Embed Size (px)
DESCRIPTION
adbms
Citation preview

INTROUDUCTION
bullThe DBMS describes the data that it manages including tables and indexes This descriptive data or metadata stored in special tables called the system catalogs is used to find the best way to evaluate a query
bullSQL queries are translated into an extended form of relational algebra and query evaluation plans are represented as trees of relational operators along with labels that identify the algorithm to use at each code
bull Relational operators serve as building blocks for evaluating queries and the implementation of these operators is carefully optimized for good performance
bullQueries are composed of several operators and the algorithms for individual operators can be combined in many ways to evaluate a query The process of finding a good evaluation plan is called query optimization
Overview of Query Evaluation
The system catalog
bull We can store a table using one of several alternative file structures and we can create one or more indexes ndash each stored as a file ndash on every table
bull In a relational DBMS every file contains either the tuples in a table or the entries in an index
bull The collection of files corresponding to users tables and indexes represents the data in the database
bull A relational DBMS maintains information about every table and index that it contains
bull The descriptive information is itself stored in a collection of special tables called the catalog tables
bull The catalog tables are also called the data dictionary the system catalog or simply the catalog
Information in the catalog
At a minimum we have system-wide information about individual tables indexes and views
bull For each table - Its table name file name and the file structure of the file in which it is stored - The attribute name and type of each of its attributes - The index name of each index on the table - The integrity constraints on the tablebull For each index - The index name and the structure of the index - The search key attributesbull For each view - Its view name and definition
In addition statistics about tables and indexes are stored in the system catalogs and updated periodically
The following information is commonly stored
bullCardiality of tuples NTuples(R) for each table RbullSize of pages NPages(R) for each table RbullIndex Cardinality of distinct key values NKeys(I) for each index Ibull Index Size of pages INPages(I) for each index Ibull Index Height of nonleap levels IHeight(I) for each tree indiex IbullIndex Range The minimum present key value ILow(I) and maximum present key value IHigh(I) for each index I
The database contains the two tables areSailors (sid integer sname string rating integer age real)Reserves (sid integer bid integer day dates rname string)
ContdContd
bullSeveral alternative algorithms are available for implementing each relational operator and for most operators no algorithm is universally superior
bullSeveral factors influence which algorithm performs best including the sizes of the tables involved existing indexes and sort orders the size of the available buffer pool and the buffer replacement policy
Algorithms for evaluating relational operators use some simple ideas extensivelybull Indexing Can use WHERE conditions to retrieve small set of tuples (selections joins)bull Iteration Sometimes faster to scan all tuples even if there is an index (And sometimes we can scan the data entries in an index instead of the table itself) Partitioning By using sorting or hashing we can partition the input tuples and replace an expensive operation by similar operations on smaller inputs
Introduction to operator Introduction to operator evaluationevaluation
Access Paths
bullAn access path is a method of retrieving tuples from a table
bull File scan or index that matches a selection condition(in the query) -A tree index matches (a conjunction of) terms that involve only attributes in a prefix of the search key Eg Tree index on lta b cgt matches the selection a=5 AND b=3 and a=5 AND bgt6 but not b=3
-A hash index matches (a conjunction of) terms that has a term attribute = value for every attribute in the search key of the index Eg Hash index on lta b cgt matches a=5 AND b=3 AND c=5 but it does not match b=3 or a=5 AND b=3 or agt5 AND b=3 AND c=5
bullA Note on Complex Selections -(daylt8994 AND rname=lsquoPaulrsquo) OR bid=5 OR sid=3) -Selection conditions are first converted to conjunctive normal form (CNF) (daylt8994 OR bid=5 OR sid=3 ) AND (rname=lsquoPaulrsquo OR bid=5 OR sid=3)
bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

The system catalog
bull We can store a table using one of several alternative file structures and we can create one or more indexes ndash each stored as a file ndash on every table
bull In a relational DBMS every file contains either the tuples in a table or the entries in an index
bull The collection of files corresponding to users tables and indexes represents the data in the database
bull A relational DBMS maintains information about every table and index that it contains
bull The descriptive information is itself stored in a collection of special tables called the catalog tables
bull The catalog tables are also called the data dictionary the system catalog or simply the catalog
Information in the catalog
At a minimum we have system-wide information about individual tables indexes and views
bull For each table - Its table name file name and the file structure of the file in which it is stored - The attribute name and type of each of its attributes - The index name of each index on the table - The integrity constraints on the tablebull For each index - The index name and the structure of the index - The search key attributesbull For each view - Its view name and definition
In addition statistics about tables and indexes are stored in the system catalogs and updated periodically
The following information is commonly stored
bullCardiality of tuples NTuples(R) for each table RbullSize of pages NPages(R) for each table RbullIndex Cardinality of distinct key values NKeys(I) for each index Ibull Index Size of pages INPages(I) for each index Ibull Index Height of nonleap levels IHeight(I) for each tree indiex IbullIndex Range The minimum present key value ILow(I) and maximum present key value IHigh(I) for each index I
The database contains the two tables areSailors (sid integer sname string rating integer age real)Reserves (sid integer bid integer day dates rname string)
ContdContd
bullSeveral alternative algorithms are available for implementing each relational operator and for most operators no algorithm is universally superior
bullSeveral factors influence which algorithm performs best including the sizes of the tables involved existing indexes and sort orders the size of the available buffer pool and the buffer replacement policy
Algorithms for evaluating relational operators use some simple ideas extensivelybull Indexing Can use WHERE conditions to retrieve small set of tuples (selections joins)bull Iteration Sometimes faster to scan all tuples even if there is an index (And sometimes we can scan the data entries in an index instead of the table itself) Partitioning By using sorting or hashing we can partition the input tuples and replace an expensive operation by similar operations on smaller inputs
Introduction to operator Introduction to operator evaluationevaluation
Access Paths
bullAn access path is a method of retrieving tuples from a table
bull File scan or index that matches a selection condition(in the query) -A tree index matches (a conjunction of) terms that involve only attributes in a prefix of the search key Eg Tree index on lta b cgt matches the selection a=5 AND b=3 and a=5 AND bgt6 but not b=3
-A hash index matches (a conjunction of) terms that has a term attribute = value for every attribute in the search key of the index Eg Hash index on lta b cgt matches a=5 AND b=3 AND c=5 but it does not match b=3 or a=5 AND b=3 or agt5 AND b=3 AND c=5
bullA Note on Complex Selections -(daylt8994 AND rname=lsquoPaulrsquo) OR bid=5 OR sid=3) -Selection conditions are first converted to conjunctive normal form (CNF) (daylt8994 OR bid=5 OR sid=3 ) AND (rname=lsquoPaulrsquo OR bid=5 OR sid=3)
bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Information in the catalog
At a minimum we have system-wide information about individual tables indexes and views
bull For each table - Its table name file name and the file structure of the file in which it is stored - The attribute name and type of each of its attributes - The index name of each index on the table - The integrity constraints on the tablebull For each index - The index name and the structure of the index - The search key attributesbull For each view - Its view name and definition
In addition statistics about tables and indexes are stored in the system catalogs and updated periodically
The following information is commonly stored
bullCardiality of tuples NTuples(R) for each table RbullSize of pages NPages(R) for each table RbullIndex Cardinality of distinct key values NKeys(I) for each index Ibull Index Size of pages INPages(I) for each index Ibull Index Height of nonleap levels IHeight(I) for each tree indiex IbullIndex Range The minimum present key value ILow(I) and maximum present key value IHigh(I) for each index I
The database contains the two tables areSailors (sid integer sname string rating integer age real)Reserves (sid integer bid integer day dates rname string)
ContdContd
bullSeveral alternative algorithms are available for implementing each relational operator and for most operators no algorithm is universally superior
bullSeveral factors influence which algorithm performs best including the sizes of the tables involved existing indexes and sort orders the size of the available buffer pool and the buffer replacement policy
Algorithms for evaluating relational operators use some simple ideas extensivelybull Indexing Can use WHERE conditions to retrieve small set of tuples (selections joins)bull Iteration Sometimes faster to scan all tuples even if there is an index (And sometimes we can scan the data entries in an index instead of the table itself) Partitioning By using sorting or hashing we can partition the input tuples and replace an expensive operation by similar operations on smaller inputs
Introduction to operator Introduction to operator evaluationevaluation
Access Paths
bullAn access path is a method of retrieving tuples from a table
bull File scan or index that matches a selection condition(in the query) -A tree index matches (a conjunction of) terms that involve only attributes in a prefix of the search key Eg Tree index on lta b cgt matches the selection a=5 AND b=3 and a=5 AND bgt6 but not b=3
-A hash index matches (a conjunction of) terms that has a term attribute = value for every attribute in the search key of the index Eg Hash index on lta b cgt matches a=5 AND b=3 AND c=5 but it does not match b=3 or a=5 AND b=3 or agt5 AND b=3 AND c=5
bullA Note on Complex Selections -(daylt8994 AND rname=lsquoPaulrsquo) OR bid=5 OR sid=3) -Selection conditions are first converted to conjunctive normal form (CNF) (daylt8994 OR bid=5 OR sid=3 ) AND (rname=lsquoPaulrsquo OR bid=5 OR sid=3)
bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

The following information is commonly stored
bullCardiality of tuples NTuples(R) for each table RbullSize of pages NPages(R) for each table RbullIndex Cardinality of distinct key values NKeys(I) for each index Ibull Index Size of pages INPages(I) for each index Ibull Index Height of nonleap levels IHeight(I) for each tree indiex IbullIndex Range The minimum present key value ILow(I) and maximum present key value IHigh(I) for each index I
The database contains the two tables areSailors (sid integer sname string rating integer age real)Reserves (sid integer bid integer day dates rname string)
ContdContd
bullSeveral alternative algorithms are available for implementing each relational operator and for most operators no algorithm is universally superior
bullSeveral factors influence which algorithm performs best including the sizes of the tables involved existing indexes and sort orders the size of the available buffer pool and the buffer replacement policy
Algorithms for evaluating relational operators use some simple ideas extensivelybull Indexing Can use WHERE conditions to retrieve small set of tuples (selections joins)bull Iteration Sometimes faster to scan all tuples even if there is an index (And sometimes we can scan the data entries in an index instead of the table itself) Partitioning By using sorting or hashing we can partition the input tuples and replace an expensive operation by similar operations on smaller inputs
Introduction to operator Introduction to operator evaluationevaluation
Access Paths
bullAn access path is a method of retrieving tuples from a table
bull File scan or index that matches a selection condition(in the query) -A tree index matches (a conjunction of) terms that involve only attributes in a prefix of the search key Eg Tree index on lta b cgt matches the selection a=5 AND b=3 and a=5 AND bgt6 but not b=3
-A hash index matches (a conjunction of) terms that has a term attribute = value for every attribute in the search key of the index Eg Hash index on lta b cgt matches a=5 AND b=3 AND c=5 but it does not match b=3 or a=5 AND b=3 or agt5 AND b=3 AND c=5
bullA Note on Complex Selections -(daylt8994 AND rname=lsquoPaulrsquo) OR bid=5 OR sid=3) -Selection conditions are first converted to conjunctive normal form (CNF) (daylt8994 OR bid=5 OR sid=3 ) AND (rname=lsquoPaulrsquo OR bid=5 OR sid=3)
bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

bullSeveral alternative algorithms are available for implementing each relational operator and for most operators no algorithm is universally superior
bullSeveral factors influence which algorithm performs best including the sizes of the tables involved existing indexes and sort orders the size of the available buffer pool and the buffer replacement policy
Algorithms for evaluating relational operators use some simple ideas extensivelybull Indexing Can use WHERE conditions to retrieve small set of tuples (selections joins)bull Iteration Sometimes faster to scan all tuples even if there is an index (And sometimes we can scan the data entries in an index instead of the table itself) Partitioning By using sorting or hashing we can partition the input tuples and replace an expensive operation by similar operations on smaller inputs
Introduction to operator Introduction to operator evaluationevaluation
Access Paths
bullAn access path is a method of retrieving tuples from a table
bull File scan or index that matches a selection condition(in the query) -A tree index matches (a conjunction of) terms that involve only attributes in a prefix of the search key Eg Tree index on lta b cgt matches the selection a=5 AND b=3 and a=5 AND bgt6 but not b=3
-A hash index matches (a conjunction of) terms that has a term attribute = value for every attribute in the search key of the index Eg Hash index on lta b cgt matches a=5 AND b=3 AND c=5 but it does not match b=3 or a=5 AND b=3 or agt5 AND b=3 AND c=5
bullA Note on Complex Selections -(daylt8994 AND rname=lsquoPaulrsquo) OR bid=5 OR sid=3) -Selection conditions are first converted to conjunctive normal form (CNF) (daylt8994 OR bid=5 OR sid=3 ) AND (rname=lsquoPaulrsquo OR bid=5 OR sid=3)
bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Access Paths
bullAn access path is a method of retrieving tuples from a table
bull File scan or index that matches a selection condition(in the query) -A tree index matches (a conjunction of) terms that involve only attributes in a prefix of the search key Eg Tree index on lta b cgt matches the selection a=5 AND b=3 and a=5 AND bgt6 but not b=3
-A hash index matches (a conjunction of) terms that has a term attribute = value for every attribute in the search key of the index Eg Hash index on lta b cgt matches a=5 AND b=3 AND c=5 but it does not match b=3 or a=5 AND b=3 or agt5 AND b=3 AND c=5
bullA Note on Complex Selections -(daylt8994 AND rname=lsquoPaulrsquo) OR bid=5 OR sid=3) -Selection conditions are first converted to conjunctive normal form (CNF) (daylt8994 OR bid=5 OR sid=3 ) AND (rname=lsquoPaulrsquo OR bid=5 OR sid=3)
bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

bull Find the most selective access path retrieve tuples using it and apply any remaining terms that donrsquot match the index
bull Most selective access path An index or file scan that we estimate will require the fewest page IOs
bull Terms that match this index reduce the number of tuples retrieved other terms are used to discard some retrieved tuples but do not affect number of tuplespages fetched
Consider daylt8994 AND bid=5 AND sid=3 A B+ tree index on day can be used then bid=5 and sid=3 must be checked for each retrieved tuple Similarly a hash index on ltbid sidgt could be used daylt8994 must then be checked
ContdContd
Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Algorithms for relational operations
1 Selection The selection operation is a simple retrieval of tuples from a table and its implementation is essentially covered in our discussion of access paths
Given a selection of the form Rattr op value(R) Rattr op value(R) if there is no index if there is no index on R attr we have to scan Ron R attr we have to scan R
If one or more indexes on R match the selection we can If one or more indexes on R match the selection we can use index to retrieve matching tuples and apply any use index to retrieve matching tuples and apply any matching selection conditions to further restrict the matching selection conditions to further restrict the result setresult set
Using an Index for Selectionsbull Cost depends on qualifying tuples and clusteringbull Cost of finding qualifying data entries (typically
small)plus cost of retrieving records (could be large wo clustering)
In example assuming uniform distribution of namesabout 10 of tuples qualify (100 pages 10000 tuples) With a clustered index cost is little more than 100 IOs if unclustered upto 10000 IOs
SELECT FROM Reserves R WHERE Rrname lt lsquoCrsquo As a rule thumb it is probably cheaper to simply scan As a rule thumb it is probably cheaper to simply scan
the entire table(instead of using an unclustered index) if the entire table(instead of using an unclustered index) if over 5 of the tuples are to be retrievedover 5 of the tuples are to be retrieved
ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

ContdContd2 Projection The projection operation requires us to drop certain fields
of the input which is easy to do The expensive part is removing duplicates
SQL systems donrsquot remove duplicates unless the keyword DISTINCT
is specified in a query SELECT DISTINCT Rsid Rbid FROM Reserves R
bull Sorting Approach Sort on ltsid bidgt and remove duplicates (Can optimize this by dropping unwanted information while sorting)
bull Hashing Approach Hash on ltsid bidgt to create partitions Load partitions into memory one at a time build in-memory hash structure and eliminate duplicates
bull If there is an index with both Rsid and Rbid in the search key may be cheaper to sort data entries
ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

ContdContd3 Join Joins are expensive operations and very common This systems
typically support several algorithms to carry out joins
bull Consider the join of Reserves and Sailors with the join condition Reservessid=Sailorssid Suppose one of the tables say Sailors has an index on the sid column We can scan Reserves and for each tuple use the index to probe Sailors for matching tuples This approach is called index nested loops join
Ex The cost of scanning Reserves and using the index to retrieve the matching Sailors tuple for each Reserves tuple The cost of scanning Reserves is 1000 There are 1001000 =100000 tuples in Reserves For each of these tuples retrieving the index page containing the rid of the matching Sailors tuple costs 12 IOs(on avg) in addition we have to retrieve the Sailors page containing the qualifying tuple Therefore we have 100000(1+12) IOs to retrieve matching Sailors tuples The total cost is 221000 IOs
bull If we do not have an index that matches the join condition on either table we cannot use index nested loops In this case we can sort both tables on the join column and then scan them to find matches This is called sort-merge join
Ex We can sort Reserves and Sailors in two passes Read and Write Reserves in each pass the sorting cost is 221000=4000 IOs Similarly we can sort Sailors at a cost of 22500=2000 IOs In addition the second phase of the sort-merge join algorithm requires an additional scan of both tables Thus the total cost is 4000+2000+1000+500=7500 IOs
Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Introduction to query optimization
bullQuery optimization is one of the most important tasks of a relational DBMS A more detailed view of the query optimization and execution layer in the DBMS architecture is as shown in Fig(1)Queries are parsed and then presented to query optimizer which is responsible for identifying an efficient execution plan The optimizer generates alternative plan and chooses the plan with the least estimated cost
bullThe space of plans considered by a typical relational query optimizer can be carried out on the result of the - - -- algebra expression Optimizing such a relational algebra expression involves two basic steps
Query Parser
Query OptimizerPlan
Generator
Plan cost Estimator
Parsed query
Query
Evaluation Plan
Query Plan Evaluator
Catalog Manager
Fig(1) Query Parsing Optimization amp Execution
1 Enumerating alternative plans for evaluating the expression Typically an optimizer considers a subset of all possible plans because the number of possible plans is very large
2 Estimating the cost of each enumerated plan and choosing the plan with the lowest estimated cost
Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Query Evaluation Plans A query evaluation plan consists of an extended relational algebra tree with additional annotations at each node indicating the access methods to use for each table and the implementation method to use for each relational operator
Ex select ssname from Reserves r Sailors s where rsid=ssid and rbid=100 and sratinggt5
The above query can be expressed in relational algebra as follows
Sname( bid=100 ^ ratinggt5(Reserves sid=sid Sailors))
This expression is shown in the form of a tree in Fig(2)
Sname
bid=100 ^ ratinggt5
sid=sid
Reserves Sailors
Fig(2) Query Expressed as a Relational Algebra Tree
The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

The algebra expression partially specifies how to evaluate the query ndash we first compute the natural join of Reserves and Sailors then perform the selections and finally project the sname field
To obtain a fully specified evaluation plan we must decide on an implementation for each of the algebra operations involved For ex we can use a page-oriented simple nested loops join with Reserves as the outer table and apply selections and projections to each tuple in the result of the join as it is produced the result of the join before the selections and projections is never stored in its entirety This query evaluation plan is shown in Fig(3)
Sname (on-the-fly)
bid=100 ^ ratinggt5 (on-the-fly)
sid=sid (simple nested loops)
(File scan)Reserves Sailors(File scan)
Fig(3) Query Evaluation Plan for Sample Query
ContdContd
Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Alternative PlansMotivating Example SELECT Ssname FROM Reserves R Sailors S WHERE Rsid=Ssid AND
Rbid=100 AND Sratinggt5
bull Cost 500+5001000 IOsbull By no means the worst plan bull Misses several opportunities selections could have been `pushedrsquo
earlier no use is made of any available indexes etcbull Goal of optimization To find more efficient plans that compute the
same answerRA Tree is as shown in fig(2) and plan is as shown in fig(3)
Alternative Plans 1 (No Indexes) as shown in fig(4)bull Main difference push selects
1 With 5 buffers cost of plan2 Scan Reserves (1000) + write temp T1 (10 pages if we have 100
boats uniform distribution)3 Scan Sailors (500) + write temp T2 (250 pages if we have 10
ratings)4 Sort T1 (2210) sort T2 (23250) merge (10+250)5 Total 3560 page IOs
bull If we used BNL join join cost = 10+4250 total cost = 2770bull If we `pushrsquo projections T1 has only sid T2 only sid and sname
1 T1 fits in 3 pages cost of BNL drops to under 250 pages total lt 2000
Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Sname (on-the-fly)
sid=sid (Sort-merge join)
(scan write to temp T1)(scan write to temp T1) bid=100 ratinggt5 (scan write to (scan write to temp T1)temp T1)
(File scan)Reserves Sailors(File scan)
Fig(4) A second query evaluation planAlternative Plans 2 With Indexes as shown in fig(5)bull With clustered index on bid of Reserves we get 100000100 = 1000 tuples on 1000100 = 10 pagesbullINL with pipelining (outer is not materialized) - Projecting out unnecessary fields from outer doesnrsquot helpbullJoin column sid is a key for Sailors - At most one matching tuple unclustered index on sid OKbullDecision not to push ratinggt5 before the join is based on availability of sid index on Sailorsbull Cost Selection of Reserves tuples (10 IOs) for each must get matching Sailors tuple (100012) total 1210 IOs
ContdContd
Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Sname (on-the-fly)
ratinggt5 (on-the-fly)
sid=sid (Index nested loops with
pipelining)
(use hash index do not write result to temp)(use hash index do not write result to temp) bid=100 Sailors(Hash index on sid)
(Hash index on sid)Reserves
Fig(6) A query evaluation plan using Indexes
ContdContd
Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Highlights of System R OptimizerbullImpact -Most widely used currently works well for lt 10 joinsbullCost estimation Approximate art at best -Statistics maintained in system catalogs used to estimate cost of operations and result sizes -Considers combination of CPU and IO costsbullPlan Space Too large must be pruned -Only the space of left-deep plans is considered -gt Left-deep plans allow output of each operator to be pipelined into the next operator without storing it in a temporary relation -Cartesian products avoidedCost EstimationFor each plan considered must estimate cost Must estimate cost of each operation in plan treebull Depends on input cardinalitiesbull Wersquove already discussed how to estimate the cost of operations (sequential scan index scan joins etc)bull Must also estimate size of result for each operation in treebull Use information about the input relationsbull For selections and joins assume independence of predicates
ContdContd
Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Summary
bullThere are several alternative evaluation algorithms for each relational operator
bullA query is evaluated by converting it to a tree of operators and evaluating the operators in the tree
bullMust understand query optimization in order to fully understand the performance impact of a given database design (relations indexes) on a workload (set of queries)bullTwo parts to optimizing a query
Consider a set of alternative plans - Must prune search space typically left-deep plans onlyMust estimate cost of each plan that is considered - Must estimate size of result and cost for each plan node
- Key issues Statistics indexes operator implementations
ContdContd
EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

EXTERNAL SORTING
Why SortbullA classic problem in computer sciencebullData requested in sorted order - eg find students in increasing gpa orderbull Sorting is first step in bulk loading B+ tree indexbullSorting useful for eliminating duplicate copies in a collection of records (Why)bullSort-merge join algorithm involves sortingbullProblem sort 1Gb of data with 1Mb of RAM - why not virtual memory
When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

When does a DBMS sort dataSorting a collection of records on some search key is a very useful operation The key can be a single attribute or an ordered list of attributes Sorting is required in a variety of situations including the following important ones
bullUsers may want answers in some order for example by increasing age
bullSorting records is the first step in bulk loading a tree index
bullSorting is useful for eliminating duplicate copies in a collection of records
bullA widely used algorithm for performing a very important relational algebra operation called join requires a sorting step
Although main memory sizes are growing rapidly the ubiquity of database systems has lead to increasingly larger datasets as well When the data to be sorted is too large to fit into available main memory we need an external sorting algorithm Such algorithm seek to minimize the cost of disk accesses
A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

A SIMPLE TWO-WAY MERGE SORT
We begin by presenting a simple algorithm to illustrate the idea behind external sorting This algorithm utilizes only three pages of main memory and it is presented only for pedagogical purposes When sorting a file several sorted subfiles are typically generated in intermediate steps Here we refer to each subfile as a run
Even if the entire file does not fit into the available main memory we can sort it by breaking it into smaller subfiles sorting these subfiles and then merging them using a minimal amount of main memory at any given time In the first pass the pages in the file are read in one at a time After a page is read in the records on it are sorted and the sorted page is written out Quicksort or any other in ndashmemory sorting technique can be used to sort the records on a page In subsequent passes pairs of runs from the output of the previous pass are read in and merged to produce runs that are twice as long This algorithm is shown in Fig(1)
proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

proc 2-way_extsort (file)
Given a file on disk sorts it using three buffer pages
Produce runs that are one page long Pass 0
Read each page into memory sort it Write it out
Merge pairs of runs to produce longer runs until only
one run ( containing all records of input file) is left
While the number of runs at end of previous pass is gt 1
Pass i=12hellip
While there are runs to be merged from previous pass
Choose next two runs (from previous pass)
Read each run into an input buffer page at a time
Merge the runs and write to the output buffer
force output buffer to disk one page at a time
endproc
Fig(1) Two-Way Merge Sort
ContdContd
ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

ContdContd
If the number of pages in the input file is 2k for some k then
Pass 0 produces 2k sorted runs of one page
each
Pass 1 produces 2k-1 sorted runs of two pages each
Pass 2 produces 2k-2 sorted runs of four pages each
And so on until
Pass K produces one sorted run of 2k pages
In each pass we read every page in the file process it and write it out Therefore we have two disk IOs per page per pass The number of passes is [log2N]+1 where N is the number of pages in the file The overall cost is 2N([log2N]+1) IOs
The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

The algorithm is illustrated on an example input file containing Two-way Merge Sort of a seven pages in fig(2)
34 62 94 87 56 31 2
34 26 49 78 56 13 2
23 47 13
46 89 56 2
23
44
67
89
12
35
6
12
23
34
45
66
78
9
Input file
Pass 0
1-page runsPass 1
2-page runs
Pass 2
4-page runs
Pass 3
8-page runs
ContdContd
The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

The sort takes four passes and in each pass we read and write seven pages for a total of 56 IOs This result agrees with the preceding analysis because 27([log27]+1)=56 The dark pages in the figure illustrate what would happen on a file of eight pages the number of passes remains at four([log28]+1=4) but we read and write an additional page in each pass for a total of 64 IOs The algorithm requires just three buffer pages in main memory as shown in fig(3) illustrates This observation raises an important point Even if we have more buffer space available this simple algorithm does not utilize it effectively
ContdContd
Input 1
Input 2
output
Disk DiskMain memory buffers
Fig(3) Two-Way Merge Sort with Three buffer pages
Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Suppose that B buffer pages are available in memory and that we need to sort large file with N pages The intuition behind the generalized algorithm that we now present is to retain the basic structure of making multiple passes while trying to minimize the number of passes There are two important modifications to the two-way merge sort algorithm
1 In pass 0 read in B pages at a time and sort internally to produce [NB] runs of B pages each (except for the last run which may contain fewer pages) This modification is illustrated in fig(4) using the input from fig(2) and a buffer pool with four pages
2 In passes i=12hellip use B-1 buffer pages for input and use the remaining page for output hence you do a (B-1)-way merge in each pass The utilization of buffer pages in the merging passes is illustrated in fig(5)
EXTERNAL MERGE SORT
Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Fig(4) External Merge Sort with B buffer pages Pass 0
34
62
94 89
87
89
56
31
2
8912
35
6
34
23
44
78
671st output run
ContdContd
Input file
2nd output runBuffer pool with B=4 pages
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3
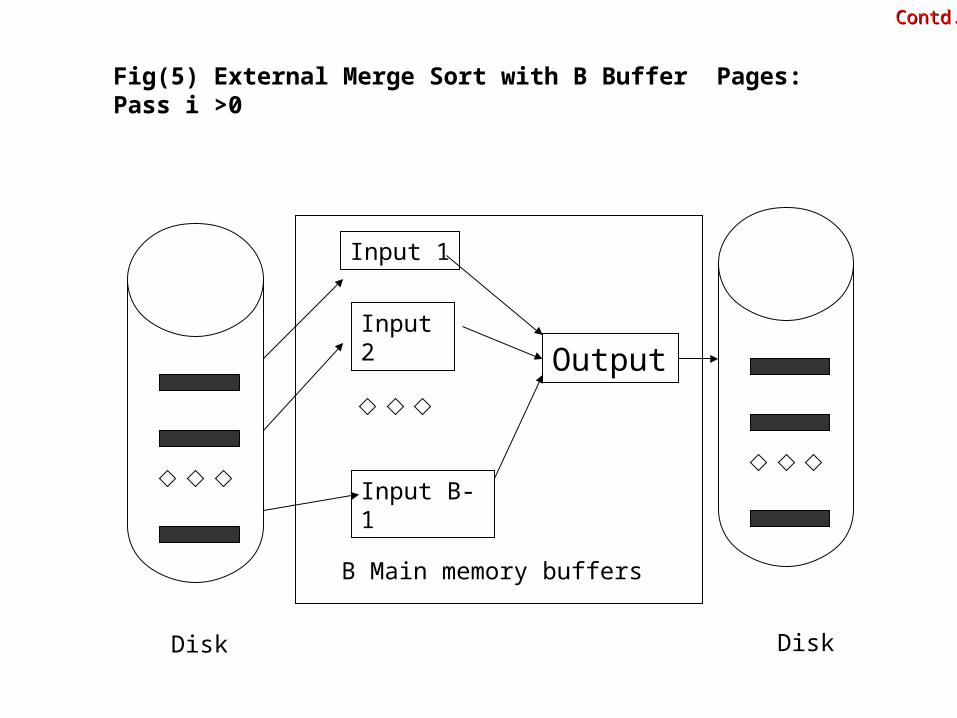
ContdContd
Input 1
Disk Disk
B Main memory buffers
Fig(5) External Merge Sort with B Buffer Pages Pass i gt0
Input 2
Input B-1
Output
The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

The first refinement reduces the
Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3

Summary1048576 External sorting is important DBMS may dedicate part of buffer pool for sorting1048576 External merge sort minimizes disk IO cost Pass 0 Produces sorted runs of size B ( buffer pages) Later passes merge runs of runs merged at a time depends on B and block size Larger block size means less IO cost per page Larger block size means smaller runs merged In practice of runs rarely more than 2 or 3





























