Embed Size (px)
Citation preview

1
Querying Text Databases and the Web: Beyond Traditional Keyword Search
Luis GravanoColumbia University
Many thanks to Eugene Agichtein, AnHai Doan, Panos Ipeirotis, and Alpa Jain!

2
Information Extraction, or Deriving Structured Information from Text Documents Natural-language text embeds “structured” data Properly trained extraction systems extract this
data Extraction output can be regarded as “relations”
BBC: May, 2006
A Cholera epidemic in Angola has now killed more than 1,200 people in the past three months …
Disease OutbreaksCholera Angola
1,200
CountryAngola
DiseaseCholera
Deaths1,200
Disease Outbreaks
Disease Country Deaths Year Virus type …
Cholera Angola 1,200 … … …
Significant progress over the last decade [MUC]
Proteus [Grishman et al., HLT 2000]

Thomson Reuters’s OpenCalaiswww.opencalais.com
<rdf:Description rdf:about="http://d.opencalais.com/dochash-1/_id_/Instance/5"> <rdf:type rdf:resource ="http://s.opencalais.com/1/type/sys/InstanceInfo"/> <c:docId rdf:resource ="http://d.opencalais.com/dochash-1/_id_"/> <c:subject rdf:resource ="http://d.opencalais.com/genericHasher-1/_id_"/> <!--CompanyLegalIssues: company_sued: IBM; company_plaintiff: TomTom; lawsuitclass: lawsuit; --> <c:detection>[court ruled against navigation systems company ]TomTom on Thursday in a patent infringement lawsuit against rival navigation device maker IBM from the United States. </c:detection> <c:offset>138</c:offset> <c:length>94</c:length></rdf:Description>
A Dutch court ruled against navigation systems company TomTom on Thursday in a patent infringement lawsuit
against rival navigation device maker IBM from
the United States.
4
Health Care Blog
Health
MTV Movies Blog
Movies
AllAfrica News Archive
Fact Tables Web
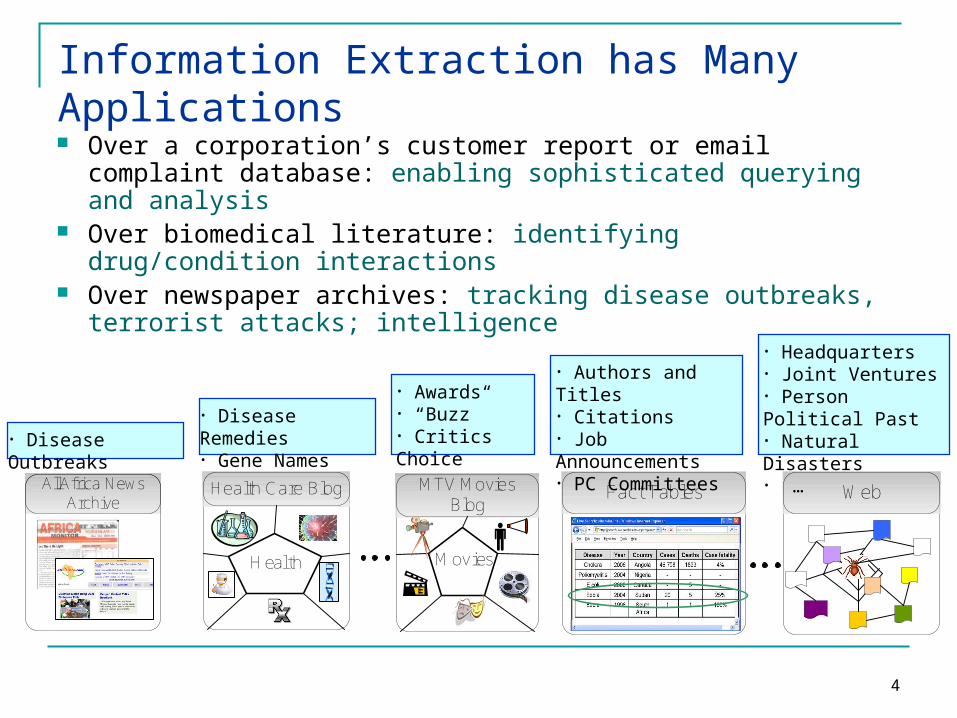
• Disease Remedies • Gene Names
• Disease Outbreaks
• Headquarters• Joint Ventures• Person Political Past• Natural Disasters• …
• Authors and Titles• Citations • Job Announcements• PC Committees
• Awards• “Buzz”• Critics Choice
Over a corporation’s customer report or email complaint database: enabling sophisticated querying and analysis
Over biomedical literature: identifying drug/condition interactions
Over newspaper archives: tracking disease outbreaks, terrorist attacks; intelligence
Information Extraction has Many Applications
5

6
Focus of this Talk: “On-The-Fly” Information Extraction Information extraction task short-lived, new
Substantial recent progress in unsupervised or semi-supervised information extraction
Text database previously unseen or too vast “Blackbox” view of information extraction systems
Not covered in talk: “Offline” information extraction (e.g., [Mansuri and Sarawagi, ICDE
2006], [Cafarella et al., CIDR 2007], [Chen et al., ICDE 2008]) Internal design of information extraction systems (effectiveness,
efficiency) (e.g., [McCallum, ACM Queue 2005], [Chandel et al., ICDE 2006], [Shen et al., SIGMOD 2008])
Entity extraction and ranking (e.g., [Stoyanovich et al., WebDB 2007], [Cheng et al., VLDB 2007], [Agrawal et al., PVLDB 2008])
7
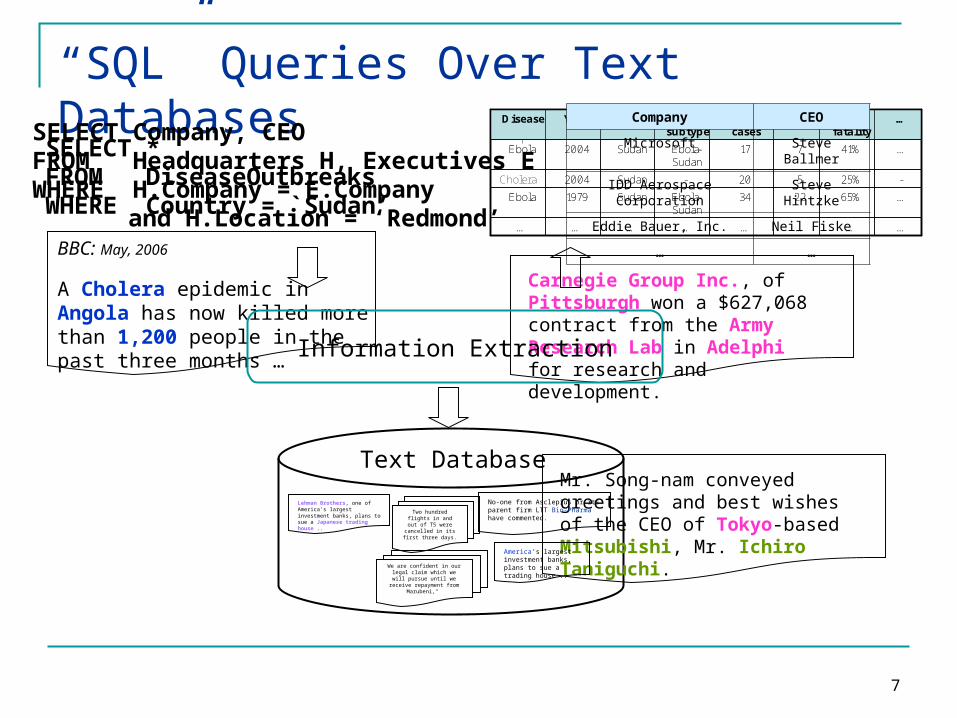
“SQL” Queries Over Text Databases
BBC: May, 2006
A Cholera epidemic in Angola has now killed more than 1,200 people in the past three months …
Carnegie Group Inc., of Pittsburgh won a $627,068 contract from the Army Research Lab in Adelphi for research and development.
Mr. Song-nam conveyed greetings and best wishes of the CEO of Tokyo-based Mitsubishi, Mr. Ichiro Taniguchi.America's largest
investment banks, plans to sue a trading house ..
No-one from Asclepius or its parent firm LTT Bio-Pharma have commented.
Text Database
Lehman Brothers, one of America's largest investment banks, plans to sue a Japanese trading house .. Two hundred flights in
and out of T5 were cancelled in its first
three days.
We are confident in our legal claim which we will pursue until
we receive repayment from Marubeni,"
Information Extraction
SELECT *FROM DiseaseOutbreaksWHERE Country = `Sudan’ …65%2234Ebola-
SudanSudan1979Ebola
……………………
-25%520-Sudan2004Cholera
Sudan
Country
…41%717Ebola-Sudan
2004Ebola
…Case fatality
DeathsIdentified cases
Virus subtype
YearDisease
…65%2234Ebola-Sudan
Sudan1979Ebola
……………………
-25%520-Sudan2004
Sudan
Country
…41%717Ebola-Sudan
2004Ebola
…Case fatality
DeathsIdentified cases
Virus subtype
YearDisease
SELECT Company, CEOFROM Headquarters H, Executives EWHERE H.Company = E.Company
and H.Location = ‘Redmond’
Company CEO
Microsoft Steve Ballmer
IDD Aerospace Corporation
Steve Hintzke
Eddie Bauer, Inc. Neil Fiske
… …

8
Processing a SQL Query over a Text Database: A Naïve Execution
For every database document: Retrieve document Feed document to all relevant information
extraction systems Add extracted tuples to corresponding
“relations” Evaluate SQL query over extracted
relationsAny problems?
9
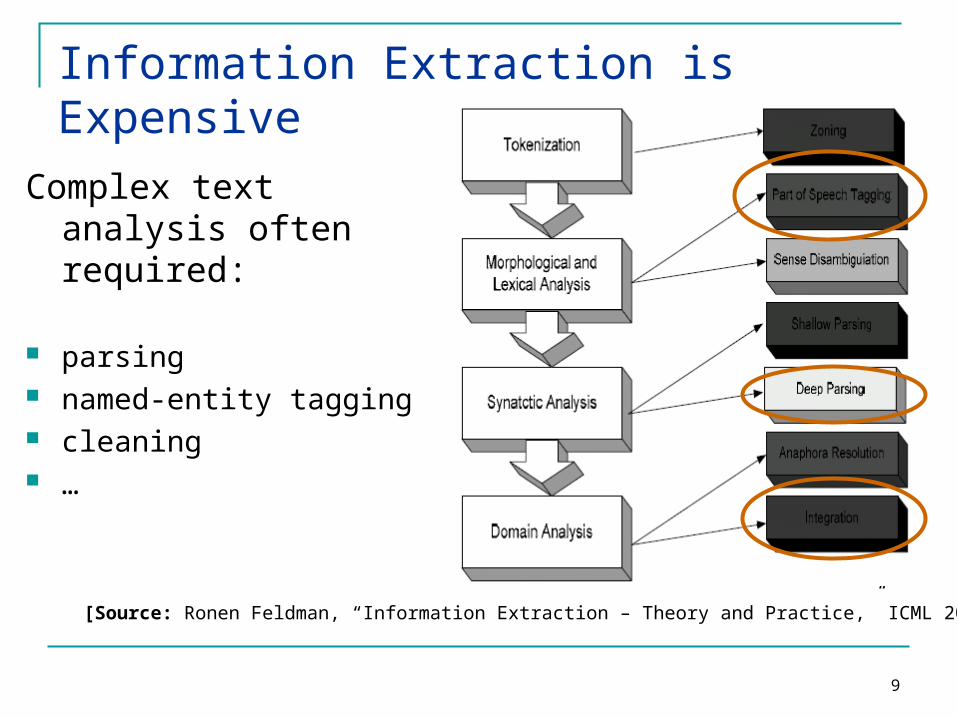
Information Extraction is Expensive
Ronen Feldman, Information Extraction – Theory and Practice, ICML 2006
[Source: Ronen Feldman, “Information Extraction – Theory and Practice,” ICML 2006]
Complex text analysis often required:
parsing named-entity tagging cleaning …
10
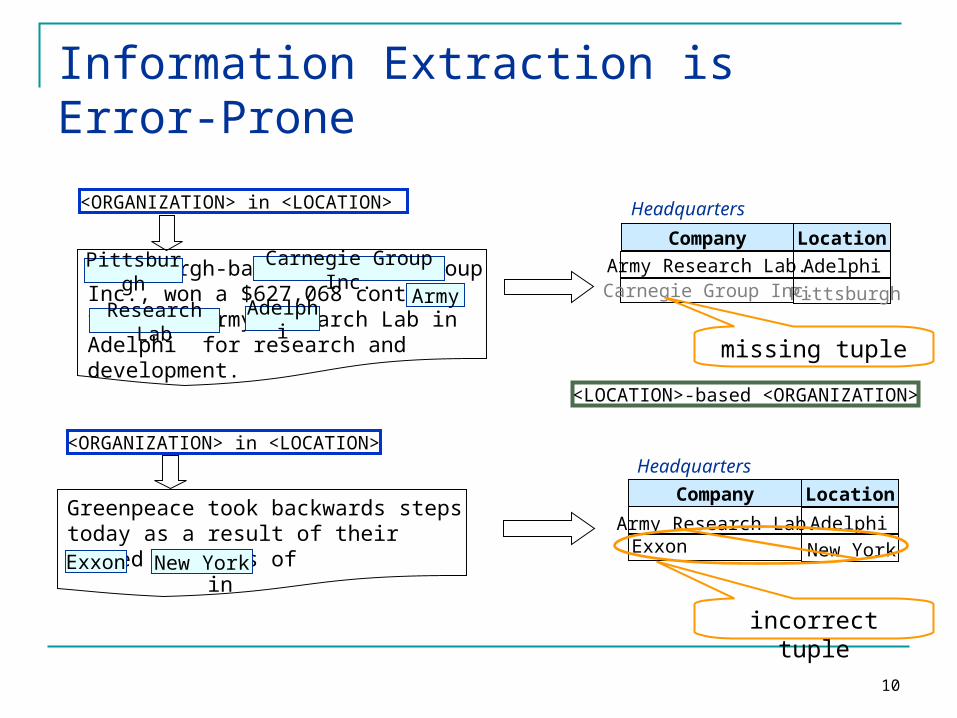
Information Extraction is Error-Prone
Pittsburgh-based Carnegie Group Inc., won a $627,068 contract from the Army Research Lab in Adelphi for research and development.
Carnegie Group Inc.Pittsburgh
Research LabArmy
Adelphi
<ORGANIZATION> in <LOCATION>
<LOCATION>-based <ORGANIZATION>
PittsburghCarnegie Group Inc.AdelphiArmy Research Lab.
Company Location
Headquarters
Greenpeace took backwards steps today as a result of their failed protests of in
<ORGANIZATION> in <LOCATION>
Army Research Lab. Adelphi
Company Location
New YorkExxonExxon New York
Headquarters
incorrect tuple
missing tuple

11
Information Extraction is Error-Prone
Recall: fraction of correct tuples that are extractedExtraction systems may miss valid tuples
Precision: fraction of extracted tuples that are correctExtraction systems may generate erroneous
tuples

12
Top-k Query Variants to the Rescue
Often “complete” query results are not necessary
Results can be sorted by expected accuracy
Top-k query results are preferable for efficiency and correctness
Appropriate value of k is user-specific Some users after relatively comprehensive
results Other users after “quick-and-dirty” results

13
Executing an “Any-k” Query over a Text Database
1. Select information extraction system for each relation in query
2. Select document retrieval strategy for each selected extraction system
3. Retrieve documents using selected retrieval strategies4. Process documents using selected extraction systems5. Clean and normalize extracted relations6. Return query results Goal: Return k correct extracted results as fast as possible:
Information extraction output is not trusted Extracted tuples are estimated to include incorrect tuples But no indication of tuple correctness is returned in results “Any-k” query results
[Ipeirotis et al., SIGMOD 2006, TODS 2007][Jain et al., ICDE 2008, 2009]
14
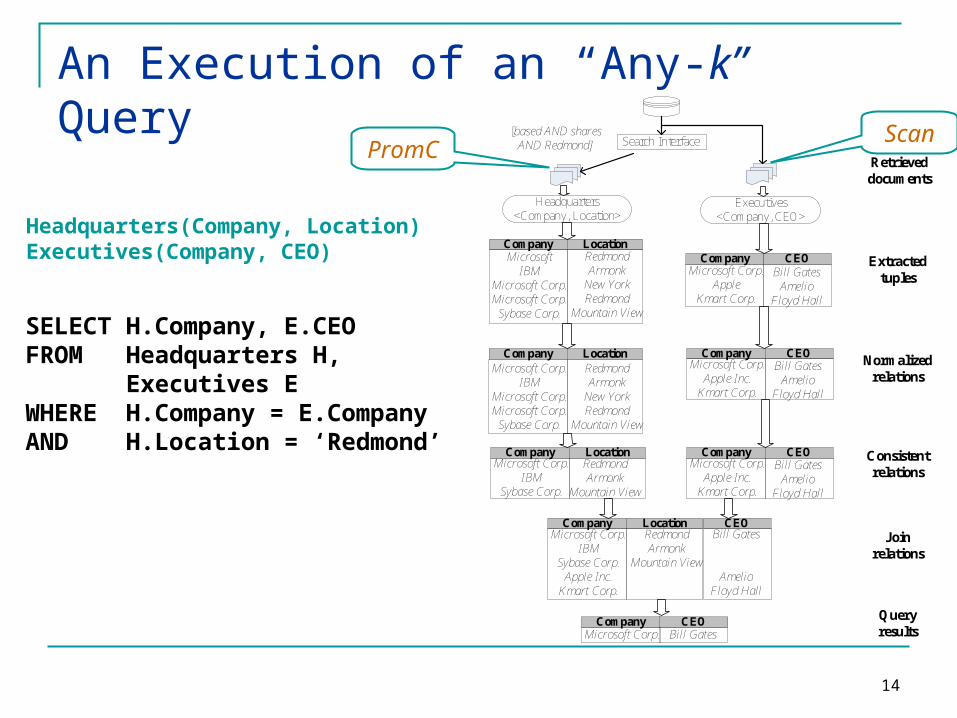
An Execution of an “Any-k” Query
SELECT H.Company, E.CEOFROM Headquarters H, Executives EWHERE H.Company = E.CompanyAND H.Location = ‘Redmond’
Search Interface
Company LocationMicrosoft
IBMMicrosoft Corp.Microsoft Corp.
Sybase Corp.
RedmondArmonk
New YorkRedmond
Mountain View
[based AND shares AND Redmond]
Headquarters<Company, Location>
Executives<Company, CEO>
Company CEOMicrosoft Corp.
AppleKmart Corp.
Bill GatesAmelio
Floyd Hall
Microsoft Corp.IBM
Microsoft Corp.Microsoft Corp.
Sybase Corp.
RedmondArmonk
New YorkRedmond
Mountain View
Company CEOMicrosoft Corp.
Apple Inc.Kmart Corp.
Bill GatesAmelio
Floyd Hall
Company LocationMicrosoft Corp.
IBMSybase Corp.
RedmondArmonk
Mountain View
Company LocationMicrosoft Corp.
IBMSybase Corp.
Apple Inc.Kmart Corp.
RedmondArmonk
Mountain View
CEOBill Gates
AmelioFloyd Hall
CompanyMicrosoft Corp.
CEOBill Gates
Company Location
Company CEOMicrosoft Corp.
Apple Inc.Kmart Corp.
Bill GatesAmelio
Floyd Hall
Retrieveddocuments
Extracted tuples
Normalized relations
Consistent relations
Joinrelations
Query results
PromC
Scan
Headquarters(Company, Location)Executives(Company, CEO)

15
Optimizing an “Any-k” Query
1. Select information extraction system for each relation in query
2. Select document retrieval strategy for each selected extraction system
3. Retrieve documents using selected retrieval strategies4. Process documents using selected extraction systems5. Clean and normalize extracted relations6. Return query results

16
Executions Vary in their Document Retrieval Strategy
Similar to relational world
Two major execution paradigms: Scan-based: Retrieve documents sequentially
(as in Naïve execution) Index-based: Retrieve documents via keyword queries (e.g., [case fatality rate])
Unlike relational world
Indexes are only “approximate”: index is on keywords, not on tuples of interest Choice of execution plan affects output completeness (not only speed)
→underlying data distribution dictates what is best

17
Document Retrieval Strategies for Any-k Queries: Outline
Scan- and index-based document retrieval strategies: Scan Filtered Scan Iterative Set Expansion Automatic Query Generation “Const” “PromC” (PromD + Const)
Analysis: execution time and number of correct extracted tuples
Scan-based
(“PromD”)Index-based
[Ipeirotis et al., SIGMOD 2006, TODS 2007][Jain et al., ICDE 2008, 2009]
18
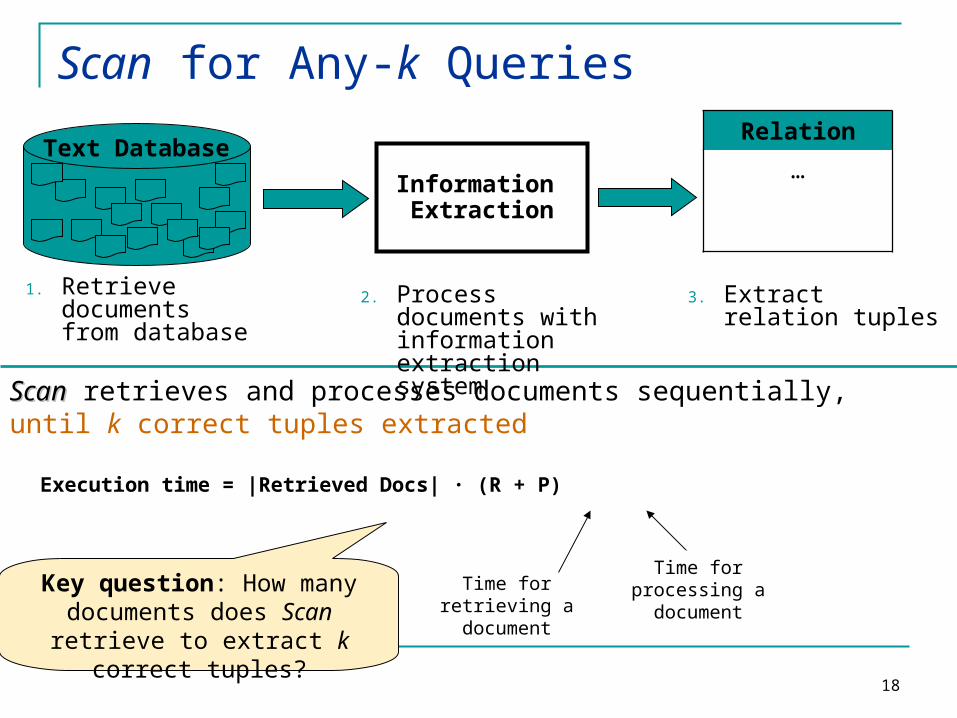
Scan for Any-k Queries
ScanScan retrieves and processes documents sequentially, until k correct tuples extracted
Execution time = |Retrieved Docs| · (R + P)
Time for retrieving a document
Key question: How many documents does Scan
retrieve to extract k correct tuples?
Time for processing a
document
Relation
…Information Extraction
Text Database
3. Extract relation tuples
2. Process documents with information extraction system
1. Retrieve documents from database
19
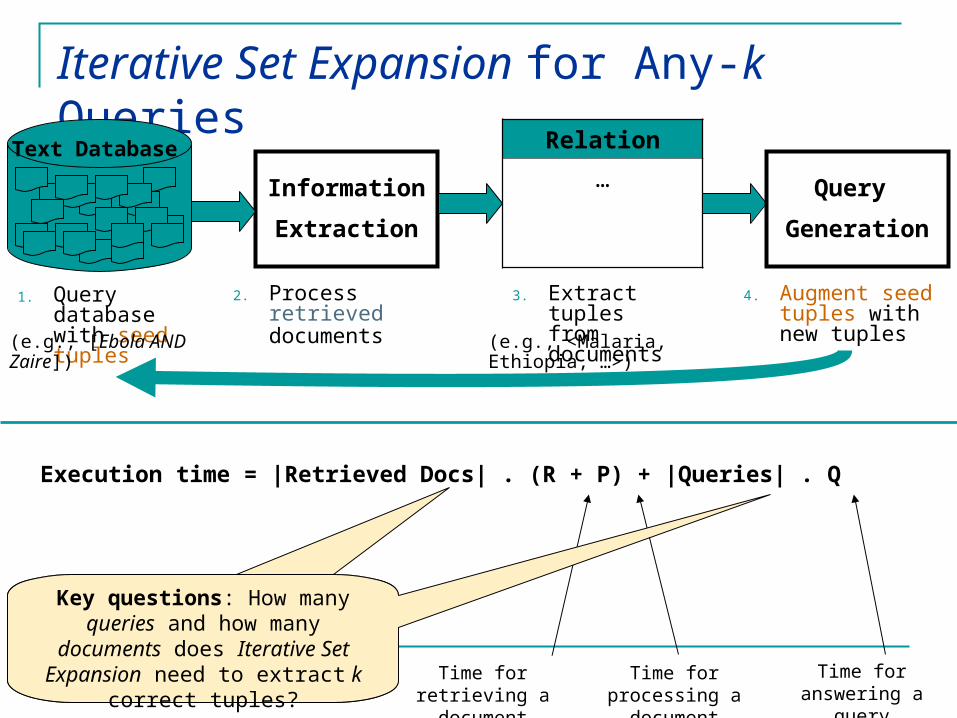
Iterative Set Expansion for Any-k Queries
Relation
…Information
Extraction
Text Database
3. Extract tuplesfrom documents
2. Process retrieved documents
1. Query database with seed tuples
Execution time = |Retrieved Docs| . (R + P) + |Queries| . Q
Time for retrieving a document
Time for answering a
query
Time for processing a
document
Query
Generation
4. Augment seed tuples with new tuples
Key questions: How many queries and how many
documents does Iterative Set Expansion need to extract k
correct tuples?
(e.g., [Ebola AND Zaire])
(e.g., <Malaria, Ethiopia, …>)
20
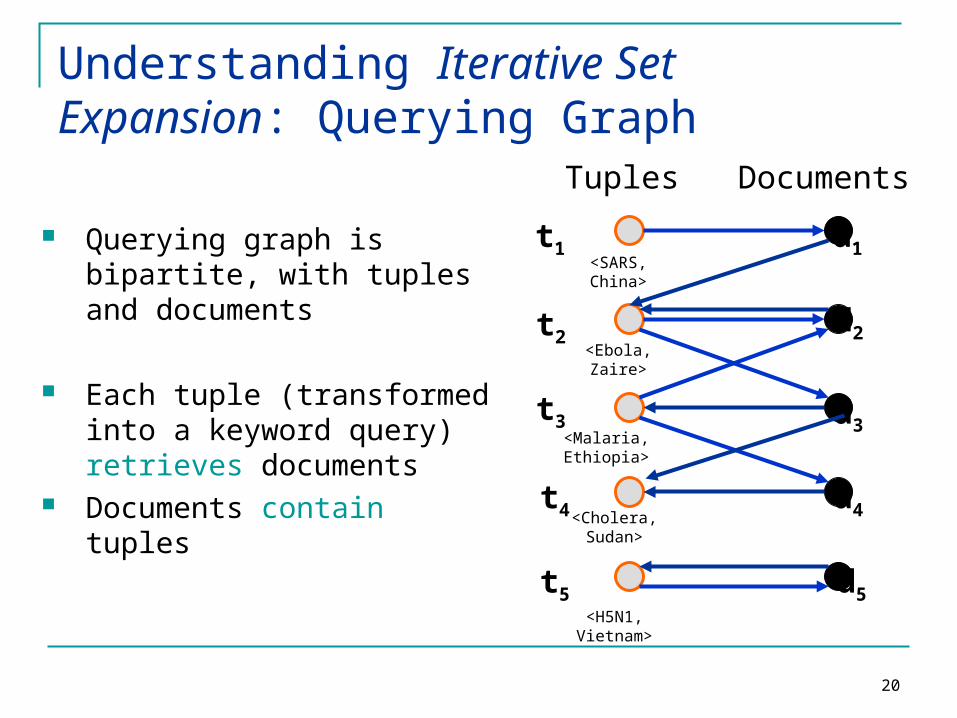
Understanding Iterative Set Expansion: Querying Graph
Querying graph is bipartite, with tuples and documents
Each tuple (transformed into a keyword query) retrieves documents
Documents contain tuples
Tuples Documents
t1
t2
t3
t4
t5
d1
d2
d3
d4
d5
<SARS, China>
<Ebola, Zaire>
<Malaria, Ethiopia>
<Cholera, Sudan>
<H5N1, Vietnam>
21
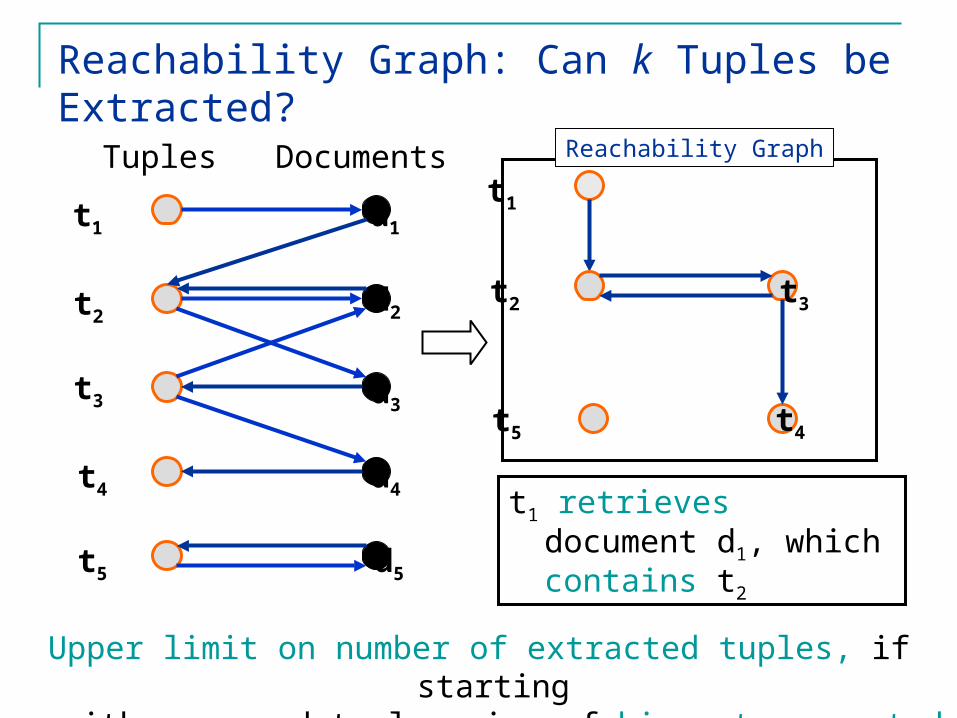
Reachability Graph: Can k Tuples be Extracted?
t1 retrieves document d1, which contains t2
t1
t2 t3
t4t5
Tuples Documents
t1
t2
t3
t4
t5
d1
d2
d3
d4
d5
Upper limit on number of extracted tuples, if starting with one seed tuple: size of biggest connected
component
Reachability Graph

22
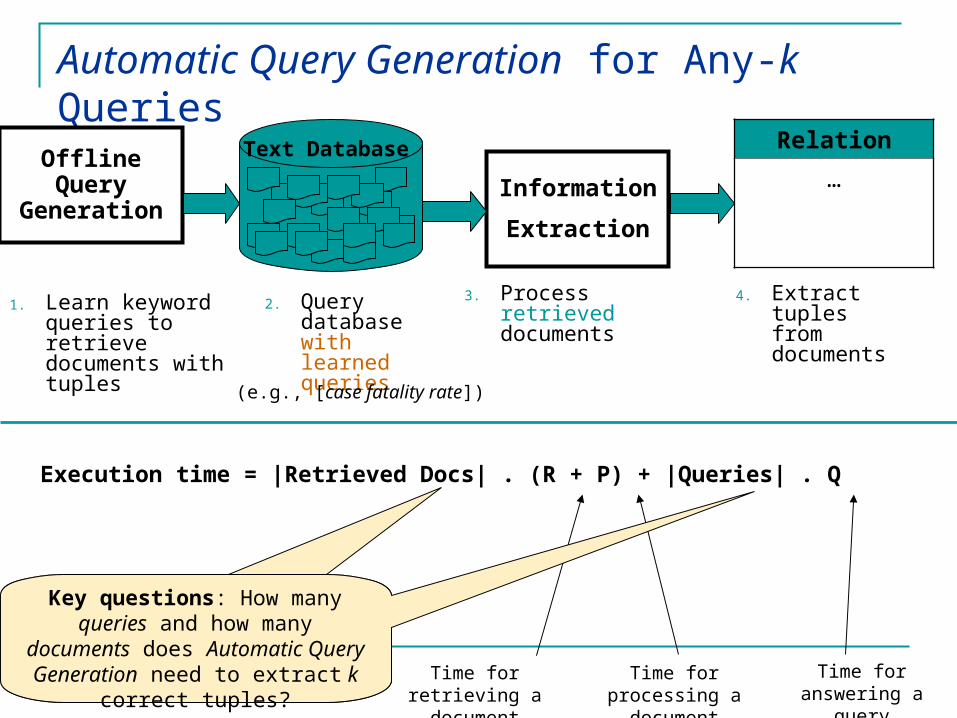
Automatic Query Generation (“PromD”) for Any-k Queries
Iterative Set ExpansionIterative Set Expansion might not fully answer an any-k query due to iterative nature of query generation
Automatic Query GenerationAutomatic Query Generation avoids this problem by learning queries offline, designed to return documents with tuples
23
Automatic Query Generation for Any-k Queries
Relation
…Information
Extraction
Text Database
4. Extract tuplesfrom documents
3. Process retrieved documents 2. Query
database with learned queries
Execution time = |Retrieved Docs| . (R + P) + |Queries| . Q
Time for retrieving a document
Time for answering a
query
Time for processing a
document
OfflineQuery
Generation
1. Learn keyword queries to retrieve documents with tuples
(e.g., [case fatality rate])
Key questions: How many queries and how many
documents does Automatic Query Generation need to extract k correct tuples?

24
Const for Any-k Tuples
Text Database
Documents that generate tuplesDocuments that do not generate tuples
Exploits selection “constants” in SQL queryDocuments without them cannot contribute tuples for
corresponding relations Avoids processing all documents, conservatively Still potentially retrieves useless documents
SELECT *FROM DiseaseOutbreaksWHERE Country = ‘Sudan’
Documents that contain SQL query constants
Keyword query: [Sudan]

25
PromC for Any-k Correct Tuples
Exploits selection “constants” in SQL query Avoids processing all documents, aggressively May miss useful documents
Text Database
Documents that generate tuplesDocuments that do not generate tuples
SELECT *FROM DiseaseOutbreaksWHERE Country = ‘Sudan’
Documents that contain SQL query constants
[case fatality rate] from PromD + [Sudan] from Const: Keyword query: [case fatality rate Sudan]

26
Properties of Alternative Execution Plans
Execution time Number of correct tuples that a plan
manages to extract
Execution plans vary in their extraction systems and document retrieval strategies
Fastest plan that produces k correct tuples for an any-k query?
[Ipeirotis et al., SIGMOD 2006, TODS 2007][Jain et al., ICDE 2008, 2009]

27
Document Retrieval Strategies for Any-k Queries: Outline
Scan- and index-based document retrieval strategies: Scan Filtered Scan Iterative Set Expansion Automatic Query Generation “Const” “PromC” (PromD + Const)
Analysis: execution time and number of correct extracted tuples
Scan-based
(“PromD”)Index-based
[Ipeirotis et al., SIGMOD 2006, TODS 2007][Jain et al., ICDE 2008, 2009]

28
Any-k Query Results Do Not Report Tuple “Correctness”
Company Location
Delta Airlines Atlanta
Lighthearted Pocahontas-Lion King
Central Park
Microsoft Redmond
NEC Corp. Indonesia
SimplisticExecution
Any-kQuery
Company Location
Delta Airlines Atlanta
Lighthearted Pocahontas-Lion King
Central Park
Microsoft Redmond
NEC Corp. Indonesia
Sun Microsystems Inc. Mountain View
Vocaltec communications Ltd. Tel Aviv
Top-k Query
Company Location Score
Microsoft Redmond 0.97
Delta Airlines Atlanta 0.89
Vocaltec communications Ltd. Tel Aviv 0.87
Sun Microsystems Inc. Mountain View
0.73
Lighthearted Pocahontas-Lion King
Central Park 0.2
NEC Corp. Indonesia 0.01
Headquarters
[Answers from New York Times archive, extracted by Snowball information extraction system]
Scoring function for top-k queries should reflect confidence in tuple correctness
k=4

29
Modeling Expected Tuple Correctness
One approach: use “confidence” scores as returned by extraction systems… handle within probabilistic databases
(e.g., [Gupta and Sarawagi, VLDB 2006], [Cafarella et al., CIDR 2007], [Ilyas et al., 2008])
Alternative approach: do some “external” computation
Company Location Score
Microsoft Redmond 0.97
Delta Airlines Atlanta 0.89
Vocaltec communications Ltd. Tel Aviv 0.87
Sun Microsystems Inc. Mountain View
0.73
Lighthearted Pocahontas-Lion King
Central Park 0.2
NEC Corp. Indonesia 0.01
Headquarters

30
Modeling Expected Tuple Correctness Redundancy in text databases is key to
counter noise and extraction errors Intuitively, the more times a tuple is
extracted (independently), the higher its expected correctness Snowball [Agichtein and Gravano, DL
2000] URNS model [Downey et al., IJCAI 2005] REALM model [Downey et al., ACL 2007],
for “sparse” data …
31
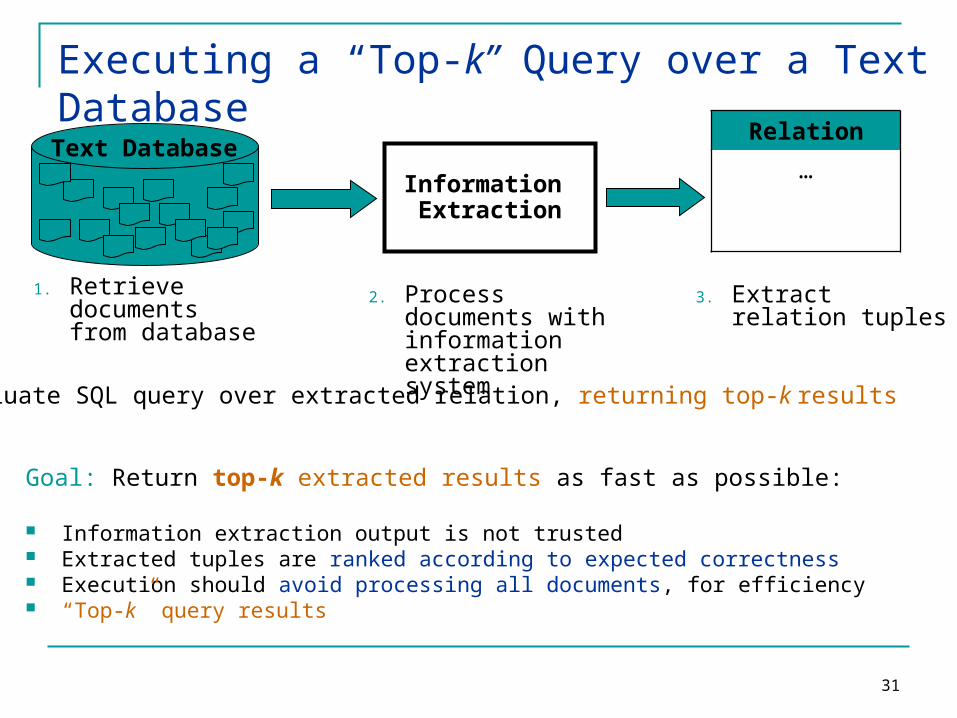
Executing a “Top-k” Query over a Text Database
Relation
…Information Extraction
Text Database
3. Extract relation tuples
2. Process documents with information extraction system
1. Retrieve documents from database
Goal: Return top-k extracted results as fast as possible:
Information extraction output is not trusted Extracted tuples are ranked according to expected correctness Execution should avoid processing all documents, for efficiency “Top-k” query results
4. Evaluate SQL query over extracted relation, returning top-k results

32
Top-k Query Processing in this Scenario is an Open Problem!
Recall “on-the-fly” extraction goal, need to avoid processing all documents, for efficiency
Can we apply well-known top-k query processing algorithms (e.g., TA, Upper)? Problem is lack of “sorted access”
No efficient access to tuples in sorted order of expected correctness
But interesting approximations, with probabilistic guarantees, are possible

“Good(k, l)” Queries
Exploit redundancy of text databases to predict tuple correctness
Define expected tuple correctness by aggregating confidence of extracted instances
Define good(k, l) query results as including any k tuples from top l%
Relaxation of top-k query definition enables efficient executions
Adaptation of Upper algorithm [Bruno et al., ICDE
2002], probabilistic formulation
33[Jain and Srivastava, ICDE 2009]

34
Processing Top-k Query Variants over Text Databases: Summary We discussed how to process top-k query variants over
text databases: “any-k,” “good(k, l),” and “top-k” queries
We focused on “on-the-fly” information extraction Information extraction task short-lived, new Text database previously unseen or too vast
So exhaustive extraction approaches may be impractical
But intriguing connection with “open information extraction” [Banko et al., IJCAI 2007] still unexplored
We focused on “blackbox” information extraction systems
But information extraction system “knobs” (e.g., for tuning precision, recall) can play important role in query optimization [Jain and Ipeirotis, TODS 2009]
Exciting research area, with many challenging open problems!

35
Thank you!





























