Embed Size (px)
Citation preview

A Comparative Study of Performance for J2EE Data Access Technologies
byDimitar Misev
Submitted in partial fulfillmentof the requirements for the degree of
M.S. in Computer Science
at
School of Computer Science and Information Systems
Pace University
May 2006

We hereby certify that this dissertation, submitted by Dimitar Misev, satisfies the dissertation requirements for the degree of M.S. in Computer Science and has been approved.
_____________________________________________-________________Dr. Lixin Tao DateChairperson of Dissertation Committee
_____________________________________________-________________Dr. Narayan Murthy, Chair, CS Dept. DateDissertation Committee Member
_____________________________________________-________________Dr. Mehdi Badii DateDissertation Committee Member
_____________________________________________-________________Dr. Susan M. Merritt DateDean, CSIS
School of Computer Science and Information SystemsPace University 2006

Abstract
A Comparative Study of Performance for J2EE Data Access Technologies
byDimitar Misev
Submitted in partial fulfillmentof the requirements for the degree of
M.S. in Computer Science
May 2006
Most businesses today are at the reach of their customers through Internet and millions of online transactions take place every day. Therefore, choosing the right technology for doing business online certainly is important. And even more, speed is a key factor in most cases.
Two key players in the field today are Microsoft and Sun Microsystems. Microsoft has its .NET platform, which supports languages like Visual Basic .NET and C# .NET. Anything written for this platform can only run on a Windows operating system. On the other hand, Sun Microsystems has its Java technology, which is much more portable and can run on any operating system.
Part of Java, known as J2EE (Java 2 Platform Enterprise Edition) server technology, emerged as separate discipline meant to satisfy business needs. This technology providesa solid backbone for building reliable business applications that meet rigorous criteria.
With speed being a key factor in most businesses offering their services on the Internet, it is crucial for a J2EE application to be able to handle a certain maximum number of users. In most the cases there is a relational database involved in the application, regardless if it is reading, writing or updating data. Usually this is the bottleneck of an application (the slowest part), and its speed reflects overall systemperformance. Choosing the right approach to work with a database can make a difference and that is the object of research in this thesis. A simple test application that uses a number of different data access technologies will be implemented. This application will then be used in tests against real data.
Using the results from these experiments, conclusions will be given along with some rules on choosing the right data access technology for the next big J2EE project.

Acknowledgements
I would like to express my sincere gratitude to my advisor, Dr. Lixin Tao. Throughout my thesis, he provided me with valuable guidance and help. He always found time for me in the middle of his busy schedule to go over the details and provide suggestions and direction. Without his help and constructive criticism, I cannot imagine completing my thesis. Whenever I was stuck and needed direction, he was there for me to guide me through.
I would like to thank the department Chairperson, Dr. Narayan Murthy, for giving me the opportunity to do my thesis and his review and comments.
I would also like to thank my research committee member, Dr. Mehdi Badii for his guidance and support.
The project wouldn’t have been completed without Tom Lombardi, our technician who setup the Blade Server.
Finally, I would like to thank IBM for their Academic Initiative program which provided the main part of software and hardware used in the thesis.

v
Table of Contents
Abstract .............................................................................................................................. iii
List of Tables .................................................................................................................... vii
List of Figures .................................................................................................................. viii
Chapter 1 Introduction................................................................................................. 1
1.1 Background..................................................................................................... 1
1.1.1 Importance of database access efficiency ................................................... 3
1.1.2 Alternative data access technologies .......................................................... 6
1.2 Problem Statement .......................................................................................... 7
1.3 Solution Strategy............................................................................................. 8
1.4 Thesis roadmap ............................................................................................... 8
Chapter 2 J2EE Data Access Technologies............................................................... 10
2.1 JDBC based data access................................................................................ 12
2.2 Stored procedures.......................................................................................... 14
2.3 EJB (Entity Java Beans)................................................................................ 16
2.4 Spring Framework ........................................................................................ 20
Chapter 3 Benchmark Application ............................................................................ 24
3.1 Design ........................................................................................................... 24
3.2 Implementation ............................................................................................. 26
Chapter 4 Experimental Study of Data Access Performance .................................... 44
4.1 Experimental environment............................................................................ 44
4.2 Testing process and results ........................................................................... 44
Chapter 5 Conclusion ................................................................................................ 57
Appendix A Benchmark Application Installation Guide................................................ 59
Creating database infrastructure ................................................................................... 59
Setting up server resources ........................................................................................... 60

vi
Application deployment & generating test data............................................................ 62
Setting up the project with RAD................................................................................... 63
Software tools used for the application......................................................................... 65
The hardware behind the code ...................................................................................... 66
Appendix B Key Source Files......................................................................................... 66
References......................................................................................................................... 90

vii
List of Tables
Table 1 - Experiment Data................................................................................................ 46

viii
List of Figures
Figure 1 J2EE application server bottleneck ...................................................................... 4
Figure 2 Life Cycle of an Entity Bean .............................................................................. 17
Figure 3 Overview of the Spring Framework ................................................................... 21
Figure 4 Benchmark application flow............................................................................... 25
Figure 5 Web Application Structure ................................................................................. 28
Figure 6 - Result Data Graph ............................................................................................ 53

1
Chapter 1
Introduction
1.1 Background
Being a free, open source technology that runs on every platform, J2EE (Java 2
Platform Enterprise Edition) server technology is becoming an industry standard in the
enterprise world. J2EE has proven successful in providing scalable, robust, portable and
reliable server-side Java applications that businesses need.
It is based on J2SE (Java 2 Platform Standard Edition) and in fact many libraries are
simply borrowed from there. J2EE provides infrastructure for easier and faster
development of distributed applications, and well-established standards for their
distribution and deployment. With its set of reusable components, transaction control,
unified security and web services support (which is the hottest new technology now) it is
very attractive to application developers, letting them focus on the business logic rather
than the underlying components and thus reducing development time.
The fact that it is free makes it appealing to many companies. Written in Java, it runs
regardless of the underlying platform and operating system, also known as the “write
once, run everywhere” motto. Any system, from cell phones and PDA devices, to super
computers, can run Java applications as long as it has a JVM (Java Virtual Machine)

2
installed. That way the applications written in Java are not limited to a specific vendor or
platform.
A typical J2EE application runs in a container or application server, such as Tomcat
(which is not a full J2EE server, but a servlet container), JBoss, WebSphere or
WebLogic, among the others. Some of these are free, while others are not. Some provide
custom features that others might not implement. All of them conform to the J2EE
specification, making it easy to deploy a J2EE application written for JBoss to a
WebSphere application server. Usually a few changes in the configuration files are
sufficient to migrate an application from one to another type of server, unless of course
the application uses some custom feature that the other application server does not have.
The same flexibility applies when choosing the operating system in which a J2EE
application server runs applications. It is completely up to the system engineer to decide
whether the application will run on a Linux or Windows OS, or something else.
In order to simplify the implementation of different vendor technologies in a J2EE
server application, J2EE specifies a connector architecture that allows using third party
systems, such as various RDBMS products (Relational Database Management Systems)
for example. In terms of data access infrastructure, a typical J2EE application server
provides everything from transaction control to resource pooling and security.
In general, J2EE server technology follows a set of well-specified, established and
accepted rules. By using it, developers can focus on the business rules of an application,
rather than the implementation details underneath.

3
1.1.1 Importance of database access efficiency
Most often, applications deal with data in one or another way. Data can reside in the
physical memory while the server is up, but it has to be stored somewhere else before the
server goes down, otherwise it will be lost permanently. One way to keep data
permanently is by storing it into a database. This is where database access efficiency
comes into play.
J2EE application servers provide scalable performance for a wide range of
applications. However, the general-purpose nature of J2EE, which aims to address the
needs of every enterprise, also limits its ability to provide a best-of-breed solution for
mission-critical applications. In particular, data-intensive applications expose a serious
data bottleneck in all J2EE server architectures.
A recent survey of 360 J2EE users found that 57 percent of application performance
and availability issues can be traced to inefficient data access problems, and only 42
percent of applications perform as planned during initial deployment. Not surprisingly,
the survey went on to state that Java applications fail to meet user expectations 60 percent
of the time. Worse yet, a 2004 survey conducted by Forrester Research found that more
than two-thirds of respondents discovered application performance problems only when a
user called the help desk.
Typically, J2EE servers convert every request for persistent data into one or more
SQL statements. For applications with complex object models and heavy request
volumes, this approach creates inevitable problems, as illustrated in Figure 1 J2EE
application server bottleneck.

4
Figure 1 J2EE application server bottleneck
The two application characteristics that most often contribute to data bottlenecks are:
1. The number of data objects, which drives the complexity of the object-relational
mapping (mapping the entity bean to a persistent store)
2. The peak transaction rate, which drives the volume of database requests
As the size of the application object model grows, the difficulty of defining an
efficient object-relational mapping increases. Highly efficient mapping is necessary to
prevent mapping bottlenecks. As the application request volume grows, the database will
become a bottleneck based on the sheer volume of database queries. Intelligent caching
can prevent query bottlenecks. For applications with both complex object models and
high request volumes, eliminating data bottlenecks requires a more systematic approach.

5
A good rule of thumb for predicting data bottlenecks is the 50/50 rule. J2EE
applications that have more than 50 data classes and/or more than 50 transactions per
second during peak times are much more likely to experience serious data bottlenecks.
A number of approaches exist to prevent data bottlenecks. Some of them are listed
here:
Use lazy loading: A common mistake is to fetch entire object hierarchies from the
database when an object slice or hierarchy node is sufficient for the application's
needs. Loading data only when absolutely needed is one way to reduce the overall
database traffic.
Database replication: Replicating the database is one way to break up a flood of
requests so they can be managed more efficiently. This also provides an effective
way for boosting performance in a particular region. However, this can be an
expensive approach, requiring additional servers and database licenses.
Object caching within a J2EE server: Caching frequently used objects in-memory
within the J2EE server reduces the database's load and improves response time.
Some J2EE servers include limited caching for CMP (container-managed
persistence) beans; however, this may not adequately address the performance
issues, as described later in this article.
Database operations are typically slow and are the bottleneck of every application.
Database read, write and update are all IO operations, and it is important that they are as
fast as possible, because they affect overall application performance. In fact, it is best to
avoid database operations unless it is necessary. Various cashing techniques exist to

6
achieve this. This can be helpful in some situations, like for example, if the server
application needs to display data that rarely changes. Instead of letting each client get
data directly from the server database, it would be a lot faster to get the data from
database once and keep it in memory for successive requests.
However, in complex applications where data rapidly changes, cashing data is not
very helpful. Even more, these operations usually happen in bursts. This means that most
of the time there is no interaction with the database, but there are short intervals when
large data transfers occur. In these cases, it is extremely important that database access is
fast.
1.1.2 Alternative data access technologies
There is more than one database access API to choose from when developing a J2EE
application. The ones that are in common use today satisfy wide range of requirements.
Some applications use data that does not change that often, but need to maintain complex
relationships, and be flexible enough to change fast. Others need real time values that
change to the second. Another kind of application might need to stream media files from
a database. And then, there are applications that need to leverage transaction control, like
banking systems for instance. In case of funds transfer from one account to another, there
are two consequtive database interactions: one that deducts the amount from the first
account, and another one that adds it to the second account. In case the second operation
fails, someone’s money will be lost by the system, which shouldn’t happen by any
means. This situation can be avoided by using transaction control. If one operation fails,
all of them are rolled back, leaving data unchanged. Traditional JDBC transaction control

7
only works for database operations. Most data access technologies provide basic JDBC
transaction control mechanism. There are situations when this is not enough.
If the application needs to send a JMS (Java Messaging System) message and
perform a database operation in a single transaction, JDBC transaction control can’t help
with this, because JMS is out of it’s scope. In this situation either the Spring API can be
used with it’s declarative transaction support or an EJB container transaction support is
needed. Furthermore, a specific 2-PC (2 Phase Commit) compliant database driver needs
to be used to connect to the database.
Another important issue with data access technologies is concurency, or how
simultaneous access is handled. There are a couple of different transaction isolation
levels that can be used to solve similar problems. The developer might choose an
isolation level where concurrent access is allowed only to read operations, while only one
user may write data at a given time. A setting like this will definitelly increase
performance as opposed to letting one user at a time regardless if they want to read or
write data.
It is also important how complex the database will be. Are there going to be complex
relationships between the tables, primary keys represented by multiple fields, as well as
how often are they going to change.
1.2 Problem Statement
There are plenty of data access technologies to choose from in J2EE server
applications. Some are more popular than others are. They all have their pros and cons.
Some are simpler to use, while others get better performance.

8
It is not always easy to choose one for an application. The right choice of data access
technology depends on how the application needs to access the data. These technologies
differ in performance and the way of data access and representation. They also differ in
the level of transaction support and isolation control. Some offer more and others less.
This in particular, is the goal of this thesis. It compares a couple of commonly used
APIs that interact with relational databases - JDBC, Stored Procedures, Enterprise Java
Beans and the Spring framework JDBC API, how they can be applied to solve a
particular problem and how to choose the right approach. However, the focus is on
performance standpoint. The most common problem in real world is the speed of
database operations. Data access operations typically happen in bursts.
1.3 Solution Strategy
Running real tests is the best way to see how fast each of these technologies is. In
order to do that, we need a simple server application to run tests against data. This simple
application will allow the user to choose a technology and the amount of data to read.
The application also needs to allow the user to select various amounts of data to use.
Using the selected technology and amount of data, the application will need to do some
processing, display the results and how much time it took to do the job. With this
application, it will be possible to do the necessary tests in order to draw conclusions. A
graph representing these findings is given for better readability and understanding.

9
1.4 Thesis roadmap
The central focus of this thesis is to establish which one, from a set of database access
technologies, performs best. For that purpose a test application that uses these database
access technologies will be developed, and then used to run tests against real data. Based
on the results, conclusions will be drawn and some rules on how to choose the right
direction when using a database will be given. Accordingly, the remainder of this thesis is
organized as follows:
Chapter 2: J2EE Data Access Technologies
Chapter 2 provides a brief introduction on each of the database access technologies-
JDBC, Stored Procedures, EJB and Spring JDBC. It also discusses how they differ
among each other.
Chapter 3: Design and Implementation of Benchmark Application
This chapter provides a detailed description of the application used to run tests.
Chapter 4: Experimental Study
Describes the testing process and summarizing data
Chapter 5: Conclusion
The final chapter is where conclusions are made based on the experiment results

10
Chapter 2
J2EE Data Access Technologies
Many real-world Java 2 Platform, Enterprise Edition need to use persistent data at
some point. In many applications, persistent storage is implemented using different
mechanisms, and there are different APIs used to access these mechanisms. For example,
the data may reside in Lightweight Directory Access Protocol (LDAP) repositories,
mainframe systems, and so forth. Another example is where data is provided by services
through external systems such as business-to-business (B2B) integration systems, credit
card bureau service, and so forth. However, the most commonly used storage mechanism
is a relational database.
Typically, applications use distributed components such as entity beans to represent
persistent data. An application is considered to employ bean-managed persistence (BMP)
for its entity beans when these beans explicitly access the persistent storage-the entity
bean includes code to directly access the persistent storage. An application with simpler
requirements may instead use session beans or servlets to directly access the persistent
storage to retrieve and modify the data. Or, the application could use entity beans with
container-managed persistence (CMP), and thus let the container handle the transaction
and persistent details.
Applications can use the JDBC API to access data residing in a relational database
management system (RDBMS). The JDBC API enables standard access and
manipulation of data in persistent storage, such as a relational database. The JDBC API
enables J2EE applications to use SQL statements, which are the standard means for

11
accessing RDBMS tables. However, even within an RDBMS environment, the actual
syntax and format of the SQL statements may vary depending on the particular database
product.
There is even greater variation with different types of persistent storage. Access
mechanisms, supported APIs, and features vary between different types of persistent
stores such as RDBMS, object-oriented databases, flat files, and so forth. Applications
that need to access data from a legacy or disparate system (such as a mainframe, or B2B
service) are often required to use APIs that may be proprietary. Such disparate data
sources offer challenges to the application and can potentially create a direct dependency
between application code and data access code. When business components-entity beans,
session beans, and even presentation components like servlets and helper objects for
JavaServer Pages (JSP) pages --need to access a data source, they can use the appropriate
API to achieve connectivity and manipulate the data source. But including the
connectivity and data access code within these components introduces a tight coupling
between the components and the data source implementation. Such code dependencies in
components make it difficult and tedious to migrate the application from one type of data
source to another. When the data source changes, the components need to be changed to
handle the new type of data source.
These problems are adressed using a Data Access Object (DAO) to abstract and
encapsulate all access to the data source. The DAO manages the connection with the data
source to obtain and store data.

12
At this time J2EE offers a couple of data access technologies. They have been around
for a while, and they are part of the J2EE specification:
1. JDBC (Java Database Conectivity)
2. Stored Procedures (JDBC is used here too except that all the database processing
is done in the database)
3. EJB (Entity Java Beans)
Some developers felt that EJB was too heavy for some situations. That is why, not that
long ago, the open source community came up with a new concept, although not part of
J2EE, but increasingly used by major Dot Com companies, known as:
4. Spring Framework JDBC –one of the APIs from the Spring Framework.
The Spring reference document claims that Spring JDBC is be lighter than the EJB
container and offers the same features of EJB at the same time.
The following is supposed to introduce the reader to each of these technologies
separately.
2.1 JDBC based data access
The first one, JDBC, is the first data access technology for Java based applications.
Every other technology is sort of an upgrade of JDBC. It offers a simple way to execute
SQL statements against a relational database and retrieve the results. It also offers
transaction control so that two or more statements can be executed atomically.
Transaction isolation is provided too, so it is possible to specify that another transaction
can not change the data while the current transaction is in progress. This will prevent

13
from having two transactions affecting the same data simultaneously. With four levels of
transaction control, JDBC has enough to provide concurrent read control. Using JDBC
business processing is done outside of the database so the developer has full control over
the processing. However, this may not always be desired.
Since the code is database specific, code changes will be needed each time the
application needs to migrate to another database. Code changes will also be needed if
some business rule changes.
And finally there is one more problem that JDBC transactions do not address. There
is no easy way to join resources that are not part of JDBC together with JDBC operations
within a single transaction. For example, a common problem in many applications is the
following: An application takes orders for widgets over the Internet. The widget order-
processing application is a legacy system that takes orders from a queue and processes
them in a batch so that they are eventually delivered to the customers. This means that the
order might have to wait some time in the queue before it gets processed.
This model doesn’t satisfy the expectations of an Internet order-entry application.
Users expect to be able to check the order of the application at any time. However, that
might not always be possible in a system where the order may sit in a queue for a long
time while in between processing steps. It would also be too cumbersome to have to
check several queues to determine the progress of the order.
Instead, what is often done is to have two different representations of the order –
when the order is first received, a record is created in a relational database to represent
the order, and the order is then placed in the first state of the queue for the order-

14
processing system to start processing it. As the order moves from one state to another, the
information in the database is updated accordingly.
So far, so good but the problem that occurs is when the database record needs to be
created and the order sent to a queue in the same transaction. It’s not acceptable if the
database record creation fails and the order processing enqueuing succeeds. That would
result in a user being billed and having widgets delivered but not being able to find out
anything about the order in the meanwhile. The two resources- the JDBC connection and
the JMS queue need to be joined in a single transaction, but JDBC transaction control
can’t do that. There is something called 2-Phase Commit (2-PC) transaction model and it
can be used to resolve the problem. 2-PC will be mentioned again when discussing EJB
(Entity Java Beans), although not in detail because that is out of the scope of this
discussion.
The conclusion is, JDBC is simple and easy to use, but there are situations where it is
not enough. It doesn’t have the flexibility some applications might require.
2.2 Stored procedures
A Stored procedure uses JDBC behind the scenes to do its job. It also requires that the
database vendor provides support for stored procedures, as is the case with most
databases today. With this technology all the business processing can be done in the
database itself. This removes unecessary network communication thus improving
performance dramatically. It also improves code reuse, because the logic is coded only
once and stored in the database where application code can call it. The benefit of this is
that the developer doesn’t have to change code (possibly at multiple locations in the

15
program) each time a business rule changes. Only the stored procedure itself has to be
changed.
Stored Procedures offer great flexibility. In case the application needs to switch from
one database vendor to another one, for example from MS SQL database to a MySQL
database, all that needs to be done is move the stored procedures to the MySQL database,
and change the appropriate driver that JDBC uses to talk to the database. Due to slight
differences in Stored Procedures semantics from one vendor to another, it may be needed
to modify the procedures accordingly, but the point is that no changes would be needed in
the client code.
When using a stored procedure, the client doesn’t know what kind of processing is
done behind the scenes. That is irrelevant. The only drawback of this scenario is that the
developer doesn’t have full control over the application. If the database is running on a
dedicated database server, the developer would need to consult a database administrator
for every change to the stored procedure or even worse, the developer might have
restricted access to the server.
Until recently the only way to write a stored procedure in a database was by using
special set of keywords similar to SQL, so everyone who wanted to write stored
procedures had to learn this language. Nowadays, more and more database vendors offer
writing Java based stored procedures. That is, all the processing can be written in a Java
class using JDBC. This class is then compiled and stored in the database for faster
processing.

16
Store Procedures are the most often data access technology used in the industry today.
They offer everything that JDBC does, plus speed, making them the choice of many
companies.
2.3 EJB (Entity Java Beans)
As a relatively new technology, EJB was developed to make it easier to write object
oriented code that interacts with relational databases. EJB specifies three kinds of beans:
session beans, entity beans and message driven. Entity beans are the ones that are used to
communicate to a relational database. Therefore this thesis will focus on entity beans
only.
Entity beans give an object-oriented representation of traditional relational databases.
The entity bean updates, inserts or deletes rows from a database table. Most often, each
table in a database maps to an entity bean and the rows of the table are different instances
of the bean. This implies that entity beans are persistent; their information is persisted in
the database after the server shuts down, similar to a database that does not lose its data
when the machine shuts down.
There are two kinds of entity beans – those with container managed persistence
(CMP) and those with bean managed persistence (BMP).
Entity beans, as all enterprise beans, must run in an EJB container, and only the
container can invoke their methods directly. Clients invoke methods through a proxy, and
then the container invokes the appropriate methods on the bean itself. An entity bean has
a sofisticated lifetime controlled by the container. Figure 2 Life Cycle of an Entity Bean
shows the stages that an entity bean passes through its lifetime. After the EJB container

17
creates the instance, it calls the setEntityContext method of the entity bean class. This
method passes the entity context to the bean.
After instantiation, the entity bean moves to a pool of available instances. While it is
in the pooled stage, this instance is not associated with any particular EJB object identity.
In the pool all instances are identical. The EJB container assigns an identity to an instance
only when moving it to the ready stage.
Figure 2 Life Cycle of an Entity Bean
There are two paths from the pooled stage to the ready stage. On the first path, the
client invokes the create method, causing the EJB container to call the ejbCreate and
ejbPostCreate methods. On the second path, the EJB container invokes the ejbActivate
method. While an entity bean is in the ready stage, it's business methods can be invoked.

18
There are also two paths from the ready stage to the pooled stage. First, a client can
invoke the remove method, which causes the EJB container to call the ejbRemove
method. Second, the EJB container can invoke the ejbPassivate method.
At the end of the life cycle, the EJB container removes the instance from the pool and
invokes the unsetEntityContext method.
While in the pooled state, an instance is not associated with any particular EJB object
identity. With bean-managed persistence, when the EJB container moves an instance
from the pooled state to the ready state, it does not automatically set the primary key.
Therefore, the ejbCreate and ejbActivate methods must assign a value to the primary key.
If the primary key is incorrect, the ejbLoad and ejbStore methods cannot synchronize the
instance variables with the database.
In the pooled state, the values of the instance variables are not needed. The user can
make these instance variables eligible for garbage collection by setting them to null in the
ejbPassivate method.
Both CMP and BMP entity beans use JDBC behind the scenes. In the case of
container managed persistence entity beans the developer doesn’t have to write JDBC
code directly. The developer codes the business logic and defines how the bean maps to
the database by defining abstract getter and setter methods for each field. Then, a
deployment tool is used to generate the tedious JDBC code which does all the work
behind the scenes. As mentioned above, EJBs live in an EJB container, and the
deployment tool generates container specific code.

19
The EJB container is part of a J2EE application server such as WebSphere, WebLogic
or JBoss, and is described in the J2EE specification. The developer can focus on writing
the business logic, defines the fields and relationships without being burdened by writing
cumbersome JDBC code. Optional finders and select methods may be specified using a
special EJB-QL syntax language. Then, this code is run through a deployment tool to
generate the complete bean including JDBC code which operates behind the scenes.
In the sample test application, IBM’s WebSphere Application Server will be used
along with Rational Application Developer as the development tool (IDE). This tool
includes the deployer needed to generate WebSphere specific bean code. If JBoss was
used instead, a little more effort would be needed to learn how to use the open source
deployment tool known as XDoclet.
The deployer tool can even create script files that create the database infrastructure
needed to support the entity beans and any relationships between them. This makes it
very simply to migrate the code to a different application server or database by just re-
running the deployment tool.
JDBC couldn’t handle the order-processing scenario discussed in JDBC based data
access, because it doesn’t have the power to define a transaction that includes a non-
JDBC operation. EJB overcomes this problem with container-managed transactions
which in turn support the 2-PC (2 Phase Commit) protocol. The only requirement is that
the JDBC driver used in a 2-PC protocol behind the scenes has to be XA compliant. Most
database vendors provide this driver nowadays. The EJB container also supports

20
transactions that span multiple remote servers, a feature that no other technology offers
till date.
Entity beans can also help a lot if complex relationships need to be maintained. There
are tools available that make this otherwise cumbersome process as easy as drawing a
graph.
Entity beans support a similar to SQL language known as EJB-QL. This language is
ment to be used in conjunction with special methods known as finder and select methods.
These methods allow selecting a particular bean instance, a set of beans or just a field.
EJB-QL queries can navigate between relationships where this is possible.
Alternatively to CMP (Container Managed Persistence) entity beans, there are BMP
(Bean Managed Persistence) entity beans where the developer doesn’t use a deployment
tool but rather writes the JDBC code manually. The advantage of using BMP entity beans
is that developers may optimize the SQL statements as they need, while having to write
the code themselves. This might be necessary in some special situations.
2.4 Spring Framework
The Spring Framework was created by a group of enthusiasts who thought existing
J2EE technologies can get better. Today Spring is being used by a large number of
companies, including major Dot Coms.
Spring contains a lot of features, which are well-organized in six modules shown in
Figure 3 Overview of the Spring Framework below.

21
Figure 3 Overview of the Spring Framework
Spring doesn’t impose itself wholly on to the design of a project. A developer can
choose to use only certain part from Spring and the rest of the application can be
implemented using any other API. No matter what other framework is used, Spring will
coexist without causing any problems. It is a comprehensive framework including an
MVC framework, a JDBC abstraction layer, EJB support, AOP integration framework, as
well as support for major O/R mapping tools such as Hibernate and JDO.
The DAO package provides a JDBC-abstraction layer that eliminates the need to
write boilerplate JDBC code and deal with database-vendor specific error codes. The,
DAO package provides a way to do programmatic as well as declarative transaction

22
management, not only for classes implementing special interfaces, but for all POJOs
(Plain Old Java Objects). Declarative transaction management is accomplished using the
AOP support built in Spring, and this is the preffered way to use a transaction since it
doesn’t couple code to any API.
The JDBC abstraction layer is included within the DAO package. This thesis will
only focus on this part of the Spring Framework, referring to it as Spring JDBC.
Spring JDBC uses JDBC behind the scenes, except that the developer doesn’t have to
write any of the boilerplate code used for handling resources with a typical JDBC
application. Perhaps the best way to show the value-add provided by Spring JDBC is by
the following list:
1. Define connection parameters
2. Open the connection
3. Specify the statement
4. Prepare and execute the statement
5. Set up the loop to iterate through the results (if any)
6. Do the work for each iteration
7. Process any exception
8. Handle transactions
9. Close the connection

23
The list shows the steps in code needed when using standard JDBC code. The bold
italicized lines show the steps needed when using Spring JDBC. It is clear that there is
substantially less code when using Spring JDBC.
All exceptions thrown during JDBC processing are translated to exceptions defined in
the org.springframework.dao package. An application that uses Spring JDBC does not
need to deal with database specific error code handling. All translated exceptions are
unchecked runtime exceptions allowing the developer to catch only recoverable
exceptions and let other exceptions to propagate to the caller.

24
Chapter 3
Benchmark Application
3.1 Design
A benchmark application will be used to run tests with different data access
technologies. This simple application will allow the user to switch between diferent data
access technologies. It will also allow the user to choose the amount of data used in the
test. In the end it would display the time it took to do the job.
In this case the application works with stock data retrieved from a database.
Obviously, the database will need to be populated with some data. Here are the guidelines
of the application:
-The user can choose whether all stocks prices to be displayed or just the cheapest
ones. This is supposed to show the difference between simply returning data from the
database and returning data after some processing is done against it.
-The user can select which data access technology (JDBC, Stored Procedures, EJB or
Spring JDBC) will be used in the test.
-The database used for testing will be populated with 20000 rows of stock records.
Obviously, we will need a piece of code that will generate and store this data in the
25
database. Since this is a benchmark application the user needs to be able to select the
number of rows included in the search.
-After each operation completes the user needs to know how much time it took.
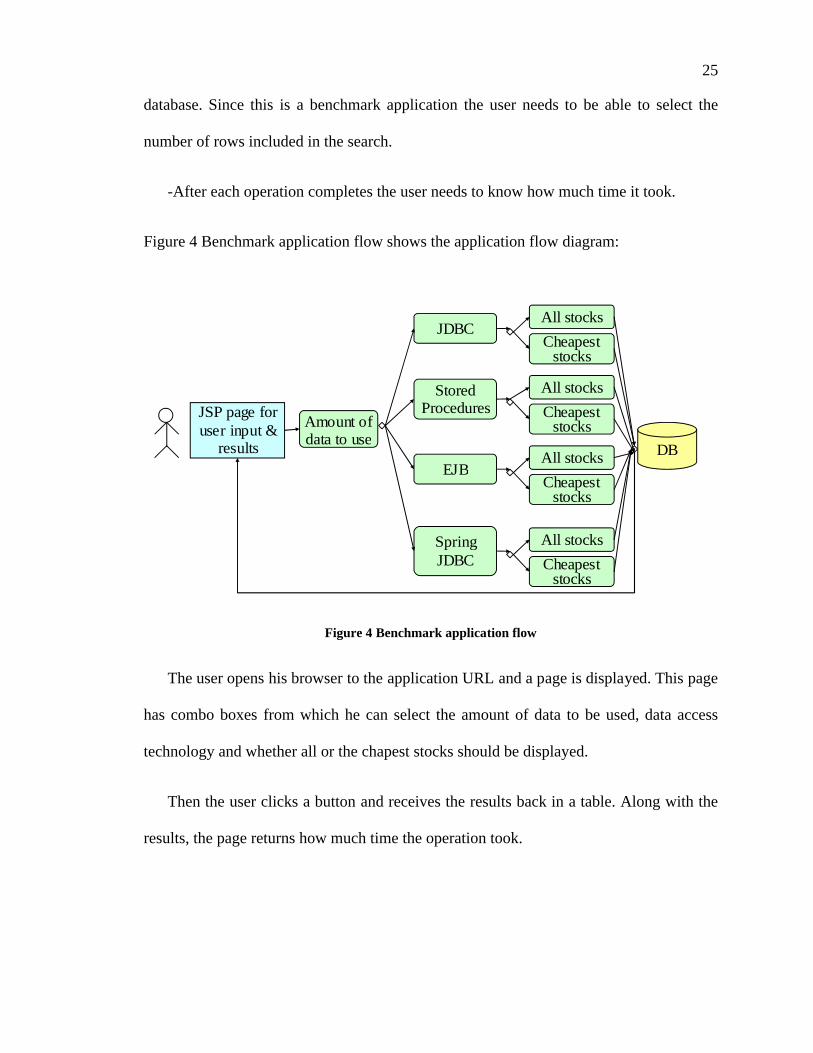
Figure 4 Benchmark application flow shows the application flow diagram:
JSP page for user input &
results
JDBC
EJB
Stored Procedures
Spring JDBC
All stocks
Cheapest stocks
All stocks
Cheapest stocks
All stocks
Cheapest stocks
All stocks
Cheapest stocks
DB
Amount of data to use
Figure 4 Benchmark application flow
The user opens his browser to the application URL and a page is displayed. This page
has combo boxes from which he can select the amount of data to be used, data access
technology and whether all or the chapest stocks should be displayed.
Then the user clicks a button and receives the results back in a table. Along with the
results, the page returns how much time the operation took.

26
3.2 Implementation
The benchmark application is implemented using the MVC (Model View Controller)
pattern. MVC is a proven pattern and is very popular nowadays. In a J2EE server
application like this one, this means that JSPs (Java Server Pages) are used for the
presentation logic. A servlet controls the execution of business rules and presentation
logic. Data itself is stored in the Model – usually JavaBean components and/or a
database.
In this application, a servlet controls what technology is used to retrieve stock data.
This servlet simply processes user selections and invokes the corresponding method.
Each of these methods will return a Vector object. This object contains the stock objects.
The servlet then passes this Vector to the JSP page to display the results by iterating the
vector.
A custom JavaBean class named StockDetails will represent each stock object in the
vector. This bean will contain all the details to describe a particular stock. In this case, it
contains the stock index, full name of the company, value, its up/down values for the day,
the value it had at the end of the previous business day, the lowest and highest value for
the day and time of retrieving the data. Being a JavaBean implies that the class will have
a getter and setter method for each of these properties and a no argument constructor.
Before running any tests, the database has to be populated with 20000 records of
stock information. A simple loop generates random stock records and writes them to the
database so that they can be used for testing later.

27
In terms of deployment, the whole application is packaged in an Enterprise Archive
(EAR) file. This is mostly because the application uses Enterprise Java Beans. If there
were no EJBs used, the application could have been deployed as a Web Archive (WAR)
file. This is because EJBs cannot be deployed as a web archive. They have their own,
separate (Java Archive) JAR module. This module contains an ejb-jar.xml descriptor file
that describes each enterprise bean, similarly as the web.xml descriptor file describes
components in a web archive.
An EAR file can include multiple WAR and JAR files. This EAR will have one JAR
file that contains the enterprise beans, a WAR file for the rest of the application and
probably some libraries that need to be used by both the web archive and enterprise beans
archive. When the enterprise archive is deployed on a J2EE application server like
WebSphere, the server extracts the archives encapsulated within and uses the descriptor
files to configure any resources used by them.
The web archive in this case contains everything except for the enterprise beans. This
includes the JSP page, a servlet and a few utility classes. What the user sees is the JSP
page. This is the page for user interaction. The same page also displays the results. The
servlet does all processing behind the scenes by processing user input and invoking
methods on the utility classes. All J2EE web applications must follow the structure
shown in Figure 5 Web Application Structure in order to be exported as a web archive
file, and deployed on a J2EE application server.

28
Figure 5 Web Application Structure
The web.xml descriptor file is present in most J2EE server applications. It can contain
important information about servlet mappings, resources, welcome pages etc… In the
benchmark application, the web.xml descriptor file contains a servlet definition and
mapping for the controller servlet. Since the application uses the Spring MVC in part, this
file also has a definition and mapping for the dispatcher servlet that comes with Spring.
The application also needs access to the enterprise beans, which are in a separate
archive. For the servlet to be able to lookup an enterprise bean, it needs a reference to its
JNDI name.
The servlet uses a data source directly when using JDBC or Stored Procedure call.
The best way to do this is to have the data source bound in the JNDI namespace, and then
provide the servlet with a reference to that name. A data source is nothing but a pool of
connections maintained on the server for better performance. Because creating
connections is an expensive operation, maintaining a pool of connections is faster and it

29
is the preferred way of connecting to a database from a J2EE application. A full listing of
the web.xml file is provided at the end of this thesis.
The controller servlet in the application is named Dispatcher. It is a typical
HttpServlet subclass used to process GET and POST requests. To get to the application, a
user browses to a URL similar to this one http://someserver.com:9080/Stock/stockList.
The port number 9080 is the default port where WebSphere listens for incoming requests.
Analyzing web.xml it is obvious that requests going to /stockList map to the Dispatcher
servlet. Its job is to process every request, validate user input, and depending on what the
user selected, get the actual stock records. Then it forwards these results along with the
request to the page, which displays them to the user.
switch(Integer.parseInt(selectedOption))
{case ALL_PRICES: stocks=TestData.getDataJDBC(rows);break;
case CHEAPEST_PRICES: stocks=TestData.getCheapestDataJDBC(rows);break;
case ALL_PRICES_SP: stocks=TestData.getDataSP(rows);break;
case CHEAPEST_PRICES_SP: stocks=TestData.getCheapestDataSP(rows);break;
case ALL_PRICES_EJB: TestData testData=new TestData(); stocks=testData.getDataEJB(rows);break;
case CHEAPEST_PRICES_EJB: testData=new TestData(); stocks=testData.getCheapestDataEJB (rows);break;
case ALL_PRICES_SPRING:
case CHEAPEST_PRICES_SPRING:
springpage=true;
try { request.getRequestDispatcher("/stockList.htm").forward(request, response); }
catch (Exception ex) { System.out.println("i crashed here "+ex.getMessage());};break;
The interesting bit here is how the Spring JDBC case is handled. Because Spring has
its own mechanisms for processing requests, in case the user chooses one of the cases
where Spring JDBC is used, the servlet simply forwards the request to “/stockList.htm”.

30
This is not a real page, but looking back at the web.xml file every URL that ends with
‘.htm’ extension is mapped to the Spring servlet. The dispatcher servlet lets Spring
handle user input, get the results and display them.
Besides processing data this servlet also calculates how much time the operation took.
This value is obtained in a very simple way:
long start=System.currentTimeMillis();
/* do some processing here */
long end=System.currentTimeMillis();
...
request.setAttribute("duration",new Long((end-start)).toString());
This last line of code passes the result to the request to be forwarded to the page.
A full listing of the dispatcher servlet is provided at the end of this document. There
are eight different ways (two for each one of the four different data access technologies)
to get the stocks depending on what the user chooses. A convenient switch statement
handles these eight cases. The last two of them, where Spring technology is used, are not
handled by the Dispatcher servlet. They are propagated to the Spring servlet instead. The
other cases are handled by the servlet by invoking various methods on a utility class
named TestData. One thing that these methods have in common is that they all return a
vector of StockDetails objects. StockDetails is just another utility class that holds details
for a particular stock record.
When a user chooses to get all data using JDBC, the servlet invokes the method
getDataJDBC(String howmany). The parameter howmany, specified by the user,
determines the number of database records to be included in the operation. The method

31
simply executes a SQL query and puts the results in a vector of StockDetails objects. The
following is an excerpt from this method:
preparedStatement = getConnection().prepareStatement("SELECT * FROM DB2ADMIN.STOCKS FETCH FIRST
"+rows+" ROWS ONLY");
resultSet = preparedStatement.executeQuery();
StockDetails stockDetails = null;
while (resultSet.next())
{stockDetails = new StockDetails(…);
stocksVector.add(stockDetails);}
A PreparedStatement object compiles and stores the SQL statement in database. This
way the same statement can be executed multiple times efficiently. In the benchmark
application, this is not very useful since all data is grabbed at once, but it doesn’t degrade
performance in any way, so it is good practice to use it. The SQL statement from this
method uses a special set of keywords - “FETCH FIRST N ROWS ONLY”. This means
that only the first N rows are used. Then the statement executes, and the code iterates
through the returned ResultSet object. For every record returned, a new StockDetails
object is created and appended to the resulting vector object.
If the user chose to get the cheapest data using JDBC the method
getCheapestDataJDBC(String howmany) is invoked. This method returns a vector of
StockDetails object too. The same SQL statement is used again to grab the records from
database. The different bit is during iteration of the results - only the cheapest stocks are
added to the vector object:
while (resultSet.next()) {
index = resultSet.getString(1);
boolean exists = false;

32
int i;
for (i = 0; i < stocksVector.size(); i++) {
StockDetails existingStockDetails = (StockDetails) stocksVector.elementAt(i);
if (existingStockDetails.getIndex().equals(index))
{exists = true;
if (existingStockDetails.getValue() > resultSet.getDouble(3))
{stocksVector.remove(existingStockDetails);
stocksVector.add(new StockDetails(…));
}
break; }
}
if (!exists) {stockDetails = new StockDetails(…);
stocksVector.add(stockDetails);}
}
The code above iterates through a ResultSet object and for each stock record it checks if it
already exists in the resulting vector object. If it does not exist, it adds it to the vector,
otherwise checks the stock price and adds it only if it is cheaper. That way the vector will
contain only the cheapest stocks.
If the user chooses to get all data using a stored procedure then the method
getDataSP(String howmany) is called. In this case, instead of executing a SQL statement,
the method calls a stored procedure. A CallableStatement object is used to call the stored
procedure getStocksLimited(int rows). The stored procedure returns a ResultSet object of
stock records from the database. Then the method simply iterates through this object
adding a StockDetails object to the vector per iteration.
callableStatement = getConnection().prepareCall("{call DB2ADMIN.getStocksLimited(?)}");
callableStatement.setInt(1,rows);
resultSet = callableStatement.executeQuery();

33
StockDetails stockDetails = null;
while (resultSet.next())
{stockDetails = new StockDetails(…);
stocksVector.add(stockDetails);}
The stored procedure getStocksLimited(int rows) is implemented as a Java class and
stored in a DB2 database. DB2 comes with its own JDK 1.2 in order to support this
feature. DB2 also supports another option – stored procedures implemented with a
specific set of SQL keywords, an option supported by most database vendors today. The
parameter rows, determines how many records will be retrieved from the database. A full
listing of the GETSTOCKSLIMITED.java class is provided at the end of this document.
If the user wants to get only the cheapest stocks from a set of n stock records using a
stored procedure, the method getCheapestDataSP(String howmany) is called. This
method uses a CallableStatement object to call another stored procedure named
getCheapestStocksLimited(int n). The parameter n means that the first n records will be
looked to get the cheapest stocks. In this case, the search for minimum prices happens in
the procedure itself. The procedure is implemented as a Java class named
GETCHEAPESTSTOCKSLIMITED.java, which is compiled and stored in the DB2
database. A listing of this class is provided at the end of this document. The following
SQL statement executes in the procedure:
SELECT DB2ADMIN.STOCK.INDEX1, DB2ADMIN.STOCK.FULLNAME, DB2ADMIN.STOCK.VALUE1,
DB2ADMIN.STOCK.UP1, DB2ADMIN.STOCK.DOWN1, DB2ADMIN.STOCK.PREVIOUSCLOSE,
DB2ADMIN.STOCK.DAYSLOWVALUE, DB2ADMIN.STOCK.DAYSHIGHVALUE,
DB2ADMIN.STOCK.TIMEOFRETRIEVAL FROM DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.VALUE1
IN (SELECT MIN(DB2ADMIN.STOCK.VALUE1) FROM DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.ID
< rows GROUP BY DB2ADMIN.STOCK.INDEX1 ) AND DB2ADMIN.STOCK.ID < rows;

34
The above statement returns the cheapest stocks from certain number of stock records
using the MIN keyword available in SQL.
In case the user wants to get all stocks using entity beans the method
getDataEJB(String n) is used to get the results. This methods uses enterprise beans to get
the first n stocks from database. When using EJB the client typically does not invoke the
entity bean directly. Usually the client invokes a session bean, which delegates the call to
the entity bean. This is to provide better security and scalability. So, the method simply
locates a session bean named StockManager and calls the method getCheapestStocks() on
this bean.
public Collection getDataEJB(String howMany) {
int rows;
try {rows=Integer.parseInt(howMany);}
catch (NumberFormatException e1) {return null;}
StockManagerLocal aStockManagerLocal = createStockManagerLocal();
return aStockManagerLocal.getAllStocksLimited(new Integer(rows));
}
The method createStockManagerLocal() locates the session beans home interface by its
JNDI name and invokes create() to get a thread safe instance of the session bean. Then it
calls the method getAllStocksLimited(Integer n) from the StockManager session bean:
public Collection getAllStocksLimited(Integer rows) {
aStockLocalHome = getStockLocalHome();
Vector result = new Vector(2000);
Collection stocks = null;
try {stocks = aStockLocalHome.findAllLimited(rows);}
catch (javax.ejb.FinderException fe) {return new Vector();}
Iterator iterator = stocks.iterator();

35
while (iterator.hasNext()) {
StockLocal stockLocal = (StockLocal) iterator.next();
StockDetails stock = new StockDetails(…);
result.add(stock);}
return result;}
The first thing this method does is locating the home interface of the Stock entity bean.
As with the session bean, again the JNDI name is used to get the home interface. Then a
special finder method named findAllLimited(Integer rows) is invoked on this interface. A
finder method is special because it does not have to be implemented when using a CMP
(Container Managed Persistence) entity bean. However, a query has to be defined in the
ejb-jar.xml descriptor. A special language known as EJB-QL (Enterprise Java Bean –
Query Language) is used to specify finder and/or select methods. The query definition is
embodied in a <query/> tag. This one takes a parameter to specify how many records will
be returned:
<query>
<description></description>
<query-method>
<method-name>findAllLimited</method-name>
<method-params>
<method-param>java.lang.Integer</method-param>
</method-params>
</query-method>
<ejb-ql>select object(o) from Stock o where o.id < ?1</ejb-ql>
</query>
The finder method returns a collection of Stock bean instances. Because the servlet
expects a vector of StockDetails objects, the method getAllStocksLimited from the
StockManager bean loops through the collection and populates the resulting vector.

36
In case the user wanted to get the cheapest stocks using EJB the method getCheapest-
DataEJB(String howmany) is called in the dispatcher servlet. Once again as when getting
all stocks using EJB, this method simply obtains a StockManager session instance and
calls a method, this time named getCheapestStocksLimited(String howmany).
public Collection getCheapestDataEJB(String howMany) {
int rows;
try {rows=Integer.parseInt(howMany);}
catch (NumberFormatException e1) {return null;}
StockManagerLocal aStockManagerLocal = createStockManagerLocal();
return aStockManagerLocal.getCheapestStocksLimited(new Integer(rows));}
Once again the method createStockManagerLocal() is used to get instance of the session
bean using its JNDI name behind the scenes. The different bit is that another method –
getCheapestStocksLimited(Integer rows) is invoked on the session bean this time. This
method first locates a home instance of the entity bean and then invokes the
findAllLimited(Integer rows) finder method from this instance. The same finder method
was invoked in the previous case when all stocks were retrieved.
One anomaly of EJB-QL is that it doesn’t provide a keyword for getting the minimum
value, something like the MIN() function in SQL. This is why the session bean method
iterates through the results from the finder method and puts the ones with lowest prices in
a vector of StockDetails objects:
public Collection getCheapestStocksLimited(Integer rows) {
aStockLocalHome = getStockLocalHome();
Vector result = new Vector(2000);
Collection stocks = null;
try {stocks = aStockLocalHome.findAllLimited(rows);} catch (javax.ejb.FinderException fe) {return new Vector();}

37
Iterator iterator = stocks.iterator();
String index = null;
while (iterator.hasNext())
{StockLocal stockLocal = (StockLocal) iterator.next();
index = stockLocal.getIndex();
double value = stockLocal.getValue().doubleValue();
boolean exists = false; int i;
for (i = 0; i < result.size(); i++)
{StockDetails existingStockDetails = (StockDetails) result.elementAt(i);
if (existingStockDetails.getIndex().equals(index))
{exists = true;
if (existingStockDetails.getValue() > value)
{result.remove(existingStockDetails);
result.add(new StockDetails(…));}
break;}
}
if (!exists)
{result.add(new StockDetails(…));}
}
return result;
}
The method initially gets all stock records using the finder method and then iterates
through the collection of StockLocal objects. For each of them it checks whether it
already exists in the vector. If it does not already exist it adds it, otherwise it replaces it
only if the existing one has a bigger price. This way the vector contains unique instances
of the cheapest stocks. The above code is nothing but a workaround to the fact that EJB-
QL does not provide a built in function to get the minimum values. That takes processing
out from the database into client code.

38
If the user chooses to use Spring JDBC to get stock data, regardless if it is all stocks
or only the cheapest ones, the dispatcher servlet forwards the request to the Spring servlet
to deal with it. This servlet is distributed with a Spring JAR file, and it is defined in the
web.xml descriptor file of the web application – deployed as a WAR file. A mapping
URL is also defined for the Spring servlet in web.xml:
<servlet>
<servlet-name>stocks</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
...
<servlet-mapping>
<servlet-name>stocks</servlet-name>
<url-pattern>*.htm</url-pattern>
</servlet-mapping>
This definition gives the name “stocks” to the Spring servlet and maps all request
ending with .htm to this servlet. That is exactly what the dispatcher servlet does – it
forwards these requests to “/stockList.htm”. During initialization, the “stocks” servlet
looks for a special configuration file, named [servlet-name]-servlet.xml, or in this case
stocks-servlet.xml. This file defines how the servlet handles requests for
“/stockList.htm”:
<bean id="urlMapping" class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping">
<property name="mappings">
<props>
<prop key="/stockList.htm">stockListController</prop>
</props>
</property>

39
</bean>
The configuration specifies that any incoming requests to this url be handled by
stockListController. The definition for this controller, and a couple of other definitions
referenced by the controller are given in the same file.
<bean id="stockListController" class="com.dimitri.controllers.StockListController">
<property name="stockManager">
<ref bean="stockManager"/>
</property>
</bean>
<bean id="stockManager" class="com.dimitri.spring.db.StockManager">
<property name="stockManagerDao">
<ref bean="stockManagerDao"/>
</property>
</bean>
<bean id="stockManagerDao" class="com.dimitri.spring.db.StockManagerDaoJdbc">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
...
<bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="java:comp/env/mybank"/>
</bean>
The concept of Inversion of Control (IoC) makes Spring different than other
frameworks. This is where it comes in action. Spring provides the Controller interface,
whose purpose is to simplify request handling. This interface specifies a method named
handleRequest(…). The StockListController class implements this interface, overriding
the handleRequest() method to get user parameters and get the data.

40
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String rows=request.getParameter("rows");
String selectedOption=request.getParameter("selectedScreen");
if(selectedOption==null)selectedOption="0";
if(rows==null)rows="1000";
int n=Integer.parseInt(rows);
Map model=new HashMap();
long start=System.currentTimeMillis();
switch(Integer.parseInt(selectedOption))
{case Dispatcher.ALL_PRICES_SPRING:model.put("stocks", stockManager.getStocks(n));break;
case Dispatcher.CHEAPEST_PRICES_SPRING:model.put("stocks", stockManager.getCheapestStocks(n));break;}
long end=System.currentTimeMillis();
model.put("duration",new Long((end-start)).toString());
return new ModelAndView("stockListSpring", "model", model);
}
The method handles two cases, all stocks or cheapest stocks using Spring JDBC,
depending what the user chooses, because those two are the only ones that ever get here
from the dispatcher servlet. The method also measures how long the operation took. It
puts all this data into a simple model (Map object) and forwards it to the view to display
them.
StockListController also has getter and setter methods for the StockManager
property. This property is set by the IoC container with a singleton instance of
StockManager. This class has a setter and getter method for the StockManagerDao
property. StockManagerDao is an interface, and an implementation of this interface is the
StockManagerDaoJdbc class. The IoC container sets this property to a singleton instance
of the implementation class. This class uses Spring JDBC to get stock records from the
database.

41
The implementation class StockManagerDaoJdbc needs a data source to connect to
the database and it has a setter and getter method for the datasource property. Once
again, the IoC container sets this property with a singleton data source instance
maintained in the configuration file. The class JndiObjectFactoryBean is part of Spring
and is useful for locating JNDI bound objects like the data source in this case. It is very
common to bind a data source to a JNDI name when using application servers.
StockManagerDaoJdbc provides implementation of the getStockList(int n) method which
is called when a user wants to get all stock records using Spring JDBC.
public List getStockList(int n) {
StockQuery stockQuery=new StockQuery(ds,n);
return stockQuery.execute();
}
The method takes a parameter that determines how many records from database will be
used in the operation.
The ds object is nothing else but a data source instance set from the IoC container
using a setter method:
public void setDataSource(DataSource ds)
{this.ds = ds;}
A nested class called StockQuery is the place where Spring JDBC API is used:
class StockQuery extends MappingSqlQuery {
StockQuery(DataSource ds, int rows) {
super(ds, "SELECT INDEX,FULLNAME,VALUE,UP,DOWN,PREVIOUSCLOSE,DAYSLOWVALUE,"
+ " DAYSHIGHVALUE,TIMEOFRETRIEVAL FROM DB2ADMIN.STOCKS FETCH FIRST "+rows+" ROWS
ONLY");
compile();}

42
protected Object mapRow(ResultSet rs, int rowNum) throws SQLException {
StockDetails stockDetails = new StockDetails();
stockDetails.setIndex(rs.getString("INDEX"));
stockDetails.setFullName(rs.getString("FULLNAME"));
stockDetails.setValue(rs.getDouble("VALUE"));
stockDetails.setUp(rs.getDouble("UP"));
stockDetails.setDown(rs.getDouble("DOWN"));
stockDetails.setPreviousClose(rs.getDouble("PREVIOUSCLOSE"));
stockDetails.setDaysLowValue(rs.getDouble("DAYSLOWVALUE"));
stockDetails.setDaysHighValue(rs.getDouble("DAYSHIGHVALUE"));
stockDetails.setTimeOfRetrieval(rs.getDate("TIMEOFRETRIEVAL"));
return stockDetails;
}
}
This class is a subclass of MappingSqlQuery, which is part of Spring JDBC. The SQL
statement is passed in the constructor, and then the method compile() is called. This
method makes sure the statement is valid and all parameters are in the proper format. The
statement isn’t executed until the method execute() is called. This method was called in
getStockList(int n).
Another inherited method is mapRow(ResultSet rs, int rowNum). Spring calls this
method for every row in the ResultSet object returned when executing the statement. In
the benchmark application, it creates a StockDetails object for every row. The method
execute() forms a list of these objects and that is what gets returned to the caller – a List
of StockDetails objects.
Otherwise if the choice was to get the cheapest stocks using Spring JDBC, the
method getCheapestStocks(int n) from StockManagerDaoJdbc is called. This method

43
gets the cheapest stocks among the first n records in database. It has very similar
implementation to the previous getStockList() method. It differs in the SQL statement that
is executed. A nested class called CheapestStockQuery is used by this method.
class CheapestStockQuery extends MappingSqlQuery {
CheapestStockQuery(DataSource ds, int rows) {
super(ds, "SELECT DB2ADMIN.STOCK.INDEX1, DB2ADMIN.STOCK.FULLNAME,
DB2ADMIN.STOCK.VALUE1, DB2ADMIN.STOCK.UP1, DB2ADMIN.STOCK.DOWN1,
DB2ADMIN.STOCK.PREVIOUSCLOSE, DB2ADMIN.STOCK.DAYSLOWVALUE,
DB2ADMIN.STOCK.DAYSHIGHVALUE, DB2ADMIN.STOCK.TIMEOFRETRIEVAL FROM
DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.VALUE1 IN (SELECT MIN(DB2ADMIN.STOCK.VALUE1)
FROM DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.ID < "+rows+ " GROUP BY
DB2ADMIN.STOCK.INDEX1) AND DB2ADMIN.STOCK.ID < "+rows);
compile();
}
protected Object mapRow(ResultSet rs, int rowNum) throws SQLException {
…
return stockDetails;}
}
This SQL statement uses a special MIN keyword to get the cheapest stocks from a given
subset of rows. The rest of the method stays same as in the previous case.
The last piece of this MVC application is the View. Two simple Java Server Pages
make up the view of the application. These pages provide the same functionality, except
that one is used to handle the cases where Spring JDBC is used, and the other one handles
the other cases. This is because Spring has structural differences compared to other
technologies. These pages list the resulting stock data in a table. They also use some of
the tags included with the Java Standard Tag Library (JSTL).

44
Chapter 4
Experimental Study of Data Access Performance
4.1 Experimental environment
Before any testing can be done, the benchmark application needs to be configured and
deployed. Like most applications, this application needs some hardware and software
resources to run. The results given further in the document are obtained using the
following environment:
Blade Station Server HS20 powered by two 3.6 GHz Intel Xeon processors, 2GB
of RAM and 2x36GB hard drives running in RAID 1 mode for maximum
performance.
Windows 2003 Server operating system.
DB2 Universal Database 8.2 – is used to hold data for stock records.
WebSphere Application Server 6.0 – using a Legacy/CLI type 2 JDBC driver
which uses OS-specific library to facilitate communication to DB2.
Gigabit connection to the outside world.
4.2 Testing process and results
The purpose of this benchmark application is to compare four different data access
technologies: JDBC, Stored Procedures, EJB and Spring JDBC. This comparison is done
by testing against a real database populated with data. The following describes the testing
process flow when using the benchmark application.

45
The user opens a browser and opens a specific JSP page. This page allows the user to
select one of eight options from a combo box:
All stock prices – JDBC is used to get all records.
Cheapest prices only – JDBC is used to get cheapest unique stocks only.
All prices (using SP) – Stored Procedures are used to get all records.
Cheapest prices (using SP) – Stored Procedures are used to get cheapest unique
stocks only.
All prices (using EJB) – Enterprise Java Beans are used to get all records.
Cheapest prices (using EJB) – Enterprise Java Beans are used to get cheapest
unique stocks only.
All prices (using Spring) – Spring JDBC is used to get all records.
Cheapest prices (using Spring) – Spring JDBC is used to get cheapest unique
stocks only.
On the same page, there is a second combo box, which allows the user to choose how
many rows of data to be included in the search. The combo box allows any number from
100 to 20000 (in increments of 100) to be selected. This selection along with the one
from the previous combo box forms a complete test case. If, for example a user selects
“All Stock Prices” from the first combo box and 300 rows from the second combo box,
then only the first 300 stocks in the database are retrieved and displayed in the table.
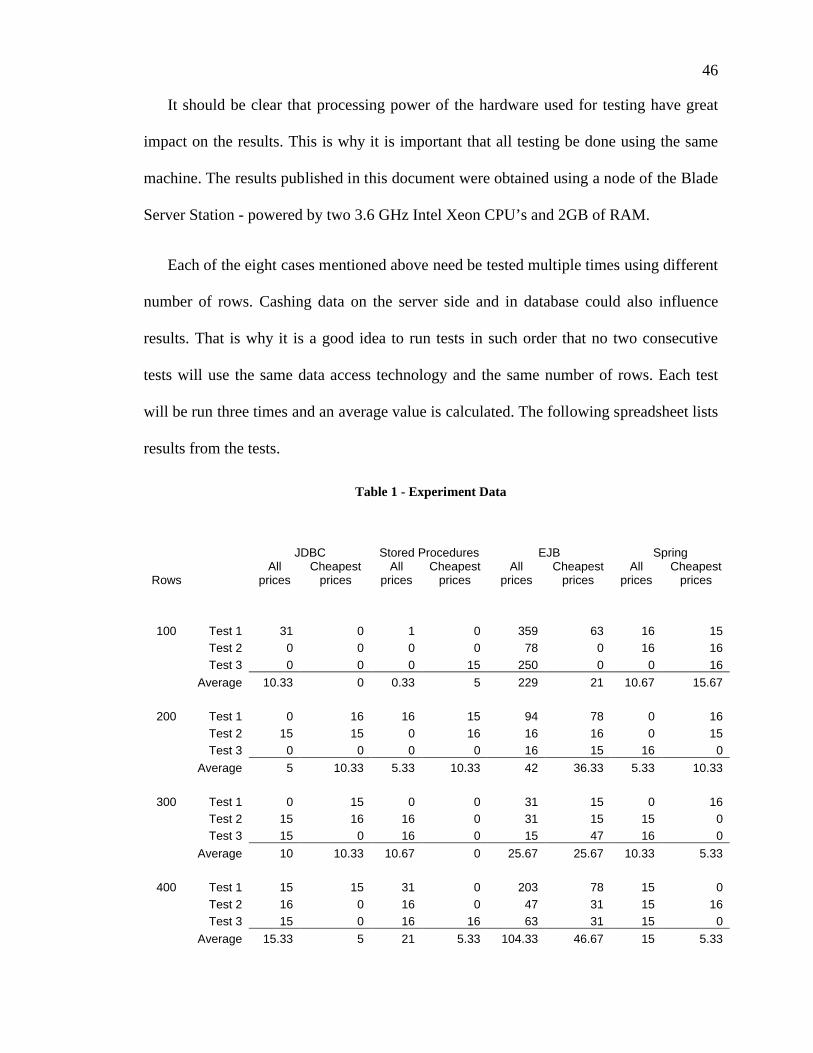
46
It should be clear that processing power of the hardware used for testing have great
impact on the results. This is why it is important that all testing be done using the same
machine. The results published in this document were obtained using a node of the Blade
Server Station - powered by two 3.6 GHz Intel Xeon CPU’s and 2GB of RAM.
Each of the eight cases mentioned above need be tested multiple times using different
number of rows. Cashing data on the server side and in database could also influence
results. That is why it is a good idea to run tests in such order that no two consecutive
tests will use the same data access technology and the same number of rows. Each test
will be run three times and an average value is calculated. The following spreadsheet lists
results from the tests.
Table 1 - Experiment Data
JDBC Stored Procedures EJB Spring
RowsAll
pricesCheapest
pricesAll
pricesCheapest
pricesAll
pricesCheapest
pricesAll
pricesCheapest
prices
100 Test 1 31 0 1 0 359 63 16 15
Test 2 0 0 0 0 78 0 16 16
Test 3 0 0 0 15 250 0 0 16
Average 10.33 0 0.33 5 229 21 10.67 15.67
200 Test 1 0 16 16 15 94 78 0 16
Test 2 15 15 0 16 16 16 0 15
Test 3 0 0 0 0 16 15 16 0
Average 5 10.33 5.33 10.33 42 36.33 5.33 10.33
300 Test 1 0 15 0 0 31 15 0 16
Test 2 15 16 16 0 31 15 15 0
Test 3 15 0 16 0 15 47 16 0
Average 10 10.33 10.67 0 25.67 25.67 10.33 5.33
400 Test 1 15 15 31 0 203 78 15 0
Test 2 16 0 16 0 47 31 15 16
Test 3 15 0 16 16 63 31 15 0
Average 15.33 5 21 5.33 104.33 46.67 15 5.33
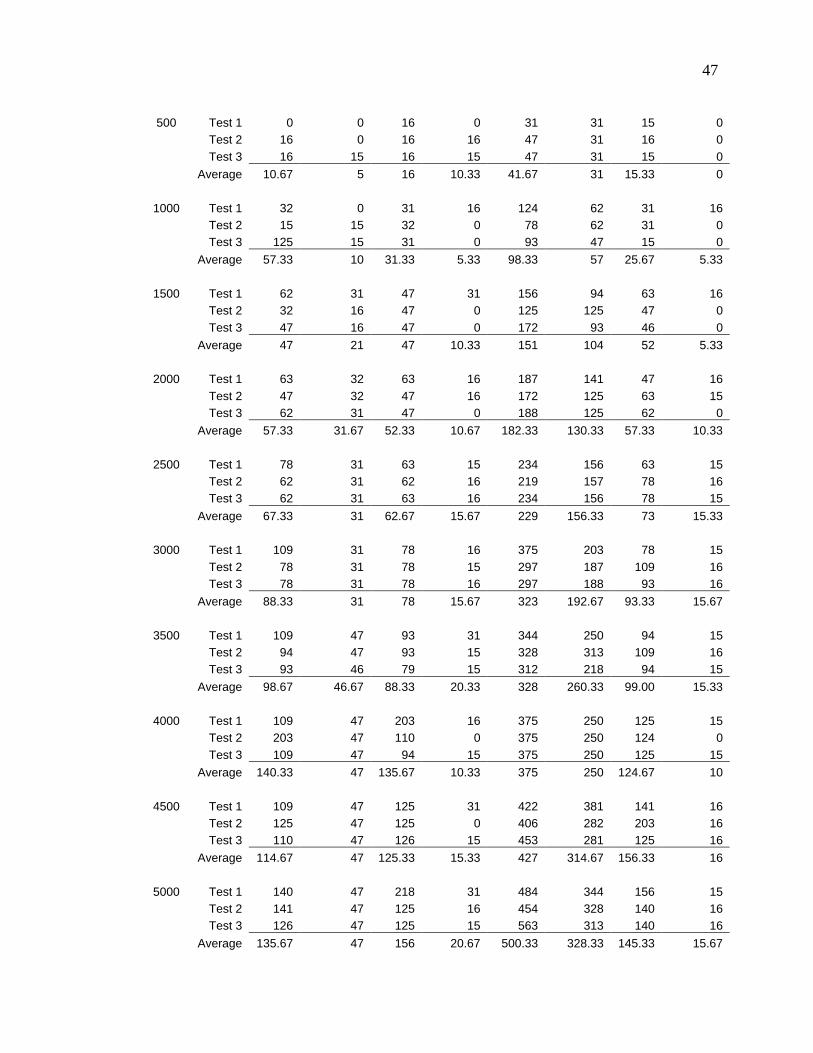
47
500 Test 1 0 0 16 0 31 31 15 0
Test 2 16 0 16 16 47 31 16 0
Test 3 16 15 16 15 47 31 15 0
Average 10.67 5 16 10.33 41.67 31 15.33 0
1000 Test 1 32 0 31 16 124 62 31 16
Test 2 15 15 32 0 78 62 31 0
Test 3 125 15 31 0 93 47 15 0
Average 57.33 10 31.33 5.33 98.33 57 25.67 5.33
1500 Test 1 62 31 47 31 156 94 63 16
Test 2 32 16 47 0 125 125 47 0
Test 3 47 16 47 0 172 93 46 0
Average 47 21 47 10.33 151 104 52 5.33
2000 Test 1 63 32 63 16 187 141 47 16
Test 2 47 32 47 16 172 125 63 15
Test 3 62 31 47 0 188 125 62 0
Average 57.33 31.67 52.33 10.67 182.33 130.33 57.33 10.33
2500 Test 1 78 31 63 15 234 156 63 15
Test 2 62 31 62 16 219 157 78 16
Test 3 62 31 63 16 234 156 78 15
Average 67.33 31 62.67 15.67 229 156.33 73 15.33
3000 Test 1 109 31 78 16 375 203 78 15
Test 2 78 31 78 15 297 187 109 16
Test 3 78 31 78 16 297 188 93 16
Average 88.33 31 78 15.67 323 192.67 93.33 15.67
3500 Test 1 109 47 93 31 344 250 94 15
Test 2 94 47 93 15 328 313 109 16
Test 3 93 46 79 15 312 218 94 15
Average 98.67 46.67 88.33 20.33 328 260.33 99.00 15.33
4000 Test 1 109 47 203 16 375 250 125 15
Test 2 203 47 110 0 375 250 124 0
Test 3 109 47 94 15 375 250 125 15
Average 140.33 47 135.67 10.33 375 250 124.67 10
4500 Test 1 109 47 125 31 422 381 141 16
Test 2 125 47 125 0 406 282 203 16
Test 3 110 47 126 15 453 281 125 16
Average 114.67 47 125.33 15.33 427 314.67 156.33 16
5000 Test 1 140 47 218 31 484 344 156 15
Test 2 141 47 125 16 454 328 140 16
Test 3 126 47 125 15 563 313 140 16
Average 135.67 47 156 20.67 500.33 328.33 145.33 15.67
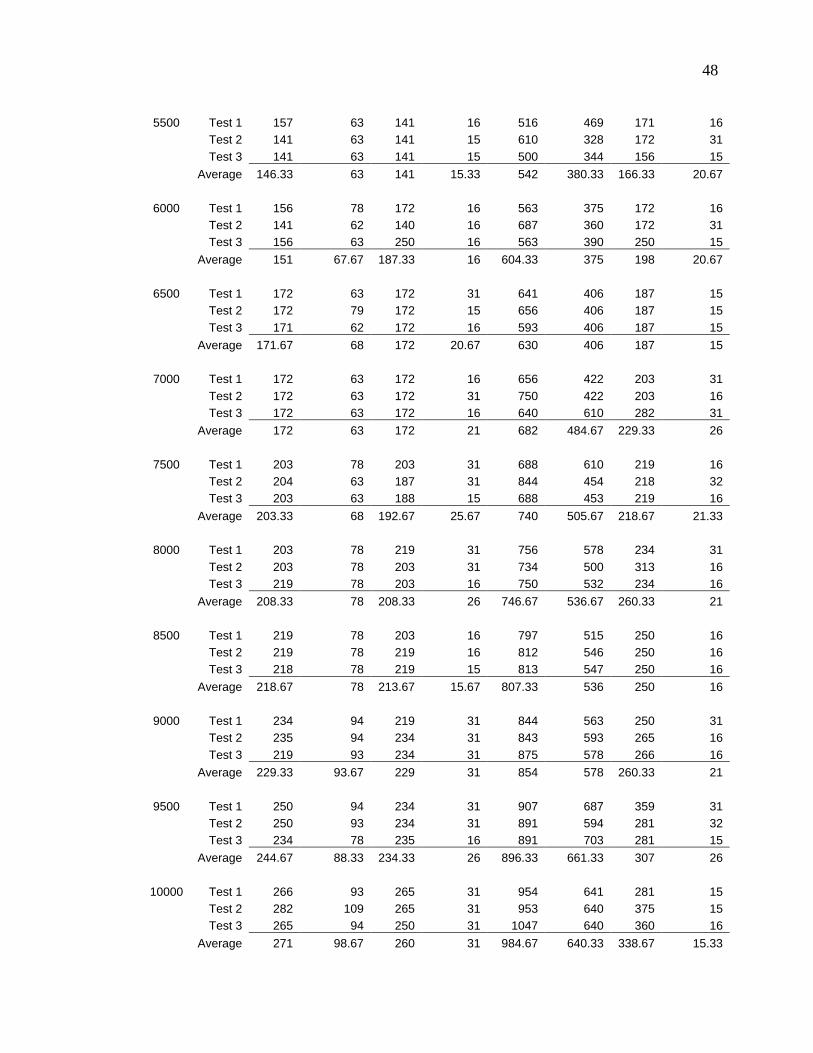
48
5500 Test 1 157 63 141 16 516 469 171 16
Test 2 141 63 141 15 610 328 172 31
Test 3 141 63 141 15 500 344 156 15
Average 146.33 63 141 15.33 542 380.33 166.33 20.67
6000 Test 1 156 78 172 16 563 375 172 16
Test 2 141 62 140 16 687 360 172 31
Test 3 156 63 250 16 563 390 250 15
Average 151 67.67 187.33 16 604.33 375 198 20.67
6500 Test 1 172 63 172 31 641 406 187 15
Test 2 172 79 172 15 656 406 187 15
Test 3 171 62 172 16 593 406 187 15
Average 171.67 68 172 20.67 630 406 187 15
7000 Test 1 172 63 172 16 656 422 203 31
Test 2 172 63 172 31 750 422 203 16
Test 3 172 63 172 16 640 610 282 31
Average 172 63 172 21 682 484.67 229.33 26
7500 Test 1 203 78 203 31 688 610 219 16
Test 2 204 63 187 31 844 454 218 32
Test 3 203 63 188 15 688 453 219 16
Average 203.33 68 192.67 25.67 740 505.67 218.67 21.33
8000 Test 1 203 78 219 31 756 578 234 31
Test 2 203 78 203 31 734 500 313 16
Test 3 219 78 203 16 750 532 234 16
Average 208.33 78 208.33 26 746.67 536.67 260.33 21
8500 Test 1 219 78 203 16 797 515 250 16
Test 2 219 78 219 16 812 546 250 16
Test 3 218 78 219 15 813 547 250 16
Average 218.67 78 213.67 15.67 807.33 536 250 16
9000 Test 1 234 94 219 31 844 563 250 31
Test 2 235 94 234 31 843 593 265 16
Test 3 219 93 234 31 875 578 266 16
Average 229.33 93.67 229 31 854 578 260.33 21
9500 Test 1 250 94 234 31 907 687 359 31
Test 2 250 93 234 31 891 594 281 32
Test 3 234 78 235 16 891 703 281 15
Average 244.67 88.33 234.33 26 896.33 661.33 307 26
10000 Test 1 266 93 265 31 954 641 281 15
Test 2 282 109 265 31 953 640 375 15
Test 3 265 94 250 31 1047 640 360 16
Average 271 98.67 260 31 984.67 640.33 338.67 15.33
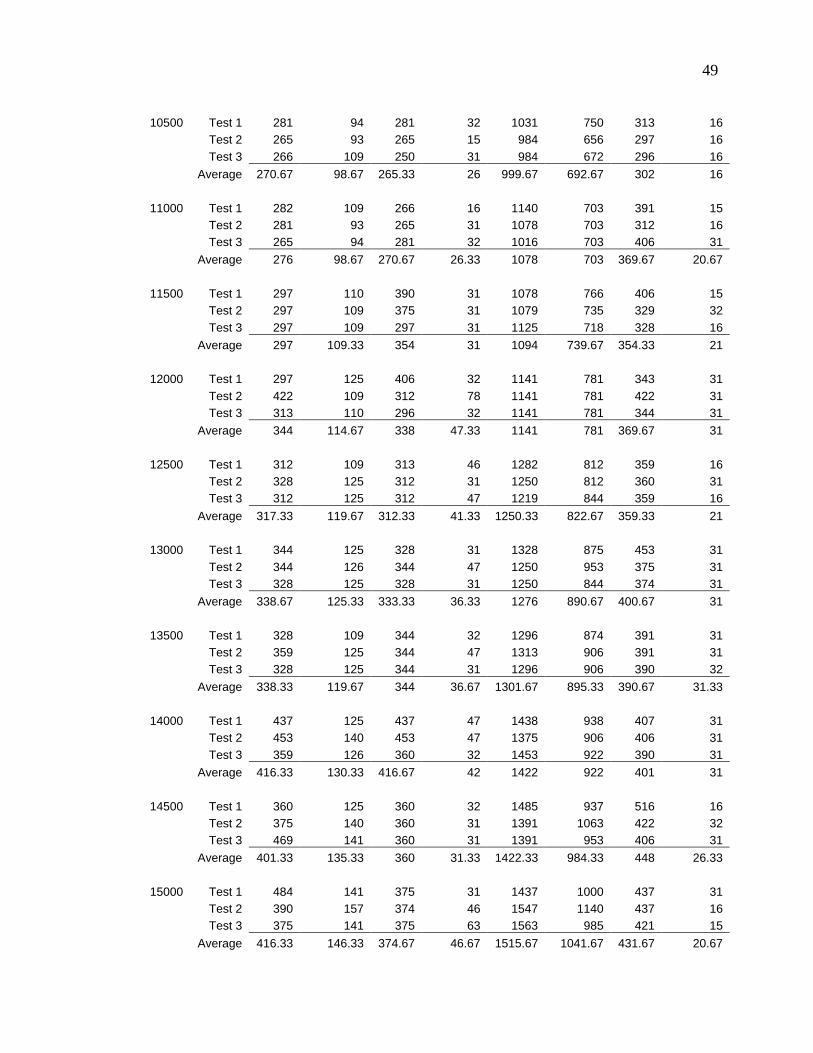
49
10500 Test 1 281 94 281 32 1031 750 313 16
Test 2 265 93 265 15 984 656 297 16
Test 3 266 109 250 31 984 672 296 16
Average 270.67 98.67 265.33 26 999.67 692.67 302 16
11000 Test 1 282 109 266 16 1140 703 391 15
Test 2 281 93 265 31 1078 703 312 16
Test 3 265 94 281 32 1016 703 406 31
Average 276 98.67 270.67 26.33 1078 703 369.67 20.67
11500 Test 1 297 110 390 31 1078 766 406 15
Test 2 297 109 375 31 1079 735 329 32
Test 3 297 109 297 31 1125 718 328 16
Average 297 109.33 354 31 1094 739.67 354.33 21
12000 Test 1 297 125 406 32 1141 781 343 31
Test 2 422 109 312 78 1141 781 422 31
Test 3 313 110 296 32 1141 781 344 31
Average 344 114.67 338 47.33 1141 781 369.67 31
12500 Test 1 312 109 313 46 1282 812 359 16
Test 2 328 125 312 31 1250 812 360 31
Test 3 312 125 312 47 1219 844 359 16
Average 317.33 119.67 312.33 41.33 1250.33 822.67 359.33 21
13000 Test 1 344 125 328 31 1328 875 453 31
Test 2 344 126 344 47 1250 953 375 31
Test 3 328 125 328 31 1250 844 374 31
Average 338.67 125.33 333.33 36.33 1276 890.67 400.67 31
13500 Test 1 328 109 344 32 1296 874 391 31
Test 2 359 125 344 47 1313 906 391 31
Test 3 328 125 344 31 1296 906 390 32
Average 338.33 119.67 344 36.67 1301.67 895.33 390.67 31.33
14000 Test 1 437 125 437 47 1438 938 407 31
Test 2 453 140 453 47 1375 906 406 31
Test 3 359 126 360 32 1453 922 390 31
Average 416.33 130.33 416.67 42 1422 922 401 31
14500 Test 1 360 125 360 32 1485 937 516 16
Test 2 375 140 360 31 1391 1063 422 32
Test 3 469 141 360 31 1391 953 406 31
Average 401.33 135.33 360 31.33 1422.33 984.33 448 26.33
15000 Test 1 484 141 375 31 1437 1000 437 31
Test 2 390 157 374 46 1547 1140 437 16
Test 3 375 141 375 63 1563 985 421 15
Average 416.33 146.33 374.67 46.67 1515.67 1041.67 431.67 20.67
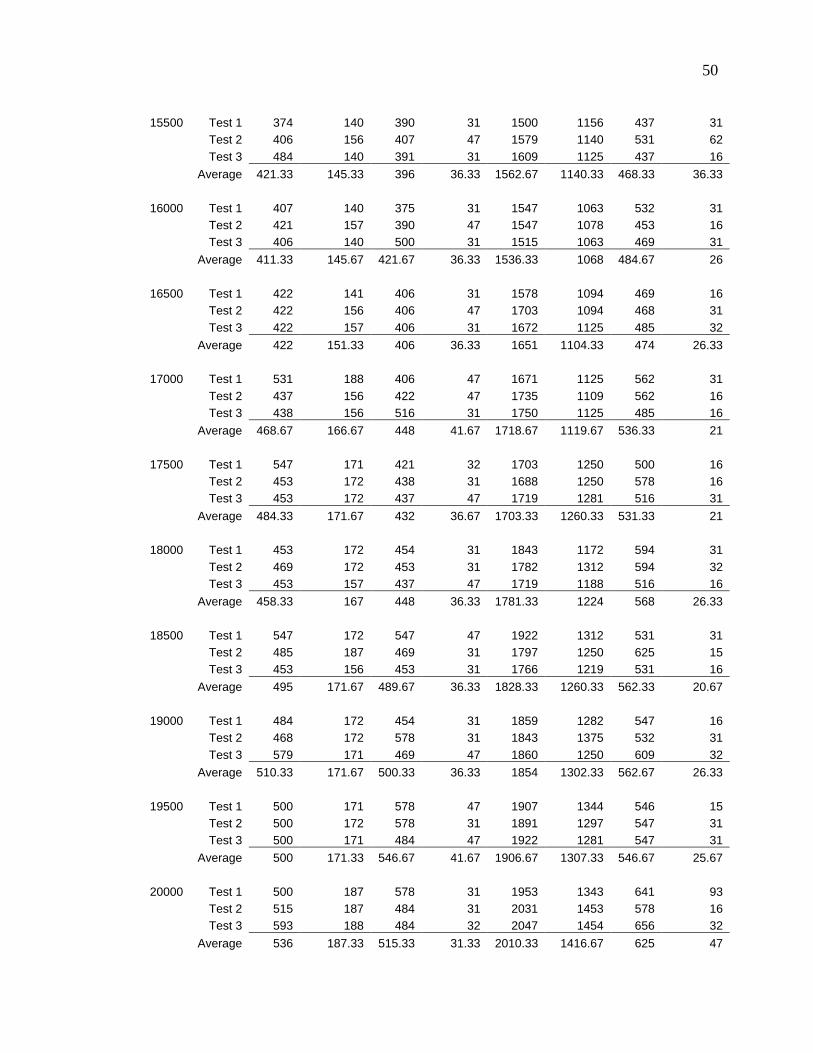
50
15500 Test 1 374 140 390 31 1500 1156 437 31
Test 2 406 156 407 47 1579 1140 531 62
Test 3 484 140 391 31 1609 1125 437 16
Average 421.33 145.33 396 36.33 1562.67 1140.33 468.33 36.33
16000 Test 1 407 140 375 31 1547 1063 532 31
Test 2 421 157 390 47 1547 1078 453 16
Test 3 406 140 500 31 1515 1063 469 31
Average 411.33 145.67 421.67 36.33 1536.33 1068 484.67 26
16500 Test 1 422 141 406 31 1578 1094 469 16
Test 2 422 156 406 47 1703 1094 468 31
Test 3 422 157 406 31 1672 1125 485 32
Average 422 151.33 406 36.33 1651 1104.33 474 26.33
17000 Test 1 531 188 406 47 1671 1125 562 31
Test 2 437 156 422 47 1735 1109 562 16
Test 3 438 156 516 31 1750 1125 485 16
Average 468.67 166.67 448 41.67 1718.67 1119.67 536.33 21
17500 Test 1 547 171 421 32 1703 1250 500 16
Test 2 453 172 438 31 1688 1250 578 16
Test 3 453 172 437 47 1719 1281 516 31
Average 484.33 171.67 432 36.67 1703.33 1260.33 531.33 21
18000 Test 1 453 172 454 31 1843 1172 594 31
Test 2 469 172 453 31 1782 1312 594 32
Test 3 453 157 437 47 1719 1188 516 16
Average 458.33 167 448 36.33 1781.33 1224 568 26.33
18500 Test 1 547 172 547 47 1922 1312 531 31
Test 2 485 187 469 31 1797 1250 625 15
Test 3 453 156 453 31 1766 1219 531 16
Average 495 171.67 489.67 36.33 1828.33 1260.33 562.33 20.67
19000 Test 1 484 172 454 31 1859 1282 547 16
Test 2 468 172 578 31 1843 1375 532 31
Test 3 579 171 469 47 1860 1250 609 32
Average 510.33 171.67 500.33 36.33 1854 1302.33 562.67 26.33
19500 Test 1 500 171 578 47 1907 1344 546 15
Test 2 500 172 578 31 1891 1297 547 31
Test 3 500 171 484 47 1922 1281 547 31
Average 500 171.33 546.67 41.67 1906.67 1307.33 546.67 25.67
20000 Test 1 500 187 578 31 1953 1343 641 93
Test 2 515 187 484 31 2031 1453 578 16
Test 3 593 188 484 32 2047 1454 656 32
Average 536 187.33 515.33 31.33 2010.33 1416.67 625 47

51
It is not easy to analyze data from a table like this one. A better way to understand the
data is to have it represented graphically. The chart from Figure 6 - Result Data Graph is
a graphical representation of the same data in a human readable format.
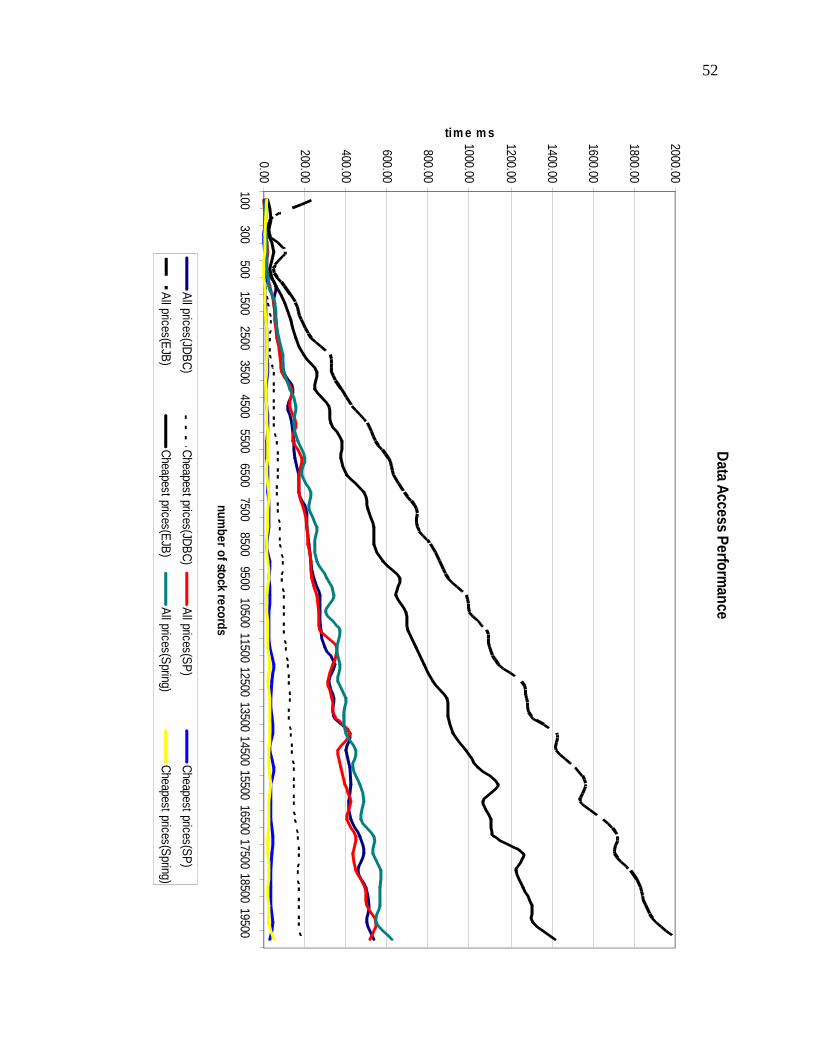
52D
ata Access P
erformance
0.00
200.00
400.00
600.00
800.00
1000.00
1200.00
1400.00
1600.00
1800.00
2000.00
100300
5001500
25003500
45005500
65007500
85009500
1050011500
1250013500
1450015500
1650017500
1850019500
number of stock records
tim e m s
All prices(JD
BC
)C
heapest prices(JDB
C)
All prices(S
P)
Cheapest prices(S
P)
All prices(E
JB)
Cheapest prices(E
JB)
All prices(S
pring)C
heapest prices(Spring)

53
Figure 6 - Result Data Graph
The graph from Figure 6 - Result Data Graph represents results obtained by
experiments. Eight curves represent each of the eight cases that the benchmark
application has. One of the axes shows how much time it took to do the operation and the
other axis shows how many rows were used.
For simplicity, the following suffixes are used throughout the text: “min” - for
cheapest stocks and “all” - for all stocks. These are used in combination with prefixes for
the appropriate technologies: “JDBC” - for Java Database Connectivity, “SP” – for
Stored Procedures, “EJB” – for Enterprise Java Beans and “Spring” – for the Spring
JDBC API.
At first glance, it is obvious from Figure 6 - Result Data Graph how the curves divert
from each other as the amount of data used grows. Some technologies perform a lot better
than others as the amount of data grows. When using only a 100 records, all curves are
about the same level except for the EJB-min access curve. This is probably due to some
initialization process that takes time in the EJB container. As the record number grows to
200 all curves stick together at the same level. At 300 hundred records the EJB-min curve
splits above the other curves and keeps going higher as the amount of data grows. Until
around 600 records, the other curves keep together and then they divert.
The SP-min curve stays at a low value until the end with just a slight increase. The
Spring-min curve follows up throughout the graph. This solution is also fast because the
SQL statement used in Spring-min does the processing at database level using a MIN
keyword. If we wanted to do other processing, Spring JDBC would have had to do it

54
outside the database and it would be slower. Using a stored procedure to get the cheapest
stocks is definitely fast, but it is not always necessary. Sometimes all processing can be
done at database level using only SQL keywords and without a stored procedure.
The JDBC-min curve is at the same level with SP-min up to around 3000 records, and
then it diverts to higher values. This is because our JDBC code does the minimum-search
processing out from the database. Up to 3000 records, this processing overhead is too
small to make an impact, but it makes a difference when using large amount of data.
The JDBC-all and SP-all curves overlap throughout the whole graph. Therefore, it
does not really make a difference whether JDBC or a Stored Procedure is used unless
there is some processing involved. In this case there is no processing, just listing the
records from the database. Spring-all follows these two curves up to about 5000 rows,
then diverts to a little bit higher value, and runs in parallel with them through most of the
graph, intersecting them occasionally. It is obvious from the graph that the Spring JDBC
introduces a small processing overhead, but this overhead stays constant and insignificant
even with large amount of data.
Next, high above all previously discussed curves on the graph is the EJB-min curve.
Obviously, this one performs worse than competitor technologies - JDBC-min, SP-min
and Spring-min. An EJB-QL query is used to get the cheapest stocks in this case.
Because EJB-QL does not have a way to specify that only the cheapest stocks be
retrieved at database level, a workaround has to be used. The workaround is to get all the
stocks using a proprietary EJB-QL query, and then do the processing using Java code

55
outside the database. Of course, this takes more time compared to when all processing
happened at database level.
There is additional processing involved when returning results from EJB-QL queries
in an entity bean. In the benchmark application, stocks are retrieved using a finder
method. This method executes an EJB-QL query that returns a Collection object
populated with StockLocal objects. Each of these is an object representation of a single
row in the database. What actually happens behind scenes is the EJB container executes a
SQL statement, gets results back in a ResultSet object, iterates through it and creates a
StockLocal object at each loop, adding all of them into one Collection object. This takes
up CPU time and memory. The interface object (StockLocal) is a Java interface class that
contains a setter and getter method for each stock attribute and relationship (if any). This
interface may also contain signatures for methods that are available to the clients. All this
functionality takes up memory, so the Collection object grows in size much faster than a
simple ResultSet object, resulting with larger JVM (Java Virtual Machine) heap size.
When using an entity bean to access a database, a client should not be allowed to
interact with the entity bean directly. Usually there is a session bean between the client
and the entity bean. The client interacts with the session bean, which then propagates the
call to an entity bean. This is mainly for security reasons and simpler JTA transaction
management, but it also introduces some processing overhead.
Above all other curves on the graph is the EJB-all curve. Only for small amount of
data (up to 300 stock records), the curve follows up with other curves. Then it diverts and
grows more and more as the amount of data grows. Obviously, it performs much slower

56
than the competition – JDBC-all, SP-all and Spring-JDBC. Here too, as with EJB-min,
finder method with the same EJB-QL query is used. The different bit is that all stocks are
returned without filtering the cheapest ones only.
At first glance, one would expect to see EJB-min perform slower than EJB-all, but the
tests prove the opposite. The only explanation for this is that it takes more time to
populate a Collection object with 20000 StockLocal instances, than to pick the cheapest
of all StockLocal objects and put only those in the Collection object.
All these factors contribute to EJB being slower than the other technologies, and that
puts the EJB-min and EJB-all curves above the other curves on the graph.

57
Chapter 5
Conclusion
It is clear that Enterprise Java Beans is not among the fastest database access
technology available. It is in fact a slow one compared to the others since there is
additional processing happening behind the scenes. However, it offers great Object-to-
Relational mapping and it can reduce development time significantly. It simplifies the
process of maintaining complex relationships, allowing developers to focus on the
business logic.
An entity bean has a complex life cycle including features such as cashing and bean
passivation. Bean cashing might improve performance in applications in which data
access has low intensity and most data is reused multiple times. If the application uses
large amounts of data at once, these techniques would become inefficient because they
take up a lot of memory.
In most applications, a better choice is to use Stored Procedures. Most databases
support them nowadays. This way all business processing happens within the database
for maximum performance. This also simplifies maintenance. If a business rule needs to
change, it only needs to change once, at database level, without any changes to the client
code.

58
JDBC might be the right choice when business processing needs to stay out of the
database. Using a stored procedure is advantageous only when some processing happens
at database level. Otherwise, it performs same as a JDBC statement. In cases where it is
possible to do the entire database processing using a simple SQL statement, (potentially
using some of the keywords) it would be simpler to use JDBC. If all processing happens
at the database level, it will perform at the same speed as when using a corresponding
stored procedure.
Spring JDBC offers an abstraction layer API over JDBC. It performs quite well
introducing just a small performance loss. Other than that, it simplifies development a lot
by removing all of the boilerplate code that goes with JDBC code. It also provides an
exception translation mechanism that translates vendor specific error messages into
standard messages. In addition, since all configuration details are in xml configuration
files instead of hard coded, it is very flexible. Spring JDBC also offers the same
transaction support as EJB except for one. It does not support transactions that span
across multiple remote machines. EJB is the only technology that has this functionality as
for now.
Spring JDBC is a good choice if the application can afford a small performance loss.
In return, it gives back a lot of flexibility and faster development.

59
Benchmark Application Installation Guide
In order to run the benchmark application, these steps need to be done.
- create database infrastructure
- configure resources on the server
- deploy the application & generate test data
The following text assumes a machine that has WebSphere Application Server 6.0 and
DB2 UDB 8.2 installed on a Windows OS.
Creating database infrastructure
First of all a database must be created to hold the data. In this application, the
database is named DBTEST. One way to do this is by using the DB2 command
console.
Start the DB2 command console by navigating to StartAll ProgramsIBM
DB2Command Line ToolsCommand Line Processor. The DB2 console
window opens.

60
Type “create database DBTEST” and hit Enter. Depending on the machine, it
may take up to 2-3 minutes to create the database.
Type “quit” and hit Enter to terminate the connection. Then close the window.
The next step is to create database infrastructure. To make the process simpler there is a
script file, named Tables.ddl, included with the distribution CD. The DB2 Command
Center will be used to run this script.
From the Windows desktop, navigate to StartAll ProgramsIBM
DB2Command Line ToolsCommand Center. Click the Script tab. Navigate to
ScriptImport from the menu bar. From the dialog, choose your System name,
locate the Tables.ddl file and click OK. Finally, execute the script by selecting
ScriptExecute. The script should execute successfully. Close the Command
Center utility.
At this point there is a database with a schema and some empty tables in it. Later on, the
benchmark application will be used to populate these tables with data.
Setting up server resources
The benchmark application needs a data source to communicate with the database.
Therefore, a data source resource must be configured and maintained by WAS. The
application looks up this resource under the JNDI name jdbc/bank. Therefore, the data
source must be bound to JNDI under this name. The WebSphere console application has
an easy way to accomplish this.

61
Make sure WAS is running, otherwise the console application will not work.
WAS can be started by clicking StartAll ProgramsIBM
WebSphereApplication Server v6.0defaultStart Server (This step assumes
running WAS as a standalone server, not the integrated testing environment that
comes with Rational Application Developer).
Start the WAS console by opening a browser to the following URL:
https://yourhost:9043/ibm/console/. In the URL, yourhost is the machine where
WAS is running. The port might be different and it is set to 9043 by default. This
points to the WAS console login screen. Unless security is enabled, it does not
require a password.
Make sure WAS knows where to look for a DB2 JDBC driver. Navigate to
EnvironmentWebSphere VariablesDB2_JDBC_Driver_Path and set this
variable value to the folder where db2java.zip is located. In a default installation,
this value should be C:/Program Files/IBM/SQLLIB/Java.
The next step is to configure the JDBC provider. Click ResourcesJDBC
ProvidersNew. Select “DB2”, “DB2 Legacy CLI-based Type 2 JDBC Driver”
and “Connection pool data source” from the three combo boxes. Click Next and
then OK on the last dialog. Save the changes when asked.
Finally, a JDBC data source needs to be created to talk to the DBTEST database.
Click the newly created provider - “DB2 Legacy CLI-based Type 2 JDBC Driver”
and navigate to DatasourcesNew. Enter jdbc/bank in the JNDI name field and

62
DBTEST in the Database name field. Save the changes and then test the
connection using the provided button. There should be a message saying that the
connection was successful. Otherwise, there is a problem.
Application deployment & generating test data
Now that the server has everything the application needs, the application can be
deployed. The StockEAR.ear file provided with the distribution CD will be used for this.
The easiest way to deploy the application is by using the WAS console.
Once again make sure WAS is running and open the browser to the WAS console
URL, https://somehost:9043/ibm/console/.
Enter the console and click ApplicationsInstall New Applications. Locate the
StockEAR.ear file and click Next. Keep clicking Next about 10 more times and at
the end click Finish. There will be a message saying that the StockEAR
application was installed successfully. Click Save to Master Configuration and
then Save. At this point the application is installed but it needs to be started.
From the list of installed applications, select the check box in front of StockEAR
and click Start.
The application is started but it still doesn’t have any data to work with. In order
to populate the database with data, browse to this url:
http://somehost:9080/Stock/populateData. It might take a couple of minutes for
this to finish. Once it is done, the data is written in to the database. There is no
need to repeat this process ever again unless the tables are deleted.

63
Finally the application is ready for testing and may be accessed from a browser using the
following url: http://somehost:9080/Stock/stockList, where somehost is the name of the
machine (possibly localhost if accessed from the same machine). The port number may
vary too, but WebSphere listens for HTTP traffic on port 9080 by default.
Setting up the project with RAD
This step is not required for running the benchmark application. However, it is
required in order to see the source code of the application. As mentioned in Experimental
environment, Rational Application Developer is the IDE used for the application.
Therefore, it needs to be installed on the machine in order to proceed with the following
steps.
Start Rational Application Developer. On a Windows machine select StartAll
ProgramsIBM RationalIBM Rational Application Developer V6.0
Rational Application Developer.
Import the application source code in to the workspace. With the distribution CD,
there is a StockEAR.zip file included. This file contains source code and other files
used by the application organized in a directory structure. Click FileImport...
From the dialog select Project Interchange and click Next. Locate the
StockEAR.zip file. Click Select All and then Finish. This imports the benchmark
application in RAD’s workspace. In the Project Explorer tree, located left by
default, expand Dynamic Web Projects and there is the Stock folder containing
our web application. In the same tree, expand EJB Projects and the StockEJB
folder containing the EJB part of the application pops up.

64
Like many IDE tools, RAD also allows deploying applications from within the tool
directly. Unlike other tools, RAD includes an integrated testing environment of the
WebSphere Application Server. The user may deploy the benchmark application to the
integrated server or a standalone instance. The integrated server is configured in the
Servers view by default when RAD is installed. If the application needs to be deployed
on a different server, RAD needs to be informed about the type and location of this
server. The following step describes setting up RAD to work with the Blade Station
Server running at Pace University. This machine has WebSphere Application Server v6.0
installed and running.
In order to be able to reach the server, a client machine (with RAD installed) must
be inside the Pace University network. This can also be achieved using a VPN
client to get in the network. For more info on setting up the Pace VPN client, see
http://appserv.pace.edu/emplibrary/VPNWin2000RR070803.pdf. Once in the
network, start RAD and open the Servers view, right click and choose
NewServer from the popup menu. A new dialog box opens. In the Host name
field type the IP address of our test server - 172.20.138.41. Select WebSphere v6.0
Server as the server type and click Next. Click Detect. RAD detects the server
automatically using the default port values. Click Finish and the new server will
appear in the Servers view.
Notice what the status of the new server is. It needs to be started before running
the application. RAD might show status - stopped although the server is in fact
running. Sometimes it needs a little push to catch up. Right click the server,
choose Add and remove projects... from the popup menu. RAD picks up the

65
server state again and it should say started this time. If not, the server might need
to be started indeed. A WAS instance cannot be started remotely from a client
machine running RAD. This can only be done onsite from the Blade Station
Server console itself. RAD may only stop or restart the server, so be careful not to
stop the server.
Having configured the remote running WAS instance it is simple to deploy an application. This remote instance is preconfigured with the required resources and data as described in Setting up server resources
. Right click the server from the Servers view and select Add and Remove
Projects... from the popup menu. A new dialog pops up. Select StockEAR from
the Available projects list, click Add and then Finish. RAD deploys the
application and if everything goes fine, the benchmark application can be
accessed through a browser using the following URL:
http://172.20.138.41:9080/Stock/stockList .
Software tools used for the application
IBM’s Rational Application Developer version 6.0 for Windows XP 32 bit edition
– a Java IDE based on the Eclipse platform, specialized for development on the
Websphere Application Server.
IBM’s DB2 Universal Database Version 8.1 – this is the database where stock
records will be stored.
IBM’s WebSphere Application Server version 6.0 – A robust J2EE compliant
application server that is used to run the application.

66
All of the above-mentioned software is available for a free 60-day evaluation from
http://www14.software.ibm.com/webapp/download/home.jsp?s=p. You will be asked to
fill out a free IBM registration form. The files are quite large so plan using a high-speed
internet connection and about 10 GB of hard drive space.
The hardware behind the code
IBM’s Blade Center Station Server – 10 clusters with two 3.6 GHz CPU’s and
2GB of RAM memory each. Although there were 10 clusters available, at the
time of testing only two clusters were used. One of the clusters runs the
WebSphere Application Server and a second cluster runs as a dedicated database
machine using DB2.
A Compaq Presario R3000 laptop – the client machine that was used to run
Rational Application Developer and deploy the application remotely on the Blade
Server.
Key Source Files
Dispatcher.java:
package com.dimitri.servlets;
import java.io.IOException;
import java.util.Collection;
import javax.servlet.Servlet;

67
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.dimitri.beans.TestData;
public class Dispatcher extends HttpServlet implements Servlet {
public static final int ALL_PRICES=0;
public static final int CHEAPEST_PRICES=1;
public static final int ALL_PRICES_SP=2;
public static final int CHEAPEST_PRICES_SP=3;
public static final int ALL_PRICES_EJB=4;
public static final int CHEAPEST_PRICES_EJB=5;
public static final int ALL_PRICES_SPRING=6;
public static final int CHEAPEST_PRICES_SPRING=7;
protected void doGet(HttpServletRequest arg0, HttpServletResponse arg1) throws ServletException, IOException {
performTask(arg0, arg1);
}
protected void doPost(HttpServletRequest arg0, HttpServletResponse arg1) throws ServletException, IOException {
performTask(arg0, arg1);
}
private void performTask(HttpServletRequest request, HttpServletResponse response)
{ String selectedScreen = request.getServletPath().trim();
String nextPage=null;
Collection stocks=null;
boolean springpage=false;
if(selectedScreen.equals("/stockList"))
{ String selectedOption=request.getParameter("selectedScreen");
if(selectedOption==null)selectedOption="0";
String rows=request.getParameter("rows");
if(rows==null)rows="1000";
long start=System.currentTimeMillis();
switch(Integer.parseInt(selectedOption))

68
{case ALL_PRICES: stocks=TestData.getDataJDBC(rows);break;
case CHEAPEST_PRICES: stocks=TestData.getCheapestDataJDBC(rows);break;
case ALL_PRICES_SP: stocks=TestData.getDataSP(rows);break;
case CHEAPEST_PRICES_SP: stocks=TestData.getCheapestDataSP(rows);break;
case ALL_PRICES_EJB: TestData testData=new TestData(); stocks=testData.getDataEJB(rows);break;
case CHEAPEST_PRICES_EJB: testData=new TestData(); stocks=testData.getCheapestDataEJB(rows);break;
case ALL_PRICES_SPRING:
case CHEAPEST_PRICES_SPRING: springpage=true;
try {request.getRequestDispatcher("/stockList.htm").forward(request, response);} catch (Exception ex) {
System.out.println("i crashed here "+ex.getMessage());};break;}
long end=System.currentTimeMillis();
request.setAttribute("stocks",stocks);
request.setAttribute("duration",new Long((end-start)).toString());
nextPage="/stockList.jsp";
}else if(selectedScreen.equals("/populateData"))
{TestData.generateDataInDatabase();
TestData.generateDataForStockEJB();}
if(springpage)return;
try {request.getRequestDispatcher(nextPage).forward(request, response);}
catch (Exception ex) {System.out.println("i crashed");}
}
}
web.xml:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>Stock</display-name>
<servlet>
<description>
the servlet that controls everything else</description>
<display-name>Dispatcher</display-name>
<servlet-name>Dispatcher</servlet-name>

69
<servlet-class>com.dimitri.servlets.Dispatcher</servlet-class>
</servlet>
<servlet>
<servlet-name>stocks</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>Dispatcher</servlet-name>
<url-pattern>/stockList</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>Dispatcher</servlet-name>
<url-pattern>/populateData</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>stocks</servlet-name>
<url-pattern>*.htm</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
<ejb-ref id="EjbRef_1152990947859">
<description>
</description>
<ejb-ref-name>ejb/StockManager</ejb-ref-name>
<ejb-ref-type>Session</ejb-ref-type>

70
<home>stocks.ejb.StockManagerHome</home>
<remote>stocks.ejb.StockManager</remote>
<ejb-link>StockEJB.jar#StockManager</ejb-link>
</ejb-ref>
<ejb-local-ref id="EJBLocalRef_1152994845609">
<description>
</description>
<ejb-ref-name>ejb/StockManager_local</ejb-ref-name>
<ejb-ref-type>Session</ejb-ref-type>
<local-home>stocks.ejb.StockManagerLocalHome</local-home>
<local>stocks.ejb.StockManagerLocal</local>
<ejb-link>StockEJB.jar#StockManager</ejb-link>
</ejb-local-ref>
<resource-env-ref id="ResourceEnvRef_1149639086468">
<description>
this is a reference to an actual db2 datasource on the server</description>
<resource-env-ref-name>mybank</resource-env-ref-name>
<resource-env-ref-type>javax.sql.DataSource</resource-env-ref-type>
</resource-env-ref>
</web-app>
TestData.java:
package com.dimitri.beans;
import java.rmi.RemoteException;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Collection;

71
import java.util.Date;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.Random;
import java.util.Vector;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.sql.DataSource;
import stocks.ejb.StockManager;
import stocks.ejb.StockManagerHome;
import stocks.ejb.StockManagerLocal;
import stocks.ejb.StockManagerLocalHome;
import com.dimitri.exceptions.DataSourceException;
import com.ibm.etools.service.locator.ServiceLocatorManager;
public class TestData {
static String[] indexes = { "ABC", "RVD", "RKM", "AFD", "FDU", "RMU",
"RPA", "WMA", "AMP", "ITL", "ROM", "JOE", "BMW", "JUM" };
static String[] fullNames = { "American Brave Consumers","Record Video Drive", "Remote Copy Machines",
"Aggravated Female Drivers", "French Driving Union","Remote Motor Union", "Radical Phillipino Association",
"Federal Bussines Association", "Antic Military Police","Italian Frozen Foods", "The Olive Merchant", "Joe Traders",
"Bavarian Motor Machines", "Jumbo Underground Mergers" };
private final static Class STATIC_StockManagerHome_CLASS = StockManagerHome.class;
static public Vector getStockData() {
Vector stocks = new Vector(10);
Random generator = new Random();
StockDetails stockDetails = null;
for (int i = 0; i < 20000; i++)
{int ranomInt = generator.nextInt(indexes.length);
double randomValue = generator.nextDouble() * 1000000;
double up = generator.nextDouble() * 100;
double down = -generator.nextDouble() * 100;

72
double previousClose = -generator.nextDouble() * 1000000;
double daysLowValue = -generator.nextDouble() * 1000000;
double daysHighValue = -generator.nextDouble() * 1000000;
Date timeOfRetrieval = new Date(System.currentTimeMillis());
stockDetails = new StockDetails(indexes[ranomInt], fullNames[ranomInt], randomValue, up, down, previousClose,
daysLowValue, daysHighValue, timeOfRetrieval);
stocks.add(stockDetails);}
return stocks;
}
public static void main(String[] args)
{generateDataInDatabase();
generateDataForStockEJB();}
static DataSource dataSource = null;
static Connection connection = null;
private final static String STATIC_StockManagerHome_REF_NAME = "ejb/StockManager";
private final static String STATIC_StockManagerLocalHome_REF_NAME = "ejb/StockManager_local";
public static DataSource getDataSource() throws DataSourceException {
if (dataSource != null) {return dataSource;}
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,"com.ibm.websphere.naming.WsnInitialContextFactory");
InitialContext ctx = null;
try{ctx = new InitialContext(env);} catch (NamingException e) {e.printStackTrace();}
try{dataSource = (DataSource) ctx.lookup("java:comp/env/mybank");}
catch (NamingException e1) {e1.printStackTrace();}
if (dataSource == null) throw new DataSourceException("Datasource not found");
else return dataSource;}
public static Connection getConnection() {
try {connection = getDataSource().getConnection();}
catch (SQLException e) {e.printStackTrace();}
catch (DataSourceException e) {e.printStackTrace();}
return connection;}
public static void close(Connection conn) {

73
if (conn != null)
{try {conn.close();} catch (Exception e) {e.printStackTrace();}}
}
public static void close(Statement stmt) {
if (stmt != null)
{try {stmt.close();} catch (Exception e) {e.printStackTrace();}}
}
public static void close(ResultSet rset) {
if (rset != null) {
try {rset.close();} catch (Exception e) {e.printStackTrace();}
}
}
public static void generateDataInDatabase() {
PreparedStatement preparedStatement = null;
Vector stocksVector = getStockData();
Iterator iterator = stocksVector.iterator();
try { preparedStatement = getConnection().prepareStatement( "INSERT INTO DB2ADMIN.STOCKS (INDEX,
FULLNAME, VALUE, UP, DOWN, PREVIOUSCLOSE,"+ "DAYSLOWVALUE, DAYSHIGHVALUE,
TIMEOFRETRIEVAL) VALUES "+ "(?,?,?,?,?,?,?,?,?)");
while (iterator.hasNext()) {
StockDetails stockDetails = (StockDetails) iterator.next();
preparedStatement.setString(1, stockDetails.getIndex());
preparedStatement.setString(2, stockDetails.getFullName());
preparedStatement.setDouble(3, stockDetails.getValue());
preparedStatement.setDouble(4, stockDetails.getUp());
preparedStatement.setDouble(5, stockDetails.getDown());
preparedStatement.setDouble(6, stockDetails.getPreviousClose());
preparedStatement.setDouble(7, stockDetails.getDaysLowValue());
preparedStatement.setDouble(8, stockDetails.getDaysHighValue());
preparedStatement.setDate(9, new java.sql.Date(stockDetails.getTimeOfRetrieval().getTime()));
preparedStatement.executeUpdate();
}

74
} catch (SQLException e) {e.printStackTrace();}
finally {close(preparedStatement);
close(connection);}
}
public static void generateDataForStockEJB() {
PreparedStatement preparedStatement = null;
Vector stocksVector = getDataJDBC("20000");
Iterator iterator = stocksVector.iterator();
try {preparedStatement = getConnection().prepareStatement("INSERT INTO DB2ADMIN.STOCK (ID, INDEX1,
FULLNAME, VALUE1, UP1, DOWN1, PREVIOUSCLOSE," + "DAYSLOWVALUE, DAYSHIGHVALUE,
TIMEOFRETRIEVAL) VALUES "+ "(?,?,?,?,?,?,?,?,?,?)");
int i = 0;
while (iterator.hasNext()) {
StockDetails stockDetails = (StockDetails) iterator.next();
preparedStatement.setInt(1, i);
preparedStatement.setString(2, stockDetails.getIndex());
preparedStatement.setString(3, stockDetails.getFullName());
preparedStatement.setDouble(4, stockDetails.getValue());
preparedStatement.setDouble(5, stockDetails.getUp());
preparedStatement.setDouble(6, stockDetails.getDown());
preparedStatement.setDouble(7, stockDetails.getPreviousClose());
preparedStatement.setDouble(8, stockDetails.getDaysLowValue());
preparedStatement.setDouble(9, stockDetails.getDaysHighValue());
preparedStatement.setDate(10, new java.sql.Date(stockDetails.getTimeOfRetrieval().getTime()));
preparedStatement.executeUpdate();
i++;}
} catch (SQLException e) {e.printStackTrace();} finally
{close(preparedStatement);
close(connection);}
}
public static Vector getDataJDBC(String howMany) {
PreparedStatement preparedStatement = null;

75
Vector stocksVector = new Vector(2000);
ResultSet resultSet = null;
int rows;
try {rows=Integer.parseInt(howMany);} catch (NumberFormatException e1) {return null;}
try {preparedStatement = getConnection().prepareStatement("SELECT * FROM DB2ADMIN.STOCKS FETCH
FIRST "+rows+" ROWS ONLY");
resultSet = preparedStatement.executeQuery();
StockDetails stockDetails = null;
while (resultSet.next())
{stockDetails = new StockDetails(resultSet.getString(1), resultSet.getString(2), resultSet.getDouble(3),
resultSet.getDouble(4), resultSet.getDouble(5), resultSet.getDouble(6), resultSet.getDouble(7),
resultSet.getDouble(8), resultSet.getDate(9));
stocksVector.add(stockDetails);
}
} catch (SQLException e) {e.printStackTrace();
} finally
{ close(resultSet);
close(preparedStatement);
close(connection);}
return stocksVector;
}
public static Vector getDataSP(String howMany) {
CallableStatement callableStatement = null;
Vector stocksVector = new Vector(2000);
int rows;
try {rows=Integer.parseInt(howMany);}
catch (NumberFormatException e1) {return null;}
ResultSet resultSet = null;
try{callableStatement = getConnection().prepareCall("{call DB2ADMIN.getStocksLimited(?)}");
callableStatement.setInt(1,rows);
resultSet = callableStatement.executeQuery();
StockDetails stockDetails = null;

76
while (resultSet.next()) {
stockDetails = new StockDetails(resultSet.getString(1), resultSet.getString(2), resultSet.getDouble(3),
resultSet.getDouble(4), resultSet.getDouble(5), resultSet.getDouble(6), resultSet.getDouble(7),
resultSet.getDouble(8), resultSet.getDate(9));
stocksVector.add(stockDetails);
}
} catch (SQLException e) {e.printStackTrace();
} finally {close(resultSet);
close(callableStatement);
close(connection);}
return stocksVector;}
public static Vector getCheapestDataJDBC(String howMany) {
PreparedStatement preparedStatement = null;
Vector stocksVector = new Vector(20);
ResultSet resultSet = null;
int rows;
try {rows=Integer.parseInt(howMany);} catch (NumberFormatException e1) {return null;}
try {preparedStatement = getConnection().prepareStatement( "SELECT * FROM DB2ADMIN.STOCKS FETCH
FIRST "+rows+" ROWS ONLY");
resultSet = preparedStatement.executeQuery();
StockDetails stockDetails = null;
String index = null;
while (resultSet.next()) {
index = resultSet.getString(1);
boolean exists = false;
int i;
for (i = 0; i < stocksVector.size(); i++) {
StockDetails existingStockDetails = (StockDetails) stocksVector.elementAt(i);
if (existingStockDetails.getIndex().equals(index)) {
exists = true;
if (existingStockDetails.getValue() > resultSet .getDouble(3)) {
stocksVector.remove(existingStockDetails);

77
stocksVector.add(new StockDetails(index, resultSet.getString(2), resultSet.getDouble(3), resultSet.getDouble(4),
resultSet.getDouble(5), resultSet.getDouble(6), resultSet.getDouble(7), resultSet.getDouble(8),
resultSet.getDate(9)));}
break;
}
}
if (!exists)
{stockDetails = new StockDetails(index, resultSet.getString(2), resultSet.getDouble(3), resultSet.getDouble(4),
resultSet.getDouble(5), resultSet.getDouble(6), resultSet.getDouble(7), resultSet.getDouble(8), resultSet.getDate(9));
stocksVector.add(stockDetails);}
}
} catch (SQLException e) {e.printStackTrace();} finally {
close(resultSet);
close(preparedStatement);
close(connection);}
return stocksVector;
}
public static Vector getCheapestDataSP(String howMany)
{CallableStatement preparedStatement = null;
Vector stocksVector = new Vector(2000);
ResultSet resultSet = null;
int rows;
try {rows=Integer.parseInt(howMany);} catch (NumberFormatException e1) {return null;}
try {preparedStatement =
getConnection().prepareCall("{call DB2ADMIN.GETCHEAPESTSTOCKSLIMITED(?)}");
preparedStatement.setInt(1,rows);
resultSet = preparedStatement.executeQuery();
StockDetails stockDetails = null;
while (resultSet.next()) { stockDetails = new StockDetails(resultSet.getString(1), resultSet.getString(2),
resultSet.getDouble(3), resultSet.getDouble(4), resultSet.getDouble(5), resultSet.getDouble(6),
resultSet.getDouble(7), resultSet.getDouble(8), resultSet.getDate(9));
stocksVector.add(stockDetails);

78
}
} catch (SQLException e) {e.printStackTrace(); } finally
{close(resultSet);
close(preparedStatement);
close(connection);}
return stocksVector;
}
protected StockManager createStockManager() {
StockManagerHome aStockManagerHome = (StockManagerHome) ServiceLocatorManager.
getRemoteHome(STATIC_StockManagerHome_REF_NAME, STATIC_StockManagerHome_CLASS);
try {
if (aStockManagerHome != null) return aStockManagerHome.create();
} catch (javax.ejb.CreateException ce) {ce.printStackTrace();} catch (RemoteException re) {
re.printStackTrace();}
return null;
}
public Collection getDataEJB(String howMany) {
int rows;
try {rows=Integer.parseInt(howMany);} catch (NumberFormatException e1) {return null;}
StockManagerLocal aStockManagerLocal = createStockManagerLocal();
return aStockManagerLocal.getAllStocksLimited(new Integer(rows));
}
public Collection getCheapestDataEJB(String howMany) {
int rows;
try {rows=Integer.parseInt(howMany);} catch (NumberFormatException e1) {return null;}
StockManagerLocal aStockManagerLocal = createStockManagerLocal();
return aStockManagerLocal.getCheapestStocksLimited(new Integer(rows));
}
private final static Class STATIC_StockManagerLocalHome_CLASS = StockManagerLocalHome.class;
protected StockManagerLocal createStockManagerLocal() {
StockManagerLocalHome aStockManagerLocalHome = (StockManagerLocalHome) ServiceLocatorManager
.getLocalHome(STATIC_StockManagerLocalHome_REF_NAME, STATIC_StockManagerLocalHome_CLASS);

79
try {if (aStockManagerLocalHome != null) return aStockManagerLocalHome.create();
} catch (javax.ejb.CreateException ce) {ce.printStackTrace();}
return null;
}
}
StockDetails:
package com.dimitri.beans;
import java.io.Serializable;
import java.util.Date;
public class StockDetails implements Serializable {
private String index;
private String fullName;
private double value;
private double up;
private double down;
private double previousClose;
private double daysLowValue;
private double daysHighValue;
private Date timeOfRetrieval;
public StockDetails() {}
public StockDetails(String index, String fullName, double value, double up, double down, double previousClose,
double daysLowValue, double daysHighValue, Date timeOfRetrieval)
{this.index = index;
this.fullName = fullName;
this.value = value;
this.up = up;
this.down = down;
this.previousClose = previousClose;
this.daysLowValue = daysLowValue;
this.daysHighValue = daysHighValue;

80
this.timeOfRetrieval = timeOfRetrieval;}
public double getDaysHighValue() {return daysHighValue;}
public void setDaysHighValue(double daysHighValue) {this.daysHighValue = daysHighValue;}
public double getDaysLowValue() {return daysLowValue;}
public void setDaysLowValue(double daysLowValue) {this.daysLowValue = daysLowValue;}
public double getDown() {return down;}
public void setDown(double down) {this.down = down;}
public String getFullName() {return fullName;}
public void setFullName(String fullName) {this.fullName = fullName;}
public String getIndex() {return index;}
public void setIndex(String index) {this.index = index;}
public double getPreviousClose() {return previousClose;}
public void setPreviousClose(double previousClose) {this.previousClose = previousClose;}
public Date getTimeOfRetrieval() {return timeOfRetrieval;}
public void setTimeOfRetrieval(Date timeOfRetrieval) {this.timeOfRetrieval = timeOfRetrieval;}
public double getUp() {return up;}
public void setUp(double up) {this.up = up;}
public double getValue() {return value;}
public void setValue(double value) {this.value = value;}
}
GETSTOCKSLIMITED.java:
package PKG60812103537421;
import java.sql.*;
public class GETSTOCKSLIMITED {
public static void gETSTOCKSLIMITED ( int rows, ResultSet[] rs1 ) throws SQLException, Exception
{Connection con = DriverManager.getConnection("jdbc:default:connection");
PreparedStatement stmt = null;
boolean bFlag;
String sql;
sql = "SELECT " + " DB2ADMIN.STOCK.INDEX1, "
+ " DB2ADMIN.STOCK.FULLNAME, "

81
+ " DB2ADMIN.STOCK.VALUE1, "
+ " DB2ADMIN.STOCK.UP1, "
+ " DB2ADMIN.STOCK.DOWN1, "
+ " DB2ADMIN.STOCK.PREVIOUSCLOSE, "
+ " DB2ADMIN.STOCK.DAYSLOWVALUE, "
+ " DB2ADMIN.STOCK.DAYSHIGHVALUE, "
+ " DB2ADMIN.STOCK.TIMEOFRETRIEVAL"
+ " FROM"
+ " DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.ID < "+rows;
stmt = con.prepareStatement( sql );
bFlag = stmt.execute();
rs1[0] = stmt.getResultSet();
}
}
GETCHEAPESTSTOCKSLIMITED.java:
package PKG6081210402578;
import java.sql.*;
public class GETCHEAPESTSTOCKSLIMITED {
public static void gETCHEAPESTSTOCKSLIMITED ( int rows, ResultSet[] rs1 ) throws SQLException, Exception
{Connection con = DriverManager.getConnection("jdbc:default:connection");
PreparedStatement stmt = null;
boolean bFlag;
String sql;
sql = "SELECT DB2ADMIN.STOCK.INDEX1, "
+ " DB2ADMIN.STOCK.FULLNAME, "
+ " DB2ADMIN.STOCK.VALUE1, "
+ " DB2ADMIN.STOCK.UP1, "
+ " DB2ADMIN.STOCK.DOWN1, "
+ " DB2ADMIN.STOCK.PREVIOUSCLOSE, "
+ " DB2ADMIN.STOCK.DAYSLOWVALUE, "

82
+ " DB2ADMIN.STOCK.DAYSHIGHVALUE, "
+ " DB2ADMIN.STOCK.TIMEOFRETRIEVAL"
+ " FROM" + " DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.VALUE1 IN "
+ " (SELECT MIN(DB2ADMIN.STOCK.VALUE1)"
+ " FROM DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.ID < "+rows
+ " GROUP BY DB2ADMIN.STOCK.INDEX1) "
+ " AND DB2ADMIN.STOCK.ID < "+rows;
stmt = con.prepareStatement( sql );
bFlag = stmt.execute();
rs1[0] = stmt.getResultSet();
}
}
StockListController.java:
package com.dimitri.controllers;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.ModelAndView;
import org.springframework.web.servlet.mvc.Controller;
import com.dimitri.beans.TestData;
import com.dimitri.servlets.Dispatcher;
import com.dimitri.spring.db.StockManager;
public class StockListController implements Controller{
private StockManager stockManager=null;
public ModelAndView handleRequest(HttpServletRequest request, HttpServletResponse response) throws
ServletException, IOException {
String rows=request.getParameter("rows");
String selectedOption=request.getParameter("selectedScreen");

83
if(selectedOption==null)selectedOption="0";
if(rows==null)rows="1000";
int n=Integer.parseInt(rows);
Map model=new HashMap();
long start=System.currentTimeMillis();
switch(Integer.parseInt(selectedOption))
{case Dispatcher.ALL_PRICES_SPRING:model.put("stocks", stockManager.getStocks(n));break;
case Dispatcher.CHEAPEST_PRICES_SPRING:model.put("stocks", stockManager.getCheapestStocks(n));break;}
long end=System.currentTimeMillis();
model.put("duration",new Long((end-start)).toString());
return new ModelAndView("stockListSpring", "model", model);}
public StockManager getStockManager() {return stockManager;}
public void setStockManager(StockManager stockManager) {this.stockManager = stockManager;}
}
StockManagerDaoJdbc.java:
package com.dimitri.spring.db;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.List;
import javax.sql.DataSource;
import org.springframework.jdbc.object.MappingSqlQuery;
import com.dimitri.beans.StockDetails;
public class StockManagerDaoJdbc implements StockManagerDao {
private DataSource ds;
public void setDataSource(DataSource ds) {this.ds = ds;}
public List getStockList(int n)
{StockQuery stockQuery=new StockQuery(ds,n);
return stockQuery.execute();}
public List getCheapestStockList(int n)
{CheapestStockQuery cheapestStockQuery=new CheapestStockQuery(ds,n);
return cheapestStockQuery.execute();}
class StockQuery extends MappingSqlQuery {

84
StockQuery(DataSource ds, int rows) {
super(ds, "SELECT INDEX,FULLNAME,VALUE,UP,DOWN,PREVIOUSCLOSE,DAYSLOWVALUE,"
+ " DAYSHIGHVALUE,TIMEOFRETRIEVAL FROM DB2ADMIN.STOCKS FETCH FIRST "+rows+" ROWS
ONLY");
compile();
}
protected Object mapRow(ResultSet rs, int rowNum) throws SQLException {
StockDetails stockDetails = new StockDetails();
stockDetails.setIndex(rs.getString("INDEX"));
stockDetails.setFullName(rs.getString("FULLNAME"));
stockDetails.setValue(rs.getDouble("VALUE"));
stockDetails.setUp(rs.getDouble("UP"));
stockDetails.setDown(rs.getDouble("DOWN"));
stockDetails.setPreviousClose(rs.getDouble("PREVIOUSCLOSE"));
stockDetails.setDaysLowValue(rs.getDouble("DAYSLOWVALUE"));
stockDetails.setDaysHighValue(rs.getDouble("DAYSHIGHVALUE"));
stockDetails.setTimeOfRetrieval(rs.getDate("TIMEOFRETRIEVAL"));
return stockDetails;
}
}
class CheapestStockQuery extends MappingSqlQuery {
CheapestStockQuery(DataSource ds, int rows) {super(ds, "SELECT "
+ " DB2ADMIN.STOCK.INDEX1, DB2ADMIN.STOCK.FULLNAME, "
+ " DB2ADMIN.STOCK.VALUE1, DB2ADMIN.STOCK.UP1, "
+ " DB2ADMIN.STOCK.DOWN1, DB2ADMIN.STOCK.PREVIOUSCLOSE, "
+ " DB2ADMIN.STOCK.DAYSLOWVALUE, DB2ADMIN.STOCK.DAYSHIGHVALUE, "
+ " DB2ADMIN.STOCK.TIMEOFRETRIEVAL FROM DB2ADMIN.STOCK WHERE"
+ " DB2ADMIN.STOCK.VALUE1 IN (SELECT MIN(DB2ADMIN.STOCK.VALUE1)"
+ " FROM DB2ADMIN.STOCK WHERE DB2ADMIN.STOCK.ID < "+rows
+ " GROUP BY DB2ADMIN.STOCK.INDEX1) AND DB2ADMIN.STOCK.ID < "+rows);
compile();
}

85
protected Object mapRow(ResultSet rs, int rowNum) throws SQLException {
StockDetails stockDetails = new StockDetails();
stockDetails.setIndex(rs.getString("INDEX1"));
stockDetails.setFullName(rs.getString("FULLNAME"));
stockDetails.setValue(rs.getDouble("VALUE1"));
stockDetails.setUp(rs.getDouble("UP1"));
stockDetails.setDown(rs.getDouble("DOWN1"));
stockDetails.setPreviousClose(rs.getDouble("PREVIOUSCLOSE"));
stockDetails.setDaysLowValue(rs.getDouble("DAYSLOWVALUE"));
stockDetails.setDaysHighValue(rs.getDouble("DAYSHIGHVALUE"));
stockDetails.setTimeOfRetrieval(rs.getDate("TIMEOFRETRIEVAL"));
return stockDetails;}
}
}
StockManagerDao.java:
package com.dimitri.spring.db;
import java.util.List;
public interface StockManagerDao {
public List getStockList(int n);
public List getCheapestStockList(int n);
}
StockManager.java:
package com.dimitri.spring.db;
import java.util.List;
public class StockManager {
private StockManagerDao stockManagerDao=null;
public StockManagerDao getStockManagerDao()
{return stockManagerDao;}
public void setStockManagerDao(StockManagerDao stockManagerDao)

86
{this.stockManagerDao = stockManagerDao;}
public List getStocks(int n)
{return stockManagerDao.getStockList(n);}
public List getCheapestStocks(int n)
{return stockManagerDao.getCheapestStockList(n);}
}
stocks-servlet.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" "http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="urlMapping" class="org.springframework.web.servlet.handler.SimpleUrlHandlerMapping">
<property name="mappings">
<props>
<prop key="/stockList.htm">stockListController</prop>
</props>
</property>
</bean>
<bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="viewClass"><value>org.springframework.web.servlet.view.JstlView</value></property>
<property name="suffix"><value>.jsp</value></property>
</bean>
<bean id="stockListController" class="com.dimitri.controllers.StockListController">
<property name="stockManager">
<ref bean="stockManager"/>
</property>
</bean>
<bean id="stockManager" class="com.dimitri.spring.db.StockManager">
<property name="stockManagerDao">
<ref bean="stockManagerDao"/>
</property>
</bean>

87
<bean id="stockManagerDao" class="com.dimitri.spring.db.StockManagerDaoJdbc">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
<bean id="dataSource" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="java:comp/env/mybank"/>
</bean>
</beans>
stockList.jsp:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<%@taglib uri="http://java.sun.com/jsp/jstl/fmt" prefix="fmt"%>
<HTML>
<HEAD>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c"%>
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<META http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<META name="GENERATOR" content="IBM Software Development Platform">
<META http-equiv="Content-Style-Type" content="text/css">
<LINK href="theme/Master.css" rel="stylesheet" type="text/css">
<TITLE>Stock List Data page</TITLE>
</HEAD>
<BODY>
<jsp:useBean id="stocks" class="java.util.Vector" scope="request"></jsp:useBean>
<jsp:useBean id="duration" class="java.lang.String" scope="request"></jsp:useBean>
<H2 align="center">Real time Stock Information</H2>
<TABLE width="90%" border="1">
<TBODY>
<TR align="center">

88
<FORM method="post" action="">
<TD colspan="9">
<SELECT name="selectedScreen">
<OPTION value="0"<c:if test="${param.selectedScreen=='0'}"> selected</c:if>>All stock prices</OPTION>
<OPTION value="1"<c:if test="${param.selectedScreen=='1'}"> selected</c:if>>Cheapest prices only</OPTION>
<OPTION value="2"<c:if test="${param.selectedScreen=='2'}"> selected</c:if>>All prices (using SP)</OPTION>
<OPTION value="3"<c:if test="${param.selectedScreen=='3'}"> selected</c:if>>Cheapest prices (using
SP)</OPTION>
<OPTION value="4"<c:if test="${param.selectedScreen=='4'}"> selected</c:if>>All prices (using EJB)</OPTION>
<OPTION value="5"<c:if test="${param.selectedScreen=='5'}"> selected</c:if>>Cheapest prices (using
EJB)</OPTION>
<OPTION value="6"<c:if test="${param.selectedScreen=='6'}"> selected</c:if>>All prices (using Spring)</OPTION>
<OPTION value="7"<c:if test="${param.selectedScreen=='7'}"> selected</c:if>>Cheapest prices (using
Spring)</OPTION>
</SELECT>
<SELECT name="rows">
<c:forEach begin="100" end="20000" step="100" var="rows">
<OPTION value="${rows}"<c:if test="${param.rows==rows}"> selected</c:if>>Using ${rows} rows</OPTION>
</c:forEach>
</SELECT>
<INPUT type="submit" name="submit" value="Go">
</FORM>
Data Retrieved in ${duration} milliseconds
</TD>
</TR>
<TR>
<TD>Index</TD>
<TD>Name</TD>
<TD>Value</TD>
<TD>Up</TD>
<TD>Down</TD>
<TD>Prev. close</TD>

89
<TD>Low</TD>
<TD>High</TD>
<TD>Time</TD>
</TR>
<c:set var="counter" scope="request">0</c:set>
<c:forEach items="${stocks}" var="stock">
<c:set var="counter" scope="request" value="${counter+1}"></c:set>
<TR <c:if test="${counter%2==0}">bgcolor="silver"</c:if>>
<TD>${stock.index}</TD>
<TD>${stock.fullName}</TD>
<TD><fmt:formatNumber value="${stock.value}" type="currency"/></TD>
<TD><fmt:formatNumber value="${stock.up}" type="currency"/></TD>
<TD><fmt:formatNumber value="${stock.down}" type="currency"/></TD>
<TD><fmt:formatNumber value="${stock.previousClose}" type="currency"/></TD>
<TD><fmt:formatNumber value="${stock.daysLowValue}" type="currency"/></TD>
<TD><fmt:formatNumber value="${stock.daysHighValue}" type="currency"/></TD>
<TD><fmt:formatDate value="${stock.timeOfRetrieval}" type="date" dateStyle="full" /></TD>
</TR>
</c:forEach>
</TBODY>
</TABLE>
</BODY>
</HTML>

90
References
Books
[1] J. Weaver, K. Mukhar, and J. Crume, Beginning J2EE 1.4: From Novice to Professional, 2nd ed., Apress Beginner Series, 2004.
[2] K. Brown, G. Craig, G. Hester et, Enterprise Java Programming with IBM WebSphere, Second Edition, IBM Press, November, 2003.
[3] J. Hunter & W. Crawford, Java Servlet Programming, 2nd ed, O’Reilly
[4] Richard Monson-Haefel, Enterprise Javabeans, 3rd ed, O’Reilly
Internet Web Sites & Resources
[5] Sun Microsystems, “The J2EE 1.4 Tutorial,”http://java.sun.com/j2ee/1.4/docs/tutorial/doc/index.html (December 2005).
[6] Sun Microsystems, “The Java Tutorial”http://java.sun.com/docs/books/tutorial/
[7] The Apache Software Foundation, “Spring Framework 2.0 - Reference Manual,” http://static.springframework.org/spring/docs/2.0.x/reference/index.html, 2006.
[8] Best practices for tackling data bottlenecks within J2EE environments http://www.javaworld.com/javaworld/jw-04-2004/jw-0405-bottleneck.html
[9] WebSphere Application Server Version 6.0.x Information Center http://www-306.ibm.com/software/webservers/appserv/was/library/library60.html
[10] Rational Application Developer for WebSphere Software http://www-128.ibm.com/developerworks/rational/products/rad/
[11] DB2 Information Centerhttp://publib.boulder.ibm.com/infocenter/db2luw/v8/index.jsp?topic=/com.ibm.db2.udb.doc/core/c0008278.htm
[12] IBM HS20 Blade Server Product Informationhttp://www.blade.org/productdetail.cfm?RecordID=59
[13] Pace Virtual Private Network for Windows 2000/XP Usershttp://appserv.pace.edu/emplibrary/VPNWinXPRR121405.pdf

91
[14] Pace VPN client download URL (accessible from the university network only) http://compinfo.pace.edu/software.html





























