Embed Size (px)
Citation preview

A Little Too Smart – The Loss of Location Privacy
in the Cellular Age
Stephen B. Wicker∗
School of Electrical and Computer EngineeringCornell University
Ithaca, NY [email protected]
December 10, 2011
Abstract
The revelation that Apple iPhones and Google Androids maintainrecords of GPS fixes highlights an effort to refine the ability of thecellular platform to track user location. Fine-grained location data en-hances location-based services, but also creates a substantial privacyproblem – location data at the level of individual addresses can re-veal a great deal about the beliefs, preferences, and behavior of thesubscriber. We note the potential implications for individual safety,then consider the harm that may occur through marketers’ use of suchdata through a brief exploration of the philosophy of place. The abil-ity of marketers to de-anonymize location traces is modeled using theShannon-theoretic concept of unicity distance. The results are used toidentify effective techniques for exploiting location-based services whilemaintaining anonymity.
∗This work was funded in part by the National Science Foundation TRUST Science andTechnology Center and the NSF Trustworthy Computing Program. The author gratefullyacknowledges the technical and editorial assistance of Sarah Wicker, Jeff Pool, NathanKarst, Bhaskar Krishnamachari, Kaveri Chaudhry, Surbhi Chaudhry, and the anonymousreviewers.
1

Our view of reality is conditioned by our position in space andtime – not by our personalities as we like to think. Thus everyinterpretation of reality is based upon a unique position. Twopaces east or west and the whole picture is changed.
Lawrence Durrell, Balthazaar [10]
... to be human is to be ‘in place’.
Tim Cresswell,Place: A Short Introduction, 2004 [7]
Apple does not track users locations – Apple has never done soand has no plans to ever do so.
Dr. Guy “Bud” Tribble, Apple Inc.Congressional Testimony, May 10, 2011 [27]
1 Introduction
On April 20, 2011 Alasdair Allan and Peter Warden created a media frenzywith the announcement of their discovery of an iPhone file – consolidated.db1
– that contained time-stamped user location data [4]. As public concernincreased, Google admitted that its own phones were doing roughly thesame thing. Many talking heads (including this author) expressed interestin the media as to why Apple and Google were collecting the data and whatthey were doing with it.
A FAQ published by Apple [3] and congressional testimony by Apple’sVice President for Software Technology [27] subsequently revealed that atleast some of the initial concerns had been groundless. Assuming that Ap-ple’s anonymity preservation techniques are adequate, Apple is not compil-ing location traces for individual users, but is instead enlisting those users asunpaid data collectors in an immense exercise in “crowd-sourcing.” Appleis creating a highly precise map of cell sites and access points in an effort to
1The file had already been identified in a 2010 text on iOS forensics written by SeanMorrissey [20], but at that time the media did not take notice.
2

improve the precision of its user location estimates and thus provide morerefined location-based services. But despite Apple’s rapid and thoroughresponse, a long-term collection of issues remain to be addressed.
In this paper we will briefly explore the evolution of location-based ser-vices (LBS), culminating in Apple and Google’s use of crowd-sourced datato create a system for obtaining location fixes that is potentially faster andmore accurate than the Global Positioning System (GPS). An intuitive senseof the potentially revelatory power of fine-grained location data is developedbefore moving on to the question of potential harm. The most obvious con-cern is the stalker – databases with detailed information about individualmovement will be a target for those who intend harm to objects of obsession.But there are also questions of manipulation and threats to autonomy to beconsidered. A brief review of the philosophy of place is provided, focusing onthe ability of Location-Based Advertising (LBA) to disrupt the individual’srelationship to his or her surroundings.
We then turn to the potential for anonymous LBS, with the aim ofsaving the benefit while avoiding the potential harm. We begin by posingthe following critical question:
How much location data must a marketer have before a correlation attackcan de-anonymize the data?
We address the question through the Shannon-theoretic concept of unic-ity distance, developing ground rules for the development of truly anony-mous LBS.
2 Cellular Telephony and the Technology of Place
Cellular telephony has always been a surveillance technology. As discussedby the author in a recent Communications article [29], cellular networkswere originally designed to track a phone’s location so that incoming callscould be routed to the most appropriate cell tower (usually the tower closestto the user). Tracking by the service provider is made possible throughthe periodic transmission of registration messages by the cell phone. Uponreceiving the message, the network notes the cell site through which theregistration message was received. The cell site ID is stored at a serviceprovider Home Location Register (HLR) in a record associated with thephone number of the user, and is thus tied to the user’s name and billing
3

account records2.Historical cell site data provides relatively coarse location information.
Cell sizes vary significantly, but the following can be used as a rough rule ofthumb4:
Urban: 1 mile radiusSuburban: 2 mile radiusRural: >4 mile radius
As most smartphone users are aware, a cell phone is capable of muchmore fine-grained location resolution. The first step toward acquiring thiscapability came with E911 - the FCC’s efforts to enhance location resolutionfor cellular 911 calls5. E911 established a requirement that cellular serviceproviders send location information to the Public Safety Answering Point(PSAP) when a subscriber makes a 911 call with his or her cell phone.The intuition underlying E911 was clear – it would be nice if emergencyservices were able to locate a victim without searching the entire coveragearea of a cell site. The technological and sociological impact, however, hasfar outstripped this intuition.
In the first phase of E911, it was sufficient that the service providerforward the location of the cell tower that was handling the subscriber’s 911call to the PSAP. In the second phase, the requirements were more strict,requiring that a majority of a service provider’s cell phones be capable oflocation estimates on the order of 50 to 100 meters6. The E911 requirement
2Cellular service providers maintain long-term, time-stamped records of the cell sitesvisited by their subscribers, even though such data is of little to no use for routing calls. Upuntil recently, this “historic cell site data” was often made available to law enforcementwithout requiring the latter to acquire a warrant [29]. But on September 7, 2010, theUnited States Court Of Appeals for the Third Circuit3 upheld a lower court’s opinionthat a cellular telephone was in fact a tracking device, and further ruled that it is withina magistrate judge’s discretion to require a showing of probable cause before granting arequest for historical cell site data. Should a magistrate judge exercise his or her discretionin this manner, a subscriber’s historical cell site data will be given roughly the same levelof protection as the actual contents of the subscriber’s conversations.
4Jeff Pool, Innopath, private correspondence. These areas are further reduced if thecell has multiple sectors.
5Notice of Proposed Rulemaking, Docket 94-102, adopted as an official report andorder in June 1996 [12]. This order and all of its subsequent incarnations will henceforthbe referred to as E911.
6The requirements were revised repeatedly as technical issues emerged. In 1999 thephase two requirements were separated into network-based and handset-based solutions.For the former, 67% of calls had to provide accuracy within 100 meters, and 95% within300 meters. For the latter, 67% of calls had to provide accuracy within 50 meters, and95% within 150 meters. Third Report and Order, adopted September 15, 1999.
4

set off a flurry of research into cellular location technologies [23, 32]. Analogand TDMA service providers developed a variety of cell tower triangulationschemes, while CDMA providers quickly realized that their handsets couldbe modified to receive Global Positioning System (GPS) signals7. Mostservice providers now use a combination of GPS and cell-site triangulationto satisfy the FCC’s E911 mandate. As a result, many cellular handsets nowhave some form of GPS capability, whether stand-alone or network assisted[31].
With GPS capability becoming ever more prevalent, service providersrecognized that a much broader (and more lucrative) range of location-based services could be provided. It should be remembered, however, thatGPS was not designed with cell phones in mind8. To begin with, GPS wasintended for outdoor use; the weak signals transmitted from the 24 spacevehicles (SVs) that constitute the GPS space segment are difficult to detectindoors, and are blocked by tall buildings [16]. GPS is also designed foruse with autonomous receivers; GPS signals are modulated to provide thereceiving unit with the locations and orbits of the SVs, information that isneeded to compute the receiver’s location9. The locations and orbits areprovided on the same carrier that is used for (civilian) distance estimation.In order to avoid interference, the data rate for these transmissions is quiteslow – 50 bps – so it takes up to twelve-and-a-half minutes for a receiverto obtain all of the information that it needs to perform a location fix.Networks often assist cellphones by providing this information over muchfaster cellular links [9], but cell phone manufacturers have apparently beenlooking to other means for getting quick and accurate location fixes for theirsubscribers.
Which brings us to the April 2011 kerfuffle over Apple and Google’suse of cellphones to collect WiFi and cell tower locations. In congressionaltestimony before the Judiciary Committee’s newly formed Subcommittee onPrivacy, Technology and the Law, Dr. Guy Tribble, Apple’s Vice Presidentfor Software Technology, confirmed what the analysts of the consolidated.dbfile had already determined: Apple iPhones record the MAC address andsignal strength10 for detected access points, and then timestamp and geo-tag
7Though the codes are different, GPS signals are spread in the same manner thatCDMA signals are spread.
8It was designed with guided missiles and bombers in mind [16].9Detailed SV orbital information is called ephemeris. Each SV transmits its own
ephemeris as well as an almanac that provides less detailed information for all activeSV’s.
10The signal strength is converted into a “horizontal accuracy number.” Interestingly,
5

the data. The geo-tag consists of a GPS/cell tower-derived location estimateof the iPhone that has detected the access point. For detected cell sites, thecell tower ID and signal strength are combined with the detecting iPhone’slocation estimate.
Dr. Tribble did not provide much technical detail, but he did suggest thatby obtaining such data from a large number of iPhones (“crowd-sourcing”),extremely accurate estimates of the location of cell sites and access pointscould be determined. With a map of these locations in hand, precise locationestimates can be generated for phones that report receiving signals fromthese cell sites and access points.
A simple analysis makes the point. Consider a data set of n records fora single access point, each record consisting of the location of a differentreceiving unit and the strength with which that unit receives the signalfrom the access point. The location of the access point can be computedby determining the weighted centroid of the measurements as follows. LetMj(x, y) be the latitude and longitude of the jth receiving unit, and let wj bea weighting associated with the strength of the received signal. An estimateP (x, y) of the location of the access point is then computed as follows:
P (x, y) =
n∑j=1
wjMj(x, y)
n∑j=1
wj
(1)
To obtain the weighting factors, we first estimate the distance betweenthe transmitter and receiving unit. Assuming isotropic (unidirectional) an-tennas and free-space propagation, the distance is computed as follows:
d = (λ/4π)√Pt/Pr, (2)
where λ is the wavelength of the access point or cell site transmission (num-bers that are well known), Pt is the transmitted power, and Pr is the receivedpower. The transmitted power of an access point is typically 100 mW, whilethat of a cell site may vary. The ratio Pt/Pr can be deduced from severalreceived measurements. The weights are then computed as
wj =
(1
dj
)g
,
Apple does not collect the user-assigned name for the network.
6

where g is a tuning parameter that takes into account the propagation en-vironment, and can be optimized through testing [5].
Once the locations of cell sites and access points are known, a positionfix for a cellular phone may then be computed through trilateration. At itssimplest, the position (x, y) of the receiving device can be computed fromthree known positions {(x1, y1), (x2, y2), (x3, y3)} for access points and/orcell towers and distance measurements {d1, d2, d3} by solving the followingset of simultaneous nonlinear equations:
d1 =√
(x− x1)2 + (y − y1)2
d2 =√
(x− x2)2 + (y − y2)2
d3 =√
(x− x3)2 + (y − y3)2 (3)
There are other means for exploiting the crowd-sourced data. Var-shavsky et al. developed and tested a fingerprinting algorithm in which atraining set establishes a mapping between measurements and locations.Localization is then performed by identifying measurements in the trainingset that are similar to the current measurements, and then weighting andaveraging the associated locations. Fingerprinting has the benefit of takinginto account unpredictable signal strength distortions caused by buildingsand other obstructions [28]. Varshavsky et al. showed that fingerprinting ap-proach can provide results that are of sufficiently fine granularity to resolveindividual addresses11.
The presence of consolidated.db in iPhones – a database containingtimestamped GPS fixes for the cellphone – gives the appearance that Ap-ple is tracking iPhone users. But according to Dr. Tribble, the “data isextracted from the database, encrypted, and transmitted – anonymously –to Apple over a Wi-Fi connection every twelve hours (or later if the devicedoes not have Wi-Fi access at that time).”
One can appreciate the use of encryption, but the extent to which thedata is anonymous is questionable without further detail. The author gen-erated the following figure using the consolidated.db database on his iPhoneand the iPhoneTracker application developed by Pete Warden12. The well-traveled path from Ithaca, New York to Washington DC (NSF and DARPA),
11In their 2006 paper, Varshavsky and his colleagues found that “fingerprinting-basedsolutions require a tedious training data collection, and centroid-based solutions requireassembling maps of locations of cellular towers or access points in the target environment”[28]. The data collection problem has apparently been solved.
12See http://petewarden.github.com/iPhoneTracker/\#5. In a FAQ on this website,
7
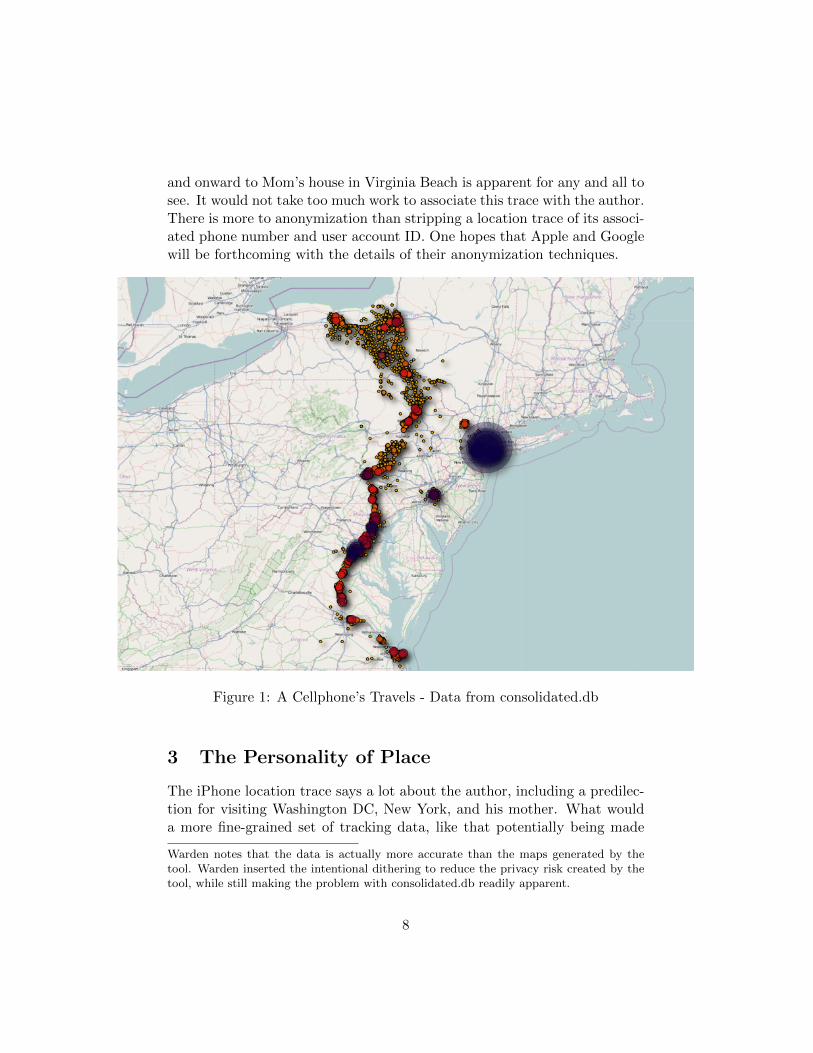
and onward to Mom’s house in Virginia Beach is apparent for any and all tosee. It would not take too much work to associate this trace with the author.There is more to anonymization than stripping a location trace of its associ-ated phone number and user account ID. One hopes that Apple and Googlewill be forthcoming with the details of their anonymization techniques.
McLuhan
Map Background © OpenStreetMap contributors, CC-BY-SAFigure 1: A Cellphone’s Travels - Data from consolidated.db
3 The Personality of Place
The iPhone location trace says a lot about the author, including a predilec-tion for visiting Washington DC, New York, and his mother. What woulda more fine-grained set of tracking data, like that potentially being made
Warden notes that the data is actually more accurate than the maps generated by thetool. Warden inserted the intentional dithering to reduce the privacy risk created by thetool, while still making the problem with consolidated.db readily apparent.
8

available to Location-Based Services (LBS) by the emerging smartphone lo-cation technology, have to say about an individual? Consider the followinginformation that can be derived through correlation of fine-grained locationdata with publicly available information:
• The location of your home. What kind of neighborhood do you live in?What is your address? Mortgage balances and tax levies are readilyavailable once the address is known. Your socio-economic status isquickly deduced.
• The location of your friends’ homes. What sort of homes do they have?Do you ever spend the night? How often?
• The location of any building you frequent that has a religious affilia-tion. Or do you frequent no such building? In either case, beliefs canbe deduced.
• The locations of the stores you frequent. Your shopping patterns re-flect your preferences, and in some cases, may reflect beliefs or vices.
• The locations of doctors and hospitals that you visit. Do you visitfrequently? How long do you stay? The fact that you have a seriousillness can be readily determined and, in some cases, even the typeof illness through visits to specialty clinics. Such information willbe of interest to insurance providers and the ubiquitous marketers ofpharmaceuticals, among others.
• The locations of your entertainment venues. Do you attend the localsymphony? Or do your tastes run more to grunge rock? Do you fre-quent bars? What type of bars? One can draw a series of conclusionsfrom the frequency of the visits and the type of venue.
One could go on and on with such a list. The bottom line is that fine-grained location information can be used to determine a great deal about anindividual’s beliefs, preferences, and behavior. Databases containing suchinformation pose a threat, as they can become a focus for hackers withharmful intent13. On a less malevolent note, such data is of immense valueto direct marketing firms. Entire businesses have been built around thecompilation of lists of such information acquired by other means.
13The murder of the actress Rebecca Schaeffer in July 1989 is a salient example of suchbehavior. See, for example, Online Privacy: A Reference Handbook by Pam Dixon andRobert Gellman, and http://learning.blogs.nytimes.com/on-this-day/july-18/.
9

So why is this a problem? Isn’t LBS data collection simply additional,perhaps redundant data collection that feeds the ordinary and tedious pro-cess of direct marketing? In the following section, we will see that this isnot the case. LBS supports location-based advertising (LBA), and fine-grained LBA has the potential for exerting substantially more power overthe individual than previous modes of advertising.
3.1 The Work of Advertising
At the time of writing, InfoUSA maintains a list of 210 million consumersthat can be sorted according into a wide variety of categories, including“Area Codes, Zip Codes, Home Value / Home Ownership, Housing Type,Mortgage, Personal Finance, Hobbies & Interests, Children / Grandparents/ Veterans, Ethnicity, Religion, and Voter Information14.” As seen fromthe above thought experiment, much of this information can now be readilyderived by correlating location data with an address database. But datacollection through location-based services takes the process of collection toa new level, while adding an additional control variable to the process ofadvertising.
To begin with, LBS data collection has the ability to substantially refinethe personal information that was already available from other sources. Forexample, one may claim to practice yoga, but now marketers may knowthe frequency with which one takes classes, pointing to a specific level ofenthusiasm that was previously known only to the individual and his fellowyogis and yoginis15. LBS also enables an approach to consumers that goeswell beyond previous marketing strategies by collecting information aboutbeliefs, preferences, and behavior while one is performing the illustrativepractice. A mailing list may indicate that you are generally a lover of Italianfood, while an LBS may have the additional knowledge that you are currentlyin an Italian restaurant. To understand why this is so important, we mustfirst consider the “work” that advertising has us do.
In her seminal work on the psychology of advertising, Judith Williamsondescribed the work of advertising as shifting meaning from one semanticnetwork to another [30]. As her book was originally written in the 1970s,Williamson focused on print advertising, with an occasional reference tobroadcast television. In a canonical example she points to an advertisementthat appears to be quite simple: a photograph of the actress Catherine
14http://www.infousa.com/15You may substitute political parties, churches, sporting events, or dog shows to obtain
a more personally relevant example.
10

Deneuve16 is juxtaposed with a bottle of perfume (Chanel No. 5). Theadvertisement encourages us to bind to the perfume the association of classand beauty that we people of a certain age associate with Catherine Deneuve.Meaning has been shifted from one semantic network (the realm of actresses)to another (brands of perfume).
LBA has the potential to perform a similar sleight-of-mind, causing usto exchange the meaning that we associate with a place for that suggestedby the advertisement. Furthermore, this location-based semantic shift istaking place through advertisements delivered to a device that can trackthe individual. This raises two new issues. First, LBA has the potential tobe a feedback system with dynamic control. The advertiser can present anadvertisement when one is near a target location, and then track the user todetermine whether the advertisement has had the desired response. To usethe language of Gilles Deleuze in “Postscript on the Societies of Control” [8],the advertiser can observe the response to the information stream presentedto the individual and then “modulate,” or refine the information streamover time, driving the individual to a desired state of behavior; in this case,movement to and consumption at the target location. Primitive examples ofsuch modulation, fueled by click tracking, can be seen by the aware observeron the web. If one fails to follow up on a pop-up window, other windowsoffer alternative proposals.
Second, and unlike click tracking, LBA exploits the user’s physical loca-tion, attempting to manipulate the user’s relationship to his or her physicalsurroundings. As we will see in the next section, here lies a potential formanipulation at an entirely new level.
3.2 The Philosophy of Place
Many people think of the field of Geography as the study of locations andfacts. For example, “Jackson is the capital of Mississippi” is the stuff ofGeography, as is the shape and size of the Arabian peninsula. In the 1970s,however, humanistic geographers began to move the field toward a consider-ation of “place” as more than a space or location, moving beyond latitude,longitude, and spatial extent [7]. In an oft-quoted definition, the geographerand political philosopher John Agnew defined place as consisting of threethings [1]:
• Location – “where” as described by, for example, latitude and longi-
16If the reader was born after 1980, just take it for granted that Catherine Deneuve isa beautiful, classy French actress.
11

tude
• Locale – the shape of the space. Shape may include defining bound-aries, such as walls, fences, or prominent geographical features such asrivers or trees.
• Sense – personal and emotional connections that one establishes withthe combination of location and locale.
Place is thus a location to which one has ascribed meaning. The processby which meaning is attached to place, and the importance of this processto the individual and to society have become a prime focus for humanisticgeographers. One stream of the latter’s efforts has built on the work of thephenomenologists. Phenomenology, generally associated with the philoso-phers Franz Brentano and Edmund Husserl, is a discipline for studying thestructures of consciousness. Phenomenology proceeds by first bracketing outour assumptions of an outside world, and then focusing on our experience ofthe world through our perceptions. Phenomenologists study consciousnessby focusing on human perception of phenomena, hence the name17.
Brentano is credited with one of the key results of the phenomenologistapproach. In his 1874 work Psychology from an Empirical Standpoint18,Brentano asserted that one of the main differences between mental andphysical phenomena is that the former has intentionality; it is about, ordirected at an object. Another way to put this is to say that one cannotbe conscious without being conscious of something. In the latter part ofthe twentieth century, humanistic geographers took this a step further. InPlace and Placelessness, Edward Relph argued that consciousness could onlybe about something in its place, making place “profound centers of humanexistence” [24, pg. 43].
Another thread in the philosophy of place originates with Martin Hei-degger. Heidegger described human existence in terms of Dasein, a Germanword that can be translated as “human existence,” or perhaps more help-fully as “being-there.” The important thing for us here is to understandthat Dasein is always in the world19. As humans we enter a pre-existent
17For a quick look at the field, see http://plato.stanford.edu/entries/
phenomenology/. For more detail, see Robert Sokolowski, Introduction to Phenomenology,Cambridge University Press, 1999.
18Psychologie vom empirischen Standpunkt, http://www.archive.org/details/
psychologievome00brengoog.19This concept has had a profound effect on the practice of artificial intelligence. Philip
Agre, for example, has explicitly applied Heideggerian thought in moving the practice ofcomputational psychology away from cognition and towards action in the world [2].
12

world of things and other people, and we develop our sense of self by (andonly by) interacting with these things and people. According to Heidegger,an inauthentic existence is one in which the individual fails to distinguishhim or herself from the surrounding crowd and their priorities.
Humanistic geographers have taken up the concept of Dasein and usedit to explore the role of place in human existence. In Place and Experience:A Philosophical Topography, Jeff Malpas invokes Dasein and the relatedconcepts of spaciality and agency to show that place is primary to the con-struction of meaning and society [19]20.
Using these concepts, we can now attempt to characterize the poten-tial impact of LBA. It is the objective of LBA to alter the ever-present,ongoing human process of interaction with one’s immediate surroundings.LBA attempts to shift intentionality, diverting consciousness from an ex-perience of the immediate surroundings to consumption. In Heideggerianterms, LBA directly interferes with the individual’s project of crafting anauthentic existence.
Consider the following example, which will be developed in two stages.A family is seated at their dining room table and enjoying dinner together.But there is an exception; the father, a relentless worker, is reading textsand emails instead of joining in the conversation. One could say that heis no longer present. He has left the place. Or to turn this around, asfar as the father is concerned, the dinner table is no longer a “place” withfamilial meaning, but instead a mere location for eating. Now complete theexample: assume that someone who wants to communicate with the fatherfrom afar knows when he is at the table, and chooses these moments to sendtexts. This texter now has the ability to disrupt the father’s relationship tothe family dinner, a relationship that is often filled with a strong, or evendefining sense of meaning.
The dinner table is a natural example for the author21, but one may justas well consider a walk through one’s home town, a visit to one’s old highschool, and so on. LBA has the potential to detract from the experienceof these familiar and meaning-filled environs. One’s surroundings may thuslose their “placeness” through LBA, losing their meaning and becoming amere path to be traversed. As places become mere locations, meaning islost to the individual. In short we lose some of ourselves as well as one ofthe critical processes through which we become a self.
20A more focused exploration of place in the thought of Martin Heidegger can be foundin Malpas’ Heidegger’s Topology: Being, Place, World , MIT Press, 2008.
21Though he would never be allowed to behave like the father in the example.
13

4 Location Anonymity
Having established the importance of location privacy, is it necessary toforgo the benefits of location based services? Fortunately the answer is“no,” but it needs to be made clear that it is not sufficient to simply scrubnames and phone numbers from location traces. As AOL [15] and NetFlix[21] have learned, supposedly anonymous datasets are often susceptible tocorrelation attacks, attacks in which datasets are associated with individ-uals by comparing the datasets to previously collected data. The NetFlixcase is particularly instructive. In 2006 NetFlix issued a public challengeto the outside world to develop a better movie recommendation system[22]. As part of this challenge, NetFlix released training data consisting“of more than 100 million ratings from over 480 thousand randomly-chosen,anonymous customers on nearly 18 thousand movie titles.” In a matter ofweeks, Arvind Narayanan and Vitaly Shmatikov showed that the data wasnot as anonymous as NetFlix may have thought. Through an elegant algo-rithm that correlated the NetFlix data with other publicly available data,Narayanan and Shmatikov were able to identify a number of users in theNetFlix training data [21]. Along the way, they developed a series of rulesof thumb for such correlation attacks, noting that (1) such attacks work wellwhen they emphasize rare attributes and (2) that the winning match shouldhave a much higher score than the second place match. The first can beunderstood intuitively - one learns more from the knowledge that someonehas purchased the author’s most recent text on error control coding thanone learns from finding that someone has purchased a Harry Potter book.The second rule is equally intuitive, as it is intended to avoid false positives.
In this section we will bear these rules in mind as we develop a Shannon-theoretic model for correlation attacks on supposedly anonymized locationtraces. In his 1949 paper “Communication Theory of Secrecy Systems,”Shannon defined unicity distance as the minimum amount of ciphertextthat was needed before the uncertainty about a piece of plaintext could bereduced to zero [25]. The translation to the de-anonymization of locationtraces is clear – the continued accumulation of location data may reach thepoint that a marketer can uniquely match an anonymous location trace toa named record in a separate database.
Our goal here will not be a specific number that will form a cutoff fordata accumulation, nor an all-encompassing framework into which all de-anonymizing attacks will have a place. Instead, we will develop an examplemodel, and then evaluate its dynamics – how the structure of the modelchanges as the amount of location data increases – in an effort to craft
14

design rules for anonymous LBS.
4.1 A Shannon-Theoretic Approach to Location Anonymity
Let a marketing database S consist of a collection of binary preference vec-tors {Xi} of length n, where the index i indicates a specific user. Theindividual vectors have the form
Xi = (xi,0, xi,1, xi,2, . . . , xi,n−1);xi,j ∈ {0, 1, e}.
Each coordinate xi,j is a binary indicator representing the user i’s preferencewith regard to some specific item, belief, or behavior. For example, xi,0 mayindicate whether the user likes cats (yes or no), xi,1 may indicate feelingsabout dogs, and so forth. Some preferences, such as the identity of theuser’s favorite rugby team, may take up several coordinates, depending onthe number of teams that can be represented in the database. If a givenpreference for a particular user is unknown, the associated coordinate isgiven the value “e” for erasure22. The marketer’s knowledge about a user’sbeliefs, preferences, and behavior are thus coded into binary vectors of afixed length (n) with a consistent semantic attribution to each coordinateor block of coordinates.
Now let Lm be a trace of length m – a sequence of m location fixesgenerated by a single subscriber:
Lm = (l0, l1, l2, . . . , lm−1)
As discussed above, marketers can associate locations with beliefs andpreferences, but clearly the amount of information derived will vary depend-ing on the type of location in the trace. We introduce a preference mappingF that maps location traces to preference vectors, while acknowledging thatthis mapping may not be one-to-one and is clearly situation-dependent. Thepreference vectors will have the the same syntactic and semantic structureas the vectors in the marketer’s database:
F : {Lm} −→ {P}P = (p0, p1, p2, . . . , pn−1); pj ∈ {0, 1, e}
22Narayanan and Shmatikov argue that most “auxiliary” databases are extremelysparse, and would thus contain a large number of erasures.
15

Narayanan and Shmatikov discuss various means for identifying theXi ∈ S that is the best match for a given P, thereby (potentially) de-anonymizing P. Here we will take a somewhat different approach, attempt-ing to characterize the dynamics of the de-anonymization problem as thelength of the location trace grows. A coding-theoretic scheme will be devel-oped.
Suppose that a location trace of length m is mapped into a preferencevector P of length n. P will have some t non-erased coordinates, and n− terased coordinates. We assume that as m increases, t will either increase orremain the same23.
We now focus on those vectors within the marketing database for whichindividual preferences on these t coordinates are known. Within S there willbe some Nm vectors that have support for all t non-erased coordinates of P.These Nm vectors form a subset C ⊂ S. For each vector in C, delete all butthe t coordinates of interest (those corresponding to the non-erased coordi-nates of P). We now have a set C ′ of Nm vectors of length t. The problemof de-anonymization now looks like an error control coding problem: whichvector in C ′ provides the closest match to the non-erased coordinates of thepreference vector P? The ability of the marketing database to distinguishbetween users can now be expressed, using coding-theoretic terminology, asthe minimum distance between the vectors in C ′. The minimum distance isthe minimum number of coordinates in which any pair of vectors differ. Inmore compact form, we can express this as follows:
dmin = minX′i,X′j∈C′,i 6=j
|{k|xi,k 6= xj,k, k ∈ (1, t)}|
Clearly the greater the value of dmin, the greater the ability of a cor-relation attack to associate a location trace with a single record, and thusa single individual. When dmin is large, the individuals represented by thevectors in C ′ are readily distinguished from each other. On the other hand,if dmin is small or zero (as will happen when there are two or more identicalvectors in C ′), then the problem of de-anonymization becomes difficult, oreven impossible. We can’t distinguish between our individuals, so we can’tdetermine with which individual to associate a given location trace.
We can now develop a set of rules of thumb for preserving anonymity inthe face of correlation attacks by exploring the dynamics of the relationship
23While useful for mathematical clarity, this assumption is not necessary to support theresults so long as there is a general tendency for t to increase with m, which will be thecase as long as the marketer’s database is not highly corrupted.
16

between location traces Lm, preference vectors P and the minimum distancedmin of the corresponding set of vectors C ′.
• As the length m of a location trace Lm increases, the number of non-erased coordinates of a preference vector P increases. The reverse isalso the case.
• As the number of non-erased coordinates of P increases, the lengthof the vectors in C ′ increases, while the cardinality of C ′ decreases(fewer vectors in C will have the requisite support as the numberof coordinates requiring support increases). The overall effect is anincrease in minimum distance, and a corresponding increase in theefficacy of correlation attacks.
• As the number of non-erased coordinates of P decreases, the length ofthe vectors in C ′ decreases, while the cardinality of C ′ increases (morevectors in C have the requisite support, as less support is required).The overall effect is a decrease in minimum distance, and a decreasein the efficacy of correlation attacks.
It follows both intuitively and analytically that the number of non-erasedcoordinates in P should be kept as small as possible. This can be done intwo ways:
• Reduce the length of location traces. If the preference map has lessinformation on which to operate, it will generate a preference vectorwith more erased coordinates.
• Reduce the ability of the preference mapping to resolve a location traceinto specific coordinate values in a preference vector. This can be doneby reducing or eliminating the extent to which each trace location canprovide preference vector information.
We exploit these results when we address the potential for anonymity-preserving location-based services. We begin by considering the basic struc-ture of LBS.
4.2 The Structure of Anonymous LBS
Consider a basic location-based service, let’s call it “The Dopio Detector,”that provides a user with directions from his or her current location to thenearest espresso shop. For this to work, two basic types of information must
17

be brought together: the subscriber’s location at an appropriate level ofgranularity, and a geographic database that contains the locations of nearbyespresso shops. With this information, the server or the user’s handset cansuperimpose the user’s location onto a geographic database, and generatedirections through a routing algorithm.
We can thus generalize the structure of an LBS as performing two basicfunctions:
• Determine subscriber location to the desired level of granularity
• Use a database to map the location to the desired information (direc-tions to an espresso shop, etc.)
Separating these two functions clarifies the anonymity problem, whileopening up the range of available anonymity-preserving techniques. Webegin with the determination of subscriber location. The best means forpreserving anonymity is to do an independent GPS fix on the cell phone. Thehandset may thus acquire an accurate location estimate without releasingany information whatsoever to the outside world. This will be a generaltheme – the more that can be done within the handset and kept within thehandset, the greater the preservation of anonymity.
As discussed earlier, however, this approach can be slow. If the handsetis to download all of the necessary space vehicle location information fromthe SVs themselves, the user may have to wait as much as twelve-and-a-halfminutes, a potentially excruciating delay when one is in need of caffeine.If the process is to be sped up through the provision of constellation in-formation by the cellular service provider, there is a need for some locationinformation to be leaked to the service provider. Such data, however, can becoarse; the network need only know the cell site that is serving the user inorder to provide the data for SVs that are potentially visible to the handset.Such coarse location information provides relatively little information aboutthe user’s beliefs and preferences. Or to use the language of our unicity dis-tance analysis, the preference mapping F operating on cell site informationwill produce a preference vector with a large number of erased coordinates.
Khoshgozaran and Shahabi [17] suggest another approach that uses thenetwork to determine the location fix, but prevents the network from know-ing the subscriber’s actual location. In this system the mobile biases thedata used for the location fix by applying a randomly selected transform tothe mobiles measurements. When the mobile receives the resulting locationfix from the network, it removes the effects of the bias by adjusting the fixaccordingly.
18

It follows that obtaining a location fix of the desired granularity on thehandset need not reduce the user’s location privacy. However, the secondpiece to LBS, the mapping function, creates two significant obstacles:
1. The mapping function requires an input granularity that is consistentwith that of the query; if one wants directions to the nearest espressoshop, one needs directions that begin with a position that has street-level resolution.
2. Many if not most LBS queries involve objects whose location is knownand fixed; for example, a bookstore has a known location and it isgenerally not in motion. A request for directions indicates that onewill be probably at that location sometime in the near future.
In what follows we will consider general means for accomplishing themapping function while retaining a measure of anonymity.
A release of data is said to provide k-anonymity protection “if the infor-mation for each person contained in the release cannot be distinguished fromat least k-1 individuals whose information also appears in the release” [26].It seems logical that such protection can be obtained for the LBS mappingfunction by stripping identifying information from k LBS requests, bundlingthem together, and submiting them all at once. The LBS server will thenprovide a combined response from which each user may extract informationresponsive to his or her specific request.
The question arises, of course, as to who or what will bundle the originalk requests. Gruteser and Grunwald [14] suggest the use of a trusted serverthat bundles and forwards requests on behalf of the users, while Ghinitaet al. [13] suggest a tamper-proof device on the front-end of an untrustedserver that combines queries based on location. Such approaches fall shortof k-anonymity in that there may be side information, such as home locationor a known place of business, that would allow the server to disaggregateone or more users from the bundled request. For example, I benefit littlefrom a bundled request if that request includes my home as a starting point;my request is easily disaggregated from the the bundle.
It is important to bear in mind that we need not completely eliminatethe transfer of location information – it is sufficient to reduce the precision ofthe location information to the point where the preference mapping gives theattacker little with which to work24. Given the decreasing cost of memory
24Privacy-preserving data mining techniques, such as those developed by Evfimievski etal. [11], may also provide solutions.
19

and bandwidth, it is both efficacious and inexpensive to simply blur thelocation estimate provided with the request for mapping functionality25. Imay, for example, submit a request to the Dopio Detector that includesmy location as “somewhere in downtown Ithaca,” as opposed to a specificaddress. The server will respond with a map that indicates the locationsof all of the espresso shops in downtown Ithaca. My handset can then useits more precise knowledge of my location to determine the nearest espressoshop and to generate directions accordingly.
The consistent use of the above approach limits the impact of the pref-erence mapping by providing a location trace Lm that contains m coarselocation estimates. There is little to be deduced about one’s preference fordogs or cats, for example, from the fact that one lives in Ithaca.
Anonymity can also be preserved by limiting the length m of each loca-tion trace. This is accomplished by preventing the LBS from determiningwhich requests, if any, come from a given user26. . As described by the au-thor in [29], public key infrastructure and encrypted authorization messagescan be used to authenticate users of a service without providing their actualidentities. Random tags can be used to route responses back to anonymoususers. Anonymity for frequent users of an LBS may thus be protected byassociating each request with a different random tag. All of the users ofthe LBS thus enjoy a form of k-anonymity. If coupled with coarse locationestimates or random location offsets, this approach provides great promisefor preserving user anonymity while allowing the user to enjoy the benefitsof location based services.
5 Conclusions
The ever-increasing precision of cellular location estimates has reached acritical threshold – with the use of access point and cell site location in-formation, it is possible for service providers to obtain location estimateswith address-level precision. The compilation of such estimates creates aserious privacy problem, as it can be highly revealing of user behavior, pref-erences, and beliefs. The subsequent danger to user safety and autonomy issubstantial.
25In their MobiCom 2011 paper, Zang and Bolot used the Shannon-theoretic conceptof entropy to show the role of both temporally and spatially coarse data in preservinganonymity [33], conclusions we corroborate with the above analysis.
26This follows the work of Kife and Machanavajjhala, who recently argued that theprivacy of an individual is preserved when it is possible to limit the inference of an attackerabout the participation of the individual in the data generating process [18].
20

To determine the extent to which location data can be anonymized, weused the Shannon-theoretic concept of unicity distance to explore the dy-namics of correlation attacks, attacks through which existing data recordsare used to attribute individual identities to allegedly anonymous informa-tion. With this model in mind, we developed a set of rules of thumb fordesigning anonymous location based services. Critical to these rules is themaintenance of a coarse level of granularity for any location estimate pro-vided to the service providers, and the disassociation of repeated requests forlocation-based services to prevent the construction of long location traces.
21

References
[1] Agnew, J. A. Place and Politics: The Geographical Mediation of Stateand Society. Unwin Hyman, 1987.
[2] Agre, P. E. Computation and Human Experience. Cambridge Uni-versity Press, 1997.
[3] Apple Q&A on Location Data. http://www.apple.com/pr/library/
2011/04/27Apple-Q-A-on-Location-Data.html.
[4] Bilton, N. 3G apple iOS devices are storing users location data. NewYork Times (April 20 2011).
[5] Blumenthal, J., Reichenbach, F., and Timmermann, D. Posi-tion estimation in ad-hoc wireless sensor networks with low complexity.In Joint 2nd Workshop on Positioning, Navigation and Communication2005 (WPNC 05) & 1st Ultra-Wideband Expert Talk 2005, pp. 41–49.
[6] Clarke, R. A. Information technology and dataveillance. Communi-cations of the ACM 31, 5 (May 1988), 498–512.
[7] Cresswell, T. Place: A Short Introduction. Wiley-Blackwell, 2004.
[8] Deleuze, G. Postscript on the societies of control. October 59 (1992),3–7. (Winter).
[9] Djuknic, G. M., and Richton, R. E. Geolocation and assistedGPS. Computer 34 (February 2001), 123–125.
[10] Durrell, L. Balthazaar. Faber & Faber, 1960.
[11] Evfimievski, A., Srikant, R., Agrawal, R., and Gehrke, J.Privacy preserving mining of association rules. In Proceedings of theeighth ACM SIGKDD international conference on Knowledge discoveryand data mining (New York, NY, USA, 2002), KDD ’02, ACM, pp. 217–228.
[12] FCC Notice of Proposed Rulemaking, Docket 94-102, 1994.
[13] Ghinita, G., Kalnis, P., Khoshgozaran, A., Shahabi, C., andTan, K.-L. Private queries in location based services: anonymizersare not necessary. In Proceedings of the 2008 ACM SIGMOD Inter-national Conference on Management of Data (New York, NY, USA,2008), SIGMOD ’08, ACM, pp. 121–132.
22

[14] Gruteser, M., and Grunwald, D. Anonymous usage of location-based services through spatial and temporal cloaking. In Proceedings ofthe 1st International Conference on Mobile Systems, Applications andServices (New York, NY, USA, 2003), MobiSys ’03, ACM, pp. 31–42.
[15] Hansell, S. AOL removes search data on vast group of web users.New York Times (August 8 2006).
[16] Kaplan, E. D. Understanding GPS Principles and Applications.Artech House Publishers, 1996.
[17] Khoshgozaran, A., and Shahabi, C. Blind evaluation of nearestneighbor queries using space transformation to preserve location pri-vacy. In Proc. 10th International Symposium on Spatial and TemporalDatabases (2007).
[18] Kifer, D., and Machanavajjhala, A. No free lunch in data privacy.In Proceedings of the 2011 international conference on Management ofdata (New York, NY, USA, 2011), SIGMOD ’11, ACM, pp. 193–204.
[19] Malpas, J. Place and Experience: A Philosophical Topography. Cam-bridge University Press, 2007.
[20] Morrissey, S. iOS Forensic Analysis: for iPhone, iPad, and iPodtouch. Apress, 2010.
[21] Narayanan, A., and Shmatikov, V. Robust de-anonymization oflarge sparse datasets. In Proceedings of the 2008 IEEE Symposium onSecurity and Privacy (Washington, DC, USA, 2008), IEEE ComputerSociety, pp. 111–125.
[22] The Netflix Prize Rules. http://www.netflixprize.com//rules.
[23] Rappaport, T. S., Reed, J. H., and Woerner, B. D. Wirelesscommunications on highways of the future. IEEE CommunicationsMagazine (October 1996), 33–41.
[24] Relph, E. Place and Placelessness. Routledge Kegan & Paul, 1976.
[25] Shannon, C. Communication theory of secrecy systems. Bell SystemTechnical Journal 28, 4 (1949), 656 – 715.
[26] Sweeney, L. k-anonymity: a model for protecting privacy. Int. J.Uncertain. Fuzziness Knowl.-Based Syst. 10 (October 2002), 557–570.
23

[27] Testimony of Dr. Guy “Bud” Tribble, Vice President for Soft-ware Technology Apple Inc. http://judiciary.senate.gov/pdf/11-5-10%20Tribble%20Testimony.pdf.
[28] Varshavsky, A., Chen, M., Froehlich, J., Haehnel, D., High-tower, J., Lamarca, A., Potter, F., Sohn, T., Tang, K., andSmith, I. Are GSM phones the solution for localization. In 7th IEEEWorkshop on Mobile Computing Systems and Applications (HotMobile(2006), IEEE Computer Society, pp. 20–28.
[29] Wicker, S. B. Cellular telephony and the question of privacy. Com-mun. ACM 54 (July 2011), 88–98.
[30] Williamson, J. Decoding Advertisements: Ideology and Meaning inAdvertising. Marion Boyars Publishers Ltd, 1978.
[31] Yoshida, J. Enhanced 911 service spurs integration of GPS into cellphones. Stanford Technology Law Review (August 16 1999).
[32] Zagami, J. M., Parl, S. A., Bussgang, J. J., and Melillo, K. D.Providing universal location services using a wireless e911 location net-work. IEEE Communications Magazine (1998), 66–71.
[33] Zang, H., and Bolot, J. C. Anonymization of location data doesnot work: a large-scale measurement study. In ACM Mobicom (2011).
24