Embed Size (px)
Citation preview

2003 Apr 8 1
Indexing the Sky
Clive Page

2003 Apr 8 2

2003 Apr 8 3
Formats of Raw Data
• Radio:
– Complex visibility for each polarisation at set of points sampling the (u,v) plane.
• Infra-red, Optical, Ultra-violet:
– Images from 1k×1k to 18k×20k, collected every few seconds or few minutes.
• X-ray, Gamma-ray:
– Lists of detected photons (x, y, time, energy) typically accumulated for several hours.
2003 Apr 8 4
Formats of Reduced Data
• Images
• Time-series
• Spectra
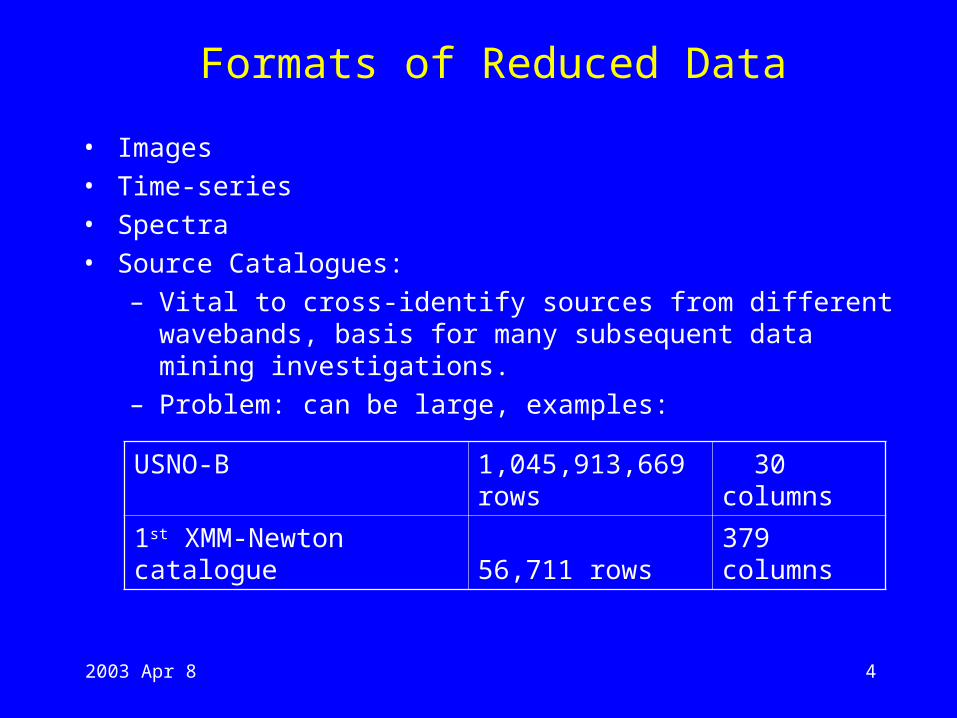
• Source Catalogues:
– Vital to cross-identify sources from different wavebands, basis for many subsequent data mining investigations.
– Problem: can be large, examples:
USNO-B 1,045,913,669 rows 30 columns
1st XMM-Newton catalogue 56,711 rows 379 columns

2003 Apr 8 5
Required Functionality
• SELECT sources in given small patch of sky (circle, rectangle, or polygon)
• JOIN two tables e.g. from different wavebands to find corresponding sources
– Principal matching criterion is positional match - typically overlap of error-circles.

2003 Apr 8 6
Problems handling source catalogues• Positions use spherical-polar coordinates (RA, Dec)
– Right Ascension corresponds to geographic longitude
– Declination corresponds to geographic latitude
• There are singularities at the poles and distortions in the scales everywhere except at the equator.
• RA wraps from 24 hours (360 degrees) to zero.
• Two-dimensional indexing is really needed.
• All source positions are imprecise points have an error radius.
• Distances between points must use a great-circle distance function not cartesian distance.

2003 Apr 8 7
Indexing Possibilities
1. Use simple B-tree on one spatial axis only
2. Use 1-d to 2-d mapping function then B-tree
3. Use spatial index such as R-tree

2003 Apr 8 8
(1) Index one spatial axis only
• For example consider USNO-B: a table of a billion rows.
• Typical search/join uses a radius of say 3 arc-seconds.
• Probability of finding a source in a circle of radius 3 arc-seconds in a random position is around 17%, so most searches find 0 or 1 rows.
• An index on just one coordinate (say Dec) will effectively search a strip 360° wide by 6 arc-seconds high, and will find some 10,000 rows matching. These have to be scanned sequentially to find at most one matching row.
• Conclusion: a true 2-d index can gain five orders of magnitude in efficiency.

2003 Apr 8 9
(2) 2-d to 1-d mapping
• Cover the space with cells (pixels) and number them.
• Create conventional B-tree on resulting set of integers.
• Each point maps to an integer.
• Areas map to a list of integers:
– Ideally a small spatial area maps to a small range of integers so one can do a range search using the B-tree.
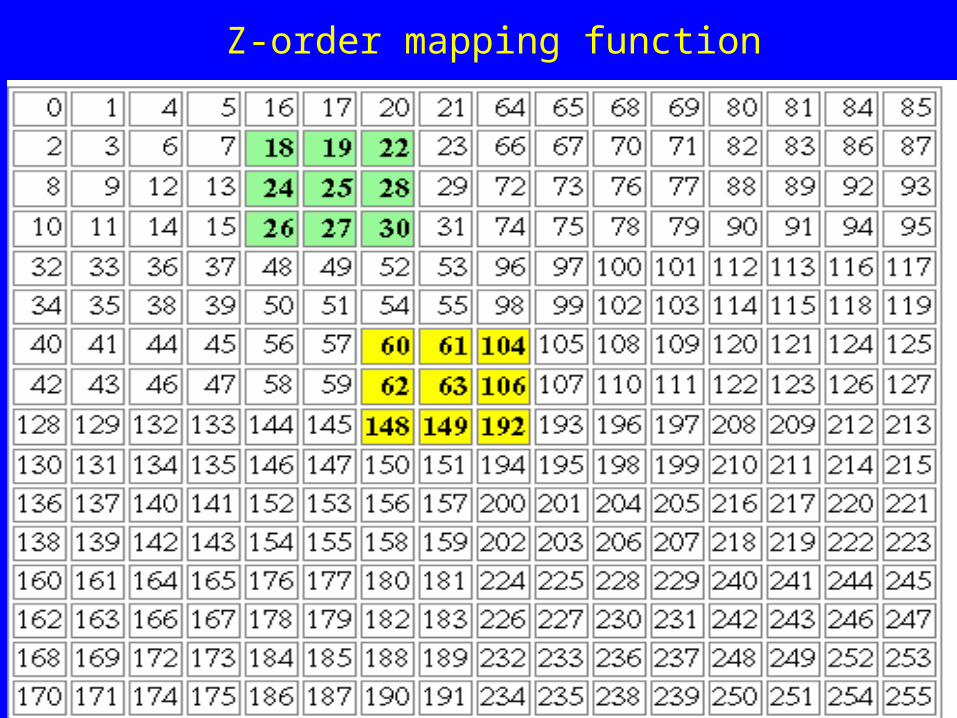
– Various space-filling curves such as the Z-ordering index and Peano Curve have been used in the hope that this works…
2003 Apr 8 10
Z-order mapping function

2003 Apr 8 11
Space-filling Curves
• All have same failing:
– At some places in the grid a high-order bit flips and the range of integers becomes huge.
– Tests confirm this defect: the worst-case performance is rather poor.
• Simple cartesian grids also unsuited to spherical-polar coordinates as there are too many tiny pixels near the poles.

2003 Apr 8 12
Covering the sky evenly with pixels
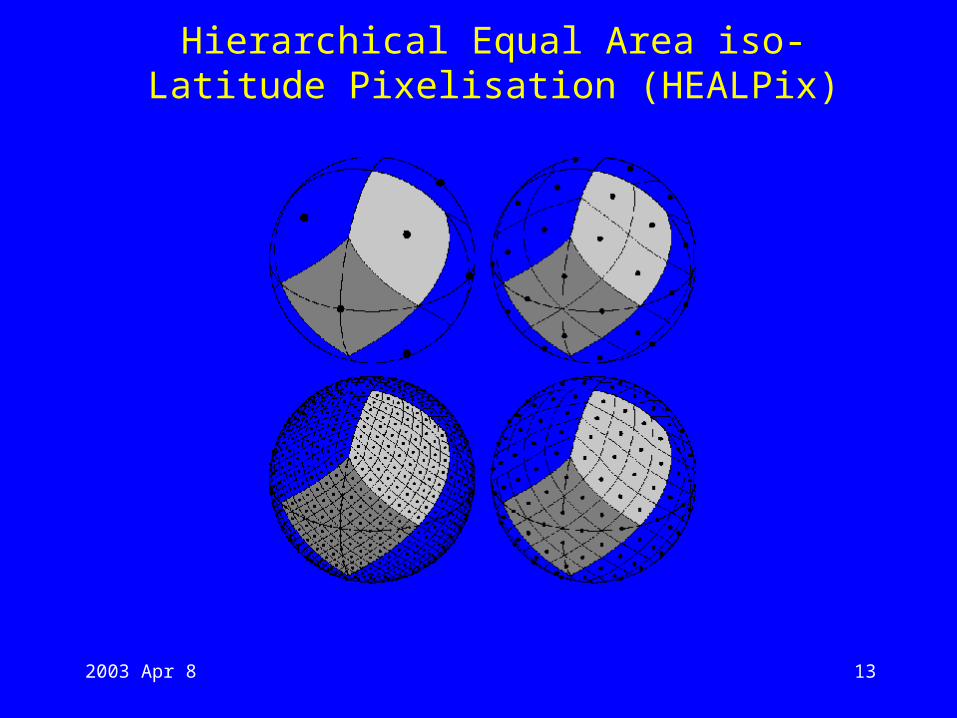
• Hierarchical Equal Area iso-Latitude Pixelisation (HEALPix) – invented at European Southern Observatory.
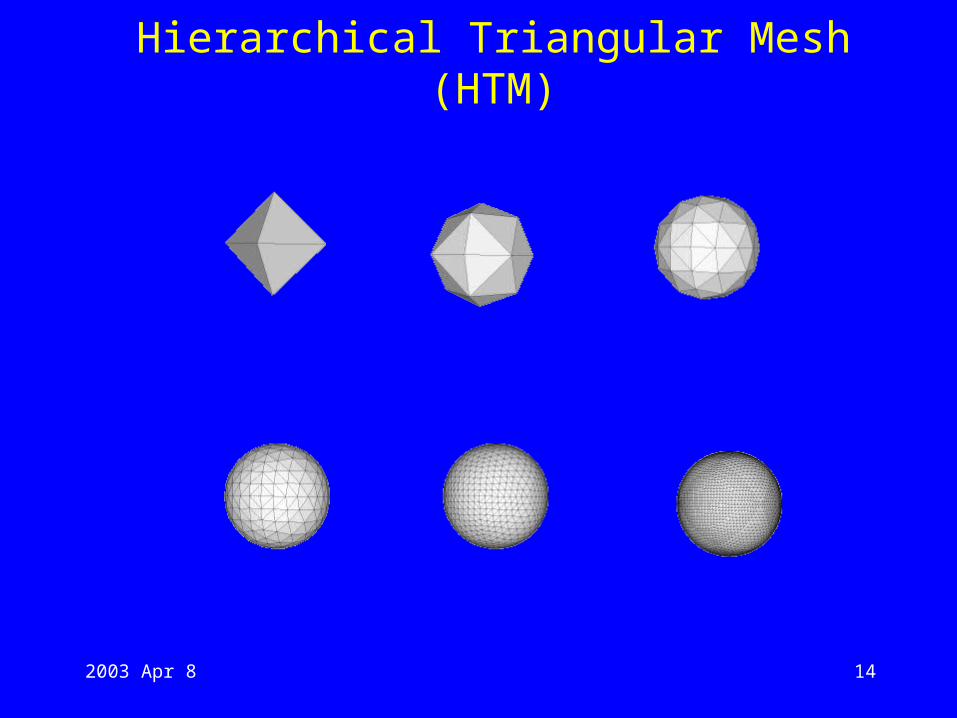
• Hierarchical Triangular Mesh (HTM) – invented at Johns Hopkins University
• Can use either algorithm – call it pixel-code or PCODE for short
– Do not try to conduct spatial range search using range of PCODE values.
2003 Apr 8 13
Hierarchical Equal Area iso-Latitude Pixelisation (HEALPix)
2003 Apr 8 14
Hierarchical Triangular Mesh (HTM)

2003 Apr 8 15
Spatial Join using PCODE
Table CAT1 has columns
• ID1
• RA
• DEC
• POSERR
• MAGNITUDE
• etc
Table CAT2 has columns
• ID2
• RA
• DEC
• POSERR
• FLUX
• etc

2003 Apr 8 16
Create additional tables with PCODE values
Table CAT1 has columns
• ID1 – primary key
• RA
• DEC
• POSERR
• MAGNITUDE
• Etc
Table P1 has columns
• ID1
• PCODE1 – primary key
• Table CAT2 has columns
• ID2 – primary key
• RA
• DEC
• POSERR
• FLUX
• Etc
Table P2 has columns
• ID2
• PCODE2 – primary key

2003 Apr 8 17
JOIN the two PCODE tables
Note: tables P1, P2 have extra rows when error-circles overlap more than one pixel.
• Join P1 and P2 on PCODE1=PCODE2 making a table PJOIN with just two columns: ID1 and ID2.
• Use SELECT DISTINCT to remove any duplicates
• Table PJOIN identifies pixels which may contain sources with overlapping error circles (or they may just be near but not overlapping)
• Create B-tree index on PJOIN(ID1)
2003 Apr 8 18
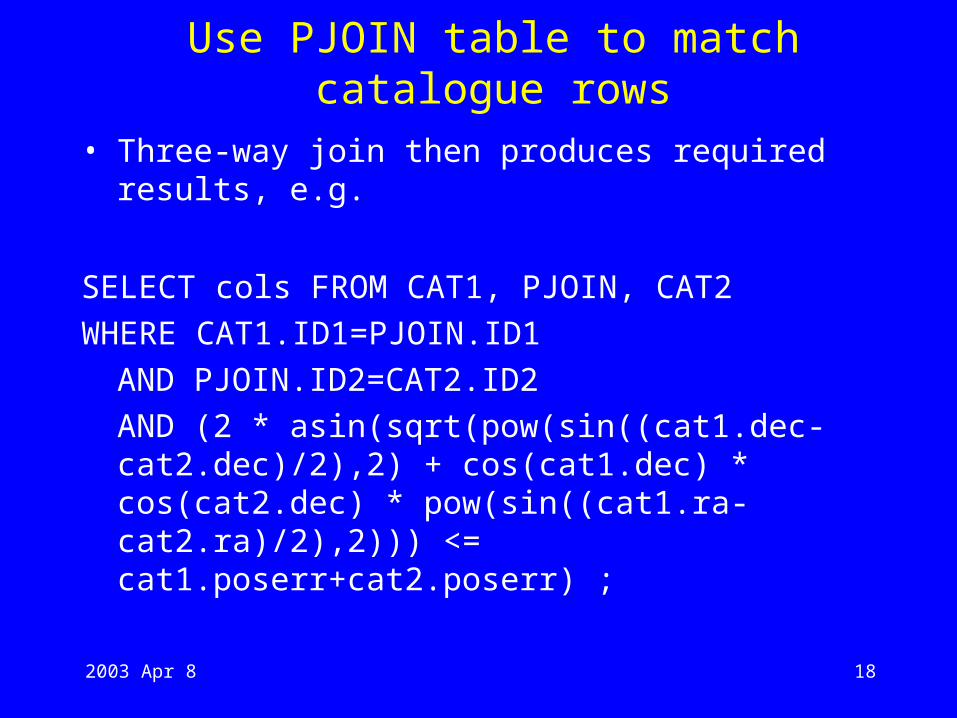
Use PJOIN table to match catalogue rows
• Three-way join then produces required results, e.g.
SELECT cols FROM CAT1, PJOIN, CAT2
WHERE CAT1.ID1=PJOIN.ID1
AND PJOIN.ID2=CAT2.ID2
AND (2 * asin(sqrt(pow(sin((cat1.dec-cat2.dec)/2),2) + cos(cat1.dec) * cos(cat2.dec) * pow(sin((cat1.ra-cat2.ra)/2),2))) <= cat1.poserr+cat2.poserr) ;

2003 Apr 8 19
(3) True Multi-dimensional Indexing
• Hot topic of research in computer science departments for more than 20 years
• Very many algorithms have been proposed:– BANG file, BV-tree, Buddy tree, Cell tree, G-tree, GBD-tree, Gridfile, hB-
tree, kd-tree, LSD-tree, P-tree, PK-tree, PLOP hashing, Pyramid tree, Q0-tree, Quadtree, R-tree, SKD-tree, SR-tree, SS-tree, TV-tree, UB-tree, Z-order index.
– So many alternatives, but none of them provides a good general solution, like the B-tree in 1-D indexing.
• R-tree indexing is built into several modern DBMS.
2003 Apr 8 20
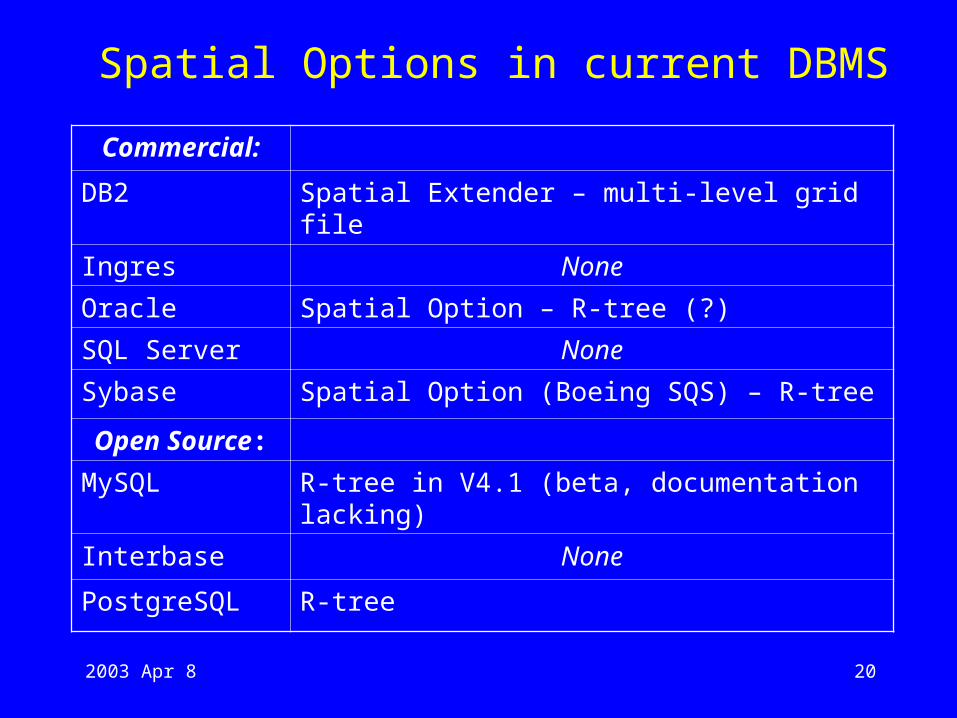
Spatial Options in current DBMS
Commercial:
DB2 Spatial Extender – multi-level grid file
Ingres None
Oracle Spatial Option – R-tree (?)
SQL Server None
Sybase Spatial Option (Boeing SQS) – R-tree
Open Source:
MySQL R-tree in V4.1 (beta, documentation lacking)
Interbase None
PostgreSQL R-tree
2003 Apr 8 21
Using R-trees
Used R-trees in Postgres – does what it says on the box.Problems/limitations include:• Object indexed by R-tree is a rectangular box, so must
draw a box outside each error circle• Boxes get rather extended (along RA axis) near poles• Need a subsequent filter to remove spurious matches where
rectangles overlap but circles do not.• R-tree indices are large, creation is slow (2 hours for table
of 3.5 million rows using Postgres). – Kalpakis et al. used Informix to load part of USNO-A2
and found data load and R-tree creation would have taken 39 days for the entire 500M row table.

2003 Apr 8 22
Comparison of PCODE and R-tree
• Advantages– PCODE join seems to be faster (but not yet
benchmarked with identical systems).– Takes up less disc space in total.– Can use any DBMS, not just those with an R-tree or
other spatial data option.• Disadvantages
– Additional tables and indices have to be created– More complex set of joins. – Needs external code as neither HTM or HEALPix can
be expressed as an SQL-callable function (they return a variable-length array of integers).

2003 Apr 8 23
Conclusions
• Indexing on just one spatial axis is simply too inefficient for large tables.
• R-trees are powerful and easy to use, but index creation times are a serious cause for concern.
• 2d1d mapping functions such as HTM or HEALPix are more complicated to use, but may be worthwhile for JOINs if they turn out to be faster.





























