxYEM8OyxpDHwXVPyJYBDm/gqX2Eeaq6P3DgTzgPg==" }
L'exemple suivant utilise l'interface de ligne de commande Amazon Redshift avec autocreate pourgénérer des informations d'identification temporaires de base de données pour un nouvel utilisateur etl'ajouter au groupe example_group.
aws redshift get-cluster-credentials --cluster-identifier examplecluster --db-user temp_creds_user -–autocreate true --db-name exampledb -–db-groups example_group --duration-seconds 3600
Le résultat est le suivant.
{ "DbUser": "IAMA:temp_creds_user:example_group", "Expiration": "2016-12-08T21:12:53Z", "DbPassword": "EXAMPLEjArE3hcnQj8zt4XQj9Xtma8oxYEM8OyxpDHwXVPyJYBDm/gqX2Eeaq6P3DgTzgPg==" }
5. Etablissez une connexion avec authentification SSL (Secure Socket Layer) avec le cluster AmazonRedshift et envoyez une demande de connexion avec le nom d'utilisateur et le mot de passe fournispar la réponse GetClusterCredentials. Incluez le préfixe IAM: ou IAMA: avec le nom d'utilisateur, parexemple, IAM:temp_creds_user ou IAMA:temp_creds_user.
Important
Configurez votre client SQL pour exiger SSL. Sinon, si votre client SQL tenteautomatiquement de se connecter avec SSL, il peut utiliser à nouveau une connexion non-SSL en cas d'échec. Dans ce cas, la première tentative de connexion peut échouer parceque les informations d'identification ont expiré ou ne sont pas valides, et une secondetentative de connexion peut échouer parce que la connexion n'est pas de type SSL. Si celase produit, le premier message d'erreur peut être manqué. Pour plus d'informations sur laconnexion à votre cluster à l'aide de SSL, consultez Configurer les options de sécurité desconnexions (p. 238).
6. Si la connexion n'utilise pas SSL, la tentative de connexion échoue.7. Le cluster envoie une demande authentication au client SQL.8. Le client SQL envoie le mot de passe temporaire au cluster.9. Si le mot de passe est valide et n'a pas expiré, le cluster établit la connexion.
Version de l'API 2012-12-01180

Amazon Redshift Guide de la gestion du clusterCréation d'un rôle IAM pour autoriser votre cluster
Amazon Redshift à accéder aux services AWS
Autorisation de Amazon Redshift àaccéder aux autres services AWS envotre nom
Certaines fonctionnalités Amazon Redshift nécessitent que Amazon Redshift accède aux autres servicesAWS en votre nom. Par exemple, les commandes COPY et UNLOAD peuvent charger ou décharger lesdonnées de votre cluster Amazon Redshift à l'aide d'un compartiment Amazon Simple Storage Service(Amazon S3). Amazon Redshift Spectrum peut utiliser un catalogue de données dans Amazon Athena ouAWS Glue. Pour que vos clusters Amazon Redshift agissent en votre nom, vous fournissez les informationsd'identification de sécurité à vos clusters. La méthode recommandée pour fournir des informationsd'identification de sécurité consiste à spécifier un rôle AWS Identity and Access Management (IAM). PourCOPY et UNLOAD, vous pouvez fournir des clés d'accès AWS.
La section suivante décrit la création d'un rôle IAM disposant des autorisations appropriées pour accéderaux autres services AWS. Vous devez également associer le rôle à votre cluster et spécifier l'AmazonResource Name (ARN) du rôle lorsque vous exécutez la commande Amazon Redshift. Pour plusd'informations, consultez Autorisation d'opérations COPY, UNLOAD et CREATE EXTERNAL SCHEMA àl'aide de rôles IAM (p. 186).
Création d'un rôle IAM pour autoriser votre clusterAmazon Redshift à accéder aux services AWS
Pour créer un rôle IAM et permettre à votre cluster Amazon Redshift de communiquer avec d'autresservices AWS en votre nom, procédez comme suit.
Pour créer un rôle IAM et permettre à Amazon Redshift d'accéder aux services AWS
1. Ouvrez la console IAM.2. Dans le volet de navigation, choisissez Roles.3. Sélectionnez Create role.4. Choisissez Service AWS, puis Redshift.5. Sous Sélectionner votre cas d'utilisation, choisissez Redshift - Personnalisable, puis Suivant :
Autorisations.6. La page Attacher une stratégie d'autorisations s'affiche. Pour accéder à Amazon S3 à l'aide de COPY
et de UNLOAD, choisissez AmazonS3ReadOnlyAccess. Pour Redshift Spectrum, en plus de l'accèsà Amazon S3, ajoutez AWSGlueConsoleFullAccess ou AmazonAthenaFullAccess. ChoisissezNext: Review.
7. Pour Nom du rôle, tapez le nom de votre rôle, par exemple RedshiftCopyUnload. SélectionnezCreate role.
8. Le nouveau rôle est disponible pour tous les utilisateurs des clusters qui utilisent ce rôle. Pour limiterl'accès à des utilisateurs spécifiques uniquement sur certains clusters, ou sur des clusters dans desrégions spécifiques, modifiez la relation d'approbation de ce rôle. Pour plus d'informations, consultezRestriction de l'accès aux rôles IAM (p. 182).
9. Associez le rôle à votre cluster. Vous pouvez associer un rôle IAM à un cluster lors de la créationdu cluster, ou vous pouvez ajouter le rôle à un cluster existant. Pour plus d'informations, consultezAssociation des rôles IAM aux clusters (p. 186).
Version de l'API 2012-12-01181

Amazon Redshift Guide de la gestion du clusterRestriction de l'accès aux rôles IAM
Restriction de l'accès aux rôles IAMPar défaut, les rôles IAM qui sont disponibles pour un cluster Amazon Redshift sont accessibles à tousles utilisateurs de ce cluster. Vous pouvez choisir de limiter des rôles IAM à des utilisateurs de base dedonnées Amazon Redshift spécifiques sur des clusters spécifiques ou dans des régions spécifiques.
Pour permettre uniquement aux utilisateurs de base de données spécifiques d'utiliser un rôle IAM,procédez comme suit.
Pour identifier les utilisateurs de base de données spécifiques avec accès à un rôle IAM
1. Identifiez l'Amazon Resource Name (ARN) pour les utilisateurs de base de données devotre cluster Amazon Redshift. L'ARN d'un utilisateur de base de données est au format :arn:aws:redshift:region:account-id:dbuser:cluster-name/user-name.
2. Ouvrez la console IAM à l'adresse url="https://console.aws.amazon.com/.3. Dans le volet de navigation, choisissez Roles.4. Sélectionnez le rôle IAM de votre choix pour restreindre l'accès aux utilisateurs de base de données
Amazon Redshift spécifiques.5. Choisissez l'onglet Trust Relationships, puis choisissez Edit Trust Relationship. Un nouveau rôle
IAM qui permet à Amazon Redshift d'accéder aux autres services AWS en votre nom a une relationd'approbation comme suit :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}
6. Ajoutez une condition à la section action sts:AssumeRole de la relation d'approbation qui limite lechamp sts:ExternalId aux valeurs que vous spécifiez. Incluez un ARN pour chaque utilisateur debase de données auquel vous voulez accorder l'accès au rôle.
Par exemple, la relation d'approbation suivante spécifie seuls les utilisateurs de base de donnéesuser1 et user2 sur le cluster my-cluster de la région us-west-2 ont l'autorisation d'utiliser ce rôleIAM.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "sts:ExternalId": [ "arn:aws:redshift:us-west-2:123456789012:dbuser:my-cluster/user1", "arn:aws:redshift:us-west-2:123456789012:dbuser:my-cluster/user2" ]
Version de l'API 2012-12-01182

Amazon Redshift Guide de la gestion du clusterRestriction d'un rôle IAM à une région AWS
} } }]}
7. Choisissez Update Trust Policy.
Restriction d'un rôle IAM à une région AWSVous pouvez restreindre un rôle IAM pour qu'il ne soit accessible que dans une région AWS spécifique. Pardéfaut, les rôles IAM pour Amazon Redshift se limitent pas à une seule région.
Pour limiter l'utilisation d'un rôle IAM par région, procédez comme suit.
Pour identifier les régions autorisées pour un rôle IAM
1. Ouvrez la console IAM à l'adresse https://console.aws.amazon.com.2. Dans le volet de navigation, choisissez Roles.3. Sélectionnez le rôle de votre choix pour modifier à l'aide de régions spécifiques.4. Choisissez l'onglet Trust Relationships, puis choisissez Edit Trust Relationship. Un nouveau rôle
IAM qui permet à Amazon Redshift d'accéder aux autres services AWS en votre nom a une relationd'approbation comme suit :
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "redshift.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}
5. Modifiez la liste Service pour Principal avec la liste des régions spécifiques pour lesquelles vousvoulez permettre l'utilisation du rôle. Chaque région de la liste Service doit être au format suivant :redshift.region.amazonaws.com.
Par exemple, la relation d'approbation modifiée suivante permet d'utiliser le rôle IAM dans les régionsus-east-1 et us-west-2 uniquement.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "redshift.us-east-1.amazonaws.com", "redshift.us-west-2.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ]}
Version de l'API 2012-12-01183

Amazon Redshift Guide de la gestion du clusterCréation de chaînes de rôles IAM
6. Choisissez Update Trust Policy
Création de chaînes de rôles IAM dans AmazonRedshift
Lorsque vous attachez un rôle à votre cluster, celui-ci peut endosser ce rôle afin d'accéder à Amazon S3,Athena et AWS Glue pour votre compte. Si un rôle attaché à votre cluster n'a pas accès aux ressourcesnécessaires, vous pouvez créer une chaîne avec un autre rôle, lequel peut appartenir à un autre compte.Votre cluster endosse alors provisoirement le rôle relié par la chaîne afin d'accéder aux données. Vouspouvez également accorder des accès entre comptes en créant des chaînes de rôles. Chaque rôle de lachaîne passe au rôle suivant, jusqu'à ce que le cluster endosse le dernier rôle de la chaîne. Une chaînecomprend 10 rôles maximum.
Supposez par exemple que l'entreprise A souhaite accéder à des données dans un compartimentAmazon S3 appartenant à l'entreprise B. L'entreprise A crée un rôle de service AWS pour Amazon Redshiftnommé RoleA et l'attache à son cluster. L'entreprise B crée un rôle nommé RoleB qui est autorisé àaccéder aux données du compartiment de l'entreprise B. Pour accéder aux données dans le compartimentde l'entreprise B, l'entreprise A exécute une commande COPY à l'aide d'un paramètre iam_role qui reliepar chaîne RoleA et RoleB. Pendant la durée de l'opération COPY, RoleA endosse temporairementRoleB pour accéder au compartiment Amazon S3.
Pour créer une chaîne de rôles, vous devez établir une relation d'approbation entre ces rôles. Un rôle quiendosse un autre rôle (par exemple, RoleA) doit disposer d'une stratégie d'autorisations qui l'autoriseà endosser le rôle relié par la chaîne suivant (par exemple, RoleB). De même, le rôle qui transmet lesautorisations (RoleB) doit avoir une stratégie d'approbation lui permettant de transmettre ses autorisationsau rôle relié par la chaîne précédent (RoleA). Pour plus d'informations, consultez Utilisation de rôles IAMdans le IAM Guide de l'utilisateur.
Le premier rôle de la chaîne doit être attaché au cluster. Le premier rôle, et chaque rôle ultérieur quiendosse le rôle suivant dans la chaîne, doivent avoir une stratégie incluant une déclaration spécifique.Cette déclaration comprend l'effet Allow sur l'action sts:AssumeRole ainsi que l'Amazon ResourceName (ARN) du rôle suivant dans un élément Resource. Dans notre exemple, RoleA comporte lastratégie d'autorisation suivante, qui l'autorise à endosser RoleB, qui appartient au compte AWS210987654321.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1487639602000", "Effect": "Allow", "Action": [ "sts:AssumeRole" ], "Resource": "arn:aws:iam::210987654321:role/RoleB" } ]}
Un rôle qui transmet à un autre rôle doit établir une relation d'approbation avec le rôle qui endosse lerôle ou avec le compte AWS à qui appartient le rôle. Dans notre exemple, RoleB possède la stratégied'approbation suivante pour établir une relation d'approbation avec RoleA.
{ "Version": "2012-10-17", "Statement": [
Version de l'API 2012-12-01184

Amazon Redshift Guide de la gestion du clusterCréation de chaînes de rôles IAM
{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::role/RoleA" } ]}
La stratégie d'approbation suivante établit une relation d'approbation avec le propriétaire de RoleA, lecompte AWS 123456789012.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:root" } ]}
Lorsque vous exécutez la commande UNLOAD, COPY ou CREATE EXTERNAL SCHEMA, vous créezdes chaînes de rôles en insérant une liste d'ARN de rôles séparés par des virgules dans le paramètreiam_role. L'exemple suivant montre la syntaxe d'une chaîne de rôles dans le paramètre iam_role.
unload ('select * from venue limit 10') to 's3://acmedata/redshift/venue_pipe_'IAM_ROLE 'arn:aws:iam::<aws-account-id-1>:role/<role-name-1>[,arn:aws:iam::<aws-account-id-2>:role/<role-name-2>][,...]';
Note
L'intégralité de la chaîne de rôle est placée entre guillemets simples et ne doit pas contenird'espaces.
Dans les exemples suivants, RoleA est attaché au cluster qui appartient au compte AWS 123456789012.RoleB, qui appartient au compte 210987654321, est autorisé à accéder au compartiment nommé s3://companyb/redshift/. L'exemple suivant crée une chaîne avec RoleA et RoleB pour décharger desdonnées dans le compartiment s3://companyb/redshift/.
unload ('select * from venue limit 10') to 's3://companyb/redshift/venue_pipe_'iam_role 'arn:aws:iam::123456789012:role/RoleA,arn:aws:iam::210987654321:role/RoleB';
L'exemple suivant utilise une commande COPY pour charger les données qui ont été déchargées dansl'exemple précédent.
copy venue from 's3://companyb/redshift/venue_pipe_'iam_role 'arn:aws:iam::123456789012:role/RoleA,arn:aws:iam::210987654321:role/RoleB';
Dans l'exemple suivant, CREATE EXTERNAL SCHEMA utilise des rôles reliés par chaîne pour endosser lerôle RoleB.
create external schema spectrumexample from data catalog database 'exampledb' region 'us-west-2' iam_role 'arn:aws:iam::123456789012:role/RoleA,arn:aws:iam::210987654321:role/RoleB';
Version de l'API 2012-12-01185

Amazon Redshift Guide de la gestion du clusterRubriques connexes
Rubriques connexes• Autorisation d'opérations COPY, UNLOAD et CREATE EXTERNAL SCHEMA à l'aide de rôles
IAM (p. 186)
Autorisation d'opérations COPY, UNLOAD etCREATE EXTERNAL SCHEMA à l'aide de rôlesIAM
Vous pouvez utiliser la commande COPY pour charger (ou importer) les données dans Amazon Redshiftet la commande UNLOAD pour décharger (ou exporter) les données à partir de Amazon Redshift. Lorsquevous utilisez Amazon Redshift Spectrum, vous utilisez la commande CREATE EXTERNAL SCHEMA pourspécifier l'emplacement d'un compartiment Amazon S3 qui contient vos données. Lorsque vous exécutezles commandes COPY, UNLOAD ou CREATE EXTERNAL SCHEMA, vous devez fournir les informationsd'identification de sécurité qui autorisent votre cluster Amazon Redshift à lire ou écrire les données verset depuis votre destination cible, comme un compartiment Amazon S3. La méthode recommandée pourfournir des informations d'identification de sécurité consiste à spécifier un rôle AWS Identity and AccessManagement (IAM). Pour COPY et UNLOAD, vous pouvez fournir des clés d'accès AWS. Pour plusd'informations sur la création d'un rôle IAM, consultez Autorisation de Amazon Redshift à accéder auxautres services AWS en votre nom (p. 181).
Les étapes de l'utilisation d'un rôle IAM sont les suivantes :
• Créer un rôle IAM à utiliser avec votre cluster Amazon Redshift.• Associer le rôle IAM au cluster.• Incluez l'ARN du rôle IAM lorsque vous appelez la commande COPY, UNLOAD ou CREATE EXTERNAL
SCHEMA.
Dans cette rubrique, vous allez apprendre à associer un rôle IAM à un cluster Amazon Redshift.
Association des rôles IAM aux clustersUne fois que vous avez créé un rôle IAM qui autorise Amazon Redshift à accéder aux autres services AWSen votre nom, vous devez associer ce rôle à un cluster Amazon Redshift cluster avant de pouvoir utiliser lerôle pour charger ou décharger les données.
Autorisations requises pour associer un rôle IAM à un clusterPour associer un rôle IAM à un cluster, un utilisateur IAM doit avoir l'autorisation iam:PassRole pour cerôle IAM. Cette autorisation permet à un administrateur de restreindre les rôles IAM qu'un utilisateur peutassocier aux clusters Amazon Redshift.
L'exemple suivant illustre une stratégie IAM qui peut être attachée à un utilisateur IAM et qui permet àl'utilisateur d'exécuter ces actions :
• Obtenez les détails de tous les clusters Amazon Redshift détenus par ce compte d'utilisateur.• Associez l'un des trois rôles IAM à l'un ou l'autre des deux clusters Amazon Redshift.
{
Version de l'API 2012-12-01186

Amazon Redshift Guide de la gestion du clusterAssociation des rôles IAM aux clusters
"Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "redshift:DescribeClusters", "Resource": "*" }, { "Effect": "Allow", "Action": [ "redshift:ModifyClusterIamRoles", "redshift:CreateCluster" ], "Resource": [ "arn:aws:redshift:us-east-1:123456789012:cluster:my-redshift-cluster", "arn:aws:redshift:us-east-1:123456789012:cluster:cluster:my-second-redshift-cluster" ] }, { "Effect": "Allow", "Action": "iam:PassRole", "Resource": [ "arn:aws:iam::123456789012:role/MyRedshiftRole", "arn:aws:iam::123456789012:role/SecondRedshiftRole", "arn:aws:iam::123456789012:role/ThirdRedshiftRole" ] } ]}
Une fois qu'un utilisateur IAM dispose des autorisations appropriées, cet utilisateur peut associer unrôle IAM à un cluster Amazon Redshift et l'utiliser avec les commandes COPY ou UNLOAD, ou autrescommandes Amazon Redshift.
Pour plus d'informations sur les stratégies IAM, consultez Présentation des stratégies IAM dans le manuelGuide de l'utilisateur IAM.
Gestion de l'association d'un rôle IAM à un clusterVous pouvez associer un rôle IAM à un cluster Amazon Redshift lorsque vous créez le cluster, ou vouspouvez modifier un cluster existant et ajouter ou supprimer une ou plusieurs associations de rôle IAM.Remarques :
• Vous pouvez associer un maximum de 10 rôles IAM à un cluster Amazon Redshift.• Un rôle IAM peut être associé à plusieurs clusters Amazon Redshift.• Un rôle IAM peut être associé à un cluster Amazon Redshift uniquement si le rôle IAM et le cluster sont
détenus par le même compte AWS.
Utilisation de la console pour gérer les associations de rôle IAM
Vous pouvez gérer les associations de rôle IAM d'un cluster avec la console à l'aide de la procéduresuivante.
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Dans la liste, sélectionnez le cluster pour lequel vous voulez gérer les associations de rôle IAM.4. Choisissez Manage IAM Roles.
Version de l'API 2012-12-01187
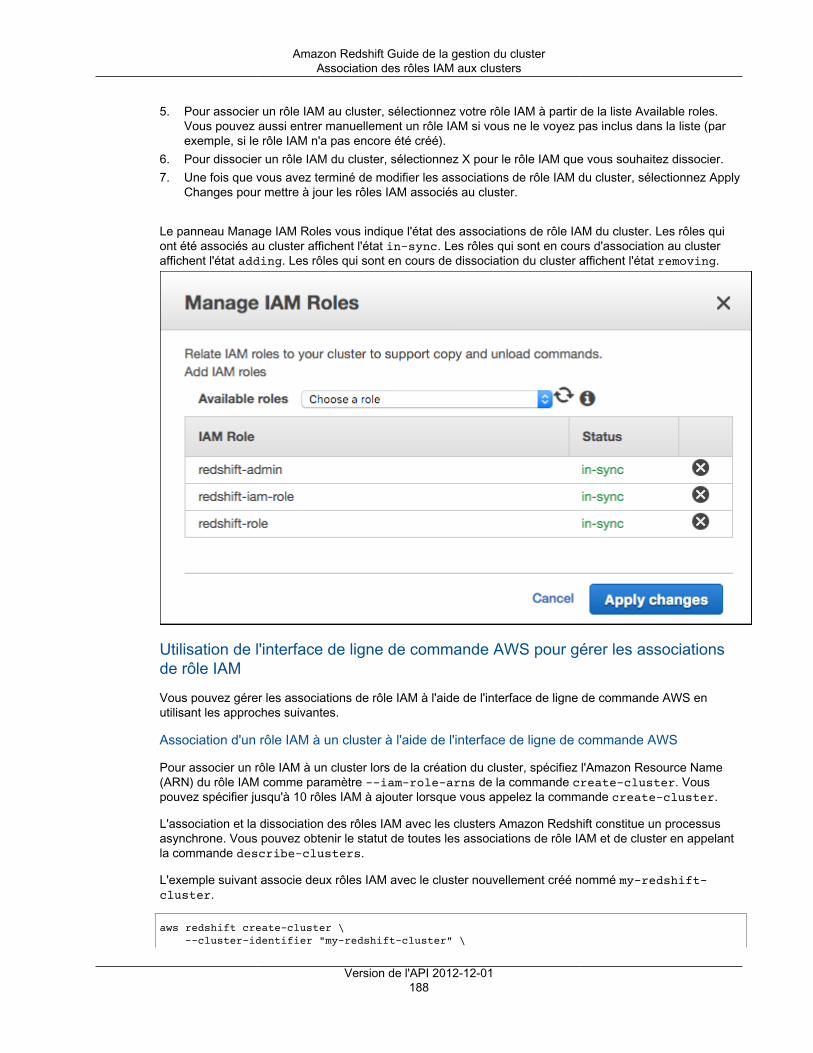
Amazon Redshift Guide de la gestion du clusterAssociation des rôles IAM aux clusters
5. Pour associer un rôle IAM au cluster, sélectionnez votre rôle IAM à partir de la liste Available roles.Vous pouvez aussi entrer manuellement un rôle IAM si vous ne le voyez pas inclus dans la liste (parexemple, si le rôle IAM n'a pas encore été créé).
6. Pour dissocier un rôle IAM du cluster, sélectionnez X pour le rôle IAM que vous souhaitez dissocier.7. Une fois que vous avez terminé de modifier les associations de rôle IAM du cluster, sélectionnez Apply
Changes pour mettre à jour les rôles IAM associés au cluster.
Le panneau Manage IAM Roles vous indique l'état des associations de rôle IAM du cluster. Les rôles quiont été associés au cluster affichent l'état in-sync. Les rôles qui sont en cours d'association au clusteraffichent l'état adding. Les rôles qui sont en cours de dissociation du cluster affichent l'état removing.
Utilisation de l'interface de ligne de commande AWS pour gérer les associationsde rôle IAM
Vous pouvez gérer les associations de rôle IAM à l'aide de l'interface de ligne de commande AWS enutilisant les approches suivantes.
Association d'un rôle IAM à un cluster à l'aide de l'interface de ligne de commande AWS
Pour associer un rôle IAM à un cluster lors de la création du cluster, spécifiez l'Amazon Resource Name(ARN) du rôle IAM comme paramètre --iam-role-arns de la commande create-cluster. Vouspouvez spécifier jusqu'à 10 rôles IAM à ajouter lorsque vous appelez la commande create-cluster.
L'association et la dissociation des rôles IAM avec les clusters Amazon Redshift constitue un processusasynchrone. Vous pouvez obtenir le statut de toutes les associations de rôle IAM et de cluster en appelantla commande describe-clusters.
L'exemple suivant associe deux rôles IAM avec le cluster nouvellement créé nommé my-redshift-cluster.
aws redshift create-cluster \ --cluster-identifier "my-redshift-cluster" \
Version de l'API 2012-12-01188

Amazon Redshift Guide de la gestion du clusterAssociation des rôles IAM aux clusters
--node-type "dc1.large" \ --number-of-nodes 16 \ --iam-role-arns "arn:aws:iam::123456789012:role/RedshiftCopyUnload" \ "arn:aws:iam::123456789012:role/SecondRedshiftRole"
Pour associer un rôle IAM à un cluster Amazon Redshift existant, spécifiez l'Amazon Resource Name(ARN) du rôle IAM comme paramètre --add-iam-roles de la commande modify-cluster-iam-roles. Vous pouvez spécifier jusqu'à 10 rôles IAM à ajouter lorsque vous appelez la commande modify-cluster-iam-roles.
L'exemple suivant associe un rôle IAM à un cluster existant nommé my-redshift-cluster.
aws redshift modify-cluster-iam-roles \ --cluster-identifier "my-redshift-cluster" \ --add-iam-roles "arn:aws:iam::123456789012:role/RedshiftCopyUnload"
Dissociation d'un rôle IAM d'un cluster à l'aide de l'interface de ligne de commande AWS
Pour dissocier un rôle IAM d'un cluster, spécifiez l'ARN du rôle IAM comme paramètre --remove-iam-roles de la commande modify-cluster-iam-roles. Vous pouvez spécifier jusqu'à 10 rôles IAM àsupprimer lorsque vous appelez la commande modify-cluster-iam-roles.
L'exemple suivant supprime l'association d'un rôle IAM pour le compte AWS 123456789012 d'un clusternommé my-redshift-cluster.
aws redshift modify-cluster-iam-roles \ --cluster-identifier "my-redshift-cluster" \ --remove-iam-roles "arn:aws:iam::123456789012:role/RedshiftCopyUnload"
Affichage des associations de rôle IAM pour un cluster à l'aide de l'interface de ligne decommande AWS
Pour afficher tous les rôles IAM associés à un cluster Amazon Redshift et l'état de l'association de rôle IAM,appelez la commande describe-clusters. L'ARN de chaque rôle IAM associé au cluster est retournédans la liste IamRoles comme illustré dans l'exemple de sortie suivant.
Les rôles qui ont été associés au cluster affichent l'état in-sync. Les rôles qui sont en cours d'associationau cluster affichent l'état adding. Les rôles qui sont en cours de dissociation du cluster affichent l'étatremoving.
{ "Clusters": [ { "ClusterIdentifier": "my-redshift-cluster", "NodeType": "dc1.large", "NumberOfNodes": 16, "IamRoles": [ { "IamRoleArn": "arn:aws:iam::123456789012:role/MyRedshiftRole", "IamRoleApplyStatus": "in-sync" }, { "IamRoleArn": "arn:aws:iam::123456789012:role/SecondRedshiftRole", "IamRoleApplyStatus": "in-sync" } ], ... }, {
Version de l'API 2012-12-01189

Amazon Redshift Guide de la gestion du clusterAssociation des rôles IAM aux clusters
"ClusterIdentifier": "my-second-redshift-cluster", "NodeType": "dc1.large", "NumberOfNodes": 10, "IamRoles": [ { "IamRoleArn": "arn:aws:iam::123456789012:role/MyRedshiftRole", "IamRoleApplyStatus": "in-sync" }, { "IamRoleArn": "arn:aws:iam::123456789012:role/SecondRedshiftRole", "IamRoleApplyStatus": "in-sync" }, { "IamRoleArn": "arn:aws:iam::123456789012:role/ThirdRedshiftRole", "IamRoleApplyStatus": "in-sync" } ], ... } ]}
Pour plus d'informations sur l'utilisation de l'interface de ligne de commande AWS, consultez Guide del'utilisateur de l'interface de ligne de commande AWS.
Version de l'API 2012-12-01190

Amazon Redshift Guide de la gestion du clusterUtilisation des interfaces de gestion Amazon Redshift
Accès aux clusters et aux bases dedonnées Amazon Redshift
Il existe plusieurs outils de gestion et d'interfaces vous pouvez utiliser pour créer, gérer et supprimer desclusters Amazon Redshift et les bases de données dans les clusters.
• Vous utilisez les outils de gestion et les interfaces Amazon Web Services pour créer, gérer et supprimerdes clusters Amazon Redshift. Ces outils permettent de gérer le travail de configuration, de gestion etde dimensionnement de l'entrepôt de données ; la mise en service de la capacité, la supervision et lasauvegarde du cluster ; et l'application des correctifs et des mises à niveau au moteur Amazon Redshift.• Vous pouvez utiliser l'AWS Management Console pour créer, gérer et supprimer des clusters de
manière interactive. Les rubriques de ce guide incluent des instructions relatives à l'utilisation de l'AWSManagement Console afin d'effectuer des tâches spécifiques.
• Vous pouvez utiliser l'une des nombreuses interfaces de gestion AWS ou les kits SDK pour créer parprogrammation, gérer et supprimer des clusters. Pour plus d'informations, consultez Utilisation desinterfaces de gestion Amazon Redshift (p. 191).
• Après avoir créé un cluster Amazon Redshift, vous pouvez créer, gérer et supprimer des bases dedonnées dans le cluster à l'aide d'applications ou d'outils clients qui exécutent des instructions SQL viales pilotes PostgreSQL ODBC ou JDBC.• Pour plus d'informations sur l'installation d'outils clients SQL et la connexion à un cluster, consultez
Connexion à un cluster (p. 201).• Pour plus d'informations sur la conception de bases de données et les instructions SQL prises en
charge par Amazon Redshift accédez au manuel Amazon Redshift Database Developer Guide.
Les interfaces utilisées avec les bases de données et les clusters Amazon Redshift respectent lesmécanismes qui contrôlent l'accès, tels que des groupes de sécurité et des stratégies IAM. Pour plusd'informations, consultez Sécurité (p. 131).
Utilisation des interfaces de gestion AmazonRedshift
Rubriques• Utilisation du kit AWS SDK pour Java avec Amazon Redshift (p. 192)• Signature d'une requête HTTP (p. 194)• Configuration de l'interface de ligne de commande Amazon Redshift (p. 197)
Amazon Redshift prend en charge plusieurs interfaces de gestion que vous pouvez utiliser à utiliserpour créer, gérer et supprimer des clusters Amazon Redshift, les kits SDK AWS, l'interface de ligne decommande AWS et l'API de gestion Amazon Redshift.
API de requête Amazon Redshift : API de gestion Amazon Redshift que vous pouvez appeler ensoumettant une demande de requête. Ces demandes de requête sont des requêtes HTTP ou HTTPS quiutilisent les verbes HTTP GET ou POST et un paramètre de requête nommé Action. L'appel de l'API derequête est le moyen le plus direct d'accéder au service Amazon Redshift, mais il nécessite que votre
Version de l'API 2012-12-01191

Amazon Redshift Guide de la gestion du clusterUtilisation du kit AWS SDK pour Java
application gère les détails de bas niveau, tels que le traitement des erreurs et la génération d'un hachagepour signer la demande.
• Pour plus d'informations sur la création et la signature d'une demande d'API de requête, consultezSignature d'une requête HTTP (p. 194).
• Pour plus d'informations sur les actions d'API de requête et les types de données pour Amazon Redshift,accédez à la section Référence de l'API Amazon Redshift.
Kits SDK AWS : Amazon Web Services fournit des kits SDK que vous pouvez utiliser pour exécuter desopérations liées au cluster Amazon Redshift. Plusieurs bibliothèques de kits SDK regroupent l'API derequête Amazon Redshift sous-jacente. Elles intègrent les fonctionnalités de l'API dans le langage deprogrammation spécifique et gèrent un grand nombre des détails de bas niveau, tels que le calcul dessignatures, la gestion des nouvelles tentatives de demande et la gestion des erreurs. L'appel des fonctionsdu wrapper dans les bibliothèques de kits SDK peut simplifier considérablement le processus d'écritured'une application pour gérer un cluster Amazon Redshift.
• Amazon Redshift est pris en charge par les kits SDK AWS pour Java, .NET, PHP, Python, Rubyet Node.js. Les fonctions du wrapper pour Amazon Redshift sont documentées dans le manuelde référence pour chaque kit SDK. Pour obtenir la liste des kits SDK AWS et des liens vers leurdocumentation, accédez au manuel Outils pour Amazon Web Services.
• Ce manuel fournit des exemples d'utilisation de Amazon Redshift à l'aide du kit SDK Java. Pour desexemples de codes de kit SDK AWS plus généraux, accédez à Exemples de codes et bibliothèques.
Interface de ligne de commande (CLI) AWS : fournit un ensemble d'outils de ligne de commande quipeuvent être utilisés pour gérer des services AWS sur des ordinateurs Windows, Mac et Linux. L'AWS CLIinclut des commandes basées sur les actions d'API de requête Amazon Redshift.
• Pour plus d'informations sur l'installation et la configuration de l'interface de ligne de commande AmazonRedshift, consultez Configuration de l'interface de ligne de commande Amazon Redshift (p. 197).
• Pour obtenir des documents de référence sur les commandes de l'interface de ligne de commandeAmazon Redshift, accédez à Amazon Redshift dans la référence sur l'AWS CLI.
Utilisation du kit AWS SDK pour Java avec AmazonRedshiftLe kit AWS SDK pour Java fournit une classe nommée AmazonRedshiftClient, que vous pouvezutiliser pour interagir avec Amazon Redshift. Pour plus d'informations sur le téléchargement du kit AWSSDK pour Java, accédez à AWS SDK pour Java.
Note
Le kit AWS SDK pour Java fournit des clients thread-safe pour accéder à Amazon Redshift. Entant que bonne pratique, vos applications doivent créer un seul client et le réutiliser entre lesthreads.
La classe AmazonRedshiftClient définit des méthodes qui sont mappées à des actions d'API derequête Amazon Redshift sous-jacentes. (Ces actions sont décrites dans la Référence d'API AmazonRedshift). Lorsque vous appelez une méthode, vous devez créer un objet de demande et un objet deréponse correspondants. L'objet de demande inclut des informations que vous devez transmettre avec lademande réelle. L'objet de réponse inclut les informations renvoyées par Amazon Redshift en réponse à lademande.
Par exemple, la classe AmazonRedshiftClient fournit la méthode createCluster permettant demettre en service un cluster. Cette méthode est mappée à l'action d'API CreateCluster sous-jacente. Vous
Version de l'API 2012-12-01192
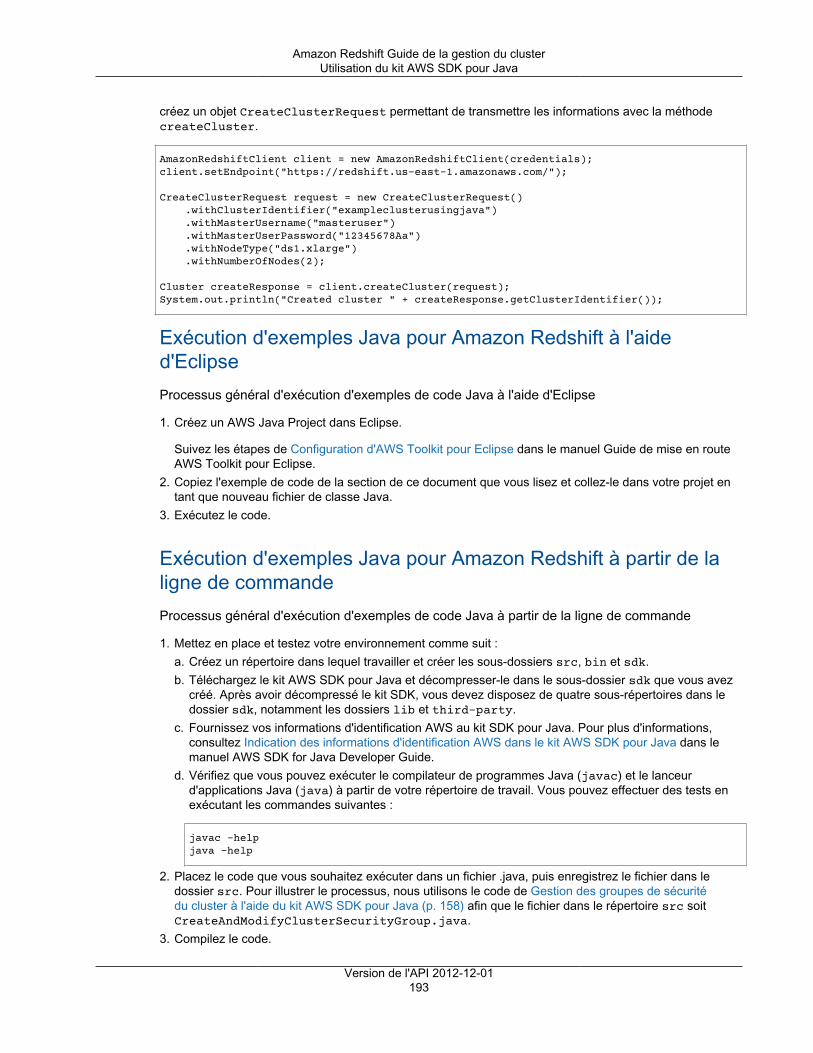
Amazon Redshift Guide de la gestion du clusterUtilisation du kit AWS SDK pour Java
créez un objet CreateClusterRequest permettant de transmettre les informations avec la méthodecreateCluster.
AmazonRedshiftClient client = new AmazonRedshiftClient(credentials);client.setEndpoint("https://redshift.us-east-1.amazonaws.com/");
CreateClusterRequest request = new CreateClusterRequest() .withClusterIdentifier("exampleclusterusingjava") .withMasterUsername("masteruser") .withMasterUserPassword("12345678Aa") .withNodeType("ds1.xlarge") .withNumberOfNodes(2); Cluster createResponse = client.createCluster(request);System.out.println("Created cluster " + createResponse.getClusterIdentifier());
Exécution d'exemples Java pour Amazon Redshift à l'aided'EclipseProcessus général d'exécution d'exemples de code Java à l'aide d'Eclipse
1. Créez un AWS Java Project dans Eclipse.
Suivez les étapes de Configuration d'AWS Toolkit pour Eclipse dans le manuel Guide de mise en routeAWS Toolkit pour Eclipse.
2. Copiez l'exemple de code de la section de ce document que vous lisez et collez-le dans votre projet entant que nouveau fichier de classe Java.
3. Exécutez le code.
Exécution d'exemples Java pour Amazon Redshift à partir de laligne de commandeProcessus général d'exécution d'exemples de code Java à partir de la ligne de commande
1. Mettez en place et testez votre environnement comme suit :a. Créez un répertoire dans lequel travailler et créer les sous-dossiers src, bin et sdk.b. Téléchargez le kit AWS SDK pour Java et décompresser-le dans le sous-dossier sdk que vous avez
créé. Après avoir décompressé le kit SDK, vous devez disposez de quatre sous-répertoires dans ledossier sdk, notamment les dossiers lib et third-party.
c. Fournissez vos informations d'identification AWS au kit SDK pour Java. Pour plus d'informations,consultez Indication des informations d'identification AWS dans le kit AWS SDK pour Java dans lemanuel AWS SDK for Java Developer Guide.
d. Vérifiez que vous pouvez exécuter le compilateur de programmes Java (javac) et le lanceurd'applications Java (java) à partir de votre répertoire de travail. Vous pouvez effectuer des tests enexécutant les commandes suivantes :
javac -helpjava -help
2. Placez le code que vous souhaitez exécuter dans un fichier .java, puis enregistrez le fichier dans ledossier src. Pour illustrer le processus, nous utilisons le code de Gestion des groupes de sécuritédu cluster à l'aide du kit AWS SDK pour Java (p. 158) afin que le fichier dans le répertoire src soit CreateAndModifyClusterSecurityGroup.java.
3. Compilez le code.
Version de l'API 2012-12-01193

Amazon Redshift Guide de la gestion du clusterSignature d'une requête HTTP
javac -cp sdk/lib/aws-java-sdk-1.3.18.jar -d bin src\CreateAndModifyClusterSecurityGroup.java
Si vous utilisez une version différente du kit AWS SDK pour Java, adaptez le chemin de classe (-cp) àvotre version.
4. Exécutez le code. Dans la commande suivante, des sauts de ligne sont ajoutés pour faciliter la lecture.
java -cp "bin; sdk/lib/*; sdk/third-party/commons-logging-1.1.1/*; sdk/third-party/httpcomponents-client-4.1.1/*; sdk/third-party/jackson-core-1.8/*" CreateAndModifyClusterSecurityGroup
Modifiez le délimiteur de chemin d'accès de classe en fonction des besoins de votre systèmed'exploitation. Par exemple, pour Windows, la délimiteur est « ; » (comme indiqué) et pour Unix, c'est« : ». D'autres exemples de code peuvent nécessiter davantage de bibliothèques que celles affichéesdans cet exemple ou la version du kit AWS SDK que vous utilisez a peut-être des noms de dossiers tiersdifférents. Dans ces cas, adaptez le chemin de classe (-cp) le cas échéant.
Pour exécuter les exemples de ce document, utilisez une version du kit AWS SDK qui prend en chargeAmazon Redshift. Pour obtenir la dernière version du kit AWS SDK pour Java, accédez à AWS SDKpour Java.
Définition du point de terminaisonPar défaut, le kit AWS SDK pour Java utilise le point de terminaison https://redshift.us-east-1.amazonaws.com/. Vous pouvez définir le point de terminaison de manière explicite avec laméthode client.setEndpoint, comme illustré dans l'extrait de code Java suivant.
Example
client = new AmazonRedshiftClient(credentials);client.setEndpoint("https://redshift.us-east-1.amazonaws.com/");
Pour obtenir une liste des régions AWS prises en charge dans lesquelles vous pouvez mettre en service uncluster, consultez la section Régions et points de terminaison du Glossaire Amazon Web Services.
Signature d'une requête HTTPAmazon Redshift exige que chaque demande que vous envoyez à l'API de gestion soit authentifiée avecune signature. Cette rubrique explique comment signer vos demandes.
Si vous utilisez l'un des kits de développement logiciel SDK AWS ou l'interface de ligne de commandeAWS, la signature de la demande est gérée automatiquement et vous pouvez ignorer cette section. Pourplus d'informations sur l'utilisation des kits SDK AWS, consultez Utilisation des interfaces de gestionAmazon Redshift (p. 191). Pour plus d'informations sur l'utilisation de l'interface de ligne de commandeAmazon Redshift, consultez Référence de la ligne de commande Amazon Redshift.
Pour signer une demande, vous calculez une signature numérique à l'aide d'une fonction de hachage dechiffrement. Un hachage de chiffrement est une fonction qui renvoie une valeur de hachage unique baséesur l'entrée. L'entrée de la fonction de hachage contient le texte de la demande et votre clé d'accès secrète.La fonction de hachage renvoie une valeur de hachage que vous incluez dans la demande comme votresignature. La signature fait partie de l'en-tête Authorization de votre demande.
Version de l'API 2012-12-01194

Amazon Redshift Guide de la gestion du clusterSignature d'une requête HTTP
Note
For API access, you need an access key ID and secret access key. Use IAM user access keysinstead of Utilisateur racine d'un compte AWS access keys. IAM lets you securely control accessto AWS services and resources in your AWS account. For more information about creating accesskeys, see How Do I Get Security Credentials? in the AWS General Reference.
Après qu'Amazon Redshift a reçu votre demande, il recalcule la signature en utilisant la même fonctionde hachage et la même entrée que celles que vous avez utilisées pour signer la demande. Si la signaturerésultante correspond à la signature de la demande, Amazon Redshift traite la demande ; sinon, lademande est rejetée.
Amazon Redshift prend en charge l'authentification à l'aide d'AWS Signature Version 4. Le processus decalcul d'une signature se compose de trois tâches. Ces tâches sont illustrées dans l'exemple qui suit.
• Tâche 1 : créer une demande canonique
Réorganisez votre demande HTTP sous forme canonique. L'utilisation d'une forme canonique estnécessaire, car Amazon Redshift utilise la même forme canonique pour calculer la signature qu'ilcompare à celle que vous avez envoyée.
• Tâche 2 : créer une chaîne de connexion
Créez une chaîne que vous utiliserez comme une des valeurs d'entrée pour votre fonction de hachagecryptographique. La chaîne, appelée la chaîne de connexion, est une concaténation du nom del'algorithme de hachage, de la date de la demande, d'une chaîne d'informations d'identification etde la demande convertie sous forme canonique de la tâche précédente. La chaîne d'informationsd'identification elle-même est une concaténation de date, de région et d'informations de service.
• Tâche 3 : créer une signature
Créez une signature pour votre demande à l'aide d'une fonction de hachage de chiffrement qui acceptedeux chaînes en entrée : votre chaîne de connexion et une clé dérivée. La clé dérivée est calculée encommençant par votre clé d'accès secrète et en utilisant la chaîne d'informations d'identification pourcréer un ensemble de codes d'authentification de message basés sur le hachage (HMAC-SHA256).
Exemple de calcul de signatureL'exemple suivant vous guide à travers les détails de la création d'une signature pour une demandeCreateCluster. Vous pouvez utiliser cet exemple comme référence pour vérifier votre propre méthode decalcul de signature. D'autres calculs de référence sont inclus dans le package Signature Version 4 TestSuite du Glossaire Amazon Web Services.
Vous pouvez utiliser une requête GET ou POST pour envoyer des demandes à Amazon Redshift. Ladifférence entre les deux requêtes est que pour la requête GET, vos paramètres sont envoyés commeparamètres de chaîne de requête. Pour la requête POST, ils sont inclus dans le corps de la demande.L'exemple suivant illustre une requête POST.
Dans cet exemple il est supposé que :
• L'horodatage de la demande est Fri, 07 Dec 2012 00:00:00 GMT.• Le point de terminaison est la région USA Est (Virginie du Nord), us-east-1.
La syntaxe générale de la demande est :
https://redshift.us-east-1.amazonaws.com/ ?Action=CreateCluster &ClusterIdentifier=examplecluster &MasterUsername=masteruser
Version de l'API 2012-12-01195

Amazon Redshift Guide de la gestion du clusterSignature d'une requête HTTP
&MasterUserPassword=12345678Aa &NumberOfNode=2 &NodeType=ds1.xlarge &Version=2012-12-01 &x-amz-algorithm=AWS4-HMAC-SHA256 &x-amz-credential=AKIAIOSFODNN7EXAMPLE/20121207/us-east-1/redshift/aws4_request &x-amz-date=20121207T000000Z &x-amz-signedheaders=content-type;host;x-amz-date
La forme canonique de la demande calculée pour Tâche 1 : Créer une demande canonique (p. 195) est :
POST/
content-type:application/x-www-form-urlencoded; charset=utf-8host:redshift.us-east-1.amazonaws.comx-amz-date:20121207T000000Z
content-type;host;x-amz-date55141b5d2aff6042ccd9d2af808fdf95ac78255e25b823d2dbd720226de1625d
La dernière ligne de la demande canonique est le hachage du corps de la demande. La troisième ligne dela requête canonique est vide, car il n'y a pas de paramètres d'interrogation pour cette API.
La chaîne de connexion de Tâche 2 : Créer une chaîne de connexion (p. 195) est :
AWS4-HMAC-SHA25620121207T000000Z20121207/us-east-1/redshift/aws4_request06b6bef4f4f060a5558b60c627cc6c5b5b5a959b9902b5ac2187be80cbac0714
La première ligne de la chaîne de connexion est l'algorithme, la deuxième ligne l'horodatage, la troisièmeligne les informations d'identification et la dernière ligne un hachage de la demande canonique issu de laTâche 1 : Créer une demande canonique (p. 195). Le nom du service à utiliser dans les informationsd'identification est redshift.
Pour Tâche 3 : Créer une signature (p. 195), la clé dérivée peut être représentée comme suit :
derived key = HMAC(HMAC(HMAC(HMAC("AWS4" + YourSecretAccessKey,"20121207"),"us-east-1"),"redshift"),"aws4_request")
La clé dérivée est calculée en tant que série de fonctions de hachage. A partir de l'instruction HMACinterne de la formule ci-dessus, vous concaténez l'expression « AWS4 » et votre clé d'accès secrète, puisutilisez le résultat obtenu comme clé de hachage des données « us-east-1 ». Le résultat de ce hachagedevient la clé de la fonction de hachage suivante.
Après que vous avez calculé la clé dérivée, vous l'utilisez dans une fonction de hachage qui acceptedeux chaînes en entrée, votre chaîne de connexion et la clé dérivée. Par exemple, si vous utilisez la cléd'accès secrète wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY et la chaîne de connexion fournieprécédemment, la signature calculée est la suivante :
9a6b557aa9f38dea83d9215d8f0eae54100877f3e0735d38498d7ae489117920
L'étape finale consiste à construire l'en-tête Authorization. Pour la clé d'accès de la démonstrationAKIAIOSFODNN7EXAMPLE, l'en-tête (avec les sauts de ligne ajoutés pour faciliter la lecture) est :
Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20121207/us-east-1/redshift/aws4_request,
Version de l'API 2012-12-01196
Amazon Redshift Guide de la gestion du clusterConfiguration de l'interface de ligne
de commande Amazon Redshift
SignedHeaders=content-type;host;x-amz-date, Signature=9a6b557aa9f38dea83d9215d8f0eae54100877f3e0735d38498d7ae489117920
Configuration de l'interface de ligne de commandeAmazon RedshiftCette section explique comment configurer et exécuter les outils de ligne de commande de l'AWS CLI àutiliser dans la gestion de Amazon Redshift. Les outils de ligne de commande Amazon Redshift s'exécutentsur l'AWS Command Line Interface (AWS CLI), qui à son tour utilise Python (https://www.python.org/).L'AWS CLI peut être exécutée sur n'importe quel système d'exploitation qui prend en charge Python.
Instructions d'installationPour commencer à utiliser les outils de ligne de commande Amazon Redshift, vous devez d'abordconfigurer l'AWS CLI, puis ajouter les fichiers de configuration qui définissent les options de l'interface deligne de commande Amazon Redshift.
Si vous avez déjà installé et configuré l'AWS CLI pour un autre service AWS, vous pouvez ignorer cetteprocédure.
Pour installer l'AWS Command Line Interface
1. Accédez à la section Configuration avec l'interface de ligne de commande AWS, puis suivez lesinstructions relatives à l'installation de l'AWS CLI.
For CLI access, you need an access key ID and secret access key. Use IAM user access keys insteadof Utilisateur racine d'un compte AWS access keys. IAM lets you securely control access to AWSservices and resources in your AWS account. For more information about creating access keys, seeUnderstanding and Getting Your Security Credentials in the AWS General Reference.
2. Créez un fichier contenant des informations de configuration telles que vos clés d'accès, la régionpar défaut et le format de sortie de commande. Puis définissez la variable d'environnementAWS_CONFIG_FILE pour faire référence à ce fichier. Pour obtenir des instructions détaillées, consultezConfiguration de l'interface de ligne de commande AWS dans le manuel AWS Command LineInterface Guide de l'utilisateur.
3. Exécutez une commande test afin de confirmer que l'interface AWS CLI fonctionne. Par exemple, lacommande suivante devrait afficher des informations d'aide pour l'AWS CLI :
aws help
La commande suivante devrait afficher des informations d'aide pour Amazon Redshift :
aws redshift help
Pour obtenir des documents de référence sur les commandes de l'interface de ligne de commande AmazonRedshift, accédez à Amazon Redshift dans la référence sur l'AWS CLI.
Mise en route avec l'interface de ligne de commande AWSPour vous familiariser avec l'interface de ligne de commande, cette section vous explique commenteffectuer des tâches administratives de base pour un cluster Amazon Redshift. Ces tâches sont trèssimilaires à celles de la section Amazon Redshift Mise en route, mais elles sont axées sur l'interface deligne de commande plutôt que sur la console Amazon Redshift.
Version de l'API 2012-12-01197
Amazon Redshift Guide de la gestion du clusterConfiguration de l'interface de ligne
de commande Amazon Redshift
Cette section explique le processus de création d'un cluster, de création de tables de base de données,de chargement des données et de test des requêtes. Vous serez amené à utiliser l'interface de ligne decommande Amazon Redshift afin de mettre en service un cluster et d'accorder les autorisations d'accèsnécessaires. Vous utiliserez ensuite le client SQL Workbench pour vous connecter au cluster et créer desexemples de tables, télécharger des exemples de données et exécuter des requêtes de test.
Étape 1 : Avant de commencer
Si vous ne disposez pas déjà d'un compte AWS, vous devez vous inscrire. Ensuite, vous aurez besoin deconfigurer les outils de ligne de commande Amazon Redshift. Enfin, vous devrez télécharger les pilotes etoutils clients afin de vous connecter à votre cluster.
Étape 1.1 : Créer un compte AWS
Pour plus d'informations sur l'inscription à un compte utilisateur AWS, accédez au manuel Amazon RedshiftMise en route.
Étape 1.2 : Télécharger et installer l'interface de ligne de commande AWS
Si vous n'avez pas installé l'interface de ligne de commande AWS, consultez Configuration de l'interface deligne de commande Amazon Redshift (p. 197).
Étape 1.3 : Télécharger les pilotes et les outils clients
Vous pouvez utiliser les outils clients SQL pour vous connecter à un cluster Amazon Redshift avec lespilotes ODBC ou JDBC pour PostgreSQL. Si vous ne disposez pas actuellement de ce type de logicielsinstallés, vous pouvez utiliser SQL Workbench, un outil inter-plateforme gratuit que vous pouvez utiliserpour les tables de requête dans un cluster Amazon Redshift. Dans cette section, les exemples utiliseront leclient SQL Workbench.
Pour télécharger SQL Workbench et les pilotes PostgreSQL, accédez au manuel Guide de démarrageAmazon Redshift.
Étape 2 : Lancer un cluster
Vous êtes maintenant prêt à lancer un cluster à l'aide de l'interface de ligne de commande (CLI) AWS.
Important
Le cluster que vous êtes sur le point de lancer sera opérationnel (et non pas exécuté dans unenvironnement de test (sandbox)). Vous devrez payer les frais d'utilisation standard pour le clusterjusqu'à ce que vous y mettiez fin. Pour obtenir des informations de tarification, consultez la pagede tarification Amazon Redshift.Si vous terminez l'exercice décrit ici en une seule fois et que vous mettez fin à votre cluster unefois que vous avez terminé, le montant total des frais sera minimal.
La commande create-cluster comporte un grand nombre de paramètres. Pour cet exercice, vous allezutiliser les valeurs des paramètres qui sont décrits dans le tableau suivant. Avant de créer un cluster dansun environnement de production, nous vous recommandons de consulter tous les paramètres obligatoireset facultatifs afin que votre configuration de cluster corresponde à vos besoins. Pour plus d'informations,consultez create-cluster
Nom du paramètre Valeur de paramètre pour cet exercice
Identifiant du cluster examplecluster
Master Username masteruser
Version de l'API 2012-12-01198

Amazon Redshift Guide de la gestion du clusterConfiguration de l'interface de ligne
de commande Amazon Redshift
Nom du paramètre Valeur de paramètre pour cet exercice
Master Password TopSecret1
Type de nœud ds1.xlarge ou la taille de nœud que vous souhaitezutiliser. Pour plus d'informations, consultez Clusters etdes nœuds dans Amazon Redshift (p. 5)
Type de cluster single-node
Pour créer votre cluster, saisissez la commande suivante :
aws redshift create-cluster --cluster-identifier examplecluster --master-username masteruser --master-user-password TopSecret1 --node-type ds1.xlarge --cluster-type single-node
Le processus de création du cluster prendra plusieurs minutes. Pour vérifier l'état, saisissez la commandesuivante :
aws redshift describe-clusters --cluster-identifier examplecluster
Le résultat sera similaire à ceci :
{ "Clusters": [ {
...output omitted...
"ClusterStatus": "creating", "ClusterIdentifier": "examplecluster",
...output omitted...
}
Lorsque le champ ClusterStatus passe de creating à available, le cluster est prêt à être utilisé.
Dans l'étape suivante, vous allez autoriser l'accès afin que de pouvoir vous connecter au cluster.
Étape 3 : Autoriser le trafic entrant pour l'accès vers le clusterVous devez explicitement accorder l'accès entrant à votre client pour vous connecter au cluster. Le clientpeut être une instance Amazon EC2 ou un ordinateur externe.
Lorsque vous avez créé un cluster à l'étape précédente, du fait que vous n'avez pas spécifié de groupe desécurité, vous avez associé le groupe de sécurité du cluster par défaut au cluster. Le groupe de sécuritédu cluster par défaut ne contient aucune règle autorisant le trafic entrant vers le cluster. Pour accéder aunouveau cluster, vous devez ajouter des règles de trafic entrant, qui sont appelées règles de trafic entrant,au groupe de sécurité du cluster.
Règles de trafic entrant pour les applications s'exécutant sur Internet
Si vous accédez à votre cluster à partir d'Internet, vous devez autoriser une plage d'adresses CIDR/IP(Classless Inter-Domain Routing). Pour cet exemple, nous utiliserons une règle CIDR/IP de 192.0.2.0/24 ;vous devrez modifier cette plage afin de tenir compte de votre adresse IP et masque réseau.
Pour autoriser le trafic entrant réseau vers votre cluster, saisissez la commande suivante :
Version de l'API 2012-12-01199
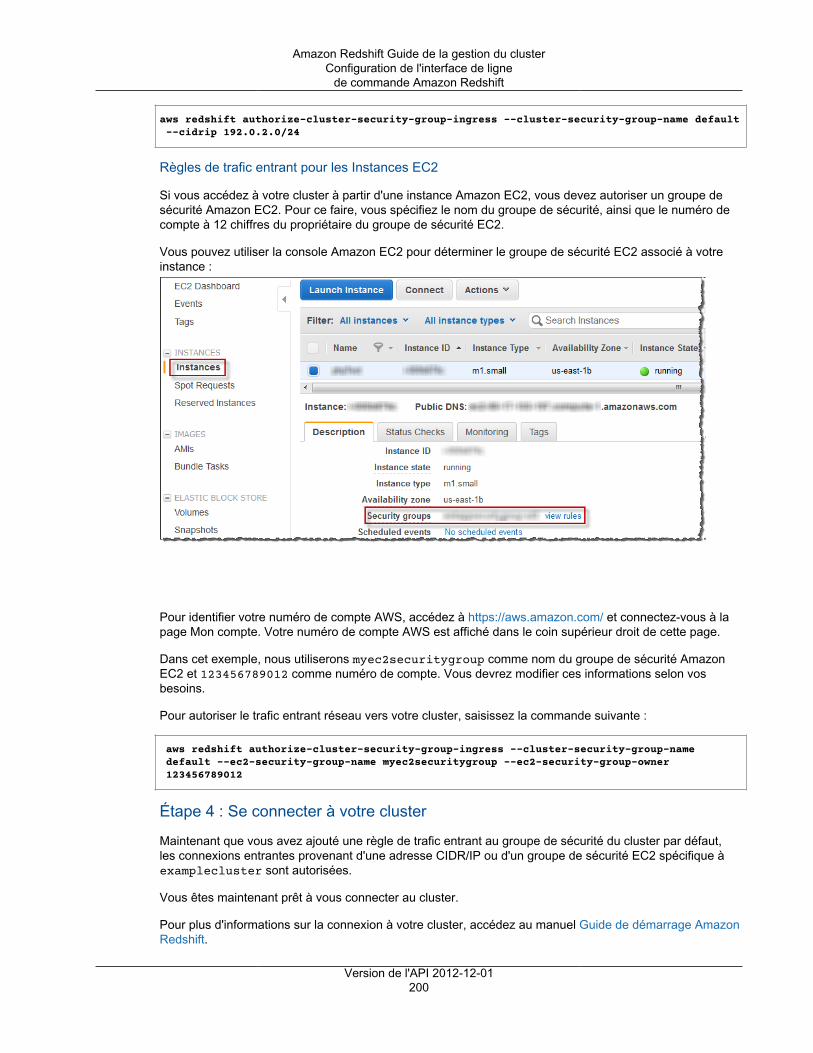
Amazon Redshift Guide de la gestion du clusterConfiguration de l'interface de ligne
de commande Amazon Redshift
aws redshift authorize-cluster-security-group-ingress --cluster-security-group-name default --cidrip 192.0.2.0/24
Règles de trafic entrant pour les Instances EC2
Si vous accédez à votre cluster à partir d'une instance Amazon EC2, vous devez autoriser un groupe desécurité Amazon EC2. Pour ce faire, vous spécifiez le nom du groupe de sécurité, ainsi que le numéro decompte à 12 chiffres du propriétaire du groupe de sécurité EC2.
Vous pouvez utiliser la console Amazon EC2 pour déterminer le groupe de sécurité EC2 associé à votreinstance :
Pour identifier votre numéro de compte AWS, accédez à https://aws.amazon.com/ et connectez-vous à lapage Mon compte. Votre numéro de compte AWS est affiché dans le coin supérieur droit de cette page.
Dans cet exemple, nous utiliserons myec2securitygroup comme nom du groupe de sécurité AmazonEC2 et 123456789012 comme numéro de compte. Vous devrez modifier ces informations selon vosbesoins.
Pour autoriser le trafic entrant réseau vers votre cluster, saisissez la commande suivante :
aws redshift authorize-cluster-security-group-ingress --cluster-security-group-name default --ec2-security-group-name myec2securitygroup --ec2-security-group-owner 123456789012
Étape 4 : Se connecter à votre cluster
Maintenant que vous avez ajouté une règle de trafic entrant au groupe de sécurité du cluster par défaut,les connexions entrantes provenant d'une adresse CIDR/IP ou d'un groupe de sécurité EC2 spécifique àexamplecluster sont autorisées.
Vous êtes maintenant prêt à vous connecter au cluster.
Pour plus d'informations sur la connexion à votre cluster, accédez au manuel Guide de démarrage AmazonRedshift.
Version de l'API 2012-12-01200

Amazon Redshift Guide de la gestion du clusterConnexion à un cluster
Étape 5 : Créer des tables, télécharger des données et essayer des exemples derequêtes
Pour plus d'informations sur la création de tables, le chargement des données et l'émission de requêtes,accédez au Amazon Redshift Mise en route.
Étape 6 : Supprimer votre exemple de cluster
Une fois que vous avez lancé un cluster et qu'il est disponible, vous êtes facturé pour la durée d'exécutiondu cluster, même si vous ne l'utilisez pas activement. Lorsque vous n'avez plus besoin du cluster, vouspouvez le supprimer.
Lorsque vous supprimez un cluster, vous devez décider si vous devez créer un instantané final. Du faitqu'il s'agit d'un exercice et que votre cluster de test ne contient pas de données importantes, vous pouvezignorer l'instantané final.
Pour supprimer votre cluster, saisissez la commande suivante :
aws redshift delete-cluster --cluster-identifier examplecluster --skip-final-cluster-snapshot
Félicitations ! Vous avez correctement lancé, autorisé l'accès, connecté et mis fin à un cluster.
Connexion à un clusterVous pouvez vous connecter aux clusters Amazon Redshift depuis les outils clients SQL via desconnexions Java Database Connectivity (JDBC) et Open Database Connectivity (ODBC). Amazon Redshiftne fournit ni n'installe les outils clients SQL ou les bibliothèques, vous devez donc les installer sur votreordinateur client ou instance Amazon EC2 pour les utiliser avec des données dans vos clusters. Vouspouvez utiliser la plupart des outils clients SQL qui prennent en charge les pilotes ODBC ou JDBC.
Vous pouvez utiliser cette section pour parcourir le processus de configuration de votre ordinateur client ouinstance Amazon EC2 afin d'utiliser une connexion ODBC ou JDBC et les options de sécurité associéespour la connexion client au serveur. De plus, dans cette section, vous trouverez des informations sur laconfiguration et la connexion dans deux exemples d'outils clients SQL tiers, SQL Workbench/J et psql, sivous ne disposez pas encore d'outil d'aide à la décision à utiliser. Vous pouvez également utiliser cettesection pour en savoir plus sur la connexion à votre cluster par programmation. Enfin, si vous rencontrezdes problèmes lorsque vous essayez de vous connecter à votre cluster, vous pouvez consulter lesinformations sur la résolution des problèmes dans cette section afin d'identifier les solutions possibles.
Rubriques• Configuration de connexions dans Amazon Redshift (p. 201)• Configurer une connexion JDBC (p. 203)• Configurer la connexion ODBC (p. 219)• Configurer les options de sécurité des connexions (p. 238)• Connexion aux clusters à partir des outils client et du code (p. 244)• Résolution des problèmes de connexion dans Amazon Redshift (p. 253)
Configuration de connexions dans Amazon RedshiftUtilisez cette section pour apprendre à configurer des connexions JDBC et ODBC afin de vous connecterà votre cluster à partir d'outils clients SQL. Cette section décrit comment configurer des connexions
Version de l'API 2012-12-01201

Amazon Redshift Guide de la gestion du clusterConfiguration de connexions dans Amazon Redshift
JDBC et ODBC et utiliser des certificats SSL (Secure Sockets Layer) et de serveur afin de chiffrer lescommunications entre le client et le serveur.
Pilotes JDBC et ODBC pour Amazon RedshiftPour utiliser les données de votre cluster, vous avez besoin de pilotes ODBC ou JDBC pour la connectivitédans votre ordinateur ou instance client. Codez vos applications afin d'utiliser des API d'accès aux donnéesODBC ou JDBC et utilisez des outils clients SQL qui prennent en charge JDBC ou ODBC.
Amazon Redshift propose des pilotes JDBC et ODBC à télécharger. Précédemment, Amazon Redshiftrecommandait les pilotes PostgreSQL pour JDBC et ODBC. Si vous utilisez actuellement ces pilotes, nousvous recommandons de passer aux nouveaux pilotes spécifiques à Amazon Redshift à l'avenir. Pour plusd'informations sur le téléchargement des pilotes JDBC et ODBC et la configuration de connexions à votrecluster, consultez Configurer une connexion JDBC (p. 203) et Configurer la connexion ODBC (p. 219).
Recherche de votre chaîne de connexion au clusterPour vous connecter à votre cluster avec votre outil client SQL, vous avez besoin de la chaîne deconnexion au cluster. La chaîne de connexion au cluster se situe dans la console Amazon Redshift, sur lapage de configuration d'un cluster.
Pour obtenir votre chaîne de connexion au cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Sur la page Clusters, cliquez sur le nom du cluster pour lequel vous souhaitez obtenir la chaîne deconnexion.
3. Sur l'onglet Configuration du cluster, sous URL JDBC ou URL ODBC, copiez la chaîne de connexion.
L'exemple suivant illustre les chaînes de connexion d'un cluster lancé dans la région Ouest des États-Unis. Si vous avez lancé votre cluster dans une autre région, la chaîne de connexion sera basée sur lepoint de terminaison de cette région.
Version de l'API 2012-12-01202

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Configurer une connexion JDBCVous pouvez utiliser une connexion JDBC pour vous connecter à votre cluster Amazon Redshift à partir denombreux outils clients SQL tiers. Pour ce faire, vous devez télécharger un pilote JDBC. Si vous souhaitezutiliser une connexion JDBC, suivez les étapes décrites dans cette section.
Rubriques• Télécharger le pilote JDBC Amazon Redshift (p. 203)• Obtenir l'URL JDBC (p. 204)• Options de configuration du pilote JDBC (p. 205)• Configuration d'une connexion JDBC avec Apache Maven (p. 211)• Versions antérieures du pilote JDBC (p. 213)
Télécharger le pilote JDBC Amazon RedshiftAmazon Redshift propose des pilotes pour les outils qui sont compatibles avec l'API JDBC 4.2, l'APIJDBC 4.1 ou l'API JDBC 4.0. Pour plus d'informations sur les fonctionnalités prises en charge par cespilotes, accédez aux Notes de mise à jour du pilote JDBC Amazon Redshift.
Les pilotes JDBC version 1.2.8.1005 et ultérieures prennent en charge l'authentification de base dedonnées à l'aide des informations d'identification AWS Identity and Access Management (IAM) ou desinformations d'identification émises par un fournisseur d'identité (IdP). Pour plus d'informations, consultezUtilisation de l'authentification IAM pour générer des informations d'identification de l'utilisateur de base dedonnées (p. 162).
Téléchargez l'un des pilotes suivants, en fonction de la version de votre API JDBC utilisée par votre outilclient SQL ou votre application. En cas de doute, téléchargez la dernière version du pilote d'API JDBC 4.2.
Note
Pour le nom de la classe du pilote, utilisez com.amazon.redshift.jdbc.Driver ou le nom de classepropre à la version mentionné avec le pilote dans la liste suivante.
• Pilote compatible avec JDBC 4.2 : https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.16.1027/RedshiftJDBC42-1.2.16.1027.jar.
Le nom de classe du pilote est 1.2.16.1027/RedshiftJDBC41-1.2.16.1027.jarcom.amazon.redshift.jdbc42.Driver.
• JDBC 4.1 – Pilote compatible : https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1027/1.2.16.1027/RedshiftJDBC41-1.2.16.1027.jar.
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc41.Driver.• Pilote compatible avec JDBC 4.0 : https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/
1.2.16.1027/RedshiftJDBC4-1.2.16.1027.jar.
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc4.Driver.
Les pilotes JDBC Amazon Redshift standard incluent le kit SDK AWS requis pour utiliser l'authentificationde base de données IAM. Nous vous recommandons d'utiliser les pilotes standard, sauf si la taille desfichiers de pilote est un problème pour votre application. Si vous avez besoin de fichiers de pilote plus petitset que vous n'utilisez pas l'authentification de base de données IAM, ou si vous disposez déjà d'un kit SDKAWS pour Java 1.11. 118 ou version ultérieure dans votre chemin de classe Java, téléchargez l'un despilotes suivants.
• Pilote compatible avec JDBC 4.2 : https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.16.1027/RedshiftJDBC42-no-awssdk-1.2.16.1027.jar.
Version de l'API 2012-12-01203
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc42.Driver.• Pilote compatible avec JDBC 4.1 : https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/
1.2.16.1027/RedshiftJDBC41-no-awssdk-1.2.16.1027.jar.
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc41.Driver.• Pilote compatible avec JDBC 4.0 : https://s3.amazonaws.com/redshift-downloads/drivers/
jbdc/1.2.16.1027/RedshiftJDBC4-no-awssdk-1.2.16.1027.jar.
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc4.Driver.
Puis téléchargez et consultez le Contrat de licence du pilote JDBC Amazon Redshift.
Si votre outil requiert une version antérieure spécifique d'un pilote, consultez Versions antérieures du piloteJDBC (p. 213).
Si vous avez besoin de distribuer ces pilotes à vos clients ou à des tiers, envoyez un e-mail à l'adressesuivante [email protected] pour prévoir une licence adaptée.
Obtenir l'URL JDBCAvant de pouvoir vous connecter à votre cluster Amazon Redshift depuis un outil client SQL, vous devezconnaître l'URL JDBC de votre cluster. L'URL JDBC a le format suivant :
jdbc:redshift://endpoint:port/databaseNote
Une URL JDBC spécifiée avec l'ancien format de jdbc:postgresql://endpoint:port/databasecontinuera de fonctionner.
Champ Value
jdbc Protocole de la connexion.
redshift Sous-protocole qui spécifie d'utiliser le pilote Amazon Redshift pour la connexion à labase de données.
endpoint Point de terminaison du cluster Amazon Redshift.
port Numéro du port que vous avez spécifié lorsque vous avez lancé le cluster. Si vousavez un pare-feu, vérifiez que ce port est ouvert pour que vous l'utilisiez.
database Base de données que vous avez créée pour votre cluster.
Voici un exemple d'URL JDBC : jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev
Pour obtenir votre URL JDBC
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. En haut à droite, sélectionnez la région dans laquelle vous avez créé votre cluster.
Si vous avez suivi les instructions du manuel Amazon Redshift Mise en route, sélectionnez USA Ouest(Oregon).
3. Dans le volet de navigation de gauche, cliquez sur Clusters, puis cliquez sur votre cluster.
Version de l'API 2012-12-01204

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Si vous avez suivi les instructions du manuel Amazon Redshift Mise en route, cliquez surexamplecluster.
4. Sur l'onglet Configuration, sous Propriétés de la base de données du cluster, copiez l'URL JDBC ducluster.
Si l'ordinateur client ne peut pas se connecter à la base de données, il se peut que vous deviez résoudred'éventuels problèmes. Pour plus d'informations, consultez Résolution des problèmes de connexion dansAmazon Redshift (p. 253).
Options de configuration du pilote JDBCPour contrôler le comportement du pilote JDBC Amazon Redshift, vous pouvez ajouter les options deconfiguration décrites dans le tableau suivant à l'URL JDBC. Par exemple, l'URL JDBC suivante seconnecte à votre cluster à l'aide de SSL (Secure Socket Layer), de l'utilisateur (UID) et du mot de passe(PWD).
jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439/dev?ssl=true&UID=your_username&PWD=your_password
Pour plus d'informations sur les options SSL, consultez Connexion à l'aide du protocole SSL (p. 238).
Option JDBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
AccessKeyID Non null ID de clé d'accès pour le rôle IAM ou l'utilisateur IAMconfiguré pour l'authentification de base de donnéesIAM. L'option AccessKeyID fait partie d'un ensembled'options utilisées pour configurer l'authentificationde base de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC visant à fournir des
Version de l'API 2012-12-01205
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Option JDBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
informations d'identification IAM (p. 175). AccessKeyIDet SecretAccessKey doivent être spécifiés ensemble.
AuthMech Non DISABLE Obsolète. Par défaut, les pilotes Amazon Redshiftutilisent SSL. Utilisez à la place ssl et sslmode.
AutoCreate Non false Spécifiez true pour créer un utilisateur de la basede données avec le nom spécifié pour DbUsers'il n'en existe pas. L'option AutoCreate fait partied'un ensemble d'options utilisées pour configurerl'authentification de base de données IAM. Pour plusd'informations, consultez Options JDBC et ODBC pourla création d'informations d'identification de l'utilisateurde base de données (p. 178).
BlockingRowsMode Non 0 USD Nombre de lignes à conserver en mémoire. Une foisqu'une ligne est ignorée, une autre ligne est chargée àsa place.
DbGroups Non null Liste séparée par des virgules des noms des groupesde bases de données existants que l'utilisateurde la base de données rejoint pour la session encours. L'option DbGroups fait partie d'un ensembled'options utilisées pour configurer l'authentificationde base de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC pour la créationd'informations d'identification de l'utilisateur de basede données (p. 178).
DbUser Non null Nom d'un utilisateur de la base de données.L'option DbUser fait partie d'un ensemble d'optionsutilisées pour configurer l'authentification debase de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC pour la créationd'informations d'identification de l'utilisateur de basede données (p. 178).
DisableIsValidQuery Non false Par défaut, DisableIsValidQuery est défini sur False,ce qui permet à la méthode Java Connection.isValid()de détecter à quel moment le pilote JDBC n'a plusde connexion valide à la base de donnée, même si laconnexion à la base de données a été interrompuede manière inattendue. Avec les pilotes JDBCAmazon Redshift JDBC antérieurs à la version 1.2.1,isValid() n'a pas détecté de façon fiable qu'uneconnexion valide avait été perdue. Pour restaurer lecomportement observé avec des pilotes antérieurs,définissez DisableIsValidQuery sur true.
Version de l'API 2012-12-01206
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Option JDBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
DSILogLevel Non 0 USD Activez la journalisation et spécifiez la quantitéde détails inclus dans les fichiers journaux. Letableau suivant répertorie les niveaux de détails de lajournalisation.
• 0 – Désactiver toute la journalisation.• 1 – Consigner les événements d'erreur grave qui
entraînent l'abandon du pilote.• 2 – Consigner les événements d'erreur qui peuvent
autoriser le pilote de continuer de s'exécuter.• 3 – Consigner les situations potentiellement
dangereuses.• 4 – Consigner les informations générales qui
décrivent la progression du pilote.• 5 – Consigner les informations détaillées qui sont
utiles pour le débogage du pilote.• 6 – Consigner toutes les activités du pilote.
FilterLevel Non NOTICE Niveau de gravité minimal d'un message que le clienttraite. Les valeurs suivantes sont possibles, dansl'ordre de la gravité la plus basse à la gravité la plusélevée :
• DEBUG• INFO• NOTICE• WARNING• LOG• ERROR
loginTimeout Oui 0 USD Nombre de secondes à attendre avant l'expirationlors de la connexion au serveur. Si l'établissementde la connexion dépasse ce seuil, la connexion estabandonnée.
Lorsque cette propriété est définie sur la valeur pardéfaut de 0, les connexions n'ont pas d'expiration.
Version de l'API 2012-12-01207
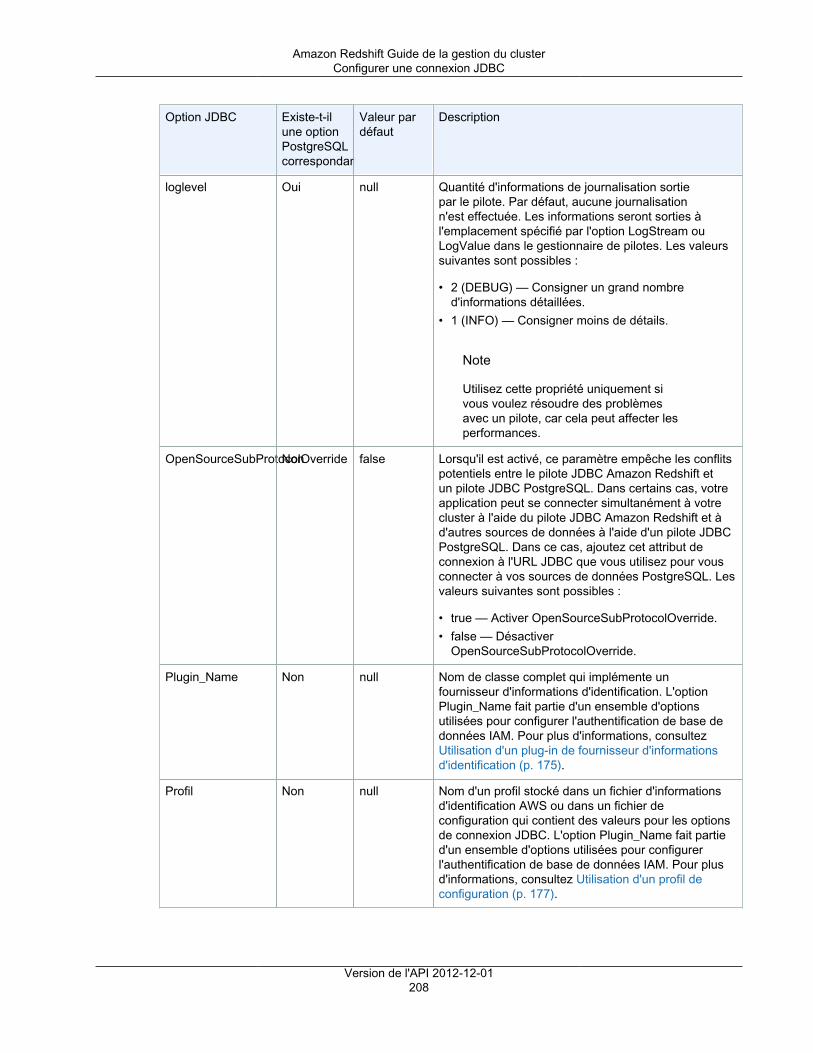
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Option JDBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
loglevel Oui null Quantité d'informations de journalisation sortiepar le pilote. Par défaut, aucune journalisationn'est effectuée. Les informations seront sorties àl'emplacement spécifié par l'option LogStream ouLogValue dans le gestionnaire de pilotes. Les valeurssuivantes sont possibles :
• 2 (DEBUG) — Consigner un grand nombred'informations détaillées.
• 1 (INFO) — Consigner moins de détails.
Note
Utilisez cette propriété uniquement sivous voulez résoudre des problèmesavec un pilote, car cela peut affecter lesperformances.
OpenSourceSubProtocolOverrideNon false Lorsqu'il est activé, ce paramètre empêche les conflitspotentiels entre le pilote JDBC Amazon Redshift etun pilote JDBC PostgreSQL. Dans certains cas, votreapplication peut se connecter simultanément à votrecluster à l'aide du pilote JDBC Amazon Redshift et àd'autres sources de données à l'aide d'un pilote JDBCPostgreSQL. Dans ce cas, ajoutez cet attribut deconnexion à l'URL JDBC que vous utilisez pour vousconnecter à vos sources de données PostgreSQL. Lesvaleurs suivantes sont possibles :
• true — Activer OpenSourceSubProtocolOverride.• false — Désactiver
OpenSourceSubProtocolOverride.
Plugin_Name Non null Nom de classe complet qui implémente unfournisseur d'informations d'identification. L'optionPlugin_Name fait partie d'un ensemble d'optionsutilisées pour configurer l'authentification de base dedonnées IAM. Pour plus d'informations, consultezUtilisation d'un plug-in de fournisseur d'informationsd'identification (p. 175).
Profil Non null Nom d'un profil stocké dans un fichier d'informationsd'identification AWS ou dans un fichier deconfiguration qui contient des valeurs pour les optionsde connexion JDBC. L'option Plugin_Name fait partied'un ensemble d'options utilisées pour configurerl'authentification de base de données IAM. Pour plusd'informations, consultez Utilisation d'un profil deconfiguration (p. 177).
Version de l'API 2012-12-01208
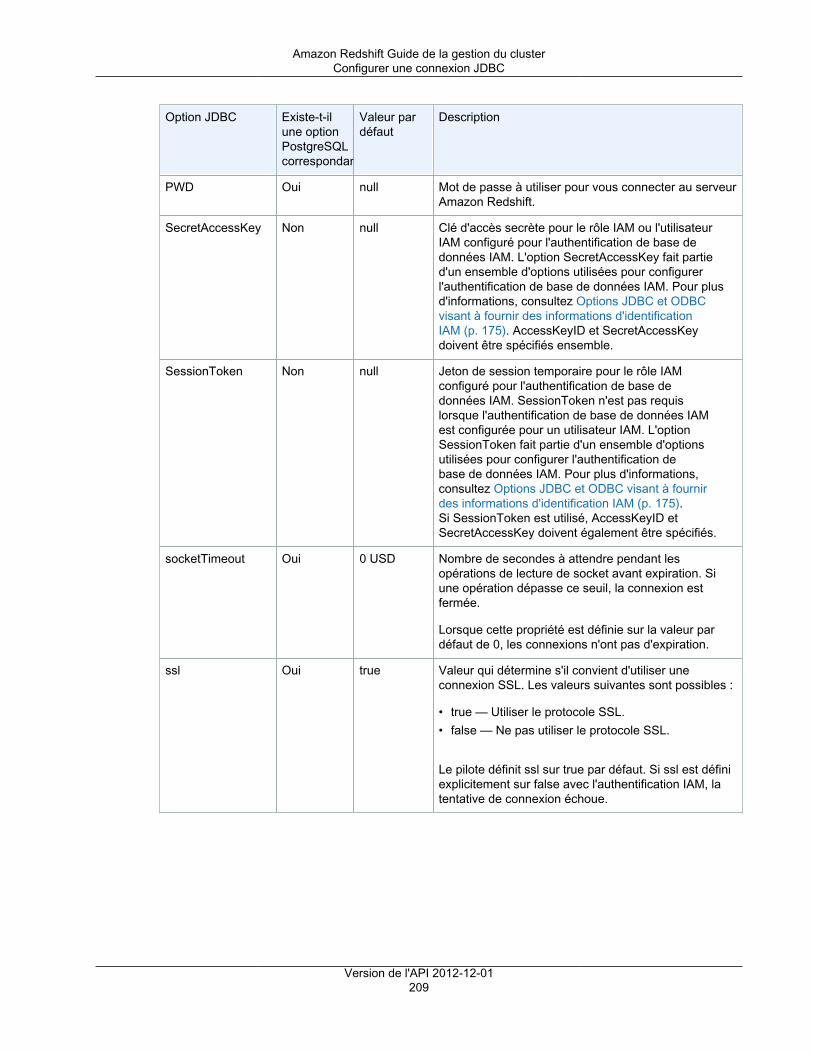
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Option JDBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
PWD Oui null Mot de passe à utiliser pour vous connecter au serveurAmazon Redshift.
SecretAccessKey Non null Clé d'accès secrète pour le rôle IAM ou l'utilisateurIAM configuré pour l'authentification de base dedonnées IAM. L'option SecretAccessKey fait partied'un ensemble d'options utilisées pour configurerl'authentification de base de données IAM. Pour plusd'informations, consultez Options JDBC et ODBCvisant à fournir des informations d'identificationIAM (p. 175). AccessKeyID et SecretAccessKeydoivent être spécifiés ensemble.
SessionToken Non null Jeton de session temporaire pour le rôle IAMconfiguré pour l'authentification de base dedonnées IAM. SessionToken n'est pas requislorsque l'authentification de base de données IAMest configurée pour un utilisateur IAM. L'optionSessionToken fait partie d'un ensemble d'optionsutilisées pour configurer l'authentification debase de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC visant à fournirdes informations d'identification IAM (p. 175).Si SessionToken est utilisé, AccessKeyID etSecretAccessKey doivent également être spécifiés.
socketTimeout Oui 0 USD Nombre de secondes à attendre pendant lesopérations de lecture de socket avant expiration. Siune opération dépasse ce seuil, la connexion estfermée.
Lorsque cette propriété est définie sur la valeur pardéfaut de 0, les connexions n'ont pas d'expiration.
ssl Oui true Valeur qui détermine s'il convient d'utiliser uneconnexion SSL. Les valeurs suivantes sont possibles :
• true — Utiliser le protocole SSL.• false — Ne pas utiliser le protocole SSL.
Le pilote définit ssl sur true par défaut. Si ssl est définiexplicitement sur false avec l'authentification IAM, latentative de connexion échoue.
Version de l'API 2012-12-01209
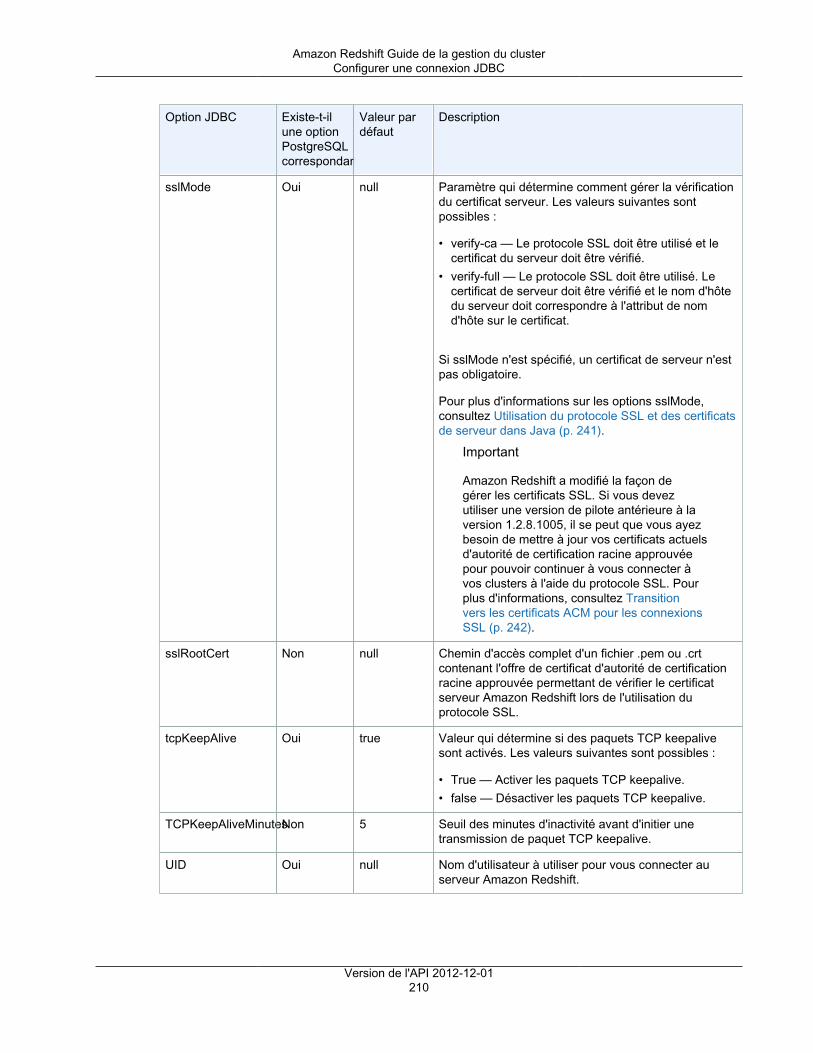
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Option JDBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
sslMode Oui null Paramètre qui détermine comment gérer la vérificationdu certificat serveur. Les valeurs suivantes sontpossibles :
• verify-ca — Le protocole SSL doit être utilisé et lecertificat du serveur doit être vérifié.
• verify-full — Le protocole SSL doit être utilisé. Lecertificat de serveur doit être vérifié et le nom d'hôtedu serveur doit correspondre à l'attribut de nomd'hôte sur le certificat.
Si sslMode n'est spécifié, un certificat de serveur n'estpas obligatoire.
Pour plus d'informations sur les options sslMode,consultez Utilisation du protocole SSL et des certificatsde serveur dans Java (p. 241).
Important
Amazon Redshift a modifié la façon degérer les certificats SSL. Si vous devezutiliser une version de pilote antérieure à laversion 1.2.8.1005, il se peut que vous ayezbesoin de mettre à jour vos certificats actuelsd'autorité de certification racine approuvéepour pouvoir continuer à vous connecter àvos clusters à l'aide du protocole SSL. Pourplus d'informations, consultez Transitionvers les certificats ACM pour les connexionsSSL (p. 242).
sslRootCert Non null Chemin d'accès complet d'un fichier .pem ou .crtcontenant l'offre de certificat d'autorité de certificationracine approuvée permettant de vérifier le certificatserveur Amazon Redshift lors de l'utilisation duprotocole SSL.
tcpKeepAlive Oui true Valeur qui détermine si des paquets TCP keepalivesont activés. Les valeurs suivantes sont possibles :
• True — Activer les paquets TCP keepalive.• false — Désactiver les paquets TCP keepalive.
TCPKeepAliveMinutesNon 5 Seuil des minutes d'inactivité avant d'initier unetransmission de paquet TCP keepalive.
UID Oui null Nom d'utilisateur à utiliser pour vous connecter auserveur Amazon Redshift.
Version de l'API 2012-12-01210

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
Configuration d'une connexion JDBC avec Apache MavenApache Maven est un outil de gestion et de compréhension de projets logiciels. Le Kit AWS SDK pour Javaprend en charge les projets Apache Maven. Pour plus d'informations, consultez Utilisation du kit SDK avecApache Maven.
Si vous utilisez Apache Maven, vous pouvez configurer et créer vos propres projets afin d'utiliser un piloteJDBC Amazon Redshift pour vous connecter à votre cluster Amazon Redshift. Pour ce faire, vous devezajouter le pilote JDBC en tant que dépendance dans le fichier pom.xml de votre projet. Suivez les étapesdécrites dans cette section si vous utilisez Maven pour créer votre projet et que vous souhaitez faire appelà une connexion JDBC.
Configuration du pilote JDBC en tant que dépendance Maven
Pour configurer le pilote JDBC en tant que dépendance Maven
1. Ajoutez le référentiel suivant dans la section de référentiels de votre fichier pom.xml.Note
L'URL dans le code suivant renvoie une erreur si elle est utilisée dans un navigateur. L'URLest destinée à être utilisée uniquement dans le contexte d'un projet Maven.
<repositories> <repository> <id>redshift</id> <url>http://redshift-maven-repository.s3-website-us-east-1.amazonaws.com/release</url> </repository></repositories>
Pour vous connecter à l'aide de SSL, ajoutez le référentiel suivant à votre fichier pom.xml.
<repositories> <repository> <id>redshift</id> <url>https://s3.amazonaws.com/redshift-maven-repository/release</url> </repository></repositories>
2. Déclarez la version du pilote à utiliser dans la section des dépendances de votre fichier pom.xml.
Amazon Redshift propose des pilotes pour les outils qui sont compatibles avec l'API JDBC 4.2, l'APIJDBC 4.1 ou l'API JDBC 4.0. Pour plus d'informations sur les fonctionnalités prises en charge par cespilotes, consultez Notes de mise à jour du pilote JDBC Amazon Redshift.
Ajoutez une dépendance pour le pilote à partir de la liste suivante.Note
Pour les versions 1.2.1.1001 et ultérieures, vous pouvez utiliser le nom de la classede pilote générique com.amazon.redshift.jdbc.Driver ou le nom de classepropre à la version mentionné avec le pilote dans la liste suivante, par exemplecom.amazon.redshift.jdbc42.Driver. Pour les versions antérieures à laversion 1.2.1001, seuls les noms de classe propres à la version sont pris à charge.
• Pilote compatible avec JDBC 4.2 :
<dependency> <groupId>com.amazon.redshift</groupId>
Version de l'API 2012-12-01211

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
<artifactId>redshift-jdbc42</artifactId> <version>1.2.10.1009</version></dependency>
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc42.Driver.• Pilote compatible avec JDBC 4.1 :
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.2.10.1009</version></dependency>
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc41.Driver.• Pilote compatible avec JDBC 4.0 :
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.2.10.1009</version></dependency>
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc4.Driver.3. Téléchargez et consultez le Contrat de licence du pilote JDBC Amazon Redshift.
Les pilotes JDBC Amazon Redshift standard incluent le kit SDK AWS requis pour utiliser l'authentificationde base de données IAM. Nous vous recommandons d'utiliser les pilotes standard, sauf si la taille desfichiers de pilote est un problème pour votre application. Si vous avez besoin de fichiers de pilote pluspetits et que vous n'utilisez pas l'authentification de base de données IAM, ou si vous disposez déjà d'un kitSDK AWS pour Java 1.11. 118 ou version ultérieure dans votre chemin de classe Java, puis ajoutez unedépendance pour le pilote depuis la liste suivante.
• Pilote compatible avec JDBC 4.2 :
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc42-no-awssdk</artifactId> <version>1.2.10.1009</version></dependency>
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc42.Driver.• Pilote compatible avec JDBC 4.1 :
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41-no-awssdk</artifactId> <version>1.2.10.1009</version></dependency>
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc41.Driver.• Pilote compatible avec JDBC 4.0 :
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4-no-awssdk</artifactId>
Version de l'API 2012-12-01212

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
<version>1.2.10.1009</version></dependency>
Le nom de la classe de ce pilote est com.amazon.redshift.jdbc4.Driver.
Les pilotes Amazon Redshift Maven sans kits SDK incluent les dépendances facultatives suivantes quevous pouvez inclure dans votre projet si nécessaire.
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-core</artifactId> <version>1.11.118</version> <scope>runtime</scope> <optional>true</optional></dependency> <dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-redshift</artifactId> <version>1.11.118</version> <scope>runtime</scope> <optional>true</optional></dependency><dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-java-sdk-sts</artifactId> <version>1.11.118</version> <scope>runtime</scope> <optional>true</optional></dependency>
Si votre outil requiert une version antérieure spécifique d'un pilote, consultez Versions antérieures du piloteJDBC avec Maven (p. 215).
Si vous avez besoin de distribuer ces pilotes à vos clients ou à des tiers, envoyez un e-mail à l'adressesuivante [email protected] pour prévoir une licence adaptée.
Mise à niveau du pilote vers la dernière versionPour mettre à niveau ou modifier le pilote JDBC Amazon Redshift avec la dernière version, modifiez lasection de version de la dépendance en indiquant la dernière version du pilote, puis nettoyez votre projetavec le plug-in de nettoyage Maven, comme illustré ci-après.
mvn clean
Versions antérieures du pilote JDBCTéléchargez une version précédente de du pilote JDBC Amazon Redshift uniquement si votre outilnécessite une version spécifique du pilote. Pour plus d'informations sur les fonctionnalités prises en chargedans les versions antérieures des pilotes, téléchargez Notes de mise à jour du pilote JDBC AmazonRedshift.
Pour l'authentification à l'aide des informations d'identification AWS Identity and Access Management (IAM)ou des informations d'identification émises par un fournisseur d'identité (IdP), utilisez les pilotes JDBCAmazon Redshift version 1.2.8.1005 ou ultérieure.
Important
Amazon Redshift a modifié la façon de gérer les certificats SSL. Si vous devez utiliser une versionde pilote antérieure à la version 1.2.8.1005, il se peut que vous ayez besoin de mettre à jour
Version de l'API 2012-12-01213

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
vos certificats actuels d'autorité de certification racine approuvée pour pouvoir continuer à vousconnecter à vos clusters à l'aide du protocole SSL. Pour plus d'informations, consultez Transitionvers les certificats ACM pour les connexions SSL (p. 242).
Les pilotes suivants sont des pilotes antérieurs compatibles avec JDBC 4.2 :
• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.15.1025/RedshiftJDBC42-1.2.15.1025.jar• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.15.1025/RedshiftJDBC42-no-
awssdk-1.2.15.1025.jar• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1017/RedshiftJDBC42-1.2.12.1017.jar• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1017/RedshiftJDBC42-no-
awssdk-1.2.12.1017.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-1.2.10.1009.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-no-awssdk-1.2.10.1009.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-1.2.8.1005.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-no-awssdk-1.2.8.1005.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-1.2.7.1003.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-no-awssdk-1.2.7.1003.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-1.2.1.1001.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-1.1.17.1017.jar.
Les pilotes suivants sont des pilotes antérieurs compatibles avec JDBC 4.1 :
• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1017/1.2.15.1025/RedshiftJDBC41-1.2.15.1025.jar.
• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.15.1025/RedshiftJDBC41-no-awssdk-1.2.15.1025.jar.
• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1017/RedshiftJDBC41-1.2.12.1017.jar• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1017/RedshiftJDBC41-no-
awssdk-1.2.12.1017.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.2.10.1009.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-no-awssdk-1.2.10.1009.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.2.8.1005.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-no-awssdk-1.2.8.1005.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.2.7.1003.jar.
https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-no-awssdk-1.2.7.1003.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.2.1.1001.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.17.1017.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.10.1010.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.9.1009.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.7.1007.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.6.1006.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.2.0002.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.1.0001.jar
Version de l'API 2012-12-01214
Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC41-1.1.0.0000.jar
Les pilotes suivants sont des pilotes antérieurs compatibles avec JDBC 4.0 :
• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.15.1025/RedshiftJDBC4-1.2.15.1025.jar• https://s3.amazonaws.com/redshift-downloads/drivers/jbdc/1.2.15.1025/RedshiftJDBC4-no-
awssdk-1.2.15.1025.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.12.1017/RedshiftJDBC4-1.2.12.1017.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/jbdc/1.2.12.1017/RedshiftJDBC4-no-
awssdk-1.2.12.1017.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.2.10.1009.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-no-awssdk-1.2.10.1009.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.2.8.1005.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-no-awssdk-1.2.8.1005.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.2.7.1003.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-no-awssdk-1.2.7.1003.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.2.1.1001.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.17.1017.jar.• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.10.1010.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.9.1009.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.7.1007.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.6.1006.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.2.0002.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.1.0001.jar• https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC4-1.1.0.0000.jar
Versions antérieures du pilote JDBC avec Maven
Ajoutez une version précédente du pilote JDBC Amazon Redshift à votre projet uniquement si votre outilnécessite une version spécifique du pilote. Pour plus d'informations sur les fonctionnalités prises en chargedans les versions antérieures des pilotes, téléchargez Notes de mise à jour du pilote JDBC AmazonRedshift.
Les pilotes suivants sont des pilotes antérieurs compatibles avec JDBC 4.2 :
• JDBC42-1.2.8.1005
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc42</artifactId> <version>1.2.8.1005</version></dependency>
• JDBC42-1.2.8.1005 sans kit SDK
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc42-no-awssdk</artifactId> <version>1.2.8.1005</version>
Version de l'API 2012-12-01215

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
</dependency>
• JDBC42-1.2.7.1003
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc42</artifactId> <version>1.2.7.1003</version></dependency>
• JDBC42-1.2.1.1001
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc42</artifactId> <version>1.2.1.1001</version></dependency>
• JDBC42-1.1.17.1017
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc42</artifactId> <version>1.1.17.1017</version></dependency>
Les pilotes suivants sont des pilotes antérieurs compatibles avec JDBC 4.1 :
• JDBC41-1.2.8.1005
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.2.8.1005</version></dependency>
• JDBC41-1.2.8.1005 sans kit SDK
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41-no-awssdk</artifactId> <version>1.2.8.1005</version></dependency>
• JDBC41-1.2.7.1003
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.2.7.1003</version></dependency>
• JDBC41-1.2.1.1001
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.2.1.1001</version></dependency>
Version de l'API 2012-12-01216

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
• JDBC41-1.1.17.1017
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.17.1017</version></dependency>
• JDBC41-1.1.10.1010
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.10.1010</version></dependency>
• JDBC41-1.1.9.1009
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.9.1009</version></dependency>
• JDBC41-1.1.7.1007
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.7.1007</version></dependency>
• JDBC41-1.1.6.1006
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.6.1006</version></dependency>
• JDBC41-1.1.2.0002
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.2.0002</version></dependency>
• JDBC41-1.1.1.0001
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc41</artifactId> <version>1.1.1.0001</version></dependency>
• JDBC41-1.1.0.0000
<dependency> <groupId>com.amazon.redshift</groupId>
Version de l'API 2012-12-01217

Amazon Redshift Guide de la gestion du clusterConfigurer une connexion JDBC
<artifactId>redshift-jdbc41</artifactId> <version>1.1.0.0000</version></dependency>
Les pilotes suivants sont des pilotes antérieurs compatibles avec JDBC 4.0 :
• JDBC4-1.2.8.1005
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.2.8.1005</version></dependency>
• JDBC4-1.2.8.1005 sans kit SDK
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4-no-awssdk</artifactId> <version>1.2.8.1005</version></dependency>
• JDBC4-1.2.7.1003
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.2.7.1003</version></dependency>
• JDBC4-1.2.1.1001
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.2.1.1001</version></dependency>
• JDBC4-1.1.17.1017
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.17.1017</version></dependency>
• JDBC4-1.1.10.1010
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.10.1010</version></dependency>
• JDBC4-1.1.9.1009
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId>
Version de l'API 2012-12-01218

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
<version>1.1.9.1009</version></dependency>
• JDBC4-1.1.7.1007
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.7.1007</version></dependency>
• JDBC4-1.1.6.1006
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.6.1006</version></dependency>
• JDBC4-1.1.2.0002
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.2.0002</version></dependency>
• JDBC4-1.1.1.0001
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.1.0001</version></dependency>
• JDBC4-1.1.0.0000
<dependency> <groupId>com.amazon.redshift</groupId> <artifactId>redshift-jdbc4</artifactId> <version>1.1.0.0000</version></dependency>
Configurer la connexion ODBCVous pouvez utiliser une connexion ODBC pour vous connecter à votre cluster Amazon Redshift à partirde nombreux outils clients SQL tiers et applications. Pour ce faire, vous devez configurer la connexion survotre ordinateur client ou instance Amazon EC2. Si votre outil client prend en charge JDBC, vous pouvezchoisir d'utiliser ce type de connexion plutôt qu'ODBC en raison de la simplicité de configuration offerte parJDBC. Toutefois, si votre outil client ne prend pas en charge JDBC, suivez les étapes de cette section pourconfigurer une connexion ODBC.
Amazon Redshift fournit des pilotes ODBC pour les systèmes d'exploitation Linux, Windows et Mac OSX. Avant d'installer un pilote ODBC, vous devez déterminer si votre outil client SQL est en 32 bits ou en64 bits. Vous devez installer le pilote ODBC correspondant aux critères de l'outil client SQL ; sinon, laconnexion ne fonctionne pas. Si vous utilisez plusieurs outils clients SQL sur le même ordinateur ou lamême instance, assurez-vous de télécharger les pilotes appropriés. Vous devrez peut-être installer lespilotes 32 bits et 64 bits, si les outils diffèrent dans leur architecture système.
Version de l'API 2012-12-01219
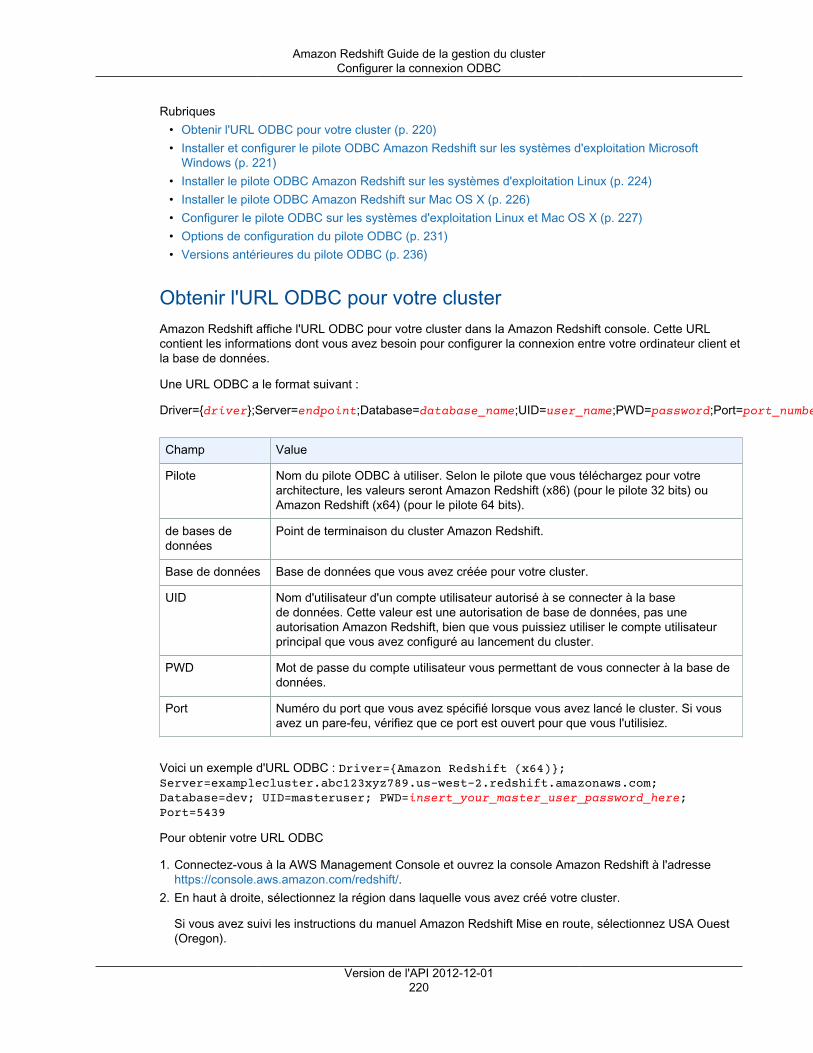
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Rubriques• Obtenir l'URL ODBC pour votre cluster (p. 220)• Installer et configurer le pilote ODBC Amazon Redshift sur les systèmes d'exploitation Microsoft
Windows (p. 221)• Installer le pilote ODBC Amazon Redshift sur les systèmes d'exploitation Linux (p. 224)• Installer le pilote ODBC Amazon Redshift sur Mac OS X (p. 226)• Configurer le pilote ODBC sur les systèmes d'exploitation Linux et Mac OS X (p. 227)• Options de configuration du pilote ODBC (p. 231)• Versions antérieures du pilote ODBC (p. 236)
Obtenir l'URL ODBC pour votre clusterAmazon Redshift affiche l'URL ODBC pour votre cluster dans la Amazon Redshift console. Cette URLcontient les informations dont vous avez besoin pour configurer la connexion entre votre ordinateur client etla base de données.
Une URL ODBC a le format suivant :
Driver={driver};Server=endpoint;Database=database_name;UID=user_name;PWD=password;Port=port_number
Champ Value
Pilote Nom du pilote ODBC à utiliser. Selon le pilote que vous téléchargez pour votrearchitecture, les valeurs seront Amazon Redshift (x86) (pour le pilote 32 bits) ouAmazon Redshift (x64) (pour le pilote 64 bits).
de bases dedonnées
Point de terminaison du cluster Amazon Redshift.
Base de données Base de données que vous avez créée pour votre cluster.
UID Nom d'utilisateur d'un compte utilisateur autorisé à se connecter à la basede données. Cette valeur est une autorisation de base de données, pas uneautorisation Amazon Redshift, bien que vous puissiez utiliser le compte utilisateurprincipal que vous avez configuré au lancement du cluster.
PWD Mot de passe du compte utilisateur vous permettant de vous connecter à la base dedonnées.
Port Numéro du port que vous avez spécifié lorsque vous avez lancé le cluster. Si vousavez un pare-feu, vérifiez que ce port est ouvert pour que vous l'utilisiez.
Voici un exemple d'URL ODBC : Driver={Amazon Redshift (x64)};Server=examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com;Database=dev; UID=masteruser; PWD=insert_your_master_user_password_here;Port=5439
Pour obtenir votre URL ODBC
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. En haut à droite, sélectionnez la région dans laquelle vous avez créé votre cluster.
Si vous avez suivi les instructions du manuel Amazon Redshift Mise en route, sélectionnez USA Ouest(Oregon).
Version de l'API 2012-12-01220

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
3. Dans le volet de navigation de gauche, cliquez sur Clusters, puis cliquez sur votre cluster.
Si vous avez suivi les instructions du manuel Amazon Redshift Mise en route, cliquez surexamplecluster.
4. Sur l'onglet Configuration, sous Propriétés de la base de données du cluster, copiez l'URL ODBC ducluster.
Installer et configurer le pilote ODBC Amazon Redshift sur lessystèmes d'exploitation Microsoft WindowsExigences en matière de système
Vous installez le pilote ODBC Amazon Redshift sur les ordinateurs clients ayant accès à un entrepôtde données Amazon Redshift. Chaque ordinateur sur lequel vous installez le pilote doit répondre auxexigences minimales suivantes :
• Système d'exploitation Microsoft Windows Vista ou ultérieur• 55 Mo d'espace disque disponible• Privilèges d'administrateur sur l'ordinateur client• Compte d'utilisateur ou d'utilisateur principal Amazon Redshift pour se connecter à la base de données
Installation du pilote Amazon Redshift sur les systèmes d'exploitation Windows
Suivez les étapes de cette section pour télécharger les pilotes ODBC Amazon Redshift pour les systèmesd'exploitation Microsoft Windows. Vous devez utiliser uniquement un pilote autre que ceux qui précèdentsi vous exécutez une application tierce qui est certifiée pour une utilisation avec Amazon Redshift et quinécessite un pilote spécifique pour celle-ci.
Pour installer le pilote ODBC
1. Téléchargez l'un des pilotes suivants, en fonction de l'architecture système de votre outil client SQL oude votre application :
Version de l'API 2012-12-01221

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
• 32 bits : https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.2.1010/AmazonRedshiftODBC32-1.4.2.1010.msi
Le nom de ce pilote est Amazon Redshift (x86).• 64 bits : https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.2.1010/
AmazonRedshiftODBC64-1.4.2.1010.msi
Le nom de ce pilote est Amazon Redshift (x64).
Note
Téléchargez le package MSI qui correspond à l'architecture système de votre application ououtil client SQL. Par exemple, si votre outil client SQL est en 64 bits, installez le pilote 64 bits.
Puis téléchargez et consultez le Contrat de licence du pilote ODBC Amazon Redshift. Si vous avezbesoin de distribuer ces pilotes à vos clients ou à des tiers, envoyez un e-mail à l'adresse [email protected] pour prévoir une licence adaptée.
2. Double-cliquez sur le fichier .msi et suivez les étapes de l'assistant pour installer le pilote.
Création d'une entrée du nom de la source de données (DSN) système pour uneconnexion ODBC sur Microsoft Windows
Après avoir téléchargé et installé le pilote ODBC, vous devez ajouter une entrée du nom de la sourcede données (DSN) à l'ordinateur client ou à l'instance Amazon EC2. Les outils clients SQL utilisent cettesource de données pour se connecter à la base de données Amazon Redshift.
Note
Pour l'authentification à l'aide des informations d'identification AWS Identity and AccessManagement (IAM) ou des informations d'identification émises par un fournisseur d'identité (IdP),des étapes supplémentaires sont requises. Pour plus d'informations, consultez Configurer uneconnexion JDBC ou ODBC pour utiliser des informations d'identification IAM (p. 168).
Pour créer une entrée DSN système
1. Dans le menu Démarrer, dans votre liste de programmes, recherchez le ou les dossiers de pilotes.
Note
Si vous avez installé le pilote 32 bits, le dossier est nommé Pilote ODBC Amazon Redshift(32 bits). Si vous avez installé le pilote 64 bits, le dossier est nommé Pilote ODBC AmazonRedshift (64 bits). Si vous avez installé les deux pilotes, vous aurez un dossier pour chacund'eux.
2. Cliquez sur Administrateur ODBC, puis entrez vos informations d'identification d'administrateur, si vousêtes invité à le faire.
3. Sélectionnez l'onglet Système DSN si vous souhaitez configurer le pilote pour tous les utilisateurs surl'ordinateur ou l'onglet Utilisateur DSN si vous souhaitez configurer le pilote correspondant à votrecompte utilisateur uniquement.
4. Cliquez sur Ajouter. La fenêtre Créer une nouvelle source de données s'ouvre.5. Sélectionnez le pilote ODBC Amazon Redshift, puis cliquez sur Terminer. La fenêtre Amazon Redshift
ODBC Driver DSN Setup s'ouvre.6. Sous Paramètres de connexion, entrez les informations suivantes :
Nom de la source de données
Entrez un nom pour la source de données. Vous pouvez utiliser n'importe quel nom de votre choixpour identifier la source de données ultérieurement, lorsque vous créez la connexion au cluster. Par
Version de l'API 2012-12-01222

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
exemple, si vous avez suivi les instructions du manuel Amazon Redshift Mise en route, vous pouvezentrer exampleclusterdsn pour vous souvenir plus facilement du cluster que vous allez associer àcette DSN.
de bases de données
Spécifiez le point de terminaison de votre cluster Amazon Redshift. Vous pouvez trouver cesinformations dans la Amazon Redshift console sur la page des détails du cluster. Pour plusd'informations, consultez Configuration de connexions dans Amazon Redshift (p. 201).
Port
Entrez le numéro de port utilisé par la base de données. Par défaut, Amazon Redshift utilise leport 5439, mais vous devez utiliser le port que le cluster a été configuré pour utiliser lors de sonlancement.
Base de données
Tapez le nom de la base de données Amazon Redshift. Si vous avez lancé votre cluster sans spécifierde nom de base de données, entrez dev ; sinon, utilisez le nom que vous avez choisi pendant leprocessus de lancement. Si vous avez suivi les instructions du manuel Amazon Redshift Mise en route,entrez dev.
7. Sous Informations d'identification, entrez les informations suivantes :
Utilisateur
Entrez le nom d'utilisateur du compte utilisateur de la base de données que vous souhaitez utiliser pouraccéder à la base de données. Si vous avez suivi les instructions du manuel Amazon Redshift Mise enroute, entrez masteruser.
Mot de passe :
Entrez le mot de passe qui correspond au compte utilisateur de la base de données.8. Sous Paramètres SSL, spécifiez une valeur pour les éléments suivants :
Authentification SSL
Sélectionnez un mode de traitement SSL (Secure Sockets Layer). Dans un environnement de test, vouspouvez utiliser prefer, mais pour les environnements de production et lorsqu'un échange de donnéessécurisé est nécessaire, utilisez verify-ca ou verify-full. Pour plus d'informations sur l'utilisationde SSL, consultez Connexion à l'aide du protocole SSL (p. 238).
9. Sous Options supplémentaires, sélectionnez l'une des options suivantes pour spécifier commentrenvoyer les résultats de la requête à votre outil client SQL ou à votre application :• Single Row Mode. Sélectionnez cette option si vous souhaitez que les résultats de la requête soient
renvoyés une ligne à la fois à l'outil client SQL ou à l'application. Utilisez cette option si vous prévoyezd'exécuter une requête sur des jeux de résultats volumineux et que vous ne voulez pas le résultatcomplet dans la mémoire. La désactivation de cette option améliore les performances, mais cela peutaugmenter le nombre d'erreurs de mémoire insuffisante.
• Use Declare/Fetch. Sélectionnez cette option si vous souhaitez que les résultats de la requête soientrenvoyés à l'outil client SQL ou à l'application dans un certain nombre de lignes à la fois. Spécifiez lenombre de lignes de Cache Size.
• Use Multiple Statements. Sélectionnez cette option pour renvoyer les résultats en fonction deplusieurs instructions SQL dans une requête.
• Retrieve Entire Result Into Memory. Sélectionnez cette option si vous souhaitez que les résultats dela requête soient tous renvoyés à la fois à l'outil client SQL ou à l'application. La valeur par défaut estActivé.
10.Dans Logging Options, spécifiez des valeurs pour les éléments suivants :Version de l'API 2012-12-01
223

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
• Log Level. Sélectionnez une option pour spécifier s'il convient d'activer la journalisation et le niveau dedétail que vous souhaitez capturer dans les journaux.
Important
Vous devez uniquement activer la journalisation lorsque vous avez besoin de capturer desinformations sur un problème. La journalisation diminue performances et peut consommerune grande quantité d'espace disque.
• Log Path. Spécifiez le chemin d'accès complet au dossier dans lequel vous souhaitez enregistrer lesfichiers journaux.
Puis cliquez sur OK.11.Dans Data Type Options, spécifiez des valeurs pour les éléments suivants :
• Use Unicode. Sélectionnez cette option pour activer la prise en charge des caractères Unicode. Lavaleur par défaut est Activé.
• Show Boolean Column As String. Sélectionnez cette option si vous souhaitez que les valeursbooléennes soient affichées sous forme de valeurs de chaîne et non de bits. Si vous activez cetteoption, "1" et "0" s'affichent au lieu de 1 et 0. La valeur par défaut est Activé.
• Text as LongVarChar. Sélectionnez cette option pour activer l'affichage du texte en tant queLongVarChar. La valeur par défaut est Activé.
• Max Varchar. Spécifiez la valeur maximale pour le type de données Varchar. Un champ Varchar dontla valeur dépasse le maximum spécifié sera promu en LongVarchar. La valeur par défaut est 255.
• Max LongVarChar. Spécifiez la valeur maximale pour le type de données LongVarChar. Une valeur dechamp LongVarChar qui dépasse le maximum spécifié sera tronquée. La valeur par défaut est 8190.
• Max Bytea. Spécifiez la valeur maximale pour le type de données Bytea. Une valeur de champ Byteaqui dépasse le maximum spécifié sera tronquée. La valeur par défaut est 255.
Note
Le type de données Bytea est utilisé uniquement par les tables et vues système AmazonRedshift, sinon il n'est pas pris en charge.
Puis cliquez sur OK.12.Cliquez sur Test. Si l'ordinateur client peut se connecter à la base de données Amazon Redshift, vous
verrez le message suivant s'afficher : Connection successful.
Si l'ordinateur client ne peut pas se connecter à la base de données, il se peut que vous deviez résoudred'éventuels problèmes. Pour plus d'informations, consultez Résolution des problèmes de connexion dansAmazon Redshift (p. 253).
Installer le pilote ODBC Amazon Redshift sur les systèmesd'exploitation LinuxExigences en matière de systèmeVous installez le pilote ODBC Amazon Redshift sur les ordinateurs clients ayant accès à un entrepôtde données Amazon Redshift. Chaque ordinateur sur lequel vous installez le pilote doit répondre auxexigences minimales suivantes :
• L'une des distributions Linux suivantes (éditions en 32 bits et 64 bits) :• Red Hat Enterprise Linux (RHEL) 5.0/6.0/7.0• CentOS 5.0/6.0/7.0• Debian 7• SUSE Linux Enterprise Server (SLES) 11
Version de l'API 2012-12-01224

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
• 75 Mo d'espace disque disponible• L'un des gestionnaires de pilotes ODBC suivants :
• iODBC Driver Manager 3.52.7 ou version ultérieure. Pour plus d'informations sur le gestionnairede pilotes iODBC et obtenir des liens pour le télécharger, accédez au site web Independent OpenDatabase Connectivity.
• unixODBC 2.3.0 ou version ultérieure. Pour plus d'informations sur le gestionnaire de pilotesunixODBC et obtenir des liens pour le télécharger, accédez au site web unixODBC.
• Compte d'utilisateur ou d'utilisateur principal Amazon Redshift pour se connecter à la base de données
Installation du pilote ODBC Amazon Redshift sur les systèmes d'exploitation Linux
Suivez les étapes décrites dans cette section pour télécharger et installer les pilotes ODBC AmazonRedshift sur une distribution Linux prise en charge. Le processus d'installation va installer les fichiers dupilote dans les répertoires suivants :
• /opt/amazon/redshiftodbc/lib/32 (pour un pilote 32 bits)• /opt/amazon/redshiftodbc/lib/64 (pour un pilote 64 bits)• /opt/Amazon/redshiftodbc/ErrorMessages• /opt/Amazon/redshiftodbc/Setup
Pour installer le pilote ODBC Amazon Redshift
1. Téléchargez l'un des pilotes suivants, en fonction de l'architecture système de votre outil client SQL oude votre application :
• Fichier .rpm 32 bits : https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.2.1010/AmazonRedshiftODBC-32-bit-1.4.2.1010-1.i686.rpm
• Fichier .rpm 64 bits : https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64-bit-1.4.2.1010-1.x86_64.rpm
• Debian 32 bit .rpm: https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.2.1010/AmazonRedshiftODBC-32-bit-1.4.2.1010-1.i686.deb
• Debian 64 bit .rpm: https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.2.1010/AmazonRedshiftODBC-64-bit-1.4.2.1010-1.x86_64.deb
Le nom de ces deux pilotes est Pilote ODBC Amazon Redshift.
Note
Téléchargez le package qui correspond à l'architecture système de votre application ou outilclient SQL. Par exemple, si votre outil client est en 64 bits, installez un pilote 64 bits.
Puis téléchargez et consultez le Contrat de licence du pilote ODBC Amazon Redshift. Si vous avezbesoin de distribuer ces pilotes à vos clients ou à des tiers, envoyez un e-mail à l'adresse [email protected] pour prévoir une licence adaptée.
2. Accédez à l'emplacement dans lequel vous avez téléchargé le package et exécutez l'une descommandes suivantes. Utilisez la commande qui correspond à votre distribution Linux.
• Sur les systèmes d'exploitation RHEL 5.0/6.0 et CentOS 5.0/6.0, exécutez la commande suivante :
yum --nogpgcheck localinstall RPMFileName
Remplacez RPMFileName par le nom de fichier du package RPM. Par exemple, la commandesuivante illustre l'installation du pilote 32 bits :
Version de l'API 2012-12-01225

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
yum --nogpgcheck localinstall AmazonRedshiftODBC-32bit-1.x.x.xxxx-x.x86_64.deb
• Le SLES 11, exécutez la commande suivante :
zypper install RPMFileName
Remplacez RPMFileName par le nom de fichier du package RPM. Par exemple, la commandesuivante illustre l'installation du pilote 64 bits :
zypper install AmazonRedshiftODBC-1.x.x.xxxx-x.x86_64.rpm
• Sur Debian 7, exécutez la commande suivante :
sudo apt install ./DEBFileName.deb
Remplacez DEBFileName.deb par le nom de fichier du package Debian. Par exemple, lacommande suivante illustre l'installation du pilote 64 bits :
sudo apt install ./AmazonRedshiftODBC-1.x.x.xxxx-x.x86_64.deb
Important
Lorsque vous avez fini d'installer les pilotes, configurez-les pour les utiliser sur votre système.Pour plus d'informations sur la configuration du pilote, consultez Configurer le pilote ODBC sur lessystèmes d'exploitation Linux et Mac OS X (p. 227).
Installer le pilote ODBC Amazon Redshift sur Mac OS X
Exigences en matière de système
Vous installez le pilote sur les ordinateurs clients ayant accès à un entrepôt de données Amazon Redshift.Chaque ordinateur sur lequel vous installez le pilote doit répondre aux exigences minimales suivantes :
• Version Mac OS X 10.6.8 ou version ultérieure• 215 Mo d'espace disque disponible• iODBC Driver Manager version 3.52.7 ou ultérieure. Pour plus d'informations sur le gestionnaire de
pilotes iODBC et obtenir des liens pour le télécharger, accédez au site web Independent Open DatabaseConnectivity.
• Compte d'utilisateur ou d'utilisateur principal Amazon Redshift pour se connecter à la base de données
Installation du pilote Amazon Redshift sur Mac OS X
Suivez les étapes décrites dans cette section pour télécharger et installer le pilote ODBC Amazon Redshiftsur une version de Mac OS X prise en charge. Le processus d'installation va installer les fichiers du pilotedans les répertoires suivants :
• /opt/Amazon/redshift/lib/Universal• /opt/amazon/redshift/ErrorMessages• /opt/Amazon/redshift/Setup
Version de l'API 2012-12-01226

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Pour installer le pilote ODBC Amazon Redshift sur Mac OS X
1. Téléchargez https://s3.amazonaws.com/redshift-downloads/drivers/odbc/AmazonRedshiftODBC-1.4.2.1010.dmg. Le nom de ce pilote est Pilote ODBC Amazon Redshift.
Puis téléchargez et consultez le Contrat de licence du pilote ODBC Amazon Redshift. Si vous avezbesoin de distribuer ces pilotes à vos clients ou à des tiers, envoyez un e-mail à l'adresse [email protected] pour prévoir une licence adaptée.
2. Double-cliquez sur AmazonRedshiftODBC.dmg pour monter l'image disque.3. Double-cliquez sur AmazonRedshiftODBC.pkg pour exécuter le programme d'installation.4. Suivez les étapes décrites dans le programme d'installation pour terminer le processus d'installation du
pilote. Vous devrez accepter les conditions générales du contrat de licence pour effectuer l'installation.
Important
Lorsque vous avez fini d'installer le pilote, configurez-le pour l'utiliser sur votre système. Pour plusd'informations sur la configuration du pilote, consultez Configurer le pilote ODBC sur les systèmesd'exploitation Linux et Mac OS X (p. 227).
Configurer le pilote ODBC sur les systèmes d'exploitation Linux etMac OS XSur les systèmes d'exploitation Linux et Mac OS X, vous utilisez un gestionnaire de pilotes ODBC pourconfigurer les paramètres de connexion ODBC. Les gestionnaires de pilotes ODBC utilisent des fichiersde configuration pour définir et configurer les pilotes et les sources de données ODBC. Le gestionnairede pilotes ODBC que vous utilisez s'appuie sur le système d'exploitation que vous utilisez. Pour plusd'informations sur les gestionnaires de pilotes ODBC pris en charge en vue de configurer le pilote ODBCAmazon Redshift, consultez Exigences en matière de système (p. 224) pour les systèmes d'exploitationLinux et Exigences en matière de système (p. 226) pour les systèmes d'exploitation Mac OS X.
Trois fichiers sont obligatoires pour la configuration du pilote ODBC Amazon Redshift :amazon.redshiftodbc.ini, odbc.ini et odbcinst.ini.
Si vous l'avez installé à l'emplacement par défaut, le fichier de configuration amazon.redshiftodbc.inise trouve dans l'un des répertoires suivants :
• /opt/Amazon/redshiftodbc/lib/32 (pour le pilote 32 bits sur les systèmes d'exploitation Linux)• /opt/Amazon/redshiftodbc/lib/64 (pour le pilote 64 bits sur les systèmes d'exploitation Linux)• /opt/Amazon/redshift/lib (pour le pilote sous Mac OS X)
En outre, sous /opt/amazon/redshiftodbc/Setup sous Linux ou /opt/amazon/redshift/Setup sous Mac OS X,il existe des exemples de fichiers odbc.ini et odbcinst.ini dont vous inspirer pour la configuration dupilote ODBC Amazon Redshift et du nom de la source de données (DSN).
Nous vous déconseillons d'utiliser le répertoire d'installation du pilote ODBC Amazon Redshift pour lesfichiers de configuration. Les exemples de fichiers dans le répertoire d'installation sont proposées à titred'exemple seulement. Si vous réinstallez le pilote ODBC Amazon Redshift ultérieurement ou que vousle mettez à niveau vers une version plus récente, le répertoire d'installation est remplacé et vous perdeztoutes les modifications apportées à ces fichiers.
Pour éviter ce problème, vous devez copier le fichier amazon.redshiftodbc.ini dans un répertoire autre quele répertoire d'installation. Si vous copiez ce fichier vers le répertoire de base de l'utilisateur, ajouter unpoint (.) au début du nom de fichier pour le masquer.
Pour les fichiers odbc.ini et odbcinst.ini, vous devez utiliser les fichiers de configuration dans le répertoirede base de l'utilisateur ou créer de nouvelles versions dans un autre répertoire. Par défaut, votre système
Version de l'API 2012-12-01227

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
d'exploitation Linux ou Mac OS X doit comporter un fichier .odbc.ini et un fichier .odbcinst.ini dans lerépertoire de base de l'utilisateur (/home/$USER ou ~/.). Ces fichiers par défaut sont des fichiers masqués,ce qui est indiqué par le point (.) devant le nom du fichier, et ils sont affichés uniquement lorsque vousutilisez l'indicateur -a pour répertorier le contenu du répertoire.
Quelle que soit l'option choisie pour les fichiers odbc.ini et odbcinst.ini, vous devrez les modifier pourajouter les informations de configuration du pilote et de la DSN. Si vous avez choisi de créer de nouveauxfichiers, vous devez également définir des variables d'environnement afin de spécifier l'emplacement danslequel se trouvent ces fichiers de configuration.
Configuration du fichier odbc.iniVous utilisez le fichier odbc.ini pour définir les noms des sources de données (DSN).
Sur les systèmes d'exploitation Linux, utilisez le format suivant :
[ODBC Data Sources]driver_name=dsn_name
[dsn_name]Driver=path/driver_file
Host=cluster_endpointPort=port_numberDatabase=database_namelocale=locale
L'exemple suivant illustre la configuration du fichier odbc.ini sur les systèmes d'exploitation Linux :
[ODBC Data Sources]Amazon_Redshift_x32=Amazon Redshift (x86)Amazon_Redshift_x64=Amazon Redshift (x64)
[Amazon Redshift (x86)]Driver=/opt/amazon/redshiftodbc/lib/32/libamazonredshiftodbc32.soHost=examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.comPort=5932Database=devlocale=en-US
[Amazon Redshift (x64)]Driver=/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.soHost=examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.comPort=5932Database=devlocale=en-US
Sur les systèmes d'exploitation Mac OS X, utilisez le format suivant :
[ODBC Data Sources]driver_name=dsn_name
[dsn_name]Driver=path/libamazonredshiftodbc.dylib
Host=cluster_endpointPort=port_numberDatabase=database_namelocale=locale
L'exemple suivant illustre la configuration du fichier odbc.ini sur les systèmes d'exploitation Mac OS X :
Version de l'API 2012-12-01228

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
[ODBC Data Sources]Amazon_Redshift_dylib=Amazon Redshift DSN for Mac OS X
[Amazon Redshift DSN for Mac OS X]Driver=/opt/amazon/redshift/libamazonredshiftodbc.dylibHost=examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.comPort=5932Database=devlocale=en-US
Configuration du fichier odbcinst.iniLe fichier odbcinst.ini vous permet de définir des pilotes ODBC.
Sur les systèmes d'exploitation Linux, utilisez le format suivant :
[ODBC Drivers]driver_name=Installed... [driver_name]Description=driver_descriptionDriver=path/driver_file ...
L'exemple suivant illustre la configuration du fichier odbcinst.ini pour les pilotes 32 bits et 64 bits installésdans les répertoires par défaut sur les systèmes d'exploitation Linux :
[ODBC Drivers]Amazon Redshift (x86)=InstalledAmazon Redshift (x64)=Installed
[Amazon Redshift (x86)]Description=Amazon Redshift ODBC Driver (32-bit)Driver=/opt/amazon/redshiftodbc/lib/32/libamazonredshiftodbc32.so
[Amazon Redshift (x64)]Description=Amazon Redshift ODBC Driver (64-bit)Driver=/opt/amazon/redshiftodbc/lib/64/libamazonredshiftodbc64.so
Sur les systèmes d'exploitation Mac OS X, utilisez le format suivant :
[ODBC Drivers]driver_name=Installed... [driver_name]Description=driver_descriptionDriver=path/libamazonredshiftodbc.dylib ...
L'exemple suivant illustre la configuration du fichier odbcinst.ini pour le pilote installé dans le répertoire pardéfaut sur les systèmes d'exploitation Mac OS X :
[ODBC Drivers]Amazon RedshiftODBC DSN=Installed
[Amazon RedshiftODBC DSN]
Version de l'API 2012-12-01229

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Description=Amazon Redshift ODBC Driver for Mac OS XDriver=/opt/amazon/redshift/libamazonredshiftodbc.dylib
Configuration des Variables d'environnement pour les fichiers de configuration dupilote
Pour que le pilote ODBC Amazon Redshift fonctionne correctement, vous devez définir un certain nombrede variables environnementales, tel que décrit ci-après.
Définissez une variable d'environnement afin de spécifier le chemin d'accès aux bibliothèques dugestionnaire de pilotes :
• Sous Linux, définissez LD_LIBRARY_PATH pour pointer vers le répertoire contenant les bibliothèquesdu gestionnaire de pilotes. Pour plus d'informations sur les gestionnaires de pilotes pris en charge,consultez Installer le pilote ODBC Amazon Redshift sur les systèmes d'exploitation Linux (p. 224).
• Sous Mac OS X, définissez DYLD_LIBRARY_PATH pour pointer vers le répertoire contenant lesbibliothèques du gestionnaire de pilotes. Pour plus d'informations sur les gestionnaires de pilotes pris encharge, consultez Installer le pilote ODBC Amazon Redshift sur Mac OS X (p. 226).
Vous pouvez aussi définir AMAZONREDSHIFTODBCINI pour pointer vers votre fichieramazon.redshiftodbc.ini. AMAZONREDSHIFTODBCINI doit spécifier le chemin d'accès complet, ycompris le nom du fichier. Vous devez définir cette variable ou placer ce fichier à un emplacement où lesystème le trouvera lors d'une recherche. L'ordre de recherche suivant est utilisé pour trouver le fichieramazon.redshiftodbc.ini :
1. Si la variable d'environnement AMAZONREDSHIFTODBCINI est définie, le pilote recherche le fichierspécifié par la variable d'environnement.
2. Si la variable d'environnement AMAZONREDSHIFTODBCINI n'est pas définie, le pilote recherche dansson propre répertoire, c'est-à-dire dans le répertoire qui contient le fichier binaire du pilote.
3. S'il est impossible de trouver le fichier amazon.redshiftodbc.ini, le pilote tente de déterminerautomatiquement les paramètres du gestionnaire de pilotes et de se connecter. Toutefois, les messagesd'erreur ne s'affichent pas correctement dans le cas présent.
Si vous décidez d'utiliser un répertoire autre que répertoire de base de l'utilisateur pour les fichiersodbc.ini et odbcinst.ini, vous devez également définir des variables d'environnement pour spécifier à quelemplacement les fichiers de configuration s'affichent :
• Définissez ODBCINI pour pointer vers votre fichier odbc.ini.• Définissez ODBCSYSINI pour pointer vers le répertoire contenant le fichier odbcinst.ini.
Si vous êtes sous Linux, les bibliothèques de votre gestionnaire de pilotes se trouvent dans le répertoire /usr/local/lib, vos fichiers odbc.ini et amazon.redshiftodbc.ini se trouvent dans le répertoire /etc etvotre fichier odbcinst.ini se trouve dans le répertoire /usr/local/odbc. Ensuite, définissez les variablesd'environnement, comme illustré dans l'exemple suivant :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/libexport ODBCINI=/etc/odbc.iniexport AMAZONREDSHIFTODBCINI=/etc/amazon.redshiftodbc.ini export ODBCSYSINI=/usr/local/odbc
Si vous êtes sous Mac OX S, les bibliothèques de votre gestionnaire de pilotes se trouvent dans lerépertoire /usr/local/lib, vos fichiers odbc.ini et amazon.redshiftodbc.ini se trouvent dans le répertoire /etcet votre fichier odbcinst.ini se trouve dans le répertoire /usr/local/odbc. Ensuite, définissez les variablesd'environnement, comme illustré dans l'exemple suivant :
Version de l'API 2012-12-01230
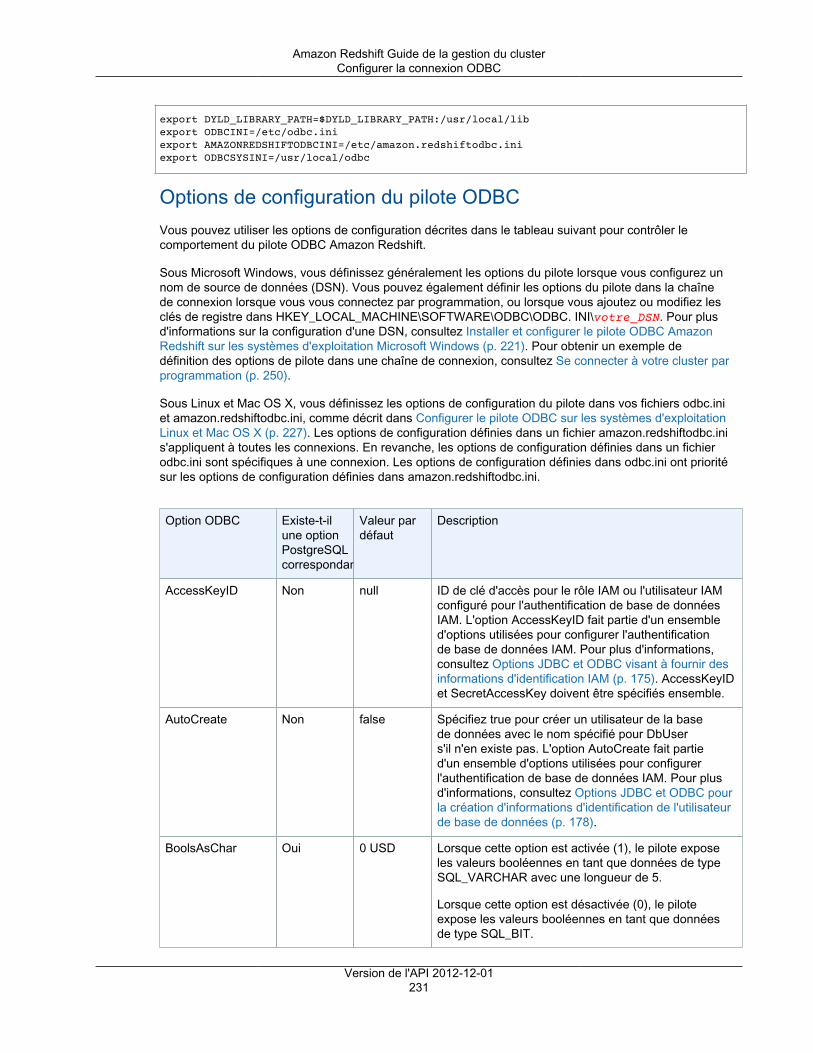
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
export DYLD_LIBRARY_PATH=$DYLD_LIBRARY_PATH:/usr/local/libexport ODBCINI=/etc/odbc.iniexport AMAZONREDSHIFTODBCINI=/etc/amazon.redshiftodbc.ini export ODBCSYSINI=/usr/local/odbc
Options de configuration du pilote ODBCVous pouvez utiliser les options de configuration décrites dans le tableau suivant pour contrôler lecomportement du pilote ODBC Amazon Redshift.
Sous Microsoft Windows, vous définissez généralement les options du pilote lorsque vous configurez unnom de source de données (DSN). Vous pouvez également définir les options du pilote dans la chaînede connexion lorsque vous vous connectez par programmation, ou lorsque vous ajoutez ou modifiez lesclés de registre dans HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC. INI\votre_DSN. Pour plusd'informations sur la configuration d'une DSN, consultez Installer et configurer le pilote ODBC AmazonRedshift sur les systèmes d'exploitation Microsoft Windows (p. 221). Pour obtenir un exemple dedéfinition des options de pilote dans une chaîne de connexion, consultez Se connecter à votre cluster parprogrammation (p. 250).
Sous Linux et Mac OS X, vous définissez les options de configuration du pilote dans vos fichiers odbc.iniet amazon.redshiftodbc.ini, comme décrit dans Configurer le pilote ODBC sur les systèmes d'exploitationLinux et Mac OS X (p. 227). Les options de configuration définies dans un fichier amazon.redshiftodbc.inis'appliquent à toutes les connexions. En revanche, les options de configuration définies dans un fichierodbc.ini sont spécifiques à une connexion. Les options de configuration définies dans odbc.ini ont prioritésur les options de configuration définies dans amazon.redshiftodbc.ini.
Option ODBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
AccessKeyID Non null ID de clé d'accès pour le rôle IAM ou l'utilisateur IAMconfiguré pour l'authentification de base de donnéesIAM. L'option AccessKeyID fait partie d'un ensembled'options utilisées pour configurer l'authentificationde base de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC visant à fournir desinformations d'identification IAM (p. 175). AccessKeyIDet SecretAccessKey doivent être spécifiés ensemble.
AutoCreate Non false Spécifiez true pour créer un utilisateur de la basede données avec le nom spécifié pour DbUsers'il n'en existe pas. L'option AutoCreate fait partied'un ensemble d'options utilisées pour configurerl'authentification de base de données IAM. Pour plusd'informations, consultez Options JDBC et ODBC pourla création d'informations d'identification de l'utilisateurde base de données (p. 178).
BoolsAsChar Oui 0 USD Lorsque cette option est activée (1), le pilote exposeles valeurs booléennes en tant que données de typeSQL_VARCHAR avec une longueur de 5.
Lorsque cette option est désactivée (0), le piloteexpose les valeurs booléennes en tant que donnéesde type SQL_BIT.
Version de l'API 2012-12-01231
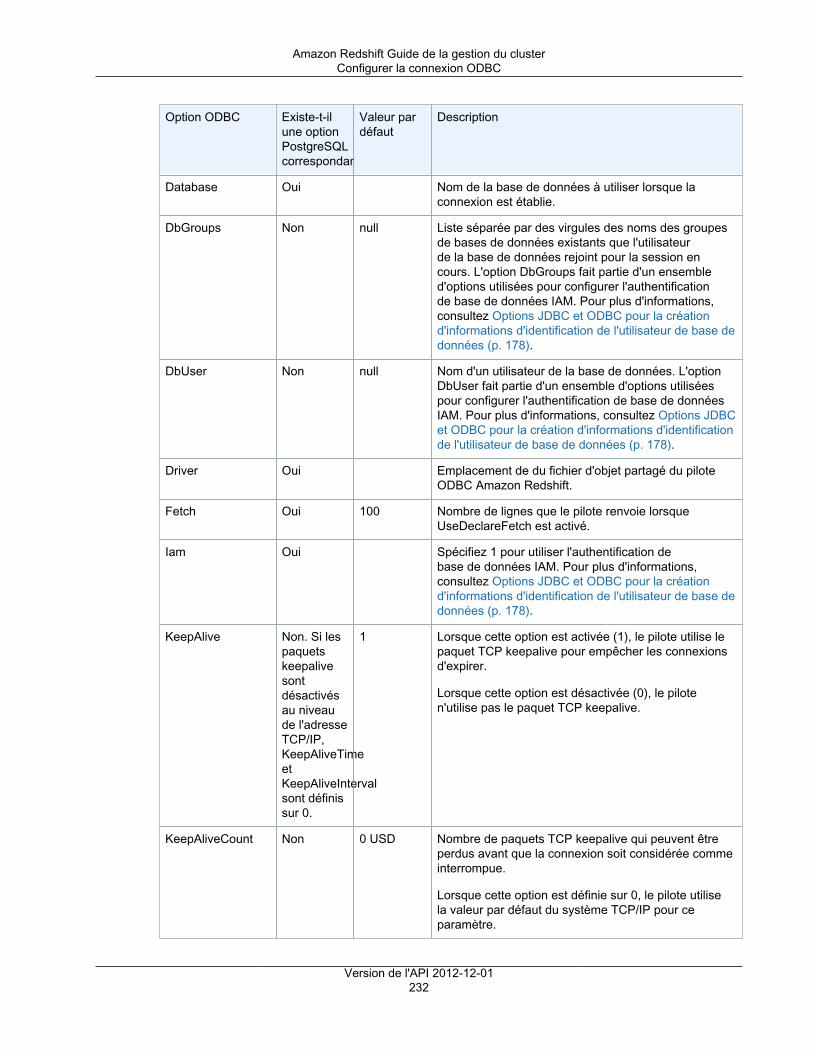
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Option ODBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
Database Oui Nom de la base de données à utiliser lorsque laconnexion est établie.
DbGroups Non null Liste séparée par des virgules des noms des groupesde bases de données existants que l'utilisateurde la base de données rejoint pour la session encours. L'option DbGroups fait partie d'un ensembled'options utilisées pour configurer l'authentificationde base de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC pour la créationd'informations d'identification de l'utilisateur de base dedonnées (p. 178).
DbUser Non null Nom d'un utilisateur de la base de données. L'optionDbUser fait partie d'un ensemble d'options utiliséespour configurer l'authentification de base de donnéesIAM. Pour plus d'informations, consultez Options JDBCet ODBC pour la création d'informations d'identificationde l'utilisateur de base de données (p. 178).
Driver Oui Emplacement de du fichier d'objet partagé du piloteODBC Amazon Redshift.
Fetch Oui 100 Nombre de lignes que le pilote renvoie lorsqueUseDeclareFetch est activé.
Iam Oui Spécifiez 1 pour utiliser l'authentification debase de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC pour la créationd'informations d'identification de l'utilisateur de base dedonnées (p. 178).
KeepAlive Non. Si lespaquetskeepalivesontdésactivésau niveaude l'adresseTCP/IP,KeepAliveTimeetKeepAliveIntervalsont définissur 0.
1 Lorsque cette option est activée (1), le pilote utilise lepaquet TCP keepalive pour empêcher les connexionsd'expirer.
Lorsque cette option est désactivée (0), le piloten'utilise pas le paquet TCP keepalive.
KeepAliveCount Non 0 USD Nombre de paquets TCP keepalive qui peuvent êtreperdus avant que la connexion soit considérée commeinterrompue.
Lorsque cette option est définie sur 0, le pilote utilisela valeur par défaut du système TCP/IP pour ceparamètre.
Version de l'API 2012-12-01232
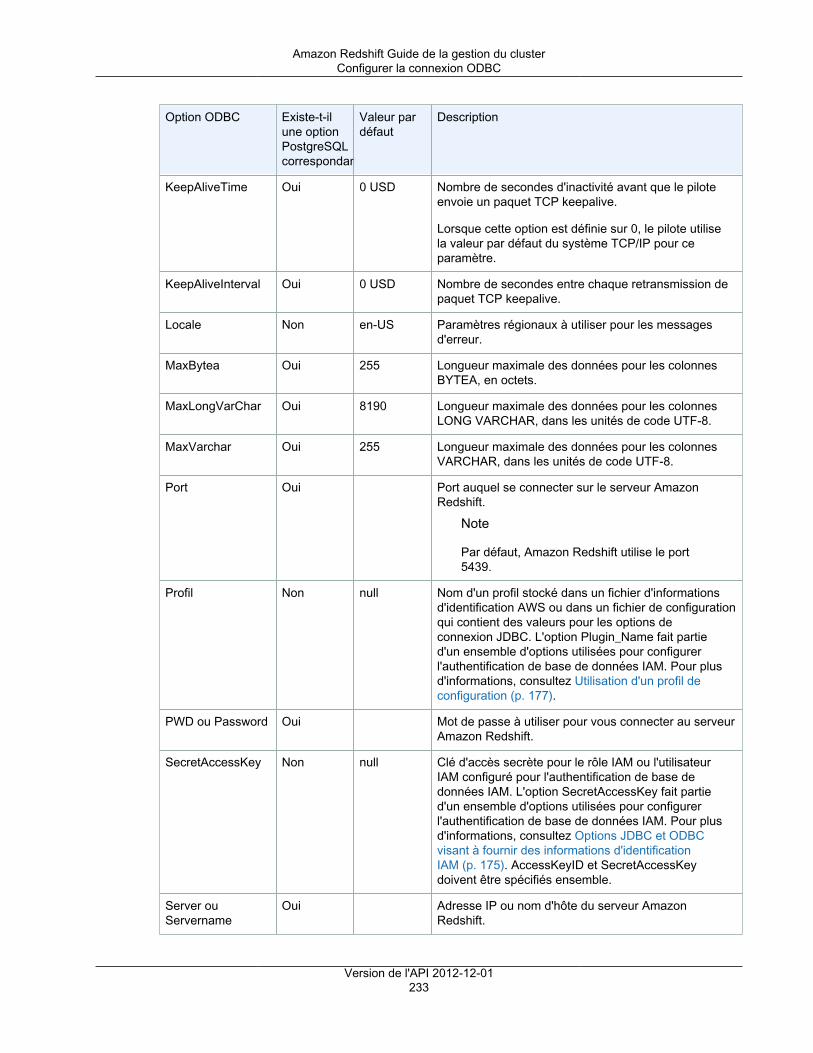
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Option ODBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
KeepAliveTime Oui 0 USD Nombre de secondes d'inactivité avant que le piloteenvoie un paquet TCP keepalive.
Lorsque cette option est définie sur 0, le pilote utilisela valeur par défaut du système TCP/IP pour ceparamètre.
KeepAliveInterval Oui 0 USD Nombre de secondes entre chaque retransmission depaquet TCP keepalive.
Locale Non en-US Paramètres régionaux à utiliser pour les messagesd'erreur.
MaxBytea Oui 255 Longueur maximale des données pour les colonnesBYTEA, en octets.
MaxLongVarChar Oui 8190 Longueur maximale des données pour les colonnesLONG VARCHAR, dans les unités de code UTF-8.
MaxVarchar Oui 255 Longueur maximale des données pour les colonnesVARCHAR, dans les unités de code UTF-8.
Port Oui Port auquel se connecter sur le serveur AmazonRedshift.
Note
Par défaut, Amazon Redshift utilise le port5439.
Profil Non null Nom d'un profil stocké dans un fichier d'informationsd'identification AWS ou dans un fichier de configurationqui contient des valeurs pour les options deconnexion JDBC. L'option Plugin_Name fait partied'un ensemble d'options utilisées pour configurerl'authentification de base de données IAM. Pour plusd'informations, consultez Utilisation d'un profil deconfiguration (p. 177).
PWD ou Password Oui Mot de passe à utiliser pour vous connecter au serveurAmazon Redshift.
SecretAccessKey Non null Clé d'accès secrète pour le rôle IAM ou l'utilisateurIAM configuré pour l'authentification de base dedonnées IAM. L'option SecretAccessKey fait partied'un ensemble d'options utilisées pour configurerl'authentification de base de données IAM. Pour plusd'informations, consultez Options JDBC et ODBCvisant à fournir des informations d'identificationIAM (p. 175). AccessKeyID et SecretAccessKeydoivent être spécifiés ensemble.
Server ouServername
Oui Adresse IP ou nom d'hôte du serveur AmazonRedshift.
Version de l'API 2012-12-01233
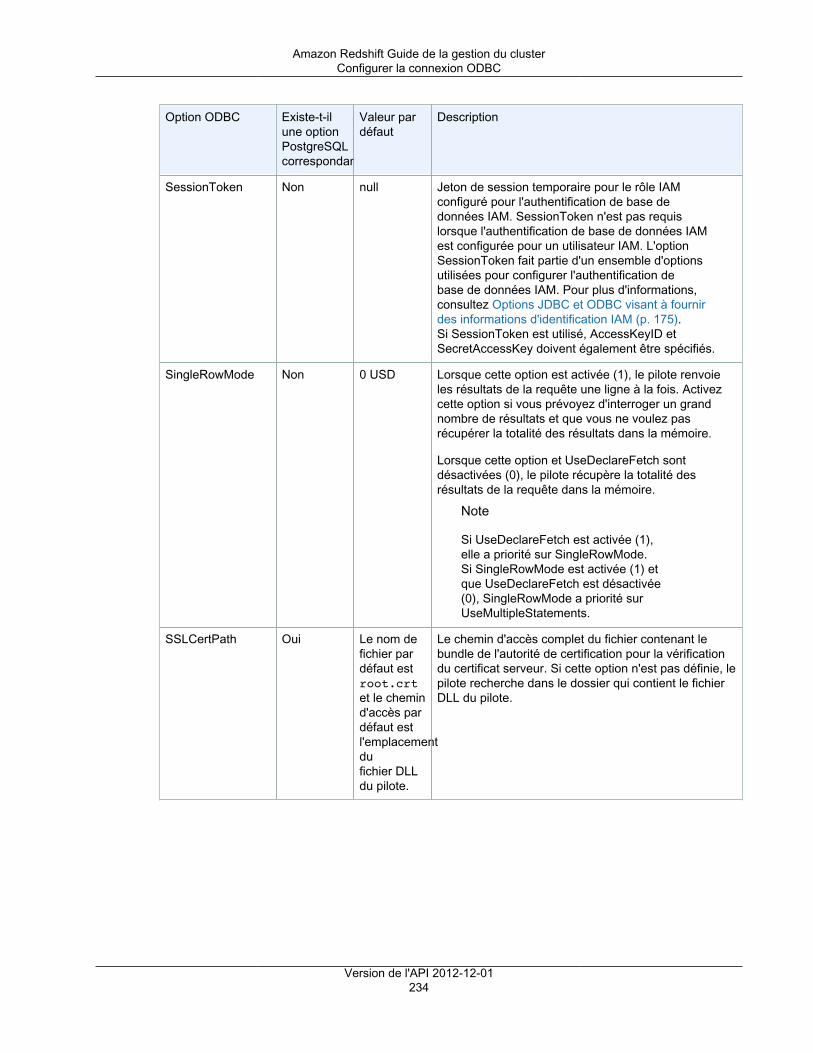
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Option ODBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
SessionToken Non null Jeton de session temporaire pour le rôle IAMconfiguré pour l'authentification de base dedonnées IAM. SessionToken n'est pas requislorsque l'authentification de base de données IAMest configurée pour un utilisateur IAM. L'optionSessionToken fait partie d'un ensemble d'optionsutilisées pour configurer l'authentification debase de données IAM. Pour plus d'informations,consultez Options JDBC et ODBC visant à fournirdes informations d'identification IAM (p. 175).Si SessionToken est utilisé, AccessKeyID etSecretAccessKey doivent également être spécifiés.
SingleRowMode Non 0 USD Lorsque cette option est activée (1), le pilote renvoieles résultats de la requête une ligne à la fois. Activezcette option si vous prévoyez d'interroger un grandnombre de résultats et que vous ne voulez pasrécupérer la totalité des résultats dans la mémoire.
Lorsque cette option et UseDeclareFetch sontdésactivées (0), le pilote récupère la totalité desrésultats de la requête dans la mémoire.
Note
Si UseDeclareFetch est activée (1),elle a priorité sur SingleRowMode.Si SingleRowMode est activée (1) etque UseDeclareFetch est désactivée(0), SingleRowMode a priorité surUseMultipleStatements.
SSLCertPath Oui Le nom defichier pardéfaut estroot.crtet le chemind'accès pardéfaut estl'emplacementdufichier DLLdu pilote.
Le chemin d'accès complet du fichier contenant lebundle de l'autorité de certification pour la vérificationdu certificat serveur. Si cette option n'est pas définie, lepilote recherche dans le dossier qui contient le fichierDLL du pilote.
Version de l'API 2012-12-01234
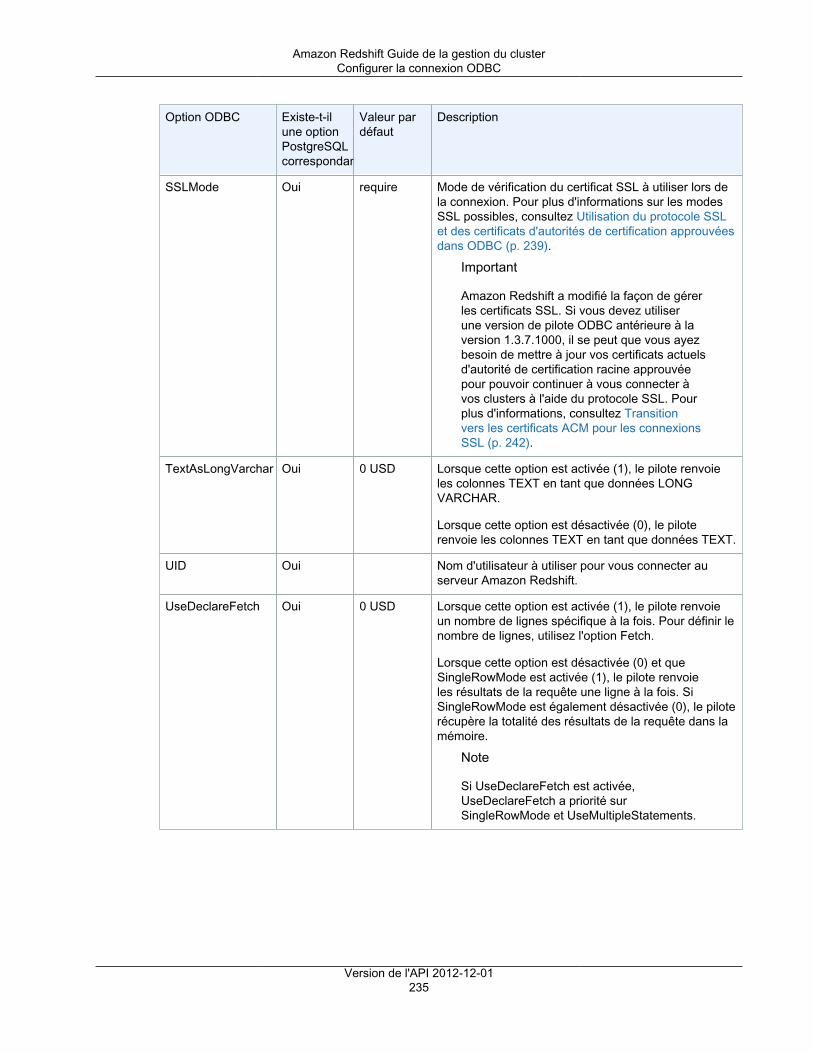
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Option ODBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
SSLMode Oui require Mode de vérification du certificat SSL à utiliser lors dela connexion. Pour plus d'informations sur les modesSSL possibles, consultez Utilisation du protocole SSLet des certificats d'autorités de certification approuvéesdans ODBC (p. 239).
Important
Amazon Redshift a modifié la façon de gérerles certificats SSL. Si vous devez utiliserune version de pilote ODBC antérieure à laversion 1.3.7.1000, il se peut que vous ayezbesoin de mettre à jour vos certificats actuelsd'autorité de certification racine approuvéepour pouvoir continuer à vous connecter àvos clusters à l'aide du protocole SSL. Pourplus d'informations, consultez Transitionvers les certificats ACM pour les connexionsSSL (p. 242).
TextAsLongVarchar Oui 0 USD Lorsque cette option est activée (1), le pilote renvoieles colonnes TEXT en tant que données LONGVARCHAR.
Lorsque cette option est désactivée (0), le piloterenvoie les colonnes TEXT en tant que données TEXT.
UID Oui Nom d'utilisateur à utiliser pour vous connecter auserveur Amazon Redshift.
UseDeclareFetch Oui 0 USD Lorsque cette option est activée (1), le pilote renvoieun nombre de lignes spécifique à la fois. Pour définir lenombre de lignes, utilisez l'option Fetch.
Lorsque cette option est désactivée (0) et queSingleRowMode est activée (1), le pilote renvoieles résultats de la requête une ligne à la fois. SiSingleRowMode est également désactivée (0), le piloterécupère la totalité des résultats de la requête dans lamémoire.
Note
Si UseDeclareFetch est activée,UseDeclareFetch a priorité surSingleRowMode et UseMultipleStatements.
Version de l'API 2012-12-01235
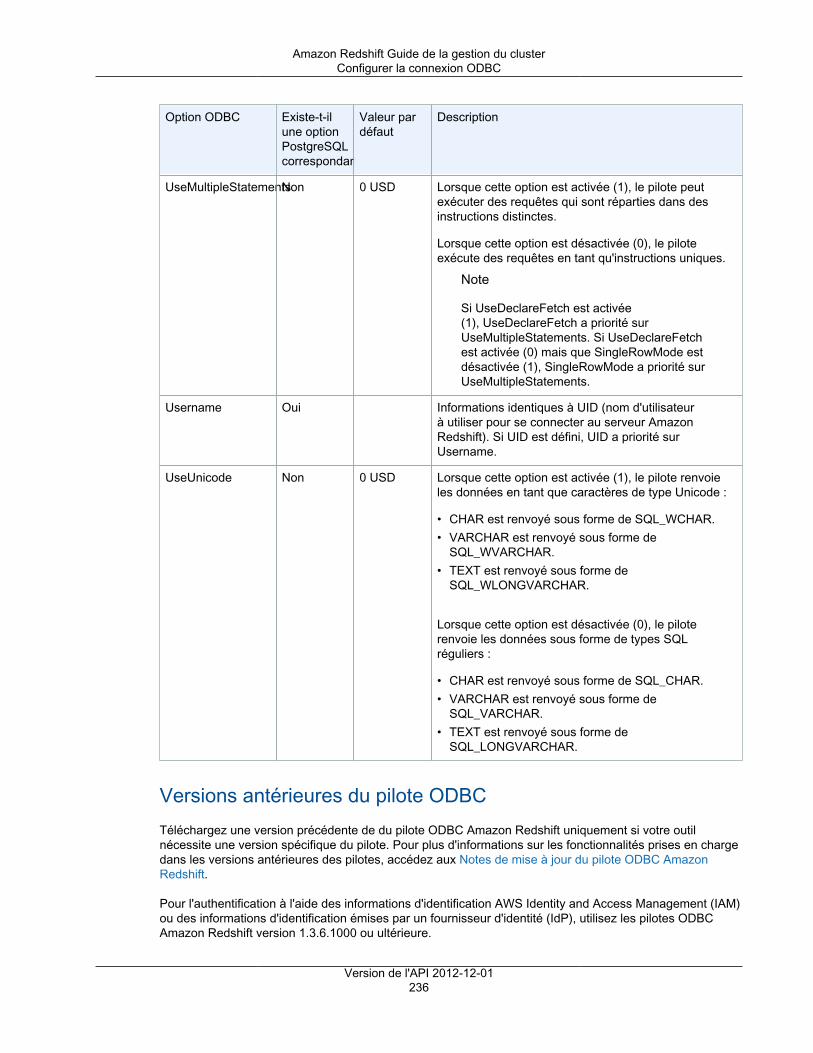
Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Option ODBC Existe-t-ilune optionPostgreSQLcorrespondante ?
Valeur pardéfaut
Description
UseMultipleStatementsNon 0 USD Lorsque cette option est activée (1), le pilote peutexécuter des requêtes qui sont réparties dans desinstructions distinctes.
Lorsque cette option est désactivée (0), le piloteexécute des requêtes en tant qu'instructions uniques.
Note
Si UseDeclareFetch est activée(1), UseDeclareFetch a priorité surUseMultipleStatements. Si UseDeclareFetchest activée (0) mais que SingleRowMode estdésactivée (1), SingleRowMode a priorité surUseMultipleStatements.
Username Oui Informations identiques à UID (nom d'utilisateurà utiliser pour se connecter au serveur AmazonRedshift). Si UID est défini, UID a priorité surUsername.
UseUnicode Non 0 USD Lorsque cette option est activée (1), le pilote renvoieles données en tant que caractères de type Unicode :
• CHAR est renvoyé sous forme de SQL_WCHAR.• VARCHAR est renvoyé sous forme de
SQL_WVARCHAR.• TEXT est renvoyé sous forme de
SQL_WLONGVARCHAR.
Lorsque cette option est désactivée (0), le piloterenvoie les données sous forme de types SQLréguliers :
• CHAR est renvoyé sous forme de SQL_CHAR.• VARCHAR est renvoyé sous forme de
SQL_VARCHAR.• TEXT est renvoyé sous forme de
SQL_LONGVARCHAR.
Versions antérieures du pilote ODBCTéléchargez une version précédente de du pilote ODBC Amazon Redshift uniquement si votre outilnécessite une version spécifique du pilote. Pour plus d'informations sur les fonctionnalités prises en chargedans les versions antérieures des pilotes, accédez aux Notes de mise à jour du pilote ODBC AmazonRedshift.
Pour l'authentification à l'aide des informations d'identification AWS Identity and Access Management (IAM)ou des informations d'identification émises par un fournisseur d'identité (IdP), utilisez les pilotes ODBCAmazon Redshift version 1.3.6.1000 ou ultérieure.
Version de l'API 2012-12-01236

Amazon Redshift Guide de la gestion du clusterConfigurer la connexion ODBC
Important
Amazon Redshift a modifié la façon de gérer les certificats SSL. Si vous devez utiliser une versionde pilote antérieure à la version 1.3.7.1000, il se peut que vous ayez besoin de mettre à jourvos certificats actuels d'autorité de certification racine approuvée pour pouvoir continuer à vousconnecter à vos clusters à l'aide du protocole SSL. Pour plus d'informations, consultez Transitionvers les certificats ACM pour les connexions SSL (p. 242).
Versions antérieures du pilote ODBC pour WindowsLes pilotes 32 bits précédents sont les suivants :
• https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.1.1001/AmazonRedshiftODBC32-1.4.1.1001.msi
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC32-1.3.7.1000.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC32-1.3.6.1000.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC32-1.3.1.1000.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC32-1.2.7.1007.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC32-1.2.6.1006.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC32-1.2.1.1001.msi
Les pilotes 64 bits précédents sont les suivants :
• https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.1.1001/AmazonRedshiftODBC64-1.4.1.1001.msi
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC64-1.3.7.1000.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC64-1.3.6.1000.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC64-1.3.1.1000.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC64-1.2.7.1007.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC64-1.2.6.1006.msi• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC64-1.2.1.1001.msi
Versions antérieures du pilote ODBC pour LinuxLes services suivants sont des versions précédentes du pilote 32 bits :
• https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.1.1001/AmazonRedshiftODBC-32-bit-1.4.1.1001-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.3.7.1000-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.1.1001/AmazonRedshiftODBC-32-bit-1.4.1.1001-1.i686.deb
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.3.7.1000-1.i686.deb
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.3.6.1000-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.3.1.1000-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.2.7.1007-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.2.6.1006-1.i686.rpm
Version de l'API 2012-12-01237

Amazon Redshift Guide de la gestion du clusterConfigurer les options de sécurité des connexions
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.2.1.1001-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-32bit-1.1.0.0000-1.i686.rpm
Les services suivants sont des versions précédentes du pilote 64 bits :
• Fichier .rpm 64 bits : https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64-bit-1.4.1.1000-1.x86_64.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.3.7.1000-1.x86_64.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/odbc/1.4.1.1001/AmazonRedshiftODBC-64-bit-1.4.1.1001-1.x86_64.deb
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.3.7.1000-1.x86_64.deb
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.3.6.1000-1.i686.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.3.1.1000-1.x86_64.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.2.7.1007-1.x86_64.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.2.6.1006-1.x86_64.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.2.1.1001-1.x86_64.rpm
• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-64bit-1.1.0.0000-1.x86_64.rpm
Versions antérieures du pilote ODBC pour Mac
Voici les versions précédentes du pilote ODBC Amazon Redshift pour Mac OS X :
• https://s3.amazonaws.com/redshift-downloads/drivers/odbc/AmazonRedshiftODBC-1.4.1.1001.dmg• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-1.3.7.1000.dmg• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-1.3.6.1000-1.i686.dmg• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-1.3.1.1000.dmg• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-1.2.7.1007.dmg• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC_1.2.6.1006.dmg• https://s3.amazonaws.com/redshift-downloads/drivers/AmazonRedshiftODBC-1.2.1.1001.dmg
Configurer les options de sécurité des connexionsAmazon Redshift prend en charge les connexions SSL (Secure Sockets Layer) pour chiffrer les données etles certificats de serveur pour valider le certificat du serveur auquel le client se connecte.
Connexion à l'aide du protocole SSLPour prendre en charge les connexions SSL, Amazon Redshift crée et installe un certificat SSL émis parAWS Certificate Manager (ACM) sur chaque cluster. L'ensemble d'autorités de certification que vous devezapprouver pour prendre en charge correctement les connexions SSL est disponible à l'adresse https://
Version de l'API 2012-12-01238

Amazon Redshift Guide de la gestion du clusterConfigurer les options de sécurité des connexions
s3.amazonaws.com/redshift-downloads/redshift-ca-bundle.crt. Si l'ensemble de certificats ne se téléchargepas, cliquez avec le bouton droit de la souris sur le lien précédent et choisissez Enregistrer le lien sous....
Important
Amazon Redshift a modifié la façon de gérer les certificats SSL. Il se peut que vous ayez besoinde mettre à jour vos certificats actuels d'autorité de certification racine approuvée pour pouvoircontinuer à vous connecter à vos clusters à l'aide du protocole SSL. Pour plus d'informations,consultez Transition vers les certificats ACM pour les connexions SSL (p. 242).
Par défaut, les bases de données du cluster acceptent une connexion qu'elle s'appuie sur le protocoleSSL ou non. Pour configurer votre cluster afin d'exiger une connexion SSL, définissez le paramètrerequire_SSL sur true dans le groupe de paramètres associé au cluster.
Amazon Redshift prend en charge un mode SSL conforme à la norme FIPS (Federal InformationProcessing Standard) 140-2. Par défaut, le mode SSL conforme à la norme FIPS est désactivé.
Important
N'activez le mode compatible FIPS que si votre système doit être compatible FIPS.
Pour activer le mode SSL conforme à la norme FIPS, définissez les paramètres use_fips_ssl etrequire_SSL sur true dans le groupe de paramètres associé au cluster. Pour plus d'informations sur lamodification d'un groupe de paramètres, consultez Groupes de paramètres Amazon Redshift (p. 61).
Amazon Redshift prend en charge le protocole d'accord de clé ECDHE (Elliptic curve Diffie—HellmanEphemeral). Avec le protocole ECDHE, le client et le serveur disposent chacun d'une paire de cléspubliques-privées à courbes elliptiques qui permettent d'établir un secret partagé via un canal non sécurisé.Vous n'avez pas besoin de configurer quoi que ce soit dans Amazon Redshift pour activer le protocoleECDHE. Si vous vous connectez à partir d'un outil client SQL qui utilise le protocole ECDHE pour chiffrerles communications entre le client et le serveur, Amazon Redshift utilise la liste de chiffrement fournie pourétablir les connexions appropriées. Pour plus d'informations, consultez l'article sur Elliptic Curve Diffie—Hellman sur Wikipedia et la page sur les chiffrements du site web d'OpenSSL.
Utilisation du protocole SSL et des certificats d'autorités decertification approuvées dans ODBCSi vous vous connectez à l'aide des derniers pilotes ODBC Amazon Redshift (version 1.3.7.1000 ouultérieure), vous pouvez ignorer cette section. Pour télécharger les pilotes les plus récents, consultezConfigurer la connexion ODBC (p. 219).
Il se peut que vous ayez besoin de mettre à jour vos certificats actuels d'autorité de certification racineapprouvée pour pouvoir continuer à vous connecter à vos clusters à l'aide du protocole SSL. Pour plusd'informations, consultez Transition vers les certificats ACM pour les connexions SSL (p. 242).
Le bundle d'autorités de certification Amazon Redshift est stocké à l'adresse https://s3.amazonaws.com/redshift-downloads/redshift-ca-bundle.crt. Si l'ensemble de certificats ne se télécharge pas, cliquezavec le bouton droit de la souris sur le lien précédent et choisissez Enregistrer le lien sous.... Le totalde contrôle MD5 attendu est e7a76d62fc7775ac54cfc4d21e89d36b. Le total de contrôle sha256 este77daa6243a940eb2d144d26757135195b4bdefd345c32a064d4ebea02b9f8a1. Vous pouvez utiliserle programme Md5sum (sur les systèmes d'exploitation Linux) ou un autre outil (sur les systèmesd'exploitation Windows et Mac OS X) pour vérifier que le certificat que vous avez téléchargé correspond aunombre de contrôle MD5.
Les DSN ODBC contiennent un paramètre sslmode permettant de déterminer comment gérer lechiffrement pour les connexions client et la vérification du certificat serveur. Amazon Redshift prend encharge les valeurs sslmode suivantes de la connexion client :
• disable
Le protocole SSL est désactivé et la connexion n'est pas chiffrée.
Version de l'API 2012-12-01239
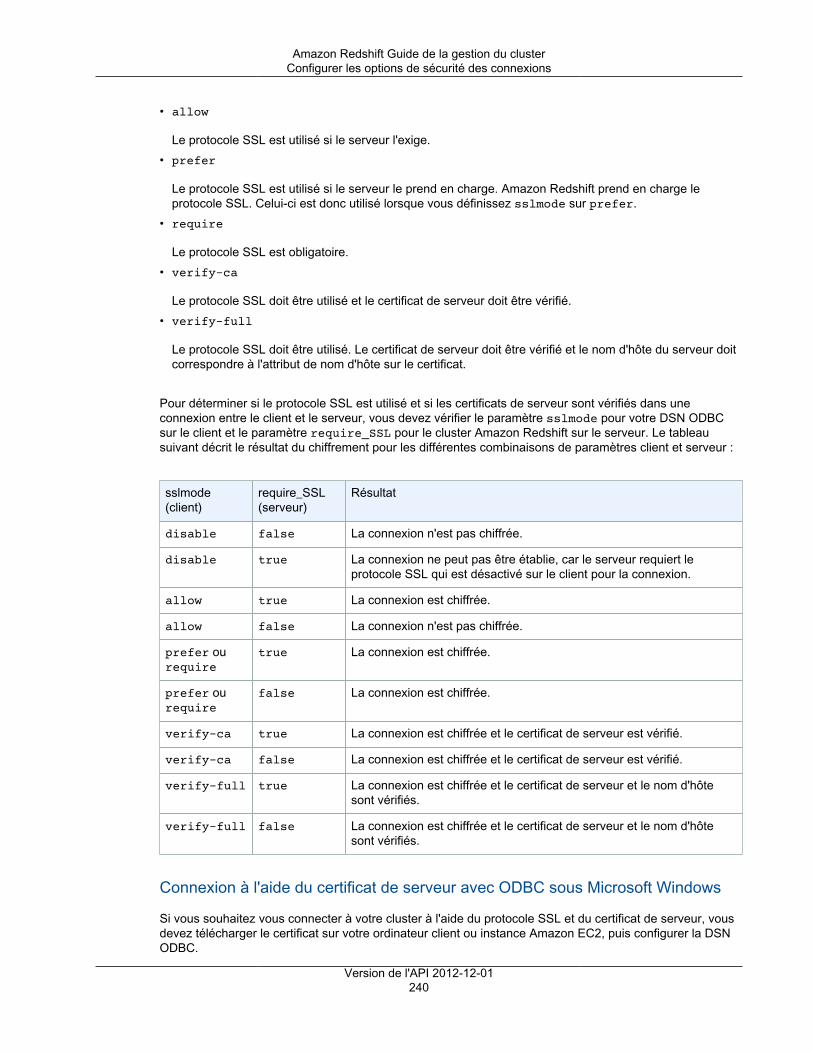
Amazon Redshift Guide de la gestion du clusterConfigurer les options de sécurité des connexions
• allow
Le protocole SSL est utilisé si le serveur l'exige.• prefer
Le protocole SSL est utilisé si le serveur le prend en charge. Amazon Redshift prend en charge leprotocole SSL. Celui-ci est donc utilisé lorsque vous définissez sslmode sur prefer.
• require
Le protocole SSL est obligatoire.• verify-ca
Le protocole SSL doit être utilisé et le certificat de serveur doit être vérifié.• verify-full
Le protocole SSL doit être utilisé. Le certificat de serveur doit être vérifié et le nom d'hôte du serveur doitcorrespondre à l'attribut de nom d'hôte sur le certificat.
Pour déterminer si le protocole SSL est utilisé et si les certificats de serveur sont vérifiés dans uneconnexion entre le client et le serveur, vous devez vérifier le paramètre sslmode pour votre DSN ODBCsur le client et le paramètre require_SSL pour le cluster Amazon Redshift sur le serveur. Le tableausuivant décrit le résultat du chiffrement pour les différentes combinaisons de paramètres client et serveur :
sslmode(client)
require_SSL(serveur)
Résultat
disable false La connexion n'est pas chiffrée.
disable true La connexion ne peut pas être établie, car le serveur requiert leprotocole SSL qui est désactivé sur le client pour la connexion.
allow true La connexion est chiffrée.
allow false La connexion n'est pas chiffrée.
prefer ourequire
true La connexion est chiffrée.
prefer ourequire
false La connexion est chiffrée.
verify-ca true La connexion est chiffrée et le certificat de serveur est vérifié.
verify-ca false La connexion est chiffrée et le certificat de serveur est vérifié.
verify-full true La connexion est chiffrée et le certificat de serveur et le nom d'hôtesont vérifiés.
verify-full false La connexion est chiffrée et le certificat de serveur et le nom d'hôtesont vérifiés.
Connexion à l'aide du certificat de serveur avec ODBC sous Microsoft Windows
Si vous souhaitez vous connecter à votre cluster à l'aide du protocole SSL et du certificat de serveur, vousdevez télécharger le certificat sur votre ordinateur client ou instance Amazon EC2, puis configurer la DSNODBC.
Version de l'API 2012-12-01240

Amazon Redshift Guide de la gestion du clusterConfigurer les options de sécurité des connexions
1. Téléchargez le bundle d'autorités de certification Amazon Redshift sur votre ordinateur client dans ledossier lib du répertoire d'installation de votre pilote et enregistrez le fichier sous root.crt.
2. Ouvrez Administrateur de sources de données ODBC et ajoutez ou modifiez l'entrée de la DSNsystème pour votre connexion ODBC. Pour Mode SSL, sélectionnez verify-full à moins que vousn'utilisiez un alias DNS. Si vous utilisez un alias DNS, sélectionnez verify-ca. Puis, cliquez surSave.
Pour plus d'informations sur la configuration de la DSN ODBC, consultez Configurer la connexionODBC (p. 219).
Utilisation du protocole SSL et des certificats de serveur dansJavaLe protocole SSL fournit une couche de sécurité en chiffrant les données qui se déplacent entre votre clientet le cluster. L'utilisation d'un certificat de serveur fournit une couche de sécurité supplémentaire en validantque le cluster est bien un cluster Amazon Redshift. Pour cela, il vérifie le certificat de serveur installéautomatiquement sur tous les clusters que vous mettez en service. Pour plus d'informations sur l'utilisationde certificats de serveur avec JDBC, accédez à la page de configuration du client de la documentation surPostgreSQL.
Connexion à l'aide de certificats d'autorités de certification approuvées dans Java
Si vous vous connectez à l'aide des derniers pilotes JDBC Amazon Redshift (version 1.2.8.1005 ouultérieure), vous pouvez ignorer cette section. Pour télécharger les pilotes les plus récents, consultezConfigurer une connexion JDBC.
Important
Amazon Redshift a modifié la façon de gérer les certificats SSL. Il se peut que vous ayez besoinde mettre à jour vos certificats actuels d'autorité de certification racine approuvée pour pouvoircontinuer à vous connecter à vos clusters à l'aide du protocole SSL. Pour plus d'informations,consultez Transition vers les certificats ACM pour les connexions SSL (p. 242).
Pour se connecter à l'aide de certificats d'autorités de certification approuvées
Vous pouvez utiliser redshift-keytool.jar pour importer les certificats de CA du bundle d'autorités decertification Redshift dans un TrustStore Java ou dans votre TrustStore privé.
1. Si vous utilisez l'option de ligne de commande Java -Djavax.net.ssl.trustStore, supprimez-lade la ligne de commande, si possible.
2. Téléchargez le fichier redshift-keytool.jar3. Effectuez l'une des actions suivantes :
• Pour importer le bundle d'autorités de certification Redshift dans un TrustStore Java, exécutez lacommande suivante :
java -jar redshift-keytool.jar -s
• Pour importer le bundle d'autorités de certification Redshift dans votre TrustStore privé, exécutez lacommande suivante :
java -jar redshift-keytool.jar -k <your_private_trust_store> -p <keystore_password>
Version de l'API 2012-12-01241

Amazon Redshift Guide de la gestion du clusterConfigurer les options de sécurité des connexions
Transition vers les certificats ACM pour les connexions SSLAmazon Redshift remplace les certificats SSL sur vos clusters par les certificats émis par AWS CertificateManager (ACM). ACM est une autorité de certification publique de confiance, approuvée par la plupartdes systèmes actuels. Il se peut que vous ayez besoin de mettre à jour vos certificats actuels d'autorité decertification racine approuvée pour pouvoir continuer à vous connecter à vos clusters à l'aide du protocoleSSL.
Cette modification ne vous affecte que si l'ensemble des conditions suivantes s'applique :
• Vos clients ou applications SQL se connectent aux clusters Amazon Redshift à l'aide du protocole SSLavec l'option de connexion sslMode définie sur l'option de configuration require, verify-ca ouverify-full.
• Vos clusters se trouvent dans n'importe quelle région AWS à l'exception des régions AWS GovCloud(Etats-Unis), Chine (Pékin) ou Chine (Ningxia).
• Vous n'utilisez pas les pilotes Amazon Redshift ODBC ou JDBC, ou vous utilisez les pilotes AmazonRedshift antérieurs à ODBC version 1.3.7.1000 ou JDBC version 1.2.8.1005.
Si cette modification vous affecte, vous devez mettre à jour vos certificats de CA approuvée actuelsavant le 23 octobre 2017. Amazon Redshift assurera la transition de vos clusters afin qu'ils utilisent lescertificats ACM entre aujourd'hui et le 23 octobre 2017. La modification n'aura aucun effet ou presque surles performances ou la disponibilité de votre cluster.
Pour mettre à jour vos certificats actuels de CA racine approuvée, identifiez votre cas d'utilisation, puissuivez les étapes de cette section.
• Utilisation des derniers pilotes ODBC ou JDBC Amazon Redshift (p. 242)• Utilisation des précédents pilotes ODBC ou JDBC Amazon Redshift (p. 242)• Utilisation d'autres types de connexion SSL (p. 243)
Utilisation des derniers pilotes ODBC ou JDBC Amazon Redshift
La méthode privilégiée consiste à utiliser les derniers pilotes ODBC ou JDBC Amazon Redshift. Les pilotesAmazon Redshift à partir des versions ODBC 1.3.7.1000 et JDBC 1.2.8.1005 gèrent automatiquementla transition entre un certificat Amazon Redshift auto-signé et un certificat ACM. Pour télécharger lespilotes les plus récents, consultez Configurer la connexion ODBC (p. 219) ou Configurer une connexionJDBC (p. 203).
Si vous utilisez le dernier pilote JDBC Amazon Redshift, il est préférable de ne pasutiliser -Djavax.net.ssl.trustStore dans les options JVM. Si vous devez utiliser -Djavax.net.ssl.trustStore, importez le bundle d'autorités de certification Redshift dans le truststorevers lequel il pointe. Pour plus d'informations, consultez Importation du bundle des autorités de certificationRedshift dans un TrustStore (p. 243).
Utilisation des précédents pilotes ODBC ou JDBC Amazon Redshift
Si vous devez utiliser un pilote ODBC Amazon Redshift antérieur à la version 1.3.7.1000, téléchargez lebundle d'autorités de certification Redshift et remplacez l'ancien fichier de certificats.
• Si votre ODBC DSN est configuré avec SSLCertPath, remplacez le fichier de certificats dans le cheminspécifié.
• Si SSLCertPath n'est pas défini, remplacez le fichier de certificat nommé root.crt dansl'emplacement DLL du pilote.
Version de l'API 2012-12-01242

Amazon Redshift Guide de la gestion du clusterConfigurer les options de sécurité des connexions
Si vous devez utiliser un pilote JDBC Amazon Redshift antérieur à la version 1.2.8.1005, effectuez l'unedes actions suivantes :
• Si votre chaîne de connexion JDBC utilise l'option sslCert, supprimez l'option sslCert. Puis, importezle bundle des autorités de certification Redshift dans votre TrustStore Java. Pour plus d'informations,consultez Importation du bundle des autorités de certification Redshift dans un TrustStore (p. 243)
• Si vous utilisez l'option de ligne de commande Java -Djavax.net.ssl.trustStore, supprimez-lade la ligne de commande, si possible. Puis, importez le bundle des autorités de certification Redshiftdans votre TrustStore Java. Pour plus d'informations, consultez Importation du bundle des autorités decertification Redshift dans un TrustStore (p. 243)
Importation du bundle des autorités de certification Redshift dans un TrustStore
Vous pouvez utiliser le fichier redshift-keytool.jar pour importer les certificats de CA du bundled'autorités de certification Redshift dans un TrustStore Java ou dans votre TrustStore privé.
Pour importer le bundle des autorités de certification Redshift dans un TrustStore :
1. Téléchargez le fichier redshift-keytool.jar2. Effectuez l'une des actions suivantes :
• Pour importer le bundle d'autorités de certification Redshift dans un TrustStore Java, exécutez lacommande suivante :
java -jar redshift-keytool.jar -s
• Pour importer le bundle d'autorités de certification Redshift dans votre TrustStore privé, exécutez lacommande suivante :
java -jar redshift-keytool.jar -k <your_private_trust_store> -p <keystore_password>
Utilisation d'autres types de connexion SSL
Si vous souhaitez vous connecter à l'aide de l'une des solutions ci-dessous, suivez les étapes décritesdans cette section :
• Pilote ODBC open source• Pilote JDBC open source• Interface de ligne de commande psql• Toute liaison de langages basée sur libpq, telle que psycopg2 (Python) et ruby-pg (Ruby)
Pour utiliser les certificats ACM avec d'autres types de connexion SSL :
1. Téléchargez le bundle d'autorités de certification Redshift .2. Placez les certificats du bundle dans votre fichier root.crt.
• Sur les systèmes d'exploitation Linux et Mac OS X, le fichier est ~/.postgresql/root.crt• Sous Microsoft Windows, le fichier est %APPDATA%\postgresql\root.crt
Version de l'API 2012-12-01243

Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
Connexion aux clusters à partir des outils client et ducodeCette section fournit des options pour des outils tiers permettant de se connecter au cluster si vous nedisposez pas déjà d'un outil d'aide à la décision pour cela. En outre, elle explique comment vous connecterà votre cluster par programmation.
Rubriques• Se connecter au cluster à l'aide de SQL Workbench/J (p. 244)• Se connecter à votre cluster à l'aide de l'outil psql (p. 247)• Se connecter à votre cluster par programmation (p. 250)
Se connecter au cluster à l'aide de SQL Workbench/JAmazon Redshift ne fournit pas ni n'installe d'outils clients SQL ou de bibliothèques, vous devez doncinstaller tout ce que vous souhaitez utiliser avec vos clusters. Si vous disposez déjà d'une application d'aideà la décision ou de toute autre application qui peut se connecter aux clusters à l'aide d'un pilote ODBCou JDBC PostgreSQL standard, vous pouvez ignorer cette section. Si vous ne disposez pas déjà d'uneapplication qui peut se connecter à votre cluster, cette section présente une option permettant de le faire àl'aide de SQL Workbench/J, un outil de requête SQL inter-plateforme gratuit, indépendant de DBMS.
Installer SQL Workbench/J
Le manuel Amazon Redshift Mise en route utilise SQL Workbench/J. Dans cette section, nous vousexpliquons en détail comment vous connecter à votre cluster à l'aide de SQL Workbench/J.
Pour installer SQL Workbench/J
1. Vérifiez la licence logicielle de SQL Workbench/J.2. Accédez au site web SQL Workbench/J et téléchargez le package approprié pour votre système
d'exploitation sur votre ordinateur client ou instance Amazon EC2.3. Accédez à la page d'installation et de démarrage de SQL Workbench/J. Suivez les instructions
relatives à l'installation de SQL Workbench/J sur votre système.
Note
SQL Workbench/J nécessite que le Java Runtime Environment (JRE) soit installé sur votresystème. Vérifiez que vous utilisez la version correcte du JRE requise par le client SQLWorkbench/J. Pour déterminer quelle version de Java Runtime Environment est en coursd'exécution sur votre système, effectuez l'une des actions suivantes :
• Mac : Dans les Préférences système, cliquez sur l'icône Java.• Windows : Dans le Panneau de configuration, cliquez sur l'icône Java.• N'importe quel système : Dans un shell de commande, entrez java -version. Vous
pouvez également visiter le site https://www.java.com, cliquer sur le lien Do I Have Java?,puis cliquez sur le bouton Verify Java.
Pour plus d'informations sur l'installation et la configuration de Java Runtime Environment,accédez à https://www.java.com.
Version de l'API 2012-12-01244
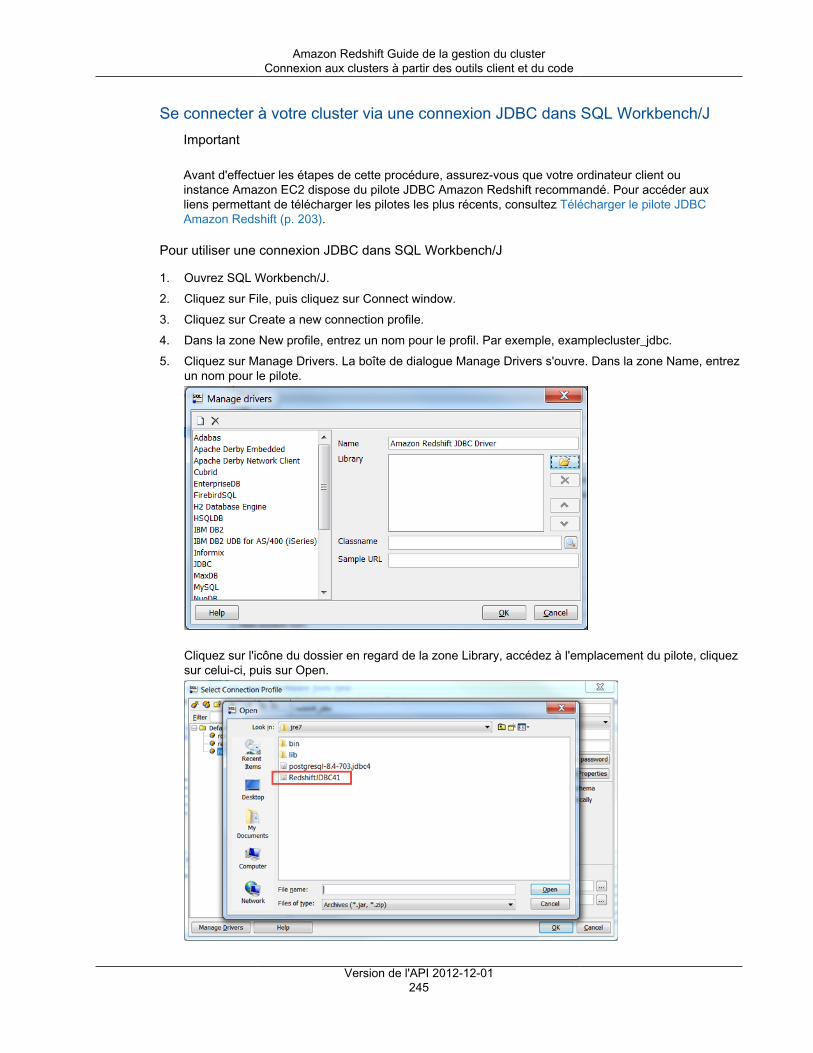
Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
Se connecter à votre cluster via une connexion JDBC dans SQL Workbench/JImportant
Avant d'effectuer les étapes de cette procédure, assurez-vous que votre ordinateur client ouinstance Amazon EC2 dispose du pilote JDBC Amazon Redshift recommandé. Pour accéder auxliens permettant de télécharger les pilotes les plus récents, consultez Télécharger le pilote JDBCAmazon Redshift (p. 203).
Pour utiliser une connexion JDBC dans SQL Workbench/J
1. Ouvrez SQL Workbench/J.2. Cliquez sur File, puis cliquez sur Connect window.3. Cliquez sur Create a new connection profile.4. Dans la zone New profile, entrez un nom pour le profil. Par exemple, examplecluster_jdbc.5. Cliquez sur Manage Drivers. La boîte de dialogue Manage Drivers s'ouvre. Dans la zone Name, entrez
un nom pour le pilote.
Cliquez sur l'icône du dossier en regard de la zone Library, accédez à l'emplacement du pilote, cliquezsur celui-ci, puis sur Open.
Version de l'API 2012-12-01245
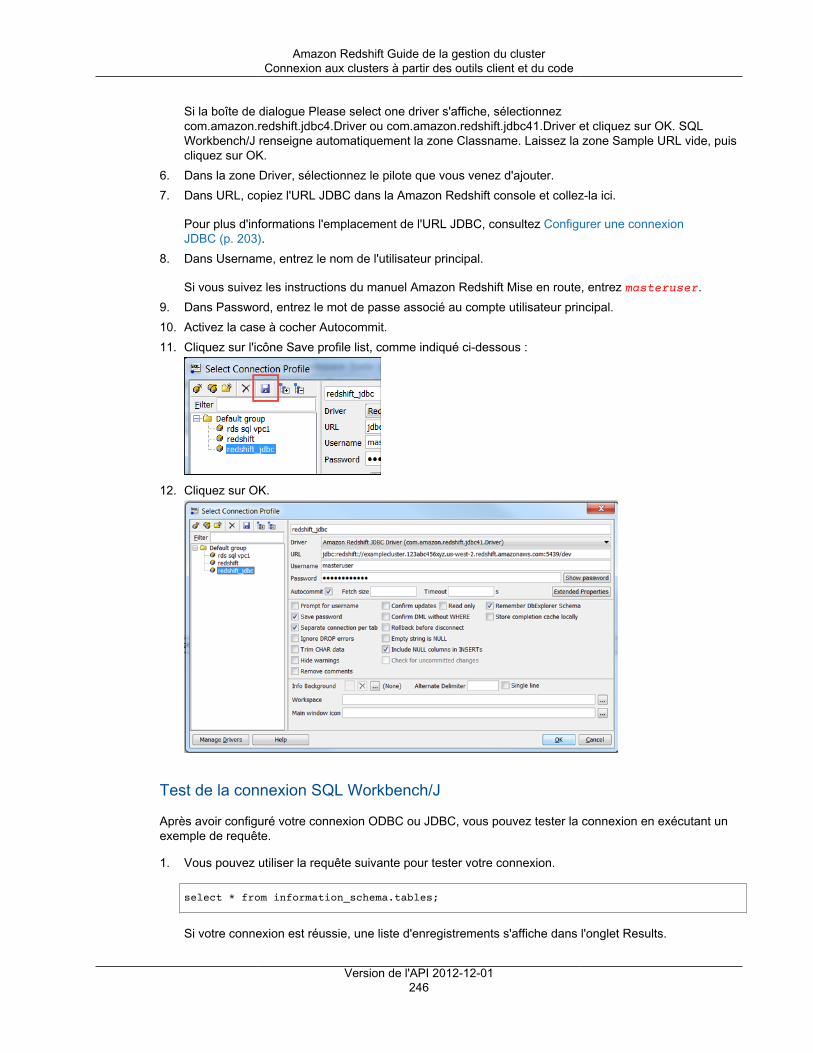
Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
Si la boîte de dialogue Please select one driver s'affiche, sélectionnezcom.amazon.redshift.jdbc4.Driver ou com.amazon.redshift.jdbc41.Driver et cliquez sur OK. SQLWorkbench/J renseigne automatiquement la zone Classname. Laissez la zone Sample URL vide, puiscliquez sur OK.
6. Dans la zone Driver, sélectionnez le pilote que vous venez d'ajouter.7. Dans URL, copiez l'URL JDBC dans la Amazon Redshift console et collez-la ici.
Pour plus d'informations l'emplacement de l'URL JDBC, consultez Configurer une connexionJDBC (p. 203).
8. Dans Username, entrez le nom de l'utilisateur principal.
Si vous suivez les instructions du manuel Amazon Redshift Mise en route, entrez masteruser.9. Dans Password, entrez le mot de passe associé au compte utilisateur principal.10. Activez la case à cocher Autocommit.11. Cliquez sur l'icône Save profile list, comme indiqué ci-dessous :
12. Cliquez sur OK.
Test de la connexion SQL Workbench/J
Après avoir configuré votre connexion ODBC ou JDBC, vous pouvez tester la connexion en exécutant unexemple de requête.
1. Vous pouvez utiliser la requête suivante pour tester votre connexion.
select * from information_schema.tables;
Si votre connexion est réussie, une liste d'enregistrements s'affiche dans l'onglet Results.
Version de l'API 2012-12-01246
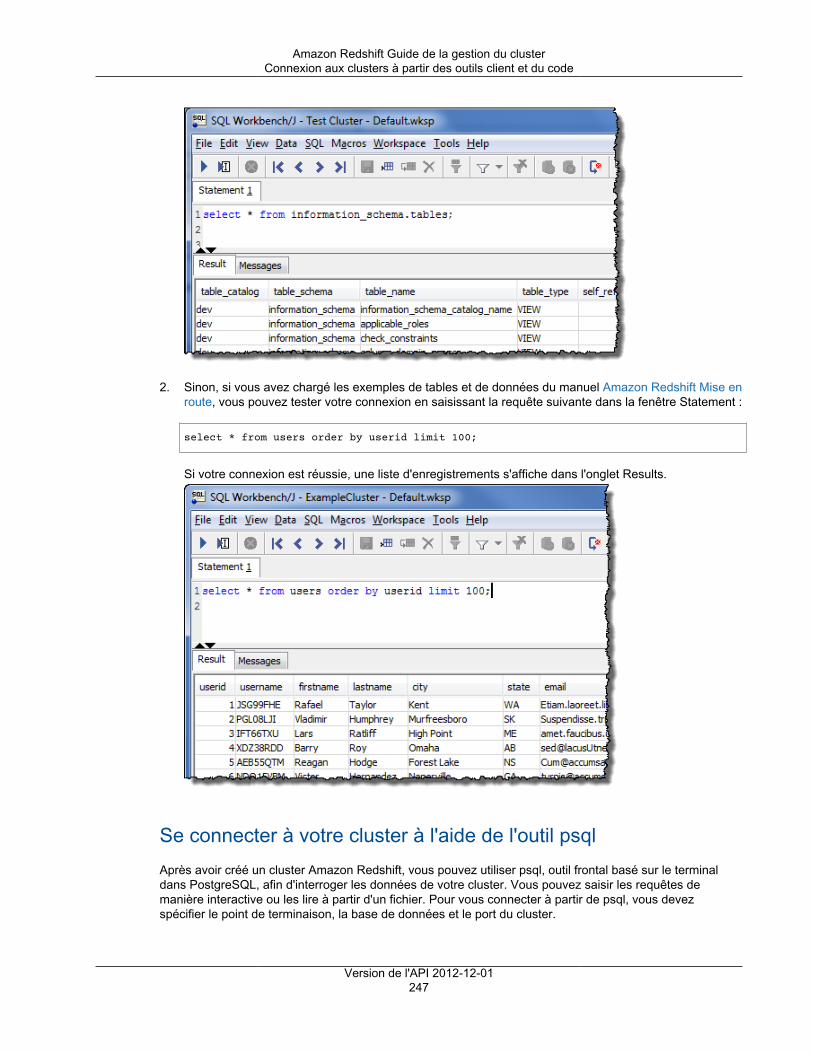
Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
2. Sinon, si vous avez chargé les exemples de tables et de données du manuel Amazon Redshift Mise enroute, vous pouvez tester votre connexion en saisissant la requête suivante dans la fenêtre Statement :
select * from users order by userid limit 100;
Si votre connexion est réussie, une liste d'enregistrements s'affiche dans l'onglet Results.
Se connecter à votre cluster à l'aide de l'outil psqlAprès avoir créé un cluster Amazon Redshift, vous pouvez utiliser psql, outil frontal basé sur le terminaldans PostgreSQL, afin d'interroger les données de votre cluster. Vous pouvez saisir les requêtes demanière interactive ou les lire à partir d'un fichier. Pour vous connecter à partir de psql, vous devezspécifier le point de terminaison, la base de données et le port du cluster.
Version de l'API 2012-12-01247

Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
Note
Amazon Redshift ne fournit pas l'outil psql ; il est installé avec PostgreSQL. Pour plusd'informations sur l'utilisation de psql, accédez à https://www.postgresql.org/docs/8.4/static/app-psql.html. Pour plus d'informations sur l'installation des outils clients PostgreSQL, sélectionnezvotre système d'exploitation dans la page des téléchargements binaires PostgreSQL à l'adressehttps://www.postgresql.org/download/.
Se connecter à l'aide des valeurs par défaut psql
Par défaut, psql ne valide pas le service Amazon Redshift ; il établit une connexion chiffrée à l'aide duprotocole SSL (Secure Sockets Layer).
Pour se connecter à l'aide des valeurs par défaut psql
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de gauche, cliquez sur Clusters. Cliquez sur votre cluster pour l'ouvrir.Sous Propriétés de la base de données du cluster, enregistrez les valeurs du Point de terminaison, duPort et du Nom de la base de données.
3. A l'invite de commande, spécifiez les informations de connexion à l'aide des paramètres de ligne decommande ou d'une chaîne d'informations de connexion. Pour utiliser les paramètres :
psql -h <endpoint> -U <userid> -d <databasename> -p <port>
Où:
• <endpoint> est le Point de terminaison que vous avez enregistré à l'étape précédente.• <userid> est un ID d'utilisateur disposant des autorisations permettant de se connecter au cluster.• <databasename> est le Nom de base de données que vous avez enregistré à l'étape précédente.• <port> est le Port que vous avez enregistré à l'étape précédente.
Exemples :
Version de l'API 2012-12-01248

Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
psql -h examplecluster.<XXXXXXXXXXXX>.us-west-2.redshift.amazonaws.com -U masteruser -d dev -p 5439
4. A l'invite du mot de passe psql, entrez le mot de passe de l'utilisateur <userid>.
Vous êtes connecté au cluster et vous pouvez entrer des commandes de manière interactive.
Se connecter à l'aide d'un certificat
Pour vérifier si psql authentifie le service à l'aide d'un certificat, vous devez utiliser une chaîned'informations de connexion pour spécifier les informations de connexion et le mot clé sslmode. Pardéfaut, psql fonctionne avec sslmode=prefer. Pour spécifier que psql ouvre une connexion chiffrée etutilise un certificat Amazon Redshift pour vérifier le service, téléchargez un certificat Amazon Redshift survotre ordinateur. Spécifiez verify-full à moins que vous n'utilisiez un alias DNS. Si vous utilisez unalias DNS, sélectionnez verify-ca. Spécifiez sslrootcert avec l'emplacement du certificat. Pour plusd'informations sur sslmode, consultez Configurer les options de sécurité des connexions (p. 238).
Pour plus d'informations sur les paramètres de chaîne de connexion d'informations, consultez https://www.postgresql.org/docs/8.4/static/libpq-connect.html.
Pour se connecter à l'aide d'un certificat
1. Enregistrez le téléchargement du bundle d'autorités de certification Redshift dans un fichier .crt survotre ordinateur. Si vous exécutez Fichier\Enregistrer sous à l'aide d'Internet Explorer, définissez letype de fichier sur Fichier texte (*.txt) et supprimez l'extension .txt. Par exemple, enregistrez-le en tantque fichier C:\MyDownloads\redshift-ca-bundle.crt.
2. Dans la console Amazon Redshift, sélectionnez le cluster pour afficher les Propriétés de la base dedonnées du cluster. Enregistrez les valeurs affichées dans les champs Point de terminaison, Port etNom de base de données.
3. A l'invite de commande, spécifiez les informations de connexion à l'aide d'une chaîne d'informations deconnexion :
Version de l'API 2012-12-01249
Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
psql "host=<endpoint> user=<userid> dbname=<databasename> port=<port> sslmode=verify-ca sslrootcert=<certificate>"
Où:
• <endpoint> est le Point de terminaison que vous avez enregistré à l'étape précédente.• <userid> est un ID d'utilisateur disposant des autorisations permettant de se connecter au cluster.• <databasename> est le Nom de base de données que vous avez enregistré à l'étape précédente.• <port> est le Port que vous avez enregistré à l'étape précédente.• <certificate> est le chemin d'accès complet au fichier du certificat. Sur les systèmes Windows,
le chemin d'accès au certificat doit être spécifié à l'aide des séparateurs Linux / au lieu du séparateurWindows \.
Sur les systèmes d'exploitation Linux et Mac OS X, le chemin est
~/.postgresql/root.crt
Sous Microsoft Windows, le chemin est
%APPDATA%/postgresql/root.crt
Exemples :
psql "host=examplecluster.<XXXXXXXXXXXX>.us-west-2.redshift.amazonaws.com user=masteruser dbname=dev port=5439 sslmode=verify-ca sslrootcert=C:/MyDownloads/redshift-ca-bundle.crt"
4. A l'invite du mot de passe psql, entrez le mot de passe de l'utilisateur <userid>.
Vous êtes connecté au cluster et vous pouvez entrer des commandes de manière interactive.
Se connecter à votre cluster par programmationCette section explique comment vous connecter à votre cluster par programmation. Si vous utilisez uneapplication comme SQL Workbench/J qui gère vos connexions client pour vous, vous pouvez ignorer cettesection.
Connexion à un Cluster à l'aide de Java
Lorsque vous utilisez Java pour vous connecter par programmation à votre cluster, vous pouvez le faireavec ou sans l'authentification du serveur. Si vous prévoyez d'utiliser l'authentification du serveur, suivezles instructions de Configurer les options de sécurité des connexions (p. 238) pour placer le certificat deserveur Amazon Redshift dans un keystore. Vous pouvez faire référence au keystore en spécifiant unepropriété lorsque vous exécutez votre code comme suit :
-Djavax.net.ssl.trustStore=<path to keystore>-Djavax.net.ssl.trustStorePassword=<keystore password>
Example : Se connecter à un cluster à l'aide de Java
L'exemple suivant se connecte à un cluster et exécute un exemple de requête qui renvoie des tablessystème. Cet exemple ne nécessite pas que vous disposiez de données dans votre base de données.
Version de l'API 2012-12-01250
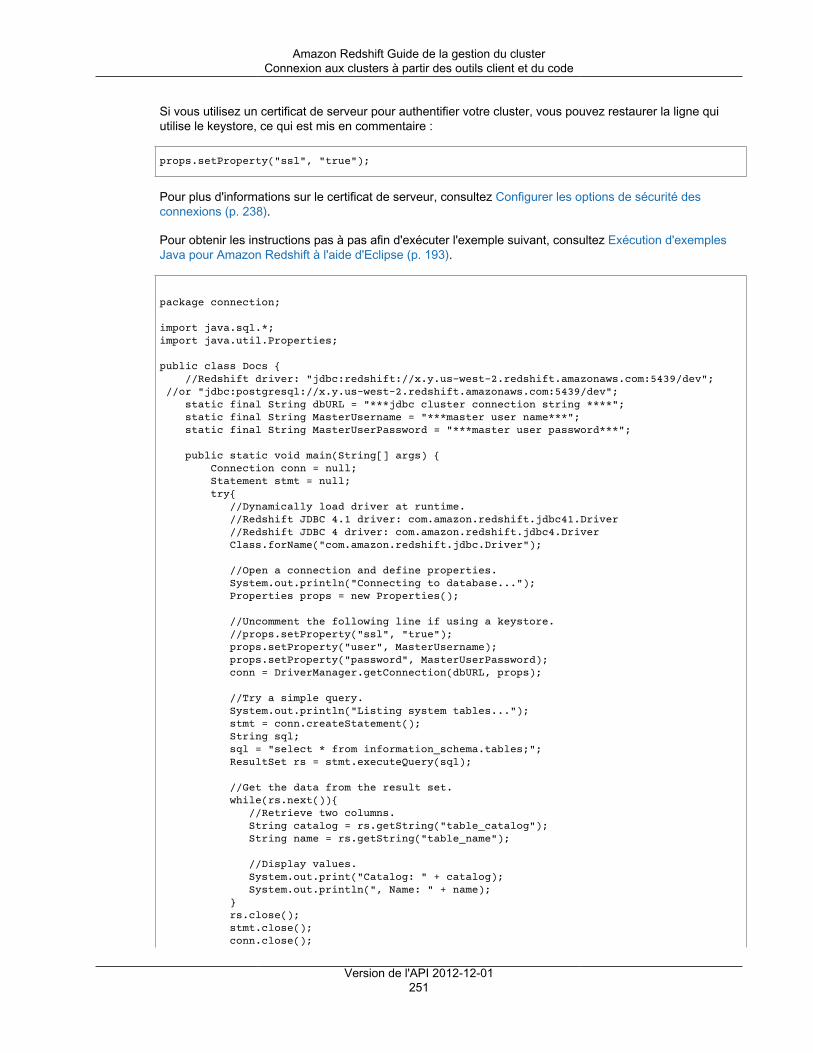
Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
Si vous utilisez un certificat de serveur pour authentifier votre cluster, vous pouvez restaurer la ligne quiutilise le keystore, ce qui est mis en commentaire :
props.setProperty("ssl", "true");
Pour plus d'informations sur le certificat de serveur, consultez Configurer les options de sécurité desconnexions (p. 238).
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193).
package connection;
import java.sql.*;import java.util.Properties;
public class Docs { //Redshift driver: "jdbc:redshift://x.y.us-west-2.redshift.amazonaws.com:5439/dev"; //or "jdbc:postgresql://x.y.us-west-2.redshift.amazonaws.com:5439/dev"; static final String dbURL = "***jdbc cluster connection string ****"; static final String MasterUsername = "***master user name***"; static final String MasterUserPassword = "***master user password***";
public static void main(String[] args) { Connection conn = null; Statement stmt = null; try{ //Dynamically load driver at runtime. //Redshift JDBC 4.1 driver: com.amazon.redshift.jdbc41.Driver //Redshift JDBC 4 driver: com.amazon.redshift.jdbc4.Driver Class.forName("com.amazon.redshift.jdbc.Driver");
//Open a connection and define properties. System.out.println("Connecting to database..."); Properties props = new Properties();
//Uncomment the following line if using a keystore. //props.setProperty("ssl", "true"); props.setProperty("user", MasterUsername); props.setProperty("password", MasterUserPassword); conn = DriverManager.getConnection(dbURL, props); //Try a simple query. System.out.println("Listing system tables..."); stmt = conn.createStatement(); String sql; sql = "select * from information_schema.tables;"; ResultSet rs = stmt.executeQuery(sql); //Get the data from the result set. while(rs.next()){ //Retrieve two columns. String catalog = rs.getString("table_catalog"); String name = rs.getString("table_name");
//Display values. System.out.print("Catalog: " + catalog); System.out.println(", Name: " + name); } rs.close(); stmt.close(); conn.close();
Version de l'API 2012-12-01251

Amazon Redshift Guide de la gestion du clusterConnexion aux clusters à partir des outils client et du code
}catch(Exception ex){ //For convenience, handle all errors here. ex.printStackTrace(); }finally{ //Finally block to close resources. try{ if(stmt!=null) stmt.close(); }catch(Exception ex){ }// nothing we can do try{ if(conn!=null) conn.close(); }catch(Exception ex){ ex.printStackTrace(); } } System.out.println("Finished connectivity test."); }}
Connexion à un Cluster à l'aide de .NETLorsque vous utilisez .NET (C#) pour vous connecter par programmation à votre cluster, vous pouvez lefaire avec ou sans l'authentification du serveur. Si vous prévoyez d'utiliser l'authentification du serveur,suivez les instructions de Configurer les options de sécurité des connexions (p. 238) pour télécharger lecertificat de serveur Amazon Redshift, puis mettez le certificat au format adéquat pour votre code .NET.
Example Se connecter à un cluster à l'aide de .NET
L'exemple suivant se connecte à un cluster et exécute un exemple de requête qui renvoie des tablessystème. Il ne présente pas l'authentification du serveur. Cet exemple ne nécessite pas que vous disposiezde données dans votre base de données. Cet exemple utilise System.Data.Odbc Namespace, unfournisseur de données .NET Framework pour ODBC.
using System;using System.Data;using System.Data.Odbc;
namespace redshift.amazon.com.docsamples{ class ConnectToClusterExample { public static void Main(string[] args) {
DataSet ds = new DataSet(); DataTable dt = new DataTable();
// Server, e.g. "examplecluster.xyz.us-west-2.redshift.amazonaws.com" string server = "***provide server name part of connection string****";
// Port, e.g. "5439" string port = "***provide port***";
// MasterUserName, e.g. "masteruser". string masterUsername = "***provide master user name***";
// MasterUserPassword, e.g. "mypassword". string masterUserPassword = "***provide master user password***";
// DBName, e.g. "dev" string DBName = "***provide name of database***";
Version de l'API 2012-12-01252

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
connexion dans Amazon Redshift
string query = "select * from information_schema.tables;";
try { // Create the ODBC connection string. //Redshift ODBC Driver - 64 bits /* string connString = "Driver={Amazon Redshift (x64)};" + String.Format("Server={0};Database={1};" + "UID={2};PWD={3};Port={4};SSL=true;Sslmode=Require", server, DBName, masterUsername, masterUserPassword, port); */
//Redshift ODBC Driver - 32 bits string connString = "Driver={Amazon Redshift (x86)};" + String.Format("Server={0};Database={1};" + "UID={2};PWD={3};Port={4};SSL=true;Sslmode=Require", server, DBName, masterUsername, masterUserPassword, port);
// Make a connection using the psqlODBC provider. OdbcConnection conn = new OdbcConnection(connString); conn.Open();
// Try a simple query. string sql = query; OdbcDataAdapter da = new OdbcDataAdapter(sql, conn); da.Fill(ds); dt = ds.Tables[0]; foreach (DataRow row in dt.Rows) { Console.WriteLine(row["table_catalog"] + ", " + row["table_name"]); }
conn.Close(); Console.ReadKey(); } catch (Exception ex) { Console.Error.WriteLine(ex.Message); Console.ReadKey(); }
} }}
Résolution des problèmes de connexion dans AmazonRedshiftSi vous rencontrez des problèmes de connexion à votre cluster avec un outil client SQL, vérifiez plusieurséléments pour cerner le problème. Si vous utilisez des certificats SSL ou serveur, commencez parsupprimer cette complexité pendant que vous résolvez le problème de connexion. Ensuite, rajoutez-la lorsque vous avez trouvé une solution. Pour plus d'informations, consultez Configurer les options desécurité des connexions (p. 238).
Important
Amazon Redshift a modifié la façon de gérer les certificats SSL. Si vous avez des difficultés àvous connecter avec SSL, il se peut que vous ayez besoin de mettre à jour vos certificats actuels
Version de l'API 2012-12-01253

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
connexion dans Amazon Redshift
d'autorité de certification racine. Pour plus d'informations, consultez Transition vers les certificatsACM pour les connexions SSL (p. 242).
La section suivante présente des exemples de messages d'erreur et des solutions possibles aux problèmesde connexion. Etant donné que différents outils clients SQL fournissent différents messages d'erreur, cetteliste n'est pas exhaustive, mais constitue un bon point de départ pour la résolution des problèmes.
Rubriques• Connexion en dehors d'Amazon EC2 — Problème d'expiration du pare-feu (p. 254)• La connexion est refusée ou échoue (p. 256)• Le client et le pilote sont incompatibles (p. 257)• Des requêtes semblent se bloquer et parfois échouent à atteindre le cluster (p. 257)
Connexion en dehors d'Amazon EC2 — Problème d'expiration dupare-feuExemple de problème
La connexion de votre client à la base de données semble se bloquer ou arriver à expiration lorsque vousexécutez de longues requêtes, par exemple une commande COPY. Dans ce cas, vous pouvez constaterque la Amazon Redshift console affiche que la requête s'est terminée, mais l'outil client lui-même sembletoujours en train d'exécuter la requête. Les résultats de la requête peuvent être manquants ou incompletsen fonction selon le moment où la connexion s'est arrêtée.
Solutions possibles
Cela se produit lorsque vous vous connectez à Amazon Redshift à partir d'un ordinateur autre qu'uneinstance Amazon EC2 et les connexions inactives sont arrêtées par un composant réseau intermédiaire,comme un pare-feu, après une période d'inactivité. Ce comportement est classique lorsque vous vousconnectez à partir d'un réseau privé virtuel (VPN) ou de votre réseau local.
Pour éviter ces délais d'attente, nous vous recommandons d'apporter les modifications suivantes :
• Augmentez les valeurs du système client qui traitent l'expiration TCP/IP. Vous devez apporter cesmodifications sur l'ordinateur que vous utilisez pour vous connecter à votre cluster. Le délai d'expirationdoit être réglé pour votre client et le réseau. Voir Modification des paramètres d'expiration de TCP/IP (p. 254).
• Le cas échéant, définissez le comportement keep-alive au niveau de la DSN. Voir Modification desparamètres d'expiration de la DSN (p. 255).
Modification des paramètres d'expiration de TCP/IP
Pour modifier les paramètres d'expiration de TCP/IP, configurez-les en fonction du système d'exploitationque vous utilisez pour vous connecter à votre cluster.
• Linux — Si votre client s'exécute sous Linux, exécutez la commande suivante en tant qu'utilisateur racinepour modifier les paramètres d'expiration de la session en cours :
/sbin/sysctl -w net.ipv4.tcp_keepalive_time=200 net.ipv4.tcp_keepalive_intvl=200 net.ipv4.tcp_keepalive_probes=5
Pour conserver les paramètres, créez ou modifiez le fichier /etc/sysctl.conf avec lesvaleurs suivantes, puis redémarrez votre système.
Version de l'API 2012-12-01254

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
connexion dans Amazon Redshift
net.ipv4.tcp_keepalive_time=200net.ipv4.tcp_keepalive_intvl=200net.ipv4.tcp_keepalive_probes=5
• Windows — Si le client s'exécute sous Windows, modifiez les valeurs des paramètres de registresuivants sous HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\ :• KeepAliveTime : 30 000• KeepAliveInterval : 1 000• TcpMaxDataRetransmissions : 10
Ces paramètres utilisent le type de données DWORD. S'ils n'existent pas sous le chemin d'accèsau registre, vous pouvez créer les paramètres et spécifiez ces valeurs recommandées. Pour plusd'informations sur la modification du registre Windows, reportez-vous à la documentation Windows.
Une fois ces valeurs définies, redémarrez votre ordinateur pour que les modifications prennent effet.
• Mac — Si le client s'exécute sur un Mac, exécutez les commandes suivantes pour modifier lesparamètres d'expiration pour la session en cours :
sudo sysctl net.inet.tcp.keepintvl=200000sudo sysctl net.inet.tcp.keepidle=200000sudo sysctl net.inet.tcp.keepinit=200000sudo sysctl net.inet.tcp.always_keepalive=1
Pour conserver les paramètres, créez ou modifiez le fichier /etc/sysctl.conf avec lesvaleurs suivantes :
net.inet.tcp.keepidle=200000net.inet.tcp.keepintvl=200000net.inet.tcp.keepinit=200000net.inet.tcp.always_keepalive=1
Redémarrez votre ordinateur, puis exécutez les commandes suivantes pour vérifier que les valeurs sontdéfinies.
sysctl net.inet.tcp.keepidlesysctl net.inet.tcp.keepintvlsysctl net.inet.tcp.keepinitsysctl net.inet.tcp.always_keepalive
Modification des paramètres d'expiration de la DSN
Vous pouvez définir un comportement keep-alive au niveau de la DSN si vous le souhaitez. Pour cela, vousajoutez ou vous modifiez les paramètres suivants dans le fichier odbc.ini :
KeepAlivesCount
Nombre de paquets TCP keep-alive qui peuvent être perdus avant que la connexion soit considéréecomme interrompue.
Version de l'API 2012-12-01255

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
connexion dans Amazon Redshift
KeepAlivesIdle
Nombre de secondes d'inactivité avant que le pilote envoie un paquet TCP keep-alive.KeepAlivesInterval
Nombre de secondes entre chaque retransmission de paquet TCP keep-alive.
Sous Windows, vous modifiez ces paramètres dans le registre en ajoutant ou en modifiant les clésde HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBC. INI\you_DSN. Sous Linux et Mac OS, vousajoutez ou modifiez ces paramètres directement dans l'entrée DSN cible du fichier odbc.ini. Pour plusd'informations sur la modification du fichier odbc.ini sur les ordinateurs Linux et Mac OS, consultezConfigurer le pilote ODBC sur les systèmes d'exploitation Linux et Mac OS X (p. 227).
Si ces paramètres n'existent pas ou s'ils ont une valeur égale à 0, le système utilise les paramètreskeep-alive spécifiés pour TCP/IP afin de déterminer le comportement DSN keep-alive. Sous Windows,les paramètres TCP/IP sont disponibles dans le registre dans HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\. Sous Linux et Mac OS, les paramètres TCP/IP sontdisponibles dans le fichier sysctl.conf.
La connexion est refusée ou échoueExemples d'erreurs :
• « Impossible d'établir une connexion à <endpoint>. »• « Impossible de se connecter au serveur : la connexion a expiré. Le serveur s'exécute-t-il sur l'hôte'<endpoint>' et accepte-t-il les connexions TCP/IP sur le port '<port>' ? »
• « Connexion refusée. Vérifiez que le nom d'hôte et le port sont corrects et que l'administrateur accepteles connexions TCP/IP. »
Solutions possibles :
En général, lorsque vous recevez un message d'erreur indiquant qu'il est impossible d'établir uneconnexion, cela signifie qu'il y a un problème d'autorisation d'accès au cluster.
Si vous tentez de vous connecter au cluster à partir d'un outil client en dehors du réseau dans lequel setrouve le cluster, vous devez ajouter une règle de trafic entrant pour le groupe de sécurité du cluster pourl'adresse CIDR/IP depuis laquelle vous vous connectez :
• Si vous avez créé votre cluster Amazon Redshift dans un Amazon Virtual Private Cloud (Amazon VPC),vous devez ajouter votre adresse CIDR/IP client dans le groupe de sécurité VPC du Amazon VPC.Pour plus d'informations sur la configuration des groupes de sécurité VPC pour votre cluster, consultezGestion des clusters dans un Amazon Virtual Private Cloud (VPC) (p. 36).
• Si vous avez créé votre cluster Amazon Redshift à l'extérieur d'un VPC, vous devez ajouter votreadresse CIDR/IP client dans le groupe de sécurité du cluster dans Amazon Redshift. Pour plusd'informations sur la configuration des groupes de sécurité de cluster, consultez Groupes de sécurité ducluster Amazon Redshift (p. 148).
Si vous tentez de vous connecter au cluster depuis un outil client dans une instance Amazon EC2, vousdevez ajouter une règle de trafic entrant dans le groupe de sécurité du cluster pour le groupe de sécuritéAmazon EC2 qui est associé à l'instance Amazon EC2. Pour plus d'informations sur la configuration desgroupes de sécurité de cluster, consultez Groupes de sécurité du cluster Amazon Redshift (p. 148).
En outre, si vous disposez d'une couche entre votre client et votre serveur, comme un pare-feu, assurez-vous que le pare-feu accepte les connexions entrantes sur le port que vous avez configuré pour votrecluster.
Version de l'API 2012-12-01256

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
connexion dans Amazon Redshift
Le client et le pilote sont incompatiblesExemple d'erreur :
« La DSN spécifiée contient une incompatibilité d'architecture entre le pilote et l'application. »
Solution possible :
Quand vous tentez de vous connecter et que vous recevez un message d'erreur concernant uneincompatibilité d'architecture, cela signifie que l'outil client et le pilote ne sont pas compatibles, car leurarchitecture système ne correspond pas. Par exemple, cela peut se produire si vous avez un outil client32 bits, alors que vous avez installé la version 64 bits du pilote. Les outils clients 64 bits utilisent parfois despilotes 32 bits, mais vous ne pouvez pas utiliser des applications 32 bits avec des pilotes 64 bits. Assurez-vous que le pilote et l'outil client utilisent la même version d'architecture système.
Des requêtes semblent se bloquer et parfois échouent à atteindrele clusterExemple de problème :
Vous rencontrez un problème pour terminer des requêtes, notamment que les requêtes semblent être encours d'exécution, mais se bloquent dans l'outil client SQL. Parfois les requêtes ne s'affichent pas dans lecluster, notamment dans les tables système ou sur la Amazon Redshift console.
Solution possible :
Ce problème peut se produire en raison d'un rejet de paquet, lorsqu'il y a une différence de taille de l'unitéde transmission maximale (MTU) dans le chemin d'accès réseau entre deux hôtes IP (Internet Protocol).La taille de la MTU détermine la taille maximale, en octets, d'un paquet pouvant être transféré dans unetrame Ethernet sur une connexion réseau. Dans AWS, certains types d'instances Amazon EC2 prennent encharge une MTU de 1 500 (trames Ethernet v2) et d'autres types d'instances prennent en charge une MTUde 9 001 (trames jumbo TCP/IP).
Pour éviter que des problèmes se produisent en raison de différences de taille de la MTU, nous vousrecommandons procéder comme suit :
• Si votre cluster utilise la plateforme EC2-VPC, configurez le groupe de sécurité Amazon VPC avec unerègle entrante ICMP (Internet Control Message Protocol) personnalisée qui renvoie DestinationUnreachable, c'est-à-dire qui demande à l'hôte d'origine d'utiliser la taille de MTU la plus petite surle chemin d'accès réseau. Pour plus d'informations sur cette approche, consultez Configuration desgroupes de sécurité pour autoriser le message ICMP « Destination inaccessible » (p. 257).
• Si votre cluster utilise la plateforme EC2-Classic ou si vous ne pouvez pas autoriser la règle de traficentrant ICMP, désactivez les trames jumbo TCP/IP afin que des trames Ethernet v2 soient utilisées. Pourplus d'informations sur cette approche, consultez Configuration de la MTU d'une instance (p. 258).
Configuration des groupes de sécurité pour autoriser le message ICMP« Destination inaccessible »
En cas de différence de taille de la MTU sur le réseau entre deux hôtes, vérifiez d'abord que vosparamètres réseau n'empêchent pas la détection de la MTU du chemin (PMTUD, path MTU discovery). LaPMTUD permet à l'hôte de réception de répondre à l'hôte d'origine avec le message suivant ICMP suivant :Destination Unreachable: fragmentation needed and DF set (ICMP Type 3, Code 4).Ce message indique que l'hôte d'origine utilise la taille de MTU la plus petite sur chemin d'accès réseaupour renvoyer la demande. Sans cette négociation, un rejet de paquet peut se produire, car la demandeest trop volumineuse pour l'hôte de réception. Pour plus d'informations sur ce message ICMP, consultezRFC792 sur le site web Internet Engineering Task Force (IETF).
Version de l'API 2012-12-01257

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
connexion dans Amazon Redshift
Si vous ne configurez pas explicitement cette règle de trafic entrant ICMP pour votre groupe de sécuritéAmazon VPC, la PMTUD est bloquée. Dans AWS, les groupes de sécurité sont des pare-feu virtuelsqui spécifient des règles de trafic entrant et sortant pour une instance. Pour les clusters qui utilisent laplateforme EC2-VPC, Amazon Redshift utilise les groupes de sécurité VPC pour autoriser ou refuser letrafic vers le cluster. Par défaut, les groupes de sécurité sont verrouillés et refusent tout trafic entrant.
Pour plus d'informations sur la procédure pour ajouter des règles aux groupes de sécurité VPC, consultezGestion des groupes de sécurité VPC pour un Cluster (p. 39). Pour plus d'informations sur les paramètresPMTUD spécifiques requis dans cette règle, consultez Détection de la MTU du chemin dans le manuelAmazon EC2 Guide de l'utilisateur pour les instances Linux.
Configuration de la MTU d'une instance
Si votre cluster utilise la plateforme EC2-Classic ou que vous ne pouvez pas autoriser la règle ICMPpersonnalisée pour le trafic entrant dans votre cas, nous vous recommandons d'ajuster la MTU à 1 500sur l'interface réseau (carte réseau) des instances Amazon EC2 à partir desquelles vous vous connectez àvotre cluster Amazon Redshift. Cet ajustement désactive les trames jumbo TCP/IP pour s'assurer que lesconnexions utilisent systématiquement la même taille de paquet. Cependant, Notez que cette option réduitle débit maximal de votre réseau pour l'ensemble de l'instance, pas uniquement les connexions à AmazonRedshift. Pour plus d'informations, consultez les procédures suivantes.
Pour définir la MTU sur un système d'exploitation Microsoft Windows
Si votre client s'exécute sur un système d'exploitation Microsoft Windows, vous pouvez vérifier et définir lavaleur de la MTU pour la carte Ethernet à l'aide de la commande netsh.
1. Exécutez la commande suivante afin de déterminer la valeur actuelle de la MTU :
netsh interface ipv4 show subinterfaces
2. Vérifiez la valeur de la MTU pour la carte Ethernet dans la sortie.3. Si la valeur n'est pas 1500, exécutez la commande suivante pour la définir :
netsh interface ipv4 set subinterface "Ethernet" mtu=1500 store=persistent
Une fois cette valeur définie, redémarrez votre ordinateur pour que les modifications prennent effet.
Pour définir la MTU sur un système d'exploitation Linux
Si le client s'exécute sur un système d'exploitation Linux, vous pouvez vérifier et définir la valeur de la MTUà l'aide de la commande ip.
1. Exécutez la commande suivante afin de déterminer la valeur actuelle de la MTU :
$ ip link show eth0
2. Vérifiez la valeur suivant mtu dans la sortie.3. Si la valeur n'est pas 1500, exécutez la commande suivante pour la définir :
$ sudo ip link set dev eth0 mtu 1500
Pour définir la MTU sur un système d'exploitation Mac
• Pour définir la valeur de la MTU sur un système d'exploitation Mac, suivez les instructions de la pageMac OS X 10.4 or later: How to change the MTU for troubleshooting purposes.
Version de l'API 2012-12-01258

Amazon Redshift Guide de la gestion du clusterPrésentation
Surveillance des performances decluster Amazon Redshift
Amazon Redshift fournit les métriques de performance et les données de telle sorte que vous puissiezsuivre l'état et les performances de vos clusters et bases de données. Dans cette section, nous abordonsles types de données que vous pouvez utiliser dans Amazon Redshift et, plus précisément, dans la consoleAmazon Redshift.
Rubriques• Présentation (p. 259)• Données de performance Amazon Redshift (p. 260)• Utilisation des données de performance dans la console Amazon Redshift (p. 265)
PrésentationLes données de performance que vous pouvez utiliser dans la console Amazon Redshift se divisent endeux catégories :
• Métriques Amazon CloudWatch : les métriques Amazon CloudWatch vous aident à surveiller les aspectsphysiques de votre cluster, comme l'utilisation de l'UC, la latence et le débit. Les données des métriquess'affichent directement dans la console Amazon Redshift. Vous pouvez également les voir dans laconsole Amazon CloudWatch. De même, vous pouvez les consommer par tout autre moyen que vousappliquez à l'utilisation des métriques, tels quel l'AWS CLI ou un des Kits de développement logiciel(SDK) AWS.
• Données de performances de requête/de chargement : les données de performance vous aident àsurveiller l'activité de la base de données et les performances. Ces données sont regroupées dans laconsole Amazon Redshift pour vous aider à facilement relier ce que vous voyez dans les métriquesAmazon CloudWatch avec les événements spécifiques de requête et de chargement de base dedonnées. Vous pouvez aussi créer vos propres requêtes de performance personnalisées et les exécuterdirectement sur la base de données. Les données de performance des requêtes et des chargess'affichent uniquement dans la console Amazon Redshift. Elles ne sont pas publiées en tant quemétriques Amazon CloudWatch.
Les données de performance sont intégrées à la console Amazon Redshift, ce qui génère une expérienceplus riche, comme illustré ci-après :
• Les données de performance associées à un cluster s'affichent contextuellement lorsque vousaffichez un cluster, où vous pouvez avoir besoin de prendre des décisions sur le cluster telles que leredimensionnement.
• Certaines métriques de performances sont affichées en unités d'échelle de façon plus appropriéedans la console Amazon Redshift par rapport comparaison avec Amazon CloudWatch. Par exemple,WriteThroughput s'affiche en Go/s (et non en octets/s comme dans Amazon CloudWatch), qui est uneunité plus appropriée pour l'espace de stockage classique d'un nœud.
• Vous pouvez aisément afficher des données de performances pour les nœuds d'un cluster ensemble surle même graphique. De cette manière, vous pouvez surveiller les performances de tous les nœuds d'uncluster. Vous pouvez également consulter les données de performances pour chaque nœud.
Amazon Redshift fournit les données de performance (les métriques Amazon CloudWatch et les donnéesde requête et de chargement), sans coût supplémentaire. Les données de performance sont enregistrées
Version de l'API 2012-12-01259

Amazon Redshift Guide de la gestion du clusterDonnées de performance
toutes les minutes. Vous pouvez accéder aux valeurs historiques des données de performance dans laconsole Amazon Redshift. Pour plus d'informations sur l'utilisation d'Amazon CloudWatch pour accéderaux données de performance Amazon Redshift exposées en tant que métriques Amazon CloudWatch,consultez Présentation d'Amazon CloudWatch dans le manuel Guide de l'utilisateur Amazon CloudWatch.
Données de performance Amazon RedshiftEn utilisant les métriques Amazon CloudWatch pour Amazon Redshift, vous pouvez obtenir desinformations sur les performances et l'état de votre cluster, et afficher des informations au niveau desnœuds. Lorsque vous utilisez ces métriques, gardez à l'esprit que chaque métrique est associée à une ouplusieurs dimensions. Ces dimensions vous indiquent à quoi la métrique est applicable, soit la portée de lamétrique. Amazon Redshift a les deux dimensions suivantes :
• Les métriques ayant une dimension NodeID sont les métriques qui fournissent les données deperformance des nœuds d'un cluster. Cet ensemble de métriques inclut les nœuds principaux et lesnœuds de calcul. Exemples de métriques : CPUUtilization, ReadIOPS, WriteIOPS.
• Les métriques qui n'ont qu'une dimension ClusterIdentifier sont celles qui fournissent les donnéesde performance des clusters. Exemples de métriques : HealthStatus et MaintenanceMode.
Note
Dans certains cas de métriques, une métrique spécifique à un cluster représente une agrégationdu comportements de nœuds. Dans ces cas, soyez attentif à l'interprétation de la valeur de lamétrique, car le comportement du nœud principal est regroupé avec celui du nœud de calcul.
Pour des informations générales sur les métriques et les dimensions CloudWatch, consultez ConceptsAmazon CloudWatch dans le Guide de l'utilisateur Amazon CloudWatch.
Pour obtenir une description plus détaillée des métriques CloudWatch pour Amazon Redshift, consultez lessections ci-dessous.
Métriques Amazon RedshiftL'espace de noms AWS/Redshift inclut les métriques suivantes.
Métrique Description
CPUUtilization Pourcentage d'utilisation de la CPU. Pour les clusters, cette métriquereprésente une agrégation de toutes les valeurs d'utilisation par l'UCdes nœuds (principal et calcul).
Unités : pourcentage
Dimensions: NodeID, ClusterIdentifier
DatabaseConnections Nombre de connexions de base de données d'un cluster.
Unités : nombre
Dimensions: ClusterIdentifier
HealthStatus Indique l'état d'intégrité du cluster. Toutes les minutes, le cluster seconnecte à sa base de données et exécute une requête simple. S'ilest en mesure d'effectuer cette opération avec succès, le clusterest considéré comme sain. Sinon, le cluster est défectueux. Un étatdéfectueux peut se produire lorsque la base de données du cluster
Version de l'API 2012-12-01260
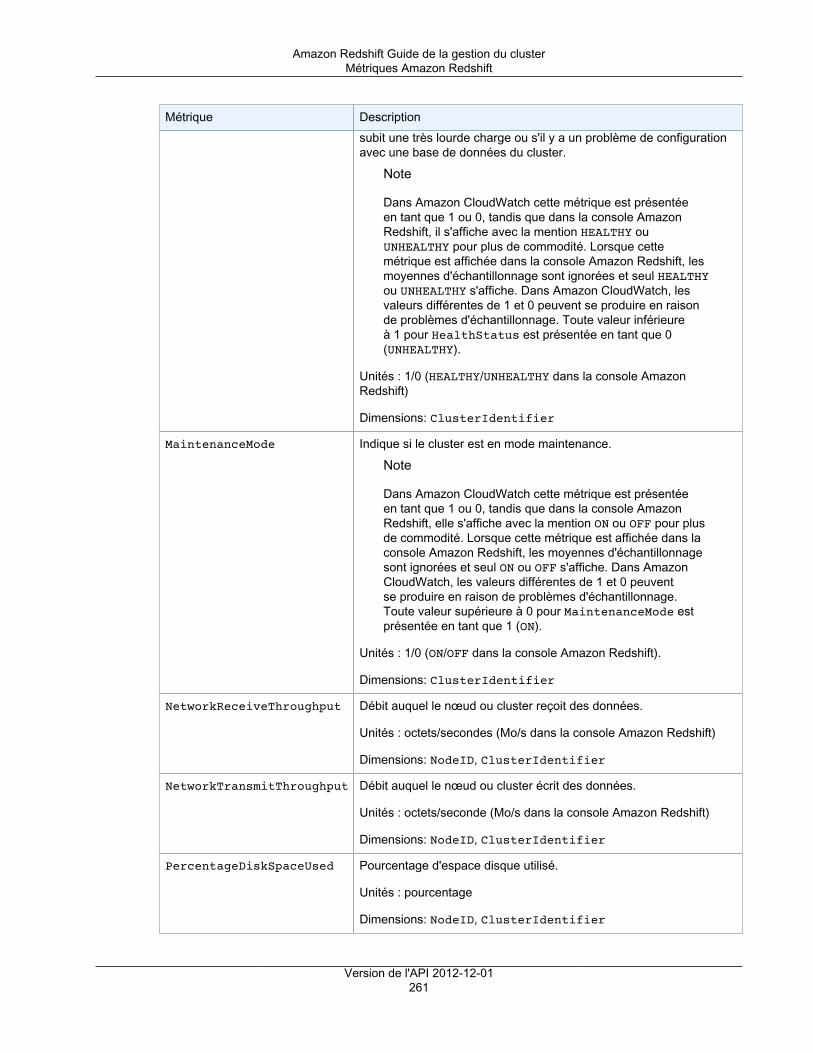
Amazon Redshift Guide de la gestion du clusterMétriques Amazon Redshift
Métrique Descriptionsubit une très lourde charge ou s'il y a un problème de configurationavec une base de données du cluster.
Note
Dans Amazon CloudWatch cette métrique est présentéeen tant que 1 ou 0, tandis que dans la console AmazonRedshift, il s'affiche avec la mention HEALTHY ouUNHEALTHY pour plus de commodité. Lorsque cettemétrique est affichée dans la console Amazon Redshift, lesmoyennes d'échantillonnage sont ignorées et seul HEALTHYou UNHEALTHY s'affiche. Dans Amazon CloudWatch, lesvaleurs différentes de 1 et 0 peuvent se produire en raisonde problèmes d'échantillonnage. Toute valeur inférieureà 1 pour HealthStatus est présentée en tant que 0(UNHEALTHY).
Unités : 1/0 (HEALTHY/UNHEALTHY dans la console AmazonRedshift)
Dimensions: ClusterIdentifier
MaintenanceMode Indique si le cluster est en mode maintenance.
Note
Dans Amazon CloudWatch cette métrique est présentéeen tant que 1 ou 0, tandis que dans la console AmazonRedshift, elle s'affiche avec la mention ON ou OFF pour plusde commodité. Lorsque cette métrique est affichée dans laconsole Amazon Redshift, les moyennes d'échantillonnagesont ignorées et seul ON ou OFF s'affiche. Dans AmazonCloudWatch, les valeurs différentes de 1 et 0 peuventse produire en raison de problèmes d'échantillonnage.Toute valeur supérieure à 0 pour MaintenanceMode estprésentée en tant que 1 (ON).
Unités : 1/0 (ON/OFF dans la console Amazon Redshift).
Dimensions: ClusterIdentifier
NetworkReceiveThroughput Débit auquel le nœud ou cluster reçoit des données.
Unités : octets/secondes (Mo/s dans la console Amazon Redshift)
Dimensions: NodeID, ClusterIdentifier
NetworkTransmitThroughput Débit auquel le nœud ou cluster écrit des données.
Unités : octets/seconde (Mo/s dans la console Amazon Redshift)
Dimensions: NodeID, ClusterIdentifier
PercentageDiskSpaceUsed Pourcentage d'espace disque utilisé.
Unités : pourcentage
Dimensions: NodeID, ClusterIdentifier
Version de l'API 2012-12-01261
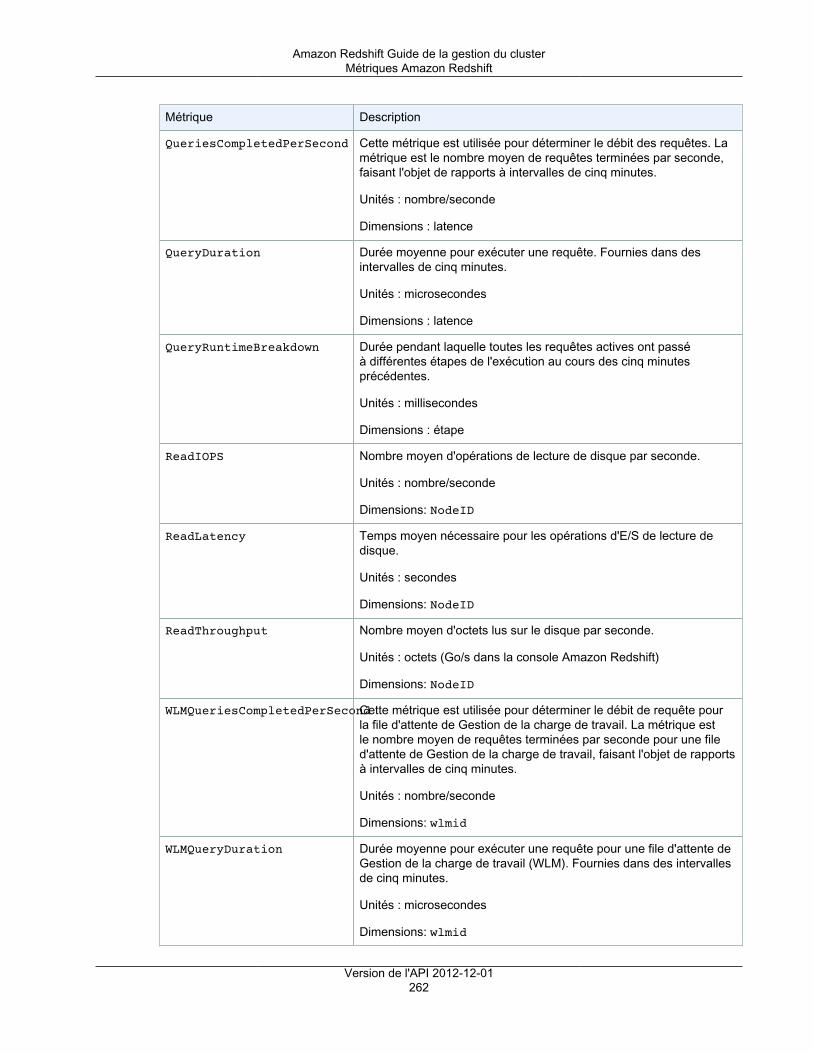
Amazon Redshift Guide de la gestion du clusterMétriques Amazon Redshift
Métrique Description
QueriesCompletedPerSecond Cette métrique est utilisée pour déterminer le débit des requêtes. Lamétrique est le nombre moyen de requêtes terminées par seconde,faisant l'objet de rapports à intervalles de cinq minutes.
Unités : nombre/seconde
Dimensions : latence
QueryDuration Durée moyenne pour exécuter une requête. Fournies dans desintervalles de cinq minutes.
Unités : microsecondes
Dimensions : latence
QueryRuntimeBreakdown Durée pendant laquelle toutes les requêtes actives ont passéà différentes étapes de l'exécution au cours des cinq minutesprécédentes.
Unités : millisecondes
Dimensions : étape
ReadIOPS Nombre moyen d'opérations de lecture de disque par seconde.
Unités : nombre/seconde
Dimensions: NodeID
ReadLatency Temps moyen nécessaire pour les opérations d'E/S de lecture dedisque.
Unités : secondes
Dimensions: NodeID
ReadThroughput Nombre moyen d'octets lus sur le disque par seconde.
Unités : octets (Go/s dans la console Amazon Redshift)
Dimensions: NodeID
WLMQueriesCompletedPerSecondCette métrique est utilisée pour déterminer le débit de requête pourla file d'attente de Gestion de la charge de travail. La métrique estle nombre moyen de requêtes terminées par seconde pour une filed'attente de Gestion de la charge de travail, faisant l'objet de rapportsà intervalles de cinq minutes.
Unités : nombre/seconde
Dimensions: wlmid
WLMQueryDuration Durée moyenne pour exécuter une requête pour une file d'attente deGestion de la charge de travail (WLM). Fournies dans des intervallesde cinq minutes.
Unités : microsecondes
Dimensions: wlmid
Version de l'API 2012-12-01262
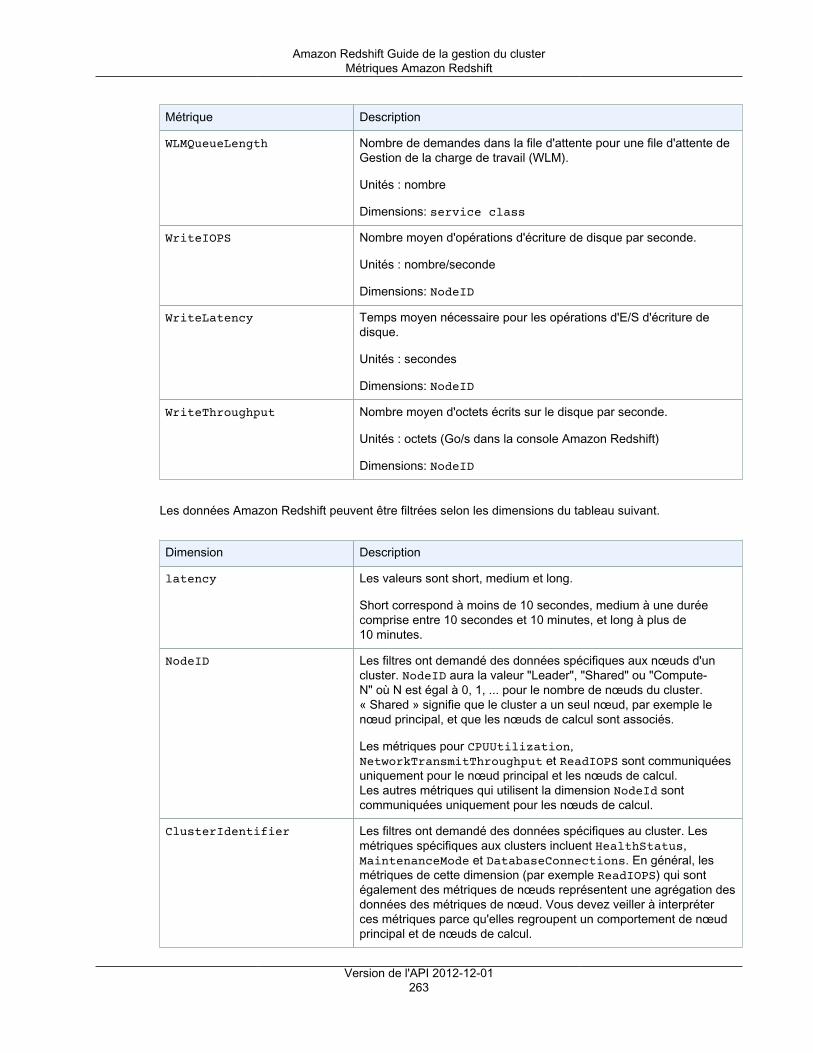
Amazon Redshift Guide de la gestion du clusterMétriques Amazon Redshift
Métrique Description
WLMQueueLength Nombre de demandes dans la file d'attente pour une file d'attente deGestion de la charge de travail (WLM).
Unités : nombre
Dimensions: service class
WriteIOPS Nombre moyen d'opérations d'écriture de disque par seconde.
Unités : nombre/seconde
Dimensions: NodeID
WriteLatency Temps moyen nécessaire pour les opérations d'E/S d'écriture dedisque.
Unités : secondes
Dimensions: NodeID
WriteThroughput Nombre moyen d'octets écrits sur le disque par seconde.
Unités : octets (Go/s dans la console Amazon Redshift)
Dimensions: NodeID
Les données Amazon Redshift peuvent être filtrées selon les dimensions du tableau suivant.
Dimension Description
latency Les valeurs sont short, medium et long.
Short correspond à moins de 10 secondes, medium à une duréecomprise entre 10 secondes et 10 minutes, et long à plus de10 minutes.
NodeID Les filtres ont demandé des données spécifiques aux nœuds d'uncluster. NodeID aura la valeur "Leader", "Shared" ou "Compute-N" où N est égal à 0, 1, ... pour le nombre de nœuds du cluster.« Shared » signifie que le cluster a un seul nœud, par exemple lenœud principal, et que les nœuds de calcul sont associés.
Les métriques pour CPUUtilization,NetworkTransmitThroughput et ReadIOPS sont communiquéesuniquement pour le nœud principal et les nœuds de calcul.Les autres métriques qui utilisent la dimension NodeId sontcommuniquées uniquement pour les nœuds de calcul.
ClusterIdentifier Les filtres ont demandé des données spécifiques au cluster. Lesmétriques spécifiques aux clusters incluent HealthStatus,MaintenanceMode et DatabaseConnections. En général, lesmétriques de cette dimension (par exemple ReadIOPS) qui sontégalement des métriques de nœuds représentent une agrégation desdonnées des métriques de nœud. Vous devez veiller à interpréterces métriques parce qu'elles regroupent un comportement de nœudprincipal et de nœuds de calcul.
Version de l'API 2012-12-01263

Amazon Redshift Guide de la gestion du clusterDonnées de performance de
chargement/requête Amazon Redshift
Dimension Description
service class Identifiant d'une classe de service WLM.
Stage Étapes de l'exécution d'une requête. Les valeurs possibles sont :
• QueryPlanning : Temps passé à analyser et à optimiser lesinstructions SQL.
• QueryWaiting : Temps passé dans la file d'attente wlm.• QueryExecutingRead : Temps passé à exécuter des requêtes en
lecture.• QueryExecutingInsert : Temps passé à exécuter des requêtes
d'insertion.• QueryExecutingDelete : Temps passé à exécuter des requêtes de
suppression.• QueryExecutingUpdate : Temps passé à exécuter des requêtes de
mise à jour.• QueryExecutingCtas : Temps passé à exécuter des requêtes de
création de tables.• QueryExecutingUnload : Temps passé à exécuter des requêtes de
déchargement.• QueryExecutingCopy : Temps passé à exécuter des requêtes de
copie.• QueryCommit : Temps passé à valider.
wmlid Identifiant d'une file d'attente de gestion de la charge de travail.
Données de performance de chargement/requêteAmazon RedshiftOutre les métriques Amazon CloudWatch, Amazon Redshift fournit les données de performance dechargement et de requête. Les données de performance de chargement et de requête peuvent vous aiderà comprendre la relation entre les performances de base de données et les métriques de cluster. Parexemple, si vous remarquez que l'UC d'un cluster a des pics, vous pouvez trouver le pic dans le graphiquede l'UC du cluster et afficher les requêtes qui s'exécutaient à ce moment-là. Inversement, si vous examinezune requête spécifique, les données des métriques (comme l'UC) s'affichent dans le contexte afin que vouspuissiez comprendre l'impact de la requête sur les métriques de cluster.
Les données de performance de chargement et de requête ne sont pas publiées sous forme de métriquesAmazon CloudWatch et ne peuvent être consultées que dans la console Amazon Redshift. Les donnéesde performance de chargement et de requête sont générées à partir de l'interrogation des tables systèmede votre base de données (voir Référence des tables système dans le Guide du développeur AmazonRedshift). Vous pouvez également générer vos propres requêtes de performances de base de données,mais nous vous recommandons de commencer par les données de performance de chargement et derequête présentées dans la console. Pour plus d'informations sur la mesure et la surveillance de vosperformances de base de données, consultez Gestion des performances dans le Guide du développeurAmazon Redshift.
Le tableau suivant décrit les différents aspects des données de chargement et de requête auxquelles vouspouvez accéder dans la console Amazon Redshift.
Version de l'API 2012-12-01264

Amazon Redshift Guide de la gestion du clusterUtilisation des données de performance
Données dechargement et derequête
Description
Résumé des requêtes Liste de requêtes sur une durée déterminée. La liste peut être triée sur desvaleurs telles que l'ID de requête, la durée d'exécution et l'état. Accédez à cesdonnées sous l'onglet Requêtes de la page des détails de cluster.
Détails de la requête Fournit des détails sur une requête donnée, notamment :
• Propriétés de la requête, telles que l'ID de requête, le type, le cluster surlequel la requête a été exécutée et la durée d'exécution.
• Détails tels que l'état de la requête et le nombre d'erreurs.• Instruction SQL exécutée.• Plan d'explication s'il est disponible.• Données de performances de cluster lors de l'exécution de la requête (voir
Données de performance Amazon Redshift (p. 260)).
Résumé des charges Répertorie toutes les charges sur une durée déterminée. La liste peut être triéesur des valeurs telles que l'ID de requête, la durée d'exécution et l'état. Accédezà ces données sous l'onglet Charges de la page des détails de cluster. Accédezà ces données sous l'onglet Requêtes de la page des détails de cluster.
Détails de charge Fournit des détails sur une opération de charge particulière, notamment :
• Propriétés de la charge, telles que l'ID de requête, le type, le cluster sur lequella requête a été exécutée et la durée d'exécution.
• Détails tels que l'état de la charge et le nombre d'erreurs.• Instruction SQL exécutée.• Liste des fichiers chargés.• Données de performances de cluster au cours de l'opération de chargement
(voir Données de performance Amazon Redshift (p. 260)).
Utilisation des données de performance dans laconsole Amazon Redshift
Cette section explique comment afficher les données de performance dans la console Amazon Redshift,lesquelles incluent les informations sur les performances de cluster et de requête. En outre, vous pouvezcréer directement des alarmes sur les métriques de cluster depuis la console Amazon Redshift.
Lorsque vous affichez les données de performance dans la console Amazon Redshift, vous les affichezpar cluster. Les graphiques des données de performances d'un cluster sont conçus pour vous permettred'accéder aux données et répondre à vos questions de performance les plus courantes. Pour certainesdonnées de performance (voir Données de performance Amazon Redshift (p. 260)), vous pouvezégalement utiliser Amazon CloudWatch pour personnaliser davantage les graphiques des métriques(choisir des durées plus longues ou combiner les métriques à travers les clusters, par exemple). Pour plusd'informations sur l'utilisation de la console Amazon CloudWatch, consultez Utilisation des métriques deperformance dans la console Amazon CloudWatch (p. 284).
Pour commencer à utiliser les données de performance, recherchez votre cluster dans le tableau de borddes performances de cluster. Le tableau de bord est une liste de clusters qui indique d'un coup d'œil l'étatdu cluster (par exemple, disponible), l'État DB du cluster (par exemple, sain), si le cluster est en cours
Version de l'API 2012-12-01265
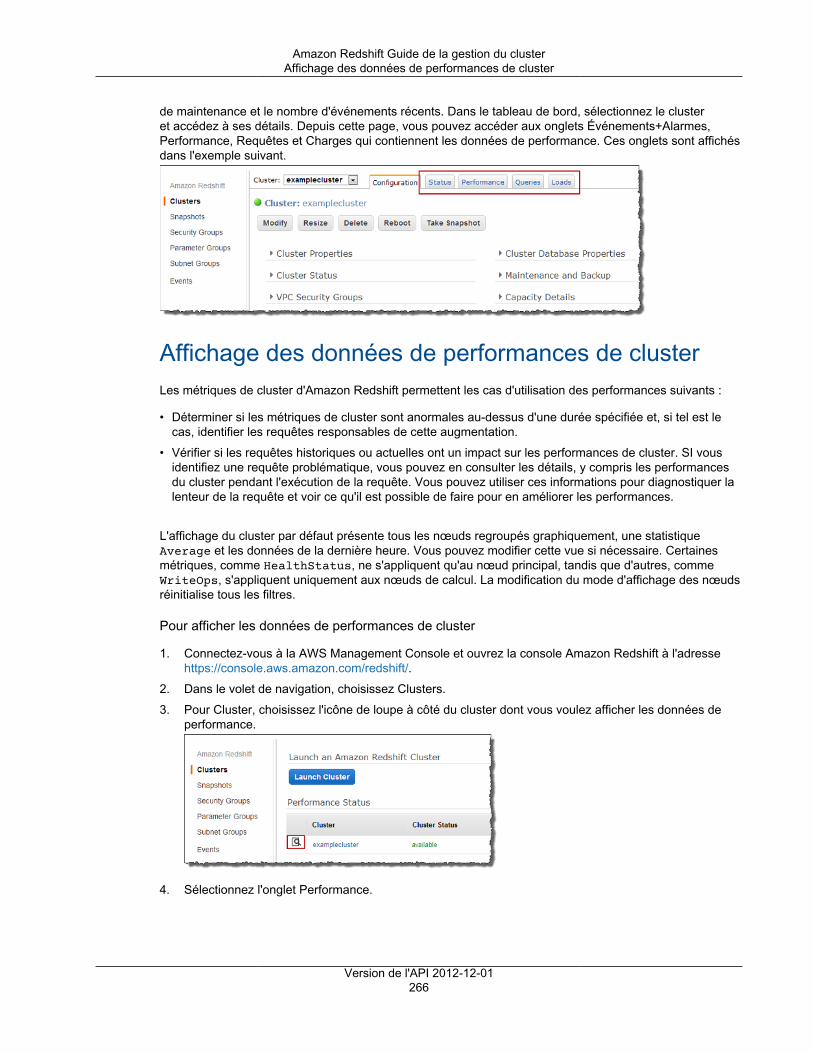
Amazon Redshift Guide de la gestion du clusterAffichage des données de performances de cluster
de maintenance et le nombre d'événements récents. Dans le tableau de bord, sélectionnez le clusteret accédez à ses détails. Depuis cette page, vous pouvez accéder aux onglets Événements+Alarmes,Performance, Requêtes et Charges qui contiennent les données de performance. Ces onglets sont affichésdans l'exemple suivant.
Affichage des données de performances de clusterLes métriques de cluster d'Amazon Redshift permettent les cas d'utilisation des performances suivants :
• Déterminer si les métriques de cluster sont anormales au-dessus d'une durée spécifiée et, si tel est lecas, identifier les requêtes responsables de cette augmentation.
• Vérifier si les requêtes historiques ou actuelles ont un impact sur les performances de cluster. SI vousidentifiez une requête problématique, vous pouvez en consulter les détails, y compris les performancesdu cluster pendant l'exécution de la requête. Vous pouvez utiliser ces informations pour diagnostiquer lalenteur de la requête et voir ce qu'il est possible de faire pour en améliorer les performances.
L'affichage du cluster par défaut présente tous les nœuds regroupés graphiquement, une statistiqueAverage et les données de la dernière heure. Vous pouvez modifier cette vue si nécessaire. Certainesmétriques, comme HealthStatus, ne s'appliquent qu'au nœud principal, tandis que d'autres, commeWriteOps, s'appliquent uniquement aux nœuds de calcul. La modification du mode d'affichage des nœudsréinitialise tous les filtres.
Pour afficher les données de performances de cluster
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez l'icône de loupe à côté du cluster dont vous voulez afficher les données de
performance.
4. Sélectionnez l'onglet Performance.
Version de l'API 2012-12-01266

Amazon Redshift Guide de la gestion du clusterAffichage des données de performances de cluster
Par défaut, l'affichage de performances affiche les performances de cluster sur la dernière heure. Sivous avez besoin d'affiner la vue, vous avez des filtres que vous pouvez utiliser comme décrit dans letableau suivant.
Pour Utilisez ce filtre
Modifier la plage de temps pour laquelle lesdonnées sont affichées
Sélectionnez une plage de temps dans la listePlage de temps. Par défaut, la dernière heure estaffichée.
Modifier la période pour laquelle les donnéessont affichées
Sélectionnez une période dans la liste Période. Pardéfaut, une période de cinq minutes est affichée.Utilisez une période inférieure à cinq minutessi vous avez besoin de plus de détails lors del'examen d'une métrique (exploration approfondie)et de l'affichage des métriques sur une période detemps réduite, par exemple dix minutes. De même,utilisez une période supérieure à cinq minuteslors de l'affichage des métriques sur une grandepériode de temps, comme les jours, par exemple.
Modifier les statistiques qui sont affichées pourles métriques
Sélectionnez une statistique dans la listeStatistique. Par défaut, la statistique Average estutilisée.
Modifier les métriques affichées (totalité desmétriques ou métrique spécifique)
Choisissez une métrique dans la liste Métriques.Par défaut, toutes les métriques sont affichées.
Modifier si les métriques de nœud sontaffichées séparément ou ensemble sur lemême graphique
Choisissez Nœuds. Par défaut, les données denœud d'une métrique s'affichent sur un graphiquecombiné. Si vous choisissez d'afficher les donnéesde nœud sur des graphiques distincts, vous pouvezafficher ou masquer chacun des nœuds.
Métriques de cluster : exemplesL'exemple suivant montre les métriques CPUUtilization et NetworkReceiveThroughput d'uncluster à nœud unique. Dans ce cas, les graphiques des métriques de cluster affichent une seule lignemarquée comme Shared, car le nœud principal et le nœud de calcul sont associés. L'exemple montreque plusieurs requêtes ont été exécutées dans la même période affichée. Sur le graphique Requêtes, lecurseur se trouve sur la requête en cours d'exécution aux valeurs de pic des deux métriques et l'ID de
Version de l'API 2012-12-01267
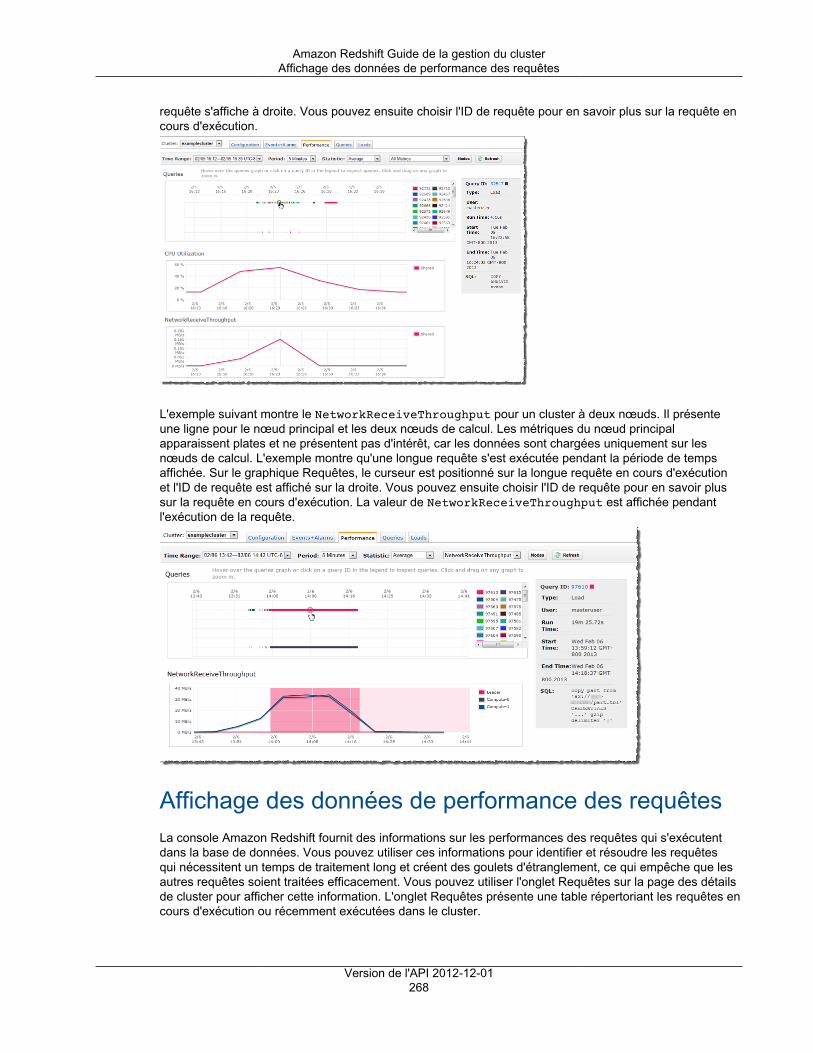
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
requête s'affiche à droite. Vous pouvez ensuite choisir l'ID de requête pour en savoir plus sur la requête encours d'exécution.
L'exemple suivant montre le NetworkReceiveThroughput pour un cluster à deux nœuds. Il présenteune ligne pour le nœud principal et les deux nœuds de calcul. Les métriques du nœud principalapparaissent plates et ne présentent pas d'intérêt, car les données sont chargées uniquement sur lesnœuds de calcul. L'exemple montre qu'une longue requête s'est exécutée pendant la période de tempsaffichée. Sur le graphique Requêtes, le curseur est positionné sur la longue requête en cours d'exécutionet l'ID de requête est affiché sur la droite. Vous pouvez ensuite choisir l'ID de requête pour en savoir plussur la requête en cours d'exécution. La valeur de NetworkReceiveThroughput est affichée pendantl'exécution de la requête.
Affichage des données de performance des requêtesLa console Amazon Redshift fournit des informations sur les performances des requêtes qui s'exécutentdans la base de données. Vous pouvez utiliser ces informations pour identifier et résoudre les requêtesqui nécessitent un temps de traitement long et créent des goulets d'étranglement, ce qui empêche que lesautres requêtes soient traitées efficacement. Vous pouvez utiliser l'onglet Requêtes sur la page des détailsde cluster pour afficher cette information. L'onglet Requêtes présente une table répertoriant les requêtes encours d'exécution ou récemment exécutées dans le cluster.
Version de l'API 2012-12-01268
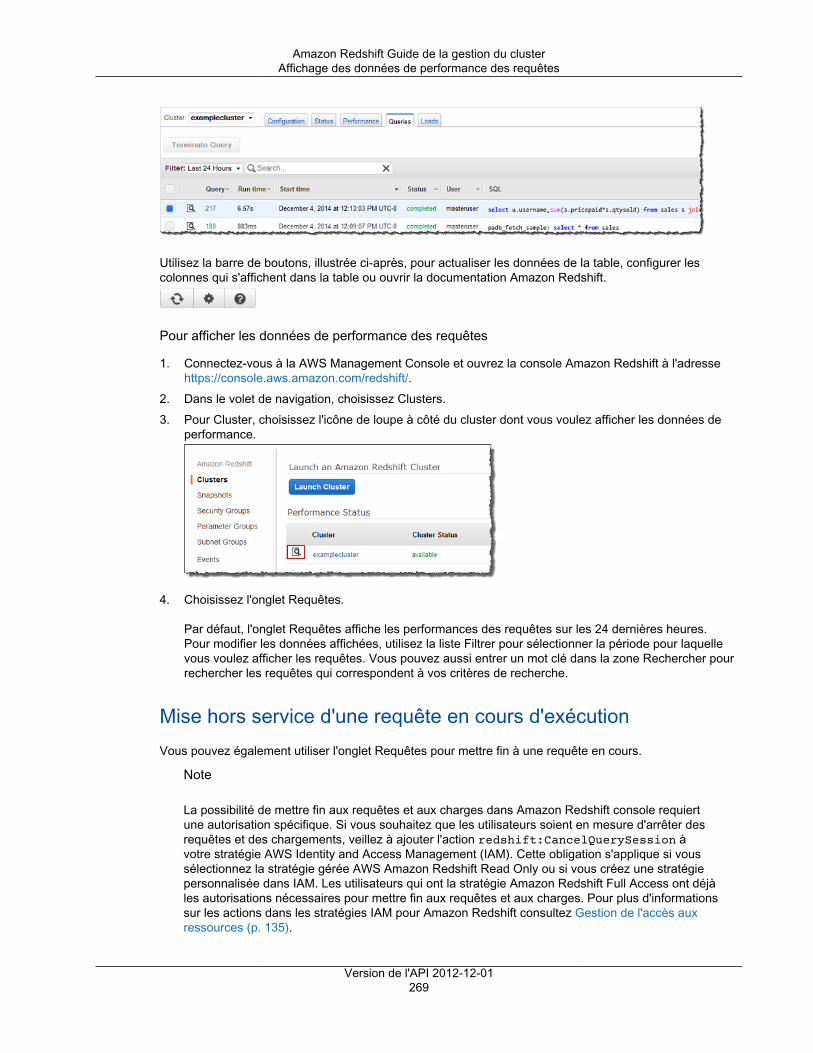
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
Utilisez la barre de boutons, illustrée ci-après, pour actualiser les données de la table, configurer lescolonnes qui s'affichent dans la table ou ouvrir la documentation Amazon Redshift.
Pour afficher les données de performance des requêtes
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez l'icône de loupe à côté du cluster dont vous voulez afficher les données de
performance.
4. Choisissez l'onglet Requêtes.
Par défaut, l'onglet Requêtes affiche les performances des requêtes sur les 24 dernières heures.Pour modifier les données affichées, utilisez la liste Filtrer pour sélectionner la période pour laquellevous voulez afficher les requêtes. Vous pouvez aussi entrer un mot clé dans la zone Rechercher pourrechercher les requêtes qui correspondent à vos critères de recherche.
Mise hors service d'une requête en cours d'exécutionVous pouvez également utiliser l'onglet Requêtes pour mettre fin à une requête en cours.
Note
La possibilité de mettre fin aux requêtes et aux charges dans Amazon Redshift console requiertune autorisation spécifique. Si vous souhaitez que les utilisateurs soient en mesure d'arrêter desrequêtes et des chargements, veillez à ajouter l'action redshift:CancelQuerySession àvotre stratégie AWS Identity and Access Management (IAM). Cette obligation s'applique si voussélectionnez la stratégie gérée AWS Amazon Redshift Read Only ou si vous créez une stratégiepersonnalisée dans IAM. Les utilisateurs qui ont la stratégie Amazon Redshift Full Access ont déjàles autorisations nécessaires pour mettre fin aux requêtes et aux charges. Pour plus d'informationssur les actions dans les stratégies IAM pour Amazon Redshift consultez Gestion de l'accès auxressources (p. 135).
Version de l'API 2012-12-01269

Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
Pour mettre fin à une requête en cours d'exécution.
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez le cluster à ouvrir.4. Choisissez l'onglet Requêtes.5. Effectuez l'une des actions suivantes :
• Dans la liste, sélectionnez les requêtes auxquelles vous voulez mettre fin, puis choisissez Arrêter larequête.
• Dans la liste, ouvrez une requête si vous souhaitez d'abord passer en revue les informations sur larequête, puis choisissez Arrêter la requête.
6. Dans la boîte de dialogue Arrêter les requêtes, choisissez Confirmer.
Affichage des détails de la requêteVous pouvez afficher les informations détaillées d'une requête donnée en cliquant sur une requête dutableau de la page Requêtes pour ouvrir la vue ID de requête. La liste suivante décrit les informationsdisponibles pour les requêtes individuelles :
• Propriétés de la requête. Affiche un résumé des informations sur la requête telles que l'ID de la requête,l'utilisateur de base de données ayant exécuté la requête et la durée.
• Détails. Affiche l'état de la requête.• SQL. Affiche le texte de la requête dans un format convivial et explicite.• Détails d'exécution de la requête. Affiche des informations sur la façon dont la requête a été traitée.
Cette section inclut les données prévues et réelles de l'exécution de la requête. Pour plus d'informationssur l'utilisation de la section Détails d'exécution de la requête, consultez Analyse de l'exécution desrequêtes (p. 271).
• Performances du cluster lors de l'exécution des requêtes. Affiche les métriques de performance deAmazon CloudWatch. Pour plus d'informations sur l'utilisation de la section Performances du cluster lorsde l'exécution des requêtes, consultez Affichage des performances de cluster pendant l'exécution desrequêtes (p. 276).
La vue Requête doit se présenter comme suit lorsque vous l'ouvrez.
Version de l'API 2012-12-01270
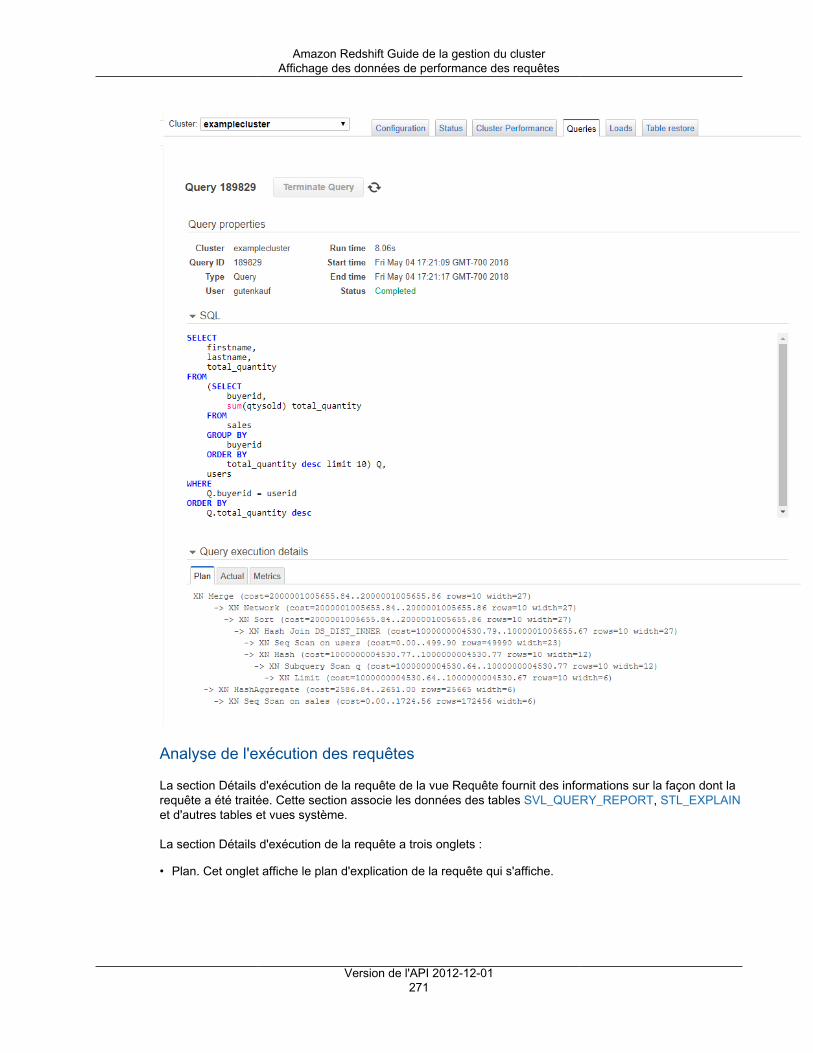
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
Analyse de l'exécution des requêtes
La section Détails d'exécution de la requête de la vue Requête fournit des informations sur la façon dont larequête a été traitée. Cette section associe les données des tables SVL_QUERY_REPORT, STL_EXPLAINet d'autres tables et vues système.
La section Détails d'exécution de la requête a trois onglets :
• Plan. Cet onglet affiche le plan d'explication de la requête qui s'affiche.
Version de l'API 2012-12-01271
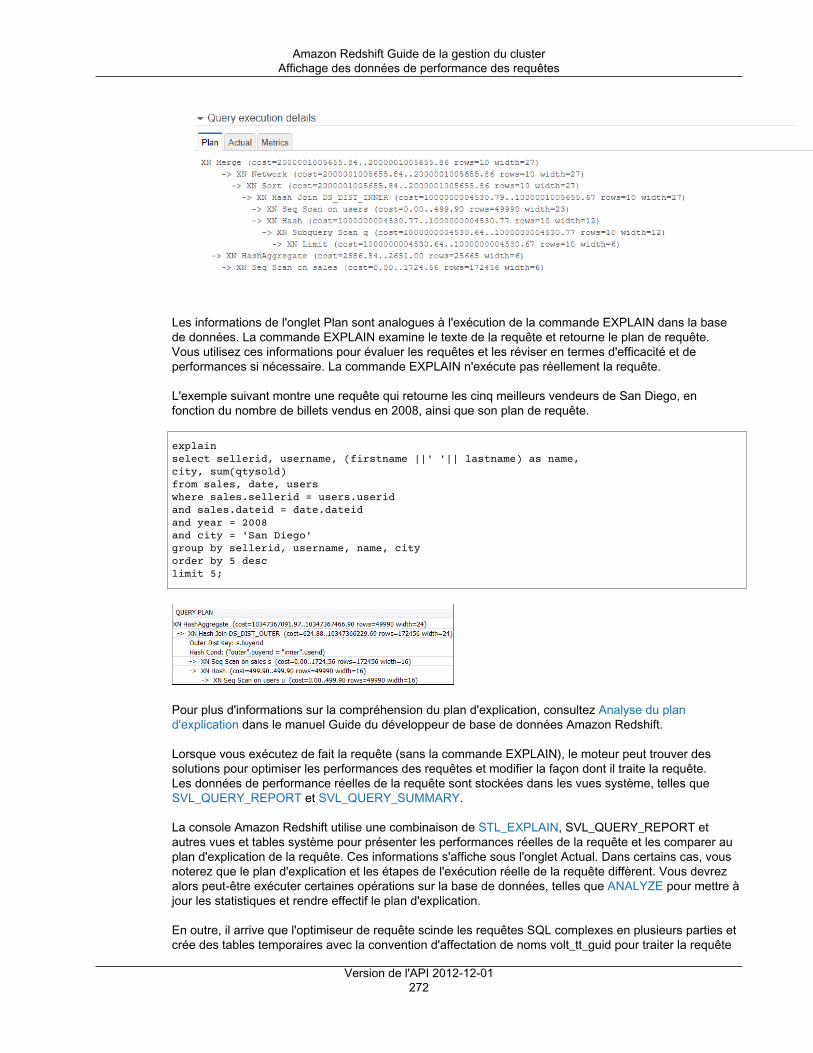
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
Les informations de l'onglet Plan sont analogues à l'exécution de la commande EXPLAIN dans la basede données. La commande EXPLAIN examine le texte de la requête et retourne le plan de requête.Vous utilisez ces informations pour évaluer les requêtes et les réviser en termes d'efficacité et deperformances si nécessaire. La commande EXPLAIN n'exécute pas réellement la requête.
L'exemple suivant montre une requête qui retourne les cinq meilleurs vendeurs de San Diego, enfonction du nombre de billets vendus en 2008, ainsi que son plan de requête.
explain select sellerid, username, (firstname ||' '|| lastname) as name,city, sum(qtysold)from sales, date, userswhere sales.sellerid = users.useridand sales.dateid = date.dateidand year = 2008and city = 'San Diego'group by sellerid, username, name, cityorder by 5 desclimit 5;
Pour plus d'informations sur la compréhension du plan d'explication, consultez Analyse du pland'explication dans le manuel Guide du développeur de base de données Amazon Redshift.
Lorsque vous exécutez de fait la requête (sans la commande EXPLAIN), le moteur peut trouver dessolutions pour optimiser les performances des requêtes et modifier la façon dont il traite la requête.Les données de performance réelles de la requête sont stockées dans les vues système, telles queSVL_QUERY_REPORT et SVL_QUERY_SUMMARY.
La console Amazon Redshift utilise une combinaison de STL_EXPLAIN, SVL_QUERY_REPORT etautres vues et tables système pour présenter les performances réelles de la requête et les comparer auplan d'explication de la requête. Ces informations s'affiche sous l'onglet Actual. Dans certains cas, vousnoterez que le plan d'explication et les étapes de l'exécution réelle de la requête diffèrent. Vous devrezalors peut-être exécuter certaines opérations sur la base de données, telles que ANALYZE pour mettre àjour les statistiques et rendre effectif le plan d'explication.
En outre, il arrive que l'optimiseur de requête scinde les requêtes SQL complexes en plusieurs parties etcrée des tables temporaires avec la convention d'affectation de noms volt_tt_guid pour traiter la requête
Version de l'API 2012-12-01272
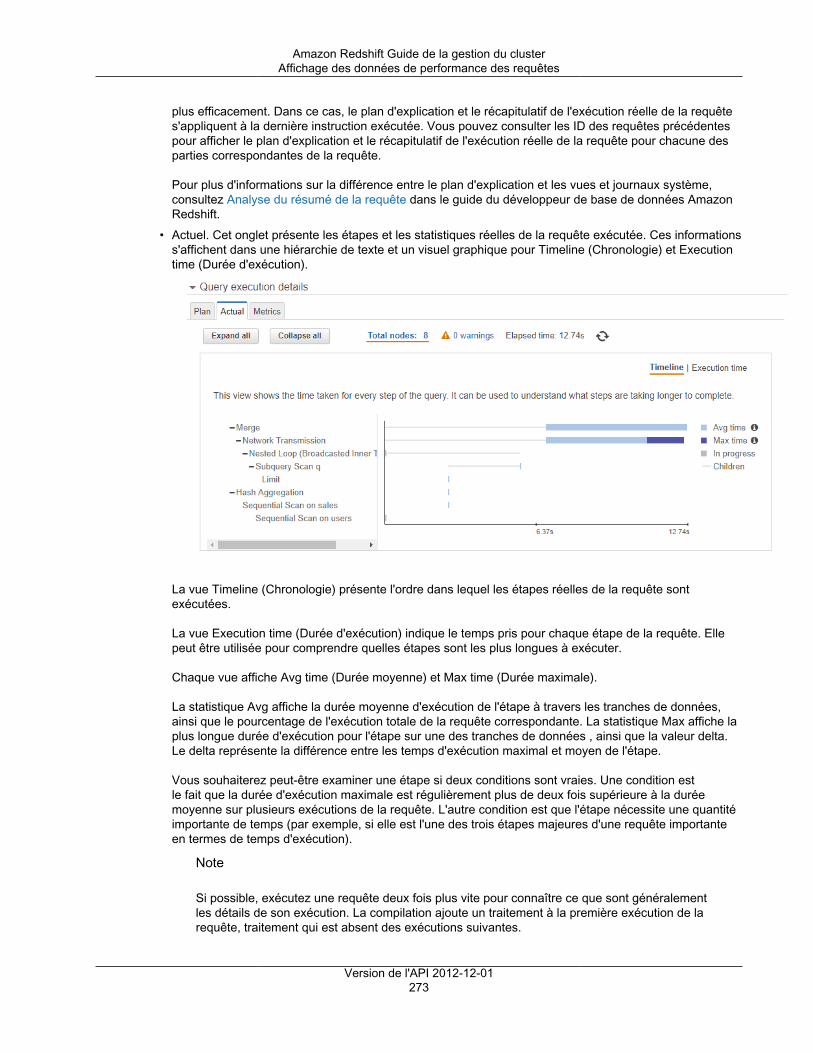
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
plus efficacement. Dans ce cas, le plan d'explication et le récapitulatif de l'exécution réelle de la requêtes'appliquent à la dernière instruction exécutée. Vous pouvez consulter les ID des requêtes précédentespour afficher le plan d'explication et le récapitulatif de l'exécution réelle de la requête pour chacune desparties correspondantes de la requête.
Pour plus d'informations sur la différence entre le plan d'explication et les vues et journaux système,consultez Analyse du résumé de la requête dans le guide du développeur de base de données AmazonRedshift.
• Actuel. Cet onglet présente les étapes et les statistiques réelles de la requête exécutée. Ces informationss'affichent dans une hiérarchie de texte et un visuel graphique pour Timeline (Chronologie) et Executiontime (Durée d'exécution).
La vue Timeline (Chronologie) présente l'ordre dans lequel les étapes réelles de la requête sontexécutées.
La vue Execution time (Durée d'exécution) indique le temps pris pour chaque étape de la requête. Ellepeut être utilisée pour comprendre quelles étapes sont les plus longues à exécuter.
Chaque vue affiche Avg time (Durée moyenne) et Max time (Durée maximale).
La statistique Avg affiche la durée moyenne d'exécution de l'étape à travers les tranches de données,ainsi que le pourcentage de l'exécution totale de la requête correspondante. La statistique Max affiche laplus longue durée d'exécution pour l'étape sur une des tranches de données , ainsi que la valeur delta.Le delta représente la différence entre les temps d'exécution maximal et moyen de l'étape.
Vous souhaiterez peut-être examiner une étape si deux conditions sont vraies. Une condition estle fait que la durée d'exécution maximale est régulièrement plus de deux fois supérieure à la duréemoyenne sur plusieurs exécutions de la requête. L'autre condition est que l'étape nécessite une quantitéimportante de temps (par exemple, si elle est l'une des trois étapes majeures d'une requête importanteen termes de temps d'exécution).
Note
Si possible, exécutez une requête deux fois plus vite pour connaître ce que sont généralementles détails de son exécution. La compilation ajoute un traitement à la première exécution de larequête, traitement qui est absent des exécutions suivantes.
Version de l'API 2012-12-01273
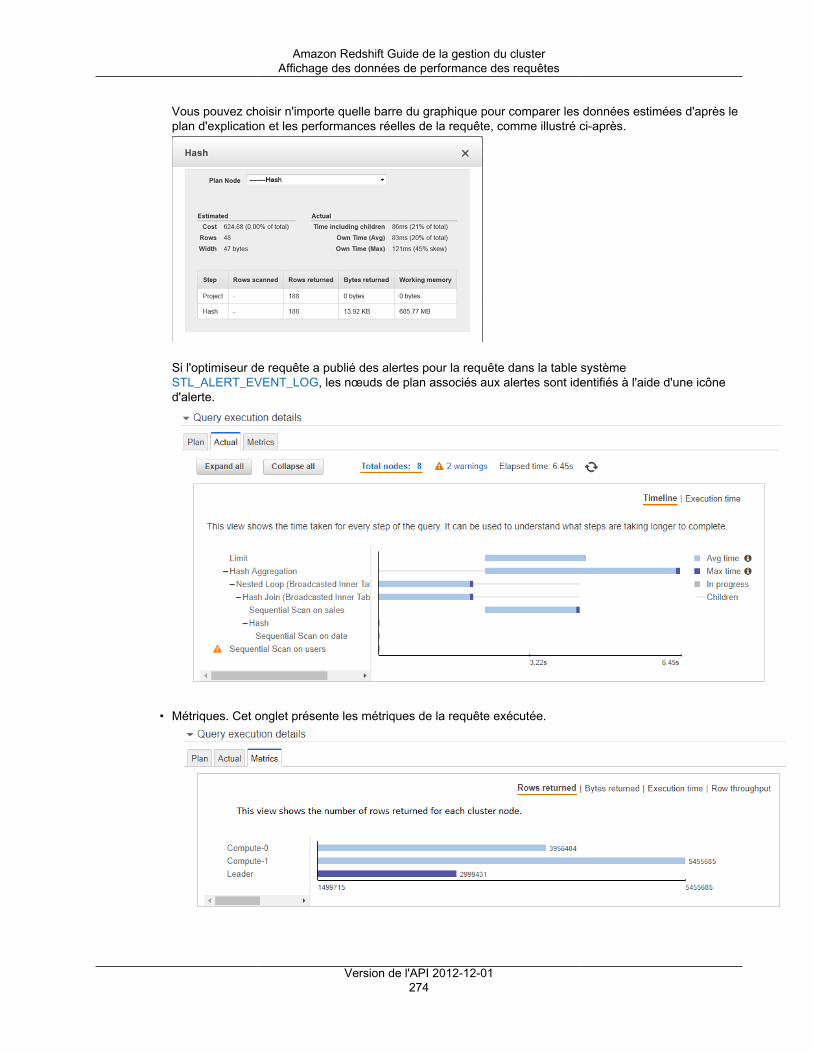
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
Vous pouvez choisir n'importe quelle barre du graphique pour comparer les données estimées d'après leplan d'explication et les performances réelles de la requête, comme illustré ci-après.
Si l'optimiseur de requête a publié des alertes pour la requête dans la table systèmeSTL_ALERT_EVENT_LOG, les nœuds de plan associés aux alertes sont identifiés à l'aide d'une icôned'alerte.
• Métriques. Cet onglet présente les métriques de la requête exécutée.
Version de l'API 2012-12-01274

Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
La métrique Lignes renvoyées est la somme du nombre de lignes générées au cours de chaque étapede la requête.
La métrique Octets renvoyés indique le nombre d'octets renvoyés pour chaque nœud de cluster.
La métrique Durée d'exécution indique la durée d'exécution des requêtes pour chaque nœud de cluster.
La métrique Débit de lignes indique le nombre de lignes renvoyées, divisé par la durée d'exécution desrequêtes pour chaque nœud de cluster.
Si une requête s'exécute moins vite que prévu, vous pouvez utiliser l'onglet Metrics (Métriques)pour en trouver la raison. Regardez la métrique Row throughput (Débit brut). Si l'un des nœuds decluster apparaît avoir un débit brut beaucoup plus élevé que les autres nœuds, la charge de travail estinégalement répartie entre les nœuds de cluster. L'une des causes possibles est que vos données soientinégalement réparties, ou biaisées, entre les tranches de nœuds. Pour plus d'informations, consultezIdentification des tables comportant des données biaisées ou des lignes non triées.
Si vos données sont également réparties, votre requête peut filtrer les lignes situées principalement surce nœud. Pour résoudre ce problème, vérifiez les styles de distribution des tables de la requête afin devoir si des améliorations peuvent être apportées. N'oubliez pas de comparer les performances de cetterequête par rapport aux performances d'autres requêtes importantes et au système global avant toutemodification. Pour plus d'informations, consultez Choix d'un style de distribution des données.
Note
L'onglet des métriques n'est pas disponible pour un cluster à un seul nœud.
Affichage des détails d'exécution d'une requête à l'aide de la console
Utilisez la procédure suivante pour examiner les détails de l'exécution d'une requête.
Pour afficher les détails d'exécution d'une requête
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez le cluster pour lequel vous souhaitez afficher les informations d'exécution de
la requête.4. Choisissez l'onglet Requêtes et ouvrez la requête pour laquelle vous souhaitez afficher les données de
performance.5. Développez la section Détails d'exécution de la requête et procédez comme suit :
a. Sous l'onglet Plan, vérifiez le plan d'explication de la requête. Dans certains cas, vous découvrirezque votre plan d'explication diffère de l'exécution réelle de la requête sur l'onglet Réel. Vousdevrez alors peut-être exécuter ANALYZE pour mettre à jour les statistiques ou exécuterd'autres opérations de maintenance sur la base de données, et optimiser ainsi les requêtes quevous exécutez. Pour plus d'informations sur l'optimisation des requêtes, consultez Réglage deperformances des requêtes dans le manuel Amazon Redshift Database Developer Guide.
b. Sous l'onglet Actual, passez en revue les données de performance associées à chacun des nœudsdu plan dans l'exécution des requêtes. Vous pouvez choisir un nœud de plan de la hiérarchiepour afficher les données de performance associées à ce nœud de plan spécifique. Ces donnéesincluent les données de performance estimées et les données réelles.
c. Sur l'onglet Métriques, passez en revue les métriques de chacun des nœuds du cluster.
Version de l'API 2012-12-01275
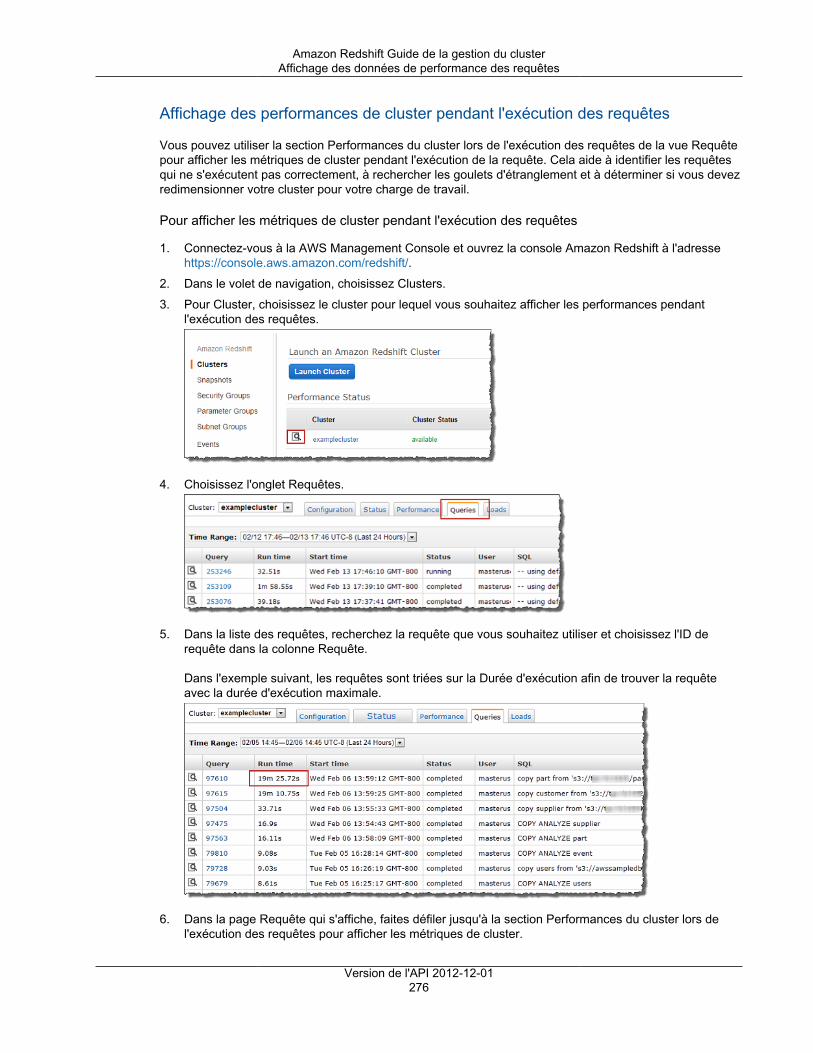
Amazon Redshift Guide de la gestion du clusterAffichage des données de performance des requêtes
Affichage des performances de cluster pendant l'exécution des requêtes
Vous pouvez utiliser la section Performances du cluster lors de l'exécution des requêtes de la vue Requêtepour afficher les métriques de cluster pendant l'exécution de la requête. Cela aide à identifier les requêtesqui ne s'exécutent pas correctement, à rechercher les goulets d'étranglement et à déterminer si vous devezredimensionner votre cluster pour votre charge de travail.
Pour afficher les métriques de cluster pendant l'exécution des requêtes
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez le cluster pour lequel vous souhaitez afficher les performances pendant
l'exécution des requêtes.
4. Choisissez l'onglet Requêtes.
5. Dans la liste des requêtes, recherchez la requête que vous souhaitez utiliser et choisissez l'ID derequête dans la colonne Requête.
Dans l'exemple suivant, les requêtes sont triées sur la Durée d'exécution afin de trouver la requêteavec la durée d'exécution maximale.
6. Dans la page Requête qui s'affiche, faites défiler jusqu'à la section Performances du cluster lors del'exécution des requêtes pour afficher les métriques de cluster.
Version de l'API 2012-12-01276

Amazon Redshift Guide de la gestion du clusterAffichage des métriques du cluster
pendant les opérations de chargement
Dans l'exemple suivant, les métriques CPUUtilization et NetworkReceiveThroughputs'affichent pour le temps d'exécution de la requête.
Tip
Vous pouvez fermer les détails des sections Détails d'exécution de la requête ou SQL afin degérer la quantité d'informations affichées dans le volet.
Affichage des métriques du cluster pendant lesopérations de chargementLorsque vous affichez les performances du cluster pendant les opérations de chargement, vous pouvezidentifier les requêtes qui consomment des ressources et prendre des mesures pour atténuer leur effet.Vous pouvez mettre fin à une charge si vous ne voulez pas qu'elle s'exécute jusqu'à la fin.
Note
La possibilité de mettre fin aux requêtes et aux charges dans Amazon Redshift console requiertune autorisation spécifique. Si vous souhaitez que les utilisateurs soient en mesure d'arrêter desrequêtes et des chargements, veillez à ajouter l'action redshift:CancelQuerySession àvotre stratégie AWS Identity and Access Management (IAM). Cette obligation s'applique si voussélectionnez la stratégie gérée AWS Amazon Redshift Read Only ou si vous créez une stratégiepersonnalisée dans IAM. Les utilisateurs qui ont la stratégie Amazon Redshift Full Access ont déjàles autorisations nécessaires pour mettre fin aux requêtes et aux charges. Pour plus d'informationssur les actions dans les stratégies IAM pour Amazon Redshift consultez Gestion de l'accès auxressources (p. 135).
Pour afficher les métriques du cluster pendant les opérations de chargement
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez le cluster pour lequel vous souhaitez afficher les performances pendant
l'exécution des requêtes.
Version de l'API 2012-12-01277
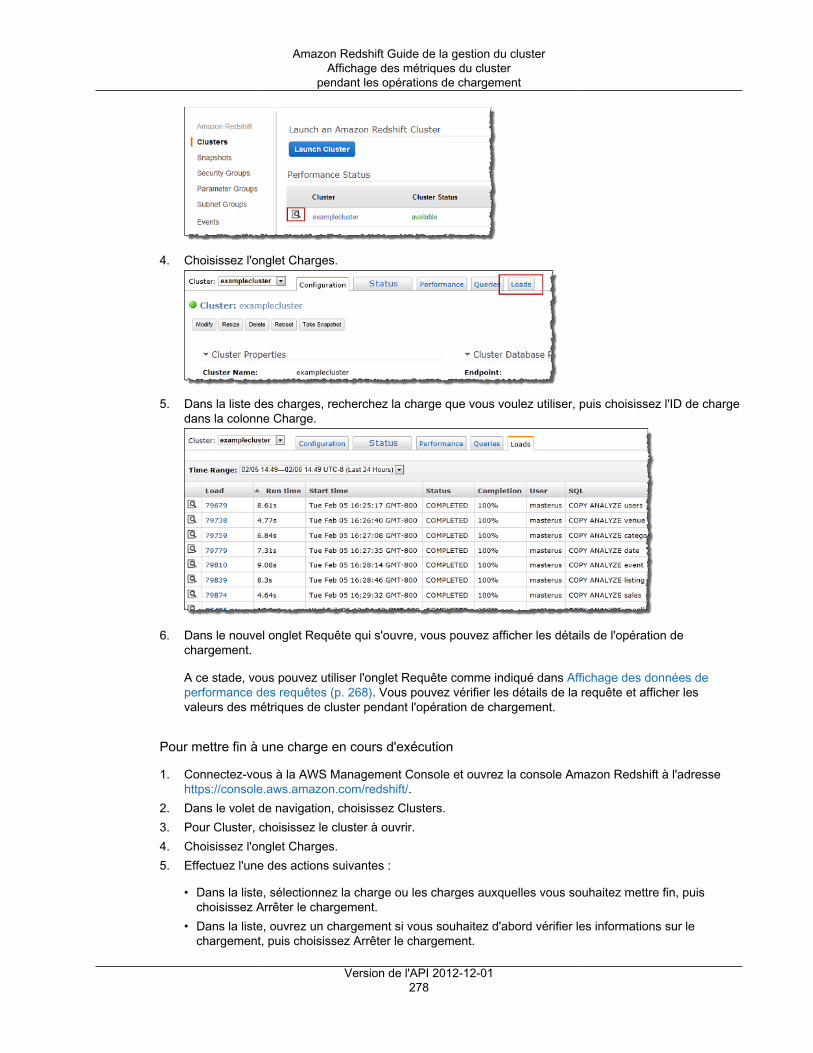
Amazon Redshift Guide de la gestion du clusterAffichage des métriques du cluster
pendant les opérations de chargement
4. Choisissez l'onglet Charges.
5. Dans la liste des charges, recherchez la charge que vous voulez utiliser, puis choisissez l'ID de chargedans la colonne Charge.
6. Dans le nouvel onglet Requête qui s'ouvre, vous pouvez afficher les détails de l'opération dechargement.
A ce stade, vous pouvez utiliser l'onglet Requête comme indiqué dans Affichage des données deperformance des requêtes (p. 268). Vous pouvez vérifier les détails de la requête et afficher lesvaleurs des métriques de cluster pendant l'opération de chargement.
Pour mettre fin à une charge en cours d'exécution
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez le cluster à ouvrir.4. Choisissez l'onglet Charges.5. Effectuez l'une des actions suivantes :
• Dans la liste, sélectionnez la charge ou les charges auxquelles vous souhaitez mettre fin, puischoisissez Arrêter le chargement.
• Dans la liste, ouvrez un chargement si vous souhaitez d'abord vérifier les informations sur lechargement, puis choisissez Arrêter le chargement.
Version de l'API 2012-12-01278

Amazon Redshift Guide de la gestion du clusterAnalyse des performances de la charge de travail
6. Dans la boîte de dialogue Arrêter les charges, choisissez Confirmer.
Analyse des performances de la charge de travailVous pouvez obtenir une vue détaillée des performances de votre charge de travail en consultant legraphique de répartition de l'exécution de la charge de travail dans la console. Nous générons le graphiqueavec les données fournies par la métrique CloudWatch QueryRuntimeBreakdown. Avec ce graphique, vouspouvez voir combien de temps vos requêtes ont consacré aux différentes étapes du traitement, commel'attente et la planification. La liste de métriques suivante décrit les caractéristiques les différentes étapesdu traitement :
• QueryPlanning : Temps passé à analyser et à optimiser les instructions SQL.• QueryWaiting : Temps passé dans la file d'attente de gestion de la charge de travail (WLM).• QueryExecutingRead : Temps passé à exécuter des requêtes en lecture.• QueryExecutingInsert : Temps passé à exécuter des requêtes d'insertion.• QueryExecutingDelete : Temps passé à exécuter des requêtes de suppression.• QueryExecutingUpdate : Temps passé à exécuter des requêtes de mise à jour.• QueryExecutingCtas : Temps passé à exécuter des requêtes CREATE TABLE AS.• QueryExecutingUnload : Temps passé à exécuter des requêtes en de déchargement.• QueryExecutingCopy : Temps passé à exécuter des requêtes de copie.
Par exemple, le graphique suivant dans la console Amazon Redshift présente le temps passé par lesrequêtes dans les états de planification, d'attente, de lecture et d'écriture. Vous pouvez combiner lesrésultats de ce graphique avec d'autres métriques pour une analyse plus approfondie. Dans certainscas, votre graphique peut montrer que les requêtes de courte durée (comme mesuré par la métriqueQueryDuration) passent beaucoup de temps à l'état d'attente. Vous pouvez alors augmenter le taux desimultanéité WLM d'une file d'attente particulière pour accroître le débit.
Version de l'API 2012-12-01279
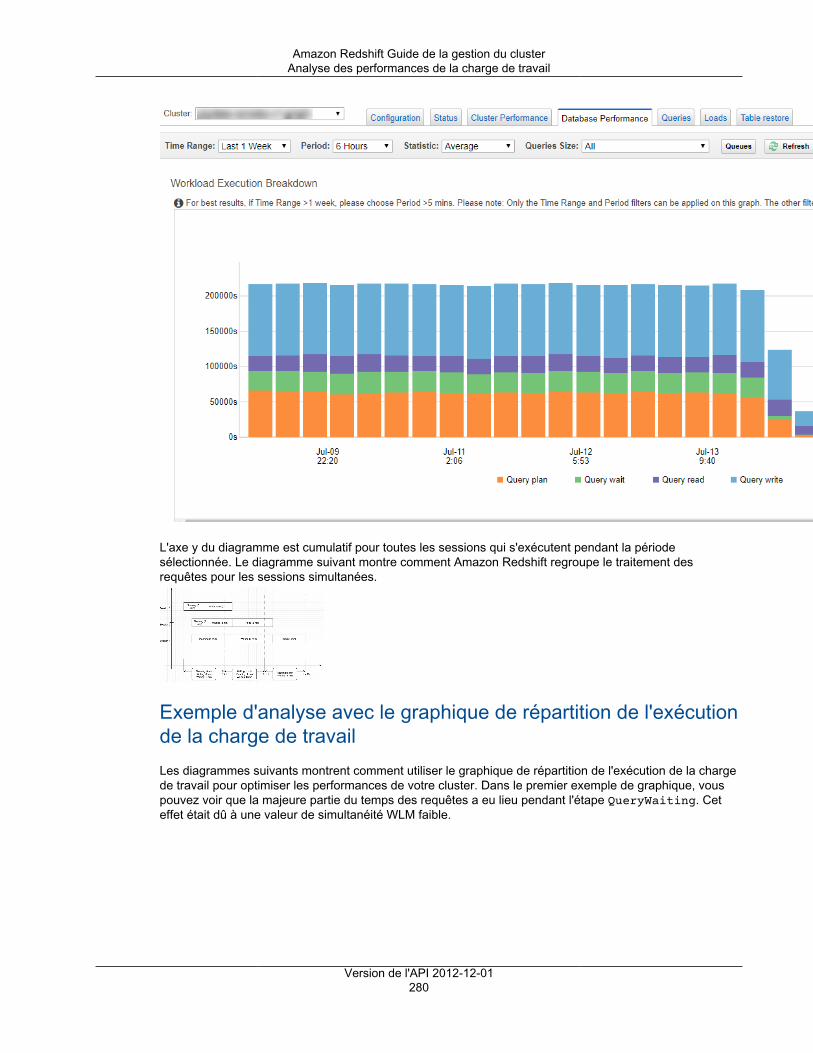
Amazon Redshift Guide de la gestion du clusterAnalyse des performances de la charge de travail
L'axe y du diagramme est cumulatif pour toutes les sessions qui s'exécutent pendant la périodesélectionnée. Le diagramme suivant montre comment Amazon Redshift regroupe le traitement desrequêtes pour les sessions simultanées.
Exemple d'analyse avec le graphique de répartition de l'exécutionde la charge de travailLes diagrammes suivants montrent comment utiliser le graphique de répartition de l'exécution de la chargede travail pour optimiser les performances de votre cluster. Dans le premier exemple de graphique, vouspouvez voir que la majeure partie du temps des requêtes a eu lieu pendant l'étape QueryWaiting. Ceteffet était dû à une valeur de simultanéité WLM faible.
Version de l'API 2012-12-01280
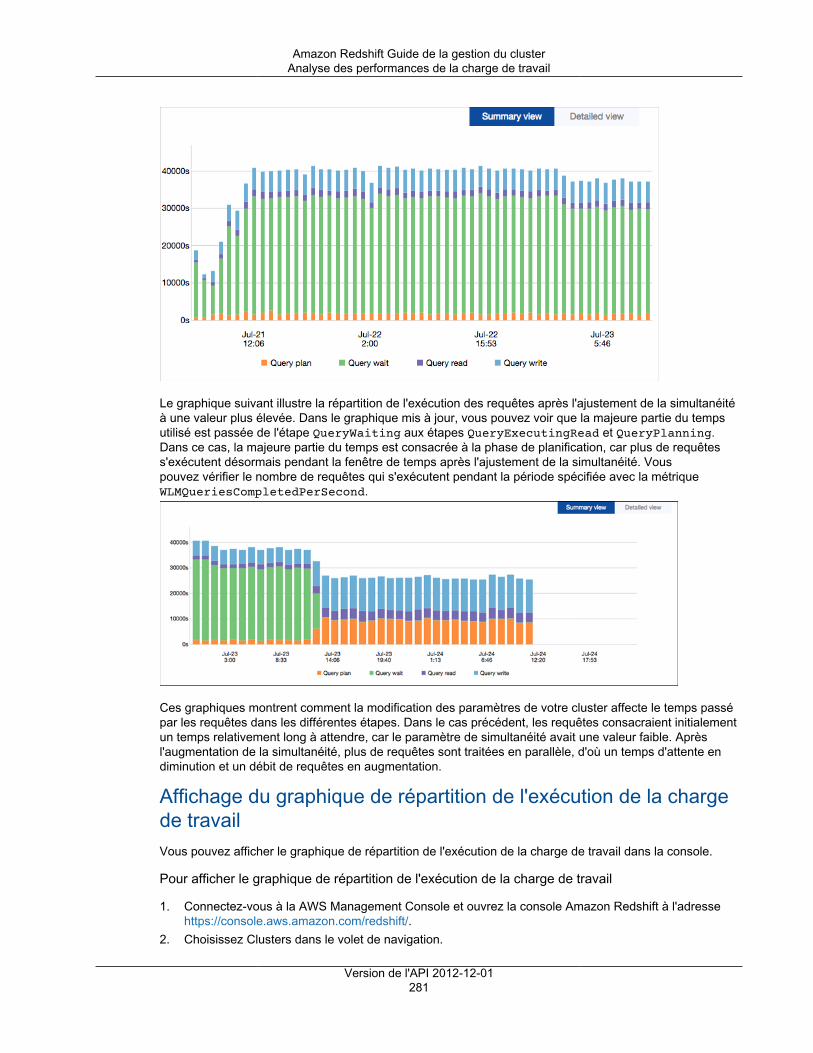
Amazon Redshift Guide de la gestion du clusterAnalyse des performances de la charge de travail
Le graphique suivant illustre la répartition de l'exécution des requêtes après l'ajustement de la simultanéitéà une valeur plus élevée. Dans le graphique mis à jour, vous pouvez voir que la majeure partie du tempsutilisé est passée de l'étape QueryWaiting aux étapes QueryExecutingRead et QueryPlanning.Dans ce cas, la majeure partie du temps est consacrée à la phase de planification, car plus de requêtess'exécutent désormais pendant la fenêtre de temps après l'ajustement de la simultanéité. Vouspouvez vérifier le nombre de requêtes qui s'exécutent pendant la période spécifiée avec la métriqueWLMQueriesCompletedPerSecond.
Ces graphiques montrent comment la modification des paramètres de votre cluster affecte le temps passépar les requêtes dans les différentes étapes. Dans le cas précédent, les requêtes consacraient initialementun temps relativement long à attendre, car le paramètre de simultanéité avait une valeur faible. Aprèsl'augmentation de la simultanéité, plus de requêtes sont traitées en parallèle, d'où un temps d'attente endiminution et un débit de requêtes en augmentation.
Affichage du graphique de répartition de l'exécution de la chargede travailVous pouvez afficher le graphique de répartition de l'exécution de la charge de travail dans la console.
Pour afficher le graphique de répartition de l'exécution de la charge de travail
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Choisissez Clusters dans le volet de navigation.
Version de l'API 2012-12-01281
Amazon Redshift Guide de la gestion du clusterCréation d'une alarme
3. Choisissez le cluster à analyser.4. Choisissez l'onglet Database Performance (Performances de la base de données).
Création d'une alarmeLes alarmes que vous créez dans la console Amazon Redshift sont des alarmes Amazon CloudWatch.Elles sont utiles, car elles vous aident à prendre des décisions proactives sur votre cluster et ses basesde données. Vous pouvez définir une ou plusieurs alarmes sur les métriques répertoriées dans Donnéesde performance Amazon Redshift (p. 260). Par exemple, définir une alarme pour une valeur élevée deCPUUtilization sur un nœud de cluster aide à indiquer quand le nœud est surutilisé. De même, définirune alarme pour une valeur faible de CPUUtilization sur un nœud de cluster aide à indiquer quand lenœud est sous-utilisé.
Dans cette section, vous trouverez comment créer une alarme à l'aide de la console Amazon Redshift.Vous pouvez créer une alarme à l'aide de la console Amazon CloudWatch ou par tout autre moyen quevous appliquez à l'utilisation des métriques, tels quel l'AWS CLI ou un Kit de développement logiciel (SDK)AWS. Pour supprimer une alarme, vous devez utiliser la console Amazon CloudWatch.
Pour créer une alarme sur une métrique de cluster dans la console Amazon Redshift
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, choisissez Clusters.3. Pour Cluster, choisissez le cluster pour lequel vous souhaitez afficher les performances pendant
l'exécution des requêtes.
4. Choisissez l'onglet Événements + alarmes.
5. Sélectionnez Create Alarm.
Version de l'API 2012-12-01282
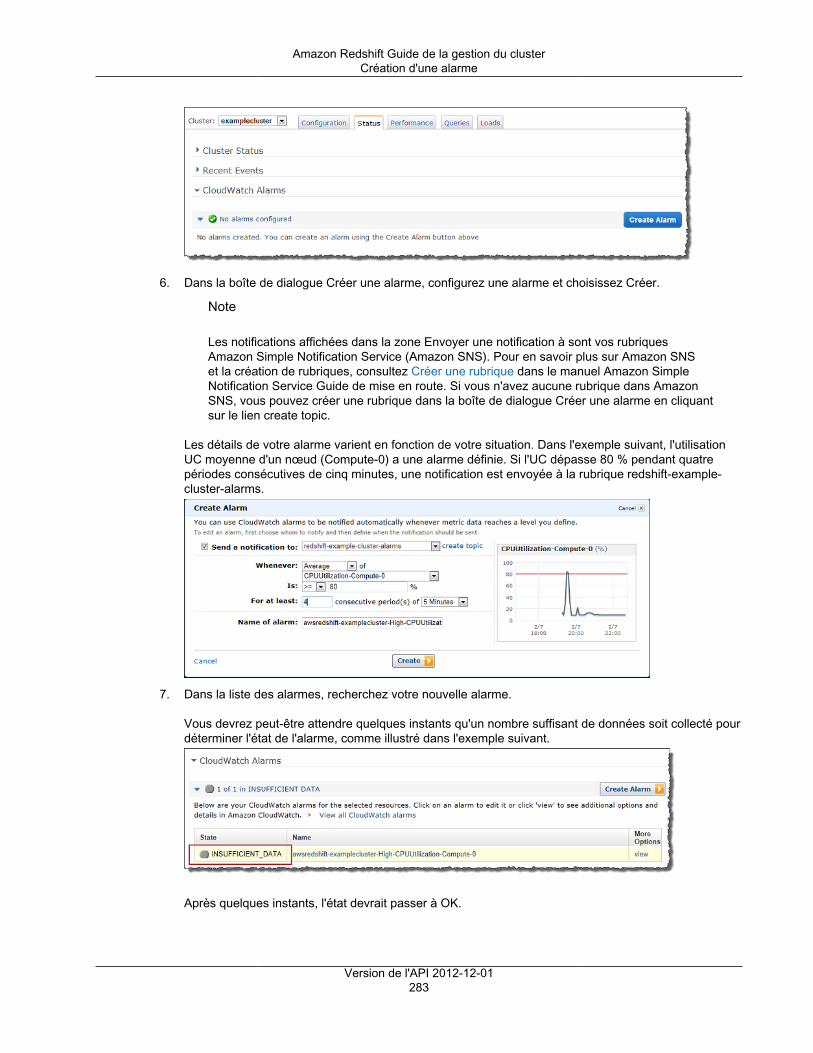
Amazon Redshift Guide de la gestion du clusterCréation d'une alarme
6. Dans la boîte de dialogue Créer une alarme, configurez une alarme et choisissez Créer.
Note
Les notifications affichées dans la zone Envoyer une notification à sont vos rubriquesAmazon Simple Notification Service (Amazon SNS). Pour en savoir plus sur Amazon SNSet la création de rubriques, consultez Créer une rubrique dans le manuel Amazon SimpleNotification Service Guide de mise en route. Si vous n'avez aucune rubrique dans AmazonSNS, vous pouvez créer une rubrique dans la boîte de dialogue Créer une alarme en cliquantsur le lien create topic.
Les détails de votre alarme varient en fonction de votre situation. Dans l'exemple suivant, l'utilisationUC moyenne d'un nœud (Compute-0) a une alarme définie. Si l'UC dépasse 80 % pendant quatrepériodes consécutives de cinq minutes, une notification est envoyée à la rubrique redshift-example-cluster-alarms.
7. Dans la liste des alarmes, recherchez votre nouvelle alarme.
Vous devrez peut-être attendre quelques instants qu'un nombre suffisant de données soit collecté pourdéterminer l'état de l'alarme, comme illustré dans l'exemple suivant.
Après quelques instants, l'état devrait passer à OK.
Version de l'API 2012-12-01283
Amazon Redshift Guide de la gestion du clusterUtilisation des métriques de performance
dans la console Amazon CloudWatch
8. (Facultatif) Choisissez Nom de l'alarme pour modifier la configuration de l'alarme ou choisissez le liensous Plus d'options pour accéder à cette alarme dans la console Amazon CloudWatch.
Utilisation des métriques de performance dans laconsole Amazon CloudWatchLors de l'utilisation des métriques Amazon Redshift dans la console Amazon CloudWatch, gardez à l'espritdeux ou trois points :
• Les données de performance des requêtes et des charges s'affichent uniquement dans la consoleAmazon Redshift
• Certaines métriques dans Amazon CloudWatch ont différentes unités que celles utilisées dans la consoleAmazon Redshift. Par exemple, WriteThroughput s'affiche en Go/s (et non en octets/s comme dansAmazon CloudWatch), qui est une unité plus appropriée pour l'espace de stockage classique d'un nœud.
Lors de l'utilisation des métriques Amazon Redshift dans la console Amazon CloudWatch, les outils deligne de commande ou un kit AWS SDK, il y a deux concepts à garder à l'esprit.
• Tout d'abord, vous spécifiez la dimension métrique à utiliser. Une dimension est une paire nom-valeurqui vous aide à identifier une métrique de façon unique. Les dimensions pour Amazon Redshift sontClusterIdentifier et NodeID. Dans la console Amazon CloudWatch, les vues Redshift Clusteret Redshift Node sont fournies pour sélectionner facilement les dimensions spécifiques au cluster etau nœud. Pour plus d'informations sur les dimensions, consultez Dimensions dans le manuel Guide dudéveloppeur Amazon CloudWatch.
• Deuxièmement, vous spécifiez le nom de la métrique, tel que ReadIOPS.
Le tableau suivant résume les types des dimensions de métrique Amazon Redshift disponibles. Toutes lesdonnées sont disponibles par période de 1 minute sans coût aucun.
Espace denom AmazonCloudWatch
Dimension Description
NodeID Les filtres ont demandé des données spécifiques aux nœudsd'un cluster. NodeID a la valeur « Leader », « Shared » ou« Compute-N » où N est égal à 0, 1, ... pour le nombre denœuds du cluster. « Shared » signifie que le cluster a un seulnœud, c'est-à-dire le nœud principal, et que les nœuds decalcul sont associés.
AWS/Redshift
ClusterIdentifierLes filtres ont demandé des données spécifiquesau cluster. Les métriques spécifiques aux clustersincluent HealthStatus, MaintenanceMode etDatabaseConnections. Les métriques générales de cette
Version de l'API 2012-12-01284

Amazon Redshift Guide de la gestion du clusterUtilisation des métriques de performance
dans la console Amazon CloudWatch
Espace denom AmazonCloudWatch
Dimension Description
dimension (par exemple ReadIOPS) qui sont égalementdes métriques de nœuds représentent une agrégation desdonnées des métriques de nœud. Veillez à interpréter cesmétriques parce qu'elles regroupent un comportement denœud principal et de nœuds de calcul.
L'utilisation des métriques de passerelle et de volume est similaire à l'utilisation des autres métriques deservice. La plupart des tâches courantes sont détaillées dans la documentation Amazon CloudWatch etsont répertoriées ci-dessous pour plus de commodité :
• Affichage des métriques disponibles• Obtention des statistiques d'une métrique• Création d'alarmes Amazon CloudWatch
Version de l'API 2012-12-01285

Amazon Redshift Guide de la gestion du clusterPrésentation
Événements Amazon RedshiftRubriques
• Présentation (p. 286)• Affichage des événements à l'aide de la console (p. 286)• Affichage d'événements à l'aide du kit AWS SDK pour Java (p. 287)• Afficher les événements à l'aide de l'API et de l'interface de ligne de commande Amazon
Redshift (p. 289)• Notifications d'événement Amazon Redshift (p. 289)
PrésentationAmazon Redshift suit les événements et conserve les informations à leur sujet dans votre compte AWSpendant plusieurs semaines. Pour chaque événement, Amazon Redshift prend en charge les informationstelles que la date à laquelle l'événement s'est produit, une description, la source de l'événement (un cluster,un groupe de paramètres ou un instantané, par exemple) et l'ID source.
Vous pouvez utiliser la console Amazon Redshift l'API Amazon Redshift ou les kits de développementlogiciel SDK AWS pour obtenir des informations sur l'événement. Vous pouvez obtenir la liste de tous lesévénements ou vous pouvez appliquer des filtres, tels que la durée de l'événement ou ses dates de débutet de fin, pour récupérer les informations sur les événements intervenus sur une période spécifique. Vouspouvez aussi obtenir les événements qui ont été générées par un type de source spécifique, comme lesévénements de cluster ou de groupe de paramètres.
Vous pouvez créer des abonnements aux notifications d'événements Amazon Redshift qui spécifientun ensemble de filtres d'événement. Quand se produit un événement qui correspond aux critères defiltre, Amazon Redshift utilise Amazon Simple Notification Service pour vous informer activement quel'événement a eu lieu.
Pour obtenir la liste des événements Amazon Redshift par type de source et par catégorie, consultez thesection called “Catégories d'événements et messages d'événements Amazon Redshift” (p. 291)
Affichage des événements à l'aide de la consoleVous pouvez afficher les événements dans la console Amazon Redshift en cliquant sur Événements dansle volet de navigation de gauche. Dans la liste des événements, vous pouvez filtrer les résultats à l'aide dufiltre Source Type d'un Filter personnalisé, qui filtre le texte dans tous les champs de la liste. Par exemple,si vous effectuez une recherche sur « 12 Dec 2012 », vous obtiendrez les champs Date contenant cettevaleur.
Un type de source d'événement indique en quoi concerne l'événement. Les types de source suivants sontpossibles : Cluster, Cluster Parameter Group, Cluster Security Group et Snapshot.
Version de l'API 2012-12-01286

Amazon Redshift Guide de la gestion du clusterFiltrage des événements
Filtrage des événementsParfois, vous voulez trouver une catégorie spécifique d'événements ou les événements d'un clusterspécifique. Dans ces cas-là, vous pouvez filtrer les événements affichés.
Pour filtrer les événements
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation, cliquez sur Events.3. Pour filtrer les événements, exécutez l'une des actions suivantes :
a. Pour filtrer par type d'événement, cliquez sur Filter Cluster, puis sélectionnez le type de source.
b. Pour filtrer sur un texte qui apparaît dans la description de l'événement, tapez-le dans la zone derecherche et la liste s'affine en fonction de votre saisie.
Affichage d'événements à l'aide du kit AWS SDKpour Java
L'exemple suivant répertorie les événements d'un cluster spécifié et du type de source d'événementspécifié. L'exemple présente l'utilisation de la pagination.
Pour obtenir les instructions pas à pas afin d'exécuter l'exemple suivant, consultez Exécution d'exemplesJava pour Amazon Redshift à l'aide d'Eclipse (p. 193). Vous devez mettre à jour le code et spécifier unidentificateur de cluster et un type d'événement source.
Example
import java.io.IOException;import java.util.Date;
import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.PropertiesCredentials;import com.amazonaws.services.redshift.AmazonRedshiftClient;
Version de l'API 2012-12-01287

Amazon Redshift Guide de la gestion du clusterAffichage d'événements à l'aide du kit AWS SDK pour Java
import com.amazonaws.services.redshift.model.*;
public class ListEvents {
public static AmazonRedshiftClient client; public static String clusterIdentifier = "***provide cluster identifier***"; public static String eventSourceType = "***provide source type***"; // e.g. cluster-snapshot public static void main(String[] args) throws IOException { AWSCredentials credentials = new PropertiesCredentials( ListEvents.class .getResourceAsStream("AwsCredentials.properties")); client = new AmazonRedshiftClient(credentials); try { listEvents(); } catch (Exception e) { System.err.println("Operation failed: " + e.getMessage()); } }
private static void listEvents() { long oneWeeksAgoMilli = (new Date()).getTime() - (7L*24L*60L*60L*1000L); Date oneWeekAgo = new Date(); oneWeekAgo.setTime(oneWeeksAgoMilli); String marker = null; do { DescribeEventsRequest request = new DescribeEventsRequest() .withSourceIdentifier(clusterIdentifier) .withSourceType(eventSourceType) .withStartTime(oneWeekAgo) .withMaxRecords(20); DescribeEventsResult result = client.describeEvents(request); marker = result.getMarker(); for (Event event : result.getEvents()) { printEvent(event); } } while (marker != null); } static void printEvent(Event event) { if (event == null) { System.out.println("\nEvent object is null."); return; }
System.out.println("\nEvent metadata:\n"); System.out.format("SourceID: %s\n", event.getSourceIdentifier()); System.out.format("Type: %s\n", event.getSourceType()); System.out.format("Message: %s\n", event.getMessage()); System.out.format("Date: %s\n", event.getDate()); }}
Version de l'API 2012-12-01288

Amazon Redshift Guide de la gestion du clusterAfficher les événements à l'aide de l'API et de
l'interface de ligne de commande Amazon Redshift
Afficher les événements à l'aide de l'API et del'interface de ligne de commande Amazon Redshift
Vous pouvez utiliser l'opération suivante d'interface de ligne de commande Amazon Redshift pour gérer lesévénements.
• describe-events
Amazon Redshift fournit l'API suivante pour afficher les événements.
• DescribeEvents
Notifications d'événement Amazon RedshiftRubriques
• Présentation (p. 289)• Catégories d'événements et messages d'événements Amazon Redshift (p. 291)• Gestion des notifications d'événement à l'aide de la console Amazon Redshift (p. 298)• Gestion des notifications d'événement à l'aide de l'interface de ligne de commande et de l'API Amazon
Redshift (p. 303)
PrésentationAmazon Redshift utilise Amazon Simple Notification Service (Amazon SNS) pour communiquer lesnotifications des événements Amazon Redshift. Vous activez les notifications en créant un abonnementaux événements Amazon Redshift. Dans l'abonnement Amazon Redshift, vous spécifiez un ensemble defiltres pour les événements Amazon Redshift et une rubrique Amazon SNS. Chaque fois qu'un événementse produit qui correspond aux critères de filtre, Amazon Redshift publie un message de notification dansla rubrique Amazon SNS. Amazon SNS transmet ensuite le message aux consommateurs Amazon SNSayant un abonnement Amazon SNS à la rubrique. Les messages envoyés aux consommateurs AmazonSNS peuvent être sous n'importe quelle forme prise en charge par Amazon SNS pour une région AWS,comme un e-mail, un SMS ou un appel à un point de terminaison HTTP. Par exemple, toutes les régionsprennent en charge les notifications par e-mail, mais les notifications par SMS ne peuvent être créées quedans la région Région USA Est (Virginie du N.).
Lorsque vous créez un abonnement aux notifications d'événement, vous spécifiez un ou plusieurs filtresd'événement. Amazon Redshift envoie les notifications via l'abonnement à tout moment où se produit unévénement qui correspond à tous les critères de filtre. Les critères de filtre incluent le type de source (parexemple, cluster ou instantané), l'ID de source (par exemple, le nom d'un cluster ou d'un instantané), lacatégorie d'événement (par exemple, Monitoring ou Security) et la gravité de l'événement (par exemple,INFO ou ERROR).
Vous pouvez facilement désactiver la notification sans supprimer un abonnement en définissant la cased'option Enabled avec la valeur No dans AWS Management Console ou en définissant le paramètreEnabled avec la valeur false à l'aide de l'interface de ligne de commande ou de l'API Amazon Redshift.
La facturation de la notification d'événement Amazon Redshift s'effectue via Amazon Simple NotificationService (Amazon SNS). Les frais Amazon SNS s'appliquent quand la notification d'événement est utilisée ;pour plus d'informations sur la facturation Amazon SNS, consultez Tarification Amazon Simple NotificationService.
Version de l'API 2012-12-01289

Amazon Redshift Guide de la gestion du clusterPrésentation
Vous pouvez également afficher les événements Amazon Redshift qui ont eu lieu à l'aide de la console degestion. Pour plus d'informations, consultez Événements Amazon Redshift (p. 286).
Abonnement aux notifications d'événement Amazon RedshiftVous pouvez créer un abonnement aux notifications d'événement Amazon Redshift afin de pouvoir êtreinformé quand un événement se produit pour un cluster, un snapshot, un groupe de sécurité ou un groupede paramètres donné. La solution la plus simple pour créer un abonnement consiste à utiliser la consoleAmazon SNS. Pour plus d'informations sur la création d'une rubrique Amazon SNS et sur l'abonnement,consultez Mise en route avec Amazon SNS.
Vous pouvez créer un abonnement aux notifications d'événement Amazon Redshift afin de pouvoirêtre informé quand un événement se produit pour un cluster, un snapshot, un groupe de sécurité ou ungroupe de paramètres donné. La solution la plus simple pour créer un abonnement consiste à utiliserAWS Management Console. Si vous choisissez de créer un abonnement à une notification d'événementà l'aide de l'interface de ligne de commande ou de l'API, vous devez créer une rubrique Amazon SimpleNotification Service et vous abonner à cette rubrique avec la console Amazon SNS ou l'API AmazonSNS. Vous devrez également conserver l'Amazon Resource Name (ARN) de la rubrique, car il est utilisélors de la soumission de commandes de l'interface de ligne de commande ou d'actions d'API. Pour plusd'informations sur la création d'une rubrique Amazon SNS et sur l'abonnement, consultez Mise en routeavec Amazon SNS.
Un abonnement aux événements Amazon Redshift peut spécifier ces critères d'événement :
• Les valeurs pour le type source sont Cluster, Snapshot, Parameter-groups et Security-groups.• ID source d'une ressource, comme my-cluster-1 ou my-snapshot-20130823. L'ID doit être pour
une ressource de la même région que l'abonnement aux événements.• Les valeurs pour la catégorie d'événement sont Configuration, Management, Monitoring et Security.• Pour la gravité de l'événement, les valeurs sont INFO ou ERROR.
Les critères d'événement peuvent être spécifiés de façon indépendante, sauf que vous devez spécifierun type de source avant de pouvoir spécifier les ID source dans la console. Par exemple, vous pouvezspécifier une catégorie d'événement sans avoir besoin de spécifier un type de source, un ID source ouune gravité. Même si vous pouvez spécifier les ID source des ressources qui ne sont pas du type spécifiédans le type de source, aucune notification ne sera envoyée pour les événements de ces ressources.Par exemple, si vous spécifiez un type de source de cluster et l'ID d'un groupe de sécurité, aucun desévénements déclenchés par ce groupe de sécurité ne correspond aux critères de filtre du type de sourceet, par conséquent, aucune notification ne sera envoyée pour ces événements.
Amazon Redshift envoie une notification pour tout événement qui correspond à tous les critères définisdans un abonnement. Quelques exemples d'ensembles d'événements renvoyés :
• L'abonnement spécifie Cluster comme type de source, my-cluster-1, comme ID source, Monitoringcomme catégorie et ERROR comme niveau de gravité. L'abonnement n'enverra les notifications qu'auxévénements de la catégorie Monitoring avec une gravité ERROR de my-cluster-1.
• L'abonnement spécifie Cluster comme type de source, Configuration comme catégorie et INFO commeniveau de gravité. L'abonnement n'enverra des notifications qu'aux événements de la catégorieConfiguration avec une gravité INFO de n'importe quel cluster Amazon Redshift du compte AWS.
• L'abonnement spécifie Configuration comme catégorie et INFO comme niveau de gravité. L'abonnementn'enverra des notifications qu'aux événements de la catégorie Configuration avec une gravité INFO den'importe quelle ressource Amazon Redshift du compte AWS.
• L'abonnement spécifie ERROR comme niveau de gravité. L'abonnement enverra des notifications pourtous les événements avec une gravité INFO de n'importe quelle ressource Amazon Redshift du compteAWS.
Version de l'API 2012-12-01290

Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
Si vous supprimez ou renommez un objet dont le nom est référencé comme ID source d'un abonnementexistant, l'abonnement demeure actif, mais n'a aucun événement à transmettre à partir de cet objet. Si,plus tard, vous créez un objet portant le même nom que celui référencé dans l'ID d'abonnement source,l'abonnement commence à envoyer les notifications pour les événements du nouvel objet.
Amazon Redshift publie les notifications d'événement sur une rubrique Amazon SNS, identifiée par sonnom Amazon Resource Name (ARN). Lorsque vous créez un abonnement aux événements en utilisant laconsole Amazon Redshift, vous pouvez spécifier une rubrique Amazon SNS existante ou demander quela console crée la rubrique quand elle crée l'abonnement. Toutes les notifications d'événement AmazonRedshift envoyées à la rubrique Amazon SNS sont à leur tour transmises à tous les clients Amazon SNSabonnés à cette rubrique. Utilisez la console Amazon SNS pour apporter des modifications à la rubriqueAmazon SNS, comme l'ajout d'abonnements de clients à la rubrique ou leur suppression. Pour plusd'informations sur la création et l'abonnement aux rubriques Amazon SNS, consultez Mise en route avecAmazon Simple Notification Service.
La section suivante répertorie l'ensemble des catégories et événements dont vous pouvez être informé.Elle contient aussi les informations sur l'abonnement et sur l'utilisation des abonnements aux événementsAmazon Redshift.
Catégories d'événements et messages d'événementsAmazon RedshiftCette section décrit les ID d'événement et les catégories de chaque type de source Amazon Redshift.
Le tableau suivant affiche la catégorie d'événement et la liste d'événements quand un cluster est le type desource.
Catégories et événements pour le type de source cluster
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Configuration REDSHIFT-EVENT-1000
INFO Le groupe de paramètres [nom du groupe deparamètres] a été mis à jour à [heure]. Lesmodifications s'appliqueront aux clusters associéslors du redémarrage.
Configuration REDSHIFT-EVENT-1001
INFO Votre cluster Amazon Redshift [nom du cluster] aété modifié pour utiliser le groupe de paramètres[nom du groupe de paramètres] à [heure].
Configuration REDSHIFT-EVENT-1500
ERROR Le [nom VPC] Amazon VPC n'existe pas. Vosmodifications de configuration du cluster [nomdu cluster] n'ont pas été appliquées. Veuillezconsulter AWS Management Console pourcorriger le problème.
Configuration REDSHIFT-EVENT-1501
ERROR Les sous-réseaux client [nom des sous-réseaux]spécifiés pour [nom du VPC] Amazon VPCn'existent pas ou ne sont pas valides. Vosmodifications de configuration du cluster [nomdu cluster] n'ont pas été appliquées. Veuillezconsulter AWS Management Console pourcorriger le problème.
Version de l'API 2012-12-01291
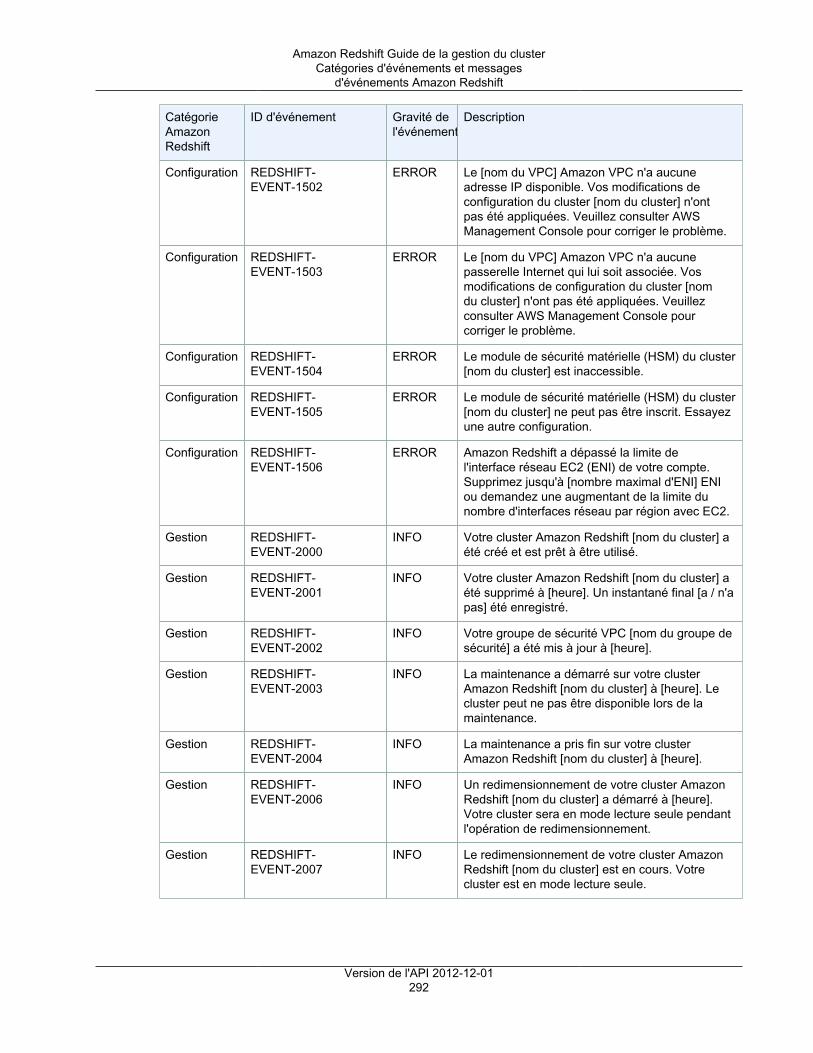
Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Configuration REDSHIFT-EVENT-1502
ERROR Le [nom du VPC] Amazon VPC n'a aucuneadresse IP disponible. Vos modifications deconfiguration du cluster [nom du cluster] n'ontpas été appliquées. Veuillez consulter AWSManagement Console pour corriger le problème.
Configuration REDSHIFT-EVENT-1503
ERROR Le [nom du VPC] Amazon VPC n'a aucunepasserelle Internet qui lui soit associée. Vosmodifications de configuration du cluster [nomdu cluster] n'ont pas été appliquées. Veuillezconsulter AWS Management Console pourcorriger le problème.
Configuration REDSHIFT-EVENT-1504
ERROR Le module de sécurité matérielle (HSM) du cluster[nom du cluster] est inaccessible.
Configuration REDSHIFT-EVENT-1505
ERROR Le module de sécurité matérielle (HSM) du cluster[nom du cluster] ne peut pas être inscrit. Essayezune autre configuration.
Configuration REDSHIFT-EVENT-1506
ERROR Amazon Redshift a dépassé la limite del'interface réseau EC2 (ENI) de votre compte.Supprimez jusqu'à [nombre maximal d'ENI] ENIou demandez une augmentant de la limite dunombre d'interfaces réseau par région avec EC2.
Gestion REDSHIFT-EVENT-2000
INFO Votre cluster Amazon Redshift [nom du cluster] aété créé et est prêt à être utilisé.
Gestion REDSHIFT-EVENT-2001
INFO Votre cluster Amazon Redshift [nom du cluster] aété supprimé à [heure]. Un instantané final [a / n'apas] été enregistré.
Gestion REDSHIFT-EVENT-2002
INFO Votre groupe de sécurité VPC [nom du groupe desécurité] a été mis à jour à [heure].
Gestion REDSHIFT-EVENT-2003
INFO La maintenance a démarré sur votre clusterAmazon Redshift [nom du cluster] à [heure]. Lecluster peut ne pas être disponible lors de lamaintenance.
Gestion REDSHIFT-EVENT-2004
INFO La maintenance a pris fin sur votre clusterAmazon Redshift [nom du cluster] à [heure].
Gestion REDSHIFT-EVENT-2006
INFO Un redimensionnement de votre cluster AmazonRedshift [nom du cluster] a démarré à [heure].Votre cluster sera en mode lecture seule pendantl'opération de redimensionnement.
Gestion REDSHIFT-EVENT-2007
INFO Le redimensionnement de votre cluster AmazonRedshift [nom du cluster] est en cours. Votrecluster est en mode lecture seule.
Version de l'API 2012-12-01292
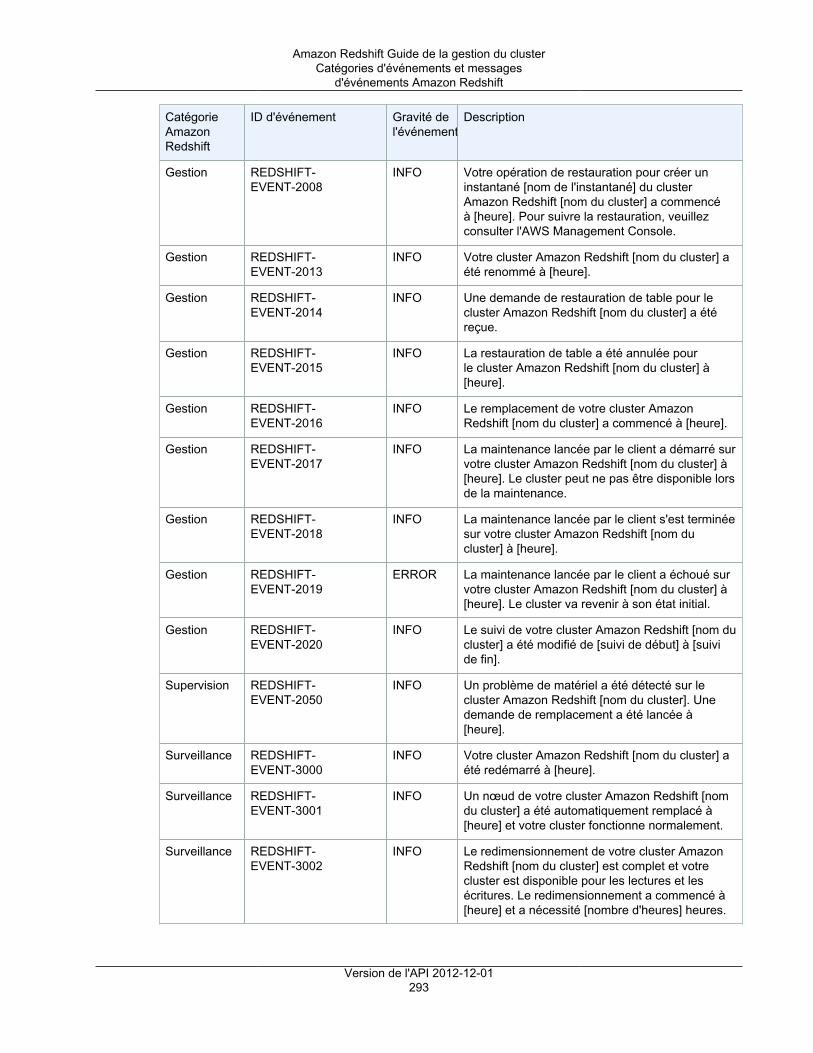
Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Gestion REDSHIFT-EVENT-2008
INFO Votre opération de restauration pour créer uninstantané [nom de l'instantané] du clusterAmazon Redshift [nom du cluster] a commencéà [heure]. Pour suivre la restauration, veuillezconsulter l'AWS Management Console.
Gestion REDSHIFT-EVENT-2013
INFO Votre cluster Amazon Redshift [nom du cluster] aété renommé à [heure].
Gestion REDSHIFT-EVENT-2014
INFO Une demande de restauration de table pour lecluster Amazon Redshift [nom du cluster] a étéreçue.
Gestion REDSHIFT-EVENT-2015
INFO La restauration de table a été annulée pourle cluster Amazon Redshift [nom du cluster] à[heure].
Gestion REDSHIFT-EVENT-2016
INFO Le remplacement de votre cluster AmazonRedshift [nom du cluster] a commencé à [heure].
Gestion REDSHIFT-EVENT-2017
INFO La maintenance lancée par le client a démarré survotre cluster Amazon Redshift [nom du cluster] à[heure]. Le cluster peut ne pas être disponible lorsde la maintenance.
Gestion REDSHIFT-EVENT-2018
INFO La maintenance lancée par le client s'est terminéesur votre cluster Amazon Redshift [nom ducluster] à [heure].
Gestion REDSHIFT-EVENT-2019
ERROR La maintenance lancée par le client a échoué survotre cluster Amazon Redshift [nom du cluster] à[heure]. Le cluster va revenir à son état initial.
Gestion REDSHIFT-EVENT-2020
INFO Le suivi de votre cluster Amazon Redshift [nom ducluster] a été modifié de [suivi de début] à [suivide fin].
Supervision REDSHIFT-EVENT-2050
INFO Un problème de matériel a été détecté sur lecluster Amazon Redshift [nom du cluster]. Unedemande de remplacement a été lancée à[heure].
Surveillance REDSHIFT-EVENT-3000
INFO Votre cluster Amazon Redshift [nom du cluster] aété redémarré à [heure].
Surveillance REDSHIFT-EVENT-3001
INFO Un nœud de votre cluster Amazon Redshift [nomdu cluster] a été automatiquement remplacé à[heure] et votre cluster fonctionne normalement.
Surveillance REDSHIFT-EVENT-3002
INFO Le redimensionnement de votre cluster AmazonRedshift [nom du cluster] est complet et votrecluster est disponible pour les lectures et lesécritures. Le redimensionnement a commencé à[heure] et a nécessité [nombre d'heures] heures.
Version de l'API 2012-12-01293
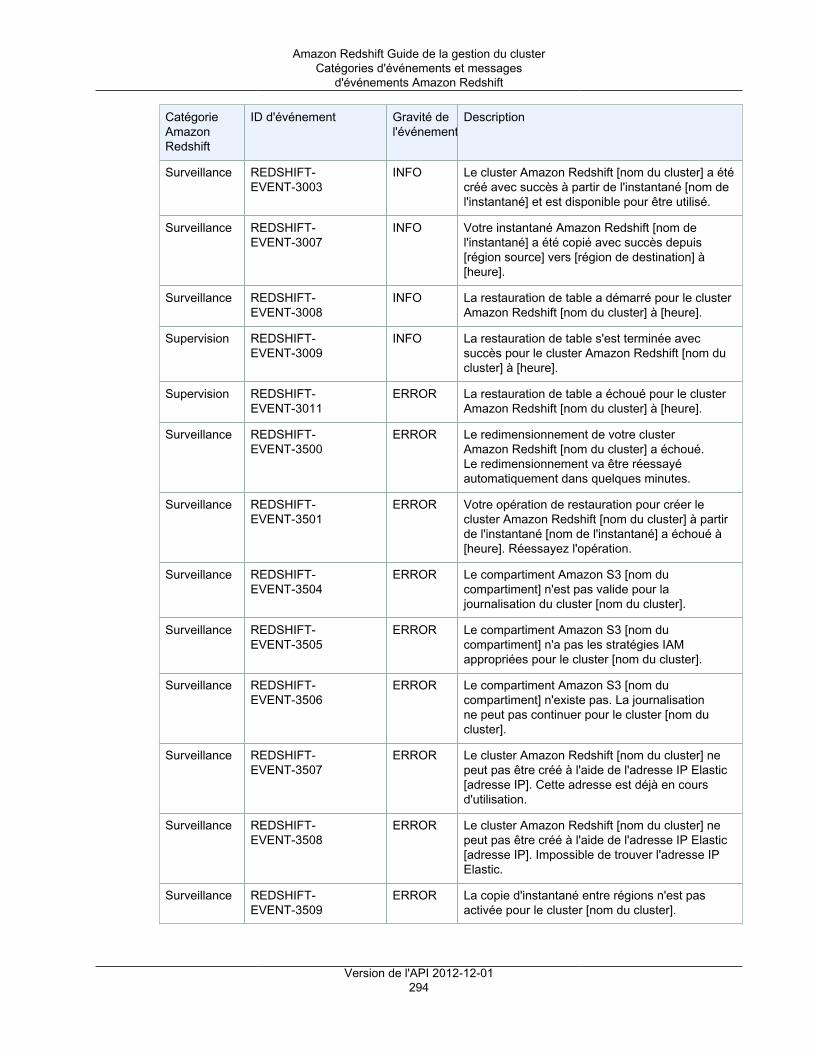
Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Surveillance REDSHIFT-EVENT-3003
INFO Le cluster Amazon Redshift [nom du cluster] a étécréé avec succès à partir de l'instantané [nom del'instantané] et est disponible pour être utilisé.
Surveillance REDSHIFT-EVENT-3007
INFO Votre instantané Amazon Redshift [nom del'instantané] a été copié avec succès depuis[région source] vers [région de destination] à[heure].
Surveillance REDSHIFT-EVENT-3008
INFO La restauration de table a démarré pour le clusterAmazon Redshift [nom du cluster] à [heure].
Supervision REDSHIFT-EVENT-3009
INFO La restauration de table s'est terminée avecsuccès pour le cluster Amazon Redshift [nom ducluster] à [heure].
Supervision REDSHIFT-EVENT-3011
ERROR La restauration de table a échoué pour le clusterAmazon Redshift [nom du cluster] à [heure].
Surveillance REDSHIFT-EVENT-3500
ERROR Le redimensionnement de votre clusterAmazon Redshift [nom du cluster] a échoué.Le redimensionnement va être réessayéautomatiquement dans quelques minutes.
Surveillance REDSHIFT-EVENT-3501
ERROR Votre opération de restauration pour créer lecluster Amazon Redshift [nom du cluster] à partirde l'instantané [nom de l'instantané] a échoué à[heure]. Réessayez l'opération.
Surveillance REDSHIFT-EVENT-3504
ERROR Le compartiment Amazon S3 [nom ducompartiment] n'est pas valide pour lajournalisation du cluster [nom du cluster].
Surveillance REDSHIFT-EVENT-3505
ERROR Le compartiment Amazon S3 [nom ducompartiment] n'a pas les stratégies IAMappropriées pour le cluster [nom du cluster].
Surveillance REDSHIFT-EVENT-3506
ERROR Le compartiment Amazon S3 [nom ducompartiment] n'existe pas. La journalisationne peut pas continuer pour le cluster [nom ducluster].
Surveillance REDSHIFT-EVENT-3507
ERROR Le cluster Amazon Redshift [nom du cluster] nepeut pas être créé à l'aide de l'adresse IP Elastic[adresse IP]. Cette adresse est déjà en coursd'utilisation.
Surveillance REDSHIFT-EVENT-3508
ERROR Le cluster Amazon Redshift [nom du cluster] nepeut pas être créé à l'aide de l'adresse IP Elastic[adresse IP]. Impossible de trouver l'adresse IPElastic.
Surveillance REDSHIFT-EVENT-3509
ERROR La copie d'instantané entre régions n'est pasactivée pour le cluster [nom du cluster].
Version de l'API 2012-12-01294
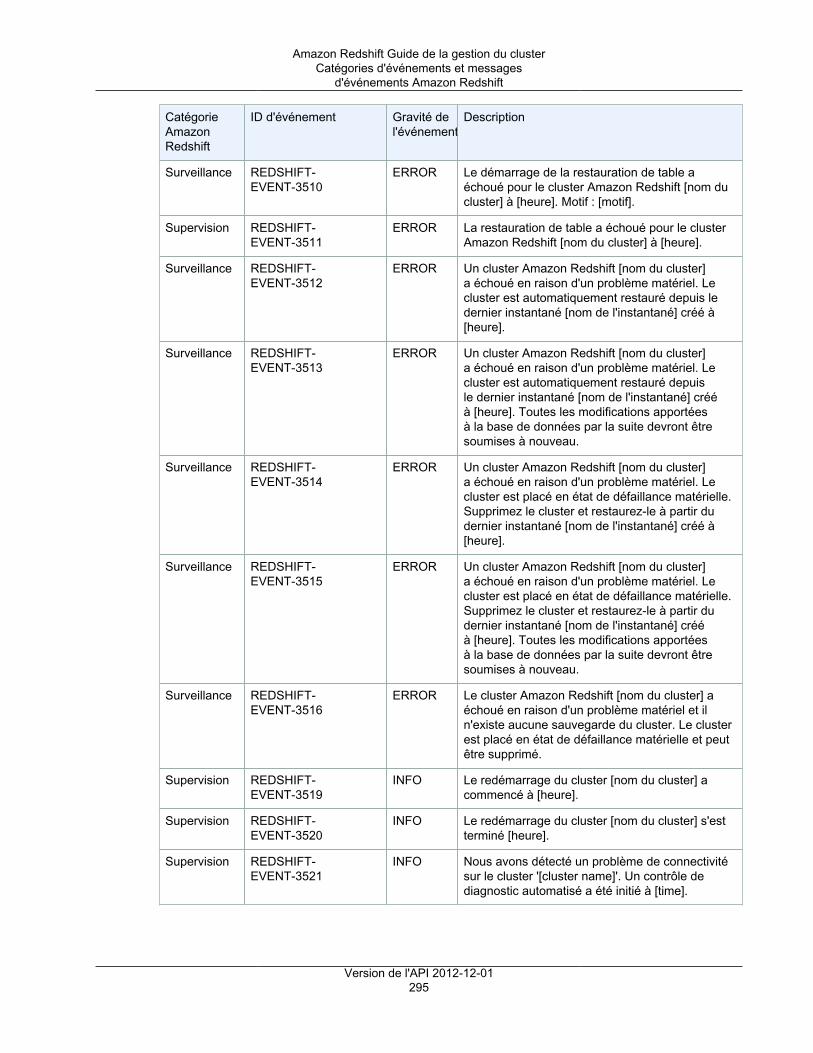
Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Surveillance REDSHIFT-EVENT-3510
ERROR Le démarrage de la restauration de table aéchoué pour le cluster Amazon Redshift [nom ducluster] à [heure]. Motif : [motif].
Supervision REDSHIFT-EVENT-3511
ERROR La restauration de table a échoué pour le clusterAmazon Redshift [nom du cluster] à [heure].
Surveillance REDSHIFT-EVENT-3512
ERROR Un cluster Amazon Redshift [nom du cluster]a échoué en raison d'un problème matériel. Lecluster est automatiquement restauré depuis ledernier instantané [nom de l'instantané] créé à[heure].
Surveillance REDSHIFT-EVENT-3513
ERROR Un cluster Amazon Redshift [nom du cluster]a échoué en raison d'un problème matériel. Lecluster est automatiquement restauré depuisle dernier instantané [nom de l'instantané] crééà [heure]. Toutes les modifications apportéesà la base de données par la suite devront êtresoumises à nouveau.
Surveillance REDSHIFT-EVENT-3514
ERROR Un cluster Amazon Redshift [nom du cluster]a échoué en raison d'un problème matériel. Lecluster est placé en état de défaillance matérielle.Supprimez le cluster et restaurez-le à partir dudernier instantané [nom de l'instantané] créé à[heure].
Surveillance REDSHIFT-EVENT-3515
ERROR Un cluster Amazon Redshift [nom du cluster]a échoué en raison d'un problème matériel. Lecluster est placé en état de défaillance matérielle.Supprimez le cluster et restaurez-le à partir dudernier instantané [nom de l'instantané] crééà [heure]. Toutes les modifications apportéesà la base de données par la suite devront êtresoumises à nouveau.
Surveillance REDSHIFT-EVENT-3516
ERROR Le cluster Amazon Redshift [nom du cluster] aéchoué en raison d'un problème matériel et iln'existe aucune sauvegarde du cluster. Le clusterest placé en état de défaillance matérielle et peutêtre supprimé.
Supervision REDSHIFT-EVENT-3519
INFO Le redémarrage du cluster [nom du cluster] acommencé à [heure].
Supervision REDSHIFT-EVENT-3520
INFO Le redémarrage du cluster [nom du cluster] s'estterminé [heure].
Supervision REDSHIFT-EVENT-3521
INFO Nous avons détecté un problème de connectivitésur le cluster '[cluster name]'. Un contrôle dediagnostic automatisé a été initié à [time].
Version de l'API 2012-12-01295
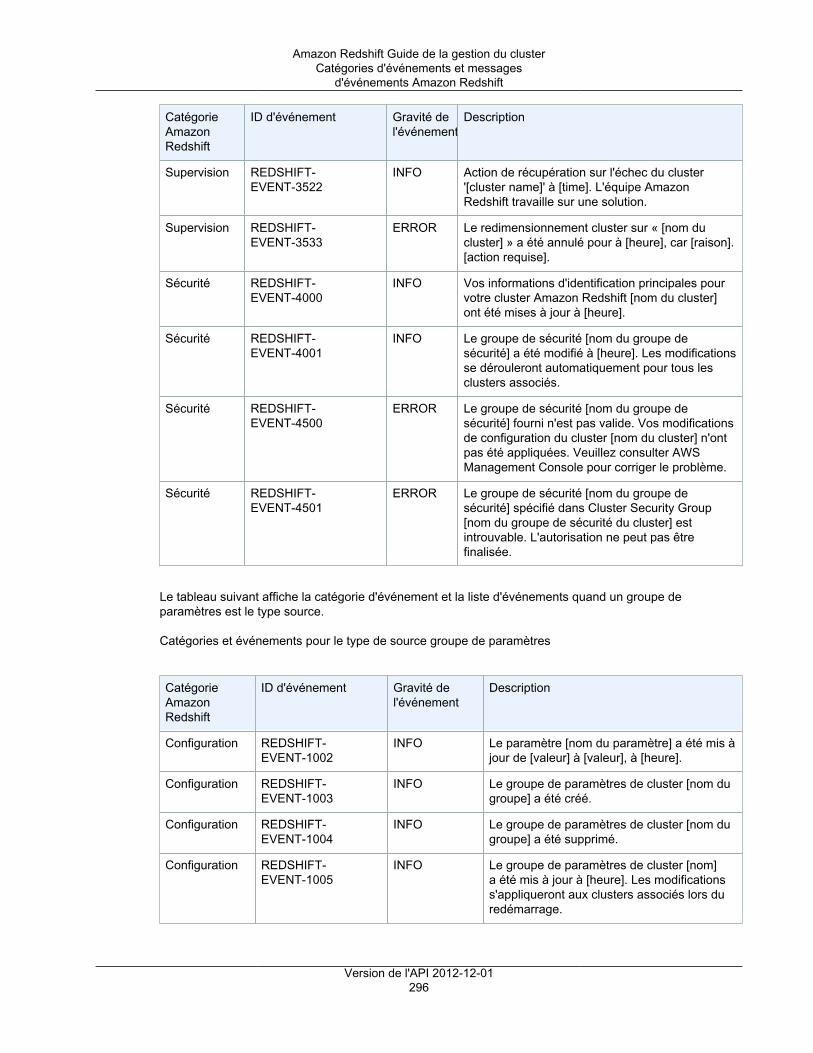
Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Supervision REDSHIFT-EVENT-3522
INFO Action de récupération sur l'échec du cluster'[cluster name]' à [time]. L'équipe AmazonRedshift travaille sur une solution.
Supervision REDSHIFT-EVENT-3533
ERROR Le redimensionnement cluster sur « [nom ducluster] » a été annulé pour à [heure], car [raison].[action requise].
Sécurité REDSHIFT-EVENT-4000
INFO Vos informations d'identification principales pourvotre cluster Amazon Redshift [nom du cluster]ont été mises à jour à [heure].
Sécurité REDSHIFT-EVENT-4001
INFO Le groupe de sécurité [nom du groupe desécurité] a été modifié à [heure]. Les modificationsse dérouleront automatiquement pour tous lesclusters associés.
Sécurité REDSHIFT-EVENT-4500
ERROR Le groupe de sécurité [nom du groupe desécurité] fourni n'est pas valide. Vos modificationsde configuration du cluster [nom du cluster] n'ontpas été appliquées. Veuillez consulter AWSManagement Console pour corriger le problème.
Sécurité REDSHIFT-EVENT-4501
ERROR Le groupe de sécurité [nom du groupe desécurité] spécifié dans Cluster Security Group[nom du groupe de sécurité du cluster] estintrouvable. L'autorisation ne peut pas êtrefinalisée.
Le tableau suivant affiche la catégorie d'événement et la liste d'événements quand un groupe deparamètres est le type source.
Catégories et événements pour le type de source groupe de paramètres
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Configuration REDSHIFT-EVENT-1002
INFO Le paramètre [nom du paramètre] a été mis àjour de [valeur] à [valeur], à [heure].
Configuration REDSHIFT-EVENT-1003
INFO Le groupe de paramètres de cluster [nom dugroupe] a été créé.
Configuration REDSHIFT-EVENT-1004
INFO Le groupe de paramètres de cluster [nom dugroupe] a été supprimé.
Configuration REDSHIFT-EVENT-1005
INFO Le groupe de paramètres de cluster [nom]a été mis à jour à [heure]. Les modificationss'appliqueront aux clusters associés lors duredémarrage.
Version de l'API 2012-12-01296
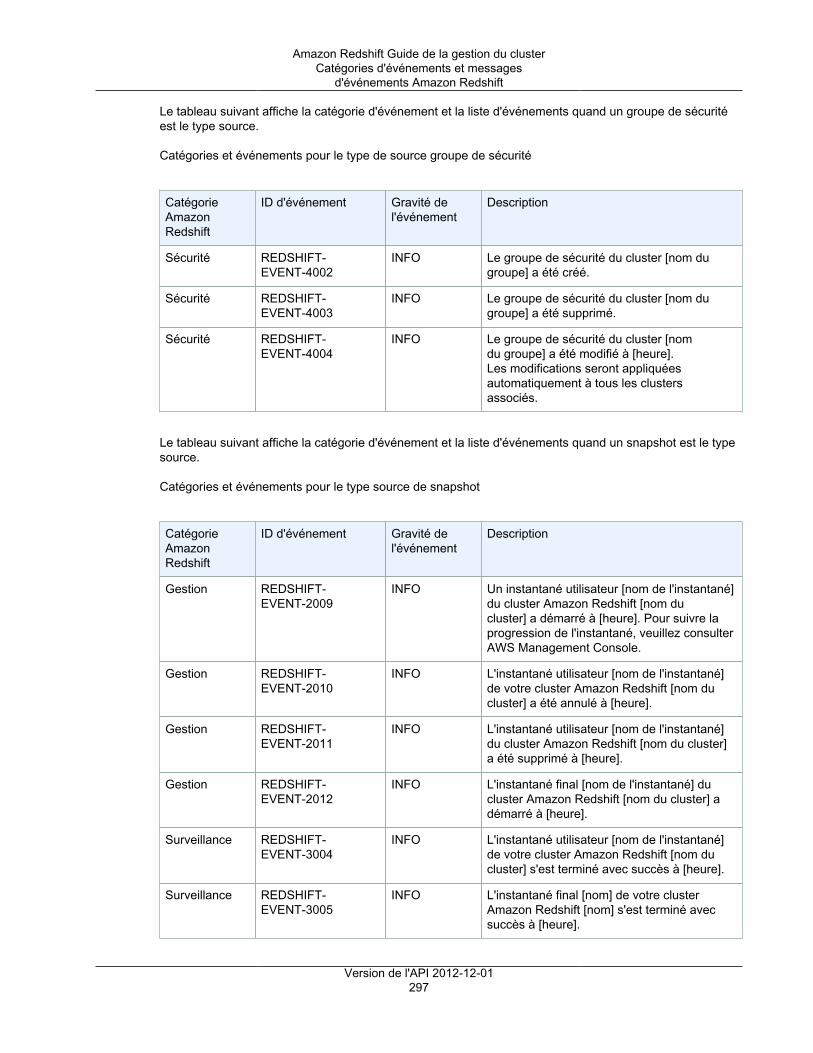
Amazon Redshift Guide de la gestion du clusterCatégories d'événements et messages
d'événements Amazon Redshift
Le tableau suivant affiche la catégorie d'événement et la liste d'événements quand un groupe de sécuritéest le type source.
Catégories et événements pour le type de source groupe de sécurité
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Sécurité REDSHIFT-EVENT-4002
INFO Le groupe de sécurité du cluster [nom dugroupe] a été créé.
Sécurité REDSHIFT-EVENT-4003
INFO Le groupe de sécurité du cluster [nom dugroupe] a été supprimé.
Sécurité REDSHIFT-EVENT-4004
INFO Le groupe de sécurité du cluster [nomdu groupe] a été modifié à [heure].Les modifications seront appliquéesautomatiquement à tous les clustersassociés.
Le tableau suivant affiche la catégorie d'événement et la liste d'événements quand un snapshot est le typesource.
Catégories et événements pour le type source de snapshot
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Gestion REDSHIFT-EVENT-2009
INFO Un instantané utilisateur [nom de l'instantané]du cluster Amazon Redshift [nom ducluster] a démarré à [heure]. Pour suivre laprogression de l'instantané, veuillez consulterAWS Management Console.
Gestion REDSHIFT-EVENT-2010
INFO L'instantané utilisateur [nom de l'instantané]de votre cluster Amazon Redshift [nom ducluster] a été annulé à [heure].
Gestion REDSHIFT-EVENT-2011
INFO L'instantané utilisateur [nom de l'instantané]du cluster Amazon Redshift [nom du cluster]a été supprimé à [heure].
Gestion REDSHIFT-EVENT-2012
INFO L'instantané final [nom de l'instantané] ducluster Amazon Redshift [nom du cluster] adémarré à [heure].
Surveillance REDSHIFT-EVENT-3004
INFO L'instantané utilisateur [nom de l'instantané]de votre cluster Amazon Redshift [nom ducluster] s'est terminé avec succès à [heure].
Surveillance REDSHIFT-EVENT-3005
INFO L'instantané final [nom] de votre clusterAmazon Redshift [nom] s'est terminé avecsuccès à [heure].
Version de l'API 2012-12-01297

Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événementà l'aide de la console Amazon Redshift
CatégorieAmazonRedshift
ID d'événement Gravité del'événement
Description
Surveillance REDSHIFT-EVENT-3006
INFO L'instantané final [nom de l'instantané] ducluster Amazon Redshift [nom du cluster] aété annulé à [heure].
Surveillance REDSHIFT-EVENT-3502
ERROR L'instantané final [nom de l'instantané] ducluster Amazon Redshift [nom du cluster]a échoué à [heure]. L'équipe étudie leproblème. Accédez à AWS ManagementConsole et réessayez l'opération.
Surveillance REDSHIFT-EVENT-3503
ERROR L'instantané utilisateur [nom de l'instantané]de votre cluster Amazon Redshift [nom ducluster] a échoué à [heure]. L'équipe étudiele problème. Accédez à AWS ManagementConsole et réessayez l'opération.
Gestion des notifications d'événement à l'aide de laconsole Amazon RedshiftRubriques
• Création d'un abonnement aux notifications d'événement (p. 298)• Affichage de vos abonnements aux notifications d'événement Amazon Redshift (p. 301)• Modification d'un abonnement aux notifications d'événement Amazon Redshift (p. 301)• Ajout d'un identificateur source à un abonnement aux notifications d'événement Amazon
Redshift (p. 302)• Suppression d'un identificateur source d'un abonnement aux notifications d'événement Amazon
Redshift (p. 303)• Suppression d'un abonnement aux notifications d'événement Amazon Redshift (p. 303)
Vous pouvez créer un abonnement aux notifications d'événement Amazon Simple Notification Service(Amazon SNS) pour envoyer des notifications quand un événement se produit pour un cluster, uninstantané, un groupe de sécurité ou un groupe de paramètres Amazon Redshift donné. Ces notificationssont envoyées à une rubrique SNS, qui à son tour transmet les messages aux clients SNS abonnés à larubrique. Les messages SNS envoyés aux clients peuvent être sous n'importe quelle forme de notificationprise en charge par Amazon SNS pour une région AWS, comme un e-mail, un SMS ou un appel à un pointde terminaison HTTP. Par exemple, toutes les régions prennent en charge les notifications par e-mail, maisles notifications par SMS ne peuvent être créées que dans la région Région USA Est (Virginie du N.). Pourplus d'informations, consultez Notifications d'événement Amazon Redshift (p. 289).
Cette section décrit comment gérer les abonnements aux notifications d'événement Amazon Redshift àpartir d'AWS Management Console.
Création d'un abonnement aux notifications d'événementPour créer un abonnement aux notifications d'événement Amazon Redshift
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
Version de l'API 2012-12-01298

Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événementà l'aide de la console Amazon Redshift
2. Dans le volet de navigation de la console Amazon Redshift, cliquez sur Événements, puis sur l'ongletAbonnements.
3. Dans le volet Subscriptions, cliquez sur Create Event Subscription.4. Dans la boîte de dialogue Create Event Subscription, exécutez l'une des actions suivantes :
a. Utilisez le volet Paramètres d'abonnement pour spécifier les critères de filtre d'événement.Lorsque vous sélectionnez les critères, la liste Événements souscrits affiche les événementsAmazon Redshift qui répondent aux critères. Procédez comme suit :
i. Sélectionnez une ou plusieurs catégories d'événement dans la zone Catégories. Pourspécifier toutes les catégories, sélectionnez le bouton Catégorie. Pour sélectionner un sous-ensemble de catégories, sélectionnez les boutons des catégories à inclure.
ii. Sélectionnez une gravité d'événement dans le menu déroulant Gravité. Si vous sélectionnezTous, les événements avec une gravité INFO ou ERROR sont publiés. Si vous sélectionnezErreur, seuls les événements avec la gravité ERROR sont publiés.
iii. Sélectionnez un type de source dans le menu déroulant Source Type. Seuls les événementsdéclenchés par les ressources de ce type, telles que les clusters ou les groupes deparamètres de cluster, sont publiés par l'abonnement aux événements.
iv. Dans le menu déroulant Ressources, spécifiez si les événements seront publiés à partirde toutes les ressources ayant le Type de source spécifié ou seulement à partir d'un sous-ensemble. Sélectionnez Tous pour publier les événements de toutes les ressources ayantle type spécifié. Sélectionnez Sélectionner spécifiques si vous voulez sélectionner desressources spécifiques.
Note
Le nom de la zone Ressource est modifié pour refléter la valeur spécifiée dans Typede source. Par exemple, si vous sélectionnez Cluster dans Type de source, le nomde la zone Ressources devient Clusters.
Si vous sélectionnez Sélectionner spécifiques, vous pouvez spécifier les ID des ressourcesspécifiques dont les événements seront publiés par l'abonnement aux événements. Vousspécifiez les ressources l'une après l'autre et les ajoutez à l'abonnement aux événements.Vous pouvez spécifier uniquement les ressources qui se trouvent dans la même région quel'abonnement aux événements. Les événements que vous avez spécifiés sont répertoriéssous la zone Spécifier les ID :.
A. Pour spécifier une ressource existante, recherchez-la dans la zone Spécifier les ID :, puiscliquez sur le bouton + dans la colonne Ajouter.
B. Pour spécifier l'ID d'une ressource avant de la créer il, tapez l'ID dans la zone sousSpécifier les ID : et cliquez sur le bouton Ajouter. Vous pouvez le faire pour ajouter desressources que vous prévoyez de créer ultérieurement.
C. Pour supprimer une ressource sélectionnée de l'abonnement aux événements, cliquezsur le X à droite de la ressource.
b. En bas du volet, entrez un nom pour l'abonnement aux notifications d'événement dans la zone detexte Nom.
c. Sélectionnez Yes pour activer l'abonnement. Si vous souhaitez créer l'abonnement, mais nepas avoir des notifications envoyées, sélectionnez No. Un message de confirmation est envoyélorsqu'un abonnement est créé, quel que soit ce paramètre.
d. Sélectionnez Suivant pour poursuivre la spécification de la rubrique Amazon SNS.
Version de l'API 2012-12-01299

Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événementà l'aide de la console Amazon Redshift
e. Utilisez l'un des trois onglets pour spécifier la rubrique Amazon SNS que l'abonnement utilise pourpublier des événements.
i. Pour sélectionner une rubrique Amazon SNS existante dans une liste, sélectionnez l'ongletUtiliser la rubrique existante et sélectionnez la rubrique dans la liste.
ii. Pour spécifier une rubrique Amazon SNS existante par son nom Amazon Resource Name(ARN), sélectionnez l'onglet Fournir l'ARN de la rubrique et spécifiez l'ARN dans la zoneARN :. Vous pouvez trouver l'ARN d'une rubrique Amazon SNS à l'aide de la consoleAmazon SNS :
A. Connectez-vous à la AWS Management Console et ouvrez la console Amazon SNS àl'adresse https://console.aws.amazon.com/sns/v2/home.
B. Dans le volet Navigation, développez Rubriques.C. Cliquez sur la rubrique à inclure dans l'abonnement aux événements Amazon Redshift.D. Dans le volet Détails de la rubrique, copiez la valeur du champ ARN de la rubrique :.
iii. Pour que l'opération de création de l'abonnement crée aussi une nouvelle rubrique AmazonSNS, sélectionnez l'onglet Créer une rubrique et procédez comme suit :
A. Entrez un nom pour la rubrique dans la zone de texte Nom.B. Pour chaque destinataire de la notification, sélectionnez la méthode de notification dans
la zone de liste Envoyer, spécifiez une adresse valide dans la zone A, puis cliquez surAjouter un destinataire. Vous ne pouvez créer des entrées SMS que dans la régionRégion USA Est (Virginie du N.).
C. Pour supprimer un destinataire, cliquez sur le X de couleur rouge dans la colonneSupprimer.
Version de l'API 2012-12-01300
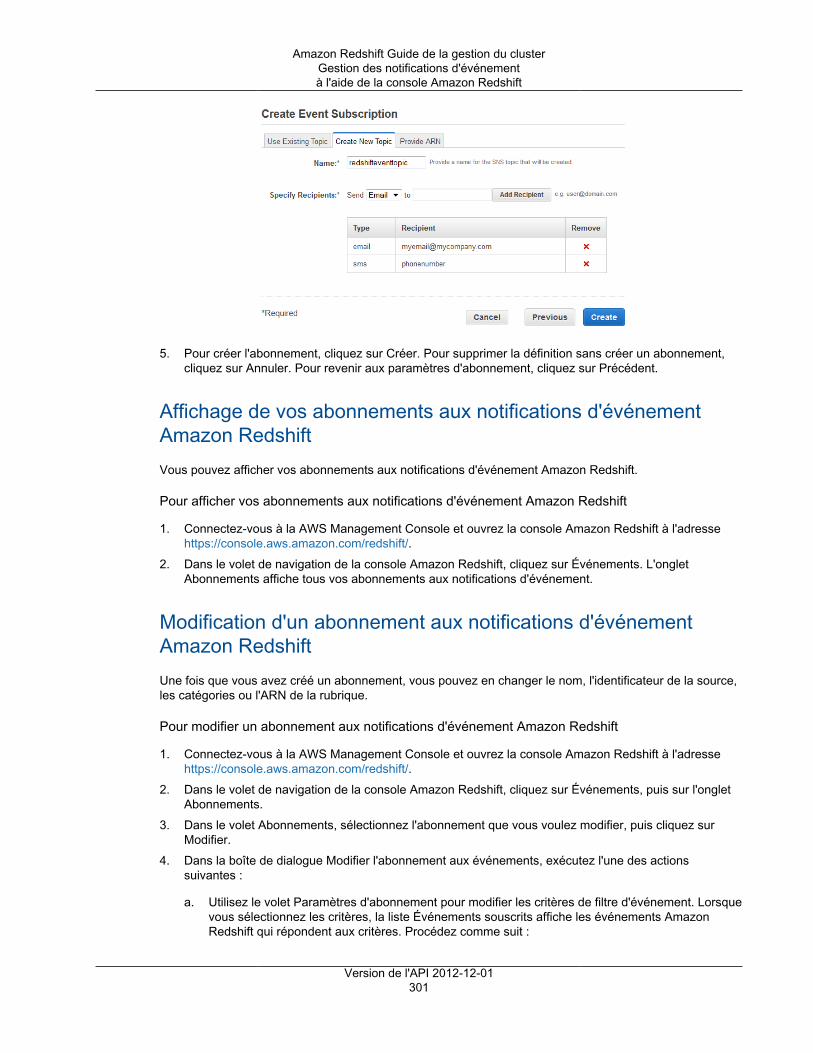
Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événementà l'aide de la console Amazon Redshift
5. Pour créer l'abonnement, cliquez sur Créer. Pour supprimer la définition sans créer un abonnement,cliquez sur Annuler. Pour revenir aux paramètres d'abonnement, cliquez sur Précédent.
Affichage de vos abonnements aux notifications d'événementAmazon RedshiftVous pouvez afficher vos abonnements aux notifications d'événement Amazon Redshift.
Pour afficher vos abonnements aux notifications d'événement Amazon Redshift
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de la console Amazon Redshift, cliquez sur Événements. L'ongletAbonnements affiche tous vos abonnements aux notifications d'événement.
Modification d'un abonnement aux notifications d'événementAmazon RedshiftUne fois que vous avez créé un abonnement, vous pouvez en changer le nom, l'identificateur de la source,les catégories ou l'ARN de la rubrique.
Pour modifier un abonnement aux notifications d'événement Amazon Redshift
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de la console Amazon Redshift, cliquez sur Événements, puis sur l'ongletAbonnements.
3. Dans le volet Abonnements, sélectionnez l'abonnement que vous voulez modifier, puis cliquez surModifier.
4. Dans la boîte de dialogue Modifier l'abonnement aux événements, exécutez l'une des actionssuivantes :
a. Utilisez le volet Paramètres d'abonnement pour modifier les critères de filtre d'événement. Lorsquevous sélectionnez les critères, la liste Événements souscrits affiche les événements AmazonRedshift qui répondent aux critères. Procédez comme suit :
Version de l'API 2012-12-01301

Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événementà l'aide de la console Amazon Redshift
i. Sélectionnez une ou plusieurs catégories d'événement dans la zone Catégories. Pourspécifier toutes les catégories, sélectionnez le bouton Catégorie. Pour sélectionner un sous-ensemble de catégories, sélectionnez les boutons des catégories à inclure.
ii. Sélectionnez une gravité d'événement dans le menu déroulant Gravité.iii. Sélectionnez un type de source dans le menu déroulant Source Type.iv. Sélectionnez les ID des ressources dans le menu déroulant Type de source. Seuls les
événements déclenchés par les ressources spécifiées seront publiés par l'abonnement.b. Pour Activé, sélectionnez Oui pour activer l'abonnement. Sélectionnez Non pour désactiver
l'abonnement.c. Sélectionnez Suivant pour poursuivre la modification de la rubrique Amazon SNS.d. Utilisez l'un des trois onglets pour modifier la rubrique Amazon SNS que l'abonnement utilise pour
publier des événements.
i. Pour sélectionner une rubrique Amazon SNS existante dans une liste, sélectionnez l'ongletUtiliser la rubrique existante et sélectionnez la rubrique dans la liste.
ii. Pour spécifier une rubrique Amazon SNS existante par son nom Amazon Resource Name(ARN), sélectionnez l'onglet Fournir l'ARN et spécifiez l'ARN dans la zone ARN :.
iii. Pour que l'opération de modification de l'abonnement crée aussi une nouvelle rubriqueAmazon SNS, sélectionnez l'onglet Créer une rubrique et procédez comme suit :
A. Entrez un nom pour la rubrique dans la zone de texte Nom.B. Pour chaque destinataire de la notification, sélectionnez la méthode de notification dans
la zone de liste Envoyer, spécifiez une adresse valide dans la zone A, puis cliquez surAjouter un destinataire. Vous ne pouvez créer des entrées SMS que dans la régionRégion USA Est (Virginie du N.).
C. Pour supprimer un destinataire, cliquez sur le X de couleur rouge dans la colonneSupprimer.
5. Pour enregistrer les modifications, cliquez sur Modifier. Pour supprimer vos modifications sans modifierl'abonnement, cliquez sur Annuler. Pour revenir aux paramètres d'abonnement, cliquez sur Précédent.
Ajout d'un identificateur source à un abonnement aux notificationsd'événement Amazon RedshiftVous pouvez ajouter un identificateur source (la source Amazon Redshift générant l'événement) à unabonnement existant.
Pour ajouter un identificateur source à un abonnement aux notifications d'événement AmazonRedshift
1. Vous pouvez facilement ajouter ou supprimer des identificateurs source à l'aide de la console AmazonRedshift en les sélectionnant ou en annulant leur sélection lors de la modification d'un abonnement.Pour plus d'informations, consultez Modification d'un abonnement aux notifications d'événementAmazon Redshift (p. 301).
2. Pour enregistrer les modifications, cliquez sur Modifier. Pour supprimer vos modifications sans modifierl'abonnement, cliquez sur Annuler. Pour revenir aux paramètres d'abonnement, cliquez sur Précédent.
Version de l'API 2012-12-01302
Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événement à l'aide de l'interface
de ligne de commande et de l'API Amazon Redshift
Suppression d'un identificateur source d'un abonnement auxnotifications d'événement Amazon RedshiftVous pouvez supprimer un identificateur source (la source Amazon Redshift générant l'événement) d'unabonnement si vous ne souhaitez plus être informé des événements de cette source.
Pour supprimer un identificateur source d'un abonnement aux notifications d'événement AmazonRedshift
• Vous pouvez facilement ajouter ou supprimer des identificateurs source à l'aide de la console AmazonRedshift en les sélectionnant ou en annulant leur sélection lors de la modification d'un abonnement.Pour plus d'informations, consultez Modification d'un abonnement aux notifications d'événementAmazon Redshift (p. 301).
Suppression d'un abonnement aux notifications d'événementAmazon RedshiftVous pouvez supprimer un abonnement lorsque vous n'en avez plus besoin. Tous les abonnés à larubrique ne reçoivent plus les notifications d'événements spécifiées par l'abonnement.
Pour supprimer un abonnement aux notifications d'événement Amazon Redshift
1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adressehttps://console.aws.amazon.com/redshift/.
2. Dans le volet de navigation de la console Amazon Redshift, cliquez sur Événements, puis sur l'ongletAbonnements.
3. Dans le volet Subscriptions, cliquez sur l'abonnement que vous souhaitez supprimer.4. Cliquez sur Delete.
Gestion des notifications d'événement à l'aide del'interface de ligne de commande et de l'API AmazonRedshiftVous pouvez utiliser les opérations d'interface de ligne de commande Amazon Redshift suivantes pourgérer les notifications d'événement.
• create-event-subscription• delete-event-subscription• describe-event-categories• describe-event-subscriptions• describe-events• modify-event-subscription
Vous pouvez utiliser les actions d'API Amazon Redshift suivantes pour gérer les notifications d'événement.
• CreateEventSubscription• DeleteEventSubscription• DescribeEventCategories
Version de l'API 2012-12-01303
Amazon Redshift Guide de la gestion du clusterGestion des notifications d'événement à l'aide de l'interface
de ligne de commande et de l'API Amazon Redshift
• DescribeEventSubscriptions• DescribeEvents• ModifyEventSubscription
Pour plus d'informations sur les notifications d'événement Amazon Redshift, consultez Notificationsd'événement Amazon Redshift (p. 289).
Version de l'API 2012-12-01304

Amazon Redshift Guide de la gestion du clusterPrésentation
Journalisation des audits de base dedonnées
Rubriques• Présentation (p. 305)• Journaux Amazon Redshift (p. 305)• Activation de la journalisation (p. 308)• Gestion des fichiers journaux (p. 308)• Résolution des problèmes de journalisation d'audit Amazon Redshift (p. 311)• Journalisation des appels d'API Amazon Redshift avec AWS CloudTrail (p. 311)• ID de compte Amazon Redshift dans les journaux AWS CloudTrail (p. 314)• Configuration d'audit à l'aide de la console (p. 316)• Configuration de la journalisation à l'aide de l'interface de ligne de commande et de l'API Amazon
Redshift (p. 318)
PrésentationAmazon Redshift consigne dans un journal les informations sur les connexions et les activités del'utilisateur dans votre base de données. Ces journaux vous permettent de surveiller la base de données àdes fins de sécurité et de résolution des problèmes, ce qui est un processus souvent appelé « audit de labase de données ». Les journaux sont stockés dans les compartiments Amazon Simple Storage Service(Amazon S3) pour un accès pratique aux fonctions de sécurité des données pour les utilisateurs qui sontresponsables de la surveillance des activités de la base de données.
Journaux Amazon RedshiftAmazon Redshift consigne les informations dans les fichiers journaux suivants :
• Journal de connexion — consigne les tentatives d'authentification et les connexions et déconnexions.• Journal de l'utilisateur — consigne les informations sur les modifications apportées aux définitions
d'utilisateur de base de données.• Journal d'activité utilisateur — consigne chaque requête avant qu'elle soit exécutée sur la base de
données.
Les journaux de connexion et utilisateur sont utiles principalement à des fins de sécurité. Vous pouvezutiliser le journal de connexion pour surveiller des informations sur les utilisateurs qui se connectent à labase de données et des informations de connexion connexes, telles que leurs adresses IP, le moment oùils ont fait la demande, le type d'authentification utilisée et ainsi de suite. Vous pouvez utiliser le journalutilisateur pour surveiller les modifications apportées aux définitions des utilisateurs de base de données.
Version de l'API 2012-12-01305
Amazon Redshift Guide de la gestion du clusterJournal de connexion
Le journal d'activité utilisateur est utile principalement à des fins de résolution de problèmes. Il effectue lesuivi d'informations sur les types de requêtes exécutées par les utilisateurs et le système dans la base dedonnées.
Les journaux de connexion et utilisateur correspondent aux informations stockées dans les tables systèmede votre base de données. Vous pouvez utiliser les tables système pour obtenir les mêmes informations,mais les fichiers journaux constituent un mécanisme de récupération et de vérification plus simple. Lesfichiers journaux s'appuient sur les autorisations Amazon S3 plutôt que sur les autorisations de base dedonnées pour exécuter des requêtes sur les tables de base de données. En outre, le fait d'afficher lesinformations dans des fichiers journaux plutôt que d'interroger les tables système vous permet de limiterl'impact de l'interaction avec la base de données.
Note
Les fichiers journaux ne sont pas aussi courants que les tables des journaux systèmes de base,STL_USERLOG et STL_CONNECTION_LOG. Les enregistrements qui sont plus anciens que lesderniers enregistrements, mais ne les incluent pas, sont copiés dans les fichiers journaux.
Journal de connexionEnregistre les tentatives d'authentification, ainsi que les connexions et déconnexions. Le tableau suivantdécrit les informations contenues dans le journal de connexion.
Nom de lacolonne
Description
event Connexion ou événement d'authentification.
recordtime Heure de l'événement.
remotehost Nom ou adresse IP de l'hôte distant.
remoteport Numéro de port de l'hôte distant.
pid ID de processus associé à l'instruction.
dbname Nom de la base de données.
username Nom d'utilisateur.
authmethod Méthode d'authentification.
duration Durée de connexion en microsecondes.
sslversion Version du protocole SSL (Secure Sockets Layer).
sslcipher Chiffrement SSL.
mtu Unité de transmission maximale (MTU).
sslcompression Type de compression SSL.
sslexpansion Type d'extension SSL.
Journal utilisateurEnregistre les détails des modifications suivantes apportées à un utilisateur de base de données :
Version de l'API 2012-12-01306
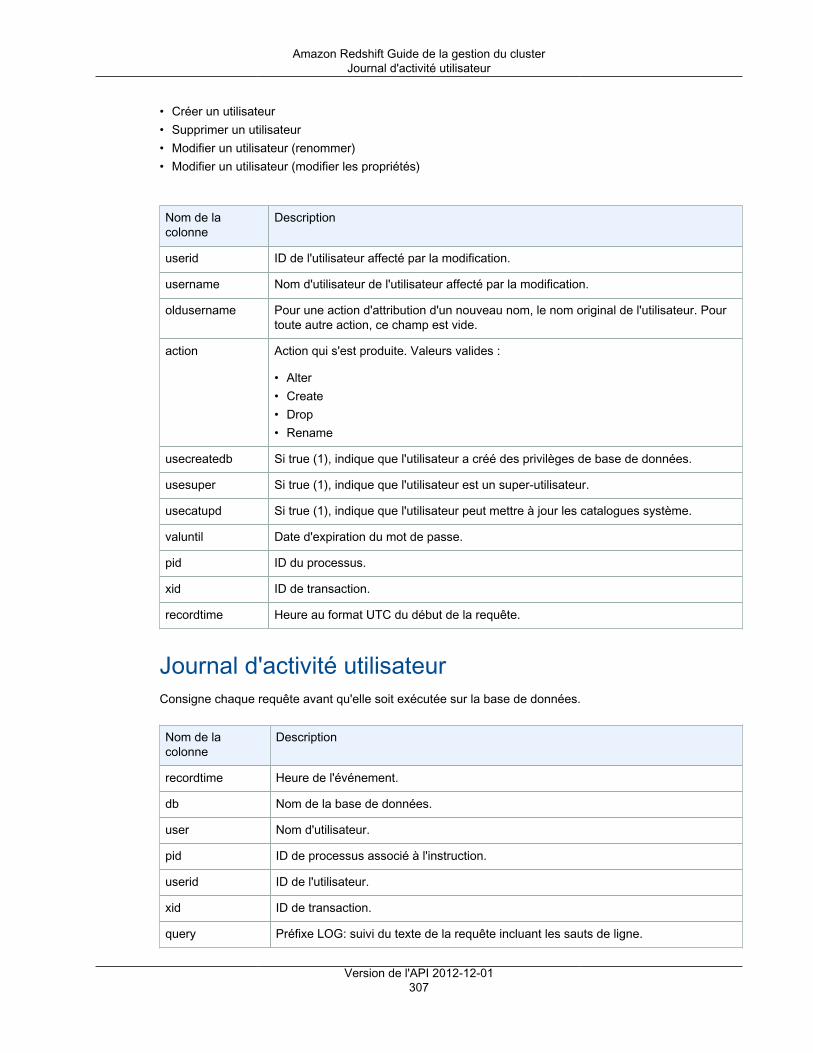
Amazon Redshift Guide de la gestion du clusterJournal d'activité utilisateur
• Créer un utilisateur• Supprimer un utilisateur• Modifier un utilisateur (renommer)• Modifier un utilisateur (modifier les propriétés)
Nom de lacolonne
Description
userid ID de l'utilisateur affecté par la modification.
username Nom d'utilisateur de l'utilisateur affecté par la modification.
oldusername Pour une action d'attribution d'un nouveau nom, le nom original de l'utilisateur. Pourtoute autre action, ce champ est vide.
action Action qui s'est produite. Valeurs valides :
• Alter• Create• Drop• Rename
usecreatedb Si true (1), indique que l'utilisateur a créé des privilèges de base de données.
usesuper Si true (1), indique que l'utilisateur est un super-utilisateur.
usecatupd Si true (1), indique que l'utilisateur peut mettre à jour les catalogues système.
valuntil Date d'expiration du mot de passe.
pid ID du processus.
xid ID de transaction.
recordtime Heure au format UTC du début de la requête.
Journal d'activité utilisateurConsigne chaque requête avant qu'elle soit exécutée sur la base de données.
Nom de lacolonne
Description
recordtime Heure de l'événement.
db Nom de la base de données.
user Nom d'utilisateur.
pid ID de processus associé à l'instruction.
userid ID de l'utilisateur.
xid ID de transaction.
query Préfixe LOG: suivi du texte de la requête incluant les sauts de ligne.
Version de l'API 2012-12-01307

Amazon Redshift Guide de la gestion du clusterActivation de la journalisation
Activation de la journalisationLa journalisation des audits n'est pas activée par défaut dans Amazon Redshift. Lorsque vous activezla journalisation sur votre cluster, Amazon Redshift crée et télécharge des journaux dans Amazon S3qui capturent les données de création du cluster à l'heure actuelle. Chaque mise à jour de journalisationconstitue la suite des informations déjà consignées.
Note
La journalisation des audits dans Amazon S3 est un processus manuel facultatif. Lorsquevous activez la journalisation sur votre cluster, vous activez la journalisation dans AmazonS3 uniquement. La journalisation dans les tables système n'est pas facultative et se faitautomatiquement pour le cluster. Pour plus d'informations sur la journalisation dans les tablessystème, consultez Référence sur les tables système dans le manuel Amazon Redshift DatabaseDeveloper Guide.
Le journal de connexion, le journal utilisateur et le journal d'activité utilisateur sont activés simultanémentà l'aide de l'AWS Management Console, de la référence d'API Amazon Redshift ou de l'AWS CommandLine Interface (AWS CLI). Pour le journal d'activité utilisateur, vous devez également activer le paramètrede base de données enable_user_activity_logging. Si vous activez uniquement la fonctionde journalisation des audits, mais pas le paramètre associé, les journaux d'audit de base de donnéesenregistreront des informations uniquement pour les journaux de connexion et utilisateur, mais pas pourle journal d'activité utilisateur. Le paramètre enable_user_activity_logging est désactivé (false)par défaut, mais vous pouvez le définir sur true pour activer le journal d'activité utilisateur. Pour plusd'informations, consultez Groupes de paramètres Amazon Redshift (p. 61).
Gestion des fichiers journauxLe nombre et la taille des fichiers journaux Amazon Redshift dans Amazon S3 dépendent fortement del'activité de votre cluster. Si vous avez un cluster actif qui génère un grand nombre de journaux, AmazonRedshift peut générer des fichiers journaux plus fréquemment. Vous pouvez disposer d'une série defichiers journaux pour le même type d'activité, par exemple plusieurs journaux de connexion au cours de lamême heure.
Etant donné que Amazon Redshift utilise Amazon S3 pour stocker des journaux, vous devrez payer desfrais pour le stockage que vous utilisez dans Amazon S3. Avant de configurer la journalisation, vous devezprévoir combien de temps vous aurez besoin de stocker les fichiers journaux et déterminer quand ilspourront être supprimés ou archivés selon vos besoins d'audit. Le plan que vous créez dépend fortementdu type de données que vous stockez, telles que les données soumises à des exigences réglementairesou de conformité. Pour en savoir plus sur les tarifs Amazon S3, consultez la Tarification Amazon SimpleStorage Service (S3).
Autorisations de compartiment pour la journalisationd'audit Amazon RedshiftLorsque vous activez la journalisation, Amazon Redshift collecte des informations de journalisation et lestélécharge dans les fichiers journaux stockés dans Amazon S3. Vous pouvez utiliser un compartimentexistant ou un nouveau compartiment. Amazon Redshift nécessite les autorisations IAM suivantesconcernant le compartiment :
• s3:GetBucketAcl Le service nécessite des autorisations de lecture pour le compartiment Amazon S3 afinde pouvoir identifier le propriétaire du compartiment.
Version de l'API 2012-12-01308
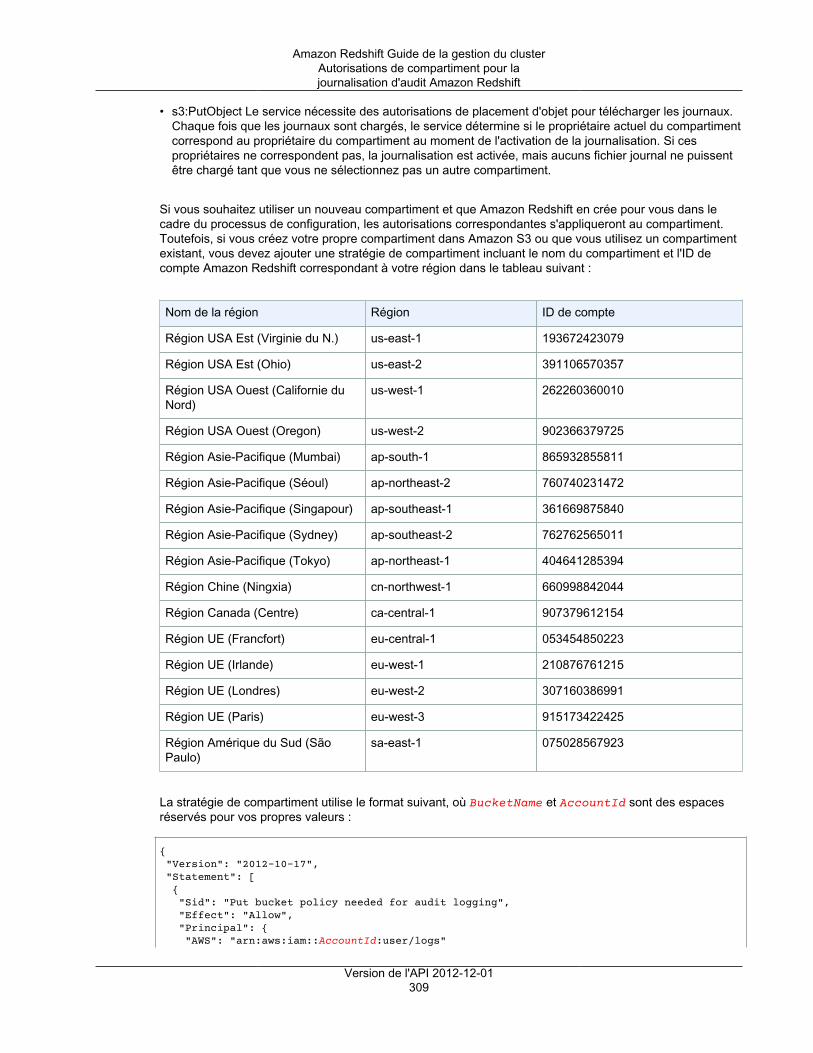
Amazon Redshift Guide de la gestion du clusterAutorisations de compartiment pour lajournalisation d'audit Amazon Redshift
• s3:PutObject Le service nécessite des autorisations de placement d'objet pour télécharger les journaux.Chaque fois que les journaux sont chargés, le service détermine si le propriétaire actuel du compartimentcorrespond au propriétaire du compartiment au moment de l'activation de la journalisation. Si cespropriétaires ne correspondent pas, la journalisation est activée, mais aucuns fichier journal ne puissentêtre chargé tant que vous ne sélectionnez pas un autre compartiment.
Si vous souhaitez utiliser un nouveau compartiment et que Amazon Redshift en crée pour vous dans lecadre du processus de configuration, les autorisations correspondantes s'appliqueront au compartiment.Toutefois, si vous créez votre propre compartiment dans Amazon S3 ou que vous utilisez un compartimentexistant, vous devez ajouter une stratégie de compartiment incluant le nom du compartiment et l'ID decompte Amazon Redshift correspondant à votre région dans le tableau suivant :
Nom de la région Région ID de compte
Région USA Est (Virginie du N.) us-east-1 193672423079
Région USA Est (Ohio) us-east-2 391106570357
Région USA Ouest (Californie duNord)
us-west-1 262260360010
Région USA Ouest (Oregon) us-west-2 902366379725
Région Asie-Pacifique (Mumbai) ap-south-1 865932855811
Région Asie-Pacifique (Séoul) ap-northeast-2 760740231472
Région Asie-Pacifique (Singapour) ap-southeast-1 361669875840
Région Asie-Pacifique (Sydney) ap-southeast-2 762762565011
Région Asie-Pacifique (Tokyo) ap-northeast-1 404641285394
Région Chine (Ningxia) cn-northwest-1 660998842044
Région Canada (Centre) ca-central-1 907379612154
Région UE (Francfort) eu-central-1 053454850223
Région UE (Irlande) eu-west-1 210876761215
Région UE (Londres) eu-west-2 307160386991
Région UE (Paris) eu-west-3 915173422425
Région Amérique du Sud (SãoPaulo)
sa-east-1 075028567923
La stratégie de compartiment utilise le format suivant, où BucketName et AccountId sont des espacesréservés pour vos propres valeurs :
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Put bucket policy needed for audit logging", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::AccountId:user/logs"
Version de l'API 2012-12-01309
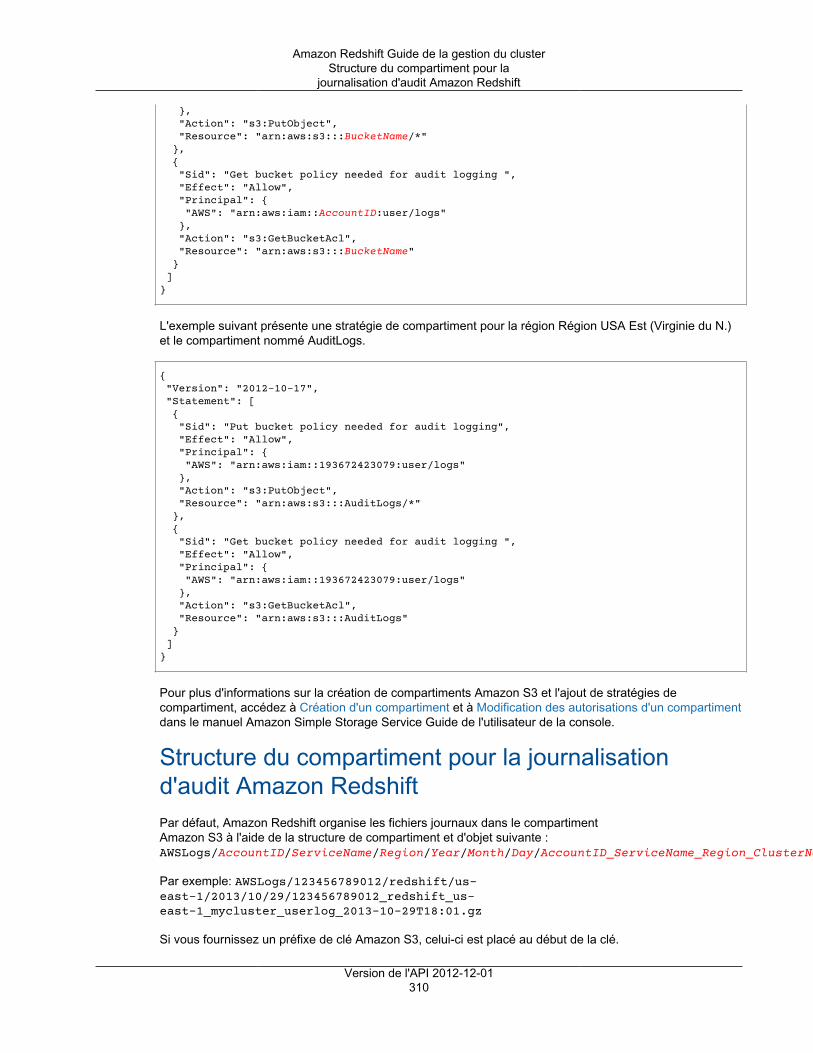
Amazon Redshift Guide de la gestion du clusterStructure du compartiment pour la
journalisation d'audit Amazon Redshift
}, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::BucketName/*" }, { "Sid": "Get bucket policy needed for audit logging ", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::AccountID:user/logs" }, "Action": "s3:GetBucketAcl", "Resource": "arn:aws:s3:::BucketName" } ]}
L'exemple suivant présente une stratégie de compartiment pour la région Région USA Est (Virginie du N.)et le compartiment nommé AuditLogs.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Put bucket policy needed for audit logging", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::193672423079:user/logs" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::AuditLogs/*" }, { "Sid": "Get bucket policy needed for audit logging ", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::193672423079:user/logs" }, "Action": "s3:GetBucketAcl", "Resource": "arn:aws:s3:::AuditLogs" } ]}
Pour plus d'informations sur la création de compartiments Amazon S3 et l'ajout de stratégies decompartiment, accédez à Création d'un compartiment et à Modification des autorisations d'un compartimentdans le manuel Amazon Simple Storage Service Guide de l'utilisateur de la console.
Structure du compartiment pour la journalisationd'audit Amazon RedshiftPar défaut, Amazon Redshift organise les fichiers journaux dans le compartimentAmazon S3 à l'aide de la structure de compartiment et d'objet suivante :AWSLogs/AccountID/ServiceName/Region/Year/Month/Day/AccountID_ServiceName_Region_ClusterName_LogType_Timestamp.gz
Par exemple: AWSLogs/123456789012/redshift/us-east-1/2013/10/29/123456789012_redshift_us-east-1_mycluster_userlog_2013-10-29T18:01.gz
Si vous fournissez un préfixe de clé Amazon S3, celui-ci est placé au début de la clé.
Version de l'API 2012-12-01310

Amazon Redshift Guide de la gestion du clusterRésolution des problèmes de
journalisation d'audit Amazon Redshift
Par exemple, si vous spécifiez un préfixe « myprefix » : myprefix/AWSLogs/123456789012/redshift/us-east-1/2013/10/29/123456789012_redshift_us-east-1_mycluster_userlog_2013-10-29T18:01.gz
Le préfixe de clé Amazon S3 ne doit pas dépasser 512 caractères. Il ne peut pas contenir d'espaces ( ),de guillemets doubles ("), d'apostrophes ('), de barre oblique inverse (\). Un certain nombre de caractèresspéciaux et de caractères de contrôle ne sont pas autorisés non plus. Les codes hexadécimaux de cescaractères sont les suivants :
• x00 à x20• x22• x27• x5c• x7f ou plus
Résolution des problèmes de journalisation d'auditAmazon Redshift
La journalisation d'audit Amazon Redshift peut être interrompue pour les raisons suivantes :
• Amazon Redshift n'est pas autorisé à charger les journaux dans le compartiment Amazon S3. Vérifiezque le compartiment est configuré avec la bonne stratégie IAM. Pour plus d'informations, consultezAutorisations de compartiment pour la journalisation d'audit Amazon Redshift (p. 308).
• Le propriétaire du compartiment a changé. Quand Amazon Redshift charge les journaux, il vérifie que lepropriétaire du compartiment est le même que lors de l'activation de la journalisation. Si le propriétaire ducompartiment a changé, Amazon Redshift ne peut pas charger les journaux tant que vous ne configurezpas d'autre compartiment à utiliser pour la journalisation d'audit. Pour plus d'informations, consultezModification du compartiment pour la journalisation d'audit (p. 318).
• Impossible de trouver le compartiment. Si le compartiment est supprimé dans Amazon S3, AmazonRedshift ne peut pas charger les journaux. Vous devez recréer le compartiment ou configurer AmazonRedshift pour charger les journaux dans un autre compartiment. Pour plus d'informations, consultezModification du compartiment pour la journalisation d'audit (p. 318).
Journalisation des appels d'API Amazon Redshiftavec AWS CloudTrail
Amazon Redshift est intégré à AWS CloudTrail, un service qui enregistre les actions effectuées par unutilisateur, un rôle ou un service AWS dans Amazon Redshift. CloudTrail capture tous les appels d'APIpour Amazon Redshift en tant qu'événements, y compris les appels émis par la console Amazon Redshiftet les appels de code transmis aux API Amazon Redshift. Si vous créez un journal de suivi, vous pouvezdiffuser en continu les événements CloudTrail sur un compartiment Amazon S3, y compris les événementspour Amazon Redshift. Si vous ne configurez pas de journal de suivi, vous pouvez toujours afficher lesévénements les plus récents dans la console CloudTrail dans Event history (Historique des événements).À l'aide des informations collectées par CloudTrail, vous pouvez déterminer la demande qui a été envoyéeà Amazon Redshift, l'adresse IP à partir de laquelle la demande a été effectuée, l'auteur et la date de lademande, ainsi que d'autres informations.
Vous pouvez utiliser CloudTrail indépendamment ou en plus de la journalisation des audits de base dedonnées Amazon Redshift.
Version de l'API 2012-12-01311

Amazon Redshift Guide de la gestion du clusterInformations Amazon Redshift dans CloudTrail
Pour plus d'informations sur CloudTrail, consultez le AWS CloudTrail User Guide.
Informations Amazon Redshift dans CloudTrailCloudTrail est activé sur votre compte AWS lorsque vous créez le compte. Quand une activité a lieu dansAmazon Redshift, cette activité est enregistrée dans un événement CloudTrail avec d'autres événementsde services AWS dans Event history (Historique des événements). Vous pouvez afficher, rechercher ettélécharger les événements récents dans votre compte AWS. Pour plus d'informations, consultez Affichagedes événements avec l'historique des événements CloudTrail.
Pour un enregistrement continu des événements dans votre compte AWS, y compris les événements pourAmazon Redshift, créez un journal de suivi. Un journal de suivi permet à CloudTrail de livrer des fichiersjournaux dans un compartiment Amazon S3. Par défaut, lorsque vous créez un journal de suivi dansla console, il s'applique à toutes les régions. Le journal de suivi consigne les événements de toutes lesrégions dans la partition AWS et livre les fichiers journaux dans le compartiment Amazon S3 de votre choix.En outre, vous pouvez configurer d'autres services AWS pour analyser plus en profondeur les donnéesd'événement collectées dans les journaux CloudTrail et agir sur celles-ci. Si votre cluster dispose deplusieurs nœuds, la localisation de vos nœuds dans différentes zones de disponibilité peut réduire l'impactdes échecs sur votre cluster.
• Présentation de la création d'un journal de suivi• Intégrations et services pris en charge par CloudTrail• Configuration des Notifications de Amazon SNS pour CloudTrail• Recevoir les fichiers journaux de CloudTrail de plusieurs régions et Recevoir les fichiers journaux de
CloudTrail de plusieurs comptes.
Toutes les actions Amazon Redshift sont consignées par CloudTrail et sont documentées dans Référenced'API Amazon Redshift. A titre d'exemple, les appels vers les actions CreateCluster, DeleteClusteret DescribeCluster génèrent des entrées dans les fichiers journaux CloudTrail.
Chaque événement ou entrée du journal contient des informations sur la personne qui a généré lademande. Les informations relatives à l'identité permettent de déterminer les éléments suivants :
• Si la demande a été effectuée avec les informations d'identification utilisateur racine ou IAM.• Si la demande a été effectuée avec des informations d'identification de sécurité temporaires pour un rôle
ou un utilisateur fédéré.• Si la demande a été effectuée par un autre service AWS.
Pour plus d'informations, consultez la section Elément userIdentity CloudTrail.
Présentation des entrées des fichiers journauxAmazon RedshiftUn journal de suivi est une configuration qui permet la livraison d'événements sous forme de fichiersjournaux vers un compartiment Amazon S3 que vous spécifiez. Les fichiers journaux CloudTrailcontiennent une ou plusieurs entrées de journal. Un événement représente une demande individuelleémise à partir d'une source quelconque et comprend des informations sur l'action demandée, la date etl'heure de l'action, les paramètres de la demande, etc. Les fichiers journaux CloudTrail ne constituent pasune série ordonnée d'appels d'API publics. Ils ne suivent aucun ordre précis.
L'exemple suivant montre une entrée de journal CloudTrail pour un exemple d'appel CreateCluster.
{
Version de l'API 2012-12-01312

Amazon Redshift Guide de la gestion du clusterPrésentation des entrées des
fichiers journaux Amazon Redshift
"eventVersion": "1.04", "userIdentity": { "type": "IAMUser", "principalId": "AIDAMVNPBQA3EXAMPLE", "arn": "arn:aws:iam::123456789012:user/Admin", "accountId": "123456789012", "accessKeyId": "AKIAIOSFODNN7EXAMPLE", "userName": "Admin", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2017-03-03T16:51:56Z" } }, "invokedBy": "signin.amazonaws.com" }, "eventTime": "2017-03-03T16:56:09Z", "eventSource": "redshift.amazonaws.com", "eventName": "CreateCluster", "awsRegion": "us-east-2", "sourceIPAddress": "52.95.4.13", "userAgent": "signin.amazonaws.com", "requestParameters": { "clusterIdentifier": "my-dw-instance", "allowVersionUpgrade": true, "enhancedVpcRouting": false, "encrypted": false, "clusterVersion": "1.0", "masterUsername": "awsuser", "masterUserPassword": "****", "automatedSnapshotRetentionPeriod": 1, "port": 5439, "dBName": "mydbtest", "clusterType": "single-node", "nodeType": "dc1.large", "publiclyAccessible": true, "vpcSecurityGroupIds": [ "sg-95f606fc" ] }, "responseElements": { "nodeType": "dc1.large", "preferredMaintenanceWindow": "sat:05:30-sat:06:00", "clusterStatus": "creating", "vpcId": "vpc-84c22aed", "enhancedVpcRouting": false, "masterUsername": "awsuser", "clusterSecurityGroups": [], "pendingModifiedValues": { "masterUserPassword": "****" }, "dBName": "mydbtest", "clusterVersion": "1.0", "encrypted": false, "publiclyAccessible": true, "tags": [], "clusterParameterGroups": [ { "parameterGroupName": "default.redshift-1.0", "parameterApplyStatus": "in-sync" } ], "allowVersionUpgrade": true, "automatedSnapshotRetentionPeriod": 1, "numberOfNodes": 1, "vpcSecurityGroups": [
Version de l'API 2012-12-01313

Amazon Redshift Guide de la gestion du clusterID de compte Amazon Redshift
dans les journaux AWS CloudTrail
{ "status": "active", "vpcSecurityGroupId": "sg-95f606fc" } ], "iamRoles": [], "clusterIdentifier": "my-dw-instance", "clusterSubnetGroupName": "default" }, "requestID": "4c506036-0032-11e7-b8bf-d7aa466e9920", "eventID": "13ba5550-56ac-405b-900a-8a42b0f43c45", "eventType": "AwsApiCall", "recipientAccountId": "123456789012"}
L'exemple suivant montre une entrée de journal CloudTrail pour un exemple d'appel DeleteCluster.
{ "eventVersion": "1.04", "userIdentity": { "type": "IAMUser", "principalId": "AIDAMVNPBQA3EXAMPLE", "arn": "arn:aws:iam::123456789012:user/Admin", "accountId": "123456789012", "accessKeyId": "AKIAIOSFODNN7EXAMPLE", "userName": "Admin", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2017-03-03T16:58:23Z" } }, "invokedBy": "signin.amazonaws.com" }, "eventTime": "2017-03-03T17:02:34Z", "eventSource": "redshift.amazonaws.com", "eventName": "DeleteCluster", "awsRegion": "us-east-2", "sourceIPAddress": "52.95.4.13", "userAgent": "signin.amazonaws.com", "requestParameters": { "clusterIdentifier": "my-dw-instance", "skipFinalClusterSnapshot": true }, "responseElements": null, "requestID": "324cb76a-0033-11e7-809b-1bbbef7710bf", "eventID": "59bcc3ce-e635-4cce-b47f-3419a36b3fa5", "eventType": "AwsApiCall", "recipientAccountId": "123456789012"}
ID de compte Amazon Redshift dans les journauxAWS CloudTrail
Quand Amazon Redshift appels un autre service AWS en votre nom, l'appel est consigné avec un ID decompte qui appartient au service Amazon Redshift au lieu de votre propre ID de compte. Par exemple,quand Amazon Redshift appelle des actions AWS Key Management Service (AWS KMS), telles queCreateGrant, Decrypt, Encrypt et RetireGrant pour gérer le chiffrement sur votre cluster, les appels sontconsignés par AWS CloudTrail dans un journal à l'aide d'un ID de compte Amazon Redshift.
Version de l'API 2012-12-01314
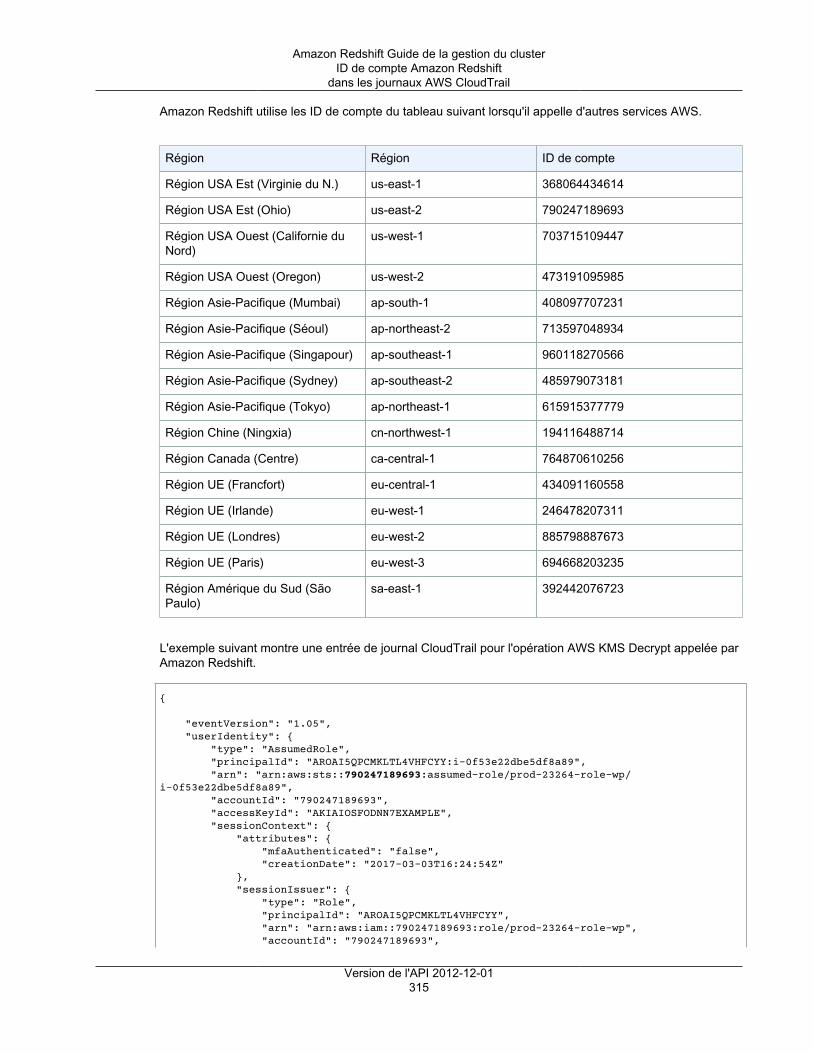
Amazon Redshift Guide de la gestion du clusterID de compte Amazon Redshift
dans les journaux AWS CloudTrail
Amazon Redshift utilise les ID de compte du tableau suivant lorsqu'il appelle d'autres services AWS.
Région Région ID de compte
Région USA Est (Virginie du N.) us-east-1 368064434614
Région USA Est (Ohio) us-east-2 790247189693
Région USA Ouest (Californie duNord)
us-west-1 703715109447
Région USA Ouest (Oregon) us-west-2 473191095985
Région Asie-Pacifique (Mumbai) ap-south-1 408097707231
Région Asie-Pacifique (Séoul) ap-northeast-2 713597048934
Région Asie-Pacifique (Singapour) ap-southeast-1 960118270566
Région Asie-Pacifique (Sydney) ap-southeast-2 485979073181
Région Asie-Pacifique (Tokyo) ap-northeast-1 615915377779
Région Chine (Ningxia) cn-northwest-1 194116488714
Région Canada (Centre) ca-central-1 764870610256
Région UE (Francfort) eu-central-1 434091160558
Région UE (Irlande) eu-west-1 246478207311
Région UE (Londres) eu-west-2 885798887673
Région UE (Paris) eu-west-3 694668203235
Région Amérique du Sud (SãoPaulo)
sa-east-1 392442076723
L'exemple suivant montre une entrée de journal CloudTrail pour l'opération AWS KMS Decrypt appelée parAmazon Redshift.
{
"eventVersion": "1.05", "userIdentity": { "type": "AssumedRole", "principalId": "AROAI5QPCMKLTL4VHFCYY:i-0f53e22dbe5df8a89", "arn": "arn:aws:sts::790247189693:assumed-role/prod-23264-role-wp/i-0f53e22dbe5df8a89", "accountId": "790247189693", "accessKeyId": "AKIAIOSFODNN7EXAMPLE", "sessionContext": { "attributes": { "mfaAuthenticated": "false", "creationDate": "2017-03-03T16:24:54Z" }, "sessionIssuer": { "type": "Role", "principalId": "AROAI5QPCMKLTL4VHFCYY", "arn": "arn:aws:iam::790247189693:role/prod-23264-role-wp", "accountId": "790247189693",
Version de l'API 2012-12-01315

Amazon Redshift Guide de la gestion du clusterConfiguration d'audit à l'aide de la console
"userName": "prod-23264-role-wp" } } }, "eventTime": "2017-03-03T17:16:51Z", "eventSource": "kms.amazonaws.com", "eventName": "Decrypt", "awsRegion": "us-east-2", "sourceIPAddress": "52.14.143.61", "userAgent": "aws-internal/3", "requestParameters": { "encryptionContext": { "aws:redshift:createtime": "20170303T1710Z", "aws:redshift:arn": "arn:aws:redshift:us-east-2:123456789012:cluster:my-dw-instance-2" } }, "responseElements": null, "requestID": "30d2fe51-0035-11e7-ab67-17595a8411c8", "eventID": "619bad54-1764-4de4-a786-8898b0a7f40c", "readOnly": true, "resources": [ { "ARN": "arn:aws:kms:us-east-2:123456789012:key/f8f4f94f-e588-4254-b7e8-078b99270be7", "accountId": "123456789012", "type": "AWS::KMS::Key" } ], "eventType": "AwsApiCall", "recipientAccountId": "123456789012", "sharedEventID": "c1daefea-a5c2-4fab-b6f4-d8eaa1e522dc"
}
Configuration d'audit à l'aide de la consoleVous pouvez configurer Amazon Redshift pour créer des fichiers journaux d'audit et les stocker dans S3.
Activation de la journalisation d'audit grâce à laconsole1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adresse
https://console.aws.amazon.com/redshift/.2. Dans le volet de navigation, cliquez sur Clusters.3. Dans la liste, cliquez sur le cluster pour lequel vous souhaitez activer la journalisation.4. Dans la page des détails de cluster, cliquez sur Base de données, puis sur Configurer la journalisation
d'audit.5. Dans la boîte de dialogue Configurer la journalisation d'audit, dans la zone Activer la journalisation
d'audit, cliquez sur Oui.6. Pour Compartiment S3, effectuez l'une des opérations suivantes :
• Si vous disposez déjà d'un compartiment S3 que vous souhaitez utiliser, sélectionnez Utiliserl'existant puis le compartiment dans la liste Compartiment.
Version de l'API 2012-12-01316
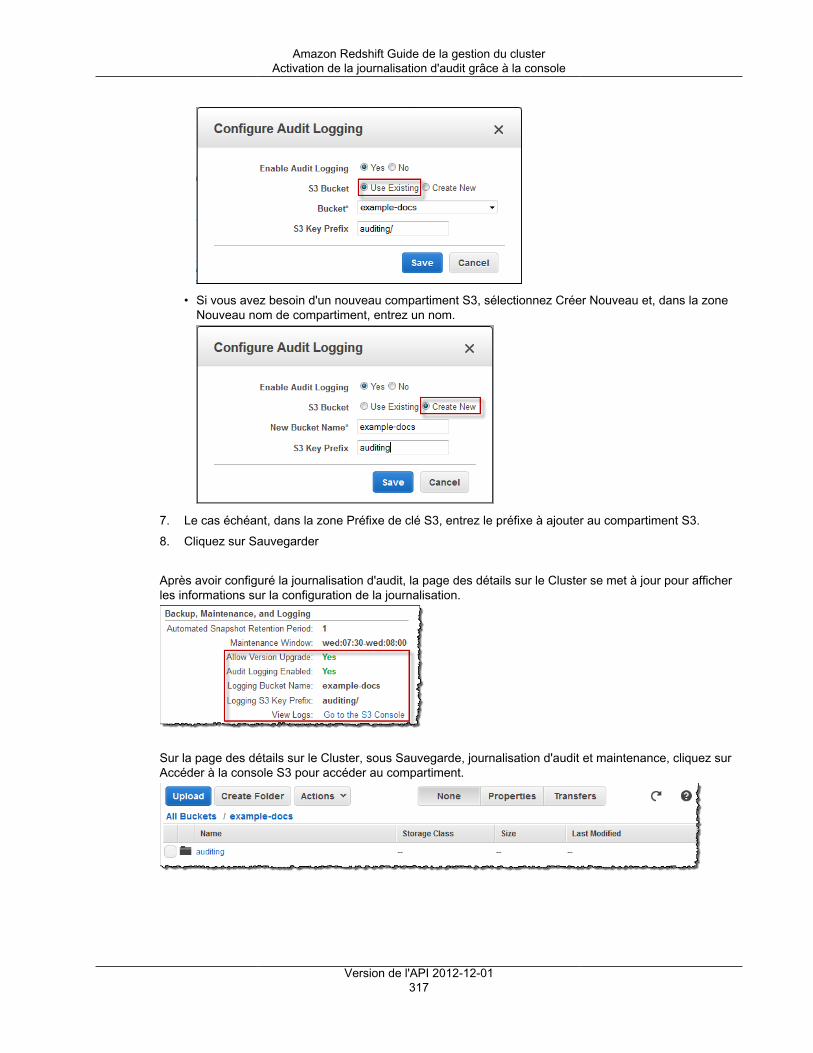
Amazon Redshift Guide de la gestion du clusterActivation de la journalisation d'audit grâce à la console
• Si vous avez besoin d'un nouveau compartiment S3, sélectionnez Créer Nouveau et, dans la zoneNouveau nom de compartiment, entrez un nom.
7. Le cas échéant, dans la zone Préfixe de clé S3, entrez le préfixe à ajouter au compartiment S3.8. Cliquez sur Sauvegarder
Après avoir configuré la journalisation d'audit, la page des détails sur le Cluster se met à jour pour afficherles informations sur la configuration de la journalisation.
Sur la page des détails sur le Cluster, sous Sauvegarde, journalisation d'audit et maintenance, cliquez surAccéder à la console S3 pour accéder au compartiment.
Version de l'API 2012-12-01317
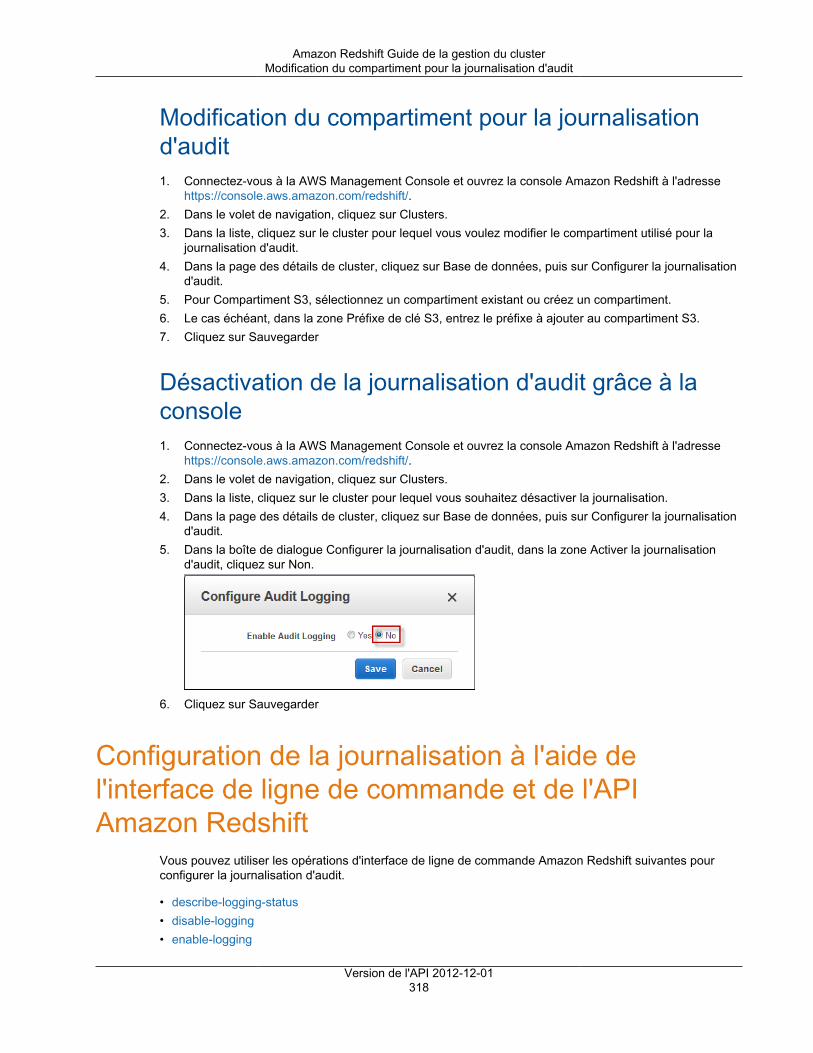
Amazon Redshift Guide de la gestion du clusterModification du compartiment pour la journalisation d'audit
Modification du compartiment pour la journalisationd'audit1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adresse
https://console.aws.amazon.com/redshift/.2. Dans le volet de navigation, cliquez sur Clusters.3. Dans la liste, cliquez sur le cluster pour lequel vous voulez modifier le compartiment utilisé pour la
journalisation d'audit.4. Dans la page des détails de cluster, cliquez sur Base de données, puis sur Configurer la journalisation
d'audit.5. Pour Compartiment S3, sélectionnez un compartiment existant ou créez un compartiment.6. Le cas échéant, dans la zone Préfixe de clé S3, entrez le préfixe à ajouter au compartiment S3.7. Cliquez sur Sauvegarder
Désactivation de la journalisation d'audit grâce à laconsole1. Connectez-vous à la AWS Management Console et ouvrez la console Amazon Redshift à l'adresse
https://console.aws.amazon.com/redshift/.2. Dans le volet de navigation, cliquez sur Clusters.3. Dans la liste, cliquez sur le cluster pour lequel vous souhaitez désactiver la journalisation.4. Dans la page des détails de cluster, cliquez sur Base de données, puis sur Configurer la journalisation
d'audit.5. Dans la boîte de dialogue Configurer la journalisation d'audit, dans la zone Activer la journalisation
d'audit, cliquez sur Non.
6. Cliquez sur Sauvegarder
Configuration de la journalisation à l'aide del'interface de ligne de commande et de l'APIAmazon Redshift
Vous pouvez utiliser les opérations d'interface de ligne de commande Amazon Redshift suivantes pourconfigurer la journalisation d'audit.
• describe-logging-status• disable-logging• enable-logging
Version de l'API 2012-12-01318

Amazon Redshift Guide de la gestion du clusterConfiguration de la journalisation à l'aide de l'interfacede ligne de commande et de l'API Amazon Redshift
Vous pouvez utiliser les actions d'API Amazon Redshift suivantes pour configurer la journalisation d'audit.
• DescribeLoggingStatus• DisableLogging• EnableLogging
Version de l'API 2012-12-01319

Amazon Redshift Guide de la gestion du clusterPrésentation
Didacticiel : Redimensionnement desclusters dans Amazon Redshift
Rubriques• Présentation (p. 320)• Présentation de l'opération de redimensionnement (p. 320)• Présentation des opérations d'instantané, de restauration et de redimensionnement (p. 321)• Didacticiel : Utilisation de l'opération Resize pour redimensionner un cluster (p. 322)• Didacticiel : Utilisation des opérations d'instantané, de restauration et de redimensionnement pour
redimensionner un cluster (p. 324)
PrésentationAu fur et à mesure que vos performances et capacités d'entrepôt de données évolue, vous pouvezredimensionner votre cluster pour tirer le meilleur parti des options de calcul et de stockage qu'AmazonRedshift fournit. Vous pouvez agrandir ou diminuer le cluster en modifiant le nombre de nœuds. Ou,vous pouvez agrandir ou diminuer le cluster en spécifiant un type de nœud différent. Vous pouvezredimensionner votre cluster en utilisant l'une des approches suivantes :
• Utilisez l'opération de redimensionnement avec un cluster existant.• Utilisez l'instantané et les opérations de restauration pour créer une copie d'un cluster existant. Puis,
redimensionnez le nouveau cluster.
L'approche du redimensionnement et l'approche de l'instantané et de la restauration copient toutes deuxles tables utilisateur et les données sur le nouveau cluster ; elles ne touchent ni aux données ni aux tablessystème. Si vous avez activé la journalisation des audits dans votre cluster source, vous serez en mesurede continuer pour accéder aux journaux dans Amazon Simple Storage Service (Amazon S3), même aprèsque vous avez supprimé le cluster source. Vous pouvez conserver ou supprimer ces journaux, selon ceque vos stratégies de données spécifient.
Présentation de l'opération de redimensionnementL'opération de redimensionnement est la méthode préférée pour redimensionner votre cluster, car il s'agitde la méthode la plus simple. Avec l'opération de redimensionnement, vos données sont copiées enparallèle depuis les nœuds de calcul de votre cluster source vers les nœuds de calcul de votre cluster cible.Le temps nécessaire au redimensionnement dépend de la quantité de données et du nombre de nœuds ducluster le plus petit. Il peut durer de quelques heures à quelques jours.
Lorsque vous démarrez l'opération de redimensionnement, Amazon Redshift place le cluster existant enmode lecture seule jusqu'à la fin du redimensionnement. Pendant ce temps, vous pouvez uniquementexécuter des requêtes en lecture à partir de la base de données ; vous ne pouvez exécuter aucune requêteen écriture sur la base de données, y compris les requêtes en lecture/écriture. Pour plus d'informations,
Version de l'API 2012-12-01320

Amazon Redshift Guide de la gestion du clusterPrésentation des opérations d'instantané,de restauration et de redimensionnement
consultez Opérations en écriture et en lecture/écriture dans le manuel Amazon Redshift DatabaseDeveloper Guide.
Note
Si vous souhaitez redimensionner avec un impact minimal sur la production, vous pouvezutiliser la section suivante, Présentation des opérations d'instantané, de restauration et deredimensionnement (p. 321), pour créer une copie de votre cluster, la redimensionner et changerle point de terminaison de la connexion au cluster redimensionné une fois le redimensionnementterminé.
Après qu'Amazon Redshift a placé le cluster source en mode lecture seule, il fournit un nouveau cluster,le cluster cible, en utilisant les informations que vous spécifiez pour le type de nœud, le type de clusteret le nombre de nœuds. Puis, Amazon Redshift copie les données depuis le cluster source vers lecluster cible. Une fois l'opération terminée, toutes les connexions basculent afin d'utiliser le cluster cible.Si vous avez des questions en cours au moment où ce basculement se produit, votre connexion estperdue et vous devez redémarrer la requête sur le cluster cible. Vous pouvez afficher la progression duredimensionnement sous l'onglet Statut d'Amazon Redshift console.
Comme Amazon Redshift ne trie pas les tables pendant une opération de redimensionnement, l'ordre detri existant est conservé. Lorsque vous redimensionnez un cluster, Amazon Redshift distribue les tablesde base de données sur les nouveaux nœuds en fonction de leurs styles de distribution et exécute unecommande ANALYZE pour mettre à jour les statistiques. Comme les lignes marquées en vue de leursuppression ne sont pas transférées, vous ne devez exécuter une commande VACUUM que si vos tablesdoivent être triées à nouveau. Pour plus d'informations, consultez Exécution de l'opération VACUUM surles tables dans le manuel Amazon Redshift Database Developer Guide.
Pour parcourir le processus de redimensionnement d'un cluster Amazon Redshift à l'aide de l'opérationde redimensionnement, consultez Didacticiel : Utilisation de l'opération Resize pour redimensionner uncluster (p. 322).
Présentation des opérations d'instantané, derestauration et de redimensionnement
Comme décrit dans la section précédente, le temps nécessaire pour redimensionner un cluster avecl'opération de redimensionnement dépend essentiellement de la quantité de données dans le cluster.Comme vous ne pouvez pas effectuer d'opérations d'écriture ou de lecture/écriture dans la base dedonnées pendant le redimensionnement, vous devez déterminer si vous voulez utiliser l'opération deredimensionnement ou une autre méthode qui réduit la durée pendant laquelle le cluster est en modelecture seule.
Si vous avez besoin presque constamment d'un accès en écriture à votre cluster Amazon Redshift, vouspouvez utiliser les opérations d'instantané et de restauration décrites dans la section suivante. Cetteapproche requiert que les données écrites sur le cluster source une fois que l'instantané a été pris soientcopiées manuellement sur le cluster cible après le basculement. En fonction de la durée de la copie, vousdevrez peut-être répéter l'opération plusieurs fois jusqu'à ce que vous ayez les mêmes données dans lesdeux clusters et que vous puissiez faire le basculement vers le cluster cible. Ce processus peut avoir unimpact négatif sur les requêtes existantes jusqu'à ce que l'ensemble complet des données soit disponibledans le cluster cible, mais il minimise bel et bien la durée pendant laquelle vous ne pouvez pas écrire sur labase de données.
L'approche via les instantanés, la restauration et le redimensionnement utilise le processus suivant :
1. Prenez un instantané de votre cluster existant. Le cluster existant est le cluster source.
Version de l'API 2012-12-01321

Amazon Redshift Guide de la gestion du clusterDidacticiel : Utilisation de l'opération
Resize pour redimensionner un cluster
2. Notez l'heure à laquelle l'instantané a été pris afin que vous puissiez identifier plus tard le point auquelvous devrez reprendre les processus d'extraction, de transformation et de chargement (ETL) pourcharger les éventuelles données post-instantané dans la base de données cible.
3. Restaurez l'instantané dans un nouveau cluster. Ce nouveau cluster est le cluster cible. Vérifiez quel'exemple de données existe dans le cluster cible.
4. Redimensionnez le cluster cible. Sélectionnez le nouveau type de nœud, le nombre de nœuds et autresparamètres du cluster cible.
5. Passez en revue les charges de vos processus ETL qui se sont produits après que vous avez prisun instantané du cluster source. Vous devrez recharger les mêmes données dans le cluster cible etdans le même ordre. Si vous avez des charges de données en cours, vous aurez besoin de répéter ceprocessus plusieurs fois jusqu'à ce que les données soient les mêmes dans les clusters source et cible.
6. Arrêtez toutes les requêtes en cours d'exécution sur le cluster source. Pour ce faire, vous pouvezredémarrer le cluster, ou vous connecter en tant que super-utilisateur et utiliser les commandesPG_CANCEL_BACKEND et PG_TERMINATE_BACKEND. Le redémarrage du cluster est la solution laplus simple pour vous assurer que le cluster n'est pas disponible.
7. Renommez le cluster source. Par exemple, renommez-le de examplecluster en examplecluster-source.
8. Renommez le cluster cible afin d'utiliser le nom du cluster source avant de le renommer. Par exemple,renommez le cluster cible en examplecluster. A partir de cet instant, toutes les applications quiutilisent le point de terminaison contenant examplecluster doivent se connecter au cluster cible.
9. Supprimez le cluster source après que vous avez basculé sur le cluster cible et vérifiez que tous lesprocessus fonctionnent comme prévu.
Sinon, vous pouvez renommer les clusters source et cible avant de recharger les données dans le clustercible si vous n'exigez pas que les systèmes et rapports dépendants soient immédiatement à jour avec ceuxdu cluster cible. Dans ce cas, l'étape 6 sera déplacée à la fin du processus décrit précédemment.
Le processus consistant à renommer le cluster n'est nécessaire que si vous voulez que les applicationscontinuent à utiliser le même point de terminaison pour se connecter au cluster. S'il ne s'agit pas de l'unede vos exigences, vous pouvez à la place mettre à jour toutes les applications qui se connectent au clusterafin d'utiliser le point de terminaison du cluster cible sans modifier le nom du cluster.
La réutilisation d'un nom de cluster présente deux avantages. Premièrement, vous n'avez pas besoin demettre à jour les chaînes de connexion d'application, car le point de terminaison ne change pas, même sile cluster sous-jacent change. Deuxièmement, comme les éléments associés tels que les alarmes AmazonCloudWatch et les notifications Amazon Simple Notification Service (Amazon SNS) sont liés au nom ducluster, vous pouvez continuer à utiliser les mêmes alarmes et notifications que celles que vous avezconfigurées pour le cluster. Cette poursuite de l'utilisation est principalement une préoccupation dans lesenvironnements de production où vous voulez avoir la possibilité de redimensionner le cluster sans avoir àreconfigurer les éléments connexes, tels que les alarmes et les notifications.
Pour parcourir le processus de redimensionnement d'un cluster Amazon Redshift à l'aide des opérationsd'instantané, de restauration et de redimensionnement, consultez Didacticiel : Utilisation des opérationsd'instantané, de restauration et de redimensionnement pour redimensionner un cluster (p. 324).
Didacticiel : Utilisation de l'opération Resize pourredimensionner un cluster
Cette section vous guide à travers le processus de redimensionnement d'un cluster à l'aide del'opération Resize dans Amazon Redshift. Dans cet exemple, vous allez agrandir votre cluster en leredimensionnement de cluster à nœud unique en cluster à plusieurs nœuds.
Version de l'API 2012-12-01322
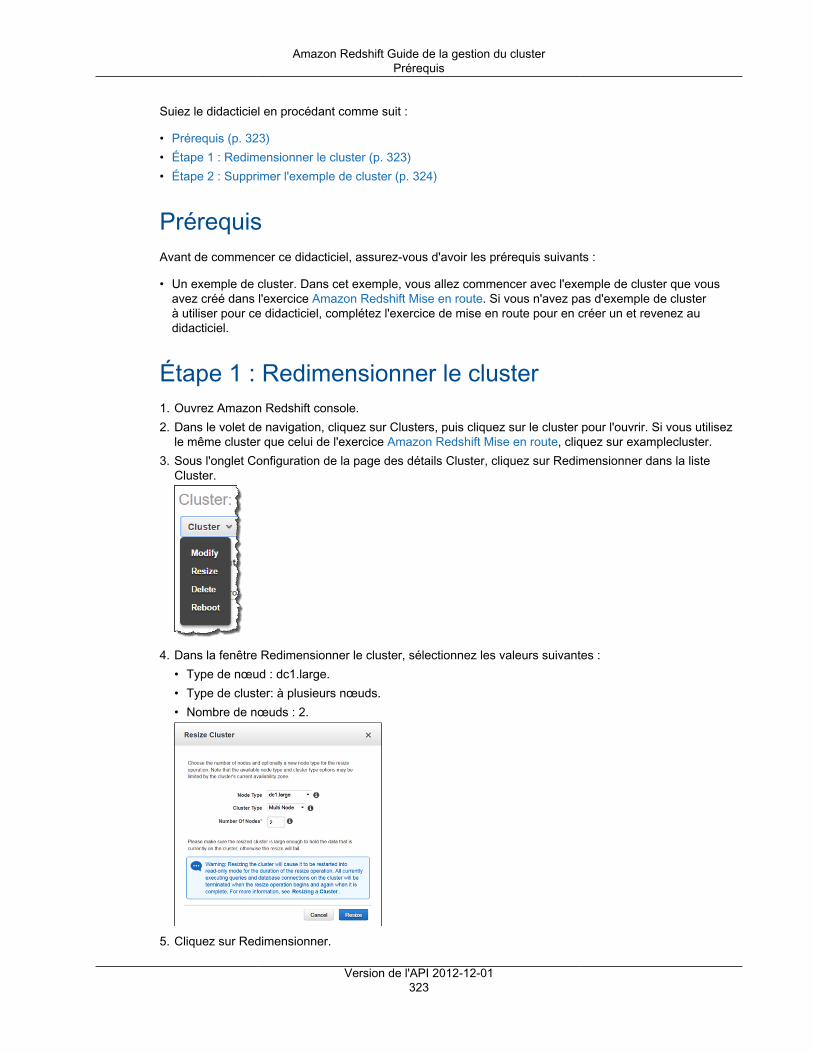
Amazon Redshift Guide de la gestion du clusterPrérequis
Suiez le didacticiel en procédant comme suit :
• Prérequis (p. 323)• Étape 1 : Redimensionner le cluster (p. 323)• Étape 2 : Supprimer l'exemple de cluster (p. 324)
PrérequisAvant de commencer ce didacticiel, assurez-vous d'avoir les prérequis suivants :
• Un exemple de cluster. Dans cet exemple, vous allez commencer avec l'exemple de cluster que vousavez créé dans l'exercice Amazon Redshift Mise en route. Si vous n'avez pas d'exemple de clusterà utiliser pour ce didacticiel, complétez l'exercice de mise en route pour en créer un et revenez audidacticiel.
Étape 1 : Redimensionner le cluster1. Ouvrez Amazon Redshift console.2. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur le cluster pour l'ouvrir. Si vous utilisez
le même cluster que celui de l'exercice Amazon Redshift Mise en route, cliquez sur examplecluster.3. Sous l'onglet Configuration de la page des détails Cluster, cliquez sur Redimensionner dans la liste
Cluster.
4. Dans la fenêtre Redimensionner le cluster, sélectionnez les valeurs suivantes :• Type de nœud : dc1.large.• Type de cluster: à plusieurs nœuds.• Nombre de nœuds : 2.
5. Cliquez sur Redimensionner.
Version de l'API 2012-12-01323

Amazon Redshift Guide de la gestion du clusterÉtape 2 : Supprimer l'exemple de cluster
6. Cliquez sur Statut et vérifiez les informations d'état du redimensionnement pour afficher sa progression.
Étape 2 : Supprimer l'exemple de clusterUne fois que vous êtes sûr de ne plus avoir besoin de l'exemple de cluster, vous pouvez le supprimer.Dans un environnement de production, la décision de garder ou pas un instantané final dépend de vosstratégies de données. Dans ce didacticiel, vous allez supprimer le cluster sans instantané final, car vousutilisez un exemple de données.
Important
Les clusters vous sont facturés jusqu'à leur suppression.
1. Ouvrez Amazon Redshift console.2. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur le cluster pour l'ouvrir. Si vous utilisez
les mêmes noms de cluster que le didacticiel, cliquez sur examplecluster.3. Sous l'onglet Configuration de la page des détails Cluster, cliquez sur Supprimer dans la liste Cluster.4. Dans la fenêtre Supprimer un cluster, cliquez sur Non pour Créer un instantané final, puis cliquez sur
Supprimer.
Didacticiel : Utilisation des opérations d'instantané,de restauration et de redimensionnement pourredimensionner un cluster
Cette section vous guide à travers le processus d'utilisation des opérations d'instantané et de restaurationdans le cadre d'un processus de redimensionnement d'un cluster Amazon Redshift. Ce processus estun processus avancé qui est principalement utile dans les environnements où vous ne pouvez pas oune souhaitez pas arrêter les opérations d'écriture et de lecture de la base de données pendant la duréenécessaire au redimensionnement de votre cluster. Si vous ne savez pas combien de temps durerale redimensionnement du cluster, vous pouvez utiliser cette procédure pour prendre un instantané,le restaurer en un nouveau cluster et le redimensionner pour obtenir une estimation. Cette sectionconduit le processus plus avant en basculant du cluster source vers le cluster cible une fois terminé leredimensionnement du cluster cible.
Important
Les clusters vous sont facturés jusqu'à leur suppression.
Suiez le didacticiel en procédant comme suit :
• Prérequis (p. 325)
Version de l'API 2012-12-01324

Amazon Redshift Guide de la gestion du clusterPrérequis
• Étape 1 : Prendre un instantané (p. 325)• Étape 2 : Restaurer l'instantané sur le cluster cible (p. 326)• Étape 3 : Vérifier les données dans le cluster cible (p. 327)• Étape 4 : Redimensionner le cluster cible (p. 328)• Étape 5 : Copier les données post-instantané du cluster source vers le cluster cible (p. 329)• Étape 6 : Renommer les clusters source et cible (p. 330)• Étape 7 : Supprimer le cluster source (p. 331)• Étape 8 : Nettoyer votre environnement (p. 332)
PrérequisAvant de commencer ce didacticiel, assurez-vous d'avoir les prérequis suivants :
• Un exemple de cluster. Dans cet exemple, vous allez commencer avec l'exemple de cluster que vousavez créé dans l'exercice Amazon Redshift Mise en route. Si vous n'avez pas d'exemple de clusterà utiliser pour ce didacticiel, complétez l'exercice de mise en route pour en créer un et revenez audidacticiel.
• Une application ou un outil client SQL pour se connecter au cluster. Ce didacticiel utilise SQLWorkbench/J, que vous avez installé si vous avez effectué les étapes de l'exercice Amazon RedshiftMise en route. Si vous n'avez pas SQL Workbench/J ou autre outil client SQL, consultez Se connecter aucluster à l'aide de SQL Workbench/J (p. 244).
• Exemples de données. Dans ce didacticiel, vous allez prendre un instantané de votre cluster, puisexécuter quelques requêtes d'écriture dans la base de données qui se traduisent par une différenceentre les données du cluster source et le nouveau cluster où vous restaurez l'instantané. Avant decommencer ce didacticiel, chargez votre cluster avec les exemples de données de Amazon S3 commedécrit dans l'exercice Amazon Redshift Mise en route.
Étape 1 : Prendre un instantané1. Ouvrez Amazon Redshift console.2. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur le cluster pour l'ouvrir. Si vous utilisez
le même cluster que celui de l'exercice Amazon Redshift Mise en route, cliquez sur examplecluster.
3. Sous l'onglet Configuration de la page de détails Cluster, cliquez sur Prendre un instantané dans la listeSauvegarde.
4. Dans la fenêtre Créer un instantané, entrez examplecluster-source dans la zone Identifiant del'instantané et cliquez sur Create.
Version de l'API 2012-12-01325
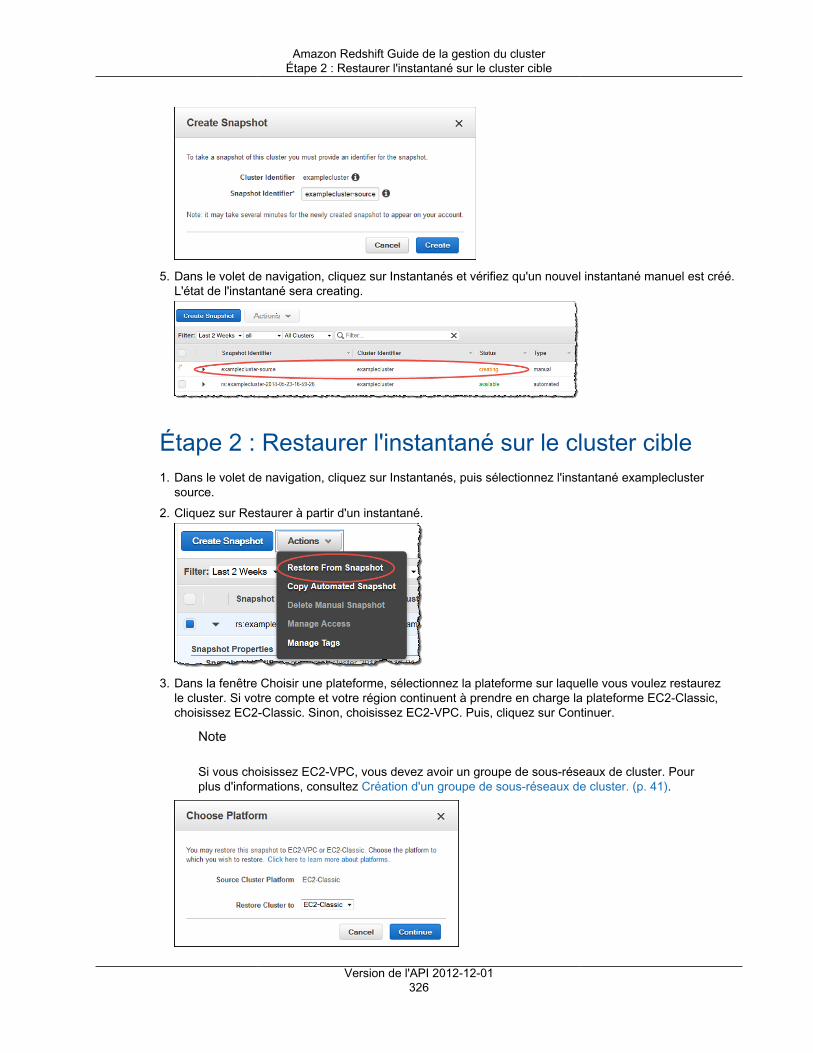
Amazon Redshift Guide de la gestion du clusterÉtape 2 : Restaurer l'instantané sur le cluster cible
5. Dans le volet de navigation, cliquez sur Instantanés et vérifiez qu'un nouvel instantané manuel est créé.L'état de l'instantané sera creating.
Étape 2 : Restaurer l'instantané sur le cluster cible1. Dans le volet de navigation, cliquez sur Instantanés, puis sélectionnez l'instantané examplecluster
source.2. Cliquez sur Restaurer à partir d'un instantané.
3. Dans la fenêtre Choisir une plateforme, sélectionnez la plateforme sur laquelle vous voulez restaurezle cluster. Si votre compte et votre région continuent à prendre en charge la plateforme EC2-Classic,choisissez EC2-Classic. Sinon, choisissez EC2-VPC. Puis, cliquez sur Continuer.
Note
Si vous choisissez EC2-VPC, vous devez avoir un groupe de sous-réseaux de cluster. Pourplus d'informations, consultez Création d'un groupe de sous-réseaux de cluster. (p. 41).
Version de l'API 2012-12-01326
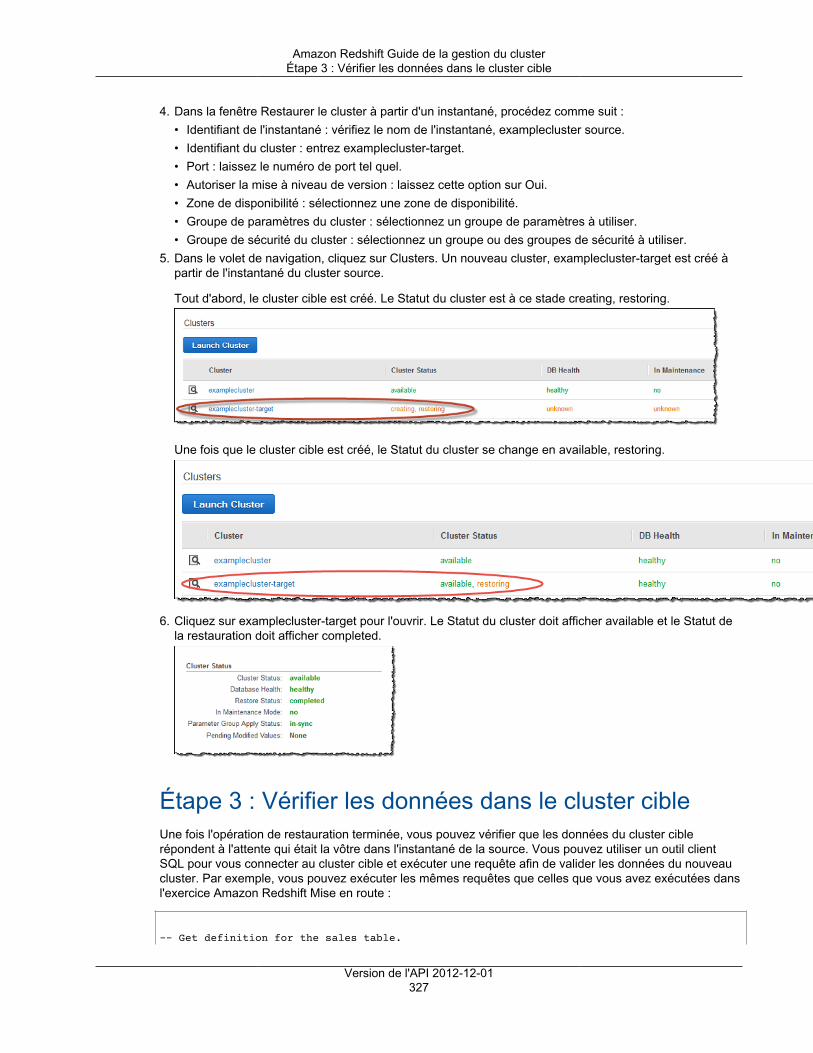
Amazon Redshift Guide de la gestion du clusterÉtape 3 : Vérifier les données dans le cluster cible
4. Dans la fenêtre Restaurer le cluster à partir d'un instantané, procédez comme suit :• Identifiant de l'instantané : vérifiez le nom de l'instantané, examplecluster source.• Identifiant du cluster : entrez examplecluster-target.• Port : laissez le numéro de port tel quel.• Autoriser la mise à niveau de version : laissez cette option sur Oui.• Zone de disponibilité : sélectionnez une zone de disponibilité.• Groupe de paramètres du cluster : sélectionnez un groupe de paramètres à utiliser.• Groupe de sécurité du cluster : sélectionnez un groupe ou des groupes de sécurité à utiliser.
5. Dans le volet de navigation, cliquez sur Clusters. Un nouveau cluster, examplecluster-target est créé àpartir de l'instantané du cluster source.
Tout d'abord, le cluster cible est créé. Le Statut du cluster est à ce stade creating, restoring.
Une fois que le cluster cible est créé, le Statut du cluster se change en available, restoring.
6. Cliquez sur examplecluster-target pour l'ouvrir. Le Statut du cluster doit afficher available et le Statut dela restauration doit afficher completed.
Étape 3 : Vérifier les données dans le cluster cibleUne fois l'opération de restauration terminée, vous pouvez vérifier que les données du cluster ciblerépondent à l'attente qui était la vôtre dans l'instantané de la source. Vous pouvez utiliser un outil clientSQL pour vous connecter au cluster cible et exécuter une requête afin de valider les données du nouveaucluster. Par exemple, vous pouvez exécuter les mêmes requêtes que celles que vous avez exécutées dansl'exercice Amazon Redshift Mise en route :
-- Get definition for the sales table.
Version de l'API 2012-12-01327

Amazon Redshift Guide de la gestion du clusterÉtape 4 : Redimensionner le cluster cible
SELECT * FROM pg_table_def WHERE tablename = 'sales';
-- Find total sales on a given calendar date.SELECT sum(qtysold) FROM sales, date WHERE sales.dateid = date.dateid AND caldate = '2008-01-05';
-- Find top 10 buyers by quantity.SELECT firstname, lastname, total_quantity FROM (SELECT buyerid, sum(qtysold) total_quantity FROM sales GROUP BY buyerid ORDER BY total_quantity desc limit 10) Q, usersWHERE Q.buyerid = useridORDER BY Q.total_quantity desc;
-- Find events in the 99.9 percentile in terms of all-time gross sales.SELECT eventname, total_price FROM (SELECT eventid, total_price, ntile(1000) over(order by total_price desc) as percentile FROM (SELECT eventid, sum(pricepaid) total_price FROM sales GROUP BY eventid)) Q, event E WHERE Q.eventid = E.eventid AND percentile = 1ORDER BY total_price desc;
Étape 4 : Redimensionner le cluster cibleUne fois que vous avez vérifié que votre cluster cible fonctionne comme prévu, vous pouvezredimensionner le cluster cible. Vous pouvez continuer à autoriser les opérations d'écriture et de lecturesur le cluster source, car, plus tard dans ce didacticiel, vous allez copier les données qui ont été chargéesaprès votre instantané sur la cible.
1. Ouvrez Amazon Redshift console.2. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur le cluster pour l'ouvrir. Si vous utilisez
les mêmes noms de cluster que le didacticiel, cliquez sur examplecluster-target.3. Sous l'onglet Configuration de la page des détails Cluster, cliquez sur Redimensionner dans la liste
Cluster.4. Dans la fenêtre Redimensionner le cluster, sélectionnez les valeurs suivantes :
• Type de nœud : dc1.large.• Type de cluster: à plusieurs nœuds.• Nombre de nœuds : 2.
Version de l'API 2012-12-01328

Amazon Redshift Guide de la gestion du clusterÉtape 5 : Copier les données post-instantané
du cluster source vers le cluster cible
5. Cliquez sur Redimensionner.6. Cliquez sur Statut et vérifiez les informations d'état du redimensionnement pour afficher sa progression.
Étape 5 : Copier les données post-instantané ducluster source vers le cluster cibleDans le cadre de ce didacticiel, cette étape fournit un ensemble simple d'instructions COPY pour chargerles données de Amazon S3 vers Amazon Redshift. Cette étape est destinée à simuler que le cluster cibleest à jour et qu'il a les mêmes données que le cluster source. Elle n'a pas pour but d'illustrer la tentativede mettre en ligne un réel environnement de production entre le cluster source et le cluster cible. Dans lesenvironnements de production, votre propre processus ETL détermine comment charger le cluster cibleavec les mêmes données que le cluster source après la prise de l'instantané.
S'il y a plusieurs charges après la prise de l'instantané, vous devez vous assurer que vous exécutez ànouveau les charges de la base de données cible dans le même ordre que celui où elles ont été exécutéesdans la base de données source. En outre, s'il continue à y avoir des charges dans la base de donnéessource tandis que vous travaillez sur la mise à jour du cluster cible, vous devrez répéter ce processusjusqu'à ce que la source et la cible correspondent, puis trouver un créneau adapté pour renommer lesclusters et basculer les applications afin de se connecter à la base de données cible.
Dans cet exemple, supposons que votre processus ETL ait chargé les données dans le cluster sourceaprès la prise de l'instantané. Peut-être Amazon Redshift était-il toujours en train de restaurer le clustercible à partir de l'instantané ou de redimensionner le cluster cible. Certains catégories, événements, dateset lieux nouveaux ont été ajoutés à la base de données TICKIT. Vous devez maintenant obtenir ces mêmesdonnées sur le cluster cible avant de basculer et de l'utiliser à l'avenir.
Tout d'abord, vous allez utiliser les instructions COPY suivantes pour charger les nouvelles données deAmazon S3 vers les tables de votre base de données Amazon Redshift TICKIT du cluster cible.
L'exemple de données de ce didacticiel sont fournies dans les compartiments Amazon S3 détenus parAmazon Redshift. Les autorisations de compartiment sont configurées afin d'accorder à tous les utilisateurs
Version de l'API 2012-12-01329

Amazon Redshift Guide de la gestion du clusterÉtape 6 : Renommer les clusters source et cible
AWS authentifiés un accès en lecture aux fichiers d'exemples de données. Pour charger les exemples dedonnées, assurez-vous que vous avez ce qui suit pour votre utilisateur IAM :
• Votre clé d'accès et votre clé d'accès secrète. Si vous ne les connaissez pas, vous pouvez en créer denouvelles. Pour plus d'informations, consultez Administration des clés d'accès pour les utilisateurs IAMdans le manuel IAM Guide de l'utilisateur.
• Au moins les autorisations LIST et GET sur les ressources Amazon S3. Vous pouvez accorder àvotre utilisateur IAM ces autorisations en associant la stratégie gérée AmazonS3ReadOnlyAccess àvotre utilisateur IAM ou au groupe auquel votre utilisateur IAM appartient. Pour plus d'informations surl'attachement des stratégies, consultez Gestion des stratégies IAM dans le IAM Guide de l'utilisateur.
Note
Sans autorisations appropriées sur Amazon S3, vous recevez le message d'erreur suivantlorsque vous exécutez la commande COPY : S3ServiceException: Access Denied.
Remplacez <access-key-id> et <secret-access-key> par la clé d'accès et la clé d'accès secrète devotre utilisateur IAM. Puis, exécutez les commandes dans votre outil client SQL.
copy venue from 's3://awssampledb/resize/etl_venue_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|' region 'us-east-1';copy category from 's3://awssampledb/resize/etl_category_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|' region 'us-east-1';copy date from 's3://awssampledb/resize/etl_date_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|' region 'us-east-1';copy event from 's3://awssampledb/resize/etl_events_pipe.txt' CREDENTIALS 'aws_access_key_id=<Your-Access-Key-ID>;aws_secret_access_key=<Your-Secret-Access-Key>' delimiter '|' timeformat 'YYYY-MM-DD HH:MI:SS' region 'us-east-1';
Étape 6 : Renommer les clusters source et cibleUne fois que vous avez vérifié que votre cluster cible a été mis à jour avec les données nécessaires duprocessus ETL, vous pouvez basculer sur le cluster cible. Si vous devez conserver le même nom que lecluster source, vous devrez procéder à quelques étapes manuelles pour faire le changement. Ces étapesimpliquent de renommer les clusters source et cible, étape pendant laquelle ils ne seront pas disponiblespour une courte période de temps. Cependant, si vous êtes capable de mettre à jour les sources dedonnées et d'utiliser le nouveau cluster cible, vous pouvez ignorer cette section.
1. Ouvrez Amazon Redshift console.2. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur le cluster pour l'ouvrir. Si vous utilisez
les mêmes noms de cluster que le didacticiel, cliquez sur examplecluster.3. Sous l'onglet Configuration de la page des détails Cluster, cliquez sur Modifier dans la liste Cluster.
Version de l'API 2012-12-01330

Amazon Redshift Guide de la gestion du clusterÉtape 7 : Supprimer le cluster source
4. Dans la fenêtre Modifier le cluster, tapez examplecluster source dans la zone Nouvel identifiant ducluster, puis cliquez sur Modifier.
5. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur examplecluster-target.6. Sous l'onglet Configuration de la page des détails Cluster, cliquez sur Modifier dans la liste Cluster.7. Dans la fenêtre Modifier le cluster, tapez examplecluster dans la zone Nouvel identifiant du cluster, puis
cliquez sur Modifier.
Si vous aviez des requêtes en cours d'exécution dans le cluster source, vous devrez les redémarrer et lesexécuter jusqu'à la fin sur le cluster cible.
Étape 7 : Supprimer le cluster sourceUne fois que vous êtes sûr de ne plus avoir besoin du cluster source, vous pouvez le supprimer. Dans unenvironnement de production, la décision de garder ou pas un instantané final dépend de vos stratégiesde données. Dans ce didacticiel, vous allez supprimer le cluster sans instantané final, car vous utilisez unexemple de données.
Important
Les clusters vous sont facturés jusqu'à leur suppression.
1. Ouvrez Amazon Redshift console.2. Dans le volet de navigation, cliquez sur Clusters, puis cliquez sur le cluster pour l'ouvrir. Si vous utilisez
les mêmes noms de cluster que le didacticiel, cliquez sur examplecluster-source.3. Sous l'onglet Configuration de la page des détails Cluster, cliquez sur Supprimer dans la liste Cluster.
Version de l'API 2012-12-01331
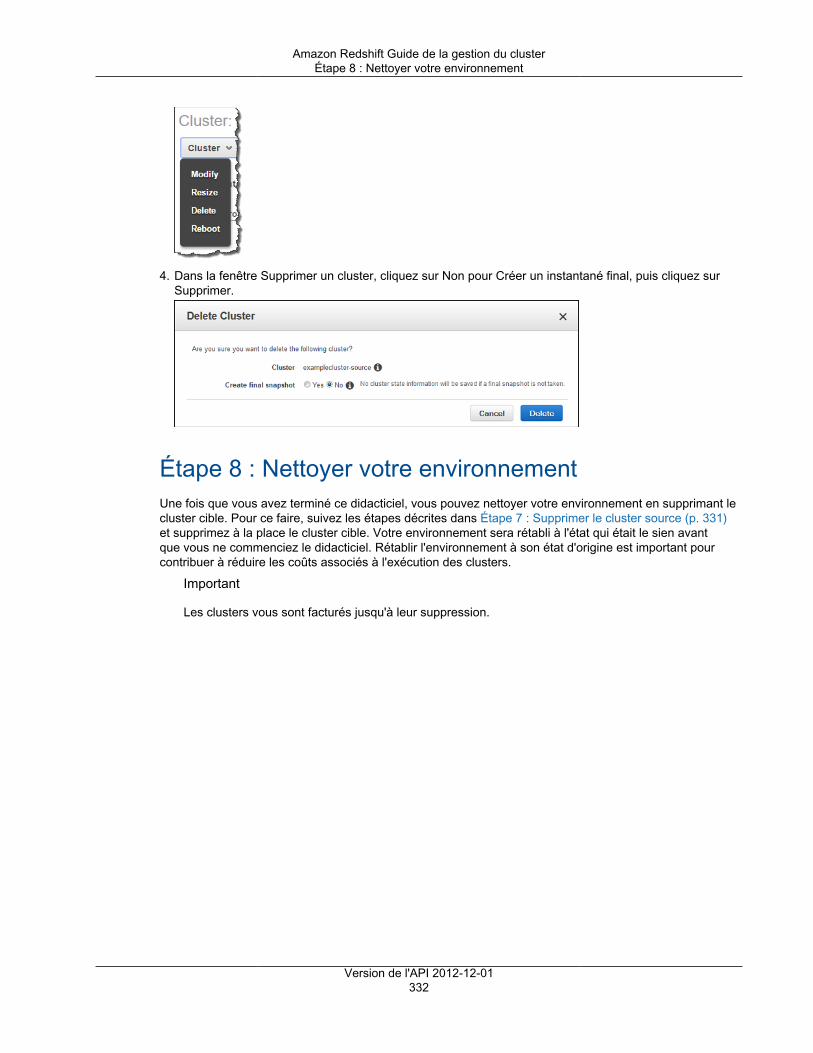
Amazon Redshift Guide de la gestion du clusterÉtape 8 : Nettoyer votre environnement
4. Dans la fenêtre Supprimer un cluster, cliquez sur Non pour Créer un instantané final, puis cliquez surSupprimer.
Étape 8 : Nettoyer votre environnementUne fois que vous avez terminé ce didacticiel, vous pouvez nettoyer votre environnement en supprimant lecluster cible. Pour ce faire, suivez les étapes décrites dans Étape 7 : Supprimer le cluster source (p. 331)et supprimez à la place le cluster cible. Votre environnement sera rétabli à l'état qui était le sien avantque vous ne commenciez le didacticiel. Rétablir l'environnement à son état d'origine est important pourcontribuer à réduire les coûts associés à l'exécution des clusters.
Important
Les clusters vous sont facturés jusqu'à leur suppression.
Version de l'API 2012-12-01332

Amazon Redshift Guide de la gestion du clusterQuotas et limites
Limites dans Amazon RedshiftQuotas et limites
Amazon Redshift a des quotas qui limitent le nombre total de nœuds que vous pouvez mettre en serviceet le nombre d'instantanés que vous pouvez créer ; ces quotas sont définis par compte AWS par région.Amazon Redshift a des quotas par défaut pour chacun d'entre eux ; ils sont recensés à l'adresse Limites deservice AWS. Si vous tentez de dépasser l'un de ces quotas, la tentative échoue. Pour accroître ces limitesde quota Amazon Redshift pour votre compte dans une région, demandez une modification en envoyant unformulaire d'augmentation Amazon Redshift.
Les quotas ci-après s'appliquent à Amazon Redshift Spectrum lors de l'utilisation du catalogue de donnéesAthena ou AWS Glue :
• 10,000 bases de données au maximum par compte.• 100,000 tables au maximum par base de données.• 1 000 000 partitions au maximum par table.• 10 000 000 partitions au maximum par compte.
Pour demander une augmentation d'une de ces restrictions, contactez AWS Support.
Ces restrictions ne s'appliquent pas à un metastore Hive.
En plus des quotas, Amazon Redshift définit des limites pour les valeurs par cluster suivantes. Ces limitesne peuvent pas être augmentées :
• Le nombre de nœuds que vous pouvez allouer par cluster, en fonction du type de nœud du cluster. Cettelimite est distincte de celle de votre compte AWS par région. Pour plus d'informations sur les limites denœud pour chaque type de nœud, consultez Clusters et des nœuds dans Amazon Redshift (p. 5).
• Le nombre maximum de tables est de 9 900 pour les nœuds de cluster de types large et xlarge et de20 000 pour les nœuds de cluster de type 8xlarge. La limite inclut les tables temporaires. Les tablestemporaires incluent les tables temporaires définies par l'utilisateur et les tables temporaires crééespar Amazon Redshift pendant le traitement des requêtes ou la maintenance du système. Les vues nesont pas incluses dans cette limite. Pour plus d'informations sur la création d'une table, consultez Notesd'utilisation sur la création d'une table dans le manuel Amazon Redshift Database Developer Guide. Pourplus d'informations sur le types de nœuds de cluster, consultez Clusters et des nœuds dans AmazonRedshift (p. 5).
• Le nombre de bases de données définies par l'utilisateur que vous pouvez créer par cluster est de 60.Pour plus d'informations sur la création d'une base de données, consultez Créer une base de donnéesdans le manuel Amazon Redshift Database Developer Guide.
• Le nombre de schémas que vous pouvez créer par cluster est de 9 900. Pour plus d'informations sur lacréation d'un schéma, consultez Créer un schéma dans le manuel Amazon Redshift Database DeveloperGuide.
• Le nombre de connexions utilisateur simultanées qu'un cluster peut accepter est de 500. Pour plusd'informations, consultez Connexion à un cluster (p. 201) dans le manuel Amazon Redshift ClusterManagement Guide.
• Une configuration WLM peut définir un niveau total de concurrence de 50 pour les files d'attente définiespar l'utilisateur. Pour plus d'informations, consultez Définition de files d'attente de requêtes dans lemanuel Amazon Redshift Database Developer Guide.
Version de l'API 2012-12-01333
Amazon Redshift Guide de la gestion du clusterContraintes d'affectation de noms
• Le nombre de comptes AWS que vous pouvez autoriser pour restaurer un instantané est de 20 pourchaque instantané et de 100 pour chaque clé AWS Key Management Service (AWS KMS). Autrementdit, si vous avez 10 instantanés chiffrés avec une seule clé KMS, vous pouvez autoriser 10 comptesAWS pour restaurer chaque instantané, ou autres combinaisons qui s'ajoutent jusqu'à 100 comptes,sans dépasser 20 comptes pour chaque instantané. Pour plus d'informations, consultez Partage d'uninstantané (p. 91) dans le manuel Amazon Redshift Cluster Management Guide.
• La taille maximale d'une seule ligne chargée à l'aide de la commande COPY est de 4 Mo. Pour plusd'informations, consultez COPY dans le manuel Amazon Redshift Database Developer Guide.
• Un maximum de 10 rôles IAM peut être associé à un cluster pour autoriser Amazon Redshift à accéderaux autres services AWS pour le compte de l'utilisateur propriétaire du cluster et du rôle IAM. Pour plusd'informations, consultez Autorisation de Amazon Redshift à accéder aux autres services AWS en votrenom (p. 181).
Contraintes d'affectation de nomsLe tableau ci-dessous décrit les contraintes d'affectation de noms dans Amazon Redshift.
Identifiant du cluster • Un identificateur de cluster ne doit contenir que descaractères minuscules.
• Il doit contenir entre 1 et 63 caractères alphanumériques outraits d'union.
• Son premier caractère doit être une lettre.• Il ne peut pas se terminer par un trait d'union ou contenir
deux traits d'union consécutifs.• Il doit être unique pour tous les clusters au sein d'un compte
AWS.
Nom de la base de données • Un nom de base de données doit contenir entre 1 et64 caractères alphanumériques.
• Il doit contenir uniquement des lettres minuscules.• Il ne peut pas être un mot réservé. Pour obtenir la liste des
mots réservés, consultez Mots réservés dans le manuelAmazon Redshift Database Developer Guide.
Nom d'utilisateur principal • Un nom d'utilisateur principal doit contenir uniquement descaractères minuscules.
• Il doit contenir entre 1 et 128 caractères alphanumériques.• Son premier caractère doit être une lettre.• Il ne peut pas être un mot réservé. Pour obtenir la liste des
mots réservés, consultez Mots réservés dans le manuelAmazon Redshift Database Developer Guide.
Mot de passe principal • Un mot de passe principal doit comporter entre 8 et64 caractères de long.
• Il doit contenir au moins une lettre en majuscule.• Il doit contenir au moins une lettre en minuscule.• Il doit comporter un chiffre.• Il peut s'agir de n'importe quel caractère ASCII affichable
(code ASCII 33 à 126), à l'exception de l'apostrophe ('), desguillemets doubles ("), de \, /, @, ou de l'espace.
Version de l'API 2012-12-01334
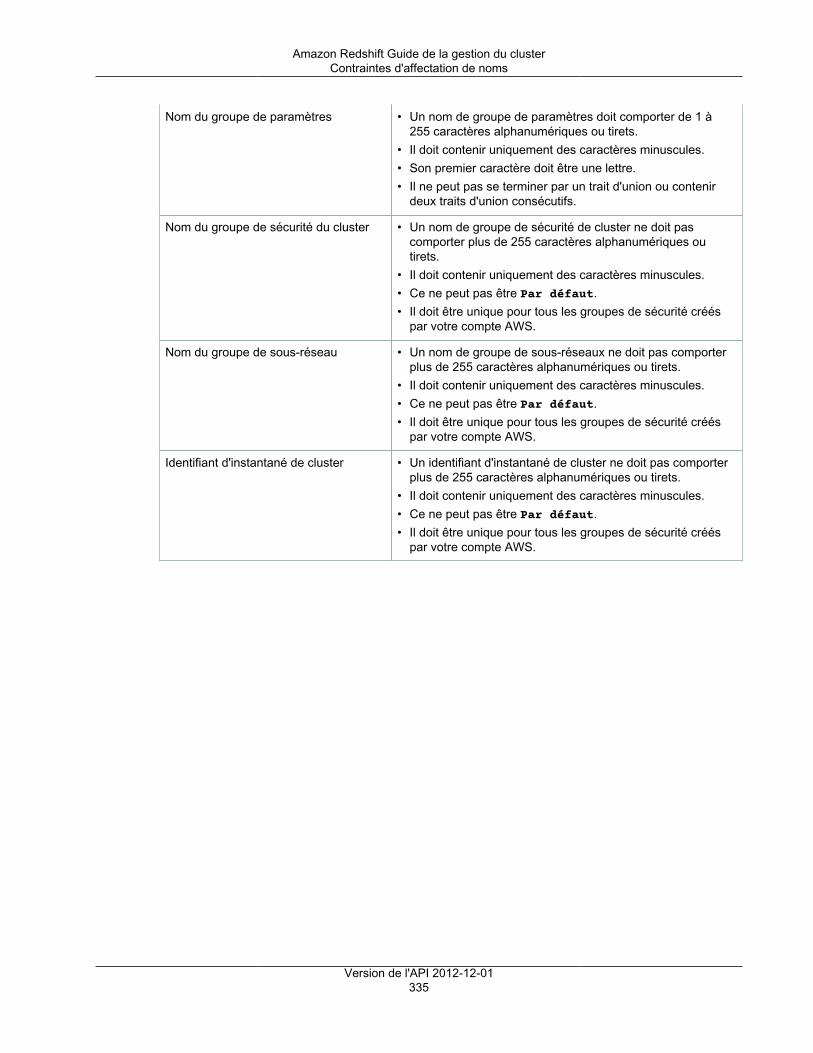
Amazon Redshift Guide de la gestion du clusterContraintes d'affectation de noms
Nom du groupe de paramètres • Un nom de groupe de paramètres doit comporter de 1 à255 caractères alphanumériques ou tirets.
• Il doit contenir uniquement des caractères minuscules.• Son premier caractère doit être une lettre.• Il ne peut pas se terminer par un trait d'union ou contenir
deux traits d'union consécutifs.
Nom du groupe de sécurité du cluster • Un nom de groupe de sécurité de cluster ne doit pascomporter plus de 255 caractères alphanumériques outirets.
• Il doit contenir uniquement des caractères minuscules.• Ce ne peut pas être Par défaut.• Il doit être unique pour tous les groupes de sécurité créés
par votre compte AWS.
Nom du groupe de sous-réseau • Un nom de groupe de sous-réseaux ne doit pas comporterplus de 255 caractères alphanumériques ou tirets.
• Il doit contenir uniquement des caractères minuscules.• Ce ne peut pas être Par défaut.• Il doit être unique pour tous les groupes de sécurité créés
par votre compte AWS.
Identifiant d'instantané de cluster • Un identifiant d'instantané de cluster ne doit pas comporterplus de 255 caractères alphanumériques ou tirets.
• Il doit contenir uniquement des caractères minuscules.• Ce ne peut pas être Par défaut.• Il doit être unique pour tous les groupes de sécurité créés
par votre compte AWS.
Version de l'API 2012-12-01335

Amazon Redshift Guide de la gestion du clusterPrésentation du balisage
Balisage des ressources dansAmazon Redshift
Rubriques• Présentation du balisage (p. 336)• Gestion des balises des ressources à l'aide de la console (p. 337)• Gestion des balises à l'aide de l'API Amazon Redshift (p. 339)
Présentation du balisageDans AWS, les balises sont des étiquettes définies par l'utilisateur et composées de paires clé-valeur.Amazon Redshift prend en charge le balisage pour fournir des métadonnées relatives aux ressources d'unseul coup d'œil et pour classer vos rapports de facturation en fonction de la répartition des coûts. Pourutiliser les balises de répartition des coûts, vous devez d'abord activer ces balises dans le service AWSBilling and Cost Management. Pour plus d'informations sur la configuration et l'utilisation des balises à desfins de facturation, consultez Utilisation des balises de répartition des coûts pour les rapports de facturationpersonnalisés et Configuration de votre rapport mensuel de répartition des coûts.
Les balises ne sont pas nécessaires pour les ressources dans Amazon Redshift mais elles contribuent àfournir un contexte. Vous voudrez peut-être baliser les ressources avec les métadonnées sur les centresde coût, les noms de projet et autres informations pertinentes associées à la ressource. Par exemple,supposons que vous souhaitiez suivre quelles ressources appartiennent à un environnement de test etquelles ressources appartiennent à un environnement de production. Vous pouvez créer une clé nomméeenvironment et fournir la valeur test ou production pour identifier les ressources utilisées danschaque environnement. Si vous utilisez le balisage dans d'autres services AWS ou avez des catégoriesstandard pour votre entreprise, nous vous recommandons de créer les mêmes paires clé-valeur pour lesressources dans Amazon Redshift à des fins de cohérence.
Les balises sont conservées pour les ressources une fois que vous avez redimensionné un cluster et queavez restauré un instantané d'un cluster au sein de la même région. Cependant, comme les balises ne sontpas conservées si vous copiez un instantané sur une autre région, vous devez recréer les balises dans lanouvelle région. Si vous supprimez une ressource, les balises associées sont supprimées.
Chaque ressource possède un ensemble de balises, lequel constitue un ensemble d'une ou de plusieursbalises affectées à la ressource. Chaque ressource peut avoir jusqu'à 50 balises par ensemble de balises.Vous pouvez ajouter des balises lorsque vous créez une ressource et après qu'une ressource a été créée.Vous pouvez ajouter des balises aux types de ressources suivants dans Amazon Redshift :
• Adresse CIDR/IP• Cluster• Groupe de sécurité du cluster• Règle de trafic entrant de groupe de sécurité de cluster• Groupe de sécurité EC2• Connexion HSM• Certificat de client HSM• Groupe de paramètres• Instantané• Groupe de sous-réseaux
Version de l'API 2012-12-01336
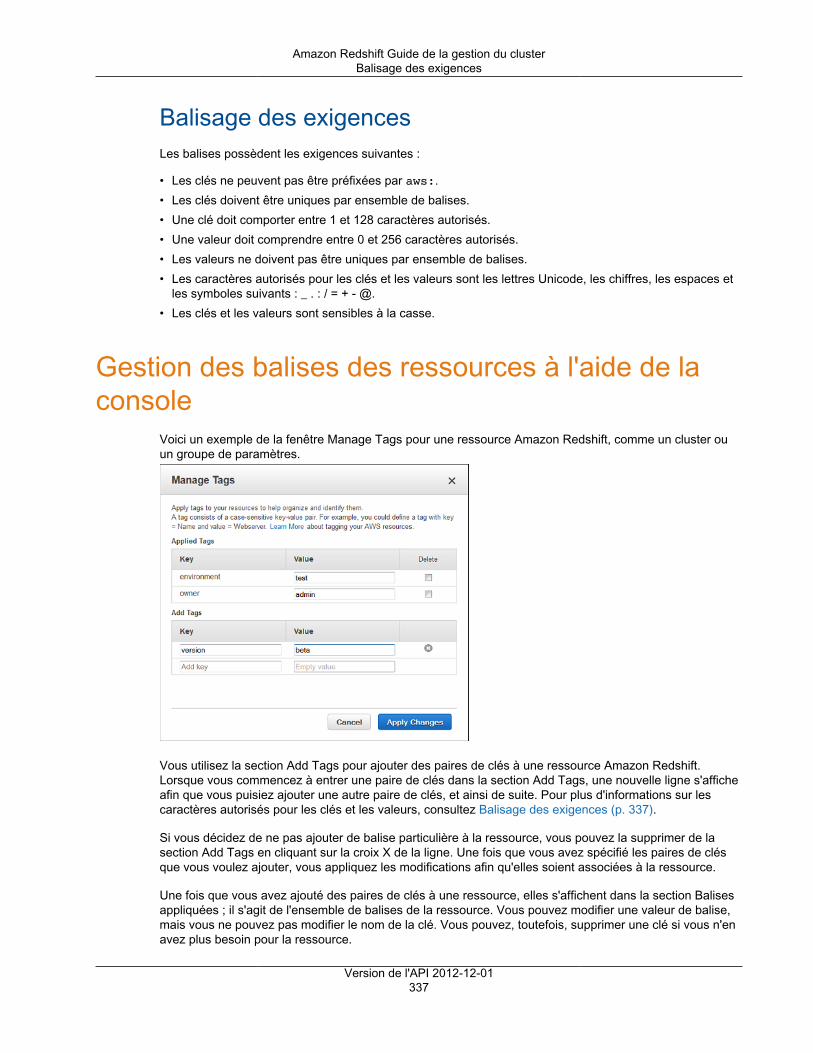
Amazon Redshift Guide de la gestion du clusterBalisage des exigences
Balisage des exigencesLes balises possèdent les exigences suivantes :
• Les clés ne peuvent pas être préfixées par aws:.• Les clés doivent être uniques par ensemble de balises.• Une clé doit comporter entre 1 et 128 caractères autorisés.• Une valeur doit comprendre entre 0 et 256 caractères autorisés.• Les valeurs ne doivent pas être uniques par ensemble de balises.• Les caractères autorisés pour les clés et les valeurs sont les lettres Unicode, les chiffres, les espaces et
les symboles suivants : _ . : / = + - @.• Les clés et les valeurs sont sensibles à la casse.
Gestion des balises des ressources à l'aide de laconsole
Voici un exemple de la fenêtre Manage Tags pour une ressource Amazon Redshift, comme un cluster ouun groupe de paramètres.
Vous utilisez la section Add Tags pour ajouter des paires de clés à une ressource Amazon Redshift.Lorsque vous commencez à entrer une paire de clés dans la section Add Tags, une nouvelle ligne s'afficheafin que vous puisiez ajouter une autre paire de clés, et ainsi de suite. Pour plus d'informations sur lescaractères autorisés pour les clés et les valeurs, consultez Balisage des exigences (p. 337).
Si vous décidez de ne pas ajouter de balise particulière à la ressource, vous pouvez la supprimer de lasection Add Tags en cliquant sur la croix X de la ligne. Une fois que vous avez spécifié les paires de clésque vous voulez ajouter, vous appliquez les modifications afin qu'elles soient associées à la ressource.
Une fois que vous avez ajouté des paires de clés à une ressource, elles s'affichent dans la section Balisesappliquées ; il s'agit de l'ensemble de balises de la ressource. Vous pouvez modifier une valeur de balise,mais vous ne pouvez pas modifier le nom de la clé. Vous pouvez, toutefois, supprimer une clé si vous n'enavez plus besoin pour la ressource.
Version de l'API 2012-12-01337
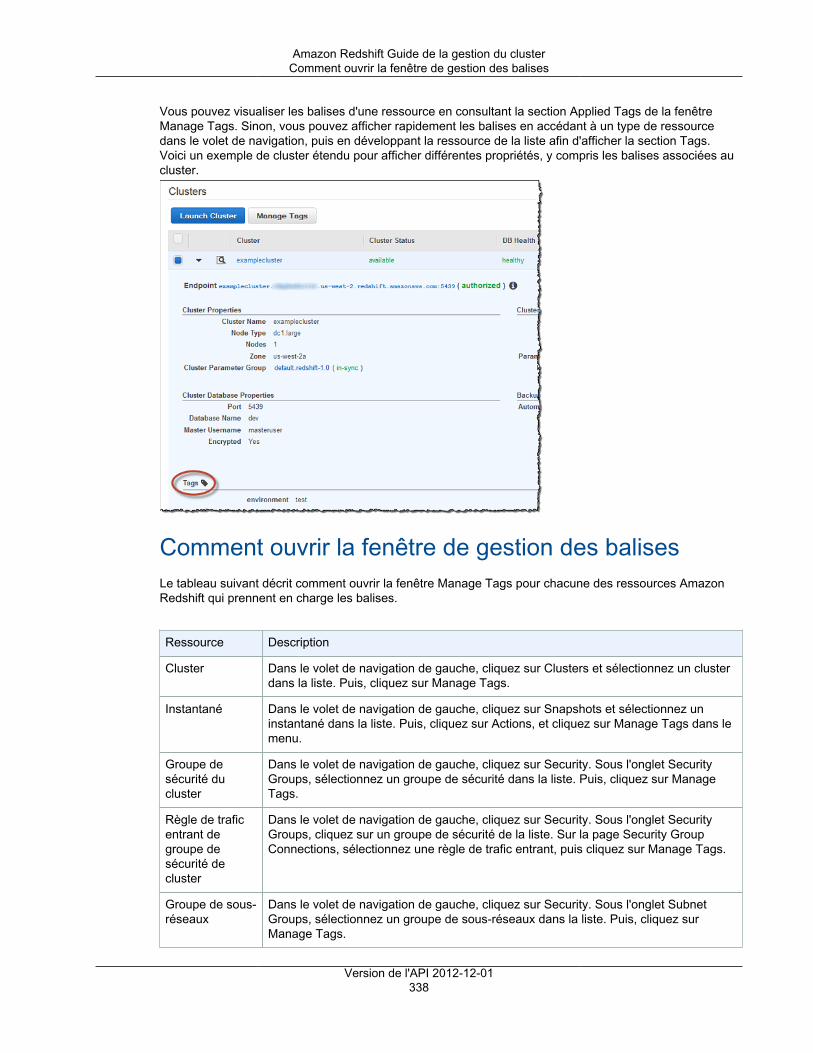
Amazon Redshift Guide de la gestion du clusterComment ouvrir la fenêtre de gestion des balises
Vous pouvez visualiser les balises d'une ressource en consultant la section Applied Tags de la fenêtreManage Tags. Sinon, vous pouvez afficher rapidement les balises en accédant à un type de ressourcedans le volet de navigation, puis en développant la ressource de la liste afin d'afficher la section Tags.Voici un exemple de cluster étendu pour afficher différentes propriétés, y compris les balises associées aucluster.
Comment ouvrir la fenêtre de gestion des balisesLe tableau suivant décrit comment ouvrir la fenêtre Manage Tags pour chacune des ressources AmazonRedshift qui prennent en charge les balises.
Ressource Description
Cluster Dans le volet de navigation de gauche, cliquez sur Clusters et sélectionnez un clusterdans la liste. Puis, cliquez sur Manage Tags.
Instantané Dans le volet de navigation de gauche, cliquez sur Snapshots et sélectionnez uninstantané dans la liste. Puis, cliquez sur Actions, et cliquez sur Manage Tags dans lemenu.
Groupe desécurité ducluster
Dans le volet de navigation de gauche, cliquez sur Security. Sous l'onglet SecurityGroups, sélectionnez un groupe de sécurité dans la liste. Puis, cliquez sur ManageTags.
Règle de traficentrant degroupe desécurité decluster
Dans le volet de navigation de gauche, cliquez sur Security. Sous l'onglet SecurityGroups, cliquez sur un groupe de sécurité de la liste. Sur la page Security GroupConnections, sélectionnez une règle de trafic entrant, puis cliquez sur Manage Tags.
Groupe de sous-réseaux
Dans le volet de navigation de gauche, cliquez sur Security. Sous l'onglet SubnetGroups, sélectionnez un groupe de sous-réseaux dans la liste. Puis, cliquez surManage Tags.
Version de l'API 2012-12-01338

Amazon Redshift Guide de la gestion du clusterComment gérer les balises dans la console Amazon Redshift
Ressource Description
Connexion HSM Dans le volet de navigation de gauche, cliquez sur Security. Sous l'onglet HSMConnections, sélectionnez une connexion dans la liste. Puis, cliquez sur ManageTags.
Certificat HSM Dans le volet de navigation de gauche, cliquez sur Security. Sous l'onglet HSMCertificates, sélectionnez un certificat dans la liste. Puis, cliquez sur Manage Tags.
Groupe deparamètres
Dans le volet de navigation de gauche, cliquez sur Groupes de paramètres, puissélectionnez un groupe de paramètres dans la liste. Puis, cliquez sur Manage Tags.
Comment gérer les balises dans la console AmazonRedshiftUtilisez le tableau de la section précédente pour accéder à la ressource que vous voulez utiliser, puisrecourez aux procédures de cette section pour ajouter, modifier, supprimer et afficher les balises de laressource.
Pour ajouter des balises à une ressource
1. Accédez à la ressource à laquelle vous souhaitez ajouter des balises, puis ouvrez la fenêtre ManageTags.
2. Sous Add Tags, tapez un nom de clé dans la zone Key et la valeur de la clé dans la zone Value. Parexemple, tapez environment dans la zone Key et production dans la zone Value. Répétez cetteétape pour ajouter des balises supplémentaires.
3. Cliquez sur Apply Changes.
Pour modifier les balises associées à une ressource
1. Accédez à la ressource pour laquelle vous souhaitez modifier des balises, puis ouvrez la fenêtreManage Tags.
2. Sous Applied Tags, recherchez la clé que vous voulez modifier. Dans la zone Value, entrez unenouvelle valeur de clé. Répétez la procédure pour toute autre balise que vous voulez modifier.
3. Cliquez sur Apply Changes.
Pour supprimer les balises associées à une ressource
1. Accédez à la ressource pour laquelle vous souhaitez supprimer des balises, puis ouvrez la fenêtreManage Tags.
2. Sous Applied Tags, recherchez la clé que vous voulez supprimer. Activez la case à cocher Delete.Répétez la procédure pour toute autre balise que vous voulez supprimer.
3. Cliquez sur Apply Changes.
Gestion des balises à l'aide de l'API AmazonRedshift
Vous pouvez utiliser les opérations de l'AWS CLI suivante pour gérer les balises dans Amazon Redshift.
Version de l'API 2012-12-01339
Amazon Redshift Guide de la gestion du clusterGestion des balises à l'aide de l'API Amazon Redshift
• create-tags• delete-tags• describe-tags
Vous pouvez utiliser les API Amazon Redshift suivantes pour gérer les balises :
• CreateTags• DeleteTags• DescribeTags• Balise• TaggedResource
En outre, vous pouvez utiliser les API Amazon Redshift suivantes pour gérer et afficher les balises d'uneressource spécifique :
• CreateCluster• CreateClusterParameterGroup• CreateClusterSecurityGroup• CreateClusterSnapshot• CreateClusterSubnetGroup• CreateHsmClientCertificate• CreateHsmConfiguration• DescribeClusters• DescribeClusterParameterGroups• DescribeClusterSecurityGroups• DescribeClusterSnapshots• DescribeClusterSubnetGroups• DescribeHsmClientCertificates• DescribeHsmConfigurations
Version de l'API 2012-12-01340

Amazon Redshift Guide de la gestion du cluster
Historique du documentLe tableau ci-après décrit les modifications importantes dans chaque édition du Amazon Redshift ClusterManagement Guide publiée après juin 2018. Pour recevoir les notifications des mises à jour de cettedocumentation, abonnez-vous à un flux RSS.
Version de l'API : 2012-12-01
Dernière mise à jour de la documentation : 8 août 2018
Pour obtenir la liste des modifications apportées au Amazon Redshift Database Developer Guide,consultez Historique du document Amazon Redshift Database Developer Guide.
Pour plus d'informations sur les nouvelles fonctions, y compris une liste des correctifs et les numéros deversion de cluster associés pour chaque version de produit, consultez le Forum Amazon Redshift.
update-history-change update-history-description update-history-date
Version decluster 1.0.3324 (p. 341)
Les notes de mise à jour de laversion de cluster 1.0.3324 sontmaintenant disponibles. Pourplus d'informations, consultezVersion 1.0.3324.
August 8, 2018
Graphique de répartition del'exécution de la charge detravail (p. 341)
Vous pouvez désormaisobtenir une vue détaillée desperformances de votre chargede travail en consultant legraphique de répartition del'exécution de la charge detravail dans la console. Pour plusd'informations, consultez Analysedes performances de la chargede travail.
July 30, 2018
Suivis de maintenance AmazonRedshift (p. 341)
Vous pouvez désormaisdéterminer si votre clustersera toujours mis à jour versla dernière version d'AmazonRedshift ou vers une versionantérieure en sélectionnant unsuivi de maintenance. Pour plusd'informations, consultez Choixdes suivis de maintenance decluster.
July 26, 2018
Version decluster 1.0.3025 (p. 341)
Les notes de mise à jour de laversion de cluster 1.0.3025 sontmaintenant disponibles. Pourplus d'informations, consultezVersion 1.0.3025.
July 19, 2018
Version de l'API 2012-12-01341
Amazon Redshift Guide de la gestion du cluster
Mise à jour des pilotes JDBC etODBC (p. 341)
Amazon Redshift prenddésormais en charge lesnouvelles versions des pilotesJDBC et ODBC. Pour plusd'informations, consultezConfigurer une connexion JDBCet Configurer une connexionODBC.
July 13, 2018
Versions de cluster à lademande (p. 341)
Vous pouvez désormais mettreà niveau votre cluster vers laversion la plus récente dès quecelle-ci est disponible. Pour plusd'informations, consultez Gestiondes versions de cluster.
June 29, 2018
Version decluster 1.0.2762 (p. 341)
Les notes de mise à jour de laversion de cluster 1.0.2762 sontmaintenant disponibles. Pourplus d'informations, consultezVersion 1.0.2762.
June 29, 2018
Le tableau suivant décrit les modifications importantes apportées au Amazon Redshift Cluster ManagementGuide publié avant juillet 2018.
Version de l'API : 2012-12-01
Dernière mise à jour de la documentation : 17 mai 2018
Pour obtenir la liste des modifications apportées à la documentation de la base de données AmazonRedshift, accédez au manuel Amazon Redshift Database Developer Guide.
Pour plus d'informations sur les nouvelles fonctions, y compris une liste des correctifs et les numéros deversion de cluster associés pour chaque version de produit, consultez le Forum Amazon Redshift.
Modification Description Date de parution
Nouvelles métriquesCloudWatch
Nouvelles métriques CloudWatch ajoutées pour lasurveillance des performances des requêtes. Pour plusd'informations, consultez Données de performanceAmazon Redshift (p. 260)
17 mai 2018
Nouveaux pilotesJDBC et ODBC
Les pilotes JDBC Amazon Redshift ont été mis à jour versla version 1.2.12.1017. Pour plus d'informations, consultezConfigurer une connexion JDBC (p. 203).
Les pilotes ODBC Amazon Redshift ont été mis à jour versla version 1.4.1.1001. Pour plus d'informations, consultezConfigurer la connexion ODBC (p. 219).
7 mars 2018
Chiffrement HSM Amazon Redshift prend uniquement en charge AWSCloudHSM pour la gestion des clés de module desécurité matérielle (HSM). Pour plus d'informations,consultez Chiffrement de base de données AmazonRedshift (p. 105).
6 mars 2018
Création de chaînesde rôles IAM
Si un rôle IAM attaché à votre cluster n'a pas accès auxressources nécessaires, vous pouvez créer une chaîne
23 février 2018
Version de l'API 2012-12-01342
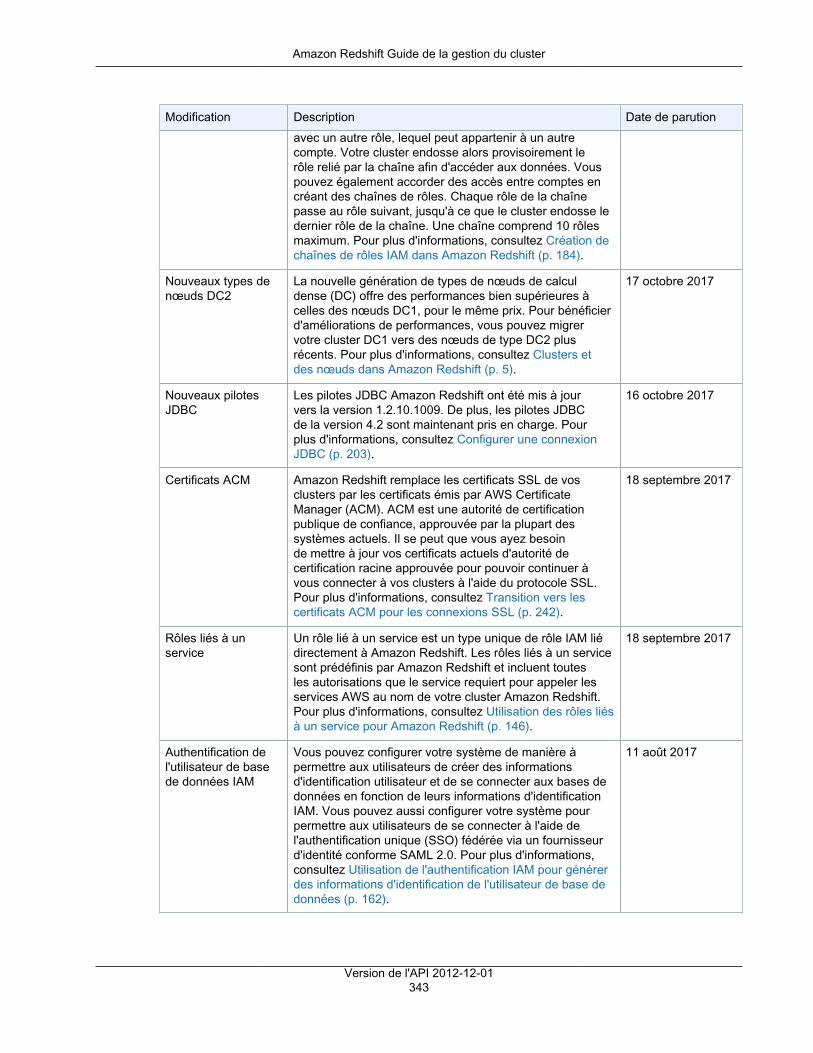
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parutionavec un autre rôle, lequel peut appartenir à un autrecompte. Votre cluster endosse alors provisoirement lerôle relié par la chaîne afin d'accéder aux données. Vouspouvez également accorder des accès entre comptes encréant des chaînes de rôles. Chaque rôle de la chaînepasse au rôle suivant, jusqu'à ce que le cluster endosse ledernier rôle de la chaîne. Une chaîne comprend 10 rôlesmaximum. Pour plus d'informations, consultez Création dechaînes de rôles IAM dans Amazon Redshift (p. 184).
Nouveaux types denœuds DC2
La nouvelle génération de types de nœuds de calculdense (DC) offre des performances bien supérieures àcelles des nœuds DC1, pour le même prix. Pour bénéficierd'améliorations de performances, vous pouvez migrervotre cluster DC1 vers des nœuds de type DC2 plusrécents. Pour plus d'informations, consultez Clusters etdes nœuds dans Amazon Redshift (p. 5).
17 octobre 2017
Nouveaux pilotesJDBC
Les pilotes JDBC Amazon Redshift ont été mis à jourvers la version 1.2.10.1009. De plus, les pilotes JDBCde la version 4.2 sont maintenant pris en charge. Pourplus d'informations, consultez Configurer une connexionJDBC (p. 203).
16 octobre 2017
Certificats ACM Amazon Redshift remplace les certificats SSL de vosclusters par les certificats émis par AWS CertificateManager (ACM). ACM est une autorité de certificationpublique de confiance, approuvée par la plupart dessystèmes actuels. Il se peut que vous ayez besoinde mettre à jour vos certificats actuels d'autorité decertification racine approuvée pour pouvoir continuer àvous connecter à vos clusters à l'aide du protocole SSL.Pour plus d'informations, consultez Transition vers lescertificats ACM pour les connexions SSL (p. 242).
18 septembre 2017
Rôles liés à unservice
Un rôle lié à un service est un type unique de rôle IAM liédirectement à Amazon Redshift. Les rôles liés à un servicesont prédéfinis par Amazon Redshift et incluent toutesles autorisations que le service requiert pour appeler lesservices AWS au nom de votre cluster Amazon Redshift.Pour plus d'informations, consultez Utilisation des rôles liésà un service pour Amazon Redshift (p. 146).
18 septembre 2017
Authentification del'utilisateur de basede données IAM
Vous pouvez configurer votre système de manière àpermettre aux utilisateurs de créer des informationsd'identification utilisateur et de se connecter aux bases dedonnées en fonction de leurs informations d'identificationIAM. Vous pouvez aussi configurer votre système pourpermettre aux utilisateurs de se connecter à l'aide del'authentification unique (SSO) fédérée via un fournisseurd'identité conforme SAML 2.0. Pour plus d'informations,consultez Utilisation de l'authentification IAM pour générerdes informations d'identification de l'utilisateur de base dedonnées (p. 162).
11 août 2017
Version de l'API 2012-12-01343
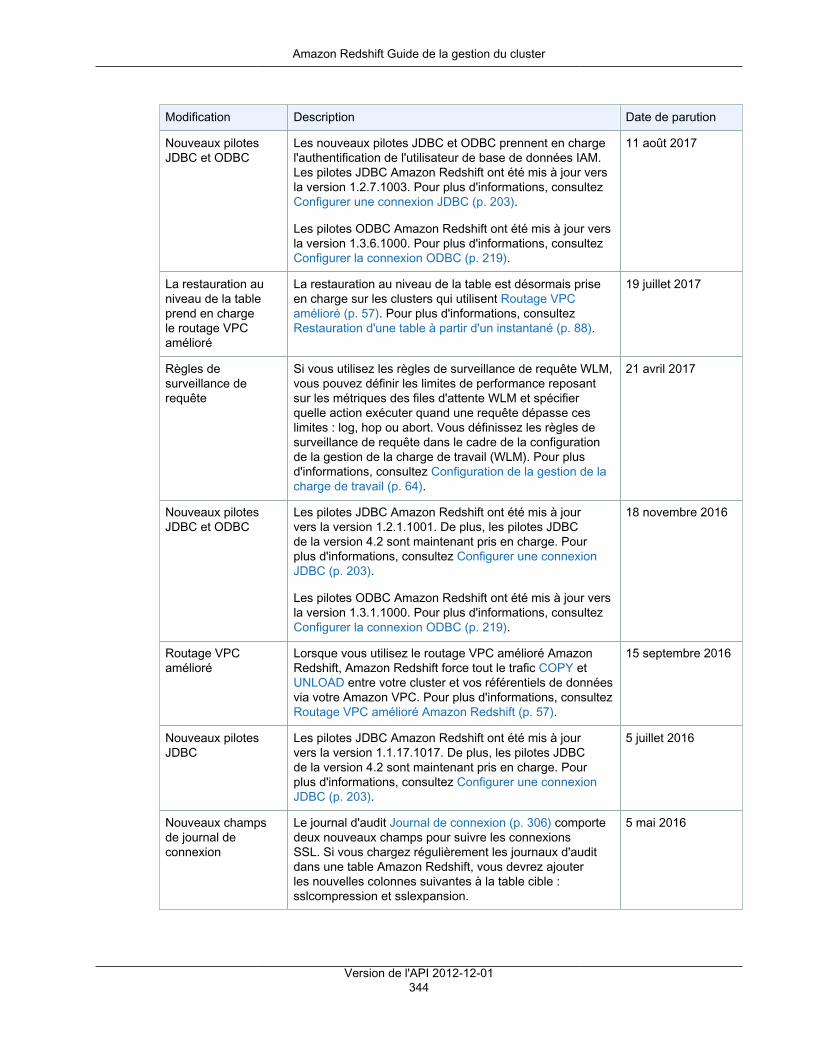
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Nouveaux pilotesJDBC et ODBC
Les nouveaux pilotes JDBC et ODBC prennent en chargel'authentification de l'utilisateur de base de données IAM.Les pilotes JDBC Amazon Redshift ont été mis à jour versla version 1.2.7.1003. Pour plus d'informations, consultezConfigurer une connexion JDBC (p. 203).
Les pilotes ODBC Amazon Redshift ont été mis à jour versla version 1.3.6.1000. Pour plus d'informations, consultezConfigurer la connexion ODBC (p. 219).
11 août 2017
La restauration auniveau de la tableprend en chargele routage VPCamélioré
La restauration au niveau de la table est désormais priseen charge sur les clusters qui utilisent Routage VPCamélioré (p. 57). Pour plus d'informations, consultezRestauration d'une table à partir d'un instantané (p. 88).
19 juillet 2017
Règles desurveillance derequête
Si vous utilisez les règles de surveillance de requête WLM,vous pouvez définir les limites de performance reposantsur les métriques des files d'attente WLM et spécifierquelle action exécuter quand une requête dépasse ceslimites : log, hop ou abort. Vous définissez les règles desurveillance de requête dans le cadre de la configurationde la gestion de la charge de travail (WLM). Pour plusd'informations, consultez Configuration de la gestion de lacharge de travail (p. 64).
21 avril 2017
Nouveaux pilotesJDBC et ODBC
Les pilotes JDBC Amazon Redshift ont été mis à jourvers la version 1.2.1.1001. De plus, les pilotes JDBCde la version 4.2 sont maintenant pris en charge. Pourplus d'informations, consultez Configurer une connexionJDBC (p. 203).
Les pilotes ODBC Amazon Redshift ont été mis à jour versla version 1.3.1.1000. Pour plus d'informations, consultezConfigurer la connexion ODBC (p. 219).
18 novembre 2016
Routage VPCamélioré
Lorsque vous utilisez le routage VPC amélioré AmazonRedshift, Amazon Redshift force tout le trafic COPY etUNLOAD entre votre cluster et vos référentiels de donnéesvia votre Amazon VPC. Pour plus d'informations, consultezRoutage VPC amélioré Amazon Redshift (p. 57).
15 septembre 2016
Nouveaux pilotesJDBC
Les pilotes JDBC Amazon Redshift ont été mis à jourvers la version 1.1.17.1017. De plus, les pilotes JDBCde la version 4.2 sont maintenant pris en charge. Pourplus d'informations, consultez Configurer une connexionJDBC (p. 203).
5 juillet 2016
Nouveaux champsde journal deconnexion
Le journal d'audit Journal de connexion (p. 306) comportedeux nouveaux champs pour suivre les connexionsSSL. Si vous chargez régulièrement les journaux d'auditdans une table Amazon Redshift, vous devrez ajouterles nouvelles colonnes suivantes à la table cible :sslcompression et sslexpansion.
5 mai 2016
Version de l'API 2012-12-01344
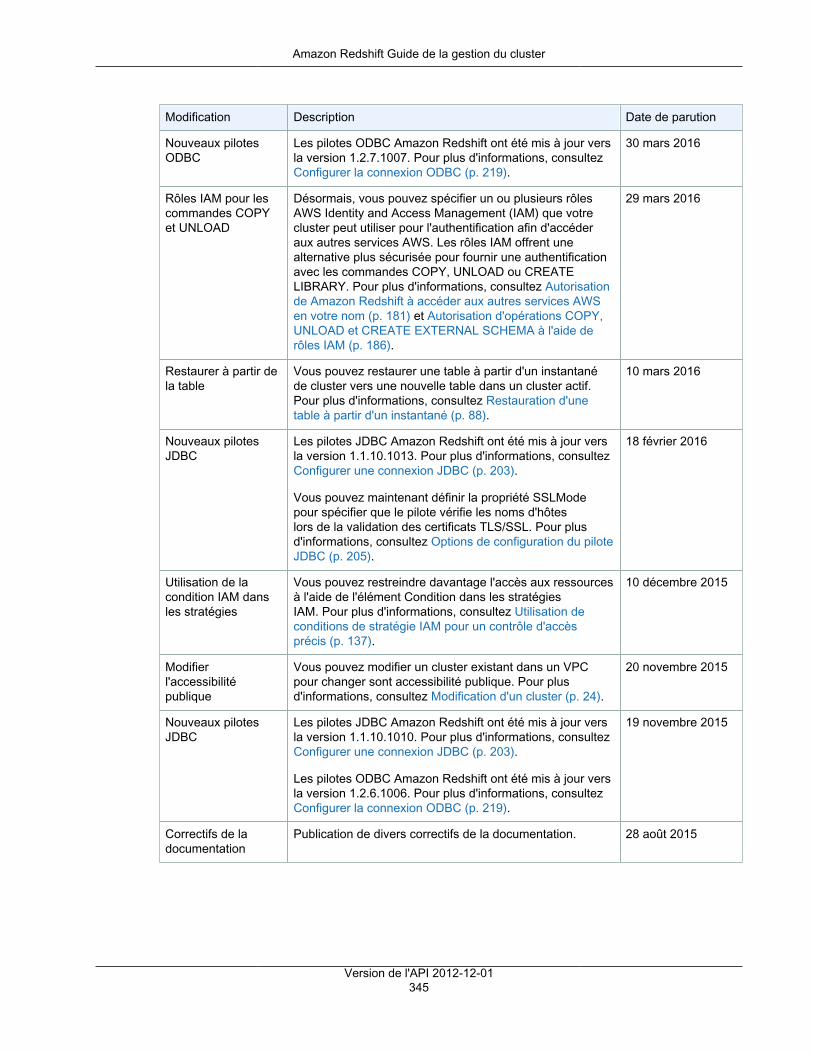
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Nouveaux pilotesODBC
Les pilotes ODBC Amazon Redshift ont été mis à jour versla version 1.2.7.1007. Pour plus d'informations, consultezConfigurer la connexion ODBC (p. 219).
30 mars 2016
Rôles IAM pour lescommandes COPYet UNLOAD
Désormais, vous pouvez spécifier un ou plusieurs rôlesAWS Identity and Access Management (IAM) que votrecluster peut utiliser pour l'authentification afin d'accéderaux autres services AWS. Les rôles IAM offrent unealternative plus sécurisée pour fournir une authentificationavec les commandes COPY, UNLOAD ou CREATELIBRARY. Pour plus d'informations, consultez Autorisationde Amazon Redshift à accéder aux autres services AWSen votre nom (p. 181) et Autorisation d'opérations COPY,UNLOAD et CREATE EXTERNAL SCHEMA à l'aide derôles IAM (p. 186).
29 mars 2016
Restaurer à partir dela table
Vous pouvez restaurer une table à partir d'un instantanéde cluster vers une nouvelle table dans un cluster actif.Pour plus d'informations, consultez Restauration d'unetable à partir d'un instantané (p. 88).
10 mars 2016
Nouveaux pilotesJDBC
Les pilotes JDBC Amazon Redshift ont été mis à jour versla version 1.1.10.1013. Pour plus d'informations, consultezConfigurer une connexion JDBC (p. 203).
Vous pouvez maintenant définir la propriété SSLModepour spécifier que le pilote vérifie les noms d'hôteslors de la validation des certificats TLS/SSL. Pour plusd'informations, consultez Options de configuration du piloteJDBC (p. 205).
18 février 2016
Utilisation de lacondition IAM dansles stratégies
Vous pouvez restreindre davantage l'accès aux ressourcesà l'aide de l'élément Condition dans les stratégiesIAM. Pour plus d'informations, consultez Utilisation deconditions de stratégie IAM pour un contrôle d'accèsprécis (p. 137).
10 décembre 2015
Modifierl'accessibilitépublique
Vous pouvez modifier un cluster existant dans un VPCpour changer sont accessibilité publique. Pour plusd'informations, consultez Modification d'un cluster (p. 24).
20 novembre 2015
Nouveaux pilotesJDBC
Les pilotes JDBC Amazon Redshift ont été mis à jour versla version 1.1.10.1010. Pour plus d'informations, consultezConfigurer une connexion JDBC (p. 203).
Les pilotes ODBC Amazon Redshift ont été mis à jour versla version 1.2.6.1006. Pour plus d'informations, consultezConfigurer la connexion ODBC (p. 219).
19 novembre 2015
Correctifs de ladocumentation
Publication de divers correctifs de la documentation. 28 août 2015
Version de l'API 2012-12-01345
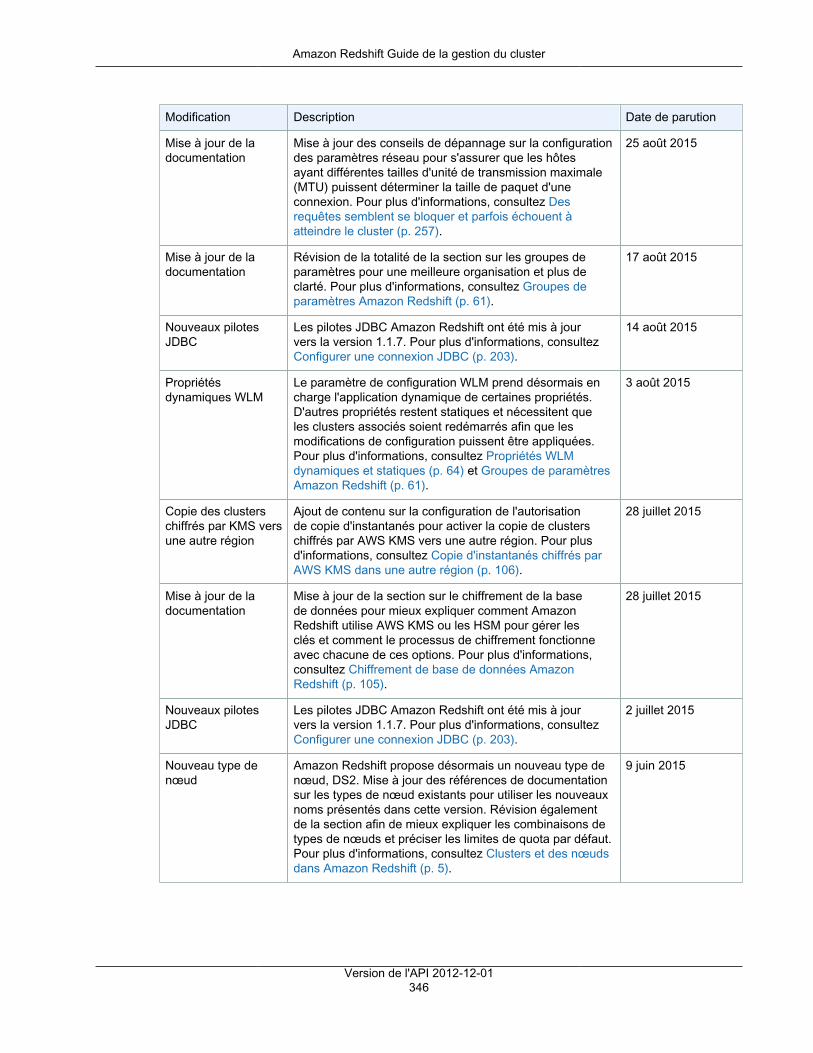
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Mise à jour de ladocumentation
Mise à jour des conseils de dépannage sur la configurationdes paramètres réseau pour s'assurer que les hôtesayant différentes tailles d'unité de transmission maximale(MTU) puissent déterminer la taille de paquet d'uneconnexion. Pour plus d'informations, consultez Desrequêtes semblent se bloquer et parfois échouent àatteindre le cluster (p. 257).
25 août 2015
Mise à jour de ladocumentation
Révision de la totalité de la section sur les groupes deparamètres pour une meilleure organisation et plus declarté. Pour plus d'informations, consultez Groupes deparamètres Amazon Redshift (p. 61).
17 août 2015
Nouveaux pilotesJDBC
Les pilotes JDBC Amazon Redshift ont été mis à jourvers la version 1.1.7. Pour plus d'informations, consultezConfigurer une connexion JDBC (p. 203).
14 août 2015
Propriétésdynamiques WLM
Le paramètre de configuration WLM prend désormais encharge l'application dynamique de certaines propriétés.D'autres propriétés restent statiques et nécessitent queles clusters associés soient redémarrés afin que lesmodifications de configuration puissent être appliquées.Pour plus d'informations, consultez Propriétés WLMdynamiques et statiques (p. 64) et Groupes de paramètresAmazon Redshift (p. 61).
3 août 2015
Copie des clusterschiffrés par KMS versune autre région
Ajout de contenu sur la configuration de l'autorisationde copie d'instantanés pour activer la copie de clusterschiffrés par AWS KMS vers une autre région. Pour plusd'informations, consultez Copie d'instantanés chiffrés parAWS KMS dans une autre région (p. 106).
28 juillet 2015
Mise à jour de ladocumentation
Mise à jour de la section sur le chiffrement de la basede données pour mieux expliquer comment AmazonRedshift utilise AWS KMS ou les HSM pour gérer lesclés et comment le processus de chiffrement fonctionneavec chacune de ces options. Pour plus d'informations,consultez Chiffrement de base de données AmazonRedshift (p. 105).
28 juillet 2015
Nouveaux pilotesJDBC
Les pilotes JDBC Amazon Redshift ont été mis à jourvers la version 1.1.7. Pour plus d'informations, consultezConfigurer une connexion JDBC (p. 203).
2 juillet 2015
Nouveau type denœud
Amazon Redshift propose désormais un nouveau type denœud, DS2. Mise à jour des références de documentationsur les types de nœud existants pour utiliser les nouveauxnoms présentés dans cette version. Révision égalementde la section afin de mieux expliquer les combinaisons detypes de nœuds et préciser les limites de quota par défaut.Pour plus d'informations, consultez Clusters et des nœudsdans Amazon Redshift (p. 5).
9 juin 2015
Version de l'API 2012-12-01346
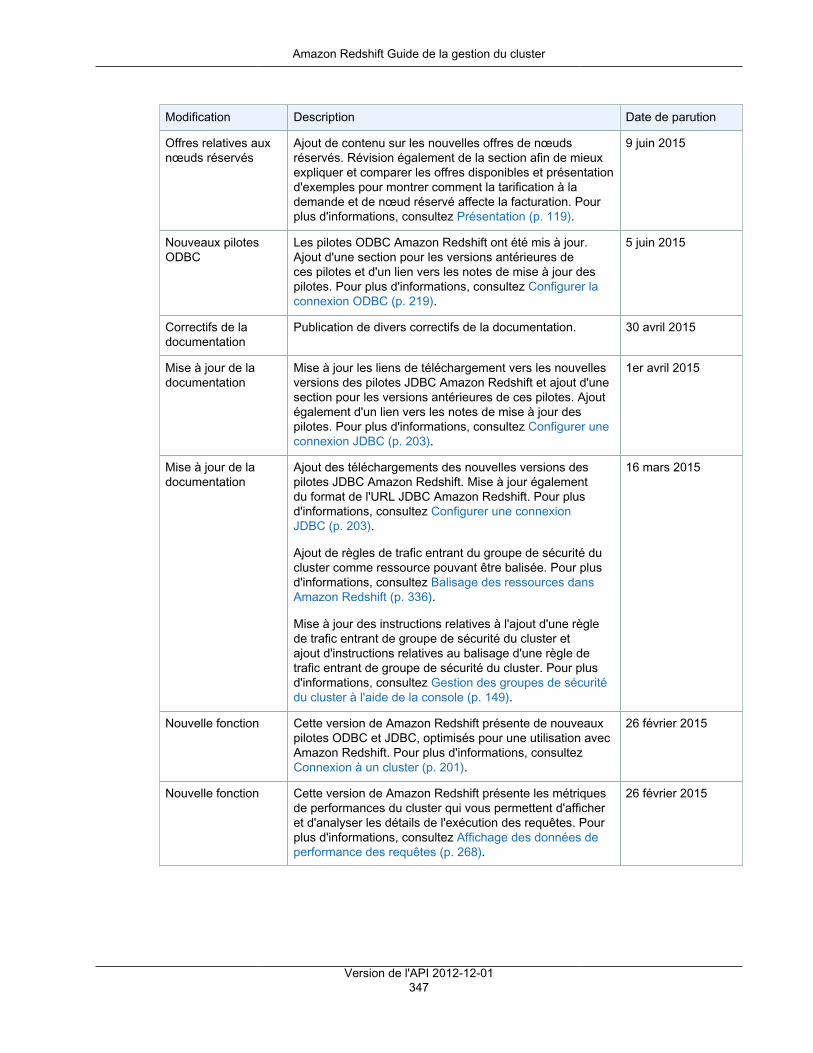
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Offres relatives auxnœuds réservés
Ajout de contenu sur les nouvelles offres de nœudsréservés. Révision également de la section afin de mieuxexpliquer et comparer les offres disponibles et présentationd'exemples pour montrer comment la tarification à lademande et de nœud réservé affecte la facturation. Pourplus d'informations, consultez Présentation (p. 119).
9 juin 2015
Nouveaux pilotesODBC
Les pilotes ODBC Amazon Redshift ont été mis à jour.Ajout d'une section pour les versions antérieures deces pilotes et d'un lien vers les notes de mise à jour despilotes. Pour plus d'informations, consultez Configurer laconnexion ODBC (p. 219).
5 juin 2015
Correctifs de ladocumentation
Publication de divers correctifs de la documentation. 30 avril 2015
Mise à jour de ladocumentation
Mise à jour les liens de téléchargement vers les nouvellesversions des pilotes JDBC Amazon Redshift et ajout d'unesection pour les versions antérieures de ces pilotes. Ajoutégalement d'un lien vers les notes de mise à jour despilotes. Pour plus d'informations, consultez Configurer uneconnexion JDBC (p. 203).
1er avril 2015
Mise à jour de ladocumentation
Ajout des téléchargements des nouvelles versions despilotes JDBC Amazon Redshift. Mise à jour égalementdu format de l'URL JDBC Amazon Redshift. Pour plusd'informations, consultez Configurer une connexionJDBC (p. 203).
Ajout de règles de trafic entrant du groupe de sécurité ducluster comme ressource pouvant être balisée. Pour plusd'informations, consultez Balisage des ressources dansAmazon Redshift (p. 336).
Mise à jour des instructions relatives à l'ajout d'une règlede trafic entrant de groupe de sécurité du cluster etajout d'instructions relatives au balisage d'une règle detrafic entrant de groupe de sécurité du cluster. Pour plusd'informations, consultez Gestion des groupes de sécuritédu cluster à l'aide de la console (p. 149).
16 mars 2015
Nouvelle fonction Cette version de Amazon Redshift présente de nouveauxpilotes ODBC et JDBC, optimisés pour une utilisation avecAmazon Redshift. Pour plus d'informations, consultezConnexion à un cluster (p. 201).
26 février 2015
Nouvelle fonction Cette version de Amazon Redshift présente les métriquesde performances du cluster qui vous permettent d'afficheret d'analyser les détails de l'exécution des requêtes. Pourplus d'informations, consultez Affichage des données deperformance des requêtes (p. 268).
26 février 2015
Version de l'API 2012-12-01347
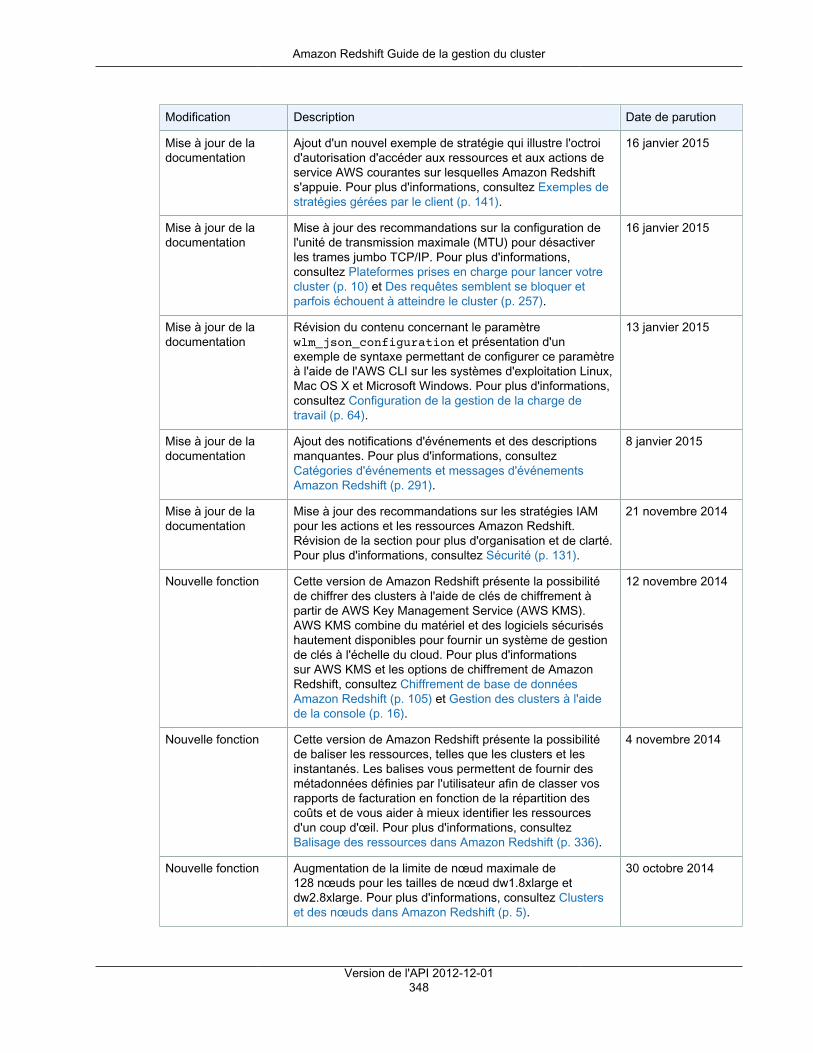
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Mise à jour de ladocumentation
Ajout d'un nouvel exemple de stratégie qui illustre l'octroid'autorisation d'accéder aux ressources et aux actions deservice AWS courantes sur lesquelles Amazon Redshifts'appuie. Pour plus d'informations, consultez Exemples destratégies gérées par le client (p. 141).
16 janvier 2015
Mise à jour de ladocumentation
Mise à jour des recommandations sur la configuration del'unité de transmission maximale (MTU) pour désactiverles trames jumbo TCP/IP. Pour plus d'informations,consultez Plateformes prises en charge pour lancer votrecluster (p. 10) et Des requêtes semblent se bloquer etparfois échouent à atteindre le cluster (p. 257).
16 janvier 2015
Mise à jour de ladocumentation
Révision du contenu concernant le paramètrewlm_json_configuration et présentation d'unexemple de syntaxe permettant de configurer ce paramètreà l'aide de l'AWS CLI sur les systèmes d'exploitation Linux,Mac OS X et Microsoft Windows. Pour plus d'informations,consultez Configuration de la gestion de la charge detravail (p. 64).
13 janvier 2015
Mise à jour de ladocumentation
Ajout des notifications d'événements et des descriptionsmanquantes. Pour plus d'informations, consultezCatégories d'événements et messages d'événementsAmazon Redshift (p. 291).
8 janvier 2015
Mise à jour de ladocumentation
Mise à jour des recommandations sur les stratégies IAMpour les actions et les ressources Amazon Redshift.Révision de la section pour plus d'organisation et de clarté.Pour plus d'informations, consultez Sécurité (p. 131).
21 novembre 2014
Nouvelle fonction Cette version de Amazon Redshift présente la possibilitéde chiffrer des clusters à l'aide de clés de chiffrement àpartir de AWS Key Management Service (AWS KMS).AWS KMS combine du matériel et des logiciels sécuriséshautement disponibles pour fournir un système de gestionde clés à l'échelle du cloud. Pour plus d'informationssur AWS KMS et les options de chiffrement de AmazonRedshift, consultez Chiffrement de base de donnéesAmazon Redshift (p. 105) et Gestion des clusters à l'aidede la console (p. 16).
12 novembre 2014
Nouvelle fonction Cette version de Amazon Redshift présente la possibilitéde baliser les ressources, telles que les clusters et lesinstantanés. Les balises vous permettent de fournir desmétadonnées définies par l'utilisateur afin de classer vosrapports de facturation en fonction de la répartition descoûts et de vous aider à mieux identifier les ressourcesd'un coup d'œil. Pour plus d'informations, consultezBalisage des ressources dans Amazon Redshift (p. 336).
4 novembre 2014
Nouvelle fonction Augmentation de la limite de nœud maximale de128 nœuds pour les tailles de nœud dw1.8xlarge etdw2.8xlarge. Pour plus d'informations, consultez Clusterset des nœuds dans Amazon Redshift (p. 5).
30 octobre 2014
Version de l'API 2012-12-01348
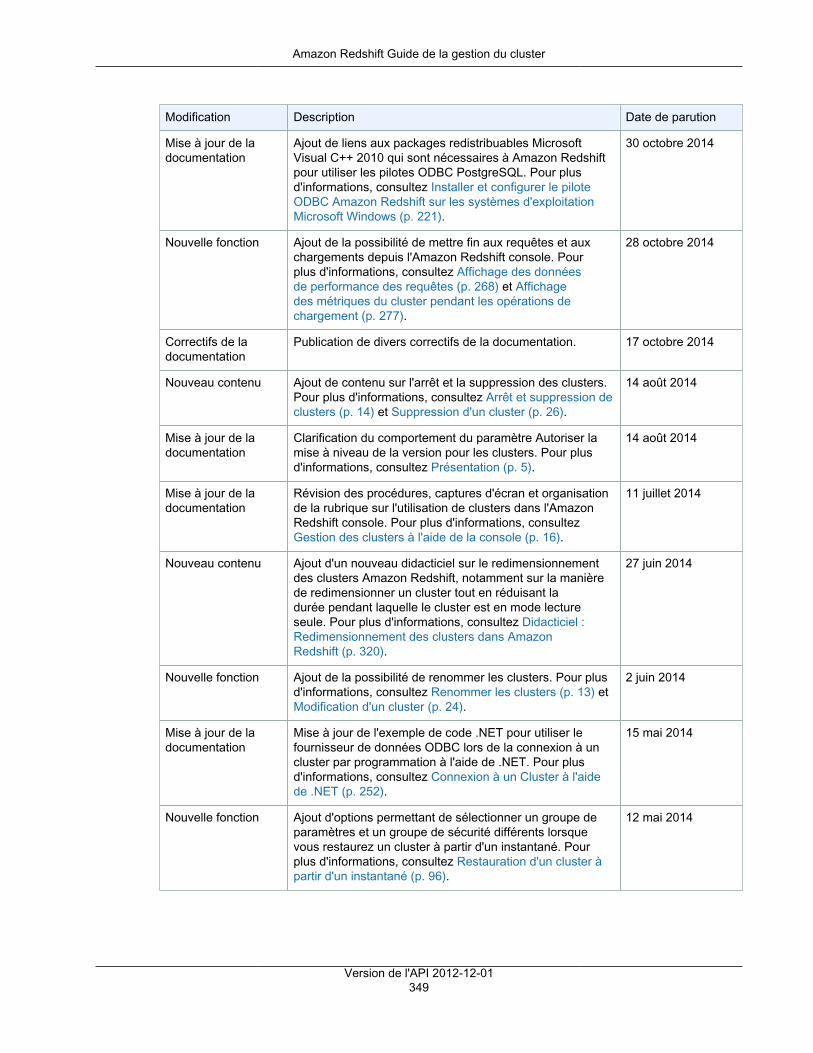
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Mise à jour de ladocumentation
Ajout de liens aux packages redistribuables MicrosoftVisual C++ 2010 qui sont nécessaires à Amazon Redshiftpour utiliser les pilotes ODBC PostgreSQL. Pour plusd'informations, consultez Installer et configurer le piloteODBC Amazon Redshift sur les systèmes d'exploitationMicrosoft Windows (p. 221).
30 octobre 2014
Nouvelle fonction Ajout de la possibilité de mettre fin aux requêtes et auxchargements depuis l'Amazon Redshift console. Pourplus d'informations, consultez Affichage des donnéesde performance des requêtes (p. 268) et Affichagedes métriques du cluster pendant les opérations dechargement (p. 277).
28 octobre 2014
Correctifs de ladocumentation
Publication de divers correctifs de la documentation. 17 octobre 2014
Nouveau contenu Ajout de contenu sur l'arrêt et la suppression des clusters.Pour plus d'informations, consultez Arrêt et suppression declusters (p. 14) et Suppression d'un cluster (p. 26).
14 août 2014
Mise à jour de ladocumentation
Clarification du comportement du paramètre Autoriser lamise à niveau de la version pour les clusters. Pour plusd'informations, consultez Présentation (p. 5).
14 août 2014
Mise à jour de ladocumentation
Révision des procédures, captures d'écran et organisationde la rubrique sur l'utilisation de clusters dans l'AmazonRedshift console. Pour plus d'informations, consultezGestion des clusters à l'aide de la console (p. 16).
11 juillet 2014
Nouveau contenu Ajout d'un nouveau didacticiel sur le redimensionnementdes clusters Amazon Redshift, notamment sur la manièrede redimensionner un cluster tout en réduisant ladurée pendant laquelle le cluster est en mode lectureseule. Pour plus d'informations, consultez Didacticiel :Redimensionnement des clusters dans AmazonRedshift (p. 320).
27 juin 2014
Nouvelle fonction Ajout de la possibilité de renommer les clusters. Pour plusd'informations, consultez Renommer les clusters (p. 13) etModification d'un cluster (p. 24).
2 juin 2014
Mise à jour de ladocumentation
Mise à jour de l'exemple de code .NET pour utiliser lefournisseur de données ODBC lors de la connexion à uncluster par programmation à l'aide de .NET. Pour plusd'informations, consultez Connexion à un Cluster à l'aidede .NET (p. 252).
15 mai 2014
Nouvelle fonction Ajout d'options permettant de sélectionner un groupe deparamètres et un groupe de sécurité différents lorsquevous restaurez un cluster à partir d'un instantané. Pourplus d'informations, consultez Restauration d'un cluster àpartir d'un instantané (p. 96).
12 mai 2014
Version de l'API 2012-12-01349
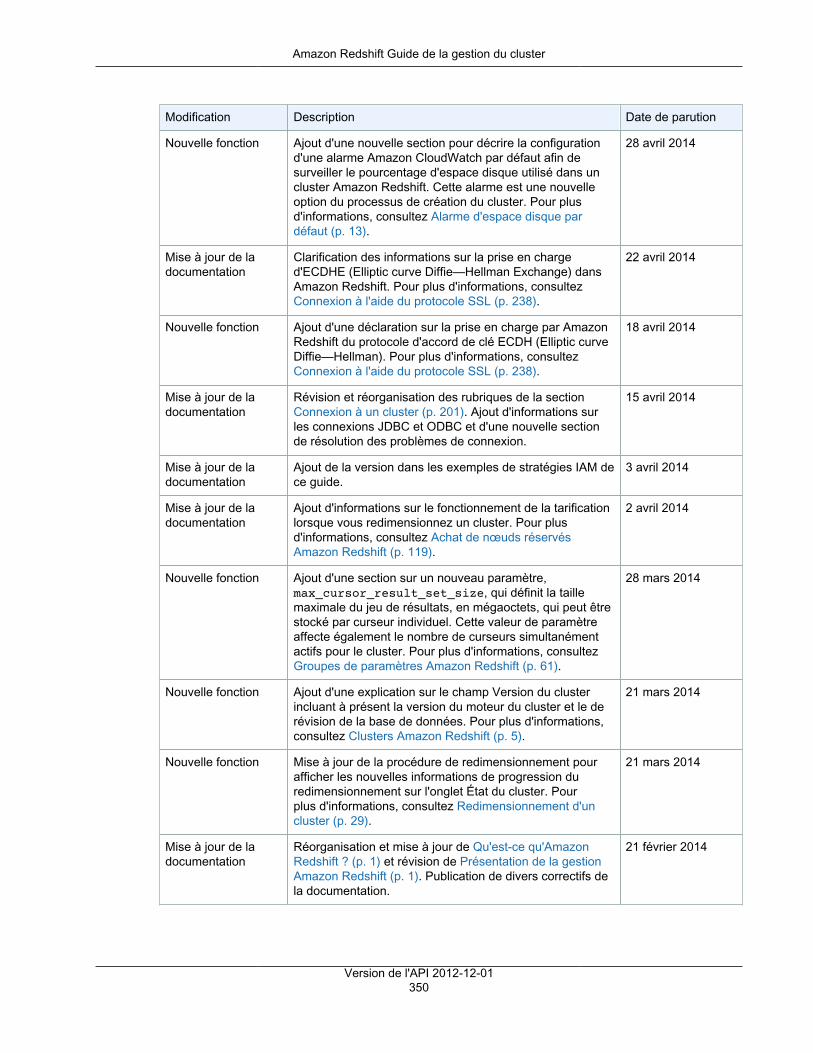
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Nouvelle fonction Ajout d'une nouvelle section pour décrire la configurationd'une alarme Amazon CloudWatch par défaut afin desurveiller le pourcentage d'espace disque utilisé dans uncluster Amazon Redshift. Cette alarme est une nouvelleoption du processus de création du cluster. Pour plusd'informations, consultez Alarme d'espace disque pardéfaut (p. 13).
28 avril 2014
Mise à jour de ladocumentation
Clarification des informations sur la prise en charged'ECDHE (Elliptic curve Diffie—Hellman Exchange) dansAmazon Redshift. Pour plus d'informations, consultezConnexion à l'aide du protocole SSL (p. 238).
22 avril 2014
Nouvelle fonction Ajout d'une déclaration sur la prise en charge par AmazonRedshift du protocole d'accord de clé ECDH (Elliptic curveDiffie—Hellman). Pour plus d'informations, consultezConnexion à l'aide du protocole SSL (p. 238).
18 avril 2014
Mise à jour de ladocumentation
Révision et réorganisation des rubriques de la sectionConnexion à un cluster (p. 201). Ajout d'informations surles connexions JDBC et ODBC et d'une nouvelle sectionde résolution des problèmes de connexion.
15 avril 2014
Mise à jour de ladocumentation
Ajout de la version dans les exemples de stratégies IAM dece guide.
3 avril 2014
Mise à jour de ladocumentation
Ajout d'informations sur le fonctionnement de la tarificationlorsque vous redimensionnez un cluster. Pour plusd'informations, consultez Achat de nœuds réservésAmazon Redshift (p. 119).
2 avril 2014
Nouvelle fonction Ajout d'une section sur un nouveau paramètre,max_cursor_result_set_size, qui définit la taillemaximale du jeu de résultats, en mégaoctets, qui peut êtrestocké par curseur individuel. Cette valeur de paramètreaffecte également le nombre de curseurs simultanémentactifs pour le cluster. Pour plus d'informations, consultezGroupes de paramètres Amazon Redshift (p. 61).
28 mars 2014
Nouvelle fonction Ajout d'une explication sur le champ Version du clusterincluant à présent la version du moteur du cluster et le derévision de la base de données. Pour plus d'informations,consultez Clusters Amazon Redshift (p. 5).
21 mars 2014
Nouvelle fonction Mise à jour de la procédure de redimensionnement pourafficher les nouvelles informations de progression duredimensionnement sur l'onglet État du cluster. Pourplus d'informations, consultez Redimensionnement d'uncluster (p. 29).
21 mars 2014
Mise à jour de ladocumentation
Réorganisation et mise à jour de Qu'est-ce qu'AmazonRedshift ? (p. 1) et révision de Présentation de la gestionAmazon Redshift (p. 1). Publication de divers correctifs dela documentation.
21 février 2014
Version de l'API 2012-12-01350
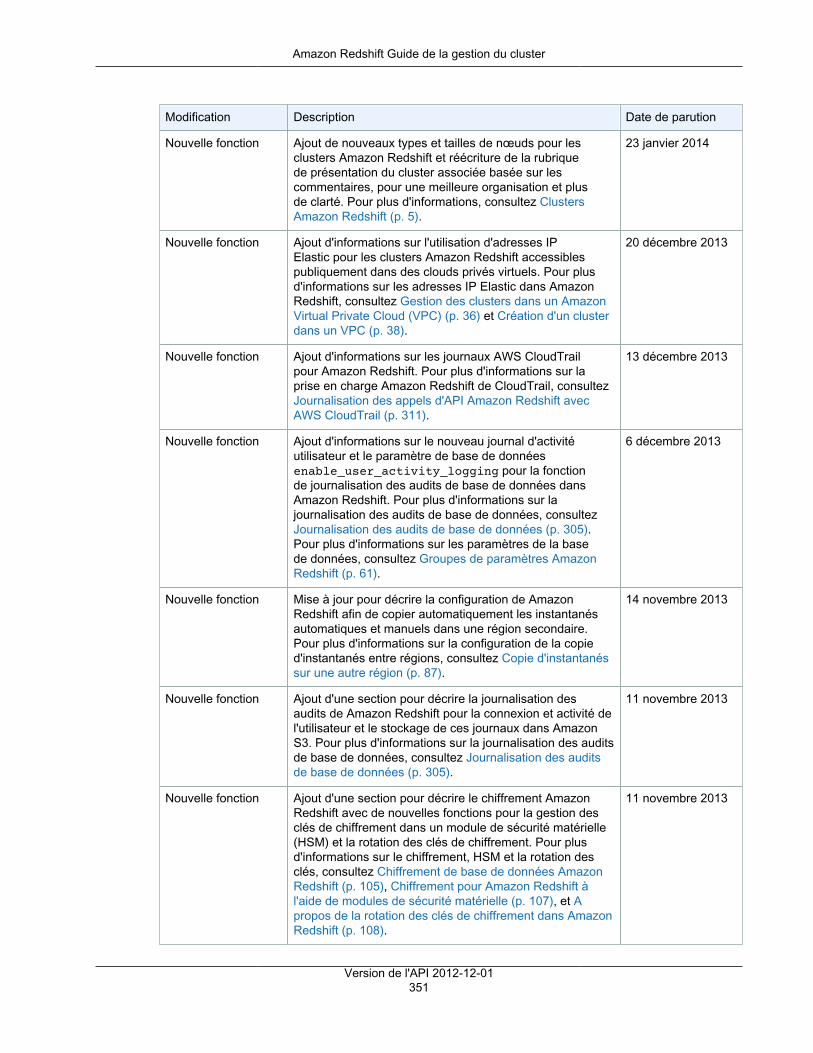
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Nouvelle fonction Ajout de nouveaux types et tailles de nœuds pour lesclusters Amazon Redshift et réécriture de la rubriquede présentation du cluster associée basée sur lescommentaires, pour une meilleure organisation et plusde clarté. Pour plus d'informations, consultez ClustersAmazon Redshift (p. 5).
23 janvier 2014
Nouvelle fonction Ajout d'informations sur l'utilisation d'adresses IPElastic pour les clusters Amazon Redshift accessiblespubliquement dans des clouds privés virtuels. Pour plusd'informations sur les adresses IP Elastic dans AmazonRedshift, consultez Gestion des clusters dans un AmazonVirtual Private Cloud (VPC) (p. 36) et Création d'un clusterdans un VPC (p. 38).
20 décembre 2013
Nouvelle fonction Ajout d'informations sur les journaux AWS CloudTrailpour Amazon Redshift. Pour plus d'informations sur laprise en charge Amazon Redshift de CloudTrail, consultezJournalisation des appels d'API Amazon Redshift avecAWS CloudTrail (p. 311).
13 décembre 2013
Nouvelle fonction Ajout d'informations sur le nouveau journal d'activitéutilisateur et le paramètre de base de donnéesenable_user_activity_logging pour la fonctionde journalisation des audits de base de données dansAmazon Redshift. Pour plus d'informations sur lajournalisation des audits de base de données, consultezJournalisation des audits de base de données (p. 305).Pour plus d'informations sur les paramètres de la basede données, consultez Groupes de paramètres AmazonRedshift (p. 61).
6 décembre 2013
Nouvelle fonction Mise à jour pour décrire la configuration de AmazonRedshift afin de copier automatiquement les instantanésautomatiques et manuels dans une région secondaire.Pour plus d'informations sur la configuration de la copied'instantanés entre régions, consultez Copie d'instantanéssur une autre région (p. 87).
14 novembre 2013
Nouvelle fonction Ajout d'une section pour décrire la journalisation desaudits de Amazon Redshift pour la connexion et activité del'utilisateur et le stockage de ces journaux dans AmazonS3. Pour plus d'informations sur la journalisation des auditsde base de données, consultez Journalisation des auditsde base de données (p. 305).
11 novembre 2013
Nouvelle fonction Ajout d'une section pour décrire le chiffrement AmazonRedshift avec de nouvelles fonctions pour la gestion desclés de chiffrement dans un module de sécurité matérielle(HSM) et la rotation des clés de chiffrement. Pour plusd'informations sur le chiffrement, HSM et la rotation desclés, consultez Chiffrement de base de données AmazonRedshift (p. 105), Chiffrement pour Amazon Redshift àl'aide de modules de sécurité matérielle (p. 107), et Apropos de la rotation des clés de chiffrement dans AmazonRedshift (p. 108).
11 novembre 2013
Version de l'API 2012-12-01351
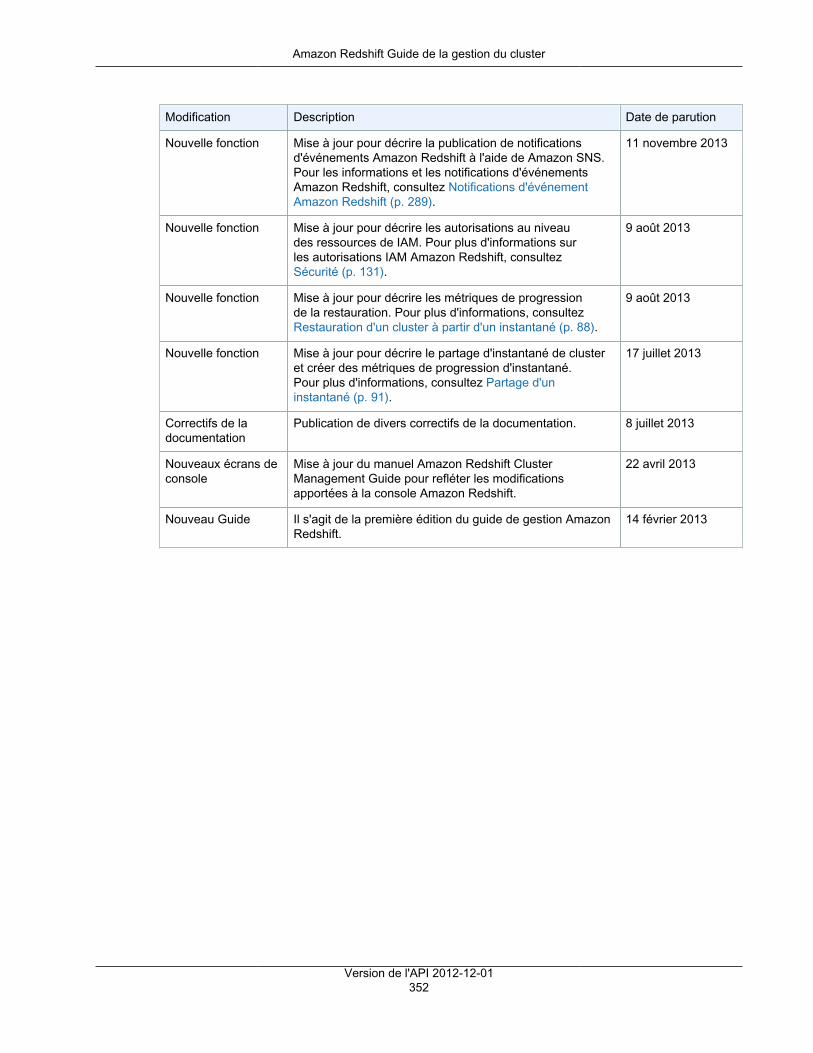
Amazon Redshift Guide de la gestion du cluster
Modification Description Date de parution
Nouvelle fonction Mise à jour pour décrire la publication de notificationsd'événements Amazon Redshift à l'aide de Amazon SNS.Pour les informations et les notifications d'événementsAmazon Redshift, consultez Notifications d'événementAmazon Redshift (p. 289).
11 novembre 2013
Nouvelle fonction Mise à jour pour décrire les autorisations au niveaudes ressources de IAM. Pour plus d'informations surles autorisations IAM Amazon Redshift, consultezSécurité (p. 131).
9 août 2013
Nouvelle fonction Mise à jour pour décrire les métriques de progressionde la restauration. Pour plus d'informations, consultezRestauration d'un cluster à partir d'un instantané (p. 88).
9 août 2013
Nouvelle fonction Mise à jour pour décrire le partage d'instantané de clusteret créer des métriques de progression d'instantané.Pour plus d'informations, consultez Partage d'uninstantané (p. 91).
17 juillet 2013
Correctifs de ladocumentation
Publication de divers correctifs de la documentation. 8 juillet 2013
Nouveaux écrans deconsole
Mise à jour du manuel Amazon Redshift ClusterManagement Guide pour refléter les modificationsapportées à la console Amazon Redshift.
22 avril 2013
Nouveau Guide Il s'agit de la première édition du guide de gestion AmazonRedshift.
14 février 2013
Version de l'API 2012-12-01352





























