Embed Size (px)
Citation preview

20 ans du Master SIAD de Toulouse
-
Big Data par l’exemple-
Julien DULOUT-
22 mars 2013
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Qui a déjà entendu parler du phénomène Big Data?
Qui a déjà mis en œuvre des technos BigData ou connait des entreprises qui l’ont déjà fait ?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

ou réalité?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Accroissement du volume d’information
Un homme en 2006 générait 5Go de données par ans
En 2011, il génère 85Go par ans
Source IDC
+ 1700 %
1.8 Zettaoctets (1 zetta =1021 ) ont été produits en 2011, un chiffre qui continue à augmenter de 50% chaque année.
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Sources multiples et Variées…
Médias
sociaux
Objets
intelligents
Open Data
…dont le format est Variable dans le temps
OPEN DATA
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

…et traitées toujours plus vite
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

…avec des modes de Visualisation toujours plus sophistiqués
…C’est là que réside la vraie valeur20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Alors Combien de V à Big Data ?
Volume Variété VélocitéVariabilité Visualisation
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Pour qui?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
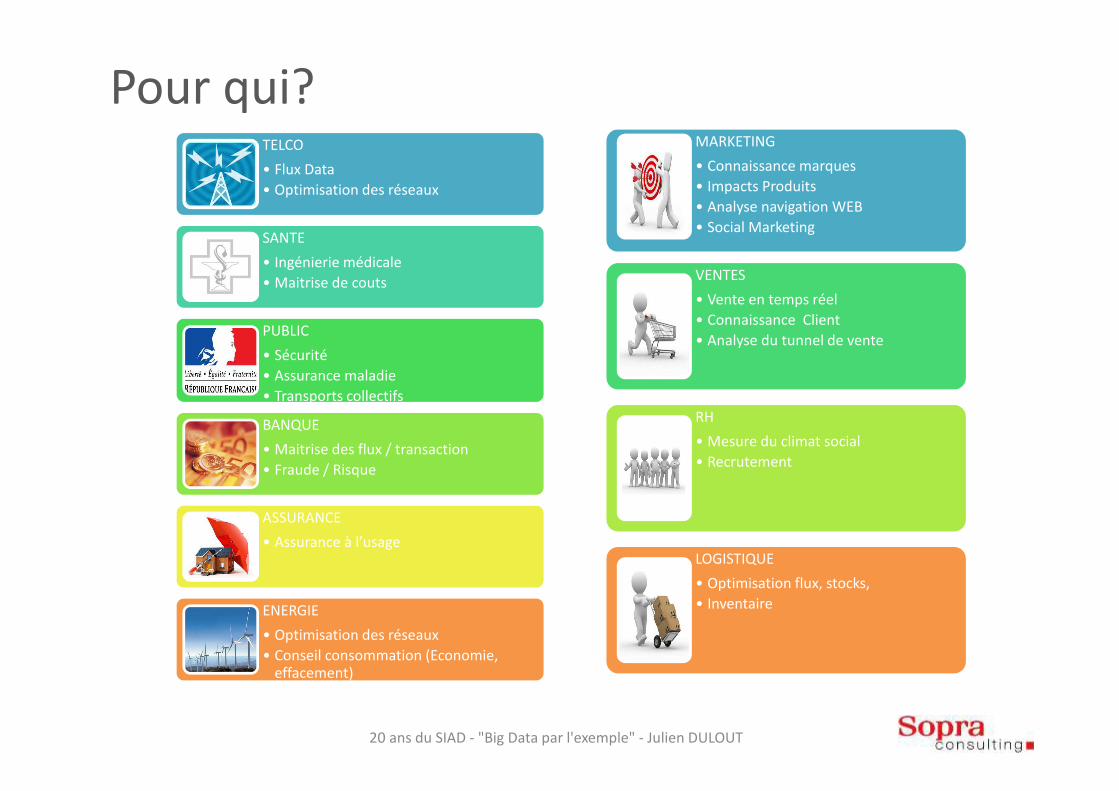
TELCO
• Flux Data
• Optimisation des réseaux
SANTE
• Ingénierie médicale
• Maitrise de couts
PUBLIC
• Sécurité
• Assurance maladie
• Transports collectifs
BANQUE
• Maitrise des flux / transaction
• Fraude / Risque
ASSURANCE
• Assurance à l’usage
ENERGIE
• Optimisation des réseaux
• Conseil consommation (Economie, effacement)
MARKETING
• Connaissance marques
• Impacts Produits
• Analyse navigation WEB
• Social Marketing
VENTES
• Vente en temps réel
• Connaissance Client
• Analyse du tunnel de vente
RH
• Mesure du climat social
• Recrutement
LOGISTIQUE
• Optimisation flux, stocks,
• Inventaire
Pour qui?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
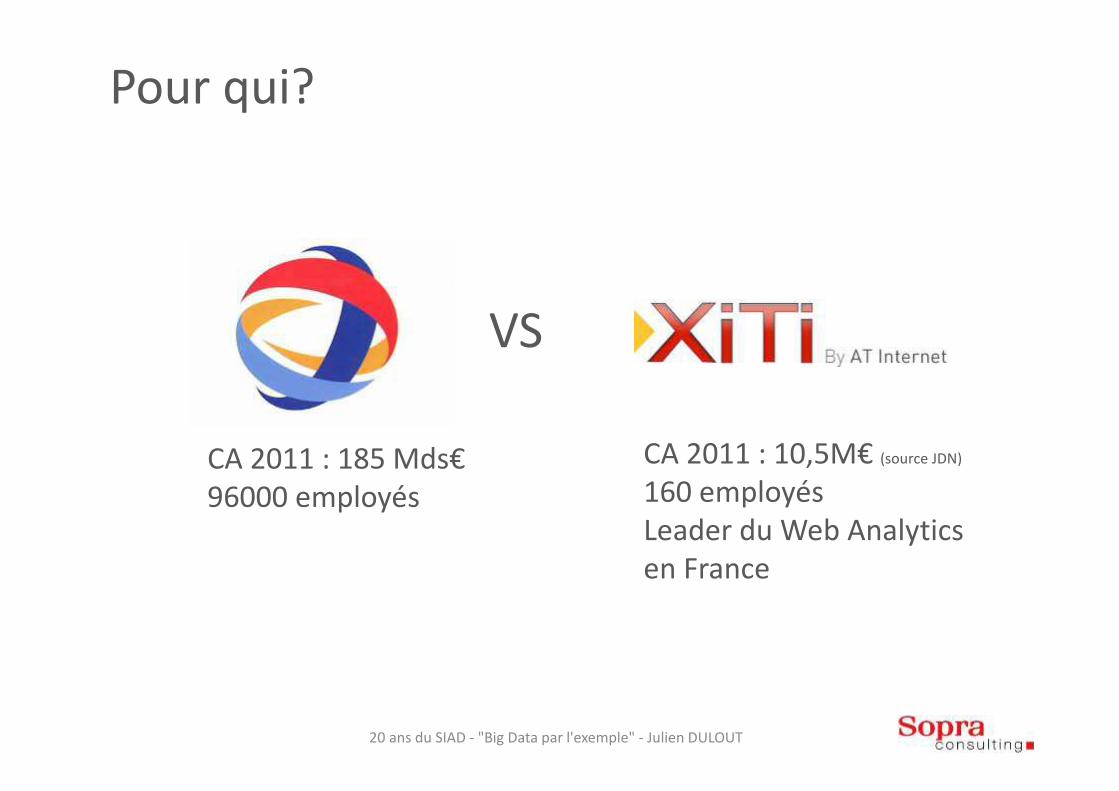
Pour qui?
VS
CA 2011 : 10,5M€ (source JDN)
160 employésLeader du Web Analyticsen France
CA 2011 : 185 Mds€96000 employés
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Internes Externes
ConsommationLocalisationPaiements
NavigationConsommation
NOUVEAUX SERVICES
NOUVEAUX USAGES
RelationsContacts
Déplacement
FoyerDomotiqueInfluence
1 2
Exploiter le capital numérique à ma disposition
OPEN DATA
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

L’exploitation des données peut être très variée
Créer un système à
recommandation
� Booster les ventes
� Répondre au besoin du client
� Améliorer l’experience utilisateur
� Augmenter la diversité des achats
Améliorer le fonctionnement du
site internet
Vision à 360°
Analyse prédictive des ventes
� Améliorer la gestion des stocks
� Mettre en avant des produits
� Estimer les ventes
� Diminuer les pertes de produits
� Connaitre ses préférences
� Prédire ses achats
� Caractériser ses besoins
� Evaluer sa satisfaction
� Utiliser des données internes et externes
� Croiser les informations
� Avoir une vision global de l’activité
� Rechercher efficacement
� Améliorer la réactivité
� Augmenter la pertinence des résultats
� Repérer les pages non visitées
� Analyser les problèmes d’ergonomie
� Réaliser des statistiques précises
Recherche d’information
Connaitre le client
Quels bénéfices à capter les données en masse?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

L’incontournable Hadoop Les atouts
� Performance
� Stockage
� Scalabilité
� Données non structurées
� Haute disponibilité
� R&D mondiale
� Open source
� Standard Web
� Système distribué
� Connectivité croissante
Les points d’attention
� Ressources spécialisées
� Langage non SQL
� Très orienté Analyse
� Orienté batch
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Connecteurs (stockage simple ou utilisation de Hadoop pour réaliser des traitements)
Intégration donnéesnon-structurées(flume, chuhwa)
Le Framework HadoopÉcosystème et distributions
Distributions
Calculs distribués(MapReduce)
Stockage distribué(HDFS)
Base NoSQL orientée colonnes(Hbase)
PseudoSQL(Hive)
Coordinattion(Zookeeper)
Flux de données(Pig)
Intégration donnéesstructurées(Sqoop)
Workflow et Scheduling(Oozie)
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

L’adoption d’Hadoop
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
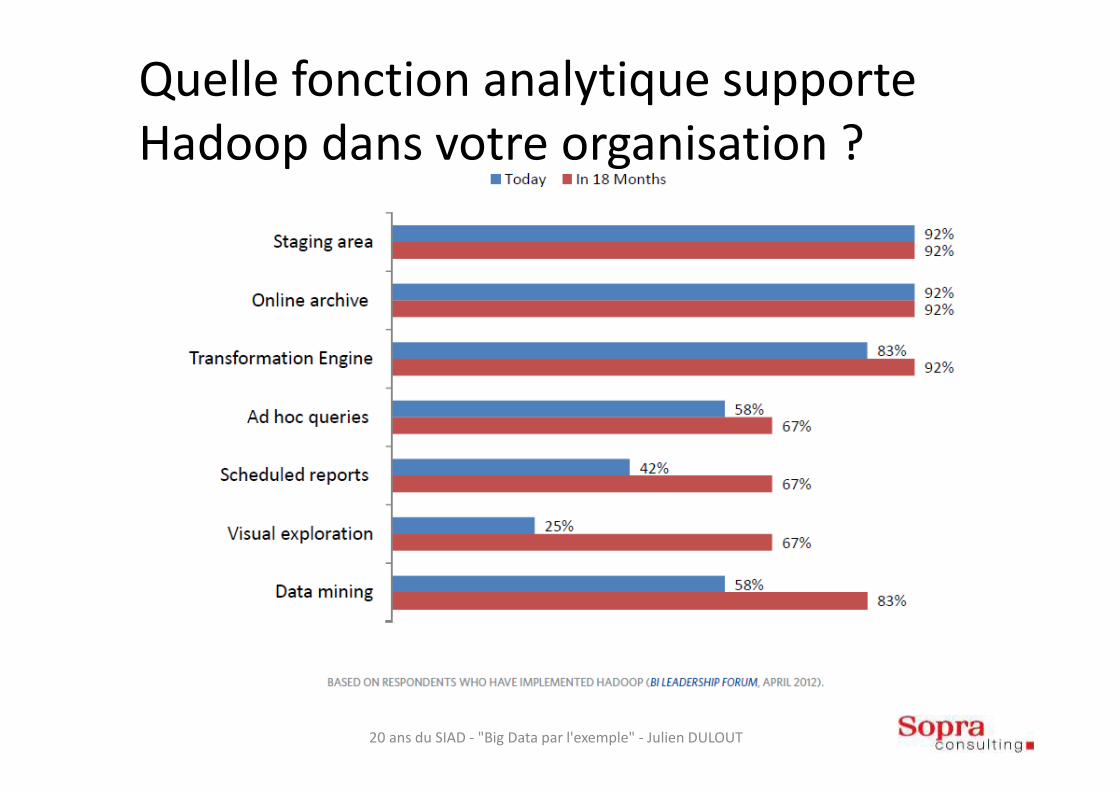
Quelle fonction analytique supporte Hadoop dans votre organisation ?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
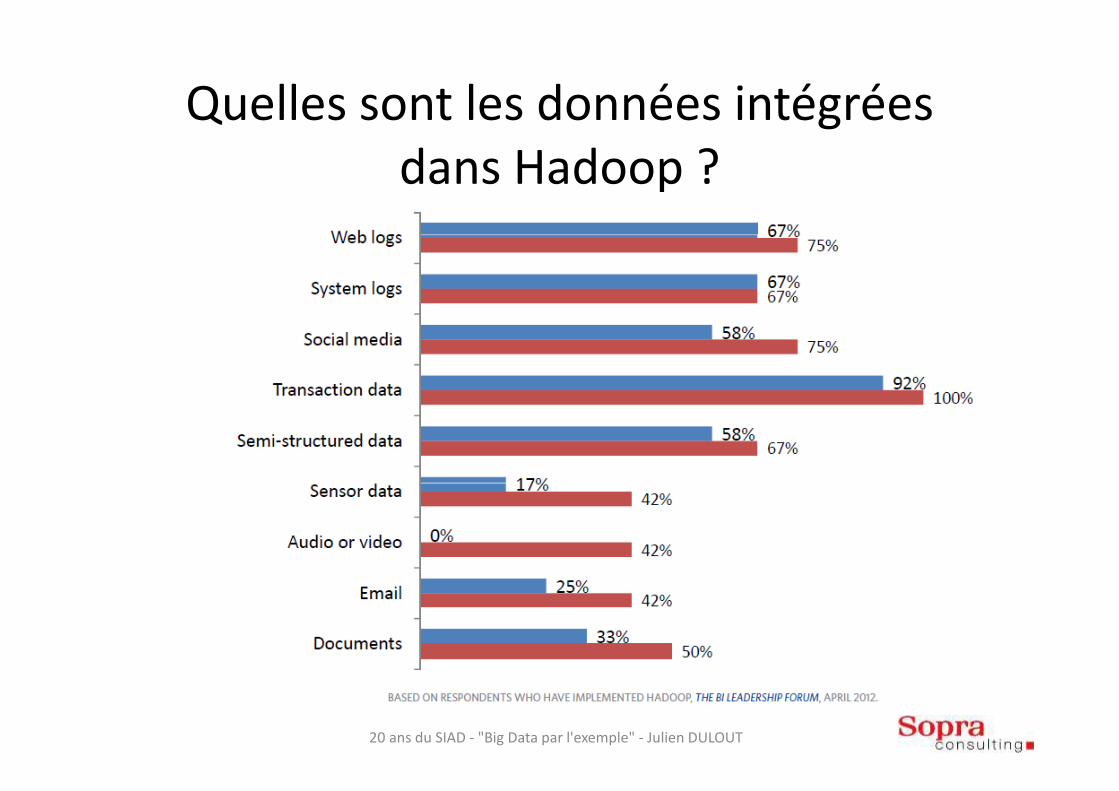
Quelles sont les données intégrées dans Hadoop ?
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
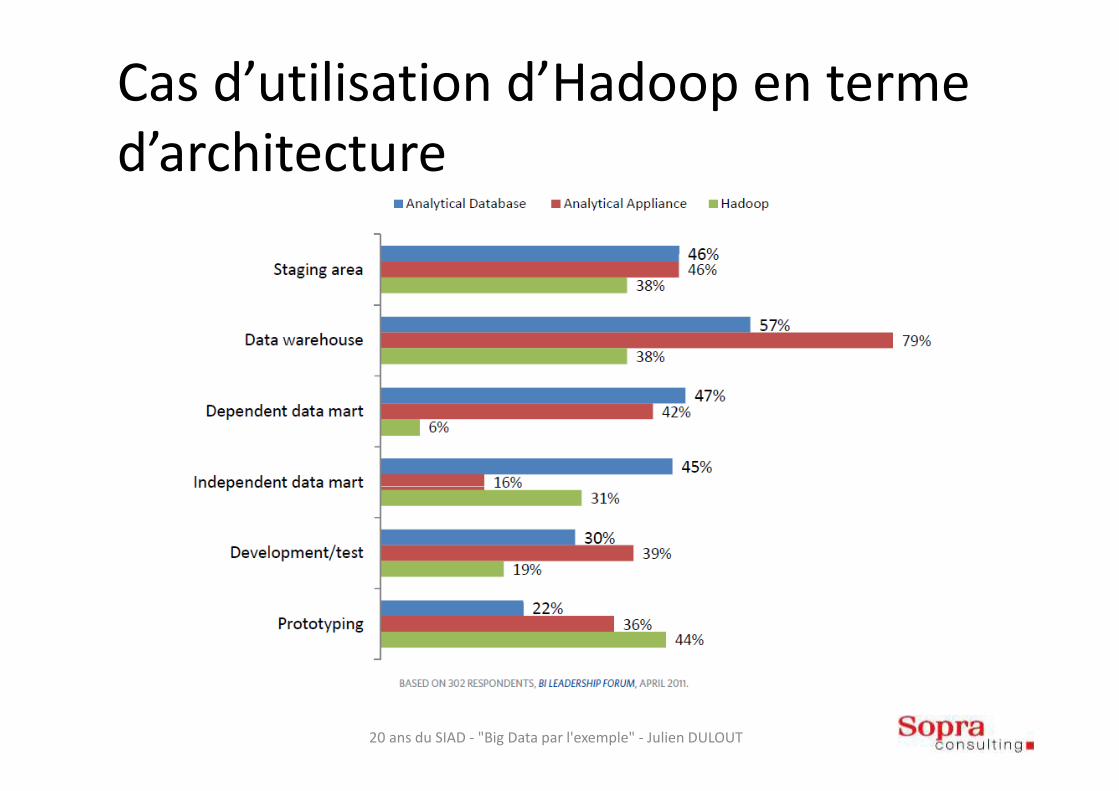
Cas d’utilisation d’Hadoop en terme d’architecture
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Cas d’utilisation HadoopPourquoi Facebook a migré vers Hadoop ?
En 2007, Facebook a préféré Hadoop aux solutions MPP pour de supporter ses données décisionnelles d’un volume de 15 To
Chiffres clés (2012)
� 210 To de données Hadoop (via Hive) manipulées…chaque heure
� 500 To de données intégrés par jour dont 300 millions de photos
� MAJ des requêtes de ciblages de publicité : chaque heure
� 100 Po de données sur une seule grappe Hadoop
Les critères de choix
� Aspect logiciel : � Open Source vs licences� Prise en main aisée par les
développeurs de FaceBook� Flexibilité
� Aspects matériel :� Cluster de machines à bas prix vs
serveurs spécialisés (~10 000 US$ par instance MySQL ou MPP vs 2 000 à 4 000 US$ par instance Hadoop)
� Scalabilité horizontale jusqu’à 4000 nœuds
� Performance accrue
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
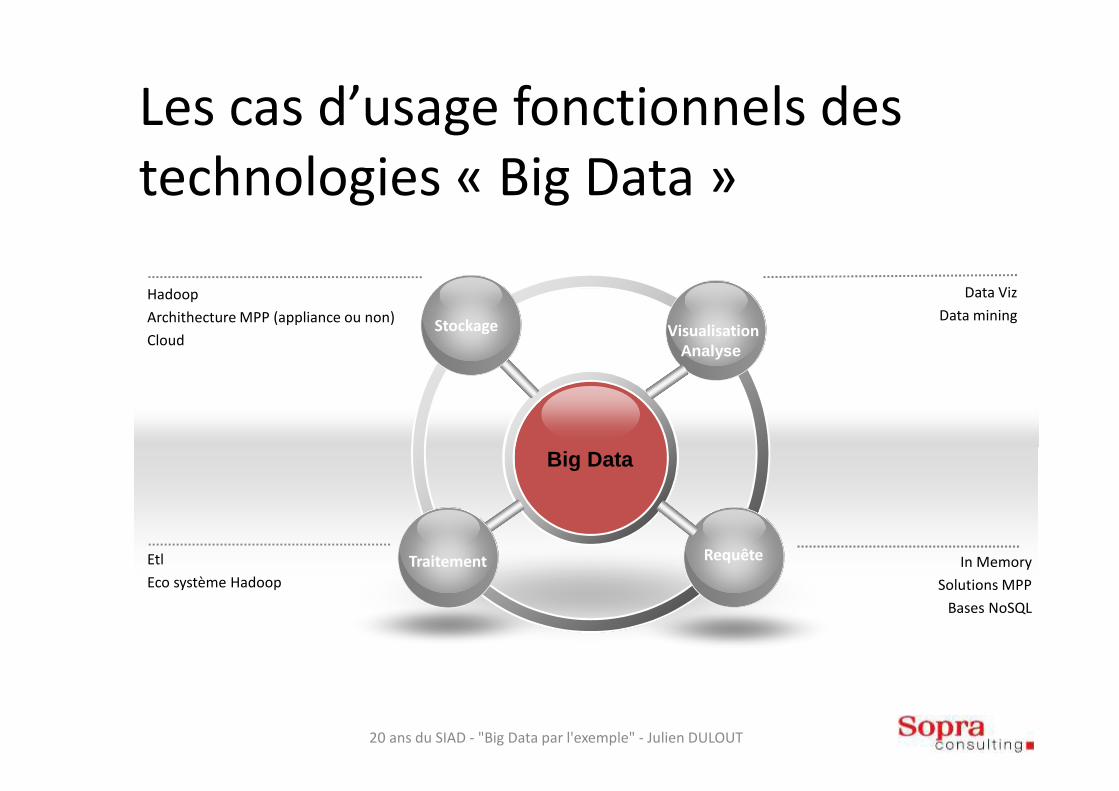
Les cas d’usage fonctionnels des technologies « Big Data »
In Memory
Solutions MPP
Bases NoSQL
Hadoop
Archithecture MPP (appliance ou non)
Cloud
Etl
Eco système Hadoop
Big Data
Stockage
RequêteTraitement
Visualisation
Analyse
Data Viz
Data mining
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Les solutions MPP
EXADATA
Appliance
Database
Sans Appliance
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Les solutions In memory
Memcached
Appliance
Visual Analytics
Cache pour cluster
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Les solutions NoSQL
Orienté Graphe
Orienté Colonne Clé / Valeurs
Orienté Documents
NOSQL
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Les solutions de traitements
� De nombreuses implémentation différentes
� Basé sur des travaux réalisés par Google
� Concept simple mais apprentissage difficile
Traitement - Map Reduce
� Pig : utilisation d’un langage de requêtage –
� ETL
� Hive : utilisation d’un langage proche du sql – Data warehouse
� Gain en productivité
� Plus accessible
Traitement
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Les solutions de Visualisation et d’analyse
Datamining Dataviz
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
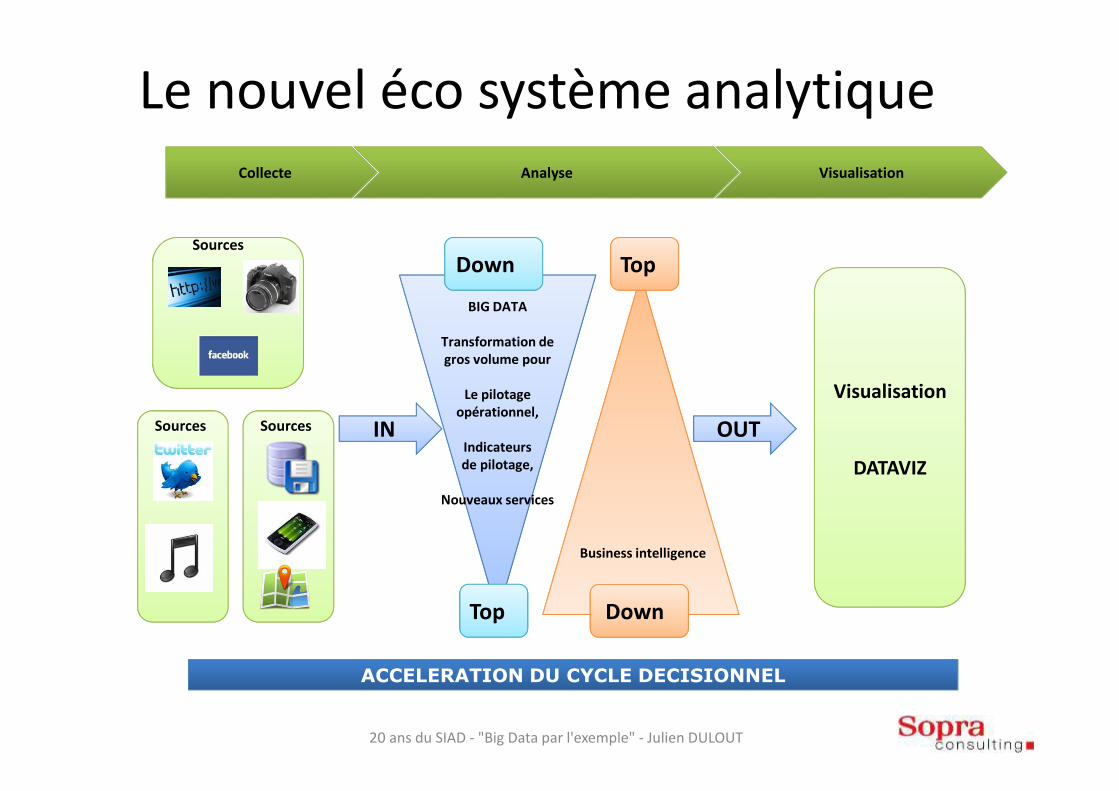
Le nouvel éco système analytique
ININ
Collecte Analyse Visualisation
BIG DATA
Transformation de
gros volume pour
Le pilotage
opérationnel,
Indicateurs
de pilotage,
Nouveaux services
Sources
Visualisation
DATAVIZ
SourcesSources
Down
Top Down
Top
Business intelligence
OUTOUT
ACCELERATION DU CYCLE DECISIONNEL
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
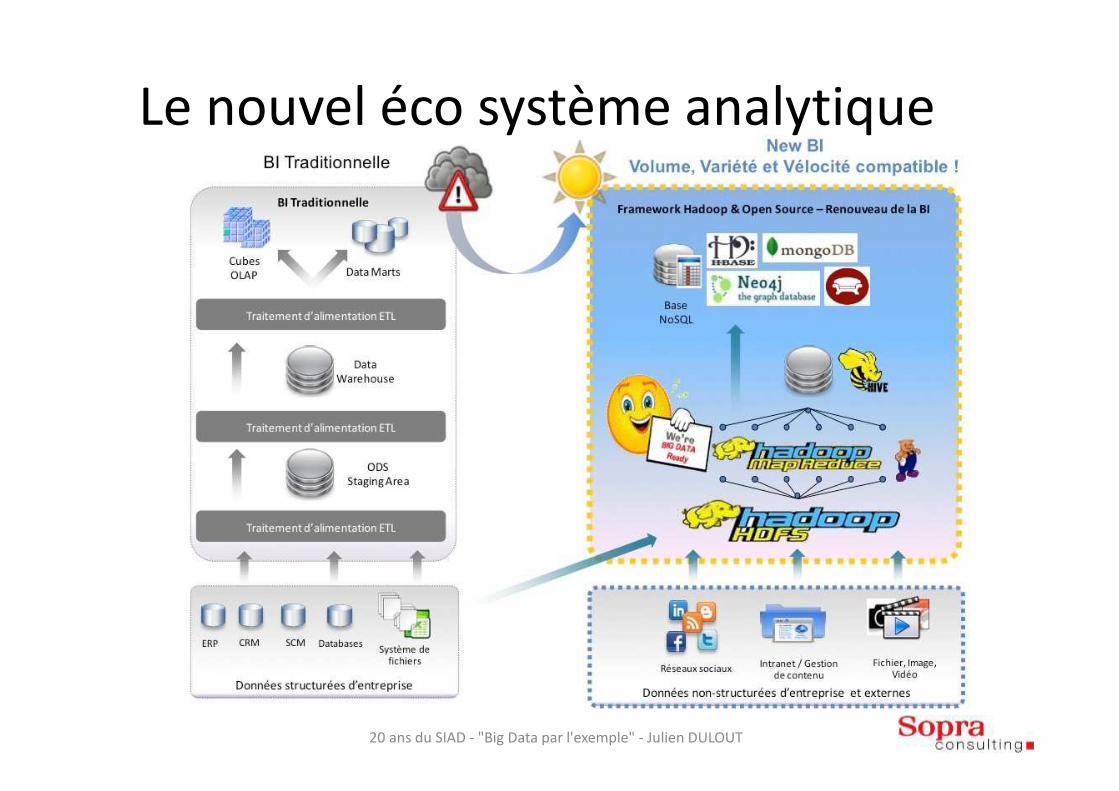
Le nouvel éco système analytique
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Le nouvel éco système analytique
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

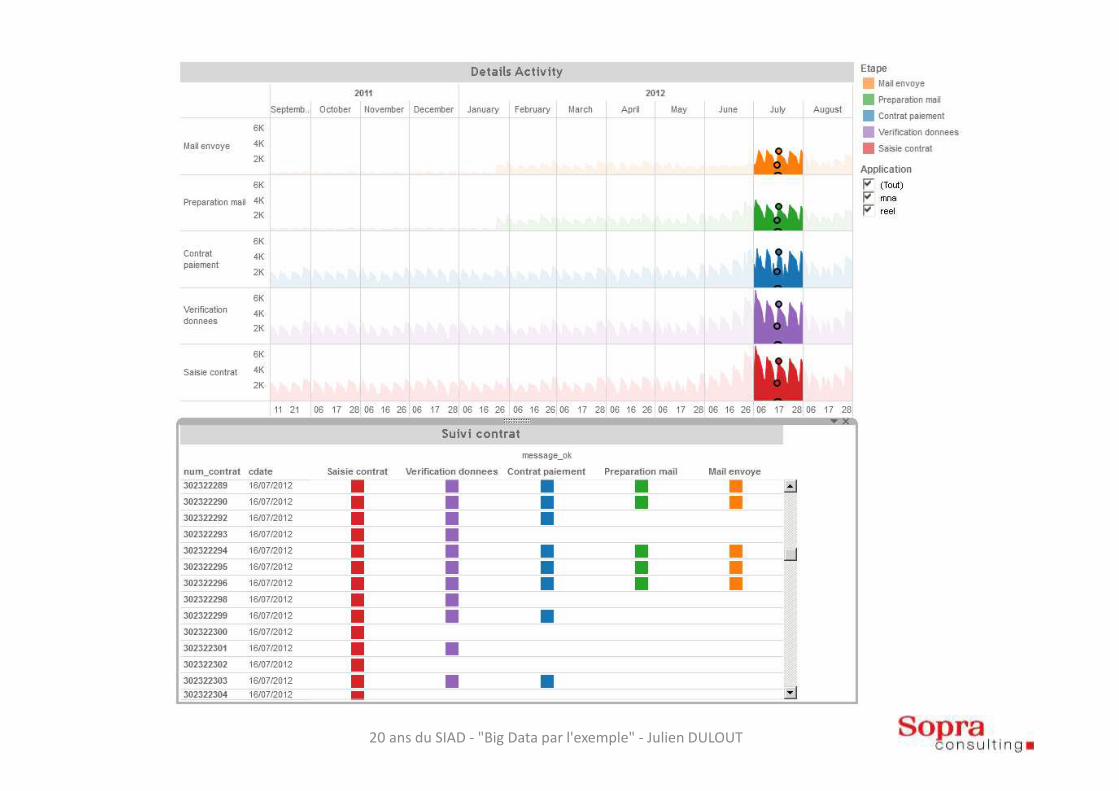
Exemple POC Big Data
• 1 Million de contrats par année
• Plus de 2 Millions de lignes de log par jour
• Des données de log en constante évolution et difficiles à analyser
• Impossibilité de visualiser le parcours client sur un temps de traitement très court
• Connaitre le trafic et la répartition des charges serveurs sur de longue période est compliqué et très couteux avec une telle volumétrie
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Objectifs du POC
• A partir des logs tomcat :
– Quantification du traffic
– Vérification du load balancing pour les serveurs d’application
– Identification des erreurs tomcat
– Analyse du parcours client
– Evolution du taux de transformation en fonction des actions marketing et des évolutions du site Web
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Solutions mises en œuvre• Hadoop distribution Cloudera CDH4
– Stockage : HDFS
– Requêtage : Hive
• Traitements : Talend BigData
• Requêtage : Vectorwise
• Visualisation : Tableau software
• Hébergement serveur : Cloud Amazon EC2
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Architecture technique
Tomcat 1
Tomcat 1
Tomcat 2
Tomcat 2
REEL
MNA
Base NoSQL
NoSQL
DataNode 1
DataNode 2
DataNode 3
NameNode
HDFS
TalendBigData
TalendBigData
Sources
Étape 1Étape 2
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Indicateurs du POC
• Temps de chargement moyen– Phase init : 8H
– Phase quotidien : 30 min
• Temps d’exécution moyen– Requête complexe : <15 min
– Requête simple : < 1 min
• Volumétrie :– 1,5 ans d’historique
– 476 Millions de lignes
– 1500 Fichiers de log4j
– 400 Go
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

La donnée est le "nouveau pétrole". En conséquence, les métiers changent. Le cabinet Gardner chiffre à 4,4 millions le nombre d'emplois dans le monde
créés d'ici à 2015 dans le secteur du Big Data
Nouveaux métiers
• CDO (chief data officer) : situé au même niveau hiérarchique que les directeurs marketing et informatique, il fait le lien entre les deux services.
• Data Scientist
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Data scientists have the skills to lead and execute projects involving:
- Design algorithms to efficiently compute metrics on big data
- Mine data to extract deep insights into user media consumption, consumer purchase behavior, user response to advertising- Perform analysis such as social network analysis, anomaly detection,
trend analysis, etc
- Develop high dimensional predictive models of user behavior
- Develop visualizations
Data scientists will develop a deep understanding of Yahoo's data. They
will have the skills to design and implement algorithms, manipulate data
in one or more programming languages. They will have deep knowledge of big data processing architectures such as map reduce, stream processing, etc.
Data scientists will have a PhD in computer science or related fields.
Data scientist selon Yahoo! labs
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Autrement dit
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Autrement dit
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Les compétences recherchées couvrent trois domaines :
• la gestion des données (les capter),
• l'analyse (statisticiens, mathématiciens)
• les compétences métiers, liées au management et à la prise de décisions.
Les deux premiers profils se trouvent en écoles d'ingénieurs et universités. Le troisième plutôt en école de commerce.
Autrement dit
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT

Autrement dit
20 ans du SIAD - "Big Data par l'exemple" - Julien DULOUT





























