Embed Size (px)
Citation preview

104/20/23 01:02
Graphics II 91.547
Paper ReviewsFacial Animation
Session 8

204/20/23 01:02
Making Faces
Brian Guenter, Cindy Grimm, Daniel Wood Henrique Malvar, Fredrick Pighin
Microsoft Corporation, University of Washington
Computer Graphics, Proceedings of SIGGRAPH, July 1998.

304/20/23 01:02
The Problem
0 Animation of human faces one of the most difficult problems in graphics
- Many degrees of freedom- Humans sensitive to small discrepancies
0 Applications- Believable animated characters for movies, television- Avatars for VR- Video compression for teleconferencing

404/20/23 01:02
Approach
0 Single 3D mesh model of speaker’s face is developed0 Key locations on face are marked by colored dots0 Video of speaking face is recorded from multiple directions0 Positions of colored dots are tracked in 3D0 Mesh is deformed accordingly0 Texture is evolved from video and applied

504/20/23 01:02
Distinctions from Previous Work
0 Not a physical or procedural model of face, as Cassell (1994), Lee (1995) and Waters (1987)
0 Williams (1990) similar, except used only a single static texture and tracked points only in 2D
0 Bregler et al. Use speech recognition techniques to locate visemes in video sequence - then blend and synthesize new video without physical 3D model
0 Primarily a method to track and recreate facial details

604/20/23 01:02
Data Capture
0 Face first digitized by Cyberware laser scanner to build 3D model
0 182 colored dots affixed to face- Fluorescent colors used - Visible & UV light to maximize color differences- Arranged so similar colors as far apart as possible- Arranged along contours of face
0 6 calibrated video cameras to capture motion0 Head held stationary

704/20/23 01:02
Cyberware scanner
• Digitizes both shape and color• 1 mm x 1 mm resolution• 30 seconds to complete scan• 3D model within seconds of completing scan

804/20/23 01:02
Camera views

904/20/23 01:02
Mesh Generation
0 Cyberware scan of head0 460,000 polygons reduced to 4800 using Hoppe’s method
(Hoppe 1996)0 Some manual adjustment where scan was inadequate
- One side of nose and ear- Inside mouth

1004/20/23 01:02
Training the color classifier
1104/20/23 01:02
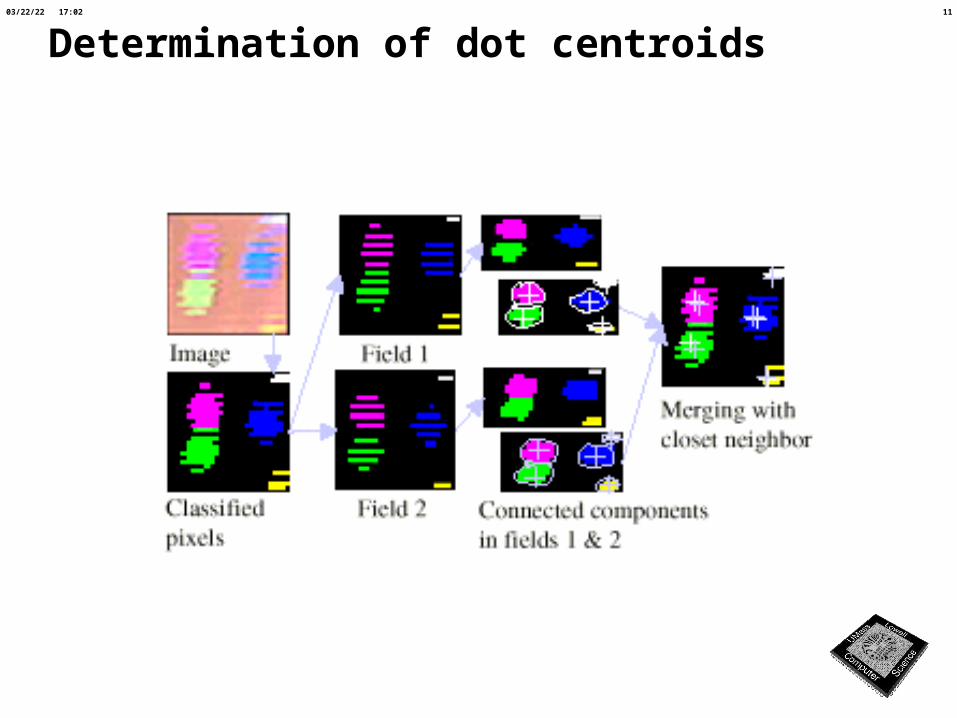
Determination of dot centroids

1204/20/23 01:02
Tracking dot movements over time

1304/20/23 01:02
Matching Dots Between Cameras
Camera 1COP
Camera 2COP
Image 1
Image 2
Match
Line of closestapproach

1404/20/23 01:02
Matching Dots Between Cameras
Camera 1COP
Camera 2COP
Image 1
Image 2
No Match
Line of closestapproach

1504/20/23 01:02
Determining frame to frame dot correspondence

1604/20/23 01:02
Mesh DeformationStep 1:

1704/20/23 01:02
Areas treated specially in frame to frame mapping

1804/20/23 01:02
Creating the texture maps

1904/20/23 01:02
Removal of dots from texture images

2004/20/23 01:02
Texture Mapping

2104/20/23 01:02
Results
0 Animated sequences from arbitrary viewpoints surprisingly realistic
0 Little evidence of the removed dots0 Some artifacts visible
- Some polygonalization artifacts due to the use of only 4500 polygons
- Occasional jitter due to algorithms chosen - and dots disappearing from view on more than 3 cameras
- Teeth incorrect when viewed from glancing angle- Shading/highlights do not move with viewpoint properly

2204/20/23 01:02
Resulting animation sequence

2304/20/23 01:02
Synthesizing Realistic Facial Expressions from Photographs
Frederic Pighin, Jamie Hecker, Dani Lischinski, Richard Szeliski, David H. Salesin
Computer Graphics, Proceedings of SIGGRAPH, July 1998.

2404/20/23 01:02
Approach
0 Based upon multiple, uncalibrated views of a human subject0 User-assisted optimization technique recovers camera
parameters and 3D point locations of selected features0 Scattered data interpolation technique is used to deform a
generic face mesh to correspond to face of subject0 Extract one or more texture maps from camera images0 Process repeated for multiple expressions of subject
- Morphing techniques developed to animate change of expression
- Expressions combined globally and locally to generate new expressions

2504/20/23 01:02
Extraction of 3D points from multiple images
0 A few distinct feature points are selected (13 in this case) on each image
0 Approximate starting point assumed- Generic head model gives starting 3D point- Camera pose parameters are approximated
0 Progressive refinement via algorithm (Szeliska and Kang, 1997)

2604/20/23 01:02
Refinement of generic mesh
0 Starting points are coordinates of feature points0 Smooth interpolation function gives 3D displacement for
other mesh vertices
f p c p p
r e
i ii
r
( ) ( )
( ) /
64

2704/20/23 01:02
View-independent texture mapping
0 Texture map defined in cylindrical coordinates0 Construct a visibility map for each image0 For each image:
- Compute 3D point on the surface of the face mesh whose cylindrical projection is (u,v)
- Project back using camera geometry to determine (x,y)- Weight by “positional certainty and visibility function

2804/20/23 01:02
View-dependent texture mapping
0 View-independent method involves blending resampled images and thus potentially looses detail
0 Alternate method:- Render model several times, each time with separate
texture map- Blend the results weighted in accordance with the viewing
direction0 Advantage: makes up for potential lack of detail in the
geometry model0 Disadvantage: requires multi-pass rendering and more
rendering time

2904/20/23 01:02
Comparison of view-independent andview-dependent texture generation
View Independent View Dependent

3004/20/23 01:02
Expression morphing
0 Because topology of models for differing expressions is equivalent, morphing can be reduced to simple linear interpolation of vertex locations
0 Face model is rendered once with one texture and once with the second. The resulting images are blended

3104/20/23 01:02
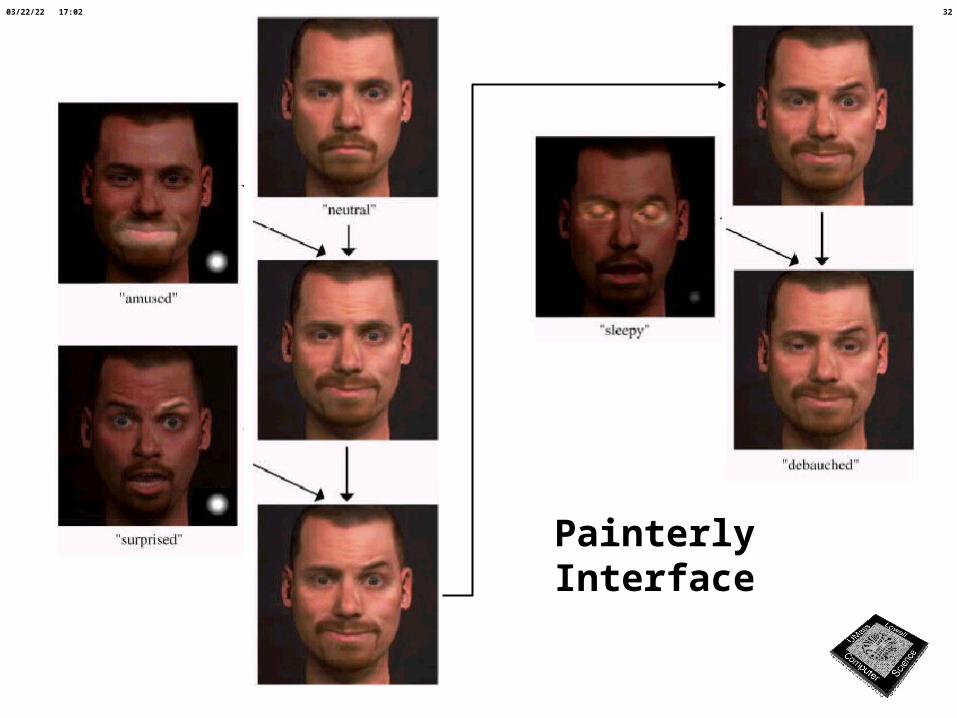
Global vs. regional expression changes
GlobalBlend
“Surprised” “Sad” “Worried”
“Neutral” “Happy” “Fake Smile”
LocalBlend
3204/20/23 01:02
PainterlyInterface

3304/20/23 01:02
User Interface

3404/20/23 01:02
Voice Puppetry
Matthew Brand, Mitsubishi Research Laboratory
Computer Graphics, Proceedings of ACM SIGGRAPH,August 1999.

3504/20/23 01:02
Background
0 Significant mutual information between vocal and facial gesture
- Facial expression adds significantly to information content of speech
- Facial expression conveys emotional content0 Synthesis of believable faces difficult problem in animation
- Human sensitivity to facial details- Central problem for the creation of avatars in virtual
environments

3604/20/23 01:02
Previous Work
0 Manual lip-synching is a laborious process0 Semi-automated systems usually based on phonemes
- Phonemic tokens mapped to lip poses- Problem of coarticulation, i.e. interaction of adjacent
speech components- Some systems deal with context using triphonemes
(Berger et al. 1997)- Discretizing to phonemes loses information on phrasing,
dynamics0 Most systems ignore upper facial expressions, which convey
a significant portion of the emotional content
3704/20/23 01:02
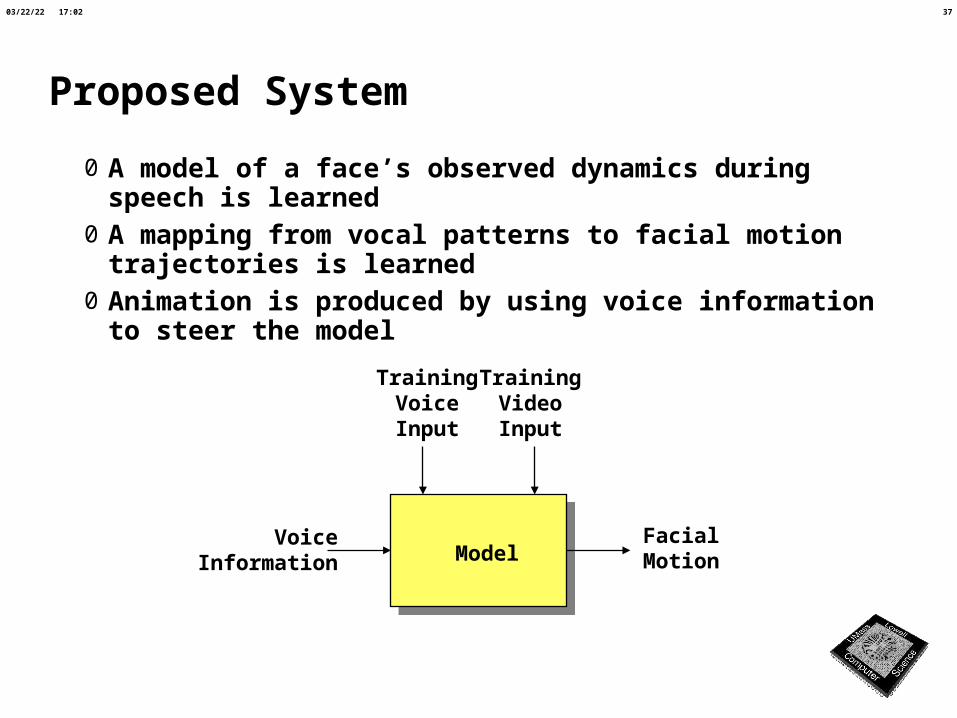
Proposed System
0 A model of a face’s observed dynamics during speech is learned
0 A mapping from vocal patterns to facial motion trajectories is learned
0 Animation is produced by using voice information to steer the model
VoiceInformation
FacialMotion
TrainingVoiceInput
TrainingVideoInput
Model

3804/20/23 01:02
Advantages
0 System makes full use of forward and backward context in speech
0 Single video training can be used to animate other persons or creatures to novel audio
0 Animates speech and non-speech sounds0 Predicts full facial motion, neck to hairline0 Can drive 2D, 3D or image-based animations

3904/20/23 01:02
Overview of the Process
Training
Remapping
Analysis
Synthesis

4004/20/23 01:02
Facial Tracking
• 26 Facial points tracked• Tracking based upon texture features• Marks added where inadequate texture variations
4104/20/23 01:02
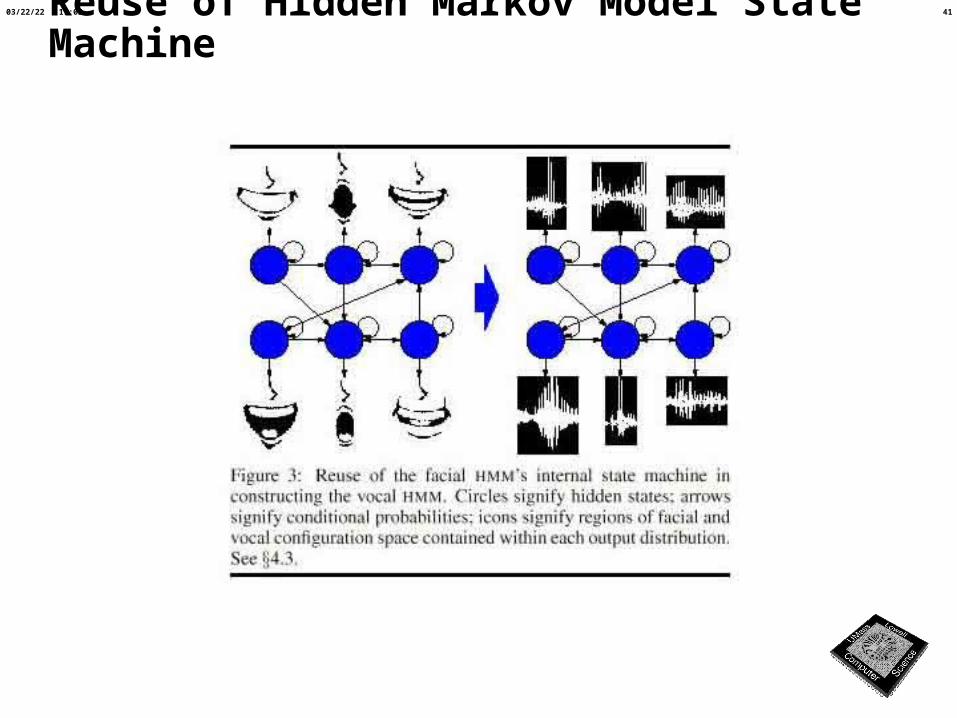
Reuse of Hidden Markov Model State Machine

4204/20/23 01:02
Mean Position Content for Learned States

4304/20/23 01:02
Results
0 Multiple readers of children’s stories were recorded for 180 seconds
- 60 seconds of video selected for training- 25 facial features tracked- Result: 26 state model
0 Using different voice, the model was used to animate Mt. Rushmore (see next slide)
0 Simple test conducted to evaluate opinions of naïve users- 6 subjects compared:
=Synthesized facial motion=Actual tracked motion
- Half found actual motion “more natural”- Half found synthetic motion “more natural”

4404/20/23 01:02
Animation of Jefferson at Mt. Rushmore
Unanimated Animated





























