Embed Size (px)
Citation preview

A Peer-to-Peer File SystemA Peer-to-Peer File System
OSCAR LAB

OverviewOverview
A short introduction to peer-to-peer (P2P) Systems
Ivy: a read/write P2P file system (OSDI’02)

What is P2P ?What is P2P ?
An architecture of equals (as opposed to client/server), each peer/node acts as– Client– Server– Router
Harness aggregate resources (e.g., CPUs, memory, disk capacities) among peers/nodes

What is P2P ?What is P2P ?
Technical trends
Creation of huge pool of available latent resources
Increasing processing power of PCs Decreasing cost and increasing capacity of disk space Widespread penetration of broadband

P2P SystemsP2P Systems
Centralized: have a centralized directory service – E.g., Napster– Limits scalability and poses a single point of failure
Decentralized and Untructured– No precise control over the network topology or data
placement– E.g., Gnutella– Controlled message flooding, limiting scalability

P2P SystemsP2P Systems
Decentralized and Structured– Tightly control the network topology and dat
a placement– Loosely structured: Freenet (the file placeme
nt is based on hints) – Highly structured: Pastry, Chord, Tapestry, a
nd CAN

Decentalized and Highly Structured P2Decentalized and Highly Structured P2P SystemsP Systems
Precise control of the network topology and data placement
A distributed hash table (DHash)– Each node has a host-ID (hash of the public key or IP a
ddr.)– Each file/object has a file-ID (hash of the file pathnam
e)– Both files and nodes are mapped into the Dhash– Basic interface
put(key, value) get(key)

Decentalized and Highly Structured P2Decentalized and Highly Structured P2P SystemsP Systems
A location and routing infrastructure– Application-level, routed by an ID not IP address– Routing effciency: O(logN)
Advantages– Good scalability (O(logN) in routing effciency and routing table)– Reliability– Self-maintenance (node addition/removal)– Good performance (compared to other P2P systems)
Issues– Routing performance (compared to IP routing)– Security– Other issues ……

P2P ApplicationsP2P Applications
Content delivery systems Application-level multicast Publishing/file sharing systems P2P storage systems (e.g., PAST, CFS, OceanSto
re) P2P file systems

Ivy: A Read/Write P2P File SystemIvy: A Read/Write P2P File System
Introduction Design Issues Performance Evaluation Summary

IntrodcutionIntrodcution
Challenges:– Previous P2P systems are either read-only or one sing
le writer, so multiple writers pose file system consistency issue
– Unreliable participants render locking unattractive (for consistency)
– Undo/ignore untrusty participants’ modifications– Security over untrusted storage of nodes– Resolve update conflicts due to network partition– High availability vs. strong consistency

Design IssuesDesign Issues
DHash infrastructure Log-based metadata and data NFS-like file system

DHashDHash
A distributed P2P hash table Stores participant’s logs Basic operations
– put(key, value)– get(key)– E.g., key = content-hash of a log, value = log record

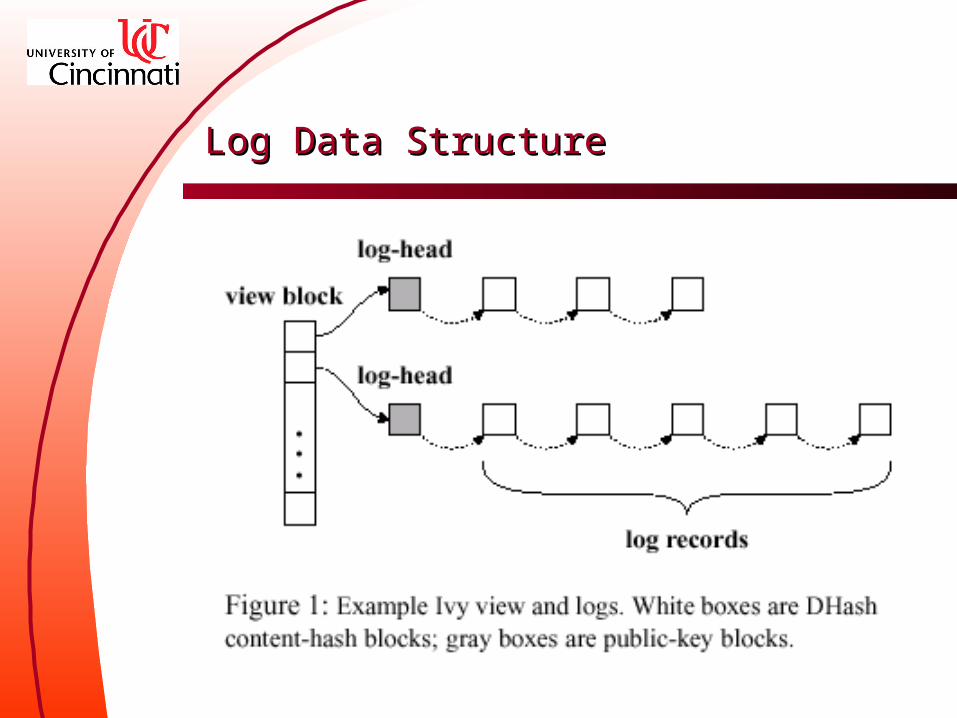
Log Data StructureLog Data Structure
One log per participant– A log contains all of one participant’s modif
ications (log records) to a file system data and metadata
– Each log record is a content-hash block– Each participant appends log records only to
its own log, but reads from all participants’ logs
Ignore some untrusty participant’s modifications by without reading its log

Log Data StructureLog Data Structure
Log Data StructureLog Data Structure
Log Data StructureLog Data Structure

Using the LogUsing the Log
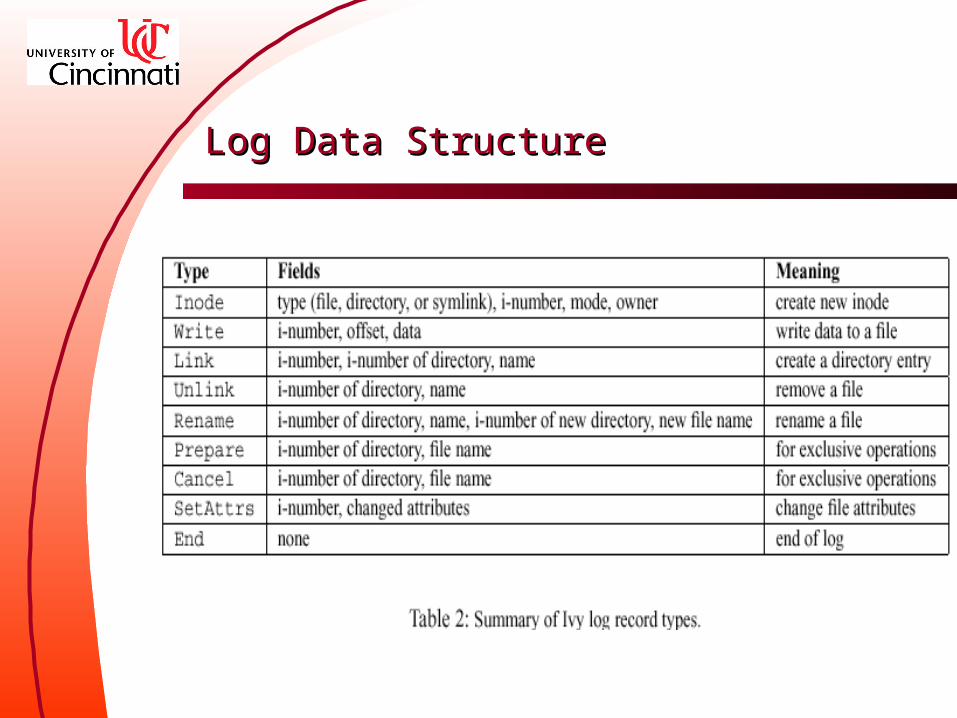
Append a log record– Derive a log record from a NFS request– Its prev field points to the last record– Insert the new log record into DHash– Sign a new log-head pointing to the new log
record– Insert the new log-head into DHash

Using the LogUsing the Log
File system creation– Create a new log with an End record– An Inode record with random i-number for th
e root directory– A log-head– Using the root i-number as the NFS root file h
andle

Using the LogUsing the Log
File creation– Request: create (directory i-number, file name)– An Inode record with a new random i-number– A Link record– Return the NFS client with the i-number as a file handle– If write the file, create a Write record
File read– Request: read (i-number, offset, length)– Scan logs accumulating data from Write records overla
pping the range of data to be read, while ignoring data hiddened by SetAttr records that indicate file trucation.

Using the LogUsing the Log
File name lookup– Request: open (directory i-number, file name) – Scan logs for a corresponding Link record– First encounter a corresponding Unlink record, indica
ting that the file doesn’t exist File attributes
– File length, mtime, ctime, etc.– Scan logs to incrementally compute attributes

User Cooperation: ViewsUser Cooperation: Views
View: the set of logs comprising a file system View block
– A DHash content-hash block containing pointers to all log-heads in the view
– Contains the root directory i-number– One Property: immutable (different file systems with
different view blocks ) Name a file system with the content-hash key of
its view block, like self-certifying file system (SFS)

Combining LogsCombining Logs
Problem: – concurrent updates result in conflicts, how to order lo
g records ? Solution: Version Vector in each log record
– Detect update conflicts– E.g., (A:5, B:7) < (A:6, B:7) compatible– (A:5, B:7) vs. (A:6, B:6) concurrent version vectors, or
der them by comparing the public keys of two logs

SnapshotsSnapshots
Problem ?– have to traverse the entire log to answer requests (hi
gh overhead and inefficiency).
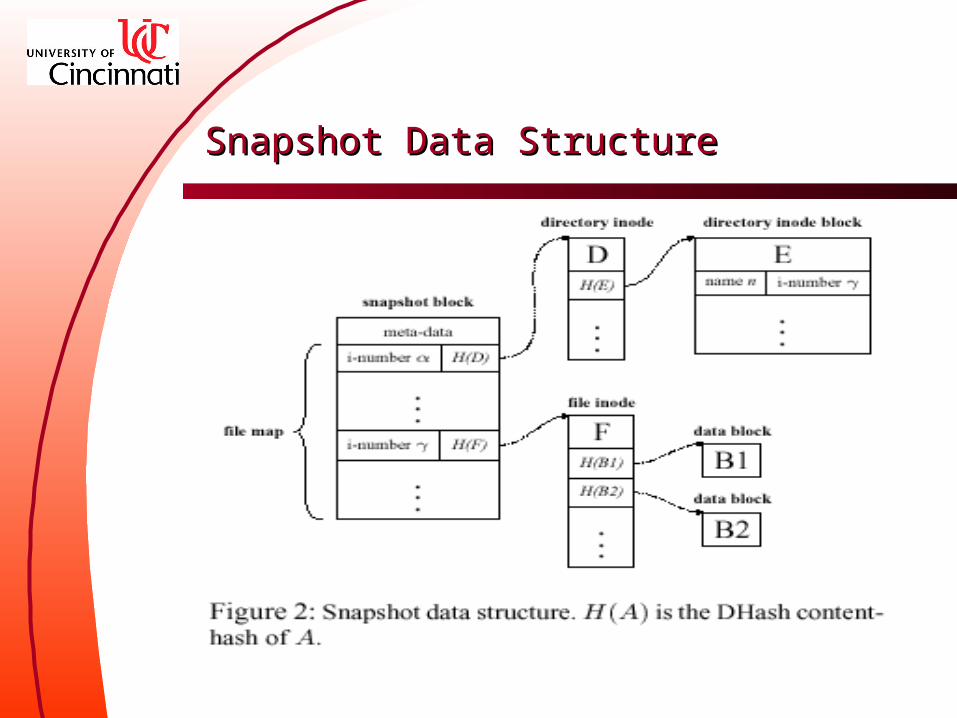
Solution: snapshots – Avoid traversing the entire log– Consistent state of the file system– Private per participant, periodically construct it– Stored in DHash, sharing contents among snapshots – Contains a file map, a set of i-nodes, and some data block
s, see Figure 2
Snapshot Data StructureSnapshot Data Structure

SnapshotsSnapshots
Building snapshots– perform all log records newer than the previous snaps
hot Using snapshots
– First traverse log records newer than current snapshot
– If this can’t fulfill a NFS request, further search information in current snapshot
– Mutually-trusted participants can share snapshots

Cache ConsistencyCache Consistency
Most updates are immediately visible– Store the new log record and update the new log-head befo
re replying to an NFS request– Query the latest log-heads for latest updates upon each NFS
operation Modified close-to-open consistency for file reads/writes
– Open() fectch all log-heads for subsequent reads/writes– Write() write data on its cache, defers writing data to DHa
sh– Close() push log records (if any by writes), update log-hea
d

Exclusive CreateExclusive Create
Requirement: create directory entries be exclusive– Some applications use this semantics to implement l
ocks Solution:

Partitioned UpdatesPartitioned Updates
Close-to-open consistency guaranteed only if network is fully connected
How if network partitioned?– Maximize availability (by allowing concurrent update
s)– Compromise consistency – After partition heals, using Version Vectors – Application-level solver to resolve conflicts (Harp)

Security and IntegritySecurity and Integrity
Form another view to exlcude bad/misbehavoring/malicious participants
Using content-hash key and public-hash key to protect data integrity

EvaluationEvaluation
Goal: understand the cost of Ivy’s design in terms of network latency and cryptographic operations
Workload: Modified Andrew Benchmark (MAB) Performance in a WAN

Many Logs, One WriterMany Logs, One Writer
The number of logs has relatively little impact– Because Ivy fetches the log-heads/log-records in parallel
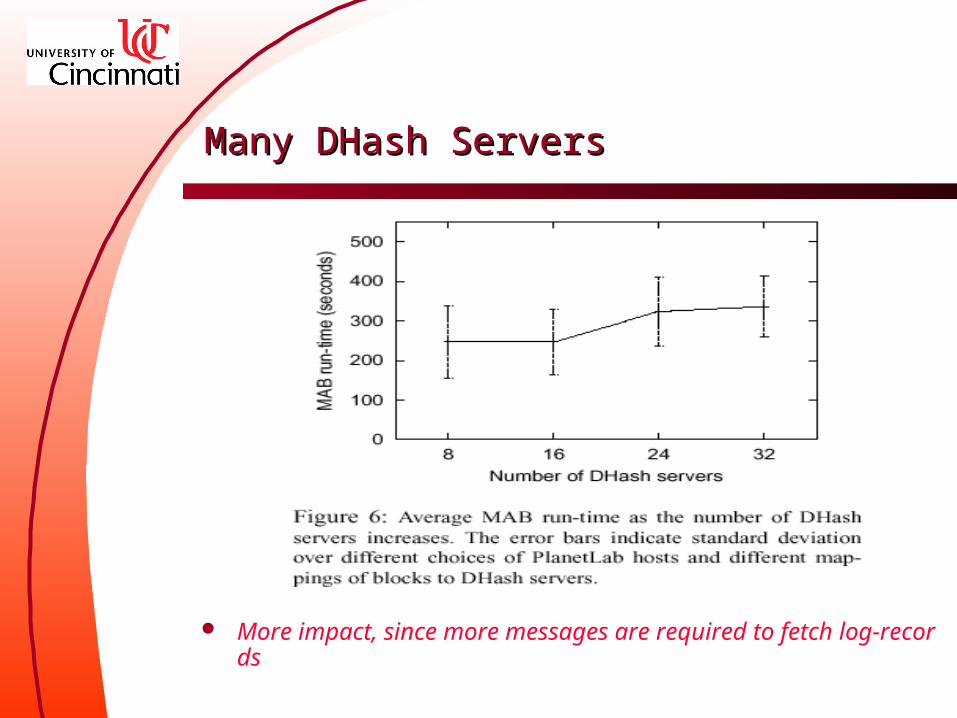
Many DHash Servers Many DHash Servers
More impact, since more messages are required to fetch log-records
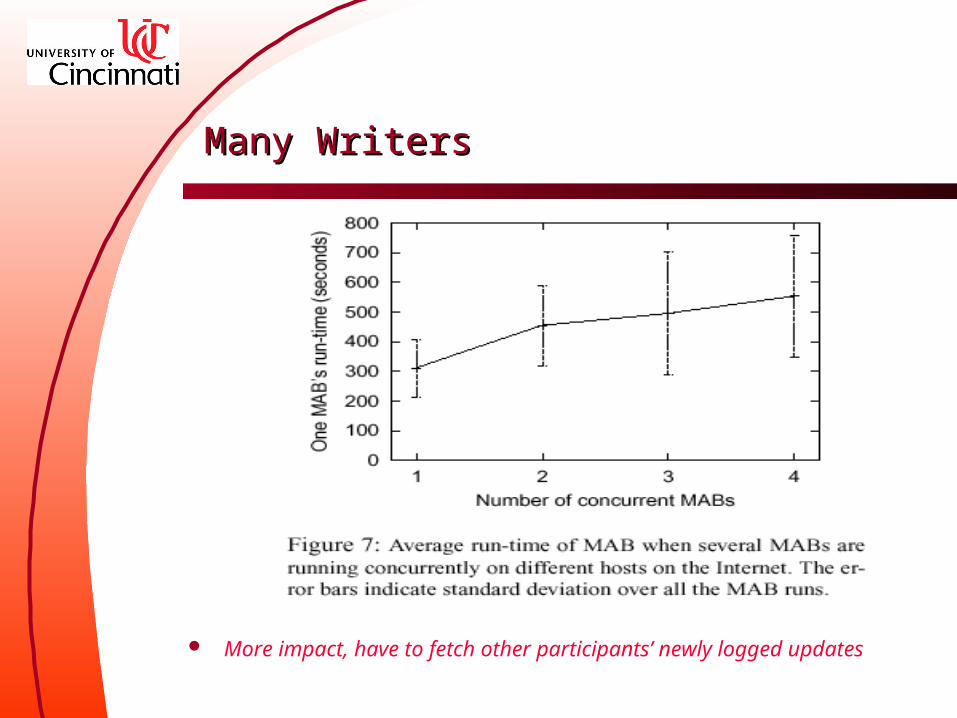
Many WritersMany Writers
More impact, have to fetch other participants’ newly logged updates

SummarySummary
Log-based data/metadata, avoiding using locking
Close-to-open consistency Tradeoff between high availabilty and strong co
nsistency Allow concurrent updates, detect and reslove u
pdate conflicts Performance: 2-3 times slower than NFS Limitations ?
– Small scale: limited to the number of logs– Hard to hide wide-area network latency

ThanksThanks





























