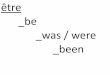Embed Size (px)
Citation preview

Apprentissage Statistique
Master IAD - Université Paris 6P. Gallinari
[email protected]://www-connex.lip6.fr/~gallinar/
Année 2012-2013Partie 2

Apprentissage dans les données structurées
IntroductionModèles discriminantsClassification dans les graphes : réseaux sociaux

Apprentissage Statistique - P. Gallinari 3
Machine learning and structured data
Different types of problems Model, classify, cluster structured data Predict structured outputs Learn to associate structured representations
Structured data and applications in many domains chemistry, biology, natural language, web, social networks,
data bases, etc
Apprentissage Statistique - P. Gallinari 4
Sequence labeling: Part Of Speech Tagging (POS)
This Workshop brings together scientists and engineersDT NN VBZ RB NNS CC NNS
interested in recent developments in exploiting MassiveVBN IN JJ NNS IN VBG JJdata setsNP NP
determiner noun Verb 3rd pers adverb Noun pluralCoord. Conj.
adjective Verb gerund
Verb plural

Apprentissage Statistique - P. Gallinari 5
PENN tag set
1. CC Coordinating conjunction 25.TO to 2. CD Cardinal number 26.UH Interjection 3. DT Determiner 27.VB Verb, base form 4. EX Existential there 28.VBD Verb, past tense 5. FW Foreign word 29.VBG Verb, gerund/present participle 6. IN Preposition/subord. 30.VBN Verb, past participle 7. JJ Adjective 31.VBP Verb, non-3rd ps. sing. present 8. JJR Adjective, comparative 32.VBZ Verb, 3rd ps. sing. present 9. JJS Adjective, superlative 33.WDT wh-determiner 10.LS List item marker 34.WP wh-pronoun 11.MD Modal 35.WP Possessive wh-pronoun 12.NN Noun, singular or mass 36.WRB wh-adverb 13.NNS Noun, plural 37. # Pound sign 14.NNP Proper noun, singular 38. $ Dollar sign 15.NNPS Proper noun, plural 39. . Sentence-final punctuation 16.PDT Predeterminer 40. , Comma 17.POS Possessive ending 41. : Colon, semi-colon 18.PRP Personal pronoun 42. ( Left bracket character 19.PP Possessive pronoun 43. ) Right bracket character 20.RB Adverb 44. " Straight double quote 21.RBR Adverb, comparative 45. ` Left open single quote 22.RBS Adverb, superlative 46. " Left open double quote 23.RP Particle 47. ' Right close single quote 24.SYM Symbol 48. " Right close double quote
Apprentissage Statistique - P. Gallinari 6
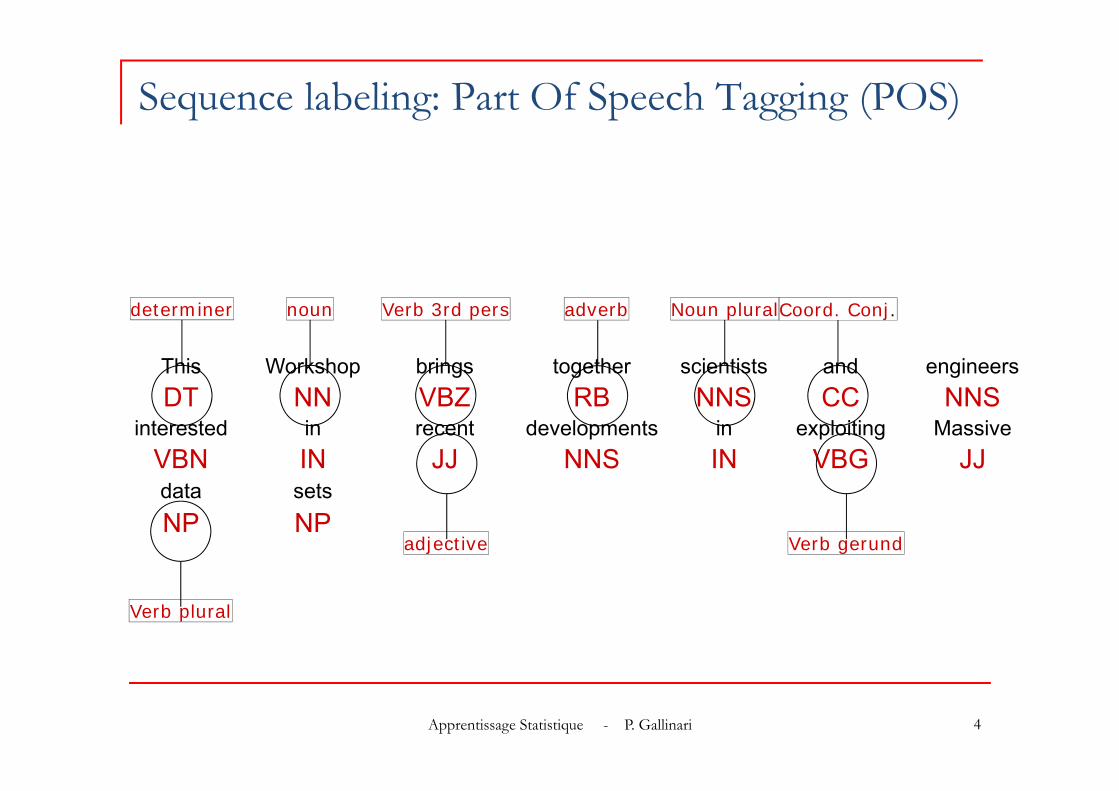
Segmentation + labeling: syntactic chunking (Washington Univ. tagger)
This Workshop brings together scientists and engineersNP VP ADVP NP
interested in recent developments inVP IN NP PNP
exploiting Massive data setsNP
Noun Phrase Verb Phrase Noun Phraseadverbial Phrase
Noun Phrase

Apprentissage Statistique - P. Gallinari 7
Segmentation + labeling: Named Entity Recognition Entities locations, persons, organizations Time expressions: dates, times Numeric expression: $ amount, percentages
NEW YORK (Reuters) - Goldman Sachs Group Inc. agreed on Thursday to pay $9.3 million to settle charges related to a former economist …. Goldman's GS.N settlement with securities regulators stemmed from charges that it failed to properly oversee John Youngdahl, a one-time economist …. James Comey, U.S.Attorney for the Southern District of New York, announced on Thursday a seven-count indictment of Youngdahl for insider trading, making false statements, perjury, and other charges. Goldman agreed to pay a $5 million fine and disgorge $4.3 million from illegal trading profits.
Apprentissage Statistique - P. Gallinari 8
Information Extraction
Apprentissage Statistique - P. Gallinari 9
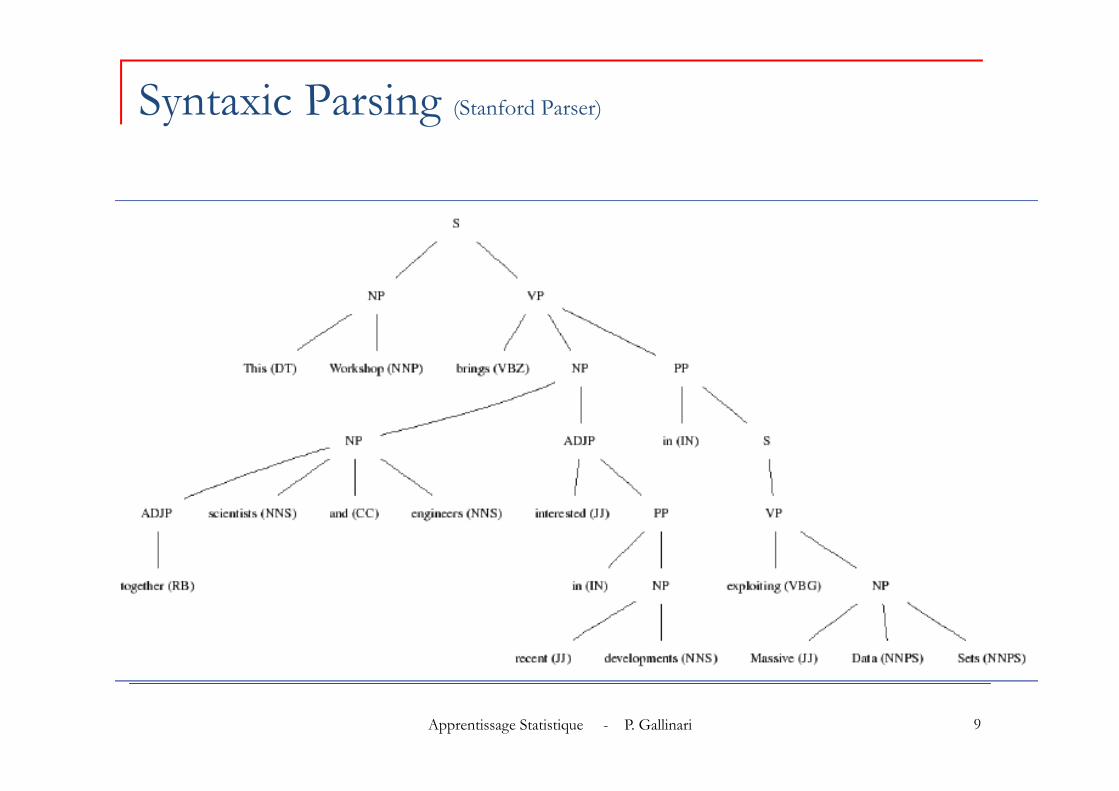
Syntaxic Parsing (Stanford Parser)

Apprentissage Statistique - P. Gallinari 10
Document mapping problem
Problem: query heterogeneous XML databases or collections Need to know the correspondence between the structured representations
uually made by hand Learn the correspondence between the different sources
Labeled tree mapping problem
<Restaurant><Name>La cantine</Name><Adress>
65 rue des pyrénées, Paris,19ème, FRANCE</Adress><Specialities>
Canard à l’orange, Lapin aumiel</ Specialities ></Restaurant>
<Restaurant><Name>La cantine</Name><Adress><City>Paris</City><Stree>pyrénées</Street><Num>65</Num></Adress><Dishes>
Canard à l’orange</Dishes><Dishes>
Lapin au miel</Dishes></Restaurant>

Apprentissage Statistique - P. Gallinari 11
Others
Taxonomies Social networks Adversial computing: Webspam, Blogspam, … Translation Biology…..

Apprentissage Statistique - P. Gallinari 12
Is structure really useful ?Can we make use of structure ? Yes Evidence from many domains or applications Mandatory for many problems e.g. 10 K classes classification problem
Yes but Complex or long term dependencies often correspond to
rare events Practical evidence for large size problems
Simple models sometimes offer competitive results Information retrievalSpeech recognition, etc

Apprentissage Statistique - P. Gallinari 13
Structured algorithms differ by: Feature encoding Hypothesis on the output structure Hypothesis on the cost function

Apprentissage dans les données structurées
IntroductionModèles discriminants pour les séquences
Conditional random fieldsRéseaux récurrents
Classification dans les graphes : réseaux sociaux

Apprentissage Statistique - P. Gallinari 15
X, Y variables aléatoires, Y prend ses valeurs dans un alphabet fini
X, Y sont structurés e.g. séquences, arbres, etc
CRF : modélise P(Y | X) Dans la plupart des travaux actuels X : séquence d’observations Y : séquence d’étiquettes

Apprentissage Statistique - P. Gallinari 16
Modèle discriminant Le conditionnement est fait sur X entier Pas d’hypothèse d’indépendance sur les composantes de
X Permet de prendre en compte des composantes globales
de la séquence X et donc (en principe) de modéliser des dépendances quelconques

Apprentissage Statistique - P. Gallinari 17
CRF : définitioncas des séquences
X et Y deux séquences aléatoires X = (X1, …, Xn), Y = (Y1, …, Yn)
G = (V,E) graphe non orienté défini sur Y (Y = (Yv)vV). (X,Y) est un CRF si on a la propriété Markovienne
suivante :
Remarques Si Y est une séquence, V = {1,…,m} et E = {(i, i+1)} On s’intéresse aux probabilités conditionnelles P(Y | X) Cas général, X et Y peuvent avoir une structure de graphe
),(),( G dans i de voisinsYXYPYXYP iiVi

Apprentissage Statistique - P. Gallinari 18
Forme des probabilités conditionnelles : théorème de Hammersley - Clifford Pour un CRF la probabilité conditionnelle suit un modèle
log-linéaire
c : clique maximale du graphe G C : ensemble des cliques maximales de G x, y : séquences yc : points de G dans la clique max de y Les fk sont des fonctions réelles, elles sont fixées à l’avance
Ce sont des caractéristiques simples des données d’entrée et de sortie – elles sont souvent à valeurs dans 0/ 1 (cf exemple)
Les k sont des paramètres à apprendreOn aura donc une somme linéaire de caractérisques simples
Cc kckk
y
Cc kckk
xycfxZ
xycfxZ
xyp
),,(exp)(
),,(exp)(
1)(

Apprentissage Statistique - P. Gallinari 19
Pour le cas des séquences on a :
kikk
ikiikk
ixygxyyf
xZxyp ),(),,(exp
)(1)( 1

Apprentissage Statistique - P. Gallinari 20
Apprentissage et inférence dans les CRF
Critère d’apprentissage Cas du MV (log(MV)) :
p(x,y) distribution empirique des exemples p(y|x) modèle conditionnel
Algorithmes : méthodes de gradients du 2nd ordre, gradients adaptatifs
Inférence Programmation dynamique (algorithme à la Viterbi)
yx
xypyxpL,
)(log),()(
k
ikkik
iikki
y
y
xygxyyf
xypy
),(),,(maxarg
))((maxargˆ
1

Apprentissage Statistique - P. Gallinari 21
Exemple CRFEtiquetage morpho-syntaxique Caractéristiques fyi,yi+1 = 1 si (yi ,yi+1 ) est dans D (ens. d’apprentissage), 0
sinon gxj,yi = 1 si (xj ,yi ) est dans D, 0 sinon Autres caractéristiques 1 si mot commençant par une majuscule, un chiffre 1 si terminaison –ing, -ed, -ly, -ies, etc On peut ajouter toutes les caractéristiques que l’on veut qui
sont des fonctions des x et y. Vecteur global de caractéristiques Vecteur binaire de grande taille et creux chaque composante correspond à une des caractéristiques
précédentes

Apprentissage dans les données structurées
IntroductionModèles discriminants
Conditional random fieldsRéseaux récurrents
Classification dans les graphes : réseaux sociaux
Apprentissage Statistique - P. Gallinari 23
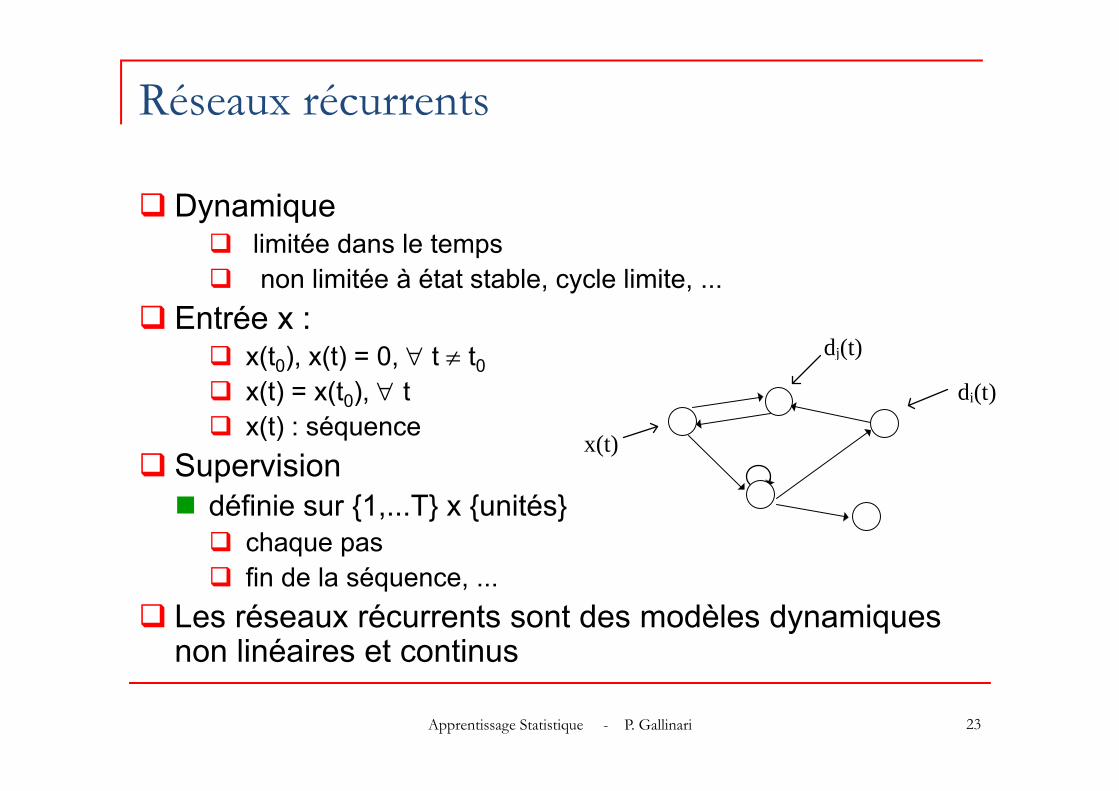
Réseaux récurrents
Dynamique limitée dans le temps non limitée à état stable, cycle limite, ...
Entrée x : x(t0), x(t) = 0, t t0 x(t) = x(t0), t x(t) : séquence
Supervision définie sur {1,...T} x {unités} chaque pas fin de la séquence, ...
Les réseaux récurrents sont des modèles dynamiques non linéaires et continus
x(t)
di(t)
dj(t)

Apprentissage Statistique - P. Gallinari 24
Deux types de modèles :
Entrée - sortie
Modèle d'état
Algorithmes Deux cas :
Récurrences locales Généraux
))(()( txfty
c t f c t x ty t g c t( ) ( ( ), ( ))( ) ( ( ))
1 1

Apprentissage Statistique - P. Gallinari 25
Réseaux récurrents simples
Connexions récurrentes fixées
2 modes d'utilisation : x fixe génération de séquences x séquence classification
y
xc
1
))(),(()())(),((1)(
txtcgtytxtcftc

Apprentissage Statistique - P. Gallinari 26
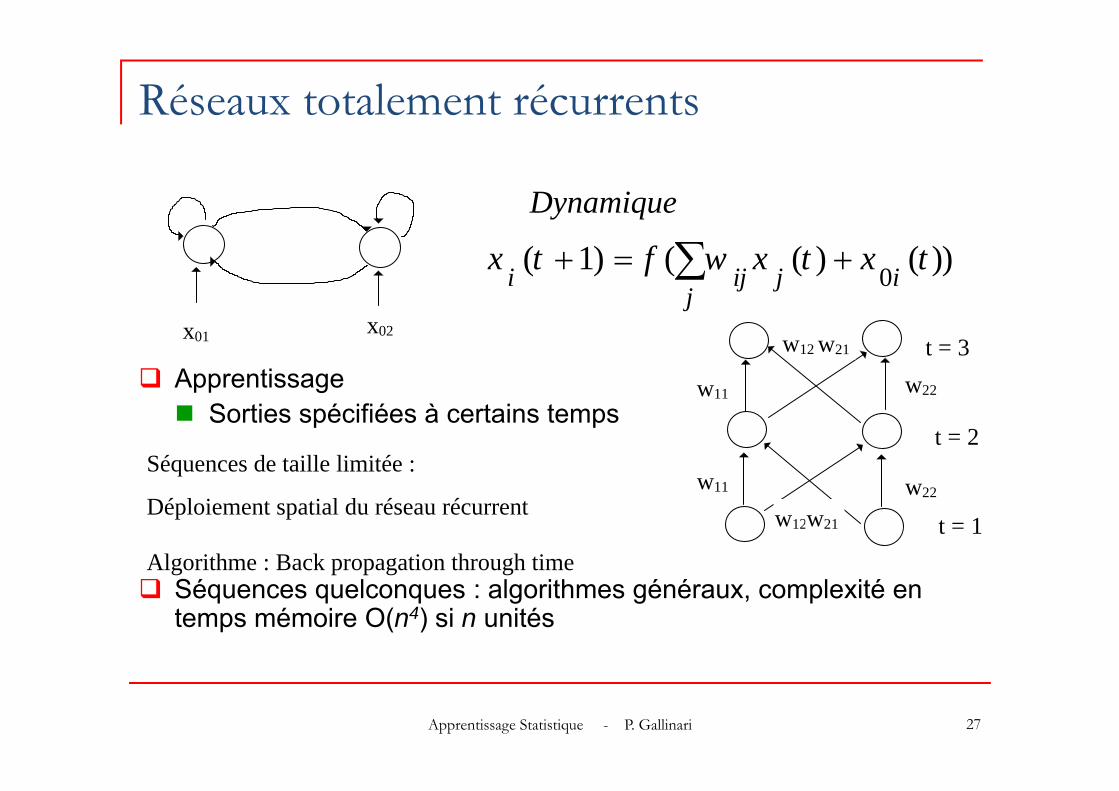
Réseaux localement récurrents
Apprentissage de connexions récurrentes simples
Apprentissage : Rétro-propagation pour les séquences Critère :
T : instants de supervision
Propriétés : Comportement d'oubli à mémoire court terme : Apprentissage de séquences de taille fixe jusqu'à la précision désirée Séquences de taille inconnue : limitations, e.g. compter le nombre d'occurrences
dans une séquence de longueur quelconque.
y
x
t-1
t-2e.g. si retard = 1
))(1 )(()( j
jijiiii txwtxwftx
Tt pi
iit tdtyQ
1..
2)()(
qj
iqtx
tx0
)()(
Apprentissage Statistique - P. Gallinari 27
Réseaux totalement récurrents
Apprentissage Sorties spécifiées à certains temps
Séquences quelconques : algorithmes généraux, complexité en temps mémoire O(n4) si n unités
x01 x02
j
ijiji txtxwftx ))()((1)( 0
Dynamique
Séquences de taille limitée :
Déploiement spatial du réseau récurrent
Algorithme : Back propagation through time
w12
t = 1
t = 3
t = 2
w11
w11 w22
w22
w21
w12w21

Apprentissage Statistique - P. Gallinari 28
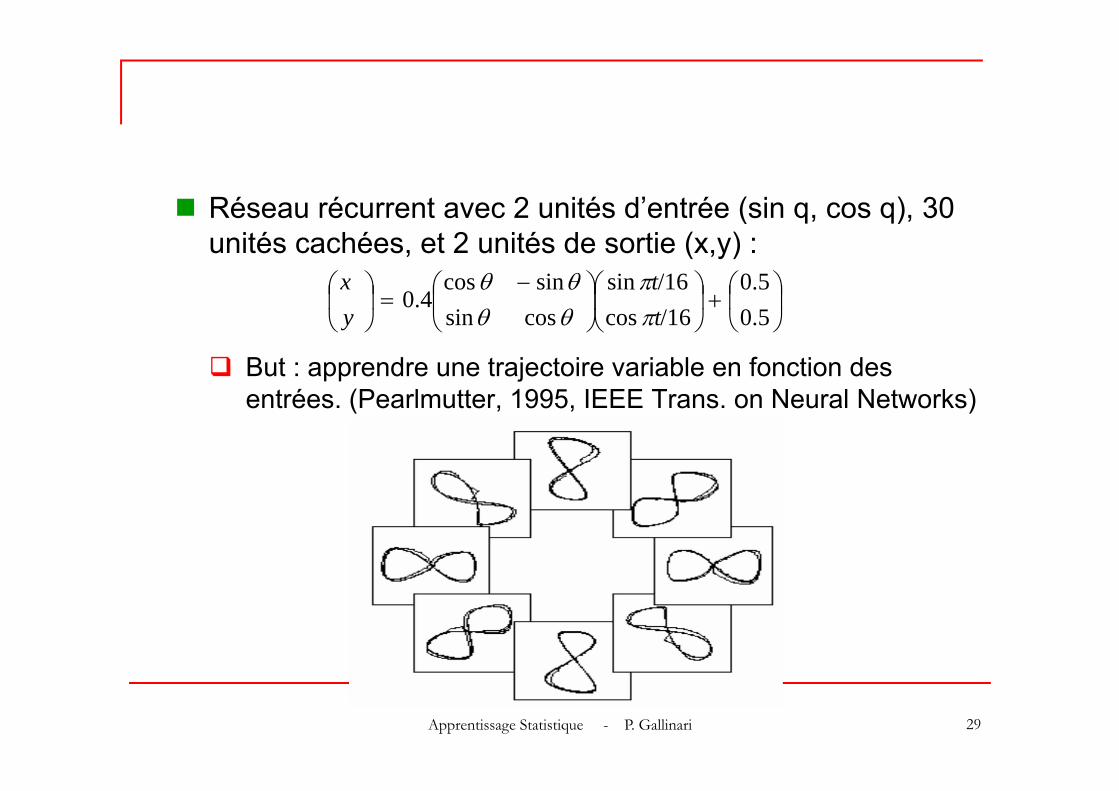
Exemple : apprentissage de trajectoire(Pearlmutter, 1995, IEEE Trans. on Neural Networks)
Réseau totalement récurrent : 2 unités de sortie, pas d’unité d’entrée
Apprentissage Statistique - P. Gallinari 29
Réseau récurrent avec 2 unités d’entrée (sin q, cos q), 30 unités cachées, et 2 unités de sortie (x,y) :
But : apprendre une trajectoire variable en fonction des entrées. (Pearlmutter, 1995, IEEE Trans. on Neural Networks)
0.50.5
/16/16
0.4tt
yx
cossin
cossinsincos

Apprentissage dans les données structurées
IntroductionModèles discriminants
Conditional random fieldsRéseaux récurrents
Classification dans les graphes : réseaux sociaux

Content Information Networks
Web Hyperlinks
Social networks Friends, comments, tags, metadata (date, geo-localization, etc.)…
Bibliographical networks Authors, co-authors, conferences, editor site, metadata,…
Blogs Comments, messages, backlinks Micro blogging: followers
E-mails To, from, subject, date, etc.
Any collection of content elements with relations Images, video, texts, … Implicit relations based on similarities
Collaborative recommendation networks Collaboration networks
32Mining Content Information Networks

Examples
33
Enron e-mail
11 K Web hosts -Webspam
Wikipedia themes classification
Flickr Friendship network
Mining Content Information Networks
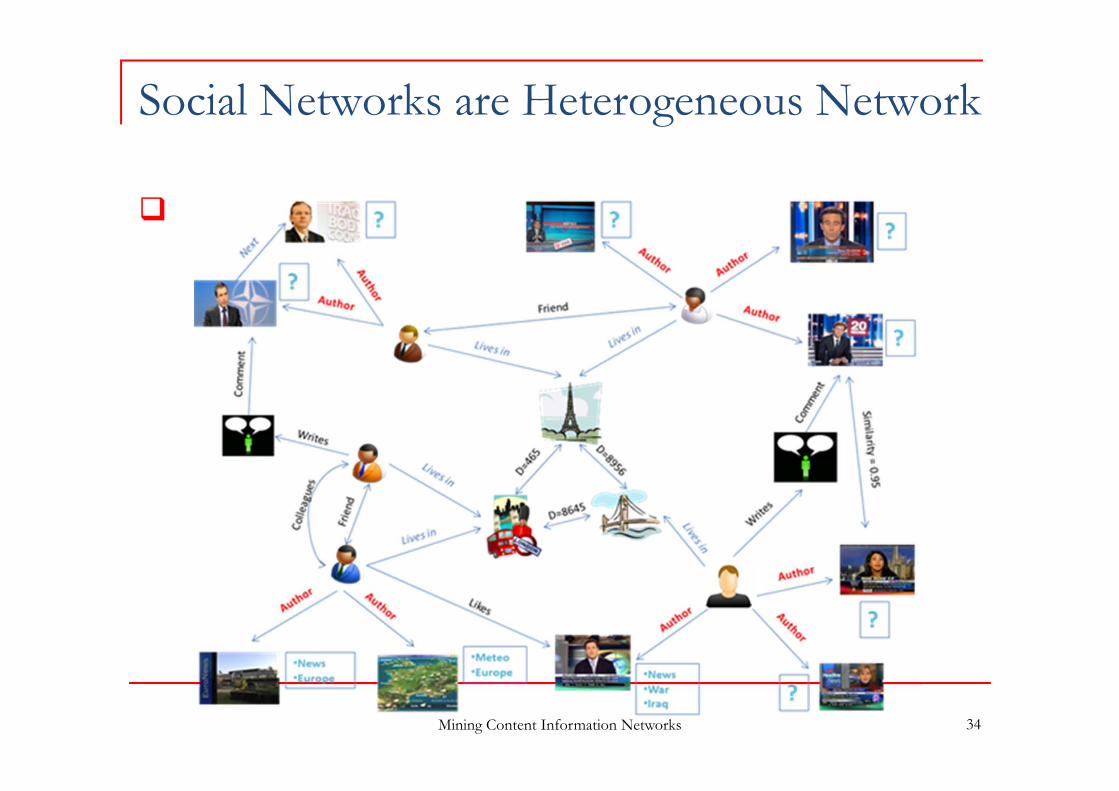
Social Networks are Heterogeneous Network
34Mining Content Information Networks
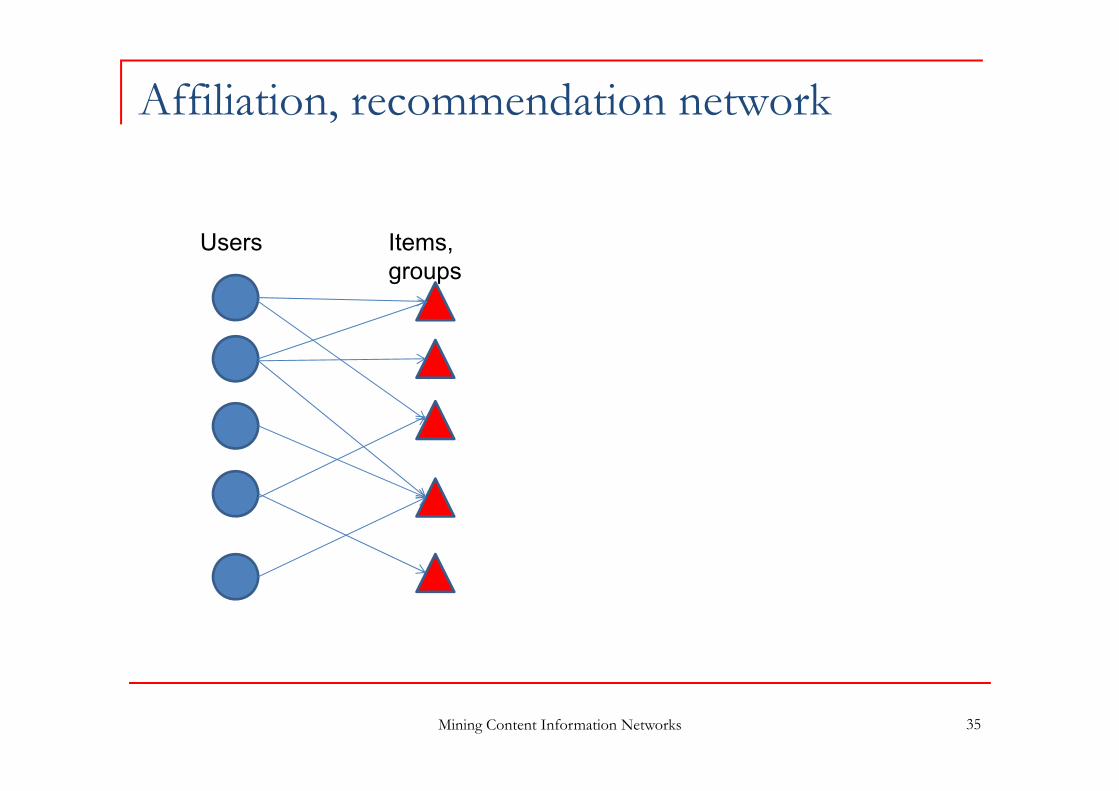
Affiliation, recommendation network
Mining Content Information Networks 35
Users Items, groups
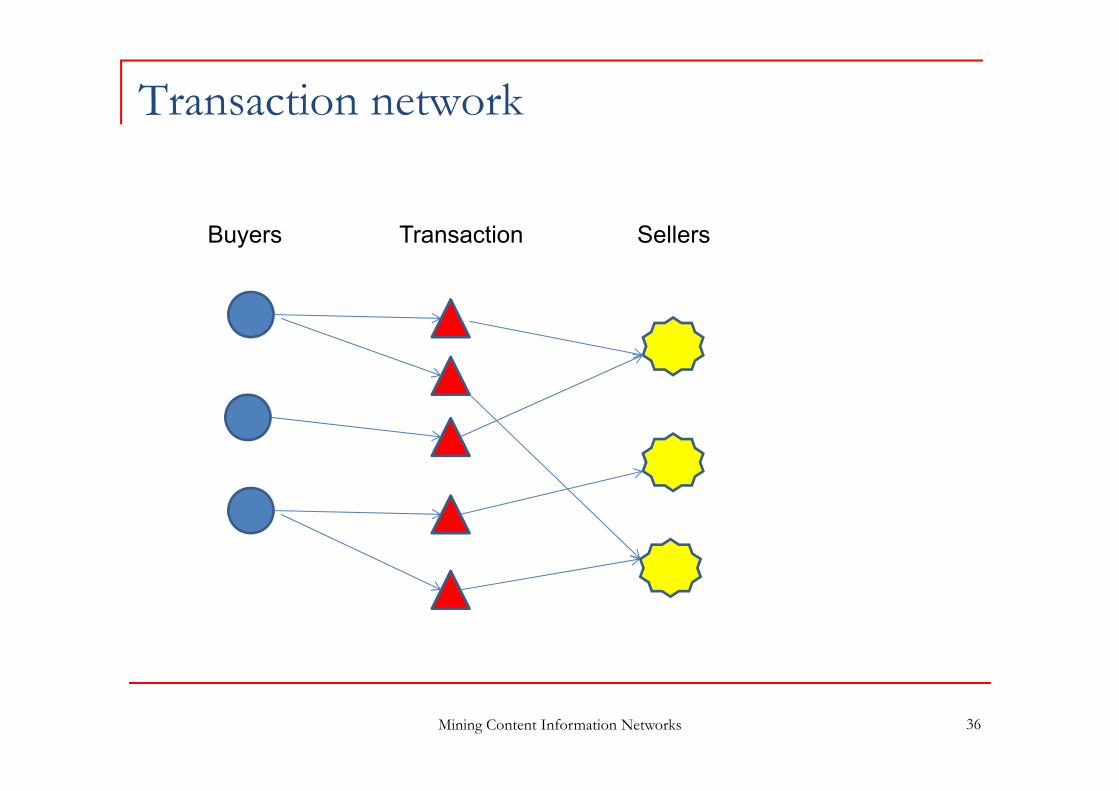
Transaction network
Mining Content Information Networks 36
Buyers Transaction Sellers
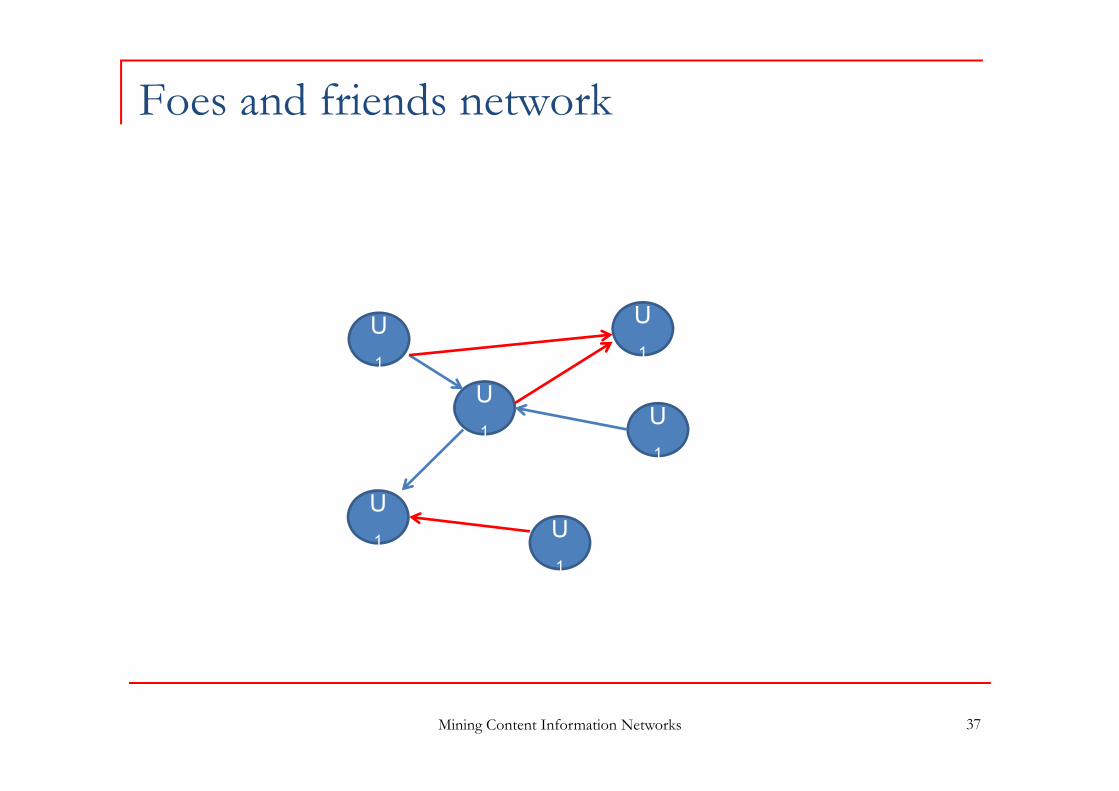
Foes and friends network
Mining Content Information Networks 37
U1
U1
U1
U1 U
1
U1

Characteristics
Large scale Tweeter (June 2010) > 65 M tweets / day > 100 M users, 300 K new user / day
Facebook > 500 M users
Complexity Heterogeneity (nodes and relations) Rich data (multiple media)
Dynamic Structure Information
Mining Content Information Networks 38
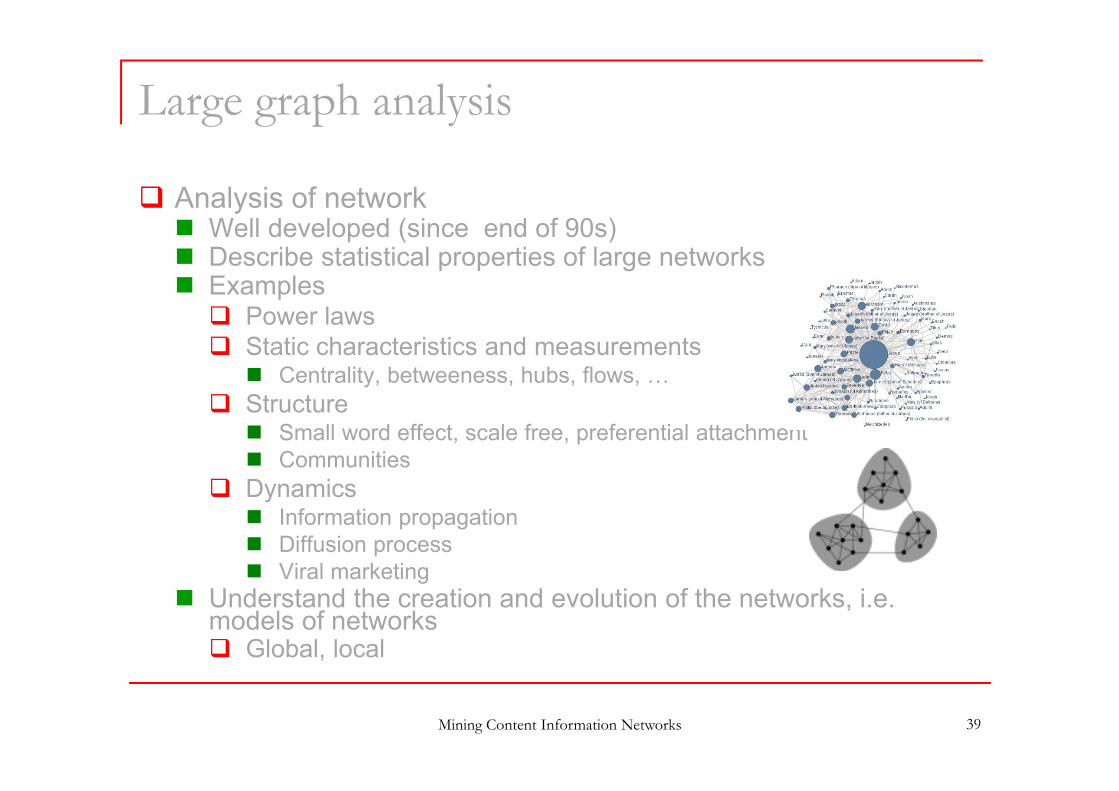
Large graph analysis
Analysis of network Well developed (since end of 90s) Describe statistical properties of large networks Examples Power laws Static characteristics and measurements Centrality, betweeness, hubs, flows, …
Structure Small word effect, scale free, preferential attachment Communities
Dynamics Information propagation Diffusion process Viral marketing
Understand the creation and evolution of the networks, i.e. models of networks Global, local
Mining Content Information Networks 39

Mining and machine learning
Inference (predictions) on networks Content information + structure HeterogeneityMulti-modal information
Mining Content Information Networks 40

Applications
Recommendation E-commerce: products / social networks: friends
Marketing Consumer targeting for new product
Social search Thematic People Sentiment
Annotation Image, video
Advertising Click prediction
Security Fraud detection Spamming
Mining Content Information Networks 41

Learning in content networks
Generic problems Compute scores on graph nodes Classification, ranking Annotation, influence, popularity, recommendation
Compute scores for links Link existence Friend recommendation
Group detection Dynamics of information, diffusion
Mining Content Information Networks 42

Classification and ranking on networked data
IntroductionRegularization based methods

Mining Content Information Networks 44
Machine learning on graph data Mainly classification Different approaches Here regularization framework
May take into account both content and connectivity
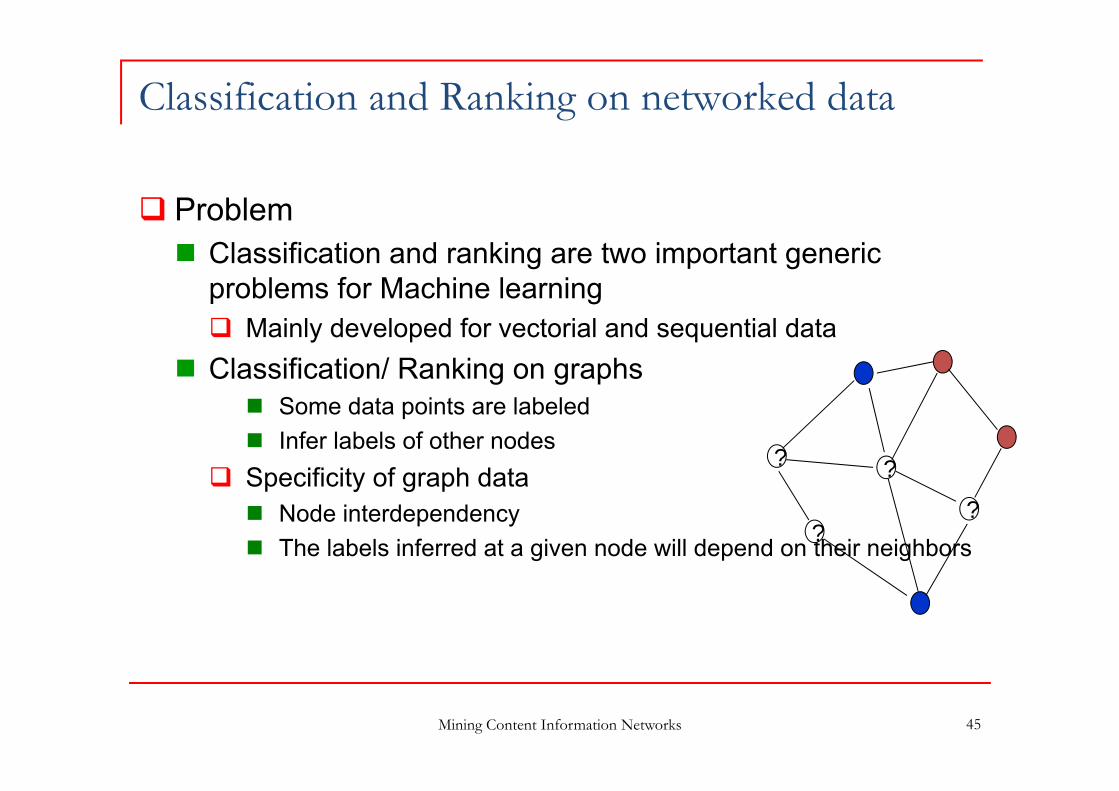
Classification and Ranking on networked data
Problem Classification and ranking are two important generic
problems for Machine learning Mainly developed for vectorial and sequential data
Classification/ Ranking on graphs Some data points are labeled Infer labels of other nodes
Specificity of graph data Node interdependency The labels inferred at a given node will depend on their neighbors
Mining Content Information Networks 45
?
??
?

Mining Content Information Networks 46
Example : webspam detection
WebSpam challenge 2007
11 K hosts 7 K labeled 26 % spam Partial view of the
host graph Black : spam White : non spam
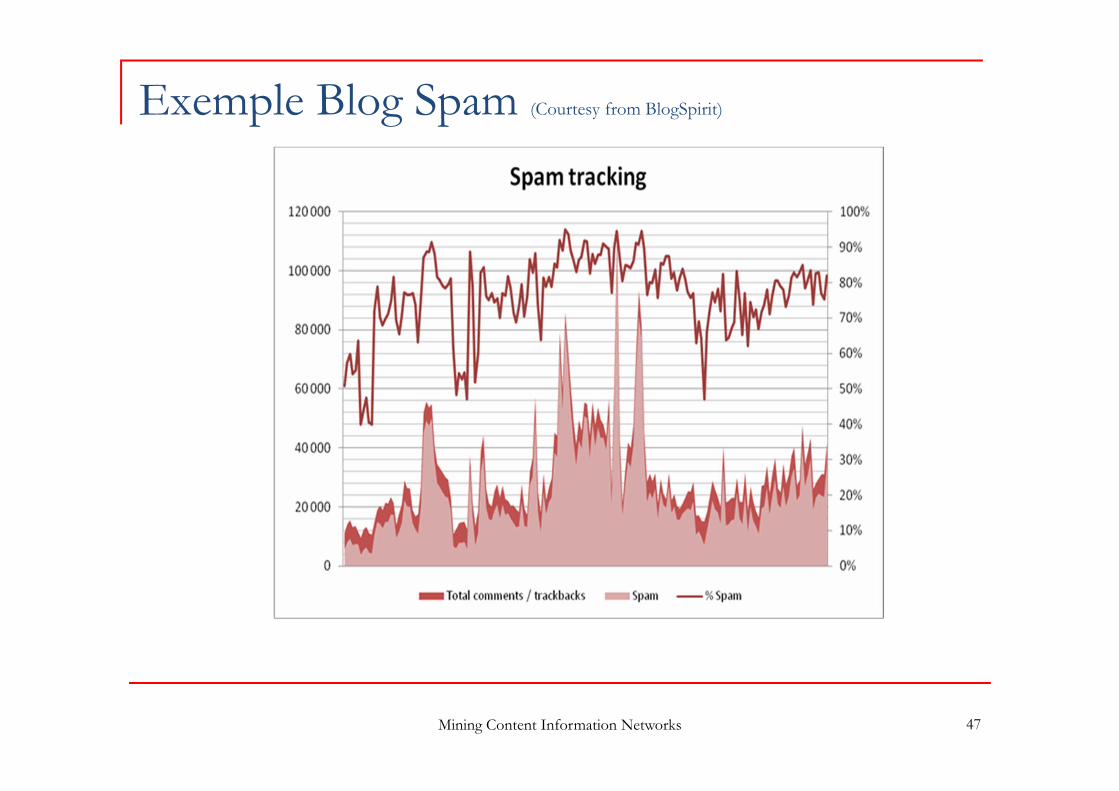
Exemple Blog Spam (Courtesy from BlogSpirit)
47Mining Content Information Networks

Mining Content Information Networks 48
Graph labeling with regularization
Initial framework comes from semi-supervised learning Later extended to other situations Classification on graphs Ranking
Formalize the problem as the optimization of a cost function
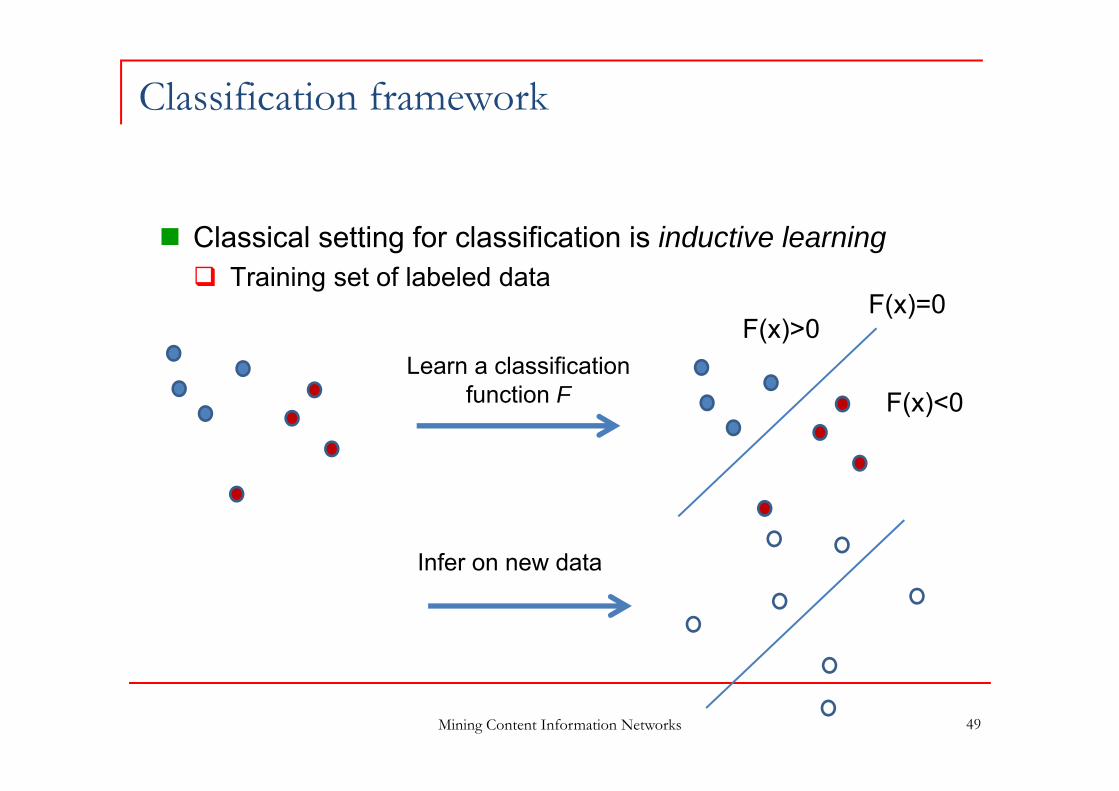
Classification framework
Classical setting for classification is inductive learning Training set of labeled data
Mining Content Information Networks 49
Learn a classification function F
Infer on new data
F(x)=0
F(x)<0
F(x)>0
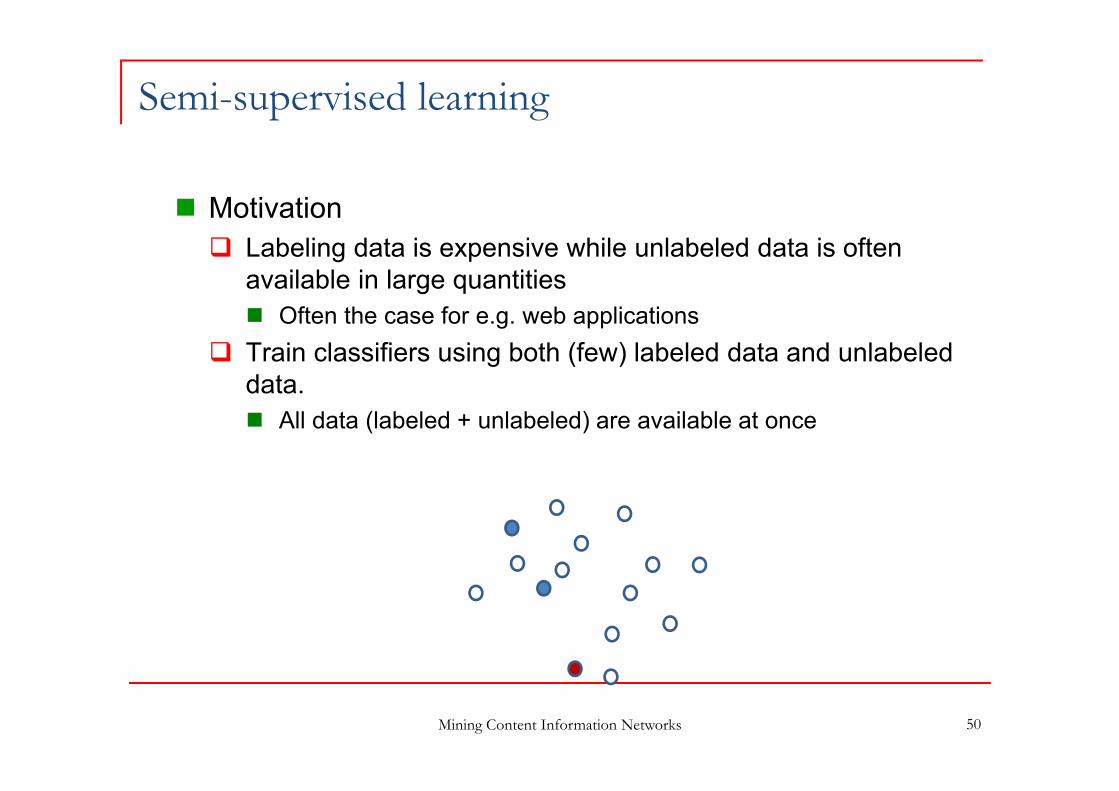
Semi-supervised learning
Motivation Labeling data is expensive while unlabeled data is often
available in large quantities Often the case for e.g. web applications
Train classifiers using both (few) labeled data and unlabeled data. All data (labeled + unlabeled) are available at once
Mining Content Information Networks 50
Mining Content Information Networks 51
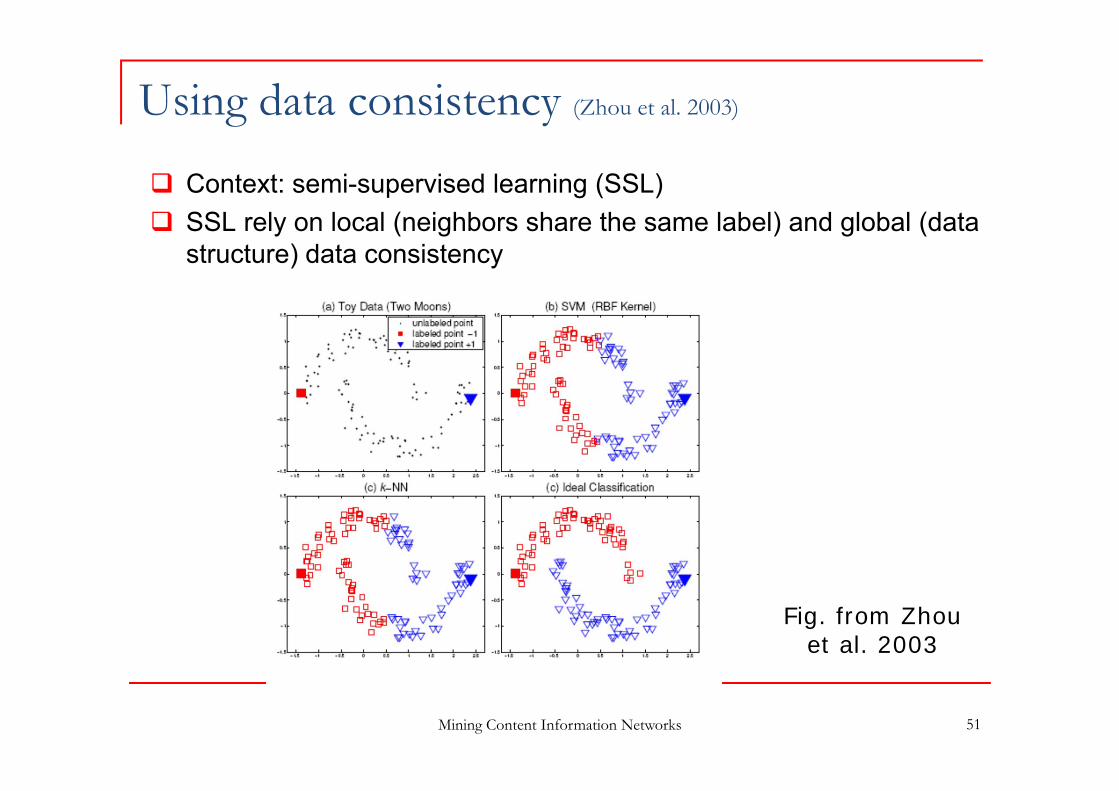
Using data consistency (Zhou et al. 2003)
Context: semi-supervised learning (SSL) SSL rely on local (neighbors share the same label) and global (data
structure) data consistency
Fig. from Zhou et al. 2003

Mining Content Information Networks 52
Graph methods for semi-supervised learning general idea Given A similarity matrix W between nodes Defines a weighted undirected graph G = (V, E) on data points Encodes local similarity between points
A set of labeled nodes on G Propagate observed labels to unlabeled nodes using local
similarities

Regularization view of the algorithm
Mining Content Information Networks 53

Mining Content Information Networks 54
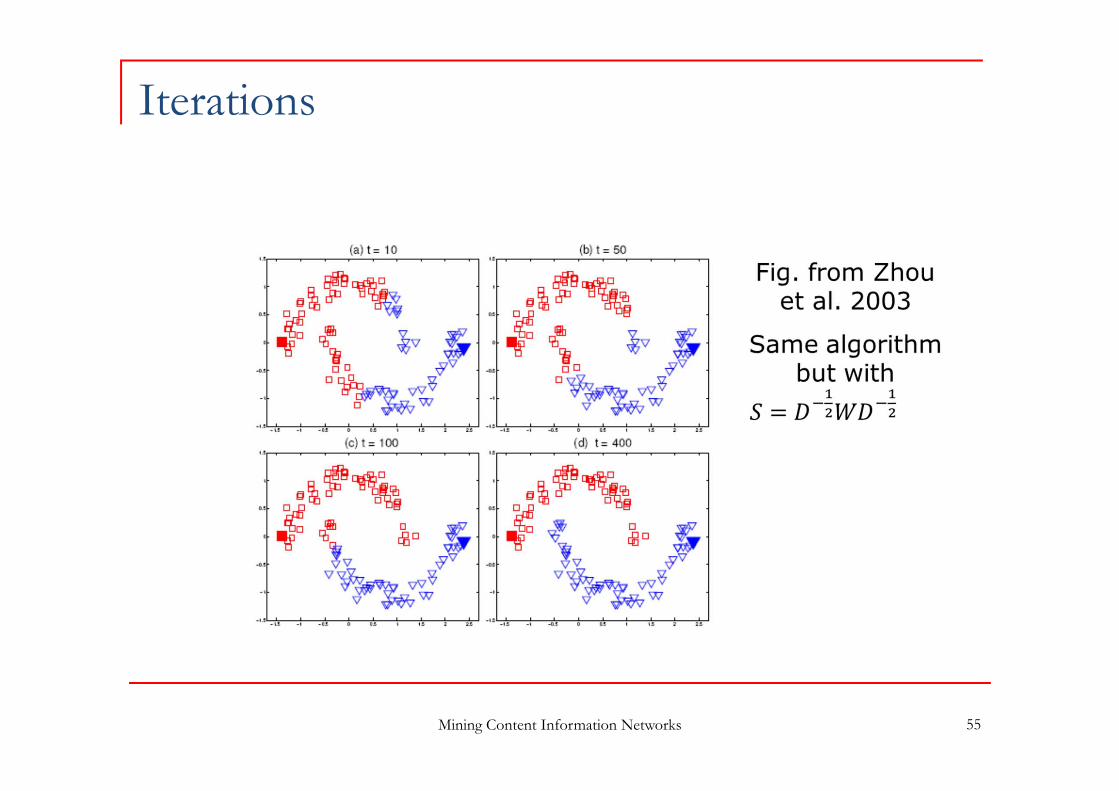
Mining Content Information Networks 55
Iterations

Extensions
Multiclass Ranking Node ranking Label ranking
Content + link Information Propagation methods do not consider directly the content of the different nodes Content only appears through the similarity or kernel matrix
It is possible to use the graph regularization idea together with content based classifiers
Directed graphsMultiple relations
Mining Content Information Networks 56

Mining Content Information Networks 57
Ranking model for image annotation in a social network (Denoyer 2009)
Problem Automatic annotation of images in large social networks
(e.g. Flickr) Consider simultaneously Explicit relations (authorship, friendship) Implicit relations (similarity) Different types of content Text, image

Mining Content Information Networks 58
Approach Regularization based method
Results Importance of social links Authors, friendship Large improvement over non relational (classical) label
ranking methods Few improvement with implicit relations
Mining Content Information Networks 59
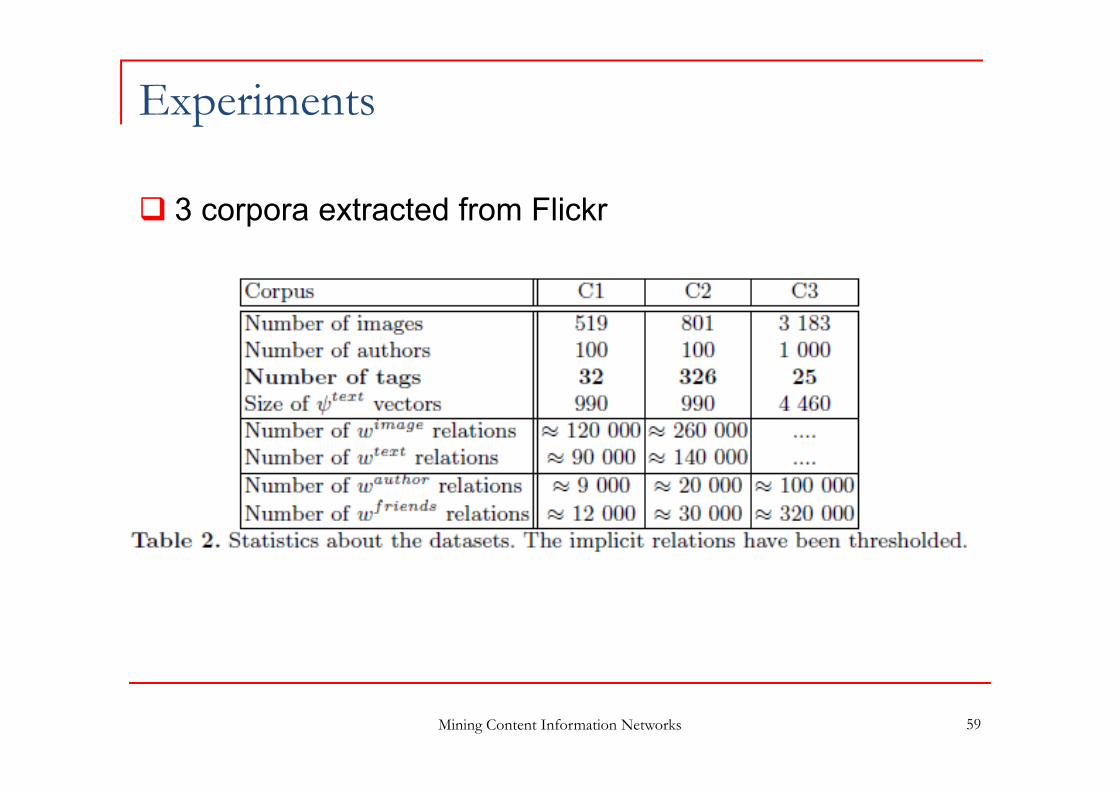
Experiments
3 corpora extracted from Flickr
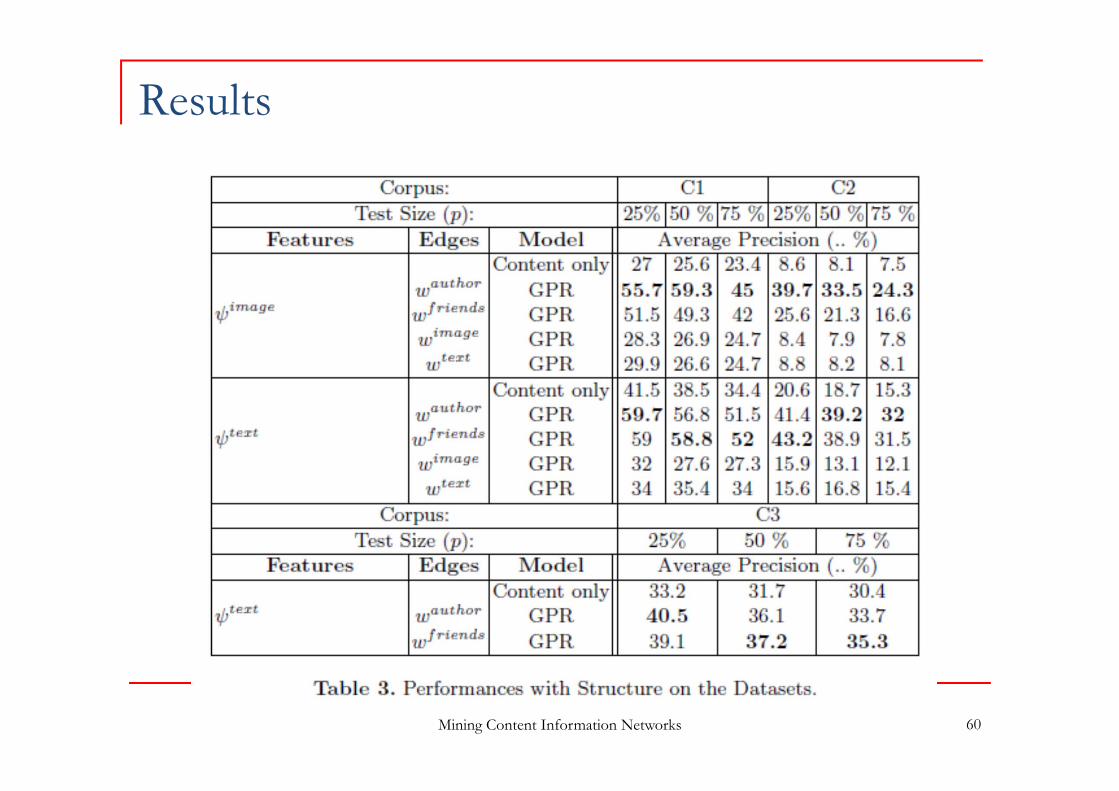
Mining Content Information Networks 60
Results

Ranking on multi-graphs with learned relations (Jacobs et al 2011)
Relations on Flickr Friendship, Comment,
Same monthStill better Considering
simultaneously multiple relations
Learning the strength of relations
Mining Content Information Networks 61

Graph kernels

Motivations
Graph Kernels allow to define similarities between nodes in a graph, based on the graph structure e.g. # paths connecting two nodes, mean weight of paths,
etc Complex similarity measures Large variety of similarity measures
Similarities allow defining distances between nodes Graph nodes may be mapped onto a metric space Clustering, classification, visualization
Mining Content Information Networks 63

Link with regularization based approaches Some graph kernels may be obtained as solutions to the
optimization of loss functions Link with random walks Some graph kernels may be defined in terms of random
walks on the graph
Mining Content Information Networks 64

Kernels
Kernels are “similarity” functions K(x,x’) s.t. K(x,x’) can be computed via an inner product of some
transformation of x and x’ in a feature space Definition K: X x X R is a kernel function if for all x, z in X, K(x,z) = <
Φ(x), Φ(z)> where Φ is a mapping from X onto an inner product feature space
(Hilbert space)
Mining Content Information Networks 65
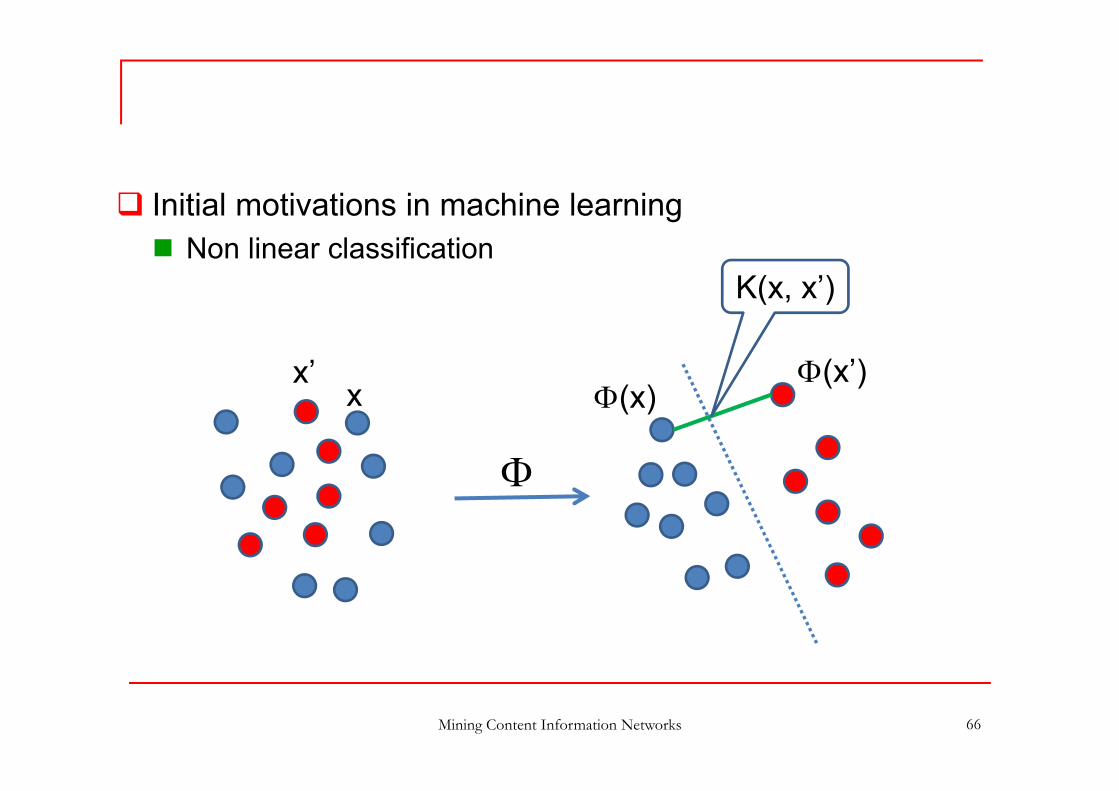
Initial motivations in machine learning Non linear classification
Mining Content Information Networks 66
xx’
(x)(x’)
K(x, x’)
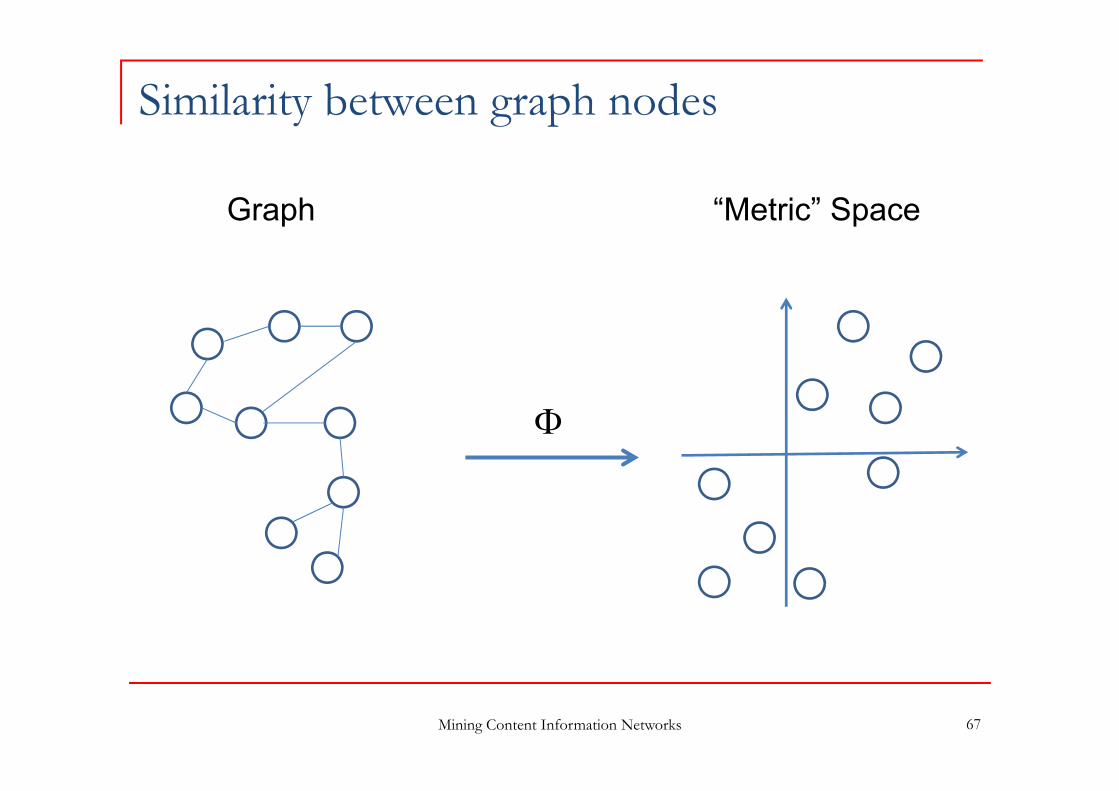
Similarity between graph nodes
Graph “Metric” Space
Mining Content Information Networks 67
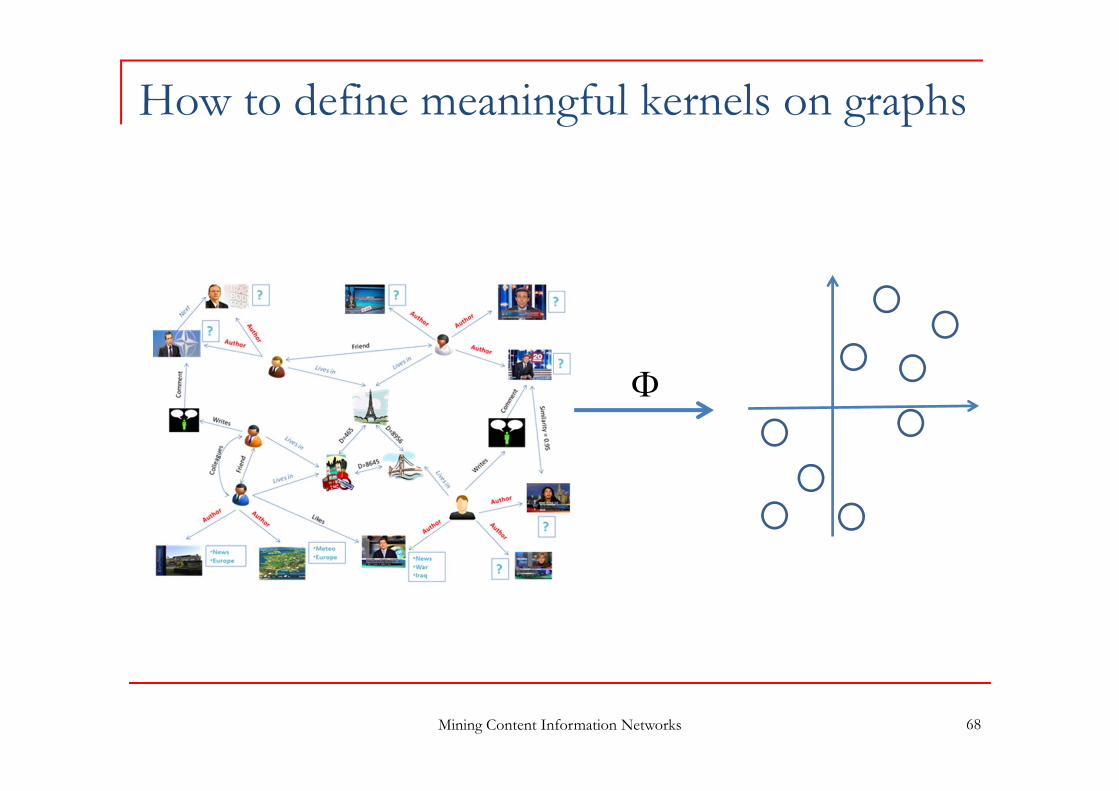
How to define meaningful kernels on graphs
Mining Content Information Networks 68
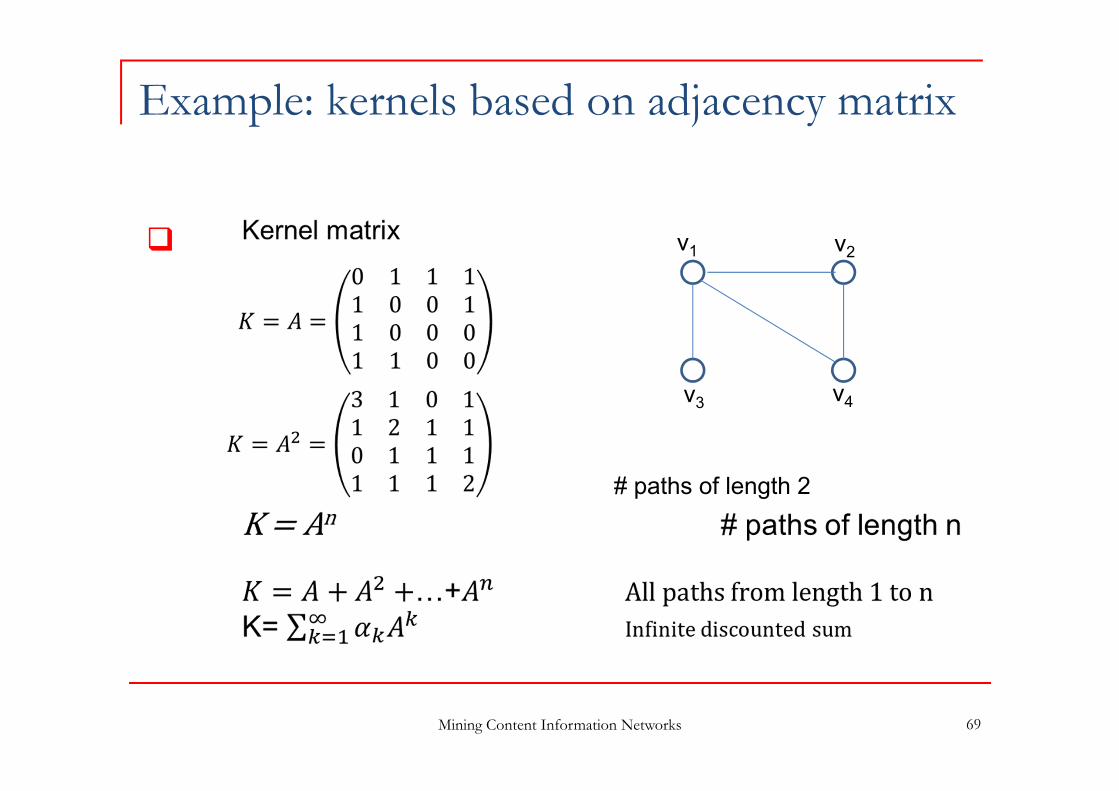
Example: kernels based on adjacency matrix
Mining Content Information Networks 69
v1
v4v3
v2
# paths of length 2

Diffusion kernels on graphs (Shawe-Taylor et al. 2004)
Mining Content Information Networks 70
v1
v4v3
v2b12
b14b13b14

Von Neumann diffusion kernel
Mining Content Information Networks 71

Random walk with restart kernel (Gori et al. 2006))
Mining Content Information Networks 72

Using graph kernels for recommendation
Collaborative filtering U a set of users I a set of items Each user rates some of the items User-item matrix - sparse
Collaborative filtering Recommend items for users Usually based on the user similarity of ratings Predict the missing ratings for users Many different techniques
Mining Content Information Networks 73
Items
USErs
1 2 3 4
1 5 3
2
3 3
4
5 1 2
Items
USErs
1 2 3 4
1 5 ? ? 32 ? ? ? ?3 ? 3 ? ?4 ? ? ? ?
5 1 2 ? ?

Popular challenges on movie recommendation CAMRa2010, 2011 NetFlix Prize (http://www.netflixprize.com) On September 21, 2009 we awarded the $1M Grand Prize to
team “BellKor’s Pragmatic Chaos”. There are currently 51051 contestants on 41305 teams from
186 different countries. We have received 44014 valid submissions from 5169 different teams;
Mining Content Information Networks 74

Using graph kernels for recommendation
Let G = (V, E) be the user-item bipartite graph Nodes V are users and items Links A adjacency matrix aij = 1 if user i has rated item I aij = 0 otherwise
Bipartite graph
Mining Content Information Networks 75

Using graph kernels for recommendation
Mining Content Information Networks 76

Using graph kernels for recommendation
Mining Content Information Networks 77

Using graph kernels for recommendation
Mining Content Information Networks 78

Using graph kernels for classification
Kernels may be used for semi-supervised classification Given a Kernel matrix K (nxn), a simple rule for
classification is: Let yc be an nx1 vector s.t. yc,I = 1 if node i is from class c and
0 otherwise (unknown or other class) K. yc is the vector of class c scores for the graph nodes It computes the similarity of any node with the labeled nodes from
class c Finally, a node may be classified into the class with highest
score This is similar to what we did with regularization based
approaches Note Other, more sophisticated classification rules might be used
Mining Content Information Networks 79

Conclusion
Statistical tools for relational learning in graphs Different families which share many relations Still limited to relatively simple tasks Challenges E.g. tools for community management
Mining Content Information Networks 80

Bibliography
Zhou D, Bousquet O, Lal TN, Weston J, Schölkopf B. Learning with local and global consistency. In: Advances in Neural Information Processing Systems 16: Proceedings of the 2003 Conference.Vol 1.; 2004:595–602.
Zhu X, Ghahramani Z. Semi-supervised learning using gaussian fields and harmonic functions. MACHINE LEARNING-. 2003;20(2):912.
Abernethy J, Chapelle O, Castillo C. Graph regularization methods for Web spam detection. Machine Learning. 2010;81(2):207-225.
Shawe-Taylor J., Cristianini N., Kernel Methods for Pattern Analysis, Cambridge University Press, 2004
Yen L, Pirotte A, Saerens M. An Experimental Investigation of Graph Kernels on Collaborative Recommendation and Semisupervised Classification. Submitted. 2009:1-39.
81Mining Content Information Networks

Apprentissage Statistique - P. Gallinari 82
Stages 2013http://www-connex.lip6.fr/~gallinar/Stages/Stages.html Très grandes masses de données Apprendre avec un budget restreint et processus séquentiels (apprentissage par
renforcement) Réseaux sociaux Apprendre un agent sur Twitter Réseaux hétérogènes
Apprentissage de représentations sémantiques Réseau de neurones profonds Sentiments Processus de décision séquentiels
Recommandation sociale

Apprentissage Statistique - P. Gallinari 83
Quelques liens utiles
Livres Cornuéjols, A and Miclet L.: Apprentissage Artificiel. Concepts et
algorithmes (2nd Ed.with revisions and additions - 2006 Eyrolles, 650 p Christopher M. Bishop, Pattern Recognition and Machine Learning,
Springer (2006). David Barber, 2012, Bayesian Reasoning and Machine Learning,
Cambridge Univ. Press. Software General Weka 3: Data Mining Software in Java
http://www.cs.waikato.ac.nz/ml/weka/ Lush (Leon Bottou)
http://lush.sourceforge.net) SVM http://www.csie.ntu.edu.tw/~cjlin/libsvm/
http://svmlight.joachims.org/http://www.torch.ch/
Test sets UCI machine learning repository …..