Embed Size (px)
Citation preview

&Electrical ComputerENGINEERING
Team 3: Spam’n’Beans
17-654: Analysis of Software Artifacts18-846: Dependability Analysis of Middleware
Gary AckleyAndrew Boyer
Charles FryPhilippe M. Wilson

3
Team Members
Gary [email protected]
Andrew [email protected]
Charles [email protected]
Philippe M. [email protected]
http://www.ece.cmu.edu/~ece846/team3/

4
Background
• Project: Spam’n’Beans
• What is it?– An E-Mail content analysis system– Benefits E-Mail servers by offloading
expensive E-Mail analysis to our system– Exhibits Fault-Tolerant, Real-Time and High-
Performance qualities

5
Background
• What makes it interesting?– E-Mail analysis is a real-world issue
• Unsolicited Commercial E-Mail (UCE) / SPAM accounts for 60-80% of all E-Mail traffic
• E-Mail viruses pose a security risk
– Such analysis is often too expensive for high-volume mail servers
– Few products yet exist to address this need:• Amavisd-new http://www.ijs.si/software/amavisd/
• Postini http://www.postini.com/

6
www.Postini.com

7
Development Environment
• Language: Java
• Middleware: EJB (JBoss)
• Database: PostgreSQL
• Content Filtering: SpamAssassin
• Operating System: GNU/Linux
• Test Data: Public Corpus– Database of real-world E-Mail– Made available by SpamAssassin

8
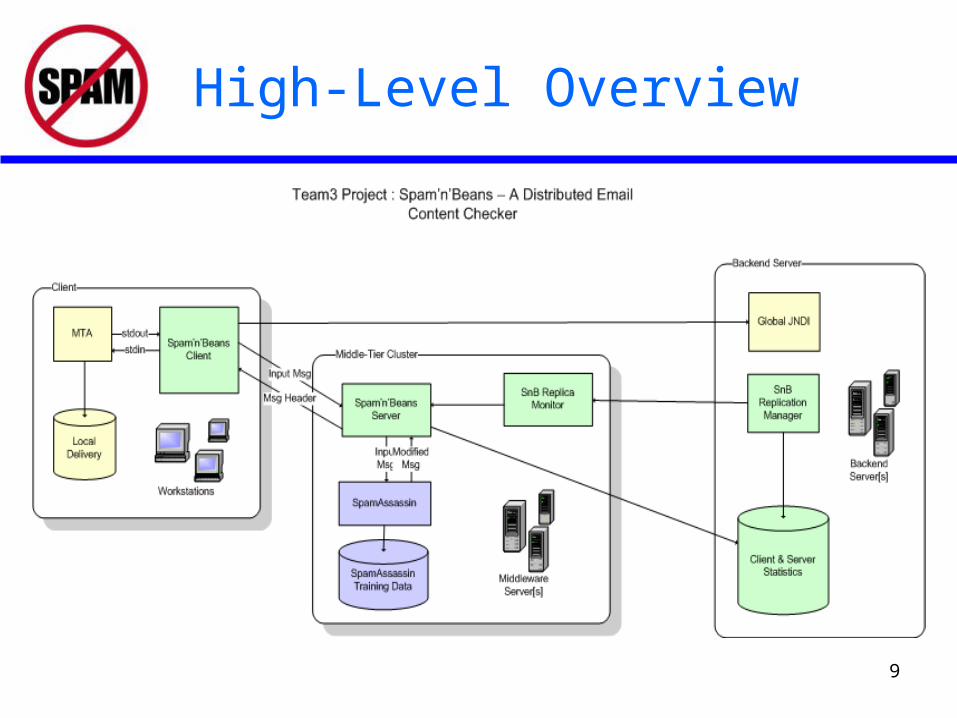
High-Level Overview
• A client’s MTA (Mail Transport Agent) uses the Spam’n’Beans client to send incoming E-Mail messages to a cluster of replicas for filtering
• Each replica runs all necessary content filters as daemon processes
• replica-side middleware accepts incoming E-Mail from clients and feeds it to the appropriate daemon processes over a local socket connection
9
High-Level Overview
10
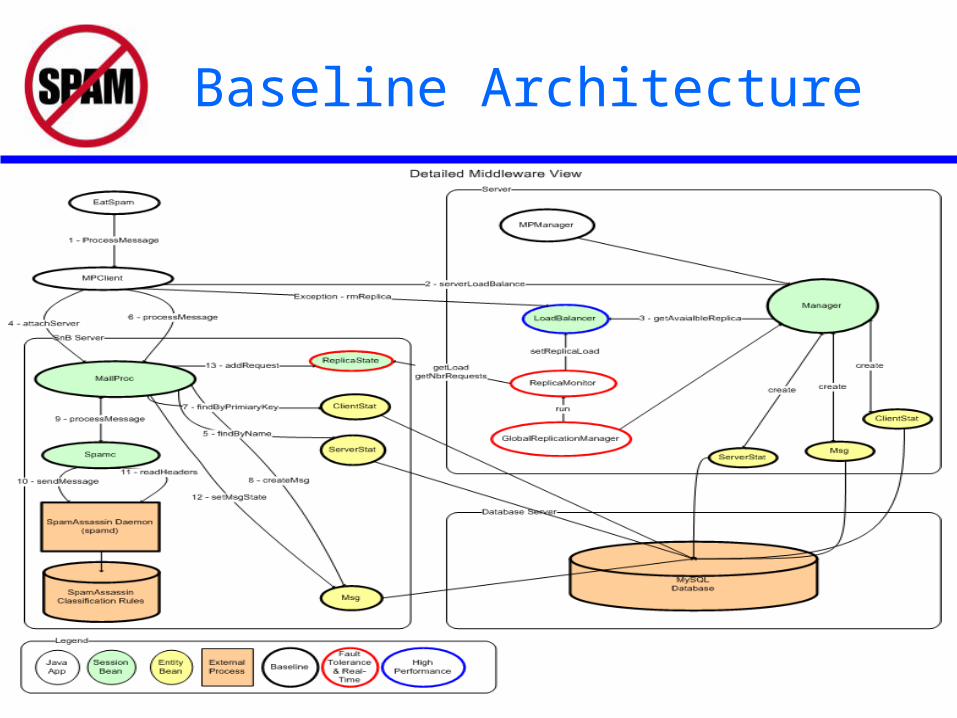
Baseline Architecture

12
Fault-Tolerance Goals
• E-Mail processing servers are replicated to guarantee availability of service despite faults on any one replica– System will continue to be available despite up to N-1 faults (N is
the number of replicas)– Clients will continue to retry when no replicas are active
• State, stored in a remote database, consists of:– Replica state and statistics– Client authentication information– Message state and statistics– Client requests are idempotent
• Non-Replicated Components– Replication Manager / Fault Detector– Database backend– EJB Nameserver

13
Fault-Tolerance Elements
• Replication Manager– A process that starts/stops replicas and manage list of
available replicas• Fault Detector
– A dedicated thread monitors each replica• Fault Recovery
– Monitor thread will re-start replica automatically as needed
• Fault Injector– A separate script used during testing– Forcefully kills a random replica every S seconds

14
FT-Baseline Architecture

15
Fault Detection
• Client application receives exception and reports it to the Replication Manager– From EJB (Remote Exception)– From server application (Fatal Exception,
Non-Fatal Exception)
• Periodic ping by Fault Detector– K failures initiates replica re-start

16
Client-Side Fail-Over
• Notify Replication Manager of replica failure
• Request another replica – Retry if none are available
• Connect to new replica and re-issue original request

17
Fail-Over Measurements
ms
Message #

19
Real-Time Baseline
• Bounded fail-over achieved by:– Removing replicas from the pool when
• Client disables replica use after receiving exception
• Fault Detector identifies unresponsive replica
– Only choosing live replicas on fail-over

20
Bounded Fail-Over Measurements
• Fail-over now bounded by 600 ms
• Fail-over time reduced by 1 order of magnitude
ms
Message #

21
Performance Strategy
• Clustering– Any middle-tier replica can handle any
request– All replicas handle requests in parallel
• Load Balancing– Minimize response latency– Adjusts to
• Static system resources• Dynamic system utilization

22
Load Balancer Implementation
• Load Balancer on golden machine– Maintains list of all live replicas and their associated
load
• Replica load is updated by Fault Detector ping• Clients request replicas from Load Balancer
– Every M messages• Load balancing strategies:
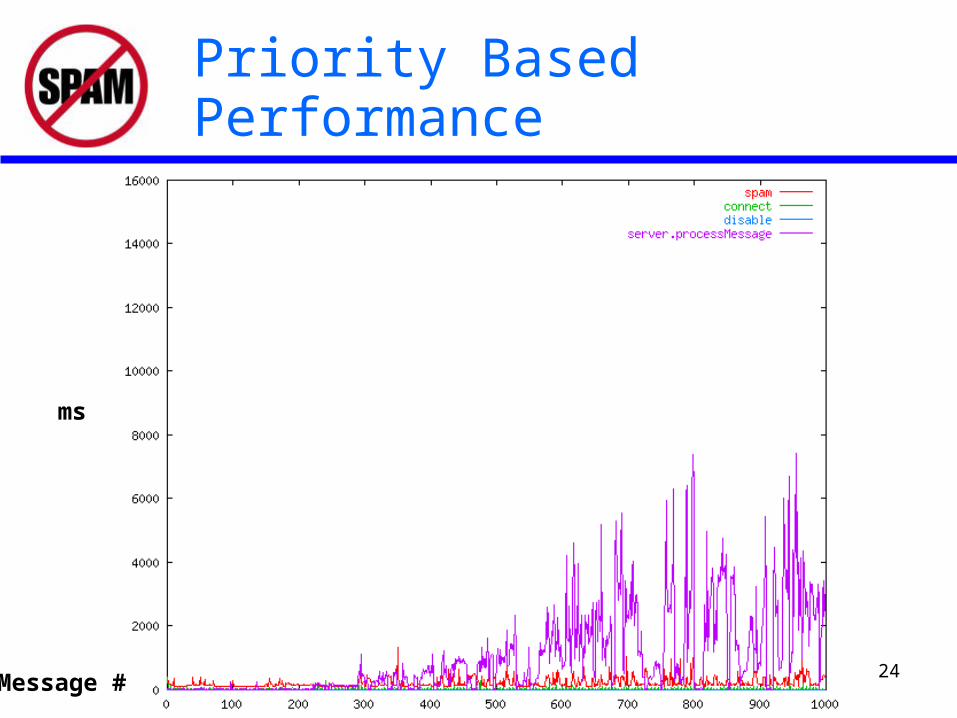
– Round-Robin– Priority (inversely proportional to relative CPU load)

23
Round Robin Performance
ms
Message #
24
Priority Based Performance
ms
Message #

26
Other Features
• Multi-threaded administrative console• Run-time replica management
– Individual replicas can be added/removed as needed
• Run-time selection of load balancing strategy
• Optimization for transient failures– Don’t restart a replica until it has been
unreachable for K pings– Verify client-reported errors

27
Insights from Measurements
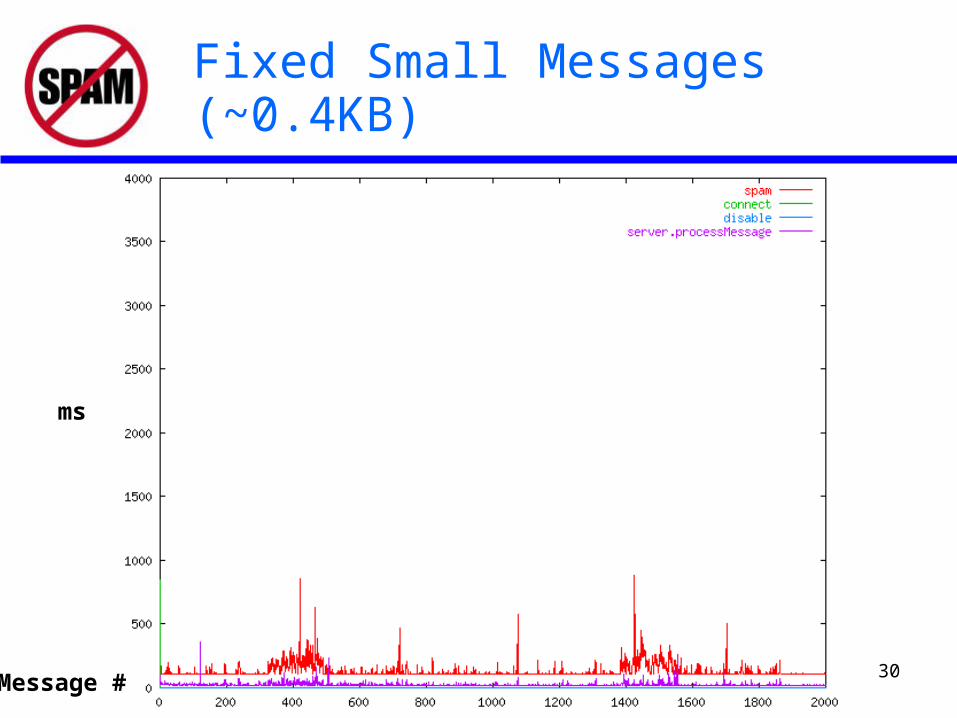
• System bottleneck is CPU-intensive E-Mail analysis
• Message processing time is highly correlated with message size
• Increases in system load cause temporary increases in jitter and delay

28
Fixed Big Message (~90KB)
ms
Message #

29
Variable Sized Messages
ms
Message #
30
Fixed Small Messages (~0.4KB)
ms
Message #

31
Open Issues
• Multiple simultaneous replica connections
• Increase throughput– Experiment with other load-balancing strategies– Add automatic capacity scaling– Enqueue client requests
• Add virus checking (via ClamAV)• Remove single points of failure• Enhance administrative consoles
– Add graphical/web interface

32
Conclusions
• What did we learn?– Tradeoffs between fault-tolerance, real-time,
and performance can be difficult to manage
• What did we accomplish?– We built a working system with fault-
tolerance, real-time and high-performance attributes to solve a real-world problem
• What would we do differently now?– Start with better architecture definition– Adhere to “KISS” principle

33
Q & A
Any questions?





























