Embed Size (px)
Citation preview

1
Programming Languages (CS 550)
Lecture 1 SummaryGrammars and Parsing
Jeremy R. Johnson

2
Theme
Context free grammars provide a nice formalism for describing syntax of programming languages. Moreover, there is a mechanism for automatically constructing a parser (a recognizer of valid strings in the grammar) from context free grammars (typically a few additional restrictions are enforced to make it easier to construct the parser and the parser more efficient). In this lecture we review grammars as a means of describing syntax and show how, either by hand or using automated tools such as bison, to construct a parser from the grammar.

3
Outline
Motivating ExampleRegular Expressions and ScanningContext Free GrammarsDerivations and Parse TreesAmbiguous GrammarsParsing
Recursive Decent ParsingShift Reduce ParsingParser Generators
Syntax Directed Translation and Attribute Grammars

4
Motivating Example
Write a function, L = ReadList(), that reads an arbitrary order list and constructs a recursive data structure L to represent it (a1,…,an), ai an integer or recursively a listAssume the input is a stream of tokens - e.g. ‘(‘, integer,
‘,’, ‘)’ and the variable Token contains the current tokenAssume the functions
GetToken() – advance to the next token Match(token) – if token = Token then GetToken() else error M = Comp(e,L) – construct list M by inserting element e in the
front of L. E.g. Comp(1,(2,3)) = (1,2,3) M = Reverse(L) – M = the reverse of the list L.

5
SolutionL = ListRead()
{
match(‘(‘); L = NULL;
while token ‘)’ do /* read element */
if Token == NUMBER then
x = Token.value; match(NUMBER);
else if Token == ‘(‘
x = ListRead();
else
error();
endif;
L = Comp(x,L);
if Token ‘)’ then match(‘,’); endif;
enddo;
match(‘)’); return Reverse(L);
}

6
List Grammar
< list > → ( < sequence > ) | ( )
< sequence > → < listelement > , < sequence > | < listelement >
< listelement > → < list > | NUMBER

7
Derivation and Parse Tree
<list> → ( < sequence > )
→ ( < listelement > , < sequence > )
→ ( NUMBER, < sequence > ) = (1, < sequence > )
→ (1, < listelement > , < sequence >)
→ (1, NUMBER, < sequence >) = (1, 2,< sequence > )
→ (1, 2, < listelement>)
→ (1, 2, NUMBER) = (1,2,3)

8
Derivation and Parse Tree<list>
( <sequence> )
<listelement> , <sequence>
1 <listelement> , <sequence>
2 <listelement>
3

9
Parsing and Scanning
Recognizing valid programming language syntax is split into two stages scanning - group input character stream into tokensparsing – group tokens into programming language
structures
Tokens are described by regular expressionsProgramming language structures by context free
grammarsSeparating into parsing and scanning simplifies both
the description and recognition and makes maintenance easier

10
Regular Expressions
Alphabet = A language over is subset of strings in Regular expressions describe certain types of
languages is a regular expression = {} is a regular expressionFor each a in , a denoting {a} is a regular expression If r and s are regular expressions denoting languages R
and S respectively then (r + s), (rs), and (r*) are regular expressions
E.G. 00, (0+1)*, (0+1)*00(0+1)*, 00*11*22*, (1+10)*

11
Grammar
Non-terminal symbolsTerminal symbolsStart symbolProductions (rules)
Context-Free Grammars (rule can not depend on context)
Regular grammar

12
Example <if_stmt> if <logic_expr> then <stmt> | if <logic_expr> then <stmt> else <stmt>
<ident_list> identifier | identifier, <ident_list>
<program> begin <stmt_list> end <stmt_list> <stmt> | <stmt> ; <stmt_list> <stmt> <var> = <expression> <var> A | B | C <expression> <var> + <var> | <var> - <var> | <var>

13
Expression Grammars
<assign> <id> = <expr> <id> A | B | C <expr> <id> + <expr>
| <id> * <expr>
| ( <expr> )
| <id> <expr> <expr> + <expr>
| <expr> * <expr>
| ( <expr> )
| <id>

14
Exercise 1
Show a derivation and corresponding parse tree, using the first expression grammar, for the string A = B*(A+C)
Show that the second expression grammar is ambiguous by showing two distinct parse trees for the stringA = B+C*A

15
Parse Tree
<assign>
<id> = <expr>
<id>A * <expr>
( <expr> )
<id> + <expr>
A
C
<id>
B
A = B * (A + C)

16
Ambiguous Grammar
<assign>
<id> = <expr>
<expr>A + <expr>
<id>
A = B + C * A
<expr> <expr>*
<id> <id>B
C A
<assign>
<id> = <expr>
<expr>A * <expr>
<id><expr> <expr>+
<id> <id> A
B C

17
Unambiguous Expression Grammar
<expr> <expr> + <term>
| <term> <term> <term> * <factor>
| <factor> <factor> ( <expr> )
| <id>

18
Exercise 2
Show the derivation and parse tree using the unambiguous expression grammar forA = B+C*A
Convince yourself that this grammar is unambiguous (ideally give a proof)

19
Solution 2A = B + C * A
<assign>
<id> = <expr>
<expr>A + <term>
<id>
<term> <factor>*
<id>
B
A
<term>
<factor>
<id>
C
<factor>

Sketch of Proof
Induction on the length of the input stringBase case: length = 1 Otherwise, 3 cases to consider
( expr1 ) Induct on expr1
expr1 + term1 (+ rightmost) Induct on expr1 and term1
term1 * factor1 (no +, * rightmost) Induct on term1 and factor1
20

21
Recursive Descent Parsing
Turn nonterminals into mutually recursive procedures corresponding to the production rules. Procedure attempts to match sequence of
terminals and nonterminals in rhs of rule. Determine which rule to apply by looking at
next token.
Predictive parsing.Not all CFGs can be parsed this way

22
List Grammar
< list > → ( < sequence > ) | ( )
< sequence > → < listelement > , < sequence > | < listelement >
< listelement > → < list > | NUMBER

23
Recursive Descent Parser
list()
{
match(‘(‘);
if token ‘)’ then
seq();
endif;
match(‘)’);
}

24
Recursive Descent Parser
seq()
{
elt();
if token = ‘,’ then
match(‘,’);
seq();
endif;
}

25
Recursive Descent Parser
elt()
{
if token = ‘(‘ then
list();
else
match(NUMBER);
endif;
}

26
Exercise 3Removing left recursion
Rules S → S [left recursive] cause an infinite loop for a recursive decent parser
Left recursion can be systematically removed
<fee> → <fee> | <fee> → <fie> <fie> → <fie> |
Remove left recursion from the unambiguous expression grammar

27
Solution 3 Remove left recursion from the unambiguous expression
grammar
<expr> → <expr> + <term> | <term> <term> → <term> * <factor> | <factor>
Gets transformed into
<expr> → <term><expr1> <expr1> → +<term><expr1> | <term> → <factor> <term1> <term1> → * <factor> <term1> |

28
EBNF List Grammar
Zero or more repetitions: { } Optional : [ ]
< list > → ( < sequence > ) | ( )
< sequence > →
< listelement > { , < listelement>}
< listelement > → < list > | NUMBER

29
Recursive Descent EBNF Parser
list()
{
match(‘(‘);
if token ‘)’ then
elt();
while token = ‘,’ do /* { ‘,’ <elt> } */
match(‘,’); elt();
enddo;
endif;
match(‘)’);
}

30
Parser and Scanner Generators
Tools exist (e.g. yacc/bison1 for C/C++, PLY for python, CUP for Java) to automatically construct a parser from a restricted set of context free grammars (LALR(1) grammars for yacc/bison and the derivatives CUP and PLY)
These tools use table driven bottom up parsing techniques (commonly shift/reduce parsing)
Similar tools (e.g. lex/flex for C/C++, Jflex for Java) exist, based on the theory of finite automata, to automatically construct scanners from regular expressions
1bison in the GNU version of yacc

31
Yacc (bison) Example
%token NUMBER /* needed to communicate with scanner */
%%
list:
'(' sequence ')' { printf("L -> ( seq )\n"); }
| '(' ')' { printf("L -> () \n "); }
sequence:
listelement ',' sequence { printf("seq -> LE,seq\n"); }
| listelement { printf("seq -> LE\n"); } ;
listelement:
NUMBER { printf("LE -> %d\n",$1); }
| list { printf("LE -> L\n"); } ;
%%
/* since no code here, default main constructed that simply calls parser. */

32
Lex (flex) Example
%{
#include "list.tab.h"
extern int yylval;
%}
%%
[0-9]+ { yylval = atoi(yytext); return NUMBER; }
[ \t\n] ;
"(" return yytext[0];
")" return yytext[0];
"," return yytext[0];
"$" return 0;
%%

33
Building bison/flex Parse
Tools available on tuxYou can download them for free Available as part of many linux distributions (if not
installed get the appropriate package)Can be used through cygwin under windows
Build instructionsbison -d list.y => list.tab.c and list.tab.h flex list.l => lex.yy.c gcc list.tab.c lex.yy.c -ly -lfl => a.out or a.exe

34
Executing Parser
Program expects user to enter string followed by ctrl D indicating end of file, or to redirect input from a file.
E.G. with valid input
$ ./a.exe
(1,2,3)
LE -> 1
LE -> 2
LE -> 3
seq -> LE
seq -> LE,seq
seq -> LE,seq
L -> ( seq )
E.G. input with syntax error
$ ./a.exe
(1,2,3(
LE -> 1
LE -> 2
LE -> 3
seq -> LE
seq -> LE,seq
seq -> LE,seq
syntax error

35
Recursive Descent Reader
List list()
{
L = NULL; match(‘(‘);
if token ≠ ‘)’ then
L = seq();
endif;
match(‘)’);
return L;
}

36
Recursive Descent Reader
List seq()
{
x = elt();
if token = ‘,’ then
match(‘,’);
M = seq(); L = Comp(x,M);
else
L = Comp(x,NULL);
endif;
return L;
}

37
Recursive Descent Reader
Element elt()
{
if token = ‘(‘ then
x = list();
else
match(NUMBER);
x = NUMBER.val;
endif;
return x;
}

38
Attribute Grammars
Associate attributes with symbols
Associate attribute computation rules with productions
Fill in values as input parsed (decorate parse tree)Synthesized vs. inherited attributes

39
Example Attribute Grammar
< list > → ( < sequence > ) | ( ) list.val = NULL list.val = sequence.val
< sequence > → < listelement > , < sequence > | < listelement > seq0.val = Comp(listelement.val,seq1.val) seq0.val = Comp(listelement.val,NULL)
< listelement > → < list > | NUMBER listelement.val = list.val listelement.val = NUMBER.val

40
Decorated Parse Tree<list>
( <sequence> )
<listelement> , <sequence>
Val = 1 <listelement> , <sequence>
Val = 2 <listelement>
Val = 3
Val = 3
Val = (3)
Val = (2,3)
Val = 2
Val = 1
Val = (1,2,3)
Val = (1,2,3)

41
Yacc Example with Attributes/* This grammar is ambiguous and will cause shift/reduce conflits */
%token NUMBER
%%
statement_list: statement '\n'
| statement_list statement '\n'
;
statement: expression { printf("= %d\n", $1); };
expression: expression '+' expression { $$ = $1 + $3; }
| expression '-' expression { $$ = $1 - $3; }
| expression '*' expression { $$ = $1 * $3; }
| expression '/' expression
{ if ($3 == 0)
yyerror("division by zero");
else $$ = $1 / $3; }
| '(' expression ')'{ $$ = $2; }
| NUMBER { $$ = $1; }
;
%%

42
Shift Reduce Parsing
Bottom up parsing LR(1), LALR(1)Conflicts & ambiguities|1+2*31|+2*3 [shift]<exp>|+2*3 [reduce]<exp>+|2*3 [shift]<exp>+2|*3 [shift]<exp>+<exp>|*3 [reduce]
<exp>+<exp>|*3 [shift/reduce conflict]
<exp>+<exp>*|3 [shift]<exp>+<exp>*3| [shift]<exp>+<exp>*<exp>
[reduce]<exp>+<exp>| [reduce]<exp> [reduce & accept]

43
Yacc Example (precedence rules)/* precedence rules added to resolve conflicts and remove ambiguity */
%token NUMBER
%left '-' '+'
%left '*' '/'
%nonassoc UMINUS
%%
statement_list: statement '\n'
| statement_list statement '\n'
;
statement: expression { printf("= %d\n", $1); };
expression: expression '+' expression { $$ = $1 + $3; }
| expression '-' expression { $$ = $1 - $3; }
| expression '*' expression { $$ = $1 * $3; }
| expression '/' expression
{ if ($3 == 0)
yyerror("division by zero");
else $$ = $1 / $3; }
| '-' expression %prec UMINUS { $$ = -$2; }
| '(' expression ')'{ $$ = $2; }
| NUMBER { $$ = $1; }
;

44
Exercise 4 Show that the following grammar is ambiguous.
<stmt> → <ifstmt> | <basicstmt> <ifstmt> → IF <expr> THEN <stmt> | → IF <expr> THEN <stmt> ELSE <stmt>
This is called the “dangling else” problem
See if.y for a yacc/bison version of this grammar
<expr> and <basicstmt> are replaced by the tokens EXP and BSstmt: ifstmt { printf("stmt -> ifstmt\n"); } | BS { printf("stmt -> BS\n"); } ;ifstmt: IF EXP THEN stmt { printf("ifstmt -> IF EXP THEN stmt\n"); } | IF EXP THEN stmt ELSE stmt { printf("ifstmt -> IF EXP THEN stmt ELSE stmt\n"); }

45
First Parse Tree

46
Second Parse Tree
47
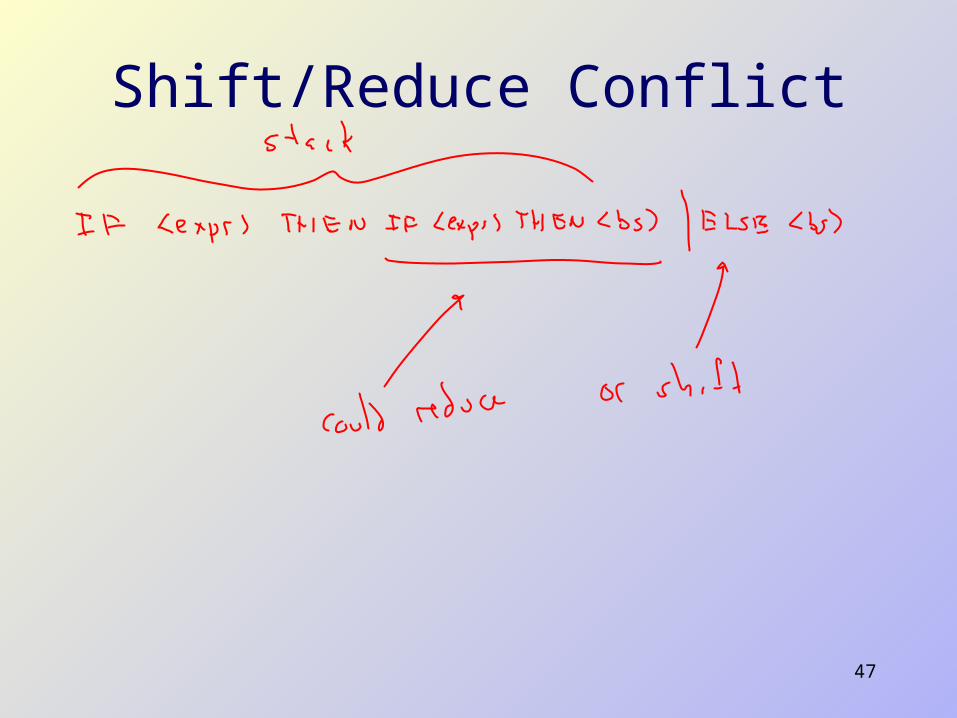
Shift/Reduce Conflict

48
Output from bison
$ bison -d if.y
if.y: conflicts: 1 shift/reduce

49
Exercise 5Can you use yacc's precedence rules to
remove the ambiguity?

50
Solution 5Convention is to associate the ELSE clause
with the nearest if statement.Force ELSE to have higher precedence than
THENThis removes the shift/reduce conflict and forces
yacc to shift on the previous example
%token IF THEN ELSE EXP BS
%nonassoc THEN
%nonassoc ELSE

51
Shift/Reduce Conflict Removed

52
Exercise 6Can you come up with an unambigous
grammar for if statements that always associates the else with the closest if?

53
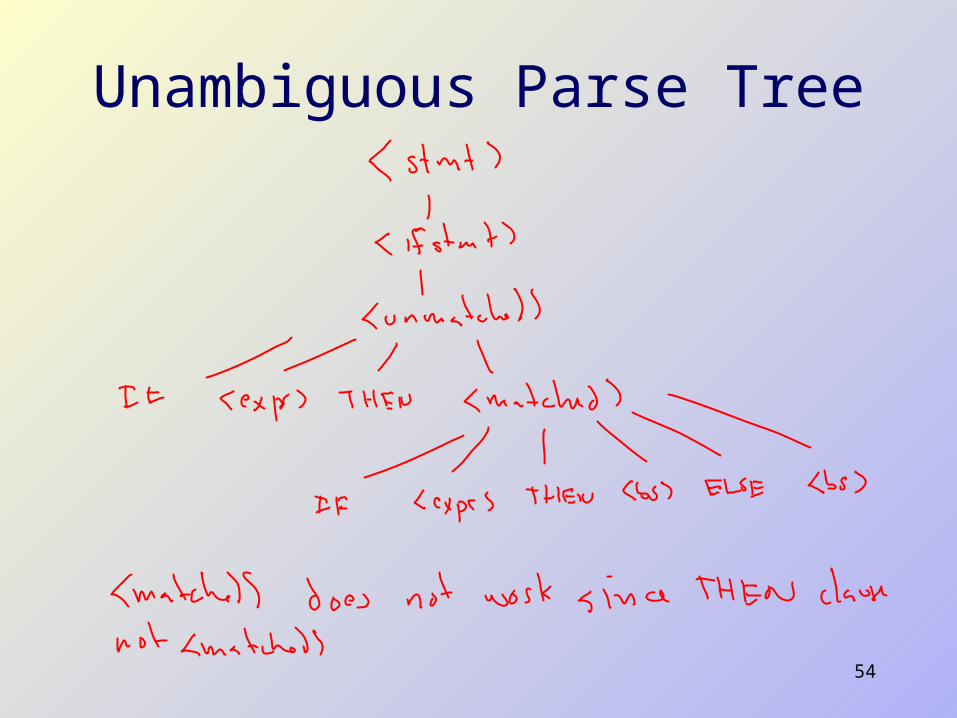
Solution 6 Separate if statements into matched (with ELSE clause and
recursively matched stmts) and unmatched This forces the matched if statement to the end
stmt: matched { printf("stmt -> matched \n "); } | unmatched { printf("stmt -> unmatched \n "); } ;
matched: BS { printf("matched -> BS \n"); } | IF EXP THEN matched ELSE matched { printf("matched -> IF EXP THEN matched ELSE matched \n"); } ;
unmatched: IF EXP THEN stmt { printf("unmatched -> IF EXP THEN stmt \n"); } | IF EXP THEN matched ELSE unmatched { printf("unmatched -> IF EXP THEN matched ELSE unmatched \n"); } ;
54
Unambiguous Parse Tree

55
No Shift/Reduce Conflict

56
Exercise 7Can you change the syntax for if statements
to remove the ambiguity. Hint - try to use syntax to denote the begin and end of the statements in the if statement?

57
Solution 7This is the best solution since the matching IF
statement and ELSE clause is visually clear. You do not have to remember unnatural precedence rules.
Such a language choice helps prevent logic bugs
stmt: ifstmt { printf("stmt -> ifstmt\n"); } | BS { printf("stmt -> BS\n"); } ;ifstmt: IF EXP THEN '{' stmt '}' { printf("ifstmt -> IF EXP THEN { stmt} \n"); } | IF EXP THEN '{' stmt '}' ELSE '{' stmt '}' { printf("ifstmt -> IF EXP THEN { stmt } ELSE { stmt }\n"); }





























