Embed Size (px)
Citation preview

1
XQuery to XAT
Xin Zhang

2
Outline XAT Data Model. XAT Operator Design. XQuery Block Identification. Equivalent Rewriting Rules.
Computation Pushdown Navigation Pushdown Groupby Operator Simplification

3
Data Model An Ordered Table in two dimensions
Tuple order Column order.
Every cell has its own domain, e.g.: SQL domains. XML Fragment.
Can be a list of XML elements. Every column binds to one variable. Comparison are done by values
Note: When values are “handles”, the comparison are done by deference of handles.
4
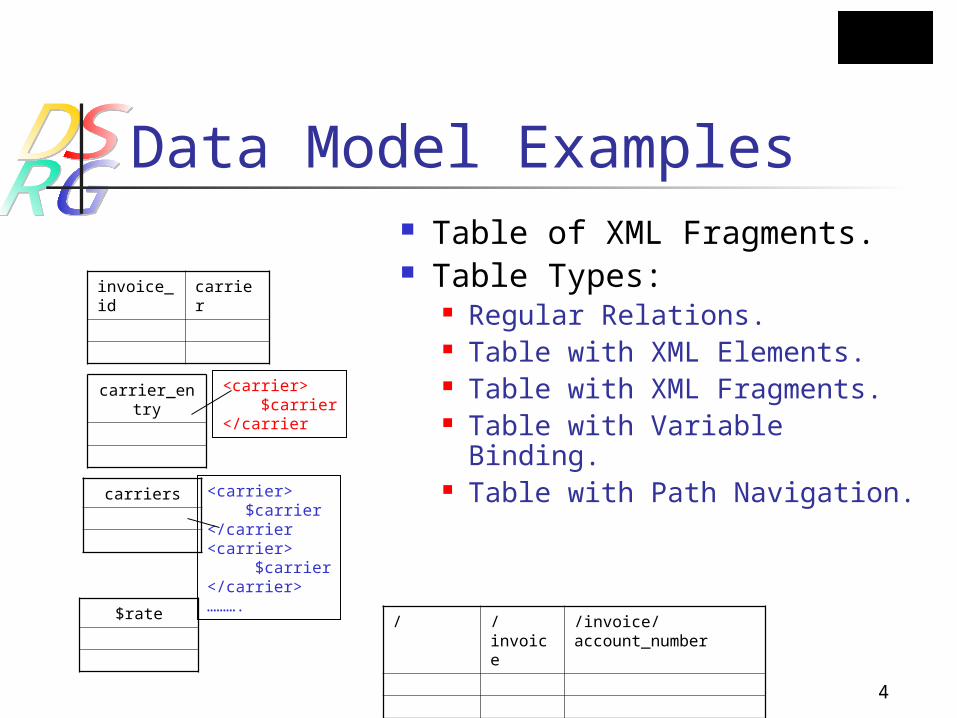
Data Model Examples Table of XML Fragments. Table Types:
Regular Relations. Table with XML Elements. Table with XML Fragments. Table with Variable Binding. Table with Path Navigation.
<carrier> $carrier</carrier
invoice_id
carrier
carrier_entry
carriers <carrier> $carrier</carrier<carrier> $carrier</carrier>……….
/ /invoice /invoice/account_number
$rate

5
Column Names A String:
“name” A Variable Binding:
“$var” Operators with their parameters:
“op(p1, p2, ..., pn)”
A XPath with Entry Point Notation. “/”, “/invoice”, “/invoice/book” “invoice:/”, “book:invoice:/”

6
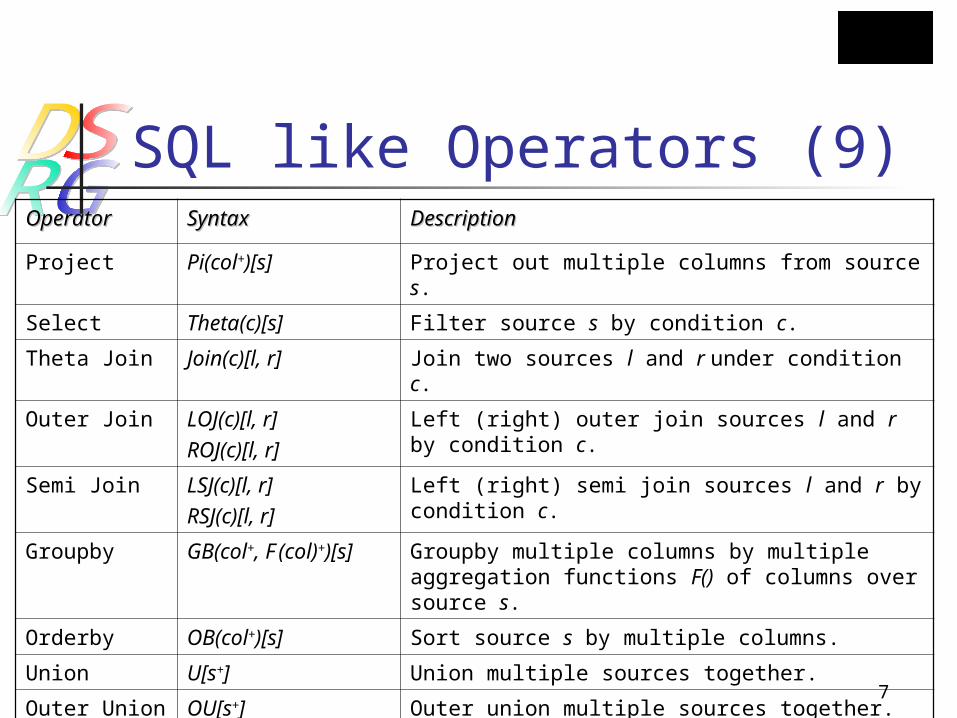
Operators SQL like (9):
Project, Select, Join (Theta, Outer, Semi), Groupby, Orderby, Union (Node, Outer), CO
XML like (3): Tagger Navigate Aggregate: Groupby without by-column.
Special (5): SQL, Function, Source, Name, FOR
7
SQL like Operators (9)OperatorOperator SyntaxSyntax DescriptionDescription
Project Pi(col+)[s] Project out multiple columns from source s.
Select Theta(c)[s] Filter source s by condition c.
Theta Join Join(c)[l, r] Join two sources l and r under condition c.
Outer Join LOJ(c)[l, r]ROJ(c)[l, r]
Left (right) outer join sources l and r by condition c.
Semi Join LSJ(c)[l, r]RSJ(c)[l, r]
Left (right) semi join sources l and r by condition c.
Groupby GB(col+, F (col)+)[s] Groupby multiple columns by multiple aggregation functions F() of columns over source s.
Orderby OB(col+)[s] Sort source s by multiple columns.
Union U[s+] Union multiple sources together.
Outer Union OU[s+] Outer union multiple sources together.
COp COp(col+, Op)[s1, s2]
Correlated Operator on columns col+. s1 is outer query, s2 is inner query.

8
XML like Operators
OperatorOperator SyntaxSyntax DescriptionDescription
Tagger Tag(p)[s] Taggering source s by pattern p.
Navigate Nav(path)[s] Navigate from source s through a XPath.
Aggregate Agg(F (col)+)[s]
Aggregate source s by multiple aggregate functions F() of columsn over source s.

9
Special Operators
OperatoOperatorr
ParametersParameters DescriptionDescription
SQL SQL(stmt)[s+] One SQL query statement stmt over multiple sources.
Function F(param+)[s+] User defined function over multiple sources with multiple parameters.
Source s(desc) Identify a data source by description desc.
Name Rho(col1, col2)[s]
Rho(s2)[s1]
Rename column col1 of source s into name col2.
Rename source s1 into s2.
FOR FOR(col+)[s1, s2] FOR operator iterate over sources s1 and execute subquery s2 with variable binding columns col1..n.

10
Project Pi(col1..n)[s] Input:
table s Output:
table s Logic:
Same as SQL. Order Handling:
Keep original tuple order, the schema order is reordered as the col1..n in the project operator.
Requirement: The col1..n should be in source s.

11
Select Theta(c)[s] Input:
table s Output:
table s Logic:
Same as SQL. Order Handling:
Keep original tuple order, keep original schema order. Requirement:
Condition c should be only reference to the source s.

12
Theta Join Join(c)[l, r] Input:
table l, and table r. Output:
One table (with temporary table name) Logic:
Same as SQL. Order Handling:
The schema order of the output table is columns of table l followed by the columns of table r.
The tuple order of the output table is iteration of tuples in r over the iteration of tuples in l, e.g., {<l1, r1>, <l1, r2>, <l2, r1>, <l2, r2>}
Requirement: Condition c should be relates to both tables l and r.

13
Outer Join LOJ(c)[l, r] Input:
table l, and table r. Output:
One table (with temporary table name) Logic:
Same as SQL. Order Handling:
The schema order of the output table is columns of table l followed by the columns of table r.
The tuple order of the output table is iteration of tuples in r over the iteration of tuples in l, e.g., {<l1, r1>, <l1, r2>, <l2, null>, <l3, r1>, <l3, r3>}
Requirement: Condition c should be relates to both tables l and r.

14
Outer Join ROJ(c)[l, r] Input:
table l, and table r. Output:
One table (with temporary table name) Logic:
Same as SQL. (Similar to LOJ) Order Handling:
The schema order of the output table is columns of table l followed by the columns of table r.
The tuple order of the output table is iteration of tuples in l over the iteration of tuples in r, e.g.,{<null, r1>, <null, r2>, <l1, r1>, <l1, r2>, <l2, r1>, <l2, r3>}, “null” is at the beginning of the output.
Requirement: Condition c should be relates to both tables l and r.

15
Semi Join LSJ(c)[l, r] Input:
table l, and table r. Output:
table l. Logic:
Same as SQL. Order Handling:
The schema order of the output table same as table l. The tuple order of the output table is same as table l.
Requirement: Condition c should be relates to both tables l and r.

16
Semi Join RSJ(c)[l, r] Input:
table l, and table r. Output:
table r. Logic:
Same as SQL. Order Handling:
The schema order of the output table same as table r. The tuple order of the output table is same as table r.
Requirement: Condition c should be relates to both tables l and r.

17
Groupby GB(col1..n, F1..m(col))[s] Input:
table s. Output:
table s. Logic:
Same as SQL. Order Handling:
The schema order of the output table is col1..n followed by F1..m(col). F1..m(col) can be nested operators, e.g., a subquery.
The tuple order of the output table is same as table s. Requirement:
col1..n and all the col in the F1..m should be in table s.

18
Groupby Example Input:
S (a, b, c) Operator:
GB (b, a, avg(c), count(c)) Output:
S (b, a, “avg(c)”, “count(c)”)

19
Orderby OB(col1..n)[s] Input:
table s. Output:
table s. Logic:
Same as SQL. Order Handling:
The schema order of the output table is same as table s.
The tuple order of the output table is as specified. Requirement:
col1..n should be in table s.

20
Union U[s1..n] Input:
Multiple tables s1..n.
Output: One table (with temporary name).
Logic: Same as SQL.
Order Handling: The schema order of the output table is same as table s1. The tuple order of the output table is in the order of table
s1..n.
Requirement: All tables s1..n have same schema.

21
Outer Union OU[s1..n] Input:
Multiple tables s1..n. Output:
One table (with temporary name). Logic:
Same as SQL. Order Handling:
The schema order of the output table is un-decidable, it depends on implementation. The schema order should be ensured by another projection node.
The tuple order of the output table is in the order of table s1..n.
Requirement: N/A.

22
Tagger Tag(p)[s] Input:
Table s. Output:
Table s. Logic:
One additional column is added with tagged information. Pattern p is only one level.
Order Handling: The tagged column is added to the end. The tuple order of the output table is same as table s.
Requirement: The columns used in pattern p should be in table s.

23
Navigate Nav(path)[s] Input:
Table s. Output:
Table s. Logic:
One additional column is added with navigation information. Tuples are multiplied if there are more than one results in the
navigation. If the navigation result is empty, put NULL in the new column.
Order Handling: The navigation column is added to the end. The tuple order of the output table is same as table s and the
navigation order. Requirement:
N/A

24
Aggregate Agg(F1..m(col))[s] Input:
table s. Output:
table s. Logic:
Merge all tuples in that table into one, and apply functions on those columns.
If there is no functions, then just merge all the content. Order Handling:
The schema order of the output table is F1..m(col). There is only one tuple.
Requirement: All the col in the F1..m should be in table s.

25
SQL SQL(stmt)[s1..n] Input:
Multiple tables s1..n. Output:
Temporary table. Logic:
Execute stmt over the multiple tables and output the result. It is assumed to be executed by a RDB engine. Usually, it’s the operator right above the source (e.g., table) operator.
Order Handling: The schema order of the output table is depends on the underlying
implementation. The schema order can be reconfirmed by additional projection node.
The tuple order is un-decidable. The tuple order can be reconfirmed by additional orderby node.
Requirement: N/A.

26
Function F(param1..m)[s1..n] Input:
Multiple tables s1..n. Output:
Temporary table. Logic:
Execute some user defined function on the data sources. Or used to represent a recursive query.
Order Handling: Schema and tuple orders are depends on the
implementation. They can be reconfirmed by projection and orderby nodes.
Requirement: N/A.

27
Source s(desc) Input:
N/A Output:
A table with a given name. Logic:
Identify following sources: view, xml document, or a table. Order Handling:
Depends on the implementation. Keep original schema and tuple order as much as possible.
Requirement: N/A.

28
Name Rho(col1, col2)[s] Input:
Table s. Output:
Table s. Logic:
Rename col1 in table s into col2. Order Handling:
Keep all the schema and tuple orders. Requirement:
Col1 in table s.

29
Name Rho(s2)[s1] Input:
Table s1. Output:
Table s2. Logic:
Rename table s1 to table s2. Order Handling:
Keep all the schema and tuple orders. Requirement:
N/A.

30
Correlated OuputFOR(col+)[s1, s2] Input:
Tables s1 and s2.
Output: Evaluation of subquery s2
for each tuple in subquery s1..
Logic: It’s a FOR iteration operator. For value in the columns col+ of
table s1, evaluate the sub-query that generates the table s2.
Order Handling: Schema order is output table s2. Tuple order is similar to the join operator without the left
part. Requirement:
N/A.

31
Steps in Translation XQuery XML Algebra Tree User View XML Algebra Tree View Composition Computation Pushdown Optimization Execution

32
<?xml version=”1.0” encoding=”US-ASCII” ?> <!DOCTYPE invoice [<!ELEMENT invoice (account_number,
bill_period, carrier+, itemized_call*, total)>
<!ELEMENT account_number (#PCDATA)><!ELEMENT bill_period (#PCDATA)><!ELEMENT carrier (#PCDATA)><!ELEMENT itemized_call EMPTY><!ATTLIST itemized_call
no ID #REQUIREDdate CDATA #REQUIREDnumber_called CDATA #REQUIREDtime CDATA #REQUIREDrate (NIGHT|DAY) #REQUIREDmin CDATA #REQUIREDamount CDATA #REQUIRED>
<!ELEMENT total (#PCDATA)>]>
<invoice>
<account_number>555 777-3158 573 234 3</account_number>
<bill_period>Jun 9 - Jul 8, 2000</bill_period>
<carrier>Sprint</carrier>
<itemized_call no=”1” date=”JUN 10” number_called=”973 555-8888” time=”10:17pm” rate=”NIGHT” min=”1” amount=”0.05” />
<itemized_call no=”2” date=”JUN 13” number_called=”973 650-2222” time=”10:19pm” rate=”DAY” min=”1” amount=”0.15” />
<itemized_call no=”3” date=”JUN 15” number_called=”206 365-9999” time=”10:25pm” rate=”NIGHT” min=”3” amount=”0.15” />
<total>$0.35</total>
</invoice>
Example of Telephone Bill

33
Example XQueryUser XQuery: <summary>{
FOR $rate IN distinct(document(“invoice”)/invoice/itemized_call@rate)
LET $itemized_call := document(“invoice”)/invoice/itemized_call[@rate=$rate]
WHERE $itemized_call/@number_called LIKE ‘973%’
RETURN<rate>$rate</rate><number_of_calls>count($itemized_call)</number_of_calls>
}</summary>
Count number of itemized_calls in calling area 973 grouped by the calling rate.

34
XQuery XML Algebra Tree Translate XQuery into XAT by
grammar. Convert each query block into XAT. Identify correlated operators. Identify query blocks. Query decorrelation.

35
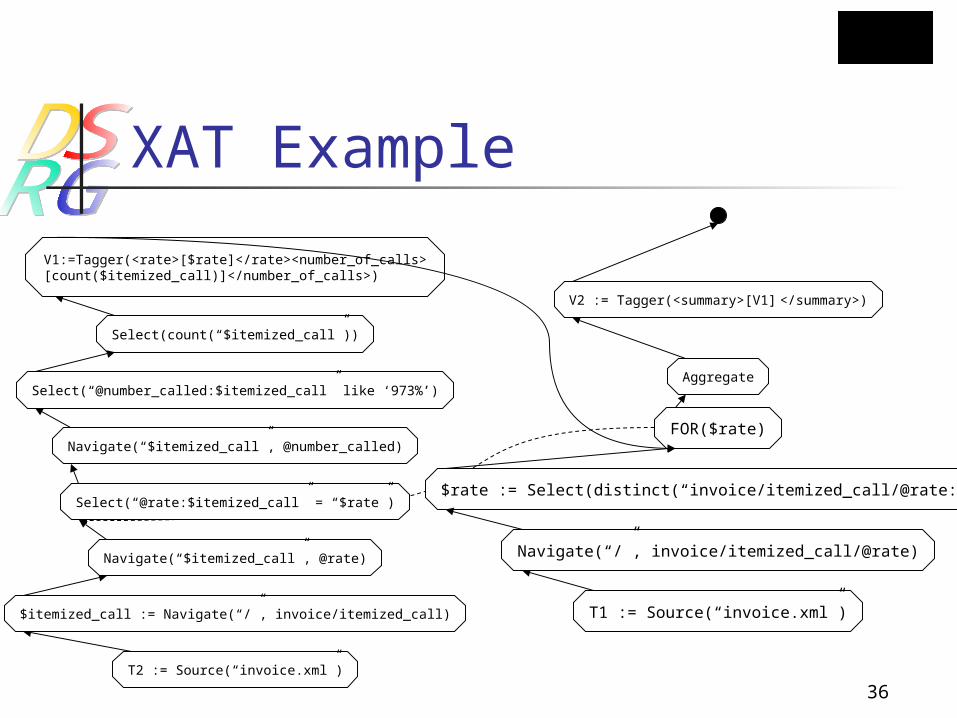
XAT Graph Notation
Unordered Graph. Nodes:
Operators with its parameters. If there is only one source name,
we ignore it. Blocks (subqueries)
We can use block name as the alias of the table name out of that block.
Terminals
V3:=Tagger(<summary>[V2] </summary>)
B2
36
XAT Example
Select(count(“$itemized_call”))
Navigate(“$itemized_call”, @number_called)
Select(“@number_called:$itemized_call” like ‘973%’)
T2 := Source(“invoice.xml”)
$itemized_call := Navigate(“/”, invoice/itemized_call)
Select(“@rate:$itemized_call” = “$rate”)
V2 := Tagger(<summary>[V1] </summary>)
$rate := Select(distinct(“invoice/itemized_call/@rate:/”))
T1 := Source(“invoice.xml”)
Navigate(“/”, invoice/itemized_call/@rate)Navigate(“$itemized_call”, @rate)
FOR($rate)
Aggregate
V1:=Tagger(<rate>[$rate]</rate><number_of_calls>[count($itemized_call)]</number_of_calls>)

37
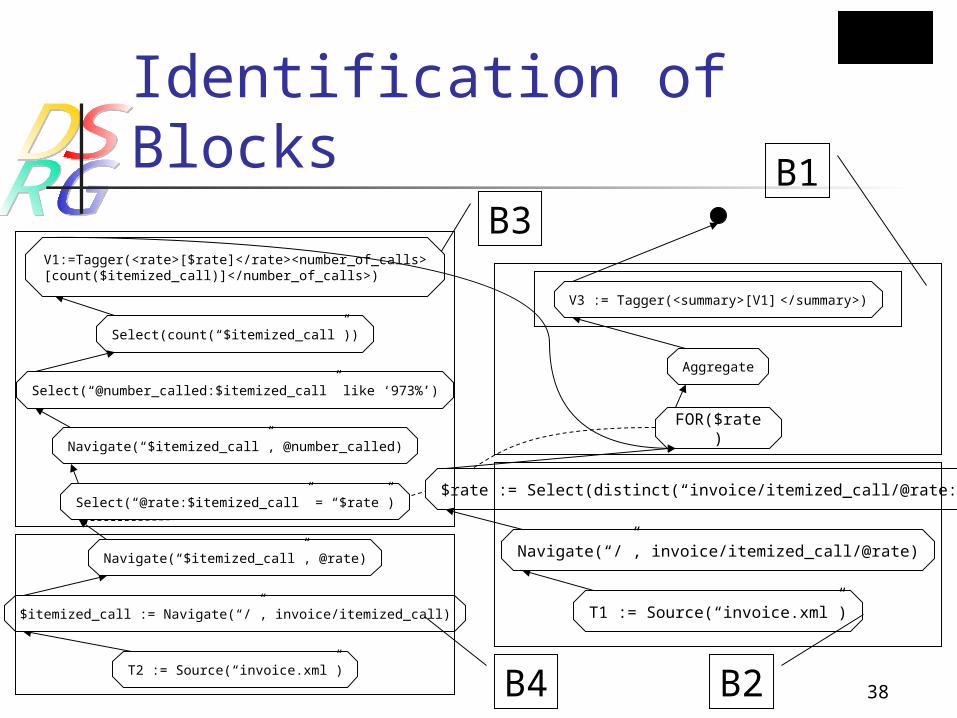
XQuery Block Identification Every query block has only one
input point and one output point. Potential Query Block Separation
Point: Independent sources. Correlated Operators.
Block is used for query optimization, e.g., cutting.
38
Identification of Blocks
Select(count(“$itemized_call”))
Navigate(“$itemized_call”, @number_called)
Select(“@number_called:$itemized_call” like ‘973%’)
T2 := Source(“invoice.xml”)
$itemized_call := Navigate(“/”, invoice/itemized_call)
Select(“@rate:$itemized_call” = “$rate”)
V3 := Tagger(<summary>[V1] </summary>)
$rate := Select(distinct(“invoice/itemized_call/@rate:/”))
T1 := Source(“invoice.xml”)
Navigate(“/”, invoice/itemized_call/@rate)Navigate(“$itemized_call”, @rate)
B1
B2
B3
FOR($rate)
Aggregate
V1:=Tagger(<rate>[$rate]</rate><number_of_calls>[count($itemized_call)]</number_of_calls>)
B4
39
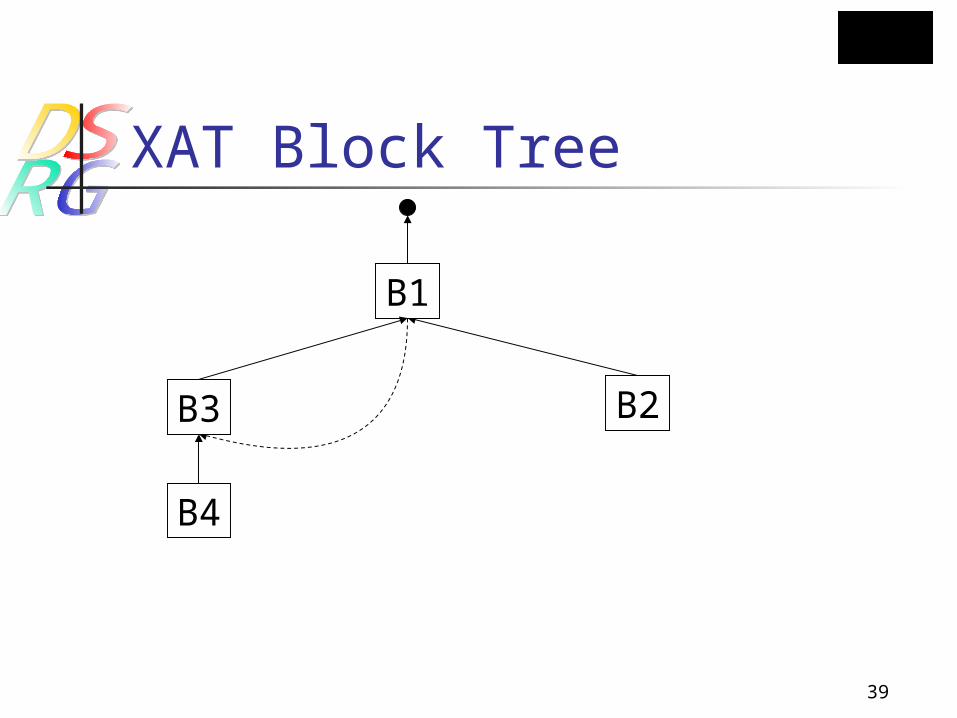
XAT Block Tree
B1
B2B3
B4

40
Equivalent Rewriting Rules Navigation Pushdown
Swap navigation operator down. Computation Pushdown
Swap SQL operator down. Groupby Operator Simplification
Pull functions (subqueries) out of Groupby function.


![Reachability in pushdown register automatawrap.warwick.ac.uk/86773/7/WRAP-reachability-pushdown... · 2017-08-04 · Higher-order pushdown automata [15] take the idea of pushdown](https://img.pdfslide.us/doc/110x75/5eb948d9ec26155c3310c6be/reachability-in-pushdown-register-2017-08-04-higher-order-pushdown-automata-15.jpg)


























