Embed Size (px)
Citation preview

A Capacity Allocation Approach for Volunteer Cloud Federations UsingPoisson-Gamma Gibbs Sampling
Abdelmounaam RezguiDepartment of Computer Science & Engineering
New Mexico Tech801 Leroy Pl., Socorro, New Mexico, 87801, USA
Email: [email protected]
M. Mustafa RafiqueIBM Research - Exascale Systems
Dublin, IrelandEmail: [email protected]
Gary QuezadaDepartment of Mathematics
New Mexico Tech801 Leroy Pl., Socorro, New Mexico, 87801, USA
Email: [email protected]
Zaki MalikDepartment of Computer Science
Wane state University5057 Woodward Avenue, Detroit, 48202, USA
Email: [email protected]
Abstract—In volunteer cloud federations (VCFs), volunteersjoin and leave without restrictions and may collectively con-tribute a large number of heterogeneous virtual machineinstances. A challenge is to efficiently allocate this dynamic,heterogeneous capacity to a flow of incoming virtual machine(VM) instantiation requests, i.e., maximize the number ofvirtual machines that may be placed on the VCF. Cloudfederations may allocate VMs far more efficiently if they canaccurately predict the demand in terms of VM instantiationrequests. In this paper, we present a stochastic technique thatforecasts future demand to efficiently allocate VMs to VMinstantiation requests. Our approach uses a Markov ChainMonte Carlo (MCMC) simulation known as the Poisson-Gamma Gibbs (PGG) sampler. The PGG sampler is used todetermine the arrival rate of each type of VM instantiationrequests. This arrival rate is then used to determine an optimalVM placement for the incoming VM instantiation requests.We compared our approach to a solution that adopts a staticsmallest-fit approach. The experimental results showed thatour solution reacts quickly to abrupt changes in the frequencyof VM instantiation requests and performs 10% better thanthe static smallest-fit approach in terms of the total number ofsatisfied requests.
Keywords-Cloud federations; Volunteer computing; VMplacement; Poisson-Gamma Gibbs sampling;
I. INTRODUCTION
Volunteer cloud computing (VCC) is a resource sharingmodel that is similar, in essence, to grid computing. Thedifference is that, in VCC, the objective is to share resourceson clouds and not on individual desktop PCs or singleservers. This difference translates into a completely newset of technical challenges that must be overcome beforevolunteer cloud computing becomes a viable computingmodel. Substantial research is needed to explore architec-tures, systems, and techniques enabling this model. In thispaper, we focus on a fundamental and complex challenge,
namely, developing a virtual machine placement techniquefor volunteer cloud federations (VCFs). Traditionally, VMplacement has been studied in the context of a single cloud.In this context, VM placement is defined as the process ofmapping virtual machines to physical machines (PMs), i.e.,the process of selecting the most suitable host for the virtualmachine [23]. A “good” mapping between VMs and PMs inthis context means one that satisfies one or more constraintsthat may be administrative (security, regulations), resource-oriented (capacity, energy), or QoS-oriented (performance).In a single cloud, efficient VM placement techniques areimportant because they help achieve one or more objectivesincluding increasing resource utilization, improving load bal-ancing, reducing the need for VM migration, improving faulttolerance, etc. In volunteer cloud federations, the problemis to determine an efficient mapping between VMs andindividual member clouds. Both inter- and intra-cloud VMplacement techniques are needed in cloud federations: oncea VM placement algorithm for federated clouds determinesin which member cloud a VM must be hosted, anotheralgorithm must determine which host of the selected cloudmust run the VM.
Solutions to the problem of VM placement in volunteercloud federations must take into account that, in VCFs,resources are volunteered and that the owner of a volunteeredresource may withdraw it from the federation at any time.Also, users access resources on a VCF with no monetaryobligations. VM placement in this case must attempt tomaximize the utilization of these resources (not profit) while,possibly, enforcing additional constraints such as fairness orproportional service, i.e., users who also volunteer resourcesmust be able to get a service from the federation that isproportional to the resources that they contribute to the cloudfederation.

A. Contribution
VM placement in single clouds has been proven to bea highly complex task [1]. Two factors contribute to thecomplexity. First, the arrival patterns of VM instantiationrequests are not easy to predict. Second, for a given load,there is a large space of VM placement scenarios. Findingthe optimal scenario may be computationally hard. Theproblem is far more difficult in volunteer cloud federations.Compared to the case of single clouds, the problem ofVM placement in VCFs remains largely unexplored. In thispaper, we focus on the problem of maximizing resourceutilization in VCFs, i.e., maximizing the number of virtualmachines that may be placed on a VCF. When no exactmatch between the requested and available VMs is possible,the federation may use a “smallest-fit” approach to allocateVMs to VM instantiation requests. This over-provisioningmay translate into a substantial “waste” of capacity. Cloudfederations may allocate VMs far more efficiently if they canaccurately predict the demand in terms of VM instantiationrequests. We present a stochastic technique that forecastsfuture demand to efficiently allocate VMs to VM instanti-ation requests. Our approach uses a Markov Chain MonteCarlo (MCMC) simulation known as the Poisson-GammaGibbs (PGG) sampler [19]. The PGG sampler is used todetermine the frequency of each type of VM instantiationrequests. This frequency is then used to determine an optimalVM placement for the incoming VM instantiation requests.MCMC methods are a class of algorithms for sampling fromprobability distributions based on constructing a Markovchain that has the desired distribution as its equilibriumdistribution. The state of the chain after a large number ofsteps is then used as a sample of the desired distribution[27], [3].
B. Motivation for Using Poisson-Gamma Gibbs (PGG)Sampling
In a volunteer cloud federation, capacity may be exposedto users as virtual machines of different sizes available forinstantiation. As we will show later, the “smallest-fit” allo-cation approach of available VMs may result in substantialcapacity waste. The fundamental idea is to correlate thenumber and type of available VMs to future demand, i.e.,delay the allocation of certain types of VMs if they may beallocated in the future with less capacity waste.
It is important to note that the problem addressed in thispaper cannot be addressed by simply adjusting the sizeof VM instances available on the volunteered clouds tomatch the size of the VM requested by users. With currentvirtualization technology, the overhead of VM resizing hasbecome negligible. However, in the context of volunteercloud federations, cloud owners generally do not allowexternal entities (e.g., a cloud federation’s controller) tomake changes that may impact their clouds, e.g., changingthe volunteered capacity.
In this paper, we use Poisson-Gamma Gibbs sampling asan example of predictive analytics methods. Gibbs samplingis a computational method that uses Markov chains toapproximate posterior distributions. The central idea is touse available information about a prior distribution anddata to construct an ergodic Markov chain whose limitingdistribution is the desired posterior distribution [24]. Thepurpose of using a Markov model is to learn about thelikelihood of receiving VM instantiation requests of eachtype of VMs. Markov models are models that assume theMarkov property. A stochastic process has the Markovproperty if the conditional probability distribution of futurestates of the process depends only upon the present state;that is, given the present, the future does not depend on thepast [28].
Because of the random and dynamic nature of the flowof requests received by the cloud federation, we formalizethe problem using a queueing model that determines the(expected) frequency of requests for each type of VMinstances using Poisson processes (PPs). Poisson processesare well suited for demand prediction. This is the casebecause we cannot assume high auto-correlation with thetime series of frequencies. Therefore, predicting arrivalfrequencies requires a model that takes advantage of thememoryless property.
C. Paper Organization
The remainder of this paper is organized as follows.Section II gives an overview of recent research related toVM placement on single and multiple clouds. In Section III,we present our model of cloud federations. In Section IV, wepresent a static greedy algorithm that uses the “smallest-fit”approach to allocate VMs to VM instantiation requests. InSection V, we present the proposed Poisson-Gamma GibbsSampling algorithm. In Section VI, we present an exper-imental evaluation of the proposed technique and discusshow it compares to the smallest-fit approach. Finally, inSection VII, we give concluding remarks and some futureresearch directions.
II. RELATED WORK
Since the emergence of cloud computing, VM placementin infrastructure clouds has been the focus of substantialresearch. To a large extent, this research has considered theproblem in the context of a single cloud. We briefly overviewprevious research that addressed the problem in both cases:single and federated clouds:
A. VM Placement in a Single Cloud
A number of algorithms have been proposed to allocateVMs to physical machines within the same cloud. Thesealgorithms address distinct problems, such as initial place-ment, load consolidation, or tradeoffs between honoring

service-level agreements and constraining provider operatingcosts [18].
Traditionally, the VM placement problem has been mod-eled is modeled as either the Constraint Satisfaction Problem(CSP) [12] or the Constraint Multiple Knapsack Problem(CMKP) [11] to maximize the utility of computing resource.
Existing techniques may be classified based on severalcriteria. For example, they may be either static or dynamic.A static VM placement algorithm takes as its input a VMinstantiation request and produces an initial placement thatholds throughout the lifetime of the VM. [18] provides asurvey comparing 18 initial VM placement algorithms foron-demand clouds. When the initial placement is allowed tochange (e.g., through VM migration and consolidation), thealgorithm is said to be dynamic. In this case, the algorithmcan be either reactive or proactive. Reactive VM placementschemes are corrective techniques that make changes toan initial placement after the system reaches a certain(undesired) state. The change may be made for performanceimprovement (e.g., [11]), maintenance, saving power (e.g.,[12], [14], [10], and [9]), load balancing, or reduction ofSLA violations (e.g., [2]). Proactive VM placement tech-niques take actions before the system reaches a certaincondition. Examples of proactive VM placement techniquesinclude [8], [1], and [17].
A recent research direction is to explore joint optimizationalgorithms that produce efficient placement plans by simul-taneously considering computing and networking aspects.Research that illustrates this direction includes [15] and [10].
B. VM Placement in Federated Clouds
Research has recently started to explore models, architec-tures, and prototypes of cloud federations [20]. In [25], theauthors present a layered cloud service model of software(SaaS), platform (PaaS), and infrastructure (IaaS) that lever-ages multiple independent clouds by creating a federationamong the providers. The proposed approach is similarto the well-established OSI open systems protocol stackmodel where different protocols are used at each layer toimplement a concrete functionality. Communication occursbetween two identical layers or between consecutive layers(either lower or higher in the stack). In the context of thecloud, the layers (i.e., building blocks of the federation)are SaaS, PaaS and IaaS. Another project is RESERVOIR(”Resources and Services Virtualization without Barriers”), aEuropean Union/IBM cloud computing research project thataims at enabling massive-scale deployment and managementof complex IT services both in a computing cloud andacross clouds under different administrative domains, ITplatforms and geographies [21], [13]. Among other aspects,the project is focusing on federations of clouds acrossvendor boundaries to seamlessly allow expansion of existingcapacity.
In [7], the authors propose technology neutral inter-faces and architectural additions for handling placement,migration, and monitoring of VMs in federated cloud en-vironments. In [6], the authors propose a framework thatcomputes the best possible placement of virtual machines ina set of federated data centers. The objective is to reduce thetotal energy consumption across all data centers. In [4], theauthors consider the case of multiple cloud providers thathave different pricing schemes for renting their resources.They present an algorithm that minimizes the cost of hostingvirtual machines in a multiple cloud provider environmentunder future demand and price uncertainty. A research thatis close to our work is [16] where the authors introducean integrated federated management and monitoring archi-tecture that enables autonomous service provisioning infederated clouds. In this architecture, cloud brokers managethe number and the location of the utilized virtual machinesfor the received service requests.
III. CLOUD FEDERATION MODEL
We propose a model of volunteer cloud federations wheremember clouds expose their capacity in terms of number andsize of computing instances (i.e., VMs) that they are willingto contribute to the cloud federation [20]. We considera cloud federation where each cloud owner contributes acertain amount of resources. When joining the federation, acloud owner contributes resources to the cloud federation inthe form of a set of VM instances of different sizes. Whena new set of instances is made available by a contributor,the cloud federation’s controller updates its list of availableinstances accordingly.
In practice, private clouds may be built using differentsoftware packages. As a result, different federation membersmay define heterogeneous VM instances, i.e., instances thatdiffer in terms of resources such as CPU speed, disk ormemory size. Let R be the list of m resources over whichinstances are defined. An instance type ITi is defined as atuple (ri1, r
i2, .., r
im) where rik is the amount of resource k
offered in instances of type ITi. For example, let R be thelist:(Number of CPU cores, CPU frequency,memory size, disk size, bandwidth).
Define instance types: IT1 and IT2 as follows:
IT1 ≡ (2, 2Ghz, 2GB, 150GB, 100MB/s)IT2 ≡ (4, 2.5Ghz, 4GB, 100GB, 500MB/s)
An instance of type IT1 would have 2 CPU cores of 2Ghz each, 2 GB of memory, 150 GB of disk, and a networkbandwidth of 100 MB/s. A volunteer may, for example,contribute ten instances of type IT1 and five instancesof type IT2. We define a contribution as a set of pairs{(IT1, c1), .., (ITn, cn)} where ci is the number of instancesof type ITi volunteered by a given cloud owner and n isthe number of VM types available on the cloud federation.

Definition 1:
Let ITi ≡ (ri1, ri2, .., r
im) and ITj ≡ (rj1, r
j2, .., r
jm) be
two instance types. ITi is said to dominate ITj if and onlyif:
∀k, 1 ≤ k ≤ m : rik ≥ rjk (1)
We note this by: ITi ∈ Dom(ITj). Note that the relation-ship dominate is a partial order over all instance types ofthe cloud federation.
Definition 2:
Let D be the set of member clouds in the federation. Atany given time, the current capacity of the federation is theunion of all contributions made by all its member cloudsand not currently allocated to any user.
Users of the federation submit their requests in termsof VM instantiation requests. Each request specifies aninstance type ITi. The federation controller then attempts todetermine a cloud member that still has capacity to createsuch an instance. Two cases may occur:
Case 1: if a member cloud is found that has capacity for,at least, one instance of the requested type, the federationmanager forwards the user’s request to that member cloud.In general, if the requested instance type is available onseveral member clouds, the federation controller chooses oneof the member clouds based on some policy such as: cloudgeographically closest to the user, round-robin, cloud withhighest remaining capacity first, etc.
Case 2: if no member cloud has available instances of therequested type, the federation controller may either reject therequest or create an instance larger than (i.e., dominating)the one requested (if, of course, one can be found). If thelatter approach is adopted, a large number of options (i.e.,combinations of member clouds and their hosted instances)may satisfy the submitted request. A significant challengeis to determine an efficient mapping that determines whichmember cloud to host the new VM and which instance inthis member cloud is the most suitable for the new VM.In this context, the term “efficient” means “in a way thatleaves as much capacity as possible available for future VMinstantiation requests.”
We assume that:• VM types are equally likely to be donated.• VM types are equally likely to be requested.We model the addition of new VMs of type i to the
federation’s capacity (i.e., the supply) as a Poisson processwith parameter λsi . Events in this process occur either whena volunteer donates a new VM of type i to the federationor when a previously instantiated VM of type i terminatesand becomes available to be instantiated again. Let Si (forsupply) be a random variable that corresponds to the numberof VMs of type i added to the federation’s capacity in a giveninterval:
P (Si = x) = e−λsi(λsi )
x
x!, x ∈ N (2)
Similarly, we model the removal of VMs of type i fromthe federation’s capacity (i.e., demand) as a Poisson processwith parameter λdi . Events in this process occur either whena volunteer withdraws a VM of type i from the federation(i.e., makes a VM unavailable for instantiation) or when aVM of type i is instantiated in response to an instantiationrequest. Let Di (for demand) be a random variable thatcorresponds to the number of VMs of type i removed fromthe federation’s capacity in a given interval:
P (Di = y) = e−λdi
(λdi )y
y!, y ∈ N (3)
Finally, the current capacity of the federation at anygiven time is noted (c1, c2, .., cn) where ci, 1 ≤ i ≤ n,is the number of VMs of type i currently available to beinstantiated.
IV. GREEDY, SMALLEST-FIT ALGORITHM
Let IT be the set of all VM instance types available on thefederation. Let REQ(i) denote a VM instantiation requestfor a VM of type ITi. REQ(i) may be satisfied by anyVM of type ITj such that ITj ∈ Dom(ITi). The greedyalgorithm (GA) is a simple algorithm that does not performany learning from the system’s past behavior. When no exactmatch is possible to satisfy the request REQ(i), the greedyalgorithm picks a VM of type ITj such that:
ITj ∈ Dom(ITi) and‖ ITj ‖= Min(‖ ITk ‖), ITk ∈ Dom(ITi)
Where ‖ ITk ‖ denotes some size metric over the VMinstance types.
A. Limitation of the Greedy Algorithm
We now show through an example (taken from [20])the limitation of the greedy algorithm. Consider a scenario(Figure 1) where m, the number of resources is 2: disk andmemory, and instance types are defined as tuples (r1, r2)where r1 and r2 are the disk and memory sizes of thegiven instance type. Assume that, at a given time, the cloudfederation’s available capacity consists of four instancesof types IT1, IT2, IT3, and IT4. Figure 1.a is a graphicrepresentation of the cloud federation’s instance types in a2D plane. First, a VM creation request is received for typeIT1. The federation has capacity to create one VM of typeIT1. It creates a VM of type IT1. Assume that the nextrequest is also the creation of a VM of type IT1. Since thereis no available instance of type IT1, the LDC approach willselect instance type IT2 to satisfy the current request sinceIT2 is the closest in terms of capacity to IT1 comparedto IT3 and IT4. The “wasted” capacity corresponds to therectangle labeled 1 in Figure 1.a. After this operation, the

Figure 1. (a) Greedy VM Allocation, (b) VM Allocation with Frequency Prediction
cloud federation has no more available instances of typeIT2. Assume that the following VM creation request is oftype IT2. Since this request cannot be satisfied as requested,the federation controller will create a larger instance of typeIT3 to satisfy the current request. Here again, there will be a“wasted” capacity that corresponds to the rectangle labeled2 in Figure 1.a. Notice that the instance IT4 cannot be usedto satisfy this third request because IT4 /∈ Dom(IT2).
Now, consider a scenario where the cloud federation isable to probabilistically predict the sequence of future VMcreation requests. In the previous example, the sequence ofrequested instance types was: IT1, IT1, and IT2. In thisnew scenario, the federation controller will process the firstrequest as it did before, i.e., create a VM of type IT1. Whenit receives the second request, the federation controller mayexploit the probabilistic knowledge that a request of type IT2is imminent and, as a result, spare the remaining availableinstance of type IT2 for that likely future request and createa VM of type IT4. Notice that this is possible since IT4 ∈Dom(IT1). When the third request of type IT2 is received,the federation controller will be able to create a VM ofthe exact requested size without over-provisioning. In thisscenario, the “wasted” capacity corresponds to the rectanglelabeled 3 in Figure 1.b. As it is shown in Figures 1.a and 1.b,the total “wasted” capacity in the second scenario (rectangle3) is much smaller than the total “wasted” capacity in thefirst scenario (sum of rectangles 1 and 2). The basic idea hereis to exploit probabilistic information about the likelihoodthat the instantiation of a VM of a certain size will berequested in the near future. The previous example showsthat the smallest-fit greedy algorithm may yield sub-optimalVM allocations resulting in substantial capacity loss.
V. POISSON-GAMMA GIBBS SAMPLING ALGORITHM
A. A Review of Poisson-Gamma Gibbs Sampling
To understand the PGG algorithm, we first present somebackground about the Markov arrival process known as thePoisson-Gamma Gibbs sampler. A Markov arrival process isa method for determining the time between system arrivals.A well known application of a Markov arrival processesis known as a Poisson process (PP). A PP measures the
time between successive arrivals as exponentially distributeddata with mean and frequency λ, or Exp(λ). It is thisfrequency parameter that we use to determine VM allocationin the cloud federation. Because, in general, λ is not aknown parameter, we incorporate a Gibbs sampler. TheGibbs sampler is a Markov Chain Monte Carlo that performsa recursive Bayesian inference to determine the steadystate probabilities of a Markov Chain which will yield thecorrect posterior estimate of a parameter. The estimate of theposterior distribution will yield a steady state approximatelyequal to the exact measurement of the parameter after therecursive algorithm has passed beyond the burn-in phase.
To find λ, the Gibbs sampler randomly samples fromits posterior, moving about λ’s state space until a localmaxima is found. It has been rigorously proved in [5] thatthe posterior distribution of a Poisson process is Gammadistributed. The burn is defined as the number of runs neededfor the Gibbs sampler to find this maxima. Because theGibbs sampler requires a sufficiently large amount of data tofind this maxima, we chose to also incorporate bootstrappinginto our algorithm.
Bootstrapping is a method for assigning measures ofaccuracy (defined in terms of bias, variance, confidenceintervals, prediction error or some other such measure)to sample estimates [26]. The process takes the system’sobserved data and performs a random re-sampling withreplacement on this data. The overall bootstrapping processis a follows ([22]): fit a model to data, use the model tocalculate the functional, then get the sampling distribution bygenerating new, synthetic data from the model and repeatingthe estimation on the simulation output.
In our case, we chose to implement bootstrapping withan exponentially distributed random decay that assigns theheaviest weights to the most recent observations. We are ableto implement this method with the Gibbs sampler becauseGibbs sampling can yield a steady estimate for λ by takingthe mean of many separate runs of the method. The Gibbssampler also works because the underlined Markov chainwill find a steady state after enough sequential runs whichwe illustrate through models presented in our experimentalevaluation given in Section VI.
B. Algorithm
The proposed Poisson-Gamma Gibbs sampling algorithmis a Markov process (MP) that takes input λi−1 (Poisson’sintensity at time ti−1) and outputs an estimate of λi. TheMarkov process uses the current state of the system togenerate a forecast of the system via Bayesian statistics.Because the probability of events occurring in the systemremains the same throughout time, then the MP to use is aPP.
The key principle in the PGG algorithm is to preserveVMs as long as possible so that they are allocated at the“best” time. Consider a VM instantiation request for VMinstance type ITi. PGG is a learning algorithm that deter-mines the frequency parameters λj for each VM instancetype ITj ∈ Dom(ITi). When the cloud federation receivesa request for a VM of type ITi, the Poisson-Gamma Gibbssampling algorithm operates as follows:
Step 1: First, PGG considers as candidates for allocationthe set of VMs ITj such that ITj ∈ Dom(ITi).
Step 2: Next, by means of Bayesian inference, PGG sam-ples the frequency of the exponentially distributed processby using a Gamma distribution. Updating only occurs for λjwhere λj is the (estimated) arrival rate of VM instantiationrequests of ITj ∈ Dom(ITi). λj is updated as follows:
λj = Gamma(α+ n, β + nx). (4)
where:• α = 1 is the shape parameter required to satisfy
the requirement that λ be an exponential frequencyparameter
• the parameter n is the number of times this process hasbeen updated
• x is the mean time during which the n updates occurred• β = 1
λj−1is the rate parameter.
Step 3: From the set of all updated arrival rates λj , thePGG sampling algorithm then selects the VM type that hasthe least frequent arrival rate. For a given request for aVM instance of type ITi, the PGG algorithm performs aset of Markov arrival processes on the set Dom(ITi) togenerate a forecast of likely requested VM instance types. Itthen determines the VM instance type ITmin ∈ Dom(ITi)such that ITmin has the least arrival frequency. PGG thenallocates to the new request a VM of type ITmin.
C. Bootstrapping the Poisson-Gamma Gibbs Sampler
Because we assume no previous knowledge of the feder-ation prior to the beginning of the PGG sampling process,we also developed a bootstrapping technique to determinethe initial frequency rates λi for all VM instance typesof the federation. The proposed bootstrapping technique isalso important because it allows us to generate accurate λiafter abrupt changes in the system occur. Bootstrapping isachieved by exponentially decreasing the weight of incoming
data which means that PGG performs more training with themost recent data.
D. Determining the Frequency λ for New VM Instance Types
In a volunteer cloud federation, member clouds may dy-namically contribute new VM instance types not previouslyavailable on the federation. The PGG algorithm deals withtraining the PP for new VM instance types entering thefederation in a similar way as described for VM instancetypes that are already available on the federation. Sincedetermining the value of λj at time ti requires the valueof λj at time ti−1, the algorithm needs an initial value forevery new VM instance type ITj . For this, we assign, foreach new VM instance type ITj , a PP parameter λj that isupdated exactly as if the federation just received a requestfor VM instance type ITj except that, in this case, no actualallocation occurs.
VI. EXPERIMENTAL EVALUATION
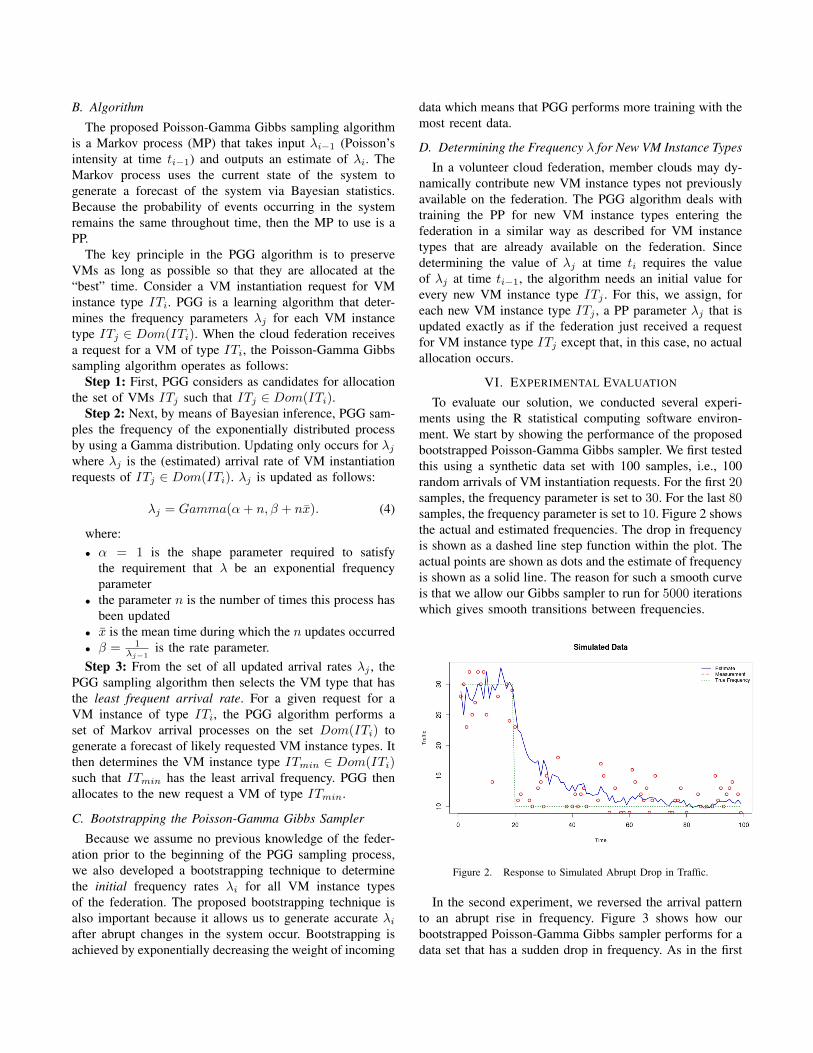
To evaluate our solution, we conducted several experi-ments using the R statistical computing software environ-ment. We start by showing the performance of the proposedbootstrapped Poisson-Gamma Gibbs sampler. We first testedthis using a synthetic data set with 100 samples, i.e., 100random arrivals of VM instantiation requests. For the first 20samples, the frequency parameter is set to 30. For the last 80samples, the frequency parameter is set to 10. Figure 2 showsthe actual and estimated frequencies. The drop in frequencyis shown as a dashed line step function within the plot. Theactual points are shown as dots and the estimate of frequencyis shown as a solid line. The reason for such a smooth curveis that we allow our Gibbs sampler to run for 5000 iterationswhich gives smooth transitions between frequencies.
Figure 2. Response to Simulated Abrupt Drop in Traffic.
In the second experiment, we reversed the arrival patternto an abrupt rise in frequency. Figure 3 shows how ourbootstrapped Poisson-Gamma Gibbs sampler performs for adata set that has a sudden drop in frequency. As in the first

set of experiments, we used a synthetic data set with 100samples. For the first 50 samples, the frequency parameter isset to 40. For the last 50 samples, the frequency parameteris set to 60. This sudden rise in frequency is shown inFigure 3 as a dashed line step function within the plot. Theactual measurements are shown as dots and the estimate offrequency is shown as a solid line.
Figure 3. Response to Simulated Abrupt Rise in Traffic.
As can be seen in Figure 2 and Figure 3, our Gibbssampler achieves an excellent job in estimating arrival fre-quencies in both scenarios. In addition to these two setsof experiments using synthetic data, we also conductedexperiments using real world data. Figure 4 shows theGibbs sampler’s performance when we used a trace of anactual arrival history of VM instantiation requests. In theexperiment, our model performs 1000 iterations and samplesfrom this jagged moving frequency. As the figure shows, wesee an accurate degradation of the frequency parameter. Thisis beneficial because it allows for the model to easily adjustto sudden spike in traffic.
Figure 4. Response to Changes in Traffic.
Finally, Figure 5 shows the results from running boththe GA and the PGG algorithms. We compared the twoalgorithms using a Monte Carlo simulation that allows us togenerate an average efficiency for both methods. As shownin the figure, after a mild burn-in time, the PGG algorithmachieves an improvement factor of about 10% over thesmallest-fit greedy algorithm in terms of VM instantiationrequests that the cloud federation is able to satisfy. When theload is relatively low, an ample number of VMs is availablefor instantiation and, as a result, the two algorithms performalmost equally.
Figure 5. Performance Advantage of Using PGG over the Smallest-fitGreedy Algorithm.
VII. CONCLUSIONS
We presented a probabilistic approach to the problem ofvirtual machine placement in volunteer cloud federations.The proposed solution evaluates the probability of futuredemand in terms of virtual machine instantiation requestsusing a Poisson-Gamma Gibbs sampler. Our experimentsshowed that our solution can potentially increase the successrate of VM placement by up to 10% compared to a smallest-fit VM allocation approach. This work gave us preliminaryinsights as to the accuracy of the proposed solution in termsof predicting future workloads.
ACKNOWLEDGMENT
This research is supported in part by a grant from the NMNASA EPSCoR.
REFERENCES
[1] Eyal Bin, Ofer Biran, Odellia Boni, Erez Hadad, Elliot K.Kolodner, Yosef Moatti, and Dean H. Lorenz. GuaranteeingHigh Availability Goals for Virtual Machine Placement. InProc. of the ICDCS, pages 700–709. IEEE Computer Society,2011.
[2] N. Bobroff, A. Kochut, and K. Beaty. Dynamic Placementof Virtual Machines for Managing SLA Violations. In Inte-grated Network Management, 2007. IM’07. 10th IFIP/IEEEInternational Symposium on, pages 119–128, 2007.

[3] Stephen P. Brookst. Markov Chain Monte Carlo Method andits Application. The Statistician, 47(1):69–100, 1998.
[4] S. Chaisiri, Bu-Sung Lee, and D. Niyato. Optimal VirtualMachine Placement Across Multiple Cloud Providers. InServices Computing Conference, 2009. APSCC 2009. IEEEAsia-Pacific, pages 103–110, 2009.
[5] Hani Doss and B. Narasimhan. Bayesian Poisson Regres-sion using the Gibbs Sampler: Sensitivity Analysis throughDynamic Graphics. Technical Report 895, Florida StateUniversity, August 1994.
[6] Corentin Dupont, Thomas Schulze, Giovanni Giuliani, An-drey Somov, and Fabien Hermenier. An Energy AwareFramework for Virtual Machine Placement in Cloud Feder-ated Data Centres. In Marco Ajmone Marsan, Suresh Goyal,Shugong Xu, Antonio Fernandez, Milan Prodanovic, and KenChristensen, editors, e-Energy, page 4. ACM, 2012.
[7] E. Elmroth and L. Larsson. Interfaces for Placement, Mi-gration, and Monitoring of Virtual Machines in FederatedClouds. In Grid and Cooperative Computing, 2009. GCC’09.Eighth International Conference on, pages 253–260, 2009.
[8] C. Engelmann, G.R. Vallee, T. Naughton, and S.L. Scott.Proactive Fault Tolerance Using Preemptive Migration. InParallel, Distributed and Network-based Processing, 200917th Euromicro International Conference on, pages 252–257,2009.
[9] Pei Fan, Zhenbang Chen, Ji Wang, and Zibin Zheng. OnlineOptimization of VM Deployment in IaaS Cloud. In Paralleland Distributed Systems (ICPADS), 2012 IEEE 18th Interna-tional Conference on, pages 760–765, 2012.
[10] Weiwei Fang, Xiangmin Liang, Shengxin Li, Luca Chiar-aviglio, and Naixue Xiong. VMPlanner: Optimizing VirtualMachine Placement and Traffic Flow Routing to ReduceNetwork Power Costs in Cloud Data Centers. ComputerNetworks, 57(1):179–196, 2013.
[11] Abhishek Gupta, Laxmikant V. Kale, Dejan S. Milojicic,Paolo Faraboschi, and Susanne M. Balle. HPC-Aware VMPlacement in Infrastructure Clouds. In IC2E, pages 11–20.IEEE, 2013.
[12] Takahiro Hirofuchi, Hidemoto Nakada, Satoshi Itoh, andSatoshi Sekiguchi. Reactive Consolidation of Virtual Ma-chines Enabled by Postcopy Live Migration. In Proceedingsof the 5th international workshop on Virtualization technolo-gies in distributed computing, VTDC ’11, pages 11–18, NewYork, NY, USA, 2011. ACM.
[13] IBM. Reservoir. http://www.research.ibm.com/haifa/projects/systech/reservoir.
[14] Dailin Jiang, Peijie Huang, Piyuan Lin, and Jiacheng Jiang.Energy Efficient VM Placement Heuristic Algorithms Com-parison for Cloud with Multidimensional Resources. InBaoxiang Liu, Maode Ma, and Jincai Chang, editors, Infor-mation Computing and Applications, volume 7473 of LectureNotes in Computer Science, pages 413–420. Springer BerlinHeidelberg, 2012.
[15] J.W. Jiang, Tian Lan, Sangtae Ha, Minghua Chen, and MungChiang. Joint VM Placement and Routing for Data CenterTraffic Engineering. In INFOCOM, 2012 Proceedings IEEE,pages 2876–2880, 2012.
[16] A. Kertesz, G. Kecskemeti, A. Marosi, M. Oriol, X. Franch,and J. Marco. Integrated Monitoring Approach for SeamlessService Provisioning in Federated Clouds. 16th EuromicroConference on Parallel, Distributed and Network-Based Pro-cessing (PDP 2012), 0:567–574, 2012.
[17] Wubin Li, Johan Tordsson, and Erik Elmroth. Virtual Ma-chine Placement for Predictable and Time-Constrained PeakLoads. In Kurt Vanmechelen, Jorn Altmann, and Omer F.Rana, editors, GECON, volume 7150 of Lecture Notes inComputer Science, pages 120–134. Springer, 2011.
[18] Kevin Mills, James J. Filliben, and Christopher Dabrowski.Comparing VM-Placement Algorithms for On-DemandClouds. In Costas Lambrinoudakis, Panagiotis Rizomiliotis,and Tomasz Wiktor Wlodarczyk, editors, CloudCom, pages91–98. IEEE, 2011.
[19] Philip Resnik and Eric Hardisty. Gibbs Sampling for theUninitiated. Technical Report CS-TR-4956, UMIACS-TR-2010-04, LAMP-153, University of Maryland, April 2010.
[20] Abdelmounaam Rezgui and Sami Rezgui. A StochasticApproach for Virtual Machine Placement in Volunteer CloudFederations. In Proc. of the IEEE International Conferenceon Cloud Engineering (IC2E), Boston, USA, March 2014.
[21] B. Rochwerger, D. Breitgand, E. Levy, A. Galis, K. Na-gin, I.M. Llorente, R. Montero, Y. Wolfsthal, E. Elmroth,J. Cceres, M. Ben-Yehuda, W. Emmerich, and F. Galn.The Reservoir Model and Architecture for Open FederatedCloud Computing. IBM Journal of Research & Development,53(4):535545, 2009.
[22] Cosma Shalizi. The Bootstrap (Advanced Data Analysis).Technical report, Carnegie Mellon University, February 2011.
[23] Anjana Shankar. Virtual Machine Placement in ComputingClouds. Master’s thesis, Indian Institute of TechnologyBombay, 2010.
[24] Eric A. Suess and Bruce E. Trumbo. Introduction to Proba-bility Simulation and Gibbs Sampling with R. Springer, 2010.
[25] David Villegas, Norman Bobroff, Ivan Rodero, Javier Del-gado, Yanbin Liu, Aditya Devarakonda, Liana Fong, S. Ma-soud Sadjadi, and Manish Parashar. Cloud Federation in aLayered Service Model. Journal of Computer and SystemSciences, 78(5):1330 – 1344, 2012.
[26] Wikipedia. Bootstrapping (Statistics), howpublished =”http://en.wikipedia.org/wiki/Bootstrapping (statistics)”.
[27] Wikipedia. Markov Chain Monte Carlo. http://en.wikipedia.org/wiki/Markov chain Monte Carlo.
[28] Wikipedia. Markov Model. http://en.wikipedia.org/wiki/Markov model.





























