Embed Size (px)
Citation preview

1
Statistics Review

2
Why We Care
• Analysts must be able to evaluate quantitative information to make predictions.
• Although statistical tools my not be sharp, they are necessary.
• The point is for you to be able to– use the tools,– Understand their limitations.

3
Statistical Background
• Two Steps– Review of the basics– Application to estimating growth
• Which will illustrate different ways of estimating growth using past data on different types of securities.
• Not surprisingly, the methods work better with certain types of securities.

4
Estimating the mean and variance
• We will begin by computing a sample mean and a sample variance.– These are estimates.– That means that there is error associated with
the estimates.– The error can be large especially
• when the time series used to estimate is short,• when you’re estimating the mean.
– This can be a problem when estimating mean growth rates.

5
Means and Variances
• Start with T numbers for earnings, Et, for t=1,…T.– For example, T could be 20, where we have quarterly
earnings numbers for the past five years.• Then the sample mean, or average earnings is:
M = (1/T)(Σt Et)• The sample variance for the same set is:
S2 = (1/(T-1))(Σt (Et-M)2)The T-1 is just to make the estimator
unbiased. • The sample standard deviation, S, is the square
root of the sample variance.

6
Samples and populations
• We estimated a sample mean
M = Sample Mean = (1/T)(Σt Et)
• and sample variance
S2 = Sample variance = (1/(T-1))(Σt (Et-M)2)
• These sample parameters are estimates of “true” population parameters (let’s call them μ and σ2.
• What we want are “good” estimates.– What makes for a good estimate?

7
Confidence
• Answer: A good estimate is accurate.• We need to to estimate the variance, or standard
deviation, of your estimate of the sample mean.– This is NOT the same as the estimate of the variance.– An estimate of the variance of earnings may change
as you add more data, but it will not shrink necessarily.
– But the variance in an estimate of the sample mean goes down as you get more data.
• If you had an infinite amount of data, this sampling error goes to ZERO under certain conditions.
– You need stationarity.• e.g. there can’t be a trend with time.

8
Confidence – Standard Errors
• Usually, the more data, the smaller the standard error (the more accurate your estimate).
• Computationally, the variance of your estimate of the sample mean is proportional to the number of observations you have:
Variance of estimate of sample mean = σ2/TIn sample, that’s S2/T
• The standard error is S/sqrt(T)– This square root is going to cause problems, because
it means you need a lot more data to get small improvements in precision.

9
Numerical example of confidence
• Suppose you have 20 observations of earnings drawn from a normal distribution with mean of $1 per share with variance of ¼ so that the standard deviation was $0.50 per share.– If you simulated data from this distribution and the std.
error would be something like– S/sqrt(20) = .50/4.47 = .11
– You’d be confident at the 5% level from looking at the data that the mean was between $0.78 and $1.22.
• Your estimate of the standard error is ¼ as much as your estimate of the std. deviation.

10
Numerical example of confidence
• If you had 100 observations (25 yrs),
std error S/sqrt(100) = .50/10 = .05– You’d be confident at the 5% level from
looking at the data that the earnings would be between $0.90 and $1.10
• Your estimate of the standard error is 1/10 as much as your estimate of the std. deviation.
• 5 times as much data and your precision only doubles.

11
Where do we go from here?
• Let’s see if we can apply this tool + our knowledge of regression to a prediction problem.
• We want to apply these tools to estimate the growth rate for a firm’s earnings.– We could apply this to dividends and use a
DDM– Or to free cash flow and price using a FCFE
model.

12
Example with real data
• You have 10 years of earnings data and you want to forecast earnings out for another few years.
• The reason is that you want to do valuation using either a free cash flow to equity approach or a dividend discount approach.
• Suppose you have no access to analyst forecasts. How would you begin?– We’ll talk about analyst forecasts later.

13
Easiest Case
• The past is like the future.– This means that you don’t have to worry about
innovations of any kind that can increase (or reduce) growth rates.
• Innovations can be important, because then past data may not be a good guide to future performance.

14
Easiest Case
• When might the past not be like the future?– new innovations affect future performance.– In the past, the company had a different product mix.
• what would you do then?
– In the past, the company had made numerous acquisitions.
– essentially, whenever the business going forward looks different from the business in the past.

15
Forecasting from past earnings
• Suppose we have quarterly earnings data for 10 years. Potential problems.– Seasonality.
• For example, 4th quarter earnings for retailers need not be the same as 2nd quarter earnings.
• Seasonality should NOT affect stock prices. Everyone knows that retailers earn the most in December – it’s no surprise to anyone.
– One fix is to use annual earnings only.

16
Annual earnings: 10 observations.
• This number, 10, is not atypical.• Strategies for estimating growth:
1. Naively assume that future earnings will be the same as earnings last year.
• This is easy, but what are the shortcomings?
2. Take the 10-year average as an estimate• This assumes that all variation in the past is just noise.• This too has shortcomings. For example?
3. Assume that earnings are growing somehow.• Figure out how.

17
A simple example
• Suppose you have a deterministic trend.– let E1=1, E2=2,...E10=10, you expect E11=11.
– Plug into the data analysis package. Results:• Using E11=E10 = 10 works well.
• Taking E11 = sample average of 5.5 does not because you’ve ignored the trend.
– What about running a regression?Column1
Mean 5.5
Standard Error 0.957
Median 5.5
Standard Deviation 3.028
Sample Variance 9.167

18
Regressions
• You could run a linear regression here and that would give you a perfect fit.– Et = a + b Et-1
– a=1, b=1 so that– Et = 1 + Et-1
• You could also de-trend the data (usually good to do) and calculate average growth rates in % terms:– g = (Et+1/Et – 1) which is not quite constant. Here,
growth is always $1 per year but growth is slowing in % terms (from 100% in year 1 to 11% in year 9)

19
Dealing with growth – summing up
• Simple regressions:Earningst+1 = a + b earningst + et
– A and b are regression coefficients, and et is the regression error term (which is different for each year).
Earnings growtht,t+1 = a + b earnings growtht-1,t
• Second, just calculate average earnings growth over the period and use that.
• In either case, make sure your quantitative estimates are– Reasonably precise (high standard errors mean you have junk)– Pass the laugh test (weird results are probably wrong)– Remember, you have so few observations that anything you get
is likely to be imprecise at best. Don’t think that just because you CAN run a regression, you should!

20
Earnings Growth
• Why do we focus so much on growth for stocks?
• The DDM: D1/(k-g)
• How reasonable is a growth rate of 10%– Sears?– Home Depot?– Google?

21
Real data
• From COMPUSTAT - annual earnings for firms from 1993-2002 for– Amgen– Colgate– Exxon– P&G
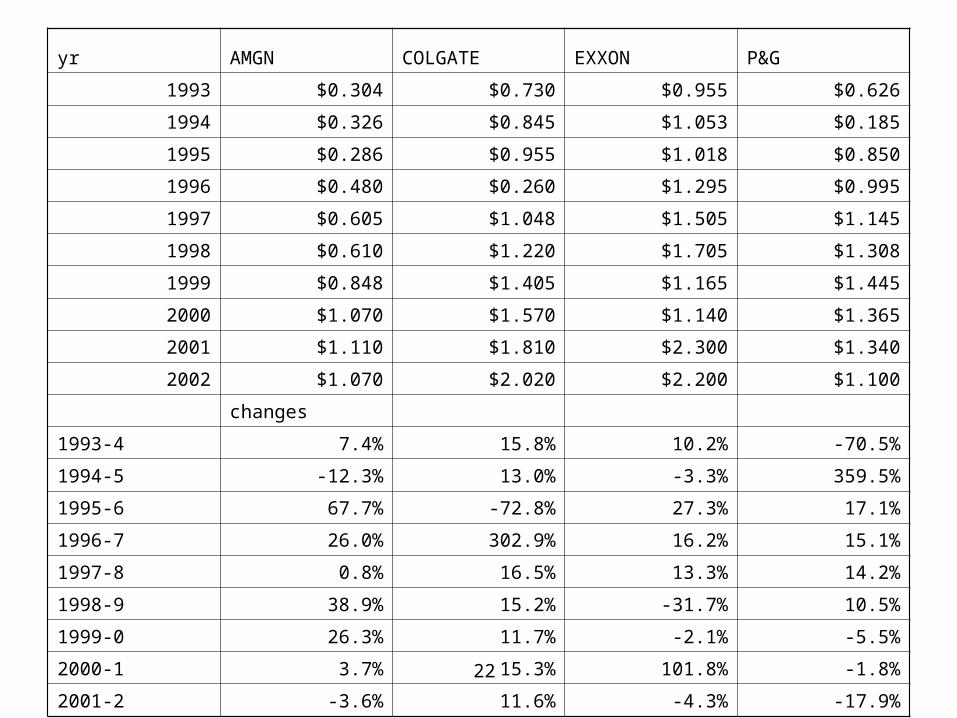
22
yr AMGN COLGATE EXXON P&G
1993 $0.304 $0.730 $0.955 $0.626
1994 $0.326 $0.845 $1.053 $0.185
1995 $0.286 $0.955 $1.018 $0.850
1996 $0.480 $0.260 $1.295 $0.995
1997 $0.605 $1.048 $1.505 $1.145
1998 $0.610 $1.220 $1.705 $1.308
1999 $0.848 $1.405 $1.165 $1.445
2000 $1.070 $1.570 $1.140 $1.365
2001 $1.110 $1.810 $2.300 $1.340
2002 $1.070 $2.020 $2.200 $1.100
changes
1993-4 7.4% 15.8% 10.2% -70.5%
1994-5 -12.3% 13.0% -3.3% 359.5%
1995-6 67.7% -72.8% 27.3% 17.1%
1996-7 26.0% 302.9% 16.2% 15.1%
1997-8 0.8% 16.5% 13.3% 14.2%
1998-9 38.9% 15.2% -31.7% 10.5%
1999-0 26.3% 11.7% -2.1% -5.5%
2000-1 3.7% 15.3% 101.8% -1.8%
2001-2 -3.6% 11.6% -4.3% -17.9%

23
What to do?
• Predict returns next period.
• Estimate average growth rates.
• These are the two things we’ll start with.
• The data are from wrds.– Past earnings are in the COMPUSTAT portion
of the database.

24
Descriptive statistics first.
• Q: for which companies are we likely to be able to predict best? Worst? Why?
• Let’s focus on– Average annual earnings per share in dollars
• The standard error for that
– Average growth rates in percent• The standard error for that• Notice for growth how the means and medians diverge. • Also, what do you do for growth when earnings are low? Or
even worse, negative?

25
yr AMGN COLGATE EXXON P&G
1993 $0.304 $0.730 $0.955 $0.626
1994 $0.326 $0.845 $1.053 $0.185
1995 $0.286 $0.955 $1.018 $0.850
1996 $0.480 $0.260 $1.295 $0.995
1997 $0.605 $1.048 $1.505 $1.145
1998 $0.610 $1.220 $1.705 $1.308
1999 $0.848 $1.405 $1.165 $1.445
2000 $1.070 $1.570 $1.140 $1.365
2001 $1.110 $1.810 $2.300 $1.340
2002 $1.070 $2.020 $2.200 $1.100
changes
1993-4 7.4% 15.8% 10.2% -70.5%
1994-5 -12.3% 13.0% -3.3% 359.5%
1995-6 67.7% -72.8% 27.3% 17.1%
1996-7 26.0% 302.9% 16.2% 15.1%
1997-8 0.8% 16.5% 13.3% 14.2%
1998-9 38.9% 15.2% -31.7% 10.5%
1999-0 26.3% 11.7% -2.1% -5.5%
2000-1 3.7% 15.3% 101.8% -1.8%
2001-2 -3.6% 11.6% -4.3% -17.9%

26
AMGN Colgate Exxon P&G
Mean
Standard Error
Median
Standard Deviation
Sample Variance
AMGN Colgate Exxon P&G
7.4% 15.8% 10.2% -70.5%
-12.3% 13.0% -3.3% 359.5%
67.7% -72.8% 27.3% 17.1%
26.0% 302.9% 16.2% 15.1%
0.8% 16.5% 13.3% 14.2%
38.9% 15.2% -31.7% 10.5%
26.3% 11.7% -2.1% -5.5%
3.7% 15.3% 101.8% -1.8%
-3.6% 11.6% -4.3% -17.9%
17.2% 36.6% 14.1% 35.6%
8.4% 34.6% 12.3% 41.5%
7.4% 15.2% 10.2% 10.5%
25.1% 103.9% 36.9% 124.5%
6.3% 108.0% 13.6% 154.9%

27
Sample statistics
• the mean is always less than the most recent observation, because there’s a trend.– so, you wouldn’t use the mean to predict, necessarily.
• the means are estimated pretty precisely.
AMGN COLGATE EXXON P&G
Mean earnings ($) 0.67086 1.18625 1.4335 1.03587
Std Error ($) 0.104812 0.167854 0.154264 0.124099
Median ($) 0.6075 1.13375 1.23 1.1225
Std Dev ($) 0.331445 0.5308 0.487826 0.392434
Sample Var 0.109856 0.281749 0.237974 0.154005

28
Regressions
• For Amgen, Et = .11 + .956 Et-1
• Our E11 guess: .11+.956(1.07) = 1.13
• Next slide, we look at % changes
Coefficients Standard Error t Stat
Intercept 0.112912937 0.091052507 1.24008597
X Variable 1 0.955677574 0.131054419 7.292219391

29
Predictions
• Here, the mean growth rate for AMGEN is 17%, so that our forecast would be $1.25.
• Colgate and P&G have mean growth rates of over 35%. Why?– Outliers – and these are often driven by
accounting items.– Look at the next page
• 1996-7 for Colgate• 1995-4 for P&G

30
Outliers create problems
• Look at Colgate in 1995, 1996, and 1997.
• Earnings were .955, .26, and 1.0475
• % changes were -73% and + 303%
• The avg percent change over the 95-6 and 96-7 was +115%.
• This number is meaningless and it drives all the results

31
yr AMGN COLGATE EXXON P&G
1993 $0.304 $0.730 $0.955 $0.626
1994 $0.326 $0.845 $1.053 $0.185
1995 $0.286 $0.955 $1.018 $0.850
1996 $0.480 $0.260 $1.295 $0.995
1997 $0.605 $1.048 $1.505 $1.145
1998 $0.610 $1.220 $1.705 $1.308
1999 $0.848 $1.405 $1.165 $1.445
2000 $1.070 $1.570 $1.140 $1.365
2001 $1.110 $1.810 $2.300 $1.340
2002 $1.070 $2.020 $2.200 $1.100
changes
1993-4 7.4% 15.8% 10.2% -70.5%
1994-5 -12.3% 13.0% -3.3% 359.5%
1995-6 67.7% -72.8% 27.3% 17.1%
1996-7 26.0% 302.9% 16.2% 15.1%
1997-8 0.8% 16.5% 13.3% 14.2%
1998-9 38.9% 15.2% -31.7% 10.5%
1999-0 26.3% 11.7% -2.1% -5.5%
2000-1 3.7% 15.3% 101.8% -1.8%
2001-2 -3.6% 11.6% -4.3% -17.9%

32
Geometric Averages.
• The geometric average growth rate for 10 years would be ((1+g)10)(1/10)
• In this case, just take (E10/E1)(.1)
• For Colgate, that’s (2.02/0.73)0.1 -1 = .107 or 10.7%, which is a lot less than the arithmetic average of over 36%.
• The difference is driven by variance:– There is a sense in which the geometric mean ignores
outliers – although you have to be careful – an outlier at either endpoint would cause problems.

33
Now, how did the professionals do?
• IBES 2003 most recent growth forecasts for– Colgate 13%– P&G 9.5%– Exxon 6%– Amgen 23%
• Actual 2003 earnings and growth:– AMGN 1.75 CL 2.60 XOM 3.16 PG 2.19
63% 28%, 43%, 16%




























