Embed Size (px)
Citation preview

Universidad TELESUP Ingeniería de Sistemas Ciclo 2017-I
Algoritmo de la gradiente descendente
Gradiente descendente es un algoritmo que nos permite resolver el problema de minimización de una función genérica J.
Dada una función J que es función de n parámetros, nuestro objetivo es encontrar el valor de los n parámetros para los cuales J tiene un valor mínimo. Por ejemplo para dos parámetros, dada la función queremos
Una aproximación es empezar con algún valor arbitrario de los parámetros e ir modificándolos para reducir J. Supongamos que la función que queremos minimizar es
y supongamos que inicializamos los parámetros a un valor arbitrario
Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
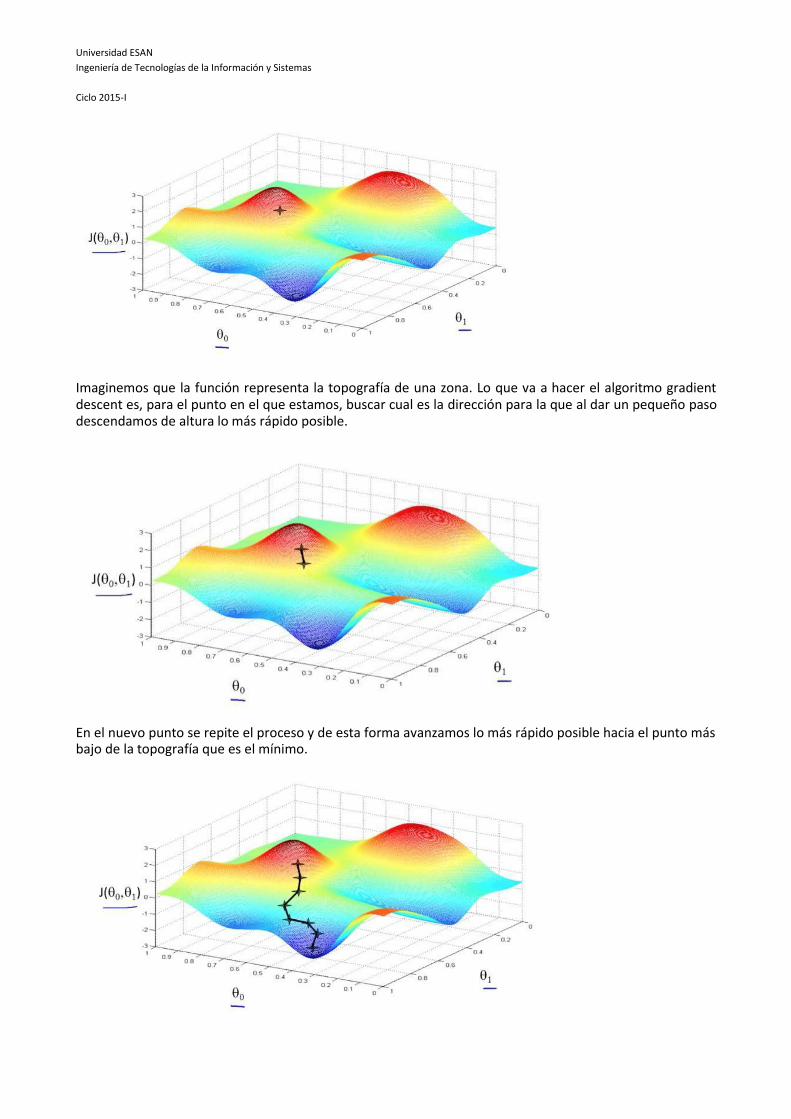
Imaginemos que la función representa la topografía de una zona. Lo que va a hacer el algoritmo gradient descent es, para el punto en el que estamos, buscar cual es la dirección para la que al dar un pequeño paso descendamos de altura lo más rápido posible.
En el nuevo punto se repite el proceso y de esta forma avanzamos lo más rápido posible hacia el punto más bajo de la topografía que es el mínimo.
Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
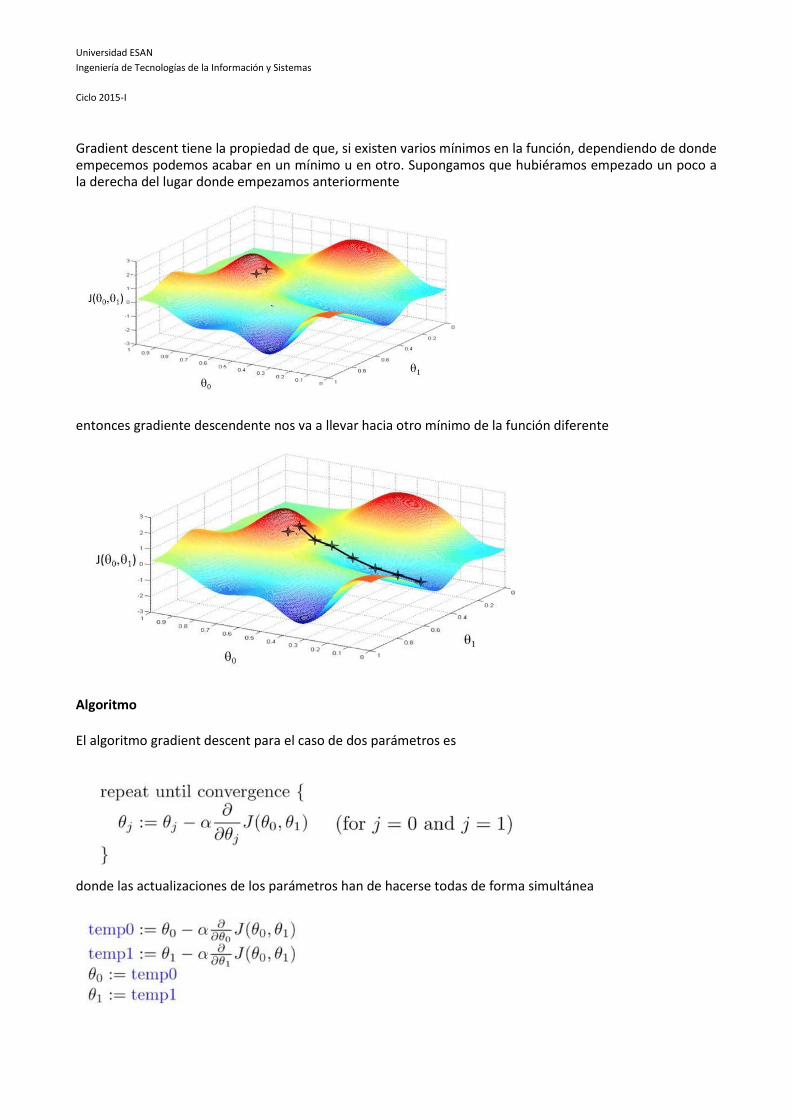
Gradient descent tiene la propiedad de que, si existen varios mínimos en la función, dependiendo de donde empecemos podemos acabar en un mínimo u en otro. Supongamos que hubiéramos empezado un poco a la derecha del lugar donde empezamos anteriormente
entonces gradiente descendente nos va a llevar hacia otro mínimo de la función diferente
Algoritmo
El algoritmo gradient descent para el caso de dos parámetros es
donde las actualizaciones de los parámetros han de hacerse todas de forma simultánea

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
es la velocidad de aprendizaje (learning rate) y controla cómo de grandes son los pasos que se dan al modificar los parámetros de la función.
Verificación de gradient descent
Para asegurarnos de que gradient descent está funcionando correctamente podemos dibujar el valor de la función de coste frente al número de iteraciones del algoritmo.
Cuando gradient descent está funcionando bien, entonces el valor de J debería disminuir con cada iteración.
Cuando la curva de J frente al número de iteraciones deja de disminuir significa que J ha convergido a algún valor y no va a cambiar, lo que significa que hemos encontrado un mínimo local de J.
Otra forma de determinar la convergencia es imponiendo un criterio por ejemplo del tipo de que si entre dos iteraciones la diferencia de J es inferior a 10^-3, podemos decir que el algoritmo ha convergido. Pero en general este límite es difícil de escoger y suele ser mejor utilizar la gráfica de la función de coste como criterio.
Interpretación del algoritmo
Para entender lo que hace gradient descent utilizaremos una función J dependiente de un sólo parámetro inicializado a un valor arbitrario
gradient descent va a actualizar el parámetro según la siguiente regla

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
El término de la derivada
Lo que está haciendo gradient descent en cada actualización al restar la derivada respecto del parámetro es movernos por la función de coste en la dirección de la tangente a la función en ese punto, pero de forma que seguimos la dirección que nos lleva hacia valores menores de J.
Si la pendiente de la tangente es positiva, significa que si aumentamos el parámetro estarías incrementando J, por eso tendríamos que ir en la dirección contraria.
Por el contrario, si la pendiente se negativa, significa que si aumentamos el parámetro estaríamos disminuyendo J, y esa es la dirección en la que queremos ir

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
Learning rate
El learning rate controla el tamaño del paso que damos en la dirección dada por el negativo de la derivada. La elección de es crítica. Un valor demasiado pequeño puede hacer que tarde demasiado en converger (encontrar un mínimo) y por lo tanto gradient descent sería demasiado lento.
Pero si el valor es demasiado grande puedo pasarme del mínimo incluso divergir en lugar de converger.
Una evidencia de que esto está ocurriendo es que J se incrementa con el número de iteraciones del algoritmo
en cuyo caso es mejor utilizar un learning rate más pequeño porque se puede demostrar que con un learning rate suficientemente pequeño, J siempre va a disminuir en cada iteración del algoritmo.

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
Una guía para escoger el learning rate es empieza por probar una serie de valores como 0.001, 0.003 0.01, 0.03, 0.1, 0.3, 1, etc. empezando en 0.001 e incrementando alfa en un factor de aproximadamente 3 cada vez que corramos gradient descent.
En el mínimo y en su entorno
Cuando gradient descent alcanza el mínimo exacto, entonces la derivada se hace 0 y deja de actualizar el parámetro.
Por otro lado, cerca del mínimo, la derivada se aproxima cada vez más a 0 y por lo tanto, el tamaño de los pasos que se dan son cada vez más pequeños en el entorno del mínimo sin necesidad de reducir el valor de la velocidad de aprendizaje.
Ejemplo
Por ejemplo, para la regresión lineal dada la función de coste
la regla de actualización sería

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
y un ejemplo de aplicación del algoritmo sería

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
Batch gradient descent
Cuando en cada paso del algoritmo utilizamos todos los datos para calcular la actualización, se denomina "Batch" gradiente descent..
Cuando el conjunto de datos es grande, gradient descent funciona mejor que el método de las ecuaciones normales, utilizando stochastic gradient descent o mini-batch gradient descent
Feature scaling
Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
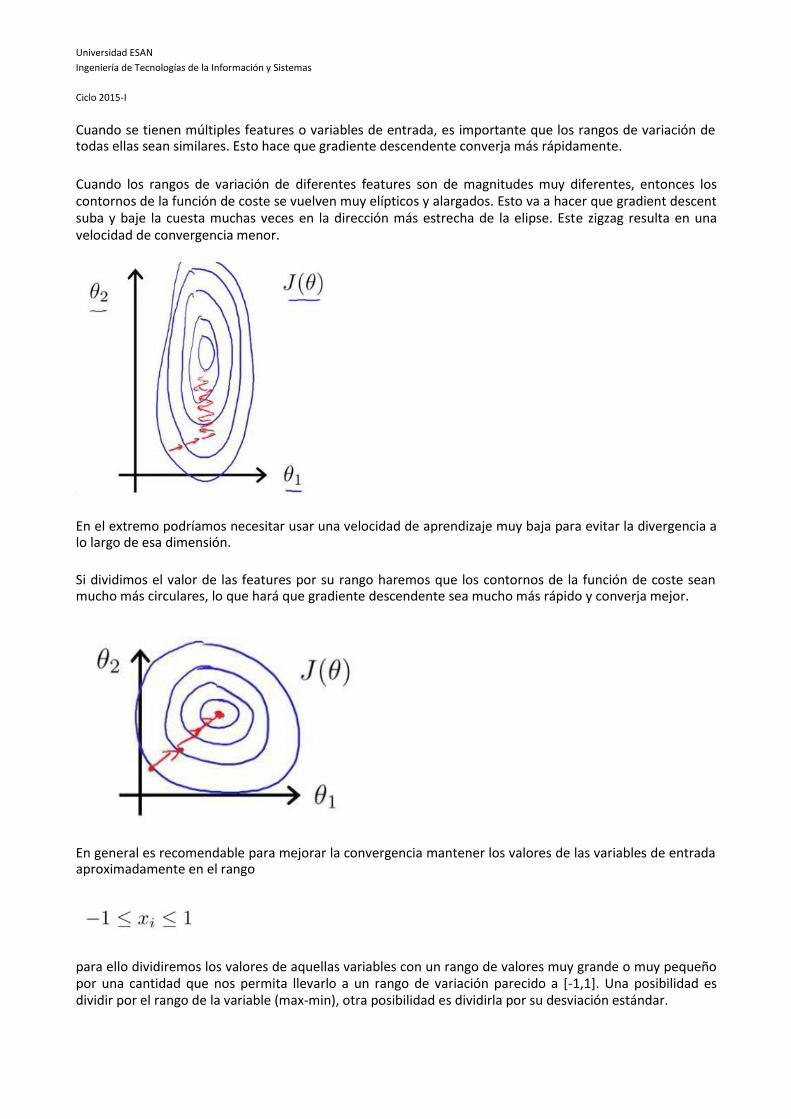
Cuando se tienen múltiples features o variables de entrada, es importante que los rangos de variación de todas ellas sean similares. Esto hace que gradiente descendente converja más rápidamente.
Cuando los rangos de variación de diferentes features son de magnitudes muy diferentes, entonces los contornos de la función de coste se vuelven muy elípticos y alargados. Esto va a hacer que gradient descent suba y baje la cuesta muchas veces en la dirección más estrecha de la elipse. Este zigzag resulta en una velocidad de convergencia menor.
En el extremo podríamos necesitar usar una velocidad de aprendizaje muy baja para evitar la divergencia a lo largo de esa dimensión.
Si dividimos el valor de las features por su rango haremos que los contornos de la función de coste sean mucho más circulares, lo que hará que gradiente descendente sea mucho más rápido y converja mejor.
En general es recomendable para mejorar la convergencia mantener los valores de las variables de entrada aproximadamente en el rango
para ello dividiremos los valores de aquellas variables con un rango de valores muy grande o muy pequeño por una cantidad que nos permita llevarlo a un rango de variación parecido a [-1,1]. Una posibilidad es dividir por el rango de la variable (max-min), otra posibilidad es dividirla por su desviación estándar.

Universidad ESAN Ingeniería de Tecnologías de la Información y Sistemas
Ciclo 2015-I
Mean normalization
Además de escalar las variables, es también una práctica habitual restarles previamente su media para hacer que tengan una media igual a 0. Por ejemplo
Es decir, calculamos la media para cada variable
y reemplazamos cada
Con
Referencias
Machine Learning class lectures by Prof Andrew Ng (Stanford,)





























