Embed Size (px)
Citation preview

A Voice Conversion Method Mapping Segmented Frames with Linear Multivariate Regression
Hung-Yan Gu Jia-Wei Chang Zan-Wei Wang
Department of Computer Science and Information Engineering
National Taiwan University of Science and Technology e-mail: {guhy, m9815064, m10015078}@mail.ntust.edu.tw
GMM(over smoothing) (linear multivariate
regression, LMR)LMR
LMR
GMMLMR_F GMM
LMR_F GMM
(voice conversion) (source speaker)(target speaker)
: (VQ) (mapping)[1] (formant) [2, 3]
(Gaussian mixture model, GMM) [4, 5] (artificial neural network, ANN) [6] (hidden Markov model, HMM) [7, 8]
GMM
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
3
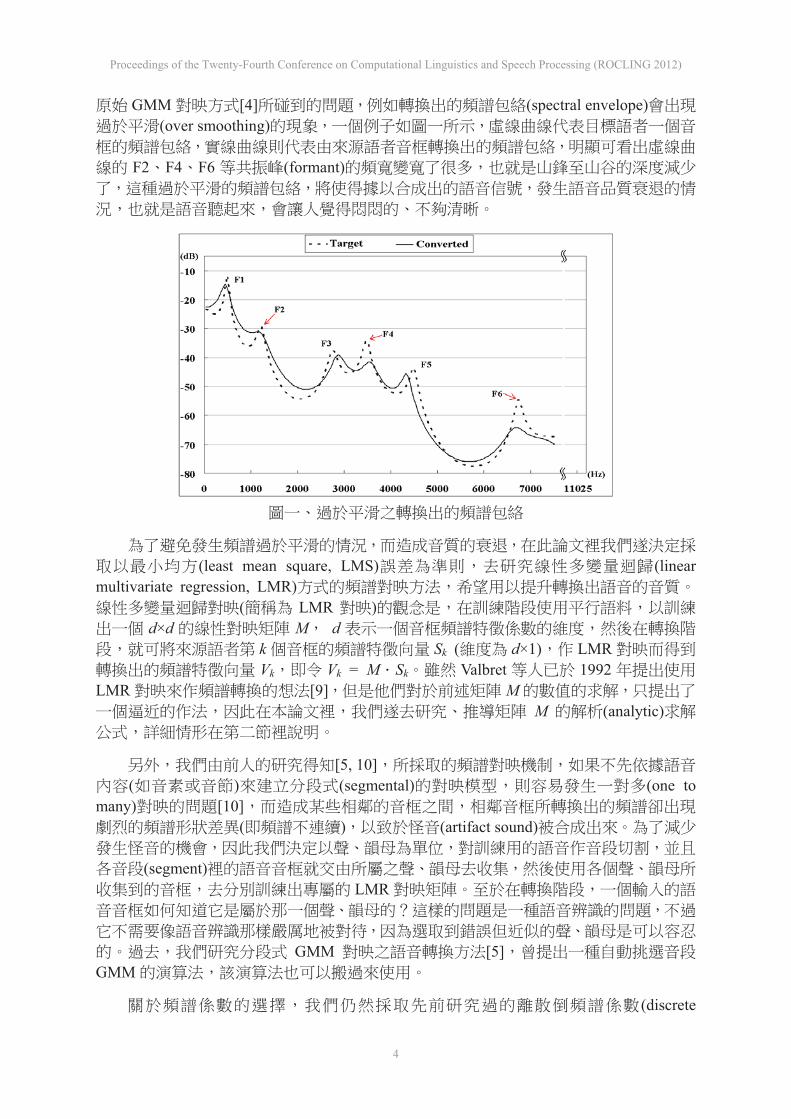
GMM [4] (spectral envelope)(over smoothing)
F2 F4 F6 (formant)
(least mean square, LMS) (linear
multivariate regression, LMR)( LMR )
d×d M dk Sk ( d×1) LMRVk Vk = M Sk Valbret 1992
LMR [9] MM (analytic)
[5, 10]( ) (segmental) (one to
many) [10]( ) (artifact sound)
(segment)LMR
GMM [5]GMM
(discrete
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
4

cepstrum coefficients, DCC)[11, 12] c0, c1, c2, …, c40
41 c1, c2, …, c40
DCC DCC[11, 12]
(harmonic plus noise model, HNM) [12, 13] [12, 13]
LMR
DCC (DTW) ( ) ( )
N : S1, S2, , SN N: T1, T2, , TN d×1 DCC Tk DTW DCC
Sk S = [S1, S2, , SN] T = [T1, T2, , TN]S T d×N d×d LMR
M
M S = T . (1)
N d ME d×N
E = M S T . (2)
M EE d×N M d×d LMS
ε :
t t = ( )( ) , t : transpose.E E M S T M S Tε ⋅ = ⋅ − ⋅ − (3)
ε (trace) 1,1 2,2 ,tr( ) ... d dε ε ε ε= + + + M0 [11, 12]
( ) ttr( )2( ) 0 ,M S T S
Mε∂
= ⋅ − ⋅ =∂
(4)
( )tr( ) / Mε∂ ∂ ( ) ,tr( ) / i jMε∂ ∂ j=1, 2, …, d i=1, 2, …, dM i j ,i jM tr( )ε (4)
M
t t = ,M S S T S⋅ ⋅ ⋅ (5)
t t 1( ) .M T S S S −= ⋅ ⋅ ⋅ (6)
(6) LMS M(a) (1) M
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
5
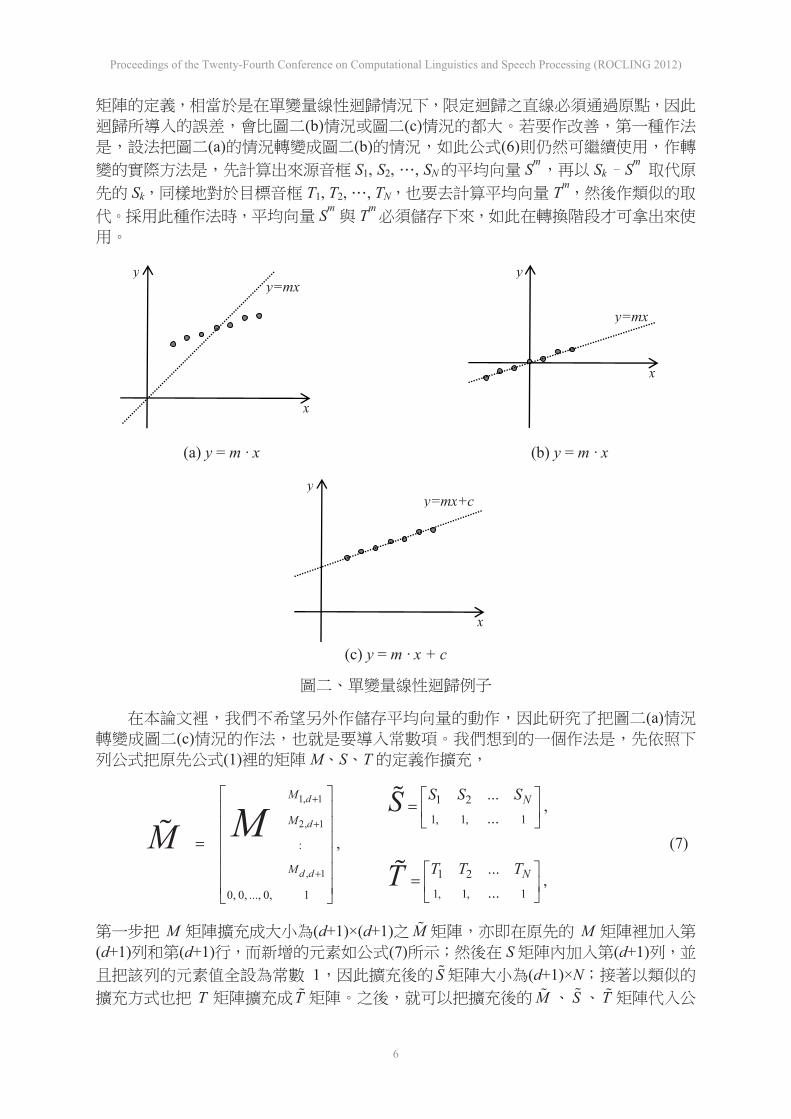
(b) (c)(a) (b) (6)
S1, S2, , SN Sm Sk Sm Sk T1, T2, , TN Tm
Sm Tm
x
y y=mx
x
y
y=mx
(a) y = m · x (b) y = m · x
x
y y=mx+c
(c) y = m · x + c
(a)(c)
(1) M S T
1, 1
2, 1
, 1
1 2
1, 1, 1
:
1 2
1, 1, 10, 0, ..., 0, 1
...,
...,
...,
...
d
d
d d
M N
M
M N
S S S
T T T
S
TM M
+
+
+
� � � �=� � � �� �� �
� �=� �
� �� � = � �� � � �� �
�
�� (7)
M (d+1)×(d+1) M� M(d+1) (d+1) (7) S (d+1)
1 S� (d+1)×NT T� M� S� T�
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
6
(6) M� M� (1)
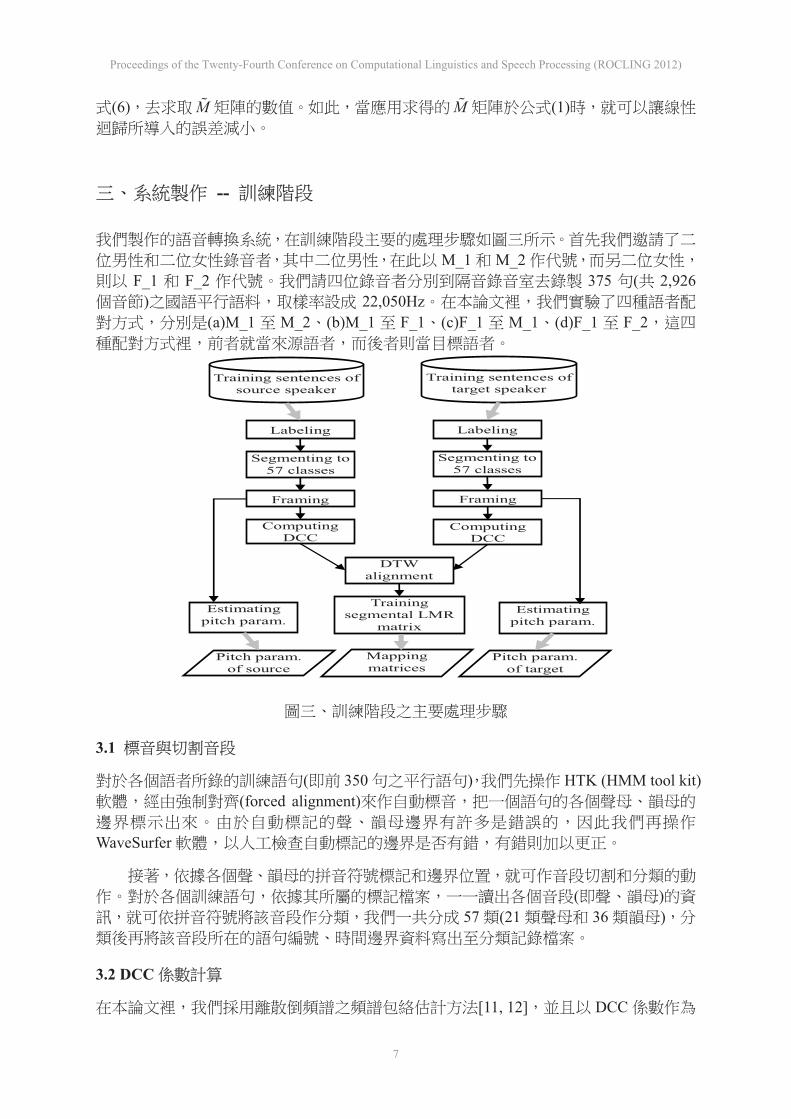
--
M_1 M_2F_1 F_2 375 ( 2,926
) 22,050Hz(a)M_1 M_2 (b)M_1 F_1 (c)F_1 M_1 (d)F_1 F_2
Training segmental LMR
matrix
Labeling
Training sentences of source speaker
Training sentences of target speaker
Labeling
Framing Framing
DTW alignment
Computing DCC
ComputingDCC
Mapping matrices
Estimating pitch param.
Estimating pitch param.
Pitch param. of target
Pitch param. of source
Segmenting to 57 classes
Segmenting to 57 classes
3.1
( 350 ) HTK (HMM tool kit)(forced alignment)
WaveSurfer
( )57 (21 36 )
3.2 DCC
[11, 12] DCC
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
7

DCC [12] 41DCC 512 (23.2ms) 128
(5.8ms)
3.3 DTW LMR
DTW LMR
( /a/) DTW Sk
DTW(Sk, Tw(k)) k=1, 2, , Kn Kn n
LMR(1) S T
(6) LMR M (7)S T S� T� (6) LMR M�
3.4
(ZCR) ZCR (unvoiced)AMDF (absolute magnitude difference function)
[14 (voiced)
--
2.2512 128
DCC
( )( ) ( )
( ) ( )y
y xt txq pσμ μ
σ= + − (8)
pt(x) (x)
(y) (y)
4.1
LMR LMR
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
8

( )
” ”HTK
HTK HTK HMM 350HMM
HNM based speech synthesis
Pitch adjusting
LMR mapping
Compute DCC
Converted voices
Detect pitch freq.
Test sentences
Framing
Segment recognition
4.2
(HNM)(maximum voiced frequency
MVF)[13] MVF6,000Hz
HNM
[5, 12] HNM
LMR (1) MLMR LMR_B
(7) M�LMR LMR_F
LMR LMR_FC
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
9

”DTW alignment” ”Train LMR matrix””VQ clustering” DCC
(joint vector, 80) K-means L DCCL DCC LMRM� L 4
”LMR mapping” ”Select mapping matrix” L
DCC ( 40) L 40LMR
5.1
375 350 LMRDCC DCC ( 350 )
( 25 209 ) R = R1, R2, , RN
DCC T = T1, T2, , TN R DCC,
1
1( , ) ,avg k kN
k ND dist R T
≤ ≤= � (9)
(9) dist( )
LMR(LMR_F) (LMR_B)
( 1.6% 1.7%)VQ LMR
(LMR_FC) 0.49560.4672 5.7% 0.5382 0.5493
2.1% LMR_FC 0.46720.5
LMR_B 0.5038 LMR_B0.5
GMMDCC GMM [4]
GMM (Segmental GMM) [5] GMM 128GMM 8
GMM
GMMGMM
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
10
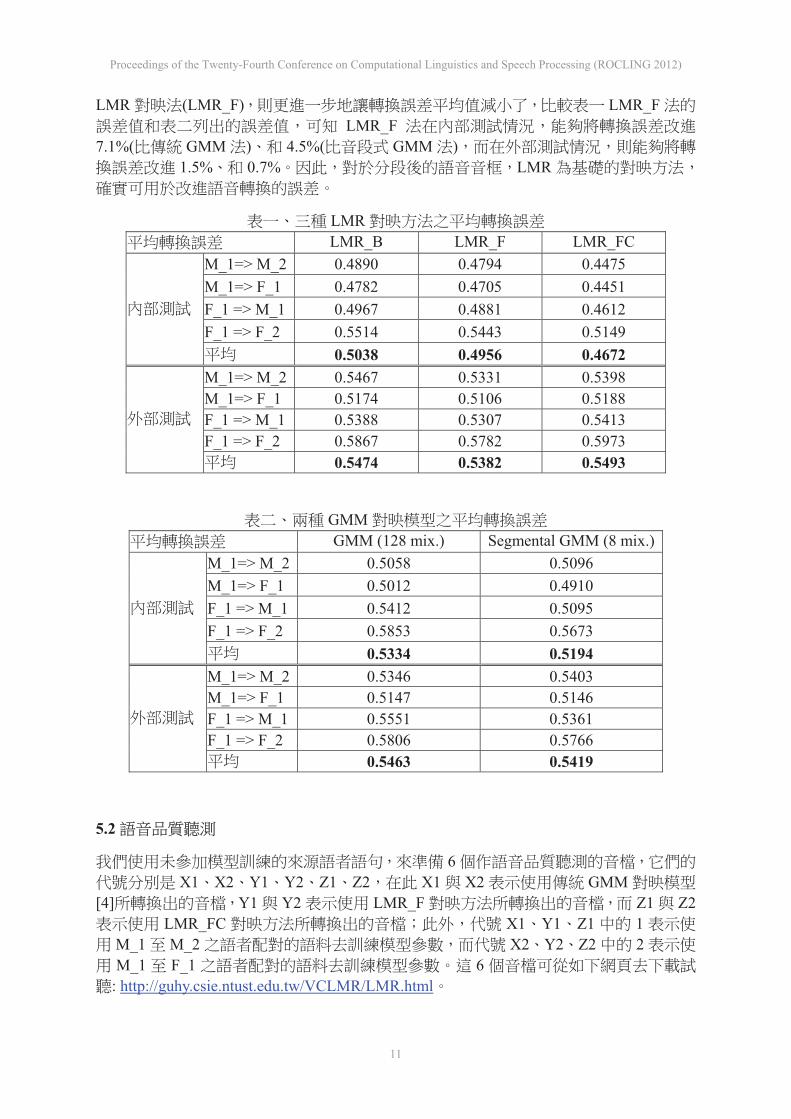
LMR (LMR_F) LMR_FLMR_F
7.1%( GMM ) 4.5%( GMM )1.5% 0.7% LMR
LMR LMR_B LMR_F LMR_FC
M_1=> M_2 0.4890 0.4794 0.4475 M_1=> F_1 0.4782 0.4705 0.4451 F_1 => M_1 0.4967 0.4881 0.4612 F_1 => F_2 0.5514 0.5443 0.5149
0.5038 0.4956 0.4672 M_1=> M_2 0.5467 0.5331 0.5398 M_1=> F_1 0.5174 0.5106 0.5188 F_1 => M_1 0.5388 0.5307 0.5413 F_1 => F_2 0.5867 0.5782 0.5973
0.5474 0.5382 0.5493
GMM GMM (128 mix.) Segmental GMM (8 mix.)
M_1=> M_2 0.5058 0.5096 M_1=> F_1 0.5012 0.4910 F_1 => M_1 0.5412 0.5095 F_1 => F_2 0.5853 0.5673
0.5334 0.5194 M_1=> M_2 0.5346 0.5403 M_1=> F_1 0.5147 0.5146 F_1 => M_1 0.5551 0.5361 F_1 => F_2 0.5806 0.5766
0.5463 0.5419
5.2
6X1 X2 Y1 Y2 Z1 Z2 X1 X2 GMM
[4] Y1 Y2 LMR_F Z1 Z2LMR_FC X1 Y1 Z1 1
M_1 M_2 X2 Y2 Z2 2M_1 F_1 6
: http://guhy.csie.ntust.edu.tw/VCLMR/LMR.html
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
11
6 X1 Y1A B A B
B A Y1 Z1A B X2 Y2 A
B Y2 Z2 A B15
2 (-2) B (A)A (B) 1 (-1) B (A) A (B)
0 A B
( 0.867 0.467) GMM
LMR_F( 0.267 0.000) LMR_F LMR_FC
LMR_FCLMR_F
GMM (128mix.) vs LMR_F LMR_F vs LMR_FC
M_1 => M_2 AVG (STD) 0.867 (0.640) 0.267 (0.915)
M_1 => F_1 AVG (STD) 0.467 (0.704) 0.000 (0.378)
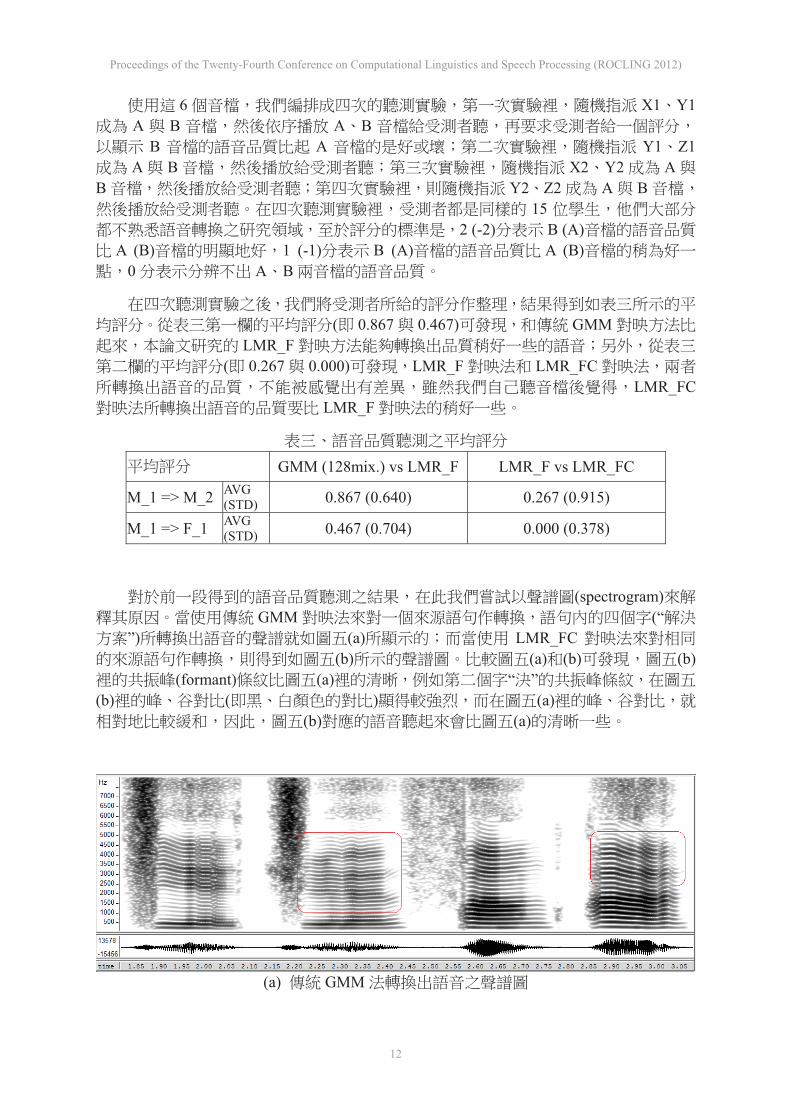
(spectrogram)GMM (“
”) (a) LMR_FC(b) (a) (b) (b)
(formant) (a) “ ”(b) ( ) (a)
(b) (a)
(a) GMM
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
12

(b) LMR_FC
/jie-3 jyei-2 fang-1 an-4/(“ ”)
(LMR)LMR DCC
LMR_F
GMM GMM7.1% GMM
1.5%LMR_F GMM
LMR_F
GMM LMR_FCLMR_FC LMR_FC
LMR_FC LMR_FLMR_F
LMR_FC
[1] M. Abe, S. Nakamura, K. Shikano, and H. Kuwabara, “Voice Conversion through Vector Quantization,” Int. Conf. Acoustics, Speech, and Signal Processing, New York, Vol. 1, pp. 655-658, 1988.
[2] H. Mizuno and M. Abe, “Voice Conversion Algorithm Based on Piecewise Linear Conversion Rules of Formant Frequency and Spectrum Tilt,” Speech Communication, Vol. 16, No. 2, pp. 153-164, 1995.
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
13

[3] ”” (ROCLING 2009) 319-3322009
[4] Y. Stylianou, O. Cappe, and E. Moulines, “Continuous Probabilistic Transform for Voice Conversion,” IEEE Trans. Speech and Audio Processing, Vol. 6, No. 2, pp.131-142, 1998.
[5] H. Y. Gu and S. F. Tsai, “An Improved Voice Conversion Method Using Segmental GMMs and Automatic GMM Selection”, Int. Congress on Image and Signal Processing, pp. 2395-2399, Shanghai, China, 2011.
[6] S. Desaiy, E. V. Raghavendray, B. Yegnanarayanay, A. W Blackz, and K. Prahallad, “Voice Conversion Using Artificial Neural Networks,” Int. Conf. Acoustics, Speech, and Signal Processing, Taipei, Taiwan, pp. 3893-3896, 2009.
[7] E. K. Kim, S. Lee, and Y. H. Oh, “Hidden Markov Model Based Voice Conversion Using Dynamic Characteristics of Speaker,” Proc. EuroSpeech, Rhodes, Greece, Vol. 5, 1997.
[8] C. H. Wu, C. C. Hsia, T. H. Liu, and J. F. Wang, “Voice Conversion Using Duration-Embedded Bi-HMMs for Expressive Speech Synthesis,” IEEE Trans. Audio, Speech, and Language Processing, Vol. 14, No. 4, pp. 1109-1116, 2006.
[9] H. Valbret, E. Moulines, J. P. Tubach, “Voice Transformation Using PSOLA Technique,” Speech Communication, Vol. 11, No. 2-3, pp. 175-187, 1992.
[10] E. Godoy, O. Rosec, and T. Chonavel, “Alleviating the One-to-many Mapping Problem in Voice Conversion with Context-dependent Modeling”, Proc. INTERSPEECH, pp. 1627-1630, Brighton, UK, 2009.
[11] O. Cappé and E. Moulines, “Regularization Techniques for Discrete Cepstrum Estimation,” IEEE Signal Processing Letters, Vol. 3, No. 4, pp. 100-102, 1996.
[12] H. Y. Gu and S. F. Tsai, “A Discrete-cepstrum Based Spectrum-envelope Estimation Scheme and Its Example Application of Voice Transformation,” International Journal of Computational Linguistics and Chinese Language Processing, Vol. 14, No. 4, pp. 363-382, 2009.
[13] Y. Stylianou, Harmonic plus noise models for speech, combined with statistical methods, for speech and speaker modification, Ph.D. thesis, Ecole Nationale Supèrieure des Télécommunications, Paris, France, 1996.
[14] H. Y. Kim, et al., “Pitch detection with average magnitude difference function using adaptive threshold algorithm for estimating shimmer and jitter,” 20-th Annual Int. Conf. of the IEEE Engineering in Medicine and Biology Society, Hong Kong, China, 1998.
Proceedings of the Twenty-Fourth Conference on Computational Linguistics and Speech Processing (ROCLING 2012)
14