Embed Size (px)
DESCRIPTION
os
Citation preview

3/30/2014
1
BITS Pilani Hyderabad Campus
CS ZG623: Advanced Operating Systems
Chittaranjan Hota, PhD
Dept. of Computer Sc. & Information Systems
Second Semester 2013-2014
• Introduction to Distributed Systems
• Theoretical Foundations
• Distributed Mutual Exclusion
• Distributed Deadlock
• Agreement Protocols
• Distributed File Systems
• Distributed Scheduling
• Distributed Shared Memory
• Recovery
• Fault tolerance
• Protection and Security
Course Overview
3/30/2014 CS ZG623, Adv OS 2
Mid-Semester

3/30/2014
2
Text and References
3/30/2014 CS ZG623, Adv OS 3
Text Book:
Advanced Concepts in Operating Systems:
Mukesh Singhal & Shivaratri, Tata Mc Graw Hill
References:
1. Distributed Operating Systems: P. K. Sinha, PHI
2. Distributed Operating Systems: The Logical Design, A.
Goscinski, AW
3. Modern Operating Systems: A.S.Tanenbaum & VAN, PHI
4. Distributed Systems: Concepts and Design: G. Coluris, AW
EC No. Evaluation
Component &
Type of
Examination
Duration Weigh-
tage
Day, Date, Session,Time
EC-1 Assignment/Quiz ** Details to be announced
on LMS Taxila
15% ** Details to be announced
on LMS Taxila
EC-2 Mid-Semester Test
(Closed Book)*
2 Hours 35% Sunday, 16/02/2014 (AN)*
2 PM – 4 PM
EC-3 Comprehensive
Exam
(Open Book)*
3 Hours 50% Sunday, 06/04/2014 (AN)*
2 PM – 5 PM
Evaluation Components
3/30/2014 CS ZG623, Adv OS 4
3/30/2014
3
3/30/2014 CS ZG623, Adv OS 5
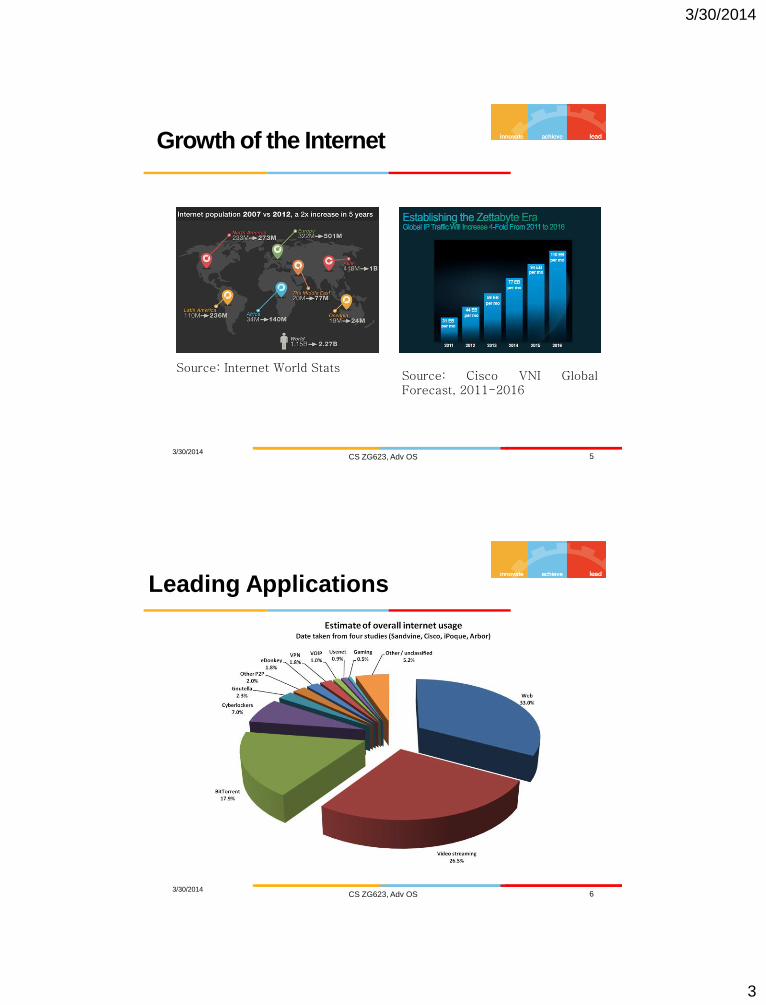
Growth of the Internet
Source: Internet World Stats Source: Cisco VNI Global Forecast, 2011-2016
3/30/2014 CS ZG623, Adv OS 6
Leading Applications

3/30/2014
4
3/30/2014 CS ZG623, Adv OS 7
Source: Traffic and Market data report Ericsson, June 2012
Growth of Mobile world
3/30/2014 CS ZG623, Adv OS 8
Powerful multi-core processors
General purpose graphic processors
Superior software methodologies
Virtualization leveraging the
powerful hardware
Wider bandwidth for communication
Proliferation of devices
Explosion of domain
applications
Source: Cloud Futures 2011, Redmond
Golden era in Computing
Tata Nano

3/30/2014
5
3/30/2014 CS ZG623, Adv OS 9
Re-imagination of computing
devices
Source: Internet Trends, Mary Meeker
3/30/2014 CS ZG623, Adv OS 10
Re-imagination of connectivity
Source: Internet Trends, Mary Meeker

3/30/2014
6
3/30/2014 CS ZG623, Adv OS 11
Re-imagination of life stories
Source: Internet Trends, Mary Meeker
3/30/2014 CS ZG623, Adv OS 12
Re-imagination of recruiting/hiring
Source: Internet Trends, Mary Meeker
3/30/2014
7
3/30/2014 CS ZG623, Adv OS 13
Re-imagination of Commerce
3/30/2014 CS ZG623, Adv OS 14
Re-imagination of Ticketing

3/30/2014
8
3/30/2014 CS ZG623, Adv OS 15
Re-imagination of Meeting people
BITS Goa
BITS Pilani
3/30/2014 CS ZG623, Adv OS 16
Re-imagination of Healthcare

3/30/2014
9
3/30/2014 CS ZG623, Adv OS 17
Re-imagination of Teaching/Learning
3/30/2014 CS ZG623, Adv OS 18
Re-imagination of watching movies

3/30/2014
10
3/30/2014 CS ZG623, Adv OS 19
Killer Applications for
Distributed Systems
Source: Distributed computing, Kai Hwang
3/30/2014 CS ZG623, Adv OS 20
Hardware Concepts
1.6
(Different organizations and memories in distributed computer systems)

3/30/2014
11
3/30/2014 CS ZG623, Adv OS 21
Uniprocessor Operating Systems
• An OS acts as a resource manager
– Manages CPU, I/O devices, and Memory
• OS provides a virtual interface that is easier to use than
hardware
• Structure of uniprocessor operating systems
– Monolithic (e.g. MS-DOS, and early UNIX)
• One large kernel that handles everything
– Layered design (Kernel based UNIX)
• Functionality is decomposed into N layers
• Each layer uses services of layer N-1 and implements
new service(s) for layer N+1
– Virtual machine (e.g. VM/370)
3/30/2014 CS ZG623, Adv OS 22
Uniprocessor OS: Microkernel based
•User level servers implement additional functionality
• Setting device regs., CPU scheduling, manipulating MMU,
capturing hardware interrupts etc .
3/30/2014
12
3/30/2014 CS ZG623, Adv OS 23
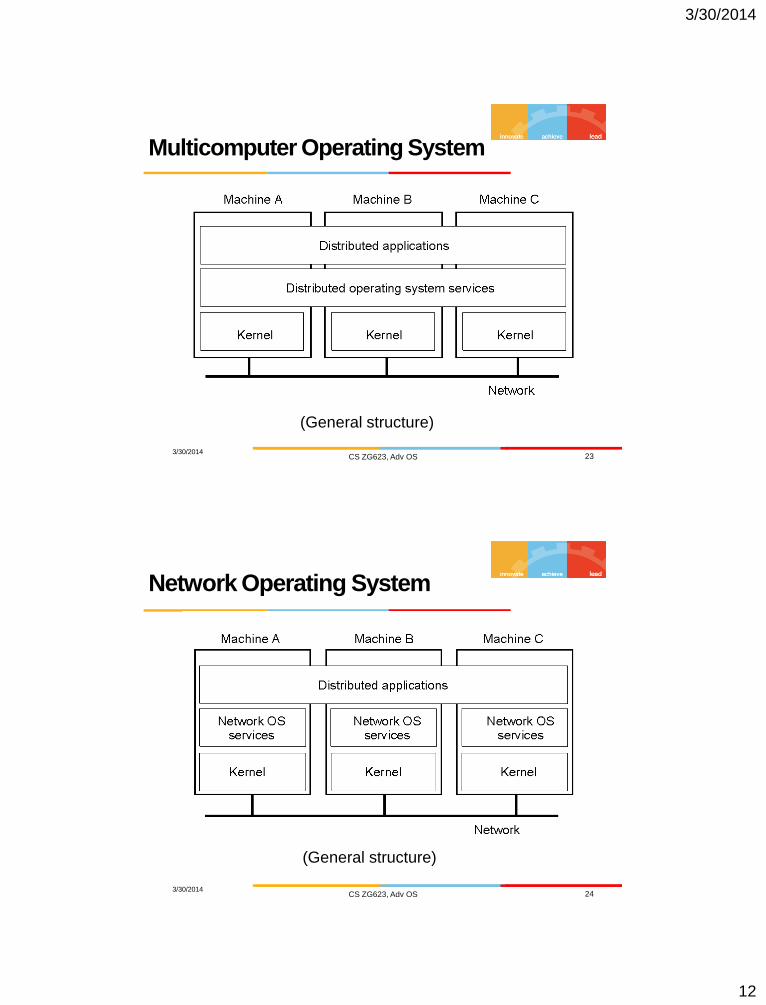
Multicomputer Operating System
(General structure)
1.14
3/30/2014 CS ZG623, Adv OS 24
Network Operating System
(General structure)
1-19

3/30/2014
13
3/30/2014 CS ZG623, Adv OS 25
What is a Distributed System?
• Loosely coupled collection of autonomous computers
connected by a network running a distributed operating
system to produce a single integrated computing
environment ( a virtual computer).
Honeycomb
3/30/2014 CS ZG623, Adv OS 26
Cluster of Cooperative Computers

3/30/2014
14
3/30/2014 CS ZG623, Adv OS 27
Computational Grids
3/30/2014 CS ZG623, Adv OS 28
GARUDA from CDAC
3/30/2014
15
3/30/2014 CS ZG623, Adv OS 29
A
D
E F
G
H
F
H G A
E C
C
B
P2P overlay layer
Native IP layer
D
B
AS1
AS2
AS3
AS4
AS5
AS6
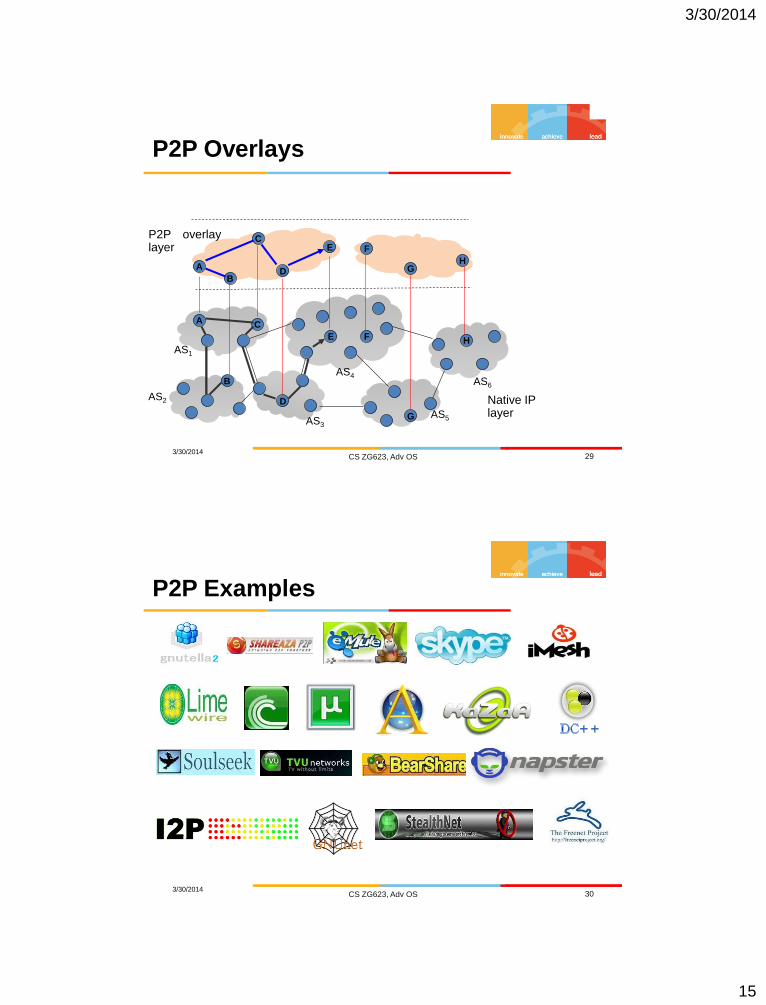
P2P Overlays
3/30/2014 CS ZG623, Adv OS 30
P2P Examples
3/30/2014
16
3/30/2014 CS ZG623, Adv OS 31
Example P2P: BitTorrent
Source: wiki
3/30/2014 CS ZG623, Adv OS 32
Allen Telescope Array
Another Example: SETI
Source: setiathome.berkeley.edu/
3/30/2014
17
3/30/2014 CS ZG623, Adv OS 33
Another Example: Seattle on Android
Source: http://boinc.berkeley.edu/
3/30/2014 CS ZG623, Adv OS 34
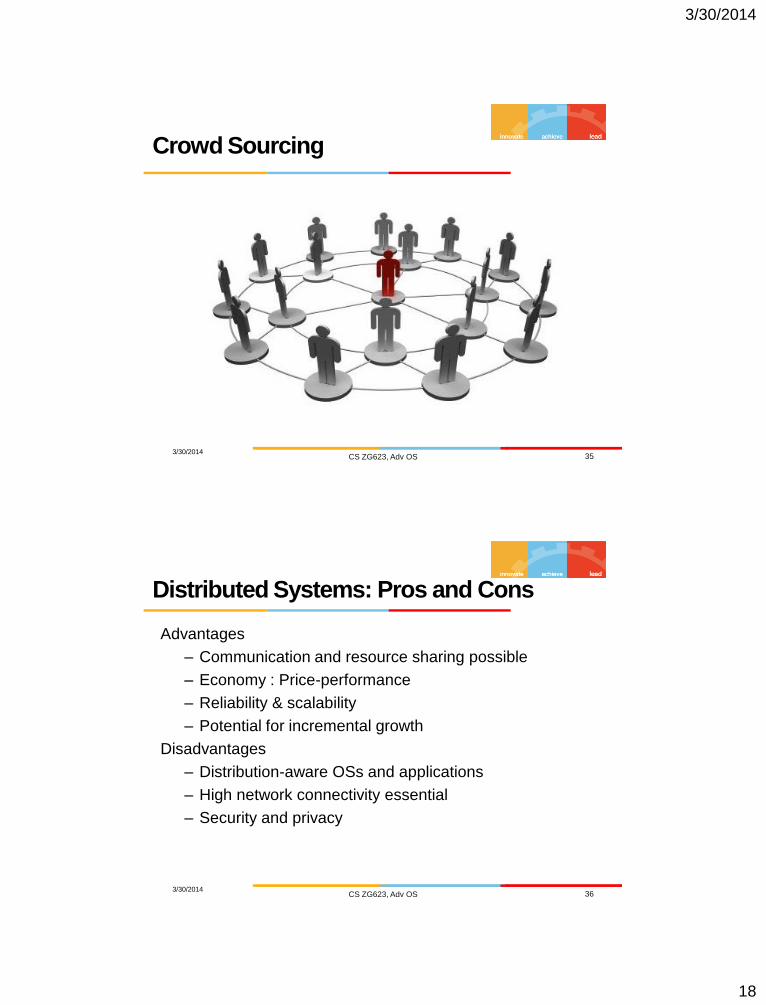
Cloud Computing
3/30/2014
18
3/30/2014 CS ZG623, Adv OS 35
Crowd Sourcing
3/30/2014 CS ZG623, Adv OS 36
Distributed Systems: Pros and Cons
Advantages
– Communication and resource sharing possible
– Economy : Price-performance
– Reliability & scalability
– Potential for incremental growth
Disadvantages
– Distribution-aware OSs and applications
– High network connectivity essential
– Security and privacy
3/30/2014
19
3/30/2014 CS ZG623, Adv OS 37
Concept Example
Centralized services A single server for all users
(medical records, bank account)
Centralized data A single on-line telephone book
Centralized
algorithms
Doing routing based on complete
information
Scalability Problems
3/30/2014 CS ZG623, Adv OS 38
Scaling Technique (1): Hiding
Communication Latency If possible, do asynchronous communication
– Not always possible if the client has nothing to do
Alternatively, by moving part of the computation
Java applets

3/30/2014
20
3/30/2014 CS ZG623, Adv OS 39
Scaling Technique (2): Distribution
Examples: DNS resolutions
3/30/2014 CS ZG623, Adv OS 40
Scaling Technique (3): Replication
Copy of information to increase availability and also to balance the load
– Example: P2P networks (Gnutella +) distribute copies uniformly or in proportion to use
– Example: Gmail caches
• replication decision made by client
Issue: Consistency of replicated information

3/30/2014
21
3/30/2014 CS ZG623, Adv OS 41
More Design Issues
• Lack of Global Knowledge
• Naming
• Compatibility
• Process Synchronization
• Resource Management
• Security
Source: www.bbc.co.uk
3/30/2014 CS ZG623, Adv OS 42
Distributed System Models
Minicomputer model
– Each computer supports many users
– Local processing but can fetch remote data (files,
databases, etc.)
Workstation model
– Most of the work is locally done
– Using a dfs, a user can access remote data
Processor pool model
– Terminals are Xterms or diskless terminals
– Pool of backend processors handle processing
3/30/2014
22
3/30/2014 CS ZG623, Adv OS 43
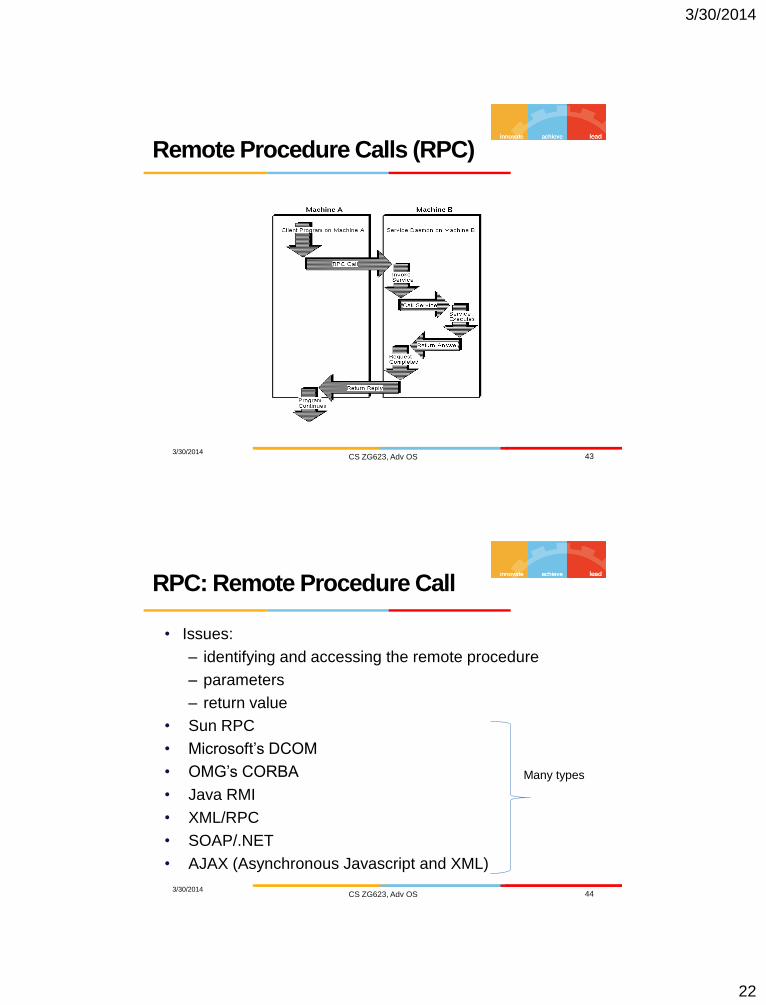
Remote Procedure Calls (RPC)
3/30/2014 CS ZG623, Adv OS 44
RPC: Remote Procedure Call
• Issues:
– identifying and accessing the remote procedure
– parameters
– return value
• Sun RPC
• Microsoft’s DCOM
• OMG’s CORBA
• Java RMI
• XML/RPC
• SOAP/.NET
• AJAX (Asynchronous Javascript and XML)
Many types
3/30/2014
23
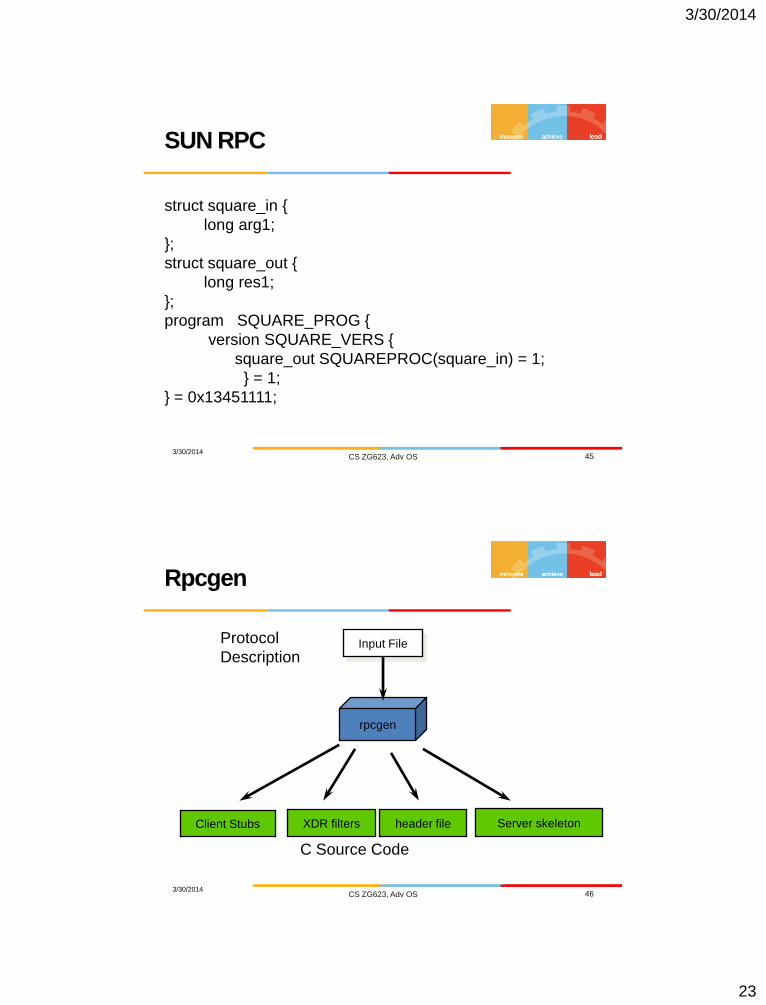
SUN RPC
3/30/2014 CS ZG623, Adv OS 45
struct square_in {
long arg1;
};
struct square_out {
long res1;
};
program SQUARE_PROG {
version SQUARE_VERS {
square_out SQUAREPROC(square_in) = 1;
} = 1;
} = 0x13451111;
Rpcgen
3/30/2014 CS ZG623, Adv OS 46
Input File
rpcgen
Client Stubs XDR filters header file Server skeleton
C Source Code
Protocol
Description

3/30/2014
24
Rpcgen continued…
3/30/2014 CS ZG623, Adv OS 47
bash$ rpcgen square.x
produces:
– square.h header
– square_svc.c server stub
– square_clnt.c client stub
– square_xdr.c XDR conversion routines
Function names derived from IDL function names and
version numbers
Square Client: Client.c
3/30/2014 CS ZG623, Adv OS 48
#include “square.h”
#include <stdio.h>
int main (int argc, char **argv)
{ CLIENT *cl;
square_in in;
square_out *out;
if (argc != 3) { printf(“client <localhost> <integer>”); exit (1); }
cl = clnt_create (argv[1], SQUARE_PROG, SQUARE_VERS, “tcp”);
in.arg1 = atol (argv [2]);
if ((out = squareproc_1(&in, cl)) == NULL)
{ printf (“Error”); exit(1); }
printf (“Result %ld\n”, out -> res1);
exit(0);
}

3/30/2014
25
Square server: server.c
3/30/2014 CS ZG623, Adv OS 49
#include “square.h”
#include <stdio.h>
square_out *squareproc_1_svc (square_in *inp, struct
svc_req *rqstp)
{
static square_out *outp;
outp.res1 = inp -> arg1 * inp -> arg1;
return (&outp);
}
Exe creation
3/30/2014 CS ZG623, Adv OS 50
• gcc –o client client.c square_clnt.c square_xdr.c –lnsl
• gcc –o server server.c square_svc.c square_xdr.c –
lrpcsvc -lnsl
3/30/2014
26
A Communication network
3/30/2014 CS ZG623, Adv OS 51
Example of layering
3/30/2014 CS ZG623, Adv OS 52
Letter
Letter Addressed
Envelope
Addressed
Envelope
3/30/2014
27
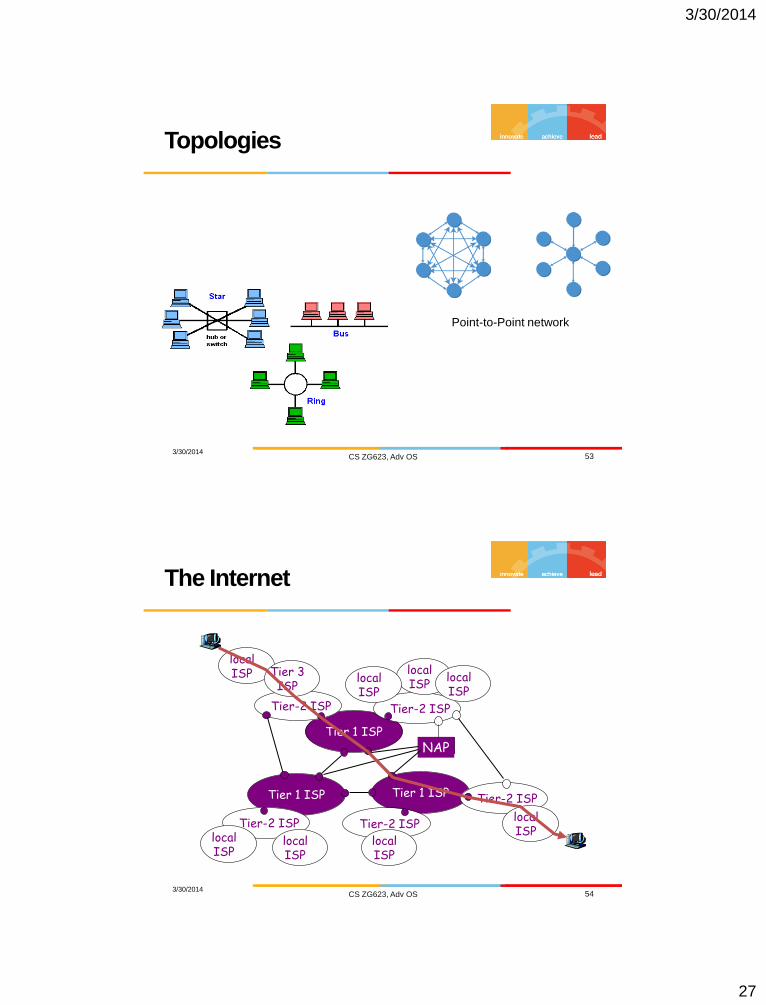
Topologies
3/30/2014 CS ZG623, Adv OS 53
Point-to-Point network
The Internet
3/30/2014 CS ZG623, Adv OS 54
Tier 1 ISP
Tier 1 ISP
Tier 1 ISP
NAP
Tier-2 ISP Tier-2 ISP
Tier-2 ISP Tier-2 ISP
Tier-2 ISP
local ISP local
ISP local ISP
local ISP
local ISP Tier 3
ISP
local ISP
local ISP
local ISP

3/30/2014
28
OSI Layers
3/30/2014 CS ZG623, Adv OS 55
7 Application
6 Presentation
5 Session
4 Transport
3 Network
2 Data-Link
1 Physical
High level protocols
Low level protocols
Headers
3/30/2014 CS ZG623, Adv OS 56
Process
Transport
Network
Data Link
Process
Transport
Network
Data Link
DATA
DATA
DATA
DATA
H
H
H
H
H H
3/30/2014
29
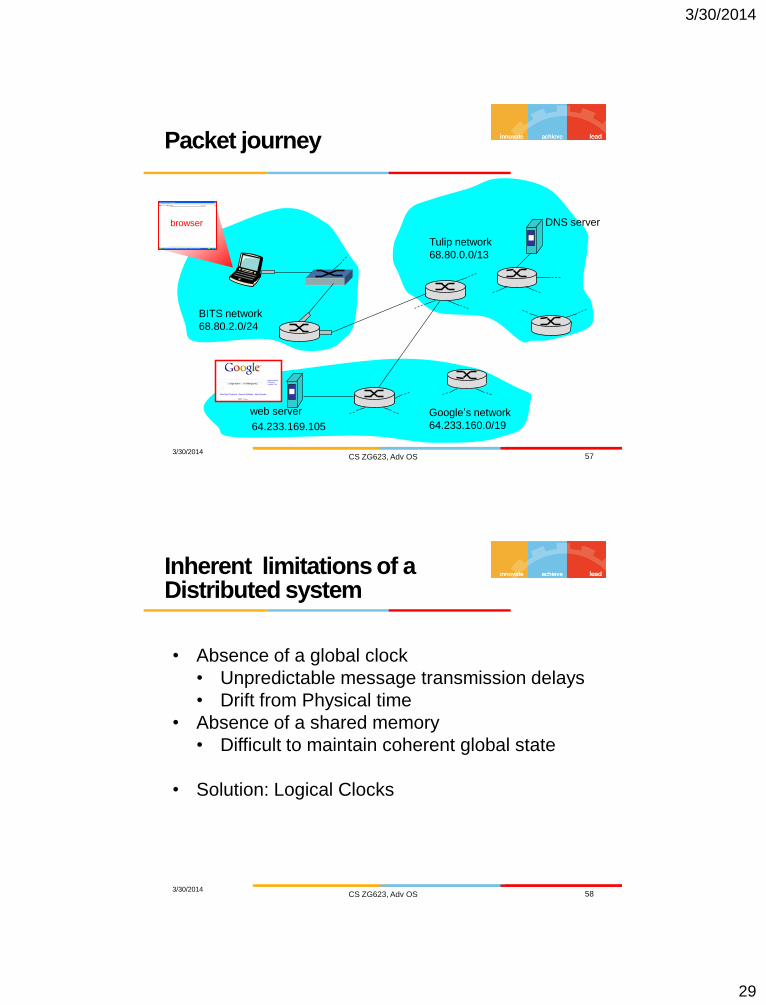
Packet journey
3/30/2014 CS ZG623, Adv OS 57
Tulip network
68.80.0.0/13
Google’s network
64.233.160.0/19 64.233.169.105
web server
DNS server
BITS network
68.80.2.0/24
browser
Inherent limitations of a Distributed system
3/30/2014 CS ZG623, Adv OS 58
• Absence of a global clock
• Unpredictable message transmission delays
• Drift from Physical time
• Absence of a shared memory
• Difficult to maintain coherent global state
• Solution: Logical Clocks

3/30/2014
30
Lamport’s Logical clocks
3/30/2014 CS ZG623, Adv OS 59
• The Happened-Before Relation ()
– Captures the behavior of underlying dependencies
between the events
• Causality
• Concurrent Events (||)
• Timestamps have no relation with physical time,
hence called Logical Clock
Implementation of Logical clocks
3/30/2014 CS ZG623, Adv OS 60
• [IR1] Clock Ci is incremented between any two
successive events in Pi :
if ab, Ci(b)=Ci(a)+d (d>0, usually 1)
• [IR2] If event ‘a’ sends a message ‘m’ to Pi, then
‘m’ is assigned a timestamp tm = Ci(a)
• When the same message is received by Pk, then
Ck = max(Ck, tm+d) (d>0, usually 1)

3/30/2014
31
Total ordering
3/30/2014 CS ZG623, Adv OS 61
defines ir-reflexive partial order among the events
– Not reflexive, antisymmetry, and transitivity
Total Ordering (antisymmetry, transitive, and total)
If ‘a’ is any event in Pi and ‘b’ in Pk, then a=>b iff
– Ci(a) < Ck(b) or
– Ci(a) = Ck(b) & Pi Pk
where denotes a relation that totally orders the
processes to break ties.
Limitations of Logical clocks
3/30/2014 CS ZG623, Adv OS 62
• If ab then C(a) < C(b) but ,if C(a) < C(b), then it
is not necessarily true that ab, if ‘a’ and ‘b’ occur
in different processes.
• Can’t determine whether two events are casually
related from timestamps.

3/30/2014
32
Vector Clocks
3/30/2014 CS ZG623, Adv OS 63
Definitions
– n = number of processes
– Pi has a clock Ci, an integer vector of length n
– Timestamp vector is assigned to each event ‘a’, Ci(a)
• Ci[i] corresponds to Pi’s own logical time
• Ci[j], j≠i is Pi’s best guess of logical time at Pj
Implementation of Vector clocks
3/30/2014 CS ZG623, Adv OS 64
• [IR1] Clock C is incremented between any two
successive events in Pi :
– Ci[i] := Ci[i] +d (d>0)
– Events include sending and receiving messages
• [IR2] If event ‘a’ is Pi sending message ‘m’, then
‘m’ is assigned tm=Ci(a)
When Pj receives ‘m’, Cj is updated:
for every k, Cj[k] := max (Cj[k], tm[k])
• For every i and j , Ci[i] ≥ Cj[i]
3/30/2014
33
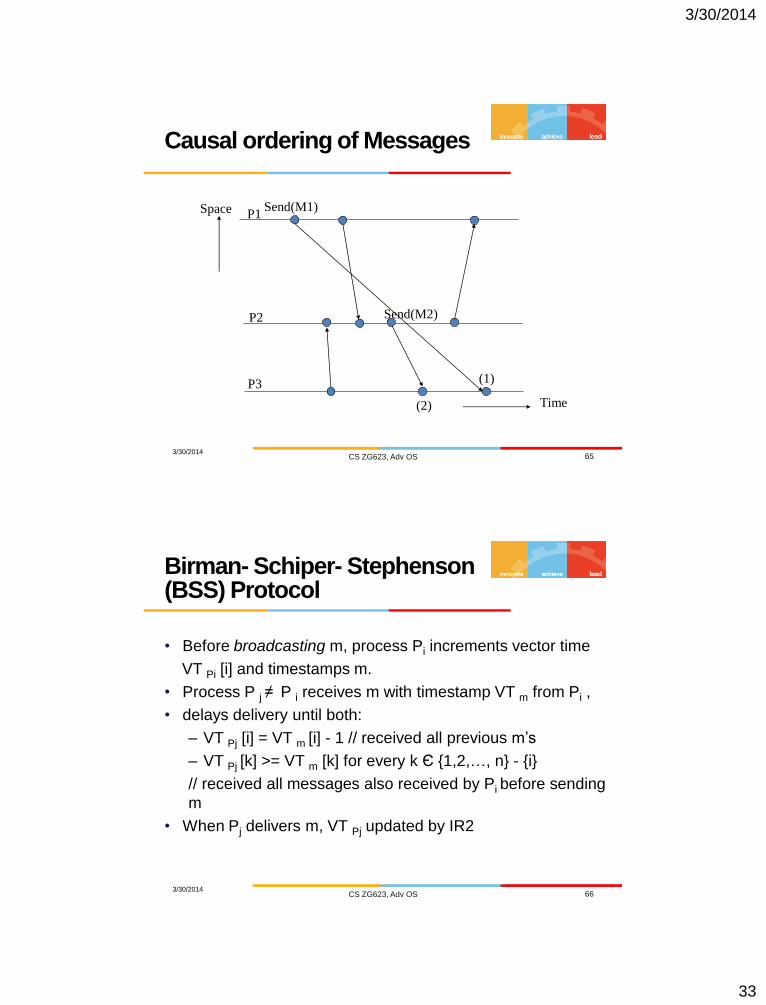
Causal ordering of Messages
3/30/2014 CS ZG623, Adv OS 65
Time
Space P1
P2
P3
(2)
(1)
Send(M1)
Send(M2)
Birman- Schiper- Stephenson (BSS) Protocol
3/30/2014 CS ZG623, Adv OS 66
• Before broadcasting m, process Pi increments vector time
VT Pi [i] and timestamps m.
• Process P j ≠ P i receives m with timestamp VT m from Pi ,
• delays delivery until both:
– VT Pj [i] = VT m [i] - 1 // received all previous m’s
– VT Pj [k] >= VT m [k] for every k Є {1,2,…, n} - {i}
// received all messages also received by Pi before sending
m
• When Pj delivers m, VT Pj updated by IR2

3/30/2014
34
Example of BSS
3/30/2014 CS ZG623, Adv OS 67
P1
P2
P3
(buffer)
(0,0,1) (0,1,1)
(0,0,1) (0,1,1)
(0,0,1) (0,1,1)
deliver
from buffer
Schiper-Eggli-Sandoz Algorithm
3/30/2014 CS ZG623, Adv OS 68
• SES: No need for broadcast messages.
• Each process maintains a vector V_P of size N - 1, N the number of processes in the system.
• V_P is a vector of tuple (P’,t): P’ the destination process id and t, a vector timestamp.
• Tm: logical time of sending message m
• Tpi: present logical time at pi
• Initially, V_P is empty.

3/30/2014
35
SES Continued…
3/30/2014 CS ZG623, Adv OS 69
Sending a Message:
– Send message M, time stamped tm, along with V_P1 to P2.
– Insert (P2, tm) into V_P1. Overwrite the previous value of (P2,t), if any.
– (P2,tm) is not sent. Any future message carrying (P2,tm) in V_P1 cannot be delivered to P2 until tm < Tp2.
Delivering a message
– If V_M (in the message) does not contain any pair (P2, t), it can be delivered.
– /* (P2, t) exists in V_M*/ If t !< Tp2, buffer the message. (Don’t deliver).
– else (t < Tp2) deliver it
Example of SES
3/30/2014 CS ZG623, Adv OS 70
P1
P2
P3
M1
(0,2,1)
(0,1,0) (0,2,0)
(2,2,2) (1,1,0)
(0,2,2)
M2
M3
V_P2
empty
V_P2:
(P1, <0,1,0>)
V_P3:
(P1,<0,1,0>)
Tp1:
Tp2:
Tp3:

3/30/2014
36
Global State: The Model
3/30/2014 CS ZG623, Adv OS 71
Node properties:
– No shared memory
– No global clock
Channel properties:
– FIFO
– loss free
– non-duplicating
The Need for Global State
• Many problems in Distributed Computing can be
• cast as executing some action on reaching a
• particular state
• e.g. -Distributed deadlock detection is finding a cycle in the
Wait For Graph.
-Termination detection
-Checkpointing
And many more…..

3/30/2014
37
Difficulties due to Non Determinism
• Deterministic Computation
• - At any point in computation there is at
most one event that can happen next.
• Non-Deterministic Computation
• - At any point in computation there can be
more than one event that can happen next.
m
Example: Initial State
3/30/2014
38
Example continued…
m
Example continued…
m
3/30/2014
39
a
Example continued…
a
Example continued…
3/30/2014
40
a
Example continued…
Deterministic state diagram
3/30/2014
41
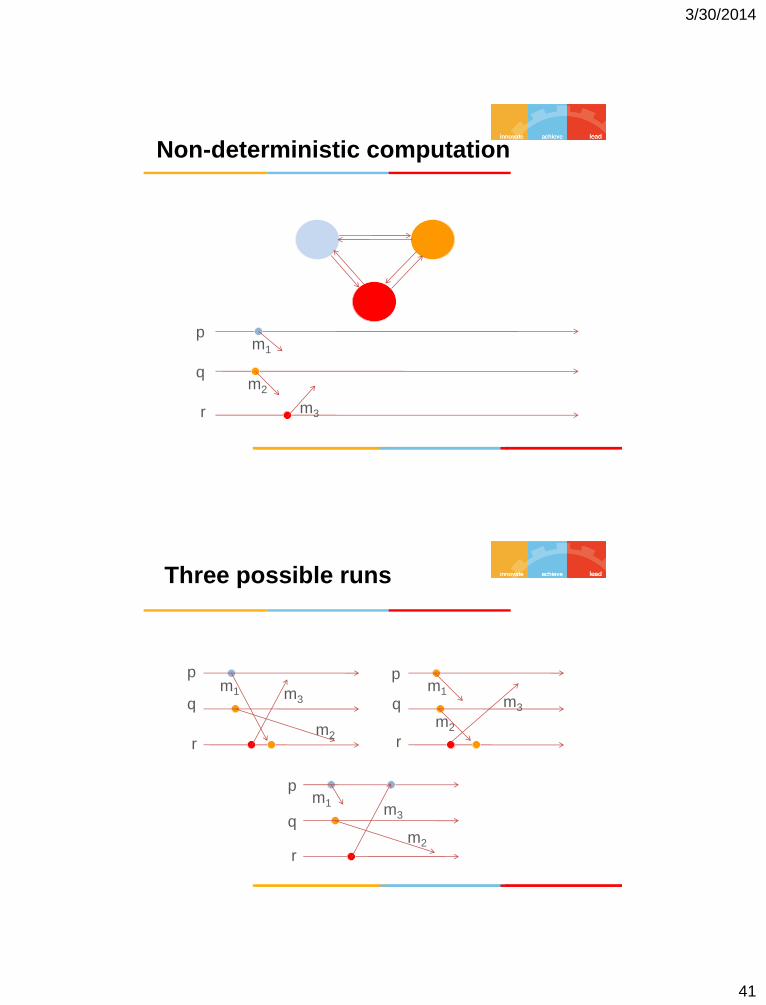
Non-deterministic computation
m1
m2
m3
p
q
r
Three possible runs
p
q
r
q
r
m1 m3
m2
m1
m2
m3
m1 m3
m2
p
r
p
q

3/30/2014
42
A Non-Deterministic Computation
All these states are feasible
Global state Example
3/30/2014 CS ZG623, Adv OS 84
Global State 3
Global State 2
Global State 1

3/30/2014
43
Recording Global state
• Let global state of A is recorded in (1) and not in (2).
– State of B, C1, and C2 are recorded in (2)
– Extra amount of $50 will appear in global state
– Reason: A’s state recorded before sending message and C1’s
state after sending message.
• Inconsistent global state if n < n’, where
– n is number of messages sent by A along channel before A’s
state was recorded
– n’ is number of messages sent by A along the channel before
channel’s state was recorded.
• Consistent global state: n = n’
Continued…
• Similarly, for consistency m = m’
– m’: no. of messages received along channel before B’s state recording
– m: no. of messages received along channel by B before channel’s state was recorded.
• Also, n’ >= m, as no. of messages sent along the channel
• be less than that of received
• Hence, n >= m
• Consistent global state should satisfy the above equation.
• Consistent global state:
– Channel state: sequence of messages sent before recording sender’s state, excluding the messages received before receiver’s state was recorded.
– Only transit messages are recorded in the channel state.
3/30/2014
44
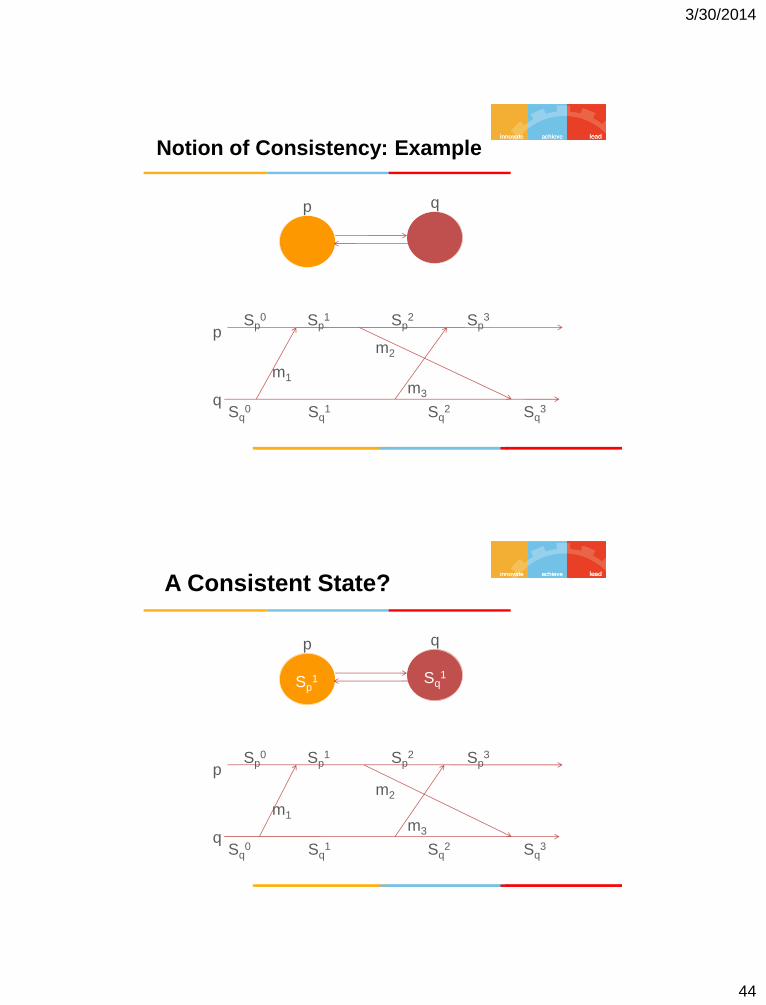
Notion of Consistency: Example
p
q
p q
Sp0 Sp
1 Sp2 Sp
3
Sq0 Sq
1 Sq2 Sq
3
m1
m2
m3
A Consistent State?
p
q
p q
Sp0 Sp
1 Sp2 Sp
3
Sq0 Sq
1 Sq2 Sq
3
m1
m2
m3
Sp1 Sq
1
3/30/2014
45
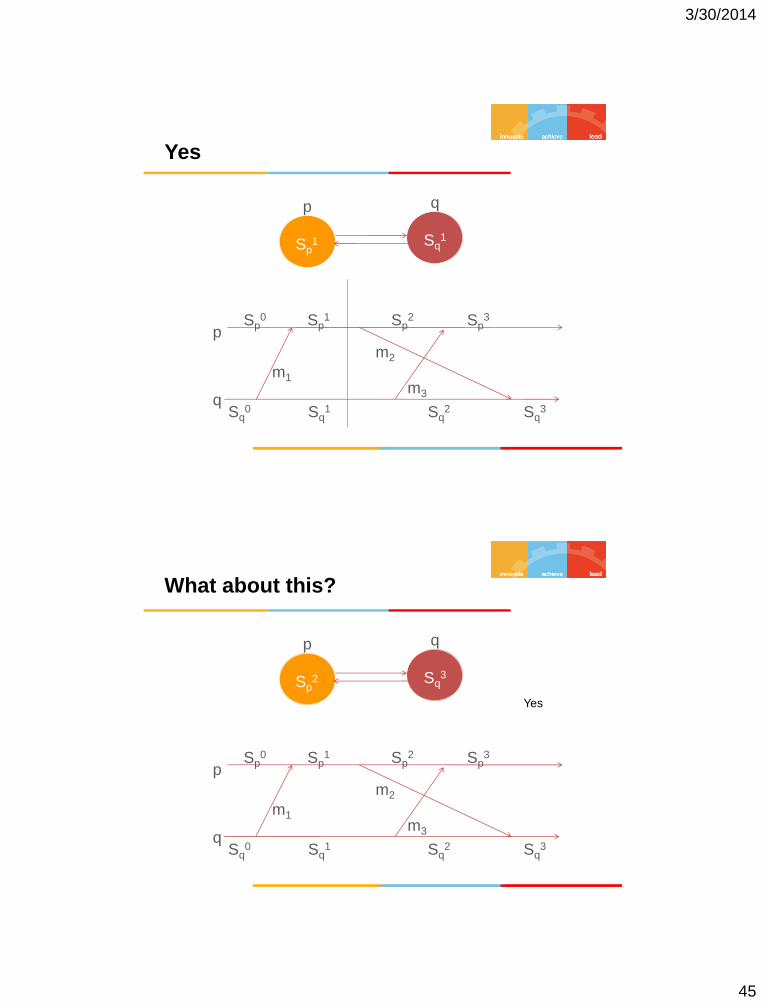
Yes
p
q
p q
Sp0 Sp
1 Sp2 Sp
3
Sq0 Sq
1 Sq2 Sq
3
m1
m2
m3
Sp1 Sq
1
What about this?
p
q
p q
Sp0 Sp
1 Sp2 Sp
3
Sq0 Sq
1 Sq2 Sq
3
m1
m2
m3
Sp2 Sq
3
Yes

3/30/2014
46
What about this?
p
q
p q
Sp0 Sp
1 Sp2 Sp
3
Sq0 Sq
1 Sq2 Sq
3
m1
m2
m3
Sp1 Sq
3
No
Chandy-Lamport GSR algorithm
3/30/2014 CS ZG623, Adv OS 92
Sender (Process ‘p’)
– Record the state of ‘p’
– For each outgoing channel (c) incident on ‘p’, send a marker
before sending any other messages
Receiver (‘q’ receives marker on c1)
– If ‘q’ has not yet recorded it’s state
• Record the state of ‘q’
• Record the state of c1 as null
• For each outgoing channel (c) incident on ‘q’ , send a
marker before sending any other message.
– If ‘q’ has already recorded it’s state
• Record the state of (c1) as all the messages received since
the last time of the state of ‘q’ was recorded.

3/30/2014
47
Uses of GSR
3/30/2014 CS ZG623, Adv OS 93
• recording a “consistent” state of the global computation
– checkpointing for fault tolerance (rollback, recovery)
– testing and debugging
– monitoring and auditing
• detecting stable properties in a distributed system via
snapshots. A property is “stable” if, once it holds in a state,
it holds in all subsequent states.
– termination
– deadlock
– garbage collection
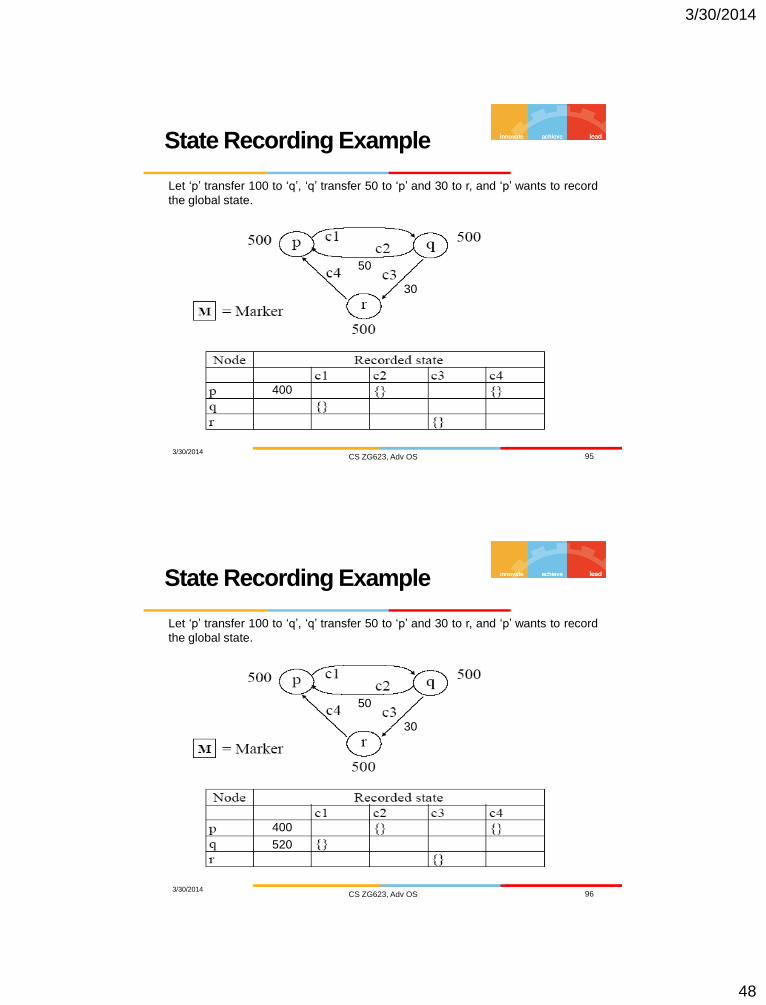
State Recording Example
3/30/2014 CS ZG623, Adv OS 94
3/30/2014
48
State Recording Example
3/30/2014 CS ZG623, Adv OS 95
Let ‘p’ transfer 100 to ‘q’, ‘q’ transfer 50 to ‘p’ and 30 to r, and ‘p’ wants to record
the global state.
400
50
30
State Recording Example
3/30/2014 CS ZG623, Adv OS 96
Let ‘p’ transfer 100 to ‘q’, ‘q’ transfer 50 to ‘p’ and 30 to r, and ‘p’ wants to record
the global state.
400
50
30
520

3/30/2014
49
State Recording Example
3/30/2014 CS ZG623, Adv OS 97
Let ‘p’ transfer 100 to ‘q’, ‘q’ transfer 50 to ‘p’ and 30 to r, and ‘p’ wants to record
the global state.
400
50
30
520
530
50
Cut
3/30/2014 CS ZG623, Adv OS 98
A cut is a set of cut events, one per node, each of which
captures the state of the node on which it occurs. It is
also a graphical representation of a global state.

3/30/2014
50
Consistent Cut
3/30/2014 CS ZG623, Adv OS 99
An inconsistent cut :
ee’ , e’ c2 , c2 -/->c3
A cut C = {c1, c2, c3, … } is consistent if for all sites there
are no events ei and ej such that:
(ei --> ej) and (ej --> cj) and (ei -/-> ci), ci , cj Є C
e
e
Ordering of Cut events
3/30/2014 CS ZG623, Adv OS 100
The cut events in a consistent cut are not causally related. Thus, the cut is a set of concurrent events and a set of concurrent events is a cut.
Note, in this inconsistent cut, c3 --> c2.

3/30/2014
51
Termination detection
3/30/2014 CS ZG623, Adv OS 101
Question:
In a distributed computation,
when are all of the processes
become idle (i.e., when has the
computation terminated)?
Huang’s algorithm
3/30/2014 CS ZG623, Adv OS 102
• The computation starts when the controlling agent sends the first message and terminates when all processes are idle.
• The role of weights:
– the controlling agent initially has a weight of 1 and all others have a weight of zero,
– when a process sends a message, a portion of the sender’s weight is put in the message, reducing the sender’s weight,
– a receiver adds to its weight the weight of a received message,
– on becoming idle, a process sends it weight to the controlling agent,
– the sum of all weights is always 1.
• The computation terminates when the weight of the controlling agent reaches 1 after the first message.

3/30/2014
52
Continued…
3/30/2014 CS ZG623, Adv OS 103
Distributed Mutual Exclusion
What is mutual exclusion?
1. simultaneous update and read of a directory
2. can you allow two/more processors to update a file simultaneously?
3. can two processes send their data to a printer?
So, it is exclusive access to a shared resource or to the critical region.

3/30/2014
53
• In uni-processor system, mutual exclusion is achieved by semaphore, monitors etc.
• An algorithm used for implementing mutual exclusion must satisfy
– Mutual exclusion
– No starvation, -Freedom from deadlock, -Fault tolerant
• To handle mutual exclusion in distributed system,
- Centralized Approach
- Distributed Approach
- Token-Passing Approach
• All use message passing approach rather than shared variable.
Continued…
Performance of DME Algorithms
• Performance of each algorithm is measured in terms of
- no. of messages required for CS invocation
- synchronization delay (leaving & entering)
- response time (arrival, sending out, Entry & Exit)
• System throughput = 1/(sd+E)

3/30/2014
54
A Centralized Algorithm
• A Central controller with a queue for deferring replies.
• Request, Reply, and Release messages.
• Reliability and Performance bottleneck.
Lamport’s DME
Requesting the critical section.
1. When a site Si wants to enter the CS, it sends a REQUEST(T=tsi, i) message to all the sites in its request set Ri and places the request on request_queuei.
2. When a site Sj receives the REQUEST(tsi , i) message from site Si, it returns a timestamped REPLY message to Si and places site Si ’s request on request_queuej.
Executing the critical section.
Site Si enters the CS when the two following conditions hold:
1. Si has received a message with timestamp larger than (tsi , i) from all other sites.
2. Si ’s request is at the top of request_queuei.

3/30/2014
55
Continued…
Releasing the critical section.
1. Site Si, upon exiting the CS, removes its’ request from the top of its’ request queue and sends a timestamped RELEASE message to all the sites in its request set.
2. When a site Sj receives a RELEASE message from site Si , it removes Si ’s request from its request queue.
3. When a site removes a request from its request queue, its own request may become the top of the queue, enabling it to enter the CS. The algorithm executes CS requests in the increasing order of timestamps.
Correctness
• Suppose that both Si and Sj were in CS at the same time (t).
• Then we have:

3/30/2014
56
Ricart-Agrawala DME
Requesting Site:
– A requesting site Pi sends a message request(ts,i) to all sites.
Receiving Site:
– Upon reception of a request(ts,i) message, the receiving site Pj will immediately send a timestamped reply(ts,j) message if and only if:
• Pj is not requesting or executing the critical section OR
• Pj is requesting the critical section but sent a request with a higher timestamp than the timestamp of Pi
– Otherwise, Pj will defer the reply message.
Maekawa’s DME
• A site requests permission only from a subset of sites.
• Request set of sites Si & Sj: Ri, Rj such that Ri and Rj will have at-least one common site (Sk). Sk mediates conflicts between Ri and Rj.
• A site can send only one REPLY message at a time, i.e., a site can send a REPLY message only after receiving a
RELEASE message for the previous REPLY message.

3/30/2014
57
Request Set
Maekawa’s Request set with
N=13
R1 = { 1, 2, 3, 4 }
R2 = { 2, 5, 8, 11 }
R3 = { 3, 6, 8, 13 }
R4 = { 4, 6, 10, 11 }
R5 = { 1, 5, 6, 7 }
R6 = { 2, 6, 9, 12 }
R7 = { 2, 7, 10, 13 }
R8 = { 1, 8, 9, 10 }
R9 = { 3, 7, 9, 11 }
R10 = { 3, 5, 10, 12 }
R11 = { 1, 11, 12, 13 }
R12 = { 4, 7, 8, 12 }
R13 = { 4, 5, 9, 13 }

3/30/2014
58
Maekawa’s DME Algo
Requesting the critical section
1. A site Si requests access to the CS by sending REQUEST(i) messages to all the sites in its request set Ri.
2. When a site Sj receives the REQUEST(i) message, it sends a
– REPLY(j) message to Si provided it hasn’t sent a REPLY message to a site from the time it received the last RELEASE message.
– Otherwise, it queues up the REQUEST for later consideration.
Executing the critical section
1. Site Si accesses the CS only after receiving REPLY
messages from all the sites in Ri .
Continued…
Releasing the critical section
1. After the execution of the CS is over, site Si sends RELEASE(i) message to all the sites in Ri .
2. When a site Sj receives a RELEASE(i) message from site Si , it sends a REPLY message to the next site waiting in the queue and deletes that entry from the queue. If the queue is empty, then the site updates its state to reflect that the site has not sent out any REPLY message.

3/30/2014
59
Deadlocks
Deadlock handling
FAILED
A FAILED message from site Si to site Sj indicates that Si cannot grant Sj’s request because it has currently granted permission to a site with a higher priority request. So that Sj will not think that it is just waiting for the message to arrive.
INQUIRE
An INQUIRE message from Si to Sj indicates that Si would like to find out from Sj if it has succeeded in locking all the sites in its request set.
YIELD
A YIELD message from site Si to Sj indicates that Si is returning the permission to Sj (to yield to a higher priority request at Sj ).

3/30/2014
60
Token based DME algorithms
• A site enters CS if it possesses the token (only
one token for the System).
• The major difference is the way the token is
searched
• Use sequence numbers instead of timestamps
– Used to distinguish requests from same site
– Keep advancing independently at each site
• The proof of mutual exclusion is trivial
Suzuki-kasami broadcast DME
3/30/2014 CS ZG623, Adv OS 120
A site has RN:
LN[j] is the sequence no. of the request that site Sj executed
most recently.

3/30/2014
61
The DME algorithm
3/30/2014 CS ZG623, Adv OS 121
Requesting the critical section.
1. If the requesting site Si does not have the token, then it increments its sequence number, RNi [i], and sends a REQUEST(i, sn) message to all other sites. (sn is the updated value of RNi [i].)
2. When a site Sj receives this message, it sets RNj [i] to max(RNj [i], sn). If Sj has the idle token, it sends the token to Si if RNj [i] = LN[i] + 1.
Executing the critical section.
3. Site Si executes the CS when it has received the token.
Releasing the critical section.
Having finished the execution of the CS, site Si takes the following actions:
4. It sets LN[i] element of the token array equal to RNi [i].
5. For every site Sj whose ID is not in the token queue, it appends its ID to the token queue if RNi [j] = LN[j] + 1.
6. If token queue is nonempty after the above update, then it deletes the top site ID from the queue and sends the token to the site indicated by the ID.
Analysis of the DME algorithm
3/30/2014 CS ZG623, Adv OS 122
Correctness
Mutex is trivial.
– Theorem:
A requesting site enters the CS in finite time.
– Proof:
A request enters the token queue in finite time. The queue is in FIFO order, and there can be a maximum N-1 sites ahead of the request.
Performance
0 or N messages per CS invocation.
Synchronous delay: 0 or T ( only 1 message)

3/30/2014
62
Analysis
• Correctness
Mutex is trivial. – Theorem:
A requesting site enters the CS in finite time. – Proof:
A request enters the token queue in finite time. The queue is in FIFO order, and there can be a maximum N-1 sites ahead of the request.
• Performance
0 or N messages per CS invocation.
Synchronous delay: 0 or T ( only 1 message)
Raymonds’ Tree Based Algo
3/30/2014 CS ZG623, Adv OS 124

3/30/2014
63
The Algo
3/30/2014 CS ZG623, Adv OS 125
Requesting the critical section.
1. When a site wants to enter the CS, it sends a REQUEST message to the node along the directed path to the root, provided it does not hold the token and its request_q is empty. It then adds to its request_q.
2. When a site on the path receives this message, it places the REQUEST in its request_q and sends a REQUEST message along the directed path to the root provided it has not sent out a REQUEST message on its outgoing edge.
3. When the root site receives a REQUEST message, it sends the token to the site from which it received the REQUEST message and sets its holder variable to point at that site.
4. When site receives the token, it deletes the top entry from its request_q, sends the token to the site indicated in this entry, and sets its holder variable to point at that site. If the request_q is nonempty at this point, then the site sends a REQUEST message to the site which is pointed at by holder variable.
Continued…
3/30/2014 CS ZG623, Adv OS 126
Executing the critical section
1. A site enters the CS when it receives the token and its own entry is at the top of its request_q. In this case, the site deletes the top entry from its request_q and enters the CS.
Releasing the critical section
1. If its’ request_q is nonempty, then it deletes the top entry from its request_q, sends the token to that site, and sets its holder variable to point at that site.
2. If the request_q is nonempty at this point, then the site sends a REQUEST message to the site which is pointed at by the holder variable.

3/30/2014
64
Example
3/30/2014 CS ZG623, Adv OS 127
Analysis
3/30/2014 CS ZG623, Adv OS 128
Proof of Correctness Mutex is trivial.
Finite waiting: all the requests in the system form a FIFO queue and the
token is passed in that order.
Performance O(logN) messages per CS invocation. (Average distance between two
nodes in a tree)
Sync. delay: (T logN) / 2
The average distance between two sites is logN / 2.

3/30/2014
65
Deadlocks in Distributed System
What is a deadlock?
One or more processes waiting indefinitely for resources to be released by other waiting processes.
Can occur on h/w or s/w resources, but mostly seen on distributed databases (Lock & Unlock).
T1 T2
…
lock(x)
…
lock(y)
…
….
lock(y)
…
lock(x)
time

3/30/2014
66
Types of Deadlock
• Communication Deadlock
• Resource Deadlock
Four Conditions : Mutual Exclusion, Hold & Wait,
No Preemption, and Circular Wait.
Ways to Handle Deadlocks
-Prevention
-Avoidance
-Detection and resolution
-Ignorance
3/30/2014
67
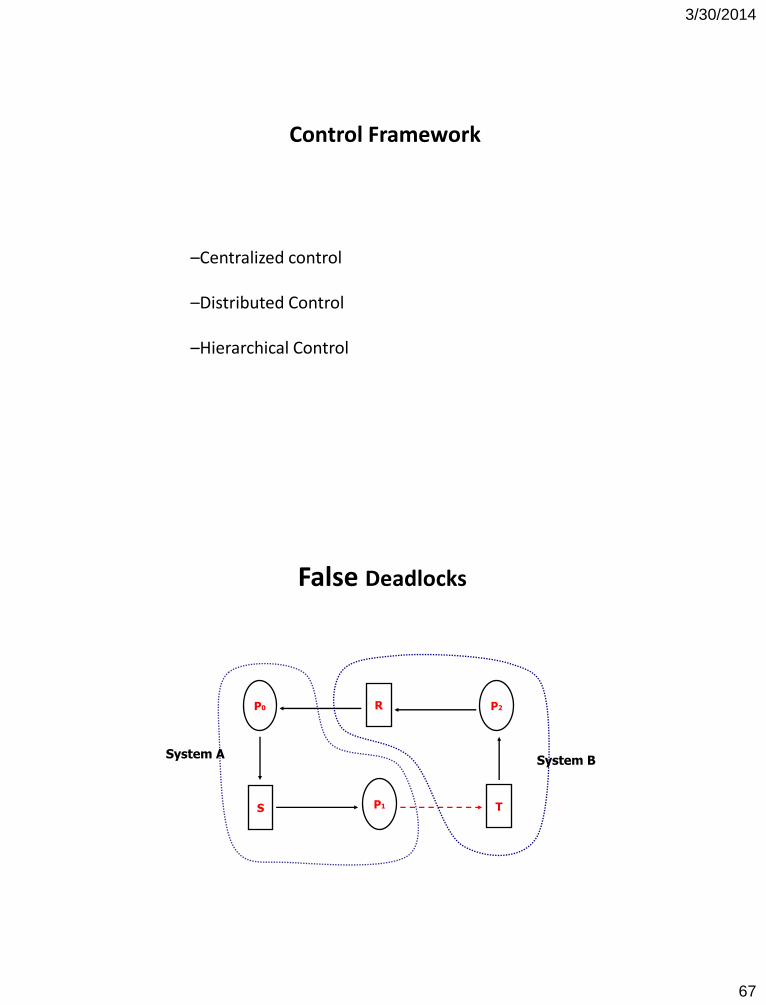
Control Framework
–Centralized control –Distributed Control –Hierarchical Control
False Deadlocks
P0 P2
P1
R
S T
System A System B

3/30/2014
68
Cycle Vs Knot
• The AND model of requests requires all resources currently being requested to be granted to un-block a computation
– A cycle is sufficient condition to declare a deadlock with this model
• The OR model of requests allows a computation making multiple different resource requests to un-block as soon as any are granted
– A cycle is a necessary condition
– A knot is a sufficient condition
A strongly connected subgraph of a directed graph, such that starting
from any node in the subset it is impossible to leave the knot by following
the edges of the graph.
Example

3/30/2014
69
Detection Requirements
•Progress
•Safety
• Individual sites maintain local WFGs – Nodes for local processes
– Node “Pex” represents external processes
• Deadlock detection: – If a site Si finds a cycle that does not involve Pex, it has found a
deadlock
– If a site Si finds a cycle that does involve Pex, there is the possibility of a deadlock
• It sends a message containing its detected cycle to the sites involved in Pex
• If site Sj receives such a message, it updates its local WFG graph, and searches it for a cycle
– If Sj finds a cycle that does not involve its Pex, it has found a deadlock
– If Sj finds a cycle that does involve its Pex, it sends out a message…
Obermarack’s Algorithm

3/30/2014
70
Example
Consider each elementary cycle containing EX. For each
such cycle EX T1 . . . Tn EX compare T1 with Tn. If
T1 > Tn, send the cycle to each site, where an agent of Tn is
waiting to receive a message from the agent of Tn at this site.
Edge-Chasing: Chandy-Misra-Haas
• Some processes wait for local resources
• Some processes wait for resources on other machines
• Algorithm invoked when a process has to wait for a resource
• Uses local WFGs to detect local deadlocks and probes to determine the existence of global deadlocks.

3/30/2014
71
Chandy-Misra-Haas’s Algorithm Sending the probe:
if Pi is locally dependent on itself then deadlock.
else for all Pj and Pk such that
(a) Pi is locally dependent upon Pj, and
(b) Pj is waiting on Pk, and
(c ) Pj and Pk are on different sites, send probe(i,j,k) to the home
site of Pk.
Receiving the probe:
if (d) Pk is blocked, and
(e) dependentk(i) is false, and
(f) Pk has not replied to all requests of Pj,
then begin
dependentk(i) := true;
if k = i then Pi is deadlocked
else ...
for all Pm and Pn such that
(a’) Pk is locally dependent upon Pm, and
(b’) Pm is waiting on Pn, and
(c’) Pm and Pn are on different sites, send probe(i,m,n)
to the home site of Pn.
end.
Example

3/30/2014
72
C-M-H Algorithm: Another Example
P1
P2
P3
P4
P5 P6
P7
probe(1,3,4) probe(1,7,1)
Advantages
1. Popular, Variants of this are used in locking schemes.
2. Easy to implement, as each message is of fixed length and requires few computational steps.
3. No graph constructing and information collection
4. False deadlocks are not detected
5. Does not require a particular structure among processes

3/30/2014
73
Disadvantages
• Two or more processes may independently
detect the same deadlock and hence while
resolving, several processes will be aborted.
• Even though a process detects a deadlock, it
does not know the full cycle
• M(n-1)/2 messages, where M= no. of processes,
n= no. of sites.
Centralized Control
3/30/2014 CS ZG623, Adv OS 146
•Simple conceptually:
–Each node reports to the master detection node
–The master detection node builds and analyzes the WFG by getting the request resource and release resource messages
–The master detection node manages resolution when a deadlock is detected
•Same serious problems:
–Single point of failure
–Network congestion issues
–False deadlock detection

3/30/2014
74
Continued…
3/30/2014 CS ZG623, Adv OS 147
• There are different ways, by which each node may send its’ WFG status to the coordinator
– Whenever an arc is added/deleted at a site, message is sent
– Periodically, every process can send list of arcs since last update
– Coordinator can ask the information when required
• None of these work well
False deadlocks
3/30/2014 CS ZG623, Adv OS 148
• False deadlocks are produced because of incomplete/delayed information
• Example :
• A solution to false deadlock is Lamport’s global time.

3/30/2014
75
The Ho-Ramamoorthy Centralized Algorithms
3/30/2014 CS ZG623, Adv OS 149
Two phase (can be for AND or OR model)
• Each site has a status table of locked and waited resources
• The control site will periodically ask for this table from each node
• The control node will search for cycles and, if found, will request the table again from each node
• Only the information common in both reports will be analyzed for confirmation of a cycle
One phase (can be for AND or OR model)
• Each site keeps 2 tables; process status and resource status
• The control site will periodically ask for these tables (both together in a single message) from each node
• The control site will then build and analyze the WFG, looking for cycles and resolving them when found
One Phase is faster than two-Phase
One Phase requires fewer messages and more storage (i.e 2 tables).
Distributed Control
3/30/2014 CS ZG623, Adv OS 150
• Responsibility is shared by all
• Not vulnerable to single point of failure
• N/W Congestion is not seen
• Only when there is a suspicion, deadlock detection starts
• Difficult to design, because of no shared memory
• All the processes may be involved in detecting a single/same deadlock
• Types :
– Path-pushing , Edge-chasing, Diffusion-computation and Global-state-detection
3/30/2014
76
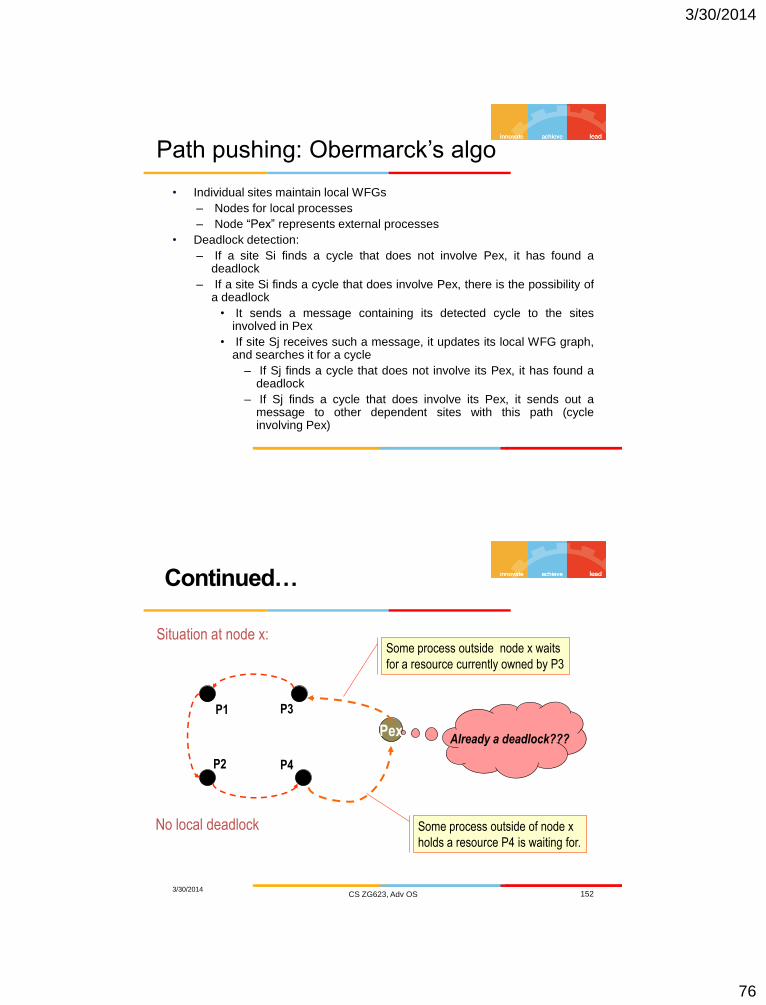
Path pushing: Obermarck’s algo
• Individual sites maintain local WFGs
– Nodes for local processes
– Node “Pex” represents external processes
• Deadlock detection:
– If a site Si finds a cycle that does not involve Pex, it has found a deadlock
– If a site Si finds a cycle that does involve Pex, there is the possibility of a deadlock
• It sends a message containing its detected cycle to the sites involved in Pex
• If site Sj receives such a message, it updates its local WFG graph, and searches it for a cycle
– If Sj finds a cycle that does not involve its Pex, it has found a deadlock
– If Sj finds a cycle that does involve its Pex, it sends out a message to other dependent sites with this path (cycle involving Pex)
Continued…
3/30/2014 CS ZG623, Adv OS 152
Situation at node x:
P1
P2 P4
P3
No local deadlock
Pex
Some process outside node x waits
for a resource currently owned by P3
Some process outside of node x
holds a resource P4 is waiting for.
Already a deadlock???

3/30/2014
77
Obermarck’s Example
Consider each elementary cycle containing Pex. For each such cycle Pex
T1 . . . Tn Pex compare T1 with Tn. If T1 > Tn, send the cycle to
each site, where an agent of Tn is waiting to receive a message from the
agent of Tn at this site.
Edge-Chasing: Chandy-Misra-Haas
• Some processes wait for local resources
• Some processes wait for resources on other machines
• Algorithm invoked when a process has to wait for a resource
• Uses local WFGs to detect local deadlocks and probes to determine the existence of global deadlocks.

3/30/2014
78
Edge-Chasing: Chandy-Misra-Haas Sending the probe:
if Pi is locally dependent on itself then deadlock,
else for all Pj and Pk such that
(a) Pi is locally dependent upon Pj, and
(b) Pj is waiting on Pk, and
(c ) Pj and Pk are on different sites, send probe(i,j,k) to the home
site of Pk.
Receiving the probe:
if (d) Pk is blocked, and
(e) dependentk(i) is false, and
(f) Pk has not replied to all requests of Pj,
then begin
dependentk(i) := true;
if (k == i) then Pi is deadlocked
else ...
for all Pm and Pn such that
(a’) Pk is locally dependent upon Pm, and
(b’) Pm is waiting on Pn, and
(c’) Pm and Pn are on different sites, send probe(i,m,n)
to the home site of Pn.
end.
C-M-H Example1
3/30/2014
79
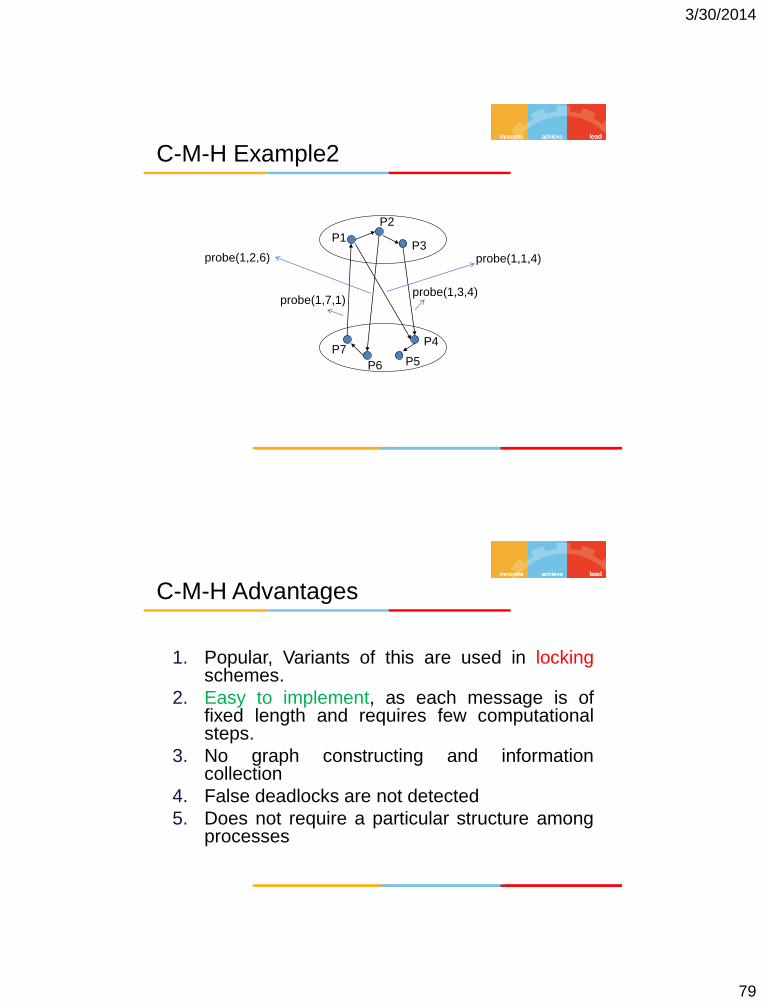
C-M-H Example2
P1
P2
P3
P4
P5 P6
P7
probe(1,3,4) probe(1,7,1)
probe(1,1,4) probe(1,2,6)
C-M-H Advantages
1. Popular, Variants of this are used in locking schemes.
2. Easy to implement, as each message is of fixed length and requires few computational steps.
3. No graph constructing and information collection
4. False deadlocks are not detected
5. Does not require a particular structure among processes

3/30/2014
80
C-M-H disadvantages
• Two or more processes may independently
detect the same deadlock and hence while
resolving, several processes will be aborted.
• Even though a process detects a deadlock, it
does not know the full cycle
• M(n-1)/2 messages, where M=no. of processes,
n= no. of sites.
Diffusion Computation: C-M-H
Initiation by a blocked process Pi:
send query(i,i,j) to all processes Pj in the dependent set DSi of Pi;
num(i) := |DSi|; waiti(i) := true;
Blocked process Pk receiving query(i,j,k):
if this is engaging query for process Pk /* first query from Pi */
then send query(i,k,m) to all Pm in DSk;
numk(i) := |DSk|; waitk(i) := true;
else if waitk(i) then send a reply(i,k,j) to Pj.
Process Pk receiving reply(i,j,k)
if waitk(i) then
numk(i) := numk(i) - 1;
if numk(i) = 0 then
if i = k then declare a deadlock.
else send reply(i, k, m) to Pm, which sent the engaging query.
3/30/2014
81
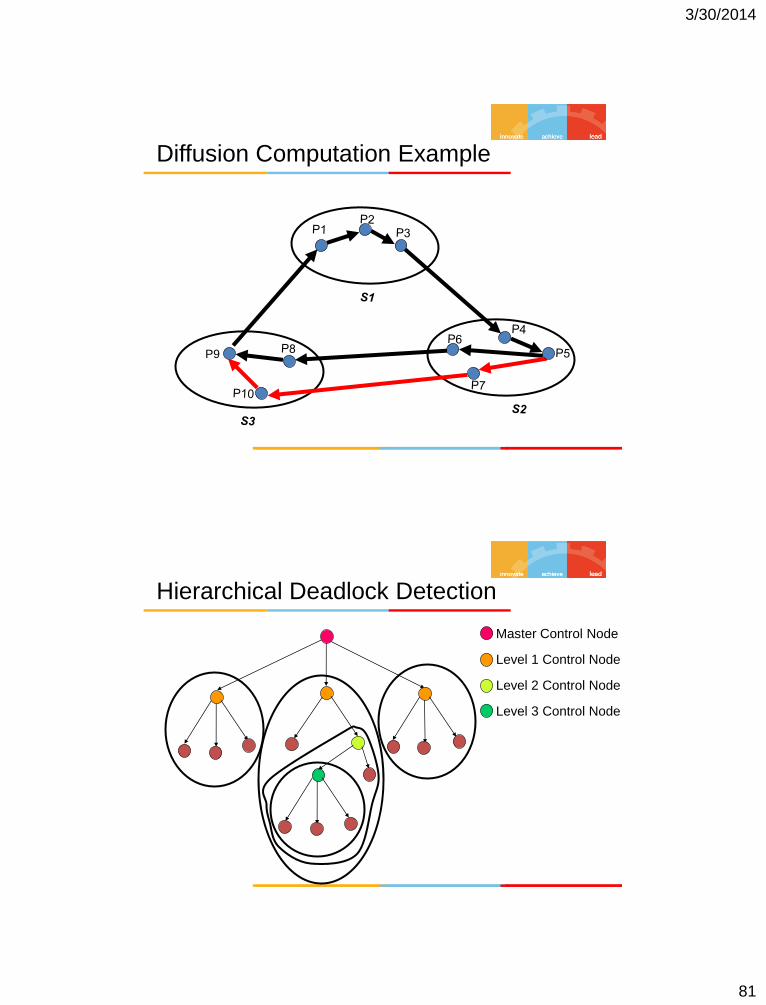
Diffusion Computation Example
P9
Hierarchical Deadlock Detection
Master Control Node
Level 1 Control Node
Level 2 Control Node
Level 3 Control Node
3/30/2014
82
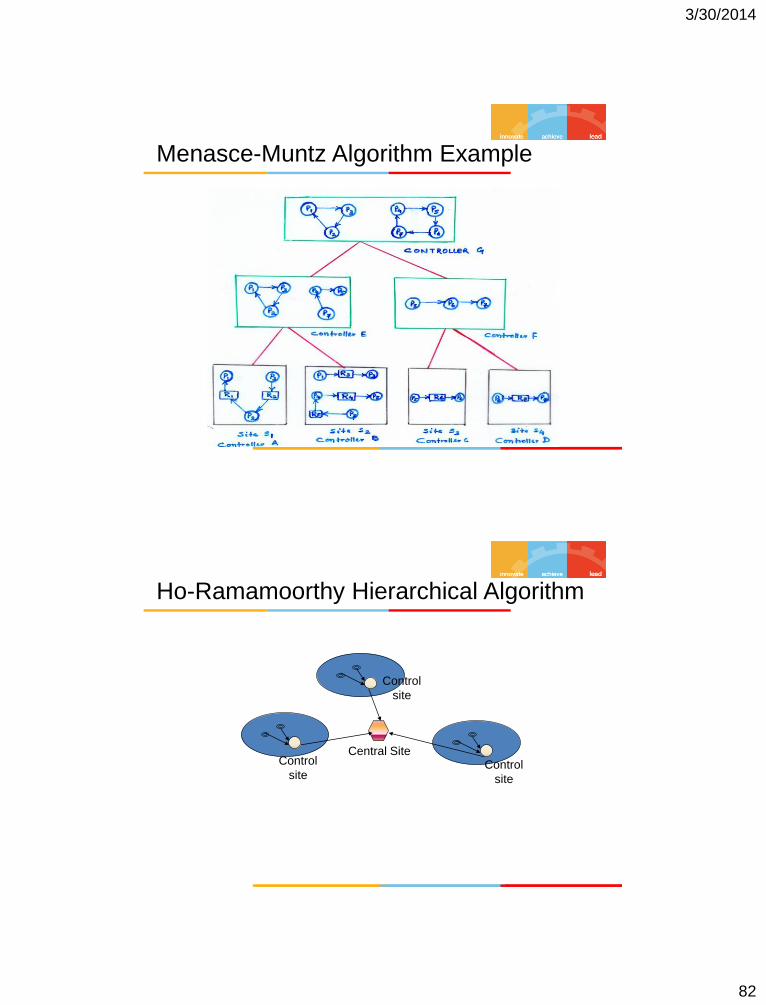
Menasce-Muntz Algorithm Example
Ho-Ramamoorthy Hierarchical Algorithm
Central Site Control
site
Control
site
Control
site

3/30/2014
83
Persistence & Resolution
Deadlock persistence:
– Average time a deadlock exists before it is resolved.
Deadlock resolution:
– Aborting at least one process/request involved in the deadlock.
– Efficient resolution of deadlock requires knowledge of all processes and resources.
– If every process detects a deadlock and tries to resolve it independently highly inefficient! Several processes might be aborted.
Agreement Protocols
3/30/2014 CS ZG623, Adv OS 166
– Have you ever wondered why vendors of (distributed)
software solutions always only offer solutions that
promise 95% reliability, 97% reliability, but never
100% reliability?
• The fault does not lie with Microsoft, Google or Yahoo
• The fault lies in the impossibility of consensus

3/30/2014
84
What happened at Byzantine?
3/30/2014 CS ZG623, Adv OS 167
• May 29th, 1453
• The Turks are besieging the city of Byzantine by making a
coordinated attack.
• Goals
– Consensus between loyal generals
– A small number of traitors cannot cause the loyals to adopt a bad plan
– Do not have to identify the traitors
Agreement Protocol: The System model
3/30/2014 CS ZG623, Adv OS 168
• The are n processors in the system and at most
m of them can be faulty
• The processors can directly communicate with
other processors via messages (fully connected
system)
• A receiver computation always knows the
identity of a sending computation
• The communication system is reliable

3/30/2014
85
Communication Requirements
3/30/2014 CS ZG623, Adv OS 169
• Synchronous communication model is assumed in this
section:
– Healthy processors receive, process and reply to
messages in a lockstep manner
– The receive, process, reply sequence is called a
round
– In the synch-comm model, processes know what
messages they expect to receive in a round
• The synch model is critical to agreement protocols, and
the agreement problem is not solvable in an
asynchronous system
Processor Failures
3/30/2014 CS ZG623, Adv OS 170
• Crash fault
– Abrupt halt, never resumes operation
• Omission fault
– Processor “omits” to send required messages
to some other processors
• Malicious fault
– Processor behaves randomly and arbitrarily
– Known as Byzantine faults

3/30/2014
86
Message Types
3/30/2014 CS ZG623, Adv OS 171
• Authenticated messages (also called signed
messages)
– assure the receiver of correct identification of
the sender
• Non-authenticated messages (also called oral
messages)
– are subject to intermediate manipulation
– may lie about their origin
Agreement Problems
3/30/2014 CS ZG623, Adv OS 172
Problem Who initiates value Final Agreement
Byzantine One Processor Single Value
Agreement
Consensus All Processors Single Value
Interactive All Processors A Vector of Values
Consistency

3/30/2014
87
BA: Impossibility condition
3/30/2014 CS ZG623, Adv OS 173
• Theorem: There is no algorithm to solve byzantine if only
oral messages are used, unless more than two thirds of
the generals are loyal.
• In other words, impossible if n 3f for n processes, f of
which are faulty
• Oral messages are under control of the sender
– sender can alter a message that it received before
forwarding it
• Let’s look at examples for special case of n=3, f=1
Case 1
3/30/2014 CS ZG623, Adv OS 174
• Traitor lieutenant tries to foil consensus by refusing to participate
Lieutenant 3
Commanding General 1
R Lieutenant 2
R R
decides to retreat
Round 1: Commanding General sends “Retreat”
“white hats” == loyal or “good guys” “black hats” == traitor or “bad guys”
Loyal lieutenant obeys commander. (good)
Round 2: L3 sends “Retreat” to L2, but L2 sends nothing
Decide: L3 decides “Retreat”
Acknowledgement: Class lectures of A.D Brown of UofT
3/30/2014
88
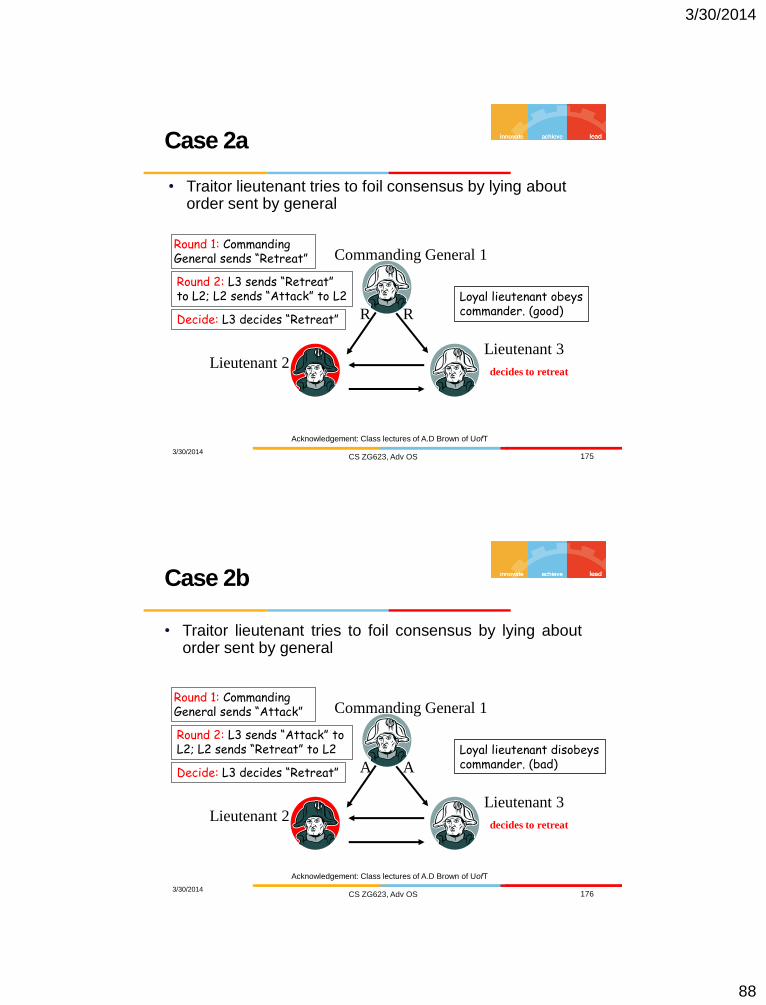
Case 2a
3/30/2014 CS ZG623, Adv OS 175
• Traitor lieutenant tries to foil consensus by lying about order sent by general
Lieutenant 3
Commanding General 1
R Lieutenant 2
R R
decides to retreat
Round 1: Commanding General sends “Retreat”
Loyal lieutenant obeys commander. (good)
Round 2: L3 sends “Retreat” to L2; L2 sends “Attack” to L2
Decide: L3 decides “Retreat”
A
Acknowledgement: Class lectures of A.D Brown of UofT
Case 2b
3/30/2014 CS ZG623, Adv OS 176
R
A
• Traitor lieutenant tries to foil consensus by lying about order sent by general
Lieutenant 3
Commanding General 1
Lieutenant 2
A A
decides to retreat
Round 1: Commanding General sends “Attack”
Loyal lieutenant disobeys commander. (bad)
Round 2: L3 sends “Attack” to L2; L2 sends “Retreat” to L2
Decide: L3 decides “Retreat”
Acknowledgement: Class lectures of A.D Brown of UofT

3/30/2014
89
Case 3
3/30/2014 CS ZG623, Adv OS 177
• Traitor General tries to foil consensus by sending different orders to loyal lieutenants
Lieutenant 3
Commanding General 1
R Lieutenant 2
A R
decides to retreat
Round 1: General sends “Attack” to L2 and “Retreat” to L3
Loyal lieutenants obey commander. (good) Decide differently (bad)
Round 2: L3 sends “Retreat” to L2; L2 sends “Attack” to L2
Decide: L2 decides “Attack” and L3 decides “Retreat”
A
decides to attack
Acknowledgement: Class lectures of A.D Brown of UofT
Oral Message Algorithm
3/30/2014 CS ZG623, Adv OS 178
Oral Message algorithm, OM(m) consists of m+1 “phases”
Algorithm OM(0) is the “base case” (no faults)
1) Commander sends value to every lieutenant
2) Each lieutenant uses value received from commander, or default
“retreat” if no value was received
Recursive algorithm OM(m) handles up to m faults
1) Commander sends value to every lieutenant
2) For each lieutenant i, let vi be the value i received from commander,
or “retreat” if no value was received. Lieutenant i acts as commander
and runs Alg OM(m-1) to send vi to each of the n-2 other lieutenants
3) For each i, and each j not equal to i, let vj be the value Lieutenant i
received from Lieutenant j in step (2) (using Alg OM(m-1)), or else
“retreat” if no such value was received. Lieutenant i uses the value
majority(v1, … , vn-1) to compute the agreed upon value.
3/30/2014
90
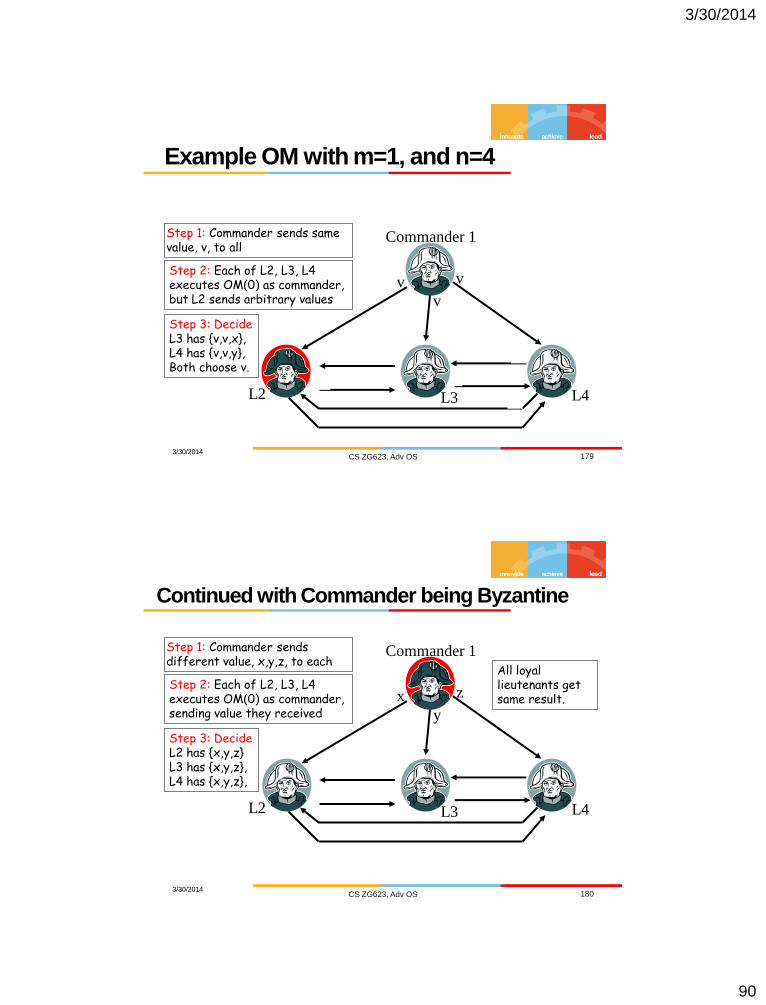
Example OM with m=1, and n=4
3/30/2014 CS ZG623, Adv OS 179
L3
Commander 1
v
L2
v v
Step 1: Commander sends same value, v, to all
Step 2: Each of L2, L3, L4 executes OM(0) as commander, but L2 sends arbitrary values
Step 3: Decide L3 has {v,v,x}, L4 has {v,v,y}, Both choose v.
x L4
v
v
v
v
y
Continued with Commander being Byzantine
3/30/2014 CS ZG623, Adv OS 180
y
x
x
z
z y
L3
Commander 1
L2
x z
Step 1: Commander sends different value, x,y,z, to each
Step 2: Each of L2, L3, L4 executes OM(0) as commander, sending value they received
Step 3: Decide L2 has {x,y,z} L3 has {x,y,z}, L4 has {x,y,z},
L4
y
All loyal lieutenants get same result.
3/30/2014
91
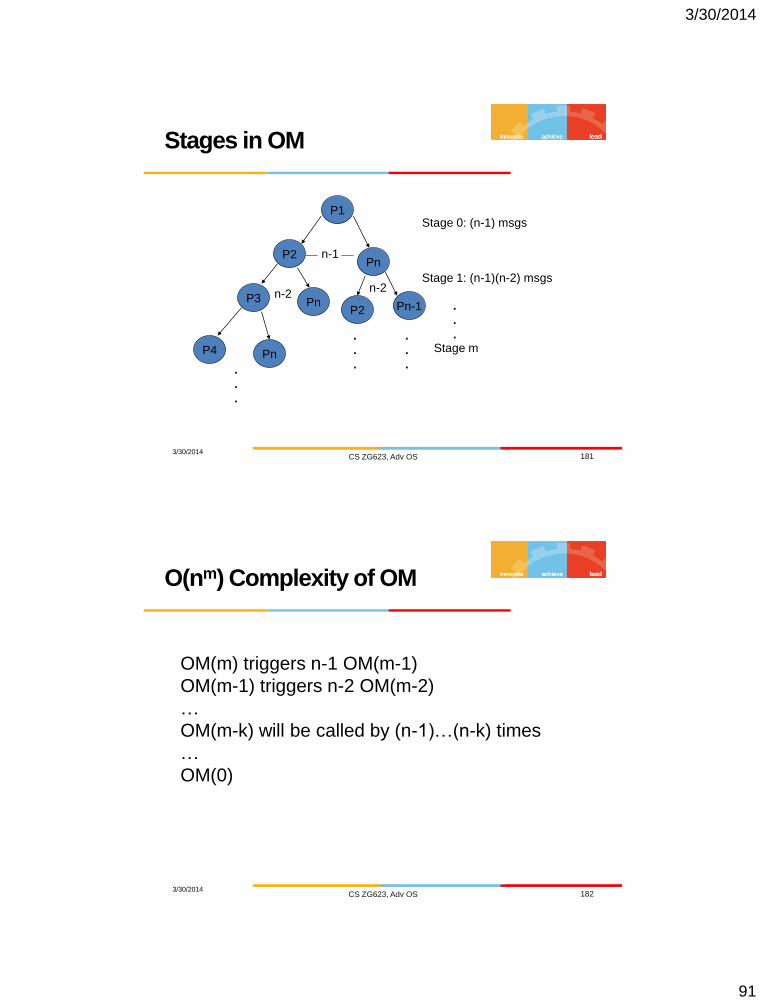
Stages in OM
3/30/2014 CS ZG623, Adv OS 181
P1
P2 Pn
Pn P4
Pn P3 Pn-1 P2
n-1
n-2
n-2
.
.
.
.
.
. .
.
.
Stage 0: (n-1) msgs
Stage 1: (n-1)(n-2) msgs
.
.
. Stage m
O(nm) Complexity of OM
3/30/2014 CS ZG623, Adv OS 182
OM(m) triggers n-1 OM(m-1)
OM(m-1) triggers n-2 OM(m-2)
…
OM(m-k) will be called by (n-1)…(n-k) times
…
OM(0)

3/30/2014
92
Interactive Consistency Model
3/30/2014 CS ZG623, Adv OS 183
Applications of BA
3/30/2014 CS ZG623, Adv OS 184
Building fault tolerant distributed services
– Hardware Clock Synchronization in presence
of faulty nodes
– Distributed commit in databases

3/30/2014
93
Distributed File Systems
3/30/2014 CS ZG623, Adv OS 185
A File?
– Named Object
– Sequence of data items together with a set of attributes
Purpose of Use
– Permanent storage of information
– Large amount of information
– Sharing of information
A File system?
– Sub system of an OS that performs file management
activities (or OS programming interface to disk storage)
Why DFS?
3/30/2014 CS ZG623, Adv OS 186
• Data sharing of multiple users
• User mobility
• Location transparency
• Location independence
• Backups and centralized management
• Not all DFS are the same:
– High-speed network DFS vs. low-speed network DFS
3/30/2014
94
DFS Features
3/30/2014 CS ZG623, Adv OS 187
A distributed file system
– Used in a distributed environment
– Complex, because users and storage devices are physically dispersed.
Features
– Remote information sharing
• Access transparency
• Location transparency
– User mobility
– Availability
• Replica
– Disk less work station
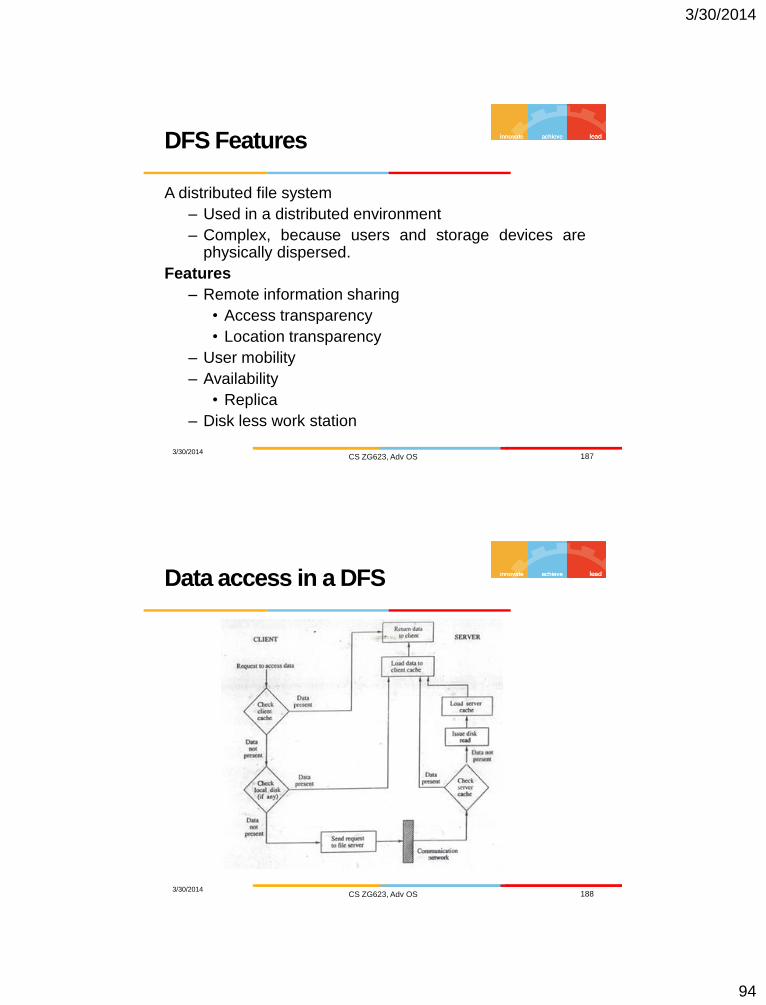
Data access in a DFS
3/30/2014 CS ZG623, Adv OS 188

3/30/2014
95
Methods of building a DFS
3/30/2014 CS ZG623, Adv OS 189
Mounting
– Binding of different file system to form a hierarchically single one
– A name space can be mounted to an internal or leaf node, called
a mount point.
– Kernel maintains a structure called mount table which maps
mount points to appropriate storage device.
– Can be done at client end or at server end
Caching
• Used for reducing frequency of access to file servers • Exploits temporal locality of reference • A copy of the data stored remotely is brought & kept in client
cache or local disk, expecting / with an anticipation of future use. • Employed at both client (sun NFS) and server (Sprite) sides • Helps in reducing the delays in accessing of data, & of-course
network latency.
Continued…
3/30/2014 CS ZG623, Adv OS 190
Hints:
• Although caching reduces the access time by providing a local copy, the major problem is it enforces consistency.
• Problem arises because different clients may be doing different operations on their data cache.
• So, the file servers and clients must be in coordination
• Alternatively, cached data is viewed as hints i.e, not completely accurate.
Bulk Data Transfer:
• Multiple consecutive data blocks are transferred
• Reducing the communication protocol overhead (including buffering,
assembly/disassembly etc).
• File access overhead(seek time etc.) are reduced
Encryption
For secure data transmission, session key are established with the help
of exchange protocols.
3/30/2014
96
DFS Design Issues
3/30/2014 CS ZG623, Adv OS 191
Components
File Service
3/30/2014 CS ZG623, Adv OS 192
3/30/2014
97
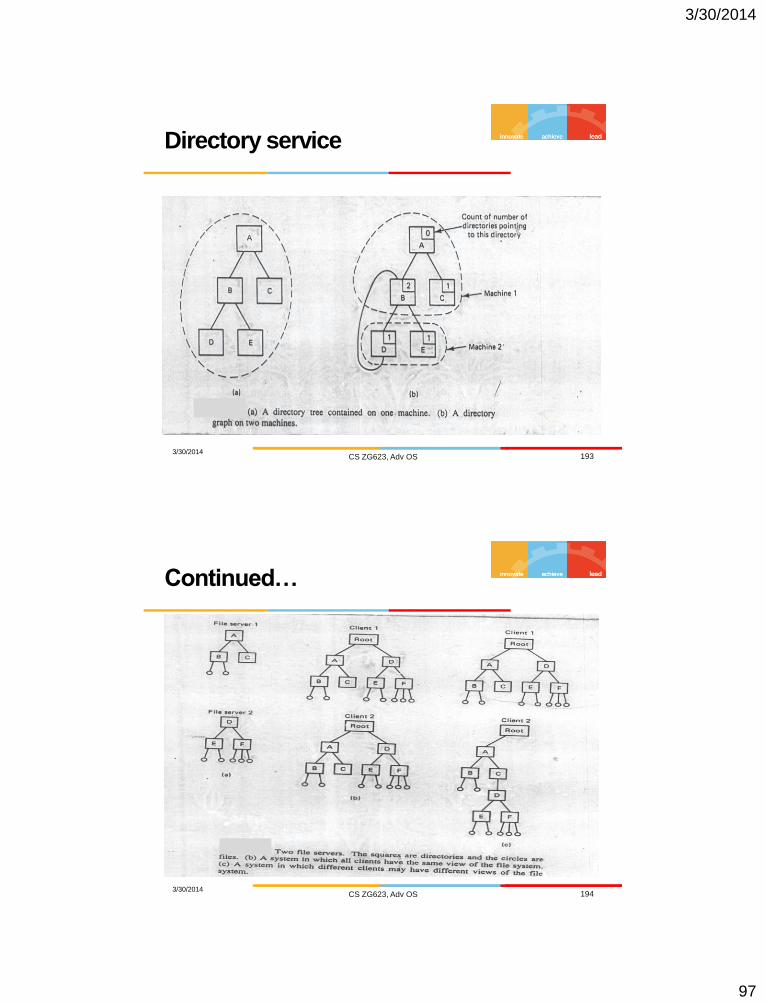
Directory service
3/30/2014 CS ZG623, Adv OS 193
Continued…
3/30/2014 CS ZG623, Adv OS 194
3/30/2014
98
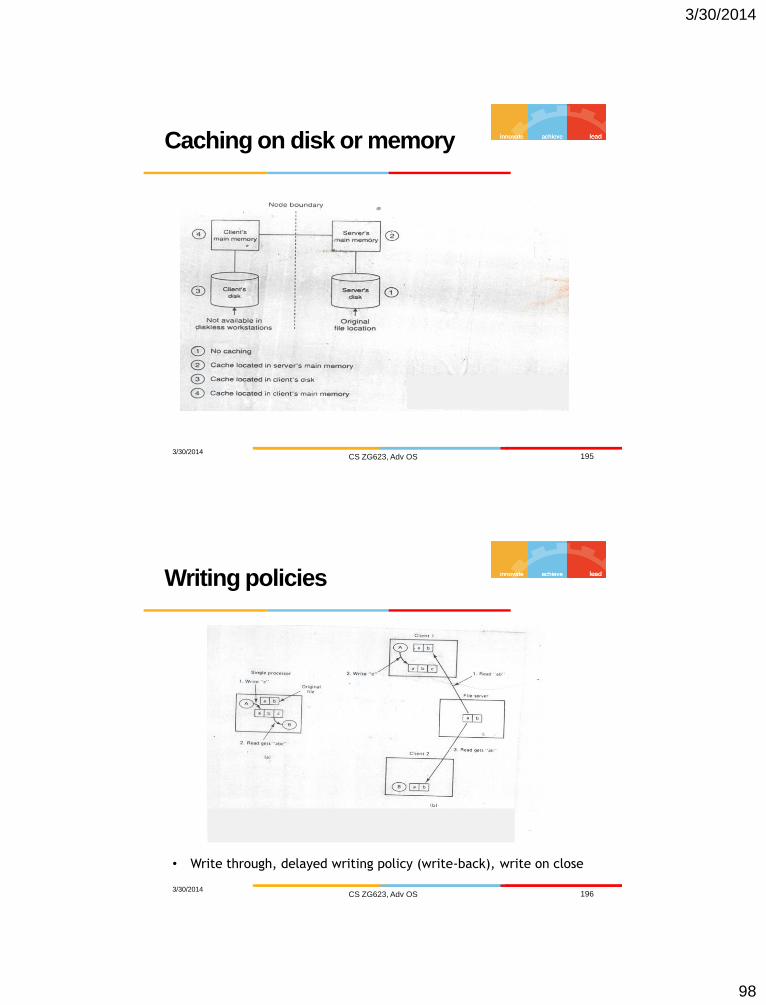
Caching on disk or memory
3/30/2014 CS ZG623, Adv OS 195
Writing policies
3/30/2014 CS ZG623, Adv OS 196
• Write through, delayed writing policy (write-back), write on close

3/30/2014
99
Cache Consistency
3/30/2014 CS ZG623, Adv OS 197
Continued…
3/30/2014 CS ZG623, Adv OS 198

3/30/2014
100
Stateful Vs Stateless
3/30/2014 CS ZG623, Adv OS 199
Scalability
3/30/2014 CS ZG623, Adv OS 200
– Client-Server design
– Client caching
– Server initiated cache invalidation
• Do not bother about read-only files
• Clients serving as servers for few
clients
– Structure of server
3/30/2014
101
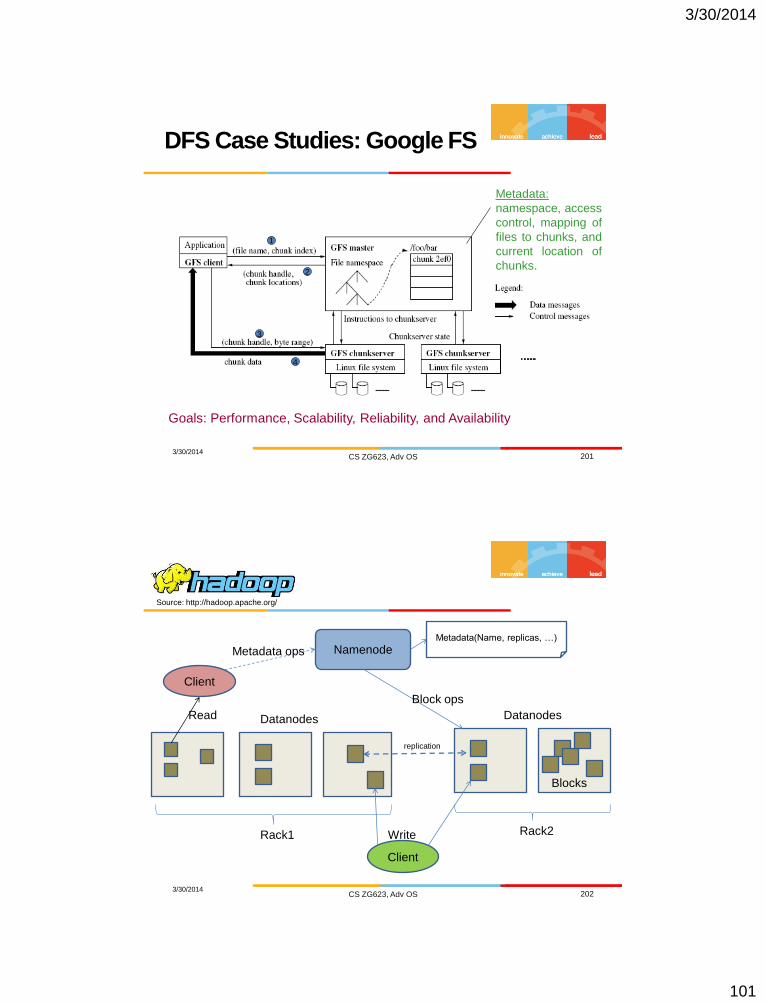
DFS Case Studies: Google FS
3/30/2014 CS ZG623, Adv OS 201
Goals: Performance, Scalability, Reliability, and Availability
Metadata:
namespace, access
control, mapping of
files to chunks, and
current location of
chunks.
1
2
3
4
3/30/2014 CS ZG623, Adv OS 202
Namenode
B
replication
Rack1 Rack2
Client
Blocks
Datanodes Datanodes
Client
Write
Read
Metadata ops
Metadata(Name, replicas, …)
Block ops
Source: http://hadoop.apache.org/
3/30/2014
102
Hadoop clusters
3/30/2014 CS ZG623, Adv OS 203
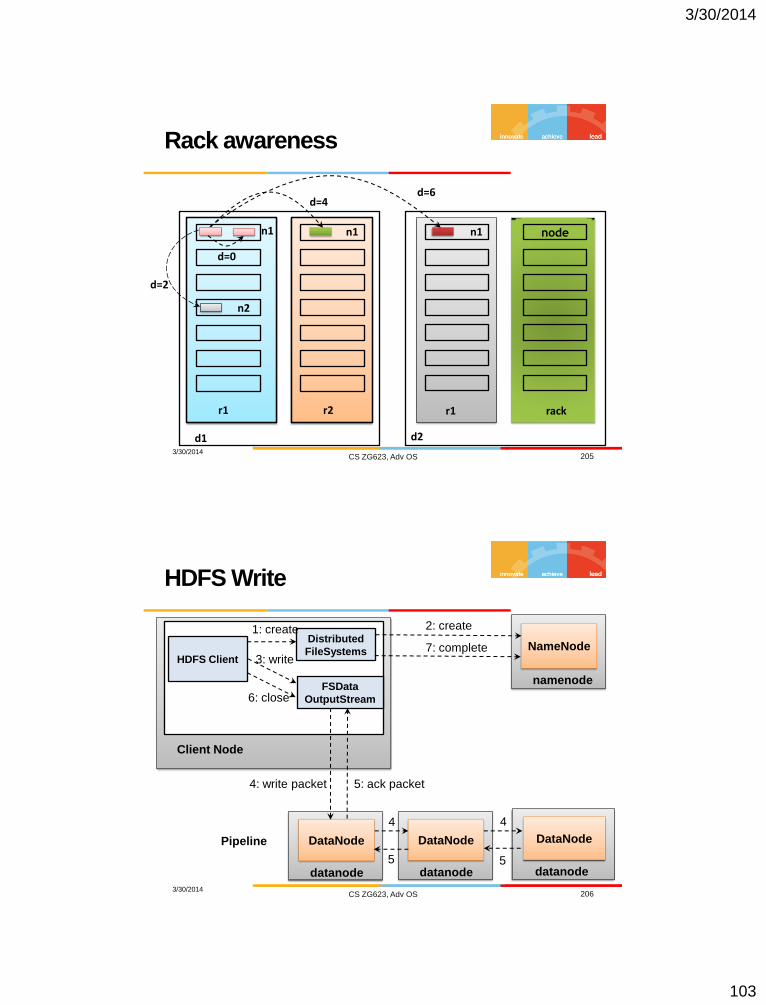
File read
3/30/2014 CS ZG623, Adv OS 204
HDFS Client
Client Node
Distributed
FileSystems
FSData
InputStream
1: open
3: read
6: close
NameNode
namenode
2: get block location
DataNode
datanode
DataNode
datanode
DataNode
datanode
4: read 5: read
3/30/2014
103
Rack awareness
3/30/2014 CS ZG623, Adv OS 205
node
r1 r2 r1 rack
n2
d1 d2
d=2
n1 n1
d=0
n1
d=4 d=6
HDFS Write
3/30/2014 CS ZG623, Adv OS 206
HDFS Client
Client Node
Distributed
FileSystems
FSData
OutputStream
1: create
3: write
6: close
NameNode
namenode
2: create
DataNode
datanode
DataNode
datanode
DataNode
datanode
4: write packet 5: ack packet
7: complete
Pipeline
4
5 5
4
3/30/2014
104
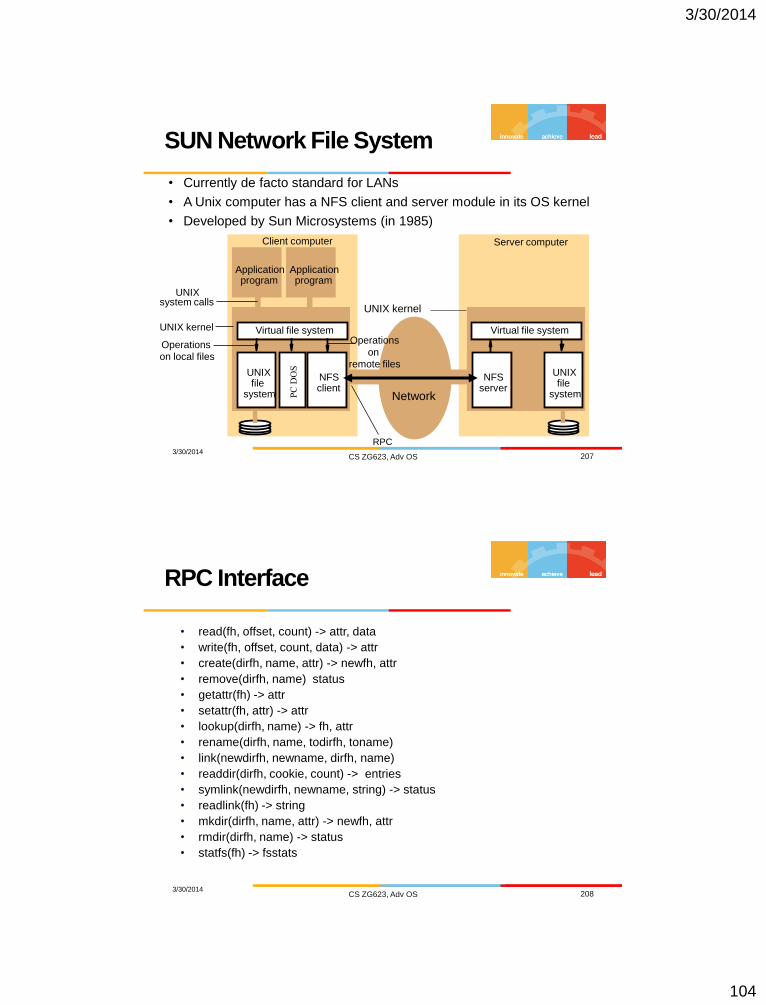
• Currently de facto standard for LANs
• A Unix computer has a NFS client and server module in its OS kernel
• Developed by Sun Microsystems (in 1985)
SUN Network File System
3/30/2014 CS ZG623, Adv OS 207
Client computer Server computer
UNIX file
system
NFS client
NFS server
UNIX file
system
Application program
Application program
Virtual file system Virtual file system
PC
DO
S
UNIX kernel
system calls
RPC
UNIX
Operations
on local files
Operations
on
remote files
UNIX kernel
Network
• read(fh, offset, count) -> attr, data
• write(fh, offset, count, data) -> attr
• create(dirfh, name, attr) -> newfh, attr
• remove(dirfh, name) status
• getattr(fh) -> attr
• setattr(fh, attr) -> attr
• lookup(dirfh, name) -> fh, attr
• rename(dirfh, name, todirfh, toname)
• link(newdirfh, newname, dirfh, name)
• readdir(dirfh, cookie, count) -> entries
• symlink(newdirfh, newname, string) -> status
• readlink(fh) -> string
• mkdir(dirfh, name, attr) -> newfh, attr
• rmdir(dirfh, name) -> status
• statfs(fh) -> fsstats
RPC Interface
3/30/2014 CS ZG623, Adv OS 208
3/30/2014
105
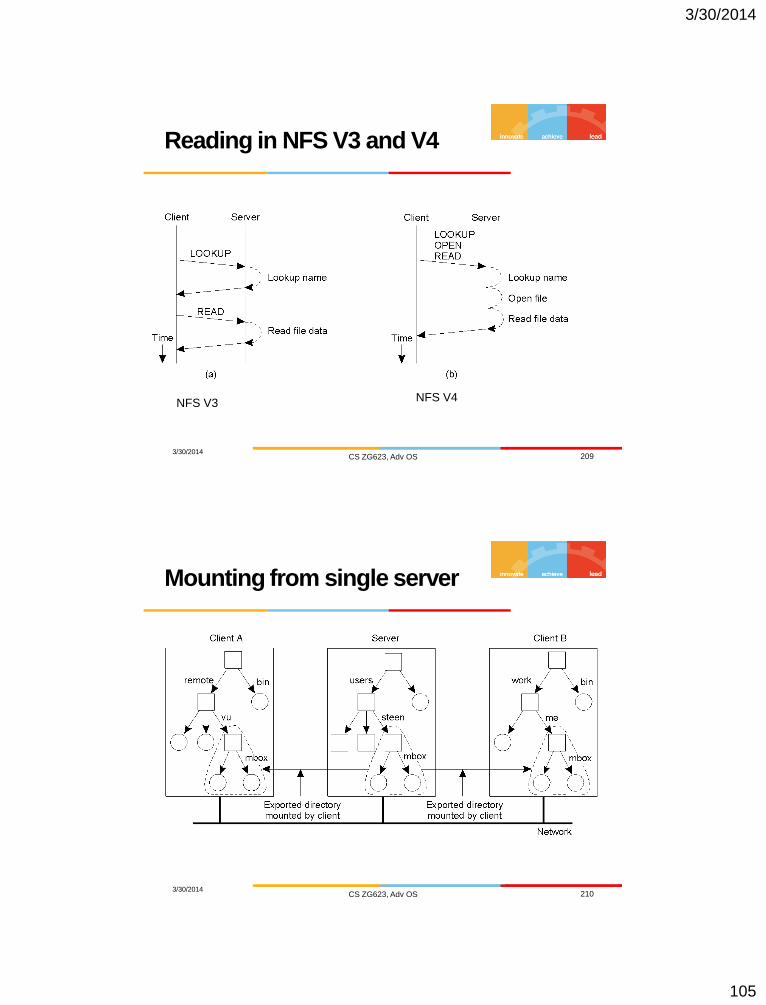
Reading in NFS V3 and V4
3/30/2014 CS ZG623, Adv OS 209
NFS V3 NFS V4
Mounting from single server
3/30/2014 CS ZG623, Adv OS 210
3/30/2014
106
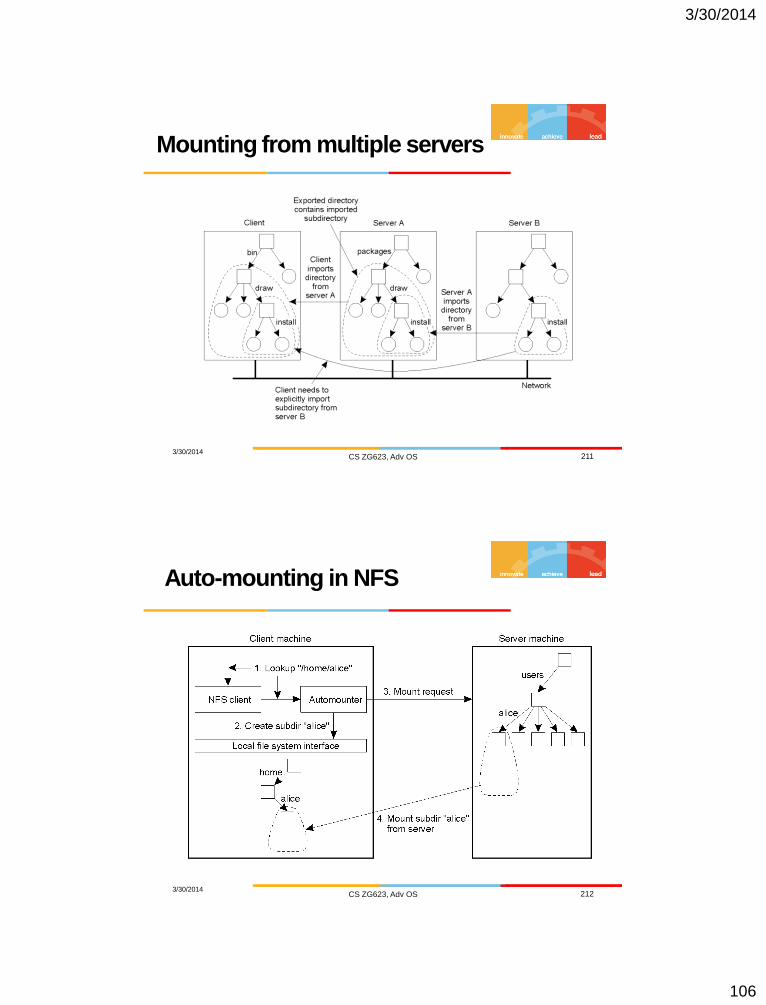
Mounting from multiple servers
3/30/2014 CS ZG623, Adv OS 211
Auto-mounting in NFS
3/30/2014 CS ZG623, Adv OS 212
3/30/2014
107
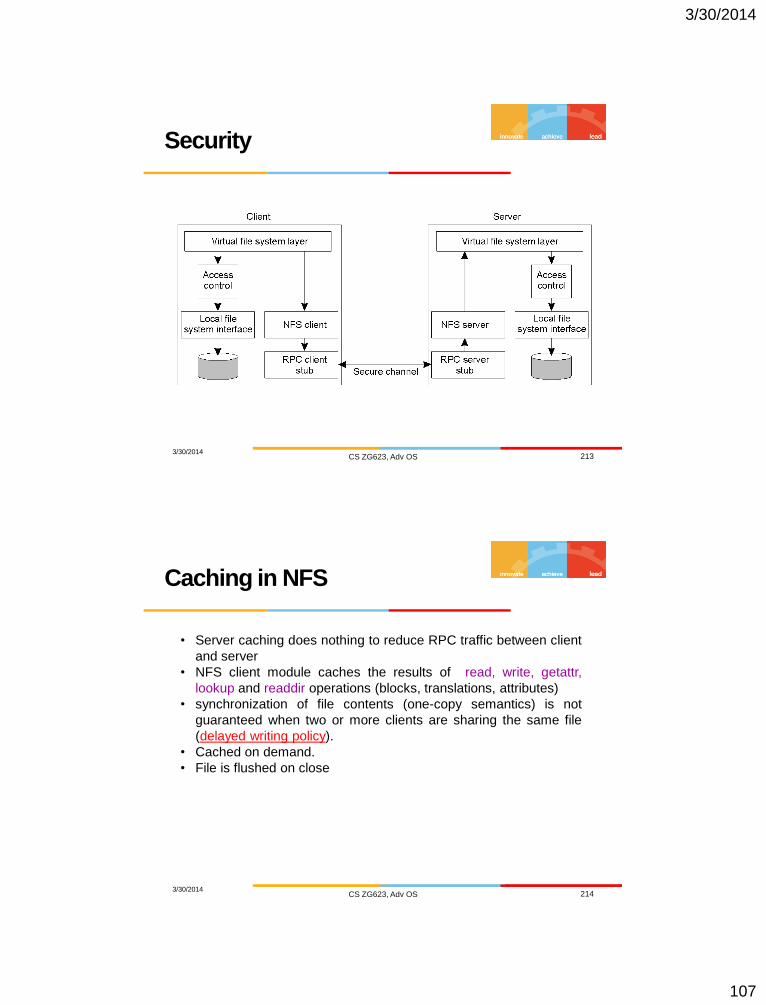
Security
3/30/2014 CS ZG623, Adv OS 213
Caching in NFS
3/30/2014 CS ZG623, Adv OS 214
• Server caching does nothing to reduce RPC traffic between client
and server
• NFS client module caches the results of read, write, getattr,
lookup and readdir operations (blocks, translations, attributes)
• synchronization of file contents (one-copy semantics) is not
guaranteed when two or more clients are sharing the same file
(delayed writing policy).
• Cached on demand.
• File is flushed on close
3/30/2014
108
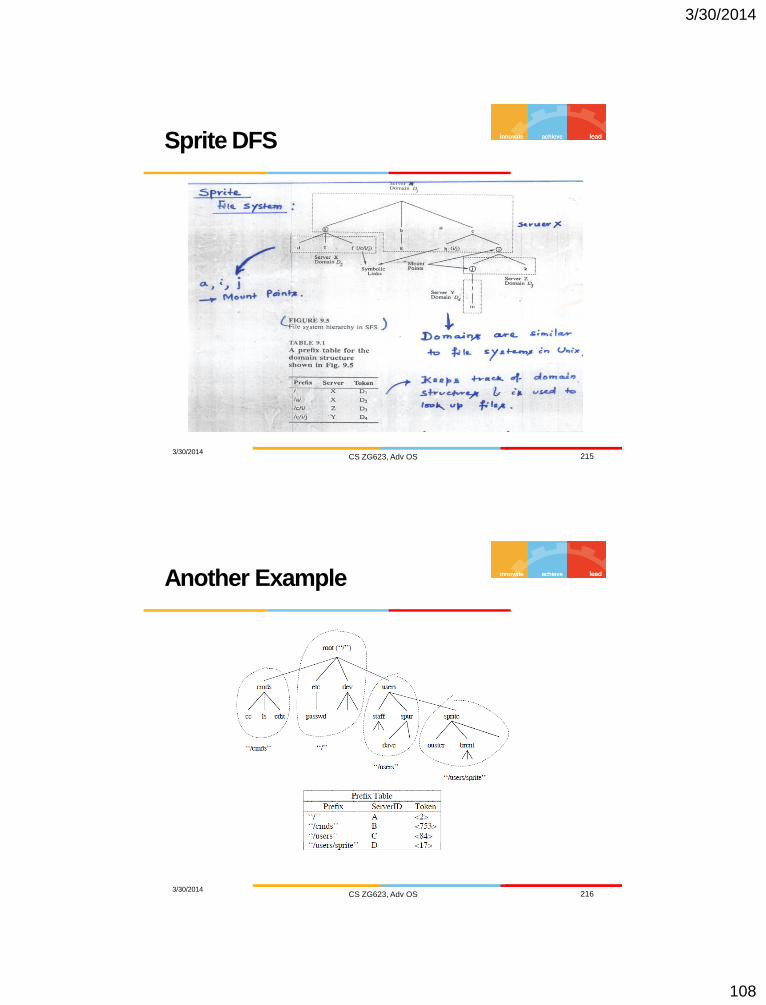
Sprite DFS
3/30/2014 CS ZG623, Adv OS 215
Another Example
3/30/2014 CS ZG623, Adv OS 216
3/30/2014
109
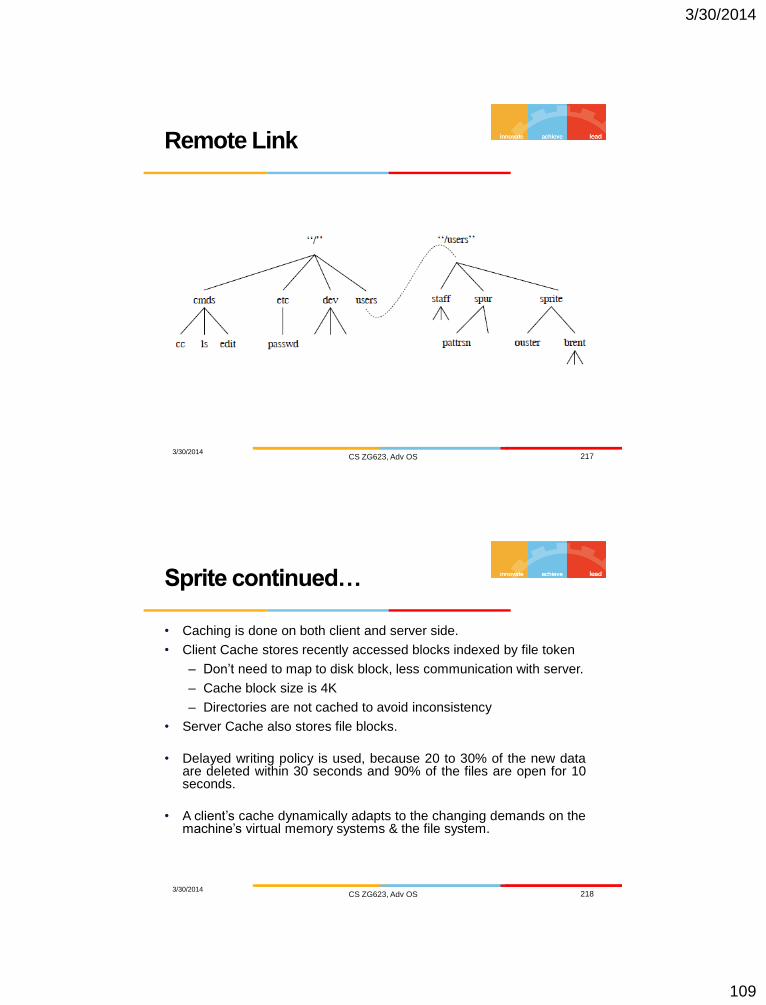
Remote Link
3/30/2014 CS ZG623, Adv OS 217
• Caching is done on both client and server side.
• Client Cache stores recently accessed blocks indexed by file token
– Don’t need to map to disk block, less communication with server.
– Cache block size is 4K
– Directories are not cached to avoid inconsistency
• Server Cache also stores file blocks.
• Delayed writing policy is used, because 20 to 30% of the new data are deleted within 30 seconds and 90% of the files are open for 10 seconds.
• A client’s cache dynamically adapts to the changing demands on the machine’s virtual memory systems & the file system.
Sprite continued…
3/30/2014 CS ZG623, Adv OS 218

3/30/2014
110
• Cache Consistency is server initiated.
• Concurrent write sharing is avoided
– When a concurrent write request is received, server instructs
– current writer to flush data, commits it, and then declares the file
uncachable to *all* clients.
– All requests now flow through the server, which will serialize
them.
– About 1% traffic overhead
• Sequential Write Sharing is overcome by using
– versions, version number is incremented upon write .
– Server also keeps track of last client doing write, and requests
that client to flush data when it gets the next file open from some
other client.
Cache consistency
3/30/2014 CS ZG623, Adv OS 219
CODA File System
3/30/2014 CS ZG623, Adv OS 220
CMU
3/30/2014
111
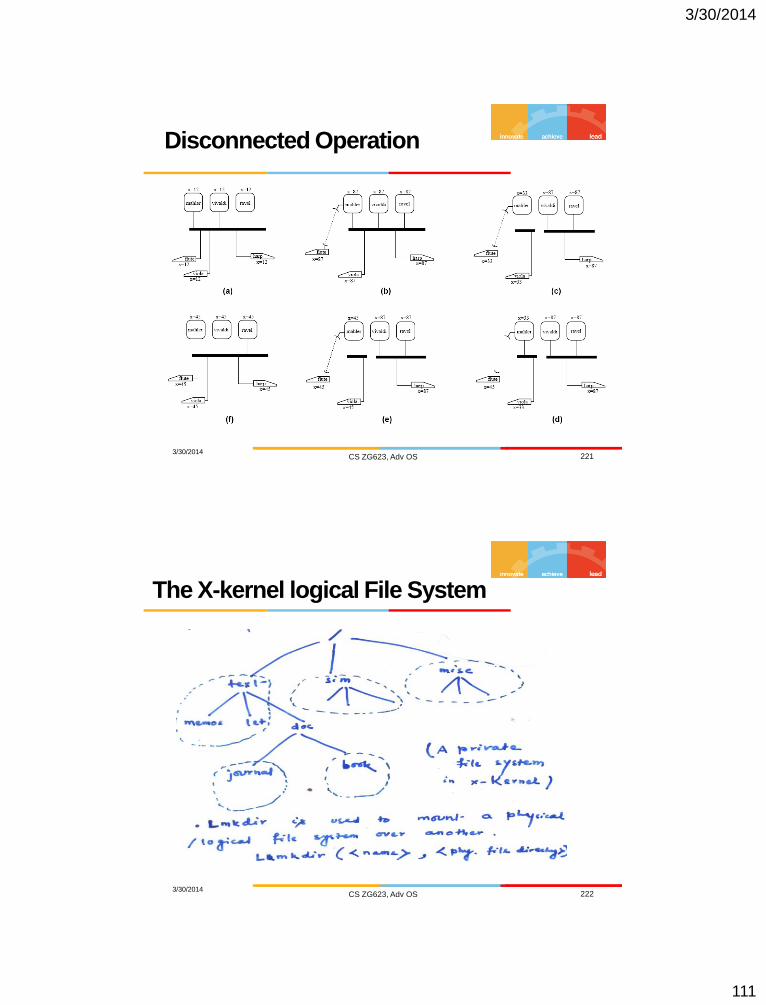
Disconnected Operation
3/30/2014 CS ZG623, Adv OS 221
The X-kernel logical File System
3/30/2014 CS ZG623, Adv OS 222

3/30/2014
112
The X-kernel logical File System
3/30/2014 CS ZG623, Adv OS 223
3/30/2014 CS ZG623, Adv OS 224
Distributed Scheduling
3/30/2014
113
Grid computing
3/30/2014 CS ZG623, Adv OS 225
“Distributed computing across networks using open
standards supporting heterogeneous resources” - IBM
[Source: IBM TJ Watson Research Center]
Linux virtual server (load balancer)
3/30/2014 CS ZG623, Adv OS 226
•WINDOWS also has load balancing features

3/30/2014
114
Examples
3/30/2014 CS ZG623, Adv OS 227
Simple Linux Utility for Resource
Management (SLURM)
Tivoli Loadleveler from IBM
SLURM is an open-source resource
manager designed for Linux clusters of all
sizes. It provides three key functions. First it
allocates exclusive and/or non-exclusive
access to resources (computer nodes) to
users for some duration of time so they can
perform work. Second, it provides a
framework for starting, executing, and
monitoring work (typically a parallel job) on a
set of allocated nodes. Finally, it arbitrates
contention for resources by managing a
queue of pending work.
When jobs are submitted to LoadLeveler, they are not
necessarily executed in the order of submission.
Instead, LoadLeveler dispatches jobs based on their
priority, resource requirements and special instructions;
for example, administrators can specify that long-
running jobs run only on off-hours, that short-running
jobs be scheduled around long-running jobs or that jobs
belonging to certain users or groups get priority. In
addition, the resources themselves can be tightly
controlled: use of individual machines can be limited to
specific times, users or job classes or LoadLeveler can
use machines only when the keyboard and mouse are
inactive.
Fundamentals
3/30/2014 CS ZG623, Adv OS 228
• Why is it required?
- Resource Sharing
- Performance Improvement
• What is a Distributed Scheduler?
- Transparently & Judiciously redistributes the load
- Useful for LAN
• Motivation
- Tasks arrived randomly and CPU service time is also random
- Applicable for both homogeneous and heterogeneous systems

3/30/2014
115
Load sharing in Homogeneous systems
3/30/2014 CS ZG623, Adv OS 229
• Load Distribution is useful in heterogeneous & non-
heterogeneous systems as well.
• Livny & Melmen Model
P (a task is waiting and a server is ideal)
= 1-(1- P0)N (1-P0
N)-P0N(2-P0)
N
• Load Index
– CPU Queue length
• Not always the current value is the right representative if task
transfer involves significant delays
– CPU Utilization
• Classification of load distributing algorithms – Static Priori knowledge is used
– Dynamic Current System state
– Adaptive Runtime Change
• Load balancing Vs Load Sharing
• Preemptive Vs Nonpreemptive
Issues in load distribution
3/30/2014 CS ZG623, Adv OS 230

3/30/2014
116
• Transfer Policy – A state to participate in task transfer
– Threshold policy
• Selection Policy – New tasks causing transfer
– Response time, execution time improvement
– Issues
• Transfer overhead should be minimal
• Location dependent calls must be executed before transfer
Components
3/30/2014 CS ZG623, Adv OS 231
Continued…
3/30/2014 CS ZG623, Adv OS 232
Location Policy
– Polling
– Broadcasting a query
Information Policy
– When, where and what
– Demand Driven
– Periodic
– State-charge driven

3/30/2014
117
Stability
3/30/2014 CS ZG623, Adv OS 233
• Queuing theoretic perspective
– The sum of load due to tasks and distribution
must be less than the system capacity, else
unbounded queues can build up
– A stable algorithm can still give worst
performance than not using it.
• Algorithmic perspective
– Processor thrashing
Sender Initiated Load sharing
3/30/2014 CS ZG623, Adv OS 234
– Initiated by a sender when load>T
– Eager , Lazowska and Zoharjan
– Three algorithms differ by location policy
• Transfer Policy
– CPU queue length
• Selection Policy
– Newly arrived tasks to be transfered

3/30/2014
118
Location Policy – Random
• No remote state information is collected by sender
• Useless task transfer – Thrashing
• Solution : No. of transfers are fixed.
– Threshold • Polling is used to avoid useless transfers
• Randomly selected and then polled to find if it is a reciever
• Poll limit limits the no. of polls
• During a searching session, a node is polled only once by sender
Continued…
3/30/2014 CS ZG623, Adv OS 235
– Shortest
• Chooses the best receiver for a task
• A no. of nodes are selected (Poll limit) and polled
to find shortest queue length
• Once selected, irrespective of it’s queue length at
the time of actual receipt, task is executed
Information Policy
– Demand Driven
Continued…
3/30/2014 CS ZG623, Adv OS 236
Stability: Instable at high system loads
• When all systems are highly loaded, the probability that a sender
gets a receiver is very low.
• Polling is increased as per the rate at which new tasks originate
• May cause instability
3/30/2014
119
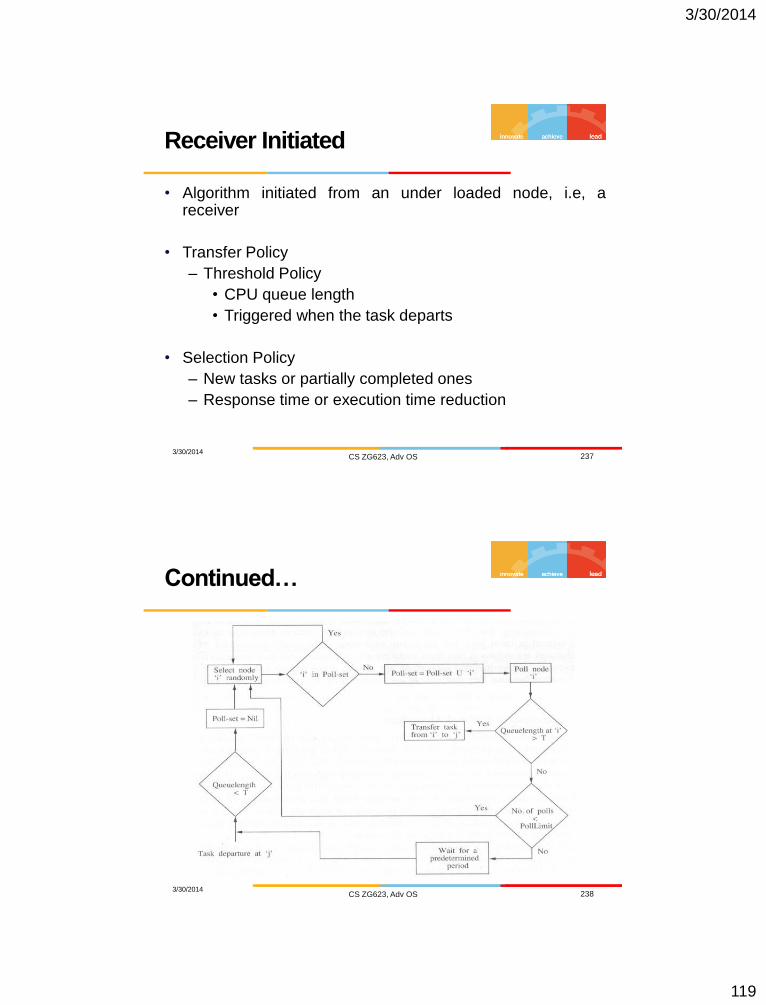
• Algorithm initiated from an under loaded node, i.e, a receiver
• Transfer Policy
– Threshold Policy
• CPU queue length
• Triggered when the task departs
• Selection Policy
– New tasks or partially completed ones
– Response time or execution time reduction
Receiver Initiated
3/30/2014 CS ZG623, Adv OS 237
Continued…
3/30/2014 CS ZG623, Adv OS 238
3/30/2014
120
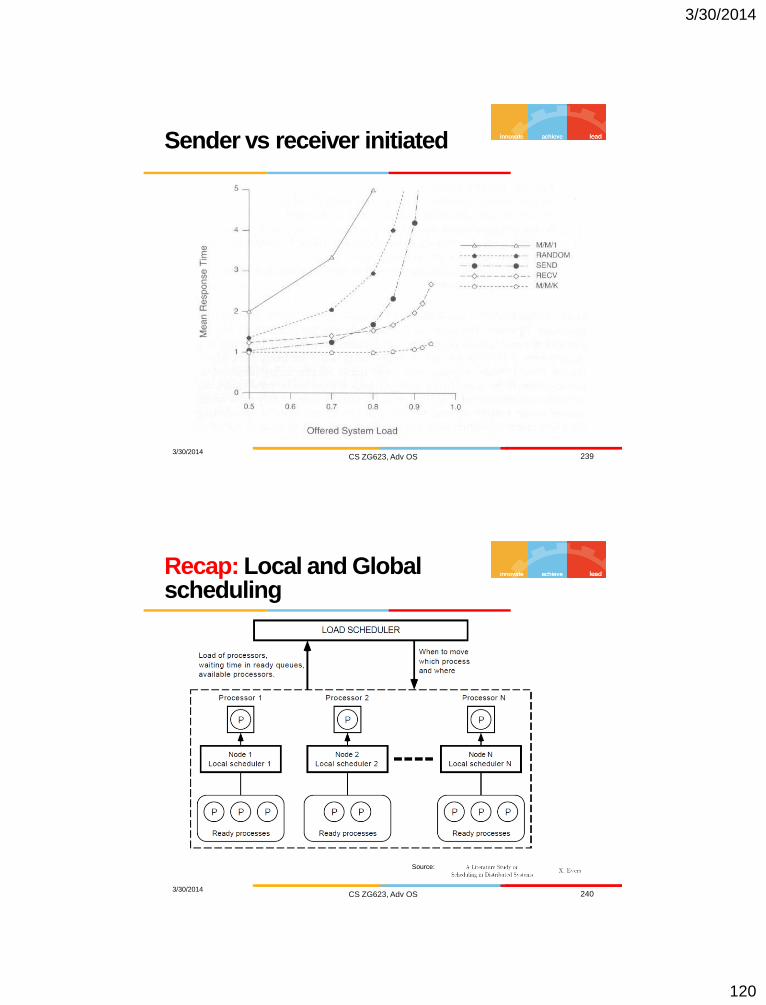
Sender vs receiver initiated
3/30/2014 CS ZG623, Adv OS 239
Recap: Local and Global scheduling
3/30/2014 CS ZG623, Adv OS 240
Source:
3/30/2014
121
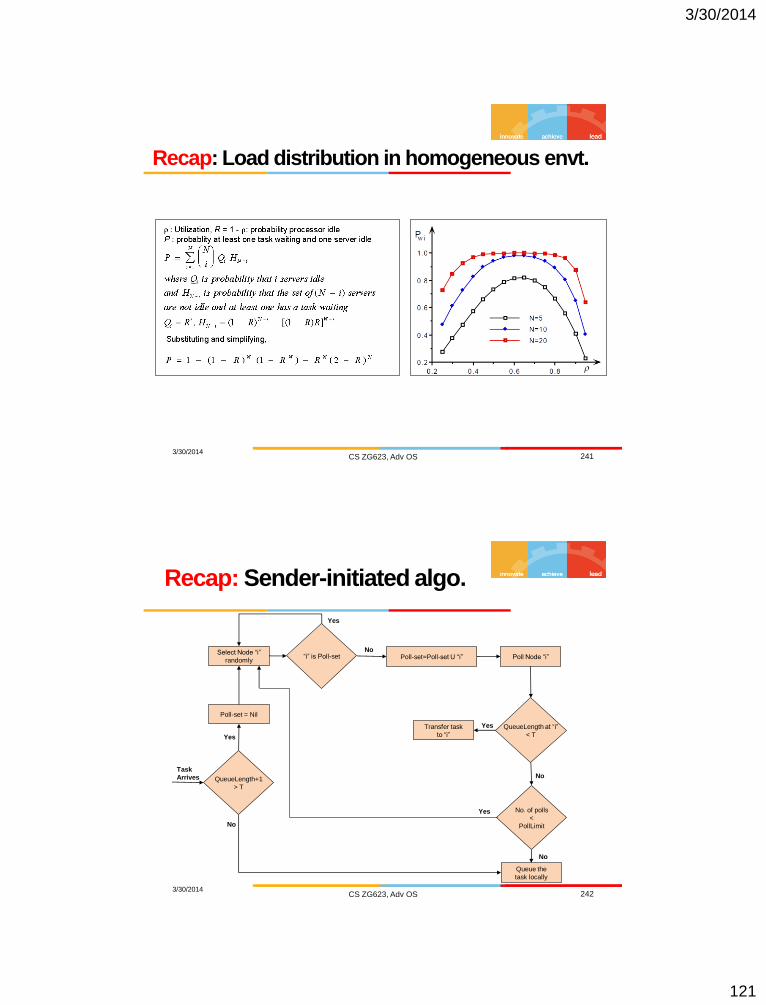
Recap: Load distribution in homogeneous envt.
3/30/2014 CS ZG623, Adv OS 241
Recap: Sender-initiated algo.
3/30/2014 CS ZG623, Adv OS 242
Select Node “i”
randomly “i” is Poll-set
QueueLength+1
> T
Poll-set = Nil
Poll-set=Poll-set U “i” Poll Node “i”
QueueLength at “i”
< T
No. of polls
<
PollLimit
Queue the
task locally
Transfer task
to “i”
Yes
Yes
Yes
Yes
No
No
No
No
Task
Arrives
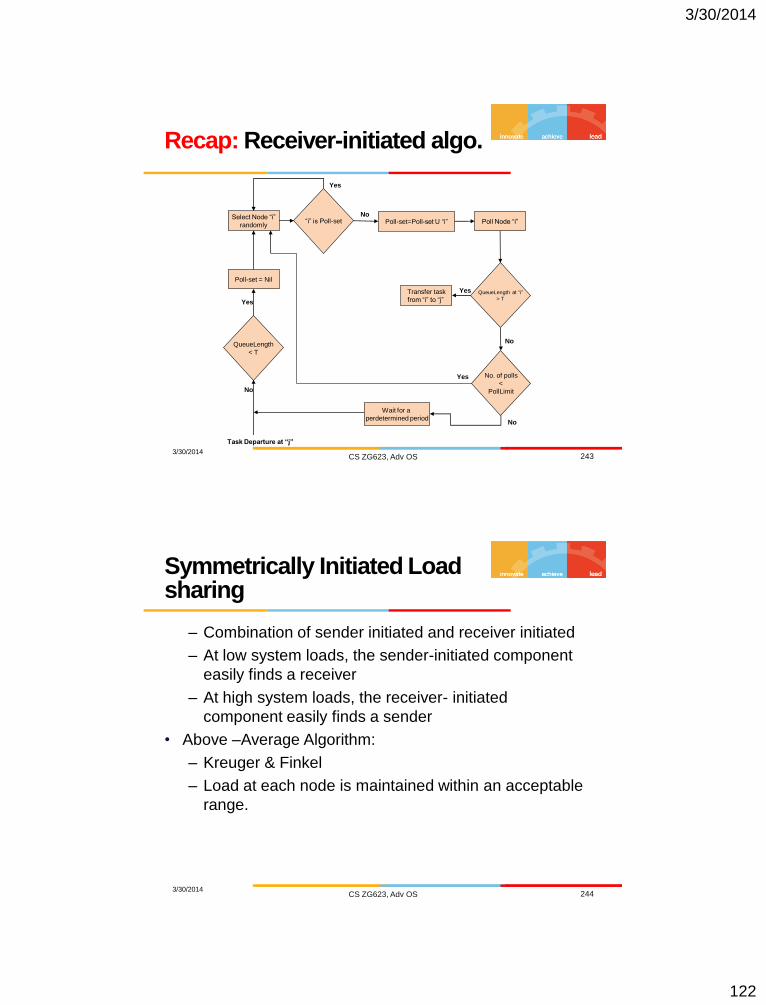
3/30/2014
122
Recap: Receiver-initiated algo.
3/30/2014 CS ZG623, Adv OS 243
Select Node “i”
randomly “i” is Poll-set
QueueLength
< T
Poll-set = Nil
Poll-set=Poll-set U “i” Poll Node “i”
QueueLength at “i”
> T
No. of polls
<
PollLimit
Wait for a
perdetermined period
Transfer task
from “i” to “j”
Yes
Yes
Yes
Yes
No
No
No
No
Task Departure at “j”
– Combination of sender initiated and receiver initiated
– At low system loads, the sender-initiated component
easily finds a receiver
– At high system loads, the receiver- initiated
component easily finds a sender
• Above –Average Algorithm:
– Kreuger & Finkel
– Load at each node is maintained within an acceptable
range.
Symmetrically Initiated Load sharing
3/30/2014 CS ZG623, Adv OS 244
3/30/2014
123
• Transfer Policy
– Threshold policy that uses two adaptive thresholds
– This is equidistant from the average load across all
the nodes
– Lower threshold and upper threshold
– Load < L.T receiver
– Load > U.T sender
Continued…
3/30/2014 CS ZG623, Adv OS 245
Continued…
3/30/2014 CS ZG623, Adv OS 246
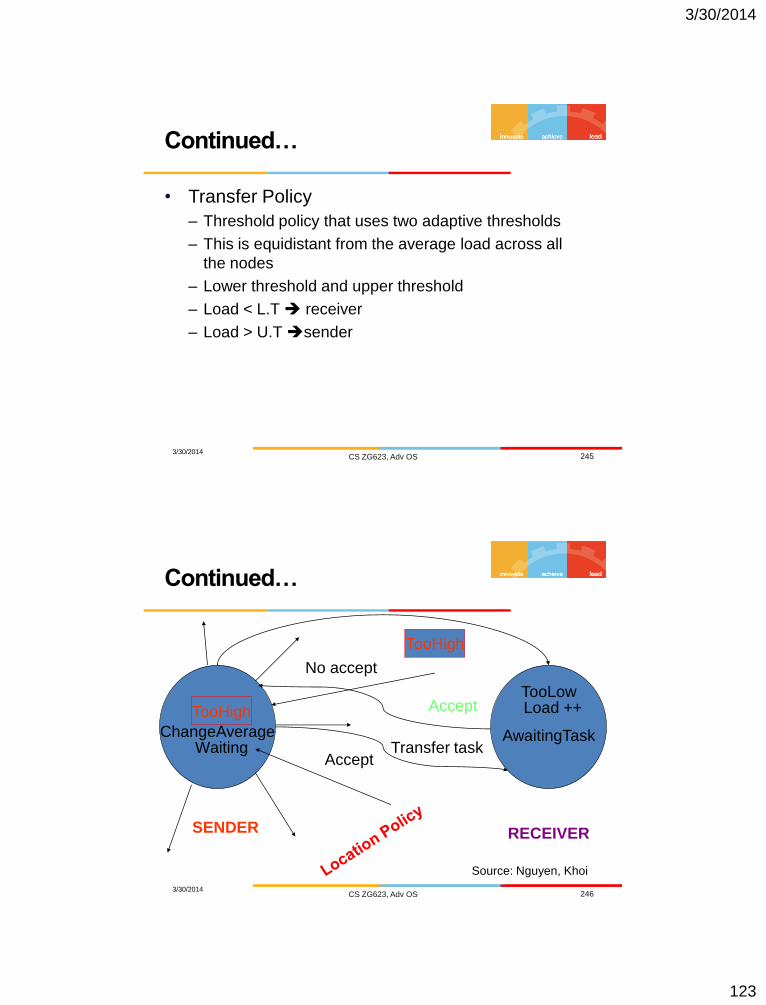
TooHigh
Waiting Accept
SENDER RECEIVER
TooHigh
TooLow Accept Load ++
AwaitingTask Transfer task
No accept
ChangeAverage
Source: Nguyen, Khoi

3/30/2014
124
• Receiver-Initiated Component
– Upon receiving, it sends, accept and sets Awaiting-
task time out
– When Too low timeout expires without receiving any
Too high message, receiver decreases the estimate
by Change Average.
• Selection Policy
– New tasks or partially executed ones
– Response time or execution time reduction
Continued…
3/30/2014 CS ZG623, Adv OS 247
• Information Policy • Demand Driven
• Each node computes the average system load individually
• Stable symmetrically initiated algorithm
– Each node maintains a structure comprising of
sender, receiver and OK lists
– Initially each node assumes every other node as
receiver, so it’s OK and sender lists will be empty
• Transfer Policy
– Uses LT and UT
Adaptive Load sharing
3/30/2014 CS ZG623, Adv OS 248
3/30/2014
125
Sender initiated component
3/30/2014 CS ZG623, Adv OS 249
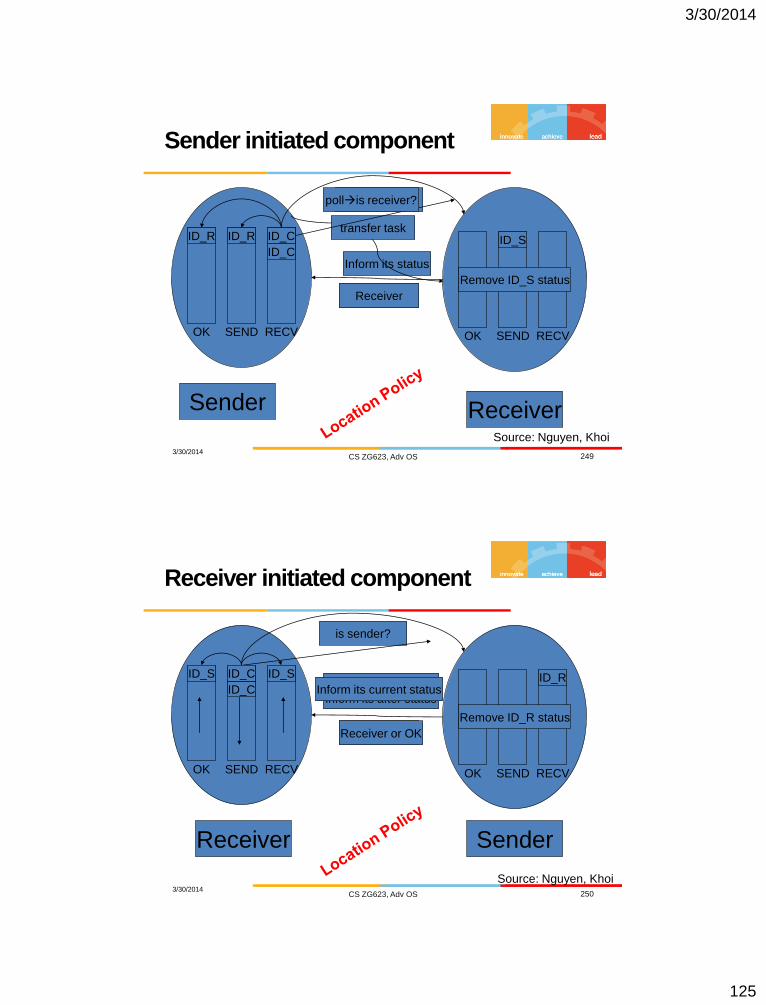
Sender Receiver
ID_R ID_S
RECV
ID_C
SEND OK OK SEND RECV
is receiver?
Inform its status
transfer task ID_R
Sender or OK
ID_R ID_C
pollis receiver?
Remove ID_S status
Receiver
Source: Nguyen, Khoi
Receiver initiated component
3/30/2014 CS ZG623, Adv OS 250
Sender Receiver
ID_R
RECV SEND OK OK SEND RECV
is sender?
Transfer task and
inform its after status
Sender
ID_S
Remove ID_R status
Receiver or OK
Inform its current status
ID_S ID_S
ID_C
ID_C
Source: Nguyen, Khoi

3/30/2014
126
• Selection Policy
– Sender initiated component
• New Tasks
– Receiver initiated component
• New Tasks or partially executed ones, response/execution time
• Information Policy – Demand Driven
• Discussion:
– At high system load, sender initiated component is deactivated.
– At low system load, receiver-initiated generally fails, but it updates
the receivers list accurately so that future sender-initiated
components get benefited.
Continued…
3/30/2014 CS ZG623, Adv OS 251
• Two desirable properties:
– It does not cause instability
– Load sharing is due to non-preemptive transfers
(which are cheaper) only.
• This algorithm uses the sender initiated load
sharing component of the stable symmetrically
initiated algorithm as it is, but has a modified
receiver initiated component to attract the future
non-preemptive task transfers from sender
nodes.
Stable adaptive sender initiated
3/30/2014 CS ZG623, Adv OS 252

3/30/2014
127
• The data structure (at each node) of the stable symmetrically initiated algorithm is augmented by an array called statevector.
• The statevector is used by each node to keep track of which list (senders, recevers, or OK) it belongs to at all the other nodes in the system.
• When a sender polls a selected node, the sender’s statevector is updated to reflect that the sender now belongs to the senders list at the selected node, the polled node updates its statevector based on the reply it sent to the sender node to reflect which list it will belong to at the sender
Continued…
3/30/2014 CS ZG623, Adv OS 253
Continued…
3/30/2014 CS ZG623, Adv OS 254
• The receiver initiated component is replaced by the following protocol: – When a node becomes a receiver, it informs all the nodes that
are misinformed about its’ current state. The misinformed nodes are those nodes whose receivers lists do not contain the receiver’s ID.
– The statevector at the receiver is then updated to reflect that it now belongs to the receivers list at all those nodes that were informed of its current state.
– By this technique, this algorithm avoids the receivers sending broadcast messages to inform other nodes that they are receivers.
• No preemptive transfers of partly executed tasks here.

3/30/2014
128
Selecting a suitable load sharing algorithm
3/30/2014 CS ZG623, Adv OS 255
• System with low load sender- initiated
• System with high load receiver-initiated
• System with wide load fluctuation stable symmetrically-
initiated
• System with wide load fluctuation and high cost for
migration of partly executed tasks stable sender-
initiated ( adaptive)
• System with heterogeneous work arrival adaptive stable
algorithms
Comparison
3/30/2014 CS ZG623, Adv OS 256
• Better than sender-initiated but unstable at high-load
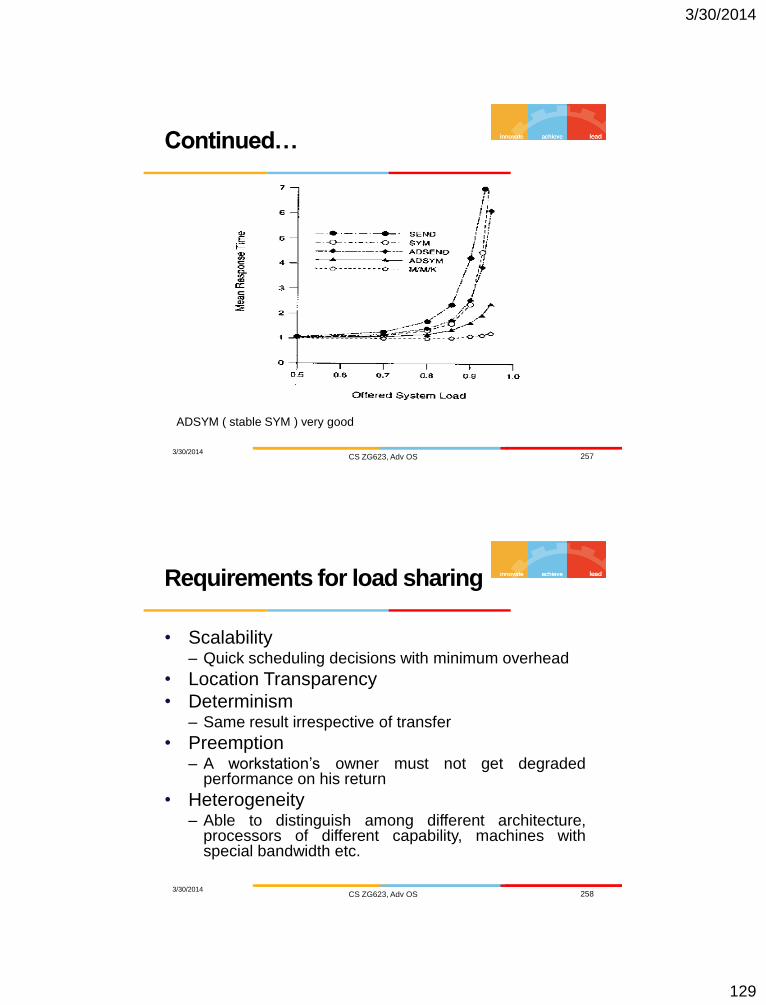
3/30/2014
129
Continued…
3/30/2014 CS ZG623, Adv OS 257
ADSYM ( stable SYM ) very good
Requirements for load sharing
3/30/2014 CS ZG623, Adv OS 258
• Scalability – Quick scheduling decisions with minimum overhead
• Location Transparency
• Determinism – Same result irrespective of transfer
• Preemption – A workstation’s owner must not get degraded
performance on his return
• Heterogeneity – Able to distinguish among different architecture,
processors of different capability, machines with special bandwidth etc.

3/30/2014
130
Case studies
3/30/2014 CS ZG623, Adv OS 259
• The V-System
– State change driven information policy
– Selection policy - new tasks are selected
– Transfer policy
• If it is among N (lightly loaded)
• Receiver
– Location Policy
• When a task arrives, local cache is consulted to find a suitable node.
• Randomly a node is selected & polled to unify, can it really become the receiver
Continued…
3/30/2014 CS ZG623, Adv OS 260
• Rarely three polls are required
• Publishing scheme has advantages over direct queries
– Publishing of state information depends on rate at
which state changes
– But for direct queries, no. of polls are decided by no. of
jobs
• Load Index
– CPU utilization (bg process with counter)

3/30/2014
131
Sprite scheduler
3/30/2014 CS ZG623, Adv OS 261
• Information policy (state change driven)
• Location Policy
– Centralized
• Selection Policy
– Tasks that are to be scheduled or run remotely are decided by the user (sender).
– Sender contacts central coordinator to know the receiver
– When the owner of w/s wants to use it, foreign jobs are evicted & sent back to their original w/s
• Transfer Policy
– senders can be manually made by the users - Sender(Semi-Automated)
– sender is a node from which job evicts - Sender (Semi-Automated)
– not active for 30 seconds & less tasks - Receiver
Condor distributed scheduler
3/30/2014 CS ZG623, Adv OS 262
• Long running CPU intensive tasks (bg jobs only)
• Transfer and selection polices
– Same as Sprite
• But centralized selection is used
– User submits big jobs to a central coordinator
– Central coordinator polls w/s every 2 minutes periodically (w/s is ideal if for 12.5 minutes user has not done any work)
• When the owner of the w/s remains active more than 5 minutes, the foreign job is evicted/transferred to the originating node

3/30/2014
132
Stealth distributed scheduler
3/30/2014 CS ZG623, Adv OS 263
• Exploits the under utilized resources of the w/s’s by their owners
• Prioritized local resource allocation
• Foreign tasks are executed even if the owners of those w/s’s are active
• Priority is higher for an owners work
• It has a prioritized CPU scheduler, prioritized V.M, prioritized file cache
• Guarantees that owner process get the resources whatever they need and remaining are given to the foreign processes
• Replaces the primitive transfer (as in sprite & condor) by a cheap operation i.e, prioritized local allocation.
Task migration
3/30/2014 CS ZG623, Adv OS 264
• Preemptive transfers are required in following situations
– In receiver initiated task transfers
– In w/s model, jobs (foreign) are preempted
– To avoid starvation
• Task placements vs Task Migration
– Yet to begin, already started
• Task migration requirements
– State transfer
• Regs, stack, state, VM address space, file descriptors,
buffered msgs, CW directory, signal mask and
handlers, resource usage statistics, etc.
– Unfreeze
3/30/2014
133
• State Transfer
• The transfer of the task’s state including information
e.g. registers, stack, ready or blocked, virtual
memory address space, file descriptors, buffered
messages etc. to the new machine.
• The task is frozen at some point during the transfer
so that the state does not change further.
• Unfreeze
• The task is installed at the new machine and is put
in the ready queue so that it can continue executing
there.
Steps in Task migration
3/30/2014 CS ZG623, Adv OS 265
Issues in Task migration
3/30/2014 CS ZG623, Adv OS 266
• State Transfer
• Location Transparency
• Structure of a Migration Mechanism
• Performance

3/30/2014
134
State transfer
3/30/2014 CS ZG623, Adv OS 267
• The Cost
– Obtaining & transferring the state, and unfreezing the task.
• Residual Dependencies
– Refers to the amount of resources a former host of a preempted or migrated task continues to dedicate to service requests from the migrated task.
• Implementations
– The V-System
• Attempts to reduce the freezing time of a migrating task by pre-copying the state.
– Sprite
• Makes use of the location-transparent file access mechanism provided by its file system
• All the modified pages of the migrating task are swapped to file server
Location transparency
3/30/2014 CS ZG623, Adv OS 268
• Location transparency in principle requires that names (e.g. process names, file names) be independent of their location (i.e. host names).
• Any operation (such as signaling) or communication that was possible before the migration of a task should be possible after its migration.
• Example – SPRITE – Location Transparency Mechanisms
– A location-transparent distributed file system is provided
– The entire state of the migrating task is made available at the new host, and therefore, any kernel calls made will be local at new host.
– Location-dependent information such as host of a task is maintained at the home machine of a task

3/30/2014
135
Structure of Migration mechanism
3/30/2014 CS ZG623, Adv OS 269
• Issues involved in Migration Mechanisms
– Decision whether to separate the policy-making modules from mechanism modules
– Where the policy and mechanisms should reside
• The migration mechanism may best fit inside the kernel
• Policy modules decide whether a task transfer should occur, this can be placed in the kernel as well
– Interplay between the task migration mechanism and various other mechanisms
• The mechanisms can be designed to be independent of one another so that if one mechanism’s protocol changes, the other’s need not.
Performance
3/30/2014 CS ZG623, Adv OS 270
• Comparing the performance of task migration mechanisms implemented in different systems is a difficult task, because of the different:
– Hardware
• Sprite consists of a collection of SPARCstation 1
– Operating systems
– IPC mechanism
– File systems
– Policy mechanisms
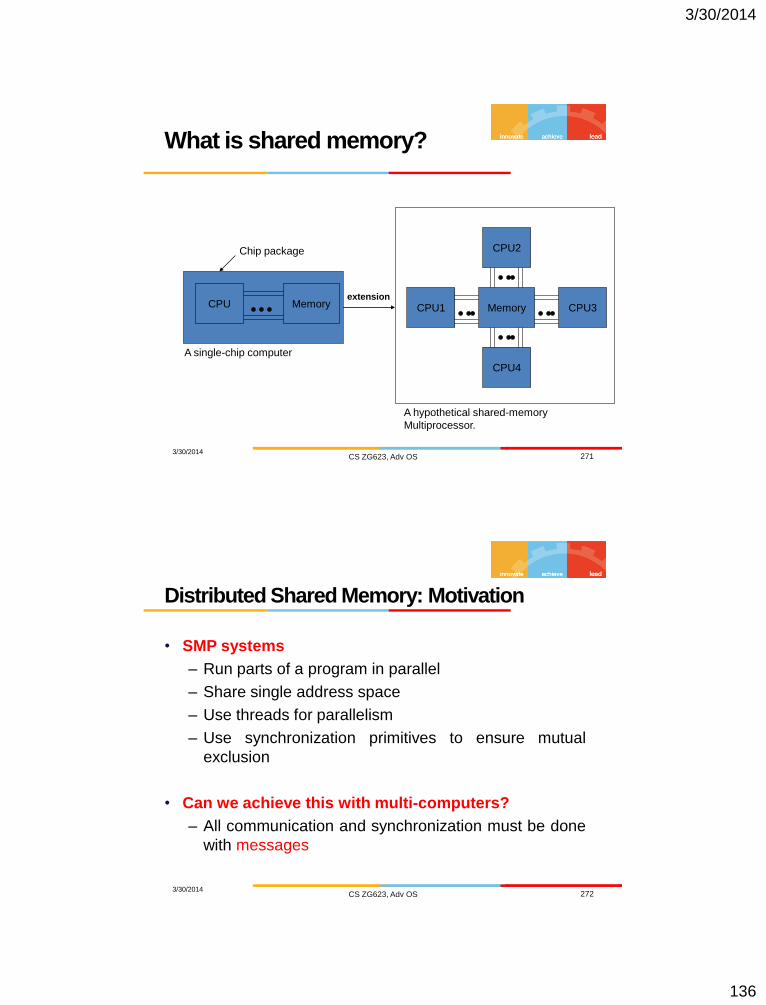
3/30/2014
136
What is shared memory?
3/30/2014 CS ZG623, Adv OS 271
CPU Memory CPU1 Memory
CPU4
CPU2
CPU3
Chip package
extension
A single-chip computer
A hypothetical shared-memory
Multiprocessor.
Distributed Shared Memory: Motivation
3/30/2014 CS ZG623, Adv OS 272
• SMP systems
– Run parts of a program in parallel
– Share single address space
– Use threads for parallelism
– Use synchronization primitives to ensure mutual
exclusion
• Can we achieve this with multi-computers?
– All communication and synchronization must be done
with messages

3/30/2014
137
• Each tiger has his own feeding through where as for the other one, a group of tigers eating from a single feeding through.
• Each student looking at his/her notebook, but for the second one, all the students looking at a black board.
Examples
3/30/2014 CS ZG623, Adv OS 273
Bus based Multi-processors
3/30/2014 CS ZG623, Adv OS 274
CPU CPU CPU Memory
Bus
A multiprocessor
CPU
Cache
CPU
CPU
Cache Cache
Memory
Bus
A multiprocessor with caching

3/30/2014
138
Write once protocol
3/30/2014 CS ZG623, Adv OS 275
A B W1 C
W1
CLEAN
Memory is correct
CPU
A B W1 C
W1 W1
CLEAN CLEAN
Memory is correct
Continued…
3/30/2014 CS ZG623, Adv OS 276
A B W1 C
W2 W1
A B W1 C
W3 W1
DIRTY INVALID
DIRTY INVALID
Memory is correct
No update to memory
Memory is correct
A writes W again. This and subsequent
writes by A are done locally, without any
bus traffic.
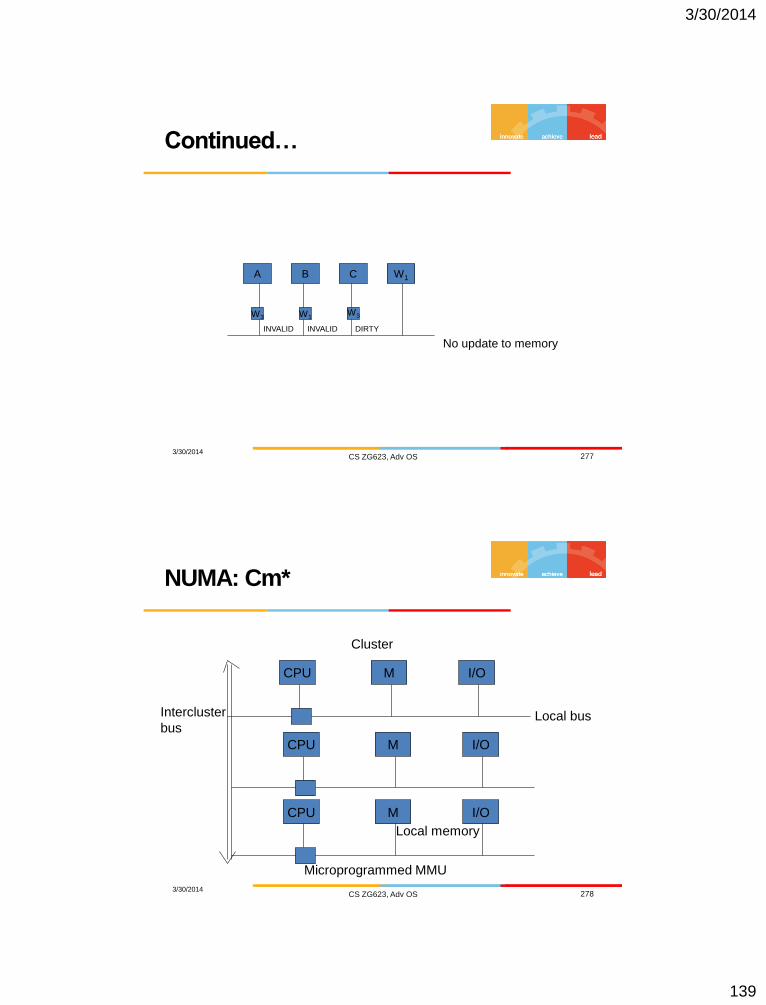
3/30/2014
139
Continued…
3/30/2014 CS ZG623, Adv OS 277
A B W1 C
W3 W1
INVALID INVALID DIRTY
W3
No update to memory
NUMA: Cm*
3/30/2014 CS ZG623, Adv OS 278
CPU M I/O
Local bus
Cluster
CPU M I/O
CPU M I/O
Intercluster
bus
Local memory
Microprogrammed MMU
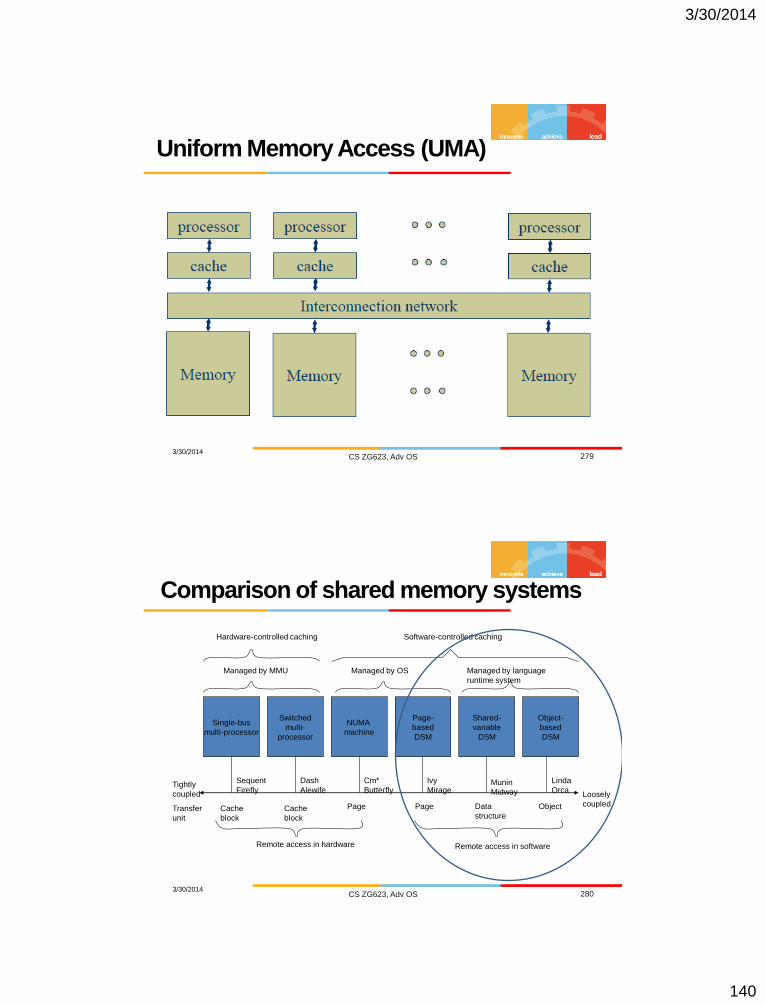
3/30/2014
140
Uniform Memory Access (UMA)
3/30/2014 CS ZG623, Adv OS 279
Comparison of shared memory systems
3/30/2014 CS ZG623, Adv OS 280
Single-bus
multi-processor
Switched
multi-
processor
NUMA
machine
Page-
based
DSM
Shared-
variable
DSM
Object-
based
DSM
Cache
block
Cache
block
Page Page Data
structure
Object
Loosely
coupled
Tightly
coupled
Transfer
unit
Sequent
Firefly
Dash
Alewife
Cm*
Butterfly
Ivy
Mirage Munin
Midway
Linda
Orca
Remote access in hardware Remote access in software
Managed by MMU Managed by OS Managed by language
runtime system
Hardware-controlled caching Software-controlled caching
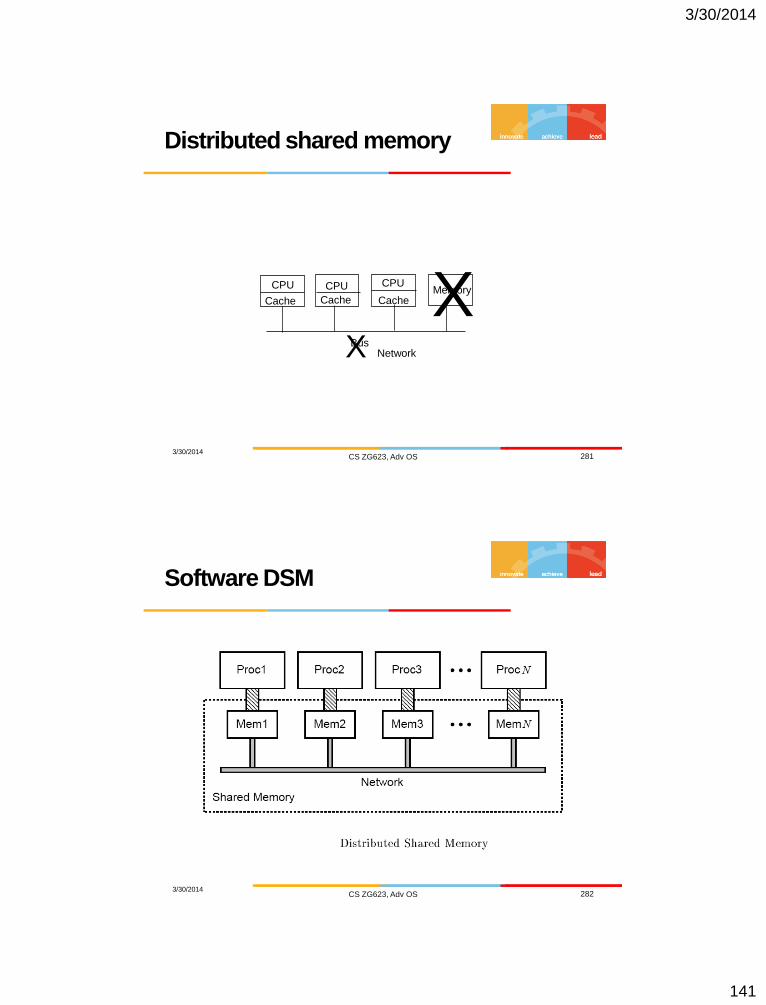
3/30/2014
141
Distributed shared memory
3/30/2014 CS ZG623, Adv OS 281
CPU CPU CPU
Cache Cache Cache Memory
Bus
X X Network
Software DSM
3/30/2014 CS ZG623, Adv OS 282
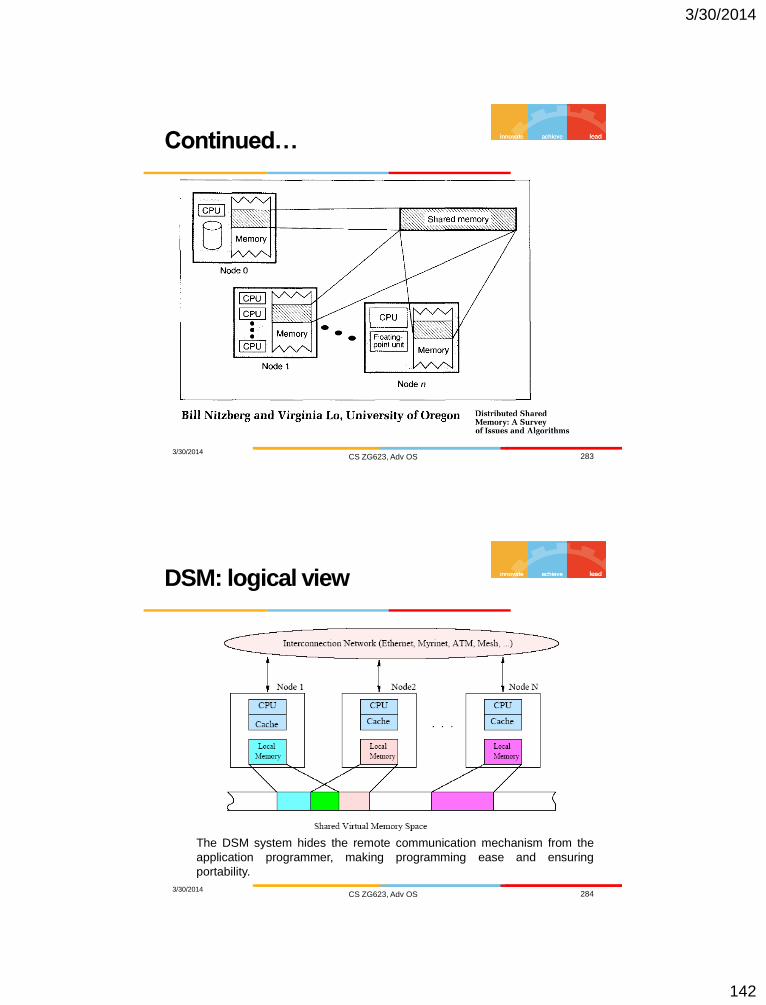
3/30/2014
142
Continued…
3/30/2014 CS ZG623, Adv OS 283
DSM: logical view
3/30/2014 CS ZG623, Adv OS 284
The DSM system hides the remote communication mechanism from the
application programmer, making programming ease and ensuring
portability.
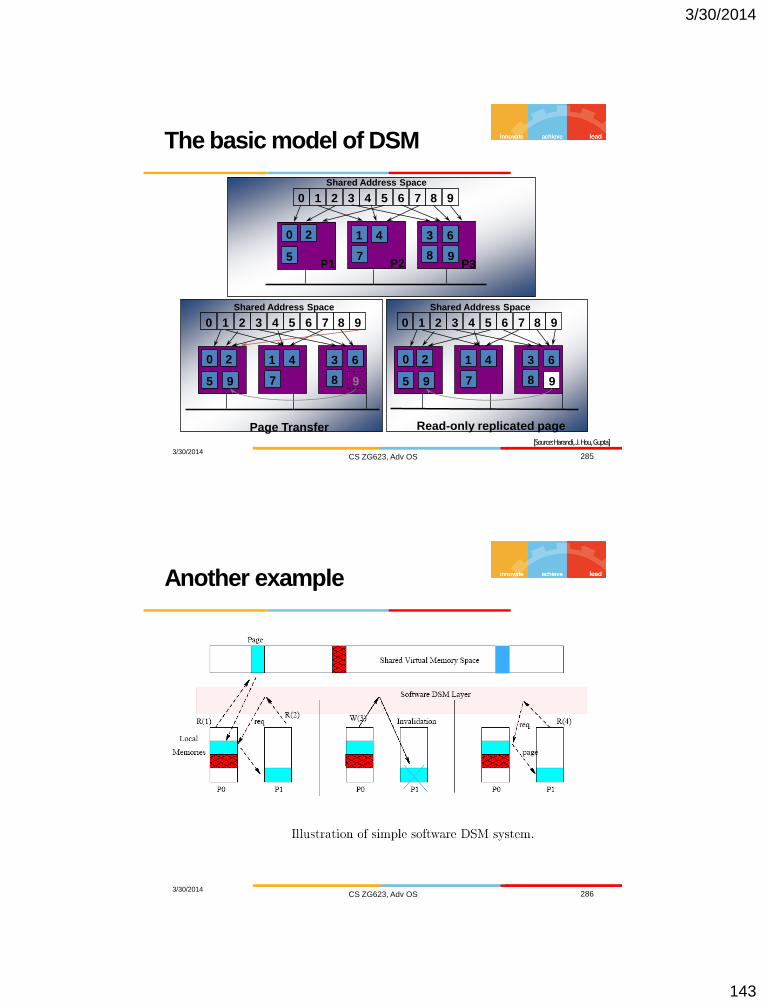
3/30/2014
143
The basic model of DSM
3/30/2014 CS ZG623, Adv OS 285
[Source: Harandi, J. Hou, Gupta]
0 1 2 3 4 5 6 7 8 9
0 2 1 4
7 5
3 6
8 9 P1 P2 P3
Shared Address Space
0 1 2 3 4 5 6 7 8 9
0 2 1 4
7 5
3 6
8 9
Shared Address Space
9
Page Transfer
0 1 2 3 4 5 6 7 8 9
0 2 1 4
7 5
3 6
8 9
Shared Address Space
9
Read-only replicated page
Another example
3/30/2014 CS ZG623, Adv OS 286

3/30/2014
144
Advantages and Disadvantages
3/30/2014 CS ZG623, Adv OS 287
Source: Kshemkalyani and Singhal
Implementing DSMs
3/30/2014 CS ZG623, Adv OS 288
Issues:
1) Keeping track of location of remote data.
2) Reducing the Communication delays.
3) Minimal execution of communication
protocols.
4) Making shared data concurrently
accessible at several nodes.
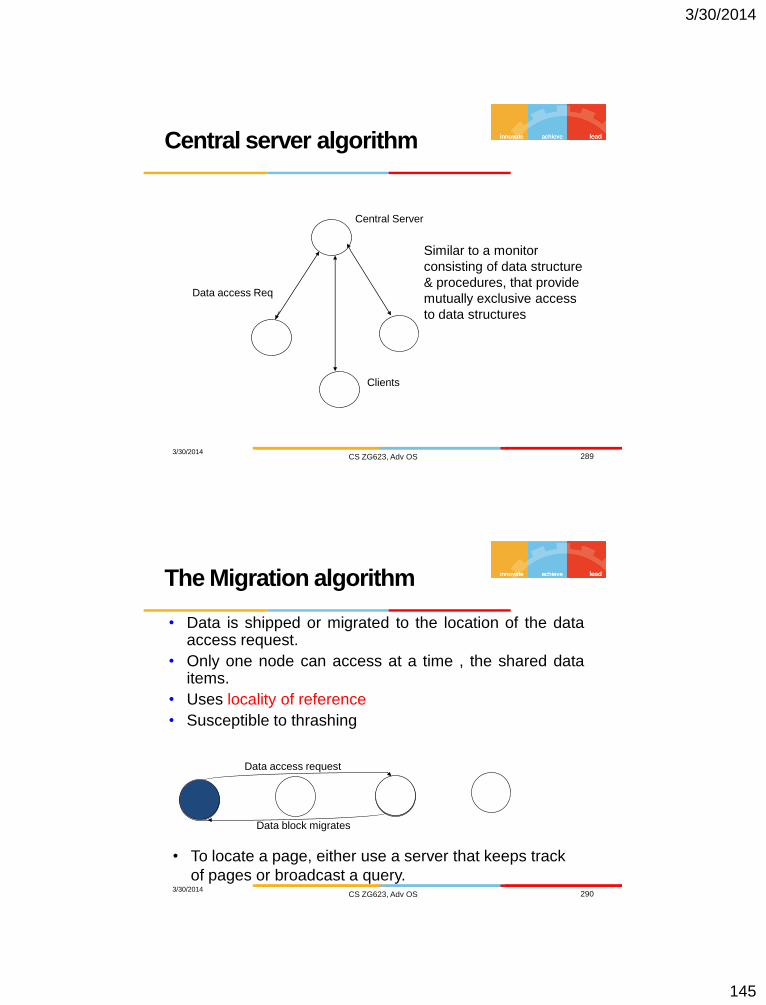
3/30/2014
145
Central server algorithm
3/30/2014 CS ZG623, Adv OS 289
Data access Req
Central Server
Clients
Similar to a monitor
consisting of data structure
& procedures, that provide
mutually exclusive access
to data structures
The Migration algorithm
3/30/2014 CS ZG623, Adv OS 290
• Data is shipped or migrated to the location of the data access request.
• Only one node can access at a time , the shared data items.
• Uses locality of reference
• Susceptible to thrashing
Data access request
Data block migrates
• To locate a page, either use a server that keeps track
of pages or broadcast a query.

3/30/2014
146
The Read-replication algo
3/30/2014 CS ZG623, Adv OS 291
• Extends the migration algorithm by replicating data blocks at various sites and allowing reading only – by multiple nodes or read–write by one node.
• Multiple nodes access data concurrently–reading only.
• Writing is expensive
– Needs all others to be invalidated.
– Updated to maintain consistency.
Continued…
3/30/2014 CS ZG623, Adv OS 292
• DSM keeps track of location of all the copies of data
blocks
• In IVY , owner of page keeps the location of all copies.

3/30/2014
147
The Full replication algorithm
3/30/2014 CS ZG623, Adv OS 293
• Extension of read replication
• Multiple nodes can have both Read & Write access to shared data blocks.
• Many nodes can write data concurrently.
• Consistency is a prime factor
• A gap free sequencer can be used
• All the nodes wishing to write, send the modifications to sequencer .
• Sequencer assigns a sequence number & multicasts the modification with the sequence number to the nodes having the copy.
• Each node processes the modifications in the sequence number order.
Continued…
3/30/2014 CS ZG623, Adv OS 294
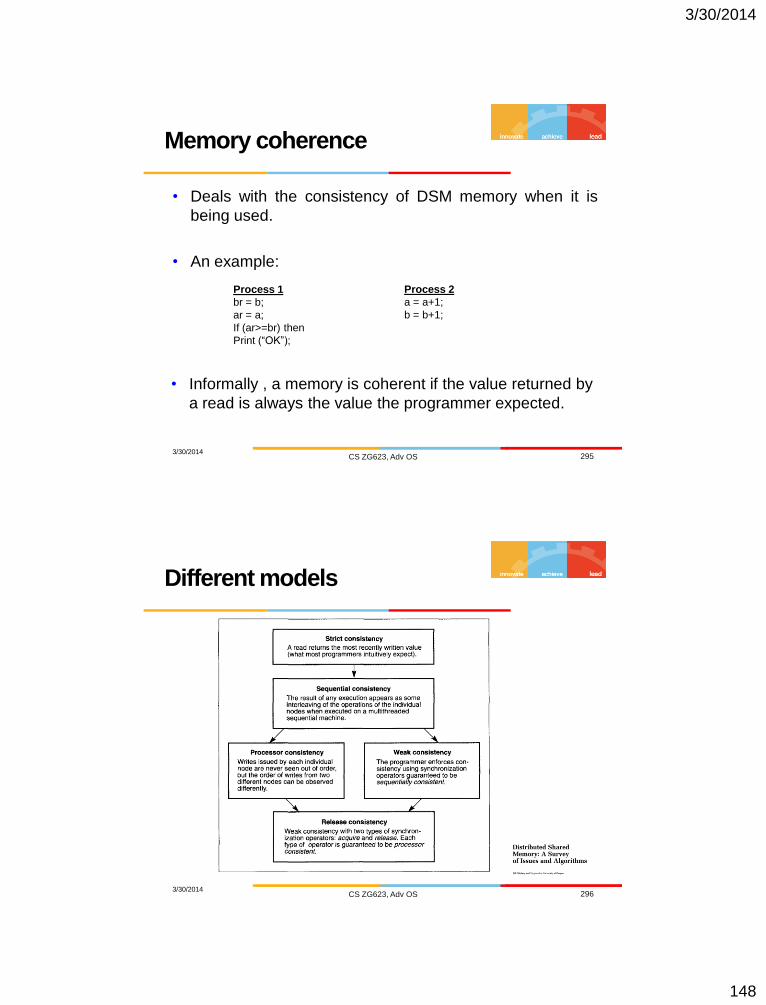
3/30/2014
148
Memory coherence
3/30/2014 CS ZG623, Adv OS 295
• Deals with the consistency of DSM memory when it is
being used.
• An example:
Process 1
br = b;
ar = a;
If (ar>=br) then
Print (“OK”);
Process 2
a = a+1;
b = b+1;
• Informally , a memory is coherent if the value returned by
a read is always the value the programmer expected.
Different models
3/30/2014 CS ZG623, Adv OS 296

3/30/2014
149
Strict consistency
3/30/2014 CS ZG623, Adv OS 297
Strict Consistency (one-copy semantics)
– Any read to a memory location x returns the value stored by the most recent write operation to x.
Examples:
1. A system to provide sports fans with up-to-the minute (not up-to-the
seconds) scores for Cricket matches (cricinfo.com) ?
2. P1 : W(x) 1 P1: W(x) 1
-------------------------- ------------------------------------
P2: R(x)1 R(x)0 R(x)1
Sequential consistency
3/30/2014 CS ZG623, Adv OS 298

3/30/2014
150
Continued…
3/30/2014 CS ZG623, Adv OS 299
Example – The combination ar = 0, br = 1, Is it possible?
Process 1
br = b;
ar = a;
If (ar>=br) then
Print (“OK”);
Process 2
a = a+1;
b = b+1;
Continued…
3/30/2014 CS ZG623, Adv OS 300

3/30/2014
151
Causal consistency
3/30/2014 CS ZG623, Adv OS 301
Writes that are potentially causally related must be seen by
all processes in the same order. Concurrent writes may be
seen in a different order on different machines.
Example 1:
P1:
P2:
P3:
P4:
W(x)1 W(x) 3
R(x)1 W(x)2
R(x)1
R(x)1
R(x)3 R(x)2
R(x)2 R(x) 3
This sequence obeys causal consistency
Concurrent writes
Continued…
3/30/2014 CS ZG623, Adv OS 302
P1:
P2:
P3:
P4:
W(x)1
R(x)1 W(x)2
R(x)2 R(x)1
R(x)1 R(x) 2
This sequence does not obey causal consistency
Causally related
P1:
P2:
P3:
P4:
W(x)1
W(x)2
R(x)2 R(x)1
R(x)1 R(x) 2
This sequence obeys causal consistency

3/30/2014
152
Pipelined RAM consistency
3/30/2014 CS ZG623, Adv OS 303
Writes done by a single processor are received by all other
processors in the same order. A pair of writes from
different processes may be seen in different orders at
different processors.
P1:
P2:
P3:
P4:
W(x)1
R(x)1 W(x)2
R(x)2 R(x)1
R(x)1 R(x) 2
This sequence is allowed with PRAM consistent memory
Cache consistency
3/30/2014 CS ZG623, Adv OS 304
• Under sequential consistency, all processors have to agree on some sequential order of execution for all accesses.
• But, coherence requires that accesses are sequentially consistent on a per location basis.
• Accesses to x and y can be linearized into R(x)0, W(x)1, and R(y)0, W(y)1
• The history is coherent (per variable), but not sequentially consistent
• SC implies coherence but not vice versa.
P1:
P2:
W(x)1 R(y)0
W(y)1 R(x)0

3/30/2014
153
Processor consistency
3/30/2014 CS ZG623, Adv OS 305
Processor Consistency:
• Combination of Coherence and PRAM (History should be coherent and PRAM simultaneously).
• Stronger than Coherence but weaker than SC.
Weak consistency
3/30/2014 CS ZG623, Adv OS 306
P1:
P2:
P3:
P4:
W(x)1 W(y) 2 S
R(y)2 R(x)0 S
R(x)0 R(y) 2 S
This sequence is allowed with weak consistent memory (but may never be coded in)
P1:
P2:
P3:
P4:
W(x)1 W(y) 2 S
S R(y)2 R(x)1
S R(x)1 R(y) 2
The memory in P3 and P4 has been brought up to date

3/30/2014
154
Release consistency
3/30/2014 CS ZG623, Adv OS 307
• Two synchronization variables are defined: Acquire and Release
– Before any read/write op is allowed to complete at a
processor, all previous acquire’s at all processors must be
completed
– Before a release is allowed to complete at a processor, all
previous read/write ops. must be propagated to all
processors
– Acquire and release ops are sequentially consistent w.r.t.
one another
P1:
P2:
P3:
P4:
Acq(L) W(x)1 W(x) 2 Rel(L)
Acq(L) R(x)2 Rel(L)
R(x) 1
This sequence is allowed with release consistent memory
Granularity of chunks
3/30/2014 CS ZG623, Adv OS 308
• On a page fault, – the missing page is just brought in from a remote node.
– A region of 2, 4, or 8 pages including the missing page may also be brought in.
• Locality of reference: if a processor has referenced one word on a page, it is likely to reference other neighboring words in the near future.
• Chunk/Page size – Small => too many page transfers
– Large => False sharing

3/30/2014
155
False sharing
3/30/2014 CS ZG623, Adv OS 309
A
B
A
B
Processor 1 Processor 2
Code using A Code using B
Two
unrelated
shared
variables
• Occurs because: Page size > locality of reference
• Unrelated variables in a region cause large number of pages
transfers
• Large pages sizes => more pairs of unrelated variables
Page consists of
two variables A
and B
Consistency
3/30/2014 CS ZG623, Adv OS 310
• Achieving consistency is not an issue if
– Pages are not replicated, or…
– Only read-only pages are replicated.
• Two approaches are taken in DSM
– Update: the write is allowed to take place locally, but the address of the modified word and its new value are broadcast to all the other processors. Each processor holding the word copies the new value, i.e., updates its local value.
– Invalidate: The address of the modified word is broadcast, but the new value is not. Other processors invalidate their copies.

3/30/2014
156
Invalidation protocol
3/30/2014 CS ZG623, Adv OS 311
• Each page is either in R or W state.
– When a page is in W state, only one copy exists, located at
one processor (called current “owner”) in read-write mode.
– When a page is in R state, the current/latest owner has a copy
(mapped read only), but other processors may have copies
too.
W
Processor 1 Processor 2
Owner
P
page
Processor 1 Processor 2
R
Owner
P
Suppose Processor 1 is attempting a read: Different scenarios
(a) (b)
Read continued…
3/30/2014 CS ZG623, Adv OS 312
Processor 1 Processor 2
R
Owner
P R
Processor 1 Processor 2
R P R
Owner
Processor 1 Processor 2
P R
Owner
Processor 1 Processor 2
P W
Owner
In the first 4 cases, the page is mapped into its address space.
1. Ask for a copy
2. Mark page as R
3. Do read
1. Ask P2 to degrade its copy to R
2. Ask for a copy
3. Mark page as R
4. Do read
(c) (d)
(e) (f)
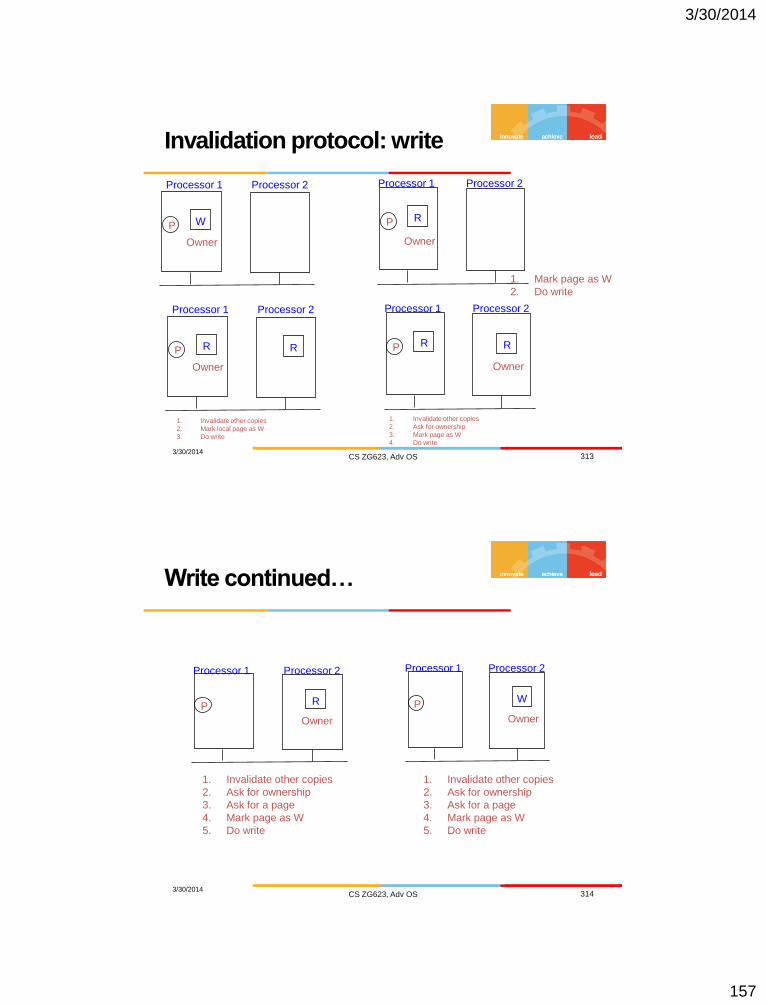
3/30/2014
157
Invalidation protocol: write
3/30/2014 CS ZG623, Adv OS 313
Processor 1 Processor 2
W
Owner
P
Processor 1 Processor 2
R P
Owner
1. Mark page as W
2. Do write
Processor 1 Processor 2
R
Owner
P R
Processor 1 Processor 2
R P R
Owner
1. Invalidate other copies
2. Mark local page as W
3. Do write
1. Invalidate other copies
2. Ask for ownership
3. Mark page as W
4. Do write
Write continued…
3/30/2014 CS ZG623, Adv OS 314
Processor 1 Processor 2
P R
Owner
Processor 1 Processor 2
P W
Owner
1. Invalidate other copies
2. Ask for ownership
3. Ask for a page
4. Mark page as W
5. Do write
1. Invalidate other copies
2. Ask for ownership
3. Ask for a page
4. Mark page as W
5. Do write
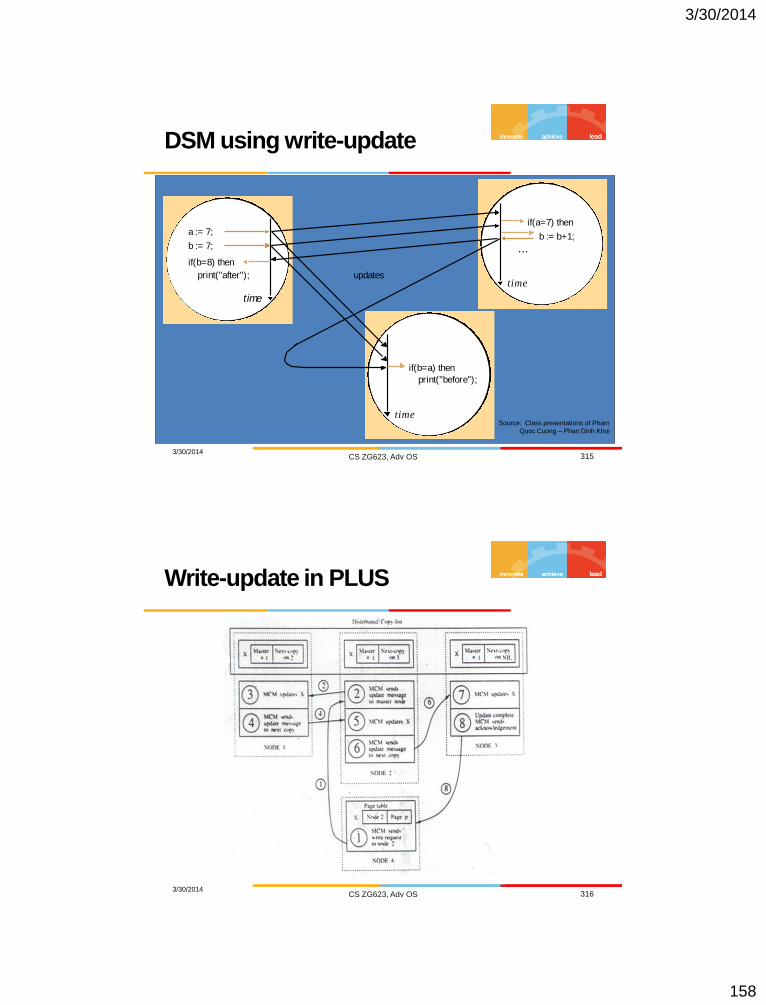
3/30/2014
158
DSM using write-update
3/30/2014 CS ZG623, Adv OS 315
time
time
a := 7;
b := 7;
if(b=8) then
print("after");
if(a=7) then
b := b+1;
...
if(b=a) then
print("before");
time
updates
Source: Class presentations of Pham
Quoc Cuong – Phan Dinh Khoi
Write-update in PLUS
3/30/2014 CS ZG623, Adv OS 316

3/30/2014
159
How does owner find copies to invalidate?
3/30/2014 CS ZG623, Adv OS 317
• Broadcast a message.
– Works only if broadcast messages are reliable and can never be lost.
• The owner (or page manager) for a page maintains a copyset list giving processors currently holding the page.
Network
3 4
2
4
2 3 4
1
3
4
1 2 3
5 2
4
2 3 4 1
Copyset Page num.
Replacement startegy
3/30/2014 CS ZG623, Adv OS 318
• Which block to replace ?
– Usage based Vs Non-Usage based
– (LRU) (FIFO)
• Some DSM systems use priority mechanism for replacement (IVy).
– Each memory block of a node is of
• Unused
• Nil -> invalidated
• Read-Only
• Read-Owned
• Writable -> has write access & obviously, it is the owner
– Replacement priority is as below
• Unused &Nil -> highest
• Read-Only
• Read-Owned & writable for which replicas exist elsewhere
• Read-Owned & writable for which there is no replica
• (LRU is used for replacement)

3/30/2014
160
Caching in DSMs
3/30/2014 CS ZG623, Adv OS 319
• For performance, DSM caches data locally
– More efficient access (locality)
– But, must keep caches consistent
– Caching of pages in case of page based DSM
• Issues
– Page size
– Consistency mechanism
Heterogeneous DSM
3/30/2014 CS ZG623, Adv OS 320
Data Conversion
• Different architectures may use different byte ordering and fl. pt. representations
• DSM can’t do this data conversion, without knowing the type of application level data contained in the block and the actual block layout
• Application programmers provide the appropriate routines
• Also DSM compiler can carry out conversion if DSM is organized into data objects.

3/30/2014
161
Thrashing in DSMs
3/30/2014 CS ZG623, Adv OS 321
• Thrashing occurs when network resources are
exhausted, and more time is spent invalidating
data and sending updates than is used doing
actual work
• Based on system specifics, one should choose
write-update or write-invalidate to avoid
thrashing
DSM Case Study

3/30/2014
162
IVy: Integrated shared virtual memory at Yale
• Apollo workstations connected in a token ring network
• DSM implemented as a region of processor’s VM.
• Page based DSM
– Granularity is 1 KB page.
• Address Space
– Private space (Local)
– Shared virtual address space (Global)
• Coherence protocol • Read-replication algorithm, multiple readers–
single writer semantics • A reader always sees the latest value written–
supports Strict consistency
Write Invalidate protocol in IVy
• A write fault to page P
– Who is the owner ?
– Owner sends the page with copy set to the requester
and does not keep it.
– Faulting (Requester) after getting the page, looks into
copy set and sends invalidation messages to all those
who are having the copy.
• A read fault to a page P
– Finds owner of p and makes a request.
– Owner sends ‘p’ & adds the requester to the copy set.
– Marks the page as read only.

3/30/2014
163
Continued…
• There are three different protocols which implement
write – invalidate
• differ only in, how the owner of the page is located.
1. Request
2. Reply
Page
Manager
P
3. Request
4. Reply
Page
Manager
Owner
1. Request
3. Reply
2. Request forwarded
Owner P
Fixed distributed manager
– Central manager’s work is distributed to every
processor in the system.
– Every processor keeps track of (maintains) owners of
a predetermined set of pages.
– A faulty processor uses H(p), a hash function to find
out the controller/ manager of the page.
– Remaining same as previous.
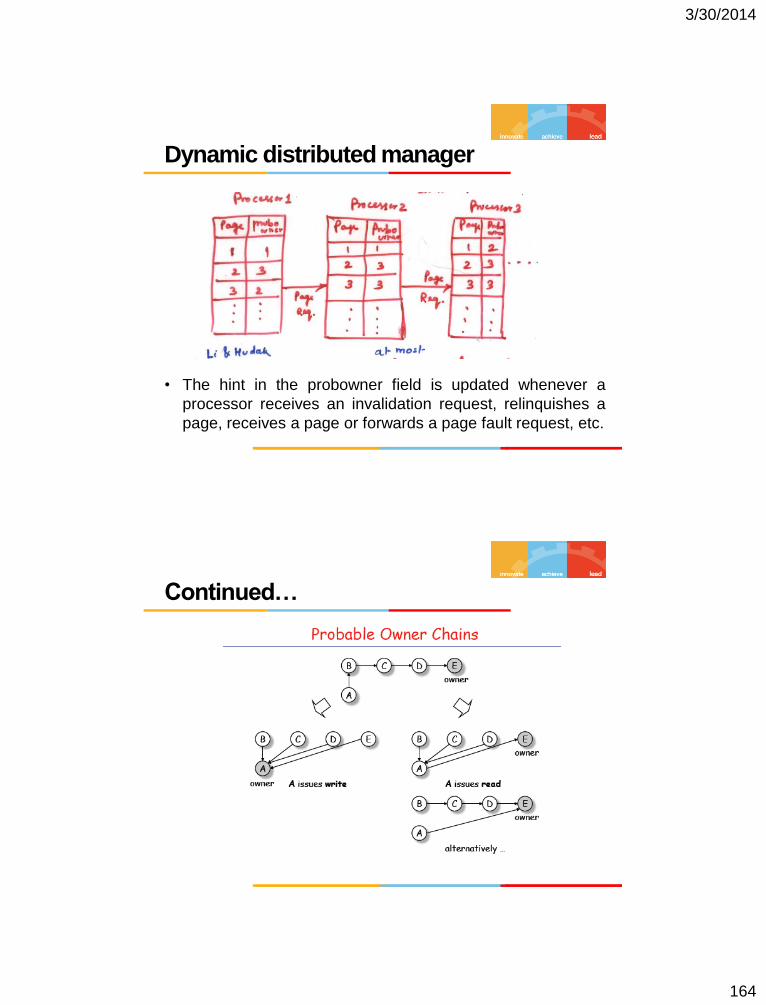
3/30/2014
164
Dynamic distributed manager
• The hint in the probowner field is updated whenever a
processor receives an invalidation request, relinquishes a
page, receives a page or forwards a page fault request, etc.
Continued…

3/30/2014
165
Double fault
• All 3 schemes -> double fault (read and written
successively )
• (has read only, needs read-write)
• Kessler & Livny -> sequence no associated with a
page
Process synchronization
• Coherence guarantees consistency amongst pages,
whereas eventcounts serialize the concurrent
accesses to a page.
• Init(ec), Read(ec), Await(ec, value), Advance(ec)

3/30/2014
166
Recovery in Distributed Systems
What is Recovery?
• Failure causes inconsistencies in the state of the distributed system.
• Recovery: bringing back the failed node to its normal operational state along with other nodes in the system.

3/30/2014
167
Failure types
• Process failure: (computation results in incorrect outcome)
• Deadlocks, protection violation, erroneous user input, etc.
• System failure:
• Full/partial amnesia.
• Pause failure
• Halting failure.
• Secondary storage failure
• Communication failure
Forward and Backward recovery
Forward Recovery:
• Difficult to do forward assessment.
Backward Recovery:
– When forward assessment not possible. Restore
processes to previous error-free state.
• Expensive to rollback states.
• Does not eliminate same fault occurring again.
• Unrecoverable actions: Cash dispensed at ATMs.

3/30/2014
168
Approaches to backward error recovery
• Operation based approach (logs or audit trails are
written)
– Stable storage and Secondary storage
– Updating in-place
– Write-ahead log
• Sate based approach (checkpointing)
– Shadow pages
State based recovery
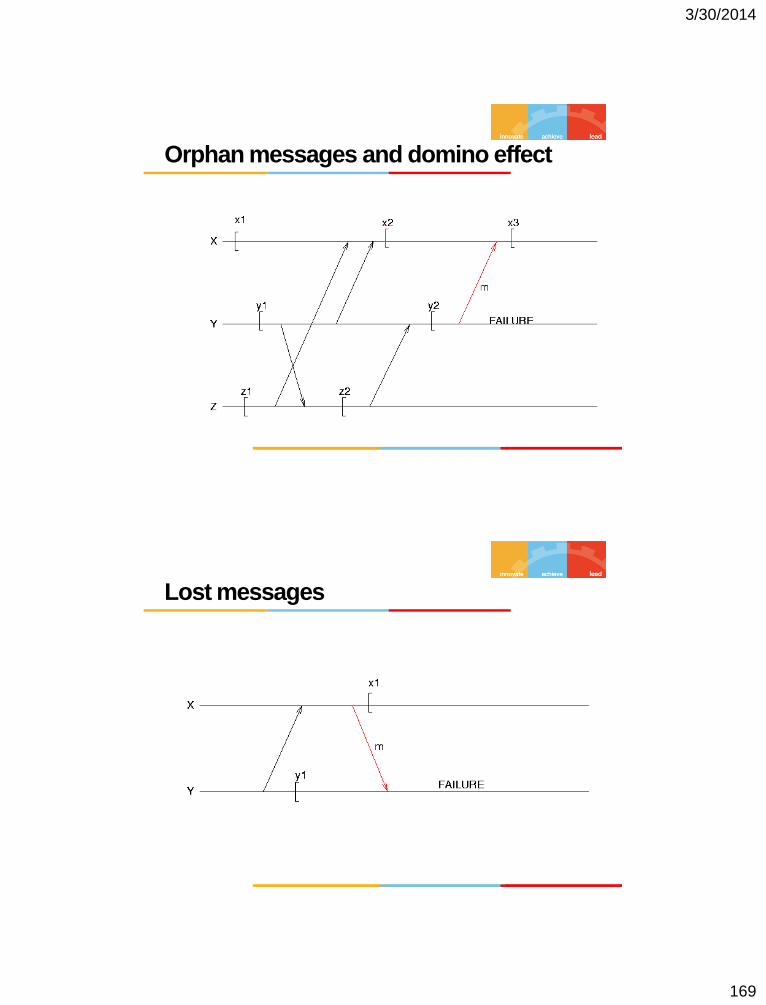
3/30/2014
169
Orphan messages and domino effect
Lost messages
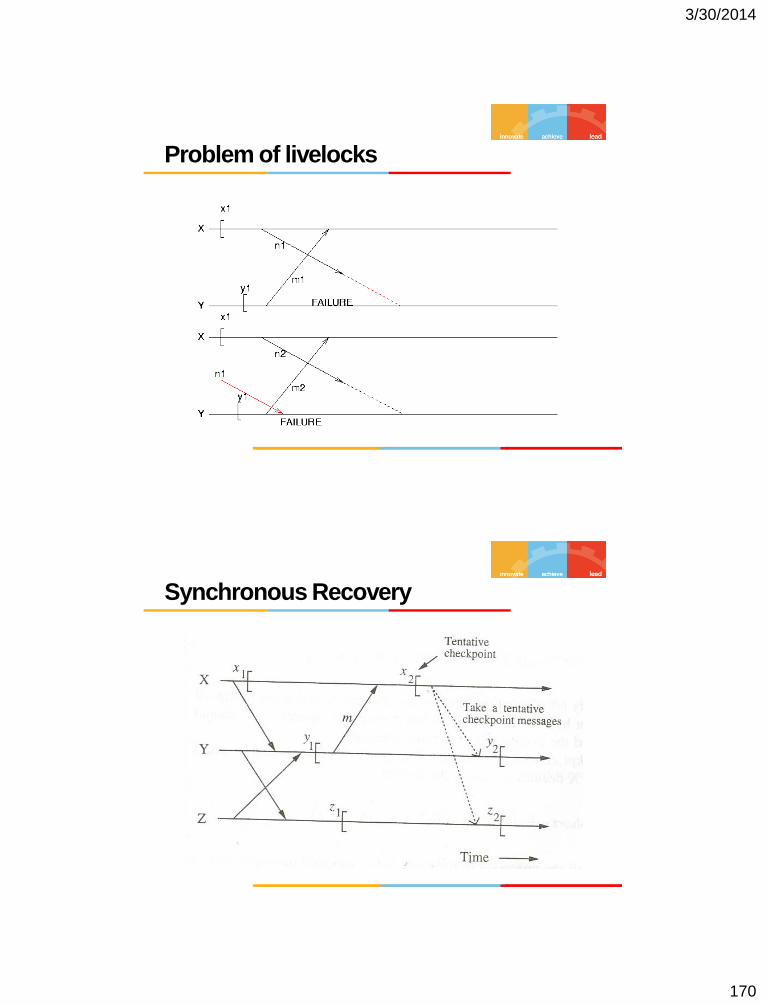
3/30/2014
170
Problem of livelocks
Synchronous Recovery

3/30/2014
171
Recap: Synchronous Recovery
Disadvantages of synchronous recovery
• Additional message exchanges for taking
checkpoints.
• Delays normal executions as messages cannot be
exchanged during checkpointing.
• Unnecessary overhead if no failures occur between
checkpoints.

3/30/2014
172
Asynchronous recovery
• Asynchronous approach: independent checkpoints at
each processor.
• Identify a consistent set of checkpoints if needed, for
rollbacks.
• e.g., {x3,y3,z2} not consistent; {x2,y2,z2}
consistent and is used for rollback
X
Y
Z
x1
y1
z1
x2 x3
y3
z2
y2
Asynchronous recovery example

3/30/2014
173
Security & Protection
• Misuses of important information and it’s
destruction should be prevented.
• Potential security violations (Anderson)
– Unauthorized information release
– Unauthorized information modification
– Unauthorized denial of service
Access Matrix Model (AMM)
3 Components
– Current objects (O)
– Current subjects (S)
• Subjects can be treated as objects & accessed like an objects by other objects
– Generic Rights (R)
R={R1, R2, ……..}
– Eg.
• O-> file
• S-> process
• R-> Read, Write, Own, delete, execute etc.
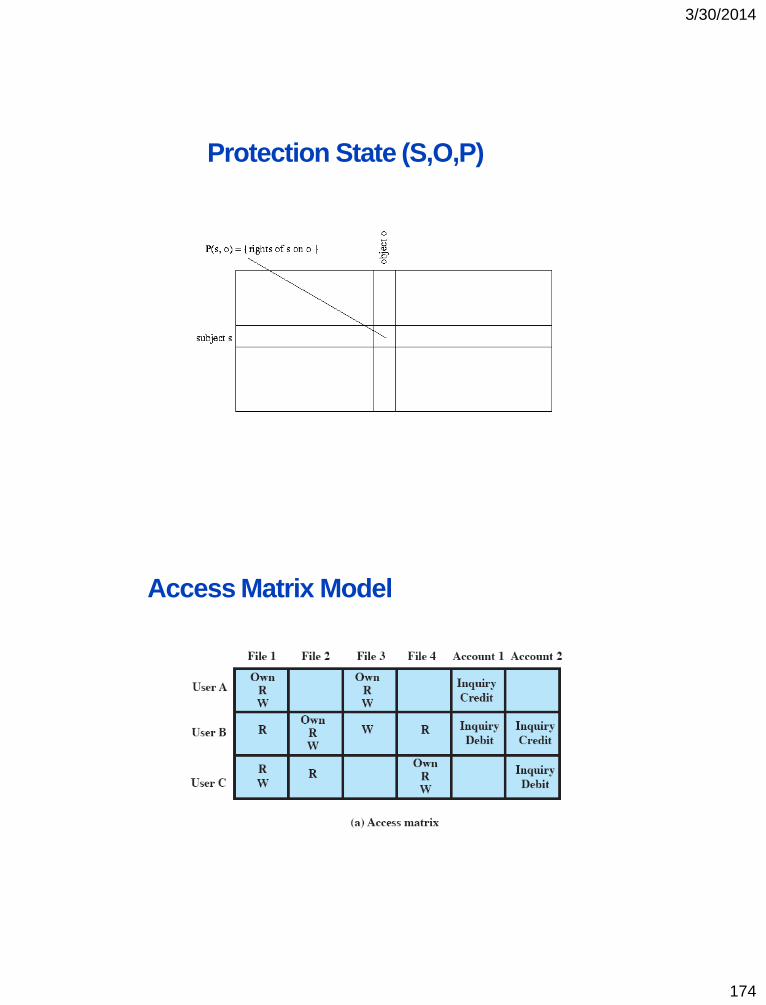
3/30/2014
174
Protection State (S,O,P)
Access Matrix Model

3/30/2014
175
Access Control Lists/Capability Lists
Capability Based AMM
• capability = tuple (o, P(s,o))
• each subject has a set of capabilities
• possession of capability confers access rights
• Capability Based Addressing:
A schematic view of a capability
Object
descriptor
Access rights
read, write, execute, etc.
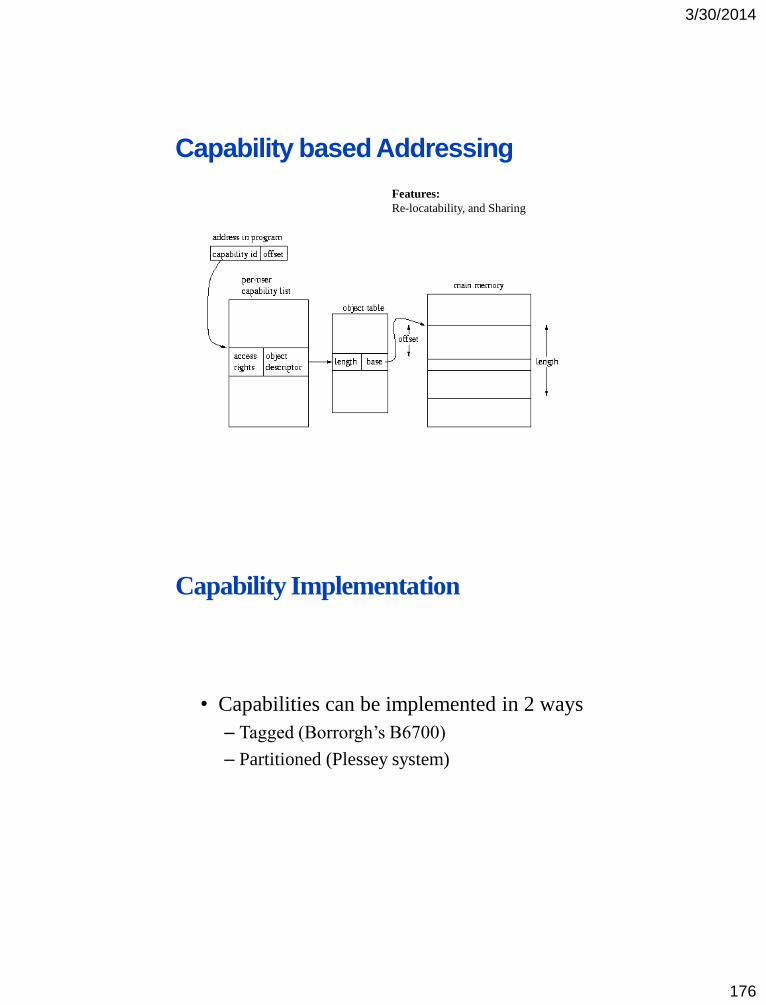
3/30/2014
176
Capability based Addressing
Features:
Re-locatability, and Sharing
Capability Implementation
• Capabilities can be implemented in 2 ways
– Tagged (Borrorgh’s B6700)
– Partitioned (Plessey system)

3/30/2014
177
Advantages of Capabilities
• Efficient: an access by a subject is implicitly
valid, if it has the capability => validity tested
easily.
• Simple: structure of a capability is same to that
of addressing mechanism.
• Flexible: A user can decide which objects/
addresses have a capability.
Disadvantages
• Control of propagation – Copy bit
– A depth counter
• Review – Determining all subjects who have access to an object (feasible in
partitioned application)
• Revocation of access rights – Delete the objects
• Garbage collection – A count of number of copies of each capability is maintained by either the
creator or the system

3/30/2014
178
Access Control List Method
Execution efficiency: Poor
Revocation and Review of access: Easy
Shadow pages
Storage
efficiency?
The Lock-Key Method
• each subject has capability list of tuples (o,k), where k is a key
• each object has ACL of tuples (k,A),where A is a set of access modes
• when s wants access a of object o – find a tuple (o,k) in s's capability list ( if not found,
access is declined )
– find a matching tuple (k,A) in o's ACL, such that a ∈ A.
• revocation is easy
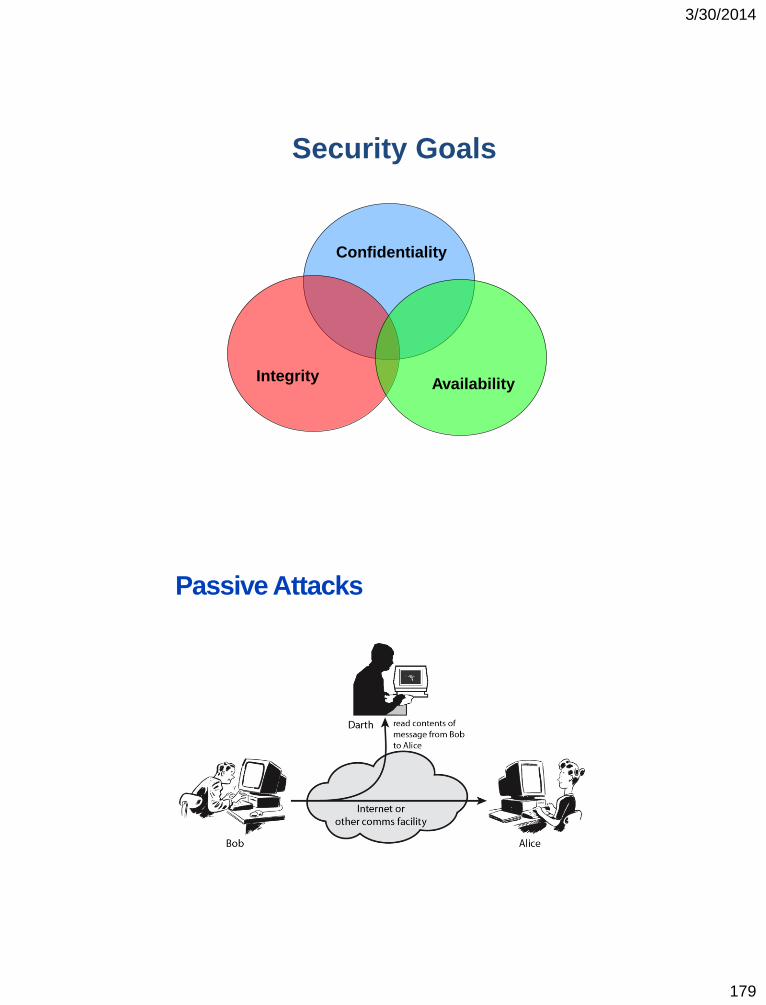
3/30/2014
179
Integrity
Confidentiality
Availability
Security Goals
Passive Attacks
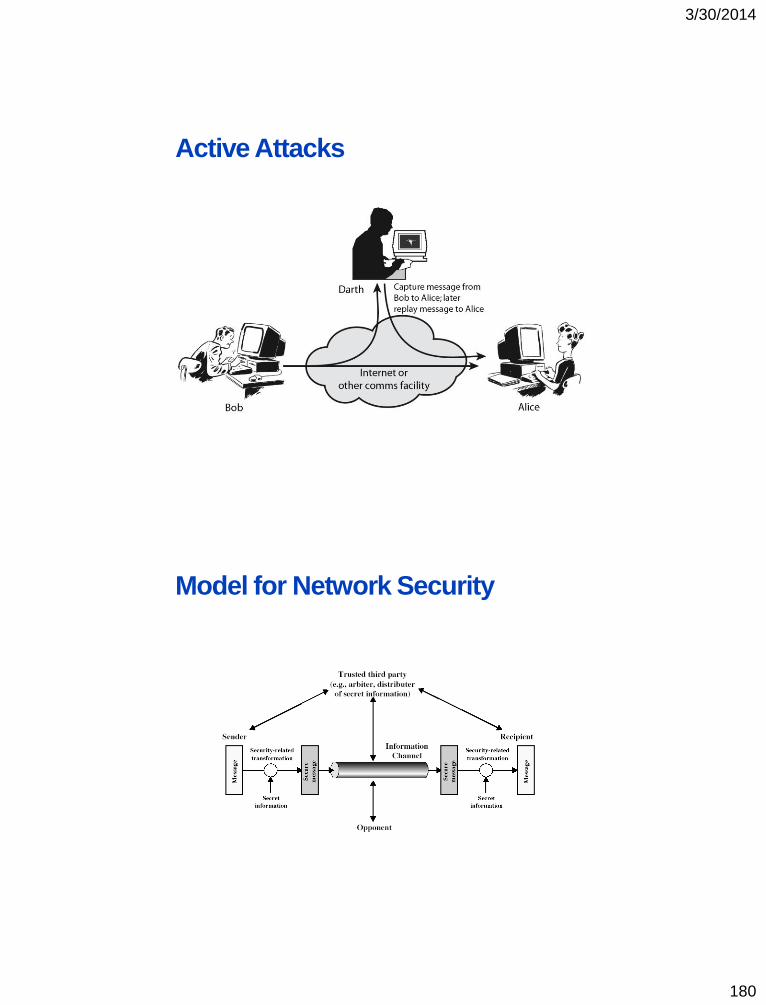
3/30/2014
180
Active Attacks
Model for Network Security
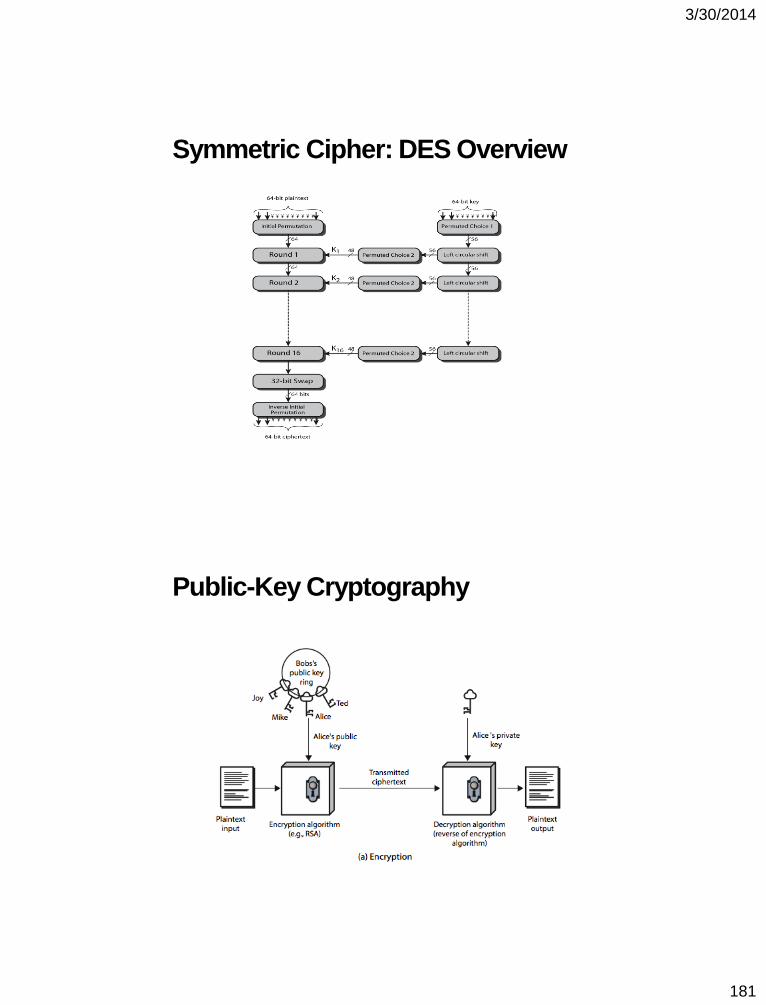
3/30/2014
181
Symmetric Cipher: DES Overview
Public-Key Cryptography
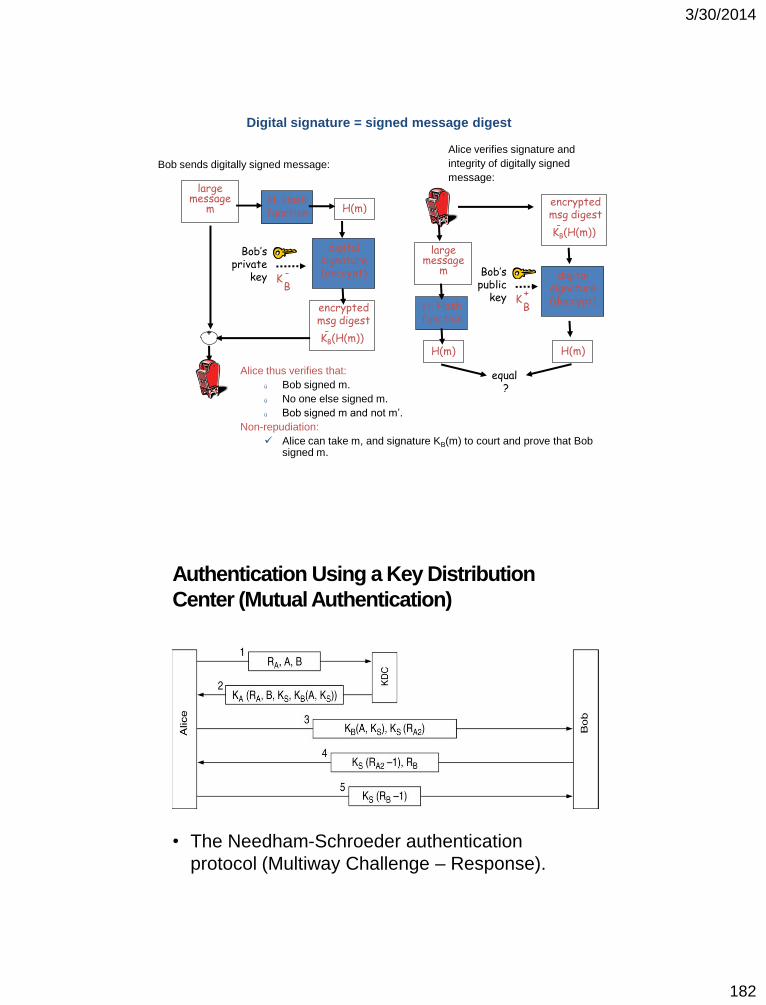
3/30/2014
182
large message
m H: Hash function H(m)
digital signature (encrypt)
Bob’s private
key K B -
+
Bob sends digitally signed message:
Alice verifies signature and
integrity of digitally signed
message:
KB(H(m)) -
encrypted msg digest
KB(H(m)) -
encrypted msg digest
large message
m
H: Hash function
H(m)
digital signature (decrypt)
H(m)
Bob’s public
key K B +
equal ?
Digital signature = signed message digest
Alice thus verifies that:
ü Bob signed m.
ü No one else signed m.
ü Bob signed m and not m’.
Non-repudiation:
Alice can take m, and signature KB(m) to court and prove that Bob signed m.
Authentication Using a Key Distribution
Center (Mutual Authentication)
• The Needham-Schroeder authentication
protocol (Multiway Challenge – Response).
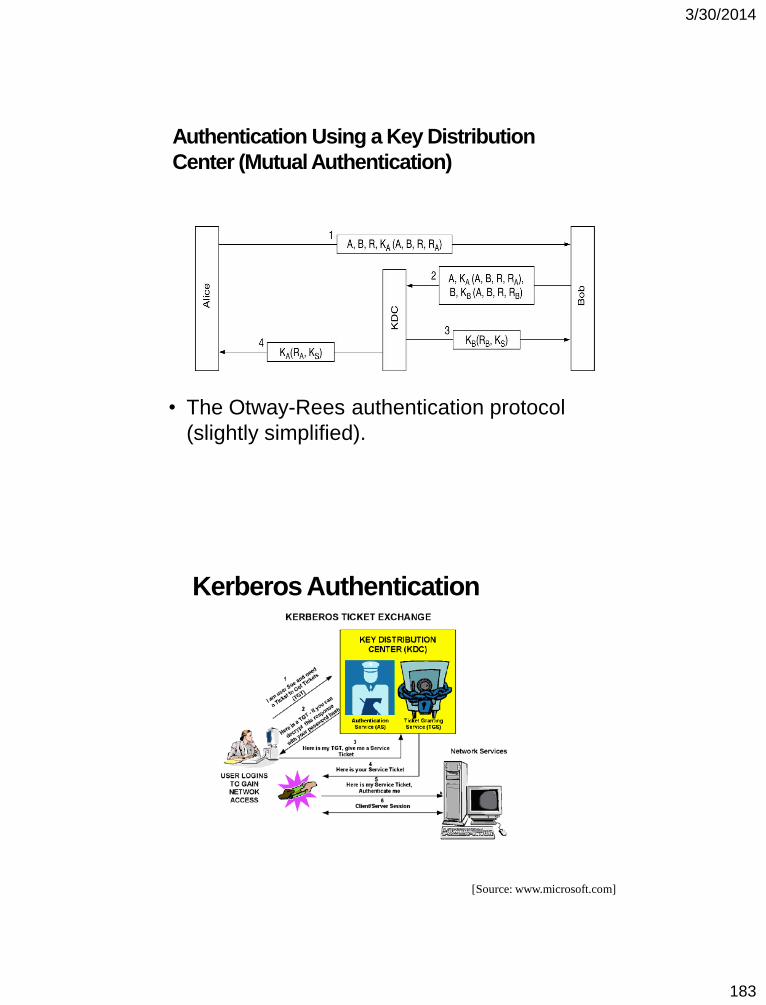
3/30/2014
183
Authentication Using a Key Distribution
Center (Mutual Authentication)
• The Otway-Rees authentication protocol
(slightly simplified).
Kerberos Authentication
[Source: www.microsoft.com]

3/30/2014
184
Public-Key Certificates
Fault Tolerance
Avoidance of disruptions due to failures and
to improve availability

3/30/2014
185
System reliability: Fault-Intolerance vs. Fault-Tolerance
• The fault intolerance (or fault-avoidance) approach
improves system reliability by removing the source of
failures (i.e., hardware and software faults) before normal
operation begins.
• The approach of fault-tolerance expect faults to be
present during system operation, but employs design
techniques which insure the continued correct execution
of the computing processes.
Approaches to fault-tolerance
Approaches:
(a) Mask failures:
– System continues to provide its specified function(s) in the presence of
failures
– Example: voting protocols
(b) Well defined failure behavior:
– System exhibits a well defined behavior in the presence of failures
– It may or may not perform its specified function(s), but facilitates actions
suitable for fault recovery
– Example: commit protocols
• A transaction made to a database is made visible only if successful and it
commits
Redundancy:
– Method for achieving fault tolerance (multiple copies of hardware,
processes, data, etc.)

3/30/2014
186
Issues
• Process Deaths: – All resources allocated to a process must be recovered when a
process dies
– Kernel and remaining processes can notify other cooperating processes
– Client-server systems: client /server process needs to be informed that the corresponding server/client process died
• Machine failure: – All processes running on that machine will die
– Client-server systems: difficult to distinguish between a process and machine failure
– Issue: detection by processes of other machines
• Network Failure: – Network may be partitioned into subnets
– Machines from different subnets cannot communicate
– Difficult for a process to distinguish between a machine and a communication link failure
Atomic actions
• System activity: sequence of primitive or atomic actions
• Atomic Action:
– Example: Two processes, P1 and P2, share a memory location ‘x’
and both modify ‘x’
Process P1 Process P2
… …
Lock(x); Lock(x);
x := x + z; x := x + y; Atomic action
Unlock(x); Unlock(x);
… …
successful exit

3/30/2014
187
Transaction Model
Transaction • A sequence of actions (typically read/write), each of which is executed at one or
more sites, the combined effect of which is guaranteed to be atomic.
Atomic Transactions • Atomicity: either all or none of the effects of the transaction are made permanent.
• Consistency: the effect of concurrent transactions is equivalent to some serial execution.
• Isolation: transactions cannot observe each other’s partial effects. • Durability: once accepted, the effects of a transaction are permanent (until changed
again, of course).
Environment
Each node is assumed to have:
• data stored in a partially/full replicated manner
• stable storage (information that survives failures) • logs (a record of the intended changes to the data: write ahead, UNDO/REDO)
• locks (to prevent access to data being used by a transaction in progress)
Committing
• Transaction: Sequence of actions treated as an atomic action to preserve consistency (e.g. access to a database)
• Commit a transaction: Unconditional guarantee that the transaction will complete successfully (even in the presence of failures)
• Abort a transaction: Unconditional guarantee to back out of a transaction, i.e., all the effects of the transaction have been removed (transaction was backed out)
– Events that may cause aborting a transaction: deadlocks, timeouts, protection violation
• Commit protocols:
– Enforce global atomicity involving several cooperating distributed processes
– Ensure that all the sites either commit or abort transaction unanimously, even in the presence of multiple and repetitive failures
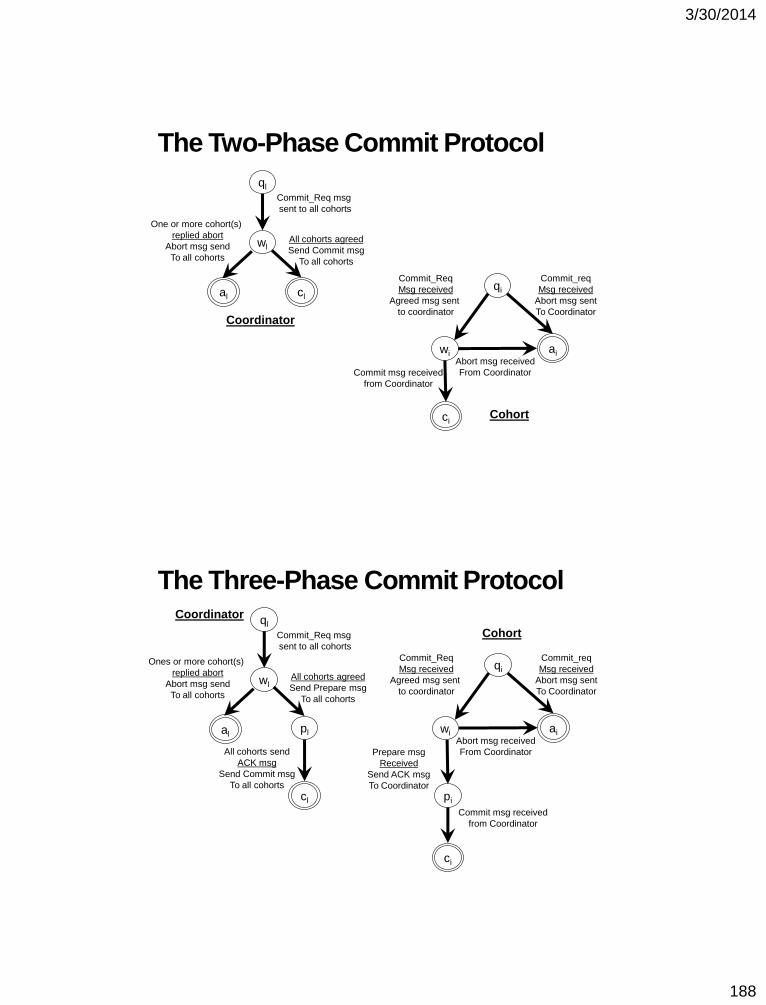
3/30/2014
188
The Two-Phase Commit Protocol
ql
wl
cl al
Commit_Req msg
sent to all cohorts
All cohorts agreed
Send Commit msg
To all cohorts
One or more cohort(s)
replied abort
Abort msg send
To all cohorts
wi
qi
ai
ci
Abort msg received
From Coordinator
Commit_req
Msg received
Abort msg sent
To Coordinator
Commit_Req
Msg received
Agreed msg sent
to coordinator
Commit msg received
from Coordinator
Coordinator
Cohort
The Three-Phase Commit Protocol
ql
wl
pl al
Commit_Req msg
sent to all cohorts
All cohorts agreed
Send Prepare msg
To all cohorts
Ones or more cohort(s)
replied abort
Abort msg send
To all cohorts
wi
qi
ai
pi
Abort msg received
From Coordinator
Commit_req
Msg received
Abort msg sent
To Coordinator
Commit_Req
Msg received
Agreed msg sent
to coordinator
Prepare msg
Received
Send ACK msg
To Coordinator
Coordinator
Cohort
cl
All cohorts send
ACK msg
Send Commit msg
To all cohorts
ci
Commit msg received
from Coordinator
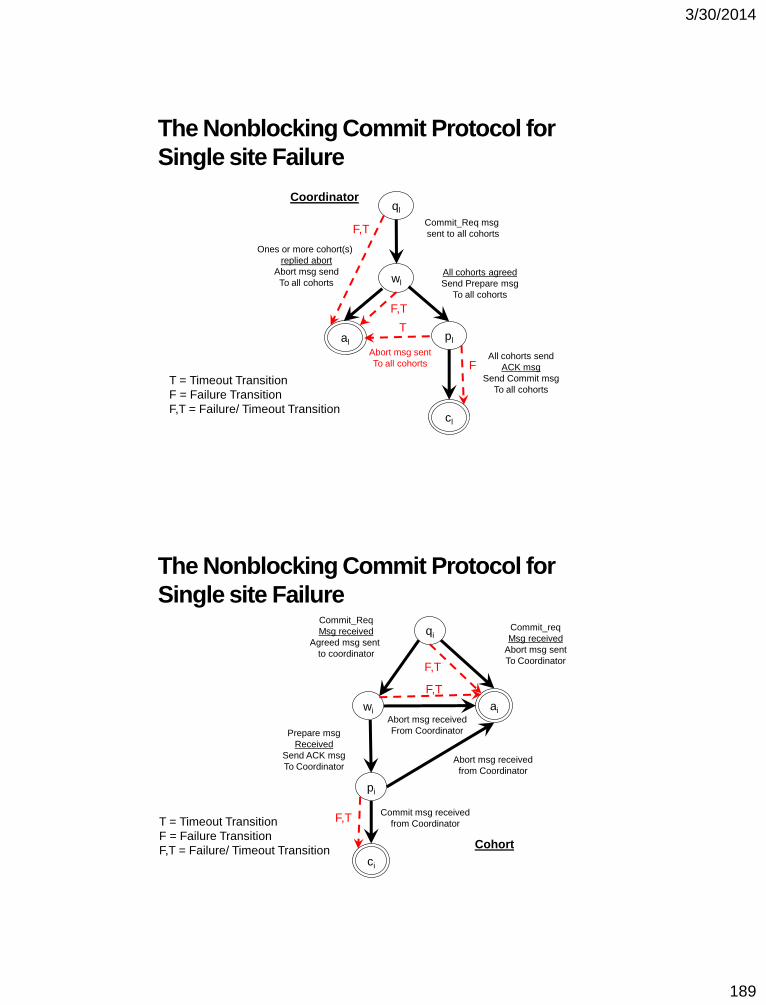
3/30/2014
189
The Nonblocking Commit Protocol for
Single site Failure
ql
wl
pl al
Commit_Req msg
sent to all cohorts
All cohorts agreed
Send Prepare msg
To all cohorts
Ones or more cohort(s)
replied abort
Abort msg send
To all cohorts
Coordinator
cl
All cohorts send
ACK msg
Send Commit msg
To all cohorts
T
F,T
F,T
Abort msg sent
To all cohorts F
T = Timeout Transition
F = Failure Transition
F,T = Failure/ Timeout Transition
The Nonblocking Commit Protocol for
Single site Failure
Cohort
wi
qi
ai
pi
Abort msg received
From Coordinator
Commit_req
Msg received
Abort msg sent
To Coordinator
Commit_Req
Msg received
Agreed msg sent
to coordinator
Prepare msg
Received
Send ACK msg
To Coordinator
ci
Commit msg received
from Coordinator T = Timeout Transition
F = Failure Transition
F,T = Failure/ Timeout Transition
Abort msg received
from Coordinator
F,T
F,T
F,T

3/30/2014
190
Voting protocols
• Principles: – Data replicated at several sites to increase reliability
– Each replica assigned a number of votes
– To access a replica, a process must collect a majority of votes
• Vote mechanism: (1) Static voting:
• Each replica has number of votes (in stable storage)
• A process can access a replica for a read or write operation if it can collect a certain number of votes (read or write quorum)
(2) Dynamic voting
• Number of votes or the set of sites that form a quorum change with the state of system (due to site and communication failures)
(2.1) Majority based approach:
– Set of sites that can form a majority to allow access to replicated data of changes with the changing state of the system
(2.2) Dynamic vote reassignment:
– Number of votes assigned to a site changes dynamically





























