Embed Size (px)
Citation preview

1
Using the Web to Reduce Data Sparseness inPattern-based Information Extraction
Sebastian Blohm, Philipp Cimiano
Universität Karlsruhe (TH), Institut [email protected]
PKDD 2007, September 20th 2007
2
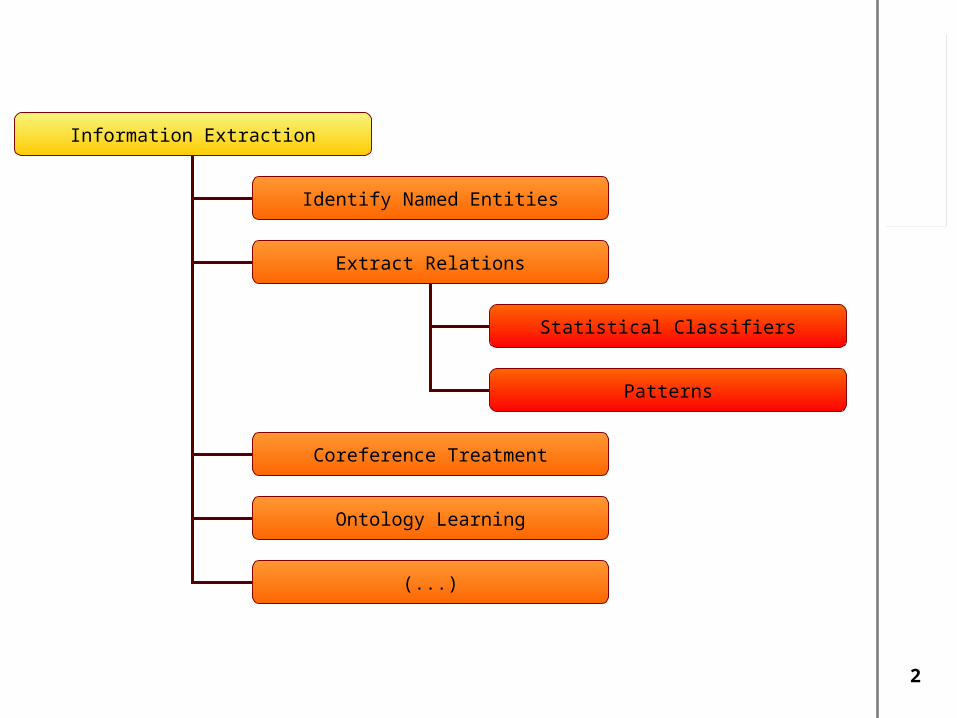
Information Extraction
Identify Named Entities
Extract Relations
Coreference Treatment
Ontology Learning
Statistical Classifiers
Patterns
(...)

3
Pattern-based Extraction
Assumption: The way relation instances occur in
• Regularity: Occurrences of relation instances have something in common
• Redundancy: Relation instances occurr frequently and in different forms
Paradigms of pattern based extraction:
• Fixed patterns (extremely successful for relations like "is-a") [Hearst92]
• Induction of Patterns
Sources:
• Large corpora (recent: [Espresso06])
• Web [DIPRE98]
Methods:
• Bootstrapping based-learning [DIPRE98]
• Bottom-up learning [LP201]
• Vector Space model [Snowball00]The happiest people in Germany live in Osnabrück .
The richest people in America live in Hollywood.
The * people in * live in * .

4
Problem statement
Assumption: The way relation instances occur in• Regularity: Occurrences of relation instances have something in
common• Redundancy: Relation instances occurr frequently and in different
forms
Problem: High-quality knowledge sources frequently lack redundancy.
Our Goal:- We use the Web as "background knowledge" to help the extraction
process bootstrap- We show that our method of integrating Web extraction has a similar
effect as strongly increasing the number of training samples.

5
Outline
- General method learning relations from Wikipedia- Comparing Web and Wikipedia- Integrating the Web as background knowledge- Experimental evaluation- Conclusion
6

7
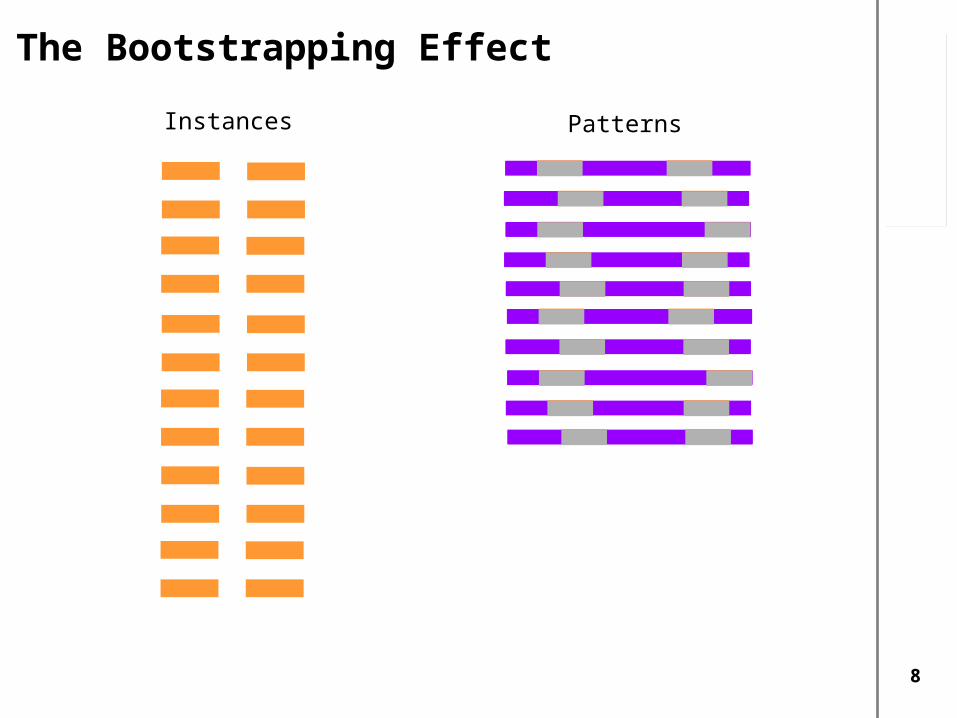
Iterative Pattern Induction
Bass America
Minnow St. Lawrence
Haddock North Atlantic
Bluegill Québec
Scrod New England
Salmon Atlantic
Hypostomus South America
Tuna Japan
match on wiki retrieve contexts
learn patterns
match patternsharvest instances
... is from the St. Lawrence and Lake Ontario south ... of which are native to North America and ...... on both sides of the North Atlantic. Haddock is ...... rarely found outside New England and New York...
... is from the * and * south ... of which are native to * and ... ... on both sides of the * . * is ... ... rarely found outside * and * ...
8
The Bootstrapping Effect
Instances Patterns
9
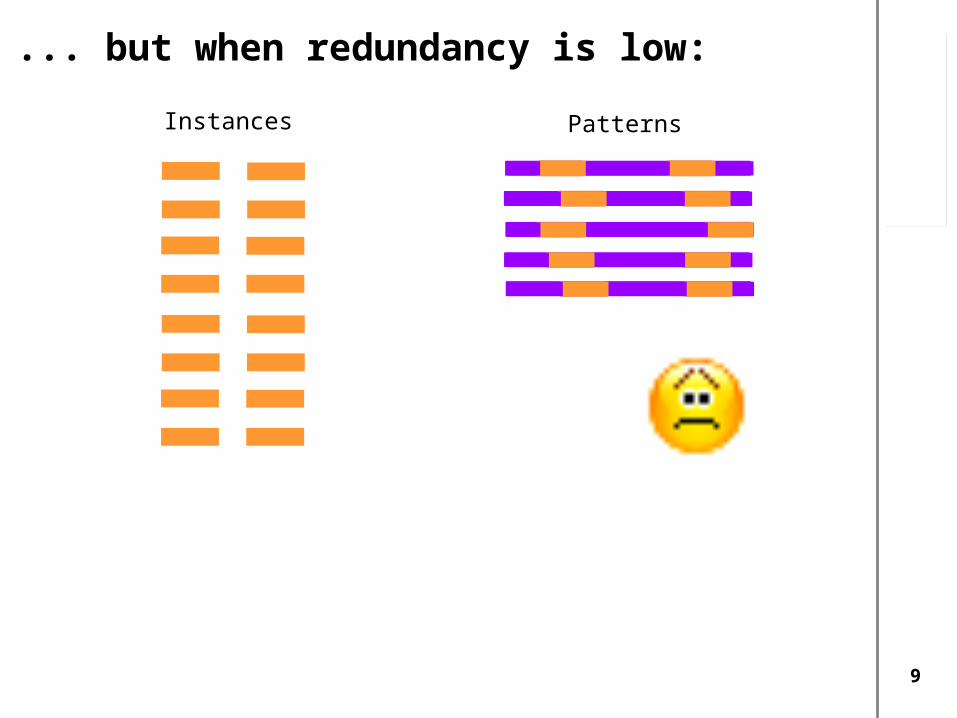
... but when redundancy is low:
Instances Patterns

10
How often do relation instance co-occur?
Wikipedia- 1.6 Mio articles (Dec
2006)- One article on each
topic. - Redundancy strictly
avoided.
Web- Billions of pages- No structure- Highly redundant
median: 15
median: 48000
11
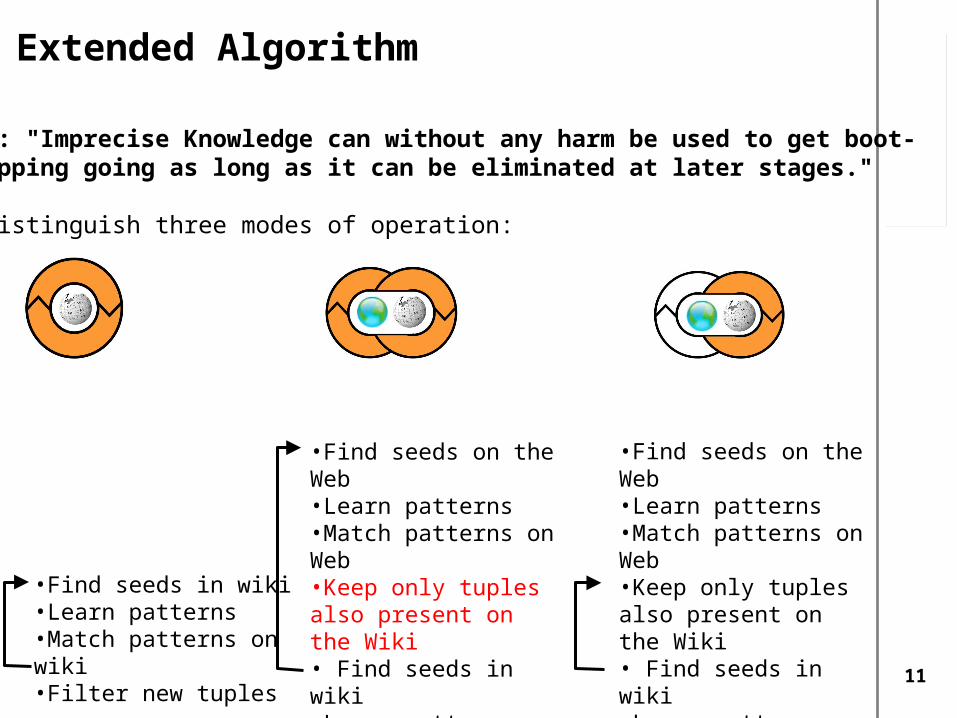
Extended Algorithm
Idea: "Imprecise Knowledge can without any harm be used to get boot-strapping going as long as it can be eliminated at later stages."
We distinguish three modes of operation:
•Find seeds in wiki•Learn patterns•Match patterns on wiki•Filter new tuples
•Find seeds on the Web•Learn patterns•Match patterns on Web•Keep only tuples also present on the Wiki• Find seeds in wiki•Learn patterns•Match patterns on wiki•Filter new tuples
•Find seeds on the Web•Learn patterns•Match patterns on Web•Keep only tuples also present on the Wiki• Find seeds in wiki•Learn patterns•Match patterns on wiki•Filter new tuples
12
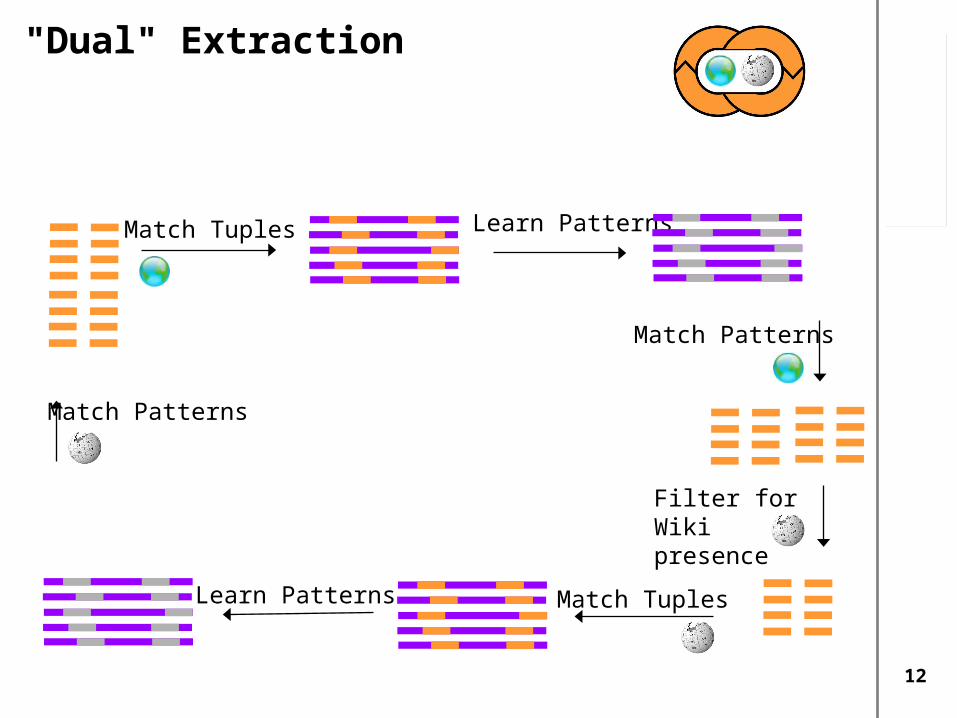
Filter for Wiki presence
"Dual" Extraction
Match Tuples Learn Patterns
Match Patterns
Match TuplesLearn Patterns
Match Patterns

13
Filter for Wiki presence
"Wiki Only" Extraction
Match Tuples Learn Patterns
Match Patterns
Match TuplesLearn Patterns
Match Patterns

14
Filter for Wiki presence
"Web Once" Extraction
Match Tuples Learn Patterns
Match Patterns
Match TuplesLearn Patterns
Match Patterns
Iteration 1 only
15
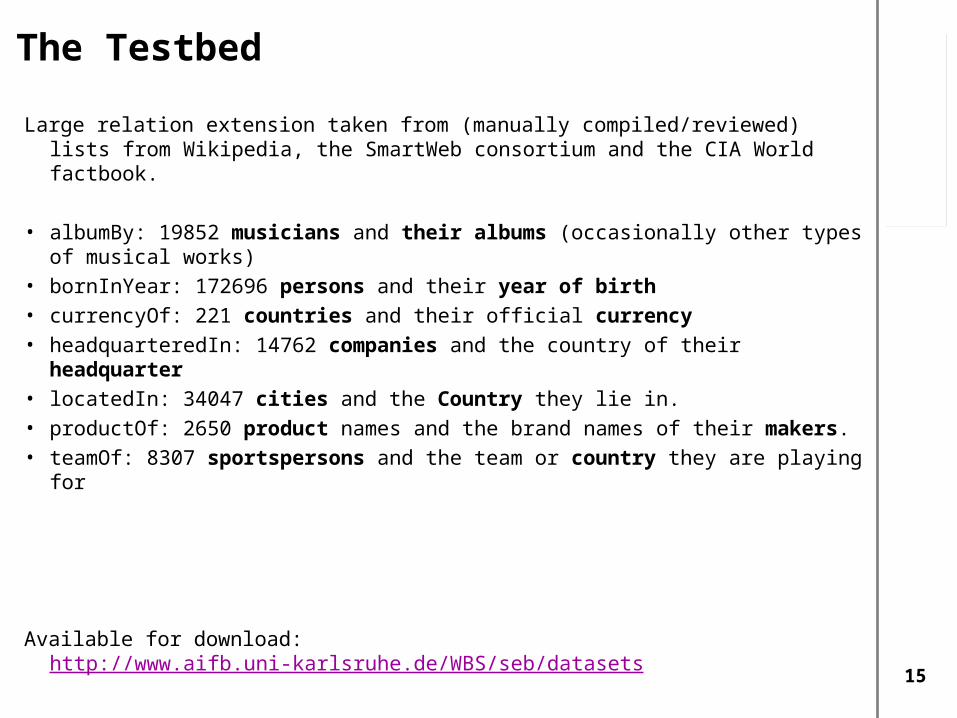
The Testbed
Large relation extension taken from (manually compiled/reviewed) lists from Wikipedia, the SmartWeb consortium and the CIA World factbook.
• albumBy: 19852 musicians and their albums (occasionally other types of musical works)
• bornInYear: 172696 persons and their year of birth
• currencyOf: 221 countries and their official currency
• headquarteredIn: 14762 companies and the country of their headquarter
• locatedIn: 34047 cities and the Country they lie in.
• productOf: 2650 product names and the brand names of their makers.
• teamOf: 8307 sportspersons and the team or country they are playing for
Available for download: http://www.aifb.uni-karlsruhe.de/WBS/seb/datasets

16
Results: Correct Extractions over Iterations
• Wiki only initally generates more correct information but shows a poor development over further iterations.
• Note: Extractions from the Web are not counted as additional correct extractions.
• Web extractions enable a more steady development of correct extractions.
• "Web once" more productive because the wiki matches are more precise.
3 iterations 6 iterations 9 iterations
900
500
0
web once
dual
wiki only

17
Precision, Recall, F-Measure
• Solely Wiki-Based extraction fails to bootstrap with small seed set.• "Web once" strategy compensates for small seed set• Continous Web-Matching does not lead to further benefit (in the 9 iterations
considered)
10 seeds 50 seeds 100 seeds

18
Conclusion
• Analyzed why it is difficult to extract information from Wikipedia with the classical bootstrapping-based approach.
• Presented method to extract from Wikipedia through supplementary extraction from the Web.
• Use the Web to retrieve further examples.
• Use them for pattern induction but not as target instances.• This generalizes to a method for using noisy background knowledge
to overcome data sparseness.
• Induce further seeds in noisy but rich dataset.
• Use them as seeds-only, not as output.• In particular it is interesting to see, that the effects of employing the
Web is similar to that of providing more seeds.

19
Outlook – this subject
Outlook – futher developments
• Improve pattern induction efficiency through optimized mining algorithms.• Richer structure in patterns (POS, semantic annotation etc.)• More automatic adaptivity of the system through automatic parametrisation.• Use negative examples where available (in particular relations that are very
close).
• Analyze to properties of the corpora to tell more precisely what make the difference.
• Add further Wikipedia features (e.g. categories)• Invesigate results over more iterations.

20
Thank you for your attention
Using the Web to Reduce Data Sparseness inPattern-based Information Extraction
Sebastian Blohm, Philipp Cimiano
Universität Karlsruhe (TH), Institut AIFB
Knowledge?located-in(dispute,resolution) product-of(football,college)
product-of(child, mapping) product-of(web service, xml)
located-in(bankruptcy, switzerland) located-in(bagdad, kentucky)
located-in(california, mississippi) located-in(her, in his)
currency-of(euro,france), currency-of(eurocent,portugal)

21
References
[Hearst92] M. A. Hearst, \Automatic acquisition of hyponyms from large text corpora," in Proceedings of the 14th conference on Computational linguistics. Morristown, NJ,USA: Association for Computational Linguistics, 1992, pp. 539-545.
[DIPRE98] S. Brin, \Extracting patterns and relations from the world wide web," in WebDB Workshop at 6th International Conference on Extending Database Technology,EDBT'98, 1998.
[KnowItAll05] O. Etzioni, M. Cafarella, D. Downey, A.-M. Popescu, T. Shaked, S. Soderland,D. S. Weld, and A. Yates, \Unsupervised named-entity extraction from the web: an experimental study," Artif. Intell., vol. 165, no. 1,
[Snowball00] E. Agichtein and L. Gravano, \Snowball: extracting relations from large plain-text collections," in DL '00: Proceedings of the ¯fth ACM conference on Digital libraries. New York, NY, USA: ACM Press, 2000
[Espresso06] M. Pennacchiotti and P. Pantel, \A bootstrapping algorithm for automatically harvesting semantic relations," in Proceedings of Inference in Computational Semantics (ICoS-06), Buxton, England.
[Etzioni et al., 2005] Oren Etzioni, Michael J. Cafarella, Doug Downey, Ana-Maria Popescu, Tal Shaked, Stephen Soderland, Daniel S. Weld, Alexander Yates: Unsupervised named-entity extraction from the Web: An experimental study. Artificial Intelligence 165(1): 91-134 (2005)
[LP201] Fabio Ciravegna: Adaptive Information Extraction from Text by Rule Induction and Generalisation, in Proceedings of 17th International Joint Conference on Artificial Intelligence (IJCAI 2001), Seattle, August 2001

22
TODO: Keep this? Challenges
• Most relation instances ocurr very sparsely.• Good trade-off between precision and recall is required.• Low redundancy in high-quality corpora like Wikipedia makes
bootstrapping difficult.
• Search-pattern based extraction allows extraction of infrequent instances without processing the entire corpus.
• Pattern filtering allows trading precision and recall.• Pattern support is a good predictor for precision.• Bootstrapping can be boosted by using background knowledge.
Results

23
TODO: Determining Factors for Extraction
TODO: use Skype Icons again (to mark what is the case in Wikipedia and what not)
TODO: re-read conclusion by Uszkoreit
TODO: re-read paper• Data richness
• How often do relation instances occurr in similar context?
• Do the same relation instances re-appear in different contexts?• Types of Target Relations
• Overlapping relations are hard to tell appart (e.g. )
• Sub- and super relations are hard to tell apart. (e.g. capitalOf and locatedIn)

24
Feedback
• We should analyze to properties of the corpora (e.g. replace Web by books, smaller subset of the web...)
• Explain the problem as there being a sets of different context that you would like to bridge
• Better treat the precision bars on slide 14• Better explain the notion of relative recall• Slide 3 is very vague

25
Possible Optimizations to improve F-Measure
• Apply Part-of-Speech and Named-Entity tagging where applicable.• Make use of sentence structure (e.g. „... live in Hollywood or Beverly
Hills")• Use negative examples where available (in particular relations that
are very close).• Take into account knowledge about the structure of the target
relation (e.g. a city can only be in one country).

26
TODO: Extended Algorithm
27
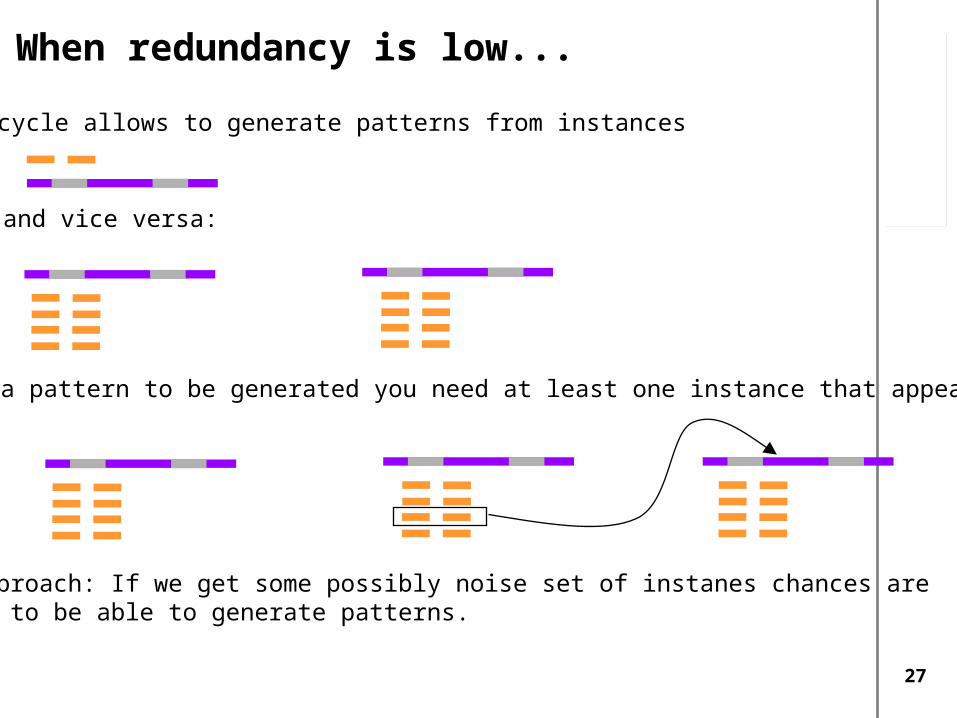
When redundancy is low...
The cycle allows to generate patterns from instances
and vice versa:
But for a pattern to be generated you need at least one instance that appears in it.
Our approach: If we get some possibly noise set of instanes chances arehigher to be able to generate patterns.





























