Embed Size (px)
Citation preview

CSCS-LCG2 (Phoenix cluster)
• Swiss Tier-2 for ATLAS, CMS and LHCb
• Currently providing 1.8PB of storage and ~26kHS06 – ~2k jobs running at all times – ~1k jobs in queue avg. / seen max of ~4k
• Has some particularities: – Using Infiniband QDR/FDR and 10GbE fabrics – GPFS 3.4 (soon 3.5) as scratch filesystem for all jobs – 20Gb/s connectivity to the world – Running ARC and CREAM CEs
© CSCS 2014 - Miguel Gila 2
ATLAS, 40%
CMS, 40%
LHCb, 20%
CPU share ATLAS, 47%
CMS, 47%
LHCb, 6%
Storage share

Moving to SLURM
• Previously running Torque/Moab for ~3 years
• Decided to move to SLURM because – License renewal implied upgrading to new Torque version – Moab license is expensive – We have SLURM knowledge and development in-house – SLURM is the site-wide reference scheduler
• Details of the migration – Tested in development environment for ~2 months
– Developed a number of scripts for monitoring – Mostly Ganglia: look at
http://wiki.chipp.ch/twiki/bin/view/LCGTier2/PhoenixMonOverview
– Migrated 76 WNs, 4 CREAM-CEs, 2 ARC-CEs and 2 LRMS
– ~2 months rollover upgrade (Sept. 4, Nov. 11)
© CSCS 2014 - Miguel Gila 3

Our evaluation of SLURM
• What we like about SLURM
– Works great with MC jobs (no configuration changes to support it!)
– SLURM itself is very easy to configure & deploy: – 1 general configuration file + optional extra configuration
files – 1 configuration file for accounting DB – RPMs easily built
– Stores accounting information on a DB (MySQL)
– HA works for the scheduler (Master/Slave) and accounting DB (Master/Slave out of the box, Master/Master easy to do)
– Easy integration with node health check scripts (~WN black hole
detector)
– Easily customizable (prolog/epilog) © CSCS 2014 - Miguel Gila 4
Our evaluation of SLURM
• More things we like – Scales up very well: Piz Daint @CSCS runs SLURM; 1 control node
with 32GB, 16 core manage 5.2k nodes, 5.2k GPUs, ~6.2PF
http://www.cscs.ch/computers/piz_daint/index.html
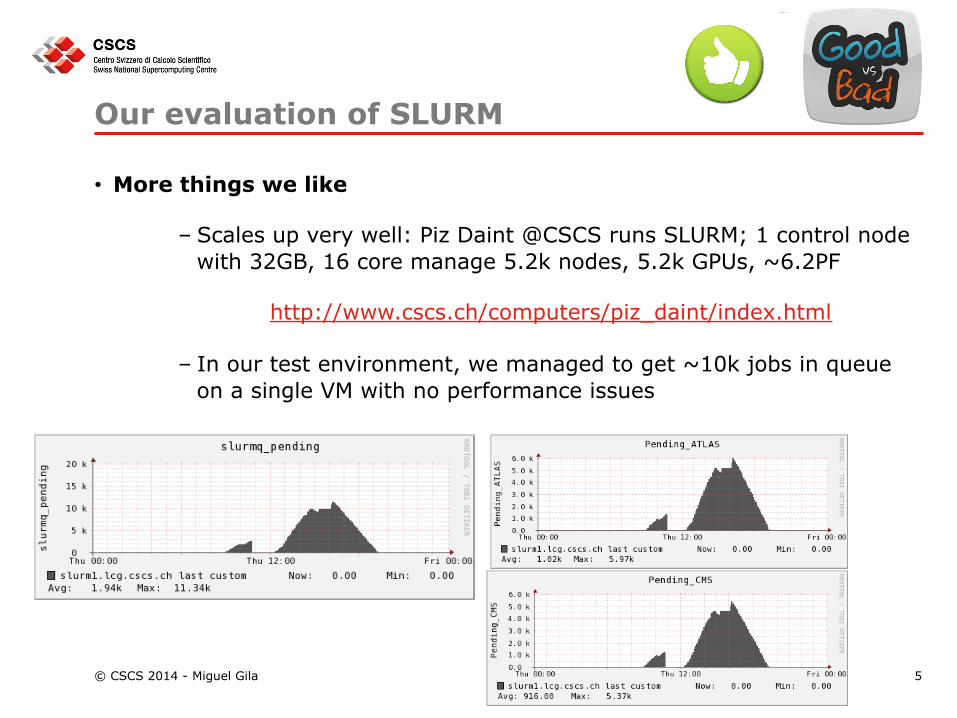
– In our test environment, we managed to get ~10k jobs in queue on a single VM with no performance issues
© CSCS 2014 - Miguel Gila 5

Our evaluation of SLURM
• What we don’t like (and problems encountered along the way)
– Some SLURM versions have serious bugs – 2.6.2 breaks when reserving single slots for OPS jobs – Stay away from new features!
– SLURM accounting, fair share and QoS are complicated to set up
– Accounting DB can become a bottleneck if not properly planned and configured
– we run it on the same servers that run the SLURM control daemons: 2 VMs with 8 core and 16GB RAM
– my.cnf needs some tweaking
– Command line syntax is not consistent across different s* tools
– Having a common API to query SLURM would be great (currently calling s* commands and parsing output)
© CSCS 2014 - Miguel Gila 6

Support & Documentation
• Support: – Rely on the community:
– [email protected] – [email protected]
– Pay SchedMD for support: – In our experience on a ‘small’ T2, it hasn’t been necessary – In the case of bigger clusters/supercomputers, it is a must
– Have development in-house: – Not always making sense, but very useful if you have special
requirements (in our case, integration with Cray systems)
• Documentation: – Excellent man pages – Excellent online docs on topics not covered by man pages:
http://slurm.schedmd.com/documentation.html © CSCS 2014 - Miguel Gila 7

The middleware
• CREAM-CE: – Recently found a serious bug in CREAM that marks jobs as failed
when they completed OK. Quickly fixed by CREAM devs – Information system didn’t fully work when we migrated (=had to
build our own glite-info-dynamic-ce) • ARC-CE:
– Worked ok from the beginning (small recent update for MC jobs) • APEL:
– Accounting migration from APEL EMI-2 to EMI-3 has been necessary and quite laborious
– Several bugs in APEL parser running on CREAM CEs spotted and solved
– SLURM had some problems managing the Daylight Saving Time changes: this messed up the APEL client DB and we spent a lot of time fixing the DB
– In general, the EMI-3 APEL was not ready for SLURM, but all major issues should be solved now thanks to the APEL support
© CSCS 2014 - Miguel Gila 8

Summarizing our experience
• Overall, SLURM itself works and scales well
• Unfortunately, the migration process has been painful as the middleware had some initial issues
• On the other hand, our experience will make it easier for other sites in the WLCG community
© CSCS 2014 - Miguel Gila 9

Questions?
© CSCS 2014 - Miguel Gila 10

Thank you for your attention.
© CSCS 2014 - Miguel Gila 11

Backup slides
© CSCS 2014 - Miguel Gila 12

SLURM processes
• slurmd: – runs on the clients (WN, ARC and CREAM)
• slurmctld: – it is the scheduler itself – runs on the control nodes (can be HA)
• slurmdbd: – it connects slurmctld and the accounting DB – runs on any node (usually control nodes, can be HA)
• mysqld: – runs anywhere (can be HA)
© CSCS 2014 - Miguel Gila 13
WN
slurmd
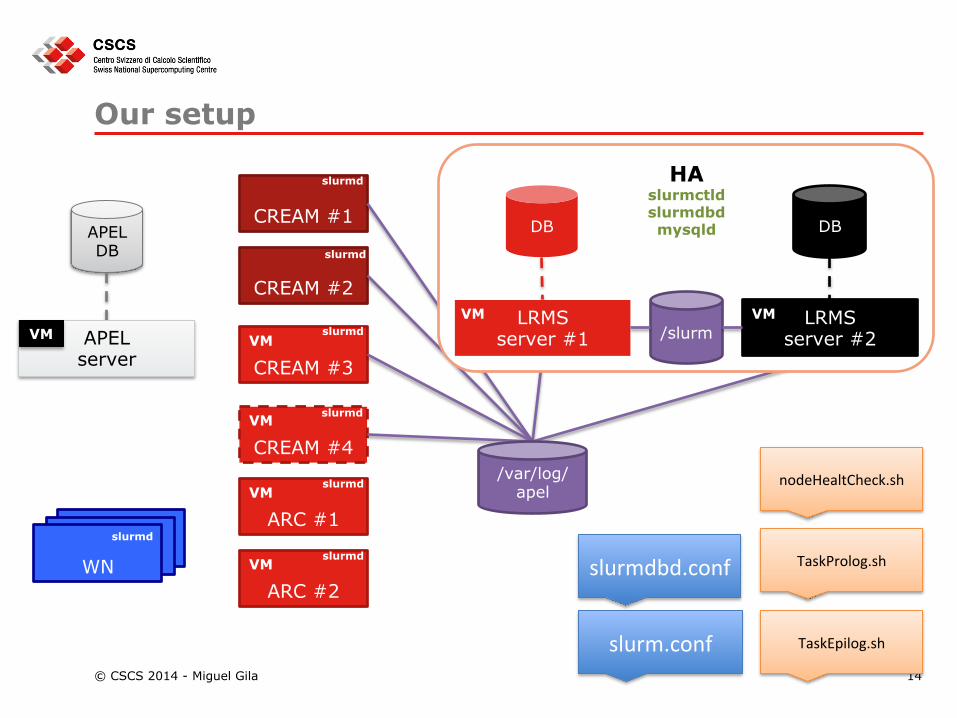
Our setup
© CSCS 2014 - Miguel Gila 14
CREAM #1
CREAM #2
CREAM #3
VM CREAM #4 VM
ARC #1 VM
ARC #2 VM
APEL DB
APEL server
VM VM
slurmd
slurmd
slurmd
slurmd
slurmd
slurmd
slurm.conf
slurmdbd.conf
nodeHealtCheck.sh
HA slurmctld slurmdbd mysqld DB DB
LRMS server #2
LRMS server #1
VM VM /slurm
/var/log/apel
TaskProlog.sh
TaskEpilog.sh
Configuration details
• 7 partitions (atlas, atlashimem, other, ops, lcgadmin, cms, lhcb) • All nodes are in all partitions/queues • 1 reservation for priority_jobs
– OPS + VO *sgm users – 2 nodes fully reserved (because of bug on slurm 2.6.2)
• TaskProlog.sh and TaskEpilog.sh empty • nodeHealthCheck.sh runs on all nodes every 3 minutes and checks for
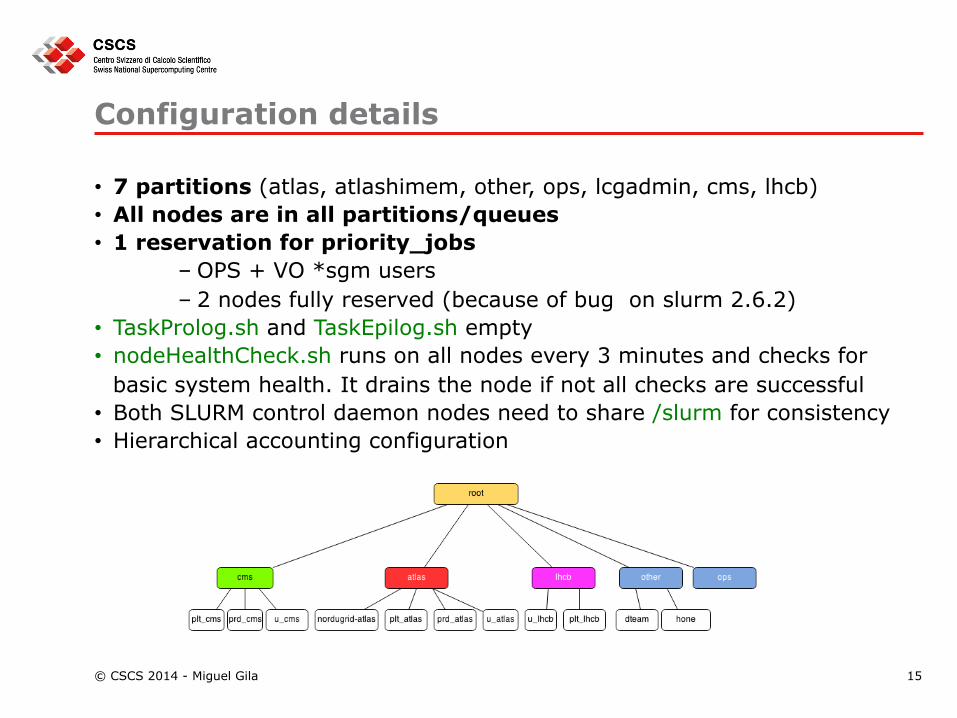
basic system health. It drains the node if not all checks are successful • Both SLURM control daemon nodes need to share /slurm for consistency • Hierarchical accounting configuration
© CSCS 2014 - Miguel Gila 15

slurm.conf
ControlMachine=slurm1 BackupController=slurm2 […] SlurmdSpoolDir=/tmp/slurmd TaskProlog=/etc/slurm/TaskProlog.sh TaskEpilog=/etc/slurm/TaskEpilog.sh AuthType=auth/munge SchedulerType=sched/backfill SelectType=select/cons_res SelectTypeParameters=CR_CPU_Memory TaskPlugin=task/none ProctrackType=proctrack/linuxproc DefaultStorageType=slurmdbd AccountingStorageType=accounting_storage/slurmdbd JobAcctGatherType=jobacct_gather/linux JobCompType=jobcomp/script JobCompLoc=/usr/share/apel/slurm_acc.sh AccountingStorageEnforce=limits HealthCheckInterval=180 HealthCheckProgram=/etc/slurm/nodeHealthCheck.sh […]
© CSCS 2014 - Miguel Gila 16
[…] PriorityType=priority/multifactor PriorityDecayHalfLife=07-12 PriorityFavorSmall=YES PriorityMaxAge=4-0 PriorityWeightAge=1000 PriorityWeightFairshare=5000 PriorityWeightJobSize=1000 PriorityWeightPartition=10000 PriorityWeightQOS=1000 FastSchedule=1 PreemptType=preempt/none […]






























