Embed Size (px)
Citation preview
1
Parser GeneratorsAurochs and ANTLR and Yaccs, Oh My
CS235 Languages and Automata
, y
Tuesday, December 1, 2009Reading: Appel 3.3
Department of Computer ScienceWellesley College
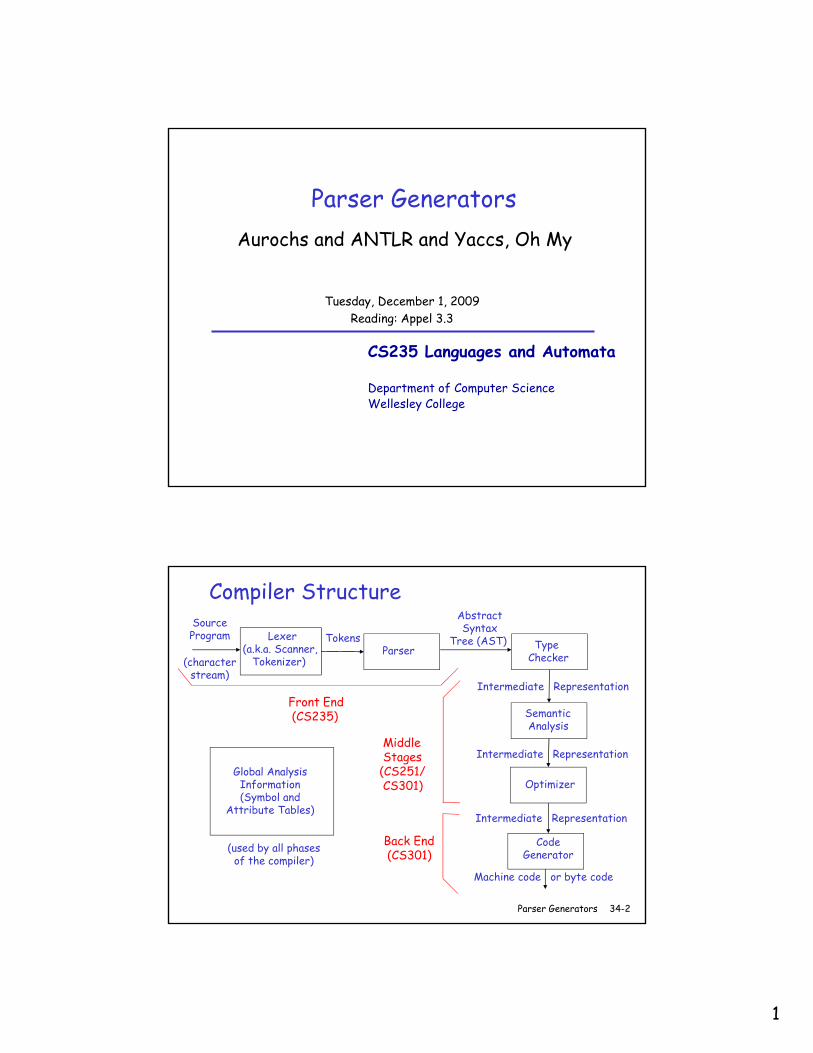
Compiler Structure
Lexer(a.k.a. Scanner,
Tokenizer)
SourceProgram
(characterstream)
ParserTokens Type
Checker
AbstractSyntax
Tree (AST)
Intermediate Representation
Optimizer
Intermediate Representation
Global Analysis Information (Symbol and
Intermediate Representation
SemanticAnalysis
Front End(CS235)
MiddleStages(CS251/CS301)
Parser Generators 34-2
CodeGenerator
Machine code or byte code
Attribute Tables)
(used by all phasesof the compiler)
Intermediate Representation
Back End(CS301)

2
Motivation We now know how to construct LL(k) and LR(k) parsers by hand.
But constructing parser tables from grammars and But constructing parser tables from grammars and implementing parsers from parser tables is tedious and error prone.
Isn’t there a better way?
Idea: Hey, aren’t computers good at automating these sorts of things?sorts of things?
Parser Generators 34-3
Parser Generators A parser generator is a program whose inputs are:
1. a grammar that specifies a tree structure for linear sequences of tokens (typically created by a separate sequences of tokens (typically created by a separate lexer program).
2. a specification of semantic actions to perform when building the parse tree.
Its output is an automatically constructed program thatparses a token sequence into a tree performing the parses a token sequence into a tree, performing the specified semantic actions along the way
In the remainder of this lecture, we will explore and compare a two parser generators: Yacc and Aurochs.
Parser Generators 34-4

3
ml-yacc: An LALR(1) Parser Generator
ml-yacc.yacc file(token datatype,
parsing rules,precedence &
Slip.yacc Slip.yacc.descLR parsing table
info for debuggingshift-reduce and
reduce-reduce conflicts
ml-lex.lex file(token rules &
token-handling code)
Slip.lex
Slip.lex.sml
associativity info)
Slip.yacc.smlSlip.yacc.sig
parsing program token datatype
program(as character
stream)
token streamscanner program(SML)
A Slip program Slip tokens
parser program(SML)
abstract syntax tree
Slip AST
ant ant
Parser Generators 34-5
Format of a .yacc FileHeader section with SML code%%Specification of terminals & variables and various declarations
(including precedence and associativity)( g p y)%%Grammar productions with semantic actions
Parser Generators 34-6

4
IntexpUnambiguousAST.yacc (Part 1) (* no SML code in this case *)%% (* separates initial section from middle section of .yacc file *)
%name Intexp
%pos int
Name used to prefix various names created by ml-yacc
Declares the type of positions for terminals. Each terminal has a left and right position. Here, position is just an int (a character position in a string or file)
%term INT of int
| ADD | SUB | MUL | DIV | EXPT| LPAREN (* "(" *)| RPAREN (* ")" *)| EOF (* End of file*)
%nonterm Start of AST.exp
| Exp of AST.exp
Specifies the terminals of the language. ml-yacc automatically constructs a Tokens module based on this specification.
Tokens specified without "of" will have a constructor of two args: (1) its left position and (2) its right position.
Tokens specified with "of" will have a constructor of three args: (1) the component datum (whose type follows "of"); (2) its left position; and (3) its the right position.
Specifies the non-terminals of the language and the kind of value that the parser will generate for them (an AST in this case) | p p
| Term of AST.exp| Factor of AST.exp| Unit of AST.exp
%start Start
(* Middle section continued on next slide *)
that the parser will generate for them (an AST in this case). The "start" non-terminal should not appear on the right-hand sides of any productions.
Start symbol of the grammar
Parser Generators 34-7
IntexpUnambiguousAST.yacc (Part 2) (* Middle section continued from previous slide *)
%keyword
%eop EOF
Lists the keywords of the language. The error handler of the ml-yacc generated parser treats keywords specially. In this example, there aren’t any keywords.
Indicates tokens that end the input%eop EOF
%noshift EOF
%nodefault
%verbose
%value INT(0)
Indicates tokens that end the input
Tells the parser never to shift the specfied tokens
Specifies default values for value-bearing terminals. Terminals with default values may be created by an
Suppresses generation of default reduction
Generates a description of the LALR parser table in filename.yacc.desc. This is helpful for debugging shift/reduce and reduce/reduce conflicts
(* Grammar productions and semantic actions on next slide *)
Terminals with default values may be created by an ml-yacc-generated parser as part of error-correction.
Note; in this middle section, you can also specify associativity and precedence of operators. See IntexpPrecedence.yacc (later slide) for an example.
Parser Generators 34-8

5
AST module for integer expressionsstructure AST =
struct
datatype exp = Int of int| BinApp of binop * exp * exp
and binop = Add | Sub | Mul | Div | Expt
(* Various AST functions omitted from this slide *)
endend
Parser Generators 34-9
IntexpUnambiguousAST.yacc (Part 3) %% (* separates middle section from final section *)(* Grammar productions and associated semantic actions (in parens) go here *)
Start: Exp (Exp) Within parens, nonterminals stand for the value generated bythe parser for the nonterminal, as specified in the %nonterm declaration (an AST expression in this case)
Exp : Term (Term)(* The following rules specify left associativity *) | Exp ADD Term (AST.BinApp(AST.Add,Exp,Term)) | Exp SUB Term (AST.BinApp(AST.Sub,Exp,Term))
Term : Factor (Factor)(* The following rules specify left associativity *) | Term MUL Factor (AST.BinApp(AST.Mul,Term,Factor)) | Term DIV Factor (AST.BinApp(AST.Div,Term,Factor))
declaration (an AST expression in this case).
Factor : Unit (Unit)(* The following rule specifies right associativity *)
| Unit EXPT Factor (AST.BinApp(AST.Expt,Unit,Factor))
Unit : INT (AST.Int(INT))| LPAREN Exp RPAREN (Exp)
Within parens, terminals stand for the component datumspecified after “of” in the %term declaration. E.g., the datum associated with INT is an integer.
Parser Generators 34-10

6
Interfacing with the Lexer(*contents of Intexp.lex *)open Tokens
type pos = inttype lexresult= (svalue,pos) token
fun eof () = Tokens EOF(0 0)fun eof () = Tokens.EOF(0,0)
fun integer(str,lexPos) = case Int.fromString(str) of
NONE => raise Fail("Shouldn't happen: sequence of digits not recognized as integer -- " ^ str)| SOME(n) => INT(n,lexPos,lexPos)
(* For scanner initialization (not needed here) *)fun init() = () %%%header (functor IntexpLexFun(structure Tokens: Intexp_TOKENS));l halpha=[a-zA-Z];
digit=[0-9];whitespace=[\ \t\n];symbol=[+*^()\[];any= [^]; %%{digit}+ => (integer(yytext,yypos));"+" => (ADD(yypos,yypos));(* more lexer rules go here *)
Parser Generators 34-11
Parser interface code, Part 1structure Intexp = struct (* Module for interfacing with parser and lexer *)
(* Most of the following is "boilerplate" code that needs to be slightly edited on a per parser basis. *)
structure IntexpLrVals = IntexpLrValsFun(structure Token = LrParser.Token)structure IntexpLex = IntexpLexFun(structure Tokens = IntexpLrVals.Tokens);structure IntexpParser =structure IntexpParser
Join(structure LrParser = LrParserstructure ParserData = IntexpLrVals.ParserDatastructure Lex = IntexpLex)
val invoke = fn lexstream => (* The invoke function invokes the parser given a lexer *)let val print_error = fn (str,pos,_) =>
TextIO.output(TextIO.stdOut,"***Intexp Parser Error at character position " ^ (Int.toString pos)
^ "***\n" ^ str^ "\n")in IntexpParser.parse(0,lexstream,print_error,())end
ml-yacc 35-12
end
fun newLexer fcn = (* newLexer creates a lexer from a given input-reading function *)let val lexer = IntexpParser.makeLexer fcn
val _ = IntexpLex.UserDeclarations.init()in lexerend
(* continued on next slide *)

7
Parser interface code, Part 2(* continued from previous slide *)fun stringToLexer str = (* creates a lexer from a string *)
let val done = ref falsein newLexer (fn n => if (!done) then "“ else (done := true; str))end
fun fileToLexer filename = (* creates a lexer from a file *)fun fileToLexer filename = ( creates a lexer from a file )let val inStream = TextIO.openIn(filename)in newLexer (fn n => TextIO.inputAll(inStream))end
fun lexerToParser (lexer) = (* creates a parser from a lexer *)let val dummyEOF = IntexpLrVals.Tokens.EOF(0,0)
val (result,lexer) = invoke lexerval (nextToken,lexer) = IntexpParser.Stream.get lexer
in if IntexpParser.sameToken(nextToken,dummyEOF) then result
else (TextIO.output(TextIO.stdOut,else (TextIO.output(TextIO.stdOut,"*** INTEXP PARSER WARNING -- unconsumed input ***\n");
result)end
val parseString = lexerToParser o stringToLexer (* parses a string *)
val parseFile = lexerToParser o fileToLexer (* parses a file *)
end (* struct *)
Parser Generators 34-13
Putting it all together: the load file(* This is the contents of load-intexp-unambiguous-ast.sml *)CM.make("$/basis.cm"); (* loads SML basis library *)CM.make("$/ml-yacc-lib.cm"); (* loads SML YACC library *)use "AST.sml"; (* datatype for integer expression abstract syntax trees *)( yp g p y )use "IntexpUnambiguousAST.yacc.sig"; (* defines Intexp_TOKENS
and other datatypes *)use "IntexpUnambiguousAST.yacc.sml"; (* defines shift-reduce parser *)
use "Intexp.lex.sml"; (* load lexer *after* parser since it uses tokens defined by parser *)
use "Intexp.sml"; (* load top-level parser interface *)Control Print printLength := 1000; (* set printing parameters so that *)Control.Print.printLength := 1000; ( set printing parameters so that )Control.Print.printDepth := 1000; (* we’ll see all details of parse trees *)Control.Print.stringDepth := 1000; (* and strings *)open Intexp; (* open the parsing module so that we can use parseString
and parseFile without qualification. *)
Parser Generators 34-14

8
Taking it for a spin[fturbak@cardinal intexp-parsers] ml-lex Intexp.lex
Number of states = 14Number of distinct rows = 3Approx. memory size of trans. table = 387 bytes
Linux shell
- use "load-intexp-unambiguous-ast.sml"; (* … lots of printed output omitted here … *)
- parseString "1+2*3^4^5*6+7";val it =BinApp
e = 387 bytes[fturbak@cardinal intexp-parsers] ml-yacc IntexpUnambiguousAST.yacc[fturbak@cardinal intexp-parsers]
SMLBinApp(Add,BinApp(Add,Int 1,BinApp(Mul,BinApp (Mul,Int 2,BinApp (Expt,Int 3,BinApp (Expt,Int 4,Int 5))),Int 6)),Int 7) : IntexpParser.result
SMLintepreter
Parser Generators 34-15
IntexpUnambiguousAST.yacc.descstate 0:
Start : . Exp
INT shift 6LPAREN shift 5
Start goto 19E t 4
… lots of states omitted …
state 18:
Unit : LPAREN Exp RPAREN . (reduce by rule 10)
ADD reduce by rule 10SUB reduce by rule 10
Exp goto 4Term goto 3Factor goto 2Unit goto 1
. error
state 1:
Factor : Unit . (reduce by rule 7)Factor : Unit . EXPT Factor
ADD reduce by rule 7
yMUL reduce by rule 10DIV reduce by rule 10EXPT reduce by rule 10RPAREN reduce by rule 10EOF reduce by rule 10
. error
state 19:
EOF acceptySUB reduce by rule 7MUL reduce by rule 7DIV reduce by rule 7EXPT shift 7RPAREN reduce by rule 7EOF reduce by rule 7
. error
EOF accept
. error
72 of 104 action table entries left after compaction21 goto table entries
Parser Generators 34-16

9
IntexpUnambiguousCalc.yacc
(* An integer exponentiation function *)fun expt (base,0) = 1| expt(base,power) =
%%
Start: Exp (Exp)
We can calculate the result of an integer expression ratherthan generating an AST.
base*(expt(base,power-1))
%%
(* Only changed parts shown *)
%nonterm Start of int
| Exp of int| Term of int
Exp : Term (Term)(* The following rules specify left associativity *) | Exp ADD Term (Exp + Term) | Exp SUB Term (Exp - Term)
Term : Factor (Factor)(* The following rules specify left associativity *) | Term MUL Factor (Term * Factor) | Term DIV Factor (Term div Factor)
(* div is integer division *)| Term of int| Factor of int| Unit of int
)
( g )
Factor : Unit (Unit)(* The following rule specifies right associativity *)
| Unit EXPT Factor (expt(Unit,Factor))
Unit : INT (INT)| LPAREN Exp RPAREN (Exp)
Parser Generators 34-17
Testing IntexpUnambiguousCalc
[fturbak@cardinal intexp-parsers] ml-yacc IntexpUnambiguousCalc.yacc[fturbak@cardinal intexp-parsers]
Linux shell
- use "load-intexp-unambiguous-calc.sml"; (* … lots of printed output omitted here … *)
- parseString "1+2*3";val it = 7 : IntexpParser result
SMLintepreter
val it = 7 : IntexpParser.result
- parseString "1-2-3";val it = ~4 : IntexpParser.result
Parser Generators 34-18

10
IntexpAmbiguousAST.yacc
%%(* Only changed parts shown *)
We can use an ambiguous grammar. (In this case, it leads to shift/reduce conflicts.)
%nonterm Start of AST.exp
| Exp of AST.exp)
%%
Start: Exp (Exp)
Exp : INT (AST.Int(INT))| Exp ADD Exp (AST.BinApp(AST.Add,Exp1,Exp2)) | Exp SUB Exp (AST.BinApp(AST.Sub,Exp1,Exp2)) | Exp MUL Exp (AST.BinApp(AST.Mul,Exp1,Exp2)) | Exp DIV Exp (AST.BinApp(AST.Div,Exp1,Exp2)) | Exp EXPT Exp (AST.BinApp(AST.Expt,Exp1,Exp2))
Parser Generators 34-19
IntexpAmbiguousAST.yacc.desc25 shift/reduce conflicts
error: state 8: shift/reduce conflict (shift EXPT, reduce by rule 6)error: state 8: shift/reduce conflict (shift DIV, reduce by rule 6)error: state 8: shift/reduce conflict (shift MUL, reduce by rule 6)error: state 8: shift/reduce conflict (shift SUB, reduce by rule 6)error: state 8: shift/reduce conflict (shift ADD, reduce by rule 6)error: state 9: shift/reduce conflict (shift EXPT reduce by rule 5)error: state 9: shift/reduce conflict (shift EXPT, reduce by rule 5)error: state 9: shift/reduce conflict (shift DIV, reduce by rule 5)error: state 9: shift/reduce conflict (shift MUL, reduce by rule 5)error: state 9: shift/reduce conflict (shift SUB, reduce by rule 5)error: state 9: shift/reduce conflict (shift ADD, reduce by rule 5)error: state 10: shift/reduce conflict (shift EXPT, reduce by rule 4)error: state 10: shift/reduce conflict (shift DIV, reduce by rule 4)error: state 10: shift/reduce conflict (shift MUL, reduce by rule 4)error: state 10: shift/reduce conflict (shift SUB, reduce by rule 4)error: state 10: shift/reduce conflict (shift ADD, reduce by rule 4)error: state 11: shift/reduce conflict (shift EXPT, reduce by rule 3)error: state 11: shift/reduce conflict (shift DIV, reduce by rule 3)error: state 11: shift/reduce conflict (shift MUL, reduce by rule 3)error: state 11: shift/reduce conflict (shift SUB, reduce by rule 3)error: state 11: shift/reduce conflict (shift ADD, reduce by rule 3)error: state 12: shift/reduce conflict (shift EXPT, reduce by rule 2)error: state 12: shift/reduce conflict (shift DIV, reduce by rule 2)error: state 12: shift/reduce conflict (shift MUL, reduce by rule 2)error: state 12: shift/reduce conflict (shift SUB, reduce by rule 2)error: state 12: shift/reduce conflict (shift ADD, reduce by rule 2)
… state descriptions omitted …
Parser Generators 34-20

11
IntexpPrecedenceAST.yacc
%%(* Only changed parts shown *)
We can resolve conflicts with precedence/associativity declarations(can also handle dangling else problem this way).
%nonterm Start of AST.exp
| Exp of AST.exp)
(* Specify associativity and precedence from low to high *)%left ADD SUB%left MUL DIV%right EXPT
%%%%
Start: Exp (Exp)
Exp : INT (AST.Int(INT))| Exp ADD Exp (AST.BinApp(AST.Add,Exp1,Exp2)) | Exp SUB Exp (AST.BinApp(AST.Sub,Exp1,Exp2)) | Exp MUL Exp (AST.BinApp(AST.Mul,Exp1,Exp2)) | Exp DIV Exp (AST.BinApp(AST.Div,Exp1,Exp2)) | Exp EXPT Exp (AST.BinApp(AST.Expt,Exp1,Exp2)) Parser Generators 34-21
Stepping Back
Whew! That’s a lot of work! Is it all worth it?
There’s a tremendous amount of initial setup and glue p gcode to get Lex and Yacc working together.
But once that’s done, we can focus on specifying and debugging high-level declarations of the token structure (in Lex) and grammar (in Yacc) rather than on SML programming.
Parser Generators 34-22
In Yacc, generally spend most of the time debugging shift/reduce and reduce/reduce conflicts – must be veryfamiliar with the LALR(1) table descriptions in the .yacc.desc file.

12
Other Parser Generators There are a plethora of other LALR parser generators for many
languages, including: GNU Bison (Yacc for C, C++) jb (Bis f J ) jb (Bison for Java) CUP (Yacc for Java)
There are also LL(k) parser generators, particularly ANTLR, which generates parsers and other tree-manipulation programs for Java, C, C++, C#, Python, Ruby, and JavaScript. There is also an sml-antlr.
There are a relatively new (starting in 2002) collection of so-
Parser Generators 34-23
There are a relatively new (starting in 2002) collection of socalled packrat parsers for Parsing Expression Grammars (PEGs) for a wide range of target languages. We will study one of these: Aurochs.
Parsing Expression Grammars (PEGs) Key problem in building top-down (recursive-descent) parsers: deciding which production to use on tokens. Three strategies:
Predictive parser: determine which production to use based on k tokens of lookahead. Often mangle grammars to make this work.
Backtracking parser: when have several choices, try them in order. If one fails try the next. Very general and high-level, but can take exponential time to parse input.
PEG Parser: have a prioritized choice operator in which unconditionally use first successful match. Can directly express common disambiguation rules like
longest-match followed-by and not-followed-by.
Parser Generators 34-24
longest match, followed by, and not followed by. Can express lexing rules and parsing rules in same grammar!
This eliminates glue code between lexer and parser. Can implement PEGs via a packrat parser that memoizes parsing
results and guarantees parsing in linear time (but possibly exponential space)

13
Aurochs: a PEG ParserWe will explore PEG parsing using the Aurochs parser generator,developed by Berke Durak and available from http://aurochs.fr.
The input to Aurochs is (1) a file to be parsed and (2) a .peg file specifying PEG declarations for lexing and parsing rules. p fy g E f g p g
The output of Aurochs is an XML parse tree representation. (It is also possible to generate parse trees in particular languages,but for simplicity we’ll stick with the XML trees.)
Parser Generators 34-25
Aurochs Example[lynux@localhost slipmm-parsers]$ aurochs -parse simple.slip SlipmmParens.pegAurochs 1.0.93- Parsing file simple.slip using Nog interpreter- Grammar loaded from file SlipmmParens.peg- RESULT
<Root><StmList><Assign var "x"><Assign var="x"><BinApp binop="+"><Int value="3"/><Int value="4"/>
</BinApp></Assign><Print><BinApp binop="*"><BinApp binop="-"><Id name="x"/><Int value="1"/>
begin x := (3+4); print ((x-1)*(x+2));
end
Contents of the filesimple.slip
Parser Generators 34-26
</BinApp><BinApp binop="+"><Id name="x"/><Int value="2"/>
</BinApp></BinApp>
</Print></StmList>
</Root>- No targets

14
Expression Meaning'c' The single ASCII character 'c'"hello" The string “hello”BOF, EOF Beginning and end of file tokenssigma Any characterpsil n Th mpt strin
Aurochs Grammar Expressions
epsilon The empty string[a-zA-Z0-9] grep-like character sets[^\n\t ] grep-like complements of character setse1 e2 Concatenation: parse e1, then e2e* Repetition: parses as many occurrences of e as possible, including zero. e+ Nonzero repetition: parses at least one occurrences of e. e? Option: parses zero or one occurrence of e.&e Conjunction: Parses e, but without consuming it. ~e Negation: Attempts to parse e. If parsing e fails, then ~e succeeds without consuming
any input. If parsing e succeeds, then ~e fails (also without consuming input). e1 | e2 Ordered disjunction (prioritized choice): Attempt to parse e1 at the current position.
If this succeeds, it will never try to parse e2 at the current position. If it fails, it will never try to parse e1 again at that position, and will try to parse e2. If e2 fails, the whole disjunction fails.
(e) Parentheses used for explicit groupingname Parse according to e from production name ::= e Parser Generators 34-27
Expression Meaning
‘-’? [1-9][0-9]* Any nonempty sequence of digits not beginning with 0, preceded by an optional minus sign
&[aeiou] [a-z]+ Any nonempty sequence of lowercase letters beginning with
Some Simple Expressions
a vowel.~0 [0-9]+ Any nonempty sequence of digits not beginning with 0
~(“begin”|”end”|”let”) &[a-z] [a-zA-Z0-9]+
Alphanumeric names beginning with lowercase letters, excluding the keywords begin, end, and let.
exp ::= (exp “+” exp) | id “=“ exp | id | num
Assume id matches identifiers and num matches numbers. Then this can parse (x=3 + x) and (x=y=3 + (1 + z=y))
exp ::= (exp “+” exp) Due to prioritized choice this will never parse x=3 exp ::= (exp + exp) | id | id “=“ exp | num
Due to prioritized choice, this will never parse x=3.
if exp then stm else stm| if exp then stm
Solves dangling else problem by specifying that else goes with the closest if.
Parser Generators 34-28

15
Numerical Expressions in Aurochs(* Tokens *)float ::= '-'? decimal+ ('.' decimal+)? ('e' ('-'|'+')? decimal+)?;integer ::= '-'? decimal+;decimal ::= [0-9]; sp ::= (' '|'\n'|'\r'|'\t')*; (* any number of whitespaces *)
ADD :: sp ' ' sp; SUB :: sp ' ' sp; MUL :: sp '*' sp; DIV :: sp '/' sp;ADD ::= sp + sp; SUB ::= sp - sp; MUL ::= sp * sp; DIV ::= sp / sp;LPAREN ::= sp '(' sp; RPAREN ::= sp ')' sp;
(* Expressions *)start ::= exp sp EOF;
exp ::= term ADD exp (* right associative *)| term SUB exp (* right associative *)| term;
term ::= factor MUL term (* right associative *)
Parser Generators 34-29
| factor DIV term (* right associative *)| SUB factor (* unary negation *)| factor;
factor ::= number| LPAREN exp RPAREN;
number ::= float|integer;
XML Parse Trees for Numexps in Aurochs(* Tokens the same as before, so omitted *)
(* Expressions *)start ::= exp sp EOF;
exp ::= <add> term ADD exp </add> (* right associative *)| <sub> term SUB exp </sub> (* right associative *)| term;
term ::= <mul> factor MUL term </mul> (* right associative *)| <div> factor DIV term </div> (* right associative *)| <neg> SUB factor </neg>| factor;
Parser Generators 34-30
factor ::= number| LPAREN exp RPAREN;
number ::= <number> value:(float|integer) </number>;

16
Testing Numexp Parser[lynux@localhost calculator]$ aurochs -quiet -parse exp.txt numexp.peg <Root><mul><sub><number value="1"/><sub><sub><number value="2"/><number value="3"/>
</sub></sub><neg><add><neg><number value="4"/>
</neg>
(1-2-3)*-(-4+5.6+7.8e-9)Contents of the file exp.txt
Parser Generators 34-31
g<add><number value="5.6"/><number value="7.8e-9"/>
</add></add>
</neg></mul>
</Root>
Transforming Left Recursion (* Expressions *)
start ::= exp sp EOF;
exp ::= term <addsub> (op:(ADD|SUB) exp)* </addsub>;p ( p ( ) p)
term ::= <neg> SUB factor </neg>| factor <muldiv> (op:(MUL|DIV) term)* </muldiv>;
factor ::= number| LPAREN exp RPAREN;
number ::= <number> value:(float|integer) </number>;
Parser Generators 34-32

17
Left Recursion Transformation Exampl[lynux@localhost calculator]$ aurochs -quiet -parse sub.txt numexp-leftrec.peg <Root><number value="1"/><muldiv/><addsub op="-"><number value="2"/><number value= 2 /><muldiv/><addsub op="-"><number value="3"/><muldiv/><addsub op="-"><number value="4"/><muldiv/><addsub/>
</addsub>
(1-2-3-4)Contents of the file sub.txt
Parser Generators 34-33
</addsub></addsub><muldiv/><addsub/>
</Root>
Moving Spaces from Tokens to Expressions(* Tokens *)float ::= '-'? decimal+ ('.' decimal+)? ('e' ('-'|'+')? decimal+)?;integer ::= '-'? decimal+;decimal ::= [0-9]; sp ::= (' '|'\n'|'\r'|'\t')*; (* any number of whitespaces *)
ADD :: ' '; SUB :: ' '; MUL :: '*'; DIV :: '/';ADD ::= + ; SUB ::= - ; MUL ::= * ; DIV ::= / ;LPAREN ::= '('; RPAREN ::= ')';
(* Expressions *)start ::= sp exp sp EOF;
exp ::= <add> sp term sp ADD sp exp sp </add> (* right associative *)| <sub> sp term sp SUB sp exp sp </sub> (* right associative *)| term;
term ::= <mul> sp factor sp MUL sp term sp </mul> (* right associative *)
Parser Generators 34-34
| <div> sp factor sp DIV sp term sp </div> (* right associative *)| <neg> sp SUB sp factor sp </neg>| sp factor sp;
factor ::= sp number sp| sp LPAREN sp exp sp RPAREN sp;
number ::= <number> sp value:(float|integer) sp </number>;

18
Modifiers: Surrounding, Outfixing, and Friends The following modifiers take an expression x as parameter and
transform each production a ::= b as follows:
appending x do ... done transforms them into a ::= b x
prepending x do done transforms them into a ::= x b prepending x do ... done transforms them into a ::= x b
surrounding x do ... done transforms them into a ::= x b x
The following modifiers transform each concatenation a b c:
outfixing x do ... done transforms them into x a x b x c x
suffixing x do ... done transforms them into a x b x c x
f d d f h
Parser Generators 34-35
prefixing x do ... done transforms them into x a x b x c
Note that these modifiers also act within implicit concatenations produced by the operators '*' and '+'.
These rules found at http://aurochs.fr
A Shorthand for all those Expression Spacesstart ::= sp exp sp EOF;
outfixing sp do surrounding sp do exp ::= <add> term ADD exp </add> (* right associative *)
| <sub> term SUB exp </sub> (* right associative *)| <sub> term SUB exp </sub> ( right associative )| term;
term ::= <mul> factor MUL term </mul> (* right associative *)| <div> factor DIV term </div> (* right associative *)| <neg> SUB factor </neg>| factor;
factor ::= number | LPAREN exp RPAREN;
Parser Generators 34-36
| p
number ::= <number> value:(float|integer) </number>;done;
done;

19
Aurochs Productions for Slip-- Tokenswhitespace ::= [ \n\r\t] | BOF; (* BOF = beginning of file token *)
(* sp is at least one ignorable unit (space or comment) *)sp ::= whitespace*;
PRINT ::= "print"; BEGIN ::= "begin"; END ::= "end";k d :: k d> l : (PRINT | BEGIN | END) /k d>; keyword ::= <keyword> value: (PRINT | BEGIN | END) </keyword>;
ADD ::= '+'; SUB ::= '-'; MUL ::= '*'; DIV ::= '/'; op ::= <op> value: (ADD | SUB | MUL | DIV) </op>;
LPAREN ::= "("; RPAREN ::= ")"; SEMI ::= ";"; GETS ::= ":=";punct ::= <punct> value: (LPAREN | RPAREN | SEMI | GETS) </punct> ;
alpha ::= [a-zA-Z];alphaNumUnd ::= [a-zA-Z0-9_];digit ::= [0-9];
Parser Generators 34-37
reserved ::= "print" | "begin" | "end";ident ::= <ident> value: (~(reserved sp) alpha alphaNumUnd*) </ident>;integer ::= <integer> value: digit+ </integer>;
token ::= sp (keyword|punct|op|ident|integer) sp;tokenList ::= <tokenList> token* </tokenList>;
start ::= tokenList EOF;
Slip-- Tokenizing example[lynux@localhost slipmm-parsers]$ aurochs -quiet -parse simple.slip SlipmmTokens.peg<Root><tokenList>
<keyword value="begin"/><ident value="x"/><punct value=":="/><punct value="("/><integer value="3"/><integer value= 3 /><op value="+"/><integer value="4"/><punct value=")"/><punct value=";"/><keyword value="print"/><punct value="("/><punct value="("/><ident value="x"/><op value="-"/><integer value="1"/><punct value=")"/><op value="*"/>
begin x := (3+4); print ((x-1)*(x+2));
end
Contents of the filesimple.slip
Parser Generators 34-38
p<punct value="("/><ident value="x"/><op value="+"/><integer value="2"/><punct value=")"/><punct value=")"/><punct value=";"/><keyword value="end"/>
</tokenList></Root>

20
Slip-- Tokens with Positions[lynux@localhost slipmm-parsers]$ aurochs -quiet -parse simple.slip SlipmmTokensPositions.peg<Root><tokenList><token start="0" stop="5"><keyword value="begin"/>
(* Only Change to .peg file. *)token ::= <token> sp <keyword value= begin />
</token><token start="9" stop="10"><ident value="x"/>
</token><token start="11" stop="13"><punct value=":="/>
</token><token start="14" stop="15"><punct value="("/>
C t t f th fil
pstart:position(keyword|punct|op|ident|integer) stop:positionsp </token>;
Parser Generators 34-39
p</token><token start="15" stop="16"><integer value="3"/>
</token><token start="16" stop="17"><op value="+"/>
</token>… many more tokens ….
begin x := (3+4); print ((x-1)*(x+2));
end
Contents of the filesimple.slip
Line Comments
begin sum := 5+3; # Set sum to 8
i t( ) # Di l
How to add line-terminated comments introduced by #?
print(sum); # Display sumend
(* Only changes in .peg file *)
whitespace ::= [ \n\r\t] | BOF; (* BOF = beginning of file token *)linecomment ::= '#' [^\n]* '\n'; (* Comment goes from '#' to end of line *)
(* sp is at least one ignorable unit (space or comment) *)sp ::= (whitespace | linecomment )*;
Parser Generators 34-40

21
Nonnestable Block Commentsbeginsum := 5+3; # Set sum to 8{ Comment out several lines: x := sum * 2; z := x * x; }
print(sum); # Display sumend
(* Only changes in .peg file *)
whitespace ::= [ \n\r\t] | BOF; (* BOF = beginning of file token *)linecomment ::= '#' [^\n]* '\n'; (* Comment goes from '#' to end of line *)linecomment :: # [ \n] \n ; ( Comment goes from # to end of line )blockcomment ::= '{' ((~ '}') sigma)* '}'; (* Nonnestable block comment *)
(* sp is at least one ignorable unit (space or comment) *)sp ::= (whitespace | linecomment | blockcomment)*;
Parser Generators 34-41
Nestable Block Commentsbeginsum := 5+3; # Set sum to 8{ Comment out several lines: x := sum * 2; { Illustrate nested block comments:
y = sum - 3:}z := x * x; }
print(sum); # Display sumend
(* Only changes in .peg file *)
whitespace ::= [ \n\r\t] | BOF; (* BOF = beginning of file token *)linecomment ::= '#' [^\n]* '\n'; (* Comment goes from '#' to end of line *)blockcomment ::= '{' (blockcomment| ((~ '}') sigma))* '}';
(* Properly nesting block comment *)
(* sp is at least one ignorable unit (space or comment) *)sp ::= (whitespace | linecomment | blockcomment)*;
Parser Generators 34-42

22
Slip -- Programs(* Assume tokens unchanged from before *)
start ::= program;
outfixing sp dooutfixing sp doappending sp do program ::= stm EOF;
stm ::= <Assign> var:ident GETS exp </Assign>| <Print> PRINT exp </Print>| <StmList> BEGIN stmList END </StmList>;
stmList ::= (stm SEMI)*;( )
exp ::= <Id> name:ident </Id>| <Int> value:integer </Int>| <BinApp> LPAREN exp binop:op exp RPAREN </BinApp>;
done;done;
Parser Generators 34-43
Aurouchs Errors
-Fatal error: exception Aurochs.Parse_error(1033)
This means that the .peg file has an error at the specified character number(1033 in this case). ( 033 n th s case).
Note: start position is 0-indexed; compared to 1-indexed emacs position in M-x goto-char.
-PARSE ERROR IN FILE nesting-block-comment-test.slip AT CHARACTER 12
This means that the parser encountered an error in parsing the input file at the specified character number. the spec f ed character number.
Parser Generators 34-44




























