Embed Size (px)
Citation preview

Contents lists available at SciVerse ScienceDirect
Signal Processing
Signal Processing 93 (2013) 1458–1470
0165-16
http://d
n Corr
E-m
230109
zhenyan
journal homepage: www.elsevier.com/locate/sigpro
Adaptive object detection by implicit sub-classsharing features
Suofei Zhang, Nijun Li, Xu Cheng, Zhenyang Wu n
School of Information Science and Engineering, Jianxiong Building, Southeast University, Si Pai Lou 2, Nanjing 210096, China
a r t i c l e i n f o
Article history:
Received 1 March 2012
Received in revised form
27 November 2012
Accepted 28 November 2012Available online 7 December 2012
Keywords:
Computer vision
Machine learning
Object detection
Boosting
84/$ - see front matter & 2012 Elsevier B.V
x.doi.org/10.1016/j.sigpro.2012.11.027
esponding author. Tel.: þ86 025 8379 4363
ail addresses: [email protected] (S. Zh
[email protected] (N. Li), [email protected]
[email protected] (Z. Wu).
a b s t r a c t
In this paper, we describe an adaptive object detection system based on boosted weak
classifiers. We formulate the learning of object detection as to find the representative
sharing features over the examples of object. Objects with low intra-class variation imply
that more generic features for detection can be selected. In contrast, more specific features
for only subset of examples should be encouraged to gain an elegant representation for the
object with high intra-class variation. In this spirit, we implement an implicit partition over
positive examples to obtain a data-driven clustering. Based on the implicit partition, we
encourage an intra-class and inter-class feature sharing between sub-categories and build an
adaptive hierarchical cascade of weak classifiers. Experimental results prove that the intra-
class sharing makes an adaptive trade-off between performance and efficiency on various
object detection tasks. The inter-class sharing allows objects to borrow semantic information
from related well labeled objects. We hope that the proposed implicit feature sharing over
sub-categories can extend the application of traditional boosting methods.
& 2012 Elsevier B.V. All rights reserved.
1. Introduction
Object detection in images is one of the fundamentalchallenges in computer vision and attracts substantialattention from the machine learning community. Anobject detection system generally contains two pivotalparts: feature based image representation and classifica-tion of features. Our work mainly focuses on the last part,more precisely, on the boosted cascade [1] based objectdetection. Boosting learning methods, such as AdaBoostand its descendant algorithms, have been proven to be anefficient solution in different machine vision tasks. Theyprovide an effective approach for building a strong non-linear classifier from a series of weak classifiers. Variousboosting based works ranging from object detection [2] tohuman action recognition [3] appeared in the literatureduring last decade. For practical application, the work
. All rights reserved.
.
ang),
(X. Cheng),
from Viola and Jones [1] demonstrates an efficient frame-work for object detection by using AdaBoost as building-blocks for the cascade of strong classifiers. For theoreticalexploration, Freund and Schapire showed that given weakclassifiers which perform better than chance, AdaBoostcan achieve arbitrarily good generalization bound [4].
However, despite the exciting performance that Ada-Boost has been witnessed in various tasks, applying it tohigh intra-class variation classification problems remainsa challenging problem. In such problems, targets can varygreatly in appearance because of the changes in view-point, deformation and other visual properties. Forinstance, some typical tasks with high variation entailmultiview object detection, human action recognition,etc. In such tasks, it is hard to learn all appearances oftarget with single descriptor, e.g. cars from two separateviews. Most of the discussions in the literature focus onproposing models with higher complexity to tackle thehigher intra-class variation. Such solutions are not adap-tive to the variability of target class and can bringunnecessary risk of over-fitting if the problem is originallystraightforward. A generic treatment of the object

S. Zhang et al. / Signal Processing 93 (2013) 1458–1470 1459
detection problems with different variations remainsabsent. In this paper we address the object detectionproblem within a boosting framework from the perspec-tive of searching for the most representative featuresshared by positive examples. For high intra-class variationproblems, our method seeks sharing features at a highgranularity while contrarily the method seeks sharingfeatures at a low granularity adaptively. As illustrated inFig. 1, based on the selected intra-class sharing features,we propose a novel adaptive hierarchical cascade detectorconsisting of hybrid weak classifiers in a boosting manner.Our experimental results show that the proposedapproach out-performs the baseline method on differentpopular high complexity object detection tasks. Mean-while, it retains a compact structure for various dailyobjects detection problems with low intra-class variation.Moreover, in the multiclass version of our method, theinter-class sharing features at a sub-class level allow thesemantic information (e.g. viewpoint information) fromwell labeled samples to be transferred across classes andhelp the learning of those global knowledge scarce objects.
The remaining part of this paper is organized as follows.Related works are described in Section 2. In Section 3, wetake a short review of the conventional JointBoost algo-rithm. In Sections 4 and 5, we implement our objectdetection model and organize some motivating experimentswith an adapted version of JointBoost. The learning methodof the proposed approach is elaborated in Section 6. Experi-mental results are reported and discussed, respectively,in Sections 7 and 8. Finally, we conclude the paper in thelast section.
2. Related work
Boosting methods have been widely explored in boththeory and application. Friedman et al. explained boosting
Fig. 1. Our method can provide adaptive structure (right) to the cascade
detector according to the variability of the target class (left). Every
column in the structure matrix corresponds to a round of iteration in
learning. A more complex structure means more features are adopted to
compose current weak classifier. For objects with high variation, e.g.
cars, it learns a cascade detector with more complex structure as in (a).
To the contrary, the complexity of the structure is constrained as in (b)
for easy identified objects, e.g. mugs.
in terms of additive logistic regression and proposedGentleBoost in [5]. Other appealing variants of theAdaBoost algorithm include FloatBoost [6], regularizedAdaBoost [7] and WeightBoost [8], etc. Torralba et al.extended boosting method from binary classification tomulticlass classification and proposed the JointBoost [2].By encouraging the inter-class transfer of knowledge(generic features), JointBoost achieved a better result thanpure specific features for every separate target class.
In past decade, numerous discussions within boostingframework can be found for a specific or generic treat-ment of the problems with high intra-class variation.Conventional AdaBoost suffers from two main drawbackson such problems. First, it always tends to find the mostdiscriminative feature for all samples on current iterativestep. This leads the learner to be trapped into a localoptimum in the candidate weak classifier space. Second, alinear combination of such weak classifiers introduces anincreasing obscurity scaling with the intra-class variation.Some existing approaches for handling this probleminclude: (1) Training classifiers for pre-defined subsetsof target class based on prior knowledge [9,10] or cluster-ing methods [11,12]. Such methods usually suffer fromimperfect clustering due to lack of global knowledge. Tooptimize the clustering, we usually deploy some dimen-sionality reduction techniques such as principal compo-nent analysis (PCA) and non-negative matrix factorization(NMF), etc. These techniques can ensure the data a moreexplicit structure and pattern. For instance, the work [13]proposed an optimal gradient method based NMF algo-rithm which shows both high efficiency and effectivenessfor dimensionality reduction and clustering. (2) Usingstructured classifier instead of linear combination. Somewell-known structures include: parallel cascade [14],pyramid [15] and width-first-search (WFS) tree [10], etc.However, structured boosting improves the detectionperformance by inputting a risk of over-fitting due toadoption of redundant structure. A more recent work [16]built a logic gate network based on the outputs of weakclassifiers. This can be thought as a more complexstructure with mitigated risk of over-fitting.
Recently, a popular solution to object detection withhigh variation is to use mixture model with deformableparts as latent variables to handle the variable appearance[17,18]. Part-based approach has been proven as a highperformance model on challenging tasks [19–21]. How-ever, as reported in [19], different number of latentvariables can seriously affect the performance on differentproblems. For those common daily objects with stableappearance, [18] is not an efficient model since it intro-duces unnecessary latent variables. We believe that ouradaptive model can be an ideal complement to suchsystems for higher flexibility.
The most similar work to ours is [22]. They proposedthe concept of weak partition analogously to that of weakclassifier in boosting framework and built a hard hier-archical cascade with decreasing complexity to tackle thehigh variation problems. Based on the work in [22], ourcontribution here is twofold. First, we integrate the Join-tBoost method into this framework and propose a noveladaptive hierarchical structure instead of hard structure.

S. Zhang et al. / Signal Processing 93 (2013) 1458–14701460
The adaptive structure shows simultaneously higher per-formance and flexibility compared to [22]. On top of that,we extend the adaptive hierarchical cascade into a multi-class object detection framework. The sharing featuresover sub-categories allow a semantic knowledge transferacross classes thus further improve the performancebased on the binary version.
A preliminary version of our system was describedin [23]. The system elaborated here differs from the one in[23] in several ways: we upgrade the system with newfeatures and a data-mining mechanism; we implement asampling based weak partition and a hybrid weak classi-fier to prompt the efficiency of our system; more config-urations are compared to inspect the behaviors ofsub-class sharing features within a multiclass framework.
3. JointBoost
Since our work follows a boosting framework, to definesome basic notations of the algorithm, we start with a briefreview of the JointBoost in Algorithm 1. JointBoost wasproposed by Torralba et al. in [2]. Based on the GentleBoostframework [5], it extends boosting method from binaryclassification problem into multiclass case in an efficientway. Given pairwise feature vectors and labels ðv,zcÞ (zc
i ¼ 1if example i has ground truth class c, �1 otherwise) astraining examples, JointBoost sequentially selects discrimina-tive features to fit the additive model:
Hðv,cÞ ¼XM
m ¼ 1
hmðv,cÞ, ð1Þ
where M is the number of boosting rounds, hmðv,cÞ are weaklearners and Hðv,cÞ is strong learner. Using multiclass logistictransformation [5], Hðv,cÞ can be reinterpreted as a functionof probability distribution over c:
Hðv,cÞ ¼ logPðzc ¼ 19vÞ=Pðzc ¼�19vÞ, ð2Þ
Pðzc ¼ 19vÞ ¼1
1þe�Hðv,cÞ: ð3Þ
At current iteration, JointBoost searches for a weak learnerhmðv,cÞ shared between classes to optimize the cost function
Fig. 2. Learning behavior matrix of JointBoost for different views of cars in a mu
to a weak classifier, i.e. a decision stump for the shared classes. The white part d
boosting.
Jwse on training set:
Jwse ¼XC
c ¼ 1
XN
i ¼ 1
e�zciHðvi ,cÞðzc
i�hmðvi,cÞÞ2, ð4Þ
Algorithm 1. JointBoost.
Require: fðvi ,zci Þ9i¼ 1 . . .N,c¼ 1 . . .C, zc
i 2 f�1,þ1gg
Ensure: Hðvi ,cÞ
Initialize wci ¼ 1, Hðvi ,cÞ ¼ 0
for m¼1 to M do
Train weak classifier hmðvi ,cÞ for all possible subsets of classes
Evaluate the error Jwse(S) for each subset of classes S
Find the best shared classes Sn
Sn¼ arg minSJwseðSÞ
Update the additive model
Hðvi ,cÞ :¼ Hðvi,cÞþhSn
m ðvi ,cÞ
Update the weight distribution of samples
wci :¼ wc
i e�zcihSn
m ðvi ,cÞ
end for
where N is the number of examples, C is the number oftarget classes. Jwse can be thought as an upper bound ofthe misclassification rate of training examples [24]. Tominimize Jwse, different forms of weak learners can beconsidered, e.g. decision trees or piecewise functions [10].In our work, we adopt the decision stump which iscommonly used in JointBoost framework:
hðv,cÞ ¼
aS if vfi 4y and c 2 SðnÞ,
bS if vfi ry and c 2 SðnÞ,
kcS if c=2SðnÞ:
8>><>>:
ð5Þ
For those shared classes (c 2 SðnÞ), the decision stumpreturns hðv,cÞ depending on the comparison of vi
fto a
threshold y. For the classes not shared (c=2SðnÞ), theconstant kS
cprevents the learning procedure from being
adversely affected by imbalance between negative andpositive training examples. Given pre-defined thresholdsy on the feature vf, a closed form solution of parametersaS, bS and kS
cto minimize Jwse in Eq. (4) has been given as
aS ¼
Pc2SðnÞ
Piw
ci zc
i dðvfi 4yÞP
c2SðnÞ
Piw
ci dðv
fi 4yÞ
, ð6Þ
lticlass object detection problem. Each column of the matrix corresponds
emonstrates which classes share the decision stump at current round of

Fig. 3. Partitions of view space on different granularities. The second
row (all views in 1) corresponds to conventional GentleBoost.
S. Zhang et al. / Signal Processing 93 (2013) 1458–1470 1461
bS ¼
Pc2SðnÞ
Piw
ci zc
i dðvfi ryÞP
c2SðnÞ
Piw
ci dðv
fi ryÞ
, ð7Þ
kcS ¼
Piw
ci zc
iPiw
ci
, ð8Þ
where wci ¼ e�zc
iHðvi ,cÞ is the training weight assigned to
example i. At the end of current iteration, the trainingexamples are re-weighted as
wci :¼ wc
i e�zcihSn
m ðvi ,cÞ, ð9Þ
to reflect the variance of classification accuracy.Differing from other boosting methods for multi-
class problems such as AdaBoost.MH, AdaBoost.MO orAdaBoost.MR [25], JointBoost considers multiple overlap-ping subsets of classes to minimize the cost function, ratherthan a hard hierarchical partition (e.g. a tree structure). Weillustrate the learning behavior of JointBoost in Fig. 2.Without any apparent pattern, such data-driven sharingbuilds an adaptive structure to the inter-class variationacross different classes. If two classes look similar they canshare more generic features, otherwise different specificfeatures are distributed, respectively. Benefiting from thisadaptive structure, JointBoost can solve the multiclassclassification problems with cost sub-linear in the numberof classes and leads to improved generalization. Inspired bythis adaptive structure, we would like to extend the sharingof classifier to binary classification problem on a sub-classlevel. Assuming a class of objects with high intra-classvariation can be divided into several sub-categories withlower variation, we are interested in how the featuresharing affects the classification performance on this level.To this end, we build a standard object detection model inSection 4 and analyze the influence by a series of experi-ments in Section 5.
4. Detection model
Given a series of learned weak classifiers, our systemslides a scanning window over the image and scores thespecified object hypothesis on each position and scale.The system works with Histogram of Oriented Gradients(HOG) features [18] as the representation of images andobjects. Since a large number of negative examples in theimage have to be considered and weeded out, the trade-off between accuracy and speed is a central aspect of theobject detection problem. To prompt the efficiency of ourmodel, we adopt the soft cascade strategy for the boostedclassifiers as in [26].
4.1. Features
The learning of boosting method is based on a largepool of visual descriptors as candidates. Recently, numer-ous popular features appeared in the literature, for exam-ple Haar features [1], Scale Invariant Feature Transform(SIFT) features [27,28] and HOG features [29], etc. In thiswork, we employ the 31-dimensional HOG features from[17,18]. Compared to the original 128-dimensional HOGalgorithm in [29], its variant in [18] implemented an
efficient summing computation to imitate the costly PCAprojection and achieved an analytic dimensionality reduc-tion from 128 to 31. The HOG features have been provento be quite effective and robust in sorts of object detectiontasks [29,17,18,30]. As one can see, we use in this work astandard feature extraction algorithm and do not focus onthe choice of features, but on the way to improve theperformance by structured complementary descriptors.
4.2. Soft cascade
The utilization of the cascade strategy for efficientdetection can be traced back to [1]. The cascade can helpthe classifier to reject the vast majority of the negativeexamples from background with a threshold sm at currentstage. In our work, we build a soft cascade decisionstrategy by learning the thresholds of partial HðviÞ assuggested in [26]. We choose the rejection threshold sm atiteration m as
sm ¼minzi ¼ 1
Xm
t ¼ 1
htðviÞ�e: ð10Þ
Here a small constant e is subtracted to make sure allpositive examples are retained after m iterations. Thisconfiguration obtains a better level of generalization forthe detector.
5. Motivating experiments of sub-class sharing
Intuitively, we know that the prior knowledge suchlike semantic information will help to tackle the highvariation. To gain some insight into how to share classi-fiers in binary classification problem and how the priorknowledge impacts, we modify the JointBoost model andorganize some motivating experiments to evaluate theperformance. We take the car detection task on theLabelMe dataset [31] into consideration. The car samplesprovided by LabelMe dataset consist of 12 different views:01, 301, 601, 901, 1201, 1501, 1801, 2101, 2401, 2701, 3001,3301. We implement a series of discretizations of the viewspace on different granularities. As illustrated in Fig. 3, carsamples from different angles are divided into differentgroups. By this way, we expect to analyze how thesemantic information affects (improve or impair) the
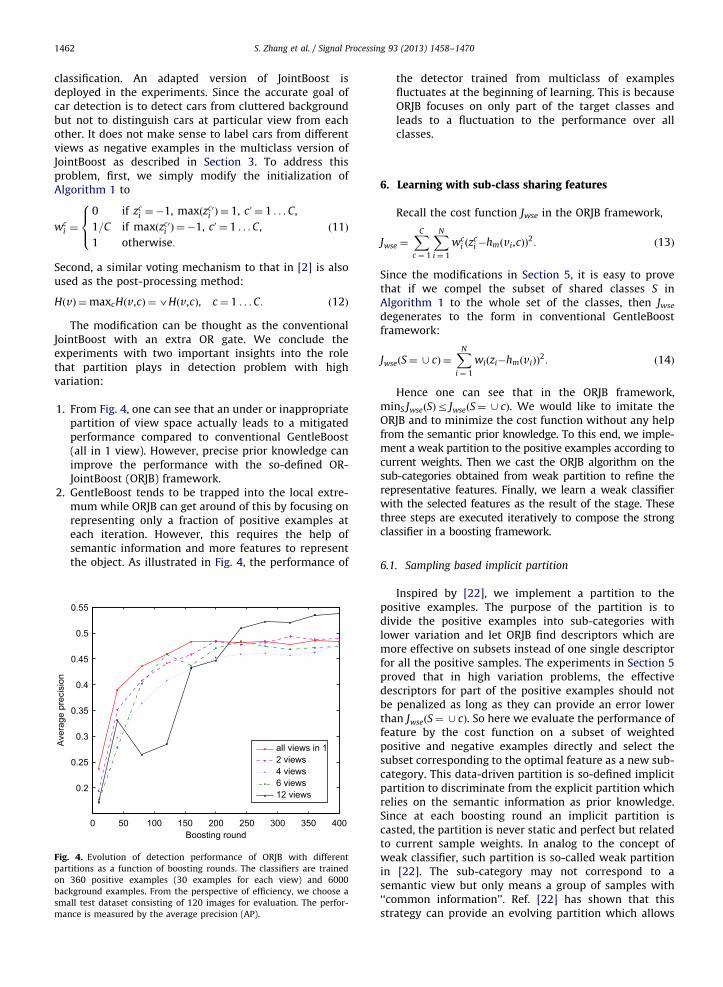
S. Zhang et al. / Signal Processing 93 (2013) 1458–14701462
classification. An adapted version of JointBoost isdeployed in the experiments. Since the accurate goal ofcar detection is to detect cars from cluttered backgroundbut not to distinguish cars at particular view from eachother. It does not make sense to label cars from differentviews as negative examples in the multiclass version ofJointBoost as described in Section 3. To address thisproblem, first, we simply modify the initialization ofAlgorithm 1 to
wci ¼
0 if zci ¼�1, maxðzc0
i Þ ¼ 1, c0 ¼ 1 . . .C,
1=C if maxðzc0i Þ ¼ �1, c0 ¼ 1 . . .C,
1 otherwise:
8><>: ð11Þ
Second, a similar voting mechanism to that in [2] is alsoused as the post-processing method:
HðvÞ ¼maxcHðv,cÞ ¼3Hðv,cÞ, c¼ 1 . . .C: ð12Þ
The modification can be thought as the conventionalJointBoost with an extra OR gate. We conclude theexperiments with two important insights into the rolethat partition plays in detection problem with highvariation:
1.
Ave
rage
pre
cisi
on
Figpar
on
bac
sma
ma
From Fig. 4, one can see that an under or inappropriatepartition of view space actually leads to a mitigatedperformance compared to conventional GentleBoost(all in 1 view). However, precise prior knowledge canimprove the performance with the so-defined OR-JointBoost (ORJB) framework.
2.
GentleBoost tends to be trapped into the local extre-mum while ORJB can get around of this by focusing onrepresenting only a fraction of positive examples ateach iteration. However, this requires the help ofsemantic information and more features to representthe object. As illustrated in Fig. 4, the performance of0 50 100 150 200 250 300 350 400
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0.55
Boosting round
all views in 12 views4 views6 views12 views
. 4. Evolution of detection performance of ORJB with different
titions as a function of boosting rounds. The classifiers are trained
360 positive examples (30 examples for each view) and 6000
kground examples. From the perspective of efficiency, we choose a
ll test dataset consisting of 120 images for evaluation. The perfor-
nce is measured by the average precision (AP).
the detector trained from multiclass of examplesfluctuates at the beginning of learning. This is becauseORJB focuses on only part of the target classes andleads to a fluctuation to the performance over allclasses.
6. Learning with sub-class sharing features
Recall the cost function Jwse in the ORJB framework,
Jwse ¼XC
c ¼ 1
XN
i ¼ 1
wci ðz
ci�hmðvi,cÞÞ
2: ð13Þ
Since the modifications in Section 5, it is easy to provethat if we compel the subset of shared classes S inAlgorithm 1 to the whole set of the classes, then Jwse
degenerates to the form in conventional GentleBoostframework:
JwseðS¼ [ cÞ ¼XN
i ¼ 1
wiðzi�hmðviÞÞ2: ð14Þ
Hence one can see that in the ORJB framework,minS JwseðSÞr JwseðS¼ [ cÞ. We would like to imitate theORJB and to minimize the cost function without any helpfrom the semantic prior knowledge. To this end, we imple-ment a weak partition to the positive examples according tocurrent weights. Then we cast the ORJB algorithm on thesub-categories obtained from weak partition to refine therepresentative features. Finally, we learn a weak classifierwith the selected features as the result of the stage. Thesethree steps are executed iteratively to compose the strongclassifier in a boosting framework.
6.1. Sampling based implicit partition
Inspired by [22], we implement a partition to thepositive examples. The purpose of the partition is todivide the positive examples into sub-categories withlower variation and let ORJB find descriptors which aremore effective on subsets instead of one single descriptorfor all the positive samples. The experiments in Section 5proved that in high variation problems, the effectivedescriptors for part of the positive examples should notbe penalized as long as they can provide an error lowerthan JwseðS¼ [ cÞ. So here we evaluate the performance offeature by the cost function on a subset of weightedpositive and negative examples directly and select thesubset corresponding to the optimal feature as a new sub-category. This data-driven partition is so-defined implicitpartition to discriminate from the explicit partition whichrelies on the semantic information as prior knowledge.Since at each boosting round an implicit partition iscasted, the partition is never static and perfect but relatedto current sample weights. In analog to the concept ofweak classifier, such partition is so-called weak partitionin [22]. The sub-category may not correspond to asemantic view but only means a group of samples with‘‘common information’’. Ref. [22] has shown that thisstrategy can provide an evolving partition which allows
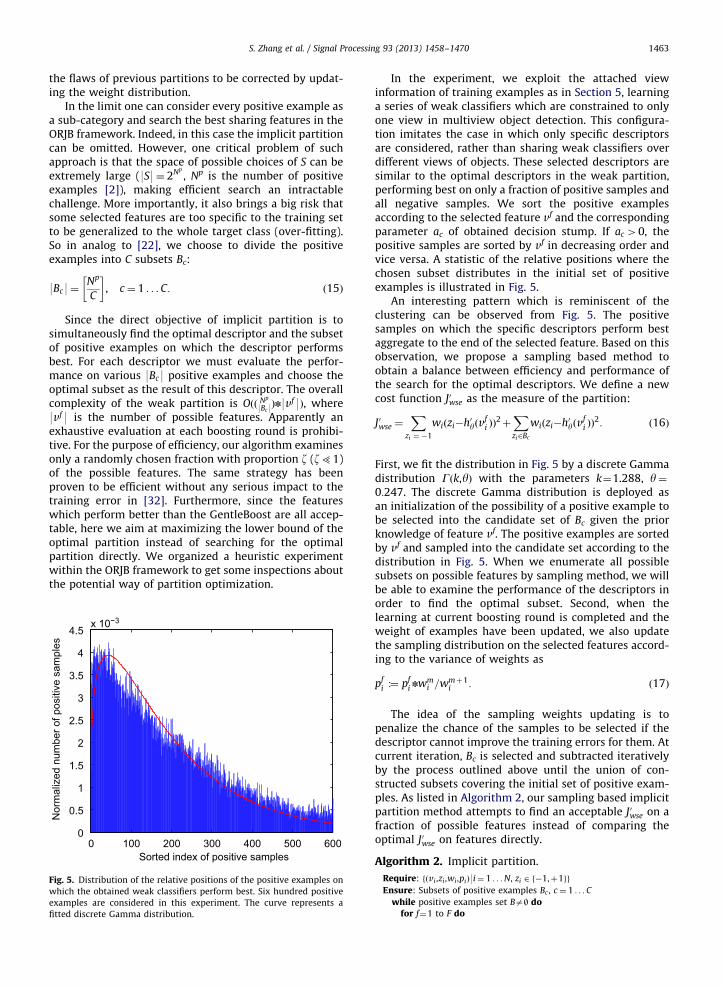
S. Zhang et al. / Signal Processing 93 (2013) 1458–1470 1463
the flaws of previous partitions to be corrected by updat-ing the weight distribution.
In the limit one can consider every positive example asa sub-category and search the best sharing features in theORJB framework. Indeed, in this case the implicit partitioncan be omitted. However, one critical problem of suchapproach is that the space of possible choices of S can beextremely large (9S9¼ 2Np
, Np is the number of positiveexamples [2]), making efficient search an intractablechallenge. More importantly, it also brings a big risk thatsome selected features are too specific to the training setto be generalized to the whole target class (over-fitting).So in analog to [22], we choose to divide the positiveexamples into C subsets Bc:
9Bc9¼Np
C
� �, c¼ 1 . . .C: ð15Þ
Since the direct objective of implicit partition is tosimultaneously find the optimal descriptor and the subsetof positive examples on which the descriptor performsbest. For each descriptor we must evaluate the perfor-mance on various 9Bc9 positive examples and choose theoptimal subset as the result of this descriptor. The overallcomplexity of the weak partition is Oðð Np
9Bc9Þn9vf 9Þ, where
9vf 9 is the number of possible features. Apparently anexhaustive evaluation at each boosting round is prohibi-tive. For the purpose of efficiency, our algorithm examinesonly a randomly chosen fraction with proportion z (z51)of the possible features. The same strategy has beenproven to be efficient without any serious impact to thetraining error in [32]. Furthermore, since the featureswhich perform better than the GentleBoost are all accep-table, here we aim at maximizing the lower bound of theoptimal partition instead of searching for the optimalpartition directly. We organized a heuristic experimentwithin the ORJB framework to get some inspections aboutthe potential way of partition optimization.
0 100 200 300 400 500 6000
0.5
1
1.5
2
2.5
3
3.5
4
4.5x 10−3
Sorted index of positive samples
Nor
mal
ized
num
ber o
f pos
itive
sam
ples
Fig. 5. Distribution of the relative positions of the positive examples on
which the obtained weak classifiers perform best. Six hundred positive
examples are considered in this experiment. The curve represents a
fitted discrete Gamma distribution.
In the experiment, we exploit the attached viewinformation of training examples as in Section 5, learninga series of weak classifiers which are constrained to onlyone view in multiview object detection. This configura-tion imitates the case in which only specific descriptorsare considered, rather than sharing weak classifiers overdifferent views of objects. These selected descriptors aresimilar to the optimal descriptors in the weak partition,performing best on only a fraction of positive samples andall negative samples. We sort the positive examplesaccording to the selected feature vf and the correspondingparameter ac of obtained decision stump. If ac 40, thepositive samples are sorted by vf in decreasing order andvice versa. A statistic of the relative positions where thechosen subset distributes in the initial set of positiveexamples is illustrated in Fig. 5.
An interesting pattern which is reminiscent of theclustering can be observed from Fig. 5. The positivesamples on which the specific descriptors perform bestaggregate to the end of the selected feature. Based on thisobservation, we propose a sampling based method toobtain a balance between efficiency and performance ofthe search for the optimal descriptors. We define a newcost function J0wse as the measure of the partition:
J0wse ¼X
zi ¼ �1
wiðzi�h0yðvfi ÞÞ
2þXzi2Bc
wiðzi�h0yðvfi ÞÞ
2: ð16Þ
First, we fit the distribution in Fig. 5 by a discrete Gammadistribution Gðk,yÞ with the parameters k¼1.288, y¼0:247. The discrete Gamma distribution is deployed asan initialization of the possibility of a positive example tobe selected into the candidate set of Bc given the priorknowledge of feature vf. The positive examples are sortedby vf and sampled into the candidate set according to thedistribution in Fig. 5. When we enumerate all possiblesubsets on possible features by sampling method, we willbe able to examine the performance of the descriptors inorder to find the optimal subset. Second, when thelearning at current boosting round is completed and theweight of examples have been updated, we also updatethe sampling distribution on the selected features accord-ing to the variance of weights as
pfi :¼ pf
i nwmi =wmþ1
i : ð17Þ
The idea of the sampling weights updating is topenalize the chance of the samples to be selected if thedescriptor cannot improve the training errors for them. Atcurrent iteration, Bc is selected and subtracted iterativelyby the process outlined above until the union of con-structed subsets covering the initial set of positive exam-ples. As listed in Algorithm 2, our sampling based implicitpartition method attempts to find an acceptable J0wse on afraction of possible features instead of comparing theoptimal J0wse on features directly.
Algorithm 2. Implicit partition.
Require: fðvi ,zi ,wi ,piÞ9i¼ 1 . . .N, zi 2 f�1,þ1gg
Ensure: Subsets of positive examples Bc , c¼ 1 . . .C
while positive examples set Ba| dofor f¼1 to F do

S. Zhang et al. / Signal Processing 93 (2013) 1458–14701464
Sample 9Bc9 positive examples according to the sampling
weights pi
fon feature vf
Evaluate the weak classifier learned from selected examples
on vf
end forFind the optimal vf and corresponding Bc to minimize J0wse
Subtract Bc from B
end while
6.2. Adaptive feature refinement
As the result of weak partition, we have C sub-categoriesand C descriptors at our disposal. In the work of [22], theylearned a multi-dimensional classifier with C descriptors asthe weak classifier directly. By adopting different C indifferent stages of learning, a strong classifier with hardhierarchical structure (constant, increasing or decreasing ofC) is obtained. Here we propose an Adaptive FeatureRefinement (AFR) with the ORJB instead of the hard struc-ture. First we re-weight the samples similarly to Eq. (11) as
wci ¼
0 if zci ¼�1, maxðzc0
i Þ ¼ 1, c0 ¼ 1 . . .C,
wi=C if maxðzc0i Þ ¼�1, c0 ¼ 1 . . .C,
wi otherwise:
8><>: ð18Þ
Then we cast the ORJB on the sub-categories iteratively tosearch the most efficient sharing features and the corre-sponding best shared subsets of sub-categories. In analog tothe weak partition, the best shared subset is subtractedfrom the initial set of sub-categories until all examples arerepresented by C0 descriptors (C0rC).
Compared to the hard one in [22], the AFR providesan adaptive hierarchical structure to the strong classifier.The advantages of adaptive hierarchical structure include:(1) the obtained strong classifier can adapt to the varia-bility of the target class; (2) it reduces the manualintervention to the training; (3) the feature shearing oversub-categories can lead to an efficient strong classifierwith the collaboration from the hybrid weak classifierstrategy as described in the next section.
6.3. Hybrid weak classifier
As the output of the AFR, we have C0 (1rC0rC)preliminary descriptors as the building blocks of a weakclassifier. In our experiments, we observe that AFR nor-mally provides an adaptive hierarchical structure with asmall C0 at the first rounds of learning (see Fig. 8). Inspiredby this quasi-increasing structure, we propose a hybridweak classifier strategy to integrate the AFR with our softcascade decision mechanism. Different types of weakclassifiers are considered according to different C0. IfC 0 ¼ 1, meaning that a single descriptor turns out to bemost effective for all samples, we deploy a decision stumpdirectly as the classical GentleBoost. If C041, we takeSVM into account as the multi-dimensional weak classi-fier. The boosting weights of examples are considered asthe constraint of the soft margin in SVM training. Morespecifically, if C0o4, a linear SVM is trained, otherwise ifC 0Z4, a SVM with Gaussian radial basis function (RBF)kernel is considered. The threshold on C0 for adoptingkernelized SVM controls a trade-off between performance
and efficiency. Above configuration is given empirically byour experiments. It provides the detector a high accuracywith acceptable time complexity. With this hybrid strat-egy, we can reject the vast majority of backgroundcontent by the linearly combined decision stumps andlinear SVMs at the beginning of the cascade. Meanwhile,the SVMs with RBF kernel ensure a good performance forthe hard samples in subsequent rounds.
In this section, we propose a novel learning modelwith the sharing features between fractions of examples.The sub-class knowledge sharing and hybrid classifierssignificantly prompt the flexibility and efficiency of oursystem compared to state-of-art approaches. We sum-marize our learning method in Algorithm 3.
Algorithm 3. Learning.
Require: fðvi ,ziÞ9i¼ 1 . . .N,zi 2 f�1,þ1gg
Ensure: HðviÞ
Initialize: wi ¼ 1, HðviÞ ¼ 0, pi �Gðk,yÞfor m¼1 to M do
Divide positive sample set B into C subsets Bc , c¼ 1 . . . C with
Algorithm 2
Re-weight the samples to C sub-categories as Eq. (18)
while Ba| doExecute ORJB on B, subtract the best shared subset of
classes Sn
Record corresponding optimal feature vf as preliminary
descriptor
end while
Train the hybrid weak classifier hmðviÞ with preliminary
descriptors
Update the additive model: HðviÞ :¼ HðviÞþhmðviÞ
Update the weight of samples: wi :¼ wie�zi hm ðvi Þ
Update the sampling weight of positive samples:
pfi :¼ pf
i nwmi =wmþ1
i
end for
6.4. Multiclass version
Since the JointBoost is an original multiclass classificationmodel, it is readily to extend our system to the multiclasscase. To learn detectors within a multiclass framework, wemodify the ORJB part in Algorithm 3 in order to let thealgorithm search for the best shared subsets over all sub-categories from different classes of examples. The multiclassversion of our method allows simultaneously intra-class andinter-class sharing features to be selected. Then differentweak classifiers are learned with related preliminary descrip-tors, respectively. Note that our model learns the multiclassproblem jointly but casts the inferences separately. This isdifferent to conventional JointBoost which allows classes ofobjects to share weak classifiers directly. As demonstrated inour experiments, such sub-class knowledge transfer betweenclasses further improves the performance based on thebinary version of our method.
7. Experimental results
7.1. Effect of sampling based implicit partition
The goal of the first experiment is to testify how thesampling based method proposed in Section 6.1 affectsthe partition of positive examples. In this experiment, weadopted the same configuration of training samples as the
0 10 20 30 40 50250
300
350
400
450
500
550
600
650
700
Boosting round
Trai
ning
err
or
method 1method 2method 3
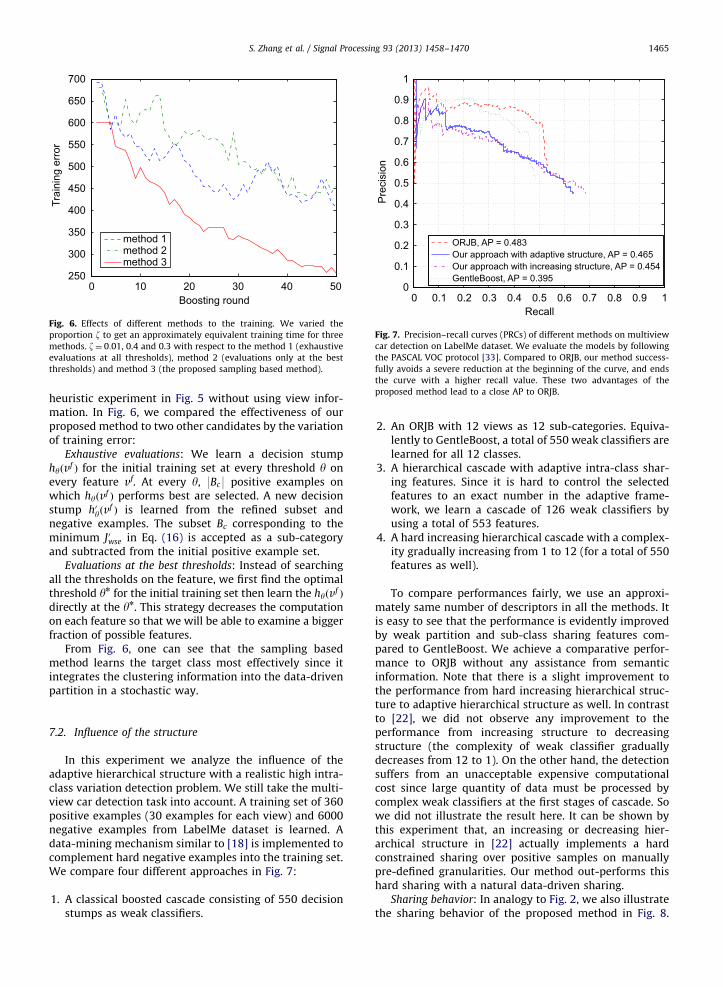
Fig. 6. Effects of different methods to the training. We varied the
proportion z to get an approximately equivalent training time for three
methods. z¼ 0:01, 0.4 and 0.3 with respect to the method 1 (exhaustive
evaluations at all thresholds), method 2 (evaluations only at the best
thresholds) and method 3 (the proposed sampling based method).
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Recall
Pre
cisi
on
ORJB, AP = 0.483Our approach with adaptive structure, AP = 0.465Our approach with increasing structure, AP = 0.454GentleBoost, AP = 0.395
Fig. 7. Precision–recall curves (PRCs) of different methods on multiview
car detection on LabelMe dataset. We evaluate the models by following
the PASCAL VOC protocol [33]. Compared to ORJB, our method success-
fully avoids a severe reduction at the beginning of the curve, and ends
the curve with a higher recall value. These two advantages of the
proposed method lead to a close AP to ORJB.
S. Zhang et al. / Signal Processing 93 (2013) 1458–1470 1465
heuristic experiment in Fig. 5 without using view infor-mation. In Fig. 6, we compared the effectiveness of ourproposed method to two other candidates by the variationof training error:
Exhaustive evaluations: We learn a decision stumphyðv
f Þ for the initial training set at every threshold y onevery feature vf. At every y, 9Bc9 positive examples onwhich hyðv
f Þ performs best are selected. A new decisionstump h0yðv
f Þ is learned from the refined subset andnegative examples. The subset Bc corresponding to theminimum J0wse in Eq. (16) is accepted as a sub-categoryand subtracted from the initial positive example set.
Evaluations at the best thresholds: Instead of searchingall the thresholds on the feature, we first find the optimalthreshold yn for the initial training set then learn the hyðv
f Þ
directly at the yn. This strategy decreases the computationon each feature so that we will be able to examine a biggerfraction of possible features.
From Fig. 6, one can see that the sampling basedmethod learns the target class most effectively since itintegrates the clustering information into the data-drivenpartition in a stochastic way.
7.2. Influence of the structure
In this experiment we analyze the influence of theadaptive hierarchical structure with a realistic high intra-class variation detection problem. We still take the multi-view car detection task into account. A training set of 360positive examples (30 examples for each view) and 6000negative examples from LabelMe dataset is learned. Adata-mining mechanism similar to [18] is implemented tocomplement hard negative examples into the training set.We compare four different approaches in Fig. 7:
1.
A classical boosted cascade consisting of 550 decisionstumps as weak classifiers.2.
An ORJB with 12 views as 12 sub-categories. Equiva-lently to GentleBoost, a total of 550 weak classifiers arelearned for all 12 classes.3.
A hierarchical cascade with adaptive intra-class shar-ing features. Since it is hard to control the selectedfeatures to an exact number in the adaptive frame-work, we learn a cascade of 126 weak classifiers byusing a total of 553 features.4.
A hard increasing hierarchical cascade with a complex-ity gradually increasing from 1 to 12 (for a total of 550features as well).To compare performances fairly, we use an approxi-mately same number of descriptors in all the methods. Itis easy to see that the performance is evidently improvedby weak partition and sub-class sharing features com-pared to GentleBoost. We achieve a comparative perfor-mance to ORJB without any assistance from semanticinformation. Note that there is a slight improvement tothe performance from hard increasing hierarchical struc-ture to adaptive hierarchical structure as well. In contrastto [22], we did not observe any improvement to theperformance from increasing structure to decreasingstructure (the complexity of weak classifier graduallydecreases from 12 to 1). On the other hand, the detectionsuffers from an unacceptable expensive computationalcost since large quantity of data must be processed bycomplex weak classifiers at the first stages of cascade. Sowe did not illustrate the result here. It can be shown bythis experiment that, an increasing or decreasing hier-archical structure in [22] actually implements a hardconstrained sharing over positive samples on manuallypre-defined granularities. Our method out-performs thishard sharing with a natural data-driven sharing.
Sharing behavior: In analogy to Fig. 2, we also illustratethe sharing behavior of the proposed method in Fig. 8.
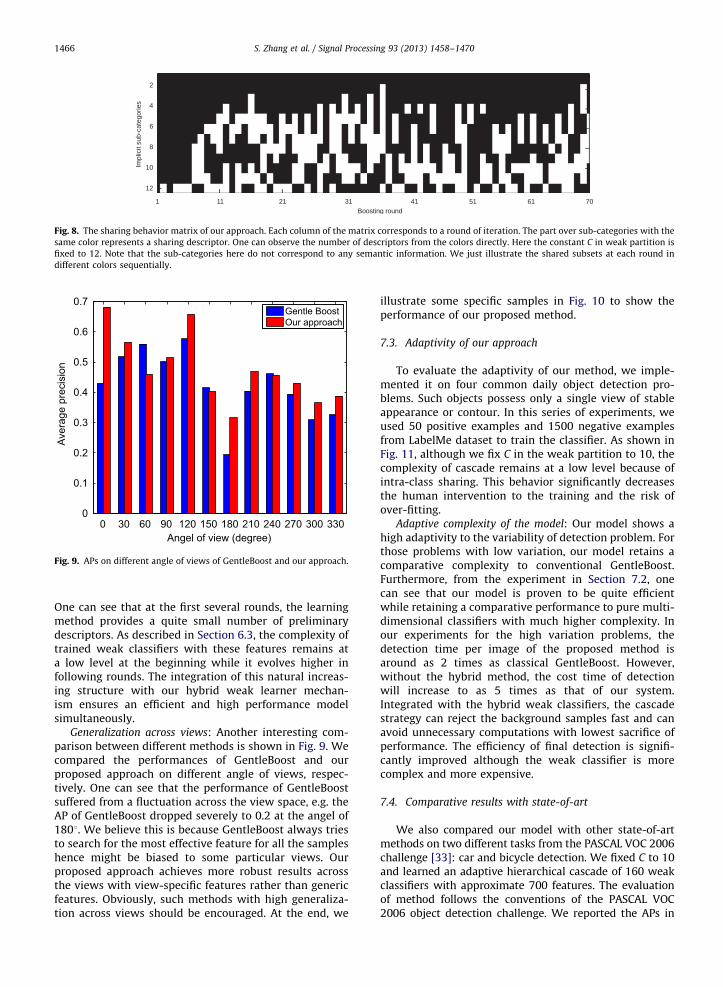
Fig. 8. The sharing behavior matrix of our approach. Each column of the matrix corresponds to a round of iteration. The part over sub-categories with the
same color represents a sharing descriptor. One can observe the number of descriptors from the colors directly. Here the constant C in weak partition is
fixed to 12. Note that the sub-categories here do not correspond to any semantic information. We just illustrate the shared subsets at each round in
different colors sequentially.
0 30 60 90 120 150 180 210 240 270 300 3300
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Angel of view (degree)
Aver
age
prec
isio
n
Gentle BoostOur approach
Fig. 9. APs on different angle of views of GentleBoost and our approach.
S. Zhang et al. / Signal Processing 93 (2013) 1458–14701466
One can see that at the first several rounds, the learningmethod provides a quite small number of preliminarydescriptors. As described in Section 6.3, the complexity oftrained weak classifiers with these features remains ata low level at the beginning while it evolves higher infollowing rounds. The integration of this natural increas-ing structure with our hybrid weak learner mechan-ism ensures an efficient and high performance modelsimultaneously.
Generalization across views: Another interesting com-parison between different methods is shown in Fig. 9. Wecompared the performances of GentleBoost and ourproposed approach on different angle of views, respec-tively. One can see that the performance of GentleBoostsuffered from a fluctuation across the view space, e.g. theAP of GentleBoost dropped severely to 0.2 at the angel of1801. We believe this is because GentleBoost always triesto search for the most effective feature for all the sampleshence might be biased to some particular views. Ourproposed approach achieves more robust results acrossthe views with view-specific features rather than genericfeatures. Obviously, such methods with high generaliza-tion across views should be encouraged. At the end, we
illustrate some specific samples in Fig. 10 to show theperformance of our proposed method.
7.3. Adaptivity of our approach
To evaluate the adaptivity of our method, we imple-mented it on four common daily object detection pro-blems. Such objects possess only a single view of stableappearance or contour. In this series of experiments, weused 50 positive examples and 1500 negative examplesfrom LabelMe dataset to train the classifier. As shown inFig. 11, although we fix C in the weak partition to 10, thecomplexity of cascade remains at a low level because ofintra-class sharing. This behavior significantly decreasesthe human intervention to the training and the risk ofover-fitting.
Adaptive complexity of the model: Our model shows ahigh adaptivity to the variability of detection problem. Forthose problems with low variation, our model retains acomparative complexity to conventional GentleBoost.Furthermore, from the experiment in Section 7.2, onecan see that our model is proven to be quite efficientwhile retaining a comparative performance to pure multi-dimensional classifiers with much higher complexity. Inour experiments for the high variation problems, thedetection time per image of the proposed method isaround as 2 times as classical GentleBoost. However,without the hybrid method, the cost time of detectionwill increase to as 5 times as that of our system.Integrated with the hybrid weak classifiers, the cascadestrategy can reject the background samples fast and canavoid unnecessary computations with lowest sacrifice ofperformance. The efficiency of final detection is signifi-cantly improved although the weak classifier is morecomplex and more expensive.
7.4. Comparative results with state-of-art
We also compared our model with other state-of-artmethods on two different tasks from the PASCAL VOC 2006challenge [33]: car and bicycle detection. We fixed C to 10and learned an adaptive hierarchical cascade of 160 weakclassifiers with approximate 700 features. The evaluationof method follows the conventions of the PASCAL VOC2006 object detection challenge. We reported the APs in
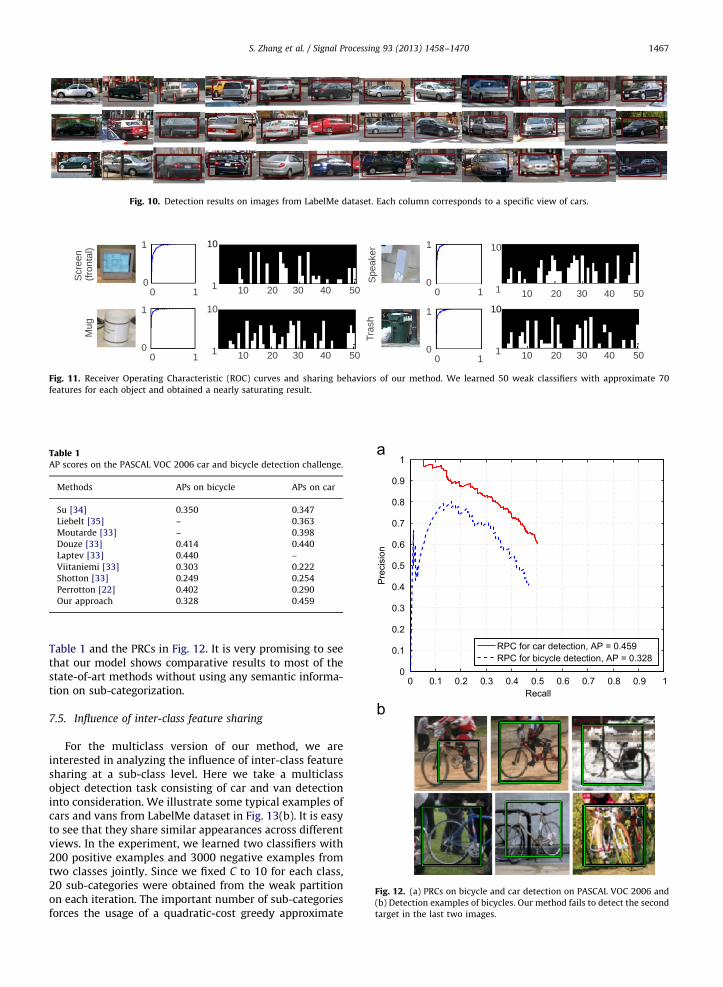
Fig. 10. Detection results on images from LabelMe dataset. Each column corresponds to a specific view of cars.
Fig. 11. Receiver Operating Characteristic (ROC) curves and sharing behaviors of our method. We learned 50 weak classifiers with approximate 70
features for each object and obtained a nearly saturating result.
Table 1AP scores on the PASCAL VOC 2006 car and bicycle detection challenge.
Methods APs on bicycle APs on car
Su [34] 0.350 0.347
Liebelt [35] – 0.363
Moutarde [33] – 0.398
Douze [33] 0.414 0.440
Laptev [33] 0.440 –
Viitaniemi [33] 0.303 0.222
Shotton [33] 0.249 0.254
Perrotton [22] 0.402 0.290
Our approach 0.328 0.459
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Recall
Pre
cisi
on
RPC for car detection, AP = 0.459 RPC for bicycle detection, AP = 0.328
Fig. 12. (a) PRCs on bicycle and car detection on PASCAL VOC 2006 and
(b) Detection examples of bicycles. Our method fails to detect the second
target in the last two images.
S. Zhang et al. / Signal Processing 93 (2013) 1458–1470 1467
Table 1 and the PRCs in Fig. 12. It is very promising to seethat our model shows comparative results to most of thestate-of-art methods without using any semantic informa-tion on sub-categorization.
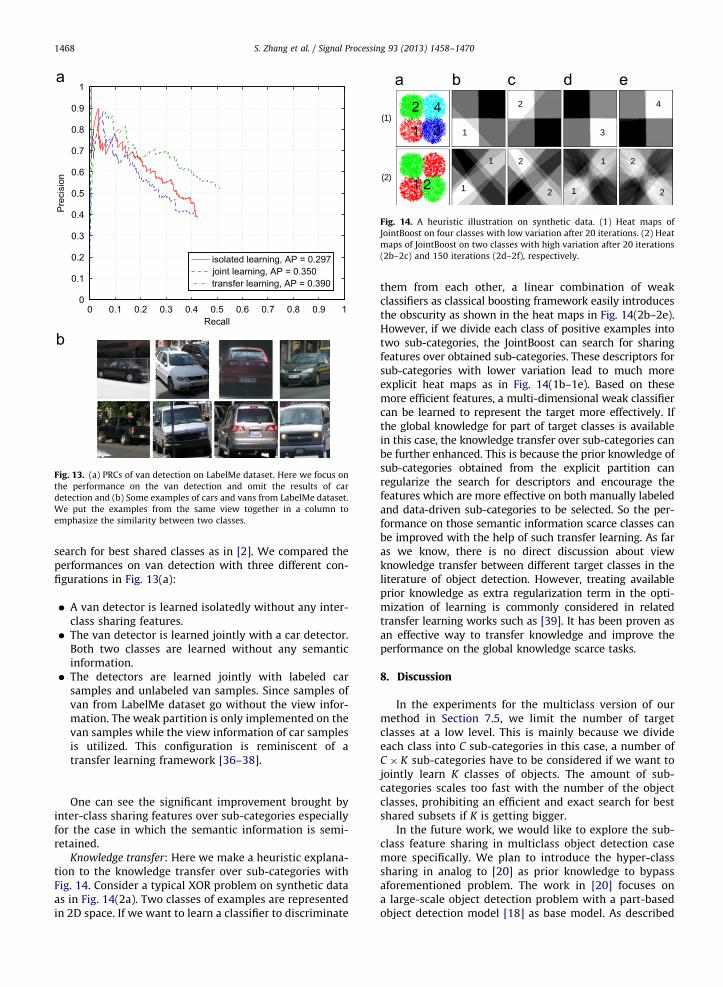
7.5. Influence of inter-class feature sharing
For the multiclass version of our method, we areinterested in analyzing the influence of inter-class featuresharing at a sub-class level. Here we take a multiclassobject detection task consisting of car and van detectioninto consideration. We illustrate some typical examples ofcars and vans from LabelMe dataset in Fig. 13(b). It is easyto see that they share similar appearances across differentviews. In the experiment, we learned two classifiers with200 positive examples and 3000 negative examples fromtwo classes jointly. Since we fixed C to 10 for each class,20 sub-categories were obtained from the weak partitionon each iteration. The important number of sub-categoriesforces the usage of a quadratic-cost greedy approximate
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Recall
Pre
cisi
on
isolated learning, AP = 0.297joint learning, AP = 0.350transfer learning, AP = 0.390
Fig. 13. (a) PRCs of van detection on LabelMe dataset. Here we focus on
the performance on the van detection and omit the results of car
detection and (b) Some examples of cars and vans from LabelMe dataset.
We put the examples from the same view together in a column to
emphasize the similarity between two classes.
Fig. 14. A heuristic illustration on synthetic data. (1) Heat maps of
JointBoost on four classes with low variation after 20 iterations. (2) Heat
maps of JointBoost on two classes with high variation after 20 iterations
(2b–2c) and 150 iterations (2d–2f), respectively.
S. Zhang et al. / Signal Processing 93 (2013) 1458–14701468
search for best shared classes as in [2]. We compared theperformances on van detection with three different con-figurations in Fig. 13(a):
�
A van detector is learned isolatedly without any inter-class sharing features. � The van detector is learned jointly with a car detector.Both two classes are learned without any semanticinformation.
� The detectors are learned jointly with labeled carsamples and unlabeled van samples. Since samples ofvan from LabelMe dataset go without the view infor-mation. The weak partition is only implemented on thevan samples while the view information of car samplesis utilized. This configuration is reminiscent of atransfer learning framework [36–38].
One can see the significant improvement brought byinter-class sharing features over sub-categories especiallyfor the case in which the semantic information is semi-retained.
Knowledge transfer: Here we make a heuristic explana-tion to the knowledge transfer over sub-categories withFig. 14. Consider a typical XOR problem on synthetic dataas in Fig. 14(2a). Two classes of examples are representedin 2D space. If we want to learn a classifier to discriminate
them from each other, a linear combination of weakclassifiers as classical boosting framework easily introducesthe obscurity as shown in the heat maps in Fig. 14(2b–2e).However, if we divide each class of positive examples intotwo sub-categories, the JointBoost can search for sharingfeatures over obtained sub-categories. These descriptors forsub-categories with lower variation lead to much moreexplicit heat maps as in Fig. 14(1b–1e). Based on thesemore efficient features, a multi-dimensional weak classifiercan be learned to represent the target more effectively. Ifthe global knowledge for part of target classes is availablein this case, the knowledge transfer over sub-categories canbe further enhanced. This is because the prior knowledge ofsub-categories obtained from the explicit partition canregularize the search for descriptors and encourage thefeatures which are more effective on both manually labeledand data-driven sub-categories to be selected. So the per-formance on those semantic information scarce classes canbe improved with the help of such transfer learning. As faras we know, there is no direct discussion about viewknowledge transfer between different target classes in theliterature of object detection. However, treating availableprior knowledge as extra regularization term in the opti-mization of learning is commonly considered in relatedtransfer learning works such as [39]. It has been proven asan effective way to transfer knowledge and improve theperformance on the global knowledge scarce tasks.
8. Discussion
In the experiments for the multiclass version of ourmethod in Section 7.5, we limit the number of targetclasses at a low level. This is mainly because we divideeach class into C sub-categories in this case, a number ofC � K sub-categories have to be considered if we want tojointly learn K classes of objects. The amount of sub-categories scales too fast with the number of the objectclasses, prohibiting an efficient and exact search for bestshared subsets if K is getting bigger.
In the future work, we would like to explore the sub-class feature sharing in multiclass object detection casemore specifically. We plan to introduce the hyper-classsharing in analog to [20] as prior knowledge to bypassaforementioned problem. The work in [20] focuses ona large-scale object detection problem with a part-basedobject detection model [18] as base model. As described

S. Zhang et al. / Signal Processing 93 (2013) 1458–1470 1469
in Section 2, the method in [18] provides a high perfor-mance model with high complexity. Based on this part-based model, a number of 200 classes of objects areclustered into small hyper-classes for learning. Eachhyper-class only consists of a few classes of objects.Although here we are more interested in an adaptiveobject detection model with flexible structure, we believethis hierarchical structure working with the concept ofhyper-class will introduce a potential way to decreasecomputation for the case with larger K in our work.
9. Conclusion
In this paper, we introduced a novel algorithm which isable to adapt to the variability of the target class in objectdetection. The algorithm learns a cascade classifier with anadaptive hierarchical structure. Based on JointBoost, ourmodel provides many properties of high interest:
�
a sampling based weak partition method keeps thebalance between performance and efficiency intraining stage; � an adaptive hierarchical cascade structure not only canimprove the performance on high intra-class variationproblems but also can retain a compact structure forlow intra-class variation problems;
� an inter-class feature sharing over sub-categories cantransfer the prior knowledge across classes thusimproves the performance for learning ‘‘tangled’’ sam-ples in multiclass object detection.
Finally, experimental results demonstrate the improve-ments brought by our approach compared to the baselinemethod. We believe our research provides a flexible way totackle problems with different variations in the machinelearning community.
Acknowledgment
The authors greatly thank the handling associateeditor and the anonymous reviewers for their construc-tive comments to this paper. This work is supported bythe National Nature Science Foundation of China (GrantNos. 60672094 & 60971098).
References
[1] P. Viola, M. Jones, Robust real-time object detection, InternationalJournal of Computer Vision 57 (2) (2002) 137–154.
[2] A. Torralba, K. Murphy, W. Freeman, Sharing visual features formulticlass and multiview object detection, IEEE Transactions onPattern Analysis and Machine Intelligence 29 (5) (2007) 854–869.
[3] J. Liu, J. Luo, M. Shah, Recognizing realistic actions from videos‘‘in the wild’’, in: IEEE Conference on Computer Vision and PatternRecognition, 2009, CVPR 2009, 2009, pp. 1996–2003.
[4] Y. Freund, R. Schapire, A decision-theoretic generalization of on-line learning and an application to boosting, in: ComputationalLearning Theory, Springer, 1995, pp. 23–37.
[5] J. Friedman, T. Hastie, R. Tibshirani, Additive logistic regression: astatistical view of boosting, The Annals of Statistics 28 (2) (2000)337–374.
[6] S. Li, Z. Zhang, Floatboost learning and statistical face detection,IEEE Transactions on Pattern Analysis and Machine Intelligence 26(9) (2004) 1112–1123, http://dx.doi.org/10.1109/TPAMI.2004.68.
[7] G. Ratsch, T. Onoda, K. Muller, Soft margins for adaboost, MachineLearning 42 (3) (2001) 287–320.
[8] Y. Liu, L. Si, J. Carbonell, A new boosting algorithm using input-dependent regularizer, in: International Conference on MachineLearning, 2003, pp. 287–320.
[9] F. Fleuret, D. Geman, Coarse-to-fine face detection, InternationalJournal of Computer Vision 41 (1) (2001) 85–107.
[10] C. Huang, H. Ai, Y. Li, S. Lao, High-performance rotation invariantmultiview face detection, IEEE Transactions on Pattern Analysis andMachine Intelligence 29 (4) (2007) 671–686, http://dx.doi.org/10.1109/TPAMI.2007.1011.
[11] E. Seemann, B. Leibe, B. Schiele, Multi-aspect detection of articu-lated objects, in: 2006 IEEE Computer Society Conference onComputer Vision and Pattern Recognition, vol. 2, 2006, pp. 1582–1588. http://dx.doi.org/10.1109/CVPR.2006.193.
[12] B. Wu, R. Nevatia, Cluster boosted tree classifier for multi-view,multi-pose object detection, in: IEEE 11th International Conferenceon Computer Vision, 2007, ICCV 2007, 2007, pp. 1–8. http://dx.doi.org/10.1109/ICCV.2007.4409006.
[13] N. Guan, D. Tao, Z. Luo, B. Yuan, Nenmf: An optimal gradientmethod for nonnegative matrix factorization, IEEE Transactions onSignal Processing 60 (6) (2012) 2882–2898, http://dx.doi.org/10.1109/TSP.2012.2190406.
[14] B. Wu, H. Ai, C. Huang, S. Lao, Fast rotation invariant multi-viewface detection based on real adaboost, in: Sixth IEEE InternationalConference on Automatic Face and Gesture Recognition, 2004,Proceedings, IEEE, 2004, pp. 79–84.
[15] S. Li, L. Zhu, Z. Zhang, A. Blake, H. Zhang, H. Shum, Statisticallearning of multi-view face detection, in: Proceedings of the 7thEuropean Conference on Computer Vision-Part IV, Springer-Verlag,2002, pp. 67–81.
[16] O. Danielsson, B. Rasolzadeh, S. Carlsson, Gated classifiers: boostingunder high intra-class variation, in: 2011 IEEE Conference on Com-puter Vision and Pattern Recognition (CVPR), 2011, pp. 2673–2680.http://dx.doi.org/10.1109/CVPR.2011.5995408.
[17] P. Felzenszwalb, D. McAllester, D. Ramanan, A discriminativelytrained, multiscale, deformable part model, in: IEEE Conference onComputer Vision and Pattern Recognition, 2008, CVPR 2008, 2008,pp. 1–8. http://dx.doi.org/10.1109/CVPR.2008.4587597.
[18] P. Felzenszwalb, R. Girshick, D. McAllester, D. Ramanan, Objectdetection with discriminatively trained part-based models, IEEETransactions on Pattern Analysis and Machine Intelligence 32 (9)(2010) 1627–1645, http://dx.doi.org/10.1109/TPAMI.2009.167.
[19] Y. Wang, G. Mori, Max-margin hidden conditional random fields forhuman action recognition, in: IEEE Conference on Computer Visionand Pattern Recognition, 2009, CVPR 2009, 2009, pp. 872–879.
[20] R. Salakhutdinov, A. Torralba, J. Tenenbaum, Learning to sharevisual appearance for multiclass object detection, in: 2011 IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2011,pp. 1481–1488. http://dx.doi.org/10.1109/CVPR.2011.5995720.
[21] W. Liu, P. Wang, H. Qiao, Part-based adaptive detection of work-pieces using differential evolution, Signal Processing 92 (2) (2012)301–307, http://dx.doi.org/10.1016/j.sigpro.2011.07.017.
[22] X. Perrotton, M. Sturzel, M. Roux, Implicit hierarchical boosting formulti-view object detection, in: 2010 IEEE Conference on ComputerVision and Pattern Recognition (CVPR), 2010, pp. 958–965. http://dx.doi.org/10.1109/CVPR.2010.5540115.
[23] S. Zhang, X. Cheng, N. Li, Z. Wu, Implicit jointboost for multiclassobject detection under high intra-class variation, in: InternationalConference on Information Science and Technology, 2012, ICIST,IEEE, 2012.
[24] R. Schapire, The boosting approach to machine learning: an over-view, in: MSRI Workshop Nonlinear Estimation and Classification,2001, pp. 149–172.
[25] R. Schapire, Y. Singer, Boostexter: a boosting-based system for textcategorization, Machine Learning 39 (2) (2000) 135–168.
[26] L. Bourdev, J. Brandt, Robust object detection via soft cascade, in:IEEE Computer Society Conference on Computer Vision and PatternRecognition, 2005, CVPR 2005, vol. 2, 2005, pp. 236–243. http://dx.doi.org/10.1109/CVPR.2005.310.
[27] D. Lowe, Distinctive image features from scale-invariant keypoints,International Journal of Computer Vision 60 (2) (2004) 91–110.
[28] D. Lowe, Object recognition from local scale-invariant features, in:IEEE International Conference on Computer Vision, vol. 2, 1999,pp. 1150–1157.

S. Zhang et al. / Signal Processing 93 (2013) 1458–14701470
[29] N. Dalal, B. Triggs, Histograms of oriented gradients for humandetection, in: IEEE Computer Society Conference on ComputerVision and Pattern Recognition, vol. 1, 2005, pp. 886–893.
[30] H. Celik, A. Hanjalic, E. Hendriks, Unsupervised and simultaneoustraining of multiple object detectors from unlabeled surveillancevideo, Computer Vision and Image Understanding 113 (10) (2009)1076–1094.
[31] B. Russell, A. Torralba, K. Murphy, W. Freeman, Labelme: a databaseand web-based tool for image annotation, International Journal ofComputer Vision 77 (1) (2008) 157–173.
[32] J. Shotton, J. Winn, C. Rother, A. Criminisi, Textonboost for imageunderstanding: multi-class object recognition and segmentation byjointly modeling texture, layout, and context, International Journalof Computer Vision 81 (1) (2009) 2–23.
[33] M. Everingham, A. Zisserman, C. Williams, L. Van Gool, The PascalVisual Object Classes Challenge 2006 (voc 2006) Results, TechnicalReport, 2006.
[34] H. Su, M. Sun, L. Fei-Fei, S. Savarese, Learning a dense multi-viewrepresentation for detection, viewpoint classification and synthesisof object categories, in: 2009 IEEE 12th International Conference on
Computer Vision, 2009, pp. 213–220. http://dx.doi.org/10.1109/ICCV.2009.5459168.
[35] J. Liebelt, C. Schmid, K. Schertler, Viewpoint-independent objectclass detection using 3d feature maps, in: IEEE Conference onComputer Vision and Pattern Recognition, 2008, CVPR 2008, 2008,pp. 1–8. http://dx.doi.org/10.1109/CVPR.2008.4587614.
[36] R. Raina, A. Battle, H. Lee, B. Packer, A. Ng, Self-taught learning:transfer learning from unlabeled data, in: Proceedings of the 24thInternational Conference on Machine Learning, ACM, 2007,pp. 759–766.
[37] J. Yu, J. Cheng, D. Tao, Interactive cartoon reusing by transferlearning, Signal Processing 92 (9) (2012) 2147–2158, http://dx.doi.org/10.1016/j.sigpro.2012.01.028.
[38] X. Tian, D. Tao, Y. Rui, Sparse transfer learning for interactive videosearch reranking, ACM Transactions on Multimedia Computing,Communications and Applications (2012).
[39] S. Si, D. Tao, B. Geng, Bregman divergence-based regularization fortransfer subspace learning, IEEE Transactions on Knowledge andData Engineering 22 (7) (2010) 929–942, http://dx.doi.org/10.1109/TKDE.2009.126.


![Adaptive Cursor Sharing: An Introduction€¢ Cure against SQL injection ... – Adaptive Cursor Sharing monitoring information. ... AdaptiveCursorSharing.ppt [Compatibility Mode]](https://img.pdfslide.us/doc/110x75/5b237b657f8b9afd2f8b49db/adaptive-cursor-sharing-an-introduction-cure-against-sql-injection-adaptive.jpg)










![Polygonization of implicit surfaces using Delaunay ... · Figure 1: Some steps of the adaptive algorithm presented in section 3. Implicit surfaces [6], or F-Reps [3] represent surfaces](https://img.pdfslide.us/doc/110x75/5eb842c88b9d8c67e84f01c2/polygonization-of-implicit-surfaces-using-delaunay-figure-1-some-steps-of-the.jpg)















