Embed Size (px)
Citation preview

Nara Institute of Science and TechnologyAugmented Human Communication LaboratoryPRESTO, Japan Science and Technology Agency
Advanced Cutting Edge
Research Seminar
Dialogue System with Deep Neural
Networks
Assistant Professor
Koichiro Yoshino
2018/1/23 ©Koichiro Yoshino AHC-Lab. NAIST,
PRESTO JSTAdvanced Cutting Edge Research Seminar 1 1

• Understand typical tasks of spoken dialogue systems
– History of spoken dialogue systems
– Types and modules of spoken dialogue systems
– Typical research problems of spoken dialogue systems
– Recent trend of research of spoken dialogue systems
• Deep neural networks based approaches
• Understand the algorithm and implementation of dialogue
management tasks using reinforcement learning
– Task of dialogue management
– Q-learning based dialogue manager
– Q-network and deep Q-network for dialogue manager
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 2
Purpose of this lecture

1. Basis of spoken dialogue systems
– Type and modules of spoken dialogue systems
2. Deep learning for spoken dialogue systems
– Basis of deep learning (deep neural networks)
– Recent approaches of deep learning for spoken dialogue systems
3. Dialogue management using reinforcement learning
– Basis of reinforcement learning
– Statistical dialogue management using intention dependency graph
4. Dialogue management using deep reinforcement learning
– Implementation of deep Q-network in dialogue management
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 3
Course works

2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 4
Motivation is important
Why do you want to build a dialogue system?
1. Replace call center officers
Are you willing to talk with the agent
that does not communicate with you?

2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 5
Motivation is important
Why do you want to build a dialogue system?
2. Make a cool receptionist
Dialogue systems cannot read atmosphere.
Can you make it clear your demand anytime?

• Want to replace call center officers
• Make a coop receptionist
• It is impossible to replace every work that humans do completely
(there are many functions to be realized)
• It is possible to reduce the cost of human works
– The ways of working that humans do are not always optimal
• Washing machine does not realize the washing by mimicking
washing of humans
• Routine works can be replaced by machine learning, but sometimes
using dialogue interface is not the best way to realize your purpose
– Button, QR-code, touch-panel etc…
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 6
Motivation is important

• Scientific motivation: investigate the intelligence of humans
by mimicking the communication between humans
– What is intelligence?
– What is emotion?
– What is the relation between communication and intelligence
• Is your motivation Scientific or Engineering?
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 7
Other motivations

2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 8
Motivation is important
Why do you want to build a dialogue system?
Your motivation is clear
OK, let’s work on dialogue systems

• History and architecture of dialogue systems• Evolutions and selections of dialogue systems
• Basic architecture of spoken dialogue systems
2018/1/23 ©Koichiro Yoshino AHC-Lab. NAIST, PRESTO JST
Advanced Cutting Edge Research Seminar 1 9
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 10
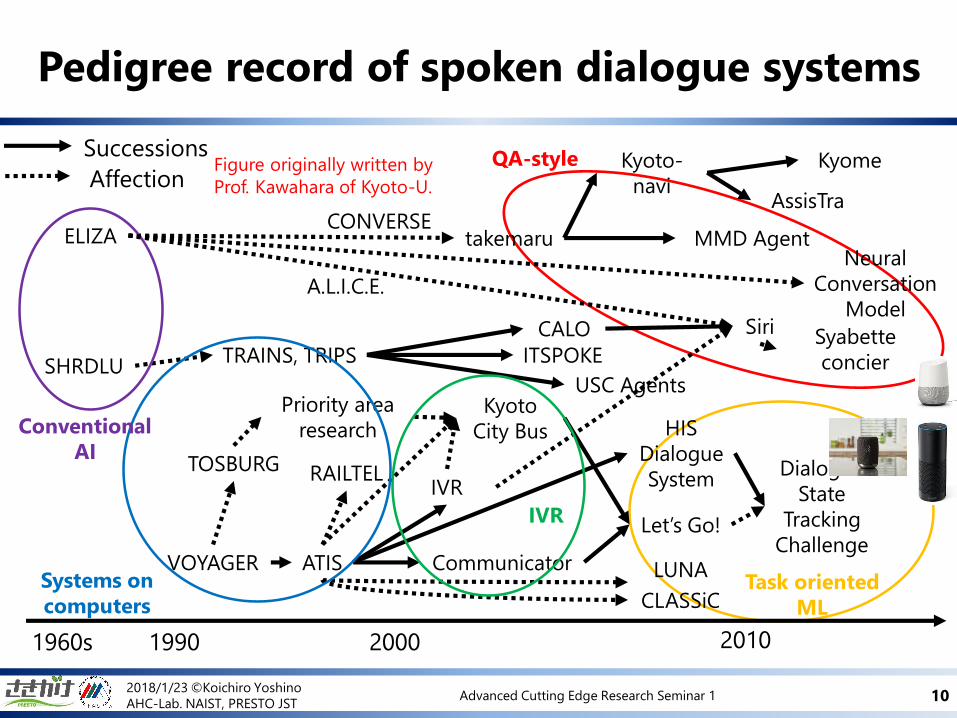
Pedigree record of spoken dialogue systems
1960s 1990 2000 2010
Successions
Affection
ELIZA
SHRDLU
VOYAGER
TOSBURG
ATIS
RAILTEL
Kyoto
City Bus
Communicator
IVR
Let’s Go!
LUNA
CLASSiC
Dialogue
State
Tracking
Challenge
Priority area
research HIS
Dialogue
System
TRAINS, TRIPS ITSPOKE
CALO
takemaru
USC Agents
Siri
MMD Agent
Syabette
concier
Kyoto-
naviAssisTra
Kyome
CONVERSE
A.L.I.C.E.
QA-style
Task oriented
ML
IVR
Systems on
computers
Conventional
AI
Figure originally written by
Prof. Kawahara of Kyoto-U.
Neural
Conversation
Model

• Basically belongs to QA-style conversation
– Try to train the matching between inputs and outputs
– It can be try from large-scale dataset
• However, there are other trends of dialogue systems
– Many dialogue researchers from old age work on this area
• What is the difference?
– Goal-oriented vs Non-goal-oriented
– One-turn conversation vs several-turns conversation
• AI systems requires both architecture
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 11
Recent trend of neural conversation

• ELIZA [Weizenbaum, 1966]
– Chatbot
– Respond with patterns
• Questions to users
• Parrot
– One-turn conversation
• SHRDLU [Winograd, 1968]
– Convert utterances to
logical expression
– Has knowledges about
the world
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 12
Conventional AI
ELIZA & SHRDLU
Young woman: Men are all alike.
Eliza: in what way?
Young woman: They’re always bugging us about
something specific or other.
Eliza: can you think of specific example?
Young woman: well, my boyfriend made me come
here.
Eliza: your boyfriend made you come here?
Young woman: He says I’m depressed much of the
time.
Eliza: I am sorry to hear you are depressed.
Person: Pick up a big red block.
Computer: OK.
Person: Grasp the pyramid.
Computer: I don’t understand
which pyramid you mean.
Person: Find a block which is taller
than the one you are holding and
put it into the box.
Computer: By “it”, I assume you
mean the block which is taller
than the one I am holding.
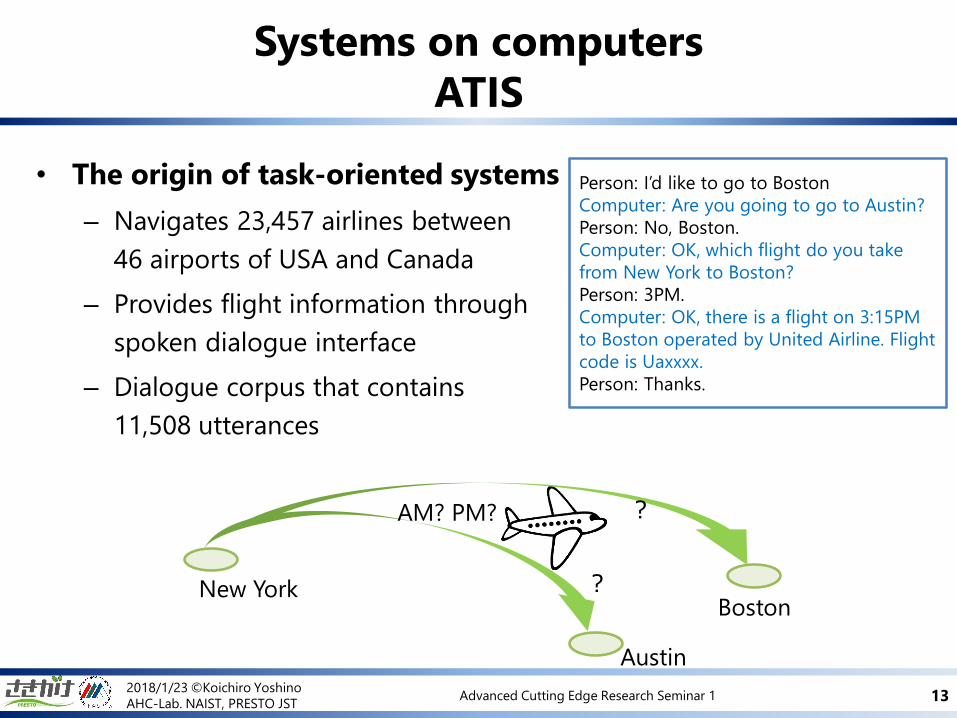
• The origin of task-oriented systems
– Navigates 23,457 airlines between
46 airports of USA and Canada
– Provides flight information through
spoken dialogue interface
– Dialogue corpus that contains
11,508 utterances
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 13
Systems on computers
ATIS
Person: I’d like to go to Boston
Computer: Are you going to go to Austin?
Person: No, Boston.
Computer: OK, which flight do you take
from New York to Boston?
Person: 3PM.
Computer: OK, there is a flight on 3:15PM
to Boston operated by United Airline. Flight
code is Uaxxxx.
Person: Thanks.
?
?
New YorkBoston
AM? PM?
Austin

• Operated as an official service of Kyoto City bus (2002-2003)
– Introduces the next bus if we call to the service number
(Automatic response)
• From stop, to stop, line number
– Inform the next bus arrival time
• management: generated VoiceXML
• vocab: bus-stops: 652, sights: 756
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 14
Interactive voice response (IVR)
Kyoto City bus navigation
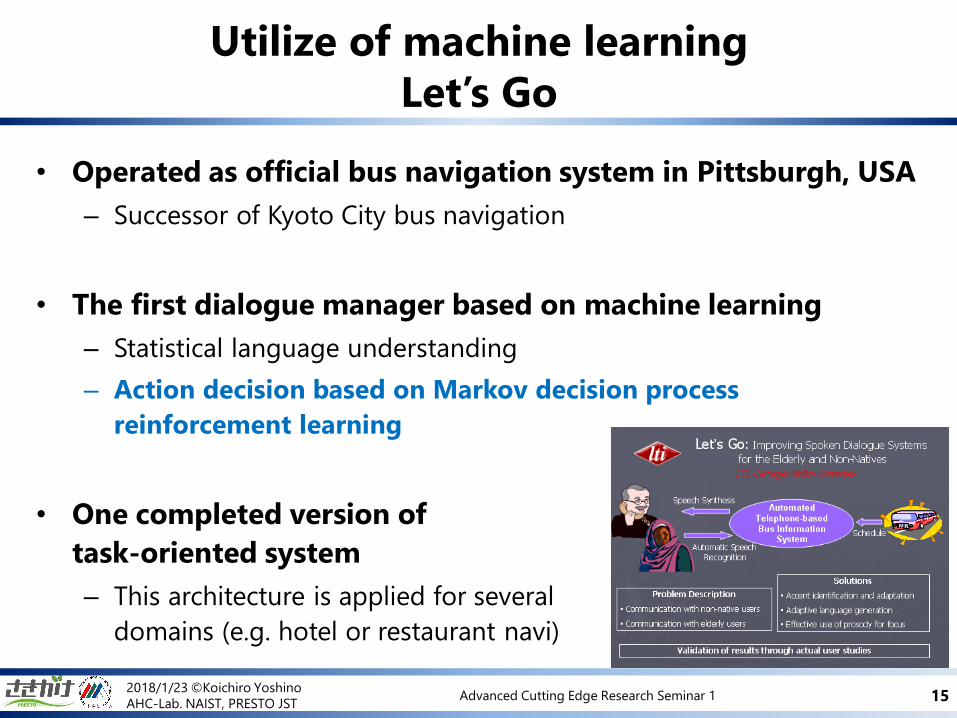
• Operated as official bus navigation system in Pittsburgh, USA
– Successor of Kyoto City bus navigation
• The first dialogue manager based on machine learning
– Statistical language understanding
– Action decision based on Markov decision process
reinforcement learning
• One completed version of
task-oriented system
– This architecture is applied for several
domains (e.g. hotel or restaurant navi)
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 15
Utilize of machine learning
Let’s Go

• Takemaru
– Dialogue system developed at
NAIST in 2002 (Shikano-lab)
– Weather forecast and navigation
of Ikoma-city
– Handcrafted patterns
• Siri
– Dialogue assistant of iPhone
from version 4S
– Application operation with speech
– Incorporating with Web search
– Handcrafted patterns
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 16
Question & answering style
Takemaru, Siri

• AssisTra
– Spoken dialogue system for sightseeing in Kyoto by NICT
– A pioneer of smartphone assistant
– Multilingual navigation with speech
• JA, EN, CH, KO
– Search of sightseeing places
– https://www.youtube.com/watch?v=kL6GuBa3VRY
• MMDAgent
– Spoken dialogue development framework
with Mikumiku-dance
– http://www.youtube.com/watch?v=hGiDMVakggE
• Smart speaker
– Google home, Amazon Echo, SONY LF-S50G
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 17
Question & answering style
AssisTra, MMDAgent, smart speaker

• Functions and types of dialogue systems
• Task-oriented, question & answering style
• Speech recognition, language understanding,
dialogue management, language generation,
speech synthesis
• end-to-end
2018/1/23 ©Koichiro Yoshino AHC-Lab. NAIST, PRESTO JST
Advanced Cutting Edge Research Seminar 1 18

• Task-oriented systems have dialogue states
– System tries to understand user intentions
by using dialogue states (frames)
– Dialogue states are designed for
the dialogue task of the system
– Dialogue systems have some actions for
the task (e.g. confirmation, navigation)
• Question & answering does not require dialogue states
– Trained from large-scale query-response dataset
– Don’t need to design the dialogue states
– It is hard to bridge the system and the system function
(phone call, play music)
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 19
Task-oriented and question & answering style
train_info{
$FROM=Ikoma
$TO_GO=NULL
$LINE=Chuo-line
}
Dialogue states
in train transit

• Goal
– Dialogue purpose of the dialogue participants (user and system)
• Bus navigation: next bus time to Ginkakuji-temple, …
• QA system: height of Mt.Fuji, entrance fee of Kinkakuji-temple, …
• Chatbot: chat itself
• Task
– Defined to reach the goal: way to reach the goal
• Task-flow, question patterns, etc.
• Required dialogue acts
• Knowledge base
– Knowledges to realize the task
• Names of bus stops etc.
• Similarities between arguments etc.
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 20
Important concepts
in spoken dialogue systems
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 21
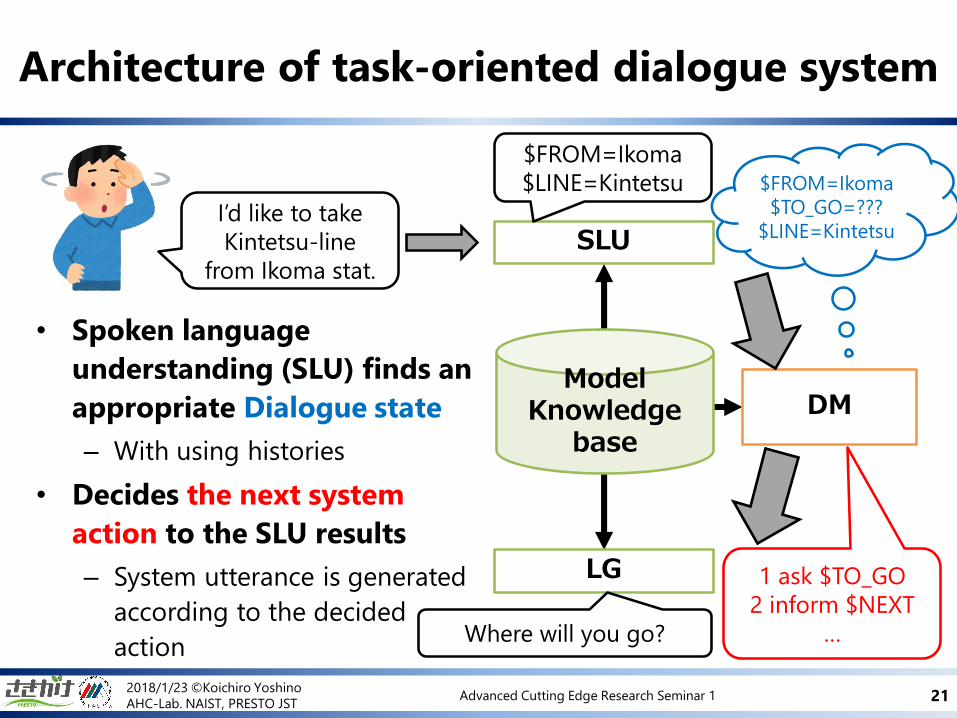
Architecture of task-oriented dialogue system
SLU
LG
ModelKnowledge
base
DM
$FROM=Ikoma
$LINE=Kintetsu
1 ask $TO_GO
2 inform $NEXT
…Where will you go?
$FROM=Ikoma
$TO_GO=???
$LINE=KintetsuI’d like to take
Kintetsu-line
from Ikoma stat.
• Spoken language
understanding (SLU) finds an
appropriate Dialogue state
– With using histories
• Decides the next system
action to the SLU results
– System utterance is generated
according to the decided
action
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 22
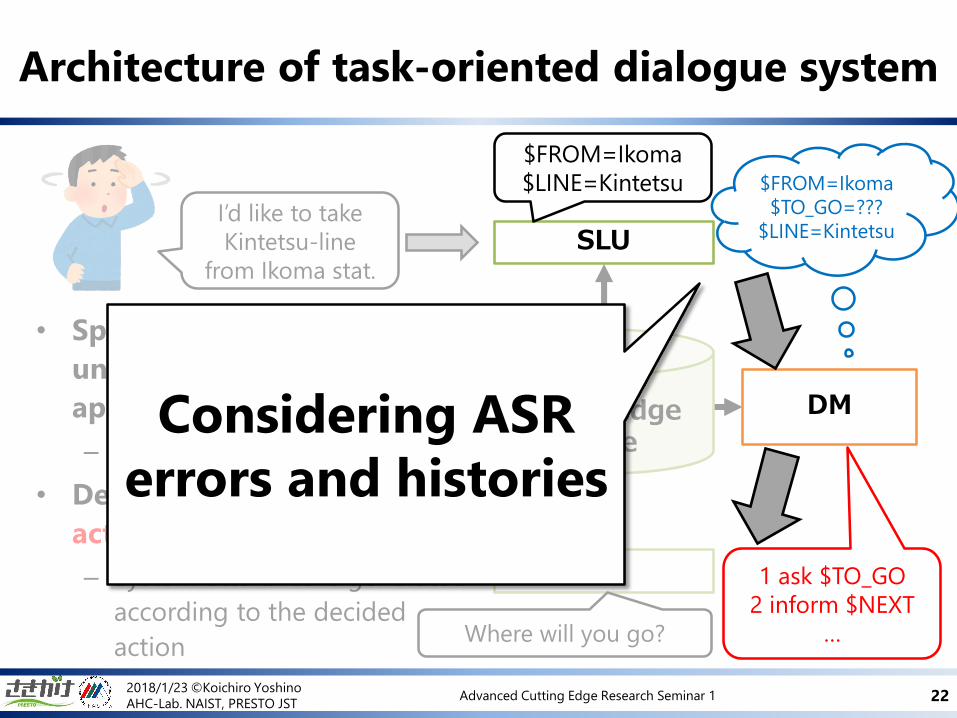
Architecture of task-oriented dialogue system
LG
ModelKnowledge
base
Where will you go?
I’d like to take
Kintetsu-line
from Ikoma stat.
• Spoken language
understanding (SLU) finds an
appropriate Dialogue state
– With using histories
• Decides the next system
action to the SLU results
– System utterance is generated
according to the decided
action
Considering ASR
errors and histories
DM
1 ask $TO_GO
2 inform $NEXT
…
SLU
$FROM=Ikoma
$LINE=Kintetsu $FROM=Ikoma
$TO_GO=???
$LINE=Kintetsu

2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 23
Automatic speech recognition
• Problem definition
𝐚𝐫𝐠𝐦𝐚𝐱𝑾𝑷(𝑾|𝑿)
𝑊 is word sequence and 𝑋 is speech
• In the discriminative modeling, we need to collect large-scale
dataset that contains pairs of a word sequence and a speech
• However, it is hard to collect data that covers every variables
– e.g. vocabulary, speaking style, individuality, sex, generation, etc…
• The problem is changed as generative model with Bayes theory
𝐚𝐫𝐠𝐦𝐚𝐱𝑾𝑷(𝑾|𝑿) = 𝐚𝐫𝐠𝐦𝐚𝐱
𝑾𝑷 𝑿 𝑾 𝑷(𝑾)
Acoustic
model
Language
model
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 24
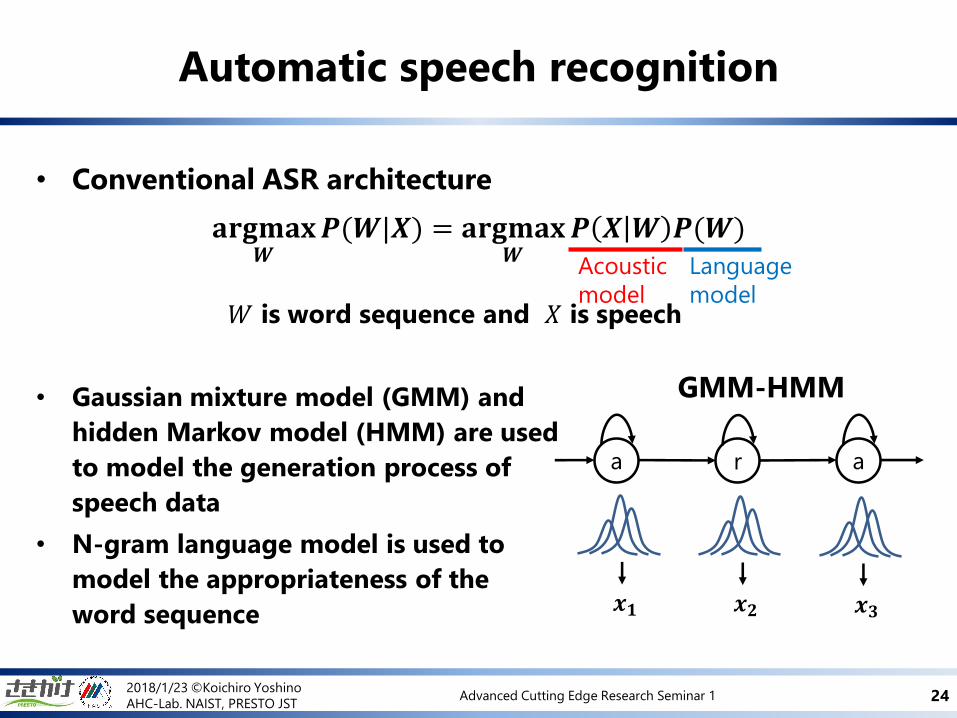
Automatic speech recognition
• Conventional ASR architecture
𝐚𝐫𝐠𝐦𝐚𝐱𝑾𝑷(𝑾|𝑿) = 𝐚𝐫𝐠𝐦𝐚𝐱
𝑾𝑷 𝑿 𝑾 𝑷(𝑾)
𝑊 is word sequence and 𝑋 is speech
• Gaussian mixture model (GMM) and
hidden Markov model (HMM) are used
to model the generation process of
speech data
• N-gram language model is used to
model the appropriateness of the
word sequence
GMM-HMM
a r a
𝒙𝟏 𝒙𝟐 𝒙𝟑
Acoustic
model
Language
model

• N-best hypotheses of speech recognition results
– with posterior probabilities, which is calculated from likelihoods of
acoustic model and language model
• ASR results often contain errors
– Insertion, deletion, replacement, …
• We have to consider the error in post processes (SLU, DM, …)
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 25
What is output of the ASR?
0.7 I want to take a flight to Austin
0.2 I want to take a flight to Boston
0.05 I want to take applied to Austin
…
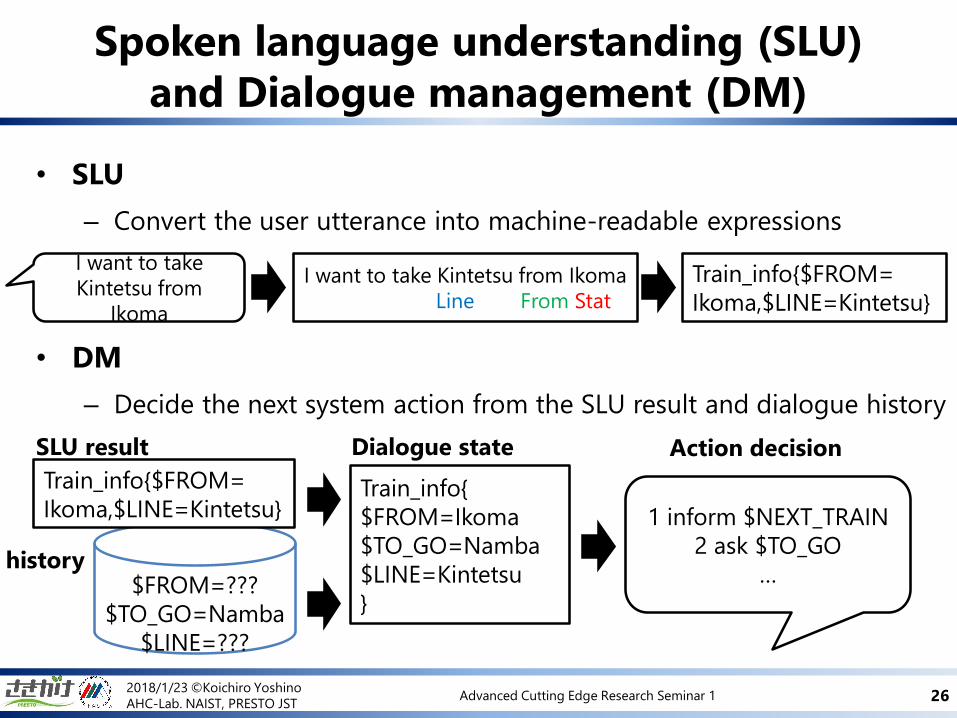
• SLU
– Convert the user utterance into machine-readable expressions
• DM
– Decide the next system action from the SLU result and dialogue history
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 26
Spoken language understanding (SLU)
and Dialogue management (DM)
I want to take
Kintetsu from
Ikoma
I want to take Kintetsu from Ikoma
Line From Stat
Train_info{$FROM=
Ikoma,$LINE=Kintetsu}
Train_info{
$FROM=Ikoma
$TO_GO=Namba
$LINE=Kintetsu
}
1 inform $NEXT_TRAIN
2 ask $TO_GO
…
SLU result Dialogue state
history
Action decision
$FROM=???
$TO_GO=Namba
$LINE=???
Train_info{$FROM=
Ikoma,$LINE=Kintetsu}
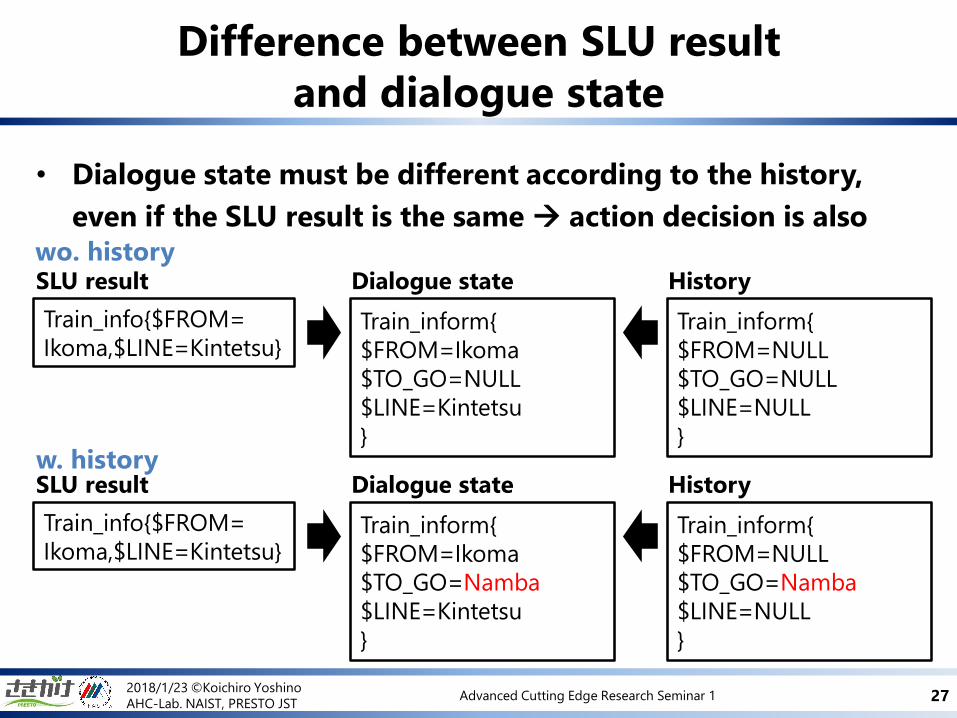
• Dialogue state must be different according to the history,
even if the SLU result is the same action decision is also
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 27
Difference between SLU result
and dialogue state
Train_inform{
$FROM=NULL
$TO_GO=NULL
$LINE=NULL
}
SLU result History
Train_inform{
$FROM=Ikoma
$TO_GO=NULL
$LINE=Kintetsu
}
Dialogue state
Train_inform{
$FROM=NULL
$TO_GO=Namba
$LINE=NULL
}
SLU result History
Train_inform{
$FROM=Ikoma
$TO_GO=Namba
$LINE=Kintetsu
}
Dialogue state
wo. history
w. history
Train_info{$FROM=
Ikoma,$LINE=Kintetsu}
Train_info{$FROM=
Ikoma,$LINE=Kintetsu}

• Dialogue states are defined by frames that have slot-values
– Frame is a domain
– States are represented by pairs of slot-value written in the frame
• System action = how the system behaves
– Actions are defined by basic behaviors (inform, confirm, etc.)
and add Slot-Value pairs if it is necessary for the action
(inform[$DEPT_TIME,$DESTINATION])
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 28
Design of dialogue state and actions
Train_inform{
$FROM=Ikoma
$TO_GO=NULL
$LINE=Kintetsu
}
Frame_name{
Slot1=Value1
Slot2=Value2
Slot3=Value3
}

• Task: Play music
1. Play music ($ALBUM=NULL, $ARTIST=NULL)
2. Play music ($ALBUM=NULL, $ARTIST=Beatles)
3. Play music ($ALBUM=yesterday, $ARTIST=NULL)
4. Play music ($ALBUM=yesterday, $ARTIST=Beatles)
5. Confirm
6. Request information ($ALBUM)
7. Request information ($ARTIST)
8. Request information ($ALBUM, $ARTIST)
• System actions are designed according to the API call of the
system (What the system can do)
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 29
Possible system actions

• As mentioned before, ASR results often contain errors
– SLU results are probably affected by the ASR error
– SLU module also causes error
• The system need to select “ask $TO_GO” or “confirmation”
action if the recognition result may contain critical errors
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 30
How do we decide the next action?
Train_info{
$FROM=Ikoma
$TO_GO=Bamba
$LINE=Kintetsu
}
1 inform $NEXT_TRAIN
2 ask $TO_GO
…
Dialogue state Action decision
I’d like to go to
Namba with
Kintetsu
?

• Problem definition: estimate the beset action given the
sequence of SLU results (ASR results)
• Variables
– 𝒔𝒕 ∈ 𝑰𝒔 SLU result of turn 𝒕
– 𝒂𝒕 ∈ 𝑲 system action of turn 𝒕
– 𝒐𝒕 ∈ 𝑰𝒔 observation (contains errors)
– 𝒃𝒔𝒕 = 𝑷(𝒔|𝒐𝟏:𝒕) Belief of state 𝒔 (statistical variable)
• How do we calculate 𝒃? belief update
• How do we find 𝒂? reinforcement learning
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 31
Problem definition of
dialogue state tracking and action selection

• Dialogue state tracking can be belief update 𝒃𝒔 = 𝑷(𝒔|𝒐𝟏:𝒕)
– Decide the current state candidates and their confidences given a
sequence of observation
– Belief update can be rewritten as:
𝒃𝒕+𝟏 = 𝑷 𝒔𝒕+𝟏 𝒐𝟏:𝒕+𝟏 =𝑷(𝒔𝒕+𝟏, 𝒐𝒕+𝟏|𝒐𝟏:𝒕)
𝑷(𝒐𝒕+𝟏|𝒐𝟏:𝒕)∝
𝒔
𝑷 𝒐𝒕+𝟏, 𝒔𝒕+𝟏 𝒔 𝑷 𝒔 𝒐𝟏:𝒕
∝
𝒔
𝑷 𝒐𝒕+𝟏, 𝒔𝒕+𝟏 𝒔 𝒃𝒕 = 𝑷 𝒐𝒕+𝟏 𝒔𝒕+𝟏, 𝒔𝒕
𝒔𝒊
𝑷 𝒔𝒋′ 𝒔𝒊 𝒃
𝒕
≈ 𝑷(𝒐𝒕+𝟏|𝒔𝒕+𝟏)
𝒔𝒊
𝑷 𝒔𝒋′ 𝒔𝒊 𝒃
𝒕
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 32
Belief update

2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 33
Dialogue state tracking with belief update
𝒔𝟏
Play_music{
$album=$ALBUM
$artist=NULL
$goal=3
}
Play_music{
$album=$ALBUM
$artist=NULL
$goal=3
}
Play_music{
$album=$ALBUM
$artist=NULL
$goal=3
}
Play_music{
$album=$ALBUM
$artist=NULL
$goal=3
}
𝒔𝟐𝒔𝟑𝒔𝟒 𝒃
𝑏1 = 0.70𝑏2 = 0.05𝑏3 = 0.03𝑏4 = 0.11…
• Dialogue state tracking is the task to estimate the dialogue
frame with actual Slot-Values with higher confidence (or 1-best)
– Given posterior probability of SLU: 𝑷(𝒐𝒊|𝒔𝒊)
– Each value of belief is a confidence score for the frame
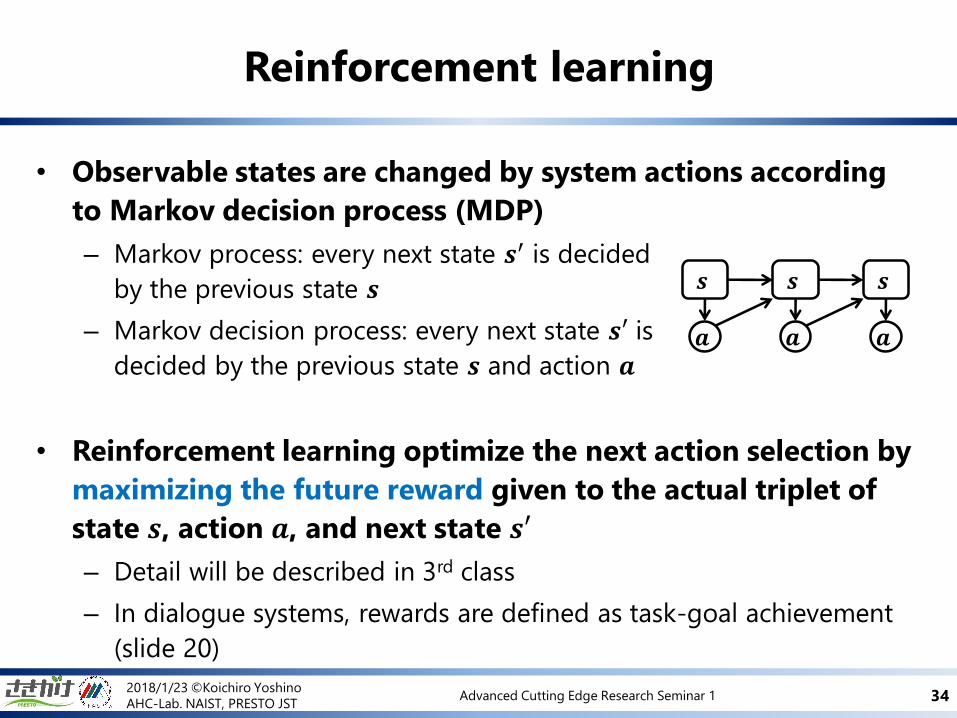
• Observable states are changed by system actions according
to Markov decision process (MDP)
– Markov process: every next state 𝒔′ is decided
by the previous state 𝒔
– Markov decision process: every next state 𝒔′ is
decided by the previous state 𝒔 and action 𝒂
• Reinforcement learning optimize the next action selection by
maximizing the future reward given to the actual triplet of
state 𝒔, action 𝒂, and next state 𝒔′
– Detail will be described in 3rd class
– In dialogue systems, rewards are defined as task-goal achievement
(slide 20)
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 34
Reinforcement learning
𝒔 𝒔 𝒔
𝒂 𝒂 𝒂

• 𝝅 𝒔, 𝒂 or 𝝅 𝒃, 𝒂 : policy function:
probability of selecting action 𝒂 given a state 𝒔
– We can use as 𝝅 𝒔 = 𝒂 if we decisively select an action
– Policy is a mapping between user state 𝒔 and system action 𝒂
• Handcrafted rules also represent the relation between 𝒔 and 𝒂
• When we optimize with reinforcement learning
– Maximizing the following reward:
• 𝑹 𝒔, 𝒂, 𝒔′ reward for the transition to 𝒔′ given 𝒔 and 𝒂
– 𝑹𝑬 𝒔, 𝒂 expected reward for 𝒔 and 𝒂
– 𝑹𝑬 𝒔 expected reward for 𝒔
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 35
System action decision

• Problem is finding optimal 𝝅 𝒔 = 𝒂
– Value function: 𝑽𝝅 𝒔 = 𝒌=𝟎∞ 𝜸𝒌𝑹𝑬(𝒔
𝒕+𝒌)
Select 𝝅∗ that gives maximum value function
• Value function is summation of expected future reward
– Action-Value function: Q-function
𝑸𝝅 𝒔, 𝒂 = 𝒌=𝟎∞ 𝜸𝒌𝑹𝑬(𝒔
𝒕+𝒌, 𝒂𝒕+𝒌)
is optimized by 𝝅∗∗. This policy is equal to 𝝅∗
• We can find the best pair of 𝒔 and 𝒂 by maximizing the Q-function
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 36
Value function

𝑽𝝅 𝒔 = 𝒌=𝟎
∞
𝜸𝒌𝑹𝑬(𝒔𝒕+𝒌)
= 𝑹𝑬(𝒔𝒕) + 𝜸
𝒌=𝟎
∞
𝜸𝒌𝑹𝑬(𝒔𝒕+𝒌+𝟏)
=
𝒂
𝝅 𝒂, 𝒔
𝒔𝒕+𝟏
𝑷 𝒔𝒕+𝟏|𝒔𝒕, 𝝅 𝒔𝒕 𝑹 𝒔𝒕, 𝝅 𝒔 , 𝒔𝒕+𝟏 + 𝜸 𝒌=𝟎
∞
𝜸𝒌𝑹𝑬(𝒔𝒕+𝒌+𝟏)
=
𝒂
𝝅 𝒂, 𝒔
𝒔𝒕+𝟏
𝑷 𝒔𝒕+𝟏|𝒔𝒕, 𝝅 𝒔𝒕 𝑹 𝒔𝒕, 𝝅 𝒔 , 𝒔𝒕+𝟏 + 𝜸𝑽𝝅 𝒔𝒕+𝟏
𝑸𝝅 𝒔, 𝒂 = 𝒌=𝟎
∞
𝜸𝒌𝑹𝑬(𝒔𝒕+𝒌, 𝒂𝒕+𝒌)
=
𝒔𝒕+𝟏
𝑷 𝒔𝒕+𝟏|𝒔𝒕, 𝒂𝒕 𝑹 𝒔𝒕, 𝒂𝒕, 𝒔𝒕+𝟏 + 𝜸 𝒌=𝟎
∞
𝜸𝒌𝑹𝑬(𝒔𝒕+𝒌+𝟏, 𝒂𝒕+𝒌+𝟏)
=
𝒔𝒕+𝟏
𝑷 𝒔𝒕+𝟏|𝒔𝒕, 𝒂𝒕 𝑹 𝒔𝒕, 𝒂𝒕, 𝒔𝒕+𝟏 + 𝜸𝑸𝝅 𝒔𝒕+𝟏, 𝒂𝒕+𝟏
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 37
Bellman equation

• Optimal value function
𝑽𝝅∗𝒔 = 𝐦𝐚𝐱
𝝅𝑽𝝅(𝒔)
𝑸𝝅∗𝒔, 𝒂 = 𝐦𝐚𝐱
𝝅𝑸𝝅(𝒔, 𝒂)
• Bellman optimal equation
𝑽𝝅∗𝒔𝒕 = 𝐦𝐚𝐱
𝒂𝑸𝝅∗(𝒔𝒕, 𝒂𝒕)
= 𝐦𝐚𝐱𝒂
𝒔𝒕+𝟏
𝑷 𝒔𝒕+𝟏|𝒔𝒕, 𝒂𝒕
𝒂
𝑹 𝒔𝒕, 𝝅 𝒔 , 𝒔𝒕+𝟏 + 𝜸𝑽𝝅∗𝒔𝒕+𝟏
𝑸𝝅∗𝒔, 𝒂 =
𝒔𝒕+𝟏
𝑷 𝒔𝒕+𝟏|𝒔𝒕, 𝒂𝒕 𝑹 𝒔𝒕, 𝒂𝒕, 𝒔𝒕+𝟏 + 𝜸𝐦𝐚𝐱𝒂𝑸𝝅∗(𝒔𝒕+𝟏, 𝒂𝒕+𝟏)
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 38
Optimal value function
We can get optimal policy with maximizing V or Q

• It is hard to calculate 𝑽𝝅 𝒔
– Combinations of future 𝒔 and 𝒂 are exponentially increase
– We cannot know 𝑷 𝒔′|𝒔, 𝒂
• Approaches
– Sampling: Q-learning 3rd class
– Function approximation: policy gradient 2nd class
– Hybrid: Q-Network 4th class
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 39
Problems of calculation

• ASR and SLU results often contains errors (repeated…)
– SLU results will be stochastic variable
– Belief 𝒃𝒔 is given (not 𝒔)
• Decision with partially observable Markov decision process
(POMDP)
• Try to train 𝝅∗ 𝒃 = 𝒂 in partially observable condition
– Famous problem in dialogue system area
– Number of dialogue data is limited
– State space defined by 𝒃 is extremely large
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 40
Processing of noisy ASR and SLU results
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 41
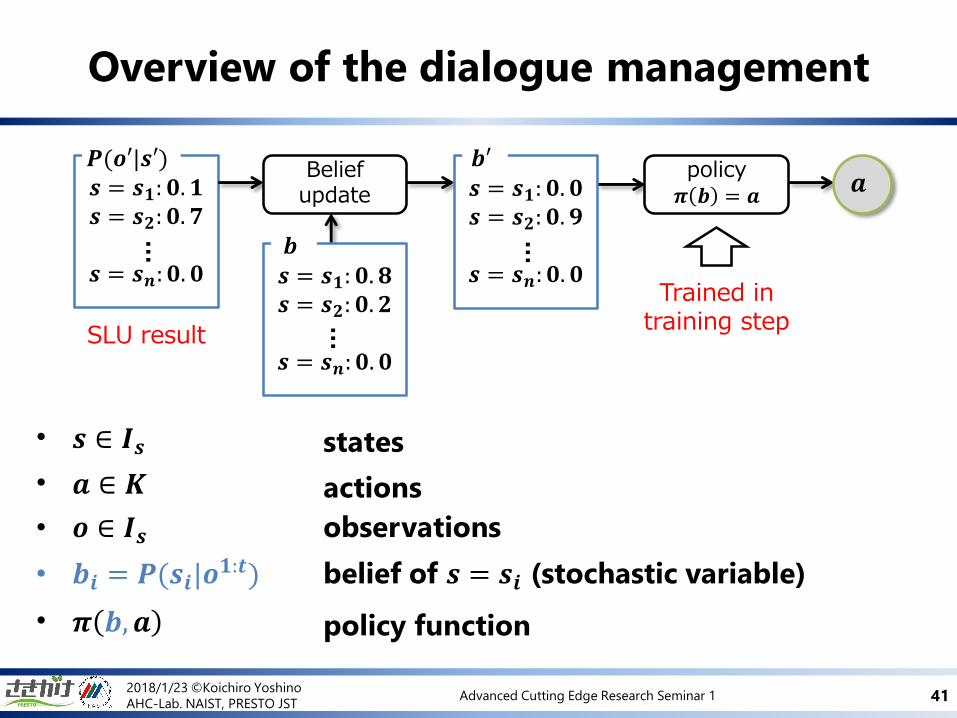
Overview of the dialogue management
• 𝒔 ∈ 𝑰𝒔 states
• 𝒂 ∈ 𝑲 actions
• 𝒐 ∈ 𝑰𝒔 observations
• 𝒃𝒊 = 𝑷(𝒔𝒊|𝒐𝟏:𝒕) belief of 𝒔 = 𝒔𝒊 (stochastic variable)
• 𝝅 𝒃,𝒂 policy function
𝒔 = 𝒔𝟏: 𝟎. 𝟏𝒔 = 𝒔𝟐: 𝟎. 𝟕
𝒔 = 𝒔𝒏: 𝟎. 𝟎
𝑷(𝒐′|𝒔′)
…
Belief update
…
𝒔 = 𝒔𝟏: 𝟎. 𝟖𝒔 = 𝒔𝟐: 𝟎. 𝟐
𝒔 = 𝒔𝒏: 𝟎. 𝟎
𝒃
policy𝝅 𝒃 = 𝒂
𝒂
Trained intraining step
SLU result
𝒔 = 𝒔𝟏: 𝟎. 𝟎𝒔 = 𝒔𝟐: 𝟎. 𝟗
𝒔 = 𝒔𝒏: 𝟎. 𝟎
𝒃′
…
…
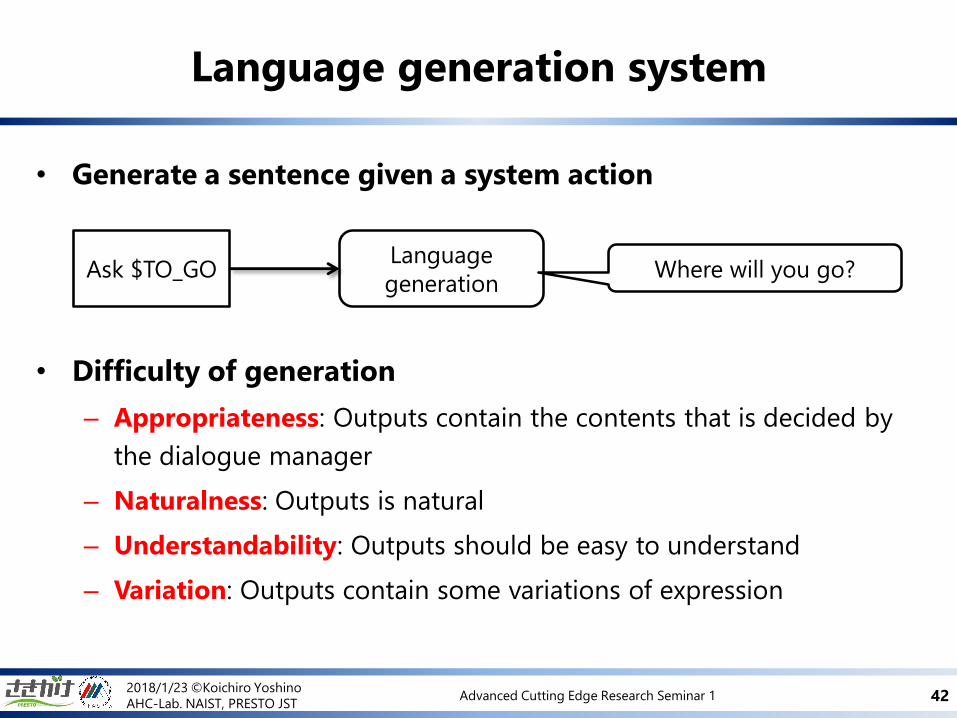
• Generate a sentence given a system action
• Difficulty of generation
– Appropriateness: Outputs contain the contents that is decided by
the dialogue manager
– Naturalness: Outputs is natural
– Understandability: Outputs should be easy to understand
– Variation: Outputs contain some variations of expression
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 42
Language generation system
Language
generationAsk $TO_GO Where will you go?

• Template
– Prepare templates with slots
• Next bus to <TO_STOP> will come on <TIME>.
– Advantage on most of problem except variation
– Hard to create a variation, handcrafting costs,
problem of conjugational words
• Statistical approach
– Language model: Find word sequence 𝑾 that has good 𝑷(𝑾)
– Advantage on variation
– Often generate ungrammatical sentences
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 43
Template vs statistical approach

• It works well if we can define actual system actions
(e.g. API calls)
– Detailed task definition is required
– It is easy to control the system behavior
• Each module is independent
• Open dataset for task oriented systems
– DSTC2 and 3: Dialogue State Tracking Task
http://camdial.org/~mh521/dstc/
– DSTC6: End-to-End Goal Oriented Dialogue Learning
http://workshop.colips.org/dstc6/call.html
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 44
Summary of task-oriented systems

• QA-style systems directly learn the mapping between a query
and a response
– Works well on open-domain systems
– Works well if we do not need history (one-to-one conversation)
• History is not necessary
– There are some recent works to consider the history
– Don’t manage the dialogue
• It is very hard to control what the system says
– There are many works in recent conferences (hot topic)
• Neural models makes it possible to learn the mapping
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 45
QA style dialogue systems
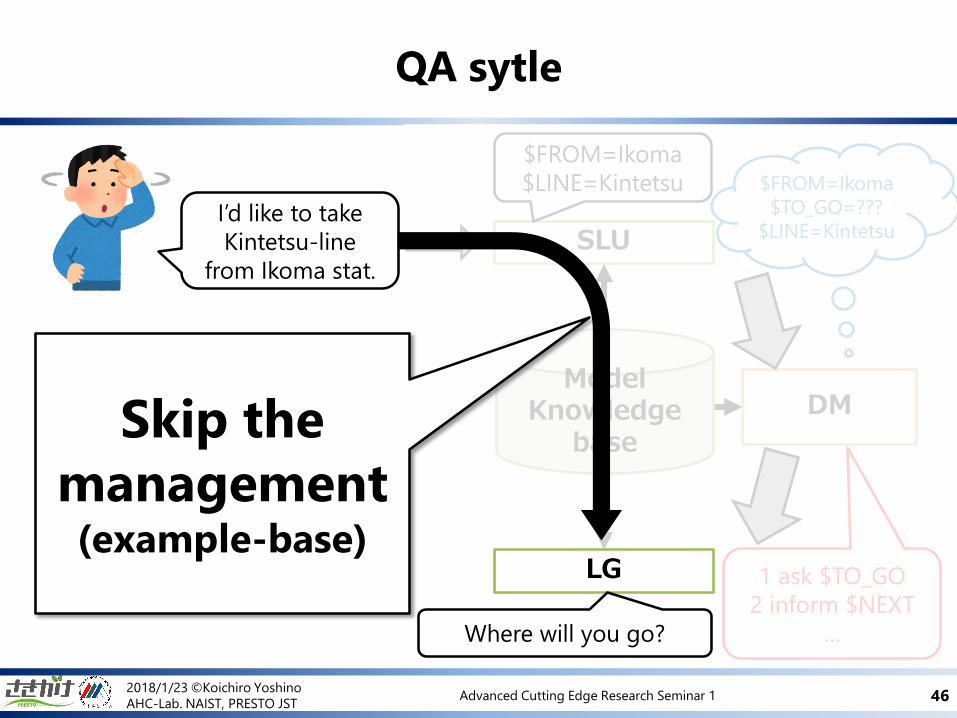
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 46
QA sytle
SLU
ModelKnowledge
base
DM
$FROM=Ikoma
$LINE=Kintetsu
1 ask $TO_GO
2 inform $NEXT
…
$FROM=Ikoma
$TO_GO=???
$LINE=KintetsuI’d like to take
Kintetsu-line
from Ikoma stat.
Skip the
management(example-base)
LG
Where will you go?

2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 47
Example-based dialogue
• Prepare query/response pairs
• Calculate similarities between the input and input candidates
• Response for the matched input
is used
Input query Output response
hello Hello
Where is the restroom? Next to the entrance
What time? Its <Hour><Minute>
hello
Where is the restroom?
What time?
0.2
0.5
0
Hello, could you tell me where is the
restroom?
Next to the entrance

• Learn the mapping functions between 𝒒𝒊 and 𝒓𝒊
– Train with some error function (e.g. 𝒓𝒊 − 𝒇 𝒒𝒊𝟐)
• Often generate a better response for unseen input query
than example base
• Hard to train in case of it is hard to define a mapping
– Data cleaning is important
– 「HiHi」「HiGood morning」
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 48
Generation based approach
Input query 𝒒𝒊 Output response 𝒓𝒊
hello Hello
Where is the restroom? Next to the entrance
What time? Its <Hour><Minute>

• < 𝒒𝒊, 𝒓𝒊 >: query and response pair in the database
• 𝒒𝒖: user query
• 𝒓𝒔: system response
• Example-based approach
– 𝒓𝒔 = 𝐚𝐫𝐠𝐦𝐚𝐱𝒊 𝑺𝒊𝒎 𝒒𝒊, 𝒒𝒖
– Find a similar query and use its response, robust, weak for OOE
• Generation-based approach
– Train 𝒓𝒊 = 𝒇(𝒒𝒊)
– Strong for OOE, but sometimes generate ungrammatical sentence
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 49
Problem definition of QA-style

• Train from large-scale query and response pairs in open-
domain
– Works if we have data
– Annotation and definition of dialogue states are not required
– We can create a good model if we can clean-up and control the
dataset for the training
• Open dataset for QA-style dialogue
– bAbI task: QA and chat dataset
– https://research.fb.com/downloads/babi/
– DSTC6: End-to-End Conversation Modeling
– http://workshop.colips.org/dstc6/call.html
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 50
Summary of QA-style

• Task-oriented
– Works well when we can define the system behavior (system action)
• e.g. If we have API calls set
– Don’t work for out domain
• Current systems incorporate with Web search
• QA-style
– We can develop a bot that reply something
– Extremely hard to control
• It is hard to link for pre-defined API call set
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 51
Task-oriented and QA-style

• Clarify your purpose to develop a dialogue system
– You have clear goal and task to achieve task oriented
– You don’t have a task and it will be open domain QA style
• Clarify the available data resource
– You can define dialogue states for your task task oriented
– You have (not small) dialogue dataset data-driven
– You can write everything with rule rule-base
• Clarify the effort that you can use
– Can you annotate dialogue states?
– Can you collect the dialogue data?
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 52
Before you plan to develop a dialogue system

• 1/25 9:20-
• Deep learning for spoken dialogue systems
– I’ll introduce some works that uses deep learning for some tasks of
dialogue systems that we learned today
2018/1/23 ©Koichiro Yoshino
AHC-Lab. NAIST, PRESTO JSTAdvanced Cutting Edge Research Seminar 1 53
Next contents