Embed Size (px)
Citation preview

A Comparison of Column, Row and Array DBMSs to Process Recursive Queries
Carlos OrdonezATT Labs

Acknowledgments
Michael Stonebraker Visited MIT 2013, 2014 Wellington Cabrera, PhD student;
Achyuth Gurram, MS student Divesh Srivastava for inviting me to
spend my sabbatical at ATT

Introduction
Recursion defined in ANSI SQL Graph algorithms: paths,
reachability, neighborhood analysis Complexity: Cubic, NP-completeness Before: Deductive databases:
datalog Harder query optimization than
traditional SPJ queries

Directed Graphs
Definitions: Directed Graph G=(V,E), maybe cyclic! A vertex in V : i or j and i,j=1..n. and edge
(i,j ) has a direction and weight v storage: adjacency list table E : |E|=N
Problems: Transitive closure: vertices j reachable
from i Power matrix Ek

Examples
V=cities,E=roads. Is there some path from San Diego to
NYC?: path from i to j? shortest one? V=employees, E=manager -> employee q1: all employees under i q2: Is j supervised by i? Bill of materials: The well-known
part/subpart manufacturing DB: all subparts Y from part X

Recursive view Rk: recursion depth n=|V|,N=|E|

Transitive Closure: G+=(V,E’)

Power matrix

Technical details
Linear recursion; Intuition: R=R*E Inner joins; no negation SELECTs must have same data types No GROUP-BY, DISTINCT, HAVING, NOT IN, OUTER
JOIN clauses inside R Any SQL query on R is valid Seminaive; recursion depth k: loop
with k-1 joins or (rarely) fixpoint

Stonebraker: One size does not fit all!!
Analytics: Row: OLTP, point queries Column: DSS/cube queries Array: math, science
Other: Stream: one pass; in-RAM MMDB: OLTP Hadoop/noSQL: yawn

DBMS storage elevator storyrow | column | array Row: old, single file, block,
B-trees/hash, horizontal partitioning Column: new, multiple files, var. size
blocks, ordered values, compressed, no row-level index!
Array: very different storage; attributes={dimensions|columns}; chunk==subarray; multidimensional; grid index in RAM

Algorithms
Semi-naïve: classical, general, reasonably efficient, expressive
Direct: very efficient; TC only; in-place update; matrix-based; requires arrays; not good for SQL; not used today! [TKDE 2010, Teradata DBMS]

Semi-naive

Seminaive in SQL

Optimizations: SPJ Relational algebra + physical operators
Join: hash or sort-merge (nested loop does not make sense with E)
Projection: push dup elimination & aggreg. Selection: push filter
To be explored later Outer joins External joins Indexing: row-level only?

Join: hash versus sort-mergeGoal: O(N)
Main computation:
Join optimization: Column: projection={unordered,
ordered values} Row: unordered, ordered versus index Array: default={ordered, indexed} choice={sparse,dense}

Projection
Duplicate elimination reachability binary edges
Aggregation shortest/longest path count # paths length vs weight/cost

SelectionReduce |Rd|, correctness

Issues with select operator
Incorrect to use a predicate involving a join expression column in recursive step
Cicles => Infinite recursion Monotonically increasing v, OK to
prune Recursion depth k: required in
practice

Benchmark with graphs
Real Skewed Complex structure; sample==different But Fixed size
Synthetic Vary n,N Vary shape NEW: Cliques!

Simulating realistic Gsocial nets, Internet
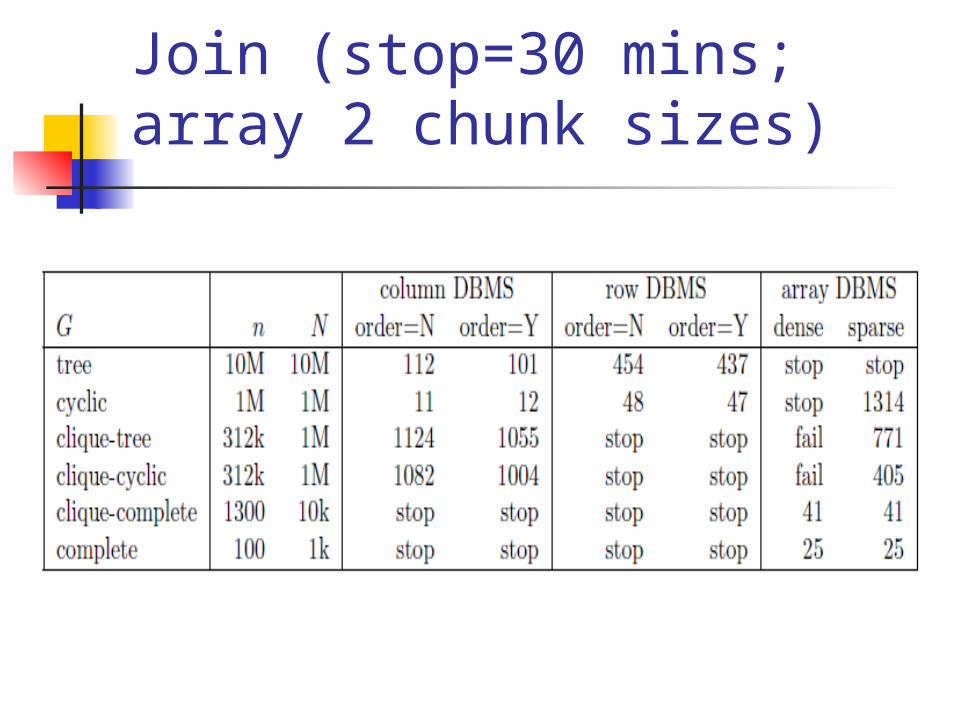
Join (stop=30 mins; array 2 chunk sizes)
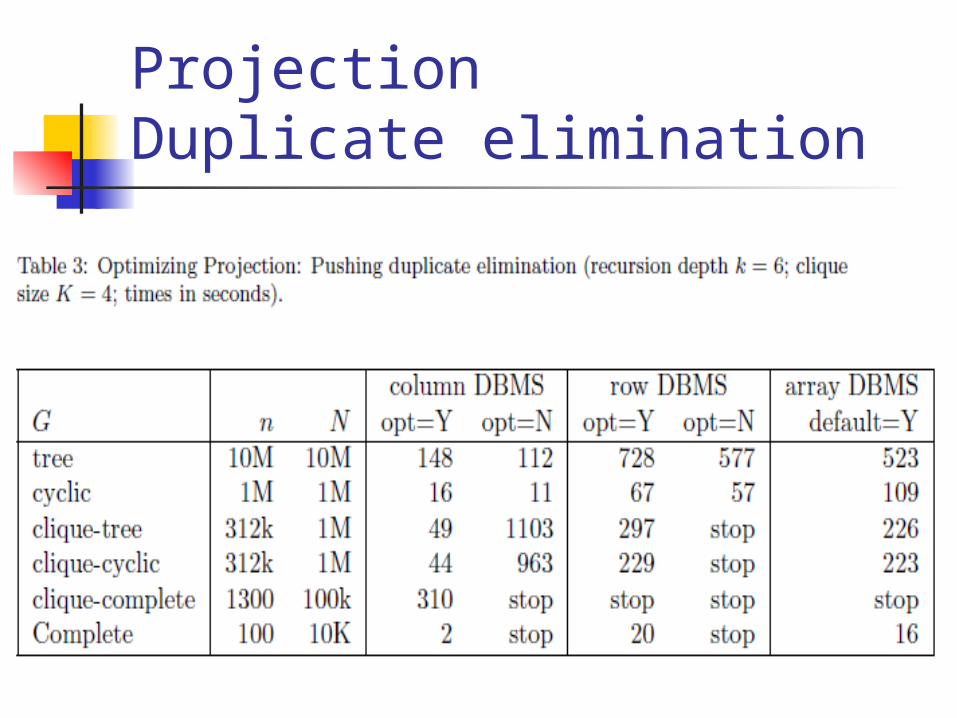
ProjectionDuplicate elimination
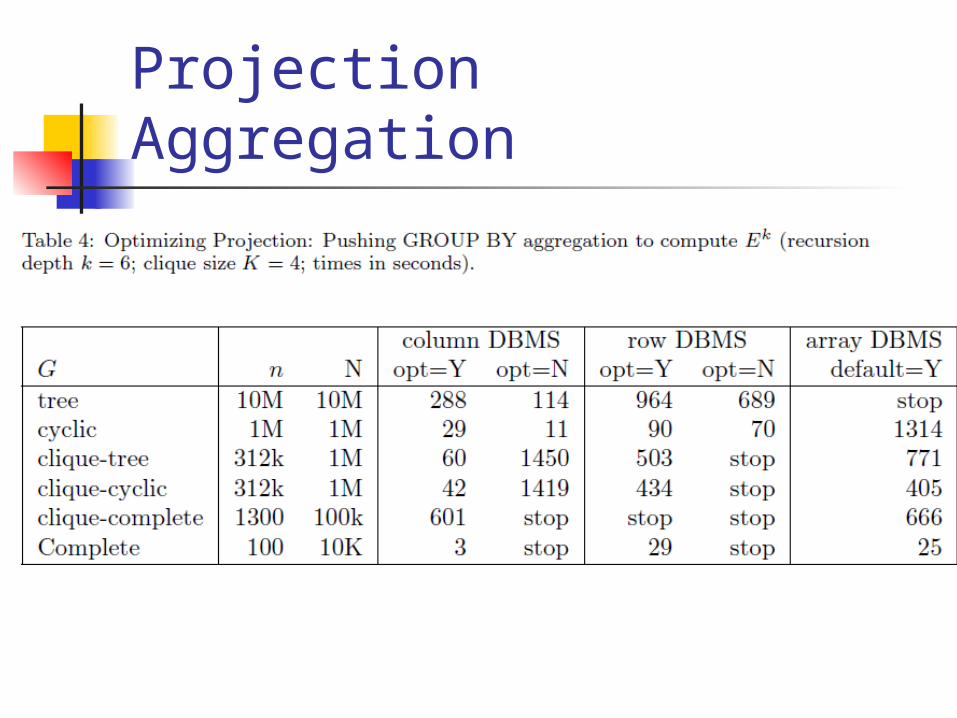
ProjectionAggregation

Selectionsimple filter i=1
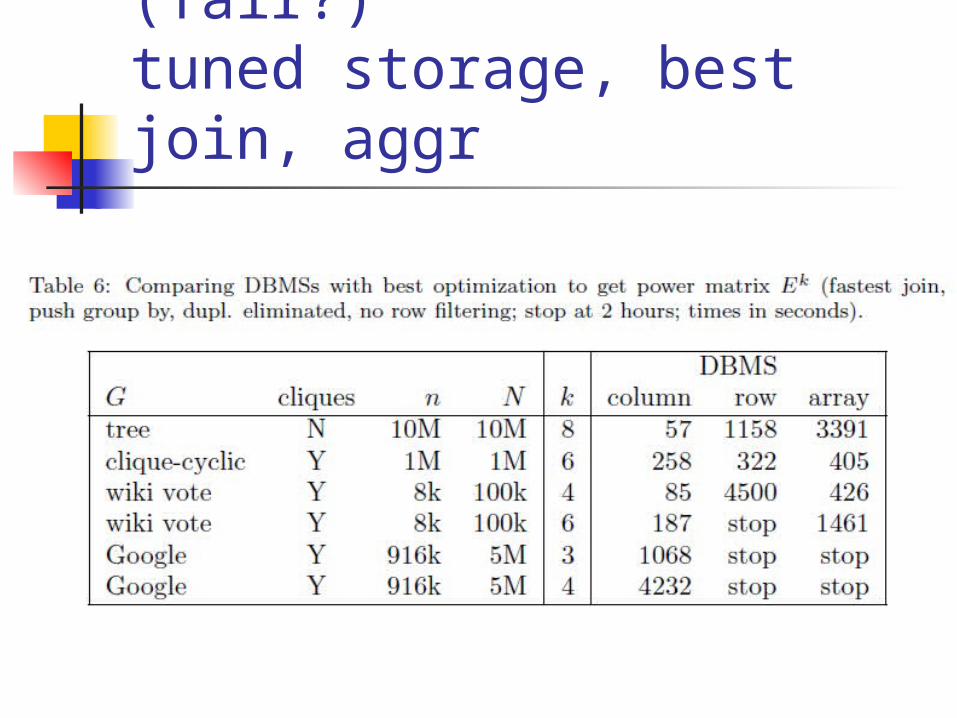
Ultimate benchmark (fair?)tuned storage, best join, aggr

Conclusions Query optimizations
Confirm decades of research: required But impact definitely varies G knowledge helps (catch 22)
Benchmark with tuned query processing Column DBMS faster; cliques/skewed
degree OK Array DBMS competitive for dense/clique G Row DBMS reasonable

Conclusions Graph features impacting time and I/O
Density: avg vertex degree; deg(i) skew Cliques: K Cycles: deep k
Recommendations Tune DBMS storage Tune join (skewed hash join) Beware of large cliques and short cycles Increment recursion depth k gradually

Future work
Develop operators for Array DBMS Time complexity based on G Beyond semi-naïve: Direct,
logarithmic More specific graph problems like
CC, Neighborhood analysis, vertex similarity
Query processing cost model

References on RQs
SIGMOD papers: IBM TKDE 2010 paper; Teradata papers DOLAP 2014: Revisiting RQs in
Column DBMS







![Comparing DBMSs and Alternative Big Data Systems: Scale Up ...ordonez/pdf/dbms-vs-nosql.pdf · 6 SASTRY: and spreadsheets [68] (which provide an interactive environment to de ne formulas](https://img.pdfslide.us/doc/110x75/5f07f7c37e708231d41fa9d9/comparing-dbmss-and-alternative-big-data-systems-scale-up-ordonezpdfdbms-vs-nosqlpdf.jpg)





















