Embed Size (px)
Citation preview

1 A Guide to Using the TClientDataSet in Delphi applicationsBy Zarko Gajic, About.com Guide
2 See More About:
delphi database programming dbexpress tclientdataset using db-aware controls
Looking for a single-file, single-user database for your next Delphi application? Need to store some application specific data but you do not want to user the Registry / INI / or something else?
Why look outside the box? Delphi already has an answer for you: the TClientDataSet component (located on the "Data Access" tab of the component palette) represents an in-memory database-independent dataset. Whether you use client datasets for file-based data, caching updates, data from an external provider (such as working with an XML document or in a multi-tiered application), or a combination of these approaches such as a "briefcase model" application, you can take advantage of broad range of features client datasets support.
Time to learn about TClientDataSet:
A ClientDataSet in Every Database ApplicationThe basic behavior of the ClientDataSet is described, and an argument is made for the extensive use of ClientDataSets in most all database applications.
Defining a ClientDataSet's Structure Using FieldDefsWhen creating a ClientDataSet's memory store on-the-fly, you must explicitly define the structure of your table. This article shows you how to do it at both runtime and design-time using FieldDefs.
Defining a ClientDataSet's Structure Using TFieldsThis article demonstrates how to define a ClientDataSet's structure at both design-time and runtime using TFields. How to create virtual and nested dataset fields is also demonstrated.
Understanding ClientDataSet IndexesA ClientDataSet does not obtain its indexes from the data it loads. Indexes, if you want them, must be explicitly defined. This article shows you how to do this at design-time or runtime.
Navigating and Editing a ClientDataSetYou navigate and edit a ClientDataSet in a manner similar to how you navigate and edit almost another other dataset. This article provides an introductory look at basic ClientDataSet navigation and editing.
Searching a ClientDataSetClientDataSets provide a number of different mechanisms for searching for and location data
in its columns. These techniques are covered in this continuation of the discussion of basic ClientDataSet manipulation.
Filtering ClientDataSetsWhen applied to a dataset, a filter limits the records that are accessible. This article explores the ins and outs of filtering ClientDataSets.
ClientDataSet Aggregates and GroupStateThis article describes how to use aggregates to calculate simple statistics, as well as how to use group state to improve your user interfaces.
Nesting DataSets in ClientDataSetsLike the name suggests, a nested dataset is a dataset within a dataset. By nesting one dataset inside another, you can reduce your overall storage needs, increase the efficiency of network communications, and simplify data operations.
Cloning ClientDatSet CursorsWhen you clone a ClientDataSet's cursor, you create not only an additional pointer to a shared memory store, but also an independent view of the data. This article shows you how to use this important capability
Deploying Applications that use ClientDataSetsDepending on what you do within your application, if you use one or more ClientDataSets you may need to deploy one or more libraries, in addition to your application's executable. This article describes when and how
Creative Solutions Using ClientDataSetsClientDataSets can be used for much more than displaying rows and columns from a database. See how they solve applications issues from selecting options to process, progress messages, creating audit trails for data changes and more.

3 A ClientDataSet in Every Database Application By: Cary Jensen
Abstract: This article is the first in an extended series designed to explore the ClientDataSet. The basic behavior of the ClientDataSet is described, and an argument is made for the extensive use of ClientDataSets in most all database applications.
The ClientDataSet is a component that holds data in an in-memory table. Until recently, it was only available in the Enterprise editions of Delphi and C++ Builder. Now, however, it is available in the professional editions of these products, as well as Kylix. This article is the first in an extended series designed to explore the capabilities and features of the ClientDataSet.
I have been playing with an idea for a while, and I wanted the title of this article to reflect this (with my apologies to Herbert Hoover for the pathetic turn of his political promise of "two chickens in every pot and a car in every garage"). In short, I believe that a very strong argument can be made for including one ClientDataSet and a corresponding DataSetProvider for each TDataSet used in an application. Doing so provides your user interface and runtime code with a consistent set of features (filters, ranges, searches, and so forth) regardless of the data access technology being employed.
Actually I have two goals in this first of many articles detailing the ClientDataSet. The first is to set forth the reasons why I believe that ClientDataSets should play a primary role in most database applications. The second goal, and the one that I hope you find useful whether or not you accept my arguments, is to provide a general introduction to the nature and features of the ClientDataSet.
It's this second goal that I will address first. Specifically, in order for my arguments to make sense, it is essential to first provide an overview of the ClientDataSet, and how it interacts with a DataSetProvider. This discussion will also serve as a primer for many of the technique-specific articles that will follow in this series. After this introduction I will return to my first premise, explaining in detail how you can improve your applications through the thoughtful use of ClientDataSets.
4 Introduction to the ClientDataSet
The ClientDataSet has been around for a while: Since Delphi 3 to be precise. But up until recently it has only been available in the Client/Server or Enterprise editions of Delphi and C++ Builder. In these editions the ClientDataSet was intended to hold data in a DataSnap (formerly called MIDAS) client application. While many Enterprise edition developers did make extensive use of the ClientDataSet's features in non-DataSnap application, that this component did not exist in the Profession edition products made recommending its widespread employment unrealistic.
With Borland's introduction of dbExpress, which first appeared in Kylix 1.0, the ClientDataSet, and its companion, the DataSetProvider, are now part of the Borland's

Professional Edition RAD (rapid application development) products, including Delphi 6, Kylix 2, and C++ Builder 6. Now all Borland RAD developers have access to this powerful and flexible component (I'm not counting the Personal or Open edition developers in this group, since those versions do not have the database-related components in the first place).
With this in mind, let's now take a closer look at how the ClientDataSet works.
The ClientDataSet is a TDataSet descendant that holds data in memory in a table-like structure consisting of rows (records) and columns (fields). Using the methods of the TDataSet class, a developer can navigate, sort, search, filter, and edit the data held in memory. Because these operations are performed on data stored in memory, they are very fast. For example, on a test machine with 512 MB of RAM running an 850 MHz Pentium 3, an index was build on an integer field containing random numbers of a 100,000 record table in just under one-half second. Once built, this index can be used to perform near instantaneous searches and set ranges on this indexed field.
The ClientDataSet actually contains two data stores. The first, named Data, contains the current view of the data in memory, including all changes to that data since it was loaded. For example, if a record was deleted from the dataset, that record is absent from Data. Likewise, records added to the ClientDataSet are visible in Data.
The second store, named Delta, represents the change log, and contains a record of those changes that have been made to Data. Specifically, for each record that was inserted or deleted from Data, there resides a corresponding record in Delta. For modified records it is slightly different. The change log contains two records for each record modified in Data. One of these is a duplicate of the record that was originally modified. The second contains the field-by-field changes made to the original record.
The change log serves two purposes. First, the information in the change log can be used to restore edits made to Data, so long as those changes have not yet been resolved to the underlying data source. By default, this change log is always maintained, meaning that in most applications the ClientDataSet is always caching updates.
The second role that the change log plays only applies to a ClientDataSet that is used in conjunction with a DataSetProvider. In this role, the change log provides sufficient detail to permit the mechanisms supported by the DataSetProvider to apply the logged changes to the dataset from which the data was loaded. This process begins when you explicitly call the ClientDataSets ApplyUpdates method.
When a ClientDataSet is used to read and write data directly from a file, a DataSetProvider is not used. In those cases, the change log is stored in this file each time you invoke the ClientDataSets SaveToFile method, and restored each time you call LoadFromFile (or if you open and close the ClientDataSet when the FileName contains the name of the file). The change log is only cleared in this scenario when you invoke MergeChangeLog or ClearChanges (this second method causes the changes to be lost).
There are quite a few differences between how you use a ClientDataSet depending on whether or not a DataSetProvider is employed. The following discussion focuses exclusively on the situation where a ClientDataSet points to a DataSetProvider with its ProviderName property. Using a ClientDataSet directly with files will be discussed in detail in a future article.

5 How a ClientDataSet and a DataSetProvider Interact
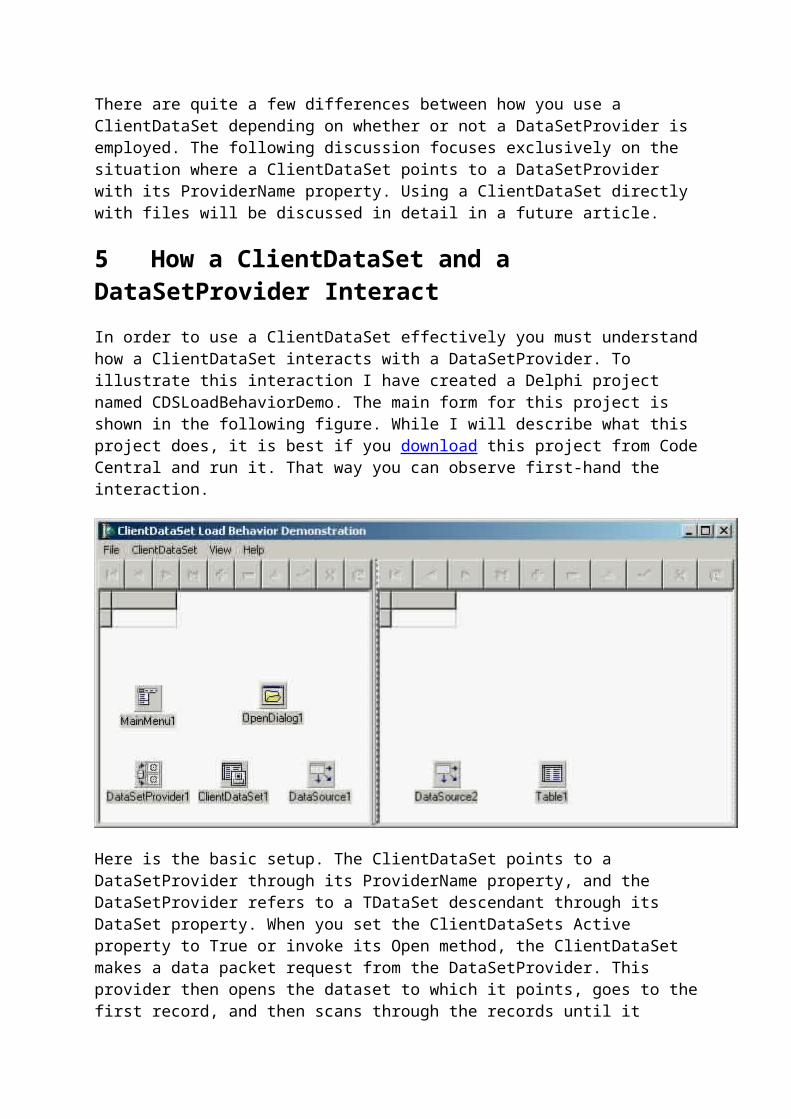
In order to use a ClientDataSet effectively you must understand how a ClientDataSet interacts with a DataSetProvider. To illustrate this interaction I have created a Delphi project named CDSLoadBehaviorDemo. The main form for this project is shown in the following figure. While I will describe what this project does, it is best if you download this project from Code Central and run it. That way you can observe first-hand the interaction.
Here is the basic setup. The ClientDataSet points to a DataSetProvider through its ProviderName property, and the DataSetProvider refers to a TDataSet descendant through its DataSet property. When you set the ClientDataSets Active property to True or invoke its Open method, the ClientDataSet makes a data packet request from the DataSetProvider. This provider then opens the dataset to which it points, goes to the first record, and then scans through the records until it reaches the end of the file. With each record it encounters the DataSetProvider encodes the data into a variant array. This variant array is sometimes referred to as the data packet. When the DataSetProvider is done scanning the records, it closes the dataset to which it points, and then passes the data packet to the ClientDataSet.
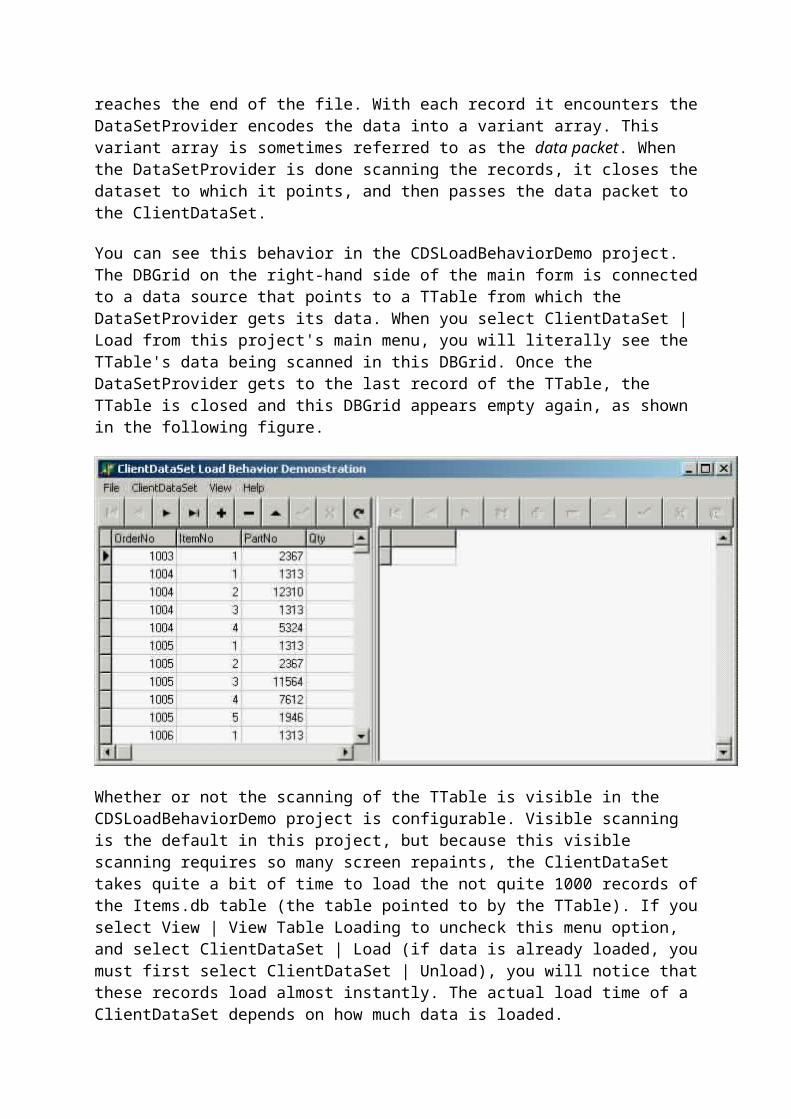
You can see this behavior in the CDSLoadBehaviorDemo project. The DBGrid on the right-hand side of the main form is connected to a data source that points to a TTable from which the DataSetProvider gets its data. When you select ClientDataSet | Load from this project's main menu, you will literally see the TTable's data being scanned in this DBGrid. Once the DataSetProvider gets to the last record of the TTable, the TTable is closed and this DBGrid appears empty again, as shown in the following figure.

Whether or not the scanning of the TTable is visible in the CDSLoadBehaviorDemo project is configurable. Visible scanning is the default in this project, but because this visible scanning requires so many screen repaints, the ClientDataSet takes quite a bit of time to load the not quite 1000 records of the Items.db table (the table pointed to by the TTable). If you select View | View Table Loading to uncheck this menu option, and select ClientDataSet | Load (if data is already loaded, you must first select ClientDataSet | Unload), you will notice that these records load almost instantly. The actual load time of a ClientDataSet depends on how much data is loaded.
Returning to a description of the ClientDataSet/DataSetProvider interaction, upon receiving the variant array, the ClientDataSet unpacks this data into memory. The structure of this dataset is based on metadata that the DataSetProvider encodes in the variant array. Even though the dataset to which the DataSetProvider pointed may contain one or more indexes, the data packet contains no index information. If you want indexes on the ClientDataSet, you must define or create them. ClientDataSet indexes can be defined at runtime using the IndexDefs property, and this topic will be discussed at length in a future article.
The ClientDataSet now behaves just like most any other opened TDataSet descendant. Its data can be navigated, filtered, edited, indexed, and so forth. As pointed out earlier, any edits made to the ClientDataSet will affect the contents of both the Data and Delta properties. In essence, these changes are cached, and are lost if the ClientDataSet is closed without specifically telling it save the changes. Changes are saved by invoking the ClientDataSet's ApplyChanges method.
6 Applying Changes to the Underlying Data Source
When you invoke ApplyChanges, the ClientDataSet passes Delta to the DataSetProvider. How the DataSetProvider applies the changes depends on how you have configured it. By default, the DataSetProvider will create an instance of the TSQLResolver class, and this class will generate SQL statements that will be executed against the underlying data source. Specifically, the SQLResolver will generate one SQL statement for each deleted, inserted, and modified record in the change log. Both the UpdateMode property of the DataSetProvider, as well as the ProviderFlags property of the TFields for the provider's dataset, dictate exactly
how this SQL statement is formed. Configuring these properties will be discussed in a future article.
If the dataset to which the DataSetProvider points is an editable dataset, you can alternatively set the provider's ResolveToDataSet property to True. With this configuration, a SQLResolver is not used. Instead, the DataSetProvider will edit the dataset to which it points directly. For example, the DataSetProvider will locate and delete each record marked for deletion in the change log, and locate and change each record marked modified in the change log.
If you download the CDSLoadBehaviorDemo project, you can see this for yourself. From your designer, select DataSetProvider1 and set its ResolveToDataSet property to True. Next, run the project and load the ClientDataSet. After making several changes to the data, select File | ApplyUpdates. Depending on the speed of your computer, you may or may not actually see the DBGrid become active as the TTable is edited. However, on most systems you will notice the DBNavigator buttons become active briefly as a result of the editing process. (If your computer is too fast, and you cannot see the DBGrid or the DBNavigator become active, you can assign an event handler to the AfterPost or AfterDelete event handlers of Table1, and issue a MessageBeep or ShowMessage call. That way you will prove to yourself that Table1 is being edited directly.)
There is a third option, which involves assigning an event handler to the DataSetProvider's BeforeUpdateRecord event handler. This event handler will then be invoked once for each record in the change log. You use this event handler to apply the changes in the change log programmatically, providing you with complete control over the resolution process. Writing BeforeUpdateRecord event handlers can be an involved process, and will be discussed in a future article.
When you invoke ApplyUpdates, you pass a single integer parameter. You use this parameter to identify your level or tolerance for resolution failures. If you cannot tolerate any failures to resolve changes to the underlying data source, pass the value 0 (zero). In this situation the DataSetProvider starts a transaction prior to applying updates. If even a single error is encountered, the transaction is rolled back, the change log remains unchanged, and the offending record is identified to the ClientDataSet (by triggering its OnReconcileError event handler, if one has been assigned).
If you pass a positive integer when calling ApplyChanges, the transaction will be rolled back only if the specified number of errors is exceeded. If fewer than the specified number of errors is encountered, the transaction is committed and the failed records are returned to the ClientDataSet. Furthermore, the applied records are removed from the change log, leaving only the changes that could not be applied.
If the number of failures exceeds the specified number, the transaction is rolled back, the change log is unchanged, and the records that could not be resolved are identified to the ClientDataSet as described earlier.
You can also pass a value of 1 when invoking ApplyUpdates. In this situation no transaction is started. Any records that can be applied are removed from the change log. Those whose resolution fail will remain in the change log, and are identified to the ClientDataSet through its OnReconcileError event handler.
That's basically how it works, although there are a number of variations that I have not considered. For example, it is possible to limit how many records the ClientDataSet gets from the DataSetProvider using the ClientDataSet's PacketRecords and FetchOnDemand properties. Similarly, you can pass additional information back and forth between the ClientDataSet and the DataSetProvider using a number of provided event handlers. Future articles in this series will describe how and when to use these properties.
7 Using ClientDataSets Nearly Everywhere
Now that we've overviewed the basic workings of the ClientDataSet and DataSetProvider components, let's return to the premise that I laid out at the beginning of this article. As I mentioned in the introduction, a strong argument can be made for using a ClientDataSet/DataSetProvider combination anytime data needs to be modified programmatically or displayed using data-aware controls.
There are three basic benefits to using ClientDataSet and DataSetProvider components for all data access.
1. The combination provides a consistent set of data access features, regardless of which data access mechanism you are using.
2. Their use provides a layer of abstraction in the data access layer, making future changes to the data access mechanism easier to implement.
3. For local file-base systems (Paradox or dBase tables, for example), the ClientDataSet can greatly reduce table and index corruption.
Let's consider each of these points separately.
8 A Consistent, Rich Feature Set
The ClientDataSet provides your applications with a consistent and powerful set of features independent of the data access mechanism you are using. Among these features are an editable result set, on-the-fly indexes, nested dataset, ranges, filters, cloneable cursors, aggregate fields, group state information, and much, much more. Specifically, even if the data access mechanism that you are using does not support a particular feature, such as aggregate fields or cloneable cursors, you have access to them through the ClientDataSet.
9 A Layer of Abstraction
In addition to the features supported by ClientDataSet, the ClientDataSet/DataSetProvider combination serves as a layer of abstraction between your application and the data access mechanism. If at a later time you find that you must change the data access mechanism you are using, such as switching from using the Borland Database Engine (BDE) to dbExpress, or from ADO to InterBase Express, your user interface features and programmatic control of data can remain largely unchanged. You simply need to hook the DataSetProvider to the new data access components, and provide any necessary adjustment to your DataSetProvider properties and event handlers.
Some people don't like the fact that a ClientDataSet holds changes in cache until you call ApplyUpdates. Fortunately, for those applications that need changes to be applied

immediately you can make a call to ApplyUpdates from the AfterPost and AfterDelete event handlers of the ClientDataSet.
10 Reduced Corruption
For developers who are still using local file-based databases, such as Paradox or dBase, there is yet another very powerful argument. Hooking a ClientDataSet/DataSetProvider pair to a TTable can reduce the likelihood of table or index corruption to near zero.
Table and index corruption occurs when something goes wrong while accessing the underlying table. Since a TTable component has an open file handle on the underlying table so long as the TTable is active, this corruption happens all too often in many applications. When the data is extracted from a TTable to a ClientDataSet, however, the TTable is active for only very short periods of time; during loading and resolution, to be precise (assuming that you set the TTable's Active property to False, leaving the activation entirely up to the DataSetProvider). As a result, in most applications, accessing a TTable's data using a ClientDataSet/DataSetProvider combination reduces the amount of time that a file handle is opened on the table to less than a fraction of one percent compared to what happens when a TTable is used alone.
11 But It's Not for Every Application
While these arguments are compelling, I must also admit that this approach is not appropriate for every application. That a ClientDataSet loads all of its data into memory makes its use much more difficult when you are working with large amounts of data. There are work-arounds that you can use if you point a ClientDataSet to, say, a multi-million record data source, but doing so sometimes requires a fair amount of coding, thereby complicating the application.
For most applications, however, the combination of features provided by the ClientDataSet outweigh the disadvantages. But even if you do not accept this argument, I think that you will find many situations where the use of a ClientDataSet enhances your application's features, and simplifies your efforts.

12 Defining a ClientDataSet's Structure Using FieldDefs By: Cary Jensen
Abstract: When creating a ClientDataSet's memory store on-the-fly, you must explicitly define the structure of your table. This article shows you how to do it at both runtime and design-time using FieldDefs.
The ClientDataSet is an in-memory data store that lets you to view, edit, and navigate data. Because these operations are performed on data held in memory, they tend to be performed very quickly.
This is the second article in a series designed to detail the use of the ClientDatSet. In the last installment, I provided you with a basic overview of ClientDataSet, with particular attention paid to how a ClientDataSet gets its data from a DataSetProvider. You use a ClientDataSet with a DataSetProvider when you obtain your data through a remote database management system (RDBMS) or a local database engine, such as the Borland Database Engine (BDE). Instead of using a DataSetProvider, it is possible to load and save the data held by a ClientDataSet from the local file system. Borland calls this mechanism MyBase.
As you learned in the preceding article in this series, a ClientDataSet loaded through a DataSetProvider get its metadata, the data that defines the fields of the dataset (commonly referred to as a table's structure), through the DataSetProvider. This metadata is produced by the DataSetProvider, based on the DataSet to which it points.
When a ClientDataSet gets its data from a local file using MyBase, the metadata is read from this file. However, neither mechanism is available when you create the in-memory dataset on-the-fly, at runtime. In these situations, it is necessary for you to explicitly define the structure of the ClientDataSet. Defining this metadata can be done either at design-time or at runtime. Once the metadata is defined, you create the in-memory dataset by calling the ClientDataSet's CreateDataSet method, or by using the ClientDataSet's component editor in the designer.
There are two ways to define the metadata of a ClientDataset. You can use the FieldDefs property of the ClientDataSet, or you can create TFields and associate them with the ClientDataSet. Creating the metadata definitions using FieldDefs is the most common. However, FieldDefs does not permit you to create virtual fields, such as calculated or aggregate fields. Similarly, using FieldDefs does not allow you to easily create nested datasets. Nested datasets represent one-to-many (sometimes called master-detail or parent-child) associations in your data. In this article you will learn how to use FieldDefs. The next article in this series will discuss the use of TFields to define the structure of a ClientDataSet.
13 Defining a Table's Structure Using FieldDefs
You can configure FieldDefs either at design time or at runtime. To define the structure of a client dataset at design time, you use the FieldDefs collection editor to create individual FieldDef instances. You then use the Object Inspector to configure each FieldDef, defining the field name, data type, size, or precision, among other options. At runtime, you define your

FieldDef objects by calling the FieldDefs AddFieldDef or Add methods. This section begins by demonstrating how to create your ClientDataSet's structure at design-time. Defining the table structure at runtime is shown later in this article.
14 Creating FieldDefs at Design-time
You create FieldDefs at design-time using the FieldDefs collection editor. To display this collection editor, select the FieldDefs property of a ClientDataSet in the Object Inspector and click the displayed ellipsis button. The FieldDefs collection editor is shown in the following figure.
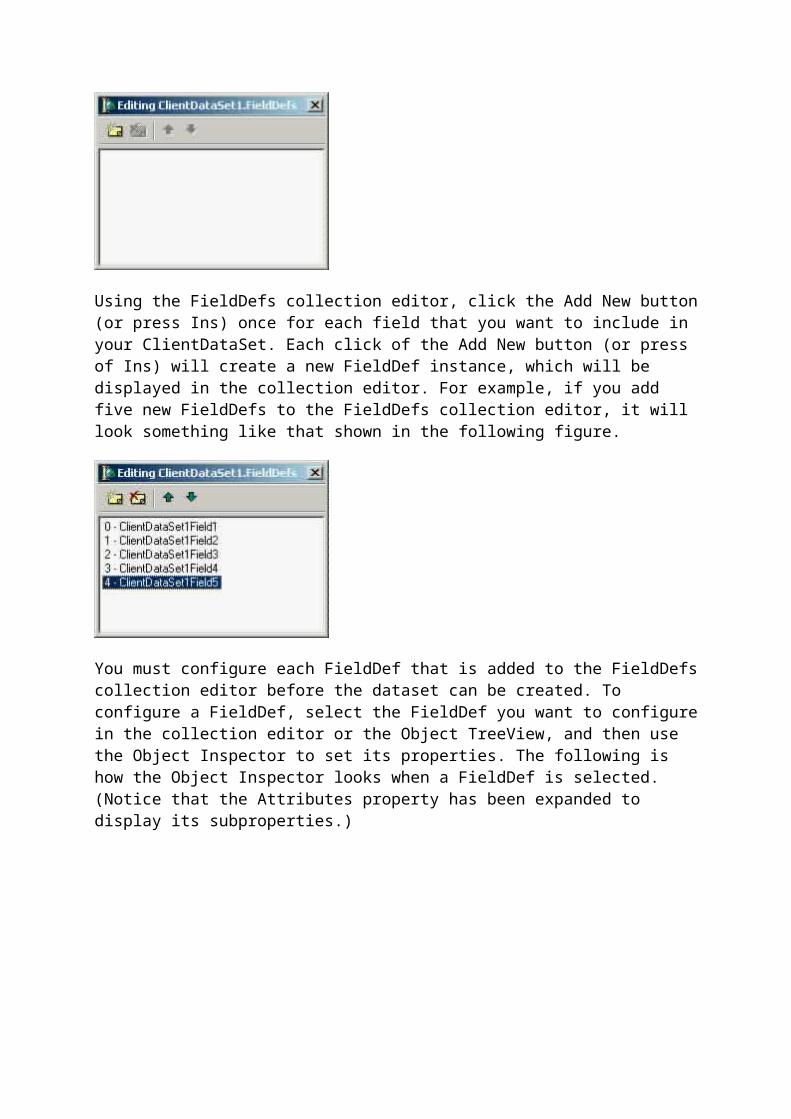
Using the FieldDefs collection editor, click the Add New button (or press Ins) once for each field that you want to include in your ClientDataSet. Each click of the Add New button (or press of Ins) will create a new FieldDef instance, which will be displayed in the collection editor. For example, if you add five new FieldDefs to the FieldDefs collection editor, it will look something like that shown in the following figure.
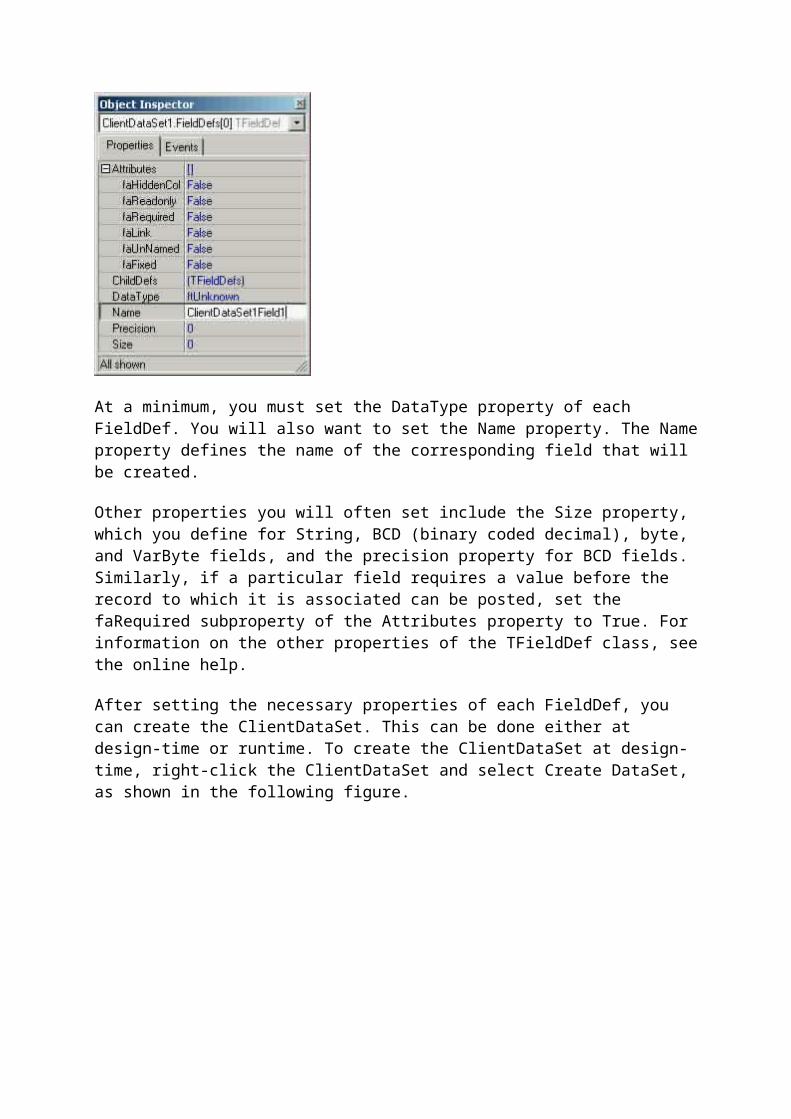
You must configure each FieldDef that is added to the FieldDefs collection editor before the dataset can be created. To configure a FieldDef, select the FieldDef you want to configure in the collection editor or the Object TreeView, and then use the Object Inspector to set its properties. The following is how the Object Inspector looks when a FieldDef is selected. (Notice that the Attributes property has been expanded to display its subproperties.)

At a minimum, you must set the DataType property of each FieldDef. You will also want to set the Name property. The Name property defines the name of the corresponding field that will be created.
Other properties you will often set include the Size property, which you define for String, BCD (binary coded decimal), byte, and VarByte fields, and the precision property for BCD fields. Similarly, if a particular field requires a value before the record to which it is associated can be posted, set the faRequired subproperty of the Attributes property to True. For information on the other properties of the TFieldDef class, see the online help.
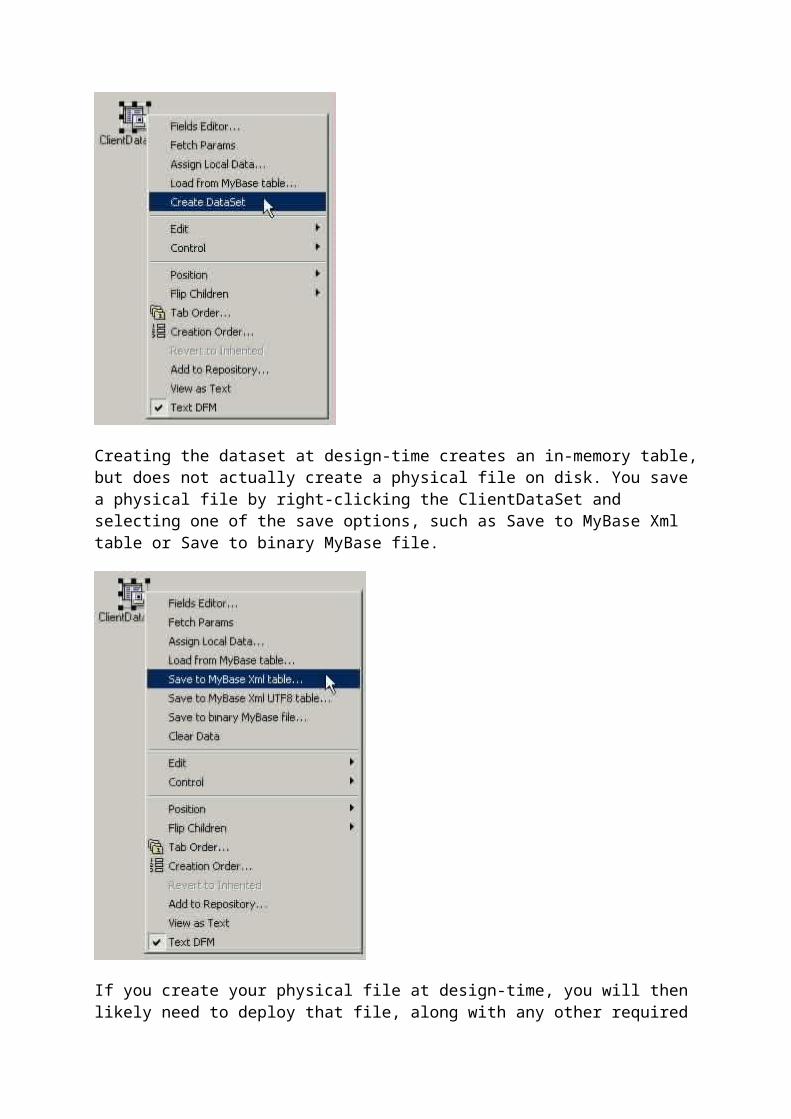
After setting the necessary properties of each FieldDef, you can create the ClientDataSet. This can be done either at design-time or runtime. To create the ClientDataSet at design-time, right-click the ClientDataSet and select Create DataSet, as shown in the following figure.
Creating the dataset at design-time creates an in-memory table, but does not actually create a physical file on disk. You save a physical file by right-clicking the ClientDataSet and

selecting one of the save options, such as Save to MyBase Xml table or Save to binary MyBase file.
If you create your physical file at design-time, you will then likely need to deploy that file, along with any other required files. As a result, many ClientDataSet users create the ClientDataSet at runtime. As mentioned earlier in this article, this task is performed by calling the ClientDataSet's CreateDataSet method. For example, consider the following event handler, which might be associated with the OnCreate event handler of the form to which it is associated.
procedure TForm1.FormCreate(Sender: TObject);const DataFile = 'mydata.xml';beginClientDataSet1.FileName := ExtractFilePath(Application.ExeName) + DataFile;if FileExists(ClientDataSet1.FileName) then ClientDataSet1.Openelse ClientDataSet1.CreateDataSet;end;
This code begins by defining the FileName property of the ClientDataSet, pointing to a file named mydata.xml in the application directory. Next, it tests to see if this file already exists. If it does, it opens the ClientDataSet, loading the specified file's metadata and data into memory. If the file does not exist, it is created through a call to CreateDataSet. When CreateDataSet is called, the in-memory structure is created based on the FieldDefs property of the ClientDataSet.
15 Creating FieldDefs at Runtime

Being able to create FieldDefs at design-time is an important feature, in that the Object Inspector provides you with assistance in defining the various properties of each FieldDef you add. However, there may be times when you do not know the structure of the dataset that you need until runtime. In those cases, you must define the FieldDefs property at runtime.
As mentioned earlier in this article, there are two methods that you can use to configure the FieldDefs property at runtime. The easiest technique is to use the Add method of the TFieldDefs class. The following is the syntax of Add:
procedure Add(const Name: String; DataType: TFieldType; Size: Integer = 0; Required: Boolean = False);
This method has two required parameters and two optional parameters. The first parameter is the name of the FieldDef and the second is its type. If you need to set the Size property, as is the case with fields of type ftString and ftBCD, set the Size property to the size of the field. For required fields, set the fourth property to a Boolean True.
The following code sample creates an in-memory table with five fields.
procedure TForm1.FormCreate(Sender: TObject);const DataFile = 'mydata.xml';beginClientDataSet2.FileName := ExtractFilePath(Application.ExeName) + DataFile;if FileExists(ClientDataSet2.FileName) then ClientDataSet2.Openelse begin with ClientDataSet2.FieldDefs do begin Clear; Add('ID',ftInteger, 0, True); Add('First Name',ftString, 20); Add('Last Name',ftString, 25); Add('Date of Birth',ftDate); Add('Active',ftBoolean); end; //with ClientDataSet2.FieldDefs ClientDataSet2.CreateDataSet; end; //elseend;
Like the previous code listing, this code begins by defining the name of the data file, and then testing whether or not it already exists. When it does not exist, the Add method of the FieldDefs property is used to define the table structure, after which the in-memory dataset is created using the CreateDataSet method.
If you consider how the Object Inspector looks when an individual FieldDef is selected in the FieldDefs collection editor, you will notice that the Add method is rather limited. Specifically, using the Add method you cannot create hidden fields, readonly fields, or BCD fields where you define precision. For these more complicated types of FieldDef definitions, you will need to use the AddFieldDef method of the FieldDefs property. The following is the syntax of AddFieldDef:
function AddFieldDef: TFieldDef;

As you can see from this syntax, this method returns a TFieldDef instance. Set the properties of this instance to configure the FieldDef. The following code sample shows you how to do this.
procedure TForm1.FormCreate(Sender: TObject);const DataFile = 'mydata.xml';beginClientDataSet2.FileName := ExtractFilePath(Application.ExeName) + DataFile;if FileExists(ClientDataSet2.FileName) then ClientDataSet2.Openelse begin with ClientDataSet2.FieldDefs do begin Clear; with AddFieldDef do begin Name := 'ID'; DataType := ftInteger; end; //with AddFieldDef do with AddFieldDef do begin Name := 'First Name'; DataType := ftString; Size := 20; end; //with AddFieldDef do with AddFieldDef do begin Name := 'Last Name'; DataType := ftString; Size := 25; end; //with AddFieldDef do with AddFieldDef do begin Name := 'Date of Birth'; DataType := ftDate; end; //with AddFieldDef do with AddFieldDef do begin Name := 'Active'; DataType := ftBoolean; end; //with AddFieldDef do end; //with ClientDataSet2.FieldDefs ClientDataSet2.CreateDataSet; end; //elseend;
16 Saving Data
If you have assigned a file name to the FileName property of a ClientDataSet whose in-memory table you create using CreateDataSet, and post at least one new record to the dataset, a physical file will be written to disk when you close or destroy the ClientDataSet. This happens automatically. Alternative, you can call the SaveToFile method of the ClientDataSet to explicitly save your data to a physical file. The following is the syntax of SaveToFile
procedure SaveToFile(const FileName: string = ''; Format TDataPacketFormat=dfBinary);
As you can see, both of the parameters of this method are optional. If you omit the first parameter, the ClientDataSet saves to a file whose name is assigned to the FileName property. If you omit the second parameter, the type of file that is written to disk will depend on the file extension of the file to which you are saving the data. If the extension is XML, an XML MyBase file is created. Otherwise, a binary MyBase file is written. You can override this behavior by specifying the type of file you want to write. If you pass dfBinary as the second parameter, a binary MyBase file is created. To create an XML MyBase file when the file extension of the file name is not XML, use dfXML.
On more than one occasion I have noticed that the XML MyBase file is not written to disk correctly if you do not explicitly call SaveToFile. Therefore, even though a ClientDataSet can save its data automatically, I make a habit of explicitly calling SaveToFile before closing or destroying a ClientDataSet.
17 An Example
An example application that demonstrates the use of the FieldDefs methods AddFieldDefs and Add can be downloaded from Code Central. The following is how the main form of this application looks after File | Create or Load is selected from the main menu.
18 Defining a ClientDataSet's Structure Using TFields By: Cary Jensen
Abstract: This article demonstrates how to define a ClientDataSet's structure at both design-time and runtime using TFields. How to create virtual and nested dataset fields is also demonstrated.
In the last installment of The Professional Developer, I described how to define the structure of a ClientDataSet using the ClientDataSet's FieldDefs property. This structure is used to create the in-memory data store when you call the ClientDataSet's CreateDataSet method. The metadata describing this structure, and any data subsequently entered into the ClientDataSet, will be saved to disk when the ClientDataSet's SaveToFile method is invoked.
While the FieldDefs property provides you with a convenient and valuable mechanism for defining a ClientDataSet's structure, it has several short-comings. Specifically, you cannot use FieldDefs to create virtual fields, which include calculated fields, lookup fields, and aggregate fields. In addition, creating nested datasets (one-to-many relationships) through FieldDefs is problematic. Specifically, while I have found it possible to create nested datasets using FieldDefs, I have not been able to successfully save and then later reload these nested datasets into a ClientDataSets. Only the TFields method appears to create nested datasets that can be reliably saved to the ClientDataSet's native local file formats and later re-loaded into memory.
Like the FieldDefs method of defining the structure of a ClientDataSet, you can define a ClientDataSet's structure using TFields either at design-time or at runtime. Since the design-time technique is the easiest to demonstrate, this article with start with it. Defining a ClientDataSet's structure using TFields at runtime is shown later in this article.
19 Defining a ClientDataSet's Structure at Design-Time
You define the TFields that represent the structure of a ClientDataSet at design-time using the Fields Editor. Unfortunately, this process is a bit more tedious than that using FieldDefs. Specifically, using the FieldDefs collection editor you can quickly add one or more FieldDef definitions, each of which defines the characteristic of a corresponding field in the ClientDataSets's structure. Using the TFields method, you must add one field at a time. All this really means is that it takes a little longer to define a ClientDataSet's structure using TFields than it does using FieldDefs.
Although using the TFields method of defining a ClientDataSet's structure is more time consuming, it has the advantage of permitting you to define both the fields of a table's structure for the purpose of storing data, as well as to define virtual fields. Virtual fields are used define dataset fields whose values are calculated at runtime -- the values are not physically stored.
The following steps demonstrate how to define a ClientDataSet's structure using TFields as design-time:
1. Place a ClientDataSet from the Data Access page of the Component Palette onto a form.
2. Right-click the ClientDataSet and select Fields Editor. The empty Fields Editor is shown in the following figure
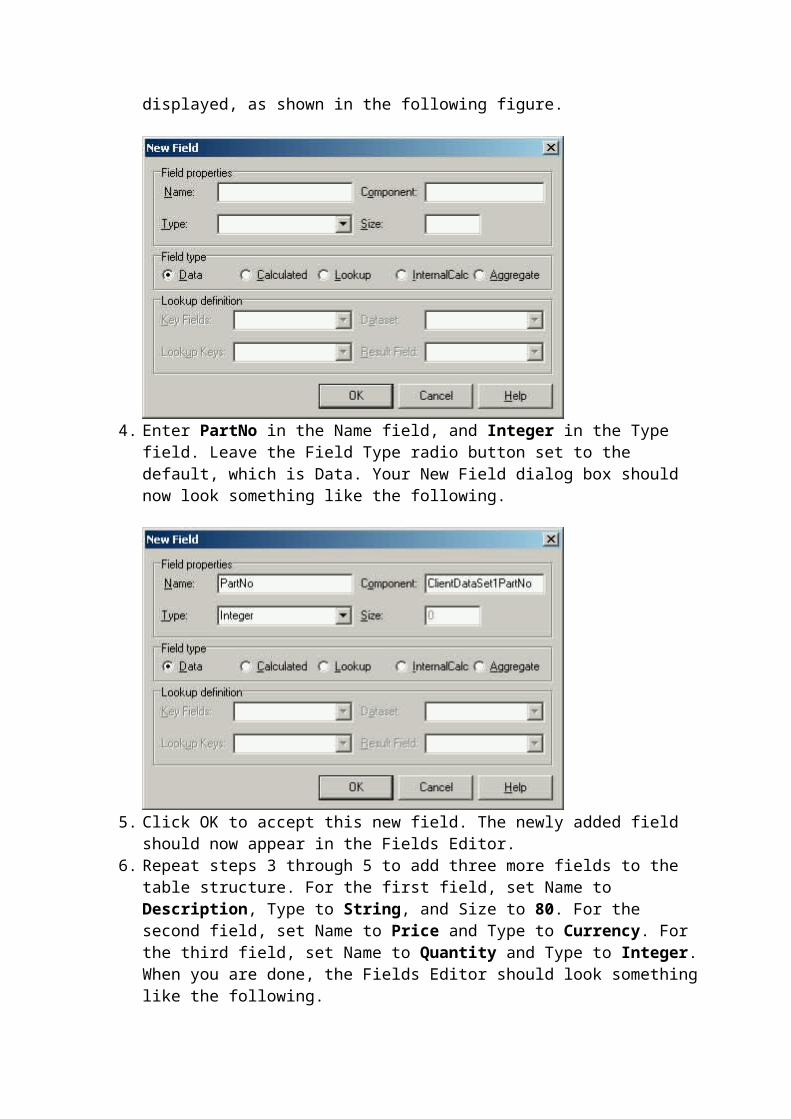
3. Right-click the Fields Editor and select New Field (or simply press the INS key). The New Field dialog box is displayed, as shown in the following figure.
4. Enter PartNo in the Name field, and Integer in the Type field. Leave the Field Type radio button set to the default, which is Data. Your New Field dialog box should now look something like the following.

5. Click OK to accept this new field. The newly added field should now appear in the Fields Editor.
6. Repeat steps 3 through 5 to add three more fields to the table structure. For the first field, set Name to Description, Type to String, and Size to 80. For the second field, set Name to Price and Type to Currency. For the third field, set Name to Quantity and Type to Integer. When you are done, the Fields Editor should look something like the following.
20 Adding a Calculated Virtual Field
Adding a virtual field to a ClientDataSet's structure at design-time is only slightly more complicated than adding a data field. This added complexity involves setting additional properties and/or adding additional event handlers.
Let's begin by adding a calculated field. Calculated fields require both a new field whose type is Calculated, and an OnCalcFields event handler, which is associated with the ClientDataSet itself. This event handler is used to calculate the value that will be displayed in this virtual field.

Note: This example demonstrates the addition of a calculated virtual field, which is available for most TDataSet descendents. Alternatively, these same basic steps can be used to add an InternalCalc field, which is a special calculated field associated with ClientDataSets. InternalCalc virtual fields can be more efficient than Calculated virtual fields, since they need to be re-calculated less often than calculated fields.
1. Begin by right-clicking the Fields Editor and selecting New Field (or press INS).2. Using the New Fields dialog box, set Name to Total Price, Type to Currency, and
Field Type to Calculated. Click OK to add the new field.
3. Now select the ClientDataSet in the Object Inspector or the Object TreeView, and display the Events page of the Object Inspector.
4. Double-click the OnCalcFields event handler to add this event handler. In Delphi or Kylix, complete this event handler as shown herecode:
procedure TDataModule2.ClientDataSet1CalcFields(DataSet: TDataSet);beginif (not ClientDataSet1.FieldbyName('Price').IsNull) and(not ClientDataSet1.FieldbyName('Quantity').IsNull) thenClientDataSet1.FieldByName('Total Price').Value :=ClientDataSet1.FieldbyName('Price').Value *ClientDataSet1.FieldByName('Quantity').Value;end;
21 Adding a Virtual Aggregate Field
Aggregate fields, which can be used to perform a number of automatic calculations across one or more records of your data, do not require event handlers, but do require that the ClientDataSet have at least one index. The following steps will walk you through adding an index, as well as an aggregate field that will use the index. A more complete discussion of ClientDataSet indexes will appear in a later article in this series.
1. With the ClientDataSet selected in the Object Inspector, choose the IndexDefs property and double-click the ellipsis button that appears. Using the IndexDefs collection editor, click the Add New button once.

2. With this newly adding IndexDef selected in the IndexDefs collection editor, use the Object Inspector to set its Name property to PNIndex, and its Fields property to PartNo.
3. Select the ClientDataSet in the Object Inspector once again. Set its IndexName property to PNIndex and its AggregatesActive property to True.
4. We are now ready to add the aggregate field. Double-click the ClientDataSet to display the Fields Editor (alternatively, you can right-click the ClientDataSet and select Fields Editor from the displayed context menu).
5. Right-click the Fields Editor and select New Field.6. Set Name to Total Parts and Data Type to Aggregate. Select OK to close the New
Field dialog box. The aggregate virtual field is displayed in its own section of the Fields Editor, as shown in the following figure.
7. Select the Total Parts aggregate field in the Fields Editor. Then, using the Object Inspector, set the Expression property to Sum(Quantity), the IndexName property to PXIndex, and Active to True.
That's all it takes. All you need to do now is call the CreateDataSet method at runtime (or alternatively, right-click the ClientDataSet at design-time and select Create DataSet). Of course, if you want to actually see the resulting ClientDataSet, you will also have to hook it up to one or more data-aware controls.
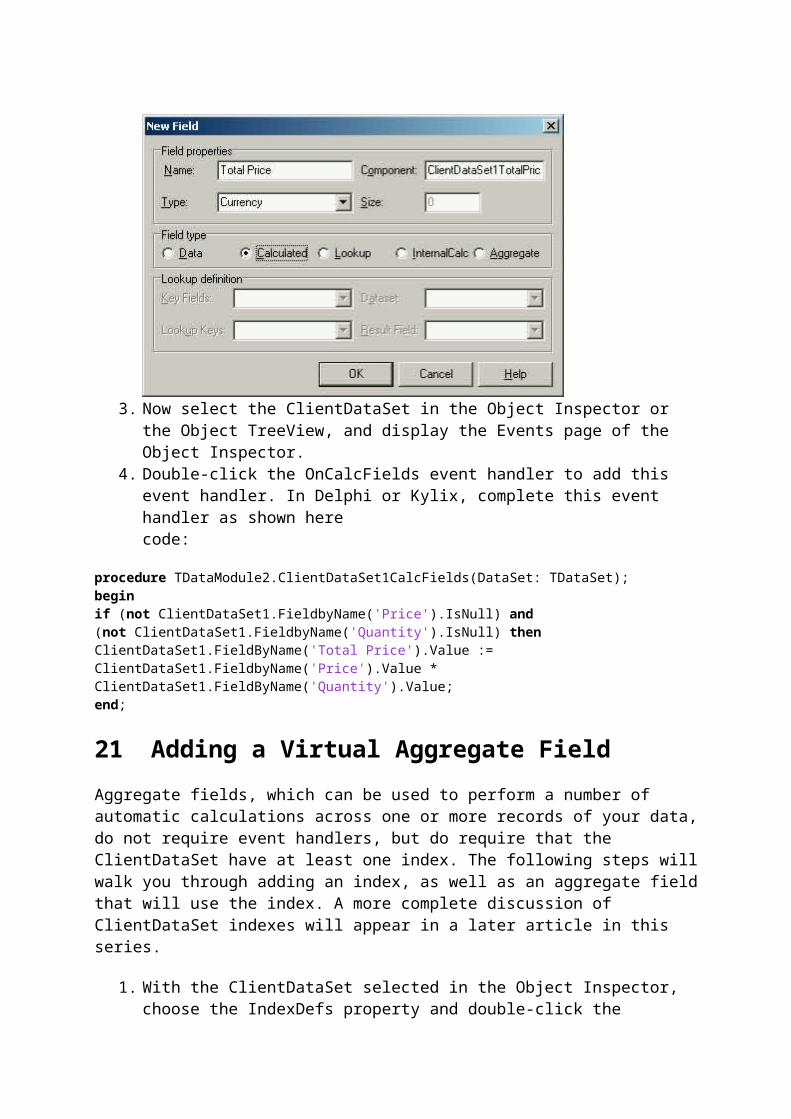
The use of the TField definitions described here are demonstrated in the FieldDemo project, which you can download from Code Central. The following is the main form of this project.

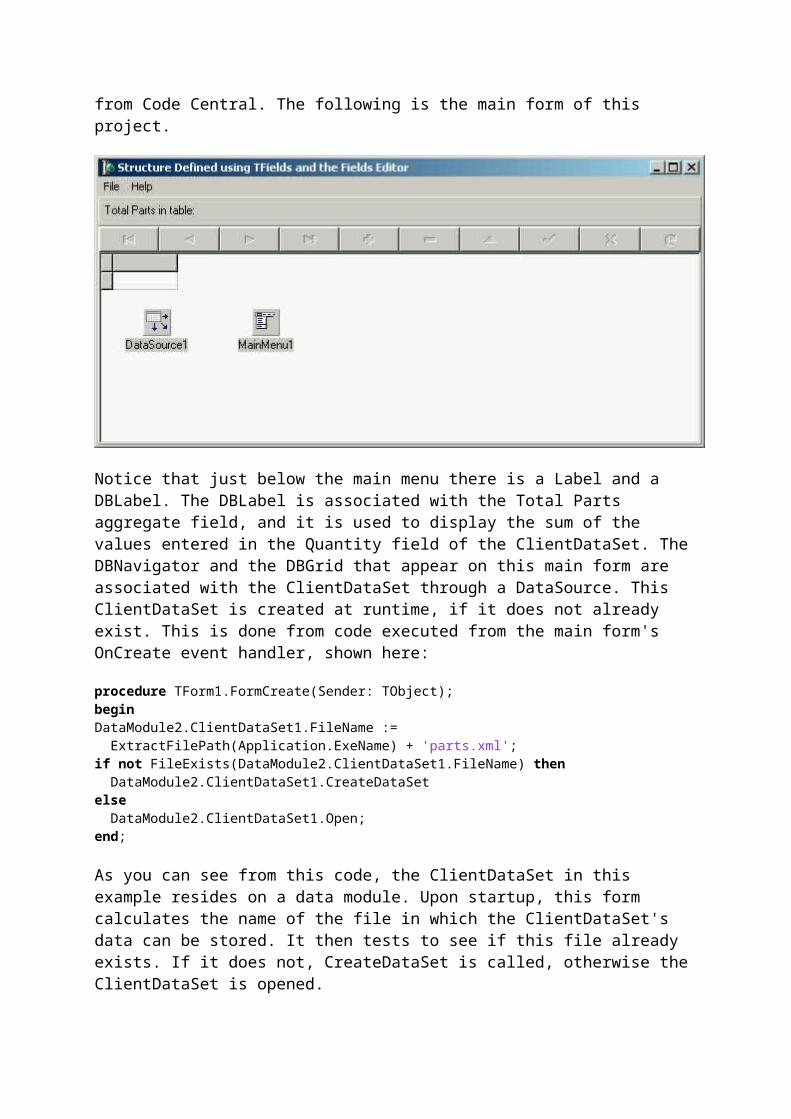
Notice that just below the main menu there is a Label and a DBLabel. The DBLabel is associated with the Total Parts aggregate field, and it is used to display the sum of the values entered in the Quantity field of the ClientDataSet. The DBNavigator and the DBGrid that appear on this main form are associated with the ClientDataSet through a DataSource. This ClientDataSet is created at runtime, if it does not already exist. This is done from code executed from the main form's OnCreate event handler, shown here:
procedure TForm1.FormCreate(Sender: TObject);beginDataModule2.ClientDataSet1.FileName := ExtractFilePath(Application.ExeName) + 'parts.xml';if not FileExists(DataModule2.ClientDataSet1.FileName) then DataModule2.ClientDataSet1.CreateDataSetelse DataModule2.ClientDataSet1.Open;end;
As you can see from this code, the ClientDataSet in this example resides on a data module. Upon startup, this form calculates the name of the file in which the ClientDataSet's data can be stored. It then tests to see if this file already exists. If it does not, CreateDataSet is called, otherwise the ClientDataSet is opened.
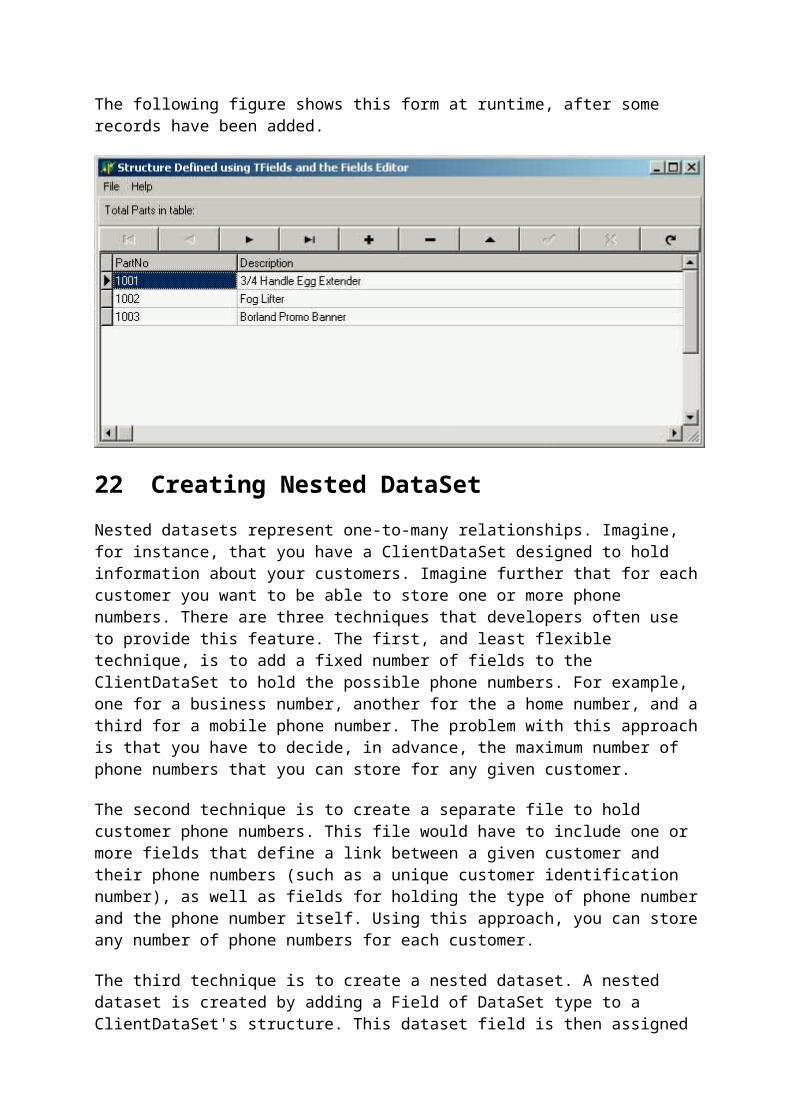
The following figure shows this form at runtime, after some records have been added.

22 Creating Nested DataSet
Nested datasets represent one-to-many relationships. Imagine, for instance, that you have a ClientDataSet designed to hold information about your customers. Imagine further that for each customer you want to be able to store one or more phone numbers. There are three techniques that developers often use to provide this feature. The first, and least flexible technique, is to add a fixed number of fields to the ClientDataSet to hold the possible phone numbers. For example, one for a business number, another for the a home number, and a third for a mobile phone number. The problem with this approach is that you have to decide, in advance, the maximum number of phone numbers that you can store for any given customer.
The second technique is to create a separate file to hold customer phone numbers. This file would have to include one or more fields that define a link between a given customer and their phone numbers (such as a unique customer identification number), as well as fields for holding the type of phone number and the phone number itself. Using this approach, you can store any number of phone numbers for each customer.
The third technique is to create a nested dataset. A nested dataset is created by adding a Field of DataSet type to a ClientDataSet's structure. This dataset field is then assigned to the DataSetField property of a second client dataset. Using this second ClientDataSet, you can define fields to store the one or more records of related data. In this example it might make sense to add two fields, one to hold the type of phone number (such as, home, cell, fax, and so forth), and a second to hold the phone number itself. Similar to the second technique, nested datasets permit a customer to have any number of phone numbers. On the other hand, unlike the second technique, in which phone numbers are stored in a separate file, there is no need for any fields to link phone numbers to customers, since the phone numbers are actually "nested" within each customer's record.
Here is how you create a nested dataset at design-time.
1. Using the technique outlined earlier in this article (using the Fields Editor), create one field of data type Data for each regular field in the dataset (such as Customer Name, Title, Address1, Address2, and so forth).

2. For each nested dataset, add a new field, using the same technique that you use for the other data fields, but set its Data Type to DataSet.
3. For each DataSet field that you add to your first ClientDataSet, add an additional ClientDataSet. Associate each of these secondary ClientDataSets with one of the primary ClientDataSet's DataSet fields using the secondary ClientDataSet's DataSetField property.
4. To define the fields of each nested dataset, add fields to each secondary ClientDataSet using its Fields Editor, just as you added fields to the primary ClientDataSet. For example, following the customer/phone numbers example discussed here, the nested dataset fields would include phone type and phone number.
For an example of a project that demonstrates how to create nested datasets at design-time, download the NestedDataSetFields project from Code Central. This project provides an example of how the customer/phone numbers application might be implemented. This project contains a data module that includes two ClientDataSets. One is used to hold the customer information, and it includes a DataSet field called PhoneNumbers. This DataSet field is associated with a second ClientDataSet through the second ClientDataSet's DataSetField property. The Fields Editor for this second ClientDataSet, shown in the following figure, displays its two String fields, one for Phone Type and the other for Phone Number.
23 Creating a ClientDataSet's Structure at Runtime using TFields
In the previous article in this series, where a ClientDataSet's structure was defined using FieldDefs, you learned that you can define the structure of a ClientDataSet both at design-time as well as at runtime. As explained in that article, the advantage of using design-time configuration is that you can use the features of the Object Inspector to assist in the definition of the ClientDataSet's structure. This approach, however, is only useful if you know the structure of your ClientDataSet in advance. If you do not, your only option is to define your structure at runtime.
You define your TFields at runtime using the methods and properties of the appropriate TField or TDataSetField class. Specifically, you call the constructor of the appropriate TField or TDataSetField object, setting the properties of the created object to define its nature. Among the properties of the constructed object, one of the most important is the DataSet property. This property defines to which TDataSet descendant you want the object associated

(which will be a ClientDataSet in this case, since we are discussing this type of TDataSet). After creating all of the TFields or TDataSetFields, you call the ClientDataSet's CreateDataSet method. Doing so creates the ClientDataSet's structure based on the TFields to which it is associated.
The following is a simple example of defining a ClientDataSet's structure using TFields.
procedure TForm1.FormCreate(Sender: TObject);beginwith ClientDataSet1 do begin with TStringField.Create(Self) do begin Name := 'ClientDataSet1FirstName'; FieldKind := fkData; FieldName := 'FieldName'; Size := 72; DataSet := ClientDataSet1; end; //FieldName with TMemoField.Create(Self) do begin Name := 'ClientDataSet1LastName'; FieldKind := fkData; FieldName := 'Last Name'; DataSet := ClientDataSet1; end; //Last Name ClientDataSet1.CreateDataSet end;end;
You can test this code for yourself easy enough. Simply create a project and place on the main form a ClientDataSet, a DataSource, a DBGrid, and a DBNavigator. Assign the DataSet property of the DBGrid and the DBNavigator to the DataSource, assign the DataSet property of the DataSource to ClientDataSet, and ensure that the ClientDataSet is named ClientDataSet1. Finally, add the preceding code to the OnCreate event handler of the form to which these components appear, and run the project.
24 TFields and FieldDefs are Different
When your structure is defined using TFields, there is an important behavior that might not be immediately obvious. Specifically, the TFields specified at design-time using the Fields Editor define objects that are created automatically when the form, data module, or frame to which they are associated is created. These objects define the ClientDataSet's structure, which in turn defines the value of the ClientDataSet's FieldDefs property.
This same behavior does not apply when a ClientDataSet's structure is defined using FieldDefs at design-time. Specifically, the TFields of a ClientDataSet whose structure is defined using FieldDefs is defined when the ClientDataSet's CreateDataSet method is invoked. But they are also created when metadata is read from a previously saved ClientDataSet file. If a ClientDataSet is loaded from a saved file, the structure defined in the metadata of the saved file takes precedence. In other words, the FieldDefs property created at design-time is replaced by FieldDefs defined by the saved metadata, and this is used to create the TFields.
When your ClientDataSet's structure is defined using TFields at design-time, metadata in a previously saved ClientDataSet is not used to define the TFields, since they already exist. As a result, when a ClientDataSet's structure is defined using TFields, and you attempt to load previously save data, it is essential that the metadata in the file being loaded be consistent with the defined TFields.
25 Creating a ClientDataSet's Structure Using TFields at Runtime
As mentioned in the preceding section, TFields defined at design-time cause the automatic creation of the corresponding TField instances at runtime (as well as FieldDefs). If you define your ClientDataSet's structure at runtime, by calling the constructor of the various TField and TDataSetField objects that you need, you must follow the call to these constructors with a call to the ClientDataSet's CreateDataSet method before the ClientDataSet can be used. This is true even when you intend to load the ClientDataSet from previously saved data.
The reason for this is that, as pointed out in the previous section, ClientDataSet structures defined using TFields do not rely on the metadata of previously saved ClientDataSets. Instead, the structure relies on the TFields and TDataSetFields that have been created for the ClientDataSet. This becomes particularly obvious when you consider that virtual fields are not stored in the files saved by a ClientDataSet. The only way that you can have virtual fields in a ClientDataSet whose structure is defined at runtime is to create these fields using the appropriate constructors, and then call CreateDataSet to build the ClientDataSet's in-memory data store. Only then can a compatible, previously saved data file be loaded into the ClientDataSet.
Here is another way to put it. When you define your ClientDataSet's structure using FieldDefs, you call CreateDataSet only if there is no previously saved data file. If there is a previously saved data file, you simply load it into the ClientDataSet - CreateDataSet does not need to be invoked. The ClientDataSet's structure is based on the saved metadata.
By comparison, when you define your ClientDataSet's structure using TFields at runtime, you always call CreateDataSet (but only after creating and configuring the TField and TDataSetField instances that define the ClientDataSet's structure). This must be done whether or not you want to load previously saved data.
26 An Example
The VideoLibrary project, which can be downloaded from Code Central, includes code that demonstrates how to create data, aggregate, lookup, and nested dataset fields at runtime using TFields. This project, whose running main form is shown in the following figure, includes two primary ClientDataSets. One is used to hold a list of videos and another holds a list of Talent (actors). The ClientDataSet that holds the video information contains two nested datasets: one to hold the list of talent for that particular video and another to hold a list of the video's special features (for instance, a music video found on a DVD).

This project is too complicated to describe adaquately in this limited space (I'll save that discussion for a future article). Instead, I;ll leave it up to you to download the project. In particular, you will want to examine the OnCreate event handler for this project's data module. There you will see how the various data fields, virtual fields, dataset fields, and indexes are created and configured.
27 Understanding ClientDataSet Indexes By: Cary Jensen
Abstract: A ClientDataSet does not obtain its indexes from the data it loads. Indexes, if you want them, must be explicitly defined. This article shows you how to do this at design-time or runtime.
In many respects, an index on a ClientDataSet is like that on any other TDataSet descendant. Specifically, an index controls the order of records in the DataSet, as well as enables or enhances a variety of other operations, such as searches, ranges, and dataset linking.
In earlier articles in this series I described how the structure of a ClientDataSet is defined. There you learned that, if a ClientDataSet is loaded through a DataSetProvider, the structure is based on the columns that the DataSetProvider obtains from its DataSet. When a DataSetProvider is not involved, the structure is either based on metadata loaded from a file previously saved by a ClientDataSet, or is defined by the ClientDataSet's FieldDefs property or by TFields associated with the ClientDataSet.
Unlike a ClientDataSet's structure, which is normally obtained from existing data, a ClientDataSet's indexes are not. Specifically, when a ClientDataSet is loaded with data obtained from a DataSetProvider, or is loaded from a previously saved ClientDataSet file, the ClientDataSet's structure is largely (and usually entirely) defined by the DataSetProvider, or loaded from the saved file. Indexes, with the exception of two default indexes, are solely the responsibility of the ClientDataSet itself. In other words, even if the DataSet from which a DataSetProvider obtains its data possesses indexes, those are unrelated to any indexes on the ClientDataSet loaded from that DataSetProvider.
Consider the CUSTOMER table found in the example EMPLOYEE.GDB InterBase database that ships with Delphi. There are four customer table-related indexes present in the database, including indexes based on the CUST_NO, COMPANY, and COUNTRY fields. Regardless of how you load the data from that table into a ClientDataSet, those indexes will be all but ignored by the DataSetProvider, and will be absent in the ClientDataSet. With the exception of the two default indexes that a ClientDataSet creates for its own use, if you want additional indexes in a ClientDataSet, you must define them explicitly.
In general, the indexes of a ClientDataSet can be divided into three categories: default indexes, temporary indexes, and persistent indexes. Each of these indexes is discussed in the following sections.
28 Default Indexes
Most ClientDataSets have two default indexes, as shown in the following image of the Object Inspector. One of these is named DEFAULT_ORDER, and the other is named CHANGEINDEX. DEFAULT_ORDER represents the original order that the records where loaded into the ClientDataSet. If the ClientDataSet is loaded through a DataSetProvider, this order matches that of the DataSet from which the DataSetProvider obtains its data. For example, if the DataSetProvider points to a SQLDataSet that includes a SQL query with an ORDER BY clause, DEFAULT_ORDER will order the records in the same order as that

defined by the ORDER BY clause. If the DataSetProvider doesn't specify an order, the default order will match the natural order of the records in the corresponding DataSet.
While DEFAULT_ORDER is associated with the records held in the Data property of the ClientDataSet, CHANGEINDEX is associated with the order of records held in the Delta property, also known as the change log. This index is maintained as changes are posted to a ClientDataSet, and it controls the order in which the changed records will be processed by the DataSetProvider when ApplyUpdates is called.
These default indexes have limited utility in most database applications. For example, DEFAULT_ORDER can be used to return data held in a ClientDataSet to the originally loaded order after having switched to some other index. In most cases, however, a ClientDataSet's natural order is of little interest. Most developers want to based indexes on specific fields, depending on the needs of the application.
CHANGEINDEX, by comparison, can be used to display only those records that appear in the change log, and in the order in which those changes will be applied if ApplyUpdates is called. Again, this order might be interesting, most developers are not concerned with the order in which changes are applied. One reason is that there is another mechanism that a ClientDataSet provides for this purpose: the StatusFilter property. StatusFilter permits you to display specific kinds of changes contained in the change log. These changes can be displayed using any ClientDataSet index, not just the order in which the changes where applied. CHANGEINDEX is really only useful when the order that the records where placed in the change log is of interest.
29 Creating Indexes
There are two types of indexes that you explicitly create: temporary indexes and persistent indexes. Each of these index types play an important role in applications, permitting you to control the order that records appear in the ClientDataSet, as well as to enable index-based operations, including searches, ranges, and dataset linking. Each of these index types is discussed in the following sections.
30 Temporary Indexes
Temporary indexes are created with the IndexFieldNames property. To create a temporary index, set the IndexFieldNames property to the name of the field or fields you want to base the index on. When you need a multi-field index, separate the field names with semicolons. For example, imagine that you have a ClientDataSet that contains customer records, including account number, first name, last name, city, state, and so on. If you want to sort this data by last name and first name (and assuming that these fields are named FirstName and LastName, respectively), you can create a temporary index by setting the client dataset's IndexFieldNames property to the following string:
LastName;FirstName
As with all published properties, this can be done at design time, or it can be done in code at runtime using a statement similar to the following:
ClientDataSet1.IndexFieldNames := 'LastName;FirstName';
When you assign a value to the ClientDataSet's IndexFieldNames property, the ClientDataSet immediately generates the index. If the contents of the ClientDataSet are being displayed, those records will appear sorted in ascending order by the fields of the index, with the first field in the index sorted first, followed the second (if present), and so on.
Indexes create this way are temporary in that when you change the value of the IndexFieldNames property, the previous index is discarded, and a new one is created. For example, imagine that if after you created the last name/first name index, you then execute the following statement:
ClientDataSet1.IndexFieldNames := 'FirstName'
This statement will cause the existing temporary index to be discarded and a new index to be generated. If the new index defines a sort order different from the previous index, the record display order is also updated. If you later set the IndexFieldNames property back to 'LastName;FirstName', the first name index will be discarded, and a new last name/first name index will be created.
Temporary indexes are extremely useful under a number of situations, such as when you want to permit your users to sort the data based on any field or field combination. There are, however, some drawbacks to temporary indexes. One of these is that indexes take some time to build, and temporary indexes must be re-built more often than persistent indexes. The time it takes a ClientDataSet to build an index is based on the number of records being indexed, the field types being indexes, and number of fields in the index. Since these indexes are built in memory, even a complicated temporary index can be built in a fraction of a second, so long as there are less than 10,000 records or so in the ClientDataSet. Even with more than 100,000, most indexes can be built in less than 10 seconds on a typical workstation.
A more important concern when deciding between temporary and persistent indexes involves index features. Specifically, you can only build ascending temporary indexes. In addition, temporary indexes do not support more advanced index options, such as unique indexes. If you need a more complicated index, you will need to create persistent indexes.
31 Persistent Indexes
Persistent indexes are index definitions that can be used to build indexes at runtime. Once a persistent index has been built, it remains available to the ClientDataSet so long as the ClientDataSet remains open. For example, if there is a persistent index based on a field named FirstName, setting the ClientDataSet to use this index causes the index to be built. If you then set the ClientDataSet to use another persistent index based on the last name/first name field combination, that index is built, but the first name-based index is not discarded. If you then set the ClientDataSet to use the first name index once again, it immediately switches to that previously created index. Unlike temporary indexes, persistent indexes are not discarded until the ClientDataSet against which they were built is closed.
You create IndexDefs at design-time using the IndexDefs collection property editor, shown in the following figure. To display this collection editor, select the IndexDefs property of a ClientDataSet in the Object Inspector and click the ellipsis button that appears.
Note that the IndexDefs collection property editor may not include default indexes. Whether or not default indexes appear depends on whether or not you have loaded data into the ClientDataSet at design-time, and where you loaded that data from.
Click the Add New button on the IndexDefs collection editor toolbar (or press the INS key) once for each persistent index that you want to define for a ClientDataSet. Each time you click the Add New button (or press INS), a new IndexDef is created. Complete the index definitions by selecting each IndexDef in the IndexDefs collection editor, one at a time, and configuring it using the Object Inspector. The Object Inspector, with an IndexDef selected, is shown in the following figure. Note that the Options property has been expanded to show its various flags.

At a minimum, you must set the Fields property of an IndexDef to the name of the field or fields to be indexed. If you are building a multi-field index, separate the field names with semicolons. You cannot include virtual fields, such as calculated or aggregate fields, in an index.
By default, indexes created using IndexDefs are ascending indexes. If you want the index to be a descending index, set the ixDesccending flag in the Options property. Alternatively, you can set the DescFields property to a semicolon-separated list of the fields that you want sorted in descending order. Using DescFields, you can define an index in which one or more, but not necessarily all fields, are sorted in descending order.
Indexed string fields normally are case sensitive. If you want string fields to be indexes without regards to the case of the strings, you can set the ixCaseInsensitive flag in the Options property. Or, you can include a semicolon-separated list of fields whose contents you want sorted case insensitive in the CaseInsFields property. Use the CaseInsFields property when you want to sort some, but not all, string fields without regards to case.
If you want the ClientDataSet to maintain information about groups, set the GroupingLevel property. Groups refer to the unique values on one or more fields of an index. Setting GroupingLevel to 0 maintains no grouping information, treating all records in a ClientDataSet as belonging to a single group. A GroupingLevel of 1 treats all records that contains the same value in the first field of the index as a group. Setting GroupingLevel to 2 treats all records with the combination of vlaues on the first two fields of the index as a group, and so on. GroupingLevel is typically only useful if you are using aggregate fields, or want to call the GetGroupState method. Grouping will be discussed in greater detail in a future article in this series.
In addition to sorting records, indexes can ensure the uniqueness of records. If you want to ensure that no two records contain the same data in the field or fields of an index, set the ixUnique flag in the IndexDef's Option property.
The remaining properties of the TIndexDef class do not apply to ClientDataSets. For example, ClientDataSets do not support expression, primary, or non-maintained indexes. As a result, do

not set the Expression property or add the ixNonMaintained or ixPrimary flags to the Options property when defining an IndexDef for a ClientDataSet. Likewise, Source only applies to DataSets that refer to dBASE tables. Do not set the Source property when defining an index for ClientDataSets.
32 Using Persistent Indexes
A persistent index is created when a ClientDataSet's IndexName property is set to the name of an IndexDef. If IndexName is set at design-time, or is set prior to opening a ClientDataSet, that index is built immediately after the ClientDataSet is opened. Note that a ClientDataSet does not build an index until it needs it. Specifically, even if you have fifty different persistent indexes defined for a ClientDataSet, no index is actually built until the ClientDataSet is opened, and then the only index that will be built will be the one whose name is assigned to the IndexName property. If IndexName is not set to the name of an index, the DEFAULT_ORDER index is used.
33 Creating Persistent Indexes at Runtime
To create IndexDefs at runtime, you use either the Add or AddIndexDef methods of the object assigned to the ClientDataSet's IndexDefs property, or you can call the ClientDataSet's AddIndex method. Like the related AddFieldDef, AddIndexDef is more flexible than AddIndex, which makes it the recommended method for adding a persistent index at runtime.
AddIndexDef returns an IndexDef instance, which you use to set the properties of the index. For example, the following statement creates an IndexDef for the data in the ClientDataSet, and then makes this the active index:
with ClientDataSet1.IndexDefs.AddIndexDef do begin Name := 'LastFirstIdx'; Fields := 'LastName;FirstName'; Options := [ixDescending, ixCaseInsensitive]; end; ClientDataSet1.IndexName := 'LastFirstIdx';
Unlike AddFieldDefs, the AddIndex method is a method of the TCustomClientDataSet class. The following is the syntax of AddIndex:
procedure AddIndex(const Name, Fields: string; Options: TIndexOptions; const DescFields: string = ''; const CaseInsFields: string = ''; const GroupingLevel: Integer = 0);
As you can see from this syntax, this method requires at least three parameters. The first parameter is the name of the index you are creating, the second is the semicolon-separated list of the index fields, and the third is the index options. Note, however, that only the ixCaseInsensitive, ixDescending, and ixUnique TIndexOptions are valid when you invoke AddIndex. Using any of the other TIndexOptions flags raises an exception.
The fourth parameter, DescFields, is an optional parameter that you can use to list the fields of the index that you want to sort in descending order. You use this parameter when you want some of the index fields to be sorted in ascending order and others in descending order. When you use DescFields, do not include the ixDescending flag in Options.

Like DescFields, CaseInsFields is an optional String property that you can use to select which fields of the index should be sorted without respect to uppercase or lowercase characters. When you use CaseInsFields, do not include the ixCaseInsensitive flag in Options.
The final parameter, GroupingLevel, is an optional parameter that you use to define the default grouping level to use when the index is selected.
34 An Example: Creating Indexes On-the-fly
One of the most requested features in a database application is the ability to sort the data displayed in a DBGrid by clicking on the column title. The CDSSort project demonstrates how you can add this feature to any DBGrid that displays data from a ClientDataSet. (Click here to download this project.) This project makes use of a generic procedure named SortCustomClientDataSet. This procedure is designed to work with any TCustomClientDataSet descendant, including ClientDataSet, SQLClientDataSet, BDEClientDataSet, and IBClientDataSet. However, some of the properties used in this code are not visible to the TCustomClientDataSet class. Specifically, the IndexDefs and IndexName properties are declared protected in TCustomClientDataSet. As a result, this code relies on runtime type information (RTTI) to work with these properties. This means that any unit implementing this procedure must use the TypInfo unit.
The following is the SortCustomClientDataSet procedure:
uses TypInfo; //TypInfo needed for RTTI GetObjectProp //IsPublishedProp, and SetStrProp methods
function SortCustomClientDataSet(DataSet: TCustomClientDataSet; const FieldName: String): Boolean;var i: Integer; IndexDefs: TIndexDefs; IndexName: String; IndexOptions: TIndexOptions; Field: TField;beginResult := False;Field := DataSet.Fields.FindField(FieldName);//If invalid field name, exit.if Field = nil then Exit;//if invalid field type, exit.if (Field is TObjectField) or (Field is TBlobField) or (Field is TAggregateField) or (Field is TVariantField) or (Field is TBinaryField) then Exit;//Get IndexDefs and IndexName using RTTIif IsPublishedProp(DataSet, 'IndexDefs') then IndexDefs := GetObjectProp(DataSet, 'IndexDefs') as TIndexDefselse Exit;if IsPublishedProp(DataSet, 'IndexName') then IndexName := GetStrProp(DataSet, 'IndexName')else Exit;//Ensure IndexDefs is up-to-dateIndexDefs.Update;//If an ascending index is already in use,//switch to a descending indexif IndexName = FieldName + '__IdxA'

then begin IndexName := FieldName + '__IdxD'; IndexOptions := [ixDescending]; endelse begin IndexName := FieldName + '__IdxA'; IndexOptions := []; end;//Look for existing indexfor i := 0 to Pred(IndexDefs.Count) dobegin if IndexDefs[i].Name = IndexName then begin Result := True; Break end; //ifend; // for//If existing index not found, create oneif not Result then begin DataSet.AddIndex(IndexName, FieldName, IndexOptions); Result := True; end; // if not//Set the indexSetStrProp(DataSet, 'IndexName', IndexName);end;
This code begins by verifying that the field passed in the second parameter exists, and that it is of the correct type. Next, the code verifies that the client dataset passed in the first formal parameter has an IndexDefs property. If so, it assigns the value of this property to a local variable. It then calculates an index name by appending the characters "__IdxA" or "__IdxD" to the name of the field to index on, with __IdxA being used for an ascending index, and __IdxD for a descending index.
Next, the IndexDefs property is scanned for an existing index with the calculated name. If one is found (because it was already created in response to a previous header click), that index is set to the IndexName property. If the index name is not found, a new index with that name is created, and then the dataset is instructed to use it.
In the CDSSort project, this code is called from within the DBGrid's OnTitleClick event handler. The following is how this event handler is implemented in the CDSSortGrid project:
procedure TForm1.DBGrid1TitleClick(Column: TColumn);begin SortCustomClientDataSet(ClientDataSet1, Column.FieldName);end;
As pointed out above, this code has the drawback of requiring RTTI, which is necessary since the IndexDefs and IndexName properties of the TCustomClientDataSet class are protected properties. The CDSSort project also includes a function named SortClientDataSet. This function, shown in the following code segment, is significantly simpler, in that it does not require RTTI. However, it can only be passed an instance of the TClientDataSet class, meaning that it cannot be used with other TCustomerClientDataSet provided by Delphi, such as BDEClientDataSets and SQLClientDataSets.

function SortClientDataSet(ClientDataSet: TClientDataSet; const FieldName: String): Boolean;var i: Integer; NewIndexName: String; IndexOptions: TIndexOptions; Field: TField;beginResult := False;Field := ClientDataSet.Fields.FindField(FieldName);//If invalid field name, exit.if Field = nil then Exit;//if invalid field type, exit.if (Field is TObjectField) or (Field is TBlobField) or (Field is TAggregateField) or (Field is TVariantField) or (Field is TBinaryField) then Exit;//Get IndexDefs and IndexName using RTTI//Ensure IndexDefs is up-to-dateClientDataSet.IndexDefs.Update;//If an ascending index is already in use,//switch to a descending indexif ClientDataSet.IndexName = FieldName + '__IdxA'then begin NewIndexName := FieldName + '__IdxD'; IndexOptions := [ixDescending]; endelse begin NewIndexName := FieldName + '__IdxA'; IndexOptions := []; end;//Look for existing indexfor i := 0 to Pred(ClientDataSet.IndexDefs.Count) dobegin if ClientDataSet.IndexDefs[i].Name = NewIndexName then begin Result := True; Break end; //ifend; // for//If existing index not found, create oneif not Result then begin ClientDataSet.AddIndex(NewIndexName, FieldName, IndexOptions); Result := True; end; // if not//Set the indexClientDataSet.IndexName := NewIndexName;end;
35 Navigating and Editing a ClientDataSet By: Cary Jensen
Abstract: You navigate and edit a ClientDataSet in a manner similar to how you navigate and edit almost another other dataset. This article provides an introductory look at basic ClientDataSet navigation and editing.
I usually try to start from the beginning, covering the more basic techniques before continuing to the more advanced, and that has been my plan with this series. In the articles that precede this one I have provided a general introduction to the use and behaviors of a ClientDataSet, as well as how to create its structure and indexes. In this installment I will take an introductory look at the manipulation of data stored in a ClientDataSet. Topics to be covered include basic programmatic navigation of the data in a ClientDataSet, as well as simple editing operations. The next two articles in this series will demonstrate record searching and ranges and filters. Only after these foundation topics are covered will I continue to the more interesting things that you can do with a ClientDataSet, such as creating nested datasets, cloning cursors, defining aggregate fields, and more.
For those of you who are already well versed in working with datasets, you will only need to quickly skim through this article to see if there is something that you find interesting. If you are fairly new to dataset programming, however, this article will provide you with essential information on the use of ClientDataSets. As an added benefit, most of these techniques are appropriate for any other datasets that you may have a chance to use.
While this article focuses primarily on the use of code to navigate and edit data in a ClientDataSet, a natural place to begin this discussion is with Delphi data-aware controls and the navigation and editing features they provide.
36 Navigating with Data-Aware Controls
There are two classes of controls that provide data navigation. The first class is navigation-specific controls. Delphi provides you with one control in this category, the DBNavigator.
The DBNavigator, shown in the following image, provides a VCR-like interface for navigating data and managing records. Record navigation is provided by the First, Next, Prior, and Last buttons. Record management is provided by the Edit, Post, Cancel, Delete, Insert, and Refresh buttons. You can control which buttons are displayed by a DBNavigator through its VisibleButtons property. For example, if you are using the DBNavigator in conjunction with a ClientDataSet that reads and writes its data from a local file (Borland calls this technology MyBase), you will want to remove the nbRefresh flag from the VisibleButtons property, since attempting to Refresh a ClientDataSet that uses MyBase raises an exception.
Another DBNavigator property whose default value you may want to change is ShowHint. Some users have difficulty interpreting the glyphs on the DBNavigator's buttons. For those

users, setting ShowHint to True supplements the glyphs with popup help hints. You can control the text of these hints by editing the Hints property.
The second category of controls that provide navigation is the multi-record controls. Delphi includes two: the DBGrid and DBCtrlGrid. A DBGrid displays data in a row/column format. By default, all fields of the ClientDataSet are displayed in the DBGrid. You can control which fields are displayed, as well as specific column characteristics, such as color, by editing the DBGrid's Columns collection property. The following is an example of a DBGrid.
A DBCtrlGrid, by comparison, is a limited, multi-record container. It is limited in that it can only hold certain Delphi components, including Labels, DBEdits, DBLabels, DBMemos, DBImages, DBComboBoxes, DBCheckBoxes, DBLookupComboBoxes, and DBCharts. It is also limited in that it is not available in Kylix. As a result, the DBCtrlGrid is little used. An example of a two-row, one-column DBCtrlGrid is shown in the following figure.

Depending on which multi-record control you are using, you can navigate between records using UpArrow, DownArrow, Tab, Ctrl-End, Ctrl-Home, PgDn, PgUp, among others. These key presses may produce the same effect as clicking the Next, Prior, Last, First, and so on, buttons in a DBNavigator. It is also possible to navigate the records of a dataset using the vertical scrollbar of these controls.
How you edit a record using these controls also depends on which type of control you are using, as well as their properties. Using the default properties of these controls, you can typically press F2 or click twice on a field in one of these controls to begin editing. Posting a record occurs when you navigate off an edited record. Inserting and deleting records, depending on the control's property settings, can also be achieved using Ins and Ctrl-Del, respectively. Other operations, such as Refresh, are not directly supported. Consequently, in most cases, multi-record controls are combined with a DBNavigator to provide a complete set of record management options.
37 Detecting Changes to Record State
Changes that occur when a user navigates or manages a record using a data-aware control is something that you may want to get involved with, programmatically. For those situations, there are a variety of event handlers that you can use to evaluate what a user is doing, and provide a customized response. ClientDataSets, as well as all other TDataSet descendents, posses the following event handlers: AfterCancel, AfterClose, AfterDelete, AfterEdit, AfterInsert, AfterOpen, AfterPost, AfterRefresh, AfterScroll, BeforeCancel, BeforeClose,
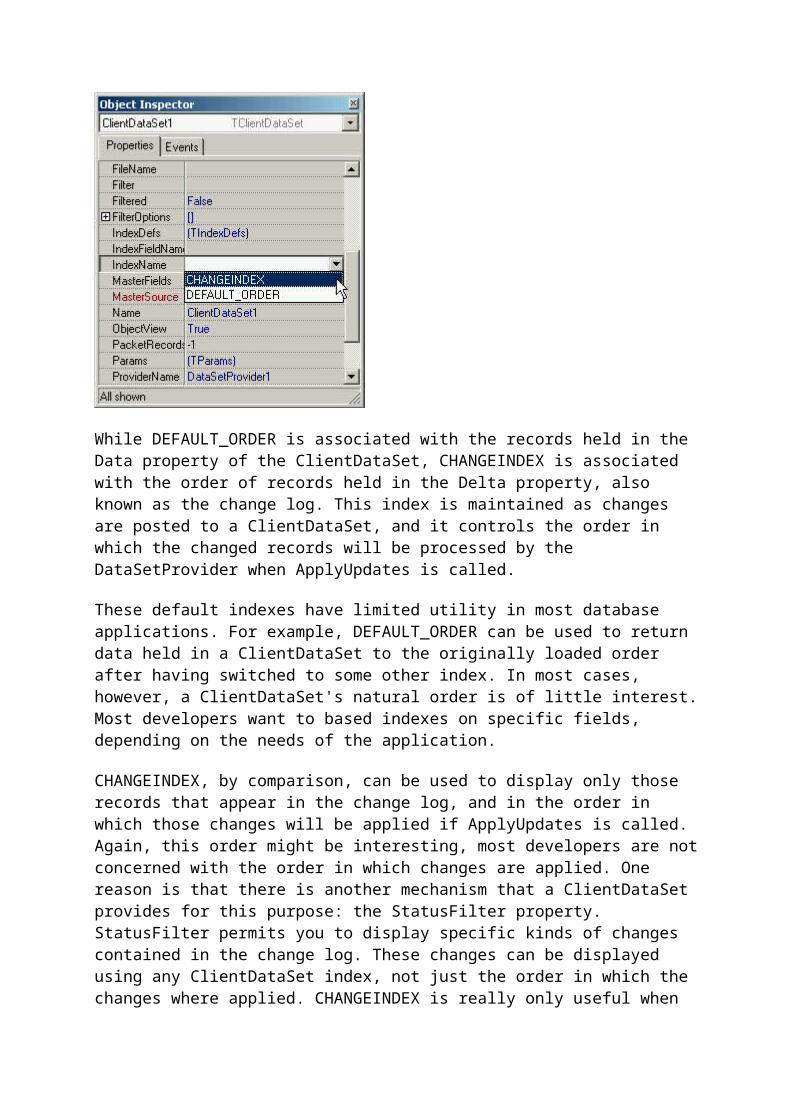
BeforeDelete, BeforeEdit, BeforeInsert, BeforeOpen, BeforePost, BeforeRefresh, BeforeScroll, OnCalcFields, OnDeleteError, OnEditError, OnFilterRecord, OnNewRecord, and OnPostError.
There are additional event handlers that are available in most situations where a ClientDataSet is being navigated and edited, and which are always available when data-aware controls are concerned. These are the event handlers associated with a DataSource. Since all data-aware controls must be connected to at least one DataSource, the event handlers of a DataSource provide you with another source of customization when a user navigates and edits records. These event handlers are OnDataChange, OnStateChange, and OnUpdateData.
OnDataChange triggers whenever a ClientDataSet arrives at a new records, as well as when a ClientDataSet arrives at the first record when it is initially opened. OnStateChange triggers when a ClientDataSet changes between state, such as when it changes from dsBrowse to dsEdit (when a user enters the edit mode), or when it changes from dsEdit to dsBrowse (following the posting or cancellation of a change). Finally, OnUpdateData triggers when the dataset to which the DataSource points is posting its data.
38 Navigating Programmatically
Whether data-aware controls are involved or not, it is sometimes necessary to use code to navigate and edit data in a ClientDataSet, or any DataSet descendent for that matter. For a ClientDataSet, these core navigation methods include First, Next, Prior, Last, MoveBy, and RecNo. The use of First, Next, Prior, and Last are pretty much self-explanatory. Each one produces an effect similar to the corresponding buttons on a DBNavigator.
MoveBy permits you to move forward and backward in a ClientDataSet, relative to the current record. For example, the following statement moves the current cursor 5 records forward in the dataset (if possible):
ClientDataSet1.MoveBy(5);
To move backwards in a dataset, pass MoveBy a negative number. For example, the following statement will move the cursor to the record that is 100 records prior to the current records (again, if possible):
ClientDataSet1.MoveBy(-100);
The use of RecNo to navigate might come as a surprise. This property, which is always returns -1 in the TDataSet class, can be used for two purposes. You can read this property to learn the position of the current record in the current record order (based on which index is currently selected). In the ClientDataSet you can also write to this property. Doing so moves the cursor to the record in the position defined by the value you assign to this property. For example, the following statement will move the cursor to the record in the 5th position of the current index order (if possible):
ClientDataSet1.RecNo := 5;
Each of the preceding examples has been qualified by the statement that the operation will succeed if possible. This qualification has two aspects to it. First, the cursor movement will not take place if the current record has been edited, but cannot be posted. For example, if data

that cannot pass at least one the ClientDataSet's Contraints has been added to a record. When you attempt to navigate off a record that cannot be posted, an exception is raised.
The second situation where the record navigation might not be possible is related to the current record position and the number of records in the dataset. For example, if the current record is the last in the dataset, it makes no sense to move 5 records forward. Similarly, if the current record is the 99th in the dataset, an attempt to move backwards by 100 records will fail. You can determine whether an attempt to navigate succeeded or failed by reading the Eof and Bof properties of the ClientDataSet. Eof (end-of-file) will return True if a navigation method attempted to move beyond the end of the table. When Eof returns True, the current record is the last record in the dataset.
Similarly, Bof will return True if a backwards navigation attempted to move before the beginning of the dataset. In that situation the current record is the first record in the dataset.
RecNo behaves differently. Attempting to set RecNo to a record beyond the end of the table, or prior to the beginning of the table, raises an exception.
39 Scanning a ClientDataSet
Combining several of the methods and properties described so far provides you with a mechanism for scanning a ClientDataSet. Scanning simply means the systematic navigation from one record to the next, until all records in the dataset have been visited. The following code segment demonstrates how to scan a ClientDataSet.
procedure TForm1.Button1Click(Sender:
TObject);beginif not ClientDataSet1.Active then ClientDataSet1.Open;ClientDataSet1.First;while not ClientDataSet1.EOF dobegin //perform some operation based on one or //more fields of the ClientDataSet ClientDataSet1.Next;end;end;
40 Editing a ClientDataSet
You edit a current record in a ClientDataSet by calling its Edit method, after which you change the values of one or more of its fields. Once your changes have been made, you can either move off the record to attempt to post the new values, or you can explicitly call the ClientDataSet's Post method. In most cases, navigating off the record and calling Post produce the same effect. But there are two instances where they do not, and it is due to these situations that an explicit call to Post should be considered essential. In the first instance, if you are editing the last record in a dataset and then call Next or Last, the edited record is not posted. The second situation is similar, and involves editing the first record in a dataset followed by a call to either Prior to First. So long as you always call Post prior to attempting to navigate, you can be assured that your edited record will be posted (or raise an exception due to a posting failure).

If you modify a record, and then decide not to post the change, or discover that you cannot post the change, you can cancel all changes to the record by calling the ClientDataSet's Cancel method. For example, if you change a record, and then find that calling Post raises an exception, you can call Cancel to cancel the changes and return the dataset to the dsBrowse state.
To insert and post a record you have several options. You can call Insert or Append, after which your cursor will be on a newly inserted record (assuming that you started from the dsBrowse state. If you were editing a record prior to calling Insert or Append, a new record will not be inserted if the record being edited can not be posted). Once it is inserted, assign data to the fields or that record and call Post to post those changes.
The alternative to calling Insert or Append is to call InsertRecord or AppendRecord. These methods insert a new record, assign data to one or more fields, and attempt to post, all in a single call. The following is the syntax of the InsertRecord method. The syntax of AppendRecord is identical.
procedure InsertRecord(const Values: array of const);
You include in the constant array the data values you want to assign to each field in the dataset. If you want to leave particular field unassigned, include the value null in the variant array. Fields you want to leave unassigned at the end of the record can be omitted from the constant array. For example, If you are inserting and posting a new record into a four-field ClientDataSet, and you want to assign the first field the value 1000 (a field associated with a unique index), leave the second and fourth fields unassigned, but assign a value of 'new' to the third record, your InsertRecord invocation may look something like this:
ClientDataSet1.InsertRecord([1001, null,
'new']);
The following code segment demonstrates another instance of record scanning, this time with edits that need to be posted to each record. In this example, Edit and Post are performed within try blocks. If the record was placed in the edit mode (which corresponds to the dsEdit state), and cannot be posted, the change is canceled. If the record cannot even be placed into edit state (which for a ClientDataSet should only happen if the dataset has its ReadOnly property set to True), the attempt to post changes is skipped.
procedure TForm1.Button1Click(Sender:
TObject);beginif not ClientDataSet1.Active then ClientDataSet1.Open;ClientDataSet1.First;while not ClientDataSet1.EOF dobegin try ClientDataSet1.Edit; try ClientDataSet1.Fields[0].Value := UpperCase(ClientDataSet1.Fields[0].Value); ClientDataSet1.Post; except //record cannot be posted. Cancel; ClientDataSet1.Cancel;

end; except //Record cannot be edited. Skip end; ClientDataSet1.Next;end; //whileend;
Note: Rather than simply canceling changes that cannot be posted, an alternative except clause would identify why the record could not post, and produce a log which can be used to apply the change at a later date. Also note that if these changes are being cached, for update in a subsequent call to ApplyUpdates, the ClientDataSet provides an OnReconcileError event handler that can be used to process failed postings.
41 Disabling Controls While Navigating
If the ClientDataSet that you are navigating programmatically is attached to data-aware controls through a DataSource, and you take no other precautions, the data-aware controls will be affected by the navigation. In the simplest case, where you move directly to another record, the update is welcome, causing the controls to repaint with the data of the newly arrived at record. However, when your navigation involves moving to two or more records in rapid succession, such as is the case when you scan a ClientDataSet, the updates can have severe results.
There are two reasons for this. First, the flicker caused by the data-aware controls repainting as the ClientDataSet arrives at each record is distracting. More importantly, however, is the overhead associated with a repaint. Repainting visual controls is one of the slowest processes in most GUI (graphic user interface) applications. If your navigation involves visiting many records, as often the case when you are scanning, the repaints of your data-aware controls represents a massive amount of unnecessary overhead.
To prevent your data-aware controls from repainting when you need to programmatically change the current record more than once you need to call the ClientDataSet's DisableControls method (this is generally try of any dataset, as DisableControls is implemented in the TDataSet class). When DisableControls is called, the ClientDataSet stops communicating with any DataSources that point to it. As a result, the data-aware controls that point to those DataSources are never made aware of the navigation. Once you are done navigating, call the ClientDataSet's EnableControls. This will resume the communication between the ClientDataSets and any DataSources that point to it. It will also result in the data-aware controls being instructed to repaint themselves. However, this repaint occurs only once, in response to the call to EnableControls, and not due to any of the individual navigations that occurred since DisableControls was called.
Is it important to recognized that between the time you call DisableControls and EnableControls, the ClientDataSet is in an abnormal state. In fact, if you call DisableControls and never call a corresponding EnableControls, the ClientDataSet will appear to the user to have stopped functioning, based on the lack of activity in the data-aware controls. As a result, it is essential that if you call DisableControls, you structure your code in such a way that a call to EnableControls is guaranteed. One way to do this it to enter a try-finally after a call to DisableControls, invoking the corresponding EnableControls in the finally block.
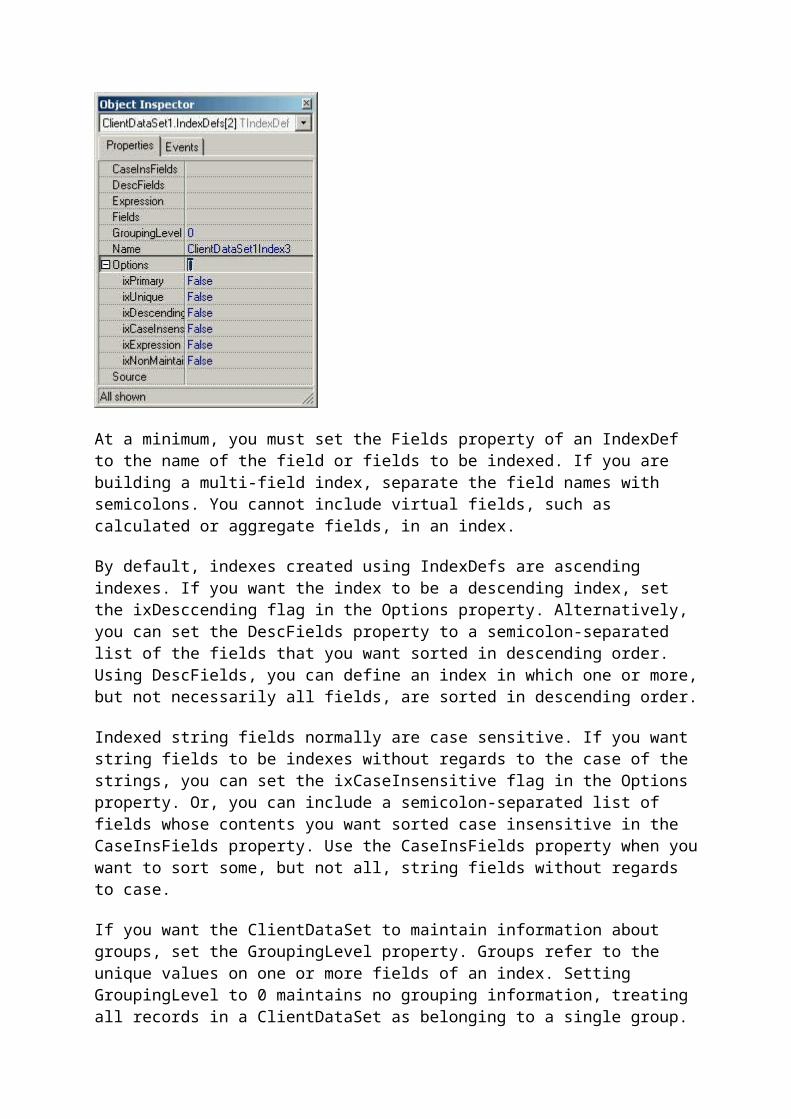
The following is an example of a scan where the user interface is not updated until all record navigation has completed.
procedure TForm1.Button1Click(Sender:
TObject);beginif not ClientDataSet1.Active then ClientDataSet1.Open;ClientDataSet1.DisableControls; try ClientDataSet1.First; while not ClientDataSet1.EOF do begin try ClientDataSet1.Edit; try ClientDataSet1.Fields[0].Value := UpperCase(ClientDataSet1.Fields[0].Value); ClientDataSet1.Post; except //record cannot be posted. Cancel; ClientDataSet1.Cancel; end; except //Record cannot be edit. Skip end; ClientDataSet1.Next; end; //while finally ClientDataSet1.EnableControls; end; //try-finallyend;
42 Navigation Demonstration
The Navigation project, which you can download from Code Central by clicking this link Navi gation Project, demonstrates the various methods and properties described in this article. The following figure shows this project when it is running.

Each of the Buttons on this form is associated with an event handler that performs the indicated type of navigation. In addition, this project includes OnDataChange and OnStateChange DataSource event handlers that are used to update the panels in the StatusBar at the bottom of the form. These event handlers are shown in the following code listing.
procedure TForm1.SelectDataFile;beginif OpenDialog1.Execute then begin if ClientDataSet1.Active then ClientDataSet1.Close; ClientDataSet1.FileName := OpenDialog1.FileName; ClientDataSet1.Open; end else Halt;end;
procedure TForm1.FormCreate(Sender: TObject);begin SelectDataFile;end;
procedure TForm1.DataSource1DataChange(Sender: TObject; Field: TField);beginStatusBar1.Panels[0].Text := 'Record ' + IntToStr(ClientDataSet1.RecNo) + ' of ' + IntToStr(ClientDataSet1.RecordCount);

StatusBar1.Panels[2].Text := 'BOF = ' + BoolToStr(ClientDataSet1.Bof, True) +
'. ' + 'EOF = ' + BoolToStr(ClientDataSet1.Eof, True) +
'. ';end;
procedure TForm1.DataSource1StateChange(Sender: TObject);beginStatusBar1.Panels[1].Text := 'State = ' + GetEnumName(TypeInfo(TDataSetState), Ord(ClientDataSet1.State));end;
procedure TForm1.FirstBtnClick(Sender: TObject);beginClientDataSet1.First;end;
procedure TForm1.NextBtnClick(Sender: TObject);beginClientDataSet1.Next;end;
procedure TForm1.PriorBtnClick(Sender: TObject);beginClientDataSet1.Prior;end;
procedure TForm1.LastBtnClick(Sender: TObject);beginClientDataSet1.Last;end;
procedure TForm1.ScanForwardBtnClick(Sender: TObject);beginif ControlsStateBtnGrp.ItemIndex = 1 then ClientDataSet1.DisableControls; try ClientDataSet1.First; while not ClientDataSet1.Eof do begin //do something with a record ClientDataSet1.Next; end; finally if ControlsStateBtnGrp.ItemIndex = 1 then ClientDataSet1.EnableControls; end;end;
procedure TForm1.ScanBackwardBtnClick(Sender: TObject);beginif ControlsStateBtnGrp.ItemIndex = 1 then ClientDataSet1.DisableControls; try ClientDataSet1.Last; while not ClientDataSet1.Bof do begin //do something with a record

ClientDataSet1.Prior; end; finally if ControlsStateBtnGrp.ItemIndex = 1 then ClientDataSet1.EnableControls; end;end;
procedure TForm1.MoveByBtnClick(Sender: TObject);beginClientDataSet1.MoveBy(UpDown1.Position);end;
procedure TForm1.RecNoBtnClick(Sender: TObject);begin ClientDataSet1.RecNo := UpDown2.Position;end;
procedure TForm1.Open1Click(Sender: TObject);begin SelectDataFile;end;
procedure TForm1.Close1Click(Sender: TObject);begin ClientDataSet1.Close;end;

43 Searching a ClientDataSet By: Cary Jensen
Abstract: ClientDataSets provide a number of different mechanisms for searching for and location data in its columns. These techniques are covered in this continuation of the discussion of basic ClientDataSet manipulation.
In this article I am continuing the coverage of basic ClientDataSet usage. In the last installment of this series I discussed how to navigate and edit a ClientDataSet. In this article I show you how to find a record based on the data it contains.
In the context of this article, searching means to either move the current record pointer to a particular record based on the data held in the record, or to read data from a record based on its data. Filtering, which shares some similarities with searching, involves restricting the accessible records in a ClientDataSet to those that contain certain data. This article does not demonstrate how to filter a ClientDataSet. That topic is be discussed in the next article in this series.
44 Scanning for Data
The simplest, and typically slowest mechanism for searching is performed by scanning. As you learned in the preceding article in this series (click here to read it), you can scan a table by moving to either the first or last record in the current index order, and then navigating record-by-record until every record in the view has been visited. If used for searching, your code reads each record's data as you scan. When a record containing the desired data is found, the scanning process can be terminated.
The following code segment provides a simple example of how a search operation like this might look.
procedure TForm1.ScanBtnClick(Sender: TObject);var Found: Boolean;beginFound := False;ClientDataSet1.DisableControls;Start;try ClientDataSet1.First; while not ClientDataSet1.Eof do begin if ClientDataSet1.Fields[FieldListComboBox.ItemIndex].Value = ScanForEdit.Text then begin Found := True; Break; end; ClientDataSet1.Next; end; Done;finally ClientDataSet1.EnableControls;

end;if Found then ShowMessage(ScanForEdit.Text + ' found at record ' + IntToStr(ClientDataSet1.RecNo))else ShowMessage(ScanForEdit.Text + ' not found');end;
As you learned from the preceding article in this series, scanning involves first moving to one end of the dataset (the first record in this example), and then navigating sequentially to each record in the view. When searching using this technique, upon arriving at a record you read one or more fields to determine whether or not the current record is the one for which you are looking. If the record contains the data you need, do something, such as terminate the search and display the located record to the user. In this particular case, the code is searching for a value entered into an Edit named ScanForEdit. The field being searched is the field name currently selected in the IndexOnComboBox combobox.
This code is taken from the CDSSearch project, available for download from Code Central (click here to download). The main form of this project is shown in the following figure.
Note that the data used in this example is found in the items.cds example file that ships with Delphi.
The only method calls within this code that are not part of the runtime library (RTL) or visual component library (VCL), are the Start and Done methods. These methods are designed to initiate and complete a performance monitor, which is used by all search-initiating event handlers in this project to provide a relative measure of performance. The performance

information is displayed in the StatusBar of this project, as can be seen in the preceding figure. The implementation of Start and Done is shown in the following code segment.
procedure TForm1.Start;begin StartTick := TimeGetTime;end;
procedure TForm1.Done;begin EndTick := TimeGetTime; StatusBar1.Panels[0].Text := 'Starting tick: ' + IntToStr(StartTick); StatusBar1.Panels[1].Text := 'Ending tick: ' + IntToStr(EndTick); StatusBar1.Panels[2].Text := 'Duration (in milliseconds): ' + IntToStr(EndTick - StartTick);end;
Both Start and Done make use of the TimeGetTime function, which is imported in the MMSystem unit. This function returns a tick count, which represents the number of milliseconds that have past since Windows was started. TimeGetTime is significantly more accurate than GetTickCount, a commonly-used timing function. Normally, TimeGetTime is accurate within five milliseconds under NT, and within one millisecond under Windows 98.
45 Finding Data
One of the oldest mechanisms for searching a dataset was introduced in Delphi 1. This method, FindKey, permits you to search one or more fields of the current index for a particular value. FindKey, and its close associate, FindNearest, both make use of the current index to perform the search. As a result, the search is always index-based, and always very fast.
Both FindKey and FindNearest take a single constant array parameter. You include in this array the values for which you want to search on the fields on the index, with the first element in the array being searched for in the first field of the index, the second field in the array (if provided) searched for in the second field of the index, and so forth. Since the search is indexed-based, the number of fields searched obviously cannot exceed the number of fields in the index (though there is no problem if you want to search on fewer fields than are contained in the index).
In the CDSSearch project, the only indexes available are temporary indexes associated with single fields in the dataset. (The current temporary index is based on the field listed in the IndexOnComboBox, shown in the preceding figure.) Consequently, the demonstrations of the FindKey and FindNearest methods in this project are limited to single fields, specifically the value entered into the ScanForEdit Edit component. The following are the event handlers associated with the FindKey and FindNearest buttons in this project, respectively.
procedure TForm1.FindKeyBtnClick(Sender:
TObject);beginStart;if ClientDataSet1.FindKey([ScanForEdit.Text]) thenbegin

Done; StatusBar1.Panels[3].Text := ScanForEdit.Text + ' found at record ' + IntToStr(ClientDataSet1.RecNo);endelsebegin Done; StatusBar1.Panels[3].Text := ScanForEdit.Text + ' not found';end;end;
procedure TForm1.FindNearestBtnClick(Sender: TObject);beginStart;ClientDataSet1.FindNearest([ScanForEdit.Text]);Done;StatusBar1.Panels[3].Text := 'The nearest match to ' + ScanForEdit.Text + ' found at record ' + IntToStr(ClientDataSet1.RecNo);end;
The following figure shows the result of a search performed on an index based on the OrderNo field. In this case, as in the preceding figure, the value being searched for is OrderNo 1278. Notice that in the StatusBar this FindKey search took significantly less time than the search using scanning.

While FindKey and FindNearest are identical in syntax, there is a subtle difference in how they operate. FindKey is a Boolean function method that returns True if a matching record is located. In that case, the cursor is repositioned in the ClientDataSet to the found record. If FindKey fails it return False, and the current record pointer does not change.
Unlike FindKey, which is a function, FindNearest is a procedure method. Technically speaking, FindNearest always succeeds, moving the cursor to the record that most closely matches the search criteria. For example, in following figure FindNearest is used to locate the record whose OrderNo most closely matches the value 99999. As you can see in this figure, the located record contains OrderNo 1860, the highest OrderNo in the table, and the last record in the current index order.
46 Going to Data
GotoKey and GotoNearest provide the same searching features as FindKey and FindNearest, respectively. The only difference between these two sets of methods is how you define your search criteria. As you have already learned, FindKey and FindNearest are passed a constant array as a parameter, and the search criteria are contained in this array.
Both GotoKey and GotoNearest take no parameters. Instead, their search criteria is defined using the search key buffer. The search key buffer contains one field for each field in the current index. For example, if the current index is based on the field OrderNo, the search key buffer contains one field: OrderNo. By comparison, if the current index contains three fields the search key buffer also contains three fields.

Fields in the search key buffer can only be modified when the ClientDataSet is in a special state called the dsSetKey state. To clear the search key buffer and enter the dsSetKey state, call the ClientDataSet's SetKey method. If you have previously assigned one or more values to the search key buffer, you can enter the dsSetKey state without clearing the search key buffer's contents by calling the ClientDataSet's EditKey method. From within the dsSetKey state, you assign data to fields in the search key buffer as if you were assigning data to the ClientDataSet's fields. For example, assuming that the current index is based on the OrderNo field, the following lines of code assign the value 1278 to the OrderNo field of the search key buffer:
ClientDataSet1.SetKey;ClientDataSet1.FieldByName('OrderNo').Value := 1278;
As should be apparent, using GotoKey or GotoNearest requires more lines of code than FindKey and FindNearest. For example, once again assuming that the current index is based on the OrderNo field, consider the following statement:
ClientDataSet1.FindKey([ScanForEdit.Text]);
Achieving the same result using GotoKey requires three lines of code, since you must first enter the dsSetKey state and edit the search key buffer. The following lines of code, which use GotoKey, perform precisely the same search as the preceding line of code:
ClientDataSet1.SetKey;ClientDataSet1.FieldByName('OrderNo').Value := ScanForEdit.Text;ClientDataSet1.GotoKey;
The following event handlers are associated with the buttons labeled Goto Key and Goto Nearest in the CDSSearch project.
procedure TForm1.GotoKeyBtnClick(Sender:
TObject);beginStart;ClientDataSet1.SetKey;ClientDataSet1.Fields[IndexOnComboBox.ItemIndex].AsString := Trim(ScanForEdit.Text);if ClientDataSet1.GotoKey thenbegin Done; StatusBar1.Panels[3].Text := ScanForEdit.Text + ' found at record ' + IntToStr(ClientDataSet1.RecNo);endelsebegin Done; StatusBar1.Panels[3].Text := ScanForEdit.Text + ' not found';end;end;
procedure TForm1.GotoNearestBtnClick(Sender: TObject);beginStart;ClientDataSet1.SetKey;
ClientDataSet1.Fields[IndexOnComboBox.ItemIndex].AsString := ScanForEdit.Text;ClientDataSet1.GotoNearest;Done;StatusBar1.Panels[3].Text := 'The nearest match to ' + ScanForEdit.Text + ' found at record ' + IntToStr(ClientDataSet1.RecNo);end;
47 Locating Data
One of the drawbacks to the Find and Goto methods is that the search is based on the current index. Depending no the data you are searching for, you might have to change the current index before performing the search. Fortunately, ClientDataSets support two generally high-performance searching mechanisms that do not require you to change the current index. These are Locate and Lookup.
Locate, like FindKey and GotoKey, makes the located record the current record if a match is found. In addition, Locate is a function method, returning a Boolean True if the search results in a match. Lookup is somewhat different, returning specific fields from a located record, but never moving the current record pointer. Lookup is described separately in the following section.
What makes Locate and Lookup so special is that they do not require you to create or switch indexes, but still provide much faster performance than scanning. In a number of tests that I have conducted, Locate found a record four times faster than did scanning. For example, when searching for data in a record at position 90,000 of a 100,000 record table, Locate located the record in about 500 milliseconds, while scanning for that record took longer than 2 seconds. Admittedly, FindKey took only 10 milliseconds to find that record. But the index that FindKey required for the search took almost 1 second to build.
The following is the syntax of Locate:
function Locate(const KeyFields: string; const KeyValues: Variant; Options: TLocateOptions): Boolean;
If you are locating a record based on a single field, the first argument is the name of that field and the second argument is the value you are searching for. To search on more than one field, pass a semicolon-separated string of field names in the first argument, and a variant array containing the search values corresponding to the field list in the second argument.
The third argument of Locate is a TLocateOptions set. This set can contain up to two flags, loCaseInsensitive and loPartialKey. Include loCaseInsensitive to ignore case in your search and loPartialKey to match any value that begins with the values you pass in the second argument.
If the search is successful, Locate makes the located record the current record and returns a value of True. If the search is not successful, Locate returns False, and the cursor does not move.

Imagine that you are searching the Customer.xml file that ships with Delphi. The following statement will locate the first record in the ClientDataSet whose Company name is Ocean Paradise.
ClientDataSet1.Locate('Company', 'Ocean Paradise',[]);
The next example demonstrates a partial match, searching for the first company whose name starts with the letter u or U.
ClientDataSet1.Locate('Company','u',[loCaseInsensitive, loPartialKey]);
Searching for two or more fields is somewhat more involved, in that you must pass the search values using a variant array. The following lines of code demonstrate how you can search for the record where the Company field contains Unisco and the City field contains Freeport.
var SearchList: Variant;beginSearchList := VarArrayCreate([0, 1], VarVariant);SearchList[0] := 'Unisco';SearchList[1] := 'Freeport';ClientDataSet1.Locate('Company;City', SearchList, [loCaseInsensitive]);
Instead of using VarArrayCreate, you can use VarArrayOf. VarArrayOf takes a constant array of the values from which to create the variant array. This means that you must know at design-time how many elements your variant array will have. By comparison, the dimensions of the variant array created using VarArrayOf can include variables, which permits you to determine the array size at runtime. The following code performs the same search as the preceding code, but makes use of an array created using VarArrayOf.
var SearchList: Variant;beginSearchList := VarArrayOf(['Unisco','Freeport']);ClientDataSet1.Locate('Company;City',SearchList,[loCaseInsensitive]);
< p>If you refer back to the CDSSearch project main form shown in the earlier figures of this article, you will notice a StringGrid in the upper-right corner. Data entered into the first two columns of this grid are used to create the KeyFields and KeyValues arguments of Locate, respectively. The following methods, found in the CDSSearch project, generate these parameters. function TForm1.GetKeyFields(var
FieldStr: String): Integer;const FieldsColumn = 0;var i : Integer; Count: Integer;begin Count := 0; for i := 1 to 20 do begin if StringGrid1.Cells[FieldsColumn,i] <> '' then begin if FieldStr = '' then FieldStr := StringGrid1.Cells[FieldsColumn,i]

else FieldStr := FieldStr + ';' + StringGrid1.Cells[FieldsColumn,i]; inc(Count); end else Break; end; Result := Count;end;
function TForm1.GetKeyValues(Size: Integer): Variant;const SearchColumn = 1;var i: Integer;begin Result := VarArrayCreate([0,Pred(Size)], VarVariant); for i := 0 to Pred(Size) do Result[i] := StringGrid1.Cells[SearchColumn, Succ(i)];end;
The following code is associated with the OnClick event handler of the button labeled Locate in the CDSSearch project. As you can see, in this code the Locate method is invoked based on the values returned by calling GetKeyFields and GetKeyValues.
procedure TForm1.LocateBtnClick(Sender:
TObject);var FieldList: String; Count: Integer; SearchArray: Variant;beginFieldList := '';Count := GetKeyFields(FieldList);SearchArray := GetKeyValues(Count);Start;if ClientDataSet1.Locate(FieldList, SearchArray, []) thenbegin Done; StatusBar1.Panels[3].Text := 'Match located at record ' + IntToStr(ClientDataSet1.RecNo);endelsebegin Done; StatusBar1.Panels[3].Text := 'No match located';end;end;
48 Using Lookup
Lookup is similar in many respects to Locate, with one very important difference. Instead of moving the current record pointer to the located record, Lookup returns a variant containing data from a located record without moving the current record pointer. The following is the syntax of Lookup.

function Lookup(const KeyFields: string; const KeyValues: Variant; const ResultFields: string): Variant;
The KeyFields and KeyValues parameters of Lookup are identical in purpose to those in the Locate method. ResultFields is a semicolon separated string of field names whose values you want returned. If Lookup fails to find the record you are searching for, it returns a null variant. Otherwise, it returns a variant containing the field values requested in the ResultFields parameter.
The event handler associated with the Lookup button in the CDSSearch project makes use of the GetKeyFields and GetKeyValues methods for defining the KeyFields and KeyValues parameters of the call to Lookup, based again on the first two columns of the StringGrid. In addition, this event handler makes use of the GetResultFields method to construct the ResultFields parameter from the third column of the grid. The following is the code associated with the GetResultFields method.
function TForm1.GetResultFields: String;const ReturnColumn = 2;var i: Integer;begin for i := 1 to Succ(StringGrid1.RowCount) do if StringGrid1.Cells[ReturnColumn, i] <> '' then if Result = '' then Result := StringGrid1.Cells[ReturnColumn, i] else Result := Result + ';' + StringGrid1.Cells[ReturnColumn, i] else Break;end;
The following is the code associated with the OnClick event handler of the button labeled Lookup.
procedure TForm1.LookupBtnClick(Sender:
TObject);var ResultFields: Variant; KeyFields: String; KeyValues: Variant; ReturnFields: String; Count, i: Integer; DisplayString: String;beginCount := GetKeyFields(KeyFields);DisplayString := '';KeyValues := GetKeyValues(Count);ReturnFields := GetResultFields;Start;ResultFields := ClientDataSet1.Lookup(KeyFields, KeyValues, ReturnFields);Done;if VarIsNull(ResultFields) then DisplayString := 'Lookup record not found'

else if VarIsArray(ResultFields) then for i := 0 to VarArrayHighBound(ResultFields,1) do if i = 0 then DisplayString := 'Lookup result: ' + VarToStr(ResultFields[i]) else DisplayString := DisplayString + ';' + VarToStr(ResultFields[i]) else DisplayString := VarToStr(ResultFields);StatusBar1.Panels[3].Text := DisplayStringend;
The following figure shows the main form of the CDSSearch project following a call to Locate. Notice that the current record is still the first record in the ClientDataSet, even though the data returned from the call to Locate was found much later in the current index order.
49 Summary
ClienDataSets provide a number of mechanisms for searching their columns. The simplest, those often slowest, is to scan the ClientDataSet for particular values. FindKey and FindNearest (and their GotoKey and GotoNearest counterparts), are extremely fast, since they use an index. However, the Find and Goto methods might require you to first select or build an appropriate index. By comparison, Locate and Lookup provide relatively good performance without requiring an index, making them the preferred searching methods in applications where speed is not critical.

50 Filtering ClientDataSets By: Cary Jensen
Abstract: When applied to a dataset, a filter limits the records that are accessible. This article explores the ins and outs of filtering ClientDataSets.
This article is part of an extended series exploring the ClientDataSet in detail. In case you are new to this series, a ClientDataSet is a component that provides an in-memory table that can be manipulated easily and efficiently. Previous articles in this series have provided a broad overview of ClientDataSet usage, but in the past two installments I have been covering the essential, basic operations involving ClientDataSet. In this article I am completing the discussion of foundation issues with a look at dataset filtering.
When you filter a dataset, you restrict access to a subset of records contained in the ClientDataSet's in-memory store. For example, imagine that you have a ClientDataSet that includes one record for every one of your company's customers, world-wide. Without filtering, all customer records are accessible in the dataset. That is, it is possible to navigate, view, and edit any customer in the dataset. Through filtering you can make the ClientDataSet appear to include only those customers who live in the United States, or in London, England, or who live on a street named Enterprise Way. This example, of course, assumes that there is a field in the ClientDataSet that contains country names, or fields containing City and Country names, or a field holding street names. In other words, a filter limits the accessible records based on data that is stored in the ClientDataSet, and is effective the the extent that the data in the ClientDataSet can be used to limit which records are accessible.
A ClientDataSet supports two fundamentally different mechanisms for creating filters. The first of these involves a range, which is an index-based filtering mechanism. The second, called a filter, is more flexible than ranges, but is slower to apply and cancel. Both of these approaches to filtering are covered in this article.
But before addressing filtering directly, there are a couple of important points that need to be made. The first is that filtering is a client-side operation. Specifically, the filters discussed in this article are applied to the data loaded into a ClientDataSet's in-memory store. For example, you may load 10,000 records into a ClientDataSet (every customer record, for instance), and then apply a filter that limits access to only those customers located in New York City. Once applied, the filter may make the ClientDataSet to appear to contain only 300 records (given that 300 of your customer's are located in New York City). Although the filtered ClientDataSet provides access only to these 300 records, all 10,000 records remain in memory. In other words, a filter does not reduce the overhead of your ClientDataSet, it simply restricts access to a subset of the ClientDataSet's records.
The second point is that instead of using a filter, you may be better off limiting how many records you load into the ClientDataSet in the first place. Consider the 10,000 customer records once again. Instead of loading all 10,000 records into memory, and then filtering on the City field, it might be better to load only a subset of the customer records into the ClientDataSet. While partial loading not available when a ClientDataSet is loaded from the local file system using MyBase, it is an option when loading a ClientDataSet through a DataSetProvider.

For example, imagine that your DataSetProvider points to a SQLDataSet whose CommandText contains the following SQL query:
SELECT * FROM CUSTOMER WHERE CITY = 'New York City'
When the ClientDataSet's Open method is called, this SQL select statement is executed, and only those 300 or so records from your New York City-based customers are loaded into the ClientDataSet. This approach greatly reduces the memory overhead of the ClientDataSet, since fewer records need to be stored in memory.
Actually, there are a number of techniques that permit you to load selected records from a dataset through a DataSetProvider into a ClientDataSet, including the use of parameterized queries, nested datasets, dynamic SQL, among others. An thorough examination of these techniques will appear in a future article in this series. Nonetheless, from the perspective of this article, these techniques are not technically filtering, since they do not limit access within the ClientDataSet to a subset of its loaded records..
So when do you use filtering as opposed to loading only selected records into a ClientDataSet? The answer boils down to three basic issues: bandwidth, source of data, and client-side features.
When loading a ClientDataSet from DataSetProvider, and bandwidth is low, as is often the case in distributed applications, it is normally best to load only selected records. In this situation, loading records that are not going to be displayed consumes bandwidth unnecessarily, affecting the performance of your application as well as that of others that share the bandwidth. On the other hand, if bandwidth is plentiful and the entire dataset is relatively small, it is often easier to load all data and filter on those records you want displayed.
The second consideration is data location. If you are loading data from a previously saved ClientDataSet (in either Borland's proprietary binary format or in XML format), you have no choice. Filtering is the only option for showing just a subset of records. Only when you are loading data through a DataSetProvider do you have a choice to use a filter or selective loading of data.
The final consideration is related to client-side features, the most common of which is speed. Once data is loaded into a ClientDataSet, most filters are applied very quickly, even when a large amount of data needs to be filtered. As a result, filtering permits you to rapidly alter which subset of records are displayed. A simple click of a button or menu selection can almost instantly switch your ClientDataSet from displaying customers from New York City to displaying customers from Frankfurt, Germany, without a network round-trip.
As mentioned earlier, there are two basic approaches to filtering: ranges and filters. Let's start by looking at ranges.
51 Setting a RangeRanges, while less flexible than filters, provide the fastest option for displaying a subset of records from a ClientDataSet. In short, a range is an index-based mechanism for defining the low and high values of records to be displayed in the ClientDataSet. For example, if the

current index is based on customer's last name, a range can be used to display all customer's whose last name is 'Jones.' Or, a range can be used to display only customer's whose last name begins with the letter 'J'. Similarly, if a ClientDataSet is indexed on an integer field called Credit Limit, a range can be used to display only those customers whose credit limit is greater than (US) $1,000, or between $0 and $1000.
There are two ways to set a range. The first, and easiest, is to use the SetRange method. SetRange defines a range using a single method invocation. The second mechanism is to enter the dsSetKey state, which requires a minimum of three method calls, and often four.
In Delphi and Kylix, SetRange has the following syntax:
procedure SetRange(const StartValues, EndValues: array of const);
As you can see from this syntax, you pass two constant arrays when you call SetRange. The first array contains the low values of the range values for the fields of the index, with the first element in the array being the low end of the range for the first field in the index, the second element being the low end of the range for the second field in the index, and so on. The second array contains the high end values for the index fields, with the first element in the second array being the high end of the range on the first field of the index, the second element being the high end on the second field of the index, and so forth. These arrays can contain fewer elements than the number of fields in the current index, but cannot contain more.
Consider again our example of a ClientDataSet that holds all customer records. Given that there is a field in this dataset named 'City,' and you want to display only records for customers who live in New York City, you can use the following statements:
ClientDataSet1.IndexFieldNames := 'City';ClientDataSet1.SetRange(['New York City'], ['New York City']);
The first statement creates a temporary index on the City field, while the second sets the range. Of course, if the ClientDataSet was already using an index where the first field of the index was the City field, you would omit the first statement in the preceding code segment.
The preceding example set the range on a single field, but it is often possible to set a range on two or more fields of the current index. For example, imagine that you want to display only those customers whose last name is Walker and who live in San Antonio, Texas. The following statements show you how:
ClientDataSet1.IndexFieldNames := 'LastName;City;State';ClientDataSet1.SetRange(['Walker', 'San Antonio', 'TX'], ['Walker', 'San Antonio', 'TX']);
In both of these preceding examples the beginning and ending ranges contained the same values. But this is not always the case. For example, imagine that you want to set a range to include only those customers whose credit limit is greater than (US) $1,000. This can be accomplished using statements similar to the following:
ClientDataSet1.IndexFieldNames := 'CreditLimit';ClientDataSet1.SetRange([1000], [MaxInt]);
52 Using ApplyRange

In a previous article in this series you learned that there are two index-based methods for locating a record based on an exact match. One, FindKey, is a self-contained statement for locating a record based on fields of the current index. By comparison, GotoKey is more involved, requiring you to first call SetKey to enter the dsSetKey state, during which you define your search criteria, and then complete the operation with a call to GotoKey. SetRange is similar to FindKey, where a single statement defines the range as well as sets it. ApplyRange, by comparison, is similar to GotoKey.
To use ApplyRange you begin by calling SetRangeStart (or EditRangeStart). Doing so places the ClientDataSet in the dsSetKey state. While in this state you assign values to one or more of the TFields involved in the current index to define the low values of the range. As is the case with SetRange, if you define a single low value, it must be to the first field of the current index. If you define a low range value for two fields, they must necessarily be the first two fields of the index.
After setting the low range values, you call SetRangeEnd (or EditRangeEnd). You now assign values to one or more fields of the current index to define the high values for the range. Once both the start values and end values have been set, you call ApplyRange to filter the ClientDataSet on the defined range.
For example, the following statements use ApplyRange to display only customers who live in New York City in the customer table.
ClientDataSet1.IndexFieldNames := 'City';ClientDataSet1.SetRangeStart;ClientDataSet1.FieldByName('City').Value := 'New York City';ClientDataSet1.SetRangeEnd;ClientDataSet1.FieldByName('City').Value := 'New York City';ClientDataSet1.ApplyRange;
Just like SetRange, ApplyRange can be used to set a range on more than one field of the index, as shown in the following example.
ClientDataSet1.IndexFieldNames := 'LastName;City;State';ClientDataSet1.SetRangeStart;ClientDataSet1.FieldByName('LastName').Value := 'Walker';ClientDataSet1.FieldByName('City').Value := 'San Antonio';ClientDataSet1.FieldByName('State').Value := 'TX';ClientDataSet1.SetRangeEnd;ClientDataSet1.FieldByName('LastName').Value := 'Walker';ClientDataSet1.FieldByName('City').Value := 'San Antonio';ClientDataSet1.FieldByName('State').Value := 'TX';ClientDataSet1.ApplyRange;
Both of the preceding examples made use of SetRangeStart and SetRangeEnd. In some cases, you can use EditRangeStart and/or EditRangeEnd instead. In short, if you have already set low and high values for a range, and want to modify some, but not all, values, you can use EditRangeStart and EditRangeEnd. Calling SetRangeStart clears any previous values in the range. By comparison, if you call EditRangeStart, the previously defined low values remain in the range fields. If you want to change some, but not all, of the low range values, call EditRangeStart and modify only those fields whose low values you want to change. Likewise, if you want to change some, but not all, of the high range values, do so by calling EditRangeEnd.

For example, the following code segment will display all records where the customer's credit limit is between (US) $1,000 and (US) $5,000.
ClientDataSet1.IndexFieldNames := 'CreditLimit';ClientDataSet1.SetRange([1000],[5000]);
If you then want to set a range between $1,000 and $10,000, you can do so using the following statements:
ClientDataSet1.EditRangeEnd;ClientDataSet1.FieldByName('CreditLimit').Value := 10000;ClientDataSet1.ApplyRange;
53 Canceling a RangeWhether you have created a range using SetRange or ApplyRange, you cancel that range by calling the ClientDataSet's CancelRange method. The following example demonstrates how a call to CancelRange looks in code:
ClientDataSet1.CancelRange;
54 A Comment About Ranges
Earlier in this article I mentioned that it is 'sometimes' possible to set a range on two or more fields. The implication of this statement is that sometimes it is not, which is true. When setting a range on two or more fields, only the last field of the range can specify a range of values, all other fields must have the same value for both the low and high ends of the range. For example, the following range will display all records where the credit limit is between $1,000 and $5,000 for customers living in New York City.
ClientDataSet1.IndexFieldNames := 'City;CreditLimit';ClientDataSet1.SetRange(['New York City', 1000], ['New York City', 5000]);
By comparison, the following statement will display all records for customers whose credit limit is between $1,000 and $5,000, regardless of which city they live in.
ClientDataSet1.IndexFieldNames := 'CreditLimit;City';ClientDataSet1.SetRange([1000, 'New York City'], [5000, 'New York City']);
The difference between these two ranges is that in the first range, the low and high value in the first field of the range was a constant value, New York City. In the second, a range appears (1000-5000). In this case, the second field of the range is ignored.
There is another aspect of ranges that is rather odd when working with ClientDataSets. This is related to the KeyExclusive property inherited by the ClientDataSet from TDataSet. Normally, this property can be used to define how ranges are applied. When KeyExclusive if False (its default value), the range includes both the low and high values of the range. For example, if you set a range on CreditLimit to 1000 and 5000, records where the credit limit is 1000 or 5000 will appear in the range. If KeyExclusive is set to True, only customer records where the credit limit is greater than 1000 but less than 5000 would appear in the range. Customers with credit limits of exactly 1000 or 5000 will not.

Maybe its me, but when I try to programmatically set the KeyExclusive property on a ClientDataSet it raises an exception. I have concluded from this that KeyExclusive does not apply to ClientDataSets. If you can get KeyExclusive to work with ClientDataSets in Delphi 6 or Delphi 7, I'd like to know.
55 Using FiltersBecause ranges rely on indexes, they are applied very quickly. For example, on a 100,000 record table, with an index on the FirstName field, setting a range to show only records for customers where the first name is Scarlett was applied in less than 10 milliseconds on a 850 MHz Pentium III with 512 MB RAM (the resulting view contained only 133 records).
Filters, by comparison, do not use indexes. Instead, they operate by evaluating the records of the ClientDataSet, displaying only those records that pass the filter. Since filters do not use indexes, they are not as fast (filtering on the first name Scarlett took just under 500 milliseconds on the same database). However, they are much more flexible.
A ClientDataSet has four properties that apply to filters. These are Filter, Filtered, FilterOptions, and OnFilterRecord (an event property). In its simplest case, a filter requires the use of two of these properties: Filter and Filtered. Filtered is a Boolean property that you use to turn on and off the filter. If you want to filter records, set Filtered to True, otherwise set Filtered to False (the default value).
Hide image
When Filtered is set to True, the ClientDataSet uses the value of the Filter property to identify which records will be displayed. You assign to this property a Boolean expression containing at least one comparison operation involving at least one field in the dataset. You can use any comparison operators, include =, >, <, >=, <=, and <>. As long as the field name does not include any spaces, you include the field name directly in the comparison without delimiters. For example, if your ClientDataSet includes a field named City, you can set the Filter property to the following expression to display only customers living in New York City:
City = 'New York City'

Note that the single quotes are required here, since New York City is a string. If you want to assign a value to the Filter property at runtime, you must include the single quotes in the string that you assign to the property. The following is one example of how to do this:
ClientDataSet1.Filter := 'City = ' + QuotedStr('New York City');
The preceding code segment used the QuotedStr function, which is located in the SysUtils unit. The alternative is to use something like the following. Personally, I prefer using QuotedStr, as it is much easier to debug and maintain.
ClientDataSet1.Filter := 'City = ''Freeport''';
In the preceding examples the field name of the field in the filter did not include spaces. If one or more fields that you want to use in a filter include spaces in their field names, enclose those field names in square braces. (Square braces can also be used around field names that do not include spaces.) For example, if your ClientDataSet contains a field named 'Last Name,' you can use a statement similar to the following to create a filter.
ClientDataSet1.Filter := '[Last Name] = ' + QuotedStr('Williams');
These examples have demonstrated only simple expressions. However, complex expressions can be used. Specifically, you can combine two or more comparisons using the AND, OR, and NOT logical operators. Furthermore, more than one field can be involved in the comparison. For example, you can use the following Filter to limit records to those where the City field is San Francisco, and the last name is Martinez:
ClientDataSet1.Filter := '[City] = '+ QuotedStr('San Francisco') + 'and [Last Name] = ' + QuotedStr('Martinez');
Assigning a value to the Filter property does not automatically mean that records will be filtered. Only when the Filtered property is set to True does the Filter property actually produce a filtered dataset. Furthermore, if the Filter property contains an empty string, setting Filtered to True has no effect.
By default, filters are case sensitive and perform a partial match to the filter criteria. You can influence this behavior using the FilterOptions property. This property is a set property that can contain zero or more of the following two flags: foCaseInsensitive and foNoPartialMatch. When foCaseInsensitive is included in the set, the filter is not case sensitive.
When foNoPartialMatch is included in the set, partial matches are excluded from the filtered DataSet. When foNoPartialCompare is absent from the FilterOptions property, partial matches are identified by an asterisk ('*') in the last character of your filter criteria. All fields whose contents match the characters to the left of the asterisk are included in the filter. For example, consider the following filter:
ClientDataSet1.Filter := 'City = '+ QuotedStr('San *');
This so long as foNoPartialCompare is absent from the FilterOptions property, this filter will include any city whose name begins 'San ,' such as San Francisco or San Antonio.

Partial matches can also be used with compound Boolean expressions. For example, the following filter will display all customer's whose names begin with the letter M, and who live in a city whose name begins with 'New,' such as Newcastle or New York City.
ClientDataSet1.Filter := 'City = '+ QuotedStr('New*') + 'and [Last Name] = ' + QuotedStr('M*');
56 Using the OnFilterRecord Event Handler
There is a second, somewhat more flexible way to define a filter. Instead of using the Filter property, you can attach code to the OnFilterRecord event handler. When Filtered is set to True, this event handler triggers for every record in the dataset. When called, this event handler is passed a Boolean parameter by reference, named Accept, that you use to indicate whether or not the current record should be included in the filtered view. From within this event handler, you can perform almost any test you can imagine. For example, you can verify that the current record is associated with a record in another table. If, based on this test, you wish to exclude the current record from the view, you set the value of the Accept formal parameter to False. This parameter is True by default.
The Filter property normally consists of one or more comparisons involving values in fields of the ClientDataSet. OnFilterRecord event handlers, however, can include any comparison you want. And there lies the danger. Specifically, if the comparison that you perform in the OnFilterRecord event handler is time consuming, the filter will be slow. In other words, you should try to optimize any code that you place in an OnFilterRecord event handler, especially if you need to filter a lot of records.
The following is a simple example of an OnFilterRecord event handler.
procedure TForm1.ClientDataSet1FilterRecord(DataSet: TDataSet; var Accept: Boolean);beginAccept := ClientDataSet1.Fields[1].AsString = 'Scarlett';end;
57 Navigating Using a Filter
Whether you have set Filtered to True or not, you can still use a Filter for the purpose of navigating selected records. For example, although you may want to view all records in a database, you may want to quickly move between records that meet specific criteria. For example, you may want to be able to quickly navigate between those records where the customer has a credit limit in excess of (US) $5,000.
A ClientDataSet exposes four methods for navigating using a filter. These methods are FindFirst, FindLast, FindNext, and FindPrior. When you execute one of these methods, the ClientDataSet will locate the requested record based on the current Filter property, or OnFilterRecord event handler. This navigation, however, does not require that the Filtered property be set to True. In other words, while all records of the ClientDataSet may be visible, the filter can be used to quickly navigate between those records that match the filter.
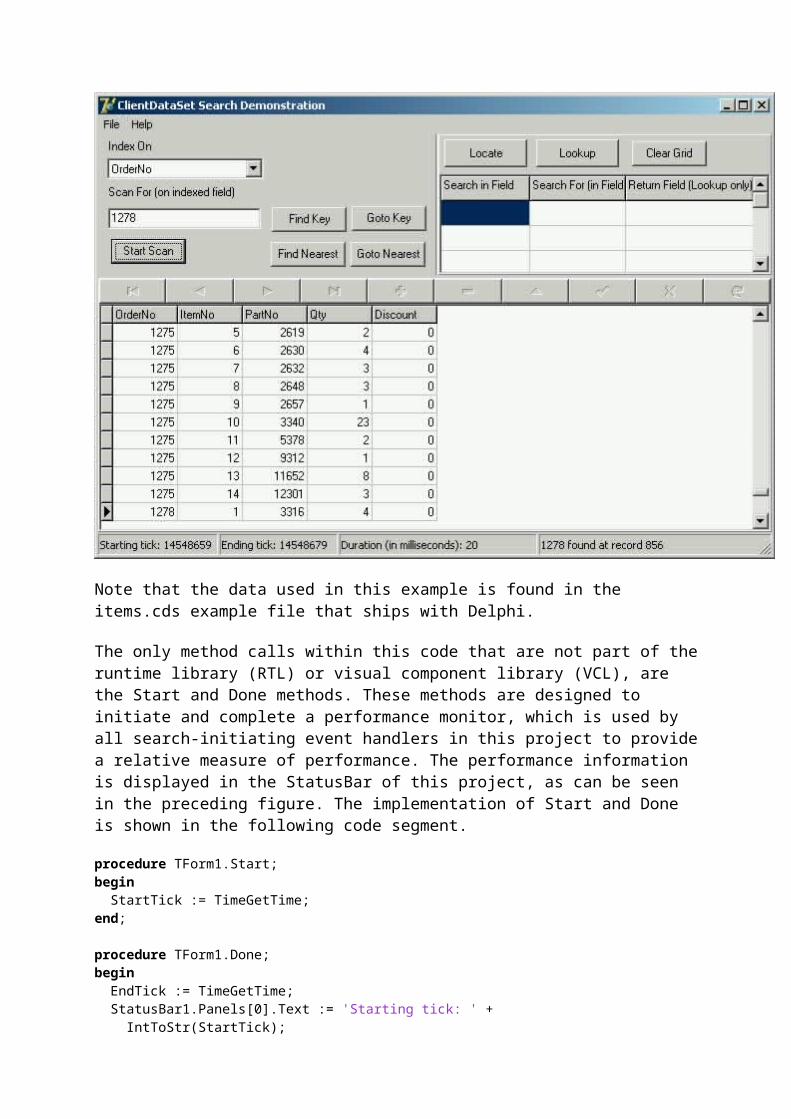
When you execute the methods FindNext or FindPrior, the ClientDataSet sets a property named Found. If Found is True, a next record or a prior record was located, and is now the current record. If Found returns False, the attempt to navigate failed.
58 Using Ranges and Filter Together
Ranges make use of indexes, and are very fast. Filters are slower, but are more flexible. Fortunately, both ranges and filters can be used together. Using ranges with filters is especially helpful when a you cannot use a range alone, and your filter is a complicated one that would otherwise take a long time to apply. In those situations, it is best to first set a range, limiting the number of records that need to be filtered to the smallest possible set that includes all records of the filter. The filter can be applied on the resulting range. Since fewer records need to be evaluated for the filter, the combined operations will be faster than using a Filter alone.
59 An Example
The various filter-related techniques discussed in this article, with the exception of the OnFilterRecord event handler, are demonstrated in the CDSFilter project, which can be downloaded from Code Central by clicking here. The main form of this project is shown in the following figure.
Hide image

In addition to demonstrating the use of SetRange, ApplyRange, Filter, Filtered, and FilterOptions, this project also provides you with feedback concerning filter performance. The following figure shows a large dataset that has not yet had its range set.
Hide image
In the following figure, a range has been applied, and only one record appears (out of 100,000 records). In this case, the range was applied in less than 10 milliseconds.

Hide image
60 ClientDataSet Aggregates and GroupState By: Cary Jensen
Abstract: This article describes how to use aggregates to calculate simple statistics, as well as how to use group state to improve your user interfaces.
One of the advantages to using a ClientDataSet in your applications is the large number of features it enables. In this article I continue my series on using ClientDataSets with a look at both aggregates and group state. Aggregates are objects that can perform the automatic calculation of basic descriptive statistics based on the data stored in a ClientDataSet. Group state, by comparison, is information that identifies the relative position of a record within a group of records, based on an index. Together, these two features permit you to add easy-to-maintain capabilities to your applications.
If you are unfamiliar with either aggregates or group state, you might be wondering why I am covering these two features together in this article. The answer is simple. Both are associated with grouping level, which is an index-related feature. Because the discussion of aggregates necessarily involves grouping level, the coverage of group state is a natural addition. This article begins with a look at aggregates. Group state is covered in a later section.
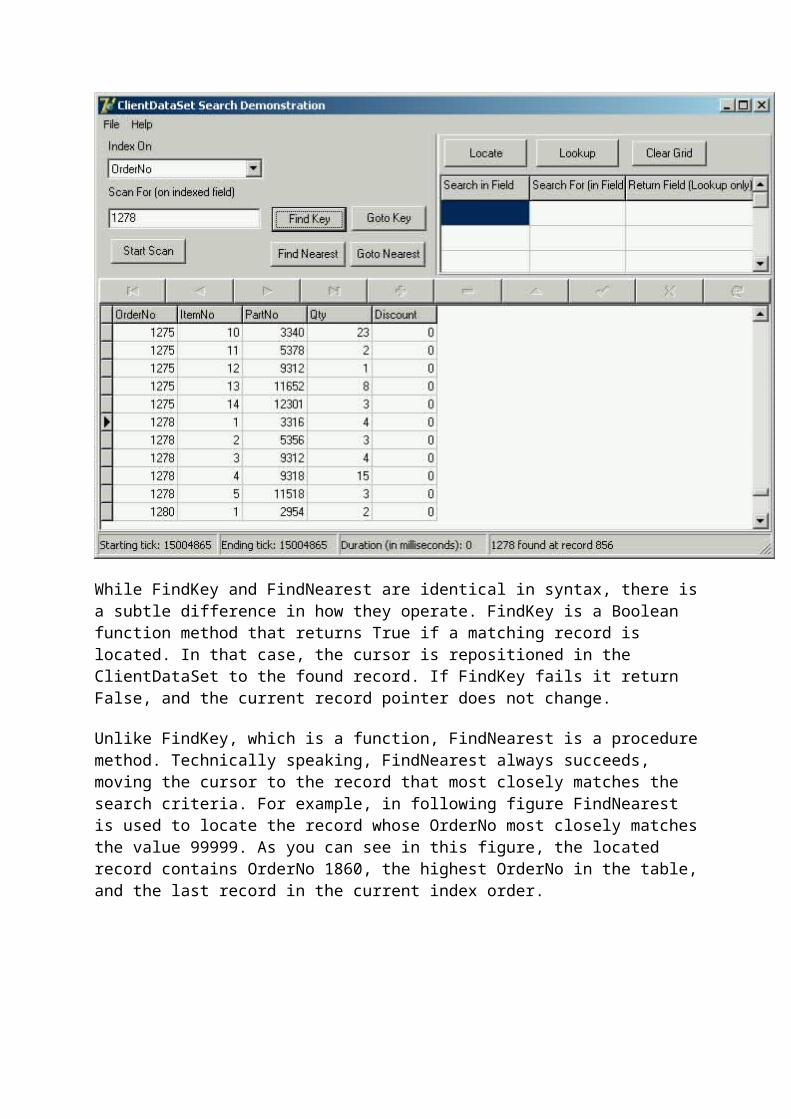
61 Understanding Aggregates
An aggregate is an object that can automatically perform simple descriptive statistical calculations across one or more records in a ClientDataSet. For example, imagine that you have a ClientDataSet that contains a list of all purchases by your customers. If each record contains a field that identifies the customer, the number of items purchased, and the total value of the purchase, an aggregate can calculate the sum of all purchases across all records in the table. Yet another aggregate can calculate the average number of items purchased by each customer. In all, a total of five statistics are supported by aggregates. These are count, minimum, maximum, sum, and average.
There are two types of objects that you can use to create aggregates: TAggregate objects and TAggregateField objects. A TAggregate is a TCollectionItem descendant, and a TAggregateField is a descendent of the TField class. While these two aggregate types are similar in how you configure them, they differ in their use. Specifically, a TAggregateField, because it is a TField descendent, can be associated with a data-aware control, permitting the value of the aggregate to be displayed automatically. By comparison, a TAggregate is an object whose value you must explicitly read at runtime.
One characteristic shared by both types of aggregates is that they require quite a few specific steps to configure. If you have never used aggregates in the past, be patient. If your aggregates do not appear to work at first, you probably missed one or more steps. However, after you get comfortable configuring aggregates, you will find that they are relatively simple to use.
Because TAggregateField instances are somewhat easier to use, they will be discussed in the following section. Using TAggregates is discussed later in this article.
62 Creating Aggregate Fields
Aggregate fields are virtual, persistent fields. While they are similar to other virtual, persistent fields, such as calculated and lookup fields, there is one very important difference. Specifically, introducing one or more aggregate fields does not preclude the automatic, runtime creation of dynamic fields. By comparison, creating at least one other type of persistent field, such as a data field, lookup field, or calculated field, prevents the ClientDataSet from creating other TFields for that ClientDataSet at runtime. As a result, it is always safe to create aggregate fields at design-time, whether or not you intend to instantiate any other TField instances at design-time.
As mentioned earlier, adding an aggregate field requires a number of specific steps in order to configure it correctly. These are:
Add the aggregate field to a ClientDataSet. This can be done at design-time using the Fields Editor, or at runtime using the TAggregateField's constructor.
Set the aggregate field's Expression property to define the calculation that the aggregate will perform
Set the aggregate field's IndexName property to identify the index to base grouping level on
Set the aggregate field's GroupingLevel property to identify which records to perform the aggregation across
Set the aggregate field's Active property to True to activate it
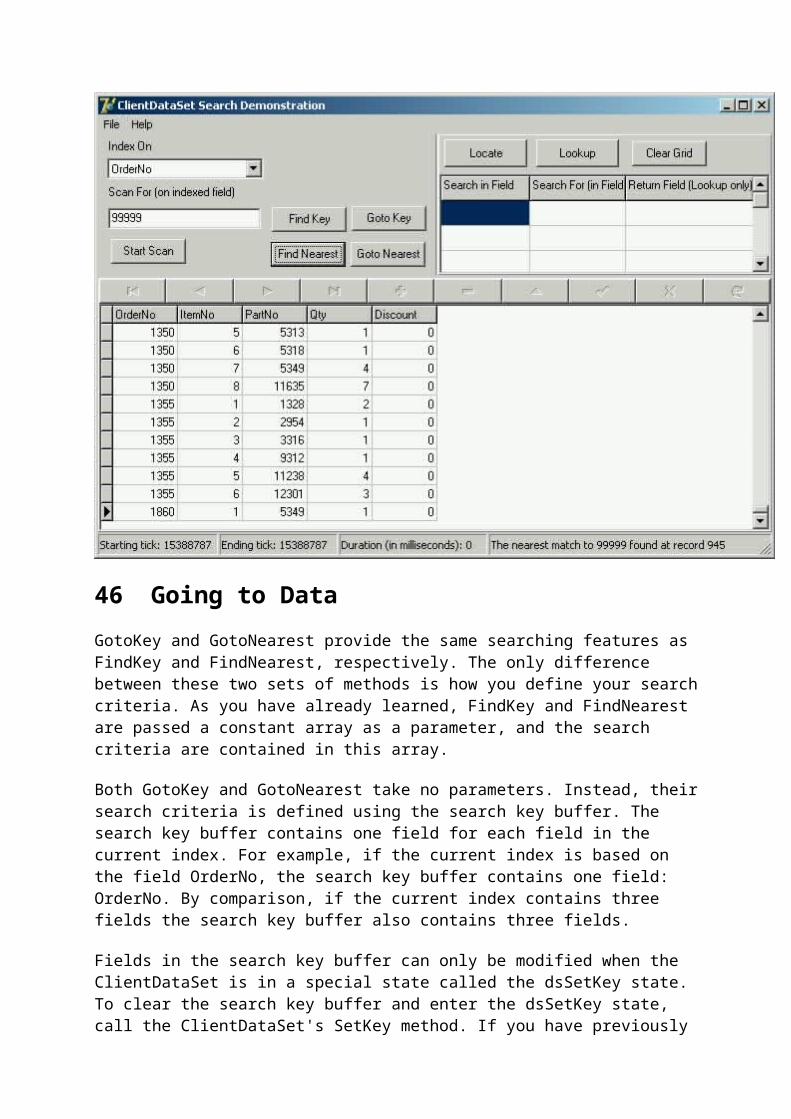
Set the aggregate field's Visible property to True Set the AggregatesActive property of the ClientDataSet to which the aggregate is
associated to True
Because there are so many steps here, it is best to discuss creating aggregate fields using an example. Use the following steps in Delphi or Kylix to create a simple project to which an aggregate field will be added.
1. Create a new project.2. Add to your main form a DBNavigator, a DBGrid, a ClientDataSet, and a DataSource.3. Set the Align property of the DBNavigator to alTop, and the Align property of the
DBGrid to Client. Next, set the DataSource property of both the DBNavigator and the DBGrid to DataSource1. Now set the DataSet property of the DataSource to ClientDataSet1.
4. Set the Filename property of the ClientDataSet to the Orders.cds table (or Orders.xml), located in Borland's shared data directory. If you installed your software using the default installation paths in Windows, you will find this file in c:Program FilesCommon FilesBorland SharedData.
Your main form should now look something like the following:
63 Adding the Aggregate Field
At design-time, you add aggregate fields using the ClientDataSet's Fields Editor. Use the following steps to add an aggregate field

1. Right-click the ClientDataSet and select Fields Editor.
2. Right-click the Fields Editor and select New Field (or press Ctrl-N). Delphi displays the New Field dialog box.
3. Set Name to CustomerTotal and select the Aggregate radio button in the Field type area. Your New Field dialog box should now look like the following

4. Click OK to close the New Field dialog box. You will now see the newly added aggregate field in the Fields Editor, as shown here.
64 Defining the Aggregate Expression
The Expression property of an aggregate defines the calculation the aggregate will perform. This expression can consist of constants, field values, and aggregate functions. The aggregate functions are AVG, MIN, MAX, SUM, and COUNT. For example, to define a calculation that will total the AmountPaid field in the Orders.cds table, you use the following expression:
SUM(AmountPaid)
The argument of the aggregate function can include two or more fields in an expression, if you like. For example, if you have two fields in your table, one named Quantity and the other named Price, you can use the following expression:
SUM(Quantity * Price)
The expression can also include constants. For example, if the tax rate is 8.25%, you can create an aggregate that calculates total plus tax, using something similar to this:

SUM(Total * 1.0825)
You can also set the Expression property to perform an operation on two aggregate functions, as shown here
MIN(SaleDate) - MIN(ShipDate)
as well as perform an operation between an expression function and a constant, as in the following
MAX(ShipDate) + 30
You cannot, however, include an aggregate function as the expression of another aggregate function. For example, the following is illegal:
SUM(AVG(AmountPaid)) //illegal
Nor can you use a calculation between an aggregate function and a field. For example, if Quantity is the name of a field, the following expression is illegal:
SUM(Price) * Quantity //illegal
In this particular case, we want to calculate the total of the AmountPaid field. To do this, use the following steps:
1. Select the aggregate field in the Fields Editor.2. Using the Object Inspector, set the Expression property to SUM(AmountPaid) and its
Currency property to True.
65 Setting Aggregate Index and Grouping Level
An aggregate needs to know across which records it will perform the calculation. This is done using the IndexName and GroupingLevel properties of the aggregate. Actually, if you want to perform a calculation across all records in a ClientDataSet, you can leave IndexName blank, and GroupingLevel set to 0.
If you want the aggregate to perform its calculation across groups of records, you must have a persistent index whose initial fields define the group. For example, if you want to calculate the sum of the AmountPaid field separately for each customer, and a customer is identified by a field name CustNo, you must set IndexName to the name of a persistent index whose first field is CustNo. If you want to perform the calculation for each customer for each purchase date, and you have fields named CustNo and SaleDate, you must set IndexName to the name of a persistent index that has CustNo and SaleDate as its first two fields.
The persistent index whose name you assign to the IndexName property can have more fields than the number of fields you want to group on. This is where GroupingLevel comes in. You set GroupingLevel to the number of fields of the index that you want to treat as a group. For example, imagine that you set IndexName to an index based on the CustNo, SaleDate, and PurchaseType fields. If you set GroupingLevel to 0, the aggregate calculation will be performed across all records in the ClientDataSet. Setting GroupingLevel to 1 performs the calculation for each customer (since CustNo is the first field in the index). Setting

GroupingLevel to 2 will perform the calculation for each customer for each sale date (since these are the first two fields in the index).
It is interesting to note that the TIndexDef class, the class used to define a persistent index, also has a GroupingLevel property. If you set this property for the index, the index will contain additional information about record grouping. So long as you are setting an aggregate's GroupingLevel to a value greater than 0, you can improve the performance of the aggregate by setting the persistent index's GroupingLevel to a value at least as high as the aggregate's GroupingLevel. Note, however, that a persistent index whose GroupingLevel property is set to a value greater than 0 takes a little longer to generate and update, since it must also produce the grouping information. This overhead is minimal, but should be considered if the speed of index generation and maintenance is a concern.
The following steps walk you through the process of creating a persistent index on the CustNo field, and then setting the aggregate field to use this index with a grouping level of 1.
1. Select the ClientDataSet in the Object Inspector and select its IndexDefs property. Click the ellipsis button of the IndexDefs property to display the IndexDefs collection editor.
2. Click the Add New button in the IndexDefs collection editor toolbar to add a new persistent index.
3. Select the newly added index in the IndexDefs collection editor. Using the Object Inspector, set the Name property of this IndexDef to CustIdx, its Fields property to CustNo, and its GroupingLevel property to 1. Close the IndexDefs collection editor.
4. With the ClientDataSet still selected, set its IndexName property to CustIdx.5. Next, using the Fields Editor, once again select the aggregate field. Set its IndexName
property to CustIdx, and its GroupingLevel property to 1. The Object Inspector should look something like the following

66 Making the Aggregate Field Available
The aggregate field is almost ready. In order for it to work, you must set the aggregate field's Active property and its Visible property to True. In addition, you must set the ClientDataSet's AggregatesActive property to True. After doing this, the aggregate will be automatically calculated when the ClientDataSet is made active.
With aggregate fields, there is one more step, which is associating the aggregate with a data-aware control (if this is what you want to do). The following steps demonstrate how to activate the aggregate, as well as make it visible in the DBGrid.
1. With the aggregate field selected in the Object Inspector, set its Active property to True and its Visible property to True.
2. Next, select the ClientDataSet and set its AggregatesActive property to True and its Active property to True.
3. Now, right-click the DBGrid and select Columns. This causes the Columns collection editor to be displayed.
4. Click the Add All button on the Columns collection editor toolbar to add persistent columns for each dynamic field in the ClientDataSet.

5. Now click the Add New button on the Columns collection editor toolbar to add one more TColumn.
6. With this new TColumn selected, set its FieldName property to CustomerTotal. In order to see this calculated field easily, drag the new column to a higher position in the Columns collection editor. For example, move this new column to the third position within the Columns collection editor.
7. That's it. If you have followed all of these steps, your newly added aggregate field should be visible in the third column of your DBGrid, as shown in the following figure.

A couple of additional comments about active aggregates are in order here. First, the ClientDataSet's AggregatesActive property is one that you might find yourself turning on and off at runtime. Setting AggregatesActive to False is extremely useful when you must add, remove, or change a number of records at runtime. If you make changes to a ClientDataSet's data, and these changes affect the aggregate calculation, these changes will be much slower if AggregatesActive is True, since the aggregate calculations will be updated with each and every change. After making your changes, setting AggregatesActive to True will cause the aggregates to be recalculated.
Rather than turning all aggregates off or on, the Active property of individual aggregates can be manipulated at runtime. This can be useful if you have many aggregates, but only need one or two to be updated during changes to the ClientDataSet. Subsequently turning other aggregates back on will immediately trigger their recalculation. At runtime you can read the ClientDataSet's ActiveAggs TList property to see which aggregates are currently active for a given grouping level.
67 Creating Aggregate Collection Items
Aggregate collection items, like aggregate fields, perform the automatic calculation of simple descriptive statistics. However, unlike aggregate fields, they must be read at runtime in order to use their value. Aggregate collection items cannot be hooked up to data-aware controls. But with that exception in mind, nearly all other aspects of the configuration of aggregate collection items is the same as for aggregate fields.
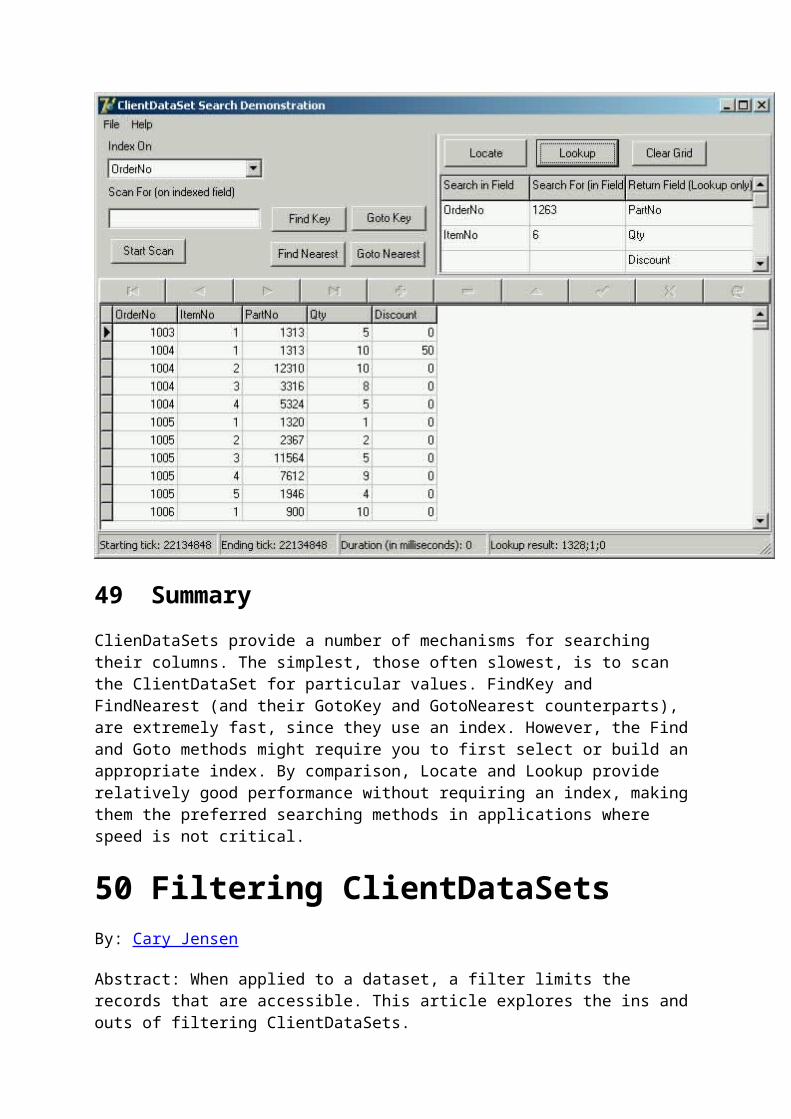
The following steps demonstrate how to add and use aggregate collection items in a project. These steps assume that you have been following along with the steps provided earlier in this article to define the aggregate field.
1. Select the ClientDataSet in the Object Inspector and select its Aggregates property. Click the ellipsis button for the Aggregates property to display the Aggregates collection editor.
2. Click the Add New button on the Aggregates collection editor's toolbar to add two aggregates to your ClientDataSet.
3. Select the first aggregate in the Aggregates collection editor. Using the Object Inspector, set the aggregate's Expression property to AVG(AmountPaid), its AggregateName property to CustAvg, its IndexName property to CustIdx, its GroupingLevel property to 1, its Active property to True, and its Visible property to True.
4. Select the second aggregate in the Aggregates collection editor. Using the Object Inspector, set its Expression property to MIN(SaleDate), its AggregateName property to FirstSale, its IndexName property to CustIdx, its GroupingLevel property to 1, its Active property to True, and its Visible property to True.
5. Add a PopupMenu from the Standard page of the component palette to your project. Using the Menu Designer (double-click the PopupMenu to display this editor), add a single MenuItem, setting its caption to About this customer.
6. Set the PopupMenu property of the DBGrid to PopUpMenu1.7. Finally, add the following event handler to the Add this customer MenuItem:
procedure TForm1.Aboutthiscustomer1Click(Sender: TObject);begin ShowMessage('The average sale to this customer is ' + Format('%.2m', [StrToFloat(ClientDataSet1.Aggregates[0].Value)]) + '. The first sale to this customer was on '+ DateToStr(ClientDataSet1.Aggregates[1].Value));end;
8. If you now run this project, your main form should look something like that shown in the follow figure.

9. To see the values calculated by the aggregate collection items, right-click a record and select About this customer. The displayed dialog box should look something like the following figure:
68 Understanding Group State
Group state refers to the relative position of a given record within its group. Using group state you can learn whether a given record is the first record in its group (given the current index), the last record in a group, neither the last nor the first record in the group, or the only record in the group. You determine group state for a particular record by calling the ClientDataSet's GetGroupState method. This method has the following syntax:
function GetGroupState(Level: Integer): TGroupPosInds;
When you call GetGroupState, you pass an integer indicating grouping level. Passing a value of 0 (zero) to GetGroupState will return the current record's relative position within the entire dataset. Passing a value of 1 will return the current record's group state with respect to the first field of the current index, passing a value of 2 will return the current record's group state with respect to the first two fields of the current index, and so on.

GetGroupState returns a set of TGroupPosInd flags. TGroupPosInd is declared as follows:
TGroupPosInd = (gbFirst, gbMiddle, gbLast);
As should be obvious, if the current record is the first record in the group, GetGroupState will return a set containing the gbFirst flag. If the record is the last record in the group, this set will contain gbLast. When GetGroupState is called for a record somewhere in the middle of a group, the gbMiddle flag is returned. Finally, if the current record is the only record in the group, GetGroupState returns a set containing both the gbFirst and gbLast flags.
GetGroupState can be particularly useful for suppressing redundant information when displaying a ClientDataSet's data in a multi-record view, like that provided by the DBGrid component. For example, consider the preceding figure of the main form. Notice that the CustomerTotal aggregate field value is displayed for each and every record, even though it is being calculated on a customer-by-customer basis. Not only is the redundant aggregate data unnecessary, it makes reading the data more difficult.
Using GetGroupState you can test whether or not a particular record is the first record for the group, and if so, display the value for CustomerTotal field. For records that are not the first record in their group (based on the CustIdx index), you simply skip printing. Determining group state and suppressing or displaying the data can be achieved by adding an OnGetText event handler to the CustomerTotal aggregate field. The following is an example of how this event handler might look:
procedure TForm1.ClientDataSet1CustomerTotalGetText(Sender: TField; var Text: String; DisplayText: Boolean);beginif gbFirst in ClientDataSet1.GetGroupState(1) then Text := Format('%.2m',[StrToFloat(Sender.Value)])else Text := '';end;
If you want to also suppress the CustNo field, you must add persistent fields for all of the fields in the ClientDataSet that you want to appear in the grid, and then add the following event handler to the CustNo field's OnGetText event handler:
procedure TForm1.ClientDataSet1CustNoGetText(Sender: TField; var Text: String; DisplayText: Boolean);beginif gbFirst in ClientDataSet1.GetGroupState(1) then Text := Sender.Valueelse Text := '';end;
The following figure shows the main form from the running CDSAggs project, which demonstrates the techniques described is the article. Notice that the CustNo and CustomerTotals fields are displayed only for the first record in each group (when grouped on CustNo). You can download this sample project from Code Central by clicking here.


69 Nesting DataSets in ClientDataSets By: Cary Jensen
Abstract: Like the name suggests, a nested dataset is a dataset within a dataset. By nesting one dataset inside another, you can reduce your overall storage needs, increase the efficiency of network communications, and simplify data operations.
To put it simply, nested datasets are one-to-many relationships embodied in a single ClientDataSet memory store. When the ClientDataSet is associated with a local file, saved as either a CDS binary file or XML, this related data is stored in a single CDS or XML file. When associated with a ClientDataSet that obtains its data through a DataSetProvider, the data packet is assembled from data retrieved through two or more related datasets.
Nested datasets provide you with a number of important advantages. For one, they typically reduce the amount of memory required to hold your data, whether it is the in-memory data store itself, or the data file saved to disk through calls to the ClientDataSet's SaveToFile method.
Second, when used with DataSnap, Borland's multitier development framework, nested datasets reduce network traffic. Specifically, nested datasets permit data from two or more related datasets to be packaged in a single data packet, which can then be transmitted between the DataSnap server and client more efficiently. For the same reason, nested datasets reduce the overall size of data stored by ClientDataSets in local files.
While these are important characteristics, a third characteristic of nested datasets is the one that is commonly considered their most valuable. Nested datasets permit the acquisition of data from, and resolution of changes to, two or more underlying tables using a single ClientDataSet.
While developers who use nested datasets value this capability, it is more difficult to appreciate if you have never worked with them before. Consider this: using nested datasets you can access data in two or more tables by calling the Open method of a single ClientDataSet. Furthermore, when you are through making changes, all updates are saved or applied with just one call to SaveToFile (for local files) or ApplyUpdates (for data obtained from a database server). In addition, if you are saving changes by calling ApplyUpdates, the changes to the two or more involved tables can be applied in an all-or-none fashion in a single transaction.
But there is more. When nested datasets are involved, data being applied as a result of a call to ApplyUpdates is resolved to the underlying datasets in the appropriate order, respecting the needs of master-detail relationships. For example, a newly created master table record is inserted before any related detail table records are inserted. Deleted records, by comparison, are removed from detail tables prior to the deletion of any master table records.
A single ClientDataSet can have up to 15 nested datasets. Each of these nested datasets can, in turn, contain up to 15 nested datasets, which in turn can have nested datasets as well. In other words, nested datasets permit you to represent a complex hierarchical relationship using one

ClientDataSet. In practice, however, nested datasets greater than two levels deep are uncommon.
70 Creating Nested DataSets
There are two distinct ways to create nested datasets, depending on how the structure of the ClientDataSet is obtained. If you are creating your ClientDataSet's structure at runtime by invoking CreateDataSet, nested datasets are defined using TFields of the type TDataSetField. These TDataSetField instances can be instantiated either at design-time or at runtime, depending on the needs of your application.
The second way to create nested datasets is to load a data into a ClientDataSet from a DataSetProvider. If the DataSetProvider is pointing to the master dataset of a master-detail relationship, and that relationship is defined using properties, the data packet returned to the ClientDataSet contains one nested dataset for each detail table linked to the master table. Each of these two approaches are covered in the following sections.
71 Defining TDataSetFields
When a ClientDataSet's structure needs to be created at runtime by calling CreateDataSet, you define its structure using TFields, where each of the nested datasets are represented by TDataSetField instances. If you are defining your structure at design time, you add the TFields that define the table's structure using the Fields Editor. If you need to define your structure at runtime, you call the constructor for each TField you want added to your table, setting the necessary properties to associate the newly created field with the ClientDataSet. In this second case, each nested dataset field is created by a call to the TDataSetField constructor.
Defining a ClientDataSet's structure using TFields was discussed at length in a previous article in this series titled "Defining a ClientDataSet's Structure Using TFields." While that article, which you can view by clicking here, mentioned the general steps used to define nested datasets using TFields, this section goes further, providing you with a step-by-step demonstration of the technique.
First, let's review the steps required to define the structure of a ClientDataSet to include nested datasets.
1. Using the Fields Editor, create one field of data type Data for each regular field in the dataset (such as Customer Name, Title, Address1, Address2, and so forth).
2. For each nested dataset, add a new field, using the same technique that you use for the other data fields, but set its Data Type to DataSet.
3. For each DataSet field that you add to your first ClientDataSet, add an additional ClientDataSet. Associate each of these secondary ClientDataSets with one of the primary ClientDataSet's DataSet fields using the secondary ClientDataSet's DataSetField property.
4. Define the fields of each nested dataset by adding individual TFields to each secondary ClientDataSets you added in step 3. Just as you did with the initial ClientDataSet, you add these fields using the Fields Editor.

The following steps walk you through creating a project that includes a ClientDataSet whose structure includes nested datasets.
1. Begin by creating a new project.2. On the main form, add two Panels from the Standard page of the Component Palette.
In each panel place a DBNavigator and a DBGrid. These components are located on the Data Controls page. Align both DBNavigators to alTop, and both DBGrids to alClient. Set the Align property of the first Panel to alTop, and the second to alClient. (If you want to be really fancy, after you align the first panel to alTop, but before aligning the second panel, place a TSplitter from the Additional page of the Component Palette on your form, and align it to top as well. The splitter permits the user to customize the percentage of the form occupied by each panel at runtime.) Your form should look something like the following.
3. Add to this form two DataSources and two ClientDataSets from the Data Access page. Set the DataSource property of the DBNavigator and DBGrid in the top panel to DataSource1, and the DataSource property of the DBNavigator and DBGrid appearing in the bottom panel to DataSource2. In addition, set the DataSet property of DataSource2 to ClientDataSet1, and the DataSet property of DataSource2 to ClientDataSet2.
4. Right-click ClientDataSet1 and select Fields Editor. Add five fields to the Field Editor, one at a time, by either pressing Ctrl-N or right-clicking the Fields Editor and selecting Add field. Use the following table to set the Name and Type fields on the New Field dialog that each of these TFields require. Make sure that the Field Type radio group is set to Data. Accept the default values for all of the remaining fields
Name Type

Invoice No Integer
Invoice Date Date
Customer No Integer
Employee No Integer
Details DataSet
5. 6. Close the Fields Editor for ClientDataSet1. 7. Select ClientDataSet2 and set its DataSetField property to ClientDataSet1Details.8. Right-click ClientDataSet2 and select Fields Editor. Add three fields to the Field
Editor, one at a time, by either pressing Ctrl-N or right-clicking the Fields Editor and selecting Add field. Use the following table to set the Name and Type field properties on the New Field dialog that each of these TFields require. Make sure that the Field Type radio group is set to Data. Accept the default values for all of the remaining fields. Close the Fields Editor for ClientDataSet2.
Name Type
Part No Integer
Quantity Integer
Price Currency
9. 10. With ClientDataSet2 still selected, set its DataSetField property to
ClientDataSet1Details.11. Add the following event handler to the OnCreate property of the main form.
procedure TForm1.FormCreate(Sender: TObject);beginClientDataSet1.FileName := ExtractFilePath(Application.ExeName) + 'data.xml';if FileExists(ClientDataSet1.FileName) then ClientDataSet1.Openelse ClientDataSet1.CreateDataSet;ClientDataSet1.LogChanges := False;end;
12. Run the form. If you have not yet added any data, this form should look something like the following.

13. Now, add some data to both tables. Once some data is added, it might look something like the following.

14. Notice that if you click the dataset field named Details associated with ClientDataSet1 twice, you will get a small grid that you can use to enter, edit, and view the nested dataset, as shown in the following figure.
If you inspected the OnCreate event handler for the main form of this project, you will have noticed that any data that you enter is stored in a file named data.xml. The following image shows how the data in this XML file looks like, once it has been formatted by the FormatXMLData function, which is found in the XMLDoc unit (this unit only ships with Enterprise and Architect versions of Delphi 6 and later).
As you can see, the <FIELDS> element of this XML file contains one empty <FIELD> element for each field in the primary dataset. In addition, the <FIELD> with the attrname

attribute value of Details itself contains a <FIELDS> element, which in turn contains the empty <FIELD> elements that describe this nested dataset's structure.
Likewise, the <ROWDATA> element, which contains the actual data, contains one empty <ROW> element for each field in the primary dataset. Here we find the <Details> element, which holds the data for the Detail nested dataset.
The source code for this project can be downloaded from Code Central by clicking here.
72 Created TDataSetFields at Runtime
One of the facts that you learn pretty early in your Delphi development is that if you can perform a task at design time you probably can perform that same task at runtime. This is certainly true with respect to nested datasets. In short, you create a nested dataset by performing the following tasks in code.
1. Call the constructor of the TDataSetField class, assigning the necessary values to the properties of the resulting object. As is the case with all TField that you create dynamically, one of the more important properties is the DataSet property, a property that identifies which TDataSet instance this field is to be associated with.
2. Assign the resulting TDataSetField to the DataSetField of the ClientDataSet that you will use to display and edit the data stored in the nested dataset.
In the article that I published previously concerning defining the structure of a ClientDataSet using TFields, I described a complicated project named VideoLibrary. This project includes two examples of a nested dataset's runtime construction. You can download this project from Code Central by clicking on this link.
All of the essential code for the process of creating a nested dataset and associating it with a ClientDataSet can be found in the OnCreate event handler of the data module for this project. The following segment, taken from this event handler, demonstrates the construction of a TDataSetField instance, including the setting of its properties.
//Note: For TDataSetFields, FieldKind is fkDataSet by default with TDataSetField.Create(Self) do begin Name := 'VideosCDSTalentByVideo'; FieldName := 'TalentByVideo'; DataSet := VideosCDS; end;
Associating this field with a ClientDataSet is even simpler. This process is demonstrated in the DataSetField property assignment appearing at the top of the following code segment. The remaining lines demonstrate the creation of the actual fields of the nested dataset.
//TalentByVideosCDS TalentByVideosCDS.DataSetField := TDataSetField(FindComponent('VideosCDSTalentByVideo')); with TStringField.Create(Self) do begin Name := 'TalentByVideosID'; FieldKind := fkData; FieldName := 'TalentID'; Size := 42;

DataSet := TalentByVideosCDS; Required := True; end; //ID with TStringField.Create(Self) do begin Name := 'TalentByVideosName'; FieldKind := fklookup; FieldName := 'Name'; Size := 50; DataSet := TalentByVideosCDS; KeyFields := 'TalentID'; LookupDataSet := TalentCDS; LookupKeyFields := 'ID'; LookupResultField := 'Name'; end; //ID with TMemoField.Create(Self) do begin Name := 'TalentByVideosComment'; FieldKind := fkData; FieldName := 'Comment'; DataSet := TalentByVideosCDS; end; //ID
73 Creating Nested DataSets Using Dynamically Linked DataSets
Nested datasets are automatically created when a dataset provider's DataSet property points to the master dataset of a master-detail relationship. A master-detail relationship, as the term is being used here, exists when one dataset, the detail dataset, is linked to another, the master dataset, through properties of the detail dataset.
For example, a master-detail relationship exists when a BDE Table component is linked to another via the MasterSource and MasterFields properties. Likewise, a master-detail relationship exists when a SQLQuery component is linked to another dataset using the DataSource property in conjunction with a parameterized query (where one or more parameter names in the detail table query match field names in the master dataset).
When a DataSetProvider points to the master table one of these mater-detail relationships, the data packet that it provides to a ClientDataSet includes one DataSetField for each detail dataset.
Creating nested datasets through dynamically linked datasets is not limited to BDE and dbExpress datasets. Nested datasets can also be created using IBExpress, ADO, and MyBase datasets, as well as many third-party TDataSet descendants. For example, the ADSTable and ADSQuery components provided by Extended System to connect to the Advantage Database Server can by linked dynamically, which will then produce nested datasets when their data is provided through a DataSetProvider.
The following steps demonstrate how to create nested datasets using dynamically linked datasets.
1. Create a new project.2. Design the main form to look similar to the one created earlier in this article.
Specifically, add two Panels from the Standard page of the Component Palette. In each

panel place a DBNavigator and a DBGrid. These components are located on the Data Controls page. Align both DBNavigators to alTop, and both DBGrids to alClient. Set the Align property of the first Panel to alTop, and the second to alClient. (Again, if you want a better interface, after you align the first panel to alTop, but before aligning the second panel, place a TSplitter from the Additional page of the Component Palette on your form, and align it to top as well. The splitter permits the user to customize the percentage of the form occupied by each panel at runtime.) Also add two DataSources from the Data Access page of the Component Palette onto this form. Set the DataSource property of the top DBNavigator and DBGrid to DataSource1, and the DataSource property of the bottom DBNavigator and DBGrid to DataSource 2. Your form should look something like the following.
3. Select File | New | Data Module to add a data module to your project. From the BDE page of the Component Palette add two Tables, and from the Data Access page add one DataSetProvider, one DataSource, and two ClientDataSets. Your data module should look something like the following.
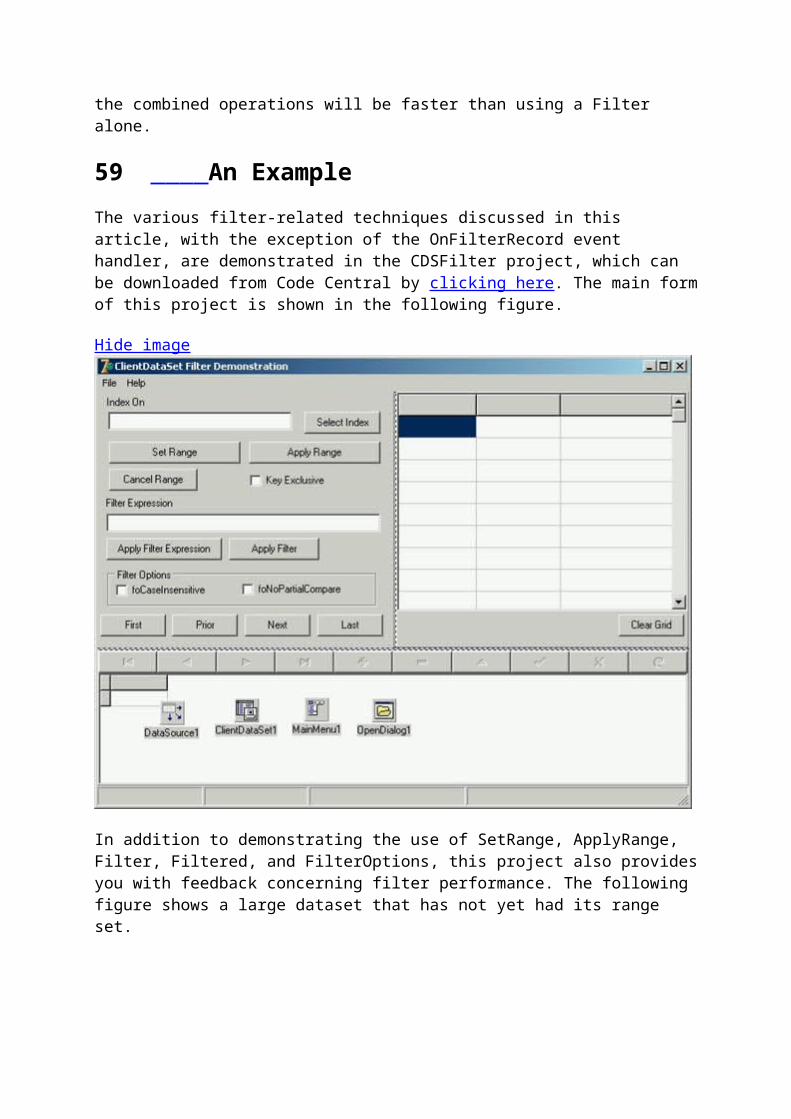
4. Set the DatabaseName property of Table1 and Table2 to DBDEMOS. Set the TableName property of Table1 to customer.db, and the TableName property of Table2 to orders.db. Also, set the IndexName property of Table2 to CustNo. Next, set the DataSet property of DataSource1 to Table1.
5. Now it is time to create the dynamic link. Select the MasterFields property of Table2 and click the ellipsis to display the Field Link Designer. Select CustNo in both the Detail Fields and Master Fields lists, and then click the Add button. After you click the Add button, the string CustNo -> CustNo will appear in the Joined Fields list. Click OK to close the Field Link Designer.
6. Set the DataSet property of the DataSetProvider to Table1, and set the ProviderName property of ClientDataSet1 to DataSetProvider1.
7. At this point, if you make ClientDataSet1 active it will contain one TField for each field in Table1, as well as an additional DataSetField for the associated records of Table2. These detail records can be associated with ClientDataSet2 at runtime by assigning the DataSetField property of ClientDataSet2 to this nested dataset. To do this at design time, however, you must create persistent fields for ClientDataSet1.
8. To create persistent field for ClientDataSet1, right-click ClientDataSet1 and select Fields Editor. Right-click in the Fields Editor and select Add all fields. After you add all fields to the Fields Editor, you will see the DataSetField at the end of the list, as shown in the following figure.
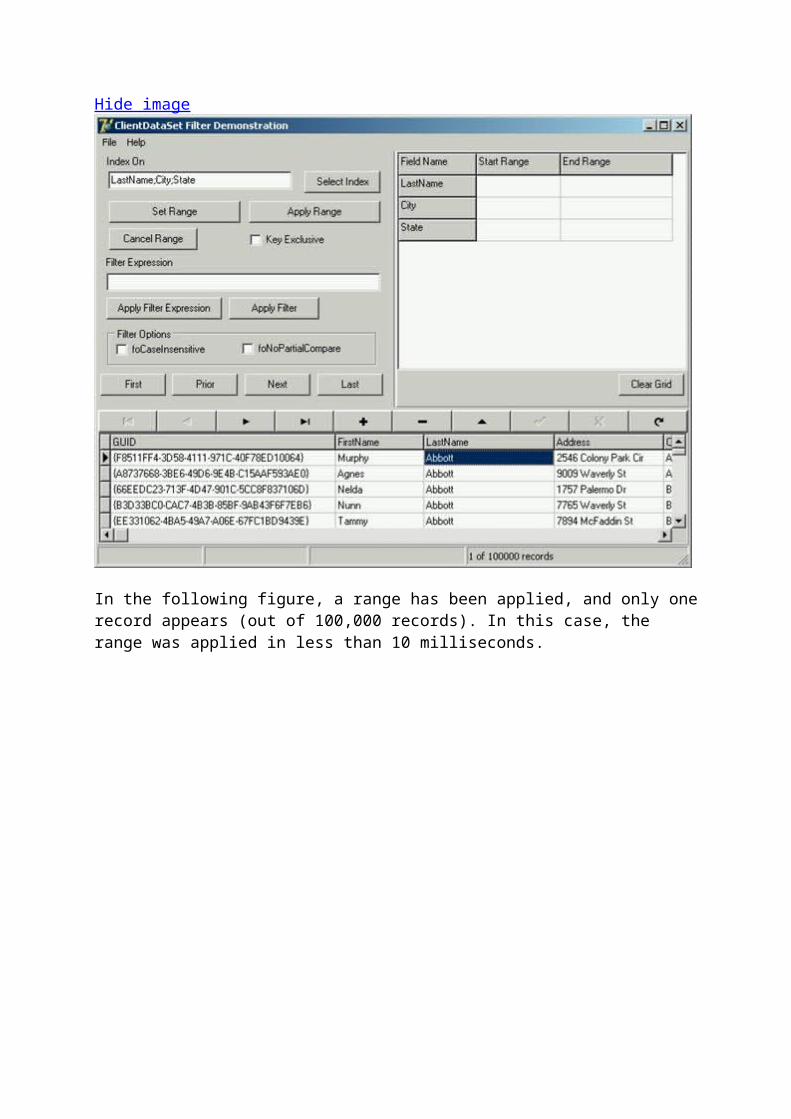
9. Select ClientDataSet2 and set its DataSetField property to ClientDataSet1Table2.10. Return to the main form. Add a main menu to this form. Right-click the main menu
and select Menu Designer. Set the Caption property of the top-level menu item to File. Add two menu items under File, with the first one having the caption Open, and the second having the Caption Apply Updates. The menu designer should look something like the following.
11. Close the menu designer. 12. Select File | Use unit, and add the data module's unit to the main form's uses clause.13. From the main form, select File | Open to add an OnClick event handler to this menu
item. Edit the event handler to look like the following:
procedure TForm1.Open1Click(Sender: TObject);begin DataModule2.ClientDataSet1.Open;end;
14. Now select File | Apply Updates from the main form's menu to create an OnClick event handler for it. Edit this event handler to look like the following.
procedure TForm1.ApplyUpdates1Click(Sender: TObject);begin DataModule2.ClientDataSet1.ApplyUpdates(0);end;
15. Finally, add an OnClose event handler to the main form. Edit this event handler to look like this:
procedure TForm1.FormClose(Sender: TObject; var Action: TCloseAction);beginwith DataModule2 dobegin if ClientDataSet1.State in [dsEdit, dsInsert] then ClientDataSet1.Post; if ClientDataSet1.ChangeCount > 0 then if MessageDlg('Save changes?', mtConfirmation, mbOKCancel, 0) = mrOK then ClientDataSet1.ApplyUpdates(0);end;

end;
16. Set the DataSet property of DataSource1 to DataModule2.ClientDataSet1, and the DataSet property of DataSource to DataModule2.ClientDataSet2.
17. Finally, since you cannot call Refresh on a ClientDataSet that does not have a DataSetProvider (and ClientDataSet2 does not have a DataSetProvider, remove the nbRefresh flag from the VisibleButtons property of DBNavigator2.
18. Save your project, and then run it. After you select File | Open from the main form's main menu, your form should look something like the following.
Just as you do when using TFields to create nested datasets, the master ClientDataSet is used to control both the master and all detail tables. Specifically, when you open ClientDataSet1, both ClientDataSet1 and ClientDataSet2 are populated with data. Similarly, you call ApplyUpdates only on ClientDataSet1. Doing so saves all changes, even those made through ClientDataSet2.
You can even use the State and ChangeCount properties of ClientDataSet1 to determine the condition of all datasets. You will notice this if you run the project, select File | Open, and then make a single change to one of the records in the detail table. Before posting this change, try to close the application. This causes the OnClose event handler to trigger, where the code will determine that an unposted record needs to be posted, and then ask you whether you want your changes saved or not. In other words, the State property of ClientDataSet1 is in dsEdit state when a unposted change appears in a nested dataset, and calling ApplyUpdates applies all changes, even those posted to the nested datasets.
You can download the source code for this project from Code Central by clicking here.
74 Nested DataSets and Referential Integrity

Referential integrity refers to the relationships of master-detail records. You control referential integrity of nested datasets using the flags of the Options property of the DataSetProvider. The following figure shows the expanded Options property of a DataSetProvider displayed in the Object Inspector.
Add poCascadeDeletes to cause a master record deletion to delete the corresponding detail records. When poCascadeDeletes is not set, master records cannot be deleted if there are associated detail records.
Add poCascadeUpdates to Options to propagate changes to the master table key fields to associated detail records. If poCascadeUpdates is not set, you cannot change master table fields involved in the master-detail link.
Note also that the Options property also contains a poFetchDetailsOnDemand property. If this flag is set, detail records are not automatically loaded when you open the master ClientDataSet. In this case, you must explicitly call the master ClientDataSet's FetchDetails method in order to load the nested datasets.

75 Cloning ClientDatSet Cursors By: Cary Jensen
Abstract: When you clone a ClientDataSet's cursor, you create not only an additional pointer to a shared memory store, but also an independent view of the data. This article shows you how to use this important capability.
If you have been following this series, you are no doubt aware that I am a huge fan of ClientDataSets. Indeed, I feel like I haven't stopped smiling since Borland added them to the Professional edition of their RAD (rapid application development) products, including Delphi, Kylix, and C++ Builder. The capabilities that ClientDataSets can add to an application are many. But of all the features made available in ClientDataSets, I like cloned cursors the most.
This is the tenth article in this series, and you might be wondering why I've waited until now to discuss cloning cursors. The answer is rather simple. The full power of cloned cursors is not obvious until you know how to navigate, edit, filter, search, and sort a ClientDataSet's data. In some respects, the preceding articles in this series have been leading up to this one.
Normally, the data that you load into a client dataset is retrieved from another dataset or from a file. But what do you do when you need two different views of essentially the same data? One alternative is to load a second copy of the data into a second ClientDataSet. This approach, however, results in an unnecessary increase in network traffic (or disk access) and places redundant data in memory. In some cases, a better option is to clone the cursor of an already populated ClientDataSet. When you clone a cursor, you create a second, independent pointer to an existing ClientDataSet's memory store, including Delta (the change log). Importantly, the cloned ClientDataSet has an independent current record, filter, index, provider, and range.
It is difficult to appreciate the power of cloned cursors without actually using them, but some examples can help. Previously you learned that the data held by a ClientDataSet is stored entirely in memory. Imagine that you have loaded 10,000 records into a ClientDataSet, and that you want to compare two separate records in the ClientDataSet programmatically. One approach is locate the first record and save some of its data into local variables. You can then locate the second record and compare the saved data to that in the second record. Yet another approach is to load a second copy of the data in memory. You can then locate the first record in one ClientDataSet, the second record in the other ClientDataSet, and then directly compare the two record.
A third approach, and one that has advantages over the first two, is to utilize the one copy of data in memory, and clone a second cursor onto this memory store. The cloned cursor acts is if it were a second copy of the data in memory, in that you now have two cursors (the original and the clone), and each can point to a different record. Importantly, only one copy of the data is stored in memory, and the cloned cursor provides a second, independent pointer into it. You can then point the original cursor to one record, the cloned cursor to the other, and directly compare the two records.
Here's another example. Imagine that you have a list of customer invoices stored in memory using a ClientDataSet. Suppose further that you need to display this data to the end user using
two different sort orders, simultaneously. For example, imagine that you want to use one DBGrid to display this data sorted by customer account number, and another DBGrid to display this data by invoice date. While your first inclination might be to load the data twice, using two ClientDataSets, a cloned cursor performs the task much more efficiently. After loading the data into a single ClientDataSet, a second ClientDataSet is used to clone the first. The first ClientDataSet can be sorted by customer account number, and the second can be sorted by invoice date. Even though the data appears in memory only once, each of the ClientDataSets contain a different view.
76 How to Clone a ClientDataSet
You clone a ClientDataSet's cursor by invoking the CloneCursor method. This method has the following syntax:
procedure CloneCursor(Source :TCustomClientDataSet; Reset: Boolean; KeepSettings: Boolean = False);
When you invoke CloneCursor, the first argument is an already active ClientDataSet that points to the memory store you want to work with. The second parameter, Reset, is used to either keep or discard the original ClientDataSet's view. If you pass a value of False, the values of the IndexName (or IndexFieldNames), Filter, Filtered, MasterSource, MasterFields, OnFilterRecord, and ProviderName properties are set to match that of the source client dataset. Passing True in the second parameter resets these properties to their default values. (A special case with respect to filters is discussed in the following section.)
For example, if you invoke CloneCursor, passing a value of True in the second parameter, the cloned ClientDataSet's IndexFieldNames property will contain an empty string, regardless of the value of the IndexFieldNames property of the original ClientDataSet. To put this another way, the cloned cursor may or may not start out with similar properties to the ClientDataSet it was cloned from, depending on the second parameter.
You include the third, optional parameter, passing a value of True, typically in conjunction with a Reset value of False. In this situation, the properties of the cloned cursor match that of the original dataset, but may not actually be valid, depending on the situation. In most cases, a call to CloneCursor only includes the first two parameters.
Although the cloned cursor may not share many view-related properties with the ClientDataSet it was cloned from, it may present a view that nearly matches the original. For example, the current record of a cloned cursor is typically the same record that was current in the original. Similarly, if a ClientDataSet uses an index to display records in a particular order, the clone's natural order will match the indexed view of the original, even though the IndexName or IndexFieldNames properties of the clone may be empty.
This view duplication also applies to ranges. Specifically, if you clone a ClientDataSet that has a range set, the clone will employ that range, regardless of the values you pass in the second and third parameters. However, you can easily change that range, either by setting a new range, or dropping the range by calling the ClientDataSet's CancelRange method. These ranges are independent, however, in that each ClientDataSet pointing to a common memory store can have a different range, or one can have a range and the other can employ no range.
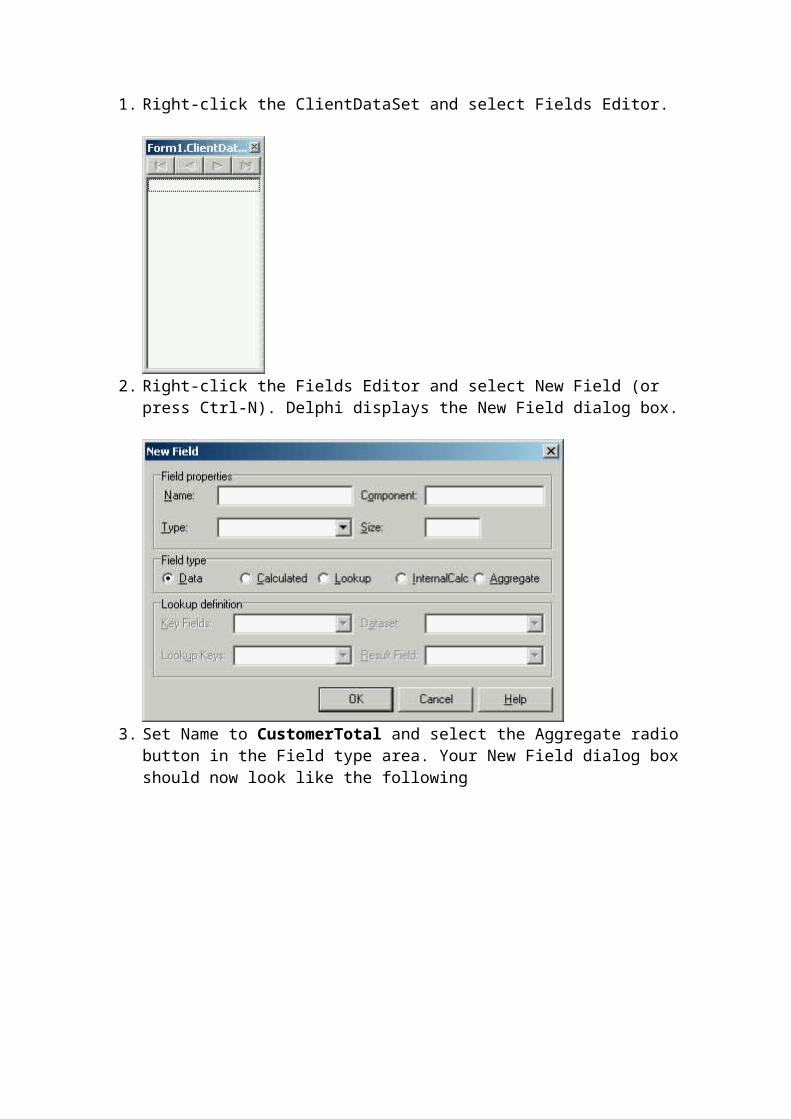
In general, I think it is a good idea to make few assumptions about the view of a cloned cursor. In other words, your safest bet is to clone a cursor passing a value of True in the Reset formal parameter. If you pass a value of False in the Reset parameter, I suggest that you insert a comment or Todo item into your code, and document how you expect the view of the clone to appear. Doing so will help you fix problems that could potentially be introduced if future implementations of the CloneCursor method change the view of the clone.
A single ClientDataSet can be cloned any number of times, creating many different views for the same data store. Furthermore, you can clone a clone to create yet another pointer to the original data store. You can even clone the clone of a clone. It really does not matter. There is a single data store, and a ClientDataSet associated with it, whether it was created by cloning or not, points to that data store.
Here is another way to think of this. Once a ClientDataSet is cloned, the clone and the original have equal status, as far as the memory store is concerned. For example, you can load one ClientDataSet with data, and then clone a second ClientDataSet from it. You can then close the original ClientDataSet, either by calling its Close method or setting its Active property to False. Importantly, the clone will remain open. To put this another way, so long as one of the ClientDataSets remain open, whether it was the original ClientDataSet used to load the data or a clone, the data and change log remain in memory.
77 Cloning a Filtered ClientDataSet: A Special Case
Similar to cloning a ClientDataSet that uses a range, there is an issue with cloning ClientDataSets that are filtered. Specifically, if you clone a ClientDataSet that is currently being filtered (its Filter property is set to a filter string, and Filtered is True), and you pass a value of False (no reset) in the second parameter of the CloneCursor invocation, the cloned ClientDataSet will employ the filter also. However, unlike when a cloned cursor has a range, which can be canceled, the cloned cursor will necessarily be filtered. In other words, in this situation, the clone can never cancel the filter it gets from the ClientDataSet it was cloned from. (Actually, you can apply a new filter to the filtered view, but that does not cancel the original filter. It merely adds an additional filter on top of the original filter.)
This effect does not occur when Filter is set to a filter expression, and Filtered is set to False. Specifically, if Filter is set to a filter expression, and Filtered is False, cloning the cursor with a Reset value of False will cause the cloned view to have a filter expression, but it will not be filtered. Furthermore, you can set an alternative Filter expression, and set or drop the filter, in which case the clone may include more records than the filtered ClientDataSet from which it was cloned.
The discrepancy between the way a non-reset clone works with respect to the Filtered property is something that can potentially cause major problems in your application. Consequently, I suggest that you pass a value of True in the Reset formal parameter of CloneCursor if you are cloning an actively filtered ClientDataSet. You can then set the filter on the clone, in which case the filters will be completely independent.
78 The Shared Data Store
The fact that all clones share a common data store has some important implications. Specifically, any changes made to the common data store directly affects all ClientDataSets that use it. For example, if you delete a record using a cloned cursor, the record instantly
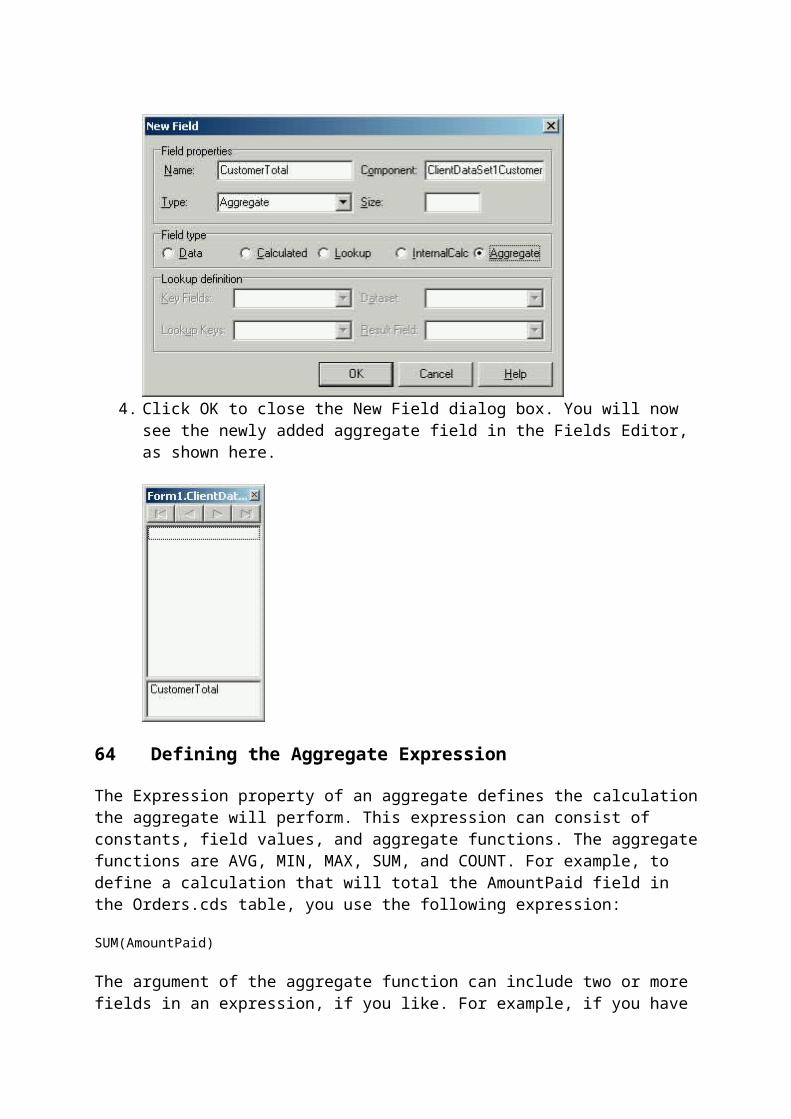
appears to be deleted from all ClientDataSets pointing to that same store and an associated record appears in the change log (assuming that the public property LogChanges is set to True, its default value). Similarly, calling ApplyUpdates from any of the ClientDataSets attempts to apply the changes in the change log. In addition, setting one of the ClientDataSet's Readonly property to True prevents any changes to the data from any of its associated ClientDataSets.
Note that the documentation states that passing a value of True in the second parameter of CloneCursor will cause the clone to employ the default ReadOnly property, rather than the ReadOnly value of the ClientDataSet that is being cloned. Nonetheless, setting ReadOnly on a ClientDataSet to True makes the data store readonly, which affects all ClientDataSets pointing to that data store.
Likewise, if you have at least one change in the change log, calling RevertRecord, or even CancelChanges, affects the single change log (represented by the Delta property). For example, if you deleted a record from a cloned ClientDataSet, it will appear to be instantly deleted from the views of all the ClientDataSets associated with the single data store. If you then call UndoLastChange on one of the ClientDataSets, that deleted record will be removed from the change log, and will instantly re-appear in all of the associated ClientDataSets.
79 Cloning Examples
Cloning a cursor is easy, but until you see it in action it is hard to really appreciate the power that cloned cursors provide. The following examples are designed to give you a feel for how you might use cloned cursors in your applications.
80 Creating Multiple Views of a Data Store
This first example, CloneAndFilter, shows how you can display many different views of a common data store using cloned cursors. You can download this project from Code Central by clicking here.. The following is the main form of this application, which permits you to select the file to load into a ClientDataSet and then clone.
Once you click the button labeled Load and Display, an instance of the TViewForm class is created, and the selected file is loaded into a ClientDataSet associated with this class. The

following is how the instance of the TViewForm looks when the customer.cds file is loaded into the ClientDataSet.
If you have been following this series, you will recognize this form as being similar to the one I used to demonstrate filters and ranges. I used this form here, of course, so that you can apply filters, set ranges, change indexes, and edit and navigate records, and then see what influence these setting have on a clone of this view.
As you can see from the preceding form, there are two buttons associated with cloning a cursor. The first, labeled CloneCursor: Reset, will call CloneCursor with a value of True passed in the second parameter. The following is the OnClick event handler associated with this button.
procedure TViewForm.CloneResetBtnClick(Sender: TObject);var ViewForm: TViewForm;beginViewForm := TViewForm.Create(Application);ViewForm.ClientDataSet1.CloneCursor(Self.ClientDataSet1, True);ViewForm.CancelRangeBtn.Enabled := Self.CancelRangeBtn.Enabled;ViewForm.Caption := 'Cloned ClientDataSet';ViewForm.Show;

end;
When you click CloneCursor: Reset, an instance of the TViewForm class is created, and the ClientDataSet that appears on this instance is cloned from the one that appears on Self. The following shows an example of what this form might look like after a cursor is cloned.
Besides this form's caption, it appears to be a separate view of the originally loaded file. You can now set filters, ranges, and change the current record. Importantly, both of the files use the single copy of the data originally loaded into memory.
The second button associated with cloning is labeled CloneCursor: No Reset. The following code is associated with the OnClick event handler of this button.
procedure TViewForm.CloneNoResetBtnClick(Sender: TObject);beginViewForm := TViewForm.Create(Application);ViewForm.ClientDataSet1.CloneCursor(Self.ClientDataSet1, False);ViewForm.CancelRangeBtn.Enabled := Self.CancelRangeBtn.Enabled;ViewForm.Caption := 'Cloned ClientDataSet';ViewForm.Show;end;
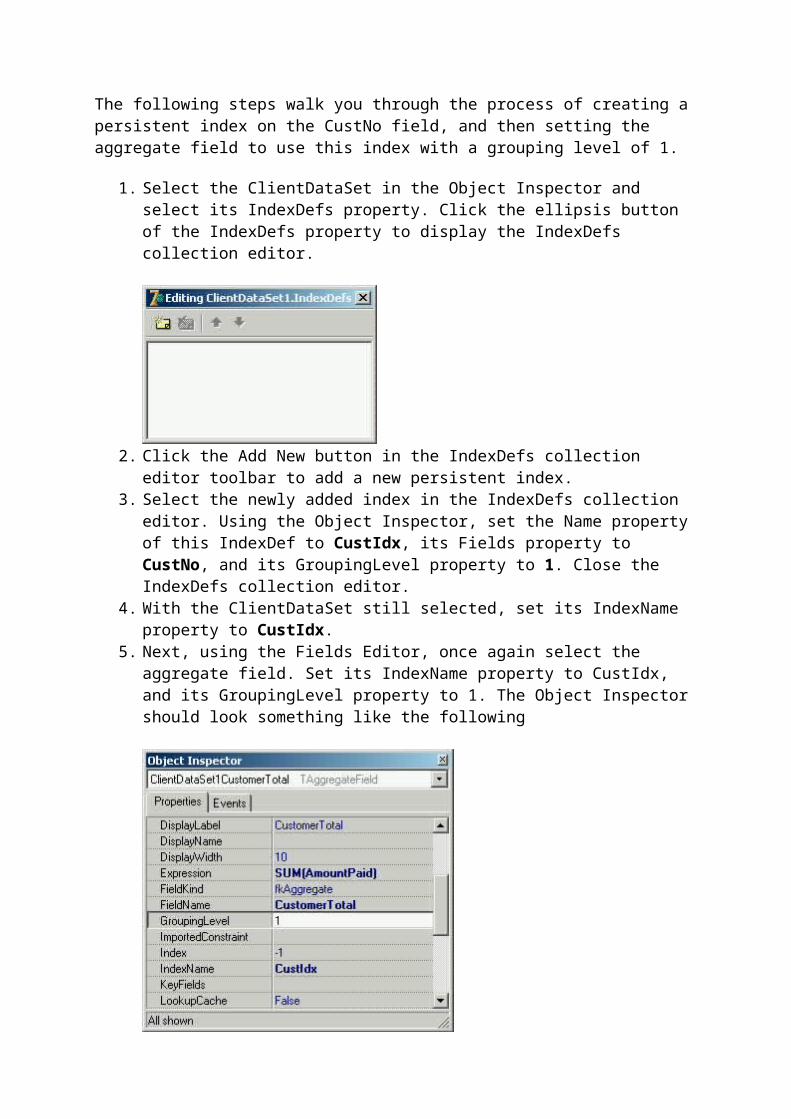
Obviously, the only difference between this method and the preceding one is the value passed in the second parameter of the call to CloneCursor.
Unfortunately, the static nature of the screenshots in this article do little to demonstrate what is going on here. I urge you to either create your own demonstration project, or to download this project, and play with cloned cursors for a while. For example, create three clones of the same cursor, and then close the original TViewForm instance. Then, with several of the TViewForm instances displayed, post a change to one of the records. You will notice that all instances of the displayed form will instantly display the updated data. Next, undo that change by clicking the button labeled Undo Last Change (try doing this on a form other than the one you posted the change on).
Here's another thing to try. Clone several cursors and then delete a record from one of the visible forms. This record will immediately disappear from all forms. Then, click the button labeled Empty Change Log (again, it does not matter on which form you click this button). The deleted record will instantly reappear on all visible forms.
81 Self-Referencing Master-Details
Most database developers have some experience create master-detail views of data. This type of view, sometimes also called a one-to-many view or a parent-child view, involves displaying the zero or more records from a detail table that are associated with the currently selected record in a master table. You can easily create this kind of view using the MasterSource and MasterFields properties of a ClientDataSet, given that you have two tables with the appropriate relationship (such as Borland's sample customer.cds and orders.cds files).
While most master-detail views involve two tables, what do you do if you want to create a similar effect using a single table. In other words, what if you want to select a record from a table and display other related records of that same table in a separate view.
Sound weird? Well, not really. Consider Borland's sample file items.cds. Each record in this file contains an order number, a part number, the quantity ordered, and so forth. Imagine that when you select a particular part associated with an given order you want to also see, in a separate view, all orders from this table in which that same part was ordered. In this example, all of the data resides in a single table (items.cds).
Fortunately, cloned cursors give you a powerful way of displaying master-detail relationships within a single table. This technique is demonstrated in the MasterDetailClone project, which can be downloaded form Code Central by clicking here..
The main form of this running project can be seen in the following figure. Notice that when a record associated with part number 12306 is selected (in this case, for order number 1009), the detail view, which appears in the lower grid on this form, displays all orders that include part number 12306 (including order number 1009).
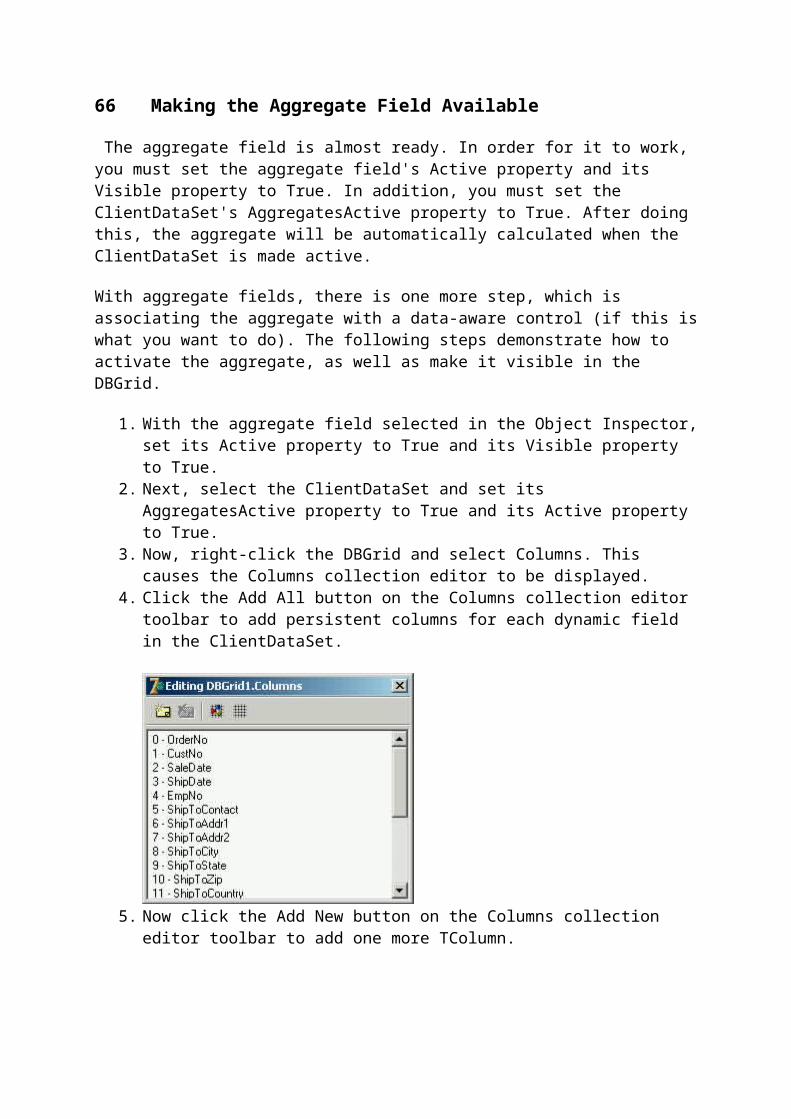
This form also contains a checkbox, which permits you to either include or exclude the current order number from the detail list. When this checkbox is not checked, the current order in the master table does not appear in the detail, as shown in the following figure.
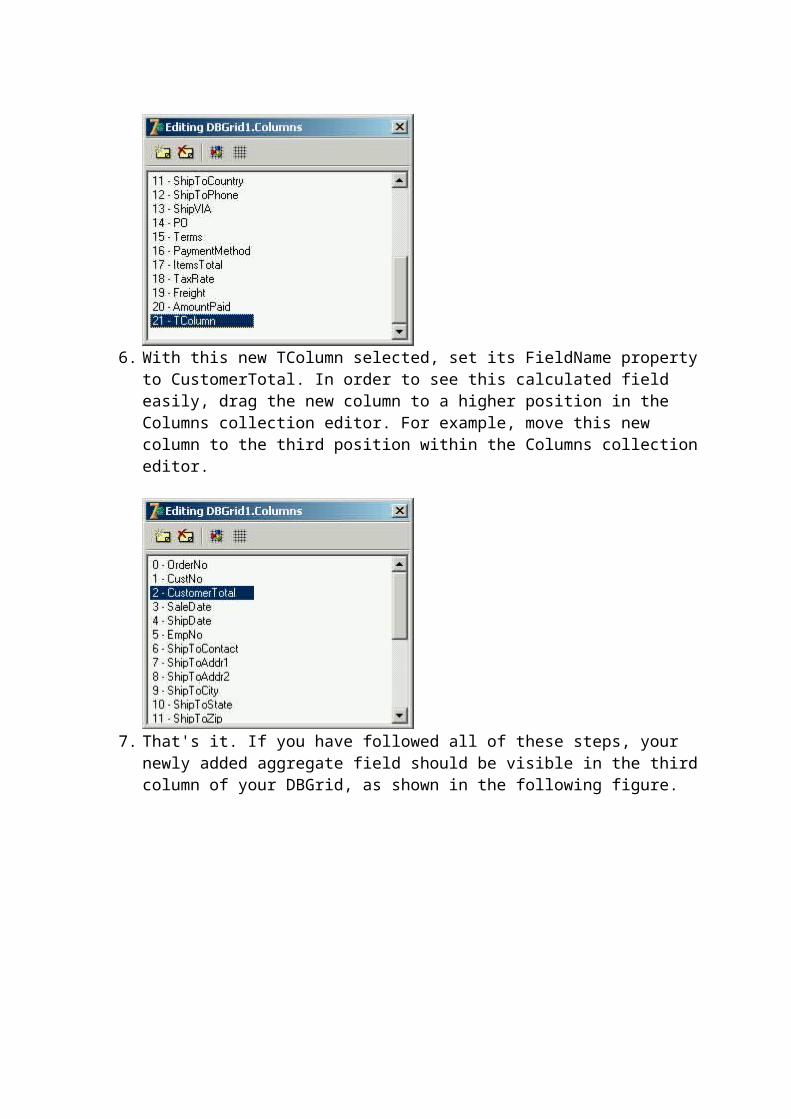
In this project, the detail view is created using a cloned cursor of the master table (ClientDataSet1) from the OnCreate event handler of the main form. The following is the code associated with this event handler.
procedure TForm1.FormCreate(Sender: TObject);beginif not FileExists(ClientDataSet1.FileName) thenbegin ShowMessage('Cannot find ' + ClientDataSet1.FileName + '. Please assign the items.cds table ' + 'to the FileName property of ClientDataSet1 ' + 'before attempting to run the application again'); Halt;end;ClientDataSet1.Open;//Assign the OnDataChange event handler _after_//opening the ClientDataSetDataSource1.OnDataChange := DataSource1DataChange;//Clone the detail cursor.ClientDataSet2.CloneCursor(ClientDataSet1, True);//Create and assign an index to the cloned cursorClientDataSet2.AddIndex('PartIndex','PartNo',[]);ClientDataSet2.IndexName := 'PartIndex';ClientDataSet2.Filtered := True;//Invoke the OnDataChange event handler to//create the detail viewDataSource1DataChange(Self, PartFld);end;
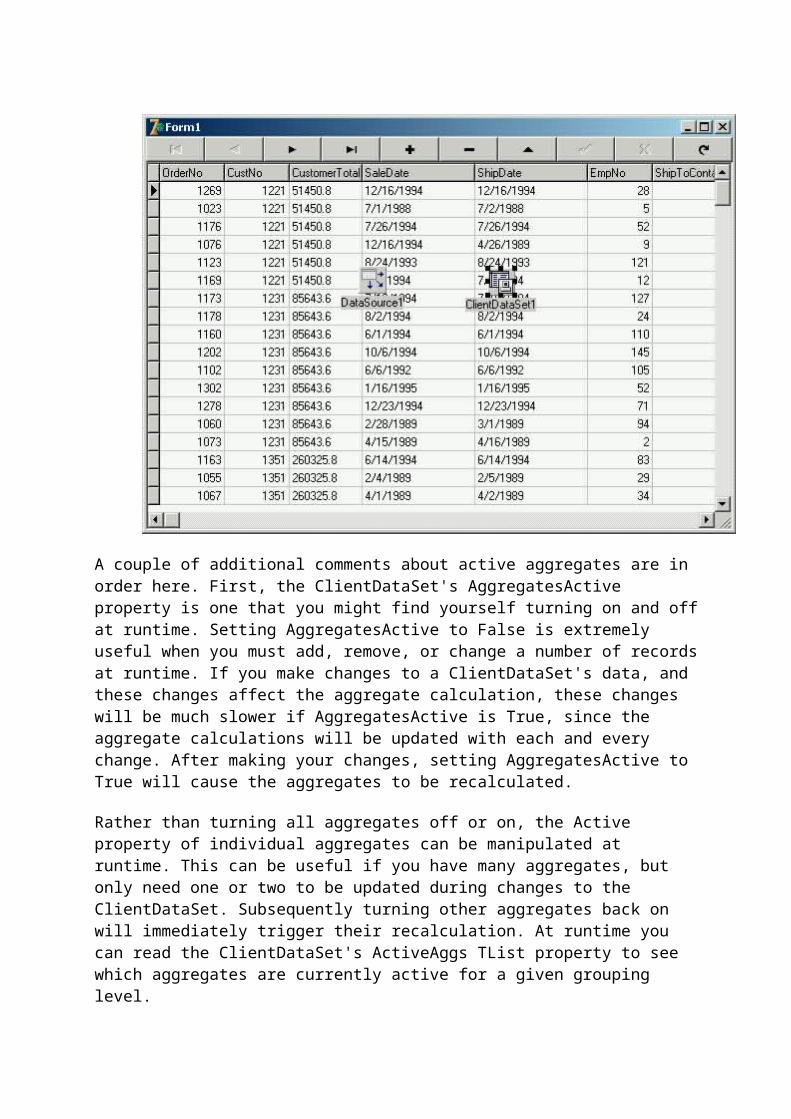
Once this event handler confirms that the file name associated with ClientDataSet1 is valid, there are four steps that are taken that contribute to the master-detail view. The first step is that ClientDataSet1 is opened, which must occur prior to cloning the cursor.
The second step is that an OnDataChange event handler, which creates the detail view, is assigned to DataSource1. This is the DataSource that points to ClientDataSet1. Once this assignment is made, the detail table view is updated each time OnDataChange is invoked (which occurs each time a change is made to a field in ClientDataSet1, as well as each time ClientDataSet1 arrives at a new current record).
The third operation performed by this event handler is the cloning of the detail table cursor, assigning an appropriate index, and setting the cloned cursor's Filtered property to True. In this project, the order of steps two and three are interchangeable.
The forth step is to invoke the OnDataChange event handler of DataSoure1. This invocation causes the cloned cursor to display its initial detail view.
As must be obvious from this discussion, the OnDataChange event handler actually creates the detail view. The following is the code associated with this event handler.
procedure TForm1.DataSource1DataChange(Sender: TObject; Field: TField);beginPartFld := ClientDataSet1.FieldByName('PartNo');ClientDataSet2.SetRange([PartFld.AsString], [PartFld.AsString]);if not IncludeCurrentOrderCbx.Checked then ClientDataSet2.Filter := 'OrderNo <> ' + QuotedStr(ClientDataSet1.FieldByName('OrderNo').AsString)else ClientDataSet2.Filter := '';end;
The first line of code in this event handler obtains a reference to the part number field of ClientDataSet1. The value of this field is then used to create a range on the cloned cursor. This produces a detail view that includes all records in the clone whose part number matches the part number of the current master table record. The remainder of this event handler is associated with the inclusion or exclusion of the order for the master table's current record from the detail table. If the Include Current OrderNo checkbox is not checked, a filter that removes the master order number is assigned to the cloned cursors Filter property (remember that Filtered is set to True). This serves to suppress the display of the master table's order number from the detail table. If Include Current OrderNo is checked, an empty string is assigned to the clone's Filter property.
That last piece of interesting code in this project is associated with the OnClick event handler of the Include Current OrderNo checkbox. This code, shown in the following method, simply invokes the OnDataChange event handler of DataSource1 to update the detail view.
procedure TForm1.IncludeCurrentOrderCbxClick(Sender: TObject);beginDataSource1DataChange(Self, ClientDataSet1.Fields[0]);end;
Although this project is really quite simple, I think the results are nothing short of fantastic.

82 Deleting a Range of Records
This third, and final example further demonstrates how creative use of a cloned cursor can provide you with an alternative mechanism for performing a task. In this case, the task is to delete a range of records from a ClientDataSet.
Without using a cloned cursor, you might delete a range of records from a ClientDataSet by searching for records in the range and deleting them, one by one. Alternatively, you might set an index and use the SetRange method to filter the ClientDataSet to include only those records you want to delete, which you then delete, one by one.
Whether you use one of these approaches, or some similar technique, your code might also need to be responsible for restoring the pre-deletion view of the ClientDataSet, in particular if the ClientDataSet was being displayed in the user interface. For example, you would probably what to note the current record before you begin the range deletion, and restore that record as the current record when done (so long as the previous current record was not one of those that was deleted). Similarly, if you had to switch indexes in order to perform the deletion, you would likely want to restore the previous index.
Using a cloned cursor to delete the range provides you with an important benefit. Specifically, you can perform the deletion using the cloned cursor without having to worry about the view of the original ClientDataSet. Specifically, once you clone the cursor, you perform all changes to the ClientDataSet's view on the clone, leaving the original view undisturbed.
The following is the CDSDeleteRange function found in the CDSDeleteRange project, which you can download from Code Central by clicking here.
function CDSDeleteRange(SourceCDS: TClientDataSet; const IndexFieldNames: String; const StartValues, EndValues: array of const): Integer;var Clone: TClientDataSet;begin//initialize number of deleted recordsResult := 0;Clone := TClientDataSet.Create(nil); try Clone.CloneCursor(SourceCDS, True); Clone.IndexFieldNames := IndexFieldNames; Clone.SetRange(StartValues, EndValues); while Clone.RecordCount > 0 do begin Clone.Delete; Inc(Result); end; finally Clone.Free; end;end;
This function begins by creating a temporary ClientDataSet, which is cloned from the ClientDataSet passed to the function in the first parameter. The clone is then indexed and filtered using a range, after which all records in the range are deleted.
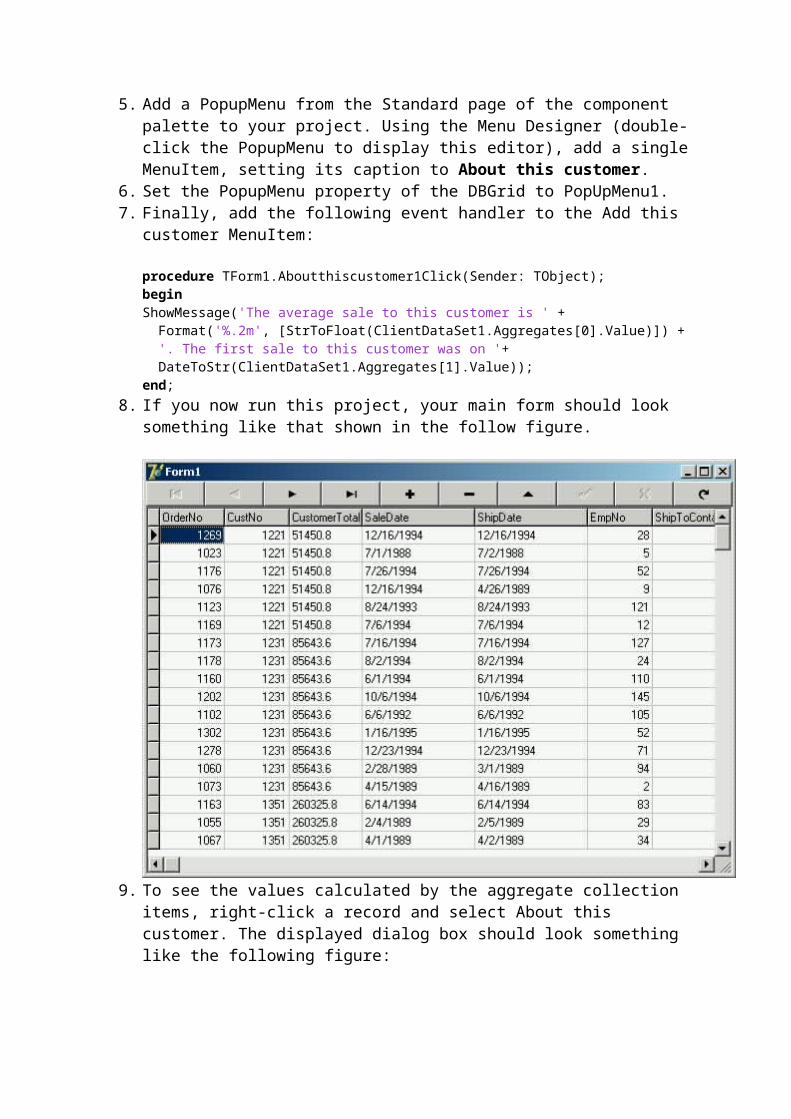
The following figure shows the running CDSDeleteRange project. This figure depicts the application just prior to clicking the button labeled Delete Range. As you can see in this figure, the range to be deleted includes all records where the State field contains the value HI.
While this example project includes only one field in the range, in practice you can have up to as many fields in the range as there are fields in the current index. For more information on SetRange, see "Searching a ClientDataSet," or refer to the SetRange entry in the online documentation.
The following is the code associated with the OnClick event handler of the button labeled Delete Range. As you can see, the deletion is performed simply by calling the CDSDeleteRange
procedure TForm1.Button1Click(Sender: TObject);beginif (Edit1.Text = '') and (Edit2.Text = '') then begin ShowMessage('Enter a range before attempting to delete'); Exit; end;CDSDeleteRange(ClientDataSet1, IndexListBox.Items[IndexListBox.ItemIndex], [Edit1.Text],[Edit2.Text]);end;
The following figure shows this same application immediately following the deletion of the range. Note that because the deletion was performed by the clone, the original view of the displayed ClientDataSet is undisturbed, with the exception, of course, of the removal of the records in the range. Also, because operations performed on the data store and change log are

immediately visible to all ClientDataSets using a shared in-memory dataset, the deleted records immediately disappear from the displayed grid, without requiring any kind of refresh.
I have to admit, I really like this example. Keep in mind, however, that the point of this example is not about deleting records. It is that a cloned cursor provided an attractive alternative mechanism for performing the task.

83 Deploying Applications that use ClientDataSets By: Cary Jensen
Abstract: Depending on what you do within your application, if you use one or more ClientDataSets you may need to deploy one or more libraries, in addition to your application's executable. This article describeswhen and how.
I've discussed a number of ClientDataSet topics in the articles that have appeared in this series, but I have not said much about how to deploy applications that use ClientDataSets. Now that I think about it, this is a topic that I should have covered earlier, but as the old saying goes, better late than never.
The fact is, if you include even one ClientDataSet in your application, you need to take at least one additional step in order to deploy that application to another machine. Fortunately, the step is pretty simple. You either have to deploy an additional library with your application, or you have to manually add the MidasLib unit to your project's uses clause.
To best understand this, let's create a simple application that includes a ClientDataSet, and then look at the modules that get loaded when you run it. Use the following steps:
1. Create a new project, and add a ClientDataSet to your main form.2. Set the FileName property of the ClientDataSet to a local ClientDataSet file. For
example, set it to the customer.cds file. If you installed Delphi using the default directory locations, this file can be found in c:Program FilesCommon FilesBorland SharedData. Under Kylix, this file is located in the demos/db/data directory under where Kylix is installed.
3. Set the ClientDataSet's Active property to True.4. Run your application.5. Select View | Debug Windows | Modules to display the Modules window. If you are
running Windows, your Modules window will look similar to that shown in the following figure.
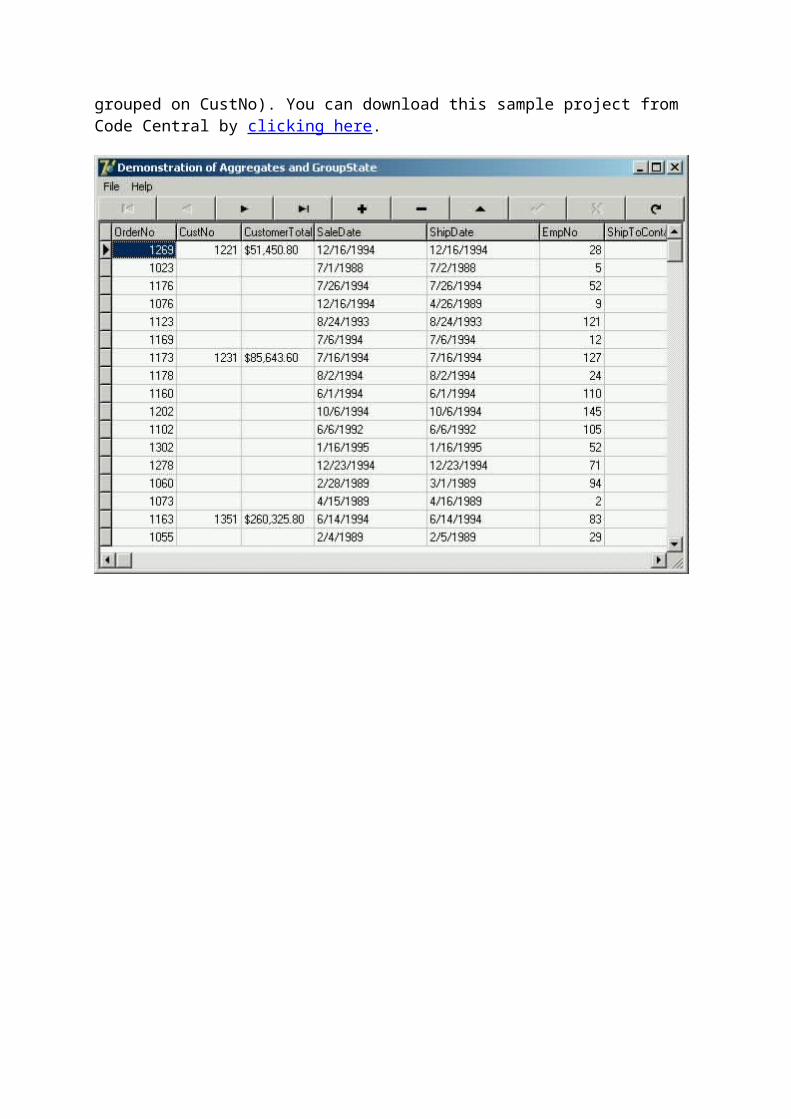
If your Modules window is empty, your integrated debugger is probably disabled. Select Tools | Debugger Options, and then enable the Integrated Debugger checkbox to turn your integrated debugger back on. You will then need to recompile and run your application.
Notice the last entry in this figure, midas.dll. Midas.dll is the DLL (dynamic link library) under Windows that contains the routines that a ClientDataSet needs. These routines are required anytime you activate a ClientDataSet, whether you are using it with local files, as in this case, or any other way. For example, if you are simply using a ClientDataSet to store data temporarily in memory, it will also need access to these routines.
If you are using Kylix, the ClientDataSet relies on a shared object library named libmidas.so.1. (Actually, libmidas.so.1 is a symbolic link. In Kylix 2, this file is symbolically linked to libmidas.so.1.0.) This is shown in the following figure.

I must admit that I think the Modules window is one of the more important in the IDE (integrated development environment). This window displays all libraries that your application has loaded, including ActiveX servers (under Windows). I make a habit of checking the Modules window before I deploy an application. This way I can verify that I will deploy all libraries required by my application.
When you installed Delphi (or Kylix), the installer also installed the midas library. As a result, if you create an application that employs a ClientDataSet and run it only on your development machine, that library is already available. If you need to distribute this application you may also need to deploy this library to a location where the application can find it. Under Windows, you will likely install this library in the Windows system directory (or system32). With Kylix, you may need to install this file to the location pointed to by the LD_LIBRARY_PATH environment variable.
84 Deploying Applications Without the Midas Library
You may have noticed that in the preceding paragraph I was equivocal about the need to install the midas library. This is because there is a simple step that you can take that will make deployment of this library unnecessary. Specifically, if you add the MidasLib unit to your project's uses clause, your application will link all of the routines required by the ClientDataSet into your executable. As a result, the midas library will not be loaded at runtime, and therefore does not need to be deployed.

You can demonstrate this easily. Take the project you created by following the steps given earlier in this article, and add MidasLib to your project's uses clause. When you are done, your project source will look something like the following.
program Project1;
uses MidasLib, Forms, Unit1 in 'Unit1.pas' {Form1};
{$R *.res}
begin Application.Initialize; Application.CreateForm(TForm1, Form1); Application.Run;end.
If you now run your application again, and then display the Modules window, it will look something like this.
As you can see, the DLL midas.dll is not listed in this window, which means that it is no longer being loaded by the application.
85 Why Not Always Use MidasLib

I'll bet you're wondering why you don't simply included MidasLib in the uses clause of all of your applications that use ClientDataSets. The reason is that using the MidasLib unit increases the size of your executable. Not by much, but it does increase its size.
How much? Well, that's easy to test. Once you compile your application, you can view the Information dialog box to get some basic statistics about the compiled executable, including its overall file size. To display this dialog box, select Project | Information for Project from Delphi's main menu. For example, the following figure shows this dialog box after compiling the simple application created earlier in this article, prior to adding MidasLib to the project's uses clause.
Displaying this dialog box again after adding MidasLib to the project's uses clause and recompiling shows that the executable has grown in size, as shown here.
The difference is a little over 200 K bytes.
There is another issue that applies when you are using Delphi. If you deploy two or more applications that make use of ClientDataSets, and you install midas.dll in a shared directory, when those applications are running at the same time they will use only one copy of the DLL in memory, using less RAM overall. Again, it's not much of a savings, but it is a savings.

Under Linux, shared libraries are not shared in memory. Each instance of the library is loaded into its own process. (They are called shared libraries because two or more applications can share the same file on disk.) As a result, this same savings in RAM is not realized when two or more Kylix applications that use ClientDataSets are running simultaneously.
My recommendation? Personally, I prefer to include MidasLib in my project's uses clause. This way I avoid potential problems associated with external DLLs, such as their being overwritten by other applications. It also makes deployment just a little bit easier.

86 Creative Solutions Using ClientDataSet By: Eric Whipple
Abstract: ClientDataSets can be used for much more than displaying rows and columns from a database. See how they solve applications issues from selecting options to process, progress messages, creating audit trails for data changes and more.�
Eric Whipple is the director of Internal Development for Barden Entertainment, makers of the Digital Video Jukebox@trade; and other distributed kiosk applications. He is responsible for the planning, design, and implementation of Web services and other distributed architectures. He is also the author of Kylix 2 Development (Wordware Publishing) and numerous articles for Delphi Informant and the Borland Developer Network.
Creative Solutions
Using ClientDataSetsby
Martin Rudy
ClientDataSets can be used for much more than displaying rows and columns from a database. They can be used to solve applications issues from selecting options to process, progress messages, creating audit trails for data changes and more.
This session shows techniques where ClientDataSets can be used for a variety of application solutions where data is to be created, stored, displayed, and used for internal processing that users never see. The intent of the session is to expand developer usage of ClientDataSets beyond the standard row/column usage.
87 Contents
The major topics covered are:
File selection and progress messages Creating master lookup tables Creating a record-copy routine Custom audit trail using change log Using xml format for CDS development Using ClientDataSet as an internal data structure Storing error codes and messages during development
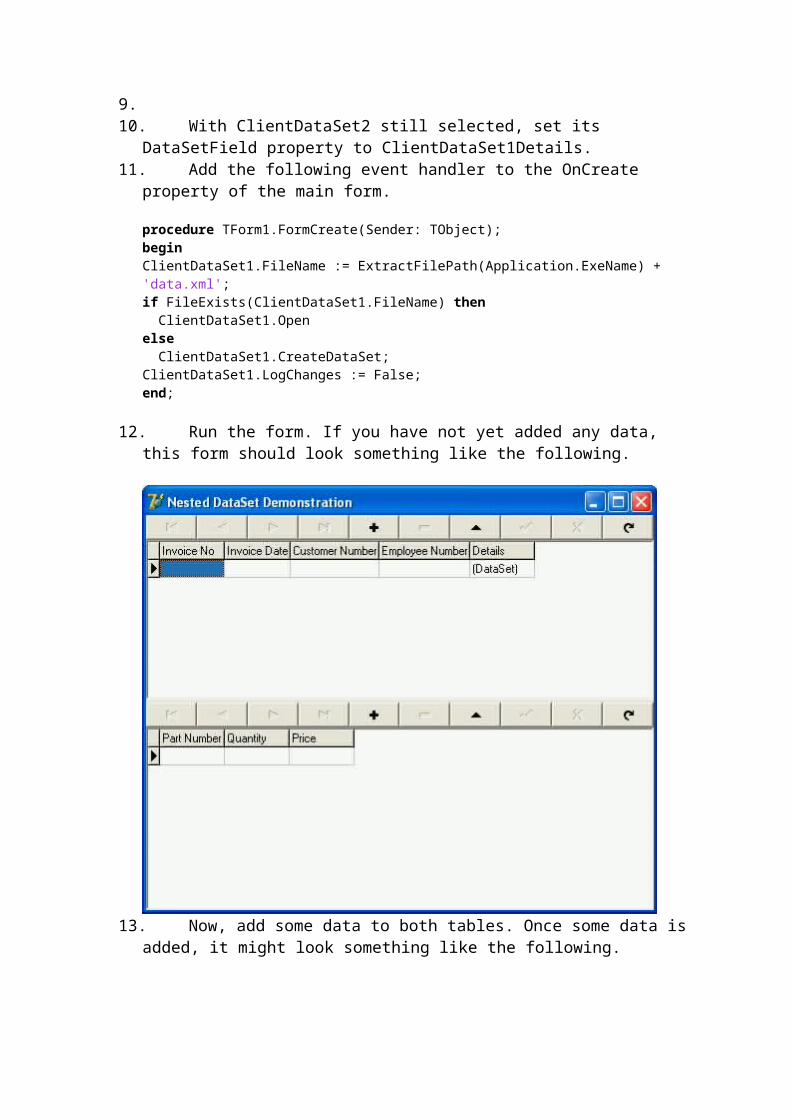
88 File selection and progress messages
Contents
ClientDataSets (CDS) provide an easy-to-use data structure that is handy for many application tasks. The first example shown is how to use a CDS to display a list of files to selection for processing and then display progress messages as each file is processed. Figure 1 shows an example of the sample form from the Filelist project.
Figure 1: File list selection and progress messages
The concept here is to retrieve a list of files to be imported from a specified directory. The Get File List button retrieves a list of files and initially selects each file name retrieved. The checkmark in the Select column indicates the file is to be selected. Users can remove any of the files form the list by changing the select column to N before selecting the Import Files button.
For each file imported, the Process Message column is updated indicating the progress of the import process and any problems with the import. In this example, the file Order1404.xml had a problem with the file indicating there is an issue with the xml formatting. As each file is processed, the grid is updated with the progress when the import starts and after finishing the import the final result.
NOTE: In this example the components that ship with Delphi were used. Third-party grids provide a checkbox option for the Select column and a multi-line cell for the Process Message column giving an improved display for messages.
The structure of the CDS contains only three fields: SelectRcd, FileName and ProcessMsg. Records are initially inserted into the CDS by retrieving all files in a specific directory and setting the SelectRcd field to Y on Post. A hidden TFileListBox is used to easily get the files in the directory. The code to load the data is shown below.
procedure TfrmFileListExample.pbGetFileListClick(Sender: TObject);var I: Integer;
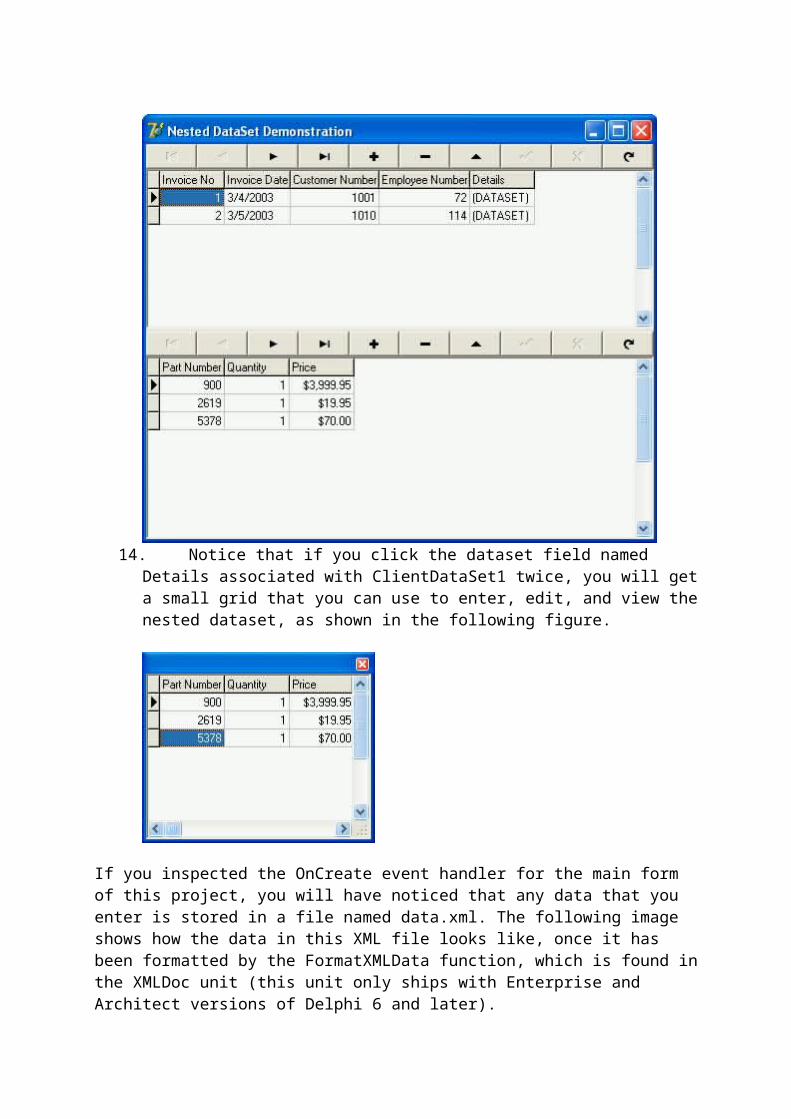
CurCursor: TCursor;begin CurCursor := Screen.Cursor; Screen.Cursor := crHourGlass; try cdsFileList.Close; cdsFileList.CreateDataSet; cdsFileList.Open; cdsFileList.LogChanges := cbxLogChanges.Checked; // put list of all available files in grid for i:=0 to FileListBox.Items.Count - 1 do begin cdsFileList.Append; cdsFileList.FieldByName('FileName').AsString := FileListBox.Items.Strings[i]; { Ensure the SelectRcd field is set last because there is an OnChange event which posts the record. This event will ensure at runtime the record is not left in edit when user changes the record selection by clicking on the checkbox.
This also means the Post method below is not necessary. } cdsFileList.FieldByName('SelectRcd').AsString := 'Y';// cdsFileList.Post; // THIS IS NOT REQUIRED, DONE IN OnChange // EVENT FOR SelectRcd Field // See AfterOpen event below end; cdsFileList.First; finally Screen.Cursor := CurCursor; end;end;
In this example, the Select column is the only field that the user can modify. When the Select column value is changed, the record in automatically posted. In the demo there is no real processing of the file, there is only a simulation of processing and displaying the progress. Normally a checkbox control would be used but the DBGrid does not support that feature. The demo project has modified the grid to include an OnDblClick event which toggles the value between Y and N.
The concept of this example is basic but using a CDS makes the creation of the selection and UI very easy to implement. After the import processing is complete, saving the CDS in an XML format creates a file with the contents shown in Figure 2:

Figure 2: CDS contents as an XML file after getting file list import simulation
There are two main sections of the xml file: data structure and actual data. The METADATA section defines the fields that are in the file (also called data packet). The field name, data type and width are included. The second section, ROWDATA, contains the values for each field and the RowState value. The RowState shows that status of the data row. Table 1 shows the values and their meaning. Any row can have a combination of RowState values to indicate multiple changes made to a row.
RowState Value
Description
1 Original record
2 Deleted record
4 Inserted record

8 Updated record
64 Detail updatesTable 1: RowState values and Description
By default, a CDS will create a change log for every modification made to the data. Each insert, delete and update is logged. If logging of the changes is not necessary, you can set the CDS LogChanges property to False. In the Filelist project, if the Log Changes checkbox is unchecked, the contents of the XML file after getting the file list and simulating the import is shown in Figure 3.
Figure 3: CDS contents with no logging
You can also achieve both the ability to log changes and before saving merge all changes to each row into a single record. This is done using the MergeChangeLog method. Executing the MergeChangeLog method before saving the file creates the same output if no logging was performed.
89 Creating master lookup tables
Contents
Lookup tables provide an excellent way to ensure valid values are entered into fields and UI support for combo and list boxes to select from. Using the built-in data-aware components that support this feature requires separate datasets for each component and sometimes DataSource components are required.
For some application requirements, creating a table that is essentially a grouping of tables can eliminate this need for multiple tables in the database. This next example, named MstrLookup, demonstrates how you can have a master lookup table and how to use CDS components and the cloning feature to support multiple lookup datasets without individual tables for each type of lookup.
The first step is to create a table in the database that contains the lookup values for the various types of groupings. The design used here is to have a field that groups the data, a field for the lookup code, and a field for a description. The following is an example of the create statement for a table named MasterLookup.
CREATE TABLE [MasterLookup] ( [LookupGroup] [char] (10) NOT NULL , [LookupCode] [char] (10) NOT NULL , [LookupDesc] [varchar] (65) NOT NULL )
There are three fields in the table. LookupGroup is used as the grouping or table name. The lookup code is in the LookupCode field. LookupDesc field contains the description for the code value. If the lookup table has codes that are self-explanatory, the code and description fields will be the same.

In this example, the ORDERS table is used from. There are two fields that can use this lookup feature: ShipVia and PaymentMethod.
The general technique is to retrieve the values from the MasterLookup table into a CDS. A separate CDS is placed in the client data module for each lookup table. The rows for each lookup CDS are set in the OnCreate of the data module. The code to create the two tables for ShipVia and PaymentMethod is shown below.
procedure TForm1.GetLkupData;begin { Get lookup data into CDS } with cdsMasterLookup do begin { Ensure MasterLookup is open } Open; Filter := 'LookupGroup = ''ShipVia'''; Filtered := True; cdsLkupShipVia.CloneCursor(cdsMasterLookup,False,True); Filter := 'LookupGroup = ''PayType'''; cdsLkupPayType.CloneCursor(cdsMasterLookup,False,True); Filtered := False; Filter := ''; cdsLkupShipVia.Open; cdsLkupPayType.Open; end;end;
A CDS named cdsMasterLookup is used for all rows in the MasterLookup table. Its source of data is a DataSetProvider (DSP) using a Table component as the DataSet. Since the number of rows is very small in MasterLookup, filtering is used to restrict the values before the CDS is cloned. Each group requires a new filter on the master table. The CloneCursor method is called to make a copy of the filtered rows. CloneCursor allows a separate lookup CDS to share the data belonging to the CDS for MasterLookup. Each of the cloned CDS does not have a DataSetProvider.
In this example the DBLookupComboBox component is uses to provide the list of lookup values. Attempting the assignment of the KeyField property generates an error indicating the CDS does not have the ProviderName assigned. Therefore, the lookup properties cannot be set. The solution to this problem is to initially use the CDS for the MasterLookup table, assign the KeyField and ListField properties then reassign the ListSource property back to the DataSource for the lookup CDS. When this is complete, the combo boxes work properly.
90 Creating a record-copy routine
Contents
Some applications have a requirement to provide a copy record feature or at least copy all but a few of the fields. ClientDataSets provide an easy solution for this type of requirement. We will look at two solutions: the first uses an existing CDS, the second is a generic function where the CDS is instantiated, used and destroyed. The code below contains the first example.
procedure TfrmCopyRcd.pbCopyRcdClick(Sender: TObject);var I: Integer;begin

with ClientDataSet1 do begin Open; Insert; for I:=0 to fieldcount-1 do Fields[I].Assign(ADODataSet1.FindField(Fields[I].FieldName)); end;
with ADODataSet1 do begin Insert; for I:=0 to fieldcount-1 do Fields[I].Assign(ClientDataSet1.FindField(Fields[I].FieldName)); end; ClientDataSet1.Cancel;end;
The basic concept here is to use the CDS as a temporary buffer to hold the data. This first example uses an existing CDS that is the same structure of the table used to copy to and from.
After putting the CDS into the Insert state, the FieldCount property is used to cycle through all the fields in the CDS and copy matching fields from the existing dataset. In this example ADO is used as the database connectivity option. After all fields are copied, a new record is inserted into the ADO dataset and the record is copiedfrom the CDS, leaving the ADO dataset in Insert mode.
For a known structure this works but is not to helpful from a generic standpoint. A general purpose function where the CDS is instantiated as needs is more useful. The function CopyDataSetRcd shown below supports this requirement.
function TfrmCopyRcd.CopyDataSetRcd(DataSet: TDataSet): Boolean;var I: Integer; cds: TClientDataSet;begin result := False; cds := TClientDataSet.Create(nil); try cds.FieldDefs.Assign(DataSet.FieldDefs); cds.CreateDataSet; with cds do begin Open; Insert; for I:=0 to fieldcount-1 do Fields[I].Assign(DataSet.FindField(Fields[I].FieldName)); end;
with DataSet do begin Insert; for I:=0 to fieldcount-1 do Fields[I].Assign(cds.FindField(Fields[I].FieldName)); end; cds.Cancel; result := True; finally cds.Free; end;
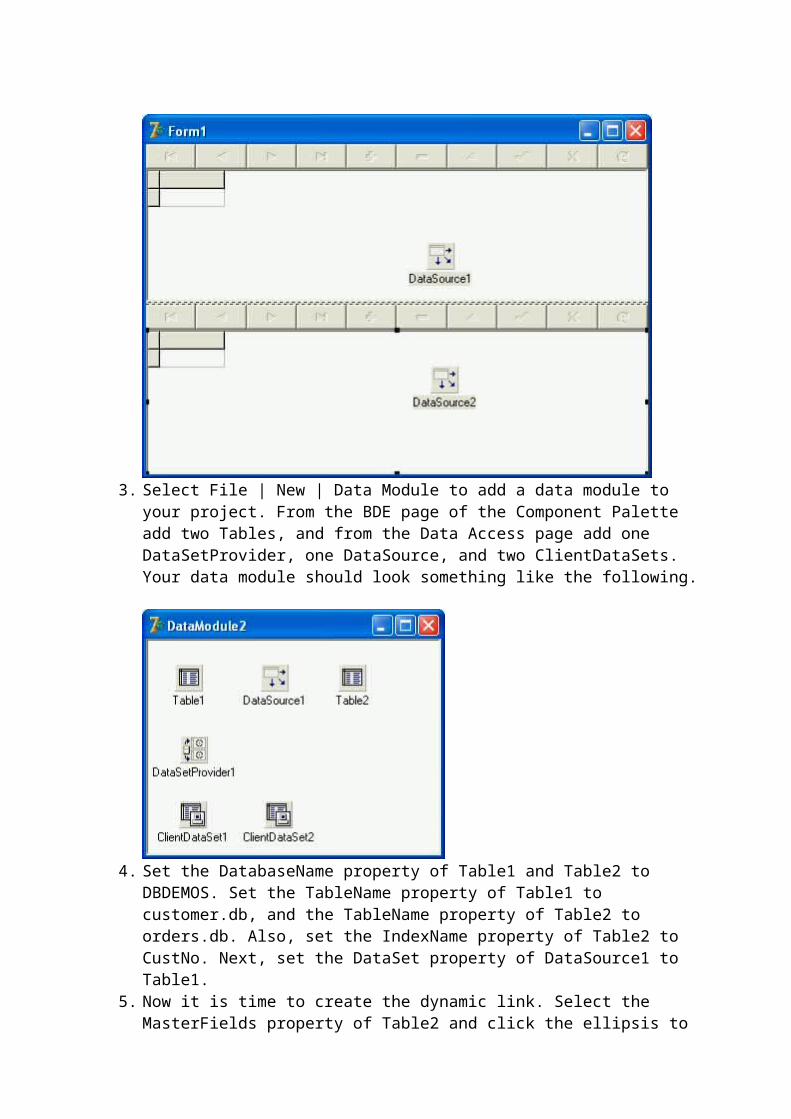
end;
In the CopyDataSetRcd, the CDS is called using the dataset that needs the current record copied. An instance of a CDS is created at the beginning of the function. The fields are assigned based on the dataset passed to the function. This allows the dynamic creation of the CDS to match any dataset passed. The same basic technique as the first example is used for the remainder of the function.
Most applications do not have a need to create exact duplicates of existing records but this basic concept can be useful where there is a need to copy many of the fields from the previous record. The basic technique can be used to create a copy of the record and either delete or prevent copying field(s) that are part of the primary key. You can also add an additional parameter which specifies the fields to copy or the fields not to copy making the duplication process generic but specific to the fields to include or exclude.
91 Custom audit trail using change log
Contents
A change log is maintained by the CDS for each insert, update, and delete. The CDS Delta property contains all records in the change log. A separate record is added to the log for each insert and delete. When an existing record is modified, two records are entered in the log. The first record, with a status of usUnmodified, contains all field values for the record before any modification was made. The second record, with a status of usModified, contains only the field values that have changed. All non-modified fields are null in the second record. The CDS Delta property is what the provider receives as the DataSet property in the OnUpdateData event.
In the demo project, the third tab displays the contents of the change log. Figure 4 shows the log after performing an edit on one row, an insert, and a delete. Note, the UpdateStatus field does not exist in the data, it is a calculated field used to display the status of each record.
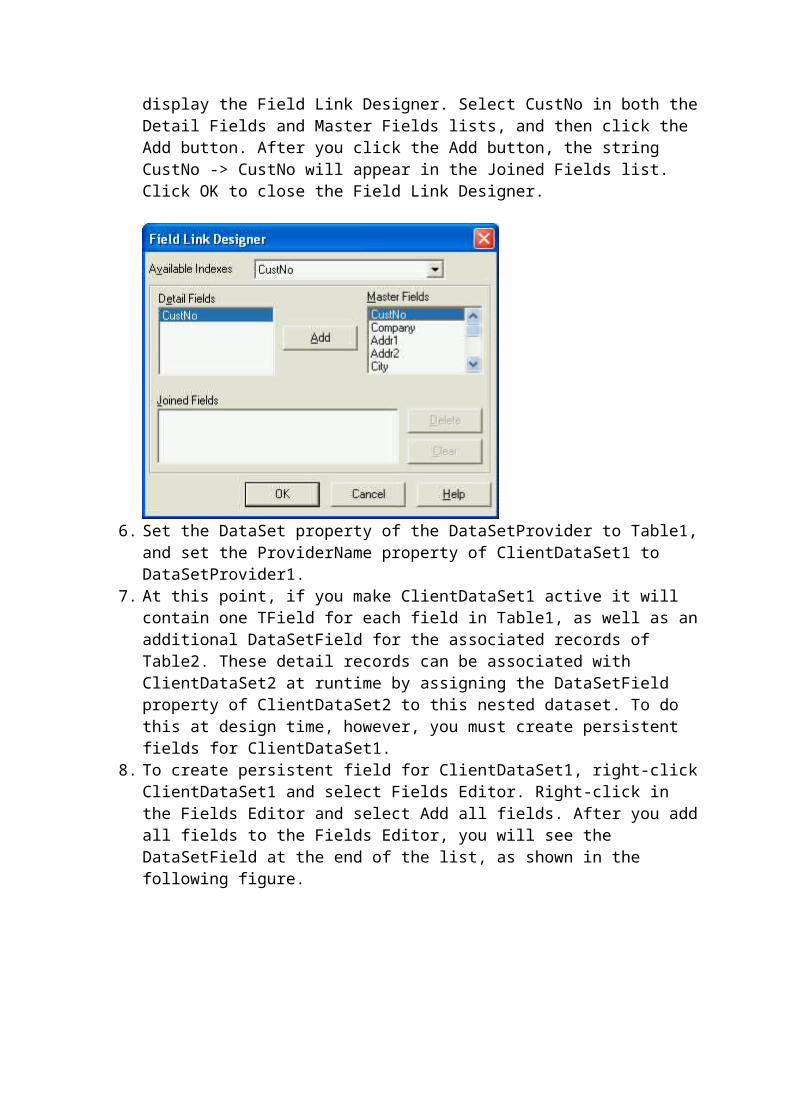
Figure 4: Change log display
The last two records are for a deleted and inserted record. On an insert, any field where data is entered is placed in the change log. For deleted records, all the original field values are placed in the log.
The first tow records are matching pair. The first record of the pair contains all the values of the record before any changes were made. The second record, with an UpdateStatus of Modified, contains the values for every field in the record that changed. In this example, the values of both Addr1 and Addr2 fields have been modified.
Displaying the change log requires an extra CDS in the application and a small amount of code. The code that is used in the demo client is as follows:
procedure TfrmMain.PageControl1Change(Sender: TObject);begin if PageControl1.ActivePage = tbsDelta then try cdsCustDelta.Close; cdsCustDelta.Data := cdsCustomer.Delta; cdsCustDelta.Open; except MessageDlg('No delta records exist.',mtWarning,[mbOK],0); end;end;
The CDS cdsCustomer contains the data from the provider. The CDS for showing the change log is named cdsCustDelta. When the third tab is selected, the Delta property of cdsCustomer is assigned to the Data property of cdsCustDelta. The try except block is used to display a simple message when there are no modifications to the data.
The value for the calculated UpdateStatus field is assigned using the CDS UpdateStatus method. Table 2 lists the four return values for UpdateStatus and a description.
UpdateStatus Value
Description
usModified Modifications made to record
usInserted Record has been inserted
usDeleted Record has been deleted
usUnModified Original recordTable 2: RowState values and Description
The OnCalcFields for the CDS is shown below.
procedure TdmMain.cdsCustomerDeltaCalcFields(DataSet: TDataSet);begin with DataSet do begin case UpdateStatus of usModified : FieldByName('UpdateStatus').AsString := 'M'; usInserted : FieldByName('UpdateStatus').AsString := 'I'; usDeleted : FieldByName('UpdateStatus').AsString := 'D';
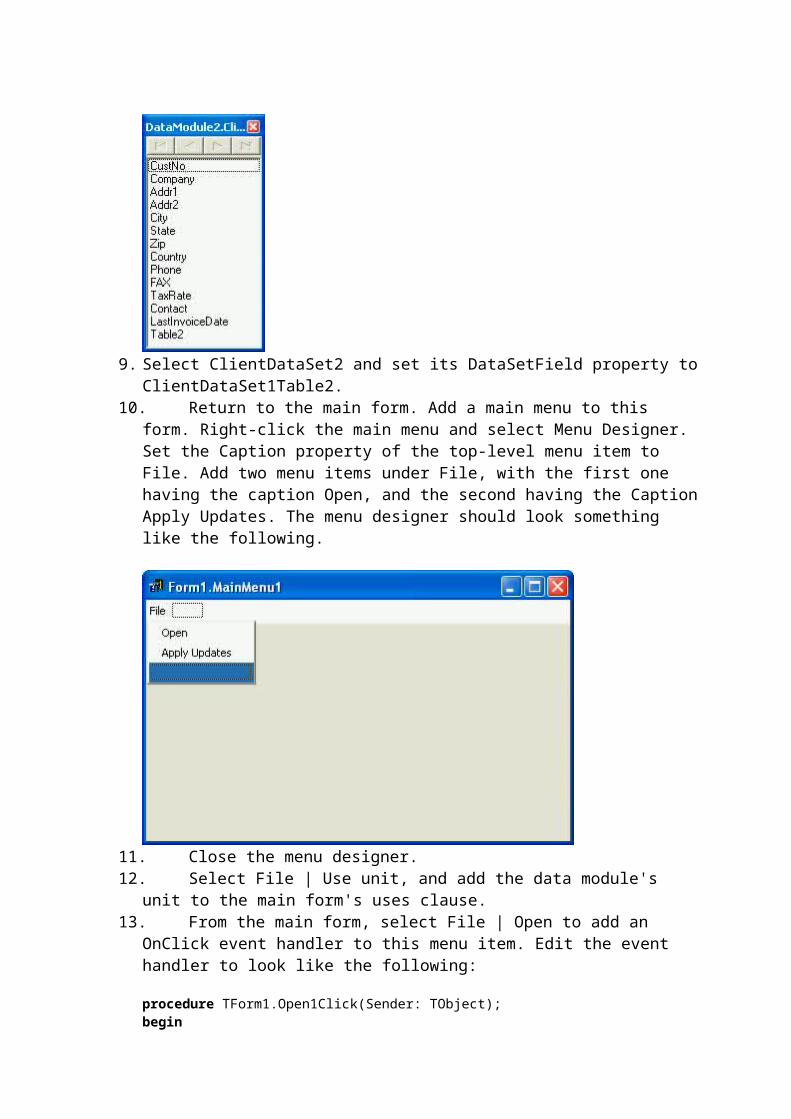
usUnModified : FieldByName('UpdateStatus').AsString := 'U'; end; end;end;
Using the CopyDataSetRcd function described in the previous section along with the CDS logging feature, you can create a custom audit trail process in your applications. The project CDS_Audit is used for this example.
The basic concept here is to copy the change log before the ApplyUpdates is executed then save the changes to an existing table. The following are two code snippets used in the example.
procedure TForm4.cdsCustBeforeApplyUpdates(Sender: TObject; var OwnerData: OleVariant);begin { Save Delta } CDSLog.Data := cdsCust.Delta;end;
procedure TForm4.pbShowChangeLogClick(Sender: TObject);begin CDSLog.Data := cdsCust.Delta;
Screen.Cursor := crHourGlass; try tblCustAudit.Open; CDSLog.First; while not CDSLog.Eof do begin try CopyDataSetRcd(CDSLog,tblCustAudit); tblCustAudit.FieldByName('ModType').AsString := CDSLog.FieldByName('UpdateStatus').AsString; tblCustAudit.FieldByName('ModDate').AsDateTime := Date; tblCustAudit.Post; except if tblCustAudit.State = dsBrowse then tblCustAudit.Cancel; raise; end; CDSLog.Next; end; finally Screen.Cursor := crDefault; end;end;
procedure TForm4.CDSLogCalcFields(DataSet: TDataSet);begin with DataSet do begin case UpdateStatus of usModified : FieldByName('UpdateStatus').AsString := 'M'; usInserted : FieldByName('UpdateStatus').AsString := 'I'; usDeleted : FieldByName('UpdateStatus').AsString := 'D'; usUnModified : FieldByName('UpdateStatus').AsString := 'U'; end; end;end;

The first procedure is used by a DSP to automatically copy the change log to an existing CDS before the updates are applied. This keeps a copy of the changes before they are applied to the database.
The second procedure is used to actually save the change log to a table. Each record in the change log is copied to the audit table. Additionally the type of modification and date of modification is added to the audit table record. The UpdateStatus field is a calculated field added to the log dataset. It is assigned using the UpdateStatus method of a CDS. The third procedure above show how the calculated UpdateStatus field is generated.
92 Using xml format for CDS development
Contents
Incremental design is part of many application development cycles. ClientDataSets provide an easy tool for structure modifications during the prototyping and proof-of-concept phases for dataset design. Using the XML format, fields can easily be added, deleted or modified. Data can easily be added or changed without having to use a database backend.
You can start designing a dataset with a new CDS. One of the options is to use is the Fields Editor to add new fields. After adding the fields, you right-mouse click on the CDS and select Create DataSet from the speed menu. This creates the in-memory dataset which is static in the form or data module.
To start getting data into the CDS, a small application is needed. This is basically a grid, DataSource and a Button containing a SaveToFile call using the XML format as follows:
CDS.SaveToFile('CDS.XML',dfXML);
The first parameter specifies the file name with optional full path. The second parameter indicates the saved format is to be XML. After entering a few records, the output is as shown in Figure 5.
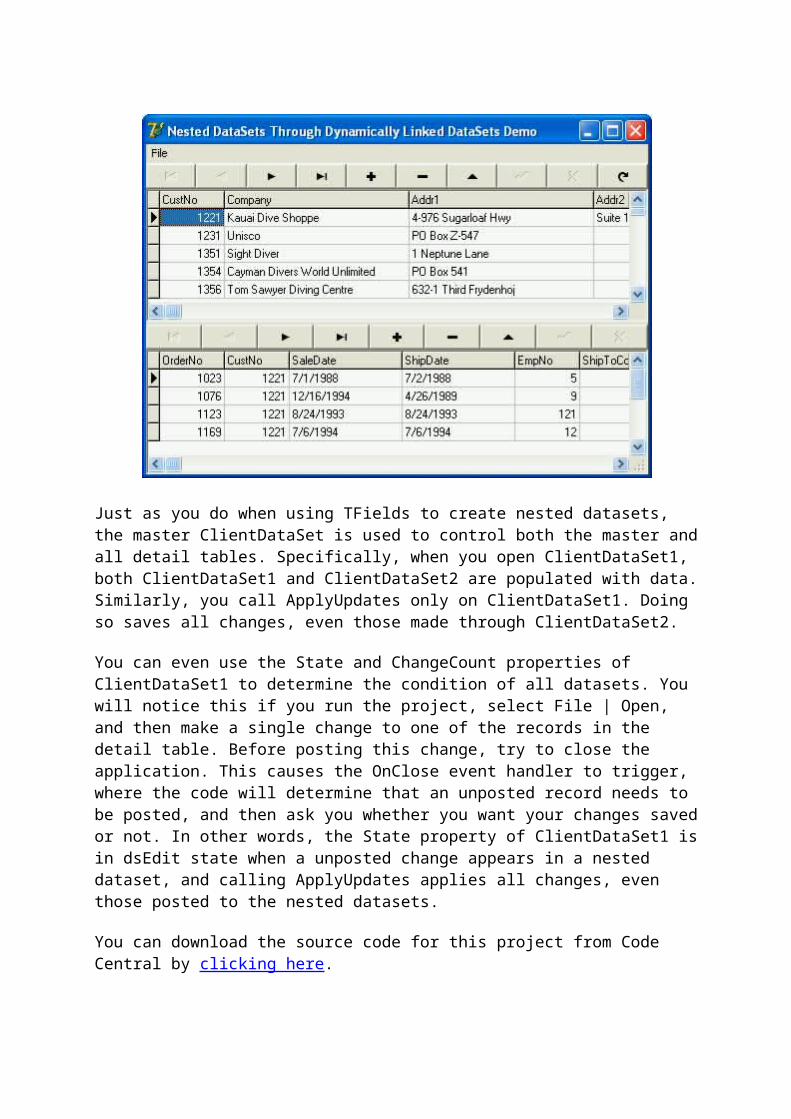
Figure 5: Saved CDS data in XML
The change log is always generated by default. You can change this default by adding to the OnCreate for the form a line setting the LogChanges property of the CDS to False or use the MergeChangeLog method to combine the data and change log before saving. The latter is used here to support undo of changes during data entry.
Saving the structure now allows both fields and data to be added. The XML file can but updated to include new fields and records, any existing data can be modified provided it follows the metadata definition.
There are two keys to getting this technique to work for you: 1) need to know what is required for the data type values; and 2) need to know if there are any formatting issues for non-text data types. Figure 6 shows lists some of the commonly used data types, the value used in the XML metadata and sample on how to format the data.
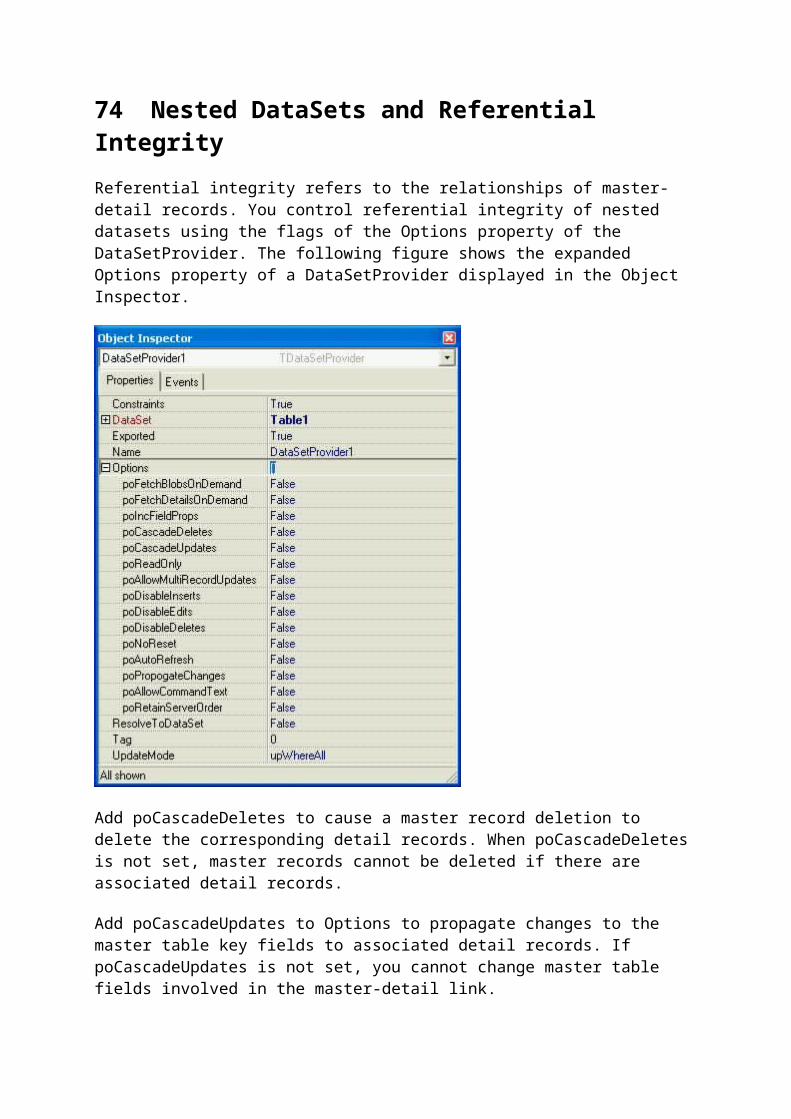
Figure 6: Common data types as shown in XML metadata
This technique is demonstrated further in the next section.
93 Using ClientDataSet as an internal data structure
Contents
This section picks up from the previous topics and expands on the usage of ClientDataSets in the development phase. The example used is an application that was a prototype for a Sunday School game for the Books of the Bible where users would test their knowledge of putting the books in the correct order and correct sections on a bookshelf.
Part of the example is how to use ClientDataSets during the development of the concept and as internal data for drag/drop information to ensure an order sequence as new UI items are added to the display dynamically and randomly at runtime.

Below is the prototype form for the example. Two grids are used: one to create the data used in the random creation of the books to display and second shows the internal data stored as the user placed the new book on the shelf in the correct position. The two white rectangles represent the separate shelves in a bookcase. When the Create Book button is clicked, a new book is created and placed next to the top shelf. The width of the component was based on the BookWidth field in the first CDS. The user then drags the book to the appropriate place and, based on the data in the internal CDS, a comparison is made if the drop of the book was in the correct sequential location.
Figure 7: Application using CDS for application prototype
NOTE: The original prototype was done with Delphi 7 and third-party components. These components did not exist with Delphi 9 so modifications were made to use what shipped with Delphi. A TMemo control replaced the third-party component used to represent the book and the book width had to be excluded.
Two ClientDataSets where used to create the prototype. The first CDS was used to store the books. It started with only the BookNo and BookName fields. The data for the books was loaded using the technique described in the previous section. To assist the drag and drop processing and development, an internal data structure was required. The second CDS was created for this purpose primarily to use a DBGrid for data display of the assigned values. This made debugging the process easier because values where displayed as they were

assigned. The Fields Editor was used to create the fields for the second dataset and CreateDataSet was added to the forms OnCreate.
During the prototype creation, fields where added to both ClientDataSets as needed using the technique described in the previous section. For example, the ObjectName field was added to the second CDS. This value is the Name property for each book added. It consists of the text Book and the book BookNo numeric value converted to a two character text value. The ObjectName value is used with a call to FindComponent during the insertion process of a new book. Another example is the BookWidth property in the first CDS. This was used to provide data to set the width of the component representing the book when it was created. This gave a visual representation of the relative size of the book when the third-party control was used.
In the prototype, all books are listed in the upper-right grid. The final version is to randomly generate which book to be placed which is not in the prototype version. Generating a book to be placed is done by either clicking the Create Book button or a double-click on the book grid. The currently selected record in the grid will be the book created to place in the shelf. This is placed to the left of the first shelf. The following code is used to generate a book.
procedure TForm1.pbCreateBookClick(Sender: TObject);var bk: TMemo;begin { Generate a new book object for selected book } bk := TMemo.Create(self); bk.Parent := self; bk.Tag := cdsBibleBooks.FieldByName('BookNo').AsInteger; if bk.Tag < 10 then bk.Name := 'Book0' + IntToStr(bk.Tag) else bk.Name := 'Book' + IntToStr(bk.Tag); bk.Lines[0] := (cdsBibleBooks.FieldByName('BookName').AsString); bk.Left := 2; bk.Top := 5; bk.Height := 160; bk.Width := 14; bk.Alignment := taCenter; bk.DragMode := dmAutomatic; bk.Color := clBlue; bk.Font.Color := clWhite; bk.Font.Name := 'Courier New';end;
The list of books is stored in the CDS named cdsBibleBooks. The current record in the CDS is used to set property values of the TMemo instance created. The Tag property is assigned the BookNo field which is a unique value. The Name property is assigned to a unique value using the BookNo field. Some of the TMemo properties assigned are to get the vertical text display. Automatic drag mode is used to simplify the prototype creation for drag-and-drop.
When a user drags the new book to a location to place in on the self, the following code is executed:
procedure TForm1.Shape1DragDrop(Sender, Source: TObject; X, Y: Integer);var L,T,S: Integer;begin with Sender as TShape do

begin L := Left; T := Top; S := Tag; end; if Source is TMemo then with Source as TMemo do begin { Look to see if book dropped in correct location } if BookLocOK(S,Tag,X+L) then begin if cdsBkShlf.RecordCount > 0 then TMemo(Source).Left := X + L else TMemo(Source).Left := 8; TMemo(Source).Top := 4 + T; { Locate BookName, if found, update position. If not found, insert into table. } if cdsBkShlf.Locate('BookName',TMemo(Source).Text,[]) then begin cdsBkShlf.Edit; cdsBkShlf.FieldByName('ShelfNo').AsInteger := S; cdsBkShlf.FieldByName('ShelfLeftPos').AsInteger := X; end else begin cdsBkShlf.Append; cdsBkShlf.FieldByName('ShelfNo').AsInteger := S; cdsBkShlf.FieldByName('BookNo').AsInteger := Tag; cdsBkShlf.FieldByName('ShelfLeftPos').AsInteger := X; cdsBkShlf.FieldByName('BookName').AsString := TMemo(Source).Text; cdsBkShlf.FieldByName('ObjectName').AsString := Name; end; cdsBkShlf.Post; ResuffleBooks(S); end else MessageDlg('Book location incorrect.',mtWarning,[mbOK],0); end;end;
After checking if the Sender is a TMemo, there is a check to see if the book is dropped in the correct position. The call to BookLocOK indicates if the position was. If the result is True, the book is placed in the correct position otherwise a simple message is displayed indicating the position is incorrect. For each new book added, there is a check if the book already has been placed. In this prototype, there is no check for the correct shelf the book is to be placed in. Therefore, a book that was originally placed in the first shelf can be moved to the second shelf and the ShelfNo and ShelfLeftPos fields need to be updated. If the book is newly added, a new record is appended to the CDS.
The data stored in cdsBkShlf is only used during the running of the application. The grid showing the contents is for development purposes only. It provides instant feedback on the values assigned and is a tool that can be adjusted during the development process to find flaws in the basic design. Other data structures that are more efficient can be used, but in a prototype, fast-paced development cycle, a CDS and DBGrid can expedite the process.

94 Storing error codes and messages during development
Contents
Some applications have a need to support error and message codes with associated text for the messages. ClientDataSets can be used to create a repository for storing both the codes and text for each message. The XML format is used in this example which allows for easy insertion and modification of error codes and descriptions. This XML file is loaded at runtime and functions are shown which use this data. Figure 8 shows the basic structure of the XML file. This data can then be moved to the shipping database when appropriate. A technique is also shown how to store this data statically in the application as a CDS thus allowing the same functions to be used when the XML was loaded at startup.
Figure 8: Sample structure for error codes and messages with sample data
A CDS is loaded with the error code and message data when the data module is created using the following:
cdsErrMsg.LoadFromFile('ErrMsg.XML');
The function in the following code retrieves the text for the specified error code.

function TdmMain.GetErrMsg(ErrCd: Integer): String;begin if cdsErrMsg.Locate('ErrorCode',ErrCd,[]) then result := cdsErrMsg.FieldByName('ErrorMessage').AsString else result := 'Invalid Error Code';end;
This function can be used in any validation process where the business rule maps to a specific error code. The following is an example of using the function in the BeforePost event of the CDS.
procedure TfrmValidation.ClientDataSet1BeforePost(DataSet: TDataSet);begin { Ensure required fields are entered } with DataSet do begin if FieldByName('Customer').AsString = '' then raise Exception.Create(dmMain.GetErrMsg(101)); if FieldByName('Contact_First').AsString = '' then raise Exception.Create(dmMain.GetErrMsg(102)); if FieldByName('Contact_Last').AsString = '' then raise Exception.Create(dmMain.GetErrMsg(103)); if (FieldByName('Address_Line1').AsString = '') and (FieldByName('Address_Line2').AsString <> '') then raise Exception.Create(dmMain.GetErrMsg(104)); end;end;
As additional business rules are added, requiring the increase in error codes, new entries can easily be inserted into the XML file. This can be done using any text editor or by creating a small application that loads the existing XML file, supports modifications to the data and saves the error codes and messages back to the XML file. This process continues during the development phase.
When time comes to ship the application, most likely you will not want to ship an XML file that is loaded on startup. Two options can be used to replace the loading of the XML data. The data can be moved to a table in the database and retrieved as the application opens or the data can be made static in the exe itself.
Moving data to the applications database requires a little bit of extra effort. You can write a small application that inserts the data from the CDS XML file by either directly inserting into the table or you can use a DataSetProvider, a second CDS and have the records inserted into the database using ApplyUpdates. Another modification is required at startup to retrieve the data into the CDS, replacing the LoadFromFile call that previously loaded the XML file.
The second option is to load the CDS at design-time and make the data part of the exe. You right-click on the CDS and select the Load from MyBase table menu option and choose the saved XML file. When the project is saved, the data becomes stored in the form/data module containing the CDS and becomes static for the released exe. Provided you dont change the Active property of the CDS, the error codes and messages exist for each exe created. When a change is required, the XML file is updated and you re-load at design time the new data.
Using the technique of an XML file provides another option during development. The developers can use the file for coding and the documentation department can review the error

messages and update per their standards. Adding another field to the CDS structure for notes allows both developers and documenters the ability to provide further information on the error and further detail about potential cause and correction if needed. This information can be added into the final documentation or provide online information for the final product.
95 Summary
ClientDataSets, they are not just for multi-tier applications any more. They can be used in applications based on Paradox or Access data, InterBase, Oracle, SQL Server, and any other database, for XML based applications and any combination of local storage to multi-tier. Any time an application needs some type of data structure to store data where the data needs to be viewed and manipulated, ClientDataSets provide an excellent solution.