Embed Size (px)
Citation preview

10417/10617IntermediateDeepLearning:
Fall2019RussSalakhutdinov
Machine Learning [email protected]
https://deeplearning-cmu-10417.github.io/
Deep Belief Networks

Neural Networks Online Course
• Hugo’s class covers many other topics: convolutional networks, neural language model, Boltzmann machines, autoencoders, sparse coding, etc.
• We will use his material for some of the other lectures.
• Disclaimer: Much of the material and slides for this lecture were borrowed from Hugo Larochelle’s class on Neural Networks: https://sites.google.com/site/deeplearningsummerschool2016/

Deep Autoencoder
Ø Pre-training initializes the optimization problem in a region with better local optima of the training objective
Ø Each RBM used to initialize parameters both in encoder and decoder (‘‘unrolling’’)
Ø Better optimization algorithms can also help: Deep learning via Hessian-free optimization. Martens, 2010
3
W
W
W +�
W
W
W
W
W +�
W +�
W +�
W
W +�
W +�
W +�
+�
W
W
W
W
W
W
1
2000
RBM
2
2000
1000
500
500
1000
1000
500
1 1
2000
2000
500500
1000
1000
2000
500
2000
T
4T
RBM
Pretraining Unrolling
1000 RBM
3
4
30
30
Fine�tuning
4 4
2 2
3 3
4T
5
3T
6
2T
7
1T
8
Encoder
1
2
3
30
4
3
2T
1T
Code layer
Decoder
RBMTop
• Pre-training can be used to initialize a deep autoencoder

Image
Low-levelfeatures:Edges
Input:Pixels
Builtfromunlabeledinputs.
DeepBeliefNetwork
(Hinton et.al. Neural Computation 2006)

Image
Higher-levelfeatures:Combinationofedges
Low-levelfeatures:Edges
Input:Pixels
Builtfromunlabeledinputs.
DeepBeliefNetwork
Internalrepresentationscapturehigher-orderstatisticalstructure
(Hinton et.al. Neural Computation 2006)
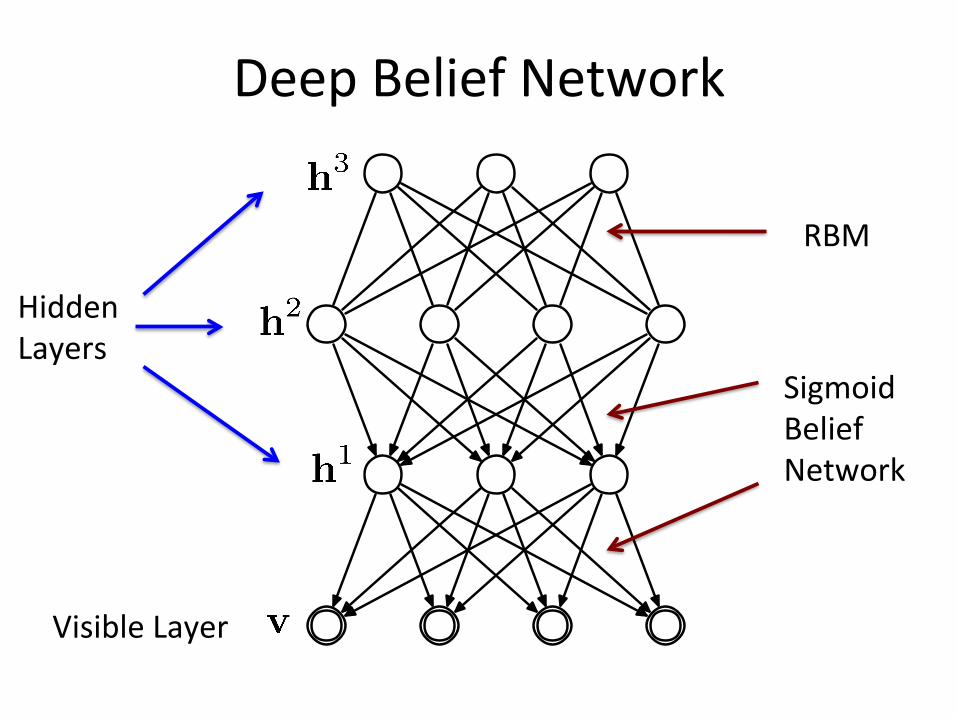
DeepBeliefNetwork
HiddenLayers
VisibleLayer
RBM
SigmoidBeliefNetwork

Deep Belief Network
7
• Deep Belief Networks:
Ø it is a generative model that mixes undirected and directed connections between variables
Ø top 2 layers’ distribution is an RBM!
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
1
Ø other layers form a Bayesian network with conditional distributions:
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
1
Ø This is not a feed-forward neural network

DeepBeliefNetwork
RBM
SigmoidBeliefNetwork
DeepBeliefNetworkØ top 2 layers’ distribution
is an RBM
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
1
Ø other layers form a Bayesian network with conditional distributions:
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
1

DeepBeliefNetwork• The joint distribution of a DBN is as follows
where
9
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
1
• As in a deep feed-forward network, training a DBN is hard

Layer-wisePretraining• This is where the RBM stacking procedure comes from:
10
Ø idea: improve prior on last layer by
adding another hidden layer
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
1
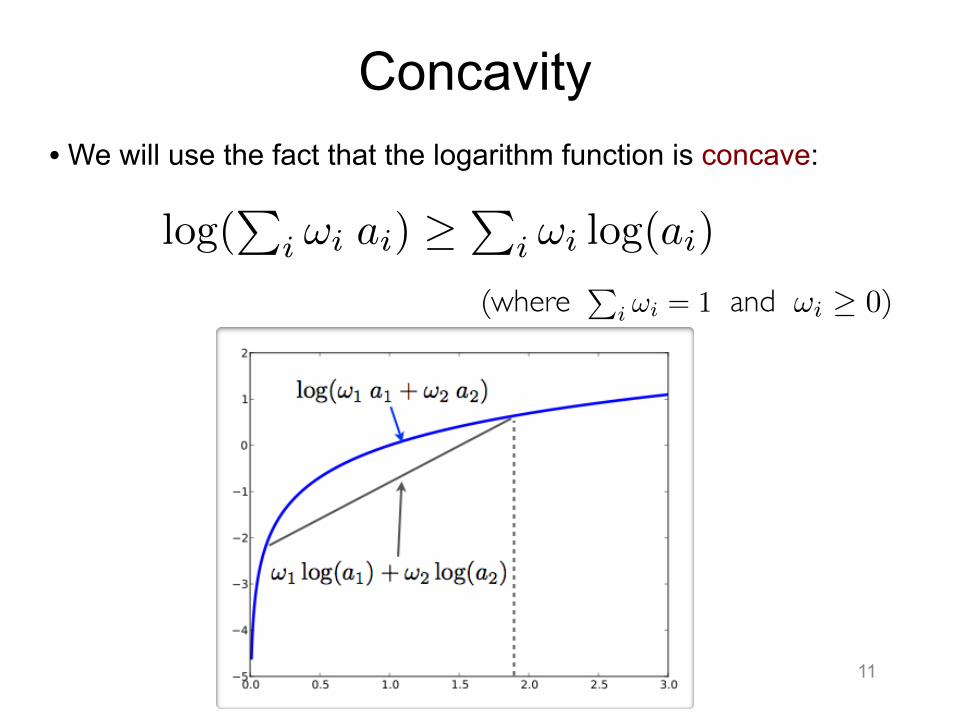
Concavity • We will use the fact that the logarithm function is concave:
11
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
• log(P
i !i ai) �P
i !i log(ai)P
i !i = 1 !i � 0
• ai ⌘ p(x|h(1))p(h(1))q(h(1)|x) !i ⌘ q(h(1)|x)
•
log p(x) = logX
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
1
(where and )
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
• log(P
i !i ai) �P
i !i log(ai)P
i !i = 1 !i � 0
• ai ⌘ p(x|h(1))p(h(1))q(h(1)|x) !i ⌘ q(h(1)|x)
•
log p(x) = logX
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
• log(P
i !i ai) �P
i !i log(ai)P
i !i = 1 !i � 0
• ai ⌘ p(x|h(1))p(h(1))q(h(1)|x) !i ⌘ q(h(1)|x)
•
log p(x) = logX
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
1

Variational Bound • For any model with latent variables we can write:
12
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x,h(1))
q(h(1)|x)
!(6)
�X
h(1)
q(h(1)|x) log✓p(x,h(1))
q(h(1)|x)
◆(7)
=X
h(1)
q(h(1)|x) log p(x,h(1)) (8)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (9)
(10)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(11)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (12)
(13)
•
log p(x) �X
h(1)
q(h(1)|x) log p(x,h(1)) (14)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (15)
(16)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
•
log p(x) = logX
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x,h(1))
q(h(1)|x)
!(6)
�X
h(1)
q(h(1)|x) log✓p(x,h(1))
q(h(1)|x)
◆(7)
=X
h(1)
q(h(1)|x) log p(x,h(1)) (8)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (9)
(10)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(11)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (12)
(13)
•
log p(x) �X
h(1)
q(h(1)|x) log p(x,h(1)) (14)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (15)
(16)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
where is any approximation to
•
log p(x) = logX
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
2
•
log p(x) = logX
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
2

Variational Bound • This is called a variational bound
13
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x,h(1))
q(h(1)|x)
!(6)
�X
h(1)
q(h(1)|x) log✓p(x,h(1))
q(h(1)|x)
◆(7)
=X
h(1)
q(h(1)|x) log p(x,h(1)) (8)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (9)
(10)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(11)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (12)
(13)
•
log p(x) �X
h(1)
q(h(1)|x) log p(x,h(1)) (14)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (15)
(16)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
Ø if is equal to the true conditional , then we
have an equality – the bound is tight!
Ø the more is different from the less tight the bound is.
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2

Variational Bound • This is called a variational bound
Ø In fact, difference between the left and right terms is the KL
divergence between and :
14
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x,h(1))
q(h(1)|x)
!(6)
�X
h(1)
q(h(1)|x) log✓p(x,h(1))
q(h(1)|x)
◆(7)
=X
h(1)
q(h(1)|x) log p(x,h(1)) (8)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (9)
(10)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(11)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (12)
(13)
•
log p(x) �X
h(1)
q(h(1)|x) log p(x,h(1)) (14)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (15)
(16)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
2

Variational Bound • This is called a variational bound
15
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
Ø for a single hidden layer DBN (i.e. an RBM), both the likelihood
and the prior depend on the parameters of
the first layer.
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
Ø we can now improve the model by building a better prior
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2

Variational Bound • This is called a variational bound
16
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
• When adding a second layer, we model using a separate set of parameters
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
Ø they are the parameters of the RBM involving and
Ø is now the marginalization of the second hidden layer
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
2
adding2ndlayermeansuntyingtheparameters

Variational Bound • This is called a variational bound
17
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
adding2ndlayermeansuntyingtheparameters
Ø we can train the parameters of the new second layer by maximizing the bound. This is equivalent to minimizing the following, since the other terms are constant:
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
• KL(q||p) =P
h(1) q(h(1)|x) log⇣
q(h(1)|x)p(h(1)|x)
⌘
• p(x|h(1)) p(h(1)) h(1) h(2) p(h(1)) =P
h(2) p(h(1),h(2))
•
�X
h(1)
q(h(1)|x) log p(h(1)) (9)
2
Ø this is like training an RBM on data generated from !
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
Layerwisepretrainingimprovesvariationallowerbound

Variational Bound • This is called a variational bound
18
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
adding2ndlayermeansuntyingtheparameters
Ø for we use the posterior of the first layer RBM. This is
equivalent to a feed-forward (sigmoidal) layer, followed by sampling
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
Ø by initializing the weights of the second layer RBM as the transpose
of the first layer weights, the bound is initially tight!
Ø a 2-layer DBN with tied weights is equivalent to a 1-layer RBM

Layer-wisePretraining• This is where the RBM stacking procedure comes from:
19
Ø idea: improve prior on last layer by
adding another hidden layer
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
1
Deep learning
Hugo Larochelle
Departement d’informatique
Universite de Sherbrooke
October 25, 2012
Abstract
Math for my slides “Deep learning”.
• x h(1) h(2) h(3)
• p(h(2),h(3))
• p(xi = 1|h(1)) = sigm(b(0) +W(1)>h(1))
• p(h(1)j = 1|h(2)) = sigm(b(1) +W(2)>h(2))
• p(x,h(1),h(2),h(3)) = p(h(2),h(3)) p(h(1)|h(2)) p(x|h(1))
• p(h(2),h(3)) = exp⇣h(2)>W(3)h(3) + b(2)>h(2) + b(3)>h(3)
⌘/Z
• p(h(1)|h(2)) =Q
j p(h(1)j |h(2))
• p(x|h(1)) =Q
i p(xi|h(1))
• p(x) =P
h(1) p(x,h(1))
• p(x,h(1)) = p(x|h(1))P
h(2) p(h(1),h(2))
• p(h(1),h(2)) = p(h(1)|h(2))P
h(3) p(h(2),h(3))
1

DeepBeliefNetworkGenerativeProcess
ApproximateInference
v
h2
h1
h3
W1
W3
W2

DBNLayer-wiseTraining• LearnanRBMwithaninputlayerv=xandahiddenlayerh.
h
v
W1

DBNLayer-wiseTraining
h1
h2
v
W1
W1⊤
• LearnanRBMwithaninputlayerv=xandahiddenlayerh.
• Treatinferredvalues asthedata
fortraining2nd-layerRBM.
• Learnandfreeze2ndlayerRBM.

DBNLayer-wiseTraining
v
h2
h1
h3
W1
W3
W2
• Proceedtothenextlayer.
• LearnanRBMwithaninputlayerv=xandahiddenlayerh.
• Learnandfreeze2ndlayerRBM.
• Treatinferredvalues asthedata
fortraining2nd-layerRBM.
UnsupervisedFeatureLearning.

DBNLayer-wiseTraining
v
h2
h1
h3
W1
W3
W2
• Proceedtothenextlayer.
• LearnanRBMwithaninputlayerv=xandahiddenlayerh.
• Learnandfreeze2ndlayerRBM.
• Treatinferredvalues asthedata
fortraining2nd-layerRBM.
UnsupervisedFeatureLearning.
Layerwisepretrainingimprovesvariationallowerbound

Deep Belief Networks • This process of adding layers can be repeated recursively
Ø we obtain the greedy layer-wise pre-training procedure for neural
networks
25
• We now see that this procedure corresponds to maximizing a bound on the likelihood of the data in a DBN
Ø in theory, if our approximation is very far from the true
posterior, the bound might be very loose
Ø this only means we might not be improving the true likelihood Ø we might still be extracting better features!
•
log p(x) = log
X
h(1)
q(h(1)|x)p(x|h(1))p(h(1))
q(h(1)|x)
!(1)
�X
h(1)
q(h(1)|x) log✓p(x|h(1))p(h(1))
q(h(1)|x)
◆(2)
=X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(3)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (4)
(5)
• h(1) q(h(1)|x) p(h(1)|x)
•
log p(x) �X
h(1)
q(h(1)|x)⇣log p(x|h(1)) + log p(h(1))
⌘(6)
�X
h(1)
q(h(1)|x) log q(h(1)|x) (7)
(8)
2
• Fine-tuning is done by the Up-Down algorithm Ø A fast learning algorithm for deep belief nets. Hinton, Teh,
Osindero, 2006.

SupervisedLearningwithDBNs• Ifwehaveaccesstolabelinformation,wecantrainthejointgenerativemodelbymaximizingthejointlog-likelihoodofdataandlabels
v
h2
h1
h3
W1
W3
W2labely
• Discriminativefine-tuning:
• UseDBNtoinitializeamultilayerneuralnetwork.
• Maximizetheconditionaldistribution:

...h2 ∼ P(h2,h3)
h1 ∼ P(h1|h2)
v ∼ P(v|h1)
h3 ∼ Q(h3|h2)
h2 ∼ Q(h2|h1)
h1 ∼ Q(h1|v)
v
h3 ∼ Q(h3|v)
h2 ∼ Q(h2|v)
h1 ∼ Q(h1|v)
v
SamplingfromDBNs• TosamplefromtheDBNmodel:
• Sampleh2usingalternatingGibbssamplingfromRBM.• Samplelowerlayersusingsigmoidbeliefnetwork.
v
h2
h1
h3
W1
W3
W2
Gibbschain

LearnedFeatures

LearningPart-basedRepresentationConvolutionalDBN
Faces
v
h2
h1
h3
W1
W3
W2
Trainedonfaceimages.
ObjectParts
Groupsofparts.
Leeet.al.,ICML2009

LearningPart-basedRepresentationFaces Cars Elephants Chairs
Leeet.al.,ICML2009

LearningPart-basedRepresentation
Trainedfrommultipleclasses(cars,faces,motorbikes,airplanes).
Class-specificobjectparts
Groupsofparts.
Leeet.al.,ICML2009

DBNsforClassification
• Afterlayer-by-layerunsupervisedpretraining,discriminativefine-tuningbybackpropagationachievesanerrorrateof1.2%onMNIST.SVM’sget1.4%andrandomlyinitializedbackpropgets1.6%.
• Clearlyunsupervisedlearninghelpsgeneralization.Itensuresthatmostoftheinformationintheweightscomesfrommodelingtheinputdata.
(Hinton and Salakhutdinov, Science 2006)
W +εW
W
W
W +ε
W +ε
W +ε
W
W
W
W
1 11
500 500
500
2000
500
500
2000
5002
500
RBM
500
20003
Pretraining Unrolling Fine−tuning
4 4
2 2
3 3
1
2
3
4
RBM
10
Softmax Output
10RBM
T
T
T
T
T
T
T
T

DBNsforRegressionPredictingtheorientationofafacepatch
TrainingData:1000facepatchesof30trainingpeople.
RegressionTask:predictorientationofanewface.
TestData:1000facepatchesof10newpeople.
GaussianProcesseswithsphericalGaussiankernelachievesaRMSE(rootmeansquarederror)of16.33degree.
(Salakhutdinov and Hinton, NIPS 2007)

DBNsforRegression
• PretrainastackofRBMs:784-1000-1000-1000.
AdditionalUnlabeledTrainingData:12000facepatchesfrom30trainingpeople.
• Featureswereextractedwithnoideaofthefinaltask.
GPwithfine-tunedcovarianceGaussiankernel: RMSE:6.42ThesameGPonthetop-levelfeatures: RMSE:11.22
StandardGPwithoutusingDBNs: RMSE:16.33
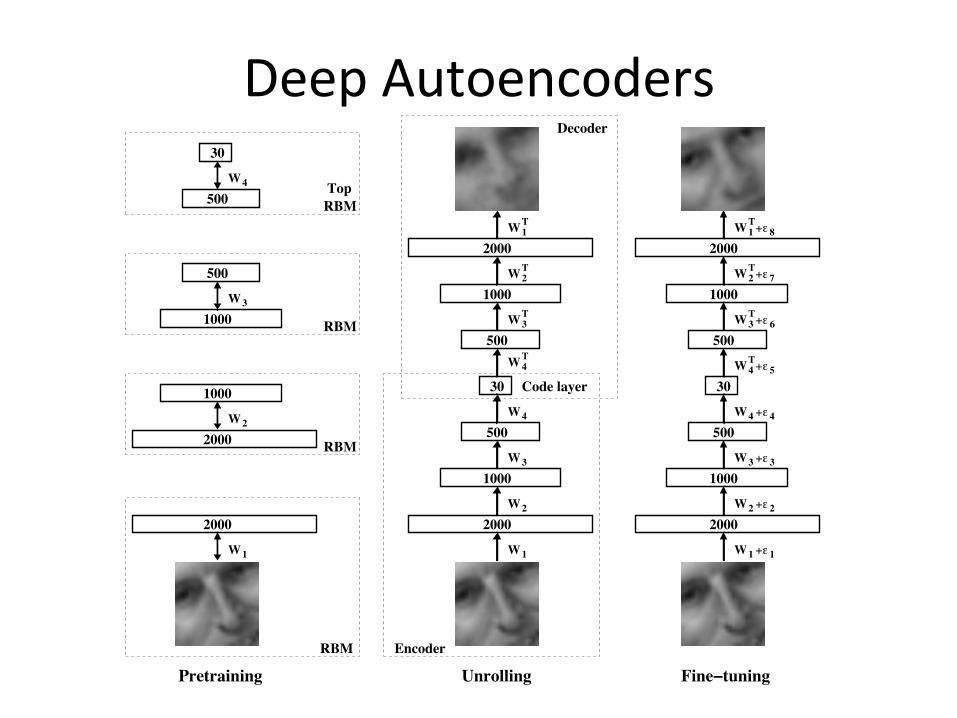
DeepAutoencoders
W
W
W +�
W
W
W
W
W +�
W +�
W +�
W
W +�
W +�
W +�
+�
W
W
W
W
W
W
1
2000
RBM
2
2000
1000
500
500
1000
1000
500
1 1
2000
2000
500500
1000
1000
2000
500
2000
T
4T
RBM
Pretraining Unrolling
1000 RBM
3
4
30
30
Fine�tuning
4 4
2 2
3 3
4T
5
3T
6
2T
7
1T
8
Encoder
1
2
3
30
4
3
2T
1T
Code layer
Decoder
RBMTop

DeepAutoencoders• Weused25x25–2000–1000–500–30autoencodertoextract30-Dreal-valuedcodesforOlivettifacepatches.
• Top:Randomsamplesfromthetestdataset.• Middle:Reconstructionsbythe30-dimensionaldeepautoencoder.
• Bottom:Reconstructionsbythe30-dimentinoalPCA.

InformationRetrieval2-DLSAspace
Legal/JudicialLeading Economic Indicators
European Community Monetary/Economic
Accounts/Earnings
Interbank Markets
Government Borrowings
Disasters and Accidents
Energy Markets
• TheReutersCorpusVolumeIIcontains804,414newswirestories(randomlysplitinto402,207trainingand402,207test).
• “Bag-of-words”representation:eacharticleisrepresentedasavectorcontainingthecountsofthemostfrequentlyused2000wordsinthetrainingset.
(Hinton and Salakhutdinov, Science 2006)





























