Embed Size (px)
Citation preview

Journal of Memory and Language41, 427–456 (1999)Article ID jmla.1999.2653, available online at http://www.idealibrary.com on
Agreement Processes in Sentence Comprehension
Neal J. Pearlmutter
Northeastern University
and
Susan M. Garnsey and Kathryn Bock
University of Illinois
Three experiments examined the processing of subject–verb agreement in sentence comprehension.Experiment 1 used a word-by-word self-paced moving window reading methodology, and partici-pants read sentences such asThe key to the {cabinet/cabinets} {was/were} rusty from many years ofdisuse.When the head noun (key), local noun (cabinet), and verb were all singular, reading times afterthe verb were faster than when either a plural local noun or plural verb was present. Experiment 2used an eyetracking paradigm and revealed a pattern like that in Experiment 1, with a finer grain ofresolution. Agreement computations influenced processing within one word after encountering theverb, and processing disruptions occurred in response to both agreement violations and locallydistracting number-marked nouns, despite the fact that neither is a priori relevant for comprehensionin English. Experiment 3 revealed an asymmetry in the pattern of disruptions that parallels errordistributions in language production (e.g., Bock & Miller, 1991). The results suggest that agreementis an early, integral component of comprehension, mediated by processes similar to those ofproduction. © 1999 Academic Press
Key Words: sentence comprehension; subject–verb agreement; feature processing; pluralmarkedness.
u-lanlik
uiteofly,hav-tve
an-
.
nsi-as
berf aon
use
cteholrsithipIHWe
, TeMy-nonaultblinlp ihgatudn folarcil-
AL-thisssif th
eal J.Uni-ail:
One intuitive way to demonstrate that hmans have some abstract knowledge of theguages they speak is to present a contrast
The experiments reported in this article were conduwhile the first author was a postdoctoral fellow in the Psycogy Department and at the Beckman Institute at the Univeof Illinois. This research was supported by NIH FellowsMH10592, a University of Illinois Research Board grant, NGrant R01-HD21011, and NSF Grant SBR 94-11627.greatly appreciate the comments and advice of Gary DellGibson, Maryellen MacDonald, Gary Marcus, Elizabethers, Christine Sevald, Michael Tanenhaus, and three amous reviewers. (None of the remaining errors are Ted’s fWe thank Susan Cho, Sandra Fleming, Jennifer HamRalda Mnayer, Daynia Sanchez, and Robin Harris for heconducting the experiments; J. Cooper Cutting, Mera Kacand Corey McCarthy for handling the preamble norming sin Experiment 1; and Steve Fadden and Gary Wolvertoassistance with eyetracking data collection. We are particuindebted to George McConkie for providing eyetracking faities (supported by the Army Research Laboratory (DA01096-2-0003) and NSF (CDA 96-24396)). Portions ofwork were presented at the 1995 CUNY Sentence ProceConference (Tucson, AZ) and at the 1995 Conference o
Psychonomic Society (Los Angeles, CA).427
-e
that in (1). Naive English speakers are qwilling to report that (1b) contains some kindproblem not present in (1a). Most notabspeakers can make such judgments despiteing no idea whatglorksmeans—it is in fact noa word of English—and thus they must hasome knowledge of the grammar of their lguage independent of its particular words.
(1) a. The glorks were in the bucket on the counterb. The glorks was in the bucket on the counter.
Example (1) relies on comprehenders’ setivity to subject–verb agreement: In English,in a wide variety of languages, the num(singular vs plural) marked on the subject oclause must agree with the number markedthe verb of that clause. The subject of a cla
d-y
d
y-.),
nl,yrly
nge
Address correspondence and reprint requests to NPearlmutter, Psychology Dept., 125 NI, Northeasternversity, Boston, MA 02115. Fax: (617) 373-8714. E-m
[email protected].0749-596X/99 $30.00Copyright © 1999 by Academic Press
All rights of reproduction in any form reserved.

it(1)
aw
eem ons nde e( reem plel risi ome be
r.r.
sinen
prordemeeen-edNPayynacatro
cticm-coer
t).se-limmaerPslar
om, fohe
kednceiners
n-onent
theter,ms.
inwn
tly0).on,con-re-in-
lytemddle
ent
gest ton-ree-het incturetemof
, b;l.,enofm-ltsnce
dersts,pre-con-n-that
428 PEARLMUTTER, GARNSEY, AND BOCK
is typically a noun phrase (NP), which has ashead a noun marked for number. Thus incomprehenders assume thatglorks is the (plu-ral) noun head of the subject, sowere is the
ppropriate plural verb form in (1a), andwas,hich is singular, is inappropriate in (1b).Of course, sensitivity to subject–verb agrent is not restricted to cases involving n
ense words. In examples like (2), comprehers judge versions containing correct agreem2a) to be better than those with incorrect agent (2b). Indeed, such judgments for exam
ike (2) are quite sharp, and thus not surpngly, linguists have taken agreement phenna to be an important source of data toxplained by linguistic theories.
(2) a. The sponge was in the bucket on the counteb. The sponge were in the bucket on the counte
From the perspective of language-procestheories, however, the importance of agreemphenomena is not so clear. While languageducers clearly must compute agreement in oto generate grammatically correct forms, coputation of, for example, subject–verb agrment is not obviously required for comprehsion. English in particular has a relatively fixword order, with the result that the subjectand the main verb of a clause are nearly alwidentifiable on the basis of positional and stactic category information alone (see also MWhinney, Bates, & Kliegl, 1984). The fact tha subject and a verb must agree in numbethen largely redundant from the perspectiveidentifying clausal constituents and syntarelations (but cf. some kinds of structural abiguity, as in Gibson, Pearlmutter, CanseGonzalez, & Hickok, 1996, where numbagreement alone disambiguates attachmen
The potential availability and therefore ufulness of agreement constraints is furtherited by the fact that English has a rather miniovert agreement system, both for subject–vagreement and for agreement within NNearly all nouns are overtly marked for singuversus plural number, but gender marking, cmon in Germanic and Romance languagesexample, is identifiable in English only in t
pronominal system (e.g.,she, itself, him). Sim-s,
---
nt-s--e
gt-r
--
s--
isf
-
-lb.
-r
ilarly, adjectives and prepositions are marfor neither number nor gender (unlike Romalanguages), and even though many determ(e.g.,many) are marked for number,the is not,and it is the most common determiner in Eglish. It is roughly three times more commthan any other determiner and more frequthan all other determiners combined inBrown corpus (Francis & Kucˇera, 1982). Moscritically, verbs are marked only for numband only in third-person present-tense forThe only exception is the copulabe, which ismarked in both first- and third-person andpresent- and past-tense forms. In the Brocorpus only 22.4% of all verbs are overmarked for number (41,727 out of 186,07Quite often, then, in English comprehensithe information necessary to use agreementstraints will be unavailable to the comphender, and, even when it is available, theformation provided will often be entireredundant. Thus the comprehension sysmight be more efficient if it largely ignoreagreement information, backtracking to hanit only when other constraints were insuffici(see also Nicol, Forster, & Veres, 1997).
On the other hand, a variety of languaseem to rely more heavily on agreemenprovide grammatical constraints. Many laguages have a much richer set of overt agment markings as well, indicating that tparser might rely more heavily on agreemensuch languages. The idea that the basic struof the human language comprehension sysis universal (i.e., uniform across speakersdifferent first languages; e.g., Frazier, 1987acf. Cuetos & Mitchell, 1988; Gibson et a1996; MacWhinney et al., 1984) would thpredict that even in English, computationagreement would be an important part of coprehension. MacWhinney et al.’s resushowed a contrasting pattern: In whole-sentejudgments, English-speaking comprehentended to rely on word-order constrainwhereas Italian- and German-speaking comhenders tended to rely more on agreementstraints. However, their stimuli pitted costraints against each other with the result
many of the stimuli were not clearly grammat-
erre
t toenbes a
o
conlin-skyththeingtiothefo
utari-
arsernififeitsnt-Ma94erm-in-toesreessinal.gibpu
uc-sorea
uresunsca
the
ofee-be-
in-k &&)ringorkter-co,ndlk,ally
ofes.er-
ple-oror
rror-
i ada
hens
s ofties
ietyhis
isa-sin-his3b)un-er-
uchthed
429AGREEMENT IN COMPREHENSION
ical, making it difficult to determine wheththeir results are applicable to normal comphension. But even if universality turns out noapply, the parser still might compute agreemin English, both because it will occasionallynecessary to use it and because it provideadditional (even though redundant) sourceinformation.
Questions about the use of agreementstraints are also directly relevant for manyguistic theories (e.g., Bresnan, 1982; Chom1965, 1995; Pollard & Sag, 1994) becausemechanisms underlying agreement in suchories, typically some form of feature processare also used more generally in the computaof many other constraints—to determinepermissibility and placement of arguments,example. The same is true for many comptional and psycholinguistic theories: The pmary processing mechanism in unification ping models (e.g., Kay, 1985/1986; Shieb1986; see also Jurafsky, 1996) is feature ucation, and Stevenson’s (1994) model usesture-based computation to control all ofstructure building. Similarly, recent constraibased sentence-processing theories (e.g.,Donald, Pearlmutter, & Seidenberg, 19Trueswell & Tanenhaus, 1994), though ctainly not explicit about the processing of gramatical constraints, rely heavily on featuralformation (including nonsyntactic features)specify constraints, and one of the strongclaims of these models is that different featuare all handled by the same underlying procing mechanisms. In other parsing models,cluding those built around more traditionsymbolic tree-construction mechanisms (eEarley, 1970/1986; Frazier, 1979, 1987a; Gson, 1991; Jurafsky, 1996), agreement comtations are typically built into the tree-constrtion rules (though they need not be) andoperate using the same mechanisms as theof the parser. Agreement thus plays a role inof these theories, and in many of them, featprocessing mechanisms are responsible forstantial proportions of the models’ operatioExaminations of agreement phenomenatherefore provide information relevant to
core mechanisms of such theories.-
t
nf
-
,e-
,n
r-
-,-a-
c-;-
ts-
-
.,--
stll-b-.n
However, despite the potential relevanceinformation about how people handle agrment, such phenomena have only recentlygun to be investigated explicitly in psycholguistic research. Bock and colleagues (BocCutting, 1992; Bock & Eberhard, 1993; BockMiller, 1991; Bock, Nicol, & Cutting, 1999examined the computation of agreement dulanguage production in English, and this whas been extended to Italian (Vigliocco, Butworth, & Semenza, 1995), Spanish (VigliocButterworth, & Garrett, 1996a), and Dutch aFrench (Vigliocco, Hartsuiker, Jarema, & Ko1996b). Participants in all of these studies orcompleted sentence beginnings [consistingsubject NPs, as in (3)] to form full sentencAcross a variety of manipulations, these expiments have revealed that producing a comtion for a beginning like (3b), where the first,head, noun (key) is singular and the second,local, noun (cabinets) is plural, is more likely toresult in a subject–verb agreement e(e.g., . . .were locked in the desk) than completng a beginning like (3a), where both the hend local noun are singular.
(3) a. The key to the cabinet . . .b. The key to the cabinets . . .
This pattern is further complicated by tfinding that beginnings with plural head noudo not create the same effect: Completion(4a) and (4b) have roughly equal probabiliof containing an agreement error.
(4) a. The keys to the cabinets . . .b. The keys to the cabinet . . .
Bock and Eberhard (1993) ruled out a varof morphophonological explanations for tasymmetry and proposed that the plural formexplicitly marked with a morphosyntactic feture during on-line processing, whereas thegular is the default unmarked form. On tproposal, the marked plural local noun in (can sometimes inappropriately override thespecified head noun form, thereby creatingrors. In (4b), however, the head noun is mless likely to be inadvertently overwritten, bobecause it is plural and thus explicitly mark
and because the local noun is unmarked and
earsand97
xpanmin
s ao(3veestiviell,art7;
scht int taenk-ol&
seyirsvityiar
nt)t,ndiv-ecton-rbtimskla-ac-m7)skosalsr oeas.
rd),ing
ingiola-rt,d,esttion.m-t al.nd
d in500ctlywithiffi-cf.s-to
theyo-ingetoor-
tedola-kingiredingom-anyentm,nal
ofrmiting
eirp hang byt der-f nte-c viola-t ands hicala ar to
430 PEARLMUTTER, GARNSEY, AND BOCK
thus has no feature to override that of the hnoun. Thishead-overwritingproposal appeato be generally compatible with the modelstheories described above. Eberhard (19tested and supported these hypotheses in eimental studies of agreement production,Vigliocco and Nicol (1997), examining thefurther, proposed an explicit implementationterms of a feature-unification mechanism.
Agreement phenomena have received lestention in comprehension, but the effectsboth head/local NP number mismatch [as inand (4)] and outright ungrammaticality harecently begun to be examined. Most of thstudies have demonstrated readers’ sensito real and/or seeming violations (BlackwBates, & Fisher, 1996; Jakubowicz & Fauss1995; Kail & Bassano, 1997; Nicol et al., 199Sevald & Garnsey, 1995; see also Deut1998, for related evidence from Hebrew), bueach of these cases an additional concurrenwas involved beyond reading for comprehsion—either grammaticality judgment (Blacwell et al., 1996; Kail & Bassano, 1997; Nicet al., 1997), lexical decision (JakubowiczFaussart, 1995), or naming (Sevald & Garn1995). This raises two relevant concerns: Fwith respect to demonstrating basic sensitito agreement in comprehension, a subsidtask (particularly grammaticality judgmemight artificially increase sensitivity. In facusing eyetracking without any task beyoreading for comprehension, Branigan, Lersedge, and Pickering (1995) found no effof head/local NP number mismatch with cstructions like (3) and (4) followed by vephrases. The second concern is that thecourse of performance for the subsidiary talimits how informative they can be about retively rapid effects of agreement. Typical retion times following the appearance of the nuber-marked verb in Nicol et al.’s (199grammaticality judgment task (the “maze” tain which participants choose between two psible words to continue a sentence; seeFreedman & Forster, 1985) were on the orde650–750 ms, and Sevald and Garnsey’s mnaming times were typically 500–550 m
These time ranges are fairly long relative tohd
)er-d
t-f)
ety
,
,
sk-
,t,
y
s
es
-
,-ofn
normal reading rates (200–250 ms per woparticularly if agreement is computed durinitial parsing.
Several event-related potential recordstudies have also considered agreement vtions (Coulson, King, & Kutas, 1998; HagooBrown, & Groothusen, 1993; Kutas & Hillyar1983; Osterhout & Mobley, 1995) and suggthat the above concerns warrant some attenWith no task involved beyond reading for coprehension, Coulson et al. (1998), Hagoort e(1993), and Osterhout and Mobley (1995) fouthat subject–verb agreement failure resulteincreased late positivity (peaking at leastms after the appearance of the incorremarked verb), a pattern also associatedsome other kinds of syntactic processing dculty (e.g., Osterhout & Holcomb, 1992;Kutas & Hillyard, 1983). However, when Oterhout and Mobley required participantsjudge the acceptability of each sentence,also found differences in two earlier compnents, P2 and a left anterior negativity peakaround 400 ms.1 This change in timing might btaken to suggest that, if anything, sensitivityagreement violations is actually delayed in nmal comprehension.
In the studies reported below, we investigacomprehenders’ sensitivity to agreement vitions using self-paced reading and eyetracmethodologies. Participants were not requto perform any additional tasks beyond readfor comprehension and then answering a cprehension question and did not receiveinstructions or examples focusing on agreemphenomena or violations. Thus at a minimuthese methodologies can provide additioconverging evidence about the processingagreement. In addition, these methods perelatively fine-grained tracking of process
1 Osterhout and Mobley were careful to instruct tharticipants to make “acceptability” judgments rather trammaticality judgments; but of the 210 stimuli read
heir participants, 95 (45%) contained number- or geneature violations involving subject–verb or pronoun–aedent pairs, and 10 (5%) contained phrase-structureions, while the remainder were both grammaticalensible, containing neither semantic nor typograpnomaly. Thus the relevant discrimination does appe
ave been on the basis of grammaticality.
&is,di-thethein
antionpemipak t, aWeionthdisichbynte
t &989ountht.an
shisiob
rucca
in,r-onans (pl
atcforeathapre
toprede-
ightn,
t (asm-lateightree-en-andmslt ofated-
tchinstsitiv-ad
eri-ram-bern offarnssub-rits
lu-ionrib-dis-ref-
isvecesllardher,erer-
ticalechd,is
nal, weim-dif-ro-
431AGREEMENT IN COMPREHENSION
difficulty over time (e.g., Just, Carpenter,Woolley, 1982; Rayner, Sereno, MorrSchmauder, & Clifton, 1989) with at least invidual-word resolution, and thus they havepotential to provide strong constraints ontiming of readers’ sensitivity to agreementnormal comprehension.
A second question is how violations are hdled if and when they are detected. In addito expected increases in processing time, Eximent 2, using eyetracking, permits an exanation of other aspects of eye-movementterns, such as how often movements bacearlier portions of text (regressions) occurwell as their starting and ending positions.can specifically examine how often regressbeginning at the agreement violation end onsubject head noun as opposed to a locallytracting noun. A hypothesis according to wheye movements are strongly controlledhigher level cognitive processes (e.g., Carpe& Just, 1977; Frazier & Rayner, 1982; JusCarpenter, 1980; see Rayner & Pollatsek, 1for discussion) would predict that the head nshould be refixated often, as it specifiesinformation relevant for checking agreemen
The following experiments also investigatedadditional set of questions about the relationbetween language production and comprehenboth by considering agreement violations andconsidering head/local NP mismatch consttions like those given above in (3), where lonoun number is varied [cabinet(s)]. If the increasein production errors created by the mismatchnumber betweenkey and cabinetsin (3b) (e.g.Bock & Miller, 1991) is the result of an interfeence effect in handling syntactic representatithen to the extent that the comprehensionproduction systems rely on the same processemake use of identical processes in separate immentations), a head/local NP number mism[as in (3b)] should result in increased difficultycomprehenders relative to the corresponding hlocal match case (3a). The alternative to this isthe two systems are quite distinct: The comhension system might not display sensitivityagreement phenomena at all in normal comhension or sensitivity might be noticeably
layed. Even if the comprehension system is sen-
r--t-os
se-
r
,
e
pn,y-l
s,dore-h
d/t-
-
sitive to agreement, the relevant processor mbe organized differently from that in productioso that head/local mismatches have little effecin Branigan et al., 1995). For example, the coprehension system might be better able to isothe head noun’s agreement features or it msimply ignore them, perhaps only checking agment if some later property of the incoming stence (e.g., ambiguity) forced it to backtrackdo so. A third alternative is that both systedisplay sensitivity to agreement, but as a resudifferent underlying mechanisms. We investigthis possibility in Experiment 3, pitting the heaoverwriting explanation of head/local mismaeffects from production, described earlier, agaan explanation based on comprehension senity to word-to-word transition probabilities insteof feature passing.
One final question examined in the expments was about the relationship between gmatical number and so-called notional num(numerosity in the conceptual representatioa speaker or hearer). This relationship isfrom perfect, which complicates questioabout number agreement. For example, theject NPthe picture on the postcardsis singulain grammatical number but ambiguous innotional number properties. It is notionally pral if the conceptual referent of the expressconsists of tokens of the same picture distuted across multiple postcards. This is thetributive sense. However, if the conceptualerent is the picture itself, the expressionnotionally singular. This is the nondistributisense. Notional number clearly influenagreement in some circumstances (see Po& Sag, 1994, for discussion and Gernsbac1991, for an empirical demonstration), but thare conflicting findings in the production liteature about the predominance of grammaand notional agreement in unstudied spe(compare Bock & Miller, 1991; Eberhar1996; and Vigliocco et al., 1996a). Nothingknown about the immediate effects of notionumber on comprehension. For this reasonincluded a notional-number contrast in the stulus materials to explore whether and howferences in notional number influence the p
-cessing of agreement during reading.
inee torofonm
ctendre
id-this
areef-ng
t inlly
-rib
reasoinseonslarut
redgtice t(lesper
ats steopw ol-l ast o
ly
on,e
h ourd byvns ort,p andM ft dis-t s-s
ares tofi nde hen-s rawp thec therp
f-er-en-
p oftedce-
iththerb-
useat-
achberernsbutntsg atic-
432 PEARLMUTTER, GARNSEY, AND BOCK
EXPERIMENT 1
This experiment was intended to examfirst, whether comprehenders are sensitivagreement violations during the course of nmal reading. The relatively fixed word orderEnglish and its minimal agreement system cspire to limit the potential usefulness to a coprehender of knowledge about the expenumber-marking on an upcoming verb. Secoif readers were sensitive to agreement, theative timing of this sensitivity could be consered. The third issue of interest was whetherpattern of interference created by number mmatches in language production also appein comprehension. Finally, to examine thefects of notional number, we included amothe materials subject NPs whose dominanterpretation was nondistributive, or notionasingular (e.g.,the key to the cabinets), and others whose dominant interpretation was distutive, or notionally plural (e.g.,the picture onthe postcards). All of these subject NPs wegrammatically singular. If notional plurality han immediate and sizable impact on the ongcomputation of agreement, we shouldgreater disruptions from agreement violatiafter notionally (and grammatically) singusubject NPs than after notionally plural (bgrammatically singular) subjects.
Method
Participants. Eighty-two University of Illi-nois undergraduates participated for class cor $5. All (in this experiment and the followintwo) were native English speakers. Two paripants were excluded from all analyses dupoor comprehension question performancethan 90% correct across all items in the eximent).
Materials. Sixteen stimulus sets like thhown in (5) were constructed. Each consif a head NP [e.g.,the keyin (5)] followed by areposition (to) and a local NP [the cabinet(s)],hich was the object of the preposition. F
owing the subject of the sentence was a pense copula (wasor were) and then a four- tnine-word completion. The word immediate
following the copula was either a past-participle,o-
--d,l-
e-d
-
-
ge
it
-os-
d
t-
verb, a nonparticipial adjective, a prepositior the determinera (four of each type). Th
ead NP was always singular, and the fifferent versions of an item were createdarying the local NP number (cabinetvs cabi-ets) and the verb number (was vs were), ashown in (5). The subject NPs were the shrepositional phrase (PP) versions of Bockiller’s (1991, Experiment 1) stimuli; half o
hese were distributive and half were nonributive, according to Bock and Miller’s claification.The full-sentence versions of the stimuli
hown in Appendix A. All items were writtent on a single 80-character display line, aach item had an associated yes/no compreion question. Because we did not wish to darticipants’ attention to agreement issues,omprehension questions asked about oarts of the sentences.
(5) a. The key to the cabinet was rusty from manyyears of disuse.
b. The key to the cabinets was rusty from manyyears of disuse.
c. The key to the cabinet were rusty from manyyears of disuse.
d. The key to the cabinets were rusty from manyyears of disuse.
Plausibility norming.To insure that any efects of local noun number were due to diffences in number marking rather than more geral plausibility differences, a separate grou68 University of Illinois undergraduates rathe subject NPs for plausibility as senteninitial fragments likeThe key to the cabinet. . . .The 16 items were combined with 32 fillers wsimilar syntactic structures as well as the o16 Bock and Miller (1991, Experiment 1) suject NPs, which contained a relative clarather than a PP modifying the head NP. Rings were conducted for four versions of eitem, created by crossing head noun num(singular vs plural) with local noun numb(singular vs plural). (The plural-head versiowere not relevant for Experiments 1 and 2,were included in Experiment 3.) Participarated exactly one version of each item usinscale of 1 (plausible) to 5 (implausible). Par
ipants were explicitly instructed to “judge plau-
nd
r-foenge
r-in
neng
lyion
.
. ,ilityan
a-t adl ouc tchg m-m c),a 16e stss sioo mi 94o ofu , inv ono es(
derreshus
s out
rry
lus
c-ts.noro orun-in aby-manon-n theord
rre-ssedordwas
hes.ealedrd.theits
par-eysom-ton-stion
par-ici-oxi-
cor-ionns;
o pre-h edf
)
)
e).
433AGREEMENT IN COMPREHENSION
sibility” and were given a clearly plausible aclearly implausible example.
The mean plausibility ratings for all four vesions are shown in Table 1, and the ratingseach version of each item are shown in Appdix A. An error in construction of the ratinforms resulted in one item [The name(s) on thbillboard(s). . .] being rated in a slightly diffeent form than that in which it was presentedthe reading time experiment:sign(s)was used iplace of billboard(s) for rating. None of thresults reported below differed when the ratiof this item were excluded.
Plausibility ratings did not differ significantbetween either the two singular-head vers[t1(67) 5 21.16,p . .20; t2(15) 5 21.25,p .20] or the two plural head versions [t1(67) 597, p . .30; t2(15) 5 .75, p . .45]. Howeveras an additional check on possible plausibeffects, correlations between reading timesplausibility ratings are considered below.
Design.We refer to conditions as combinions of the factors grammaticality and heocal NP number match (NP-match), so the fonditions in the experiment were NP-marammatical [as in (5a)], NP-mismatch graatical (5b), NP-match ungrammatical (5nd NP-mismatch ungrammatical (5d). Thexperimental stimuli were placed into four liuch that each list contained exactly one verf each item, and each list contained four ite
n a given condition. Each list also containedther (filler) items, 74 of which were partnrelated experiments reported elsewhereolving ambiguous and unambiguous versif one of two different temporary ambiguiti
TABLE 1
Subject NP Plausibility Ratings
Head noun number Local noun numberMean(SD)
Singular Singular 1.11 (.23Plural 1.16 (.29)
Plural Singular 1.13 (.22Plural 1.10 (.19)
Note.Rating scale was 1 (plausible) to 5 (implausibl
direct object vs sentential complement, or main
r-
s
s
d
/r
ns
-s
verb vs reduced relative clause). The remainof the items incorporated a variety of structuand were always grammatical sentences. Teach subject saw 8 ungrammatical sentenceof 110 items total (7.3%).
Apparatus. An IBM-compatible computerunning the MicroExperimental Laborato(MEL) software package controlled stimupresentation and response collection.
Procedure.Participants read 10 initial pratice items followed by one of the 110-item lisNeither the instructions for the experimentthe practice items contained any reference texample of agreement violations or othergrammaticality. The stimuli were presentedrandom order using a noncumulative word-word self-paced moving window paradig(Just et al., 1982). At the beginning of a trial,item was displayed on the screen with all nspace characters replaced by dashes. Wheparticipant pressed the space bar, the first wof the item was displayed, replacing the cosponding dashes. When the participant prethe space bar a second time, the first wreverted to dashes, and the second worddisplayed in place of the appropriate dasEach subsequent press of the space bar revthe next word and removed the previous woPressing the space bar on the last word ofitem caused the item to be replaced byYes/No comprehension question, which theticipant answered by pressing one of two kabove the space bar on the keyboard. The cputer recorded the time between each butpress as well as the comprehension queresponse and presented feedback about theticipant’s answer to the question. Most partpants completed the experiment in apprmately 35 min.
Results
Comprehension performance was 96%rect for the NP-match ungrammatical conditand 95% correct for the other three conditiothese values did not differ (allps . .20). Trials
n which the participant answered the comension question incorrectly were exclud
rom reading time analyses.
To adjust for differences in word length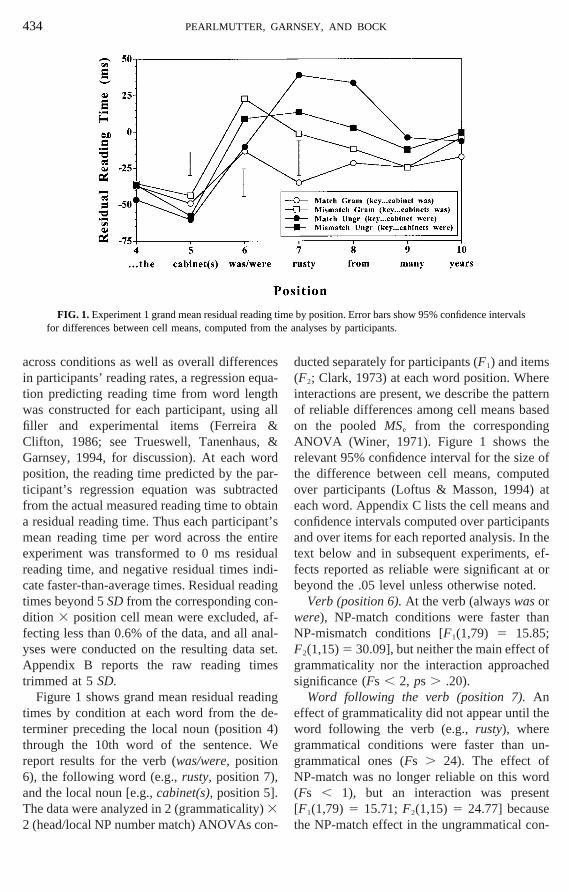
cequatha&&
ordar
ctetaint’tiruadidinn-af-nasees
dinde-
4)We
,
)
eretternsedgeoftedat
andntsthe
, ef-t ord.
an
ofhed
e hewg un-g fN ord( nt
e
alsm
434 PEARLMUTTER, GARNSEY, AND BOCK
across conditions as well as overall differenin participants’ reading rates, a regression etion predicting reading time from word lengwas constructed for each participant, usingfiller and experimental items (FerreiraClifton, 1986; see Trueswell, Tanenhaus,Garnsey, 1994, for discussion). At each wposition, the reading time predicted by the pticipant’s regression equation was subtrafrom the actual measured reading time to oba residual reading time. Thus each participamean reading time per word across the enexperiment was transformed to 0 ms residreading time, and negative residual times incate faster-than-average times. Residual reatimes beyond 5SDfrom the corresponding codition 3 position cell mean were excluded,fecting less than 0.6% of the data, and all ayses were conducted on the resulting dataAppendix B reports the raw reading timtrimmed at 5SD.
Figure 1 shows grand mean residual reatimes by condition at each word from theterminer preceding the local noun (positionthrough the 10th word of the sentence.report results for the verb (was/were,position6), the following word (e.g.,rusty, position 7)and the local noun [e.g.,cabinet(s),position 5].The data were analyzed in 2 (grammaticality3
FIG. 1. Experiment 1 grand mean residual readifor differences between cell means, computed fro
2 (head/local NP number match) ANOVAs con-t
s-
ll
-dnsel-g
l-t.
g
ducted separately for participants (F1) and items(F2; Clark, 1973) at each word position. Whinteractions are present, we describe the paof reliable differences among cell means baon the pooledMSe from the correspondinANOVA (Winer, 1971). Figure 1 shows threlevant 95% confidence interval for the sizethe difference between cell means, compuover participants (Loftus & Masson, 1994)each word. Appendix C lists the cell meansconfidence intervals computed over participaand over items for each reported analysis. Intext below and in subsequent experimentsfects reported as reliable were significant abeyond the .05 level unless otherwise note
Verb (position 6).At the verb (alwayswasorwere), NP-match conditions were faster thNP-mismatch conditions [F1(1,79) 5 15.85;F2(1,15)5 30.09], but neither the main effectgrammaticality nor the interaction approacsignificance (Fs , 2, ps . .20).
Word following the verb (position 7).Anffect of grammaticality did not appear until tord following the verb (e.g.,rusty), whererammatical conditions were faster thanrammatical ones (Fs . 24). The effect oP-match was no longer reliable on this w
Fs , 1), but an interaction was prese[F1(1,79) 5 15.71;F2(1,15) 5 24.77] becaus
ime by position. Error bars show 95% confidence intervthe analyses by participants.
ng t
he NP-match effect in the ungrammatical con-

attchthendierbdidns
y toat
,g wlyt
ef-ostillati-e inwe
in-ad-unbleadmsofla
redltynseringal
gnaserbs
dis
t
asati-ederandbyoneent
ro-con-ati-P-re,thatant
ter-nois-thatrt ofagelylin-tic
ten-ased
toNPspe-bleIndu-Aandlty,er-
For, anNP-
tob thep aine etect
435AGREEMENT IN COMPREHENSION
ditions was the reverse of that in the grammical conditions: As Fig. 1 shows, the NP-magrammatical condition was easier than the othree, but the NP-match ungrammatical cotion was the most difficult. Thus across the vand the following word, comprehendersshow sensitivity to both agreement violatioand distracting local nouns, but the sensitivitagreement violations appeared later than thhead/local mismatches.
Local noun (position 5).At the local nounrammatical conditions were read more slo
han ungrammatical ones [F1(1,79) 5 5.32;F2(1,15) 5 4.86], but neither an NP-matchfect nor an interaction was present at this ption (Fs , 1). Because the stimuli were sidentical at this point with respect to grammcality and because this effect did not replicatExperiment 2, it is likely to be spurious, anddo not discuss it further.
Correlations with plausibility.Although thetwo different versions of the subject NPs (sgular head–singular local and singular heplural local) did not differ significantly in plausibility, the singular head–singular local noversions were rated as slightly more plausiwhich might have made them easier to reHowever, correlations computed across iteat the verb and at the following word, in eachthe four conditions, revealed no reliable retionships (allps . .35).
Distributivity effects.To determine whethedistributive and nondistributive items differin the degree to which they displayed difficufor NP-match versus NP-mismatch conditioanalyses of residual reading times at the vand the next word were conducted includdistributivity as a factor. Because of the smnumber of items (2) in each cell of this desifive participants were missing all data in at leone cell and were excluded. At both the vand the following word, distributive itemtended to be read more quickly than nontributive items [verb:F1(1,74) 5 7.28, MSe 56445,p , .01; F2(1,14) 5 2.45,MSe 5 2246,p , .15; following word: F1(1,74) 5 3.60,MS 5 7818,p , .10; F (1,14)5 3.71,MS 5
e 2 e t-
r-
to
i-
–
,.,
-
,b
l,t
-
1194,p , .10], but distributivity did not interacwith any other factors (allFs , 1).2
Discussion
The clearest result from Experiment 1 wthat readers were sensitive to both ungrammcality and a locally distracting number-marknoun. Sensitivity to head/local NP numbmatch appeared immediately on the verb,sensitivity to grammaticality, as controlledthe number marking on the verb, appearedword later. Thus readers did attend to agreeminformation during comprehension, and pcessing was disrupted when agreementstraints were violated in cases of ungrammcality or appeared to be violated as in the Nmismatch grammatical condition. Furthermothese effects occurred despite the factagreement constraints were logically redundfor the purposes of computing syntax and inpreting the stimuli and despite the fact thatgrammaticality judgment or other metalingutic task was required. These results suggestcomputation of agreement is a necessary palanguage comprehension, even in a langulike English, where it is often not particularuseful. This provides some support for theguistic, computational, and psycholinguistheories described earlier, which make exsive use of agreement and other feature-bcomputation.
Beyond the general finding of sensitivityboth agreement violations and head/localmismatches, Experiment 1 also revealed acific interaction between the two factors, visiat the word following the verb (position 7).the two grammatical conditions, the patternplicated that at the verb itself (position 6):mismatch in number between the head nounthe local noun created processing difficuwhich parallels the increases in verb numbmarking errors found in production studies.the two ungrammatical conditions, howeverNP mismatch eased processing, so that the
2 Note that the lack of reliable interactions is unlikelye the result of (just) a lack of power, at least forarticipants’ analysis: This design’s power to detect a mffect (as at the verb) is the same as its power to d
wo-factor interactions, assuming comparable effect sizes.

sieononadilityhecedonss inthis
hato
lauis-didis-nda
nrer-tch
ev-tort elsoth
ategy,ghar1
ati-op-y oofar
ngoregsof
theorve
l-or-ntsof aigh
vingne
e-.sRIanonourew-aspo-iteini-wasw-llyreeof
ob-ox-
leftin-g ad ain itsen,
theand
singed
min-to
ngt 1,re-nts
ed
436 PEARLMUTTER, GARNSEY, AND BOCK
mismatch ungrammatical condition was eathan the NP-match ungrammatical conditiThis pattern across the four conditions is csistent with the idea that the effect of a helocal NP-mismatch is to increase the probabof an error in computing the number of tsubject NP, resulting in more mismatch-induseeming errors in the grammatical conditibut fewer mismatch-induced seeming errorthe ungrammatical conditions. We return topoint in Experiment 3.
Experiment 1 also tested the possibility teffects of agreement might be attributablesemantic factors. However, differences in psibility between the NP-match and NP-mmatch conditions were minimal, and theynot predict differences in reading time. Dtributivity did have some effect at the verb athe following word, with those items allowingdistributive interpretation (e.g.,The slogan othe posters. . .) tending to be read moquickly. However, distributivity never inteacted with either head/local NP number maor with grammaticality. Thus there was noidence that these particular semantic faccould account for the observed agreemenfects. Similar analyses in Experiment 2 arevealed the same patterns, so we return toissue only in the General Discussion.
EXPERIMENT 2
This experiment was intended to replicExperiment 1 using a different methodoloeyetracking. From the standpoint of the titiming made possible by eyetracking, one pticularly interesting finding from Experimentis the one-word delay in effects of grammcality. This pattern might be ascribed to prerties of the self-paced reading methodologmight instead reflect the underlying timingsuch effects. Reading times in eyetrackinggenerally shorter than in self-paced moviwindow paradigms and presumably mclosely reflect reading in nonlaboratory settinThis should allow us to measure the timingeffects more tightly and also to examineresponses to real or seeming violations in mdetail by considering regressive eye mo
ments.r.-/
t
-
sf-
is
t-
r
e-
.
e-
Method
Participants.Seventy-eight University of Ilinois students participated for $5. All had nmal, uncorrected vision. Fourteen participawere excluded from all analyses becausecombination of excessive trackloss and a herror rate on comprehension questions, lea64 participants, all of whom had at least ousable trial in each condition.
Materials and design.The materials and dsign were identical to those in Experiment 1
Apparatus and procedure.Eye movementwere monitored with a Fifth Generation SDual Purkinje Eyetracker interfaced withIBM-compatible PC. Stimuli were displayeda Conrac 1000 color monitor such that fcharacters subtended 1° of visual angle. Viing was binocular but only the right eye wmonitored, and vertical and horizontal eyesition was sampled every millisecond. A bbar was prepared for each participant to mmize head movements, and the roomslightly dimmed to provide a comfortable vieing environment. The eyetracker was initiacalibrated by having participants fixate thpositions distributed across the middle linethe screen until stable position values weretained. The calibration procedure took apprimately 5 min.
Each trial began with a trial number at theside of the screen, and participants werestructed to fixate the number before pressinbutton to indicate that they were ready to reasentence. The sentence was then presentedentirety across the middle line of the screalong with a fixation box at the right edge ofscreen. Participants read at their own pacewere instructed to fixate the box before presa button to indicate when they had finishreading the sentence. This was intended toimize recording of eye movements madeposition the eyes at the left margin followicompletion of the sentence. As in Experimeneach item was followed by its Yes/No comphension question with feedback; participaused two handheld buttons to answer.
Participants read 10 practice items follow
by one of the 110-item lists; a single pseudo-
arthefte
aaftth
r-tioertchtchwonoatingcalls,nd
ls.al-ndnly
F re
cali O-V
-a
onw-
alnesdalho
evctefhese
atedsuresWeichiontilad-a
a-ht)mesl., wes ineree
sid-and
weive
on.erallytheylty,g.,&meram-g ins ofonsar-
82;
ingm-
ityap-verbse
theion-
etthe
e thm(
437AGREEMENT IN COMPREHENSION
random order was used for all participants. Pticipants took a scheduled break followingpractice items and every 30 items thereaand they were free to take other breaksneeded. The eyetracker was recalibratedeach break. Most participants completedexperiment in approximately 40 min.
Results
As in Experiment 1, trials on which the paticipant answered the comprehension quesincorrectly were excluded. Comprehension pformance was 90% correct in the NP-magrammatical condition, 91% in the NP-maungrammatical condition, and 93% in the tNP-mismatch conditions. These values diddiffer (ps . .10). Trials involving trackloss inregion of interest were also excluded, resulin the loss of 11% of NP-match grammatitrials, 15% of NP-mismatch grammatical tria16% of NP-match ungrammatical trials, a13% of NP-mismatch ungrammatical tria3
These values did not differ significantly,though the interaction of grammaticality aNP-match was marginal by participants o[F1(1,63) 5 2.98, MSe 5 275, p , .10;
2(1,15) 5 2.56, MSe 5 79, p . .10; otheffects: allps . .25].The data were analyzed in 2 (grammati
ty) 3 2 (head/local NP number match) ANAs conducted separately for participants (F1)
and items (F2). The ANOVAs and cell-meandifference confidence intervals are reportedin Experiment 1 (see Appendix C). We focusanalyses of the verb (position 6) and the folloing word (position 7). However, individuwords (especially short high-frequency osuch aswas and were) are not always fixateduring normal reading, and thus for many anyses, we excluded additional participants whad no data for a particular condition. For seral measures, we therefore also conduanalyses of theverb region,which consisted othe verb and the following word combined. Tnumber of participants excluded from analyis noted where relevant.
3 Tracklosses were identified using a combination ofyetracker’s trackloss signal and a trial-filtering algori
available from the authors).-
r,sere
n-
t
-
s
-
-d
s
Analyses were conducted on several relreading time and regressive saccade mea(see Rayner et al., 1989, for discussion).report results for first-pass reading time, whis the sum of the time spent fixating a regfrom the first occasion when it is fixated unsome other region is fixated, and for total reing time, which is the total time spent fixatingregion during a trial. First-pass time is afor-ward-sweepmeasure: It does not include fixtions which occur after some later (farther rigposition has been fixated, whereas total tiinclude all fixations in a region during a tria
For each of these measures separatelycomputed trimmed residual reading times aExperiment 1. Less than 0.4% of the data wexcluded by trimming, and all reading-timanalyses were conducted on the trimmed reual times. Appendix B reports raw first-passtotal reading times by position trimmed at 5SD.
In addition to processing-time measures,also analyzed the probability of a regresssaccade following fixations in the verb regiRegressive saccade measures are gencoarser than reading-time measures, buthave been shown to index processing difficuparticularly for fairly severe disruptions (e.Altmann, Garnham, & Dennis, 1992; FrazierRayner, 1982). They thus may provide soindication of participants’ difficulty with real oseeming agreement violations. We also exined the endpoints of regressions originatinthe verb region, which are possible indicatorwhere participants expected to find resolutifor problems which triggered regressions (Cpenter & Just, 1977; Frazier & Rayner, 19Just & Carpenter, 1980).
First-Pass Reading Times
Figure 2 shows first-pass residual readtimes for the words around the verb. To exaine how rapidly sensitivity to ungrammaticaland head/local NP number mismatchespeared, we examined first-pass times at theposition, the word following the verb, and thetwo words combined (the verb region). Forverb region, we also performed a regresscontingent first-pass time analysis (Altmann
al., 1992; see also Altmann, 1994; Rayner &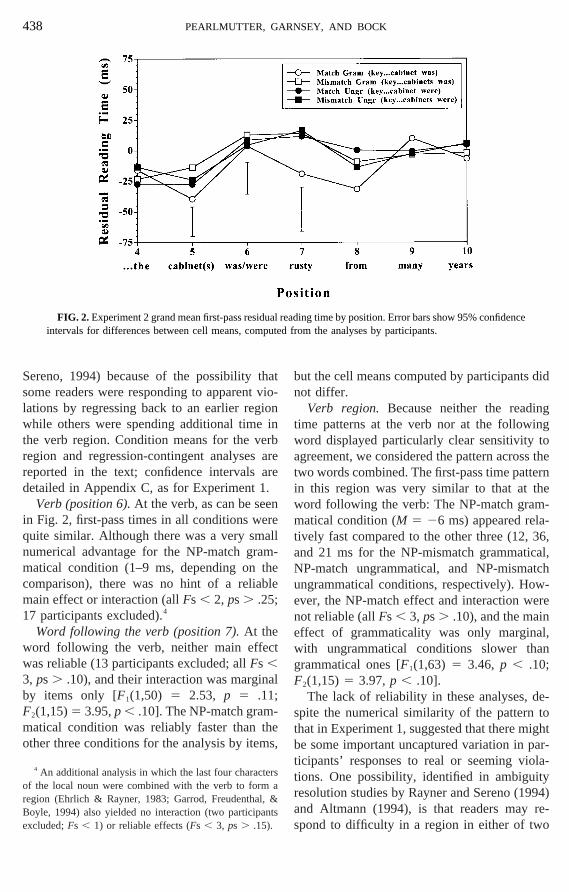
thaviionin
erba
are.enreall
amtheble
1
ct
nal
-m theo ms
b didn
ingt ingw toa s thet terni hew m-m a-t 36,a cal,N tchu w-e eren n
al,an
Fe-
s tot ightb ar-t ola-t ityr 994)a re-
terso ar , &B ntse
ncepu
438 PEARLMUTTER, GARNSEY, AND BOCK
Sereno, 1994) because of the possibilitysome readers were responding to apparentlations by regressing back to an earlier regwhile others were spending additional timethe verb region. Condition means for the vregion and regression-contingent analysesreported in the text; confidence intervalsdetailed in Appendix C, as for Experiment 1
Verb (position 6).At the verb, as can be sein Fig. 2, first-pass times in all conditions wequite similar. Although there was a very smnumerical advantage for the NP-match grmatical condition (1–9 ms, depending oncomparison), there was no hint of a reliamain effect or interaction (allFs , 2, ps . .25;
7 participants excluded).4
Word following the verb (position 7).At theword following the verb, neither main effewas reliable (13 participants excluded; allFs ,3, ps . .10), and their interaction was margiby items only [F1(1,50) 5 2.53, p 5 .11;F2(1,15)5 3.95,p , .10]. The NP-match gram
atical condition was reliably faster thanther three conditions for the analysis by ite
4 An additional analysis in which the last four characf the local noun were combined with the verb to formegion (Ehrlich & Rayner, 1983; Garrod, Freudenthaloyle, 1994) also yielded no interaction (two participa
FIG. 2. Experiment 2 grand mean first-pass residintervals for differences between cell means, com
sxcluded;Fs , 1) or reliable effects (Fs , 3, ps . .15).
to-
re
-
,
ut the cell means computed by participantsot differ.Verb region. Because neither the read
ime patterns at the verb nor at the followord displayed particularly clear sensitivitygreement, we considered the pattern acros
wo words combined. The first-pass time patn this region was very similar to that at tord following the verb: The NP-match graatical condition (M 5 26 ms) appeared rel
ively fast compared to the other three (12,nd 21 ms for the NP-mismatch grammatiP-match ungrammatical, and NP-mismangrammatical conditions, respectively). Hover, the NP-match effect and interaction wot reliable (allFs , 3, ps . .10), and the mai
effect of grammaticality was only marginwith ungrammatical conditions slower thgrammatical ones [F1(1,63) 5 3.46, p , .10;
2(1,15)5 3.97,p , .10].The lack of reliability in these analyses, d
pite the numerical similarity of the patternhat in Experiment 1, suggested that there me some important uncaptured variation in p
icipants’ responses to real or seeming viions. One possibility, identified in ambiguesolution studies by Rayner and Sereno (1nd Altmann (1994), is that readers may
l reading time by position. Error bars show 95% confideted from the analyses by participants.
ua
pond to difficulty in a region in either of two
ingrawdinwaal.P-
suby are
anin
nnin
sin.
dethest-ndesulta-ssen
m-al
tchandre-
sid-hemeverbsig-ordasor
ear-ndedthe
herevi-ithins in
rap-ortal
nalt 1vio-tal
lsm
439AGREEMENT IN COMPREHENSION
ways: by spending more time in it, or by leavit with a regressive saccade. In order to sepaeffects of regressions from first-pass times,examined first-pass times separately depenon whether the first pass in the verb regionended by a regression or not (Altmann et1992). Collapsing over grammaticality and Nmatch, first passes in the verb region werestantially shorter when they were ended bregression (M 5 250 ms) than when they weended by a forward saccade [M 5 32 ms;F1(1,41) 5 14.41;F2(1,15) 5 11.98; only the42 participants with both regression-endednonregression-ended first-pass data werecluded]. This matched the findings of Altma(1994, p. 288) and Rayner and Sereno anddicated that some participants were regresrather than spending time in the verb region
We did not analyze the regression-enpasses separately by condition becausecomprised only about 14% of the overall firpass data. However, the nonregression-efirst-pass data were analyzed further. The reing pattern was numerically similar to, but stistically stronger than, that for the full first-padata set: A reliable interaction was pres[eight participants excluded;F1(1,55) 5 5.31;F2(1,15)5 8.86] as was a main effect of gramaticality (Fs. 4). The NP-match grammatic
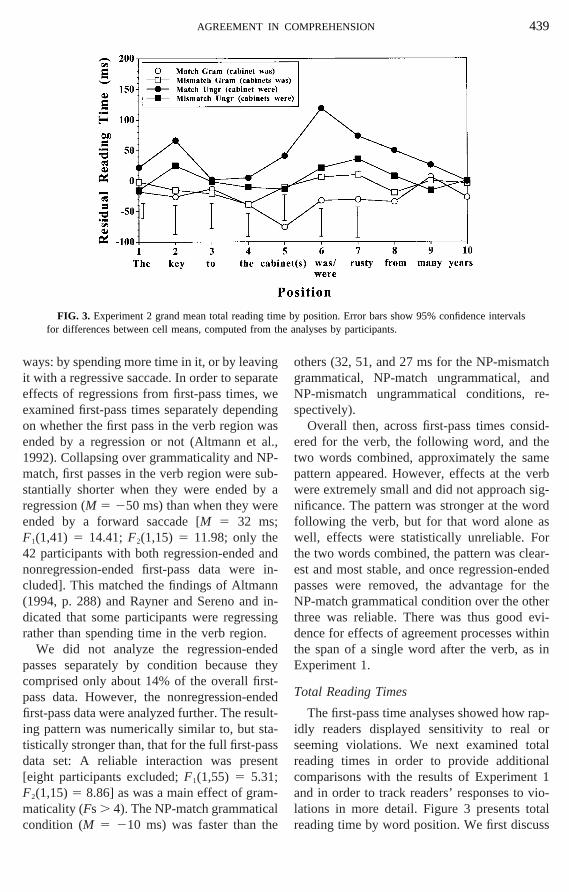
FIG. 3. Experiment 2 grand mean total readingfor differences between cell means, computed fro
condition (M 5 210 ms) was faster than the
teeg
s,
-
d-
-g
dy
dt-
t
others (32, 51, and 27 ms for the NP-mismagrammatical, NP-match ungrammatical,NP-mismatch ungrammatical conditions,spectively).
Overall then, across first-pass times conered for the verb, the following word, and ttwo words combined, approximately the sapattern appeared. However, effects at thewere extremely small and did not approachnificance. The pattern was stronger at the wfollowing the verb, but for that word alonewell, effects were statistically unreliable. Fthe two words combined, the pattern was clest and most stable, and once regression-epasses were removed, the advantage forNP-match grammatical condition over the otthree was reliable. There was thus gooddence for effects of agreement processes wthe span of a single word after the verb, aExperiment 1.
Total Reading Times
The first-pass time analyses showed howidly readers displayed sensitivity to realseeming violations. We next examined toreading times in order to provide additiocomparisons with the results of Experimenand in order to track readers’ responses tolations in more detail. Figure 3 presents to
e by position. Error bars show 95% confidence intervathe analyses by participants.
tim
reading time by word position. We first discuss

wcts
aerb
redias
unm-
erytchheat
heain
ofg
v edt onp t vo thes rel rdsp cab
ad-i rdsp di-t s atb oun( de-t ofN d atb 1)a adn NP-m elys r-e thev
R
dif-fi re-g Alt-m 82;R rob-a rstp erbr e
ion
verba fourc pat-t verys een
escell
nts.
440 PEARLMUTTER, GARNSEY, AND BOCK
reading time results at the verb and the folloing word and then briefly summarize the effeacross the words preceding the verb.
Verb (position 6).As indicated in Fig. 3,reliable interaction was present at the v[eight participants excluded;F1(1,55)5 21.43;F2(1,15)5 24.62], and total reading times welongest in the NP-match ungrammatical contion. The NP-match grammatical condition walso reliably faster than the NP-mismatchgrammatical condition. Main effects of gramaticality (Fs . 19) and NP-match (Fs . 4)were also present.
Word following the verb (position 7).Thepattern at the word following the verb was vsimilar to that at the verb, with the NP-maungrammatical condition more difficult than tother three. In addition, the NP-match grammical condition was reliably less difficult than tother conditions. An interaction was agpresent [10 participants excluded;F1(1,53) 513.44,F2(1,15)5 7.05] as was a main effect
rammaticality (Fs . 8).Words preceding the verb.In addition to the
erb and the following word, we also examinhe positions leading up to the verb, becauseossible response to a perceived agreemenlation would be to reread earlier parts ofentence. In first-pass times, there were noiable main effects or interactions on woreceding the verb, so effects in total times
FIG. 4. Experiment 2 grand mean regressive sa(left panel) and all passes (right panel). Error barmeans, computed from the analyses by participa
e attributed to rereading. c
-
-
-
-
ei-
-
n
As Fig. 3 indicates, the pattern of total reng times was similar across the five woreceding the verb, with grammatical con
ions reliably faster than ungrammatical oneoth the head noun (position 2) and local nposition 5), as well as at the local noun’serminer (position 4). There were no effectsP-match, but reliable interactions appeareoth the head noun’s determiner (positionnd the local noun (position 5). At the heoun’s determiner, this was because theatch ungrammatical condition was relativ
low. At the local noun, the pattern of diffences matched that at the word followingerb.
egressive Saccade Probability
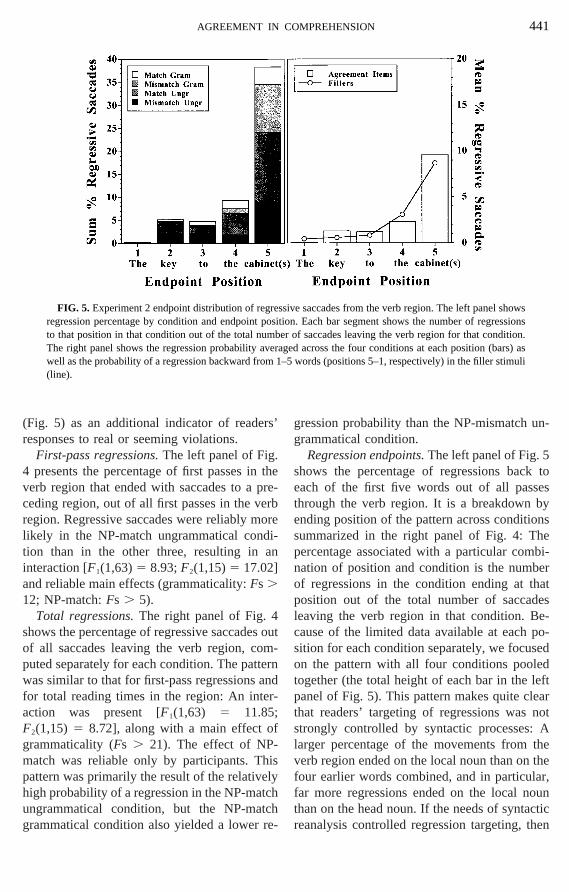
Because of the possibility that processingculty might be reflected in an increase inressive saccades (e.g., Altmann, 1994;ann et al., 1992; Frazier & Rayner, 19ayner & Sereno, 1994), we analyzed the pbility of a regressive saccade following fiasses and following all passes on the vegion (Fig. 4).5 In addition, we examined th
endpoints of regressions from the verb reg
5 We also examined regression probabilities for thelone and on the region formed by combining the lastharacters of the local noun with the verb. While theerns of regressions using these regions were generallyimilar to those reported in the text, differences betw
de probability from the verb region following first passow 95% confidence intervals for differences between
ccas sh
onditions usually did not approach significance.
rs
.th
preerbo
di-an
a
4s s oo mp terw anf r-a
ofg -m hisp elyh tchu tchg
un-
5k tosesbyonshebi-
berhatdese-po-sededleftlearnot
: Athethe
lar,ounctic
wssionsn.
s) asli
441AGREEMENT IN COMPREHENSION
(Fig. 5) as an additional indicator of readeresponses to real or seeming violations.
First-pass regressions.The left panel of Fig4 presents the percentage of first passes inverb region that ended with saccades to aceding region, out of all first passes in the vregion. Regressive saccades were reliably mlikely in the NP-match ungrammatical contion than in the other three, resulting ininteraction [F1(1,63)5 8.93;F2(1,15)5 17.02]
nd reliable main effects (grammaticality:Fs .12; NP-match:Fs . 5).
Total regressions.The right panel of Fig.hows the percentage of regressive saccadef all saccades leaving the verb region, couted separately for each condition. The patas similar to that for first-pass regressions
or total reading times in the region: An intection was present [F1(1,63) 5 11.85;
F2(1,15) 5 8.72], along with a main effectrammaticality (Fs . 21). The effect of NPatch was reliable only by participants. Tattern was primarily the result of the relativigh probability of a regression in the NP-mangrammatical condition, but the NP-ma
FIG. 5. Experiment 2 endpoint distribution of regregression percentage by condition and endpointto that position in that condition out of the total nuThe right panel shows the regression probabilitywell as the probability of a regression backward fro(line).
rammatical condition also yielded a lower re-
’
e-
re
ut-nd
gression probability than the NP-mismatchgrammatical condition.
Regression endpoints.The left panel of Fig.shows the percentage of regressions baceach of the first five words out of all pasthrough the verb region. It is a breakdownending position of the pattern across conditisummarized in the right panel of Fig. 4: Tpercentage associated with a particular comnation of position and condition is the numof regressions in the condition ending at tposition out of the total number of saccaleaving the verb region in that condition. Bcause of the limited data available at eachsition for each condition separately, we focuon the pattern with all four conditions pooltogether (the total height of each bar in thepanel of Fig. 5). This pattern makes quite cthat readers’ targeting of regressions wasstrongly controlled by syntactic processeslarger percentage of the movements fromverb region ended on the local noun than onfour earlier words combined, and in particufar more regressions ended on the local nthan on the head noun. If the needs of synta
sive saccades from the verb region. The left panel shosition. Each bar segment shows the number of regreser of saccades leaving the verb region for that conditioraged across the four conditions at each position (bar1–5 words (positions 5–1, respectively) in the filler stimu
respombavem
reanalysis controlled regression targeting, then

anavabioning
ounan
gesye
me tof
hatesl osiomeenhatsesin-
ysifilleacx-
.e.,is-tly
heamendgeprot th
allbycalaraherepighvedepooca
atatar-ofde-
en-nal-
blex-
ndffectat-is-di-althat
in-ingn’s
pro-
orend
surethat
icalreent of
on
442 PEARLMUTTER, GARNSEY, AND BOCK
the head noun, which contained the relevnumber information for agreement, should hbeen targeted more often. Instead, the probity of ending a regression on a given positappeared to be primarily a rapidly decreasfunction of distance, although the head nregression probability was slightly higher thmight be expected on such an account, suging that the needs of reanalysis may have plaa small role in directing regressions.
To provide a comparison pattern, we coputed the probability of a regression back onfive words out of all movements leaving anypositions 6 through 11 in the 20 filler items twere not part of any other experiment. Thvalues are plotted as the line in the right paneFig. 5, which also shows (as bars) the regrespercentage averaged across the four experital conditions. The pattern from the experimtal stimuli appears to be quite similar to tfrom the fillers, indicating that the procescontrolling regression targeting were largelydependent of specifically syntactic (re-)analprocesses. Furthermore, even using theprobabilities as a baseline and subtracting efrom the corresponding probability for the eperimental items in the right panel of Fig. 5 (iperforming an approximate correction for dtance), the local noun still received a slighhigher percentage of regressions than thenoun. Thus, even though the total reading tiand total regression percentages in Figs. 3 aindicated that the decision about when to triga regression was influenced by syntacticcesses, the decision about where to targeregression appeared not to be.
On the other hand, readers did eventureexamine the head noun, as suggestedcomparison of its total time to that on the lonoun (see Fig. 3). This can also be seen clein Fig. 6, which shows the probability ofsecond pass on each of positions 1 throug(i.e., the probability of fixating a position aftmoving beyond it during the forward swethrough the sentence). In contrast to the rpanel of Fig. 5, the two nouns each receirelatively many passes compared to the prsition and determiners. Nevertheless, the l
noun still received slightly more passes than thteil-
t-d
-o
efnn--
srh
ds4r-e
ya
ly
5
t
-l
head noun. Together with the endpoint dabove, these results indicate that regressiongeting was not tightly controlled by the needssyntactic processing, at least soon after thetection of a violation, but that readers did evtually target the appropriate locations for reaysis.
Discussion
Experiment 2 revealed a variety of notaresults. First, it replicated the pattern from Eperiment 1 in that both ungrammaticality ahead/local NP number mismatches had an eon reading times, with ungrammaticality creing additional difficulty, and a head/local mmatch creating difficulty in grammatical contions but easing difficulty in ungrammaticconditions. This again supported the ideathe presence of a head/local NP mismatchcreased the probability of an error in computthe subject NP’s number from the head nounumber-marking, as has been claimed induction.
In addition, this experiment revealed mabout the time course of sensitivity to real aseeming violations. The first-pass time meaexcluding regression-ended cases showedearly in processing, the NP-match grammatcondition was relatively fast, and the other thconditions all created about the same amou
FIG. 6. Experiment 2 probability of a second passwords preceding the verb (positions 1 through 5).
edisruption. Over time, however, as indicated in

eeden-theed
lesuner-.enthelf,
dinre-s dveedbleiontheyth
ctsne
&ts,blylewiturero-wese
engray og tlt-th
ionenotimreseribu, bea
ofre notfulst,ere
dingbjectThepen-teadingss ala-k to
milarhead
ro-es toionstch.sult.g.,2
sonionseaduc-ead/thendon-g auc-giestheest,cedaintheer-on
ola-
eri-ible
443AGREEMENT IN COMPREHENSION
the total reading times, the difference betwthe two grammatical conditions tended tocrease, while the relative difficulty of the ugrammatical conditions, and particularlyNP-match ungrammatical condition, increasThus overall, NP-mismatch tended to bedisruptive than ungrammaticality, and angrammaticality with unmistakable numbmarking created the most severe problems
This experiment also confirmed the Experim1 finding that effects primarily appeared atword following the verb, but not at the verb itseindicating that properties of the self-paced reatask from Experiment 1 were not artificially cating a delay. Thus agreement computationnot seem to have reliably influenced eye moments during the first fixation, which includinformation about the verb. However, the reliaeffects in first-pass time excluding regressended passes for the verb region indicatedagreement computations had influencedmovements before the eyes moved beyondverb region. Given that other syntactic effe(e.g., garden-path effects, as in Frazier & Ray1982, and Garnsey, Pearlmutter, Myers,Lotocky, 1997; and syntactic complexity effecas in Holmes & O’Regan, 1981) appear reliawithin one word following their earliest possiblocations, these results are clearly compatiblethe requirements of theories which rely on featbased computation for all of their syntactic pcessing (e.g., feature-unification parsers) asas with theories which rely less on feature-baprocessing.
Beyond evidence about time course, Experim2 also showed that the response to seeming unmaticality could be either an increased probabilita regression or an increase in time spent readinseemingly ungrammatical region (replicating Amann et al.’s, 1992, results in regions other thandisambiguation of their referential context conditsee Altmann, 1994, p. 288, and Rayner & Ser1994, for discussion). The fact that the first-passeffects were stronger after the exclusion of regsion-ended trials suggested that these alternativsponses tended to be in complementary disttion—readers either slowed down or regressednot both. Furthermore, the overall regression m
sures indicated that while real or seeming agreemen-
.s-
t
g
o-
-atee
r,
h-
lld
tm-fhe
e;,
e-
re--
ut-
violations could certainly influence the probabilitya regression, the targets of those regressions wecontrolled by knowledge of where potentially useinformation might be found (cf. Carpenter & Ju1977): Regressions from the verb region wmostly directed back to the local noun just precethe region and not to the head noun of the suNP, which carried the relevant number marking.choice of regression target appeared to be indedent of the needs of syntactic processing, insfollowing a rapidly and monotonically decreasfunction of distance much like that seen acrosample of fillers which did not contain any viotions. Readers did eventually make their way bacthe head noun, however, as indicated by the simean number of passes and total time on theand local nouns.
EXPERIMENT 3
The combination of Experiments 1 and 2 pvided strong evidence about readers’ responsagreement violations and to seeming violatcreated by a head/local NP number mismaThis latter result parallels the most basic refrom the language production literature (eBock & Miller, 1991), but Experiments 1 andonly examined half of the pattern: the comparibetween NP-match and NP-mismatch conditwhen the head NP was singular. When the hNP was instead plural, the proportion of prodtion errors did not increase in response to a hlocal NP-mismatch. Experiment 3 examinedeffect of NP mismatches for both singular aplural head NPs, replicating the grammatical cditions of the first two experiments and allowincomparison of the complete pattern with prodtion results. Because the different methodoloof Experiments 1 and 2 yielded essentiallysame pattern in the primary region of interExperiment 3 used the simpler one, self-pareading. In addition, Experiment 3 did not contany ungrammatical items, so a replication ofNP-mismatch effect found in the first two expiments would rule out the idea that it dependedparticipants being sensitive to agreement vitions.
The use of plural head conditions in Expment 3 also allows us to examine two poss
ntexplanations for NP-mismatch effects. One possi-
f aobaheachcanun’theo
ocnon thw-caou
kedther to
atcult-htheill
NPdid-
terd 2d fo&ted
of aandtheon-edetenplu-t–
se-
woNP--
d ceso
inplelessceson-hann,
ndi-the
hisan
ac-
11
11
33
s
444 PEARLMUTTER, GARNSEY, AND BOCK
bility, mentioned earlier, is that the effect ohead/local NP mismatch is to increase the prbility of an error in computing the number of tsubject NP. On such a head-overwriting approthe number specification of the local nounoccasionally incorrectly replace the head nonumber-marking as the number-marking forwhole subject NP. In the NP-match conditionsExperiments 1 and 2, where the head and lnoun were both singular, this would have noticeable effect because the number-marking owhole subject NP would still be singular. Hoever, in the NP-mismatch conditions, if the lonoun’s specification replaces that of the head non the subject NP, the subject NP will be marplural. In the grammatical conditions, whensingular verb is then encountered, it will appeaviolate agreement more often in the NP-mismcondition than in the NP-match condition, resing in additional difficulty in the NP-mismatccondition. In the ungrammatical conditions, onother hand, the verb is plural, and thus it wappear to agree properly more often in themismatch condition than in the NP-match contion, making the former less difficult. This heaoverwriting approach can thus explain the patof NP-mismatch effects in Experiments 1 anwith essentially the same mechanism proposeproduction (Bock & Eberhard, 1993; ViglioccoNicol, 1997). Table 2 summarizes the predicpattern.
TAB
NP-Mismatch Effect Predictions of Head-O
Exp. TextGrammat-
icality Match
–3 key to the cabinet was Gram. Match–3 key to the cabinets was Gram. Mismatch
, 2 key to the cabinet were Ungr. Match, 2 key to the cabinets were Ungr. Mismatch
keys to the cabinets were Gram. Matchkeys to the cabinet were Gram. Mismatch
Note. Easy and Hard refer to difficulty within eachingular; P5 plural.
However, an alternative explanation for NP-
-
,
s
fal-e
ln
h
--
n
r
mismatch effects is that they are the resultmismatch in number between the local nounthe verb, as opposed to the local noun andhead noun. Because of English word order cstraints, head nouns often immediately prectheir verbs, and thus the parser will quite ofencounter singular noun–singular verb andral noun–plural verb sequences (e.g.,cabinewas, cabinets were), whereas singular nounplural verb and plural noun–singular verbquences (e.g.,cabinets was, cabinet were) willbe rarer. In the first two experiments, the tmore common sequences occurred in thematch grammatical (cabinet was) and the NPmismatch ungrammatical (cabinets were) con-
itions, whereas the two rarer sequenccurred in the NP-match ungrammatical (cab-
inet were) and NP-mismatch grammatical (cab-inets was) conditions. Thus thisword-to-wordtransition probability approach might explaNP-mismatch effects as a matter of fairly simserial association, with the parser havingdifficulty processing more common sequen(see Table 2): The NP-match grammatical cdition involved a more common sequence tthe NP-mismatch grammatical conditiowhereas the NP-match ungrammatical cotion involved a less common sequence thanNP-mismatch ungrammatical condition. Texplanation still requires the postulation ofindependent sensitivity to grammaticality to
2
writing and Word-to-Word Transition Probability
eadmber
Localnumber
Verbnumber
Head-overwriting& markedness
Transitionprobability
S S S Easy EasyS P S Hard Hard
S S P Hard HardS P P Easy Easy
P P P Easy EasyP S P Easy Hard
tch/Mismatch pair. Abbreviations: Exp5 experiment; S5
LE
ver
Hnu
Ma
count for the overall greater difficulty with un-

al-o
bilul
sseto
ncy
notosx-thanjuslocP--
thep larnc tos adn nst heh red adn erw thep 7)p gu-l is ib de eo isn le to
t onts
ed.en-s inandfor-ic-ar-
-2,
ed inwasayssen-s 1r or(6),theberulartch
twotwo
eri-er-ting
in
y
ntolistof
entm-theand
dent
eri-
tionf rkeb o nd un-g mue houb
445AGREEMENT IN COMPREHENSION
grammatical conditions, but it provides anternative to the head-overwriting explanationNP-mismatch effects. On a transition probaity approach, the comprehension system wotrack head number and hence agreement etially perfectly, but it would also be sensitivemore local inconsistencies (i.e., low-frequeword-to-word transition probabilities).
The stimuli in Experiments 1 and 2 weresufficient to distinguish between these two psibilities, but the plural head conditions in Eperiment 3 can do so. As Table 2 indicates,transition probability explanation predictsNP-mismatch effect for plural head nounsas for singular head nouns because thenoun–verb transition for the plural head Nmatch condition will be relatively more common (plural noun–plural verb, e.g.,cabinetswere) than the corresponding transition for
lural head NP-mismatch condition (singuoun–plural verb, e.g.,cabinet were). If insteadomprehension parallels production in failinghow an NP-mismatch effect for plural heouns, this would be evidence against a tra
ion probability explanation. Of course, tead-overwriting explanation alone also picts an NP-mismatch effect for plural heouns, but the combination of the head-ovriting explanation and the proposal thatlural is explicitly marked (Eberhard, 199redicts an NP-mismatch effect only for sin
ar heads, and no effect for plural heads. Thecause in the plural head case, the heaxplicitly marked, making it less likely to bverwritten, and the mismatching local nounot marked, so that it has no feature availabverwrite that of the head.6
Method
Participants.Fifty University of Illinois un-dergraduates participated for class credi$5. To balance the number of participa
6 The predictions of the transition probability explanaor plural head cases do not change if plurals are maecause head noun number and local noun number directly interact. To explain the Experiment 1 and 2rammatical singular head cases, a plural local nounase processing when the verb is also plural, and this s
e the case regardless of head noun number.f-dn-
-
e
tal
i-
-
-
sis
o
r
across lists, two participants were excludOne of these had relatively poor comprehsion question performance across all itemthe experiment (less than 87% correct),the other had poor comprehension permance for the experimental stimuli in partular (88% correct). Thus, data from 48 pticipants were analyzed.
Materials and design.The experimental stimuli were the same as in Experiments 1 andexcept that head noun number was manipulatplace of grammaticality. Thus, the head nouneither singular or plural, and the verb alwagreed with the head noun in number, so alltences were grammatical. As in Experimentand 2, the local noun could be either singulaplural. An example stimulus set is shown inwhere the four conditions, formed by crossingfactors head number and head/local NP nummatch, are singular head NP-match (6a), singhead NP-mismatch (6b), plural head NP-ma(6c), and plural head NP-mismatch (6d). Thesingular head conditions are the same as thecorresponding grammatical conditions in Expments 1 and 2. The plausibility of the four diffent subject NPs, obtained in the plausibility rastudy in Experiment 1, is shown for each itemAppendix A.
(6) a. The key to the cabinet was rusty from manyyears of disuse.
b. The key to the cabinets was rusty from manyyears of disuse.
c. The keys to the cabinets were rusty from manyears of disuse.
d. The keys to the cabinet were rusty from manyyears of disuse.
The 16 experimental stimuli were placed ifour lists as in Experiments 1 and 2. Eachalso contained 94 other (filler) items, 60which were part of an unrelated experiminvolving direct object versus sentential coplement ambiguities. The remainder ofitems incorporated a variety of structureswere always grammatical sentences.
Apparatus and procedure.The apparatus anprocedure were identical to those in Experim1. Participants typically completed the exp
dot
stld
ment in approximately 30 min.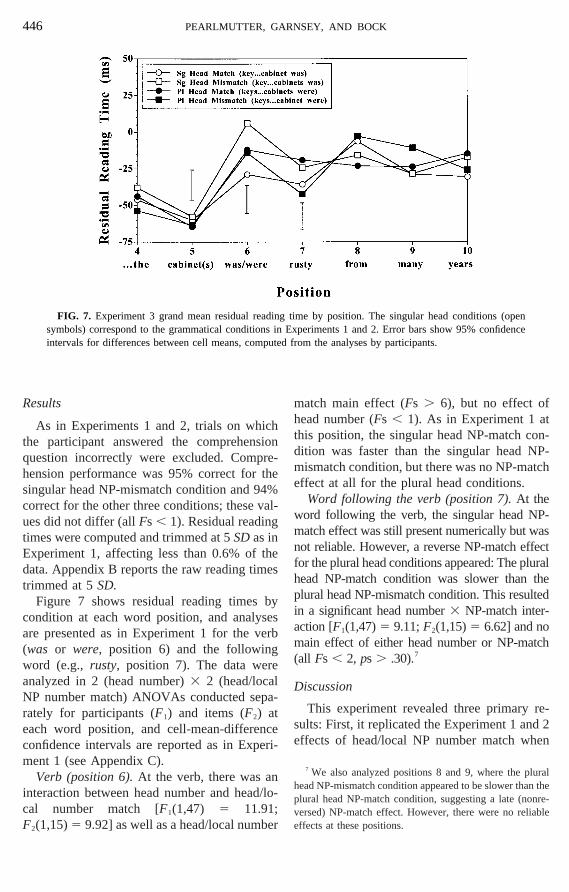
chsioreth4%valg
thee
byseer
grelpa
nceer
ni d/locF
m fh tt on-d P-m tche
w P-m asn fectf luralh thep ltedi -a
tch
re-d 2hen
luralh n thep nre-v iable
ennce
446 PEARLMUTTER, GARNSEY, AND BOCK
Results
As in Experiments 1 and 2, trials on whithe participant answered the comprehenquestion incorrectly were excluded. Comphension performance was 95% correct forsingular head NP-mismatch condition and 9correct for the other three conditions; theseues did not differ (allFs , 1). Residual readintimes were computed and trimmed at 5SDas inExperiment 1, affecting less than 0.6% ofdata. Appendix B reports the raw reading timtrimmed at 5SD.
Figure 7 shows residual reading timescondition at each word position, and analyare presented as in Experiment 1 for the v(was or were, position 6) and the followinword (e.g., rusty, position 7). The data weanalyzed in 2 (head number)3 2 (head/locaNP number match) ANOVAs conducted serately for participants (F1) and items (F2) ateach word position, and cell-mean-differeconfidence intervals are reported as in Expment 1 (see Appendix C).
Verb (position 6).At the verb, there was anteraction between head number and heaal number match [F1(1,47) 5 11.91;
FIG. 7. Experiment 3 grand mean residual reasymbols) correspond to the grammatical conditiointervals for differences between cell means, com
2(1,15)5 9.92] as well as a head/local numbere
n-e
-
s
sb
-
i-
-
atch main effect (Fs . 6), but no effect oead number (Fs , 1). As in Experiment 1 a
his position, the singular head NP-match cition was faster than the singular head Nismatch condition, but there was no NP-maffect at all for the plural head conditions.Word following the verb (position 7).At the
ord following the verb, the singular head Natch effect was still present numerically but wot reliable. However, a reverse NP-match ef
or the plural head conditions appeared: The pead NP-match condition was slower thanlural head NP-mismatch condition. This resu
n a significant head number3 NP-match interction [F1(1,47)5 9.11;F2(1,15)5 6.62] and no
main effect of either head number or NP-ma(all Fs , 2, ps . .30).7
Discussion
This experiment revealed three primarysults: First, it replicated the Experiment 1 aneffects of head/local NP number match w
7 We also analyzed positions 8 and 9, where the pead NP-mismatch condition appeared to be slower thalural head NP-match condition, suggesting a late (noersed) NP-match effect. However, there were no rel
g time by position. The singular head conditions (opn Experiments 1 and 2. Error bars show 95% confideted from the analyses by participants.
dinns ipu
ffects at these positions.

id ss ohe
onswandias
is-cts
astheththterferis
ol-2;
1;ndra
f athieaee
thethopucth
calt oth
rdonthisis
ec
e aank ohe
opr
vio-ead/
thearlyw-rn ofun-
o io-l e
la-am--reeionsram-ionsper-zierioneast
rlyis-
sy-Ofdif-ms
t re-ingtin-ego-nt
f sions thes eenc Theh onp ctsd hiscm um-b tialp n av n-t k-
ing
447AGREEMENT IN COMPREHENSION
the head noun and verb were singular and din the absence of any ungrammatical iteminstructions or references to agreement pnomena. Second, in the plural head conditiNP-match also had an effect, but the effectthe reverse of that for the singular head cotions: The plural head NP-match condition wmore difficult than the plural head NP-mmatch condition. Third, the timing of the effein the singular and plural head conditions wdifferent: In the singular head conditions,NP-match effect appeared immediately atverb, whereas in the plural head conditions,(reverse) effect did not appear until a word laand the two plural head conditions did not difat the verb itself. This combination of effectscompatible with that found by Bock and cleagues in production (Bock & Cutting, 199Bock & Eberhard, 1993; Bock & Miller, 199Eberhard, 1997), where singular head cotions showed an NP-mismatch effect, but pluhead conditions did not differ in probability osubject–verb agreement error. Of course,leaves open the question of why the plural hconditions showed a reverse NP-mismatchfect on the word following the verb, and wreturn to this point below.
The combination of this experiment andprevious two also provided evidence aboutmechanism by which NP-mismatch effectserate in comprehension, suggesting that seffects are the result of interference betweenhead noun’s number-marking and the lonoun’s number-marking rather than the resua (mis-)match between the local noun andimmediately following verb (i.e., word-to-wotransition probability). The latter explanatipredicted that the plural head conditions inexperiment should be impaired by an NP mmatch, and there was no hint of such an eff
GENERAL DISCUSSION
The three experiments in this article providrange of data about readers’ sensitivity to realseeming agreement violations. Despite the lacany task beyond reading to answer a compresion question and the fact that computationagreement was not a priori necessary to com
hend the stimuli, readers displayed substantial dimor-,
s-
ee,
i-l
sdf-
e-helfe
-t.
df
n-fe-
ruption in response to both actual agreementlations and seeming violations created by hlocal NP number mismatches, at least whenhead noun was singular. This sensitivity cleaffected processing by the time the word folloing the verb was being read. The general pattethe disruptions was that real violations (thegrammatical conditions; e.g.,the key. . .were)verall created more difficulty than seeming v
ations (NP-mismatch grammatical;the key to thcabinets was), with cases of unmistakable viotion being the most severe (NP-match ungrmatical; the key to the cabinet were). These disruptions were reflected in reading times in all thexperiments, and mismatch-induced disruptappeared in Experiment 3 even when no ungmatical stimuli were presented. These disruptalso appeared in regression probabilities in Eximent 2 (see also Altmann et al., 1992, and Fra& Rayner, 1982), but the choice of regresstarget did not appear to be influenced at linitially by syntactic constraints.
This pattern of sensitivity, and particulathe timing revealed in Experiment 2, is constent with the linguistic, computational, and pcholinguistic theories described earlier.course, these theories suggest a variety offerent (and often theory-internal) mechanisfor agreement computation, and the currensults do not provide strong evidence implicatany one in particular. However, we can disguish between two general processing catries: In acompute-on-the-flysystem, agreemeeatures are processed by the comprehenystem as they are encountered, so thatubject NP’s number-marking has already bomputed when the verb is processed. (ead-overwriting and word-to-word transitirobability explanations for mismatch effeiscussed above would both apply within tategory.) Alternatively, if a backtrackingechanism is used to handle agreement, ner-marking would only be checked after iniarsing and only when possible (e.g., wheerb overtly marked for number is encouered).8 In English, given the paucity of chec
8 Note that Nicol et al.’s (1997) proposed backtrack
s-echanism for comprehension is a compute-on-the-fly sys-
yont toou
dlyino
de-ckn-usig
tertchntit ien
andityP
er iacas
e-tw
ugmsd bweP’so
thedeuld
conerben
ionthto
outrse,fromis-
um-is
een-the
am-anap-eri-ectsect
ug-tingro-t
pla-s offor
ati-heforer-omerb
fornott thatcallthatrd,ms.P-
oretch
atchap-theraldif-ear-ave
comthebe
448 PEARLMUTTER, GARNSEY, AND BOCK
able cases noted earlier and the redundancagreement information with other syntactic cstraints, a backtracking system might turn oube more efficient, depending on how onerthe agreement-checking process is.
The current data are most straightforwarhandled by a compute-on-the-fly processwhich both reading times and the incidenceregressions simply reflect the probability oftecting an agreement violation. The backtraing hypothesis specifically has difficulty hadling the Experiment 2 regression data. Becait assumes that the comprehension systemnores agreement information until it encounan overtly number-marked verb, the NP-maand NP-mismatch conditions should be idecal with respect to agreement properties, buExperiment 2, regressions were more frequin NP-match than NP-mismatch conditions,NP-match also interacted with grammaticalThe backtracking hypothesis can explain Nmatch effects in first-passreading timearoundthe verb by assuming that subject NP numbcomputed without making any regressive scades. However, trying to use this samesumption to explain why the probability of rgressions after first passes varied createsinteracting problems: First, first passes throthe verb region were much shorter (by 82when ended by a regression than when endea forward saccade, suggesting that readersnot spending time computing the subject Nnumber before regressing. Second, and mcritically, if readers did manage to computesubject NP’s number in the regression-entrials, then first-pass times on those trials shohave been affected. But the first passes enderegressions were the cases which did nottribute to the first-pass time effects at the vregion (reliable effects appeared only whthose trials were removed, in the regresscontingent analyses). Thus the number ofsubject NP was probably computed priorencountering the verb.
tem in our terms because the subject NP’s number isputed as the NP is initially processed. For Nicol et al.,backtracking arises in the actual check of the verb’s num
against the subject NP’s, while the verb is being processeof-
s
f
-
e-
s
-nt
.-
s--
oh)yre
re
ddby-
-e
Comprehension and Production
In addition to the evidence they provide abcomprehension and related theories, of couthese results can also be compared to thoseproduction studies, where a head/local NP mmatch creates a higher proportion of verb-nber-marking errors only when the head NPsingular, not when it is plural. All three of thcurrent experiments also showed difficultygendered by a head/local mismatch whenhead NP was singular and the verb was grmatically correct. In Experiments 1 and 3,NP-mismatch effect for singular head NPspeared immediately at the verb; and in Expment 2, despite the absence of significant effat the verb itself, a reliable NP-mismatch effemerged at the next word.
The three experiments together also sgested that the same kind of head-overwriexplanation of NP-mismatch effects as in pduction (e.g., Vigliocco & Nicol, 1997) mighapply as well in comprehension. Such an exnation, along with the proposed markednesthe plural relative to the singular, accountedboth the NP-match interaction with grammcality in the first two experiments and for tlack of an NP-match effect (at the verb)plural heads in the third experiment. An altnative, that NP-mismatch effects result frdifferences in the frequency of local noun–vsequences, predicted an NP-match effectboth singular and plural heads and wassupported. Together, these patterns suggesthe comprehension and production systemson similar mechanisms for agreement andthe markedness of the plural (Bock & Eberha1993; Eberhard, 1997) applies to both syste
Experiment 3, however, showed that the Nmismatch effect for plural-head NPs was mcomplicated: At the verb, a head/local mismahad no effect, but a surprising reverse mismeffect (NP-match harder than NP-mismatch)peared at the following word. The fact thatNP-mismatch effects for singular and pluheads were in opposite directions and hadferent onset times with respect to the appance of the verb suggests that they may h
-
r
different origins, and one possibility is that thed.
for3
eadetsd,
w isn ndt rer nglq ulahd ofc ons bjeN th)t thed en-t hep nto thv ent orc thep w-i lityi
ctt anp thu othc thai elys andc d-v luei umb P’ss dlyp thr vew recv inc di-t rp na reg enI
m sta veni ne ostn de-t eN er,w ysb ille r, sot gh( theN woN rrorp el ’sn ert de-tm ed-e ofi thed is-m
nts1 on-d at-i di-t erem d-f set-t go to. att ct-e fc entc thet omp er-r ler( m-b eirs ndo werr
urea on
449AGREEMENT IN COMPREHENSION
complexity of the discourse model requiredthe different subject NPs of Experimentplayed a role. For example, in the plural hNP-match condition, two multiple-member s(e.g., keys and cabinets) must be postulate
hereas only one multiple-member seteeded in the plural head NP-mismatch co
ion (keys, cabinet). Complexity differences aeversed for the singular head cases: The siar head NP-match condition (key, cabinet) re-uires no multiple-member sets, but the singead NP-mismatch condition (key, cabinets)oes require one. Although the difficultyonstructing these discourse representatihould be spread across the words of the suP (and is correlated with subject NP leng
he effects in the verb region might reflectifficulty of combining the discourse repres
ation of the subject with the content of tredicate. Critically for our stimuli, this contenly appeared following the verb, becauseerb itself (always the copula) provided essially none. Thus discourse effects of this sould conceivably explain the reversal oflural head mismatch effect at the word follo
ng the verb. We are examining this possibin ongoing work.
An additional point to consider with respeo similarities between the comprehensionroduction systems concerns the idea thatnderlying computation mechanism in bases involves discrete features and “slots”;s, that an NP is identified as either definitingular or plural and that production errorsomprehension difficulty result from an inaertent overwriting process in which one vas replaced by another (e.g., the head NP’s ner specification is replaced by the local Npecification). This approach straightforwarredicts production results (in part becauseesponses are discrete): When incorrect oriting occurs, producers generate the incorerb form. If the same mechanism is usedomprehension, then the difficulty of a conion will be a function of its detected-errorobability: the probability of noticing that agreement error is present in the condition,ardless of whether an error is actually pres
n Experiments 1 and 2, in the NP-match gramc
i-
u-
r
sct,
e-t
de
t
-
er-t
-t.
atical condition, the subject NP will almolways be correctly identified as singular (e
nappropriate overwriting will not result in arror), as will the verb, so readers will almever think an error is present. Thus the
ected-error probability will be very low. In thP-match ungrammatical condition, howevhile the subject NP will again almost alwae correctly identified as singular, the verb wssentially never be misidentified as singula
he detected-error probability will be very hi1.00 minus the detected-error probability inP-match grammatical condition). In the tP-mismatch conditions, the detected-erobability will depend on the probability of th
ocal NP’s number overwriting the head NPumber: The higher this probability, the high
he NP-mismatch grammatical condition’sected-error probability, and thelower the NP-ismatch ungrammatical condition’s detectrror probability. Thus as the probability
ncorrect overwriting increases toward .50,etected-error probabilities in the two NP-match conditions will approach each other.The concern here is that in both Experimeand 2, while the NP-match grammatical c
ition was easier and the NP-match ungrammcal condition was harder than the other conions, the two NP-mismatch conditions wostly indistinguishable. A discrete slot-an
eature approach could account for this bying the probability of inadvertent overwritinf a head NP’s number by a local NP close
50. This would straightforwardly predict thhe two conditions should be similar in deted-error probability and thus difficulty. Oourse, this suggests a fairly inept agreemomputation system—it fails close to halfime—but more directly relevant, the data frroduction suggest that mismatch-inducedors are much less frequent: Bock & Mil1991), for example, found a maximum nuer-marking error rate of about 25% for thingular head NP-mismatch condition, ather studies have found comparable or loates.
An alternative to the discrete slot-and-featpproach is to allow number features to take
-ontinuous activation (or probability) values

odetatanuc-ilityoisrous
o-
wilonth
metheal
enot
guociurentyca
g o
anerwiltheera-usa
ervedsein
theuaicho
er-
ntromnt
vingureetebetedon isuf-t thedel,tc.)
ng
anap-tionP-2,
ch.l toof
fer-meling
ven-evelfs,
heeth-s oft theofionNPP-er-
at-blehisn-
oastn-w-the
ish
450 PEARLMUTTER, GARNSEY, AND BOCK
during processing, as in constraint-based mels of ambiguity resolution (e.g., MacDonaldal., 1994; see Trueswell, 1996, for similar trement of verb tense markers; and Dell, 1986,Roelofs, 1992, for conceptually similar prodtion models). On this approach, the possibof perceptual error and the existence of nwithin the activation system make feature pcessing, even for objectively unambiguowords (e.g.,keys), a matter of ambiguity reslution. For example, in most cases, whenkeysisprocessed in the lexicon, the plural featurebecome very active, but because of occasierrors and general noise within the system,singular possibility may also receive sosmall amount of support. This situation issame as that for a strongly biased semanticambiguous word (e.g.,boxer): One possiblmeaning is very strongly preferred, but it isthe only possibility. Other words (e.g.,deer,you, most verbs) can be more clearly ambious, and in addition to the uncertainty assated with activating the appropriate featwhen a word is identified, potential uncertaiwill also arise because later words (e.g., a lonoun) must be processed while the markinearlier words is maintained.
Because of these sources of interferenceambiguity, identifying the subject NP’s numbwhen it must be checked against the verb’sbe more difficult and more error prone toextent that its activation level is no longclearly differentiated from that of any alterntives. Noun phrase-mismatch effects will tharise as interference increases, and grammcality effects will arise when the verb’s numbspecification fails to correspond to that retriefor the subject NP. The combination of theeffects will match those described aboveterms of detected-error-probability, butcompetition between alternatives on individtrials provides a source of nonlinearity whcan account for the similar difficulty of the twNP-mismatch conditions, despite their diffence in grammaticality.
This approach can handle the Experimeresult that plural head nouns are insulated fNP-mismatch effects, essentially by impleme
ing Eberhard’s (1997; Bock & Eberhard, 1993)-
-d
e-
lale
ly
--
lf
d
l
ti-
l
3
-
plural-markedness proposal. Instead of haboth a plural feature and a singular featwhich can be activated and which can compwith each other, only a plural feature wouldavailable. When the plural feature is activaabove a set threshold, the element in questiidentified as plural; when the plural is not sficiently activated, the system assumes thaelement in question is singular. In such a moall sources of interference (noise, decay, eact directly on the plural feature, either driviits activation up or down.
While this description is just a sketch ofalternative to a discrete slot-and-featureproach, it does provide a potential explanafor the lack of difference between the two Nmismatch conditions in Experiments 1 andwhich is problematic for the discrete approaIn addition, this framework has the potentiaexplain ambiguity resolution and a varietyfeature-processing effects, including interence and grammaticality effects, with the samechanisms that have been used in modegeneral syntactic comprehension (e.g., Steson, 1994) as well as word- and sentence-leffects in production (e.g., Dell, 1986; Roelo1992).
Empirical and Methodological Issues
In addition to theoretical implications, tcurrent results have several empirical and modological consequences. First, the resultExperiments 1 and 2 bear on questions abourole of notional number in the computationagreement in English. We found no interactbetween notional number of the subject(distributivity) and either grammaticality or Nmatch at the local noun position, at the numbmarked verb, or at the following word, indicing that notional number had no measuraimpact on the computation of agreement. Taccords with production results for similar Eglish materials (Bock & Miller, 1991; Viglioccet al., 1996a), results which in turn contrinterestingly with findings in several other laguages (Vigliocco et al., 1995, 1996a,b). Hoever, Eberhard (1996) offers evidence thatappearance of distributivity effects in Engl
production may depend on the relative con-
entalsticenconslystreelu
ttleinger
eyeialsomhe
ereal-to
eaderse
nto
elasioof
s foef
icandse
enceprout
Thringwitlin-thafaex
eaus
ara
uesam-rre-er-
tedlarrb).onscaltheum-thetheter-calive.entectitemr:larlo-heehe
et
h
e
e
t
s
e
451AGREEMENT IN COMPREHENSION
creteness of the speaker’s number represtion. This was not manipulated in our materiCoupled with the conflicting cross-linguispatterns in the production data and the absof converging evidence from other workcomprehension, our null interactions obviouwarrant further scrutiny. But from this firglance at how notional number affects agment computation during reading, the concsion must be that notional number has lipower to deflect the robust feature-matchprocesses set in train by grammatical numb
Second, the use of both self-paced andtracking methodologies with the same materin the current studies allows a direct compariof the two. The clearest result of such a coparison is that the differences are minimal. Tpatterns of difficulty in the two measures wmostly identical, except that eyetrackinglowed for finer-grained timing and a chanceexamine a wider range of measures. Both ring times and regression probabilities in Expiment 2 revealed the same pattern as thepaced studies.
Overall, then, the three reported experimeprovide substantial data about the handlingagreement in comprehension, about the rtionship between agreement in comprehenand in production, and about the timingagreement processing. The pattern of resultsingular versus plural head NPs paralleledfects in language production using identsubject NPs (e.g., Bock & Miller, 1991) asuggested that the two systems rely on clorelated mechanisms for processing agreeminformation. In both systems there is evidethat NP-mismatch effects are mediated bycesses responsible for subject-number comption, rather than by mere serial association.time course of agreement computation ducomprehension appears to be compatiblemany linguistic, computational, and psychoguistic theories, but it challenges theoriesassume agreement to be checked after theIn particular, comprehenders in the presentperiment displayed early sensitivity to both rand seeming violations of agreement. Becathe agreement system of English is comp
tively meager and rarely constrains the interprea-.
e
--
.-
sn-
--lf-
sf-n
r-l
lynt
-a-e
h
tct.-le-
tation of sentences, this early sensitivity argfor a system that continuously integrates grmatical features during comprehension, ispective of their eventual relevance to undstanding.
APPENDIX A
Stimuli
The stimuli used in the experiments are lisbelow in their fully singular versions (singuhead noun, singular local noun, singular veFor Experiments 1 and 2, the other versiwere created by varying the number of the lonoun and/or the verb. For Experiment 3,other versions were created by varying the nber of the head noun and/or local noun (verb’s number-marking matched that onhead noun). Items 1–8 have a distributive inpretation in their singular head–plural lonoun versions; items 9–16 are nondistributThe plausibility ratings described in Experim1 for the four different versions of the subjNPs are shown in parentheses after each(1 5 plausible, 55 implausible) in the ordesingular head–singular local noun, singuhead–plural local noun, plural head–singularcal noun, plural head–plural local noun. Tratings shown for item 6 (The name on thbillboard . . .) were actually collected using tfragmentThe name on the sign. . . asdescribedin the Method section of Experiment 1.
1. The slogan on the poster was designed to gattention. (1.18, 1.06, 1, 1.06)2. The picture on the postcard was of a village churcin the south of France. (1, 1, 1, 1)3. The mistake in the program was disastrous for thsmall software company. (1, 1.12, 1, 1.12)4. The label on the bottle was a warning about thtoxic effects of the drug. (1, 1.06, 1.24, 1)5. The problem in the school was solved by firing thesuperintendent. (1.18, 1.12, 1.12, 1)6. The name on the billboard was of a prominenlocal politician. (1.18, 1.24, 1, 1)7. The crime in the city was a reflection of the vio-lence in today’s society. (1.06, 1.06, 1.06, 1.12)8. The defect in the car was unknown to consumerand government regulators. (1.12, 1.23, 1.18, 1.06)9. The door to the office was left unlocked by thecleaning service. (1, 1, 1, 1)10. The memo from the accountant was about th
- delinquent tax return. (1.06, 1.18, 1.29, 1.06)
d
s
te
e
f
452 PEARLMUTTER, GARNSEY, AND BOCK
11. The check from the stockbroker was a dividenon a long-term bond. (1.06, 1.47, 1.53, 1.29)12. The key to the cabinet was rusty from many yearof disuse. (1.06, 1.18, 1.12, 1.24)13. The letter from the lawyer was received in SanFrancisco in late March. (1.12, 1, 1, 1.06)
14. The entrance to the laboratory was hard to locaon the diagram. (1, 1, 1.06, 1)15. The warning from the expert was a shock to thresidents of the city. (1.25, 1, 1.06, 1.29)16. The bridge to the island was about ten miles ofthe main highway. (1.59, 2, 1.47, 1.41)
2942
3846
5759
6871
281316
310313
APPENDIX B
Trimmed Raw Reading Times
TABLE B1
Experiment 1 Trimmed Raw Reading Time (in Milliseconds)
Condition
Position
4 5 6 7 8 9 10
GrammaticalMatch 297 317 324 313 324 328 3Mismatch 299 336 361 344 329 327 3
UngrammaticalMatch 291 311 333 389 382 345 3Mismatch 300 326 356 361 344 337 3
TABLE B2
Experiment 2 Trimmed Raw First-Pass Reading Time (in Milliseconds)
Condition
Position
4 5 6 7 8 9 10
GrammaticalMatch 219 246 241 247 237 282 2Mismatch 213 289 251 281 258 269 2
UngrammaticalMatch 207 253 257 283 259 267 2Mismatch 219 274 255 284 248 272 2
TABLE B3
Experiment 2 Trimmed Raw Total Reading Time (in Milliseconds)
Condition
Position
1 2 3 4 5 6 7 8 9 10
GrammaticalMatch 240 306 257 233 280 248 286 280 331Mismatch 256 314 249 241 374 284 337 298 322
UngrammaticalMatch 273 383 268 277 385 409 391 351 333Mismatch 237 353 268 263 361 318 356 315 319
9813
2106
onds)
eviation:
3
2
3
viations:
453AGREEMENT IN COMPREHENSION
TABLE B4
Experiment 3 Trimmed Raw Reading Time (in Milliseconds)
Condition
Position
4 5 6 7 8 9 10
Singular headMatch 275 288 290 293 319 300 2Mismatch 281 300 325 310 308 305 3
Plural headMatch 276 301 320 316 308 311 3Mismatch 265 286 312 291 321 314 3
APPENDIX C
Condition Means and Confidence Intervals by Participants and ItemsTABLE C1
Experiment 1 Residual Reading Time Means and Confidence Intervals by Participants and Items (in Millisec
Condition
Position
5 6 7
GrammaticalMatch 250 248 212 213 236 234Mismatch 244 243 22 23 21 1
UngrammaticalMatch 260 260 211 210 40 38Mismatch 257 258 9 8 13 13
CI 16 19 19 16 24 21
Note.At each position, the left and right columns show analyses by participants and items, respectively. AbbrCI 5 95% confidence interval for individual mean comparisons.
TABLE C2
Experiment 2 First-Pass Residual Reading Time Means and Confidence Intervalsby Participants and Items (in Milliseconds)
Condition
Position Verb region
5 6 7 All NoRegr
GrammaticalMatch 235 241 5 3 218 220 24 22 29 27Mismatch 217 215 13 18 11 22 17 14 36 3
UngrammaticalMatch 225 227 10 5 14 16 35 38 71 5Mismatch 227 224 21 7 4 18 19 21 29 27
CI 24 24 26 27 36 36 37 34 49 3
Note.At each position, the left and right columns show analyses by participants and items, respectively. AbbreAll 5 including all first passes; NoRegr5 including only first passes not ended by regressive saccades; CI5 95%
confidence interval for individual mean comparisons.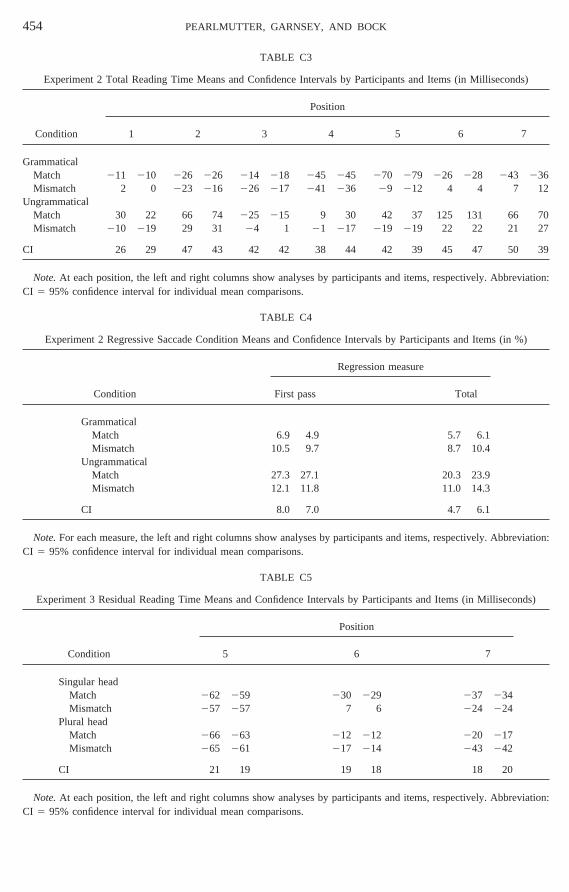
ds)
0
39
eviation:
n %)
reviation:C
onds)
eviation:
454 PEARLMUTTER, GARNSEY, AND BOCK
TABLE C3
Experiment 2 Total Reading Time Means and Confidence Intervals by Participants and Items (in Millisecon
Condition
Position
1 2 3 4 5 6 7
GrammaticalMatch 211 210 226 226 214 218 245 245 270 279 226 228 243 236Mismatch 2 0 223 216 226 217 241 236 29 212 4 4 7 12
UngrammaticalMatch 30 22 66 74 225 215 9 30 42 37 125 131 66 7Mismatch 210 219 29 31 24 1 21 217 219 219 22 22 21 27
CI 26 29 47 43 42 42 38 44 42 39 45 47 50
Note.At each position, the left and right columns show analyses by participants and items, respectively. AbbrCI 5 95% confidence interval for individual mean comparisons.
TABLE C4
Experiment 2 Regressive Saccade Condition Means and Confidence Intervals by Participants and Items (i
Condition
Regression measure
First pass Total
GrammaticalMatch 6.9 4.9 5.7 6.1Mismatch 10.5 9.7 8.7 10.4
UngrammaticalMatch 27.3 27.1 20.3 23.9Mismatch 12.1 11.8 11.0 14.3
CI 8.0 7.0 4.7 6.1
Note.For each measure, the left and right columns show analyses by participants and items, respectively. AbbI 5 95% confidence interval for individual mean comparisons.
TABLE C5
Experiment 3 Residual Reading Time Means and Confidence Intervals by Participants and Items (in Millisec
Condition
Position
5 6 7
Singular headMatch 262 259 230 229 237 234Mismatch 257 257 7 6 224 224
Plural headMatch 266 263 212 212 220 217Mismatch 265 261 217 214 243 242
CI 21 19 19 18 18 20
Note.At each position, the left and right columns show analyses by participants and items, respectively. AbbrCI 5 95% confidence interval for individual mean comparisons.

yseep
A 2).ext
B ed
B en-
B ndd
B
B at
B . J.and
nuasing
B of
C pre-nte
C
C ,
C y: Are-v-
C thephoo-
C if-Lat
D re-,
D He
E inger
ut-
E itstion.f the
E on-
E entve-
l
F e of-
F of-
F cticalis-
F iew.II:,
F rom
F ingove-sen-
F ical
G ky,ndm-e,
G e ofof
-
G tual
G n-ingne-
G ., &an
.H The
455AGREEMENT IN COMPREHENSION
REFERENCES
Altmann, G. T. M. (1994). Regression-contingent analof eye movements during sentence processing: Rto Rayner and Sereno.Memory & Cognition,22,286–290.
ltmann, G. T. M., Garnham, A., & Dennis, Y. (199Avoiding the garden path: Eye movements in contJournal of Memory and Language,31, 685–712.
lackwell, A., Bates, E., & Fisher, D. (1996). The timcourse of grammaticality judgement.Language anCognitive Processes,11, 337–406.
ock, K., & Cutting, J. C. (1992). Regulating mentalergy: Performance units in language production.Jour-nal of Memory and Language,31, 99–127.
ock, K., & Eberhard, K. M. (1993). Meaning, sound asyntax in English number agreement.Language anCognitive Processes,8, 57–99.
ock, K., & Miller, C. A. (1991). Broken agreement.Cog-nitive Psychology,23, 45–93.
ock, K., Nicol, J. L., & Cutting, J. C. (1999). The ties thbind: Creating number agreement in speech.Journal ofMemory and Language,40, 330–346.
ranigan, H. P., Liversedge, S. P., & Pickering, M(1995). Verb agreement in written comprehensionproduction. Poster presented at the Eighth AnCUNY Conference on Human Sentence ProcesTucson, AZ.
resnan, J. (Ed.). (1982).The mental representationgrammatical relations.Cambridge, MA: MIT Press.
arpenter, P. A., & Just, M. A. (1977). Reading comhension as eyes see it. In M. A. Just, & P. A. Carpe(Eds.), Cognitive processes in comprehension(pp.109–139). Hillsdale, NJ: Erlbaum.
homsky, N. (1965).Aspects of the theory of syntax.Cam-bridge, MA: MIT Press.
homsky, N. (1995).The minimalist program.CambridgeMA: MIT Press.
lark, H. H. (1973). The language-as-fixed-effect fallaccritique of language statistics in psychologicalsearch.Journal of Verbal Learning and Verbal Behaior, 12, 335–359.
oulson, S., King, J. W., & Kutas, M. (1998). Expectunexpected: Event-related brain response to morsyntactic violations.Language and Cognitive Prcesses,13, 21–58.
uetos, F., & Mitchell, D. C. (1988). Cross-linguistic dferences in parsing: Restrictions on the use of theClosure strategy in Spanish.Cognition,30, 73–105.
ell, G. S. (1986). A spreading-activation theory oftrieval in sentence production.Psychological Review93, 283–321.
eutsch, A. (1998). Subject-predicate agreement inbrew: Interrelations with semantic processes.Lan-guage and Cognitive Processes,13, 575–597.
arley, J. (1970/1986). An efficient context-free parsalgorithm. In B. Grosz, K. S. Jones, & B. L. Webb(Eds.),Readings in natural language processing(pp.
25–33). Los Altos, CA: Morgan Kaufmann. (Reprintedsly
.
l,
r
-
e
-
from Communications of the Association for Comping Machinery,13, 94–102.)
berhard, K. M. (1996). Conceptual accessibility andcontrol of syntactic processing in sentence producPoster presented at the 37th Annual Conference oPsychonomic Society, Chicago, IL.
berhard, K. M. (1997). The marked effect of numbersubject–verb agreement.Journal of Memory and Language,36, 147–164.
hrlich, S. F., & Rayner, K. (1983). Pronoun assignmand semantic integration during reading: Eye moments and immediacy of processing.Journal of VerbaLearning and Verbal Behavior,22, 75–87.
erreira, F., & Clifton, C., Jr. (1986). The independencsyntactic processing.Journal of Memory and Language,25, 348–368.
rancis, W. N., & Kucˇera, H. (1982).Frequency analysisEnglish usage: Lexicon and grammar.Boston: Houghton–Mifflin.
razier, L. (1979).On comprehending sentences: Syntaparsing strategies.University of Connecticut doctordissertation. Bloomington, IN: Indiana Univ. Lingutics Club.
razier, L. (1987a). Sentence processing: A tutorial revIn M. Coltheart (Ed.),Attention and performance XThe psychology of reading(pp. 559–586). HillsdaleNJ: Erlbaum.
razier, L. (1987b). Syntactic processing: Evidence fDutch. Natural Language and Linguistic Theory,5,519–559.
razier, L., & Rayner, K. (1982). Making and correcterrors during sentence comprehension: Eye mments in the analysis of structurally ambiguoustences.Cognitive Psychology,14, 178–210.
reedman, S. E., & Forster, K. I. (1985). The psychologstatus of overgenerated sentences.Cognition,19,101–131.
arnsey, S. M., Pearlmutter, N. J., Myers, E., & LotocM. A. (1997). The contributions of verb bias aplausibility to the comprehension of temporarily abiguous sentences.Journal of Memory and Languag37, 58–93.
arrod, S., Freudenthal, D., & Boyle, E. (1994). The roldifferent types of anaphor in the on-line resolutionsentences in a discourse.Journal of Memory and Language,33, 39–68.
ernsbacher, M. A. (1991). Comprehending concepanaphors.Language and Cognitive Processes,6, 81–105.
ibson, E. (1991).A computational theory of human liguistic processing: Memory limitations and processbreakdown.Unpublished doctoral dissertation, Cargie Mellon Univ., Pittsburgh, PA.
ibson, E., Pearlmutter, N. J., Canseco-Gonzalez, EHickok, G. (1996). Recency preference in the humsentence processing mechanism.Cognition,59,23–59
agoort, P., Brown, C., & Groothusen, J. (1993).
syntactic positive shift (SPS) as an ERP measure of
o-
onsenv-
J ompreon
nd-
J ng:l
2).sio
singg-
ionber
e-y-
K inma
L ncel-
M . Ses-
M va-an
al
N erb
O rain
O ain-
P c-.
R f
R ove-sion-
R . R.,ined
R ma
S tax:en-ighth
Pro-
S d).of
S forge
ck,
T ind
T s aam-.
sing
T M.the-on.
V a).Dif-
V 5).The
V lk,les?d
V ticree-
W al
((
456 PEARLMUTTER, GARNSEY, AND BOCK
syntactic processing.Language and Cognitive Prcesses,8, 439–483.
Holmes, V. M., & O’Regan, J. K. (1981). Eye fixatipatterns during the reading of relative-clausetences.Journal of Verbal Learning and Verbal Behaior, 20, 417–430.
akubowicz, C., & Faussart, C. (1995). Agreement phenena in the processing of spoken French. Papersented at the Eighth Annual CUNY ConferenceHuman Sentence Processing, Tucson, AZ.
Jurafsky, D. (1996). A probabilistic model of lexical asyntactic access and disambiguation.Cognitive Science,20, 137–194.
ust, M. A., & Carpenter, P. A. (1980). A theory of readiFrom eye fixations to comprehension.PsychologicaReview,87, 329–354.
Just, M. A., Carpenter, P. A., & Woolley, J. D. (198Paradigms and processes in reading comprehenJournal of Experimental Psychology: General,111,228–238.
Kail, M., & Bassano, D. (1997). Verb agreement procesin French: A study of on-line grammaticality judments.Language and Speech,40, 25–46.
Kay, M. (1985/1986). Parsing in functional unificatgrammar. In B. Grosz, K. S. Jones, & B. L. Web(Eds.),Readings in natural language processing(pp.125–138). Los Altos, CA: Morgan Kaufmann. (Rprinted from D. R. Dowty, L. Kartunnen, & A. Zwick(Eds.),Natural language parsing(pp. 251–278), Cambridge, UK: Cambridge Univ. Press.)
utas, M., & Hillyard, S. A. (1983). Event-related brapotentials to grammatical errors and semantic anolies. Memory & Cognition,11, 539–550.
oftus, G. R., & Masson, M. E. (1994). Using confideintervals in within-subject designs.Psychonomic Buletin & Review,1, 476–490.
acDonald, M. C., Pearlmutter, N. J., & Seidenberg, M(1994). The lexical nature of syntactic ambiguity rolution. Psychological Review,101,676–703.
acWhinney, B., Bates, E., & Kliegl, R. (1984). Cuelidity and sentence interpretation in English, Germand Italian.Journal of Verbal Learning and VerbBehavior,23, 127–150.
icol, J. L., Forster, K. I., & Veres, C. (1997). Subject–vagreement processes in comprehension.Journal ofMemory and Language,36, 569–587.
sterhout, L., & Holcomb, P. J. (1992). Event-related bpotentials elicited by syntactic anomaly.Journal ofMemory and Language,31, 785–806.
sterhout, L., & Mobley, L. A. (1995). Event-related brpotentials elicited by failure to agree.Journal of Memory and Language,34, 739–773.
ollard, C., & Sag, I. A. (1994).Head-driven phrase struture grammar.Chicago, IL: Univ. of Chicago Press
ayner, K., & Pollatsek, A. (1989).The psychology oreading.Hillsdale, NJ: Erlbaum.
-
--
n.
-
.
,
ayner, K., & Sereno, S. C. (1994). Regressive eye mments and sentence parsing: On the use of regrescontingent analyses.Memory & Cognition,22, 281–285.
ayner, K., Sereno, S. C., Morris, R. K., Schmauder, A& Clifton, C., Jr. (1989). Eye movements and on-llanguage comprehension processes.Language anCognitive Processes,4, SI21–49.
oelofs, A. (1992). A spreading-activation theory of lemretrieval in speaking.Cognition,42, 107–142.
evald, C. A., & Garnsey, S. M. (1995). Safe synEncapsulation of number-marking information in stence comprehension. Paper presented at the EAnnual CUNY Conference on Human Sentencecessing, Tucson, AZ.
hieber, S. M. (1986).An introduction to unification-baseapproaches to grammar(CSLI Lecture Notes No. 4Stanford, CA: Stanford Univ., Center for the StudyLanguage and Information.
tevenson, S. (1994).A competitive attachment modelresolving syntactic ambiguities in natural languaparsing(Tech. Rep. RuCCS TR-18). New BrunswiNJ: Rutgers Univ., Center for Cognitive Science.
rueswell, J. C. (1996). The role of lexical frequencysyntactic ambiguity resolution.Journal of Memory anLanguage,35, 566–585.
rueswell, J. C., & Tanenhaus, M. K. (1994). Towardlexicalist framework of constraint-based syntacticbiguity resolution. In C. Clifton, L. Frazier, & KRayner (Eds.),Perspectives on sentence proces(pp. 155–179). Hillsdale, NJ: Erlbaum.
rueswell, J. C., Tanenhaus, M. K., & Garnsey, S.(1994). Semantic influences on parsing: Use ofmatic role information in syntactic disambiguatiJournal of Memory and Language,33, 285–318.
igliocco, G., Butterworth, B., & Garrett, M. F. (1996Subject–verb agreement in Spanish and English:ferences in the role of conceptual constraints.Cogni-tion, 61, 261–298.
igliocco, G., Butterworth, B., & Semenza, C. (199Constructing subject-verb agreement in speech:role of semantic and morphological factors.Journal ofMemory and Language,34, 186–215.
igliocco, G., Hartsuiker, R. J., Jarema, G., & KoH. H. J. (1996b). One or more labels on the bottNotional concord in Dutch and French.Language anCognitive Processes,11, 407–442.
igliocco, G., & Nicol, J. L. (1997). The role of syntactree structure in the construction of subject–verb agment. Unpublished manuscript.
iner, B. J. (1971).Statistical principles in experimentdesign(2nd ed.). New York: McGraw–Hill.
Received March 3, 1997)Revision received February 3, 1999)













![research.gold.ac.ukresearch.gold.ac.uk/12342/1/EDU_Lytra_2015b.docxWeb view[Final Draft] In: Jacomine Nortier and Bente Ailin Svendsen (eds.) (2015) Language Youth & Identity in the](https://img.pdfslide.us/doc/110x75/5ae95a237f8b9a36698b81b1/viewfinal-draft-in-jacomine-nortier-and-bente-ailin-svendsen-eds-2015-language.jpg)















