Embed Size (px)
Citation preview

A Low-Cost Memory A Low-Cost Memory Remapping Scheme for Remapping Scheme for Address Bus ProtectionAddress Bus Protection
Lan Gao*, Jun Yang§, Marek Chrobak*, Youtao Zhang§, San Nguyen*, Hsien-Hsin S. Lee¶
*University of California, Riverside§University of Pittsburgh
¶Georgia Institute of Technology
2
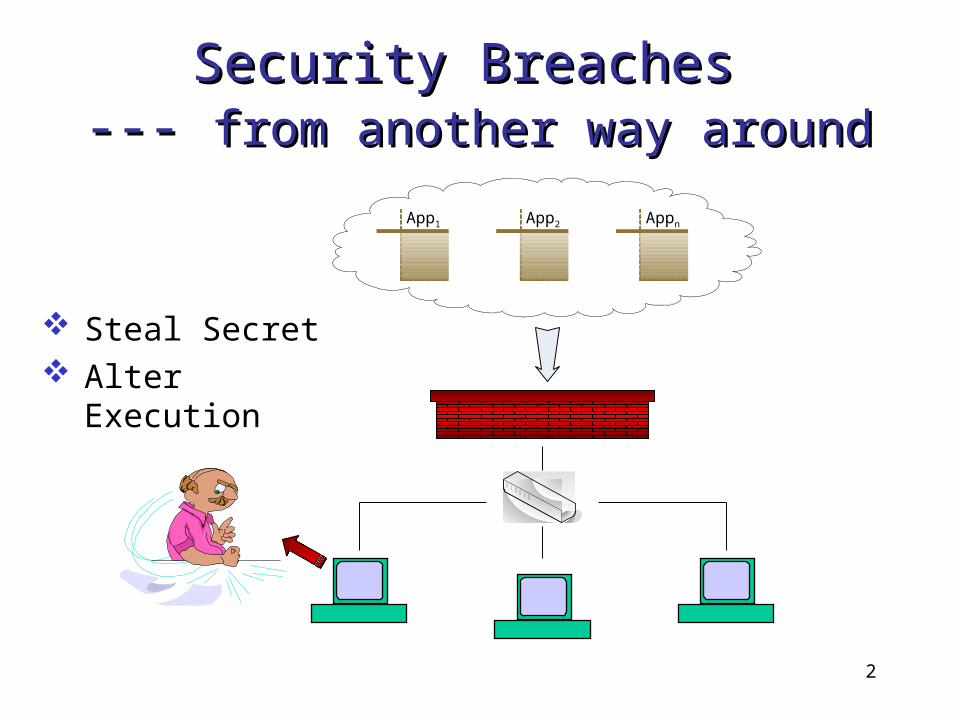
Security Breaches Security Breaches --- --- from another way aroundfrom another way around
App1 App2 Appn
Steal Secret Alter Execution

3
OutlineOutline
Background & Motivation Secure Processor Model Address Information Leakage
Previous Address Bus Protection Solutions The HIDE Scheme The Shuffle Scheme
Our Low-Cost Address Permutation Scheme Performance Evaluation Conclusion
4
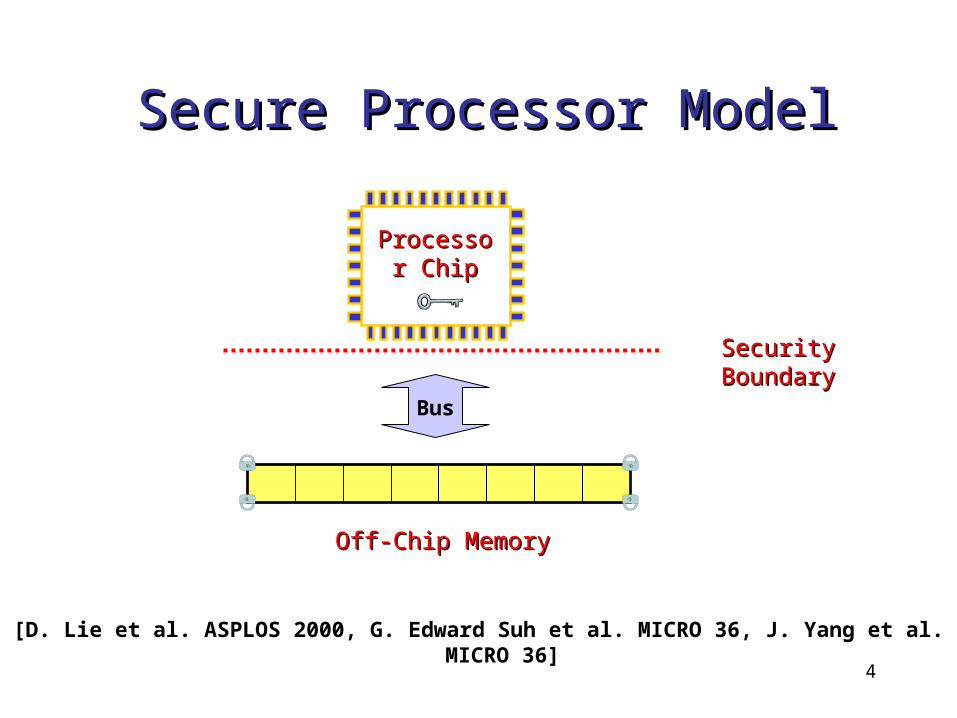
Secure Processor ModelSecure Processor Model
Bus
Off-Chip MemoryOff-Chip Memory
Processor Processor ChipChip
Security BoundarySecurity Boundary
[D. Lie et al. ASPLOS 2000, G. Edward Suh et al. MICRO 36, J. Yang et al. MICRO 36]
5
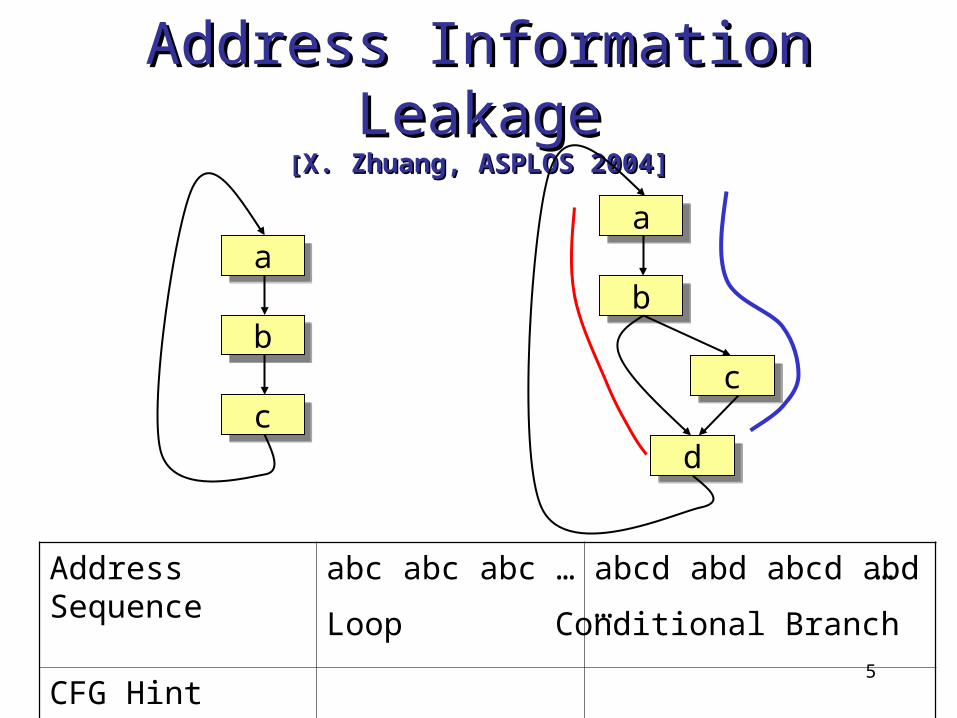
Address Information Address Information LeakageLeakage
[[X. Zhuang, ASPLOS 2004]X. Zhuang, ASPLOS 2004]
Address Sequence
abc abc abc … abcd abd abcd abd …
CFG Hint
aa
bb
cc
dd
Conditional Branch
…
aa
bb
cc
Loop

6
Oblivious Memory AccessOblivious Memory Access
The idea: [Oded Goldreich et al.]
Replace each memory access by a sequence of redundant accesses
Satisfactory from a theoretical perspective
Overhead:
“naive”
“square root”
“hierarchical”
Memory
Runtime
mm 2
mt
tt 2log
tt 3logmt
m

7
The HIDE CacheThe HIDE Cache
The Idea: break the correlation between repeated addresses [Xiaotong Zhuang et al. ASPLOS 2004]
Permute the address space at suitable intervals Permute blocks within a “chunk”
How: Lock and Permute Lock a block in the cache
• A new read from memory• A dirty block since last permutation
Permute a chunk when replacing a locked block
8
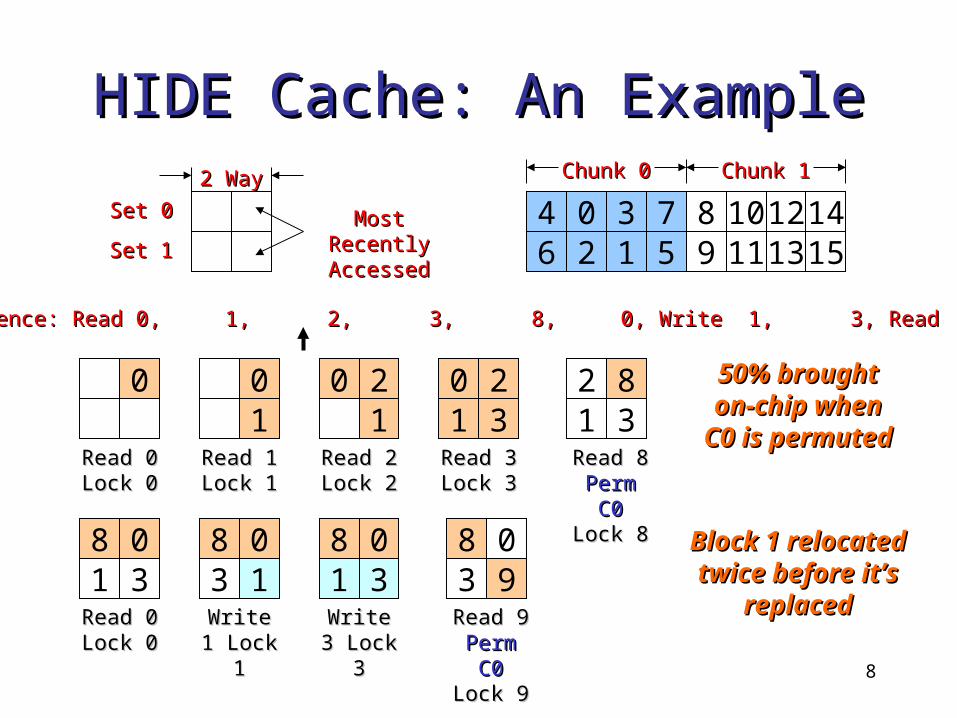
HIDE Cache: An ExampleHIDE Cache: An Example
0 21 3
4 65 7
8 109 11
12141315
Chunk 0Chunk 0 Chunk 1Chunk 1
Most Recently Most Recently AccessedAccessed
2 Way2 Way
Set 0Set 0
Set 1Set 1
0
Read 0 Read 0 Lock 0Lock 0
01
Read 1 Read 1 Lock 1Lock 1
0 21
Read 2 Read 2 Lock 2Lock 2
0 21 3Read 3 Read 3 Lock 3Lock 3
2 81 3Read 8 Read 8
Perm C0Perm C0 Lock 8Lock 8
8 01 3Read 0 Read 0 Lock 0Lock 0
8 03 1Write 1 Write 1 Lock 1Lock 1
8 01 3Write 3 Write 3 Lock 3Lock 3
8 03 9Read 9 Read 9
Perm C0Perm C0 Lock 9Lock 9
50% brought 50% brought on-chip when on-chip when
C0 is permutedC0 is permuted
Block 1 relocated Block 1 relocated twice before it’s twice before it’s
replacedreplaced
CPU Sequence: Read 0, 1, 2, 3, 8, 0, Write 1, 3, Read 9CPU Sequence: Read 0, 1, 2, 3, 8, 0, Write 1, 3, Read 9
6 74 5
1 03 2
4 06 2
3 71 5
9
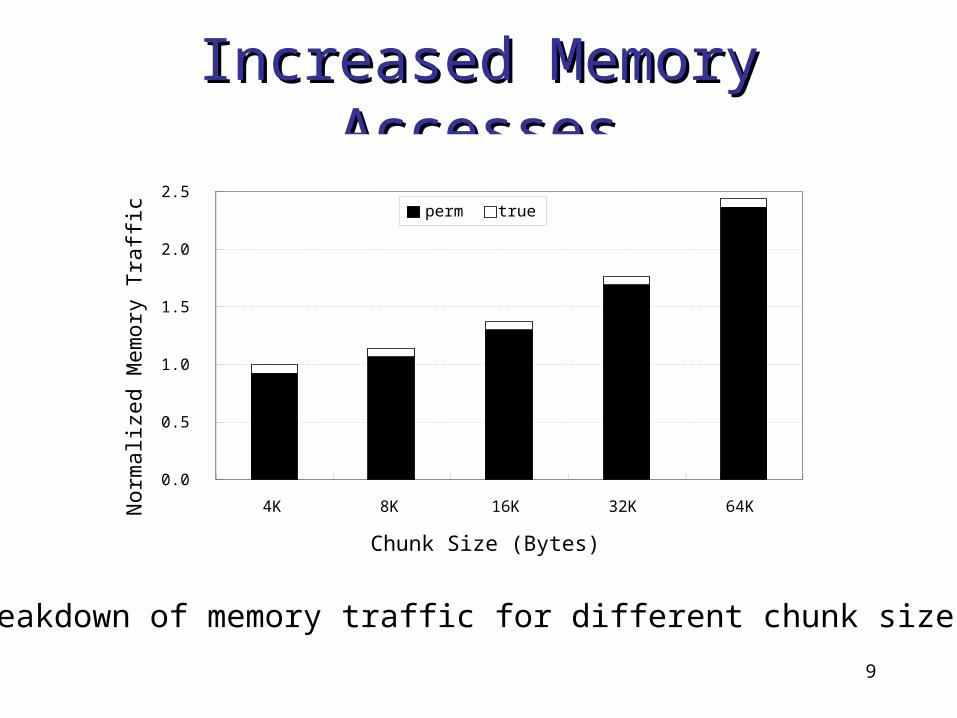
Increased Memory Increased Memory AccessesAccesses
0.0
0.5
1.0
1.5
2.0
2.5
4K 8K 16K 32K 64K
Chunk Size (Bytes)
Nor
mal
ized
Mem
ory
Tra
ffic
perm true
Breakdown of memory traffic for different chunk sizes
11
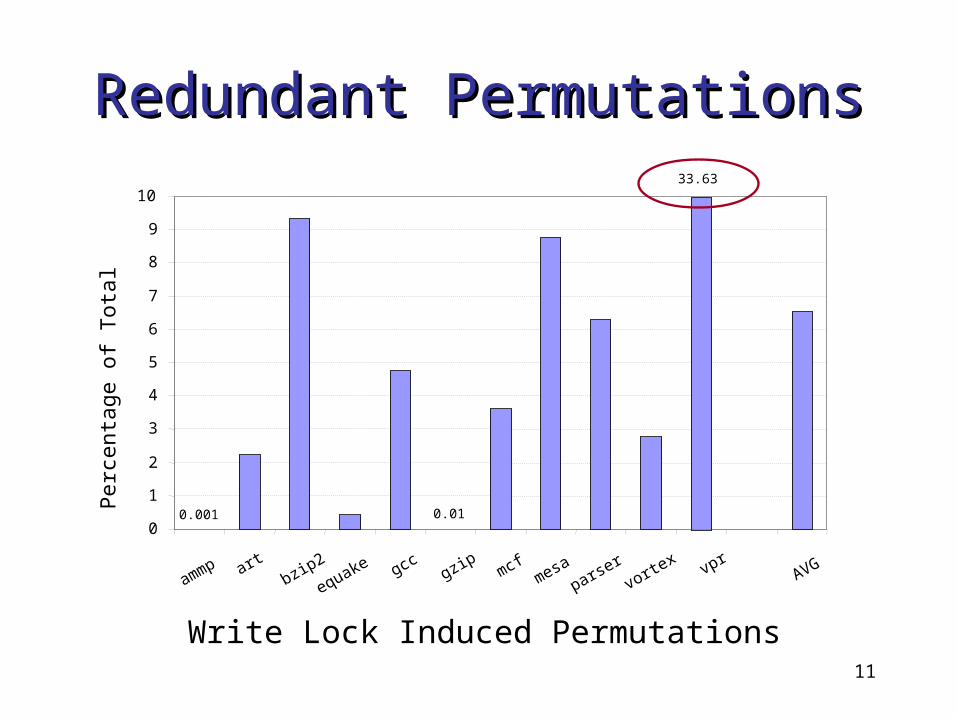
Redundant PermutationsRedundant Permutations
Write Lock Induced Permutations
33.63
0.010.0010
1
2
3
4
5
6
7
8
9
10
ammp artbzip2
equake gccgzip mcf
mesaparser
vortex vpr
AVG
Per
cent
age
of T
otal

12
The Shuffle BufferThe Shuffle Buffer The Idea: dynamic control flow
obfuscation [X. Zhuang et al., CASES 2004]
Relocate a block if they appeared on the bus once
How: Random Swap Any newly read block is inserted into a
shuffle buffer A buffered block is written back to the
address of the newly read block Only read/write access pairs are observed
on the address bus
13
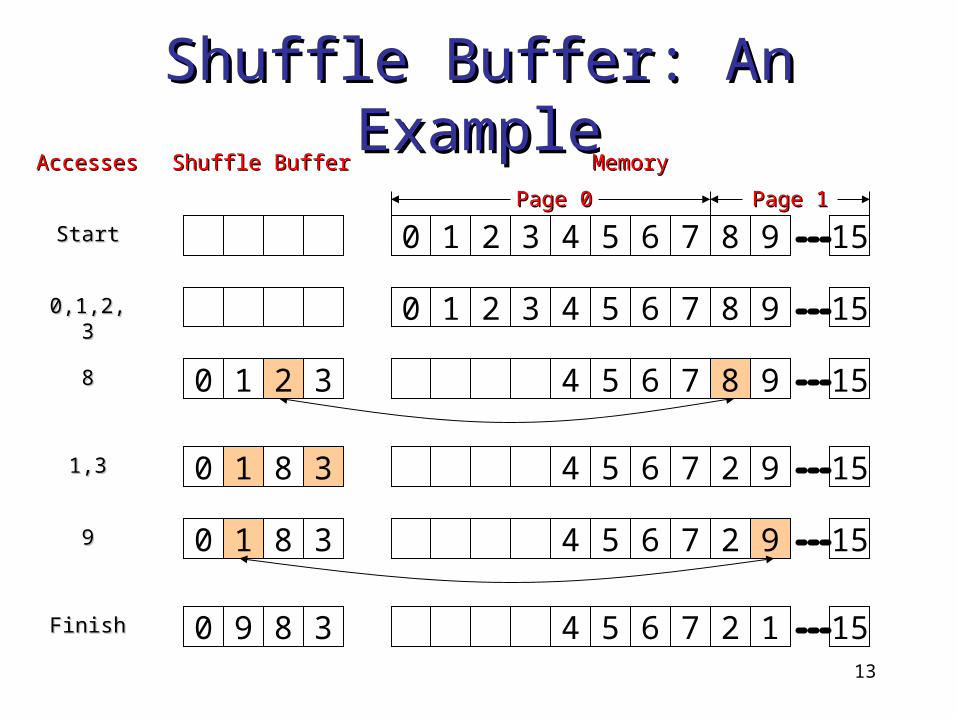
Shuffle Buffer: An ExampleShuffle Buffer: An Example
0 21 3 4 65 7 8 9 15Page 0Page 0 Page 1Page 1
Shuffle BufferShuffle BufferAccessesAccesses MemoryMemory
StartStart
4 65 7 2 9 151 80 31,31,3
91 4 65 7 2 1580 399
4 65 7 9 1510 388 82
4 65 7 2 1 15FinishFinish 0 89 3
4 65 7 8 9 150,1,2,30,1,2,3 1 20 3
14
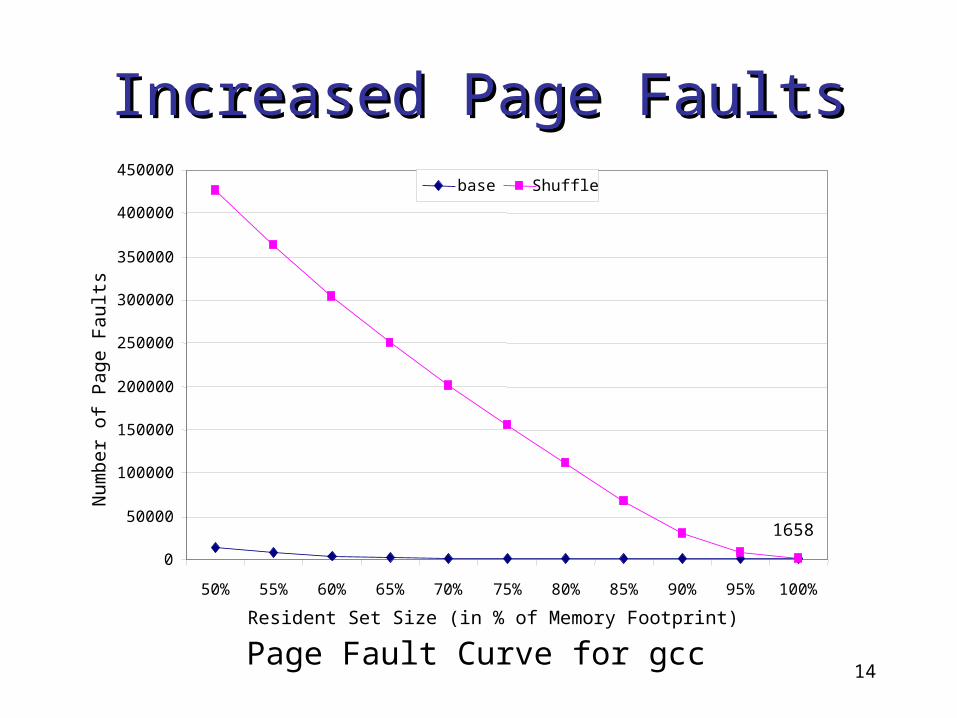
Increased Page FaultsIncreased Page Faults
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
50% 55% 60% 65% 70% 75% 80% 85% 90% 95% 100%
Resident Set Size (in % of Memory Footprint)
Num
ber
of
Pag
e F
aults
base Shuffle
Page Fault Curve for gcc
1658

15
OutlineOutline Background & Motivation
Secure Processor ModelAddress Information Leakage
Previous Address Bus Protection SolutionsThe HIDE SchemeThe Shuffle Scheme
Our Low-Cost Address Permutation Scheme
Performance Evaluation Conclusion

16
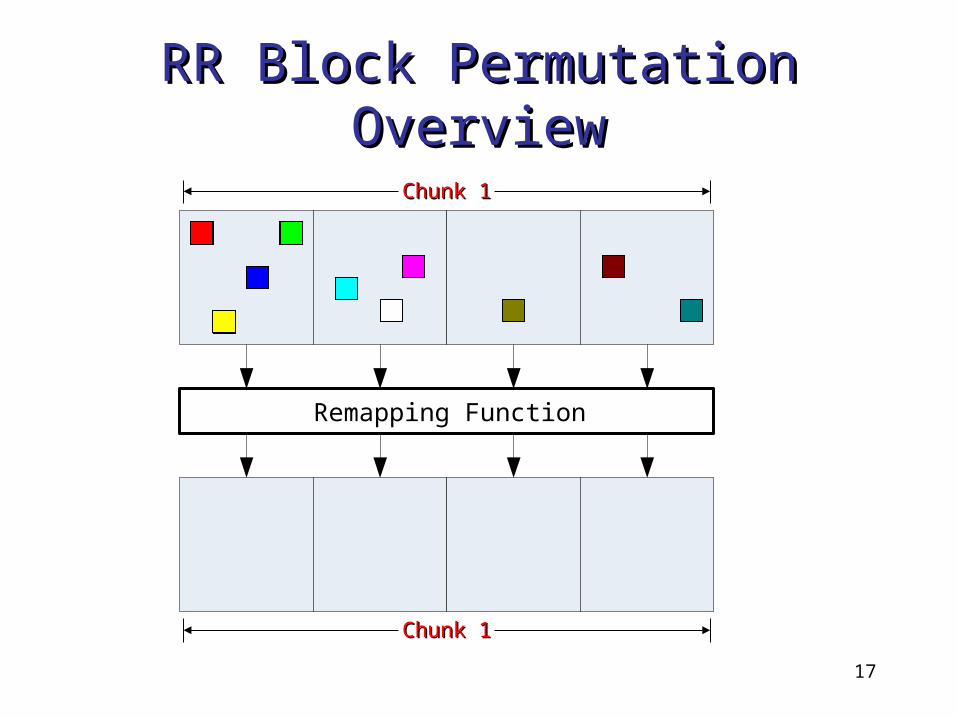
Our SchemeOur Scheme Goals:
Avoid wasteful memory traffic• Eliminate wasteful permutations• Avoid wasteful reads/writes in each
permutationPreserve locality and keep the page
fault rate low How: RR Block Permutation
Permute only on-chip blocks of the same chunk
Permute only when an RR (Recently Read) block is to be replaced
17
RR Block Permutation RR Block Permutation OverviewOverview
Remapping Function
Chunk 1Chunk 1
Chunk 1Chunk 1

18
RR Block Permutation: An RR Block Permutation: An ExampleExample
Events Initially
Cache
Mem
m[a1]=x
m[a2]=y
m[a3]=z
Only x is written back
Only y is written back
m[b1]=xm[b2]=ym[b3]=z
m[b1]=xm[b2]=ym[b3]=z
yz
x x
y
(1)
load x,y,z from memory
(2)
yz
x
read miss replace x
(3)
yz
permutation
(4)
yz
write hit
(5)
z
read miss replace y
(6)
19
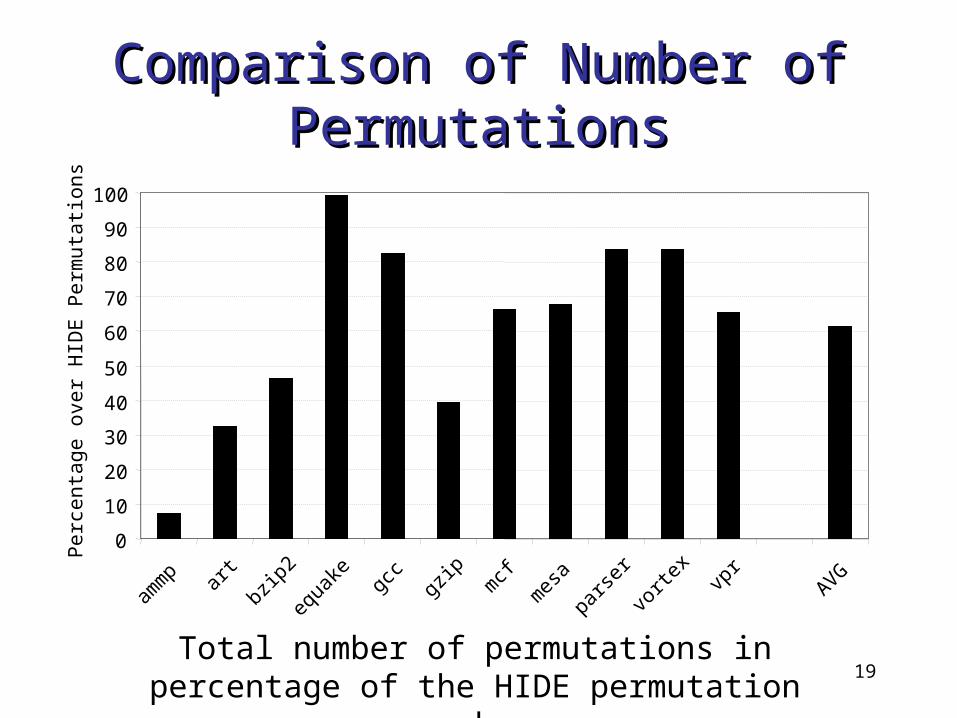
Comparison of Number of Comparison of Number of PermutationsPermutations
Total number of permutations in percentage of the HIDE permutation number
0
10
20
30
40
50
60
70
80
90
100
amm
p art
bzip2
equa
ke gcc
gzip
mcf
mes
a
pars
er
vorte
xvp
rAVG
Pe
rce
nta
ge
ove
r H
IDE
Pe
rmu
tatio
ns
20
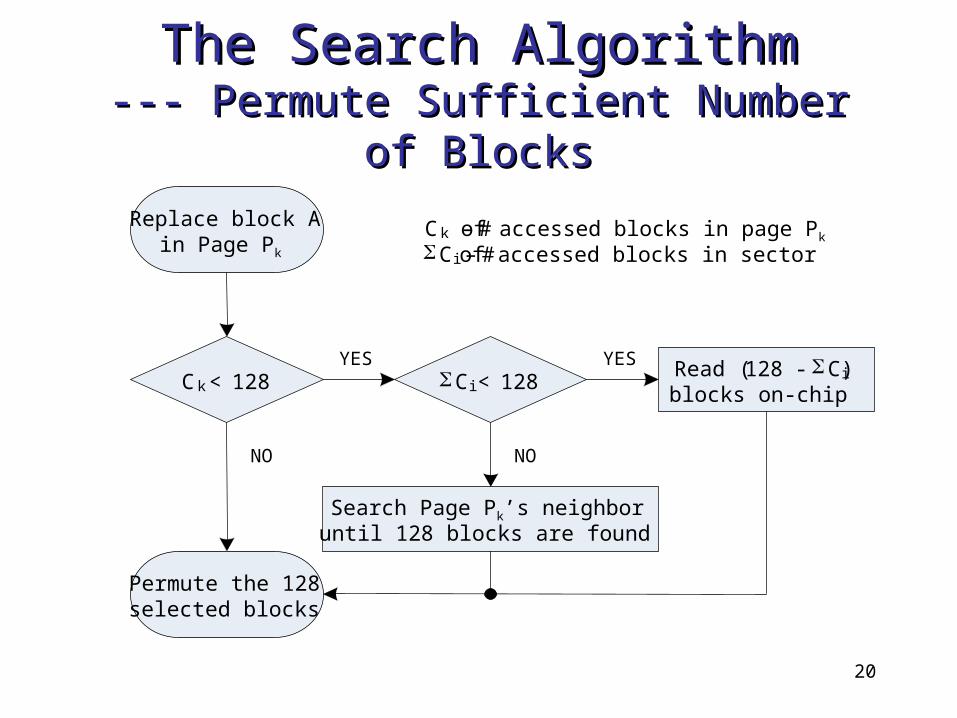
The Search AlgorithmThe Search Algorithm--- Permute Sufficient Number of --- Permute Sufficient Number of
BlocksBlocks
C k < 128 C i < 128Read (128 - C i)
blocks on-chip
Search Page Pk’s neighboruntil 128 blocks are found
YES YES
NONO
Replace block A in Page Pk
Permute the 128selected blocks
C k – # of accessed blocks in page Pk
C i – # of accessed blocks in sector
21
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Number of Pages
Perc
enta
ge o
f Tota
l
ammp art bzip2 eqake gcc gzip
mcf mesa parser vortex vpr
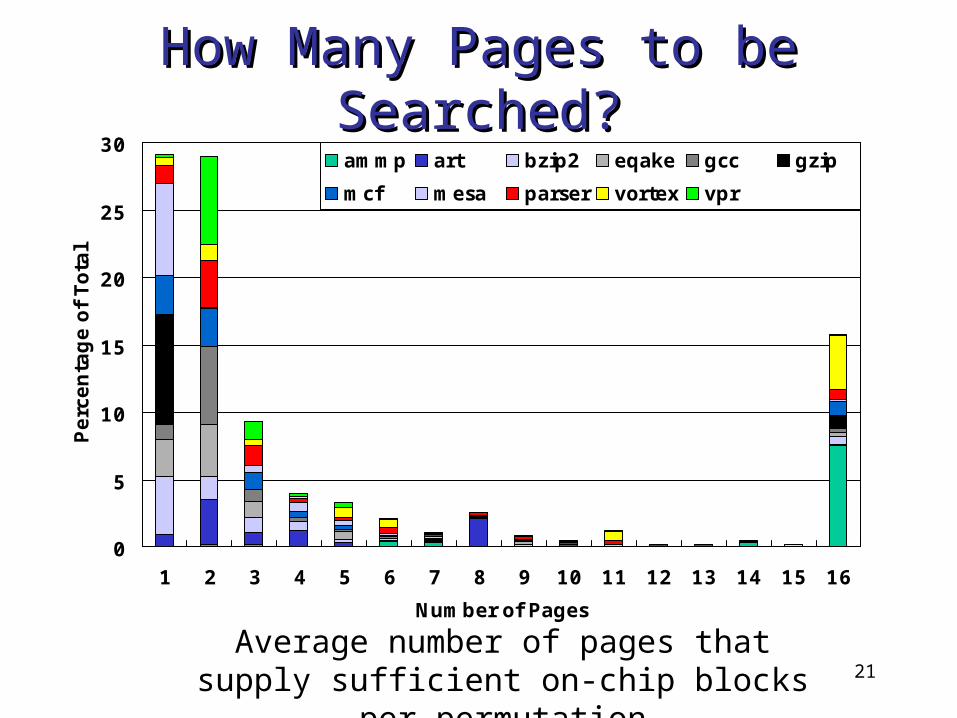
How Many Pages to be How Many Pages to be Searched?Searched?
Average number of pages that supply sufficient on-chip blocks per permutation

22
Security StrengthSecurity Strength
Between two permutations, all addresses on the bus are different
The easiest case: A block being mapped to the nth writeback ->
It becomes more difficult to make a correct guess with these uncertainties: No clear indication when a permutation
happens No fixed set of on-chip blocks that
participate in a permutation
128
1)
128
11( 1 n
23
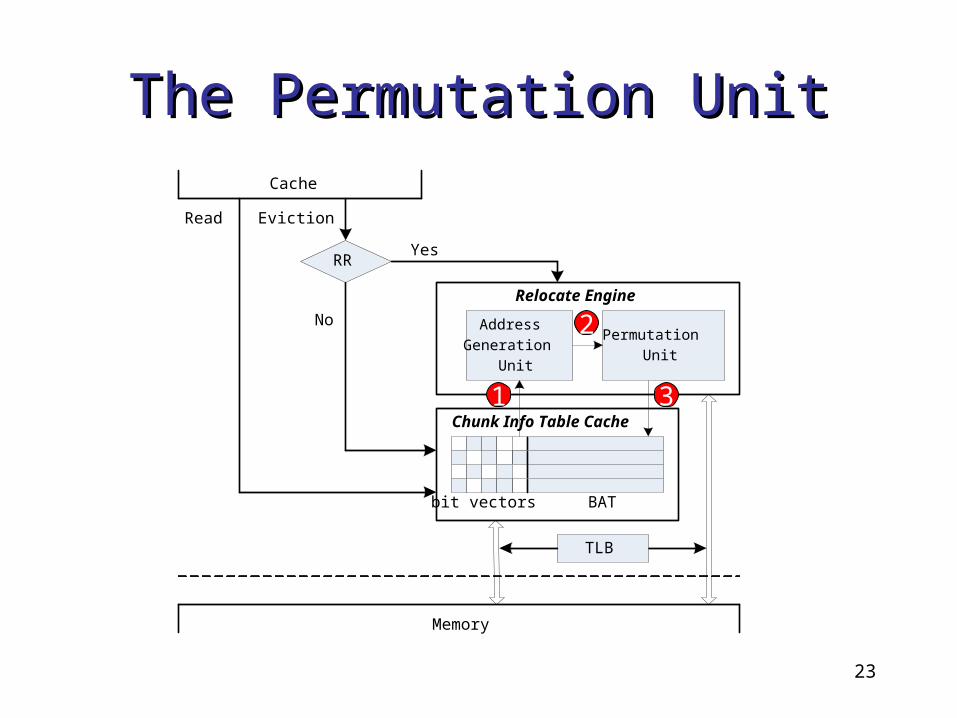
The Permutation UnitThe Permutation Unit
Address
Generation
Unit
Permutation
Unit
Relocate Engine
TLB
RRYes
No
Cache
Memory
bit vectors BAT
Chunk Info Table Cache
EvictionRead
1 3
2

24
OutlineOutline
Background & Motivation Secure Processor Model Address Information Leakage
Previous Address Bus Protection Solutions The HIDE Scheme The Shuffle Scheme
Our Low-Cost Address Permutation Scheme Performance Evaluation Conclusion

25
Experiment EnvironmentExperiment Environment Tools
Simplescalar Toolset 3.0SPEC2K benchmarks
ConfigurationCache
• Separate L1 I- and D-cache: 8K, 32B line• Integrated L2 Cache: 1M, 32B line• Chunk Size: 8K, 16K, 32K, 64K
Other Settings• Page Settings: 4KB, perfect LRU repl policy• Perfect auxiliary on-chip storage for all
schemes
26
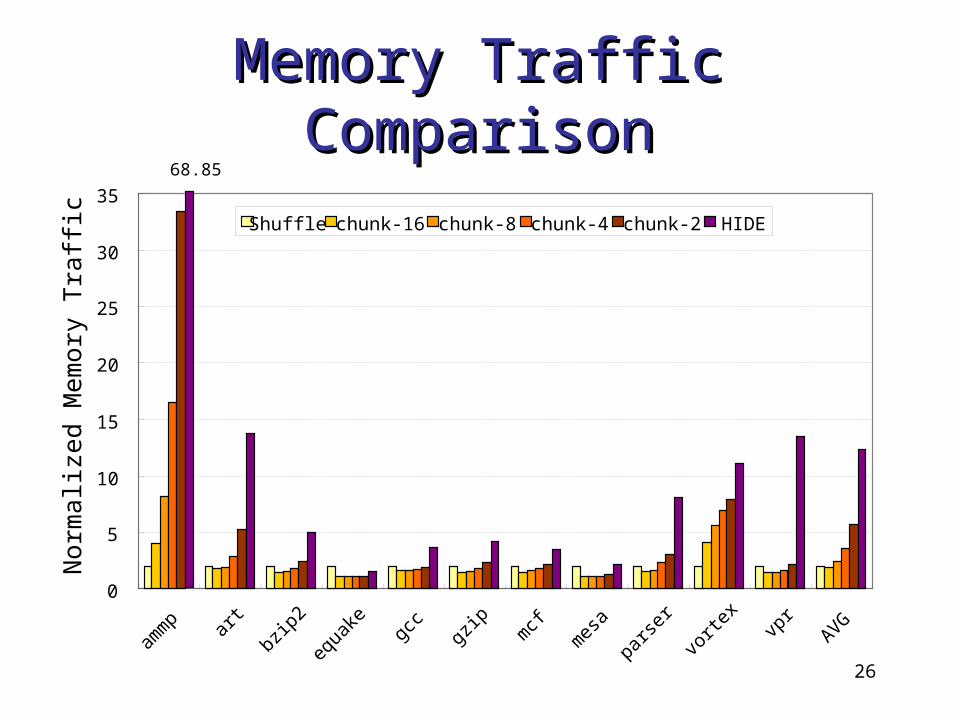
Memory Traffic Memory Traffic ComparisonComparison
0
5
10
15
20
25
30
35
amm
p art
bzip2
equa
ke gcc
gzip
mcf
mes
a
pars
er
vorte
xvp
rAVG
Nor
mal
ized
Mem
ory
Tra
ffic
Shuffle chunk-16 chunk-8 chunk-4 chunk-2 HIDE
68.85
27
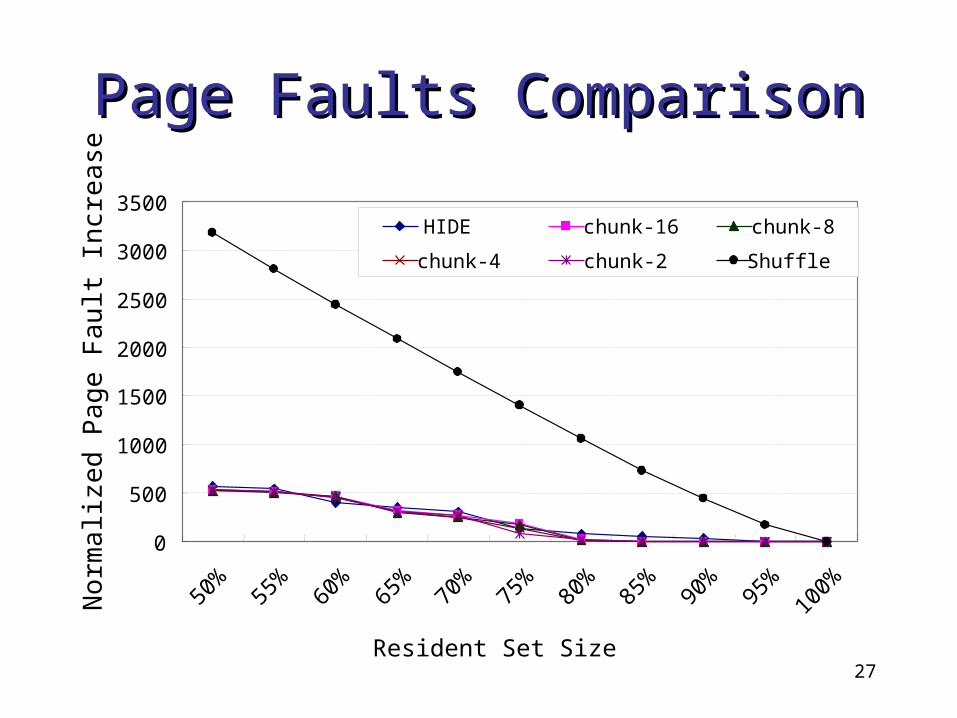
Page Faults ComparisonPage Faults Comparison
0
500
1000
1500
2000
2500
3000
3500
50%
55%
60%
65%
70%
75%
80%
85%
90%
95%
100%
Resident Set Size
No
rma
lize
d P
age
Fau
lt In
cre
ase
HIDE chunk-16 chunk-8
chunk-4 chunk-2 Shuffle

28
ConclusionConclusion Proposed an efficient address
permutation scheme to combat the information leakage on the address bus
Tackled two main problems of the previous schemes: The excessive memory traffic in the HIDE
scheme The increased page faults in the Shuffle
scheme Preliminary experiments:
Reduce the memory traffic in HIDE from 12X to 1.88X
Keep the page fault rate as low as the base settings

29
Questions Questions
??





























