Embed Size (px)
Citation preview

Outline
• Basic principle of MPI• Mixing MPI and CUDA• 1st example : parallel GPU detect• 2nd example: heat2D• CUDA-‐aware MPI, how and why• 3rd example: Jacobi• GPU Direct over RDMA
Examples are located here /scratch/id004914/cuda-‐mpiSee CREDITS.txt for proper acknowledgments
2

MPI OverviewMPI = Message Passing Interface • A specification of a set of functions with prescribed behavior (MPI 1.0, 1.1, 2.0, 2.1, 3.0, …)• Point-‐to-‐point, collective, one-‐sided, RDMA,…
• Not a library – there are multiple competing implementations of the specification • Two popular open-‐source implementations are OpenMPI(1.8) and MVAPICH2 (2.1)• Most MPI implementations from vendors are customized versions of these (e.g. Intel MPI)• Almost all open-‐source MPI implementation support Ethernet and high-‐speed interconnect (e.g. Infiniband)
3
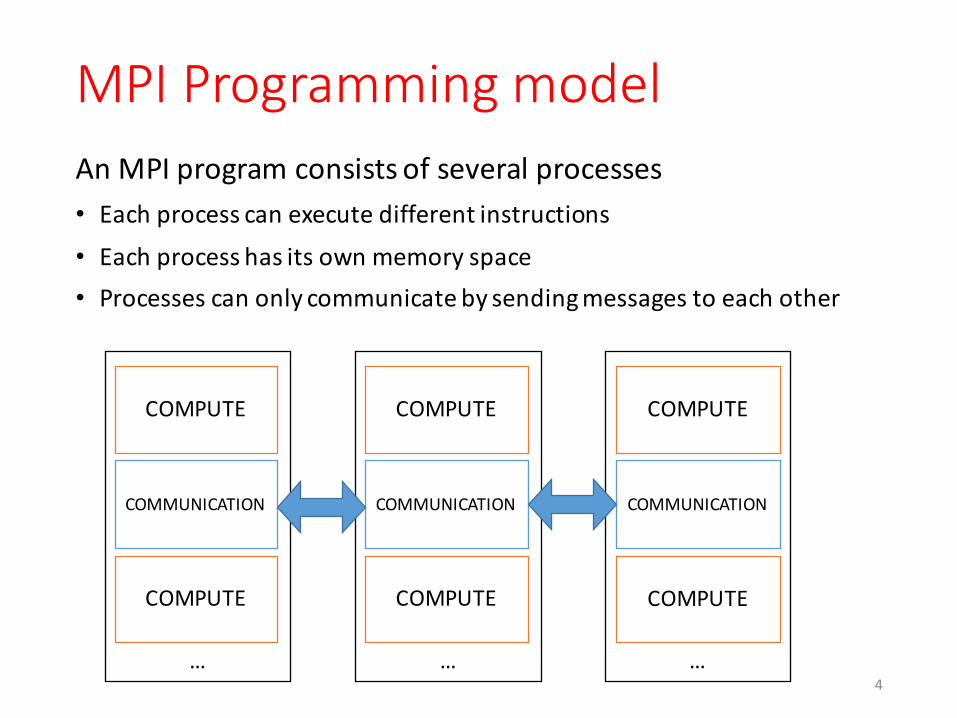
MPI Programming modelAn MPI program consists of several processes• Each process can execute different instructions• Each process has its own memory space• Processes can only communicate by sending messages to each other
4… …
COMPUTE COMPUTE
COMPUTE COMPUTE
COMMUNICATION COMMUNICATION
…
COMPUTE
COMPUTE
COMMUNICATION

Very common MPI routines
You can do (almost) everything with these MPI routines…• MPI_Init• MPI_Comm_Size• MPI_Comm_Rank• MPI_Send• MPI_Recv• MPI_Barrier• MPI_Finalize
5

An simple MPI program
6
int main(int argc, char *argv[]){
int myid, numprocs;int buffer[100];int tag=1234;MPI_Status status;
MPI_Init(&argc,&argv);MPI_Comm_size(MPI_COMM_WORLD,&numprocs);MPI_Comm_rank(MPI_COMM_WORLD,&myid);
if (myid == 0){MPI_Send(&buffer,100,MPI_INT,1,tag,MPI_COMM_WORLD);}
if (myid == 1){MPI_Recv(&buffer,100,MPI_INT,0,tag,MPI_COMM_WORLD,&status);
}
MPI_Finalize();}

A “slightly complex” MPI program
7
int main(int argc, char *argv[]) { MPI_Request req_in, req_out; MPI_Status stat_in, stat_out; float a[10], b[10];int mpi_rank, mpi_size;
MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &mpi_rank);MPI_Comm_size(MPI_COMM_WORLD, &mpi_size);
if (mpi_rank == 0) { MPI_Irecv(b, 10, MPI_FLOAT, 1, 200, MPI_COMM_WORLD, &req_in); MPI_Isend(a, 10, MPI_FLOAT, 1, 300, MPI_COMM_WORLD, &req_out);
} if (mpi_rank == 1) {
MPI_Irecv(b, 10, MPI_FLOAT, 0, 300, MPI_COMM_WORLD, &req_in); MPI_Isend(a, 10, MPI_FLOAT, 0, 200, MPI_COMM_WORLD, &req_out);
}
MPI_Waitall(1, &req_in, &stat_in); MPI_Waitall(1, &req_out, &stat_out); MPI_Finalize();
}

A closer look…
intMPI_Init ( int *argc, char ***argv )Initialises the MPI execution environment intMPI_Comm_size ( MPI_Comm comm, int *size )Determines the size of the group associated with a communicator intMPI_Comm_rank ( MPI_Comm comm, int *rank )Determines the rank of the calling process in the communicator intMPI_Finalize ()Terminates MPI execution environment
8

A closer look…
int MPI_Irecv ( void *buf, int count, MPI_Datatypedatatype, intsource, int tag, MPI_Commcomm, MPI_Request*request ) • buf: memory location for message• count: number of elements in message• datatype: type of elements in message (e.g. MPI_FLOAT)• source: rank of source• tag: message tag• comm: communicator• request: communication request (used for checking message status)
9

Compile and run MPI program
• MPI implementations provide wrappers for popular compilers • These are normally named mpicc/mpicxx/mpif77 etc. • Wrappers call normal compilers and add automatically everything is needed to link MPI library
• Running an MPI program normally through mpirun or mpiexec• Commands slightly change parameters based of MPI library• Always be aware and careful about process binding and task affinity
• MPI runtimes manage the utilization of the best interconnect available on the node
10

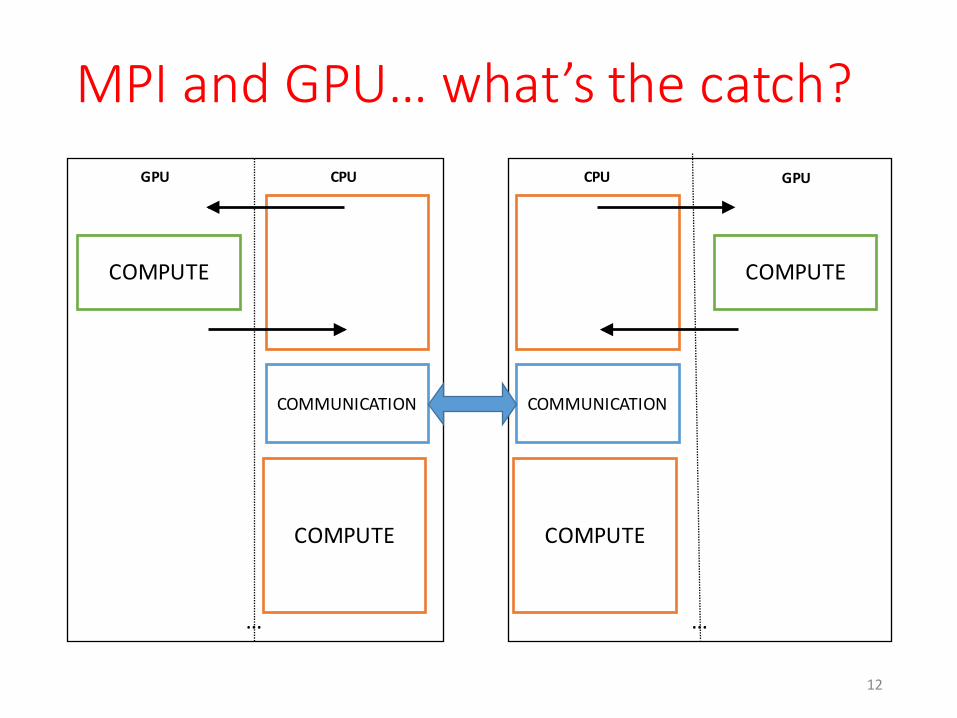
MPI and GPU… what’s the catch?• MPI processes have their own separate memory space• CPU and GPU have their own memory space• I distribute data across MPI processes (coarse-‐grain parallelism)• I can move some (or all?) local computation from CPU to GPU to accelerate it (fine-‐grain parallelism)• MPI communication occur on the HOST sides
11
12. April 2013
MPI + CUDA
PCI-e
GPUGPU
GDDR5Memory
SystemSystem
MemoryMemory
CPUCPU
NetworkNetwork
CardCard
Node 0
PCI-e
GPUGPU
GDDR5Memory
SystemSystem
MemoryMemory
CPUCPU
NetworkNetwork
CardCard
Node n-1
PCI-e
GPUGPU
GDDR5Memory
SystemSystem
MemoryMemory
CPUCPU
NetworkNetwork
CardCard
Node 1
…
MPI and GPU… what’s the catch?
12
…
COMMUNICATION
…
COMMUNICATION
COMPUTECOMPUTE
CPU CPU
COMPUTE COMPUTE
GPUGPU
MPI and GPU
1312. April 2013
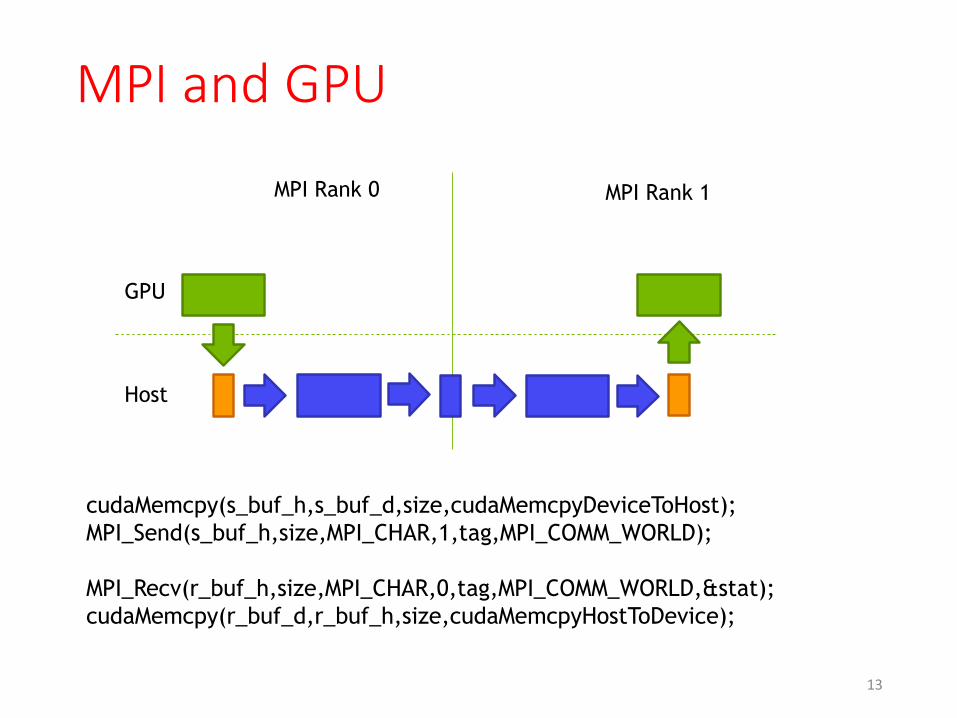
Regular MPI GPU to local GPU
MPI Rank 0 MPI Rank 1
GPU
Host
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost);
MPI_Send(s_buf_h,size,MPI_CHAR,1,tag,MPI_COMM_WORLD);
MPI_Recv(r_buf_h,size,MPI_CHAR,0,tag,MPI_COMM_WORLD,&stat);
cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost);MPI_Send(s_buf_h,size,MPI_CHAR,1,tag,MPI_COMM_WORLD);
MPI_Recv(r_buf_h,size,MPI_CHAR,0,tag,MPI_COMM_WORLD,&stat);
cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost);
MPI_Send(s_buf_h,size,MPI_CHAR,1,tag,MPI_COMM_WORLD);
MPI_Recv(r_buf_h,size,MPI_CHAR,0,tag,MPI_COMM_WORLD,&stat);cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost);
MPI_Send(s_buf_h,size,MPI_CHAR,1,tag,MPI_COMM_WORLD);
MPI_Recv(r_buf_h,size,MPI_CHAR,0,tag,MPI_COMM_WORLD,&stat);
cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost);
MPI_Send(s_buf_h,size,MPI_CHAR,1,tag,MPI_COMM_WORLD);
MPI_Recv(r_buf_h,size,MPI_CHAR,0,tag,MPI_COMM_WORLD,&stat);
cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);

Example 1: query GPU (BASIC)
For each MPI process (order by rank):
Check how many GPU are visible by each MPI process
For each visible GPU:
Query GPU information and print them
Questions:• How can I print output ordered by rank?• How many GPU each MPI see?• How can I assign a specific GPU to a specific MPI?
14
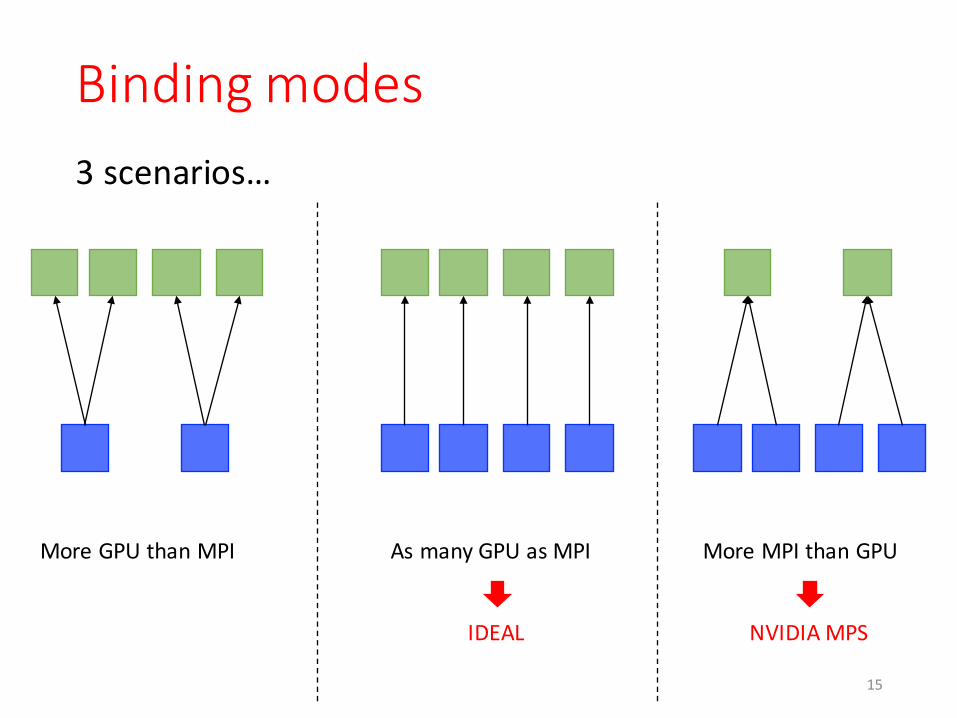
Binding modes3 scenarios…
15
More GPU than MPI As many GPU as MPI More MPI than GPU
IDEAL NVIDIA MPS

Assign GPUs to MPI processes
How can I assign GPU to MPI?• Internally in the application using cudaSetDevice()
• You need to know what you are doing…
• Externally from a “scheduler point of view” by change environment variable CUDA_VISIBLE DEVICES based on local MPI rank on a node• MV2_COMM_WORLD_LOCAL_RANK for MVAPICH2• OMPI_COMM_WORLD_LOCAL_RANK for OpenMPI
• Externally from a “system perspective” by changing COMPUTE mode of a GPU to exclusive• This force 1:1 MPI-‐GPU binding
16

Example 2: heat2D (COMPLEX)
In 2D:
For which a possible finite difference approximation is:
where the temperature change over a time interval and i,j are indices into a uniform structured grid
17
2D heat conduction
• In 2D:
• For which a possible finite difference approximation is:
where ΔT is the temperature change over a time Δt and i,j are indices into a uniform structured grid (see next slide)
€
∂T
∂t=α
∂ 2T
∂x 2+∂ 2T
∂y 2
€
ΔT
Δt=α
Ti+1, j − 2Ti, j + Ti−1, j
Δx 2+Ti, j+1 − 2Ti, j + Ti, j−1
Δy 2
2D heat conduction
• In 2D:
• For which a possible finite difference approximation is:
where ΔT is the temperature change over a time Δt and i,j are indices into a uniform structured grid (see next slide)
€
∂T
∂t=α
∂ 2T
∂x 2+∂ 2T
∂y 2
€
ΔT
Δt=α
Ti+1, j − 2Ti, j + Ti−1, j
Δx 2+Ti, j+1 − 2Ti, j + Ti, j−1
Δy 2
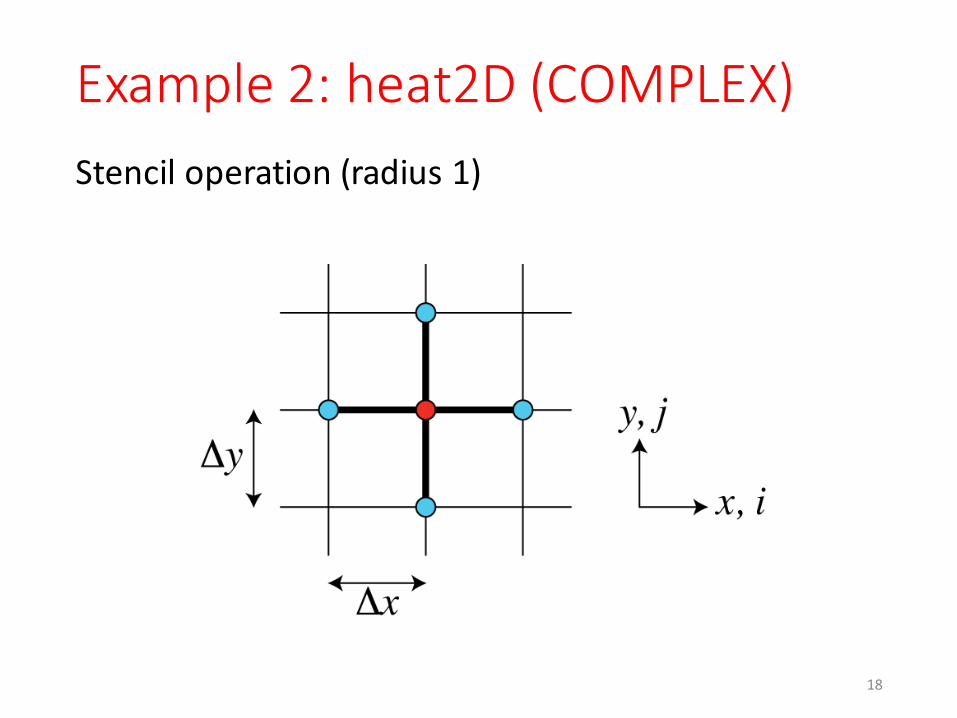
Example 2: heat2D (COMPLEX)Stencil operation (radius 1)
18
Stencil
Update red point using data from blue points (and red point)
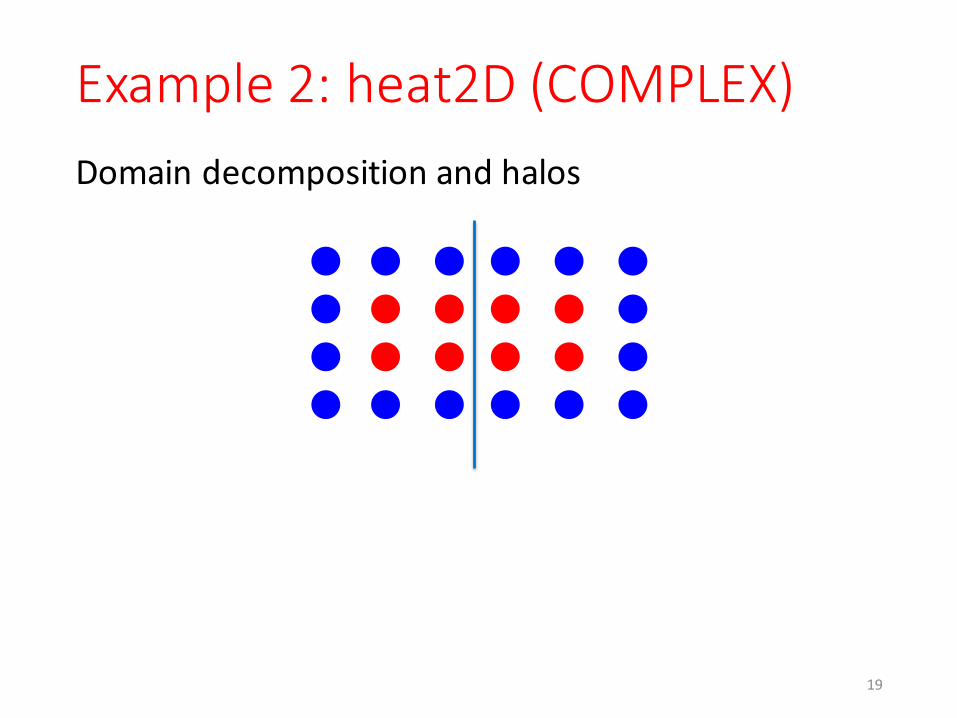
Example 2: heat2D (COMPLEX)Domain decomposition and halos
19
Domain decomposition and halos
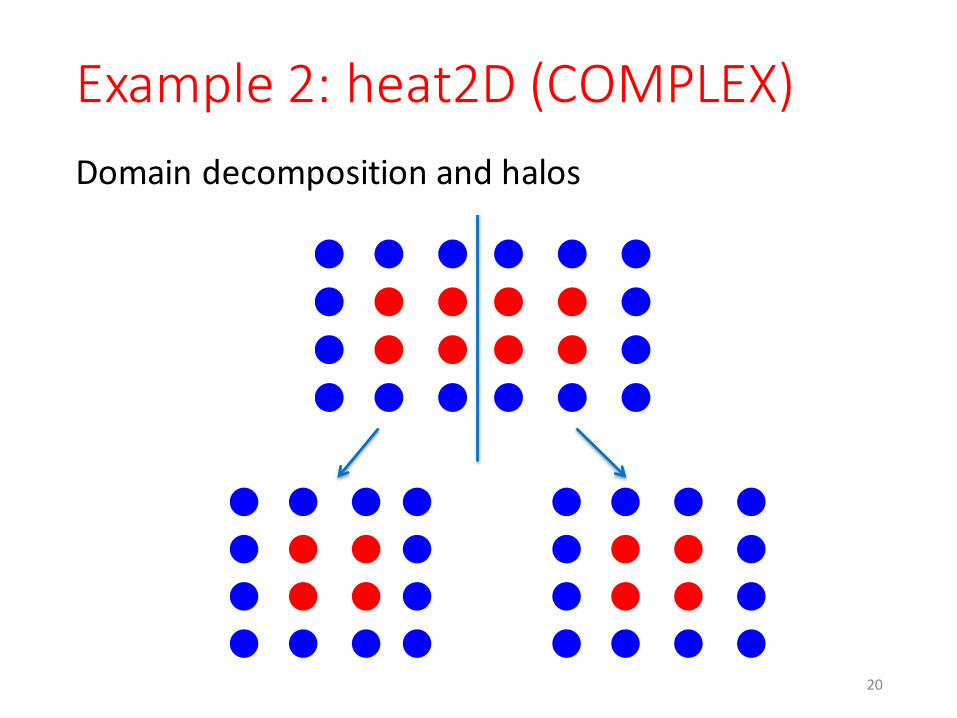
Example 2: heat2D (COMPLEX)
20
Domain decomposition and halosDomain decomposition and halos
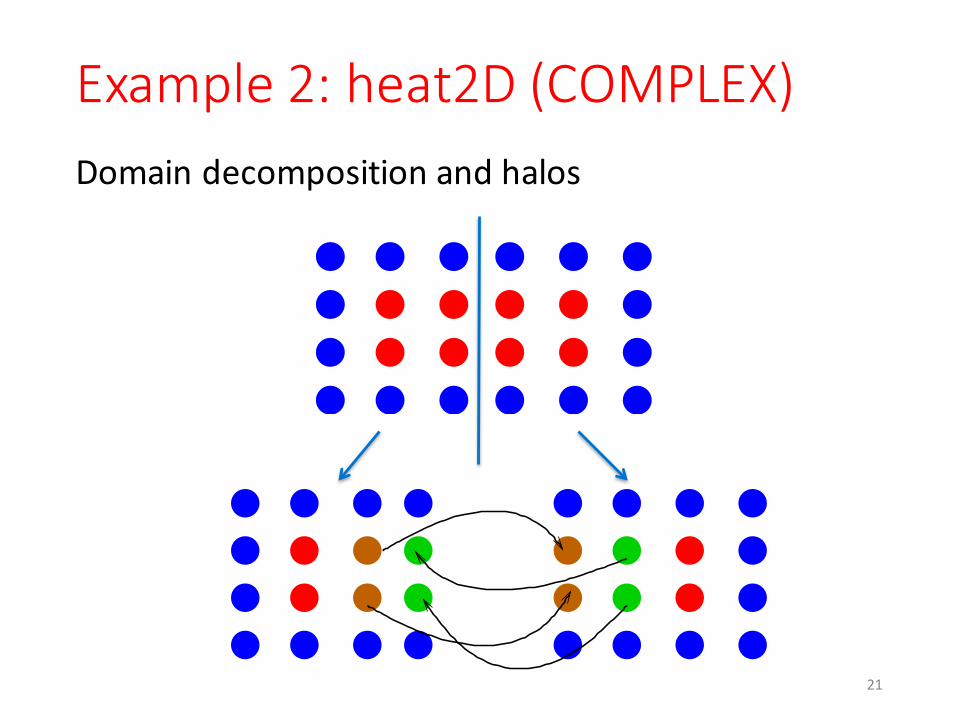
Example 2: heat2D (COMPLEX)
21
Domain decomposition and halosDomain decomposition and halos

Example 2: heat2D (COMPLEX)Communication pattern: • The left-‐most rank sends data to the right• The inner ranks send data to both the left and the right• The right-‐most rank sends data to the left
MPI can read and write directly from 2D arrays using an advanced feature called datatypes (but this is complicated for GPUs).
Message-‐passing strategy: • Fill outgoing buffers (2D -‐> 1D)• Send from outgoing buffers, receive into incoming buffers• Wait• Fill arrays from incoming buffers (1D -‐> 2D)
22

Example 2: heat2D (COMPLEX)
Message-‐passing strategy with GPUs:• Fill outgoing buffers on GPU using a kernel (2D -‐> 1D)• Copy buffers to CPU -‐ cudaMemcpy(DeviceToHost)• Send from outgoing buffers, receive into incoming buffers• Wait• Copy buffers to GPU -‐ cudaMemcpy(HostToDevice)• Fill arrays from incoming buffers on GPU using a (1D -‐> 2D)
PLUS (not implemented)• Pinned memory and asynchronous data-‐transfer
23

Scaling and GPU
When benchmarking MPI applications, we look at two issues:• Strong scaling – how well does the application scale with multiple processors for a fixed problem size?
• Weak scaling – how well does the application scale with multiple processors for a fixed problem size per processor?
Achieving good scaling is more difficult with GPUs for mainly two reasons: • There is an extra memory copy (H2D/D2H) involved for every message • If CUDA kernels are much faster then the MPI communication becomes a larger fraction of the overall runtime
24

MPI and GPU
25
12. April 2013
Regular MPI GPU to local GPU
memcpy H->DMPI_Sendrecvmemcpy D->H
Time
Can I do better? Can this be “simpler”?
We learnt that we need to copy back/forward from/to GPU before communicate data to other MPI processes…
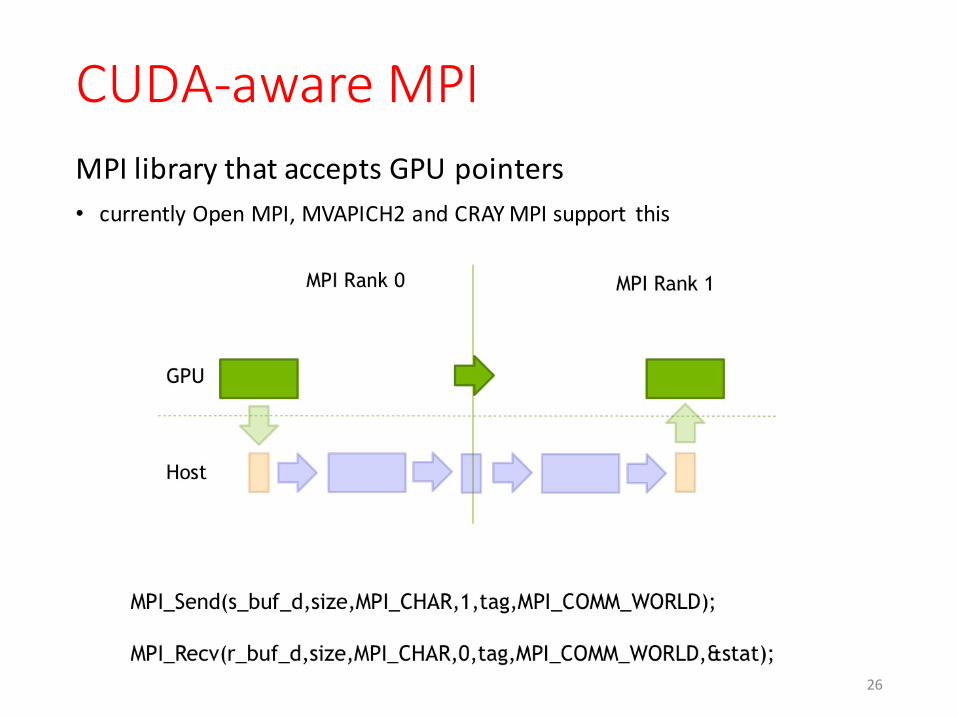
CUDA-‐aware MPIMPI library that accepts GPU pointers• currently Open MPI, MVAPICH2 and CRAY MPI support this
26
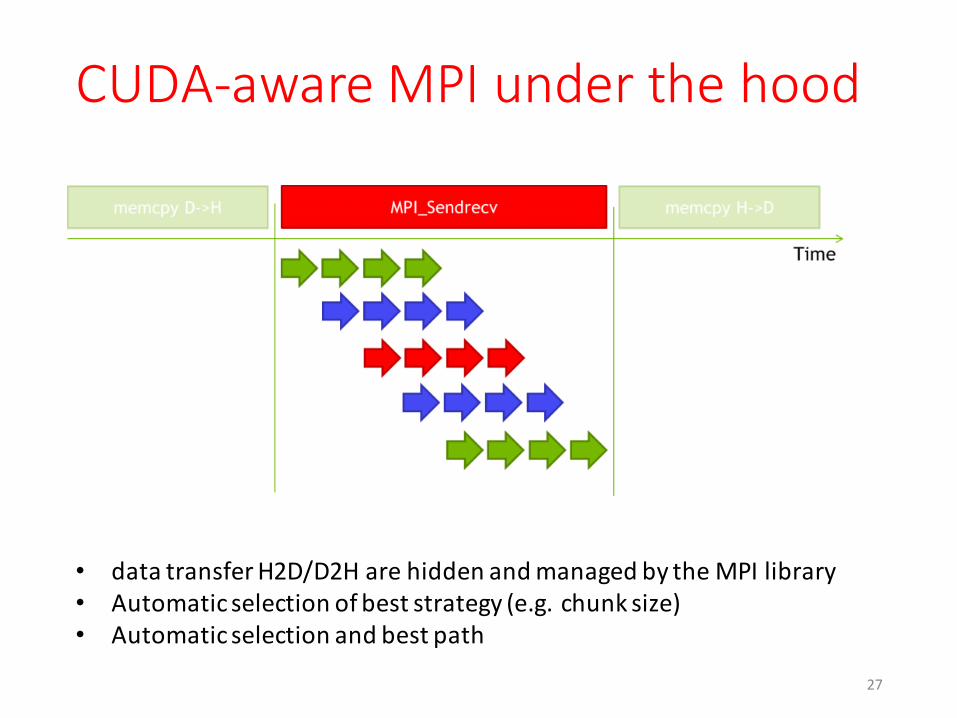
CUDA-‐aware MPI under the hood
27
• data transfer H2D/D2H are hidden and managed by the MPI library• Automatic selection of best strategy (e.g. chunk size)• Automatic selection and best path

Example 3: Jacobi (ADVANCED)It solves the Poisson equation on a rectangle with Dirichletboundary conditions.
2D data decompositionhalo exchange
What to do…• Play with/without CUDA-‐aware• Play with local/global domain sizes• check performance and scalability
28

Can I do even better?No matter if you do explicitly H2D/D2H copies or you let MPI do it for you… you always need to reallocate some memory on the HOST! Waste of resources!
2912. April 2013
NVIDIA GPUDirectTM
Accelerated communication with network & storage devices
GPUDirect technology, introduced with CUDA 3.1. This feature allows the network fabric driver and the CUDA driver to share a common pinned buffer in order to avoids an unnecessary memcpy within host
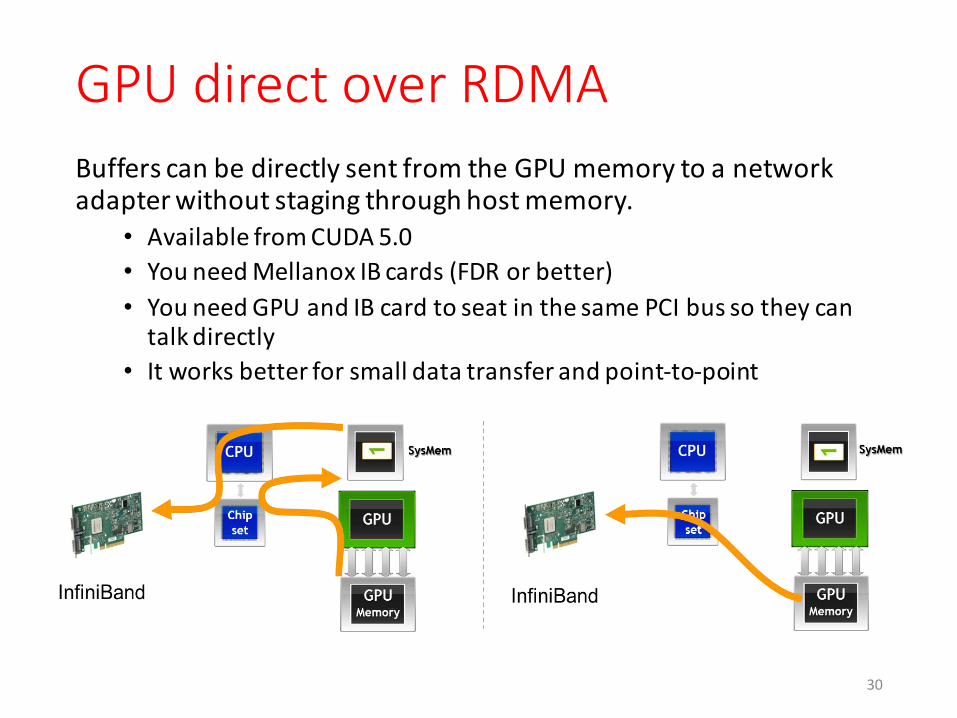
GPU direct over RDMABuffers can be directly sent from the GPU memory to a network adapter without staging through host memory.
• Available from CUDA 5.0 • You need Mellanox IB cards (FDR or better)• You need GPU and IB card to seat in the same PCI bus so they can talk directly
• It works better for small data transfer and point-‐to-‐point
30
12. April 2013
NVIDIA GPUDirectTM
Support for RDMA

CUDA-‐aware MPI conclusions
• CUDA-‐aware MPI works thank to UVA -‐-‐ Unified Virtual Addressing (introduced since CUDA 4.0)• host memory and the memory of all GPUs in a system (a single node) are combined into one large (virtual) address space.
• Easy programmability of MPI+CUDA applications• Small (manageable) constrain in portability
• MPI libraries need to support such functionality
• Better performance all operations that are required to carry out the message transfer can be pipelined• In principle always true but highly dependent by the quality of MPI implementation
• Acceleration technologies like GPU Direct over RDMA can be utilized by the MPI library transparently to the user.
31

Resources onlineTop 3 must-‐read links:
http://devblogs.nvidia.com/parallelforall/introduction-‐cuda-‐aware-‐mpi/
http://devblogs.nvidia.com/parallelforall/benchmarking-‐cuda-‐aware-‐mpi/
http://devblogs.nvidia.com/parallelforall/benchmarking-‐gpudirect-‐rdma-‐on-‐modern-‐server-‐platforms/
32






























