Embed Size (px)
Citation preview

Active Learning for Preferences Elicitation in Recommender Systems
Lior RokachDepartment of Information System Engineering
:

Agenda
• Background - Active Learning and Recommender Systems• Proposed Method• Experimental Procedure• Results and Discussion• Conclusions and Future Work

Recommender Systems
• Users are overloaded by options to consider before making a decision – such as item to purchase
• Recommender systems aim at supporting the user in the processes of– decision-making– planning– purchasing

Collaborative Filtering
• Maintain users’ ratings of a variety of items.
• For a given user:– Find other similar users whose ratings strongly
correlate with the current user– Recommend items rated highly by these similar
users, but not rated by the current user.
• Almost all existing commercial recommenders use this approach (e.g. Amazon).

Collaborative Filtering
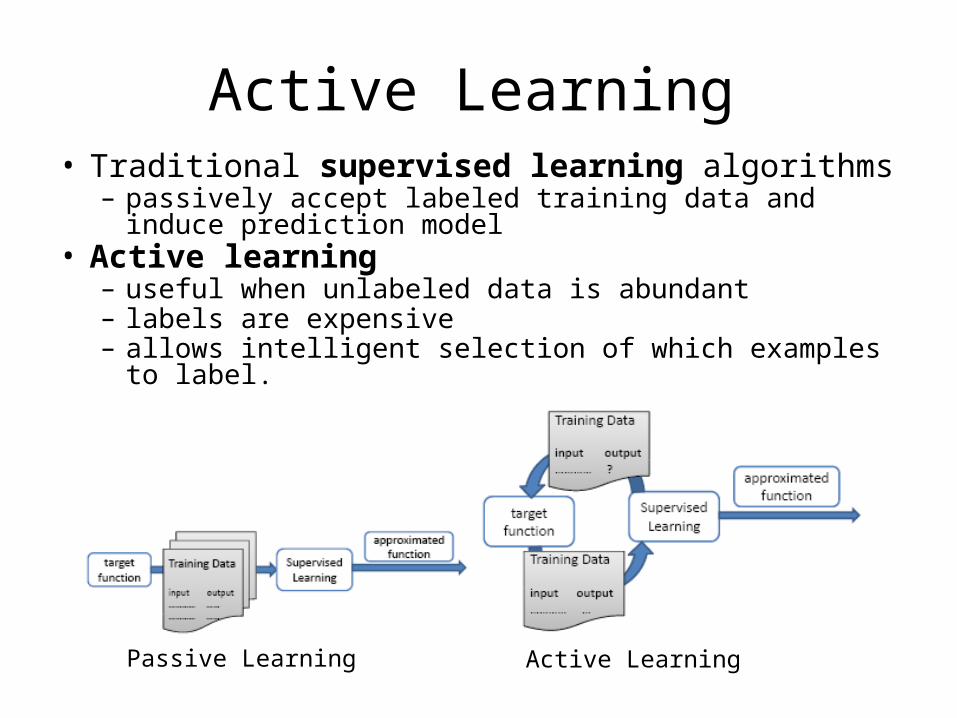
Active Learning• Traditional supervised learning algorithms
– passively accept labeled training data and induce prediction model
• Active learning – useful when unlabeled data is abundant – labels are expensive – allows intelligent selection of which examples to label.
Passive Learning Active Learning

Using Active Learning for Initial Preferences Elicitation
• The cold start problem– very little is known about the preferences of new
users
• Possible modus operandi – Ask the user to rate a few items– Which items ? Active Learning

Using Active Learning for Initial Preferences Elicitation
Active Learning
Active Learning
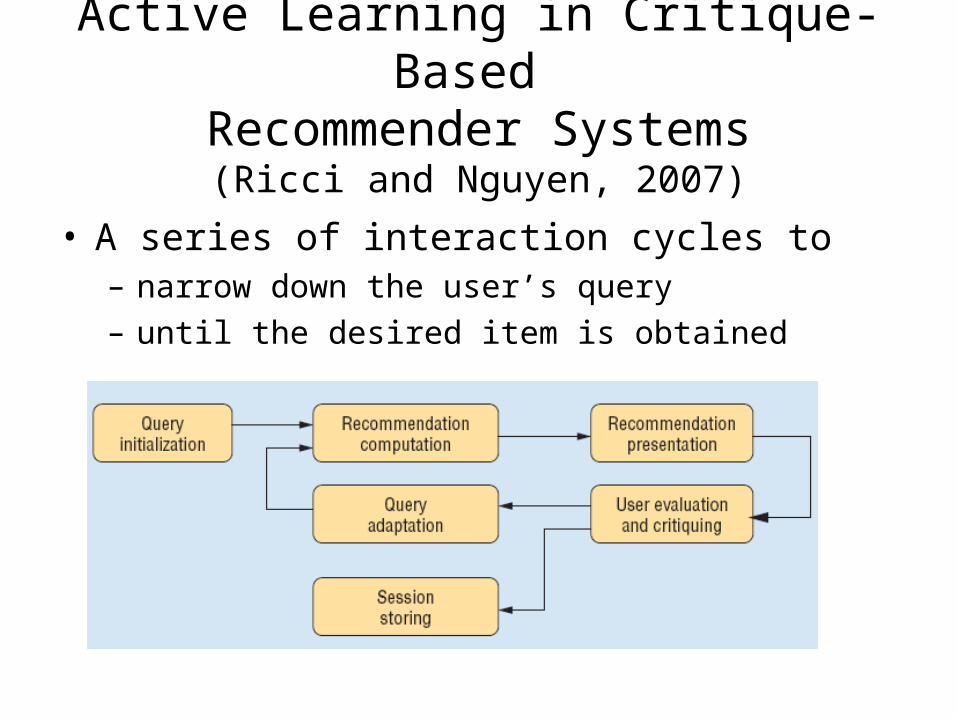
Active Learning in Critique-Based Recommender Systems
(Ricci and Nguyen, 2007)
• A series of interaction cycles to– narrow down the user’s query
– until the desired item is obtained

Integrating Active Learning in CF-based Recommender Systems
• Active Learning (AL) in RecSys– accurately predicts items of interest to the user – while gaining information about her preferences.
• In this lecture we focus on – Uncertainty Active Collaborative Filtering
• Boutilier et al. (2003)
• Rong and Luo (2004)
• …

• Incorporate exploration and exploitation trade-off.
• Work local – think global– Use the ratings of one user to contribute to other users
• Introduce Cost-Sensitivity (Not going to talk about that)
Our Contributions
the value of information of new ratings
the alternative utility for not presenting the best items
VS

Agenda
• Background - Active Learning and Recommender Systems• Proposed Method• Experimental Procedure• Results and Discussion• Conclusions and Future Work

Preliminaries
• Binary rating: Like/Dislike – – Explicit– Implicit - Based on user actions such as:
• Buy• Click the item for additional details
• Provide a recommendation of top n items – User selects from this list – Ignore the fact she can browse the remaining items.
• We use a simple item-to-item NN CF – similarity measure such as Pearson correlation.

Item-to-Item NN CF with Binary Ratings
If {0,1}uir
rui* can be used to approximate the probability that user u would like item i.
Some use
Jaccard
coeff
icien
t inste
ad

Probabilistic Approach
• Employ rule of succession (Laplace correction)– find the conditional probability for positive response
in the next presentation of item i to user u:
where itemSim should be normalized such that:
,j ratedItems u
itemSim i j ratedItems u

Mathematical interlude: Rule of succession
• The proportion p of positive response is treated as a uniformly distributed random variable– Some claim that p is not random, but uncertain
– We assign a probability distribution to p to express uncertainty, not to attribute randomness
• Let Xi,j indicator variable – equals 1 when user i positively responded to an item j with
probability pj of success (0 otherwise)
– has a Bernoulli distribution.

Mathematical interlude: Rule of succession – cont.
• Suppose these Xs are conditionally independent given pj thus the likelihood is:
• The conditional probability distribution of pj given the data Xi,j, i = 1, ..., n, is the multiplication of the "prior" (i.e., marginal) probability measure assigned to pj by the likelihood function (Bayes' theorem)

• The posterior probability density function is
• This is a beta distribution with expected value
• Rule of succession implies– the conditional probability for positive response in the
next presentation of item j given pj, is just pj.
Mathematical interlude: Rule of succession – cont.

The Benefit and Risk of a Top 1 Recommendation
• A simple scenario:– Recommend the best (top 1) item from only two possible
itemsItemr*uiP(u,i)
11020.20.25
22030.150.182
The risk: The presented item (item1) is not selected by the user, but if item 2 was presented to the user it would have been chosen
Risk of presenting item1 1 0.25 0.182 0.136 Benefit of presenting item1 0.25
uratedItemsjjiitemSim ,

Risk Reduction
• Risk reduces as more ratings become available
Itemr*uiP(u,i)
12040.20.227
24060.150.166
Risk of presenting item1 1 0.227 0.167 0.129
Risk reduction 0.136 0.129 0.007
uratedItemsjjiitemSim ,
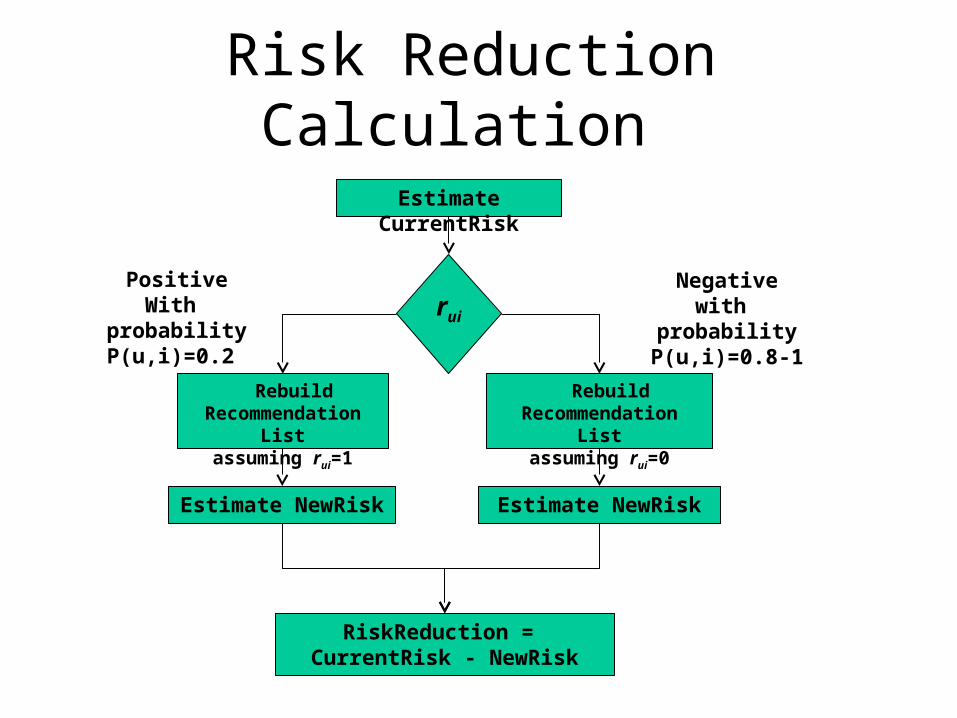
Risk Reduction Calculation
rui
Positive With probability
P(u,i)=0.2
Estimate CurrentRisk
Estimate NewRisk
RiskReduction = CurrentRisk - NewRisk
Estimate NewRisk
Negativewith probability
1-P(u,i)=0.8
Rebuild Recommendation List
assuming rui=0
Rebuild Recommendation List
assuming rui=1

Loss/Utility
• If the net revenues of the items are known, the risk/benefit is easily converted into loss/utility.
Itemr*uiP(u,i)Price
11020.20.252
22030.150.183
1 1 0.25 0.182 0.136Risk of presenting item
1 0.25Benefit of presenting item
uratedItemsjjiitemSim ,
408.03136.01 itempresentingforLoss
5.0225.01 itempresentingofUtility

The Benefit and Risk of Top 1 Recommendation
• Extended scenario:– Recommending the best (top 1) item from n possible items
25.01itempresentingofBenefit
Itemr*uiP(u,i)
11020.20.25
22030.150.182
52020.10.13631010.10.16742010.050.091
uratedItemsjjiitemSim ,
As Before
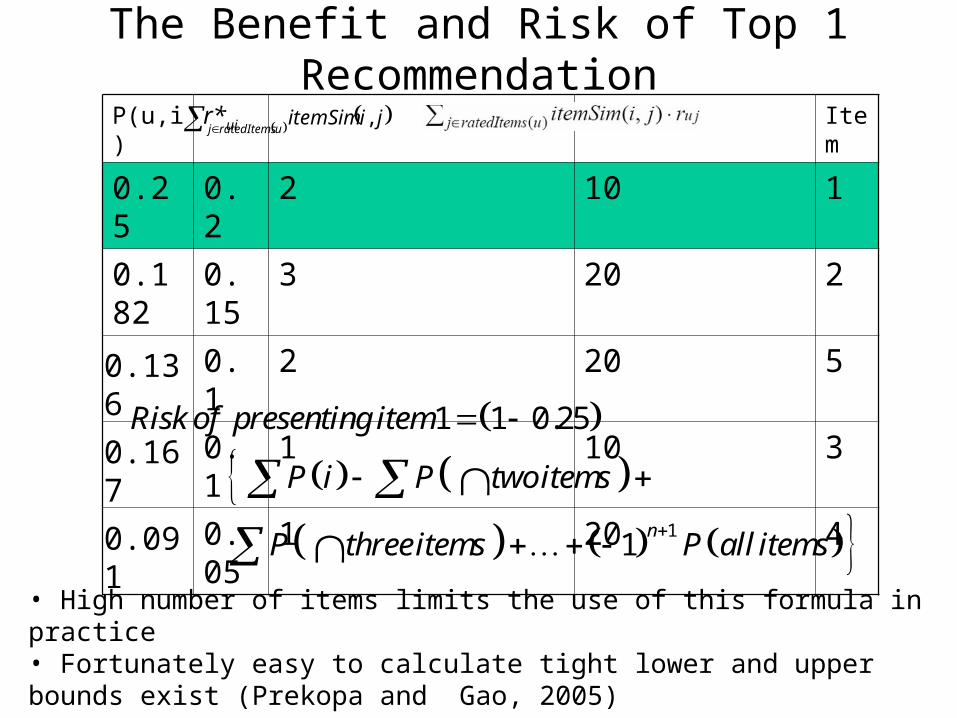
The Benefit and Risk of Top 1 Recommendation
Itemr*uiP(u,i)
11020.20.25
22030.150.182
52020.10.13631010.10.16742010.050.091
uratedItemsjjiitemSim ,
1
1 1 0.25
1n
Risk of presenting item
P i P twoitems
P threeitems P all items
• High number of items limits the use of this formula in practice • Fortunately easy to calculate tight lower and upper bounds exist (Prekopa and Gao, 2005)

The Benefit and Risk of Top n Recommendation
Itemr*uiP(u,i)
11020.20.25
22030.150.182
52020.10.13631010.10.16742010.050.091
uratedItemsjjiitemSim ,

Cascaded risk reduction for top n• Assumptions:
– User selects only one item (positive response)
– User reviews the items according to the their order in the list
ru1
P(u,1)
Estimate CurrentRisk
Estimate NewRisk
1-P(u,1)
ru2
Estimate NewRiskru3
Estimate NewRisk
P(u,2) 1-P(u,2)
P(u,3) 1-P(u,3)
.
.
.

Multiple Users
• When user u provides an additional rating,– not only the risk/benefit of user u evolves– but also the risk/benefit of other users
(Collaborative Filtering)

Goal Formulation
• U – set of Users
• I – set of Items
• DRLj – default ranked list for user j.
– For example the list which would be selected by CF according to r*ui.
– A Ranked List is an ordered set of pairs
jj rIiriri ;thatsuch,,,, 2211

Goal Formulation – cont.
• Find PRLu (ranked list to be presented to user u) such that:
• wv – weight for user v – Frequent users should have larger weights.
• Tk is used to control the exploration/exploitation tradeoff – We employ simulated annealing with a simple and common exponential
schedule:
,
max
1 ,
,
u
k v v u vv Users v u
k v v v uv Users
Benefit PRL
T w NewBenefit DRL PRL Benefit DRL
T w Risk DRL NewRisk DRL PRL
1 kk TT

Switching from active to passive
• Risk reduction converges to zero as number of ratings tends to infinity.
• When sufficient ratings are achieved, go from active to passive

Proposition 1: Who is affected?
• When a new rating for item i by user u, is added to an item-to-item NN CF, – the recommendation list of user v≠u is revised iff
user v has rated at least one item that has been rated by user u.
• Proof:– Straightforward

Illustration of Proposition 1
U1U2U3U4U5U6U7
IAXXXX
IBXXX
ICXXX
IDXX
X
Not affected

Proposition 2: How many are affected?
• Assumption: the provided ratings are scattered uniformly over the item-users matrix,
• Expected proportion of users affected by adding a new rating is:
• where – N is the total number of items – n is the mean number of ratings provided by a single user
• Example– N=2,000,000, n=210 prop=2% – N=17,000, n=210 prop=91%
1
1
11 1
1
n
n
in n N
i
N i nN n
propN
N i

A Greedy Algorithm
• Finding the optimal ranked list for user u is a computationally intractable problem
• Approximated solution– Greedily select the items to be presented from the top k·l
items of user u, • l is the number of items presented in a single page,
• k is a small integer
– Calculate the risk reduction for a sample of m users selected randomly from all potentially affected users
– Approximate the actual reduction by simple scaling

Computational Complexity
2 2 4 4O kl m kl kl O k l m
Greedily select items in the list
Risk reduction
Benefit
Assuming hash map structures for:• Rated items for each user• Rating users for each item• DRL for each user

Agenda
• Background - Active Learning and Recommender Systems• Proposed Method• Experimental Procedure• Results and Discussion• Conclusions and Future Work

The Experiments’ Goals
• Compare the proposed active learning algorithm to passive learning.
• Evaluate – contribution of the global effect – Monte-Carlo procedure for selecting the affected
users– scalability of the greedy algorithm
• Our main evaluation criterion: – Precision

Data
• We actively select items to be presented to the user and expect to obtain the user’s response to these items.
• Available offline datasets (such as Netflix) are sparse and therefore cannot guarantee response to all items we present.
• Three options:• Find several sub-matrices that are dense
• Filter DRLs according to the items known to be rated by the user.
• Work online.

Offline evaluation
• Six mutually exclusive dense submatrices of 50 users over 50 movies were extracted from Netflix
• Provided ratings where transform it into a binary scale (ratings above user’s average are considered positive).
• In each iteration we randomly selected a user and simulate a request for obtaining a recommendation assuming l=5, k=5.
• Initial probability estimation of items for all users is assumed to be uniform.

Agenda
• Background - Active Learning and Recommender Systems• Proposed Method• Experimental Procedure• Results and Discussion• Conclusions and Future Work

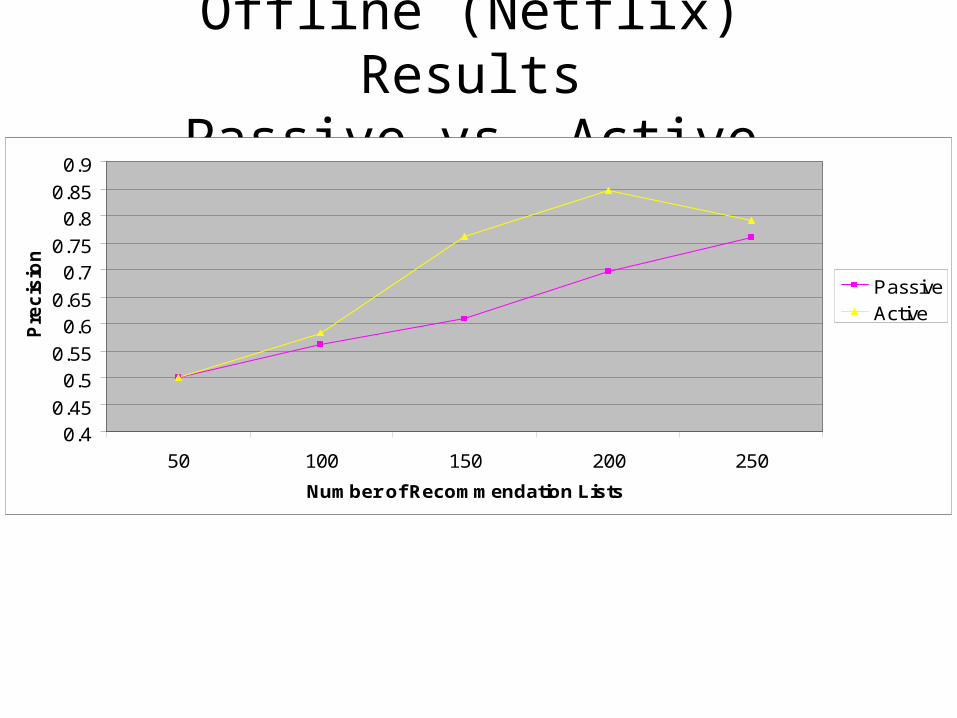
Offline (Netflix) ResultsPassive vs. Active
Both methods display a unimodal peak quadratic-like growth.
Both converges to the same value.
The positive effect of active learning is maximally observed around of 200 sessions with an improvement of 15%.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
50 100 150 200 250 300 350 400 450 500
Number of Recommendation Lists
Pre
cis
ion
Passive
Active
Offline (Netflix) ResultsPassive vs. Active
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
50 100 150 200 250
Number of Recommendation Lists
Pre
cis
ion
Passive
Active

Offline (Netflix) ResultsThe effect of recommendation list size (k)
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
50 100 150 200 250
Number of Recommendation Lists
Pre
cis
ion Active k=5
Active k=4
Active k=3
Active k=2

Offline (Netflix) ResultsThe effect of number of referred users (m)
0.4
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
50 100 150 200 250
Number of Recommendation Lists
Pre
cis
ion Active m=50
Active m=40
Active m=30
Active m=20

How much time it really takes?
• In a real application– 8,000,000 items– 1,000,000 users
• l=10,k=10,m=200– About 12 msec with Intel Core Duo CPU E7400 @
2.80GHz.
• l=10,k=5,m=200– About 1.5 msec

Agenda
• Background - Active Learning and Recommender Systems• Proposed Method• Experimental Procedure• Results and Discussion• Conclusions and Future Work

Conclusions
• A new Uncertainty Active Collaborative Filtering method has been developed.
• The new method takes into consideration the global effect.
• The new method can improve objective and subjective performance.

Drawbacks
• Like any Uncertainty-based AL reducing uncertainty may not always improve accuracy (Rubens et al., 2010)
• A more intensive calculation than the passive CF.

Future Work
• Evaluate on a large dataset (under investigation) • Extends the method to other CF algorithms and compare
to other Active Learning CF (under investigation)• Evaluate the method on a large scale online system
(Scheduled to 4/2010)• Extend the algorithm to a non-binary scale (5 stars)• Develop a batch mode algorithm• Develop a better sampling method for selection of the
affected users• Consider other heuristics• Taking into consideration the temporal aspect (Netflix)

References
• Boutilier, C., Zemel, R., & Marlin, B. (2003). Active collaborative filtering. Proceedings of the Nineteenth Annual Conference on Uncertainty in Artificial Intelligence (pp. 98–106).
• Francesco Ricci, Quang Nhat Nguyen: Acquiring and Revising Preferences in a Critique-Based Mobile Recommender System. IEEE Intelligent Systems 22(3): 22-29 (2007)
• Rong J. and Luo S. (2004), A Bayesian approach toward active learning for collaborative filtering, Proceedings of the 20th conference on Uncertainty in artificial intelligence, pp. 278—285.
• Andras Prekopa, Linchun Gao, Bounding the probability of the union of events by aggregation and disaggregation in linear programs, Discrete Applied Mathematics, Volume 145, Issue 3, 30 January 2005, Pages 444-454






























