Embed Size (px)
Citation preview

Accedere a documenti XML: XSL, DOM e Java
API Dott. Nicole NOVIELLI
[email protected] http://www.di.uniba.it/intint/people/nicole.html
XSL eXstensible Stylesheet Language
! Specify how programs have to render XML document data
! XSL is a group of three technologies: ! XSL Formatting Objects (XSL-FO): a vocabulary for
specifying formatting ! XPath: a sting-based language of expressions for
locating structures and data in XML documents ! XSL Transformations (XSLT): a language for
transforming XML documents

l'XSLT (Extensible Stylesheet Language transformation) serve proprio a trasformare un documento XML in altri formati come l'HTML, PDF, RTF o ancora XML
l'XSL-FO (Extensible Stylesheet Language Formatting Object) viene utilizzato per formattare e applicare degli stili ai dati XML.
l'XSLT come sottoinsieme dell'XSL che utilizzato nel contesto delle traformazioni da XML ad HTML si comporta come un linguaggio autonomo senza utilizzare funzioni che appartengono all'XSL-FO.
! CSS = Style Sheets for HTML ! HTML uses predefined tags, and the meaning of each tag is well
understood.
! The <table> tag in HTML defines a table - and a browser knows how to display it.
! Adding styles to HTML elements is simple. Telling a browser to display an element in a special font or color, is easy with CSS
! XSL = Style Sheets for XML
! XML does not use predefined tags: the meaning of each tag is not well understood.
! A <table> tag could mean an HTML table, a piece of furniture, or something else - and a browser does not know how to display it.
! XSL describes how the XML document should be displayed
CSS vs. XSL

XSLT
! A technology for transforming documents into other documents
! It transforms an XML source tree into another structure
! Useful for data employed in multiple applications or platforms designed to work with a given vocabulary
! XSLT uses XPath to find information in an XML document. XPath is used to navigate through elements and attributes in XML documents.
Transforming an XML document
! Source tree: the XML document to be transformed
! Result tree: the XML document to be created
! XPath is used to locate part of the source-tree document that match templates defined in an XSL style sheet. When a match occurs (for example a node matches a template): ! the matching templates executes and ! it adds its results to the result tree
When there are no more matches the XSLT has transformed the source tree into the result tree

Transforming an XML document
! XSLT does not analyze every node of the source tree ! It selectively navigates the source tree using the
XPath select and match attributes
! The source tree must be properly structured ! Schemas, DTDs and validating parsers can validat
document structure before using XPath and XSLT
XSLT and browsers
! All major browsers have support for XML and XSLT. ! Mozilla Firefox supports XML, XSLT, and XPath from
version 3.
! Internet Explorer supports XML, XSLT, and XPath from version 6.Internet Explorer 5 is NOT compatible with the official W3C XSL Recommendation.
! Google Chrome supports XML, XSLT, and XPath from version 1.
! Opera supports XML, XSLT, and XPath from version 9. Opera 8 supports only XML + CSS.
! Apple Safari Safari supports XML and XSLT from version 3.
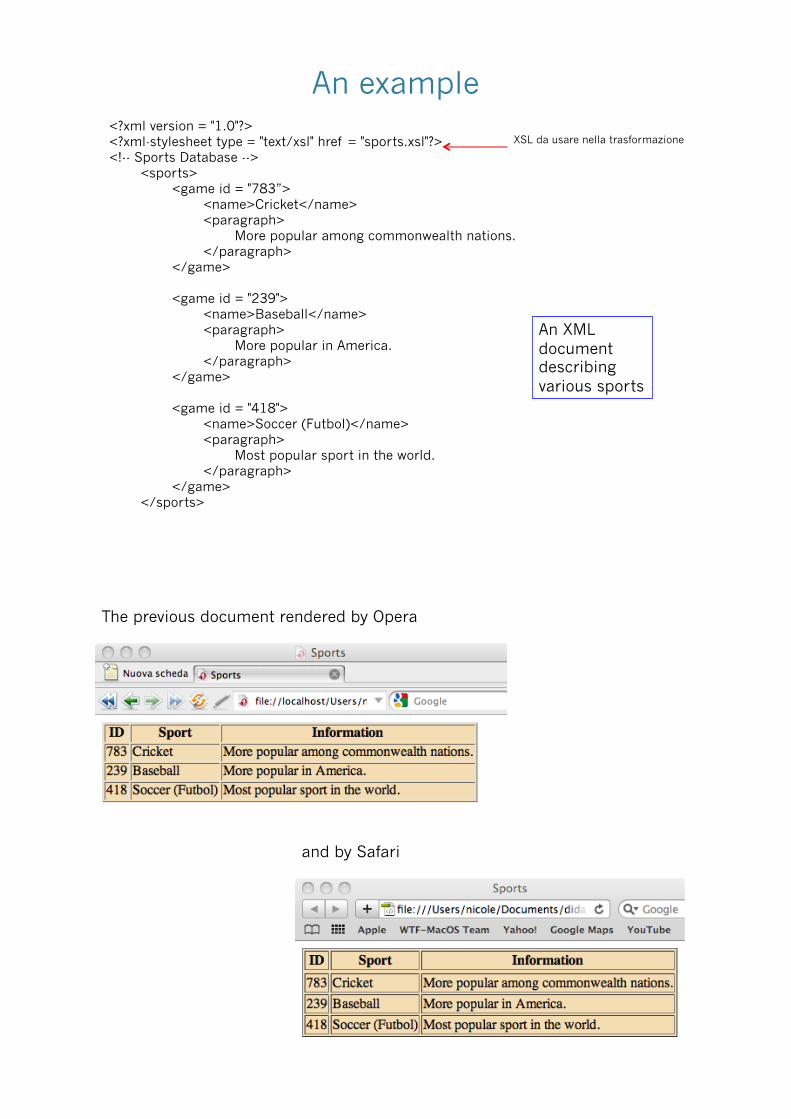
An example <?xml version = "1.0"?> <?xml-stylesheet type = "text/xsl" href = "sports.xsl"?> <!-- Sports Database -->
<sports> <game id = "783”> <name>Cricket</name> <paragraph> More popular among commonwealth nations. </paragraph> </game>
<game id = "239"> <name>Baseball</name> <paragraph> More popular in America. </paragraph> </game>
<game id = "418"> <name>Soccer (Futbol)</name> <paragraph> Most popular sport in the world. </paragraph> </game> </sports>
An XML document describing various sports
XSL da usare nella trasformazione
The previous document rendered by Opera
and by Safari

! To perform transformations an XSLT processor is required
! A processing instruction (PI) is embedded in an XML document and provides application-specific information to XML processors
! In the example the following PI is used to reference the XSL style sheet ‘sports.xsl’ in ‘sports.xml’
<?xml-stylesheet type = "text/xsl" href = "sports.xsl”?>
<? ?> are used to delimit the processing instruction
PI target PI value
sports.xsl indica al processore che il documento è un documento XML, che la sua versione è la 1.0
Elemento radice, nel caso dell’xslt è necessariamente questo
Con xsl:value-of accedo al contenuto di un determinato elemento del sorgente XML.
Inserisce nella tabella, ogni nodo del node-set ‘/sports/game’
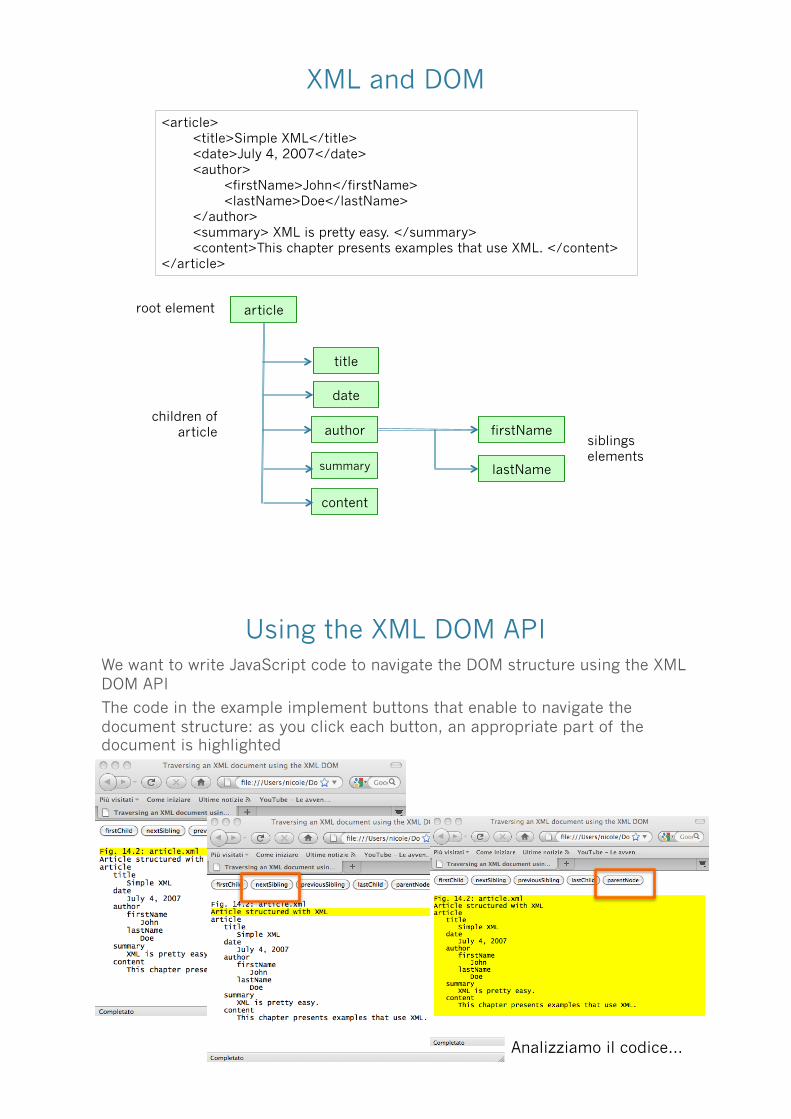
XML and DOM
<article> <title>Simple XML</title> <date>July 4, 2007</date> <author> <firstName>John</firstName> <lastName>Doe</lastName> </author> <summary> XML is pretty easy. </summary> <content>This chapter presents examples that use XML. </content>
</article>
article
title
date
author
summary
content
lastName
firstName
root element
children of article
siblings elements
Using the XML DOM API We want to write JavaScript code to navigate the DOM structure using the XML DOM API
The code in the example implement buttons that enable to navigate the document structure: as you click each button, an appropriate part of the document is highlighted
Analizziamo il codice…

article.xml
<?xml version = "1.0"?> <!-- Fig. 14.2: article.xml --> <!-- Article structured with XML --> <article> <title>Simple XML</title> <date>July 4, 2007</date> <author> <firstName>John</firstName> <lastName>Doe</lastName> </author> <summary>XML is pretty easy.</summary> <content>This chapter presents examples that use XML.</content> </article>
The body element When the body loads the ‘loadXMLDocument’ function is called
A form is defined: each button is associated to the call of a JavaScript functions
This div will contain the content of the ‘article.xml’ file passed as argument to the function invoked on the onload event

Global script variables
• doc: references a DOM object representation of article.xml • outputHTML stores the markup elements and their content as they will be placed in the div • idCounter is used to track the id of each element included in ouputHTML • depth determines the identation level for article.xml • current and previous track, respectively, the current and the previous nodes in the article.xml corresponding DOM structure
The function loadXMLDocument Receives the url of the .xml file to load
For Firefox and many other browsers
In case of browser not supporting the script
Loading instructions for Internet Explorer (the presence of the ActiveXObject indicates that we are using IE)

If the ActiveX object exists
A new ActiveXObject is created usig the MSXML parser for XML
Asking the JavaScript to perform synchronous loading By default, when you ask JavaScript to load an XML file, the browser won't wait for the loading to complete and will run the next line of the script. To ask the browser to wait for the loading to complete, assign the async property to false. Otherwise, the browser will run the script in parallel while loading the XML file.
Loading an XML using IE
When the loading (doc.load(url)) is complete the buildHTML method is invoked to construct an XHTML representation of the XML document in input. The expression doc.childNodes denotes a list of all the XML top-level nodes
Finally, the displayDoc function is called to display the content of article.xml in the div defined in the body

Loading an XML using Firefox or other browsers
c
These two method of document will exist if we are using Firefox
createDocument creates an empty XML document object The first argument is the namespace (if needed) and the second is the root element of the xml. The third argument is not implemented yet so it should always be null
c
The load method loads article.xml in doc
c
Loading an XML using Firefox or other browsers
Firefox supports asynchronous loading so we need to define a function to complete the loading of the document the function will be executed when the document finishes loading (doc.onload)
c

The function buildHTML
Recoursive function that receives a list of nodes as arguments
nodeType determines wether the current node is an element, a text or a comment node
if it is an element, then begin a new div element in our XHTML and give it a unique id. Then spaceOutput appends spaces ( ) and finally the nodeName property is used to append the current node to the outputHTML global variable
The function is recoursively called if the node has children
Function displayDoc
// display the XML document and highlight the first child function displayDoc() {
document.getElementById( "outputDiv" ).innerHTML = outputHTML; current = document.getElementById( 'id1' ); setCurrentNodeStyle( current.id, true );
} // end function displayDoc
The DOM’s getElementById method is employed to obtain the outputDiv element of the document
Then the innerHTML property of the object is set to the new markup generated by the function build HTML

processFirstChild
If the current node has only one child and this child is a text node
firstChild is used to refere to the current node’s first child (if not text node)
nextSibling to get its next sibling
remove highlight on the previous node and set it on the current
processLastChild
This function works analogously to the previous one but uses the lastChild property to get the new current node

processNextSibling Ensures that the current node is not the outputDiv and that the nextSibling exists
processPreviousSibling Ensures that the current node is not the outputDiv and that the nextPrevious exists and that it is not a text node
processParentNode
Checks whether the current node’s parentNode is the ‘body’ of the HTML being processed If not, it adjust the previous and the current node accrodingly and updates their highlighing
// highlight parent of current node function processParentNode() {
if ( current.parentNode.id != "body" ) { previous = current; // save currently highlighted node current = current.parentNode; // get new current node setCurrentNodeStyle( previous.id, false ); // remove highlight setCurrentNodeStyle( current.id, true ); // add highlight } // end if else alert( "There is no parent node" );
} // end function processParentNode
function setCurrentNodeStyle( id, highlight ) {
document.getElementById( id ).className = ( highlight ? "highlighted" : "" ); } // end function setCurrentNodeStyle
setCurrentNodeStyle

XPath
! An Xpath is an expression to return a node result set to the calling method or application.
! A node is a complete element within an XML document.
For instance, if you have an XML Document that looks like this: <customers> <customer id="1"> <companyName>DotNetJohn</companyName> </customer> <customer id="2"> <companyName>Microsoft</companyName> </customer> </customers>
A node could be <companyName>DotNetJohn</companyName> or DotNetJohn or id="1"
The calling method or application specifies an XPath expression, and XPath returns a single or group of nodes that satisifies the expression.
Think of XPath as a query language: by specifying a statement, XPath will retrieve whatever data you request in a given XML document, which is very similar to a select clause in SQL.
Let's take a look at a sample XPath statement. If we were to execute the following XPath query:
/customers/firstName
XPath would traverse down an XML document looking first for the <customers> node.
Once found, it will search inside of the customers node for the <firstName> node.
Once it reaches the firstName node, XPath will return all of the nodes back to the caller.
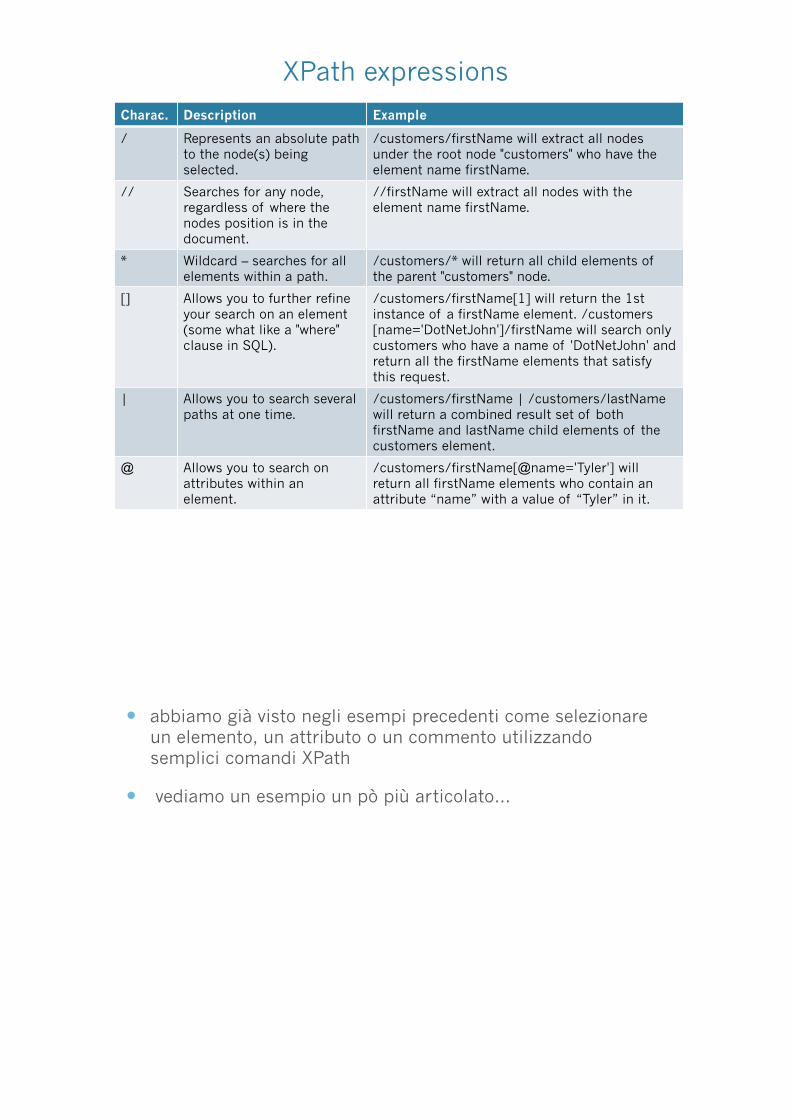
XPath expressions
Charac. Description Example
/ Represents an absolute path to the node(s) being selected.
/customers/firstName will extract all nodes under the root node "customers" who have the element name firstName.
// Searches for any node, regardless of where the nodes position is in the document.
//firstName will extract all nodes with the element name firstName.
* Wildcard – searches for all elements within a path.
/customers/* will return all child elements of the parent "customers" node.
[] Allows you to further refine your search on an element (some what like a "where" clause in SQL).
/customers/firstName[1] will return the 1st instance of a firstName element. /customers[name='DotNetJohn']/firstName will search only customers who have a name of 'DotNetJohn' and return all the firstName elements that satisfy this request.
| Allows you to search several paths at one time.
/customers/firstName | /customers/lastName will return a combined result set of both firstName and lastName child elements of the customers element.
@ Allows you to search on attributes within an element.
/customers/firstName[@name='Tyler'] will return all firstName elements who contain an attribute “name” with a value of “Tyler” in it.
! abbiamo già visto negli esempi precedenti come selezionare un elemento, un attributo o un commento utilizzando semplici comandi XPath
! !vediamo un esempio un pò più articolato…

<?xml version="1.0" encoding="UTF-8"?> <!-- Prologo XML --> <?xml-stylesheet type="text/xsl" href="listacd_es1.xslt"?> <!-- Istruzione che indica il documento XSLT da associare -->
<listacd> <artista> <nome>Stanley Jordan</nome> <albums> <album> <titolo>Magic Touch</titolo> <anno>1985</anno> <etichetta>Blue Note</etichetta> </album>
<album> … </album> </albums>
</artista>
<artista> <nome>Nick Drake</nome> <albums>
<album> … </album> <album> … </album> <album>… </album> </albums> </artista>
<artista> ...</artista> <artista> … </artista> </listacd>
listacd.xml
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <xsl:apply-templates select="//artista"/> </html> </xsl:template>
<xsl:template match="//artista"> <strong> <xsl:value-of select="position()"/> <!-- Seleziona il numero progressivo del nodo --> ) <xsl:value-of select="name()"/> <!-- Seleziona il nome del nodo ovvero il nome del TAG --> : </strong>
<xsl:value-of select="@nome"/> <br /> </xsl:template> </xsl:stylesheet>
listacd.xsl
1) artista : Stanley Jordan 2) artista : Nick Drake 3) artista : Jeff Buckley 4) artista : Joe Satriani
output
Using ‘match’ to access a node
! match contiene il percorso dei nodi che deve prendere in esame.!
! usiamo carattere / per indicare che un nodo è figlio di un altro nodo, oppure utilizzare il carattere * per indicare che è nipote.
! Modo rapido: albums//titolo indica di cercare il nodo <titolo> indifferentemente dalla sua profondità rispetto al nodo <albums>. Questo è un modo molto più flessibile di scrivere il codice XSLT che, nel caso vengano fatte delle modifiche alla struttura dell'albero XML, ci permette magari di evitare future modifiche nel codice del documento stesso.
! l'attributo select nell'elemento xsl:apply-templates ci permette di specificare in che ordine applicare i vari modelli ai vari nodi dell'XML.! !
! Le parti di codice HTML verrano inserite nell'output senza essere interpretati dal processore non essendo elementi XSLT.!!

apply-templates
<?xml version="1.0" encoding="UTF-8"?>!!! <!-- Prologo XML --> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
!!! <xsl:template match="/">!! <!-- Applica questo template al nodo radice indicato dal carattere / --> !!!!!! <html> !!!!!!!! <xsl:apply-templates>!!! <!-- Richiama e applica gli altri templates --> !!!!!!!! </xsl:apply-templates> !!!!!! </html> !!! </xsl:template>
!!! <xsl:template match="artista">!!! <!-- Quando trova un nodo artista applica questa
regola --> !!!!!!!! <xsl:value-of select="nome"> !!!!!!!! </xsl:value-of> !!!!!!!! <br></br> !!! </xsl:template>
</xsl:stylesheet>
listacd2.xsl L'elemento xsl:template definisce delle regole che vengono applicate al nodo specificato nell'attributo match del documento sorgente XML.
L'utilizzo del carattere / indica al processore di applicare queste regole all'elemento radice dell'XML (nel nostro caso <listacd>).
All'interno dell'elemento xsl:template per prima cosa mettiamo i TAG <html> e all'interno di questi utilizziamo l'elemento xsl:apply-templates per richiamare gli altri modelli che saranno applicati agli elementi figli.
Abbiamo definito un altro modello che viene applicato agli elementi <artista> e come regole utilizziamo l'elemento xsl:value-of con l'attributo select per dire al processore di prendere il valore contenuto all'interno dell'elemento <nome>. Infine utilizziamo il <br> per andare a capo dopo ogni nome.
Questo XSLT esegue le seguenti azioni sul file XML: prende l'elemento radice e ogni volta che trova un elemento <artista> calcola il valore contenuto dentro l'elemento figlio <nome> e lo indirizza in output sul browser.
quando un Template non corrisponde a nessun elemento dell'XML non viene applicato, non crea quindi nessun errore
DOM e SAX ! DOM è un’interfaccia programmatica (API) per
la manipolazione della struttura e del contenuto di documenti XML ! Occorre invocare direttamente i metodi per accedere
alle o modificare le componenti del documento
! SAX (Simple API for XML) consente soltanto di effettuare il parsing di documenti XML ! Il parser genera degli eventi => occorre (sovra)
scrivere degli event handler (callback) per decidere cosa fare
! I parser DOM usano SAX per il parsing e la creazione dell’oggetto associato al documento

DOM o SAX? ! Usate un parser DOM quando:
! Si ha bisogno di manipolarne la struttura del documento
! E’ fondamentale conoscerne la struttura ! Si ha bisogno di accedere alle informazioni più di una
volta
! Usate un parser SAX se si intende soltanto estrarre pochi elementi da un documento XML ! E’ appropriato in caso di poca memoria o se i dati
letti dal documento sono usati solo una volta
Pro & Contro di DOM ! Pro
! Intero documento in memoria ! Completamente navigabile ed editabile nella
struttura e nel contenuto
! Contro ! Intero documento in memoria

DOM API in Java
DOM API in Java

Esempio: Agenda XML
<?xml version="1.0" encoding="UTF-8"?> <!--This is a simple contact list--> <addressbook> <?myInstruction action silent?> ...
<contact gender="F"> <FirstName>Sue</FirstName> <LastName>Green</LastName> </contact> ... <![CDATA[I can add <, >, and ?]]>
</addressbook>
DOM: struttura gerarchica ad albero
! DOM consente di rappresentare un documento XML mediante una struttura gerarchica ad albero:
<contact>
<FirstName>Sue</FirstName>
<FamilyName>Smith</FamilyName>
</contact>
! Contact è padre dell’elemento figlio FirstName (primo figlio) e di FamilyName (figlio successivo)
! FirstName è padre dell’elemento figlio Sue
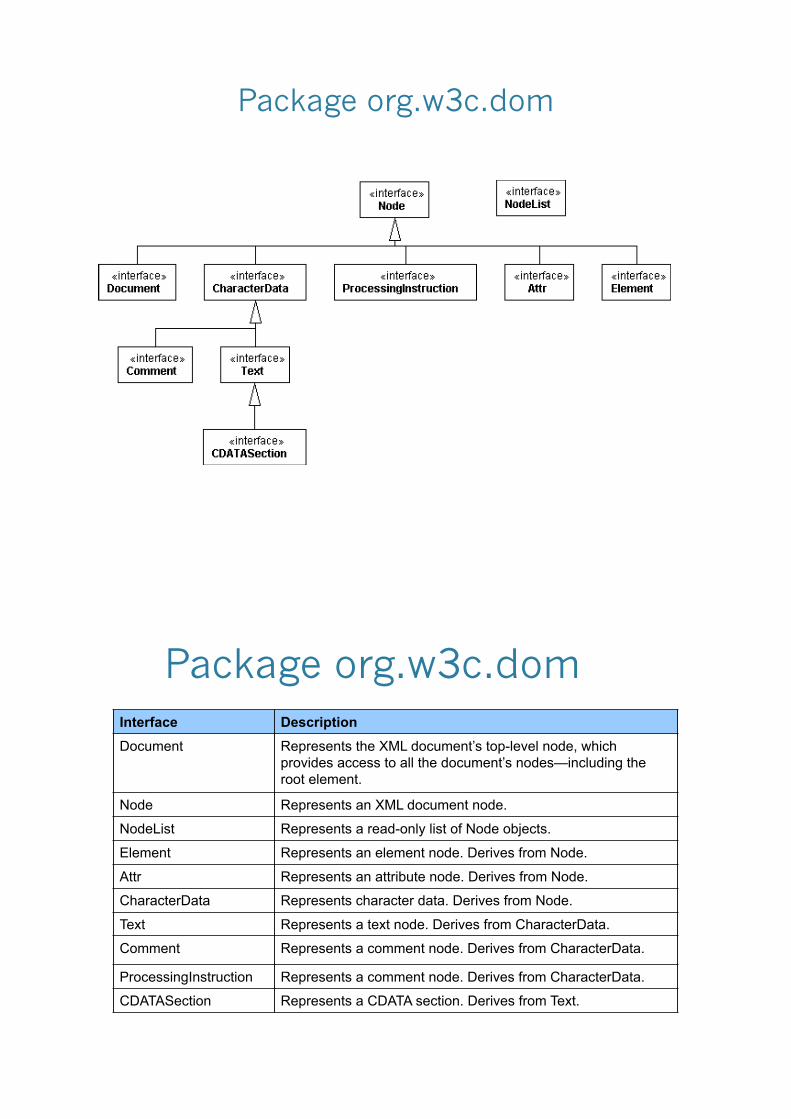
Package org.w3c.dom
Package org.w3c.dom Interface Description
Document Represents the XML document’s top-level node, which provides access to all the document’s nodes—including the root element.
Node Represents an XML document node.
NodeList Represents a read-only list of Node objects.
Element Represents an element node. Derives from Node.
Attr Represents an attribute node. Derives from Node.
CharacterData Represents character data. Derives from Node.
Text Represents a text node. Derives from CharacterData.
Comment Represents a comment node. Derives from CharacterData.
ProcessingInstruction Represents a comment node. Derives from CharacterData.
CDATASection Represents a CDATA section. Derives from Text.

Esempio: Agenda XML
Metodi di Document
Method Name Description
createElement Creates an element node. createAttribute Creates an attribute node. createTextNode Creates a text node. createComment Creates a comment node. createProcessingInstruction Creates a processing instruction node
createCDATASection Creates a CDATA section node. getDocumentElement Returns the document’s root element. getElementsByTagName Returns a node list of elements with matching
tag name appendChild Appends a child node. getChildNodes Returns the child nodes.
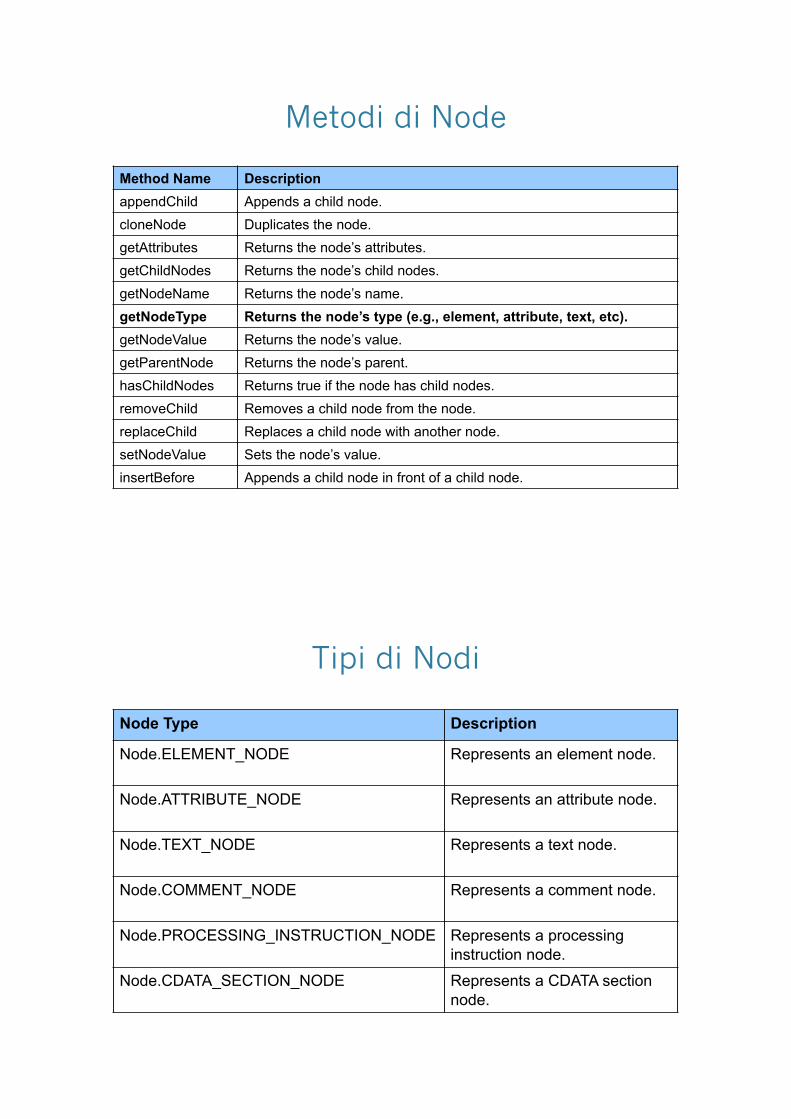
Metodi di Node
Method Name Description
appendChild Appends a child node. cloneNode Duplicates the node. getAttributes Returns the node’s attributes. getChildNodes Returns the node’s child nodes. getNodeName Returns the node’s name. getNodeType Returns the node’s type (e.g., element, attribute, text, etc).
getNodeValue Returns the node’s value. getParentNode Returns the node’s parent. hasChildNodes Returns true if the node has child nodes. removeChild Removes a child node from the node. replaceChild Replaces a child node with another node. setNodeValue Sets the node’s value. insertBefore Appends a child node in front of a child node.
Tipi di Nodi
Node Type Description
Node.ELEMENT_NODE Represents an element node.
Node.ATTRIBUTE_NODE Represents an attribute node.
Node.TEXT_NODE Represents a text node.
Node.COMMENT_NODE Represents a comment node.
Node.PROCESSING_INSTRUCTION_NODE Represents a processing instruction node.
Node.CDATA_SECTION_NODE Represents a CDATA section node.

Metodi di Element
Method Name Description
getAttribute Returns an attribute’s value.
getTagName Returns an element’s name.
removeAttribute Removes an element’s attribute.
setAttribute Sets an attribute’s value.
Esempio: navigazione di un documento XML
<root> <!--Ciao--> <elem attr="Java">DOM</elem> <?istruzioni instr1 instr2?> <![CDATA[Posso usare <, >, e ?]]>
</root>

Esempio: navigazione di un documento XML
private Document document; … processNode( document ); … public void processNode( Node currentNode ) {
switch ( currentNode.getNodeType() ) {
// process a Document node case Node.DOCUMENT_NODE: Document doc = ( Document ) currentNode;
System.out.println("Document node: " + doc.getNodeName() + "\nRoot element: " +doc.getDocumentElement().getNodeName() );
processChildNodes( doc.getChildNodes() ); break;
Esempio: navigazione di un documento XML
// process an Element node case Node.ELEMENT_NODE: System.out.println( "\nElement node: " +
currentNode.getNodeName() );
NamedNodeMap attributeNodes = currentNode.getAttributes();
for ( int i = 0; i < attributeNodes.getLength(); i++) { Attr attribute = ( Attr ) attributeNodes.item( i );
System.out.println( "\tAttribute: " + attribute.getNodeName() + " ; Value = " + attribute.getNodeValue() ); }
processChildNodes( currentNode.getChildNodes() );
break;

Esempio: navigazione di un documento XML
// process a text node and a CDATA section case Node.CDATA_SECTION_NODE: case Node.TEXT_NODE: Text text = ( Text ) currentNode;
if ( !text.getNodeValue().trim().equals( "" ) ) System.out.println( "\tText: " + text.getNodeValue() ); break; } }
public void processChildNodes( NodeList children ) { if ( children.getLength() != 0 ) { for ( int i = 0; i < children.getLength(); i++) { processNode( children.item( i ) ); } } }
Esempio: creare un documento XML
// crea un documento con radice // <root> ... // </root> private Document document; ...// creo documento con DocumentBuilder.newDocument();... Element root = document.createElement("root"); document.appendChild(root);

Esempio: creare un documento XML
// aggiunge un commento al // documento XML // <root> // <!--Ciao--> // </root> Comment simpleComment = document.createComment("Ciao"); root.appendChild( simpleComment );
Esempio: creare un documento XML
// Aggiunge un elemento al doc // <root> // <elem attr="Java">DOM</elem> // </root> Element elem = document.createElement("elem"); elem.appendChild( document.createTextNode("DOM"));

Esempio: creare un documento XML
// crea e setta l’attributo Attr attr = document.createAttribute("attr"); attr.setValue("Java"); elem.setAttributeNode(attr);
// appende elem alla radice root.appendChild(elem);
Esempio: creare un documento XML
// aggiunge processing instruction
ProcessingInstruction pi =
document.createProcessingInstruction(
"istruzioni", "instr1 instr2" );
root.appendChild(pi);
// aggiunge sezione CDATA
CDATASection cdata = document.createCDATASection(
"Posso usare <, > e ?" );
root.appendChild(cdata);

JAXP DOM Parser
! Import necessari per usare il parser DOM JAXP (contenute di default in Java " 1.4.x):
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
JAXP DOM Parser try {
Document document;
// obtain the default parser DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance(); // set desired properties for parsing factory.setValidating( true );
DocumentBuilder builder = factory.newDocumentBuilder(); // obtain document object from XML document document = builder.parse( new File( file ) );
} catch ( SAXParseException spe ) { System.err.println("Parse error: " + spe.getMessage() ); System.exit( 1 ); } catch ( SAXException se ) { se.printStackTrace(); }

Serializzazione di un documento XML
! Problema: serializzare un documento DOM in uno stream di output (e.g., System.out)
! La serializzazione è una feature standardizzata di recente nel DOM, livello 3
! In alternativa sono state realizzate diverse soluzioni dipendenti dalla particolare implementazione: ! Usare la classe XmlDocument in JAXP (Non è più
supportata a partire da Java 5!!!) ! Usare il package org.apache.xml.serialize in Apache Xerces
(DEPRECATO!)
! Nessuna di questa soluzione è portabile ! Non implementano le specifiche di load e save del DOM
livello 3
Apache Xerces ! Includendo la libreria di xercesImpl.jar nel
classpath della propria applicazione, si ottiene AUTOMATICAMENTE l’ovverriding del parser di default di Java ! In tal caso, anche usando le classi DocumentBuilderFactory e DocumentBuilder si ottiene in realtà un’istanza del parser di Apache
! Questo “stile” è consigliato per maggiore portabilità

Gestione errori
Gestione degli errori ! E’ possibile personalizzare la gestione delle eccezioni durante il
parsing di un file
! Occorre implementare l’interfaccia org.xml.sax.ErrorHandler public class MyErrHandler implements ErrorHandler {
public void fatalError(SAXParseException spe )
throws SAXException { …
public void error( SAXParseException spe )
throws SAXParseException { …
public void warning( SAXParseException spe )
throws SAXParseException { …

Gestione degli errori
// JAXP parser
DocumentBuilder builder = factory.newDocumentBuilder();
builder.setErrorHandler( new MyErrHandler() );
// Xerces parser
DOMParser parserDOM = new DOMParser();
parserDOM.setErrorHandler( new MyErrHandler());
Validazione con XSD <?xml version="1.0" encoding="UTF-8"?>
<meeting xmlns="http://conferencing.di.uniba.it/meeting" xmlns:conference="http://conferencing.di.uniba.it/base" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance” xsi:schemaLocation="http://conferencing.di.uniba.it/meeting meeting.xsd">
<conference:name>jabber_meet</conference:name>
<conference:schedule>
2005-01-01T10:00:00+01:00
</conference:schedule>
…

Abilitare namespace e validazione nel parser
private final String W3C_XML_SCHEMA = "http://www.w3.org/2001/XMLSchema";
private final String JAXP_SCHEMA_LANGUAGE = "http://java.sun.com/xml/jaxp/properties/schemaLanguage";
private final String JAXP_SCHEMA_SOURCE = "http://java.sun.com/xml/jaxp/properties/schemaSource";
private final String[] xsd = {“uno.xsd“, “due.xsd”};
Abilitare namespace e validazione nel parser
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
factory.setNamespaceAware(true);
factory.setAttribute(JAXP_SCHEMA_LANGUAGE, W3C_XML_SCHEMA);
factory.setValidating(true); // default DTD!
factory.setAttribute(JAXP_SCHEMA_SOURCE, xsd);
} catch (IllegalArgumentException x) {
// Happens if parser doesnt support a feature
…
}

Gestione dei Namespace ! org.w3c.dom.Node
! Informazioni sul namespace ! String getPrefix();
! The namespace prefix of this node, or null if it is unspecified
! String getLocalName(); ! Returns the local part of the qualified name of this
node ! String getNamespaceURI();
! The namespace URI of this node, or null if it is unspecified
Gestione dei Namespace: esempi
! Nodo corrente è <conference:name>jabber_meet</conference:name>
! currentNode.getPrefix();
! Resituisce “conference”
! currentNode.getLocalName();
! Restituisce “name”
! currentNode.getNamespaceURI();
! Restituisce “http://conferencing.di.uniba.it/base”

Gestione dei Namespace ! Query methods
! Senza indicare NS
NodeList getElementsByTagName(String name);
! Indicando il NS
NodeList getElementsByTagNameNS(String nsURI, String localName);
! Es. document.getElementsByTagNameNS(“http://
conferencing.di.uniba.it/base”,“schedule”);
Riferimenti ! Harvey M. Deitel and Paul J. Deitel, Internet & World
Wide Web: How to Program, Ed. Pearson International Edition
! Carey, Blatnik, Guida a XML, Ed. McGraw-Hill
! http://www.w3.org/
! www.deitel.com/books/iw3htp4 (per il codice di esempio degli esercizi)
! http://www.w3schools.com/xsl

Riferimenti ! JAXP - http://java.sun.com/xml/jaxp/
! JAXP DOM tutorial - http://java.sun.com/j2ee/1.4/docs/tutorial/doc/index.html http://java.sun.com/j2ee/1.4/docs/tutorial/doc/JAXPIntro5.html#wp66704
! Xerces2 Java DOM - http://xml.apache.org/xerces2-j/dom.html
! http://download.oracle.com/javase/1.4.2/docs/api/org/w3c/dom/package-summary.html





























