Embed Size (px)
Citation preview

A Topic Model for Melodic Sequences
Athina Spiliopoulou and Amos StorkeyICML 2012
Presented by Xin Yuan
1 July 2013

Outline
1 Problem & Solution
2 Variable-gram Topic Model
3 Inference & Learning
4 Experiments
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 2 / 21

Problem & Solution
Problem: Learn a probabilistic model for melody directly from musicalsequences belonging to the same genre.
I Capture the rich temporal structure evident in music;I Capture the complex statistical dependencies among different music
components.
Solution: The Variable-gram Topic Model.It couples the latent topic formalism with a systematic model for contextualinformation.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 3 / 21

Outline
1 Problem & Solution
2 Variable-gram Topic Model
3 Inference & Learning
4 Experiments
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 4 / 21
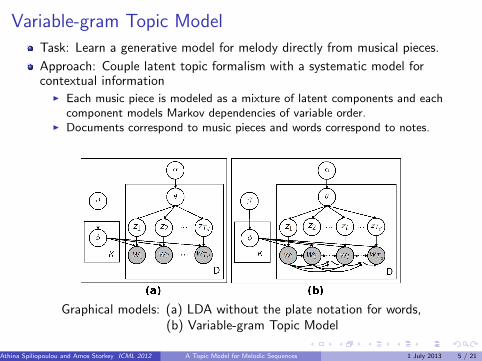
Variable-gram Topic Model
Task: Learn a generative model for melody directly from musical pieces.
Approach: Couple latent topic formalism with a systematic model forcontextual information
I Each music piece is modeled as a mixture of latent components and eachcomponent models Markov dependencies of variable order.
I Documents correspond to music pieces and words correspond to notes.
Graphical models: (a) LDA without the plate notation for words,(b) Variable-gram Topic Model
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 5 / 21
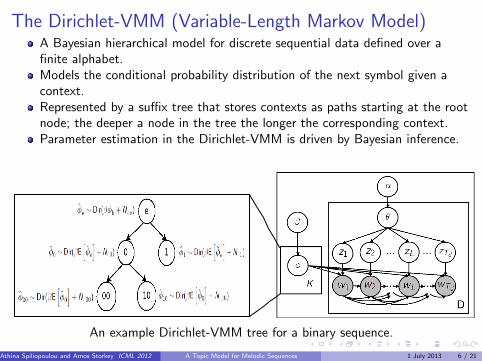
The Dirichlet-VMM (Variable-Length Markov Model)A Bayesian hierarchical model for discrete sequential data defined over afinite alphabet.Models the conditional probability distribution of the next symbol given acontext.Represented by a suffix tree that stores contexts as paths starting at the rootnode; the deeper a node in the tree the longer the corresponding context.Parameter estimation in the Dirichlet-VMM is driven by Bayesian inference.
An example Dirichlet-VMM tree for a binary sequence.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 6 / 21

Generative ProcessSimilarly to LDA, each document is modelled as a mixture of latent topicsand the latent topics are shared among documents.
On the other hand, each topic is now represented by a Dirichlet-VMM;instead of a single probability distribution over words, we now have a set ofconditional probability distributions encoding contextual information ofvariable order.
If we consider only first order (` = L = 1) dependencies, instead of variableorder ones, then we retrieve the Bigram Topic model.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 7 / 21

Joint Probability
j index of the leaf nodecwt = wt−1 . . .wt−`, ` ∈ {1, . . . , L} the context of word wt
φi|j,k = P(wt = i |cwt = j , zt = k) word generation within topic kK the number of latent topicsC the number of leaf nodesW the number of words in the vocabulary
This results a tensor Φ with KC (W − 1) free parameters.The joint probability of a corpus ω and a set of corresponding latent topicassignments z under a variable-gram topic model with parameters Φ and Θ is
P(ω, z|Φ,Θ) =∏d
∏t
P(zt,d |θd)P(wt,d |φcwt,d ,zt,d)
=∏d
∏i
∏j
∏k
φNi|j,ki|j,k θ
Nk|dk|d ,
Ni|j,k is the number of times word i has been assigned to topic k when precededby context j ; Nk|d is the number of times topic k has occurred in document d andt indexes word positions (time-steps).
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 8 / 21

Prior
Prior over Θ, (same as in LDA)
P(Θ|αn) =∏d
Dirichlet(θd |αn)
n is set as the uniform distribution.
Prior over the Φ parameters is now defined in terms of the Dirichlet-VMM.Let mj,k = φpa(j),k denote the measure for the Dirichlet prior of node j in thek-th Dirichlet-VMM.
P(Φ|β{mj,k}) =∏k
∏j
Dirichlet(φj,k |βmj,k)
This prior produces a hierarchical Dirichlet-VMM tree for each topic k.The parameters for the children of a node are coupled through the sharedDirichlet prior.Hence, within a topic, information regarding prediction is shared among allcontexts, through the mutual prior at the root node.The prior for the root node of each topic, m0,k , to a uniform distribution.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 9 / 21

Outline
1 Problem & Solution
2 Variable-gram Topic Model
3 Inference & Learning
4 Experiments
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 10 / 21

Inference & Learning
Total probability:
P(ω, z,Φ,Θ|αn, β{mj,k}) =∏d
P(θd |αn)∏k,j
P(φj,k |βmj,k)
×∏t
P(zt,d |θd)P(wt,d |φcwt,d ,zt,d)
Integrate over the model parameter, Θ,Φ,
P(ω, z|αn, β{mj,k}) =∏k
∏j
Γ(β)∏i Γ(βmi|j,k)
∏i Γ(Ni|j,k + βmi|j,k)
Γ(Nj,k + β)
×∏d
Γ(α)∏k γ(αnk)
∏k Γ(Nk|d + αnk)
Γ(Nd |α)
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 11 / 21

Gibbs Sampling
Start by randomly initializing the latent topic assignments,
Sequentially sampling each latent variable zt given the current values of allother latent variables z−t , the data ω and a set of hyperparameters{αn, β{mj,k},Sample zt according to
P(zt = k|z−t ,ω, αn, β{mj,k}) ∝{Ni|j,k}−t + βmi,j,k
{Nj,k}−t + β
{Nk|d}}−t + αnk
{Nd}−t + α
Approximate the posterior distribution of model parameter, Θ,Φ, throughthe predictive distributions:
P(θk|d |ω, z, αn) =Nk|d + αnk
Nd + α
P(φi|j,k |ω, z, β{mj,k}) =Ni|j,kβmi|j,k
Nj,k + β
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 12 / 21

Outline
1 Problem & Solution
2 Variable-gram Topic Model
3 Inference & Learning
4 Experiments
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 13 / 21
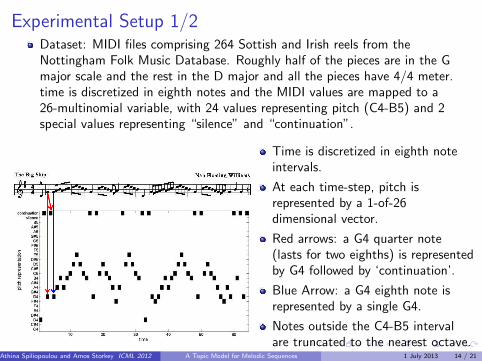
Experimental Setup 1/2Dataset: MIDI files comprising 264 Sottish and Irish reels from theNottingham Folk Music Database. Roughly half of the pieces are in the Gmajor scale and the rest in the D major and all the pieces have 4/4 meter.time is discretized in eighth notes and the MIDI values are mapped to a26-multinomial variable, with 24 values representing pitch (C4-B5) and 2special values representing “silence” and “continuation”.
Time is discretized in eighth noteintervals.
At each time-step, pitch isrepresented by a 1-of-26dimensional vector.
Red arrows: a G4 quarter note(lasts for two eighths) is representedby G4 followed by ‘continuation’.
Blue Arrow: a G4 eighth note isrepresented by a single G4.
Notes outside the C4-B5 intervalare truncated to the nearest octave.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 14 / 21

Experimental Setup 2/2
Hyperparameters {α, β}, a 10-fold cross-validation procedure and performgrid search over the product space of the values {0.01, 1, 5, 10, 50, 100}.Present results for topic models with 5, 10 and 50 topics.
For the Variable-gram Topic model and the Dirichlet-VMM, we presentresults using two tree structures, obtained by changing the threshold that therelative frequency of a context must exceed, in order to include the context inthe tree. The first tree is relatively shallow (threshold: 1e − 03) and isreferred to as .Sh, whereas the second tree is deeper (threshold: 1e − 04) andis referred to by .De.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 15 / 21

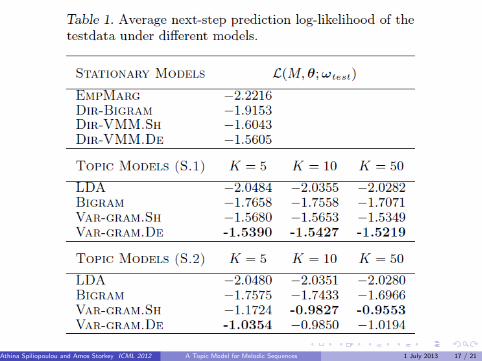
Next-Step Prediction Task
The average next-step prediction log-likelihood of a test corpus ωtest under amodel M with parameters θ is given by:
L =1
N
N∑d=1
1
TdlogP(wt,d |w1,d , . . . ,wt−1,d). (1)
Approximate (1) through a sampling procedure, where we initialize θd at theprior and at each time-step we sample s topics from our current estimate ofθd , use these samples to compute the log-likelihood of time-step t andsubsequently update θd with the mean of the posterior distribution from eachsample.
First approach (S.1): Do not update the word distribution during testing,that is the information from the observed part of a test piece is only used toupdate the θd parameters.
Second approach (S.2): After each time-step we also update the distributionsover words, by adding to φi|j,k of the observed word-context, countsproportional to the posterior probability of topic k .
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 16 / 21
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 17 / 21

Maximum Mean Discrepancy of String Kernels
A new approach for evaluating model generation. The string kernels and theMaximum Mean Discrepancy are employed estimate the distance between themodel distribution, Q, and the true “theoretical” data distribution, P, basedon finite samples drawn i.i.d. from each.
Given the two populations -model samples and test data- we first compute asimilarity score between each pair of sequences, which is proportional to thenumber of matching subsequences. Then we quantify the distance betweenthe two populations by comparing the intra-population similarity scores to theinter-population scores.
A small distance indicates that a model generates many of the differentsubstructures that occur in the data.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 18 / 21

Maximum Mean Discrepancy (MMD)The Maximum Mean Discrepancy (MMD) is a distance metric betweenprobability distribution embeddings on a Reproducing Kernel Hilbert Space(RKHS). Given a set of observed data sequences X := {x1, . . . , xm} drawni.i.d. from P and a set of sampled sequences X′ := {x′1, . . . , x′n} drawn i.i.d.from Q, an unbiased empirical estimate of the squared population MMD canbe computed as:
MMD2u [F ,X,X′] =
1
m(m − 1)
m∑i=1
m∑j 6=i
K (xi , xj) +1
n(n − 1)
n∑i=1
n∑j 6=i
K (x′i , x′j)
− 2
mn
m∑i=1
n∑j=1
K (xi , x′j)
where F is a RKHS and K (x , x ′) = 〈φ(x), phi(x ′)〉F is a positive definitekernel defined as the inner product between feature mapping φ(x) ∈ F .
The normalized mismatch kernels (k : the fixed length, m, the mismatchnumbers):
K̃(k,m)(x, x′) =
K(k,m)(x, x′)√
K(k,m)(x, x)√
K(k,m)(x′, x′)
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 19 / 21
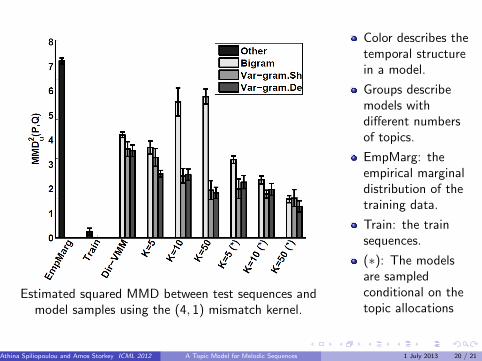
Estimated squared MMD between test sequences andmodel samples using the (4, 1) mismatch kernel.
Color describes thetemporal structurein a model.
Groups describemodels withdifferent numbersof topics.
EmpMarg: theempirical marginaldistribution of thetraining data.
Train: the trainsequences.
(∗): The modelsare sampledconditional on thetopic allocations
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 20 / 21
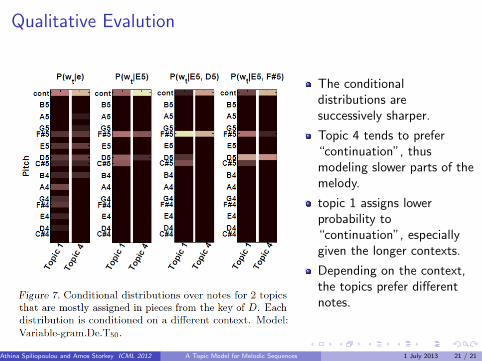
Qualitative Evalution
The conditionaldistributions aresuccessively sharper.
Topic 4 tends to prefer“continuation”, thusmodeling slower parts of themelody.
topic 1 assigns lowerprobability to“continuation”, especiallygiven the longer contexts.
Depending on the context,the topics prefer differentnotes.
Athina Spiliopoulou and Amos Storkey ICML 2012 Presented by Xin Yuan ()A Topic Model for Melodic Sequences 1 July 2013 21 / 21





























