Embed Size (px)
Citation preview

1
Why and How to Build a Trusted Database System on Untrusted Storage?
Radek Vingralek
STAR Lab, InterTrust Technologies
In collaboration with U. Maheshwari and W. Shapiro

Stanford Database Seminar 2
What?
Trusted Storage
can be read and written only by trusted programs
Stanford Database Seminar 3
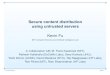
Why?
Digital Rights Management
content
contract
Stanford Database Seminar 4
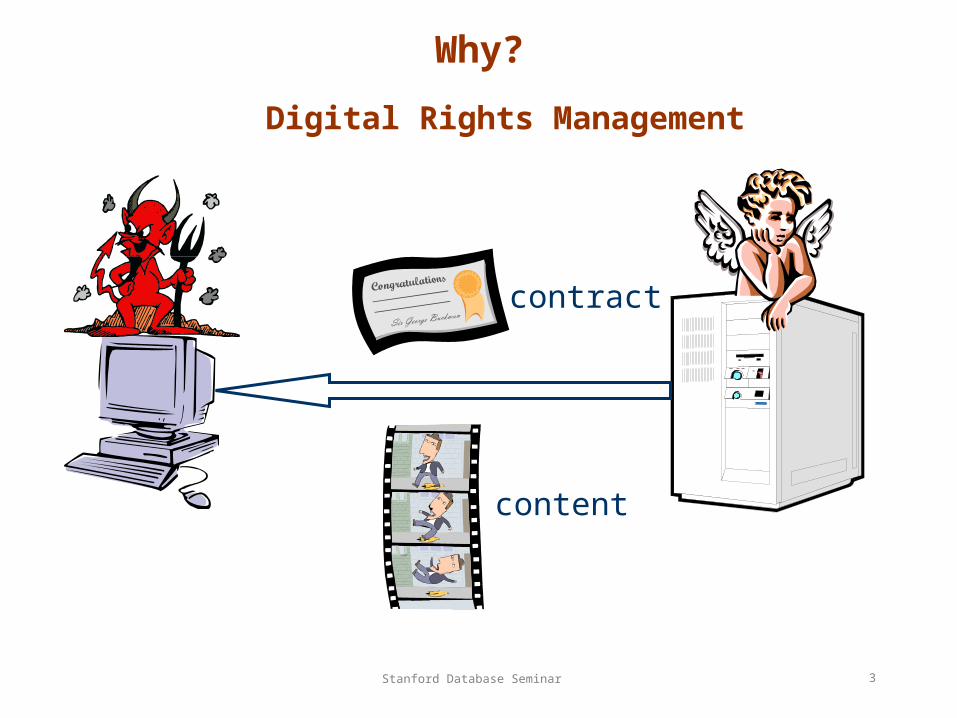
What? Revisited
processor
trusted storage
volatile memory
untrusted storage
<50B

Stanford Database Seminar 5
What? Refined
Must protect also against accidental data corruption
• atomic updates• efficient backups• type-safe interface• automatic index maintenance
Must run in an embedded environment
• small footprint
Must provide acceptable performance

Stanford Database Seminar 6
What? Refined
Can assume single-user workload
• none or a simple concurrency control• optimized for response time, not throughput• lots of idle time (can be used for database
reorganization)
Can assume a small database
• 100 KB to 10 MB• can cache the working set
– no-steal buffer management
Stanford Database Seminar 7
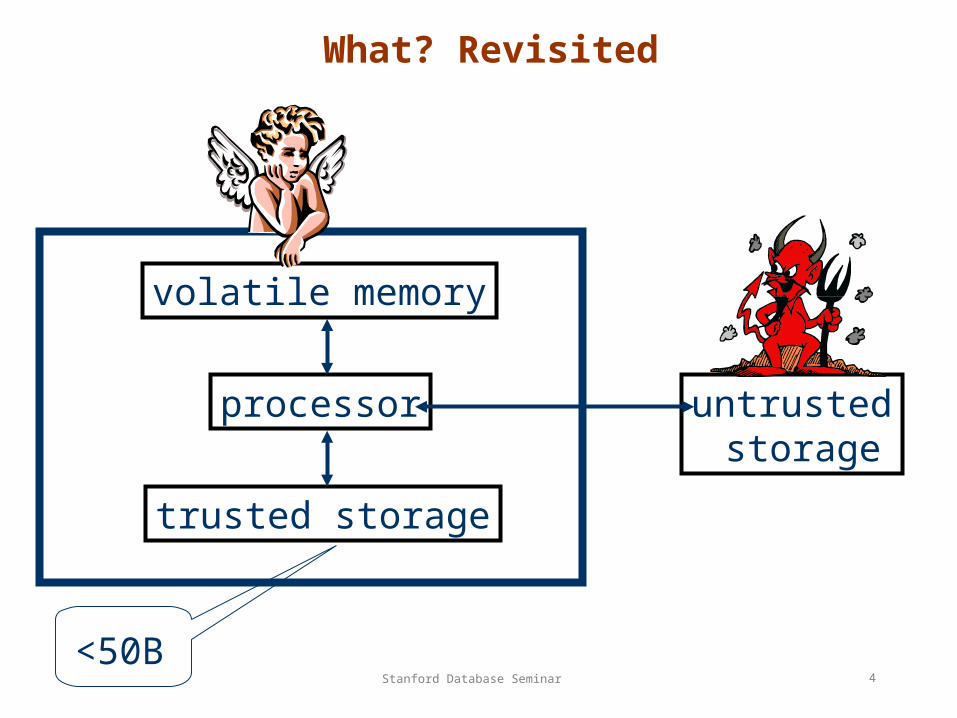
A Trivial Solution
Critique:
• does not protect metadata
• cannot use sorted indexes
untrusted storage
COTS dbms
encryption, hashingkey
H(db)
plaintext data
trusted storage
db
Stanford Database Seminar 8
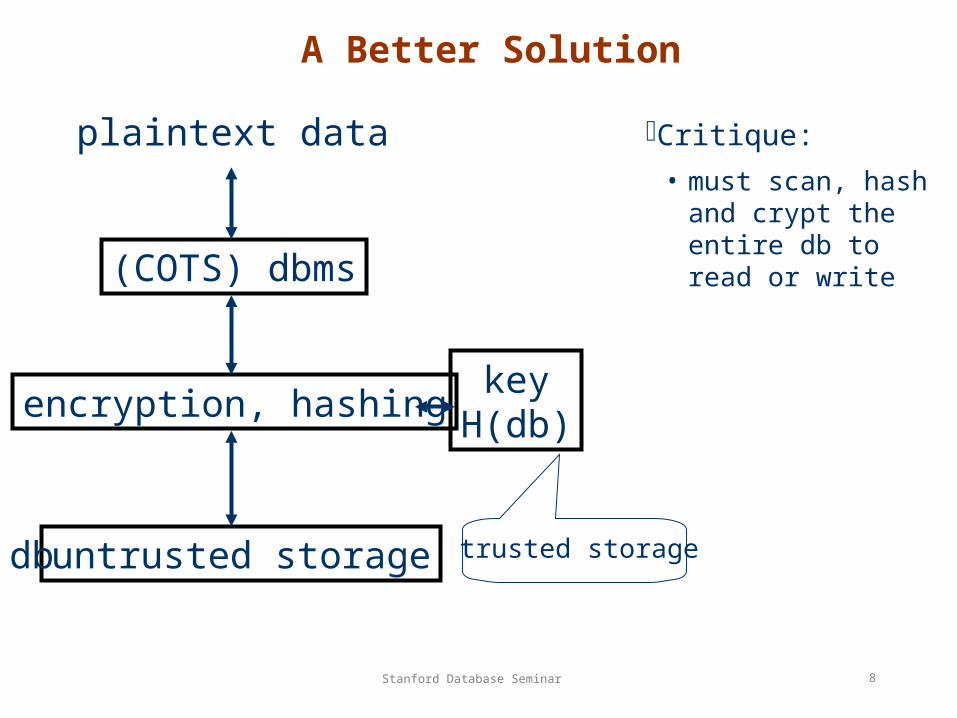
A Better Solution
Critique:
• must scan, hash and crypt the entire db to read or write
untrusted storage
(COTS) dbms
encryption, hashingkey
H(db)
plaintext data
trusted storagedb
Stanford Database Seminar 9
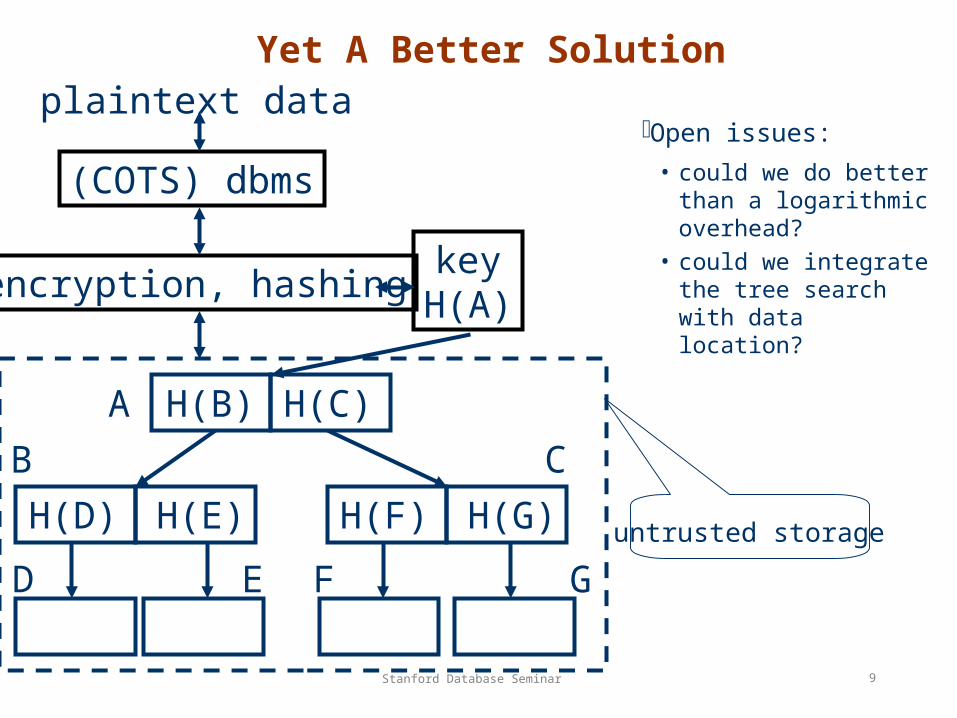
Yet A Better Solution
Open issues:
• could we do better than a logarithmic overhead?
• could we integrate the tree search with data location?
(COTS) dbms
encryption, hashingkeyH(A)
plaintext data
H(B) H(C)
H(D) H(E) H(F) H(G)
A
D
CB
E F Guntrusted storage
Stanford Database Seminar 10
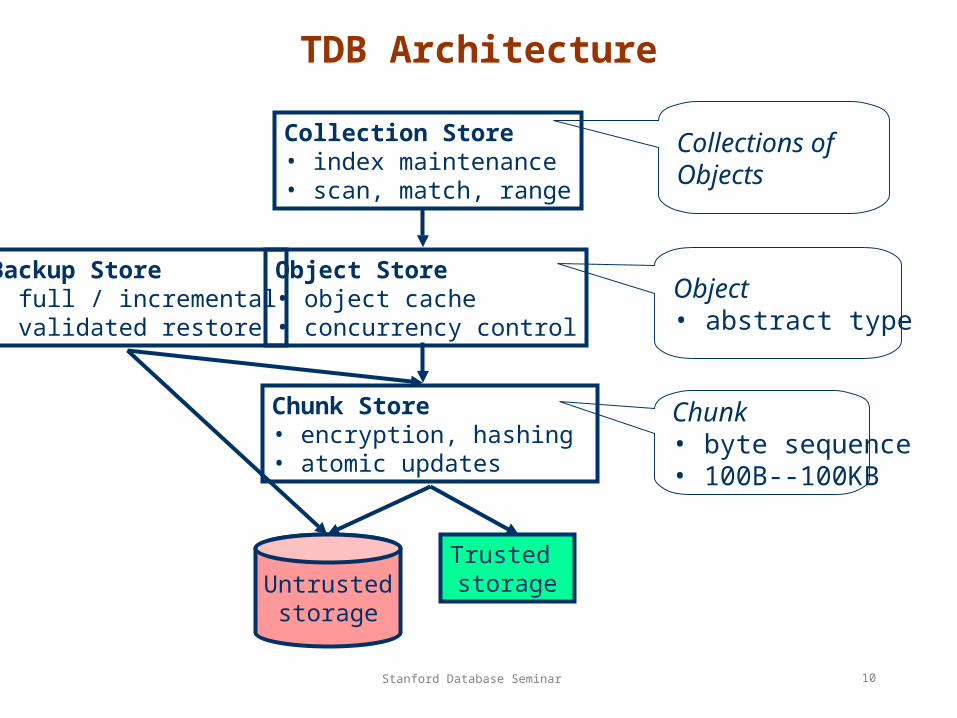
TDB Architecture
Trusted storageUntrusted
storage
Chunk Store• encryption, hashing • atomic updates
Object Store• object cache• concurrency control
Collection Store• index maintenance• scan, match, range
Chunk• byte sequence• 100B--100KB
Object• abstract type
Backup Store• full / incremental• validated restore
Collections of Objects

Stanford Database Seminar 11
Chunk Store - Specification
Interface• allocate() -> ChunkId• write( ChunkId, Buffer )• read( ChunkId ) -> Buffer• deallocate( ChunkId )
Crash atomicity• commit = [ write | deallocate ]*
Tamper detection
• raise an exception if chunk validation fails

Stanford Database Seminar 12
Chunk Store – Storage Organization
Log-structured Storage Organization
• no static representation of chunks outside of the log• log in the untrusted storage
Advantages
• traffic analysis cannot link updates to the same chunk• atomic updates for free• easily supports variable-sized chunks • copy-on-write snapshots for fast backups• integrates well with hash verification (see next slide)
Disadvantages
• destroys clustering (cacheable working set)• cleaning overhead (expect plenty of idle time)
Stanford Database Seminar 13
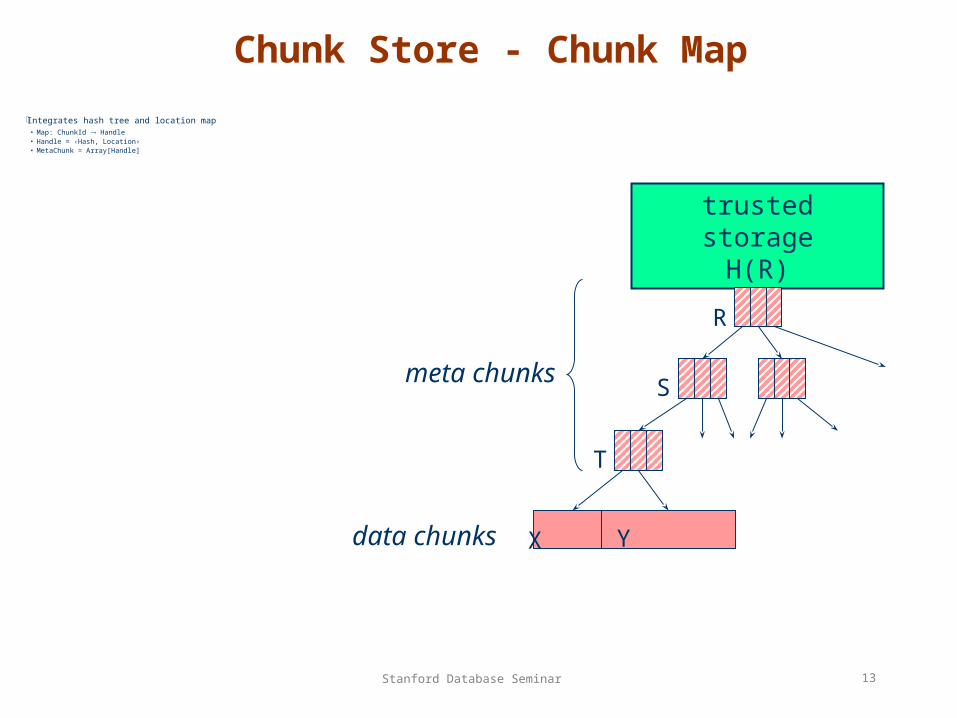
Chunk Store - Chunk Map
Integrates hash tree and location map• Map: ChunkId Handle• Handle = ‹Hash, Location›• MetaChunk = Array[Handle]
trusted storageH(R)
X Y
meta chunks
data chunks
T
S
R
Stanford Database Seminar 14
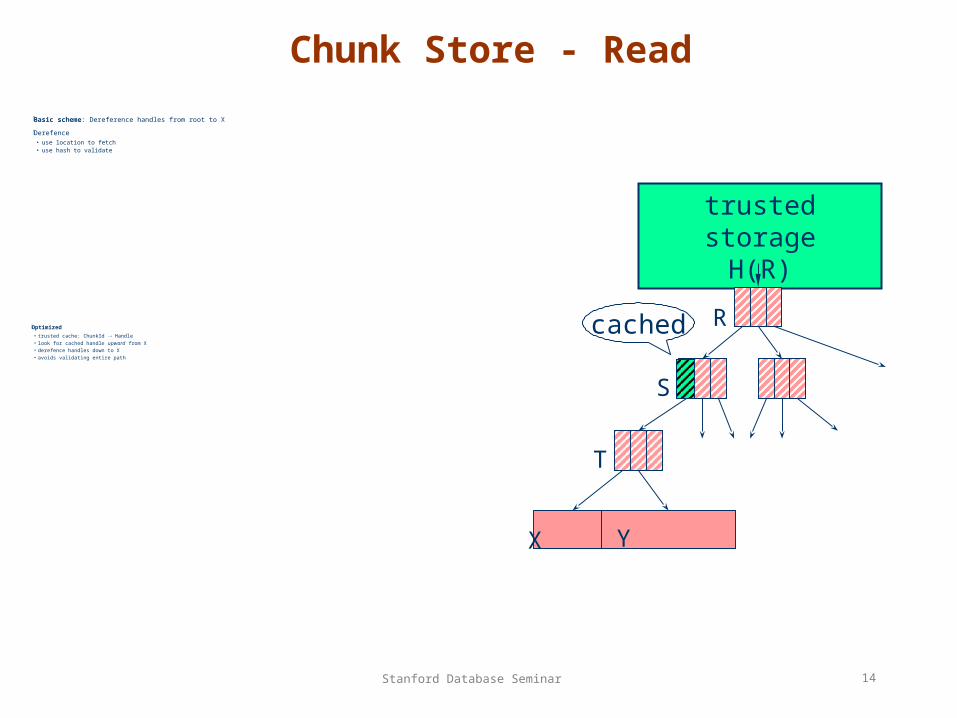
Chunk Store - Read
Basic scheme: Dereference handles from root to X
Derefence• use location to fetch• use hash to validate
trusted storageH(R)
X Y
T
S
RcachedOptimized• trusted cache: ChunkId Handle• look for cached handle upward from X• derefence handles down to X• avoids validating entire path
Stanford Database Seminar 15
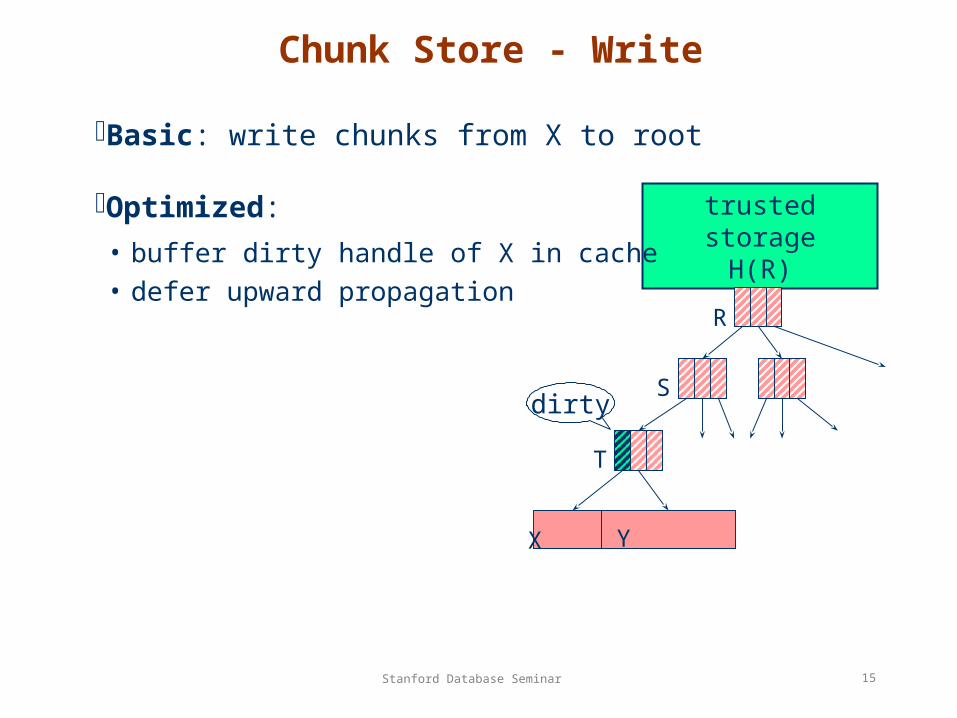
Chunk Store - Write
Basic: write chunks from X to root
trusted storageH(R)
X Y
T
S
R
dirty
Optimized:
• buffer dirty handle of X in cache • defer upward propagation
Stanford Database Seminar 16
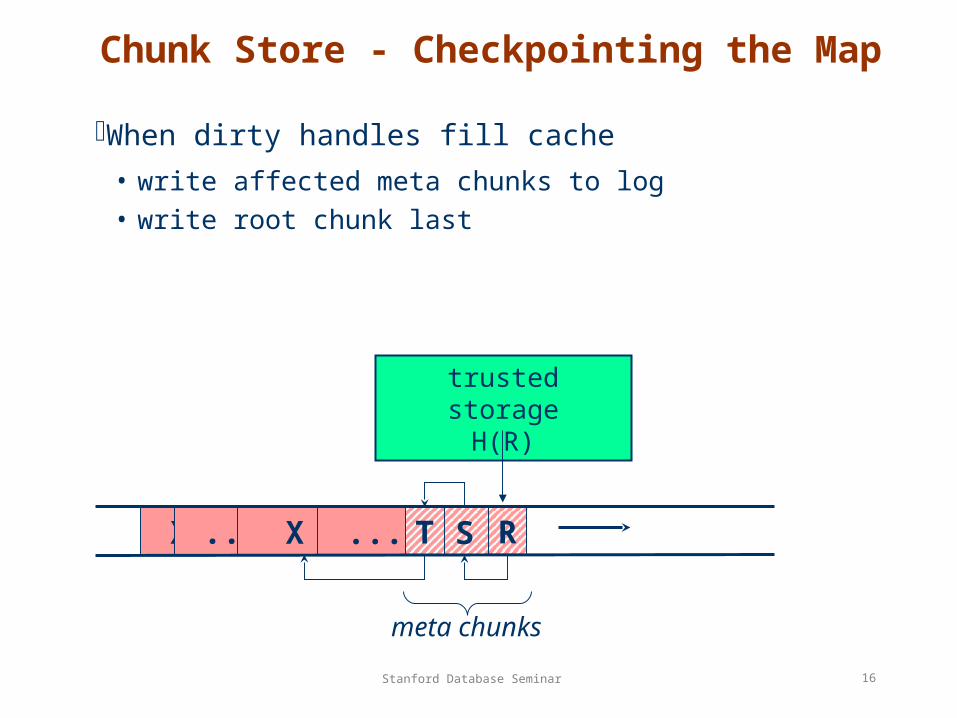
Chunk Store - Checkpointing the Map
When dirty handles fill cache
• write affected meta chunks to log• write root chunk last
X ... X ... S RT
meta chunks
trusted storageH(R)
Stanford Database Seminar 17
... Y ...
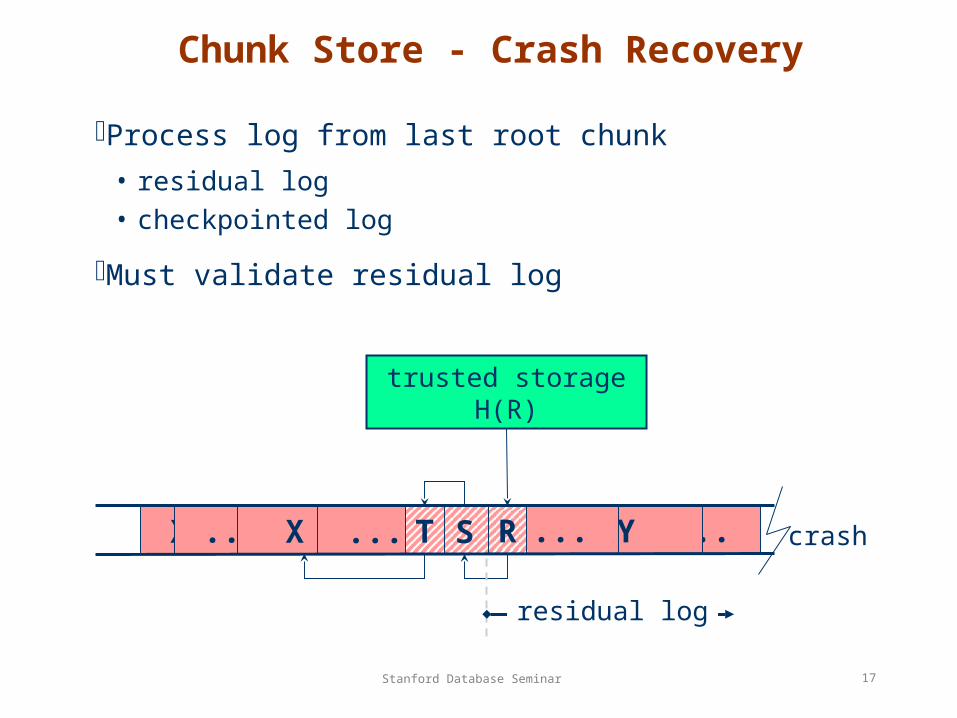
Chunk Store - Crash Recovery
Process log from last root chunk
• residual log• checkpointed log
Must validate residual log
crash X ... X ... S RT
trusted storageH(R)
residual log
Stanford Database Seminar 18
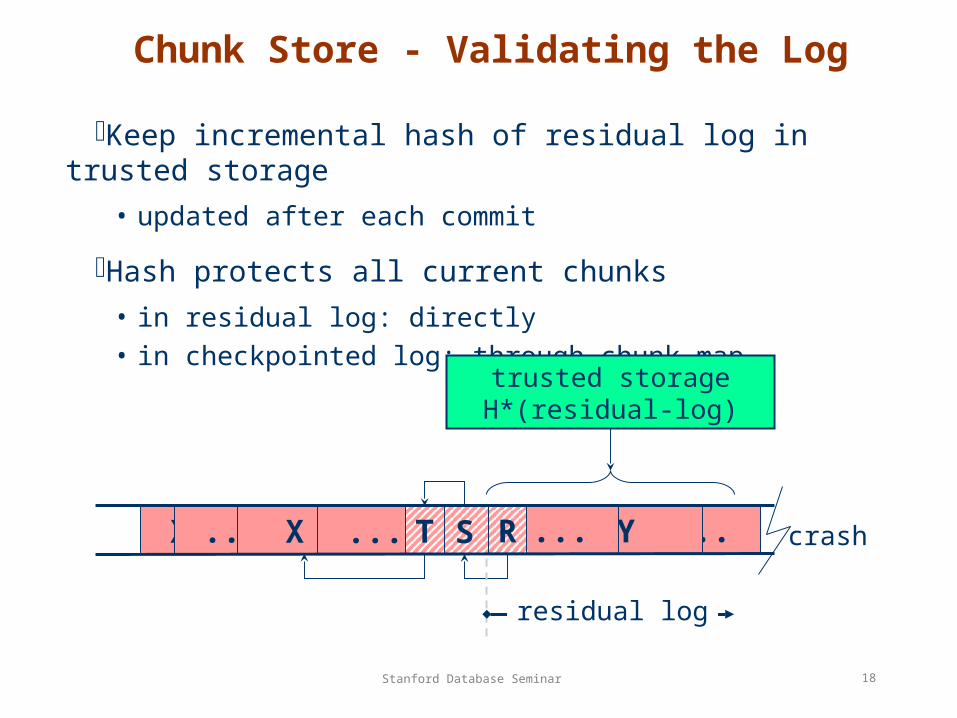
Chunk Store - Validating the Log
Keep incremental hash of residual log in trusted storage
• updated after each commit
Hash protects all current chunks
• in residual log: directly• in checkpointed log: through chunk map
... Y ... crash X ... X ... S RT
trusted storageH*(residual-log)
residual log

Stanford Database Seminar 19
... c.c.74Xc.c.
73
Chunk Store - Counter-Based Log Validation
A commit chunk is written with each commit
• contains a sequential hash of commit set• signed with system secret key
One-way counter used to prevent replays
Benefits:
• allows bounded discrepancy between trusted and untrusted storage
• doesn’t require writing to trusted storage after each transaction
crash X ... X ... S RT
residual log
hash hash

Stanford Database Seminar 20
Chunk Store - Log Cleaning
Log cleaner creates free space by reclaiming obsolete chunk versions
Segments• Log divided into fixed-sized regions called segments ( ~100 KB)• Segments are securely linked in the residual log for recovery
Cleaning step• read 1 or more segments• check chunk map to find live chunk versions
– ChunkId’s in the headers of chunk versions• write live chunk versions to the end of log• mark segments as free
May not clean segments in residual log
Stanford Database Seminar 21
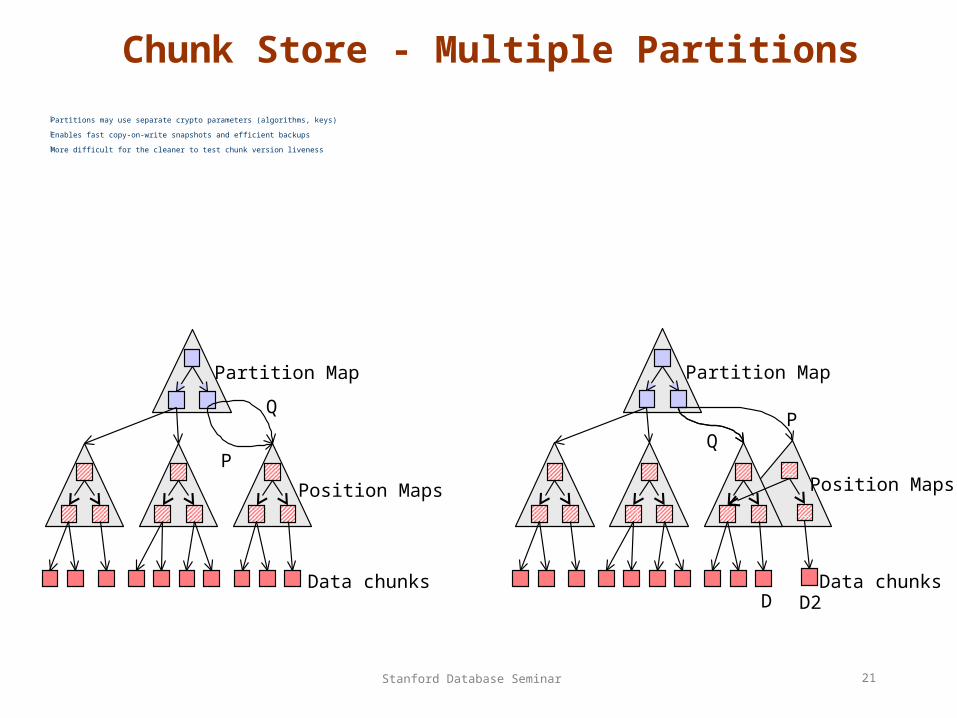
Chunk Store - Multiple Partitions
Partitions may use separate crypto parameters (algorithms, keys)
Enables fast copy-on-write snapshots and efficient backups
More difficult for the cleaner to test chunk version liveness
Partition Map
Position Maps
Data chunks
P
Q
Partition Map
Position Maps
Data chunks
PQ
D D2
Stanford Database Seminar 22
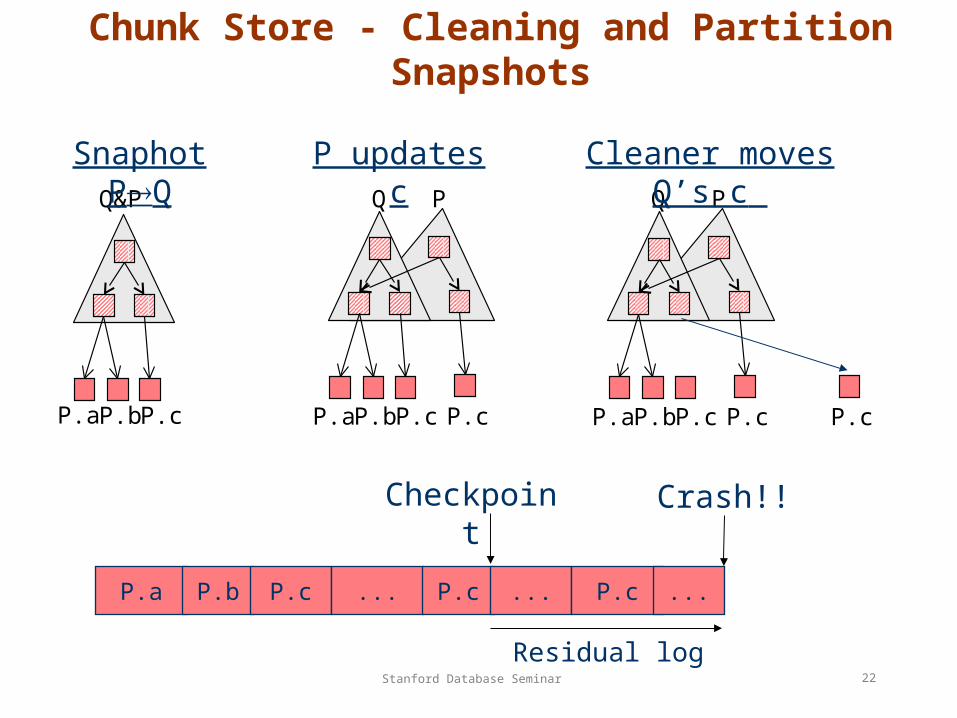
Chunk Store - Cleaning and Partition Snapshots
Q&P
P.a P.b P.c
PQ
P.c P.cP.a P.b
PQ
P.c P.cP.a P.b P.c
Snaphot PQ
P updates c
Cleaner moves Q’s c
P.a P.b P.c ... P.c ... P.c ...
Checkpoint
Crash!!
Residual log

Stanford Database Seminar 23
Backup Store
Creates and restores backups of partitions
Backups can be full or incremental
Backup creation utilizes snapshots to guarantee backup consistency (wrt concurrent updates) without locking
Supports full and incremental backups of partitions
Backup Store must verify during a backup restore
• integrity of the backup (using a signature)• correctness of incremental restore sequencing

Stanford Database Seminar 24
Object Store
Provides type-safe access to named C++ objects
• objects provide pickle and unpickle methods for persistence
• but no transparent persistence
Implements full transactional semantics
• in addition to atomic updates
Maps each object into a single chunk
• less data written and read from the log • simplifies concurrency control
Provides an in-memory cache of decrypted, validated, unpickled, type-checked C++ objects
Implements no-steal buffer management policy

Stanford Database Seminar 25
Collection Store
Provides access to indexed collections of C++ objects using scan, exact match and range queries
Performs automatic index maintenance during updates
• implements insensitive iterators
Uses functional indices
• an extractor function is used to obtain a key from an object
Collections and indexes are represented as objects
• index nodes locked according to 2PL

Stanford Database Seminar 26
Performance Evaluation - Benchmark
Compared TDB to BerkeleyDB using TPC-B
Used TPC-B because:
• implementation included with BerkeleyDB• BerkeleyDB functionality limited choice of benchmarks
(e.g., 1 index per collection)

Stanford Database Seminar 27
Performance Evaluation - Setup
Evaluation platform• 733 MHz Pentium II, 256 MB• Windows NT 4.0, NTFS files• EIDE disk, 8.9 ms (read), 10.9 ms write seek time• 7200 RPM (4.2 ms avg. rot. latency)• one-way counter: file on NTFS
Both systems used a 4 MB cache
Crypto parameters (for secure version of TDB):• SHA-1 for hashing (hash truncated to 12 B)• 3DES for encryption
Stanford Database Seminar 28
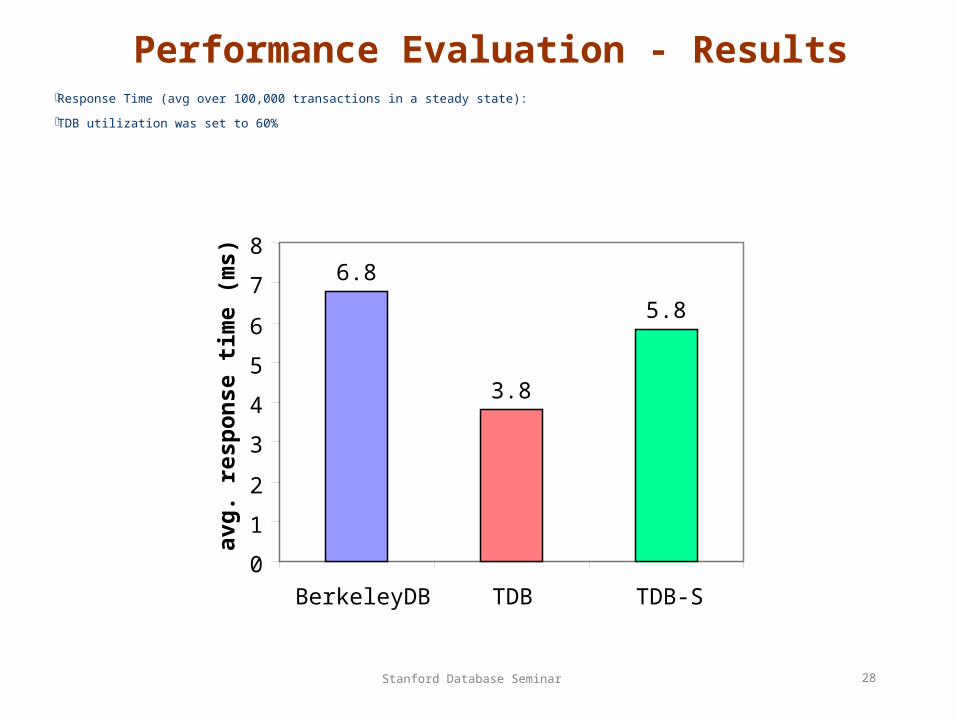
Performance Evaluation - ResultsResponse Time (avg over 100,000 transactions in a steady state):
TDB utilization was set to 60%
6.8
3.8
5.8
0
1
2
3
4
5
6
7
8
BerkeleyDB TDB TDB-S
avg
. re
sp
on
se t
ime (
ms)
Stanford Database Seminar 29
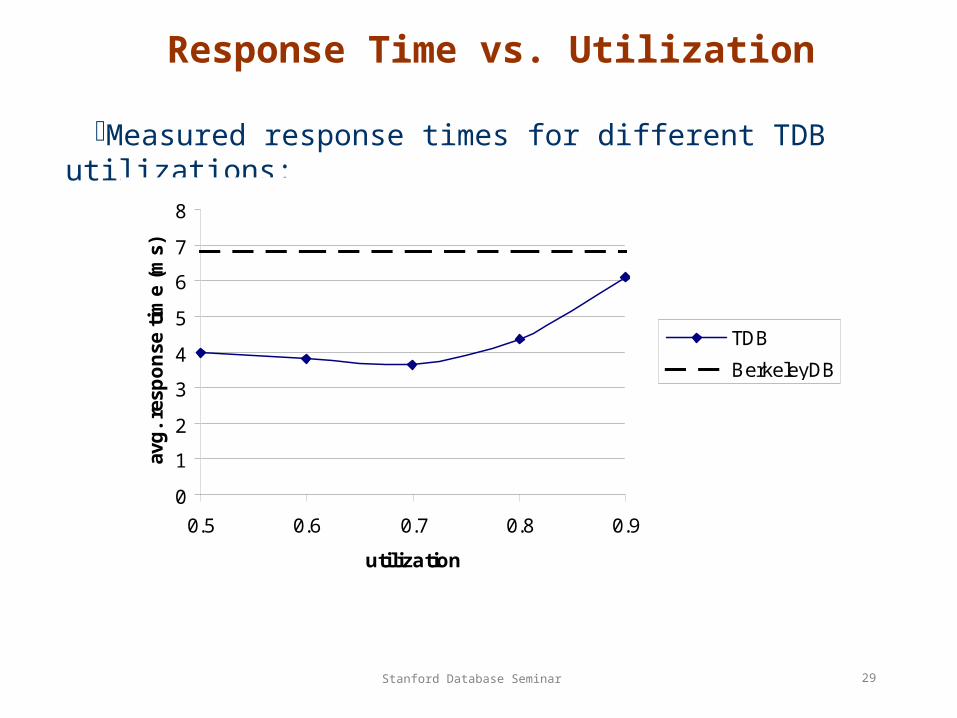
Response Time vs. Utilization
Measured response times for different TDB utilizations:
0
1
2
3
4
5
6
7
8
0.5 0.6 0.7 0.8 0.9
utilization
avg
. re
spo
nse
tim
e (m
s)
TDB
BerkeleyDB

Stanford Database Seminar 30
Related Work
Theoretical work
• Merkle Tree 1980• Checking correctness of memory (Blum, et. al. 1992)
Secure audit logs, Schneier & Kelsey 1998
• append-only data• read sequentially
Secure file systems
• Cryptographic FS, Blaze ‘93• Read-only SFS, Fu et al. ‘00• Protected FS, Stein et al. ‘01

Stanford Database Seminar 31
A Retrospective Instead of Conclusions
Got lots of mileage from using log-structured storage
Partitions add lots of complexity
Cleaning not a big problem
Crypto overhead small on modern PCs (< 6%)
Code footprint too large for many embedded systems• needs to be within 10 KB• GnatDb (see a TR)
For More Information:• OSDI 2000 -- “How to Build a Trusted Database System on
Untrusted Storage.” U. Maheshwari, R. Vingralek, W. Shapiro• Technical Reports available at http://www.star-lab.com/tr/
Stanford Database Seminar 32
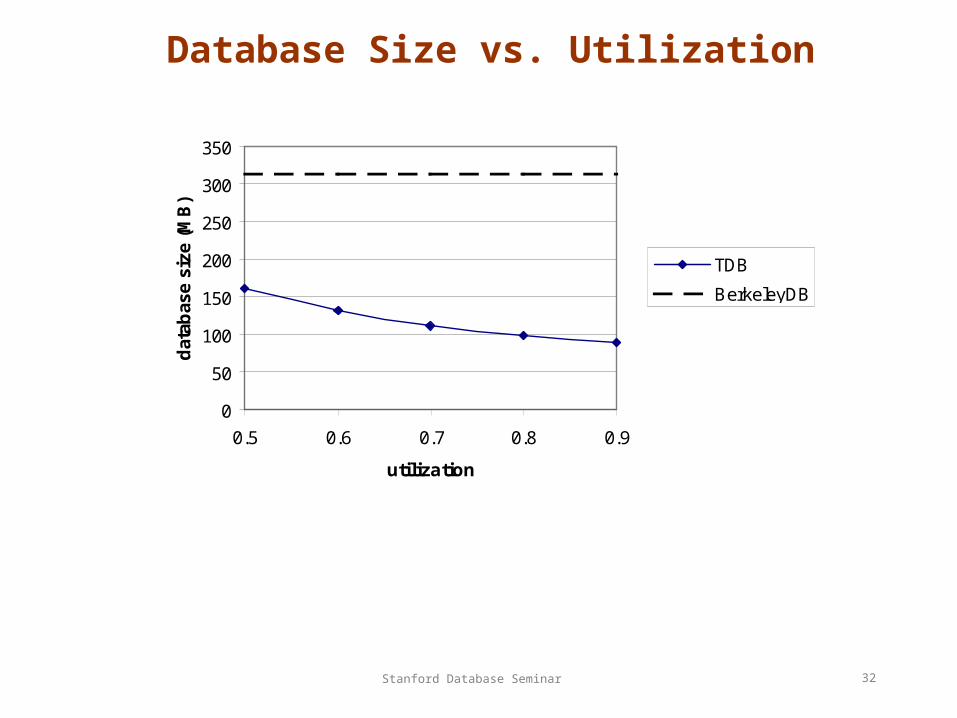
Database Size vs. Utilization
0
50
100
150
200
250
300
350
0.5 0.6 0.7 0.8 0.9
utilization
dat
abas
e si
ze (
MB
)
TDB
BerkeleyDB

Stanford Database Seminar 33