Embed Size (px)
Citation preview

ARTICLE IN PRESS
Journal of Network and Computer Applications 32 (2009) 770– 779
Contents lists available at ScienceDirect
Journal of Network and Computer Applications
1084-80
doi:10.1
� Tel.:
E-m
journal homepage: www.elsevier.com/locate/jnca
Adaptive hierarchical scheduling policy for enterprise gridcomputing systems
J.H. Abawajy �
School of Engineering and Information technology, Deakin University, Geelong, Vic. 3072, Australia
a r t i c l e i n f o
Article history:
Received 22 November 2007
Received in revised form
1 March 2008
Accepted 25 April 2008
Keywords:
Enterprise grid computing
Parallel job scheduling
Coordinated CPU–I/O resources scheduling
High-performance computing
45/$ - see front matter & 2008 Elsevier Ltd. A
016/j.jnca.2008.04.009
+613 5227 1376; fax: +613 5227 2167.
ail address: [email protected]
a b s t r a c t
In an enterprise grid computing environments, users have access to multiple resources that may be
distributed geographically. Thus, resource allocation and scheduling is a fundamental issue in achieving
high performance on enterprise grid computing. Most of current job scheduling systems for enterprise
grid computing provide batch queuing support and focused solely on the allocation of processors to
jobs. However, since I/O is also a critical resource for many jobs, the allocation of processor and I/O
resources must be coordinated to allow the system to operate most effectively. To this end, we present a
hierarchical scheduling policy paying special attention to I/O and service-demands of parallel jobs in
homogeneous and heterogeneous systems with background workload. The performance of the
proposed scheduling policy is studied under various system and workload parameters through
simulation. We also compare performance of the proposed policy with a static space–time sharing
policy. The results show that the proposed policy performs substantially better than the static
space–time sharing policy.
& 2008 Elsevier Ltd. All rights reserved.
1. Introduction
Advances in computational and communication technologieshas made it economically feasible to conglomerate multipleclusters of heterogeneous networked resources and servicesleading to the development of large-scale distributed systemsknown as enterprise grid computing. This new computing plat-form creates a virtual supercomputing, at a fraction of the cost ofthe conventional supercomputers, by harnessing geographicallydistributed computational and storage resources of the enterprise.Fully realized, the enterprise grid computing enables a computingplatform in which all of the enterprise IT resources (i.e., servers,storage, network devices, data stores, and applications) areavailable when and where they are needed most. It enablesenterprises to fully leverage their hardware and software assets aswell as increasing access to distributed data, promoting opera-tional flexibility and collaboration to meet variable demands. Thisenables organizations to reap greater utilization of existinginfrastructure, delays the need to purchase new infrastructureand lower operating costs because of better capacity utilization.
As deployments of enterprise grid computing mature and theirscope expands, the wider benefits of using enterprise gridcomputing are becoming apparent. For example, pharmaceutical
ll rights reserved.
researchers combine knowledge, experience, and scientific pro-cesses with cutting edge instrumentation, software, and compu-ters to discover and develop novel treatments for patients. Whilethe notion of enterprise grid computing is simple enough, thepractical realization poses a number of challenges. At the core ofthe enterprise grid computing challenges and the focus of thispaper is the ability to deploy commodity compute, network, andstorage resources, to provision them on demand, and to efficientlymanage and effectively share those resources among multipleapplications.
The motivation for addressing this problem is that the resourceallocation and scheduling on enterprise grid computing is acomplex problem yet fundamental for sustaining and improvingthe benefits of enterprise grid computing (Chang et al., 2007). Anincreasing number of production applications are being deployedevery day on enterprise grid computing (Gore, 2005). Asenterprise grid computing gains popularity, it is increasinglybeing used for parallel and sequential applications with signifi-cant I/O requirements in addition to compute-intensive paralleland sequential applications (Allcock et al., 2001). This requiresthat grid computing schedulers must bring jobs and data in closeproximity in order to satisfy throughput, scalability, and policyrequirements (Thain et al., 2001). With a large number of usersattempting to concurrently execute jobs on the enterprise gridcomputing, parallelism of the applications and their respectivecomputational and storage requirements, an effective on-linecoordinated allocation of processor and I/O resources that enables

ARTICLE IN PRESS
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779 771
these applications to dynamically share resources with local jobsis required (Abawajy and Dandamudi, 2003).
In this paper, we address the resource allocation and schedul-ing problem. Our contribution is twofold: First, we propose avertically distributed framework that defines bindings betweencomputing power and data resources in heterogeneous enterprisegrid computing. Second, based on this framework, we propose anapproach to scheduling jobs with CPU and I/O resource require-ments in shared heterogeneous enterprise grid computing. Theproposed policy is demand driven, in order to take into accountdynamicity of computing resources, and shares the systemresources both spatially and temporally. It also combines self-scheduling and affinity-scheduling approaches into a unifiedframework such that data locality is taken into account whenmapping jobs to resources while balancing the load among theclusters in the system. Moreover, the decision making process isalso distributed among several schedulers thereby improvingfault-tolerance and scalability of the system. This approach alsoimproves overall resource utilization. Performance of the pro-posed scheduling policy is studied under various system andworkload parameters. Also, we compare the proposed schedulingpolicy against static space–time sharing policy (Rosti et al., 1998).The results show that the proposed policy performs substantiallybetter than the static space–time sharing policy.
The rest of the paper is organized as follows. In Section 2, thebackground and related work is presented. In Section 3, theproposed vertically distributed framework that defines bindingsbetween computing power and data resources is discussed. InSection 4, we discuss the proposed scheduling policy. In Section 5,the baseline scheduling algorithms used to compare the proposedscheduling policy is discussed (Rosti et al., 1998). In Sections 6and 7, the performance analysis of the proposed policy and resultsof the experiments are discussed, respectively. The conclusionsand future directions are given in Section 8.
2. Background
In this section, we will formulate the job scheduling problemand discuss related work. The grid infrastructure that couplesenterprise distributed resource is discussed. Related work is alsodiscussed.
2.1. Distributed resource federation infrastructure
Enterprise grid computing consist of resources spread acrossan enterprise and provide services to users within that enterpriseand are managed by a single organization (Alliance, 2005). Theycan be deployed within large corporations that have a globalpresence though they are limited to a single enterprise. Anefficient mechanism that loosely couples disparate resources andallocate them to user jobs are important components of theenterprise grid computing.
Existing grid infrastructure deployments simply couple adistributed resource manager with a cluster of dedicatedmachines (Gore, 2005). The grid-federation (Ranjan et al., 2008)system defined a grid computing that consists of cluster resourcesthat are distributed over multiple administrative domains,managed and owned by different organizations having differentresource management policies. It has no functions for accessingremote data repositories and for optimizing on data transfer. Incontrast, the proposed framework defines bindings betweencomputing power and data resources.
The condor team (Thain et al., 2001) described a system whichmatches data and jobs. However, many applications will requirenot just the discovery of data but also of more arbitrary types of
resources as well. We believe that aggregation of many resourcesis not enough to get good performance—careful scheduling of thejobs must be employed to achieve the best performance possible.Moreover, the users are expected to express relationships betweenthe jobs and the data.
In this paper, we discuss an infrastructure (Section 3) togetherwith resource allocation and scheduling (Section 4) that offers asingle, cohesive management environment that allocates theshared resources across geographically dispersed sites for allmission-critical enterprise applications, services, and workloads.The proposed framework does not require user intervention and itnicely complements the work of Thain et al. (2001).
2.2. Resource scheduling problem
The scheduling problem of interest is defined as the process ofmaking scheduling decision involving resources and services overmultiple sites. Specifically, given a system composed of multipleclusters, each cluster with P sharable workstations and D disks, wewant to design an online scheduling policy that schedules a set ofJ jobs that arrive into the system in a stochastic manner with theobjectives of minimizing the average job completion times andmaximizing the system utilization. Job scheduling is generallycomposed of at least two interdependent steps:
�
the allocation of tasks to the processors (i.e., space sharing) and � the scheduling of the tasks over time (i.e., time sharing).There are various forms of space-sharing approaches wherethe processors are partitioned into disjoint sets and eachapplication executes in isolation on one of these sets (e.g.,Abawajy, 2008). In time-sharing policies, processors are sharedover time by executing different applications on the sameprocessors during different time intervals. As space-sharing andtime-sharing approaches are orthogonal to each other, it is alsopossible to combine them in various ways as in Thanalapati andDandamudi (2001).
As note in Gore (2005), enterprises follow a tiered procurementstrategy of computing resources under the assumptions that mostworkers can get by with a basic machine (a single processor and alittle memory), some users require more power (a faster processorand more memory), and a small number of workers—likeengineers, designers, and planners—might need the fastestmachines with two processors and lots of memory. This in factleads to a heterogenous resources. Therefore, an enterprise gridcomputing scheduling policy must take into account the resourceheterogeneous when allocating resources to jobs.
In this paper, we are interested on parallel jobs that requirecomputing facilities and data access and storage to be executed.For such applications, scheduling involves effective and coordi-nated computation and data management mechanisms (Abawajyand Dandamudi, 2003; Chang et al., 2007). With a large number ofusers attempting to concurrently execute jobs on the enterprisegrid computing, parallelism of the applications and their respec-tive computational and storage requirements are all issues thatmake the resource scheduling problem difficult in these systems.
Therefore, the problem of coordinated job and data schedulingis very complex one (Desprez and Vernois, 2005). The on-lineaspect of the scheduling as well as the heterogeneity anddynamically changing load of the resources increase the complex-ity of the scheduling problem on enterprise grid computing. To thebest of our knowledge, there is no resource allocation mechanismthat addresses the problem of on-line coordinated allocation ofprocessor and I/O resources in large-scale shared heterogeneousenterprise grid computing systems.

ARTICLE IN PRESS
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779772
2.3. Related work
Although many scheduling techniques for various computingsystems exist, traditional scheduling systems are inappropriate forscheduling tasks onto grid resources (Abawajy, 2003; Jiang et al.,2007). Most of current job scheduling systems for enterprise gridcomputing provide batch queuing support and focused solely onthe allocation of processors to jobs. For example, an efficient two-level adaptive space-sharing processor scheduling policy for non-dedicated heterogeneous commodity-based high-performanceclusters is discussed in Abawajy (2008). A number of economic-based resource allocation and scheduling approaches have alsobeen proposed (Liang et al., 2007). The approach taken here is toincorporate economic mechanisms into the resource allocationsystem.
Economic-based resource allocation and scheduling are said tomotivate users to reveal the true job value, promote thecontribution of surplus resources, and meet the multiple objec-tives of end users by optimizing the aggregated user job value.However, often the resource performance characteristics areassumed to be perfectly predictable and full knowledge of currentloads, network conditions and topology are assumed. Theseassumptions do not reflect the dynamic and heterogeneousnature of cluster computing systems, thus making them imprac-tical for the environments of interest to us. Similarly, variousmechanisms such as data replication (Deris et al., 2008) and I/Oscheduling (Abawajy, 2006) have been studied to address the I/Obottleneck problems.
However, the allocation of processor and I/O resources must becoordinated to allow the system to operate most effectively. Tothis end, a number of approaches that combine job and datascheduling algorithms on the conventional grid computing hasbeen reported (Mohamed and Epema, 2004; Venugopal et al.,2006; Ranganathan and Foster, 2002). In the close-to-filesalgorithm (Mohamed and Epema, 2004), a job is scheduled tothe clusters with enough idle processors which are close to thesites where the input files present. A scheduling of sequential jobsusing a simplified first-in-first-out (FIFO) strategy with a singleCPU–I/O phase in isolation under the assumption that the jobsarrive into a homogeneous dedicated system in a predictablemanner is discussed in Ranganathan and Foster (2002). Anothersimilar work is the data grid resource broker (Venugopal et al.,2006) but under heterogeneous resources that are shared bymultiple user jobs. However, performance is analyzed with theassumption that jobs have been allocated to certain computingelements.
Another set of studies have focused on data replication toimprove the performance of jobs in data grid environments(Chang et al., 2007; Chakrabarti et al., 2004). In Tang et al. (2005),the performances of the data replication algorithms combinedwith different Grid scheduling heuristics were evaluated throughsimulations. Network and storage capacities limits both thenumber of replicas that may be made as well as the number ofjobs that may use each replica (Thain et al., 2001).
There is very little work in coordinated allocation of processorsand I/O resources that addresses the problem of on-linecoordinated allocation of processor and I/O resources in large-scale shared heterogeneous enterprise grid computing systems(Abawajy and Dandamudi, 2003). The few centralized staticspace-sharing approaches that exist are based on simplifiedsystem and workload assumptions. Moreover, static space-sharing policies can lead to the resource fragmentation problem(Thanalapati and Dandamudi, 2001) that has serious impact onthe system performance. This is specially true in enterprise gridcomputing environments where resource availability can changedynamically. Our work does not require information collection as
we use demand-driven approach. Also, we assume a sharedheterogeneous system in which a mix of compute and CPU–I/Obound jobs arrive to the system in a stochastic manner. Inaddition, we concentrate on a distributed and more scalablemodel, in which each site takes informed decisions based on itsview of the system state. Unlike existing approaches in which jobsare assumed deterministic, we assume that job completion timesare not predictable. Last but not least, our approach combinesboth space-sharing and time-sharing scheduling policies.
The closest approach to our work is that of Rosti et al. (1998).However, there are several differences between our work and thatof Rosti et al. (1998). For example, we consider affinity scheduling,whereas Rosti et al. (1998) does not as they assume that the dataneeded by the jobs are already present locally. In addition, thework of Rosti et al. (1998) is concerned with dedicated andhomogeneous parallel systems, whereas we consider sharedheterogeneous cluster computing systems. Job scheduling oncluster computing systems, unlike the traditional multiprocessorsystems, poses several technical challenges in achieving goodperformance and higher system utilizations. For example, perfor-mance of I/O in multiprocessor systems is most often limited bydisk bandwidth, though the performance of other components ofthe system such as the interconnection network can at times be alimiting factor. However, on shared heterogeneous cluster com-puting, the heterogeneity of the processors and the I/O resources,the dynamically varying demands on resources, and the run-timevariations of resource availability further complicates the jobscheduling problem.
Moreover, jobs may execute at sites that are distant from theirdata. This leads to a remote I/O access across networks, thus theI/O cost is many times worse than a local I/O cost. Therefore, whatis lacking is an approach that combines processor and I/Oresources scheduling while addressing the unique requirementsof the cluster computing environments, which is the goal of ourwork.
3. System architecture
With the large scale growth of networks and their connectivity,it is possible to couple dispersed enterprise resources as a part ofone large enterprise grid computing. In this section, we propose aframework that defines bindings between computing power anddata resources for large-scale enterprise grid computing.
Fig. 1 shows an abstract model of the enterprise gridcomputing architecture of interest. There are P shareable(i.e., community-based) workstations that can be grouped intoclusters according to their architectures, processing speed, andphysical locations. In our case, a cluster is geographically compactand contains a set of workstations of similar architecture. Weassume the enterprise grid system is composed of a set ofprocessors connected to local area networks (LANs), where theLANs are connected into a wide area network (WAN). Processes ondifferent processor can only communicate by sending messagesover the network.
We organize the system resources logically in the form ofL-levels deep tree of schedulers, where LX1 as shown in Fig. 1. Werefer to the resulting system architecture as a cluster tree. Thenumber of children of any node in the cluster tree is referred to asits branching factor and all processors reachable from a givenscheduler as its partition-reach.
At the top of the cluster tree, there is a system scheduler (SS)while at the leaf level, local schedulers run on each processor. Inbetween these two schedulers, there exists a hierarchy of clusterschedulers (CS). The internal nodes represent the higher levelorganizational structure and each node acts as a negotiator for the

ARTICLE IN PRESS
Data Scheduler
Local I/O
P4 P5 P6
LAN
Cluster N
Cluster Scheduler
Cluster Scheduler
Cluster Scheduler
Cluster Scheduler
Cluster Scheduler
Cluster Scheduler
Cluster Scheduler
Cluster Scheduler
System Scheduler
Level 3
Level 2
Data Scheduler
Local I/O
P1 P2 P3
LAN
Cluster 1
Remote I/O
Level 1
Level 0
Cluster Scheduler
Fig. 1. An overview of the enterprise grid computing system architecture.
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779 773
nodes below it. These nodes can only make requests for resourcesprovided by the lower level nodes, not demands.
We say that a node is in sender state if it has unassignedcomputation while a node that has initiated self-scheduling is saidto be in pending state. A node that is not in sender or pendingstate is said to be in neutral state. We assume that each processorin the system runs a round-robin time sharing local schedulingpolicy.
We use the parameter multiprogramming level (MPL) tocontrol the number of tasks among which the processor is time-shared at any given time. Since the processors may have differentprocessing speed, the MPL of a given processors is determined asfollows:
MPL ¼CPU speed� Basic MPL
slowest processor speed(1)
The proposed scheduling model is hierarchical in nature, as isthe grid itself. In fact, it has a recursive structure for the internalnodes. The external nodes, or leaves, are the lowest level at whicha resource can be addressed, for example, a machine (note that thepicture only goes down to the ‘‘real’’ leaves for one small portionof the graph). The leaves themselves have true control over theresources represented there. That is where the ultimate schedul-ing decision is made.
Jobs are submitted to the SS where they are placed in the jobwait queue until a placement decision is made. For the most part,applications in enterprises maintain their data on persistentstorage–in file systems or databases. These applications increas-ingly reside on networked storage (SAN and/or NAS architectures).Any data required to run a job is fetched before the task is run if itis not already present.
All I/O requests from a job are sent to the data scheduler in theI/O subsystem, which coordinates the I/O requests on multiple I/Onodes for greater efficiency. Upon arrival, if an I/O request cannotbe serviced immediately, it is placed in an I/O wait queue. Whenan I/O device becomes available, the scheduler schedules apending request from the wait queue using the FCFS policy. Whenthe job and the I/O server are located in different clusters we saythat the I/O request is a remote request but if they are in the samecluster we say that the I/O request is a local request.
The proposed infrastructure enables virtualization of theenterprise resources so that they may be provisioned for specifictasks as demands require. It provides fully integrated manage-ment of the whole compute and storage grid as if it were a singlesystem whether the network scales out by adding disks and otherstorage devices, or scales up by aggregating the performance and
other capabilities of its component. The infrastructure togetherwith the resource allocation and scheduling provide coordinationof resources, application load balancing and data managementservices that controls data access and movement around anetwork. Leveraging enterprise grid computing solutions canprovide an opportunity to solve problems previously out of reachwith stand alone resources. Business problems that could besolved include: time to market for portfolio analysis, wealthmanagement analysis and risk reports for capital markets; speedand accuracy for actuarial analysis; bottlenecks in product designand development cycles; elapsed time, accuracy and frequency forengineering simulations and tests (Gore, 2005).
4. Enterprise grid computing scheduling policy
In this section, based on the vertically distributed frameworkpresented in the previous section, we propose an approach toscheduling jobs with CPU and I/O resource requirements in thepresence of other jobs (e.g., local jobs) in heterogeneousenterprise grid computing environment.
4.1. Adaptive hierarchical scheduling policy
We refer to the proposed scheduling algorithm as adaptivehierarchical scheduling (AHS) policy. Algorithm 1 shows the AHSpolicy in a pseudo-code form. AHS integrates job assignment,affinity-scheduling, and self-scheduling approaches into a unifiedframework to assign resources to parallel jobs. This is achieved byexploring the parent–child relationship between the nodes in thecluster tree (see Fig. 1). In the algorithm, we have a queue formaintaining unscheduled jobs/tasks (i.e., QUEUE (job)) and aqueue for maintaining unsatisfied request for work (i.e., QUEUE(RFC)). The level ( ) is a Boolean function that takes in ‘‘root’’ or‘‘leaf’’ as input and returns true or false.
Algorithm 1. Adaptive hierarchical scheduling.1: if state(neutral)¼¼true then2: if level (root) ¼¼true then3: if (QUEUE(job)¼¼ �) then4: Backlogs the request5: else6: Perform job/task assignment7: end if8: end if (level (root) a true) ^ (level (leaf) a true) then9: if (QUEUE(job)¼¼ �) then

ARTICLE IN PRESS
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779774
10: if (QUEUE(RFC)¼¼ �) then11: Send request for computation to parent node12: end if13: Backlogs the request14: else15: Perform job/task assignment16: end if17: else18: Request computation from parent node19: end if20: end if
When a non-root node is in an neutral state, it initiates self-scheduling by sending a request for computation (RFC) message toits parent node requesting for Rwork ¼ 1 computation. If the parentnode is in the neutral state at the time of receiving the RFC, it inturn generates its own RFC and sends it to its parent on the nextlevel of the cluster tree. This process is recursively followed untilthe RFC reaches the SS or a node with unassigned computation isencountered along the path. In case the RFC reaches the SS, itbacklogs the request if there are no jobs waiting to be scheduled.
If the SS or a node along the hierarchy with unassignedcomputation is found, the scheduler applies the space-sharingpolicy (i.e., job/task assignment) to the waiting jobs. The job/taskassignment component of the algorithm allows a set of jobs/tasksto be selected for transfer from a parent node to a child node. Thealgorithm first determines an ideal number of jobs that can bemoved down one level from the parent node to the child node as asingle assignment as follows:
Nideal ¼ Tr � Nwork
� �. (2)
where Nwork is the number of jobs waiting to be scheduled whenthe RFC from a child node arrives at the parent node and Tr is thetransfer factor, which is defined as follows:
Tr ¼partition-reach of the child node
partition-reach of the parent node(3)
Once the ideal number of computations to be transferred isdetermined as per Eq. (2), the algorithm applies affinity schedul-ing, which selects Nsend jobs from the parent job wait queuedetermined as follows:
Nsend ¼minðNhome;NidealÞ if affinity
Rwork otherwise
((4)
where Nhome are jobs that have their data within the partition-reach of the child node. The Jsend jobs are then assigned apartition-size (i.e., a set of processors) equal to the partition-reachof the child node on which these jobs can possibly execute. Notethat if there is no computation that meets the affinity condition,the actual number transferred down one level from the parent tothe child node is set to 1. At the last level CS, each job ispartitioned into its constituent tasks and are assigned toprocessors on demand from the later. Each processor appliestime-sharing policy on the tasks in its local ready queue.
4.2. Illustration of AHS policy
We now illustrate how the AHS policy works through a simpleexample. Assume that there are nine unscheduled jobs at the SSwhile first-level and second-level CS are both in the neutral state.Also assume that there are nine clusters in the system, eachcluster has four processors. Further assume four out of the ninejobs at the SS have their data located at cluster 2.
Suppose that at some point in time, processor P1 sends an RFCmessage to its parent which is the CS at level 1. Since the CS at
both levels are in the neutral state, the RFC will eventually reachthe SS. When the SS receives the RFC, it applies space-sharing tothe nine jobs in the job waiting queue, which results in three jobsbeing transferred one level down to CS. By this move, these threejobs are assigned a partition-size equal to the number ofprocessors reachable from CS at level 2.
When CS receives the three jobs, it also applies space-sharingto the three jobs, which results in one of the jobs being dispatchedto CS at level 1. This means the partition-size of the job is now setto the four processors in cluster 2. At this point, the job is split intofour tasks and one of the tasks is then sent to P1 while theremaining three tasks are queued in the task wait queue so thatany of the four processors within the cluster 2 can execute them.Notice that this process leaves varying number of tasks and jobsalong the path. Thus, it is not necessary for some queries fromother processors to reach the SS to get work.
5. Baseline scheduling algorithm
The complexity and dynamic nature of the system make itinfeasible to compare the proposed policy against an optimalschedule. For instance, the differences in processor load andavailable memory across the machines in the testbeds changefrequently. Finding the optimal schedule requires a way to predictthese changes in order to choose the optimal node for each task.Such a prediction in even a simple cluster system is difficult, if notimpossible. For these reasons, we compare our scheduling policywith the static space sharing with time-sharing (SST) policyproposed in Rosti et al. (1998). The reason for choosing the SSTpolicy is that it is the closest policy to our policy discussed in theprevious subsection.
The SST policy is a two-level scheduling policy and partitionsthe set of P processors and N disks in the system into a set ofdisjoint clusters and assigns parallel jobs to a processor-disk pairpartition such that at most MPL number of jobs are present in agiven processor-disk pair partition at any given time. Since theoriginal policy did not consider data locality as well as hetero-geneity, we slightly modified the original SST policy such thataffinity scheduling and heterogeneity of the systems are takeninto account when making the job placement decisions.
The modified SST policy works as follows: When the scheduleris activated by the arrival of new jobs or completion of a job, apartition where the data associated with the job is located ischosen first. If this fails, a job is assigned to processor-disk pairpartition where both partitions are idle and if there are more thanone such pairs, the fastest partition is chosen. Last but not least, ifthere is no idle processor-disk pair, a pair where at least one of thetwo partitions is idle is selected. Otherwise, if there is ascheduling slot where both partitions are already busy with lessthan MPL jobs each, then the job is scheduled onto it. If the jobcannot be assigned to a partition upon arrival, it then waits in theFCFS queue until a partition becomes free.
6. Performance evaluation
6.1. Experimental methodology
We used a discrete event simulation to compare the AHS andSST scheduling policies. The simulator was written in C and hasbeen used in many studies including (Abawajy and Dandamudi,2003; Abawajy, 2008). In the simulation, a set of J parallel jobsarrive at a system. Each job is defined by the arrival time (i.e., thesubmission time), the number of processors requested(i.e., maximum parallelism), and the execution time of the job

ARTICLE IN PRESS
Table 2Processor type and speed used in the simulation
System name Base Relative
SE440BX-2 (650 MHz, P3) 204 0.40
VC820 (1.0 GHz, P3) 273 0.53
OR840 (1 GHz, P3) 327 0.62
D850GB (1.4 GHz, P4) 529 1.00
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779 775
(i.e., service demand). We assume that none of these parametersare known in advance. Also there is no correlation between thedifferent parameters. For example, with small number of tasksmay have a long execution time. In real systems, the degree ofparallelism, the inter-arrival rates and the service demands of thejobs can vary (Karatza, 2004) and these variabilities have beencaptured in the simulation by using the coefficient of variation ofthe inter-arrival times and the coefficient of variation of servicedemand.
In the results below, we consider aggregate performancemeasures, i.e., average statistics computed for an entire simula-tion run, giving a single quantifiable measure for the entireworkload. The performance measure of interest to compare theperformance of the scheduling policies discussed in this paper isthe mean response time (MRT) (Thanalapati and Dandamudi,2001; Rosti et al., 1998). We define the MRT as the averageresponse time of N jobs as follows:
MRT ¼1
N�XN
i¼1
RðJiÞ (5)
where RðJiÞ, is the response time of a given job Ji and is defined asfollows:
RðJiÞ ¼ TfinishðJiÞ � TsubmitðJiÞ (6)
where TfinishðJiÞ and TsubmitðJiÞ denote the completion and submis-sion times of job Ji, respectively.
We used the independent replication method to validate theresults. For every mean value, a 95% confidence interval wascomputed. All confidence intervals were within 5% of the meanvalues.
6.2. System model
We assume the enterprise grid computing of interest iscomposed of a set of processors connected to LANs, where theLANs are connected into a WAN. Processes on different processorcan only communicate by sending messages over the network.
Table 1 shows the default system and workload parametersused in the simulation. The system consists of eight clusters, eachwith eight workstations. Each cluster also has one high perfor-mance community storage server (i.e., disk). We create a 4-levelscluster tree with the root as the SS, four second-level CS that act aschildren of the SS, and 64 local schedulers at the bottom.
Each workstation is connected to a 100 Mbps fast Ethernetswitch, which in turn is connected via gigabit Ethernet switches.Also, each workstation is equipped with a disk delivering atransfer rate of approximately 5 MBytes/s. We used 200ms for thecontext switch overhead and 100 ms for the time-slice, which isconsistent with most of modern operating system for work-stations.
6.2.1. Heterogeneity
We study a HETR based only on CPU speed of the workstations.In order to model processor speeds, we used the SPECfp2000results for a family of Intel Pentium 3 and 4 processors with
Table 1Default parameter values used in the experiments
Parameters Values Parameters Values
Parallel job mean service demand 20.0 I/O factor 50%
Local job mean service demand 2.0 Latency 50ms
Parallel job arrival CV 1.0 Bandwidth 100 Mbps
Number of clusters 8 Disks in a cluster 1
Service demand CV 3.5 MPL 2
different clock speeds. Table 2 shows the four types of Pentiumprocessors used in our experiments. The relative ratings column inthis table gives the node rating relative to the slowest node in thesystem.
6.2.2. Communication cost
We assume that intra-cluster interconnect is myrinet and atthe MPI level, we get one-way latency of 7:0ms and one-waybandwidth of 250 MBytes/s. For the inter-cluster, the commu-nication time (Tcomm) is modeled as the time required fortransferring data across the available network bandwidth asfollows (Ranganathan and Foster, 2002):
Tcomm ¼ StartupþMessage size
Bandwidth(7)
It has been shown that this simple communication model, whichaccounts for message startup time and network bandwidth, givesadequate results (Thanalapati and Dandamudi, 2001). In all theexperiments discussed here, the inter-cluster communicationnetwork latency is set to 50ms and the transfer rate to100 MBytes/s. These values are typical of modern light-weightmessaging layers running on top of gigabit switched LANs.
6.3. Workload models
In this subsection, we describe the workload types andcharacteristics that the enterprise grid computing is expected tobe processing.
6.3.1. Background workload models
Each workstation services a stream of background tasks thatarrive at individual workstations independently. As in Ryu andHollingsworth (2000), we model the arrival process and servicedemand of the background jobs with an exponential distributionand a 2-stage hyper-exponential distribution, respectively. Unlessotherwise specified, background load utilization is fixed at 30%.This is reasonable as workstation utilization studies have foundthat workstations are available two-thirds of the time (Ryu andHollingsworth, 2000). We study the impact of backgroundworkload utilization on the performance of the two policies inSection 7.6.
6.3.2. Parallel workload models
The parallel workload considered in this paper is characterizedby the following three parameters: the arrival time, the maximumdegree of parallelism, and the service demand. These parametersalong with the job structure define the parallel workload. Jobsarrive into the SS with Poisson inter-arrival times. The maximumparallelism of the jobs is uniformly distributed over the range of1–32, while the service demands of the jobs are generated usinghyper-exponential distribution with mean 20.0 and CVs ¼ 3:5.These distributions represent real parallel system workloads asdiscussed in Karatza (2004), Kwong and Majumdar (1999) andThanalapati and Dandamudi (2001).
ARTICLE IN PRESS
0
100
200
300
400
500
600
700
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Mea
n R
espo
nse
Tim
e
Utilization
W1-Workload
AHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 2. Performance as a function of system utilization for W1.
0
200
400
600
800
1000
1200
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Mea
n R
espo
nse
Tim
e
Utilization
W2-Workload
AHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 3. Performance as a function of system utilization for W2.
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779776
In the simulation, we used a percentage of the arriving jobs areCPU–I/O intensive while the remaining ð1� aÞ fraction of the jobsare CPU-bound, where a is uniformly distributed over the range of0–1.0 (Kwong and Majumdar, 1999). We studied two CPU–I/Obound workloads referred to as W1 and W2, which are the sameworkloads used in Kwong and Majumdar (1999). These twoworkloads are characterized by alternating CPU and I/O phasesthat repeat K times as observed in Rosti et al. (2002).
In W1 workload, the number of phases is set to two while inW2 workload, it is set to 12. Each phase consists of a single burstof I/O with a minimal amount of computation followed by a singleburst of computation with a minimal amount of I/O. For example,each task uses the CPU for an average of 5 ms between making20-ms I/O request. We use the model presented in Rosti et al.(2002) and Kwong and Majumdar (1999) to determine theproportion of the computation and I/O times for each task asfollows:
Tn ¼ TIOn þ TCPU
n (8)
where Tn is the time or length of the nth phase, TIOn is the time it
takes to service the I/O request, and TCPUn is the computation
service time of the phase. We can define the fraction of the nthphase that represents the length of the I/O burst in a given phaseas follows:
TIOn ¼ Tn � f IO (9)
where f IO is the I/O factor, which defines the I/O to CPU ratio per agiven phase (Kwong and Majumdar, 1999). Each task of the jobbegins execution by reading its input data from an I/O device andthen execution proceeds by alternating cycles of computation andI/O. We assume that a job requires a single input file as the work ofMohamed and Epema (2004) shows that usually most fileoperations are performed by a process on a single file. The lastoperation of each task is writing its data to an I/O device andwhen all the tasks of the job have finished their last writes, the jobterminates.
Any data required to run a job is fetched before the task is runif it is not already present locally. The location of the data for agiven job is determined uniformly between 1 to the number ofclusters in the system. Note that when W1 and W2 jobs are splitinto n tasks, the number of I/Os do not change, but the amount ofdata being written/read changes. This is captured in our model byincreasing/decreasing the service requirements at the I/O center.A lot of parallel scientific codes work this way, and this is the sameapproach used in Rosti et al. (2002).
7. Simulation results and discussions
In this section, we present performance characteristics of thescheduling algorithm on the simulated enterprise grid computingand a comparison with the baseline scheduling strategy. We havecarried out extensive simulation analysis of the proposedscheduling policy but due to space limitations, we present a fewsample results in this section.
In all graphs, we append HOMO and HETR to the names of theworkloads (e.g., W1-HOMO) to denote the performance of theworkload in shared homogeneous (HOMO) environments andshared heterogeneous environments (HETR), respectively. Also,parameters are set to their default values as shown in Table 1unless explicitly stated otherwise.
7.1. Relative performance as a function of utilization
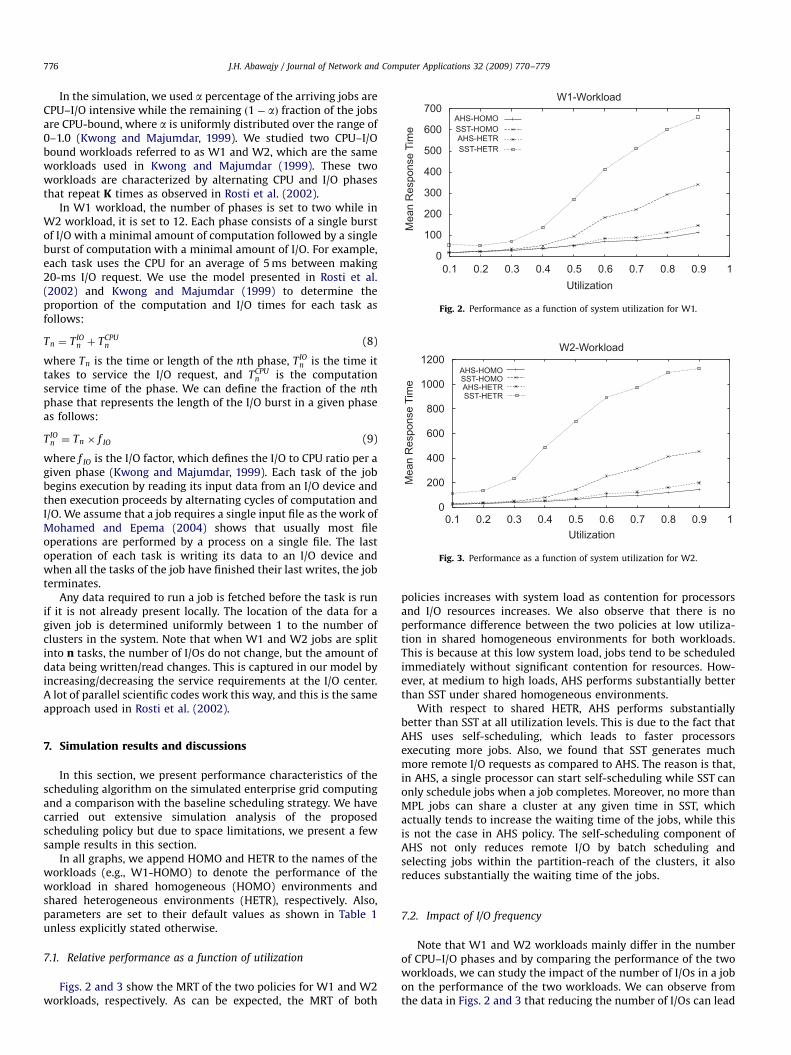
Figs. 2 and 3 show the MRT of the two policies for W1 and W2workloads, respectively. As can be expected, the MRT of both
policies increases with system load as contention for processorsand I/O resources increases. We also observe that there is noperformance difference between the two policies at low utiliza-tion in shared homogeneous environments for both workloads.This is because at this low system load, jobs tend to be scheduledimmediately without significant contention for resources. How-ever, at medium to high loads, AHS performs substantially betterthan SST under shared homogeneous environments.
With respect to shared HETR, AHS performs substantiallybetter than SST at all utilization levels. This is due to the fact thatAHS uses self-scheduling, which leads to faster processorsexecuting more jobs. Also, we found that SST generates muchmore remote I/O requests as compared to AHS. The reason is that,in AHS, a single processor can start self-scheduling while SST canonly schedule jobs when a job completes. Moreover, no more thanMPL jobs can share a cluster at any given time in SST, whichactually tends to increase the waiting time of the jobs, while thisis not the case in AHS policy. The self-scheduling component ofAHS not only reduces remote I/O by batch scheduling andselecting jobs within the partition-reach of the clusters, it alsoreduces substantially the waiting time of the jobs.
7.2. Impact of I/O frequency
Note that W1 and W2 workloads mainly differ in the numberof CPU–I/O phases and by comparing the performance of the twoworkloads, we can study the impact of the number of I/Os in a jobon the performance of the two workloads. We can observe fromthe data in Figs. 2 and 3 that reducing the number of I/Os can lead
ARTICLE IN PRESS
0
50
100
150
200
250
300
350
400
2 3 4 5 6 7 8 9 10
Mea
n R
espo
nse
Tim
e
Service Demand CV
W1-Workload-CVS
AHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 4. W1 sensitivity to service demand variations.
0
100
200
300
400
500
600
700
2 3 4 5 6 7 8 9 10
Mea
n R
espo
nse
Tim
e
Service Demand CV
W2-Workload-CVS
AHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 5. W2 sensitivity to service demand variations.
50
100
150
200
250
300
2 2.5 3 3.5 4 4.5 5 5.5 6
Mea
n R
espo
nse
Tim
e
Arrival Time CV
W1-Workload-CVA
AHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 6. W1 sensitivity to service demand variations.
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779 777
to lower mean response under both scheduling policies. In otherwords, W1 workload. The number of phases is set to 2 in W1while it is set to 12 in W2. Each phase consists of a single burst ofI/O with a minimal amount of computation followed by a singleburst of computation with a minimal amount of I/O. By keepingthe arrival time and service demand the same for both W1 andW2, we observed that W2 always take longer to complete. This isbecause W2 experiences degradation in the performance as itperformers greater number of I/Os. As the number of I/Os in a jobincrease, there tends to be more contention for I/O resources,which may lead to longer execution time of the jobs. The longer ajob experiences delays the more likely that a job can beinterrupted by a background workload leading to even longercompletion time of the jobs. In summary, this result suggests thatalthough reducing I/Os per job is important in reducing responsetime, the impact of the job scheduling policy used is moreimportant than simply reducing the number of I/O operations.
7.3. Sensitivity to service demand variations
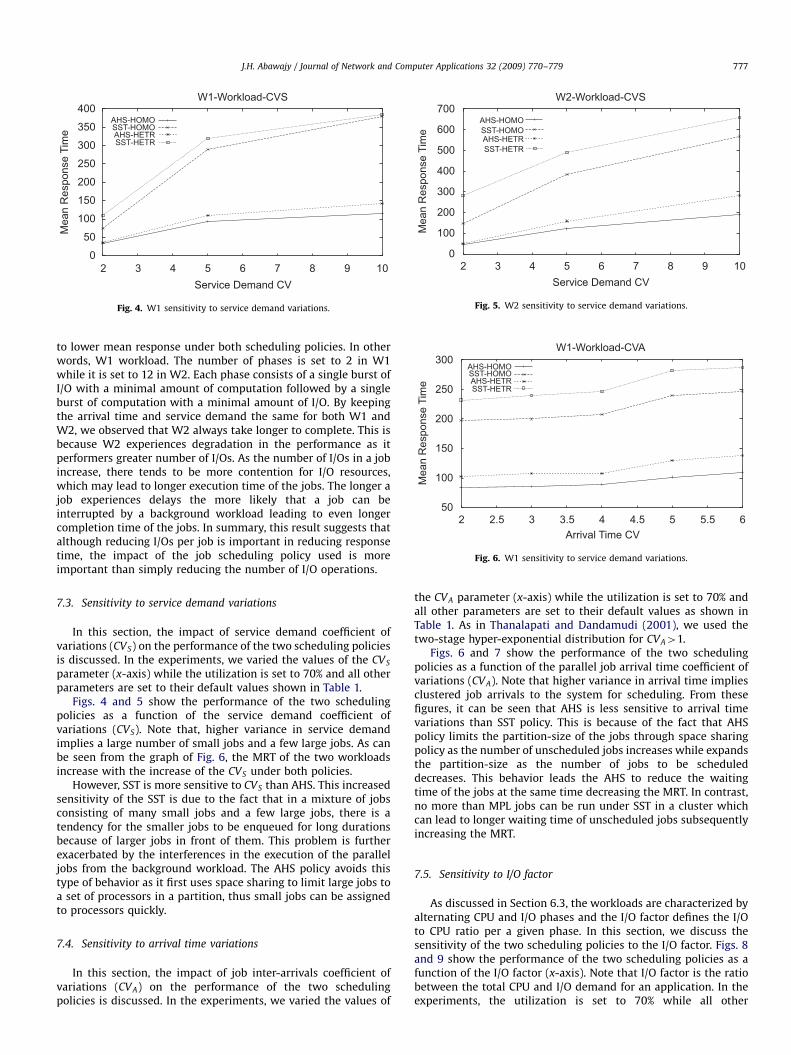
In this section, the impact of service demand coefficient ofvariations (CVS) on the performance of the two scheduling policiesis discussed. In the experiments, we varied the values of the CVS
parameter (x-axis) while the utilization is set to 70% and all otherparameters are set to their default values shown in Table 1.
Figs. 4 and 5 show the performance of the two schedulingpolicies as a function of the service demand coefficient ofvariations (CVS). Note that, higher variance in service demandimplies a large number of small jobs and a few large jobs. As canbe seen from the graph of Fig. 6, the MRT of the two workloadsincrease with the increase of the CVS under both policies.
However, SST is more sensitive to CVS than AHS. This increasedsensitivity of the SST is due to the fact that in a mixture of jobsconsisting of many small jobs and a few large jobs, there is atendency for the smaller jobs to be enqueued for long durationsbecause of larger jobs in front of them. This problem is furtherexacerbated by the interferences in the execution of the paralleljobs from the background workload. The AHS policy avoids thistype of behavior as it first uses space sharing to limit large jobs toa set of processors in a partition, thus small jobs can be assignedto processors quickly.
7.4. Sensitivity to arrival time variations
In this section, the impact of job inter-arrivals coefficient ofvariations (CVA) on the performance of the two schedulingpolicies is discussed. In the experiments, we varied the values of
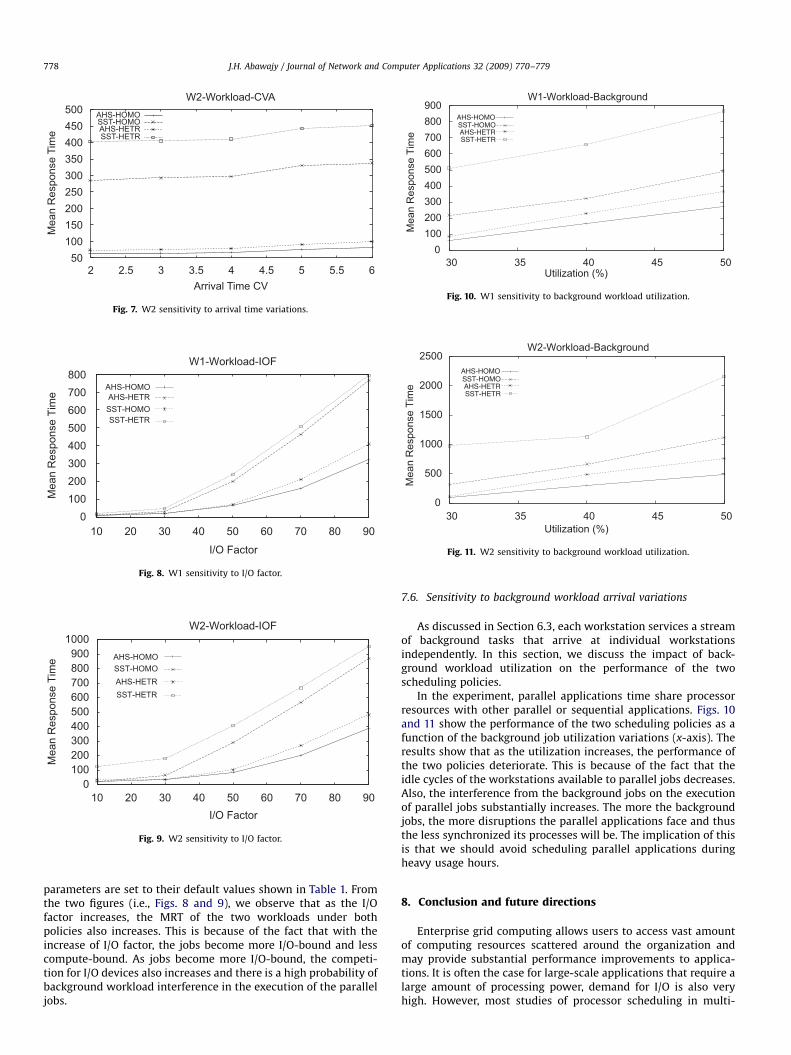
the CVA parameter (x-axis) while the utilization is set to 70% andall other parameters are set to their default values as shown inTable 1. As in Thanalapati and Dandamudi (2001), we used thetwo-stage hyper-exponential distribution for CVA41.
Figs. 6 and 7 show the performance of the two schedulingpolicies as a function of the parallel job arrival time coefficient ofvariations (CVA). Note that higher variance in arrival time impliesclustered job arrivals to the system for scheduling. From thesefigures, it can be seen that AHS is less sensitive to arrival timevariations than SST policy. This is because of the fact that AHSpolicy limits the partition-size of the jobs through space sharingpolicy as the number of unscheduled jobs increases while expandsthe partition-size as the number of jobs to be scheduleddecreases. This behavior leads the AHS to reduce the waitingtime of the jobs at the same time decreasing the MRT. In contrast,no more than MPL jobs can be run under SST in a cluster whichcan lead to longer waiting time of unscheduled jobs subsequentlyincreasing the MRT.
7.5. Sensitivity to I/O factor
As discussed in Section 6.3, the workloads are characterized byalternating CPU and I/O phases and the I/O factor defines the I/Oto CPU ratio per a given phase. In this section, we discuss thesensitivity of the two scheduling policies to the I/O factor. Figs. 8and 9 show the performance of the two scheduling policies as afunction of the I/O factor (x-axis). Note that I/O factor is the ratiobetween the total CPU and I/O demand for an application. In theexperiments, the utilization is set to 70% while all other
ARTICLE IN PRESS
50100150200250300350400450500
2 2.5 3 3.5 4 4.5 5 5.5 6
Mea
n R
espo
nse
Tim
e
Arrival Time CV
W2-Workload-CVAAHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 7. W2 sensitivity to arrival time variations.
0100200300400500600700800
10 20 30 40 50 60 70 80 90
Mea
n R
espo
nse
Tim
e
I/O Factor
W1-Workload-IOF
AHS-HOMO
SST-HOMOAHS-HETR
SST-HETR
Fig. 8. W1 sensitivity to I/O factor.
0100200300400500600700800900
1000
10 20 30 40 50 60 70 80 90
Mea
n R
espo
nse
Tim
e
I/O Factor
W2-Workload-IOF
AHS-HOMOSST-HOMOAHS-HETRSST-HETR
Fig. 9. W2 sensitivity to I/O factor.
0100200300400500600700800900
30 35 40 45 50
Mea
n R
espo
nse
Tim
e
Utilization (%)
W1-Workload-Background
Fig. 10. W1 sensitivity to background workload utilization.
0
500
1000
1500
2000
2500
30 35 40 45 50
Mea
n R
espo
nse
Tim
e
Utilization (%)
W2-Workload-Background
Fig. 11. W2 sensitivity to background workload utilization.
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779778
parameters are set to their default values shown in Table 1. Fromthe two figures (i.e., Figs. 8 and 9), we observe that as the I/Ofactor increases, the MRT of the two workloads under bothpolicies also increases. This is because of the fact that with theincrease of I/O factor, the jobs become more I/O-bound and lesscompute-bound. As jobs become more I/O-bound, the competi-tion for I/O devices also increases and there is a high probability ofbackground workload interference in the execution of the paralleljobs.
7.6. Sensitivity to background workload arrival variations
As discussed in Section 6.3, each workstation services a streamof background tasks that arrive at individual workstationsindependently. In this section, we discuss the impact of back-ground workload utilization on the performance of the twoscheduling policies.
In the experiment, parallel applications time share processorresources with other parallel or sequential applications. Figs. 10and 11 show the performance of the two scheduling policies as afunction of the background job utilization variations (x-axis). Theresults show that as the utilization increases, the performance ofthe two policies deteriorate. This is because of the fact that theidle cycles of the workstations available to parallel jobs decreases.Also, the interference from the background jobs on the executionof parallel jobs substantially increases. The more the backgroundjobs, the more disruptions the parallel applications face and thusthe less synchronized its processes will be. The implication of thisis that we should avoid scheduling parallel applications duringheavy usage hours.
8. Conclusion and future directions
Enterprise grid computing allows users to access vast amountof computing resources scattered around the organization andmay provide substantial performance improvements to applica-tions. It is often the case for large-scale applications that require alarge amount of processing power, demand for I/O is also veryhigh. However, most studies of processor scheduling in multi-

ARTICLE IN PRESS
J.H. Abawajy / Journal of Network and Computer Applications 32 (2009) 770–779 779
programmed parallel systems have ignored the I/O performed byapplications. In this paper, we presented a combined CPU and I/Oresource scheduling policy and compared its performance with astatic space–time sharing policy. We showed that the proposedpolicy performs substantially better than static space–timesharing policy under all system and workload parameters.
We presented the following results derived from our designand performance analysis of the proposed job scheduling policy:(1) We were able to verify previous results that the I/Orequirements of parallel jobs can significantly affect the jobefficiency, scalability and system performances (Smirni and Reed,1998). (2) We were able to determine that performance improvesif both the processors and the I/O subsystems are explicitly co-scheduled. (3) There are potential performance benefits of movingcomputation across the I/O bottleneck and closer to the data ituses. (4) Through time-sharing, the I/O and CPU requirements canbe overlapped as such increasing the system utilization whileminimizing response time. (5) Heterogeneity combined withbackground loads can have quite substantial impact on theperformance of the scheduling policies.
In this paper, we did not consider how the application data isdistributed among the D disks nor did we deal with howreplicated data are managed. The impact of these issues on thescheduling policy need to be addressed, which we plan to do inthe future. Another area of future work is to use the complexitytime instead of run time to evaluate the introduced algorithmwithout depending on the used computer specification.
Acknowledgment
This paper would not have been possible without the help ofMaliha Omar.
References
Abawajy JH. Scheduling in cluster systems. In: Dandamudi SP, editor. Hierarchicalscheduling in parallel and cluster systems. Berlin: Springer; 2003 [chapter 9].
Abawajy JH. Adaptive parallel i/o scheduling algorithm for multiprogrammedsystems. Int J Future Gener Comput Syst 2006;22(5):611–9.
Abawajy JH. An efficient adaptive scheduling policy for high performancecomputing. Int J Future Gener Comput Syst 2008;22(5).
Abawajy JH, Dandamudi SP. Scheduling parallel jobs with cpu and i/o resourcerequirements in cluster computing systems. In: Proceedings of the IEEEcomputer society’s annual international symposium on modeling analysis andsimulation of computer and telecommunications systems; 2003. p. 336–43.
Allcock W, Chervenak A, Foster I, Kesselman C, Salisbury C, Tuecke S. The data grid:towards an architecture for the distributed management and analysis of largescientific datasets. J Network Comput Appl 2001;23:187–200.
Alliance EG. Enterprise grid alliance reference model v1, April 2005.Chakrabarti A, Dheepak R, Sengupta S. Integration of scheduling and replication in
data grids. In: Lecture notes in computer science, vol. 3296, Berlin: Springer;2004, p. 375–85.
Chang R-S, Chang J-S, Lin S-Y. Job scheduling and data replication on data grids. IntJ Future Gener Comput Syst 2007;23(7):846–60.
Deris MM, Abawajy JH, Mamat A. An efficient replicated data access approach forlarge-scale distributed systems. Future Gener Comp Syst 2008;24(1):1–9.
Desprez F, Vernois A. Simultaneous scheduling of replication and computation fordata-intensive applications on the grid; 2005.
Gore B. Grid today, vol. 4, August 15, 2005.Jiang C, Wang C, Liu X, Zhao Y. A survey of job scheduling in grids. In: Lecture notes
in computer science, vol. 4505. Berlin: Springer; 2007. p. 419–27.Karatza HD. Scheduling in distribute systems. In: Calzarossa MC, Gelenbe E,
editors. Performance tools and applications to networked systems: revisedtutorial. Berlin: Springer; 2004. p. 337–56.
Kwong P, Majumdar S. Scheduling of I/O in multiprogrammed parallel systems.Informatica (Slovenia) 1999;23(1):104–13.
Liang Y, Fan J, Meng D, Di R. A strategy-proof combinatorial auction-based gridresource allocation system. in: Lecture notes in computer science, vol. 3296,Berlin: Springer; 2007. p. 254–66.
Mohamed D, Epema HH. An evaluation of the close-to-files processor and data co-allocation policy in multiclusters. In: IEEE international conference on clustercomputing; 2004. p. 287–2983.
Ranganathan K, Foster I. Decoupling computation and data scheduling indistributed data-intensive applications. In: Symposium for high performancedistributed computing; 2002. p. 352–61.
Ranjan R, Harwood A, Buyya R. A case for cooperative and incentive-based federation of distributed clusters. Future Gener Comp Syst 2008;24(4):280–95.
Rosti E, Serazzi G, Smirni E, Squillante MS. The impact of I/O on program behaviorand parallel scheduling. ACM Press; 1998. p. 56–65.
Rosti E, Serazzi G, Smirni E, Squillante MS. Models of parallel applications withlarge computation and i/o requirements. J IEEE Trans Software Eng 2002;28(3):286–307.
Ryu K, Hollingsworth J. Exploiting fine-grained idle periods in networks ofworkstations. IEEE Trans Parallel Distributed Syst 2000;11(7):683–98.
Smirni E, Reed DA. Lessons from characterizing the input/output behavior ofparallel scientific applications. Perform Eval 1998;33:27–44.
Tang M, Lee B.-S, Tang X, Yeo1 C.-K. Combining data replication algorithms and jobscheduling heuristics in the data grid. in: Proceedings of the Euro-Par 2005parallel processing. Lecture notes in computer science, vol. 3648. Berlin:Springer; 2005. p. 381–90.
Thain D, Bent J, Arpaci-Dusseau A, Arpaci-Dusseau R, Livny M. Gathering at thewell: creating communities for grid i/o. In: Proceedings of supercomputing,Denver, Colorado, November 2001.
Thanalapati T, Dandamudi S. An efficient adaptive scheduling scheme fordistributed memory multicomputers. IEEE Trans Parallel Distributed Syst2001;12(7):758–68.
Venugopal S, Buyya R, Winton L. A grid service broker for scheduling e-scienceapplications on global data grids. Concurrency Comput Pract Exper 2006;18(6):685–99.








![Hierarchical Scheduling for Diverse Datacenter Workloadsalig/papers/h-drf.pdf · Hierarchical Scheduling for Diverse Datacenter Workloads ... DRF [1], to support hi- ... book cluster](https://img.pdfslide.us/doc/110x75/5b2580d47f8b9a5c428b49d1/hierarchical-scheduling-for-diverse-datacenter-workloads-aligpapersh-drfpdf.jpg)



![Towards Hierarchical Scheduling in VxWorksrbril/publications/[Behnam et al 08].pdf · Towards Hierarchical Scheduling in VxWorks ∗ Moris Behnam†, Thomas Nolte, Insik Shin, Mikael](https://img.pdfslide.us/doc/110x75/5e6fa360fb4f7f5dbc46c773/towards-hierarchical-scheduling-in-rbrilpublicationsbehnam-et-al-08pdf-towards.jpg)















