Embed Size (px)
Citation preview
제13회
13th Asian Institute in Statistical Genetics and Genomics
Graduate School of Public Health, Seoul National University, Seoul, Korea
July 16 (Mon) – 21(Sat), 2018
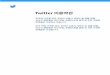
2018 Module Schedule
Session 1 (July 16-17)
1. Biostatistics using R Jinheum Kim
Ju-Hyun Park
Univ. of Suwon
Dongguk Univ.
2. Introduction to Genetics Bermseok Oh Kyung Hee Univ.
3. Analysis of High Throughput Sequencing Data in
Population Scale
Hyunmin Kang
Goo Jun
Univ. of Michigan
Univ. of Texas Health
Science Center
4. NGS-based Immune Information Analysis Sangwoo Kim Yonsei Univ.
Session 2 (July 18-19)
5. Applications of NGS in Translational Genomics Murim Choi Seoul National Univ.
6. Multi-omics Data Analysis Hokeun Sun
SungHwan Kim
Pusan National Univ.
Keimyung Univ.
7. Large-scale Genome Data Analysis using KoreanChip Bong Jo Kim KNIH
8. Metagenome Analysis Woo Jun Sul Chung-Ang Univ.
Session 3 (July 20-21)
9. NGS Cancer Gene Panel Analysis and Applications Yeun-Jun Chung
Seung-Hyun Jung The Catholic Univ.
10. Genomic Epidemiology Ji Wan Park Hallym Univ.
11. Getting Your Papers Published Peter Park Harvard Medical School
12. Cancer Genomics Sanghyuk Lee Ewha Womans Univ.
제13회
1. R을 이용한 기초통계학 (Biostatistics using R)
강사: 김진흠, 박주현
소속: 수원대학교 데이터과학부, 동국대학교 통계학과
강의 개요: 본 강좌에서는 기초통계학의 기본 개념을 학습하고 상용 소프트웨어인 R을 이용한 실
습을 병행하고자 한다. 본 강좌에서 사용하는 R 패키지는 SAS, SPSS, MINITAB, STATA 등과 달리
무료로 제공되며 저장 공간이 많이 필요하지 않기 때문에 현재 가장 널리 사용되고 있는 소프트
웨어이다. 또한 R 패키지는 다른 통계패키지와 달리 개발이 용이하고 최근 연구 결과들이 패키지
에 탑재될 때까지 소요되는 시간이 짧아 통계 관련 연구에 매우 유용하게 사용되고 있다. 본 강
좌에서는 R 설치와 기본 사용법, R을 활용한 그래픽스, 일변량 자료의 정리와 요약 방법 등 R을
활용한 자료 처리 방법과 상관분석 및 회귀분석, 범주형 자료의 독립성 검정을 포함하는 이변량
자료의 분석 방법, 추정과 가설검정, 두 집단의 비교, 분산분석 등 기초 통계 이론에 대하여 강의
할 것이다.
준비물: 개인 노트북
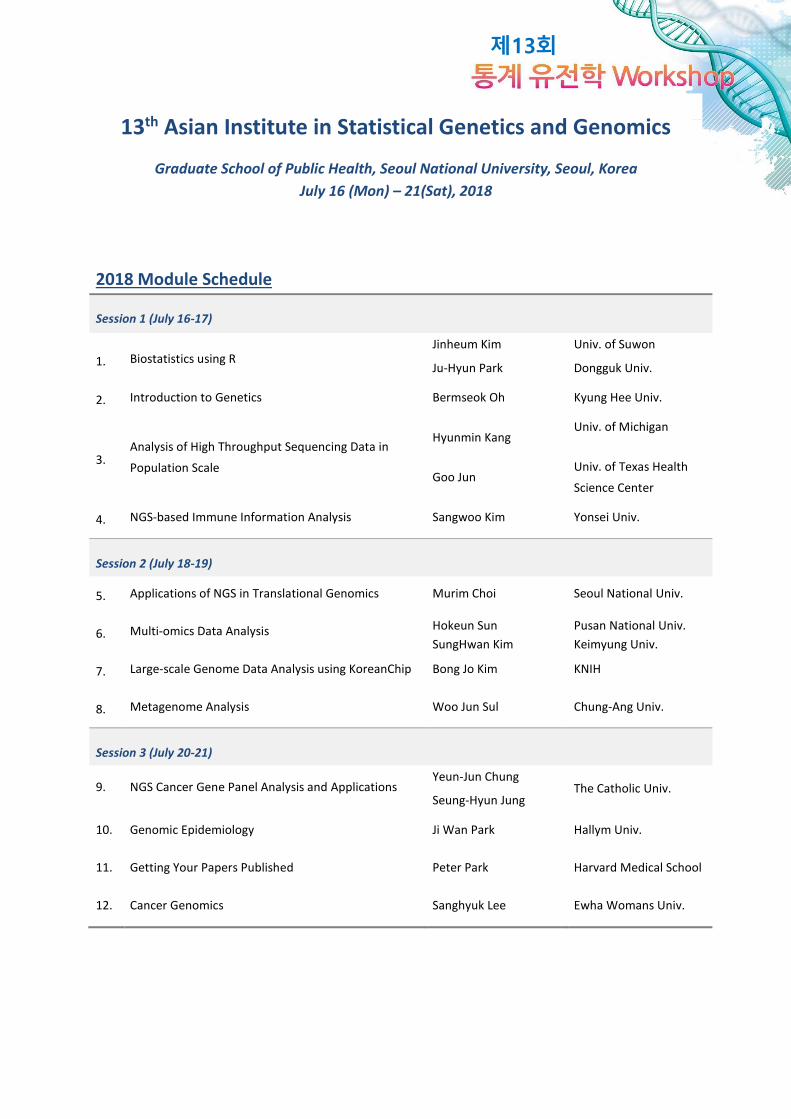
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Day 1
Session 1
(09:20-10:50) R 설치 및 소개 박주현 인터넷접속필요
Session 2
(11:00-12:30) R 을 활용한 그래픽스 박주현 인터넷접속필요
Session 3
(14:00-15:30) 일변량 자료의 정리 및 요약 박주현 인터넷접속필요
Session 4
(15:40-17:10) 확률과 확률분포, 표본분포 박주현 인터넷접속필요
Day 2
Session 5
(09:20-10:50) 추정 김진흠 인터넷접속필요
Session 6
(11:00-12:30) 가설검정 김진흠 인터넷접속필요
Session 7
(14:00-15:30) 두 집단의 비교 및 분산분석 김진흠 인터넷접속필요
Session 8
(15:40-17:10)
이변량 자료의 분석: 상관분석,
회귀분석, 독립성검정 김진흠 인터넷접속필요

제13회
2. 유전학 기초 (Introduction to Genetics)
강사: 오범석
소속: 경희대학교 의과대학
강의 개요: 유전학 비전공자를 위하여 전달유전학, 분자유전학, 집단유전학, 질병유전학, 통계유전
학 등의 기본 개념을 이해시킨다. 멘델의 유전법칙, 가계도, 유전자의 구조 및 발현, 염색체의 구
조, Human Genome Project 및 유전변이, 유전질환의 기전 및 Genetic counseling, 복합질환의 유
전학적 이해 등의 주제를 다룬다. 표현형질이 세대간 어떻게 전달되는가, 표현형질을 결정하는 유
전자는 유전체 상에서 어떤 모양으로 존재하는가 그리고 유전자가 어떻게 발현되는가, 인간유전
체 사업 이후 활발하게 진행되고 있는 질병유전체는 우리에게 어떤 교훈을 주고 있는가 등을 강
의하고자 한다. 이들 주제를 통하여, 유전학적인 기초 지식을 가르치고 분석 결과에 대한 생물학
적인 이해를 높여 적절한 실험디자인을 하도록 도와주고자 한다. 그 외에도 최신 지견으로
Personalized Medicine/Precision Medicine에 대한 설명도 포함된다.
준비물: 없음
제13회
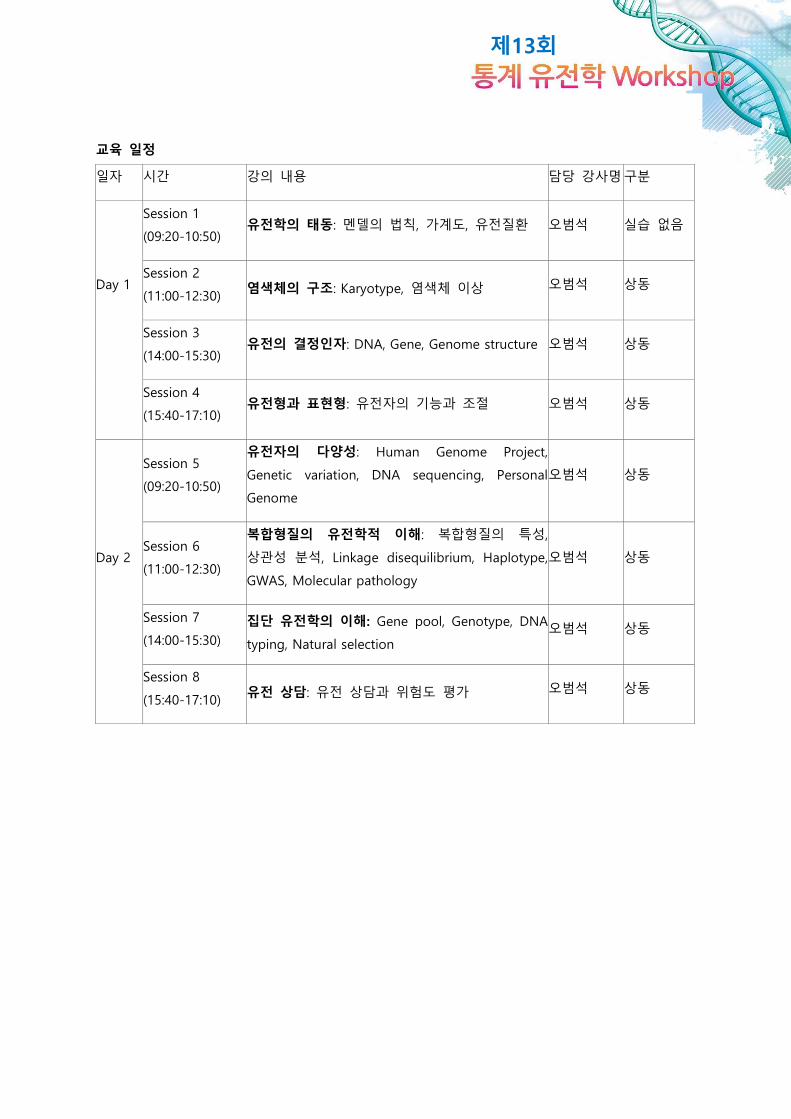
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50) 유전학의 태동: 멘델의 법칙, 가계도, 유전질환 오범석 실습 없음
Day 1 Session 2
(11:00-12:30) 염색체의 구조: Karyotype, 염색체 이상 오범석 상동
Session 3
(14:00-15:30) 유전의 결정인자: DNA, Gene, Genome structure 오범석 상동
Session 4
(15:40-17:10) 유전형과 표현형: 유전자의 기능과 조절 오범석 상동
Session 5
(09:20-10:50)
유전자의 다양성: Human Genome Project,
Genetic variation, DNA sequencing, Personal
Genome
오범석 상동
Day 2 Session 6
(11:00-12:30)
복합형질의 유전학적 이해: 복합형질의 특성,
상관성 분석, Linkage disequilibrium, Haplotype,
GWAS, Molecular pathology
오범석 상동
Session 7
(14:00-15:30)
집단 유전학의 이해: Gene pool, Genotype, DNA
typing, Natural selection 오범석 상동
Session 8
(15:40-17:10) 유전 상담: 유전 상담과 위험도 평가 오범석 상동

제13회
3. 고출력 시퀀싱 데이터의 집단 규모 분석
(Analysis of High Throughput Sequencing Data in Population Scale)
강사: 강현민(Hyun Min Kang), 전구(Goo Jun)
소속: 미시건대학교 생물통계학과(Department of Biostatistics, School of Public Health,
University of Michigan), UT 휴스턴 인간유전학센터(Human Genetics Center, School of Public
Health, University of Texas Health Science Center Houston)
수강생 수준: 본 강좌는 유전체/유전학 연구에 현재 종사하고 있는 연구자 혹은 유전체/유전학
연구에 관심이 있는 초보자를 대상으로 합니다. 이 강좌를 잘 소화하기 위해서는 유전학과
관련된 기본적 지식 (예: 멘델의 법칙), 기본적인 통계학 지식 (예: p-value), 그리고 UNIX 에 대한
기본적인 지식 (예: https://www.codecademy.com/learn/learn-the-command-line 의 무료 강좌
부분) 을 갖추는 것을 권해드립니다.
[ This course is intended for researchers who are actively engaged in genomics/genetics research
and interested beginners. Ideally, participants are expected to have some basic knowledge of
human genetics (such as Mendelian inheritance), core statistical principles (such as p-values), and
basic UNIX skills) ]
강의 개요: 최근 급속도로 발전한 고출력 시퀀싱 기술은 유전체, 전사체, 후생 유전체 데이터
등을 전대미문의 규모로 양산하고 있습니다. 자연발생하는 유전적 변이가 질병에 미치는 영향을
이해하기 위해서는 어떻게 많은 유전체를 조화롭고 검정력이 높은 방법으로 적절히 분석할 수
있는지 아는 것이 필요합니다. 이 강좌는 전장유전체 혹은 엑솜유전체 데이터를 집단 규모로
설계하고 분석하는데 필요한 개념과 지식을 배우는 것을 목표로 합니다. 시퀀스 정렬, 데이터
품질관리, 변이 추출 (SNP, Indel, 구조적변이 등) 분석을 위한 실용적인 지식과 실습에 초점을
맞춥니다. 또한, 집단 규모의 다중 오믹스 분석의 일환으로 시퀀싱된 유전체와 전사체 간의
연관분석을 시행합니다.
[ The dramatic advance of high-throughput sequencing technologies in the last decade has
produced tremendous amount genomic, transcriptomic, and epigenomic sequence data at an
unprecedented scale. To investigate the impact of naturally occurring genetic variants on disease
traits, it is important to understand how to properly analyze many sequenced genomes together
in a harmonized manner so that powerful statistical methods can be applied. In this short course,
we aim to learn the key concepts and knowledge to design and analyze whole-genome or whole-
exome sequence reads for genetic mapping in population-based studies. We will focus on
practical knowledge and hands-on experiences in analyzing sequence data, including alignment,
quality control, calling genetic variants such as SNPs, Indels, and structural variants. We will use
publicly available RNA-seq datasets learn how to perform association analysis between sequence
genomes and transcriptomes as examples of multi-omics sequence analysis at population-scale. ]
제13회
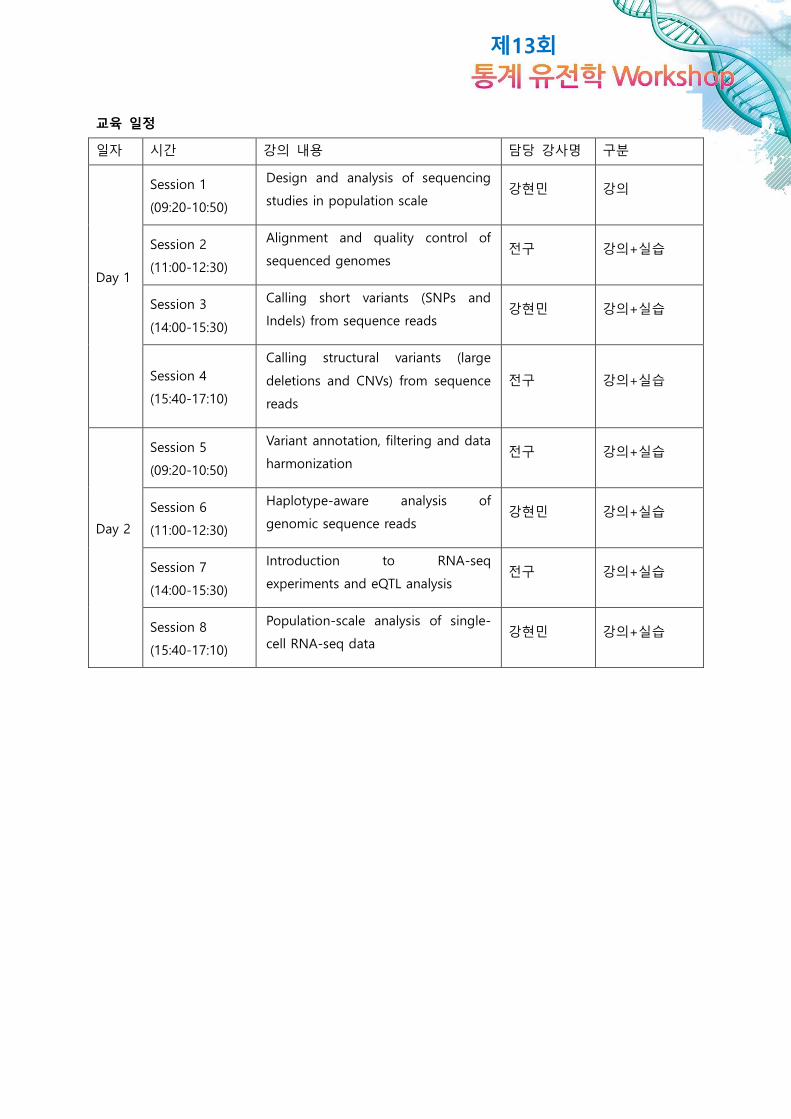
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Day 1
Session 1
(09:20-10:50)
Design and analysis of sequencing
studies in population scale 강현민 강의
Session 2
(11:00-12:30)
Alignment and quality control of
sequenced genomes 전구 강의+실습
Session 3
(14:00-15:30)
Calling short variants (SNPs and
Indels) from sequence reads 강현민 강의+실습
Session 4
(15:40-17:10)
Calling structural variants (large
deletions and CNVs) from sequence
reads
전구 강의+실습
Day 2
Session 5
(09:20-10:50)
Variant annotation, filtering and data
harmonization 전구 강의+실습
Session 6
(11:00-12:30)
Haplotype-aware analysis of
genomic sequence reads 강현민 강의+실습
Session 7
(14:00-15:30)
Introduction to RNA-seq
experiments and eQTL analysis 전구 강의+실습
Session 8
(15:40-17:10)
Population-scale analysis of single-
cell RNA-seq data 강현민 강의+실습
제13회
4. NGS 를 이용한 면역정보 분석 (NGS-based Immune Information Analysis)
강사: 김상우, 김소라, 김은영
소속: 연세대학교 의과대학 의생명시스템정보학교실
강의 개요: 최근 생물정보학 기술의 발달로 in silico 상태에서 암환자의 면역상태, 면역치료반응
예측, 면역 세포 구성 등을 알아낼 수 있는 여러 알고리즘과 소프트웨어가 발표되었다. 본 강좌는
면역항암치료 등에서 최근 많은 관심을 받고 있는 다양한 면역정보 분석을 NGS, microarray 등
대규모 생물정보 데이터를 이용하여 분석하는 방법을 이론과 실습을 병행하여 진행하고자 한다.
특히 IEDB 등 대규모 데이터베이스의 내용과 이용 방법, RNA-seq 을 이용한 HLA typing, NGS 를
이용한 somatic mutation 의 burden 측정, 신항원(neoantigen) 예측 및 발현량을 이용한 면역세포
구성 예측을 통하여 실제 환자 데이터에 적용할 수 있는 프로그램 및 파이프라인 구축 수준의
분석 능력을 배가한다.
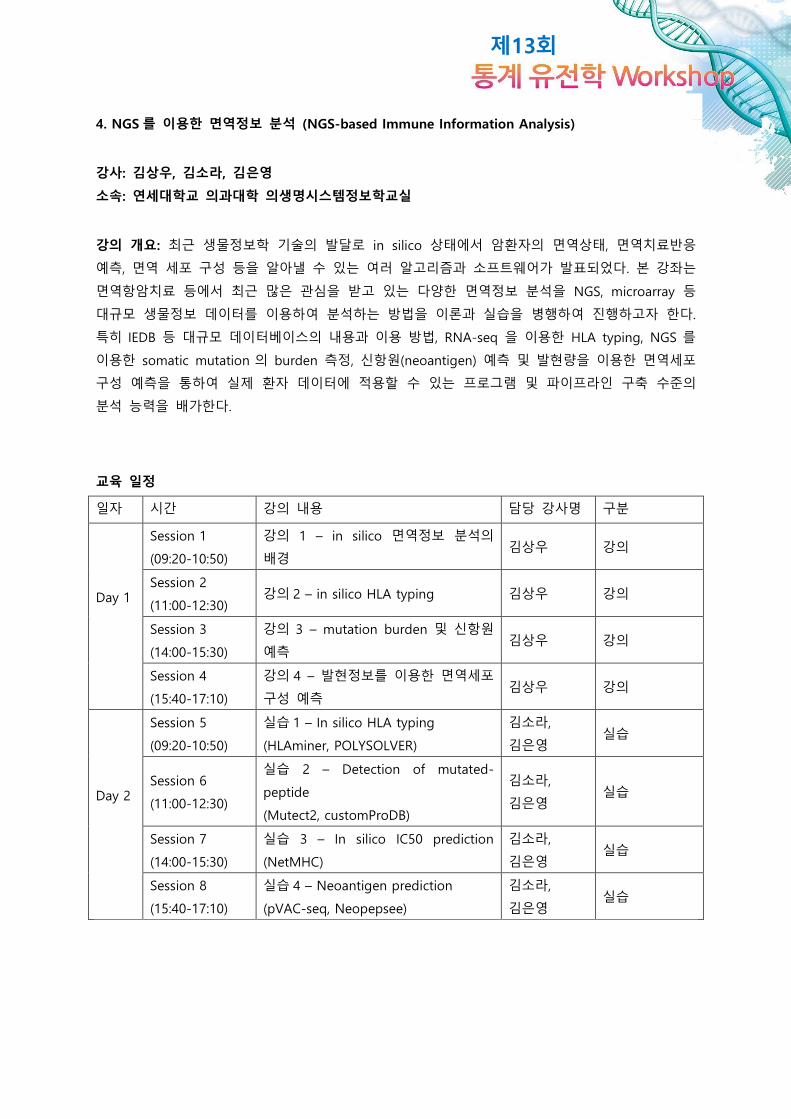
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Day 1
Session 1
(09:20-10:50)
강의 1 – in silico 면역정보 분석의
배경 김상우 강의
Session 2
(11:00-12:30) 강의 2 – in silico HLA typing 김상우 강의
Session 3
(14:00-15:30)
강의 3 – mutation burden 및 신항원
예측 김상우 강의
Session 4
(15:40-17:10)
강의 4 – 발현정보를 이용한 면역세포
구성 예측 김상우 강의
Day 2
Session 5
(09:20-10:50)
실습 1 – In silico HLA typing
(HLAminer, POLYSOLVER)
김소라,
김은영 실습
Session 6
(11:00-12:30)
실습 2 – Detection of mutated-
peptide
(Mutect2, customProDB)
김소라,
김은영 실습
Session 7
(14:00-15:30)
실습 3 – In silico IC50 prediction
(NetMHC)
김소라,
김은영 실습
Session 8
(15:40-17:10)
실습 4 – Neoantigen prediction
(pVAC-seq, Neopepsee)
김소라,
김은영 실습

제13회
5. NGS 를 통한 중개연구 (Application of NGS in Translational Genomics)
강사: 최무림, 유용진, 이영하, 유태경, 조재소, Jana Kneissl, 이정은, 이초롱
소속: 서울대학교 의과학과
강의 개요: NGS를 기반으로 하는 유전체학의 발전에 의하여 질병 원인의 유전적 이해도가
가파르게 상승하고 있다. 이러한 경향에 힘입어 유전체학을 이용한 중개연구도 활발히
이루어지고 있으며 이를 통하여 정밀의학으로 대표되는 기초적, 임상적 발전이 이루어지고 있다.
본 강좌에서는 질병의 유전학적 이해를 통한 최근 동향을 알아본 후 중개연구를 위한 여러
종류의 질환 연구의 예시와 실습을 수행할 것이다. 또한 중개연구의 발전에 힘입은 정밀의학의
예시와 실습, 최근 연구 동향을 학습한다. 이를 위하여 NGS 데이터의 해석과 이를 위한 공공
DB의 사용법, 다양한 유전성 질환(희귀질환, 복합질환, 암을 비롯한 somatic 질환)의 연구 디자인,
분석법, 데이터 해석과 결과의 의생명적 의미 부여 과정을 다룰 것이다. 각 실습 시간은 주강사에
의한 약간의 이론적인 강의와 참여강사에 의한 실제 데이터를 이용한 실습으로 구성되어 있다.
준비물: 노트북 지참
실습: 인터넷 접속, linux, R 사용
수강생수준: 제한 없음
제13회
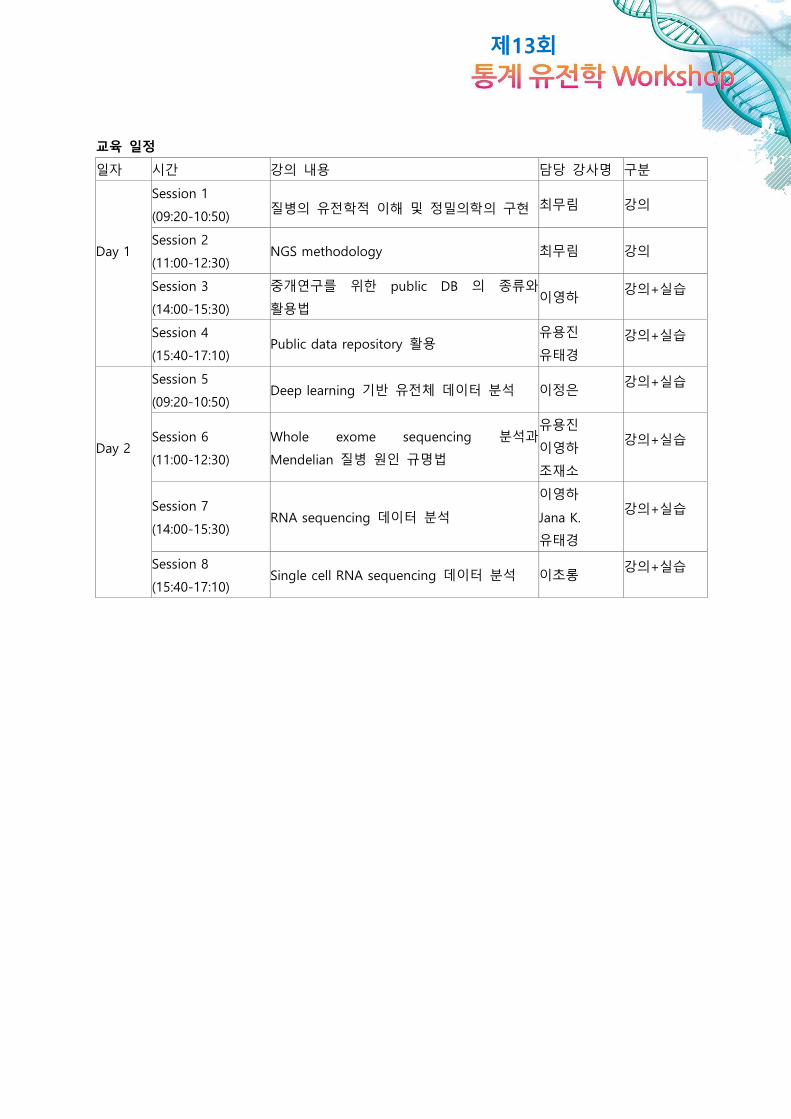
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50) 질병의 유전학적 이해 및 정밀의학의 구현 최무림 강의
Day 1 Session 2
(11:00-12:30) NGS methodology 최무림 강의
Session 3
(14:00-15:30)
중개연구를 위한 public DB 의 종류와
활용법 이영하
강의+실습
Session 4
(15:40-17:10) Public data repository 활용
유용진
유태경
강의+실습
Session 5
(09:20-10:50) Deep learning 기반 유전체 데이터 분석 이정은
강의+실습
Day 2 Session 6
(11:00-12:30)
Whole exome sequencing 분석과
Mendelian 질병 원인 규명법
유용진
이영하
조재소
강의+실습
Session 7
(14:00-15:30) RNA sequencing 데이터 분석
이영하
Jana K.
유태경
강의+실습
Session 8
(15:40-17:10) Single cell RNA sequencing 데이터 분석 이초롱
강의+실습

제13회
6. 빅데이터 분석 기법을 활용한 다중 오믹스 데이터 분석(Multi-omics Data Analysis)
강사: 선호근, 김성환
소속: 부산대학교 통계학과, 건국대학교 응용통계학과
강의 개요: 본 강좌에서는 빅데이터 통계 분석 기법을 활용하여 다중 유전체 (multiple omics)
데이터를 분석하는 여러 가지 방법들을 학습한다. 주로 통계 패키지인 R 프로그램을 이용하여
실제 데이터 및 모의 분석을 병행 실습하고, 현재 많은 관심을 받고 있는 유전체 빅데이터 분석
및 이종 유전체 결합 분석에 대한 그 현황과 방법론을 다루고자 한다. 또한 실제 데이터 분석
실습을 통하여 의생명과학적 의미를 도출하는 방법도 함께 다룬다. 강의는 크게 두가지 파트로
나뉜다. 첫번째 파트는 주로 빅데이터 통계 분석에 사용하는 regularization technique 을 학습한다.
구체적으로는 penalized likelihood 에 기반을 둔 lasso (least absolute shrinkage and selection
operator), elastic-net, group lasso 등의 변수 선택 방법들을 다루며 또한 이를 고차원 유전체
빅데이터 연관 분석 (genetic association study with high-dimensional genomic data)에
적용시키는 방법을 R 실습을 통해 학습한다. 두번째 파트는 주로 다른 종류의 유전체 데이터를
결합하여 분석하는 이종 유전체 결합 분석에 대해 학습한다. 구체적으로는 메타품질관리
(MetaQC), 메타 유전자 탐색 (MetaDE), 메타 군집분석 (Meta clustering), 메타판별분석 (Meta
prediction) 및 메타시각화 (Meta visualization) 등의 방법론을 살펴볼 예정이다.
준비물: 노트북 지참 (통계 패키지 R 설치)
실습: 인터넷 접속 (웹서핑 및 CRAN/bioconductor에서 통계 패키지 다운로드 및 설치)
수강생 수준: R프로그램에 대한 경험 및 기초 지식을 가지고 있어야 한다.
제13회
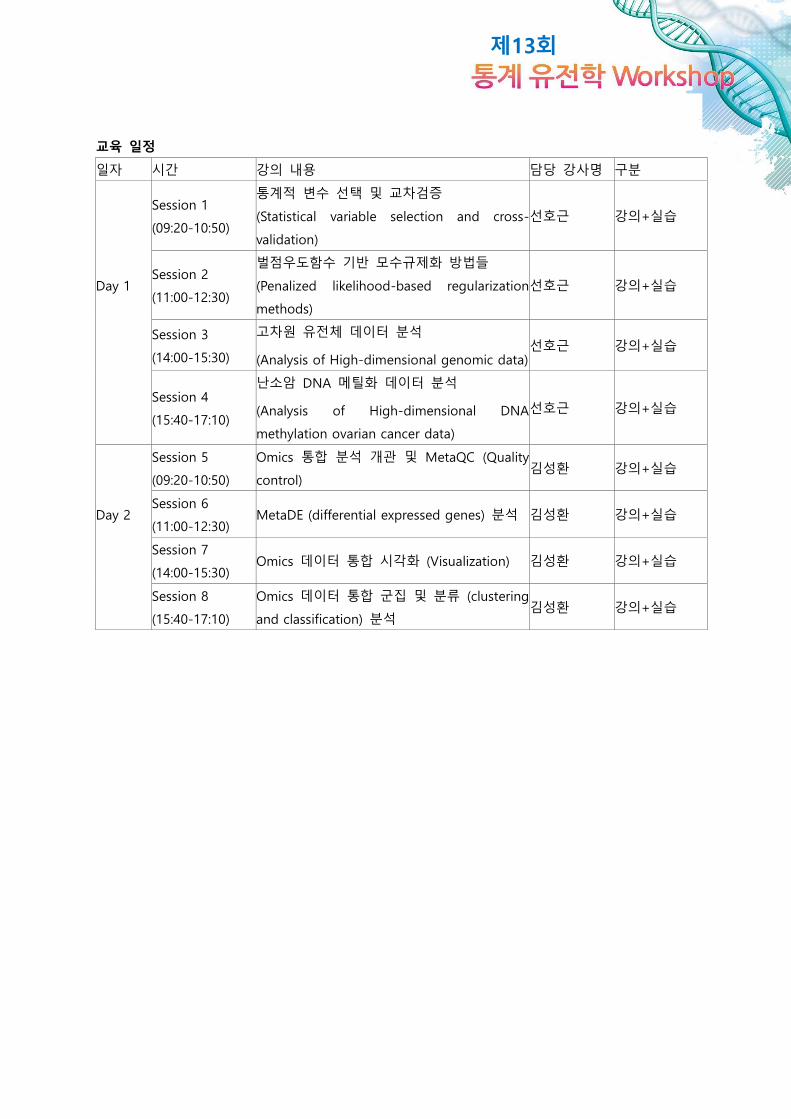
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50)
통계적 변수 선택 및 교차검증
(Statistical variable selection and cross-
validation)
선호근 강의+실습
Day 1 Session 2
(11:00-12:30)
벌점우도함수 기반 모수규제화 방법들
(Penalized likelihood-based regularization
methods)
선호근 강의+실습
Session 3
(14:00-15:30)
고차원 유전체 데이터 분석
(Analysis of High-dimensional genomic data) 선호근 강의+실습
Session 4
(15:40-17:10)
난소암 DNA 메틸화 데이터 분석
(Analysis of High-dimensional DNA
methylation ovarian cancer data)
선호근 강의+실습
Session 5
(09:20-10:50)
Omics 통합 분석 개관 및 MetaQC (Quality
control) 김성환 강의+실습
Day 2 Session 6
(11:00-12:30) MetaDE (differential expressed genes) 분석 김성환 강의+실습
Session 7
(14:00-15:30) Omics 데이터 통합 시각화 (Visualization) 김성환 강의+실습
Session 8
(15:40-17:10)
Omics 데이터 통합 군집 및 분류 (clustering
and classification) 분석 김성환 강의+실습
제13회
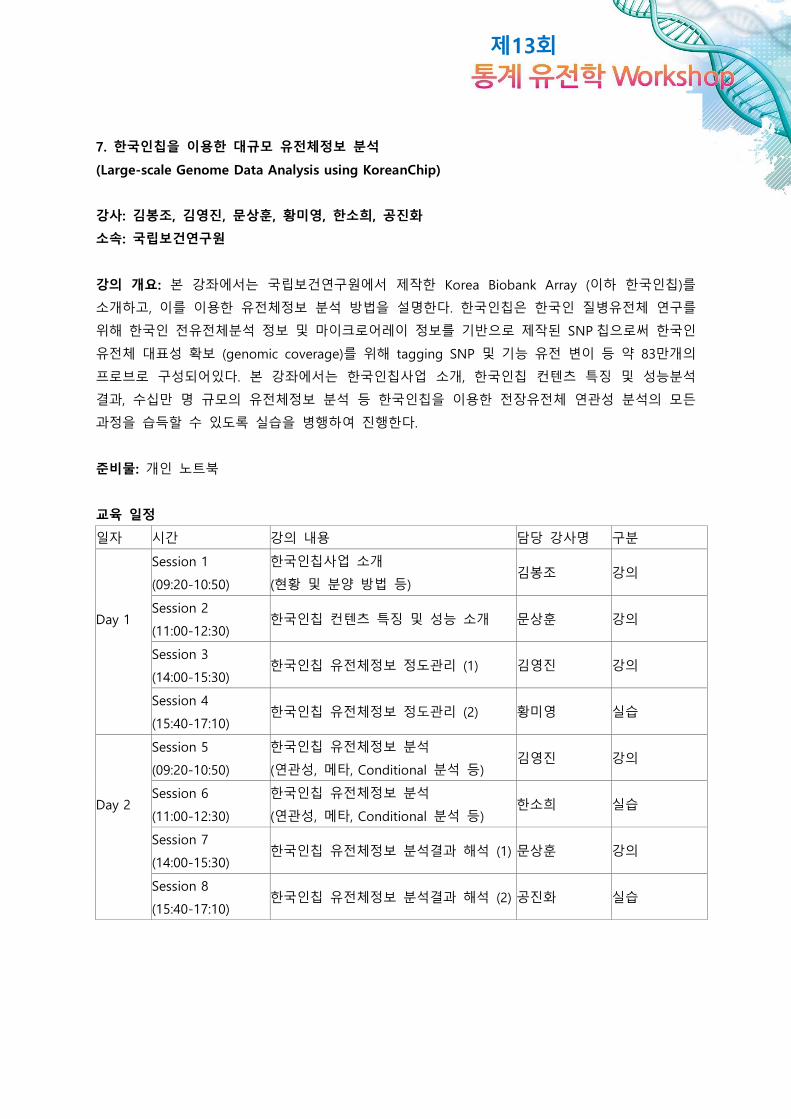
7. 한국인칩을 이용한 대규모 유전체정보 분석
(Large-scale Genome Data Analysis using KoreanChip)
강사: 김봉조, 김영진, 문상훈, 황미영, 한소희, 공진화
소속: 국립보건연구원
강의 개요: 본 강좌에서는 국립보건연구원에서 제작한 Korea Biobank Array (이하 한국인칩)를
소개하고, 이를 이용한 유전체정보 분석 방법을 설명한다. 한국인칩은 한국인 질병유전체 연구를
위해 한국인 전유전체분석 정보 및 마이크로어레이 정보를 기반으로 제작된 SNP 칩으로써 한국인
유전체 대표성 확보 (genomic coverage)를 위해 tagging SNP 및 기능 유전 변이 등 약 83만개의
프로브로 구성되어있다. 본 강좌에서는 한국인칩사업 소개, 한국인칩 컨텐츠 특징 및 성능분석
결과, 수십만 명 규모의 유전체정보 분석 등 한국인칩을 이용한 전장유전체 연관성 분석의 모든
과정을 습득할 수 있도록 실습을 병행하여 진행한다.
준비물: 개인 노트북
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50)
한국인칩사업 소개
(현황 및 분양 방법 등) 김봉조 강의
Day 1 Session 2
(11:00-12:30) 한국인칩 컨텐츠 특징 및 성능 소개 문상훈 강의
Session 3
(14:00-15:30) 한국인칩 유전체정보 정도관리 (1) 김영진 강의
Session 4
(15:40-17:10) 한국인칩 유전체정보 정도관리 (2) 황미영 실습
Session 5
(09:20-10:50)
한국인칩 유전체정보 분석
(연관성, 메타, Conditional 분석 등) 김영진 강의
Day 2 Session 6
(11:00-12:30)
한국인칩 유전체정보 분석
(연관성, 메타, Conditional 분석 등) 한소희 실습
Session 7
(14:00-15:30) 한국인칩 유전체정보 분석결과 해석 (1) 문상훈 강의
Session 8
(15:40-17:10) 한국인칩 유전체정보 분석결과 해석 (2) 공진화 실습
제13회
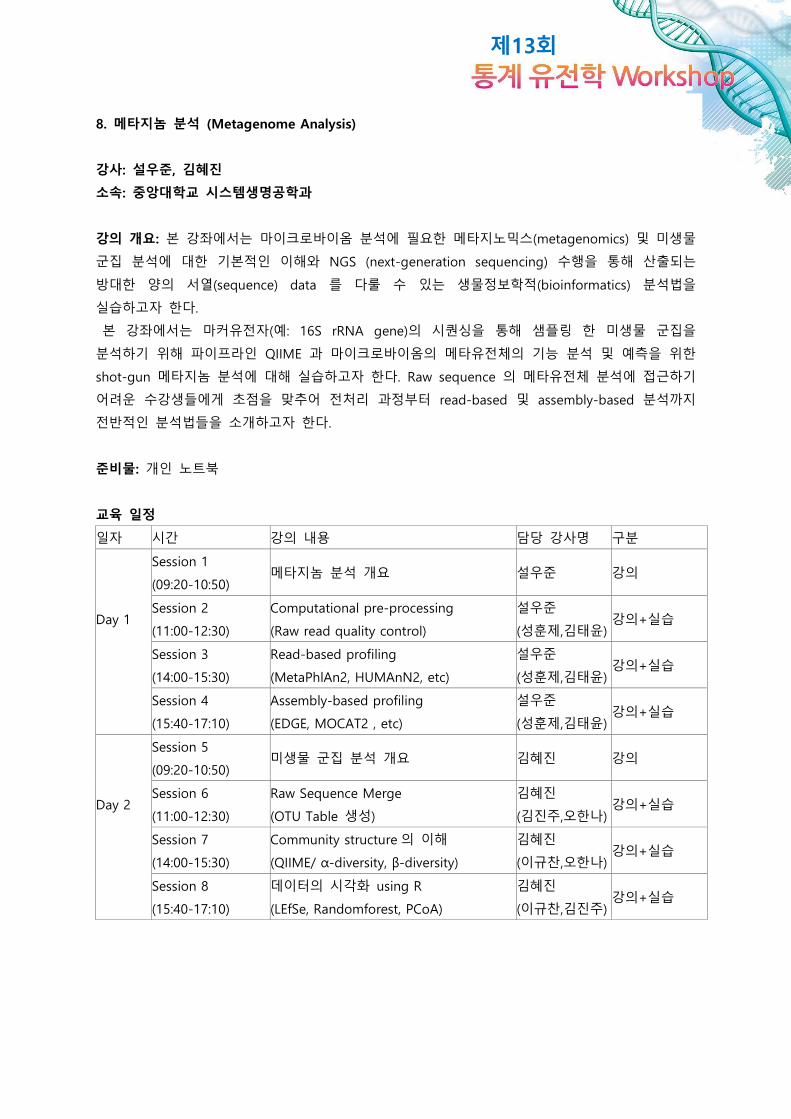
8. 메타지놈 분석 (Metagenome Analysis)
강사: 설우준, 김혜진
소속: 중앙대학교 시스템생명공학과
강의 개요: 본 강좌에서는 마이크로바이옴 분석에 필요한 메타지노믹스(metagenomics) 및 미생물
군집 분석에 대한 기본적인 이해와 NGS (next-generation sequencing) 수행을 통해 산출되는
방대한 양의 서열(sequence) data 를 다룰 수 있는 생물정보학적(bioinformatics) 분석법을
실습하고자 한다.
본 강좌에서는 마커유전자(예: 16S rRNA gene)의 시퀀싱을 통해 샘플링 한 미생물 군집을
분석하기 위해 파이프라인 QIIME 과 마이크로바이옴의 메타유전체의 기능 분석 및 예측을 위한
shot-gun 메타지놈 분석에 대해 실습하고자 한다. Raw sequence 의 메타유전체 분석에 접근하기
어려운 수강생들에게 초점을 맞추어 전처리 과정부터 read-based 및 assembly-based 분석까지
전반적인 분석법들을 소개하고자 한다.
준비물: 개인 노트북
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50) 메타지놈 분석 개요 설우준 강의
Day 1 Session 2
(11:00-12:30)
Computational pre-processing
(Raw read quality control)
설우준
(성훈제,김태윤) 강의+실습
Session 3
(14:00-15:30)
Read-based profiling
(MetaPhlAn2, HUMAnN2, etc)
설우준
(성훈제,김태윤) 강의+실습
Session 4
(15:40-17:10)
Assembly-based profiling
(EDGE, MOCAT2 , etc)
설우준
(성훈제,김태윤) 강의+실습
Session 5
(09:20-10:50) 미생물 군집 분석 개요 김혜진 강의
Day 2 Session 6
(11:00-12:30)
Raw Sequence Merge
(OTU Table 생성)
김혜진
(김진주,오한나) 강의+실습
Session 7
(14:00-15:30)
Community structure 의 이해
(QIIME/ α-diversity, β-diversity)
김혜진
(이규찬,오한나) 강의+실습
Session 8
(15:40-17:10)
데이터의 시각화 using R
(LEfSe, Randomforest, PCoA)
김혜진
(이규찬,김진주) 강의+실습
제13회
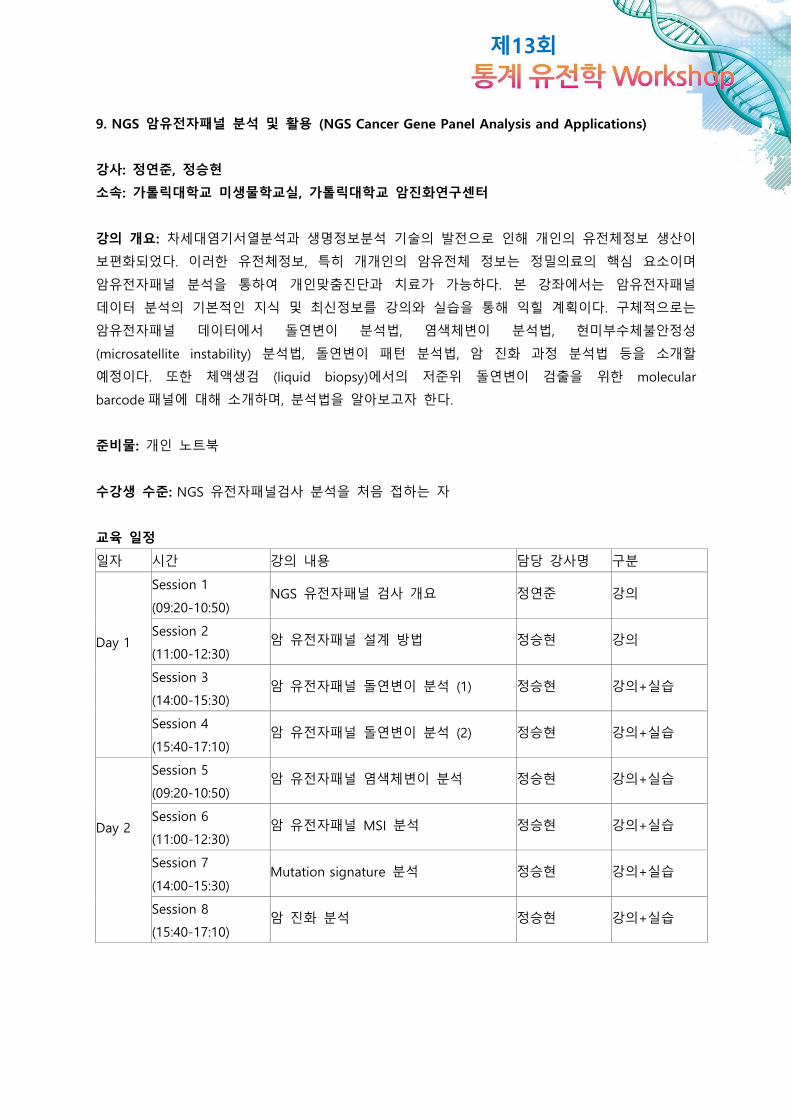
9. NGS 암유전자패널 분석 및 활용 (NGS Cancer Gene Panel Analysis and Applications)
강사: 정연준, 정승현
소속: 가톨릭대학교 미생물학교실, 가톨릭대학교 암진화연구센터
강의 개요: 차세대염기서열분석과 생명정보분석 기술의 발전으로 인해 개인의 유전체정보 생산이
보편화되었다. 이러한 유전체정보, 특히 개개인의 암유전체 정보는 정밀의료의 핵심 요소이며
암유전자패널 분석을 통하여 개인맞춤진단과 치료가 가능하다. 본 강좌에서는 암유전자패널
데이터 분석의 기본적인 지식 및 최신정보를 강의와 실습을 통해 익힐 계획이다. 구체적으로는
암유전자패널 데이터에서 돌연변이 분석법, 염색체변이 분석법, 현미부수체불안정성
(microsatellite instability) 분석법, 돌연변이 패턴 분석법, 암 진화 과정 분석법 등을 소개할
예정이다. 또한 체액생검 (liquid biopsy)에서의 저준위 돌연변이 검출을 위한 molecular
barcode 패널에 대해 소개하며, 분석법을 알아보고자 한다.
준비물: 개인 노트북
수강생 수준: NGS 유전자패널검사 분석을 처음 접하는 자
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50) NGS 유전자패널 검사 개요 정연준 강의
Day 1 Session 2
(11:00-12:30) 암 유전자패널 설계 방법 정승현 강의
Session 3
(14:00-15:30) 암 유전자패널 돌연변이 분석 (1) 정승현 강의+실습
Session 4
(15:40-17:10) 암 유전자패널 돌연변이 분석 (2) 정승현 강의+실습
Session 5
(09:20-10:50) 암 유전자패널 염색체변이 분석 정승현 강의+실습
Day 2 Session 6
(11:00-12:30) 암 유전자패널 MSI 분석 정승현 강의+실습
Session 7
(14:00-15:30) Mutation signature 분석 정승현 강의+실습
Session 8
(15:40-17:10) 암 진화 분석 정승현 강의+실습

제13회
10. 유전체 역학 (Genomic Epidemiology)
강사: 박지완, 조윤신, 지선하
소속: 한림대학교 의과대학, 한림대학교 자연과학대학, 연세대학교 보건대학원
강의 개요: 유전체역학은 유전과 환경의 상호작용이 질병의 발생과 분포에 미치는 영향을 밝히기
위한 학문이다. 본 강좌에서는 질병유전체학의 기본 개념을 설명하고 최신 유전체역학연구에서
보편적으로 사용되는 연구방법론과 대표적인 분석 tool 을 이용하여 임상-역학-유전변이 데이터를
분석하고 결론을 추론하는 방법을 습득한다. 질병위험요인을 밝히기 위한 Study design(가족,
환자-대조군, 코호트 연구)과 연구유형(유전적 연관성, 멘델리안 무작위분석법, 시계열분석, 유전-
환경 상호작용)에 적합한 분석 tool 사용법, 표본 수 산정, 통계분석법을 중심으로 중급수준의
분석능력 습득을 목표로 한다.
준비물: 개인 노트북
제13회
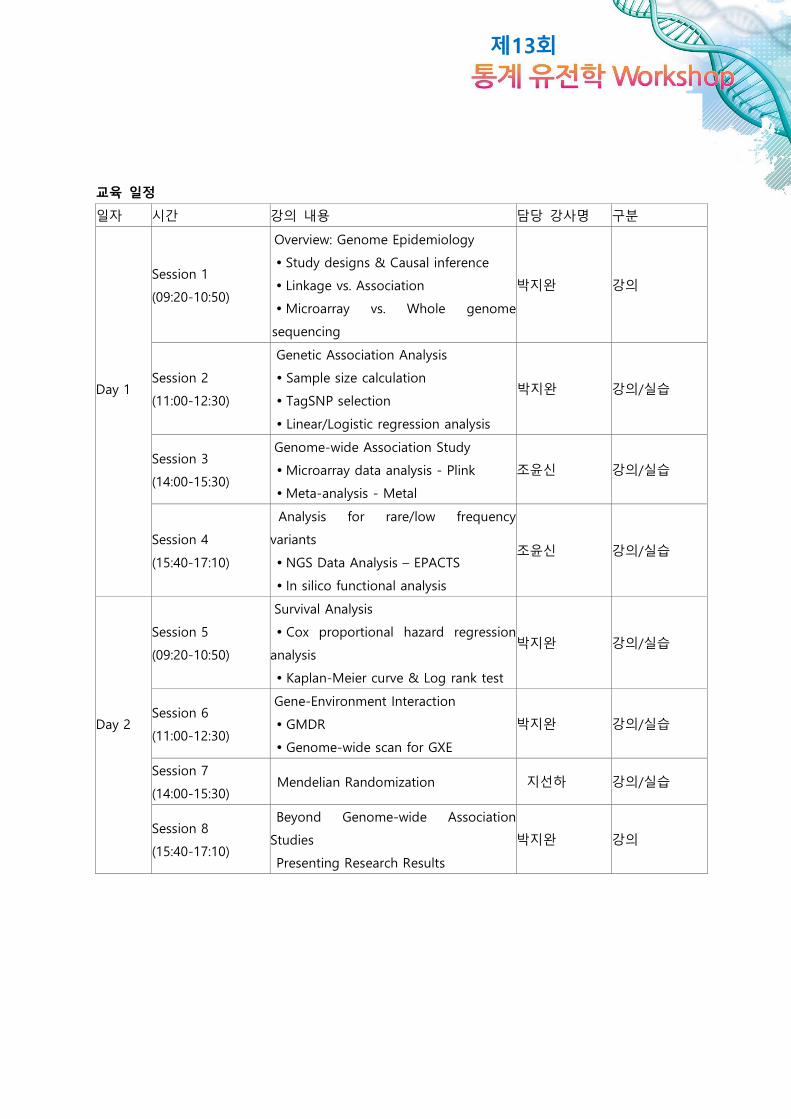
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50)
Overview: Genome Epidemiology
Study designs & Causal inference
Linkage vs. Association
Microarray vs. Whole genome
sequencing
박지완 강의
Day 1 Session 2
(11:00-12:30)
Genetic Association Analysis
Sample size calculation
TagSNP selection
Linear/Logistic regression analysis
박지완 강의/실습
Session 3
(14:00-15:30)
Genome-wide Association Study
Microarray data analysis - Plink
Meta-analysis - Metal
조윤신 강의/실습
Session 4
(15:40-17:10)
Analysis for rare/low frequency
variants
NGS Data Analysis – EPACTS
In silico functional analysis
조윤신 강의/실습
Session 5
(09:20-10:50)
Survival Analysis
Cox proportional hazard regression
analysis
Kaplan-Meier curve & Log rank test
박지완 강의/실습
Day 2 Session 6
(11:00-12:30)
Gene-Environment Interaction
GMDR
Genome-wide scan for GXE
박지완 강의/실습
Session 7
(14:00-15:30) Mendelian Randomization 지선하 강의/실습
Session 8
(15:40-17:10)
Beyond Genome-wide Association
Studies
Presenting Research Results
박지완 강의

제13회
11. Getting Your Papers Published
강사: Peter J Park
소속: Harvard Medical School
강의 개요: As many young researchers realize in due time, running one's own lab requires a new
set of skills--e.g., obtaining grants, recruiting and training students, and managing collaborations.
In particular, one typically finds that being smart and working many long nights is necessary but
not sufficient for publishing papers in top journals.
The aim of this course is to discuss these challenges and learn from one another on how to be
more productive in our academic pursuits. I will share what I have learned about how to run a lab
effectively and to publish in "high-impact" journals. The topics I will cover include picking a
research topic, writing a clear manuscript, writing cover letters, selecting reviewers, responding to
reviewers' comments, and communicating with editors. Depending on the interest of the audience,
I will also discuss ideas for writing effective letters of recommendations, finding and dealing with
experimental collaborators, and applying for positions overseas. I will present numerous case
studies of successful and not-so-successful emails/letters/projects, and will invite others to share
theirs. I will provide case studies of genomics papers, but the lessons should be understandable
to a general audience.
My laboratory focuses on computational analysis of genome and epigenome data. My
qualifications include reviewing >100 manuscripts, getting a multitude of manuscripts rejected
(~70 times at Nature family journals), and reading >1000 graduate school applications. My
trainees have gone on to faculty positions at top institutions including three at Harvard.
This course is intended for principal investigators (PhDs and MDs) and advanced postdoctoral
fellows, but others may be considered if there is space. If the number of applicants exceeds the
number of available slots, preference will be given to those in more advanced career stages.
Requirements: Willingness to speak freely and constructively.
Note: In the past, I have offered a course in cancer genomics. As there are other courses in
cancer genomics now, I decided to offer a course on a different topic that I think will be of
interest to a broad audience. The course will be conducted mostly in Korean.
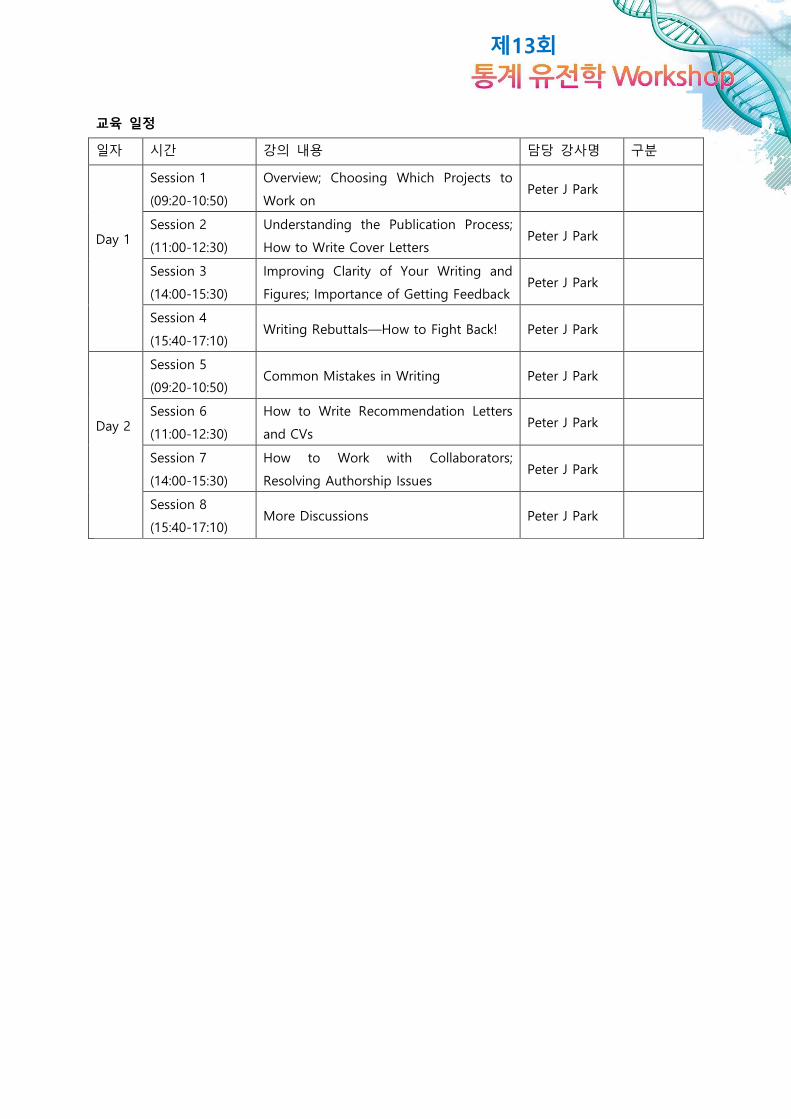
제13회
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Day 1
Session 1
(09:20-10:50)
Overview; Choosing Which Projects to
Work on Peter J Park
Session 2
(11:00-12:30)
Understanding the Publication Process;
How to Write Cover Letters Peter J Park
Session 3
(14:00-15:30)
Improving Clarity of Your Writing and
Figures; Importance of Getting Feedback Peter J Park
Session 4
(15:40-17:10) Writing Rebuttals—How to Fight Back! Peter J Park
Day 2
Session 5
(09:20-10:50) Common Mistakes in Writing Peter J Park
Session 6
(11:00-12:30)
How to Write Recommendation Letters
and CVs Peter J Park
Session 7
(14:00-15:30)
How to Work with Collaborators;
Resolving Authorship Issues Peter J Park
Session 8
(15:40-17:10) More Discussions Peter J Park
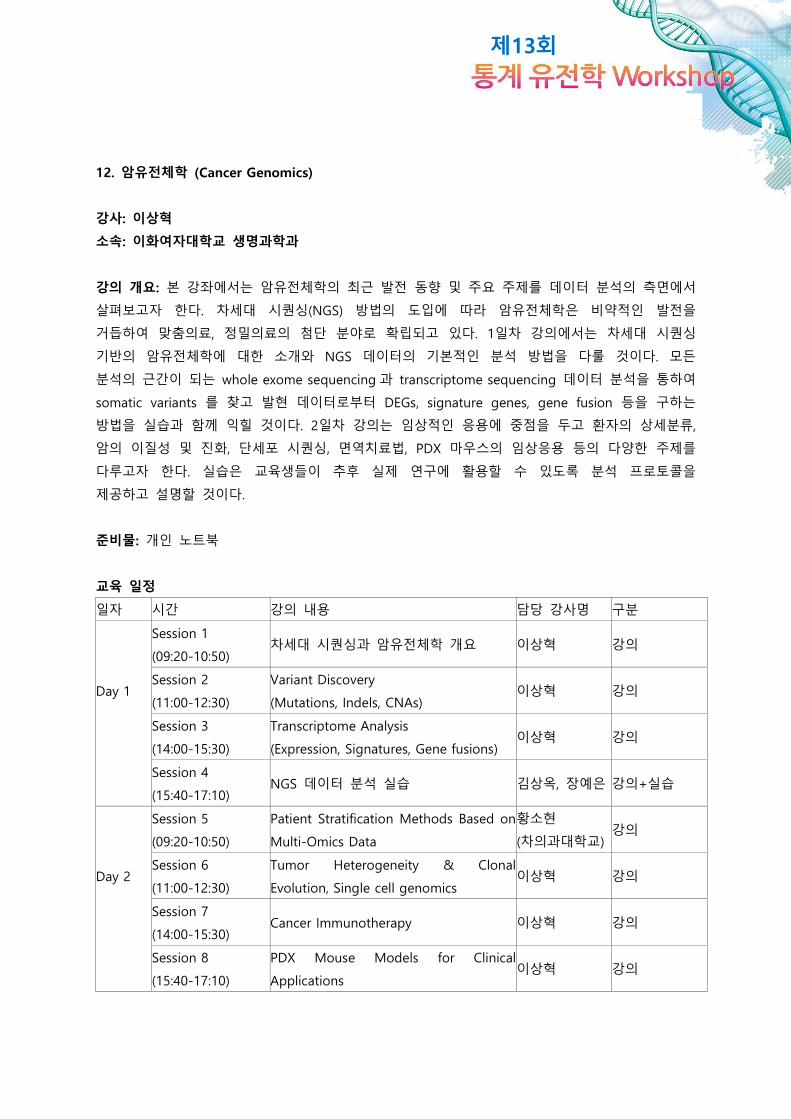
제13회
12. 암유전체학 (Cancer Genomics)
강사: 이상혁
소속: 이화여자대학교 생명과학과
강의 개요: 본 강좌에서는 암유전체학의 최근 발전 동향 및 주요 주제를 데이터 분석의 측면에서
살펴보고자 한다. 차세대 시퀀싱(NGS) 방법의 도입에 따라 암유전체학은 비약적인 발전을
거듭하여 맞춤의료, 정밀의료의 첨단 분야로 확립되고 있다. 1일차 강의에서는 차세대 시퀀싱
기반의 암유전체학에 대한 소개와 NGS 데이터의 기본적인 분석 방법을 다룰 것이다. 모든
분석의 근간이 되는 whole exome sequencing 과 transcriptome sequencing 데이터 분석을 통하여
somatic variants 를 찾고 발현 데이터로부터 DEGs, signature genes, gene fusion 등을 구하는
방법을 실습과 함께 익힐 것이다. 2일차 강의는 임상적인 응용에 중점을 두고 환자의 상세분류,
암의 이질성 및 진화, 단세포 시퀀싱, 면역치료법, PDX 마우스의 임상응용 등의 다양한 주제를
다루고자 한다. 실습은 교육생들이 추후 실제 연구에 활용할 수 있도록 분석 프로토콜을
제공하고 설명할 것이다.
준비물: 개인 노트북
교육 일정
일자 시간 강의 내용 담당 강사명 구분
Session 1
(09:20-10:50) 차세대 시퀀싱과 암유전체학 개요 이상혁 강의
Day 1 Session 2
(11:00-12:30)
Variant Discovery
(Mutations, Indels, CNAs) 이상혁 강의
Session 3
(14:00-15:30)
Transcriptome Analysis
(Expression, Signatures, Gene fusions) 이상혁 강의
Session 4
(15:40-17:10) NGS 데이터 분석 실습 김상옥, 장예은 강의+실습
Session 5
(09:20-10:50)
Patient Stratification Methods Based on
Multi-Omics Data
황소현
(차의과대학교) 강의
Day 2 Session 6
(11:00-12:30)
Tumor Heterogeneity & Clonal
Evolution, Single cell genomics 이상혁 강의
Session 7
(14:00-15:30) Cancer Immunotherapy 이상혁 강의
Session 8
(15:40-17:10)
PDX Mouse Models for Clinical
Applications 이상혁 강의



![교육분야 가명·익명정보 처리 가이드라인ksoms.org/NFUpload/nfupload_down.php?tmp_name... · 2020. 12. 1. · /0) xy 78z2[()p\-g ] < 관 련 법 령 > 개인정보](https://img.pdfslide.us/doc/110x75/6094b1250a50a225707848e3/eoee-eeee-e-eeoeeksomsorgnfuploadnfuploaddownphptmpname.jpg)