Embed Size (px)
Citation preview

Amazon GlacierGuia do desenvolvedor doVersão da API 2012-06-01

Amazon Glacier Guia do desenvolvedor do
Amazon Glacier: Guia do desenvolvedor doCopyright © 2018 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any mannerthat is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks notowned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored byAmazon.

Amazon Glacier Guia do desenvolvedor do
Table of ContentsO que é Amazon Glacier? ................................................................................................................... 1
Você é usuário iniciante do Amazon Glacier? ................................................................................. 1Modelo de dados ........................................................................................................................ 2
Cofre ................................................................................................................................ 2Arquivo ............................................................................................................................. 3Trabalho ............................................................................................................................ 3Configuração de notificação ................................................................................................. 4
Operações compatíveis ............................................................................................................... 5Operações de cofre ............................................................................................................ 5Operações de arquivo ......................................................................................................... 5Trabalhos .......................................................................................................................... 5
Acessar o Amazon Glacier ........................................................................................................... 5Regiões e endpoints ........................................................................................................... 6
Conceitos básicos ............................................................................................................................... 7Etapa 1: Antes de começar .......................................................................................................... 7
Configurar uma conta da AWS ............................................................................................. 8Fazer download do AWS SDK apropriado ............................................................................ 10
Etapa 2: criar um cofre .............................................................................................................. 11Etapa 3: fazer upload de um arquivo para um cofre ....................................................................... 12
Fazer upload de um arquivo usando o Java ......................................................................... 13Fazer upload de um arquivo usando o .NET ......................................................................... 14
Etapa 4: fazer download de um arquivo de um cofre ...................................................................... 15Fazer download de um arquivo usando-se o Java ................................................................. 16Fazer download de um arquivo usando o .NET ..................................................................... 17
Etapa 5: excluir um arquivo de um cofre ...................................................................................... 18Seções relacionadas ......................................................................................................... 19Excluir um arquivo usando Java ......................................................................................... 19Excluir um arquivo usando o .NET ...................................................................................... 20
Etapa 6: excluir um cofre ........................................................................................................... 21Para onde ir agora? .................................................................................................................. 21
Trabalhar com cofres ........................................................................................................................ 23Operações de cofre no Amazon Glacier ....................................................................................... 23
Criar e excluir cofres ......................................................................................................... 23Recuperar metadados do cofre ........................................................................................... 24Fazer download de um inventário de cofre ........................................................................... 24Configurar notificações de cofre .......................................................................................... 24
Criar um cofre .......................................................................................................................... 25Criar um cofre usando o Java ............................................................................................ 25Criar um cofre usando o .NET ............................................................................................ 27Criar um cofre usando REST .............................................................................................. 31Criar um cofre usando o console ........................................................................................ 31
Recuperar metadados do cofre ................................................................................................... 31Recuperar metadados de cofre usando Java ........................................................................ 31Recuperar metadados de cofre usando o .NET ..................................................................... 33Recuperar metadados do cofre usando REST ....................................................................... 35
Fazer download de um inventário de cofre ................................................................................... 35Sobre o inventário ............................................................................................................. 36Fazer download de um inventário de cofre usando o Java ...................................................... 37Fazer download de um inventário de cofre usando o .NET ...................................................... 42Fazer download de um inventário de cofre usando REST ....................................................... 47
Configurar notificações de cofre .................................................................................................. 47Conceitos gerais ............................................................................................................... 47Configurar notificações de cofre usando-se o Java ................................................................. 48Configurar notificações de cofre usando o .NET .................................................................... 50
Versão da API 2012-06-01iii

Amazon Glacier Guia do desenvolvedor do
Configurar notificações de cofre usando a API REST ............................................................. 52Configurar notificações de cofre usando o console ................................................................. 53
Excluir um cofre ....................................................................................................................... 55Excluir um cofre usando o Java .......................................................................................... 55Excluir um cofre usando o .NET .......................................................................................... 56Excluir um cofre usando REST ........................................................................................... 57Excluir um cofre usando o console ...................................................................................... 58
Marcar cofres ........................................................................................................................... 58Marcar cofres usando o console do Amazon Glacier .............................................................. 58Marcar cofres usando a Amazon Glacier API ........................................................................ 59Seções relacionadas ......................................................................................................... 59
Vault Lock ............................................................................................................................... 59Visão geral do bloqueio de cofre ......................................................................................... 59Bloquear um cofre usando a API ........................................................................................ 60
Trabalhar com arquivos ..................................................................................................................... 62Operações de arquivo ............................................................................................................... 62
Fazer upload de um arquivo ............................................................................................... 62Fazer download de um arquivo ........................................................................................... 63Excluir um arquivo ............................................................................................................ 63Atualizar um arquivo ......................................................................................................... 63
Manter metadados de arquivo no lado do cliente ........................................................................... 63Fazer upload de um arquivo ....................................................................................................... 63
Opções de upload de um arquivo ........................................................................................ 64Fazer upload de um arquivo em uma única operação ............................................................. 65Fazer upload de arquivos grandes em partes ........................................................................ 70
Fazer download de um arquivo ................................................................................................... 79Recuperar arquivos ........................................................................................................... 79Fazer download de um arquivo usando o Java ...................................................................... 83Fazer download de um arquivo usando o .NET ..................................................................... 94Fazer download de um arquivo usando REST ..................................................................... 105
Excluir um arquivo .................................................................................................................. 105Excluir um arquivo usando Java ........................................................................................ 106Excluir um arquivo usando o .NET ..................................................................................... 107Excluir um arquivo usando REST ...................................................................................... 110
Consulta de um arquivo ........................................................................................................... 110Uso dos AWS SDKs ........................................................................................................................ 111
SDKs da AWS compatíveis com o Amazon Glacier ...................................................................... 111Bibliotecas de SDKs da AWS para Java e .NET .......................................................................... 111
O que é API de nível inferior? .......................................................................................... 112O que é API de nível superior? ......................................................................................... 112Quando usar as APIs de nível superior e de nível inferior ...................................................... 112
Usar o AWS SDK for Java ....................................................................................................... 112Usar a API de nível inferior .............................................................................................. 113Usar a API de nível superior ............................................................................................. 113Execução de exemplos de Java usando o Eclipse ............................................................... 114Definição do endpoint ...................................................................................................... 114
Usar o AWS SDK para .NET .................................................................................................... 115Usar a API de nível inferior .............................................................................................. 115Usar a API de nível superior ............................................................................................. 116Executar exemplos do .NET .............................................................................................. 116Definição do endpoint ...................................................................................................... 117
Autenticação e controle de acesso .................................................................................................... 118Autenticação ........................................................................................................................... 118Controle de acesso ................................................................................................................. 119Visão geral do gerenciamento de acesso .................................................................................... 119
Recursos e operações do Amazon Glacier .......................................................................... 120Entender a propriedade de recursos .................................................................................. 120
Versão da API 2012-06-01iv

Amazon Glacier Guia do desenvolvedor do
Gerenciar o acesso aos recursos ...................................................................................... 120Especificação de elementos da política: ações, efeitos, recursos e principais ............................ 123Especificação de condições em uma política ....................................................................... 124
Como usar políticas com base em identidade (políticas do IAM) ..................................................... 124Permissões obrigatórias para usar o console do Amazon Glacier ............................................ 125Políticas gerenciadas da AWS (políticas predefinidas) para o Amazon Glacier ........................... 126Exemplos de política gerenciada pelo cliente ....................................................................... 126
Usar políticas baseadas em recurso (políticas de cofre) ................................................................ 128Políticas de acesso ao cofre ............................................................................................. 129Política de bloqueio de cofre ............................................................................................. 131
Referência de permissões da API do Amazon Glacier .................................................................. 133Consulta em arquivos com o Amazon Glacier Select ............................................................................ 139
Requisitos e limites do Amazon Glacier Select ............................................................................ 139Como consultar dados usando o Amazon Glacier Select? ............................................................. 140
Saída do Amazon Glacier Select ...................................................................................... 140Como tratar erros .................................................................................................................... 141Mais informações .................................................................................................................... 141
Políticas de recuperação dos dados ................................................................................................... 142Escolher uma política de recuperação de dados do Amazon Glacier ............................................... 142
Política Free Tier Only ..................................................................................................... 143Política Max Retrieval Rate ............................................................................................... 143Política No Retrieval Limit ................................................................................................ 143
Usar o console do Amazon Glacier para configurar uma política de recuperação de dados .................. 143Usar a API do Amazon Glacier para configurar uma política de recuperação de dados ....................... 144
Usar a API REST do Amazon Glacier para configurar uma política de recuperação de dados ....... 144Usar os SDKs da AWS para configurar uma política de recuperação de dados .......................... 145
Marcação de recursos ..................................................................................................................... 146Conceitos básicos da marcação ................................................................................................ 146Restrições de tag .................................................................................................................... 146Monitoramento de custos com marcação .................................................................................... 147Gerenciar controle de acesso com marcação .............................................................................. 147Seções relacionadas ................................................................................................................ 147
Registro em log de auditoria com o AWS CloudTrail ............................................................................ 148Informações do Amazon Glacier no CloudTrail ............................................................................ 148Compreender entradas de arquivo de log do Amazon Glacier ........................................................ 149
API Reference ................................................................................................................................ 152Cabeçalhos de solicitação comuns ............................................................................................ 152Cabeçalhos de resposta comuns ............................................................................................... 155Solicitações de assinatura ........................................................................................................ 155
Cálculo de assinatura de exemplo ..................................................................................... 156Calcular assinaturas para as operações de streaming ........................................................... 157
Computar somas de verificação ................................................................................................ 159Exemplo do hash de árvore 1: fazer upload de um arquivo em uma única solicitação .................. 160Exemplo do hash de árvore 2: fazer upload de um arquivo usando um multipart upload .............. 160Computar o hash de árvore de um arquivo ......................................................................... 161Receber somas de verificação durante o download de dados ................................................. 167
Respostas de erro ................................................................................................................... 169Exemplo 1: descrever solicitação de trabalho com um ID de trabalho não existente .................... 171Exemplo 2: solicitação List Jobs com um valor inválido para o parâmetro da solicitação .............. 172
Operações de cofre ................................................................................................................. 172Abort Vault Lock ............................................................................................................. 173Add Tags To Vault .......................................................................................................... 175Create Vault ................................................................................................................... 177Complete Vault Lock ....................................................................................................... 179Delete Vault ................................................................................................................... 181Política de acesso de exclusão do cofre ............................................................................. 183Delete Vault Notifications .................................................................................................. 185
Versão da API 2012-06-01v

Amazon Glacier Guia do desenvolvedor do
Describe Vault ................................................................................................................ 187Get Vault Access Policy ................................................................................................... 190Get Vault Lock ................................................................................................................ 192Get Vault Notifications ..................................................................................................... 195Initiate Vault Lock ........................................................................................................... 198Listar tags para cofre ....................................................................................................... 201List Vaults ...................................................................................................................... 203Remove Tags From Vault ................................................................................................. 208Set Vault Access Policy ................................................................................................... 210Definir configuração de notificação de cofre ........................................................................ 212
Operações de arquivo .............................................................................................................. 215Delete Archive ................................................................................................................ 215Upload Archive ............................................................................................................... 217
Operações de multipart upload .................................................................................................. 220Anular multipart upload .................................................................................................... 221Concluir multipart upload .................................................................................................. 223Iniciar o multipart upload .................................................................................................. 226Listar partes ................................................................................................................... 230Listar multipart uploads .................................................................................................... 234Upload de parte .............................................................................................................. 239
Operações de trabalho ............................................................................................................. 243Trabalho de descrição ..................................................................................................... 243Get Job Output ............................................................................................................... 251Initiate Job ..................................................................................................................... 257List Jobs ........................................................................................................................ 267
Tipos de dados usados em operações de trabalho ....................................................................... 274CSVInput ....................................................................................................................... 274CSVOutput ..................................................................................................................... 276Criptografia ..................................................................................................................... 276GlacierJobDescription ...................................................................................................... 277Grant ............................................................................................................................. 280Grantee ......................................................................................................................... 280InputSerialization ............................................................................................................. 281InventoryRetrievalJobInput ................................................................................................ 281jobParameters ................................................................................................................ 283OutputLocation ................................................................................................................ 285OutputSerialization .......................................................................................................... 285S3Location ..................................................................................................................... 285SelectParameters ............................................................................................................ 287
Operações de recuperação de dados ......................................................................................... 287Política de recuperação para obter dados ........................................................................... 288List Provision Capacity ..................................................................................................... 290Purchase Provisioned Capacity ......................................................................................... 293Set Data Retrieval Policy .................................................................................................. 295
SQL Reference ............................................................................................................................... 299Comando SELECT .................................................................................................................. 299
Lista SELECT ................................................................................................................. 299Cláusula FROM .............................................................................................................. 299Cláusula WHERE ............................................................................................................ 300Cláusula LIMIT (apenas Amazon S3 Select) ........................................................................ 300Acesso de atributo .......................................................................................................... 300Diferenciação de letras maiúsculas e minúsculas de cabeçalho/nomes de atributo ..................... 301Usar palavras-chave reservadas como termos definidos pelo usuário ...................................... 302Expressões escalares ...................................................................................................... 302
Tipos de dados ....................................................................................................................... 303Conversões de tipo de dados ........................................................................................... 303Tipos de dados compatíveis ............................................................................................. 303
Versão da API 2012-06-01vi

Amazon Glacier Guia do desenvolvedor do
Operadores ............................................................................................................................ 304Operadores lógicos ......................................................................................................... 304Operadores de comparação .............................................................................................. 304Operadores de correspondência de padrões ....................................................................... 304Operadores matemáticos .................................................................................................. 304Precedência do operador ................................................................................................. 304
Palavras-chave reservadas ....................................................................................................... 305Funções SQL ......................................................................................................................... 309
Funções agregadas (apenas Amazon S3 Select) ................................................................. 309Funções condicionais ....................................................................................................... 310Funções da conversão ..................................................................................................... 311Funções de data ............................................................................................................. 312Funções de string ........................................................................................................... 318
Histórico do documento .................................................................................................................... 321Atualizações anteriores ............................................................................................................ 321
AWS Glossary ................................................................................................................................ 324
Versão da API 2012-06-01vii

Amazon Glacier Guia do desenvolvedor doVocê é usuário iniciante do Amazon Glacier?
O que é Amazon Glacier?Bem-vindo ao Guia do desenvolvedor do Amazon Glacier. Amazon Glacier é um serviço dearmazenamento otimizado para dados pouco usados, ou "dados frios".
O Amazon Glacier é um serviço de armazenamento de custo extremamente baixo que oferecearmazenamento com recursos de segurança para arquivamento de dados e backup. Com o AmazonGlacier, os clientes podem armazenar os dados de maneira econômica por meses, anos ou até décadas.O Amazon Glacier permite que os clientes transfiram as cargas administrativas de operar e escalararmazenamento para a AWS, de maneira que não precisem se preocupar com planejamento decapacidade, provisionamento de hardware, replicação de dados, detecção e recuperação de falhas dehardware ou migrações de hardware demoradas. Para obter mais destaques do serviço e informações dadefinição de preço, vá até a página de detalhes de produto do Amazon Glacier.
Tópicos• Você é usuário iniciante do Amazon Glacier? (p. 1)• Modelo de dados do Amazon Glacier (p. 2)• Operações compatíveis no Amazon Glacier (p. 5)• Acessar o Amazon Glacier (p. 5)
Você é usuário iniciante do Amazon Glacier?Se você for um usuário iniciante do Amazon Glacier, recomendaremos começar lendo as seguintesseções:
• O que é Amazon Glacier—O restante desta seção descreve o modelo de dados subjacente, asoperações compatíveis e os SDKs da AWS que você pode usar para interagir com o serviço.
• Conceitos básicos—A seção Conceitos básicos com Amazon Glacier (p. 7) orienta você em meio aoprocesso de criar um cofre, fazer upload de arquivos, criar trabalhos para fazer download de arquivos,recuperar a saída do trabalho e a excluir arquivos.
Important
O Amazon Glacier oferece um console, que você pode usar para criar e excluir cofres. Noentanto, todas as outras interações com o Amazon Glacier exigem que você use a AWSCommand Line Interface (AWS CLI) ou escreva código. Por exemplo, para fazer upload dedados, como fotos, vídeos e outros documentos, você deve usar a AWS CLI ou escrever códigopara fazer solicitações usando a API REST diretamente ou usando os SDKs da AWS. Paraobter mais informações sobre como usar o Amazon Glacier com a AWS CLI, vá até Referênciada AWS CLI do Amazon Glacier. Para instalar a AWS CLI, vá para a AWS Command LineInterface.
Além da seção de conceitos básicos, você provavelmente desejará saber mais sobre as operações doAmazon Glacier. As seguintes seções oferecem informações detalhadas sobre como trabalhar com oAmazon Glacier usando a API REST e os Software Development Kits (SDKs – Kits de desenvolvimento desoftware) da AWS para Java e Microsoft .NET:
• Usar os SDKs da AWS com o Amazon Glacier (p. 111)
Esta seção apresenta uma visão geral dos SDKs da AWS usados em diversos exemplos de códigoneste guia. Uma revisão desta seção ajudará durante a leitura das seções a seguir. Isso inclui umavisão geral das APIs de níveis superior e inferior que esses SDKs oferecem, quando usá-las e as etapascomuns para executar os exemplos de código fornecidos neste guia.
Versão da API 2012-06-011

Amazon Glacier Guia do desenvolvedor doModelo de dados
• Trabalhar com cofres no Amazon Glacier (p. 23)
Esta seção apresenta detalhes de diversas operações de cofre, como criar um cofre, recuperarmetadados, usar trabalhos para recuperar o inventário de cofre e configurar notificações de cofre. Alémde usar o console do Amazon Glacier, você pode usar os AWS SDKs em diversas operações de cofre.Esta seção descreve a API e apresenta exemplos de como trabalhar usando o AWS SDK for Java eo .NET.
• Trabalhar com arquivos no Amazon Glacier (p. 62)
Esta seção apresenta detalhes das operações de arquivo, como fazer upload de um arquivo em umaúnica solicitação ou usar uma operação multipart upload para fazer upload de arquivos grandes empartes. A seção também explica como criar trabalhos para fazer download de arquivos de maneiraassíncrona. Esta seção apresenta exemplos de como usar o AWS SDK for Java e o .NET.
• Referência de API do Amazon Glacier (p. 152)
Amazon Glacier é um serviço RESTful. Esta seção descreve as operações REST, inclusive a sintaxe, eas solicitações de exemplo, além de respostas para todas as operações. Observe que as bibliotecas doAWS SDK encapsulam essa API, simplificando as tarefas de programação.
O Amazon Simple Storage Service (Amazon S3) dá suporte à configuração do ciclo de vida em umbucket do S3, o que permite a você transitar objetos para a classe de armazenamento GLACIER doAmazon S3 para arquivamento. Quando você faz a transição de objetos do Amazon S3 para a classe dearmazenamento do GLACIER, o Amazon S3 usa o Amazon Glacier internamente para a durabilidade doarmazenamento por um custo menor. Embora os objetos sejam armazenados no Amazon Glacier, elescontinuam sendo objetos do Amazon S3 que você gerencia no Amazon S3, e não é possível acessá-losdiretamente por meio do Amazon Glacier.
Para obter mais informações sobre a configuração do ciclo de vida do Amazon S3 e como fazer a transiçãode objetos para a classe de armazenamento GLACIER, acesse Gerenciamento do ciclo de vida de objetose Transição de objetos no Guia do desenvolvedor do Amazon Simple Storage Service.
Modelo de dados do Amazon GlacierEntre os conceitos básicos do modelo de dados do Amazon Glacier estão cofres e arquivos. AmazonGlacier é um web service baseado em REST. Em termos de REST, cofres e arquivos são os recursos.Além disso, o modelo de dados do Amazon Glacier inclui recursos de configuração da notificação. Essesrecursos complementam os recursos básicos.
Tópicos• Cofre (p. 2)• Arquivo (p. 3)• Trabalho (p. 3)• Configuração de notificação (p. 4)
CofreNo Amazon Glacier, cofre é um contêiner para armazenar arquivos. Ao criar um cofre, você especifica umnome e escolhe uma região da AWS em que deseja criar o cofre.
Cada recurso do cofre tem um endereço exclusivo. A forma geral é:
https://<region-specific endpoint>/<account-id>/vaults/<vaultname>
Versão da API 2012-06-012

Amazon Glacier Guia do desenvolvedor doArquivo
Por exemplo, suponhamos que você crie um cofre (examplevault) no Região Oeste dos EUA (Oregon).Em seguida, esse cofre pode ser endereçado pelo seguinte URI:
https://glacier.us-west-2.amazonaws.com/111122223333/vaults/examplevault
No URI,
• glacier.us-west-2.amazonaws.com identifica o Região Oeste dos EUA (Oregon).• 111122223333 é o ID da conta da AWS que detém o cofre.• vaults se refere ao conjunto de cofres de propriedade da conta da AWS.• examplevault identifica um cofre específico no conjunto de cofres.
Uma conta da AWS pode criar cofres em qualquer região da AWS compatível. Para obter uma lista dasregiões da AWS compatíveis, consulte Acessar o Amazon Glacier (p. 5). Em uma região, uma contadeve usar nomes de cofre exclusivos. Uma conta da AWS pode criar cofres de mesmo nome em regiõesdiferentes.
Você pode armazenar um número ilimitado de arquivos em um cofre. Dependendo das necessidades denegócios ou do aplicativo, você pode armazenar esses arquivos em um cofre ou em vários cofres.
O Amazon Glacier dá suporte a diversas operações de cofre. As operações de cofre são específicas daregião. Por exemplo, ao criar um cofre, você faz isso em uma região específica. Ao solicitar uma lista decofres, você a solicita em uma região da AWS específica, e a lista resultante inclui somente os cofrescriados nessa região.
ArquivoUm arquivo pode conter dados, como uma foto, um vídeo ou um documento, e é uma unidade básica dearmazenamento no Amazon Glacier. Cada arquivo tem uma ID exclusiva e uma descrição opcional. Vocêpode especificar somente a descrição opcional durante o upload de um arquivo. O Amazon Glacier atribuiao arquivo um ID, que é exclusivo na região da AWS na qual está armazenado.
Cada arquivo tem um endereço exclusivo. O formato geral é o seguinte:
https://<region-specific endpoint>/<account-id>/vaults/<vault-name>/archives/<archive-id>
Este é um URI de exemplo de um arquivo armazenado no cofre examplevault no Região Oeste dosEUA (Oregon):
https://glacier.us-west-2.amazonaws.com/111122223333/vaults/examplevault/archives/NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId
Você pode armazenar um número ilimitado de arquivos em um cofre.
Além disso, o modelo de dados do Amazon Glacier inclui recursos de configuração da notificação. Essesrecursos complementam os recursos de cofre e arquivo básicos.
TrabalhoOs trabalhos do Amazon Glacier podem executar uma consulta select em um arquivo, recuperar umarquivo ou obter um inventário de um cofre. Ao executar uma consulta em um arquivo, você inicia umtrabalho fornecendo uma consulta SQL e a lista de objetos de arquivo do Amazon Glacier O AmazonGlacier Select executa a consulta em vigor e grava os resultados de saída no Amazon S3.
Versão da API 2012-06-013

Amazon Glacier Guia do desenvolvedor doConfiguração de notificação
Recuperar um arquivo e um inventário de cofre (lista de arquivos) são operações assíncronas no AmazonGlacier nas quais você deve primeiro iniciar um trabalho e fazer download da saída do trabalho depois queo Amazon Glacier concluir o trabalho.
Note
O Amazon Glacier oferece uma solução de arquivamento de dados de armazenamento a frio.Se o aplicativo precisar de uma solução de armazenamento que exija recuperação de dados emtempo real, você poderá considerar o uso do Amazon S3. Para obter mais informações, consulteAmazon Simple Storage Service (Amazon S3).
Para iniciar um trabalho de inventário de cofre, você fornece um nome de cofre. Os trabalhos de seleçãoe de recuperação de arquivo exigem o nome do cofre e o ID do arquivo. Você também pode fornecer umadescrição de trabalho opcional para ajudar a identificar os trabalhos.
Os trabalhos de seleção, de recuperação de arquivo e de inventário de cofre são associados a umcofre. Um cofre pode ter vários trabalhos em andamento a qualquer momento. Quando você envia umasolicitação de trabalho de recuperação (iniciar um trabalho), o Amazon Glacier retorna um ID do trabalhopara rastreá-lo. Cada trabalho é identificado com exclusividade por um URI da forma:
https://<region-specific endpoint>/<account-id>/vaults/<vault-name>/jobs/<job-id>
Este é um exemplo de um trabalho associado a um cofre examplevault.
https://glacier.us-west-2.amazonaws.com/111122223333/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID
Para cada trabalho, o Amazon Glacier mantém informações como tipo de trabalho, descrição, datade criação, data de conclusão e status do trabalho. Você pode obter informações sobre um trabalhoespecífico ou uma lista de todos os trabalhos associados a um cofre. A lista de trabalhos retornados peloAmazon Glacier inclui todos os trabalhos em andamento e concluídos recentemente.
Configuração de notificaçãoComo os trabalhos demoram para serem concluídos, o Amazon Glacier dá suporte a um mecanismode notificação para notificá-lo quando um trabalho for concluído. Você pode configurar um cofre paraenviar uma notificação para um tópico do Amazon Simple Notification Service (Amazon SNS) quandoesses trabalhos forem concluídos. Você pode especificar um tópico do SNS por cofre na configuração denotificação.
O Amazon Glacier armazena a configuração de notificação como um documento JSON. Este é umexemplo de configuração de notificação de cofre:
{ "Topic": "arn:aws:sns:us-west-2:111122223333:mytopic", "Events": ["ArchiveRetrievalCompleted", "InventoryRetrievalCompleted"] }
As configurações de notificação são associadas a cofres; você pode ter uma para cada cofre. Cadarecurso de configuração de notificação é identificado com exclusividade por um URI da forma:
https://<region-specific endpoint>/<account-id>/vaults/<vault-name>/notification-configuration
O Amazon Glacier dá suporte a operações para definir, obter e excluir uma configuração de notificação.Quando você exclui uma configuração de notificação, nenhuma notificação é enviada quando qualqueroperação de recuperação de dados no cofre é concluída.
Versão da API 2012-06-014

Amazon Glacier Guia do desenvolvedor doOperações compatíveis
Operações compatíveis no Amazon GlacierPara trabalhar com cofres e arquivos (consulte Modelo de dados do Amazon Glacier (p. 2)), o AmazonGlacier dá suporte a um conjunto de operações. Dentre todas as operações compatíveis, somente asseguintes operações são assíncronas:
• Recuperar um arquivo• Recuperar um inventário de cofre (lista de arquivos)
Essas operações exigem que você inicie primeiro um trabalho e, em seguida, faça download da saída dotrabalho. As seguintes seções resumem as operações do Amazon Glacier:
Operações de cofreO Amazon Glacier oferece operações para criar e excluir cofres. Você pode obter uma descrição do cofreespecífico ou de todos os cofres em uma região. A descrição do cofre fornece informações, como data decriação, número de arquivos no cofre, tamanho total em bytes usado por todos os arquivos no cofre e adata em que o Amazon Glacier gerou o inventário de cofre. O Amazon Glacier também oferece operaçõespara definir, recuperar e excluir uma configuração de notificação no cofre. Para obter mais informações,consulte Trabalhar com cofres no Amazon Glacier (p. 23).
Operações de arquivoO Amazon Glacier oferece operações para fazer upload e excluir arquivos. Você não pode atualizar umarquivo existente; você deve excluir o arquivo existente e fazer upload de um novo arquivo. Sempreque você faz upload de um arquivo, o Amazon Glacier gera um novo ID de arquivo. Para obter maisinformações, consulte Trabalhar com arquivos no Amazon Glacier (p. 62).
TrabalhosVocê pode iniciar um trabalho do Amazon Glacier para executar uma consulta select em um arquivo,recuperar um arquivo ou obter um inventário de um cofre.
Estes são os tipos de trabalhos do Amazon Glacier:
• select— Executa uma consulta select em um arquivo.
Para obter mais informações, consulte Consulta em arquivos com o Amazon Glacier Select (p. 139).• archive-retrieval— Recupera um arquivo.
Para obter mais informações, consulte Fazer download de um arquivo no Amazon Glacier (p. 79).• inventory-retrieval— Cria um inventário de um cofre.
Para obter mais informações, consulte Fazer download de um inventário de cofre no AmazonGlacier (p. 35).
Acessar o Amazon GlacierAmazon Glacier é um web service RESTful que usa HTTP e HTTPS como um transporte e JavaScriptObject Notation (JSON) como um formato de serialização de mensagem. O código de aplicativo pode fazersolicitações diretamente à API de web service do Amazon Glacier. Quando usar a API REST diretamente,
Versão da API 2012-06-015

Amazon Glacier Guia do desenvolvedor doRegiões e endpoints
você deverá gravar o código necessário para assinar e autenticar suas solicitações. Para obter maisinformações sobre o recurso API, consulte Referência de API do Amazon Glacier (p. 152).
Você também pode simplificar o desenvolvimento do aplicativo usando os SDKs da AWS que encapsulamas chamadas da API REST do Amazon Glacier. Você fornece suas credenciais, e essas bibliotecascuidarão da assinatura das solicitações e das autenticações. Para obter mais informações sobre comousar os SDKs da AWS, consulte Usar os SDKs da AWS com o Amazon Glacier (p. 111).
O Amazon Glacier também oferece um console. Você pode usar o console para criar e excluir cofres. Noentanto, todas as operações de arquivo e trabalho exigem que você escreva o código e faça solicitaçõesusando a API REST diretamente ou as bibliotecas wrapper do AWS SDK. Para acessar o console doAmazon Glacier, vá até Console do Amazon Glacier.
Regiões e endpointsCrie um cofre em uma região da AWS específica. Você sempre envia as solicitações do Amazon Glacierpara o endpoint de uma região específica. Para obter uma lista de regiões da AWS compatíveis com oAmazon Glacier, vá até Regiões e endpoints na Referência geral da AWS.
Versão da API 2012-06-016

Amazon Glacier Guia do desenvolvedor doEtapa 1: Antes de começar
Conceitos básicos com AmazonGlacier
No Amazon Glacier, cofre é um contêiner para armazenar arquivos, e arquivo é qualquer objeto, comouma foto, um vídeo ou um documento que você armazena em um cofre. Arquivo é a unidade básica dearmazenamento no Amazon Glacier. Este exercício de conceitos básicos apresenta instruções para vocêexplorar as operações básicas do Amazon Glacier nos cofres e nos recursos de arquivo descritos na seçãoModelo de dados do Amazon Glacier (p. 2).
No exercício de conceitos básicos, você vai criar um cofre, fazer upload e download de um arquivo e,por fim, excluir o arquivo e o cofre. Você pode fazer todas essas operações de maneira programática.No entanto, o exercício de conceitos básicos usa o console de gerenciamento do Amazon Glacier paracriar e excluir um cofre. Para fazer upload e download de um arquivo, esta seção de conceitos básicosusa Software Development Kits (SDKs – Kits de desenvolvimento de software) da AWS para a API denível superior do Java e do .NET. A API de nível superior proporciona uma experiência de programaçãosimplificada ao trabalhar com o Amazon Glacier. Para obter mais informações sobre essas APIs, consulteUsar os SDKs da AWS com o Amazon Glacier (p. 111).
Important
O Amazon Glacier oferece um console de gerenciamento. Você pode usar o console para criare excluir cofres, conforme mostrado neste exercício de conceitos básicos. No entanto, todas asoutras interações com o Amazon Glacier exigem que você use a AWS Command Line Interface(CLI) ou escreva código. Por exemplo, para fazer upload de dados, como fotos, vídeos e outrosdocumentos, você deve usar a AWS CLI ou escrever código para fazer solicitações usando a APIREST diretamente ou usando os SDKs da AWS. Para obter mais informações sobre como usar oAmazon Glacier com a AWS CLI, vá até Referência da AWS CLI do Amazon Glacier. Para instalara AWS CLI, vá para a AWS Command Line Interface.
Este exercício de conceitos básicos oferece exemplos de código em Java e C # para você fazer uploade download de um arquivo. A última seção de conceitos básicos apresenta etapas nas quais você podesaber mais sobre a experiência de desenvolvedor com o Amazon Glacier.
Tópicos• Etapa 1: antes de começar com o Amazon Glacier (p. 7)• Etapa 2: criar um cofre no Amazon Glacier (p. 11)• Etapa 3: fazer upload de um arquivo para um cofre no Amazon Glacier (p. 12)• Etapa 4: fazer download de um arquivo de um cofre no Amazon Glacier (p. 15)• Etapa 5: excluir um arquivo de um cofre no Amazon Glacier (p. 18)• Etapa 6: excluir um cofre no Amazon Glacier (p. 21)• Para onde ir agora? (p. 21)
Etapa 1: antes de começar com o Amazon GlacierPara começar este exercício, você deve se cadastrar em uma conta da AWS (se ainda não tiver uma) efazer download de um dos SDKs da AWS. As seções a seguir dão instruções.
Tópicos• Configurar uma conta da AWS e um usuário administrador (p. 8)• Fazer download do AWS SDK apropriado (p. 10)
Versão da API 2012-06-017

Amazon Glacier Guia do desenvolvedor doConfigurar uma conta da AWS
Important
O Amazon Glacier oferece um console de gerenciamento que você pode usar para criar e excluircofres. No entanto, todas as outras interações com o Amazon Glacier exigem que você use aAWS Command Line Interface (CLI) ou escreva código. Por exemplo, para fazer upload de dados,como fotos, vídeos e outros documentos, você deve usar a AWS CLI ou escrever código parafazer solicitações usando a API REST diretamente ou usando os SDKs da AWS. Para obter maisinformações sobre como usar o Amazon Glacier com a AWS CLI, vá até Referência da AWS CLIdo Amazon Glacier. Para instalar a AWS CLI, vá para a AWS Command Line Interface.
Configurar uma conta da AWS e um usuárioadministradorSe você ainda não tiver feito isso, precisa cadastrar-se em uma conta da AWS e criar um usuárioadministrador na conta.
Para concluir a configuração, siga as instruções nos seguintes tópicos:
Configurar uma conta da AWS e criar um usuário administradorCadastre-se na AWSQuando você se cadastra na Amazon Web Services (AWS), sua conta da AWS é cadastradaautomaticamente em todos os serviços da AWS, inclusive o Amazon Glacier. Você será cobrado apenaspelos serviços que usar. Para mais informações sobre as taxas de uso do Amazon Glacier, consulte apágina do produto Amazon Glacier.
Se você já tem uma conta da AWS e criou um usuário do IAM para a conta, vá para a próxima tarefa. Sevocê ainda não possui uma conta da AWS, use o procedimento a seguir para criar uma.
Para criar uma conta da AWS
1. Abra o https://aws.amazon.com/ e escolha em Criar uma conta da AWS.Note
Isso pode estar indisponível no seu navegador se, anteriormente, você iniciou a sessãono Console de gerenciamento da AWS. Nesse caso, escolha Fazer login com uma contadiferente e, em seguida, Criar uma nova conta da AWS.
2. Siga as instruções online.
Parte do procedimento de cadastro envolve uma chamada telefônica e a digitação de um PIN usandoo teclado do telefone.
Observe o ID da conta da AWS, pois você precisará dele na próxima etapa.
Criar um usuário do IAMOs serviços na AWS, como o Amazon Glacier, exigem que você forneça credenciais ao acessá-los, paraque o serviço possa determinar se você tem permissões para acessar os recursos pertencentes a esseserviço. O console requer sua senha. Você pode criar chaves de acesso para a conta da AWS a fimde acessar a AWS CLI ou a API. No entanto, não recomendamos que você acesse a AWS usando ascredenciais da conta da AWS. Em vez disso, recomendamos que você use AWS Identity and AccessManagement (IAM). Crie um usuário do IAM, adicione o usuário a um grupo do IAM com permissõesadministrativas e, em seguida, conceda permissões administrativas ao usuário do IAM criado. Em seguida,você pode acessar a AWS usando um URL especial e as credenciais desse usuário do IAM.
Versão da API 2012-06-018

Amazon Glacier Guia do desenvolvedor doConfigurar uma conta da AWS
Se tiver se cadastrado na AWS, mas não tiver criado um usuário do IAM para si, você poderá criar umusando o console do IAM.
Os exemplos de conceitos básicos deste guia pressupõem que você tenha um usuário com privilégios deadministrador.
Para criar um usuário IAM para você mesmo e adicionar o usuário a um grupo de Administradores
1. Use seu endereço de e-mail e senha da conta da AWS para fazer login como Usuário raiz da conta daAWS no console do IAM em https://console.aws.amazon.com/iam/.
Note
Recomendamos que você siga as melhores práticas para utilizar o usuário do IAMAdministrador abaixo e armazene as credenciais do usuário raiz com segurança.Cadastre-se como usuário raiz para executar somente algumas tarefas de gerenciamento deserviços e contas.
2. No painel de navegação do console, escolha Users e Add user.3. Para User name, digite Administrator.4. Marque a caixa de seleção ao lado do acesso do Console de gerenciamento da AWS, selecione
Personalizar senha e digite nova senha de usuário na caixa de texto. Também é possível selecionarRequire password reset (Exigir redefinição de senha) para forçar o usuário a criar uma nova senha napróxima vez em que fizer login.
5. Escolha Próximo: Permissões.6. Na página Set permissions, escolha Add user to group.7. Escolha Criar grupo.8. Na caixa de diálogo Create group (Criar grupo), em Group name (Nome do grupo), digite
Administradores.9. Em Filter policies (Filtrar políticas), marque a caixa de seleção em AWS managed - job function
(Função de trabalho gerenciada pela AWS).10. Na lista de políticas, marque a caixa de seleção AdministratorAccess. A seguir escolha Criar grupo.11. Suporte a lista de grupos, selecione a caixa de seleção para seu novo grupo. Escolha Atualizar caso
necessário, para ver o grupo na lista.12. Escolha Próximo: Análise para ver uma lista de associações de grupos a serem adicionadas ao novo
usuário. Quando você estiver pronto para continuar, selecione Criar usuário.
Você pode usar esse mesmo processo para criar mais grupos e usuários, e conceder aos seus usuáriosacesso aos seus recursos de conta AWS. Para obter informações sobre como usar políticas para restringiras permissões de usuários a funcionalidades específicas da AWS, acesse Access Management e ExamplePolicies.
Para fazer login como o novo usuário do IAM
1. Saia do Console de gerenciamento da AWS.2. Use o seguinte formato de URL para fazer login no console:
https://aws_account_number.signin.aws.amazon.com/console/
O aws_account_number é o ID de sua conta da AWS sem hífen. Por exemplo, se o ID de sua contada AWS for 1234-5678-9012, o número de sua conta da AWS será 123456789012. Para obtermais informações sobre como localizar o número de sua conta, consulte ID da sua conta da AWS eseu alias no Guia do usuário do IAM.
3. Insira o nome e a senha de usuário do IAM que você acabou de criar. Quando você está conectado, abarra de navegação exibe your_user_name @ your_aws_account_id.
Versão da API 2012-06-019

Amazon Glacier Guia do desenvolvedor doFazer download do AWS SDK apropriado
Se não quiser que o URL da página de cadastro contenha o ID da sua conta da AWS, crie um alias daconta.
Para criar ou remover um alias de conta
1. Faça login no Console de gerenciamento da AWS e abra o console da IAM em https://console.aws.amazon.com/iam/.
2. No painel de navegação, escolha Dashboard.3. Encontre o link de login dos usuários do IAM.4. Para criar o alias, clique em Customize, insira o nome que você deseja usar como seu alias e, em
seguida, selecione Yes, Create.5. Para remover o alias, escolha Customize e, em seguida, escolha Yes, Delete. A URL de login será
revertida para o ID da sua conta da AWS.
Para fazer o login depois de criar o alias de uma conta, use o seguinte URL:
https://your_account_alias.signin.aws.amazon.com/console/
Para verificar o link de login para usuários do IAM de sua conta, abra o console do IAM e consulte IAMusers sign-in link: no painel.
Para obter mais informações sobre IAM, consulte o seguinte:
• AWS Identity and Access Management (IAM)• Conceitos básicos• Guia do usuário do IAM
Para obter informações sobre como usar o IAM com o Amazon Glacier, consulte Autenticação e controlede acesso para o Amazon Glacier (p. 118).
Fazer download do AWS SDK apropriadoPara tentar o exercício de conceitos básicos, você deve decidir qual linguagem de programação desejausar e fazer download do AWS SDK apropriado à plataforma de desenvolvimento.
O exercício de conceitos básicos oferece exemplos em Java e C#.
Fazer download do AWS SDK for JavaPara testar os exemplos do Java neste guia do desenvolvedor, você precisa do AWS SDK for Java. Vocêtem as seguintes opções de download:
• Se estiver usando o Eclipse, você poderá fazer download e instalar o AWS Toolkit for Eclipse usando osite de atualização http://aws.amazon.com/eclipse/. Para obter mais informações, vá até AWS Toolkit forEclipse.
• Se você estiver usando qualquer outro IDE para criar o aplicativo, faça download do AWS SDK for Java.
Fazer download do AWS SDK para .NETPara testar os exemplos do C# neste guia do desenvolvedor, você precisa do AWS SDK para .NET. Vocêtem as seguintes opções de download:
• Se estiver usando o Visual Studio, você poderá instalar o AWS SDK para .NET e o AWS Toolkit forVisual Studio. O toolkit fornece o AWS Explorer for Visual Studio e modelos de projeto que você pode
Versão da API 2012-06-0110
Amazon Glacier Guia do desenvolvedor doEtapa 2: criar um cofre
usar no desenvolvimento. Para fazer download do AWS SDK para .NET, acesse http://aws.amazon.com/sdkfornet. Por padrão, o script de instalação instala o AWS SDK e o AWS Toolkit for Visual Studio. Parasaber mais sobre o toolkit, vá até Guia do usuário do AWS Toolkit for Visual Studio.
• Se estiver usando qualquer outro IDE para criar o aplicativo, você poderá usar o mesmo link fornecidona etapa anterior e instalar somente o AWS SDK para .NET.
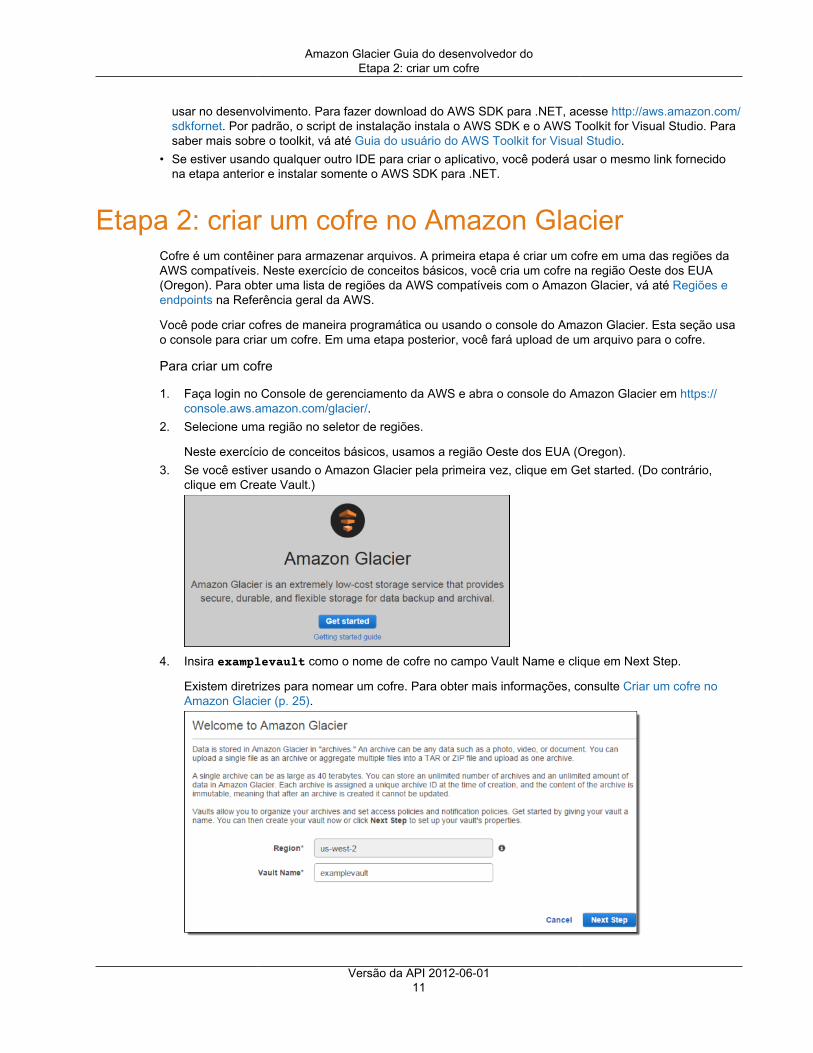
Etapa 2: criar um cofre no Amazon GlacierCofre é um contêiner para armazenar arquivos. A primeira etapa é criar um cofre em uma das regiões daAWS compatíveis. Neste exercício de conceitos básicos, você cria um cofre na região Oeste dos EUA(Oregon). Para obter uma lista de regiões da AWS compatíveis com o Amazon Glacier, vá até Regiões eendpoints na Referência geral da AWS.
Você pode criar cofres de maneira programática ou usando o console do Amazon Glacier. Esta seção usao console para criar um cofre. Em uma etapa posterior, você fará upload de um arquivo para o cofre.
Para criar um cofre
1. Faça login no Console de gerenciamento da AWS e abra o console do Amazon Glacier em https://console.aws.amazon.com/glacier/.
2. Selecione uma região no seletor de regiões.
Neste exercício de conceitos básicos, usamos a região Oeste dos EUA (Oregon).3. Se você estiver usando o Amazon Glacier pela primeira vez, clique em Get started. (Do contrário,
clique em Create Vault.)
4. Insira examplevault como o nome de cofre no campo Vault Name e clique em Next Step.
Existem diretrizes para nomear um cofre. Para obter mais informações, consulte Criar um cofre noAmazon Glacier (p. 25).
Versão da API 2012-06-0111

Amazon Glacier Guia do desenvolvedor doEtapa 3: fazer upload de um arquivo para um cofre
5. Selecione Do not enable notifications. Para este exercício de conceitos básicos, você não vaiconfigurar notificações para o cofre.
Se quisesse ter notificações enviadas para você ou para o aplicativo sempre que determinadostrabalhos do Amazon Glacier fossem concluídos, você selecionaria Enable notifications and create anew SNS topic ou Enable notifications and use an existing SNS topic para configurar notificações doAmazon Simple Notification Service (Amazon SNS). Em etapas subsequentes, você fará upload deum arquivo e, em seguida, download dele usando a API de nível superior do AWS SDK. Usar a API denível superior não exige que você configure a notificação de cofre para recuperar os dados.
6. Se a região e o nome de cofre estiverem corretos, clique em Submit.
7. O novo cofre é listado na página Amazon Glacier Vaults.
Etapa 3: fazer upload de um arquivo para um cofreno Amazon Glacier
Nesta etapa, você faz upload de um arquivo de amostra para o cofre criado por você na etapa anterior(consulte Etapa 2: criar um cofre no Amazon Glacier (p. 11)). Dependendo da plataforma dedesenvolvimento que você esteja usando, clique em um dos links ao final desta seção.
Versão da API 2012-06-0112

Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo usando o Java
Important
Qualquer operação de arquivo, como upload, download, ou exclusão, exige que você use aAWS Command Line Interface (CLI) ou escreva um código. Não há suporte ao console paraoperações de arquivo. Por exemplo, para fazer upload de dados, como fotos, vídeos e outrosdocumentos, você deve usar a AWS CLI ou escrever código para fazer solicitações usando aAPI REST diretamente ou usando os SDKs da AWS. Para instalar a AWS CLI, consulte AWSCommand Line Interface. Para obter mais informações sobre como usar o Amazon Glacier coma AWS CLI, consulte Referência da AWS CLI do Amazon Glacier. Para obter exemplos de comousar a AWS CLI para carregar arquivos no Amazon Glacier, consulte Usar o Amazon Glacier coma AWS Command Line Interface.
Um arquivo é qualquer objeto, como uma foto, um vídeo ou um documento, armazenado por você em umcofre. Trata-se de uma unidade básica de armazenamento no Amazon Glacier. Você pode fazer uploadde um arquivo em uma única solicitação. Para arquivos grandes, o Amazon Glacier fornece uma API demultipart upload que permite fazer upload de um arquivo em partes. Nesta seção de conceitos básicos,você faz upload de um arquivo de amostra em uma única solicitação. Para este exercício, você especificaum arquivo menor. Para arquivos maiores, multipart upload é indicado. Para obter mais informações,consulte Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70).
Tópicos• Fazer upload de um arquivo para um cofre no Amazon Glacier usando o AWS SDK for Java (p. 13)• Fazer upload de um arquivo para um cofre no Amazon Glacier usando o AWS SDK
para .NET (p. 14)
Fazer upload de um arquivo para um cofre no AmazonGlacier usando o AWS SDK for JavaO exemplo de código do Java a seguir usa a API de nível superior do AWS SDK for Java para fazer uploaddo arquivo de amostra para o cofre. No exemplo de código, observe o seguinte:
• O exemplo cria uma instância da classe AmazonGlacierClient.• O exemplo usa o método upload da classe ArchiveTransferManager da API de nível superior do
AWS SDK for Java.• O exemplo usa a região Oeste dos EUA (Oregon) (us-west-2) de acordo com o local onde você criou o
cofre anteriormente em Etapa 2: criar um cofre no Amazon Glacier (p. 11).
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos do Java parao Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o código conforme mostrado com onome do arquivo cujo upload deseja fazer.
Note
O Amazon Glacier mantém um inventário de todos os arquivos nos cofres. Quando vocêfizer upload do arquivo no exemplo a seguir, ele não será exibido em um cofre no console degerenciamento até o inventário de cofre ter sido atualizado. Essa atualização normalmenteacontece uma vez por dia.
Example – Fazer upload de um arquivo usando o AWS SDK for Java
import java.io.File;import java.io.IOException;
Versão da API 2012-06-0113

Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo usando o .NET
import java.util.Date;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.transfer.ArchiveTransferManager;import com.amazonaws.services.glacier.transfer.UploadResult;
public class AmazonGlacierUploadArchive_GettingStarted {
public static String vaultName = "examplevault2"; public static String archiveToUpload = "*** provide name of file to upload ***"; public static AmazonGlacierClient client; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider(); client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-west-2.amazonaws.com/");
try { ArchiveTransferManager atm = new ArchiveTransferManager(client, credentials); UploadResult result = atm.upload(vaultName, "my archive " + (new Date()), new File(archiveToUpload)); System.out.println("Archive ID: " + result.getArchiveId()); } catch (Exception e) { System.err.println(e); } }}
Fazer upload de um arquivo para um cofre no AmazonGlacier usando o AWS SDK para .NETO exemplo de código do C# a seguir usa a API de nível superior do AWS SDK para .NET para fazerupload do arquivo de amostra para o cofre. No exemplo de código, observe o seguinte:
• O exemplo cria uma instância da classe ArchiveTransferManager para o endpoint de região doAmazon Glacier especificado.
• O exemplo de código usa a região Oeste dos EUA (Oregon) (us-west-2) de acordo com o local ondevocê criou o cofre anteriormente em Etapa 2: criar um cofre no Amazon Glacier (p. 11).
• O exemplo usa o método Upload da classe ArchiveTransferManager para fazer upload do arquivo.Para arquivos pequenos, esse método faz upload do arquivo diretamente no Amazon Glacier. Paraarquivos maiores, esse método usa a multipart upload API do Amazon Glacier para dividir o upload emvárias partes a fim de melhorar a recuperação de erros, caso algum seja encontrado durante o streamingdos dados para o Amazon Glacier.
Para obter instruções passo a passo sobre como executar o exemplo a seguir, consulte Executar exemplosde código (p. 116). Você precisa atualizar o código conforme mostrado com o nome do cofre e o nomedo arquivo cujo upload deve ser feito.
Note
O Amazon Glacier mantém um inventário de todos os arquivos nos cofres. Quando vocêfizer upload do arquivo no exemplo a seguir, ele não será exibido em um cofre no console de
Versão da API 2012-06-0114

Amazon Glacier Guia do desenvolvedor doEtapa 4: fazer download de um arquivo de um cofre
gerenciamento até o inventário de cofre ter sido atualizado. Essa atualização normalmenteacontece uma vez por dia.
Example – Fazer upload de um arquivo usando a API de nível superior do AWS SDK para .NET
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveUploadHighLevel_GettingStarted { static string vaultName = "examplevault"; static string archiveToUpload = "*** Provide file name (with full path) to upload ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2); // Upload an archive. string archiveId = manager.Upload(vaultName, "getting started archive test", archiveToUpload).ArchiveId; Console.WriteLine("Copy and save the following Archive ID for the next step."); Console.WriteLine("Archive ID: {0}", archiveId); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } }}
Etapa 4: fazer download de um arquivo de um cofreno Amazon Glacier
Nesta etapa, você faz download do arquivo de amostra cujo upload tenha sido feito anteriormente emEtapa 3: fazer upload de um arquivo para um cofre no Amazon Glacier (p. 12).
Important
Qualquer operação de arquivo, como upload, download, ou exclusão, exige que você use a AWSCommand Line Interface (AWS CLI) ou escreva um código. Não há suporte ao console paraoperações de arquivo. Por exemplo, para fazer upload de dados, como fotos, vídeos e outrosdocumentos, você deve usar a AWS CLI ou escrever código para fazer solicitações usando a APIREST diretamente ou os SDKs da AWS. Para obter mais informações sobre como usar o AmazonGlacier com a AWS CLI, consulte Referência da AWS CLI do Amazon Glacier. Para instalar aAWS CLI, consulte AWS Command Line Interface.
Em geral, recuperar os dados do Amazon Glacier é um processo de duas etapas:
1. Inicie um trabalho de recuperação.
Versão da API 2012-06-0115

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando-se o Java
2. Depois que o trabalho for concluído, faça download dos bytes de dados.
Para recuperar um arquivo do Amazon Glacier, você primeiro inicia um trabalho. Depois que o trabalho forconcluído, você fará download dos dados. Para obter mais informações sobre recuperações de arquivo,consulte Recuperar arquivos do Amazon Glacier (p. 79).
O tempo de acesso da solicitação depende da opção de recuperação escolhida por você: expressa,padrão ou em massa. Exceto para os arquivos maiores (mais de 250 MB), os dados acessados usando-se recuperações expressas costumam ser disponibilizados dentro de 1 a 5 minutos. Arquivos recuperadosusando-se recuperações padrão normalmente são concluídos entre 3 e 5 horas. As recuperações emmassa normalmente são concluídas dentro de 5 a 12 horas. Para obter mais informações sobre as opçõesde recuperação, consulte as Perguntas frequentes do Amazon Glacier. Para obter mais informações sobrecobranças pela recuperação de dados, consulte a página de detalhes do Amazon Glacier.
Os exemplos de código mostrados nos tópicos a seguir iniciam o trabalho, aguardam a conclusão e fazemdownload dos dados de arquivo.
Tópicos• Fazer download de um arquivo de um cofre no Amazon Glacier usando-se o AWS SDK for
Java (p. 16)• Fazer download de um arquivo de um cofre no Amazon Glacier usando o AWS SDK
para .NET (p. 17)
Fazer download de um arquivo de um cofre noAmazon Glacier usando-se o AWS SDK for JavaO exemplo de código do Java a seguir usa a API de nível superior do AWS SDK for Java para fazerdownload do arquivo cujo upload você fez na etapa anterior. No exemplo de código, observe o seguinte:
• O exemplo cria uma instância da classe AmazonGlacierClient.• O código usa a região Oeste dos EUA (Oregon) (us-west-2) de acordo com o local onde você criou o
cofre em Etapa 2: criar um cofre no Amazon Glacier (p. 11).• O exemplo usa o método download da classe ArchiveTransferManager da API de nível superior
do AWS SDK for Java. O exemplo cria um tópico do Amazon SNS e uma fila do Amazon Simple QueueService inscrita nesse tópico. Se você criou um usuário administrativo do IAM conforme as instruçõesem Etapa 1: antes de começar com o Amazon Glacier (p. 7), seu usuário tem as permissõesnecessárias do IAM para criar e usar o tópico do Amazon SNS e a fila do Amazon SQS.
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos do Javapara o Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o código conforme mostradocom o ID do arquivo cujo upload fez em Etapa 3: fazer upload de um arquivo para um cofre no AmazonGlacier (p. 12).
Example – Fazer download de um arquivo usando-se o AWS SDK for Java
import java.io.File;import java.io.IOException;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.transfer.ArchiveTransferManager;import com.amazonaws.services.sns.AmazonSNSClient;import com.amazonaws.services.sqs.AmazonSQSClient;
public class AmazonGlacierDownloadArchive_GettingStarted {
Versão da API 2012-06-0116

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
public static String vaultName = "examplevault"; public static String archiveId = "*** provide archive ID ***"; public static String downloadFilePath = "*** provide location to download archive ***"; public static AmazonGlacierClient glacierClient; public static AmazonSQSClient sqsClient; public static AmazonSNSClient snsClient; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider(); glacierClient = new AmazonGlacierClient(credentials); sqsClient = new AmazonSQSClient(credentials); snsClient = new AmazonSNSClient(credentials); glacierClient.setEndpoint("glacier.us-west-2.amazonaws.com"); sqsClient.setEndpoint("sqs.us-west-2.amazonaws.com"); snsClient.setEndpoint("sns.us-west-2.amazonaws.com");
try { ArchiveTransferManager atm = new ArchiveTransferManager(glacierClient, sqsClient, snsClient); atm.download(vaultName, archiveId, new File(downloadFilePath)); } catch (Exception e) { System.err.println(e); } }}
Fazer download de um arquivo de um cofre noAmazon Glacier usando o AWS SDK para .NETO exemplo de código do C# a seguir usa a API de nível superior do AWS SDK para .NET para fazerdownload do arquivo cujo upload você fez anteriormente em Fazer upload de um arquivo para um cofre noAmazon Glacier usando o AWS SDK para .NET (p. 14). No exemplo de código, observe o seguinte:
• O exemplo cria uma instância da classe ArchiveTransferManager para o endpoint de região doAmazon Glacier especificado.
• O exemplo de código usa a região Oeste dos EUA (Oregon) (us-west-2) de acordo com o local ondevocê criou o cofre anteriormente em Etapa 2: criar um cofre no Amazon Glacier (p. 11).
• O exemplo usa o método Download da classe ArchiveTransferManager para fazer download doarquivo. O exemplo cria um tópico do Amazon SNS e uma fila do Amazon Simple Queue Service inscritanesse tópico. Se você criou um usuário administrativo do IAM conforme as instruções em Etapa 1: antesde começar com o Amazon Glacier (p. 7), seu usuário tem as permissões necessárias do IAM paracriar e usar o tópico do Amazon SNS e a fila do Amazon SQS.
• Em seguida, o exemplo inicia o trabalho de recuperação do arquivo e sonda a fila em busca do arquivodisponível. Assim que o arquivo estiver disponível, o download começará. Para obter informações sobretempos de recuperação, consulte Opções de recuperação de arquivos (p. 80)
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com o ID do arquivo cujo upload fezem Etapa 3: fazer upload de um arquivo para um cofre no Amazon Glacier (p. 12).
Versão da API 2012-06-0117

Amazon Glacier Guia do desenvolvedor doEtapa 5: excluir um arquivo de um cofre
Example – Fazer download de um arquivo usando a API de nível superior do AWS SDK para .NET
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveDownloadHighLevel_GettingStarted { static string vaultName = "examplevault"; static string archiveId = "*** Provide archive ID ***"; static string downloadFilePath = "*** Provide the file name and path to where to store the download ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2);
var options = new DownloadOptions(); options.StreamTransferProgress += ArchiveDownloadHighLevel_GettingStarted.progress; // Download an archive. Console.WriteLine("Intiating the archive retrieval job and then polling SQS queue for the archive to be available."); Console.WriteLine("Once the archive is available, downloading will begin."); manager.Download(vaultName, archiveId, downloadFilePath, options); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static int currentPercentage = -1; static void progress(object sender, StreamTransferProgressArgs args) { if (args.PercentDone != currentPercentage) { currentPercentage = args.PercentDone; Console.WriteLine("Downloaded {0}%", args.PercentDone); } } }}
Etapa 5: excluir um arquivo de um cofre no AmazonGlacier
Nesta etapa, você exclui o arquivo de amostra cujo upload tenha sido feito em Etapa 3: fazer upload de umarquivo para um cofre no Amazon Glacier (p. 12).
Versão da API 2012-06-0118

Amazon Glacier Guia do desenvolvedor doSeções relacionadas
Important
Você não pode excluir um arquivo usando o console do Amazon Glacier. Qualquer operaçãode arquivo, como upload, download ou exclusão, exige que você use a AWS Config (CLI) ouescreva um código. Por exemplo, para fazer upload de dados, como fotos, vídeos e outrosdocumentos, você deve usar a AWS CLI ou escrever código para fazer solicitações usando a APIREST diretamente ou usando os SDKs da AWS. Para obter mais informações sobre como usar oAmazon Glacier com a AWS CLI, vá até Referência da AWS CLI do Amazon Glacier. Para instalara AWS CLI, vá para a AWS Command Line Interface.
Dependendo do SDK que você esteja usando, exclua o arquivo de amostra seguindo uma destas etapas:
• Excluir um arquivo de um cofre no Amazon Glacier usando o AWS SDK for Java (p. 19)• Excluir um arquivo de um cofre no Amazon Glacier usando o AWS SDK para .NET (p. 20)
Seções relacionadas• Etapa 3: fazer upload de um arquivo para um cofre no Amazon Glacier (p. 12)• Excluir um arquivo no Amazon Glacier (p. 105)
Excluir um arquivo de um cofre no Amazon Glacierusando o AWS SDK for JavaO exemplo de código a seguir usa o AWS SDK for Java para excluir o arquivo. No código, observe oseguinte:
• O objeto DeleteArchiveRequest descreve a solicitação de exclusão, inclusive o nome do cofre emque o arquivo está localizado e o ID do arquivo.
• O método deleteArchive envia a solicitação ao Amazon Glacier para excluir o arquivo.• O exemplo usa a região Oeste dos EUA (Oregon) (us-west-2) de acordo com o local onde você criou o
cofre em Etapa 2: criar um cofre no Amazon Glacier (p. 11).
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos do Javapara o Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o código conforme mostradocom o ID do arquivo cujo upload fez em Etapa 3: fazer upload de um arquivo para um cofre no AmazonGlacier (p. 12).
Example – Excluir um arquivo usando o AWS SDK for Java
import java.io.IOException;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.model.DeleteArchiveRequest;
public class AmazonGlacierDeleteArchive_GettingStarted {
public static String vaultName = "examplevault"; public static String archiveId = "*** provide archive ID***"; public static AmazonGlacierClient client; public static void main(String[] args) throws IOException {
Versão da API 2012-06-0119

Amazon Glacier Guia do desenvolvedor doExcluir um arquivo usando o .NET
ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-west-2.amazonaws.com/");
try {
// Delete the archive. client.deleteArchive(new DeleteArchiveRequest() .withVaultName(vaultName) .withArchiveId(archiveId)); System.out.println("Deleted archive successfully."); } catch (Exception e) { System.err.println("Archive not deleted."); System.err.println(e); } }}
Excluir um arquivo de um cofre no Amazon Glacierusando o AWS SDK para .NETO exemplo de código do C# a seguir usa a API de nível superior do AWS SDK para .NET para excluir oarquivo cujo upload você fez na etapa anterior. No exemplo de código, observe o seguinte:
• O exemplo cria uma instância da classe ArchiveTransferManager para o endpoint de região doAmazon Glacier especificado.
• O exemplo de código usa a região Oeste dos EUA (Oregon) (us-west-2) de acordo com o local ondevocê criou o cofre anteriormente em Etapa 2: criar um cofre no Amazon Glacier (p. 11).
• O exemplo usa o método Delete da classe ArchiveTransferManager fornecido como parte da APIde nível superior do AWS SDK para .NET.
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com o ID do arquivo cujo upload fezem Etapa 3: fazer upload de um arquivo para um cofre no Amazon Glacier (p. 12).
Example – Excluir um arquivo usando a API de nível superior do AWS SDK para .NET
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveDeleteHighLevel_GettingStarted { static string vaultName = "examplevault"; static string archiveId = "*** Provide archive ID ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2); manager.DeleteArchive(vaultName, archiveId); }
Versão da API 2012-06-0120

Amazon Glacier Guia do desenvolvedor doEtapa 6: excluir um cofre
catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } }}
Etapa 6: excluir um cofre no Amazon GlacierCofre é um contêiner para armazenar arquivos. Você poderá excluir um cofre do Amazon Glacier somentese não houver arquivos no cofre desde o inventário computado mais recentemente pelo Amazon Glacier enão houver gravações no cofre desde o inventário mais recente.
Note
O Amazon Glacier prepara um inventário para cada cofre periodicamente, a cada 24 horas. Comoo inventário talvez não reflita as informações mais recentes, o Amazon Glacier garante que ocofre esteja realmente vazio verificando se houve alguma operação de gravação desde o últimoinventário do cofre.
Você pode excluir um cofre de maneira programática ou usando o console do Amazon Glacier. Esta seçãousa o console para excluir um cofre. Para obter informações sobre como excluir um cofre de maneiraprogramática, consulte Excluir um cofre no Amazon Glacier (p. 55).
Para excluir um cofre
1. Faça login no Console de gerenciamento da AWS e abra o console do Amazon Glacier em https://console.aws.amazon.com/glacier.
2. No seletor de regiões, selecione a região da AWS onde está o cofre que você deseja excluir.
Neste exercício de conceitos básicos, usamos a região Oeste dos EUA (Oregon).3. Selecione o cofre que você deseja excluir.
Neste exercício de conceitos básicos, temos usado um cofre chamado examplevault.
4. Clique em Delete Vault.
Para onde ir agora?Agora que fez o exercício de conceitos básicos, você pode explorar as seções a seguir para saber maissobre o Amazon Glacier.
• Trabalhar com cofres no Amazon Glacier (p. 23)
Versão da API 2012-06-0121

Amazon Glacier Guia do desenvolvedor doPara onde ir agora?
• Trabalhar com arquivos no Amazon Glacier (p. 62)
Versão da API 2012-06-0122

Amazon Glacier Guia do desenvolvedor doOperações de cofre no Amazon Glacier
Trabalhar com cofres no AmazonGlacier
Cofre é um contêiner para armazenar arquivos. Ao criar um cofre, você especifica um nome de cofre euma região na qual deseja criar o cofre. Para ver uma lista de regiões compatíveis, consulte Acessar oAmazon Glacier (p. 5).
Você pode armazenar um número ilimitado de arquivos em um cofre.
Important
O Amazon Glacier oferece um console de gerenciamento. Você pode usar o console para criare excluir cofres. No entanto, todas as outras interações com o Amazon Glacier exigem que vocêuse a AWS Command Line Interface (CLI) ou escreva código. Por exemplo, para fazer upload dedados, como fotos, vídeos e outros documentos, você deve usar a AWS CLI ou escrever códigopara fazer solicitações usando a API REST diretamente ou usando os SDKs da AWS. Para obtermais informações sobre como usar o Amazon Glacier com a AWS CLI, vá até Referência da AWSCLI do Amazon Glacier. Para instalar a AWS CLI, vá para a AWS Command Line Interface.
Tópicos• Operações de cofre no Amazon Glacier (p. 23)• Criar um cofre no Amazon Glacier (p. 25)• Recuperar metadados do cofre no Amazon Glacier (p. 31)• Fazer download de um inventário de cofre no Amazon Glacier (p. 35)• Configurar notificações de cofre no Amazon Glacier (p. 47)• Excluir um cofre no Amazon Glacier (p. 55)• Marcar os cofres do Amazon Glacier (p. 58)• Amazon Glacier Vault Lock (p. 59)
Operações de cofre no Amazon GlacierO Amazon Glacier dá suporte a diversas operações de cofre. As operações de cofre são específicas daregião. Por exemplo, ao criar um cofre, você faz isso em uma região específica. Quando você lista cofres,o Amazon Glacier retorna a lista de cofres da região especificada na solicitação.
Criar e excluir cofresUma conta da AWS pode criar até 1.000 cofres por região. Para obter uma lista de regiões da AWScompatíveis com o Amazon Glacier, consulte Regiões e endpoints na Referência geral da AWS.
Você poderá excluir um cofre somente se não houver arquivos no cofre desde o inventário computadomais recentemente pelo Amazon Glacier e não houver gravações no cofre desde o inventário maisrecente.
Versão da API 2012-06-0123

Amazon Glacier Guia do desenvolvedor doRecuperar metadados do cofre
Note
O Amazon Glacier prepara um inventário para cada cofre periodicamente, a cada 24 horas. Comoo inventário talvez não reflita as informações mais recentes, o Amazon Glacier garante que ocofre esteja realmente vazio verificando se houve alguma operação de gravação desde o últimoinventário do cofre.
Para obter mais informações, consulte Criar um cofre no Amazon Glacier (p. 25) e Excluir um cofre noAmazon Glacier (p. 55).
Recuperar metadados do cofreVocê pode recuperar informações do cofre, como a data de criação do cofre, o número de arquivos nocofre e o tamanho total de todos os arquivos no cofre. O Amazon Glacier fornece chamadas de API paravocê recuperar essas informações de um cofre específico ou de todos os cofres em uma determinadaregião na conta. Para obter mais informações, consulte Recuperar metadados do cofre no AmazonGlacier (p. 31).
Fazer download de um inventário de cofreInventário de cofre se refere à lista de arquivos em um cofre. Para cada arquivo na lista, o inventáriofornece informações de arquivo, como ID, data de criação e tamanho. O Amazon Glacier atualiza oinventário de cofre aproximadamente uma vez por dia, começando no primeiro dia de upload para o cofre.Deve haver um inventário de cofre para que você possa fazer download dele.
Fazer download de um inventário de cofre é uma operação assíncrona. Você deve primeiro iniciar umtrabalho para fazer download do inventário. Depois de receber a solicitação de trabalho, o Amazon Glaciervai preparar o inventário para download. Depois que o trabalho for concluído, você poderá fazer downloaddos dados de inventário.
Dada a natureza assíncrona do trabalho, você pode usar as notificações do Amazon Simple NotificationService (Amazon SNS) para notificar quando o trabalho for concluído. Você pode especificar um tópico doAmazon SNS para cada solicitação de trabalho individual ou configurar o cofre para enviar uma notificaçãoquando ocorrerem eventos de cofre específicos.
O Amazon Glacier prepara um inventário para cada cofre periodicamente, a cada 24 horas. Se nãohouver adições ou exclusões de arquivo no cofre desde o último inventário, a data do inventário nãoserá atualizada. Quando você inicia um trabalho para um inventário de cofre, o Amazon Glacier retornao último inventário gerado, que é um snapshot point-in-time, e não dados em tempo real. Talvez vocênão ache útil recuperar um inventário de cofre para cada upload de arquivo. No entanto, suponhamosque você mantenha um banco de dados no lado do cliente associando metadados sobre os arquivos cujoupload fez para o Amazon Glacier. Em seguida, você talvez ache o inventário de cofre útil para reconciliarinformações no banco de dados com o inventário de cofre.
Para obter mais informações sobre como recuperar um inventário de cofre, consulte Fazer download deum inventário de cofre no Amazon Glacier (p. 35).
Configurar notificações de cofreRecuperar qualquer coisa do Amazon Glacier, como um arquivo de um cofre ou um inventário de cofre, éum processo de duas etapas em que você primeiro inicia um trabalho. Depois que o trabalho for concluído,você poderá fazer download da saída. Você pode usar o suporte a notificações do Amazon Glacier parasaber quando o trabalho está concluído. O Amazon Glacier envia mensagens de notificação para umtópico do Amazon Simple Notification Service (Amazon SNS) fornecido por você.
Você pode configurar notificações em um cofre e identificar eventos de cofre, além do tópico do AmazonSNS a ser notificado quando o evento ocorrer. Sempre que o evento de cofre ocorre, o Amazon Glacier
Versão da API 2012-06-0124

Amazon Glacier Guia do desenvolvedor doCriar um cofre
envia uma notificação para o tópico do Amazon SNS especificado. Para obter mais informações, consulteConfigurar notificações de cofre no Amazon Glacier (p. 47).
Criar um cofre no Amazon GlacierCriar um cofre adiciona um cofre ao conjunto de cofres na conta. Uma conta da AWS pode criar até 1.000cofres por região. Para obter uma lista de regiões da AWS compatíveis com o Amazon Glacier, vá atéRegiões e endpoints na Referência geral da AWS. Para obter mais informações sobre como criar maiscofres, vá até a página de detalhes de produto do Amazon Glacier.
Ao criar um cofre, você deve fornecer um nome. Estes são os requisitos de nomenclatura do cofre:
• Os nomes podem ter de 1 a 255 caracteres.• Os caracteres permitidos incluem a-z, A-Z, 0-9, '_' (sublinhado), '-' (hífen), '/' (barra) e '.' (período).
Os nomes de cofres devem ser exclusivos dentro de uma conta e da região na qual o cofre está sendocriado. Ou seja, uma conta pode criar cofres com o mesmo nome em regiões diferentes, mas não namesma região.
Tópicos• Criar um cofre no Amazon Glacier usando o AWS SDK for Java (p. 25)• Criar um cofre no Amazon Glacier usando o AWS SDK para .NET (p. 27)• Criar um cofre no Amazon Glacier usando a API REST (p. 31)• Criar um cofre usando o console do Amazon Glacier (p. 31)
Criar um cofre no Amazon Glacier usando o AWSSDK for JavaA API de nível inferior fornece métodos para todas as operações de cofre, inclusive criar e excluir cofres,obter uma descrição de cofre e uma lista de cofres criados em uma região específica. Estas são as etapaspara criar um cofre usando o AWS SDK for Java.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS na qual deseja criar um cofre. Todas as operaçõesrealizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe CreateVaultRequest.
O Amazon Glacier exige que você forneça um nome de cofre e o ID da conta. Se você não fornecerum ID da conta, o ID da conta associado às credenciais fornecidas por você para assinar a solicitaçãoserá usado. Para obter mais informações, consulte Usar o AWS SDK for Java com o AmazonGlacier (p. 112).
3. Execute o método createVault fornecendo o objeto de solicitação como um parâmetro.
A resposta retornada pelo Amazon Glacier está disponível no objeto CreateVaultResult.
O trecho de código Java a seguir ilustra as etapas anteriores. O trecho cria um cofre na região us-west-2. O Location impresso por ele é o URI relativo do cofre que inclui o ID da conta, a região e onome do cofre.
AmazonGlacierClient client = new AmazonGlacierClient(credentials);
Versão da API 2012-06-0125

Amazon Glacier Guia do desenvolvedor doCriar um cofre usando o Java
client.setEndpoint("https://glacier.us-west-2.amazonaws.com");
CreateVaultRequest request = new CreateVaultRequest() .withVaultName("*** provide vault name ***");CreateVaultResult result = client.createVault(request);
System.out.println("Created vault successfully: " + result.getLocation());
Note
Para obter informações sobre a API REST subjacente, consulte Create Vault (PUTvault) (p. 177).
Exemplos: criar um cofre usando o AWS SDK for JavaO exemplo de código do Java a seguir cria um cofre na região us-west-2 (para obter mais informaçõessobre regiões, consulte Acessar o Amazon Glacier (p. 5)). Além disso, o exemplo de código recupera asinformações do cofre, lista todos os cofres na mesma região e exclui o cofre criado.
Para obter instruções passo a passo sobre como executar o exemplo a seguir, consulte Executar exemplosdo Java para o Amazon Glacier usando o Eclipse (p. 114).
Example
import java.io.IOException;import java.util.List;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.model.CreateVaultRequest;import com.amazonaws.services.glacier.model.CreateVaultResult;import com.amazonaws.services.glacier.model.DeleteVaultRequest;import com.amazonaws.services.glacier.model.DescribeVaultOutput;import com.amazonaws.services.glacier.model.DescribeVaultRequest;import com.amazonaws.services.glacier.model.DescribeVaultResult;import com.amazonaws.services.glacier.model.ListVaultsRequest;import com.amazonaws.services.glacier.model.ListVaultsResult;
public class AmazonGlacierVaultOperations {
public static AmazonGlacierClient client;
public static void main(String[] args) throws IOException {
ProfileCredentialsProvider credentials = new ProfileCredentialsProvider(); client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-east-1.amazonaws.com/"); String vaultName = "examplevaultfordelete";
try { createVault(client, vaultName); describeVault(client, vaultName); listVaults(client); deleteVault(client, vaultName);
} catch (Exception e) { System.err.println("Vault operation failed." + e.getMessage()); } }
Versão da API 2012-06-0126

Amazon Glacier Guia do desenvolvedor doCriar um cofre usando o .NET
private static void createVault(AmazonGlacierClient client, String vaultName) { CreateVaultRequest createVaultRequest = new CreateVaultRequest() .withVaultName(vaultName); CreateVaultResult createVaultResult = client.createVault(createVaultRequest);
System.out.println("Created vault successfully: " + createVaultResult.getLocation()); }
private static void describeVault(AmazonGlacierClient client, String vaultName) { DescribeVaultRequest describeVaultRequest = new DescribeVaultRequest() .withVaultName(vaultName); DescribeVaultResult describeVaultResult = client.describeVault(describeVaultRequest);
System.out.println("Describing the vault: " + vaultName); System.out.print( "CreationDate: " + describeVaultResult.getCreationDate() + "\nLastInventoryDate: " + describeVaultResult.getLastInventoryDate() + "\nNumberOfArchives: " + describeVaultResult.getNumberOfArchives() + "\nSizeInBytes: " + describeVaultResult.getSizeInBytes() + "\nVaultARN: " + describeVaultResult.getVaultARN() + "\nVaultName: " + describeVaultResult.getVaultName()); }
private static void listVaults(AmazonGlacierClient client) { ListVaultsRequest listVaultsRequest = new ListVaultsRequest(); ListVaultsResult listVaultsResult = client.listVaults(listVaultsRequest);
List<DescribeVaultOutput> vaultList = listVaultsResult.getVaultList(); System.out.println("\nDescribing all vaults (vault list):"); for (DescribeVaultOutput vault : vaultList) { System.out.println( "\nCreationDate: " + vault.getCreationDate() + "\nLastInventoryDate: " + vault.getLastInventoryDate() + "\nNumberOfArchives: " + vault.getNumberOfArchives() + "\nSizeInBytes: " + vault.getSizeInBytes() + "\nVaultARN: " + vault.getVaultARN() + "\nVaultName: " + vault.getVaultName()); } }
private static void deleteVault(AmazonGlacierClient client, String vaultName) { DeleteVaultRequest request = new DeleteVaultRequest() .withVaultName(vaultName); client.deleteVault(request); System.out.println("Deleted vault: " + vaultName); }
}
Criar um cofre no Amazon Glacier usando o AWSSDK para .NETAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para .NETfornecem um método para criar um cofre.
Tópicos• Criar um cofre usando a API de nível superior do AWS SDK para .NET (p. 28)• Criar um cofre usando a API de nível inferior do AWS SDK para .NET (p. 28)
Versão da API 2012-06-0127

Amazon Glacier Guia do desenvolvedor doCriar um cofre usando o .NET
Criar um cofre usando a API de nível superior do AWS SDKpara .NETA classe ArchiveTransferManager da API de nível superior fornece o método CreateVault que vocêpode usar para criar um cofre em uma região da AWS.
Exemplo: operações de cofre usando a API de nível superior do AWS SDKpara .NET
O exemplo de código do C# a seguir cria e exclui um cofre na região Região Oeste dos EUA (Oregon).Para obter uma lista de regiões da AWS em que você pode criar cofres, consulte Acessar o AmazonGlacier (p. 5).
Para obter instruções passo a passo sobre como executar o exemplo a seguir, consulte Executar exemplosde código (p. 116). Você precisa atualizar o código conforme mostrado com um nome de cofre.
Example
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class VaultCreateDescribeListVaultsDeleteHighLevel { static string vaultName = "*** Provide vault name ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2); manager.CreateVault(vaultName); Console.WriteLine("Vault created. To delete the vault, press Enter"); Console.ReadKey(); manager.DeleteVault(vaultName); Console.WriteLine("\nVault deleted. To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } }}
Criar um cofre usando a API de nível inferior do AWS SDKpara .NETA API de nível inferior fornece métodos para todas as operações de cofre, inclusive criar e excluir cofres,obter uma descrição de cofre e uma lista de cofres criados em uma região específica. Estas são as etapaspara criar um cofre usando o console do AWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Versão da API 2012-06-0128

Amazon Glacier Guia do desenvolvedor doCriar um cofre usando o .NET
Você precisa especificar uma região da AWS na qual deseja criar um cofre. Todas as operaçõesrealizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe CreateVaultRequest.
O Amazon Glacier exige que você forneça um nome de cofre e o ID da conta. Se você não fornecerum ID da conta, o ID da conta associado às credenciais fornecidas por você para assinar a solicitaçãoserá pressuposto. Para obter mais informações, consulte Usar o AWS SDK para .NET com o AmazonGlacier (p. 115).
3. Execute o método CreateVault fornecendo o objeto de solicitação como um parâmetro.
A resposta retornada pelo Amazon Glacier está disponível no objeto CreateVaultResponse.
Exemplo: operações de cofre usando a API de nível inferior do AWS SDKpara .NET
O exemplo do C# a seguir ilustra as etapas anteriores. O exemplo cria um cofre na região Região Oestedos EUA (Oregon). Além disso, o exemplo de código recupera as informações do cofre, lista todos oscofres na mesma região e exclui o cofre criado. O Location impresso é o URI relativo do cofre que incluio ID da conta, a região e o nome do cofre.
Note
Para obter informações sobre a API REST subjacente, consulte Create Vault (PUTvault) (p. 177).
Para obter instruções passo a passo sobre como executar o exemplo a seguir, consulte Executar exemplosde código (p. 116). Você precisa atualizar o código conforme mostrado com um nome de cofre.
Example
using System;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class VaultCreateDescribeListVaultsDelete { static string vaultName = "*** Provide vault name ***"; static AmazonGlacierClient client;
public static void Main(string[] args) { try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Creating a vault."); CreateAVault(); DescribeVault(); GetVaultsList(); Console.WriteLine("\nVault created. Now press Enter to delete the vault..."); Console.ReadKey(); DeleteVault(); } } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); }
Versão da API 2012-06-0129

Amazon Glacier Guia do desenvolvedor doCriar um cofre usando o .NET
catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static void CreateAVault() { CreateVaultRequest request = new CreateVaultRequest() { VaultName = vaultName }; CreateVaultResponse response = client.CreateVault(request); Console.WriteLine("Vault created: {0}\n", response.Location); }
static void DescribeVault() { DescribeVaultRequest describeVaultRequest = new DescribeVaultRequest() { VaultName = vaultName }; DescribeVaultResponse describeVaultResponse = client.DescribeVault(describeVaultRequest); Console.WriteLine("\nVault description..."); Console.WriteLine( "\nVaultName: " + describeVaultResponse.VaultName + "\nVaultARN: " + describeVaultResponse.VaultARN + "\nVaultCreationDate: " + describeVaultResponse.CreationDate + "\nNumberOfArchives: " + describeVaultResponse.NumberOfArchives + "\nSizeInBytes: " + describeVaultResponse.SizeInBytes + "\nLastInventoryDate: " + describeVaultResponse.LastInventoryDate ); }
static void GetVaultsList() { string lastMarker = null; Console.WriteLine("\n List of vaults in your account in the specific region ..."); do { ListVaultsRequest request = new ListVaultsRequest() { Marker = lastMarker }; ListVaultsResponse response = client.ListVaults(request); foreach (DescribeVaultOutput output in response.VaultList) { Console.WriteLine("Vault Name: {0} \tCreation Date: {1} \t #of archives: {2}", output.VaultName, output.CreationDate, output.NumberOfArchives); } lastMarker = response.Marker; } while (lastMarker != null); }
static void DeleteVault() { DeleteVaultRequest request = new DeleteVaultRequest() { VaultName = vaultName }; DeleteVaultResponse response = client.DeleteVault(request); } }
Versão da API 2012-06-0130

Amazon Glacier Guia do desenvolvedor doCriar um cofre usando REST
}
Criar um cofre no Amazon Glacier usando a API RESTPara criar um cofre usando a API REST, consulte Create Vault (PUT vault) (p. 177).
Criar um cofre usando o console do Amazon GlacierPara criar um cofre usando o console do Amazon Glacier, consulte Etapa 2: criar um cofre no AmazonGlacier (p. 11) no tutorial Conceitos básicos.
Recuperar metadados do cofre no Amazon GlacierVocê pode recuperar informações do cofre, como a data de criação do cofre, o número de arquivos nocofre e o tamanho total de todos os arquivos no cofre. O Amazon Glacier fornece chamadas de API paravocê recuperar essas informações de um cofre específico ou de todos os cofres em uma determinadaregião na conta.
Se você recuperar uma lista de cofres, o Amazon Glacier retornará a lista classificada pelos valoresASCII dos nomes de cofre. A lista contém até 1.000 cofres. Você deve sempre verificar a resposta paraum marcador no qual continuar a lista; se não houver mais itens, o campo do marcador será null.Você também pode limitar o número de cofres retornados na resposta. Se houver mais cofres do que osretornados na resposta, o resultado será paginado. Você precisa enviar solicitações adicionais para buscaro próximo conjunto de cofres.
Tópicos• Recuperar metadados de cofre no Amazon Glacier usando o AWS SDK for Java (p. 31)• Recuperar metadados de cofre no Amazon Glacier usando o AWS SDK para .NET (p. 33)• Recuperar metadados do cofre usando a API REST (p. 35)
Recuperar metadados de cofre no Amazon Glacierusando o AWS SDK for JavaTópicos
• Recuperar metadados de um cofre (p. 31)• Recuperar metadados de todos os cofres em uma região (p. 32)• Exemplo: recuperar metadados de cofre usando o AWS SDK para Java (p. 33)
Recuperar metadados de um cofreVocê pode recuperar metadados de um cofre específico ou de todos os cofres em uma região específica.Estas são as etapas para recuperar metadados de um cofre específico usando a API de nível inferior doAWS SDK para Java.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde o cofre reside. Todas as operações realizadas porvocê usando esse cliente se aplicam a essa região.
Versão da API 2012-06-0131

Amazon Glacier Guia do desenvolvedor doRecuperar metadados de cofre usando Java
2. Forneça informações sobre a solicitação criando uma instância da classe DescribeVaultRequest.
O Amazon Glacier exige que você forneça um nome de cofre e o ID da conta. Se você não fornecerum ID da conta, o ID da conta associado às credenciais fornecidas por você para assinar a solicitaçãoserá pressuposto. Para obter mais informações, consulte Usar o AWS SDK for Java com o AmazonGlacier (p. 112).
3. Execute o método describeVault fornecendo o objeto de solicitação como um parâmetro.
As informações de metadados de cofre retornadas pelo Amazon Glacier estão disponíveis no objetoDescribeVaultResult.
O trecho de código Java a seguir ilustra as etapas anteriores.
DescribeVaultRequest request = new DescribeVaultRequest() .withVaultName("*** provide vault name***");
DescribeVaultResult result = client.describeVault(request);
System.out.print( "\nCreationDate: " + result.getCreationDate() + "\nLastInventoryDate: " + result.getLastInventoryDate() + "\nNumberOfArchives: " + result.getNumberOfArchives() + "\nSizeInBytes: " + result.getSizeInBytes() + "\nVaultARN: " + result.getVaultARN() + "\nVaultName: " + result.getVaultName());
Note
Para obter informações sobre a API REST subjacente, consulte Describe Vault (GETvault) (p. 187).
Recuperar metadados de todos os cofres em uma regiãoVocê também pode usar o método listVaults para recuperar metadados de todos os cofres em umaregião específica.
O trecho de código do Java a seguir recupera uma lista de cofres na região us-west-2. A solicitaçãolimita o número de cofres retornados na resposta a 5. Em seguida, o trecho de código faz uma série dechamadas listVaults para recuperar toda a lista de cofres da região.
AmazonGlacierClient client;client.setEndpoint("https://glacier.us-west-2.amazonaws.com/");
String marker = null;do { ListVaultsRequest request = new ListVaultsRequest() .withLimit("5") .withMarker(marker); ListVaultsResult listVaultsResult = client.listVaults(request); List<DescribeVaultOutput> vaultList = listVaultsResult.getVaultList(); marker = listVaultsResult.getMarker(); for (DescribeVaultOutput vault : vaultList) { System.out.println( "\nCreationDate: " + vault.getCreationDate() + "\nLastInventoryDate: " + vault.getLastInventoryDate() + "\nNumberOfArchives: " + vault.getNumberOfArchives() + "\nSizeInBytes: " + vault.getSizeInBytes() + "\nVaultARN: " + vault.getVaultARN() +
Versão da API 2012-06-0132

Amazon Glacier Guia do desenvolvedor doRecuperar metadados de cofre usando o .NET
"\nVaultName: " + vault.getVaultName()); }} while (marker != null);
No segmento de código anterior, se você não especificar o valor Limit na solicitação, o Amazon Glacierretornará até 10 cofres, conforme definido pela API do Amazon Glacier. Se houver mais cofres a seremlistados, o campo marker de resposta conterá o nome de recurso da Amazon (ARN) do cofre no qualdeve continuar a lista com uma nova solicitação; do contrário, o campo marker será nulo.
As informações retornadas para cada cofre na lista são as mesmas obtidas por você chamando o métododescribeVault para um cofre específico.
Note
O método listVaults chama a API REST subjacente (consulte List Vaults (GETvaults) (p. 203)).
Exemplo: recuperar metadados de cofre usando o AWS SDKpara JavaPara obter um exemplo de código funcional, consulte Exemplos: criar um cofre usando o AWS SDK forJava (p. 26). O exemplo de código do Java cria um cofre e recupera os metadados do cofre.
Recuperar metadados de cofre no Amazon Glacierusando o AWS SDK para .NETTópicos
• Recuperar metadados de um cofre (p. 33)• Recuperar metadados de todos os cofres em uma região (p. 34)• Exemplo: recuperar metadados de cofre usando a API de nível inferior do AWS SDK para .NET
(p. 35)
Recuperar metadados de um cofreVocê pode recuperar metadados de um cofre específico ou de todos os cofres em uma região específica.Estas são as etapas para recuperar metadados de um cofre específico usando a API de nível inferior doAWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde o cofre reside. Todas as operações realizadas porvocê usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe DescribeVaultRequest.
O Amazon Glacier exige que você forneça um nome de cofre e o ID da conta. Se você não fornecerum ID da conta, o ID da conta associado às credenciais fornecidas por você para assinar a solicitaçãoserá pressuposto. Para obter mais informações, consulte Usar o AWS SDK para .NET com o AmazonGlacier (p. 115).
3. Execute o método DescribeVault fornecendo o objeto de solicitação como um parâmetro.
As informações de metadados de cofre retornadas pelo Amazon Glacier estão disponíveis no objetoDescribeVaultResult.
Versão da API 2012-06-0133

Amazon Glacier Guia do desenvolvedor doRecuperar metadados de cofre usando o .NET
O trecho de código do C# a seguir ilustra as etapas anteriores. O trecho recupera informações demetadados de um cofre existente no Região Oeste dos EUA (Oregon).
AmazonGlacierClient client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2);
DescribeVaultRequest describeVaultRequest = new DescribeVaultRequest(){ VaultName = "*** Provide vault name ***"}; DescribeVaultResponse describeVaultResponse = client.DescribeVault(describeVaultRequest);Console.WriteLine("\nVault description...");Console.WriteLine( "\nVaultName: " + describeVaultResponse.VaultName + "\nVaultARN: " + describeVaultResponse.VaultARN + "\nVaultCreationDate: " + describeVaultResponse.CreationDate + "\nNumberOfArchives: " + describeVaultResponse.NumberOfArchives + "\nSizeInBytes: " + describeVaultResponse.SizeInBytes + "\nLastInventoryDate: " + describeVaultResponse.LastInventoryDate );
Note
Para obter informações sobre a API REST subjacente, consulte Describe Vault (GETvault) (p. 187).
Recuperar metadados de todos os cofres em uma regiãoVocê também pode usar o método ListVaults para recuperar metadados de todos os cofres em umaregião específica.
O trecho de código do C# recupera uma lista de cofres no Região Oeste dos EUA (Oregon). A solicitaçãolimita o número de cofres retornados na resposta a 5. Em seguida, o trecho de código faz uma série dechamadas ListVaults para recuperar toda a lista de cofres da região.
AmazonGlacierClient client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2);string lastMarker = null;Console.WriteLine("\n List of vaults in your account in the specific region ...");do{ ListVaultsRequest request = new ListVaultsRequest() { Limit = 5, Marker = lastMarker }; ListVaultsResponse response = client.ListVaults(request); foreach (DescribeVaultOutput output in response.VaultList) { Console.WriteLine("Vault Name: {0} \tCreation Date: {1} \t #of archives: {2}", output.VaultName, output.CreationDate, output.NumberOfArchives); } lastMarker = response.Marker;} while (lastMarker != null);
No segmento de código anterior, se você não especificar o valor Limit na solicitação, o Amazon Glacierretornará até 10 cofres, conforme definido pela API do Amazon Glacier.
As informações retornadas para cada cofre na lista são as mesmas obtidas por você chamando o métodoDescribeVault para um cofre específico.
Versão da API 2012-06-0134

Amazon Glacier Guia do desenvolvedor doRecuperar metadados do cofre usando REST
Note
O método ListVaults chama a API REST subjacente (consulte List Vaults (GETvaults) (p. 203)).
Exemplo: recuperar metadados de cofre usando a API de nívelinferior do AWS SDK para .NETPara obter um exemplo de código funcional, consulte Exemplo: operações de cofre usando a API denível inferior do AWS SDK para .NET (p. 29). O exemplo de código do C# cria um cofre e recupera osmetadados do cofre.
Recuperar metadados do cofre usando a API RESTPara listar cofres usando a API REST, consulte List Vaults (GET vaults) (p. 203). Para descrever umcofre, consulte Describe Vault (GET vault) (p. 187).
Fazer download de um inventário de cofre noAmazon Glacier
Depois que você fizer upload do primeiro arquivo para o cofre, o Amazon Glacier vai criar e atualizarautomaticamente um inventário de cofre uma vez por dia, aproximadamente. Depois que o AmazonGlacier criar o primeiro inventário, normalmente levará de meio dia a um dia até que esse inventário estejadisponível para recuperação. Você pode recuperar um inventário de cofre do Amazon Glacier com oseguinte processo de duas etapas:
1. Inicie um trabalho de recuperação de inventário usando a operação Initiate Job (trabalhosPOST) (p. 257).
Important
Uma política de recuperação de dados pode causar uma falha na solicitação do trabalho derecuperação de inicialização com uma exceção PolicyEnforcedException. Para obtermais informações sobre políticas de recuperação de dados, consulte Políticas de recuperaçãodos dados do Amazon Glacier (p. 142). Para obter mais informações sobre a exceçãoPolicyEnforcedException, consulte Respostas de erro (p. 169).
2. Após a conclusão do trabalho, faça download dos bytes usando a operação Get Job Output (GEToutput) (p. 251).
Por exemplo, recuperar um arquivo ou um inventário de cofre exige que você primeiro inicie um trabalhode recuperação. A solicitação de trabalho é executada de maneira assíncrona. Quando você inicia umtrabalho de recuperação, o Amazon Glacier cria um trabalho e retorna um ID de trabalho na resposta.Quando o Amazon Glacier conclui o trabalho, você pode receber a saída do trabalho, os bytes do arquivoou os dados do inventário de cofre.
O trabalho deverá ser concluído para você obter a saída. Para determinar o status do trabalho, você temas seguintes opções:
• Aguardar a notificação de conclusão do trabalho– Você pode especificar um tópico do Amazon SimpleNotification Service (Amazon SNS) no qual o Amazon Glacier poderá publicar uma notificação depoisque o trabalho for concluído. Você pode especificar o tópico do Amazon SNS usando os seguintesmétodos:
Versão da API 2012-06-0135

Amazon Glacier Guia do desenvolvedor doSobre o inventário
• Especifique um tópico do Amazon SNS por trabalho.
Ao iniciar um trabalho, você também pode especificar um tópico do Amazon SNS.• Defina a configuração de notificação no cofre.
Você pode definir a configuração de notificação para eventos específicos no cofre (consulte Configurarnotificações de cofre no Amazon Glacier (p. 47)). O Amazon Glacier enviará uma mensagem parao tópico do SNS especificado sempre que o evento específico ocorrer.
Se você tiver a configuração de notificação definida no cofre e também especificar um tópico do AmazonSNS ao iniciar um trabalho, o Amazon Glacier enviará uma mensagem de conclusão do trabalho paraambos os tópicos.
Você pode configurar o tópico do SNS para notificá-lo por e-mail ou armazenar a mensagem em umAmazon Simple Queue Service (Amazon SQS) que o aplicativo pode sondar. Quando uma mensagemfor exibida na fila, você poderá verificar se o trabalho foi concluído com êxito e, em seguida, fazerdownload da saída do trabalho.
• Solicitar informações do trabalho explicitamente—O Amazon Glacier também oferece uma operaçãodescribe job (Trabalho de descrição (GET JobID) (p. 243)) que permite sondar informações detrabalho. Periodicamente, você pode enviar essa solicitação para obter informações de trabalho. Noentanto, usar notificações do Amazon SNS é a opção recomendada.
Note
As informações obtidas por você por meio da notificação do SNS são as mesmas recebidasquando se chama Describe Job.
Tópicos• Sobre o inventário (p. 36)• Fazer download de um inventário de cofre no Amazon Glacier usando o AWS SDK for Java (p. 37)• Fazer download de um inventário de cofre no Amazon Glacier usando o AWS SDK
para .NET (p. 42)• Fazer download de um inventário de cofre usando a API REST (p. 47)
Sobre o inventárioO Amazon Glacier atualiza um inventário de cofre aproximadamente uma vez por dia, começando no diaem que você faz o primeiro upload para o cofre. Se não houver adições ou exclusões de arquivo no cofredesde o último inventário, a data do inventário não será atualizada. Quando você inicia um trabalho paraum inventário de cofre, o Amazon Glacier retorna o último inventário gerado, que é um snapshot point-in-time, e não dados em tempo real. Depois que o Amazon Glacier criar o primeiro inventário para o cofre,normalmente levará de meio dia a um dia até que esse inventário esteja disponível para recuperação.
Talvez você não ache útil recuperar um inventário de cofre para cada upload de arquivo. No entanto,suponhamos que você mantenha um banco de dados no lado do cliente associando metadados sobre osarquivos cujo upload fez para o Amazon Glacier. Nesse caso, talvez você ache o inventário de cofre útilpara reconciliar informações, conforme necessário, no seu banco de dados com o inventário de cofre real.Você pode limitar o número de itens do inventário recuperados filtrando a data de criação do arquivo oudefinindo um limite. Para obter mais informações sobre como limitar a recuperação do inventário, consulteRecuperação do inventário de intervalo (p. 260).
O inventário pode ser retornado em dois formatos: valores separados por vírgula (CSV) ou JSON. Vocêtambém pode especificar o formato ao iniciar o trabalho de inventário. O formato padrão é JSON. Paraobter mais informações sobre os campos de dados retornados em uma saída do trabalho de inventário,consulte Corpo da resposta (p. 254) da Get Job Output API.
Versão da API 2012-06-0136

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o Java
Fazer download de um inventário de cofre no AmazonGlacier usando o AWS SDK for JavaEstas são as etapas para recuperar um inventário de cofre usando a API de nível inferior do AWS SDK forJava. A API de nível superior não dá suporte à recuperação de um inventário de cofre.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde o cofre reside. Todas as operações realizadas porvocê usando esse cliente se aplicam a essa região.
2. Inicie um trabalho de recuperação de inventário executando o método initiateJob.
Execute initiateJob fornecendo informações de trabalho em um objeto InitiateJobRequest.
Note
Se um inventário não tiver sido concluído para o cofre, um erro será retornado. O AmazonGlacier prepara um inventário para cada cofre periodicamente, a cada 24 horas.
Em resposta, o Amazon Glacier retorna um ID de trabalho. A resposta está disponível em uma instânciada classe InitiateJobResult.
InitiateJobRequest initJobRequest = new InitiateJobRequest() .withVaultName("*** provide vault name ***") .withJobParameters( new JobParameters() .withType("inventory-retrieval") .withSNSTopic("*** provide SNS topic ARN ****") );
InitiateJobResult initJobResult = client.initiateJob(initJobRequest);String jobId = initJobResult.getJobId();
3. Aguarde a conclusão do trabalho.
Você deve aguardar até a saída do trabalho estar pronta para download. Se você tiver definido umaconfiguração de notificação no cofre ou especificado um tópico do Amazon Simple Notification Service(Amazon SNS) quando tiver iniciado o trabalho, o Amazon Glacier enviará uma mensagem para o tópicodepois de concluir o trabalho.
Você também pode sondar o Amazon Glacier chamando o método describeJob para determinaro status de conclusão do trabalho. No entanto, usar um tópico do Amazon SNS para notificação é aabordagem recomendada. O exemplo de código indicado na seção a seguir usa o Amazon SNS para oAmazon Glacier para publicar uma mensagem.
4. Faça download da saída do trabalho (dados de inventário de cofre) executando o métodogetJobOutput.
Você fornece o ID da conta, o ID do trabalho e o nome do cofre criando uma instância da classeGetJobOutputRequest. Se você não fornecer um ID da conta, o ID da conta associado àscredenciais fornecidas por você para assinar a solicitação será usado. Para obter mais informações,consulte Usar o AWS SDK for Java com o Amazon Glacier (p. 112).
A saída retornada pelo Amazon Glacier está disponível no objeto GetJobOutputResult.
GetJobOutputRequest jobOutputRequest = new GetJobOutputRequest() .withVaultName("*** provide vault name ***") .withJobId("*** provide job ID ***");
Versão da API 2012-06-0137

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o Java
GetJobOutputResult jobOutputResult = client.getJobOutput(jobOutputRequest);// jobOutputResult.getBody(); provides the output stream.
Note
Para obter informações sobre a API REST subjacente relacionada ao trabalho, consulteOperações de trabalho (p. 243).
Exemplo: recuperar um inventário de cofre usando o AWS SDKpara JavaO exemplo de código do Java a seguir recupera o inventário do cofre especificado.
O exemplo realiza as seguintes tarefas:
• Cria um tópico do Amazon Simple Notification Service (Amazon SNS).
O Amazon Glacier enviará uma notificação para esse tópico depois de concluir o trabalho.• Cria uma fila do Amazon Simple Queue Service (Amazon SQS).
O exemplo anexa uma política à fila para permitir que o tópico do Amazon SNS publique mensagens nafila.
• Inicia um trabalho para fazer download do arquivo especificado.
Na solicitação de trabalho, o tópico do Amazon SNS criado é especificado, de maneira que o AmazonGlacier possa publicar uma notificação no tópico depois de concluir o trabalho.
• Verifica a fila do Amazon SQS em busca de uma mensagem que contenha o ID do trabalho.
Se houver uma mensagem, analise o JSON e verifique se o trabalho foi concluído com êxito. Secontiver, faça download do arquivo.
• Limpa excluindo o tópico do Amazon SNS e a fila do Amazon SQS criada por ele.
import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.FileWriter;import java.io.IOException;import java.io.InputStreamReader;import java.util.HashMap;import java.util.List;import java.util.Map;
import com.fasterxml.jackson.core.JsonFactory;import com.fasterxml.jackson.core.JsonParseException;import com.fasterxml.jackson.core.JsonParser;import com.fasterxml.jackson.databind.JsonNode;import com.fasterxml.jackson.databind.ObjectMapper;
import com.amazonaws.AmazonClientException;import com.amazonaws.auth.policy.Policy;import com.amazonaws.auth.policy.Principal;import com.amazonaws.auth.policy.Resource;import com.amazonaws.auth.policy.Statement;import com.amazonaws.auth.policy.Statement.Effect;import com.amazonaws.auth.policy.actions.SQSActions;import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.model.GetJobOutputRequest;import com.amazonaws.services.glacier.model.GetJobOutputResult;
Versão da API 2012-06-0138

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o Java
import com.amazonaws.services.glacier.model.InitiateJobRequest;import com.amazonaws.services.glacier.model.InitiateJobResult;import com.amazonaws.services.glacier.model.JobParameters;import com.amazonaws.services.sns.AmazonSNSClient;import com.amazonaws.services.sns.model.CreateTopicRequest;import com.amazonaws.services.sns.model.CreateTopicResult;import com.amazonaws.services.sns.model.DeleteTopicRequest;import com.amazonaws.services.sns.model.SubscribeRequest;import com.amazonaws.services.sns.model.SubscribeResult;import com.amazonaws.services.sns.model.UnsubscribeRequest;import com.amazonaws.services.sqs.AmazonSQSClient;import com.amazonaws.services.sqs.model.CreateQueueRequest;import com.amazonaws.services.sqs.model.CreateQueueResult;import com.amazonaws.services.sqs.model.DeleteQueueRequest;import com.amazonaws.services.sqs.model.GetQueueAttributesRequest;import com.amazonaws.services.sqs.model.GetQueueAttributesResult;import com.amazonaws.services.sqs.model.Message;import com.amazonaws.services.sqs.model.ReceiveMessageRequest;import com.amazonaws.services.sqs.model.SetQueueAttributesRequest;
public class AmazonGlacierDownloadInventoryWithSQSPolling {
public static String vaultName = "*** provide vault name ***"; public static String snsTopicName = "*** provide topic name ***"; public static String sqsQueueName = "*** provide queue name ***"; public static String sqsQueueARN; public static String sqsQueueURL; public static String snsTopicARN; public static String snsSubscriptionARN; public static String fileName = "*** provide file name ***"; public static String region = "*** region ***"; public static long sleepTime = 600; public static AmazonGlacierClient client; public static AmazonSQSClient sqsClient; public static AmazonSNSClient snsClient; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier." + region + ".amazonaws.com"); sqsClient = new AmazonSQSClient(credentials); sqsClient.setEndpoint("https://sqs." + region + ".amazonaws.com"); snsClient = new AmazonSNSClient(credentials); snsClient.setEndpoint("https://sns." + region + ".amazonaws.com"); try { setupSQS(); setupSNS();
String jobId = initiateJobRequest(); System.out.println("Jobid = " + jobId); Boolean success = waitForJobToComplete(jobId, sqsQueueURL); if (!success) { throw new Exception("Job did not complete successfully."); } downloadJobOutput(jobId); cleanUp(); } catch (Exception e) { System.err.println("Inventory retrieval failed."); System.err.println(e);
Versão da API 2012-06-0139

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o Java
} }
private static void setupSQS() { CreateQueueRequest request = new CreateQueueRequest() .withQueueName(sqsQueueName); CreateQueueResult result = sqsClient.createQueue(request); sqsQueueURL = result.getQueueUrl(); GetQueueAttributesRequest qRequest = new GetQueueAttributesRequest() .withQueueUrl(sqsQueueURL) .withAttributeNames("QueueArn"); GetQueueAttributesResult qResult = sqsClient.getQueueAttributes(qRequest); sqsQueueARN = qResult.getAttributes().get("QueueArn"); Policy sqsPolicy = new Policy().withStatements( new Statement(Effect.Allow) .withPrincipals(Principal.AllUsers) .withActions(SQSActions.SendMessage) .withResources(new Resource(sqsQueueARN))); Map<String, String> queueAttributes = new HashMap<String, String>(); queueAttributes.put("Policy", sqsPolicy.toJson()); sqsClient.setQueueAttributes(new SetQueueAttributesRequest(sqsQueueURL, queueAttributes));
} private static void setupSNS() { CreateTopicRequest request = new CreateTopicRequest() .withName(snsTopicName); CreateTopicResult result = snsClient.createTopic(request); snsTopicARN = result.getTopicArn();
SubscribeRequest request2 = new SubscribeRequest() .withTopicArn(snsTopicARN) .withEndpoint(sqsQueueARN) .withProtocol("sqs"); SubscribeResult result2 = snsClient.subscribe(request2); snsSubscriptionARN = result2.getSubscriptionArn(); } private static String initiateJobRequest() { JobParameters jobParameters = new JobParameters() .withType("inventory-retrieval") .withSNSTopic(snsTopicARN); InitiateJobRequest request = new InitiateJobRequest() .withVaultName(vaultName) .withJobParameters(jobParameters); InitiateJobResult response = client.initiateJob(request); return response.getJobId(); } private static Boolean waitForJobToComplete(String jobId, String sqsQueueUrl) throws InterruptedException, JsonParseException, IOException { Boolean messageFound = false; Boolean jobSuccessful = false; ObjectMapper mapper = new ObjectMapper(); JsonFactory factory = mapper.getFactory(); while (!messageFound) {
Versão da API 2012-06-0140

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o Java
List<Message> msgs = sqsClient.receiveMessage( new ReceiveMessageRequest(sqsQueueUrl).withMaxNumberOfMessages(10)).getMessages();
if (msgs.size() > 0) { for (Message m : msgs) { JsonParser jpMessage = factory.createJsonParser(m.getBody()); JsonNode jobMessageNode = mapper.readTree(jpMessage); String jobMessage = jobMessageNode.get("Message").textValue(); JsonParser jpDesc = factory.createJsonParser(jobMessage); JsonNode jobDescNode = mapper.readTree(jpDesc); String retrievedJobId = jobDescNode.get("JobId").textValue(); String statusCode = jobDescNode.get("StatusCode").textValue(); if (retrievedJobId.equals(jobId)) { messageFound = true; if (statusCode.equals("Succeeded")) { jobSuccessful = true; } } } } else { Thread.sleep(sleepTime * 1000); } } return (messageFound && jobSuccessful); } private static void downloadJobOutput(String jobId) throws IOException { GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest() .withVaultName(vaultName) .withJobId(jobId); GetJobOutputResult getJobOutputResult = client.getJobOutput(getJobOutputRequest); FileWriter fstream = new FileWriter(fileName); BufferedWriter out = new BufferedWriter(fstream); BufferedReader in = new BufferedReader(new InputStreamReader(getJobOutputResult.getBody())); String inputLine; try { while ((inputLine = in.readLine()) != null) { out.write(inputLine); } }catch(IOException e) { throw new AmazonClientException("Unable to save archive", e); }finally{ try {in.close();} catch (Exception e) {} try {out.close();} catch (Exception e) {} } System.out.println("Retrieved inventory to " + fileName); } private static void cleanUp() { snsClient.unsubscribe(new UnsubscribeRequest(snsSubscriptionARN)); snsClient.deleteTopic(new DeleteTopicRequest(snsTopicARN)); sqsClient.deleteQueue(new DeleteQueueRequest(sqsQueueURL)); }}
Versão da API 2012-06-0141

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o .NET
Fazer download de um inventário de cofre no AmazonGlacier usando o AWS SDK para .NETEstas são as etapas para recuperar um inventário de cofre usando a API de nível inferior do AWS SDKpara .NET. A API de nível superior não dá suporte à recuperação de um inventário de cofre.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde o cofre reside. Todas as operações realizadas porvocê usando esse cliente se aplicam a essa região.
2. Inicie um trabalho de recuperação de inventário executando o método InitiateJob.
Você pode fornecer informações de trabalho em um objeto InitiateJobRequest. Em resposta, oAmazon Glacier retorna um ID de trabalho. A resposta está disponível em uma instância da classeInitiateJobResponse.
AmazonGlacierClient client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2);
InitiateJobRequest initJobRequest = new InitiateJobRequest(){ VaultName = vaultName, JobParameters = new JobParameters() { Type = "inventory-retrieval", SNSTopic = "*** Provide Amazon SNS topic arn ***", }};InitiateJobResponse initJobResponse = client.InitiateJob(initJobRequest);string jobId = initJobResponse.JobId;
3. Aguarde a conclusão do trabalho.
Você deve aguardar até a saída do trabalho estar pronta para download. Se você tiver definido umaconfiguração de notificação no cofre identificando um tópico do Amazon Simple Notification Service(Amazon SNS) ou especificado um tópico do Amazon SNS quando tiver iniciado um trabalho, o AmazonGlacier enviará uma mensagem para esse tópico depois de concluir o trabalho. O exemplo de códigoindicado na seção a seguir usa o Amazon SNS para o Amazon Glacier para publicar uma mensagem.
Você também pode sondar o Amazon Glacier chamando o método DescribeJob para determinaro status de conclusão do trabalho. Apesar disso, usar o tópico do Amazon SNS para notificação é aabordagem recomendada.
4. Faça download da saída do trabalho (dados de inventário de cofre) executando o métodoGetJobOutput.
Você fornece o ID da conta, o nome do cofre e as informações do ID do trabalho criando uma instânciada classe GetJobOutputRequest. Se você não fornecer um ID da conta, o ID da conta associadoàs credenciais fornecidas por você para assinar a solicitação será pressuposto. Para obter maisinformações, consulte Usar o AWS SDK para .NET com o Amazon Glacier (p. 115).
A saída retornada pelo Amazon Glacier está disponível no objeto GetJobOutputResponse.
GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest(){ JobId = jobId, VaultName = vaultName};
Versão da API 2012-06-0142
Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o .NET
GetJobOutputResponse getJobOutputResponse = client.GetJobOutput(getJobOutputRequest); using (Stream webStream = getJobOutputResponse.Body){ using (Stream fileToSave = File.OpenWrite(fileName)) { CopyStream(webStream, fileToSave); }}
Note
Para obter informações sobre a API REST subjacente relacionada ao trabalho, consulteOperações de trabalho (p. 243).
Exemplo: recuperar um inventário de cofre usando a API de nívelinferior do AWS SDK para .NETO exemplo de código do C# a seguir recupera o inventário do cofre especificado.
O exemplo realiza as seguintes tarefas:
• Configure um tópico do Amazon SNS.
O Amazon Glacier enviará uma notificação para esse tópico depois de concluir o trabalho.• Configure uma fila do Amazon SQS.
O exemplo anexa uma política à fila para permitir que o tópico do Amazon SNS publique mensagens.• Inicie um trabalho para fazer download do arquivo especificado.
Na solicitação de trabalho, o exemplo especifica o tópico do Amazon SNS, de maneira que o AmazonGlacier possa enviar uma mensagem depois de concluir o trabalho.
• Periodicamente, verifique a fila do Amazon SQS em busca de uma mensagem.
Se houver uma mensagem, analise o JSON e verifique se o trabalho foi concluído com êxito. Se houver,faça download do arquivo. O exemplo de código usa a biblioteca do JSON.NET (consulte JSON.NET)para analisar o JSON.
• Limpe excluindo o tópico do Amazon SNS e a fila do Amazon SQS criada por ele.
Example
using System;using System.Collections.Generic;using System.IO;using System.Threading;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Glacier.Transfer;using Amazon.Runtime;using Amazon.SimpleNotificationService;using Amazon.SimpleNotificationService.Model;using Amazon.SQS;using Amazon.SQS.Model;using Newtonsoft.Json;
namespace glacier.amazon.com.docsamples{ class VaultInventoryJobLowLevelUsingSNSSQS {
Versão da API 2012-06-0143

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o .NET
static string topicArn; static string queueUrl; static string queueArn; static string vaultName = "*** Provide vault name ***"; static string fileName = "*** Provide file name and path where to store inventory ***"; static AmazonSimpleNotificationServiceClient snsClient; static AmazonSQSClient sqsClient; const string SQS_POLICY = "{" + " \"Version\" : \"2012-10-17\"," + " \"Statement\" : [" + " {" + " \"Sid\" : \"sns-rule\"," + " \"Effect\" : \"Allow\"," + " \"Principal\" : \"*\"," + " \"Action\" : \"sqs:SendMessage\"," + " \"Resource\" : \"{QuernArn}\"," + " \"Condition\" : {" + " \"ArnLike\" : {" + " \"aws:SourceArn\" : \"{TopicArn}\"" + " }" + " }" + " }" + " ]" + "}";
public static void Main(string[] args) { AmazonGlacierClient client; try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Setup SNS topic and SQS queue."); SetupTopicAndQueue(); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); Console.WriteLine("Retrieve Inventory List"); GetVaultInventory(client); } Console.WriteLine("Operations successful."); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } finally { // Delete SNS topic and SQS queue. snsClient.DeleteTopic(new DeleteTopicRequest() { TopicArn = topicArn }); sqsClient.DeleteQueue(new DeleteQueueRequest() { QueueUrl = queueUrl }); } }
static void SetupTopicAndQueue() { long ticks = DateTime.Now.Ticks; // Setup SNS topic. snsClient = new AmazonSimpleNotificationServiceClient(Amazon.RegionEndpoint.USWest2); sqsClient = new AmazonSQSClient(Amazon.RegionEndpoint.USWest2);
topicArn = snsClient.CreateTopic(new CreateTopicRequest { Name = "GlacierDownload-" + ticks }).TopicArn; Console.Write("topicArn: "); Console.WriteLine(topicArn);
Versão da API 2012-06-0144

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o .NET
CreateQueueRequest createQueueRequest = new CreateQueueRequest(); createQueueRequest.QueueName = "GlacierDownload-" + ticks; CreateQueueResponse createQueueResponse = sqsClient.CreateQueue(createQueueRequest); queueUrl = createQueueResponse.QueueUrl; Console.Write("QueueURL: "); Console.WriteLine(queueUrl);
GetQueueAttributesRequest getQueueAttributesRequest = new GetQueueAttributesRequest(); getQueueAttributesRequest.AttributeNames = new List<string> { "QueueArn" }; getQueueAttributesRequest.QueueUrl = queueUrl; GetQueueAttributesResponse response = sqsClient.GetQueueAttributes(getQueueAttributesRequest); queueArn = response.QueueARN; Console.Write("QueueArn: ");Console.WriteLine(queueArn);
// Setup the Amazon SNS topic to publish to the SQS queue. snsClient.Subscribe(new SubscribeRequest() { Protocol = "sqs", Endpoint = queueArn, TopicArn = topicArn });
// Add the policy to the queue so SNS can send messages to the queue. var policy = SQS_POLICY.Replace("{TopicArn}", topicArn).Replace("{QuernArn}", queueArn); sqsClient.SetQueueAttributes(new SetQueueAttributesRequest() { QueueUrl = queueUrl, Attributes = new Dictionary<string, string> { { QueueAttributeName.Policy, policy } } });
} static void GetVaultInventory(AmazonGlacierClient client) { // Initiate job. InitiateJobRequest initJobRequest = new InitiateJobRequest() { VaultName = vaultName, JobParameters = new JobParameters() { Type = "inventory-retrieval", Description = "This job is to download a vault inventory.", SNSTopic = topicArn, } }; InitiateJobResponse initJobResponse = client.InitiateJob(initJobRequest); string jobId = initJobResponse.JobId;
// Check queue for a message and if job completed successfully, download inventory. ProcessQueue(jobId, client); }
private static void ProcessQueue(string jobId, AmazonGlacierClient client) { ReceiveMessageRequest receiveMessageRequest = new ReceiveMessageRequest() { QueueUrl = queueUrl, MaxNumberOfMessages = 1 }; bool jobDone = false; while (!jobDone)
Versão da API 2012-06-0145

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando o .NET
{ Console.WriteLine("Poll SQS queue"); ReceiveMessageResponse receiveMessageResponse = sqsClient.ReceiveMessage(receiveMessageRequest); if (receiveMessageResponse.Messages.Count == 0) { Thread.Sleep(10000 * 60); continue; } Console.WriteLine("Got message"); Message message = receiveMessageResponse.Messages[0]; Dictionary<string, string> outerLayer = JsonConvert.DeserializeObject<Dictionary<string, string>>(message.Body); Dictionary<string, object> fields = JsonConvert.DeserializeObject<Dictionary<string, object>>(outerLayer["Message"]); string statusCode = fields["StatusCode"] as string;
if (string.Equals(statusCode, GlacierUtils.JOB_STATUS_SUCCEEDED, StringComparison.InvariantCultureIgnoreCase)) { Console.WriteLine("Downloading job output"); DownloadOutput(jobId, client); // Save job output to the specified file location. } else if (string.Equals(statusCode, GlacierUtils.JOB_STATUS_FAILED, StringComparison.InvariantCultureIgnoreCase)) Console.WriteLine("Job failed... cannot download the inventory.");
jobDone = true; sqsClient.DeleteMessage(new DeleteMessageRequest() { QueueUrl = queueUrl, ReceiptHandle = message.ReceiptHandle }); } }
private static void DownloadOutput(string jobId, AmazonGlacierClient client) { GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest() { JobId = jobId, VaultName = vaultName }; GetJobOutputResponse getJobOutputResponse = client.GetJobOutput(getJobOutputRequest); using (Stream webStream = getJobOutputResponse.Body) { using (Stream fileToSave = File.OpenWrite(fileName)) { CopyStream(webStream, fileToSave); } } }
public static void CopyStream(Stream input, Stream output) { byte[] buffer = new byte[65536]; int length; while ((length = input.Read(buffer, 0, buffer.Length)) > 0) { output.Write(buffer, 0, length); } } }}
Versão da API 2012-06-0146

Amazon Glacier Guia do desenvolvedor doFazer download de um inventário de cofre usando REST
Fazer download de um inventário de cofre usando aAPI RESTPara fazer download de um inventário de cofre usando a API REST
Fazer download de um inventário de cofre é um processo de duas etapas.
1. Inicie um trabalho do tipo inventory-retrieval. Para obter mais informações, consulte Initiate Job(trabalhos POST) (p. 257).
2. Depois que o trabalho for concluído, faça download dos dados de inventário. Para obter maisinformações, consulte Get Job Output (GET output) (p. 251).
Configurar notificações de cofre no Amazon GlacierRecuperar qualquer dado do Amazon Glacier, como um arquivo de um cofre ou um inventário de cofre, éum processo de duas etapas.
1. Inicie um trabalho de recuperação.2. Depois que o trabalho for concluído, faça download da saída do trabalho.
Você pode definir uma configuração de notificação em um cofre, de maneira que, quando um trabalho forconcluído, uma mensagem será enviada para um tópico do Amazon Simple Notification Service (AmazonSNS).
Tópicos• Configurar notificações de cofre no Amazon Glacier: conceitos gerais (p. 47)• Configurar notificações de cofre no Amazon Glacier usando-se o AWS SDK for Java (p. 48)• Configurar notificações de cofre no Amazon Glacier usando o AWS SDK para .NET (p. 50)• Configurar notificações de cofre no Amazon Glacier usando a API REST (p. 52)• Configurar notificações de cofre usando o console do Amazon Glacier (p. 53)
Configurar notificações de cofre no Amazon Glacier:conceitos geraisUma solicitação de trabalho de recuperação do Amazon Glacier é executada de maneira assíncrona.Você deve aguardar o Amazon Glacier concluir o trabalho para obter a saída. Periodicamente, você podesondar o Amazon Glacier para determinar o status do trabalho, mas essa não é uma abordagem ideal. OAmazon Glacier também dá suporte a notificações. Quando um trabalho é concluído, ele pode publicaruma mensagem em um tópico do Amazon Simple Notification Service (Amazon SNS). Isso exige que vocêdefina a configuração de notificação no cofre. Na configuração, você identifica um ou mais eventos e umtópico do Amazon SNS para o qual você deseja que o Amazon Glacier envie uma mensagem quando oevento ocorrer.
O Amazon Glacier define eventos especificamente relacionados à conclusão da tarefa(ArchiveRetrievalCompleted, InventoryRetrievalCompleted) que você pode adicionar àconfiguração de notificação do cofre. Quando um trabalho específico é concluído, o Amazon Glacierpublica uma mensagem de notificação no tópico do SNS.
A configuração de notificação é um documento JSON conforme mostrado no exemplo a seguir.
Versão da API 2012-06-0147

Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando-se o Java
{ "Topic": "arn:aws:sns:us-west-2:012345678901:mytopic", "Events": ["ArchiveRetrievalCompleted", "InventoryRetrievalCompleted"] }
Você pode configurar somente um tópico do Amazon SNS para um cofre.
Note
Adicionar uma configuração de notificação a um cofre faz o Amazon Glacier enviar umanotificação sempre que o evento especificado na configuração de notificação ocorrer. Vocêtambém pode especificar um tópico do Amazon SNS em cada solicitação de iniciação do trabalho.Se você adicionar a configuração de notificação no cofre e também especificar um tópico doAmazon SNS na solicitação do trabalho de iniciação, o Amazon Glacier enviará ambas asnotificações.
A mensagem de conclusão do trabalho que o Amazon Glacier envia inclui informações como o tipo detrabalho (InventoryRetrieval, ArchiveRetrieval), o status de conclusão do trabalho, o nome dotópico do SNS, o código de status do trabalho e o ARN do cofre. Esta é uma notificação de exemplo que oAmazon Glacier enviou para um tópico do SNS após a conclusão de um trabalho InventoryRetrieval.
{ "Action": "InventoryRetrieval", "ArchiveId": null, "ArchiveSizeInBytes": null, "Completed": true, "CompletionDate": "2012-06-12T22:20:40.790Z", "CreationDate": "2012-06-12T22:20:36.814Z", "InventorySizeInBytes":11693, "JobDescription": "my retrieval job", "JobId":"HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID", "SHA256TreeHash":null, "SNSTopic": "arn:aws:sns:us-west-2:012345678901:mytopic", "StatusCode":"Succeeded", "StatusMessage": "Succeeded", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault"}
Se o campo Completed for verdadeiro, você também deverá verificar o StatusCode para examinar se otrabalho foi concluído com êxito ou falhou.
O tópico do Amazon SNS deve permitir que o cofre publique uma notificação. Por padrão, somente oproprietário do tópico do SNS pode publicar uma mensagem no tópico. Porém, se o tópico do SNS e ocofre forem de propriedade de contas da AWS diferentes, você deverá configurar o tópico do SNS paraaceitar publicações do cofre. Você pode configurar a política de tópico do SNS no console do AmazonSNS.
Para obter mais informações sobre o Amazon SNS, consulte Conceitos básicos do Amazon SNS.
Configurar notificações de cofre no Amazon Glacierusando-se o AWS SDK for JavaEstas são as etapas para configurar notificações em um cofre usando-se a API de nível inferior do AWSSDK for Java.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Versão da API 2012-06-0148

Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando-se o Java
Você precisa especificar uma região da AWS onde o cofre reside. Todas as operações realizadas porvocê usando esse cliente se aplicam a essa região.
2. Forneça informações de configuração da notificação criando uma instância da classeSetVaultNotificationsRequest.
Você precisa fornecer o nome do cofre, as informações de configuração da notificação e o ID da conta.Especificando uma configuração de notificação, você fornece o nome de recurso da Amazon (ARN) deum tópico do Amazon SNS existente e um ou mais eventos para os quais deseja ser notificado. Paraobter uma lista de eventos compatíveis, consulte Definir configuração de notificação de cofre (PUTnotification-configuration) (p. 212).
3. Execute o método setVaultNotifications fornecendo o objeto de solicitação como um parâmetro.
O trecho de código Java a seguir ilustra as etapas anteriores. O trecho define uma configuraçãode notificação em um cofre. A configuração solicita que o Amazon Glacier envie uma notificaçãopara o tópico do Amazon SNS especificado quando o evento ArchiveRetrievalCompleted ouInventoryRetrievalCompleted ocorre.
SetVaultNotificationsRequest request = new SetVaultNotificationsRequest() .withAccountId("-") .withVaultName("*** provide vault name ***") .withVaultNotificationConfig( new VaultNotificationConfig() .withSNSTopic("*** provide SNS topic ARN ***") .withEvents("ArchiveRetrievalCompleted", "InventoryRetrievalCompleted") );client.setVaultNotifications(request);
Note
Para obter informações sobre a API REST subjacente, consulte Operações de cofre (p. 172).
Exemplo: definir a configuração de notificação em um cofreusando-se o AWS SDK for JavaO exemplo de código do Java a seguir define uma configuração de notificação de cofre, exclui aconfiguração e restaura a configuração. Para obter instruções passo a passo sobre como executar oexemplo a seguir, consulte Usar o AWS SDK for Java com o Amazon Glacier (p. 112).
Example
import java.io.IOException;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.model.DeleteVaultNotificationsRequest;import com.amazonaws.services.glacier.model.GetVaultNotificationsRequest;import com.amazonaws.services.glacier.model.GetVaultNotificationsResult;import com.amazonaws.services.glacier.model.SetVaultNotificationsRequest;import com.amazonaws.services.glacier.model.VaultNotificationConfig;
public class AmazonGlacierVaultNotifications {
public static AmazonGlacierClient client; public static String vaultName = "*** provide vault name ****"; public static String snsTopicARN = "*** provide sns topic ARN ***";
Versão da API 2012-06-0149

Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando o .NET
public static void main(String[] args) throws IOException {
ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-east-1.amazonaws.com/");
try {
System.out.println("Adding notification configuration to the vault."); setVaultNotifications(); getVaultNotifications(); deleteVaultNotifications(); } catch (Exception e) { System.err.println("Vault operations failed." + e.getMessage()); } }
private static void setVaultNotifications() { VaultNotificationConfig config = new VaultNotificationConfig() .withSNSTopic(snsTopicARN) .withEvents("ArchiveRetrievalCompleted", "InventoryRetrievalCompleted"); SetVaultNotificationsRequest request = new SetVaultNotificationsRequest() .withVaultName(vaultName) .withVaultNotificationConfig(config); client.setVaultNotifications(request); System.out.println("Notification configured for vault: " + vaultName); }
private static void getVaultNotifications() { VaultNotificationConfig notificationConfig = null; GetVaultNotificationsRequest request = new GetVaultNotificationsRequest() .withVaultName(vaultName); GetVaultNotificationsResult result = client.getVaultNotifications(request); notificationConfig = result.getVaultNotificationConfig();
System.out.println("Notifications configuration for vault: " + vaultName); System.out.println("Topic: " + notificationConfig.getSNSTopic()); System.out.println("Events: " + notificationConfig.getEvents()); }
private static void deleteVaultNotifications() { DeleteVaultNotificationsRequest request = new DeleteVaultNotificationsRequest() .withVaultName(vaultName); client.deleteVaultNotifications(request); System.out.println("Notifications configuration deleted for vault: " + vaultName); }}
Configurar notificações de cofre no Amazon Glacierusando o AWS SDK para .NETEstas são as etapas para configurar notificações em um cofre usando a API de nível inferior do AWS SDKpara .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Versão da API 2012-06-0150

Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando o .NET
Você precisa especificar uma região da AWS onde o cofre reside. Todas as operações realizadas porvocê usando esse cliente se aplicam a essa região.
2. Forneça informações de configuração da notificação criando uma instância da classeSetVaultNotificationsRequest.
Você precisa fornecer o nome do cofre, as informações de configuração da notificação e o ID da conta.Se você não fornecer um ID da conta, o ID da conta associado às credenciais fornecidas por vocêpara assinar a solicitação será pressuposto. Para obter mais informações, consulte Usar o AWS SDKpara .NET com o Amazon Glacier (p. 115).
Especificando uma configuração de notificação, você fornece o nome de recurso da Amazon (ARN) deum tópico do Amazon SNS existente e um ou mais eventos para os quais deseja ser notificado. Paraobter uma lista de eventos compatíveis, consulte Definir configuração de notificação de cofre (PUTnotification-configuration) (p. 212).
3. Execute o método SetVaultNotifications fornecendo o objeto de solicitação como um parâmetro.4. Depois de definir a configuração de notificação em um cofre, você poderá recuperar informações
de configuração chamando o método GetVaultNotifications e removê-la chamando o métodoDeleteVaultNotifications fornecido pelo cliente.
Exemplo: definir a configuração de notificação em um cofreusando o AWS SDK para .NETO exemplo de código do C# a seguir ilustra as etapas anteriores. O exemplo define a configuraçãode notificação no cofre ("examplevault") na região Região Oeste dos EUA (Oregon), recuperaa configuração e a exclui. A configuração solicita que o Amazon Glacier envie uma notificaçãopara o tópico do Amazon SNS especificado quando o evento ArchiveRetrievalCompleted ouInventoryRetrievalCompleted ocorre.
Note
Para obter informações sobre a API REST subjacente, consulte Operações de cofre (p. 172).
Para obter instruções detalhadas sobre como executar o exemplo a seguir, consulte Executar exemplosde código (p. 116). Você precisa atualizar o código conforme mostrado e fornecer um nome de cofreexistente, além de um tópico do Amazon SNS.
Example
using System;using System.Collections.Generic;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class VaultNotificationSetGetDelete { static string vaultName = "examplevault"; static string snsTopicARN = "*** Provide Amazon SNS topic ARN ***";
static IAmazonGlacier client;
public static void Main(string[] args) { try {
Versão da API 2012-06-0151

Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando a API REST
using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Adding notification configuration to the vault."); SetVaultNotificationConfig(); GetVaultNotificationConfig(); Console.WriteLine("To delete vault notification configuration, press Enter"); Console.ReadKey(); DeleteVaultNotificationConfig(); } } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static void SetVaultNotificationConfig() {
SetVaultNotificationsRequest request = new SetVaultNotificationsRequest() { VaultName = vaultName, VaultNotificationConfig = new VaultNotificationConfig() { Events = new List<string>() { "ArchiveRetrievalCompleted", "InventoryRetrievalCompleted" }, SNSTopic = snsTopicARN } }; SetVaultNotificationsResponse response = client.SetVaultNotifications(request); }
static void GetVaultNotificationConfig() { GetVaultNotificationsRequest request = new GetVaultNotificationsRequest() { VaultName = vaultName, AccountId = "-" }; GetVaultNotificationsResponse response = client.GetVaultNotifications(request); Console.WriteLine("SNS Topic ARN: {0}", response.VaultNotificationConfig.SNSTopic); foreach (string s in response.VaultNotificationConfig.Events) Console.WriteLine("Event : {0}", s); }
static void DeleteVaultNotificationConfig() { DeleteVaultNotificationsRequest request = new DeleteVaultNotificationsRequest() { VaultName = vaultName }; DeleteVaultNotificationsResponse response = client.DeleteVaultNotifications(request); } }}
Configurar notificações de cofre no Amazon Glacierusando a API RESTPara configurar notificações de cofre usando a API REST, consulte Definir configuração de notificaçãode cofre (PUT notification-configuration) (p. 212). Além disso, você também pode obter (Get Vault
Versão da API 2012-06-0152
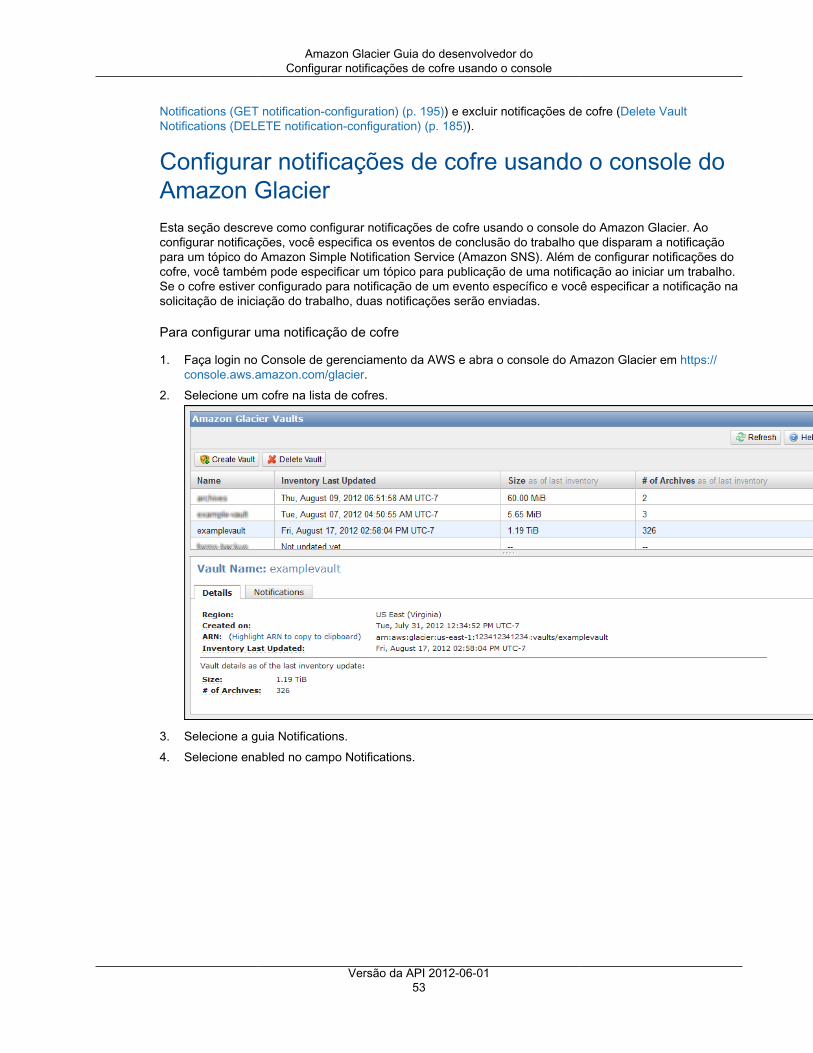
Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando o console
Notifications (GET notification-configuration) (p. 195)) e excluir notificações de cofre (Delete VaultNotifications (DELETE notification-configuration) (p. 185)).
Configurar notificações de cofre usando o console doAmazon GlacierEsta seção descreve como configurar notificações de cofre usando o console do Amazon Glacier. Aoconfigurar notificações, você especifica os eventos de conclusão do trabalho que disparam a notificaçãopara um tópico do Amazon Simple Notification Service (Amazon SNS). Além de configurar notificações docofre, você também pode especificar um tópico para publicação de uma notificação ao iniciar um trabalho.Se o cofre estiver configurado para notificação de um evento específico e você especificar a notificação nasolicitação de iniciação do trabalho, duas notificações serão enviadas.
Para configurar uma notificação de cofre
1. Faça login no Console de gerenciamento da AWS e abra o console do Amazon Glacier em https://console.aws.amazon.com/glacier.
2. Selecione um cofre na lista de cofres.
3. Selecione a guia Notifications.4. Selecione enabled no campo Notifications.
Versão da API 2012-06-0153

Amazon Glacier Guia do desenvolvedor doConfigurar notificações de cofre usando o console
5. Na guia Notifications, faça o seguinte:
Para... Fazer isso...
Especificar um tópico do Amazon SNSexistente
Insira o tópico do Amazon SNS na caixa de texto AmazonSNS Topic ARN.
O tópico é um Amazon Resource Name (ARN – Nome derecurso da Amazon) na forma mostrada abaixo.
arn:aws:sns:region:accountId:topicname
Você pode encontrar o ARN de um tópico do AmazonSNS pelo console do Amazon Simple Notification Service(Amazon SNS).
Criar um novo tópico do Amazon SNS a. Clique em create a new SNS topic.
Uma caixa de diálogo Create Notifications SNS Topic éexibida.
b. No campo Topic Name, especifique o nome do novotópico.
Se você for assinar o tópico usando assinaturas SMS,coloque um nome no campo Display Name.
c. Clique em Create Topic.
A caixa de texto Amazon SNS Topic ARN é preenchidacom o ARN do novo tópico.
Versão da API 2012-06-0154
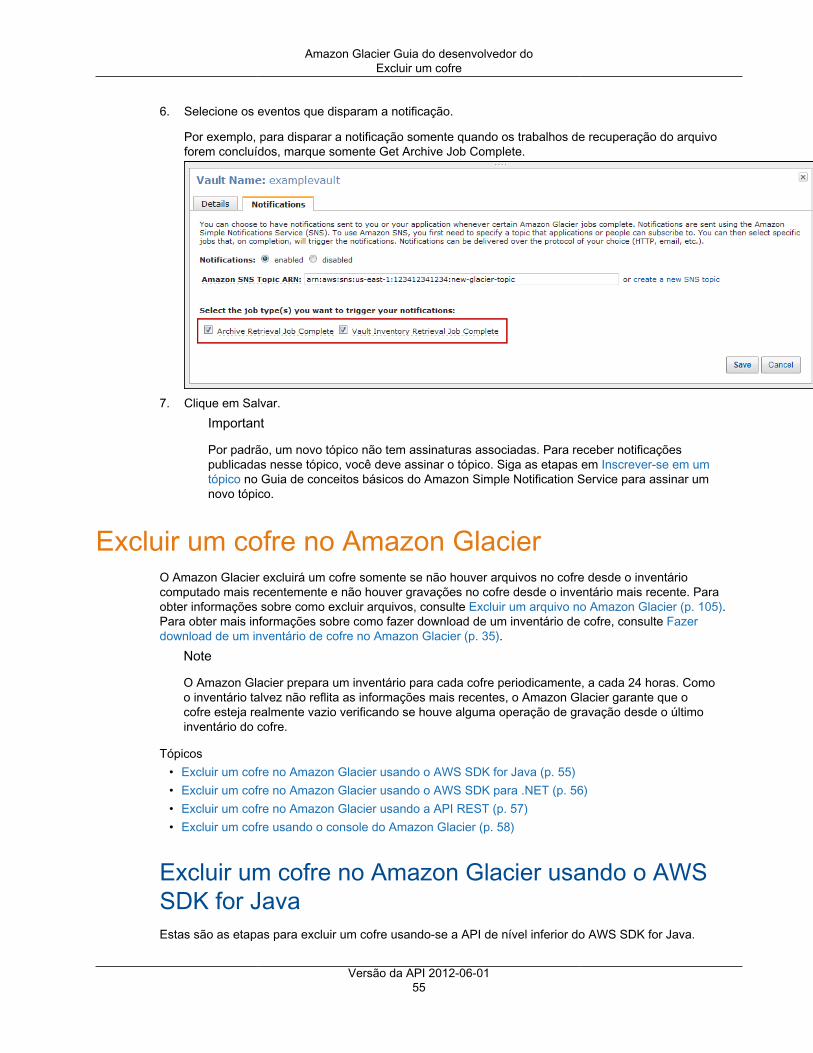
Amazon Glacier Guia do desenvolvedor doExcluir um cofre
6. Selecione os eventos que disparam a notificação.
Por exemplo, para disparar a notificação somente quando os trabalhos de recuperação do arquivoforem concluídos, marque somente Get Archive Job Complete.
7. Clique em Salvar.Important
Por padrão, um novo tópico não tem assinaturas associadas. Para receber notificaçõespublicadas nesse tópico, você deve assinar o tópico. Siga as etapas em Inscrever-se em umtópico no Guia de conceitos básicos do Amazon Simple Notification Service para assinar umnovo tópico.
Excluir um cofre no Amazon GlacierO Amazon Glacier excluirá um cofre somente se não houver arquivos no cofre desde o inventáriocomputado mais recentemente e não houver gravações no cofre desde o inventário mais recente. Paraobter informações sobre como excluir arquivos, consulte Excluir um arquivo no Amazon Glacier (p. 105).Para obter mais informações sobre como fazer download de um inventário de cofre, consulte Fazerdownload de um inventário de cofre no Amazon Glacier (p. 35).
Note
O Amazon Glacier prepara um inventário para cada cofre periodicamente, a cada 24 horas. Comoo inventário talvez não reflita as informações mais recentes, o Amazon Glacier garante que ocofre esteja realmente vazio verificando se houve alguma operação de gravação desde o últimoinventário do cofre.
Tópicos• Excluir um cofre no Amazon Glacier usando o AWS SDK for Java (p. 55)• Excluir um cofre no Amazon Glacier usando o AWS SDK para .NET (p. 56)• Excluir um cofre no Amazon Glacier usando a API REST (p. 57)• Excluir um cofre usando o console do Amazon Glacier (p. 58)
Excluir um cofre no Amazon Glacier usando o AWSSDK for JavaEstas são as etapas para excluir um cofre usando-se a API de nível inferior do AWS SDK for Java.
Versão da API 2012-06-0155

Amazon Glacier Guia do desenvolvedor doExcluir um cofre usando o .NET
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS de onde deseja excluir um cofre. Todas as operaçõesrealizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe DeleteVaultRequest.
Você precisa fornecer o nome do cofre e o ID da conta. Se você não fornecer um ID da conta, o ID daconta associado às credenciais fornecidas por você para assinar a solicitação será pressuposto. Paraobter mais informações, consulte Usar o AWS SDK for Java com o Amazon Glacier (p. 112).
3. Execute o método deleteVault fornecendo o objeto de solicitação como um parâmetro.
O Amazon Glacier somente excluirá o cofre se ele estiver vazio. Para obter mais informações, consulteDelete Vault (DELETE vault) (p. 181).
O trecho de código Java a seguir ilustra as etapas anteriores.
try { DeleteVaultRequest request = new DeleteVaultRequest() .withVaultName("*** provide vault name ***");
client.deleteVault(request); System.out.println("Deleted vault: " + vaultName);} catch (Exception e) { System.err.println(e.getMessage());}
Note
Para obter informações sobre a API REST subjacente, consulte Delete Vault (DELETEvault) (p. 181).
Exemplo: excluir um cofre usando o AWS SDK for JavaPara obter um exemplo de código funcional, consulte Exemplos: criar um cofre usando o AWS SDK forJava (p. 26). O exemplo de código do Java mostra as operações de cofre básicas, inclusive criar eexcluir cofre.
Excluir um cofre no Amazon Glacier usando o AWSSDK para .NETAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para .NETfornecem um método para excluir um cofre.
Tópicos• Excluir um cofre usando a API de nível superior do AWS SDK para .NET (p. 56)• Excluir um cofre usando a API de nível inferior do AWS SDK para .NET (p. 57)
Excluir um cofre usando a API de nível superior do AWS SDKpara .NETA classe ArchiveTransferManager da API de nível superior fornece o método DeleteVault que vocêpode usar para excluir um cofre.
Versão da API 2012-06-0156

Amazon Glacier Guia do desenvolvedor doExcluir um cofre usando REST
Exemplo: excluir um cofre usando a API de nível superior do AWS SDKpara .NET
Para obter um exemplo de código funcional, consulte Exemplo: operações de cofre usando a API de nívelsuperior do AWS SDK para .NET (p. 28). O exemplo de código do C# mostra as operações de cofrebásicas, inclusive criar e excluir cofre.
Excluir um cofre usando a API de nível inferior do AWS SDKpara .NETVeja a seguir as etapas para excluir um cofre usando o console do AWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS de onde deseja excluir um cofre. Todas as operaçõesrealizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe DeleteVaultRequest.
Você precisa fornecer o nome do cofre e o ID da conta. Se você não fornecer um ID da conta, o ID daconta associado às credenciais fornecidas por você para assinar a solicitação será pressuposto. Paraobter mais informações, consulte Usar o AWS SDK para .NET com o Amazon Glacier (p. 115).
3. Execute o método DeleteVault fornecendo o objeto de solicitação como um parâmetro.
O Amazon Glacier somente excluirá o cofre se ele estiver vazio. Para obter mais informações, consulteDelete Vault (DELETE vault) (p. 181).
O trecho de código do C# a seguir ilustra as etapas anteriores. O trecho recupera informações demetadados de um cofre existente na região da AWS padrão.
AmazonGlacier client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USEast1);
DeleteVaultRequest request = new DeleteVaultRequest(){ VaultName = "*** provide vault name ***"};
DeleteVaultResponse response = client.DeleteVault(request);
Note
Para obter informações sobre a API REST subjacente, consulte Delete Vault (DELETEvault) (p. 181).
Exemplo: excluir um cofre usando a API de nível inferior do AWS SDK para .NET
Para obter um exemplo de código funcional, consulte Exemplo: operações de cofre usando a API de nívelinferior do AWS SDK para .NET (p. 29). O exemplo de código do C# mostra as operações de cofrebásicas, inclusive criar e excluir cofre.
Excluir um cofre no Amazon Glacier usando a APIRESTPara excluir um cofre usando a API REST, consulte Delete Vault (DELETE vault) (p. 181).
Versão da API 2012-06-0157

Amazon Glacier Guia do desenvolvedor doExcluir um cofre usando o console
Excluir um cofre usando o console do Amazon GlacierO Amazon Glacier excluirá um cofre somente se não houver arquivos no cofre desde o inventáriocomputado mais recentemente e não houver gravações no cofre desde o inventário mais recente. Paraobter informações sobre como excluir arquivos, consulte Excluir um arquivo no Amazon Glacier (p. 105).Para obter mais informações sobre como fazer download de um inventário de cofre, consulte Fazerdownload de um inventário de cofre no Amazon Glacier (p. 35).
Veja a seguir as etapas para excluir um cofre usando o console do Amazon Glacier.
1. Faça login no Console de gerenciamento da AWS e abra o console do Amazon Glacier em https://console.aws.amazon.com/glacier.
2. No seletor de regiões, selecione a região da AWS onde o cofre existe.3. Selecione o cofre.4. Clique em Delete Vault.
Marcar os cofres do Amazon GlacierVocê pode atribuir os próprios metadados a cofres do Amazon Glacier na forma de tags. Tag é um par dechave/valor definido por você para um cofre. Para obter informações básicas sobre como marcar, inclusiverestrições sobre tags, consulte Marcar recursos do Amazon Glacier (p. 146).
Os tópicos a seguir descrevem como você pode adicionar, listar e remover tags de cofres.
Tópicos• Marcar cofres usando o console do Amazon Glacier (p. 58)• Marcar cofres usando a Amazon Glacier API (p. 59)• Seções relacionadas (p. 59)
Marcar cofres usando o console do Amazon GlacierVocê pode adicionar, listar e remover tags usando o console do Amazon Glacier conforme descrito nosprocedimentos a seguir.
Para visualizar as tags de um cofre
1. Faça login no Console de gerenciamento da AWS e abra o console do Amazon Glacier em https://console.aws.amazon.com/glacier.
2. No seletor da região, escolha uma região.3. Na página Amazon Glacier Vaults, escolha um cofre.4. Escolha a guia Tags. As tags desse cofre serão exibidas.
Para adicionar uma tag a um cofre
1. Abra o console do Amazon Glacier e escolha uma região usando o seletor.2. Na página Amazon Glacier Vaults, escolha um cofre.3. Escolha a guia Tags.4. Especifique a chave de tag no campo Key; como opção, especifique um valor de tag no campo Value
e escolha Save.
Versão da API 2012-06-0158

Amazon Glacier Guia do desenvolvedor doMarcar cofres usando a Amazon Glacier API
Se o botão Save não estiver habilitado, a chave ou o valor da tag especificado por você não atenderáàs restrições de tag. Para saber mais sobre restrições de tag, consulte Restrições de tag (p. 146).
Para remover uma tag de um cofre
1. Abra o console do Amazon Glacier e escolha uma região usando o seletor.2. Na página Amazon Glacier Vaults, escolha um cofre.3. Escolha a guia Tags e o x ao final da linha que descreve a tag que você deseja excluir.4. Escolha Delete.
Marcar cofres usando a Amazon Glacier APIVocê pode adicionar, listar e remover tags usando a Amazon Glacier API. Para obter exemplos, consulte aseguinte documentação:
Add Tags To Vault (POST tags add) (p. 175)
Adiciona ou atualiza tags do cofre especificado.Listar tags para cofre (GET tags) (p. 201)
Lista as tags do cofre especificado.Remove Tags From Vault (POST tags remove) (p. 208)
Remove as tags do cofre especificado.
Seções relacionadas• Marcar recursos do Amazon Glacier (p. 146)
Amazon Glacier Vault LockOs tópicos a seguir descrevem como bloquear um cofre no Amazon Glacier e como usar políticas do VaultLock.
Tópicos• Visão geral do bloqueio de cofre (p. 59)• Bloquear um cofre usando a API do Amazon Glacier (p. 60)
Visão geral do bloqueio de cofreO Amazon Glacier Vault Lock permite implantar e impor facilmente controles de conformidade para cofresdo Amazon Glacier individuais com uma política de bloqueio do cofre. Você pode especificar controlescomo "Write Once Read Many" (WORM – Uma gravação e muitas leituras) em uma política de bloqueiodo cofre e bloquear a política de edições futuras. Depois de bloqueada, a política não poderá mais seralterada.
O Amazon Glacier impõe os controles definidos na política de bloqueio do cofre para ajudar você a atingiros objetivos de conformidade, por exemplo, de retenção dos dados. Você pode implantar uma grandevariedade de controles de conformidade em uma política de bloqueio do cofre usando a linguagem de
Versão da API 2012-06-0159

Amazon Glacier Guia do desenvolvedor doBloquear um cofre usando a API
política do AWS Identity and Access Management (IAM). Para obter mais informações sobre políticasde bloqueio de cofre, consulte Controle de acesso do Amazon Glacier com políticas de bloqueio decofre (p. 131).
A política de bloqueio de cofre é diferente de uma política de acesso ao cofre. Ambas as políticas regemos controles de acesso ao cofre. No entanto, uma política de bloqueio de cofre pode ser bloqueada paraimpedir alterações futuras, o que proporciona uma imposição rígida para os controles de conformidade.Você pode usar a política de bloqueio de cofre para implantar controles regulatórios e de conformidade,que normalmente exigem controles rígidos sobre o acesso aos dados. Por outro lado, você usa umapolítica de acesso ao cofre para implementar controles de acesso não relacionados à conformidade,temporários e sujeitos a uma modificação frequente. As políticas de bloqueio e acesso ao cofre podem serusadas juntas. Por exemplo, você pode implementar regras de retenção de dados baseadas em tempona política de bloqueio de cofre (deny deletes) e conceder acesso de leitura a terceiros designados ouparceiros de negócios (allow reads).
Bloquear um cofre utiliza duas etapas:
1. Inicie o bloqueio anexando uma política de bloqueio ao cofre, que define o bloqueio como um estado emandamento e retorna um ID de bloqueio. No estado em andamento, você tem 24 horas para validar apolítica de bloqueio de cofre até o ID de bloqueio expirar.
2. Use o ID de bloqueio para concluir o processo de bloqueio. Se a política de bloqueio do cofre nãofuncionar conforme o esperado, você poderá anular o bloqueio e reiniciar desde o início. Para obterinformações sobre como usar a API do Amazon Glacier para bloquear um cofre, consulte Bloquear umcofre usando a API do Amazon Glacier (p. 60).
Bloquear um cofre usando a API do Amazon GlacierPara bloquear o cofre com a API do Amazon Glacier, você primeiro chama Initiate Vault Lock (POST lock-policy) (p. 198) com uma política de bloqueio de cofre que especifica os controles que deseja implantar.Initiate Vault Lock (POST lock-policy) (p. 198) anexa a política ao cofre, faz a transição do bloqueiode cofre para o estado em andamento e retorna um ID de bloqueio exclusivo. Depois que o bloqueio decofre entra no estado em andamento, você tem 24 horas para concluir o bloqueio chamando CompleteVault Lock (POST lockId) (p. 179) com o ID de bloqueio retornado de Initiate Vault Lock (POST lock-policy) (p. 198). Depois que for bloqueado, o cofre não poderá ser desbloqueado.
Se você não concluir o processo de bloqueio do cofre dentro de 24 horas depois de inserir o estado emandamento, o cofre sairá automaticamente do estado em andamento, e a política de bloqueio do cofre seráremovida. Você pode chamar Initiate Vault Lock (POST lock-policy) (p. 198) novamente para instalar umanova política de bloqueio de cofre e fazer a transição para o estado em andamento.
O estado em andamento oferece a oportunidade de testar a política de bloqueio de cofre antes de bloqueá-la. A política de bloqueio de cofre entra totalmente em vigor durante o estado em andamento como seo cofre tivesse sido bloqueado, exceto por você poder remover a política chamando Abort Vault Lock(DELETE lock-policy) (p. 173). Para ajustar a política, você pode repetir a combinação Abort Vault Lock(DELETE lock-policy) (p. 173)/Initiate Vault Lock (POST lock-policy) (p. 198) quantas vezes foremnecessárias a fim de validar as alterações feitas na política de bloqueio do cofre.
Depois de validar a política de bloqueio do cofre, você poderá chamar Complete Vault Lock (POSTlockId) (p. 179) com o ID de bloqueio mais recente para concluir o processo de bloqueio do cofre. O cofrefaz a transição para um estado bloqueado em que a política de bloqueio de cofre é inalterável e não podemais ser removida chamando-se Abort Vault Lock (DELETE lock-policy) (p. 173).
Seções relacionadas• Controle de acesso do Amazon Glacier com políticas de bloqueio de cofre (p. 131)• Abort Vault Lock (DELETE lock-policy) (p. 173)
Versão da API 2012-06-0160

Amazon Glacier Guia do desenvolvedor doBloquear um cofre usando a API
• Complete Vault Lock (POST lockId) (p. 179)• Get Vault Lock (GET lock-policy) (p. 192)• Initiate Vault Lock (POST lock-policy) (p. 198)
Versão da API 2012-06-0161

Amazon Glacier Guia do desenvolvedor doOperações de arquivo
Trabalhar com arquivos no AmazonGlacier
Um arquivo é qualquer objeto, como uma foto, um vídeo ou um documento, armazenado por você emum cofre. Trata-se de uma unidade básica de armazenamento no Amazon Glacier. Cada arquivo temuma ID exclusiva e uma descrição opcional. Ao fazer upload de um arquivo, o Amazon Glacier retornauma resposta que inclui um ID de arquivo. Esse ID de arquivo é exclusivo na região onde o arquivo estáarmazenado. Este é um ID de arquivo de exemplo.
TJgHcrOSfAkV6hdPqOATYfp_0ZaxL1pIBOc02iZ0gDPMr2ig-nhwd_PafstsdIf6HSrjHnP-3p6LCJClYytFT_CBhT9CwNxbRaM5MetS3I-GqwxI3Y8QtgbJbhEQPs0mJ3KExample
Os IDs de arquivo têm 138 bytes. Ao fazer upload de um arquivo, você pode apresentar uma descriçãoopcional. Você pode recuperar um arquivo usando o ID, mas não a descrição.
Important
O Amazon Glacier oferece um console de gerenciamento. Você pode usar o console para criare excluir cofres. No entanto, todas as outras interações com o Amazon Glacier exigem que vocêuse a AWS Command Line Interface (CLI) ou escreva código. Por exemplo, para fazer upload dedados, como fotos, vídeos e outros documentos, você deve usar a AWS CLI ou escrever códigopara fazer solicitações usando a API REST diretamente ou usando os SDKs da AWS. Para obtermais informações sobre como usar o Amazon Glacier com a AWS CLI, vá até Referência da AWSCLI do Amazon Glacier. Para instalar a AWS CLI, vá para a AWS Command Line Interface.
Tópicos• Operações de arquivo no Amazon Glacier (p. 62)• Manter metadados de arquivo no lado do cliente (p. 63)• Fazer upload de um arquivo no Amazon Glacier (p. 63)• Fazer download de um arquivo no Amazon Glacier (p. 79)• Excluir um arquivo no Amazon Glacier (p. 105)• Consulta de arquivos no Amazon Glacier (p. 110)
Operações de arquivo no Amazon GlacierO Amazon Glacier dá suporte às seguintes operações de arquivo básicas: upload, download e exclusão.Fazer download de um arquivo é uma operação assíncrona.
Fazer upload de um arquivo no Amazon GlacierVocê pode fazer upload de um arquivo em uma única operação ou fazer upload dele em partes. Achamada à API usada por você para fazer upload de um arquivo em partes é conhecida como MultipartUpload. Para obter mais informações, consulte Fazer upload de um arquivo no Amazon Glacier (p. 63).
Important
O Amazon Glacier oferece um console de gerenciamento. Você pode usar o console para criare excluir cofres. No entanto, todas as outras interações com o Amazon Glacier exigem que vocêuse a AWS Command Line Interface (CLI) ou escreva código. Por exemplo, para fazer upload dedados, como fotos, vídeos e outros documentos, você deve usar a AWS CLI ou escrever código
Versão da API 2012-06-0162

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo
para fazer solicitações usando a API REST diretamente ou usando os SDKs da AWS. Para obtermais informações sobre como usar o Amazon Glacier com a AWS CLI, vá até Referência da AWSCLI do Amazon Glacier. Para instalar a AWS CLI, vá para a AWS Command Line Interface.
Fazer download de um arquivo no Amazon GlacierFazer download de um arquivo é uma operação assíncrona. Você deve primeiro iniciar um trabalho parafazer download de um arquivo específico. Depois de receber a solicitação de trabalho, o Amazon Glaciervai preparar o arquivo para download. Depois que o trabalho é concluído, você pode fazer download dosdados do arquivo. Por causa da natureza assíncrona do trabalho, você pode solicitar ao Amazon Glacierpara enviar uma notificação para um tópico do Amazon Simple Notification Service (Amazon SNS) quandoo trabalho for concluído. Você pode especificar um tópico do SNS para cada solicitação de trabalhoindividual ou configurar o cofre para enviar uma notificação quando ocorrerem eventos específicos. Paraobter mais informações sobre como fazer download de um arquivo, consulte Fazer download de umarquivo no Amazon Glacier (p. 79).
Excluir um arquivo no Amazon GlacierO Amazon Glacier fornece uma chamada à API que você pode usar para excluir um arquivo por vez. Paraobter mais informações, consulte Excluir um arquivo no Amazon Glacier (p. 105).
Atualizar um arquivo no Amazon GlacierDepois de fazer upload de um arquivo, você não poderá atualizar o conteúdo nem a descrição. A únicamaneira como você pode atualizar o conteúdo do arquivo ou a descrição é excluindo o arquivo e fazendoupload de outro arquivo. Sempre que você faz upload de um arquivo, o Amazon Glacier retorna um ID dearquivo exclusivo.
Manter metadados de arquivo no lado do clienteExceto para a descrição de arquivo opcional, o Amazon Glacier não dá suporte a metadados adicionaisdos arquivos. Quando você faz upload de um arquivo, o Amazon Glacier atribui um ID, uma sequênciade caracteres invisível, do qual não pode inferir nenhum significado sobre o arquivo. Você pode mantermetadados sobre os arquivos no lado do cliente. Os metadados podem incluir o nome do arquivo ealgumas outras informações significativas sobre o arquivo.
Note
Se for um cliente do Amazon Simple Storage Service (Amazon S3), você saberá que, aofazer upload de um objeto em um bucket, você pode atribuir ao objeto uma chave, comoMyDocument.txt ou SomePhoto.jpg. No Amazon Glacier, você não pode atribuir um nome dechave nos arquivos cujo upload faz.
Se você mantiver metadados de arquivo no lado do cliente, observe que o Amazon Glacier manterá uminventário de cofre que inclui IDs de arquivo e todas as descrições fornecidas durante o upload do arquivo.Ocasionalmente, você pode fazer download do inventário de cofre para reconciliar todos os problemasno banco de dados no lado do cliente dos metadados do arquivo. No entanto, o Amazon Glacier utilizao inventário de cofre aproximadamente diário. Quando você solicita um inventário de cofre, o AmazonGlacier retorna o inventário preparado mais recentemente, um snapshot point-in-time.
Fazer upload de um arquivo no Amazon GlacierO Amazon Glacier oferece um console de gerenciamento que você pode usar para criar e excluir cofres.No entanto, você não pode fazer upload de arquivos para o Amazon Glacier usando o console de
Versão da API 2012-06-0163

Amazon Glacier Guia do desenvolvedor doOpções de upload de um arquivo
gerenciamento. Para fazer upload de dados, como fotos, vídeos e outros documentos, você deve usar aAWS CLI ou escrever código para fazer solicitações usando a API REST diretamente ou usando os SDKsda AWS.
Para obter informações sobre como usar o Amazon Glacier com a AWS CLI, vá até Referência da AWSCLI do Amazon Glacier. Para instalar a AWS CLI, vá para a AWS Command Line Interface. Os tópicosa seguir Fazer upload de um arquivo descrevem como fazer upload de arquivos para o Amazon Glacierusando o AWS SDK para Java, o AWS SDK para .NET e a API REST.
Tópicos• Opções de upload de um arquivo para o Amazon Glacier (p. 64)• Fazer upload de um arquivo em uma única operação (p. 65)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)
Opções de upload de um arquivo para o AmazonGlacierDependendo do tamanho dos dados cujo upload você está fazendo, o Amazon Glacier oferece asseguintes opções:
• Fazer upload de arquivos em uma única operação – Em uma única operação, você pode fazer upload dearquivos de 1 byte até 4 GB. Porém, recomendamos que os clientes do Amazon Glacier usem multipartupload para fazer upload de arquivos maiores que 100 MB. Para obter mais informações, consulte Fazerupload de um arquivo em uma única operação (p. 65).
• Fazer upload de arquivos em partes – Usando a multipart upload API, você pode fazer upload dearquivos grandes de até aproximadamente 40.000 GB (10.000 * 4 GB).
A chamada da API de multipart upload foi projetada para melhorar a experiência de upload para arquivosmaiores. Você pode fazer upload de arquivos em partes. O upload dessas partes pode ser feito demaneira independente, em qualquer ordem, e em paralelo. Em caso de falha de um upload da parte,você precisa refazer upload dessa parte, e não de todo o arquivo. Você pode usar um multipart uploadpara arquivos de 1 byte até aproximadamente 40.000 GB. Para obter mais informações, consulte Fazerupload de arquivos grandes em partes (Multipart Upload) (p. 70).
Important
O inventário de cofre do Amazon Glacier é atualizado somente uma vez por dia. Ao fazer uploadde um arquivo, você não verá imediatamente o novo arquivo adicionado ao cofre (no console ouna lista de inventários de cofre obtido por download) até o inventário de cofre ter sido atualizado.
Usar o serviço do AWS SnowballO AWS Snowball acelera a movimentação de grandes volumes de dados para dentro e para fora da AWSusando dispositivos de propriedade da Amazon, sem a necessidade de passar pela Internet. Para obtermais informações, consulte a página de detalhes do AWS Snowball.
Para fazer upload de dados existentes para o Amazon Glacier, convém considerar usar um dos tiposde dispositivo do AWS Snowball para importar dados para o Amazon Simple Storage Service (AmazonS3) e, em seguida, movê-lo para a classe de armazenamento GLACIER do Amazon S3 para fins dearquivamento usando regras de ciclo de vida. Quando você faz a transição de objetos do Amazon S3para a classe de armazenamento do GLACIER, o Amazon S3 usa o Amazon Glacier internamente para adurabilidade do armazenamento por um custo menor. Embora os objetos sejam armazenados no AmazonGlacier, eles continuam sendo objetos do Amazon S3 que você gerencia no Amazon S3, e não é possívelacessá-los diretamente por meio do Amazon Glacier.
Versão da API 2012-06-0164

Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo em uma única operação
Para obter mais informações sobre a configuração do ciclo de vida do Amazon S3 e como fazer a transiçãode objetos para a classe de armazenamento GLACIER, acesse Gerenciamento do ciclo de vida de objetose Transição de objetos no Guia do desenvolvedor do Amazon Simple Storage Service.
Fazer upload de um arquivo em uma única operaçãoConforme descrito em Fazer upload de um arquivo no Amazon Glacier (p. 63), você pode fazer uploadde arquivos menores em uma única operação. No entanto, recomendamos que os clientes do AmazonGlacier usem Multipart Upload para fazer upload de arquivos maiores que 100 MB.
Tópicos• Fazer upload de um arquivo em uma única operação usando-se o AWS SDK for Java (p. 65)• Fazer upload de um arquivo em uma única operação usando o AWS SDK para .NET no Amazon
Glacier (p. 68)• Fazer upload de um arquivo em uma única operação usando a API REST (p. 70)
Fazer upload de um arquivo em uma única operação usando-seo AWS SDK for JavaAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para Javafornecem um método para fazer upload de um arquivo.
Tópicos• Fazer upload de um arquivo usando a API de nível superior do AWS SDK for Java (p. 65)• Fazer upload de um arquivo em uma única operação usando-se a API de nível inferior do AWS SDK
for Java (p. 66)
Fazer upload de um arquivo usando a API de nível superior do AWS SDK for JavaA classe ArchiveTransferManager da API de nível superior fornece o método upload, que você podeusar para fazer upload de um arquivo em um cofre.
Note
Você pode usar o método upload para fazer upload de arquivos grandes ou pequenos.Dependendo do tamanho do arquivo que você estiver fazendo upload, esse método determina seé necessário fazer upload dele em uma única operação ou usar a multipart upload API para fazerupload do arquivo em partes.
Exemplo: fazer upload de um arquivo usando a API de nível superior do AWS SDK for Java
O exemplo de código do Java a seguir faz upload de um arquivo em um cofre (examplevault) na regiãoOeste dos EUA (Oregon) (us-west-2). Para obter uma lista de regiões e endpoints compatíveis, consulteAcessar o Amazon Glacier (p. 5).
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos do Java parao Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o código conforme mostrado com onome do cofre cujo upload você deseja fazer e o nome do arquivo cujo upload deseja fazer.
Example
import java.io.File;import java.io.IOException;import java.util.Date;
Versão da API 2012-06-0165

Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo em uma única operação
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.transfer.ArchiveTransferManager;import com.amazonaws.services.glacier.transfer.UploadResult;
public class ArchiveUploadHighLevel { public static String vaultName = "*** provide vault name ***"; public static String archiveToUpload = "*** provide name of file to upload ***"; public static AmazonGlacierClient client; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider(); client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-west-2.amazonaws.com/");
try { ArchiveTransferManager atm = new ArchiveTransferManager(client, credentials); UploadResult result = atm.upload(vaultName, "my archive " + (new Date()), new File(archiveToUpload)); System.out.println("Archive ID: " + result.getArchiveId()); } catch (Exception e) { System.err.println(e); } }}
Fazer upload de um arquivo em uma única operação usando-se a API de nívelinferior do AWS SDK for Java
A API de nível inferior fornece métodos para todas as operações de arquivo. Veja a seguir as etapas paracarregar um arquivo usando o AWS SDK for Java.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS de onde deseja fazer upload do arquivo. Todas asoperações realizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe UploadArchiveRequest.
Além dos dados cujo upload deseja fazer, você precisa fornecer uma soma de verificação (hash deárvore SHA-256) da carga útil, o nome do cofre, o tamanho do conteúdo dos dados e o ID da conta.
Se você não fornecer um ID da conta, o ID da conta associado às credenciais fornecidas por você paraassinar a solicitação será pressuposto. Para obter mais informações, consulte Usar o AWS SDK forJava com o Amazon Glacier (p. 112).
3. Execute o método uploadArchive fornecendo o objeto de solicitação como um parâmetro.
Em resposta, o Amazon Glacier retorna um ID do arquivo recém-carregado.
O trecho de código Java a seguir ilustra as etapas anteriores.
AmazonGlacierClient client;
Versão da API 2012-06-0166

Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo em uma única operação
UploadArchiveRequest request = new UploadArchiveRequest() .withVaultName("*** provide vault name ***") .withChecksum(checksum) .withBody(new ByteArrayInputStream(body)) .withContentLength((long)body.length);
UploadArchiveResult uploadArchiveResult = client.uploadArchive(request);
System.out.println("Location (includes ArchiveID): " + uploadArchiveResult.getLocation());
Exemplo: fazer upload de um arquivo em uma única operação usando-se a API de nível inferior doAWS SDK for Java
O exemplo de código do Java a seguir usa o AWS SDK for Java para fazer upload de um arquivo em umcofre (examplevault). Para instruções detalhadas sobre como executar esse exemplo, consulte Executarexemplos do Java para o Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o códigoconforme mostrado com o nome do cofre cujo upload você deseja fazer e o nome do arquivo cujo uploaddeseja fazer.
import java.io.ByteArrayInputStream;import java.io.File;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStream;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.TreeHashGenerator;import com.amazonaws.services.glacier.model.UploadArchiveRequest;import com.amazonaws.services.glacier.model.UploadArchiveResult;public class ArchiveUploadLowLevel {
public static String vaultName = "*** provide vault name ****"; public static String archiveFilePath = "*** provide to file upload ****"; public static AmazonGlacierClient client; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-east-1.amazonaws.com/");
try { // First open file and read. File file = new File(archiveFilePath); InputStream is = new FileInputStream(file); byte[] body = new byte[(int) file.length()]; is.read(body); // Send request. UploadArchiveRequest request = new UploadArchiveRequest() .withVaultName(vaultName) .withChecksum(TreeHashGenerator.calculateTreeHash(new File(archiveFilePath))) .withBody(new ByteArrayInputStream(body)) .withContentLength((long)body.length); UploadArchiveResult uploadArchiveResult = client.uploadArchive(request); System.out.println("ArchiveID: " + uploadArchiveResult.getArchiveId()); } catch (Exception e) {
Versão da API 2012-06-0167
Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo em uma única operação
System.err.println("Archive not uploaded."); System.err.println(e); } }}
Fazer upload de um arquivo em uma única operação usando oAWS SDK para .NET no Amazon GlacierAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para .NETfornecem um método para fazer upload de um arquivo em uma única operação.
Tópicos• Fazer upload de um arquivo usando a API de nível superior do AWS SDK para .NET (p. 68)• Fazer upload de um arquivo em uma única operação usando a API de nível inferior do AWS SDK
para .NET (p. 69)
Fazer upload de um arquivo usando a API de nível superior do AWS SDKpara .NETA classe ArchiveTransferManager da API de nível superior fornece o método Upload que você podeusar para fazer upload de um arquivo em um cofre.
Note
Você pode usar o método Upload para fazer upload de arquivos pequenos ou grandes.Dependendo do tamanho do arquivo que você estiver fazendo upload, esse método determina seé necessário fazer upload dele em uma única operação ou usar a API de multipart upload parafazer upload do arquivo em partes.
Exemplo: fazer upload de um arquivo usando a API de nível superior do AWS SDK para .NET
O exemplo de código do C# a seguir faz upload de um arquivo em um cofre (examplevault) no RegiãoOeste dos EUA (Oregon).
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com o nome do arquivo cujo uploaddeseja fazer.
Example
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveUploadHighLevel { static string vaultName = "examplevault"; static string archiveToUpload = "*** Provide file name (with full path) to upload ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2); // Upload an archive.
Versão da API 2012-06-0168

Amazon Glacier Guia do desenvolvedor doFazer upload de um arquivo em uma única operação
string archiveId = manager.Upload(vaultName, "upload archive test", archiveToUpload).ArchiveId; Console.WriteLine("Archive ID: (Copy and save this ID for use in other examples.) : {0}", archiveId); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } }}
Fazer upload de um arquivo em uma única operação usando a API de nívelinferior do AWS SDK para .NET
A API de nível inferior fornece métodos para todas as operações de arquivo. Estas são as etapas parafazer upload de um arquivo usando-se o AWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS de onde deseja fazer upload do arquivo. Todas asoperações realizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe UploadArchiveRequest.
Além dos dados cujo upload deseja fazer, você precisa fornecer uma soma de verificação (hash deárvore SHA-256) da carga útil, o nome do cofre e o ID da conta.
Se você não fornecer um ID da conta, o ID da conta associado às credenciais fornecidas por vocêpara assinar a solicitação será pressuposto. Para obter mais informações, consulte Usar o AWS SDKpara .NET com o Amazon Glacier (p. 115).
3. Execute o método UploadArchive fornecendo o objeto de solicitação como um parâmetro.
Em resposta, o Amazon Glacier retorna um ID do arquivo recém-carregado.
Exemplo: fazer upload de um arquivo em uma única operação usando a API de nível inferior doAWS SDK para .NET
O exemplo de código do C# a seguir ilustra as etapas anteriores. O exemplo usa o AWS SDK para .NETpara fazer upload de um arquivo em um cofre (examplevault).
Note
Para obter informações sobre a API REST subjacente para fazer upload de um arquivo em umaúnica solicitação, consulte Upload Archive (POST archive) (p. 217).
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com o nome do arquivo cujo uploaddeseja fazer.
Example
using System;using System.IO;using Amazon.Glacier;using Amazon.Glacier.Model;
Versão da API 2012-06-0169

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveUploadSingleOpLowLevel { static string vaultName = "examplevault"; static string archiveToUpload = "*** Provide file name (with full path) to upload ***";
public static void Main(string[] args) { AmazonGlacierClient client; try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Uploading an archive."); string archiveId = UploadAnArchive(client); Console.WriteLine("Archive ID: {0}", archiveId); } } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static string UploadAnArchive(AmazonGlacierClient client) { using (FileStream fileStream = new FileStream(archiveToUpload, FileMode.Open, FileAccess.Read)) { string treeHash = TreeHashGenerator.CalculateTreeHash(fileStream); UploadArchiveRequest request = new UploadArchiveRequest() { VaultName = vaultName, Body = fileStream, Checksum = treeHash }; UploadArchiveResponse response = client.UploadArchive(request); string archiveID = response.ArchiveId; return archiveID; } } }}
Fazer upload de um arquivo em uma única operação usando aAPI RESTVocê pode usar a chamada de API Upload Archive do Amazon Glacier para fazer upload de um arquivoem uma única operação. Para obter mais informações, consulte Upload Archive (POST archive) (p. 217).
Fazer upload de arquivos grandes em partes (MultipartUpload)Tópicos
• Processo Multipart Upload (p. 71)• Fatos rápidos (p. 72)
Versão da API 2012-06-0170

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
• Fazer upload de arquivos grandes em partes usando o AWS SDK para Java (p. 72)• Fazer upload de arquivos grandes usando o AWS SDK para .NET (p. 76)• Fazer upload de arquivos grandes em partes usando a API REST (p. 79)
Processo Multipart UploadConforme descrito em Fazer upload de um arquivo no Amazon Glacier (p. 63) recomendamos que osclientes do Amazon Glacier usem Multipart Upload para fazer upload de arquivos maiores que 100 MB.
1. Iniciar o multipart upload
Quando você envia uma solicitação para iniciar um multipart upload, o Amazon Glacier retorna umID de multipart upload, que é um identificador exclusivo do multipart upload. Todas as operações demultipart upload subsequentes exigirão esse ID. O ID é válido por pelo menos 24 horas.
Na solicitação para iniciar um multipart upload, você deve especificar o tamanho da parte em númerode bytes. Cada parte do upload, exceto a última, deve ser desse tamanho.
Note
Você não precisa saber o tamanho do arquivo geral ao usar o Multipart Upload. Issopossibilita casos de uso nos quais o tamanho de arquivo não seja conhecido quando vocêinicia o upload do arquivo. Você precisa decidir somente o tamanho da parte no momento emque inicia um multipart upload.
Na solicitação de multipart upload de iniciação, você também pode fornecer uma descrição de arquivoopcional.
2. Partes de upload
Para cada solicitação de upload da parte, você deve incluir o ID de multipart upload obtido na etapa1. Na solicitação, você também deve especificar o intervalo de conteúdo, em bytes, identificando aposição da parte no arquivo final. O Amazon Glacier usará as informações do intervalo de conteúdopara montar o arquivo na sequência apropriada. Como você fornece o intervalo de conteúdo paracada parte do upload, ele determina a posição da parte na montagem final do arquivo e, assim, podefazer upload de partes em qualquer ordem. Você também pode fazer upload de partes em paralelo.Se você fizer upload de uma nova parte usando o mesmo intervalo de conteúdo como uma partecarregada anteriormente, a parte cujo upload foi feito anteriormente será substituída.
3. Concluir (ou anular) Multipart Upload
Depois de fazer upload de todas as partes do arquivo, você usará a operação completa. Maisuma vez, você deve especificar o ID de upload na solicitação. O Amazon Glacier cria um arquivoconcatenando partes em ordem crescente com base no intervalo de conteúdo fornecido por você.A resposta do Amazon Glacier a uma solicitação Complete Multipart Upload inclui um ID do arquivorecém-criado. Se você tiver fornecido uma descrição de arquivo opcional na solicitação InitiateMultipart Upload, o Amazon Glacier o associará ao arquivo montado. Depois de concluir com êxito ummultipart upload, você não poderá se referir ao ID de multipart upload. Isso significa você não podeacessar partes associadas ao ID de multipart upload.
Se anular um multipart upload, você não poderá fazer mais upload de partes usando esse ID demultipart upload. Todo o armazenamento consumido por todas as partes associadas ao multipartupload anulado é liberado. Se algum upload de parte estiver em andamento, ele ainda poderá serbem-sucedido ou falhar mesmo depois da anulação.
Operações de multipart upload adicionais
O Amazon Glacier oferece as chamadas de API de multipart upload adicionais a seguir.
Versão da API 2012-06-0171
Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
• List Parts—Usando essa operação, você pode listar as partes de um multipart upload. Isso retornainformações sobre as partes cujo upload você fez para um multipart upload. Para cada solicitação departes da lista, o Amazon Glacier retorna informações para até 1.000 partes. Se houver mais partesa serem listadas para o multipart upload, o resultado será paginado, e um marcador será retornadona resposta na qual a lista deve continuar. Você precisa enviar solicitações adicionais para recuperarpartes subsequentes. Observe que a lista de partes retornada não inclui partes que não tiveram o uploadconcluído.
• List Multipart Uploads—Usando essa operação, você pode obter uma lista de multipart uploads emandamento. Um multipart upload em andamento é um upload que você iniciou, mas que ainda nãoconcluiu ou anulou. Para cada solicitação de multipart uploads da lista, o Amazon Glacier retorna até1.000 multipart uploads. Se houver mais multipart uploads a serem listadas, o resultado será paginado, eum marcador será retornado na resposta na qual a lista deve continuar. Você precisa enviar solicitaçõesadicionais para recuperar os multipart uploads restantes.
Fatos rápidosA tabela a seguir fornece especificações básicas do multipart upload.
Item Especificação
Tamanho de arquivo máximo 10,000 x 4 GB
Número máximo de partes por upload 10.000
Tamanho da parte De 1 MB a 4 GB; a última parte podem ter < 1 MB. Vocêespecifica o valor de tamanho em bytes.
O tamanho da parte deve ser um megabyte (1.024 KB)elevado a uma potência de 2. Por exemplo, 1048576 (1 MB),2097152 (2 MB), 4194304 (4 MB), 8388608 (8 MB).
Número máximo de partes retornadasem uma solicitação de listagem departes
1.000
Número máximo de multipart uploadsretornados em uma solicitação delistagem de multipart uploads
1.000
Fazer upload de arquivos grandes em partes usando o AWS SDKpara JavaAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para Javafornecem um método para fazer upload de um arquivo grande (consulte Fazer upload de um arquivo noAmazon Glacier (p. 63)).
• A API de nível superior fornece um método que você pode usar para fazer upload de arquivos dequalquer tamanho. Dependendo do arquivo que você estiver fazendo upload, o método faz upload deum arquivo em uma única operação ou usa o suporte a multipart upload no Amazon Glacier para fazerupload do arquivo em partes.
• A API de nível inferior é mapeada junto à implementação de REST subjacente. Dessa forma, ela forneceum método para fazer upload de arquivos menores em uma operação e um grupo de métodos que dãosuporte a multipart upload para arquivos maiores. Esta seção explica como fazer upload de arquivosgrandes em partes usando a API de nível inferior.
Versão da API 2012-06-0172

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
Para obter mais informações sobre as APIs de níveis superior e inferior, consulte Usar o AWS SDK forJava com o Amazon Glacier (p. 112).
Tópicos• Fazer upload de arquivos grandes em partes usando a API de nível superior do AWS SDK for Java
(p. 73)• Fazer upload de arquivos grandes em partes usando a API de nível inferior do AWS SDK for
Java (p. 73)
Fazer upload de arquivos grandes em partes usando a API de nível superior doAWS SDK for Java
Você pode usar os mesmos métodos da API de nível superior para fazer upload de arquivos grandesou pequenos. Com base no tamanho do arquivo, os métodos da API de nível superior decidem se énecessário fazer upload do arquivo em uma única operação ou usar a multipart upload API fornecida peloAmazon Glacier. Para obter mais informações, consulte Fazer upload de um arquivo usando a API de nívelsuperior do AWS SDK for Java (p. 65).
Fazer upload de arquivos grandes em partes usando a API de nível inferior doAWS SDK for Java
Para controle granular do upload, você pode usar a API de nível inferior, em que pode configurar asolicitação e processar a resposta. Estas são as etapas para fazer upload de arquivos grandes em partesusando o AWS SDK for Java.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde deseja salvar o arquivo. Todas as operaçõesrealizadas por você usando esse cliente se aplicam a essa região.
2. Inicie multipart upload chamando o método initiateMultipartUpload.
Você precisa fornecer o nome do cofre no qual deseja fazer upload do arquivo, o tamanho da parte quedeseja usar para fazer upload das partes do arquivo e uma descrição opcional. Você precisa forneceressas informações criando uma instância da classe InitiateMultipartUploadRequest. Emresposta, o Amazon Glacier retorna um ID de upload.
3. Faça upload de partes chamando o método uploadMultipartPart.
Para cada parte cujo upload faz, você precisa fornecer o nome do cofre, o intervalo de bytes no arquivomontado final cujo upload será feito nessa parte, a soma de verificação dos dados da parte e o ID deupload.
4. Conclua multipart upload chamando o método completeMultipartUpload.
Você precisa fornecer o ID de upload, a soma de verificação de todo o arquivo, o tamanho do arquivo(tamanho combinado de todas as partes cujo upload você fez) e o nome do cofre. O Amazon Glaciercria o arquivo a partir das partes carregadas e retorna um ID de arquivo.
Exemplo: fazer upload de um arquivo grande em partes usando o AWS SDK for Java
O exemplo de código do Java a seguir usa o AWS SDK for Java para fazer upload de um arquivo em umcofre (examplevault). Para instruções detalhadas sobre como executar esse exemplo, consulte Executarexemplos do Java para o Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o códigoconforme mostrado com o nome do arquivo cujo upload deseja fazer.
Versão da API 2012-06-0173

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
Note
Este exemplo é válido para tamanhos de parte de 1 MB a 1 GB. No entanto, o Amazon Glacier dásuporte a tamanhos de parte de até 4 GB.
Example
import java.io.ByteArrayInputStream;import java.io.File;import java.io.FileInputStream;import java.io.IOException;import java.security.NoSuchAlgorithmException;import java.util.Arrays;import java.util.Date;import java.util.LinkedList;import java.util.List;
import com.amazonaws.AmazonClientException;import com.amazonaws.AmazonServiceException;import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.TreeHashGenerator;import com.amazonaws.services.glacier.model.CompleteMultipartUploadRequest;import com.amazonaws.services.glacier.model.CompleteMultipartUploadResult;import com.amazonaws.services.glacier.model.InitiateMultipartUploadRequest;import com.amazonaws.services.glacier.model.InitiateMultipartUploadResult;import com.amazonaws.services.glacier.model.UploadMultipartPartRequest;import com.amazonaws.services.glacier.model.UploadMultipartPartResult;import com.amazonaws.util.BinaryUtils;
public class ArchiveMPU {
public static String vaultName = "examplevault"; // This example works for part sizes up to 1 GB. public static String partSize = "1048576"; // 1 MB. public static String archiveFilePath = "*** provide archive file path ***"; public static AmazonGlacierClient client; public static void main(String[] args) throws IOException {
ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-west-2.amazonaws.com/");
try { System.out.println("Uploading an archive."); String uploadId = initiateMultipartUpload(); String checksum = uploadParts(uploadId); String archiveId = CompleteMultiPartUpload(uploadId, checksum); System.out.println("Completed an archive. ArchiveId: " + archiveId); } catch (Exception e) { System.err.println(e); }
} private static String initiateMultipartUpload() { // Initiate InitiateMultipartUploadRequest request = new InitiateMultipartUploadRequest() .withVaultName(vaultName) .withArchiveDescription("my archive " + (new Date())) .withPartSize(partSize);
Versão da API 2012-06-0174

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
InitiateMultipartUploadResult result = client.initiateMultipartUpload(request); System.out.println("ArchiveID: " + result.getUploadId()); return result.getUploadId(); }
private static String uploadParts(String uploadId) throws AmazonServiceException, NoSuchAlgorithmException, AmazonClientException, IOException {
int filePosition = 0; long currentPosition = 0; byte[] buffer = new byte[Integer.valueOf(partSize)]; List<byte[]> binaryChecksums = new LinkedList<byte[]>(); File file = new File(archiveFilePath); FileInputStream fileToUpload = new FileInputStream(file); String contentRange; int read = 0; while (currentPosition < file.length()) { read = fileToUpload.read(buffer, filePosition, buffer.length); if (read == -1) { break; } byte[] bytesRead = Arrays.copyOf(buffer, read);
contentRange = String.format("bytes %s-%s/*", currentPosition, currentPosition + read - 1); String checksum = TreeHashGenerator.calculateTreeHash(new ByteArrayInputStream(bytesRead)); byte[] binaryChecksum = BinaryUtils.fromHex(checksum); binaryChecksums.add(binaryChecksum); System.out.println(contentRange); //Upload part. UploadMultipartPartRequest partRequest = new UploadMultipartPartRequest() .withVaultName(vaultName) .withBody(new ByteArrayInputStream(bytesRead)) .withChecksum(checksum) .withRange(contentRange) .withUploadId(uploadId); UploadMultipartPartResult partResult = client.uploadMultipartPart(partRequest); System.out.println("Part uploaded, checksum: " + partResult.getChecksum()); currentPosition = currentPosition + read; } fileToUpload.close(); String checksum = TreeHashGenerator.calculateTreeHash(binaryChecksums); return checksum; }
private static String CompleteMultiPartUpload(String uploadId, String checksum) throws NoSuchAlgorithmException, IOException { File file = new File(archiveFilePath);
CompleteMultipartUploadRequest compRequest = new CompleteMultipartUploadRequest() .withVaultName(vaultName) .withUploadId(uploadId) .withChecksum(checksum) .withArchiveSize(String.valueOf(file.length())); CompleteMultipartUploadResult compResult = client.completeMultipartUpload(compRequest); return compResult.getLocation(); }
Versão da API 2012-06-0175

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
}
Fazer upload de arquivos grandes usando o AWS SDKpara .NETAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para .NETfornecem um método para fazer upload de arquivos grandes em partes (consulte Fazer upload de umarquivo no Amazon Glacier (p. 63)).
• A API de nível superior fornece um método que você pode usar para fazer upload de arquivos dequalquer tamanho. Dependendo do arquivo que você estiver fazendo upload, o método faz upload doarquivo em uma única operação ou usa o suporte a multipart upload no Amazon Glacier para fazerupload do arquivo em partes.
• A API de nível inferior é mapeada junto à implementação de REST subjacente. Dessa forma, ela forneceum método para fazer upload de arquivos menores em uma operação e um grupo de métodos que dãosuporte a multipart upload para arquivos maiores. Esta seção explica como fazer upload de arquivosgrandes em partes usando a API de nível inferior.
Para obter mais informações sobre as APIs de níveis superior e inferior, consulte Usar o AWS SDKpara .NET com o Amazon Glacier (p. 115).
Tópicos• Fazer upload de arquivos grandes em partes usando a API de nível superior do AWS SDK para .NET
(p. 76)• Fazer upload de arquivos grandes em partes usando a API de nível inferior do AWS SDK para .NET
(p. 76)
Fazer upload de arquivos grandes em partes usando a API de nível superior doAWS SDK para .NETVocê pode usar os mesmos métodos da API de nível superior para fazer upload de arquivos grandesou pequenos. Com base no tamanho do arquivo, os métodos da API de nível superior decidem se énecessário fazer upload do arquivo em uma única operação ou usar a multipart upload API fornecida peloAmazon Glacier. Para obter mais informações, consulte Fazer upload de um arquivo usando a API de nívelsuperior do AWS SDK para .NET (p. 68).
Fazer upload de arquivos grandes em partes usando a API de nível inferior doAWS SDK para .NETPara controle granular do upload, você pode usar a API de nível inferior, em que pode configurar asolicitação e processar a resposta. Estas são as etapas para fazer upload de arquivos grandes em partesusando o AWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde deseja salvar o arquivo. Todas as operaçõesrealizadas por você usando esse cliente se aplicam a essa região.
2. Inicie multipart upload chamando o método InitiateMultipartUpload.
Você precisa fornecer o nome do cofre para o qual deseja fazer upload do arquivo, o tamanho daparte que deseja usar para fazer upload das partes do arquivo e uma descrição opcional. Você precisafornecer essas informações criando uma instância da classe InitiateMultipartUploadRequest.Em resposta, o Amazon Glacier retorna um ID de upload.
3. Faça upload de partes chamando o método UploadMultipartPart.
Versão da API 2012-06-0176

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
Para cada parte cujo upload faz, você precisa fornecer o nome do cofre, o intervalo de bytes no arquivomontado final cujo upload será feito nessa parte, a soma de verificação dos dados da parte e o ID deupload.
4. Conclua o multipart upload chamando o método CompleteMultipartUpload.
Você precisa fornecer o ID de upload, a soma de verificação de todo o arquivo, o tamanho do arquivo(tamanho combinado de todas as partes cujo upload você fez) e o nome do cofre. O Amazon Glaciercria o arquivo a partir das partes carregadas e retorna um ID de arquivo.
Exemplo: fazer upload de um arquivo grande em partes usando o AWS SDK para .NET
O exemplo de código do C# a seguir usa o AWS SDK para .NET para fazer upload de um arquivo em umcofre (examplevault). Para instruções detalhadas sobre como executar esse exemplo, consulte Executarexemplos de código (p. 116). Você precisa atualizar o código conforme mostrado com o nome de umarquivo cujo upload deseja fazer.
Example
using System;using System.Collections.Generic;using System.IO;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveUploadMPU { static string vaultName = "examplevault"; static string archiveToUpload = "*** Provide file name (with full path) to upload ***"; static long partSize = 4194304; // 4 MB.
public static void Main(string[] args) { AmazonGlacierClient client; List<string> partChecksumList = new List<string>(); try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Uploading an archive."); string uploadId = InitiateMultipartUpload(client); partChecksumList = UploadParts(uploadId, client); string archiveId = CompleteMPU(uploadId, client, partChecksumList); Console.WriteLine("Archive ID: {0}", archiveId); } Console.WriteLine("Operations successful. To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static string InitiateMultipartUpload(AmazonGlacierClient client) { InitiateMultipartUploadRequest initiateMPUrequest = new InitiateMultipartUploadRequest()
Versão da API 2012-06-0177

Amazon Glacier Guia do desenvolvedor doFazer upload de arquivos grandes em partes
{
VaultName = vaultName, PartSize = partSize, ArchiveDescription = "Test doc uploaded using MPU." };
InitiateMultipartUploadResponse initiateMPUresponse = client.InitiateMultipartUpload(initiateMPUrequest);
return initiateMPUresponse.UploadId; }
static List<string> UploadParts(string uploadID, AmazonGlacierClient client) { List<string> partChecksumList = new List<string>(); long currentPosition = 0; var buffer = new byte[Convert.ToInt32(partSize)];
long fileLength = new FileInfo(archiveToUpload).Length; using (FileStream fileToUpload = new FileStream(archiveToUpload, FileMode.Open, FileAccess.Read)) { while (fileToUpload.Position < fileLength) { Stream uploadPartStream = GlacierUtils.CreatePartStream(fileToUpload, partSize); string checksum = TreeHashGenerator.CalculateTreeHash(uploadPartStream); partChecksumList.Add(checksum); // Upload part. UploadMultipartPartRequest uploadMPUrequest = new UploadMultipartPartRequest() {
VaultName = vaultName, Body = uploadPartStream, Checksum = checksum, UploadId = uploadID }; uploadMPUrequest.SetRange(currentPosition, currentPosition + uploadPartStream.Length - 1); client.UploadMultipartPart(uploadMPUrequest);
currentPosition = currentPosition + uploadPartStream.Length; } } return partChecksumList; }
static string CompleteMPU(string uploadID, AmazonGlacierClient client, List<string> partChecksumList) { long fileLength = new FileInfo(archiveToUpload).Length; CompleteMultipartUploadRequest completeMPUrequest = new CompleteMultipartUploadRequest() { UploadId = uploadID, ArchiveSize = fileLength.ToString(), Checksum = TreeHashGenerator.CalculateTreeHash(partChecksumList), VaultName = vaultName };
CompleteMultipartUploadResponse completeMPUresponse = client.CompleteMultipartUpload(completeMPUrequest); return completeMPUresponse.ArchiveId; } }
Versão da API 2012-06-0178

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo
}
Fazer upload de arquivos grandes em partes usando a API RESTConforme descrito em Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70), multipartupload se refere a um conjunto de operações do Amazon Glacier que permitem fazer upload de umarquivo em partes e realizar operações relacionadas. Para obter mais informações sobre essas operações,consulte os seguintes tópicos de referência da API:
• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Part (PUT uploadID) (p. 239)• Complete Multipart Upload (POST uploadID) (p. 223)• Abort Multipart Upload (DELETE uploadID) (p. 221)• List Parts (GET uploadID) (p. 230)• List Multipart Uploads (GET multipart-uploads) (p. 234)
Fazer download de um arquivo no Amazon GlacierO Amazon Glacier oferece um console de gerenciamento que você pode usar para criar e excluircofres. No entanto, você não pode fazer download de arquivos do Amazon Glacier usando o console degerenciamento. Para fazer download de dados, como fotos, vídeos e outros documentos, você deve usar aAWS CLI ou escrever código para fazer solicitações usando a API REST diretamente ou usando os SDKsda AWS.
Para obter informações sobre como usar o Amazon Glacier com a AWS CLI, consulte Referência da AWSCLI do Amazon Glacier. Para instalar a AWS CLI, consulte AWS Command Line Interface. Os tópicos aseguir Fazer download de um arquivo descrevem como fazer download de arquivos para o Amazon Glacierusando o AWS SDK para Java, o AWS SDK para .NET e a API REST.
Recuperar arquivos do Amazon GlacierRecuperar um arquivo do Amazon Glacier é uma operação assíncrona na qual você primeiro iniciaum trabalho e, em seguida, faz download da saída depois de concluí-lo. Para iniciar um trabalhode recuperação de arquivo, você deve usar a Initiate Job (trabalhos POST) (p. 257) API REST ouequivalente na CLI da AWS ou nos SDKs da AWS.
Tópicos• Opções de recuperação de arquivos (p. 80)• Recuperações de arquivo no intervalo (p. 82)
Recuperar um arquivo do Amazon Glacier é um processo de duas etapas.
Para recuperar um arquivo
1. Inicie um trabalho de recuperação de arquivo.
a. Obtenha o ID do arquivo que você deseja recuperar. Você pode obter o ID de arquivo de uminventário de cofre. Para obter mais informações, consulte Fazer download de um inventário decofre no Amazon Glacier (p. 35).
b. Inicie um trabalho solicitando que o Amazon Glacier prepare um arquivo inteiro ou uma parte delepara download subsequente usando a operação Initiate Job (trabalhos POST) (p. 257).
Versão da API 2012-06-0179

Amazon Glacier Guia do desenvolvedor doRecuperar arquivos
Quando você inicia um trabalho, o Amazon Glacier cria um ID de trabalho na resposta e executa otrabalho de maneira assíncrona. (Você não poderá fazer download da saída do trabalho depois daconclusão do trabalho conforme descrito na Etapa 2.)
Important
Somente para recuperações Padrão, uma política de recuperação de dados pode causaruma falha na solicitação do trabalho de recuperação de inicialização com uma exceçãoPolicyEnforcedException. Para obter mais informações sobre políticas de recuperaçãode dados, consulte Políticas de recuperação dos dados do Amazon Glacier (p. 142). Paraobter mais informações sobre a exceção PolicyEnforcedException, consulte Respostasde erro (p. 169).
2. Após a conclusão do trabalho, faça download dos bytes usando a operação Get Job Output (GEToutput) (p. 251).
Você pode fazer download de todos os bytes ou especificar um intervalo de bytes para fazer downloadsomente de uma parte da saída do trabalho. Para uma saída maior, fazer download da saída emblocos ajudará se houver uma falha no download, como uma falha de rede. Se obtiver a saída dotrabalho em uma única solicitação e houver uma falha na rede, você precisará reiniciar o downloadda saída desde o início. No entanto, se fizer download da saída em blocos, em caso de alguma falha,você precisará somente reiniciar o download da parte menor, e não de toda a saída.
O Amazon Glacier deve concluir o trabalho para você obter a saída. Depois da conclusão, um trabalho nãovai expirar por pelo menos 24 horas após a conclusão, o que significa que você pode fazer download dasaída dentro do período de 24 horas depois da conclusão do trabalho. Para determinar se o trabalho estáconcluído, verifique o status usando uma das seguintes opções:
• Aguardar a notificação de conclusão de um trabalho– Você pode especificar um tópico do AmazonSimple Notification Service (Amazon SNS) no qual o Amazon Glacier poderá publicar uma notificaçãodepois que o trabalho for concluído. O Amazon Glacier enviará uma notificação somente depois deconcluir o trabalho.
Você pode especificar um tópico do Amazon SNS para um trabalho ao iniciá-lo. Além de especificarum tópico do Amazon SNS na solicitação de trabalho, se o cofre tiver uma configuração de notificaçãodefinida para eventos de recuperação do arquivo, o Amazon Glacier também publicará uma notificaçãopara esse tópico do SNS. Para obter mais informações, consulte Configurar notificações de cofre noAmazon Glacier (p. 47).
• Solicitar informações do trabalho explicitamente — Você também pode usar a operação describejob do Amazon Glacier (Trabalho de descrição (GET JobID) (p. 243)) para sondar periodicamenteinformações de trabalho. No entanto, recomendamos usar as notificações do Amazon SNS.
Note
As informações obtidas por você usando a notificação do SNS são as mesmas recebidas quandose chama Describe Job.
Opções de recuperação de arquivosVocê pode especificar um dos seguintes ao iniciar um trabalho para recuperar um arquivo com base nosrequisitos de tempo e custo de acesso. Para obter informações sobre definição de preço da recuperação,consulte Definição de preço do Amazon Glacier.
• Expressa — As recuperações expressas permitem acessar rapidamente os dados quando foremnecessárias solicitações urgentes ocasionais para um subconjunto de arquivos. Exceto para os arquivos
Versão da API 2012-06-0180

Amazon Glacier Guia do desenvolvedor doRecuperar arquivos
maiores (mais de 250 MB), os dados acessados usando-se recuperações expressas costumam serdisponibilizados dentro de 1 a 5 minutos. Há dois tipos de recuperações expressas: sob demandae provisionadas. As solicitações sob demandas são semelhantes às instâncias sob demanda doEC2 e estão disponíveis na maior parte do tempo. As solicitações provisionadas estarão disponíveisgarantidamente quando você precisar delas. Para obter mais informações, consulte Capacidadeprovisionada (p. 81).
• Padrão — As recuperações padrão permitem acessar qualquer um dos arquivos em algumas horas. Asrecuperações padrão normalmente são concluídas dentro de 3 a 5 horas. Esta é a opção padrão parasolicitações de recuperação que não especificam a opção de recuperação.
• Em massa — As recuperações em massa são a opção de recuperação de menor custo do AmazonGlacier, que você pode usar para recuperar grandes quantidades de dados, até mesmo petabytes, emum dia. As recuperações em massa normalmente são concluídas dentro de 5 a 12 horas.
Para fazer uma recuperação expressa, padrão ou em massa, defina o parâmetro Tier na solicitaçãoInitiate Job (trabalhos POST) (p. 257) API REST como a opção desejada por você, ou o equivalentena AWS CLI, ou nos SDKs da AWS. Você não precisa designar se uma recuperação expressa é sobdemanda ou provisionada. Se você tiver adquirido a capacidade provisionada, todas as recuperaçõesexpressas serão fornecidas automaticamente por meio da capacidade provisionada.
Capacidade provisionada
A capacidade provisionada garante que sua capacidade de recuperação para recuperações expressasestará disponível quando você precisar dela. Cada unidade de capacidade garante que pelo menos trêsrecuperações expressas possam ser realizadas a cada cinco minutos e fornece até 150 MB/s de taxa detransferência de recuperação.
Você deve comprar a capacidade de recuperação provisionada se sua carga de trabalho exigir acessoaltamente confiável e previsível a um subconjunto de seus dados em minutos. As recuperações expressassão aceitas sem capacidade provisionada, exceto para situações raras de demanda incomumente alta.Contudo, se precisar de acesso a recuperações expressas em todas as circunstâncias, você deve comprara capacidade de recuperação provisionada.
Comprar capacidade provisionada
Você pode comprar unidades de capacidade provisionadas usando o console do Amazon Glacier, aPurchase Provisioned Capacity (POST provisioned-capacity) (p. 293) API REST, os SDKs do AWS oua AWS CLI. Para obter informações sobre a definição de preço da capacidade provisionada, consulteDefinição de preço do Amazon Glacier.
Uma unidade de capacidade provisionada dura um mês a partir da data e hora da compra, que é a datade início. A unidade expira na data de expiração, que é exatamente um mês depois da data de início até osegundo mais próximo.
Se a data de início é dia 31 de um mês, a data de expiração será o último dia do mês seguinte. Porexemplo, se a data de início é dia 31 de agosto, a data de expiração será dia 30 de setembro. Se a data deinício é dia 31 de janeiro, a data de expiração será dia 28 de fevereiro.
Para usar o console do Amazon Glacier a fim de comprar capacidade provisionada, escolha Settings eProvisioned capacity.
Versão da API 2012-06-0181
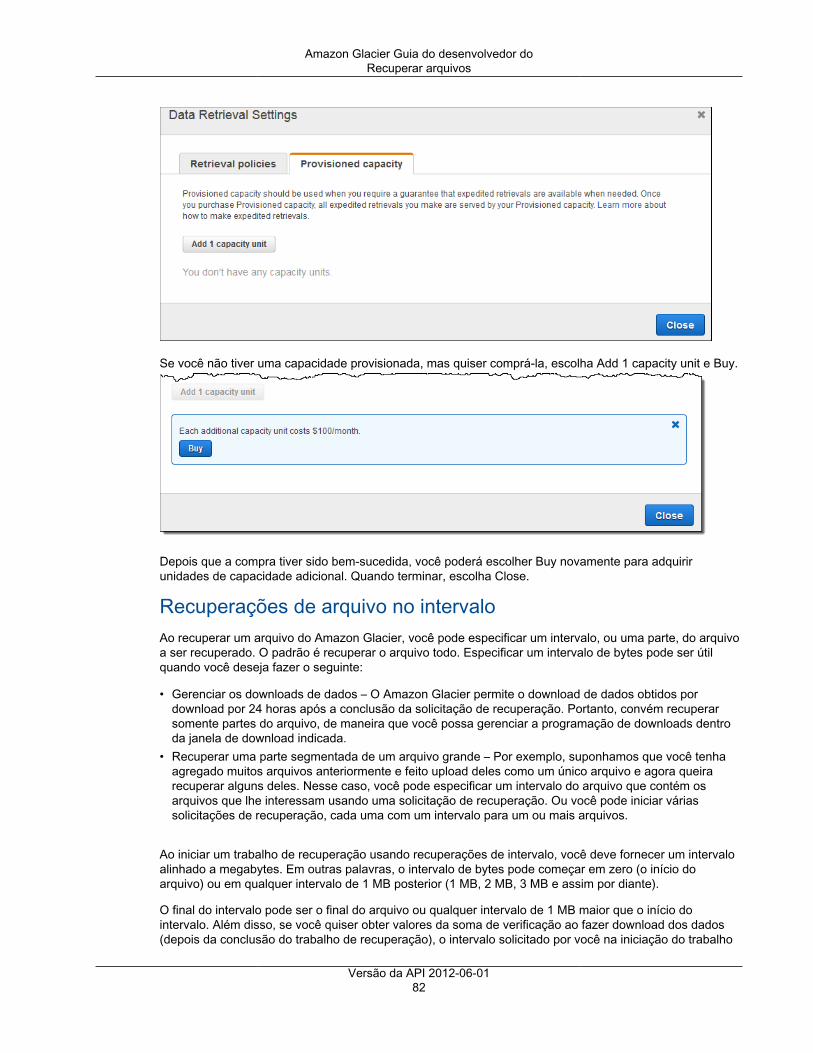
Amazon Glacier Guia do desenvolvedor doRecuperar arquivos
Se você não tiver uma capacidade provisionada, mas quiser comprá-la, escolha Add 1 capacity unit e Buy.
Depois que a compra tiver sido bem-sucedida, você poderá escolher Buy novamente para adquirirunidades de capacidade adicional. Quando terminar, escolha Close.
Recuperações de arquivo no intervaloAo recuperar um arquivo do Amazon Glacier, você pode especificar um intervalo, ou uma parte, do arquivoa ser recuperado. O padrão é recuperar o arquivo todo. Especificar um intervalo de bytes pode ser útilquando você deseja fazer o seguinte:
• Gerenciar os downloads de dados – O Amazon Glacier permite o download de dados obtidos pordownload por 24 horas após a conclusão da solicitação de recuperação. Portanto, convém recuperarsomente partes do arquivo, de maneira que você possa gerenciar a programação de downloads dentroda janela de download indicada.
• Recuperar uma parte segmentada de um arquivo grande – Por exemplo, suponhamos que você tenhaagregado muitos arquivos anteriormente e feito upload deles como um único arquivo e agora queirarecuperar alguns deles. Nesse caso, você pode especificar um intervalo do arquivo que contém osarquivos que lhe interessam usando uma solicitação de recuperação. Ou você pode iniciar váriassolicitações de recuperação, cada uma com um intervalo para um ou mais arquivos.
Ao iniciar um trabalho de recuperação usando recuperações de intervalo, você deve fornecer um intervaloalinhado a megabytes. Em outras palavras, o intervalo de bytes pode começar em zero (o início doarquivo) ou em qualquer intervalo de 1 MB posterior (1 MB, 2 MB, 3 MB e assim por diante).
O final do intervalo pode ser o final do arquivo ou qualquer intervalo de 1 MB maior que o início dointervalo. Além disso, se você quiser obter valores da soma de verificação ao fazer download dos dados(depois da conclusão do trabalho de recuperação), o intervalo solicitado por você na iniciação do trabalho
Versão da API 2012-06-0182
Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
também deverá estar alinhado ao hash de árvore. Somas de verificação são uma maneira de você garantirque os dados não tenham sido corrompidos durante a transmissão. Para obter mais informações sobreos alinhamentos a megabytes e ao hash de árvore, consulte Receber somas de verificação durante odownload de dados (p. 167).
Fazer download de um arquivo no Amazon Glacierusando o AWS SDK for JavaAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para Javafornecem um método para fazer download de um arquivo.
Tópicos• Fazer download de um arquivo usando a API de nível superior do AWS SDK for Java (p. 83)• Fazer download de um arquivo usando a API de nível inferior do AWS SDK for Java (p. 84)
Fazer download de um arquivo usando a API de nível superior doAWS SDK for JavaA classe ArchiveTransferManager da API de nível superior fornece o método download que vocêpode usar para fazer download de um arquivo.
Important
A classe ArchiveTransferManager cria um tópico do Amazon Simple Notification Service(Amazon SNS), além de uma fila do Amazon Simple Queue Service (Amazon SQS) inscritanesse tópico. Em seguida, ela inicia o trabalho de recuperação do arquivo e sonda a fila embusca do arquivo disponível. Assim que o arquivo estiver disponível, o download começará.Para obter informações sobre tempos de recuperação, consulte Opções de recuperação dearquivos (p. 80).
Exemplo: fazer download de um arquivo usando a API de nível superior do AWSSDK for Java
O exemplo de código do Java a seguir faz download de um arquivo de um cofre (examplevault) naregião Oeste dos EUA (Oregon) (us-west-2).
Para obter instruções passo a passo a fim de executar essa amostra, consulte Executar exemplos do Javapara o Amazon Glacier usando o Eclipse (p. 114). Você precisa atualizar o código conforme mostradocom um ID de arquivo existente e o caminho do arquivo local onde deseja salvar o arquivo obtido pordownload.
Example
import java.io.File;import java.io.IOException;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.transfer.ArchiveTransferManager;import com.amazonaws.services.sns.AmazonSNSClient;import com.amazonaws.services.sqs.AmazonSQSClient;
public class ArchiveDownloadHighLevel { public static String vaultName = "examplevault";
Versão da API 2012-06-0183

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
public static String archiveId = "*** provide archive ID ***"; public static String downloadFilePath = "*** provide location to download archive ***"; public static AmazonGlacierClient glacierClient; public static AmazonSQSClient sqsClient; public static AmazonSNSClient snsClient; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider(); glacierClient = new AmazonGlacierClient(credentials); sqsClient = new AmazonSQSClient(credentials); snsClient = new AmazonSNSClient(credentials); glacierClient.setEndpoint("glacier.us-west-2.amazonaws.com"); sqsClient.setEndpoint("sqs.us-west-2.amazonaws.com"); snsClient.setEndpoint("sns.us-west-2.amazonaws.com");
try { ArchiveTransferManager atm = new ArchiveTransferManager(glacierClient, sqsClient, snsClient); atm.download(vaultName, archiveId, new File(downloadFilePath)); System.out.println("Downloaded file to " + downloadFilePath); } catch (Exception e) { System.err.println(e); } }}
Fazer download de um arquivo usando a API de nível inferior doAWS SDK for JavaEstas são as etapas para recuperar um inventário de cofre usando a API de nível inferior do AWS SDK forJava.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS de onde deseja fazer download do arquivo. Todas asoperações realizadas por você usando esse cliente se aplicam a essa região.
2. Inicie um trabalho archive-retrieval executando o método initiateJob.
Você fornece informações do trabalho, como o ID do arquivo cujo download você deseja fazere o tópico do Amazon SNS no qual deseja que o Amazon Glacier publique uma mensagem deconclusão do trabalho criando uma instância da classe InitiateJobRequest. Em resposta, oAmazon Glacier retorna um ID de trabalho. A resposta está disponível em uma instância da classeInitiateJobResult.
JobParameters jobParameters = new JobParameters() .withArchiveId("*** provide an archive id ***") .withDescription("archive retrieval") .withRetrievalByteRange("*** provide a retrieval range***") // optional .withType("archive-retrieval");
InitiateJobResult initiateJobResult = client.initiateJob(new InitiateJobRequest() .withJobParameters(jobParameters) .withVaultName(vaultName));
Versão da API 2012-06-0184

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
String jobId = initiateJobResult.getJobId();
Você também pode especificar um intervalo de bytes para solicitar ao Amazon Glacier que preparesomente uma parte do arquivo. Por exemplo, você pode atualizar a solicitação anterior adicionandoa instrução a seguir para solicitar que o Amazon Glacier prepare somente a parte de 1 MB a 2 MB doarquivo.
int ONE_MEG = 1048576;String retrievalByteRange = String.format("%s-%s", ONE_MEG, 2*ONE_MEG -1);
JobParameters jobParameters = new JobParameters() .withType("archive-retrieval") .withArchiveId(archiveId) .withRetrievalByteRange(retrievalByteRange) .withSNSTopic(snsTopicARN);
InitiateJobResult initiateJobResult = client.initiateJob(new InitiateJobRequest() .withJobParameters(jobParameters) .withVaultName(vaultName)); String jobId = initiateJobResult.getJobId();
3. Aguarde a conclusão do trabalho.
Você deve aguardar até a saída do trabalho estar pronta para download. Se você tiver definido umaconfiguração de notificação no cofre identificando um tópico do Amazon Simple Notification Service(Amazon SNS) ou especificado um tópico do Amazon SNS quando tiver iniciado um trabalho, o AmazonGlacier enviará uma mensagem para esse tópico depois de concluir o trabalho.
Você também pode sondar o Amazon Glacier chamando o método describeJob para determinar ostatus de conclusão do trabalho. Apesar disso, usar um tópico do Amazon SNS para notificação é aabordagem recomendada.
4. Faça download da saída do trabalho (dados de arquivo) executando o método getJobOutput.
Você fornece as informações da solicitação, como o ID de trabalho e o nome do cofre, criando umainstância da classe GetJobOutputRequest. A saída retornada pelo Amazon Glacier está disponívelno objeto GetJobOutputResult.
GetJobOutputRequest jobOutputRequest = new GetJobOutputRequest() .withJobId("*** provide a job ID ***") .withVaultName("*** provide a vault name ****");GetJobOutputResult jobOutputResult = client.getJobOutput(jobOutputRequest);
// jobOutputResult.getBody() // Provides the input stream.
O trecho de código anterior faz download de toda a saída do trabalho. Opcionalmente, você poderecuperar somente uma parte da saída ou fazer download de toda a saída em blocos menoresespecificando o intervalo de bytes em GetJobOutputRequest.
GetJobOutputRequest jobOutputRequest = new GetJobOutputRequest() .withJobId("*** provide a job ID ***") .withRange("bytes=0-1048575") // Download only the first 1 MB of the output. .withVaultName("*** provide a vault name ****");
Em resposta à chamada GetJobOutput, o Amazon Glacier retornará a soma de verificação daparte dos dados obtidos por download, se determinadas condições forem atendidas. Para obter maisinformações, consulte Receber somas de verificação durante o download de dados (p. 167).
Versão da API 2012-06-0185

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
Para verificar se não há erros no download, você pode computar a soma de verificação no lado docliente e compará-la com a soma de verificação enviada pelo Amazon Glacier na resposta.
Para um trabalho de recuperação de arquivo com o intervalo opcional especificado, quando vocêobtém a descrição de trabalho, ele inclui a soma de verificação do intervalo que está recuperando(SHA256TreeHash). Você pode usar esse valor para verificar a precisão de todo o intervalo de bytescujo download fará depois. Por exemplo, se iniciar um trabalho para recuperar um intervalo alinhadoao hash de árvore e fizer download de saída em blocos, de maneira que cada uma das solicitaçõesGetJobOutput retorne uma soma de verificação, você poderá computar a soma de verificação de cadaparte cujo download você faz no lado do cliente e o hash de árvore. Você pode compará-la com a somade verificação retornada pelo Amazon Glacier em resposta à solicitação do trabalho de descrição paraverificar se todo o intervalo de bytes obtido por download é igual ao intervalo de bytes armazenado noAmazon Glacier.
Para obter um exemplo de trabalho, consulte Exemplo 2: recuperar um arquivo usando a API de nívelinferior do AWS SDK for Java – Fazer download da saída em blocos (p. 90).
Exemplo 1: recuperar de um arquivo usando a API de nível inferior do AWS SDKfor JavaO exemplo de código do Java a seguir faz download de um arquivo do cofre especificado. Depois que otrabalho for concluído, o exemplo fará download de toda a saída em uma única chamada getJobOutput.Para obter um exemplo de como fazer download de saída em blocos, consulte Exemplo 2: recuperarum arquivo usando a API de nível inferior do AWS SDK for Java – Fazer download da saída em blocos (p. 90).
O exemplo realiza as seguintes tarefas:
• Cria um tópico do Amazon Simple Notification Service (Amazon SNS).
O Amazon Glacier enviará uma notificação para esse tópico depois de concluir o trabalho.• Cria uma fila do Amazon Simple Queue Service (Amazon SQS).
O exemplo anexa uma política à fila para permitir que o tópico do Amazon SNS publique mensagens nafila.
• Inicia um trabalho para fazer download do arquivo especificado.
Na solicitação de trabalho, o tópico do Amazon SNS criado é especificado, de maneira que o AmazonGlacier possa publicar uma notificação no tópico depois de concluir o trabalho.
• Verifica periodicamente a fila do Amazon SQS em busca de uma mensagem que contenha o ID dotrabalho.
Se houver uma mensagem, analise o JSON e verifique se o trabalho foi concluído com êxito. Secontiver, faça download do arquivo.
• Limpa excluindo o tópico do Amazon SNS e a fila do Amazon SQS criada por ele.
import java.io.BufferedInputStream;import java.io.BufferedOutputStream;import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.FileOutputStream;import java.io.FileWriter;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.io.OutputStream;
Versão da API 2012-06-0186

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
import java.util.HashMap;import java.util.List;import java.util.Map;
import org.codehaus.jackson.JsonFactory;import org.codehaus.jackson.JsonNode;import org.codehaus.jackson.JsonParseException;import org.codehaus.jackson.JsonParser;import org.codehaus.jackson.map.ObjectMapper;
import com.amazonaws.AmazonClientException;import com.amazonaws.auth.policy.Policy;import com.amazonaws.auth.policy.Principal;import com.amazonaws.auth.policy.Resource;import com.amazonaws.auth.policy.Statement;import com.amazonaws.auth.policy.Statement.Effect;import com.amazonaws.auth.policy.actions.SQSActions;import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.model.GetJobOutputRequest;import com.amazonaws.services.glacier.model.GetJobOutputResult;import com.amazonaws.services.glacier.model.InitiateJobRequest;import com.amazonaws.services.glacier.model.InitiateJobResult;import com.amazonaws.services.glacier.model.JobParameters;import com.amazonaws.services.sns.AmazonSNSClient;import com.amazonaws.services.sns.model.CreateTopicRequest;import com.amazonaws.services.sns.model.CreateTopicResult;import com.amazonaws.services.sns.model.DeleteTopicRequest;import com.amazonaws.services.sns.model.SubscribeRequest;import com.amazonaws.services.sns.model.SubscribeResult;import com.amazonaws.services.sns.model.UnsubscribeRequest;import com.amazonaws.services.sqs.AmazonSQSClient;import com.amazonaws.services.sqs.model.CreateQueueRequest;import com.amazonaws.services.sqs.model.CreateQueueResult;import com.amazonaws.services.sqs.model.DeleteQueueRequest;import com.amazonaws.services.sqs.model.GetQueueAttributesRequest;import com.amazonaws.services.sqs.model.GetQueueAttributesResult;import com.amazonaws.services.sqs.model.Message;import com.amazonaws.services.sqs.model.ReceiveMessageRequest;import com.amazonaws.services.sqs.model.SetQueueAttributesRequest;
public class AmazonGlacierDownloadArchiveWithSQSPolling { public static String archiveId = "*** provide archive ID ****"; public static String vaultName = "*** provide vault name ***"; public static String snsTopicName = "*** provide topic name ***"; public static String sqsQueueName = "*** provide queue name ***"; public static String sqsQueueARN; public static String sqsQueueURL; public static String snsTopicARN; public static String snsSubscriptionARN; public static String fileName = "*** provide file name ***"; public static String region = "*** region ***"; public static long sleepTime = 600; public static AmazonGlacierClient client; public static AmazonSQSClient sqsClient; public static AmazonSNSClient snsClient; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier." + region + ".amazonaws.com"); sqsClient = new AmazonSQSClient(credentials);
Versão da API 2012-06-0187

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
sqsClient.setEndpoint("https://sqs." + region + ".amazonaws.com"); snsClient = new AmazonSNSClient(credentials); snsClient.setEndpoint("https://sns." + region + ".amazonaws.com"); try { setupSQS(); setupSNS();
String jobId = initiateJobRequest(); System.out.println("Jobid = " + jobId); Boolean success = waitForJobToComplete(jobId, sqsQueueURL); if (!success) { throw new Exception("Job did not complete successfully."); } downloadJobOutput(jobId); cleanUp(); } catch (Exception e) { System.err.println("Archive retrieval failed."); System.err.println(e); } }
private static void setupSQS() { CreateQueueRequest request = new CreateQueueRequest() .withQueueName(sqsQueueName); CreateQueueResult result = sqsClient.createQueue(request); sqsQueueURL = result.getQueueUrl(); GetQueueAttributesRequest qRequest = new GetQueueAttributesRequest() .withQueueUrl(sqsQueueURL) .withAttributeNames("QueueArn"); GetQueueAttributesResult qResult = sqsClient.getQueueAttributes(qRequest); sqsQueueARN = qResult.getAttributes().get("QueueArn"); Policy sqsPolicy = new Policy().withStatements( new Statement(Effect.Allow) .withPrincipals(Principal.AllUsers) .withActions(SQSActions.SendMessage) .withResources(new Resource(sqsQueueARN))); Map<String, String> queueAttributes = new HashMap<String, String>(); queueAttributes.put("Policy", sqsPolicy.toJson()); sqsClient.setQueueAttributes(new SetQueueAttributesRequest(sqsQueueURL, queueAttributes));
} private static void setupSNS() { CreateTopicRequest request = new CreateTopicRequest() .withName(snsTopicName); CreateTopicResult result = snsClient.createTopic(request); snsTopicARN = result.getTopicArn();
SubscribeRequest request2 = new SubscribeRequest() .withTopicArn(snsTopicARN) .withEndpoint(sqsQueueARN) .withProtocol("sqs"); SubscribeResult result2 = snsClient.subscribe(request2); snsSubscriptionARN = result2.getSubscriptionArn(); } private static String initiateJobRequest() {
Versão da API 2012-06-0188

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
JobParameters jobParameters = new JobParameters() .withType("archive-retrieval") .withArchiveId(archiveId) .withSNSTopic(snsTopicARN); InitiateJobRequest request = new InitiateJobRequest() .withVaultName(vaultName) .withJobParameters(jobParameters); InitiateJobResult response = client.initiateJob(request); return response.getJobId(); } private static Boolean waitForJobToComplete(String jobId, String sqsQueueUrl) throws InterruptedException, JsonParseException, IOException { Boolean messageFound = false; Boolean jobSuccessful = false; ObjectMapper mapper = new ObjectMapper(); JsonFactory factory = mapper.getJsonFactory(); while (!messageFound) { List<Message> msgs = sqsClient.receiveMessage( new ReceiveMessageRequest(sqsQueueUrl).withMaxNumberOfMessages(10)).getMessages();
if (msgs.size() > 0) { for (Message m : msgs) { JsonParser jpMessage = factory.createJsonParser(m.getBody()); JsonNode jobMessageNode = mapper.readTree(jpMessage); String jobMessage = jobMessageNode.get("Message").getTextValue(); JsonParser jpDesc = factory.createJsonParser(jobMessage); JsonNode jobDescNode = mapper.readTree(jpDesc); String retrievedJobId = jobDescNode.get("JobId").getTextValue(); String statusCode = jobDescNode.get("StatusCode").getTextValue(); if (retrievedJobId.equals(jobId)) { messageFound = true; if (statusCode.equals("Succeeded")) { jobSuccessful = true; } } } } else { Thread.sleep(sleepTime * 1000); } } return (messageFound && jobSuccessful); } private static void downloadJobOutput(String jobId) throws IOException { GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest() .withVaultName(vaultName) .withJobId(jobId); GetJobOutputResult getJobOutputResult = client.getJobOutput(getJobOutputRequest); InputStream input = new BufferedInputStream(getJobOutputResult.getBody()); OutputStream output = null; try { output = new BufferedOutputStream(new FileOutputStream(fileName));
byte[] buffer = new byte[1024 * 1024];
Versão da API 2012-06-0189

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
int bytesRead = 0; do { bytesRead = input.read(buffer); if (bytesRead <= 0) break; output.write(buffer, 0, bytesRead); } while (bytesRead > 0); } catch (IOException e) { throw new AmazonClientException("Unable to save archive", e); } finally { try {input.close();} catch (Exception e) {} try {output.close();} catch (Exception e) {} } System.out.println("Retrieved archive to " + fileName); } private static void cleanUp() { snsClient.unsubscribe(new UnsubscribeRequest(snsSubscriptionARN)); snsClient.deleteTopic(new DeleteTopicRequest(snsTopicARN)); sqsClient.deleteQueue(new DeleteQueueRequest(sqsQueueURL)); }}
Exemplo 2: recuperar um arquivo usando a API de nível inferior do AWS SDK forJava – Fazer download da saída em blocos
O exemplo de código do Java a seguir recupera um arquivo do Amazon Glacier. O exemplo de códigofaz download da saída do trabalho em blocos especificando um intervalo de bytes em um objetoGetJobOutputRequest.
import java.io.BufferedInputStream;import java.io.ByteArrayInputStream;import java.io.FileOutputStream;import java.io.IOException;import java.util.HashMap;import java.util.List;import java.util.Map;
import com.fasterxml.jackson.core.JsonFactory;import com.fasterxml.jackson.core.JsonParseException;import com.fasterxml.jackson.core.JsonParser;import com.fasterxml.jackson.databind.JsonNode;import com.fasterxml.jackson.databind.ObjectMapper;
import com.amazonaws.auth.policy.Policy;import com.amazonaws.auth.policy.Principal;import com.amazonaws.auth.policy.Resource;import com.amazonaws.auth.policy.Statement;import com.amazonaws.auth.policy.Statement.Effect;import com.amazonaws.auth.policy.actions.SQSActions;import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.TreeHashGenerator;import com.amazonaws.services.glacier.model.GetJobOutputRequest;import com.amazonaws.services.glacier.model.GetJobOutputResult;import com.amazonaws.services.glacier.model.InitiateJobRequest;import com.amazonaws.services.glacier.model.InitiateJobResult;import com.amazonaws.services.glacier.model.JobParameters;import com.amazonaws.services.sns.AmazonSNSClient;import com.amazonaws.services.sns.model.CreateTopicRequest;import com.amazonaws.services.sns.model.CreateTopicResult;import com.amazonaws.services.sns.model.DeleteTopicRequest;import com.amazonaws.services.sns.model.SubscribeRequest;import com.amazonaws.services.sns.model.SubscribeResult;
Versão da API 2012-06-0190

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
import com.amazonaws.services.sns.model.UnsubscribeRequest;import com.amazonaws.services.sqs.AmazonSQSClient;import com.amazonaws.services.sqs.model.CreateQueueRequest;import com.amazonaws.services.sqs.model.CreateQueueResult;import com.amazonaws.services.sqs.model.DeleteQueueRequest;import com.amazonaws.services.sqs.model.GetQueueAttributesRequest;import com.amazonaws.services.sqs.model.GetQueueAttributesResult;import com.amazonaws.services.sqs.model.Message;import com.amazonaws.services.sqs.model.ReceiveMessageRequest;import com.amazonaws.services.sqs.model.SetQueueAttributesRequest;
public class ArchiveDownloadLowLevelWithRange { public static String vaultName = "*** provide vault name ***"; public static String archiveId = "*** provide archive id ***"; public static String snsTopicName = "glacier-temp-sns-topic"; public static String sqsQueueName = "glacier-temp-sqs-queue"; public static long downloadChunkSize = 4194304; // 4 MB public static String sqsQueueARN; public static String sqsQueueURL; public static String snsTopicARN; public static String snsSubscriptionARN; public static String fileName = "*** provide file name to save archive to ***"; public static String region = "*** region ***"; public static long sleepTime = 600; public static AmazonGlacierClient client; public static AmazonSQSClient sqsClient; public static AmazonSNSClient snsClient; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier." + region + ".amazonaws.com"); sqsClient = new AmazonSQSClient(credentials); sqsClient.setEndpoint("https://sqs." + region + ".amazonaws.com"); snsClient = new AmazonSNSClient(credentials); snsClient.setEndpoint("https://sns." + region + ".amazonaws.com"); try { setupSQS(); setupSNS();
String jobId = initiateJobRequest(); System.out.println("Jobid = " + jobId); long archiveSizeInBytes = waitForJobToComplete(jobId, sqsQueueURL); if (archiveSizeInBytes==-1) { throw new Exception("Job did not complete successfully."); } downloadJobOutput(jobId, archiveSizeInBytes); cleanUp(); } catch (Exception e) { System.err.println("Archive retrieval failed."); System.err.println(e); } }
private static void setupSQS() { CreateQueueRequest request = new CreateQueueRequest()
Versão da API 2012-06-0191

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
.withQueueName(sqsQueueName); CreateQueueResult result = sqsClient.createQueue(request); sqsQueueURL = result.getQueueUrl(); GetQueueAttributesRequest qRequest = new GetQueueAttributesRequest() .withQueueUrl(sqsQueueURL) .withAttributeNames("QueueArn"); GetQueueAttributesResult qResult = sqsClient.getQueueAttributes(qRequest); sqsQueueARN = qResult.getAttributes().get("QueueArn"); Policy sqsPolicy = new Policy().withStatements( new Statement(Effect.Allow) .withPrincipals(Principal.AllUsers) .withActions(SQSActions.SendMessage) .withResources(new Resource(sqsQueueARN))); Map<String, String> queueAttributes = new HashMap<String, String>(); queueAttributes.put("Policy", sqsPolicy.toJson()); sqsClient.setQueueAttributes(new SetQueueAttributesRequest(sqsQueueURL, queueAttributes));
} private static void setupSNS() { CreateTopicRequest request = new CreateTopicRequest() .withName(snsTopicName); CreateTopicResult result = snsClient.createTopic(request); snsTopicARN = result.getTopicArn();
SubscribeRequest request2 = new SubscribeRequest() .withTopicArn(snsTopicARN) .withEndpoint(sqsQueueARN) .withProtocol("sqs"); SubscribeResult result2 = snsClient.subscribe(request2); snsSubscriptionARN = result2.getSubscriptionArn(); } private static String initiateJobRequest() { JobParameters jobParameters = new JobParameters() .withType("archive-retrieval") .withArchiveId(archiveId) .withSNSTopic(snsTopicARN); InitiateJobRequest request = new InitiateJobRequest() .withVaultName(vaultName) .withJobParameters(jobParameters); InitiateJobResult response = client.initiateJob(request); return response.getJobId(); } private static long waitForJobToComplete(String jobId, String sqsQueueUrl) throws InterruptedException, JsonParseException, IOException { Boolean messageFound = false; Boolean jobSuccessful = false; long archiveSizeInBytes = -1; ObjectMapper mapper = new ObjectMapper(); JsonFactory factory = mapper.getFactory(); while (!messageFound) { List<Message> msgs = sqsClient.receiveMessage( new ReceiveMessageRequest(sqsQueueUrl).withMaxNumberOfMessages(10)).getMessages();
Versão da API 2012-06-0192

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o Java
if (msgs.size() > 0) { for (Message m : msgs) { JsonParser jpMessage = factory.createJsonParser(m.getBody()); JsonNode jobMessageNode = mapper.readTree(jpMessage); String jobMessage = jobMessageNode.get("Message").textValue(); JsonParser jpDesc = factory.createJsonParser(jobMessage); JsonNode jobDescNode = mapper.readTree(jpDesc); String retrievedJobId = jobDescNode.get("JobId").textValue(); String statusCode = jobDescNode.get("StatusCode").textValue(); archiveSizeInBytes = jobDescNode.get("ArchiveSizeInBytes").longValue(); if (retrievedJobId.equals(jobId)) { messageFound = true; if (statusCode.equals("Succeeded")) { jobSuccessful = true; } } } } else { Thread.sleep(sleepTime * 1000); } } return (messageFound && jobSuccessful) ? archiveSizeInBytes : -1; } private static void downloadJobOutput(String jobId, long archiveSizeInBytes) throws IOException { if (archiveSizeInBytes < 0) { System.err.println("Nothing to download."); return; }
System.out.println("archiveSizeInBytes: " + archiveSizeInBytes); FileOutputStream fstream = new FileOutputStream(fileName); long startRange = 0; long endRange = (downloadChunkSize > archiveSizeInBytes) ? archiveSizeInBytes -1 : downloadChunkSize - 1;
do {
GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest() .withVaultName(vaultName) .withRange("bytes=" + startRange + "-" + endRange) .withJobId(jobId); GetJobOutputResult getJobOutputResult = client.getJobOutput(getJobOutputRequest);
BufferedInputStream is = new BufferedInputStream(getJobOutputResult.getBody()); byte[] buffer = new byte[(int)(endRange - startRange + 1)];
System.out.println("Checksum received: " + getJobOutputResult.getChecksum()); System.out.println("Content range " + getJobOutputResult.getContentRange());
int totalRead = 0; while (totalRead < buffer.length) { int bytesRemaining = buffer.length - totalRead; int read = is.read(buffer, totalRead, bytesRemaining); if (read > 0) { totalRead = totalRead + read; } else { break;
Versão da API 2012-06-0193

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
} } System.out.println("Calculated checksum: " + TreeHashGenerator.calculateTreeHash(new ByteArrayInputStream(buffer))); System.out.println("read = " + totalRead); fstream.write(buffer); startRange = startRange + (long)totalRead; endRange = ((endRange + downloadChunkSize) > archiveSizeInBytes) ? archiveSizeInBytes : (endRange + downloadChunkSize); is.close(); } while (endRange <= archiveSizeInBytes && startRange < archiveSizeInBytes); fstream.close(); System.out.println("Retrieved file to " + fileName);
} private static void cleanUp() { snsClient.unsubscribe(new UnsubscribeRequest(snsSubscriptionARN)); snsClient.deleteTopic(new DeleteTopicRequest(snsTopicARN)); sqsClient.deleteQueue(new DeleteQueueRequest(sqsQueueURL)); }}
Fazer download de um arquivo no Amazon Glacierusando o AWS SDK para .NETAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para .NETfornecem um método para fazer download de um arquivo.
Tópicos• Fazer download de um arquivo usando a API de nível superior do AWS SDK para .NET (p. 94)• Fazer download de um arquivo usando a API de nível inferior do AWS SDK para .NET (p. 95)
Fazer download de um arquivo usando a API de nível superior doAWS SDK para .NETA classe ArchiveTransferManager da API de nível superior fornece o método Download que vocêpode usar para fazer download de um arquivo.
Important
A classe ArchiveTransferManager cria um tópico do Amazon Simple Notification Service(Amazon SNS), além de uma fila do Amazon Simple Queue Service (Amazon SQS) inscritanesse tópico. Em seguida, ela inicia o trabalho de recuperação do arquivo e sonda a fila embusca do arquivo disponível. Assim que o arquivo estiver disponível, o download começará.Para obter informações sobre tempos de recuperação, consulte Opções de recuperação dearquivos (p. 80)
Exemplo: fazer download de um arquivo usando a API de nível superior do AWSSDK para .NET
O exemplo de código do C# a seguir faz download de um arquivo de um cofre (examplevault) na regiãoRegião Oeste dos EUA (Oregon).
Versão da API 2012-06-0194

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com um ID de arquivo existente e ocaminho do arquivo local onde deseja salvar o arquivo obtido por download.
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveDownloadHighLevel { static string vaultName = "examplevault"; static string archiveId = "*** Provide archive ID ***"; static string downloadFilePath = "*** Provide the file name and path to where to store the download ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2);
var options = new DownloadOptions(); options.StreamTransferProgress += ArchiveDownloadHighLevel.progress; // Download an archive. Console.WriteLine("Intiating the archive retrieval job and then polling SQS queue for the archive to be available."); Console.WriteLine("Once the archive is available, downloading will begin."); manager.Download(vaultName, archiveId, downloadFilePath, options); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static int currentPercentage = -1; static void progress(object sender, StreamTransferProgressArgs args) { if (args.PercentDone != currentPercentage) { currentPercentage = args.PercentDone; Console.WriteLine("Downloaded {0}%", args.PercentDone); } } }}
Fazer download de um arquivo usando a API de nível inferior doAWS SDK para .NETEstas são as etapas para fazer download de um arquivo do Amazon Glacier usando a API de nível inferiordo AWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Versão da API 2012-06-0195

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
Você precisa especificar uma região da AWS de onde deseja fazer download do arquivo. Todas asoperações realizadas por você usando esse cliente se aplicam a essa região.
2. Inicie um trabalho archive-retrieval executando o método InitiateJob.
Você fornece informações do trabalho, como o ID do arquivo cujo download você deseja fazere o tópico do Amazon SNS no qual deseja que o Amazon Glacier publique uma mensagem deconclusão do trabalho criando uma instância da classe InitiateJobRequest. Em resposta, oAmazon Glacier retorna um ID de trabalho. A resposta está disponível em uma instância da classeInitiateJobResponse.
AmazonGlacierClient client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2);
InitiateJobRequest initJobRequest = new InitiateJobRequest(){ VaultName = vaultName, JobParameters = new JobParameters() { Type = "archive-retrieval", ArchiveId = "*** Provide archive id ***", SNSTopic = "*** Provide Amazon SNS topic ARN ***", }};
InitiateJobResponse initJobResponse = client.InitiateJob(initJobRequest);string jobId = initJobResponse.JobId;
Você também pode especificar um intervalo de bytes a fim de solicitar que o Amazon Glacier preparesomente uma parte do arquivo, conforme mostrado na solicitação a seguir. A solicitação especifica queo Amazon Glacier prepare somente a parte de 1 a 2 MB do arquivo.
AmazonGlacierClient client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2);
InitiateJobRequest initJobRequest = new InitiateJobRequest(){ VaultName = vaultName, JobParameters = new JobParameters() { Type = "archive-retrieval", ArchiveId = "*** Provide archive id ***", SNSTopic = "*** Provide Amazon SNS topic ARN ***", }};// Specify byte range.int ONE_MEG = 1048576;initJobRequest.JobParameters.RetrievalByteRange = string.Format("{0}-{1}", ONE_MEG, 2 * ONE_MEG -1);
InitiateJobResponse initJobResponse = client.InitiateJob(initJobRequest);string jobId = initJobResponse.JobId;
3. Aguarde a conclusão do trabalho.
Você deve aguardar até a saída do trabalho estar pronta para download. Se você tiver definido umaconfiguração de notificação no cofre identificando um tópico do Amazon Simple Notification Service(Amazon SNS) ou especificado um tópico do Amazon SNS quando tiver iniciado um trabalho, o AmazonGlacier enviará uma mensagem para esse tópico depois de concluir o trabalho. O exemplo de códigoindicado na seção a seguir usa o Amazon SNS para o Amazon Glacier para publicar uma mensagem.
Versão da API 2012-06-0196

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
Você também pode sondar o Amazon Glacier chamando o método DescribeJob para determinar ostatus de conclusão do trabalho. Apesar disso, usar um tópico do Amazon SNS para notificação é aabordagem recomendada.
4. Faça download da saída do trabalho (dados de arquivo) executando o método GetJobOutput.
Você fornece as informações da solicitação, como o ID de trabalho e o nome do cofre, criando umainstância da classe GetJobOutputRequest. A saída retornada pelo Amazon Glacier está disponívelno objeto GetJobOutputResponse.
GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest(){ JobId = jobId, VaultName = vaultName};
GetJobOutputResponse getJobOutputResponse = client.GetJobOutput(getJobOutputRequest);using (Stream webStream = getJobOutputResponse.Body){ using (Stream fileToSave = File.OpenWrite(fileName)) { CopyStream(webStream, fileToSave); }}
O trecho de código anterior faz download de toda a saída do trabalho. Opcionalmente, você poderecuperar somente uma parte da saída ou fazer download de toda a saída em blocos menoresespecificando o intervalo de bytes em GetJobOutputRequest.
GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest(){ JobId = jobId, VaultName = vaultName};getJobOutputRequest.SetRange(0, 1048575); // Download only the first 1 MB chunk of the output.
Em resposta à chamada GetJobOutput, o Amazon Glacier retornará a soma de verificação daparte dos dados obtidos por download, se determinadas condições forem atendidas. Para obter maisinformações, consulte Receber somas de verificação durante o download de dados (p. 167).
Para verificar se não há erros no download, você pode computar a soma de verificação no lado docliente e compará-la com a soma de verificação enviada pelo Amazon Glacier na resposta.
Para um trabalho de recuperação de arquivo com o intervalo opcional especificado, quando vocêobtém a descrição do trabalho, ela inclui a soma de verificação do intervalo que você está recuperando(SHA256TreeHash). Você também pode usar esse valor para verificar a precisão de todo o intervalode bytes cujo download fará depois. Por exemplo, se iniciar um trabalho para recuperar um intervaloalinhado ao hash de árvore e fizer download de saída em blocos, de maneira que cada uma dassolicitações GetJobOutput retorne uma soma de verificação, você poderá computar a soma deverificação de cada parte cujo download você faz no lado do cliente e o hash de árvore. Você podecompará-la com a soma de verificação retornada pelo Amazon Glacier em resposta à solicitação dotrabalho de descrição para verificar se todo o intervalo de bytes obtido por download é igual ao intervalode bytes armazenado no Amazon Glacier.
Para obter um exemplo de trabalho, consulte Exemplo 2: recuperar um arquivo usando a API de nívelinferior do AWS SDK para .NET – Fazer download da saída em blocos (p. 101).
Versão da API 2012-06-0197

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
Exemplo 1: recuperar de um arquivo usando a API de nível inferior do AWS SDKpara .NET
O exemplo de código do C# a seguir faz download de um arquivo do cofre especificado. Depois que otrabalho for concluído, o exemplo fará download de toda a saída em uma única chamada GetJobOutput.Para obter um exemplo de como fazer download de saída em blocos, consulte Exemplo 2: recuperarum arquivo usando a API de nível inferior do AWS SDK para .NET – Fazer download da saída emblocos (p. 101).
O exemplo realiza as seguintes tarefas:
• Configura um tópico do Amazon Simple Notification Service (Amazon SNS)
O Amazon Glacier enviará uma notificação para esse tópico depois de concluir o trabalho.• Configura uma fila do Amazon Simple Queue Service (Amazon SQS).
O exemplo anexa uma política à fila para permitir que o tópico do Amazon SNS publique mensagens.• Inicia um trabalho para fazer download do arquivo especificado.
Na solicitação de trabalho, o exemplo especifica o tópico do Amazon SNS, de maneira que o AmazonGlacier possa enviar uma mensagem depois de concluir o trabalho.
• Verifica periodicamente a fila do Amazon SQS em busca de uma mensagem.
Se houver uma mensagem, analise o JSON e verifique se o trabalho foi concluído com êxito. Se houver,faça download do arquivo. O exemplo de código usa a biblioteca do JSON.NET (consulte JSON.NET)para analisar o JSON.
• Limpa excluindo o tópico do Amazon SNS e a fila do Amazon SQS criada por ele.
using System;using System.Collections.Generic;using System.IO;using System.Threading;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Runtime;using Amazon.SimpleNotificationService;using Amazon.SimpleNotificationService.Model;using Amazon.SQS;using Amazon.SQS.Model;using Newtonsoft.Json;
namespace glacier.amazon.com.docsamples{ class ArchiveDownloadLowLevelUsingSNSSQS { static string topicArn; static string queueUrl; static string queueArn; static string vaultName = "*** Provide vault name ***"; static string archiveID = "*** Provide archive ID ***"; static string fileName = "*** Provide the file name and path to where to store downloaded archive ***"; static AmazonSimpleNotificationServiceClient snsClient; static AmazonSQSClient sqsClient; const string SQS_POLICY = "{" + " \"Version\" : \"2012-10-17\"," + " \"Statement\" : [" + " {" +
Versão da API 2012-06-0198

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
" \"Sid\" : \"sns-rule\"," + " \"Effect\" : \"Allow\"," + " \"Principal\" : \"*\"," + " \"Action\" : \"sqs:SendMessage\"," + " \"Resource\" : \"{QuernArn}\"," + " \"Condition\" : {" + " \"ArnLike\" : {" + " \"aws:SourceArn\" : \"{TopicArn}\"" + " }" + " }" + " }" + " ]" + "}";
public static void Main(string[] args) { AmazonGlacierClient client; try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Setup SNS topic and SQS queue."); SetupTopicAndQueue(); Console.WriteLine("To continue, press Enter"); Console.ReadKey(); Console.WriteLine("Retrieving..."); RetrieveArchive(client); } Console.WriteLine("Operations successful. To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } finally { // Delete SNS topic and SQS queue. snsClient.DeleteTopic(new DeleteTopicRequest() { TopicArn = topicArn }); sqsClient.DeleteQueue(new DeleteQueueRequest() { QueueUrl = queueUrl }); } }
static void SetupTopicAndQueue() { snsClient = new AmazonSimpleNotificationServiceClient(Amazon.RegionEndpoint.USWest2); sqsClient = new AmazonSQSClient(Amazon.RegionEndpoint.USWest2);
long ticks = DateTime.Now.Ticks; topicArn = snsClient.CreateTopic(new CreateTopicRequest { Name = "GlacierDownload-" + ticks }).TopicArn; Console.Write("topicArn: "); Console.WriteLine(topicArn);
CreateQueueRequest createQueueRequest = new CreateQueueRequest(); createQueueRequest.QueueName = "GlacierDownload-" + ticks; CreateQueueResponse createQueueResponse = sqsClient.CreateQueue(createQueueRequest); queueUrl = createQueueResponse.QueueUrl; Console.Write("QueueURL: "); Console.WriteLine(queueUrl);
GetQueueAttributesRequest getQueueAttributesRequest = new GetQueueAttributesRequest(); getQueueAttributesRequest.AttributeNames = new List<string> { "QueueArn" }; getQueueAttributesRequest.QueueUrl = queueUrl; GetQueueAttributesResponse response = sqsClient.GetQueueAttributes(getQueueAttributesRequest); queueArn = response.QueueARN; Console.Write("QueueArn: "); Console.WriteLine(queueArn);
Versão da API 2012-06-0199

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
// Setup the Amazon SNS topic to publish to the SQS queue. snsClient.Subscribe(new SubscribeRequest() { Protocol = "sqs", Endpoint = queueArn, TopicArn = topicArn });
// Add policy to the queue so SNS can send messages to the queue. var policy = SQS_POLICY.Replace("{TopicArn}", topicArn).Replace("{QuernArn}", queueArn);
sqsClient.SetQueueAttributes(new SetQueueAttributesRequest() { QueueUrl = queueUrl, Attributes = new Dictionary<string, string> { { QueueAttributeName.Policy, policy } } }); }
static void RetrieveArchive(AmazonGlacierClient client) { // Initiate job. InitiateJobRequest initJobRequest = new InitiateJobRequest() { VaultName = vaultName, JobParameters = new JobParameters() { Type = "archive-retrieval", ArchiveId = archiveID, Description = "This job is to download archive.", SNSTopic = topicArn, } }; InitiateJobResponse initJobResponse = client.InitiateJob(initJobRequest); string jobId = initJobResponse.JobId;
// Check queue for a message and if job completed successfully, download archive. ProcessQueue(jobId, client); }
private static void ProcessQueue(string jobId, AmazonGlacierClient client) { ReceiveMessageRequest receiveMessageRequest = new ReceiveMessageRequest() { QueueUrl = queueUrl, MaxNumberOfMessages = 1 }; bool jobDone = false; while (!jobDone) { Console.WriteLine("Poll SQS queue"); ReceiveMessageResponse receiveMessageResponse = sqsClient.ReceiveMessage(receiveMessageRequest); if (receiveMessageResponse.Messages.Count == 0) { Thread.Sleep(10000 * 60); continue; } Console.WriteLine("Got message"); Message message = receiveMessageResponse.Messages[0]; Dictionary<string, string> outerLayer = JsonConvert.DeserializeObject<Dictionary<string, string>>(message.Body); Dictionary<string, object> fields = JsonConvert.DeserializeObject<Dictionary<string, object>>(outerLayer["Message"]); string statusCode = fields["StatusCode"] as string;
Versão da API 2012-06-01100

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
if (string.Equals(statusCode, GlacierUtils.JOB_STATUS_SUCCEEDED, StringComparison.InvariantCultureIgnoreCase)) { Console.WriteLine("Downloading job output"); DownloadOutput(jobId, client); // Save job output to the specified file location. } else if (string.Equals(statusCode, GlacierUtils.JOB_STATUS_FAILED, StringComparison.InvariantCultureIgnoreCase)) Console.WriteLine("Job failed... cannot download the archive.");
jobDone = true; sqsClient.DeleteMessage(new DeleteMessageRequest() { QueueUrl = queueUrl, ReceiptHandle = message.ReceiptHandle }); } }
private static void DownloadOutput(string jobId, AmazonGlacierClient client) { GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest() { JobId = jobId, VaultName = vaultName }; GetJobOutputResponse getJobOutputResponse = client.GetJobOutput(getJobOutputRequest); using (Stream webStream = getJobOutputResponse.Body) { using (Stream fileToSave = File.OpenWrite(fileName)) { CopyStream(webStream, fileToSave); } } }
public static void CopyStream(Stream input, Stream output) { byte[] buffer = new byte[65536]; int length; while ((length = input.Read(buffer, 0, buffer.Length)) > 0) { output.Write(buffer, 0, length); } } }}
Exemplo 2: recuperar um arquivo usando a API de nível inferior do AWS SDKpara .NET – Fazer download da saída em blocos
O exemplo de código do C# a seguir recupera um arquivo do Amazon Glacier. O exemplo de códigofaz download da saída do trabalho em blocos especificando o intervalo de bytes em um objetoGetJobOutputRequest.
using System;using System.Collections.Generic;using System.IO;using System.Threading;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Glacier.Transfer;using Amazon.Runtime;using Amazon.SimpleNotificationService;using Amazon.SimpleNotificationService.Model;
Versão da API 2012-06-01101

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
using Amazon.SQS;using Amazon.SQS.Model;using Newtonsoft.Json;using System.Collections.Specialized;
namespace glacier.amazon.com.docsamples{ class ArchiveDownloadLowLevelUsingSQLSNSOutputUsingRange { static string topicArn; static string queueUrl; static string queueArn; static string vaultName = "*** Provide vault name ***"; static string archiveId = "*** Provide archive ID ***"; static string fileName = "*** Provide the file name and path to where to store downloaded archive ***"; static AmazonSimpleNotificationServiceClient snsClient; static AmazonSQSClient sqsClient; const string SQS_POLICY = "{" + " \"Version\" : \"2012-10-17\"," + " \"Statement\" : [" + " {" + " \"Sid\" : \"sns-rule\"," + " \"Effect\" : \"Allow\"," + " \"Principal\" : \"*\"," + " \"Action\" : \"sqs:SendMessage\"," + " \"Resource\" : \"{QuernArn}\"," + " \"Condition\" : {" + " \"ArnLike\" : {" + " \"aws:SourceArn\" : \"{TopicArn}\"" + " }" + " }" + " }" + " ]" + "}";
public static void Main(string[] args) { AmazonGlacierClient client;
try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Setup SNS topic and SQS queue."); SetupTopicAndQueue(); Console.WriteLine("To continue, press Enter"); Console.ReadKey();
Console.WriteLine("Download archive"); DownloadAnArchive(archiveId, client); } Console.WriteLine("Operations successful. To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } finally { // Delete SNS topic and SQS queue. snsClient.DeleteTopic(new DeleteTopicRequest() { TopicArn = topicArn }); sqsClient.DeleteQueue(new DeleteQueueRequest() { QueueUrl = queueUrl }); } }
Versão da API 2012-06-01102

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
static void SetupTopicAndQueue() { long ticks = DateTime.Now.Ticks; // Setup SNS topic. snsClient = new AmazonSimpleNotificationServiceClient(Amazon.RegionEndpoint.USWest2); sqsClient = new AmazonSQSClient(Amazon.RegionEndpoint.USWest2);
topicArn = snsClient.CreateTopic(new CreateTopicRequest { Name = "GlacierDownload-" + ticks }).TopicArn; Console.Write("topicArn: "); Console.WriteLine(topicArn);
CreateQueueRequest createQueueRequest = new CreateQueueRequest(); createQueueRequest.QueueName = "GlacierDownload-" + ticks; CreateQueueResponse createQueueResponse = sqsClient.CreateQueue(createQueueRequest); queueUrl = createQueueResponse.QueueUrl; Console.Write("QueueURL: "); Console.WriteLine(queueUrl);
GetQueueAttributesRequest getQueueAttributesRequest = new GetQueueAttributesRequest(); getQueueAttributesRequest.AttributeNames = new List<string> { "QueueArn" }; getQueueAttributesRequest.QueueUrl = queueUrl; GetQueueAttributesResponse response = sqsClient.GetQueueAttributes(getQueueAttributesRequest); queueArn = response.QueueARN; Console.Write("QueueArn: "); Console.WriteLine(queueArn);
// Setup the Amazon SNS topic to publish to the SQS queue. snsClient.Subscribe(new SubscribeRequest() { Protocol = "sqs", Endpoint = queueArn, TopicArn = topicArn });
// Add the policy to the queue so SNS can send messages to the queue. var policy = SQS_POLICY.Replace("{TopicArn}", topicArn).Replace("{QuernArn}", queueArn);
sqsClient.SetQueueAttributes(new SetQueueAttributesRequest() { QueueUrl = queueUrl, Attributes = new Dictionary<string, string> { { QueueAttributeName.Policy, policy } } }); }
static void DownloadAnArchive(string archiveId, AmazonGlacierClient client) { // Initiate job. InitiateJobRequest initJobRequest = new InitiateJobRequest() {
VaultName = vaultName, JobParameters = new JobParameters() { Type = "archive-retrieval", ArchiveId = archiveId, Description = "This job is to download the archive.", SNSTopic = topicArn, } }; InitiateJobResponse initJobResponse = client.InitiateJob(initJobRequest); string jobId = initJobResponse.JobId;
Versão da API 2012-06-01103

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando o .NET
// Check queue for a message and if job completed successfully, download archive. ProcessQueue(jobId, client); }
private static void ProcessQueue(string jobId, AmazonGlacierClient client) { var receiveMessageRequest = new ReceiveMessageRequest() { QueueUrl = queueUrl, MaxNumberOfMessages = 1 }; bool jobDone = false; while (!jobDone) { Console.WriteLine("Poll SQS queue"); ReceiveMessageResponse receiveMessageResponse = sqsClient.ReceiveMessage(receiveMessageRequest); if (receiveMessageResponse.Messages.Count == 0) { Thread.Sleep(10000 * 60); continue; } Console.WriteLine("Got message"); Message message = receiveMessageResponse.Messages[0]; Dictionary<string, string> outerLayer = JsonConvert.DeserializeObject<Dictionary<string, string>>(message.Body); Dictionary<string, object> fields = JsonConvert.DeserializeObject<Dictionary<string, object>>(outerLayer["Message"]); string statusCode = fields["StatusCode"] as string; if (string.Equals(statusCode, GlacierUtils.JOB_STATUS_SUCCEEDED, StringComparison.InvariantCultureIgnoreCase)) { long archiveSize = Convert.ToInt64(fields["ArchiveSizeInBytes"]); Console.WriteLine("Downloading job output"); DownloadOutput(jobId, archiveSize, client); // This where we save job output to the specified file location. } else if (string.Equals(statusCode, GlacierUtils.JOB_STATUS_FAILED, StringComparison.InvariantCultureIgnoreCase)) Console.WriteLine("Job failed... cannot download the archive."); jobDone = true; sqsClient.DeleteMessage(new DeleteMessageRequest() { QueueUrl = queueUrl, ReceiptHandle = message.ReceiptHandle }); } }
private static void DownloadOutput(string jobId, long archiveSize, AmazonGlacierClient client) { long partSize = 4 * (long)Math.Pow(2, 20); // 4 MB. using (Stream fileToSave = new FileStream(fileName, FileMode.Create, FileAccess.Write)) {
long currentPosition = 0; do { GetJobOutputRequest getJobOutputRequest = new GetJobOutputRequest() { JobId = jobId, VaultName = vaultName };
long endPosition = currentPosition + partSize - 1; if (endPosition > archiveSize) endPosition = archiveSize;
getJobOutputRequest.SetRange(currentPosition, endPosition);
Versão da API 2012-06-01104

Amazon Glacier Guia do desenvolvedor doFazer download de um arquivo usando REST
GetJobOutputResponse getJobOutputResponse = client.GetJobOutput(getJobOutputRequest);
using (Stream webStream = getJobOutputResponse.Body) { CopyStream(webStream, fileToSave); } currentPosition += partSize; } while (currentPosition < archiveSize); } }
public static void CopyStream(Stream input, Stream output) { byte[] buffer = new byte[65536]; int length; while ((length = input.Read(buffer, 0, buffer.Length)) > 0) { output.Write(buffer, 0, length); } } }}
Fazer download de um arquivo usando a API RESTPara fazer download de um arquivo usando a API REST
Fazer download de um arquivo é um processo de duas etapas.
1. Inicie um trabalho do tipo archive-retrieval. Para obter mais informações, consulte Initiate Job(trabalhos POST) (p. 257).
2. Depois que o trabalho for concluído, faça download dos dados de arquivo. Para obter maisinformações, consulte Get Job Output (GET output) (p. 251).
Excluir um arquivo no Amazon GlacierVocê não pode excluir um arquivo usando o console de gerenciamento do Amazon Glacier. Para excluirum arquivo, você deve usar a AWS Command Line Interface (CLI) ou escrever um código para fazer umasolicitação de exclusão usando a API REST diretamente ou as bibliotecas wrapper do AWS SDK for Javae do .NET. Para obter informações sobre como usar a CLI com o Amazon Glacier, consulte Referênciada AWS CLI do Amazon Glacier. Os tópicos a seguir explicam como usar as bibliotecas wrapper do AWSSDK for Java e do .NET, além da API REST.
Tópicos• Excluir um arquivo no Amazon Glacier usando o AWS SDK for Java (p. 106)• Excluir um arquivo no Amazon Glacier usando o AWS SDK para .NET (p. 107)• Excluir um arquivo usando a API REST (p. 110)
Você pode excluir um arquivo por vez de um cofre. Para excluir o arquivo, você deve fornecer o ID dearquivo na solicitação de exclusão. Você pode obter o ID de arquivo fazendo download do inventário docofre que contém o arquivo. Para obter mais informações sobre como fazer download do inventário decofre, consulte Fazer download de um inventário de cofre no Amazon Glacier (p. 35).
Depois de excluir um arquivo, você ainda poderá fazer uma solicitação bem-sucedida para iniciar umtrabalho a fim de recuperar o arquivo excluído, mas o trabalho de recuperação de arquivo falhará.
Versão da API 2012-06-01105

Amazon Glacier Guia do desenvolvedor doExcluir um arquivo usando Java
Recuperações de arquivo que estejam em andamento para um ID de arquivo quando você exclui o arquivopodem ser bem-sucedidas ou não, de acordo com os seguintes cenários:
• Se o trabalho de recuperação de arquivo estiver preparando ativamente os dados para downloadquando o Amazon Glacier receber a solicitação de arquivo, a operação de recuperação de arquivopoderá falhar.
• Se o trabalho de recuperação de arquivo tiver preparado com êxito o arquivo para download quando oAmazon Glacier receber a solicitação de arquivo de exclusão, você poderá fazer download da saída.
Para obter mais informações sobre recuperação de arquivo, consulte Fazer download de um arquivo noAmazon Glacier (p. 79).
Essa operação é idempotente. Excluir um arquivo já excluído não resulta em um erro.
Depois de excluir um arquivo, se você fizer download imediatamente do inventário de cofre, ele poderáincluir o arquivo excluído na lista porque o Amazon Glacier prepara o inventário de cofre somente uma vezpor dia.
Excluir um arquivo no Amazon Glacier usando o AWSSDK for JavaEstas são as etapas para excluir um arquivo usando a API de nível inferior do AWS SDK for Java.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde o arquivo que deseja excluir está armazenado.Todas as operações realizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe DeleteArchiveRequest.
Você precisa fornecer um ID de arquivo, um nome de cofre e o ID da conta. Se você não fornecer umID da conta, o ID da conta associado às credenciais fornecidas por você para assinar a solicitaçãoserá pressuposto. Para obter mais informações, consulte Usar o AWS SDK for Java com o AmazonGlacier (p. 112).
3. Execute o método deleteArchive fornecendo o objeto de solicitação como um parâmetro.
O trecho de código Java a seguir ilustra as etapas anteriores.
AmazonGlacierClient client;
DeleteArchiveRequest request = new DeleteArchiveRequest() .withVaultName("*** provide a vault name ***") .withArchiveId("*** provide an archive ID ***");
client.deleteArchive(request);
Note
Para obter informações sobre a API REST subjacente, consulte Delete Archive (DELETEarchive) (p. 215).
Exemplo: excluir um arquivo usando o AWS SDK for JavaO exemplo de código do Java a seguir usa o AWS SDK for Java para excluir um arquivo. Para instruçõesdetalhadas sobre como executar esse exemplo, consulte Executar exemplos do Java para o Amazon
Versão da API 2012-06-01106

Amazon Glacier Guia do desenvolvedor doExcluir um arquivo usando o .NET
Glacier usando o Eclipse (p. 114). Você precisa atualizar o código conforme mostrado com um nome decofre e o ID do arquivo que deseja excluir.
Example
import java.io.IOException;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;import com.amazonaws.services.glacier.AmazonGlacierClient;import com.amazonaws.services.glacier.model.DeleteArchiveRequest;
public class ArchiveDelete {
public static String vaultName = "*** provide vault name ****"; public static String archiveId = "*** provide archive ID***"; public static AmazonGlacierClient client; public static void main(String[] args) throws IOException { ProfileCredentialsProvider credentials = new ProfileCredentialsProvider();
client = new AmazonGlacierClient(credentials); client.setEndpoint("https://glacier.us-east-1.amazonaws.com/");
try {
// Delete the archive. client.deleteArchive(new DeleteArchiveRequest() .withVaultName(vaultName) .withArchiveId(archiveId)); System.out.println("Deleted archive successfully."); } catch (Exception e) { System.err.println("Archive not deleted."); System.err.println(e); } }}
Excluir um arquivo no Amazon Glacier usando o AWSSDK para .NETAmbas as APIs de nível superior e de nível inferior (p. 111) fornecidas pelo AWS SDK para .NETfornecem um método para excluir um arquivo.
Tópicos• Excluir um arquivo usando a API de nível superior do AWS SDK para .NET (p. 107)• Excluir um arquivo usando a API de nível inferior do AWS SDK para .NET (p. 108)
Excluir um arquivo usando a API de nível superior do AWS SDKpara .NETA classe ArchiveTransferManager da API de nível superior fornece o método DeleteArchive quevocê pode usar para excluir um arquivo.
Versão da API 2012-06-01107

Amazon Glacier Guia do desenvolvedor doExcluir um arquivo usando o .NET
Exemplo: excluir um arquivo usando a API de nível superior do AWS SDKpara .NET
O exemplo de código do C# a seguir usa a API de nível superior do AWS SDK para .NET para excluir umarquivo. Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com o ID do arquivo que desejaexcluir.
Example
using System;using Amazon.Glacier;using Amazon.Glacier.Transfer;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveDeleteHighLevel { static string vaultName = "examplevault"; static string archiveId = "*** Provide archive ID ***";
public static void Main(string[] args) { try { var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2); manager.DeleteArchive(vaultName, archiveId); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); } }}
Excluir um arquivo usando a API de nível inferior do AWS SDKpara .NETVeja a seguir as etapas para excluir um arquivo usando o AWS SDK para .NET.
1. Crie uma instância da classe AmazonGlacierClient (o cliente).
Você precisa especificar uma região da AWS onde o arquivo que deseja excluir está armazenado.Todas as operações realizadas por você usando esse cliente se aplicam a essa região.
2. Forneça informações sobre a solicitação criando uma instância da classe DeleteArchiveRequest.
Você precisa fornecer um ID de arquivo, um nome de cofre e o ID da conta. Se você não fornecer umID da conta, o ID da conta associado às credenciais fornecidas por você para assinar a solicitaçãoserá pressuposto. Para obter mais informações, consulte Usar os SDKs da AWS com o AmazonGlacier (p. 111).
3. Execute o método DeleteArchive fornecendo o objeto de solicitação como um parâmetro.
Versão da API 2012-06-01108

Amazon Glacier Guia do desenvolvedor doExcluir um arquivo usando o .NET
Exemplo: excluir um arquivo usando a API de nível inferior do AWS SDKpara .NET
O exemplo do C# a seguir ilustra as etapas anteriores. O exemplo usa a API de nível inferior do AWS SDKpara .NET para excluir um arquivo.
Note
Para obter informações sobre a API REST subjacente, consulte Delete Archive (DELETEarchive) (p. 215).
Para instruções detalhadas sobre como executar esse exemplo, consulte Executar exemplos decódigo (p. 116). Você precisa atualizar o código conforme mostrado com o ID do arquivo que desejaexcluir.
Example
using System;using Amazon.Glacier;using Amazon.Glacier.Model;using Amazon.Runtime;
namespace glacier.amazon.com.docsamples{ class ArchiveDeleteLowLevel { static string vaultName = "examplevault"; static string archiveId = "*** Provide archive ID ***";
public static void Main(string[] args) { AmazonGlacierClient client; try { using (client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2)) { Console.WriteLine("Deleting the archive"); DeleteAnArchive(client); } Console.WriteLine("Operations successful. To continue, press Enter"); Console.ReadKey(); } catch (AmazonGlacierException e) { Console.WriteLine(e.Message); } catch (AmazonServiceException e) { Console.WriteLine(e.Message); } catch (Exception e) { Console.WriteLine(e.Message); } Console.WriteLine("To continue, press Enter"); Console.ReadKey(); }
static void DeleteAnArchive(AmazonGlacierClient client) { DeleteArchiveRequest request = new DeleteArchiveRequest() { VaultName = vaultName, ArchiveId = archiveId }; DeleteArchiveResponse response = client.DeleteArchive(request); } }}
Versão da API 2012-06-01109
Amazon Glacier Guia do desenvolvedor doExcluir um arquivo usando REST
Excluir um arquivo usando a API RESTVocê pode usar a API Delete Archive do Amazon Glacier para excluir um arquivo.
• Para obter mais informações sobre a API Delete Archive, consulte Delete Archive (DELETEarchive) (p. 215).
• Para obter informações sobre como usar API REST do Amazon Glacier, consulte Referência de API doAmazon Glacier (p. 152).
Consulta de arquivos no Amazon GlacierPara obter mais informações sobre como consultar arquivos do Amazon Glacier com SQL, consulteConsulta em arquivos com o Amazon Glacier Select (p. 139).
Versão da API 2012-06-01110

Amazon Glacier Guia do desenvolvedor doSDKs da AWS compatíveis com o Amazon Glacier
Usar os SDKs da AWS com oAmazon Glacier
A Amazon Web Services oferece SDKs para você desenvolver aplicativos para o Amazon Glacier.As bibliotecas de SDKs encapsulam a API do Amazon Glacier subjacente simplificando as tarefas deprogramação. Por exemplo, para cada solicitação enviada ao Amazon Glacier, você deve incluir umaassinatura a fim de autenticar as solicitações. Ao usar as bibliotecas do SDK, você precisa fornecersomente as credenciais de segurança da AWS no código e as bibliotecas computam a assinaturanecessária, além de incluí-la na solicitação enviada para o Amazon Glacier. Os SDKs da AWS oferecembibliotecas mapeadas para uma API REST subjacente e fornecem objetos que você pode usar paraconstruir facilmente solicitações e processar respostas.
Tópicos• SDKs da AWS compatíveis com o Amazon Glacier (p. 111)• Bibliotecas de SDKs da AWS para Java e .NET (p. 111)• Usar o AWS SDK for Java com o Amazon Glacier (p. 112)• Usar o AWS SDK para .NET com o Amazon Glacier (p. 115)
SDKs da AWS compatíveis com o Amazon GlacierO Amazon Glacier é compatível com os seguintes SDKs da AWS:
• AWS SDK for C++• AWS SDK para Go• AWS SDK para Java• AWS SDK para JavaScript no Node.js• AWS SDK para .NET• AWS SDK para PHP• AWS SDK para Python (Boto)• AWS SDK para Ruby
Você pode encontrar exemplos de como trabalhar com o Amazon Glacier usando os SDKs do Java edo .NET ao longo deste guia do desenvolvedor. Para obter bibliotecas e códigos de exemplo em todas aslinguagens, acesse Sample Code & Libraries.
A AWS Command Line Interface (AWS CLI) é uma ferramenta unificada para gerenciar os serviços daAWS, inclusive o Amazon Glacier. Para obter informações sobre como fazer download da AWS CLI,consulte AWS Command Line Interface. Para obter uma lista de comandos da CLI do Amazon Glacier,consulte Referência de comandos da CLI da AWS.
Bibliotecas de SDKs da AWS para Java e .NETOs SDKs da AWS para Java e .NET oferecem bibliotecas wrapper de níveis superior e inferior.
Versão da API 2012-06-01111

Amazon Glacier Guia do desenvolvedor doO que é API de nível inferior?
O que é API de nível inferior?As bibliotecas wrapper de nível inferior são mapeadas de maneira próxima à API REST subjacente(Referência de API do Amazon Glacier (p. 152)) compatível com o Amazon Glacier. Para cada operaçãoREST do Amazon Glacier, a API de nível inferior oferece um método correspondente, um objeto desolicitação para você fornecer informações de solicitação e um objeto de resposta para processar aresposta do Amazon Glacier. As bibliotecas wrapper de nível inferior são a implementação mais completadas operações do Amazon Glacier subjacentes.
Para obter informações sobre essas bibliotecas do SDK, consulte Usar o AWS SDK for Java com oAmazon Glacier (p. 112) e Usar o AWS SDK para .NET com o Amazon Glacier (p. 115).
O que é API de nível superior?Para simplificar ainda mais o desenvolvimento do aplicativo, essas bibliotecas oferecem uma abstração denível superior para algumas das operações. Por exemplo,
• Fazer upload de um arquivo – Para fazer upload de um arquivo usando a API de nível inferior, além donome de arquivo e o nome do cofre onde deseja salvar o arquivo, você precisa fornecer uma soma deverificação (hash de árvore SHA-256) da carga útil. No entanto, a API de nível superior computa a somade verificação para você.
• Fazer download de um arquivo ou inventário de cofre – Para fazer download de um arquivo usando aAPI de nível inferior, você primeiro inicia um trabalho, aguarda a conclusão do trabalho e obtém a saídado trabalho. Você precisa escrever um código adicional para configurar um tópico do Amazon SimpleNotification Service (Amazon SNS) para o Amazon Glacier a fim de notificá-lo quando o trabalho estáconcluído. Você também precisa um mecanismo de sondagem para verificar se uma mensagem deconclusão do trabalho foi publicada no tópico. A API de nível superior oferece um método para fazerdownload de um arquivo que cuida de todas essas etapas. Você especifica somente um ID de arquivo eum caminho de pasta onde deseja salvar os dados obtidos por download.
Para obter informações sobre essas bibliotecas do SDK, consulte Usar o AWS SDK for Java com oAmazon Glacier (p. 112) e Usar o AWS SDK para .NET com o Amazon Glacier (p. 115).
Quando usar as APIs de nível superior e de nívelinferiorEm geral, se a API de nível superior oferece métodos dos quais precisa para realizar uma operação,você deverá usá-la em função da simplicidade proporcionada. No entanto, se a API de nível superiornão oferece a funcionalidade, você poderá usar a API de nível inferior. Além disso, a API de nível inferiorpermite o controle granular da operação, como a lógica de nova tentativa em caso de falha. Por exemplo,ao fazer upload de um arquivo, a API de nível superior usa o tamanho do arquivo para determinar se énecessário fazer upload do arquivo em uma única operação ou usar a API de multipart upload. A APItambém tem uma lógica de nova tentativa integrada em caso de falha no upload. No entanto, o aplicativopode precisar de controle granular sobre essas decisões, quando você pode usar a API de nível inferior.
Usar o AWS SDK for Java com o Amazon GlacierO AWS SDK for Java fornece APIs de níveis superior e inferior para o Amazon Glacier, conforme descritoem Usar os SDKs da AWS com o Amazon Glacier (p. 111). Para obter informações sobre como fazerdownload do AWS SDK for Java, consulte AWS SDK para Java.
Versão da API 2012-06-01112

Amazon Glacier Guia do desenvolvedor doUsar a API de nível inferior
Note
O AWS SDK for Java fornece clientes thread-safe para acessar o Amazon Glacier. De acordocom as melhores práticas, seus aplicativos devem criar um único cliente e reutilizá-lo entre osthreads.
Tópicos• Usar a API de nível inferior (p. 113)• Usar a API de nível superior (p. 113)• Executar exemplos do Java para o Amazon Glacier usando o Eclipse (p. 114)• Definição do endpoint (p. 114)
Usar a API de nível inferiorA classe AmazonGlacierClient de nível inferior fornece todos os métodos mapeados para asoperações REST subjacentes do Amazon Glacier ( Referência de API do Amazon Glacier (p. 152)). Aochamar qualquer um desses métodos, você deve criar um objeto de solicitação correspondente e fornecerum objeto de resposta no qual o método possa retornar a resposta do Amazon Glacier à operação.
Por exemplo, a classe AmazonGlacierClient fornece o método createVault para criar umcofre. Esse método é mapeado para a operação REST Create Vault (consulte Create Vault (PUTvault) (p. 177)). Para usar esse método, você deve criar instâncias do objeto CreateVaultResult querecebe a resposta do Amazon Glacier conforme mostrado no seguinte trecho de código do Java:
AmazonGlacierClient client = new AmazonGlacierClient(credentials);client.setEndpoint("https://glacier.us-west-2.amazonaws.com/");
CreateVaultRequest request = new CreateVaultRequest() .withAccountId("-") .withVaultName(vaultName);CreateVaultResult result = client.createVault(createVaultRequest);
Todos os exemplos de nível inferior no guia usam esse padrão.
Note
O segmento do código anterior especifica AccountID durante a criação da solicitação. Noentanto, durante o uso do AWS SDK for Java, o AccountId na solicitação é opcional e, assim,todos os exemplos de nível inferior neste guia não definem esse valor. O AccountId é o ID daconta da AWS. Esse valor deve corresponder ao ID da conta da AWS associado às credenciaisusadas para assinar a solicitação. Você pode especificar o ID da conta da AWS ou opcionalmenteum '-', quando o Amazon Glacier usa o ID da conta da AWS associado às credenciais usadaspara assinar a solicitação. Se você especificar o ID da conta, não inclua hifens nele. Ao usar oAWS SDK for Java, se você não fornecer o ID da conta, a biblioteca definirá o ID da conta como'-'.
Usar a API de nível superiorPara simplificar ainda mais o desenvolvimento do aplicativo, o AWS SDK for Java fornece a classeArchiveTransferManager que implementa uma abstração de nível superior para alguns dos métodosna API de nível inferior. Ele fornece métodos úteis, como os métodos upload e download, paraoperações de arquivo.
Por exemplo, o trecho de código do Java a seguir usa o método de nível superior upload para fazerupload de um arquivo.
Versão da API 2012-06-01113

Amazon Glacier Guia do desenvolvedor doExecução de exemplos de Java usando o Eclipse
String vaultName = "examplevault";String archiveToUpload = "c:/folder/exampleArchive.zip";
ArchiveTransferManager atm = new ArchiveTransferManager(client, credentials);String archiveId = atm.upload(vaultName, "Tax 2012 documents", new File(archiveToUpload)).getArchiveId();
Todas as operações realizadas por você se aplicam à região especificada ao criar o objetoArchiveTransferManager. Se você não especificar uma região, o AWS SDK for Java definirá us-east-1 como a região padrão.
Todos os exemplos de nível superior neste guia usam esse padrão.
Note
A classe ArchiveTransferManager de nível superior pode ser construída com uma instânciaAmazonGlacierClient ou AWSCredentials.
Executar exemplos do Java para o Amazon Glacierusando o EclipseA maneira mais fácil de começar a usar os exemplos de código Java é instalar o AWS Toolkit for Eclipsemais recente. Para obter informações sobre como instalar ou atualizar para o toolkit mais recente, vá atéhttp://aws.amazon.com/eclipse. As tarefas a seguir orientam você em meio à criação e aos testes dosexemplos de código do Java fornecidos nesta seção.
Processo geral de criação de exemplos de código Java
1 Crie um perfil de credenciais padrão para as credenciais da AWS conforme descrito notópico do AWS SDK for Java Fornecer credenciais da AWS no AWS SDK para Java.
2 Crie um novo projeto Java da AWS no Eclipse. O projeto é pré-configurado com o AWS SDKfor Java.
3 Copie o código da seção que você está lendo ao projeto.
4 Atualize o código fornecendo todos os dados necessários. Por exemplo, se estiver fazendoo upload de um arquivo, forneça o caminho do arquivo e o nome do bucket.
5 Execute o código. Verifique se o objeto é criado usando o Console de gerenciamento daAWS. Para obter mais informações sobre o Console de gerenciamento da AWS, vá atéhttp://aws.amazon.com/console/.
Definição do endpointPor padrão, o AWS SDK for Java usa o endpoint https://glacier.us-east-1.amazonaws.com.Você pode definir o endpoint explicitamente conforme mostrado nos trechos de código do Java a seguir.
O trecho de código a seguir mostra como definir o endpoint como a região Oeste dos EUA (Oregon) (us-west-2) na API de nível inferior.
Example
client = new AmazonGlacierClient(credentials);client.setEndpoint("glacier.us-west-2.amazonaws.com");
Versão da API 2012-06-01114

Amazon Glacier Guia do desenvolvedor doUsar o AWS SDK para .NET
O trecho de código a seguir mostra como definir o endpoint como a região Oeste dos EUA (Oregon) na APIde nível superior.
glacierClient = new AmazonGlacierClient(credentials);sqsClient = new AmazonSQSClient(credentials);snsClient = new AmazonSNSClient(credentials); glacierClient.setEndpoint("glacier.us-west-2.amazonaws.com");sqsClient.setEndpoint("sqs.us-west-2.amazonaws.com");snsClient.setEndpoint("sns.us-west-2.amazonaws.com");
ArchiveTransferManager atm = new ArchiveTransferManager(glacierClient, sqsClient, snsClient);
Para obter uma lista de regiões e endpoints compatíveis, consulte Acessar o Amazon Glacier (p. 5).
Usar o AWS SDK para .NET com o Amazon GlacierA API do AWS SDK para .NET está disponível em AWSSDK.dll. Para obter informações sobre comofazer download do AWS SDK para .NET, vá até Bibliotecas de códigos de exemplo. Conforme descrito emUsar os SDKs da AWS com o Amazon Glacier (p. 111), o AWS SDK para .NET fornece APIs de níveissuperior e inferior.
Note
As APIs de nível inferior e superior fornecem clientes thread-safe para acessar o Amazon Glacier.De acordo com as melhores práticas, seus aplicativos devem criar um único cliente e reutilizá-loentre os threads.
Tópicos• Usar a API de nível inferior (p. 115)• Usar a API de nível superior (p. 116)• Executar exemplos de código (p. 116)• Definição do endpoint (p. 117)
Usar a API de nível inferiorA classe AmazonGlacierClient de nível inferior fornece todos os métodos mapeados para asoperações REST subjacentes do Amazon Glacier ( Referência de API do Amazon Glacier (p. 152)). Aochamar qualquer um desses métodos, você deve criar um objeto de solicitação correspondente e fornecerum objeto de resposta no qual o método possa retornar uma resposta do Amazon Glacier à operação.
Por exemplo, a classe AmazonGlacierClient fornece o método CreateVault para criar umcofre. Esse método é mapeado para a operação REST Create Vault (consulte Create Vault (PUTvault) (p. 177)). Para usar esse método, você deve criar instâncias das classes CreateVaultRequeste CreateVaultResponse para fornecer informações de solicitação e receber uma resposta do AmazonGlacier conforme mostrado no seguinte trecho de código do C#:
AmazonGlacierClient client;client = new AmazonGlacierClient(Amazon.RegionEndpoint.USEast1);
CreateVaultRequest request = new CreateVaultRequest(){ AccountId = "-", VaultName = "*** Provide vault name ***"
Versão da API 2012-06-01115

Amazon Glacier Guia do desenvolvedor doUsar a API de nível superior
};
CreateVaultResponse response = client.CreateVault(request);
Todos os exemplos de nível inferior no guia usam esse padrão.Note
O segmento do código anterior especifica AccountId durante a criação da solicitação. Noentanto, durante o uso do AWS SDK para .NET, o AccountId na solicitação é opcional e, assim,todos os exemplos de nível inferior neste guia não definem esse valor. O AccountId é o ID daconta da AWS. Esse valor deve corresponder ao ID da conta da AWS associado às credenciaisusadas para assinar a solicitação. Você pode especificar o ID da conta da AWS ou opcionalmenteum '-', quando o Amazon Glacier usa o ID da conta da AWS associado às credenciais usadaspara assinar a solicitação. Se você especificar o ID da conta, não inclua hifens nele. Ao usar oAWS SDK para .NET, se você não fornecer o ID da conta, a biblioteca definirá o ID da conta como'-'.
Usar a API de nível superiorPara simplificar ainda mais o desenvolvimento do aplicativo, o AWS SDK para .NET fornece a classeArchiveTransferManager que implementa uma abstração de nível superior para alguns dos métodosna API de nível inferior. Ele fornece métodos úteis, como Upload e Download, para as operações dearquivo.
Por exemplo, o trecho de código do C# a seguir usa o método de nível superior Upload para fazer uploadde um arquivo.
string vaultName = "examplevault";string archiveToUpload = "c:\folder\exampleArchive.zip";
var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USEast1);string archiveId = manager.Upload(vaultName, "archive description", archiveToUpload).ArchiveId;
Todas as operações realizadas por você se aplicam à região especificada ao criar o objetoArchiveTransferManager. Todos os exemplos de nível superior neste guia usam esse padrão.
Note
A classe ArchiveTransferManager de nível superior ainda precisa do clienteAmazonGlacierClient de nível inferior, que você pode passar explicitamente, ou oArchiveTransferManager criará o cliente.
Executar exemplos de códigoA maneira mais fácil de começar a usar os exemplos de código .NET é instalar o AWS SDK para .NET.Para obter mais informações, visite AWS SDK para .NET.
O procedimento a seguir descreve as etapas para você testar os exemplos de código fornecidos nesteguia.
Processo geral de criação dos exemplos de código do .NET (usando o Visual Studio)
1 Crie um perfil de credenciais para suas credenciais da AWS conforme descrito no tópicoComo configurar credenciais da AWS do AWS SDK para .NET.
2 Crie um novo projeto do Visual Studio usando o modelo Projeto vazio da AWS.
Versão da API 2012-06-01116

Amazon Glacier Guia do desenvolvedor doDefinição do endpoint
3 Substitua o código no arquivo do projeto, Program.cs, com o código da seção que vocêestá lendo.
4 Execute o código. Verifique se o objeto é criado usando o Console de gerenciamento daAWS. Para obter mais informações sobre o Console de gerenciamento da AWS, vá atéhttp://aws.amazon.com/console/.
Definição do endpointPor padrão, o AWS SDK para .NET define o endpoint como o Região Oeste dos EUA (Oregon) (https://glacier.us-west-2.amazonaws.com). Você pode definir o endpoint como outras regiões conformemostrado nos trechos do C# a seguir.
O trecho de código a seguir mostra como definir o endpoint como a região Oeste dos EUA (Oregon) (us-west-2) na API de nível inferior.
Example
AmazonGlacierClient client = new AmazonGlacierClient(Amazon.RegionEndpoint.USWest2);
O trecho de código a seguir mostra como definir o endpoint como a região Oeste dos EUA (Oregon) na APIde nível superior.
var manager = new ArchiveTransferManager(Amazon.RegionEndpoint.USWest2);
Para obter uma lista atual de regiões e endpoints compatíveis, consulte Acessar o Amazon Glacier (p. 5).
Versão da API 2012-06-01117

Amazon Glacier Guia do desenvolvedor doAutenticação
Autenticação e controle de acessopara o Amazon Glacier
O acesso ao Amazon Glacier exige credenciais que a AWS possa usar para autenticar as solicitações.Essas credenciais devem ter permissões para acessar os recursos da AWS, como um cofre do AmazonGlacier ou um bucket do Amazon S3. As seções a seguir dão detalhes sobre como você pode usar oAWS Identity and Access Management (IAM) e o Amazon Glacier para ajudar a proteger os recursoscontrolando quem pode acessá-los:
• Autenticação (p. 118)• Controle de acesso (p. 119)
AutenticaçãoVocê pode acessar a AWS como alguns dos seguintes tipos de identidade:
• Usuário raiz da conta da AWS – Ao criar uma conta do AWS pela primeira vez, você começa com umaúnica identidade de login que tem acesso completo a todos os serviços e recursos da AWS na conta.Essa identidade é denominada usuário raiz da conta da AWS e é acessada pelo login com o endereçode e-mail e a senha que você usou para criar a conta. Recomendamos que não use o usuário raiz parasuas tarefas diárias, nem mesmo as administrativas. Em vez disso, siga as melhores práticas de usaro usuário raiz apenas para criar seu primeiro usuário do IAM. Depois, armazene as credenciais usuárioraiz com segurança e use-as para executar apenas algumas tarefas de gerenciamento de contas e deserviços.
• Usuário IAM – um usuário IAM é uma identidade na sua conta da AWS que tem permissõespersonalizadas específicas (por exemplo, para criar a vault no Amazon Glacier). Você pode usar umnome e uma senha de usuário IAM para fazer login em páginas Web seguras da AWS, como Console degerenciamento da AWS, Fóruns de discussão AWS ou o AWS Support Center.
Além de um nome e uma senha de usuário, você também pode gerar chaves de acesso para cadausuário. Você pode usar essas chaves ao acessar serviços da AWS de forma programática, seja comum dos vários SDKs ou usando a AWS Command Line Interface (CLI). As ferramentas de SDK e deCLI usam as chaves de acesso para o cadastramento criptográfico da sua solicitação. Se você nãoutilizar ferramentas da AWS, cadastre a solicitação você mesmo. Amazon Glacier supports Assinaturaversão 4, um protocolo para autenticar solicitações de API de entrada. Para mais informações sobreautenticação de solicitações, consulte Processo de cadastramento de Assinatura versão 4 no AWSGeneral Reference.
• IAM role – Uma função do IAM é uma identidade do IAM que você pode criar em sua conta que tenha
permissões específicas. É semelhante a um usuário IAM, mas não está associada a uma pessoaespecífica. Uma função do IAM permite obter chaves de acesso temporárias que podem ser usadas paraacessar os serviços e recursos da AWS. As funções do IAM com credenciais temporária são úteis nasseguintes situações:
Versão da API 2012-06-01118

Amazon Glacier Guia do desenvolvedor doControle de acesso
• Acesso de usuário federado – Em vez de criar um usuário do IAM, você pode usar identidades deusuário existentes do AWS Directory Service da sua empresa ou de um provedor de identidadesda web. Estes são conhecidos como usuários federados. A AWS atribui uma função a um usuáriofederado quando o acesso é solicitado por meio de um provedor de identidades. Para obter maisinformações sobre usuários federados, consulte Usuários federados e funções em Guia do usuário doIAM.
• Acesso de serviço à AWS – Você pode usar uma função do IAM em sua conta para conceder
permissões a um serviço da AWS para acessar os recursos da sua conta. Por exemplo, você podecriar uma função que permita que Amazon Redshift acesse um bucket do Amazon S3 em seu nomee carregue dados desse bucket em um cluster Amazon Redshift. Para mais informações, consulteCriação de uma função para delegar permissões a um serviço da AWS no Guia do usuário do IAM.
• Aplicativos em execução no Amazon EC2 – Você pode usar uma função do IAM para gerenciar
credenciais temporárias para aplicativos que estão sendo executados em uma instância do EC2 eque fazem solicitações de API da AWS. É preferível fazer isso do que armazenar chaves de acessona instância do EC2. Para atribuir uma função da AWS a uma instância do EC2 e disponibilizá-lapara todos os seus aplicativos, crie um perfil de instância que esteja anexado à instância. Um perfilde instância contém a função e permite que programas que estão em execução na instância do EC2obtenham credenciais temporárias. Para mais informações, consulte Uso de uma função do IAM paraconceder permissões aos aplicativos em execução nas instâncias do Amazon EC2 no Guia do usuáriodo IAM.
Controle de acessoVocê pode ter credenciais válidas para autenticar as solicitações, mas só poderá criar ou acessar osrecursos do Amazon Glacier se tiver permissões. Por exemplo, você deve ter permissões para criar umcofre do Amazon Glacier.
As seções a seguir descrevem como gerenciar permissões. Recomendamos que você leia a visão geralprimeiro.
• Visão geral de como gerenciar permissões de acesso aos recursos do Amazon Glacier (p. 119)• Usar políticas baseadas em identidade para o Amazon Glacier (políticas do IAM) (p. 124)• Usar políticas baseadas em recurso para Amazon Glacier (políticas de cofre) (p. 128)
Visão geral de como gerenciar permissões deacesso aos recursos do Amazon Glacier
Cada recurso da AWS é de propriedade de uma conta da AWS, e as permissões para criar ou acessarum recurso são regidas por políticas de permissões. Um administrador de conta pode anexar políticas depermissões a identidades do IAM (ou seja, usuários, grupos e funções), e alguns serviços (como AmazonGlacier) também dão suporte à anexação de políticas de permissões a recursos.
Note
Um administrador da conta (ou usuário administrador) é um usuário com privilégios deadministrador. Para obter mais informações, consulte Melhores práticas do IAM no Guia dousuário do IAM.
Versão da API 2012-06-01119

Amazon Glacier Guia do desenvolvedor doRecursos e operações do Amazon Glacier
Ao conceder permissões, você decide quem recebe as permissões, os recursos relacionados àspermissões concedidas e as ações específicas que deseja permitir nesses recursos.
Tópicos• Recursos e operações do Amazon Glacier (p. 120)• Entender a propriedade de recursos (p. 120)• Gerenciar o acesso aos recursos (p. 120)• Especificação de elementos da política: ações, efeitos, recursos e principais (p. 123)• Especificação de condições em uma política (p. 124)
Recursos e operações do Amazon GlacierNo Amazon Glacier, o principal recurso é um cofre. O Amazon Glacier dá suporte somente a políticas nonível do cofre. Ou seja, em uma política do IAM, o valor Resource especificado por você pode ser umcofre específico ou um conjunto de cofres em uma determinada região da AWS. O Amazon Glacier não dásuporte a permissões no nível de arquivo.
Para todas as ações do Amazon Glacier, Resource especifica o cofre no qual você deseja conceder aspermissões. Esses recursos têm Amazon Resource Names (ARNs – Nomes de recursos da Amazon)exclusivos associados conforme mostrado na tabela a seguir, e você pode usar um caractere curinga (*) noARN para corresponder a qualquer nome de cofre.
O Amazon Glacier fornece um conjunto de operações para trabalhar com recursos do Amazon Glacier.Para obter informações sobre as operações disponíveis, consulte Referência de API do AmazonGlacier (p. 152).
Entender a propriedade de recursosO proprietário do recurso é a conta da AWS que criou o recurso. Ou seja, o proprietário do recurso é aconta da AWS da entidade principal (a conta-raiz, um usuário do IAM ou uma função do IAM) que autenticaa solicitação que cria o recurso. Os exemplos a seguir ilustram como isso funciona:
• Se você usar as credenciais de conta raiz da conta da AWS para criar um cofre do Amazon Glacier,a conta da AWS será a proprietária do recurso (no Amazon Glacier, o recurso é o cofre do AmazonGlacier).
• Se você criar um usuário do IAM na conta da AWS e conceder permissões para criar um cofre doAmazon Glacier a esse usuário, o usuário poderá criar um cofre do Amazon Glacier. No entanto, a contada AWS, à qual o usuário pertence, detém o recurso de cofre do Amazon Glacier.
• Se você criar uma função do IAM na conta da AWS com permissões para criar um cofre do AmazonGlacier, qualquer pessoa que possa assumir a função poderá criar um cofre do Amazon Glacier. A contada AWS, à qual a função pertence, detém o recurso de cofre do Amazon Glacier.
Gerenciar o acesso aos recursosA política de permissões descreve quem tem acesso a quê. A seção a seguir explica as opçõesdisponíveis para a criação das políticas de permissões.
Note
Esta seção aborda como usar o IAM no contexto do Amazon Glacier. Não são fornecidasinformações detalhadas sobre o serviço IAM. Para obter a documentação completa do IAMconsulte O que é IAM? no Guia do usuário do IAM. Para obter informações sobre a sintaxe e as
Versão da API 2012-06-01120

Amazon Glacier Guia do desenvolvedor doGerenciar o acesso aos recursos
descrições da política do IAM, consulte Referência de política do IAM da AWS no Guia do usuáriodo IAM.
As políticas anexadas a uma identidade do IAM são conhecidas como políticas com base em identidade(políticas do IAM) e as políticas anexadas a um recurso são conhecidas como políticas com base emrecurso. O Amazon Glacier dá suporte a políticas baseadas em identidade (políticas do IAM) e em recurso.
Tópicos• Políticas baseadas em identidade (políticas do IAM) (p. 121)• Políticas baseadas em recurso (Políticas de cofre do Amazon Glacier) (p. 122)
Políticas baseadas em identidade (políticas do IAM)Você pode anexar políticas a identidades do IAM. Por exemplo, você pode fazer o seguinte:
• Anexar uma política de permissões a um usuário ou a um grupo na conta – Um administrador de contapode usar uma política de permissões associada a um determinado usuário para conceder permissõespara que esse usuário crie um cofre do Amazon Glacier.
• Anexar uma política de permissões a uma função (grant cross-account permissions) – Você podeanexar uma política de permissões baseada em identidade a uma função do IAM para concederpermissões entre contas. Por exemplo, o administrador na Conta A pode criar uma função paraconceder permissões entre contas a outra conta da AWS (por exemplo, Conta B) ou um serviço da AWSda seguinte forma:1. Um administrador da Conta A cria uma função do IAM e anexa uma política de permissões à função
que concede permissões em recursos da Conta A.2. Um administrador da Conta A anexa uma política de confiança à função identificando a Conta B como
a principal, que pode assumir a função.3. A seguir, o administrador da Conta B pode delegar permissões para assumir a função para todos os
usuários na Conta B. Isso permite que os usuários na Conta B criem ou acessem recursos na ContaA. O principal na política de confiança também poderá ser um principal do serviço da AWS, se vocêquiser conceder a um serviço da AWS permissões para assumir a função.
Para obter mais informações sobre o uso do IAM para delegar permissões, consulte Gerenciamento doacesso no Guia do usuário do IAM.
Esta é uma política de exemplo que concede permissões para três ações relacionadas ao cofre doAmazon Glacier (glacier:CreateVaultglacier:DescribeVault e glacier:ListVaults) em umrecurso, usando o nome de recurso da Amazon (ARN) que identifica todos os cofres na região da AWSus-west-2. Os ARNs identificam exclusivamente os recursos da AWS. Para obter mais informaçõessobre ARNs usados com o Amazon Glacier, consulte Recursos e operações do Amazon Glacier (p. 120).
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glacier:CreateVault", "glacier:DescribeVault", "glacier:ListVaults" ], "Resource": "arn:aws:glacier:us-west-2:123456789012:vaults/*" } ]}
Versão da API 2012-06-01121

Amazon Glacier Guia do desenvolvedor doGerenciar o acesso aos recursos
A política concede permissões para criar, listar e obter descrições de cofres na região us-west-2. Ocaractere curinga (*) ao final do ARN do significa que essa instrução pode corresponder a qualquer nomede cofre.
Important
Ao conceder permissões para criar um cofre usando a operação glacier:CreateVault, vocêdeve especificar um caractere curinga (*) porque você não saberá o nome do cofre até criar ocofre.
Para obter mais informações sobre políticas baseadas em identidade com o Amazon Glacier, consulteUsar políticas baseadas em identidade para o Amazon Glacier (políticas do IAM) (p. 124). Para obtermais informações sobre usuários, grupos, funções e permissões, consulte Identidades (usuários, grupos efunções) no Guia do usuário do IAM.
Políticas baseadas em recurso (Políticas de cofre do AmazonGlacier)Cada cofre do Amazon Glacier pode ter políticas de permissão baseadas em recurso associadas. Para oAmazon Glacier, cofre do Amazon Glacier é o recurso principal, e as políticas baseadas em recurso sãoconhecidas como políticas de cofre.
Você pode usar políticas de cofre do Amazon Glacier para gerenciar permissões das seguintes maneiras:
• Gerencie permissões de usuário na conta em uma única política de cofre, em vez de políticas de usuárioindividuais.
• Gerencie permissões entre contas como uma alternativa a usar funções do IAM.
Um cofre do Amazon Glacier pode ter uma política de acesso ao cofre e uma política do Vault Lockassociada. Política de acesso ao cofre do Amazon Glacier é uma política baseada em recurso que vocêpode usar para gerenciar permissões do cofre. Política do Vault Lock é uma política de acesso ao cofreque pode ser bloqueada. Depois que você bloqueia uma política do Vault Lock, ela não pode ser alterada.Você pode usar a política do Vault Lock para impor controles de conformidade.
Você pode usar políticas de cofre para conceder permissões a todos os usuários, ou pode limitar o acessoa um cofre a algumas contas da AWS anexando uma política diretamente a um recurso de cofre. Porexemplo, você pode usar uma política de cofre do Amazon Glacier para conceder permissões somenteleitura a todas as contas da AWS ou para conceder permissões a fim de fazer upload de arquivos paraalgumas contas da AWS.
As políticas de cofre facilitam a concessão do acesso entre contas quando você precisa compartilhar ocofre com outras contas da AWS. Por exemplo, você pode conceder acesso somente leitura em um cofre aum parceiro de negócios com uma conta da AWS diferente simplesmente incluindo essa conta e permitidoações na política de cofre. Você pode conceder acesso entre contas a vários usuários dessa forma e terum único local para visualizar todos os usuários com acesso entre contas na política de acesso ao cofre.Para obter um exemplo de uma política de cofre para acesso entre contas, consulte Exemplo 1: concederpermissões entre contas para ações do Amazon Glacier específicas (p. 129).
Este é um exemplo de uma política de cofre do Amazon Glacier (uma política baseada em recurso).A política de exemplo concede todas as permissões de contas da AWS para realizar as açõesglacier:InitiateJob e glacier:GetJobOutput. Essa política permite que qualquer conta da AWSrecupere dados do cofre especificado.
{ "Version":"2012-10-17", "Statement":[
Versão da API 2012-06-01122

Amazon Glacier Guia do desenvolvedor doEspecificação de elementos da política:
ações, efeitos, recursos e principais
{ "Sid": "add-read-only-perm", "Principal": "*", "Effect": "Allow", "Action": [ "glacier:InitiateJob", "glacier:GetJobOutput" ], "Resource": [ "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault" ] } ] }
Para obter mais informações sobre como usar políticas de cofre com o Amazon Glacier, consulte Usarpolíticas baseadas em recurso para Amazon Glacier (políticas de cofre) (p. 128). Para obter informaçõesadicionais sobre funções do IAM (políticas baseadas em identidade), ao contrário de políticas baseadasem recurso, consulte Em que funções do IAM se diferem de políticas baseadas em recurso no Guia dousuário do IAM.
Especificação de elementos da política: ações, efeitos,recursos e principaisPara cada tipo de recurso do Amazon Glacier, o serviço define um conjunto de operações da API (consulteReferência de API do Amazon Glacier (p. 152)). Para conceder permissões para essas operações daAPI, o Amazon Glacier define um conjunto de ações que você pode especificar em uma política. Observeque a execução de uma operação de API pode exigir permissões para mais de uma ação. Ao concederpermissões para ações específicas, você também identifica o recurso no qual as ações são permitidas ourecusadas.
Estes são os elementos de política mais básicos:
• Recurso – Em uma política, você usa um Amazon Resource Name (ARN – Nome de recurso daAmazon) para identificar o recurso a que a política se aplica. Para obter mais informações, consulteRecursos e operações do Amazon Glacier (p. 120).
• Ações – Você usa palavras-chave de ação para identificar operações de recurso que deseja permitir ounegar.
Por exemplo, a permissão glacier:CreateVault permite que as permissões do usuário realizem aoperação Create Vault do Amazon Glacier.
• Efeito - Você especifica o efeito quando o usuário solicita a ação específica - que pode ser permitirou negar. Se você não conceder (permitir) explicitamente acesso a um recurso, o acesso estaráimplicitamente negado. Você também pode negar explicitamente o acesso a um recurso, o que podefazer para ter a certeza de que um usuário não consiga acessá-lo, mesmo que uma política diferenteconceda acesso.
• Principal – Em políticas baseadas em identidade (políticas do IAM), o usuário ao qual a política estáanexada é automática e implicitamente o principal. Para as políticas baseadas em recursos, vocêespecifica quais usuários, contas, serviços ou outras entidades deseja que recebam permissões (aplica-se somente a políticas baseadas em recursos).
Para saber mais sobre a sintaxe da política do IAM e as descrições, consulte Referência de política do IAMda AWS no Guia do usuário do IAM.
Para obter uma tabela que mostre todas as ações da API do Amazon Glacier e os recursos a queelas se aplicam, consulte Permissões da API do Amazon Glacier: referência de ações, recursos econdições (p. 133).
Versão da API 2012-06-01123

Amazon Glacier Guia do desenvolvedor doEspecificação de condições em uma política
Especificação de condições em uma políticaAo conceder permissões, você pode usar a linguagem da política do IAM para especificar as condições dequando uma política deverá entrar em vigor. Por exemplo, convém que uma política só seja aplicada apósuma data específica. Para obter mais informações sobre como especificar condições em uma linguagemde política, consulte Condição no Guia do usuário do IAM.
A AWS oferece um conjunto de chaves de condição predefinidas, chamadas chaves de condição emtoda a AWS, para todos os serviços da AWS que dão suporte ao IAM para controle de acesso. As chavesde condição em toda a AWS usam o prefixo aws. O Amazon Glacier dá suporte a todas as chaves decondição em toda a AWS nas políticas de acesso ao cofre e do Vault Lock. Por exemplo, você pode usara chave de condição aws:MultiFactorAuthPresent para exigir a Multi-Factor Authentication (MFA– Autenticação multifator) ao solicitar uma ação. Para obter mais informações e uma lista das chaves decondição em toda a AWS, consulte Chaves disponíveis para condições no Guia do usuário do IAM.
Note
As chaves de condição diferenciam maiúsculas de minúsculas.
Além disso, o Amazon Glacier também oferece as próprias chaves de condição que você pode incluirem elementos Condition de uma política de permissões do IAM. As chaves de condição específicasdo Amazon Glacier são aplicáveis somente durante a concessão de permissões específicas do AmazonGlacier. Os nomes de chave de condição do Amazon Glacier têm o prefixo glacier:. A tabela a seguirmostra as chaves de condição do Amazon Glacier que se aplicam a recursos do Amazon Glacier.
Chave de condiçãodo Amazon Glacier
Description Tipo de valor
glacier:ArchiveAgeInDaysUsado para avaliar por quanto tempo um arquivo foiarmazenado no cofre, em dias.
Inteiro
glacier:ResourceTag/TagKey
Permite usar uma tag na política. Para obter informaçõessobre a marcação do recurso, consulte Gerenciar controle deacesso com marcação (p. 147).
String
Para obter exemplos de como usar chaves de condição específicas do Amazon Glacier, consulte Controlede acesso do Amazon Glacier com políticas de bloqueio de cofre (p. 131).
Tópicos relacionados
• Usar políticas baseadas em identidade para o Amazon Glacier (políticas do IAM) (p. 124)• Usar políticas baseadas em recurso para Amazon Glacier (políticas de cofre) (p. 128)• Permissões da API do Amazon Glacier: referência de ações, recursos e condições (p. 133)
Usar políticas baseadas em identidade para oAmazon Glacier (políticas do IAM)
Este tópico fornece exemplos de políticas baseadas em identidade em que um administrador de contapode anexar políticas de permissões a identidades do IAM (ou seja, usuários, grupos e funções).
Important
Recomendamos que você analise primeiro os tópicos introdutórios que explicam os conceitosbásicos e as opções disponíveis para gerenciar o acesso aos recursos do Amazon Glacier. Para
Versão da API 2012-06-01124

Amazon Glacier Guia do desenvolvedor doPermissões obrigatórias para usar
o console do Amazon Glacier
obter mais informações, consulte Visão geral de como gerenciar permissões de acesso aosrecursos do Amazon Glacier (p. 119).
As seções neste tópico abrangem o seguinte:
• Permissões obrigatórias para usar o console do Amazon Glacier (p. 125)• Políticas gerenciadas da AWS (políticas predefinidas) para o Amazon Glacier (p. 126)• Exemplos de política gerenciada pelo cliente (p. 126)
A seguir, um exemplo de uma política de permissões.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "glacier:CreateVault", "glacier:DescribeVault", "glacier:ListVaults" ], "Resource": "arn:aws:glacier:us-west-2:123456789012:vaults/*" } ]}
A política concede permissões para três ações relacionadas ao cofre do Amazon Glacier(glacier:CreateVaultglacier:DescribeVault e glacier:ListVaults), em um recurso usandoo nome de recurso da Amazon (ARN) que identifica todos os cofres na região da AWS us-west-2.
O caractere curinga (*) ao final do ARN do significa que essa instrução pode corresponder a qualquernome de cofre. A instrução permite a ação glacier:DescribeVault em qualquer cofre na regiãoespecificada, us-west-2. Se quiser limitar permissões para essa ação somente a um cofre específico,você substituirá o caractere curinga (*) por um nome de cofre.
Permissões obrigatórias para usar o console doAmazon GlacierO console do Amazon Glacier oferece um ambiente integrado para você criar e gerenciar cofres doAmazon Glacier. No mínimo, os usuários do IAM criados por você devem receber permissões para a açãoglacier:ListVaults para visualizar o console do Amazon Glacier, conforme mostrado no exemplo aseguir.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "glacier:ListVaults" ], "Effect": "Allow", "Resource": "*" } ]}
Ambas as políticas gerenciadas da AWS do Amazon Glacier abordadas na próxima seção concedempermissões para glacier:ListVaults.
Versão da API 2012-06-01125

Amazon Glacier Guia do desenvolvedor doPolíticas gerenciadas da AWS (políticas
predefinidas) para o Amazon Glacier
Políticas gerenciadas da AWS (políticas predefinidas)para o Amazon GlacierA AWS resolve muitos casos de uso comuns fornecendo políticas do IAM autônomas criadas eadministradas pela AWS. As políticas gerenciadas concedem permissões necessárias para casos de usocomuns, de maneira que você possa evitar a necessidade de investigar quais permissões são necessárias.Para obter mais informações, consulte as Políticas gerenciadas da AWS no Guia do usuário do IAM.
As seguintes políticas gerenciadas da AWS, que você pode associar a usuários na conta, são específicasdo Amazon Glacier:
• AmazonGlacierReadOnlyAccess – Concede acesso somente leitura ao Amazon Glacier por meio doConsole de gerenciamento da AWS.
• AmazonGlacierFullAccess – Concede acesso completo ao Amazon Glacier por meio do Console degerenciamento da AWS.
Note
Você pode analisar essas políticas de permissões fazendo login no console do IAM e procurandopolíticas específicas.
Você também pode criar as próprias políticas do IAM personalizadas a fim de conceder permissõespara ações e recursos da API do Amazon Glacier. Você pode anexar essas políticas personalizadas aosusuários ou grupos do IAM que exigem essas permissões ou a funções de execução personalizadas(funções do IAM) criadas por você para os cofres do Amazon Glacier.
Exemplos de política gerenciada pelo clienteNesta seção, você pode encontrar políticas de usuário de exemplo que concedem permissões paradiversas ações do Amazon Glacier. Essas políticas funcionam quando você está usando a API RESTdo Amazon Glacier, os SDKs da AWS, a CLI da AWS ou, se aplicável, o console de gerenciamento doAmazon Glacier.
Note
Todos os exemplos usam a região Oeste dos EUA (Oregon) (us-west-2) e contêm IDs de contafictícios.
Exemplos• Exemplo 1: permitir que um usuário faça download de arquivos de um cofre (p. 126)• Exemplo 2: permitir que um usuário crie um cofre e configure notificações (p. 127)• Exemplo 3: permitir que um usuário faça upload para um cofre específico (p. 127)• Exemplo 4: conceder a um usuário permissões completas em um cofre específico (p. 128)
Exemplo 1: permitir que um usuário faça download de arquivosde um cofrePara fazer download de um arquivo, você primeiro inicia um trabalho a fim de recuperar o arquivo. Depoisque o trabalho de recuperação for concluído, você poderá fazer download dos dados. A política deexemplo a seguir concede permissões para a ação glacier:InitiateJob a fim de iniciar um trabalho(que permite ao usuário recuperar um arquivo ou um inventário de cofre do cofre) e permissões paraa ação glacier:GetJobOutput a fim de fazer download dos dados recuperados. A política também
Versão da API 2012-06-01126

Amazon Glacier Guia do desenvolvedor doExemplos de política gerenciada pelo cliente
concede permissões para realizar a ação glacier:DescribeJob, de maneira que o usuário possa obtero status do trabalho. Para obter mais informações, consulte Initiate Job (trabalhos POST) (p. 257).
A política concede essas permissões em um cofre chamado examplevault. Você pode obter o ARN docofre junto ao console do Amazon Glacier , ou de maneira programática chamando a ação da API DescribeVault (GET vault) (p. 187) ou List Vaults (GET vaults) (p. 203).
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Resource": "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault", "Action":["glacier:InitiateJob", "glacier:GetJobOutput", "glacier:DescribeJob"] } ]}
Exemplo 2: permitir que um usuário crie um cofre e configurenotificaçõesA política de exemplo a seguir concede permissões para criar um cofre na região us-west-2 conformeespecificado no elemento Resource e configurar notificações. Para obter mais informações sobre comotrabalhar com notificações, consulte Configurar notificações de cofre no Amazon Glacier (p. 47). A políticatambém concede permissões para listar cofres na região e obter a descrição do cofre específico.
Important
Ao conceder permissões para criar um cofre usando a operação glacier:CreateVault, vocêdeve especificar um caractere curinga (*) no valor Resource porque você não saberá o nome docofre até criar o cofre.
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Resource": "arn:aws:glacier:us-west-2:123456789012:vaults/*", "Action":["glacier:CreateVault", "glacier:SetVaultNotifications", "glacier:GetVaultNotifications", "glacier:DeleteVaultNotifications", "glacier:DescribeVault", "glacier:ListVaults"] } ]}
Exemplo 3: permitir que um usuário faça upload para um cofreespecíficoA política de exemplo a seguir concede permissões a fim de fazer upload de arquivos para umdeterminado cofre na região us-west-2. Essas permissões permitem que um usuário faça upload de umarquivo ao mesmo tempo usando a operação da API Upload Archive (POST archive) (p. 217) ou empartes usando a operação da API Initiate Multipart Upload (POST multipart-uploads) (p. 226).
{
Versão da API 2012-06-01127

Amazon Glacier Guia do desenvolvedor doUsar políticas baseadas em recurso (políticas de cofre)
"Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Resource": "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault", "Action":["glacier:UploadArchive", "glacier:InitiateMultipartUpload", "glacier:UploadMultipartPart", "glacier:ListParts", "glacier:ListMultipartUploads", "glacier:CompleteMultipartUpload"] } ]}
Exemplo 4: conceder a um usuário permissões completas em umcofre específicoA política de exemplo a seguir concede permissões a todas as ações do Amazon Glacier em um cofrechamado examplevault.
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Resource": "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault", "Action":["glacier:*"] } ]}
Usar políticas baseadas em recurso para AmazonGlacier (políticas de cofre)
Um cofre do Amazon Glacier, é o recurso principal no Amazon Glacier. Você pode adicionar permissõesà política associada a um cofre do Amazon Glacier. As políticas de permissões anexadas a cofres doAmazon Glacier são conhecidas como políticas baseadas em recurso (ou políticas de cofre no AmazonGlacier). Cada cofre do Amazon Glacier pode ter políticas de permissão baseadas em recurso associadas.Para obter informações sobre opções da política de permissões disponíveis, consulte Gerenciar o acessoaos recursos (p. 120).
Important
Antes de criar políticas baseadas em recurso, recomendamos analisar primeiro os tópicosintrodutórios que explicam os conceitos básicos e as opções disponíveis para gerenciar acessoa recursos do Amazon Glacier. Para obter mais informações, consulte Visão geral de comogerenciar permissões de acesso aos recursos do Amazon Glacier (p. 119).
Um cofre do Amazon Glacier pode ter uma política de acesso ao cofre e uma política do Vault Lockassociada. Política de acesso ao cofre do Amazon Glacier é uma política baseada em recurso que vocêpode usar para gerenciar permissões do cofre. Política do Vault Lock é uma política de acesso ao cofreque pode ser bloqueada. Depois que você bloqueia uma política do Vault Lock, ela não pode ser alterada.Você pode usar a política do Vault Lock para impor controles de conformidade.
Para obter mais informações, consulte os tópicos a seguir.
Versão da API 2012-06-01128

Amazon Glacier Guia do desenvolvedor doPolíticas de acesso ao cofre
Tópicos• Controle de acesso do Amazon Glacier com políticas de acesso ao cofre (p. 129)• Controle de acesso do Amazon Glacier com políticas de bloqueio de cofre (p. 131)
Controle de acesso do Amazon Glacier com políticasde acesso ao cofrePolítica de acesso ao cofre do Amazon Glacier é uma política baseada em recurso que você pode usarpara gerenciar permissões do cofre. Para obter informações sobre as diferentes opções de política depermissões disponíveis, consulte Gerenciar o acesso aos recursos (p. 120).
Você pode criar uma política de acesso ao cofre para cada cofre a fim de gerenciar permissões. Você podemodificar permissões em uma política de acesso ao cofre a qualquer momento. O Amazon Glacier tambémdá suporte a uma política do Vault Lock em cada cofre que, depois de bloqueada por você, não poderá seralterada. Para obter mais informações sobre como trabalhar com políticas do Vault Lock, consulte Controlede acesso do Amazon Glacier com políticas de bloqueio de cofre (p. 131).
Você pode usar a Amazon Glacier API, os SDKs da AWS, a CLI da AWS ou o console do Amazon Glacierpara criar e gerenciar políticas de acesso ao cofre. Para obter uma lista de operações do Amazon Glacierpermitidas para políticas baseadas em recursos de acesso ao cofre, consulte Permissões da API doAmazon Glacier: referência de ações, recursos e condições (p. 133).
Exemplos• Exemplo 1: conceder permissões entre contas para ações do Amazon Glacier específicas (p. 129)• Exemplo 2: conceder permissões somente leitura a todas as contas da AWS (p. 130)• Exemplo 3: conceder permissões entre contas para operações de exclusão MFA (p. 130)
Exemplo 1: conceder permissões entre contas para ações doAmazon Glacier específicasA política de exemplo a seguir concede permissões entre contas a duas contas da AWS para um conjuntode operações do Amazon Glacier em um cofre chamado examplevault.
Note
A conta que detém o cofre é cobrada por todos os custos associados ao cofre. Todas assolicitações, transferências de dados e custos de recuperação feitos por contas externaspermitidas são cobrados na conta que detém o cofre.
{ "Version":"2012-10-17", "Statement":[ { "Sid":"cross-account-upload", "Principal": { "AWS": [ "arn:aws:iam::123456789012:root", "arn:aws:iam::444455556666:root" ] }, "Effect":"Allow", "Action": [ "glacier:UploadArchive", "glacier:InitiateMultipartUpload", "glacier:AbortMultipartUpload",
Versão da API 2012-06-01129

Amazon Glacier Guia do desenvolvedor doPolíticas de acesso ao cofre
"glacier:CompleteMultipartUpload" ], "Resource": [ "arn:aws:glacier:us-west-2:999999999999:vaults/examplevault" ] } ]}
Exemplo 2: conceder permissões somente leitura a todas ascontas da AWSA política de exemplo a seguir concede permissões que permitem a todas as contas da AWS realizaroperações do Amazon Glacier para recuperar qualquer arquivo em um cofre chamado examplevault. Osarquivos recuperados serão somente leitura para essas contas.
{ "Version":"2012-10-17", "Statement":[ { "Sid": "add-read-only-perm", "Principal": "*", "Effect": "Allow", "Action": [ "glacier:InitiateJob", "glacier:GetJobOutput" ], "Resource": [ "arn:aws:glacier:us-west-2:999999999999:vaults/examplevault" ] } ]}
Exemplo 3: conceder permissões entre contas para operações deexclusão MFAVocê pode usar a Multi-Factor Authentication (MFA – Autenticação multifator) para proteger os recursos doAmazon Glacier. Para oferecer um nível extra de segurança, o MFA exige que os usuários provem a possefísica de um dispositivo MFA fornecendo um código MFA válido. Para obter mais informações sobre comoconfigurar acesso MFA, consulte Configurar acesso à API protegido por MFA no Guia do usuário do IAM.
A política de exemplo concede a uma conta da AWS permissão de credenciais temporária para excluirarquivos de um cofre chamado examplevault, desde que a solicitação seja autenticada com um dispositivoMFA. A política usa a chave de condição aws:MultiFactorAuthPresent para especificar esserequisito adicional. Para obter mais informações, consulte Chaves disponíveis para condições no Guia dousuário do IAM.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "add-mfa-delete-requirement", "Principal": { "AWS": [ "arn:aws:iam::123456789012:root" ] },
Versão da API 2012-06-01130

Amazon Glacier Guia do desenvolvedor doPolítica de bloqueio de cofre
"Effect": "Allow", "Action": [ "glacier:Delete*" ], "Resource": [ "arn:aws:glacier:us-west-2:999999999999:vaults/examplevault" ], "Condition": { "Bool": { "aws:MultiFactorAuthPresent": true } } } ]}
Seções relacionadas
• Política de acesso de exclusão do cofre (DELETE access-policy) (p. 183)• Get Vault Access Policy (GET access-policy) (p. 190)• Set Vault Access Policy (PUT access-policy) (p. 210)
Controle de acesso do Amazon Glacier com políticasde bloqueio de cofreUm cofre do Amazon Glacier pode ter uma política de acesso ao cofre baseada no recurso e umapolítica do Vault Lock anexada. A política do Vault Lock é uma política de acesso ao cofre que vocêpode bloquear. Usar uma política do Vault Lock pode ajudar você a impor requisitos regulatórios e deconformidade. O Amazon Glacier oferece um conjunto de operações da API para gerenciar as políticas doVault Lock. Consulte Bloquear um cofre usando a API do Amazon Glacier (p. 60).
Como exemplo de uma política do Vault Lock, suponhamos que você precise manter arquivos por umano antes de excluí-los. Para implementar esse requisito, você pode criar uma política do Vault Lock quenegue a usuários permissões para excluir um arquivo até que o arquivo exista por um ano. Você podetestar essa política antes de bloqueá-la. Depois de bloquear a política, ela se tornará imutável. Para obtermais informações sobre o processo de bloqueio, consulte Amazon Glacier Vault Lock (p. 59). Se quisergerenciar outras permissões de usuário que possam ser alteradas, você poderá usar a política de acessoao cofre (consulte Controle de acesso do Amazon Glacier com políticas de acesso ao cofre (p. 129)).
Você pode usar a API do Amazon Glacier, os SDKs da AWS, a CLI da AWS ou o console do AmazonGlacier para criar e gerenciar políticas do Vault Lock. Para obter uma lista de ações do Amazon Glacierpermitidas para políticas baseadas em recursos do cofre, consulte Permissões da API do Amazon Glacier:referência de ações, recursos e condições (p. 133).
Exemplos• Exemplo 1: negar permissões de exclusão para arquivos com menos de 365 dias (p. 131)• Exemplo 2: negar permissões de exclusão com base em uma tag (p. 132)
Exemplo 1: negar permissões de exclusão para arquivos commenos de 365 diasSuponhamos que você tenha um requisito regulatório para reter arquivos por até um ano antes de excluí-los. Você pode impor esse requisito implementando a política do Vault Lock a seguir. A política negaráa ação glacier:DeleteArchive no cofre examplevault se o arquivo que estiver sendo excluído tiver
Versão da API 2012-06-01131

Amazon Glacier Guia do desenvolvedor doPolítica de bloqueio de cofre
menos de um ano. A política usa a chave de condição específica do Amazon Glacier ArchiveAgeInDayspara impor o requisito de retenção de um ano.
{ "Version":"2012-10-17", "Statement":[ { "Sid": "deny-based-on-archive-age", "Principal": "*", "Effect": "Deny", "Action": "glacier:DeleteArchive", "Resource": [ "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault" ], "Condition": { "NumericLessThan" : { "glacier:ArchiveAgeInDays" : "365" } } } ]}
Exemplo 2: negar permissões de exclusão com base em uma tagSuponhamos que você tenha uma regra de retenção baseada em tempo de que um arquivo possa serexcluído caso tenha menos de um ano. Ao mesmo tempo, suponhamos que você precise impor umaretenção legal sobre os arquivos a fim de evitar a exclusão ou a modificação por uma duração indefinidadurante uma investigação legal. Nesse caso, a retenção legal tem precedência sobre a regra de retençãobaseada em tempo especificada na política do Vault Lock.
Para impor essas duas regras, a seguinte política de exemplo tem duas instruções:
• A primeira instrução nega permissões de exclusão a todos, bloqueando o cofre. Esse bloqueio érealizado usando a tag LegalHold.
• A segunda instrução concede permissões de exclusão quando o arquivo tem menos de 365 dias. Mas,mesmo quando arquivos têm menos de 365 dias, ninguém pode excluí-los porque o cofre foi bloqueadopela primeira instrução.
{ "Version":"2012-10-17", "Statement":[ { "Sid": "no-one-can-delete-any-archive-from-vault", "Principal": "*", "Effect": "Deny", "Action": [ "glacier:DeleteArchive" ], "Resource": [ "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault" ], "Condition": { "StringLike": { "glacier:ResourceTag/LegalHold": [ "true", "" ] } }
Versão da API 2012-06-01132

Amazon Glacier Guia do desenvolvedor doReferência de permissões da API do Amazon Glacier
}, { "Sid": "you-can-delete-archive-less-than-1-year-old", "Principal": "*", "Effect": "Allow", "Action": [ "glacier:DeleteArchive" ], "Resource": [ "arn:aws:glacier:us-west-2:123456789012:vaults/examplevault" ], "Condition": { "NumericLessThan": { "glacier:ArchiveAgeInDays": "365" } } } ]}
Seções relacionadas
• Amazon Glacier Vault Lock (p. 59)• Abort Vault Lock (DELETE lock-policy) (p. 173)• Complete Vault Lock (POST lockId) (p. 179)• Get Vault Lock (GET lock-policy) (p. 192)• Initiate Vault Lock (POST lock-policy) (p. 198)
Permissões da API do Amazon Glacier: referênciade ações, recursos e condições
Ao configurar Controle de acesso (p. 119) e escreve uma política de permissões que pode ser anexada auma identidade do IAM (políticas baseadas em identidade) ou um recurso (políticas baseadas em recurso),você pode usar a tabela a seguir como referência. A lista inclui todas as operações da API do AmazonGlacier, as ações correspondentes às quais você pode conceder permissões para realizar a ação, e orecurso da AWS ao qual você pode conceder as permissões.
Você especifica as ações no elemento Action da política, além do valor do recurso no elementoResource da política. Além disso, você pode usar o elemento Condition da linguagem da política doIAM para especificar quando uma política deve entrar em vigor.
Para especificar uma ação, use o prefixo glacier: seguido do nome da operação da API (por exemplo,glacier:CreateVault). Para a maioria das ações do Amazon Glacier, Resource é o cofre no qualvocê deseja conceder as permissões. Você especifica um cofre como o valor Resource usando o ARN docofre. Para expressar condições, você usa chaves de condição predefinidas. Para obter mais informações,consulte Visão geral de como gerenciar permissões de acesso aos recursos do Amazon Glacier (p. 119).
A tabela a seguir lista as ações que podem ser usadas com políticas baseadas em identidade e recurso.
Note
Algumas ações podem ser usadas somente com políticas baseadas em identidade. Essas açõessão marcadas por um asterisco vermelho (*) depois do nome da operação da API na primeiracoluna.
API do Amazon Glacier e permissões obrigatórias para ações
Versão da API 2012-06-01133

Amazon Glacier Guia do desenvolvedor doReferência de permissões da API do Amazon Glacier
Abort Multipart Upload (DELETE uploadID) (p. 221)
Permissões necessárias (Ações da API): glacier:AbortMultipartUpload
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Abort Vault Lock (DELETE lock-policy) (p. 173)
Permissões necessárias (Ações da API): glacier:AbortVaultLock
Recursos:
Chaves de condição do Amazon Glacier:Add Tags To Vault (POST tags add) (p. 175)
Permissões necessárias (Ações da API):glacier:AddTagsToVault
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyComplete Multipart Upload (POST uploadID) (p. 223)
Permissões necessárias (Ações da API):glacier:CompleteMultipartUpload
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyComplete Vault Lock (POST lockId) (p. 179)
Permissões necessárias (Ações da API):glacier:CompleteVaultLock
Recursos:
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyCreate Vault (PUT vault) (p. 177) *
Permissões necessárias (Ações da API):glacier:CreateVault
Recursos:
Chaves de condição do Amazon Glacier:Delete Archive (DELETE archive) (p. 215)
Permissões necessárias (Ações da API):glacier:DeleteArchive
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ArchiveAgeInDays,glacier:ResourceTag/TagKey
Versão da API 2012-06-01134

Amazon Glacier Guia do desenvolvedor doReferência de permissões da API do Amazon Glacier
Delete Vault (DELETE vault) (p. 181)
Permissões necessárias (Ações da API):glacier:DeleteVault
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyPolítica de acesso de exclusão do cofre (DELETE access-policy) (p. 183)
Permissões necessárias (Ações da API):glacier:DeleteVaultAccessPolicy
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyDelete Vault Notifications (DELETE notification-configuration) (p. 185)
Permissões necessárias (Ações da API):glacier:DeleteVaultNotifications
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyTrabalho de descrição (GET JobID) (p. 243)
Permissões necessárias (Ações da API):glacier:DescribeJob
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Describe Vault (GET vault) (p. 187)
Permissões necessárias (Ações da API):glacier:DescribeVault
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Política de recuperação para obter dados (GET policy) (p. 288) *
Permissões necessárias (Ações da API):glacier:GetDataRetrievalPolicy
Recursos: arn:aws:glacier:region:account-id:policies/retrieval-limit-policy
Chaves de condição do Amazon Glacier:Get Job Output (GET output) (p. 251)
Permissões necessárias (Ações da API):glacier:GetJobOutput
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Versão da API 2012-06-01135

Amazon Glacier Guia do desenvolvedor doReferência de permissões da API do Amazon Glacier
Chaves de condição do Amazon Glacier:Get Vault Access Policy (GET access-policy) (p. 190)
Permissões necessárias (Ações da API):glacier:GetVaultAccessPolicy
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Get Vault Lock (GET lock-policy) (p. 192)
Permissões necessárias (Ações da API):glacier:GetVaultLock
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Get Vault Notifications (GET notification-configuration) (p. 195)
Permissões necessárias (Ações da API):glacier:GetVaultNotifications
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Initiate Job (trabalhos POST) (p. 257)
Permissões necessárias (Ações da API):glacier:InitiateJob
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ArchiveAgeInDays,glacier:ResourceTag/TagKey
Initiate Multipart Upload (POST multipart-uploads) (p. 226)
Permissões necessárias (Ações da API):glacier:InitiateMultipartUpload
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyInitiate Vault Lock (POST lock-policy) (p. 198)
Permissões necessárias (Ações da API):glacier:InitiateVaultLock
Recursos:
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyList Jobs (GET jobs) (p. 267)
Permissões necessárias (Ações da API):glacier:ListJobs
Versão da API 2012-06-01136

Amazon Glacier Guia do desenvolvedor doReferência de permissões da API do Amazon Glacier
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:List Multipart Uploads (GET multipart-uploads) (p. 234)
Permissões necessárias (Ações da API):glacier:ListMultipartUploads
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:List Parts (GET uploadID) (p. 230)
Permissões necessárias (Ações da API):glacier:ListParts
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:Listar tags para cofre (GET tags) (p. 201)
Permissões necessárias (Ações da API):glacier:ListTagsForVault
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier:List Vaults (GET vaults) (p. 203)
Permissões necessárias (Ações da API):glacier:ListVaults
Recursos:
Chaves de condição do Amazon Glacier:Remove Tags From Vault (POST tags remove) (p. 208)
Permissões necessárias (Ações da API):glacier:RemoveTagsFromVault
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeySet Data Retrieval Policy (PUT policy) (p. 295) *
Permissões necessárias (Ações da API):glacier:SetDataRetrievalPolicy
Recursos:arn:aws:glacier:region:account-id:policies/retrieval-limit-policy
Chaves de condição do Amazon Glacier:Set Vault Access Policy (PUT access-policy) (p. 210)
Permissões necessárias (Ações da API):glacier:SetVaultAccessPolicy
Versão da API 2012-06-01137

Amazon Glacier Guia do desenvolvedor doReferência de permissões da API do Amazon Glacier
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyDefinir configuração de notificação de cofre (PUT notification-configuration) (p. 212)
Permissões necessárias (Ações da API):glacier:SetVaultNotifications
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyUpload Archive (POST archive) (p. 217)
Permissões necessárias (Ações da API):glacier:UploadArchive
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKeyUpload Part (PUT uploadID) (p. 239)
Permissões necessárias (Ações da API):glacier:UploadMultipartPart
Recursos: arn:aws:glacier:region:account-id:vaults/vault-name, arn:aws:glacier:region:account-id:vaults/example*,arn:aws:glacier:region:account-id:vaults/*
Chaves de condição do Amazon Glacier: glacier:ResourceTag/TagKey
Versão da API 2012-06-01138

Amazon Glacier Guia do desenvolvedor doRequisitos e limites do Amazon Glacier Select
Consulta em arquivos com o AmazonGlacier Select
Com o Amazon Glacier Select, você pode executar operações de filtragem usando instruções emlinguagem de consulta estruturada (SQL) simples diretamente nos dados do Amazon Glacier. Ao forneceruma consulta SQL para um objeto de arquivo do Amazon Glacier, o Amazon Glacier Select executará aconsulta em vigor e gravará os resultados de saída no Amazon S3. Com o Amazon Glacier Select, vocêpode executar consultas e análises personalizadas nos dados armazenados no Amazon Glacier semprecisar restaurar os dados para um nível mais quente, como o Amazon S3.
Ao executar consultas de seleção, o Amazon Glacier oferece três níveis de acesso a dados: expresso,padrão e em massa. Todos esses níveis fornecem diferentes tempos de acesso aos dados e custos,e você pode escolher qualquer um deles dependendo da rapidez com que deseja que os dados sejamdisponibilizados. Exceto para os arquivos maiores (mais de 250 MB), os dados acessados por meio deníveis expressos são disponibilizados geralmente entre 1 e 5 minutos. O nível padrão é concluído entre 3e 5 horas. As recuperações em massa são concluídas entre 5 e 12 horas. Para obter informações sobre adefinição de preço em camadas, consulte Definição de preço do Amazon Glacier.
Você pode usar o Amazon Glacier Select com os SDKs da AWS, a API REST do Amazon Glacier e a AWSCommand Line Interface (AWS CLI).
Tópicos• Requisitos e limites do Amazon Glacier Select (p. 139)• Como consultar dados usando o Amazon Glacier Select? (p. 140)• Como tratar erros (p. 141)• Mais informações (p. 141)
Requisitos e limites do Amazon Glacier SelectEstes são os requisitos para uso do Amazon Glacier Select:
• Os objetos de arquivo consultados pelo Amazon Glacier Select devem ser formatados como valoresseparados por vírgulas (CSV) descompactados.
• Você deve ter um bucket do S3 para trabalhar. Além disso, a conta da AWS usada para iniciar umtrabalho do Amazon Glacier Select deve ter permissões de gravação no bucket do S3. O bucket doAmazon S3 deve estar na mesma região da AWS do cofre que contém o objeto de arquivo que estásendo consultado.
• Você deve ter permissão para chamar Get Job Output (GET output) (p. 251).
Os seguintes limites se aplicam ao uso do Amazon Glacier Select:
• Não há limites para o número de registros que o Amazon Glacier Select pode processar. Um registro deentrada ou de saída não deve exceder 1 MB. Caso contrário, a consulta reporta uma falha. Existe umlimite de 1.048.576 colunas por registro.
• Não há limite para o tamanho do resultado final. No entanto, os resultados são divididos em váriaspartes.
Versão da API 2012-06-01139

Amazon Glacier Guia do desenvolvedor doComo consultar dados usando o Amazon Glacier Select?
• Uma expressão SQL limita-se a 128 KB.
Como consultar dados usando o Amazon GlacierSelect?
Usando o Amazon Glacier Select, você pode usar comandos SQL para consultar objetos de arquivo doAmazon Glacier em formato CSV não compactado. Com essa restrição, você pode executar operações deconsulta simples nos dados baseados em textos no Amazon Glacier. Por exemplo, você pode procurar umID ou um nome específico em um conjunto de arquivos de texto.
Para consultar os dados do Amazon Glacier, crie um trabalho de seleção usando a operação Initiate Job(trabalhos POST) (p. 257). Ao iniciar um trabalho de seleção, você fornece a expressão SQL, o arquivo aser consultado e o local em que serão armazenados os resultados no Amazon S3.
O exemplo de expressão a seguir retorna todos os registros do arquivo especificado pelo ID de arquivo emInitiate Job (trabalhos POST) (p. 257).
SELECT * FROM archive
O Amazon Glacier Select oferece suporte a um subconjunto da linguagem SQL ANSI. Ele é compatívelcom a filtragem comum de cláusulas SQL, como SELECT, FROM e WHERE. Mas não é compatívelcom SUM, COUNT, GROUP BY, JOINS, DISTINCT, UNION, ORDER BY e LIMIT. Para obter maisinformações sobre suporte a SQL, consulte Referência SQL para o Amazon S3 Select e o Amazon GlacierSelect (p. 299).
Saída do Amazon Glacier SelectAo iniciar um trabalho de seleção, você define um local de saída para os resultados da consulta select.Esse local deve ser um bucket do Amazon S3 na mesma região da AWS do cofre que contém o objetode arquivo que está sendo consultado. A conta da AWS que inicia o trabalho deve ter permissões paragravação no bucket do S3.
Você pode especificar a classe de armazenamento e a criptografia do S3 nos objetos de saídaarmazenados no Amazon S3. O Amazon Glacier Select é compatível com as criptografias SSE-KMSe SSE-S3. O Amazon Glacier Select não oferece suporte à criptografia SSE-C e no lado do cliente.Para obter mais informações sobre classes de armazenamento e criptografia do Amazon S3, consulteClasses de armazenamento e Proteção de dados usando criptografia no lado do servidor no Guia dodesenvolvedor do Amazon Simple Storage Service.
Os resultados do Amazon Glacier Select são armazenados no bucket do S3 por meio do prefixo fornecidono local de saída especificado em Initiate Job (trabalhos POST) (p. 257). A partir dessas informações,o Amazon Glacier Select cria um prefixo exclusivo em referência ao ID do trabalho. Esse prefixo deID de trabalho é retornado no cabeçalho x-amz-job-output-path em uma resposta Initiate Job(trabalhos POST) (p. 257). (Os prefixos são usados para agrupar os objetos do S3 iniciando os nomesde objeto com uma string comum.) Nesse prefixo exclusivo, há dois novos prefixos criados, resultspara resultados e errors para logs e erros. Após a conclusão do trabalho, é gravado um manifesto deresultado que contém a localização de todos os resultados.
Há também um arquivo de espaço reservado chamado job.txt gravado no local de saída. Esse arquivoé gravado, mas nunca é atualizado. O arquivo de espaço reservado é usado para:
• A validação da permissão para gravação e a maioria dos erros de sintaxe SQL de forma síncrona.• Fornece uma saída estática semelhante a Trabalho de descrição (GET JobID) (p. 243) que você pode
facilmente referenciar sempre que quiser.
Versão da API 2012-06-01140

Amazon Glacier Guia do desenvolvedor doComo tratar erros
Suponhamos, por exemplo, que você inicie um trabalho do Amazon Glacier Select com o local de saídados resultados especificado como s3://example-bucket/my-prefix e a resposta do trabalho retorneo ID do trabalho como examplekne1209ualkdjh812elkassdu9012e. Após a conclusão do trabalho deseleção, você pode visualizar os seguintes objetos do Amazon S3 no bucket:
s3://example-bucket/my-prefix/examplekne1209ualkdjh812elkassdu9012e/job.txts3://example-bucket/my-prefix/examplekne1209ualkdjh812elkassdu9012e/results/abcs3://example-bucket/my-prefix/examplekne1209ualkdjh812elkassdu9012e/results/defs3://example-bucket/my-prefix/examplekne1209ualkdjh812elkassdu9012e/results/ghis3://example-bucket/my-prefix/examplekne1209ualkdjh812elkassdu9012e/result_manifest.txt
Os resultados da consulta de seleção são divididos em várias partes. No exemplo, o Amazon GlacierSelect usa o prefixo especificado ao definir o local de saída e anexa o ID do trabalho e o prefixo results.Em seguida, ela grava os resultados em três partes, com abc, def e ghi no final dos nomes de objeto. Omanifesto de resultado contém os três arquivos que permitirão a recuperação programática. Se o trabalhoreportar falha com qualquer tipo de erro, um arquivo ficará visível com o prefixo de erro e um arquivoerror_manifest.txt será gerado.
A presença de um arquivo result_manifest.txt juntamente com a ausência deerror_manifest.txt garante que a tarefa foi concluída com êxito. Não há nenhuma garantia quanto àmaneira em que os resultados são ordenados.
Note
O tamanho de um nome de objeto do Amazon S3, também conhecido como chave, não pode termais de 1024 bytes. O Amazon Glacier reserva 128 bytes para prefixos. Além disso, o tamanhodo caminho do local do Amazon S3 não pode maior do que 512 bytes. Uma solicitação maior doque 512 bytes retornará uma exceção e não será aceita.
Como tratar errosO Amazon Glacier Select informará a você sobre dois tipos de erros. O primeiro conjunto de erros éenviado de forma síncrona quando você envia a consulta em Initiate Job (trabalhos POST) (p. 257).Esses erros são enviados como parte da resposta HTTP. Outro conjunto de erros pode ocorrer após aconsulta ter sido aceita, mas eles ocorrem durante a execução da consulta. Nesse caso, os erros sãogravados no local de saída especificado com o prefixo errors.
O Amazon Glacier Select interromperá a execução da consulta após a detecção de um erro. Para executara consulta com êxito, você deve resolver todos os erros. Verifique os logs para identificar quais registroscausaram a falha.
Como as consultas são executadas paralelamente em vários nós de computação, os erros obtidos nãoestão em ordem sequencial. Por exemplo, se a consulta falhar com um erro na linha 6234, isso nãosignifica que todas as linhas anteriores à linha 6234 foram processadas com êxito. A próxima execução daconsulta pode mostrar um erro em outra linha.
Mais informações• Initiate Job (trabalhos POST) (p. 257)• Trabalho de descrição (GET JobID) (p. 243)• List Jobs (GET jobs) (p. 267)• Trabalhar com arquivos no Amazon Glacier (p. 62)
Versão da API 2012-06-01141

Amazon Glacier Guia do desenvolvedor doEscolher uma política de recuperação
de dados do Amazon Glacier
Políticas de recuperação dos dadosdo Amazon Glacier
Com políticas de recuperação de dados do Amazon Glacier, você pode definir facilmente limites derecuperação de dados e gerenciar as atividades de recuperação de dados entre as contas da AWSem cada região. Para obter mais informações sobre cobranças pela recuperação de dados do AmazonGlacier, consulte a definição de preço do Amazon Glacier.
Important
Uma política de recuperação de dados se aplica somente a recuperações padrão e gerenciasolicitações de recuperação feitas diretamente ao Amazon Glacier. Ela não gerencia solicitaçõesde restauração de dados para a classe de armazenamento do Amazon Simple Storage Service(Amazon S3) GLACIER. Para obter mais informações sobre a classe de armazenamentoGLACIER, consulte Classe de armazenamento GLACIER e Transição de objetos no Guia dodesenvolvedor do Amazon Simple Storage Service.
Tópicos• Escolher uma política de recuperação de dados do Amazon Glacier (p. 142)• Usar o console do Amazon Glacier para configurar uma política de recuperação de dados (p. 143)• Usar a API do Amazon Glacier para configurar uma política de recuperação de dados (p. 144)
Escolher uma política de recuperação de dados doAmazon Glacier
Você pode escolher dentre três tipos de políticas de recuperação de dados do Amazon Glacier: Free TierOnly, Max Retrieval Rate e No Retrieval Limit. Usando uma política Free Tier Only, você pode manteras recuperações dentro da franquia do nível gratuito diariamente, e isso não incorrerá em um custo derecuperação de dados. Se quiser recuperar mais dados do que o nível gratuito, você poderá usar umapolítica Max Retrieval Rate para definir um limite da taxa de recuperação de bytes por hora. A políticaMax Retrieval Rate garante que a taxa de recuperação de pico de todos os trabalhos de recuperaçãoem toda a conta em uma região não exceda o limite de bytes por hora definido. Se não quiser definir umlimite de recuperação, você poderá usar uma política No Retrieval Limit em que todas as solicitações derecuperação de dados serão aceitas.
Com as políticas Free Tier Only e Max Retrieval Rate, as solicitações de recuperação de dados queexcederiam os limites de recuperação não serão aceitas. Se você usar uma política Free Tier Only, oAmazon Glacier vai rejeitar de maneira síncrona solicitações de recuperação que excederiam a franquiade nível gratuito. Se você usar uma política Max Retrieval Rate, o Amazon Glacier rejeitará solicitações derecuperação que fariam a taxa de recuperação de pico dos trabalhos em andamento exceder o limite debytes por hora definido pela política. Essas políticas ajudam a simplificar o gerenciamento de custos darecuperação de dados.
Estes são alguns fatos úteis sobre políticas de recuperação de dados:
• As configurações da recuperação de dados não alteram o período de 3 a 5 horas utilizado pararecuperar dados do Amazon Glacier usando recuperações padrão.
• Definir uma nova política de recuperação de dados não afeta os trabalhos de recuperação aceitosanteriormente já em andamento.
• Se uma solicitação do trabalho de recuperação for rejeitada por causa de uma política de recuperaçãode dados, você não será cobrado pelo trabalho ou pela solicitação.
Versão da API 2012-06-01142

Amazon Glacier Guia do desenvolvedor doPolítica Free Tier Only
• Você pode definir uma política de recuperação de dados para cada região da AWS, que vai reger todasas atividades de recuperação de dados na região na conta. Uma política de recuperação de dados éespecífica da região porque os custos de recuperação de dados variam entre regiões da AWS. Paraobter mais informações, consulte Definição de preço do Amazon Glacier.
Política Free Tier OnlyVocê pode definir uma política de recuperação de dados como Free Tier Only para garantir que asrecuperações permaneçam sempre dentro da franquia de nível gratuito, de maneira que não incorra emcobranças pela recuperação de dados. Se uma solicitação de recuperação for rejeitada, você receberáuma mensagem de erro informando que a solicitação foi negada pela política de recuperação de dadosatual.
Você pode definir a política de recuperação de dados como Free Tier Only para uma determinada regiãoda AWS. Assim que a política for definida, você não poderá recuperar mais dados em um dia do quea franquia de recuperação gratuita diária pro-rata para essa região e não incorrerá em cobranças derecuperação de dados.
Você poderá alternar para uma política Free Tier Only depois de ter incorrido em cobranças pelarecuperação de dados em um mês. A política Free Tier Only entrará em vigor para novas solicitações derecuperação, mas não afetará as solicitações anteriores. Você será cobrado pelos encargos incorridosanteriormente.
Política Max Retrieval RateVocê pode definir a política de recuperação de dados como Max Retrieval Rate para controlar a taxade recuperação de pico especificando um limite de recuperação de dados que tenha um máximo debytes por hora. Quando você definir a política de recuperação de dados como Max Retrieval Rate, umanova solicitação de recuperação será rejeitada se fizer a taxa de recuperação de pico dos trabalhos emandamento exceder o limite de bytes por hora especificado pela política. Se uma solicitação de trabalho forrejeitada, você receberá uma mensagem de erro informando que a solicitação foi negada pela política derecuperação de dados atual.
Definir a política de recuperação de dados como a política Max Retrieval Rate pode afetar o quando denível gratuito você pode usar em um dia. Por exemplo, suponhamos que você defina Max Retrieval Ratecomo 1 MB por hora. Isso é menor que a taxa da política de nível gratuito de 14 MB por hora. Para garantirque faça bom uso da franquia de nível gratuito diária, você pode primeiro definir a política como Free TierOnly e, em seguida, alternar para a política Max Retrieval Rate, se precisar. ou obter mais informaçõessobre como a franquia de recuperação é calculada, vá até Perguntas frequentes do Amazon Glacier.
Política No Retrieval LimitSe a política de recuperação de dados estiver definida como No Retrieval Limit, todas as solicitações derecuperação de dados válidos serão aceitas, e os custos de recuperação de dados vão variar com base nouso.
Usar o console do Amazon Glacier para configuraruma política de recuperação de dados
Você pode visualizar e atualizar as políticas de recuperação de dados no console do Amazon Glacierou usando a API do Amazon Glacier. Para configurar uma política de recuperação de dados no console,escolha uma região da AWS e clique em Settings.
Versão da API 2012-06-01143

Amazon Glacier Guia do desenvolvedor doUsar a API do Amazon Glacier para configurar
uma política de recuperação de dados
Você pode selecionar uma das três políticas de recuperação de dados: Free Tier Only, Max Retrieval Rateou No Retrieval Limit. Se clicar em Max Retrieval Rate, você precisa especificar um valor na caixa GB/Hour. Ao digitar um valor em GB/Hour, o console calculará um custo estimado para você. Clique em NoRetrieval Limit se você não quiser restrições quanto à taxa das recuperações de dados.
Você pode configurar uma política de recuperação de dados para cada região. Toda política entrará emvigor dentro de alguns minutos depois que você clicar em Save.
Usar a API do Amazon Glacier para configurar umapolítica de recuperação de dados
Você pode visualizar e definir uma política de recuperação de dados usando a API REST do AmazonGlacier ou os SDKs do AWS.
Usar a API REST do Amazon Glacier para configuraruma política de recuperação de dadosVocê pode visualizar e definir uma política de recuperação de dados usando a API REST do AmazonGlacier. Você pode visualizar uma política de recuperação de dados existente usando a operação Políticade recuperação para obter dados (GET policy) (p. 288). Você define uma política de recuperação dedados usando a operação Set Data Retrieval Policy (PUT policy) (p. 295).
Usando a operação de política PUT, você seleciona o tipo de política de recuperação de dados definindo ovalor de campo JSON Strategy como BytesPerHour, FreeTier ou None. BytesPerHour equivale aselecionar Max Retrieval Rate no console, FreeTier para selecionar Free Tier Only e None selecionar NoRetrieval Policy.
Quando você usar a operação Initiate Job (trabalhos POST) (p. 257) para iniciar um trabalho derecuperação de dados que exceder a taxa de recuperação máxima definida na política de recuperação dedados, a operação Initiate Job será anulada e lançará uma exceção.
Versão da API 2012-06-01144

Amazon Glacier Guia do desenvolvedor doUsar os SDKs da AWS para configuraruma política de recuperação de dados
Usar os SDKs da AWS para configurar uma política derecuperação de dadosA AWS oferece SDKs para você desenvolver aplicativos para o Amazon Glacier. Esses SDKs oferecembibliotecas mapeadas para uma API REST subjacente e fornecem objetos que permitem construirfacilmente solicitações e processar respostas. Para obter mais informações, consulte Usar os SDKs daAWS com o Amazon Glacier (p. 111).
Versão da API 2012-06-01145

Amazon Glacier Guia do desenvolvedor doConceitos básicos da marcação
Marcar recursos do Amazon GlacierTag é um rótulo atribuído por você a um recurso da AWS. Cada tag consiste em uma chave e um valor,ambos definidos por você. Você pode atribuir as tags definidas a recursos de cofre do Amazon Glacier.O uso de marcas é uma forma simples, mas eficiente, de gerenciar os recursos da AWS e organizar osdados, incluindo dados de faturamento.
Tópicos• Conceitos básicos da marcação (p. 146)• Restrições de tag (p. 146)• Monitoramento de custos com marcação (p. 147)• Gerenciar controle de acesso com marcação (p. 147)• Seções relacionadas (p. 147)
Conceitos básicos da marcaçãoVocê usa o console do Amazon Glacier, a AWS Command Line Interface (AWS CLI) ou a Amazon GlacierAPI para concluir as seguintes tarefas:
• Adicionar tags a um cofre• Listar as tags de um cofre• Remover tags de um cofre
Para obter informações sobre como adicionar, listar e remover tags, consulte Marcar os cofres do AmazonGlacier (p. 58).
Você pode usar tags para categorizar os cofres. Por exemplo, você pode categorizar cofres por finalidade,proprietário ou ambiente. Como você define a chave e o valor para cada marca, você pode criar umconjunto de categorias personalizado para atender às suas necessidades específicas. Por exemplo,convém definir um conjunto de tags que ajude a acompanhar cofres por proprietário e finalidade para ocofre. Estes são alguns exemplos de tags:
• Proprietário: nome• Finalidade: arquivos de vídeo• Ambiente: produção
Restrições de tagAs restrições de tag básicas são as seguintes:
• O número máximo de tags de um recurso (cofre) é 50.• As chaves e os valores de tags diferenciam maiúsculas de minúsculas.
As restrições da chave de tag são as seguintes:
• Dentro de um conjunto de tags de um cofre, cada chave de tag deve ser exclusiva. Se você adicionaruma marca com uma chave que já estiver em uso, sua nova marca existente substituirá o par de chave-valor.
Versão da API 2012-06-01146

Amazon Glacier Guia do desenvolvedor doMonitoramento de custos com marcação
• As chaves de tag não podem começar com aws: porque esse prefixo está reservado para uso pelaAWS. A AWS pode criar tags que comecem com esse prefixo em seu nome, mas você não pode editarnem excluí-las.
• As chaves de tag devem ter entre 1 e 128 caracteres Unicode.• As chaves de marca devem conter os seguintes caracteres: letras Unicode, dígitos, espaço em branco e
os seguintes caracteres especiais: _ . / = + - @.
As restrições de valor da tag são as seguintes:
• Os valores de tag devem ter entre 0 e 255 caracteres Unicode.• Os valores de marca podem estar em branco. Caso contrário, elas devem conter os seguintes
caracteres: letras Unicode, dígitos, espaço em branco e qualquer um dos seguintes caracteresespeciais: _ . / = + - @.
Monitoramento de custos com marcaçãoVocê pode usar marcas para categorizar e monitorar seus custos da AWS. Quando você aplica tagsa qualquer recurso da AWS, inclusive cofres, o relatório de alocação de custos da AWS inclui o uso eos custos agregados por tags. É possível aplicar tags que representem categorias de negócios (comocentros de custos, nomes de aplicativo e proprietários) para organizar os custos entre vários serviços.Para obter mais informações, consulte Usar marcas de alocação de custos para relatórios de faturamentopersonalizados no Guia do usuário do AWS Billing and Cost Management.
Gerenciar controle de acesso com marcaçãoVocê pode usar tags como uma condição em uma declaração de política de acesso. Por exemplo,você pode configurar uma tag hold legal e incluí-la como uma condição em uma política de retençãode dados que afirma que "arquivar a exclusão de todos será negado se o valor da tag hold legal estiverdefinido como True". Você pode implantar a política de retenção de dados e definir a tag hold legalcomo False em condições normais. Se os dados precisarem ser colocados em espera para auxiliaruma investigação, você poderá ativar facilmente a retenção legal definindo o valor de tag como True eremovendo a retenção de uma maneira semelhante depois. Para ver um exemplo, consulte Exemplo 2:negar permissões de exclusão com base em uma tag (p. 132).
Seções relacionadas• Marcar os cofres do Amazon Glacier (p. 58)
Versão da API 2012-06-01147

Amazon Glacier Guia do desenvolvedor doInformações do Amazon Glacier no CloudTrail
Registro de chamadas de APIdo Amazon Glacier com o AWSCloudTrail
O Amazon Glacier é integrado ao AWS CloudTrail, um serviço que fornece um registro das açõesrealizadas por um usuário, função ou serviço da AWS no Amazon Glacier. O CloudTrail captura todasas chamadas de API para o Amazon Glacier como eventos, incluindo chamadas do console do AmazonGlacier e as chamadas de código para as APIs do Amazon Glacier. Se você criar uma trilha, poderáhabilitar a entrega contínua de eventos do CloudTrail para um bucket do Amazon S3, incluindo eventosdo Amazon Glacier. Se não configurar uma trilha, você ainda poderá visualizar os eventos mais recentesno console do CloudTrail em Event history (Histórico de eventos). Com as informações coletadas peloCloudTrail, você pode determinar a solicitação feita para o Amazon Glacier, o endereço IP do qual asolicitação foi feita, quem fez a solicitação, quando ela foi feita e detalhes adicionais.
Para saber mais sobre o CloudTrail, consulte o AWS CloudTrail User Guide.
Informações do Amazon Glacier no CloudTrailO CloudTrail está habilitado na sua conta da AWS ao criá-la. Quando ocorre uma atividade no AmazonGlacier, ela é registrada em um evento do CloudTrail junto com outros eventos de serviços da AWS noEvent history (Histórico de eventos). Você pode visualizar, pesquisar e fazer download de eventos recentesem sua conta da AWS. Para obter mais informações, consulte o tópico sobre como Exibir eventos com ohistórico de eventos do CloudTrail.
Para obter um registro contínuo de eventos em sua conta da AWS, incluindo eventos do Amazon Glacier,crie uma trilha. Uma trilha permite que o CloudTrail forneça arquivos de log para um bucket do AmazonS3. Por padrão, quando você cria uma trilha no console, ela é aplicada a todas as regiões. A trilha registraeventos de todas as regiões na partição da AWS e fornece os arquivos de log para o bucket do AmazonS3 que você especificar. Além disso, você pode configurar outros serviços da AWS para analisar maisprofundamente e agir sobre os dados de evento coletados nos logs do CloudTrail. Para obter maisinformações, consulte:
• Visão geral da criação de uma trilha• Serviços compatíveis e integrações do CloudTrail• Configuração de notificações do Amazon SNS para o CloudTrail• Recebimento de arquivos de log do CloudTrail de várias regiões e Recebimento de arquivos de log do
CloudTrail de várias contas
Todas as ações do Amazon Glacier são registradas pelo CloudTrail e documentadas no Referênciade API do Amazon Glacier (p. 152). Por exemplo, as chamadas para as ações Create Vault (PUTvault) (p. 177), Delete Vault (DELETE vault) (p. 181) e List Vaults (GET vaults) (p. 203) geramentradas nos arquivos de logs do CloudTrail.
Cada entrada de log ou evento contém informações sobre quem gerou a solicitação. As informações deidentidade ajudam a determinar:
• Se a solicitação foi feita com credenciais de usuário da raiz ou do IAM.
Versão da API 2012-06-01148

Amazon Glacier Guia do desenvolvedor doCompreender entradas de
arquivo de log do Amazon Glacier
• Se a solicitação foi feita com credenciais de segurança temporárias de uma função ou de um usuáriofederado.
• Se a solicitação foi feita por outro serviço da AWS.
Para obter mais informações, consulte o CloudTrail userIdentity Element.
Compreender entradas de arquivo de log doAmazon Glacier
Uma trilha é uma configuração que permite a entrega de eventos como registros de log a um bucket doAmazon S3 especificado. Os arquivos de log do CloudTrail contêm uma ou mais entradas de log. Umevento representa uma única solicitação de qualquer origem e inclui informações sobre a ação solicitada,a data e a hora da ação, os parâmetros de solicitação e assim por diante. Os arquivos de log do CloudTrailnão são um rastreamento de pilha ordenada das chamadas de API pública. Dessa forma, eles não sãoexibidos em uma ordem específica.
O exemplo a seguir mostra uma entrada de log do CloudTrail que demonstra as ações de Create Vault(PUT vault) (p. 177), Delete Vault (DELETE vault) (p. 181), List Vaults (GET vaults) (p. 203) eDescribe Vault (GET vault) (p. 187).
{ "Records": [ { "awsRegion": "us-east-1", "eventID": "52f8c821-002e-4549-857f-8193a15246fa", "eventName": "CreateVault", "eventSource": "glacier.amazonaws.com", "eventTime": "2014-12-10T19:05:15Z", "eventType": "AwsApiCall", "eventVersion": "1.02", "recipientAccountId": "999999999999", "requestID": "HJiLgvfXCY88QJAC6rRoexS9ThvI21Q1Nqukfly02hcUPPo", "requestParameters": { "accountId": "-", "vaultName": "myVaultName" }, "responseElements": { "location": "/999999999999/vaults/myVaultName" }, "sourceIPAddress": "127.0.0.1", "userAgent": "aws-sdk-java/1.9.6 Mac_OS_X/10.9.5 Java_HotSpot(TM)_64-Bit_Server_VM/25.25-b02/1.8.0_25", "userIdentity": { "accessKeyId": "AKIAIOSFODNN7EXAMPLE", "accountId": "999999999999", "arn": "arn:aws:iam::999999999999:user/myUserName", "principalId": "A1B2C3D4E5F6G7EXAMPLE", "type": "IAMUser", "userName": "myUserName" } }, { "awsRegion": "us-east-1", "eventID": "cdd33060-4758-416a-b7b9-dafd3afcec90", "eventName": "DeleteVault", "eventSource": "glacier.amazonaws.com", "eventTime": "2014-12-10T19:05:15Z", "eventType": "AwsApiCall",
Versão da API 2012-06-01149

Amazon Glacier Guia do desenvolvedor doCompreender entradas de
arquivo de log do Amazon Glacier
"eventVersion": "1.02", "recipientAccountId": "999999999999", "requestID": "GGdw-VfhVfLCFwAM6iVUvMQ6-fMwSqSO9FmRd0eRSa_Fc7c", "requestParameters": { "accountId": "-", "vaultName": "myVaultName" }, "responseElements": null, "sourceIPAddress": "127.0.0.1", "userAgent": "aws-sdk-java/1.9.6 Mac_OS_X/10.9.5 Java_HotSpot(TM)_64-Bit_Server_VM/25.25-b02/1.8.0_25", "userIdentity": { "accessKeyId": "AKIAIOSFODNN7EXAMPLE", "accountId": "999999999999", "arn": "arn:aws:iam::999999999999:user/myUserName", "principalId": "A1B2C3D4E5F6G7EXAMPLE", "type": "IAMUser", "userName": "myUserName" } }, { "awsRegion": "us-east-1", "eventID": "355750b4-e8b0-46be-9676-e786b1442470", "eventName": "ListVaults", "eventSource": "glacier.amazonaws.com", "eventTime": "2014-12-10T19:05:15Z", "eventType": "AwsApiCall", "eventVersion": "1.02", "recipientAccountId": "999999999999", "requestID": "yPTs22ghTsWprFivb-2u30FAaDALIZP17t4jM_xL9QJQyVA", "requestParameters": { "accountId": "-" }, "responseElements": null, "sourceIPAddress": "127.0.0.1", "userAgent": "aws-sdk-java/1.9.6 Mac_OS_X/10.9.5 Java_HotSpot(TM)_64-Bit_Server_VM/25.25-b02/1.8.0_25", "userIdentity": { "accessKeyId": "AKIAIOSFODNN7EXAMPLE", "accountId": "999999999999", "arn": "arn:aws:iam::999999999999:user/myUserName", "principalId": "A1B2C3D4E5F6G7EXAMPLE", "type": "IAMUser", "userName": "myUserName" } }, { "awsRegion": "us-east-1", "eventID": "569e830e-b075-4444-a826-aa8b0acad6c7", "eventName": "DescribeVault", "eventSource": "glacier.amazonaws.com", "eventTime": "2014-12-10T19:05:15Z", "eventType": "AwsApiCall", "eventVersion": "1.02", "recipientAccountId": "999999999999", "requestID": "QRt1ZdFLGn0TCm784HmKafBmcB2lVaV81UU3fsOR3PtoIiM", "requestParameters": { "accountId": "-", "vaultName": "myVaultName" }, "responseElements": null, "sourceIPAddress": "127.0.0.1", "userAgent": "aws-sdk-java/1.9.6 Mac_OS_X/10.9.5 Java_HotSpot(TM)_64-Bit_Server_VM/25.25-b02/1.8.0_25", "userIdentity": { "accessKeyId": "AKIAIOSFODNN7EXAMPLE",
Versão da API 2012-06-01150

Amazon Glacier Guia do desenvolvedor doCompreender entradas de
arquivo de log do Amazon Glacier
"accountId": "999999999999", "arn": "arn:aws:iam::999999999999:user/myUserName", "principalId": "A1B2C3D4E5F6G7EXAMPLE", "type": "IAMUser", "userName": "myUserName" } } ]}
Versão da API 2012-06-01151

Amazon Glacier Guia do desenvolvedor doCabeçalhos de solicitação comuns
Referência de API do AmazonGlacier
O Amazon Glacier dá suporte a um conjunto de operações – mais especificamente, um conjunto dechamadas API RESTful – que permitem interagir com o serviço.
Você pode usar qualquer biblioteca de programação capaz de enviar solicitações HTTP para enviar assolicitações REST ao Amazon Glacier. Ao enviar uma solicitação REST, o Amazon Glacier exige quevocê autentique toda solicitação com uma assinatura. Além disso, ao fazer o upload de um arquivo, vocêtambém deve computar a soma de verificação da carga útil e incluí-la na solicitação. Para obter maisinformações, consulte Solicitações de assinatura (p. 155).
Se ocorrer algum erro, você precisará saber o que o Amazon Glacier enviará em uma resposta de erropara que seja possível processá-lo. Esta seção fornece todas essas informações, além de documentar asoperações REST, de maneira que você possa fazer chamadas API REST diretamente.
Você pode usar as chamadas API REST diretamente ou usar os SDKs da AWS que fornecem bibliotecaswrapper para simplificar a tarefa de codificação. Essas bibliotecas assinam cada solicitação enviadapor você e calculam a soma de verificação da carga útil na solicitação. Por isso, usar os SDKs daAWS simplifica a tarefa de codificação. Este guia do desenvolvedor apresenta exemplos funcionaisde operações do Amazon Glacier básicas usando o AWS SDK for Java e o .NET. Para obter maisinformações, consulte, Usar os SDKs da AWS com o Amazon Glacier (p. 111).
Tópicos• Cabeçalhos de solicitação comuns (p. 152)• Cabeçalhos de resposta comuns (p. 155)• Solicitações de assinatura (p. 155)• Computar somas de verificação (p. 159)• Respostas de erro (p. 169)• Operações de cofre (p. 172)• Operações de arquivo (p. 215)• Operações de multipart upload (p. 220)• Operações de trabalho (p. 243)• Tipos de dados usados em operações de trabalho (p. 274)• Operações de recuperação de dados (p. 287)
Cabeçalhos de solicitação comunsEntre as solicitações REST do Amazon Glacier estão cabeçalhos que contêm informações básicas sobrea solicitação. A tabela a seguir descreve os cabeçalhos que podem ser usados por todas as solicitaçõesREST do Amazon Glacier.
Nome do cabeçalho Descrição Obrigatório
Authorization O cabeçalho obrigatório para assinar solicitações.O Amazon Glacier exige o Signature versão 4. Paraobter mais informações, consulte Solicitações deassinatura (p. 155).
Sim
Versão da API 2012-06-01152
Amazon Glacier Guia do desenvolvedor doCabeçalhos de solicitação comuns
Nome do cabeçalho Descrição ObrigatórioTipo: string
Content-Length O tamanho do corpo da solicitação (sem oscabeçalhos).
Tipo: string
Condição: obrigatório somente para a API UploadArchive (POST archive) (p. 217).
Condicional
Date A data que pode ser usada para criar a assinaturacontida no cabeçalho Authorization. Se ocabeçalho Date precisar ser usado na assinatura,ele deverá ser especificado no formato básico ISO8601. Neste caso, o cabeçalho x-amz-date não énecessário. Quando x-amz-date está presente, elesempre substitui o valor do cabeçalho Date.
Se não for usado para assinar, o cabeçalho Datepoderá ser um dos formatos de data completaespecificado por RFC 2616, seção 3.3. Por exemplo,a data/hora Wed, 10 Feb 2017 12:00:00 GMT aseguir é um cabeçalho de data/hora válido a ser usadocom o Amazon Glacier.
Se você estiver usando o cabeçalho Datepara assinatura, ele deverá estar no formatoYYYYMMDD'T'HHMMSS'Z' básico ISO 8601.
Tipo: string
Condição: se Date for especificado, mas não estiverem formato básico ISO 8601, você também deveráincluir o cabeçalho x-amz-date. Se Date forespecificado em formato básico ISO 8601, issoserá suficiente para assinar solicitações e você nãoprecisar do cabeçalho x-amz-date. Para obter maisinformações, consulte Processar datas no Signatureversão 4 no Glossário da Amazon Web Services.
Condicional
Host Este cabeçalho especifica o endpoint de serviço parao qual você envia as solicitações. O valor deve ser daforma"glacier.region.amazonaws.com", em queregion é substituída por uma designação de região,como us-west-2.
Tipo: string
Sim
Versão da API 2012-06-01153
Amazon Glacier Guia do desenvolvedor doCabeçalhos de solicitação comuns
Nome do cabeçalho Descrição Obrigatório
x-amz-content-sha256 A soma de verificação SHA256 computada de todaa carga útil cujo upload é feito com Upload Archive(POST archive) (p. 217) ou Upload Part (PUTuploadID) (p. 239). Esse cabeçalho não é igual aocabeçalho x-amz-sha256-tree-hash, embora,para algumas pequenas cargas úteis, os valores sejamos mesmos. Quando x-amz-content-sha256 éobrigatório, x-amz-content-sha256 e x-amz-sha256-tree-hash devem ser especificados.
Tipo: string
Condição: obrigatório para API de streaming, UploadArchive (POST archive) (p. 217) e Upload Part (PUTuploadID) (p. 239).
Condicional
x-amz-date A data usada para criar a assinatura no cabeçalho deautorização. O formato deve ser ISO 8601 básico noformato YYYYMMDD'T'HHMMSS'Z'. Por exemplo, adata/hora a seguir 20170210T120000Z é um x-amz-date válido a ser usado com o Amazon Glacier.
Tipo: string
Condição: x-amz-date é opcional para todas assolicitações; ele pode ser usado para substituir a datausada em solicitações de assinatura. Se o cabeçalhoDate for especificado no formato básico ISO 8601,x-amz-date não será necessário. Quando x-amz-date está presente, ele sempre substitui o valordo cabeçalho Date. Para obter mais informações,consulte Processar datas no Signature versão 4 noGlossário da Amazon Web Services.
Condicional
x-amz-glacier-version A versão da Amazon Glacier API a ser usada. Aversão atual é 2012-06-01.
Tipo: string
Sim
x-amz-sha256-tree-hash
A soma de verificação do hash de árvore SHA256para um arquivo cujo upload foi feito (Upload Archive(POST archive) (p. 217)) ou uma parte do arquivo(Upload Part (PUT uploadID) (p. 239)). Paraobter mais informações sobre como calcular essasoma de verificação, consulte Computar somas deverificação (p. 159).
Tipo: string
Padrão: nenhum
Condição: obrigatório para API de streaming, UploadArchive (POST archive) (p. 217) e Upload Part (PUTuploadID) (p. 239).
Condicional
Versão da API 2012-06-01154

Amazon Glacier Guia do desenvolvedor doCabeçalhos de resposta comuns
Cabeçalhos de resposta comunsA tabela a seguir descreve os cabeçalhos de resposta comuns à maioria das respostas do AmazonGlacier.
Nome Descrição
Content-Length O tamanho em bytes do corpo da resposta.
Tipo: string
Date A data e hora em que o Amazon Glacier respondeu; por exemplo, Wed, 10Feb 2017 12:00:00 GMT. O formato da data deve ser um dos formatos dedata completa especificado pela RFC 2616, seção 3.3. A Date retornada podevariar um pouco em relação a outras datas. Dessa forma, por exemplo, a dataretornada de uma solicitação Upload Archive (POST archive) (p. 217) talvez nãocorresponda à data mostrada para o arquivo em uma lista de inventários para ocofre.
Tipo: string
x-amzn-RequestId
Um valor criado pelo Amazon Glacier que identifica com exclusividade asolicitação. Se você tiver um problema com o Amazon Glacier, a AWS poderáusar esse valor para solucioná-lo. É recomendável registrar em log esses valores.
Tipo: string
x-amz-sha256-tree-hash
A soma de verificação do hash de árvore SHA256 do arquivo ou o corpo doinventário. Para obter mais informações sobre como calcular essa soma deverificação, consulte Computar somas de verificação (p. 159).
Tipo: string
Solicitações de assinaturaO Amazon Glacier exige que você autentique toda solicitação enviada assinando-a. Para assinar umasolicitação, calcule uma assinatura digital usando a função de hash criptográfico. Hash criptográfico é umafunção que retorna um valor de hash exclusivo com base na entrada. A entrada da função de hash incluio texto da solicitação e a chave de acesso secreta. A função de hash retorna um valor de hash que vocêinclui na solicitação como sua assinatura. A assinatura é parte do cabeçalho Authorization de suasolicitação.
Depois de receber a solicitação, o Amazon Glacier recalculará a assinatura usando a mesma função dehash e a entrada que você usou para assinar a solicitação. Quando a assinatura resultante corresponde àassinatura na solicitação, o Amazon Glacier processa a solicitação. Do contrário, a solicitação é rejeitada.
O Amazon Glacier dá suporte à autenticação usando AWS Signature versão 4. O processo para calcularuma assinatura pode ser dividido em três tarefas:
• Tarefa 1: Criar uma solicitação canônica
Reorganize sua solicitação HTTP em um formato canônico. Usar uma forma canônica é necessárioporque o Amazon Glacier usa a mesma forma canônica quando recalcula uma assinatura para compararcom a enviada por você.
• Tarefa 2: Criar uma string para assinar
Versão da API 2012-06-01155

Amazon Glacier Guia do desenvolvedor doCálculo de assinatura de exemplo
Crie uma string que será usada como um dos valores de entrada para sua função hash criptográfica. Astring, chamada string-to-sign, é uma concatenação do nome do algoritmo hash, da data da solicitação,de uma string do escopo da credencial e da solicitação canonizada da tarefa anterior. A string do escopocredencial em si é uma concatenação da data, da região e de informações do serviço.
• Tarefa 3: Crie uma assinatura
Crie uma assinatura para sua solicitação usando uma função hash criptográfica que aceita duas stringsde entrada: sua string para assinar e uma chave derivada. Para calcular a chave derivada, inicie suachave de acesso secreta e use a string do escopo credencial para criar uma série de códigos deautenticação de mensagem baseados em hash (HMACs). A função de hash de assinatura usada nestaetapa de assinatura não é o algoritmo de hash de árvore usado em Amazon Glacier APIs que fazemupload de dados.
Tópicos• Cálculo de assinatura de exemplo (p. 156)• Calcular assinaturas para as operações de streaming (p. 157)
Cálculo de assinatura de exemploO exemplo a seguir mostra os detalhes da criação de uma assinatura para Create Vault (PUTvault) (p. 177). Esse exemplo pode ser usado como referência para verificar o método de cálculo daassinatura. Outros cálculos de referência estão incluídos no Signature Version 4 Test Suite do AmazonWeb Services Glossary.
O exemplo supõe o seguinte:
• O timestamp da solicitação é Fri, 25 May 2012 00:24:53 GMT.• O endpoint é Leste dos EUA (Norte da Virgínia) Região us-east-1.
A sintaxe de solicitação geral (incluindo o corpo JSON) é:
PUT /-/vaults/examplevault HTTP/1.1Host: glacier.us-east-1.amazonaws.comDate: Fri, 25 May 2012 00:24:53 GMTAuthorization: SignatureToBeCalculatedx-amz-glacier-version: 2012-06-01
O formato canônico da solicitação calculada para Tarefa 1: Crie uma solicitação canônica (p. 155) é:
PUT/-/vaults/examplevault
host:glacier.us-east-1.amazonaws.comx-amz-date:20120525T002453Zx-amz-glacier-version:2012-06-01
host;x-amz-date;x-amz-glacier-versione3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
A última linha da solicitação canônica é o hash do corpo da solicitação. Além disso, observe a terceira linhavazia na solicitação canônica. Isso porque não há parâmetros de consulta para essa API.
A string de assinatura de Tarefa 2: criar uma string de assinatura (p. 155) é:
Versão da API 2012-06-01156

Amazon Glacier Guia do desenvolvedor doCalcular assinaturas para as operações de streaming
AWS4-HMAC-SHA25620120525T002453Z20120525/us-east-1/glacier/aws4_request5f1da1a2d0feb614dd03d71e87928b8e449ac87614479332aced3a701f916743
A primeira linha da string-to-sign é o algoritmo, a segunda linha é a timestamp, a terceira linha é oescopo da credencial e a última linha é o hash da solicitação canônica da Tarefa 1: Crie uma solicitaçãocanônica (p. 155). O nome do serviço a usar no escopo da credencial é glacier.
Para a Tarefa 3: Crie uma assinatura (p. 156), a chave derivada pode ser representada como:
derived key = HMAC(HMAC(HMAC(HMAC("AWS4" + YourSecretAccessKey,"20120525"),"us-east-1"),"glacier"),"aws4_request")
Se a chave de acesso secreta, wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY, for usada, aassinatura calculada será:
3ce5b2f2fffac9262b4da9256f8d086b4aaf42eba5f111c21681a65a127b7c2a
A etapa final é construir o cabeçalho Authorization. Para a chave de acesso de demonstraçãoAKIAIOSFODNN7EXAMPLE, o cabeçalho (com quebras de linha adicionadas por motivo de legibilidade) é:
Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20120525/us-east-1/glacier/aws4_request, SignedHeaders=host;x-amz-date;x-amz-glacier-version, Signature=3ce5b2f2fffac9262b4da9256f8d086b4aaf42eba5f111c21681a65a127b7c2a
Calcular assinaturas para as operações de streamingUpload Archive (POST archive) (p. 217) e Upload Part (PUT uploadID) (p. 239) são operações destreaming que exigem que você inclua um cabeçalho adicional x-amz-content-sha256 ao assinar eenviar a solicitação. As etapas de assinatura das operações de streaming são exatamente as mesmas deoutras operações, com a adição do cabeçalho de streaming.
O cálculo do cabeçalho de streaming x-amz-content-sha256 se baseia no hash SHA256 de todoo conteúdo (carga útil) cujo upload deve ser feito. Esse cálculo é diferente do hash de árvore SHA256(Computar somas de verificação (p. 159)). Além de casos triviais, o valor de hash SHA 256 dos dados dacarga útil será diferente do hash de árvore SHA256 dos dados da carga útil.
Se os dados da carga útil forem especificados como uma matriz de bytes, você poderá usar o trecho decódigo do Java a seguir para calcular o hash SHA256.
public static byte[] computePayloadSHA256Hash2(byte[] payload) throws NoSuchAlgorithmException, IOException { BufferedInputStream bis = new BufferedInputStream(new ByteArrayInputStream(payload)); MessageDigest messageDigest = MessageDigest.getInstance("SHA-256"); byte[] buffer = new byte[4096]; int bytesRead = -1; while ( (bytesRead = bis.read(buffer, 0, buffer.length)) != -1 ) { messageDigest.update(buffer, 0, bytesRead); } return messageDigest.digest();}
Da mesma maneira, no C#, você pode calcular o hash SHA256 dos dados da carga útil, conformemostrado no trecho de código a seguir.
Versão da API 2012-06-01157

Amazon Glacier Guia do desenvolvedor doCalcular assinaturas para as operações de streaming
public static byte[] CalculateSHA256Hash(byte[] payload){ SHA256 sha256 = System.Security.Cryptography.SHA256.Create(); byte[] hash = sha256.ComputeHash(payload);
return hash;}
Cálculo da assinatura de exemplo para Streaming APIO exemplo a seguir orienta você em meio aos detalhes de como criar uma assinatura para Upload Archive(POST archive) (p. 217), uma das duas APIs de streaming no Amazon Glacier. O exemplo supõe oseguinte:
• O timestamp da solicitação é Mon, 07 May 2012 00:00:00 GMT.• O endpoint é o Leste dos EUA (Norte da Virgínia) Região, us-east-1.• O conteúdo da carga útil é uma string "Welcome to Amazon Glacier".
A sintaxe da solicitação geral (inclusive o corpo JSON) é mostrada no exemplo abaixo. O cabeçalho x-amz-content-sha256 está incluído. Neste exemplo simplificado, x-amz-sha256-tree-hash e x-amz-content-sha256 têm o mesmo valor. No entanto, para uploads de arquivos maiores que 1 MB, estenão é o caso.
POST /-/vaults/examplevault HTTP/1.1Host: glacier.us-east-1.amazonaws.comDate: Mon, 07 May 2012 00:00:00 GMTx-amz-archive-description: my archivex-amz-sha256-tree-hash: SHA256 tree hashx-amz-content-sha256: SHA256 payload hash Authorization: SignatureToBeCalculatedx-amz-glacier-version: 2012-06-01
A forma canônica da solicitação calculada para Tarefa 1: criar uma solicitação canônica (p. 155) émostrada abaixo. O cabeçalho de streaming x-amz-content-sha256 é incluído com o valor. Issosignifica que você deve ler a carga útil e calcular o hash SHA256 primeiro e, em seguida, computar aassinatura.
POST/-/vaults/examplevault
host:glacier.us-east-1.amazonaws.comx-amz-content-sha256:726e392cb4d09924dbad1cc0ba3b00c3643d03d14cb4b823e2f041cff612a628x-amz-date:20120507T000000Zx-amz-glacier-version:2012-06-01
host;x-amz-content-sha256;x-amz-date;x-amz-glacier-version726e392cb4d09924dbad1cc0ba3b00c3643d03d14cb4b823e2f041cff612a628
O restante do cálculo da assinatura segue as etapas descritas em Cálculo de assinatura deexemplo (p. 156). O cabeçalho Authorization que usa a chave de acesso secreta wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY e a chave de acesso AKIAIOSFODNN7EXAMPLE é mostrado abaixo(com quebras de linha adicionadas para fins de legibilidade):
Authorization=AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20120507/us-east-1/glacier/aws4_request, SignedHeaders=host;x-amz-content-sha256;x-amz-date;x-amz-glacier-version,
Versão da API 2012-06-01158

Amazon Glacier Guia do desenvolvedor doComputar somas de verificação
Signature=b092397439375d59119072764a1e9a144677c43d9906fd98a5742c57a2855de6
Computar somas de verificaçãoAo fazer upload de um arquivo, você deve incluir os cabeçalhos x-amz-sha256-tree-hash e x-amz-content-sha256. O cabeçalho x-amz-sha256-tree-hash é uma soma de verificação da carga útilno corpo de solicitação. Este tópico descreve como calcular o cabeçalho x-amz-sha256-tree-hash. Ocabeçalho x-amz-content-sha256 é um hash de toda a carga útil e é obrigatório para a autorização.Para obter mais informações, consulte Cálculo da assinatura de exemplo para Streaming API (p. 158).
A carga útil da solicitação pode ser:
• Todo o arquivo— Ao fazer upload de um arquivo em uma única solicitação usando a Upload ArchiveAPI, você envia todo o arquivo no corpo da solicitação. Nesse caso, você deve incluir a soma deverificação de todo o arquivo.
• Parte do arquivo— Ao fazer upload de um arquivo em partes usando a multipart upload API, você enviasomente uma parte do arquivo no corpo da solicitação. Nesse caso, você inclui a soma de verificação daparte do arquivo. E, depois de fazer upload de todas as partes, você enviará uma solicitação CompleteMultipart Upload, que deve incluir a soma de verificação de todo o arquivo.
A soma de verificação da carga útil é um hash de árvore SHA-256. Ele se chama hash de árvore porque,no processo de computação da soma de verificação, você computa uma árvore de valores de hashSHA-256. O valor do hash na raiz é a soma de verificação de todo o arquivo.
Note
Esta seção descreve uma maneira de computar o hash de árvore SHA-256. Porém, você podeusar qualquer procedimento, desde que ele produza o mesmo resultado.
Você computa o hash de árvore SHA-256 da seguinte maneira:
1. Para cada bloco de 1 MB de dados de carga útil, compute o hash SHA-256. O último bloco de dadospode ser menor que 1 MB. Por exemplo, se estiver fazendo upload de um arquivo de 3,2 MB, vocêcomputará os valores de hash SHA-256 para cada um dos três primeiros blocos de 1 MB de dados e,em seguida, computará o hash SHA-256 do 0,2 MB de dados restantes. Esses valores de hash formamos nós folha da árvore.
2. Compile o próximo nível da árvore.a. Concatene dois valores de hash do nó filho consecutivos e compute o hash SHA-256 dos valores de
hash concatenados. Essa concatenação e a geração do hash SHA-256 produzem um nó pai para osdois nós filho.
b. Quando somente um nó filho permanece, você promove esse valor de hash para o próximo nível naárvore.
3. Repita a etapa 2 até a árvore resultante ter uma raiz. A raiz da árvore fornece um hash de todo oarquivo, e uma raiz da subárvore apropriada fornece o hash para a parte em um multipart upload.
Tópicos• Exemplo do hash de árvore 1: fazer upload de um arquivo em uma única solicitação (p. 160)• Exemplo do hash de árvore 2: fazer upload de um arquivo usando um multipart upload (p. 160)• Computar o hash de árvore de um arquivo (p. 161)• Receber somas de verificação durante o download de dados (p. 167)
Versão da API 2012-06-01159

Amazon Glacier Guia do desenvolvedor doExemplo do hash de árvore 1: fazer upload
de um arquivo em uma única solicitação
Exemplo do hash de árvore 1: fazer upload de umarquivo em uma única solicitaçãoQuando você faz upload de um arquivo em uma única solicitação usando a Upload Archive API (consulteUpload Archive (POST archive) (p. 217)), a carga útil da solicitação inclui todo o arquivo. Dessa forma,você deve incluir o hash de árvore de todo o arquivo no cabeçalho de solicitação x-amz-sha256-tree-hash. Suponhamos que você queira fazer upload de um arquivo de 6,5 MB. O diagrama a seguir ilustrao processo de criação do hash SHA-256 do arquivo. Você lê o arquivo e computa o hash SHA-256 decada bloco de 1 MB. Você também computa o hash do 0,5 MB de dados restante e, em seguida, compila aárvore conforme descrito no procedimento anterior.
Exemplo do hash de árvore 2: fazer upload de umarquivo usando um multipart uploadO processo de computar o hash de árvore durante o upload de um arquivo usando-se multipart uploadé o mesmo do upload do arquivo em uma única solicitação. A única diferença é que, em um multipartupload, você faz upload somente de uma parte do arquivo em cada solicitação (usando a API UploadPart (PUT uploadID) (p. 239)) e, assim, fornece a soma de verificação somente da parte no cabeçalhoda solicitação x-amz-sha256-tree-hash. No entanto, depois de fazer upload de todas as partes,você deverá enviar a solicitação Complete Multipart Upload (consulte Complete Multipart Upload (POSTuploadID) (p. 223)) com um hash de árvore de todo o arquivo no cabeçalho da solicitação x-amz-sha256-tree-hash.
Versão da API 2012-06-01160
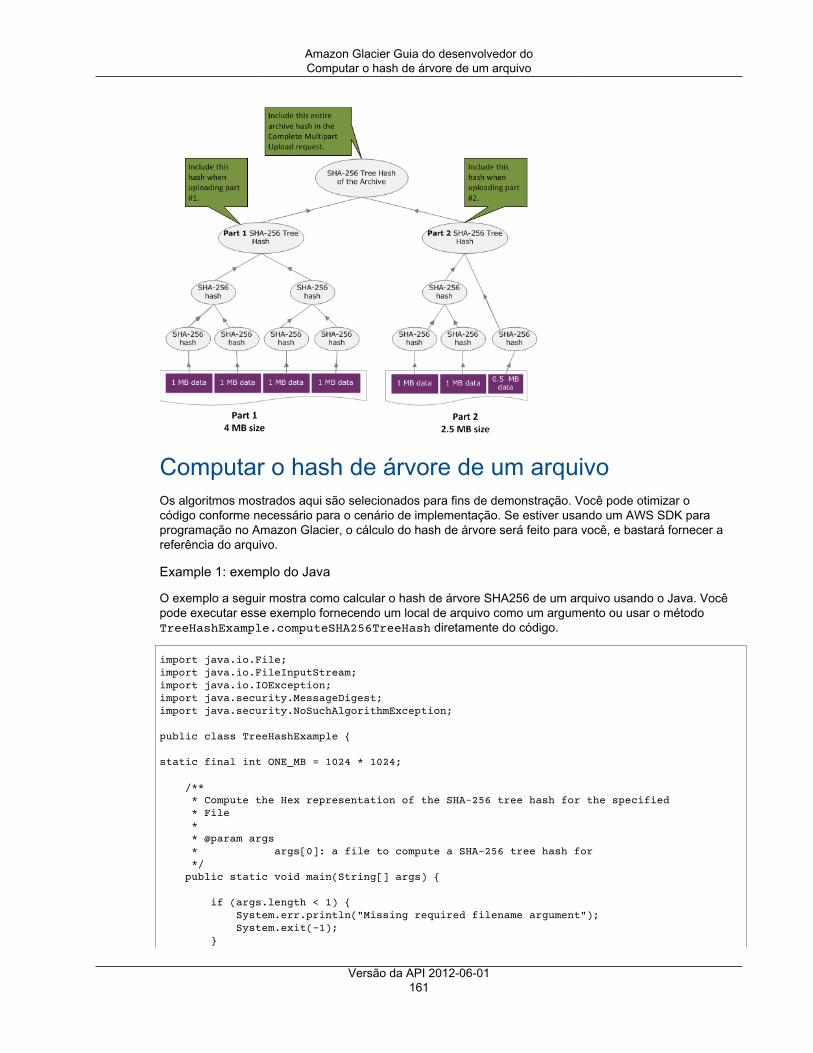
Amazon Glacier Guia do desenvolvedor doComputar o hash de árvore de um arquivo
Computar o hash de árvore de um arquivoOs algoritmos mostrados aqui são selecionados para fins de demonstração. Você pode otimizar ocódigo conforme necessário para o cenário de implementação. Se estiver usando um AWS SDK paraprogramação no Amazon Glacier, o cálculo do hash de árvore será feito para você, e bastará fornecer areferência do arquivo.
Example 1: exemplo do Java
O exemplo a seguir mostra como calcular o hash de árvore SHA256 de um arquivo usando o Java. Vocêpode executar esse exemplo fornecendo um local de arquivo como um argumento ou usar o métodoTreeHashExample.computeSHA256TreeHash diretamente do código.
import java.io.File;import java.io.FileInputStream;import java.io.IOException;import java.security.MessageDigest;import java.security.NoSuchAlgorithmException;
public class TreeHashExample {
static final int ONE_MB = 1024 * 1024;
/** * Compute the Hex representation of the SHA-256 tree hash for the specified * File * * @param args * args[0]: a file to compute a SHA-256 tree hash for */ public static void main(String[] args) {
if (args.length < 1) { System.err.println("Missing required filename argument"); System.exit(-1); }
Versão da API 2012-06-01161

Amazon Glacier Guia do desenvolvedor doComputar o hash de árvore de um arquivo
File inputFile = new File(args[0]); try {
byte[] treeHash = computeSHA256TreeHash(inputFile); System.out.printf("SHA-256 Tree Hash = %s\n", toHex(treeHash));
} catch (IOException ioe) { System.err.format("Exception when reading from file %s: %s", inputFile, ioe.getMessage()); System.exit(-1);
} catch (NoSuchAlgorithmException nsae) { System.err.format("Cannot locate MessageDigest algorithm for SHA-256: %s", nsae.getMessage()); System.exit(-1); } }
/** * Computes the SHA-256 tree hash for the given file * * @param inputFile * a File to compute the SHA-256 tree hash for * @return a byte[] containing the SHA-256 tree hash * @throws IOException * Thrown if there's an issue reading the input file * @throws NoSuchAlgorithmException */ public static byte[] computeSHA256TreeHash(File inputFile) throws IOException, NoSuchAlgorithmException {
byte[][] chunkSHA256Hashes = getChunkSHA256Hashes(inputFile); return computeSHA256TreeHash(chunkSHA256Hashes); }
/** * Computes a SHA256 checksum for each 1 MB chunk of the input file. This * includes the checksum for the last chunk even if it is smaller than 1 MB. * * @param file * A file to compute checksums on * @return a byte[][] containing the checksums of each 1 MB chunk * @throws IOException * Thrown if there's an IOException when reading the file * @throws NoSuchAlgorithmException * Thrown if SHA-256 MessageDigest can't be found */ public static byte[][] getChunkSHA256Hashes(File file) throws IOException, NoSuchAlgorithmException {
MessageDigest md = MessageDigest.getInstance("SHA-256");
long numChunks = file.length() / ONE_MB; if (file.length() % ONE_MB > 0) { numChunks++; }
if (numChunks == 0) { return new byte[][] { md.digest() }; }
byte[][] chunkSHA256Hashes = new byte[(int) numChunks][]; FileInputStream fileStream = null;
try {
Versão da API 2012-06-01162

Amazon Glacier Guia do desenvolvedor doComputar o hash de árvore de um arquivo
fileStream = new FileInputStream(file); byte[] buff = new byte[ONE_MB];
int bytesRead; int idx = 0;
while ((bytesRead = fileStream.read(buff, 0, ONE_MB)) > 0) { md.reset(); md.update(buff, 0, bytesRead); chunkSHA256Hashes[idx++] = md.digest(); }
return chunkSHA256Hashes;
} finally { if (fileStream != null) { try { fileStream.close(); } catch (IOException ioe) { System.err.printf("Exception while closing %s.\n %s", file.getName(), ioe.getMessage()); } } } }
/** * Computes the SHA-256 tree hash for the passed array of 1 MB chunk * checksums. * * This method uses a pair of arrays to iteratively compute the tree hash * level by level. Each iteration takes two adjacent elements from the * previous level source array, computes the SHA-256 hash on their * concatenated value and places the result in the next level's destination * array. At the end of an iteration, the destination array becomes the * source array for the next level. * * @param chunkSHA256Hashes * An array of SHA-256 checksums * @return A byte[] containing the SHA-256 tree hash for the input chunks * @throws NoSuchAlgorithmException * Thrown if SHA-256 MessageDigest can't be found */ public static byte[] computeSHA256TreeHash(byte[][] chunkSHA256Hashes) throws NoSuchAlgorithmException {
MessageDigest md = MessageDigest.getInstance("SHA-256");
byte[][] prevLvlHashes = chunkSHA256Hashes;
while (prevLvlHashes.length > 1) {
int len = prevLvlHashes.length / 2; if (prevLvlHashes.length % 2 != 0) { len++; }
byte[][] currLvlHashes = new byte[len][];
int j = 0; for (int i = 0; i < prevLvlHashes.length; i = i + 2, j++) {
// If there are at least two elements remaining if (prevLvlHashes.length - i > 1) {
// Calculate a digest of the concatenated nodes
Versão da API 2012-06-01163

Amazon Glacier Guia do desenvolvedor doComputar o hash de árvore de um arquivo
md.reset(); md.update(prevLvlHashes[i]); md.update(prevLvlHashes[i + 1]); currLvlHashes[j] = md.digest();
} else { // Take care of remaining odd chunk currLvlHashes[j] = prevLvlHashes[i]; } }
prevLvlHashes = currLvlHashes; }
return prevLvlHashes[0]; }
/** * Returns the hexadecimal representation of the input byte array * * @param data * a byte[] to convert to Hex characters * @return A String containing Hex characters */ public static String toHex(byte[] data) { StringBuilder sb = new StringBuilder(data.length * 2);
for (int i = 0; i < data.length; i++) { String hex = Integer.toHexString(data[i] & 0xFF);
if (hex.length() == 1) { // Append leading zero. sb.append("0"); } sb.append(hex); } return sb.toString().toLowerCase(); }}
Example 2: exemplo do C# .NET
O exemplo a seguir mostra como calcular o hash de árvore SHA256 de um arquivo. Você pode executaresse exemplo fornecendo um local de arquivo como um argumento.
using System;using System.IO;
using System.Security.Cryptography;
namespace ExampleTreeHash{ class Program { static int ONE_MB = 1024 * 1024;
/** * Compute the Hex representation of the SHA-256 tree hash for the * specified file * * @param args * args[0]: a file to compute a SHA-256 tree hash for */ public static void Main(string[] args) {
Versão da API 2012-06-01164

Amazon Glacier Guia do desenvolvedor doComputar o hash de árvore de um arquivo
if (args.Length < 1) { Console.WriteLine("Missing required filename argument"); Environment.Exit(-1); } FileStream inputFile = File.Open(args[0], FileMode.Open, FileAccess.Read); try { byte[] treeHash = ComputeSHA256TreeHash(inputFile); Console.WriteLine("SHA-256 Tree Hash = {0}", BitConverter.ToString(treeHash).Replace("-", "").ToLower()); Console.ReadLine(); Environment.Exit(-1); } catch (IOException ioe) { Console.WriteLine("Exception when reading from file {0}: {1}", inputFile, ioe.Message); Console.ReadLine(); Environment.Exit(-1); } catch (Exception e) { Console.WriteLine("Cannot locate MessageDigest algorithm for SHA-256: {0}", e.Message); Console.WriteLine(e.GetType()); Console.ReadLine(); Environment.Exit(-1); } Console.ReadLine(); }
/** * Computes the SHA-256 tree hash for the given file * * @param inputFile * A file to compute the SHA-256 tree hash for * @return a byte[] containing the SHA-256 tree hash */ public static byte[] ComputeSHA256TreeHash(FileStream inputFile) { byte[][] chunkSHA256Hashes = GetChunkSHA256Hashes(inputFile); return ComputeSHA256TreeHash(chunkSHA256Hashes); }
/** * Computes a SHA256 checksum for each 1 MB chunk of the input file. This * includes the checksum for the last chunk even if it is smaller than 1 MB. * * @param file * A file to compute checksums on * @return a byte[][] containing the checksums of each 1MB chunk */ public static byte[][] GetChunkSHA256Hashes(FileStream file) { long numChunks = file.Length / ONE_MB; if (file.Length % ONE_MB > 0) { numChunks++; }
if (numChunks == 0) { return new byte[][] { CalculateSHA256Hash(null, 0) };
Versão da API 2012-06-01165

Amazon Glacier Guia do desenvolvedor doComputar o hash de árvore de um arquivo
} byte[][] chunkSHA256Hashes = new byte[(int)numChunks][];
try { byte[] buff = new byte[ONE_MB];
int bytesRead; int idx = 0;
while ((bytesRead = file.Read(buff, 0, ONE_MB)) > 0) { chunkSHA256Hashes[idx++] = CalculateSHA256Hash(buff, bytesRead); } return chunkSHA256Hashes; } finally { if (file != null) { try { file.Close(); } catch (IOException ioe) { throw ioe; } } }
}
/** * Computes the SHA-256 tree hash for the passed array of 1MB chunk * checksums. * * This method uses a pair of arrays to iteratively compute the tree hash * level by level. Each iteration takes two adjacent elements from the * previous level source array, computes the SHA-256 hash on their * concatenated value and places the result in the next level's destination * array. At the end of an iteration, the destination array becomes the * source array for the next level. * * @param chunkSHA256Hashes * An array of SHA-256 checksums * @return A byte[] containing the SHA-256 tree hash for the input chunks */ public static byte[] ComputeSHA256TreeHash(byte[][] chunkSHA256Hashes) { byte[][] prevLvlHashes = chunkSHA256Hashes; while (prevLvlHashes.GetLength(0) > 1) {
int len = prevLvlHashes.GetLength(0) / 2; if (prevLvlHashes.GetLength(0) % 2 != 0) { len++; }
byte[][] currLvlHashes = new byte[len][];
int j = 0; for (int i = 0; i < prevLvlHashes.GetLength(0); i = i + 2, j++) {
Versão da API 2012-06-01166

Amazon Glacier Guia do desenvolvedor doReceber somas de verificação durante o download de dados
// If there are at least two elements remaining if (prevLvlHashes.GetLength(0) - i > 1) {
// Calculate a digest of the concatenated nodes byte[] firstPart = prevLvlHashes[i]; byte[] secondPart = prevLvlHashes[i + 1]; byte[] concatenation = new byte[firstPart.Length + secondPart.Length]; System.Buffer.BlockCopy(firstPart, 0, concatenation, 0, firstPart.Length); System.Buffer.BlockCopy(secondPart, 0, concatenation, firstPart.Length, secondPart.Length);
currLvlHashes[j] = CalculateSHA256Hash(concatenation, concatenation.Length);
} else { // Take care of remaining odd chunk currLvlHashes[j] = prevLvlHashes[i]; } }
prevLvlHashes = currLvlHashes; }
return prevLvlHashes[0]; }
public static byte[] CalculateSHA256Hash(byte[] inputBytes, int count) { SHA256 sha256 = System.Security.Cryptography.SHA256.Create(); byte[] hash = sha256.ComputeHash(inputBytes, 0, count); return hash; } }}
Receber somas de verificação durante o download dedadosAo recuperar um arquivo usando a Initiate Job API (consulte Initiate Job (trabalhos POST) (p. 257)),você pode especificar um intervalo para recuperação do arquivo. Da mesma maneira, ao fazer downloaddos dados usando a Get Job Output API (consulte Get Job Output (GET output) (p. 251)), você podeespecificar um intervalo de dados para download. Existem duas características desses intervalos queprecisam ser compreendidas quando você está recuperando e fazendo download dos dados do arquivo.O intervalo a ser recuperado precisa estar alinhado em megabytes ao arquivo. O intervalo de recuperaçãoe o intervalo de download devem estar alinhados ao hash de árvore para receber valores da soma deverificação quando você faz download dos dados. A definição desses dois tipos de alinhamentos deintervalo é a seguinte:
• Alinhado a megabytes – Um intervalo [StartByte, EndBytes] está alinhado a megabytes (1024*1024)quando StartBytes é divisível por 1 MB e EndBytes mais 1 é divisível por 1 MB ou é igual ao final doarquivo especificado (tamanho de bytes do arquivo menos 1). Um intervalo usado na Initiate Job API, seespecificado, é deverá estar alinhado a megabytes.
• Alinhado ao hash de árvore – Um intervalo [StartBytes, EndBytes] estará alinhado ao hash de árvoreem relação a um arquivo se e somente se a raiz do hash de árvore compilada ao longo do intervalo forequivalente a um nó no hash de árvore de todo o arquivo. O intervalo de recuperação e o intervalo dedownload devem estar alinhados ao hash de árvore para receber valores da soma de verificação dos
Versão da API 2012-06-01167

Amazon Glacier Guia do desenvolvedor doReceber somas de verificação durante o download de dados
dados cujo download você fez. Para obter um exemplo de intervalos e a relação com o hash de árvoredo arquivo, consulte Exemplo de hash de árvore: recuperar um intervalo de arquivo que esteja alinhadoao hash de árvore (p. 168).
Um intervalo alinhado ao hash de árvore também está alinhado a megabytes. No entanto, um intervaloalinhado a megabytes não necessariamente está alinhado ao hash de árvore.
Os seguintes casos descrevem quando você recebe um valor da soma de verificação ao fazer downloaddos dados do arquivo:
• Se você não especificar um intervalo a ser recuperado na solicitação Initiate Job e fizer download detodo o arquivo na solicitação Get Job.
• Se você não especificar um intervalo a ser recuperado na solicitação Initiate Job e especificar umintervalo alinhado ao hash de árvore para download na solicitação Get Job.
• Se você especificar um intervalo alinhado ao hash de árvore a ser recuperado na solicitação Initiate Jobe fizer download de todo o intervalo na solicitação Get Job.
• Se você especificar um intervalo alinhado ao hash de árvore a ser recuperado na solicitação Initiate Jobe especificar um intervalo alinhado ao hash de árvore para download na solicitação Get Job.
Se especificar um intervalo a ser recuperado na solicitação Initiate Job que não esteja alinhado ao hash deárvore, você ainda poderá obter os dados do arquivo, mas nenhum valor de soma de verificação retornaráquando fizer download dos dados na solicitação Get Job.
Exemplo de hash de árvore: recuperar um intervalo de arquivoque esteja alinhado ao hash de árvoreSuponhamos que você tenha um arquivo de 6,5 MB no cofre e queira recuperar 2 MB do arquivo. Amaneira como você especifica o intervalo de 2 MB na solicitação Initiate Job determina se recebe valoresde soma de verificação de dados quando faz download dos dados. O diagrama a seguir ilustra doisintervalos de 2 MB para o arquivo de 6,5 MB cujo download você pode fazer. Ambos os intervalos estãoalinhados a megabytes, mas somente um está alinhado ao hash de árvore.
Especificação do intervalo alinhado ao hash de árvoreEsta seção fornece a especificação exata para o que constitui um intervalo alinhado ao hash de árvore. Osintervalos alinhados ao hash de árvore são importantes quando você está fazendo download de uma partede um arquivo e especifica o intervalo de dados a serem recuperados, além do intervalo de download dos
Versão da API 2012-06-01168

Amazon Glacier Guia do desenvolvedor doRespostas de erro
dados recuperados. Se ambos os intervalos estiverem alinhados ao hash de árvore, você receberá dadosda soma de verificação ao fazer download dos dados.
Um intervalo [A, B] estará alinhado ao hash de árvore em relação a um arquivo se e somente se quandoum novo hash de árvore for compilado ao longo do [A, B], a raiz do hash de árvore desse intervalo forequivalente a um nó no hash de árvore de todo o arquivo. Você pode ver isso mostrado no diagramaem Exemplo de hash de árvore: recuperar um intervalo de arquivo que esteja alinhado ao hash deárvore (p. 168). Nesta seção, fornecemos a especificação do alinhamento do hash de árvore.
Considere [P, Q) como a consulta de intervalo de um arquivo de N megabytes (MB) e que P e Q sejammúltiplos de um MB. O intervalo inclusivo real é [P MB, Q MB – 1 byte], mas por uma questão desimplicidade, mostramos esse intervalo como [P, Q). Assim, com essas considerações,
• Se P for um número ímpar, haverá somente um intervalo alinhado ao hash de árvore possível – ou seja,[P, P +1 MB).
• Se P for um número par e k for o número máximo, em que P pode ser gravado como 2k * X, haverá, nomáximo, k intervalos alinhados ao hash de intervalo começando com P. X é um inteiro maior que 0. Osintervalos alinhados ao hash de árvore estão nas seguintes categorias:• Para cada i, em que (0 <= i <= k) e P + 2i < N, [P, Q + 2i) é um intervalo alinhado ao hash de árvore.• P = 0 é o caso especial em que A = 2[lgN]*0
Respostas de erroNo caso de um erro, a API do Amazon Glacier retorna uma das seguintes exceções:
Code Descrição Código de statusHTTP
Type
AccessDeniedException Retornado se tiver ocorrido umatentativa de acessar um recurso nãoé permitido por uma política do AWSIdentity and Access Management(IAM) incorreta, ou o ID da contada AWS tenha sido usado no URIda solicitação. Para obter maisinformações, consulte Autenticaçãoe controle de acesso para o AmazonGlacier (p. 118).
403Forbidden
Cliente
BadRequest Retornado se a solicitação nãopuder ser processada.
400 BadRequest
Cliente
ExpiredTokenException Retornado se o token de segurançausado na solicitação tiver expirado.
403Forbidden
Cliente
InsufficientCapacityExceptionRetornado se houver capacidadeinsuficiente para processar asolicitação expressa. Esse erro seaplica somente a recuperaçõesexpressas, e não a recuperaçõespadrão ou em massa.
503 ServiceUnavailable
deaplicativos
InvalidParameterValueExceptionRetornado se um parâmetro dasolicitação estiver especificadoincorretamente.
400 BadRequest
Cliente
Versão da API 2012-06-01169

Amazon Glacier Guia do desenvolvedor doRespostas de erro
Code Descrição Código de statusHTTP
Type
InvalidSignatureException Retornado se a assinatura dasolicitação for inválida.
403Forbidden
Cliente
LimitExceededException Retornado se a solicitação resultarem um dos limites a seguir excedido,um limite de cofre, um limite detags ou o limite da capacidadeprovisionada.
400 BadRequest
Cliente
MissingAuthenticationTokenExceptionRetornado se dados da autenticaçãonão forem encontrados para asolicitação.
400 BadRequest
Cliente
MissingParameterValueExceptionRetornado se um cabeçalhoobrigatório ou um parâmetro não forencontrado na solicitação.
400 BadRequest
Cliente
PolicyEnforcedException Retornado se um trabalho derecuperação excederá o limite dataxa de recuperação da políticade dados atual. Para obter maisinformações sobre políticas derecuperação de dados, consultePolíticas de recuperação dos dadosdo Amazon Glacier (p. 142).
400 BadRequest
Cliente
ResourceNotFoundException Retornado se o recursoespecificado, como um cofre, um IDde upload ou um ID de trabalho, nãoexistir.
404 NotFound
Cliente
RequestTimeoutException Retornado em caso de upload de umarquivo e o Amazon Glacier expireenquanto recebe o upload.
408 RequestTimeout
Cliente
SerializationException Retornado se o corpo da solicitaçãofor inválido. Em caso de inclusão deuma carga útil JSON, verifique seela está bem formada.
400 BadRequest
Cliente
ServiceUnavailableException Retornado se o serviço não puderconcluir a solicitação.
500 InternalServer Error
deaplicativos
ThrottlingException Retornado se você precisar reduzir ataxa de solicitações para o AmazonGlacier.
400 BadRequest
Cliente
UnrecognizedClientException Retornado se o ID de chave deacesso ou o token de segurança forinválido.
400 BadRequest
Cliente
Diversas APIs do Amazon Glacier retornam a mesma exceção, mas com mensagens de exceçãodiferentes, para ajudar você a solucionar o erro específico encontrado.
Versão da API 2012-06-01170

Amazon Glacier Guia do desenvolvedor doExemplo 1: descrever solicitação de trabalho
com um ID de trabalho não existente
O Amazon Glacier retorna informações do erro no corpo da resposta. Os exemplos a seguir mostramalgumas das respostas de erro.
Exemplo 1: descrever solicitação de trabalho com umID de trabalho não existenteSuponhamos que você envie uma solicitação Trabalho de descrição (GET JobID) (p. 243) para umtrabalho não existente. Ou seja, você especifica um ID de trabalho não existente.
GET /-/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVEXAMPLEbadJobID HTTP/1.1Host: glacier.us-west-2.amazonaws.comDate: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Em resposta, o Amazon Glacier retorna a resposta de erro a seguir.
HTTP/1.1 404 Not Foundx-amzn-RequestId: AAABaZ9N92Iiyv4N7sru3ABEpSQkuFtmH3NP6aAC51ixfjgContent-Type: application/jsonContent-Length: 185Date: Wed, 10 Feb 2017 12:00:00 GMT{ "code": "ResourceNotFoundException", "message": "The job ID was not found: HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVEXAMPLEbadJobID", "type": "Client" }
Onde:
Code
Uma das exceções em geral.
Type: StringMessage
Uma descrição genérica da condição do erro específica da API que retorna o erro.
Type: StringType
A origem do erro. O campo pode ter um dos seguintes valores: Client, Server ou Unknown.
Tipo: string.
Observe o seguinte na resposta anterior:
• Para a resposta de erro, o Amazon Glacier retorna valores de código de status 4xx e 5xx. Nesteexemplo, o código de status é 404 Not Found.
• O application/json do valor de cabeçalho Content-Type indica JSON no corpo
Versão da API 2012-06-01171

Amazon Glacier Guia do desenvolvedor doExemplo 2: solicitação List Jobs com um
valor inválido para o parâmetro da solicitação
• O JSON no corpo fornece as informações de erro.
Na solicitação anterior, em vez de um ID de trabalho inválido, suponhamos que você especifique um cofrenão existente. A resposta retorna uma mensagem diferente.
HTTP/1.1 404 Not Foundx-amzn-RequestId: AAABBeC9Zw0rp_5D0L8VfB3FA_WlTupqTKAUehMcPhdgni0Content-Type: application/jsonContent-Length: 154Date: Wed, 10 Feb 2017 12:00:00 GMT{ "code": "ResourceNotFoundException", "message": "Vault not found for ARN: arn:aws:glacier:us-west-2:012345678901:vaults/examplevault", "type": "Client"}
Exemplo 2: solicitação List Jobs com um valor inválidopara o parâmetro da solicitaçãoNeste exemplo, você envia uma solicitação List Jobs (GET jobs) (p. 267) para recuperar trabalhos decofre com um statuscode específico e fornece um valor statuscode finished, em vez dos valoresaceitáveis InProgress, Succeeded ou Failed.
GET /-/vaults/examplevault/jobs?statuscode=finished HTTP/1.1 Host: glacier.us-west-2.amazonaws.com Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
O Amazon Glacier retorna o InvalidParameterValueException com uma mensagem apropriada.
HTTP/1.1 400 Bad Requestx-amzn-RequestId: AAABaZ9N92Iiyv4N7sru3ABEpSQkuFtmH3NP6aAC51ixfjgContent-Type: application/jsonContent-Length: 141Date: Wed, 10 Feb 2017 12:00:00 GMT{ "code": "InvalidParameterValueException", "message": "The job status code is not valid: finished", "type: "Client"}
Operações de cofreEstas são as operações de cofre disponíveis para serem usadas no Amazon Glacier.
Tópicos• Abort Vault Lock (DELETE lock-policy) (p. 173)• Add Tags To Vault (POST tags add) (p. 175)• Create Vault (PUT vault) (p. 177)
Versão da API 2012-06-01172

Amazon Glacier Guia do desenvolvedor doAbort Vault Lock
• Complete Vault Lock (POST lockId) (p. 179)• Delete Vault (DELETE vault) (p. 181)• Política de acesso de exclusão do cofre (DELETE access-policy) (p. 183)• Delete Vault Notifications (DELETE notification-configuration) (p. 185)• Describe Vault (GET vault) (p. 187)• Get Vault Access Policy (GET access-policy) (p. 190)• Get Vault Lock (GET lock-policy) (p. 192)• Get Vault Notifications (GET notification-configuration) (p. 195)• Initiate Vault Lock (POST lock-policy) (p. 198)• Listar tags para cofre (GET tags) (p. 201)• List Vaults (GET vaults) (p. 203)• Remove Tags From Vault (POST tags remove) (p. 208)• Set Vault Access Policy (PUT access-policy) (p. 210)• Definir configuração de notificação de cofre (PUT notification-configuration) (p. 212)
Abort Vault Lock (DELETE lock-policy)DescriçãoEsta operação anulará o processo de bloqueio do cofre se o bloqueio do cofre não estiver no estadoLocked. Se o bloqueio do cofre estiver no estado Locked quando essa operação for solicitada, aoperação retornará um erro AccessDeniedException. Anular o processo de bloqueio do cofre remove apolítica de bloqueio do cofre especificado.
Um bloqueio de cofre é colocado no estado InProgress chamando Initiate Vault Lock (POST lock-policy) (p. 198). Um bloqueio de cofre é colocado no estado Locked chamando Complete Vault Lock(POST lockId) (p. 179). Você pode obter o estado de um bloqueio de cofre chamando Get Vault Lock(GET lock-policy) (p. 192). Para obter mais informações sobre o processo de bloqueio de cofre, consulteAmazon Glacier Vault Lock (p. 59). Para obter mais informações sobre políticas de bloqueio de cofre,consulte Controle de acesso do Amazon Glacier com políticas de bloqueio de cofre (p. 131).
Essa operação é idempotente. Você poderá chamar essa operação com êxito várias vezes, se o bloqueiode cofre estiver no estado InProgress ou se não houver política associada ao cofre.
SolicitaçõesPara excluir a política de bloqueio de cofre, envie uma solicitação DELETE HTTP para o URI do sub-recurso lock-policy do cofre.
Sintaxe
DELETE /AccountId/vaults/vaultName/lock-policy HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o ID
Versão da API 2012-06-01173

Amazon Glacier Guia do desenvolvedor doAbort Vault Lock
de conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSe a política for excluída com êxito, o Amazon Glacier retornará uma resposta HTTP 204 No Content.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como anular o processo de bloqueio do cofre.
Exemplo de solicitaçãoNeste exemplo, uma solicitação DELETE é enviada para o sub-recurso lock-policy do cofre chamadoexamplevault.
DELETE /-/vaults/examplevault/lock-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Versão da API 2012-06-01174

Amazon Glacier Guia do desenvolvedor doAdd Tags To Vault
x-amz-glacier-version: 2012-06-01
Exemplo de respostaSe a política for excluída com êxito, o Amazon Glacier retornará uma resposta HTTP 204 No Contentconforme mostrado no exemplo a seguir.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Complete Vault Lock (POST lockId) (p. 179)
• Get Vault Lock (GET lock-policy) (p. 192)
• Initiate Vault Lock (POST lock-policy) (p. 198)
Add Tags To Vault (POST tags add)Esta operação adiciona as tags especificadas a um cofre. Cada tag é composta de uma chave e de umvalor. Cada cofre pode ter até 50 tags. Se a solicitação excedesse o limite de tags do cofre, a operaçãolançaria o erro LimitExceededException.
Se uma tag já existir no cofre em uma chave especificada, o valor da chave existente será substituído.Para obter mais informações sobre tags, consulte Marcar recursos do Amazon Glacier (p. 146).
Sintaxe da solicitaçãoPara adicionar tags a um cofre, envie uma solicitação HTTP POST para o URI das tags conformemostrado no exemplo da sintaxe a seguir.
POST /AccountId/vaults/vaultName/tags?operation=add HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01 { "Tags": { "string": "string", "string": "string" } }
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Versão da API 2012-06-01175

Amazon Glacier Guia do desenvolvedor doAdd Tags To Vault
Parâmetros de solicitação
Nome Descrição Obrigatório
operation=add Um parâmetro de string de consulta única operation com umvalor de add para diferenciá-lo de Remove Tags From Vault (POSTtags remove) (p. 208).
Sim
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
O corpo da solicitação contém os seguintes campos JSON:
Tags
As tags a serem adicionadas ao cofre. Cada tag é composta de uma chave e de um valor. O valorpode ser uma string vazia.
Tipo: mapa de string para string
Restrições de tamanho: tamanho mínimo de 1. Tamanho máximo 10.
Obrigatório: sim
RespostasSe a solicitação de operação for bem-sucedida, o serviço retornará uma resposta 204 No ContentHTTP.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
Versão da API 2012-06-01176

Amazon Glacier Guia do desenvolvedor doCreate Vault
ExemplosExemplo de solicitação
O exemplo a seguir envia uma solicitação HTTP POST com as tags a serem adicionadas ao cofre.
POST /-/vaults/examplevault/tags?operation=add HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2Content-Length: lengthx-amz-glacier-version: 2012-06-01 { "Tags": { "examplekey1": "examplevalue1", "examplekey2": "examplevalue2" } }
Exemplo de resposta
Se a solicitação for bem-sucedida, o Amazon Glacier retornará um HTTP 204 No Content conformemostrado no exemplo a seguir.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMT
Seções relacionadas• Listar tags para cofre (GET tags) (p. 201)
• Remove Tags From Vault (POST tags remove) (p. 208)
Create Vault (PUT vault)DescriçãoEsta operação cria um novo cofre com o nome especificado. O nome do cofre deve ser exclusivo dentrode uma região para uma conta da AWS. Você pode criar até 1.000 cofres por conta. Para obter maisinformações sobre como criar mais cofres, vá até a página de detalhes de produto do Amazon Glacier.
Você deve usar as diretrizes a seguir ao nomear um cofre.
• Os nomes podem ter de 1 a 255 caracteres.• Os caracteres permitidos incluem a-z, A-Z, 0-9, '_' (sublinhado), '-' (hífen), '/' (barra) e '.' (período).
Essa operação é idempotente; você pode enviar a mesma solicitação várias vezes, e ela não terá maisefeito depois da primeira vez em que o Amazon Glacier criar o cofre.
Versão da API 2012-06-01177

Amazon Glacier Guia do desenvolvedor doCreate Vault
SolicitaçõesSintaxe
Para criar um cofre, envie uma solicitação PUT HTTP para o URI do cofre a ser criado.
PUT /AccountId/vaults/VaultName HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
O corpo da solicitação dessa operação deve estar vazio (0 byte).
RespostasSintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: DateLocation: Location
Cabeçalhos de resposta
Uma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Nome Descrição
Location O caminho do URI relativo do cofre que foi criado.
Tipo: string
Versão da API 2012-06-01178

Amazon Glacier Guia do desenvolvedor doComplete Vault Lock
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitaçãoO exemplo a seguir envia uma solicitação PUT HTTP para criar um cofre chamado examplevault.
PUT /-/vaults/examplevault HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Content-Length: 0Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de respostaO Amazon Glacier cria o cofre e retorna o caminho do URI relativo do cofre no cabeçalho Location. O IDda conta sempre é exibido no cabeçalho Location, independentemente do ID da conta ou de um hífen('-') ter sido especificado na solicitação.
HTTP/1.1 201 Createdx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTLocation: /111122223333/vaults/examplevault
Seções relacionadas• List Vaults (GET vaults) (p. 203)• Delete Vault (DELETE vault) (p. 181)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Complete Vault Lock (POST lockId)DescriçãoEsta operação conclui o processo de bloqueio de cofre fazendo a transição do bloqueio de cofre do estadoInProgress para o estado Locked, o que torna a política de bloqueio de cofre inalterável. Um bloqueiode cofre é colocado no estado InProgress chamando Initiate Vault Lock (POST lock-policy) (p. 198).Você pode obter o estado do bloqueio de cofre chamando Get Vault Lock (GET lock-policy) (p. 192).Para obter mais informações sobre o processo de bloqueio de cofre, consulte Amazon Glacier VaultLock (p. 59).
Essa operação é idempotente. Essa solicitação sempre será bem-sucedida se o bloqueio de cofre estiverno estado Locked e o ID de bloqueio fornecido corresponder ao ID de bloqueio usado originalmente parabloquear o cofre.
Versão da API 2012-06-01179

Amazon Glacier Guia do desenvolvedor doComplete Vault Lock
Se um ID de bloqueio inválido for passado na solicitação quando o bloqueio cofre estiver no estadoLocked, a operação retornará um erro AccessDeniedException. Se um ID de bloqueio inválido forpassado na solicitação quando o bloqueio cofre estiver no estado InProgress, a operação lançará umerro InvalidParameter.
SolicitaçõesPara concluir o processo de bloqueio de cofre, envie uma solicitação HTTP POST para o URI do sub-recurso lock-policy do cofre com um ID de bloqueio válido.
Sintaxe
POST /AccountId/vaults/vaultName/lock-policy/lockId HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
O lockId valor é o ID de bloqueio obtido por meio de uma solicitação Initiate Vault Lock (POST lock-policy) (p. 198).
Parâmetros de solicitaçãoCabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSe a solicitação de operação for bem-sucedida, o serviço retornará uma resposta 204 No ContentHTTP.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Versão da API 2012-06-01180
Amazon Glacier Guia do desenvolvedor doDelete Vault
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitaçãoO exemplo a seguir envia uma solicitação HTTP POST com o ID de bloqueio para concluir o processo debloqueio do cofre.
POST /-/vaults/examplevault/lock-policy/AE863rKkWZU53SLW5be4DUcW HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2Content-Length: lengthx-amz-glacier-version: 2012-06-01
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier retornará uma resposta HTTP 204 No Content,conforme mostrado no exemplo a seguir.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMT
Seções relacionadas• Abort Vault Lock (DELETE lock-policy) (p. 173)
• Get Vault Lock (GET lock-policy) (p. 192)
• Initiate Vault Lock (POST lock-policy) (p. 198)
Delete Vault (DELETE vault)DescriçãoEssa operação exclui um cofre. O Amazon Glacier excluirá um cofre somente se não houver arquivosno cofre de acordo com último inventário mais recentemente e não houver gravações no cofre desde oinventário mais recente. Se qualquer uma dessas condições não for atendida, a exclusão do cofre falhará(ou seja, o cofre não será removido), e o Amazon Glacier retornará um erro.
Você pode usar a operação Describe Vault (GET vault) (p. 187) que fornece informações do cofre,inclusive o número de arquivos no cofre. No entanto, as informações se baseiam no inventário de cofregerado pelo Amazon Glacier mais recentemente.
Versão da API 2012-06-01181
Amazon Glacier Guia do desenvolvedor doDelete Vault
Essa operação é idempotente.
Note
Quando você exclui um cofre, a política de acesso ao cofre anexada ao cofre também é excluída.Para obter mais informações sobre políticas de acesso ao cofre, consulte Controle de acesso doAmazon Glacier com políticas de acesso ao cofre (p. 129).
SolicitaçõesPara excluir um cofre, envie uma solicitação DELETE para o URI do recurso de cofre.
Sintaxe
DELETE /AccountId/vaults/VaultName HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Versão da API 2012-06-01182

Amazon Glacier Guia do desenvolvedor doPolítica de acesso de exclusão do cofre
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitação
O exemplo a seguir exclui um cofre chamado examplevault. A solicitação de exemplo é uma solicitaçãoDELETE para o URI do recurso (o cofre) para exclusão.
DELETE /-/vaults/examplevault HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMT
Seções relacionadas• Create Vault (PUT vault) (p. 177)• List Vaults (GET vaults) (p. 203)• Initiate Job (trabalhos POST) (p. 257)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Política de acesso de exclusão do cofre (DELETEaccess-policy)DescriçãoEssa operação exclui a política de acesso associada ao cofre especificado. A operação acaba sendoconsistente, ou seja, pode levar algum tempo até o Amazon Glacier remover completamente a política deacesso, e você ainda poderá ver o efeito da política por um curto período depois de enviar a solicitação deexclusão.
Essa operação é idempotente. Você poderá invocar a exclusão várias vezes, mesmo se não houverpolítica associada ao cofre. Para obter mais informações sobre políticas de acesso ao cofre, consulteControle de acesso do Amazon Glacier com políticas de acesso ao cofre (p. 129).
Versão da API 2012-06-01183
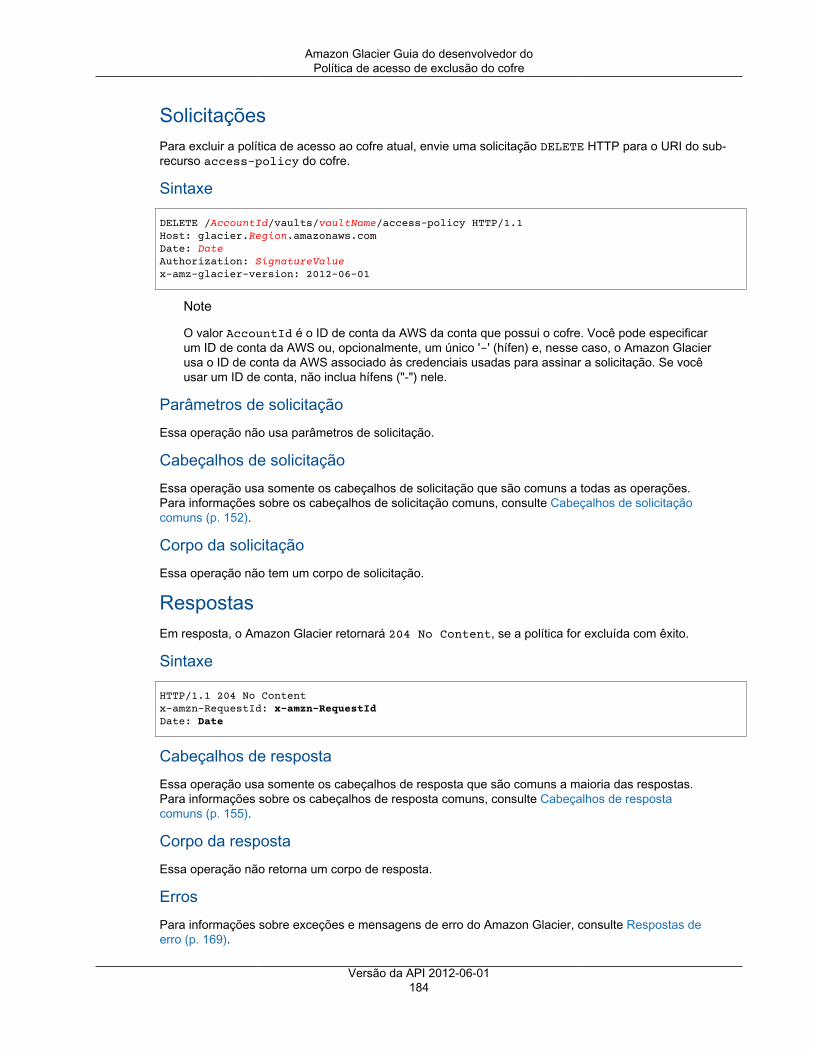
Amazon Glacier Guia do desenvolvedor doPolítica de acesso de exclusão do cofre
SolicitaçõesPara excluir a política de acesso ao cofre atual, envie uma solicitação DELETE HTTP para o URI do sub-recurso access-policy do cofre.
Sintaxe
DELETE /AccountId/vaults/vaultName/access-policy HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasEm resposta, o Amazon Glacier retornará 204 No Content, se a política for excluída com êxito.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
Versão da API 2012-06-01184
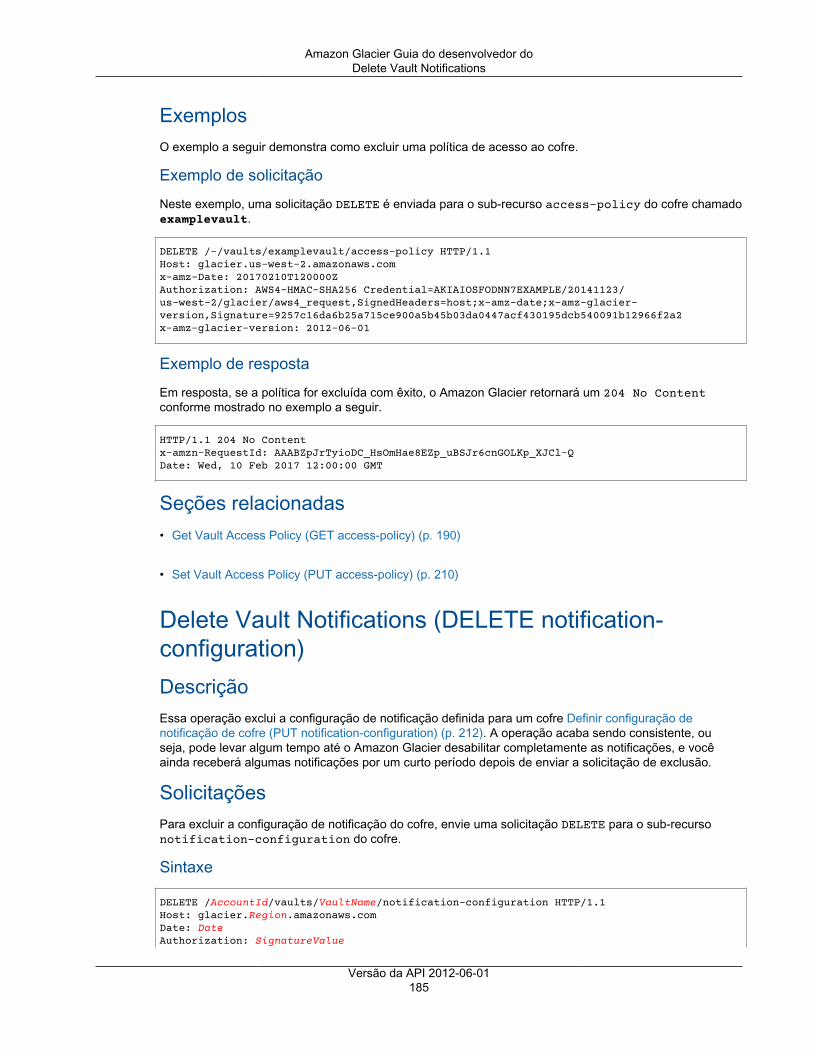
Amazon Glacier Guia do desenvolvedor doDelete Vault Notifications
ExemplosO exemplo a seguir demonstra como excluir uma política de acesso ao cofre.
Exemplo de solicitaçãoNeste exemplo, uma solicitação DELETE é enviada para o sub-recurso access-policy do cofre chamadoexamplevault.
DELETE /-/vaults/examplevault/access-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2x-amz-glacier-version: 2012-06-01
Exemplo de respostaEm resposta, se a política for excluída com êxito, o Amazon Glacier retornará um 204 No Contentconforme mostrado no exemplo a seguir.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Get Vault Access Policy (GET access-policy) (p. 190)
• Set Vault Access Policy (PUT access-policy) (p. 210)
Delete Vault Notifications (DELETE notification-configuration)DescriçãoEssa operação exclui a configuração de notificação definida para um cofre Definir configuração denotificação de cofre (PUT notification-configuration) (p. 212). A operação acaba sendo consistente, ouseja, pode levar algum tempo até o Amazon Glacier desabilitar completamente as notificações, e vocêainda receberá algumas notificações por um curto período depois de enviar a solicitação de exclusão.
SolicitaçõesPara excluir a configuração de notificação do cofre, envie uma solicitação DELETE para o sub-recursonotification-configuration do cofre.
Sintaxe
DELETE /AccountId/vaults/VaultName/notification-configuration HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValue
Versão da API 2012-06-01185

Amazon Glacier Guia do desenvolvedor doDelete Vault Notifications
x-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como remover a configuração de notificação de um cofre.
Exemplo de solicitação
Neste exemplo, uma solicitação DELETE é enviada para o sub-recurso notification-configurationdo cofre chamado examplevault.
DELETE /111122223333/vaults/examplevault/notification-configuration HTTP/1.1
Versão da API 2012-06-01186

Amazon Glacier Guia do desenvolvedor doDescribe Vault
Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Z x-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Get Vault Notifications (GET notification-configuration) (p. 195)• Definir configuração de notificação de cofre (PUT notification-configuration) (p. 212)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Describe Vault (GET vault)DescriçãoEssa operação retorna informações sobre um cofre, inclusive o Amazon Resource Name (ARN – Nome derecurso da Amazon), a data na qual o cofre foi criado, o número de arquivos contidos no cofre e o tamanhototal de todos os arquivos no cofre. O número de arquivos e o tamanho total são desde o inventáriode cofre gerado mais recentemente pelo Amazon Glacier (consulte Trabalhar com cofres no AmazonGlacier (p. 23)). O Amazon Glacier gera inventários de cofre aproximadamente diários. Isso significa que,se você adicionar ou remover um arquivo de um cofre e enviar imediatamente uma solicitação DescribeVault, a resposta poderá não refletir as alterações.
SolicitaçõesPara obter informações sobre um cofre, envie uma solicitação GET para o URI do recurso de cofreespecífico.
Sintaxe
GET /AccountId/vaults/VaultName HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Versão da API 2012-06-01187

Amazon Glacier Guia do desenvolvedor doDescribe Vault
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length
{ "CreationDate" : String, "LastInventoryDate" : String, "NumberOfArchives" : Number, "SizeInBytes" : Number, "VaultARN" : String, "VaultName" : String}
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaO corpo da resposta contém os seguintes campos JSON:
CreationDate
A data UTC quando o cofre foi criado.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
LastInventoryDate
A data UTC quando o Amazon Glacier concluiu o inventário de cofre mais recente. Para obtermais informações sobre como iniciar um inventário para um cofre, consulte Initiate Job (trabalhosPOST) (p. 257).
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
NumberOfArchives
O número de arquivos no cofre de acordo com o último inventário de cofre. Esse campo retornará nulose um inventário ainda não tiver sido executado no cofre; por exemplo, se você tiver acabado de criaro cofre.
Tipo: número
Versão da API 2012-06-01188

Amazon Glacier Guia do desenvolvedor doDescribe Vault
SizeInBytes
O tamanho total em bytes dos arquivos no cofre, inclusive eventuais custos indiretos por arquivo,desde a data do último inventário. Esse campo retornará null se um inventário ainda não tiver sidoexecutado no cofre; por exemplo, se você tiver acabado de criar o cofre.
Tipo: númeroVaultARN
O nome de recurso da Amazon (ARN) do cofre.
Type: StringVaultName
O nome do cofre que foi especificado no momento da criação. O nome do cofre também é incluído noARN do cofre.
Type: String
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitaçãoO exemplo a seguir demonstra como obter informações sobre o cofre chamado examplevault.
GET /-/vaults/examplevault HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTContent-Type: application/jsonContent-Length: 260
{ "CreationDate" : "2012-02-20T17:01:45.198Z", "LastInventoryDate" : "2012-03-20T17:03:43.221Z", "NumberOfArchives" : 192, "SizeInBytes" : 78088912, "VaultARN" : "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault", "VaultName" : "examplevault"}
Seções relacionadas• Create Vault (PUT vault) (p. 177)
Versão da API 2012-06-01189
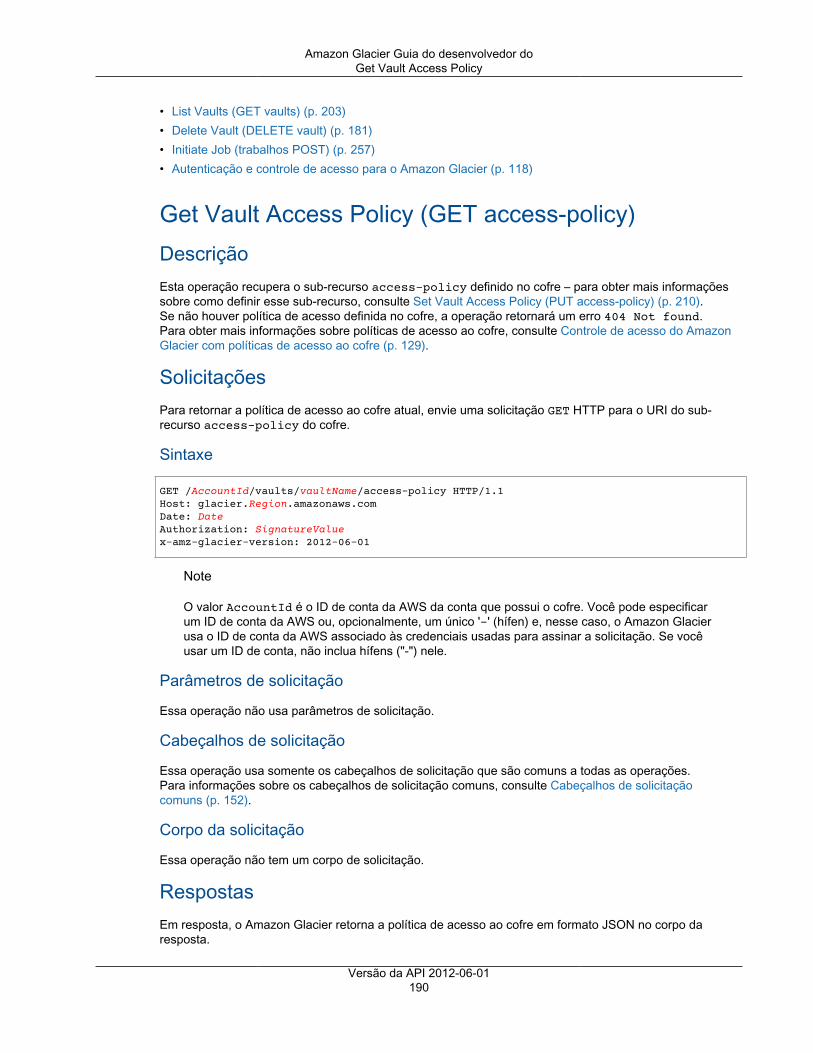
Amazon Glacier Guia do desenvolvedor doGet Vault Access Policy
• List Vaults (GET vaults) (p. 203)• Delete Vault (DELETE vault) (p. 181)• Initiate Job (trabalhos POST) (p. 257)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Get Vault Access Policy (GET access-policy)DescriçãoEsta operação recupera o sub-recurso access-policy definido no cofre – para obter mais informaçõessobre como definir esse sub-recurso, consulte Set Vault Access Policy (PUT access-policy) (p. 210).Se não houver política de acesso definida no cofre, a operação retornará um erro 404 Not found.Para obter mais informações sobre políticas de acesso ao cofre, consulte Controle de acesso do AmazonGlacier com políticas de acesso ao cofre (p. 129).
SolicitaçõesPara retornar a política de acesso ao cofre atual, envie uma solicitação GET HTTP para o URI do sub-recurso access-policy do cofre.
Sintaxe
GET /AccountId/vaults/vaultName/access-policy HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasEm resposta, o Amazon Glacier retorna a política de acesso ao cofre em formato JSON no corpo daresposta.
Versão da API 2012-06-01190
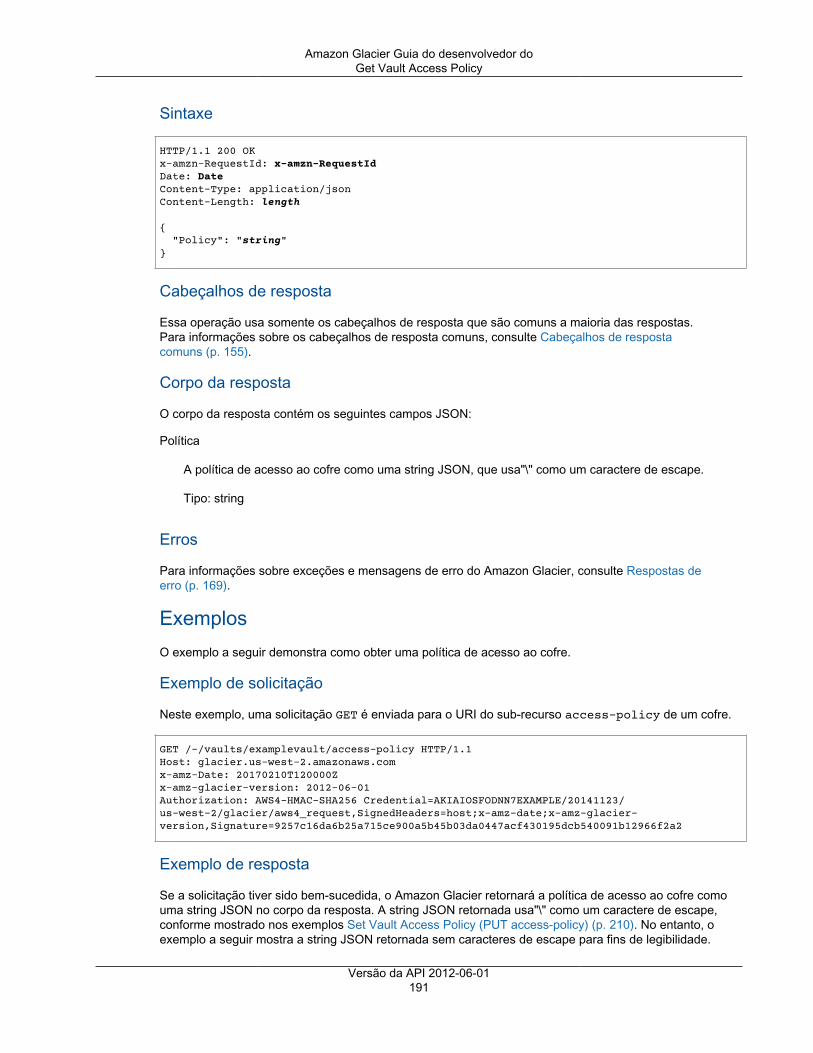
Amazon Glacier Guia do desenvolvedor doGet Vault Access Policy
Sintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: length { "Policy": "string"}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
Política
A política de acesso ao cofre como uma string JSON, que usa"\" como um caractere de escape.
Tipo: string
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como obter uma política de acesso ao cofre.
Exemplo de solicitação
Neste exemplo, uma solicitação GET é enviada para o URI do sub-recurso access-policy de um cofre.
GET /-/vaults/examplevault/access-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Se a solicitação tiver sido bem-sucedida, o Amazon Glacier retornará a política de acesso ao cofre comouma string JSON no corpo da resposta. A string JSON retornada usa"\" como um caractere de escape,conforme mostrado nos exemplos Set Vault Access Policy (PUT access-policy) (p. 210). No entanto, oexemplo a seguir mostra a string JSON retornada sem caracteres de escape para fins de legibilidade.
Versão da API 2012-06-01191

Amazon Glacier Guia do desenvolvedor doGet Vault Lock
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: length
{ "Policy": " { "Version": "2012-10-17", "Statement": [ { "Sid": "allow-time-based-deletes", "Principal": { "AWS": "999999999999" }, "Effect": "Allow", "Action": "glacier:Delete*", "Resource": [ "arn:aws:glacier:us-west-2:999999999999:vaults/examplevault" ], "Condition": { "DateGreaterThan": { "aws:CurrentTime": "2018-12-31T00:00:00Z" } } } ] } "}
Seções relacionadas• Política de acesso de exclusão do cofre (DELETE access-policy) (p. 183)
• Set Vault Access Policy (PUT access-policy) (p. 210)
Get Vault Lock (GET lock-policy)DescriçãoEsta operação recupera os seguintes atributos do sub-recurso lock-policy definido no cofreespecificado:
• A política do bloqueio de cofre definida no cofre.• O estado do bloqueio de cofre, que é InProgess ou Locked.• Quando o ID de bloqueio expira. O ID de bloqueio é usado para concluir o processo de bloqueio do
cofre.• Quando o bloqueio de cofre foi iniciado e colocado no estado InProgress.
Um bloqueio de cofre é colocado no estado InProgress chamando Initiate Vault Lock (POST lock-policy) (p. 198). Um bloqueio de cofre é colocado no estado Locked chamando Complete Vault Lock(POST lockId) (p. 179). Você pode anular o processo de bloqueio de cofre chamando Abort Vault Lock(DELETE lock-policy) (p. 173). Para obter mais informações sobre o processo de bloqueio de cofre,consulte Amazon Glacier Vault Lock (p. 59).
Versão da API 2012-06-01192
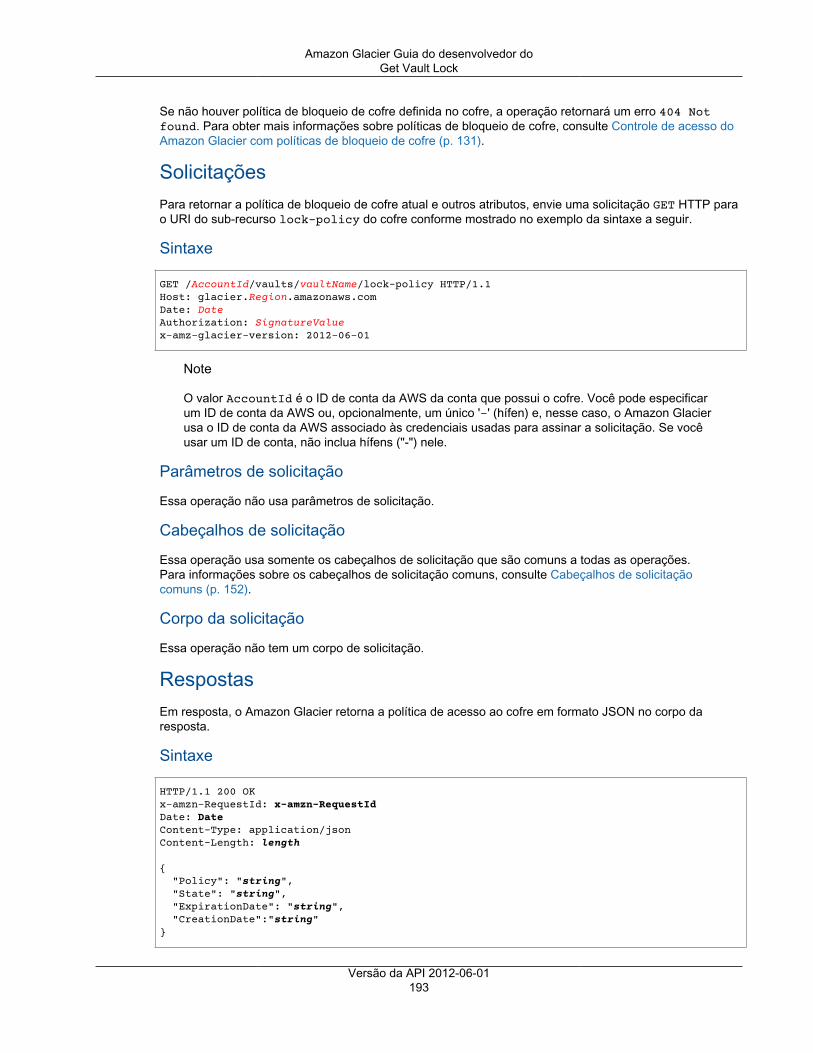
Amazon Glacier Guia do desenvolvedor doGet Vault Lock
Se não houver política de bloqueio de cofre definida no cofre, a operação retornará um erro 404 Notfound. Para obter mais informações sobre políticas de bloqueio de cofre, consulte Controle de acesso doAmazon Glacier com políticas de bloqueio de cofre (p. 131).
SolicitaçõesPara retornar a política de bloqueio de cofre atual e outros atributos, envie uma solicitação GET HTTP parao URI do sub-recurso lock-policy do cofre conforme mostrado no exemplo da sintaxe a seguir.
Sintaxe
GET /AccountId/vaults/vaultName/lock-policy HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasEm resposta, o Amazon Glacier retorna a política de acesso ao cofre em formato JSON no corpo daresposta.
Sintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: length { "Policy": "string", "State": "string", "ExpirationDate": "string", "CreationDate":"string"}
Versão da API 2012-06-01193

Amazon Glacier Guia do desenvolvedor doGet Vault Lock
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
Política
A política de bloqueio de cofre como uma string JSON, que usa"\" como um caractere de escape.
Tipo: stringEstado
O estado do bloqueio de cofre.
Tipo: string
Valores válidos: InProgress|LockedExpirationDate
A data e hora UTC em que o ID de bloqueio expira. Esse valor poderá ser null, se o bloqueio decofre estiver em um estado Locked.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
CreationDate
A data e hora UTC em que o bloqueio de cofre foi colocado no estado InProgress.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como obter uma política de bloqueio de cofre.
Exemplo de solicitação
Neste exemplo, uma solicitação GET é enviada para o URI do sub-recurso lock-policy de um cofre.
GET /-/vaults/examplevault/lock-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Versão da API 2012-06-01194

Amazon Glacier Guia do desenvolvedor doGet Vault Notifications
Exemplo de resposta
Se a solicitação tiver sido bem-sucedida, o Amazon Glacier retornará a política de acesso ao cofre comouma string JSON no corpo da resposta. A string JSON retornada usa"\" como um caractere de escape,conforme mostrado na solicitação de exemplo Initiate Vault Lock (POST lock-policy) (p. 198). No entanto,o exemplo a seguir mostra a string JSON retornada sem caracteres de escape para fins de legibilidade.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: length
{ "Policy": " { "Version": "2012-10-17", "Statement": [ { "Sid": "example-vault-lock-policy", "Principal": { "AWS": "*" }, "Effect": "Deny", "Action": "glacier:DeleteArchive", "Resource": [ "arn:aws:glacier:us-west-2:999999999999:vaults/examplevault" ], "Condition": { "NumericLessThanEquals": { "glacier:ArchiveAgeInDays": "365" } } } ] } ", "State": "InProgress", "ExpirationDate": "exampledate", "CreationDate": "exampledate" }
Seções relacionadas• Abort Vault Lock (DELETE lock-policy) (p. 173)
• Complete Vault Lock (POST lockId) (p. 179)
• Initiate Vault Lock (POST lock-policy) (p. 198)
Get Vault Notifications (GET notification-configuration)DescriçãoEssa operação recupera o sub-recurso notification-configuration definido no cofre (consulteDefinir configuração de notificação de cofre (PUT notification-configuration) (p. 212). Se a configuraçãode notificação de um cofre não estiver definida, a operação retornará um erro 404 Not Found. Para
Versão da API 2012-06-01195
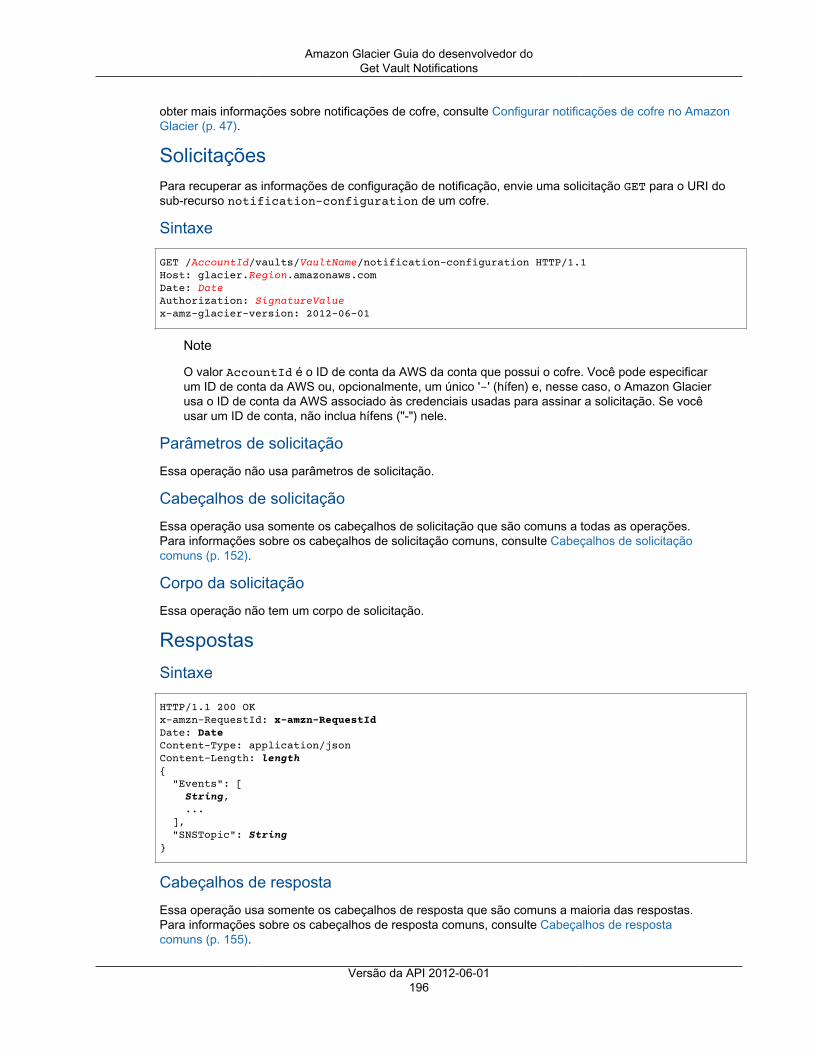
Amazon Glacier Guia do desenvolvedor doGet Vault Notifications
obter mais informações sobre notificações de cofre, consulte Configurar notificações de cofre no AmazonGlacier (p. 47).
SolicitaçõesPara recuperar as informações de configuração de notificação, envie uma solicitação GET para o URI dosub-recurso notification-configuration de um cofre.
Sintaxe
GET /AccountId/vaults/VaultName/notification-configuration HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: length{ "Events": [ String, ... ], "SNSTopic": String}
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Versão da API 2012-06-01196

Amazon Glacier Guia do desenvolvedor doGet Vault Notifications
Corpo da respostaO corpo da resposta contém os seguintes campos JSON:
Eventos
Uma lista de um ou mais eventos para os quais o Amazon Glacier enviará uma notificação ao tópicodo Amazon SNS especificado. Para obter mais informações sobre eventos de cofre para os quaisvocê possa configurar um cofre a fim de publicar notificações, consulte Definir configuração denotificação de cofre (PUT notification-configuration) (p. 212).
Tipo: matrizSNSTopic
O nome de recurso da Amazon (ARN) do tópico do Amazon Simple Notification Service (AmazonSNS). Para obter mais informações, consulte Conceitos básicos do Amazon SNS no Guia deconceitos básicos do Amazon Simple Notification Service.
Type: String
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como recuperar a configuração de notificação de um cofre.
Exemplo de solicitaçãoNeste exemplo, uma solicitação GET é enviada para o sub-recurso notification-configuration deum cofre.
GET /-/vaults/examplevault/notification-configuration HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de respostaUma resposta bem-sucedida mostra o documento de configuração de registro em log da auditoria no corpoda resposta em formato JSON. Neste exemplo, a configuração mostra que as notificações de dois eventos(ArchiveRetrievalCompleted e InventoryRetrievalCompleted) são enviadas para o tópico doAmazon SNS arn:aws:sns:us-west-2:012345678901:mytopic.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 150 { "Events": [ "ArchiveRetrievalCompleted",
Versão da API 2012-06-01197

Amazon Glacier Guia do desenvolvedor doInitiate Vault Lock
"InventoryRetrievalCompleted" ], "SNSTopic": "arn:aws:sns:us-west-2:012345678901:mytopic"}
Seções relacionadas• Delete Vault Notifications (DELETE notification-configuration) (p. 185)• Definir configuração de notificação de cofre (PUT notification-configuration) (p. 212)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Initiate Vault Lock (POST lock-policy)DescriçãoEsta operação inicia o processo de bloqueio do cofre fazendo o seguinte:
• Instalar uma política de bloqueio de cofre no cofre especificado.• Definir o estado de bloqueio do cofre como InProgress.• Retornar um ID de bloqueio, usado para concluir o processo de bloqueio do cofre.
Você pode definir uma política de bloqueio para cada cofre, e essa política pode ter até 20 KB. Para obtermais informações sobre políticas de bloqueio de cofre, consulte Controle de acesso do Amazon Glaciercom políticas de bloqueio de cofre (p. 131).
Você deverá concluir o processo de bloqueio do cofre dentro de 24 horas depois que o bloqueio de cofreentrar no estado InProgress. Depois da janela de 24 horas, o ID de bloqueio vai expirar, o cofre sairáautomaticamente do estado InProgress e a política de bloqueio do cofre será removida do cofre. Vocêchama Complete Vault Lock (POST lockId) (p. 179) para concluir o processo de bloqueio do cofredefinindo o estado do bloqueio de cofre como Locked.
Note
Depois que um bloqueio de cofre estiver no estado Locked, você não poderá iniciar um novobloqueio para o cofre.
Você pode anular o processo de bloqueio de cofre chamando Abort Vault Lock (DELETE lock-policy) (p. 173). Você pode obter o estado do bloqueio de cofre chamando Get Vault Lock (GET lock-policy) (p. 192). Para obter mais informações sobre o processo de bloqueio de cofre, consulte AmazonGlacier Vault Lock (p. 59).
Se essa operação for chamada quando o bloqueio de cofre estiver no estado InProgress, a operaçãoretornará um erro AccessDeniedException. Quando o bloqueio de cofre está no estado InProgress,você deverá chamar Abort Vault Lock (DELETE lock-policy) (p. 173) antes de iniciar uma nova política debloqueio de cofre.
SolicitaçõesPara iniciar o processo de bloqueio de cofre, envie uma solicitação HTTP POST para o URI do sub-recursolock-policy do cofre, conforme mostrado no exemplo de sintaxe a seguir.
Sintaxe
POST /AccountId/vaults/vaultName/lock-policy HTTP/1.1
Versão da API 2012-06-01198
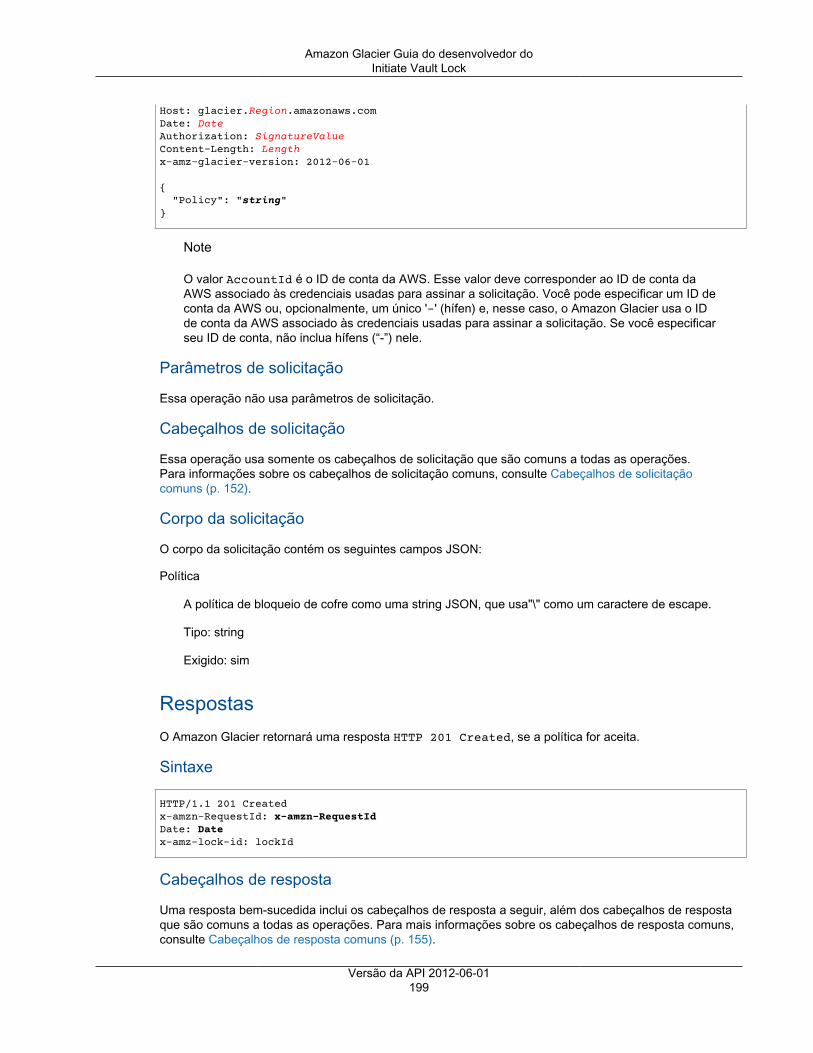
Amazon Glacier Guia do desenvolvedor doInitiate Vault Lock
Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01 { "Policy": "string"}
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
O corpo da solicitação contém os seguintes campos JSON:
Política
A política de bloqueio de cofre como uma string JSON, que usa"\" como um caractere de escape.
Tipo: string
Exigido: sim
RespostasO Amazon Glacier retornará uma resposta HTTP 201 Created, se a política for aceita.
Sintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: Datex-amz-lock-id: lockId
Cabeçalhos de resposta
Uma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Versão da API 2012-06-01199
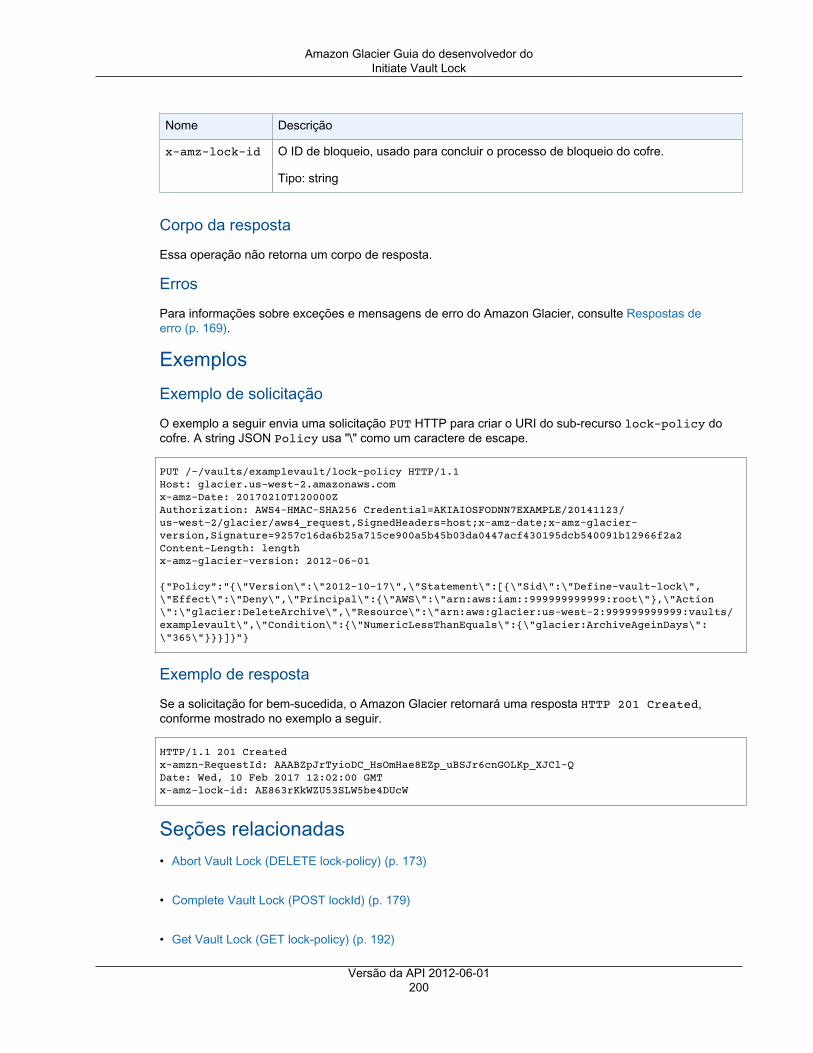
Amazon Glacier Guia do desenvolvedor doInitiate Vault Lock
Nome Descrição
x-amz-lock-id O ID de bloqueio, usado para concluir o processo de bloqueio do cofre.
Tipo: string
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitação
O exemplo a seguir envia uma solicitação PUT HTTP para criar o URI do sub-recurso lock-policy docofre. A string JSON Policy usa "\" como um caractere de escape.
PUT /-/vaults/examplevault/lock-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2Content-Length: lengthx-amz-glacier-version: 2012-06-01
{"Policy":"{\"Version\":\"2012-10-17\",\"Statement\":[{\"Sid\":\"Define-vault-lock\",\"Effect\":\"Deny\",\"Principal\":{\"AWS\":\"arn:aws:iam::999999999999:root\"},\"Action\":\"glacier:DeleteArchive\",\"Resource\":\"arn:aws:glacier:us-west-2:999999999999:vaults/examplevault\",\"Condition\":{\"NumericLessThanEquals\":{\"glacier:ArchiveAgeinDays\":\"365\"}}}]}"}
Exemplo de resposta
Se a solicitação for bem-sucedida, o Amazon Glacier retornará uma resposta HTTP 201 Created,conforme mostrado no exemplo a seguir.
HTTP/1.1 201 Createdx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTx-amz-lock-id: AE863rKkWZU53SLW5be4DUcW
Seções relacionadas• Abort Vault Lock (DELETE lock-policy) (p. 173)
• Complete Vault Lock (POST lockId) (p. 179)
• Get Vault Lock (GET lock-policy) (p. 192)
Versão da API 2012-06-01200

Amazon Glacier Guia do desenvolvedor doListar tags para cofre
Listar tags para cofre (GET tags)Esta operação lista todas as tags anexadas a um cofre. A operação retornará um mapa vazio, senão houver tags. Para obter mais informações sobre tags, consulte Marcar recursos do AmazonGlacier (p. 146).
Sintaxe da solicitaçãoPara listar as tags de um cofre, envie uma solicitação GET HTTP para o URI das tags conforme mostradono exemplo da sintaxe a seguir.
GET /AccountId/vaults/vaultName/tags HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSe a operação for bem-sucedida, o serviço reenviará uma resposta 200 OK HTTP.
Sintaxe da resposta
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length{ "Tags": {
Versão da API 2012-06-01201

Amazon Glacier Guia do desenvolvedor doListar tags para cofre
"string" : "string", "string" : "string" }}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
Tags
As tags anexadas ao cofre. Cada tag é composta de uma chave e de um valor.
Tipo: mapa de string para string
Obrigatório: sim
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo: listar tags de um cofre
O exemplo a seguir lista as tags de um cofre.
Exemplo de solicitação
Neste exemplo, uma solicitação GET é enviada para recuperar uma lista de tags do cofre especificado.
GET /-/vaults/examplevault/tags HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Se a solicitação for bem-sucedida, o Amazon Glacier retornará um HTTP 200 OK com uma lista de tagsdo cofre conforme mostrado no exemplo a seguir.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTContent-Type: application/json
Versão da API 2012-06-01202

Amazon Glacier Guia do desenvolvedor doList Vaults
Content-Length: length
{ "Tags", { "examplekey1": "examplevalue1", "examplekey2": "examplevalue2" } }
Seções relacionadas• Add Tags To Vault (POST tags add) (p. 175)
• Remove Tags From Vault (POST tags remove) (p. 208)
List Vaults (GET vaults)DescriçãoEssa operação lista todos os cofres próprios chamando a conta do usuário. A lista retornada na resposta éclassificada por nome de cofre ASCII.
Por padrão, essa operação retorna até 10 itens por solicitação. Se houver mais cofres a serem listados,o campo marker no corpo da resposta conterá o Amazon Resource Name (ARN – Nome de recurso daAmazon) do cofre no qual deve continuar a lista com uma nova solicitação List Vaults; do contrário, ocampo marker será null. Na próxima solicitação List Vaults, você define o parâmetro marker como ovalor retornado pelo Amazon Glacier nas respostas à solicitação List Vaults anterior. Você também podelimitar o número de cofres retornados na resposta especificando o parâmetro limit na solicitação.
SolicitaçõesPara obter uma lista de cofres, você envia uma solicitação GET para o recurso vaults.
Sintaxe
GET /AccountId/vaults HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitação
Essa operação usa os parâmetros de solicitação a seguir.
Versão da API 2012-06-01203
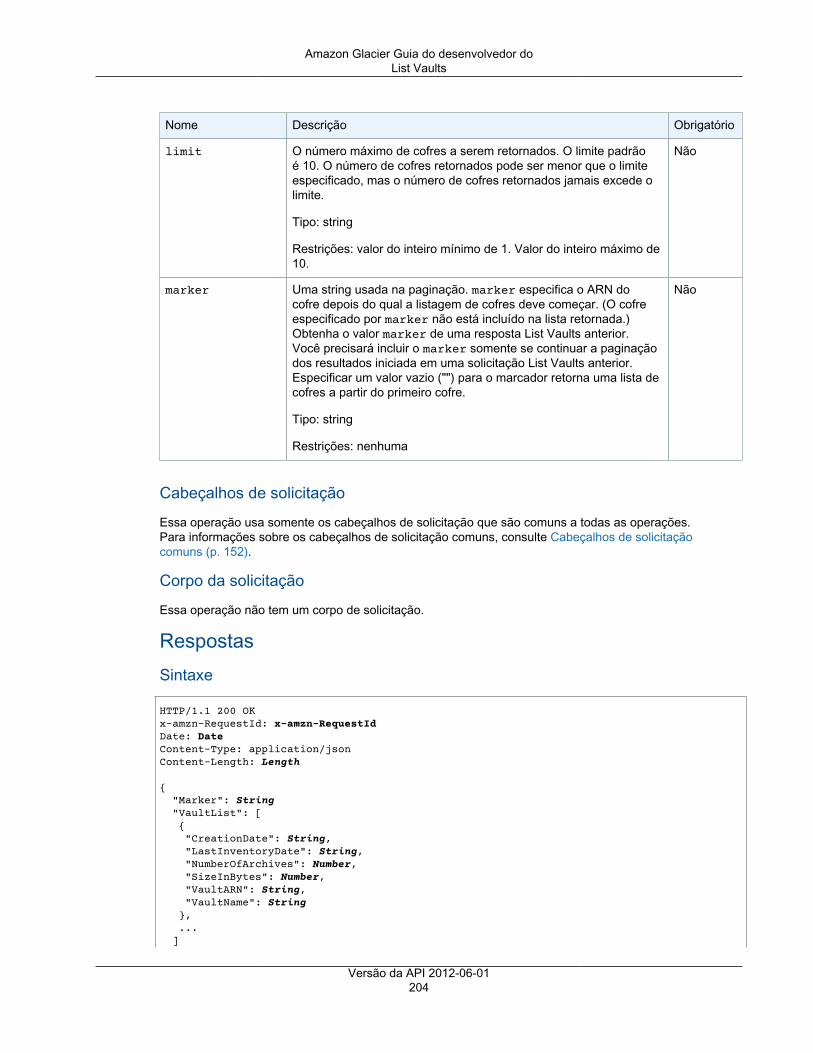
Amazon Glacier Guia do desenvolvedor doList Vaults
Nome Descrição Obrigatório
limit O número máximo de cofres a serem retornados. O limite padrãoé 10. O número de cofres retornados pode ser menor que o limiteespecificado, mas o número de cofres retornados jamais excede olimite.
Tipo: string
Restrições: valor do inteiro mínimo de 1. Valor do inteiro máximo de10.
Não
marker Uma string usada na paginação. marker especifica o ARN docofre depois do qual a listagem de cofres deve começar. (O cofreespecificado por marker não está incluído na lista retornada.)Obtenha o valor marker de uma resposta List Vaults anterior.Você precisará incluir o marker somente se continuar a paginaçãodos resultados iniciada em uma solicitação List Vaults anterior.Especificar um valor vazio ("") para o marcador retorna uma lista decofres a partir do primeiro cofre.
Tipo: string
Restrições: nenhuma
Não
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length
{ "Marker": String "VaultList": [ { "CreationDate": String, "LastInventoryDate": String, "NumberOfArchives": Number, "SizeInBytes": Number, "VaultARN": String, "VaultName": String }, ... ]
Versão da API 2012-06-01204

Amazon Glacier Guia do desenvolvedor doList Vaults
}
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaO corpo da resposta contém os seguintes campos JSON:
CreationDate
A data em que o cofre foi criado, em Coordinated Universal Time (UTC – Tempo universalcoordenado).
Type: String. Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
LastInventoryDate
A data do inventário de cofre mais recente, em UTC. Esse campo poderá ser nulo se um inventárioainda não tiver sido executado no cofre; por exemplo, se você tiver acabado de criar o cofre. Paraobter mais informações sobre como iniciar um inventário para um cofre, consulte Initiate Job (trabalhosPOST) (p. 257).
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
Marker
O vaultARN que representa onde continuar a paginação dos resultados. Você usa o marker emoutra solicitação List Vaults para obter mais cofres na lista. Se não houver cofres, esse valor seránull.
Type: StringNumberOfArchives
O número de arquivos no cofre desde a data do último inventário de cofre.
Tipo: númeroSizeInBytes
O tamanho total, em bytes, de todos os arquivos no cofre, inclusive eventuais custos indiretos porarquivo, desde a data do último inventário.
Tipo: númeroVaultARN
O nome de recurso da Amazon (ARN) do cofre.
Type: StringVaultList
Uma matriz de objetos, com cada objeto apresentando uma descrição de um cofre.
Tipo: matrizVaultName
O nome do cofre.
Versão da API 2012-06-01205

Amazon Glacier Guia do desenvolvedor doList Vaults
Type: String
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo: List All Vaults
O exemplo a seguir lista os cofres. Como os parâmetros marker e limit não são especificados nasolicitação, até 10 cofres são retornados.
Exemplo de solicitação
GET /-/vaults HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
O Marker é null, o que indica não haver mais cofres a serem listados.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTContent-Type: application/jsonContent-Length: 497
{ "Marker": null, "VaultList": [ { "CreationDate": "2012-03-16T22:22:47.214Z", "LastInventoryDate": "2012-03-21T22:06:51.218Z", "NumberOfArchives": 2, "SizeInBytes": 12334, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault1", "VaultName": "examplevault1" }, { "CreationDate": "2012-03-19T22:06:51.218Z", "LastInventoryDate": "2012-03-21T22:06:51.218Z", "NumberOfArchives": 0, "SizeInBytes": 0, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault2", "VaultName": "examplevault2" }, { "CreationDate": "2012-03-19T22:06:51.218Z", "LastInventoryDate": "2012-03-25T12:14:31.121Z", "NumberOfArchives": 0, "SizeInBytes": 0, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault3", "VaultName": "examplevault3"
Versão da API 2012-06-01206

Amazon Glacier Guia do desenvolvedor doList Vaults
} ]}
Exemplo: Partial List of Vaults
O exemplo a seguir retorna dois cofres começando pelo cofre especificado pelo marker.
Exemplo de solicitação
GET /-/vaults?limit=2&marker=arn:aws:glacier:us-west-2:012345678901:vaults/examplevault1 HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Dois cofres são retornados na lista. O Marker contém o ARN do cofre para continuar a paginação emoutra solicitação List Vaults.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTContent-Type: application/jsonContent-Length: 497
{ "Marker": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault3", "VaultList": [ { "CreationDate": "2012-03-16T22:22:47.214Z", "LastInventoryDate": "2012-03-21T22:06:51.218Z", "NumberOfArchives": 2, "SizeInBytes": 12334, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault1", "VaultName": "examplevault1" }, { "CreationDate": "2012-03-19T22:06:51.218Z", "LastInventoryDate": "2012-03-21T22:06:51.218Z", "NumberOfArchives": 0, "SizeInBytes": 0, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault2", "VaultName": "examplevault2" } ]}
Seções relacionadas• Create Vault (PUT vault) (p. 177)• Delete Vault (DELETE vault) (p. 181)• Initiate Job (trabalhos POST) (p. 257)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Versão da API 2012-06-01207
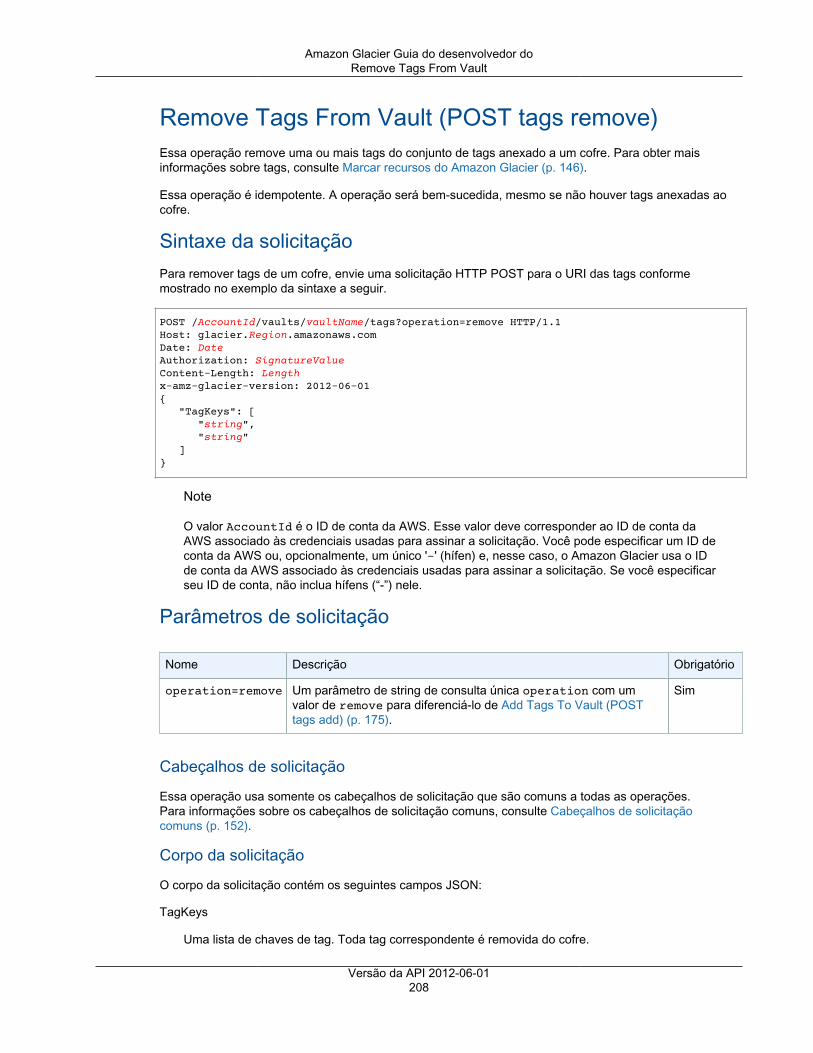
Amazon Glacier Guia do desenvolvedor doRemove Tags From Vault
Remove Tags From Vault (POST tags remove)Essa operação remove uma ou mais tags do conjunto de tags anexado a um cofre. Para obter maisinformações sobre tags, consulte Marcar recursos do Amazon Glacier (p. 146).
Essa operação é idempotente. A operação será bem-sucedida, mesmo se não houver tags anexadas aocofre.
Sintaxe da solicitaçãoPara remover tags de um cofre, envie uma solicitação HTTP POST para o URI das tags conformemostrado no exemplo da sintaxe a seguir.
POST /AccountId/vaults/vaultName/tags?operation=remove HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01{ "TagKeys": [ "string", "string" ]}
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitação
Nome Descrição Obrigatório
operation=remove Um parâmetro de string de consulta única operation com umvalor de remove para diferenciá-lo de Add Tags To Vault (POSTtags add) (p. 175).
Sim
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
O corpo da solicitação contém os seguintes campos JSON:
TagKeys
Uma lista de chaves de tag. Toda tag correspondente é removida do cofre.
Versão da API 2012-06-01208
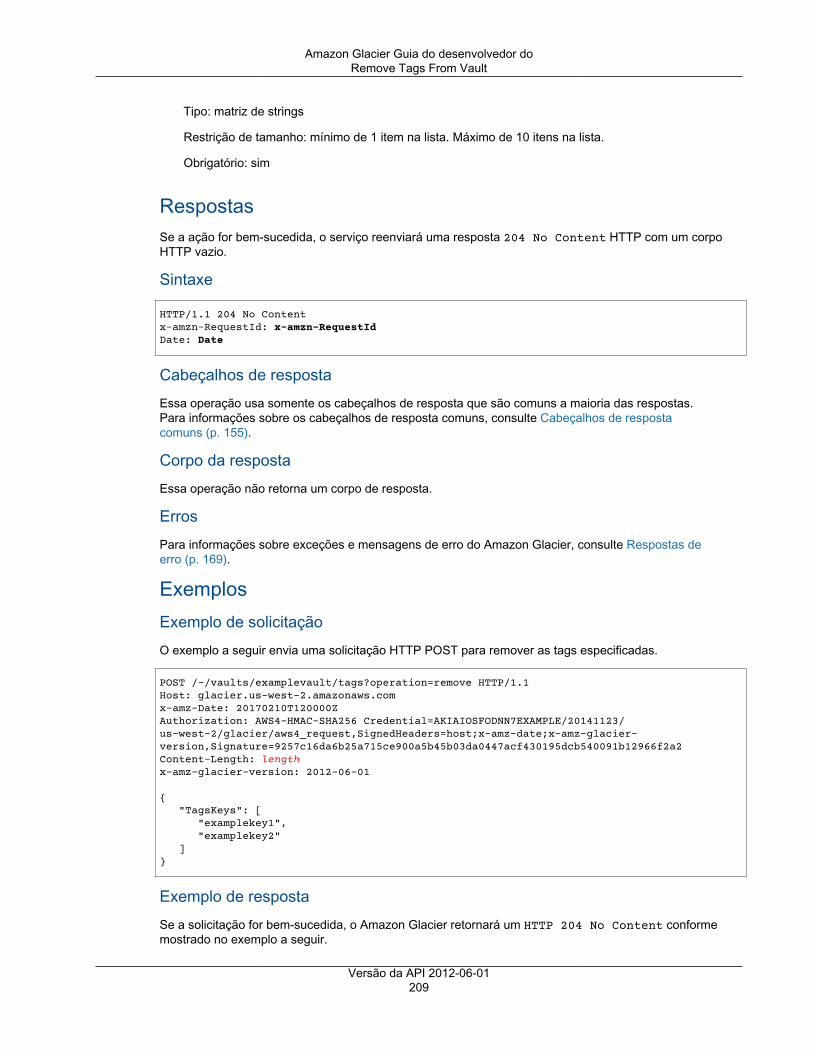
Amazon Glacier Guia do desenvolvedor doRemove Tags From Vault
Tipo: matriz de strings
Restrição de tamanho: mínimo de 1 item na lista. Máximo de 10 itens na lista.
Obrigatório: sim
RespostasSe a ação for bem-sucedida, o serviço reenviará uma resposta 204 No Content HTTP com um corpoHTTP vazio.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitaçãoO exemplo a seguir envia uma solicitação HTTP POST para remover as tags especificadas.
POST /-/vaults/examplevault/tags?operation=remove HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2Content-Length: lengthx-amz-glacier-version: 2012-06-01 { "TagsKeys": [ "examplekey1", "examplekey2" ] }
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier retornará um HTTP 204 No Content conformemostrado no exemplo a seguir.
Versão da API 2012-06-01209
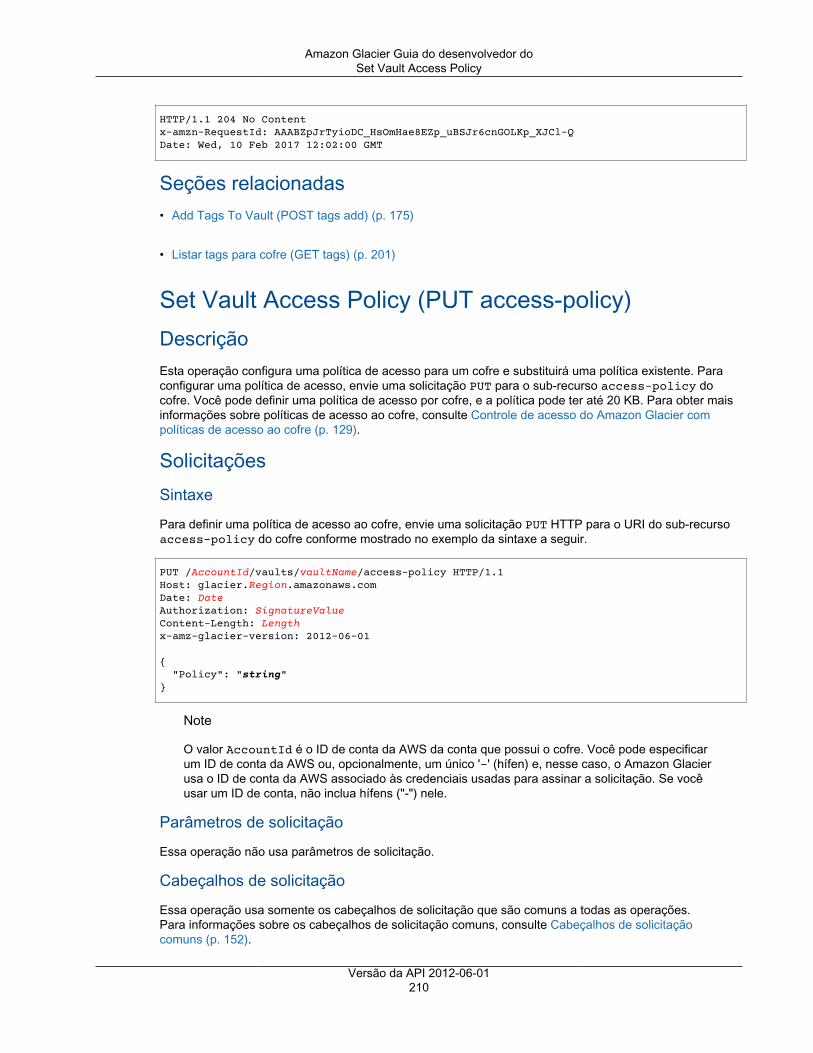
Amazon Glacier Guia do desenvolvedor doSet Vault Access Policy
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMT
Seções relacionadas• Add Tags To Vault (POST tags add) (p. 175)
• Listar tags para cofre (GET tags) (p. 201)
Set Vault Access Policy (PUT access-policy)DescriçãoEsta operação configura uma política de acesso para um cofre e substituirá uma política existente. Paraconfigurar uma política de acesso, envie uma solicitação PUT para o sub-recurso access-policy docofre. Você pode definir uma política de acesso por cofre, e a política pode ter até 20 KB. Para obter maisinformações sobre políticas de acesso ao cofre, consulte Controle de acesso do Amazon Glacier compolíticas de acesso ao cofre (p. 129).
SolicitaçõesSintaxe
Para definir uma política de acesso ao cofre, envie uma solicitação PUT HTTP para o URI do sub-recursoaccess-policy do cofre conforme mostrado no exemplo da sintaxe a seguir.
PUT /AccountId/vaults/vaultName/access-policy HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01 { "Policy": "string"}
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Versão da API 2012-06-01210
Amazon Glacier Guia do desenvolvedor doSet Vault Access Policy
Corpo da solicitaçãoO corpo da solicitação contém os seguintes campos JSON:
Política
A política de acesso ao cofre como uma string JSON, que usa"\" como um caractere de escape.
Tipo: string
Exigido: sim
RespostasEm resposta, o Amazon Glacier retornará 204 No Content, se a política for aceita.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitaçãoO exemplo a seguir envia uma solicitação PUT HTTP para criar o URI do sub-recurso access-policy docofre. A string JSON Policy usa "\" como um caractere de escape.
PUT /-/vaults/examplevault/access-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2Content-Length: lengthx-amz-glacier-version: 2012-06-01
{"Policy":"{\"Version\":\"2012-10-17\",\"Statement\":[{\"Sid\":\"Define-owner-access-rights\",\"Effect\":\"Allow\",\"Principal\":{\"AWS\":\"arn:aws:iam::999999999999:root\"},\"Action\":\"glacier:DeleteArchive\",\"Resource\":\"arn:aws:glacier:us-west-2:999999999999:vaults/examplevault\"}]}"}
Versão da API 2012-06-01211

Amazon Glacier Guia do desenvolvedor doDefinir configuração de notificação de cofre
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier retornará um HTTP 204 No Content conformemostrado no exemplo a seguir.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMT
Seções relacionadas• Política de acesso de exclusão do cofre (DELETE access-policy) (p. 183)
• Get Vault Access Policy (GET access-policy) (p. 190)
Definir configuração de notificação de cofre (PUTnotification-configuration)DescriçãoRecuperar um arquivo e um inventário de cofre são operações assíncronas no Amazon Glacier paraas quais você deve primeiro iniciar um trabalho e aguardar a conclusão do trabalho para poder fazerdownload da saída do trabalho. Você pode configurar um cofre para publicar uma mensagem em umtópico do Amazon Simple Notification Service (Amazon SNS) quando esses trabalhos forem concluídos.Você pode usar essa operação para definir a configuração de notificação no cofre. Para obter maisinformações, consulte Configurar notificações de cofre no Amazon Glacier (p. 47).
Para configurar notificações de cofre, envie uma solicitação PUT para o sub-recurso notification-configuration do cofre. Uma configuração de notificação é específica de um cofre; por isso, elatambém é conhecida como um sub-recurso de cofre. A solicitação deve incluir um documento JSON queforneça um tópico do Amazon Simple Notification Service (Amazon SNS) e os eventos para os quais vocêdeseja que o Amazon Glacier envie notificações ao tópico.
Você pode configurar um cofre a fim de publicar uma notificação para os seguintes eventos de cofre:
• ArchiveRetrievalCompleted— Este evento ocorre quando um trabalho que tenha sido iniciado parauma recuperação de arquivo é concluído (Initiate Job (trabalhos POST) (p. 257)). O status do trabalhoconcluído pode ser Succeeded ou Failed. A notificação enviada para o tópico do SNS é a mesmasaída retornada de Trabalho de descrição (GET JobID) (p. 243).
• InventoryRetrievalCompleted— Este evento ocorre quando um trabalho que tenha sido iniciadopara uma recuperação de inventário é concluído (Initiate Job (trabalhos POST) (p. 257)). O status dotrabalho concluído pode ser Succeeded ou Failed. A notificação enviada para o tópico do SNS é amesma saída retornada de Trabalho de descrição (GET JobID) (p. 243).
Os tópicos do Amazon SNS devem conceder permissão ao cofre para poder publicar notificações notópico.
SolicitaçõesPara definir a configuração de notificação no cofre, envie uma solicitação PUT para o URI do sub-recursonotification-configuration do cofre. Você especifica a configuração no corpo da solicitação.A configuração inclui o nome do tópico do Amazon SNS e um conjunto de eventos que disparam umanotificação para cada tópico.
Versão da API 2012-06-01212

Amazon Glacier Guia do desenvolvedor doDefinir configuração de notificação de cofre
Sintaxe
PUT /AccountId/vaults/VaultName/notification-configuration HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
{ "SNSTopic": String, "Events":[String, ...] }
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
O JSON no corpo da solicitação contém os campos a seguir.
Eventos
Uma matriz de um ou mais eventos para os quais você deseja que o Amazon Glacier envie umanotificação.
Valores válidos: ArchiveRetrievalCompleted | InventoryRetrievalCompleted
Obrigatório: sim
Tipo: matrizSNSTopic
O ARN do tópico do Amazon SNS. Para obter mais informações, vá até Conceitos básicos do AmazonSNS no Guia de conceitos básicos do Amazon Simple Notification Service.
Obrigatório: sim
Type: String
RespostasEm resposta, o Amazon Glacier retornará 204 No Content, se a configuração de notificação for aceita.
Versão da API 2012-06-01213

Amazon Glacier Guia do desenvolvedor doDefinir configuração de notificação de cofre
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como configurar uma notificação de cofre.
Exemplo de solicitaçãoA solicitação a seguir define a configuração de notificação examplevault, de maneira que notificaçõespara dois eventos (ArchiveRetrievalCompleted e InventoryRetrievalCompleted ) sejamenviadas para o tópico do Amazon SNS arn:aws:sns:us-west-2:012345678901:mytopic.
PUT /-/vaults/examplevault/notification-policy HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
{ "Events": ["ArchiveRetrievalCompleted", "InventoryRetrievalCompleted"], "SNSTopic": "arn:aws:sns:us-west-2:012345678901:mytopic" }
Exemplo de respostaUma resposta bem-sucedida retorna um 204 No Content.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Get Vault Notifications (GET notification-configuration) (p. 195)• Delete Vault Notifications (DELETE notification-configuration) (p. 185)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Versão da API 2012-06-01214
Amazon Glacier Guia do desenvolvedor doOperações de arquivo
Operações de arquivoEstas são as operações de arquivo disponíveis para serem usadas no Amazon Glacier.
Tópicos• Delete Archive (DELETE archive) (p. 215)• Upload Archive (POST archive) (p. 217)
Delete Archive (DELETE archive)DescriçãoEssa operação exclui um arquivo de um cofre. Você pode excluir um arquivo por vez de um cofre. Paraexcluir o arquivo, você deve fornecer o ID de arquivo na solicitação de exclusão. Você pode obter o IDde arquivo fazendo download do inventário do cofre que contém o arquivo. Para obter mais informaçõessobre como fazer download do inventário de cofre, consulte Fazer download de um inventário de cofre noAmazon Glacier (p. 35).
Depois de excluir um arquivo, você ainda poderá fazer uma solicitação bem-sucedida para iniciar umtrabalho a fim de recuperar o arquivo excluído, mas o trabalho de recuperação de arquivo falhará.
Recuperações de arquivo que estejam em andamento para um ID de arquivo quando você exclui o arquivopodem ser bem-sucedidas ou não, de acordo com os seguintes cenários:
• Se o trabalho de recuperação de arquivo estiver preparando ativamente os dados para downloadquando o Amazon Glacier receber a solicitação de exclusão de arquivo, a operação de recuperação dearquivo poderá falhar.
• Se o trabalho de recuperação de arquivo tiver preparado com êxito o arquivo para download quando oAmazon Glacier receber a solicitação de exclusão de arquivo, você poderá fazer download da saída.
Para obter mais informações sobre recuperação de arquivo, consulte Fazer download de um arquivo noAmazon Glacier (p. 79).
Essa operação é idempotente. Tentar excluir um arquivo já excluído não resulta em um erro.
SolicitaçõesPara excluir um arquivo, você envia uma solicitação DELETE para o URI do recurso.
Sintaxe
DELETE /AccountId/vaults/VaultName/archives/ArchiveID HTTP/1.1Host: glacier.Region.amazonaws.comx-amz-Date: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Versão da API 2012-06-01215

Amazon Glacier Guia do desenvolvedor doDelete Archive
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como excluir um arquivo do cofre chamado examplevault.
Exemplo de solicitaçãoO ID do arquivo a ser excluído é especificado como um sub-recurso de archives.
DELETE /-/vaults/examplevault/archives/NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier responderá com 204 No Content para indicar queo arquivo é excluído.
Versão da API 2012-06-01216

Amazon Glacier Guia do desenvolvedor doUpload Archive
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Archive (POST archive) (p. 217)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Upload Archive (POST archive)DescriçãoEssa operação adiciona um arquivo a um cofre. Para um upload bem-sucedido, os dados são mantidos demaneira durável. Em resposta, o Amazon Glacier retorna o ID de arquivo no cabeçalho x-amz-archive-id da resposta. Você deve salvar o ID do arquivo retornado, de maneira que possa acessar o arquivodepois.
Você deve fornecer um hash de árvore SHA256 dos dados cujo upload está fazendo. Para obterinformações sobre como computar um hash de árvore SHA256, consulte Computar somas deverificação (p. 159).
Ao fazer upload de um arquivo, você pode especificar uma descrição de arquivo de até 1.024 caracteresASCII imprimíveis. O Amazon Glacier retorna a descrição do arquivo quando você recupera o arquivoou obtém o inventário de cofre. O Amazon Glacier não interpreta a descrição de maneira alguma. Umadescrição de arquivo não precisa ser exclusiva. Você não pode usar a descrição para recuperar ouclassificar a lista de arquivos.
Exceto para a descrição de arquivo opcional, o Amazon Glacier não dá suporte a metadados adicionaisdos arquivos. O ID de arquivo é uma sequência de caracteres invisível da qual você não pode inferirnenhum significado sobre o arquivo. Assim, convém manter metadados sobre os arquivos no lado docliente. Para obter mais informações, consulte Trabalhar com arquivos no Amazon Glacier (p. 62).
Os arquivos são imutáveis. Depois de fazer upload de um arquivo, você não poderá editar o arquivo nem adescrição.
SolicitaçõesPara fazer upload de um arquivo, use o método HTTP POST e delimite a solicitação ao sub-recursoarchives do cofre no qual você deseja salvar o arquivo. A solicitação deve incluir o tamanho da carga útildo arquivo, a soma de verificação (hash de árvore SHA256) e pode incluir uma descrição do arquivo.
Sintaxe
POST /AccountId/vaults/VaultName/archivesHost: glacier.Region.amazonaws.comx-amz-glacier-version: 2012-06-01Date: DateAuthorization: SignatureValuex-amz-archive-description: Descriptionx-amz-sha256-tree-hash: SHA256 tree hashx-amz-content-sha256: SHA256 linear hashContent-Length: Length
Versão da API 2012-06-01217

Amazon Glacier Guia do desenvolvedor doUpload Archive
<Request body.>
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa implementação da operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa os cabeçalhos de solicitação a seguir, além dos cabeçalhos de solicitação que sãocomuns a todas as operações. Para mais informações sobre os cabeçalhos de solicitação comuns,consulte Cabeçalhos de solicitação comuns (p. 152).
Nome Descrição Obrigatório
Content-Length O tamanho do objeto em bytes. Para obter mais informações,vá até http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html#sec14.13.
Tipo: Número
Padrão: nenhum
Restrições: nenhuma
Sim
x-amz-archive-description
A descrição opcional do arquivo cujo upload você estáfazendo. Ela pode ser uma descrição em linguagem simplesou algum identificador que você opta por atribuir. A descriçãonão precisa ser exclusiva entre os arquivos. Quando vocêrecupera um inventário de cofre (consulte Initiate Job (trabalhosPOST) (p. 257)), ela inclui essa descrição para cada um dosarquivos retornados em resposta.
Tipo: string
Padrão: nenhum
Restrições: a descrição deve ser menor que ou igual a 1.024bytes caracteres. Os caracteres permitidos são ASCII 7 bits semcódigos de controle – mais especificamente, valores ASCII 32—126 decimais ou 0x20—0x7E hexadecimais.
Não
x-amz-content-sha256
A soma de verificação SHA256 (um hash linear) da carga útil.Ele não é o mesmo valor especificado por você no cabeçalho x-amz-sha256-tree-hash.
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Sim
Versão da API 2012-06-01218

Amazon Glacier Guia do desenvolvedor doUpload Archive
Nome Descrição Obrigatório
x-amz-sha256-tree-hash
A soma de verificação computada pelo usuário, hash de árvoreSHA256, da carga útil. Para obter informações sobre comocomputar o hash de árvore SHA256, consulte Computar somasde verificação (p. 159). Se calcular uma soma de verificaçãodiferente da carga útil, o Amazon Glacier rejeitará a solicitação.
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Sim
Corpo da solicitaçãoO corpo da solicitação contém os dados cujo upload deve ser feito.
RespostasEm resposta, o Amazon Glacier armazena de maneira durável o arquivo e retorna um caminho de URIpara o ID de arquivo.
Sintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: Datex-amz-sha256-tree-hash: ChecksumComputedByAmazonGlacierLocation: Locationx-amz-archive-id: ArchiveId
Cabeçalhos de respostaUma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Nome Descrição
Location O caminho do URI relativo do recurso de arquivo recém-adicionado.
Tipo: string
x-amz-archive-id
O ID do arquivo. Esse valor também está incluído como parte do cabeçalhoLocation.
Tipo: string
x-amz-sha256-tree-hash
A soma de verificação do arquivo computada pelo Amazon Glacier.
Tipo: string
Corpo da respostaEssa operação não retorna um corpo de resposta.
Versão da API 2012-06-01219

Amazon Glacier Guia do desenvolvedor doOperações de multipart upload
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitação
O exemplo a seguir mostra uma solicitação para fazer upload de um arquivo.
POST /-/vaults/examplevault/archives HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-sha256-tree-hash: beb0fe31a1c7ca8c6c04d574ea906e3f97b31fdca7571defb5b44dca89b5af60x-amz-content-sha256: 7f2fe580edb35154041fa3d4b41dd6d3adaef0c85d2ff6309f1d4b520eeecda3Content-Length: 2097152x-amz-glacier-version: 2012-06-01Authorization: Authorization=AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-content-sha256;x-amz-date;x-amz-glacier-version,Signature=16b9a9e220a37e32f2e7be196b4ebb87120ca7974038210199ac5982e792cace
<Request body (2097152 bytes).>
Exemplo de resposta
A resposta bem-sucedida abaixo tem um cabeçalho Location onde você pode obter o ID atribuído peloAmazon Glacier ao arquivo.
HTTP/1.1 201 Createdx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTx-amz-sha256-tree-hash: beb0fe31a1c7ca8c6c04d574ea906e3f97b31fdca7571defb5b44dca89b5af60Location: /111122223333/vaults/examplevault/archives/NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveIdx-amz-archive-id: NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId
Seções relacionadas• Trabalhar com arquivos no Amazon Glacier (p. 62)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Delete Archive (DELETE archive) (p. 215)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Operações de multipart uploadEstas são as operações de multipart upload disponíveis para serem usadas no Amazon Glacier.
Tópicos• Abort Multipart Upload (DELETE uploadID) (p. 221)• Complete Multipart Upload (POST uploadID) (p. 223)
Versão da API 2012-06-01220

Amazon Glacier Guia do desenvolvedor doAnular multipart upload
• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• List Parts (GET uploadID) (p. 230)• List Multipart Uploads (GET multipart-uploads) (p. 234)• Upload Part (PUT uploadID) (p. 239)
Abort Multipart Upload (DELETE uploadID)DescriçãoEsta operação de multipart upload anula um multipart upload identificado pelo ID de upload.
Depois que a solicitação Abort Multipart Upload for bem-sucedida, você não poderá usar o ID de uploadpara fazer upload de mais partes ou realizar outras operações. Anular um multipart upload concluído falha.No entanto, anular um upload já anulado será bem-sucedido, por um curto período.
Essa operação é idempotente.
Para obter informações sobre o multipart upload, consulte Fazer upload de arquivos grandes em partes(Multipart Upload) (p. 70).
SolicitaçõesPara anular um multipart upload, envie uma solicitação DELETE HTTP para o URI do sub-recursomultipart-uploads do cofre e identifique o ID de multipart upload específico como parte do URI.
Sintaxe
DELETE /AccountId/vaults/VaultName/multipart-uploads/uploadID HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
Versão da API 2012-06-01221
Amazon Glacier Guia do desenvolvedor doAnular multipart upload
RespostasSintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemploExemplo de solicitação
No exemplo a seguir, uma solicitação DELETE é enviada para o URI de um recurso de ID de multipartupload.
DELETE /-/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Part (PUT uploadID) (p. 239)• Complete Multipart Upload (POST uploadID) (p. 223)• List Multipart Uploads (GET multipart-uploads) (p. 234)
Versão da API 2012-06-01222

Amazon Glacier Guia do desenvolvedor doConcluir multipart upload
• List Parts (GET uploadID) (p. 230)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Complete Multipart Upload (POST uploadID)DescriçãoVocê chama essa operação multipart upload para informar ao Amazon Glacier que o upload de todasas partes do arquivo foi feito e que o Amazon Glacier agora pode montar o arquivo com base nas partescarregadas.
Para obter informações sobre o multipart upload, consulte Fazer upload de arquivos grandes em partes(Multipart Upload) (p. 70).
Depois da montagem e da gravação do arquivo no cofre, o Amazon Glacier retornará o ID de arquivo dorecurso de arquivo recém-criado. Depois de fazer upload de um arquivo, você deve salvar o ID do arquivoretornado para recuperar o arquivo mais tarde.
Na solicitação, você deve incluir o hash de árvore SHA256 computado de todo o arquivo cujo upload foifeito. Para obter informações sobre como computar um hash de árvore SHA256, consulte Computar somasde verificação (p. 159). No lado do servidor, o Amazon Glacier também cria o hash de árvore SHA256do arquivo montado. Se os valores forem correspondentes, o Amazon Glacier salvará o arquivo no cofre;do contrário, ele retornará um erro, e a operação falhará. A operação List Parts (GET uploadID) (p. 230)retorna uma lista de partes cujo upload foi feito para um multipart upload específico. Ela inclui informaçõesda soma de verificação de cada parte carregada que podem ser usadas para depurar um problema desoma de verificação inválida.
Além disso, o Amazon Glacier também verifica se há intervalos de conteúdo não encontrados. Ao fazerupload de partes, você especifica valores de intervalo identificando onde cada parte fica na montagem finaldo arquivo. Ao montar o arquivo final, o Amazon Glacier verifica se há algum intervalo de conteúdo nãoencontrado e, se houver algum intervalo de conteúdo não encontrado, o Amazon Glacier retornará um erroe a operação Complete Multipart Upload falhará.
Complete Multipart Upload é uma operação idempotente. Depois do primeiro complete multipart uploadbem-sucedido, se você chamar a operação novamente dentro de um curto período, a operação será bem-sucedida e retornará o mesmo ID do arquivo. Isso será útil se você enfrentar um problema de rede quecause uma conexão anulada ou receba um erro de servidor 500, quando poderá repetir a solicitaçãoComplete Multipart Upload e obter o mesmo ID de arquivo sem criar arquivos duplicados. No entanto,depois que o multipart upload for concluído, você não poderá chamar a operação List Parts, e o multipartupload não será exibido na resposta List Multipart Uploads, mesmo se for possível uma conclusãoidempotente.
SolicitaçõesPara concluir um multipart upload, você envia uma solicitação HTTP POST para o URI do ID de uploadcriado pelo Amazon Glacier em resposta à solicitação Initiate Multipart Upload. Esse é o mesmo URIusado por você ao fazer upload das partes. Além dos cabeçalhos obrigatórios comuns, você deve incluir oresultado do hash de árvore SHA256 de todo o arquivo e o tamanho total do arquivo em bytes.
Sintaxe
POST /AccountId/vaults/VaultName/multipart-uploads/uploadIDHost: glacier.Region.amazonaws.com
Versão da API 2012-06-01223

Amazon Glacier Guia do desenvolvedor doConcluir multipart upload
Date: dateAuthorization: SignatureValuex-amz-sha256-tree-hash: SHA256 tree hash of the archivex-amz-archive-size: ArchiveSize in bytesx-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa os cabeçalhos de solicitação a seguir, além dos cabeçalhos de solicitação que sãocomuns a todas as operações. Para mais informações sobre os cabeçalhos de solicitação comuns,consulte Cabeçalhos de solicitação comuns (p. 152).
Nome Descrição Obrigatório
x-amz-archive-size
O tamanho total, em bytes, de todo o arquivo. Esse valor deve ser asoma de todos os tamanhos das partes individuais cujo upload vocêfez.
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Sim
x-amz-sha256-tree-hash
O hash de árvore SHA256 de todo o arquivo. Trata-se do hash deárvore SHA256 das partes individuais. Se o valor especificado porvocê na solicitação não corresponder ao hash de árvore SHA256 doarquivo montado final computado pelo Amazon Glacier, o AmazonGlacier retornará um erro e a solicitação falhará.
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Sim
Elementos da solicitação
Essa operação não usa elementos de solicitação.
RespostasO Amazon Glacier cria um hash de árvore SHA256 de todo o arquivo. Se o valor corresponder ao hashde árvore SHA256 de todo o arquivo especificado por você na solicitação, o Amazon Glacier adicionaráo arquivo ao cofre. Em resposta, ele retorna o cabeçalho Location HTTP com o caminho de URL
Versão da API 2012-06-01224

Amazon Glacier Guia do desenvolvedor doConcluir multipart upload
do recurso de arquivo recém-adicionado. Se o tamanho do arquivo ou SHA256 enviado por você nasolicitação não for correspondente, o Amazon Glacier retornará um erro, e o upload permanecerá noestado incompleto. Será possível tentar novamente a operação Complete Multipart Upload depoiscom valores corretos, quando você poderá criar um arquivo com êxito. Se um multipart upload não forconcluído, o Amazon Glacier acabará recuperando o ID do upload.
Sintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: DateLocation: Locationx-amz-archive-id: ArchiveId
Cabeçalhos de resposta
Uma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Nome Descrição
Location O caminho do URI relativo do arquivo recém-criado. Esse URL inclui o ID dearquivo gerado pelo Amazon Glacier.
Tipo: string
x-amz-archive-id
O ID do arquivo. Esse valor também está incluído como parte do cabeçalhoLocation.
Tipo: string
Campos de resposta
Essa operação não retorna um corpo de resposta.
ExemploExemplo de solicitação
Neste exemplo, uma solicitação HTTP POST é enviada para o URI que foi retornado por uma solicitaçãoInitiate Multipart Upload. A solicitação especifica o hash de árvore SHA256 de todo o arquivo e o tamanhototal do arquivo.
POST /-/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE HTTP/1.1Host: glacier.us-west-2.amazonaws.comz-amz-Date: 20170210T120000Zx-amz-sha256-tree-hash:1ffc0f54dd5fdd66b62da70d25edacd0x-amz-archive-size:8388608x-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Versão da API 2012-06-01225

Amazon Glacier Guia do desenvolvedor doIniciar o multipart upload
Exemplo de resposta
A resposta de exemplo a seguir mostra que o Amazon Glacier criou com êxito um arquivo das partes cujoupload você fez. A resposta inclui o ID de arquivo com caminho completo.
HTTP/1.1 201 Createdx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTLocation: /111122223333/vaults/examplevault/archives/NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveIdx-amz-archive-id: NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId
Agora você pode enviar solicitações HTTP para o URI do recurso/arquivo recém-adicionado. Por exemplo,você pode enviar uma solicitação GET para recuperar o arquivo.
Seções relacionadas• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Part (PUT uploadID) (p. 239)• Abort Multipart Upload (DELETE uploadID) (p. 221)• List Multipart Uploads (GET multipart-uploads) (p. 234)• List Parts (GET uploadID) (p. 230)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Delete Archive (DELETE archive) (p. 215)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Initiate Multipart Upload (POST multipart-uploads)DescriçãoEssa operação inicia um multipart upload (consulte Fazer upload de arquivos grandes em partes (MultipartUpload) (p. 70)). O Amazon Glacier cria um recurso de multipart upload e retorna o ID na resposta. Vocêusará esse ID de upload em operações de multipart upload subsequentes.
Ao iniciar um multipart upload, você especifica o tamanho da parte em número de bytes. O tamanhoda parte deve ser um megabyte (1.024 KB) elevado à potência de 2; por exemplo, 1.048.576 (1 MB),2.097.152 (2 MB), 4.194.304 (4 MB), 8.388.608 (8 MB) e assim por diante. O tamanho da parte mínimopermitido é 1 MB, e o máximo é 4 GB.
Toda parte cujo upload você faz usando esse ID de upload, exceto a última, deve ter o mesmo tamanho. Aúltima pode ser do mesmo tamanho ou menor. Por exemplo, suponhamos que você queira fazer upload deum arquivo de 16,2 MB. Se iniciar o multipart upload com um tamanho de parte de 4 MB, você fará uploadde quatro partes de 4 MB cada e uma parte de 0,2 MB.
Note
Você não precisa saber o tamanho do arquivo ao iniciar um multipart upload porque o AmazonGlacier não exige que especifique o tamanho de todo o arquivo.
Depois de concluir o multipart upload, o Amazon Glacier removerá o recurso de multipart uploadreferenciado pelo ID. O Amazon Glacier também removerá o recurso de multipart upload se você cancelar
Versão da API 2012-06-01226

Amazon Glacier Guia do desenvolvedor doIniciar o multipart upload
o multipart upload, ou ele poderá ser removido se não houver atividade por um período de 24 horas.O ID ainda poderá estar disponível depois de 24 horas, mas os aplicativos não devem esperar essecomportamento.
SolicitaçõesPara iniciar um multipart upload, você envia uma solicitação HTTP POST para o URI do sub-recursomultipart-uploads do cofre no qual deseja salvar o arquivo. A solicitação deve incluir o tamanho daparte e pode incluir uma descrição do arquivo.
Sintaxe
POST /AccountId/vaults/VaultName/multipart-uploads Host: glacier.us-west-2.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01x-amz-archive-description: ArchiveDescriptionx-amz-part-size: PartSize
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa os cabeçalhos de solicitação a seguir, além dos cabeçalhos de solicitação que sãocomuns a todas as operações. Para mais informações sobre os cabeçalhos de solicitação comuns,consulte Cabeçalhos de solicitação comuns (p. 152).
Nome Descrição Obrigatório
x-amz-part-size O tamanho de cada parte, exceto a última, embytes. A última parte pode ser menor que otamanho dessa parte.
Tipo: string
Padrão: nenhum
Restrições: o tamanho da parte deve ser ummegabyte (1.024 KB) elevado à potência de2; por exemplo, 1.048.576 (1 MB), 2.097.152(2 MB), 4.194.304 (4 MB), 8.388.608 (8 MB) eassim por diante. O tamanho da parte mínimopermitido é 1 MB, e o máximo é 4 GB (4.096MB).
Sim
x-amz-archive-description Descrição do arquivo cujo upload você estáfazendo em partes. Ela pode ser uma descrição
Não
Versão da API 2012-06-01227

Amazon Glacier Guia do desenvolvedor doIniciar o multipart upload
Nome Descrição Obrigatórioem linguagem simples ou algum identificadorexclusivo que você opta por atribuir. Quandovocê recupera um inventário de cofre (consulteInitiate Job (trabalhos POST) (p. 257)), oinventário inclui essa descrição para cada umdos arquivos retornados em resposta. O espaçoem branco à esquerda em descrições de arquivoé removido.
Tipo: string
Padrão: nenhum
Restrições: a descrição deve ser menor que ouigual a 1.024 bytes. Os caracteres permitidossão ASCII 7 bits sem códigos de controle – maisespecificamente, valores ASCII 32-126 decimaisou 0x20-0x7E hexadecimais.
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasNa resposta, o Amazon Glacier cria um recurso de multipart upload identificado por um ID e retorna ocaminho do URI relativo do ID de multipart upload.
Sintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: DateLocation: Locationx-amz-multipart-upload-id: multiPartUploadId
Cabeçalhos de respostaUma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Nome Descrição
Location O caminho do URI relativo do ID de multipart upload criado pelo Amazon Glacier.Você pode usar esse caminho do URI para delimitar as solicitações a fim de fazerupload de partes e concluir o multipart upload.
Tipo: string
x-amz-multipart-upload-id
O ID do multipart upload. Esse valor também está incluído como parte do cabeçalhoLocation.
Tipo: string
Versão da API 2012-06-01228

Amazon Glacier Guia do desenvolvedor doIniciar o multipart upload
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemploExemplo de solicitaçãoO exemplo a seguir inicia um multipart upload enviando uma solicitação HTTP POST para o URI do sub-recurso multipart-uploads de um cofre chamado examplevault. A solicitação inclui cabeçalhos paraespecificar o tamanho da parte de 4 MB (4.194.304 bytes) e a descrição de arquivo opcional.
POST /-/vaults/examplevault/multipart-uploads Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-archive-description: MyArchive-101x-amz-part-size: 4194304x-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de respostaO Amazon Glacier cria um recurso de multipart upload e o adiciona ao sub-recurso multipart-uploadsdo cofre. O cabeçalho de resposta Location inclui o caminho do URI relativo para o ID de multipartupload.
HTTP/1.1 201 Createdx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTLocation: /111122223333/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLEx-amz-multipart-upload-id: OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE
Para obter informações sobre como fazer upload de partes individuais, consulte Upload Part (PUTuploadID) (p. 239).
Seções relacionadas• Upload Part (PUT uploadID) (p. 239)• Complete Multipart Upload (POST uploadID) (p. 223)• Abort Multipart Upload (DELETE uploadID) (p. 221)• List Multipart Uploads (GET multipart-uploads) (p. 234)• List Parts (GET uploadID) (p. 230)• Delete Archive (DELETE archive) (p. 215)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Versão da API 2012-06-01229

Amazon Glacier Guia do desenvolvedor doListar partes
List Parts (GET uploadID)DescriçãoEssa operação multipart upload lista as partes de um arquivo cujo upload foi feito em um multipart uploadespecífico identificado por um ID de upload. Para obter informações sobre o multipart upload, consulteFazer upload de arquivos grandes em partes (Multipart Upload) (p. 70).
Você pode fazer essa solicitação a qualquer momento durante um multipart upload em andamento antesde concluir o multipart upload. O Amazon Glacier retorna a lista de partes classificada pelo intervaloespecificado por você em cada upload da parte. Se você enviar uma solicitação List Parts depois deconcluir o multipart upload, o Amazon Glacier retornará um erro.
A operação List Parts dá suporte à paginação. Você deve sempre verificar o campo Marker no corpo deresposta para um marcador no qual continuar a lista. Se não houver mais itens, o campo marker seránull. Se o marker não for nulo, para buscar o próximo conjunto de partes, você enviou outra solicitaçãoList Parts com o parâmetro da solicitação marker definido como o valor do marcador retornado peloAmazon Glacier em resposta à solicitação List Parts anterior.
Você também pode limitar o número de partes retornadas na resposta especificando o parâmetro limitna solicitação.
SolicitaçõesSintaxePara listar as partes de um multipart upload em andamento, você envia uma solicitação GET para o URIdo recurso de ID de multipart upload. O ID de multipart upload é retornado quando você inicia um multipartupload (Initiate Multipart Upload (POST multipart-uploads) (p. 226)). Você também pode especificarparâmetros marker e limit.
GET /AccountId/vaults/VaultName/multipart-uploads/uploadID HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Nome Descrição Obrigatório
limit O número máximo de partes a serem retornadas. O limite padrãoé 50. O número de partes retornadas pode ser menor que o limiteespecificado, mas o número de partes retornadas jamais excede olimite.
Tipo: string
Restrições: valor do inteiro mínimo de 1. Valor do inteiro máximo de50.
Não
Versão da API 2012-06-01230
Amazon Glacier Guia do desenvolvedor doListar partes
Nome Descrição Obrigatório
marker Uma string invisível usada na paginação. marker especifica aparte na qual a listagem de partes deve começar. Obtenha o valormarker da resposta de uma resposta List Parts anterior. Vocêsomente precisará incluir o marker se continuar a paginação dosresultados iniciada em uma solicitação List Parts anterior.
Tipo: string
Restrições: nenhuma
Não
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length
{ "ArchiveDescription" : String, "CreationDate" : String, "Marker": String, "MultipartUploadId" : String, "PartSizeInBytes" : Number, "Parts" : [ { "RangeInBytes" : String, "SHA256TreeHash" : String }, ... ], "VaultARN" : String}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
Versão da API 2012-06-01231

Amazon Glacier Guia do desenvolvedor doListar partes
ArchiveDescription
A descrição do arquivo que tiver sido especificada na solicitação Initiate Multipart Upload. Este camposerá null se nenhuma descrição de arquivo tiver sido especificada na operação Initiate MultipartUpload.
Type: StringCreationDate
A hora UTC em que o multipart upload foi iniciado.
Type: String. Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
Marker
Uma string invisível que representa onde continuar a paginação dos resultados. Você usa o markerem uma nova solicitação List Parts para obter mais trabalhos na lista. Se não houver partes, essevalor será null.
Type: StringMultipartUploadId
O ID do upload ao qual as partes estão associadas.
Type: StringPartSizeInBytes
O tamanho da parte em bytes. Trata-se do mesmo valor especificado por você na solicitação InitiateMultipart Upload.
Tipo: númeroPartes
A lista dos tamanhos de partes do multipart upload. Cada objeto na matriz contém um RangeBytes eum par de nome/valor sha256-tree-hash.
Tipo: matrizRangeInBytes
O intervalo de bytes de uma parte, inclusive do valor máximo do intervalo.
Type: StringSHA256TreeHash
O valor do hash de árvore SHA256 que o Amazon Glacier calculou para a parte. Esse campo jamaisserá null.
Type: StringVaultARN
O nome de recurso da Amazon (ARN) do cofre para o qual o multipart upload foi iniciado.
Type: String
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
Versão da API 2012-06-01232

Amazon Glacier Guia do desenvolvedor doListar partes
ExemplosExemplo: List Parts de um multipart uploadO exemplo a seguir lista todas as partes de um upload. O exemplo envia uma solicitação GET HTTP para oURI do ID de multipart upload específico de um multipart upload em andamento e retorna até 1.000 partes.
Exemplo de solicitação
GET /-/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Na resposta, o Amazon Glacier retorna uma lista de partes cujo upload foi feito associadas ao ID demultipart upload especificado. Neste exemplo, existem apenas duas partes. O campo Marker é null, oque indica não haver mais partes do multipart upload.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 412 { "ArchiveDescription" : "archive description", "CreationDate" : "2012-03-20T17:03:43.221Z", "Marker": null, "MultipartUploadId" : "OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE", "PartSizeInBytes" : 4194304, "Parts" : [ { "RangeInBytes" : "0-4194303", "SHA256TreeHash" : "01d34dabf7be316472c93b1ef80721f5d4" }, { "RangeInBytes" : "4194304-8388607", "SHA256TreeHash" : "0195875365afda349fc21c84c099987164" }], "VaultARN" : "arn:aws:glacier:us-west-2:012345678901:vaults/demo1-vault"}
Exemplo: List Parts de um multipart upload (especificar o marcador e limitar osparâmetros de solicitação)O exemplo a seguir demonstra como usar a paginação para obter um número limitado de resultados. Oexemplo envia uma solicitação GET HTTP para o URI do ID de multipart upload específico de um multipartupload em andamento para retornar uma parte. Um parâmetro marker de partida especifica em qual partea lista de partes deve ser iniciada. Você pode obter o valor marker da resposta de uma solicitação anteriorpara uma lista de partes. Além disso, neste exemplo, o parâmetro limit é definido como 1 e retorna umaparte. O campo Marker não é null, o que indica haver pelo menos mais uma parte a ser obtida.
Versão da API 2012-06-01233

Amazon Glacier Guia do desenvolvedor doListar multipart uploads
Exemplo de solicitação
GET /-/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE?marker=1001&limit=1 HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Na resposta, o Amazon Glacier retorna uma lista de partes cujo upload foi feito associadas ao ID demultipart upload em andamento especificado.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: text/jsonContent-Length: 412 { "ArchiveDescription" : "archive description 1", "CreationDate" : "2012-03-20T17:03:43.221Z", "Marker": "MfgsKHVjbQ6EldVl72bn3_n5h2TaGZQUO-Qb3B9j3TITf7WajQ", "MultipartUploadId" : "OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE", "PartSizeInBytes" : 4194304, "Parts" : [ { "RangeInBytes" : "4194304-8388607", "SHA256TreeHash" : "01d34dabf7be316472c93b1ef80721f5d4" }], "VaultARN" : "arn:aws:glacier:us-west-2:012345678901:vaults/demo1-vault"}
Seções relacionadas• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Part (PUT uploadID) (p. 239)• Complete Multipart Upload (POST uploadID) (p. 223)• Abort Multipart Upload (DELETE uploadID) (p. 221)• List Multipart Uploads (GET multipart-uploads) (p. 234)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
List Multipart Uploads (GET multipart-uploads)DescriçãoEsta operação de multipart upload lista multipart uploads em andamento para o cofre. Multipart uploadem andamento é um multipart upload que foi iniciado por uma solicitação Initiate Multipart Upload (POSTmultipart-uploads) (p. 226), mas que ainda não foi concluído ou anulado. A lista retornada na respostaList Multipart Upload não tem ordem garantida.
Versão da API 2012-06-01234
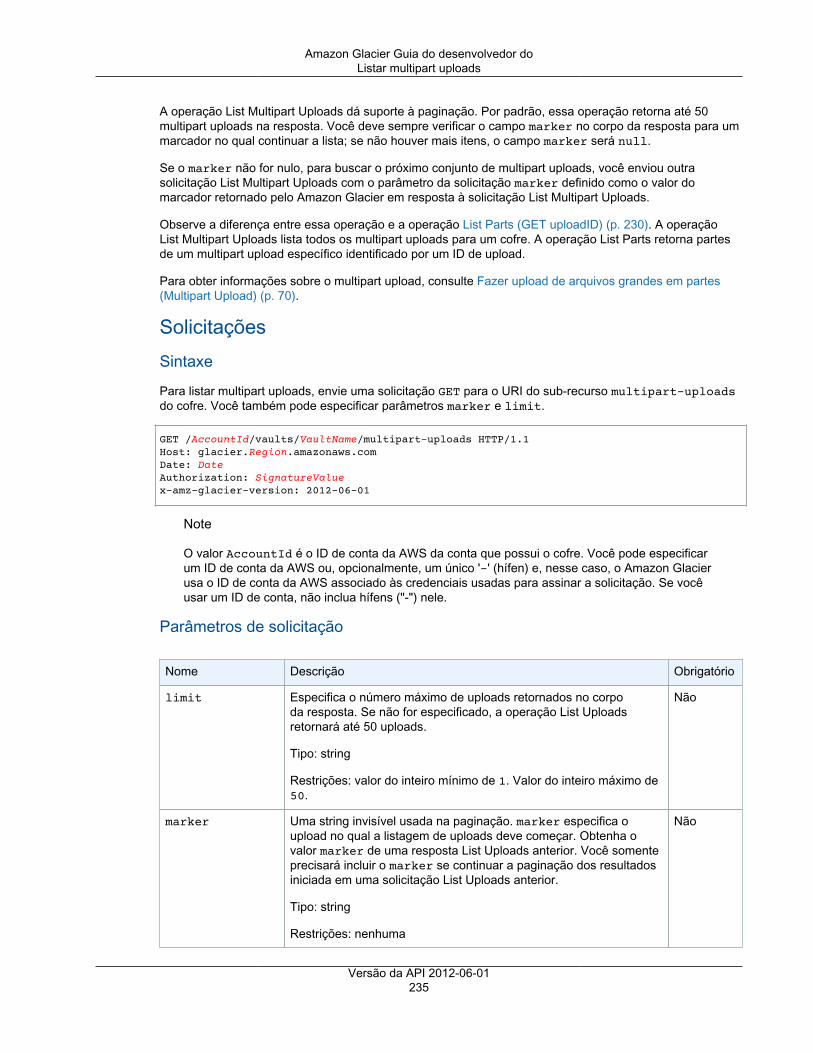
Amazon Glacier Guia do desenvolvedor doListar multipart uploads
A operação List Multipart Uploads dá suporte à paginação. Por padrão, essa operação retorna até 50multipart uploads na resposta. Você deve sempre verificar o campo marker no corpo da resposta para ummarcador no qual continuar a lista; se não houver mais itens, o campo marker será null.
Se o marker não for nulo, para buscar o próximo conjunto de multipart uploads, você enviou outrasolicitação List Multipart Uploads com o parâmetro da solicitação marker definido como o valor domarcador retornado pelo Amazon Glacier em resposta à solicitação List Multipart Uploads.
Observe a diferença entre essa operação e a operação List Parts (GET uploadID) (p. 230). A operaçãoList Multipart Uploads lista todos os multipart uploads para um cofre. A operação List Parts retorna partesde um multipart upload específico identificado por um ID de upload.
Para obter informações sobre o multipart upload, consulte Fazer upload de arquivos grandes em partes(Multipart Upload) (p. 70).
SolicitaçõesSintaxe
Para listar multipart uploads, envie uma solicitação GET para o URI do sub-recurso multipart-uploadsdo cofre. Você também pode especificar parâmetros marker e limit.
GET /AccountId/vaults/VaultName/multipart-uploads HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Nome Descrição Obrigatório
limit Especifica o número máximo de uploads retornados no corpoda resposta. Se não for especificado, a operação List Uploadsretornará até 50 uploads.
Tipo: string
Restrições: valor do inteiro mínimo de 1. Valor do inteiro máximo de50.
Não
marker Uma string invisível usada na paginação. marker especifica oupload no qual a listagem de uploads deve começar. Obtenha ovalor marker de uma resposta List Uploads anterior. Você somenteprecisará incluir o marker se continuar a paginação dos resultadosiniciada em uma solicitação List Uploads anterior.
Tipo: string
Restrições: nenhuma
Não
Versão da API 2012-06-01235

Amazon Glacier Guia do desenvolvedor doListar multipart uploads
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length
{ "Marker": String, "UploadsList" : [ { "ArchiveDescription": String, "CreationDate": String, "MultipartUploadId": String, "PartSizeInBytes": Number, "VaultARN": String }, ... ]}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
ArchiveDescription
A descrição do arquivo que tiver sido especificada na solicitação Initiate Multipart Upload. Este camposerá null se nenhuma descrição de arquivo tiver sido especificada na operação Initiate MultipartUpload.
Type: StringCreationDate
A hora UTC em que o multipart upload foi iniciado.
Type: String. Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
Versão da API 2012-06-01236
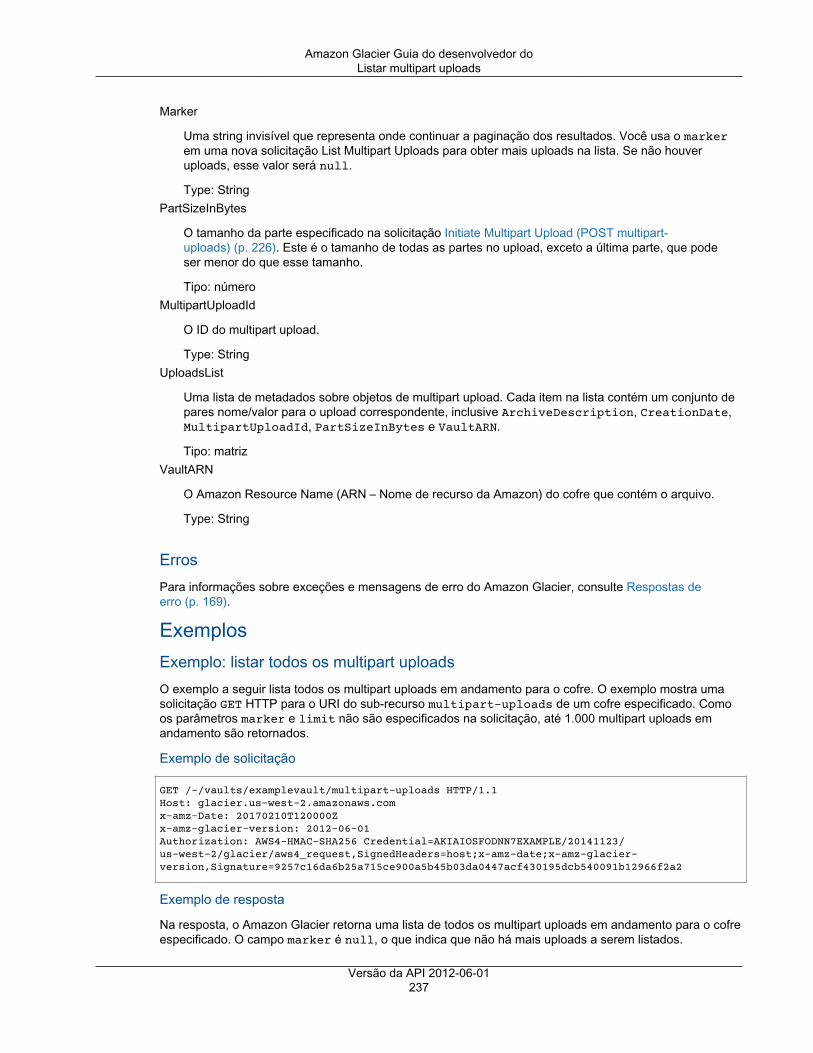
Amazon Glacier Guia do desenvolvedor doListar multipart uploads
Marker
Uma string invisível que representa onde continuar a paginação dos resultados. Você usa o markerem uma nova solicitação List Multipart Uploads para obter mais uploads na lista. Se não houveruploads, esse valor será null.
Type: StringPartSizeInBytes
O tamanho da parte especificado na solicitação Initiate Multipart Upload (POST multipart-uploads) (p. 226). Este é o tamanho de todas as partes no upload, exceto a última parte, que podeser menor do que esse tamanho.
Tipo: númeroMultipartUploadId
O ID do multipart upload.
Type: StringUploadsList
Uma lista de metadados sobre objetos de multipart upload. Cada item na lista contém um conjunto depares nome/valor para o upload correspondente, inclusive ArchiveDescription, CreationDate,MultipartUploadId, PartSizeInBytes e VaultARN.
Tipo: matrizVaultARN
O Amazon Resource Name (ARN – Nome de recurso da Amazon) do cofre que contém o arquivo.
Type: String
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo: listar todos os multipart uploadsO exemplo a seguir lista todos os multipart uploads em andamento para o cofre. O exemplo mostra umasolicitação GET HTTP para o URI do sub-recurso multipart-uploads de um cofre especificado. Comoos parâmetros marker e limit não são especificados na solicitação, até 1.000 multipart uploads emandamento são retornados.
Exemplo de solicitação
GET /-/vaults/examplevault/multipart-uploads HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Na resposta, o Amazon Glacier retorna uma lista de todos os multipart uploads em andamento para o cofreespecificado. O campo marker é null, o que indica que não há mais uploads a serem listados.
Versão da API 2012-06-01237

Amazon Glacier Guia do desenvolvedor doListar multipart uploads
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 1054 { "Marker": null, "UploadsList": [ { "ArchiveDescription": "archive 1", "CreationDate": "2012-03-19T23:20:59.130Z", "MultipartUploadId": "xsQdFIRsfJr20CW2AbZBKpRZAFTZSJIMtL2hYf8mvp8dM0m4RUzlaqoEye6g3h3ecqB_zqwB7zLDMeSWhwo65re4C4Ev", "PartSizeInBytes": 4194304, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" }, { "ArchiveDescription": "archive 2", "CreationDate": "2012-04-01T15:00:00.000Z", "MultipartUploadId": "nPyGOnyFcx67qqX7E-0tSGiRi88hHMOwOxR-_jNyM6RjVMFfV29lFqZ3rNsSaWBugg6OP92pRtufeHdQH7ClIpSF6uJc", "PartSizeInBytes": 4194304, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" }, { "ArchiveDescription": "archive 3", "CreationDate": "2012-03-20T17:03:43.221Z", "MultipartUploadId": "qt-RBst_7yO8gVIonIBsAxr2t-db0pE4s8MNeGjKjGdNpuU-cdSAcqG62guwV9r5jh5mLyFPzFEitTpNE7iQfHiu1XoV", "PartSizeInBytes": 4194304, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" } ]}
Exemplo: lista parcial de multipart uploadsO exemplo a seguir demonstra como usar a paginação para obter um número limitado de resultados. Oexemplo mostra uma solicitação GET HTTP para o URI do sub-recurso multipart-uploads de um cofreespecificado. Neste exemplo, o parâmetro limit é definido como 1, o que significa que somente umupload é retornado na lista, e o parâmetro marker indica o ID de multipart upload no qual a lista retornadacomeça.
Exemplo de solicitação
GET /-/vaults/examplevault/multipart-uploads?limit=1&marker=xsQdFIRsfJr20CW2AbZBKpRZAFTZSJIMtL2hYf8mvp8dM0m4RUzlaqoEye6g3h3ecqB_zqwB7zLDMeSWhwo65re4C4Ev HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Na resposta, o Amazon Glacier retorna uma lista de não mais do que dois multipart uploads em andamentopara o cofre especificado, começando pelo marcador especificado e retornando dois resultados.
HTTP/1.1 200 OK
Versão da API 2012-06-01238

Amazon Glacier Guia do desenvolvedor doUpload de parte
x-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 470
{ "Marker": "qt-RBst_7yO8gVIonIBsAxr2t-db0pE4s8MNeGjKjGdNpuU-cdSAcqG62guwV9r5jh5mLyFPzFEitTpNE7iQfHiu1XoV", "UploadsList" : [ { "ArchiveDescription": "archive 2", "CreationDate": "2012-04-01T15:00:00.000Z", "MultipartUploadId": "nPyGOnyFcx67qqX7E-0tSGiRi88hHMOwOxR-_jNyM6RjVMFfV29lFqZ3rNsSaWBugg6OP92pRtufeHdQH7ClIpSF6uJc", "PartSizeInBytes": 4194304, "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" } ]}
Seções relacionadas• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Part (PUT uploadID) (p. 239)• Complete Multipart Upload (POST uploadID) (p. 223)• Abort Multipart Upload (DELETE uploadID) (p. 221)• List Parts (GET uploadID) (p. 230)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Upload Part (PUT uploadID)DescriçãoEsta operação de multipart upload faz upload de uma parte de um arquivo. Você pode fazer upload departes de arquivo em qualquer ordem porque, na solicitação Upload Part, especifica o intervalo de bytesno arquivo montado cujo upload será feito nessa parte. Você também pode fazer upload dessas partes emparalelo. Você pode fazer upload de até 10.000 partes de um multipart upload.
Para obter informações sobre o multipart upload, consulte Fazer upload de arquivos grandes em partes(Multipart Upload) (p. 70).
O Amazon Glacier rejeitará a parte de upload se qualquer uma das seguintes condições for verdadeira:
• Hash de árvore SHA256 não correspondente—Para garantir que dados da parte não sejam corrompidosna transmissão, você computa um hash de árvore SHA256 da parte e o inclui na solicitação. Medianteo recebimento dos dados da parte, o Amazon Glacier também computa um hash de árvore SHA256. Seos dois valores de hash não forem correspondentes, a operação vai falhar. Para obter informações sobrecomo computar um hash de árvore SHA256, consulte Computar somas de verificação (p. 159).
• Hash linear SHA256 não correspondente—Obrigatório para autorização, você computa o hash linearSHA256 de toda a carga útil cujo upload foi feito e o inclui na solicitação. Para obter informações sobrecomo computar um hash linear SHA256, consulte Computar somas de verificação (p. 159).
• Tamanho da parte não correspondente—O tamanho de cada parte, exceto a última, deve corresponderao tamanho especificado na solicitação Initiate Multipart Upload (POST multipart-uploads) (p. 226)correspondente. O tamanho da última parte deve ser igual a ou menor que o tamanho especificado.
Versão da API 2012-06-01239

Amazon Glacier Guia do desenvolvedor doUpload de parte
Note
Se fizer upload de uma parte cujo tamanho seja menor que o tamanho especificado por você nasolicitação de multipart upload de iniciação e que a parte não seja a última, a solicitação uploadpart será bem-sucedida. No entanto, a solicitação Complete Multipart Upload subsequentefalhará.
• Intervalo não alinhado—O valor do intervalo de bytes na solicitação não se alinha ao tamanho daparte especificado na solicitação de iniciação correspondente. Por exemplo, se você especificar umtamanho de parte de 4.194.304 bytes (4 MB), de 0 a 4.194.303 bytes (4 MB —1) e de 4.194.304 (4MB) a 8.388.607 (8 MB —1) serão intervalos de partes válidos. No entanto, se você definir um valor deintervalo de 2 MB a 6 MB, o intervalo não se alinhará ao tamanho da parte, e o upload falhará.
Essa operação é idempotente. Se você fizer upload da mesma parte várias vezes, os dados incluídos nasolicitação mais recente substituirão os dados cujo upload foi feito anteriormente.
SolicitaçõesVocê envia essa solicitação PUT HTTP para o URI do ID de upload retornado pela solicitação InitiateMultipart Upload. O Amazon Glacier usa o ID de upload para associar uploads de partes a um multipartupload específico. A solicitação deve incluir um hash de árvore SHA256 dos dados da parte (cabeçalho x-amz-SHA256-tree-hash), um hash linear SHA256 de toda a carga útil (cabeçalho x-amz-content-sha256), o intervalo de bytes (cabeçalho Content-Range) e o tamanho da parte em bytes (cabeçalhoContent-Length).
Sintaxe
PUT /AccountId/vaults/VaultName/multipart-uploads/uploadID HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Range: ContentRangeContent-Length: PayloadSizeContent-Type: application/octet-streamx-amz-sha256-tree-hash: Checksum of the partx-amz-content-sha256: Checksum of the entire payload x-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa os cabeçalhos de solicitação a seguir, além dos cabeçalhos de solicitação que sãocomuns a todas as operações. Para mais informações sobre os cabeçalhos de solicitação comuns,consulte Cabeçalhos de solicitação comuns (p. 152).
Nome Descrição Obrigatório
Content-Length Identifica o tamanho da parte em bytes. Não
Versão da API 2012-06-01240
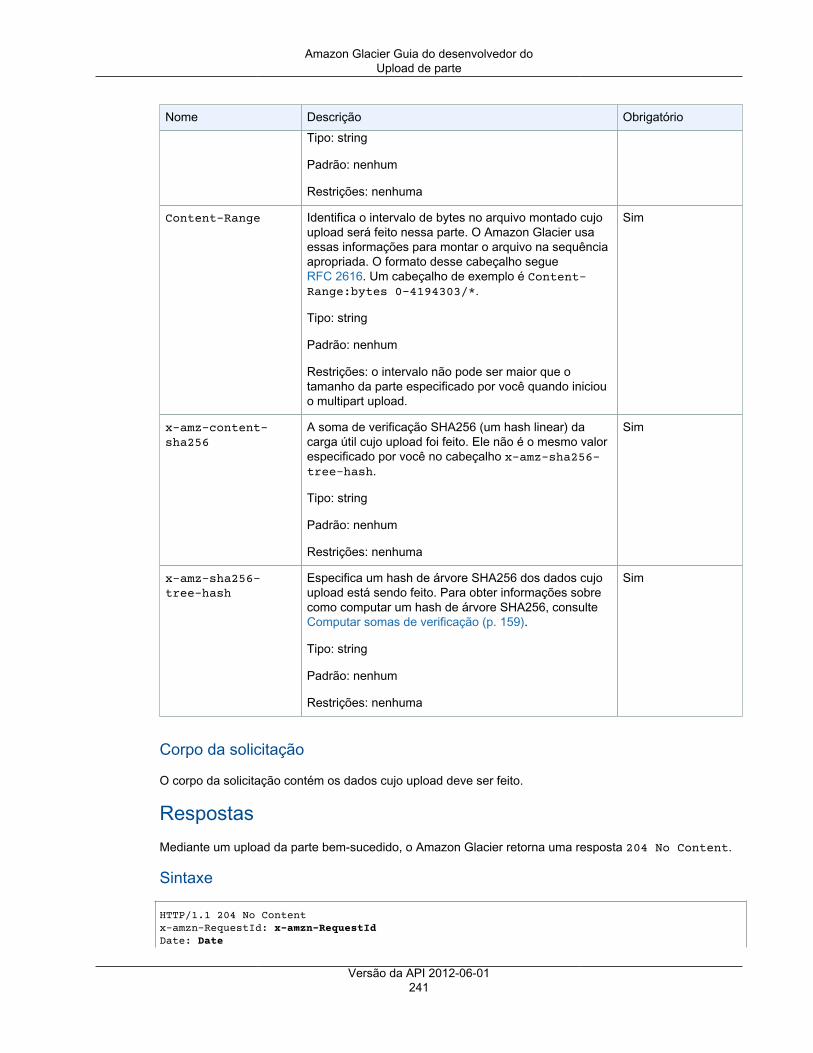
Amazon Glacier Guia do desenvolvedor doUpload de parte
Nome Descrição ObrigatórioTipo: string
Padrão: nenhum
Restrições: nenhuma
Content-Range Identifica o intervalo de bytes no arquivo montado cujoupload será feito nessa parte. O Amazon Glacier usaessas informações para montar o arquivo na sequênciaapropriada. O formato desse cabeçalho segueRFC 2616. Um cabeçalho de exemplo é Content-Range:bytes 0-4194303/*.
Tipo: string
Padrão: nenhum
Restrições: o intervalo não pode ser maior que otamanho da parte especificado por você quando iniciouo multipart upload.
Sim
x-amz-content-sha256
A soma de verificação SHA256 (um hash linear) dacarga útil cujo upload foi feito. Ele não é o mesmo valorespecificado por você no cabeçalho x-amz-sha256-tree-hash.
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Sim
x-amz-sha256-tree-hash
Especifica um hash de árvore SHA256 dos dados cujoupload está sendo feito. Para obter informações sobrecomo computar um hash de árvore SHA256, consulteComputar somas de verificação (p. 159).
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Sim
Corpo da solicitação
O corpo da solicitação contém os dados cujo upload deve ser feito.
RespostasMediante um upload da parte bem-sucedido, o Amazon Glacier retorna uma resposta 204 No Content.
Sintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Versão da API 2012-06-01241

Amazon Glacier Guia do desenvolvedor doUpload de parte
x-amz-sha256-tree-hash: ChecksumComputedByAmazonGlacier
Cabeçalhos de respostaUma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Nome Descrição
x-amz-sha256-tree-hash
O hash de árvore SHA256 computado pelo Amazon Glacier para a parte cujoupload foi feito.
Tipo: string
Corpo da respostaEssa operação não retorna um corpo de resposta.
ExemploA solicitação a seguir faz upload de uma parte de 4 MB. A solicitação define o intervalo de bytes para fazerdessa a primeira parte no arquivo.
Exemplo de solicitaçãoO exemplo envia uma solicitação PUT HTTP para fazer upload de uma parte de 4 MB. A solicitação éenviada para o URI do ID de upload retornado pela solicitação Initiate Multipart Upload. O cabeçalhoContent-Range identifica a parte como a primeira parte dos 4 MB de dados do arquivo.
PUT /-/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE HTTP/1.1Host: glacier.us-west-2.amazonaws.comDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Range:bytes 0-4194303/*x-amz-sha256-tree-hash:c06f7cd4baacb087002a99a5f48bf953x-amz-contentsha256:726e392cb4d09924dbad1cc0ba3b00c3643d03d14cb4b823e2f041cff612a628Content-Length: 4194304Authorization: Authorization=AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-content-sha256;x-amz-date;x-amz-glacier-version,Signature=16b9a9e220a37e32f2e7be196b4ebb87120ca7974038210199ac5982e792cace
Para fazer upload da próxima parte, o procedimento é o mesmo; no entanto, você deve calcular um novohash de árvore SHA256 da parte cujo upload está sendo feito e também especificar um novo intervalode bytes onde a parte entrará no conjunto final. A solicitação a seguir faz upload de outra parte usando omesmo ID de upload. A solicitação especifica os próximos 4 MB do arquivo após a solicitação anterior eum tamanho da parte de 4 MB.
PUT /-/vaults/examplevault/multipart-uploads/OW2fM5iVylEpFEMM9_HpKowRapC3vn5sSL39_396UW9zLFUWVrnRHaPjUJddQ5OxSHVXjYtrN47NBZ-khxOjyEXAMPLE HTTP/1.1Host: glacier.us-west-2.amazonaws.comDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Range:bytes 4194304-8388607/*Content-Length: 4194304x-amz-sha256-tree-hash:f10e02544d651e2c3ce90a4307427493
Versão da API 2012-06-01242

Amazon Glacier Guia do desenvolvedor doOperações de trabalho
x-amz-contentsha256:726e392cb4d09924dbad1cc0ba3b00c3643d03d14cb4b823e2f041cff612a628x-amz-glacier-version: 2012-06-01Authorization: Authorization=AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20120525/us-west-2/glacier/aws4_request, SignedHeaders=host;x-amz-content-sha256;x-amz-date;x-amz-glacier-version, Signature=16b9a9e220a37e32f2e7be196b4ebb87120ca7974038210199ac5982e792cace
O upload das partes pode ser feito em qualquer ordem; o Amazon Glacier usa a especificação do intervalopara cada parte a fim de determinar a ordem na qual montá-las.
Exemplo de resposta
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-Qx-amz-sha256-tree-hash: c06f7cd4baacb087002a99a5f48bf953Date: Wed, 10 Feb 2017 12:00:00 GMT
Seções relacionadas• Initiate Multipart Upload (POST multipart-uploads) (p. 226)• Upload Part (PUT uploadID) (p. 239)• Complete Multipart Upload (POST uploadID) (p. 223)• Abort Multipart Upload (DELETE uploadID) (p. 221)• List Multipart Uploads (GET multipart-uploads) (p. 234)• List Parts (GET uploadID) (p. 230)• Fazer upload de arquivos grandes em partes (Multipart Upload) (p. 70)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Operações de trabalhoEstas são as operações de trabalho disponíveis para serem usadas no Amazon Glacier.
Tópicos• Trabalho de descrição (GET JobID) (p. 243)• Get Job Output (GET output) (p. 251)• Initiate Job (trabalhos POST) (p. 257)• List Jobs (GET jobs) (p. 267)
Trabalho de descrição (GET JobID)DescriçãoEsta operação retorna informações sobre um trabalho iniciado por você anteriormente, incluindo a data deinício do trabalho, o usuário que iniciou o trabalho, o código de status do trabalho/mensagem e o tópico doAmazon Simple Notification Service (Amazon SNS) para notificação depois que o Amazon Glacier concluiro trabalho. Para obter mais informações sobre como iniciar um trabalho, consulte Initiate Job (trabalhosPOST) (p. 257).
Note
Essa operação permite verificar o status do trabalho. No entanto, é altamente recomendávelconfigurar um tópico do Amazon SNS e especificá-lo na solicitação do trabalho de inicializaçãopara que o Amazon Glacier possa notificar o tópico após a conclusão do trabalho.
Versão da API 2012-06-01243

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
Um ID do trabalho não vai expirar por pelo menos 24 horas depois que o Amazon Glacier concluir otrabalho.
SolicitaçõesSintaxe
Para obter informações sobre um trabalho, você usa o método GET HTTP e delimita a solicitação aotrabalho específico. O caminho do URI relativo é o mesmo retornado pelo Amazon Glacier quando vocêiniciou o trabalho.
GET /AccountID/vaults/VaultName/jobs/JobID HTTP/1.1Host: glacier.Region.amazonaws.comDate: dateAuthorization: signatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Note
Na solicitação, se você omitir o JobID, a resposta retornará uma lista de todos os trabalhos ativosno cofre especificado. Para obter mais informações sobre como listar trabalhos, consulte List Jobs(GET jobs) (p. 267).
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length
{ "Action": "string", "ArchiveId": "string",
Versão da API 2012-06-01244

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
"ArchiveSHA256TreeHash": "string", "ArchiveSizeInBytes": number, "Completed": boolean, "CompletionDate": "string", "CreationDate": "string", "InventoryRetrievalParameters": { "EndDate": "string", "Format": "string", "Limit": "string", "Marker": "string", "StartDate": "string" }, "InventorySizeInBytes": number, "JobDescription": "string", "JobId": "string", "JobOutputPath": "string", "OutputLocation": { "S3": { "AccessControlList": [ { "Grantee": { "DisplayName": "string", "EmailAddress": "string", "ID": "string", "Type": "string", "URI": "string" }, "Permission": "string" } ], "BucketName": "string", "CannedACL": "string", "Encryption": { "EncryptionType": "string", "KMSContext": "string", "KMSKeyId": "string" }, "Prefix": "string", "StorageClass": "string", "Tagging": { "string": "string" }, "UserMetadata": { "string": "string" } } }, "RetrievalByteRange": "string", "SelectParameters": { "Expression": "string", "ExpressionType": "string", "InputSerialization": { "csv": { "Comments": "string", "FieldDelimiter": "string", "FileHeaderInfo": "string", "QuoteCharacter": "string", "QuoteEscapeCharacter": "string", "RecordDelimiter": "string" } }, "OutputSerialization": { "csv": { "FieldDelimiter": "string", "QuoteCharacter": "string", "QuoteEscapeCharacter": "string",
Versão da API 2012-06-01245

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
"QuoteFields": "string", "RecordDelimiter": "string" } } }, "SHA256TreeHash": "string", "SNSTopic": "string", "StatusCode": "string", "StatusMessage": "string", "Tier": "string", "VaultARN": "string"}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
Ação
O tipo de trabalho. É ArchiveRetrieval, InventoryRetrieval ou Select.
Type: StringArchiveId
O ID de arquivo solicitado para um trabalho de seleção ou de recuperação de arquivo. Do contrário,esse campo será null.
Type: StringArchiveSHA256TreeHash
O hash de árvore SHA256 de todo o arquivo de um trabalho de recuperação do arquivo. Paratrabalhos de recuperação do inventário, esse campo é null.
Type: StringArchiveSizeInBytes
Para um trabalho ArchiveRetrieval, trata-se do tamanho em bytes do arquivo solicitado paradownload. Para o trabalho InventoryRetrieval, o valor é null.
Tipo: númeroCompleted
O status do trabalho. Quando um trabalho de recuperação de arquivo ou inventário for concluído, vocêobterá a saída do trabalho usando o Get Job Output (GET output) (p. 251).
Tipo: booleanoCompletionDate
A hora UTC (Horário Coordenado Universal) em que a solicitação de trabalho foi concluída. Enquantoo trabalho estiver em andamento, o valor será nulo.
Type: String
Versão da API 2012-06-01246

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
CreationDate
A hora UTC em que o trabalho foi criado.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
InventoryRetrievalParameters
Os parâmetros de entrada usados em uma recuperação de inventário de intervalo.
Tipo: InventoryRetrievalJobInput (p. 281) objetoInventorySizeInBytes
Para um trabalho InventoryRetrieval, trata-se do tamanho em bytes do inventário solicitado paradownload. No trabalho ArchiveRetrieval ou Select, o valor é null.
Tipo: númeroJobDescription
A descrição do trabalho fornecida por você quando iniciou o trabalho.
Type: StringJobId
O ID que identifica o trabalho no Amazon Glacier.
Type: StringJobOutputPath
Contém o local de saída do trabalho.
Type: StringOutputLocation
Um objeto com informações sobre o local onde os resultados e os erros do trabalho de seleção sãoarmazenados.
Tipo: OutputLocation (p. 285) objetoRetrievalByteRange
O intervalo de bytes recuperado em trabalhos de recuperação de arquivo no formato"StartByteValue-EndByteValue". Se você não especificar um intervalo na recuperação dearquivo, todo o arquivo será recuperado; além disso, StartByteValue será igual a 0 e EndByteValueserá igual ao tamanho do arquivo menos 1. Em trabalhos de seleção ou de recuperação de inventário,este campo é null.
Type: StringSelectParameters
Um objeto com informações sobre os parâmetros usados em uma seleção.
Tipo: SelectParameters (p. 287) objetoSHA256TreeHash
O valor do hash de árvore SHA256 para o intervalo solicitado de um arquivo. Se a solicitação InitiateJob (trabalhos POST) (p. 257) para um arquivo tiver especificado um intervalo alinhado ao hash de
Versão da API 2012-06-01247

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
árvore, esse campo retornará um valor. Para obter mais informações sobre o alinhamento ao hash deárvore para recuperações do intervalo de arquivos, consulte Receber somas de verificação durante odownload de dados (p. 167).
Para o caso específico quando todo o arquivo for recuperado, esse valor será igual ao valorArchiveSHA256TreeHash.
Esse campo é null nas seguintes situações:• Os trabalhos de recuperação de arquivo que especificam um intervalo não alinhado ao hash de
árvore.• Trabalhos de arquivamento que especificam um intervalo igual a todo o arquivamento e cujo status
do trabalho seja InProgress.• Trabalhos de inventário.• Trabalhos de seleção.
Type: StringSNSTopic
Um tópico do Amazon SNS que recebe notificação.
Type: StringStatusCode
O código que indica o status do trabalho.
Valores válidos: InProgress | Succeeded | Succeeded
Type: StringStatusMessage
Uma mensagem amigável que descreve o status do trabalho.
Type: StringNível
O nível de acesso a dados a ser usado na seleção ou na recuperação de arquivo.
Valores válidos: Bulk | Expedited | Standard
Type: StringVaultARN
O nome de recurso da Amazon (ARN) do cofre do qual o trabalho é um sub-recurso.
Type: String
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir mostra a solicitação de um trabalho que recupera um arquivo.
Versão da API 2012-06-01248

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
Solicitação de exemplo: obter descrição do trabalho
GET /-/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
O corpo da resposta inclui JSON que descreve o trabalho especificado. Observe que, nos trabalhos derecuperação de inventário e de arquivo, os campos JSON são iguais. No entanto, quando um camponão se aplica ao tipo de trabalho, o valor é null. Esta é uma resposta de exemplo para um trabalho derecuperação de arquivo. Observe o seguinte:
• O valor do campo Action é ArchiveRetrieval.• O campo ArchiveSizeInBytes mostra o tamanho do arquivo solicitado no trabalho de recuperação
do arquivo.• O campo ArchiveSHA256TreeHash mostra o hash de árvore SHA256 de todo o arquivo.• O campo RetrievalByteRange mostra o intervalo solicitado no pedido Initiate Job. Neste exemplo,
todo o arquivo é solicitado.• O campo SHA256TreeHash mostra o hash de árvore SHA256 do intervalo solicitado no pedido Initiate
Job. Neste exemplo, ele é igual ao campo ArchiveSHA256TreeHash, o que significa que todo oarquivo foi solicitado.
• O valor do campo InventorySizeInBytes é null porque não se aplica a um trabalho derecuperação de arquivo.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 419{ "Action": "ArchiveRetrieval", "ArchiveId": "NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId", "ArchiveSizeInBytes": 16777216, "ArchiveSHA256TreeHash": "beb0fe31a1c7ca8c6c04d574ea906e3f97b31fdca7571defb5b44dca89b5af60", "Completed": false, "CompletionDate": null, "CreationDate": "2012-05-15T17:21:39.339Z", "InventorySizeInBytes": null, "JobDescription": "My ArchiveRetrieval Job", "JobId": "HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID", "RetrievalByteRange": "0-16777215", "SHA256TreeHash": "beb0fe31a1c7ca8c6c04d574ea906e3f97b31fdca7571defb5b44dca89b5af60", "SNSTopic": "arn:aws:sns:us-west-2:012345678901:mytopic", "StatusCode": "InProgress", "StatusMessage": "Operation in progress.", "Tier": "Bulk", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault"}
Versão da API 2012-06-01249

Amazon Glacier Guia do desenvolvedor doTrabalho de descrição
Esta é uma resposta de exemplo para um trabalho de recuperação de inventário. Observe o seguinte:
• O valor do campo Action é InventoryRetrieval.• Os valores de campo ArchiveSizeInBytes, ArchiveSHA256TreeHash e RetrievalByteRange
são nulos porque não se aplicam a um trabalho de recuperação de inventário.• O valor de campo InventorySizeInBytes é null porque o trabalho ainda está em andamento e
não preparou totalmente o inventário para download. Se o trabalho tivesse sido concluído antes dasolicitação do trabalho de descrição, esse campo informaria o tamanho do resultado.
{ "Action": "InventoryRetrieval", "ArchiveId": null, "ArchiveSizeInBytes": null, "ArchiveSHA256TreeHash": null, "Completed": false, "CompletionDate": null, "CreationDate": "2012-05-15T23:18:13.224Z", "InventorySizeInBytes": null, "JobDescription": "Inventory Description", "JobId": "HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID", "RetrievalByteRange": null, "SHA256TreeHash": null, "SNSTopic": "arn:aws:sns:us-west-2:012345678901:mytopic", "StatusCode": "InProgress", "StatusMessage": "Operation in progress.", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault"}
Esta é uma resposta de exemplo para um trabalho de recuperação de inventário completo que contém ummarcador usado para continuar a paginação da recuperação do inventário de cofre.
{ "Action": "InventoryRetrieval", "ArchiveId": null, "ArchiveSHA256TreeHash": null, "ArchiveSizeInBytes": null, "Completed": true, "CompletionDate": "2013-12-05T21:51:13.591Z", "CreationDate": "2013-12-05T21:51:12.281Z", "InventorySizeInBytes": 777062, "JobDescription": null, "JobId": "sCC2RZNBF2nildYD_roe0J9bHRdPQUbDRkmTdg-mXi2u3lc49uW6TcEhDF2D9pB2phx-BN30JaBru7PMyOlfXHdStzu8", "NextInventoryRetrievalMarker": null, "RetrievalByteRange": null, "SHA256TreeHash": null, "SNSTopic": null, "StatusCode": "Succeeded", "StatusMessage": "Succeeded", "Tier": "Bulk", "VaultARN": "arn:aws:glacier-devo:us-west-2:836579025725:vaults/inventory-icecube-2", "InventoryRetrievalParameters": { "StartDate": "2013-11-12T13:43:12Z", "EndDate": "2013-11-20T08:12:45Z", "Limit": "120000", "Format": "JSON", "Marker": "vyS0t2jHQe5qbcDggIeD50chS1SXwYMrkVKo0KHiTUjEYxBGCqRLKaiySzdN7QXGVVV5XZpNVG67pCZ_uykQXFMLaxOSu2hO_-5C0AtWMDrfo7LgVOyfnveDRuOSecUo3Ueq7K0" }, }
Versão da API 2012-06-01250

Amazon Glacier Guia do desenvolvedor doGet Job Output
Seções relacionadas• Get Job Output (GET output) (p. 251)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Get Job Output (GET output)DescriçãoEssa operação faz download da saída do trabalho iniciado por você usando a operação Initiate Job(trabalhos POST) (p. 257). Dependendo do tipo de trabalho especificado por você quando iniciou otrabalho, a saída será o conteúdo de um arquivo ou um inventário de cofre.
Você pode fazer download de toda a saída do ou de uma parte da saída especificando um intervalo debytes. Para trabalhos de recuperação de arquivo e inventário, você deve verificar o tamanho obtido pordownload em relação ao tamanho retornado nos cabeçalhos da resposta Get Job Output.
Para trabalhos de recuperação de arquivo, você também deve verificar se o tamanho é o esperado.Se você fizer download de uma parte da saída, o tamanho esperado se baseará no intervalo de bytesespecificado. Por exemplo, se especificar um intervalo de bytes=0-1048575, você deverá verificar seo tamanho do download é de 1.048.576 bytes. Se você fizer download de um arquivo inteiro, o tamanhoesperado será o tamanho do arquivo quando fez upload dele no Amazon Glacier. O tamanho esperadotambém é retornado nos cabeçalhos da resposta Get Job Output.
No caso de um trabalho de recuperação de arquivo, dependendo do intervalo de bytes especificado porvocê, o Amazon Glacier retorna a soma de verificação da parte dos dados. Para garantir que a parte obtidapor download seja de dados corretos, compute a soma de verificação no cliente, verifique se os valoressão correspondentes e se o tamanho é o esperado.
Um ID do trabalho não vai expirar por pelo menos 24 horas depois que o Amazon Glacier concluir otrabalho. Ou seja, você pode fazer download da saída do trabalho dentro do período de 24 horas depoisque o Amazon Glacier concluir o trabalho.
SolicitaçõesSintaxe
Para recuperar uma saída de trabalho, você envia a solicitação GET HTTP para o URI do output dotrabalho específico.
GET /AccountId/vaults/VaultName/jobs/JobID/output HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueRange: ByteRangeToRetrievex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Versão da API 2012-06-01251

Amazon Glacier Guia do desenvolvedor doGet Job Output
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa os cabeçalhos de solicitação a seguir, além dos cabeçalhos de solicitação que sãocomuns a todas as operações. Para mais informações sobre os cabeçalhos de solicitação comuns,consulte Cabeçalhos de solicitação comuns (p. 152).
Nome Descrição Obrigatório
Range O intervalo de bytes a ser recuperado da saída. Por exemplo,se você quiser fazer download dos primeiros 1.048.576 bytes,especifique o intervalo como bytes=0-1048575. Para obtermais informações, vá até Definição do campo de cabeçalho dointervalo. O intervalo se refere a qualquer intervalo especificado nasolicitação Initiate Job. Por padrão, essa operação faz download detoda a saída.
Se a saída do trabalho for grande, você poderá usar o cabeçalhoda solicitação Range para recuperar uma parte da saída. Issopermite fazer download de toda a saída em blocos de bytesmenores. Por exemplo, suponhamos que você tenha 1 GB desaída de trabalho cujo download deseja fazer e opte por fazerdownload de blocos de 128 MB de dados por vez, em um total deoito solicitações Get Job Output. Você usará o seguinte processopara fazer download da saída do trabalho:
1. Faça download de uma saída de bloco de 128 MB de dadosespecificando o intervalo de bytes apropriado com o cabeçalhoRange. Verifique se todos os 128 MB de dados foram recebidos.
2. Com os dados, a resposta incluirá uma soma de verificaçãoda carga útil. Você computa a soma de verificação da cargaútil no cliente e a compara com a soma de verificação recebidana resposta para garantir que tenha recebido todos os dadosesperados.
3. Repita as etapas 1 e 2 para todos os oito blocos de 128 MBde dados de saída, sempre especificando o intervalo de bytesapropriado.
4. Depois do download de todas as partes da saída do trabalho,você terá uma lista de oito valores de soma de verificação.Compute o hash de árvore desses valores para encontrara soma de verificação de toda a saída. Usando a operaçãoTrabalho de descrição (GET JobID) (p. 243), obtenhainformações do trabalho que forneceu a saída. A respostainclui a soma de verificação de todo o arquivo armazenadono Amazon Glacier. Você compara esse valor com a soma deverificação computada para garantir que tenha feito download detodo o conteúdo do arquivo sem erros.
Tipo: string
Padrão: nenhum
Restrições: nenhuma
Não
Versão da API 2012-06-01252

Amazon Glacier Guia do desenvolvedor doGet Job Output
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSintaxePara uma solicitação de recuperação que retorne todos os dados do trabalho, a resposta da saída dotrabalho retorna um código de resposta 200 OK. Quando o conteúdo parcial é solicitado, por exemplo, sevocê tiver especificado o cabeçalho Range na solicitação, o código de resposta 206 Partial Contentserá retornado.
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: ContentTypeContent-Length: Lengthx-amz-sha256-tree-hash: ChecksumComputedByAmazonGlacier
[Body containing job output.]
Cabeçalhos de resposta
Cabeçalho Descrição
Content-Range O intervalo de bytes retornado pelo Amazon Glacier. Se somente o downloadda saída parcial tiver sido feito, a resposta fornecerá o intervalo de bytesretornado pelo Amazon Glacier.
Por exemplo, bytes 0-1048575/8388608 retorna o primeiro 1 MB de 8MB.
Para obter mais informações sobre o cabeçalho Content-Range, vá atéDefinição do campo de cabeçalho Content-Range.
Tipo: string
Content-Type O Content-Type depende da saída do trabalho ser um arquivo ou uminventário de cofre.
• Para dados de arquivo, o Content-Type é application/octet-stream.• Para inventário de cofre, se você tiver solicitado o formato CSV quando
iniciou o trabalho, o Content-Type será text/csv. Do contrário, porpadrão, o inventário de cofre é retornado como JSON, e o Content-Typeserá application/json.
Tipo: string
x-amz-sha256-tree-hash
A soma de verificação dos dados na resposta. Esse cabeçalho é retornadosomente quando se recupera a saída de um trabalho de recuperação dearquivo. Além disso, esse cabeçalho é exibido quando o intervalo de dadosrecuperados solicitado no pedido Initiate Job está alinhado ao hash de árvoree o intervalo para download no Get Job Output também está alinhado aohash de árvore. Para obter mais informações sobre intervalos alinhados aohash de árvore, consulte Receber somas de verificação durante o downloadde dados (p. 167).
Versão da API 2012-06-01253

Amazon Glacier Guia do desenvolvedor doGet Job Output
Cabeçalho DescriçãoPor exemplo, se na solicitação Initiate Job, tiver especificado um intervaloalinhado ao hash de árvore (o que inclui todo o arquivo), você receberá asoma de verificação dos dados cujo download fez nas seguintes condições:
• Você recebe todo o intervalo dos dados recuperados.• Você solicita um intervalo de bytes dos dados recuperados que tem um
tamanho de um megabyte (1.024 KB) multiplicado por uma potência de 2 eque começa e termina em um múltiplo do tamanho do intervalo solicitado.Por exemplo, se tiver 3,1 MB de dados recuperados e especificar umintervalo a ser retornado que comece em 1 MB e termine em 2 MB, ox-amz-sha256-tree-hash será retornado como um cabeçalho deresposta.
• Você solicita um intervalo a ser retornado dos dados recuperados que vaipara o final dos dados, e o início do intervalo é um múltiplo do tamanhodo intervalo a ser recuperado arredondado para a próxima potência dedois, mas não menor que um megabyte (1.024 KB). Por exemplo, se tiver3,1 MB de dados recuperados e especificar um intervalo a ser retornadoque comece em 2 MB e termine em 3,1 MB (o final dos dados), o x-amz-sha256-tree-hash será retornado como um cabeçalho de resposta.
Tipo: string
Corpo da resposta
O Amazon Glacier retorna a saída do trabalho no corpo da resposta. Dependendo do tipo de trabalho, asaída pode ser o conteúdo do arquivo ou o inventário de cofre. No caso de um inventário de cofre, porpadrão, a lista de inventários é retornada como o corpo JSON a seguir.
{ "VaultARN": String, "InventoryDate": String, "ArchiveList": [ {"ArchiveId": String, "ArchiveDescription": String, "CreationDate": String, "Size": Number, "SHA256TreeHash": String }, ... ]}
Se você tiver solicitado o formato de saída Comma-Separated Values (CSV – Valores separados porvírgula) quando iniciou o trabalho de inventário, o inventário de cofre será retornado em formato CSVno corpo. O formato CSV tem cinco colunas "ArchiveId", "ArchiveDescription", "CreationDate", "Size" e"SHA256TreeHash" com as mesmas definições dos campos JSON correspondentes.
Note
No formato CSV retornado, os campos podem ser retornados com o campo inteiro entre aspasduplas. Os campos que contenham uma vírgula ou aspas duplas sempre são retornadosentre aspas duplas. Por exemplo, my archive description,1 é retornado como "myarchive description,1". Caracteres de aspas duplas que estejam entre campos entreaspas duplas têm escape com um caractere de barra invertida antes. Por exemplo, my archivedescription,1"2 é retornado como "my archive description,1\"2" e my archive
Versão da API 2012-06-01254

Amazon Glacier Guia do desenvolvedor doGet Job Output
description,1\"2 é retornado como "my archive description,1\\"2". O caractere debarra invertida não é de escape.
O corpo da resposta JSON contém os seguintes campos JSON:
ArchiveDescription
A descrição de um arquivo.
Type: StringArchiveId
O ID de um arquivo.
Type: StringArchiveList
Uma matriz de metadados de arquivo. Cada objeto na matriz representa metadados de um arquivocontido no cofre.
Tipo: matrizCreationDate
A data e hora UTC em que o arquivo foi criado.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
InventoryDate
A data e hora UTC do inventário mais recente do cofre que foi concluído após alterações terem sidofeitas no cofre. Embora o Amazon Glacier prepare um inventário de cofre uma vez por dia, a data doinventário será atualizada somente se tiver ocorrido adições ou exclusões de arquivo no cofre desde oúltimo inventário.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
SHA256TreeHash
O hash de árvore do arquivo.
Type: StringTamanho
O tamanho em bytes do arquivo.
Tipo: númeroVaultARN
O Amazon Resource Name (ARN – Nome de recurso da Amazon) do qual a recuperação do arquivofoi solicitada.
Type: String
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
Versão da API 2012-06-01255

Amazon Glacier Guia do desenvolvedor doGet Job Output
ExemplosO exemplo a seguir mostra a solicitação de um trabalho que recupera um arquivo.
Exemplo 1: fazer download da saída
Este exemplo recupera dados preparados pelo Amazon Glacier em resposta à solicitação do trabalho derecuperação de arquivo de iniciação.
Exemplo de solicitação
GET /-/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID/output HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Esta é uma resposta de exemplo de um trabalho de recuperação de arquivo. O cabeçalho Content-Type é application/octet-stream e esse cabeçalho x-amz-sha256-tree-hash está incluído naresposta, o que significa que todos os dados do trabalho são retornados.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-Qx-amz-sha256-tree-hash: beb0fe31a1c7ca8c6c04d574ea906e3f97b31fdca7571defb5b44dca89b5af60Date: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/octet-streamContent-Length: 1048576
[Archive data.]
Esta é uma resposta de exemplo de um trabalho de recuperação de inventário. O cabeçalho Content-Type é application/json. A resposta também não inclui o cabeçalho x-amz-sha256-tree-hash.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 906
{ "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault", "InventoryDate": "2011-12-12T14:19:01Z", "ArchiveList": [ { "ArchiveId": "DMTmICA2n5Tdqq5BV2z7og-A20xnpAPKt3UXwWxdWsn_D6auTUrW6kwy5Qyj9xd1MCE1mBYvMQ63LWaT8yTMzMaCxB_9VBWrW4Jw4zsvg5kehAPDVKcppUD1X7b24JukOr4mMAq-oA", "ArchiveDescription": "my archive1", "CreationDate": "2012-05-15T17:19:46.700Z", "Size": 2140123, "SHA256TreeHash": "6b9d4cf8697bd3af6aa1b590a0b27b337da5b18988dbcc619a3e608a554a1e62" }, {
Versão da API 2012-06-01256

Amazon Glacier Guia do desenvolvedor doInitiate Job
"ArchiveId": "2lHzwhKhgF2JHyvCS-ZRuF08IQLuyB4265Hs3AXj9MoAIhz7tbXAvcFeHusgU_hViO1WeCBe0N5lsYYHRyZ7rrmRkNRuYrXUs_sjl2K8ume_7mKO_0i7C-uHE1oHqaW9d37pabXrSA", "ArchiveDescription": "my archive2", "CreationDate": "2012-05-15T17:21:39.339Z", "Size": 2140123, "SHA256TreeHash": "7f2fe580edb35154041fa3d4b41dd6d3adaef0c85d2ff6309f1d4b520eeecda3" } ]}
Exemplo 2: fazer download somente da saída parcialEste exemplo recupera somente uma parte do arquivo preparado pelo Amazon Glacier em resposta àsolicitação do trabalho de recuperação de arquivo de iniciação. A solicitação usa o cabeçalho Rangeopcional para recuperar somente os primeiros 1.024 bytes.
Exemplo de solicitação
GET /-/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID/output HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZRange: bytes=0-1023 x-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
A resposta bem-sucedida a seguir mostra a resposta 206 Partial Content. Nesse caso, a respostatambém inclui um cabeçalho Content-Range que especifica o intervalo de bytes retornado pelo AmazonGlacier.
HTTP/1.1 206 Partial Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Range: bytes 0-1023/8388608Content-Type: application/octet-streamContent-Length: 1024
[Archive data.]
Seções relacionadas• Trabalho de descrição (GET JobID) (p. 243)• Initiate Job (trabalhos POST) (p. 257)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Initiate Job (trabalhos POST)Esta operação inicia os seguintes tipos de trabalhos do Amazon Glacier:
• select— Executa uma consulta select em um arquivo• archive-retrieval— Recupera um arquivo
Versão da API 2012-06-01257

Amazon Glacier Guia do desenvolvedor doInitiate Job
• inventory-retrieval— Cria um inventário de um cofre
Tópicos• Trabalhar com trabalhos do Amazon Glacier Select (p. 258)• Inicialização de um trabalho de recuperação de arquivo ou inventário de cofre (p. 259)• Solicitações (p. 261)• Respostas (p. 263)• Exemplos (p. 264)• Seções relacionadas (p. 267)
Trabalhar com trabalhos do Amazon Glacier SelectUse um trabalho do Amazon Glacier Select para executar consultas SQL em objetos de arquivo. Osobjetos de arquivo que estão sendo consultados pelo trabalho de seleção devem ser formatados comoarquivos de valores separados por vírgulas (CSV) descompactados. Para obter informações de visãogeral sobre trabalhos do Amazon Glacier Select, consulte Consulta em arquivos com o Amazon GlacierSelect (p. 139).
Ao iniciar um trabalho de seleção, faça o seguinte:
• Defina um local para a saída da consulta select. Esse local deve ser um bucket do Amazon S3 namesma região da AWS do cofre que contém o objeto de arquivo que está sendo consultado. A conta daAWS que inicia o trabalho deve ter permissões para gravação no bucket do S3. Você pode especificar aclasse de armazenamento e a criptografia nos objetos de saída armazenados no Amazon S3. Ao definirS3Location (p. 285), talvez seja útil ler os seguintes tópicos na documentação do Amazon S3:• PUT Object no Amazon Simple Storage Service API Reference• Gerenciar o acesso com ACLs no Guia do desenvolvedor do Amazon Simple Storage Service• Proteção de dados usando criptografia no lado do servidor no Guia do desenvolvedor do Amazon
Simple Storage Service• Defina a expressão SQL a ser usada para SELECT na sua consulta em SelectParameters (p. 287). É
possível usar expressões como os exemplos a seguir:• O exemplo de expressão a seguir retorna todos os registros do objeto especificado.
SELECT * FROM archive
• Supondo que você não está usando nenhum cabeçalho para dados armazenados no objeto, épossível especificar colunas usando cabeçalhos posicionais.
SELECT s._1, s._2 FROM archive s WHERE s._3 > 100
• Se houver cabeçalhos e você definir fileHeaderInfo em CSVInput (p. 274) para Use, especifiquecabeçalhos na consulta. (Se você definir o campo fileHeaderInfo para Ignore, a primeira linhaserá ignorado na consulta.) Você não pode combinar posições ordinais com nomes de coluna decabeçalho.
SELECT s.Id, s.FirstName, s.SSN FROM archive s
Para obter mais informações sobre como usar SQL com o Amazon Glacier Select, consulte ReferênciaSQL para o Amazon S3 Select e o Amazon Glacier Select (p. 299).
Ao iniciar um trabalho de seleção, você também poderá fazer o seguinte:
Versão da API 2012-06-01258

Amazon Glacier Guia do desenvolvedor doInitiate Job
• Especifique o nível Expedited para agilizar as consultas. Para obter mais informações, consulte Níveisexpressos, padrão e em massa (p. 261).
• Especifica detalhes sobre o formato de serialização de dados do objeto de entrada que está sendoconsultado e da serialização dos resultados de consulta codificados por CSV.
• Especifique um tópico do Amazon Simple Notification Service (Amazon SNS) no qual o Amazon Glacierpoderá publicar uma notificação depois que o trabalho for concluído. Você pode especificar um tópicodo SNS para cada solicitação de trabalho. A notificação será enviada somente depois que o AmazonGlacier concluir o trabalho.
• Você pode usar Trabalho de descrição (GET JobID) (p. 243) para obter informações sobre o statusdo trabalho enquanto ele estiver em andamento. No entanto, é mais eficiente usar uma notificação doAmazon SNS para determinar quando um trabalho está concluído.
Durante um trabalho de seleção, você não poderá fazer o seguinte:
• Chamar a operação GetJobOutput. A saída do trabalho é gravada no local de saída.• Use a seleção no intervalo.
Para obter um exemplo de como iniciar um trabalho de seleção, consulte Exemplo de solicitação: Iniciarum trabalho de seleção (p. 266).
Inicialização de um trabalho de recuperação de arquivo ouinventário de cofreRecuperar um arquivo ou um inventário de cofre são operações assíncronas que exigem que você inicieum trabalho. A recuperação é um processo de duas etapas:
1. Inicie um trabalho de recuperação usando a operação Initiate Job (trabalhos POST) (p. 257).
Important
Uma política de recuperação de dados pode fazer com que a solicitação do trabalho derecuperação de inicialização apresente falha com PolicyEnforcedException. Para obtermais informações sobre políticas de recuperação de dados, consulte Políticas de recuperaçãodos dados do Amazon Glacier (p. 142). Para obter mais informações sobre a exceçãoPolicyEnforcedException, consulte Respostas de erro (p. 169).
2. Após a conclusão do trabalho, faça download dos bytes usando a operação Get Job Output (GEToutput) (p. 251).
A solicitação de recuperação é executada de maneira assíncrona. Quando você inicia um trabalho derecuperação, o Amazon Glacier cria um trabalho e retorna um ID de trabalho na resposta. Quando oAmazon Glacier conclui o trabalho, você pode receber a saída do trabalho (dados do arquivo ou doinventário). Para saber informações sobre como obter a saída do trabalho, consulte a operação Get JobOutput (GET output) (p. 251).
O trabalho deverá ser concluído para você obter a saída. Para determinar quando um trabalho estáconcluído, você tem as seguintes opções:
• Usar uma notificação do Amazon SNS — Você pode especificar um tópico do Amazon SNS no qualo Amazon Glacier poderá publicar uma notificação depois que o trabalho for concluído. Você podeespecificar um tópico do SNS por solicitação de trabalho. A notificação será enviada somente depoisque o Amazon Glacier concluir o trabalho. Além de especificar um tópico do SNS por solicitação detrabalho, você pode configurar notificações para um cofre, de maneira que as notificações de trabalhosejam enviadas para todas as recuperações. Para obter mais informações, consulte Definir configuraçãode notificação de cofre (PUT notification-configuration) (p. 212).
Versão da API 2012-06-01259

Amazon Glacier Guia do desenvolvedor doInitiate Job
• Obter detalhes do trabalho— Você pode fazer uma solicitação Trabalho de descrição (GETJobID) (p. 243) para obter informações de status do trabalho enquanto um trabalho está emandamento. No entanto, é mais eficiente usar uma notificação do Amazon SNS para determinar quandoum trabalho está concluído.
Note
As informações obtidas por você por meio da notificação são as mesmas recebidas quando sechama Trabalho de descrição (GET JobID) (p. 243).
Se, para um evento específico, você adicionar a configuração de notificação no cofre e tambémespecificar um tópico do SNS na solicitação do trabalho de iniciação, o Amazon Glacier enviará ambasas notificações. Para obter mais informações, consulte Definir configuração de notificação de cofre (PUTnotification-configuration) (p. 212).
O inventário de cofre
O Amazon Glacier atualiza um inventário de cofre aproximadamente uma vez por dia, começando no diaem que você faz o primeiro upload para o cofre. Se não houver adições ou exclusões de arquivo no cofredesde o último inventário, a data do inventário não será atualizada. Quando você inicia um trabalho paraum inventário de cofre, o Amazon Glacier retorna o último inventário gerado, que é um snapshot point-in-time, e não dados em tempo real.
Depois que o Amazon Glacier criar o primeiro inventário para o cofre, normalmente levará de meio dia aum dia para que esse inventário esteja disponível para recuperação.
Talvez você não ache útil recuperar um inventário de cofre para cada upload de arquivo. No entanto,suponhamos que você mantenha um banco de dados no lado do cliente associando metadados sobreos arquivos cujo upload fez para o Amazon Glacier. Nesse caso, talvez você ache o inventário de cofreútil para reconciliar informações, conforme necessário, no seu banco de dados com o inventário de cofrereal. Para obter mais informações sobre os campos de dados retornados em uma saída do trabalho deinventário, consulte Corpo da resposta (p. 254).
Recuperação do inventário de intervalo
Você pode limitar o número de itens do inventário recuperados filtrando a data de criação do arquivo oudefinindo um limite.
Filtrar por data de criação do arquivo
Você pode recuperar itens de inventário para arquivos criados entre StartDate e EndDate especificandovalores para esses parâmetros na solicitação Initiate Job. Os arquivos criados em StartDate ou apósessa data e antes de EndDate serão retornados. Se fornecer somente StartDate sem EndDate,recuperará o inventário de todos os arquivos criados em StartDate ou após essa data. Se fornecersomente EndDate sem StartDate, terá de volta o inventário de todos os arquivos criados antes deEndDate.
Limitar itens de inventário por recuperação
Você pode limitar o número de itens de inventário retornados definindo o parâmetro Limit na solicitaçãoInitiate Job. A saída do trabalho de inventário contém itens de inventário até o Limit especificado.Se houver mais itens de inventário disponíveis, o resultado será paginado. Depois que um trabalho forconcluído, você poderá usar a operação Trabalho de descrição (GET JobID) (p. 243) para obter ummarcador usado em uma solicitação Initiate Job subsequente. O marcador indicará o ponto de partidapara recuperar o próximo conjunto de itens de inventário. Você pode percorrer todo o inventário váriasvezes fazendo solicitações de Trabalho de inicialização com o marcador da saída anterior de Trabalho dedescrição. Para fazer isso, obtenha um marcador em Trabalho de descrição que retorne um valor nulo,indicando que não há mais itens de inventário disponíveis.
Versão da API 2012-06-01260

Amazon Glacier Guia do desenvolvedor doInitiate Job
Você pode usar o parâmetro Limit com os parâmetros do intervalo de datas.
Recuperação do arquivo no intervaloVocê pode iniciar a recuperação de todo o arquivo ou de um intervalo do arquivo. No caso da recuperaçãode um intervalo do arquivo, você especifica um intervalo de bytes a ser retornado ou todo o arquivo.O intervalo especificado deve ser alinhado a megabyte (MB). Em outras palavras, o valor de início dointervalo deve ser divisível por 1 MB e o valor final do intervalo mais 1 deve ser divisível por 1 MB ouigual ao final do arquivo. Se a recuperação do arquivo no intervalo não estiver alinhada a megabyte,essa operação retornará uma resposta 400. Além disso, para garantir que você obtenha valores dasoma de verificação dos dados cujo download você faz usando Get Job Output (Get Job Output (GEToutput) (p. 251)), o intervalo deve estar alinhado ao hash de árvore. Para obter mais informações sobreintervalos alinhados ao hash de árvore, consulte Receber somas de verificação durante o download dedados (p. 167).
Níveis expressos, padrão e em massaAo iniciar um trabalho de seleção ou de recuperação de arquivo, você pode especificar uma das seguintesopções no campo Tier do corpo da solicitação:
• Expedited – As recuperações expressas permitem que você acesse rapidamente dados quando umsubconjunto de arquivos for solicitado com urgência. Exceto para os arquivos maiores (mais de 250 MB),os dados acessados por meio de níveis expressos são disponibilizados geralmente entre 1 e 5 minutos.
• Standard – As recuperações padrão permitem acessar qualquer um dos arquivos em algumas horas.Os dados acessados usando o nível Padrão normalmente são disponibilizados entre 3 e 5 horas. Essa éa opção padrão para solicitações de trabalho que não especificam a opção de nível.
• Bulk – As recuperações em massa são o nível de menor custo do Amazon Glacier, permitindorecuperar grandes quantidades de dados, até mesmo petabytes, em um dia e com um custo baixo. Osdados acessados usando o nível Em massa normalmente são disponibilizados entre 5 e 12 horas.
Para obter mais informações recuperações expressas e em massa, consulte Recuperar arquivos doAmazon Glacier (p. 79).
SolicitaçõesPara iniciar um trabalho, você usa o método POST HTTP e delimita a solicitação ao sub-recurso jobs docofre. Você especifica detalhes da solicitação de trabalho no documento JSON da solicitação. O tipo detrabalho é especificado com o campo Type. Se desejar, você pode especificar um campo SNSTopic paraindicar um tópico do Amazon SNS no qual o Amazon Glacier poderá publicar uma notificação depois que otrabalho for concluído.
Note
Para publicar uma notificação no Amazon SNS, você deve criar o tópico por conta própria, casoele ainda não exista. O Amazon Glacier não cria o tópico para você. O tópico deve ter permissõespara receber publicações de um cofre do Amazon Glacier. O Amazon Glacier não verifica seo cofre tem permissão para publicação no tópico. Se as permissões não forem configuradascorretamente, talvez você não receba uma notificação, mesmo depois da conclusão do trabalho.
SintaxeEsta é a sintaxe de solicitação para iniciar um trabalho.
POST /AccountId/vaults/VaultName/jobs HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Versão da API 2012-06-01261

Amazon Glacier Guia do desenvolvedor doInitiate Job
{ "jobParameters": { "ArchiveId": "string", "Description": "string", "Format": "string", "InventoryRetrievalParameters": { "EndDate": "string", "Limit": "string", "Marker": "string", "StartDate": "string" }, "OutputLocation": { "S3": { "AccessControlList": [ { "Grantee": { "DisplayName": "string", "EmailAddress": "string", "ID": "string", "Type": "string", "URI": "string" }, "Permission": "string" } ], "BucketName": "string", "CannedACL": "string", "Encryption": { "EncryptionType": "string", "KMSContext": "string", "KMSKeyId": "string" }, "Prefix": "string", "StorageClass": "string", "Tagging": { "string" : "string" }, "UserMetadata": { "string" : "string" } } }, "RetrievalByteRange": "string", "SelectParameters": { "Expression": "string", "ExpressionType": "string", "InputSerialization": { "csv": { "Comments": "string", "FieldDelimiter": "string", "FileHeaderInfo": "string", "QuoteCharacter": "string", "QuoteEscapeCharacter": "string", "RecordDelimiter": "string" } }, "OutputSerialization": { "csv": { "FieldDelimiter": "string", "QuoteCharacter": "string", "QuoteEscapeCharacter": "string", "QuoteFields": "string", "RecordDelimiter": "string" } }
Versão da API 2012-06-01262
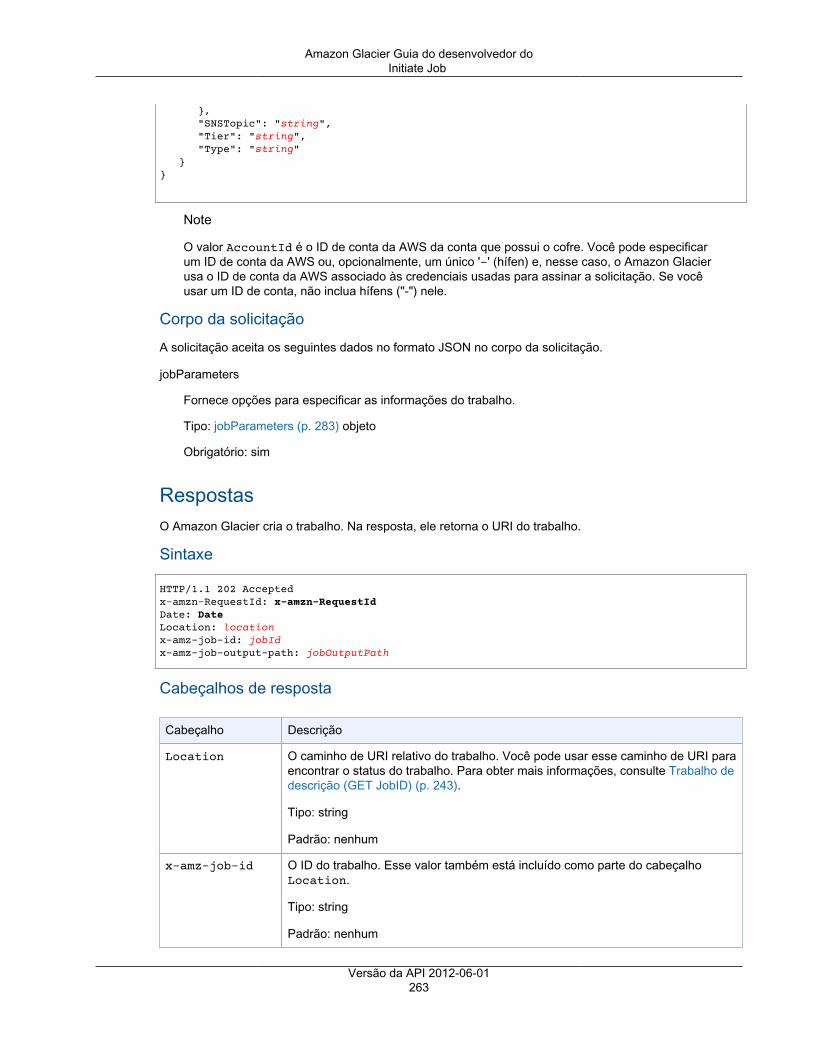
Amazon Glacier Guia do desenvolvedor doInitiate Job
}, "SNSTopic": "string", "Tier": "string", "Type": "string" }}
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Corpo da solicitaçãoA solicitação aceita os seguintes dados no formato JSON no corpo da solicitação.
jobParameters
Fornece opções para especificar as informações do trabalho.
Tipo: jobParameters (p. 283) objeto
Obrigatório: sim
RespostasO Amazon Glacier cria o trabalho. Na resposta, ele retorna o URI do trabalho.
Sintaxe
HTTP/1.1 202 Acceptedx-amzn-RequestId: x-amzn-RequestIdDate: DateLocation: locationx-amz-job-id: jobIdx-amz-job-output-path: jobOutputPath
Cabeçalhos de resposta
Cabeçalho Descrição
Location O caminho de URI relativo do trabalho. Você pode usar esse caminho de URI paraencontrar o status do trabalho. Para obter mais informações, consulte Trabalho dedescrição (GET JobID) (p. 243).
Tipo: string
Padrão: nenhum
x-amz-job-id O ID do trabalho. Esse valor também está incluído como parte do cabeçalhoLocation.
Tipo: string
Padrão: nenhum
Versão da API 2012-06-01263

Amazon Glacier Guia do desenvolvedor doInitiate Job
Cabeçalho Descrição
x-amz-job-output-path
Este cabeçalho só é retornado para os tipos de trabalho de seleção. O caminhopara o local onde os resultados de seleção são armazenados.
Tipo: string
Padrão: nenhum
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Essa operação inclui os erros a seguir, além de erros possíveis comuns a todas as operações do AmazonGlacier. Para informações sobre erros do Amazon Glacier e uma lista de códigos de erro, consulteRespostas de erro (p. 169).
Code Descrição Código de statusHTTP
Type
InsufficientCapacityExceptionRetornado se houver capacidadeinsuficiente para processar essasolicitação expressa. Esse erro seaplica somente a recuperaçõesexpressas, e não a recuperaçõespadrão ou em massa.
503 ServiceUnavailable
deaplicativos
ExemplosSolicitação de exemplo: iniciar um trabalho de recuperação do arquivo
POST /-/vaults/examplevault/jobs HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
{ "Type": "archive-retrieval", "ArchiveId": "NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId" "Description": "My archive description", "SNSTopic": "arn:aws:sns:us-west-2:111111111111:Glacier-ArchiveRetrieval-topic-Example", "Tier" : "Bulk"}
Este é um exemplo do corpo de uma solicitação que especifica um intervalo do arquivo a ser recuperadousando-se o campo RetrievalByteRange.
{ "Type": "archive-retrieval",
Versão da API 2012-06-01264

Amazon Glacier Guia do desenvolvedor doInitiate Job
"ArchiveId": "NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId" "Description": "My archive description", "RetrievalByteRange": "2097152-4194303", "SNSTopic": "arn:aws:sns:us-west-2:111111111111:Glacier-ArchiveRetrieval-topic-Example", "Tier" : "Bulk"}
Exemplo de resposta
HTTP/1.1 202 Acceptedx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTLocation: /111122223333/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobIDx-amz-job-id: HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID
Solicitação de exemplo: iniciar um trabalho de recuperação do inventárioA solicitação a seguir inicia um trabalho de recuperação do inventário para obter uma lista de arquivosdo cofre examplevault. O Format definido como CSV no corpo da solicitação indica que o inventário éretornado no formato CSV.
POST /-/vaults/examplevault/jobs HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZContent-Type: application/x-www-form-urlencodedx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
{ "Type": "inventory-retrieval", "Description": "My inventory job", "Format": "CSV", "SNSTopic": "arn:aws:sns:us-west-2:111111111111:Glacier-InventoryRetrieval-topic-Example"}
Exemplo de resposta
HTTP/1.1 202 Acceptedx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT Location: /111122223333/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobIDx-amz-job-id: HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID
Exemplos de solicitações: Iniciar um trabalho de recuperação de inventáriousando a filtragem de dados com um limite definido e uma solicitação posteriorpara recuperar a próxima página dos itens de inventário.A solicitação a seguir inicia um trabalho de recuperação de inventário de cofre usando a filtragem de data edefinindo um limite.
Versão da API 2012-06-01265

Amazon Glacier Guia do desenvolvedor doInitiate Job
{ "ArchiveId": null, "Description": null, "Format": "CSV", "RetrievalByteRange": null, "SNSTopic": null, "Type": "inventory-retrieval", "InventoryRetrievalParameters": { "StartDate": "2013-12-04T21:25:42Z", "EndDate": "2013-12-05T21:25:42Z", "Limit" : "10000" }, }
A solicitação a seguir é um exemplo de uma solicitação subsequente para recuperar a próxima página deitens de inventário usando um marcador obtido de Trabalho de descrição (GET JobID) (p. 243).
{ "ArchiveId": null, "Description": null, "Format": "CSV", "RetrievalByteRange": null, "SNSTopic": null, "Type": "inventory-retrieval", "InventoryRetrievalParameters": { "StartDate": "2013-12-04T21:25:42Z", "EndDate": "2013-12-05T21:25:42Z", "Limit": "10000", "Marker": "vyS0t2jHQe5qbcDggIeD50chS1SXwYMrkVKo0KHiTUjEYxBGCqRLKaiySzdN7QXGVVV5XZpNVG67pCZ_uykQXFMLaxOSu2hO_-5C0AtWMDrfo7LgVOyfnveDRuOSecUo3Ueq7K0" }, }
Exemplo de solicitação: Iniciar um trabalho de seleçãoA solicitação a seguir inicia um trabalho de seleção.
POST /-/vaults/examplevault/jobs HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZContent-Type: application/x-www-form-urlencodedx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
{ "Type": "select", "ArchiveId": "NkbByEejwEggmBz2fTHgJrg0XBoDfjP4q6iu87-TjhqG6eGoOY9Z8i1_AUyUsuhPAdTqLHy8pTl5nfCFJmDl2yEZONi5L26Omw12vcs01MNGntHEQL8MBfGlqrEXAMPLEArchiveId", "Description": null, "SNSTopic": null,
"Tier": "Bulk", "SelectParameters": { "Expression": "select * from archive", "ExpressionType": "SQL", "InputSerialization": { "csv": { "Comments": null, "FileHeaderInfo": "None",
Versão da API 2012-06-01266

Amazon Glacier Guia do desenvolvedor doList Jobs
"QuoteEscapeCharacter": "\"", "RecordDelimiter": "\n", "FieldDelimiter": ",", "QuoteCharacter": "\"" } }, "OutputSerialization": { "csv": { "QuoteFields": "AsNeeded", "QuoteEscapeCharacter": null, "RecordDelimiter": "\n", "FieldDelimiter": ",", "QuoteCharacter": "\"" } } }, "OutputLocation": { "S3": { "BucketName": "bucket-name", "Prefix": "test", "Encryption": { "EncryptionType": "AES256" }, "CannedACL": "private", "StorageClass": "STANDARD" } }}
Exemplo de resposta
HTTP/1.1 202 Acceptedx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT Location: /111122223333/vaults/examplevault/jobs/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobIDx-amz-job-id: HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobIDx-amz-job-output-path: test/HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID/
Seções relacionadas• Trabalho de descrição (GET JobID) (p. 243)• Get Job Output (GET output) (p. 251)• Referência SQL para o Amazon S3 Select e o Amazon Glacier Select (p. 299)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
List Jobs (GET jobs)DescriçãoEssa operação lista trabalhos de um cofre, incluindo os trabalhos em andamento e os que foramconcluídos recentemente.
Note
O Amazon Glacier mantém trabalhos concluídos recentemente por um período antes de excluí-los; no entanto, ele acaba removendo os trabalhos concluídos. A saída de trabalhos concluídos
Versão da API 2012-06-01267
Amazon Glacier Guia do desenvolvedor doList Jobs
pode ser recuperada. Manter os trabalhos por um período após eles terem sido concluídospermite obter uma saída de trabalho caso você perca a notificação de conclusão do trabalhoou caso a primeira tentativa de download apresente falha. Por exemplo, suponhamos que vocêinicie um trabalho de recuperação de arquivo para fazer download de um arquivo. Depois que otrabalho é concluído, você começa a fazer download do arquivo, mas encontra um erro de rede.Nesse cenário, você poderá tentar novamente e fazer download do arquivo enquanto o trabalhoexistir.
A operação List Jobs oferece suporte à paginação. Você deve sempre verificar o campo de respostaMarker. Se não houver mais trabalhos a serem listados, o campo Marker será definido como null. Sehouver mais trabalhos a serem listados, o campo Marker será definido como um valor não nulo, que vocêpode usar para continuar a paginação da lista. Para retornar uma lista de trabalhos que comece em umespecífico, defina o parâmetro de solicitação marker como o valor Marker para esse trabalho que vocêobteve de uma List Jobssolicitação anterior.
Você pode definir um limite máximo para o número de trabalhos retornados na resposta especificando oparâmetro limit na solicitação. O limite padrão é 50. O número de trabalhos retornados pode ser menorque o limite, mas o número de trabalhos retornados jamais excede o limite.
Além disso, você pode filtrar a lista de trabalhos retornados especificando o parâmetro statuscodeopcional ou o parâmetro completed, ou ambos. Usando o parâmetro statuscode, você pode especificarpara retornar somente trabalhos correspondentes ao status InProgress, Succeeded ou Failed.Usando o completed parâmetro, você pode especificar para retornar somente trabalhos que tenham sidoconcluídos (true) ou trabalhos que não tenham sido concluídos (false).
SolicitaçõesSintaxe
Para retornar uma lista de trabalhos de todos os tipos, envie uma solicitação GET para o URI do sub-recurso jobs do cofre.
GET /AccountId/vaults/VaultName/jobs HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS da conta que possui o cofre. Você pode especificarum ID de conta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacierusa o ID de conta da AWS associado às credenciais usadas para assinar a solicitação. Se vocêusar um ID de conta, não inclua hífens ("-") nele.
Parâmetros de solicitação
Nome Descrição Obrigatório
completed O estado dos trabalhos a serem retornados. É possível especificartrue ou false.
Tipo: Booleano
Restrições: nenhuma
Não
Versão da API 2012-06-01268

Amazon Glacier Guia do desenvolvedor doList Jobs
Nome Descrição Obrigatório
limit O número máximo de trabalhos a serem retornados. O limite padrãoé 50. O número de trabalhos retornados pode ser menor que o limiteespecificado, mas o número de trabalhos retornados jamais excedeo limite.
Tipo: string
Restrições: valor do inteiro mínimo de 1. Valor do inteiro máximo de50.
Não
marker Uma string invisível usada na paginação que especifica o trabalhono qual a listagem dos trabalhos deve começar. Você obtém ovalor marker de uma List Jobsresposta anterior. Você somenteprecisará incluir o marker se continuar a paginação dos resultadosiniciada em uma List Jobssolicitação anterior.
Tipo: string
Restrições: nenhuma
Não
statuscode O tipo de status do trabalho a ser retornado.
Tipo: string
Restrições: um dos valores InProgress, Succeeded ou Failed.
Não
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateLocation: Location Content-Type: application/jsonContent-Length: Length
{ "JobList": [ { "Action": "string", "ArchiveId": "string", "ArchiveSHA256TreeHash": "string", "ArchiveSizeInBytes": number, "Completed": boolean, "CompletionDate": "string",
Versão da API 2012-06-01269

Amazon Glacier Guia do desenvolvedor doList Jobs
"CreationDate": "string", "InventoryRetrievalParameters": { "EndDate": "string", "Format": "string", "Limit": "string", "Marker": "string", "StartDate": "string" }, "InventorySizeInBytes": number, "JobDescription": "string", "JobId": "string", "JobOutputPath": "string", "OutputLocation": { "S3": { "AccessControlList": [ { "Grantee": { "DisplayName": "string", "EmailAddress": "string", "ID": "string", "Type": "string", "URI": "string" }, "Permission": "string" } ], "BucketName": "string", "CannedACL": "string", "Encryption": { "EncryptionType": "string", "KMSContext": "string", "KMSKeyId": "string" }, "Prefix": "string", "StorageClass": "string", "Tagging": { "string": "string" }, "UserMetadata": { "string": "string" } } }, "RetrievalByteRange": "string", "SelectParameters": { "Expression": "string", "ExpressionType": "string", "InputSerialization": { "csv": { "Comments": "string", "FieldDelimiter": "string", "FileHeaderInfo": "string", "QuoteCharacter": "string", "QuoteEscapeCharacter": "string", "RecordDelimiter": "string" } }, "OutputSerialization": { "csv": { "FieldDelimiter": "string", "QuoteCharacter": "string", "QuoteEscapeCharacter": "string", "QuoteFields": "string", "RecordDelimiter": "string" } }
Versão da API 2012-06-01270

Amazon Glacier Guia do desenvolvedor doList Jobs
}, "SHA256TreeHash": "string", "SNSTopic": "string", "StatusCode": "string", "StatusMessage": "string", "Tier": "string", "VaultARN": "string" } ], "Marker": "string"}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
JobList
Uma lista de objetos de trabalho. Cada objeto de trabalho contém metadados que descrevem otrabalho.
Tipo: matriz de objetos GlacierJobDescription (p. 277)Marker
Uma string invisível que representa onde continuar a paginação dos resultados. Você usa o valormarker em uma nova List Jobssolicitação para obter mais trabalhos na lista. Se não houver maistrabalhos a serem listados, esse valor será null.
Type: String
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosOs exemplos a seguir demonstram como retornar informações sobre trabalhos de cofre. O primeiroexemplo retorna uma lista de dois trabalhos, e o segundo exemplo retorna um subconjunto de trabalhos.
Exemplo: retornar todos os trabalhos
Exemplo de solicitação
A solicitação GET a seguir retorna os trabalhos de um cofre.
GET /-/vaults/examplevault/jobs HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01
Versão da API 2012-06-01271

Amazon Glacier Guia do desenvolvedor doList Jobs
Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
A resposta a seguir inclui um trabalho de recuperação de arquivo e um trabalho de recuperação deinventário que contém um marcador usado para continuar a paginação da recuperação do inventário decofre. A resposta também mostra o campo Marker definido como null, o que indica que não há maistrabalhos a serem listados.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT Content-Type: application/jsonContent-Length: 1444
{ "JobList": [ { "Action": "ArchiveRetrieval", "ArchiveId": "BDfaUQul0dVzYwAMr8YSa_6_8abbhZq-i1oT69g8ByClfJyBgAGBkWl2QbF5os851P7Y7KdZDOHWJIn4rh1ZHaOYD3MgFhK_g0oDPesW34uHQoVGwoIqubf6BgUEfQm_wrU4Jlm3cA", "ArchiveSizeInBytes": 1048576, "ArchiveSHA256TreeHash": "25499381569ab2f85e1fd0eb93c5406a178ab77c5933056eb5d6e7d4adda609b", "Completed": true, "CompletionDate": "2012-05-01T00:00:09.304Z", "CreationDate": "2012-05-01T00:00:06.663Z", "InventorySizeInBytes": null, "JobDescription": null, "JobId": "hDe9t9DTHXqFw8sBGpLQQOmIM0-JrGtu1O_YFKLnzQ64548qJc667BRWTwBLZC76Ygy1jHYruqXkdcAhRsh0hYv4eVRU", "RetrievalByteRange": "0-1048575", "SHA256TreeHash": "25499381569ab2f85e1fd0eb93c5406a178ab77c5933056eb5d6e7d4adda609b", "SNSTopic": null, "StatusCode": "Succeeded", "StatusMessage": "Succeeded", "Tier": "Bulk", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" }, { "Action": "InventoryRetrieval", "ArchiveId": null, "ArchiveSizeInBytes": null, "ArchiveSHA256TreeHash": null, "Completed": true, "CompletionDate": "2013-05-11T00:25:18.831Z", "CreationDate": "2013-05-11T00:25:14.981Z", "InventorySizeInBytes": 1988, "JobDescription": null, "JobId": "2cvVOnBL36btzyP3pobwIceiaJebM1bx9vZOOUtmNAr0KaVZ4WkWgVjiPldJ73VU7imlm0pnZriBVBebnqaAcirZq_C5", "RetrievalByteRange": null, "SHA256TreeHash": null, "SNSTopic": null, "StatusCode": "Succeeded", "StatusMessage": "Succeeded", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" "InventoryRetrievalParameters": { "StartDate": "2013-11-12T13:43:12Z", "EndDate": "2013-11-20T08:12:45Z", "Limit": "120000", "Format": "JSON",
Versão da API 2012-06-01272

Amazon Glacier Guia do desenvolvedor doList Jobs
"Marker": "vyS0t2jHQe5qbcDggIeD50chS1SXwYMrkVKo0KHiTUjEYxBGCqRLKaiySzdN7QXGVVV5XZpNVG67pCZ_uykQXFMLaxOSu2hO_-5C0AtWMDrfo7LgVOyfnveDRuOSecUo3Ueq7K0" } ], "Marker": null }
Exemplo: retornar uma lista parcial de trabalhos
Exemplo de solicitação
A solicitação GET a seguir retorna o trabalho especificado pelo parâmetro marker. Definir olimitparâmetro como 2especifica que até dois trabalhos são retornados.
GET /-/vaults/examplevault/jobs?marker=HkF9p6o7yjhFx-K3CGl6fuSm6VzW9T7esGQfco8nUXVYwS0jlb5gq1JZ55yHgt5vP54ZShjoQzQVVh7vEXAMPLEjobID&limit=2 HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
A resposta a seguir mostra dois trabalhos retornados e o campo Marker definido como um valor não nuloque pode ser usado para continuar a paginação da lista de trabalhos.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMT Content-Type: application/jsonContent-Length: 1744
{ "JobList": [ { "Action": "ArchiveRetrieval", "ArchiveId": "58-3KpZfcMPUznvMZNPaKyJx9wODCsWTnqcjtx2CjKZ6b-XgxEuA8yvZOYTPQfd7gWR4GRm2XR08gcnWbLV4VPV_kDWtZJKi0TFhKKVPzwrZnA4-FXuIBfViYUIVveeiBE51FO4bvg", "ArchiveSizeInBytes": 8388608, "ArchiveSHA256TreeHash": "106086b256ddf0fedf3d9e72f461d5983a2566247ebe7e1949246bc61359b4f4", "Completed": true, "CompletionDate": "2012-05-01T00:25:20.043Z", "CreationDate": "2012-05-01T00:25:16.344Z", "InventorySizeInBytes": null, "JobDescription": "aaabbbccc", "JobId": "s4MvaNHIh6mOa1f8iY4ioG2921SDPihXxh3Kv0FBX-JbNPctpRvE4c2_BifuhdGLqEhGBNGeB6Ub-JMunR9JoVa8y1hQ", "RetrievalByteRange": "0-8388607", "SHA256TreeHash": "106086b256ddf0fedf3d9e72f461d5983a2566247ebe7e1949246bc61359b4f4", "SNSTopic": null, "StatusCode": "Succeeded", "StatusMessage": "Succeeded", "Tier": "Bulk", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" }, { "Action": "ArchiveRetrieval",
Versão da API 2012-06-01273

Amazon Glacier Guia do desenvolvedor doTipos de dados usados em operações de trabalho
"ArchiveId": "2NVGpf83U6qB9M2u-Ihh61yoFLRDEoh7YLZWKBn80A2i1xG8uieBwGjAr4RkzOHA0E07ZjtI267R03Z-6Hxd8pyGQkBdciCSH1-Lw63Kx9qKpZbPCdU0uTW_WAdwF6lR6w8iSyKdvw", "ArchiveSizeInBytes": 1048576, "ArchiveSHA256TreeHash": "3d2ae052b2978727e0c51c0a5e32961c6a56650d1f2e4ceccab6472a5ed4a0", "Completed": true, "CompletionDate": "2012-05-01T16:59:48.444Z", "CreationDate": "2012-05-01T16:59:42.977Z", "InventorySizeInBytes": null, "JobDescription": "aaabbbccc", "JobId": "CQ_tf6fOR4jrJCL61Mfk6VM03oY8lmnWK93KK4gLig1UPAbZiN3UV4G_5nq4AfmJHQ_dOMLOX5k8ItFv0wCPN0oaz5dG", "RetrievalByteRange": "0-1048575", "SHA256TreeHash": "3d2ae052b2978727e0c51c0a5e32961c6a56650d1f2e4ceccab6472a5ed4a0", "SNSTopic": null, "StatusCode": "Succeeded", "StatusMessage": "Succeeded", "Tier": "Standard", "VaultARN": "arn:aws:glacier:us-west-2:012345678901:vaults/examplevault" } ], "Marker": "CQ_tf6fOR4jrJCL61Mfk6VM03oY8lmnWK93KK4gLig1UPAbZiN3UV4G_5nq4AfmJHQ_dOMLOX5k8ItFv0wCPN0oaz5dG"}
Seções relacionadas• Trabalho de descrição (GET JobID) (p. 243)• Autenticação e controle de acesso para o Amazon Glacier (p. 118)
Tipos de dados usados em operações de trabalhoEstes são os tipos de dados usados com as operações de trabalho no Amazon Glacier.
Tópicos• CSVInput (p. 274)• CSVOutput (p. 276)• Criptografia (p. 276)• GlacierJobDescription (p. 277)• Grant (p. 280)• Grantee (p. 280)• InputSerialization (p. 281)• InventoryRetrievalJobInput (p. 281)• jobParameters (p. 283)• OutputLocation (p. 285)• OutputSerialization (p. 285)• S3Location (p. 285)• SelectParameters (p. 287)
CSVInputContém informações sobre o arquivo de valores separados por vírgulas (CSV).
Versão da API 2012-06-01274

Amazon Glacier Guia do desenvolvedor doCSVInput
TópicosComentários
Um único caractere usado para indicar que uma linha deve ser ignorada quando o caractere estápresente no início da linha.
Type: String
Obrigatório: nãoFieldDelimiter
Um único caractere usado para separar campos individuais em um registro. O caractere deve ser \n,\r ou um caractere ASCII no intervalo 32 – 126. O padrão é uma vírgula (,).
Type: String
Padrão: ,
Obrigatório: nãoFileHeaderInfo
Um valor que descreve o que fazer com a primeira linha da entrada.
Type: String
Valores válidos: Use | Ignore | None
Obrigatório: nãoQuoteCharacter
Um único caractere usado como um caractere de escape em que o delimitador de campo é parte dovalor.
Type: String
Obrigatório: nãoQuoteEscapeCharacter
Um único caractere usado para fazer o escape do caractere de aspas em um valor que já recebeuescape.
Type: String
Obrigatório: nãoRecordDelimiter
Um único caractere usado para separar registros individuais.
Type: String
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
Versão da API 2012-06-01275

Amazon Glacier Guia do desenvolvedor doCSVOutput
CSVOutputContém informações sobre o formato de valores separados por vírgulas (CSV) em que os resultados dotrabalho são armazenados.
TópicosFieldDelimiter
Um único caractere usado para separar campos individuais em um registro.
Type: String
Obrigatório: nãoQuoteCharacter
Um único caractere usado como um caractere de escape em que o delimitador de campo é parte dovalor.
Type: String
Obrigatório: nãoQuoteEscapeCharacter
Um único caractere usado para fazer o escape do caractere de aspas em um valor que já recebeuescape.
Type: String
Obrigatório: nãoQuoteFields
Um valor que indica se todos os campos de saída devem ser colocados entre aspas.
Valores válidos: ALWAYS | ASNEEDED
Type: String
Obrigatório: nãoRecordDelimiter
Um único caractere usado para separar registros individuais.
Type: String
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
CriptografiaContém informações sobre a criptografia usada para armazenar os resultados do trabalho no Amazon S3.
Versão da API 2012-06-01276

Amazon Glacier Guia do desenvolvedor doGlacierJobDescription
TópicosCriptografia
O algoritmo de criptografia no lado do servidor usado para armazenar os resultados do trabalho noAmazon S3. O padrão é sem criptografia.
Type: String
Valores válidos: aws:kms | AES256
Obrigatório: nãoKMSContext
Optional. Se o tipo de criptografia for aws:kms, você poderá usar esse valor para especificar ocontexto da criptografia nos resultados do trabalho.
Type: String
Obrigatório: nãoKMSKeyId
O ID da chave do AWS Key Management Service (AWS KMS) a ser usado na criptografia do objeto.
Type: String
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
GlacierJobDescriptionContém a descrição de um trabalho do Amazon Glacier.
TópicosAção
O tipo de trabalho. É ArchiveRetrieval, InventoryRetrieval ou Select.
Type: StringArchiveId
O ID de arquivo solicitado para um trabalho de seleção ou de recuperação de arquivo. Do contrário,esse campo será null.
Type: StringArchiveSHA256TreeHash
O hash de árvore SHA256 de todo o arquivo de uma recuperação do arquivo. Para trabalhos derecuperação do inventário, esse campo é null.
Type: String
Versão da API 2012-06-01277

Amazon Glacier Guia do desenvolvedor doGlacierJobDescription
ArchiveSizeInBytes
Para um trabalho ArchiveRetrieval, trata-se do tamanho em bytes do arquivo solicitado paradownload. Para o trabalho InventoryRetrieval, o valor é null.
Tipo: númeroCompleted
true se o trabalho for concluído;, do contrário false.
Tipo: booleanoCompletionDate
A data em que o trabalho foi concluído.
A hora UTC (Horário Coordenado Universal) em que a solicitação de trabalho foi concluída. Enquantoo trabalho estiver em andamento, o valor será nulo.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
CreationDate
A data UTC quando o trabalho foi iniciado.
Tipo: Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
InventoryRetrievalParameters
Os parâmetros de entrada usados em uma recuperação de inventário de intervalo.
Tipo: InventoryRetrievalJobInput (p. 281) objetoInventorySizeInBytes
Para um trabalho InventoryRetrieval, trata-se do tamanho em bytes do inventário solicitado paradownload. No trabalho ArchiveRetrieval ou Select, o valor é null.
Tipo: númeroJobDescription
A descrição do trabalho que você forneceu quando iniciou o trabalho.
Type: StringJobId
O ID que identifica o trabalho no Amazon Glacier.
Type: StringJobOutputPath
Contém o local de saída do trabalho.
Type: StringOutputLocation
Um objeto com informações sobre o local onde os resultados e os erros do trabalho de seleção sãoarmazenados.
Tipo: OutputLocation (p. 285) objeto
Versão da API 2012-06-01278

Amazon Glacier Guia do desenvolvedor doGlacierJobDescription
RetrievalByteRange
O intervalo de bytes recuperado em trabalhos de recuperação de arquivo no formato"StartByteValue-EndByteValue". Se nenhum intervalo tiver sido especificado na recuperação dearquivo, todo o arquivo será recuperado, StartByteValue será igual a 0 e EndByteValue será igual aotamanho do arquivo menos 1. Para trabalhos de recuperação do inventário, esse campo é null.
Type: StringSelectParameters
Um objeto com informações sobre os parâmetros usados em uma seleção.
Tipo: SelectParameters (p. 287) objetoSHA256TreeHash
O valor do hash de árvore SHA256 para o intervalo solicitado de um arquivo. Se a solicitação InitiateJob (trabalhos POST) (p. 257) para um arquivo tiver especificado um intervalo alinhado ao hash deárvore, esse campo retornará um valor. Para obter mais informações sobre o alinhamento ao hash deárvore para recuperações do intervalo de arquivos, consulte Receber somas de verificação durante odownload de dados (p. 167).
Quando todo o arquivo for recuperado, esse valor será igual ao valor de ArchiveSHA256TreeHash.
Esse campo é null nas seguintes situações:• Os trabalhos de recuperação de arquivo que especificam um intervalo não alinhado ao hash de
árvore.• Trabalhos de arquivamento que especificam um intervalo igual a todo o arquivamento e cujo status
do trabalho seja InProgress.• Trabalhos de inventário.• Trabalhos de seleção.
Type: StringSNSTopic
O Amazon Resource Name (ARN – Nome de recurso da Amazon) que representa um tópico doAmazon SNS em que a notificação da conclusão ou da falha do trabalho é enviada, se a notificaçãotiver sido configurada na iniciação do trabalho (Initiate Job (trabalhos POST) (p. 257)).
Type: StringStatusCode
O código que indica o status do trabalho.
Valores válidos: InProgress | Succeeded | Succeeded
Type: StringStatusMessage
A mensagem de status do trabalho.
Type: StringNível
O nível de acesso a dados a ser usado na seleção ou na recuperação de arquivo.
Valores válidos: Expedited | Standard | Bulk
Type: String
Versão da API 2012-06-01279

Amazon Glacier Guia do desenvolvedor doGrant
VaultARN
O ARN do cofre do qual o trabalho é um sub-recurso.
Type: String
Mais informações• Initiate Job (trabalhos POST) (p. 257)
GrantContém informações sobre uma concessão.
TópicosGrantee
O favorecido.
Tipo: Grantee (p. 280) objeto
Obrigatório: nãoPermissão
A permissão concedida ao favorecido.
Type: String
Valores válidos: FULL_CONTROL | WRITE | WRITE_ACP | READ | READ_ACP
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
GranteeContém informações sobre um favorecido.
TópicosDisplayName
O nome da tela do favorecido.
Type: String
Obrigatório: nãoEmailAddress
O endereço de e-mail do favorecido.
Versão da API 2012-06-01280

Amazon Glacier Guia do desenvolvedor doInputSerialization
Type: String
Obrigatório: nãoID
O ID de usuário canônico do favorecido.
Type: String
Obrigatório: nãoType
O tipo do favorecido.
Type: String
Valores válidos: AmazonCustomerByEmail | CanonicalUser | Group
Obrigatório: nãoURI
O URI do grupo do favorecido.
Type: String
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
InputSerializationDescreve como o arquivo será serializado.
TópicosCSV
Um objeto que descreve a serialização de um objeto codificado por CSV.
Tipo: CSVInput (p. 274) objeto
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
InventoryRetrievalJobInputFornece opções para especificar um trabalho de recuperação de inventário de intervalo.
Versão da API 2012-06-01281
Amazon Glacier Guia do desenvolvedor doInventoryRetrievalJobInput
TópicosEndDate
O final do intervalo de datas, em UTC, para uma recuperação de inventário de cofre que inclua osarquivos criados antes dessa data.
Valores válidos: Uma representação de string no formato de data ISO 8601 (YYYY-MM-DDThh:mm:ssTZD) em segundos, por exemplo, 2013-03-20T17:03:43Z.
Type: String. Uma representação de string no formato de data ISO 8601 (YYYY-MM-DDThh:mm:ssTZD) em segundos, por exemplo, 2013-03-20T17:03:43Z.
Obrigatório: nãoFormato
O formato de saída da lista de inventários de cofre, definido pela solicitação Initiate Job (trabalhosPOST) (p. 257) durante a inicialização de um trabalho para recuperação de um inventário de cofre.
Valores válidos: CSV | JSON
Obrigatório: não
Type: StringLimite
O número máximo de itens de inventário que podem ser retornados para cada solicitação derecuperação de inventário de cofre.
Valores válidos: um valor inteiro maior ou igual a 1.
Type: String
Obrigatório: nãoMarker
Uma string invisível que representa onde continuar a paginação dos resultados da recuperação deinventário do cofre. Você usa esse marcador em uma nova solicitação Initiate Job para obteritens de inventário adicionais. Se não houver itens de inventário, esse valor será nulo.
Type: String
Obrigatório: nãoStartDate
O início do intervalo de datas, em UTC, para uma recuperação de inventário de cofre que incluaarquivos criados nessa ou após essa data.
Valores válidos: Uma representação de string no formato de data ISO 8601 (YYYY-MM-DDThh:mm:ssTZD) em segundos, por exemplo, 2013-03-20T17:03:43Z.
Type: String. Uma representação de string no formato de data ISO 8601 (YYYY-MM-DDThh:mm:ssTZD) em segundos, por exemplo, 2013-03-20T17:03:43Z.
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
Versão da API 2012-06-01282

Amazon Glacier Guia do desenvolvedor dojobParameters
jobParametersFornece opções para definir um trabalho.
TópicosArchiveId
O ID do arquivo desejado. Este campo só será obrigatório se o campo Type estiver definido comoselect ou archive-retrieval. Um erro ocorrerá se você especificar esse campo para umasolicitação de trabalho de recuperação de inventário.
Valores válidos: devem ser um ID de arquivo válido obtido por você junto a uma solicitação anteriorpara o Amazon Glacier.
Type: String
Obrigatório: sim quando Type for definido como select ou archive-retrieval.Description
A descrição opcional do trabalho.
Valores válidos: a descrição deve ser menor ou igual a 1.024 bytes. Os caracteres permitidos sãoASCII de 7 bits sem códigos de controle, especificamente valores ASCII 32–126 decimal ou 0x20–0x7E hexadecimal.
Type: String
Obrigatório: nãoFormato
(Opcional) O formato da saída, ao iniciar um trabalho para recuperar um inventário de cofre. Se vocêestiver iniciando um trabalho de inventário e não especificar um campo Format, JSON será o formatopadrão.
Valores válidos: CSV | JSON
Type: String
Obrigatório: nãoInventoryRetrievalParameters
Os parâmetros de entrada usados em uma recuperação de inventário de intervalo.
Tipo: InventoryRetrievalJobInput (p. 281) objeto
Obrigatório: nãoOutputLocation
Um objeto com informações sobre o local onde os resultados do trabalho de seleção sãoarmazenados.
Tipo: OutputLocation (p. 285) objeto
Obrigatório: sim para trabalhos select.RetrievalByteRange
O intervalo de bytes a ser recuperado em uma archive-retrieval, no formato"StartByteValue-EndByteValue". Se esse campo não for especificado, todo o arquivo será
Versão da API 2012-06-01283

Amazon Glacier Guia do desenvolvedor dojobParameters
recuperado. Se esse campo for especificado, o intervalo de bytes deverá ser alinhado a megabyte(1024*1024). Alinhado a megabyte significa que StartByteValue deve ser divisível por 1 MB eEndByteValue mais 1 deve ser divisível por 1 MB ou ser o final do arquivo especificado como o valordo tamanho de bytes do arquivo menos 1. Se RetrievalByteRange não estiver alinhado a megabyte,essa operação retornará a resposta 400.
Um erro ocorrerá se você especificar esse campo em uma solicitação de trabalho inventory-retrieval ou select.
Type: String
Obrigatório: nãoSelectParameters
Um objeto com informações sobre os parâmetros usados em uma seleção.
Tipo: SelectParameters (p. 287) objeto
Obrigatório: nãoSNSTopic
O nome de recurso da Amazon (ARN) do tópico do Amazon SNS, em que o Amazon Glacier enviauma notificação quando o trabalho é concluído e a saída fica pronta para você fazer download. Otópico especificado publica a notificação para os assinantes.
O tópico do SNS deve existir. Do contrário, o Amazon Glacier não o criará para você. Além disso, otópico do SNS deve ter uma política que permita à conta que criou o trabalho publicar mensagens notópico. Para obter informações sobre nomes de tópico do SNS, consulte CreateTopic na Referência deAPI do Amazon Simple Notification Service.
Type: String
Obrigatório: nãoNível
O nível a ser usado em um trabalho de seleção ou de recuperação de arquivo. Standard é o valorpadrão usado.
Valores válidos: Expedited | Standard | Bulk
Type: String
Obrigatório: nãoType
O tipo de trabalho. Você pode iniciar um trabalho para executar uma consulta select em um arquivo,recuperar um arquivo ou obter um inventário de um cofre.
Valores válidos: select | archive-retrieval | inventory-retrieval
Type: String
Obrigatório: sim
Mais informações• Initiate Job (trabalhos POST) (p. 257)
Versão da API 2012-06-01284
Amazon Glacier Guia do desenvolvedor doOutputLocation
OutputLocationContém informações sobre o local em que os resultados e os erros de trabalho são armazenados.
TópicosS3
Um objeto que descreve um local do Amazon S3 para receber os resultados da solicitação derestauração.
Digite: S3Location (p. 285)
Obrigatório: sim
Mais informações• Initiate Job (trabalhos POST) (p. 257)
OutputSerializationDescreve como a saída será serializada.
TópicosCSV
Um objeto que descreve a serialização dos resultados de consulta codificados por valores separadospor vírgulas (CSV).
Tipo: CSVOutput (p. 276) objeto
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
S3LocationContém informações sobre o local do Amazon S3 em que os resultados do trabalho são armazenados.
TópicosAccessControlList
Uma lista de concessões que controlam o acesso aos resultados armazenados.
Tipo: matriz de objetos Grant (p. 280)
Obrigatório: não
Versão da API 2012-06-01285

Amazon Glacier Guia do desenvolvedor doS3Location
BucketName
O nome do bucket do Amazon S3 no qual os resultados do trabalho são armazenados. O bucket deveestar na mesma região da AWS do cofre que contém o objeto de arquivo de entrada.
Type: String
Obrigatório: simCannedACL
A lista de controle de acesso pré-configurada a ser aplicada aos resultados do trabalho.
Type: String
Os valores válidos são: private | public-read | public-read-write | aws-exec-read |authenticated-read | bucket-owner-read | bucket-owner-full-control
Obrigatório: nãoCriptografia
Um objeto com informações sobre a criptografia usada para armazenar os resultados do trabalho noAmazon S3.
Tipo: Criptografia (p. 276) objeto
Obrigatório: nãoPrefixo
O prefixo que precede os resultados dessa solicitação. O tamanho máximo do prefixo é 512 bytes.
Type: String
Obrigatório: simStorageClass
A classe de armazenamento usada para armazenar os resultados do trabalho.
Type: String
Valores válidos: STANDARD | REDUCED_REDUNDANCY | STANDARD_IA
Obrigatório: nãoAtribuição de tags (tagging)
O conjunto de tags aplicado aos resultados do trabalho.
Tipo:: mapa de string para string
Obrigatório: nãoUserMetadata
Um mapa de metadados a ser armazenado com os resultados do trabalho no Amazon S3.
Tipo:: mapa de string para string
Obrigatório: não
Mais informações• Initiate Job (trabalhos POST) (p. 257)
Versão da API 2012-06-01286

Amazon Glacier Guia do desenvolvedor doSelectParameters
SelectParametersContém informações sobre os parâmetros usados na seleção.
TópicosExpressão
A expressão usada para selecionar o objeto. A expressão não deve exceder o limite de 128.000caracteres.
Type: String
Obrigatório: simExpressionType
O tipo da expressão fornecida; por exemplo, SQL.
Valores válidos: SQL
Type: String
Obrigatório: simInputSerialization
Descreve o formato de serialização do objeto na seleção.
Tipo: InputSerialization (p. 281) objeto
Obrigatório: nãoOutputSerialization
Descreve como os resultados do trabalho de seleção são serializados.
Obrigatório: não
Tipo: OutputSerialization (p. 285) objeto
Mais informações• Initiate Job (trabalhos POST) (p. 257)
Operações de recuperação de dadosEstas são as operações relacionadas à recuperação de dados disponíveis no Amazon Glacier.
Tópicos• Política de recuperação para obter dados (GET policy) (p. 288)• List Provisioned Capacity (GET provisioned-capacity) (p. 290)• Purchase Provisioned Capacity (POST provisioned-capacity) (p. 293)• Set Data Retrieval Policy (PUT policy) (p. 295)
Versão da API 2012-06-01287

Amazon Glacier Guia do desenvolvedor doPolítica de recuperação para obter dados
Política de recuperação para obter dados (GET policy)DescriçãoEsta operação retorna a política de recuperação de dados atual da conta e da região especificada nasolicitação GET. Para obter mais informações sobre políticas de recuperação de dados, consulte Políticasde recuperação dos dados do Amazon Glacier (p. 142).
SolicitaçõesPara retornar a política de recuperação de dados atual, envie uma solicitação GET HTTP para o URI dapolítica de recuperação de dados conforme mostrado no exemplo de sintaxe a seguir.
Sintaxe
GET /AccountId/policies/data-retrieval HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitação
Essa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSintaxe
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: length{ "Policy": { "Rules":[
Versão da API 2012-06-01288

Amazon Glacier Guia do desenvolvedor doPolítica de recuperação para obter dados
{ "BytesPerHour": Number, "Strategy": String } ] }}
Cabeçalhos de respostaEssa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da respostaO corpo da resposta contém os seguintes campos JSON:
BytesPerHour
O número máximo de bytes que podem ser recuperados em uma hora.
Este campo estará presente somente se o valor do campo Strategy for BytesPerHour.
Tipo: númeroRegras
A regra da política. Embora esse seja um tipo de lista, atualmente deve haver somente uma regra, quecontém um campo Strategy e, como opção, um campo BytesPerHour.
Tipo: matrizStrategy
O tipo de política de recuperação de dados.
Type: String
Valores válidos: BytesPerHour|FreeTier|None. BytesPerHour equivale a selecionar MaxRetrieval Rate no console. FreeTier equivale a selecionar Free Tier Only no console. None equivalea selecionar No Retrieval Policy no console. Para obter mais informações sobre como selecionarpolíticas de recuperação de dados no console, consulte Políticas de recuperação dos dados doAmazon Glacier (p. 142).
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir demonstra como obter uma política de recuperação de dados.
Exemplo de solicitaçãoNeste exemplo, uma solicitação GET é enviada para o URI do local de uma política.
GET /-/policies/data-retrieval HTTP/1.1Host: glacier.us-west-2.amazonaws.com
Versão da API 2012-06-01289

Amazon Glacier Guia do desenvolvedor doList Provision Capacity
x-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de resposta
Uma resposta bem-sucedida mostra a política de recuperação de dados no corpo da resposta em formatoJSON.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:00:00 GMTContent-Type: application/jsonContent-Length: 85 { "Policy": { "Rules":[ { "BytesPerHour":10737418240, "Strategy":"BytesPerHour" } ] }}
Seções relacionadas• Set Data Retrieval Policy (PUT policy) (p. 295)
• Initiate Job (trabalhos POST) (p. 257)
List Provisioned Capacity (GET provisioned-capacity)Esta operação lista as unidades de capacidade provisionadas para a conta da AWS especificada.Para obter mais informações sobre a capacidade provisionada, consulte Opções de recuperação dearquivos (p. 80).
Uma unidade de capacidade provisionada dura um mês a partir da data e hora da compra, que é a datade início. A unidade expira na data de expiração, que é exatamente um mês depois da data de início até osegundo mais próximo.
Se a data de início é dia 31 de um mês, a data de expiração será o último dia do mês seguinte. Porexemplo, se a data de início é dia 31 de agosto, a data de expiração será dia 30 de setembro. Se a datade início é dia 31 de janeiro, a data de expiração será dia 28 de fevereiro. Você pode consultar essafuncionalidade em Exemplo de resposta (p. 292).
Sintaxe da solicitaçãoPara listar a capacidade de recuperação provisionada para uma conta, envie uma solicitação GET HTTPpara o URI de capacidade provisionado conforme mostrado no exemplo de sintaxe a seguir.
GET /AccountId/provisioned-capacity HTTP/1.1
Versão da API 2012-06-01290

Amazon Glacier Guia do desenvolvedor doList Provision Capacity
Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValuex-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoEssa operação não tem um corpo de solicitação.
RespostasSe a operação for bem-sucedida, o serviço reenviará uma resposta 200 OK HTTP.
Sintaxe da resposta
HTTP/1.1 200 OKx-amzn-RequestId: x-amzn-RequestIdDate: DateContent-Type: application/jsonContent-Length: Length{ "ProvisionedCapacityList": { "CapacityId" : "string", "StartDate" : "string" "ExpirationDate" : "string" }}
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
O corpo da resposta contém os seguintes campos JSON:
Versão da API 2012-06-01291

Amazon Glacier Guia do desenvolvedor doList Provision Capacity
CapacityId
O ID que identifica a unidade de capacidade provisionada.
Tipo: string.StartDate
A data em que a unidade de capacidade provisionada foi comprada, em Coordinated Universal Time(UTC – Tempo universal coordenado).
Type: String. Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
ExpirationDate
A data em que a unidade de capacidade provisionada expira, em UTC.
Type: String. Uma representação de string no formato de data ISO 8601, por exemplo,2013-03-20T17:03:43.221Z.
ErrosPara informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosO exemplo a seguir lista as unidades de capacidade provisionada para uma conta.
Exemplo de solicitaçãoNeste exemplo, uma solicitação GET é enviada para recuperar uma lista das unidades de capacidadeprovisionada para a conta especificada.
GET /123456789012/priority-capacity HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier retornará um HTTP 200 OK com uma lista deunidades de capacidade provisionada para a conta, conforme mostrado no exemplo a seguir.
A unidade de capacidade provisionada listada primeiro é um exemplo de unidade com data de início nodia 31 de janeiro de 2017 e data de expiração no dia 28 de fevereiro de 2017. Conforme mencionadoanteriormente, se a data de início é dia 31 de um mês, a data de expiração será o último dia do mêsseguinte.
HTTP/1.1 200 OKx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTContent-Type: application/jsonContent-Length: length
{
Versão da API 2012-06-01292

Amazon Glacier Guia do desenvolvedor doPurchase Provisioned Capacity
"ProvisionedCapacityList", { "CapacityId": "zSaq7NzHFQDANTfQkDen4V7z", "StartDate": "2017-01-31T14:26:33.031Z", "ExpirationDate": "2017-02-28T14:26:33.000Z", }, { "CapacityId": "yXaq7NzHFQNADTfQkDen4V7z", "StartDate": "2016-12-13T20:11:51.095Z"", "ExpirationDate": "2017-01-13T20:11:51.000Z" ", }, ...}
Seções relacionadas• Purchase Provisioned Capacity (POST provisioned-capacity) (p. 293)
Purchase Provisioned Capacity (POST provisioned-capacity)Esta operação adquire uma unidade de capacidade provisionada para uma conta da AWS.
Uma unidade de capacidade provisionada dura um mês a partir da data e hora da compra, que é a datade início. A unidade expira na data de expiração, que é exatamente um mês depois da data de início até osegundo mais próximo.
Se a data de início é dia 31 de um mês, a data de expiração será o último dia do mês seguinte. Porexemplo, se a data de início é dia 31 de agosto, a data de expiração será dia 30 de setembro. Se a data deinício é dia 31 de janeiro, a data de expiração será dia 28 de fevereiro.
A capacidade provisionada garante que sua capacidade de recuperação para recuperações expressasestará disponível quando você precisar dela. Cada unidade de capacidade garante que pelo menos trêsrecuperações expressas possam ser realizadas a cada cinco minutos e fornece até 150 MB/s de taxa detransferência de recuperação. Para obter mais informações sobre a capacidade provisionada, consulteOpções de recuperação de arquivos (p. 80).
SolicitaçõesPara adquirir uma unidade de capacidade provisionada para uma conta da AWS, envie uma solicitaçãoPOST HTTP para o URI de capacidade provisionada.
Sintaxe
POST /AccountId/provisioned-capacity HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValueContent-Length: Lengthx-amz-glacier-version: 2012-06-01
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o ID
Versão da API 2012-06-01293

Amazon Glacier Guia do desenvolvedor doPurchase Provisioned Capacity
de conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitação
Cabeçalhos de solicitação
Essa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitação
Essa operação não tem um corpo de solicitação.
RespostasSe a solicitação de operação for bem-sucedida, o serviço retornará uma resposta 201 Created HTTP.
Sintaxe
HTTP/1.1 201 Createdx-amzn-RequestId: x-amzn-RequestIdDate: Datex-amz-capacity-id: CapacityId
Cabeçalhos de respostaUma resposta bem-sucedida inclui os cabeçalhos de resposta a seguir, além dos cabeçalhos de respostaque são comuns a todas as operações. Para mais informações sobre os cabeçalhos de resposta comuns,consulte Cabeçalhos de resposta comuns (p. 155).
Nome Descrição
x-amz-capacity-id O ID que identifica a unidade de capacidade provisionada.
Tipo: string
Corpo da respostaEssa operação não retorna um corpo de resposta.
ErrosEssa operação inclui os erros a seguir, além de erros possíveis comuns a todas as operações do AmazonGlacier. Para informações sobre erros do Amazon Glacier e uma lista de códigos de erro, consulteRespostas de erro (p. 169).
Code Descrição Código de statusHTTP
Type
LimitExceededException Retornado se a determinadasolicitação excederia o limite daconta de unidades de capacidadeprovisionada.
400 BadRequest
Cliente
Versão da API 2012-06-01294
Amazon Glacier Guia do desenvolvedor doSet Data Retrieval Policy
ExemplosO exemplo a seguir compra a capacidade provisionada para uma conta.
Exemplo de solicitaçãoO exemplo a seguir envia uma solicitação POST HTTP para comprar uma unidade de capacidadeprovisionada.
POST /123456789012/provisioned-capacity HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000ZAuthorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2Content-Length: lengthx-amz-glacier-version: 2012-06-01
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier retornará uma resposta HTTP 201 Created,conforme mostrado no exemplo a seguir.
HTTP/1.1 201 Createdx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMTx-amz-capacity-id: zSaq7NzHFQDANTfQkDen4V7z
Seções relacionadas• List Provisioned Capacity (GET provisioned-capacity) (p. 290)
Set Data Retrieval Policy (PUT policy)DescriçãoEsta operação define e impõe uma política de recuperação de dados na região especificada na solicitaçãoPUT. Você pode definir uma política por região para uma conta da AWS. A política é imposta após algunsminutos de uma operação PUT bem-sucedida.
A operação set policy não afeta trabalhos de recuperação que estavam em andamento antes da imposiçãoda política. Para obter mais informações sobre políticas de recuperação de dados, consulte Políticas derecuperação dos dados do Amazon Glacier (p. 142).
SolicitaçõesSintaxePara definir uma política de recuperação de dados, envie uma solicitação HTTP PUT para o URI da políticade recuperação de dados conforme mostrado no exemplo de sintaxe a seguir.
PUT /AccountId/policies/data-retrieval HTTP/1.1Host: glacier.Region.amazonaws.comDate: DateAuthorization: SignatureValue
Versão da API 2012-06-01295

Amazon Glacier Guia do desenvolvedor doSet Data Retrieval Policy
Content-Length: Lengthx-amz-glacier-version: 2012-06-01 { "Policy": { "Rules":[ { "Strategy": String, "BytesPerHour": Number } ] }}
Note
O valor AccountId é o ID de conta da AWS. Esse valor deve corresponder ao ID de conta daAWS associado às credenciais usadas para assinar a solicitação. Você pode especificar um ID deconta da AWS ou, opcionalmente, um único '-' (hífen) e, nesse caso, o Amazon Glacier usa o IDde conta da AWS associado às credenciais usadas para assinar a solicitação. Se você especificarseu ID de conta, não inclua hífens (“-”) nele.
Parâmetros de solicitaçãoEssa operação não usa parâmetros de solicitação.
Cabeçalhos de solicitaçãoEssa operação usa somente os cabeçalhos de solicitação que são comuns a todas as operações.Para informações sobre os cabeçalhos de solicitação comuns, consulte Cabeçalhos de solicitaçãocomuns (p. 152).
Corpo da solicitaçãoO corpo da solicitação contém os seguintes campos JSON:
BytesPerHour
O número máximo de bytes que podem ser recuperados em uma hora.
Este campo somente será obrigatório se o valor do campo Strategy for BytesPerHour. A operaçãoPUT será rejeitada se o campo Strategy não for definido como BytesPerHour e você definir essecampo.
Tipo: número
Obrigatório: sim, se o campo Strategy for definido como BytesPerHour. Do contrário, não.
Valores válidos: valor do inteiro mínimo de 1. Valor do inteiro máximo de 2^63 - 1 inclusive.Regras
A regra da política. Embora esse seja um tipo de lista, atualmente deve haver somente uma regra, quecontém um campo Strategy e, como opção, um campo BytesPerHour.
Tipo: matriz
Obrigatório: simStrategy
O tipo de política de recuperação de dados a ser definido.
Versão da API 2012-06-01296

Amazon Glacier Guia do desenvolvedor doSet Data Retrieval Policy
Tipo: string
Obrigatório: sim
Valores válidos: BytesPerHour|FreeTier|None. BytesPerHour equivale a selecionar MaxRetrieval Rate no console. FreeTier equivale a selecionar Free Tier Only no console. None equivalea selecionar No Retrieval Policy no console. Para obter mais informações sobre como selecionarpolíticas de recuperação de dados no console, consulte Políticas de recuperação dos dados doAmazon Glacier (p. 142).
RespostasSintaxe
HTTP/1.1 204 No Contentx-amzn-RequestId: x-amzn-RequestIdDate: Date
Cabeçalhos de resposta
Essa operação usa somente os cabeçalhos de resposta que são comuns a maioria das respostas.Para informações sobre os cabeçalhos de resposta comuns, consulte Cabeçalhos de respostacomuns (p. 155).
Corpo da resposta
Essa operação não retorna um corpo de resposta.
Erros
Para informações sobre exceções e mensagens de erro do Amazon Glacier, consulte Respostas deerro (p. 169).
ExemplosExemplo de solicitação
O exemplo a seguir envia uma solicitação HTTP PUT com o campo Strategy definido comoBytesPerHour.
PUT /-/policies/data-retrieval HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2 { "Policy": { "Rules":[ { "Strategy":"BytesPerHour", "BytesPerHour":10737418240 } ]
Versão da API 2012-06-01297

Amazon Glacier Guia do desenvolvedor doSet Data Retrieval Policy
}}
O exemplo a seguir envia uma solicitação HTTP PUT com o campo Strategy definido como FreeTier.
PUT /-/policies/data-retrieval HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2 { "Policy": { "Rules":[ { "Strategy":"FreeTier" } ] }}
O exemplo a seguir envia uma solicitação HTTP PUT com o campo Strategy definido como None.
PUT /-/policies/data-retrieval HTTP/1.1Host: glacier.us-west-2.amazonaws.comx-amz-Date: 20170210T120000Zx-amz-glacier-version: 2012-06-01Authorization: AWS4-HMAC-SHA256 Credential=AKIAIOSFODNN7EXAMPLE/20141123/us-west-2/glacier/aws4_request,SignedHeaders=host;x-amz-date;x-amz-glacier-version,Signature=9257c16da6b25a715ce900a5b45b03da0447acf430195dcb540091b12966f2a2 { "Policy": { "Rules":[ { "Strategy":"None" } ] }}
Exemplo de respostaSe a solicitação for bem-sucedida, o Amazon Glacier definirá a política e retornará um HTTP 204 NoContent conforme mostrado no exemplo a seguir.
HTTP/1.1 204 No Contentx-amzn-RequestId: AAABZpJrTyioDC_HsOmHae8EZp_uBSJr6cnGOLKp_XJCl-QDate: Wed, 10 Feb 2017 12:02:00 GMT
Seções relacionadas• Política de recuperação para obter dados (GET policy) (p. 288)
• Initiate Job (trabalhos POST) (p. 257)
Versão da API 2012-06-01298

Amazon Glacier Guia do desenvolvedor doComando SELECT
Referência SQL para o Amazon S3Select e o Amazon Glacier Select
Essa referência contém uma descrição de elementos (SQL) de linguagem de consulta estruturada que sãocompatíveis com o Amazon S3 Select e o Amazon Glacier Select.
Tópicos• Comando SELECT (p. 299)• Tipos de dados (p. 303)• Operadores (p. 304)• Palavras-chave reservadas (p. 305)• Funções SQL (p. 309)
Comando SELECTO Amazon S3 Select e o Amazon Glacier Select são compatíveis somente com o comando SQL SELECT.As seguintes cláusulas padrão ANSI são compatíveis com SELECT:
• SELECT lista• Cláusula FROM• Cláusula WHERE• Cláusula LIMIT (apenas Amazon S3 Select)
Note
As consultas do Amazon S3 Select e do Amazon Glacier Select não oferecem suporte asubconsultas ou junções.
Lista SELECTA lista SELECT nomeia as colunas, as funções e as expressões que a consulta deve retornar. A listarepresenta o resultado da consulta.
SELECT *SELECT projection [ AS column_alias | column_alias ] [, ...]
O primeiro formulário com * (asterisco) retorna todas as linhas que passaram na cláusula WHERE, damaneira como estão. O segundo formulário cria uma linha com expressões escalares de saída definidaspelo usuário projection para cada coluna.
Cláusula FROMO Amazon S3 Select e o Amazon Glacier Select são compatíveis com os seguintes formatos da cláusulaFROM:
FROM table_nameFROM table_name aliasFROM table_name AS alias
Versão da API 2012-06-01299

Amazon Glacier Guia do desenvolvedor doCláusula WHERE
Em que table_name é um S3Object (para o Amazon S3 Select), ARCHIVE ou OBJECT (para o AmazonGlacier Select) que faz referência ao arquivo que está sendo consultado. Os usuários provenientes debancos de dados relacionais tradicionais podem pensar nisso como um esquema de banco de dados quecontém várias visualizações em uma tabela.
Seguindo o SQL padrão, a cláusula FROM cria linhas filtradas na cláusula WHERE e projetadas na listaSELECT.
Cláusula WHEREA cláusula WHERE segue esta sintaxe:
WHERE condition
A cláusula WHERE filtra as linhas com base na condição. Uma condição é uma expressão com um valorbooliano. Somente linhas para as quais a condição é avaliada como TRUE são retornadas no resultado.
Cláusula LIMIT (apenas Amazon S3 Select)A cláusula LIMIT segue esta sintaxe:
LIMIT number
A cláusula LIMIT limita o número de registros que você deseja que a consulta retorne com base nonúmero.
Note
O Amazon Glacier Select não é compatível com a cláusula LIMIT.
Acesso de atributoAs cláusulas SELECT e WHERE podem se referir a dados de registro usando um dos métodos nas seções aseguir, dependendo se o arquivo que está sendo consultado está no formato CSV ou JSON.
CSV• Column Numbers (Números de coluna) – Você pode se referir à enésima coluna de uma linha com
o nome _N, em que N é a posição da coluna. A contagem da posição começa em 1. Por exemplo, aprimeira coluna é denominada _1 e a segunda coluna é denominada _2.
Você pode se referir a uma coluna como _N ou alias._N. Por exemplo, _2 e myAlias._2 sãomaneiras válidas de fazer referência a uma coluna na lista SELECT e na cláusula WHERE.
• Column Headers (Cabeçalhos de coluna) – Para objetos no formato CSV que possuem uma linha decabeçalho, os cabeçalhos estão disponíveis para a lista SELECT e a cláusula WHERE. Especificamente,como no SQL tradicional, nas expressões de cláusula WHERE e SELECT, você pode consultar as colunaspor alias.column_name ou column_name.
JSON (apenas Amazon S3 Select)• Document (Documento) – Você pode acessar os campos do documentos JSON como alias.name. Os
campos aninhados também podem ser acessados, por exemplo, alias.name1.name2.name3• List (Lista) – Você pode acessar elementos em uma lista JSON usando índices baseados em zero com
o operador []. Por exemplo, você pode acessar o segundo elemento de uma lista como alias[1].Acessar elementos de lista pode ser combinado com campos como alias.name1.name2[1].name3.
Versão da API 2012-06-01300

Amazon Glacier Guia do desenvolvedor doDiferenciação de letras maiúsculas e
minúsculas de cabeçalho/nomes de atributo
• Exemplos: Considere esse objeto JSON como um exemplo de conjunto de dados:
{"name": "Susan Smith","org": "engineering","projects": [ {"project_name":"project1", "completed":false}, {"project_name":"project2", "completed":true} ]}
Exemplo 1: A consulta a seguir retorna estes resultados:
Select s.name from S3Object s
{"name":"Susan Smith"}
Exemplo 2: A consulta a seguir retorna estes resultados:
Select s.projects[0].project_name from S3Object s
{"project_name":"project1"}
Diferenciação de letras maiúsculas e minúsculas decabeçalho/nomes de atributoCom o Amazon S3 Select e o Amazon Glacier Select, você pode usar aspas duplas para indicar quecabeçalhos de coluna (para objetos CSV) e atributos (para objetos JSON) fazem diferenciação entreletras maiúsculas e minúsculas. Sem as aspas duplas, os cabeçalhos/atributos de objeto não fazemdiferenciação entre letras maiúsculas e minúsculas. Um erro ocorre em casos de ambiguidade.
Os exemplos a seguir são 1) objetos do Amazon S3 ou do Amazon Glacier no formato CSV com oscabeçalhos de coluna especificados e com FileHeaderInfo definido como "Usar" para a solicitação deconsulta ou 2) objetos do Amazon S3 no formato JSON com os atributos especificados.
Exemplo 1: O objeto que está sendo consultado tem o cabeçalho/atributo "NAME".
• A expressão a seguir retorna com êxito valores do objeto (sem aspas: não diferenciando entre letrasmaiúsculas e minúsculas):
SELECT s.name from S3Object s
• Os seguintes resultados de expressão em um erro 400 MissingHeaderName (aspas: diferenciaçãoentre letras maiúsculas e minúsculas):
SELECT s."name" from S3Object s
Exemplo 2: O objeto do Amazon S3 que está sendo consultado tem um cabeçalho/atributo com "NAME" eoutro cabeçalho/atributo com "name".
• A seguinte expressão resulta em um erro 400 AmbiguousFieldName (sem aspas: sem diferenciaçãoentre letras maiúsculas e minúsculas, mas há duas correspondências):
Versão da API 2012-06-01301

Amazon Glacier Guia do desenvolvedor doUsar palavras-chave reservadas
como termos definidos pelo usuário
SELECT s.name from S3Object s
• A expressão a seguir retorna com êxito valores do objeto (aspas: diferenciação entre letras maiúsculas eminúsculas, portanto, resolve a ambiguidade):
SELECT s."NAME" from S3Object s
Usar palavras-chave reservadas como termosdefinidos pelo usuárioO Amazon S3 Select e o Amazon Glacier Select possuem um conjunto de palavras-chave reservadasque são necessárias para executar as expressões SQL usadas para consultar o conteúdo do objeto. Aspalavras-chave reservadas incluem nomes de função, tipos de dados, operadores, e assim por diante. Emalguns casos, os termos definidos pelo usuário como os cabeçalhos de coluna (para arquivos CSV) ou osatributos (para objeto JSON) podem entrar em conflito com uma palavra-chave reservada. Quando issoocorrer, é necessário usar as aspas duplas para indicar que você está usando intencionalmente um termodefinido pelo usuário que entra em conflito com uma palavra-chave reservada. Caso contrário, ocorrerá umerro de análise 400.
Para obter a lista completa de palavras-chave, consulte Palavras-chave reservadas (p. 305).
O exemplo a seguir é 1) um objeto do Amazon S3 ou do Amazon Glacier no formato CSV com oscabeçalhos de coluna especificados, com FileHeaderInfo definido como "Usar" para a solicitação deconsulta ou 2) um objeto do Amazon S3 no formato JSON com os atributos especificados.
Exemplo: o objeto que está sendo consultado tem o cabeçalho/atributo nomeado como "CAST", que é umapalavra-chave reservada.
• A expressão a seguir retorna com êxito valores do objeto (aspas: usar cabeçalho/atributo definido pelousuário):
SELECT s."CAST" from S3Object s
• Os seguintes resultados de expressão resultam em um erro de análise 400 (sem aspas: entram emconflito com palavra-chave reservada):
SELECT s.CAST from S3Object s
Expressões escalaresNa cláusula WHERE e na lista SELECT, você terá expressões escalares SQL, que são expressões queretornam valores escalares. Elas têm o seguinte formato:
• literal
Um literal SQL.• column_reference
Uma referência a uma coluna no formato column_name ou alias.column_name.• unary_op expression
Em que unary_op é um operador unário SQL.
Versão da API 2012-06-01302

Amazon Glacier Guia do desenvolvedor doTipos de dados
• expression binary_op expression
Em que binary_op é um operador binário SQL.• func_name
Em que func_name é o nome de uma função escalar a ser invocada.• expression [ NOT ] BETWEEN expression AND expression• expression LIKE expression [ ESCAPE expression ]
Tipos de dadosO Amazon S3 Select e o Amazon Glacier Select são compatíveis com vários tipos de dados primitivos.
Conversões de tipo de dadosA regra geral é seguir a função CAST se definida. Se CAST não estiver definido, todos os dados de entradaserão tratados como uma string. Ele deve ser convertido em tipos de dados relevantes quando necessário.
Para obter mais informações sobre a função CAST, consulte CAST (p. 311).
Tipos de dados compatíveisO Amazon S3 Select e o Amazon Glacier Select são compatíveis com o conjunto de tipos de dadosprimitivos a seguir.
Nome Descrição Exemplos
bool TRUE ou FALSE FALSE
int, inteiro Número inteiro assinado de 8 bytes no intervalo de-9.223.372.036.854.775.808 a 9.223.372.036.854.775.807.
100000
string String de tamanho variável codificada por UTF8. O limite padrãoé um caractere. O limite máximo de caracteres é 2.147.483.647.
'xyz'
flutuante Número de ponto flutuante de 8 bytes. CAST(0.456AS FLOAT)
decimal,numérico
Número de base 10, com precisão máxima de 38 (ou seja, aquantidade máxima de dígitos significativos) e com escala nointervalo de -231 a 231-1 (ou seja, o expoente de base 10).
123.456
timestamp Os time stamps representam um momento específico, sempreincluem um deslocamento local e são capazes de oferecerprecisão arbitrária.
No formato de texto, os time stamps seguem a nota W3C sobreformatos de data e hora, mas devem terminar com o literal "T",se não for pelo menos a precisão de dia inteiro. As frações desegundos são permitidas, com pelo menos um dígito de precisãoe um máximo ilimitado. Os deslocamentos de hora local podemser representados como deslocamentos de hora:minuto em UTCou como o literal "Z" para indicar uma hora local em UTC. Eles
CAST('2007-04-05T14:30Z'ASTIMESTAMP)
Versão da API 2012-06-01303

Amazon Glacier Guia do desenvolvedor doOperadores
Nome Descrição Exemplossão necessários em time stamps com hora e não são permitidosem valores de data.
OperadoresO Amazon S3 Select e o Amazon Glacier Select são compatíveis com os operadores a seguir.
Operadores lógicos• AND
• NOT
• OR
Operadores de comparação• <
• >
• <=
• >=
• =
• <>
• !=
• BETWEEN
• IN – Por exemplo: IN ('a', 'b', 'c')
Operadores de correspondência de padrões• LIKE
Operadores matemáticosA adição, a subtração, a multiplicação, a divisão e o módulo são compatíveis.
• +• –• *• %
Precedência do operadorA tabela a seguir mostra a precedência dos operadores em ordem decrescente.
Versão da API 2012-06-01304

Amazon Glacier Guia do desenvolvedor doPalavras-chave reservadas
Operador/elemento
Capacidade de associação Obrigatório
– direita menos unário
*, /, % esquerda multiplicação,divisão, módulo
+, - esquerda adição,subtração
IN associação deconjunto
BETWEEN contenção deintervalo
LIKE correspondênciade padrões destring
<> menor que,maior que
= direita igualdade,atribuição
NOT direita negação lógica
AND esquerda conjunção lógica
OU esquerda disjunção lógica
Palavras-chave reservadasVeja abaixo a lista de palavras-chave reservadas para o Amazon S3 Select e o Amazon Glacier Select.Estes incluem os nomes de função, tipos de dados, operadores, etc., necessários para executar asexpressões SQL usadas para consultar o conteúdo do objeto.
absoluteactionaddallallocatealterandanyareasascassertionatauthorizationavgbagbeginbetweenbit
Versão da API 2012-06-01305

Amazon Glacier Guia do desenvolvedor doPalavras-chave reservadas
bit_lengthblobboolbooleanbothbycascadecascadedcasecastcatalogcharchar_lengthcharactercharacter_lengthcheckclobclosecoalescecollatecollationcolumncommitconnectconnectionconstraintconstraintscontinueconvertcorrespondingcountcreatecrosscurrentcurrent_datecurrent_timecurrent_timestampcurrent_usercursordatedaydeallocatedecdecimaldeclaredefaultdeferrabledeferreddeletedescdescribedescriptordiagnosticsdisconnectdistinctdomaindoubledropelseendend-execescapeexceptexceptionexecexecute
Versão da API 2012-06-01306

Amazon Glacier Guia do desenvolvedor doPalavras-chave reservadas
existsexternalextractfalsefetchfirstfloatforforeignfoundfromfullgetglobalgogotograntgrouphavinghouridentityimmediateinindicatorinitiallyinnerinputinsensitiveinsertintintegerintersectintervalintoisisolationjoinkeylanguagelastleadingleftlevellikelimitlistlocallowermatchmaxminminutemissingmodulemonthnamesnationalnaturalncharnextnonotnullnullifnumericoctet_length
Versão da API 2012-06-01307

Amazon Glacier Guia do desenvolvedor doPalavras-chave reservadas
ofononlyopenoptionororderouteroutputoverlapspadpartialpivotpositionprecisionpreparepreserveprimarypriorprivilegesprocedurepublicreadrealreferencesrelativerestrictrevokerightrollbackrowsschemascrollsecondsectionselectsessionsession_usersetsexpsizesmallintsomespacesqlsqlcodesqlerrorsqlstatestringstructsubstringsumsymbolsystem_usertabletemporarythentimetimestamptimezone_hourtimezone_minutetotrailingtransactiontranslatetranslation
Versão da API 2012-06-01308
Amazon Glacier Guia do desenvolvedor doFunções SQL
trimtruetupleunionuniqueunknownunpivotupdateupperusageuserusingvaluevaluesvarcharvaryingviewwhenwheneverwherewithworkwriteyearzone
Funções SQLO Amazon S3 Select e o Amazon Glacier Select são compatíveis com várias funções SQL.
Tópicos• Funções agregadas (apenas Amazon S3 Select) (p. 309)• Funções condicionais (p. 310)• Funções da conversão (p. 311)• Funções de data (p. 312)• Funções de string (p. 318)
Funções agregadas (apenas Amazon S3 Select)O Amazon S3 Select é compatível com as seguintes funções agregadas.
Note
O Amazon Glacier Select não é compatível com as funções agregadas.
Função Tipo de argumento Tipo de retorno
AVG(expression)INT, FLOAT, DECIMAL DECIMAL paraum argumentoINT, FLOAT paraum argumentode pontoflutuante, caso
Versão da API 2012-06-01309
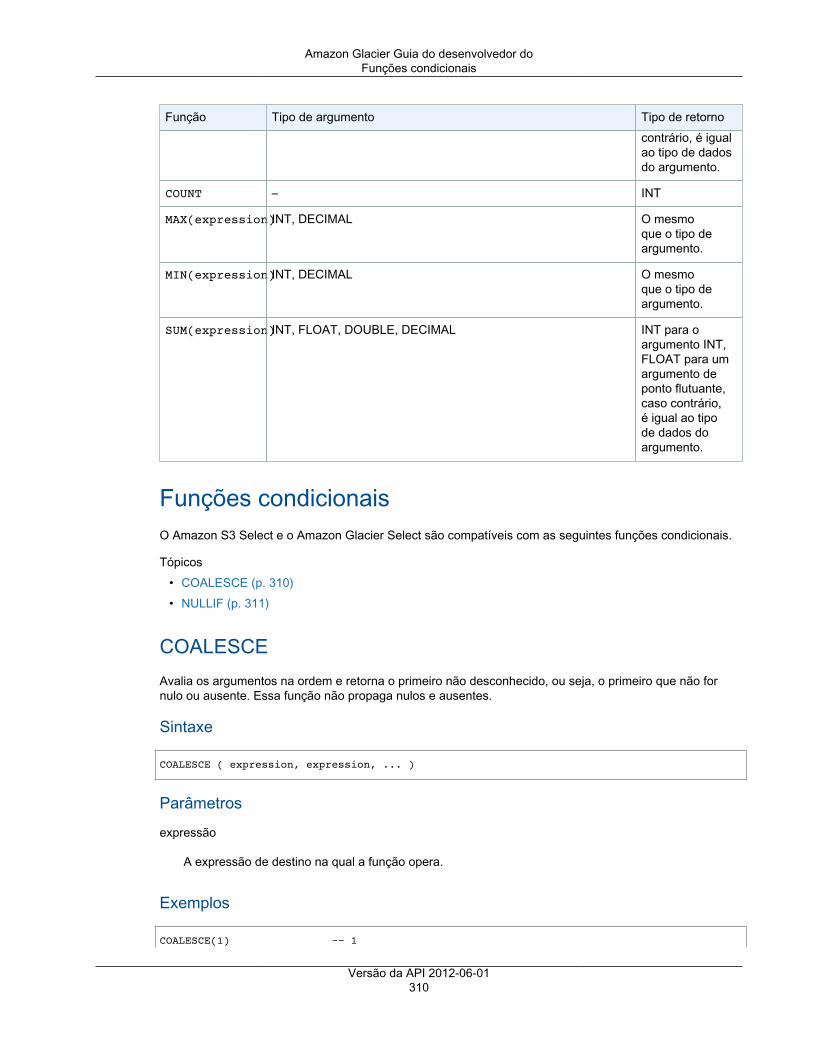
Amazon Glacier Guia do desenvolvedor doFunções condicionais
Função Tipo de argumento Tipo de retornocontrário, é igualao tipo de dadosdo argumento.
COUNT – INT
MAX(expression)INT, DECIMAL O mesmoque o tipo deargumento.
MIN(expression)INT, DECIMAL O mesmoque o tipo deargumento.
SUM(expression)INT, FLOAT, DOUBLE, DECIMAL INT para oargumento INT,FLOAT para umargumento deponto flutuante,caso contrário,é igual ao tipode dados doargumento.
Funções condicionaisO Amazon S3 Select e o Amazon Glacier Select são compatíveis com as seguintes funções condicionais.
Tópicos• COALESCE (p. 310)• NULLIF (p. 311)
COALESCEAvalia os argumentos na ordem e retorna o primeiro não desconhecido, ou seja, o primeiro que não fornulo ou ausente. Essa função não propaga nulos e ausentes.
Sintaxe
COALESCE ( expression, expression, ... )
Parâmetros
expressão
A expressão de destino na qual a função opera.
Exemplos
COALESCE(1) -- 1
Versão da API 2012-06-01310
Amazon Glacier Guia do desenvolvedor doFunções da conversão
COALESCE(null) -- nullCOALESCE(null, null) -- nullCOALESCE(missing) -- nullCOALESCE(missing, missing) -- nullCOALESCE(1, null) -- 1COALESCE(null, null, 1) -- 1COALESCE(null, 'string') -- 'string'COALESCE(missing, 1) -- 1
NULLIFDadas as duas expressões, retorna NULL se as duas forem avaliadas para o mesmo valor. Caso contrário,retorna o resultado da avaliação da primeira expressão.
Sintaxe
NULLIF ( expression1, expression2 )
Parâmetros
expression1, expression2
As expressões de destino nas quais a função opera.
Exemplos
NULLIF(1, 1) -- nullNULLIF(1, 2) -- 1NULLIF(1.0, 1) -- nullNULLIF(1, '1') -- 1NULLIF([1], [1]) -- nullNULLIF(1, NULL) -- 1NULLIF(NULL, 1) -- nullNULLIF(null, null) -- nullNULLIF(missing, null) -- nullNULLIF(missing, missing) -- null
Funções da conversãoO Amazon S3 Select e o Amazon Glacier Select são compatíveis com as seguintes funções de conversão.
Tópicos• CAST (p. 311)
CASTA função CAST converte uma entidade, como uma expressão que retorna um único valor, de um tipo emoutro.
Sintaxe
CAST ( expression AS data_type )
Versão da API 2012-06-01311

Amazon Glacier Guia do desenvolvedor doFunções de data
Parâmetros
expressão
Uma combinação de um ou mais valores, operadores e funções SQL que retornam um valor.tipo_dados
O tipo de dados de destino, como INT, no qual a expressão será convertida. Para obter uma lista dostipos de dados compatíveis, consulte Tipos de dados (p. 303).
Exemplos
CAST('2007-04-05T14:30Z' AS TIMESTAMP)CAST(0.456 AS FLOAT)
Funções de dataO Amazon S3 Select e o Amazon Glacier Select são compatíveis com as seguintes funções de data.
Tópicos• DATE_ADD (p. 312)• DATE_DIFF (p. 313)• EXTRACT (p. 314)• TO_STRING (p. 314)• TO_TIMESTAMP (p. 317)• UTCNOW (p. 318)
DATE_ADDDada uma parte da data, uma quantidade e um time stamp, retorna um time stamp atualizado, alterando aparte da data pela quantidade.
Sintaxe
DATE_ADD( date_part, quantity, timestamp )
Parâmetros
date_part
Especifica que parte da data deve ser modificada. Pode ser uma das partes a seguir:• year• mês• dia• hora• minuto• segundos
Versão da API 2012-06-01312

Amazon Glacier Guia do desenvolvedor doFunções de data
quantity (quantidade)
O valor a ser aplicado a um time stamp atualizado. Os valores positivos para a quantidade sãoadicionados à date_part do time stamp e os valores negativos são subtraídos.
timestamp
O time stamp de destino no qual a função opera.
Exemplos
DATE_ADD(year, 5, `2010-01-01T`) -- 2015-01-01 (equivalent to 2015-01-01T)DATE_ADD(month, 1, `2010T`) -- 2010-02T (result will add precision as necessary)DATE_ADD(month, 13, `2010T`) -- 2011-02TDATE_ADD(day, -1, `2017-01-10T`) -- 2017-01-09 (equivalent to 2017-01-09T)DATE_ADD(hour, 1, `2017T`) -- 2017-01-01T01:00-00:00DATE_ADD(hour, 1, `2017-01-02T03:04Z`) -- 2017-01-02T04:04ZDATE_ADD(minute, 1, `2017-01-02T03:04:05.006Z`) -- 2017-01-02T03:05:05.006ZDATE_ADD(second, 1, `2017-01-02T03:04:05.006Z`) -- 2017-01-02T03:04:06.006Z
DATE_DIFFDada uma parte da data e dois time stamps, retorna a diferença nas partes da data. O valor de retornoé um inteiro negativo quando o valor date_part do timestamp1 for maior que o valor date_part dotimestamp2. O valor de retorno é um inteiro positivo quando o valor date_part do timestamp1 formenor que o valor date_part do timestamp2.
Sintaxe
DATE_DIFF( date_part, timestamp1, timestamp2 )
Parâmetros
date_part
Especifica que parte dos time stamps deve ser comparada. Para a definição de date_part, consulteDATE_ADD (p. 312).
timestamp1
O primeiro time stamp a ser comparado.timestamp2
O segundo time stamp a ser comparado.
Exemplos
DATE_DIFF(year, `2010-01-01T`, `2011-01-01T`) -- 1DATE_DIFF(year, `2010T`, `2010-05T`) -- 4 (2010T is equivalent to 2010-01-01T00:00:00.000Z)DATE_DIFF(month, `2010T`, `2011T`) -- 12DATE_DIFF(month, `2011T`, `2010T`) -- -12DATE_DIFF(day, `2010-01-01T23:00T`, `2010-01-02T01:00T`) -- 0 (need to be at least 24h apart to be 1 day apart)
Versão da API 2012-06-01313

Amazon Glacier Guia do desenvolvedor doFunções de data
EXTRACTDada uma parte da data e um time stamp, retorna o valor da parte da data do time stamp.
Sintaxe
EXTRACT( date_part FROM timestamp )
Parâmetros
date_part
Especifica que parte dos time stamps deve ser extraída. Pode ser uma das partes a seguir:• year• mês• dia• hora• minuto• segundos• timezone_hour• timezone_minute
timestamp
O time stamp de destino no qual a função opera.
Exemplos
EXTRACT(YEAR FROM `2010-01-01T`) -- 2010EXTRACT(MONTH FROM `2010T`) -- 1 (equivalent to 2010-01-01T00:00:00.000Z)EXTRACT(MONTH FROM `2010-10T`) -- 10EXTRACT(HOUR FROM `2017-01-02T03:04:05+07:08`) -- 3EXTRACT(MINUTE FROM `2017-01-02T03:04:05+07:08`) -- 4EXTRACT(TIMEZONE_HOUR FROM `2017-01-02T03:04:05+07:08`) -- 7EXTRACT(TIMEZONE_MINUTE FROM `2017-01-02T03:04:05+07:08`) -- 8
TO_STRINGDado um time stamp e um padrão de formato, retorna uma representação de string do time stamp noformato especificado.
Sintaxe
TO_STRING ( timestamp time_format_pattern )
Parâmetros
timestamp
O time stamp de destino no qual a função opera.
Versão da API 2012-06-01314
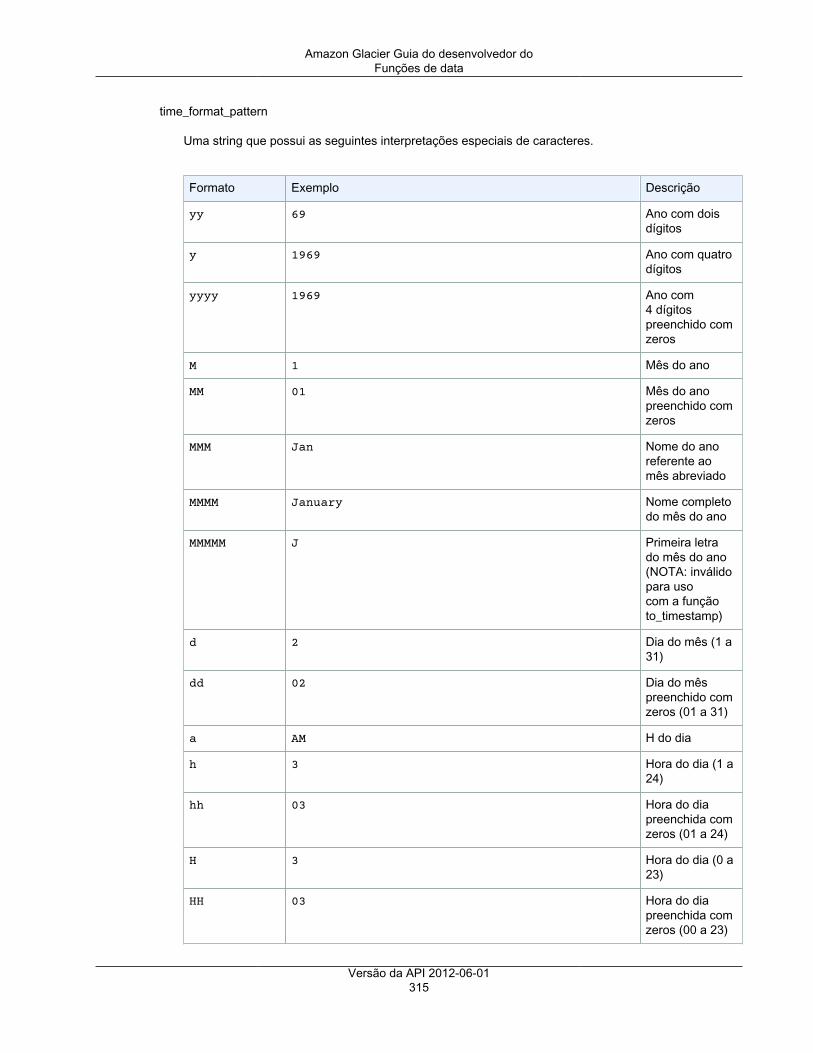
Amazon Glacier Guia do desenvolvedor doFunções de data
time_format_pattern
Uma string que possui as seguintes interpretações especiais de caracteres.
Formato Exemplo Descrição
yy 69 Ano com doisdígitos
y 1969 Ano com quatrodígitos
yyyy 1969 Ano com4 dígitospreenchido comzeros
M 1 Mês do ano
MM 01 Mês do anopreenchido comzeros
MMM Jan Nome do anoreferente aomês abreviado
MMMM January Nome completodo mês do ano
MMMMM J Primeira letrado mês do ano(NOTA: inválidopara usocom a funçãoto_timestamp)
d 2 Dia do mês (1 a31)
dd 02 Dia do mêspreenchido comzeros (01 a 31)
a AM H do dia
h 3 Hora do dia (1 a24)
hh 03 Hora do diapreenchida comzeros (01 a 24)
H 3 Hora do dia (0 a23)
HH 03 Hora do diapreenchida comzeros (00 a 23)
Versão da API 2012-06-01315

Amazon Glacier Guia do desenvolvedor doFunções de data
Formato Exemplo Descrição
m 4 Minuto da hora(0 a 59)
mm 04 Minuto da horapreenchido comzeros (00 a 59)
s 5 Segundo dominuto (0 a 59)
ss 05 Segundodo minutopreenchido comzeros (00 a 59)
S 0 Fração desegundos(precisão: 0,1,intervalo: 0,0 a0,9)
SS 6 Fração desegundos(precisão: 0,01,intervalo: 0,0 a0,99)
SSS 60 Fração desegundos(precisão:0,001, intervalo:0,0 a 0,999)
… … …
SSSSSSSSS 60000000 Fração desegundos(precisãomáxima: 1nanossegundo,intervalo: 0,0 a0,999999999)
n 60000000 Nano desegundo
X +07 or Z Deslocamentoem horasou "Z" se odeslocamentofor 0
Versão da API 2012-06-01316

Amazon Glacier Guia do desenvolvedor doFunções de data
Formato Exemplo Descrição
XX or XXXX +0700 or Z Deslocamentoem horase minutosou "Z" se odeslocamentofor 0
XXX or XXXXX +07:00 or Z Deslocamentoem horase minutosou "Z" se odeslocamentofor 0
x 7 Deslocamentoem horas
xx or xxxx 700 Deslocamentoem horas eminutos
xxx or xxxxx +07:00 Deslocamentoem horas eminutos
Exemplos
TO_STRING(`1969-07-20T20:18Z`, 'MMMM d, y') -- "July 20, 1969"TO_STRING(`1969-07-20T20:18Z`, 'MMM d, yyyy') -- "Jul 20, 1969"TO_STRING(`1969-07-20T20:18Z`, 'M-d-yy') -- "7-20-69"TO_STRING(`1969-07-20T20:18Z`, 'MM-d-y') -- "07-20-1969"TO_STRING(`1969-07-20T20:18Z`, 'MMMM d, y h:m a') -- "July 20, 1969 8:18 PM"TO_STRING(`1969-07-20T20:18Z`, 'y-MM-dd''T''H:m:ssX') -- "1969-07-20T20:18:00Z"TO_STRING(`1969-07-20T20:18+08:00Z`, 'y-MM-dd''T''H:m:ssX') -- "1969-07-20T20:18:00Z"TO_STRING(`1969-07-20T20:18+08:00`, 'y-MM-dd''T''H:m:ssXXXX') -- "1969-07-20T20:18:00+0800"TO_STRING(`1969-07-20T20:18+08:00`, 'y-MM-dd''T''H:m:ssXXXXX') -- "1969-07-20T20:18:00+08:00"
TO_TIMESTAMPDada uma string, converte-a em um time stamp. Esta é a operação inversa de TO_STRING.
Sintaxe
TO_TIMESTAMP ( string )
Parâmetros
string
A string de destino na qual a função opera.
Versão da API 2012-06-01317

Amazon Glacier Guia do desenvolvedor doFunções de string
Exemplos
TO_TIMESTAMP('2007T') -- `2007T`TO_TIMESTAMP('2007-02-23T12:14:33.079-08:00') -- `2007-02-23T12:14:33.079-08:00`
UTCNOWRetorna o tempo atual em UTC como um time stamp.
Sintaxe
UTCNOW()
Parâmetros
none
Exemplos
UTCNOW() -- 2017-10-13T16:02:11.123Z
Funções de stringO Amazon S3 Select e o Amazon Glacier Select são compatíveis com as seguintes funções de string.
Tópicos• CHAR_LENGTH, CHARACTER_LENGTH (p. 318)• LOWER (p. 319)• SUBSTRING (p. 319)• TRIM (p. 320)• UPPER (p. 320)
CHAR_LENGTH, CHARACTER_LENGTHConta o número de caracteres na string especificada.
Note
CHAR_LENGTH e CHARACTER_LENGTH são sinônimos.
Sintaxe
CHAR_LENGTH ( string )
Parâmetros
string
A string de destino na qual a função opera.
Versão da API 2012-06-01318

Amazon Glacier Guia do desenvolvedor doFunções de string
Exemplos
CHAR_LENGTH('') -- 0CHAR_LENGTH('abcdefg') -- 7
LOWERDada uma string, converte todos os caracteres maiúsculos em minúsculos. Todos os caracteresminúsculos permanecem inalterados.
Sintaxe
LOWER ( string )
Parâmetros
string
A string de destino na qual a função opera.
Exemplos
LOWER('AbCdEfG!@#$') -- 'abcdefg!@#$'
SUBSTRINGDada uma string, um índice inicial e, opcionalmente, um tamanho, retorna a substring do índice inicial até ofinal da string ou até o tamanho fornecido.
Note
O primeiro caractere da string de entrada tem o índice 1. Se start for < 1, será definido para 1.
Sintaxe
SUBSTRING( string FROM start [ FOR length ] )
Parâmetros
string
A string de destino na qual a função opera.start
A posição inicial da string.length
O tamanho da substring a ser retornada. Se não estiver presente, prossiga para o final da string.
Exemplos
SUBSTRING("123456789", 0) -- "123456789"SUBSTRING("123456789", 1) -- "123456789"SUBSTRING("123456789", 2) -- "23456789"
Versão da API 2012-06-01319

Amazon Glacier Guia do desenvolvedor doFunções de string
SUBSTRING("123456789", -4) -- "123456789"SUBSTRING("123456789", 0, 999) -- "123456789" SUBSTRING("123456789", 1, 5) -- "12345"
TRIMCorta os caracteres iniciais ou finais de uma string. O caractere padrão a ser removido é ' '.
Sintaxe
TRIM ( [[LEADING | TRAILING | BOTH remove_chars] FROM] string )
Parâmetros
string
A string de destino na qual a função opera.LEADING | TRAILING | BOTH
Se é necessário cortar os caracteres iniciais ou finais, ou ambos.remove_chars
O conjunto de caracteres a ser removido. Observe que remove_chars pode ser uma string comtamanho > 1. Essa função retorna a string com qualquer caractere de remove_chars encontrado noinício ou final da string que foi removida.
Exemplos
TRIM(' foobar ') -- 'foobar'TRIM(' \tfoobar\t ') -- '\tfoobar\t'TRIM(LEADING FROM ' foobar ') -- 'foobar 'TRIM(TRAILING FROM ' foobar ') -- ' foobar'TRIM(BOTH FROM ' foobar ') -- 'foobar'TRIM(BOTH '12' FROM '1112211foobar22211122') -- 'foobar'
UPPERDada uma string, converte todos os caracteres minúsculos em maiúsculos. Todos os caracteresmaiúsculos permanecem inalterados.
Sintaxe
UPPER ( string )
Parâmetros
string
A string de destino na qual a função opera.
Exemplos
UPPER('AbCdEfG!@#$') -- 'ABCDEFG!@#$'
Versão da API 2012-06-01320

Amazon Glacier Guia do desenvolvedor doAtualizações anteriores
Histórico do documento• Última atualização da documentação: 5 de julho de 2018• Versão do produto atual: 2012-06-01
A tabela a seguir descreve as alterações importantes em cada versão do Guia do desenvolvedor doAmazon Glacier de 5 de julho de 2018 em diante. Para receber notificações sobre atualizações dessadocumentação, você pode se inscrever em um feed RSS.
update-history-change update-history-description update-history-date
Atualizações agora disponíveisem RSS (p. 321)
Agora, você pode assinarum feed RSS para recebernotificações sobre atualizaçõesno guia Guia do desenvolvedordo Amazon Glacier.
July 5, 2018
Atualizações anterioresA tabela a seguir descreve as alterações importantes em cada versão do Guia do desenvolvedor doAmazon Glacier antes de 5 de julho de 2018.
Alteração Descrição Data de lançamento
Consulta dearquivos com SQL
Agora o Amazon Glacier oferece suporte à consulta dearquivos de dados com SQL. Para obter mais informações,consulte Consulta em arquivos com o Amazon GlacierSelect (p. 139).
As seguintes APIs serão atualizadas apropriadamente:
• Trabalho de descrição (GET JobID) (p. 243)• Initiate Job (trabalhos POST) (p. 257)• List Jobs (GET jobs) (p. 267)
29 de novembro de2017
Recuperações dedados expressas eem massa
O Amazon Glacier agora dá suporte a recuperações dedados expressas e em massa, além de recuperaçõespadrão. Para obter mais informações, consulte Opções derecuperação de arquivos (p. 80).
21 de novembro de2016
Vault Lock O Amazon Glacier agora dá suporte ao Vault Lock,que permite implantar e impor facilmente controles deconformidade em cofres do Amazon Glacier individuaiscom uma política do Vault Lock. Para obter maisinformações, consulte Amazon Glacier Vault Lock (p. 59)e Controle de acesso do Amazon Glacier com políticas debloqueio de cofre (p. 131).
8 de julho de 2015
Marcação do cofre O Amazon Glacier agora permite marcar os cofres doAmazon Glacier para um gerenciamento mais fácil derecursos e custos. Tags são rótulos que você pode definir
22 de junho de 2015
Versão da API 2012-06-01321

Amazon Glacier Guia do desenvolvedor doAtualizações anteriores
Alteração Descrição Data de lançamentoe associar aos cofres, e usar tags adiciona recursos defiltragem a operações como relatórios de custos da AWS.Para obter mais informações, consulte Marcar recursos doAmazon Glacier (p. 146) e Marcar os cofres do AmazonGlacier (p. 58).
Políticas de acessoao cofre
O Amazon Glacier agora dá suporte ao gerenciamento deacesso aos cofres do Amazon Glacier individuais usandopolíticas de acesso ao cofre. Agora você pode definiruma política de acesso diretamente em um cofre, o quefacilita a concessão de acesso ao cofre para usuários egrupos de negócios internos da organização, bem comopara parceiros de negócios externos. Para obter maisinformações, consulte Controle de acesso do AmazonGlacier com políticas de acesso ao cofre (p. 129).
27 de abril de 2015
Políticas derecuperação dedados e registro emlog de auditoria
O Amazon Glacier agora dá suporte a políticas derecuperação de dados e registro em log de auditoria.As políticas de recuperação de dados permitem definirfacilmente limites de recuperação de dados e simplificaro gerenciamento de custos da recuperação de dados.Você pode definir os próprios limites da recuperação dedados com alguns cliques no console da AWS ou usandoa Amazon Glacier API. Para obter mais informações,consulte Políticas de recuperação dos dados do AmazonGlacier (p. 142).
Além disso, o Amazon Glacier agora dá suporte ao registroem log de auditoria com o AWS CloudTrail, que registraas chamadas de API do Amazon Glacier para a conta efornece os arquivos de log para um bucket do AmazonS3 especificado por você. Para obter mais informações,consulte Registro de chamadas de API do Amazon Glaciercom o AWS CloudTrail (p. 148).
11 de dezembro de2014
Atualizações feitasem amostras doJava
Atualizadas as amostras de código do Java neste guia queusam o AWS SDK for Java.
27 de junho de 2014
Limitar recuperaçãodo inventário decofre
Agora você pode limitar o número de itens do inventário decofre recuperados filtrando a data de criação do arquivoou definindo um limite. Para obter mais informaçõessobre como limitar a recuperação do inventário, consulteRecuperação do inventário de intervalo (p. 260) no tópicoInitiate Job (trabalhos POST) (p. 257).
31 de dezembro de2013
Removidos URLsobsoletos
Removidos os URLs que apontavam para a página decredenciais de segurança anterior de exemplos de código.
26 de julho de 2013
Versão da API 2012-06-01322

Amazon Glacier Guia do desenvolvedor doAtualizações anteriores
Alteração Descrição Data de lançamento
Suporte pararecuperações deintervalos
O Amazon Glacier agora dá suporte à recuperação deintervalos específicos dos arquivos. Você pode iniciar umtrabalho solicitando ao Amazon Glacier para prepararum arquivo inteiro ou uma parte dele para downloadsubsequente. Quando um arquivo é muito grande, vocêpode achar mais econômico iniciar vários trabalhossequenciais a fim de preparar o arquivo.
Para obter mais informações, consulte Fazer download deum arquivo no Amazon Glacier (p. 79).
Para obter informações sobre definição de preço, vá até apágina de detalhes do Amazon Glacier.
13 de novembro de2012
Novo guia Esta é a primeira versão do Guia do desenvolvedor doAmazon Glacier.
20 de agosto de2012
Versão da API 2012-06-01323

Amazon Glacier Guia do desenvolvedor do
AWS GlossaryFor the latest AWS terminology, see the AWS Glossary in the AWS General Reference.
Versão da API 2012-06-01324