Embed Size (px)
Citation preview

I. INFORMATIQUE DECISIONNELLE I.1. Présentation
On qualifie d'informatique décisionnelle (en anglais "Business intelligence", parfois appelé tout simplement "le décisionnel") l'exploitation des données de l'entreprise dans le but de faciliter la prise de décision par les décideurs, c'est-à-dire la compréhension du fonctionnement actuel et l'anticipation des actions pour un pilotage éclairé de l'entreprise. On parle de système informatique décisionnel, ou système OLAP (On Line Analytical Processing), par opposition au système informatique transactionnel (système OLTP).
I.1.1. Systèmes OLTP versus systèmes OLAP
Les systèmes transactionnels sont souvent qualifiés par le terme OLTP pour indiquer qu’ils servent à traiter des processus transactionnels en ligne. Ces systèmes sont caractérisés par un nombre d’utilisateurs important, des mises à jour de données fréquentes et des volumes de données par transaction relativement faibles.
L’exploitation des informations contenues dans ces systèmes transactionnels est réalisée par des processus d’analyse en ligne de données, en d’autres termes par des systèmes OLAP. Ces systèmes OLAP doivent permettre l’analyse des données de manière interactive et rapide, pour des données quelconques et des données historisées. Ils sont utilisés par un nombre restreint d’utilisateurs, traitent des enregistrements volumineux dont la structure est complexe et procèdent par interrogation des données.
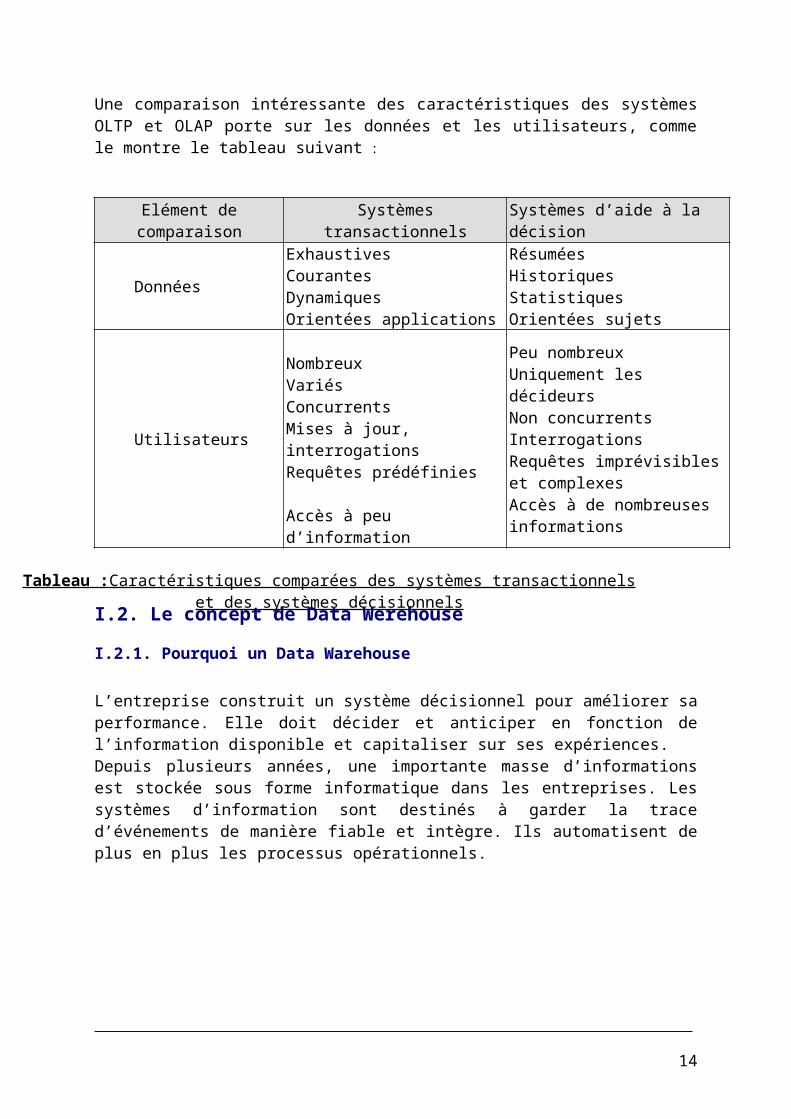
Une comparaison intéressante des caractéristiques des systèmes OLTP et OLAP porte sur les données et les utilisateurs, comme le montre le tableau suivant :
Elément de comparaison Systèmes transactionnels Systèmes d’aide à la décision
Données
ExhaustivesCourantesDynamiquesOrientées applications
RésuméesHistoriquesStatistiquesOrientées sujets
Utilisateurs
NombreuxVariésConcurrentsMises à jour, interrogationsRequêtes prédéfinies
Accès à peu d’information
Peu nombreuxUniquement les décideursNon concurrentsInterrogationsRequêtes imprévisibles et complexesAccès à de nombreuses informations
I.2. Le concept de Data WerehouseI.2.1. Pourquoi un Data Warehouse
13
Tableau : Caractéristiques comparées des systèmes transactionnels et des systèmes décisionnels
L’entreprise construit un système décisionnel pour améliorer sa performance. Elle doit décider et anticiper en fonction de l’information disponible et capitaliser sur ses expériences.Depuis plusieurs années, une importante masse d’informations est stockée sous forme informatique dans les entreprises. Les systèmes d’information sont destinés à garder la trace d’événements de manière fiable et intègre. Ils automatisent de plus en plus les processus opérationnels.
Les différentes données de l'entreprise
L’informatique a un rôle à jouer, en permettant à l’entreprise de devenir plus entreprenante et d’avoir une meilleure connaissance de ses partenaires, de sa compétitivité ou de son environnement.
A ce titre, le Data Warehouse doit être rapproché de tous les concepts visant à établir une association entre le système d’information et sa stratégie.
I.2.2. Définition du Data Warehouse
La définition classique du Data Warehouse donnée par Bill Inmon.
« Un Data Warehouse est une collection de données orientées sujet, intégrées, non volatiles et historisées, organisées pour le support de processus d’aide à la décision».
En effet le Data Warehouse est un entrepôt de données. Il s'agit d'un stockage intermédiaire des données issues des applications de production, dans lesquelles les utilisateurs finaux puisent avec des outils de restitution et d'analyse.
14

Orientées sujet
Le Data Warehouse est organisé autour des sujets majeurs et des métiers de l'entreprise. Les données sont organisées par thème. L'intérêt de cette organisation réside dans le fait qu'il devient possible de réaliser des analyses sur des sujets transversaux aux structures fonctionnelles et organisationnelles de l'entreprise. Cette orientation permet également de faire des analyses par itération, sujet après sujet.
Données intégrées
Un Data Warehouse est un projet d'entreprise. Il concerne les différents services et métiers de l'entreprise. Avant d'être intégrées dans le Data Warehouse, les données doivent êtres mises en forme et unifiées afin d'avoir un état cohérent. L'intégration nécessite une forte normalisation, une bonne gestion des référentiels et de la cohérence, une parfaite maîtrise de la sémantique et des règles de gestion s'appliquant aux données manipulées. C'est ainsi que l'on pourra donner une bonne vision de l'entreprise via l'utilisation d'indicateurs.
Données historisées
L'historisation est nécessaire pour suivre dans le temps l'évolution des différentes valeurs des indicateurs à analyser. Ainsi, un référentiel temps doit être associé aux données afin de permettre l'identification dans la durée de valeurs précises.
Données non volatiles
Afin de conserver la traçabilité des informations et des décisions prises, les informations stockées au sein du Data Warehouse ne peuvent pas être mises à jour. Une requête lancée à différentes dates sur les mêmes données doit toujours retourner les mêmes résultats. Une donnée introduite dans le Data Warehouse ne pourra donc plus être supprimée ni même modifiée.
15

I.2.3. La structure du Data Warehouse
La structure du Data Warehouse
Un Data Warehouse peut se structurer en quatre classes de données, organisées selon un axe historique et un axe de synthèse.
Les données détaillées
Elles reflètent les événements les plus récents. Les intégrations régulières des données issues des systèmes de production vont habituellement être réalisées à ce niveau.
Les données agrégées
Elles correspondent à des éléments d’analyse représentatifs des besoins utilisateurs. Elles constituent déjà un résultat d’analyse et une synthèse de l’information contenue dans le système décisionnel, et doivent être facilement accessibles et compréhensibles.
Les métadonnées
Très souvent les données à fédérer dans le Data Warehouse proviennent de sources très hétérogènes. Cela rend indispensable la présence d'un dictionnaire unique qui sait gérer l'ensemble des fonctions du Data Warehouse. Cette cohérence du dictionnaire est décrite au sein des métadonnées du dictionnaire du Data Warehouse.
Les métadonnées constituent l'ensemble des données qui décrivent des règles attachées à d'autres données. Ces dernières constituent la finalité du système d'information.
16
M
étad
onné
es

I.2.4. Les architectures
Pour implémenter un Data Warehouse, trois types d’architectures sont possibles :
- L’architecture réelle,- L’architecture virtuelle,- L’architecture remote.
L’architecture réelle
Elle est généralement retenue pour les systèmes décisionnels. "Le stockage des données est réalisé dans un SGBD séparé du système de production. Le SGBD est alimenté par des extractions périodiques. Avant le chargement, les données subissent d’importants processus d’intégration, de nettoyage et de transformation.
L’avantage de cette solution est de disposer de données préparées pour les besoins de la décision et répondant aux objectifs du Data Warehouse".
Les inconvénients sont le coût de stockage supplémentaire et le manque d’accès en temps réel.
L’architecture virtuelle
Cette architecture n’est pratiquement pas utilisée pour le Data Warehouse. "Les données résident dans le système de production. Elles sont rendues visibles par des produits middleware 1 ou par des passerelles".
Il en résulte deux avantages : pas de coût de stockage supplémentaire et l’accès se fait en temps réel.
L’inconvénient est que les données ne sont pas préparées ainsi que le problème d’accès pour l’exploitation.
L’architecture remote
C’est une combinaison de l’architecture réelle et de l’architecture virtuelle. Elle est rarement utilisée.
"L’objectif est d’implémenter physiquement les niveaux agrégés afin d’en faciliter l’accès et de garder le niveau de détail dans le système de production en y donnant l’accès par le biais de middleware ou de passerelle".
I.3. Le concept de Data Mart
Le terme de Data Mart est réservé à des bases plus petites. C’est une petite structure très ciblée et pilotée par les besoins utilisateurs. Il a la même vocation que le Data Warehouse
17

(fournir une architecture décisionnelle), mais vise une problématique précise avec un nombre d’utilisateurs plus restreint.
Construire un ou plusieurs Data Marts au lieu d’un Data Warehouse permet de valider rapidement le concept d’informatique décisionnelle, puisque les Data Marts sont moins complexes et plus facile à déployer que les Data Warehouse.
Data Warehouse Data MartCible utilisateur Toute l’entreprise DépartementImplication du
service informatiqueElevée Faible ou moyen
Base de donnéesd’entreprise
SQL type serveur SQL milieu de gamme, basesmultidimensionnelles
Modèles de données A l’échelle de l’entreprise DépartementChamp applicatif Multi sujets, neutre Quelques sujets, spécifique
Sources de données Multiples Quelques unesStockage Base de données Plusieurs bases distribuées
1 middleware : outil logiciel de connectivité : dans un contexte décisionnel, il est situé entre les outils d’aide à la décision et la base de données décisionnelle. Un bon middleware permet de conserver l’indépendance de ces deux types de composants.
I.4. Système d'alimentation de Data warehouse
Le système d'alimentation à pour but de transformer les données primaires (par exemple issues des systèmes de production) en informations stockées dans le Data Warehouse. Pour cela il est nécessaire de réaliser les fonctions suivantes :
- Recherche et identification des données- Contrôle de qualité (épuration et validation)- Extraction- Transformation- Chargement
18

Le système d'alimentation Data warehouse
La phase d'identification et d'épuration des données consiste à définir et identifier la donnée la plus pertinente en fonction de sa source.
La phase de transformation regroupe les opérations de mise au format nécessaires des données, de calcul des données secondaires et de fusion ou d'éclatement des informations composites.
Enfin la phase de chargement à pour rôle de stocker les informations de manière correcte dans
les tables de faits du Data Warehouse.
I.5. Présentation du Modèle multidimensionnel
I.5.1. DéfinitionLa modélisation multidimensionnelle été introduite par Ralph Kimball. Elle consiste en deux
nouveaux concepts tels que les faits et les dimensions. Chaque modèle multidimensionnel est
composé d’une table contenant une clé, la table des faits qui permettent de mesurer l’activité
et d’un ensemble de tables dimensionnelles qui contiennent les informations contextuelles
faisant varier les mesures de l’activité en question. Chaque table de faits possède une clé qui
la relie avec la clé primaire de chaque table de dimension.
Selon l'architecture de Ralph Kimball, les structures de données dimensionnelles sont la
destination ultime des processus ETL et ces tables se positionnent à la frontière entre le Back
Room et le Front Room. En général les tables dimensionnelles sont l'étape finale de stockage
19

physique de données avant leur transfert vers l'environnement des utilisateurs finaux.
Le modèle dimensionnel est la structure de données la plus utilisée et la plus appropriée aux
requêtes et analyses des utilisateurs d'entrepôts de données. Elles sont simples à créer, stables
et intuitivement compréhensibles par les utilisateurs finaux. Le modèle dimensionnel est la
fondation même pour la construction des cubes OLAP.
iL consiste en une grande table de faits ( fact table) et un cercle d’autres tables qui contiennent
les éléments descriptifs du fait, appelées « dimensions ». Quand illustré, le modèle ressemble
à une étoile, c’est d’ailleurs l’origine du terme « En étoile ».
I.5.2. Pourquoi la Modélisation Dimensionnelle?Du point de vue des performances, les modèles dimensionnels peuvent être utiles de plusieurs
manières. La dénormalisation des tables de dimension au cours du processus de chargement
réduit le nombre de jointures que le moteur de requêtes doit effectuer au moment des
interrogations. Au-delà de cet aspect, l’optimiseur relationnel comprend que le modèle
dimensionnel est une grande table de faits, avec des jointures simples vers plusieurs tables de
dimension relativement petites dans lesquelles se trouvent la majorité des contraintes ;
l’optimiseur peut formuler une stratégie de requête qui tire parti de cette structure. Cette
stratégie, appelé jointure en étoile, peut améliorer considérablement la vitesse d’exécution de
la majorité des requêtes d’analyse décisionnelle.
I.5.3 Les quatre étapes de la Modélisation Dimensionnelle
Pour bien réussir le modèle dimensionnel il est nécessaire de réaliser les quatre étapes suivantes :I.5.3.1 : Choisir le Processus à Modéliser
Il s'agit de choisir le processus d'affaire à étudier. Le choix du processus est en général
effectué par les utilisateurs finaux. D'ailleurs c'est à ce stade que l'on essaye de traduire les
objectifs des tableaux de bord en indicateurs de performances (KPI) (sont des instantanés qui
donnent une vision globale d’une activité ou d’une organisation, à partir de mesures
spécifiques et prédéfinies.)Dans le cas des DSS d'indicateurs de gestion...
I.5.3.2 : Définir la granularité du processusIl s'agit de répondre à la question : Que représente un enregistrement de la table de fait ?
20

La granularité définit le niveau de détail contenu dans la table de fait. Voici quelques
exemples :
Une ligne de commande par produit, par client et par jour.
Une transaction bancaire par client par type de retrait et par mois.
Il s'agit de l'étape la plus critique lors de la création du modèle.
I.5.3.3 : Choisir les DimensionsDans cette étape on doit choisir les différentes dimensions qui représentent le contexte dans
lequel le fait a eu lieu.
I.5.3.4 : Identifier les FaitsPour identifier les faits, il faut répondre à la question : Qu'est ce qu'on mesure ?
I.5.4. Modèle multidimensionnel conceptuel
I.5.4. 1. Concept de cube
Il s'agit d'une modélisation multidimensionnelle des données facilitant l'analyse d'une quantité selon différentes dimensions. Cette vision correspond à une structuration des données selon plusieurs axes d'analyses (ou dimensions) pouvant représenter des notions variées telles que le temps, les clients, les produits,…
schéma de cube
I.5.4. 2.Les Types De Modélisation Multi-dimensionnelle
21

I.5.4. 2.1.Star Schéma ou Schéma en étoile
Il consiste en une grande table de faits et un cercle d’autres tables qui contient les éléments
descriptifs du fait, appelées « dimensions ». Quand illustré, le modèle ressemble à une étoile,
c’est d’ailleurs l’origine du terme « En étoile ».
La figure suivante illustre le schéma en étoile :
Représentation schema en etoile
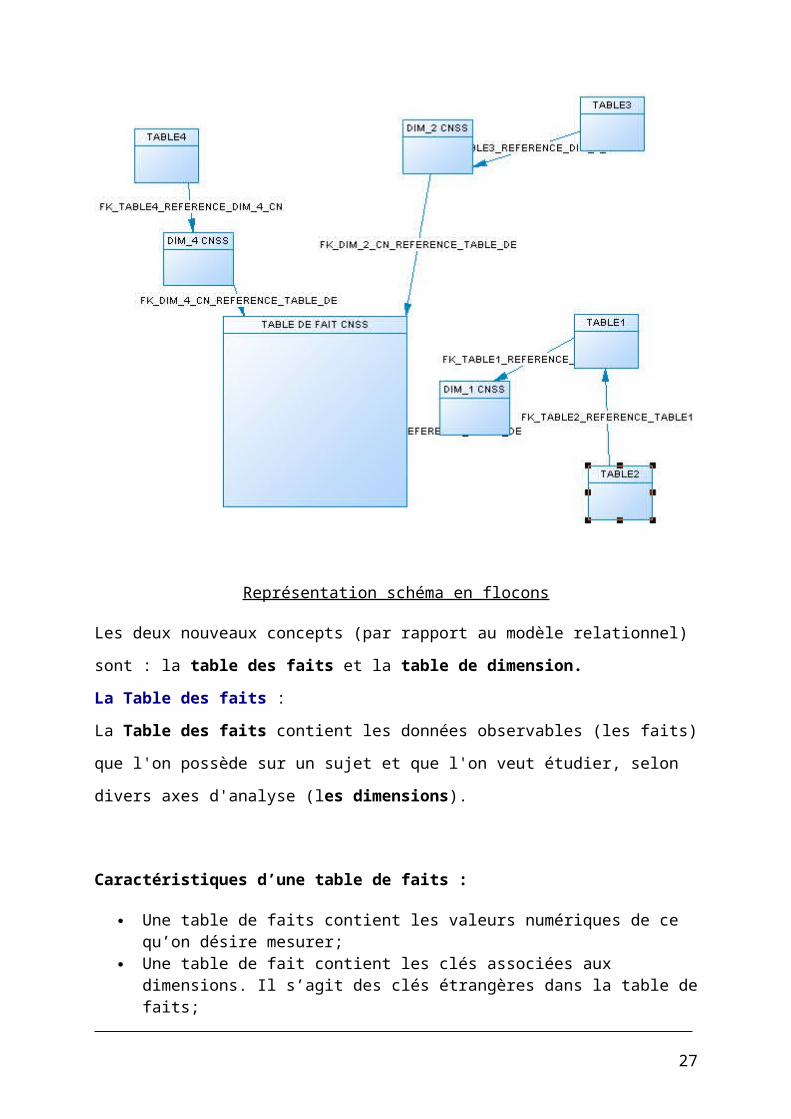
I.5.4. 2.2.Le schéma en flocons de neige
22

Le schéma en flocons de neige est une variante du schéma en étoile. Dans la théorie la
différence réside dans la simple normalisation des tables de dimensions. Il est donc tout
simplement question de mettre les attributs de chaque niveau hiérarchique dans une table de
dimension à part.
Représentation schéma en flocons
Les deux nouveaux concepts (par rapport au modèle relationnel) sont : la table des faits et la
table de dimension.
La Table des faits :La Table des faits contient les données observables (les faits) que l'on possède sur un sujet et
que l'on veut étudier, selon divers axes d'analyse (les dimensions).
Caractéristiques d’une table de faits :
Une table de faits contient les valeurs numériques de ce qu’on désire mesurer; Une table de fait contient les clés associées aux dimensions. Il s’agit des clés
étrangères dans la table de faits;
23

En général une table de fait contient un petit nombre de colonnes; Une table de fait contient plus d’enregistrements qu’une table de dimension; Les informations dans une table de fait sont caractérisées par : Elles sont numériques et sont utilisées pour faire des SUM, AVG… Les données doivent être additives ou semi-additives; Toutes les colonnes représentant les faits (mesure1, mesure2.. dans la figure 1) dans la
table de fait doivent référer et avoir un lien direct aux clés de dimensions
exemple de table de fait
Structure de base d’une table de faits
Une table de faits devrait avoir la structure suivante :
24

Figure 18 : Représentation de la structure de table de fait
Dimension dégénérée :
La dimension dégénérée est une clé de dimension dans la table de fait qui est en général sans attribut. Par exemple No de bon de commande, No d’interruption de service, etc. Dans le cas de numéro de l’interruption de service, les utilisateurs veulent savoir par exemple « combien de fois un client a été interrompu dans une période de temps précise».Vu qu’il s’agit d’une seule clé de dimension, nous évitons alors de créer une table de dimension, ce qui fait que cette table de dimension a dégénéré dans la table de fait, c’est pour cette raison que cette clé est appelée « dimension dégénérée »
La Table de dimension :La Table de dimension contient les axes d'analyse (les dimensions) selon lesquels on
veut étudier des données observables (les faits) qui, soumises à une analyse
multidimensionnelle, donnent aux utilisateurs des renseignements nécessaires à la prise de
décision. On appelle « dimension » un axe d'analyse. Il peut s'agir des clients ou des produits
d'une entreprise…, etc.
Caractéristiques d’une dimension :
Une table de dimension contient le détail sur les faits; Une table de dimension contient les informations descriptives des valeurs numériques
de la table de faits; Vu que les données dans la table de dimensions sont normalisées, elle contient un plus
grand nombre de colonnes; Une table de dimension contient en général beaucoup moins d’enregistrement qu’une
table de faits;
25

Les attributs d’une table de dimension sont souvent utilisés comme « Lignes » et « Colonne » dans un rapport ou résultat de requête. Par exemple, les attributs textuels d’un rapport proviennent souvent d’une dimension.
II. LA MODELISATION DES DATA MARTS DE LA DB
Après avoir établir des dialogues avec des Administrateurs nous avons déterminé les différentes dimensions et axes d’analyse de notre modélisation.
Les décideurs, qui sont les futurs utilisateurs de notre système, souhaitent estimer la maîtrise des coûts, la mesure du rendement, La segmentation des patients ainsi niveau de fidélisation des patients suivant plusieurs axes d’analyse.
Ces axes d’analyse constituent les dimensions de nos modèles des Data Marts.
Le modèle que nous avons adapté à notre système décisionnel c’est le modèle en Etoile.
Ce choix est justifié par : la présence des dimensions sans sous-dimensions. la présence des tables de dimensions non volumineuses.
En se référant aux besoins exprimés et présentés au niveau de l’étude des besoins (Objectifs et champ d’étude), nous avons conçu Data Marts suivant :
26
Modélisation du Data Mart de la DB Polyclinique:
Schéma conceptuel du Data Mart de la DB Polyclinique
27





















