Embed Size (px)
Citation preview

Pokok Bahasan
1. Running Code Program Pada Hadoop Single/Multi
Node Cluster Pada Linux:
o Klasifikasi: NB, KNN
o Clustering: K-Means
o WordCount: Load+Simpan Hasil di HDFS Folder (Pert. Ke-
12-13)
o WordCount: Load+Simpan Hasil di NoSQL (MongoDB)
o Movie Ratings: Load di HDFS Folder+Simpan Hasil di
NoSQL (MongoDB)
2. Studi Kasus
3. Tugas

Siapkan semua file *.java (dari algoritma Naive_Bayes_Classifier_MapReduce, link
kode: https://goo.gl/CEdr2R ) untuk dicompile ke *.jar:
Note: cek pada setiap file *.java tersebut, apakah terdapat package atau tidak
Study Kasus
Klasifikasi: NB

Jika tidak terdapat package, langsung file *.java tersebut dicopy-paste ke folder
/usr/local/hadoop
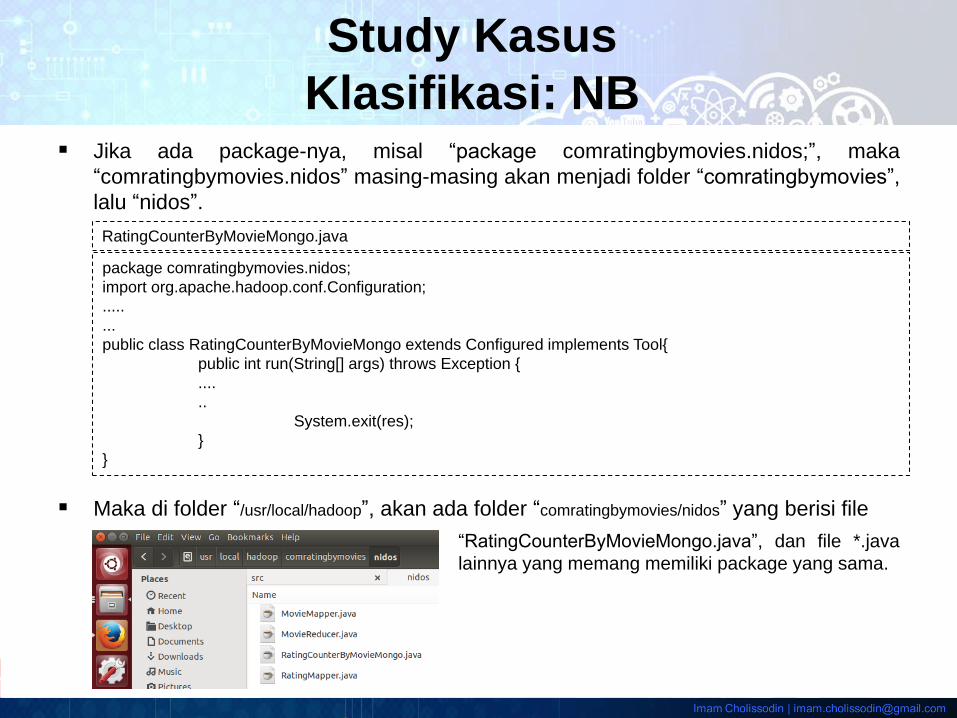
Jika ada package-nya, misal “package comratingbymovies.nidos;”, maka
“comratingbymovies.nidos” masing-masing akan menjadi folder “comratingbymovies”,
lalu “nidos”.
Study Kasus
Klasifikasi: NB
NBCDriver.java NBCMap.java NBCReduce.java
Jika ada package-nya, misal “package comratingbymovies.nidos;”, maka
“comratingbymovies.nidos” masing-masing akan menjadi folder “comratingbymovies”,
lalu “nidos”.
Maka di folder “/usr/local/hadoop”, akan ada folder “comratingbymovies/nidos” yang berisi file
Study Kasus
Klasifikasi: NB
package comratingbymovies.nidos;
import org.apache.hadoop.conf.Configuration;
.....
...
public class RatingCounterByMovieMongo extends Configured implements Tool{
public int run(String[] args) throws Exception {
....
..
System.exit(res);
}
}
RatingCounterByMovieMongo.java
“RatingCounterByMovieMongo.java”, dan file *.java
lainnya yang memang memiliki package yang sama.
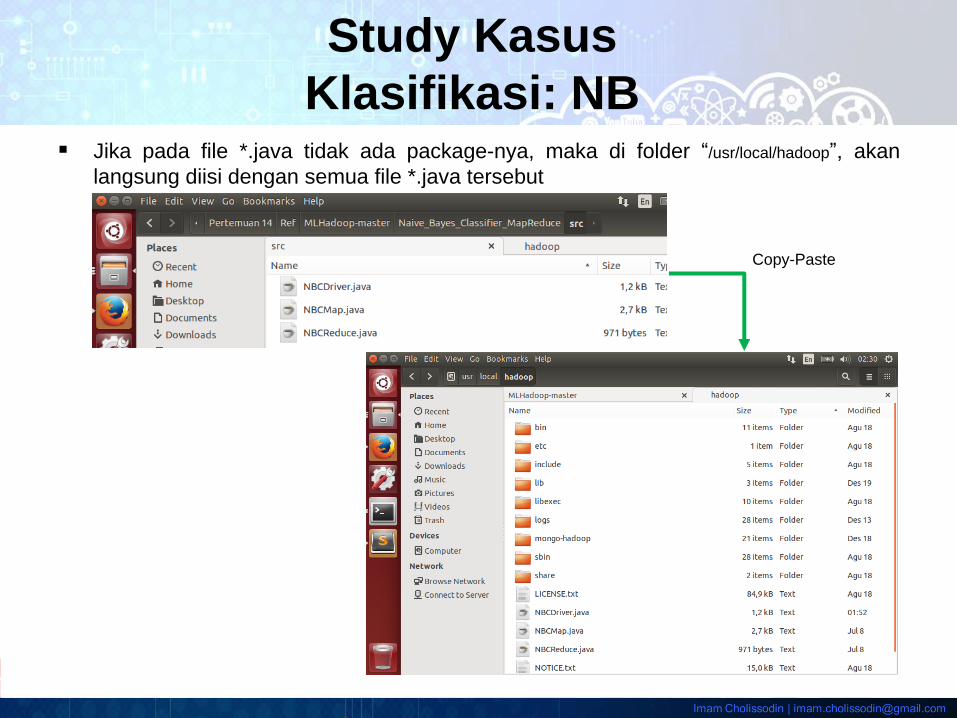
Jika pada file *.java tidak ada package-nya, maka di folder “/usr/local/hadoop”, akan
langsung diisi dengan semua file *.java tersebut
Study Kasus
Klasifikasi: NB
Copy-Paste

Lakukan perintah (Membuat file *.class):
Study Kasus
Klasifikasi: NB
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main *.java
Note: NBCDriver.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.

Lakukan perintah (Membuat file *.class *.jar):
Study Kasus
Klasifikasi: NB
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main *.java
Note: NBCDriver.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
Atau bisa dengan
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main -Xlint:deprecation *.java
nidos@master:/usr/local/hadoop$ jar cf NB.jar *.class
NBCDriver.java:16: warning: [deprecation] Job(Configuration) in Job has been deprecated
Job job = new Job(conf);
^
1 warning
Buat folder HDFS, “nb” dan “input”
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user/nidos/nb
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user/nidos/input
-copyFromLocal, misal file“1.txt” ada difolder
“/home/nidos/Desktop/kode/Naive_Bayes_Classifier_MapReduce/input” “1.txt” sebagai data training
nidos@master:/usr/local/hadoop$ bin/hadoop jar NB.jar NBCDriver Urgent,Yes,Yes /user/nidos/nb/input/1.txt
/user/nidos/nb/output
Untuk mengecek kode yang
deprecated dimana saja
Main Class

Hasil 1 of 2:
Study Kasus
Klasifikasi: NB

Hasil 2 of 2:
Study Kasus
Klasifikasi: NB

Siapkan semua file *.java (dari algoritma KNN, link kode: https://goo.gl/N0QjY8 )
untuk dicompile ke *.jar:
Note: dalam folder “mapreduce”, semua file java-nya terdapat package “com.
clustering.mapreduce”, dan dalam folder “model”, semua file java-nya terdapat
package “com.clustering.model”, jadi copy paste-nya ke folder “/usr/local/hadoop”
mulai dari folder “com”
Study Kasus
Klasifikasi: KNN

Jika pada file *.java yang ada package-nya sesuai penjelasan slide sebelumnya,
maka di folder “/usr/local/hadoop”, akan langsung diisi dengan folder “com” tersebut
Study Kasus
Clustering: K-Means
Copy-Paste

Lakukan perintah (Membuat file *.class):
Study Kasus
Clustering: K-Means
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main com/clustering/mapreduce/*.java
com/clustering/model/*.java
Note: Some input files use or override a deprecated API.
Note: Recompile with -Xlint:deprecation for details.

Lakukan perintah (Membuat file *.class *.jar):
Study Kasus
Clustering: K-Means
nidos@master:/usr/local/hadoop$ jar cf KMeans.jar com/clustering/mapreduce/*.class com/clustering/model/*.class
nidos@master:/usr/local/hadoop$ bin/hadoop jar KMeans.jar com/clustering/mapreduce/KMeansClusteringJob
Main Class

Hasil 1 of 2:
Study Kasus
Clustering: K-Means

Siapkan semua file *.java (dari algoritma K-Means, link kode: https://goo.gl/N0QjY8 )
untuk dicompile ke *.jar:
Note: dalam folder “mapreduce”, semua file java-nya terdapat package “com.
clustering.mapreduce”, dan dalam folder “model”, semua file java-nya terdapat
package “com.clustering.model”, jadi copy paste-nya ke folder “/usr/local/hadoop”
mulai dari folder “com”
Study Kasus
Clustering: K-Means

Jika pada file *.java yang ada package-nya sesuai penjelasan slide sebelumnya,
maka di folder “/usr/local/hadoop”, akan langsung diisi dengan folder “com” tersebut
Study Kasus
Clustering: K-Means
Copy-Paste

Lakukan perintah (Membuat file *.class):
Study Kasus
Clustering: K-Means
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main com/clustering/mapreduce/*.java
com/clustering/model/*.java
Note: Some input files use or override a deprecated API.
Note: Recompile with -Xlint:deprecation for details.

Lakukan perintah (Membuat file *.class *.jar):
Study Kasus
Clustering: K-Means
nidos@master:/usr/local/hadoop$ jar cf KMeans.jar com/clustering/mapreduce/*.class com/clustering/model/*.class
nidos@master:/usr/local/hadoop$ bin/hadoop jar KMeans.jar com/clustering/mapreduce/KMeansClusteringJob
Main Class

Hasil 1 of 2:
Study Kasus
Clustering: K-Means

Hasil 2 of 2:
Study Kasus
Clustering: K-Means

NoSQL (Not Only SQL, atau maknanya kurang lebih adalah "tidak
hanya SQL") adalah kelas yang luas dari sistem manajemen basis
data yang di identifikasikan tidak mematuhi aturan pada model
sistem manajemen basis data relasional yang banyak digunakan.
NoSQL tidak dibangun terutama dengan table dan umumnya tidak
menggunakan SQL untuk memanipulasi data.
Teorema CAP menyatakan bahwa, tidak mungkin untuk sebuah
sistem komputer terdistribusi secara bersamaan, memberikan ketiga
jaminan sebagai berikut :
o Consistency: Semua node melihat data yang sama dalam
waktu yang bersamaan.
o Availability: Jaminan pada setiap permintaan, menerima
tanggapan tentang apakah itu berhasil atau tidak.
o Partition tolerance: Sistem terus beroperasi meski sistem yang
lain gagal.
NoSQL dan MongoDB

Visual NoSQL System:
NoSQL dan MongoDB

MongoDB merupakan open-source document database dari keluarga
NoSQL, yang memberikan kinerja tinggi, high availability, dan automatic
scaling.
Document, Data pada MongoDB dikenal sebagai document. MongoDB
menggunakan BSON (Binary JSON) serialization sebagai format
penyimpanan data untuk document, mirip dengan JSON (JavaScript Object
Notation). Contoh document:
Contoh Penggunaan
NoSQL dan MongoDB
{
"_id": ObjectId('58520a516a2ea8e208cd6c26'),
"name": "Employee One",
"salary": 20000
}
SQL:
SELECT *
FROM employeedetails
WHERE name = "Employee One"
OR salary = 20000
MongoDB:
db.employeedetails.find(
{
$or: [
{ name: "Employee One" },
{ nomor: 20000 }
]
})

SQL Vs MongoDB:
SQL Vs MongoDB
SQL MongoDB
database database
table collection
row document
column field
index Index
table joins Embedded documents
dan linking
primary key primary key

Case Study: Mengolah data dan menyimpan hasilnya ke MongoDB:
o Wordcount
o Rating By Movie
Note: Secara default, Map Reduce akan menyimpan hasilnya di file teks biasa di
HDFS. Hal ini sangat tidak praktis jika memang hasilnya ingin dimasukkan ke
NoSQL supaya mudah dibaca.
MongoDB dan Big Data

Lakukan perintah (Install MongoBD untuk simpan file hasil running kode
program di Hadoop):
Running Hadoop
(Save hasil di MongoDB)
nidos@master:~$ sudo apt-get install mongodb
nidos@master:~$ sudo apt-get update
nidos@master:~$ sudo service mongodb start
start: Job is already running: mongodb
nidos@master:~$ mongo
MongoDB shell version: 2.4.9
connecting to: test
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
http://docs.mongodb.org/
Questions? Try the support group
http://groups.google.com/group/mongodb-user
> use mydb;
switched to db mydb
> db;
mydb
> db.employeedetails.insert({name:"Employee One",salary:20000});
> db.employeedetails.find();
{ "_id" : ObjectId("58520a516a2ea8e208cd6c26"), "name" : "Employee One", "salary" : 20000 }
> exit
bye

Lakukan perintah:
Running Hadoop
(Install GUI MongoDB)
nidos@master:~$ sudo apt-get install curl
nidos@master:~$ curl http://packages.litixsoft.de/installer.sh | sh
Enter ´sudo ./bbs-installer.sh´ to start installation...
nidos@master:~$ sudo ./bbs-installer.sh
nidos@master:~$ sudo tar xvzf /home/nidos/Desktop/GUI\ Mongo/mms-v1.9.4-community-linux.tar.gz
nidos@master:~$ sudo tar xvzf mms-v1.9.4-community-linux-x86_64.tar.gz
nidos@master:~$ cd mms-v1.9.4-community-linux-x86_64/
nidos@master:~$ sudo ./bbs-installer.sh
BaboonStack Installer for Linux/MacOS
Local Packet found...
Install baboonstack-v1.5.1-linux-x64.tar.gz...
Create /opt/litixsoft/baboonstack...
Extract Files...
Execute Installscript bbs/lxscript.sh...
SUCCESS: Enter ´bbs´ for package updates.
Install MongoDB v2.6.7?: [Y/n] n Jika sudah Install
Install RedisIO v2.8.4?: [Y/n] Y
Install Node.js v0.12.0?: [Y/n] Y
Activate Io.js support?: [Y/n] Y
lxManager for BaboonStack - Litixsoft GmbH 2015
Upgrade successfull...

Lakukan perintah:
Running Hadoop
(Install GUI MongoDB)
nidos@master:~/mms-v1.9.4-community-linux-x86_64$ cd lx-mms
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo nano config.js
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo ./start

Lakukan perintah:
Running Hadoop
(Install GUI MongoDB)
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo ./start

Lakukan perintah (http://127.0.0.1:3333/):
Running Hadoop
(Install GUI MongoDB)
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo ./start

Lakukan perintah (http://127.0.0.1:3333/):
Running Hadoop
(Install GUI MongoDB)
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo ./start
Create/Edit connection
Name: ..........., misal “test”
Server connection*: [username:password@]host1[:port1][,host2[:port2],....,[,hostN[:portN]]], misal “localhost”
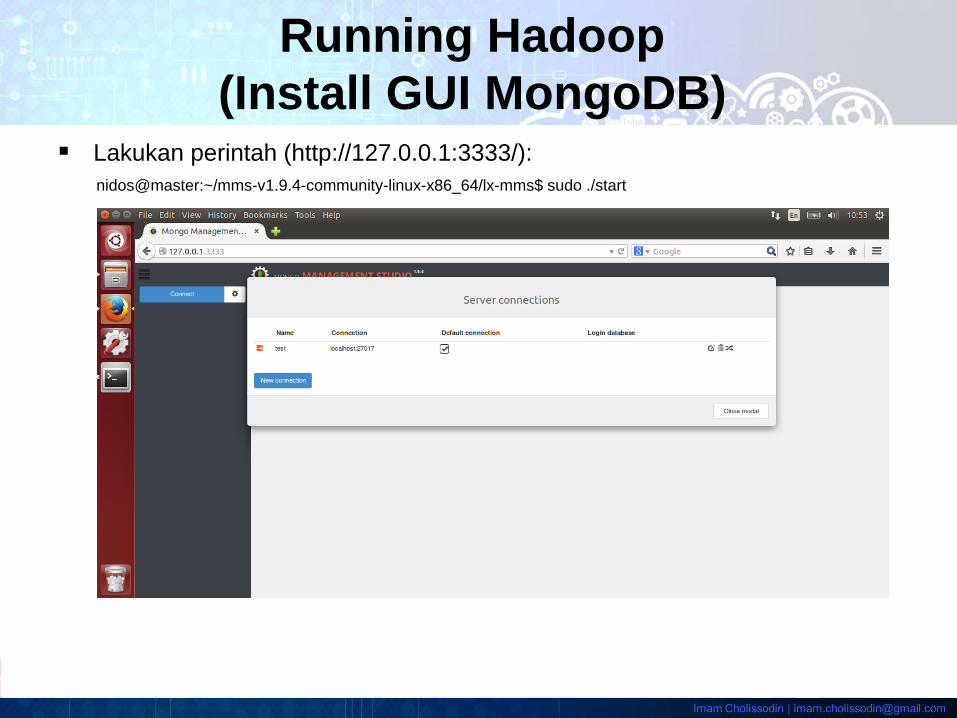
Lakukan perintah (http://127.0.0.1:3333/):
Running Hadoop
(Install GUI MongoDB)
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo ./start

Lakukan perintah (http://127.0.0.1:3333/):
Running Hadoop
(Install GUI MongoDB)
nidos@master:~/mms-v1.9.4-community-linux-x86_64/lx-mms$ sudo ./start

Lakukan perintah:
Konfigurasi Koneksi
(Hadoop + MongoDB)
nidos@master:/usr/local/hadoop$ sudo apt-get install git
nidos@master:/usr/local/hadoop$ git clone https://github.com/mongodb/mongo-hadoop
nidos@master:/usr/local/hadoop$ cd mongo-hadoop
nidos@master:/usr/local/hadoop/mongo-hadoop$ ./gradlew jar

Lakukan perintah:
Konfigurasi Koneksi
(Hadoop + MongoDB)
Copy file “mongo-hadoop-core-2.0.1.jar” dari
/usr/local/hadoop/mongo-hadoop/core/build/libs
File hasil compile dari slide sebelumnya:
nidos@master:/usr/local/hadoop/mongo-hadoop$ ./gradlew jar

Lakukan perintah:
Konfigurasi Koneksi
(Hadoop + MongoDB)
Download file “mongo-java-driver” dari link http://central.maven.org/maven2/org/mongodb/mongo-java-driver/ dan
pilih versi terbaru, misal “mongo-java-driver-3.4.0.jar”

Lakukan perintah:
Konfigurasi Koneksi
(Hadoop + MongoDB)
Setelah selesai build, copy-kan file jars (“mongo-hadoop-core-2.0.1.jar” dan “mongo-java-driver-3.4.0.jar”) ke directory lib
pada setiap node (master, node1, node2, node3) di hadoop cluster. Berikut lokasinya yang bergantung pada versi Hadoop:
$HADOOP_PREFIX/lib/
$HADOOP_PREFIX/share/hadoop/mapreduce/
$HADOOP_PREFIX/share/hadoop/lib/
Misal 2 file jar tersebut sudah disiapkan di “/home/nidos/Desktop/kode/WordCountMongo/”
nidos@master:~/Desktop/kode/WordCountMongo$ ls
mongo-hadoop-core-2.0.1.jar WordCountMongo.java
mongo-java-driver-3.4.0.jar
Untuk PC master:
nidos@master:~$ cp /home/nidos/Desktop/kode/WordCountMongo/mongo* /usr/local/hadoop/lib
nidos@master:~$ cp /home/nidos/Desktop/kode/WordCountMongo/mongo* /usr/local/hadoop/share/hadoop/mapreduce
nidos@master:~$ mkdir r /usr/local/hadoop/share/hadoop/lib
nidos@master:~$ cp /home/nidos/Desktop/kode/WordCountMongo/mongo* /usr/local/hadoop/share/hadoop/lib
Untuk PC node1: Lakukan juga pada node2 dan node3
nidos@node1:~$ scp nidos@master:/home/nidos/Desktop/kode/WordCountMongo/mongo* /usr/local/hadoop/lib
nidos@node1:~$ scp nidos@master:/home/nidos/Desktop/kode/WordCountMongo/mongo*
/usr/local/hadoop/share/hadoop/mapreduce
nidos@node1:~$ mkdir r /usr/local/hadoop/share/hadoop/lib
nidos@node1:~$ scp nidos@master:/home/nidos/Desktop/kode/WordCountMongo/mongo*
/usr/local/hadoop/share/hadoop/lib

Lakukan perintah:
Konfigurasi Koneksi
(Hadoop + MongoDB)
Untuk PC node3:
nidos@node3:~$ scp nidos@master:/home/nidos/Desktop/kode/WordCountMongo/mongo* /usr/local/hadoop/lib
nidos@node3:~$ scp nidos@master:/home/nidos/Desktop/kode/WordCountMongo/mongo*
/usr/local/hadoop/share/hadoop/mapreduce
nidos@node3:~$ mkdir r /usr/local/hadoop/share/hadoop/lib
nidos@node3:~$ scp nidos@master:/home/nidos/Desktop/kode/WordCountMongo/mongo*
/usr/local/hadoop/share/hadoop/lib

Lakukan perintah:
Running Hadoop WordCount
(Save hasil di MongoDB)
Buat DB “testmr”

Lakukan perintah:
Running Hadoop WordCount
(Save hasil di MongoDB)
Buat Collecton “in” on DB “testmr”
Klik kanan pada DB “testmr”, lalu pilih “Add collection..”, beri nama misal “in”, lalu klik Save

Lakukan perintah:
Running Hadoop WordCount
(Save hasil di MongoDB)
Import file “*.json” as collection pada DB “testmr” ke collection “in” sebagai file input untuk diproses oleh
WordCountMongo.java

Lakukan perintah:
Running Hadoop WordCount
(Save hasil di MongoDB)
Import file “*.json” as collection pada DB “testmr” sebagai file input untuk diproses oleh WordCountMongo.java
Untuk file “in.json” tidak standar Mongo:
Klik kanan pada database atau DB “testmr”, lalu pilih “Import documents...”, lalu Isikan Name of destination-
collection*, misal “in”, lalu pilih “Import documents from textbox”, lalu isikan pada “Text Input”, dengan:
lalu Klik Import
{"x": "hello world"},
{"x": "nice to meet you"},
{"x": "good to see you"},
{"x": "world war 2"},
{"x": "see you again"},
{"x": "bye bye"}
in.json tidak standar Mongo in_standard.json standar Mongo
{ "x" : "hello world", "_id" : { "$oid" : "5856c34689b0ce4a6e000001" } }
{ "x" : "nice to meet you", "_id" : { "$oid" : "5856c34689b0ce4a6e000002" } }
{ "x" : "good to see you", "_id" : { "$oid" : "5856c34689b0ce4a6e000003" } }
{ "x" : "world war 2", "_id" : { "$oid" : "5856c34689b0ce4a6e000004" } }
{ "x" : "see you again", "_id" : { "$oid" : "5856c34689b0ce4a6e000005" } }
{ "x" : "bye bye", "_id" : { "$oid" : "5856c34689b0ce4a6e000006" } }
[{"x": "hello world"},
{"x": "nice to meet you"},
{"x": "good to see you"},
{"x": "world war 2"},
{"x": "see you again"},
{"x": "bye bye"}]

Lakukan perintah:
Running Hadoop WordCount
(Save hasil di MongoDB)
Untuk file “in.json” tidak standar Mongo:

Lakukan perintah:
Running Hadoop WordCount
(Save hasil di MongoDB)
Untuk file “in.json” tidak standar Mongo:

Lakukan perintah (Klik kanan pada database atau DB “testmr”, lalu pilih “Import documents...”, lalu
Isikan Name of destination-collection*, misal “in”, lalu klik Browse..):
Running Hadoop WordCount
(Save hasil di MongoDB)
Untuk file in_standard.json standar Mongo

Lakukan perintah (klik Open):
Running Hadoop WordCount
(Save hasil di MongoDB)
in_standard.json standar Mongo

Lakukan perintah (klik Import):
Running Hadoop WordCount
(Save hasil di MongoDB)
in_standard.json standar Mongo

Lakukan perintah (hasil klik Import):
Running Hadoop WordCount
(Save hasil di MongoDB)
in_standard.json standar Mongo

Siapkan file *.java (misal WordCountMongo.java Part 1 of 2) untuk dicompile ke *.jar:
Running Hadoop WordCount
(Save hasil di MongoDB)
import java.util.*;
import java.io.*;
import org.bson.*;
import com.mongodb.hadoop.MongoInputFormat;
import com.mongodb.hadoop.MongoOutputFormat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
/**
* test.in
db.insert( { x: "eliot was here" } )
db.insert( { x: "eliot is here" } )
db.insert( { x: "who is here" } )
*
*/
public class WordCountMongo {
public static class TokenizerMapper extends Mapper<Object, BSONObject, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, BSONObject value, Context context )
throws IOException, InterruptedException {
System.out.println( "key: " + key );
System.out.println( "value: " + value );
StringTokenizer itr = new StringTokenizer(value.get( "x" ).toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}

Siapkan file *.java (misal WordCountMongo.java Part 2 of 2) untuk dicompile ke *.jar:
Running Hadoop WordCount
(Save hasil di MongoDB)
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context )
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set( "mongo.input.uri" , "mongodb://localhost/testmr.in" );
conf.set( "mongo.output.uri" , "mongodb://localhost/testmr.out" );
@SuppressWarnings("deprecation")
Job job = new Job(conf, "word count");
job.setJarByClass(WordCountMongo.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass( MongoInputFormat.class );
job.setOutputFormatClass( MongoOutputFormat.class );
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

Menghitung Kemunculan Kata dalam file dokumen:
o file “WordCountMongo.java”:
Running Hadoop WordCount
(Save hasil di MongoDB)

WordCountMongo.java dicompile ke *.jar:
o Lakukan hal berikut:
Running Hadoop WordCount
(Save hasil di MongoDB)
nidos@master:~$ cd /usr/local/hadoop
nidos@master:/usr/local/hadoop$ cp /home/nidos/Desktop/kode/WordCountMongo/WordCountMongo.java /usr/local/hadoop
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main WordCountMongo.java
Jika muncul error:
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main WordCountMongo.Java
error: Class names, 'WordCountMongo.Java', are only accepted if annotation processing is explicitly requested
1 error
Solusi: ubah “WordCountMongo.Java” “WordCountMongo.java”

WordCountMongo.java dicompile ke *.jar:
o Lakukan hal berikut:
Running Hadoop WordCount
(Save hasil di MongoDB)
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main WordCountMongo.java
Jika muncul error:nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main WordCountMongo.java
WordCountMongo.java:4: error: package org.bson does not exist
import org.bson.*;
^
WordCountMongo.java:6: error: package com.mongodb.hadoop does not exist
import com.mongodb.hadoop.MongoInputFormat;
^
WordCountMongo.java:7: error: package com.mongodb.hadoop does not exist
import com.mongodb.hadoop.MongoOutputFormat;
^
WordCountMongo.java:22: error: cannot find symbol
public static class TokenizerMapper extends Mapper<Object, BSONObject, Text, IntWritable> {
^
symbol: class BSONObject
location: class WordCountMongo
WordCountMongo.java:25: error: cannot find symbol
public void map(Object key, BSONObject value, Context context )
^
symbol: class BSONObject
location: class TokenizerMapper
WordCountMongo.java:60: error: cannot find symbol
job.setInputFormatClass( MongoInputFormat.class );
^
symbol: class MongoInputFormat
location: class WordCountMongo
WordCountMongo.java:61: error: cannot find symbol
job.setOutputFormatClass( MongoOutputFormat.class );
^
symbol: class MongoOutputFormat
location: class WordCountMongo
7 errors
Solusi: kembali ke langkah “Konfigurasi Koneksi (Hadoop + MongoDB)” SCP

Hasil: nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main
WordCountMongo.java
Running Hadoop WordCount
(Save hasil di MongoDB)

Hasil: nidos@master:/usr/local/hadoop$ jar cf wcmongo.jar WordCountMongo*.class
Running Hadoop WordCount
(Save hasil di MongoDB)

Running proses perhitungan kata dalam file dokumen dalam MongoDB:
o Lakukan hal berikut:
Running Hadoop WordCount
(Save hasil di MongoDB)
Jika menggunakan hdfs, maka gunakan dfs
Jika menggunakan hadoop, maka gunakan fs
nidos@master:/usr/local/hadoop$ bin/hadoop jar wcmongo.jar WordCountMongo
{"_id":"2","value":1}
{"_id":"again","value":1}
{"_id":"bye","value":2}
{"_id":"good","value":1}
{"_id":"hello","value":1}
{"_id":"meet","value":1}
{"_id":"nice","value":1}
{"_id":"see","value":2}
{"_id":"to","value":2}
{"_id":"war","value":1}
{"_id":"world","value":2}
{"_id":"you","value":3}

Lihat hasil dari MongoDB melalui terminal:
Running Hadoop WordCount
(Save hasil di MongoDB)

Cek di browser:
Running Hadoop WordCount
(Save hasil di MongoDB)

Cek di browser:
Running Hadoop WordCount
(Save hasil di MongoDB)

Cek di browser:
Running Hadoop WordCount
(Save hasil di MongoDB)

Case Study 2: Rating By Movie
o List dataset (dari MovieLens) dan Link ( https://goo.gl/Jd8GOI ):
Membuat Directories “ratemovie/dataset” di HDFS harus satu demi satu:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:~$ cd /usr/local/hadoop
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -mkdir /user/nidos/ratemovie
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -mkdir
/user/nidos/ratemovie/dataset
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -ls /user/nidos
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -ls /user/nidos/ratemovie

Copy semua file dataset dari local folder
(/home/nidos/Desktop/data/ratemovie/dataset) ke HDFS folder
(/user/nidos/ratemovie/dataset)
o List dataset (dari MovieLens) dan Link ( https://goo.gl/Jd8GOI ):
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -copyFromLocal
/home/nidos/Desktop/data/ratemovie/dataset/* /user/nidos/ratemovie/dataset

Copy semua file dataset dari local folder
(/home/nidos/Desktop/data/ratemovie/dataset) ke HDFS folder
(/user/nidos/ratemovie/dataset)
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:/usr/local/hadoop$ bin/hdfs dfs -copyFromLocal
/home/nidos/Desktop/data/ratemovie/dataset/* /user/nidos/ratemovie/dataset
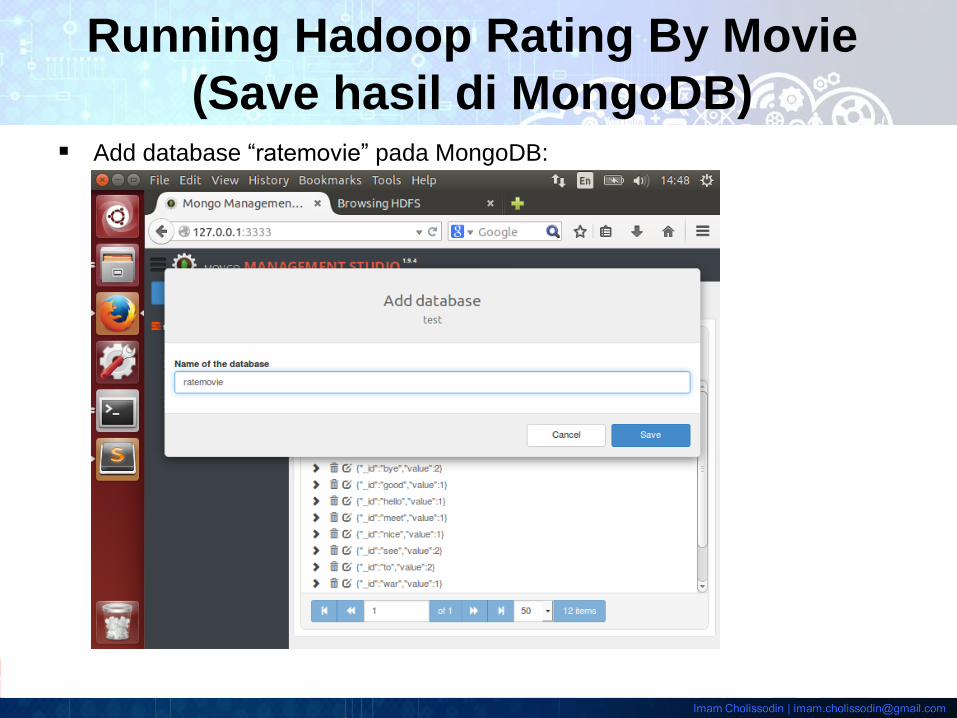
Add database “ratemovie” pada MongoDB:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Add database “ratemovie” pada MongoDB:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Siapkan file *.java untuk dicompile ke *.jar:
dari “package comratingbymovies.nidos;”
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Siapkan file (MovieMapper.java Part 1 of 1) untuk dicompile ke *.jar:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
package comratingbymovies.nidos;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MovieMapper extends Mapper<LongWritable,Text,Text,Text>{
Text keyEmit = new Text();
Text valEmit = new Text();
public void map(LongWritable k, Text value, Context context) throws IOException, InterruptedException{
String line=value.toString();
String[] words=line.split("::");
keyEmit.set(words[0]);
valEmit.set(words[1]);
context.write(keyEmit, valEmit);
}
}

Siapkan file (MovieReducer.java Part 1 of 2) untuk dicompile ke *.jar:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
package comratingbymovies.nidos;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapreduce.Reducer;
public class MovieReducer extends Reducer<Text,Text,Text,IntWritable>
{
Text valTitle = new Text();
Text valEmit = new Text();
String merge;
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException ,
InterruptedException{
int counter = 0;
merge = "";
for(Text value:values){
if (value.toString().startsWith("#")){ //from rating
counter++;
}

Siapkan file (MovieReducer.java Part 2 of 2) untuk dicompile ke *.jar:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
else if ("".equalsIgnoreCase(merge)){// from movies get the title
merge = value.toString();
}
}
valTitle.set(merge);
context.write(valTitle, new IntWritable(counter));
}
}

Siapkan file (RatingCounterByMovieMongo.java Part 1 of 2) untuk dicompile ke *.jar:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
package comratingbymovies.nidos;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.mongodb.hadoop.io.BSONWritable;
import com.mongodb.hadoop.mapred.MongoOutputFormat;
public class RatingCounterByMovieMongo extends Configured implements Tool{
public int run(String[] args) throws Exception {
final Configuration conf = getConf();
conf.set("mongo.output.uri", args[2]);
Path p1=new Path(args[0]);
Path p2=new Path(args[1]);
Job job = new Job(conf,"Multiple Job");
job.setJarByClass(RatingCounterByMovieMongo.class);
MultipleInputs.addInputPath(job, p1, TextInputFormat.class, RatingMapper.class);
MultipleInputs.addInputPath(job, p2, TextInputFormat.class, MovieMapper.class);

Siapkan file (RatingCounterByMovieMongo.java Part 2 of 2) untuk dicompile ke *.jar:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
job.setReducerClass(MovieReducer.class);
job.setOutputFormatClass(com.mongodb.hadoop.MongoOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
boolean success = job.waitForCompletion(true);
return success?0:1;
}
public static void main(String[] args) throws Exception {
if (args.length != 3 ){
System.err.println ("Usage :<inputlocation1> <inputlocation2> <outputlocation>
>");
System.exit(0);
}
int res = ToolRunner.run(new Configuration(), new RatingCounterByMovieMongo(), args);
System.exit(res);
}
}

Siapkan file (RatingMapper.java Part 1 of 1) untuk dicompile ke *.jar:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
package comratingbymovies.nidos;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapreduce.Mapper;
public class RatingMapper extends Mapper<LongWritable,Text,Text,Text>{
Text keyEmit = new Text();
Text valEmit = new Text();
public void map(LongWritable k, Text v, Context context) throws IOException, InterruptedException{
String line=v.toString();
String[] words=line.split("::");
keyEmit.set(words[1]);
valEmit.set("#");
context.write(keyEmit, valEmit);
}
}

Semua file *.java dicompile ke *.jar:
o Lakukan hal berikut:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:~$ cd /usr/local/hadoop
nidos@master:/usr/local/hadoop$ cp -r /home/nidos/Desktop/kode/RatingByMovies/comratingbymovies /usr/local/hadoop

Semua file *.java dicompile ke *.jar:
o Lakukan hal berikut:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:/usr/local/hadoop$ bin/hdfs com.sun.tools.javac.Main comratingbymovies/nidos/*.java
Note: comratingbymovies/nidos/RatingCounterByMovieMongo.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.

Hasil: nidos@master:/usr/local/hadoop$ jar cf ratemovie.jar comratingbymovies/nidos/*.class
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Hasil: nidos@master:/usr/local/hadoop$ jar cf ratemovie.jar comratingbymovies/nidos/*.class
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Running proses perhitungan rating movie:
o Lakukan hal berikut:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:/usr/local/hadoop$ bin/hadoop jar ratemovie.jar
comratingbymovies/nidos/RatingCounterByMovieMongo /user/nidos/ratemovie/dataset/ratings.dat
/user/nidos/ratemovie/dataset/movies.dat mongodb://localhost/ratemovie.out

Running proses perhitungan rating movie:
o Lakukan hal berikut:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)
nidos@master:/usr/local/hadoop$ bin/hadoop jar ratemovie.jar
comratingbymovies/nidos/RatingCounterByMovieMongo /user/nidos/ratemovie/dataset/ratings.dat
/user/nidos/ratemovie/dataset/movies.dat mongodb://localhost/ratemovie.out2

Lihat hasil dari MongoDB melalui terminal:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Cek di browser:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Cek di browser:
Running Hadoop Rating By Movie
(Save hasil di MongoDB)

Tugas Kelompok
1. Lakukan Studi Kasus WordCount dengan dokumen yang berbeda (pada file > 0.5
MB, file > 1 MB, file > 10 MB, file > 100 MB, file > 1000 MB) pada Hadoop Single
atau Multi Node Cluster dan simpan hasilnya dalam MongoDB! dan berilah
penjelasan untuk setiap langkah-langkahnya disertai screenshot! Optional
2. Lakukan dan ulangi kembali Studi Kasus RateMovie dengan dokumen yang sama
seperti dicontoh pada Hadoop Single atau Multi Node Cluster dan simpan hasilnya
dalam MongoDB! dan berilah penjelasan untuk setiap langkah-langkahnya disertai
screenshot! Optional