Embed Size (px)
Citation preview

04/18/23 20:57 1
CSE 574 Extracting, Managing & Personalizing Web Information
• Staffing– Dan Weld– Raphael Hoffmann
• Content – Intersection of AI, ML, DB & HCI
• Student Responsibilities– Reading, Reports, Discussion– Project (for those taking 3 credits)

Class Focus
Extracting, Managing & Personalizing Web Information
04/18/23 20:57 2

Why Information Extraction• Next-Generation Search
– Citeseer, Google scholar, MSRA Libra– Google product search– Flipdog– Zvents– Zoominfo
• Question Answering
04/18/23 20:57 3

04/18/23 20:57 5

People
04/18/23 20:57 6

…Continued
04/18/23 20:57 7

…Continued Some More
04/18/23 20:57 8

Making Structured Content • Information Extraction
– E.g. Google Scholar– Cons: Noisy
• Communal Content Creation– E.g. Wikipedia– Cons: Bootstrapping & Incentives
04/18/23 20:57 9

Why Managing ?• Select• Store, Index, Aggregate• Search, Query, Explore• Share, Collaborate, “Publish”
Example: Personalized Portalscf DBlife, Rexa, Dontcheva UIST-07
04/18/23 20:57 10
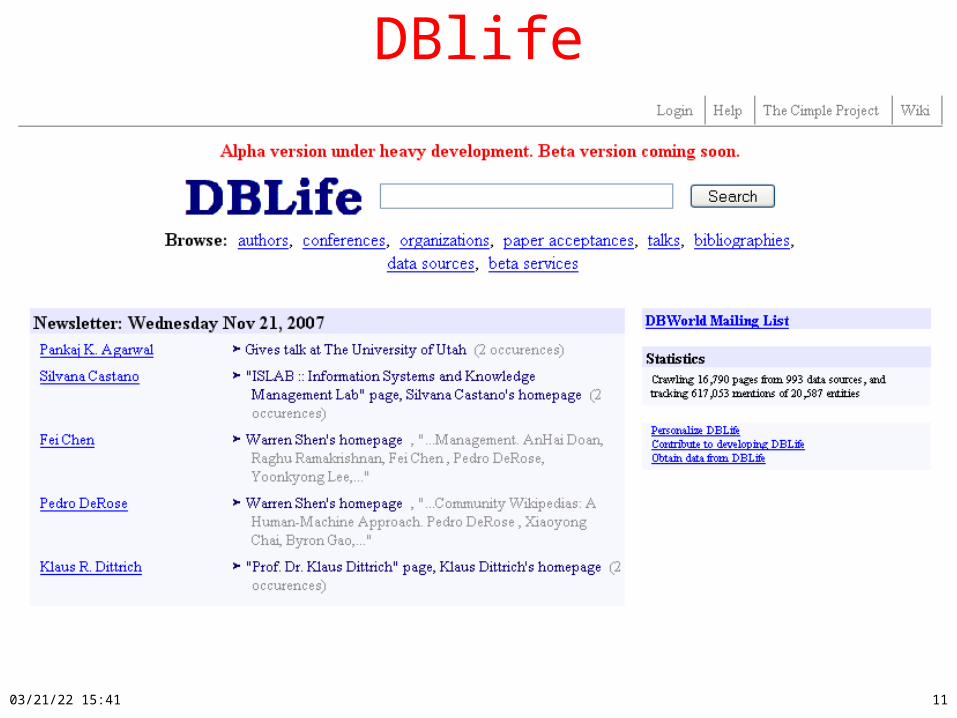
DBlife
04/18/23 20:57 11

Summaries - 1
04/18/23 20:57 12

Summaries - 2
04/18/23 20:57 13

Summaries - 3
04/18/23 20:57 14

Summaries - 4
04/18/23 20:57 15

Summaries - 5
04/18/23 20:57 16

Summaries - 6
04/18/23 20:57 17

Why Personalize?• Because we can.
04/18/23 20:57 18

Preliminary Schedule• Information Extraction
– Traditional Machine Learning Approaches– Self-Supervised Methods– Other Issues: Coreference & Ontology
• Collaborative Content Creation & UI Issues– Applying Contraints from Interaction to Learning– Decision Theoretic Interaction– Faceted Interfaces
• Community Information Management – Extraction over Evolving Text– Data Provenance – Mashups & Personalized Web
• Next-Generation Search – Inference, Textual Entailment, Machine Reading – Entity Search
04/18/23 20:57 19

04/18/23 20:57 20
For next time• Read
– Agichtein, Gravano. Snowball: Extracting Relations from Large Plain-Text Collections.
• Add yourself to mailing list• Look at papers on website wiki
– Add new ones– Add summary (different from report)– Notate if you wish to present one
• Think about project / (form a group?)