Embed Size (px)
Citation preview

A Scalable Semantic Indexing Framework for Peer-to-Peer
Information Retrieval
University of Illinoisat Urbana-Champain
Zhichen XuYan Chen
Northwestern University
ACM SIGIR HDIR 2005
Chengxiang Zhai
Yahoo! Inc.

Motivation
• Rapid information growth requires scalable and robust retrieval architecture
• Problems with centralized retrieval architecture– Hard to maintain freshness of information
– Single-point-of-failure
• Peer-to-Peer IR may be a possible solution – No need for centralized indexing
– Easy to maintain freshness of information
– Resistant to single-point-of-failure
• Challenge: P2P IR architecture?

Term Index vs. Document Index
• Term index– Fast query execution
– Insufficient for supporting sophisticated algorithms such as feedback
– Hard to update (e.g., adding a doc) in a distributed environment
• Document index– Easy to update
– Support advanced retrieval algorithms
– Slow query matching

What is the Right Indexing Architecture for P2P IR?

Previous Work: pSearch [Tang et al. 03]
• Based on document indexing• Address the problem of “slow query
execution” by– Dimension reduction (using LSI)– Exploiting distributed hash tables (DHT)
• Problems– Lack of semantic locality (semantically similar
documents may be stored in quite different nodes)
– Slow index generation– Hard to add a new concept

Proposed Solution: P2PIR, Scalable Semantic Indexing Framework for
IR• Semantic locality
– Achieved through a novel two-phase distributed semantic indexing
– Documents with similar semantics will have indices stored on nearby nodes
• Flexible tradeoff between search accuracy and efficiency
• Support of sophisticated retrieval methods– E.g., feedback and personalized search
• Adaptation to document dynamics– Incrementally incorporate new
documents/concepts

Background on Sample DHTContent-Addressable Network
A B
C D E
• Two key operations• Put (key, object)• Object = get (key)
• Partition Cartesian space into zones
• Each zone is assigned to a computer
• Neighboring zones are routing neighbors
• Object lookup is done through routing

Routing and Location Properties on DHT
• Log(N) hops need to route a key where N is the number of nodes in the overlay
• Log(N) maintenance overhead for routing• Guaranteed success• Fault-tolerant and robust• DoS attack resilient
Becoming increasingly practical for serious use
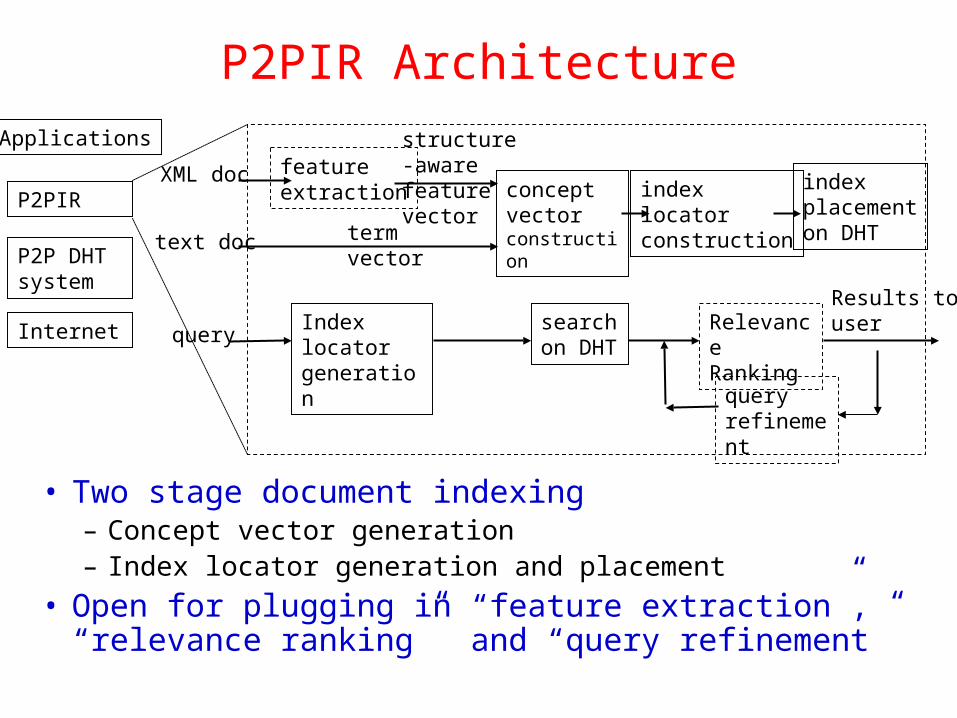
P2PIR Architecture
• Two stage document indexing– Concept vector generation– Index locator generation and placement
• Open for plugging in “feature extraction”, “relevance ranking” and “query refinement”
XML doc
text doc
featureextraction
structure-awarefeaturevector
termvector
conceptvector construction
indexlocator construction
indexplacementon DHT
queryIndex locator generation
searchon DHT
RelevanceRanking
Applications
P2PIR
P2P DHT system
Internet
Results touser
queryrefinement

Assumptions about the Retrieval Models
• Documents and queries are both represented as vectors – Naturally occurring in the vector-space model– Probabilistic models can be computed as
vector matching as well
• Euclidean distances are reasonably accurate in capturing document topic similarity– Euclidean distances are only used to prune
non-promising documents– Final relevance ranking can be based on more
accurate retrieval functions

Concept Vector Construction
• Group document into k clusters based on the feature vectors
• The centroid of each cluster corresponds to a concept
• Given a document d, the similarity between its feature vector and a concept c (e.g., cosine value between them) defines the weight of d on concept c
• The concept vector of d is composed of its weights on all the concepts

Two-Stage Semantic Indexing
• Stage 1: Fast dimension reduction– Document clustering to identify n*d clusters (d=
DHT dimension)– Represent each document with a vector on this
n*d dimensional space
• Stage 2: Semantic index locator construction– Further partition the n*d clusters into n equal-size
semantically coherent groups, each with size d – Each group forms an index locator (key for
searching DHT)

Fast Dimension Reduction• Regular k-means clustering
– Randomly start with k centroids– Iteratively re-assign documents to each cluster
and re-compute the centroids– Can stop at anytime to obtain rough clusters
• Modification– Start with k relatively different centroids
• Complexity at each iteration: O(kN), where N >>k is the number of documents
• Can be run on a sample of documents• Vector(D)= (sim(D,C1), …, sim(D,Ck))

Index Locator Construction
• Motivation: the dimensionality of concept vectors (e.g., a few hundreds) may be much larger than that of DHT, so hard to place index directly with concept vector
• Basic idea: break the concept vector into multiple chunks with the same dimensionality as that of DHT, and each chunk contains related concepts
• With such division, each document only has a small number of chunks with non-negligible weights for indexing
• Such chunks are called index locators

Index Placement on DHT
• For each index locator of a document d• If its norm (i.e., length of the vector) is
over certain threshold, we put the index locator of d along with its feature vector on the peer node whose DHT address vector matches best with the index locator.
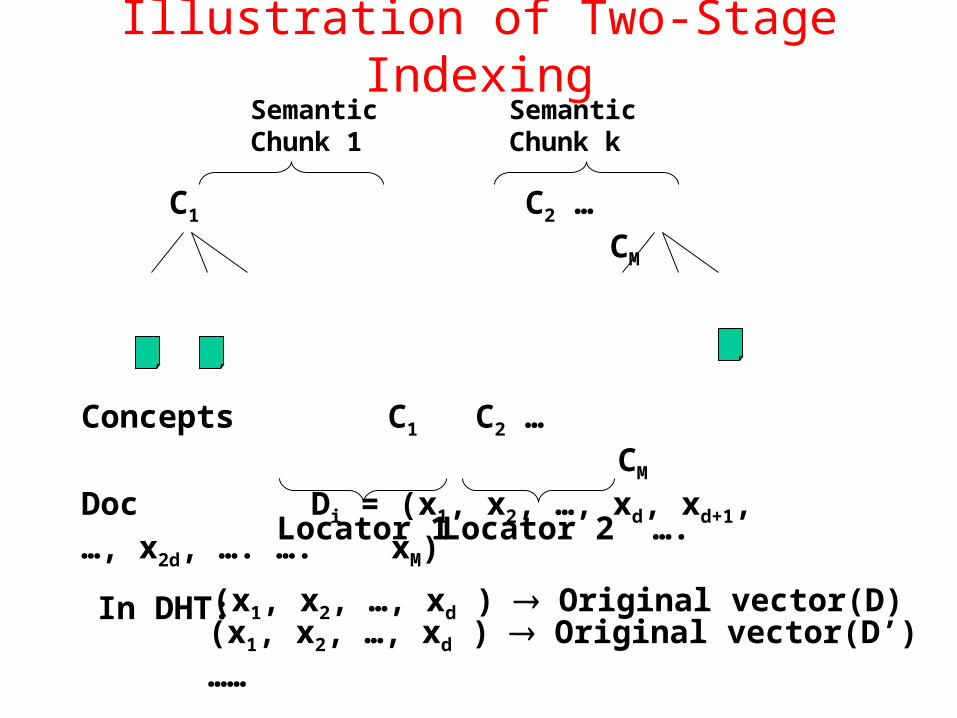
Illustration of Two-Stage Indexing
D1 D2 … DN
C1 C2 … CM
SemanticChunk 1
Semantic Chunk k
Concepts C1 C2 … CM
Doc Di = (x1, x2, …, xd, xd+1, …, x2d, …. …. xM)
Locator 1 Locator 2 ….
(x1, x2, …, xd ) Original vector(D)(x1, x2, …, xd ) Original vector(D’)……
In DHT:

Querying
• Contact any node on the DHT• Project the query vector to find related
concepts, and form the index locators• Use index locators to route to DHT nodes
with the indices and feature vectors of related documents
• Use original query vector and document vectors to perform relevance ranking
• This local retrieval process can expand to neighboring DHT nodes until enough relevant results have been identified

Adaptation to Corpus Dynamics
• Basic idea: Incrementally add new documents/concepts without affecting existing indices, and periodically (very infrequently) rebuild index locators for all documents
• When a set of new documents emerge, we check1. whether they contain new frequently-used terms
or new heavy weighted terms2. whether their concept vectors belong to any
existing cluster in the existing semantic space

Adaptation to Corpus Dynamics (II)
• To add and index a new concept c– If c belongs to an existing concept chunk whose
size is less than that of the underlying DHT, we can add c to that cluster by using the next available entry of the index locator.
– Otherwise, we generate a new concept group and a new set of index locators to represent c
• Generate the index locators for the new documents, and deploy their indices on DHT
• Finally, multicast the addition of the new concept c, and the addition of new concept group to all DHT nodes, so that they can route queries about c

Example for Corpus Dynamics
• When new documents on “Bin Larden” appear, we detect it as a new concept relating to the concept group “terrorism”.
• If the dimensionality of DHT is 20, and the size of “terrorism” concept group is 17– Just add “Bin Larden” to that group as dimension
18 of the index locator. – The corresponding index locators of existing
documents have weight zero as default on dimension 18, and thus remain the same.
• Otherwise, the terrorism concept group already full, we generate a new concept group for “Bin Larden” (i.e., a new set of index locators).

Summary
• Propose a scalable semantic indexing framework for peer-to-peer information retrieval: P2PIR– Index placement with good semantic locality,
leading to good retrieval accuracy and efficiency
– Tunable framework and flexibility– Incremental adaptation to document/concept
dynamics
• Prototype and evaluation of P2PIR in progress





























