Embed Size (px)
Citation preview

Uniprocessor Scheduling
•Basic Concepts•Scheduling Criteria •Scheduling Algorithms
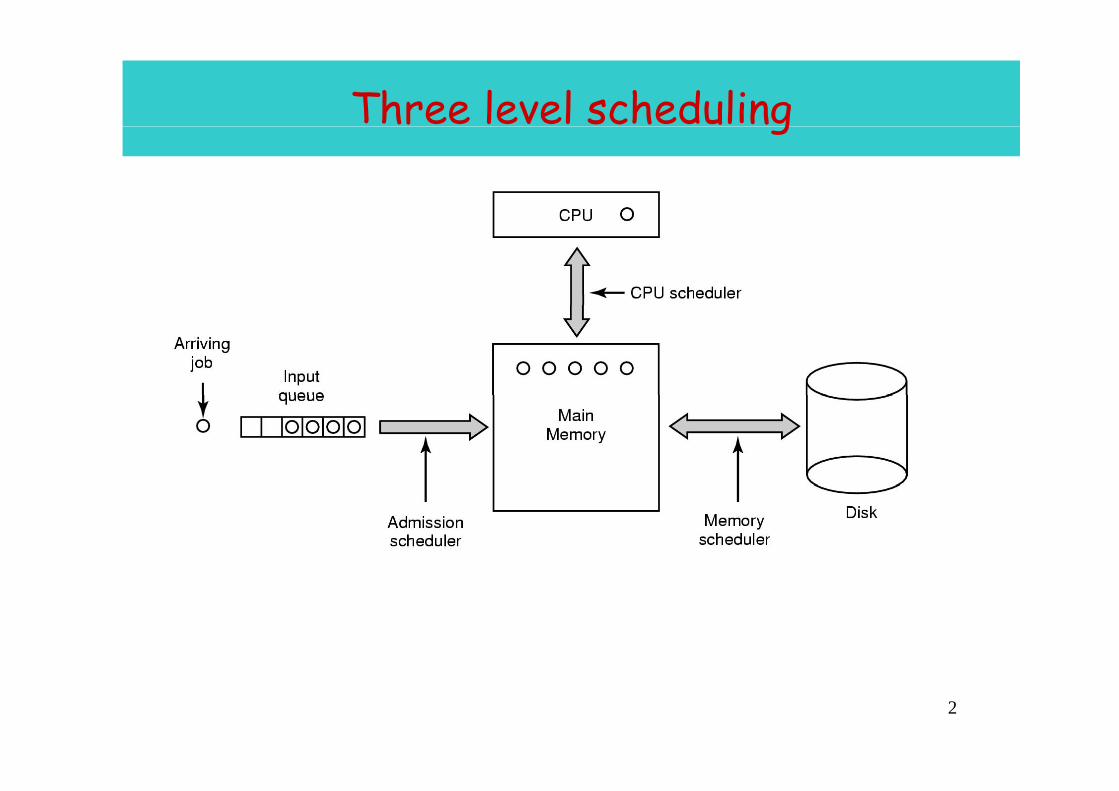
Three level schedulingg
2
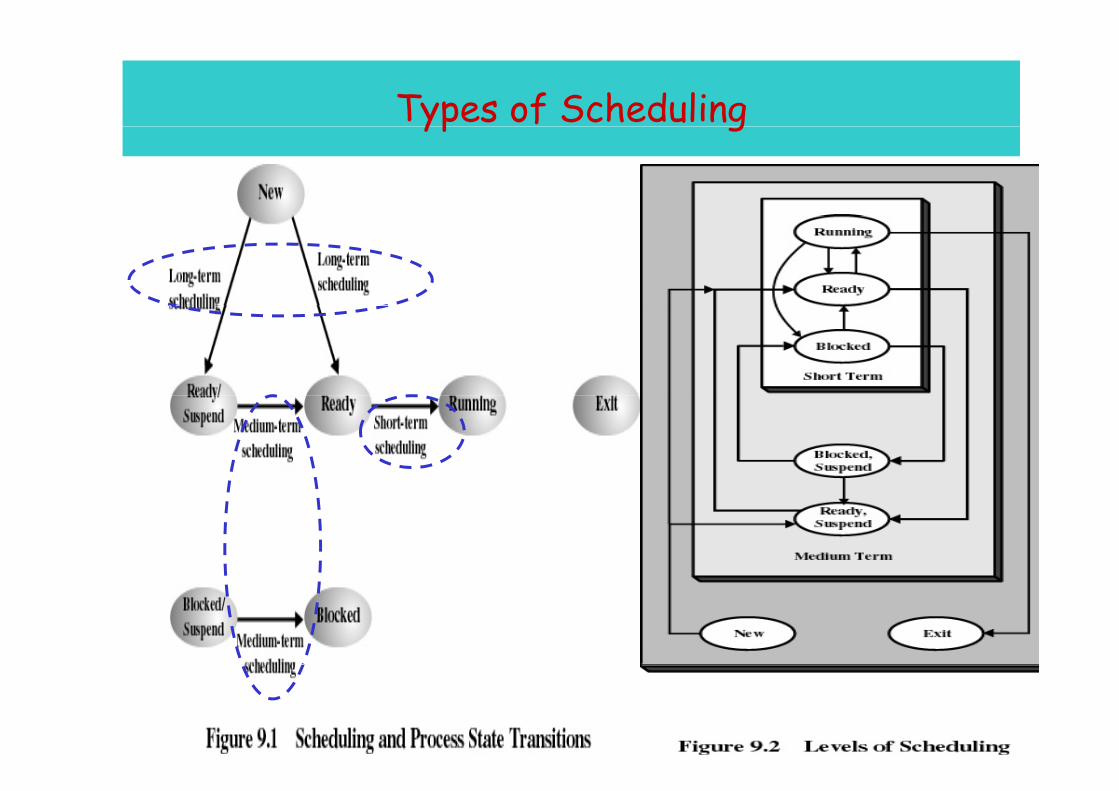
Types of Schedulingyp g
3

Long- and Medium-Term Schedulersg
Long-term scheduler• Determines which programs are admitted to the system
(ie to become processes) b d d f h h l d• requests can be denied if e.g. thrashing or overload
Medium-term scheduler• decides when/which processes to suspend/resume
• Both control the degree of multiprogramming– More processes, smaller percentage of time each process is
executedexecuted
4

Short-Term Scheduler
• Decides which process will be dispatched; invoked upon– Interrupts, Operating system calls, Signals, ..
• Dispatch latency – time it takes for the dispatcher to stop one process and start another running; the to stop one process and start another running; the dominating factors involve:– switching contextg– selecting the new process to dispatch
5
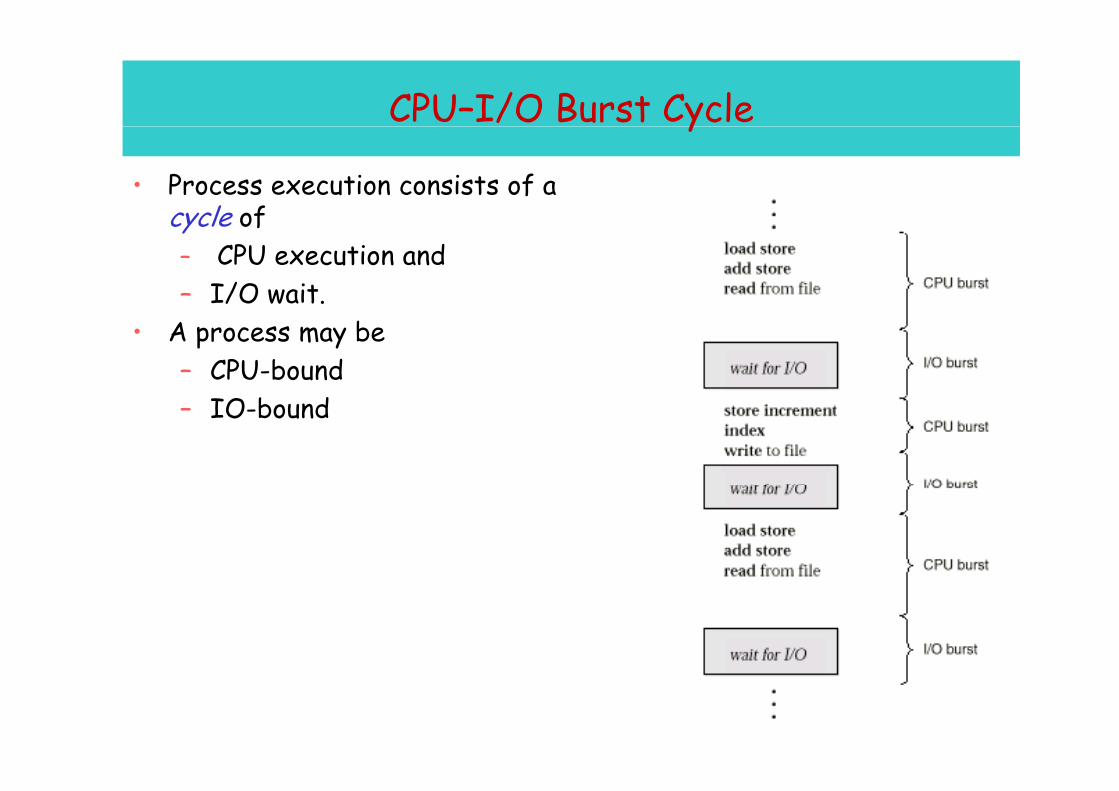
CPU–I/O Burst Cycley
• Process execution consists of a cycle ofcycle of– CPU execution and – I/O wait.
• A process may be – CPU-bound – IO-bound
6

Scheduling Criteria- Optimization goalsg p g
CPU utilization – keep CPU as busy as possibleThroughput – # of processes that complete their execution per
time unitResponse time – amount of time it takes from when a request was Response time amount of time it takes from when a request was
submitted until the first response is produced (execution + waiting time in ready queue)
T d ti t f ti t t ti l – Turnaround time – amount of time to execute a particular process (execution + all the waiting); involves IO schedulers also
Fairness - watch priorities, avoid starvation, ...Scheduler Efficiency - overhead (e.g. context switching, computing
priorities, …)
7

Decision ModeNonpreemptive
O i i th i t t it ill ti til it • Once a process is in the running state, it will continue until it terminates or blocks itself for I/O
Preemptive• Currently running process may be interrupted and moved to the
R d t t b th ti tReady state by the operating system• Allows for better service since any one process cannot monopolize
the processor for very longp y g
8
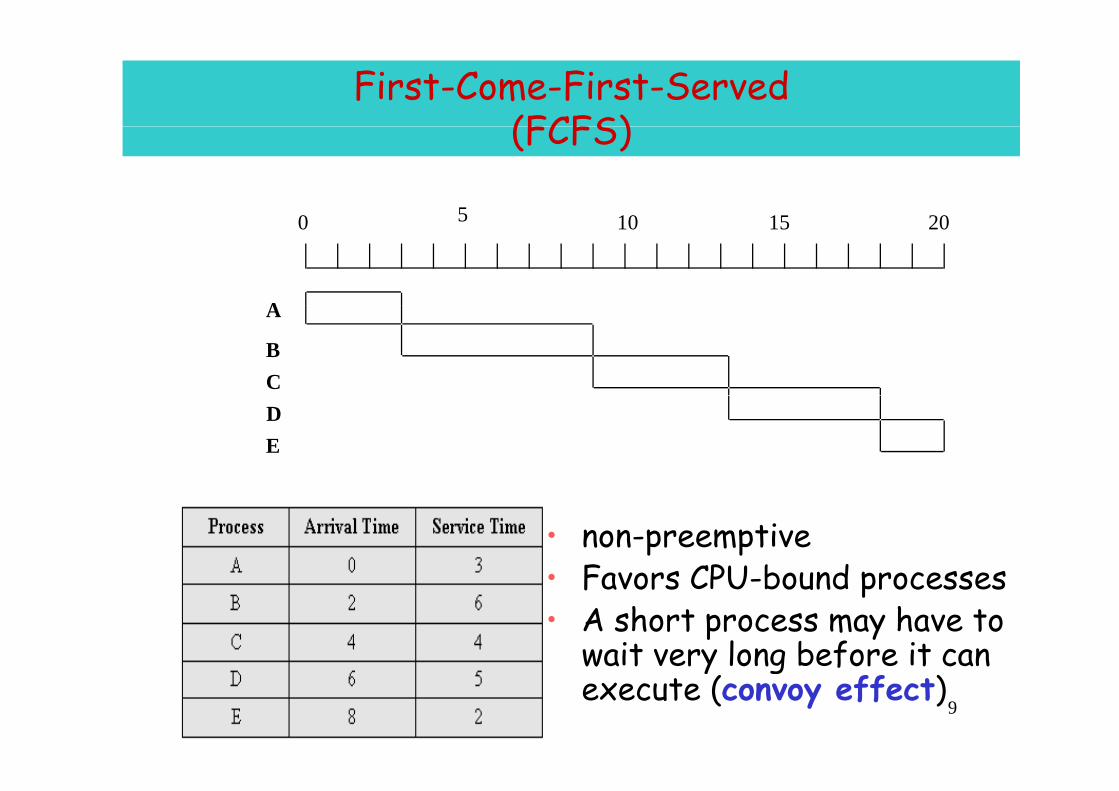
First-Come-First-Served(FCFS)(FCFS)
0 5 10 15 200 5 10 15 20
AA
BC
ED
• non-preemptive• Favors CPU bound processes • Favors CPU-bound processes • A short process may have to
wait very long before it can 9
wait very long before it can execute (convoy effect)
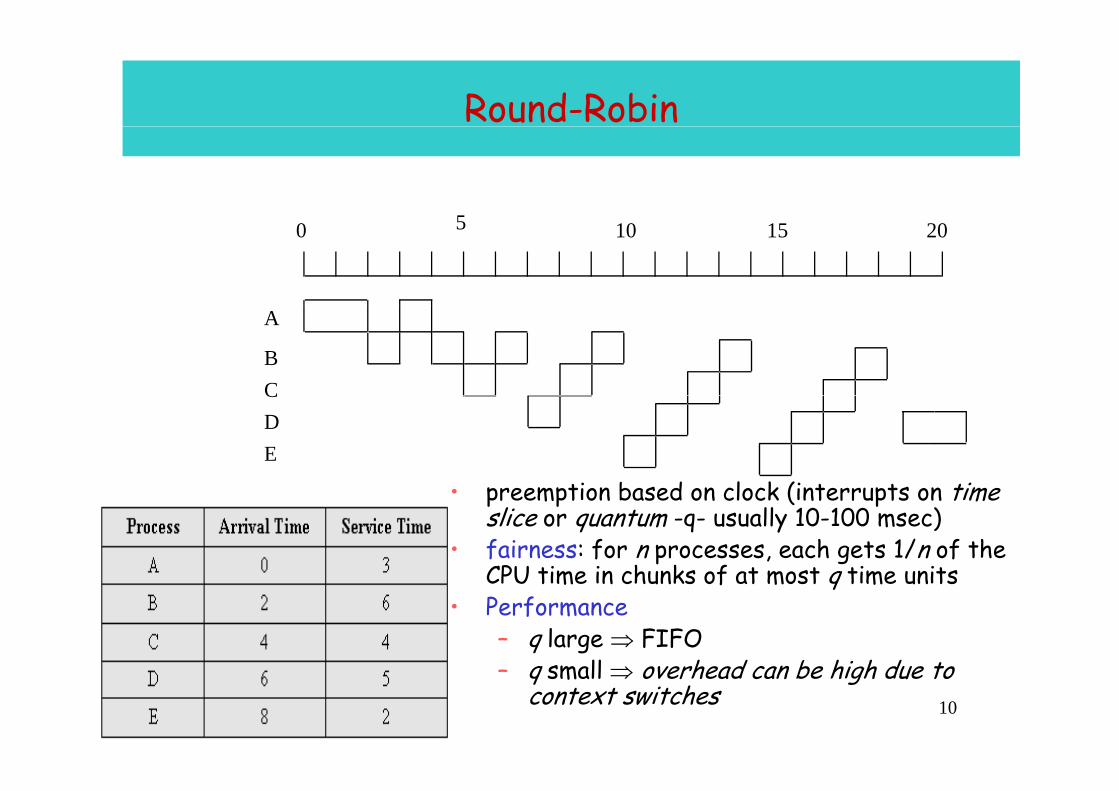
Round-Robin
50 5 10 15 20
A
BCCDE
ti b d l k (i t t ti • preemption based on clock (interrupts on time slice or quantum -q- usually 10-100 msec)
• fairness: for n processes, each gets 1/n of the CPU time in chunks of at most q time units CPU time in chunks of at most q time units
• Performance– q large ⇒ FIFO
ll h d b hi h d t 10
– q small ⇒ overhead can be high due to context switches
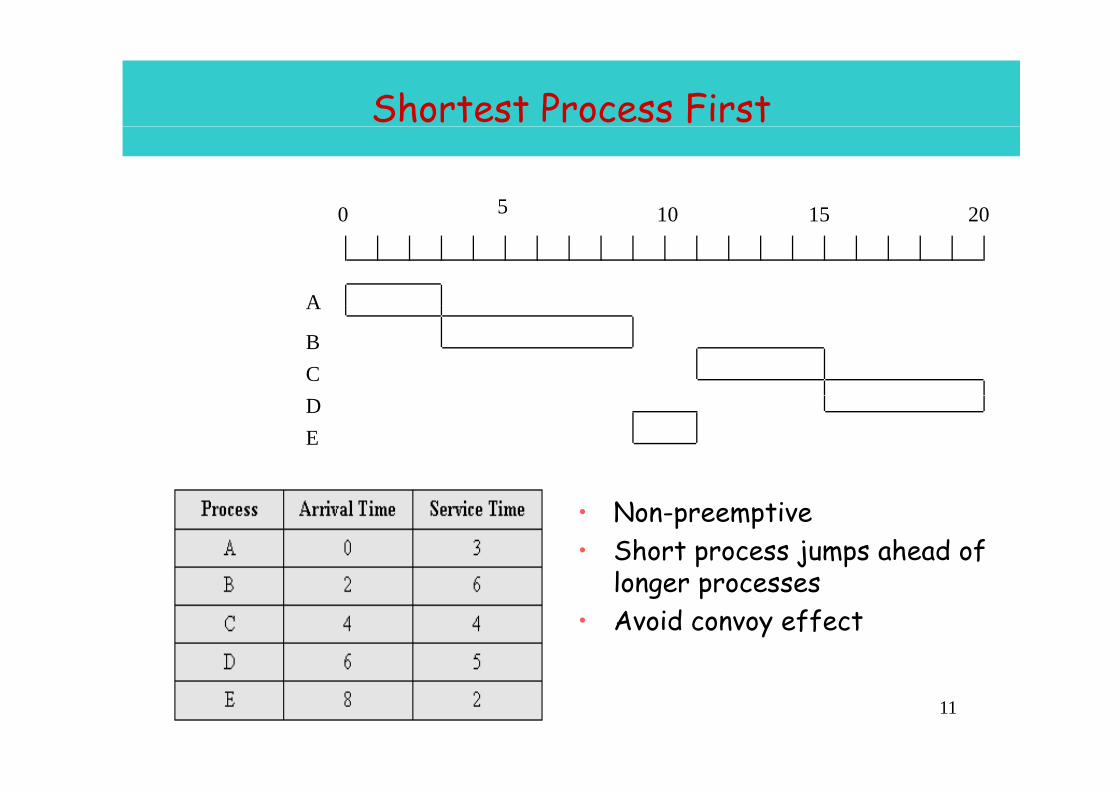
Shortest Process First
0 5 10 15 200 10 15 20
AA
BCDE
• Non-preemptive• Short process jumps ahead of
l longer processes• Avoid convoy effect
11
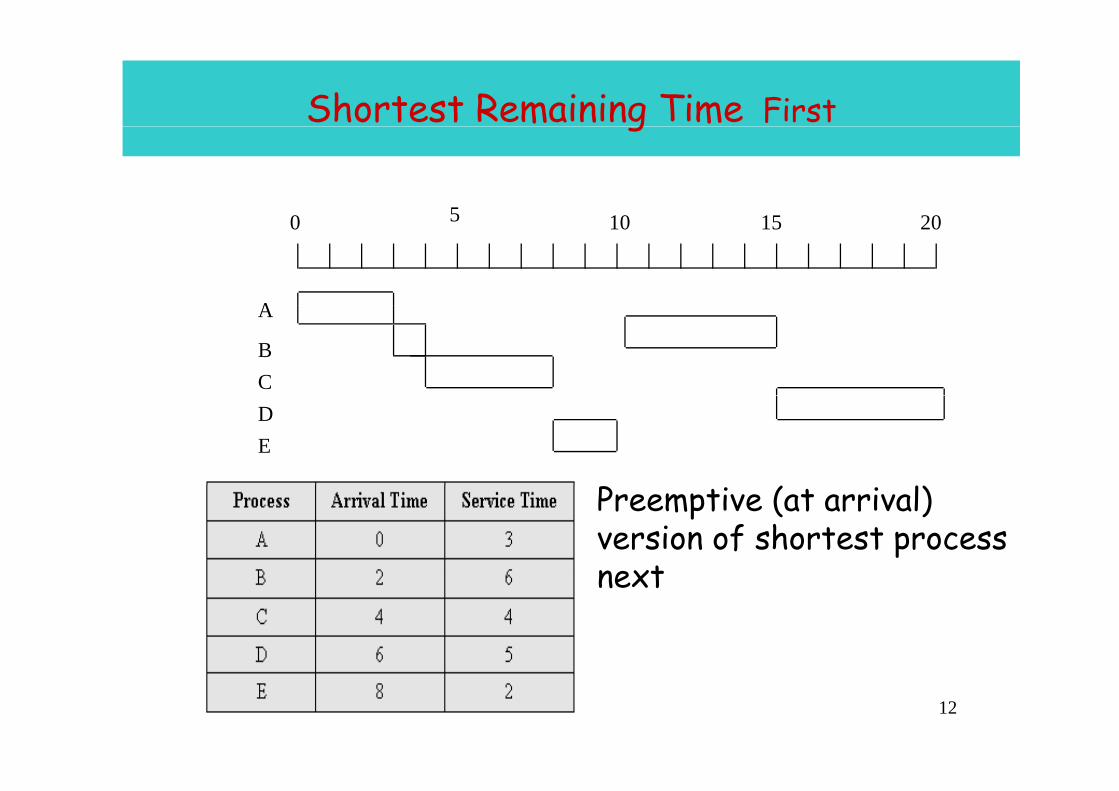
Shortest Remaining Time Firstg
0 5 10 15 200 5 10 15 20
AA
BCDE
• Preemptive (at arrival) version of shortest process nextnext
12

On SPF Schedulingg
• gives high throughputg s h gh throughput• gives minimum (optimal) average response (waiting) time
for a given set of processes g p– Proof (non-preemptive): analyze the summation giving the waiting time
• must estimate processing time (next cpu burst)– Can be done automatically (exponential averaging)– If estimated time for process (given by the user in a batch
system) not correct the operating system may abort itsystem) not correct, the operating system may abort it• possibility of starvation for longer processes
13

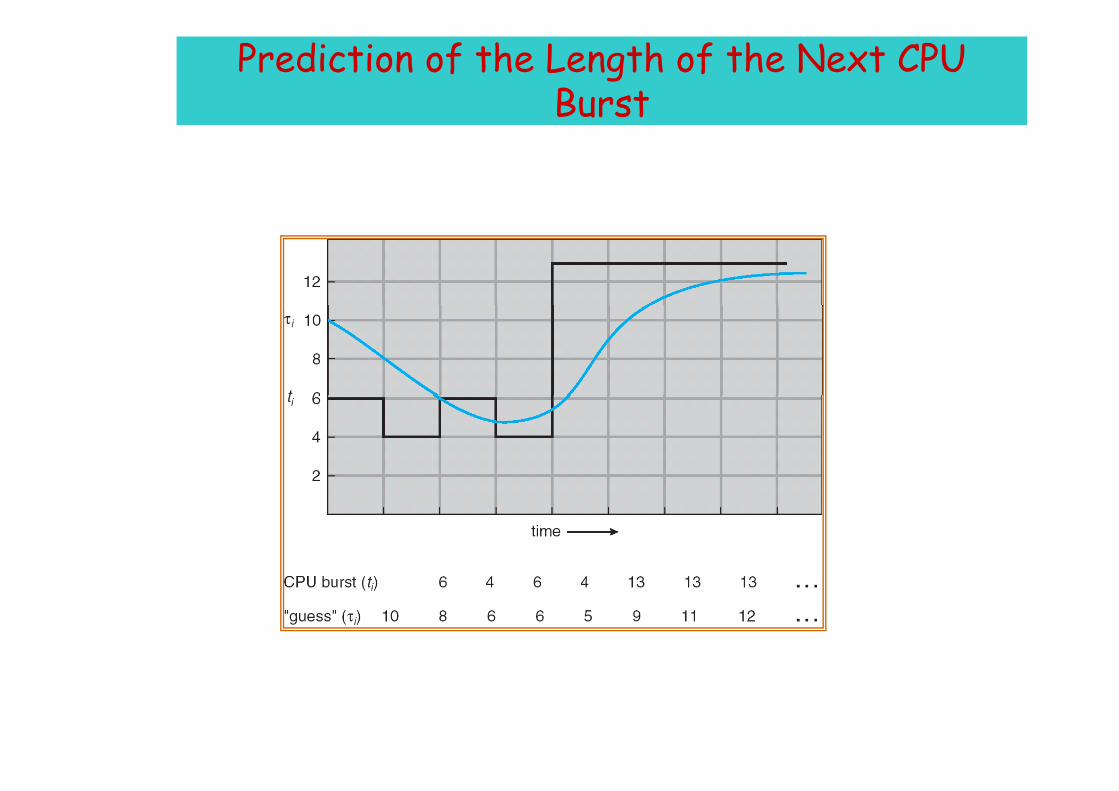
Determining Length of Next CPU Burstg g
• Can be done by using the length of previous CPU bursts, using exponential averagingexponential averaging.
burstCPUnexttheforvaluepredicted2burst CPU of lenght actual 1.
==
τ 1
thn nt
:Define 4.10 , 3.
burstCPU nexttheforvaluepredicted 2.≤≤
+
αατ 1n
( ) .t nnn ταατ −+== 11
14

On Exponential Averagingp g g
• α =0 – τn+1 = τn
– history does not count, only initial estimation counts• α =1α 1
– τn+1 = tn
– Only the actual last CPU burst counts.• If we expand the formula, we get:
τn+1 = α tn+(1 - α) α tn -1 + …+(1 α )j α t + +(1 - α )j α tn -i + …+(1 - α )n τ0
• Since both α and (1 - α) are less than or equal to 1, each successive term has less weight than its predecessor.
15
Prediction of the Length of the Next CPU Burst

Priority Scheduling: General Rulesy g
• Scheduler can choose a process of higher priority f l i itover one of lower priority
– can be preemptive or non-preemptive– can have multiple ready queues to represent multiple level of – can have multiple ready queues to represent multiple level of
priority• Example Priority Scheduling: SPF, where priority is p y g , p y
the predicted next CPU burst time.• Problem ≡ Starvation – low priority processes may p y p y
never execute.• A solution ≡ Aging – as time progresses increase the
f h priority of the process.
17
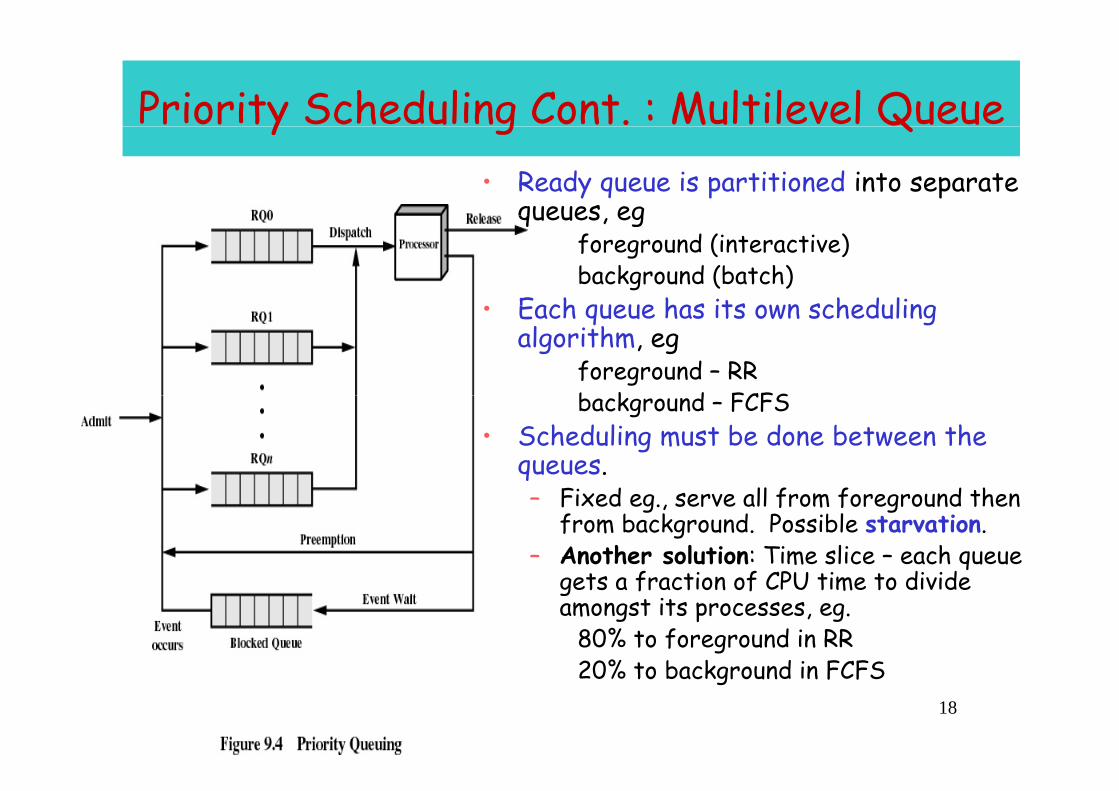
Priority Scheduling Cont. : Multilevel Queuey g Q• Ready queue is partitioned into separate
queues egqueues, egforeground (interactive)background (batch)
• Each queue has its own scheduling • Each queue has its own scheduling algorithm, eg
foreground – RRb k d FCFSbackground – FCFS
• Scheduling must be done between the queues.– Fixed eg., serve all from foreground then
from background. Possible starvation.– Another solution: Time slice – each queue
t f ti f CPU ti t di id gets a fraction of CPU time to divide amongst its processes, eg.
80% to foreground in RR20% t b k d i FCFS
18
20% to background in FCFS
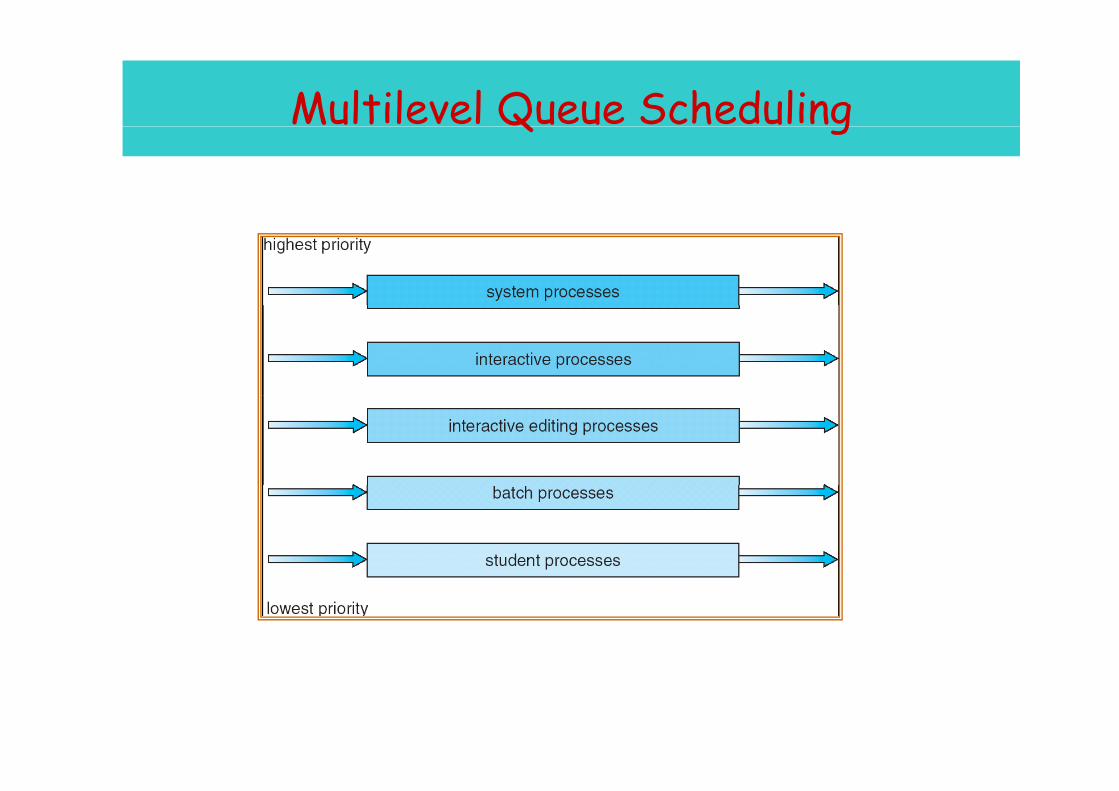
Multilevel Queue SchedulingQ g
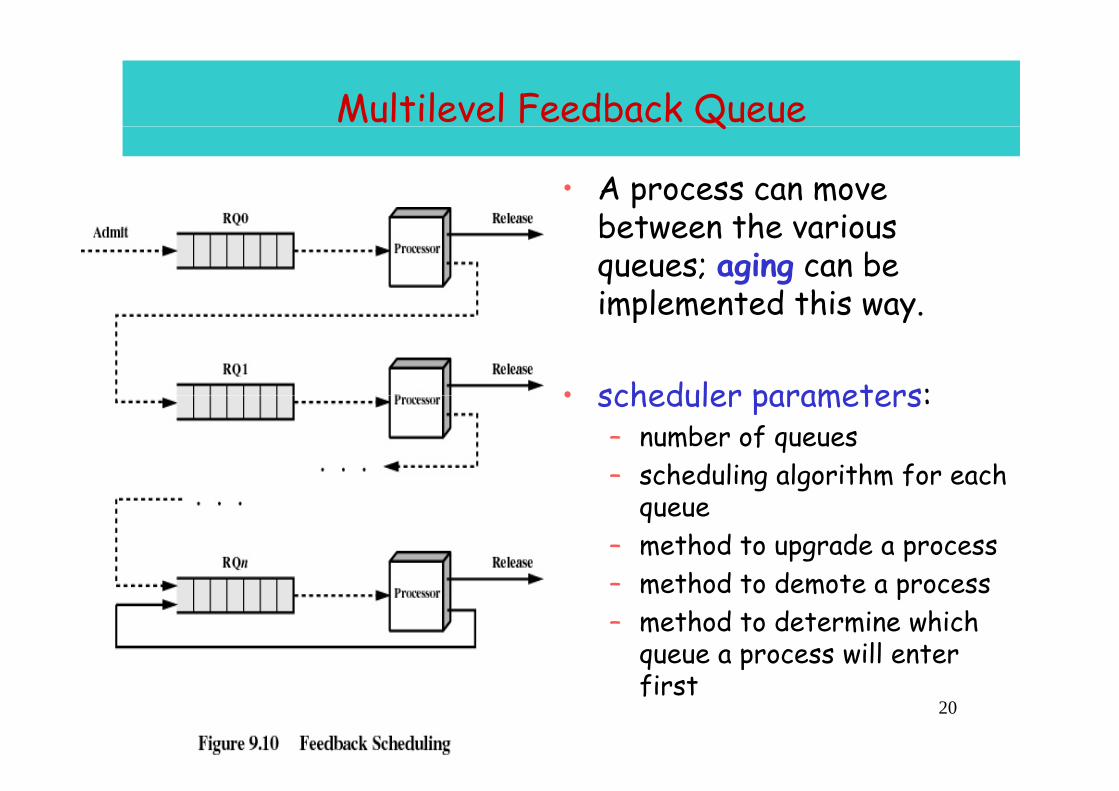
Multilevel Feedback QueueQ
• A process can move b t th i between the various queues; aging can be implemented this wayimplemented this way.
• scheduler parameters:• scheduler parameters:– number of queues– scheduling algorithm for each g g m f
queue– method to upgrade a process
th d t d t – method to demote a process– method to determine which
queue a process will enter
20
q pfirst
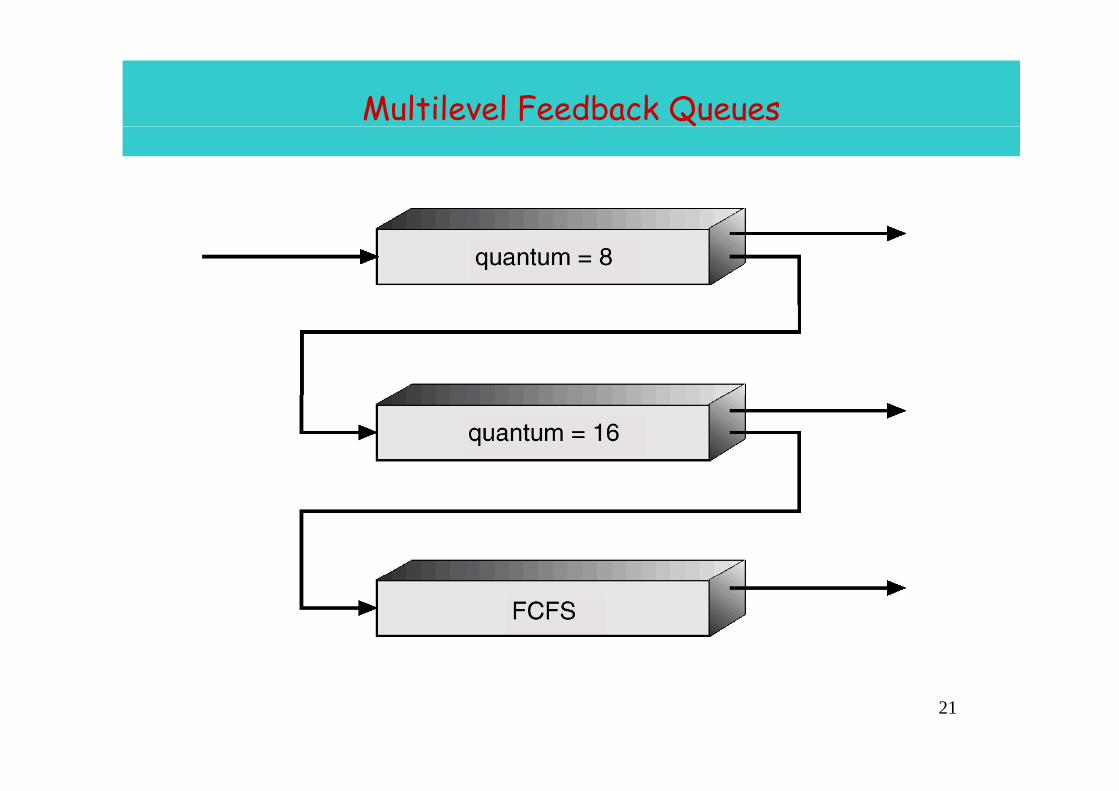
Multilevel Feedback QueuesQ
21

Thread Schedulingg
M t d t d l th d • Many-to-one and many-to-many models, thread library schedules user-level threads to run on LWPLWP– Known as process-contention scope (PCS) since
scheduling competition is within the process
• Kernel thread scheduled onto available CPU is system-contention scope (SCS) – competition among all threads in system
• E.g. Pthreads scheduling API allows specifying ith PCS SCS d i th d tieither PCS or SCS during thread creation

Fair-Share Schedulingg
• extention of multi-level queues with feedback + t nt on of mu t qu u s w th f ac priority recomputation– application runs as a collection of processes (threads)– concern: the performance of the application, user-groups, …
(ie. group of processes/threads)– scheduling decisions based on process sets rather than scheduling decisions based on process sets rather than
individual processes• eg. “traditional” unix shedulingg g
23
Real-Time Scheduling

Real-Time Systemsy
• Tasks or processes attempt to interact with outside-world events , which occur in “real time”; process must be able to keep up e gwhich occur in real time ; process must be able to keep up, e.g.– Control of laboratory experiments, Robotics, Air traffic control, Drive-by-
wire systems, Tele/Data-communications, Military command and control systemsy
• Correctness of the RT system depends not only on the logical result of the computation but also on the time at which the results are produced
i.e. Tasks or processes come with a deadline (for starting or completion)Requirements may be hard or soft
25
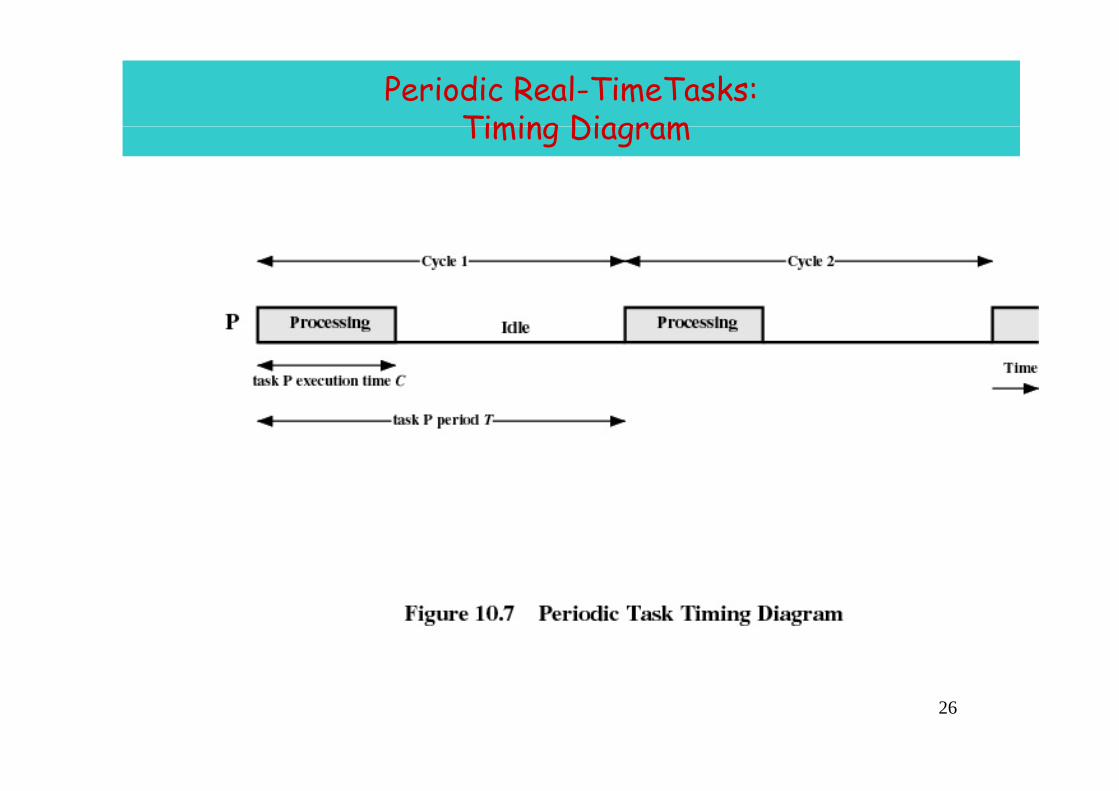
Periodic Real-TimeTasks:Timing DiagramTiming Diagram
26

E.g. Multimedia Process Scheduling
27A movie may consist of several files
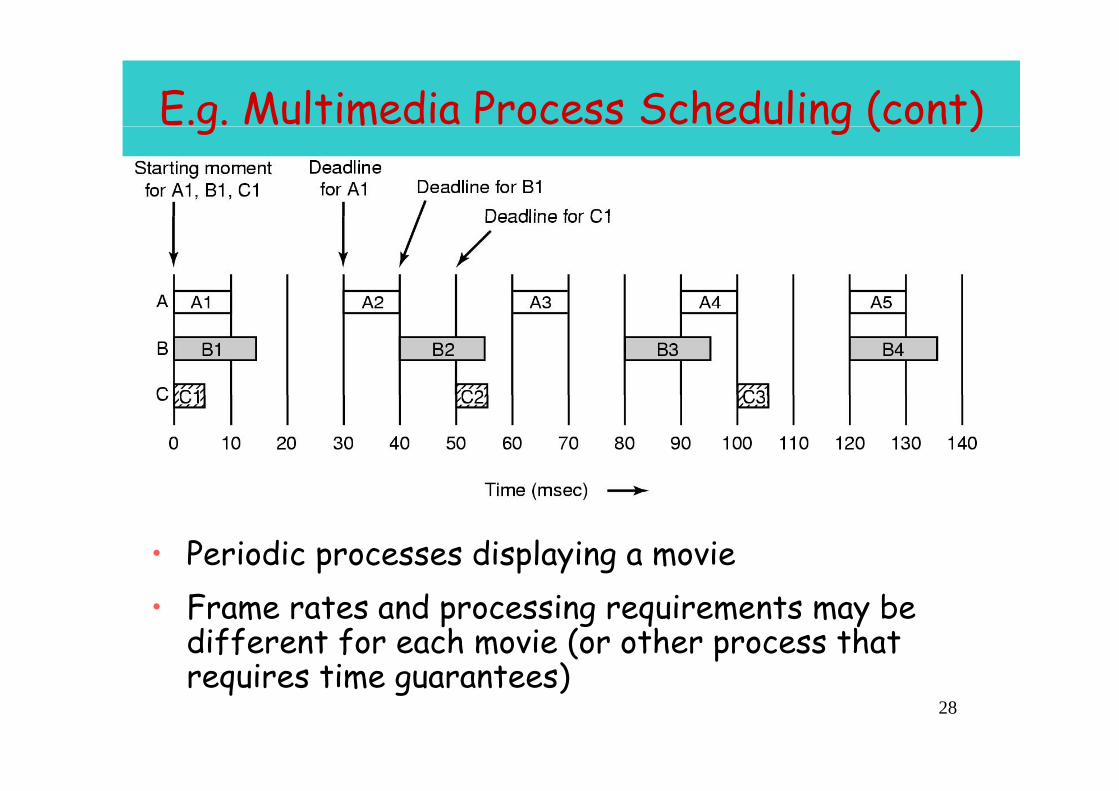
E.g. Multimedia Process Scheduling (cont)g g ( )
• Periodic processes displaying a movie• Frame rates and processing requirements may be
different for each movie (or other process that i i )
28requires time guarantees)

Scheduling in Real-Time Systems
Schedulable real-time system• Given
– m periodic eventsm per od c events– event i occurs within period Pi and requires Ci seconds
• Then the load can only be handled ifThen the load can only be handled if
1m
iCP≤∑Utilization =
1i iP=∑
29
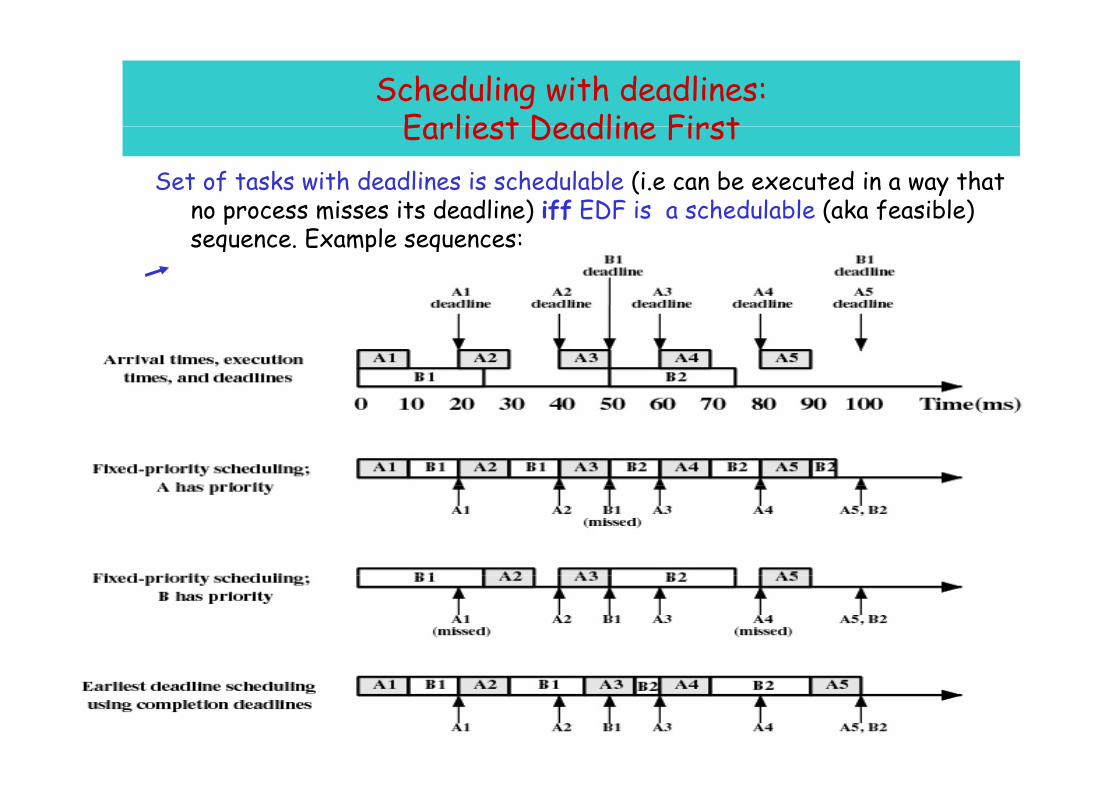
Scheduling with deadlines:Earliest Deadline FirstEarliest Deadline First
Set of tasks with deadlines is schedulable (i.e can be executed in a way that no process misses its deadline) iff EDF is a schedulable (aka feasible) no process misses its deadline) iff EDF is a schedulable (aka feasible) sequence. Example sequences:
30
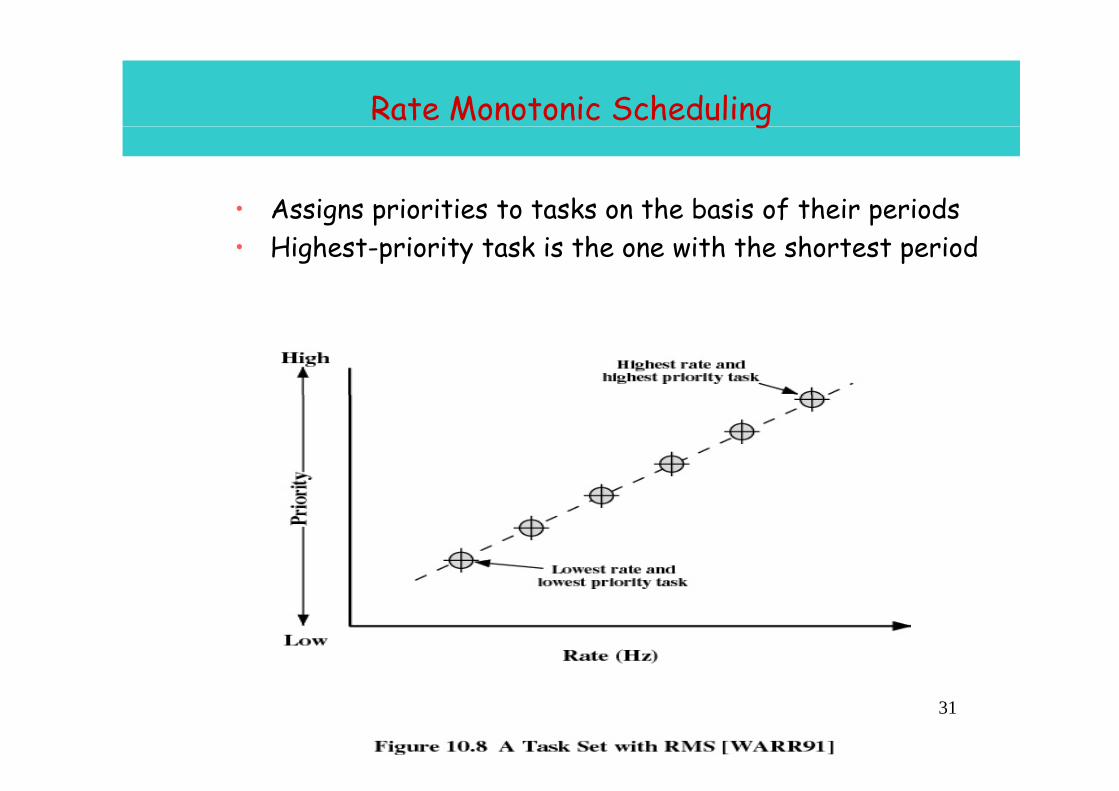
Rate Monotonic Schedulingg
• Assigns priorities to tasks on the basis of their periodsAssigns priorities to tasks on the basis of their periods• Highest-priority task is the one with the shortest period
31
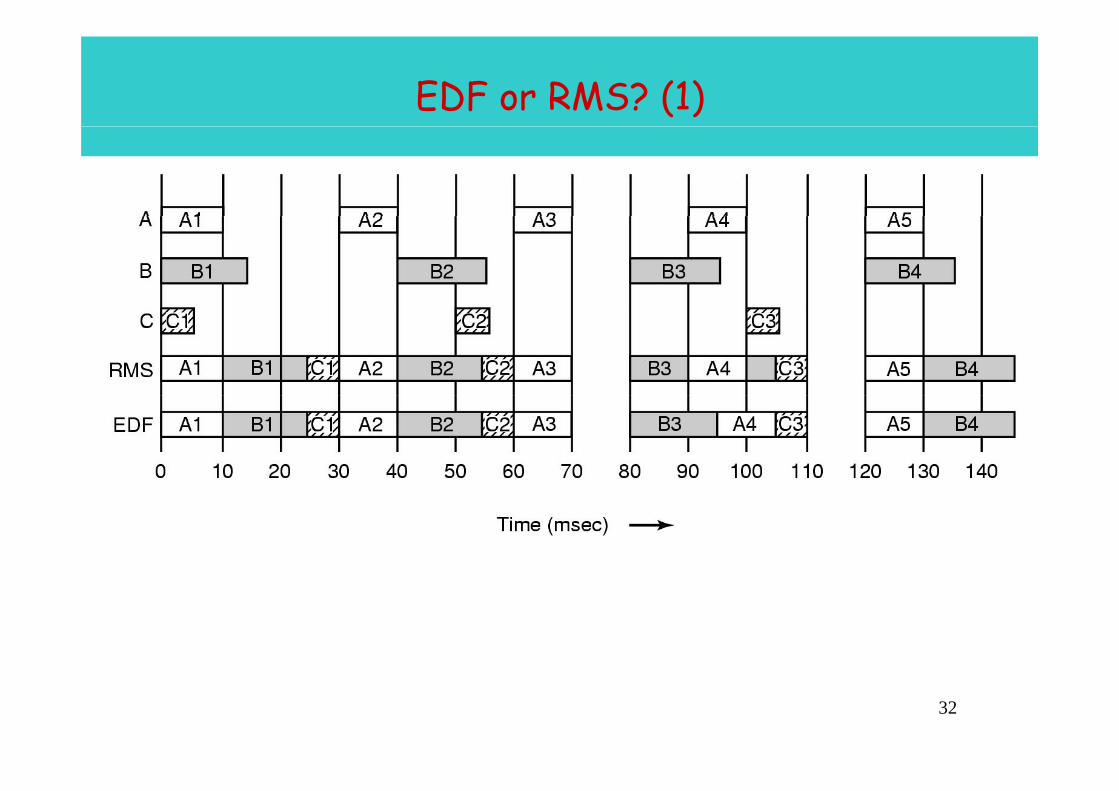
EDF or RMS? (1)
32
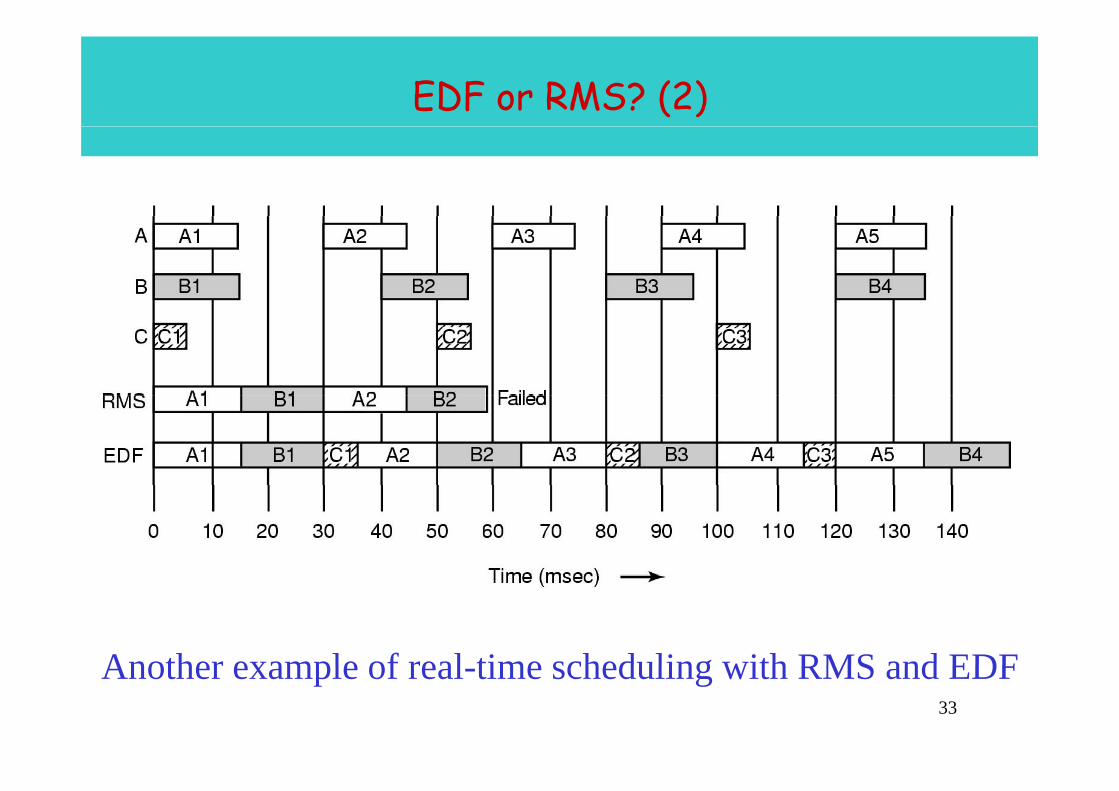
EDF or RMS? (2)
Another example of real time scheduling with RMS and EDF33
Another example of real-time scheduling with RMS and EDF

EDF or RMS? (3)
• RMS “accomodates” task set with less utilization
1m
iC≤∑ 0.7
1i iP=∑
– (recall: for EDF that is up to 1)
• RMS is often used in practice; – main reason: stability is easier to meet with RMS; priorities
are static hence under transient period with deadline misses are static, hence, under transient period with deadline-misses, critical tasks can be “saved” by being assigned higher (static) priorities
34– it is ok for combinations of hard and soft RT tasks

Multipr cess r SystemsMultiprocessor SystemsScheduling

Multiprocessors
Definition:A computer system in which two or more CPUs share full access to a common RAMCPUs share full access to a common RAM
36
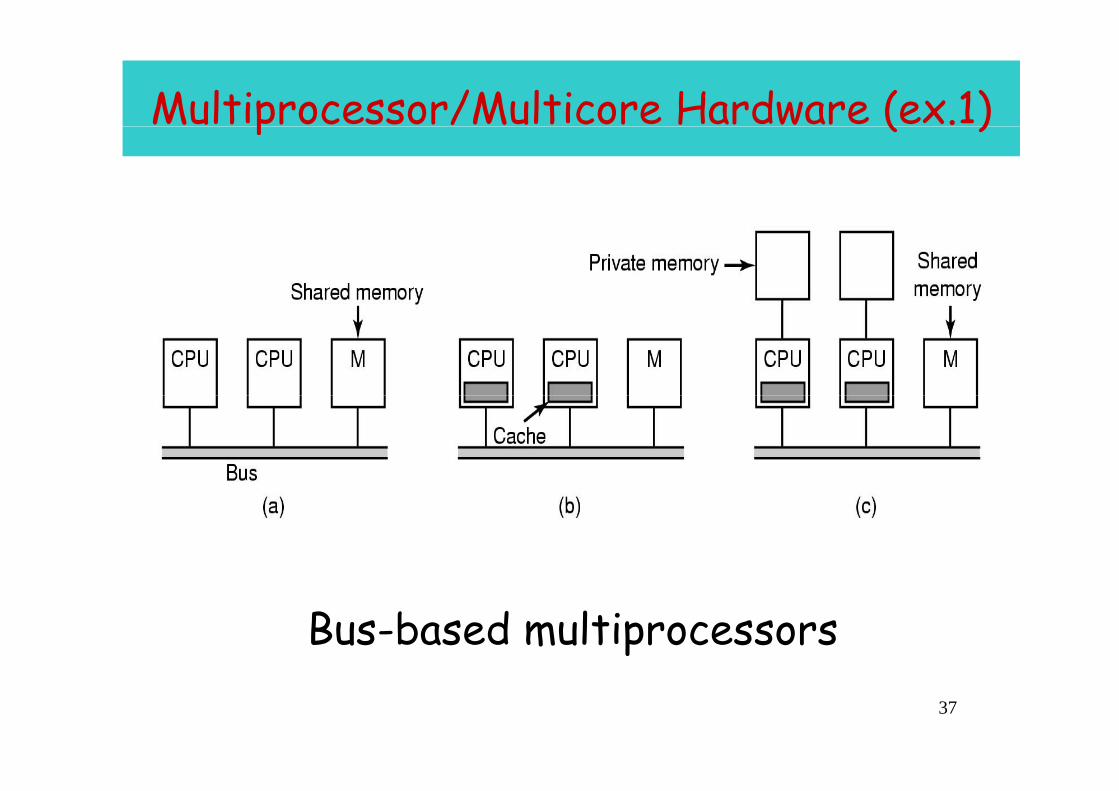
Multiprocessor/Multicore Hardware (ex.1)p ( )
Bus-based multiprocessors37
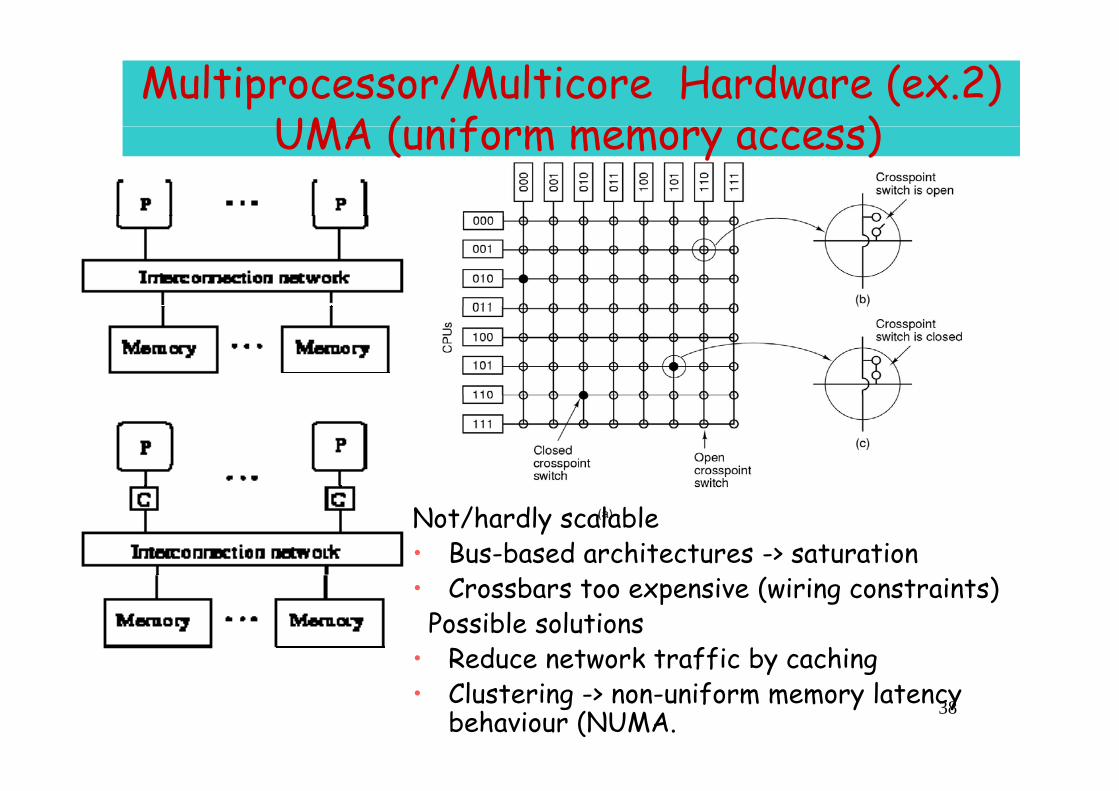
Multiprocessor/Multicore Hardware (ex.2)UMA ( nif m m m ss) UMA (uniform memory access)
Not/hardly scalable• Bus-based architectures -> saturation• Crossbars too expensive (wiring constraints)Possible solutions
• Reduce network traffic by caching38
Reduce network traffic by caching• Clustering -> non-uniform memory latency
behaviour (NUMA.
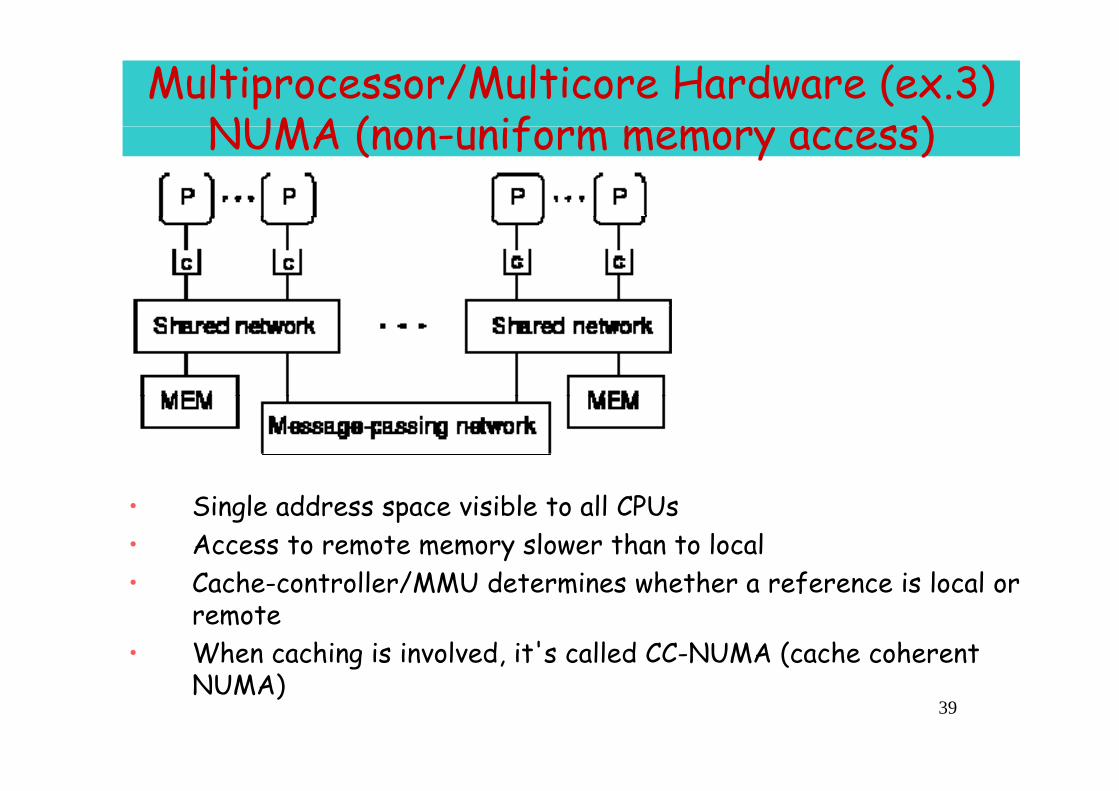
Multiprocessor/Multicore Hardware (ex.3) NUMA (n n nif m m m ss) NUMA (non-uniform memory access)
• Single address space visible to all CPUs• Access to remote memory slower than to local
C h t ll /MMU d t i h th f i l l • Cache-controller/MMU determines whether a reference is local or remote
• When caching is involved, it's called CC-NUMA (cache coherent
39
g , (NUMA)
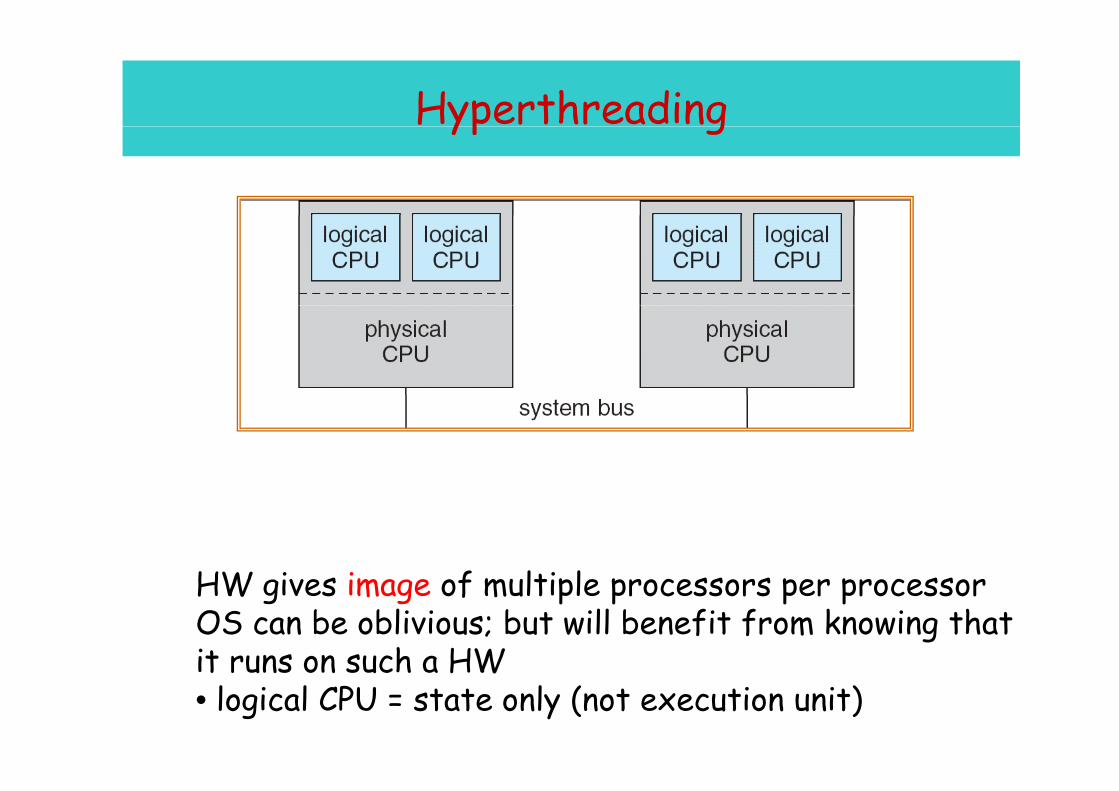
Hyperthreadingyp g
HW i i f lti l HW gives image of multiple processors per processorOS can be oblivious; but will benefit from knowing that it runs on such a HWit runs on such a HW• logical CPU = state only (not execution unit)
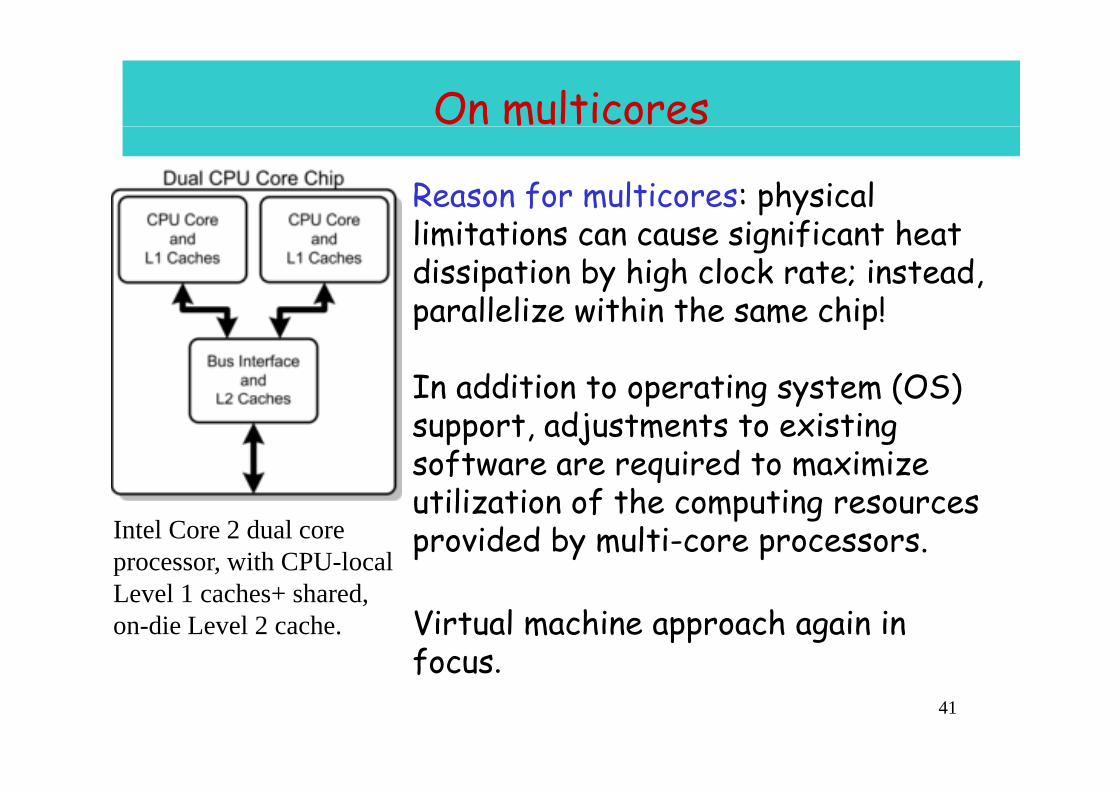
On multicores
Reason for multicores: physical limitations can cause significant heat dissipation by high clock rate; instead, parallelize within the same chip!parallelize within the same chip!
In addition to operating system (OS) In addition to operating system (OS) support, adjustments to existing software are required to maximize utilization of the computing resources provided by multi-core processors.Intel Core 2 dual core
processor, with CPU-local
Virtual machine approach again in focus
pLevel 1 caches+ shared, on-die Level 2 cache.
41
focus.
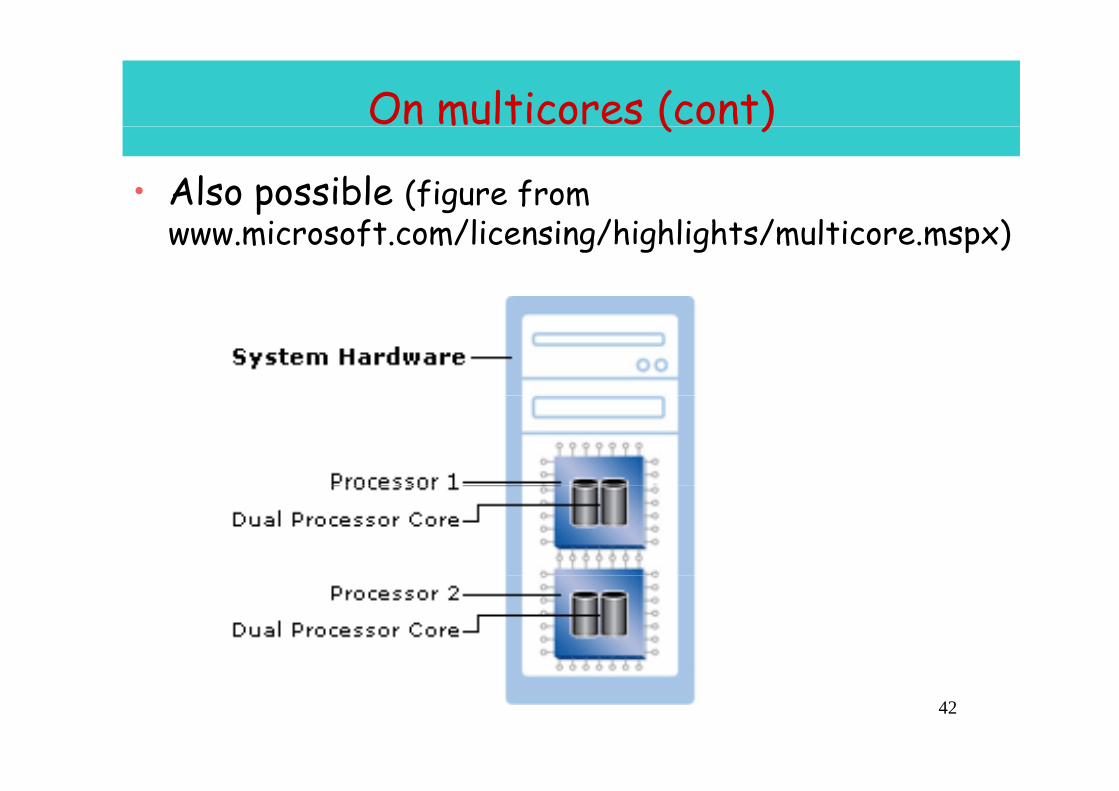
On multicores (cont)( )
• Also possible (figure from www.microsoft.com/licensing/highlights/multicore.mspx)
42

OS Design issues (1):Who executes the OS/scheduler(s)?Who executes the OS/scheduler(s)?
• Master/slave architecture: Key kernel functions always run on a • Master/slave architecture: Key kernel functions always run on a particular processor– Master is responsible for scheduling; slave sends service request to
th tthe master– Disadvantages
• Failure of master brings down whole system• Master can become a performance bottleneck
• Peer architecture: Operating system can execute on any processor– Each processor does self-schedulingEach processor does self scheduling– New issues for the operating system
• Make sure two processors do not choose the same process
43
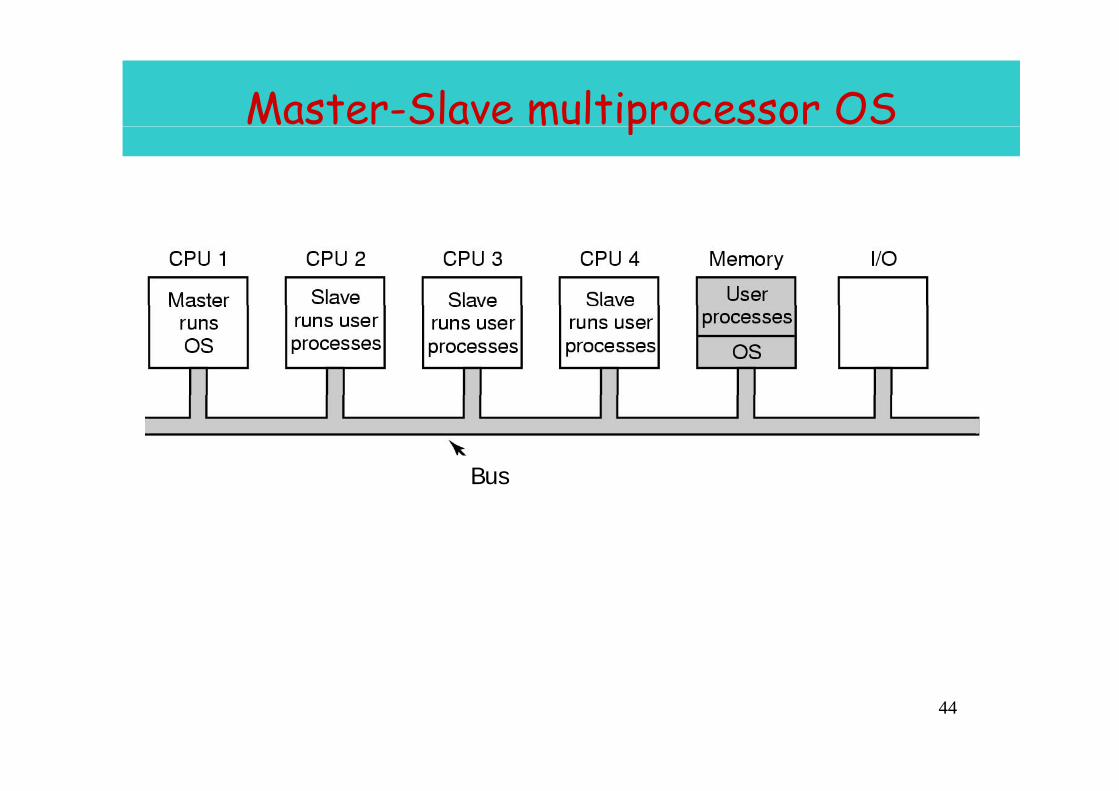
Master-Slave multiprocessor OSp
Bus
44
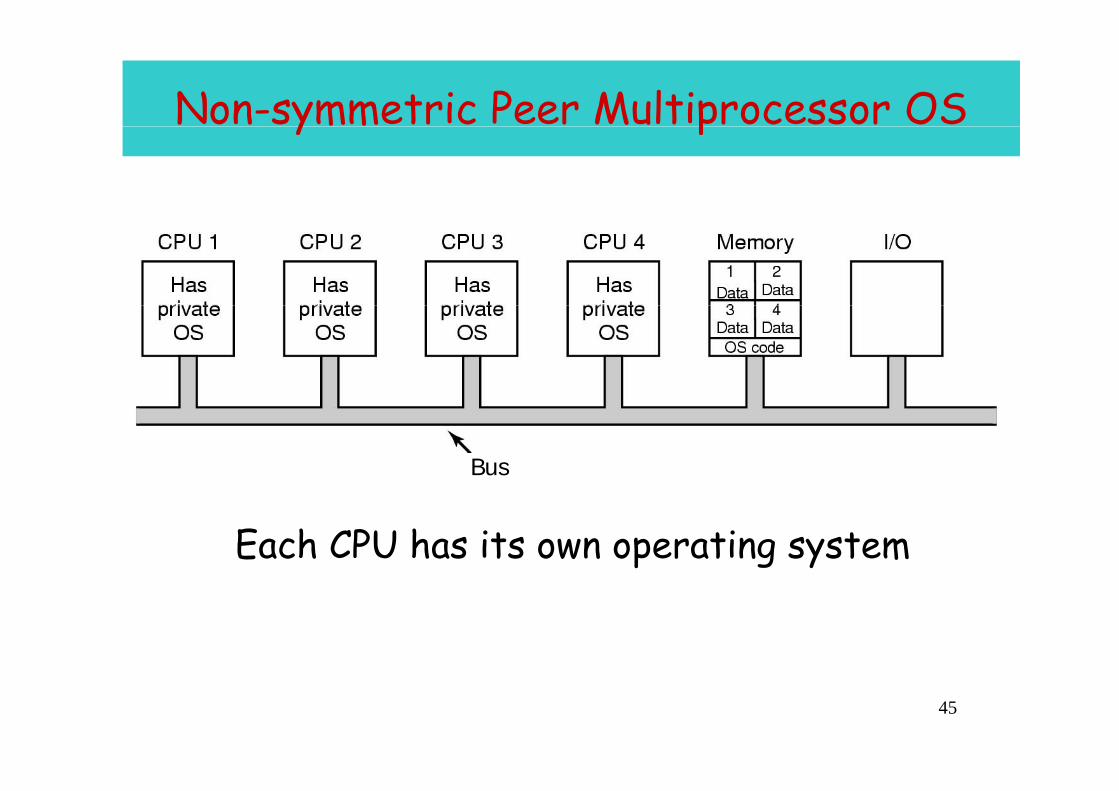
Non-symmetric Peer Multiprocessor OS y p
Bus
Each CPU has its own operating system
45
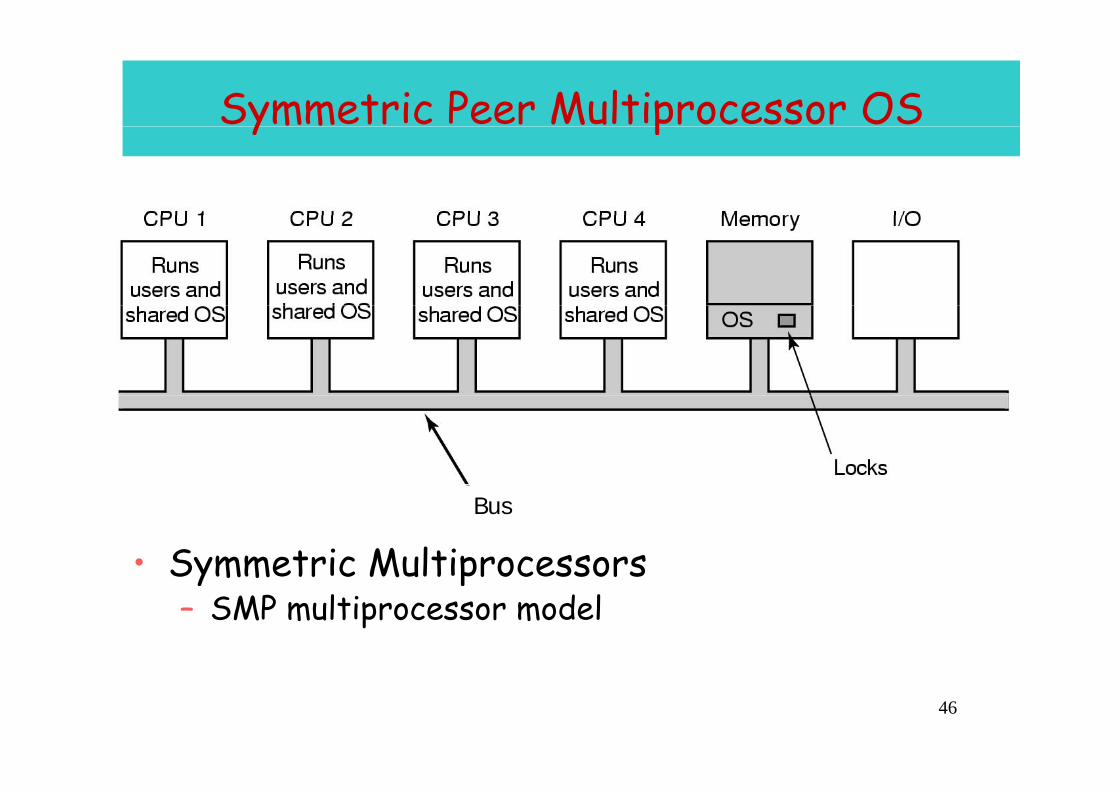
Symmetric Peer Multiprocessor OS y p
• Symmetric MultiprocessorsBus
Symmetric Multiprocessors– SMP multiprocessor model
46

Scheduling in Multiprocessorsg pRecall: Tightly coupled multiprocessing (SMPs)
– Processors share main memory – Processors share main memory – Controlled by operating system
Different degrees of parallelism– Independent and Coarse-Grained Parallelism
• no or very limited synchronization• no or very limited synchronization• can by supported on a multiprocessor with little change (and a bit
of salt ☺)Medium Grained Parallelism– Medium-Grained Parallelism
• collection of threads; usually interact frequently– Fine-Grained Parallelism
• Highly parallel applications; specialized and fragmented area
47
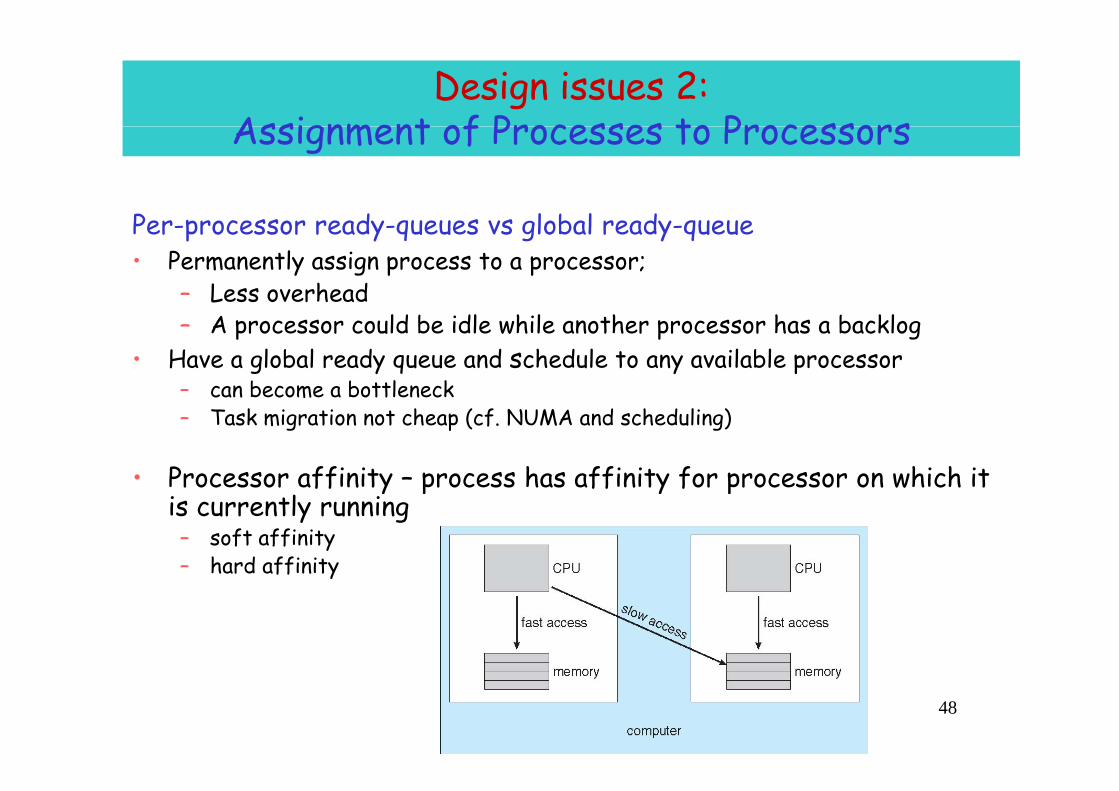
Design issues 2: Assignment of Processes to ProcessorsAssignment of Processes to Processors
P d l b l dPer-processor ready-queues vs global ready-queue• Permanently assign process to a processor;
– Less overhead– A processor could be idle while another processor has a backlog
• Have a global ready queue and schedule to any available processor– can become a bottleneckcan become a bottleneck– Task migration not cheap (cf. NUMA and scheduling)
• Processor affinity – process has affinity for processor on which it Processor affinity process has affinity for processor on which it is currently running– soft affinity– hard affinityy
48
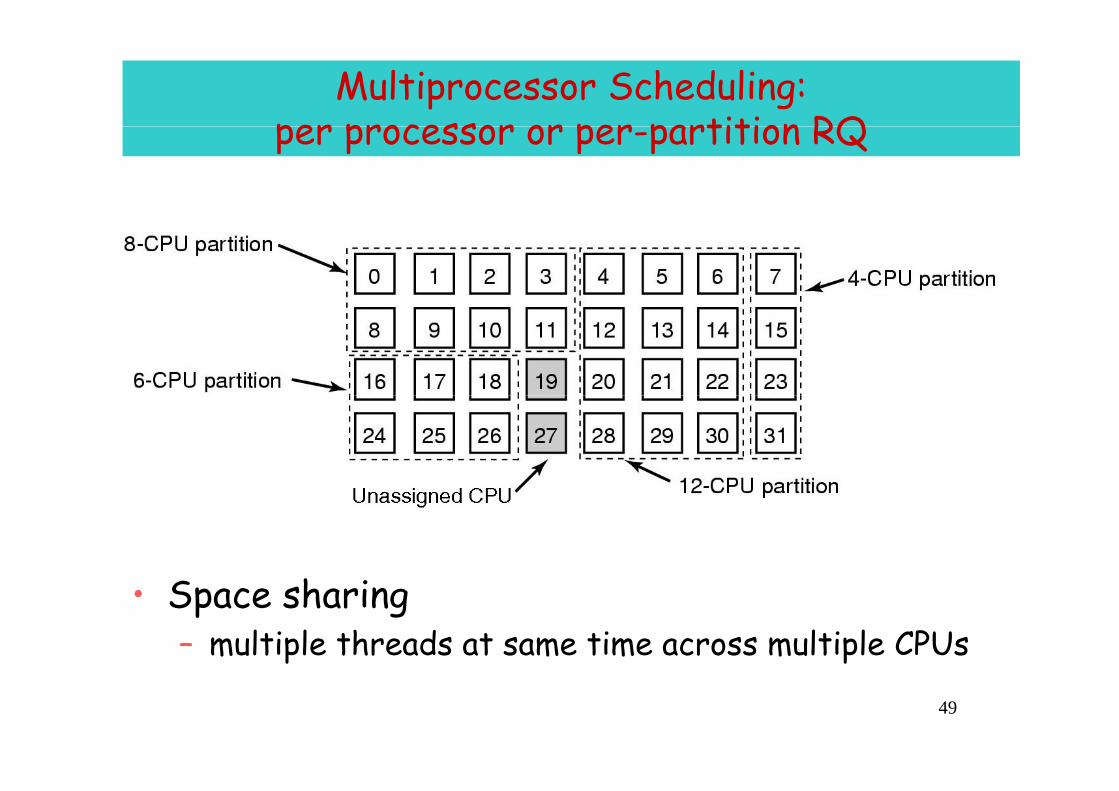
Multiprocessor Scheduling:per processor or per partition RQper processor or per-partition RQ
• Space sharing– multiple threads at same time across multiple CPUs
49
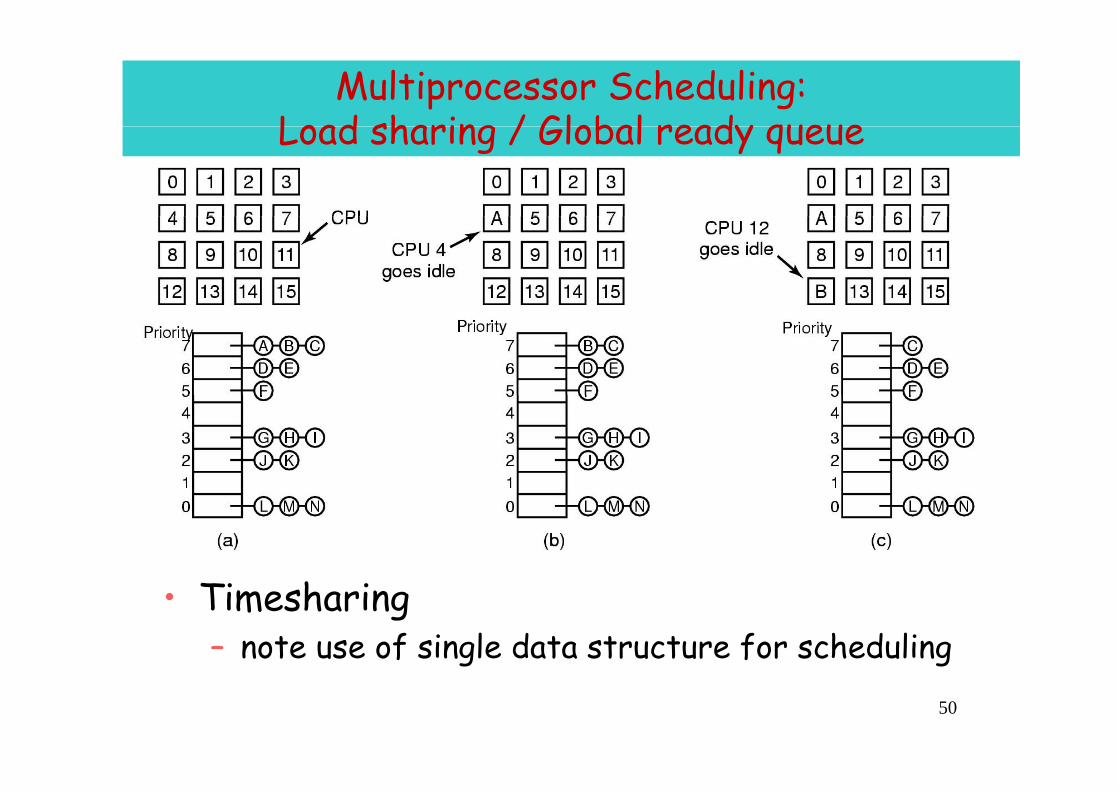
Multiprocessor Scheduling:Load sharing / Global ready queueLoad sharing / Global ready queue
• Timesharing– note use of single data structure for scheduling
50
g g
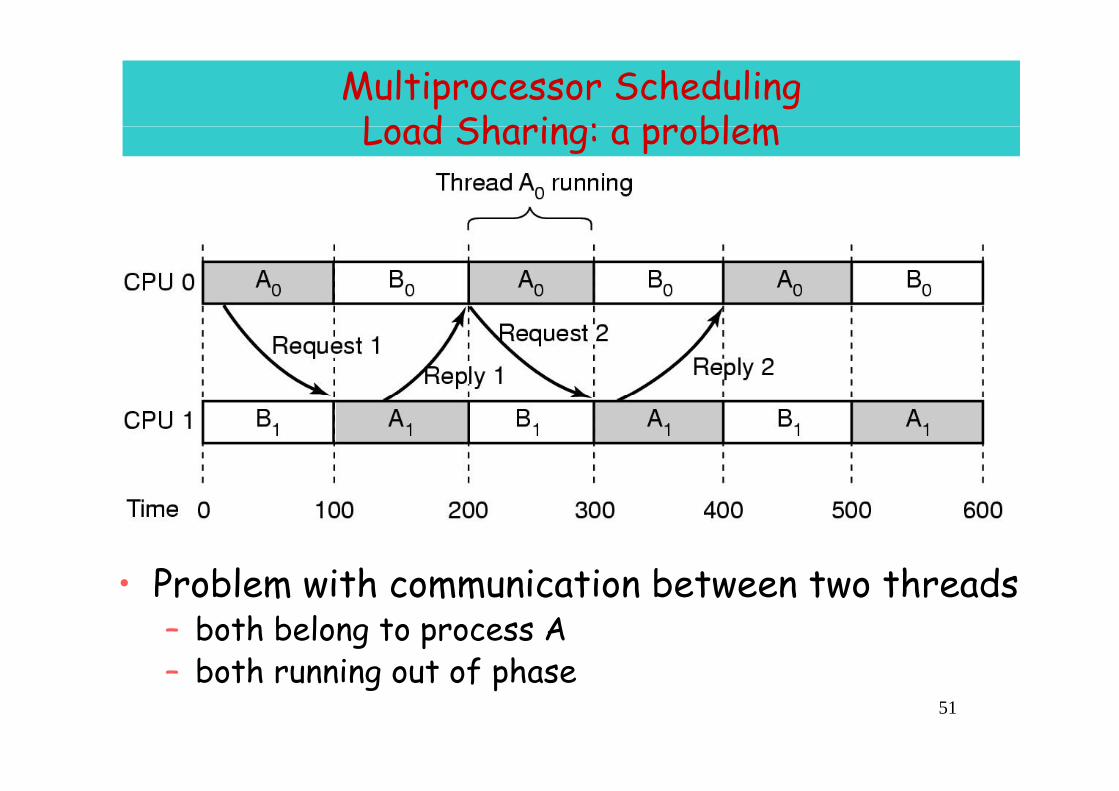
Multiprocessor Scheduling Load Sharing: a problemLoad Sharing: a problem
P bl ith i ti b t t th d• Problem with communication between two threads– both belong to process A
b th i t f h s51
– both running out of phase

Design issues 3:Multiprogramming on processors?Multiprogramming on processors?
Experience shows:Experience shows:– Threads running on separate processors (to the extend of
dedicating a processor to a thread) yields dramatic gains in performanceperformance
– Allocating processors to threads ~ allocating pages to ( ki d l?)processes (can use working set model?)
– Specific scheduling discipline is less important with more than on processor; the decision of “distributing” tasks is more important
52
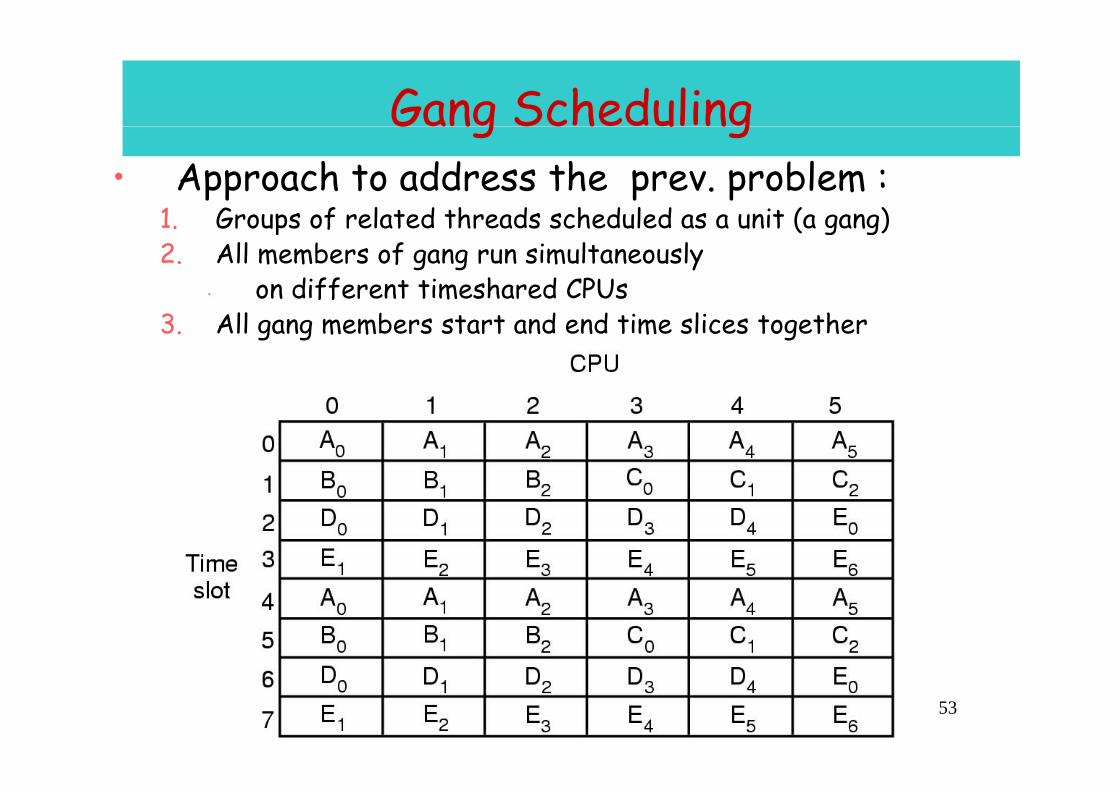
Gang SchedulingGang Sch u ng• Approach to address the prev. problem :
1 Groups of related threads scheduled as a unit (a gang)1. Groups of related threads scheduled as a unit (a gang)2. All members of gang run simultaneously
• on different timeshared CPUs3. All gang members start and end time slices together
53
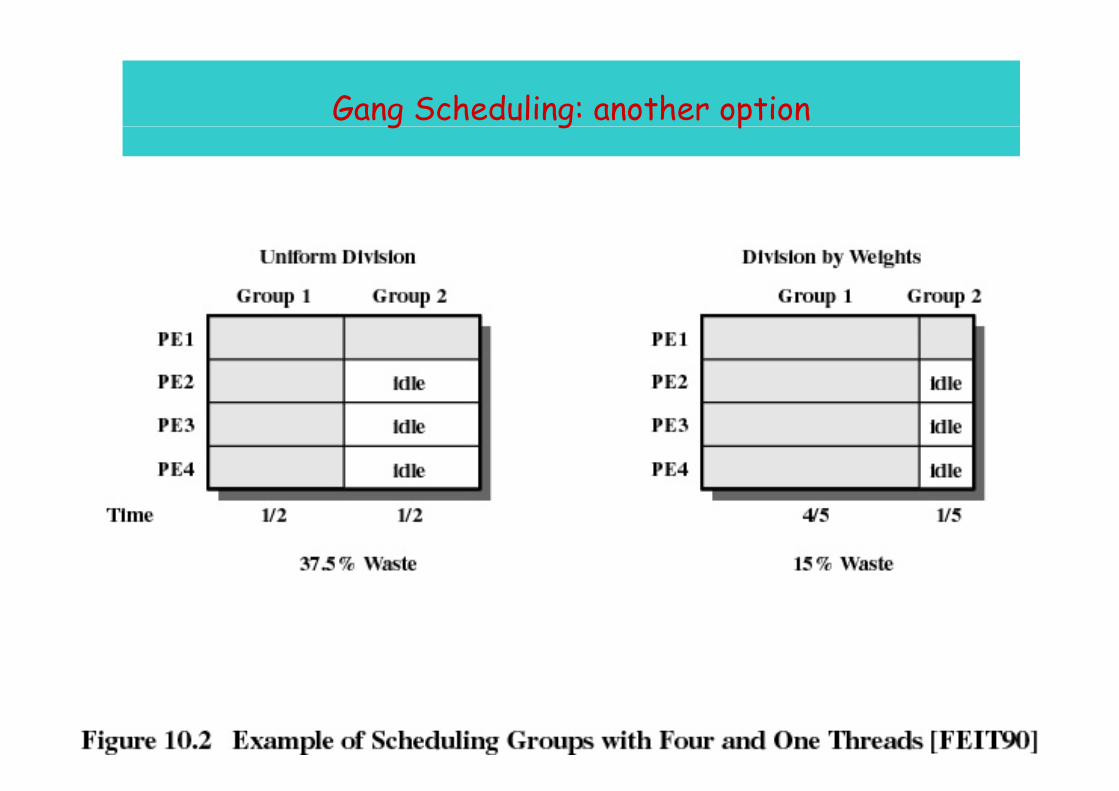
Gang Scheduling: another optiong g p
54
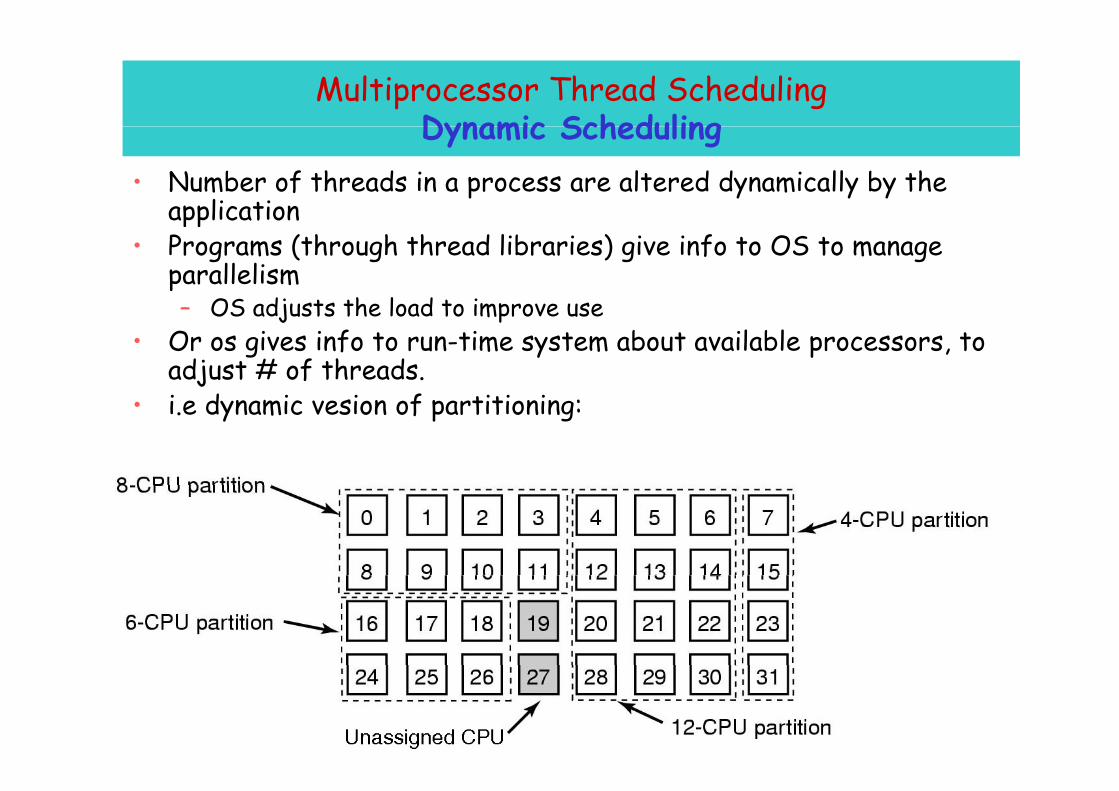
Multiprocessor Thread Scheduling Dynamic SchedulingDynamic Scheduling
• Number of threads in a process are altered dynamically by the applicationapplication
• Programs (through thread libraries) give info to OS to manage parallelism
OS adjusts the load to improve use– OS adjusts the load to improve use• Or os gives info to run-time system about available processors, to
adjust # of threads.i d i i f i i i• i.e dynamic vesion of partitioning:
55

Multithreaded Multicore Systemy
Solution by architecture: hyperthreadingNeeds OS awareness though to get the corresponding efficiency

Summary: Multiprocessor Thread Schedulingy p g
Load sharing: processors/threads not assigned to particular Load sharing: processors/threads not assigned to particular processors
• load is distributed evenly across the processors;n ds central queue; m b b ttl n ck • needs central queue; may be a bottleneck
• preemptive threads are unlikely to resume execution on the same processor; cache use is less efficient
G h d li A i th d t ti l Gang scheduling: Assigns threads to particular processors (simultaneous scheduling of threads that make up a process)
• Useful where performance severely degrades when any part of the p y g y papplication is not running (due to synchronization)
• Extreme version: Dedicated processor assignment (no multiprogramming of processors)p g g p )
57

Operating System Examplesp g y p
• Solaris scheduling• Windows XP schedulingg• Linux scheduling
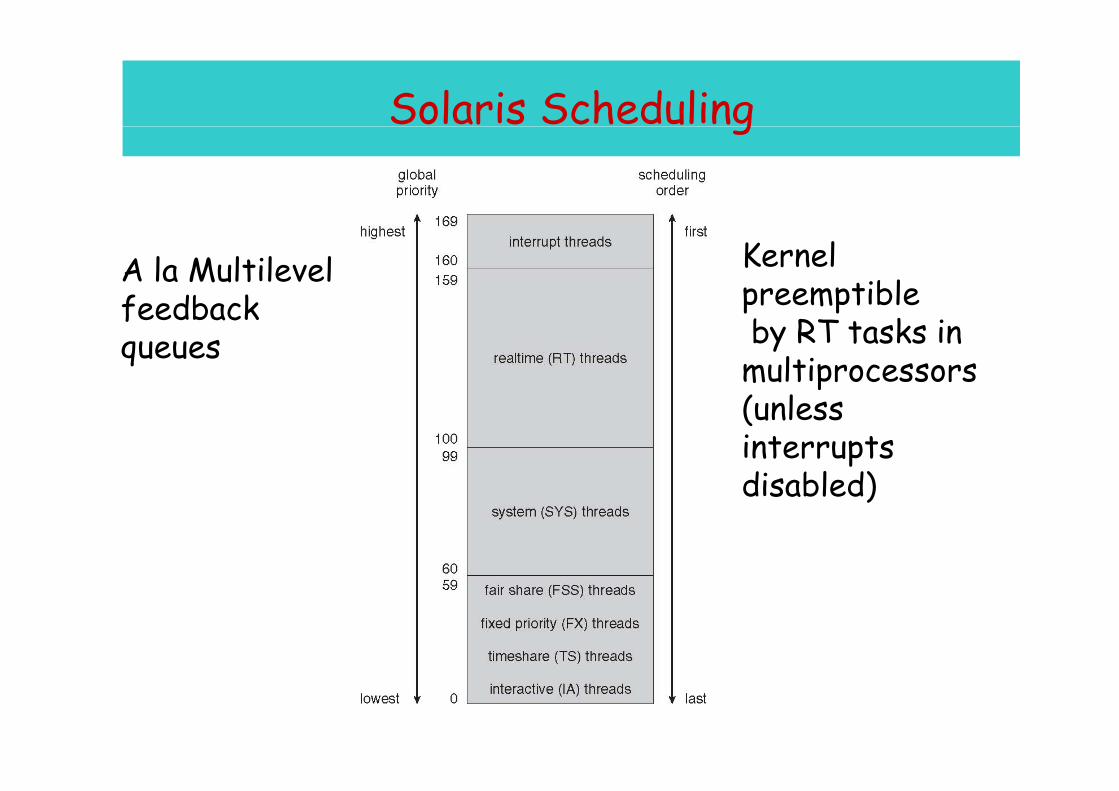
Solaris Schedulingg
Kernel preemptible
A la Multilevel feedback p mp
by RT tasks in multiprocessors( l
feedback queues
(unless interrupts disabled)disabled)
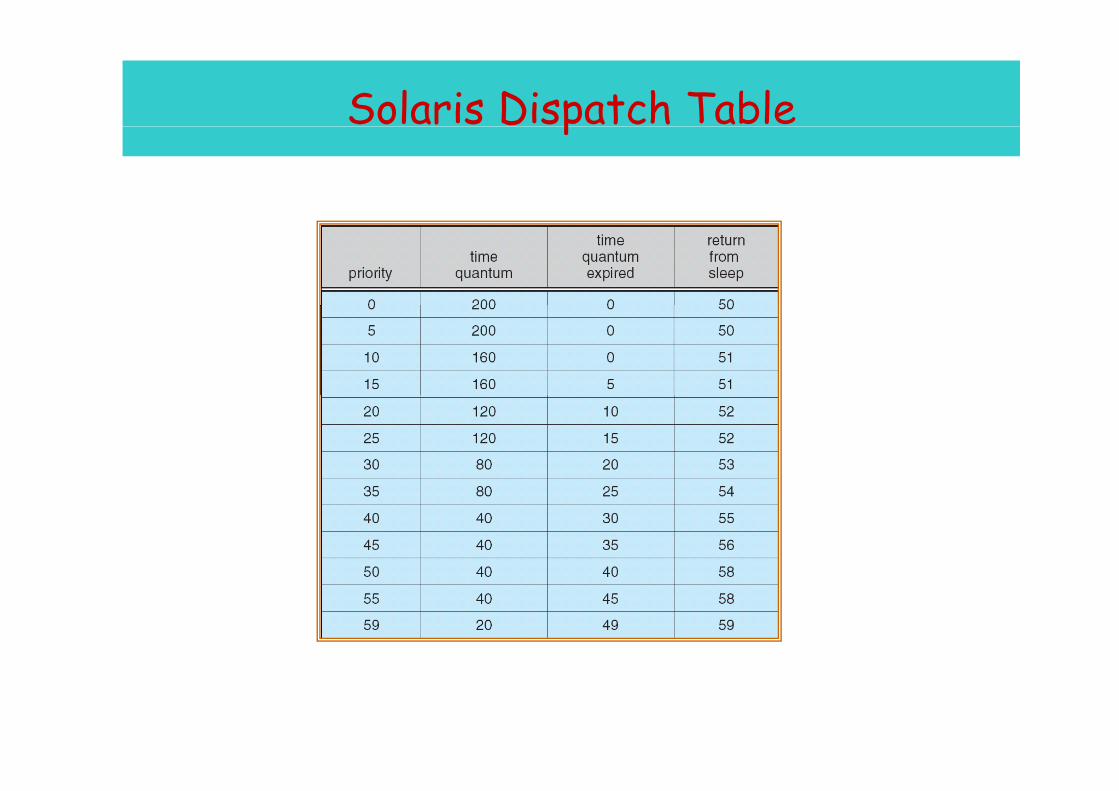
Solaris Dispatch Table p
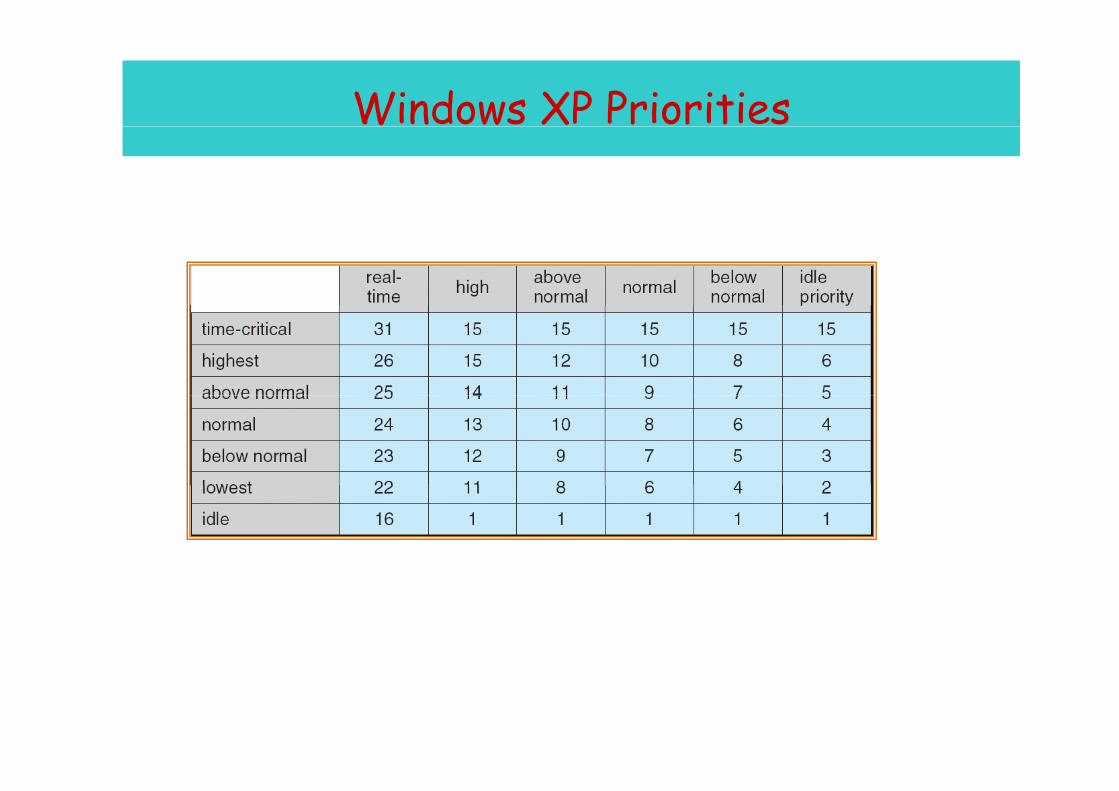
Windows XP Priorities

Linux Schedulingg
• Two priority ranges: time-sharing and Two priority ranges: time sharing and real-time
• One queue per processor/coreOne queue per processor/core
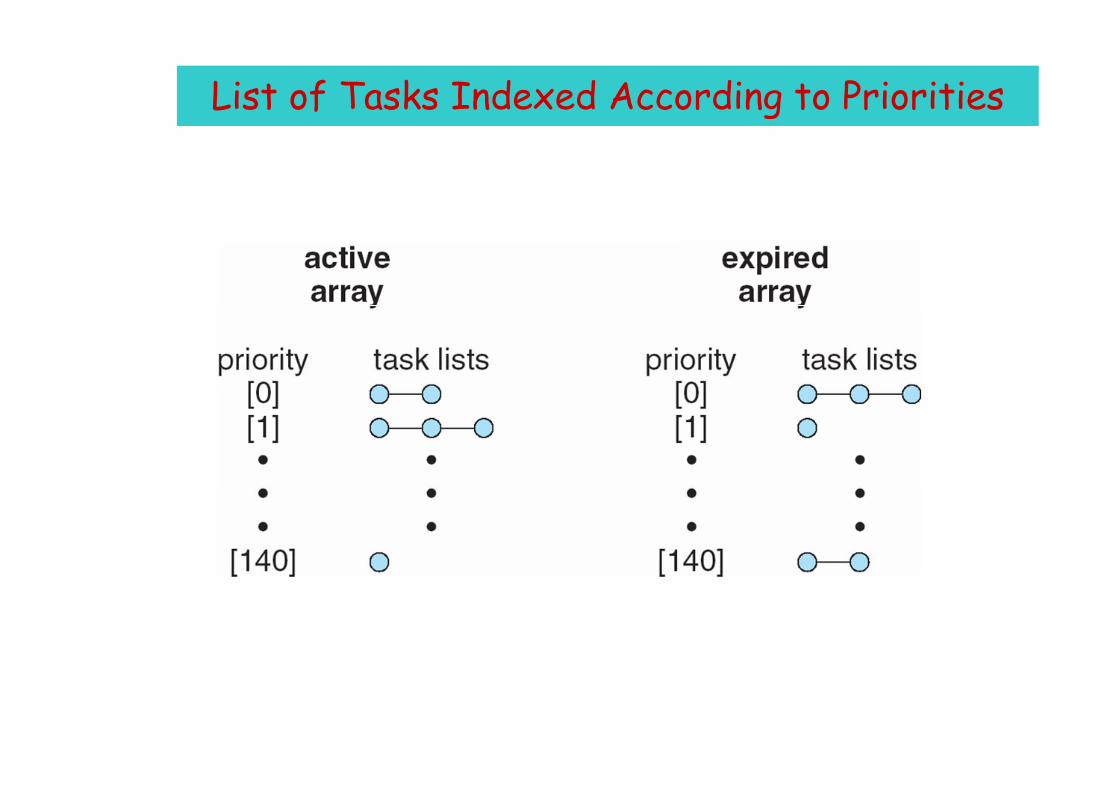
List of Tasks Indexed According to Priorities





























