Embed Size (px)
Citation preview

3/24
Project 3 released; Due in two weeks

Blog Questions
• You have been given the topology of a bayes network, but haven't yet gotten the conditional probability tables (to be concrete, you may think of the pearl alarm-earth quake scenario bayes net). Your friend shows up and says he has the joint distribution all ready for you. You don't quite trust your friend and think he is making these numbers up. Is there any way you can prove that your friends' joint distribution is not correct?
• Answer:– Check to see if the joint
distribution given by your friend satisfies all the conditional independence assumptions.
– For example, in the Pearl network, Compute P(J|A,M,B) and P(J|A). These two numbers should come out the same!
• Notice that your friend could pass all the conditional indep assertions, and still be cheating re: the probabilities
– For example, he filled up the CPTs of the network with made up numbers (e.g. P(B)=0.9; P(E)=0.7 etc) and computed the joint probability by multiplying the CPTs. This will satisfy all the conditional indep assertions..!
– The main point to understand here is that the network topology does put restrictions on the joint distribution.

Blog Questions (2)
• Continuing bad friends, in the question above, suppose a second friend comes along and says that he can give you the conditional probabilities that you want to complete the specification of your bayes net. You ask him a CPT entry, and pat comes a response--some number between 0 and 1. This friend is well meaning, but you are worried that the numbers he is giving may lead to some sort of inconsistent joint probability distribution. Is your worry justified ( i.e., can your friend give you numbers that can lead to an inconsistency?)
(To understand "inconsistency", consider someone who insists on giving you P(A), P(B), P(A&B) as well as P(AVB) and they wind up not satisfying the P(AVB)= P(A)+P(B) -P(A&B)[or alternately, they insist on giving you P(A|B), P(B|A), P(A) and P(B), and the four numbers dont satisfy the bayes rule]
• Answer: No—as long as we only ask the friend to fill up the CPTs in the bayes network, there is no way the numbers won’t makeup a consistent joint probability distribution
– This should be seen as a feature..• Personal Probabilities
– John may be an optimist and believe that P(burglary)=0.01 and Tom may be a pessimist and believe that P(burglary)=0.99
– Bayesians consider both John and Tom to be fine (they don’t insist on an objective frequentist interpretation for probabilites)
– However, Bayesians do think that John and Tom should act consistently with their own beliefs
• For example, it makes no sense for John to go about installing tons of burglar alarms given his belief, just as it makes no sense for Tom to put all his valuables on his lawn

Blog Questions (3)
• Your friend heard your claims that Bayes Nets can represent any possible conditional independence assertions exactly. He comes to you and says he has four random variables, X, Y, W and Z, and only TWO conditional independence assertions:
X .ind. Y | {W,Z}W .ind. Z | {X, Y}
He dares you to give him a bayes network topology on these four nodes that exactly represents these and only these conditional independencies. Can you? (Note that you only need to look at 4 vertex directed graphs).
• Answer: No this is not possible.• Here are two “wrong” answers
– Consider a disconnected graph where X, Y, W, Z are all unconnected. In this graph, the two CIAs hold. However, unfortunately so do many other CIAs
– Consider a graph where W and Z are both immediate parents of X and Y. In this case, clearly, X .ind. Y| {W,Z}. However, W and Z are definitely dependent given X and Y (Explaining away).
• Undirected models can capture these CIA exactly. Consider a graph X is connected to W and Z; and Y is connected to W and Z (sort of a diamond).
– In undirected models CIA is defined in terms of graph separability
– Since X and Y separate W and Z (i.e., every path between W and Z must pass through X and Y), W .ind. Z|{X,Y}. Similarly the other CIA
• Undirected graphs will be unable to model some scenarios that directed ones can; so you need both…
• There are also distributions that neither undirected nor directed models can perfect-map (see picture above)
• If we can’t have perfect map, we can consider giving up either I-map or a d-map
– Giving up I-map leads to loss of accuracy (since your model assumes CIAs that don’t exist in the distribution). It can however increase efficiency (e.g. naïve bayes models)
– Giving up D- map leads to loss of efficiency but preserves accuracy (if you think more things are connected than really are, you will assess more probabilities—and some of them wind up being redundant anyway because of the CIAs that hold in the distribution)
Given a graphical model G, and a distribution D,G is an I-map of D if every CIA reflected in G actually holds in D [“soundness”]G is a D-map of D if every CIA of D is reflected in G [“completeness”]G is a perfect map of D if it is both I-map and D-map
BN
All distributions
MN
Distributions that can have a perfect map in terms of a bayes network X
Y
WZ
An MN that BN can’t represent
X Y
Z
A BN that MN can’t represent

Bayes Nets are not sufficient to model all sets of CIAs
• We said that a bayes net implicitly represents a bunch of CIA
• Qn. If I tell you exactly which CIA hold in a domain, can you give me a bayes net that exactly models those and only those CIA?– Unfortunately, NO. (See the example to the right)– This is why there is another type of graphical
models called “undirected graphical models”• In an undirected graphical model, also called a
markov random field, nodes correspond to random variables, and the immediate dependencies between variables are represented by undirected edges.
– The CIA modeled by an undirected graphical model are different
» X || Y | Z in an undirected graph if every path from a node in X to a node in Y must pass through a node in Z (so if we remove the nodes in Z, then X and Y will be disconnected)
– Undirected models are good to represent “soft constraints” between random variables (e.g. the correlation between different pixels in an image) while directed models are good for representing causal influences between variables
Give a bayes net onX,Y,Z,W s.t. X||Y|(Z,W) Z||W|(X,Y)And no other C.I.
Impossible
!
X
Y
WZ
Added after class

Factorization as the basis for Graphical Models
• Both Bayes Nets and Markov Nets can be thought of representing joint distributions that have a particular way of being factorized– Analogy: Think of an integer that can be factorized in a certain way
• Bayes netsThe factors are CPTs (for each node given its immediate parents). Joint distribution is the product of CPTs.– Analogy: Think of an integer that can be factorized into a product of 4
unique prime numbers• Markov netsThe factors are potential functions (for cliques of nodes
in the net, we give “numbers” roughly representing the weight for each of their joint configurations.). They have no probabilistic interpretation. The joint is the normalized product of these potential functions.– Analogy: Think of an integer that can be factorized into a product of 4
unique prime numbers.
Added after class

Conjunctive queries are essentially computing joint distributions on sets of query variables. A special case of computing the full joint on query variables is finding just the query variable configuration that isMost likely given the evidence. There are two special cases here
MPE—Most Probable Explanation Most likely assignment to all other variables given the evidence Mostly involves max/product
MAP—Maximum a posteriori Most likely assignment to some variables given the evidence
Can involve, max/product/sum operations

0th idea for Bayes Net Inference
• Given a bayes net, we can compute all the entries of the joint distribution (by just multiplying entries in CPTs)
• Given the joint distribution, we can answer any probabilistic query.
• Ergo, we can do inference on bayes networks• Qn: Can we do better?
– Ideas: • Implicity enumerate only the part of the joint that is needed• Use sampling techniques to compute the probabilities

Network Topology & Complexity of Inference
Singly Connected Networks (poly-trees – At most one path between any pair of nodes)Inference is polynomial
Cloudy
Sprinklers Rain
Wetgrass
Multiply- connectedInference NP-hard
Can be convertedto singly-connected(by merging nodes)
Cloudy
Wetgrass
Sprinklers+Rain (takes 4 values 2x2)
The “size” of the m
erged network can be
Exponentially larger (so polynom
ial inferenceon that netw
ork isn’t exactly god’s gift

Examples of singly connected networks include Markov Chains and Hidden Markov Models

Overview of BN Inference Algorithms
Exact Inference• Algorithms
– Enumeration– Variable elimination
• Avoids the redundant computations of Enumeration
– [Many others such as “message passing” algorithms, Constraint-propagation based algorithms etc.]
Approximate Inference • Algorithms
– Based on Stochastic Simulation• Sampling from empty networks• Rejection sampling• Likelihood weighting • MCMC [And many more]
TONS OF APPROACHES
• Complexity– NP-hard (actually #P-Complete; since we “count” models)
• Polynomial for “Singly connected” networks (one path between each pair of nodes)
– NP-hard also for absolute and relative approximation

3/26

Independence in Bayes Networks:Causal Chains; Common Causes;
Common Effects
Causal chain (linear) X causes Y through Z is blocked if Z is given
Common Cause (diverging) X and Y are caused by Z is blocked if Z is given
Common Effect (converging) X and Y cause Z is blocked only if neither Z nor its descendants are given

D-sep (direction dependent Separation)• X || Y | E if every
undirected path from X to Y is blocked by E
– A path is blocked if there is a node Z on the path s.t.
1. [Z] Z is in E and Z has one arrow coming in and another going out
2. [Z] is in E and Z has both arrows going out
3. [Z] Neither Z nor any of its descendants are in E and both path arrows lead to Z
B||M|A(J,M)||E | AB||E
B||E | AB||E | M

Topological Semantics
Indep
enden
ce fr
om
Non-d
esce
dants
holds
Given ju
st th
e par
ents
Indep
enden
ce fr
om
Every
nod
e hold
s
Given m
arkov
blan
ket
These two conditions are equivalent Many other conditional indepdendence assertions follow from these
Markov Blanket Parents;Children;Children’s other parents


If the expression tree is evaluated in a depth first fashion, then the space requirement is linear..

fA(a,b,e)*fj(a)*fM(a)+fA(~a,b,e)*fj(~a)*fM(~a)+

Complexity depends on the size of the largest factor which in turn depends on the order in which variables are eliminated..
A join..


*Read Worked Out Example of Variable Elimination in the Lecture
Notes*

A More Complex Example
Visit to Asia
Smoking
Lung CancerTuberculosis
Abnormalityin Chest
Bronchitis
X-Ray Dyspnea
• “Asia” network:
[From Lise Getoor’s notes]

V S
LT
A B
X D
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: v,s,x,t,l,a,b
Initial factors

V S
LT
A B
X D
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: v,s,x,t,l,a,b
Initial factors
Eliminate: v
Note: fv(t) = P(t)In general, result of elimination is not necessarily a probability term
Compute: v
v vtPvPtf )|()()(
),|()|(),|()|()|()()( badPaxPltaPsbPslPsPtfv

V S
LT
A B
X D
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: s,x,t,l,a,b
• Initial factors
Eliminate: s
Summing on s results in a factor with two arguments fs(b,l)In general, result of elimination may be a function of several variables
Compute: s
s slPsbPsPlbf )|()|()(),(
),|()|(),|()|()|()()( badPaxPltaPsbPslPsPtfv
),|()|(),|(),()( badPaxPltaPlbftf sv
V S
LT
A B
X D
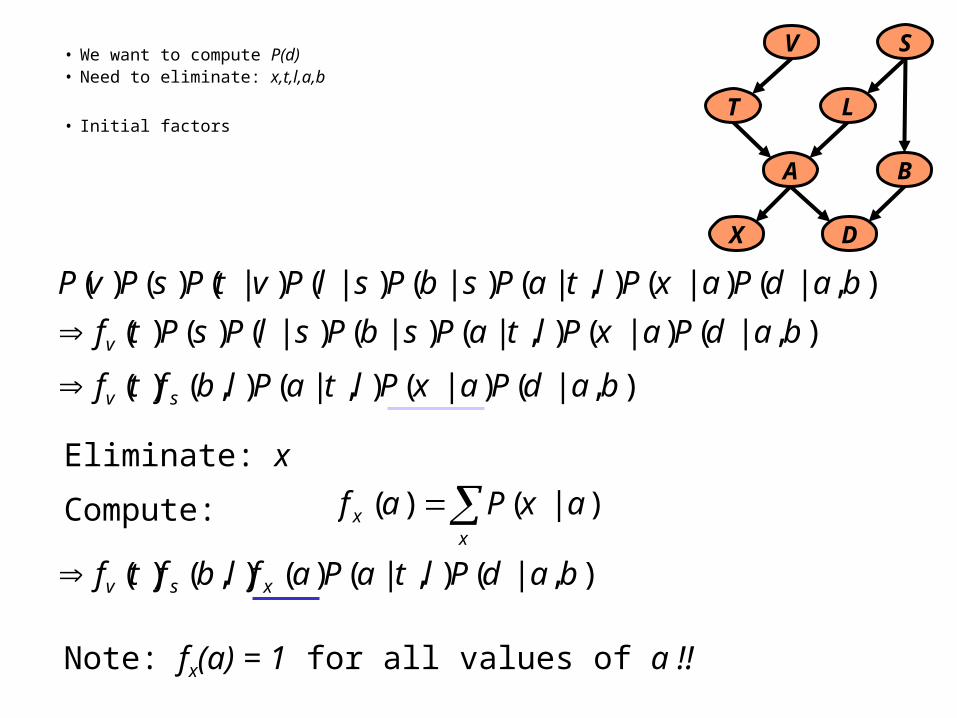
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: x,t,l,a,b
• Initial factors
Eliminate: x
Note: fx(a) = 1 for all values of a !!
Compute: x
x axPaf )|()(
),|()|(),|()|()|()()( badPaxPltaPsbPslPsPtfv
),|()|(),|(),()( badPaxPltaPlbftf sv
),|(),|()(),()( badPltaPaflbftf xsv

V S
LT
A B
X D
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: t,l,a,b
• Initial factors
Eliminate: t
Compute: t
vt ltaPtflaf ),|()(),(
),|()|(),|()|()|()()( badPaxPltaPsbPslPsPtfv
),|()|(),|(),()( badPaxPltaPlbftf sv
),|(),|()(),()( badPltaPaflbftf xsv
),|(),()(),( badPlafaflbf txs
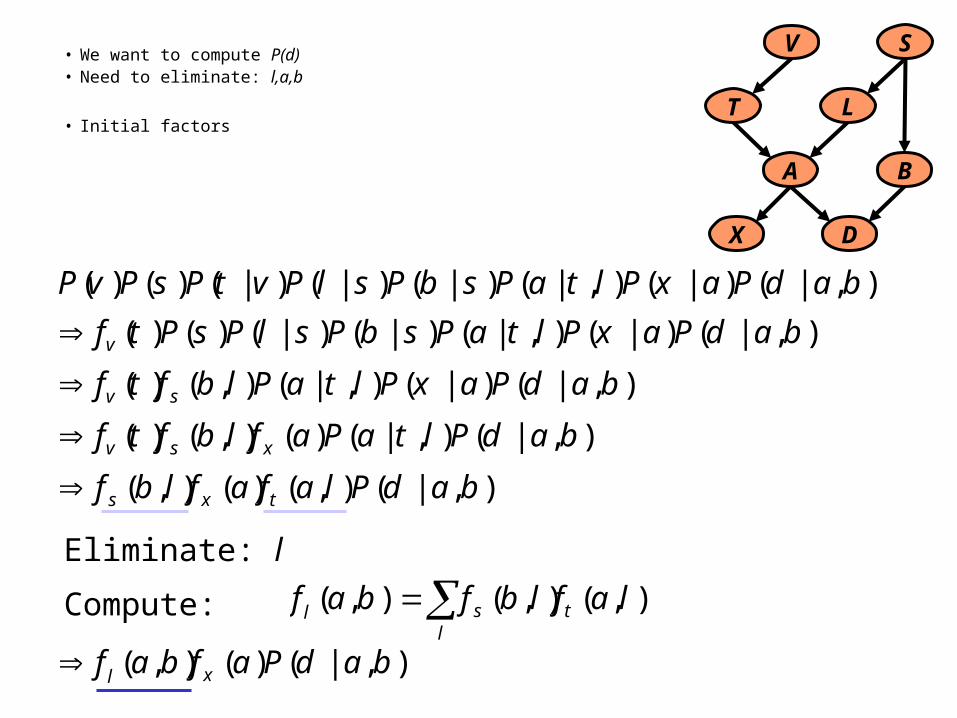
V S
LT
A B
X D
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: l,a,b
• Initial factors
Eliminate: l
Compute: l
tsl laflbfbaf ),(),(),(
),|()|(),|()|()|()()( badPaxPltaPsbPslPsPtfv
),|()|(),|(),()( badPaxPltaPlbftf sv
),|(),|()(),()( badPltaPaflbftf xsv
),|(),()(),( badPlafaflbf txs
),|()(),( badPafbaf xl
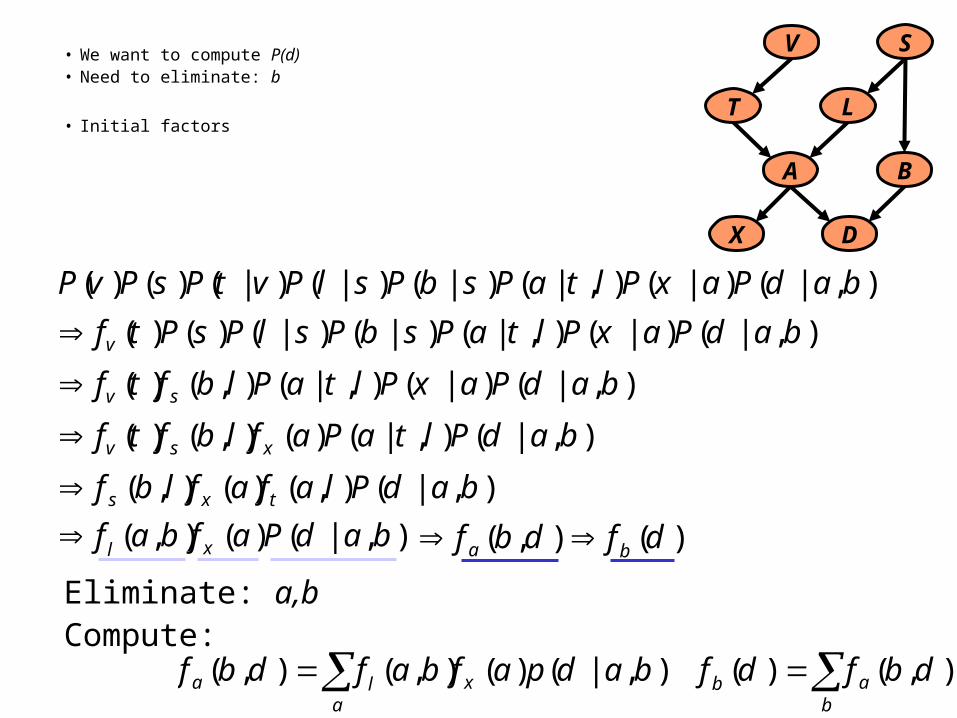
V S
LT
A B
X D
),|()|(),|()|()|()|()()( badPaxPltaPsbPslPvtPsPvP
• We want to compute P(d)• Need to eliminate: b
• Initial factors
Eliminate: a,bCompute:
b
aba
xla dbfdfbadpafbafdbf ),()(),|()(),(),(
),|()|(),|()|()|()()( badPaxPltaPsbPslPsPtfv
),|()|(),|(),()( badPaxPltaPlbftf sv
),|(),|()(),()( badPltaPaflbftf xsv
),|()(),( badPafbaf xl),|(),()(),( badPlafaflbf txs
)(),( dfdbf ba

Variable Elimination
• We now understand variable elimination as a sequence of rewriting operations
• Actual computation is done in elimination step
• Computation depends on order of elimination– Optimal elimination order can be computed—but is
NP-hard to do so
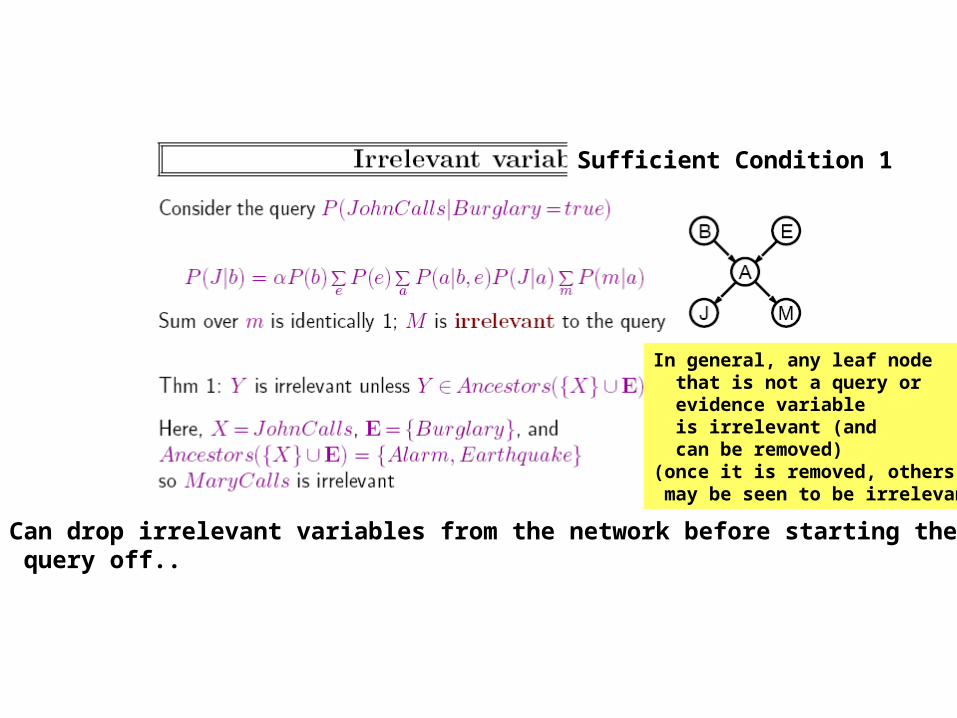
In general, any leaf node that is not a query or evidence variable is irrelevant (and can be removed)(once it is removed, others may be seen to be irrelevant)
Can drop irrelevant variables from the network before starting the query off..
Sufficient Condition 1

Sufficient Condition 2
Note that condition 2 doesn’t subsume condition 1. In particular, it won’t allow us to say that M is irrelevant for the query P(J|B)





























