Embed Size (px)
Citation preview

A workflow management system to feed digital
libraries: proposal and case study Ángeles S. Places, Antonio Fariña, Miguel R. Luaces, Óscar Pedreira, Diego Seco
Database Laboratory, Facultade de Informática, University of A Coruña
Campus de Elviña, s/n, 15071 A Coruña, Spain
Tlf: +34981167000 ext. 1306
email: {asplaces, fari, opedreira, luaces, dseco}@udc.es
ABSTRACT
Building a digital library of antique documents involves not only technical
implementation issues, but also aspects related to the digitization of large
collections of documents. Antique documents are usually delicate and need to be
handled with care. Also, a poor state of preservation and the use of unrecognizable
font types make automatic text recognition more difficult, hence requiring a further
human revision to perform text corrections. This makes the participation of experts
in the digitization process mandatory and, therefore, costly. In this paper, we
present a framework for managing the workflow of the digitization of large
collections of antique documents. We describe the digitization process, and a tool
supporting all of its phases and tasks. We also present a case study in which we
describe how the workflow management system was applied to the digitization of
more than 10,000 documents from journals of the 19th century. In addition, we
describe the resulting digital library, focusing on the most important technological
issues.
Keywords- Digital libraries, text retrieval, workflow management system.
1 Introduction
Interest and research on digital libraries have experienced a significant growth, mainly due to
the advances in document digitization, information retrieval and web publishing technologies.
There are many types of digital libraries. Among them, many are created by real or traditional
libraries that digitize their collections and make them public through a digital library. In some
cases, the motivation behind the construction of these digital libraries is more complex than the
simple desire of a web-based access to these documents. For instance, antique documents are
usually kept in museums and libraries and the access to them is very restricted. Therefore, the
publication of their digitized pages in the Internet serves the important purpose of providing
access to these documents to the world community (Baird, 2003; Borgman, 2002). Additionally,
it helps to preserve such documents preventing their disappearance due to their antiquity and
fragility (Baird, 2003; Sankar, et al., 2006; Ross and Hedstrom, 2005). There are many
examples of this type of digital libraries; among others, the Spanish National Library1, the
Library of Congress2 (Arms, 2000), the Digital Library of India
3, the University of Chicago
Library4, or the Stanford Digital Repository
5 (Cramer, 2010).
1 http://bdh.bne.es/
2 http://memory.loc.gov/ammem/about/techIn.html
3 http://www.dli.gov.in/
4 http://www.lib.uchicago.edu/e/ets/eos/
5 http://www.dlib.org/dlib/september10/cramer/09cramer.html

In the past decades, much research effort was put in creating techniques and software supporting
the process of building digital libraries (Witten and Bainbridge, 2003). In some cases, the digital
library is created from scratch with software developed ad hoc. In other cases, developers use
software packages that provide a software infrastructure for creating digital libraries such as
Greenstone6, Fedora-Commons
7 or DSpace
8. In any case, many researchers and developers
consider that there is a need for a more formal framework. In order to achieve such
formalization, standards represent an important tool. Unfortunately, in the field of digital
libraries, they usually deal only with data interchange (Van de Sompel and Lagoze, 2000;
Library of Congress, 2007), although many researchers consider that standards need to cover a
wider range of issues (Delos, 2008; CCSDS, 2002). As pointed out in (Ross, 2014), "after more
than twenty years of research in digital curation and preservation, the actual theories, methods
and technologies that can either foster or ensure digital longevity remain startlingly limited".
The process of feeding digital libraries is one of the processes that should be formalized
(Duguid, 1997; CCSDS, 2002), and some authors have been working in this direction
(Buchanan, et al., 2005; CCSDS, 2002). For example, Ross (Ross, 2014) also points out that
"automation in preservation" is one of the nine main themes for the research agenda in digital
libraries for the next years.
Digitizing a large collection of documents to feed a digital library poses many problems if done
without a tool supporting the process. The construction of a repository requires the sequential
execution of a set of activities on the source documents with several people participating in each
of them: scanning the physical documents, gathering and recording metadata, automatic text
recognition with OCR (Optical Character Recognition) software, text revision to correct errors
from the automatic text recognition, and document storage and indexing. Most of these
activities require the direct intervention of a person, and may require a significant time to be
completed. Therefore, the digitization of the documents to be incorporated to the repository
usually involves a high cost and the interaction of many people. In addition, in such a complex
process, the lack of control on the workflow can result in dead times, errors in the obtained
results and loss of data. In general, an unsatisfactory coordination of the people increases the
overall cost and decreases the quality of the results. From our previous experiences (Parama, et
al., 2006; Places, et al., 2007), we identified typical errors such as the digitization of the same
document several times with different names, the introduction of errors regarding file naming
conventions, the publication of documents that were not still reviewed, the loss of files or
documents, among others. Since feeding a digital library requires a significant effort, the more
automated tools that can be built and used, the better the use of human resources (McCray and
Gallagher, 2001; Baird, 2003).
The problems described in the paragraph above may be amplified if the documents composing
the repository are ancient physical documents. These documents are usually very old and their
state of preservation is, in general, poor. For that reason, the scanning has to be done carefully
to avoid new damages to the documents. Also, the conversion of the obtained images to text
through character recognition technologies becomes especially difficult due to the deterioration
of the documents. Therefore, the results of this task must be reviewed in order to correct
possible errors. This process is sometimes carried out step by step by a small group of experts
with a deep knowledge on the documents, and their skills and knowledge guarantee the quality
of the results. However, when the digital library has to be built from thousands of documents,
the creation of the document repository involves a large digitization process carried out by a
large group of people who are not always so skilled due to financial restrictions (Chang and
Hopkinson, 2006; Sankar, et al., 2006). One of the main challenges we have to face in the
development of digital libraries that store ancient documents is the importance and complexity
6 http://www.greenstone.org
7 http://fedora-commons.org/
8 http://www.dspace.org

of the digitization and processing of documents. In these situations, the use of support tools to
guide the workflow of the process and to facilitate the labor of the workers is mandatory.
Controlling the workflow inside this digitization team is a key factor in the success of the
process. This control can be achieved using a workflow management tool specially designed for
this purpose. That is, a system to coordinate and control all the involved people, to monitor and
manage factors such as the current state of each page, to store intermediate results, to maintain
significant statistics on the progress of each task, to control the average time to process each
document, to track all the people who have worked in each document, etc.
In this paper we face the issues we have described, and we propose a framework for effectively
and efficiently feeding a digital library. The purpose of this workflow management system is to
automatically coordinate all activities involved in the digitization and indexing process.
Therefore, the main contributions of this paper are:
We present a workflow management framework supporting the process of creating a
document repository. This framework is composed of a process comprising the
digitization, revision and edition activities, and a system architecture supporting the
process. This proposal is based on an analysis of the potential problems that may arise
during the digitization of large collections of documents, based in real cases and
previous experiences. This framework improves the performance of the process, and
ensures that all required tasks are correctly performed, facilitating the work of the
people involved in these activities.
We have implemented a tool based on this proposal, called Digiflow. We present the
details of this tool in the paper, relating each of its components with the different parts
of the system architecture.
Finally, we present the results of a real case study in which our framework has been
used for the digitization of a large collection of ancient documents of the Royal Galician
Academy (RAG) in order to make them available online.
The rest of the paper is structured as follows. Section 2 describes related work focusing on
existing import and digitization tools for digital libraries. Section 3 presents our framework for
feeding digital libraries, presenting an analysis of the potential problems it addresses, its
requirements, a system architecture, and a comparison of the proposed framework and other
existing systems. In Section 4 we present Digiflow, a tool implementing the framework we
propose. The description of this tool focuses on the implementation of each module composing
the system architecture presented in Section 3. Section 5 presents a case study on the application
of Digiflow in a real scenario, in which the tool was used to digitize a collection of 10,000
ancient documents from the nineteenth century to be incorporated in the digital library of the
RAG. Finally, we conclude the paper by summarizing the main conclusions and directions for
future work.
2 Related work
In this Section we review existing works tackling the process of building and feeding digital
libraries. Some of them, such as (Larson, R. and Carson, C., 1999) and (Sankar, et al. , 2006),
guide the whole process from the digitalization of the documents to its publication in the digital
library. Other works, such as (Bainbridge et al., 2003) and (Buchanan, et.al., 2005) skip the
digitization step, assuming the works were previously digitized and focusing in the remaining
steps (we can see these proposals as import tools).
2.1 Import tools
Bainbridge and his colleagues presented in (Bainbridge et al., 2003) a tool called “Gatherer”
that facilitates the entire process of building digital library collections. This tool was designed to
feed a digital library built with Greenstone, though the underlying ideas can be used in any case.
However, this tool (and the underlying procedure) does not take into account the digitization
process, and assumes that the documents are already in electronic format. The authors explicitly

point out that the process of feeding a digital library usually starts with a process of digitization,
but they do not address it. The tool supports four administrative tasks:
Copying documents from the computer file space into the new collection. Any existing
metadata remains “attached” to these documents. Documents can also be harvested
from the web.
Enriching the documents by adding further metadata to individual documents or groups
of documents.
Designing the collection allows the specification of the structure, organization, and
presentation of the collection.
Building the collection as a final step, the collection is built in Greenstone; this step
includes the indexation of the collection.
With the appearance of Greenstone 3, Buchanan and his colleagues (Buchanan, et al., 2005)
presented a framework for building digital libraries with Greenstone 3, this time without any
specific tool. Again, their starting point considers that the source files are already in an
electronic format. The process is more elaborated, it begins with an Expansion process where
compressed source files are decompressed, and links to web sites are expanded into lists of web
pages. This stage gathers the source files for the next phases. The Recognition phase joins all
the files that form a document, for example, the JPEG files that are included in a web page are
considered as part of the document which includes that web page. The obtained documents are
sent to the Encoding process, which converts these documents into the METS (Metadata
Encoding and Transmission Standard) format (Library of Congress, 2007). The Extraction
stage processes automatically the documents in order to extract information from the document
(e.g. title, keyphrases). Next, the Classification stage processes the documents using classifiers
in order to assign each document to a node of a browsing structure. The Indexation phase can
index the collection with different indexers. Finally, a Validation process provides a quality
control.
As it can be seen, this process is general enough to be suitable for an automatic feeding of
digital libraries in many different situations or cases. However, we found that at least two
processes are not considered. First, the process of scanning documents from their original
versions (in many cases, in very bad conditions and with an old typography). Second, dealing
with those cases where electronic metadata are not available.
2.2 Digitization tools
Larson and Carson (Larson, R., and Carson, C., 1999) presented the feeding process of the
Cheshire II project. This process is composed of the following six stages:
1. The scanning of each document. As a result, a directory named with the Electronic ID
assigned to the document is created. In the directory, there is a list of files created by the
scan software and a file (bib.elib) with the associated metadata introduced by the person
responsible of the scanning procedure. Each page of the document is stored in a TIFF
file numbered sequentially.
2. TIFF files are turned into GIF.
3. The OCR (Optical Character Recognition) process is run. Two directories are produced:
a. OCR ASCII text.
b. OCR XDOC, which contains word position information.
4. Each document is merged with its images. That is, links are inserted in the text to give
access to images.
5. The document is moved to its final location, from where the digital library will make it
available.
6. The indexation process is run.

The main drawback of this process is the absence of control mechanisms or tools to help us to
carry out the tasks. The result is that many errors may arise due to wrong placement of files, file
names with errors, scanning wrong pages, etc.
Sankar and his colleagues (Sankar, et al., 2006) were involved on a project that pretends to
digitize one million books. In this case, they face the problem of scanning the documents. They
divided the digitization process into logical steps, which are distributed in several places. They
also designed a tool to control the workflow. The phases of their workflow start with the
scanning. Next, a post-processing of the scanned images is carried out to remove noise and
other artifacts in the scanned images. After cleaning the images, the OCR is run. Then, a quality
check is performed. Finally, the resulting documents are stored in a web server. In (Sankar, et
al., 2006) no further details about the workflow management are given, and only an automatic
tool for quality control is presented. The quality control is based on automatically verifiable
parameters such as dimensions, dpi, skew, etc. However, there is no quality control over the
OCR process, and therefore they admit that due to OCR errors, they store texts with some
mistakes. Although the transcribed version of the text is only used to assist in the search
process, this process is obviously burdened by the presence of such OCR errors. Thus, as the
authors pointed out, they have to rely on the scanned version for presentation purposes.
The Stanford Digital Repository (SDR) (Cramer, 2010) is other representative system for
building and feeding digital libraries including the digitization activities. SDR allows to
integrate in an institutional digital library contents coming from different sources (either internal
or external). Given the large scope of SDR, it also provides management functions that allow
the system administrators to manage and control different activities, such as the progression of
feeding tasks. However, (Cramer, 2010) does not provide details on how the digitization process
is managed. That is, SDR would be able to accommodate the documents resulting from other
systems managing the digitization, but it does not directly support the digitization process.
3 A framework to feed digital libraries
In this Section we present our framework for feeding digital libraries. First, we analyze the
potential problems that may appear during the digitization of large collections of documents.
From this result, we describe the requirements for a workflow system for managing digitization.
We then present the system architecture of our framework. Finally, we present a comparison of
our proposal with existing systems and models.
3.1 Problems in massive digitization of documents
During the digitization process, each page of the physical documents is scanned, then they are
processed using OCR technologies for text extraction, and finally, revised and corrected in order
to fix errors from the automatic text recognition. Other activities such as metadata definition or
document markup are also necessary. Finally, the text is stored in the repository, and its content
(text and images) is indexed and published.
Taking into account that the collection of documents can have hundreds of thousands of pages,
the digitization of documents becomes a complex and costly process, usually requiring the
intervention of experts with deep domain knowledge. From our previous experience in the
development of digital libraries (Parama, et al., 2006; Places, et al., 2007), we have identified
several typical problems in this process:
Problems with the file naming protocol. Due to the high number of files to be managed
during the digitization, such a protocol is necessary. When few people participate in the
digitization, the file naming conventions are usually followed, and small errors can be
easily managed. However, when tens of people are working together, small errors are
likely to appear and their management can produce a significant waste of time.
Loss of files. Without support tools, each participant is responsible for the files obtained
in each activity. If the management of hundreds or thousands of files is done manually
typical errors will frequently occur, such as overwriting files, saving files with the

wrong name or in the wrong folder. If the experience of the participants with computers
is limited, these errors will be very common.
Task specification. There are different ways to carry out a task. A bad specification of
the task parameters is also a source of typical problems. For example, scanning with an
incorrect orientation of the pages, scanning two pages together instead of one,
reviewing an already reviewed document, or writing again the document metadata when
they were already available in the database. These problems worsen when several
people work with the same document.
Lack of coordination. Coordination is difficult when a large group of people work in the
project. Each person can be devoted to specific activities and have a different timetable.
For example, a given person can be responsible for scanning a document in the morning
and other person can deal with its correction in the afternoon. An effective task
management to avoid dead times and waste of resources is necessary.
Effective resource control. Since the number of resources used for the digitization is
limited, the lack of control can be a source of dead times in some activities of the
workflow. For example, some workers could have to wait for free scanners or
computers, or even for the availability of the physical document. In addition, without
this resource management, reports about the particular resources used in each activity
would not be available.
Management of responsibilities. The correct definition of the person in charge of each
task is also important, especially when checking the extracted texts is difficult and it
requires deep knowledge of the type of literature being digitized.
Perhaps most of these problems seem trivial and easy to solve. However, taking into account
that they can be repeated thousands of times during the whole digitization process, their
consequences can have a great impact in factors such as the process time and the quality of the
digitized documents.
3.2 Requirements for the workflow management system
As a solution to the problems presented in the previous section, we describe here the
requirements for the workflow management architecture we propose in this paper.
Automated results management. As we pointed out, errors due to not following the file
naming conventions and loss of files are common in a group of people working together
in a digitization chain. A workflow management system for document digitization must
automatically manage the files produced in each activity. Thus, when a person starts a
new task, the system must automatically bring the inputs needed for such a task, which
could be the outputs of previous tasks, without any kind of human interaction. This
avoids problems regarding the lost of intermediate products.
Task control and monitoring. The system must provide the administrator with the tools
needed to continuously monitor all the information about the state of each document
task. For example, the person assigned to the task, the progress of the results and the
recorded problems.
Effective resource management. This requirement is related to the previous one. The
system must continuously control the availability of the necessary resources for each
activity, identifying and reporting immediately on potential conflicts between tasks due
to the resources needed. For example, if several documents are being scanned at the
same time and a rescanning is needed to correct OCR errors, the system must identify a
time slot in which the hardware will be available.
Work dedication reporting. It is important to provide the possibility of generating
reports about indicators such as the average time devoted to each task, the average
number of pages in a period of time, the number of corrections made on the results of
the OCR process (that is, the number of errors found and fixed from the OCR result),
the average dedication of each person in a given period of time, etc.

Product quality control. Although research in OCR is continuously reducing the error
rate, the output of OCR systems is still far from perfect (Kolak, et. al., 2003; Banerjee
et. al., 2009). This is especially harmful when we deal with ancient documents.
Therefore, the review of the results obtained from the digitization is really important.
The system must facilitate this review process by providing the reviewer with both the
image and the extracted text, and ensuring that the document is not published until the
review is successfully finished.
3.3 System architecture
According to Hollingsworth (1995), workflow is the computerized facilitation or automation of
a business process either in whole or in part, and it is concerned with the automation of
procedures where documents, information, or tasks are passed between participants following a
defined set of rules to achieve, or contribute to, an overall business goal.
Collaborative workflow systems automate business processes where a group of people
participate to achieve a common goal (Aalst and Hee, 2002; Fischer, 2003). This type of
business processes involves a chain of activities where the documents, which hold the
information, are processed and transformed until that goal is achieved. As the problematic of
feeding digital libraries fits perfectly in this model, we based the architecture of the system on
this model.
We can differentiate three user profiles involved in the repository building scenario:
Administrator. Administrators are the persons who are responsible for the digitization
process as a whole. They are the responsible for assigning tasks to different workers and
controlling the state of each digitized document.
Advanced users. The advanced users are the people in charge of carrying out critical
activities such as the metadata storage or the review of the texts obtained from the OCR
processes. The rationale behind this user type is that they usually need a thorough
knowledge of the documents to carry out these tasks (for example, a deep knowledge of
the Galician literature of the 19th century is needed if the user is going to review this
type of documents).
Standard users. The standard users are the workers who carry out tasks such as
scanning or the OCR correction. This role is played by users with some knowledge in
the document field, but without any responsibility on the management of the system (for
example, granted students could carry out these activities).
Index
Text Repository
Image Repository
Document Database
System users (standard, advanced and administrator users)
Documents
Indexing and Web publishing
Correction
OCR
Scanning
Metadata storage
Workflow
Database
Workflow management
Workflow Administration
module
Reports 0
5
10
15
20
25
30
35
Ene Feb Mar Abr May Jun
Comida
Transporte
Alojamiento
Statistics
Administrators
Markup
Figure 1. System architecture.
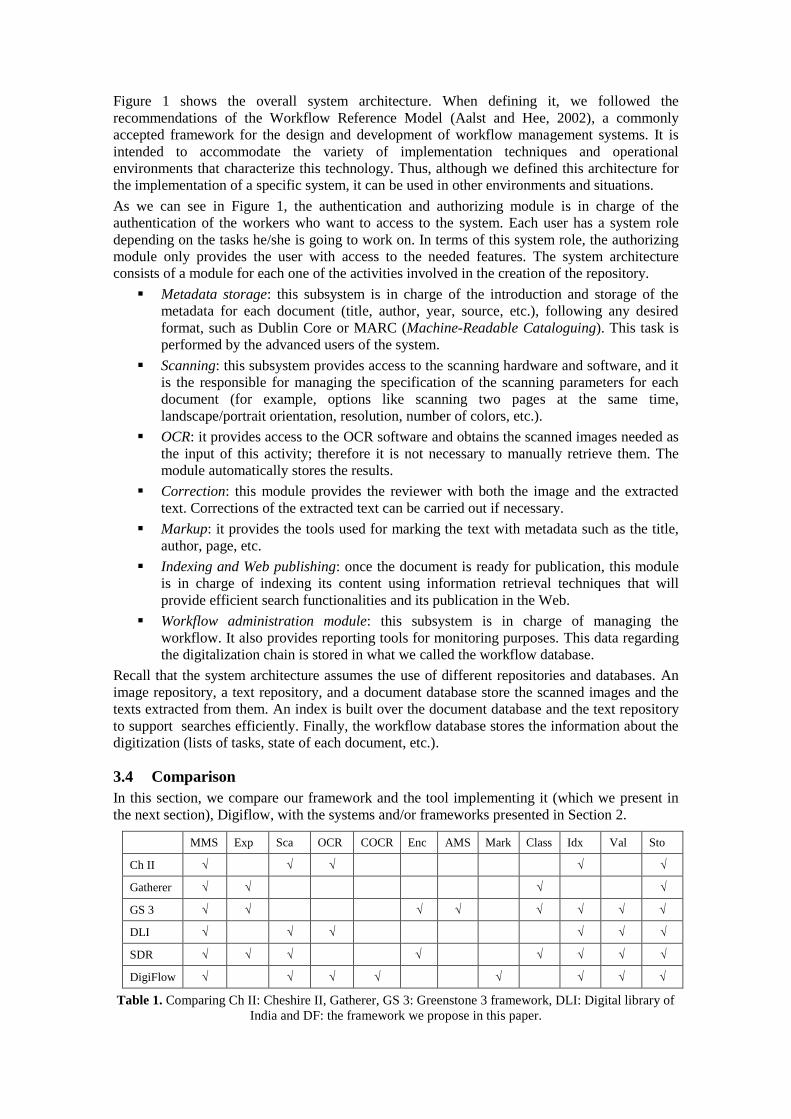
Figure 1 shows the overall system architecture. When defining it, we followed the
recommendations of the Workflow Reference Model (Aalst and Hee, 2002), a commonly
accepted framework for the design and development of workflow management systems. It is
intended to accommodate the variety of implementation techniques and operational
environments that characterize this technology. Thus, although we defined this architecture for
the implementation of a specific system, it can be used in other environments and situations.
As we can see in Figure 1, the authentication and authorizing module is in charge of the
authentication of the workers who want to access to the system. Each user has a system role
depending on the tasks he/she is going to work on. In terms of this system role, the authorizing
module only provides the user with access to the needed features. The system architecture
consists of a module for each one of the activities involved in the creation of the repository.
Metadata storage: this subsystem is in charge of the introduction and storage of the
metadata for each document (title, author, year, source, etc.), following any desired
format, such as Dublin Core or MARC (Machine-Readable Cataloguing). This task is
performed by the advanced users of the system.
Scanning: this subsystem provides access to the scanning hardware and software, and it
is the responsible for managing the specification of the scanning parameters for each
document (for example, options like scanning two pages at the same time,
landscape/portrait orientation, resolution, number of colors, etc.).
OCR: it provides access to the OCR software and obtains the scanned images needed as
the input of this activity; therefore it is not necessary to manually retrieve them. The
module automatically stores the results.
Correction: this module provides the reviewer with both the image and the extracted
text. Corrections of the extracted text can be carried out if necessary.
Markup: it provides the tools used for marking the text with metadata such as the title,
author, page, etc.
Indexing and Web publishing: once the document is ready for publication, this module
is in charge of indexing its content using information retrieval techniques that will
provide efficient search functionalities and its publication in the Web.
Workflow administration module: this subsystem is in charge of managing the
workflow. It also provides reporting tools for monitoring purposes. This data regarding
the digitalization chain is stored in what we called the workflow database.
Recall that the system architecture assumes the use of different repositories and databases. An
image repository, a text repository, and a document database store the scanned images and the
texts extracted from them. An index is built over the document database and the text repository
to support searches efficiently. Finally, the workflow database stores the information about the
digitization (lists of tasks, state of each document, etc.).
3.4 Comparison
In this section, we compare our framework and the tool implementing it (which we present in
the next section), Digiflow, with the systems and/or frameworks presented in Section 2.
MMS Exp Sca OCR COCR Enc AMS Mark Class Idx Val Sto
Ch II √ √ √ √ √
Gatherer √ √ √ √
GS 3 √ √ √ √ √ √ √ √
DLI √ √ √ √ √ √
SDR √ √ √ √ √ √ √ √
DigiFlow √ √ √ √ √ √ √ √
Table 1. Comparing Ch II: Cheshire II, Gatherer, GS 3: Greenstone 3 framework, DLI: Digital library of
India and DF: the framework we propose in this paper.

Table 1 shows for each framework/system the steps it includes. Each column corresponds to one
of the following stages:
MMS: Manual metadata storage or extraction from previous electronic metadata files.
Exp: Expansion, which includes decompression and URL expansion.
Sca: Scanning.
OCR: Optical Character Recognition.
COCR: Correction of OCR errors.
Enc: Encoding, this translates the documents into a standard representation like METS.
AMS: Automatic metadata extraction and storage.
Mark: Markup.
Class: Classification, this uses metadata to site a document within the browsing
structures.
Idx: Indexation.
Val: Validation, which corrects different issues such as skew, dpi and other parameters.
Sto: Storage, from where the digital library will make the document available.
From Table 1, we can conclude that our focus is in the quality of the scanning process. Our
framework and the associated tool (Digiflow, which will be reviewed in Section 4) represent the
only approach that considers the correction of the unavoidable OCR errors. Other existing
systems, like Greenstone, for example, put their emphasis in the automatic ingestion by means
of a bulk process. This requirement comes into conflict with the scanning process, which
requires much human interaction.
Our proposal and the tool implementing it put the emphasis on digital library feeding processes
in which the documents go through a complex scanning, text recognition, correction, and
indexing process, which is the case in digital libraries built for cultural heritage preservation.
Due to the need of participation of experts and the complexity of the process, our framework
aims at make this process manageable, efficient, and effective.
4 Digiflow: A tool for building document repositories
The framework presented in the previous section was applied in the implementation of
Digiflow, a workflow management system supporting the creation of digital libraries. This tool
provides an integrated environment where all the tasks necessary to create a document
repository and feed a digital library can be executed. This application provides the user all the
tools needed to carry out each task without being necessary to use other software applications
nor to manually manage the results of each task.
Digiflow is focused on the digitization of documents, which we will also call works in the rest
of the paper. A work can be a book, a volume of a journal, or any other unit on which the
digitization process can be made.
In the development of Digiflow we addressed the main problems that arise during the massive
digitization of documents. In the description of Digiflow, we first present the digitization
workflow it supports. Then, we present how the tool was designed and developed, and how the
different modules of the architecture presented in the previous section were addressed.
4.1 User profiles and responsibilities
According to the proposal we presented in the previous Section, Digiflow distinguishes between
three different user profiles: administrator, advanced, and standard users.
Administrator: the administrator profile is responsible for the administrative activities
of the digitization process, such as creating new digitization works in the system and
requiring the needed tasks (subtasks, priority, etc.). The administrator can also access a
set of monitoring tools that allows him/her to supervise of the whole process (task
revision, reports about the progress of a work, work done by each user, alerts of

problems, etc). Digiflow allows the administrator to avoid problems related with the
lack of coordination, and it makes it easier to follow an effective resource control since
the administrator can modify the priority of any task or even change the user that should
perform it. Digiflow also allows the administrator to know the list of tasks in
charge/done by each user, hence providing support to an effective management of
responsibilities. In addition, it also brings the capability to generate reports about work
dedication. Details about user interface provided by Digiflow to the administrator can
be seen in Section 5.2.2.
Advanced and standard users: they conform a low-level profile and have access to the
basic functionalities of Digiflow. Digiflow shows these users a list with the pending
tasks they have to perform, and for each task they are completely guided through the
process by the instructions provided by the system. Among other tasks, advanced users
are in charge of metadata of each work, such as the title or the author, but also more
interesting metadata for the digitalization process such as the orientation of the page and
other parameters about how the scanning should be done. Once this is done, Digiflow
can guide a standard user through the digitalization of a work. For example, when a
scanning task is being done by a user, Digiflow indicates which page of a book must be
scanned and how (orientation, two pages at a time, etc.). The user only has to put the
book over the scanner and push a "scan button". After that, Digiflow automatically
saves the scanned page in the corresponding repository with the proper name.
Therefore, problems related to file naming, or to the loss of files in the system are
avoided.
Other basic tasks within the basic functionalities in Digiflow are the OCR and the
correction of the obtained text for a given page. In the former task, Digiflow
automatically fetches the previously scanned page and launches the OCR process. Then,
following the guidelines to ensure an effective product quality control, it presents in
parallel both the text and the scanned page so that the corresponding user could validate
its correction or modify it if needed. Again the result is automatically stored in the
corresponding text repository.
In the next subsection we focus in the flow of activities carried out during the creation of a
document repository according to the system architecture defined in Section 3.3.
4.2 Digitization workflow
The UML activity diagram of Figure 2 shows the activities involved in the Digiflow digitization
workflow, and the order in which those activities must be carried out to create the document
repository. Each of the activities in the diagram is a stage of the workflow.
Activities can have different execution modes, that is, an activity can be carried out using
different applications. In addition, activities can be either divisible or indivisible. An activity
that can be done by more than one user is called a divisible activity. These activities are divided
into tasks, which are performed by only one user. Next, we describe the activities involved in
the workflow:
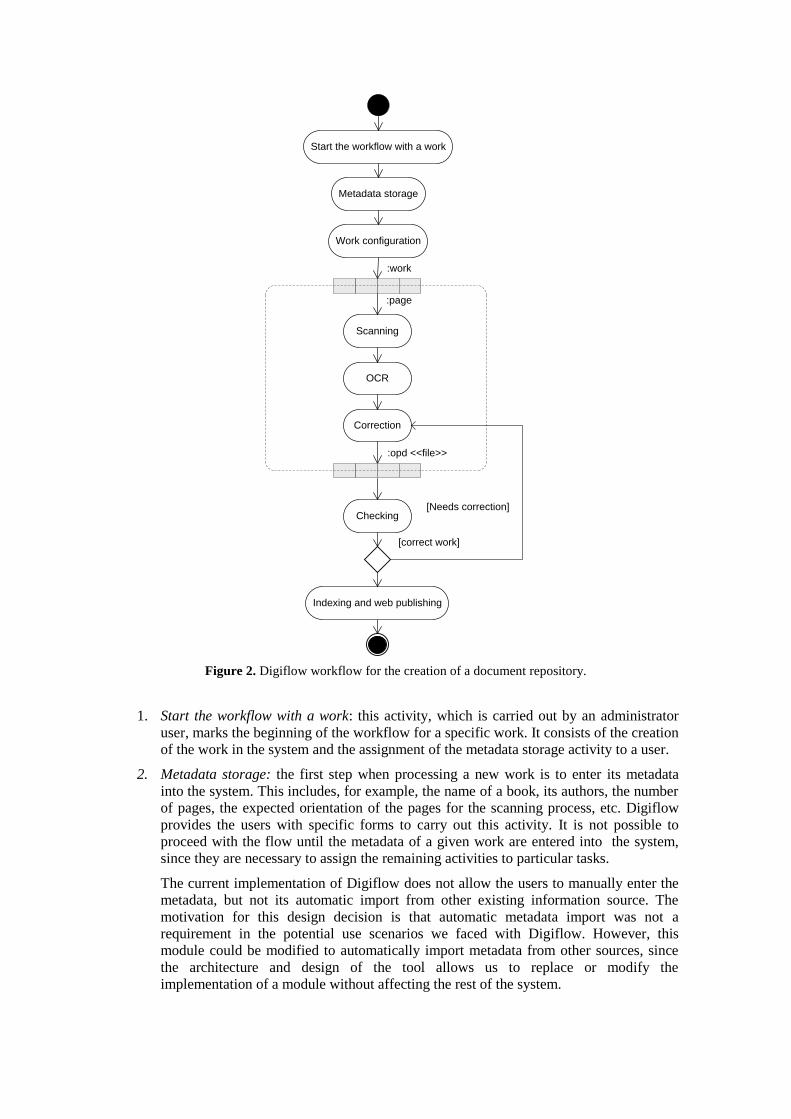
Start the workflow with a work
Metadata storage
Work configuration
Scanning
OCR
Correction
:work
:page
:opd <<file>>
Checking[Needs correction]
Indexing and web publishing
[correct work]
Figure 2. Digiflow workflow for the creation of a document repository.
1. Start the workflow with a work: this activity, which is carried out by an administrator
user, marks the beginning of the workflow for a specific work. It consists of the creation
of the work in the system and the assignment of the metadata storage activity to a user.
2. Metadata storage: the first step when processing a new work is to enter its metadata
into the system. This includes, for example, the name of a book, its authors, the number
of pages, the expected orientation of the pages for the scanning process, etc. Digiflow
provides the users with specific forms to carry out this activity. It is not possible to
proceed with the flow until the metadata of a given work are entered into the system,
since they are necessary to assign the remaining activities to particular tasks.
The current implementation of Digiflow does not allow the users to manually enter the
metadata, but not its automatic import from other existing information source. The
motivation for this design decision is that automatic metadata import was not a
requirement in the potential use scenarios we faced with Digiflow. However, this
module could be modified to automatically import metadata from other sources, since
the architecture and design of the tool allows us to replace or modify the
implementation of a module without affecting the rest of the system.

3. Work configuration: this activity consists in the generation of the necessary tasks to
complete the digitization. In the case of a divisible activity, the system will allow
generating different tasks, and assigning them to different users.
4. Scanning a page: the tasks associated to this activity are performed by either standard
or advanced users. We used an UML expansion area (the area surrounded by a dotted
line) in the activity diagram to represent the repetitive process of scanning each page
composing a work. This UML notation also indicates that the three activities inside the
expansion area (scanning, OCR, and correction) can be done in parallel by more than
one person when possible (that is, these are divisible tasks):
a) Scanning: this activity comprises the creation of the digital images that correspond
with each page in a work. As expected, the system frees the users from the task of
assigning a name and a storage location to those images.
b) OCR: this activity involves the application of an OCR process on the images
generated in the previous activity. The OCR software used in the first release of
Digiflow was OmniPage Pro.
c) Correction: in this activity, a user revises the results obtained from the OCR
activity. The OCR tools do not always provide the expected results, especially if the
typography of the work is not standard or if the quality of the original document
was not good. Therefore, it becomes necessary to manually review all the pages
trying to find and correct the mistakes.
The result of these tasks is an OmniPage file ("opd" file in the rest of the paper) that
includes the image, the associated text and the coordinates of each word within the
image obtained from the scanner. This is the source for the text repository, the image
repository, and the indexing subsystem of Digiflow (described below). The scanning -
OCR - correction group of activities is the part of the workflow demanding more time
from the users. In the next Section, we will show how Digiflow guides the users
through this part of the process in a real scenario.
5. Checking: this activity involves a second revision of the pages to verify the correction
of the process. The purpose of this activity is to add an additional guarantee of
correctness before publishing the works in the web.
6. Indexing and web publishing: the obtained data (that consists in an image and/or
transcribed text) is finally indexed and published in the Web. Note that after the
previous acquiring steps, we obtain both an image repository and a text repository. In
addition, in the OCR phase our system is also able to provide the coordinates of each
word within its corresponding image of the document. Therefore, we can build an index
on the text that enables retrieving the documents containing a given word, and
additionally we can mark the positions where such pattern occurs within the
corresponding source images. This allows the publishing system to not only permit
access to the repositories, but also boost search capabilities. More details are provided
in Section 5.3.
4.3 Digiflow architecture, design and development
In Section 3 we presented a framework and a general system architecture for a digitization
workflow management system without tying it to a particular technology, Digiflow refines the
system architecture with particular technologies and design decisions. In this subsection we
describe how the design and development of Digiflow addresses each of the components
defined in the general system architecture, and we describe the reasons for certain
implementation decisions.
Figure 3 shows a detailed architecture diagram of Digiflow. The lower part of the diagram
shows how all the data generated during the digitization process is persistently stored. Digiflow
uses three storage subcomponents:

Document and workflow database: all data related to the document's metadata, and to
the management of the workflow is stored in a relational database. In particular, we
used Microsoft SQL Server. Note, however, that this component can be easily replaced
by any other DBMS.
Scanning and OCR repository: the images obtained from the scanning of the works, and
the corresponding OPD files obtained from the OCR software are stored in an external
file repository.
Indexing and publishing: this module is responsible for storing and indexing the text of
the works. One of our goals in the development of the system was to provide the users a
set of rich search functionalities. Since Digiflow was designed to be used specially with
ancient documents, we wanted to be able to show search results on the original images
of the works, for example. The implementation of this module is based on modifications
we developed on the open source indexing library Lucene9. The details of this module
will be presented in the last subsection of this section. Since this module can be of
interest for other developments even if the rest of Digiflow is not used, it was developed
as a separate component that can be used alone. That is, the rest of the tool
communicates with this module to enter the texts into it when the scanning, text
recognition and correction activities have been correctly completed.
SQL Server
Document DB Workflow DB
Indexing and Publishing
Text and
Image Index
Text
Repository
Workflow Management
CorrectionIndexing and
Publishing
Scanning and OCR repository
Images OPD Files
Metadata Scanning and OCR
OmniPage
Figure 3. Digiflow architecture and implementation
The remaining modules shown in the architecture implement the functionalities presented to the
different users of the system:
Workflow management: this module implements all the workflow controls, guiding the
users through the digitization process, and providing access to the rest of the modules.
Metadata: this module allows the users to enter the metadata of the works into the
system. It currently supports the storage of metadata related to literary works and
periodical publications, as journals. In the case of literary works, Digiflow allows to
enter data about its authors, the literary work itself, and each of its pages. In the case of
periodical publications, it allows to store data related to each journal, volumes of each
journal, numbers composing each volume, articles published in each of the numbers,
and finally, each page of the article.
9 http://lucene.apache.org/core/

Scanning and OCR: this module encapsulates all the details needed to access the scan
and OCR functions through the OmniPage suite. The purpose of this module is to act as
a black box hiding all low-level details and providing a simple interface to the rest of
the modules. Digiflow was implemented in C# and the communication with the
OmniPage suite was implemented through OLE (Object Linking and Embedding) and
COM (Component Object Model) automation components.
Correction: this module allows the users to access the opd files resulting from the
scanning and OCR module, and to revise and correct those files.
Indexing and publishing: this small module interacts with the storage module in charge
of indexing and publishing, which we describe with more detail in the next subsection.
Other aspect related to the design and development of Digiflow is our choice of technologies.
We implemented Digiflow in C# using the Microsoft .NET platform. We also used the
OmniPage OCR suite, and Lucene open source indexing library. Some of these decisions
resulted from constraints on the project sponsor's available technological environment.
However, the architecture and design of the system allows to replace any of its modules
without affecting the rest. Some modules can be replaced easier than others. For example, the
database containing the documents metadata and the workflow management could be easily
replaced by other relational DBMS. Other modules, such as the one managing the interaction
with the scanning and OCR software, should be reimplemented in case of adapting Digiflow to
other platform with a different operating system and scanning software.
It is also important to note that the scope of Digiflow is only that of managing the digitization
process. That is, it does not provide a public digital library the general public can directly
access. In the next Section we present how a large collection of ancient documents was digitized
with Digiflow, and how a public digital library (developed in a different technology, Java) was
built on the result.
4.4 Digiflow search and indexing capabilities
The text retrieval subsystem of Digiflow is based on an inverted index built with the Lucene
open source library for text indexing. Since this module of the system can be useful in other
developments without using the rest of the tool, it was implemented as a separate software
component. In this way, the texts obtained by using Digiflow are entered in this module, which
acts as a black box that indexes the documents, their corresponding images, and provides a set
of search functionalities.
In order to build such a inverted index, the opd files generated by the OmniPage software are
processed firstly. These opd files have three components: text, image, and the coordinates of
each word in the image. After a first preprocess of the opd files, we transform those files into
XML files, which are the source for the process that constructs the inverted file. This translation
makes the manipulation of the obtained information much easier.
As we show in Figure 4, a document is represented in Lucene as an instance of a class
Document that aggregates a collection of objects belonging to the class Field. Each field
contains a name and a string of characters. Examples of names could be title, author, etc. The
text of the work is always one of these fields. The exact list of fields is chosen by the developer
for each case.
Figure 4. Representation of a document (literary work in our case) in Lucene.

In the case of Digiflow, each edition of a literary work or the number of a journal is represented
by an object of the Document class. The fields we associated to each document are the content
of the work and the identifier of the work in the database of the digital library. In order to obtain
the content (that will the indexed), the XML files containing the text of the literary work or
journal article have to be pre-processed to remove the XML tags. Additionally, the resulting text
is also converted to lower case.
Once we have the document objects of all the literary works and journal articles, it is possible to
build the inverted index. For each word in the vocabulary (list of all different words that appear
in the indexed collection of documents) the index stores the list of documents where those
words occur. In addition to this list of documents, the inverted index stores other additional
information depending on the nature of the indexed text. When designing this module, we
wanted to support the cases in which the text could be either transcribed text or text included in
an image obtained from a scanner.
If the indexed text is plain transcribed text, the inverted index stores the relative positions of
each word inside each document. In the case of scanned images, instead of storing the relative
position of each word, the inverted index keeps the position (coordinates) of each word in each
scanned image.
During the search process, once the inverted index has supplied the documents where a word or
phrase occurs, the system presents to the user the sections (a page or a group of pages, in the
case of literary works, or articles, if it is a periodic journal) where the word or phrase occurs.
From here on, the process that computes the response to a given query follows two different
ways depending on the nature of the text.
4.4.1 Plain text retrieval
The global search process for plain text (that is, text not coming from a scanned image) can be
seen in Figure 5. From the index, as we have already pointed out, we obtain the identifiers of the
literary works containing the searched patterns. With those identifiers the system accesses the
metadata of the literary works to build a list of retrieved works. The user selects one of these
literary works, and then the system shows the list of pages where the pattern occurs.
Unfortunately, the inverted index is not enough to generate this list of pages since it only stores
which documents contain the searched words and the relative positions of the words inside
those documents.
Relative positions do not represent the exact physical position of the word, but the order of that
word within the text. The first word in the text is numbered with 1, the second one with 2 and so
on. Relative positions are used to seek phrases, where the searched words should be present in a
certain order in the text, but they are not useful to know the physical position of the words. Thus
we cannot know the page and the exact position of the occurrences of a word.
Then, to find the pages containing a given pattern, a pattern-matching algorithm is needed to
find the first occurrence of the pattern in each page, if it exists. Once the first occurrence is
found, that page is reported as one of the pages including the pattern, and the search skips the
rest of the page to continue from the beginning of the next page.
Figure 5. Search system process in plain text.
Query
List of literary works
Index Work1 Work1 Work1 Work1
Pattern Matching Algorithm
List of pages
Pag 1 Pag 2 Pag 3 ...
Marked Text
A beautiful house close to our house

After the selection of one page by the user, the system highlights the searched word/s. Now, the
system should search across the text for the occurrences of the pattern. Again a pattern matching
algorithm is used and the whole page is always processed in this case.
We performed a study including some of the most well-known pattern matching algorithms to
choose the most suitable ones for our system (Places, et al., 2007). Finally, we decided to use
Backward Nondeterministic Dawg Matching Algorithm (BNDM) for patterns of up to 32
characters and Knuth-Morris-Pratt (KMP) for longer patterns (Navarro, et al., 2002).
This system was empirically shown to be very effective (Places, et al., 2007) with response
times below 1 millisecond for typical searches including one word. Table 3 shows the average
time needed to search for phrases composed of 1, 2, or 4 words.
Search type Simple
words
2 words
phrases
4 words
phrases
Average time
(milliseconds) < 1.00 44.75 62.63
Table 2. Average time for 100 random searches.
4.4.2 Scanned text retrieval
When the search is performed over images, no text is available to perform searches inside it (it
is obtained during the OCR, used for indexing, and finally discarded), and consequently, pattern
matching algorithms are not useful. Then, we have to use the inverted index to look for the
exact location of each word in the images. The process is depicted in Figure 6.
Figure 6. Search system in image text.
For each occurrence of a given word, the inverted index contains: the journals or newspapers
where it takes place, the numbers and pages inside those numbers, and the coordinates inside the
pages. Observe that in this case, the inverted index does not actually store the relative position
of the word inside the document text, as searches of phrases are not considered.
Once the system recovers the coordinates of the location of the searched words within the
scanned image, it generates a new image with the searched words surrounded by colored
rectangles. This image can finally be sent to the client browser.
5 Case study: A digital library with ancient documents for the RAG
In this Section we present a case study in which we show how Digiflow was used to digitize a
collection of 10,000 documents from the 19th century. After briefly presenting the context in
Query
List of literary works
Index
Work1 Work1 Work1 Work1
List of pages
Pag 1 Pag 2 Pag 3 ...
Marked Text
A beautiful house close to our house

which the case study was carried out, we show how the digitization workflow was managed
with Digiflow. Then, we present statistics related to the performance obtained in the
digitization. Finally, we show how the final digital library was built, and the search
functionalities it provides by relying on the indexing and searching module of Digiflow.
5.1 Context: digital library requirements and settings
The Royal Galician Academy (RAG) is a scientific organization whose main objective is the
study of the Galician culture and specially the defense and promotion of the Galician language,
an official language that comes from an ancient language called Galician-Portuguese, and that is
nowadays spoken in Galicia (a region in the north-west of Spain) by around 2.5 million people
(85% of the population).
The RAG has built a digital library (accessible at http://www.lbd.udc.es/RAG-2004-
2012/Hemeroteca/) containing literary works, newspapers and periodic journals, all of them of
great cultural value. The newspapers and periodicals section of this library is of particular
interest because it is mainly composed of journals from the 19th century. These journals (some
of them are the only existing copy) constitute a valuable patrimony that permits to show the
historical, social, and economic situation in Galicia in the last centuries. Due to their antiquity
and poor state of preservation (an example is shown in Figure 7), these copies cannot be
accessed by the public in general. In order to preserve them and to make them available for
researchers, the RAG decided to create a digital library.
Figure 7. Images from “El Patriota Compostelano” (1810).
Digiflow was used to support the digitalization process of both periodicals and literary works. In
Section 5.2 we show how Digiflow guides the different users through the process. Note that the
RAG digital library contains two versions of the original literary works: i) plain transcribed
(error-free) text and ii) scanned images of the original text. Due to financial restrictions for
periodicals only the scanned images were created (no corrections are done upon the OCR phase,
and the obtained text is not finally kept).
Apart from the support to the digitization process, some of the most interesting aspects of the
RAG digital library are related to the search capabilities built upon the Digiflow indexing and
publishing subsystem. In addition to the typical searches based on metadata, a retrieval system
was included that permits to perform content based searches on both transcribed text and
images. We describe the search subsystem in Section 5.3.
5.2 Feeding the repositories of the RAG digital library with Digiflow
The first step to start the process of introducing a work in the digital library is to store its
metadata in the appropriate database. At the time of starting the creation of the RAG digital
library, the traditional RAG library already had an electronic catalogue. Therefore, we decided
that, to save time and errors, it was worth the development of an ad hoc system for extracting
the data from the RAG catalogue in order to feed the metadata database of DigiFlow. Once the
metadata was stored, starting the scanning process became possible.
5.2.1 Using Digiflow to create the RAG repositories
As we have explained in the previous section, after the administrator users register in the system
the different works to be done, the other participants log in the system to access the tasks that
were assigned to them. Once a user is validated by the system, a table appears showing the
pending tasks assigned to him. By clicking on one of them, the corresponding interface that
permits to perform such task is displayed.
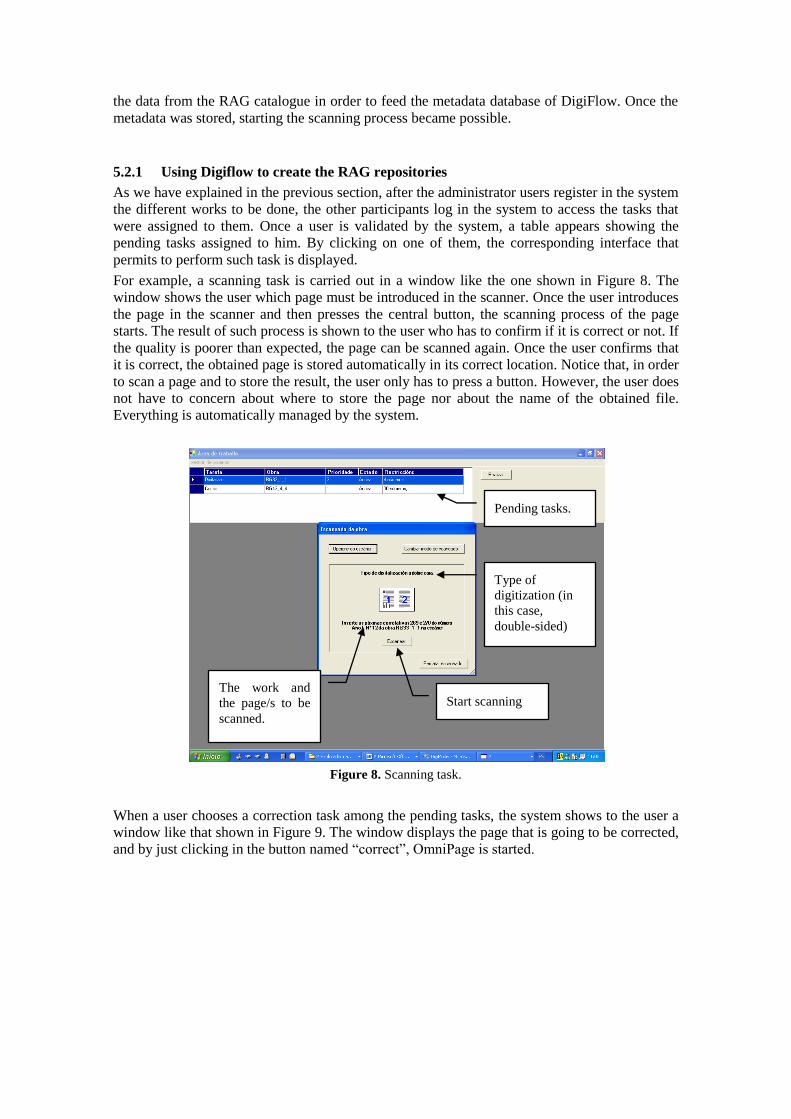
For example, a scanning task is carried out in a window like the one shown in Figure 8. The
window shows the user which page must be introduced in the scanner. Once the user introduces
the page in the scanner and then presses the central button, the scanning process of the page
starts. The result of such process is shown to the user who has to confirm if it is correct or not. If
the quality is poorer than expected, the page can be scanned again. Once the user confirms that
it is correct, the obtained page is stored automatically in its correct location. Notice that, in order
to scan a page and to store the result, the user only has to press a button. However, the user does
not have to concern about where to store the page nor about the name of the obtained file.
Everything is automatically managed by the system.
Figure 8. Scanning task.
When a user chooses a correction task among the pending tasks, the system shows to the user a
window like that shown in Figure 9. The window displays the page that is going to be corrected,
and by just clicking in the button named “correct”, OmniPage is started.
Type of
digitization (in
this case,
double-sided)
The work and
the page/s to be
scanned.
Pending tasks.
Start scanning

Figure 9. Correction task.
Finally, the window in Figure 10 is displayed. The system shows the scanned text in the upper
part of the interface and its transcription in the bottom part. If the user finds an error, the
transcribed text can be replaced by the correct version. By clicking over a word either in the
upper part (image) or in the lower part (transcribed text), the other version of the word is
highlighted in the corresponding part of the interface.
Figure 10. Scanned and transcribed text during the review.
Figure 8, Figure 9, and Figure 10 show the user interfaces corresponding to the three main
activities discussed in the system architecture: scanning, OCR, and correction. These are the
most common activities since they must be repeated for each source page in the processed work.
The first two are solved with just a pair of clicks because the rest of the work is automatically
done by the system. In the last one, the user has only to focus in the correction of the words, the
The work and
the page/s to be
corrected.

rest of the work (starting OmniPage, opening the scanned image and the transcribed text, and
saving the result) is automatically arranged by Digiflow.
5.2.2 Using Digiflow to monitor and control the digitalization process
The administrators of Digiflow can get summarized information about the process in order to
control and improve the workflow. Unexpected situations in workflow management systems are
likely to appear (Mourão, et al., 2003), and it is impossible to predict every possible cause of
failure or exception during the design of the system. In Digiflow, the approach chosen to
address these deviations is the adoption of an adaptive workflow system, which provides the
system administrator with tools to correct such failures if they occur. The administrator, on the
presence of these situations, can change the system behavior.
In order to manage the workflow, the administrator can benefit from three crucial aspects that
are controlled by the system: the status of the open works in the system, the status of the
workflow tasks, and the work of the users of the system.
Related to the first of these aspects, the system provides a group of reports, like the one shown
on the top of Figure 11, where all the works in the system and the status of the activities
assigned to those works can be seen. By using this report, the system administrator can know
which works are completed, who is working in each work, and how much time has been used
for processing the work.
Figure 11. Reports.
The system also allows the administrator to watch the tasks that are currently being performed
by the users the system. On the bottom of Figure 11, a report is shown with the pending tasks
assigned to each of the users. By means of these reports the system administrator can know the
workload of the users.
Users Task captions
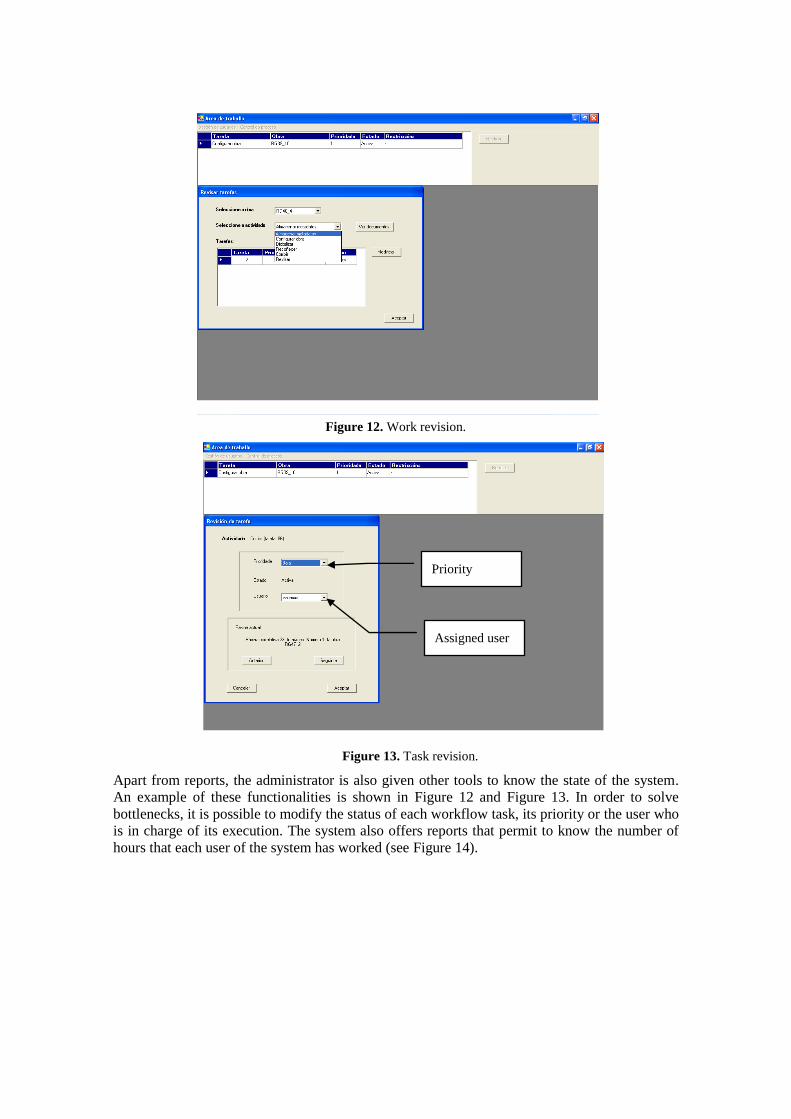
Figure 12. Work revision.
Figure 13. Task revision.
Apart from reports, the administrator is also given other tools to know the state of the system.
An example of these functionalities is shown in Figure 12 and Figure 13. In order to solve
bottlenecks, it is possible to modify the status of each workflow task, its priority or the user who
is in charge of its execution. The system also offers reports that permit to know the number of
hours that each user of the system has worked (see Figure 14).
Priority
Assigned user

Figure 14. Interface to show the periods worked by a given user.
5.2.3 Summary of the digitization process
During the digitization process we gathered data of the performance obtained. Table 2 shows
the results obtained by a group of twenty graduates in Galician Arts and Philology using the
system during 5 months. The first column indicates the activity, the second column shows the
total number of processed pages, the third column presents the total amount of hours devoted to
each activity, and finally, the fourth column gives the performance in pages per hour. Without
DigiFlow, this process would have been longer and it would probably include many errors.
ACTIVITIES PAGES HOURS PAGES/HOUR
Metadata storage 13304 135.99 97.83
Scanning 13304 255.77 52.01
OCR 13093 380.83 34.38
Correction 12192 4402.87 2.77
Table 3. Statistics on the digitization process.
5.3 Search support in the RAG digital library
One of the goals in the development of the RAG's digital library was to provide advanced
search functionalities, that is, not only the typical search based on the metadata of the works, but
also the capability of seeking literary works by their content, taking advantage of the digital
nature of the stored documents.
5.3.1 Description of the metadata model
Figure 15 and Figure 16 shows Entity-Relationship diagrams for two types of works, namely
journals and literary works.
In the case of journals, Digiflow allows us to store all information related to the journal (title,
first date and last dates in which the journal was published, and ISSN if applicable), each of its
volumes (title and number of pages), the numbers composing each volume (title and date of
publication), the articles published in each number (title, authors, and pages), and each of the

pages of the articles (page identifier and a path allowing to access the image of the scanned
page).
JOURNAL
Start date
Title
JOURNAL
NUMBER
1
N
Date
Identifier
Title
ARTICLE
End Page Initial Page
Title
Author
1
N
issn
Publishing
Publishing
place
Subject
PAGE
Path
N M
VOLUME
Signature
TitleNumber of
initial pages
Number of
final pagesIdentifier
IdentifierIdentifier
1
N
1
N
Figure 15. Entity-Relationship diagram for newspapers and periodicals database.
In the case of general literary works, it allows us to store information related to the authors of
the work (name, surname, dates of birth and death, a biography of the author and even a
photography), the work itself (title and genre), and each of its pages (order of the pages, and
links to their corresponding images).
ID
AUTHOR
Name
NameDate of
birth
Date of
death
LITERARY
WORK
M N
Photo
Biography IDTitle
Genre
Epoch
PAGE
N
1
File Name Order format
Figure 16. Entity-Relationship diagram for the database of literary works.

5.3.2 Indexing and searching
As we have explained in the previous section, Digiflow provides search capabilities that allow
the user to locate the document in which a query appears, including the text of the document and
also the image corresponding to the page in which the page appears. The works digitized with
Digiflow are stored in a module devoted to indexing and publishing. As explained in the
previous section, we developed this module by extending the Lucene inverted index. The index
was modified in order to store the coordinates of each word in the scanned image the word
comes from. As we will see later in this section, this allows us to show the results of the search
directly in the scanned images of the relevant works. This inverted index is constructed using
the stored metadata and the opd files provided by the scanning process. As said before, this
module implements the functionality to perform content-based queries. In the next section we
describe in more detail the text retrieval module and the public web interface.
Metadata
Text Repository *.html, *.txt
Image Repository *.gif, *.jpg
LUCENE Index
TEXT RETRIEVAL
SUBSYSTEM
Lucene
WEB INTERFACE
FOR RAG ADMINISTRATION
WEB INTERFACE
FOR PUBLIC
Figure 17. RAG digital library architecture.
The RAG digital library was mainly implemented using Java, and it accesses the underlying
database (MS SQL Server in its current implementation) and a set of file repositories. Figure 17
shows the general architecture of RAG digital library. It is fully modularized and comprises
three main subsystems. The first module is a web interface to manage the digital library; this
module is only used by authorized users. Administrators can introduce changes in the RAG
digital library, such as introducing news, sections, and new works in the digital library. The
second module is in charge of the public web interface. The third module is a text retrieval
module based in an inverted index built using the Lucene libraries.
5.3.3 Search Interfaces
As explained above, the RAG digital library provides typical searches using metadata, that is,
searches by author, title, editor, etc. It also supports searches by content, that is, it is possible to
seek works containing a list of words.
Obviously, the RAG digital library provides different search interfaces; Figure 18 shows an
example of a metadata search. These interfaces are different depending on the type of searched
work. In fact, literary works and periodic works have their own subsection inside the digital
library and then, due to the peculiarities of each type of work, the interfaces inside those
subsections are slightly different.

Figure 18. List of newspapers and journals sorted by name.
5.3.3.1 Searching a literary work
To describe the process that comes after a query, we are going to consider content-based
searches because they are more complex and include all the stages of the simpler ones. Once the
query is issued, the system returns a list of works matching the query. When the user selects a
literary work, its index card is displayed (see Figure 19). The index card informs about the
available digital versions of the work, which can be scanned images and/or transcribed text. The
user selects the desired version, and then the system presents an index to access individual
pages or groups of pages of the work (see Figure 20). In the case of searches by content, the
user might be interested in checking only the pages that contain the words specified in the
query. Observe in Figure 20 that some groups of pages have an asterisk just in its right. This
means that such a group of pages contains the searched words. Obviously, by clicking on the
label, the system gives access to those pages.
List of Journals
with a name that
begins with ‘A’.

Figure 19. An index card of a literary work.
Figure 20. Index of pages. Asterisks indicate pages that contain the searched patterns.
.
Only text version is
available for this work
Metadata
Index to group of pages

Figure 21. A page with marked words (“Galicia”, “amar”, and “terra”).
Figure 22. An image page with marked terms (“Revista” and “Galicia”).

Continuing with a content-based search, when the displayed version of the work is a plain text,
the system highlights the searched words with colors (see Figure 21). In the case of the image
version of a work, the system allows the user to display the images with or without marking the
searched words. If the marked option is chosen, the image is displayed with the searched words
surrounded by colored rectangles. All occurrences of the same word have the same rectangle
color, as it can be observed in Figure 22.
5.3.3.2 Searching a periodical work
The process of searching a periodical work differs depending on the type of search. If the search
is carried through metadata, the user starts selecting one newspaper or journal. Then, the list of
numbers of such newspaper or journal is displayed. Once the user selects a number, the system
displays the list of articles in that number. Finally, by clicking in one of the article names, the
system displays its contents. If the search is done by content, the articles containing the searched
words are displayed directly (see Figure 23) and then the user can access them without selecting
the journal and number.
Figure 23. List of article journals containing the word “Galicia”.
There is no transcribed text version of periodical works. Therefore, the interface associated to
the visualization of a periodical work is similar to that of the scanned literary works.
5.3.3.3 Other searches: the RAG catalogue
Another service included in the digital library is the possibility of querying the actual catalogue
of the library by means of two interfaces: simple and advanced. This service is important since
the RAG digital library does not contain the whole collection of the RAG library.
6 Conclusions and future work
The creation of a document repository is not a simple process. It requires the coordination of
people and tools to carry out every activity that is part of the process. These activities include
digitization of documents, optical character recognition, results correction, and indexing to
perform content-based searches. The use of support tools that facilitate the work of each
List of
articles
matching the
query.
List of searched
words (in this case)

participant and ensure the quality of the obtained results is necessary for those processes to be
correctly and efficiently done. The proposed workflow strategies and system architecture
support the control and coordination of the people and tasks involved in the digitization process.
The use of this architecture automates the completion of activities prone to errors and optimizes
the performance of the digitization process and the quality of the obtained results.
This architecture was applied to the design and development of DigiFlow, a collaborative
workflow management system designed to create document repositories. This system was built
as a desktop application, which provides an integrated environment for the execution of all the
tasks needed to create a digital library. DigiFlow was successfully applied to the building of the
digital library of the RAG.
In this paper, we also presented some remarkable technological issues applied in the RAG
digital library, which can be of interest for any team facing the challenge of building a digital
library.
As future work, we want to adapt our current system technology, permitting to maintain our
transcribed plain texts in a compressed form. Nowadays there are compression techniques
(Moura, et al., 2000; Brisaboa, et al., 2007) that allow searching the compressed text up to eight
times faster than searching the plain version of the text. At the same time, these techniques
compress the text to around 30% of the original size. The interest of those compression
techniques comes up because they can be integrated with an inverted index. Particularly in our
case, our document-grained inverted index can be built on the compressed documents. Then
during searches, the efficiency of pattern-matching algorithms over the compressed text would
permit to speed up the retrieval. In addition, due to the good features of those compressors, once
an occurrence is found during the sequential search, decompression can be done from such a
position on for presentation purposes. That is, it is not necessary to decompress the whole
document from the beginning.
7 References
Aalst, W.M.P. and Hee, K.M. (2002), Workflow Management: Models, Methods, and Systems,
MIT press, Cambridge, MA.
Arms, C. R. (2000), “Keeping Memory Alive: Practices for Preserving Digital Content at the
National Digital Library Program of the Library of Congress”, RLG DigiNews, Vol 4 No
3, available at: http://www.rlg.org/legacy/preserv/diginews/diginews4-3.html#feature1
(accessed 11 May 2007).
Baeza-Yates, R. and Ribeiro-Neto, B. (1999), Modern Information Retrieval, Addison-Wesley,
New York, NY.
Bainbridge, D., Thompson, J. and Witten, I. H. (2003), “Assembling and Enriching Library
Collections”, Proceedings of JCDL’03: Joint Conference on Digital Libraries, May 27-
31, Houston, Texas, USA.
Baird, H. S. (2003), “Digital Libraries and Document Image Analysis”, Proceedings of the
Seventh International Conference on Document Analysis and Recognition, August 3-6,
Edinburgh, UK.
Banerjee, J., Namboodiri, A. and Jawahar C. (2009), "Contextual Restoration of Severely
Degraded Document Images", Proceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, CVPR 2009, June 20-25, Miami, Fl, pp. 517 - 524.
Borgman, C. (1999), “What are digital libraries? Competing visions”, Information Processing
and Management, Vol 35 No 3, pp. 227-243.
Borgman, C. (2002), “Challenges in Building Digital Libraries for the 21st Century”,
Proceedings of 5th International Conference on Asian Digital Libraries, ICADL 2002,
December 11-14, Singapore, pp. 1-13.

Buchanan, G., Bainbridge, D. and Don, K. J. (2005), “A New Framework for Building Digital
Library Collections”, Proceedings of JCDL’05: Joint Conference on Digital Libraries,
June 7-11, Denver, Colorado, USA.
Brisaboa, N. R., Fariña, A., Navarro, G. and Paramá, J. R. (2007), “Lightweight Natural
Language Text Compression”, Information Retrieval, Vol 10 No 1, Springer,
Netherlands, pp 1-33.
Chang, N. and Hopkinson, A. (2006), “Reskilling staff for digital libraries”, Digital Libraries:
Achievements, Challenges and Opportunities, Lecture Notes in Computer Science, Vol.
4312, Springer-Verlag, Berlin, pp. 531-532.
CCSDS: Consultative Committee for Space Data Systems (2002), “Referente Model an Open
Archival información System (OAIS)”, Available at:
http://public.ccsds.org/publications/archive/650x0m1.pdf (accessed January 2014).
Cramer, T. and Kott, K. (2010), "Designing and Implementing Second Generation Digital
Preservation Services: A Scalable Model for the Stanford Digital Repositor", D-Lib
Magazine, Vol 16 No 9/10, online. Available at
http://www.dlib.org/dlib/september10/cramer/09cramer.html
Delos (2008), “A Reference Model for Digital Library Management Systems”, Available at:
http://www.delos.info/index.php?option=com_content&task=view&id=345&Itemid=
(accessed January 2014).
Duguid, P. (1997), “Report of the Santa Fe Planning Workshop on Distributed Knowledge
Work Enviroments: Digital Libraries”, School of Information, University of Michigan.
Ellis, C. A. and Keddara, K. (2000), “A Workflow Change Is a Workflow”, Business Process
Management, Models, Techniques, and Empirical Studies, Lecture Notes in Computer
Science, Vol. 1806, Springer-Verlag, Berlin, pp. 201-217
Fischer, L. ed. (2003), Workflow Handbook 2003, Workflow Management Coalition, Future
Strategies, Lighthouse Point, Florida.
Gonçalves, M., Fox, E., Watsom, L. and Kipp, N. (2001), Streams, structures, spaces,
scenarios, societies (5S): A formal model for digital libraries. Technical Report TR-01-
12, Virginia Tech, Blacksburg, VA.
Gonçalves, M., Mather, P., Wang, J., Zou, Y., Luo, M., Richardson, R., Shen, R., Xu, L. and
Fox, E. (2002), “Java MARIAN: From an OPAC to a modern digital library system”,
Proceedings of the 9th International Symposium on String Processing and Information
Retrieval (SPIRE 2002), Lecture Notes in Computer Science, Vol. 2476, Springer-Verlag,
Berlin, pp. 194-209.
Hollingsworth, D. (1995), “WFMC Reference Model”. January 1995, available at:
www.wfmc.org/standards/docs/tc003v11.pdf. (accessed January 2014).
Kolak, O., Byrne, W. J. and Resnik, P. (2003), “A Generative Probabilistic OCR Model for
NLP Applications”, Proceedings of HLT-NAACL, May 27-June 1, Edmonton, Canada.
Larson, R. and Carson, C (1999), “Information Access for A Digital Library: Cheshire II and
the Berkeley Environmental Digital Library”, Proceedings of ASIS’99, October 31-
November 4, Washington D.C, USA.
Lesk, M. (1997), Practical Digital Libraries: Books, Bytes, and Bucks, Morgan Kaufmann
Publishers, San Mateo, CA.
Library of Congress (2007), “Metadata Encoding and Transmission Standard (METS)”,
available: http://www.loc.gov/standards/mets/
Lucene (2006), Lucene project, available at: http://lucene.apache.org/ (accessed January 2014).
McCray, A.T. and Gallagher, M.E. (2001), “Principles for digital library development”
Communications of the ACM, Vol 44 No 4, ACM, NEW YORK, NY, pp. 49-54.

Moura, E. S., Navarro G., Ziviani, N. and Baeza-Yates, R. (2000), “Fast and flexible word
searching on compressed text” ACM Transactions on Information Systems, Vol 18 No 2,
ACM, NEW YORK, NY, pp.113-139.
Mourão, H. and Antunes, P. (2003), “Workflow Recovery Framework for Exception Handling:
Involving the User”, Groupware: Design, Implementation, and Use, 9th International
Workshop, CRIWG 2003, Lecture Notes in Computer Science, Vol. 2806, Springer-
Verlag, Berlin, pp. 159-167.
Navarro, G. and Raffinot, M. (2002). Flexible Pattern Matching in Strings, Cambridge
University Press, Cambridge.
Paramá, J. R., Places, A. S., Brisaboa, N. R. and Penabad, M. R. (2006), “The Desing of a
Virtual Library of Emblem Books”, Software: Practice and Experience, Vol 36 No 5,
John Willey & Sons, Sussex, England, pp 473-494.
Places, A. S., Brisaboa, N. R., Fariña, A., Luaces, M. R., Paramá, J. R. and Penabad, M. R.
(2007), “The Galician Virtual Library”, Online Information review, Vol 31 No 3,
Emerald Group Publishing Limited, Yorkshire, England, pp. 333-352.
Ross, S. and M. Hedstrom (2005), “Preservation research and sustainable digital libraries”,
International Journal on Digital Libraries, Vol 5 No 4, Springer, pp. 317-324.
Ross, S. (2014), "Digital preservation, archival science and methodological foundations for
digital libraries", New Review of Information Networking, Vol. 17, Taylor & Francis
Group, pp. 43-68.
Sankar, K. P., Ambati, V., Pratha, L. and Jawahar, C. V. (2006), “Digitizing a Million Books:
Challenges for Document Analysis”, Proceedings of Development and Application
Systems, DAS 2006, Lecture Notes in Computer Science, Vol. 3872, Springer-Verlag,
Berlin, pp. 425-436.
Van de Sompel, H. and Lagoze, C. (2000), “The Santa Fe Convention of the Open Archives
Initiative”, Dlib Magazine, Vol 6 No 2, available
http://www.dlib.org/dlib/february00/vandesompel-oai/02vandesompel-oai.html (accesed
January 2014).
Vázquez, E., Places, A. S., Fariña, A., Brisaboa, N. R. and Paramá, J. R. (2005),
“Recuperación de Textos en la Biblioteca Virtual Galega”. Revista IEEE América Latina,
Vol 3 No 1, IEEE Press.
Witten, I. H. and Bainbridge, D. (2003), How to Build a Digital Library, Morgan Kaufmann
Publishers, San Mateo, CA.









![Creating web-based GIS applications using automatic code ...lbd.udc.es/Repository/Publications/Drafts/... · the platform [8], and implemented in components or software assets. To](https://img.pdfslide.us/doc/110x75/5f096a377e708231d426ba3e/creating-web-based-gis-applications-using-automatic-code-lbdudcesrepositorypublicationsdrafts.jpg)



















